

Abstract
In this article, we develop a generator to suggest a generalization of the Gumbel type-II model known as generalized log-exponential transformation of Gumbel Type-II (GLET-GTII), which extends a more flexible model for modeling life data. Owing to basic transformation containing an extra parameter, every existing lifetime model can be made more flexible with suggested development. Some specific statistical attributes of the GLET-GTII are investigated, such as quantiles, uncertainty measures, survival function, moments, reliability, and hazard function etc. We describe two methods of parametric estimations of GLET-GTII discussed by using maximum likelihood estimators and Bayesian paradigm. The Monte Carlo simulation analysis shows that estimators are consistent. Two real life implementations are performed to scrutinize the suitability of our current strategy. These real life data is related to Infectious diseases (COVID-19). These applications identify that by using the current approach, our proposed model outperforms than other well known existing models available in the literature.
Keywords: Generalized log-exponential distribution, Gumbel type-II model, Stochastic order, Entropies, Bayesian analysis
Introduction
Lifetime phenomenon modeling and interpretation is an important component of statistical research in a broad variety of scientific and technical fields. The study of lifetime data analysis has developed rapidly and expanded in terms of methodology, theory, and application fields. Continuous distributions of probabilities and other methods of generalization or transformation have been introduced in the framework of characterising real life events. Such generalizations derived either by incorporating one or more than one shape parameters, or by adjusting distribution’s functional form, improve model flexibility and model the phenomena more precisely. Extensive software innovations made less emphasis on computational details and thus simplified estimation methods.
The below are popular and frequently referenced transformations presented during recent past in statistical studies for characterizing real life models. Marshal and Olkin [1] transform survival function by putting an additional parameter. Gupta et al. [2] introduced the exponentiated family of models by adding the extra shape parameter like an exponent to basic cdf. Beta-generated family by Eugene et al. [3] focused on Beta type-I and II models. On the other side, Kumaraswamy-generated family by Cordeiro and Castro [4] prefers the Kumaraswamy model instead of the Beta model. Zografos and Balakrishnan [5] introduced a versatile gamma-G class of models focused on GG (Generalized Gamma) model.
Here, our goal is to suggest a novel class of model that accommodates different kinds of hazard rates for suitable selection of shape parameter. The transformation of generalized logarithmic exponential is suggested on Gumbel type-II cdf, hereafter referred as Generalized log-exponential (GLE) transformation. The model, thus produced, is supposed to have both monotone and upside bathtub shaped hazard rates and based on the selection of parametric values. Let Y is a random variable (r.v.) with cdf and pdf ( respectively) taken as baseline model.
| (1) |
with
| (2) |
Motivated from [6], who taken into account less flexible transformation. Whereas their approach allows only fixed modulation of shape of distributions, our approach is more versatile because it incorporates additional shape parameter. To explain our perspective, we consider Gumbel type-II [7], [8], [9], [10], [11] as base model due to its simplicity and usability in life testing problem. Our proposed model known as generalized log-exponential transformation of Gumbel Type-II (GLET-GTII), which extends a more flexible model for modeling life data.
Infectious diseases are disorders induced by organisms, like viruses, parasites, bacteria, fungi etc. A lot of species are living in and on our bodies. Normally, they are harmless, or some times they are helpful. In certain conditions, however, some organisms may cause illness. However, under certain scenarios, some organisms may develop disease. Some infectious diseases can be transferred from one person to another. Some are disseminated by bugs or other animals. And one may have others by eating tainted water or food or being exposed to toxic organisms. Intimations and symptoms change widely depending on microbes resulting infection, but commonly involve fatigue and fever. Slight infections can lead to relax and home medication, while some life-threatening infections may require hospitalization. Certain infectious diseases, like measles, pneumonia and chickenpox, can be restrained using vaccinations. Regular and detailed hand-washing also succours protect you from certain infectious diseases. Only minor complications are present in most infectious diseases. But some infections, such as pneumonia, AIDS and meningitis can become life-threatening. Recently a new novel infectious disease which appeared in late 2019 named as the Covid-19 has widen to majority of southeast and East Asian countries, and resulted in a substantial number of deaths [12]. In December, first case of pneumonia,respiratory disease, with symptoms close to severe acute respiratory SARS 34-CoV, was confirmed in Wuhan City, China [13]. Fever, cough, shortness of breath and occasional watery diarrhea are often symptoms of COVID-19 [14]. 17,238 cases of COVID-19 infection and 361 deaths in China were declared in February 2020 [15]. Here we used daily deaths data because of COVID-19 for China (January to March ) and Europe ( March). For these two data sets, we used over new proposed four parametric model known as GLET-GTII. Some specific statistical attributes of the GLET-GTII are investigated, like moments and associated measures, reliability function, cumulative hazard rate function, linear representation of model, measure of skewness, Quantile function, measure of kurtosis, moments generating function, non-central moments, central moments, mean, variance, factorial generating function, characteristic function, mean deviation and conditional moments are obtained and studied. Furthermore, measures of uncertainty containing entropy measures namely Reny, Mathai-Houbold Entropy, Tsallis, Verma, Kapur Entropy and -Entropy are obtained. In addition, model parameters are calculated by employing maximum likelihood and the Bayesian framework. To study efficiency of GLET-GTII model a simulation study was carried out. Finally, using the deaths number data set because of COVID-19 for China and Europe to unveil adaptability of proposed distribution. The outcomes revealed that it might better fit than various known distributions. For both data sets, density, Log-likelihood and trace graphs are plotted.
