

Abstract
Quantile regression offers a useful alternative strategy for analyzing survival data. Compared to traditional survival analysis methods, quantile regression allows for comprehensive and flexible evaluations of covariate effects on a survival outcome of interest, while providing simple physical interpretations on the time scale. Moreover, many quantile regression methods enjoy easy and stable computation. These appealing features make quantile regression a valuable practical tool for delivering in-depth analyses of survival data. In this paper, I review a comprehensive set of statistical methods for performing quantile regression with different types of survival data. This review covers various survival scenarios, including randomly censored data, data subject to left truncation or censoring, competing risks and semi-competing risks data, and recurrent events data. Two real examples are presented to illustrate the utility of quantile regression for practical survival data analyses.
Keywords: Quantile regression, estimating equation, randomly censored data, competing risks data, semi-competing risks data, recurrent events data
1. Background and motivation
The problem of analyzing survival (or time-to-event) data arises in a number of scientific fields. For example, an event time of interest can be survival time of a cancer patient recorded in a medical study, time to high school dropout studied by sociologists, “survival” time of new business addressed in economic research, or lifetime of a part under stress evaluated in an engineering reliability study. A common feature of survival data is that they often contain incomplete time-to-event information due to censoring or truncation. Censoring occurs when an event time is known to have occurred only within certain intervals. Truncation is defined as a condition which excludes certain subjects from the study population. Statistical methods for analyzing survival data need to appropriately account for various forms of censoring and truncation.
To evaluate the association between a survival outcome and a set of explanatory variables (or covariates), the accelerated failure time (AFT) model has been extensively studied in literature as a counterpart of linear regression in survival analysis (Miller 1976, Buckley & James 1979, Prentice 1978, Wei & Gail 1983, Tsiatis 1990, Ritov 1990, Wei et al. 1990, among others). Consider an event time T and a p × 1 covariate vector . The AFT model regresses a survival response, Y ≐ log(T), or another monotone transformation of T, over ; that is,
where b is a vector of unknown regression coefficients and ϵ is an error term with an unknown distribution independent of . The assumption that ϵ is independent of confines covariates to affect only the location of the distribution of Y. However, this is often too restrictive in real applications. For example, an analysis of a dialysis dataset presented in Section 5.1 suggests that the symptom severity of restless leg syndrome (RLS) may only impact the lower range but not the upper range of the survival function of dialysis patients. The AFT model, which assumes pure location shift effects, would fail to accommodate such an inhomogeneous effect of RLS.
An alternative regression strategy for survival data is to use the Cox proportional hazards (PH) model (Cox 1972, Andersen & Gill 1982) Specifically, the Cox PH model relates the conditional hazard function of T, , to covariates in multiplicatively without specifying a parametric baseline hazard; that is,
where λ0(t) is an unspecified baseline hazard function, and b is an unknown regression coefficient vector. The Cox PH model is widely used in the practice of survival analysis. Nevertheless, the Cox regression model requires covariate-specific hazards be proportional. This key assumption essentially exerts a location shift model for a monotonically transformed survival function of T. This limits the applications of the Cox PH model in scenarios with inhomogeneous covariate effects as exemplified above. Under the Cox PH model, covariate effects are formulated on the conditional hazard function of T, which lacks a physical interpretation on event times (Reid 1994).
Quantile regression (Koenker & Bassett 1978) offers a natural remedy for accommodating heterogeneous covariate effects, while retaining straightforward physical interpretations. A comprehensive review of quantile regression methodology was provided by Koenker (2017). Quantile regression has received increased attention in survival analysis because event times themselves are often of scientific interest, and quantiles are more flexible and robust quantitative tools for characterizing event times than mean-based devices. For example, in the presence of censoring with bounded support, mean survival time may not be identifiable, while quantiles may be identifiable.
For a survival time T, a standard quantile regression model assumes that the τ-th conditional quantile of Y ≐ log(T) given , defined as QY (τ|Z) ≐ inf{t : Pr(Y ⩽ t|Z) ⩾ τ), is linearly related to covariates in Z. That is,
| (1) |
where 0 ⩽ τL ⩽ τU < 1 and β0(τ) is a (p + 1) × 1 vector of unknown regression coefficients. A non-intercept coefficient in β0(τ) represents a covariate effect on the τ-th conditional quantile of log(T). By allowing β0(τ) to change with τ, quantile regression permits varying covariate effects on different segments of the response distribution. This feature renders the flexibility to accommodate inhomogeneous covariate effects
When τL = τU, model (1) is referred to as a locally linear quantile regression model because it only asserts “local” linearity between the conditional quantile of log(T) and Z at a single quantile level. When τL < τU, model (1) imposes a “global” linearity for the conditional quantile of log(T) throughout the τ-interval [τL, τU], and thus is referred to as a globally linear quantile regression model. A globally linear quantile regression model can provide a platform for investigating the dynamic pattern of covariate effects, while paying the price of imposing a stronger model assumption compared to a locally linear quantile regression model.
