

Abstract
While web surveys have become increasingly popular as a method of data collection, there is concern that estimates obtained from web surveys may not reflect the target population of interest. Web survey estimates can be calibrated to existing national surveys using a propensity score adjustment, although requirements for the size and collection timeline of the reference data set have not been investigated. We evaluate health outcomes estimates from the National Center for Health Statistics’ Research and Development web survey. In our study, the 2016 National Health Interview Survey as well as its quarterly subsets are considered as reference datasets for the web data. It is demonstrated that the calibrated health estimates overall vary little when using the quarterly or yearly data, suggesting that there is flexibility in selecting the reference dataset. This finding has many practical implications for constructing reference data, including the reduced cost and burden of a smaller sample size and a more flexible timeline.
Keywords: National Health Interview Survey, Research and Development Survey, propensity score models, health survey, web survey, calibration
1. Introduction
Surveys are important tools for collecting information, particularly at the national level. Probability surveys allow one to estimate outcomes for a specified population of interest which is an important function for federal agencies. For example, the National Health Interview Survey (NHIS) conducted by the National Center for Health Statistics (NCHS) has been used since 1957 to gauge the overall health of the United States. The NHIS is a multipurpose survey covering a range of health topics through in person interviews (https://www.cdc.gov/nchs/nhis/). While national surveys such as the NHIS are often conducted using face-to-face interviews, telephone interviews or mail surveys, more recently web collection has become an increasingly popular mode for surveys. Web surveys, which utilize questionnaires through an online interface, have potential advantages over traditional survey collection methods including lower cost and expedited collection and processing (Callegaro et al. 2015). Although there has been an increasing interest in web-based applications, web surveys have some limitations. For example, since web surveys require Internet access, there may be coverage error (Groves 1989) as non-Internet users are not represented among all survey participants. Although household Internet access has been steadily increasing over the past few decades, 19 percent of households reported not having a broadband Internet subscription (cable, fiber optic, DSL, cellular data plan, satellite, or fixed wireless) in 2016. Lower income households and households led by an individual 65 years and older are less likely to have broadband Internet access and would be underrepresented in online surveys (Ryan 2017). In addition, web surveys administered via opt-in panels do not utilize a statistical sampling method and cannot produce estimates representative of the target population (Cornesse et al. 2020).
In order to study the properties of web survey estimates for health outcomes, the National Center for Health Statistics (NCHS) has been conducting a series of panel survey studies in the U.S. referred to as the Research and Development Survey (RANDS). The RANDS have been administered by external contractors, including Gallup and the National Opinion Research Center (NORC), using probability-sampled commercial panels. Three rounds of web surveys have been completed. The first two studies were administered by Gallup in quarter 4 of 2015 and in quarter 2 of 2016. The RANDS questionnaires in the first two rounds included a subset of questions from the NHIS as well as probe questions for cognitive evaluation. The third web survey was conducted by NORC in quarter 2 of 2018 and included split sample experiments in addition to select NHIS questions and probe questions. The surveys were conducted as probability surveys using the Gallup Panel and the AmeriSpeak Panel, proprietary sampling frames for Gallup and NORC, respectively. While Gallup and NORC calibrated the data using post-stratification weighting to maintain proportionality of demographic groups in the population, the panels and sample weighting methods differ between the external contractors. In this paper, we provide comparisons from the second round of RANDS collected by Gallup.
To adjust for potential selection bias in web survey estimates, methods such as propensity score weighting can be implemented (Taylor 2000, Terhanian and Bremer 2000). This technique utilizes a reference dataset, often a high-quality probability survey, to calibrate the web survey covariates to resemble the covariate distribution in the reference sample. Demographic variables are often specified in the propensity score model, although other variables can also be used (Rubin and Thomas 1996). There are many benefits to using propensity score weighting techniques including flexibility in model formation and small bias under model misspecification (Drake 1993). Previous studies have indicated that propensity score adjustments can reduce or remove biases due to noncoverage, nonresponse, or nonprobability sampling of web surveys (Lee 2006, Lee and Valliant 2009). But while calibration techniques have frequently been utilized to reweight web survey data, limited research has been performed to evaluate the impact of the properties of a reference dataset on the calibrated web survey estimates. In particular, there is interest in understanding how the size and collection timeframe of the reference dataset impact the calibrated web survey estimates. We consider situations where a limited subset of a reference dataset is available, such as one quarter of an annual survey, and compare the web survey estimates across the varying subsets to identify any differences. The usability of smaller reference datasets or reference datasets collected in different time periods would allow for flexibility in selecting a calibration dataset for propensity score weighting. This is particularly important for timely analyses as previous years of data or subsets of national health surveys could be utilized to produce calibrated web estimates without waiting for upcoming data releases.
This paper implements the propensity score adjustment method for estimation of health outcomes from probability-based survey panel data and evaluates the impact of implementing calibration datasets of varying sizes. We posit that reference surveys with well-matched covariate distributions will produce similar propensity score weighted estimates, even if the reference surveys vary in size or are collected over different time periods. In this paper, this is evaluated through the numerical investigation of the RANDS data. We focus on comparisons using the second round of RANDS which was collected in the second quarter of 2016. To compare health outcomes estimates across different reference datasets, we consider the NHIS 2016 public use file and evaluate five calibration datasets: the full year of NHIS 2016 data (NHIS 2016) as well as the four quarterly subsets (NHIS 2016 quarter 1 data, NHIS 2016 quarter 2 data, NHIS 2016 quarter 3 data, and NHIS 2016 quarter 4 data). This study assesses differences in the estimates based on the size of the reference dataset (full year versus quarterly) as well as on the collection period (quarter 2 versus other time periods).
In this paper, the RANDS data collected by Gallup in 2016 and the NHIS data from 2016 are introduced. Methods used to compare the RANDS and NHIS data, including comparisons of demographic features of respondents and major health outcomes are discussed. To assess similarities and differences between the propensity score calibrated health outcome estimates across the five reference datasets, the propensity score adjustment factors are evaluated. The results of these evaluations are reported followed by a summary and discussion of the findings of this study.
2. Data
2.1. RANDS
The second round of RANDS was conducted in the U.S. using the Gallup Panel. Gallup started the Panel in 2004 as a probability-based survey panel that is representative of the U.S. population. Potential panel members are selected using random-digit-dialing or address-based sampling. The panel is multimodal, and members of the panel are contacted using telephone, web, or mail about specific surveys. Approximately 80 percent of members can be reached by email to complete a web survey (“How Does the Gallup Panel Work?” 2019).
The RANDS questionnaire was developed by selecting a set of 88 questions from the NHIS as well as a series of 21 probe questions to conduct response pattern assessments (Scanlon 2017). The NHIS questions selected included questions on the topics of general health, food security, health insurance, working status, chronic conditions, smoking, physical activity, alcohol consumption, and mental health. Gallup invited 8,231 panel members to complete the RANDS web questionnaire. Only panel members who could complete the questionnaire by web were included; panel members who typically responded using telephone or mail modes were not sampled. Sampling strata were assigned by race, ethnicity, age group, and education level. The data collection began on March 16, 2016 and ended on April 13, 2016. Of the members contacted, 2,480 completed the survey, resulting in a 30.1 percent response rate. Gallup provided post-stratified weights which were raked to match characteristics of the U.S. population aged 18 and older from the Current Population Survey by age, race, ethnicity, sex, education level, and geographic region. The post-stratification steps were performed iteratively to converge to the target population proportions. Extreme weights were trimmed and provided as final weights for estimation (National Center for Health Statistics 2020).
2.2. NHIS
The NHIS is a cross-sectional health survey used to monitor health trends in the United States for the civilian noninstitutionalized population and to track progress toward achieving national health objectives. The survey has been conducted continuously since 1957 and collects data on a broad range of health topics annually including health status, health care access, and health care utilization. From 1997 to 2018, the NHIS had four main components including the Household Composition, Family, Sample Adult, and Sample Child. The survey content includes core questions as well as supplemental sections sponsored by other agencies. The 2016 NHIS contained supplementary questions on topics including health care access and utilization, functioning and disability, food security, mental health, balance, immunization, vision, blood donation, chronic pain, Crohn’s Disease, diabetes, e-cigarettes and use of tobacco products, hepatitis B/C screening, internet access and email usage, and heart disease and stroke prevention (National Center for Health Statistics 2017). We focus on a subset of questions that overlap with round 2 of RANDS.
