

Abstract
ASL-LEX is a publicly available, large-scale lexical database for American Sign Language (ASL). We report on the expanded database (ASL-LEX 2.0) that contains 2,723 ASL signs. For each sign, ASL-LEX now includes a more detailed phonological description, phonological density and complexity measures, frequency ratings (from deaf signers), iconicity ratings (from hearing non-signers and deaf signers), transparency (“guessability”) ratings (from non-signers), sign and videoclip durations, lexical class, and more. We document the steps used to create ASL-LEX 2.0 and describe the distributional characteristics for sign properties across the lexicon and examine the relationships among lexical and phonological properties of signs. Correlation analyses revealed that frequent signs were less iconic and phonologically simpler than infrequent signs and iconic signs tended to be phonologically simpler than less iconic signs. The complete ASL-LEX dataset and supplementary materials are available at https://osf.io/zpha4/ and an interactive visualization of the entire lexicon can be accessed on the ASL-LEX page: http://asl-lex.org/.
Understanding the structure and organization of the mental lexicon is critical to both linguistic and psycholinguistic theories of language. Linguistic theories have predominantly been built on research examining spoken languages and may have consequentially underrepresented linguistic properties that are characteristic and pervasive traits of sign language, such as iconicity—motivated relations between form and meaning (Ferrara & Hodge, 2018). Although many aspects of sign language processing are fundamentally the same as spoken languages, specific effects of modality-independent properties (e.g., lexical frequency, lexical class) and modality-dependent properties (e.g., iconicity, simultaneous phonological structure) on lexical organization and processing remain unclear. Lexical databases (systematically organized repositories of information about words in a language) have been crucial to making advances in linguistic and psycholinguistic research. Many lexical databases for spoken languages have been created, compiling a large amount of detailed information about spoken and written words that allows researchers to examine and control for effects of variables like lexical frequency, neighborhood density (ND), orthographic or phonological length, morphological structure or lexical class (e.g., the English Lexicon Project, Balota et al., 2007). Numerous studies have demonstrated the importance of these properties for spoken and written language processing, making lexical databases critical tools for testing hypotheses about the structure of the lexicon and the nature of word recognition and production.
Large, publicly available normative databases for sign languages that provide information about a variety of lexical and phonological properties of lexical signs have been lacking. A few smaller resources have been available for some sign languages, some of which may not be publicly available (Gutiérrez-Sigut, Costello, Baus, & Carreiras, 2015; Mayberry, Hall, & Zvaigzne, 2014; Morford & MacFarlane, 2003; Vinson, Cormier, Denmark, Schembri, & Vigliocco, 2008). Crucially, quantitative analyses of sign properties that capitalize on large-scale lexical databases are needed to advance theoretical and experimental work and generalize findings across spoken and signed language lexicons. As a result, there continue to be serious gaps in our understanding of sign language processing.
To address these gaps for American Sign Language (ASL), we have developed ASL-LEX, a publicly available large-scale, searchable lexical database, a tool that enables both linguistic and psycholinguistic inquiry into the lexical and phonological properties of signs and offers the possibility to conduct quantitative analyses of the ASL lexicon. Here, we report on the expanded database (which we refer to as ASL-LEX 2.0) that contains lexical and phonological information for 2,723 signs. The original ASL-LEX database contained 993 ASL signs and is described in Caselli, Sevcikova Sehyr, Cohen-Goldberg, and Emmorey (2017); we refer to this original version as ASL-LEX 1.0. Similar to the original version, ASL-LEX 2.0 includes a theoretically guided phonological description of each sign (Brentari, 1998), along with subjective frequency ratings by deaf ASL signers, iconicity ratings from hearing non-signers, videoclip and sign duration, lexical class, whether the sign is initialized, a fingerspelled sign, or a complex sign (e.g., compounds), along with phonological descriptions that allow unique identification of signs in the ASL lexicon. The ASL-LEX 2.0 expansion now also contains iconicity ratings from deaf ASL signers and transparency (“guessability”) ratings from hearing non-signers as alternative measures of sign iconicity (Sehyr & Emmorey, 2019; definitions of these concepts are provided in the Iconicity section below). The phonological descriptions for each sign are substantially more detailed than in ASL-LEX 1.0 and were used to derive more accurate sublexical frequency, phonological ND, and phonological complexity calculations. ASL-LEX 2.0 now also contains information about English translations for 640 signs (~25%) from deaf ASL signers who also rated the signs for frequency. Furthermore, ASL-LEX is now compatible with ASL Signbank (https://aslsignbank.haskins.yale.edu/) and the SLAAASh project (Sign Language Acquisition, Annotation, Archiving, and Sharing; http://slla.lab.uconn.edu/slaaash); we cross-referenced ID glosses and phonological coding so that signs that are common across the databases can be easily identified and accessed. Finally, the database is accessible to the public via a rebuilt and considerably improved interactive website (http://asl-lex.org/) that allows for visual exploration of the lexicon, filtered searches, scatterplot visualizations, tutorials, and more. Data files (.csv) from ASL-LEX 2.0, supporting documentation and supplementary figures and tables are publicly available through the Open Science Framework (OSF) Supplementary Materials page (https://osf.io/zpha4/). Throughout the paper, we refer to numerous examples of ASL signs. The reference videos for these signs originate from ASL-LEX 2.0 and are also available on the OSF page (“ASL examples”: https://osf.io/zpha4/).
In the next section, we provide an overview of the major properties of the ASL-LEX 2.0 database and the steps we took to create it. Further details about these properties follow in Results and Discussion. We report descriptive statistics and the distributional characteristics for a variety of sign properties, and we then provide lexicon-wide analyses of the relationships among the lexical and phonological variables for the entire ASL database.
Major Properties of Signs in ASL-LEX 2.0
Lexical Frequency
Frequency is arguably one of the most important variables in linguistic processing and has been used to determine how the mental lexicon is acquired, organized, and processed. High-frequency items are perceived and produced more quickly and efficiently than low-frequency items in spoken languages (Balota & Chumbley, 1984) as well as sign languages (Mayberry et al., 2014). Objective counts of frequency of occurrence based on text or spoken language corpora have been abundant for spoken languages. In contrast, large annotated corpora have been available for only a limited number of signed languages, e.g., British Sign Language (Schembri, Fenlon, Rentelis, & Cormier, 2014), Sign Language of the Netherlands (Crasborn, Zwitserlood, & Ros, 2008), or German Sign Language (Prillwitz et al., 2008). In cases where corpus estimates are not available, sign language researchers have relied on subjective frequency estimates instead ( Carreiras, Gutiérrez-Sigut, Baquero, & Corina, 2008). Subjective frequency ratings are correlated with corpus frequency counts in spoken language (Balota, Pilotti, & Cortese, 2001) and in sign language (Fenlon, Schembri, Rentelis, Vinson, & Cormier, 2014). ASL-LEX 2.0 provides average frequency ratings, standard deviation (SD), Z-score, and the number of deaf participants who rated the sign for all deaf signers, and separately for native and early-exposed signers.
Iconicity
A motivated (non-arbitrary) relationship between form and meaning—iconicity—is a pervasive property in sign languages, but it also occurs in spoken languages, albeit to a much lesser extent (Monaghan, Shillcock, Christiansen, & Kirby, 2014). Sign languages offer a unique opportunity to study the impact of iconicity on linguistic structure and processing. Despite the recent surge of studies on iconicity in signed and spoken languages (Dingemanse, Blasi, Lupyan, Christiansen, & Monaghan, 2015; Occhino, Anible, Wilkinson, & Morford, 2017; Occhino, Annible, & Morford, 2020) relatively little is still known about how iconicity might shape the lexicon or how it relates to other variables, such as frequency or phonology. There has been a debate about whether iconicity plays a role in sign comprehension, production, or first language acquisition (Caselli & Pyers, 2017; Emmorey, 2014). Iconicity also appears to have a complex relationship with phonological regularity (Brentari, 2007), semantics and syntax (Wilbur, 2010).
Subjective ratings of iconicity by hearing sign-naïve participants have provided an indirect, holistic, but highly useful and easily obtained measure of iconicity. ASL-LEX 2.0 includes this measure for all 2,723 signs (“Iconicity”). However, the ability to apprehend an iconic relationship between form and meaning may depend on one’s linguistic, cultural, or sensory (e.g., auditory) experience (Occhino et al., 2017; Sehyr & Emmorey, 2019). Deaf ASL signers might be sensitive to aspects of iconicity that are not immediately apparent to non-signers. Therefore, ASL-LEX 2.0 now also provides iconicity data collected from deaf ASL signers (“D.Iconicity”) for the original subset of 993 signs from Caselli et al. (2017).
Finally, an alternative measure to capture the strength of resemblance between form and meaning is sign transparency, typically defined as the extent to which sign-naive individuals can guess the correct meaning based on the sign form alone (Klima & Bellugi, 1979). Sign transparency is a new set of variables added to ASL-LEX 2.0 for a subset of 430 signs. Namely, the accuracy of guesses (proportion of non-signers who correctly guessed the sign meaning; “GuessAccuracy”), a measure of the consistency of participants’ guesses (“Guess Consistency”), and sign “Transparency” (a subjective rating of how obvious a guessed meaning would be to others); see Sehyr and Emmorey (2019) for details and discussion of these iconicity measures.
Phonological Properties
Phonological structure is undoubtedly an important variable in language processing and organization of the lexicon. For spoken languages, phonological ND (the number of phonological competitors) influences word identification and recognition (Vitevitch, 2002), but little is known about its role in sign language processing. Several studies have provided evidence for phonological priming in sign production or comprehension (Baus, Gutiérrez-Sigut, Quer, & Carreiras, 2008; Dye & Shih, 2006; Gutiérrez-Sigut, Müller, Baus, & Carreiras, 2012). However, the direction of the priming effect (i.e., facilitatory or inhibitory) has been inconsistent, possibly due to the different ways in which phonological similarity has been defined (Caselli & Cohen-Goldberg, 2014).
ASL-LEX provides a theoretically guided phonological coding system (Brentari, 1998) that captures a large amount of information while minimizing coding variability and effort. The original phonological properties that were coded in ASL-LEX 1.0 (selected fingers, flexion, major location, minor location, sign type, and path movement) were sufficient to uniquely identify only about half (52%) of the 993 signs. In order to more fully describe each sign’s formational properties, we have added the following new phonological properties (if present in the sign): 1) a second minor location, 2) a change in abduction as in SCISSORS (open-close), 3) a change in flexion as in MILK (extended flexed), 4) ulnar rotation as in APPLE (wrist twisting), 5) contact between the hand and major location, 6) thumb position (open, closed), 7) thumb contact with the selected fingers (contact, no contact), 8) the handshape of the dominant hand, and 9) the handshape of the non-dominant hand. We also revised the flexion coding for all signs and added a complete phonological description of all fifteen properties for the second morpheme (and all following morphemes) of compounds. The new phonological coding system is substantially different from ASL-LEX 1.0 and uniquely identifies 70% of signs; the remaining signs are homophonous or differ on non-coded phonological properties.
