

Summary
High-dimensional multi-source data are encountered in many fields. Despite recent developments on the integrative dimension reduction of such data, most existing methods cannot easily accommodate data of multiple types (e.g. binary or count-valued). Moreover, multi-source data often have block-wise missing structure, i.e. data in one or more sources may be completely unobserved for a sample. The heterogeneous data types and presence of block-wise missing data pose significant challenges to the integration of multi-source data and further statistical analyses. In this article, we develop a low-rank method, called generalized integrative principal component analysis (GIPCA), for the simultaneous dimension reduction and imputation of multi-source block-wise missing data, where different sources may have different data types. We also devise an adapted Bayesian information criterion (BIC) criterion for rank estimation. Comprehensive simulation studies demonstrate the efficacy of the proposed method in terms of rank estimation, signal recovery, and missing data imputation. We apply GIPCA to a mortality study. We achieve accurate block-wise missing data imputation and identify intriguing latent mortality rate patterns with sociological relevance.
Keywords: Block-wise missing imputation, Exponential family, Exponential principal component analysis, Joint and individual variation explained, Multi-view data
1. Introduction
With technological developments, data acquisition becomes easier and cheaper. In numerous studies, people collect data from multiple sources on the same group of objects, obtaining the so-called multi-source (or multi-view) data. The analysis of multi-source data presents many challenges. One major challenge is the coexistence of heterogeneous data types in different data sources, such as continuous, binary, and count-valued data. For instance, in genomic studies, data at different molecular levels such as RNA sequencing and DNA methylation data are collected from the same samples. The next-generation RNA sequencing data typically take count values, while DNA methylation data are usually in the form of proportions between  and
and 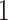 . In addition to the diversity of data types, another challenge is the presence of block-wise missing data. For the same genomic example mentioned above, not all samples are completely observed in both data sets. Some may only have gene expression measurements, while others may only have methylation profiles. For such a missing structure, it is very difficult to impute or integrate different data sources in a principled, unified fashion.
. In addition to the diversity of data types, another challenge is the presence of block-wise missing data. For the same genomic example mentioned above, not all samples are completely observed in both data sets. Some may only have gene expression measurements, while others may only have methylation profiles. For such a missing structure, it is very difficult to impute or integrate different data sources in a principled, unified fashion.
Integrative analysis of multi-source data has drawn more attention to the statistical learning literature lately. Many recent approaches have been developed for integrated analysis of multi-source data (Tseng and others, 2015). For example, Shen and others (2009) introduced an integrative clustering model (iCluster), which incorporates all of the data sources in a single clustering analysis. It captures the association and shared clustering between different data sets through a joint latent variable model, but does not consider the unique aspects of each data set. Several recent methods strive to identify not only the shared structure across multiple sources (i.e. joint) but the structure that is specific to each source (i.e. individual). Lock and others (2013) developed the joint and individual variation explained (JIVE) method, which is an extension of the principal component analysis (PCA) to the multi-source data. Supervised integrated factor analysis (Li and Jung, 2017) is another method, which focuses on the integrative dimension reduction of multi-source data. Several other approaches that capture joint and individual latent structures have been developed, including extensions of partial least squares (Löfstedt and Trygg, 2011), canonical correlation analysis (Zhou and others, 2016a), non-parametric Bayesian modeling (Ray and others, 2014), non-negative factorization (Yang and Michailidis, 2016), common orthogonal basis extraction (Zhou and others, 2016b), and simultaneous component analysis (Schouteden and others, 2014). However, these approaches either explicitly assume a Gaussian model or are only appropriate for continuous data.
Batch adjustment techniques (Leek and others, 2010; Johnson and others, 2007; Fan and others, 2018) also involve the integration of different sources of data. They adjust raw data across different sample sets by removing batch effects caused by different laboratories or other sources of artificial heterogeneity. However, those approaches handling batch effects are designed for Gaussian data only and cannot handle block-wise missing structure.
More efforts are needed for the integrative analysis of data with different types (e.g. count and binary), as heterogeneous data are often encountered due to the disparate nature of multi-source data. The iCluster+ approach (Mo and others, 2013), which enhanced iCluster, provides a feasible approach to the clustering of multi-source data with both discrete and continuous values. Very recently, Li and Gaynanova (2017) developed a generalized association study (GAS) framework for the multivariate association analysis of heterogeneous multi-source data. However, none of the existing methods can easily accommodate block-wise missing values.
Block-wise missing structure is ubiquitous in multi-source data sets. Some well-known missing value imputation approaches, such as expectation–maximum, iterative singular value decomposition (SVD), and matrix completion (Mazumder and others, 2010) are effective to impute data that are missing at random in a single data set. However, the assumption of missing at random is not valid for block-wise missing data and most existing imputation methods are not robust when the missing rate is high (Xiang and others, 2014). The standard imputation methods are inappropriate and inefficient for block-wise missing data imputation (Yuan and others, 2012). In many applications, a common practice to deal with block-wise missing data is to simply remove the observations with missing entries. However, such a procedure may greatly reduce the number of observations and lead to a loss of information. The incomplete multi-task feature learning (iMSF, Yuan and others, 2012) framework conducted a consistent feature selection procedure by avoiding direct block-wise missing imputation. A bi-level learning model (Xiang and others, 2014) further extended the iMSF approach to performing covariates-level and source-level analyses at the same time.
However, both methods bypass the imputation step when encountering data sets with block-wise missing entries, and thus may have limited generalizability in other contexts. Recently, Cai and others (2016) developed a structured matrix completion (SMC) method for imputing structured missing data using a Schur completion. SMC can potentially be used for block-wise missing data imputation. However, by design, SMC is only suitable for Gaussian data, and cannot easily handle more than two data sets with heterogeneous data types.
In this article, we develop a flexible approach for the dimension reduction of multi-source data that allows different sources to have different data types. By assuming each data source comes from one type of distribution in the exponential family, we simultaneously model joint and individual patterns of the underlying natural parameters across data sources. The proposed method can be applied to block-wise missing data and achieve superior imputation performance. We devise a computationally efficient algorithm for model fitting. We also introduce an adapted BIC to select the underlying ranks of the model (i.e. the ranks of latent joint and individual structures in the model).
The rest of the article is organized as follows. In Section 2, the proposed models and identifiability issues are introduced for non-missing and block-wise missing data. In Section 3, we introduce the algorithm and the rank selection. In Section 4, we conduct comprehensive simulation studies to evaluate the performance of the proposed method and compare with existing methods. In Section 5, we apply the proposed method to a mortality study and discuss the performance of estimation and imputation by comparison with several ad hoc methods.
2. Generalized integrative PCA model
Let 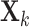
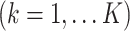 be an
be an  data matrix, with
data matrix, with  being the number of samples and
being the number of samples and  being the number of variables. Samples are matched across
being the number of variables. Samples are matched across  data sources. Each entry in the data matrix
data sources. Each entry in the data matrix  is a realization of a random variable from an exponential family distribution. The entries of different data matrices may follow different distributions (e.g. Gaussian, Poisson, and binomial), while those in the same data matrix are assumed to have the same distributional form. That is, each entry
is a realization of a random variable from an exponential family distribution. The entries of different data matrices may follow different distributions (e.g. Gaussian, Poisson, and binomial), while those in the same data matrix are assumed to have the same distributional form. That is, each entry 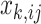 in the
in the 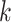 th data set is a realization of a random variable following a single-parameter distribution in the exponential family with an underlying natural parameter
th data set is a realization of a random variable following a single-parameter distribution in the exponential family with an underlying natural parameter  . The canonical form of the probability density function for each entry can be expressed as,
. The canonical form of the probability density function for each entry can be expressed as,
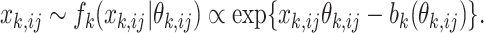 |
where 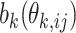 is a convex function which defines the distribution. The canonical link function for the generalized linear regression is
is a convex function which defines the distribution. The canonical link function for the generalized linear regression is 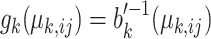 , where
, where 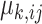 is the mean of
is the mean of  . The entries are assumed independent given the underlying natural parameters. We denote the underlying natural parameters matrix for
. The entries are assumed independent given the underlying natural parameters. We denote the underlying natural parameters matrix for  as
as 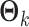 . The natural parameter matrix for all data is denoted as
. The natural parameter matrix for all data is denoted as 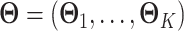 , which has
, which has  columns.
columns.
