

Abstract
Human activity recognition (HAR) is essential in many health-related fields. A variety of technologies based on different sensors have been developed for HAR. Among them, fusion from heterogeneous wearable sensors has been developed as it is portable, non-interventional and accurate for HAR. To be applied in real-time use with limited resources, the activity recognition system must be compact and reliable. This requirement can be achieved by feature selection (FS). By eliminating irrelevant and redundant features, the system burden is reduced with good classification performance (CP). This manuscript proposes a two-stage genetic algorithm-based feature selection algorithm with a fixed activation number (GFSFAN), which is implemented on the datasets with a variety of time, frequency and time-frequency domain features extracted from the collected raw time series of nine activities of daily living (ADL). Six classifiers are used to evaluate the effects of selected feature subsets from different FS algorithms on HAR performance. The results indicate that GFSFAN can achieve good CP with a small size. A sensor-to-segment coordinate calibration algorithm and lower-limb joint angle estimation algorithm are introduced. Experiments on the effect of the calibration and the introduction of joint angle on HAR shows that both of them can improve the CP.
Keywords: feature selection, human activity recognition, activity of daily living, sensor fusion, wearable sensors, genetic algorithm, coordinate calibration
1. Introduction
Recently, with the rapid development of sensing, machine learning and micro-manufacturing technologies, the human activity recognition (HAR) and activity recognition system (ARS) have been greatly developed and applied in many fields, such as ergonomics, elder care, rehabilitation, internet of things, military, health monitoring, sports, etc. Basically, activity data from different dimensions are collected and analyzed to recognize and supervise different types of postures and motions. Therefore, recognition of activities of daily living (ADL), such as standing, sitting, squatting and walking, are particularly important for rehabilitations and health monitoring. For example, in fall detection, it is important to recognize and predict falls in real time from a large number of normal ADLs [1,2,3]; in artificial limbs and exoskeletons, it is necessary to identify human movement intentions and amplitudes to guide the movement of robots [4,5,6]; and in the disease monitoring and assessment, non-interventional identification of ADLs is essential because the extraction of motion characteristics of autonomous activities at home or in the community is beneficial for obtaining sufficient information on disease development [7,8,9].
At present, a variety of HAR technologies have been developed according to the different types of sensors and devices, for instance, wearable sensors, videos, and smartphones [10]. Compared with video, wearable devices are portable, low cost, have better privacy and little interference to users, which makes them applicable to non-laboratory environments and an appropriate solution for regular remote monitoring and guidance of rehabilitation. In addition, compared with smartphones, wearable sensors have better accuracy and robustness due to their more stable installation and positioning.
Two major processes are contained in HAR, which are, data processing and activity recognition. To be specific, data processing includes data acquisition, preprocessing, segmentation, feature calculation and selection. While activity recognition includes classification and evaluation. The HAR begins with collecting the motion information and bio-signals via variety of sensors, the most commonly used of which are accelerometer (ACC), gyroscope (GYR), magnetometer (MAG), pressure sensor, cardiotachometer and surface Electromyogram (sEMG). For example, quite a few studies use independent inertial measurement unit (IMU, which consists of ACCs and GYRs, sometimes MAGs), sEMG or IMU embedded in smart devices (e.g., smart bracelets) to identify multiple activities. According to the different sensor locations, these studies have achieved good recognition performances for different movements, such as gestures [11,12,13,14], upper limb movements [15], lower limb movements, comprehensive ADLs [16,17] and complex activities consisting of multiple movements.
In addition to using one kind of sensor or several homogeneous sensors (e.g., using ACCs and GYRs for rotation information), data fusion from heterogeneous sensors are continuously being developed to improve the accuracy of ARS. By collecting and filtering information from different physical dimensions, the impact of errors from homogeneous information is reduced [10]. For instance, Ai Qingsong et al. [18] fused the sEMG and ACC signals to identify the motion patterns of lower limbs and prove that the fused feature-based classification outperforms classification with only homogeneous sensors. Jia and Liu [19] achieved 99.57% accuracy in HAR by fusing ECG and ACC sensors, so that they could not only improve the recognition performance but also monitor more physiological signals of human activity. Meanwhile, Md. Al-Amin et al. [20] used a multimodal sensor system (which consists of 16 sEMG sensors, two 3-axis ACC, two 3-axis GYR, two 3-axis MAG and a Kinect sensor) to recognize worker actions in performing complex manufacturing tasks, and reached better performance than recognition using single type of sensor. For similar activities, walking and ascending/descending stairs, for instance, that are difficult to distinguish by using only one type of sensor, Lara et al. [21] noted that the fusion of vital signs and IMUs can greatly improve the performance of recognition of descending stairs. Furthermore, several studies have proposed technologies to fuse multimode sensors for both HAR and health-related applications, which include disease management, health status monitoring and disease assessment [7,22,23,24].
In terms of features, researchers prefer to extract features from the raw time-serial data rather than using the data itself for recognition. These features can be divided into two kinds [10]: one is the hand-extracted shallow features such as time-domain (TD), frequency domain (FD) and time-frequency domain (TFD) features; the other is the deep features automatically obtained by using artificial intelligence tools such as principal component analysis, independent component analysis and deep learning. Compared with the latter, although the former requires a large amount of labelled data to select features through a priori heuristic learning, it has smaller computation complexity for feature calculation and classification. To be specific, deep learning-based feature extraction can automatically learn feature representation from big data and achieve good accuracy, yet including millions of parameters or even more [25,26], which creates additional storage and computing requirements. Therefore, on the basis of ensuring the recognition performance, the shallow features may be more suitable for real-time applications with low power consumption, especially for real-time applications that need to extract corresponding features in the subsequent works, such as automatic disease assessment or health monitoring based on identification of specific activities. At present, most approaches extract the shallow features in IMU or sEMG for HAR based on the recommendation of the literature. Meanwhile, some studies discussed the influence of sensor and feature selection in activity recognition, and presented feature subset selection methods [27,28,29]. However, most of them focus on homogeneous sensors, and the selection results of feature subsets tend to end at a large scale. Besides, in addition to extracting features directly from the raw data, IMUs can also be used to calculate the rotation of the limbs [30,31]. Similar to the video-based method, this can be used to calculate the kinematic information, joint angles, for example, as a supplement for HAR without increasing the number of sensors and complexity of ARS. Particularly, it is worth mentioning that the method used to acquire the kinematic information of limbs by fusing the IMU data can also be used to correct the coordinate system deviation caused by the unrepeatable and inaccurate installation of sensors and devices, which are commonly exist. However, most HAR studies rarely describe the alignment approach of IMUs or do not align them.
The present study proposes a genetic algorithm-based feature selection algorithm with fixed activation number (GFSFAN) to select appropriate feature subsets for HAR with small scales and good classification performance. Besides, a sensor-to-body segment coordinate calibration algorithm for IMU is proposed to eliminate errors caused by the coordinate misalignment, and a lower limb joint angle estimation algorithm is introduced as well to expand the source of human motion information used in HAR. The experimental results indicate that (i) the proposed feature selection algorithm can achieve good classification performance with small feature subsets of manually set size, and (ii) the calibration algorithm and fusion of multiple heterogeneous sensors are both beneficial for improving HAR performance.
2. Algorithm Description
2.1. Calculation of the Joint Angle
Joint angles are calculated by fusing the acceleration and angular velocity data from the adjacent body segments, which are lower back (LB), left thigh (LT) and left shank (LS) in this work. Magnetometers are abandoned because of the uncertain magnetic field changes caused by concrete reinforced and metalware. In the proposed method, orientation of sensors are represented by quaternions, initialized by setting the 30 s standing phase at the beginning to be the initial state and updated through an attitude estimation algorithm presented by Mahony [32]. In addition, a sensor-to-segment coordinate calibration algorithm is required to eliminate errors caused by the unprecise and poorly repeatable alignment between the segment reference frame (SMRF) and the sensor reference frame (SSRF) [33,34].
