

Abstract
Internet memes have become an increasingly pervasive form of contemporary social communication that attracted a lot of research interest recently. In this paper, we analyze the data of 129,326 memes collected from Reddit in the middle of March, 2020, when the most serious coronavirus restrictions were being introduced around the world. This article not only provides a looking glass into the thoughts of Internet users during the COVID-19 pandemic but we also perform a content-based predictive analysis of what makes a meme go viral. Using machine learning methods, we also study what incremental predictive power image related attributes have over textual attributes on meme popularity. We find that the success of a meme can be predicted based on its content alone moderately well, our best performing machine learning model predicts viral memes with AUC=0.68. We also find that both image related and textual attributes have significant incremental predictive power over each other.
Keywords: Memes, Popularity prediction, Machine learning, Sentiment analysis, Image analysis, Content-based analysis, Social media, Visual humor, COVID-19
Introduction
Over the past decade, Internet memes have become a pervasive phenomenon in contemporary Web culture (Laineste and Voolaid 2017). Due to their popularity, memes have received considerable attention in areas such as pop culture, marketing, sociology, and computer science (Bauckhage et al. 2013; Journell and Clark 2019). In the time of the COVID-19 pandemic, memes have become an even more important part of social life since due to social distancing orders more people turned to the Internet for everyday interactions. As a result, Web culture is moving faster than ever and social media sites have exploded with coronavirus memes as people all over the world try to take this serious situation with a pinch of humor (Bischetti et al. 2020).
The increasingly participatory nature of the Internet has made memes into a social phenomenon, created, altered, and spread by Internet users themselves. Today, memes are not only a source of humor but also draw attention to poignant cultural and political themes (Brodie 2009). Memes tend to reflect pressing global issues and while they are not always loyal to the facts (Simmons et al. 2011), they often show what the public is noticing most. Many authors have explored the social network factors that lead a meme to go viral but bracketed the impact that meme content may have on popularity (Gleeson et al. 2015, 2014; Weng et al. 2012). In other areas of human achievement viral success is closely linked with merit (Yucesoy and Barabási 2016), but it is unclear what characteristics lead a meme to have merit. This paper investigates the relationship between a meme’s content, excluding social network features, and its popularity. Along the way, it exposes what topics were popular on the Internet during the global COVID-19 pandemic.
Our paper joins a growing body of literature that employs network science and data science techniques to predict the popularity of Internet memes (Weng et al. 2012; Maji et al. 2018; Tsur and Rappoport 2015; Wang and Wood 2011). Here we analyze the popularity of coronavirus memes based on 129,326 records scraped from Reddit, the largest social news and entertainment site. The main contributions of this work can be summarized as follows:
Using advanced machine learning techniques (such as convolutional neural networks, gradient boosting, and random forest), we perform a content-based analysis of what makes a meme successful, considering several features from both text and image data.
We stand apart from other authors by investigating whether the success of a meme can be predicted based on its content alone, excluding social network factors.
We not only study what makes a meme viral, but we also analyze what incremental predictive power image related attributes have over textual attributes on memes popularity.
Our study provides a looking glass into the thoughts of Internet users during the COVID-19 pandemic.
Related work
The term “meme” precedes the digital age, stemming from the Greek mim-ma, something imitated. Thus, memes are pieces of cultural information that remain relatively unchanged as they are passed between individuals in society through imitation. In the modern age, the term has been co-opted by Internet users to mean snippets of information that self-replicate on the Internet (Dawkins 2016; Shifman 2014). When memes took the form of hashtags, tweets, photos, quotes or jokes shared repetitively on the web they became highly visible and a common source of data for social computer science researchers. They are transmitted from person to person through social media sites, online news, or blog posts and can reach extremely large audiences in short amounts of time. These viral memes are important, shared social phenomena. They can represent common opinions, cultural norms (Dynel and Messerrli 2020), carry political power or motivate social change (Dynel 2020; Simmons et al. 2011; McClure 2016; Du et al. 2020). Humorous content may play a crucial role in the spread of memes as it encourages user interaction and creates a sense of in-group connection (Vásquez 2019). However, little is understood about what kind of information is so appealing to Internet users as to become viral. Ours is among few studies that places the content of memes under scholarly analysis.
The journey of Internet popularity is commonly framed in network science as competition between memes for limited user attention (Gleeson et al. 2014, 2015). Memes are analogous to genes (Wang and Wood 2011), cultural fragments passed down through generations. In itself, the Darwinian frame through which memes are understood recognizes the importance of meme content. However, most studies focus on how memes diffuse through online social networks (Wang and Wood 2011) taking into account user interests (Weng et al. 2012), memory (Gleeson et al. 2015), and other social factors.
Many studies have successfully predicted the viral Internet memes based on social network factors (Maji et al. 2018; Weng et al. 2014) and others have designed mathematical models that closely align with the actual transmission of memes through the Internet (Weng et al. 2012; Wang and Wood 2011; Bauckhage 2011). Even when measured in many ways, meme popularity displays a long-tailed distribution. Few memes actually become viral, and most are only appreciated by a few tens of people (Gleeson et al. 2015). Memes distributed in more diverse and well-connected audiences are more likely to go viral (Weng et al. 2014). Additionally, people are more likely to share memes related to content that they have shared in the past (Weng et al. 2012). All of these studies put forth neutral models: they assumed no inherent advantage in terms of memes’ attractiveness to individuals.
In addition to social network factors, the content and formatting of a meme can effect its popularity. Tsur and Rappoport (2015) analyzed hashtags on Twitter, and found that brevity is the most important feature for the memes’ popularity followed by certain legibility characteristics such as capitalization. Berger and Milkman (2012) found that more emotionally arousing text segments from online news are more likely to go viral . Our analysis of meme captions’ length replicates the finding by Tsur et al. but our meme sentiment analysis differs from the Berger and Milkman finding. Others note that there is ever increasing engagement with political memes among adults on the Internet and express concern that political memes will be used to promote extremism or spread misinformation. According to a recent look at Twitter data, 30 percent of image-with-text memes contain political content (Du et al. 2020). There are also disparities among what political and demographic groups share those memes (McClure 2016).
While many papers investigate short text data like hashtags (Tsur and Rappoport 2015; Weng et al. 2014), quotes (Simmons et al. 2011), and Google searches (Wang and Wood 2011), few look at the combination image-with-text memes we consider here. Qualitative studies describe the symbols used in meme sub-genres and how their used but do not analyze the impact of these symbols on the memes popularity (Dynel 2016; Dynel and Messerrli 2020). A study by Bauckhage et. al. models how users’ attention to image-with-text memes fluctuates over time (Bauckhage et al. 2013). It shows that evolving memes (slightly different versions of the same meme) are more likely to gain popularity and stay popular for longer. Du et al. (2020) only study the text within image-with-text memes, claiming that the image is merely a neutral background or further emphasizes information already addressed in the text. Our paper contests this claim. Another study by Khosla et al. investigates the content and social contexts of popular images alone, using data from Khosla et al. (2014). They found that certain colors, low-level image properties like hue, and represented objects correlate with increased image popularity. However, popularity on a photo-appreciation sight like Flickr is much different than the social undertones that go into memes. In our model, similar features to those considered by Khosla et al. show different relationships to image popularity.
Our study considers the widest array of content-based attributes in image-with-text memes so far. Furthermore, our data represents the intense political moment at the start of the global coronavirus pandemic.
