

Abstract
Emotion plays an important role in communication. For human–computer interaction, facial expression recognition has become an indispensable part. Recently, deep neural networks (DNNs) are widely used in this field and they overcome the limitations of conventional approaches. However, application of DNNs is very limited due to excessive hardware specifications requirement. Considering low hardware specifications used in real-life conditions, to gain better results without DNNs, in this paper, we propose an algorithm with the combination of the oriented FAST and rotated BRIEF (ORB) features and Local Binary Patterns (LBP) features extracted from facial expression. First of all, every image is passed through face detection algorithm to extract more effective features. Second, in order to increase computational speed, the ORB and LBP features are extracted from the face region; specifically, region division is innovatively employed in the traditional ORB to avoid the concentration of the features. The features are invariant to scale and grayscale as well as rotation changes. Finally, the combined features are classified by Support Vector Machine (SVM). The proposed method is evaluated on several challenging databases such as Cohn-Kanade database (CK+), Japanese Female Facial Expressions database (JAFFE), and MMI database; experimental results of seven emotion state (neutral, joy, sadness, surprise, anger, fear, and disgust) show that the proposed framework is effective and accurate.
1. Introduction
Emotion recognition plays an important role in communication and is still a challenging research field. Facial expression is an indicator of feelings, providing valuable emotional information of human [1, 2]. Therefore, people can immediately recognize the emotional state of another person based on his/her facial expression. Consequently, information on facial expressions is often used in automatic systems of emotion recognition. With the development of technology, it has become convenient for us to solve problems with automatic systems, such as recognizing a person's emotion from a facial image. A machine can accurately interact with humans if it has the ability to recognize human emotions. The real-world applications that involve such interactions include human–computer interaction (HCI) [3, 4], virtual reality (VR) [5], augmented reality (AR) [6], advanced driver assistant systems (ADASs) [7], and entertainment [8, 9]. For facial expression recognition system, faces are detected and recorded as 2D images by using various devices, such as electromyographs (EMGs), electrocardiographs (ECGs), electroencephalographs (EEG), and cameras.
Based on these 2D images, there are three main research directions in facial expression recognition. The first approach defines the movement of facial muscles as an action unit (AU), and the facial expression is represented by the movements of several AUs. According to the movements of AUs from an input image, the corresponding facial expression can be determined by decoding the detected AUs. However, since muscle movements are often slight, detecting AUs has accurate problems [10], which have severely restricted the development of this approach. The second approach is feature-based methods, which include three steps. In the first stage, the face is detected from an input image, and landmarks are identified in the face area. In the second stage, features are extracted from the face region by using Histogram of Oriented Gradient (HOG), LBP, and Gabor wavelet methods. In the third stage, facial expressions are finally recognized and classified by using classifiers such as SVMs, AdaBoost, and random forests. The third approach is DNN-based methods, which perform very well in facial expression recognition. Different from conventional approaches, a feature map of the input image is produced through filter collection in the convolution layers [11–13].
Although DNN-based methods generally perform better than conventional methods, they have problems related to the processing time and memory consumption. Considering low hardware specifications used in some real-life conditions, to gain better results without DNNs, we aim to recognize seven basic emotional states (neutral, happy, surprise, sadness, fear, anger, and disgust) based on facial expressions using the second (feature based) approach. As we knew, the LBP is a powerful feature for texture representation. When facial expression appears, different textures are generated by the actions of the related muscles on the face. For this reason, we chose LBP in our study for facial expression recognition. In addition, to achieve the requirements of real time that are usually overlooked in previous studies, we combine LBP and OBR, since the ORB has been shown to have high computing speed.
However, the traditional ORB is more concentrated on the distribution of the extracted feature points. As traditional ORB, abundant feature points are extracted to achieve a higher accuracy, but the excessively dense feature points are very inconvenient for feature description. To solve this problem, we innovatively employed region division in the traditional ORB. This improved ORB algorithm calculates the number of feature points extracted from each region according to the total number of feature points to be extracted and the number of regions to be divided. In the present study, we did not just combine LBP and ORB, but combined LBP with improved ORB which solved the problem of feature point overlap and redundancy in the extraction process. Moreover, to test our improved LBP and ORB algorithm, we conducted experiments on several facial expressions in CK+ database, JAFFE database, and MMI database.
This paper is organized as follows. Section 2 summarizes some of the previous works. Section 3 presents the algorithm framework of facial expression recognition. Faces are detected and extracted using the Dlib library because of its fast processing speed, and LBP and improved ORB features are extracted separately from the face region. Then, the Z-score method is used to fuse both types of features. The facial expression databases are given in Section 4, and the experimental results and comparison with state-of-the-art methods are presented in Section 5. Finally, conclusions are stated in Section 6.
2. Related Work
We describe related works of facial expression recognition systems that have been studied to date. These algorithms can largely be divided into three directions: the geometric feature extraction method, the appearance feature extraction method, and the deep learning-based method. The geometric feature extraction method extracts geometric elements of the facial structure and motion of the facial muscles, the appearance feature extraction method extracts the features of the entire facial criterion, and the deep learning-based method uses convolutional neural network (CNN) to achieve the automatic learning of the extracted facial features. Some of the recent algorithms involving the aforementioned algorithms are described in the following subsections.