Proposed distribution and its properties
For illustration, the pdf of GTII model with parameters is
| (3) |
with cdf as
| (4) |
Using transformation (GLE), suggested in Eq. (1), resulting distribution have pdf and cdf of the following form
| (5) |
| (6) |
It is obvious that differentiable and grows from 0 to .
Reliability Function
The reliability function , of the GLET-GTII is defined by
| (7) |
Hazard rate function (hrf)
The hrf is a particularly valuable tool for lifetime study and is given as
| (8) |
The odd ratio is defined as
| (9) |
Cumulative hrf
The cumulative hrf is defined as
Therefore,
| (10) |
Where andis defined in Eqs. (. Utilizing MATLAB, Mathematica, Maple, R and Minitab computing packages, Eqs. (1), (2), (3), (4), (5), (6), (7), (8), (9), (10) are being evaluated readily. The sketches of Eq. , Eq. and Eq. are shown in Figs. 1 2 and 3 for different options of the parameters. Fig. 1 shows influence of on density of GLET-GTII and demonstrates flexibility of the pdf in Eq. forms where low symmetry, modality, high tails and skewness can be evaluated directly. Such figures show the flexibility of the GLET-GTII model. Fig. 2, Fig. 3 are plotted for the and CDF of the GLET-GTII. On the other hand, decreasing and upside bathtub pattern of hrfs are noted in Fig. 4 . It is also observed that for given value of and indicates the uni-modal behavior.
Fig. 1.

Plots of of GLET-GTII at different parameteric values.
Fig. 2.

Graphs of of GLET-GTII at different values of parameters.
Fig. 3.

Plots of CDF of GLET-GTII at different values of parameters.
Fig. 4.

Graphs of hrf of GLET-GTII for different values of parameter.
Expansion for pdf
Using geometric infinite sum of series for . The pdf responds to the following expansion
| (11) |
| (12) |
and now using exponential series in Eq. (12) we have
| (13) |
Random number generator
Let r.v. . Then Y is obtained as
| (14) |
| (15) |
Particularly, by placing in Eq. (15), and quartile and median are attained.
Significant measurements of kurtosis and skewness are and , respectively, in which fundamental moment represents by and standard deviation represents by . As moments of GLET-GTII model can not occur for some values of parameter, suitable indicators for quantile-based and are more appropriate. These indicators are more robust and do exists for distributions in the absence of moments. (Bowley’s Skewness) and (Moors’ Kurtosis) measures are specified as
| (16) |
| (17) |
When and , then model is left and right skewed respectively and is symmetrical for . Instead, a large indicates a heavy tail for the distribution and a mild tail for a low .
Fig. 5 is plotted to analyze the influence of and in light of GLET-GTII model and as per parametric values. In Fig. 6 , the behavior of median in relation of GLET-GTII model is sketched.
Fig. 5.

Plots of skewness and kurtosis of GLET-GTII model.
Fig. 6.

graphs for Median of GLET-GTII model.
Table 1 displays the numerical values of , Variance, ., and for GLET-GTII distribution. From Table 1, the considerable effects of and are noted on abovementioned measures.
Table 1.