It is easy to see that the AFT model is a special case of model (1) with β0(τ) = {Qϵ(τ), b⊤}⊤, where Qϵ(τ) denotes the τth-percentile of ϵ. Under the standard Cox PH model, , where . Given Λ0(·) is an unknown function, the quantile interpretation of the Cox PH model is vague. Moreover, many interesting forms of heterogeneous covariate effects are excluded by the restrictive forms of QT (τ|Z) designated by the AFT model and the Cox PH model. In contrast, quantile regression modeling offers straightforward physical interpretations as well as greater flexibility to accommodate heterogeneous associations between covariates and the survival response. This serves as the key motivation for considering quantile regression as an alternative approach to analyzing survival data.
In this paper, we present a comprehensive methodological framework that has been developed to perform quantile regression with survival data. Due to space limit, the review is rather selective but yet cover a wide range of survival scenarios. More specifically, section 2 is focused on the standard survival setting with randomly censored data. Section 3 includes discussions of quantile regression methods applicable to more complex survival settings that involve left truncation or left censoring, competing risks and semi-competing risks. Recent method developments for recurrent events data are presented in Section 4. Two real data examples are presented in section 5 to illustrate the practical utility of quantile regression methods for survival analyses. Section 6 concludes this paper with a brief summary and a few remarks.
2. Quantile regression for randomly censored data
Let T denote time to event subject to right censoring by C, and let Y = log(T). Define and Δ = I(T ⩽ C), where ∧ is the minimum operator. The observed data consist of n i.i.d. replicates of (, Δ, Z), denoted by (, Δi, Zi), i = 1, …, n. Define , , U = log(C), and Ui = log(Ci).
2.1. Random right censoring with C always known
In the absence of censoring, the regression quantile β0(τ) in model (1) is defined as the minimizer of the standard quantile loss function, , with respect to b, where ρτ(x) = x{τ − I(x < 0)} (Koenker & Bassett 1978).
When censoring is present and the censoring time C is fixed at prespecified values, by utilizing the fact that , Powell (1984, 1986) proposed an adaptation of the standard quantile loss function, which led to an estimator of β0(τ) given by arg minb r(b, τ), where
This estimation method is directly applicable to a more general case where C is always known but not necessarily fixed, and is independent of T given Z. Unlike the standard quantile loss function, r(b, τ) is not convex in b and thus it may have multiple local minima. Several authors, for example, Fitzenberger (1997), Buchinsky & Hahn (1998), Chernozhukov & Hong (2001), contributed strategies to improve the numerical performance of Powell’s estimator. An implementation of Powell’s method is available in the crq function in the R package quantreg (Koenker et al. 2019).
2.2. Unconditionally random right censoring
Censoring time C is not always observed in most survival settings. Under the assumption that T and C are independent and C is independent of Z (i.e. unconditionally random right censoring), Ying et al. (1995) proposed to estimate β0(τ) by solving the following estimating equation,
| (2) |
where is the Kaplan-Meier estimate for G(·), which denotes the survival function of U. Since equation (2) is not continuous and may not have an exact zero-crossing, Ying et al. (1995) suggested obtaining the estimator of β0(τ) by minimizing the L2 norm of the estimating function in (2). The resulting objective function however may have multiple minima.
Employing the inverse probability of censoring weighting (IPCW) technique (Robins & Rotnitzky 1992), Zhou (2006) studied an alternative estimating equation for β0(τ), which is given by
| (3) |
The estimating function in (3) is monotone (Fygenson & Ritov 1994). Consequently, the solution to equation (3) can be reformulated as the minimizer of a convex L1-type convex function of b,
where M* is an extremely large positive number selected to bound for all b’s in a compact parameter space. This minimization problem can be readily solved by the l1fit() function in S-PLUS or the rq() function in the R package quantreg (Koenker et al. 2019).