Survey administration is conducted by the U.S. Census Bureau under contract with NCHS through in-person household interviews. Face-to-face interviews are conducted in the respondent’s home, although follow up interviews may be conducted over the phone. The household response rate for the 2016 NHIS was 67.9 percent, with an 80.9 percent response rate of adults in responding households (54.3 percent unconditional response rate of sample adults). There were 33,028 adult NHIS respondents in 2016 selected for comparison to RANDS. Of this sample, 8,227 responded in quarter one, 8,256 responded in quarter two, 8,351 responded in quarter three, and 8,194 responded in quarter four.
The NHIS sample weights are derived from the probability of selection at each sampling stage. The final weights were calibrated for nonresponse and post-stratified by age, sex, race, and ethnicity classes using 2010 census-based population estimates (National Center for Health Statistics 2017). Quarterly weights were calculated as a function of the final annual weights.
3. Methods
3.1. Comparison of Demographics
Seven demographic variables and two general health variables were selected to evaluate differences between the characteristics of the RANDS and NHIS respondents. The variables considered included age group (18–34; 35–54; 55–64; 65–74; 75 and over), sex (male; female), race and ethnicity (non-Hispanic white; non-Hispanic black; non-Hispanic Asian; non-Hispanic other; Hispanic), education level (less than high school or GED; high school graduate; associate degree or some college; bachelor’s or higher degree), family income (<$50,000; $50,000-$99,999; >=$100,000), geographic region (Northeast; Midwest, South; West), marital status (married/living with partner; single/never married; separated/divorced/widowed), self-rated health status (excellent; very good; good; fair; poor), and body mass index (BMI) category (underweight, BMI<18.5; normal, 18.5<= BMI <25; overweight, (25<= BMI <30; obese, BMI>=30) which was determined using reported height and reported weight from both surveys. The RANDS had item nonresponse for race and ethnicity, family income, geographic region, marital status, self-rated health status, and BMI category (due to missing values in reported height and weight). The NHIS had item nonresponse for education level, family income, marital status, self-rated health status, and BMI category (due to missing values in reported height and weight). Item nonresponse for family income was used to directly compare missingness in RANDS, however, National Health Interview Survey imputed income files are available online to address item nonresponse.
Estimates for RANDS and NHIS were obtained using SAS PROC SURVEYFREQ, which incorporates the survey weights and sample design into the estimation procedure. A sample design with stratification and clustering was specified. All estimates in this paper meet the NCHS standards of reliability (Parker et al. 2017). Differences in the observed demographics and general health covariates between RANDS and each of the NHIS datasets (2016 quarter 1, 2016 quarter 2, 2016 quarter 3, 2016 quarter 4, and the full year of 2016 data) were evaluated using the Rao-Scott chi-square test which is survey design adjusted (Rao and Scott 1981, 1984, 1987). Differences across the four NHIS quarters are also assessed using the Rao-Scott chi-square test, although the demographic distribution of the full year of NHIS 2016 data is not statistically compared to the quarterly subsets due to the overlapping sample.
3.2. Comparison of Health Outcomes
To evaluate the use of RANDS and web surveys to estimate major health measures, we consider six health outcomes related to smoking status, food security, health insurance, hypertension, asthma and diabetes. The six survey questions included on both RANDS and NHIS associated with these outcomes (with the possible categorical responses) are:
Have you smoked at least 100 cigarettes in your entire life? How often do you now smoke cigarettes? (Current smoker, former smoker, never smoker)
I worried whether my food would run out before I got money to buy more. (Often true, sometimes true, never true)
Do you have any of the following kinds of health insurance or health care coverage? Private health insurance, Medicare, Medi-Gap, Medicaid, SCHIP (CHIP/Children’s Health Insurance Program), Military health care (TRICARE/VA/CHAMP-VA), Indian Health Service, State-sponsored health plan, Other government program, Single service plan (e.g., dental, vision, prescriptions)? (Yes, no)
Have you ever been told by a doctor or other health professional that you had hypertension, also called high blood pressure? (Yes, no)
Have you ever been told by a doctor or other health professional that you had asthma? (Yes, no)
Have you ever been told by a doctor or other health professional that you have diabetes or sugar diabetes? (Yes, no)
Differences between the RANDS estimates and the NHIS estimates were assessed using the Rao-Scott chi-square test. Propensity score adjustments were applied to the health outcomes estimates to calibrate the RANDS estimates to the NHIS. In this study, we consider various reference samples for the calibration, including the NHIS 2016 data and each of the subsets of quarterly data from the 2016 NHIS.
3.3. Propensity Score Adjustment
Propensity score weighting is a statistical method that has been used for calibrating survey weights to a reference survey. This approach is similar to post-stratification as it balances the covariates included in the propensity score model to the covariate distribution of a reference survey. For models that contain all potential confounders, the propensity score adjustment on the survey weights produces unbiased estimates of the treatment effect that are generalizable to the target population of the reference survey (Lee 2006, DuGoff, Schuler, and Stuart 2014). The probability of inclusion in the survey of interest (e.g., RANDS) is modeled using logistic regression on common covariates from the two surveys. This propensity score model is used for prediction of the estimated probability for adjusting the survey weights, although statistical tests on the model parameters can be used to evaluate significant associations between covariates and the odds of responding to the survey of interest. The inverse of propensity weighting method (Valliant and Dever 2011) is often utilized to adjust the survey weight to the target population represented by the benchmark survey through the adjustment factor . Final propensity score adjusted weights are obtained by multiplying the original survey weight by the propensity adjustment factor.
For the RANDS data, the propensity score model was formed using the demographic covariates and general health variables (age group, sex, race and ethnicity, education level, family income, geographic region, marital status, self-rated health status, and BMI category) to adjust for any differences identified between RANDS and NHIS. Item nonresponse was treated as a separate category in the estimation procedure to account for differences in missing values. Prior to fitting the propensity score model, the NHIS weights were normalized to the sample size of the survey. A first order logistic model was formed using the nine demographic and health covariates to estimate the propensity of participating in RANDS compared to NHIS. The reference category for each categorical variable was selected as the last nonmissing category shown in Table A1 (see Appendix). The RANDS weights were multiplied by the propensity adjustment factor to produce the pseudo sampling weights for calculating calibrated RANDS mean and variance estimates for each of the health outcomes. This process was repeated to calibrate RANDS to each of the NHIS datasets for comparison.
3.4. Comparison of Calibrated Estimates
The calibrated RANDS outcome estimates were not statistically compared to NHIS estimates as the calibrated dataset and the NHIS are not independent. However, differences between the propensity score calibrated RANDS estimates over the five reference surveys were statistically evaluated through an analysis of variance (ANOVA) of the propensity adjustment factors. Since the propensity score calibrated estimates are a function of the propensity adjustment factor, reference surveys that produce similar adjustment factors should be expected to result in similar calibrated estimates. Thus significant differences between the adjustment factors derived from the propensity score models indicate differences in the calibrated RANDS estimates due to the various reference surveys (NHIS 2016 quarter 1, NHIS 2016 quarter 2, NHIS 2016 quarter 3, NHIS 2016 quarter 4, and the full year of NHIS 2016 data) while a lack of statistically significant differences indicate that the reference surveys produced consistent calibrated RANDS estimates for the six health outcomes within the detection limits of the test.
4. Results
4.1. Comparison of Demographics
Table A1 reports the weighted estimates for demographic and general health covariates in RANDS and NHIS. For NHIS, the estimates are reported for surveys collected during each quarter of 2016 as well as an overall estimate from all surveys collected during 2016. The count of item nonresponse is also recorded in Table A1. While family income and marital status were missing in both surveys, the two demographic variables were missing more often in RANDS.
The distribution of demographic and health variables in the NHIS full year and quarterly data are very similar. The weighted estimates among the NHIS quarterly subsets are consistent with the estimates from the full year of NHIS data for most of the demographic variables, including age group, sex, race and ethnicity, and geographic region. More differences were seen between the NHIS full year data and the quarterly data for education level, family income, marital status, self-rated health status, and BMI category. Demographic variables across the four NHIS quarters were compared using the Rao-Scott chi-square test. This test confirmed that the weighted estimates for the demographic variables were consistent across the NHIS quarters, except for education level which differed significantly at the 5 percent significance level. Post hoc Rao-Scott chi-square tests with a Bonferroni correction did not identify statistically significant differences in education level between specific quarters as the Bonferroni correction is conservative, although we observe that quarters 1 and 2 had larger percent estimates for persons with less than high school education while quarter 4 had a larger percent estimate for persons with an associate degree or some college.