2.1. Model for non-missing data
We first discuss our proposed model in the context of non-missing (complete) data. For the integrated analysis of multi-source data sets, both shared and individual structure should be considered in the decomposition procedure (Lock and others, 2013). The natural parameter matrix  for each data set, is decomposed into joint and individual latent components as follows:
for each data set, is decomposed into joint and individual latent components as follows:
 |
(2.1) |
In Model (2.1),  is the column means of natural parameters and
is the column means of natural parameters and 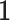 is an
is an 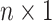 vector of all
vector of all 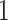 s. Thus, natural parameters within one matrix may have different column means. The second term
s. Thus, natural parameters within one matrix may have different column means. The second term 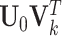 represents the shared structure among different data sources, where
represents the shared structure among different data sources, where 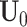 is an
is an 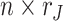 joint score matrix among
joint score matrix among 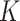 data sets and
data sets and 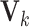 is a
is a 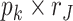 joint loading matrix for
joint loading matrix for  th data set, with
th data set, with  being the rank of the joint structure. The individual structure is denoted by
being the rank of the joint structure. The individual structure is denoted by  , where
, where  is an
is an 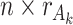 individual score matrix and
individual score matrix and 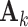 is a
is a  individual loading matrix. The individual rank for each data set is
individual loading matrix. The individual rank for each data set is 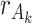 , and
, and  .
.
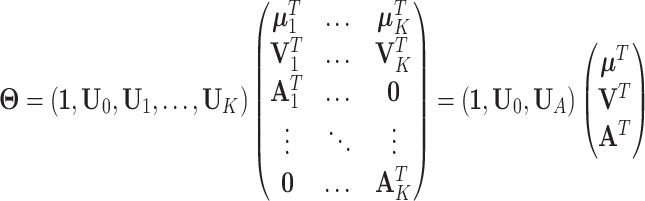
Equivalently, the decomposition of the natural parameter matrix  can be expressed as follows:
can be expressed as follows:
 |
(2.2) |
where 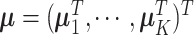 is the concatenation of the column means for each data set,
is the concatenation of the column means for each data set, 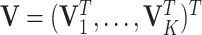 is the concatenation of the joint loading matrices,
is the concatenation of the joint loading matrices, 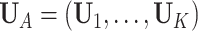 is the concatenation of the individual score matrices,
is the concatenation of the individual score matrices, 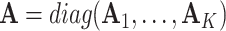 is a block-wise diagonal matrix, and
is a block-wise diagonal matrix, and 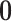 represents any zero matrix with compatible size.
represents any zero matrix with compatible size.
In particular, when there is only one data set, our proposed generalized integrative principal component analysis (GIPCA) reduces to the decomposition of one natural parameter matrix, which coincides with the exponential family principal component analysis (EPCA, Collins and others, 2002). Under the Gaussian assumption with equal variance, the decomposition of natural parameter matrix reduces to a factorization of the original multi-source data set. Thus, our Model (2.2) is identical to JIVE (Lock and others, 2013) in this context. With just two data sets, Model (2.2) coincides with the GAS model (Li and Gaynanova, 2017) applied to data sets without missing values.
2.2. Model with block-wise missing data
We extend the model described in Section 2.1 to allow for block-wise missing structure. Figure 1 is an illustrative picture of data sets with block-wise missing. Due to the block-wise missing entries in the data sets, the corresponding rows in the individual score matrices 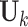 in Model (2.2) are missing. Thus, we denote the submatrix of
in Model (2.2) are missing. Thus, we denote the submatrix of 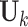 containing only rows without block-wise missing as
containing only rows without block-wise missing as  . The joint score matrix
. The joint score matrix 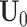 remains the same as in Model (2.2) because for all samples at least one data source is with complete observations, which helps us identify joint structure.
remains the same as in Model (2.2) because for all samples at least one data source is with complete observations, which helps us identify joint structure.
Fig. 1.

GIPCA for block-wise missing data. The three big rectangles represent three data sets 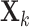
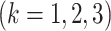 with block-wise missing values (i.e. blank strips). The horizontal direction (rows) represents samples in the three data sets. And the vertical direction (columns) represents variables. The grey color in the big rectangles means that the data are observed for the corresponding samples in the corresponding sources. The blank rectangles are the block-wise missing entries. Those rectangles on the side are joint score and loading matrices
with block-wise missing values (i.e. blank strips). The horizontal direction (rows) represents samples in the three data sets. And the vertical direction (columns) represents variables. The grey color in the big rectangles means that the data are observed for the corresponding samples in the corresponding sources. The blank rectangles are the block-wise missing entries. Those rectangles on the side are joint score and loading matrices  ,
, 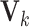 and individual score and loading matrices
and individual score and loading matrices  ,
, 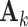 .
.
With block-wise missing data, for each data set 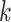 , the decomposition of the natural parameter matrix underlying the observed data becomes
, the decomposition of the natural parameter matrix underlying the observed data becomes
 |
(2.3) |
where 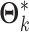 is an
is an  matrix (a submatrix of
matrix (a submatrix of 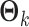 in Model (2.1)). The joint score matrix
in Model (2.1)). The joint score matrix  is an
is an 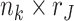 submatrix of
submatrix of 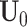 , where only the rows corresponding to the complete samples in the
, where only the rows corresponding to the complete samples in the 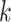 th data source are kept. The individual score matrix
th data source are kept. The individual score matrix 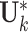 is an
is an 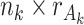 matrix. The means
matrix. The means 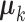 , the joint and individual loading matrices
, the joint and individual loading matrices 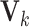 ,
, 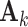 remain the same as in Model (2.2). We also note that
remain the same as in Model (2.2). We also note that 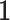 is an
is an 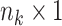 vector of all
vector of all  s. When there is no missing value, Model (2.3) exactly coincides with Model (2.2).
s. When there is no missing value, Model (2.3) exactly coincides with Model (2.2).
We remark that despite the block-wise missingness, the joint structure in Model (2.3) across data sources is 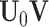 . For a sample with block-wise missing values, as long as it has observations in some data sources, it provides information towards the shared structure. Thus, the underlying joint score matrix is complete, regardless of the block-wise missing structure. The mechanism of block-wise missing imputation relies on the joint structure. Such shared information among different data sets informs the missing data for each data source. Specifically, once estimated, the means and the joint structure can be effectively used to impute block-wise missing data.
. For a sample with block-wise missing values, as long as it has observations in some data sources, it provides information towards the shared structure. Thus, the underlying joint score matrix is complete, regardless of the block-wise missing structure. The mechanism of block-wise missing imputation relies on the joint structure. Such shared information among different data sets informs the missing data for each data source. Specifically, once estimated, the means and the joint structure can be effectively used to impute block-wise missing data.
2.3. Identifiability conditions
In order to ensure identifiability of the estimation, the model parameters should satisfy certain conditions. Following the discussion in Lock and others (2013) and Li and Gaynanova (2017), we provide the identifiability conditions for Model (2.3) as the following.