Numerical values of descriptive measures.
| Var | C.V. | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 0.5 | 0.2 | 0.1 | 0.55998 | 0.36764 | 0.33854 | 31888.2 | 0.05407 | 41.5235 | 0.21837 | 1.40271 |
| 4 | 0.5 | 0.3 | 0.5 | 0.82490 | 0.79528 | 1.07101 | 146747 | 0.11481 | 41.0760 | 0.21985 | 1.40681 |
| 4 | 0.5 | 0.5 | 1.0 | 0.95479 | 1.05892 | 1.62699 | 251366 | 0.14730 | 40.1976 | 0.22174 | 1.41427 |
| 4 | 0.5 | 0.7 | 2.0 | 1.10831 | 1.41826 | 2.49258 | 434625 | 0.18991 | 39.3201 | 0.22231 | 1.42059 |
| 5 | 0.5 | 0.2 | 0.1 | 0.62253 | 0.42404 | 0.334708 | 0.36499 | 0.03649 | 30.6842 | 0.20018 | 1.37502 |
| 5 | 1.0 | 0.3 | 0.5 | 0.97511 | 1.03837 | 1.27836 | 2.16801 | 0.08753 | 30.3398 | 0.20201 | 1.37923 |
| 5 | 1.5 | 0.5 | 1.0 | 1.18923 | 1.53875 | 2.29114 | 4.67117 | 0.12449 | 29.6684 | 0.20456 | 1.38702 |
| 5 | 2.0 | 0.7 | 2.0 | 1.41984 | 2.18552 | 3.85298 | 9.24075 | 0.169578 | 29.0031 | 0.20575 | 1.39382 |
| 6 | 3.5 | 0.2 | 1.0 | 1.36045 | 1.96148 | 3.07591 | 5.54933 | 0.11066 | 24.4514 | 0.18799 | 1.35782 |
| 6 | 3.5 | 0.3 | 1.5 | 1.44154 | 2.19945 | 3.64442 | 6.93488 | 0.12140 | 24.17 | 0.19226 | 1.36207 |
| 6 | 3.5 | 0.5 | 2.0 | 1.48619 | 2.33203 | 3.96212 | 7.70249 | 0.12326 | 23.6234 | 0.19305 | 1.37001 |
| 6 | 3.5 | 0.7 | 2.5 | 1.51871 | 2.42939 | 4.19528 | 8.25804 | 0.12291 | 23.0847 | 0.19465 | 1.37707 |
Order statistics
Order statistics (OS) exist in several fields of theory and functional statistics. Suppose is OS of a random sample of n size from . Then, for , probability density function of OS, is given by
| (18) |
where , where and are cdf and pdf of GLET-GTII, accordingly.Utilizing the specification of binomial expansion for term:. Thus from Eq. (5), Eq. (6) and Eq. (18), probability density function of as
The cdf of is
| (19) |
In particular, cummulative density functions of and respectively, are given by
| (20) |
Let is quantile function of (for . Then, from Eq.
where quantile function of Y is . For i.i.d. random values case, it is feasible to obtain ordinary moment expression of the order statistics for . So, as Silva et al. [16], the moment of order statistic as
 |
(21) |
where 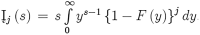 . In particular, for the GLET-GTII distribution, we obtain
. In particular, for the GLET-GTII distribution, we obtain
| (22) |
Stochastic ordering (SO)
The notion of SO for continuous positive random variables is a common and effective concept for calculating relative behavior. We must recall some basic meanings. Suppose that r.v. Y is greater than X
(i) Stochastic order (S-O) . if y; (ii) hazard rate order (Hr-O) if y; (iii) likelihood ratio order (LHr-O) , if reduces in y. The below mentioned results are known (see [17]):
| (23) |
The GLET-GTII distributions are ordered with respect to the strongest “likelihood ratio” ordering as mentioned in the following theorem.
Theorem 1
Let GLET-GTII , and GLET-GTII . If , then .
Proof
Consider likelihood ratio (LHr) as
(24) now differentiate Eq. (24) w.r.t y, we attain the expression given below
(25)
Hence it demonstrates that , and according to Eq. (23), , and are also hold.
Moments, central moments and certain related measures
For any statistical consideration, moments are profoundly significant, usually in applications. The special parameters that can be used to describe a homogeneous data set’s behaviour are called moments. Consequently, for GLET-GTII model, the which is non-central moment is obtain as follows. If Y has probability density function in Eq. (5), we get
| (26) |
The belowmentioned outcome gives ( non-central moment) of Y in G-F (gamma function) form.
Theorem 2
For , the of Y is translated as
(27) where, usual G-F is .
Proof
Consider
By using the expansion form of pdf that given in Eq. (13) yields
(28) Allowing using the result and after some algebraic manipulation we have
(29) Since, , therefore the above integral provides the sth moment given by Eq. (27).
In particular, the first four moments of Y are:
(30)
(31)
(32) and
(33)
Proposition 1
Let Y be a random variable following the GLET-GTII distribution, then the central moments is
(34) where, is usual gamma function.
(35)
Substituting by the Eq. (27) into Eq. (35) after certain simple calculations, we get
| (36) |
Remark 1
The variance of GLET-GTII model is obtained from Equation (36) for .