Rao-Scott chi-square tests were used to compare the demographic and general health variables from RANDS to each of the five NHIS datasets (four quarters and the full year data). Significant differences in the observed samples were identified between RANDS and each NHIS dataset for all variables except sex and geographic region. We observe that RANDS reported a weighted estimate of 26.9 percent for the 18–34 age group and 5.0 percent for the 75 and over age group, while NHIS reported estimates ranging from 29.9 percent to 30.0 percent for the 18–34 age group and 7.9 percent to 8.0 percent for the 75 and over age group. In addition, RANDS reported an estimate of 73.2 percent non-Hispanic white adults while the NHIS datasets reported estimates ranging from 64.7 to 65.3 percent. For education level, RANDS reported a weighted estimate of 2.2 percent for less than high school or GED, while NHIS estimates ranged from 13.9 percent to 16.3 percent. The RANDS estimate for “Excellent” self-rated health status was 12.8 percent while the NHIS estimates ranged from 26.9 percent to 28.1 percent and the RANDS estimate for obesity (BMI category=obese) was 37.2 percent while NHIS estimates ranged from 29.7 percent to 30.6 percent.
4.2. Comparison of Health Outcomes
The unadjusted health outcome estimates in RANDS and NHIS are reported in Table A2 (see Appendix). The estimates of the observed health outcomes significantly differ between the two surveys for smoking status, food security, hypertension, and asthma. RANDS tends to underestimate the proportion of the population who have never smoked and overestimates the proportion that has had concerns about their food running out before they had money to buy more (food security responses “often true” or “sometimes true”) compared to NHIS. Moreover, the estimates produced from RANDS tended to overestimate hypertension prevalence and asthma prevalence in the population compared to NHIS. Health insurance estimates and diabetes prevalence estimates were not found to significantly differ between RANDS and any of the five NHIS datasets.
Both RANDS and NHIS are missing reported health outcomes, although RANDS is missing a higher percentage of responses. The percent of missing health outcomes in RANDS ranged from 0.69 percent (health insurance and diabetes) to 1.41 percent (smoking status). Missing data patterns were fairly consistent between the full year of NHIS data and the quarterly subsets. Health insurance had the highest percent of missing responses for all five NHIS datasets (0.41 percent, 0.47 percent, 0.38 percent, 0.56 percent, and 0.46 percent for NHIS Q1, Q2, Q3, Q4, and full year, respectively). NHIS quarter 2, quarter 3, and the full year data had the lowest percent missingness in the outcome food security (0.01 percent, 0.06 percent, and 0.05 percent, respectively) while quarter 4 was missing asthma for only 0.02 percent of records. NHIS quarter 1 had the lowest percent of missing responses for the outcomes food security and asthma (0.06 percent for each).
4.3. Propensity Score Adjustment
Most demographic and health variables included in the propensity score models were identified as being significantly associated with the probability of inclusion in RANDS except sex which was not significant in any of the five propensity score models and BMI category which was not significant in four of the five propensity score models (mildly significant in the model using NHIS 2016 Q1 as a reference dataset). The parameter estimates for missing values for some of the covariates were relatively larger than other estimates due to the small number of missing values. Fit statistics indicated covariates improved model fit compared to the intercept model (not shown). The fit of each propensity score model varied slightly by reference dataset, although the fit for the propensity score models for the quarterly reference datasets were comparable (Table A3 in the Appendix).
4.4. Comparison of Calibrated Estimates
The calibrated RANDS estimates which use the full year of 2016 NHIS data as well as the quarter 1, quarter 2, quarter 3, and quarter 4 data from the 2016 NHIS as reference datasets are reported in Table 1. The extent of the calibration of the RANDS estimates compared to the NHIS health outcome estimates (reported in Table A2) varied. The propensity score weighting resulted in improved web estimates for smoking status that more closely reflected the NHIS estimates. Although the propensity weighting decreased the estimates for health insurance coverage, hypertension prevalence, and diabetes prevalence, the adjusted estimates were further from the NHIS estimates than the unadjusted estimates. While the RANDS estimates differed from the NHIS, this decrease due to weighting reflects the impact of calibrating to the NHIS as these outcomes were previously overestimated in RANDS. In the case of measures for food security and asthma, calibration to the reference datasets did not improve the RANDS estimates relative to the NHIS. The varied performance of the calibrated estimates suggests that additional research could be performed to improve propensity score weighting methods for web survey calibration of some outcomes.
Table 1.
Propensity Score Adjusted RANDS Health Outcome Estimates
| Variable | Unadjusted | Reference Dataset for Adjusted Estimates | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NHIS 2016 Q1 | NHIS 2016 Q2 | NHIS 2016 Q3 | NHIS 2016 Q4 | NHIS 2016 | ||||||||
| Est | SE | Est | SE | Est | SE | Est | SE | Est | SE | Est | SE | |
| Smoking Status | ||||||||||||
| Current | 15.2 | 1.12 | 15.5 | 3.19 | 15.1 | 2.76 | 14.7 | 2.61 | 15.4 | 2.97 | 14.9 | 2.75 |
| Former | 30.2 | 1.43 | 26.3 | 2.06 | 26.3 | 1.96 | 26.1 | 1.86 | 26.3 | 1.90 | 26.3 | 1.90 |
| Never | 54.6 | 1.55 | 58.1 | 3.05 | 58.6 | 2.82 | 59.2 | 2.67 | 58.3 | 2.84 | 58.8 | 2.75 |
| Food Security | ||||||||||||
| Often true | 4.3 | 0.63 | 3.2 | 0.62 | 3.2 | 0.59 | 3.1 | 0.56 | 3.2 | 0.58 | 3.2 | 0.59 |
| Sometimes true | 14.6 | 1.10 | 16.0 | 3.30 | 15.7 | 2.94 | 15.2 | 2.76 | 15.6 | 2.99 | 15.5 | 2.87 |
| Never true | 81.1 | 1.19 | 80.8 | 3.26 | 81.1 | 2.92 | 81.7 | 2.74 | 81.2 | 2.96 | 81.3 | 2.85 |
| Health Insurance | ||||||||||||
| Yes | 92.5 | 0.85 | 87.6 | 3.52 | 87.6 | 3.18 | 88.3 | 2.96 | 88.3 | 3.20 | 88.3 | 3.06 |
| No | 7.5 | 0.85 | 12.4 | 3.52 | 12.4 | 3.18 | 11.7 | 2.96 | 11.7 | 3.20 | 11.7 | 3.06 |
| Hypertension | ||||||||||||
| Yes | 35.2 | 1.42 | 26.7 | 1.92 | 27.0 | 1.84 | 26.5 | 1.74 | 27.0 | 1.79 | 26.9 | 1.79 |
| No | 64.8 | 1.42 | 73.3 | 1.92 | 73.0 | 1.84 | 73.5 | 1.74 | 73.0 | 1.79 | 73.1 | 1.79 |
| Asthma | ||||||||||||
| Yes | 19.2 | 1.28 | 20.7 | 2.67 | 21.1 | 2.68 | 20.9 | 2.47 | 20.8 | 2.53 | 20.7 | 2.48 |
| No | 80.8 | 1.28 | 79.3 | 2.67 | 78.9 | 2.68 | 79.1 | 2.47 | 79.2 | 2.53 | 79.3 | 2.48 |
| Diabetes | ||||||||||||
| Yes | 10.3 | 0.95 | 6.3 | 0.77 | 6.7 | 0.79 | 6.5 | 0.76 | 6.8 | 0.84 | 6.6 | 0.79 |
| No | 89.7 | 0.95 | 93.7 | 0.77 | 93.3 | 0.79 | 93.5 | 0.76 | 93.2 | 0.84 | 93.4 | 0.79 |
Note: Est stands for estimate, SE stands for standard error, estimates and standard errors are presented as percentages (%)
However, while the calibrated health outcome estimates in RANDS differed from the NHIS estimates, the estimates across the five reference datasets were similar. Figure 1 displays the calibrated estimates for the health outcomes using each calibration dataset and the corresponding 95 percent confidence intervals. Estimates for all six health outcomes were consistent across the five NHIS datasets. Using the full year versus a single quarter of NHIS data did not greatly impact the calibrated RANDS estimates. In addition, estimates using reference datasets collected over different time periods than RANDS (i.e. quarters 1, 3, and 4) were similar. The standard errors were larger for the adjusted estimates compared to the unadjusted RANDS data, although the standard errors tended to be slightly lower when using the full year of NHIS 2016 data as the calibration dataset.