The columns of the score matrices
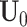 ,
,  are linearly independent and the columns of the means
are linearly independent and the columns of the means 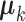 and the loading matrices
and the loading matrices 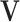 ,
, 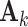 within each data set are linearly independent.
within each data set are linearly independent.All the score matrices are column-centered and the column space of the joint score matrix is orthogonal to the column space of the individual score matrices.
All the separate score and loading matrices have orthogonal columns.
The first condition ensures the joint and individual structures are clearly separable. The second orthogonality condition enhances the interpretability by requiring that the means, joint and individual structures are orthogonal to each other. The third condition rules out arbitrary rotations within each subspace. The above conditions guarantee that the model is fully identifiable (up to some trivial order switch and scale change).
3. Algorithm
In this section, we explain how we estimate each parameter in Model (2.3). We first assume the ranks for the shared and individual structures are known and devise an iterative algorithm for model fitting. Then we introduce an adaptive BIC procedure for rank selection, which is tailored for the proposed approach.
3.1. GIPCA algorithm
The unknown parameters in Model (2.3) are estimated by maximizing the joint log likelihood. Under the assumption that individual measurements are mutually independent given the underlying natural parameter matrix, the maximum likelihood estimators are
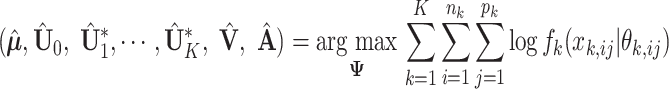 |
(3.1) |
where 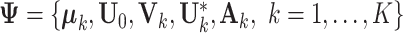 is the set of unknown parameters,
is the set of unknown parameters, 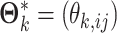 has the decomposition structure in Model (2.3) and
has the decomposition structure in Model (2.3) and  is the probability density function in each data source.
is the probability density function in each data source.
It is computationally prohibitive to directly maximize the log likelihood because the objective function is not convex with respect to all the parameters. As a remedy, we exploit a block coordinate descent algorithm to estimate the parameters. Namely, we alternatively estimate the joint structure along with the intercept and the individual structures until converge. More specifically, we
fix
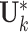 and
and 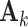 for all data sets, and estimate
for all data sets, and estimate 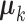 ,
, 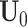 and
and 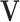 ;
;fix
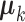 ,
, 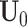 and
and 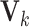 , and estimate
, and estimate  and
and  in each data set.
in each data set.
Consequently, the computation is significantly simplified. We shall provide more details below.
We first estimate the intercept and the joint structure with the individual structures fixed. To further alleviate the computational burden, we fix the joint score matrix  to estimate the joint loading matrix
to estimate the joint loading matrix 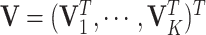 and the intercept
and the intercept  . The estimation of each row in
. The estimation of each row in 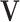 paired with the corresponding entry in
paired with the corresponding entry in  can be cast as a generalized linear model (GLM) estimation problem. More specifically, let
can be cast as a generalized linear model (GLM) estimation problem. More specifically, let 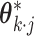 be
be  th column of
th column of 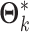 . We have
. We have  , where
, where  is the
is the 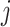 th entry of
th entry of  ,
, 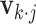 is the
is the 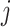 th row of
th row of 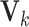 , and
, and 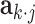 is the
is the  th row of
th row of  . The estimation of
. The estimation of 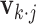 and
and 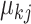 can be obtained by fitting a GLM with the canonical link function, and
can be obtained by fitting a GLM with the canonical link function, and 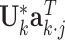 being the offset. Similarly, when we fix the joint loading matrix
being the offset. Similarly, when we fix the joint loading matrix 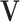 to estimate the joint score matrix
to estimate the joint score matrix 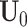 , again this can be formulated as a GLM problem. Let
, again this can be formulated as a GLM problem. Let 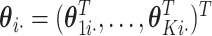 , where
, where  is the column vector of
is the column vector of  th row of
th row of  . We have
. We have 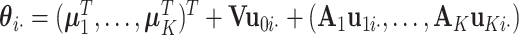 , where
, where 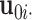 is the column vector of the
is the column vector of the  th row in joint score matrix
th row in joint score matrix  and
and 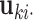 is the column vector of the
is the column vector of the  th row in individual score matrix
th row in individual score matrix  . We remark that the standard GLM model fitting procedure cannot be directly applied to the estimation of
. We remark that the standard GLM model fitting procedure cannot be directly applied to the estimation of 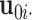 since the canonical link functions are different for different data types across multiple sources. To address this, we follow Li and Gaynanova (2017) and adopt an iteratively reweighted least squares algorithm (IRLS, McCullagh and Nelder, 1989) to accommodate heterogeneous link functions.
since the canonical link functions are different for different data types across multiple sources. To address this, we follow Li and Gaynanova (2017) and adopt an iteratively reweighted least squares algorithm (IRLS, McCullagh and Nelder, 1989) to accommodate heterogeneous link functions.
Then, we estimate individual structures with fixed  and the joint score
and the joint score  and loading
and loading 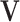 . Based on Model (2.3), the estimation of individual structures is directly separable for each data source. We still exploit the alternating algorithm to estimate
. Based on Model (2.3), the estimation of individual structures is directly separable for each data source. We still exploit the alternating algorithm to estimate  and
and  . Similar to the estimation of the joint structure, the estimation of
. Similar to the estimation of the joint structure, the estimation of 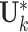 can be parallelized as
can be parallelized as 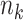 GLMs, and the estimation of
GLMs, and the estimation of  can be parallelized as
can be parallelized as  GLMs. The estimated parameters are then plugged into the log likelihood in Model (3.1).
GLMs. The estimated parameters are then plugged into the log likelihood in Model (3.1).
The estimates in 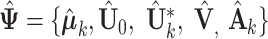 in each iteration may not meet the identifiability conditions in Section 2.3. Some regularization procedure is desired so that the conditions are satisfied and the likelihood values are unchanged. In order to achieve that, after each iteration, we transform the estimated parameters
in each iteration may not meet the identifiability conditions in Section 2.3. Some regularization procedure is desired so that the conditions are satisfied and the likelihood values are unchanged. In order to achieve that, after each iteration, we transform the estimated parameters 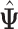 as follows. Define the projection matrix of the column space of
as follows. Define the projection matrix of the column space of  as
as  . We want to project the individual score matrices to the orthogonal complement of the column space of
. We want to project the individual score matrices to the orthogonal complement of the column space of  . However, the individual score matrix
. However, the individual score matrix 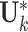 does not have the same dimension as the column space of
does not have the same dimension as the column space of  . To address this, we define a new estimated individual score matrix
. To address this, we define a new estimated individual score matrix  based on
based on  , where the missing observations are filled with
, where the missing observations are filled with 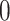 . Then we get the projected individual score matrix
. Then we get the projected individual score matrix 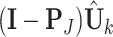 . Column-center the submatrix of the projected individual score matrix containing only complete samples and denote it as
. Column-center the submatrix of the projected individual score matrix containing only complete samples and denote it as 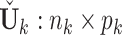 . Apply SVD to the new individual structures
. Apply SVD to the new individual structures 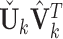 , let the left singular vectors absorb the singular values. Let a score matrix
, let the left singular vectors absorb the singular values. Let a score matrix  be based on the left singular vector and corresponding block-wise missing rows filled
be based on the left singular vector and corresponding block-wise missing rows filled 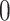 . The new joint structure after identifiability modification is the concatenation of
. The new joint structure after identifiability modification is the concatenation of  matrices where each is
matrices where each is 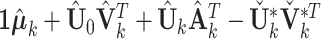 . The column mean of each new joint structure is
. The column mean of each new joint structure is 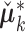 . Apply SVD to the concatenation of each column-centered joint structure, and let the left singular vectors absorb the singular values. We denote the new score and loading matrices as
. Apply SVD to the concatenation of each column-centered joint structure, and let the left singular vectors absorb the singular values. We denote the new score and loading matrices as 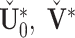 . Consequently, the modified estimators
. Consequently, the modified estimators  satisfy all the conditions.
satisfy all the conditions.