The hip/knee joint can be modeled as a three-/one-dimensional joint connected two rigid segments; the knee joint is modeled as a one-dimensional joint because the range of motion in the flexion and extension direction is much larger than that in the other two directions. A set of SMRF and SSRF are defined as the right-handed Cartesian coordinate systems, as shown in Figure 1. The SMRF is defined as X-axis points up from feet to head in vertical axis, Y-axis points to medial in frontal axis and Z-axis points to forward in sagittal axis. Meanwhile, the SSRF is defined by the manufacturer.
Figure 1.
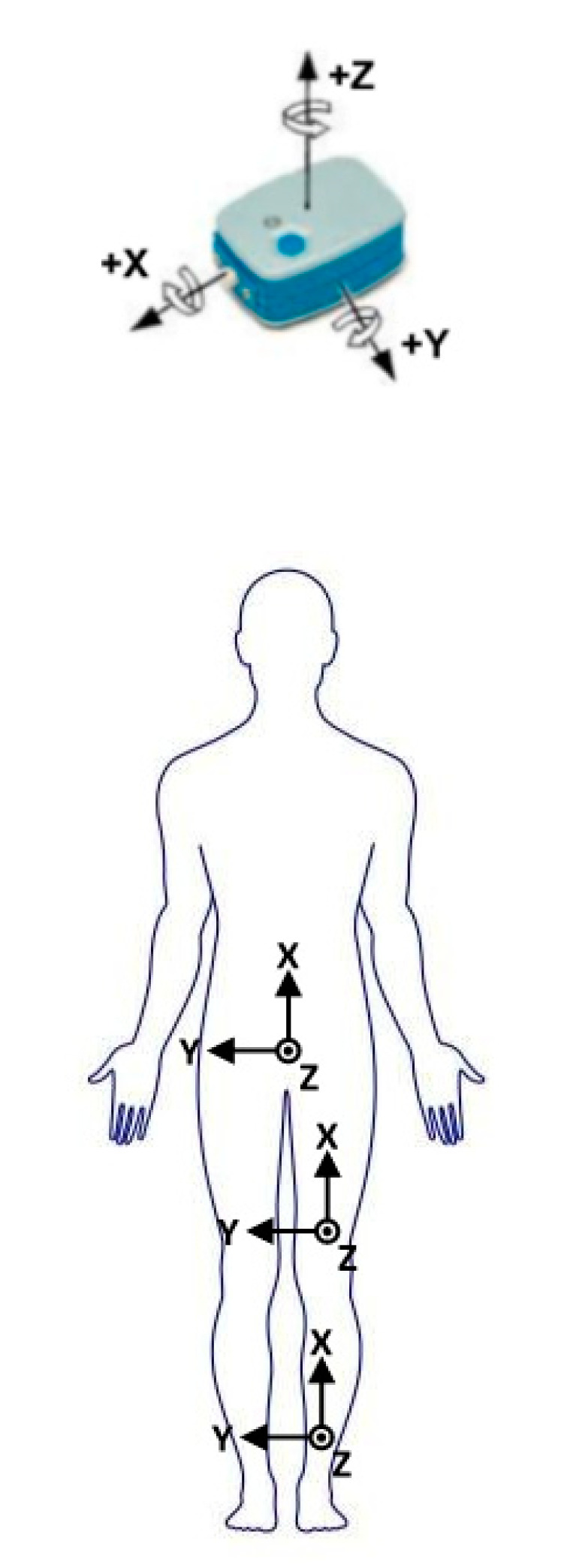
The segment reference frames and sensor reference frames.
Figure 2 shows the schematic of joint angle calculation by taking the knee joint as an example. , , and represent the reference frames of different segments and sensors (seg1 and seg2 are left thigh and left shank, sen1 and sen2 are the Ultium sensors mounted on the corresponding segments). represents the reference frame defined by the initial state, that is, all of the SMRF are set as unit matrix at that moment. Joint angle can be calculated as:
| (1) |
where and denote the orientation of the two segments, with defined as the coordinate axis and calculated from the relative rotation between and :
| (2) |
where represents the orientation matrix of frame B with respect to frame A. (i = 1,2), the orientation matrix of segment frame with respect to the reference frame, is calculated by:
| (3) |
where can be transformed from the quaternion of the sensor, and is computed by figuring out the representation of the rotation axis of the segment (the coordinate axis of the SMRF) in the SSRF, as we assume that the relative orientation between the sensor and corresponding segment remains invariant while the sensor is fixed, though slight errors may be introduced by the displacement of soft tissue. Firstly, of all segments and of low back are computed by measuring the gravitational acceleration vector for corresponding segments in the 30 s standing phase and lying phase, respectively. Particularly, of thigh and shank, which are regarded as the representation of the knee flexion/extension axis in local reference frame, are computed by using an self-calibrating optimization algorithm proposed by Thomas Seel [35,36]. Subsequently, the third rotation axis of each segment is calculated by taking the cross product of the other two axes:
| (4) |
Figure 2.

Schematic of joint angle calculation.
Besides, an orthogonalization process is introduced to correct the possible deviation of the second axis. Finally, the orientation matrix is obtained as:
| (5) |
In addition to calculating the joint angle, is also used to correct all the IMU data as mentioned before. Two datasets were generated from the same original data: one with calibration and the other without calibration. The same subsequent processes were used for both datasets and the results of classification under different conditions (e.g., different ADLs, feature subsets, classification algorithms or sensor combinations) were obtained to verify the effect of calibration algorithm on the HAR performance.
2.2. Features
2.2.1. Feature Calculation
The processed data are a set of labelled time series with fixed length, each series contains a large amount of sensor data. By extracting high-order features from each series, the data dimensions can be greatly reduced and the system robustness and classification accuracy can be improved. In this work, several widely used TD features, FD features and TFD features are selected to figure out the optimal or suboptimal feature subset for ADL classification.
TD Features
The selected TD features are Mean Value (MV), Standard Deviation (SD), Variance (VAR), Root Mean Square (RMS), Skewness (SKE), Kurtosis (KUR), Interquartile Range (IQR), Peak to Peak(P2P), Mean Absolute Value (MAV), Zero Crossing (ZC), Waveform Length (WL), Slope Sign Change (SSC), Wilson Amplitude (WAMP), Log Detector (LD), 4-th order Auto Regressive Coefficient (ARC), Energy and Modified Mean Absolute Value (MMAV). In addition, Jerk, Correlation Coefficient (CC) and Signal Magnitude Area (SMA) are also calculated.
FD Features
Fast Fourier Transform algorithm (FFT) is used to transform the raw time series data x(t) of each epoch into FD data p(f). Based on this, we extract several FD features, which are Mean Power Frequency (MPF), Median Frequency (MDF), One Quarter of Frequency (F25), Three Quarters of Frequency (F75), Top 3 Largest Value of DFT (3LVD) and Entropy.
TFD Features
Wavelet transformation (WT) is a commonly used TFD analysis tool in biomedical signal processing [37,38]. It decomposes signals into two sets of data, detail D[k] and approximation A[k]. To achieve optimal performance, a suitable wavelet function should be employed. According to the recommendations of previous reports [18,39,40,41], we adopted the sym4 mother wavelet as the wavelet basis at fourth decomposition level. An example of wavelet decomposition of WT is shown in Figure 3.
Figure 3.