Moment generating function (mgf)
The mgf of GLET-GTII distribution may be indicated as
| (37) |
Characteristic function (cf)
For GLET-GTII model, cf is evaluated as
| (38) |
After using exponential series, we have
| (39) |
Hence, we obtain
| (40) |
Factorial generating function (fgf)
For GLET-GTII model, fgf is extracted as follows
| (41) |
so,
| (42) |
Incomplete non-central moments (INCM)
The INCM of model serve as a key role in determining inequality, namely Lorenz and Bonferroni’s income quantiles and curves, which concentrate on incomplete moments.
Proposition 2
The incomplete moment is
(43) where, is upper incomplete G-F.
Proof
By definition
(44) Substituting by the Eq. (13) into Eq. (44) after some simple calculations, we have
Allowing using the result and after some algebraic manipulation we have
(45) The above integral provides the sth moment given by Eq. (45).
Lemma 1
we have
(46) where is lower incomplete gamma function.
Conditional moments and mean deviations
In predictive inference, the estimation of conditional moments is useful in interaction with lifetime models. The is obtained as
| (47) |
where , and are defined in Eqs. (7), (27), (43). The mean deviations about mean and (median) are stated as
| (48) |
and
| (49) |
respectively. The quantity and are calculated as follows,
| (50) |
| (51) |
using Lemma 1, we have
| (52) |
| (53) |
where is specified in .
Uncertainty measures
In this section, entropies such as Verma, Renyi entropy, Tsallis etc for GLET-GTII model are being investigated.
Entropy measures
Entropy is a significant idea in several relevant fields communications, measure-preserving dynamical systems, information theory, topological dynamics, thermodynamics, statistical mechanics etc, as a calculation of different characteristics such as uncertainty, disorder, randomness, energy that cannot produce work, complexity, etc. There are many definitions of entropy and they are not inherently ideal for all applications.
Renyi entropy
For GLET-GTII model, the is
| (54) |
where
| (55) |
By using the above information, we have
| (56) |
Now substituting, , the above integral becomes
| (57) |
After simplification, we have
| (58) |
Finally, becomes
| (59) |
It should be remembered that Shannon entropy of a . Y is attained as a special case of when .
Verma Entropy
For GLET-GTII model, the is
| (60) |
where
| (61) |
It is significant to remember that, when , in (60), it reduces to . On the other hand, if and , in (60), then it approaches to the Shannon entropy. By using abovementioned information, we get
| (62) |
Now substituting, ,the above integral becomes
| (63) |
After simplification, we have
| (64) |
Finally, becomes
| (65) |
Tsallis entropy
For GLET-GTII model, Tsallis entropy is defined as
| (66) |
As, and are given in (57)-(60) respectively. Hence, using these information, the final form of is
| (67) |
Mathai-Houbold entropy
For GLET-GTII model, (see Mathai and Haubold [18]) is defined as
| (68) |
Similar arguments to gives
| (69) |
Therefore, the final form of becomes
| (70) |
Kapur entropy
Kapur entropy of Y with GLET-GTII model is defined as
| (71) |
| (72) |
Similar arguments to using in Eq. , we get
| (73) |
-entropy
-entropy of Y with GLET-GTII model is defined as
| (74) |
As, and are calculated in Eqs. (55), (56), (57), (58) respectively. Therefore, by using these information, takes the following form
| (75) |
Estimation
We proceed by presenting estimates of the parameters of suggested model via different techniques. The maximum likelihood (MLH) estimation and Bayesian methodology for estimation objective. Working the Matlab (log_lik), the Ox program (subroutine MaxBFGS), R (optimum and MaxLik features), or SAS (PROC NLMIXED), the GLET-GTII model parameters is assessed from log-likelihood depending on sample. Additionally, some statistics are applied to compare density estimates and selection of models.
Maximum likelihood (ML) estimation
The ML estimates are presented via optimization of equation corresponding to and . They are also described as the maximum of log-likelihood function (LLHF) and defined by .
| (76) |
The LLHF for GLET-GTII distribution is given by data set .
| (77) |
By differentiating Eq. (77), we get MLEs of the corresponding parameters and . The components of score vector is as follows
| (78) |
| (79) |
| (80) |
| (81) |
Setting and after solving theses equations, it gives the MLEs for GLET-GTII model parameters. An iterative method such as the Newton–Raphson approach is needed to solve them numerically. Now, utilizing simulation, we investigate performance of MLEs with respect to sample size n. The following steps are followed to conduct simulation study: stimulate it 5000,samples of size and 350 from GLET-GTII; give the MLEs for 5000 samples, say and for ; quantify estimate biases and squared errors (MSEs); where average absolute and . Table 2 shows the Bias and MSEs for various estimates. We directly noticed that Bias and MSEs reduce by enhancement of sample size n. (see Table 3 ).