The iterative algorithm terminates when the difference of the log likelihood between the previous step and current step is smaller than a prefixed threshold. Our proposed algorithm is a block coordinate descent algorithm, which ensures the log likelihood in each step of the algorithm is non-decreasing. Thus, the algorithm is guaranteed to converge. We summarize the model fitting algorithm with known ranks for our proposed method in Algorithm 1.

Algorithm 1 GIPCA algorithm
After obtaining the estimates of the parameters in 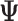 , we impute the block-wise missing entries using the shared parameters. More specifically, we use the same procedure as the regularization step mentioned above to get
, we impute the block-wise missing entries using the shared parameters. More specifically, we use the same procedure as the regularization step mentioned above to get 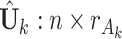 . Then, we can have the estimated complete natural parameter matrix,
. Then, we can have the estimated complete natural parameter matrix, 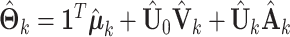 . In particular, the estimated natural parameter matrix for block-wise missing entries is,
. In particular, the estimated natural parameter matrix for block-wise missing entries is, 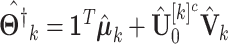 , where
, where 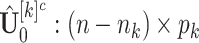 is the complement submatrix of
is the complement submatrix of 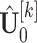 in terms of
in terms of  . Each vector
. Each vector 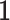 is with the compatible size. By taking the inverse of the link function, the imputed data is
is with the compatible size. By taking the inverse of the link function, the imputed data is 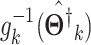 .
.
3.2. Rank estimation: BIC
There are many approaches in the PCA literature to determine the number of principal components or the rank of the latent structure. For example, one may exploit scree plots of eigenvalues to choose the rank that explains a certain proportion of the total variation (Jolliffe, 1986), or use a hypothesis testing procedure (e.g. Bartlett’s test) to determine the rank. There is a large amount of literature on selecting ranks for matrix decomposition with Gaussian assumption. However, there is only a little considering rank estimation for non-Gaussian data. Landgraf and Lee (2015) proposed an approach for binary data based on the percentage of deviance explained by some principal components. As to the rank selection for multi-source data, a permutation testing approach was proposed to JIVE (Lock and others, 2013). BIC is another approach that is adapted to JIVE to implement rank selection (O’Connell and Lock, 2016). A two-step cross-validation method (Li and Gaynanova, 2017) used the sum of squared Pearson residuals as the criterion to select ranks when modeling heterogeneous data with exponential family distributions assumption. Nevertheless, none of the literature mentioned rank estimation for a multi-source data with block-wise missing entries.
Here, we develop an adapted BIC approach to estimate the joint and individual ranks of the underlying natural parameter matrices for multi-source data. The key to the adapted BIC criterion is to calculate the number of parameters to be estimated in the model. The joint score matrix 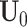 has
has 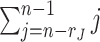 entries to estimate since it has centered columns, which are orthogonal of each other. For each data set, there are
entries to estimate since it has centered columns, which are orthogonal of each other. For each data set, there are 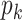 unknown means in Model (2.3). Similarly for the joint and individual loading matrices, they have
unknown means in Model (2.3). Similarly for the joint and individual loading matrices, they have  and
and 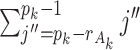 parameters to estimate. The individual score matrix
parameters to estimate. The individual score matrix 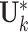 is required to be orthogonal to the joint score matrix and the columns of individual score matrix are centralized and linearly independent of each other. Thus the number of free parameter in the individual score matrix is
is required to be orthogonal to the joint score matrix and the columns of individual score matrix are centralized and linearly independent of each other. Thus the number of free parameter in the individual score matrix is 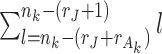 . The number of free parameters in the data sets is,
. The number of free parameters in the data sets is,
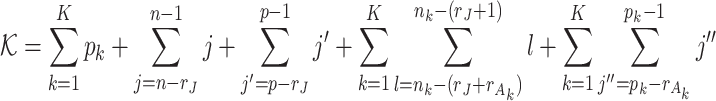 |
The number observations in data set  is
is 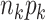 . If there is no block-wise missing in the data sets,
. If there is no block-wise missing in the data sets, 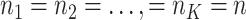 . For each combination of
. For each combination of 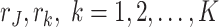 , a BIC score could be calculated. The value of BIC is calculated as,
, a BIC score could be calculated. The value of BIC is calculated as,
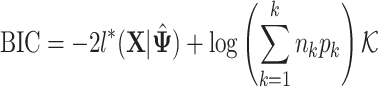 |
(3.2) |
where 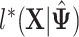 is the value of log likelihood given
is the value of log likelihood given 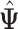 .
.
In practice, we use a stepwise selection approach to select the ranks via BIC. We first compute BIC for the null model 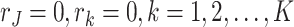 . We add one to or deduct one from each of the ranks at a time and choose the next rank combination with the smallest BIC value. For instance, assume we have two data sets and start from the BIC score for
. We add one to or deduct one from each of the ranks at a time and choose the next rank combination with the smallest BIC value. For instance, assume we have two data sets and start from the BIC score for  . Next, we calculate the BIC value for
. Next, we calculate the BIC value for 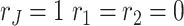 ,
, 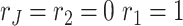 and
and  and choose the ranks with smallest BIC score. The selection procedure is terminated when the BIC score reaches a local minimum. Then the ranks combination when the procedure is stopped is the estimated ranks.
and choose the ranks with smallest BIC score. The selection procedure is terminated when the BIC score reaches a local minimum. Then the ranks combination when the procedure is stopped is the estimated ranks.
4. Simulation
In this section, we conduct comprehensive simulation studies to validate the proposed method. Since there is no existing method that directly addresses the multi-source multi-type data imputation problem, we come up with two ad hoc approaches to compare with our method.
Ad Hoc 1 (EPCA-PCA): First, we estimate a low-rank approximation to the natural parameter matrix of each data set via EPCA. Then, we apply PCA to the concatenated approximations across different data sources.
Ad Hoc 2 (EPCA-SMC): EPCA is first applied to each data set. Then, SMC (Cai and others, 2016) is applied to the estimated natural parameter matrices to impute the block-wise missing entries.
The data sets are generated from Model (2.2) and we apply three different methods to the data and impute the block-wise missing entries. For both Ad Hoc 1 and Ad Hoc 2 methods, if the Gaussian assumption is satisfied for some data sets, then EPCA step is ignored for such data sets and the original data sets are used in the next step (PCA or SMC). The application of SMC is limited to two data sets when only one of them has block-wise missing entries. Therefore, when we apply SMC to more than one data set has block-wise missing entries, we proceed with one data source at a time. For example, if we have two data sources where both have missing observations, apply SMC approach twice to do imputation for both data sets.
4.1. Settings
We set the sample size to be  and the number of variables in each data source to be
and the number of variables in each data source to be 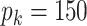 . The joint and individual ranks for the natural parameter matrices are
. The joint and individual ranks for the natural parameter matrices are 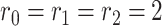 . Joint and individual score matrices
. Joint and individual score matrices 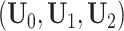 are filled with uniform random numbers
are filled with uniform random numbers  and normalized to have orthonormal columns. In Scenario 4, we try three data sets with similar settings as the other scenarios. We generate different singular values of joint structure and each individual structure for different scenarios, and the singular values are absorbed by the score matrices.
and normalized to have orthonormal columns. In Scenario 4, we try three data sets with similar settings as the other scenarios. We generate different singular values of joint structure and each individual structure for different scenarios, and the singular values are absorbed by the score matrices.