Based on the improved phonological coding, we are able to calculate significantly more refined measures of phonological ND, i.e., the number of signs that differ in formational structure from another sign based on at most one phonological feature. Like words (Luce & Pisoni, 1998), signs can reside in denser or sparser neighborhoods according to how many similar signs they have as neighbors. A more refined measure of phonological ND will assist future research addressing theories of lexical access and representation and offer a better understanding of how ND might interact with other lexical variables, such as frequency.
While ASL phonology is widely studied, only a few studies have investigated phonotactic probabilities and the phonotactic constraints on the formation of ASL signs (Ann, 1996; Henner, Geer, & Lillo-Martin, 2013). Phonotactic probability is the frequency with which a phonological feature or combinations of features occur in the lexicon. Phonotactic probability can impact lexical recognition, production, and acquisition (for a review, see Vitevitch & Luce, 1999). It has been an important factor in understanding how children acquire new words, e.g., children use bigram probability to help detect word boundaries, as adjacent phonemes are generally less probable when they span a word boundary than when both phonemes are within a word. However, the role of phonotactic probability in sign language processing and acquisition is currently unknown. Research on spoken languages has shown that speakers are sensitive to the phonotactics of their language. For example, information about the legality and probability of phonotactic patterns affects the speed and accuracy with which words are recognized. Documenting the phonotactics of a sign language is critical because some of the most fundamental linguistic questions about phonological grammars have been answered with phonotactic data. The large number of signs in ASL-LEX 2.0 increases the accuracy of phonotactic probability estimates. ASL-LEX 2.0 provides data on sub-lexical frequency, which is defined as the likelihood that a sign will contain a particular value for a given feature (e.g., how likely a sign is to have both the index and middle fingers specified as Selected Fingers), as well as the combined phonotactic probability of all of the features in the signs. Such data indicate what feature values and feature combinations are relatively common or rare in ASL. This more accurate and quantitative phonotactic data can be used to address theoretical questions about phonological structure in sign language, and to link phonotactic patterns in the lexicon to behavioral patterns observed in a plethora of paradigms, e.g., well-formedness judgments, reaction times in lexical production and recognition tasks, or phonological priming tasks.
A different but related way of considering the phonological structure of a sign is to evaluate its phonological complexity. Phonological complexity in spoken languages has been approached via different definitions, such as markedness, articulatory effort, or naturalness. An example from spoken language would be voiced /d/ as the more complex (marked) member relative to the voiceless (unmarked) /t/. Phonological complexity could influence language processing and learnability. Phonological complexity may also play an important role in specific language disorders because complex or “marked” items may be harder to perceive, produce, and/or acquire (for a review, see Gierut, 2007). ASL-LEX provides a measure of phonological complexity that identifies particular sets of complex features and awards the sign a complexity value based on the number of these complex features. For example, Battison (1978) observed that two-handed signs are more complex than one-handed signs (from an articulatory perspective) and that signs in which the hands act independently require greater articulatory dexterity than signs with symmetrical movement. We coded phonological complexity according to Morgan, Novogrodsky, and Sandler’s (2019) operational definition, which provides a more nuanced measure of complexity. In summary, the refined phonological coding in ASL-LEX 2.0 allowed us to calculate three phonological measures: ND, phonotactic probability, and phonological complexity.
ASL-LEX Signs
The signs in ASL-LEX originated from several resources: previous published databases (Mayberry et al., 2014; Vinson et al., 2008), the ASL Communicative Development Inventory (CDI) (Anderson & Reilly, 2002; Caselli, Lieberman, & Pyers, 2020), an ASL vocabulary test (Hoffmeister, 1999; Novogrodsky, Caldwell-Harris, Fish, & Hoffmeister, 2014), ASL Signbank (Hochgesang, Crasborn, & Lillo-Martin, 2019), and from previous in-house psycholinguistic experiments (Meade, Lee, Midgley, Holcomb, & Emmorey, 2018).
All ASL signs were modeled by the same deaf native signer who produced the signs for ASL-LEX 1.0. A new set of 1,806 signs were rated for ASL-LEX 2.0 (N = 1,735; 14 catch items and another 57 items that were later excluded). Items were excluded if many participants (≥75%) indicated that they did not know the sign, and some items were excluded because they were duplicate entries. There are 2,723 sign entries in the ASL-LEX 2.0 database.
For some measures (e.g., frequency ratings), data were collected in subsets of the lexicon at a time. Signs were divided into ten batches; four batches (A, B, C, and D) were included in ASL-LEX 1.0, and six batches (E, F, G, H, J, and Ki) were included in ASL-LEX 2.0. Each batch contained approximately 300 items and for ease of rating and to create breaks, the items in each batch were evenly divided into three sections. The order of presentation of signs within each section was constant. Items were evenly distributed across the sections in terms of lexical frequency, which was based on the log10 word frequency in SUBTLEX-US (Brysbaert & New, 2009) of the English translations as a proxy for ASL frequency. The sections did not differ significantly in frequency, F (2, 2,405) < 1, p = .76.
The signs in ASL-LEX were cross-referenced with the ASL-Signbank (Hochgesang et al., 2019) and the ASL-CDI 2.0 (Caselli et al., 2020). Signbank IDs are listed in ASL-LEX. Semantic categories for the signs in the ASL-CDI 2.0 are also listed (e.g., action or animal signs).
Rating Methods
Frequency Ratings
Participants. A total of 129 deaf adults (87 female; M age = 38 years, SD = 13 years; age range 18–67 years) participated in the online frequency rating study (ASL-LEX 1.0 and 2.0 combined). Each of the 2,723 ASL signs was rated for subjective frequency by 25–35 deaf participants. Two additional participants completed the online surveys but were excluded from the analyses because they did not use the rating scale appropriately (i.e., they did not use the whole range). Deaf participants were either congenitally deaf (N = 101) or became deaf before age 3 years (N = 27), and one participant (who acquired ASL from birth) became deaf at age 10 years. All participants reported using ASL as their preferred and primary language, and the average ASL fluency rating was 6.7 on a 1–7 self-evaluation scale (7 = fluent). Sixty-one participants acquired ASL from birth, i.e., “native” signers (39 female; M age = 34 years, SD = 12), 63 participants (45 female; M age = 39 years, SD = 12 years) were early-exposed signers who acquired ASL before age 6 years, and five participants learned ASL after age 8 (3 female; M age = 47 years, SD = 10 years). The average number of years of formal education for participants was 18 (SD = 2.5 years). Finally, Table 1 provides information about the regions in the United States where the participants grew up and where they resided at the time they completed the surveys. Note that ASL-LEX data were collected from a limited sample of deaf, college-educated individuals with native or early exposure to ASL, which may not be representative of the deaf population as a whole. Thus, norming diverse populations based on this sample may not be appropriate.
Table 1.
Summary of US regions where participants originated (i.e., grew up) and where they resided at the time of completing the surveys (N = 129)
| Originated | Reside | |
|---|---|---|
| Mid-West | 16% | 4% |
| North-East | 28% | 33% |
| South | 9% | 11% |
| West | 36% | 42% |
| South-East | 2% | 3% |
| North-West | 1% | 1% |
| South-Central | 1% | |
| Abroad | 4% | 2% |
| Not reported | 5% | 4% |
Stimuli and procedure. The procedure to collect the frequency ratings for signs in ASL-LEX 2.0 was identical to that reported in Caselli et al. (2017) for the original database ASL-LEX 1.0. Briefly, frequency ratings were collected online, and each video was presented individually on a page. Participants rated the sign on a 7-point scale based on how often they felt that sign appears in everyday conversation (1 = very infrequently; 7 = very frequently). Participants may have rated more than one batch, and at least three months separated each batch. Instructions were published as an Appendix in Caselli et al. (2017).
Of the 84,960 total trials, only a small proportion was flagged as unknown by participants (5%) or as having technical difficulties, e.g., video failed to load (<1%). To obtain a measure of the internal validity of the participants’ frequency ratings across the different batch sections, we included a small number of repeated signs in each section. The same ten signs were repeated for batches A and B, and five of these signs were repeated in batches C through to K. Ratings for the repeated items were consistent across all ten batches and did not statistically differ, F (9, 50) = .47, p = .88, ηp2 = .1. Finally, we obtained one-word English translations for a subset of 651 ASL signs (25%). The percent agreement for the dominant English translation is given in ASL-LEX for all participants and separately for native and early-exposed (non-native) signers.
Iconicity Ratings
Participants. A group of 950 hearing English speakers rated the 2,723 ASL signs for iconicity, and each sign was rated by an average of 28 people (SD = 8). All participants lived in the United States and did not know ASL. The hearing participants in the iconicity rating survey rated one section each (~100 signs).
Another group of 56 deaf ASL signers rated the iconicity of the original 993 signs from ASL-LEX 1.0, and the participant details are reported in Sehyr and Emmorey (2019). Each sign was rated by average of 29 deaf native or early signers (SD = 2, range = 26–31). The average participant age was 35 years (SD = 13, age range = 20–58 years; 34 female). Participants were either congenitally deaf or became deaf before age three years, except one participant (who acquired ASL from birth) who became deaf at age 10 years.
Stimuli and procedure. Iconicity ratings were collected from hearing non-signers for all 2,723 ASL signs (The same signs that were presented for frequency ratings.) Due to issues during data collection (missing/mislabeled videos), ratings for 24 signs had to be dropped from the dataset. Signs were presented via Mechanical Turk using the same batches and sections that were used to collect frequency ratings. Instructions for the hearing participants were published as an Appendix in Caselli et al. (2017). Briefly, participants were shown a video of the sign, and asked to rate how much the sign looks like its meaning (indicated by an English translation of the sign) on a scale of 1 (not iconic at all) to 7 (very iconic). In cases where possible English synonyms for EntryIDs exist, we added disambiguating cue words or phrases. For example, the sign FOUL refers only to a rule violation in sports, not to an odor, (e.g., “foul (in a game)”). These cues are listed for a total of 668 entries in ASL-LEX 2.0 (under Iconicity IDs). To confirm that raters provided sensible ratings and did not simply rate all signs as highly iconic, we included mislabeled signs as catch trials (e.g., participants were asked to rate the iconicity of the sign GUESS_1 when given “screwdriver” as its English translation). As expected, if participants were performing the task correctly, these items were rated as less iconic (Mdnmislabeled = 1.637) than the correctly labeled signs (Mdncorrectlabel = 3.24, W = 4,392, p < .001). Catch trials were excluded from the main analysis.