Data description and preparation
All data for this project were collected from Reddit, the so called “front page of the Internet.” More precisely, the image-with-text memes came from the largest meme subreddits, namely r/MemeEconomy, r/memes, r/me_irl, r/dankmeme, and r/dank_meme. The subreddits represent communities devoted to the creation of memes and consequently, the development of a shared sense of humor on Reddit. Most popular Internet content first went viral on Reddit, hence the websites catchphrase, so popular memes from these subreddits are likely representative of the content on many other Internet sites too. Additionally the strict etiquette implemented by the Reddit community and moderators ensures that posts align with the subreddit description (Sanderson and Rigby 2013). Thus, only image-with-text memes populate the five subreddits from which we scraped data.
We employed the Pushshift API (Baumgartner et al. 2020) to scrape data from posts in the five meme subreddits. In total we scraped 129,326 unique posts from March 17th, 2020 to March 23rd, 2020 which constituted the beginning of the global coronavirus outbreak. For each post we retrieved the features found in lines 1–10 of Table 1. Additional features such as urls to access the post on Reddit and unique meme ids were scraped as well, but only the features we use for analysis are included in Table 1. Likewise, the features downvotes, meme awards, and posting author were scraped from Reddit and eliminated early on because they were incomplete, populated mostly with zeros. Many of the features scraped from Reddit metadata were already numerical, such as created_utc and ups. The categorical features is_nsfw and subreddit were one-hot-encoded into a numerical representation.
Table 1.
Features extracted from Pushshift API together with processed features
| Feature | Type | Description | |
|---|---|---|---|
| 1 | created_utc | utc timestamp | Time of post submission |
| 2 | ups | integer | Number of upvotes received |
| 3 | is_nsfw | Boolean | Indicates if only suitable for 18+ |
| 4 | subreddit | String | Subreddit of the submission |
| 5 | subscribers | Integer | Number of subscribers to the subreddit |
| 6 | thumbnail.height | Floating point value | Height of the thumbnail |
| 7 | thumbnail.thumbnail | String | Thumbnail media |
| 8 | thumbnail.widith | Floating point value | Width of thumbnail |
| 9 | title | string | Title of the submission |
| 10 | media | String | Link to associated meme media |
| 11 | ups_normed | Floating point value | ups normalized with subscribers |
| 12 | dankornot | Integer | Label ups_normed for binary classification |
| 13 | processed_words | List of strings | Filtered and stemmed words from title and image |
| 14 | word_count | Integer | Number of words in title and image |
| 15 | TextLength | Integer | Number of characters in title |
| 16 | Sentiment | Floating point value | Text valence score |
| 17 | avg_H | Floating point value | Average HSV hue value of meme |
| 18 | avg_S | Floating point value | Average HSV saturation value of meme |
| 19 | avg_V | Floating point value | Average HSV value value of meme |
| 20 | 30 colors | Floating point value | Normalized pixels of color in image |
| 21 | VGG_features | List of strings | VGG-16’s first three guesses about image content |
| 22 | VGG_probs | List of floating point values | The probabilities of the VGG-16’s first three guesses |
We further processed the meme images, titles, and text from the images to enrich our feature set with more content-based features. These extracted features are listed in lines 13–22 of Table 1 and discussed in more detail in the “Models and results” section. In the process of extracting the content-based features, we made a GET request on each link and observed the status code. Any post with a link that returned a 404 or other similar error was removed from the data set in order to avoid evaluating dead links. Further, any post with a media other than images, such as gifs, was removed as we only wished to consider image-based memes. These cleaning steps resulted in a total of 80,362 records for training and testing the machine learning models. After numerically encoding the image and text based content features that will be discussed in detail in the next couple sections, there were a total of 97 data attributes.
Some conclusions could be made based on the Reddit metadata alone. The created_utc feature contains the timestamp when the post appeared on Reddit in the Coordinated Universal Time zone (UTC). Since most active Reddit users reside in the USA (Tankovska 2020), we converted this to North American Central Time Zone. Based on this feature we created a categorical feature representing the time of day, in four hour increments, when the post was created. The bottom subfigure of Fig. 1 shows the effect of time of day on the normalized upvotes that posts received. Posts published on Reddit from midnight to noon Central US time have a higher chance to attract great attention. This result could mean that most upvotes on Reddit are accumulated during the course of the day, in USA time zones. The memes posted during daytime (Central US time) have more chance to receive moderate attention, while memes posted at night are more exposed to extreme events, meaning that receiving very low attention or great attention. The observation that memes posted at night have more chance to be dank is in line with the phenomenon that was observed by Sabate et al. (2014) based on the analysis of popularity of Facebook content. The authors argue that if content is posted during periods with low user activity (at night), when users will connect in peak hours the post appears at the top of the news wall, that makes it more likely to be liked, commented or shared.
Fig. 1.

Upper figure shows the number of upvotes for each scraped subreddit. Bottom figure presents the normalized upvotes for each time frame
The more subscribers, the more social exposure, so the number of upvotes a post received was likely influenced by the number of subscribers to the subreddit where it was posted. In our data, r/memes has the most subscribers, around 10,000,000, followed by r/me_irl with around 4,000,000, and r/Meme_Economy with around 1,000,000 subscribers; r/dank_meme and r/dankmeme have the least subscribers, less than 500,000 and less than 1000 subscribers respectively. Indeed, we can observe a positive correlation between upvotes and subscribers, as the subreddits with more subscribers tend to get more upvotes (see Fig. 1 upper subfigure). To confirm this observation, we determined the median number of upvotes for each respective subreddit and calculated a Pearson correlation coefficient between these values and the number of subscribers for each subreddit. We received a value of 0.977 for the Pearson correlation coefficient, which indicates a strong near-linear relationship between the upvotes of a post and the number of subscribers to the subreddit. To eliminate this network effect, we normalized the number of upvotes by dividing by the number of subscribers from the respective subreddit where it was posted. In modifying the upvotes feature, we were able to better gauge the popularity of a meme based upon its content alone.
The viral nature of image-and-text memes on Reddit makes this data well suited for a binary classification task. The distribution of normalized upvotes follows a long-tailed distribution: most memes received few upvotes while few memes received many upvotes as shown in Fig. 2. Therefore, viral memes usually differ by two or more orders of magnitude from not viral memes, as defined by our binary classification label, called dank or not in Table 1, and used for the supervised learning models. Using the the normalized upvotes feature as our criteria, any posts with a normalized upvotes value in the top 5% of all posts was classified as dank (positive label, 1), and the rest were classified as not_dank (negative label, 0). Our data set contains 4019 dank entries, and 76343 not_dank entries. Formulating our prediction labels in this way assured that we investigate the phenomenon of viral popularity (rather than moderately successful or mediocre memes) as proposed in the introduction.
Fig. 2.

The distribution of the normalized upvotes for dank and not dank memes
We will use three supervised learning models to predict whether memes fall into the dank or not dank categories: gradient boosting, random forest, and convolutional neural network models. The former two use the entire feature set described in Table 1 for training (except the media link feature). The neural network model uses only the meme images, accessed via the media feature, as its input and it is based on a smaller sample of data records. This subset of data will be discussed in more detail in the “Transfer Learning with convolutional neural network” section.
Models and results
In this section we present the results of our analysis. First, an explanatory analysis is provided for the textual and image related attributes with a focus on the impact they have on meme popularity. We also present feature engineering steps. Next, we briefly describe the applied machine learning models together with their performance in predicting the success of memes.
Text analysis
A large portion of the humor and meaning of memes are contained in the text which appears inside a meme image. This text differs from the caption of the meme which was written by the user who created the post and can be scraped directly from Reddit. Both the caption and the text contained within the meme itself may affect popularity. In this section, we study the predictive power of the attributes derived from the caption and the text extracted from the images on meme popularity.