Scenario 1: Gaussian–Gaussian: The individual loading matrices
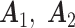 are filled with
are filled with 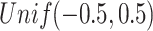 and normalized to have orthonormal columns. The joint loading matrix
and normalized to have orthonormal columns. The joint loading matrix  is generated similarly to have orthonormal columns and is projected to the complement of the column space for the individual loading matrices
is generated similarly to have orthonormal columns and is projected to the complement of the column space for the individual loading matrices 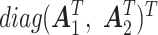 . The singular values of the joint structure were set to be
. The singular values of the joint structure were set to be  , the singular values of the individual structures to be
, the singular values of the individual structures to be 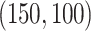 and
and  .
.Scenario 2: Gaussian–Poisson: The procedure to generate individual loading matrices is similar to Scenario 1. The joint loading matrices
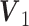 for Gaussian and
for Gaussian and 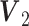 for Poisson are generated from
for Poisson are generated from 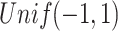 , and
, and 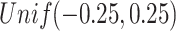 , respectively. The singular values of the joint structure are set to be
, respectively. The singular values of the joint structure are set to be 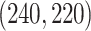 for joint, the singular values of the individual structures to be
for joint, the singular values of the individual structures to be 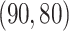 for Gaussian, and
for Gaussian, and 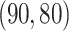 for Poisson.
for Poisson.Scenario 3: Gaussian–binomial: The procedure to generate individual loading matrices is similar to Scenario 1. The joint loading matrices
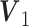 for Gaussian,
for Gaussian, 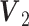 for binomial are generated from
for binomial are generated from 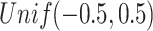 , and
, and  , respectively. The singular values of the joint structure are set to be
, respectively. The singular values of the joint structure are set to be 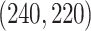 for joint, and the singular values of the individual structures to be
for joint, and the singular values of the individual structures to be 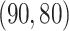 for Gaussian, and
for Gaussian, and 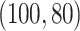 for binomial.
for binomial.Scenario 4: Gaussian–Poisson–binomial: The joint loading matrices
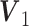 for Gaussian,
for Gaussian, 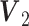 for Poisson are generated from
for Poisson are generated from  , and
, and  for binomial is generated from
for binomial is generated from  . The individual loading matrices
. The individual loading matrices 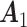 (Gaussian),
(Gaussian), 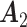 (Poisson),
(Poisson),  (binomial) are generated from
(binomial) are generated from 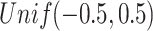 ,
,  , and
, and 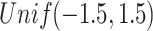 correspondingly. The singular values of the joint structure are set to be
correspondingly. The singular values of the joint structure are set to be 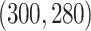 , the singular values of the individual structures to be
, the singular values of the individual structures to be  for Gaussian,
for Gaussian, 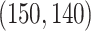 for Poisson, and
for Poisson, and 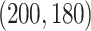 for binomial.
for binomial.Scenario 5: Poisson–binomial: The joint loading matrices
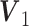 for binomial,
for binomial, 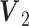 for Poisson are generated from
for Poisson are generated from  , and
, and  respectively.
respectively.
The means for Gaussian data set in each scenario that contains Gaussian data are generated from 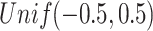 . For Poisson distribution, the inverse of the canonical function makes the realizations skewed to
. For Poisson distribution, the inverse of the canonical function makes the realizations skewed to  if the natural parameter is a negative number with large absolute value and skewed to a large positive number if the natural parameter is a large positive number. Thus, the scale of the natural parameter matrix for Poisson distribution is required to be smaller in Scenarios 2, 4, 5. We also set the means of Poisson distribution to be positive (from
if the natural parameter is a negative number with large absolute value and skewed to a large positive number if the natural parameter is a large positive number. Thus, the scale of the natural parameter matrix for Poisson distribution is required to be smaller in Scenarios 2, 4, 5. We also set the means of Poisson distribution to be positive (from  ) to mimic Poisson data in reality. For binomial distribution, we increase the singular values to boost the signal level of binomial data in Scenarios 3, 4, 5. The means for binomial data set are generated from
) to mimic Poisson data in reality. For binomial distribution, we increase the singular values to boost the signal level of binomial data in Scenarios 3, 4, 5. The means for binomial data set are generated from  .
.
When the natural parameters are fixed, data are generated from the corresponding distributions. For Gaussian data, we set the variance for the generated data to be  . For binomial data, we set the number of trials to be
. For binomial data, we set the number of trials to be 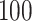 . For each simulation, we randomly pick some rows in each data set to be missing. Those rows should not be overlapped over all the data sets to ensure that for each sample, data from at least one data set are without missing. Different missing rates (
. For each simulation, we randomly pick some rows in each data set to be missing. Those rows should not be overlapped over all the data sets to ensure that for each sample, data from at least one data set are without missing. Different missing rates (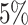 or
or  for rank selection and
for rank selection and  or
or 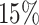 for missing imputation) are applied to the generated data when we compare our proposed method with other existing methods. We repeat the procedure multiple times to evaluate the rank selection performance and compare the imputation accuracy of different methods.
for missing imputation) are applied to the generated data when we compare our proposed method with other existing methods. We repeat the procedure multiple times to evaluate the rank selection performance and compare the imputation accuracy of different methods.
4.2. Result
When the natural parameter matrix for each scenario is fixed, we apply the rank selection procedure mentioned in Section 3.2 to the data generated from corresponding distribution independently for 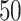 times. BIC criterion (Model (3.2) is used to estimate ranks for each simulation scenarios with different missing rates. We apply the proposed BIC criterion to all the scenarios with different missing rate
times. BIC criterion (Model (3.2) is used to estimate ranks for each simulation scenarios with different missing rates. We apply the proposed BIC criterion to all the scenarios with different missing rate 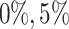 ,
, 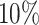 . The results of rank estimation with different simulation scenarios and missing rates are shown in Table S1 in the supplementary material available at Biostatistics online.
. The results of rank estimation with different simulation scenarios and missing rates are shown in Table S1 in the supplementary material available at Biostatistics online.
Overall, the adapted BIC criterion performs well for different settings. The stepwise selection procedure correctly identifies the true ranks for joint structure and individual structures almost all the times for scenarios with two data types with various missing rates. We also apply the selection procedure to Scenario 4 with three data types: Gaussian, Poisson, and binomial. However, for this scenario the BIC-selected ranks tend to be close to the truth but misallocated; the majority of the 50 simulations select the joint rank to be 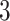 , individual ranks to be
, individual ranks to be 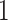 for Gaussian and Poisson, and 2 for binomial. This may be because the signal-to-noise ratio for the binomial data is relatively low compared to the other data sets. Alternative approaches to rank selection that can accommodate to multiple (
for Gaussian and Poisson, and 2 for binomial. This may be because the signal-to-noise ratio for the binomial data is relatively low compared to the other data sets. Alternative approaches to rank selection that can accommodate to multiple (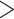 2) sources of data call for more investigation.
2) sources of data call for more investigation.
When the natural parameter matrix is fixed, we generate data from corresponding distributions independently for 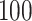 replications. We compare the two ad hoc methods and our proposed method by applying them to the simulated data to estimate elements of
replications. We compare the two ad hoc methods and our proposed method by applying them to the simulated data to estimate elements of 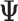 in Model (2.3). We evaluate the imputation accuracy by the relative Frobenius loss. Mathematically, the relative Frobenius loss is defined as,
in Model (2.3). We evaluate the imputation accuracy by the relative Frobenius loss. Mathematically, the relative Frobenius loss is defined as,
 |
(4.1) |
where 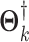 and
and  are true and estimated natural parameter matrices for block-wise missing entries.
are true and estimated natural parameter matrices for block-wise missing entries.