Table 2.
Bias and MSEs for GLET-GTII parameters.
| n | Estimates | MSE | MSE | ||
|---|---|---|---|---|---|
| 25 | 0.05349 | 0.04131 | 0.05195 | 0.03889 | |
| 0.02363 | 0.05389 | 0.48473 | 0.47003 | ||
| 0.06983 | 0.27452 | 0.05833 | 0.19709 | ||
| 0.17637 | 0.08444 | 0.16527 | 0.24835 | ||
| 100 | 0.00893 | 0.00665 | 0.05155 | 0.01360 | |
| 0.08816 | 0.01505 | 0.44401 | 0.24933 | ||
| 0.01703 | 0.06209 | 0.01002 | 0.04344 | ||
| 0.11184 | 0.01978 | 0.15599 | 0.07652 | ||
| 150 | 0.00581 | 0.00442 | 0.04392 | 0.00909 | |
| 0.07367 | 0.01356 | 0.42902 | 0.21545 | ||
| 0.01222 | 0.04402 | 0.00560 | 0.02818 | ||
| 0.10633 | 0.01609 | 0.14010 | 0.06064 | ||
| 250 | 0.00368 | 0.00265 | 0.03419 | 0.00456 | |
| 0.06702 | 0.01225 | 0.41674 | 0.19044 | ||
| 0.00351 | 0.02534 | 0.00287 | 0.01758 | ||
| 0.10298 | 0.01344 | 0.13326 | 0.05035 | ||
| 350 | 0.00174 | 0.00187 | 0.02768 | 0.00261 | |
| 0.04001 | 0.01197 | 0.40509 | 0.17547 | ||
| 0.00282 | 0.01843 | 0.00175 | 0.01260 | ||
| 0.09998 | 0.01197 | 0.12491 | 0.04937 |
Table 3.
Descriptive measures for Data Sets.
| Descriptive statistics | Data I | Data II |
|---|---|---|
| Q1 | 13.00 | 120.8 |
| Q3 | 82.75 | 1414.0 |
| Median | 33 | 385.0 |
| Mean | 49.74 | 841.4 |
| Trimmed | 44.8 | 703.96 |
| Minimum | 3 | 6 |
| Maximum | 150 | 2824 |
| SD | 43.87 | 938.69 |
| Range | 147 | 2818 |
| Skewness | 0.82 | 0.92 |
| Kurtosis | −0.62 | −0.63 |
Bayesian mechanism
Here, we proceed by providing estimation of proposed structure parameters via Bayesian mechanism. Let and are random variables. Therefore, the following independent priors are supposed as gamma gamma gamma and gamma , where . The joint posterior density of and is as follows
The BE (Bayes estimator) of is given under SELF [21], [22], [23], [24], [25], [26] as
in a similar fashion and . Additionally, Bayes risk is evaluated by , where
One might notice that estimates are not analytically predictable, so we also use the Adaptive Metropolis Hasting algorithm MCMC (Monte Carlo Markov Chain) to attain estimates. Fig. 12, Fig. 13 are sketched for trace plots and estimated posterior densities for Monte Carlo Markov Chain estimates of model parameters using real data sets. These figures showed the good convergence of estimates. On the other side, Table 7 provided the posterior summaries for both data sets. We provide Bayes estimates, LCL (lower credible limit), posterior variance, UCL (upper credible limit) of credible intervals. The behaviour of the estimated densities of all the parameters are slightly positively skewed.
Fig. 12.

Density plots and Trace plots of parameters and for data set I.
Fig. 13.

Density plots and Trace plots of parameters and for data set II.
Table 7.
Posterior summaries of the GLET-GTII model for data set I and II.