The text from the images was extracted using Optical Character Recognition (OCR) (a9t9 software GmbH 2020). We combined the text obtained by OCR with the caption of the meme, to gather all text associated with a meme. Then we performed tokenization, lemmatization, and stemming to simplify all of the words. This was done using the NLTK and gensim Python libraries (Rehurek and Sojka 2011; Loper and Bird 2002). Tokenization is used to split the text into a list of words, make all characters lowercase, and remove punctuation. Words that have fewer than 3 characters and stopwords were removed. Words were lemmatized so that all verbs occur in their first person, present tense form. Finally, words were stemmed, or reduced to their root form. For example, the “processed words” extracted from three memes using OCR, tokenization, lemmatization, and stemming can be seen in Fig. 3.
Fig. 3.

Examples for negative, neutral, and positive sentiment memes along with a few example words obtained from OCR. The memes have been collected from Reddit.com
Using the processed text data we can extract some potentially predictive attributes such as sentiment and word count. First, we calculated the sentiment scores that quantify the feeling or tone of the text (Liu and Zhang 2012). If the text is positive or happy, it scores closer to 1, and negative or sad texts score closer to 0. Examples for different sentiment scores are shown in Fig. 3. The sentiment model we used to analyze the processed meme text uses a recurrent neural network known as LSTM (Long short term memory) (Shreyas 2019). This network remembers the sequences of past words in order to make predictions about the sentiment of new words. The model was trained on dictionaries with hundreds of thousands of words that were already scored for sentiment.
Figure 4 illustrate the relationship between the extracted text features and the normalized upvotes. The framework in which memes compete for limited user attention suggests that users may respond best to memes with shorter texts. Indeed, we found that the amount of text a viewer is required to read correlates negatively with upvotes. This is in alignment with the findings of Kruizinga-de Vries et al. (2012) on the popularity of brand posts in the social media.
Fig. 4.

The relationship between the extracted text features and the normalized upvotes
In Fig. 4 we can also observe that neutral memes perform better than extreme ones, but of the extremes, negative sentiments perform better than positive sentiments. These results contradict previous finding that online news content which evokes high arousal, especially negative, is more viral than neutral content (Berger and Milkman 2012). Another paper found that popular memes tend to be unique, in terms of sentiment and other features, whereas memes that are similar to most other memes perform poorly (Coscia 2014). It is unlikely that humor is usually helped by neutral charged content, instead its associated with surprise which is related to arousal (Chandrasekaran et al. 2015). This result suggests that the jokes in memes particularly are about mundane, not arousing topics.
The words extracted from the text were encoded as numerical attributes and analysed for their relationship with meme content and popularity. Similar groups of words such as “coronavirus”, “virus”, and “pandemic” were grouped together under one name. The 7 word categories can be viewed in Table 2. Then, these categories, along with the top 28 most frequently occurring words in the processed_words attribute (in Table 1), were one hot encoded into 35 numerical feature attributes. In total, including text length, word count, and sentiment scores, there are 38 numerical text features.
Table 2.
Description of word category features
| Category name | Content |
|---|---|
| Current politics |
’econom’, ’world’,’global’,’emperor’,’countri’, ’trump’, ’crash’,’berni’, ’dollar’, ’stock’, ’profit’,’market’, ’bailout’, ’sander’, ’senat’, ’democrat’, ’presidenti’, ’debat’,’govern’,’congress’, ’pass’, ’govern’,’privaci’ |
| Temporal moment | ’2020’,’time’,’year’, ’month’, ’week’, ’day’ |
| Covid culture | ’distanc’, ’social’, ’quarantin’,’isol’,’hand’, ’sanit’,’tp’, ’toilet’, ’paper’ |
| Synonyms, sick |
’fever’, ’cough’, ’short’,’sick’, ’health’,’outbreak’,’exposur’,’breath’, ’diseas’, ’transmiss’, ’symptom’, ’ill’, ’infect’,’cough’ |
| Synonyms, covid-19 | ’corona’, ’coronaviru’, ’viru’, ’vaccin’,’covid-19’, ’covid’,’outbreak’, ’pandem’ |
| Pronouns |
’we’, ’us’, ’our’, ”we’r”, ’i’, ”i’m”, ’i’m’, ’my’, “i’ll”,’you’, “you’r”, ’you’r’, ’your’, ’u’, ’y’all’ |
| About memes | ’meme’, ’reddit’, ’repost’, ’comment’, ’upvot’, ’redditor’, ’post’ |
A word cloud in Fig. 5 created from every word we gathered indicates certain topics are especially prevalent in the memes from late March, 2020. For instance, “coronavirus”, “toilet paper”, “quarantine”, “work”, “home”, “school”, and “friend” all appear most prominently in the word cloud, though some appear in slightly different versions due to our processing. “Memat” is notably one of the prominent words in the word cloud. A popular meme-making website entitled mematic is used by many Reddit users, and each meme produced from the website contains a mematic watermark to indicate its origin. The watermark was apparently read by the OCR as text from the meme. Hence, “memat” is one of the more prominent texts found among the memes. The largest words in Fig. 5 shows that current events do play a great role in the content of memes, though whether this sort of content has a great effect on popularity is another question. An initial analysis showed than in most cases, the words included in table 2 are just as prevalent in the top 5% viral memes as in non-viral memes. The largest difference we found was for the category COVID-19 synonyms in which 23% of dank memes contained at least one word from the category and 17% of not dank memes contained a word from that category. We aim to answer this question further in the following sections by studying the importance of these features to machine learning models.
Fig. 5.

Wordcloud generated from all text in our scraped memes
Image analysis
Most images on the Internet are not neutrally charged. Subtle differences in color, definition or setting can convey vastly different meanings to the viewer. In general unique, bright, high definition images with a low depth of field are ranked more aesthetic by viewers (Datta et al. 2006). Additionally, the presence of certain objects in a photo lead to greater or lesser popularity on Flickr (Khosla et al. 2014). However, memes often have comedic, relatable or reactionary value which is not necessarily aesthetic. The importance of image features may differ for memes as opposed to other types of Internet images.
The image is an important part of a meme. An initial analysis of thumbnail area in our data showed that the majority of memes had the largest thumbnail size available on Reddit. The more popular memes also tend to have larger thumbnail areas.
In addition to thumbnail area, we looked at the colors present in the most popular meme images. Color and thumbnail area are examples of simple image features, aspects of an image that are easily interpreted by human viewers. The colors that the human vision system perceives as distinct have larger value coordinates in HSV (hue, saturation, value) color space, therefore we extracted colors from the HSV versions of our meme images. We used an OpenCV image segmentation technique (Stone 2018) to isolate 30 colors, including a small range around the specific HSV value of the color. This range was used to mask the images, revealing only pixels within that color range. The number of pixels in the mask was normalized for images of differing sizes by dividing by the total number of pixels in the image. These color attributes represent the amount of each of the 30 given colors present in the meme images.
Figure 6 shows the amount of each color attribute in the upper 95 percentile of popular memes. In general, muted colors are more abundant than bright colors in viral memes. Perhaps because memes tend to be mundane photos, often blurry in self-made way, unlike professional photography. This result differs from the similar analysis done by Khosla et al. (2014) in which reds and colors that are more striking to the eye showed the greatest importance. However our results both present blues and greens as less important. Another paper found that images with animate objects tend to be ranked as more funny than images with inanimate objects (Chandrasekaran et al. 2015). Some of the colors found in the most popular memes may be colors that are more common in animate things like animals or human skin and hair tones. Black and off-white were also most present in the bottom 5% of least popular memes, but other parts of the color profile differed. Greens and especially blues were more abundant in these memes, and some shades of orange and brown with large values in Fig. 6 were not present at all in the least popular memes.
Fig. 6.