The simulation results for two data sets are shown in Table 1 and for three data sets are shown in Table S2 in the supplementary material available at Biostatistics online. For all scenarios, the imputation accuracy of GIPCA outperforms the other Ad hoc methods with different distribution combinations and different missing rates. Neither EPCA-PCA nor SMC considers partitioning the joint association from individual structure. We also check the Frobenius norm for the difference between the estimated and true means, the relative Frobenius loss for natural parameter matrix without missing entries. We note that under Scenario 1, both EPCA-PCA and GIPCA have similar performance. Under the Gaussian assumption, EPCA-PCA reduces to PCA with the sum of ranks and GIPCA reduces to JIVE without missing entry (Section 2.1). Therefore, their estimation accuracy to estimate natural parameter matrix corresponding to samples without block-wise missing is close to each other.
Table 1.
Simulation results
| Ad Hoc 1 | Ad Hoc 2 | GIPCA | |||||
|---|---|---|---|---|---|---|---|
| Source 1 | Source 2 | Source 1 | Source 2 | Source 1 | Source 2 | ||
| Scenario 1 (5%M) |
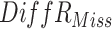
|
8.46 (2.21) | 8.78 (2.07) | 1.13(0.15) | 1.00(0.00) | 0.69 (0.01) | 0.69 (0.00) |
| Gaussian–Gaussian | Running time | 98.12 (12.06) | 3.25 (0.04) | 96.66 (21.79) | |||
| Scenario 1 (15%M) |
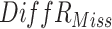
|
7.44 (0.45) | 7.64 (0.46) | 1.36 (0.00) | 1.01 (0.00) | 0.65 (0.00) | 0.72 (0.00) |
| Gaussian–Gaussian | Running time | 98.12 (12.06) | 3.25 (0.04) | 96.66 (21.79) | |||
| Scenario 2 (5%M) |

|
8.13 (5.20) | 2.87 (1.00) | 0.49 (0.01) | 1.31 (0.88) | 0.45 (0.00) | 0.28 (0.01) |
| Gaussian–Poisson | Running time | 238.69 (53.45) | 2.23 (0.05) | 209.77 (65.14) | |||
| Scenario 2 (15%M) |
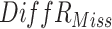
|
9.40 (3.01) | 3.64 (0.29) | 0.72 (0.08) | 0.58 (0.03) | 0.46 (0.00) | 0.47 (0.00) |
| Gaussian–Poisson | Running time | 245.42 (53.78) | 1.84 (0.05) | 221 (54.84) | |||
| Scenario 3 (5%M) |

|
1.11 (0.40) | 1.02 (0.32) | 0.84 (0.00) | 0.99 (0.00) | 0.77 (0.00) | 0.43 (0.00) |
| Gaussian–binomial | Running time | 464.97 (93.89) | 1.82(0.11) | 193.94 (110.07) | |||
| Scenario 3 (15%M) |

|
1.11 (0.40) | 1.02 (0.32) | 0.84 (0.00) | 0.99 (0.00) | 0.77 (0.00) | 0.43 (0.00) |
| Gaussian–binomial | Running time | 473.5 (99.23) | 1.83 (0.11) | 189.65 (106.73) | |||
| Scenario 5 (5%M) |
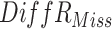
|
6.1 (2.07) | 4.84 (0.88) | 0.58 (0.03) | 4.58 (1.10) | 0.57 (0.01) | 0.84 (0.00) |
| Poisson–binomial | Running time | 188.99 (27.49) | 0.38 (0.03) | 914.98 (177.24) | |||
| Scenario 5 (15%M) |

|
5.66 (1.66) | 5.35 (1.36) | 0.63 (0.02) | 1.47 (0.21) | 0.61 (0.01) | 0.86 (0.00) |
| Poisson–binomial | Running time | 191.19 (33.53) | 0.30 (0.01) | 808.15 (210.31) | |||
Simulation results for two data sets based on  simulation runs when the natural parameter matrices are fixed for each data source. 5%M, 15%M represent the 5% and 15% missing rate correspondingly. The median and the median absolute deviation (MAD) for the relative Frobenius loss under each scenario are calculated. MAD is in parenthesis. The best results are highlighted in bold.
simulation runs when the natural parameter matrices are fixed for each data source. 5%M, 15%M represent the 5% and 15% missing rate correspondingly. The median and the median absolute deviation (MAD) for the relative Frobenius loss under each scenario are calculated. MAD is in parenthesis. The best results are highlighted in bold.
In addition to the simulation settings above, we also explore the scenarios when the signals of the joint and individual structures are distinct. We set the true singular values of the natural parameter matrix of the joint structure relatively small (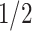 ,
, 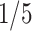 or
or  of the singular values in the original setting in different scenarios). The results are shown in Table S3 in the supplementary material available at Biostatistics online. The results show that the performance of missing imputation for Gaussian–Gaussian and Gaussian–Poisson scenarios is relatively robust against the change of singular values. For scenarios involving binomial distributions, the performance is sensitive to the change of signal.
of the singular values in the original setting in different scenarios). The results are shown in Table S3 in the supplementary material available at Biostatistics online. The results show that the performance of missing imputation for Gaussian–Gaussian and Gaussian–Poisson scenarios is relatively robust against the change of singular values. For scenarios involving binomial distributions, the performance is sensitive to the change of signal.
In order to evaluate how sensitive the algorithm is to initial values, we use different initial values and evaluate the estimation performance. Data are generated in the same way in Section 4.1. For each scenario, we fix the simulated data and generate different initial values based on different random seeds. Table S4 in the supplementary material available at Biostatistics online shows that the performance of missing imputation by the proposed method is stable, which indicates that our algorithm is not sensitive to different initial values.
5. Real data analysis
In this section, we apply our proposed method to a mortality study, where the data are publicly available from human mortality database (HMD, 2011). We focus on exposure-to-risk and population size data sets in two countries, Italy and Switzerland, and analyze the commonality and specificity of the mortality rate patterns in both countries. The chosen data set, exposure-to-risk data set contains realizations of binomial random variables with the number of trials equal to the corresponding entries in population size data set. The Italian data have 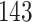 rows where each row represents a year between 1872 and 2014; the Switzerland data have
rows where each row represents a year between 1872 and 2014; the Switzerland data have 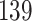 rows where each row represents a year between 1876 and 2014. Since the number of exposure-to-risk becomes quite small at older ages, we only focus on the data at age of 0–90. Therefore, there are
rows where each row represents a year between 1876 and 2014. Since the number of exposure-to-risk becomes quite small at older ages, we only focus on the data at age of 0–90. Therefore, there are  columns each for Italy and Switzerland where each column represents an age group. The mortality data are not available for Switzerland in 1872–1875. We use our proposed method to impute the missing mortality rates.
columns each for Italy and Switzerland where each column represents an age group. The mortality data are not available for Switzerland in 1872–1875. We use our proposed method to impute the missing mortality rates.