Figure 1:
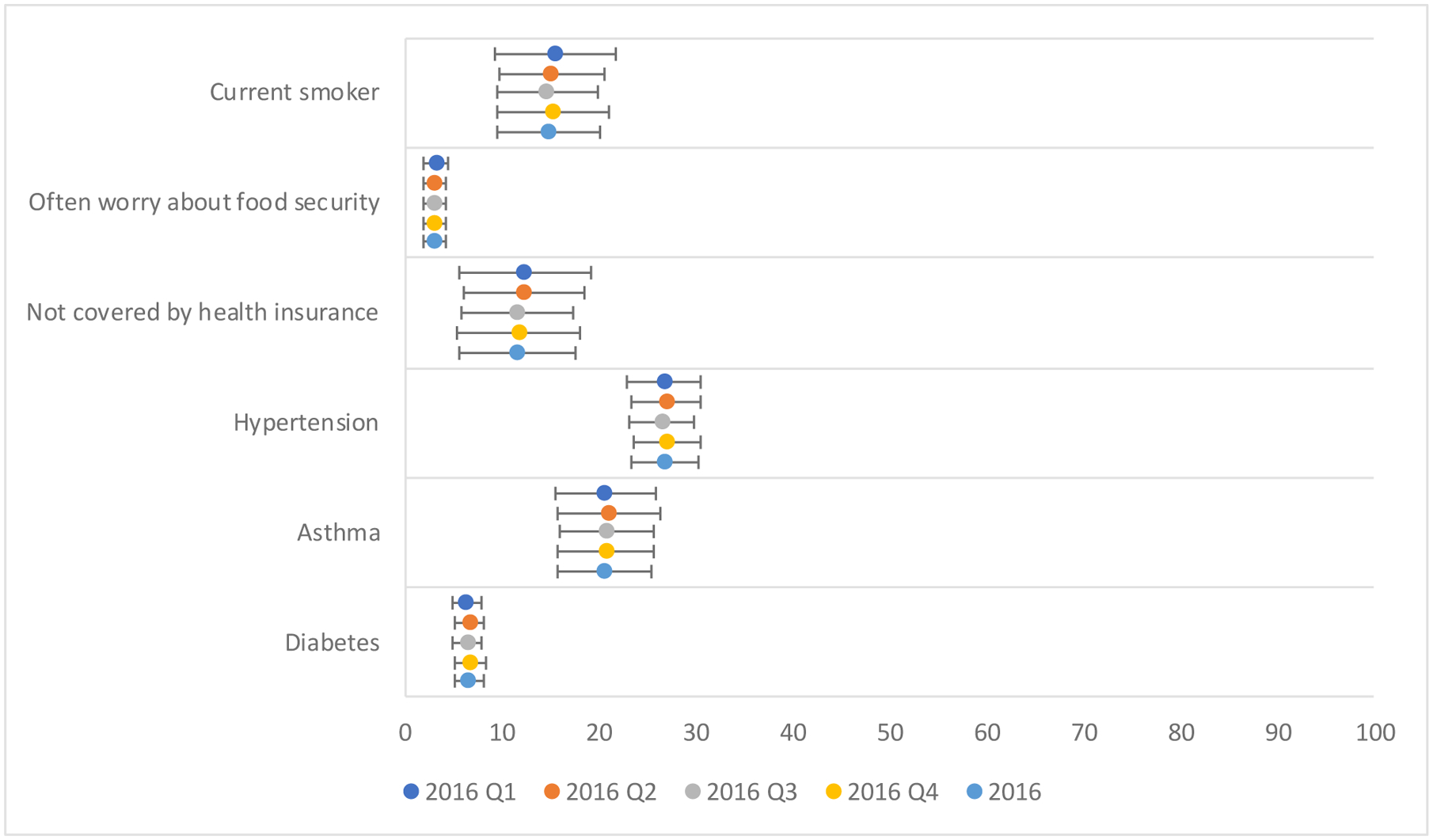
Calibrated RANDS estimates and 95% confidence intervals by reference dataset
To further evaluate the effect of the reference dataset on propensity score weighting, we compare the propensity adjustment factors across the five reference datasets. The adjustment factors were normalized to the RANDS sample size (n=2,480) for comparison. The mean, standard deviation, minimum, maximum, and quartiles for each of the normalized propensity adjustment factors are reported in Table 2. Statistical testing of the propensity adjustment factors using ANOVA indicate that the adjustment factors from each of the reference datasets do not significantly differ despite differences in the size and collection time period of the reference datasets. Figure 2 displays box plots for the adjustment factors ranging between 0 and 2.5 by reference dataset (full range of propensity adjustment factors is described in Table 2). The plot shows that the overall spread of the propensity adjustment factors is similar across all five reference datasets, which similarly suggests that the propensity score calibrated estimates are consistent across the reference datasets.
Table 2.
Descriptive Statistics of Normalized Propensity Adjustment Factors ((1-p)/p) by Reference Dataset
| Reference Data | Mean | Standard Deviation | Minimum | Lower Quart ile | Median | Upper Quartile | Maximum |
|---|---|---|---|---|---|---|---|
| NHIS 2016 Q1 | 1.00 | 1.75 | 5.57E-10 | 0.45 | 0.69 | 1.09 | 44.45 |
| NHIS 2016 Q2 | 1.00 | 1.65 | 9.73E-10 | 0.52 | 0.72 | 1.04 | 41.37 |
| NHIS 2016 Q3 | 1.00 | 1.54 | 1.53E-10 | 0.50 | 0.72 | 1.05 | 34.39 |
| NHIS 2016 Q4 | 1.00 | 1.51 | 1.05E-10 | 0.47 | 0.73 | 1.10 | 35.75 |
| NHIS 2016 | 1.00 | 1.54 | 1.12E-12 | 0.48 | 0.72 | 1.08 | 34.76 |
Figure 2:
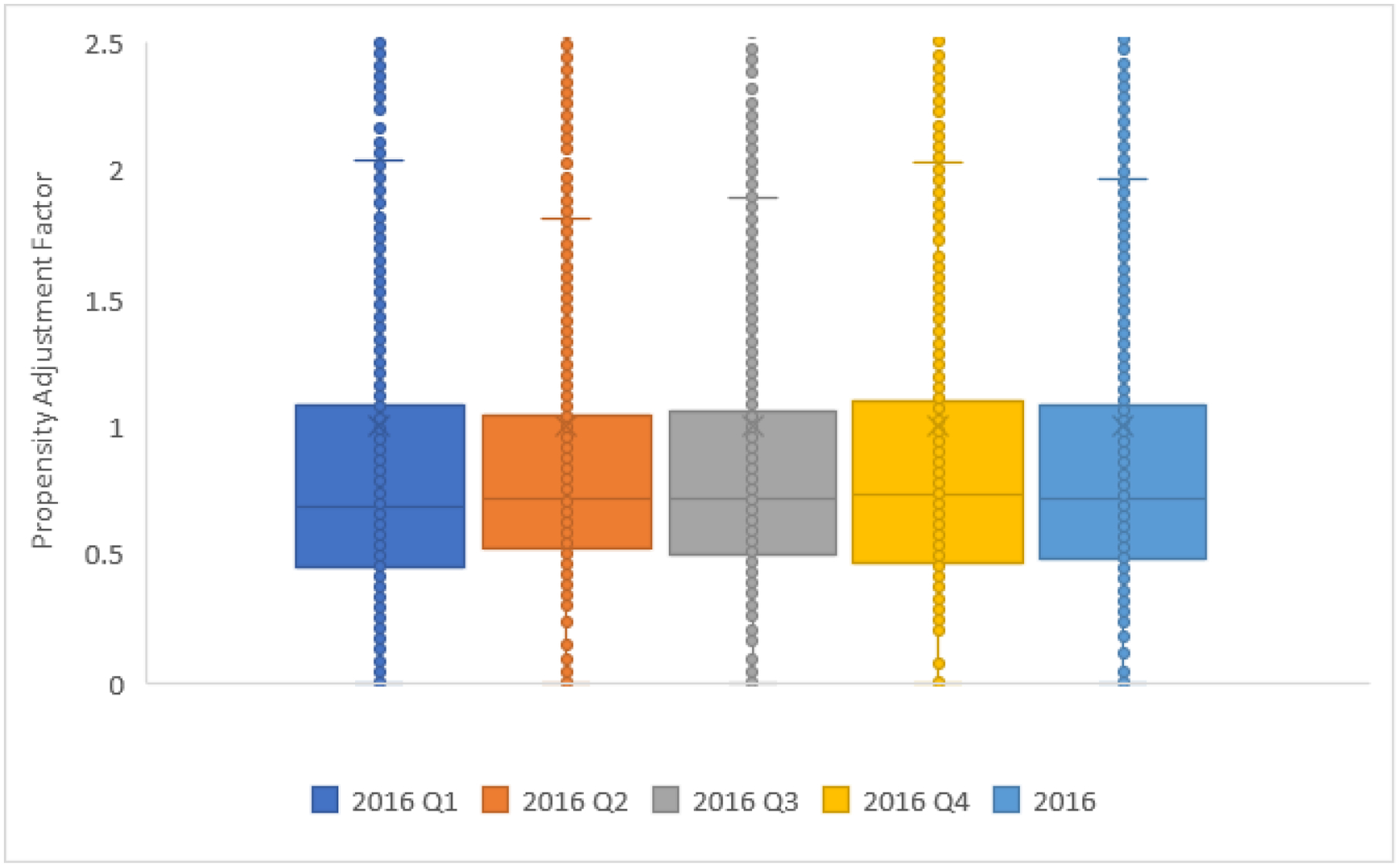
Boxplot of normalized propensity adjustment factors ((1-p)/p) by reference dataset
5. Discussion
While calibration techniques have been developed and used to improve survey estimates, research related to the selection of a calibration dataset has been limited. In this paper we consider propensity score adjusted estimates from the 2016 RANDS, a probability-based panel survey conducted by web, for five calibration datasets, including the NHIS data collected over the full year of 2016 and quarterly subsets of the 2016 NHIS data. Through a comparison of the calibrated estimates and statistical testing of the propensity adjustment factors using ANOVA, it is demonstrated that the estimates among the five reference datasets do not vary significantly. Although the Rao-Scott chi-square test identified statistically significant differences between estimates of education level between the four NHIS quarters, most demographic and health variable estimates were consistent across the reference datasets. Since the propensity adjustment factor is a function of the weighted marginal totals of the reference survey, the similar covariate distributions may have resulted in similar propensity adjustment factors and hence comparable calibrated estimates. This finding suggests flexibility in the selection of the reference dataset, under the condition that the selected reference dataset reflects the target population of interest. In this case the covariate distributions for the full year of NHIS as well as NHIS subsets by quarter were well-matched and comparisons demonstrated no significant differences between the propensity weighted estimates. Although the calibrated estimates of the health outcomes were similar, the standard errors of the calibrated estimates using the full year of NHIS 2016 as the reference dataset were smaller than the standard error estimates using the quarterly reference datasets which indicates that the reference dataset may impact the calibrated standard error estimates.
It is important to note that the NHIS is designed to have a similar demographic distribution in each quarter and to be a representative sample by quarter. However, while the results of this study may be dependent on the survey design of the NHIS, the findings may have implications for other surveys. This comparison indicates that a smaller reference dataset may be used for calibration, such as quarterly data rather than annual data from a national health survey, depending on the survey design. Based on the results from the RANDS study, panel survey estimates could be calibrated with data from NHIS as it became available rather than waiting for the entire year of data to be collected. The study results also suggest that for the health outcomes investigated, the reference data did not necessarily need to be collected over the same