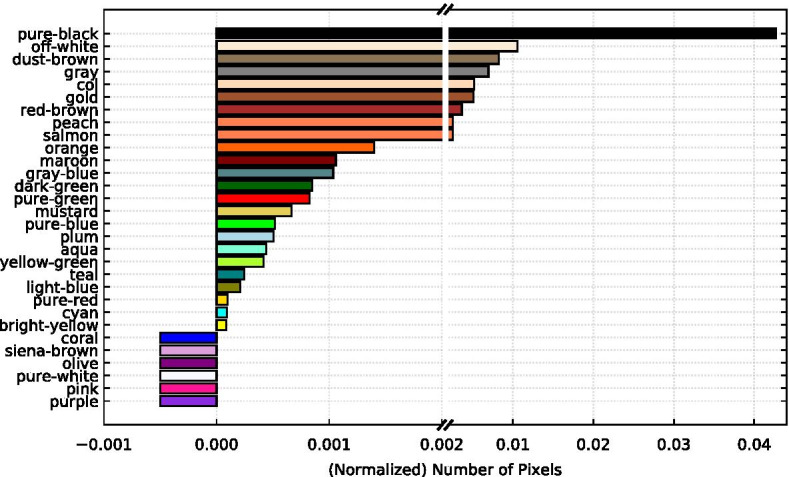
Color content of popular memes. The average amount of each color attribute in the top 5% of memes, 3728 records, with the most normalized upvotes. Bars that go below 0 indicate that none of that color was present in the dank memes
In addition to colors, we extracted the average hue, saturation, and value components of the meme images. These are low level image features because while HSV mimics the way human (and now computer) vision works, these components of an image are not always obvious to the viewer. The relationship between these attributes and meme popularity is visualized in Fig. 7. Hue and saturation show a slight negative correlation with upvotes, indicating that yellow-green hued, less saturated images have a positive impact on popularity. Value shows a slight positive correlation, indicating that images with higher value, more distinct and less dark colors may get more upvotes. These features tended to have significant predictive power in the machine learning models.
Fig. 7.

Average HSV and normalized upvotes. The relationship between meme popularity, measured by normalized ups, and components of the HSV color space
We also analyzed high level image attributes that aim to describe the semantic meaning present in images. By processing the images with the pre-trained Keras’ VGG-16 neural network, we were able to roughly identify what objects are present in the meme images (Chollet et al. 2015). Figure 8 shows the neural net’s meme content predictions, with the associated probability of that prediction. This categorical data is not necessarily accurate, but does convey some level of information about the subject matter of each meme image. Table 3 lists which VGG-identified content was most common in the top 5 percent most popular memes and lower 5 percent least popular memes. These two columns list the top 10 unique values in each of these groups. The most and least popular memes also shared some VGG-identified content, such as the categories website, comic book, and book jacket. This is not surprising as many memes are created using meme-making websites like Mimetic. The top ten shared content categories are listed in the third column of Table 3. Many of the overlapping categories reflect the formatting of the meme and these were the most common categories identified by the VGG-16 neural network across all of the data records. Because terms about the image formatting were so common, we combined these terms into one category called formatted. The neural net identified specific objects within the images less frequently, but these observations, as shown in Table 3, did tend to differ between the most and least popular 5 percent of memes.
Fig. 8.

Neural net high level image features. We extracted high-level, categorical image features from the memes using the pre-trained keras neural network. Examples show the three most certain predicted image components and their probabilities by Keras VGG Neural Net. The memes have been collected from Reddit.com
Table 3.
VGG-identified content in popular and unpopular memes
| Top 5% | Bottom 5% | Shared content |
|---|---|---|
| Balance beam | Iron | web_site |
| Military uniform | Academic gown | comic_book |
| chihuahua | Bow tie | book_jacket |
| Street sign | Matchstick | envelope |
| Cash machine | Hair spray | menu |
| Crossword puzzle | Desktop computer | scoreboard |
| Bakery | Digital clock | laptop |
| Refrigerator | Torch | toyshop |
| Library | Barbell | theater_curtain |
| Toilet tissue | Basketball | packet |
While much of the VGG-identified content referred to miscellaneous items, some of the top categories related to the growing culture around the COVID-19 pandemic. Along with toilet_tissue, lab_coat and mask were within the top 40 most common VGG-identified components in the whole dataset. Many medical masks such as are worn to prevent the spread of COVID-19 were also misidentified as muzzels, gas masks or neck braces by the neural net. Thus these components were combined under one numerical attribute category, masks.
The categorical VGG-identified data was converted to numerical data in a number of ways. Upon observing that many of the VGG-identified objects belonged to similar categories, such as the meme formatting and masks mentioned before, we grouped these into 9 VGG content categories: animals, formatted, sports, clothes, masks, technology, violent content, food and vehicles. Note that some of the content identified in Image 8 would be encoded in one or more of these categories. The categories were then one-hot-encoded into numerical features columns along with the next 8 most common VGG-identified content. These features were somewhat sparse, as the binary one-hot-encoding indicated whether or not a certain vgg prediction, or category, was found in the top three vgg content predictions for the meme. In addition to the binary features, we included the probabilities associated with the top 3 vgg content predictions for an additional 3 vgg related features. These probabilities tended to be ranked as important to the machine learning models discussed in the nextt section.
After these alterations to the raw image data, there were a total of 53 numerical image attributes. The abundance of features leaves room for fine-tuning and eliminating some of them to improve the models. Here, we suggested that certain colors and objects may be associated with viral memes, but the machine learning models will provide more clarity as to what characteristics are actually influential in determining the popularity of a meme.
Gradient boosting and random forest
We selected Gradient Boosting and Random Forest models to perform the binary classification task of placing a memes in the dank or not_dank categories. Both models are ensemble learners that benefit from the accumulated results of weak-learners. The models are trained and tested using the full array of data attributes listed in Table 1, and discussed in the image and text analysis sections. They make predictions based on the same set of labels in which viral memes in the top 5% of normalized upvotes are considered dank, labeled 1, and the rest are not_dank, labeled 0. By observing how these ensemble models make their predictions we can garner insights about the most important features that make memes go viral. Using two models for this task will further validate our results.
Gradient boosting is an ensemble method of weak learners with the optimization of a loss function (Natekin and Knoll 2013). Boosting models fit a new learner on the observations that the previous learner could not handle. The model serves as a good classifier for rank, which suited our binary classification task. The gradient boosting classifier of sklearn’s ensemble package builds in a forward stage-wise manner, which means that a user-defined number of regression trees are fitted on the negative gradient of either the binomial or multi-nominal deviance loss function at each stage and the weighted sum of the learners will be the output (Pedregosa et al. 2011).
The Random Forest is an ensemble method made up of many decision trees. The success of the ensemble depends on the strength of the individual trees and the level of dependence between them. This model is a good choice for our data set because it performs well with a mix of categorical and continuous features, it can handle many features and large amounts of data without risk of over-fitting, and the tree structure is easily interpreted (Breiman 2001). It is quite similar to the Gradient Boosting model, meaning they can be easily compared, and the differences between the models serve to reinforce our results, as our findings are replicated by two models.
Performance and features importance
A limitation to the Random Forest and Gradient Boosting ensemble classifiers is that in their original form they do not perform that well with unbalanced data (Brownlee 2020; Liu et al. 2017). However, many methods for learning unbalanced data with these ensembles have been developed (Chen and Breiman 2004). We modified the models to reduce the effect of skewed data, and generally improve the prediction results. Firstly, we used the BalancedRandomForestClassifier from imblearn as our Random Forest model. This classifier uses random undersampling to train on more balanced subsets of data by resampling data from the training set for each tree classifier in the ensemble. The distribution of positive and negative labels in the training sets can by controlled by the parameter sampling_strategy which represents the proportion of majority to minority class labels. Both the Random Forest and the Gradient Boosting models used 5-fold cross validation, the class weight parameter, and GridSearchCV from sklearn to fine-tune the classifiers’ parameters.