Figure 2 illustrates the mortality rates across age groups in different years in each country. The mortality rates are calculated by taking the ratio of the number of exposure-to-risk and corresponding population size. Figures 2a and b are the curve plots, which show the mortality rate as a function of age and each curve represents a year. They show that the mortality rate is relatively high at an early age and decreases dramatically after birth time. The death rate remains stable after birth time to age 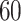 and gradually increases after that time. For Italy, several curves (dashed line and dotted line in Figure 2a) have a surge around 20 years old. Those curves are mortality rate curves in the year from
and gradually increases after that time. For Italy, several curves (dashed line and dotted line in Figure 2a) have a surge around 20 years old. Those curves are mortality rate curves in the year from  to
to 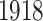 and from
and from  to
to  , when World War I (WWI) and World War II (WWII) happened. The two world wars led to a mass death of young adults in these years. A curve (black solid) in Figure 2a and b stands out against the other curves across all age groups. This black solid curve is the mortality rate curve in
, when World War I (WWI) and World War II (WWII) happened. The two world wars led to a mass death of young adults in these years. A curve (black solid) in Figure 2a and b stands out against the other curves across all age groups. This black solid curve is the mortality rate curve in 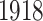 when Spanish flu pandemic happened and led to a mass death for people of all age groups. Figure 2c and d are the heat maps for the true mortality rate of Italy and Switzerland. In the heat map for Italy, the two outlying periods are shown by two horizontal strips in Figure 2c. The first strip around age
when Spanish flu pandemic happened and led to a mass death for people of all age groups. Figure 2c and d are the heat maps for the true mortality rate of Italy and Switzerland. In the heat map for Italy, the two outlying periods are shown by two horizontal strips in Figure 2c. The first strip around age  is the period during the time of WWI. Within this period, there is an outlying line across all the age groups, which is the time of Spanish flu pandemic. The second strip around
is the period during the time of WWI. Within this period, there is an outlying line across all the age groups, which is the time of Spanish flu pandemic. The second strip around 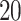 years old is the period during the time of WWII. There is only one thin horizontal line in Figure 2d, which is the period during the flu pandemic.
years old is the period during the time of WWII. There is only one thin horizontal line in Figure 2d, which is the period during the flu pandemic.
Fig. 2.

Spaghetti plots and heat maps for the mortality rate over age for Italy and Switzerland. Black solid line represents the Spanish flu pandemic. Dashed lines represent the WWI. Dotted lines represent the WWII. Grey solid lines represent regular years. (a) Mortality rate over age for Italy. (b) Mortality rate over age for Switzerland. (c) True mortality rate for Italy. (d) True mortality rate for Switzerland.
We apply GIPCA to the mortality in both countries. First, we use BIC to estimate the ranks of the underlying structures. By using the stepwise BIC algorithm, we reach to a rank estimation such that  . We check the trajectory of stepwise BIC values. By comparing the BIC values of
. We check the trajectory of stepwise BIC values. By comparing the BIC values of  and
and 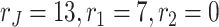 , we figure out that the improvement in BIC for the more complex decomposition is negligible. Thus, we choose
, we figure out that the improvement in BIC for the more complex decomposition is negligible. Thus, we choose 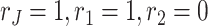 , which leads to a simple and intuitive decomposition of the raw data.
, which leads to a simple and intuitive decomposition of the raw data.
The data types for both data sets are binomial. The link functions for both data sets are logit function. Following Algorithm 1 with rank 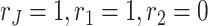 , we get the estimates for the means, joint score and loading matrices, and individual score and loading matrices for Italy and Switzerland. Figure 3 visualizes the estimation results. Figure 3a and b are the estimations of the column means for Italy and Switzerland correspondingly. The two figures demonstrate the overall age-dependent component of mortality rate. It decreases for early age groups and after a certain age, it increases exponentially. The pattern agrees with the Gompertz–Makeham law of mortality, which states that the mortality rate consists of an age-independent component and age-dependent component, increasing with age exponentially (Gompertz, 1825). Figure 3c illustrates the estimated left singular vector (score matrix) for joint structure (i.e. the shared time-varying pattern of mortality rates in different countries). The score vector has a clear dip around year
, we get the estimates for the means, joint score and loading matrices, and individual score and loading matrices for Italy and Switzerland. Figure 3 visualizes the estimation results. Figure 3a and b are the estimations of the column means for Italy and Switzerland correspondingly. The two figures demonstrate the overall age-dependent component of mortality rate. It decreases for early age groups and after a certain age, it increases exponentially. The pattern agrees with the Gompertz–Makeham law of mortality, which states that the mortality rate consists of an age-independent component and age-dependent component, increasing with age exponentially (Gompertz, 1825). Figure 3c illustrates the estimated left singular vector (score matrix) for joint structure (i.e. the shared time-varying pattern of mortality rates in different countries). The score vector has a clear dip around year 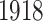 , which is the period of Spanish flu pandemic.
, which is the period of Spanish flu pandemic.
Fig. 3.

Estimated result. (a) Estimated means for Italy. (b) Estimated means for Switzerland. (c) Estimated joint score matrix. (d) Estimated joint loading matrix for Italy. (d) Estimated joint loading matrix for Switzerland. (f) Estimated individual score matrix for Italy. (g) Estimated individual loading matrix for Italy.
Figure 3d and e are the joint loading vector for the two countries. The estimated loading vectors demonstrate that Spanish flu pandemic resulted in a mass death to younger people such as infants and teenagers. The estimated individual score vector for Italy is shown in Figure 3f. It has two apparent dips around 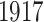 and
and  , which correspond to the periods of WWI and WWII. The individual loading vector for Italy is shown in Figure 3g. It shows that the population aged around
, which correspond to the periods of WWI and WWII. The individual loading vector for Italy is shown in Figure 3g. It shows that the population aged around 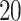 to
to  was mostly affected, probably because they were directly involved in the wars. Switzerland remained neutral during both wars and therefore does not express this mortality pattern.
was mostly affected, probably because they were directly involved in the wars. Switzerland remained neutral during both wars and therefore does not express this mortality pattern.
Next, we evaluate the imputation performance of the proposed method. In particular, we consider three ad hoc methods for imputing missing mortality rates that are commonly used in practice: mean, adjacent years, and same year imputation. More specifically,
Ad Hoc 1 (Mean imputation): The missing entries are imputed with the mean of mortality rate at the same age within the same data set.
Ad Hoc 2 (Adjacent years imputation): The missing entries are imputed with the average of mortality rate within minus/plus
 years of the same age group within the same data set.
years of the same age group within the same data set.Ad Hoc 3 (Same year imputation): The missing entries are imputed with the mortality rate in the same year of the other data set.
We randomly pick 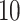 rows (i.e. years) for each data set and set them to be missing. Our proposed method and three Ad hoc methods are applied to the block-wise missing data. We repeat the procedure
rows (i.e. years) for each data set and set them to be missing. Our proposed method and three Ad hoc methods are applied to the block-wise missing data. We repeat the procedure 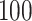 times. The estimated mortality rates are the inverse logit of the estimated natural parameter matrix. The block-wise missing entries are imputed by the inverse logit of the corresponding estimated joint structure. We calculate
times. The estimated mortality rates are the inverse logit of the estimated natural parameter matrix. The block-wise missing entries are imputed by the inverse logit of the corresponding estimated joint structure. We calculate 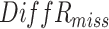 (Model (4.1)) to the imputed and true data and running time for GIPCA and other approaches.
(Model (4.1)) to the imputed and true data and running time for GIPCA and other approaches.
Imputation performance results in Table 2 show that GIPCA outperforms the other three ad hoc approaches in terms of the relative Frobenius loss. Among the three ad hoc methods, the imputation accuracy for Ad Hoc 3 is the closest to what we have for GIPCA. The better performance validates the assumption we make for Ad Hoc 3 that the mortality rates are similar between Italy and Switzerland in the same year. On the other hand, it also agrees with the imputation mechanism implemented by GIPCA that we use the joint association to impute the missing entries. Ad Hoc 2 performs the worst among all the methods. The unsatisfactory results of Ad Hoc 1 and Ad Hoc 2 indicate that simply using average across different years within one data set to impute the missing mortality is limited. When we have two or more data sets, which share the same samples, imputing missing entries by taking the advantage of the shared traits among different data sets is better than using the average within one data set.
Table 2.