| Data | n | Parameter | 2.5% | 97.5 | Posterior Mean | Posterior Variance |
|---|---|---|---|---|---|---|
| 0.228357 | 0.481515 | 0.343964 | 0.004009 | |||
| I | 30 | 0.129464 | 0.357515 | 0.220179 | 0.002465 | |
| 1.858141 | 4.526620 | 3.052603 | 0.380427 | |||
| 0.013755 | 0.044269 | 0.025770 | 0.000051 | |||
| 0.184741 | 0.431814 | 0.295535 | 0.004113 | |||
| II | 66 | 0.382319 | 0.876892 | 0.602914 | 0.016561 | |
| 0.391735 | 0.885013 | 0615787 | 0.015930 | |||
| 0.064211 | 0.141740 | 0.098712 | 0.000397 |
Implementations of real data
Two examples are presented here to describe the efficiency of suggested distribution. The R software is used to show the improved efficiency of GLET-GTII distribution and numerical calculations. Consider the following models (i) GIWD (generalized inverse Weibull distribution) [19] (ii) Frechet model (Frechet), (iii) Additive Gumbel Type-II (AGT-II) (iv) GT-II (Gumbel Type-II) and (v) EB-XII (Exponentiated Burr XII) model for comparative purposes. Different methodologies of segregation based on LLHF (log-likelihood function) assessed at MLEs were also taken into account: Akaike Information Criterion (AIC) computed through , and Bayesian Information Criterion , Corrected Akaike information Criterion , Hannan Quinn Information Criterion , where represents the number of parameters to be fitted and the estimates of and . The best model is the one which provides the minimum values of those benchmarks. The outputs revealed that GLET-GTII distribution is a bestest model than the abovementioned models in each case. To check whether the data fits GLET-GTII model, we use Kolmogorov–Smirnov (K-S) distances among empirical distribution function and fitted distribution function. In Table 5, Table 6 , the K-S test value and the corresponding critical value are given. The small K-S distance and the large critical-value for the test indicate that this data matches perfectly almost well with GLET-GTII model. Now standardized of measures are utilized to validate which model fits these data best. Cramér-Von Mises and Anderson-Darling test statistics are taken into acount (for more detail see Chen and Balakrishnan [20]). Generally, the smallest values of Cramér-Von Mises and Anderson-Darling , indicates the better fit of data. The values of the statistics and are listed inTable 5, Table 6. The summary statistics are graphed via box plots for data sets ”I and II” and shown in Fig. 7 . A very useful tool for interpreting our data is the box plot. In a single clear and concise diagram, the box plot contains all the knowledge about data. A boxplot is a systematic way to view data distribution based on a summary of five numbers (“minimum”, first quartile (Q1), median, third quartile (Q3), and “maximum”). A box plot is a visualization that provides a real indication of how the values are distributed out in the data. In Fig. 9, Fig. 10 , the estimated densities of GLET-GTII and competitor models were graphed for more visual comparison. The mentioned below data sets are given in Sindhu et al. [27]. (see Fig. 11, Fig. 8 ).
Table 5.
Values of the considered measures for Data Set I.
| Distribution | GLET-GTII | GIWD | Frechet | AGT-II | GT-II | EB-XII |
|---|---|---|---|---|---|---|
| 0.10657 | 0.28434 | 0.28433 | 0.28444 | 0.28434 | 0.23364 | |
| 0.79738 | 1.75835 | 1.75829 | 1.75861 | 1.75835 | 1.48713 | |
| 0.08904 | 0.12843 | 0.12845 | 0.12888 | 0.12843 | 0.11457 | |
| p-value | 0.67210 | 0.22640 | 0.22620 | 0.22290 | 0.22640 | 0.35170 |
| AIC | 656.367 | 668.203 | 666.203 | 670.162 | 666.203 | 664.695 |
| CAIC | 657.023 | 668.590 | 666.394 | 670.818 | 666.397 | 665.082 |
| BIC | 665.126 | 674.772 | 670.583 | 678.921 | 670.583 | 671.264 |
| HQIC | 659.828 | 670.799 | 667.934 | 673.623 | 667.934 | 667.291 |
Table 6.
Values of the considered measures for Data Set II.
| Distribution | GLET-GTII | GIWD | Frechet | AGT-II | GT-II | EB-XII |
|---|---|---|---|---|---|---|
| 0.06748 | 0.15402 | 0.15425 | 0.15404 | 0.15402 | 0.12913 | |
| 0.49019 | 0.98445 | 0.98601 | 0.98453 | 0.98444 | 0.84641 | |
| 0.11845 | 0.15964 | 0.17716 | 0.15960 | 0.15964 | 0.14954 | |
| p-value | 0.75020 | 0.38800 | 0.26980 | 0.38820 | 0.38790 | 0.46870 |
| AIC | 469.175 | 475.394 | 474.074 | 477.394 | 473.394 | 473.437 |
| CAIC | 470.775 | 476.317 | 474.518 | 478.994 | 473.838 | 474.360 |
| BIC | 474.780 | 479.597 | 476.876 | 482.998 | 476.196 | 477.641 |
| HQIC | 470.969 | 476.738 | 474.970 | 479.187 | 474.290 | 474.782 |
Fig. 7.

Box plots for data sets I and II.
Fig. 9.

Estimated densities (left) and cdf (right) for data set II.
Fig. 10.

The profiles of the Log-likelihood plots for the parameters of data set I.
Fig. 11.

The profiles of the Log-likelihood plots for the parameters of data set 2.
Fig. 8.