Following these modifications, we split the data into a 53,843 record training set and 26,520 record test set, a 67–33% split. Both models predicted labels on the test set with an AUC of around 0.7 as shown in Fig. 9. Accuracy, recall, precision, and F-1 scores for the highest performing (Random Forest) model can been seen in Table 4, and scores for the gradient boosting model were quite similar. Both models performed poorly in precision. Consistently, the models predicted a larger proportion of positive labels than was realistic for the data set despite the measures we took. Some of the measures we took to to counteract this effect, such as re-assigning thresholds, were adjustable at a cost. Increasing the probability which was sufficient for a positive label would improve the model’s precision but adjusting too much led the recall and accuracy scores to decrease.
Fig. 9.

ROC curve and features importance of gradient boosting and random forest models. a The ROC curves of the models without undersampling techniques. b Features importance for both models
Table 4.
Metrics for the highest performing random forest models
| Accuracy | Precision | Recall | F-1 score | AUC | |
|---|---|---|---|---|---|
| Without undersample | 0.6638 | 0.0854 | 0.5897 | 0.1492 | 0.6804 |
| Undersample train | 0.6043 | 0.0789 | 0.6486 | 0.1408 | 0.6689 |
| Undersample test + train | 0.6366 | 0.6269 | 0.6742 | 0.6497 | 0.6814 |
The difficulty of predicting the imbalanced data, indicated by low precision scores, may be due to the lack of social network features. Perhaps while content-based features can predict whether a meme has a chance at going viral (has merit), social network features are what determines which of those memes actually do go viral. This supports Barabási’s theory on success in general in which merit is the first step to becoming successful, but social networks determine who among those with merit becomes a superstar (Yucesoy and Barabási 2016).
In addition to the modifications listen above, we tried a few undersampling methods. We performed a 67–33% train-test split for all models. The undersampling results for the best performing models, the Random Forest, are listed in Table 4 and the results for the gradient boosting model were very similar. Using the random undersampler module from sklearn, we undersampled only the training data. This did not have a large effect on the models’ performance, indicating that the other measures we took to counteract the imbalanced dataset, and generally improve results, were effective. We also tried undersampling both the test and train data, this improved the precision, and consequently F-1 scores immensely but had only a small effect on our AUC. (Of course, changing the distribution of the test set alters the nature of our prediction goals, therefore we do not report on the results of these tests extensively). We also note that while the precision value might look quite small without adjusting for the unbalanced distribution, but it means a more than 70% improvement to random guessing dank memes.
The features importance plot in Fig. 9 shows the relative importance of the data features from Table 1 for the Gradient Boosting and Random Forest models trained without undersampling. The two models showed similar features importance, with some variability. Additionally, many of the points explored in earlier sections about the features’ relation to upvotes are reinforced by the importance scores. Simple features such as text length and image size (thumbnail.height) showed great importance for predicting viral memes. The important colors in Fig. 9 also align with the most abundant colors in Fig. 6. Gray, off-white, and pure-black are some of the most important colors for the model and are most abundant in viral memes. Figure 9 also indicates that overall more image-based than text-based features are important. However, this could be due to the fact that we included more image based than text based features overall, 53 as opposed to 38.
Incremental predictive power of image and text features
In addition to the most important features shown in Fig. 9, we investigated whether image or text features have more predictive power for determining viral memes. We used the Gradient Boosting and Random Forest models discussed previously with the full amount of train and test data. Differing from the earlier analysis, we trained four Gradient Boosting and four Random Forest models, each of the four with different subsets of features. The models are trained with image-only attributes, text-only attributes, both, and all attributes from Table 1 to show the incremental predictive benefit of these feature groups. The viral nature of memes makes predicting high performing memes more difficult, but since the skew is an inherent part of the data we decided against undersampling the data for this part of the analysis as changing the distribution alters the nature of our prediction question.
As for the previous models presented in Fig. 9, the models were trained with a set of 53,843 and test set of 26,520 data records, a 67–33% split. All of the modifications and fine-tuning, including class-weight and GridSearchCV, efforts used in those models are the same here. The exact feature description differs slightly between versions of these models due to fine-tuning efforts in which certain colors or processed words may have been eliminated if they showed no importance to the model. These slight differences did not disrupt the organization in which the four models had either only text related features, only image related features, both or all features including social network features scraped from the Reddit metadata such as subscribers.
Figure 10 shows the results of the incremental predictive ability analysis. Not surprisingly, the model trained with all data outperformed the other models. This aligns with previous results in which text and network data held more predictive power for image popularity on Flickr (Khosla et al. 2014). It is impressive that adding only four network features (subscribers, created_utc, is_nsfw, and time_of_day) increased the AUC by 0.02 for the Random Forest Model. Given the results that social network features have shown in predicting meme popularity in past papers (Weng et al. 2012, 2014), it is likely we would have seen a much greater increase in AUC if we had included other social network features, too. Surprisingly, it is not obvious whether image related or textual attributes have the stronger predictive power since the Random forest model performed better with the image related attributes, while the Gradient Boosting model performed better with textual attributes. However, it is clear that they both have incremental predictive power over each other in both models.
Fig. 10.

Incremental importance of image and text based features. a Random Forest model and b Gradient Boosting model
Transfer learning with convolutional neural network
Convolutional neural network
Convolutional neural network (CNN) is a class of artificial neural networks that has gathered attention in recent years due to its versatility and ability to achieve excellent performance in a multitude of problems. Among others, it had been used by computational linguistics to model sentences’ semantics (Kalchbrenner et al. 2014), by radiologists to segment organs (Yamashita et al. 2018), by ophthalmologists to identify diabetic retinopathy in patients (Gulshan et al. 2016). CNN’s success lies in its architecture that allows it to learn inherent spatial hierarchies from its training data through recognizing and learning low-level patterns that build up to high-level patterns (Yamashita et al. 2018). This ability to extract important features means that the CNN is able to identify different levels of image representation and capture the relevant ones in the training data, making this model family especially suitable for computer vision tasks (Jogin et al. 2018). Past research has shown that CNN is also able to perform well when it comes to identify an image’s popularity (Khosla et al. 2014). Following this vein of research, in this section, we examine whether we could classify a meme’s dankness solely based on raw image data, ignoring the attributes that we used in previous sections.
Sampling the dataset
The dataset contained approximately 76,000 downloadable images. Because of the imbalanced distribution in posts’ upvotes as can be seen in Fig. 2, we chose to make the not_dank class to be the same size as the dank class by randomly sampling from the 70,000+ images in the not_dank class. We then divided this sub-dataset into training set, validation set, and test set in the following ratio: 50%, 25%, 25%. The exact number of images used in each set is shown in Table 5.
Table 5.
Training, validation, and test set for the CNNs
| dank | not_dank | Total | |
|---|---|---|---|
| Training set | 1856 | 1856 | 3712 |
| Validation set | 928 | 928 | 1856 |
| Test set | 929 | 929 | 1858 |
| Total | 3713 | 3713 | 7426 |
Transfer learning
Deep CNNs normally require a larger amount of training data than we had. Previous research has shown that in cases where there is limited training data, transfer learning is an effective method to significantly improve the performance of the neural network (Tammina 2019) as well as reduce overfitting (Han et al. 2018). Several transfer learning methods have been proposed throughout the years. Here, we adopt the method proposed by Yosinski et al. (2014): using the top layers of the pre-trained CNNs as feature extractors, then fine-tuning the bottom layers with our own dataset, and adding a set of fully connected layers for prediction. The main reason we used this approach is the domain difference between our dataset and the ImageNet dataset which makes it necessary to retrain some of the last layers.