Imputation result for mortality data
| Method | Italy | Switzerland |
|---|---|---|
| GIPCA | 0.137 (0.037) | 0.084 (0.009) |
| Ad Hoc 1 Mean imputation | 0.314 (0.056) | 0.319 (0.046) |
| Ad Hoc 2 Adjacent year imputation | 0.468 (0.140) | 0.490 (0.127) |
| Ad Hoc 3 Same year imputation | 0.163 (0.035) | 0.164 (0.024) |
We randomly pick 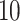 rows for each data set and set them to be missing. Impute the block-wise missing for Italy and Switzerland using GIPCA and 3 ad hoc approaches. The above procedure is repeated
rows for each data set and set them to be missing. Impute the block-wise missing for Italy and Switzerland using GIPCA and 3 ad hoc approaches. The above procedure is repeated  times. The median and the median absolute deviation (MAD, in the parenthesis) for the relative Frobenius loss mentioned in Section 4.2 are calculated. The best results are highlighted in bold.
times. The median and the median absolute deviation (MAD, in the parenthesis) for the relative Frobenius loss mentioned in Section 4.2 are calculated. The best results are highlighted in bold.
6. Discussion
In this article, we develop a GIPCA approach for dimension reduction of data sets from multiple sources with different data types. Our proposed method is also able to deal with multi-source data sets containing block-wise missing entries. We apply the proposed method to mortality data in Italy and Switzerland and identify some meaningful signals, and achieve good missing data imputation accuracy. We also develop a rank selection approach derived from BIC, which accommodates multi-source data of different distributional types.
Based on the result in Section 4.2, the stepwise BIC approach performs well in most scenarios. However, when we have data from more than two sources, the accuracy tends to lower. Alternative rank selection methods call for more investigation. As to the proposed algorithm, although the current GIPCA algorithm only applies to the exponential family distributions, the general idea can be extended to more general non-Gaussian distributions. Extensions to other distributions are future research directions.
7. Software
R code is available on GitHub (https://github.com/zhuhuichenecho/GeneralizedIntegrativePCA).
Supplementary Material
Acknowledgments
Conflict of Interest: None declared.
Funding
This work was supported in part by NIH grant ULI RR033183/KL2 RR0333182 (to E.F.L).
References
- Cai T., Cai T. T. and Zhang A. (2016). Structured matrix completion with applications to genomic data integration. Journal of the American Statistical Association 111, 621–633. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Collins M., Dasgupta S. and Schapire R. E. (2002). A generalization of principal components analysis to the exponential family In: Dietterich T.G.,Becker S. and Ghahramani Z. (editors), Advances in Neural Information Processing Systems, Cambridge, MA: MIT press, pp. 617–624. [Google Scholar]
- Fan J., Liu H., Wang W. and Zhu Z. (2018). Heterogeneity adjustment with applications to graphical model inference. Preprint arXiv:1602.05455. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gompertz B. (1825). On the nature of the function expressive of the law of human mortality, and on a new mode of determining the value of life contingencies. Philosophical Transactions of the Royal Society of London 115, 513–583. [DOI] [PMC free article] [PubMed] [Google Scholar]
- HMD (2011). Human Mortality Database. http://www.mortality.org.
- Johnson W. E., Li C. and Rabinovic A. (2007). Adjusting batch effects in microarray expression data using empirical bayes methods. Biostatistics 8, 118–127. [DOI] [PubMed] [Google Scholar]
- Jolliffe I. T. (1986). Principal component analysis and factor analysis In: Jolliffe I. T. (editor), Principal Component Analysis, Berlin, Germany: Springer, pp. 115–128. [Google Scholar]
- Landgraf A. J. and Lee Y. (2015). Dimensionality reduction for binary data through the projection of natural parameters. Preprint arXiv:1510.06112. [Google Scholar]
- Leek J. T., Scharpf R. B., Bravo H. C., Simcha D., Langmead B., Johnson W. E., Geman D., Baggerly K. and Irizarry R. A. (2010). Tackling the widespread and critical impact of batch effects in high-throughput data. Nature Reviews Genetics 11, 733. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li G. and Gaynanova I. (2017). A general framework for association analysis of heterogeneous data. Annals of Applied Statistics (to appear). [Google Scholar]
- Li G. and Jung S. (2017). Incorporating covariates into integrated factor analysis of multi-view data. Biometrics 73, 1433–1442. [DOI] [PubMed] [Google Scholar]
- Lock E. F., Hoadley K. A., Marron J. S. and Nobel A. B. (2013). Joint and individual variation explained (JIVE) for integrated analysis of multiple data types. The Annals of Applied Statistics 7, 523. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Löfstedt T. and Trygg J. (2011). Onpls—a novel multiblock method for the modelling of predictive and orthogonal variation. Journal of Chemometrics 25, 441–455. [Google Scholar]
- Mazumder R., Hastie T. and Tibshirani R. (2010). Spectral regularization algorithms for learning large incomplete matrices. Journal of Machine Learning Research 11, 2287–2322. [PMC free article] [PubMed] [Google Scholar]
- McCullagh P. and Nelder J. A. (1989). Generalized Linear Models, 2nd edition CRC Press. [Google Scholar]
- Mo Q., Wang S., Seshan V. E., Olshen A. B., Schultz N., Sander C., Powers R. S., Ladanyi M. and Shen R. (2013). Pattern discovery and cancer gene identification in integrated cancer genomic data. Proceedings of the National Academy of Sciences of the United States of America 110, 4245–4250. [DOI] [PMC free article] [PubMed] [Google Scholar]
- O’Connell M. J. and Lock E. F. (2016). R. jive for exploration of multi-source molecular data. Bioinformatics 32, 2877–2879. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ray P., Zheng L., Lucas J. and Carin L. (2014). Bayesian joint analysis of heterogeneous genomics data. Bioinformatics 30, 1370–1376. [DOI] [PubMed] [Google Scholar]
- Schouteden M., Van Deun K., Wilderjans T. F. and Van Mechelen I. (2014). Performing disco-sca to search for distinctive and common information in linked data. Behavior Research Methods 46, 576–587. [DOI] [PubMed] [Google Scholar]
- Shen R., Olshen A. B. and Ladanyi M. (2009). Integrative clustering of multiple genomic data types using a joint latent variable model with application to breast and lung cancer subtype analysis. Bioinformatics 25, 2906–2912. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tseng G. C., Ghosh D. and Zhou X. J. (2015). Integrating Omics Data. Cambridge: Cambridge University Press. [Google Scholar]
- Xiang S., Yuan L.,Fan W.,Wang Y.,Thompson P. M.,Ye J.; Alzheimer’s Disease Neuroimaging Initiative. (2014). Bi-level multi-source learning for heterogeneous block-wise missing data. NeuroImage 102, 192–206. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yang Z. and Michailidis G. (2016). A non-negative matrix factorization method for detecting modules in heterogeneous omics multi-modal data. Bioinformatics 32, 1–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yuan L., Wang Y., , Thompson P. M.,Narayan V. A,Ye J.,Alzheimer’s Disease Neuroimaging Initiative. (2012). Multi-source feature learning for joint analysis of incomplete multiple heterogeneous neuroimaging data. NeuroImage 61, 622–632. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhou G., Cichocki A., Zhang Y. and Mandic D. P. (2016a). Group component analysis for multiblock data: common and individual feature extractiong. IEEE Transactions on Neural Networks and Learning Systems 27, 2426–2439. [DOI] [PubMed] [Google Scholar]
- Zhou G., Cichocki A., Zhang Y. and Mandic D. P. (2016b). Group component analysis for multiblock data: common and individual feature extraction. IEEE Transactions on Neural Networks and Learning Systems 27, 2426–2439. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.