The procedure for obtaining iconicity ratings from deaf ASL signers for the 993 signs from ASL-LEX 1.0 was identical to the procedure described above for hearing non-signers, with the exception that deaf participants did not receive English glosses (translations) for the ASL signs (see Sehyr & Emmorey, 2019, for details). The deaf ASL participants were instructed to rate sign iconicity based on the version of the sign produced by the model, rather than their own knowledge of the sign and its use in context.
Transparency (“Guessability”) Ratings
Participants. The participant details are reported in Sevcikova Sehyr and Emmorey (2019). Eighty hearing monolingual English speakers (M age = 35.3, SD = 8.5, age range 21–53; 32 female) participated in the online rating study, and twenty participants rated each sign. All reported no prior knowledge of any sign language.
Stimuli and procedure. A subset of 430 ASL signs from the 993 ASL signs in ASL-LEX 1.0 were rated for transparency by hearing non-signers via Mechanical Turk. Participants were instructed to guess the meaning of that sign and type it into a response box using only one English word. For each guess, they were subsequently asked to rate how obvious the meaning they guessed would be to others on a 1–7 scale (1 = not obvious at all, 7 = very obvious). For each sign, the following was calculated: a) the average accuracy of guesses as the proportion of participants who correctly guessed the sign meaning, b) the consistency of participants’ guesses (H statistic; values closer to 0 represent high consistency of guesses), and c) the mean transparency rating (and Z scores). There were a total of 8,600 trials (twenty participants rated and guessed the meaning of 430 signs each). The methods of obtaining transparency ratings and participant instructions are detailed in Sehyr and Emmorey (2019).
Sign Duration
Sign duration was calculated as the time (number of video frames) between sign onset and offset, converted into milliseconds (for coding procedure, see Caselli et al., 2017, p. 790). Agreement for sign onset coding between two independent, trained coders for 511 signs was 90.4%, Cronbach’s alpha = .872. Agreement for sign offset between two independent coders for these same signs was 99%, Cronbach’s alpha = .957. This measure of sign length is based on the model’s articulation of the sign, and thus should be treated with caution, as sign duration is susceptible to phonetic and individual variation.
Phonological Properties Coding
Describing the phonological composition of signs may be done for different purposes (e.g., to make generalizations about the structural composition of signs or to enable cross- and within-language comparisons). Each purpose lends itself to a different set of coding decisions. The guiding principles in developing the ASL-LEX phonological coding system were: 1) to try to uniquely describe each sign, 2) to be as efficient as possible (i.e., not to provide information that can be surmised based on other features, or to code information that does not substantially help distinguish between signs), 3) to provide a value for every feature for every sign (or to specify “not applicable” (NA) as appropriate), 4) to operationalize terms explicitly enough that a naïve coder could reliably code without additional guidance, and 5) to be faithful to existing phonological theories. In the process of developing these procedures, we found that it was frequently impossible to achieve all of these goals, and that tradeoffs were necessary. Nevertheless, we hope that the coding system that we arrived upon maximizes each of these principles despite the necessary tradeoffs.
The ASL-LEX 2.0 coding includes nine new phonological features that were not previously coded. Additionally, rather than only coding the first instance of a property, properties that change throughout the sign were also encoded, and a complete coding was generated for the entire sign rather than only the first part of the sign (e.g., subsequent morphemes in compound signs). As in ASL-LEX 1.0, the coding scheme was guided by the Prosodic Model (Brentari, 1998), with the modifications and elaborations described below. We have also made a handful of clarifications and modifications to the coding for the six features that were originally available in ASL-LEX 1.0. All signs have been coded according to the complete, updated system. The new system is a substantial improvement, but we caution readers that even after providing more than three times the amount of phonological detail than was in ASL-LEX 1.0, the new system still will not capture every phonological property, and more work needs to be done to create a definitive and complete description.
A team of linguistically trained, non-native, hearing signers coded the phonological properties for all signs. During training, if raters were not consistent, the phonological coding manual, described below, was jointly edited for clarity and precision until all raters could code consistently. A hearing native signer (NC) checked all of the final codes. A subset of 50 signs (1.8%) was coded by two raters, and Cohen’s Kappa tests showed that all properties were rated reliably (all κ’s > .6, all p’s < .01). What follows is a description of the phonological features coded in ASL-LEX. We provide the distribution of the coded phonological features across the lexicon on the OSF Supplementary Materials page in Figure S1.
Identifying units of analysis: sequential morphemes. Many signs include multiple sequential units over which phonological constraints apply (e.g., the number of locations). For various constraints, these units have been referred to the literature as the “word” (Battison, 1978), the “prosodic word” (Brentari, 1998), the “syllable” (van der van der Kooij & Crasborn, 2008), and the “morpheme” (Sandler, 1989). For practical and not theoretical reasons, we chose to refer to these sequential units as “morphemes” and signs with multiple sequential units as “multimorphemic.” However, we acknowledge that this term is imprecise, somewhat disparate from the traditional definition of morpheme, and fits some types of signs (e.g., compounds) better than others (e.g., fingerspelled signs). We classify signs this way primarily because the phonological coding system was designed around simple signs, and this system expects only one value for most features (e.g., a maximum of one major location). Please refer to the OSF Supplementary Materials Documentation folder (Section 1) for details regarding how signs were divided into constituent sequential “morphemes,” and some limits inherent to our approach. We caution readers that in many signs there is also simultaneous morphology that is not reflected in our classification system or morpheme counts, e.g., signs with numerical incorporation (9_OCLOCK) or depicting signs (MEET).
Fingerspelled signs. Fingerspelled signs included both items in which all letters of the word are expressed (e.g., CANCER_1) and those that only include a subset of letters (e.g., the letters W and S in WORKSHOP). Each “letter” of a fingerspelled sign was coded for hand configuration features (see below). The other features were only coded once, in the first “morpheme” coding, e.g., the curved path movement of the sign WORKSHOP was coded under the first “morpheme” path movement. Transitional movements between letters (e.g., abduction and flexion changes) were not coded.
Sign type. Signs were coded using the four Sign Types described by Battison (1978): one-handed, two-handed symmetrical or alternating, two-handed asymmetrical with the same hand configuration, and two-handed asymmetrical with different hand configurationsii. We added a clarification rule that stated: if the Major Location of the sign (see below) was the arm (e.g., TRASH) or if the non-dominant hand made contact with the dominant arm (e.g., TREE), then the Sign Type was one handed. This rule alleviated pressure to code the non-dominant handshape in these signs, which was often in a lax position (e.g., MUSCLE). Finally, we clarified the definition of symmetry, which was not defined in ASL-LEX 1.0 (for more information, see OSF Supplementary Materials, Documentation, Section 2.1).
Location. Location was divided into two categories (major and minor), following Brentari (1998).
Major location. The major location of the dominant hand relative to the body comprised five possible values: head, arm, body, non-dominant hand, and neutral space.iii Signs may or may not have made contact with the major location, and the non-dominant hand was only considered the major location if the Sign Type was asymmetrical (i.e., if the non-dominant hand was stationary). If the non-dominant hand made contact with the dominant arm (e.g., TREE), location should be neutral and not the non-dominant hand.
Minor location. Each of the five major locations, except neutral space, was divided into eight minor locations as laid out by The Prosodic Model (Brentari, 1998)iv. See the Supplementary Materials for illustrations of the boundaries of each minor location.
The first minor location corresponds to what was called “minor location” in ASL-LEX 1.0 and refers to the sub-region of the major location where the dominant handmade contact at sign onset. Signs with a neutral major location also had a neutral minor location. However, in ASL-LEX 2.0, some clarifications and updates to the way the minor location was coded were added and are described in the OSF Supplementary Materials (Documentation, Sections 2.2 and 2.3). The minor locations are also illustrated in Figure S2. The minor location “away” was used to describe signs that were produced near, but not in contact with, a location. See the Supplementary Materials (Documentation, section 2.3) for details about how “away” was coded.
Second minor location is a new addition to ASL-LEX 2.0. A Second Minor Location was coded if there was a non-transitional path movement away from the first minor location during sign production (e.g., YESTERDAY). The inventory of second minor locations is the same as that of first minor locations. If the location was constant throughout the sign, then there was no second location (i.e., second minor location was coded as NA). If the hand departed the first minor location and did not make contact again, then “away” was coded as the second location (e.g., CONCEPT). If the hand made contact twice, only the points of contact were considered minor locations, and no transitional points along the path were considered (i.e., in the sign IMPROVE, the second minor location is the upper arm). If the sign included a path movement from one location to a slightly different location that fell within the same minor location classification (e.g., RESTAURANT, CHEERLEADER_1), the second minor location was coded the same as the first (e.g., “chin” and “chin” in RESTAURANT; “neutral” and “neutral” in CHEERLEADER_1). Finally, some signs never made contact with their major location. If there was path movement, they had a first and second minor location of “away” (e.g., VIOLIN, PERSPECTIVE). If there was no path movement, the second minor location was NA (e.g., CAMERA). The distribution of minor locations across the lexicon is shown in Figure S3.
Contact. Contact is a new addition to ASL-LEX. Signs were coded as [+/− contact] depending on whether the dominant hand made contact with the major location at any point during the sign (e.g., FUNNY). Signs in neutral space were coded as no contact, except for symmetrical or alternating signs if contact was made between the two hands (e.g., BOOK). Contact was similar to, but not the same as, the minor location value “away.” Contact refers to whether or not the hands ever touched one another or their major location at any point during the sign. The minor location “away” was used to identify signs that were produced in locations near but not touching a major location. For example, the sign ATTITUDE has contact, but at the onset of the sign the minor location is away from the body.
Hand configuration. selected fingers. The three rules that were used to identify selected fingers were as follows: 1) selected fingers were the group of fingers that moved (e.g., in FROG, the index and middle fingers are selected because they move). 2) If none of the fingers moved, the selected fingers were determined on the basis of the non-selected finger position. Non-selected fingers must either be fully open or fully closed (Brentari, 1998), so by process of elimination the selected fingers were the ones that were neither fully extended nor fully flexed. For example, in the sign FRANCE, the middle, ring, and pinky are fully extended so these must be the non-selected fingers, and the index finger must be selected because it is neither fully extended nor fully flexed. 3) In some signs, the first two criteria were not sufficient, as there were two groups of fingers that could be non-selected (i.e., one group of fingers was fully extended and the other was fully flexed as in the sign FOR). In these cases, selected fingers were those that were “extended.” The three rules were necessarily applied in order. The thumb was only coded as a selected finger if it was the only selected finger in the sign or if it was the only moving finger in the sign (e.g., GUN). See Supplementary Materials, Documentation, Section 2.4 for more information.