An example of wavelet decomposition of one sequence of LRF signal during walking.
The selected TFD feature is Energy of Wavelet Coefficient (EWC), which is defined as the Energy of the final approximation and all four details.
The mathematical definitions of selected features are shown in Table 1. Where N and n denote the number of samples of raw data and number of sampling points of FFT, the and in ARC represent the AR parameters and white noise, while and in IQR are the first and third quartile of the raw signal. Besides, the threshold , and are set to reduce the noise for computing ZC, SSC and WAMP [14,18,42,43,44].
Table 1.
Mathematical definitions of features.
| Feature | Mathematical Definition | Feature | Mathematical Definition |
|---|---|---|---|
| Mean Value (MV) | Standard Deviation (SD) | ||
| Variance (VAR) | Root Mean Square (RMS) | ||
| Skewness (SKE) | Kurtosis (KUR) | ||
| Interquartile Range (IQR) | Peak to Peak(P2P) | ||
| Mean Absolute Value (MAV) | Waveform Length (WL) | ||
| Zero Crossing (ZC) | Slope Sign Change (SSC) | ||
| Wilson Amplitude (WAMP) | Log Detector (LD) | ||
| Auto Regressive Coefficient (ARC) | Energy | ||
| Modified Mean Absolute Value (MMAV) | Correlation Coefficient (CC) | ||
| Jerk | Signal Magnitude Area (SMA) | ||
| Mean Power Frequency (MPF) | Entropy | ||
| Median Frequency (MDF) | One Quarter of Frequency (F25) | ||
| Three Quarters of Frequency (F75) |
All features are normalized with Min–Max Normalization. The initial feature sets of each sensor type are shown in the Table 2, 776 features are selected. To remove redundancy of the feature sets, we selected the suboptimal feature subset for ADL classification with method presented in Section 2.3.
Table 2.
The initial select feature sets of each sensor data category.
| Feature | sEMG | ACC | GYR | Joint |
|---|---|---|---|---|
| MV | ● | ● | ● | ● |
| SD | ● | ● | ● | ● |
| VAR | ● | ● | ● | ● |
| RMS | ● | ● | ● | ● |
| SKE | ● | ● | ● | ● |
| KUR | ● | ● | ● | ● |
| IQR | ● | ● | ● | ● |
| P2P | ● | ● | ● | ● |
| MAV | ● | ● | ● | ● |
| WL | ● | ● | ● | ● |
| ZC | ● | ● | ||
| SSC | ● | ● | ||
| WAMP | ● | ● | ||
| LD | ● | ● | ● | ● |
| ARC | ● | ● | ● | ● |
| Energy | ● | ● | ● | ● |
| MMAV | ● | ● | ● | ● |
| CC | ● | ● | ||
| Jerk | ● | |||
| SMA | ● | ● | ||
| MPF | ● | ● | ● | ● |
| MDF | ● | ● | ● | ● |
| Entropy | ● | ● | ● | ● |
| F25 | ● | ● | ● | ● |
| F75 | ● | ● | ● | ● |
| Top 3 Largest Value of DFT (3LVD) | ● | ● | ● | ● |
| Energy of Wavelet Coefficient (EWC) | ● | ● | ● |
CC of ACC and GYR denote the correlation coefficient of different axes in each sensor, such as CCxy, CCxz, CCyz.
2.2.2. Resampling
Noticing that the mean value of ratio of the largest class to smallest class for data with different window parameters is larger than 5 (6 for the parameters we used), taking the imbalanced raw data as training set can easily lead to the classification bias towards the majority class [45]. Existing solutions include methods at data level and algorithm level; in this paper, we select the most commonly used data-level method: resampling. Specifically, the minority class is oversampled through the ADASYN algorithm proposed by Haibo He [46], while the majority class is undersampled by random sampling with replacement. The deviation caused by random algorithm is eliminated by an ensemble algorithm. Specifically, k times undersampling operations are performed firstly, then each set of the undersampling data is combined with the oversampling data calculated by ADASYN algorithm, respectively, to obtain k groups of resampled data. All subsequent algorithm operations run once for each group of resampled data, and the results are represented by the mean value of k results. Particularly, the resampling scale are set equal for each class and calculated as the geometric mean of the largest and smallest class. K is set to 10 in this study.
2.2.3. Feature Evaluation
A class separability index is needed to preliminary evaluate the appropriateness of each feature. Several kinds of index were established in previous study, such as FI, Relief-F, Bhattacharyya Index, Chernoff Index, Divergence and Entropy. Among them, FI is used in this work due to the simplicity and stability. FI is computed by dividing the trace of the between-class scatter matrix by the trace of the within-class scatter matrix. The higher FI is, the better of the class separability of the feature.
The between-class scatter matrix and within-class scatter matrix are defined as:
| (6) |
| (7) |
where is the mean of i-th class and is the mean of all classes, while is the prior probability of i-th class. FI is defined as:
| (8) |
2.3. Feature Selection
Raw feature vector is multidimensional data with a lot of redundant and irrelevant information, methods that are commonly used for feature reduction include feature selection and feature extraction. Considering that feature extraction usually produces new features calculated by combining multiple raw features, which may increase the system burden in real-time use, feature selection is adopted.
Feature selection methods consist of filter-based, wrapper-based and embedded-based algorithm [47]. The evaluation criteria of filter-based feature selection are independent of the learning algorithm and obtained directly from the data set. Due to its high efficiency, the filter-based method is suitable for large-scale data set. However, searching for feature subsets related to classes and searching for feature subsets of optimal classification performance are two different tasks [48]. The wrapper-based method takes the performance of the learning algorithm as evaluation criterion and adopts a searching technology for feature selection. Compared to the filter-based method, the wrapper-based method is more accurate but less efficient. In the embedded-based method, feature selection algorithm is embedded into the learning process. Therefore, in order to meet the requirements of embedded algorithm, the learning algorithm suitable for embedded-based method is less than that for the wrapper-based method. To combine the advantages of filter-based and wrapper-based method, a two-stage feature selection algorithm is introduced in this work, as shown in Figure 4.
Figure 4.

Block diagram of the two-stage genetic-based feature selection method.
Firstly, a filter-based method is adopted to generate an initial feature subset rather than to eliminate some of the poorly performing features; therefore, it can not only expedite the wrapper-based search process, but also avoid the accidental deletion of important information. Specifically, all features are ranked by FI from most to least and given the probabilities of being selected into the initial feature subsets. The selection probability (SP) is set as: SPs of features with largest and smallest FI are P1 and P2, respectively, SPs for the remaining features in the rank are calculated according to the arithmetic sequence rule. P1 and P2 are set to 0.8 and 0.4, respectively. Subsequently, a wrapper-based method based on genetic algorithm (GA) is introduced. The reason for choosing GA algorithm among existing methods is because it is suitable for large-scale problems and has a better chance to find optimal solutions [49]. The full process of GA-based wrapper method is described as follows:
Initialization
Binary coding is used, and each bit of the individual represents one of the raw features, where “1” means selected and “0” means unselected. Each individual is initialized by weighting random sampling without replacement presented by Efraimidis and Spirakis [50], the features are selected with the largest weights, where the weight is calculated as:
| (9) |
Considering the system burden and performance requirements, the population size and the maximum number of iterations are set to 80 and 100, respectively.
-
2.