Estimated densities (left) and cdf (right) for data set I.
Data I: Daily deaths number because of COVID-19 in China {23rd January to 28th March}
This data is taken from given website ( https://www.worldometers.info/coronavirus/country/china/), which indicates the daily number of deaths because of COVID-19 in China. The data is given below:
Data II:Daily deaths number because of COVID-19 in Europe { March}
This data is taken from given website (https://covid19.who.int/), which indicates daily deaths number because of COVID-19 in Europe.
For each distribution, we estimate the unknown parameters using maximum likelihood. The MLEs with their respective standard errors of the above models are listed in Table 4 . These calculations were made using the R programming language.
Table 4.
Parameters estimates and Standard errors for both Data Sets.
| MLE |
Error |
MLE |
Error |
||
|---|---|---|---|---|---|
| Model | Parameter | Data I | Data II | ||
| GLET-GTII | 0.206478 | 0.04659 | 0.14714 | 0.10045 | |
| 3.354146 | 1.96348 | 3.50279 | 2.61427 | ||
| 3.354146 | 1.96347 | 3.50279 | 2.61427 | ||
| 134.0219 | 160.264 | 98.9773 | 362.710 | ||
| GIWD | 9.10197 | 811.843 | 2.70212 | 334.481 | |
| 0.91594 | 0.08369 | 0.57051 | 0.07536 | ||
| 1.78997 | 146.234 | 9.18399 | 648.661 | ||
| Frechet | 17.1868 | 2.45283 | 99.7713 | 29.7155 | |
| 0.91589 | 0.08368 | 0.59186 | 0.07787 | ||
| AGT-II | 7.47910 | 116.202 | 9.79414 | 8033.73 | |
| 13.4320 | 3.46155 | 6.40543 | 8033.75 | ||
| 4.48651 | 6.66264 | 0.57062 | 0.11674 | ||
| 0.91372 | 0.09052 | 0.57071 | 0.21937 | ||
| GT-II | 0.91595 | 0.08369 | 0.57057 | 0.07536 | |
| 13.5324 | 3.10943 | 16.1933 | 5.71448 | ||
| EB-XII | 0.42854 | 0.16904 | 0.29162 | 0.13471 | |
| 59.0695 | 58.8060 | 52.0316 | 54.4001 | ||
| 2.74026 | 1.33481 | 2.39459 | 1.36109 | ||
Conclusion
Here, we have suggested a new general construction of flexible lifetime models by rendering any existing baseline model more versatile via simple transformation. A generalized log-exponential transformation model is introduced and its implementation is demonstrated by taking Gumbel Type-II model. The mathematical properties of proposed model have been analyzed in detail. Additionally, some figures for density and hazard function are included. The general non-central incomplete and complete moments are also included. Uncertainty measures such as entropies (like Renyi, Tsallis, Verma, and Kumar entropy Mathai-Houbold) are calculated. The estimation of parameters is accessed by utilizing two techniques such as maximum likelihood method and Bayesian framework. Through utilizing classical goodness of fit indicators, we evaluate the efficiency of GLET-GTII model with its five significant counterparts. The posterior densities, Log-likelihood and trace plots are drawn for considered data sets. These findings are in line with fact that proposed model is quite suitable for implementations of real life data.
Credit authorship contribution statement
Tabassum Naz Sindhu, Anum Shafiq and Qasem M. Al-Mdallal contributed to the conceptualization, design and implementation of the research, to the analysis of the results and to the writing of the manuscript.
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgement
The authors would like to thank Editor and the referees for their careful reading and useful comments which improved the paper.
References
- 1.Marshall A.W., Olkin I. A new method for adding a parameter to a family of distributions with application to the exponential and Weibull families. Biometrika. 1997;84:641–652. [Google Scholar]
- 2.Gupta R.C., Gupta P.I., Gupta R.D. Modeling failure time data by Lehmann alternatives. Commun Stat Theory Methods. 1998;27:887–904. [Google Scholar]
- 3.Eugene N., Lee C., Famoye F. Beta-normal distribution and its applications. Commun Stat Theory Methods. 2002;31:497–512. [Google Scholar]
- 4.Cordeiro G.M., de Castro M. A new family of generalized distributions. J Stat Comput Sim. 2011;81:883–898. [Google Scholar]
- 5.Zografos K., Balakrishnan N. On families of beta and generalized gamma generated distributions and associated inference. Stat Methodol. 2009;6:344–362. [Google Scholar]
- 6.Aslam M., Ley C., Hussain Z., Shah S.F., Asghar Z. A new generator for proposing flexible lifetime distributions and its properties. PLoS ONE. 2020;15(4) doi: 10.1371/journal.pone.0231908. e0231908. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Gumbel E. Les valeurs extremes des distributions statistiques. Annales de l’Institut Henri Poincare. 1935;5(2):115–158. [Google Scholar]
- 8.Gumbel E.J. The return period of flood flows. Ann Math Stat. 1941;12:163–190. [Google Scholar]
- 9.E.J. Gumbel, Statistical Theory of Extreme Values and Some Practical Applications, vol. 33 of Applied Mathematics, U.S. Department of Commerce, National Bureau of Standards, ASIN B0007DSHG4, Gaithersburg, Md, USA, 1st ed., 1954.