Flexion. Flexion corresponds to the position of the selected fingers at morpheme onset. Because the possible flexion settings for the thumb are different from the other fingers, Flexion was coded as NA if the selected finger was the thumb (see Documentation, Section 2.5 for further information, and Table S1).
Spread (Abduction). Spread coding was a new addition to ASL-LEX. The selected fingers of a sign were separated into two categories: spread (e.g., the letter sign V) or not spread (e.g., the letter sign U). If there was only one selected finger, or the selected fingers were not adjacent to each other (e.g., the index and pinky finger are selected in the sign AIRPLANE), spread was coded as NA. If the flexion was crossed (e.g., CIGAR), it was coded as not spread. If the flexion was stacked (e.g., BORROW) or fully closed (e.g., ACCORDION), spread was coded as NA. Spread corresponds to the position of the selected fingers at morpheme onset.
Thumb position and contact. Phonological coding for the thumb is a new addition to ASL-LEX. Thumb position at the onset of the sign (or morpheme) was coded as open or closed. Closed requires that the thumb either made contact with the palm (e.g., the sign for the letter B) or rested on top of any fully flexed fingers. The fully flexed fingers could be selected (e.g., the letter sign S) or unselected (e.g., the letter signs V, N). If the thumb did not make contact with the palm or top of any fully flexed fingers, it was open. If the thumb contacted fully flexed fingers without resting on top of them (e.g., the letter sign A), it was coded as open. If the thumb was a selected finger (e.g., NOT), it was by definition open.
Whether the thumb made contact with the selected fingers at any point during the sign was coded as binary [+/− contact]. If the thumb made contact, the thumb position could either be closed (e.g., the letter sign E) or open (e.g., the letter sign F). If the thumb did not make contact, the position could either be open (e.g., the number sign 5) or closed (e.g., the number sign 4). Contact was considered when the tip or pad of the thumb touched the selected fingers, not the side of the thumb (e.g., there is no thumb contact in EVENING). Note that in some signs the thumb made contact with unselected fingers (e.g., ALCOHOL). These were coded as having no contact as the thumb did not make contact with the selected fingers.
Handshape. We added a handshape coding for ASL-LEX 2.0 because it is a phonological property that is familiar to many people, but a few cautionary notes are warranted. The advantage of using features in our phonological descriptions is that features are designed to accommodate the dynamic nature of hand configurations (e.g., the handshape in UNDERSTAND changes), but it is not clear how best to determine a single handshape (or even set of handshapes) to represent such signs. We coded handshape by first automatically proposing handshapes based on the distinct combinations of selected fingers, flexion, spread, and thumb position. We found these automatically generated handshapes to be unsatisfactory partly because they differentiated between configurations that did not appear contrastive (e.g., two variants of the manual letter D that differ in the position of the pinky and ring finger) and also because they did not differentiate between configurations that appeared contrastive (e.g., see Figure 1 for five pairs of strikingly different handshapes that were not distinguishable based on these phonological featuresv). We then manually corrected the automatically generated handshapes by collapsing some handshapes and separating others (see Table S2 for a handshape translation key). We caution readers that these static handshapes are not an ideal representation of dynamic signs and acknowledge that the resulting set of handshapes may not be congruent with readers’ intuitions. The distribution of handshapes across the lexicon is provided in OSF Supplementary Materials, Figure S4.
Figure 1.
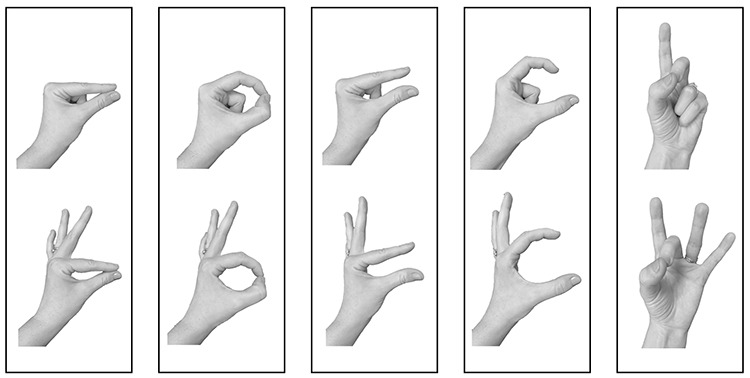
These five pairs of handshapes were indistinguishable from the phonological coding, so handshape was manually coded for signs using these handshapes.
Non-dominant handshape. Non-dominant handshape was also a new addition to ASL-LEX. The non-dominant handshape was coded manually using the Battison inventory (BAS1C05) when the Sign Type was asymmetrical with a different handshape. For signs with other Sign Types, the handshape was surmised from the specifications of the dominant hand (i.e., the handshape was generated by copying the settings of the dominant hand in symmetrical signs and asymmetrical signs with the same handshape). For signs whose Sign Type violates the Symmetry Condition or Dominance Condition (see Endnote ii), the non-dominant handshape was coded as “SymmetryViolation” or “DominanceViolation” accordingly.vi
Movement. Signs can have a path movement in which the hand moves through x-y-z space, and/or an internal movement in which the fingers change in flexion or abduction or the wrist twists (ulnar rotation). We describe movement coding for both types of movement below.
Path movement. Three movement categories (“arc,” “circular,” and “straight”) corresponded to the “path feature” from Brentari (1998). We added categories for “z-shaped” and “x-shaped.” The “Z” movement applied to signs that had a single or multiple Z shapes (e.g., DOLPHIN). An additional category “X” shape movement was added to account for signs like SWITZERLAND. Signs in which the hand did not move through x-y-z space were coded as “none” (e.g., APPLE). Signs that did not fit any of these categories or that included more than one path movement were coded as “other” (e.g., SCARF). The length of the movement was ignored (i.e., a straight movement could be short (e.g., ZERO) or long (e.g., NORTH).
Internal movement. We coded the two types of internal movements that correspond to finger position (flexion change and abduction change) plus ulnar rotation. These were all new additions to ASL-LEX 2.0. The coding of flexion and abduction change applied to all fingers, because if there is a change in finger position, all selected fingers move in the same way (Mandel, 1981).
Signs were coded as having a flexion change if the flexion of the selected fingers changed throughout the sign. The amount of change did not need to be so much that a different flexion category would be assigned. For example, in the sign NEWSPAPER the base knuckle of the index finger changes in flexion but does not change enough that it would have been coded as anything other than “flat” throughout the sign. Flexion change is coded as NA if Flexion is NA (e.g., EMPHASIS), except if the thumb is the only selected finger (e.g., A_LITTLE_BIT). Signs were coded as having a spread change if the spread of the fingers changed throughout the sign (from spread to not spread or vice versa; e.g., SCISSORS, BLINDS_1). Spread change was coded as NA if abduction was NA (e.g., AIRPLANE), except if the flexion at morpheme onset was fully closed. Signs were coded as having an ulnar rotation if the wrist twists during the sign (e.g., APPLE, RADIO). Other types of wrist movements (deviation as in VITAMINS, extension/flexion as in YES) were coded as path movements.
Repeated movement. A new addition to ASL-LEX 2.0, repeated movement, was a binary variable [+/− repetition] and reflects exact repetition of the path movement (e.g., AIRPLANE), ulnar rotation (e.g., ACCENT), or handshape change (e.g., ACQUIRE). Signs that had repeated handshapes (but not handshape change) like POP_2 were coded as not repeated. If the path movement was not exactly the same (e.g., SNAKE), it was coded as having no repetition. The phonological coding for path movement and minor locations of repeated signs corresponds to the portion of the sign that is repeated. As in multimorphemic signs, transitional movements between the repeated elements were not coded. The addition of the repeated movement category and recoding of path movement addresses issues raised by Becker, Catt, & Hochgesang (2020). See OSF Supplementary Materials, Documentation, Section 2.6 for more information.
Finally, the phonological coding for each sequential morpheme was the same as for monomorphemic signs. Exceptions to this rule and details regarding coding of multiple morphemes are provided in the OSF Supplementary Materials, Documentation, Section 1.2.
Age of Acquisition
Age of acquisition, collected and reported in Caselli et al. (2020), is also included in the dataset for the 533 signs that appear on the ASL-CDI 2.0, an ASL adaptation of the MacArthur Bates Communicative Development Inventory. Both the empirical calculation (based on the proportion of children in an age bin that knew the sign) and Bayesian generalized linear model calculation (a more sophisticated statistical prediction of age of acquisition for each item) are included (see Caselli et al., 2020, for details).
Results and Discussion
In this section, we present the descriptive statistics and distributional patterns for each of the primary lexical and phonological properties, and then present analyses of the relationships among these properties. The trial level and aggregate data for these variables are available for download from the OSF Supplementary Materials, Data Files (https://osf.io/zpha4/).
Descriptive Characteristics of ASL-LEX 2.0
Two types of glosses (or entry identifiers) are available for each sign entry: an Entry Identifier (Entry ID) that uniquely identifies each sign entry and a Lemma Identifier (Lemma ID) to identify each lemma in the database (a lemma groups together phonological and inflectional variants; for the lemmatization procedure, see Caselli et al., 2017, p. 789). There are a total of 2,723 unique sign entries and 2,663 lemmas in ASL-LEX 2.0. The database currently includes 58 lemmas that have more than one entry. A lemma had more than one entry if we identified either phonological variants (e.g., ABOUT_1 versus ABOUT_2, differing in non-dominant handshape), or synonyms (e.g., there are five variants of PINEAPPLE). Entry IDs and Lemma IDs are not intended to be accurate translations of the ASL signs and serve merely for identification and disambiguation purposes. Additionally, each entry is also uniquely identifiable by a numerical code that indicates the position of each item in the section and in a batch (e.g., A_01_001).