time period as the web survey. For the RANDS comparison, estimates using NHIS data from quarters 1, 3, 4, and the full year of data were consistent with the health estimates produced using the quarter 2 subset of NHIS. Although one may prefer to select a reference dataset that overlaps the collection time frame of the panel survey, this finding is important for situations in which the collection time frames do not overlap or in situations where it is beneficial to use data from shorter (such as quarter vs. year) or prior time periods to expedite the production of panel survey estimates without waiting for upcoming data releases. While future studies should compare estimates using alternative calibration datasets to identify the importance of the survey design, this finding has many practical implications for the use of web surveys to produce national level estimates.
There are limitations in this study which should be evaluated before selecting a reference dataset for calibration to web surveys. As indicated previously, the estimates for the demographic and general health covariates were similar between the full year and quarterly NHIS subsets and statistical testing indicated that the quarterly estimates were consistent for all variables except education level. This is a feature of the survey design of the NHIS, and alternative calibration datasets which are not representative samples or that represent very different populations than the web survey may not result in similar estimates. In addition, calibration datasets that represent populations that change over time could impact the calibrated estimates. In this analysis, the demographic and health variables used in the calibration were time invariant and thus calibrated outcomes did not reflect variation in the estimates over time. Moreover, the NHIS datasets ranged in size from approximately 8,200 respondents per quarter to more than 33,000 respondents over the full year. These reference datasets are much larger than the RANDS survey, with a sample size in quarter 4 that was 3.3 times larger than the sample size of RANDS. Studies investigating the impact of small sample sizes in reference datasets may find that smaller reference surveys do not have the same level of estimation accuracy.
Appendix
Table A1.
Weighted Estimates of Demographic and General Health Covariates
| Variable | RANDS (n=2480) | NHIS 2016 Q1 (n=8227) | NHIS 2016 Q2 (n=8256) | NHIS 2016 Q3 (n=8351) | NHIS 2016 Q4 (n=8194) | NHIS 2016 (n=33028) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N | Est | SE | n | Est | SE | n | Est | SE | n | Est | SE | N | Est | SE | n | Est | SE | |
| Age Groupa,b,c,d,e | ||||||||||||||||||
| 18–34 | 703 | 26.9 | 0.93 | 2103 | 30.0 | 0.74 | 1979 | 30.0 | 0.78 | 1993 | 29.9 | 0.77 | 2024 | 29.9 | 0.78 | 8099 | 29.9 | 0.41 |
| 35–54 | 836 | 34.7 | 1.02 | 2530 | 33.6 | 0.70 | 2516 | 33.7 | 0.73 | 2566 | 33.6 | 0.70 | 2491 | 33.5 | 0.72 | 10103 | 33.6 | 0.37 |
| 55–64 | 548 | 17.9 | 1.02 | 1423 | 17.0 | 0.54 | 1502 | 16.7 | 0.54 | 1521 | 16.9 | 0.51 | 1478 | 16.9 | 0.51 | 5924 | 16.8 | 0.28 |
| 65–74 | 298 | 15.5 | 1.06 | 1226 | 11.5 | 0.40 | 1305 | 11.5 | 0.42 | 1326 | 11.7 | 0.40 | 1264 | 11.8 | 0.42 | 5121 | 11.6 | 0.22 |
| 75 and over | 95 | 5.0 | 0.71 | 945 | 7.9 | 0.32 | 954 | 8.0 | 0.36 | 945 | 7.9 | 0.33 | 937 | 8.0 | 0.32 | 3781 | 8.0 | 0.18 |
| Sex | ||||||||||||||||||
| Male | 1351 | 49.4 | 1.57 | 3805 | 48.2 | 0.69 | 3708 | 48.2 | 0.75 | 3726 | 48.2 | 0.69 | 3752 | 48.2 | 0.71 | 14991 | 48.2 | 0.37 |
| Female | 1129 | 50.6 | 1.57 | 4422 | 51.8 | 0.69 | 4548 | 51.8 | 0.75 | 4625 | 51.8 | 0.69 | 4442 | 51.8 | 0.71 | 18037 | 51.8 | 0.37 |
| Race and Ethnicitya,b,c,d,e | ||||||||||||||||||
| Non-Hispanic White | 1587 | 73.2 | 0.91 | 5832 | 65.3 | 1.07 | 5805 | 65.0 | 1.11 | 5925 | 64.9 | 1.04 | 5812 | 64.7 | 1.05 | 23374 | 65.0 | 0.82 |
| Non-Hispanic Black | 503 | 11.7 | 0.64 | 877 | 12.1 | 0.67 | 983 | 12.2 | 0.64 | 917 | 12.2 | 0.64 | 876 | 12.2 | 0.65 | 3653 | 12.2 | 0.45 |
| Non-Hispanic Asian | 56 | 1.1 | 0.16 | 419 | 5.9 | 0.45 | 432 | 6.0 | 0.45 | 419 | 6.0 | 0.43 | 414 | 6.1 | 0.45 | 1684 | 6.0 | 0.30 |
| Non-Hispanic Other | 27 | 0.6 | 0.22 | 118 | 0.9 | 0.14 | 133 | 1.1 | 0.16 | 123 | 1.0 | 0.15 | 137 | 1.2 | 0.15 | 511 | 1.0 | 0.10 |
| Hispanic | 294 | 13.3 | 0.70 | 981 | 15.7 | 0.92 | 903 | 15.8 | 0.88 | 967 | 15.8 | 0.87 | 955 | 15.9 | 0.88 | 3806 | 15.8 | 0.70 |
| Missing | 13 | - | - | 0 | - | - | 0 | - | - | 0 | - | - | 0 | - | - | 0 | - | - |
| Education Levela,b,c,d,e,f | ||||||||||||||||||
| Less than high school or GED | 30 | 2.2 | 0.51 | 1307 | 16.3 | 0.62 | 1273 | 16.3 | 0.63 | 1191 | 14.2 | 0.59 | 1122 | 13.9 | 0.55 | 4893 | 15.2 | 0.34 |