The pre-trained CNN models that serve as our feature extractors were trained using data from the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) (Russakovsky et al. 2015). This dataset consists of roughly 1.2 million training images, 50,000 validation images, and 150,000 testing images in 1000 categories (Krizhevsky et al. 2017). The pre-trained CNN models we picked—namely, InceptionV3, VGG16, ResNet, Xception, MobileNet—are top performers in previous ILSVRC competitions, and their weights trained with this dataset are all available in Keras (Chollet 2015). Out of these models, VGG16, InceptionV3, and Xception proved to be the best performing feature extractors for our dataset. For further information about the models see Table 6. We will provide more details about how we fine-tuned each of these neural networks in a later section.
Table 6.
Information about each network
| Network name | Top 5 accuracy on ImageNet | Parameters | Depth |
|---|---|---|---|
| VGG16 | 0.901 | 138,357,544 | 23 |
| Xception | 0.945 | 22,910,480 | 126 |
| InceptionV3 | 0.937 | 23,851,784 | 159 |
Image data augmentation
Data augmentation is used to expand the dataset by generating and including similar yet slightly modified entries in the training process. In regard to image recognition tasks, the most traditional methods are to add noise or to apply affine transformations (e.g. translation, zoom, rotation, mirror, flip) (Suk and Flusser 2003). Previous research has shown that this procedure could reduce error rate, helps with overfitting, and allows the model to converge faster (van Dyk and Meng 2001). Yosinski et al. (2015) has reported that after augmenting the dataset with randomly translated images, their model see a decrease in error rate from 28 to 20%. Another example is in the design of the VGG16 neural network that was among the winners of the ILSVRC 2014 competition, Simonyan and Zisserman also employed image augmentation techniques such as flipping the images, including randomly cropped patches of the images, or changing color intensity (Simonyan and Zisserman 2014). The authors claimed that this data augmentation helped decreased the error rate by 1%. Similarly, our best three models are all trained using a dataset augmented with the following Keras ImageGenerator transformations:
Rescale the pixel values (between 0 and 255) to the [0, 1] interval.
Zoom into the image randomly by a factor of 0.3.
Rotate the image randomly by 50 degrees.
Translate the image horizontally randomly by a ratio of 0.2 factor the image width.
Translate the image vertically randomly by a ratio of 0.2 factor the image height.
Shear the image randomly.
Flip the image horizontally randomly.
Fine-tuning strategies
Since each network has different architectures, we needed to employ different fine-tuning strategies to each of them. The fine-tuning strategies we used are listed below:
For VGG16, freezing the first three convolution blocks, fine-tuning the weights of all the other layers (in the two other convolution blocks in the network, plus the last three fully-connected layers).
For Xception, freezing the weights of all convolutional layers, and fine-tuning the weights of only the last three fully-connected layers.
For InceptionV3, freezing the weights of all the layers up until the “mixed7” layer, then fine-tuning the rest of the layers in the InceptionV3 network plus the last three manually-defined fully-connected layers.
For all networks, dropout is implemented after the first and the second layer of the last three fully-connected layers.
For all networks (VGG16, Xception, InceptionV3), the last “softmax” layer is removed, and replaced by a “sigmoid” layer for prediction.
The images are resized to fit the default input size for each of the network (299x299 for Xception and InceptionV3, 224x224 for VGG16).
All networks include ReduceLROnPlateau functionality from Keras that reduces the current learning rate by 25% whenever the validation accuracy does not increase in the span of 3 epochs.
Results
All of the neural networks tested for this research were evaluated on the test set using several metrics (Accuracy, Precision, Recall, and F-1 Score). The results are recorded in Table 7. We also calculated the ROC curve of the best 3 models along with their AUC scores which are shown in Fig. 11a. Figure 11b, c show the change in the training and validation accuracy and loss during fine-tuning the VGG16-based model, which produced the best AUC score.
Table 7.
Test set performance for each neural network
| Metrics | VGG16 | Xception | InceptionV3 |
|---|---|---|---|
| Accuracy | 0.5721 | 0.5608 | 0.5327 |
| Precision | 0.5732 | 0.5752 | 0.5362 |
| Recall | 0.5721 | 0.5608 | 0.5327 |
| F-1 Score | 0.5706 | 0.5388 | 0.5212 |
Fig. 11.

ROC curves of the 3 best CNN models and the training curves of the best model. ROC curves and AUC scores a of the best models based on pre-trained CNN models. The accuracy (b) and loss (c) during training of the best VGG16-based model
From Table 7 and Fig. 11, we can conclude that the VGG16-based model seems to slightly outperform the other models, while the Xception-based model comes in second, and the InceptionV3-based model in third place. We can also conclude that the best neural network (AUC = 0.63) performs equally with the best performing ensemlbe model trained on hand-crafted image features (AUC = 0.63).
From our experiments with different models, we have observed that using image augmentation helps with making the models converge faster and achieve a higher accuracy. Fine-tuning the last few layers of the CNN models with the transfer learning methodology also improved the performance of our models. The over-fitting issues we encountered were depressed by adding a dropout rate between layers and reducing the learning rate between epochs. Although we have experimented with several models and parameters, the model performances show that it is hard to predict the dankness of image-and-text memes using the image content alone. This finding is in line with similar previous research where image-content has smaller significant compared to social contexts and other features for predicting image popularity on Flickr (Khosla et al. 2014). The difficulty of content based popularity prediction of memes is also illustrated by the memes where the model prediction does not match the true class label (see Fig. 12). It is a difficult task to tell the true class of these memes both for humans and machines.
Fig. 12.
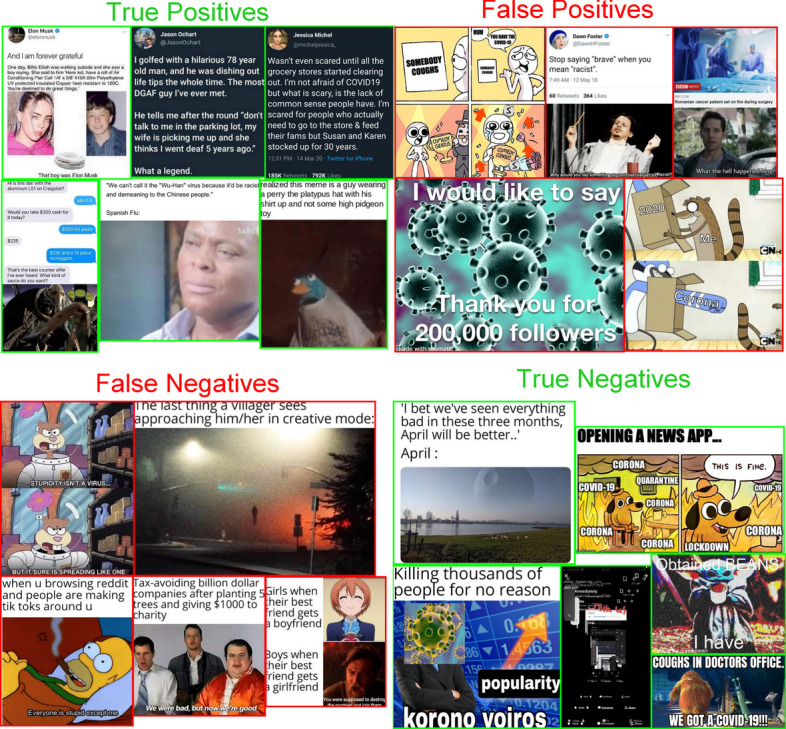
A confusion matrix with example memes according to the CNN model. The green bordered parts show True Positive and True Negative instances where the model prediction is the same as the real target label. The red-bordered parts are False Positive and False Negative instances where the predicted and true class labels do not match. The memes have been collected from Reddit.com
Conclusion
In this paper, we analyzed image-with-text memes collected from Reddit. Using machine learning models we investigated whether viral memes can be predicted based on their content alone. We considered the problem as a binary classification task defining viral memes as the top 5% of all posts in terms of upvotes. Our best performing model is a random forest model that performs moderately well with an AUC of 0.6804, accuracy of 0.6638, precision of 0.0854, recall of 0.5897. While the precision value might seem quite low at first sight, it is a 70% improvement to random guessing dank memes.