All of the signs and Entry IDs were cross-referenced with sign entries in Signbank (Hochgesang et al., 2019) to ensure compatibility across these two databases. Currently, 73% of the ASL-LEX signs (1,989 entries) appear in Signbank. The remaining ASL-LEX signs will be integrated into Signbank as that database expands. We linked each Entry ID in ASL-LEX with a lemma in Signbank using the lemmatization principles described in Hochgesang, Crasborn, and Lillo-Martin (2018). Signs were matched if they shared both meaning and form, or if the meaning was shared but the form differed slightly (e.g., one-handed versus two-handed symmetrical signs). Lexical class is provided for each sign entry and was determined by a deaf native ASL signer. However, this coding should be interpreted with caution because in many cases, the lexical class of a sign depends on the context in which it is used. ASL-LEX 2.0 contains 1,279 ASL nouns, 905 verbs, 300 adjectives, 118 minor class signs (e.g., conjunctions), 50 adverbs, 42 names, 24 numbers, and 5 signs for which lexical class could not be determined. For each sign entry, we provide information about whether the sign is a complex sign (i.e., consists of two or more morphemes, see below), an initialized sign (e.g., ASL sign WATER is signed with the manual letter “W” touching the chin), or a fingerspelled sign (STAFF includes the manual letters S and F, see below). The database contains 225 signs with multiple sequential morphemes, 363 initialized signs, and 38 fingerspelled signs.
Sign frequency. Frequency ratings (Z scores) did not statistically differ across sections, F (2,288) = 3.1, p = .05, reducing the possibility that participants rated signs higher, or lower, as they progressed through each Batch. The distribution of frequency ratings is plotted in Figure 2. As expected, based on the original ASL-LEX dataset, frequency ratings for the entire ASL-LEX 2.0 dataset (2,723 signs) were normally distributed, similar to the distribution of frequency ratings for the 432 ASL reported by Mayberry et al. (2014). Note that ASL-LEX contains a curated selection of highly lexicalized, open-class signs that are mostly nouns and verbs. There are other types of signs, such as depicting constructions or fingerspelled signs that might occur frequently in ASL but were not included in ASL-LEX, and it remains unclear whether including these signs would have shaped the distribution curve differently.
Figure 2.
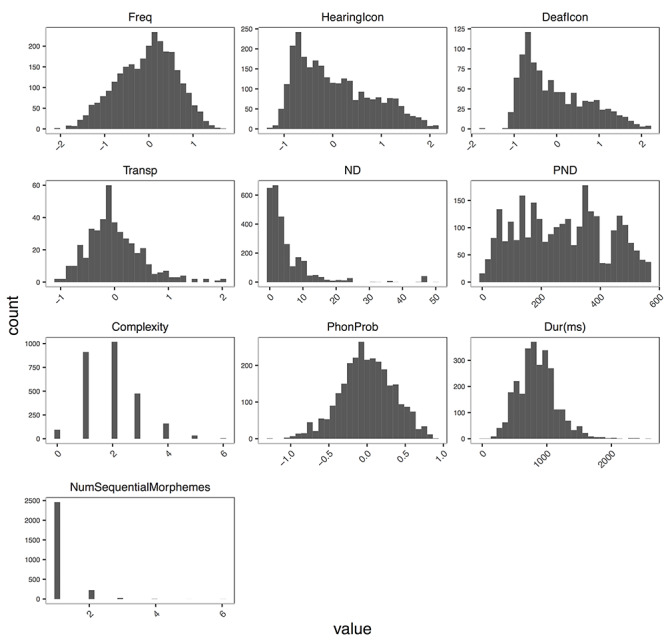
Distribution of the lexical variables across the lexicon. Variables from top to bottom are: frequency (Freq), iconicity rated by hearing non-signers (HearingIcon; n = 2,723), iconicity rated by deaf signers (DeafIcon; n = 993 signs), transparency (Transp; n = 430 signs), Neighborhood Density (ND), Parameter Neighborhood Density (PND), phonological complexity (Complexity), phonotactic probability (Phonprob), sign duration in milleseconds (Dur(ms)), and number of sequential morphemes (NumSequentialMorphemes). Frequency, iconicity, and transparency rating scores were Z transformed across participants.
Importantly, we also corroborated and indirectly replicated previous findings (Mayberry et al., 2014) that native and early-exposed deaf ASL signers had similar intuitions about the frequency of signs; we found no difference in frequency ratings by the two groups; B = .008; SE = .007; t = 1.22; p = .224, and ratings by native signers (M = 4.21, SD = 1.9, 95% CI [4.19; 4.23]; Z = −.005) were highly correlated with ratings by early-exposed signers (M = 4.22, SD = 2, 95% CI [4.20; 4.24]; Z = −.003) (r = .87, p < .001).
Iconicity. The distribution of iconicity ratings by hearing non-signers for 2,723 signs is plotted in Figure 2. The distribution of iconicity ratings by deaf signers for the original 993 signs in ASL-LEX 1.0 is also plotted in Figure 2. Iconicity ratings by both groups were heavily skewed, with most signs rated as less iconic. These patterns of distribution for hearing and deaf participants were congruent with Caselli and Pyers (2017). This replication confirmed that the skewness of iconicity ratings was not an artifact of stimulus selection in ASL-LEX 1.0. Rather, counter to common misconceptions (Brown, 1979), most signs in ASL were judged as not iconic when frequency was normally distributed and the sign meaning was known to the participant.
Transparency (“guessability”). Transparency ratings were normally distributed (Figure 2). Only a small proportion of ASL signs (3%) in this dataset were guessed correctly by a majority of participants, and only four signs (CRY, DRINK, FOUR, and SAD) were guessed correctly by all participants (H = 0). In contrast, the ASL sign MOCK was guessed with 0% accuracy, and the H statistic was three because all 20 participants gave different, unrelated translations (e.g., “wrong,” “confirm,” “poke,” “sit,” “calm,” etc.). The sign SUSPECT (0% accuracy) is an example of an H statistic of 1.5 as participants’ converged on a few consistent albeit incorrect guesses (e.g., “confused,” “think,” and “why”). For further discussion of these results, see Sehyr and Emmorey (2019).
Neighborhood density. ND in spoken language is typically calculated as the number of words in the lexicon that share all but one phoneme with the target word (Luce & Pisoni, 1998). In ASL-LEX 2.0, we define ND in two ways. The generic ND measure defines neighbors as the number of signs that share all but a maximum of one phonological feature with the target. The set of features included in this calculation was all of the features that correspond to the first morpheme. Major location and second minor location were excluded from the calculation because of the dependency between these and minor location, making it unlikely for signs to differ in only one location feature. This estimate (“Neighborhood Density 2.0”) is the one used to generate the visualization on the website. Because much of the literature on sign language appeals to the notion of parameters, not features, we also included a measure of PND (“Parameter.Neighborhood.Density”). Under this definition, signs must share all or all but one of the following: Handshape, Major Location, and Path Movement. Both of these definitions differ from those used in ASL-LEX 1.0, because more phonological features were used in the ASL-LEX 2.0 calculations. A complete comparison of the phonological composition (matches and mismatches) of every sign pair in ASL-LEX is available in Supplementary Materials, Data Files.
Both estimates of phonological ND were skewed such that most signs had few neighbors (Figure 2). This distribution is comparable with the distribution of phonological ND in English, e.g., The English Lexicon Project (Balota et al., 2007). The monomorphemic signs with the most neighbors included MISS (50) and OFFHAND (46), and many signs had zero neighbors (UNDER, ACCOMPLISH).
Phonological complexity. To calculate phonological complexity, we employed Morgan et al.’s (2019) operationalization of phonological complexity of signs. Under this definition, signs are scored in seven complexity categories, receiving 1 point if they met the category description and 0 points if they did not; a sign’s total complexity could thus range from 0 to 7. The seven categories were two-handed signs that have different handshapes, violation of the symmetry or dominance condition, selected fingers groupings other than all (index, middle, ring, and pinky) or just index, flexion values other than fully extended or fully closed, flexion values that are stacked or crossed, path movement other than straight, and more than one type of movement (e.g., flexion change and a path movement). Only the phonological features of the first morpheme were counted in the phonological complexity ratings.
The distribution of phonological complexity is skewed (Figure 2): most signs are not at all complex, i.e., had complexity ratings of 1 or 2. Among the least complex monomorphemic signs were 5_DOLLARS and ACCEPT, which all had a complexity rating of 1. The most complex monomorphemic signs included KITE and PROGRAM, which all had a rating of 6. Many low complexity signs included canonically unmarked handshapes, and the more complex signs included several initialized handshapes. Although the maximum possible complexity score is 7, the maximum observed score was 6. This result could reflect a cognitive dis-preference for phonological complexity, preventing signs from becoming too complex. It could also be a function of the relative rarity of many of these features, e.g., stacked or crossed—the combined probability of encountering all seven features is extremely low even in a dataset of this size.
Phonotactic probability. We provide two categories of phonotactic probabilities derived from ASL-LEX 2.0: sub-lexical frequency and phonotactic probability. For each of the coded phonological features, we provided an estimate of the sub-lexical frequency, which counted the frequency with which the value occurred in the lexicon, for example, “movement frequency,” “flexion frequency,” etc. The sub-lexical frequency is akin to a “one shared feature” definition of phonological ND (i.e., the number of signs that share a value of the feature). The phonotactic probability estimate is the mean of the scaled sub-lexical frequencies (NA values were ignored) and represents a single estimate of the likelihood of the entire sign’s phonological composition. Only the phonological features of the first morpheme were calculated in this estimate.
Phonotactic probability was normally distributed (Figure 2). The monomorphemic signs with the highest phonotactic probability included TRUCK_2 (.821) and COUCH_1 (.821). The monomorphemic signs with the lowest phonotactic probability included CHASE (−1.269) and SUIT (−1.054).
Sign duration. The distribution of sign duration (milliseconds) (Figure 2) was normally distributed. The average duration of signs was 851 msec (SD = 301). The signs FOUR (200 ms) and STUPID_1 (167 ms) were among the shortest signs in the database. The signs BATHTUB (2,402 msec) and ROAST (2,603 msec) were the longest; these items also included multiple sequential morphemes.
Relationship Among Lexical and Phonological Variables
We analyzed the relationships among the following lexical and phonological properties: Sign Frequency, Iconicity, Deaf Iconicity (subset of 993 signs), Transparency (subset of 430 signs), Guess Consistency (H statistic; subset of 430 signs), ND, Phonotactic Probability, Phonological Complexity, and Sign Duration. Table 2 shows correlations among the variables (scatterplots are provided in Figure S5).
Table 2.