| High school graduate | 564 | 36.5 | 1.10 | 1762 | 21.4 | 0.66 | 1839 | 22.9 | 0.68 | 1899 | 23.1 | 0.68 | 1729 | 21.2 | 0.61 | 7229 | 22.1 | 0.35 |
| Associate degree or some college | 913 | 30.7 | 0.92 | 2630 | 31.0 | 0.73 | 2593 | 30.9 | 0.74 | 2571 | 30.8 | 0.68 | 2708 | 33.2 | 0.77 | 10502 | 31.5 | 0.40 |
| Bachelor’s or higher degree | 973 | 30.5 | 1.01 | 2502 | 31.4 | 0.86 | 2524 | 30.0 | 0.84 | 2664 | 31.9 | 0.79 | 2602 | 31.6 | 0.78 | 10292 | 31.2 | 0.51 |
| Missing | 0 | - | - | 26 | 27 | - | - | 26 | - | - | 33 | - | - | 112 | - | - | ||
| Family Incomea,b,c,d,e | ||||||||||||||||||
| <$50,000 | 562 | 32.1 | 1.60 | 3925 | 43.1 | 0.90 | 3890 | 43.2 | 0.93 | 3750 | 41.1 | 0.86 | 3762 | 41.9 | 0.89 | 15327 | 42.3 | 0.56 |
| $50,000-$99,999 | 715 | 34.1 | 1.62 | 2105 | 30.1 | 0.73 | 2082 | 30.1 | 0.71 | 2223 | 31.0 | 0.72 | 2101 | 30.2 | 0.74 | 8511 | 30.3 | 0.40 |
| >=$100,000 | 702 | 33.7 | 1.58 | 1563 | 26.8 | 0.87 | 1618 | 26.7 | 0.84 | 1695 | 27.9 | 0.86 | 1694 | 27.9 | 0.81 | 6570 | 27.3 | 0.53 |
| Missing | 501 | - | - | 634 | - | - | 666 | - | - | 683 | - | - | 637 | - | - | 2620 | - | - |
| Geographic Region | ||||||||||||||||||
| Northeast | 377 | 17.7 | 1.29 | 1418 | 18.4 | 0.75 | 1381 | 17.3 | 0.61 | 1425 | 18.1 | 0.64 | 1366 | 17.9 | 0.67 | 5590 | 17.9 | 0.50 |
| Midwest | 532 | 21.8 | 1.25 | 1837 | 22.2 | 0.62 | 1864 | 22.6 | 0.62 | 1850 | 22.3 | 0.59 | 1794 | 21.5 | 0.62 | 7345 | 22.1 | 0.46 |
| South | 925 | 37.0 | 1.50 | 2854 | 35.2 | 0.88 | 2846 | 36.1 | 0.84 | 2893 | 35.3 | 0.83 | 2894 | 36.5 | 0.87 | 11487 | 35.8 | 0.72 |
| West | 643 | 23.6 | 1.26 | 2118 | 24.3 | 0.78 | 2165 | 24.0 | 0.78 | 2183 | 24.3 | 0.77 | 2140 | 24.0 | 0.77 | 8606 | 24.2 | 0.66 |
| Missing | 3 | - | - | 0 | - | - | 0 | - | - | 0 | - | - | 0 | - | - | 0 | - | - |
| Marital Statusa,b,c,d,e | ||||||||||||||||||
| Married/living with partner | 1395 | 65.6 | 1.58 | 4134 | 60.6 | 0.77 | 4070 | 59.9 | 0.74 | 4244 | 60.8 | 0.76 | 4241 | 62.0 | 0.76 | 16689 | 60.8 | 0.43 |
| Single/never married | 454 | 21.4 | 1.36 | 1912 | 22.2 | 0.69 | 1898 | 23.2 | 0.67 | 1845 | 22.1 | 0.68 | 1808 | 21.3 | 0.66 | 7463 | 22.2 | 0.37 |
| Separated/divorced/widowed | 311 | 13.0 | 1.10 | 2159 | 17.2 | 0.46 | 2272 | 16.9 | 0.46 | 2241 | 17.1 | 0.49 | 2136 | 16.7 | 0.45 | 8808 | 17.0 | 0.24 |
| Missing | 320 | - | - | 22 | - | - | 16 | - | - | 21 | - | - | 9 | - | - | 68 | - | - |
| Self-Rated Health Statusa,b,c,d,e | ||||||||||||||||||
| Excellent | 308 | 12.8 | 1.04 | 2105 | 28.1 | 0.70 | 2057 | 26.9 | 0.71 | 2074 | 27.7 | 0.74 | 2091 | 27.4 | 0.69 | 8327 | 27.5 | 0.39 |
| Very Good | 939 | 37.2 | 1.50 | 2766 | 33.2 | 0.68 | 2667 | 31.8 | 0.70 | 2807 | 32.9 | 0.71 | 2834 | 34.7 | 0.71 | 11074 | 33.1 | 0.37 |
| Good | 895 | 36.1 | 1.50 | 2187 | 25.8 | 0.67 | 2278 | 27.5 | 0.67 | 2281 | 26.6 | 0.64 | 2148 | 25.5 | 0.60 | 8894 | 26.3 | 0.35 |
| Fair | 258 | 10.5 | 0.96 | 895 | 9.9 | 0.43 | 957 | 10.7 | 0.47 | 928 | 10.2 | 0.45 | 847 | 9.3 | 0.43 | 3627 | 10.0 | 0.25 |
| Poor | 61 | 3.4 | 0.59 | 270 | 3.0 | 0.23 | 294 | 3.1 | 0.24 | 260 | 2.7 | 0.23 | 270 | 3.1 | 0.26 | 1094 | 2.9 | 0.13 |
| Missing | 19 | - | - | 4 | - | - | 3 | - | - | 1 | - | - | 4 | - | - | 12 | - | - |
| BMI Categorya,b,c,d,e | ||||||||||||||||||
| Underweight (BMI 18.5) | 24 | 1.3 | 0.40 | 151 | 2.0 | 0.24 | 134 | 1.8 | 0.19 | 133 | 1.9 | 0.23 | 148 | 1.9 | 0.20 | 566 | 1.9 | 0.11 |
| Normal (18.5<= BMI <25) | 668 | 29.6 | 1.48 | 2562 | 31.8 | 0.70 | 2685 | 34.1 | 0.69 | 2686 | 33.5 | 0.74 | 2640 | 33.1 | 0.70 | 10573 | 33.1 | 0.38 |
| Overweight (25<= BMI <30) | 812 | 31.8 | 1.47 | 2791 | 35.9 | 0.71 | 2735 | 33.6 | 0.65 | 2808 | 34.9 | 0.74 | 2807 | 35.2 | 0.70 | 11141 | 34.9 | 0.36 |
| Obese (BMI>= 30) | 890 | 37.2 | 1.54 | 2399 | 30.2 | 0.74 | 2426 | 30.6 | 0.68 | 2447 | 29.7 | 0.69 | 2345 | 29.8 | 0.68 | 9617 | 30.1 | 0.38 |
| Missing | 86 | - | - | 324 | - | - | 276 | - | - | 277 | - | - | 254 | - | - | 1131 | - | - |
Note: Est stands for estimate, SE stands for standard error, estimates and standard errors are presented as percentages (%);
denotes significance at the 5% level from the Rao-Scott chi-square test between RANDS and NHIS 2016 Q;
denotes significance at the 5% level from the Rao-Scott chi-square test between RANDS and NHIS 2016 Q2;
denotes significance at the 5% level from the Rao-Scott chi-square test between RANDS and NHIS 2016 Q3;
denotes significance at the 5% level from the Rao-Scott chi-square test between RANDS and NHIS 2016 Q4;
denotes significance at the 5% level from the Rao-Scott chi-square test between RANDS and NHIS 2016;
denotes significance at the 5% level from the Rao-Scott chi-square test between NHIS 2016 Q1, Q2, Q3, and Q4
Table A2.