The geometric features algorithm extracts the temporal or dynamic changes of the landmark of the face. Geometric relationship between landmark points which are detected from face regions are exploited for expression representation. Tang et al. designed geometric features based on psychology and physiology [14]. Liang et al. focused on fine-grained facial expression recognition in the wild and built a brand-new benchmark FG-Emotions, extended the original six classes to more elaborate thirty-three classes, and proposed a new end-to-end Multiscale Action Unit- (AU-) Based Network (MSAU-Net) for facial expression recognition [15]. Zhang et al. proposed an end-to-end deep learning model that allows to synthesize simultaneous facial images and pose-invariant facial expression recognition by exploiting shape geometry of the face image [16]. However, when the landmark points are detected incorrectly, the recognition accuracies will be decreased.
The appearance features are extracted from facial image intensities to represent a discriminative textural pattern. Mandal et al. extracted the adaptive positional thresholds for a facial image; threshold parameters in the local neighborhood can be adaptively adjusted for different images; then multidistance magnitude features are encoded. SVM is used as a classifier for the facial expression recognition [17]. Tsai combined the Haar-like features method with the self-quotient image (SQI) filter for facial expression recognition. The angular radial transform (ART), the discrete cosine transform (DCT), and the Gabor filter (GF) are simultaneously employed in the system. An SVM is used to achieve the best results [18]. Chen et al. used visual modalities (face images) and audio modalities (speech) for facial expression recognition. They proposed a descriptor named Histogram of Oriented Gradients from Three Orthogonal Planes (HOG-TOP) to extract dynamic textures from video sequences to characterize facial appearance changes [19]. Ryu et al. used a coarse grid for stable codes (highly related to nonexpression), and a finer one for active codes (highly related to expression) as the features for facial expression recognition [20]. Liu et al. extracted LBP and HOG features from the salient areas that were defined on the faces; then Principal Component Analysis (PCA) is used to reduce the dimensions of the features which fused with LBP and HOG [21]. Ghimire et al. divided the whole face region into domain-specific local regions; then region-specific appearance features and geometric features are extracted from the domain-specific regions for facial expression recognition [22]. Nigam et al. retrieved Histogram of Oriented Gradients (HOG) feature in DWT domain and an SVM was used for expression recognition [23]. Kamarol et al. proposed spatiotemporal texture map (STTM) to capture subtle spatial and temporal variations of facial expressions with low computational complexity. And an SVM was used for classification [24]. Turan and Lam performed 27 local descriptors while the Local Phase Quantization (LPQ) and Local Gabor Binary Pattern Histogram Sequence (LGBPHS) achieved the best results [25]. Bougourzi et al. combined histogram of oriented gradients, local phase quantization, and binarized statistical image features to recognize the facial expressions from the static images [26]. Meena et al. used graph signal processing along with the curvelet transform for recognizing the facial expressions. Not only the dimension of the feature vectors has been reduced but also recognition of the facial expression has been significantly improved [27]. Ashir et al. used the compressive sensing technique with statistical analysis of the extracted compressed facial signal to represent a more robust feature representation for each individual facial expression class [28].
Recently, deep learning is widely used in many computer vision tasks including facial expression recognition and achieves remarkable success. The facial expression features are learned automatically by Convolutional Neural Networks (CNN). Dong et al. introduced dense connectivity across pooling to enforce feature sharing in a relatively shallow CNN structure for effective representation of facial expressions under limited training data [29]. Xie et al. embedded the feature sparseness into deep feature learning to boost the generalization ability of the convolutional neural network for facial expression recognition [30]. Yu et al. designed a multitask learning framework for global–local representation of facial expressions [31]. Wen et al. designed a new neural network with domain information loss and dynamic objectives learning; the network can avoid the gradient disappearance and obtain the higher semantic features [32]. Wang et al. proposed a simple yet efficient Self-Cure Network (SCN) which suppresses the uncertainties efficiently and prevented deep networks from overfitting uncertain facial images [33]. Although deep learning based methodology may achieve higher recognition rate, more computing resources and data are needed. For these reasons, our research uses the former framework.
3. Methodology
In this section, the proposed methodology is introduced in detail. As shown in Figure 1, before LBP and ORB features extraction, the input images should be preprocessed (face detection and face extraction). The LBP is a fine-scale descriptor that captures small textural details. Local spatial invariance is achieved by locally pooling (e.g., with a histogram). Given that this approach is very resistant to lighting changes, LBP is a good choice for coding the fine details of facial appearance information over a range of coarse scales. In addition, ORB methods are 2 orders of magnitude faster than SIFT methods, and they perform as well in many situations. Moreover, our improved ORB avoided feature point overlap and redundancy in extraction processing. Then, features fusion of LBP and improved ORB were performed. Finally, by using the SVM, the classification accuracy was calculated to estimate whether our method can achieve outstanding results in facial expression recognition.
Figure 1.

Flow diagram of emotion recognition.