Summary of correlations among lexical and phonological properties of signs. Variables from top to bottom are: frequency (Freq), iconicity rated by hearing non-signers (HearingIcon), iconicity rated by deaf signers (DeafIcon; n = 993 signs), transparency (Transp; n = 430 signs), Guess Consistency (H_Stat; n = 430 signs), Neighborhood Density (ND), Parameter Neighborhood Density (PND), phonological complexity (Complexity), phonotactic probability (PhonProb), and sign duration in milliseconds (Dur(ms)). Frequency, iconicity, and transparency were Z transformed across participants.
| Variable | M | SD | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1. Freq | −.05 | 0.66 | |||||||||
| 2. HearingIcon | 0.05 | 0.77 | −.14** | ||||||||
| [−.18, −.10] | |||||||||||
| 3. DeafIcon | −.03 | 0.77 | −.24** | .82** | |||||||
| [−.30, −.18] | [.80, .84] | ||||||||||
| 4. Transp | 0 | 0.5 | 0.04 | .60** | .55** | ||||||
| [−.06, .13] | [.53, .66] | [.48, .62] | |||||||||
| 5. H.stat. | 2.19 | 0.57 | 0.02 | −.56** | −.51** | −.78** | |||||
| [−.08, .11] | [−.62, −.49] | [−.57, −.43] | [−.81, −.74] | ||||||||
| 6. ND | 5 | 7.43 | .10** | .06** | 0.03 | .12* | −.04 | ||||
| [.06, .13] | [.02, .10] | [−.04, .09] | [.03, .21] | [−.13, .05] | |||||||
| 7. PND | 273.5 | 149.48 | .07** | 0.01 | 0.04 | 0.05 | −.02 | .30** | |||
| [.04, .11] | [−.02, .05] | [−.02, .10] | [−.04, .15] | [−.12, .07] | [.26, .33] | ||||||
| 8. Complexity | 1.93 | 1.01 | −.06** | −.10** | −.05 | −.18** | .11* | −.36** | −.47** | ||
| [−.10, −.03] | [−.13, −.06] | [−.11, .02] | [−.27, −.08] | [.02, .21] | [−.39, −.33] | [−.50, −.44] | |||||
| 9. PhonProb | 0 | 0.35 | .05** | .08** | 0.06 | .10* | 0 | .24** | .37** | −.30** | |
| [.02, .09] | [.04, .11] | [−.00, .12] | [.00, .19] | [−.10, .09] | [.20, .28] | [.34, .40] | [−.33, −.27] | ||||
| 10. Dur(ms) | 850.9 | 301.08 | −.21** | .06** | .09** | −.01 | 0.01 | 0.03 | −.13** | .09** | −.06** |
| [−.25, −.17] | [.02, .10] | [.03, .16] | [−.10, .09] | [−.09, .10] | [−.00, .07] | [−.17, −.09] | [.06, .13] | [−.09, −.02] |
First, the four phonological variables (two measures of ND, Phonotactic Probability, and Phonological Complexity) were by definition expected to be correlated (Table 2). While each of these measures was motivated by a different theory and body of literature (for a review, see Brentari, 2019), the way they were each calculated was highly interdependent as all three measures were determined in part by the probability of phonological features. Phonotactic probability does this in the most straightforward way, as it reflects the frequency of a sign’s features within the language. Phonological complexity reflects how “marked” a sign is overall, and markedness is in part informed by the frequency of various phonological features. Phonological ND reflects how similar the sign is to other signs in the lexicon. A sign that is phonologically complex will, by definition, have largely infrequent features, which translates mathematically to a low phonotactic probability. Similarly, signs that are phonotactically improbable are unlikely to be neighbors to many other signs.
Second, all four iconicity measures in ASL-LEX 2.0 (deaf-and-hearing iconicity ratings, guess consistency (H statistic), and transparency ratings) were also intercorrelated. Although these measures have different methodological considerations because they capture form-meaning relations in distinct ways, the high correlations show that these measures are sensitive to the perceivers’ ability to infer meaning based on the sign form even if the inferred meaning might variably align with the conventional meaning of the sign. For further results and discussion of iconicity measures for the original 993 signs in ASL-LEX see Sehyr and Emmorey (2019).
Frequent signs were rated as less iconic than infrequent signs, replicating the results from the smaller ASL-LEX 1.0 dataset (Caselli et al., 2017). This pattern is compatible with the long-standing notion in sign language research that iconicity erodes with frequent use. Signs evolve to become more efficient for communication perhaps due to linguistic pressures to become more integrated into the phonological system and, as a result, their iconic origins may become obscured (Frishberg, 1975). In contrast, infrequent signs have had fewer opportunities to evolve (or may experience less communicative pressure to simplify) than frequent signs, and so their iconic motivations are relatively well preserved.
Frequency inversely correlated with iconicity, but this correlation was stronger for deaf raters (993 signs; r = −.24) than for hearing raters for all 2,327 signs (r = −.14) and for the original 993 signs (r = −.14) published in Caselli et al. (2017). This difference suggests that deaf signers might possess a greater sensitivity to the coupling between these two properties than hearing non-signers. This finding also emphasizes the need to consider deaf signers’ iconicity data in future research. Frequency did not correlate with measures of transparency (“guessability”) or guess consistency (H statistic). The ability to conjure up meaning based on the signs’ form alone is unrelated to sign frequency (Sehyr & Emmorey, 2019).
Higher frequency signs were shorter, phonologically simpler, and resided in denser phonological neighborhoods, as we found a negative correlation between frequency, sign duration, and the phonological variables of complexity and ND. These patterns align with previously reported results from ASL-LEX 1.0 (Caselli et al., 2017) and are consistent with work on spoken languages showing that frequency and phonetic duration tend to be inversely, although weakly, related (Gahl, Yao, & Johnson, 2012). We found that denser phonological neighborhoods also consisted of more frequent and less complex signs. The finding that frequent signs were less phonologically complex was consistent with the idea that languages evolve to result in structures that maximize communicative efficiency (Bybee, 2006; Gibson et al., 2019). Efficient communication is achieved when the intended message is recovered with almost no loss of information and with minimal effort by the sender and receiver. Complex signs thus evolve to become phonologically simpler and shorter to aid communicative efficiency.
While in ASL-LEX 1.0, we did not find a relationship between sign duration and the less precise estimate of ND (r = −.01, p = .69), sign duration was correlated with three of the four phonological variables in this larger dataset. Specifically, signs with shorter durations tended to reside in larger phonological neighborhoods, have higher phonotactic probabilities, and were less phonologically complex. The correlations observed here might be due to differences in phonological coding and/or to the larger set of signs. While the direction of these correlations appears to be in line with the spoken language literature, a direct comparison with spoken languages is not straightforward. In spoken languages, the length of a word (usually measured in number of phonemes or letters) is directly related to phonological structure; because phonemes in spoken language are ordered in sequence, longer words have more phonological information and so are generally more complex, less probable, and have fewer neighbors. Because much of the phonological information about signs is not sequential, it was not a foregone conclusion that phonological structure would be related to sign duration in the way it relates in spoken languages. In addition, the sign duration measures were based on the productions of a single signer. More work using naturally produced signs should be done to confirm and better understand the relationship between phonological structure and sign duration.
Iconic signs were longer, phonologically simpler, more phonotactically probable, and have more neighbors than less iconic signs. First, iconic signs may be longer because some of the most iconic signs tend to depict handling or manipulation of objects that might incorporate gradient, gestural elements or depiction and thus take longer to articulate than non-handling signs. Second, looking at the lexicon as a whole, we suggest that phonologically simpler sign features may lend themselves to greater iconicity than more complex features. As an example, signs with that depict handling are among the most iconic signs (Caselli & Pyers, 2017), and these signs also tend to be phonologically simple and involve all of the selected fingers that occur in common configurations (CANOE, HAMMER, PULL) (see Brentari, 2012). However, we note that some highly phonologically complex sign forms appear to be allowed because of their iconicity (e.g., CURL). Nonetheless, even the most unusual sign forms were not typically rated as highly iconic (CURL has an iconicity value of 3.5), which is in line with the finding that signs rated as less iconic tended to be more phonologically complex. Thus according to phonological theories of sign languages, there may be both phonological and iconic pressure on sign forms, and some phonologically marked signs exist in order to maintain iconicity (Eccarius & Brentari, 2008). Finally, the tendency for iconic signs to have more phonological neighbors is congruent with the idea that simpler and more frequent forms might lend themselves more easily to iconic depiction. In sum, the complex interplay between iconicity and phonology suggests that iconicity plays a key role in shaping the ASL lexicon, and these results provide support for theoretical accounts of sign language phonology that call for systematic integration of iconicity in phonological analyses of signs (van der Kooij, 2002).
Visualizing the ASL-LEX 2.0 Database (Website Description)
The ASL-LEX database is publicly available for browsing, searching, and downloading from http://asl-lex.org/. As shown in Figure S6, signs are represented visually by nodes, with larger nodes indicating signs with higher subjective frequency. Signs are organized into phonological neighborhoods, where proximity between nodes indicates their phonological similarity.vii Sign pairs that have a high degree of similarity (a maximum of one mismatched feature) are connected by a line when hovering on either sign node. In the first version of ASL-LEX, signs were connected if they shared only four features, so neighborhoods in the new version are more precise, though a few uncoded features that differ between two neighbors remain (e.g., signs that differ in unselected finger position might appear to be more similar than they truly are). Because the ASL-LEX 1.0 visualization required that signs must share all four features to be connected, each neighborhood was either fully or not at all connected to other neighborhoods, and the proximity between neighborhoods was not meaningful. The 2.0 visualization now allows signs to be proximal to one another if they share just a subset of features, which means that a) neighborhoods are not necessarily fully connected (a sign might be related to one sign in the neighborhood but not to another), b) signs can be connected to multiple neighborhoods, and c) the proximity between neighborhoods is now meaningful. Colors were assigned to nodes using a Louvain modularity algorithm that divided the lexicon up into neighborhoods of densely connected nodes. Additionally, due to the many features that were coded, there are also many hermits—signs that are not close neighbors with any other sign. By hovering over a node, users can view a video of each sign and a list of other possible English translations, either from the English glosses provided by deaf raters or by the English translations made available by Signbank (Figure S6). More information about the lexical and phonological properties of the sign is also available in the main menu on the website.
The visualization can be filtered to disable signs that do not match a desired set of characteristics. To allow non-specialist audiences to interact comfortably with the website, we reduced the use of technical terms in the menus by including sliding bars to indicate minimum/maximum values of continuous variables, and by including images illustrating the phonological features. Lastly, it is also possible to view scatterplots for some of the lexical features of each sign. As illustrated in Figure S7, users can toggle between the network and scatterplot views, selecting a subset of signs from one view to explore in another. For example, users can brush to select a set of nodes from the network visualization to view the scatterplots illustrating the relationships among the signs’ specific lexical or phonological properties. This might be useful if users want to explore the relationship between frequency and iconicity in signs residing in a particular phonological neighborhood. Similarly, users might want to examine the phonological composition of signs that have high-frequency but low-iconicity ratings. Web-based tutorials on how to use the visualization tool are available on the website.