Fitness evaluation function
The most important two factors that affect fitness of an individual are feature number and classification performance of the feature subset. Some studies integrated the two factors into one fitness evaluation function which combines a monotone decreasing function about feature number with a monotone increasing function about classification performance by a weight coefficient [49,51]. However, it is difficult to choose an appropriate weight coefficient in practical application and many of the results end up at large feature numbers. We assume that when the feature number of the optimal feature subset increases within a threshold (some point where redundancy is as important as new information), the classification effect and the system burden will both increase. Therefore, we propose the GFSFAN to meet the different requirements in practical applications. Where the “activation” denotes the feature is selected and its genetic locus in the individual is set to “1”. In this case, the fitness of an individual is calculated as follows:
Firstly, the selected data group is generated by combining the resampled data groups and the selected feature subsets defined by the individual. Then, Linear Discriminant Analysis (LDA) and Naive Bayes (NB) are applied to test the classification performance of the individual. In addition, the 10-fold cross validation is used to avoid overfitting. That is, each group of the selected data are randomly divided into ten folds, and each time, one of all folds is used as test set with the remaining nine folds used for training. The classification performance is then determined by averaging the F-measure (FM) for all folds of all resampled data groups. The FM is computed as the weighted harmonic average of Precision and Recall:
| (10) |
| (11) |
| (12) |
where represents the number of samples identified as class j and actually class i. Finally, the fitness of an individual is computed by:
| (13) |
where and are the mean and minimum of all classes, respectively. The weight coefficient is set to 0.1 to make the overall classification performance as the main part of evaluation, and the worst classification performance in all classes as a supplement when the overall classification effect is similar.
-
3.
Genetic operators
Tournament selection operator, crowding method and adaptive probability based approach are used to prevent the premature convergence [52]. Where the adapting probabilities are determined by the fitness of the individual, as well as the upper limits and lower limits of the probability:
| (14) |
where the probability range [,] is set as [0.4,0.8] for crossover operation and [0.1,0.4] for mutation operation, and are the maximum and mean fitness in the population, respectively. In particular, is the larger fitness of the two parents in crossover operation.
A crossover operator with fixed activation number (COFAN) and a mutation operator with fixed activation number (MOFAN) are proposed to ensure that the feature activation number of each individual in the genetic operation is equal to the initial activation number .
COFAN: Firstly, the gene bits activated in each parent individual are extracted to form an intermediate individual of length , each of whose gene bits represents the sequence number of an activated gene bits in the parent. Then, the same genes were selected from the intermediate individuals of the two parents to form the homogeneous gene pair, and remaining gens of each intermediate individuals are made into the heterogeneous gene pairs. The two-point crossover operation is performed on the two heterogeneous gene pairs to produce the progeny heterogeneous gene pairs, which are then combined with the homogeneous gene pair to form progeny intermedia individuals. Finally, each of the children is produced by setting the corresponding gene bits of an unactivated individual to “1” according to the progeny intermedia individual.
MOFAN: Mutation operation is performed on each activated gene bits of the parent individual according to the mutation probability and the actual number of mutations is recorded firstly. Subsequently, the same number of unactivated bits are randomly selected to perform the mutation operation and the child individual is finally generated.
Six widely used classifiers are applied to test the classification performance of the selected feature subsets: Center-Nearest Neighbors, K-Nearest Neighbors (KNN), LDA, NB, Random Forests (RF) and Linear Support Vector Machine (SVM). Specifically, K is set to 1 in KNN, the tree number is set to 8 in RFs and the one-against-the rest strategy is used in SVM in the present study. Five groups of feature subsets with different fixed numbers (five features, eight features, 10 features, 15 features and 20 features) are generated with the proposed GFSFAN. The aim of this process is to verify the performance of the proposed approach in case of different system burden requirements. Besides, filter-based and wrapper-based selection processes are implemented as comparisons. The filter-based process is a two-stage algorithm: features not relevant to the classification are removed by a Relief-F algorithm, firstly, and then the correlations between remaining features are calculated to remove the redundancy. The criterion for removing redundant features is that feature with highest Relief-F value is retained among several strongly related features. The wrapper-based process is a Sequential Forward Selection (SFS) algorithm [53,54], the evaluation criterion of the wrapper process is the FM of selected feature subsets with LDA and NB.
3. Experiments Description
3.1. Participants
Thirteen healthy male participants and four female participants were recruited in this study. The participant characteristics are presented in Table 3. All participants were screened according to the following criteria: (1) healthy adult with no myopathies, orthopedic or metabolic disease or injury within six months before the tests start; (2) has no or litter previous experiences in relevant experiments. Participants were informed of the benefits and risks of the study prior to signing the informed consent. All experiment procedures covered in this study were evaluated and approved by the Ethic Committee of the Affiliated Hospital of Institute of Neurology, Anhui University of Chinese Medicine, which is the project partner of the fund supporting this research. The approval of the ethics committee is in accordance with the guidelines of Declaration of Helsinki and the National law of China.
Table 3.
The participant characteristics (Mean Standard-Deviation).
| Gender | Number | Age (Year) | Weight (kg) | Height (cm) |
|---|---|---|---|---|
| Male | 13 | 27.5 2.53 | 69.8 7.65 | 176.5 6.23 |
| Female | 4 | 29.3 4.79 | 59.6 4.03 | 159.8 2.75 |
| All | 17 | 27.6 3.10 | 66.8 7.95 | 172.5 9.17 |
3.2. Data Collection
3.2.1. Activities and Procedure
Walking (WLK), ascending stairs (AS), descending stairs (DS), ascending ramps (AR), descending ramps (DR), standing (STD), sitting (SIT), squatting (SQT) and lying (LY) were examined in this work. The selected ADLs are shown in Figure 5.
Figure 5.


The selected ADLs: (a) standing, (b) sitting, (c) squatting, (d) lying, (e) walking, (f) ascending stairs, (g) descending stairs, (h) ascending ramps, and (i) descending ramps.
Participants performed each activity according to the following standard: (1) WLK (10 m straight walking), AS/DS (10 conventional building stairs with 16cm height of each) and AR/DR (15 m slope of about 8 degrees) were performed at preferred speed. (2) During STD, participants were required to stand straightly with feet shoulder-width apart and look ahead. (3) Upper limbs were not allowed to exert force while SIT or SQT. (4) Hold all four postures (STD, SIT, SQT and LY) at least 3 s each time.
The tasks were divided into three parts and carried out in three adjacent places at the same laboratory building. WLK and all of the four postures were carried out in the activity lab provided by the Research Center for Information Technology of Sports and Health. During the experiments, participants randomly performed activities and completed each activity at least 10 times. AS/DS and AR/DR were carried out at least 15 min each time on the staircase and garage ramp, respectively. Before starting each part, participants were requested to stand still for 30 s. Specially, a 3 s standing period between each activity was required to allow video tagging. All wearable sensors could not be disassembled or moved after installation until all activities are completed.
Participants were informed to report feeling tired or unwell at any time during the experiments, the tests would then be suspended until they recover or postponed. Before the formal experiments began, participants were required to be familiar with the criteria and procedures under the guidance of the experimenter. Eight participants completed a total of 10 experiments within one week.
3.2.2. Sensors Configuration and Data Acquisition
Muscle activities were recorded by NORAXON Ultium wireless sensors (Noraxon, Scottsdale, AZ, USA) at 2000Hz. The Ultium sensors, which were placed on the skin over osseous structures or tendons, are reference electrodes as well as EMG signal processing and wireless transmission devices. Disposable, self-adhesive Ag/AgCL dual electrodes were placed on the skin over the belly of the target muscles along the major orientation of muscle fibers. The dual electrode is a pair of electrodes with 2 cm apart, center to center. Before positioned the electrodes or Ultium sensors, participants’ skin over the target muscles was cleaning with an alcohol-soaked pad to keep the impedance of the skin low and stable. The target muscles are left rectus femoris (LRF, near the midline of the left thigh, approximately halfway between the ASIS and the proximal patella), left semitendinosus (LSEM, on the medial aspect of the left thigh, located approximately 3 cm from the lateral border of the thigh and approximately half the distance from hip to the back of the knee.), left tibialis anterior (LTA, lateral to the medial shaft of the left tibia, at approximately one-third the distance between the knee and the ankle), and left lateral gastrocnemius (LLGA, lateral to the back of left shank, at approximately half the distance between the back of knee and heel).