Moreover, we studied the most important features and we found that gray content, image size, saturation, and text length have the greatest impact on the prediction. While there was a lot of COVID-19 related content in the dataset overall, visible in the word cloud, and some vgg-identified image content, features related to COVID-19 proved less important to the performance of the models. Thus, we estimate that while memes often reflect pressing world issues, the presence of this sort of content has little impact on whether memes will go viral. We also investigated the predictive and incremental predictive power of image and text features. While we cannot conclude whether image related or textual attributes are the stronger predictors of a meme’s success, we have shown that they both have incremental predictive power over each other. If we use only the images as an input with a convolutional neural network we can reach AUC = 0.63, and that agrees with the performance of the best performing random forest model trained on hand-crafted image features. Comparing our results with other works where social network and community features were also used for predicting popularity (Weng et al. 2012, 2014), we can conclude that while the content-based analysis can also predict success with reasonable efficiency, social network features could improve the performance significantly. While content based features could predict memes with merit, social network features determine which among those with merit actually go viral.
It is also fair to acknowledge some limitations of this study. Due to the the short time period in which we collected data—in the intense moment at the beginning of the coronavirus outbreak—our results cannot necessarily be universally generalized. However, we believe that many of our findings are relevant for meme popularity in general. Moreover, the short time period of the collected data did not allow us to study the temporal and dynamic aspects of meme success or identify so-called “sleeping beauties”. The latter is a phenomenon of information spread in which a meme will remain unnoticed for a long period and then suddenly spike in popularity long after it was originally posted (Zhang et al. 2016). We propose these aspects of meme popularity prediction for future research. Furthermore, an other stream of relevant future research would be to analyze memes inspired by COVID-19 alone.
Acknowledgements
Not applicable.
Abbreviations
- HSV
Hue saturation, value
- OCR
Optical character recognition
- LSTM
Long short term memory
- ROC
Receiver operating characteristic
- AUC
Area under the curve
- CNN
Convolutional neural network
Authors’ contributions
MDT have conceived the study. KB and RM reviewed the literature. TR and MDT collected the data. KB and EL performed the text analysis. KB performed the image analysis. KB and TR trained and analyzed the Gradient Boosting and Random Forest models. MDT trained and analyzed the convolutional neural network model. NB designed the figures and helped supervise the project. RM supervised the project. All authors contributed to the writing of the manuscript, read and approved the final version.
Funding
The research reported in this paper and carried out at the BME has been supported by the NRDI Fund (TKP2020) based on the charter of bolster issued by the NRDI Office under the auspices of the Ministry for Innovation and Technology. RM was also supported by the NKFIH K123782 research grant.
Availability of data and materials
The datasets analysed during the current study are available in the GitHub repository: https://www.github.com/dimaTrinh/dank_data.
Competing interests
The authors declare that they have no competing interests.
Footnotes
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Kate Barnes, Email: k_barnes@coloradocollege.edu.
Tiernon Riesenmy, Email: triesenmy@ku.edu.
Minh Duc Trinh, Email: dtrinh@haverford.edu.
Eli Lleshi, Email: eliriana.lleshi@tufts.edu.
Nóra Balogh, Email: balogh.nora@dmlab.hu.
Roland Molontay, Email: molontay@math.bme.hu.
References
- a9t9 software GmbH (2020) OCR.space free OCR API and online OCR. https://ocr.space/. Accessed 2020-10-01
- Bauckhage C (2011) Insights into internet memes. In: ICWSM
- Bauckhage C, Kersting K, Hadiji F (2013) Mathematical models of fads explain the temporal dynamics of Internet memes. In: Seventh international AAAI conference on weblogs and social media
- Baumgartner J, Zannettou S, Keegan B, Squire M, Blackburn J (2020) The pushshift Reddit dataset. In: Proceedings of the international AAAI conference on web and social media, vol 14, pp 830–839
- Berger J, Milkman KL. What makes online content viral? J Mark Res. 2012;49(2):192–205. doi: 10.1509/jmr.10.0353. [DOI] [Google Scholar]
- Bischetti L, Canal P, Bambini V. Funny but aversive: a large-scale survey of the emotional response to COVID-19 humor in the Italian population during the lockdown. Lingua. 2020 doi: 10.1016/j.lingua.2020.102963. [DOI] [Google Scholar]
- Breiman L (2001) Random forests. University of Californa Berkeley, Statistics Department Thesis, pp 1–33. Accessed 2020-10-01
- Brodie R. Virus of the mind: the new science of the meme. Oxford: Hay House; 2009. [Google Scholar]
- Brownlee J (2020) Bagging and Random Forest for imbalanced classification. Machine Learning Mastery. https://machinelearningmastery.com/bagging-and-random-forest-for-imbalanced-classification/. Accessed 2020-10-01
- Chandrasekaran A, Vijayakumar AK, Antol S, Bansal M, Batra D, Zitnick L, Parikh D. We are humor beings: understanding and predicting visual humor. Comput Vis Pattern Recogn. 2015;4:4603–4612. doi: 10.1109/CVPR.2016.498. [DOI] [Google Scholar]
- Chen C, Breiman L. Using random forest to learn imbalanced data. Berkeley: University of California; 2004. [Google Scholar]
- Chollet F (2015) Keras applications. https://keras.io/api/applications/. Accessed 1 Oct 2020
- Chollet F et al (2015) Keras VGG13 model. GitHub. https://github.com/fchollet/keras. Accessed 1 Oct 2020
- Coscia M. Average is boring: how similarity kills a meme’s success. Sci Rep. 2014 doi: 10.1038/srep06477. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Datta R, Joshi D, Li J, Wang JZ (2006) Studying aesthetics in photographic images using a computational approach. In: 9th European conference on computer vision, vol 3953, pp 288–301
- Dawkins R. The selfish gene. Oxford: Oxford University Press; 2016. [Google Scholar]
- Du Y, Masood MA, Joseph K (2020) Understanding visual memes: an empirical analysis of text superimposed on memes shared on Twitter. In: Proceedings of the fourteenth international AAAI conference on web and social media, vol 14, pp 153–164
- Dynel M. “I has seen image macros!” advice animal memes as visual-verbal jokes. Int J Commun. 2016;10:660–688. [Google Scholar]
- Dynel M. Vigilante disparaging humour at r/inceltears: humour as critique of incel ideology. Lang Commun. 2020;74:1–14. doi: 10.1016/j.langcom.2020.05.001. [DOI] [Google Scholar]
- Dynel M, Messerrli TC. On a cross-cultural memescape: Switzerland through nation memes from within and from the outside. Contrastive Pragmat. 2020;1:210–241. doi: 10.1163/26660393-BJA10007. [DOI] [Google Scholar]
- Gleeson JP, Ward JA, O’Sullivan KP, Lee WT. Competition-induced criticality in a model of meme popularity. Phys Rev Lett. 2014;112(NA):4–31. doi: 10.1103/PhysRevLett.112.048701. [DOI] [PubMed] [Google Scholar]