Conclusion
This article documents the ASL-LEX 2.0 database, whose primary aim is to provide a large, searchable, and publicly available lexical database for ASL. ASL-LEX represents the largest collection of ASL signs (2,723) that provides extensive information about lexical and phonological sign properties. Our analyses of these properties revealed a complex interplay between iconicity, frequency, and phonological features, and highlighted a possible role of iconicity in shaping and structuring the lexicon. Frequent signs may become phonologically simpler and less iconic, while there might be specific pressures from iconicity on certain signs to remain complex. Such patterns might not have been detectable with smaller datasets. The quantitative approach of ASL-LEX allows researchers to identify modality-dependent and modality-independent factors that affect lexical structure and processing. An ongoing effort by our group is to examine how lexical, phonological, and iconic patterns intersect with the semantic properties of signs.
As we encountered in ASL-LEX 1.0 and as Becker et al. (2020) describe, translating phonological theory into a phonological coding system that suits the goals of a lexical database is not always straightforward. Like Crasborn, van der Hulst, and van der Kooij (2002), we too “never had the ambition or illusion that we would come up with a coding system that would be satisfactory for everyone” (p. 226). Our guiding principles—to uniquely describe each sign, to code efficiently, to code each sign completely, to operationalize the coding system explicitly, and to be faithful to existing phonological theories—were likely different than those used in developing phonological theories. We also frequently had to make tradeoffs between our own guiding principles. The places where these discrepancies arise are fertile ground for future work, and point to places where the development of phonological theories and phonological coding systems can be mutually informed.
Lexical databases serve a crucial purpose, yet they are not a replacement for a corpus. Without a large-scale, labeled dataset of spontaneous signing from a diverse set of signers, it is difficult to estimate the extent to which signs in ASL-LEX are representative of the ASL lexicon, as well as which signs (and sign types) are not yet included. ASL-LEX does not contain a representative sample of complex constructions (e.g., depicting signs or classifier constructions) or fingerspelled signs that are important parts of the ASL lexicon. In addition, as a single sign repository, ASL-LEX cannot provide information related to the context in which signs naturally occur, or how the context interacts with sign properties, e.g., co-articulation in spontaneous discourse. Nevertheless, ASL-LEX and its accompanying interactive website, presents a highly impactful and valuable resource and is compatible with other sign language resources. ASL-LEX is designed to be accessible and relatively jargon free, and it is intended for multiple uses and a variety of audiences. Scientists and educators can use ASL-LEX to create well-controlled stimuli for use in research and the classroom; clinicians and early intervention specialists might utilize it to develop benchmarks for assessing vocabulary development in signing children (e.g., do children know the most frequent signs?) and to support literacy development (e.g., to find sign-based “rhymes”). ASL learners can use it as an additional resource to springboard vocabulary growth. The database will serve to advance searchable dynamic stimuli, automatic tagging, and machine learning. We hope that ASL-LEX will also foster the establishment of similar lexical databases for other sign languages, permitting quantitative cross-linguistic comparisons of lexical and phonological patterns.
Acknowledgments
This work was supported by the National Science Foundation Grants: BCS-1625954 and BCS-1918556 to KE and ZS, BCS-1918252 and BCS-1625793 to NC, and BCS-1625761 and BCS-1918261 to ACG. The original ASL-LEX project was partly supported by the National Institutes of Health Grant R01-DC010997. We would like to thank Cindy Farnady O'Grady, Natalie Vinson, and all deaf-and-hearing participants without whom this research would not be possible. Many thanks to the Boston University Software & Application Innovation Lab (SAIL) at the Hariri Institute for Computing (Shreya Pandit, Xinyun Cao, Jeff Simeon, Raj Vipani, Megan Fantes, Frederick Joossen, Fanonx Rogers, San Tran, Motunrola Bulomole, Andrei Lapets) for software development, and to Ben Tanen for his help developing the [original website]. Thanks to Chelsea Hammond, Megan Canne, Talia Cowen, Anna Lim Frank for their efforts in the phonological coding and their contributions to the phonological coding manual, and to Jennifer Feeney Petrich for her help in the initial stages of the project. The current version of ASL-LEX 2.0 can be accessed on: http://asl-lex.org/. For videos of ASL signs cited in this paper, and other supplementary materials, please go to the OSF Supplementary Materials page: DOI 10.17605/OSF.IO/ZPHA4 (https://osf.io/zpha4/).
Endnotes
iThe letter I was skipped in our naming conventions to avoid confusion between alphanumeric characters.
iiMost two-handed signs adhered to either the Symmetry or Dominance Conditions (Battison, 1978). The Symmetry Condition states that if both hands in a sign move, the movement must be symmetrical or in 180° asynchrony, and the other parameters of both hands (handshape, movement, location) must match. The Dominance condition states that if two hands have different handshapes, then only one may move, and the non-dominant handshapes are limited to the manual letters/numbers B, A, S, 1, C, O, and 5. Violations were coded with respect to type (dominance/symmetry).
iiiOne sign (TAIL) was coded as “other” because it did not fit into these categories.
ivWe note that while some minor locations are clearly contrastive (e.g., “Eye” and “CheekNose” differentiate the minimal pair ONION and APPLE), some may not be (e.g., the bands on the torso, e.g., “torso top” versus “torso mid”, see Figure S2 in Supplementary Materials). In addition, some minor location contrasts are missing (e.g., the location “cheek/nose” could be divided into cheek and nose, which are contrastive in the minimal pair DOLL and SHAVE_3).
vInterestingly, the need to recode these handshapes reveals an exception to the unselected fingers constraint, which states that if selected fingers are in any position other than extended, the unselected fingers are closed (Corina, 1993).
viIn nine signs produced on the hand, the non-dominant handshape was “Lax,” indicating that the hand was relaxed and did not match any of the handshapes.
viiPhonological similarity was based on: Sign Type, Minor Location, Major Location, Second Minor Location, Movement, Contact with the Major Location, Selected Fingers, Thumb Position, Thumb Contact, Flexion, Flexion Change, Spread, Spread Change, Ulnar Rotation, Repeated Movement and Non-Dominant Handshape.
References
- Anderson, D., & Reilly, J. (2002). The MacArthur communicative development inventory: Normative data for American sign language. Journal of Deaf Studies and Deaf Education, 7(2), 83–106. doi: 10.1093/deafed/7.2.83 [DOI] [PubMed] [Google Scholar]
- Ann, J. (1996). On the relation between ease of articulation and frequency of occurrence of handshapes in two sign languages. Lingua, 98(1–3), 19–41. doi: 10.1016/0024-3841(95)00031-3 [DOI] [Google Scholar]
- Balota, D. A., & Chumbley, J. (1984). Are lexical decisions agood measure of lexical access? The role of word-frequency in the neglected decision stage. Journal of Experimental Psychology: Human Perception and Performance, 10, 340–357. doi: 10.1037//0096-1523.10.3.340 [DOI] [PubMed] [Google Scholar]
- Balota, D. A., Pilotti, M., & Cortese, M. J. (2001). Subjective frequency estimates for 2,938 monosyllabic words. Memory & Cognition, 29(4), 639–647. doi: 10.3758/BF03200465 [DOI] [PubMed] [Google Scholar]
- Balota, D. A., Yap, M. J., Cortese, M. J., Hutchison, K. A., Kessler, B., Loftis, B. et al. (2007). The English lexicon project. Behavior Research Methods, 39(3), 445–459. http://www.ncbi.nlm.nih.gov/pubmed/17958156 [DOI] [PubMed] [Google Scholar]
- Battison, R. (1978). Lexical borrowing in American Sign Language. Linstok Press. [Google Scholar]
- Baus, C., Gutiérrez-Sigut, E., Quer, J., & Carreiras, M. (2008). Lexical access in Catalan signed language (LSC) production. Cognition, 108(3), 856–865. doi: 10.1016/j.cognition.2008.05.012 [DOI] [PubMed] [Google Scholar]
- Becker, A., Catt, D. H., & Hochgesang, J. A., (2020). Back and forth between theory and application: Shared phonological coding between ASL Signbank and ASL-LEX. Proceedings of the 9th Workshop on the Representation and Processing of Sign Languages, Language Resources and Evaluation Conference (LREC 2020), Marseille, 11–16 May 2020. [Google Scholar]
- Brentari, D. (1998). A prosodic model of sign language phonology. MIT Press. [Google Scholar]
- Brentari, D. (2007). Sign language phonology: Issues of iconicity and universality. In E. Pizzuto, P. Pietrandrea & R. Simone (Eds.), Verbal and signed languages: Comparing structures, constructs and methodologies. Mouton de Gruyter. [Google Scholar]
- Brentari, D. (2012). Phonology. In R. Pfau, M. Steinbach & B. Woll (Eds.), Sign langauge: An International Handbook. Walter de Gruyter. [Google Scholar]
- Brentari, D. (2019). Sign Language Phonology. Cambridge University Press. [Google Scholar]
- Brown, R. (1979). Why are signed languages easier to learn than spoken languages? In E. Carney (Ed.), Proceedings of the National Symposium on Sign Language Research and Teaching. National Association of the Deaf. [Google Scholar]
- Brysbaert, M., & New, B. (). Moving beyond Kučera and Francis: A critical evaluation of current word frequency norms and the introduction of a new and improved word frequency measure for American English Behavior Research Methods, 41, 977–990. 10.3758/BRM.41.4.977. [DOI] [PubMed] [Google Scholar]
- Bybee, J. (2006). From usage to grammar: The mind’s response to repetition. Language, 82(4), 711–733. doi: 10.1353/lan.2006.0186 [DOI] [Google Scholar]