2.3. Conditionally random right censoring
Conditionally random right censoring, which assumes C is independent of T given Z, is the most commonly adopted random censoring mechanism. This censoring mechanism is less restrictive than those considered in Sections 2.1 and 2.2.
In this section, we first consider a globally linear quantile regression model,
| (4) |
and then discuss a locally linear quantile regression model with τL = τU.
2.3.1. Self-consistent approaches.
By adapting the idea of redistributing censoring probability in the self-consistent Kaplan-Meier estimator (Efron 1967), Portnoy (2003) made the first attempt to estimate the globally linear quantile regression model (4) under the conditionally random right censoring assumption. The initial iterative self-consistent algorithm (Portnoy 2003) was simplified into a grid-based sequential estimation procedure (Neocleous et al. 2006), and the corresponding asymptotic studies was conducted by Portnoy & Lin (2010).
The grid-based estimation procedure of Neocleous et al. (2006) is outlined as follows. First, define a grid of τ-values, , as . Let . Without further mentioning, will be adopted throughout Section 2.3. Assuming no censoring occurs below the τ1-th conditional quantile of T, one can obtain an estimate for β0(τ1) from applying uncensored quantile regression. Next, one can estimate β0(τk+1) sequentially for k = 1, 2, …, Mn by minimizing
| (5) |
where Y* is an extremely large value and K denotes the set of indices of censored observations that have been previously crossed (i.e. ). The weight wk+1,i takes the form (τk+1−τl)/(1−τl) to approximate the conditional probability, Pr(Ci < Ti < exp{Ziβ0(τk+1)}|Ci < Ti, Zi) based on the estimates for β0(τ1), …, β0(τk).
Peng (2012) proposed alternative formulations of the self-consistent approach based on stochastic integral equations. First, using stochastic integral formulation and applying stochastic integral by parts, Efron (1967)’s self-consistent estimating equation for FY (t) in the one-sample case can be re-expressed as
where , , and FY (t) = Pr(Y ⩽ t).
With t replaced by , this equation evolves into an estimating equation for β0(τ),
| (6) |
Peng (2012) further justified several asymptotically equivalent variants of the estimating equation (6), one of which takes the form of
| (7) |
Here ψi(β, τ) = sup{Ai(β, τ)} · I(Ai(β, τ) is not empty) + τI(Ai(β, τ) is empty) with . The estimation procedure derived from equation (7) is identical to Neocleous et al. (2006)’s procedure except for the estimation of β0(τ1). That is, Neocleous et al. (2006)’s procedure estimates β0(τ1) as the minimizer of (5) with w1,i = 1, while estimating β0(τ1) based on equation (7) is equivalent to minimizing (5) with w1,i = 0.
Large sample studies for the estimator obtained from solving equation (6) are facilitated by the stochastic integral equation representation of . Specifically, under certain regularity conditions and given , , where 0 < ν < τU. If is further satisfied, then converges weakly to a Gaussian process for τ ∈ [ν, τU]. Estimator defined based on (7) is asymptotically equivalent to .
2.3.2. Martingale-based approach.
Peng & Huang (2008) proposed to utilize the martingale structure underlying randomly censored data to construct an estimating equation for model (4). Define ΛY (t|Z) = −log{1−Pr(Y ⩽ t|Z)}, , and M(t) = N(t) − ΛY (t ∧ Y|Z). Let Ni(t) and Mi(t) be sample analogs of N(t) and M(t) respectively, i = 1, …, n. Note that Mi(t) is the martingale process associated with the counting process Ni(t). Thus, E{Mi(t)|Zi} = 0 for all t > 0, and for τ[0, τU]. Since is monotone in τ ∈ [0, τU], we have , where H(x) = −log(1 − x). These findings suggest a stochastic integral based estimating equation,
| (8) |
An estimator of β0(τ), denoted by , can be obtained through approximating the stochastic solution to equation (8). Specifically, let be a cadlag (i.e. right continuous with finite left limits) step function of τ that jumps only at the grid points of . The procedure to obtain follows.
Set for all i. Set k = 0.
-
Given for l ⩽ k, obtain as the minimizer of the following L1-type convex objective function:
where Y* is an extremely large value.
Replace k by k + 1 and repeat step 2 until k = Mn or no feasible solution can be found for minimizing lk(h).