Motion information of trunk and lower limbs was collected by MPU9250 (Invensense, San Jose, CA, USA) embedded in Ultium sensors at 200 Hz. The Ultium sensors which acted as IMUs were installed at L5/S1 of the spine at LB, at the distal end of the front of LT (2cm from the LRF electrodes) and at the distal end of the left tibia in the crus inside, which shared the same Ultium sensor as the reference electrode at LTA (LS). The X-axis of IMUs aligned the vertical axis pointing to the head direction and Z-axis aligned the sagittal axis pointing forward direction.
All sensors were attached to the participant’s skin by double-sided adhesive tape and secured with a self-viscoelastic sports bandage. The experiment system and arrangement of sensors is shown in Figure 6.
Figure 6.

Experiment system and the arrangement of sensors.
Sensor data was sent via Bluetooth to the NORAXON Ultium Receiver, which was connected to a laptop via USB3.0 and synchronized with a 720P webcam for recording video. Raw data was collected and marked using the myoRESEARCH 3.12 (Noraxon USA). Two assistants who were not involved in the experiment were recruited, one marked the participants’ activities according to the synchronized video recording, the other checked the marked video and discussed with the first in case of disagreement.
3.3. Preprocessing and Segmentation
All signal processing were performed on the Matlab software (MATLAB R2018a, The MathWorks, Inc., Novi, MI, USA). Raw sEMG signals were filtered through a 4th order Butterworth 10–500 Hz bandpass filter and smoothed with a 50 ms moving average window. Raw IMU signals were elliptically corrected to remove the static error before using. Acceleration and angular velocity signals were filtered through an 8-order Butterworth 10 Hz lower filter and an 8-order Butterworth 30 Hz lower filter, respectively. The 30 s standing phase was used for normalization, which was dividing all acceleration data by the average resultant acceleration and subtracting all angular velocity data from the average angular velocity over the 30 s standing phase. Posture information was calculated by fusing the acceleration and angular velocity data from both sides of the target joints, which is described in Section 2.1.
The processed data were then segmented into epochs by a moving window to extract features. In this case, the window width and overlap rate play great roles in classification. For instance, a window with larger width may contains more than one activity and reduces the accuracy of classification, while small window width may result in insignificant features and overburdened systems.
Different window parameters were set to figure out the appropriate ones, the criteria for the window parameters to be selected are: (1) the increment of moving window should be lower than 300ms to avoid introducing perceivable delay [55]; (2) the overlap rates were 50%, 60%, 70%, 75% and 80%; (3) window widths were set as integer multiples of 80ms (160 sample points for EMG and 16 sample points for IMU). Fisher Index (FI), which is described in detail in Section 2.2.3, were used to evaluate the class separability of features. Specifically, summations of Fisher Index (SFI) of different sets of features distinguished by different window parameter pairs were calculated to evaluate the effects of these window parameters. Meanwhile, the Friedman test and Wilcoxon signed-rank test were used to check the influence of window parameters on the SFIs of all features. Finally, the most appropriate window parameter pairs were determined by analyzing these results and the rest of this work was based on these parameters.
4. Results
Figure 7 shows the SFIs of all features with different window parameter pairs. The purpose of this diagram is to figure out the most appropriate window parameters. The significance probability of Friedman test on all the five overlap rates and significance probabilities of Wilcoxon signed-rank tests on each pair of overlap rates are below 0.05. In Friedman test, the average ranks of SFIs distinguished by the five overlap rates are sorted from largest to smallest as: 80%, 75%, 70%, 60% and 50%, which is the same as the order of average SFIs of the five groups. The most appropriate window parameters were selected and all the following results were calculated with the datasets generated with the selected window parameters.
Figure 7.

(a) SFI of all features with different window parameter pairs with and without calibration of IMUs. (b) Enlarge details of the black box in (a) at the window length of 400 ms. Where red means calibrated and blue means uncalibrated.
Effect of calibration on classification are shown in Figure 8. Mean FM derived from the classification of the two datasets described in Section 2.1 with different conditions are shown in the following order: Figure 8a shows mean FM of different activities, Figure 8b shows mean FM of different feature subsets, Figure 8c shows mean FM of different classification algorithms and Figure 8d shows mean FM of different sensor combinations. Significance probability of Wilcoxon signed-rank tests on FMs of classification on datasets with or without calibration at each condition is below 0.05. Additionally, in almost all conditions, FM of classification on datasets with calibration is higher than that without calibration.
Figure 8.

(a) F-measure per activity for dataset with calibration and without calibration. (b) F-measure per feature subset for dataset with calibration and without calibration. (c) F-measure per classification algorithm for dataset with calibration and without calibration. (d) F-measure per sensor combination for dataset with calibration and without calibration.
Figure 8c revealed that among all the classification algorithm used in this work, KNN, Random Forest and SVM end up with the best performance (their FM are 0.982, 0.982 and 0.976, respectively), which is similar with the result in [17]. Therefore, to simplify the diagram, only the three best classification algorithms are considered. The classification results of different sensor combinations and different feature subsets with KNN, RF and SVM are listed in Table 4. For GFSFAN only 10 features are listed as an example in the table. Next, mean FM of all feature subsets per sensor combinations and classification algorithms are shown in Figure 9. From this figure, the effect of different sensor combinations on the classification performance can be revealed. Particularly, mean FM of multiple sensors combinations per activity are shown in Figure 10.
Table 4.
The classification performance of different sensor combinations and different feature subsets with KNN, RF and SVM.
| GFSFAN 10 Features |
Filter | SFS | All Features | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Sensor Comb. | Algo. | FN | FM | FN | FM | FN | FM | FN | FM |
| sEMG | KNN | 10 | 0.977 | 59 | 0.98 | 19 | 0.981 | 132 | 0.973 |
| RF | 0.977 | 0.98 | 0.981 | 0.973 | |||||
| SVM | 0.933 | 0.957 | 0.984 | 0.960 | |||||
| ACC | KNN | 10 | 0.985 | 114 | 0.984 | 36 | 0.986 | 285 | 0.985 |
| RF | 0.985 | 0.984 | 0.986 | 0.985 | |||||
| SVM | 0.980 | 0.981 | 0.985 | 0.984 | |||||
| GYR | KNN | 10 | 0.945 | 121 | 0.948 | 55 | 0.965 | 309 | 0.977 |
| RF | 0.946 | 0.948 | 0.965 | 0.977 | |||||
| SVM | 0.943 | 0.949 | 0.978 | 0.977 | |||||
| Joint Ang. | KNN | 10 | 0.993 | 20 | 0.993 | 34 | 0.994 | 50 | 0.934 |
| RF | 0.993 | 0.993 | 0.994 | 0.934 | |||||
| SVM | 0.983 | 0.988 | 0.986 | 0.881 | |||||
| IMU (ACC+GYR) | KNN | 10 | 0.987 | 231 | 0.991 | 31 | 0.992 | 594 | 0.991 |
| RF | 0.989 | 0.991 | 0.992 | 0.991 | |||||
| SVM | 0.987 | 0.988 | 0.991 | 0.989 | |||||
| sEMG+IMU | KNN | 10 | 0.993 | 289 | 0.994 | 37 | 0.994 | 726 | 0.988 |
| RF | 0.993 | 0.994 | 0.994 | 0.988 | |||||
| SVM | 0.989 | 0.991 | 0.993 | 0.992 | |||||
| sEMG+IMU+Joint Ang. | KNN | 10 | 0.994 | 307 | 0.994 | 36 | 0.995 | 776 | 0.988 |
| RF | 0.994 | 0.994 | 0.995 | 0.988 | |||||
| SVM | 0.983 | 0.991 | 0.994 | 0.983 | |||||
| Mean Value | KNN | 10 | 0.982 | 163 | 0.986 | 35.4 | 0.987 | 410 | 0.977 |
| RF | 0.982 | 0.986 | 0.987 | 0.977 | |||||
| SVM | 0.971 | 0.977 | 0.987 | 0.966 | |||||
Figure 9.