- Carreiras, M., Gutiérrez-Sigut, E., Baquero, S., & Corina, D. (2008). Lexical processing in Spanish sign language (LSE). Journal of Memory and Language, 58(1), 100–122. http://www.sciencedirect.com/science/article/pii/S0749596X07000678 [Google Scholar]
- Caselli, N. K., & Cohen-Goldberg, A. M. (2014). Lexical access in sign language: A computational model . Frontiers in Psychology, 5. 428 doi: 10.3389/fpsyg.2014.00428 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Caselli, N. K., Lieberman, A. M., & Pyers, J. E. (2020). The ASL-CDI 2.0: An updated, normed adaptation of the MacArthur bates communicative development inventory for American sign language. Behavior Research Methods, Instruments, & Computers, 52, 2074–2084. doi: 10.3758/s13428-020-01376-6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Caselli, N. K., & Pyers, J. E. (2017). The road to language learning is not entirely iconic: Iconicity, neighborhood density, and frequency facilitate acquisition of sign language. Psychological Science, 28(7), 1–9. doi: 10.1177/095679761770049 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Caselli, N. K., Sevcikova Sehyr, Z., Cohen-Goldberg, A. M., & Emmorey, K. (2017). ASL-LEX: A lexical database of American sign language. Behavior Research Methods, 49, 784–801. doi: 10.3758/s13428-016-0742-0 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Corina, D. (1993). To branch or not to branch: Underspecification in ASL handshape contours. In G. Coulter (Ed.), Current issues in ASL phonology (pp. 63–95). Academic Press. [Google Scholar]
- Crasborn, O., Zwitserlood, I., & Ros, J. (2008). Corpus NGT. A digital open access corpus of movies and annotations of Sign Language of the Netherlands. Nijmegen: Radboud University, Centre for Language Studies. https://repository.ubn.ru.nl/handle/2066/68356
- Dingemanse, M., Blasi, D. E., Lupyan, G., Christiansen, M. H., & Monaghan, P. (2015). Arbitrariness, iconicity, and Systematicity in language. Trends in Cognitive Science, 19(10), 603–615. doi: 10.1016/j.tics.2015.07.013 [DOI] [PubMed] [Google Scholar]
- Dye, M. W. G., & Shih, S. (2006). Phonological priming in British Sign Language. In L. Goldstein, D. H. Whalen & C. T. Best (Eds.), Laboratory Phonology (Vol. 8, pp. 243–263). Mouton de Gruyter (Phonology and Phonetics 4). [Google Scholar]
- Eccarius, P., & Brentari, D. (2008). Handshape coding made easier a theoretically based notation for phonological transcription. Sign Language & Linguistics, 11(1), 69–101. doi: 10.1075/sll.11.1.11ecc [DOI] [Google Scholar]
- Emmorey, K. (2014). Iconicity as structure mapping. Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences, 369(1651), 20130301. doi: 10.1098/rstb.2013.0301 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fenlon, J., Schembri, A., Rentelis, R., Vinson, D., & Cormier, K. (2014). Using conversational data to determine lexical frequency in British sign language: The influence of text type. Lingua, 143, 187–202. doi: 10.1016/j.lingua.2014.02.003 [DOI] [Google Scholar]
- Ferrara, L., & Hodge, G. (2018). Language as description, indication, and depiction. Frontiers in Psychology, 9(716), 1–15. doi: 10.3389/fpsyg.2018.00716 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Frishberg, N. (1975). Arbitrariness and iconicity: Historical change in American sign language. Language, 51(3), 696–719. doi: 10.2307/412894 [DOI] [Google Scholar]
- Gahl, S., Yao, Y., & Johnson, K. (2012). Why reduce? Phonological neighborhood density and phonetic reduction in spontaneous speech. Journal of Memory and Language, 66(4), 789–806. doi: 10.1016/j.jml.2011.11.006 [DOI] [Google Scholar]
- Gibson, E., Futrell, R., Piandadosi, S. P., Dautriche, I., Mahowald, K., Bergen, L., & Levy, R. (2019). How efficiency shapes human language. Trends in Cognitive Sciences, 23(5), 389–407. doi: 10.1016/j.tics.2019.02.003 [DOI] [PubMed] [Google Scholar]
- Gierut, J. A. (2007). Phonological complexity and language learnability. American Journal of Speech-Language Pathology, 16(1), 6–17. doi: 10.1044/1058-0360(2007/003) [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gutiérrez-Sigut, E., Costello, B., Baus, C., & Carreiras, M. (2015). LSE-sign: A lexical database for Spanish sign language. Behavior Research Methods. 48, 123–137. doi: 10.3758/s13428-014-0560-1 [DOI] [PubMed] [Google Scholar]
- Gutiérrez-Sigut, E., Müller, O., Baus, C., & Carreiras, M. (2012). Electrophysiological evidence for phonological priming in Spanish sign language lexical access. Neuropsychologia, 50(7), 1335–1346. doi: 10.1016/j.neuropsychologia.2012.02.018 [DOI] [PubMed] [Google Scholar]
- Henner, J., Geer, L. C., & Lillo-Martin, D. (2013). Calculating frequency of occurrence of ASL handshapes. LSA Annual Meeting Extended Abstracts, pp. 1–4. http://journals.linguisticsociety.org/proceedings/index.php/ExtendedAbs/article/viewFile/764/562 [Google Scholar]
- Hochgesang, J., Crasborn, O., & Lillo-Martin, D. (2018). Building the ASL Signbank: Lemmatization Principles for ASL. In M. Bono, E. Efthimiou, S.-E. Fotinea, T. Hanke, J. Hochgesang, J. Kristoffersen, J. Mesch & Y. Osugi (Eds.), Proceedings of the Language Resources and Evaluation Conference 8th Workshop on the Representation and Processing of Sign Languages: Involving the Language Community (pp. 69–74).
- Hochgesang, J., Crasborn, O., & Lillo-Martin, D. (2019). ASL Signbank. Haskins Lab: Yale University. [Google Scholar]
- Hoffmeister, R. J. (1999). American Sign Language Assessment Instrument (ASLAI). Boston University, Center for the Study of Communication and the Deaf.
- Klima, E., & Bellugi, U. (1979). The Signs of Language. Harvard University Press. [Google Scholar]
- Luce, P. A., & Pisoni, D. B. (1998). Recognizing spoken words: The neighborhood activation model. Ear and Hearing, 19(1), 1–36. http://www.ncbi.nlm.nih.gov/pubmed/9504270 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mandel, M. (1981). Phonotactics and morphophonology in American Sign Language. Berkeley: University of California. [Google Scholar]
- Mayberry, R. I., Hall, M. L., & Zvaigzne, M. (2014). Subjective frequency ratings for 432 ASL signs. Behavior Research Methods, 46(2), 526–539. doi: 10.3758/s13428-013-0370-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- Meade, G., Lee, B., Midgley, K. J., Holcomb, P. J., & Emmorey, K. (2018). Phonological and semantic priming in American sign language: N300 and N400 effects. Language, Cognition and Neuroscience, 33(9), 1092–1106. doi: 10.1080/23273798.2018.1446543 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Monaghan, P., Shillcock, R. C., Christiansen, M. H., & Kirby, S. (2014). How arbitrary is language? Philosophical Transactions of the Royal Society, B: Biological Sciences, 369(1651), 1–15. doi: 10.1098/rstb.2013.0299 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Morford, J. P., & MacFarlane, J. (2003). Frequency characteristics of American sign language. Sign Language Studies, 3(2), 213–225. doi: 10.1353/sls.2003.0003 [DOI] [Google Scholar]
- Morgan, H., Novogrodsky, R., & Sandler, W. (2019). Phonological complexity and frequency in the lexicon: A quantitative cross-linguistic study (pp. 26–28). Hamburg, Germany: Paper presented at TISLR13: Theoretical Issues in Sign Language Research. [Google Scholar]
- Novogrodsky, R., Caldwell-Harris, C., Fish, S., & Hoffmeister, R. J. (2014). The development of antonym knowledge in American sign language (ASL) and its relationship to reading comprehension in English. Language Learning, 64(4), 749–770. doi: 10.1111/lang.12078 [DOI] [Google Scholar]
- Occhino, C., Anible, B., Wilkinson, E. P., & Morford, J. (2017). Iconicity is in the eye of the beholder. Gesture, 16(1), 100–126. doi: 10.1075/gest.16.1.04occ [DOI] [Google Scholar]
- Occhino, C., Annible, B., & Morford, J. P. (2020). The role of iconicity, construal, and proficiency in the online processing of handshape. Language and Cognition, 12, 114–137. doi: 10.1017/langcog.2020.1 [DOI] [Google Scholar]
- Prillwitz, S., Hanke, T., König, S., Konrad, R., Langer, G., & Schwarz, A. (2008). DGS Corpus Project – Development of a Corpus Based Electronic Dictionary German Sign Language/German. 3rd Workshop on Representation and Processing of Sign Languages: Corpora and Sign Language Technologies, Marrakech – Morocco (pp. 159–164). Paris: ELRA. [Google Scholar]
- Sandler, W. (1989). Phonological representation of the sign: linearity and nonlinearity in American Sign Language (Vol. 32). Foris Publications. doi: 10.1515/9783110250473 [DOI] [Google Scholar]
- Schembri, A., Fenlon, J., Rentelis, R., & Cormier, K. (2014). British Sign Language Corpus Project: A corpus of digital video data and annotations of British Sign Language 2008–2014 (2nd Ed). University College London. http://www.bslcorpusproject.org. [Google Scholar]
- Sehyr, S. Z., & Emmorey, K. (2019). The perceived mapping between form and meaning in American sign language depends on linguistic knowledge and task: Evidence from iconicity and transparency judgments. Language and Cognition, 11(2) (Special Issue on Iconicity) 1–27. doi: 10.1017/langcog.2019.18 [DOI] [PMC free article] [PubMed] [Google Scholar]
- van der Kooij, E. (2002). Phonological Categories in Sign Language of the Netherlands. The role of phonetic implementation and iconicity LOT: Utrecht. [Google Scholar]
- van der Kooij, E., & Crasborn, O. (2008). Syllables and the word-prosodic system in sign language of the Netherlands. Lingua, 118(9), 1307–1327. doi: 10.1016/j.lingua.2007.09.013 [DOI] [Google Scholar]
- Vinson, D. P., Cormier, K., Denmark, T., Schembri, A., & Vigliocco, G. (2008). The British sign language (BSL) norms for age of acquisition, familiarity, and iconicity. Behavior Research Methods, 40(4), 1079–1087. doi: 10.3758/brm.40.4.1079 [DOI] [PubMed] [Google Scholar]
- Vitevitch, M. S. (2002). The influence of phonological similarity neighborhoods on speech production. Journal of Experimental Psychology: Learning, Memory, and Cognition, 28(4), 735–747. doi: 10.1037//0278-7393.28.4.73 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vitevitch, M. S., & Luce, P. A. (1999). Probabilistic phonotactics and neighborhood activation in spoken word recognition. Journal of Memory and Language, 40(3), 374–408. doi: 10.1006/jmla.1998.2618 [DOI] [Google Scholar]
- Wilbur, R. B. (2010). The semantics–phonology interface. In D. Brentari (Ed.), Sign Languages. Cambridge University Press. doi: 10.1017/CBO9780511712203.017 [DOI] [Google Scholar]