- 10.Sindhu T.N., Riaz M., Aslam M., Ahmed Z. Bayes estimation of Gumbel mixture models with industrial applications. Trans Inst Meas Control. 2016;38(2):201–214. [Google Scholar]
- 11.Sindhu T.N., Feroze N., Aslam M. Study of the left censored data from the gumbel type II distribution under a bayesian approach. J Modern Appl Statist Methods. 2016;15(2):1–10. [Google Scholar]
- 12.European Centre for Disease Prevention and Control. “Situation Update—Worldwide. 2020. Available online:https://www.ecdc.europa.eu/en/geographical-distribution-2019-ncov-cases [accessed on 13 February 2020].
- 13.Wang C, Horby PW, Hayden FG, et al. A novel coronavirus outbreak of global health concern. Lancet (London, England); 2020. [DOI] [PMC free article] [PubMed]
- 14.Huang C., Wang Y., Li X. Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. Lancet. 2020;395:497–506. doi: 10.1016/S0140-6736(20)30183-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.World Health Organization. Novel Coronavirus (2019-nCoV) Situation Report – 14. Available online:https://www.who.int/docs/default-source/coronaviruse/situationreports/20200203-sitrep-14-ncov.pdf?sfvrsn=f7347413_4. February 3rd, 2020.
- 16.Silva G.O., Ortega E.M.M., Cordeiro G.M. The beta modified Weibull distribution. Lifetime Data Anal. 2010;16:409–430. doi: 10.1007/s10985-010-9161-1. [DOI] [PubMed] [Google Scholar]
- 17.Ross S.M. 2nd ed. Wiley; New York: 1996. Stochastic processes. [Google Scholar]
- 18.Mathai A.M., Haubold H.J. On a generalized entropy measure leading to the pathway model with a preliminary application to solar neutrino data. Entropy. 2013;15(10):4011–4025. [Google Scholar]
- 19.De Gusmao F.R., Ortega E.M., Cordeiro G.M. The generalized inverse Weibull distribution. Stat Pap. 2011;52(3):591–619. [Google Scholar]
- 20.Chen Gemai, Balakrishnan N. A general purpose approximate goodness-of-fit test. J Qual Technol. 1995;27(2):154–161. doi: 10.1080/00224065.1995.11979578. [DOI] [Google Scholar]
- 21.Sindhu T.N., Hussain Z. Predictive inference and parameter estimation from the half-normal distribution for the left censored data. Ann. Data. Sci. 2020 doi: 10.1007/s40745-020-00309-6. [DOI] [Google Scholar]
- 22.Sindhu T.N., Hussain Z. Mixture of two generalized inverted exponential distributions with censored sample: properties and estimation. Statistica Applicata – Italian J Appl Stat. 2018;30(3):373–391. doi: 10.26398/IJAS.0030-019. [DOI] [Google Scholar]
- 23.Sindhu T.N., Aslam M., Shafiq A. Bayesian Analysis of two Censored Shifted Gompertz Mixture Distributions using Informative and Noninformative Priors. Pakistan J Stat Oper Res. 2017:227–243. [Google Scholar]
- 24.Sindhu T.N., Aslam M., Hussain Z. A simulation study of parameters for the censored shifted Gompertz mixture distribution: a Bayesian approach. J Stat Manage Syst. 2016;19(3):423–450. [Google Scholar]
- 25.Sindhu T.N., Khan H.M., Hussain Z., Lenzmeier T. Bayesian prediction from the inverse rayleigh distribution based on type-II trim censoring. J Stat Manage Syst. 2017;20(5):995–1008. [Google Scholar]
- 26.Sindhu T.N., Hussain Z., Aslam M. Parameter and reliability estimation of inverted Maxwell mixture model. J Stat Manage Syst. 2019;22(3):459–493. [Google Scholar]
- 27.Sindhu TN, Shafiq A, Al-Mdallal QM. Exponentiated transformation of Gumbel Type-II distribution for modeling COVID-19 data. Alexand Eng J (accepted); 2020.https://doi.org/10.1016/j.aej.2020.09.060.