Unadjusted RANDS and NHIS Health Outcome Estimates
| Variable | RANDS (n=2480) | NHIS 2016 Q1 (n=8227) | NHIS 2016 Q2 (n=8256) | NHIS 2016 Q3 (n=8351) | NHIS 2016 Q4 (n=8194) | NHIS 2016 (n=33028) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| N | Est | SE | n | Est | SE | n | Est | SE | n | Est | SE | n | Est | SE | n | Est | SE | |
| Smoking Statusa,b,c,d,e | ||||||||||||||||||
| Current | 370 | 15.2 | 1.12 | 1321 | 15.2 | 0.53 | 1378 | 16.7 | 0.57 | 1338 | 14.8 | 0.54 | 1303 | 16.0 | 0.52 | 5340 | 15.7 | 0.31 |
| Former | 701 | 30.2 | 1.43 | 2077 | 22.8 | 0.57 | 2004 | 21.8 | 0.60 | 2090 | 22.4 | 0.59 | 1983 | 22.3 | 0.57 | 8154 | 22.3 | 0.33 |
| Never | 1374 | 54.6 | 1.55 | 4796 | 62.0 | 0.73 | 4845 | 61.4 | 0.79 | 4897 | 62.8 | 0.72 | 4885 | 61.7 | 0.71 | 19423 | 62.0 | 0.46 |
| Missing | 35 | - | - | 33 | - | - | 29 | - | - | 26 | - | - | 23 | - | - | 111 | - | - |
| Food Securitya,b,c,d,e | ||||||||||||||||||
| Often true | 96 | 4.3 | 0.63 | 326 | 4.0 | 0.32 | 321 | 3.9 | 0.30 | 355 | 4.0 | 0.28 | 313 | 3.8 | 0.29 | 1315 | 3.9 | 0.15 |
| Sometimes true | 356 | 14.6 | 1.10 | 820 | 9.5 | 0.42 | 794 | 9.6 | 0.49 | 814 | 10.1 | 0.49 | 748 | 9.6 | 0.48 | 3176 | 9.7 | 0.26 |
| Never true | 2003 | 81.1 | 1.19 | 7076 | 86.5 | 0.54 | 7140 | 86.5 | 0.56 | 7177 | 85.9 | 0.60 | 7129 | 86.6 | 0.56 | 28522 | 86.4 | 0.32 |
| Missing | 25 | - | - | 5 | - | - | 1 | - | - | 5 | - | - | 4 | - | - | 15 | - | - |
| Health Insurance | ||||||||||||||||||
| Yes | 2316 | 92.5 | 0.85 | 7561 | 91.6 | 0.44 | 7564 | 90.7 | 0.48 | 7717 | 91.7 | 0.46 | 7506 | 91.1 | 0.48 | 30348 | 91.3 | 0.28 |
| No | 147 | 7.5 | 0.85 | 632 | 8.4 | 0.44 | 653 | 9.3 | 0.48 | 602 | 8.3 | 0.46 | 642 | 8.9 | 0.48 | 2529 | 8.7 | 0.28 |
| Missing | 17 | - | - | 34 | - | - | 39 | - | - | 32 | - | - | 46 | - | - | 151 | - | - |
| Hypertensiona,b,c,d,e | ||||||||||||||||||
| Yes | 901 | 35.2 | 1.42 | 2893 | 31.4 | 0.67 | 2924 | 31.2 | 0.68 | 2968 | 31.0 | 0.68 | 2879 | 31.1 | 0.67 | 11664 | 31.2 | 0.38 |
| No | 1546 | 64.8 | 1.42 | 5320 | 68.6 | 0.67 | 5319 | 68.8 | 0.68 | 5370 | 69.0 | 0.68 | 5306 | 68.9 | 0.67 | 21315 | 68.8 | 0.38 |
| Missing | 33 | - | - | 14 | - | - | 13 | - | - | 13 | - | - | 9 | - | - | 49 | - | - |
| Asthmaa,b,c,d,e | ||||||||||||||||||
| Yes | 442 | 19.2 | 1.28 | 1117 | 13.7 | 0.53 | 1122 | 13.9 | 0.56 | 1144 | 13.6 | 0.51 | 1126 | 14.2 | 0.52 | 4509 | 13.9 | 0.28 |
| No | 2006 | 80.8 | 1.28 | 7105 | 86.3 | 0.53 | 7130 | 86.1 | 0.56 | 7197 | 86.4 | 0.51 | 7066 | 85.8 | 0.52 | 28498 | 86.1 | 0.28 |
| Missing | 32 | - | - | 5 | - | - | 4 | . | . | 10 | - | - | 2 | - | - | 21 | - | - |
| Diabetes | ||||||||||||||||||
| Yes | 266 | 10.3 | 0.95 | 853 | 9.2 | 0.40 | 885 | 9.4 | 0.41 | 904 | 9.5 | 0.39 | 877 | 9.6 | 0.41 | 3519 | 9.4 | 0.21 |
| No | 2197 | 89.7 | 0.95 | 7367 | 90.8 | 0.40 | 7364 | 90.6 | 0.41 | 7434 | 90.5 | 0.39 | 7310 | 90.4 | 0.41 | 29475 | 90.6 | 0.21 |
| Missing | 17 | - | - | 7 | - | - | 7 | - | - | 13 | - | - | 7 | - | - | 34 | - | - |
Note: Est stands for estimate, SE stands for standard error, estimates and standard errors are presented as percentages (%);
denotes significance at the 5% level from the Rao-Scott chi-square test between RANDS and NHIS 2016 Q1;
denotes significance at the 5% level from the Rao-Scott chi-square test between RANDS and NHIS 2016 Q2;
denotes significance at the 5% level from the Rao-Scott chi-square test between RANDS and NHIS 2016 Q3;
denotes significance at the 5% level from the Rao-Scott chi-square test between RANDS and NHIS 2016 Q4;
denotes significance at the 5% level from the Rao-Scott chi-square test between RANDS and NHIS 2016
Table A3.