3.1. Face Detection and Face Extraction
Many algorithms have been proposed for face detection, such as the Haar cascade algorithm, HOG method with an SVM, and CNN models. In this paper, we use the Dlib library to detect faces because of its fast processing speed as shown in Figure 2. The Dlib library contains a facial landmark detector with a pretrained model [34, 35]. This model marks 68 points on the face, and the points specify regions of the face. The jaw line is highlighted using points 1–17, the left eyebrow is highlighted using points 18–22, the right eyebrow is highlighted using points 23–27, the left eye region is highlighted using points 37–42, the right eye region is highlighted using points 43–48, the region of the nose is highlighted using points 28–36, the outer lip area is highlighted using points 49–60, and the inner lip structure is highlighted using points 61–68. In this method, a regression tree model is created to find these facial landmark points directly from the pixel intensities without feature extraction; thus, the detection process may be fast enough to overcome the accuracy and quality problems associated with real-time analysis.
Figure 2.
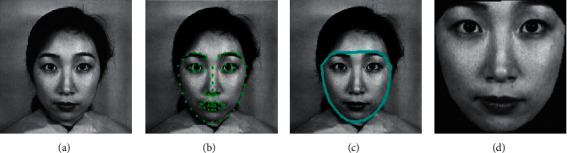
The framework of face detection and face extraction. (a) The original image. (b) The detected face with 68 landmarks. (c) The face region using points 1–27. (d) The extracted face region.
Usually, emotions are mainly conveyed via the eyes, nose, eyebrows, and some facial regions, so other parts of the face, such as the ears and forehead, can be excluded in further analysis. This face detection algorithm is appropriate for obtaining exact facial regions, and points 1–27 are used to extract the face region from original images.
3.2. Fusion with LBP and ORB Features
3.2.1. Local Binary Patterns (LBPs)
LBPs, which were introduced by Ojala, can effectively describe the texture information of an image [36–38]. The LBP operator is defined for 3 × 3 neighborhoods, takes each pixel as the central pixel, and assesses the 8 pixels around the selected pixel based on a given threshold. The resulting binary-valued image patch forms a local image descriptor [39]. The LBP operator takes the following form:
| (1) |
For the 8 neighbors of the central pixel c, ic and in are the gray values at c and n, and s(u) is 1 if u ≥ 0 and 0 otherwise. An original LBP operator that is shown in Figures 3 and 4 depicts the original LBP features of facial expressions.
Figure 3.
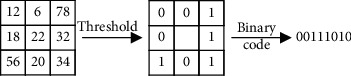
Original LBP operation.
Figure 4.
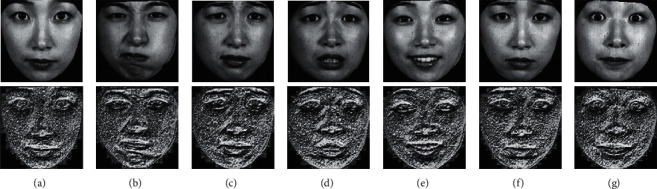
Original LBP features of facial expressions. (a) Neutral. (b) Anger. (c) Disgust. (d) Fear. (e) Happy. (f) Sad. (g) Surprise.
If an LBP operator contains at most one 0-1 and one 1-0 transition in a binary code, then a uniform pattern exists. The uniform pattern contains primitive structural information for edges and corners. This information can be used to reduce the length of the feature vector and implement a simple rotation-invariant descriptor. In our research, a uniform-pattern LBP descriptor is applied to obtain features from faces, and the length of the feature vector for a single cell can be reduced from 256 in the traditional method to 59. The size of the face region is 130 × 130, and the LBP face is 128 × 128, which is separated into small 16 × 16 patches with a resolution of 8 × 8. The uniform LBP features are extracted from each small patch and mapped to a 59-dimensional histogram.
3.2.2. Oriented FAST and Rotated BRIEF (ORB) Features
FAST features are widely used because of their computational properties. The FAST operation uses one parameter, the intensity threshold between the center pixel and each pixel in circular ring around the center, as a simple but effective measure of corner orientation. This parameter is called the intensity centroid. The intensity centroid assumes that the intensity of a corner is different from that of a pixel center, and this vector may be used to determine an orientation [40].
(1) FAST Detector. The FAST detector first proposed by Rosten is widely used in corner detection for computer vision because of its rapid operations and low computational complexity compared to other corner detectors. The segment test criterion is based on analyzing a circle of sixteen pixels around the candidate corner p. The original detector classifies p as a corner if a set of n contiguous pixels that are brighter than the intensity of the candidate corner Ip plus a threshold t or are darker than Ip minus t exists in the circle. Notably, n is chosen as 12 because it yields a high-speed test that can be used to exclude a very large number of noncorners. The expression of the FAST detector is presented as follows:
| (2) |
where Ip is the intensity of p, Ip⟶x is the intensity of the sixteen pixels around the corner, and t is a threshold. If Sp⟶x is equal to d, the pixel belongs to the darker group; if Sp⟶x is equal to s, the pixel belongs to the similar group. If Sp⟶x is equal to b, the pixel belongs to the brighter group. If 12 continuous pixels that belong to the darker or brighter group exist, p is regarded as a corner.