Peng & Huang (2008) established the uniform consistency and weak convergence of . Moreover, Peng (2012) showed that is asymptotically equivalent to the self-consistent estimator in that with 0 < ν < τU. This theoretical result is consistent with the numerical results reported in Koenker (2008) and Peng (2012).
The crq() function in the R package quantreg (Koenker et al. 2019) provides an implementation of based on an algorithm slightly different from the one presented above. An asymptotically equivalent grid-free estimation procedure for model (4) was developed by Huang (2010).
2.3.3. Data augmentation approach.
Yang et al. (2018) employed a variation of the data augmentation algorithm to tackle the estimation of model (4) with τU = 1. The basic idea is to apply the general principle of data augmentation (Tanner & Wong 1987), and employ an alternating process between imputation of censored values from the quantile functions and refitting of the quantile model using the imputed values. More specifically, the algorithm starts with a set of initial values, , obtained by parallel quantile regression estimators or existing quantile regression estimators. For h = 1, …, H, draw from the quantile process approximated by conditional on the set of possible values for Yi. Then, based on a pairwise bootstrapping sample of size n from , obtain updated estimates via standard uncensored quantile regression. Lastly, take the final estimates as .
An appealing feature of Yang et al. (2018)’s approach is that it can handle different forms of censoring, including random censoring, double censoring, and interval censoring. As demonstrated by Monte Carlo simulations, the resulting estimator can achieve significant efficiency gains over the existing methods. The algorithm of Yang et al. (2018) is implemented by the R function DArq().
2.3.4. Adjusted loss function methods.
Assume a locally linear quantile regression model, which is model (1) with τL = τU equal to a prespecified τ, i.e.
| (9) |
To account for random censoring in the estimation of model (9), Wang & Wang (2009) proposed to modify the standard quantile loss function by twisting the idea of the self-consistent Kaplan-Meier estimator (Efron 1967). That is, one may redistribute the probability mass associated with each censored case, Pr(Ti > Ci|Ci, Zi), to the right through a local weighting scheme by wi(F0), where
with F0(t|z) = Pr(T > t|Z = z). Suppose F0(t|z) is known. An estimator of β0(τ) in model (9) can be obtained by minimizing the following objective function of β:
| (10) |
In practice, F0(t|z) is usually unknown. In this case, Wang & Wang (2009) proposed to minimize the objective function (10) with F0(·) replaced by , the local Kaplan-Meier estimator, namely,
Here Bnk(z) is a sequence of nonnegative weights adding up to 1, for example, Nadaraya-Watson’s type weight, , where K(·) is a density kernel function and hn is a positive bandwidth converging to 0 as n → ∞. The resulting estimator is shown to be consistent and asymptotically normal with root n rate under regularity conditions.
De Backer et al. (2019) and De Backer et al. (2020) investigated different strategies for adjusting the standard quantile loss function in order to accommodate randomly censored data. More specifically, letting GU(u|Z) = Pr(U > u|Z), De Backer et al. (2019) noted that the derivative of with respect to a equals −{I(Y > a) − GU(a|Z)(1 − τ)}, which, conditional on Z, has expectation zero with under model (9). This key fact leads to an adjusted loss function for censored quantile regression,
| (11) |
where is a consistent estimator of GU(·|z). When C is independent Z, can be obtained through the Kaplan-Meier estimator of the survival distribution of C. Without assuming the independence between C and Z, can be obtained through semiparametric modeling of C given Z, or by directly using Beran’s conditional Kaplan-Meier estimator (Beran 1981). De Backer et al. (2019) developed a numerically robust MM algorithm to solve the minimization of the non-convex adjusted loss function (11). Following a different view, De Backer et al. (2020) proposed to estimate model (9) based on a minimum distance loss function, given by . De Backer et al. (2020) further suggested using a smooth double kernel version of . They also discussed how to handle high-dimensional covariates by employing the effective dimension reduction technique (Li et al. 1999, Xia et al. 2010). Desirable asymptotic properties, consistency and asymptotic normality, were established for these estimators of β0(τ) in model (9).
2.4. Inference procedures
2.4.1. Variance estimation.
Bootstrapping procedures have been justified and commonly used to make inferences under quantile regression with either uncensored response or censored survival response. For example, to estimate the asymptotic variance of the estimators discussed in sections 2.1–2.3, one may use resampling methods that follow the idea of Parzen & Ying (1994) or apply the standard bootstrapping procedures that use resampling with replacement (Koenker 2005, Peng & Huang 2008).