Mean F-Measure of all feature subsets per sensor combination and classification algorithms (KNN, RF and SVM).
Figure 10.

Mean F-Measure per activity and multiple sensors combination with different classification algorithms: (a) KNN; (b) RF; (c) SVM.
All the feature selection and classification algorithms were implemented in Matlab R2018a, and the statistical processes were performed in SPSS 22.0 on a 3.0 GHz Inter(R) Core (TM) i5 processor with 8GB RAM. The segmentation and feature calculation steps required 50 min for the datasets with the selected window parameters. The resampling step required 37 s and the GFSFAN algorithm required at most 226 s (20 features for the combination of all sensors).
5. Discussion
The present study proposes a feature selection process from multiple types of wearable sensors to recognize nine activities of daily living. The purpose of this process is to reduce the system burden of ARS by significantly discarding the number of features, while keeping appropriate classification performance at the same time. Different classification algorithms with different sensor combinations were applied on the datasets generated from the experiment described above to analyze the influence of classifiers and sensor combinations on the classification performance. Besides, a sensor-to-body segment coordinate calibration algorithm for IMUs is proposed and the effect of this calibration process on the classification performance of HAR was also analyzed.
In Figure 7, the order of SFIs with different overlap rates from largest to smallest is: 80%, 75%, 70%, 60% and 50%, which can be seen in the enlarged detail in Figure 7b. Besides, the results of significance difference analysis on overlap rates show that the differences between each overlap rate are significance. Thus, SFI with 80% overlap rate is significantly higher than that with other overlap rates, although the differences are small. In addition, the highest overlap rate means the largest number of sliding windows, which is conducive to the classification. In Figure 7a, the SFI increases with the increase of window length, and this growth trend slows down greatly at 1040 ms. In sum, considering the separability of features and the number of windows, the window parameters selected in this work are 1040 ms of window length with an 80% overlap rate.
For the calibration process, the significance tests for classification results with or without calibration at each condition revealed that the former was significantly superior to the latter, which can also be seen in Figure 8, except for the sEmg features as the calibration algorithm only corrects the coordinate deviation of the inertial sensors.
In Figure 8b, the classification of ADLs can achieve acceptable results with the feature subsets obtained through the GFSFAN algorithm (the FM are 0.901 for 5 features, 0.941 for 10 features, 0.952 for 15 features and 0.955 for 20 features) compare to that through the Filter based feature selection (0.959) and SFS (0.969). Among them, the result is worst for 5 features, which may be due to the prematurity of GA process and information loss caused by the extremely small number of features. From Table 4, all three feature selection methods reduced the number of features, while also improve the performance of classification. Besides, the GFSFAN significantly discarded most of the features and generated small feature subsets with manually set size. With these features, the classification models building time and system burden for real-time HAR can be greatly lowered while the classification performance will not be adversely affected greatly.
In Figure 9 and Figure 10, among all the four single types of sensors, ACC achieved the best classification performance while GYR achieved the worst. Joint angle had the second highest FM as data fusion of ACC and GYR. As expected earlier, HAR with the combination of ACC and GYR (IMU) had significantly higher FM compared to that with only ACC or GYR. Furthermore, HAR with combination of sEMG and IMU showed slight improvement over HAR with the combination of IMU, and the improvement was also evident when comparing HAR with the combination of all sensors and HAR with combination of sEMG and IMU. However, this improvement was non-significant when joint angles are added. This may be due to the fact that joint angles are generated through IMU data fusion. Additionally, the positive impact of newly useful information provided by these new features may be almost equal to the negative impact of the increase in the number of features on the estimation of the optimal subset of features.
For classifiers, KNN, RF and SVM provide significantly higher performance, as well as longer training or predicting time than the CenterNearest, LDA and NB. In terms of classification performance, KNN and RF are the best of all, however KNN requires a large amount of memory to store the training sets and may be the slowest when dealing with large data. LDA and NB provide lower performance, yet not as low as CenterNearest, but are very fast. Thus, LDA and NB are appropriate as wrapper algorithms in the feature selection process and as the classifiers in case of limited computing resources.
The proposed feature selection algorithm for HAR can be also used in human health-related applications which may require compact ARS. For example, extracting features of users performing specific tasks on the basis of identifying and segmenting related activities to assess the disease progression is an important process towards automated disease monitoring. In this case, establishing ARS by using features that are also useful for subsequent assessing process with a few additional features can significantly reduce the system burden. Thus, according to the requirements of classification performance and system burden, it can be a good method to use the proposed algorithm to select the optimal feature subsets from various features for building ARS.
6. Conclusions
This study proposes a feature selection method that can obtain feature subsets for HAR as well as a sensor-to-segment coordinate alignment algorithm and a joint angle estimation algorithm. Comparing with other feature selection algorithms, the proposed algorithm can greatly discard features and maintain comparable classification performance. The sensor coordinate calibration algorithm is proved to be beneficial for HAR. Although some cases do not show significant improvement when sensor types are adding, comprehensive results indicate that the fusion of heterogeneous sensors (sEMG and Joint angel in this case) exhibits satisfactory performance for HAR. Six different classifiers are introduced to recognize human activities of daily living, and the results suggest RF and SVM appropriate classifiers for HAR, while using LDA and NB when memory and computing resources are limited. Adding more types of vital sign sensors and studying relevant open databases will be further explored in future research.
Author Contributions
Conceptualization, J.C.; Funding acquisition, S.S.; Methodology, J.C.; Project administration, S.S.; Software, J.C.; Supervision, Y.S.; Writing—Original Draft, J.C.; Writing—Review and Editing, J.C., Y.S. and S.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Anhui Provincial Key Research and Development Plan (grant 202004a07020037) and National Key R&D Program of China (grant 2018YFC2001304).
Institutional Review Board Statement
All experiment procedures covered in this study were evaluated and approved by the Ethic Committee of the Affiliated Hospital of Institute of Neurology, Anhui University of Chinese Medicine.
Informed Consent Statement
Written informed consent has been obtained from the participants involved in this study.
Conflicts of Interest
The authors declare no conflict of interest.