The corners are determined when all image pixels are tested using the above process. The corners will converge in some areas. To find the most robust corners, a nonmaximal suppression method based on a score function is adopted. The score values of each detected corner are calculated, and the corners with the low score values are removed. The corners with high score values are kept using the nonmaximal suppression method. There are several intuitive definitions for the score value:
The maximum value of n for which p is still a corner,
The minimum value of t for which p is still a corner,
The sum of the absolute difference between pixels in a contiguous arc and the center pixel.
Definitions (1) and (2) are highly quantifiable measures, and many pixels share these same values. To improve the computational speed, a slightly modified version of (3) is used. The score value is calculated as follows:
| (3) |
where Ip is the intensity of p, Ip⟶x is the intensity of the sixteen pixels around the corner, and t is a threshold.
(2) BRIEF Descriptor. The BRIEF descriptor first proposed by M. Calonder is adopted to describe the detected corners. The form of the BRIEF descriptor consists of “1” and “0” values, and the length of the BRIEF descriptor is generally defined as 128 bits, 256 bits, or 512 bits. The following formula clearly shows the definition of the BRIEF descriptor:
| (4) |
where I(r1, c1) and I(r2, c2) are the intensities of the pixels at (r1, c1) and (r2, c2), respectively. If I(r1, c1) is less than I(r2, c2), then λ=1; otherwise, λ=0. The length of λ is designated as 256 bits in this paper.
In the description of one point, a subimage with a size of 35 columns × 35 rows (here, the definition in the following situation is the same) is used. Because the BRIEF descriptor is sensitive to noise, the intensity value of each patch pair is calculated using a smoothing filter with a 5 × 5 subwindow centered at (ri, ci), where (i=1,2, Λ, 512). To reduce the impact of the image boundary, the intensity values of the image boundary are removed from the computation; thus, the actual size of the subimage is reduced to 31 × 31. Next, {(r1, c1), (r2, c2)} is defined as a patch pair instead of a point pair, and there is a total of 256 patch pairs in the subimage. The locations (ri, ci) of the 256 point pairs are determined by a Gaussian distribution, where (ri, ci) ~ i.i.d. Additionally, Gaussian (0, S2/25) : (ri, ci) values are determined from an isotropic Gaussian distribution, where S is the size of a patch. Details regarding how to determine the locations of the 256 patch pairs can be found in [40]. Figure 5 depicts the ORB features of facial expressions.
Figure 5.

ORB features of facial expressions. (a) Neutral. (b) Anger. (c) Disgust. (d) Fear. (e) Happy. (f) Sad. (g) Surprise.
3.2.3. Region-Based ORB
Traditional ORB is more concentrated on the distribution of the extracted feature points. In traditional ORB, abundant feature points are extracted to achieve a higher accuracy, but the excessively dense feature points are very inconvenient for feature description. To solve this problem, we innovatively employed region division in the traditional ORB. This improved ORB algorithm calculates the number of feature points to be extracted for each region according to the total number of feature points to be extracted and the number of regions to be divided. The steps are described as follows.
Step 1. Evenly divide the images intoM × Nregions of the same size. M is the row and N is the column of the division. Feature points are randomly distributed in the divided regions, and the regions are sequenced as{h1, h2,…, hM×N}.
- Step 2. Set a threshold T
(5) where n is the number of feature points.
Step 3. The feature points are detected in each region; if the number of features is not less than T , we choose Tas the feature number. If the number of features is less than T, the threshold should be smaller and repeat this step.
Step 4. When the number of feature points is bigger than n, nonmaximal suppression method is used to select the best feature points.
Step 5. All regions are traversed until the number of feature points meets the conditions.
3.2.4. Feature Fusion Scheme
Feature normalization is used to increase the recognition rate before feature fusion. In this article, the LBP features are normalized to the range of 0-1, and the following formula is applied to normalize the LBP and ORB features:
| (6) |
where l is the value of a feature.
Feature fusion is usually performed because one type of feature cannot describe every image characteristic. In this article, the LBP and ORB descriptors are fused by using the Z-score method.
| (7) |
where fj is an LBP feature or ORB feature and is the feature data after fusion. K is a factor multiplied by , and K is 100 in the following experiments.
4. Database of Facial Expressions
4.1. Japanese Female Facial Expressions (JAFFE) Database
The JAFFE database contains 213 images from ten different Japanese female subjects, and each subject has 3 or 4 examples of seven facial emotions (six basic facial emotions and one neutral emotion). The images are gray with a resolution of 256 × 256 [41]. In our experiment, the total 213 images (anger: 30 images; disgust: 29 images; fear: 32 images; happiness: 31 images; neutral: 30 images; sad: 31 images; and surprise: 30 images) are used to evaluate the proposed algorithm. Some images from the JAFFE database are shown in Figure 6.
Figure 6.
Some images from the JAFFE database. (a) Neutral. (b) Anger. (c) Disgust. (d) Fear. (e) Happy. (f) Sad. (g) Surprise.