Propensity Score Model Estimates
| Reference Dataset | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| NHIS 2016 Q1 | NHIS 2016 Q2 | NHIS 2016 Q3 | NHIS 2016 Q4 | NHIS 2016 | ||||||
| Model Fit (AIC) | 9597.9 | 9688.6 | 9768.3 | 9599.0 | 15185.6 | |||||
| Variable (Reference Category) | Est | SE | Est | SE | Est | SE | Est | SE | Est | SE |
| Intercept | −1.2 | 0.33 | −1.3 | 0.33 | −1.3 | 0.33 | −1.6 | 0.34 | −2.7 | 0.31 |
| Age Group (75 and over) | ||||||||||
| 18–34 | 0.3 | 0.20 | 0.3 | 0.20 | 0.2 | 0.19 | 0.2 | 0.20 | 0.3 | 0.19 |
| 35–54 | 0.4 | 0.18 | 0.4 | 0.18 | 0.4 | 0.18 | 0.4 | 0.18 | 0.4 | 0.17 |
| 55–64 | 0.4 | 0.19 | 0.3 | 0.18 | 0.3 | 0.18 | 0.4 | 0.19 | 0.4 | 0.18 |
| 65–74 | 0.7 | 0.19 | 0.6 | 0.19 | 0.6 | 0.19 | 0.6 | 0.19 | 0.7 | 0.18 |
| Sex (Female) | ||||||||||
| Male | 0.1 | 0.08 | 0.1 | 0.08 | 0.1 | 0.08 | 0.1 | 0.08 | 0.1 | 0.07 |
| Race and Ethnicity (Hispanic) | ||||||||||
| Non-Hispanic White | 0.1 | 0.13 | 0.1 | 0.13 | 0.2 | 0.13 | 0.2 | 0.13 | 0.2 | 0.12 |
| Non-Hispanic Black | −0.1 | 0.17 | −0.1 | 0.17 | −0.1 | 0.16 | 0.0 | 0.17 | −0.1 | 0.15 |
| Non-Hispanic Asian | −1.6 | 0.27 | −1.7 | 0.26 | −1.6 | 0.26 | −1.5 | 0.26 | −1.6 | 0.25 |
| Non-Hispanic Other | −0.7 | 0.54 | −0.9 | 0.58 | −1.0 | 0.57 | −1.2 | 0.67 | −0.9 | 0.55 |
| Missing | 16.3 | 0.41 | 15.3 | 0.40 | 17.4 | 0.42 | 16.4 | 0.39 | 22.2 | 0.40 |
| Education Level (Bachelor’s or higher degree) | ||||||||||
| Less than high school or GED | −2.3 | 0.29 | −2.3 | 0.29 | −2.1 | 0.29 | −2.1 | 0.31 | −2.1 | 0.26 |
| High school graduate | 0.4 | 0.10 | 0.3 | 0.10 | 0.4 | 0.10 | 0.4 | 0.10 | 0.4 | 0.09 |
| Associate degree or some college | −0.1 | 0.09 | −0.1 | 0.09 | 0.0 | 0.09 | −0.2 | 0.09 | −0.1 | 0.08 |
| Missing | −13.4 | 0.29 | −12.3 | 0.26 | −25.4 | 1.11 | −14.5 | 0.80 | −10.4 | 0.43 |
| Family Income (>=$100,000) | ||||||||||
| <$50,000 | −0.5 | 0.11 | −0.4 | 0.11 | −0.4 | 0.11 | −0.4 | 0.11 | −0.5 | 0.10 |
| $50,000-$99,999 | −0.2 | 0.10 | −0.2 | 0.10 | −0.2 | 0.10 | −0.1 | 0.10 | −0.2 | 0.09 |
| Missing | 0.3 | 0.14 | 0.2 | 0.14 | 0.2 | 0.14 | 0.2 | 0.14 | 0.2 | 0.12 |
| Geographic Region (West) | ||||||||||
| Northeast | −0.2 | 0.13 | −0.1 | 0.12 | −0.1 | 0.12 | −0.2 | 0.13 | −0.1 | 0.11 |
| Midwest | −0.2 | 0.11 | −0.2 | 0.11 | −0.2 | 0.11 | −0.2 | 0.11 | −0.2 | 0.10 |
| South | −0.1 | 0.10 | −0.1 | 0.10 | −0.1 | 0.10 | −0.1 | 0.10 | −0.1 | 0.09 |
| Missing | 16.1 | 0.92 | 15.1 | 0.91 | 17.4 | 0.93 | 16.2 | 0.92 | 22.3 | 0.92 |
| Marital Status (Separated/divorced/Widowed) | ||||||||||
| Married/living with partner | 0.2 | 0.12 | 0.2 | 0.12 | 0.3 | 0.12 | 0.2 | 0.12 | 0.2 | 0.11 |
| Single/never married | 0.5 | 0.14 | 0.3 | 0.15 | 0.4 | 0.15 | 0.5 | 0.15 | 0.4 | 0.14 |
| Missing | 4.4 | 0.36 | 5.0 | 0.36 | 4.8 | 0.36 | 6.2 | 0.50 | 4.9 | 0.24 |
| Self-Rated Health Status (Poor) | ||||||||||
| Excellent | −1.2 | 0.24 | −1.0 | 0.24 | −1.2 | 0.24 | −0.9 | 0.25 | −1.2 | 0.22 |
| Very Good | −0.3 | 0.23 | −0.1 | 0.23 | −0.3 | 0.23 | −0.1 | 0.24 | −0.3 | 0.21 |
| Good | 0.0 | 0.22 | 0.1 | 0.23 | 0.0 | 0.22 | 0.3 | 0.24 | 0.0 | 0.21 |
| Fair | 0.0 | 0.24 | 0.0 | 0.25 | −0.1 | 0.24 | 0.2 | 0.25 | 0.0 | 0.22 |
| Missing | 1.7 | 0.91 | 2.1 | 0.73 | 14.5 | 0.50 | 3.7 | 0.61 | 2.5 | 0.67 |
| BMI Category (Obese, BMI>= 30) | ||||||||||
| Underweight (BMI< 18.5) | −0.5 | 0.36 | −0.4 | 0.36 | −0.5 | 0.36 | −0.4 | 0.37 | −0.4 | 0.33 |
| Normal (18.5<= BMI<25) | 0.0 | 0.10 | −0.1 | 0.10 | −0.1 | 0.10 | 0.0 | 0.10 | −0.1 | 0.09 |
| Overweight (25<= BMI <30) | −0.2 | 0.09 | −0.2 | 0.09 | −0.2 | 0.09 | −0.2 | 0.09 | −0.2 | 0.08 |
| Missing | −0.2 | 0.21 | −0.1 | 0.21 | −0.1 | 0.22 | −0.2 | 0.22 | −0.2 | 0.20 |
Note: Est stands for estimate, SE stands for standard error
Footnotes
Publisher's Disclaimer: Disclaimer:
The findings and conclusions in this paper are those of the authors and do not necessarily represent the views of the National Center for Health Statistics, Centers for Disease Control and Prevention.
References
- Callegaro M, Manfreda KL, and Vehovar V (2015). Web Survey Methodology. London: Sage. [Google Scholar]
- Cornesse C, Blom AG, Dutwin D, Krosnick JA, De Leeuw ED, Legleye S, Pasek J, Pennay D, Philips B, Sakshaug JW, Struminskaya B, and Wenz A (2020). A Review of Conceptual Approaches and Empirical Evidence on Probability and Nonprobability Sample Survey Research. Journal of Survey Statistics and Methodology, 8(1):4–36. [Google Scholar]
- Drake C (1993). Effects of Misspecification of the Propensity Score on Estimators of Treatment Effect. Biometrics, 49:1231–1236. [Google Scholar]
- DuGoff EH, Schuler M, Stuart EA (2014). Generalizing Observational Study Results: Applying Propensity Score Methods to Complex Surveys. Health Services Research 49(1):284–303. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Groves RM (1989). Survey errors and survey costs. New York: Wiley. [Google Scholar]
- How Does the Gallup Panel Work? Gallup Methodology, 2019, https://www.gallup.com/174158/gallup-panel-methodology.aspx. Accessed 22 October 2019. [Google Scholar]
- Lee S (2006). Propensity Score Adjustment as a Weighting Scheme for Volunteer Panel Web Surveys. Journal of Official Statistics 22(2):329–349. [Google Scholar]
- Lee S and Valliant R (2009). Estimation for Volunteer Panel Web Surveys Using Propensity Score Adjustment and Calibration Adjustment. Sociological Methods & Research 37(3):319–343. [Google Scholar]
- National Center for Health Statistics. (2017). Survey Description, National Health Interview Survey, 2016. Hyattsville, Maryland. [Google Scholar]
- National Center for Health Statistics. (2020). RANDS 2 Technical Documentation. Hyattsville, Maryland. [Google Scholar]
- Parker JD, Talih M, Malec DJ, et al. National Center for Health Statistics Data Presentation Standards for Proportions. National Center for Health Statistics. Vital Health Stat 2(175). 2017. [PubMed] [Google Scholar]
- Rao JNK, and Scott AJ (1981). The Analysis of Categorical Data from Complex Surveys: Chi-Squared Tests for Goodness of Fit and Independence in Two-Way Tables. Journal of the American Statistical Association 76:221–230. [Google Scholar]
- Rao JNK, and Scott AJ (1984). On Chi-Squared Tests for Multiway Contingency Tables with Cell Properties Estimated from Survey Data. Annals of Statistics 12:46–60. [Google Scholar]
- Rao JNK, and Scott AJ (1987). On Simple Adjustments to Chi-Square Tests with Survey Data. Annals of Statistics 15:385–397. [Google Scholar]
- Rubin DB and Thomas N (1996). Matching Using Estimated Propensity Scores: Relating Theory to Practice. Biometrics, 52:254–268. [PubMed] [Google Scholar]
- Ryan Camille, Computer and Internet Use in the United States: 2016, American Community Survey Reports, ACS-39, US Census Bureau, Washington, DC, 2017. [Google Scholar]
- Scanlon P (2017). Cognitive Evaluation of the 2015–2016 National Center for Health Statistics’ Research and Development Survey. National Center for Health Statistics, Hyattsville, MD. Available at: https://wwwn.cdc.gov/qbank/report/Scanlon_2017_NCHS_RANDS.pdf. [Google Scholar]
- Taylor H (2000). Does Internet Research Work? Comparing Online Survey Result with Telephone Survey. International Journal of Market Research, 42, 58–63. [Google Scholar]
- Terhanian G and Bremer J (2000). Confronting the Selection-Bias and Learning Effects Problems Associated with Internet Research. Research paper: Harris Interactive. [Google Scholar]
- Valliant R and Dever JA (2011). Estimating Propensity Adjustments for Volunteer Web Surveys. Sociological Methods & Research, 40, 105–137. [Google Scholar]