- Gleeson JP, O’Sullivan KP, Baños RA, Moreno Y. Determinants of meme popularity. Phys Soc. 2015;3(NA):1501–1508. [Google Scholar]
- Gulshan V, Peng L, Coram M, Stumpe MC, Wu D, Narayanaswamy A, Venugopalan S, Widner K, Madams T, Cuadros J, Kim R, Raman R, Nelson PC, Mega JL, Webster DR. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA. 2016;316(22):2402–2410. doi: 10.1001/jama.2016.17216. [DOI] [PubMed] [Google Scholar]
- Han D, Liu Q, Fan W. A new image classification method using cnn transfer learning and web data augmentation. Expert Syst Appl. 2018;95:43–56. doi: 10.1016/j.eswa.2017.11.028. [DOI] [Google Scholar]
- Jogin M, Mohana Madhulika MS, Divya GD, Meghana RK, Apoorva S (2018) Feature extraction using convolution neural networks (cnn) and deep learning. In: 2018 3rd IEEE international conference on recent trends in electronics, information communication technology (RTEICT), pp 2319–2323
- Journell W, Clark CH. Political memes and the limits of media literacy. In: Journell W, editor. Unpacking fake news: an educator’s guide to navigating the media with students. New York: Teachers College Press; 2019. pp. 109–125. [Google Scholar]
- Kalchbrenner N, Grefenstette E, Blunsom P (2014) A convolutional neural network for modelling sentences. CoRR . arXiv:1404.2188. Accessed 2020-10-01
- Khosla A, Sarma AD, Hamid R (2014) What makes an image popular? In: International World Wide Web Conference Committee, pp 867–876
- Krizhevsky A, Sutskever I, Hinton GE. Imagenet classification with deep convolutional neural networks. Commun ACM. 2017;60(6):84–90. doi: 10.1145/3065386. [DOI] [Google Scholar]
- Kruizinga-de Vries L, Gensler S, Leeflang P. Popularity of brand posts on brand fan pages: an investigation of the effects of social media marketing. J Interact Mark. 2012;26(2):83–91. doi: 10.1016/j.intmar.2012.01.003. [DOI] [Google Scholar]
- Laineste L, Voolaid P. Laughing across borders: intertextuality of internet memes. Eur J Humour Res. 2017;4(4):26–49. doi: 10.7592/EJHR2016.4.4.laineste. [DOI] [Google Scholar]
- Liu B, Zhang L. A survey of opinion mining and sentiment analysis. In: Aggarwal CC, Zhai CX, editors. Mining text data. Berlin: Springer; 2012. pp. 415–463. [Google Scholar]
- Liu S, Wang Y, Zhang J, Chen C, Xiang Y. Addressing the class imbalance problem in twitter spam detection using ensemble learning. Comput Secur. 2017;69:35–49. doi: 10.1016/j.cose.2016.12.004. [DOI] [Google Scholar]
- Loper E, Bird S (2002) Nltk: the natural language toolkit. In: Proceedings of the ACL-02 workshop on effective tools and methodologies for teaching natural language processing and computational linguistics, pp 63–70
- Maji B, Bhattacharya I, Nag K, Prabhat U, Dasgupta M. Study of information diffusion and content popularity in memes. Comput Intell Commun Bus Anal. 2018;1031:462–478. [Google Scholar]
- McClure B (2016) Discovering the discourse of internet political memes. In: Adult educational research conference, vol 12, pp 291–293
- Natekin A, Knoll A. Gradient boosting machines, a tutorial. Front Neurorobotics. 2013 doi: 10.3389/fnbot.2013.00021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, et al. Scikit-learn: machine learning in Python. J Mach Learn Res. 2011;12:2825–2830. [Google Scholar]
- Rehurek R, Sojka P (2011) Gensim-statistical semantics in python, vol 8, pp 25–28. Accessed 2020-10-01
- Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, Huang Z, Karpathy A, Khosla A, Bernstein M, Berg AC, Fei-Fei L. ImageNet large scale visual recognition challenge. Int J Comput Vis: IJCV. 2015;115(3):211–252. doi: 10.1007/s11263-015-0816-y. [DOI] [Google Scholar]
- Sabate F, Berbegal-Mirabent J, Cañabate A, Lebherz PR. Factors influencing popularity of branded content in Facebook fan pages. Eur Manag J. 2014;32(6):1001–1011. doi: 10.1016/j.emj.2014.05.001. [DOI] [Google Scholar]
- Sanderson B, Rigby M. We’ve Reddit, have you?: what librarians can learn from a site full of memes. Coll Res Libr News. 2013;74(10):518–521. doi: 10.5860/crln.74.10.9024. [DOI] [Google Scholar]
- Shifman L. Memes in digital culture. Cambridge: MIT press; 2014. [Google Scholar]
- Shreyas P (2019) Sentiment analysis for text with deep learning. Medium https://towardsdatascience.com/sentiment-analysis-for-text-with-deep-lear ning-2f0a0c6472b5. Accessed 2020-10-01
- Simmons M, Adamic L, Adar E (2011) Memes online: extracted, subtracted, injected, and recollected. In: Fifth international AAAI conference on weblogs and social media. Association for the Advancement of Artificial Intelligence, pp 353–360
- Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. arXvi:1409.1556
- Stone R (2018) Image segmentation using color spaces in OpenCv+Python. https://realpython.com/python-opencv-color- spaces/. Accessed 2020-10-01
- Suk T, Flusser J. Combined blur and affine moment invariants and their use in pattern recognition. Pattern Recogn. 2003;36:2895–2907. doi: 10.1016/S0031-3203(03)00187-0. [DOI] [Google Scholar]
- Tammina S. Transfer learning using vgg-16 with deep convolutional neural network for classifying images. Int J Sci Res Publ: IJSRP. 2019;9:9420. [Google Scholar]
- Tankovska H (2020) Regional distribution of desktop traffic to Reddit.com as of May 2020, by country. Statistica. https://www.statista.com/statistics/325144/reddit-global-active-user-distribution/. Accessed 1 Oct 2020
- Tsur O, Rappoport A (2015) Don’t let me be# misunderstood: linguistically motivated algorithm for predicting the popularity of textual memes. In: Ninth international AAAI conference on web and social media
- van Dyk DA, Meng X-L. The art of data augmentation. J Comput Graph Stat. 2001;10(1):1–50. doi: 10.1198/10618600152418584. [DOI] [Google Scholar]
- Vásquez C. Language, creativity and humour online. London: Routledge; 2019. [Google Scholar]
- Wang L, Wood BC. An epidemiological approach to model the viral propagation of memes. Appl Math Model. 2011;35(11):5442–5447. doi: 10.1016/j.apm.2011.04.035. [DOI] [Google Scholar]
- Weng L, Flammini A, Vespignani A, Menczer F. Competition among memes in a world with limited attention. Sci Rep. 2012;2:335. doi: 10.1038/srep00335. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Weng L, Menczer F, Ahn Y-Y (2014) Predicting successful memes using network and community structure. In: Eighth international AAAI conference on weblogs and social media. Association for the Advancement of Artificial Intelligence, pp 535–544
- Yamashita R, Nishio M, Do RKG, Togashi K. Convolutional neural networks: an overview and application in radiology. Insights Imaging. 2018;9(4):611–629. doi: 10.1007/s13244-018-0639-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yosinski J, Clune J, Bengio Y, Lipson H (2014) How transferable are features in deep neural networks? CoRR . arXiv:1411.1792. Accessed 2020-10-01
- Yosinski J, Clune J, Nguyen AM, Fuchs TJ, Lipson H (2015) Understanding neural networks through deep visualization. CoRR. arXiv:1506.06579. Accessed 2020-10-01
- Yucesoy B, Barabási A-L. Untangling performance from success. EPJ Data Sci. 2016 doi: 10.1140/epjds/s13688-016-0079-z. [DOI] [Google Scholar]
- Zhang L, Xu K, Zhao J. Sleeping beauties in meme diffusion. Scientometrics. 2016;112:383–402. doi: 10.1007/s11192-017-2390-2. [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The datasets analysed during the current study are available in the GitHub repository: https://www.github.com/dimaTrinh/dank_data.