4.2. The Extended Cohn-Kanade (CK+) Database
The CK+ database contains 593 sequences from 123 subjects from 18 to 30 years of age. Overall, 327 sequences are labeled with anger (45), contempt (18), disgust (59), fear (25), happiness (69), sad (28), and surprise (83). Different facial expressions have different numbers in the corresponding sequences, and each expression contains images from neutral to the peak expression. The neutral and three peak frames sampled from each sequence are used for testing while contempt is not considered. In our experiments, we selected 309 sequences which are labeled as one of the six basic facial expressions excluding contempt. We chose the three last frames of each sequence, so there were 927 images for anger, disgust, fear, happiness, sad, and surprise. In addition, we defined the first frame of each sequence as neutral facial expression (309 images). Taken together, 1236 images from CK+ database were used in our experiments. The images have resolution of 640 × 490 or 640 × 480 [42, 43].
4.3. MMI Database
The MMI facial expression database [44, 45] includes 208 videos of both genders aged from 19 to 62 years. Each sequence labels as one of the six basic emotions and begins with the neutral expression and ends with it, while the expression is in the middle. In our experiments, we approximated the three peak frames from the middle of each sequence. Thus, we obtained 624 color images in total with the resolution 720 × 576 pixels. The MMI database has more challenging conditions including illumination, gender, age, ethnicities, and insufficient number of subjects, of which many wear accessories (e.g., glasses, moustache). Figure 7 shows some images from the MMI database.
Figure 7.

Some images from the MMI database.
In the collection of the static image from the sequences, the most commonly used method is to select the first frame (as the neutral expression) and the three-peak frame in each sequence. Also, ten-fold person-independent cross-validation is conducted for the experiments.
5. Experiments
This section gives the details of the experiments performed. Two experiments involving the JAFFE, CK+, and MMI databases were conducted to verify the effectiveness of the proposed facial expression recognition method. In the first experiment, the subjects used for training were part of the testing set. In the second experiment, the subjects used for training were not used for testing. That means subject-dependent (SD) and subject-independent (SI), and cross-validation schemes are used in Experiment 1 and Experiment 2, respectively. The subject-independent experimental scheme has been widely investigated in the past years because it is more plausible for the real applications, which need to recognize the facial expressions from new persons. An SVM was the basic classifier used in the experiments, and 10-fold cross-validation procedure was used in all experiments.
5.1. Experiments Based on the JAFFE Database
All the facial region images were resized to 128 × 128 pixels, and the classifiers were trained using LibSVM [46]. The parameters were defined through a grid search, and 10-fold cross-validation was used to improve algorithm performance. Each experiment was repeated 10 times, and the results were reported as the average of these 10 replications. Fusion features were used in the proposed algorithm, and the input data were fused with LBP and ORB features.
The accuracy of experiments with different features is shown in Table 1. Results of LBP + ORB were better than the results of LBP/ORB in Experiment 1 (LBP + ORB: 92.4%; LBP: 86.7%; and ORB: 89.2%) and Experiment 2 (LBP + ORB: 88.5%; LBP: 65.4%; and ORB: 73.1%).
Table 1.
The accuracy of experiments with different features.
| Experiment 1 | Experiment 2 | ||
|---|---|---|---|
| Features | Accuracy (%) | Features | Accuracy (%) |
| LBP | 86.7 | LBP | 65.4 |
| ORB | 89.2 | ORB | 73.1 |
| LBP + ORB | 92.4 | LBP + ORB | 88.5 |
A comparison of our results with those of other methods from the literature is shown in Table 2. Recognition rate based on JAFFE dataset suggested the proposed method obtained higher accuracy (88.5%) than recent methods (73.24%, 55.71%, and 87.6%).
Table 2.
Recognition rate based on JAFFE.
5.2. Experiments Based on the CK+ Database
The procedure for the experiments based on the CK+ database was the same as that for the JAFFE database. All facial expression images were extracted from video sequences. The accuracy of experiments with different features is shown in Table 3. Results of LBP + ORB were better than the results of LBP/ORB in Experiment 1 (LBP + ORB: 99.2%; LBP: 97.3%; and ORB: 98.5%) and Experiment 2 (LBP + ORB: 93.2%; LBP: 86.7%; and ORB: 88.4%).
Table 3.
The accuracy of experiments with different features.
| Experiment 1 | Experiment 2 | ||
|---|---|---|---|
| Features | Accuracy (%) | Features | Accuracy (%) |
| LBP | 97.3 | LBP | 86.7 |
| ORB | 98.5 | ORB | 88.4 |
| LBP + ORB | 99.2 | LBP + ORB | 93.2 |
A comparison of our results with those of other methods from the literature is shown in Table 4. Recognition rate based on CK+ dataset suggested the proposed method obtained higher accuracy (93.2%) than one recent method (84.6%), but lower than three recent methods (95.96%, 94.5%, and 95.1%).
Table 4.
Recognition rate based on CK+.
5.3. Experiments Based on the MMI Database
The procedure for the experiments based on the MMI database was the same as that for the JAFFE database and CK+ database. All facial expression images were extracted from video sequences. The accuracy of experiments with different features is shown in Table 5. Results of LBP + ORB were better than the results of LBP/ORB in Experiment 1 (LBP + ORB: 84.2%; LBP: 73.3%; and ORB: 78.5%) and Experiment 2 (LBP + ORB: 79.8%; LBP: 69.9%; and ORB: 73.3%).