Alternative methods without involving resampling have been developed for variance estimation under quantile regression. A main challenge is how to estimate the unknown densities involved in the formulas for asymptotic variances. Under random right censoring with known censoring time or unconditionally random censoring, Huang (2002)’s technique can be directly applied to avoid smoothing-based density estimation, which may be unstable with small or moderate sample sizes. Specifically, let denote an estimator of β0(τ), and Sn{β(τ), τ} denote the estimating function associated with , for example, the left-hand side of (2) and (3). Generally it can be shown that Sn{β0(τ), τ} converges to a mean-zero multivariate normal distribution with covariance matrix Σ(τ), which may be consistently estimated by . The following are the main steps to obtain a sample-based variance estimator:
-
A.1
Find a symmetric and nonsingular (p + 1) × (p + 1) matrix En(τ) ≐ {en,1(τ), …, en,p+1(τ)} such that .
-
A.2
Calculate , where is defined as the solution to Sn(b, τ) − e = 0.
-
A.3
Estimate the asymptotic variance matrix of by n{Dn(τ)}⊗2.
Under conditionally random censoring, the self-consistent estimators and the martingale-based estimator for model (4) take much more complex forms than those developed under the stronger censoring mechanism with either known censoring time or unconditionally independent censoring. To estimate the asymptotic variances of these estimators, it requires much more sophisticated twists of Huang (2002)’s technique to address the challenge associated with unknown densities. A sample-based variance estimation procedure for Peng & Huang (2008)’s estimator is available through adapting Sun et al. (2016)’s sample-based inference procedure for recurrent events data to the setting with randomly censored data.
2.4.2. Second-stage inference.
Globally linear quantile regression model (4) provides a platform to explore the varying pattern of covariate effects across different quantile levels. Second-stage inference can be performed to address such interests. For example, one may estimate a functional of β0(·), say Ψ(β0), to provide a meaningful summary of covariate effects over a range of τ. It is often of interest to determine whether some covariates have constant effects so that a simpler model may be considered. In this case, the problem can be formulated as testing the null hypothesis , τ ∈ [τL, τU], where the superscript (j) indicates the jth component of a vector, and ρ0 is an unspecified constant, j = 2, …, or p+1. Of note, accepting H0,j for all j ∈ {2, …, p+1} may indicate the adequacy of an AFT model. Peng & Huang (2008) presented second-stage inference procedures for estimating Ψ(β0) and testing H0 under model (4), which can be readily adapted to many other quantile regression settings.
3. Quantile regression in complex survival settings
In practice, survival data often involve complications beyond random censoring, such as truncation, competing risks or semi-competing risks. Various methods have developed for quantile regression in more complex survival scenarios. In this section, we present a set of quantile regression methods developed for analyzing for doubly censored data with left truncation, competing risks data, and semi-competing risks data.
3.1. Quantile regression with doubly censored data with left truncation
Ji et al. (2012) proposed an extension of Peng & Huang (2008)’s method to handle doubly censored data subject to left truncation. Such survival scenarios often arise in observational studies, where the event of interest can occur before study entry. Let T denote the event time of interest and C denote time to random right censoring. In addition, let L denote left censoring time, always observed, and A denote left truncation time. Define X = L ∨ (T ∧ C) and Δ as the censoring indicator which equals 1 if L < T ⩽ C, 2 if T ⩽ L, and 3 if T > C, where ∨ is the maximum operator. When X is subject to left truncation by A, the observed data include n i.i.d. replicates of (X′, L′, A′, δ′, Z), denoted by , where {X′, L′, A′, δ′, Z′} follows the conditional distribution of {X, L, A, δ, Z} given X ⩾ A. It is assumed that (L, C, A) is independent of T given Z. We refer to such data as doubly censored data with left truncation. With L = 0, the data reduce to the usual randomly left truncated right censored data.
To estimate model (4) with doubly censored data subject to left truncation, an estimating equation can be constructed based on the martingale structure underlying the observed survival data, namely, , where N′(t) = I(log(X′) ⩽ t, δ′ = 1), R′(t) = I{log(L′ ∨ A′) < t ⩽ log(X′)) denoting an at-risk process, and ΛY (·|Z) denotes the cumulative hazard function of Y ≐ log(T) given Z. It can be shown that M′(t) is a martingale process. This fact suggests an estimating equation for β0(·),
| (12) |
To obtain an estimator of β0(τ) based on equation (12), denoted by , one may follow the algorithm for (presented in section 2.3) with the objective function in Step 2 modified to
Theoretical properties, such as uniform consistency and weak convergence to a Gaussian process, can be established for with similar lines of Peng & Huang (2008).