Footnotes
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Martínez-Villaseñor L., Ponce H. Design and Analysis for Fall Detection System Simplification. J. Vis. Exp. 2020;2020:e60361. doi: 10.3791/60361. [DOI] [PubMed] [Google Scholar]
- 2.Jackson K., Sample R., Bigelow K. Use of an Instrumented Timed Up and Go (iTUG) for Fall Risk Classification. Phys. Occup. Ther. Geriatr. 2018;36:354–365. doi: 10.1080/02703181.2018.1528325. [DOI] [Google Scholar]
- 3.Khan Z.A., Sohn W. Abnormal human activity recognition system based on R-transform and independent component features for elderly healthcare. J. Chin. Inst. Eng. 2013;36:441–451. doi: 10.1080/02533839.2012.731880. [DOI] [Google Scholar]
- 4.Mazumder O., Kundu A.S., Lenka P.K., Bhaumik S. Ambulatory activity classification with dendogram-based support vector machine: Application in lower-limb active exoskeleton. Gait Posture. 2016;50:53–599. doi: 10.1016/j.gaitpost.2016.08.010. [DOI] [PubMed] [Google Scholar]
- 5.Tang Z.-C., Sun S., Sanyuan Z., Chen Y., Li C., Chen S. A Brain-Machine Interface Based on ERD/ERS for an Upper-Limb Exoskeleton Control. Sensors. 2016;16:2050. doi: 10.3390/s16122050. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Zhang Z., Sup F.C. Activity recognition of the torso based on surface electromyography for exoskeleton control. Biomed. Signal Process. Control. 2014;10:281–288. doi: 10.1016/j.bspc.2013.10.002. [DOI] [Google Scholar]
- 7.Salarian A., Horak F.B., Zampieri C., Carlson-Kuhta P., Nutt J.G., Aminian K. iTUG, a Sensitive and Reliable Measure of Mobility. IEEE Trans. Neural Syst. Rehabil. Eng. 2010;18:303–310. doi: 10.1109/TNSRE.2010.2047606. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Han Y., Han M., Lee S., Sarkar A.M.J., Lee Y.-K. A Framework for Supervising Lifestyle Diseases Using Long-Term Activity Monitoring. Sensors. 2012;12:5363–5379. doi: 10.3390/s120505363. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Kumari P., Mathew L., Syal P. Increasing trend of wearables and multimodal interface for human activity monitoring: A review. Biosens. Bioelectron. 2017;90:298–307. doi: 10.1016/j.bios.2016.12.001. [DOI] [PubMed] [Google Scholar]
- 10.Nweke H.F., Teh Y.W., Mujtaba G., Al-Garadi M.A. Data fusion and multiple classifier systems for human activity detection and health monitoring: Review and open research directions. Inf. Fusion. 2019;46:147–170. doi: 10.1016/j.inffus.2018.06.002. [DOI] [Google Scholar]
- 11.Siu H.C., Shah J.A., Stirling L.A. Classification of Anticipatory Signals for Grasp and Release from Surface Electromyography. Sensors. 2016;16:1782. doi: 10.3390/s16111782. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Too J., Abdullah A.R., Saad N.M. Classification of Hand Movements Based on Discrete Wavelet Transform and Enhanced Feature Extraction. Int. J. Adv. Comput. Sci. Appl. 2019;10:83–89. doi: 10.14569/IJACSA.2019.0100612. [DOI] [Google Scholar]
- 13.Xue Y., Ji X., Zhou D., Li J., Ju Z. SEMG-Based Human In-Hand Motion Recognition Using Nonlinear Time Series Analysis and Random Forest. IEEE Access. 2019;7:176448–176457. doi: 10.1109/ACCESS.2019.2957668. [DOI] [Google Scholar]
- 14.Narayan Y., Mathew L., Chatterji S. sEMG signal classification with novel feature extraction using different machine learning approaches. J. Intell. Fuzzy Syst. 2018;35:5099–5109. doi: 10.3233/JIFS-169794. [DOI] [Google Scholar]
- 15.Biswas D., Cranny A., Gupta N., Maharatna K., Achner J., Klemke J., Jöbges M., Ortmann S. Recognizing upper limb movements with wrist worn inertial sensors using k-means clustering classification. Hum. Mov. Sci. 2015;40:59–76. doi: 10.1016/j.humov.2014.11.013. [DOI] [PubMed] [Google Scholar]
- 16.Janidarmian M., Roshan Fekr A., Radecka K., Zilic Z. A Comprehensive Analysis on Wearable Acceleration Sensors in Human Activity Recognition. Sensors. 2017;17:529. doi: 10.3390/s17030529. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Chung S., Lim J., Noh K.J., Kim G., Jeong H. Sensor Data Acquisition and Multimodal Sensor Fusion for Human Activity Recognition Using Deep Learning. Sensors. 2019;19:1716. doi: 10.3390/s19071716. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Ai Q., Zhang Y., Qi W., Liu Q. Research on Lower Limb Motion Recognition Based on Fusion of sEMG and Accelerometer Signals. Symmetry. 2017;9:147. doi: 10.3390/sym9080147. [DOI] [Google Scholar]
- 19.Jia R., Liu B. Human daily activity recognition by fusing accelerometer and multi-lead ECG data; Proceedings of the 2013 IEEE International Conference on Signal Processing, Communication and Computing (ICSPCC 2013); KunMing, China. 5–8 August 2013; pp. 1–4. [Google Scholar]
- 20.Al-Amin M., Tao W., Doell D., Lingard R., Yin Z., Leu M.C., Qin R. Action Recognition in Manufacturing Assembly using Multimodal Sensor Fusion. Procedia Manuf. 2019;39:158–167. doi: 10.1016/j.promfg.2020.01.288. [DOI] [Google Scholar]
- 21.Lara Ó.D., Perez A., Labrador M.A., Posada J.D. Centinela: A human activity recognition system based on acceleration and vital sign data. Pervasive Mob. Comput. 2012;8:717–729. doi: 10.1016/j.pmcj.2011.06.004. [DOI] [Google Scholar]
- 22.Bellos C., Papadopoulos A., Rosso R., Fotiadis D.I. Heterogeneous data fusion and intelligent techniques embedded in a mobile application for real-time chronic disease man-agement; Proceedings of the 2011 Annual International Conference of the IEEE Engineering in Medicine and Biology Society; Boston, MA, USA. 30 August–3 September 2011; [DOI] [PubMed] [Google Scholar]
- 23.Gong J., Cui L., Xiao K., Wang R. MPD-Model: A Distributed Multipreference-Driven Data Fusion Model and Its Application in a WSNs-Based Healthcare Monitoring System. Int. J. Distrib. Sens. Netw. 2012;8:5965–5971. doi: 10.1155/2012/602358. [DOI] [Google Scholar]
- 24.Chernbumroong S., Cang S., Yu H. A practical multi-sensor activity recognition system for home-based care. Decis. Support Syst. 2014;66:61–70. doi: 10.1016/j.dss.2014.06.005. [DOI] [Google Scholar]
- 25.Liang H., Sun X., Sun Y., Gao Y. Text feature extraction based on deep learning: A review. EURASIP J. Wirel. Commun. Netw. 2017;2017:1–12. doi: 10.1186/s13638-017-0993-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Mohammad Y., Matsumoto K., Hoashi K. Deep Feature Learning and Selection for Activity Recognition; Proceedings of the 33rd Annual Acm Symposium on Applied Computing; Pau, France. 9–13 April 2018; New York, NY, USA: Assoc Computing Machinery; 2018. pp. 930–939. [Google Scholar]
- 27.Zdravevski E., Lameski P., Trajkovik V., Kulakov A., Chorbev I., Goleva R., Pombo N., Garcia N. Improving Activity Recognition Accuracy in Ambient Assisted Living Systems by Automated Feature Engineering. IEEE Access. 2017;5:5262–5280. doi: 10.1109/ACCESS.2017.2684913. [DOI] [Google Scholar]