Table 5.
The accuracy of experiments with different features.
| Experiment 1 | Experiment 2 | ||
|---|---|---|---|
| Features | Accuracy (%) | Features | Accuracy (%) |
| LBP | 73.3 | LBP | 69.9 |
| ORB | 78.5 | ORB | 73.3 |
| LBP + ORB | 84.2 | LBP + ORB | 79.8 |
A comparison of our results with those of other methods from the literature is shown in Table 6. The proposed method obtained higher accuracy (79.8%) than all four recent methods (73.57%, 70.63%, 76.3%, and 58.98%). Notably, the proposed method performed better than the other methods based on MMI dataset.
Table 6.
Recognition rate based on MMI.
5.4. Discussion
Based on the results of our experiments, it is obvious that our proposed method can deal with the facial expression recognition efficiently. In this paper, we proposed a new framework of emotion recognition system from static images by using feature-based approach. We combined LBP and improved ORB features extracted by descriptors possessing different properties. Recently, numerous studies have reported that DNN-based approach performed well in facial expression recognition. However, DNN-based approach needs excessive hardware specifications requirement. Considering low hardware specifications used in real-life condition, to gain better results without DNNs, in this paper, we proposed an algorithm with the combination of the improved ORB features and LBP features extracted from facial expression.
Compared with other methods, LBP is more effective to extract facial expression. However, the speed is also important for effective facial expression recognition. Instead of using LBP only, ORB is also employed for facial expression recognition in our system since the ORB has been shown to have high computing speed. Notably, compared with LBP/ORB, experimental results based on JAFFE, CK+, and MMI databases showed that our method can enhance the accuracy of facial expression recognition, in other words, can improve the discriminative ability. Meanwhile, based on JAFFE, CK+, and MMI databases, we found that our method was in general better than recent studies on facial expression recognition. Our method improved the accuracy of facial expression recognition based on JAFFE database; results of recognition rate based on CK+ database indicated that our method was not as good as the previous methods but outperformed [17] which used similar experiment. Recognition rate based on MMI database suggested the proposed method achieved superior recognition accuracy than all four state-of-the-art approaches. Considering the characteristics of the facial expression and the requirements of real time, we combined LBP and improved OBR as the features of facial expression to improve recognition performance, but there are still much more challenges. In the future research, we will focus on how to improve the accuracy and increase the speed at the same time.
6. Conclusions
This paper proposed a framework for facial expression recognition with fused features. LBP and improved ORB descriptors were used for feature extraction, and SVM classification was performed for facial expression recognition. The experimental results showed that the proposed framework performed better than some widely used methods based on the JAFFE database, CK+ database, and MMI database.
This article mainly focused on facial expressions from static images. In our future work, facial expressions from video sequences will be further considered, as will calculation times for embedded systems.
Acknowledgments
This work was supported by the High-Level Talent Foundation of Jinling Institute of Technology (no. jit-b-201704) and the National Natural Science Foundation of China (nos. 31700993 and U1733122).
Data Availability
The data used to support the findings of this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare that they have no conflicts of interest regarding the publication of this paper.
References
- 1.Mehrabian A. Communication without words. Psychology Today. 1968;2:53–56. [Google Scholar]
- 2.Kaulard K., Cunningham D. W., Bülthoff H. H., Wallraven C. The MPI facial expression database-avalidated database of emotional and conversational facial expression. PLoS One. 2012;7 doi: 10.1371/journal.pone.0032321.e32321 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Dornaika F., Raducanu B. Efficient facial expression recognition for human robot interaction. Proceedings of the 9th International Work-Conference onArtificial Networks on Computational and Ambient Intelligence; June 2007; San Sebastián, Spain. pp. 700–708. [Google Scholar]
- 4.Bartneck C., Lyons M. J. HCI and the face: towards an art of the soluble. Proceedings of the International Comference on Human-Computer Interaction: Interaction Design and Usability; July 2017; Beijing, China. pp. 20–29. [Google Scholar]
- 5.Hickson S., Dufour N., Sud A., Kwatra V., Essa I. A. Eyemotion: classifying facial expressions in VR using eye-tracking cameras. 2017. https://arxiv.org/abs/1707.07204.