3.2. Quantile regression with competing risks data
Competing risks data arise in scientific studies involving multiple types of failures that are mutually exclusive. For example, a cancer patient may die from tumor recurrence or nonrecurrence-related reasons. This gives rise to a competing risks scenario, where death from tumor recurrence and death from nonrecurrence-related reasons are two competing failure types.
We adopt standard formulation of competing risks data. Let Tk denote the latent time to failure of type k (k = 1, …, K). Define T = min(T1, …, TK). Let ϵ denote the failure type corresponding to T (i.e. T = Tϵ), C denote independent censoring to T, and denote a p×1 vector of covariates. Define X = T ∧ C, δ = I(T ⩽ C)ϵ, and . Here ∧ is the minimum operator and I(·) is the indicator function. The observed competing risks data consist of n iid replicates of (X, δ, Z), denoted by {(Xi, δi, Zi), i = 1, …, n}.
Analysis of competing risks data generally follows two different perspectives. One perspective focuses on crude quantities, such as the cumulative incidence function or cause-specific hazard function. Studying crude quantities for a failure type naturally accounts for the presence of competing risks from the other types of failure. The other perspective concerns net quantities defined upon latent failure times Tk’s. Inference on the latent failure time for a failure type however implicitly hypothesizes a setting where the other types of failure do not exist. Such a setting may be controversial but can be meaningful in some situations. For example, patient dropouts can be a competing risk for time to death but may be avoided by diligent follow-up efforts. When the elimination of other types of failures is not possible, competing risks analysis oriented to crude quantities would be more appropriate. In the following, we discuss quantile regression methods for competing risks data developed under these two different perspectives.
3.2.1. Competing risks quantile regression based on cumulative incidence functions.
Peng & Fine (2009) proposed to formulate competing risks quantile regression using cumulative incidence function, which is the cause-specific analog of the usual survival function for an event time. Specifically, the type-k cumulative incidence conditional quantile function is defined as Qk(τ|Z) ≐ inf{t : Fk(t|Z) ⩾ τ}, where Fk(t|Z) ≐ Pr(T ⩽ t, ϵ = k|Z) denotes the type-k cumulative incidence function (k = 1, …, K). This quantity can be interpreted as the first time given covariate Z at which the probability of type-k failure having occurred exceeds τ, in the presence of other types of failures.
A competing risks quantile regression model based on type-k cumulative incidence function takes the form,
| (13) |
where β0(τ) is a (p+1)×1 vector of unknown regression coefficients, and 0 ⩽ τL ⩽ τU < 1. Under model (13), the non-intercept coefficients in β0(τ) represent covariate effects on the τth-cumulative incidence quantile, Qk(τ|Z), which may change with τ. The exp(·) function in (13) can be replaced by any other monotone link function.
To estimate β0(τ) in model (13), Peng & Fine (2009) proposed the following estimating equation,
| (14) |
where is a reasonable estimate for G(x|Z) ≐ Pr(C ⩾ x|Z), which can be obtained by following the discussions about in Section 2.3.4.
Solving equation (14) can be reformulated as locating the minimizer of the convex L1-type function,
where M* is an extremely large positive number.
Peng & Fine (2009) showed that the resulting estimator is uniformly consistent in τ ∈ [τL, τU], and converges weakly to a tight mean-zero Gaussian process. They developed inference procedures about β0(τ) in model (13), which follow similar lines to those presented in section 2.4 for randomly censored data with known or unconditional independent censoring. Following the same framework, Sun et al. (2012) studied model (13) for the competing risks setting with missing failure types, where IPCW technique was used to to deal with unobserved failure types under the missing at random assumption.
3.2.2. Quantile regression based on latent failure time distributions in the presence of competing risks.
The analysis of competing risks data based on net quantities, such as the marginal distributions of Tk’s (k = 1, …, K), is complicated by their nonparametric nonidentifiability (Tsiatis 1975). Without loss of generality, we consider the situation with K = 2. This special case coincides with the typical dependent censoring scenario, where the dependent censoring event and the event of interest can be viewed as a pair of competing risks.