- 28.Fang H., He L., Si H., Liu P., Xie X. Human activity recognition based on feature selection in smart home using back-propagation algorithm. ISA Trans. 2014;53:1629–1638. doi: 10.1016/j.isatra.2014.06.008. [DOI] [PubMed] [Google Scholar]
- 29.Wang A., Chen G., Wu X., Liu L., An N., Chang C.-Y. Towards Human Activity Recognition: A Hierarchical Feature Selection Framework. Sensors. 2018;18:3629. doi: 10.3390/s18113629. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Versteyhe M., De Vroey H., DeBrouwere F., Hallez H., Claeys K. A Novel Method to Estimate the Full Knee Joint Kinematics Using Low Cost IMU Sensors for Easy to Implement Low Cost Diagnostics. Sensors. 2020;20:1683. doi: 10.3390/s20061683. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Mohammadzadeh F.F., Liu S., Bond K.A., Nam C.S. Feasibility of a wearable, sensor-based motion tracking system. In: Ahram T., Karwowski W., Schmorrow D., editors. Proceedings of the 6th International Conference on Applied Human Factors and Ergonomics; Las Vegas, NV, USA. 26–30 July 2015; 2015. pp. 192–199. [Google Scholar]
- 32.Mahony R., Euston M., Kim J., Coote P., Hamel T. A non-linear observer for attitude estimation of a fixed-wing unmanned aerial vehicle without GPS measurements. Trans. Inst. Meas. Control. 2010;33:699–717. doi: 10.1177/0142331209343660. [DOI] [Google Scholar]
- 33.Wu G., Cavanagh P.R. ISB recommendations for standardization in the reporting of kinematic data. J. Biomech. 1995;28:1257–1261. doi: 10.1016/0021-9290(95)00017-C. [DOI] [PubMed] [Google Scholar]
- 34.Narvaez F., Arbito F., Proano R. A Quaternion-Based Method to IMU-to-Body Alignment for Gait Analysis. In: Duffy V.G., editor. Digital Human Modeling: Applications in Health, Safety, Ergonomics, and Risk Management. Springer; Cham, Switzerland: 2018. pp. 217–231. [Google Scholar]
- 35.Seel T., Raisch J., Schauer T. IMU-Based Joint Angle Measurement for Gait Analysis. Sensors. 2014;14:6891–6909. doi: 10.3390/s140406891. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Müller P., Bégin M.A., Schauer T., Seel T. Alignment-free, self-calibrating elbow angles measurement using inertial sensors; Proceedings of the 2016 IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI); Las Vegas, NV, USA. 24–27 February 2016; [DOI] [PubMed] [Google Scholar]
- 37.Xi X., Yang C., Shi J., Luo Z., Zhao Y.-B. Surface Electromyography-Based Daily Activity Recognition Using Wavelet Coherence Coefficient and Support Vector Machine. Neural Process. Lett. 2019;50:2265–2280. doi: 10.1007/s11063-019-10008-w. [DOI] [Google Scholar]
- 38.Wang J., Sun Y., Sun S. Recognition of Muscle Fatigue Status Based on Improved Wavelet Threshold and CNN-SVM. IEEE Access. 2020;8:207914–207922. doi: 10.1109/ACCESS.2020.3038422. [DOI] [Google Scholar]
- 39.Jiang C., Lin Y.-C., Yu N.-Y. Multi-Scale Surface Electromyography Modeling to Identify Changes in Neuromuscular Activation with Myofascial Pain. EEE Trans. Neural Syst. Rehabil. Eng. 2012;21:88–95. doi: 10.1109/TNSRE.2012.2211618. [DOI] [PubMed] [Google Scholar]
- 40.Phinyomark A., Nuidod A., Phukpattaranont P., Limsakul C. Feature Extraction and Reduction of Wavelet Transform Coefficients for EMG Pattern Classification. Elektron. Elektrotechnika. 2012;122:27–32. doi: 10.5755/j01.eee.122.6.1816. [DOI] [Google Scholar]
- 41.Schimmack M., Mercorelli P. An on-line orthogonal wavelet denoising algorithm for high-resolution surface scans. J. Frankl. Inst. 2018;355:9245–9270. doi: 10.1016/j.jfranklin.2017.05.042. [DOI] [Google Scholar]
- 42.Phukpattaranont P., Thongpanja S., Anam K., Al-Jumaily A., Limsakul C. Evaluation of feature extraction techniques and classifiers for finger movement recognition using surface electromyography signal. Med. Biol. Eng. Comput. 2018;56:2259–2271. doi: 10.1007/s11517-018-1857-5. [DOI] [PubMed] [Google Scholar]
- 43.Xi X., Tang M., Miran S.M., Miran S.M. Evaluation of Feature Extraction and Recognition for Activity Monitoring and Fall Detection Based on Wearable sEMG Sensors. Sensors. 2017;17:1229. doi: 10.3390/s17061229. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Xi X., Yang C., Miran S.M., Zhao Y.B., Lin S., Luo Z. sEMG-MMG State-Space Model for the Continuous Estimation of Multijoint Angle. Complexity. 2020;2020:1–12. doi: 10.1155/2020/4503271. [DOI] [Google Scholar]
- 45.Cao H., Li X.-L., Woon Y.-K., Ng S.-K. SPO: Structure Preserving Oversampling for Imbalanced Time Series Classification; Proceedings of the IEEE International Conference on Data Mining; Vancouver, BC, Canada. 11–14 December 2011. [Google Scholar]
- 46.He H., Bai Y., Garcia E.A., Li S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning; Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence) (IJCNN 2008); Hong Kong, China. 1–8 June 2008. [Google Scholar]
- 47.Pourpanah F., Shi Y., Lim C.P., Hao Q., Tan C.J. Feature selection based on brain storm optimization for data classification. Appl. Soft Comput. 2019;80:761–775. doi: 10.1016/j.asoc.2019.04.037. [DOI] [Google Scholar]
- 48.Kohavi R., John G.H. Wrappers for feature subset selection. Artif. Intell. 1997;97:273–324. doi: 10.1016/S0004-3702(97)00043-X. [DOI] [Google Scholar]
- 49.Kudo M., Sklansky J. Comparison of algorithms that select features for pattern classifiers. Pattern Recognit. 2000;33:25–41. doi: 10.1016/S0031-3203(99)00041-2. [DOI] [Google Scholar]
- 50.Efraimidis P.S., Spirakis P.G. Weighted Random Sampling with a Reservoir. Inf. Process. Lett. 2006;97:181–185. doi: 10.1016/j.ipl.2005.11.003. [DOI] [Google Scholar]
- 51.Lixin Z., Yannan Z., Zehong Y., Jiaxin W., Shaoqing C., Hongyu L. Classification of traditional Chinese medicine by nearest-neighbour classifier and genetic algorithm; Proceedings of the Fifth International Conference on Information Fusion (FUSION 2002); Annapolis, MD, USA. 8–11 July 2002. [Google Scholar]
- 52.Pandey H.M., Chaudhary A., Mehrotra D. A comparative review of approaches to prevent premature convergence in GA. Appl. Soft Comput. 2014;24:1047–1077. doi: 10.1016/j.asoc.2014.08.025. [DOI] [Google Scholar]
- 53.Altun K., Barshan B. Human Activity Recognition Using Inertial/Magnetic Sensor Units. In: Gevers T., Salah A.A., Sebe N., Vinciarelli A., editors. Human Behavior Understanding. Springer; Berlin/Heidelberg, Germany: 2010. pp. 38–51. [Google Scholar]
- 54.Sahin U., Sahin F., IEEE Pattern Recognition with surface EMG Signal based Wavelet Transformation; Proceedings of the 2012 IEEE International Conference on Systems, Man, and Cybernetics (SMC); Seoul, Korea. 14–17 October 2012; New York, NY, USA: IEEE; pp. 303–308. [Google Scholar]
- 55.Englehart K., Hudgins B. A robust, real-time control scheme for multifunction myoelectric control. IEEE Trans. Biomed. Eng. 2003;50:848. doi: 10.1109/TBME.2003.813539. [DOI] [PubMed] [Google Scholar]