- 6.Chen C.-H., Lee I.-J., Lin L.-Y. Augmented reality-based self-facial modeling to promote the emotional expression and social skills of adolescents with autism spectrum disorders. Research in Developmental Disabilities. 2015;36:396–403. doi: 10.1016/j.ridd.2014.10.015. [DOI] [PubMed] [Google Scholar]
- 7.Assari M. A., Rahmati M. Driver drowsiness detection using face expression recognition. Proceedings of the IEEE International Conference on Signal and Image Processing Applications; November 2011; Kuala Lumpur, Malaysia. pp. 337–341. [Google Scholar]
- 8.Zhang C., Li W., Ogunbona P., Safaei F. A real-time facial expression recognition system for online games. International Journal of Computer Games Technology. 2008;2008:7. doi: 10.1155/2008/542918.542918 [DOI] [Google Scholar]
- 9.Mouráo A., Magalháes J. Competitive affective gaming: winning with a smile. Proceedings of the ACM International Conference on Multimedia; October 2013; Barcelona, Spain. pp. 83–92. [Google Scholar]
- 10.Zhao K., Chu W. S., Zhang H. Deep region and multi-label learning for facial action unit detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR); June 2016; Las Vegas, NV, USA. pp. 3391–3339. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Viola P., Jones M. J. Robust real-time face detection. International Journal of Computer Vision. 2004;57(2):137–154. doi: 10.1023/b:visi.0000013087.49260.fb. [DOI] [Google Scholar]
- 12.Kahou S. E., Michalski V., Konda K. Recurrent neural networks for emotion recognition in video. Proceedings of the ACM on International Conference Multimodal Interaction; November 2015; Seattle, WA, USA. pp. 467–474. [Google Scholar]
- 13.Walecki R., Rudovic O., Pavlovic V., Schuller B. Deep structured learning for facial expression intensity estimation. Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); July 2017; Honolulu, HI, USA. pp. 143–154. [Google Scholar]
- 14.Tang Y., Zhang X. M., Wang H. Geometric-convolutional feature fusion based on learning propagation for facial expression recognition. IEEE Access. 2018;6:42532–42540. doi: 10.1109/access.2018.2858278. [DOI] [Google Scholar]
- 15.Liang L., Lang C., Li Y., Feng S., Zhao J. Fine-grained facial expression recognition in the wild. IEEE Transactions on Information Forensics and Security. 2021;16:482–494. doi: 10.1109/tifs.2020.3007327. [DOI] [Google Scholar]
- 16.Zhang F., Zhang T., Mao Q., Xu C. Geometry guided pose-invariant facial expression recognition. IEEE Transactions on Image Processing. 2020;29:4445–4460. doi: 10.1109/tip.2020.2972114. [DOI] [PubMed] [Google Scholar]
- 17.Mandal M., Verma M., Mathur S., Vipparthi S. K., Murala S., Kranthi Kumar D. Regional adaptive affinitive patterns (RADAP) with logical operators for facial expression recognition. IET Image Processing. 2019;13(5):850–861. doi: 10.1049/iet-ipr.2018.5683. [DOI] [Google Scholar]
- 18.Tsai H.-H., Chang Y.-C. Facial expression recognition using a combination of multiple facial features and support vector machine. Soft Computing. 2018;22(13):4389–4405. doi: 10.1007/s00500-017-2634-3. [DOI] [Google Scholar]
- 19.Chen J., Chen Z., Chi Z., Fu H. Facial expression recognition in video with multiple feature fusion. IEEE Transactions on Affective Computing. 2018;9(1):38–50. doi: 10.1109/taffc.2016.2593719. [DOI] [Google Scholar]
- 20.Ryu B., Rivera A. R., Kim J., Chae O. Local directional ternary pattern for facial expression recognition. IEEE Transactions on Image Processing. 2017;26(12):6006–6018. doi: 10.1109/tip.2017.2726010. [DOI] [PubMed] [Google Scholar]
- 21.Liu Y., Li Y., Ma X., Song R. Facial expression recognition with fusion features extracted from salient facial areas. Sensors. 2017;17(4):p. 712. doi: 10.3390/s17040712. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Ghimire D., Jeong S., Lee J., Park S. H. Facial expression recognition based on local region specific features and support vector machines. Multimedia Tools and Applications. 2017;76(6):7803–7821. doi: 10.1007/s11042-016-3418-y. [DOI] [Google Scholar]
- 23.Nigam S., Singh R., Misra A. K. Efficient facial expression recognition using histogram of oriented gradients in wavelet domain. Multimedia Tools and Applications. 2018;77(21):28725–28747. doi: 10.1007/s11042-018-6040-3. [DOI] [Google Scholar]
- 24.Kamarol S. K. A., Parkkinen J., Jaward M. H., Parthiban R. Spatiotemporal feature extraction for facial expression recognition. IET Image Processing. 2016;10(7):534–541. doi: 10.1049/iet-ipr.2015.0519. [DOI] [Google Scholar]
- 25.Turan C., Lam K.-M. Histogram-based local descriptors for facial expression recognition (FER): a comprehensive study. Journal of Visual Communication and Image Representation. 2018;55:331–341. doi: 10.1016/j.jvcir.2018.05.024. [DOI] [Google Scholar]
- 26.Bougourzi F., Mokrani K., Ruichek Y., Dornaika F., Ouafi A., Taleb-Ahmed A. Fusion of transformed shallow features for facial expression recognition. IET Image Processing. 2019;13(9):1479–1489. doi: 10.1049/iet-ipr.2018.6235. [DOI] [Google Scholar]
- 27.Meena H. K., Sharma K. K., Joshi S. D. Effective curvelet-based facial expression recognition using graph signal processing. Signal, Image and Video Processing. 2020;14(2):241–247. doi: 10.1007/s11760-019-01547-9. [DOI] [Google Scholar]
- 28.Ashir A. M., Eleyan A., Akdemir B. Facial expression recognition with dynamic cascaded classifier. Neural Computing and Applications. 2020;32(10):6295–6309. doi: 10.1007/s00521-019-04138-4. [DOI] [Google Scholar]
- 29.Dong J., Zheng H., Lian L. Dynamic facial expression recognition based on convolutional neural networks with dense connections. Proceedings of the International Conference on Pattern Recognition; 2018; Stockholm, Sweden. pp. 3433–3438. [Google Scholar]
- 30.Xie W., Jia X., Shen L., Yang M. Sparse deep feature learning for facial expression recognition. Pattern Recognition. 2019;96 doi: 10.1016/j.patcog.2019.106966.106966 [DOI] [Google Scholar]
- 31.Yu M., Zheng H., Peng Z., Dong J., Du H. Facial expression recognition based on a multi-task global-local network. Pattern Recognition Letters. 2020;131:166–171. doi: 10.1016/j.patrec.2020.01.016. [DOI] [Google Scholar]
- 32.Wen G., Chang T., Li H., Jiang L. Dynamic objectives learning for facial expression recognition. IEEE Transactions on Multimedia. 2020;22(11):2914–2925. doi: 10.1109/tmm.2020.2966858. [DOI] [Google Scholar]
- 33.Wang K., Peng X., Yang J., Lu S., Qiao Y. Suppressing uncertainties for large-scale facial expression recognition. 2020. https://arxiv.org/abs/2002.10392.
- 34.King D. E. Dlib-ml: a machine learning toolkit. Journal of Machine Learning Research. 2009;10:1755–1758. [Google Scholar]
- 35.Kazemi V., Sullivan J. One millisecond face alignment with an ensemble of regression trees. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; June 2014; Columbus, OH, USA. pp. 1867–1874. [Google Scholar]
- 36.Ojala T., Pietikäinen M., Harwood D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognition. 1996;29(1):51–59. doi: 10.1016/0031-3203(95)00067-4. [DOI] [Google Scholar]
- 37.Ojala T., Pietikainen M., Maenpaa T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2002;24(7):971–987. doi: 10.1109/tpami.2002.1017623. [DOI] [Google Scholar]
- 38.Topi M., Timo O., Matti P., Maricor S. Robust texture classification by subsets of local binary pattern. Pattern Recognition. 2000;3(7):935–338. [Google Scholar]
- 39.Shan C., Gong S., McOwan P. W. Facial expression recognition based on local binary patterns: a comprehensive study. Image and Vision Computing. 2009;27(6):803–816. doi: 10.1016/j.imavis.2008.08.005. [DOI] [Google Scholar]
- 40.Rublee E., Rabaud V., Konolige K. ORB: an efficient alternative to SIFT or SURF. Proceedings of the International Conference of Computer Vision; November 2011; Barcelona, Spain. pp. 2564–2571. [Google Scholar]
- 41.Lyons M., Akemastu S., Kamachi M. Coding facial expressions with gabor wavelets. Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition; April 1998; Nara, Japan. pp. 200–205. [Google Scholar]
- 42.Kanade T., Cohn J. F., Tian Y. Comprehensive database for facial expression analysis. Proceedings of the Fourth IEEE International Conference on Automatic Face and Gesture Recognition; March 2000; Grenoble, France. pp. 46–53. [Google Scholar]
- 43.Lucey P., Cohn F., Kanade T. The Extended Cohn-Kanade Dataset (CK+): a complete expression dataset for action unit and emotion-specified expression. Proceedings of the Third International Workshop on CVPR for Human Communicative Behavior Analysis (CVPR4HB 2010); 2010; San Francisco, CA, USA. pp. 94–101. [Google Scholar]
- 44.Pantic M., Valstar M., Rademaker R. Web-based database for facial expression analysis. Proceedings of the IEEE International Conference on Multimedia & Expo (ICME); 2005; Amsterdam, Netherlands. [Google Scholar]
- 45.Valstar M., Pantic M. Induced disgust, happiness and surprise: an addition to the mmi facial expression database. Proceedings of the Third International Workshop on EMOTION (Satellite of LREC): Corpora for Research on Emotion and Affect; May 2010; Valletta, Malta. [Google Scholar]
- 46.Chang C.-C., Lin C.-J. LIBSVM: a library for support vector machines. ACM Transactions on Intelligent Systems and Technology. 2011;2(27):1–27. doi: 10.1145/1961189.1961199. [DOI] [Google Scholar]
- 47.Tong Y., Chen R. Local dominant directional symmetrical coding patterns for facial expression recognition. Computational Intelligence and Neuroscience. 2019;2019:13. doi: 10.1155/2019/3587036.3587036 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48.Makhmudkhujaev F., Abdullah-Al-Wadud M., Iqbal M. T. B., Ryu B., Chae O. Facial expression recognition with local prominent directional pattern. Signal Processing: Image Communication. 2019;74:1–12. doi: 10.1016/j.image.2019.01.002. [DOI] [Google Scholar]
- 49.Ji Y., Hu Y., Yang Y., Shen F., Shen H. T. Cross-domain facial expression recognition via an intra-category common feature and inter-category distinction feature fusion network. Neurocomputing. 2019;333:231–239. doi: 10.1016/j.neucom.2018.12.037. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The data used to support the findings of this study are available from the corresponding author upon reasonable request.