Concerning the latent failure times T1 and T2, one may consider the following quantile regression models:
| (15) |
where β0,k(τ) is an vector of unknown coefficients, representing covariate effects on . Here, exp(·) can be replaced by another monotone link function, which may take different forms in the models for and .
Ji et al. (2014) studied the estimation of the marginal quantile regression models (15) with competing risks data. To mitigate the identifiability issue, additional modeling is imposed for the dependence structure between T1 and T2. Specifically, it is assumed that
| (16) |
where H(·, ·) is a known copula function, for example, the Clayton copula (Clayton 1978), i.e. , r > 0, and the Frank copula (Genest 1987), i.e., , r > 0 and r ≠ 1. Here r is a known copula parameter, which may be specified based on prior knowledge on the strength of the association between T1 and T2. In practice, one may perform a sensitivity analysis to obtain bounds for QT (τ|Z) by varying r in a plausible range.
To estimate β0,k(τ) in (15), Ji et al. (2014) utilized the martingales associated with cause-specific hazard functions. Let Nk(t) ≐ I(X ⩽ t, ϵ = k) denote the counting process for Tk and define , where , which is the cause-specific hazard function for type-k failure. As shown by Kalbfleisch & Prentice (2002), Mk(t) is a martingale with respect to the filtration, . This implies for all t ⩾ 0. Under models (15) and (16), it can be shown with stochastic integral manipulations that
where , , and k = 1, 2. These facts motivate the estimating equations,
| (17) |
where .
Note that β0,k(τ) may not be identifiable for all τ ∈ (0, 1) due to censoring to Tk (k = 1, 2). Truncating the time scale by an upper bound, min(exp{Z⊤β0,1(τU,1)}, exp{Z⊤β0,2(τU,2)}), leading to a modified estimating equation,
| (18) |
where .
Equations in (18) may be solved via an iterative algorithm:
-
Step B.1
Set m = 0. Choose the initial value .
-
Step B.2
Solve for . Update τU,1 with .
-
Step B.3
Solve for . Update τU,2 with .
-
Step B.4
Let m = m + 1. Repeat Steps B.2 and B.3 until convergence criteria are met.
Here, the initial value in Step B.1 can be set as Peng & Huang (2008)’s estimator which treats T1 and T2 are independent. The equations in Steps B.2–B.3 can be solved by L1 minimization problems along similar lines of Peng & Huang (2008).
Asymptotic properties were established for the resulting estimators of β0,k (k = 1, 2), including uniform consistency and weak convergence to a Gaussian process. Inference can be conducted through a standard bootstrapping procedure.
3.3. Quantile regression with semi-competing risks data
Semi-competing risks (Fine et al. 2001) refers to as a situation where time to a nonterminal event (e.g. a non-fetal disease landmark event) can be censored by time to a terminal event (e.g. death or dropout) but not vice versa. Let T1, T2, and C denote time to the nonterminal event, time to the terminal event, and time to random censoring, respectively. Let be a p × 1 vector of covariates and . Define X = T1 ∧ T2 ∧ C, Y = T2 ∧ C, δ = I(T1 < Y), and η = I(T2 < C). The standard semi-competing risks data consist of n replicates of (X, Y, δ, η, ), denoted by {(Xi, Yi, δi, ηi, ), i = 1, …, n}. In a standard semi-competing risks setting, T2 is only subject to random censoring by C; thus quantile regression for T2 can follow the approaches developed for randomly censored data; see section 2.
Semi-competing risks methods are usually focused on the inference about T1, which is complicated by the dependent censoring by T2. Intuitively, one may first coerce semi-competing risks data into classic competing risk data by ignoring the extra information on T2 when δ = 1, and then apply quantile regression approaches developed for competing risks data. For example, targeting crude quantities for the nonterminal event, one can directly perform competing risks cumulative incidence quantile regression presented in section 3.2.1. Of note, this approach does not incur information loss from only using the competing risks portion of the data. This is because when δ = 1, the cumulative incidence function for the non-terminal event, by definition, does not involve the extra information on the terminal event after the occurrence of the non-terminal event. An exception arises when left truncation is present. In that case, the semi-competing risks data are observable only when Y > L, where L is a known left truncation time. Coercing semi-competing risks data into competing risks data induces artificial left truncation defined as X > L, thereby leading to information loss.
Li & Peng (2011) developed an extension of Peng & Fine (2009)’s method for competing risks cumulative incidence quantile regression tailored to semi-competing risks data subject to left truncation. In this case, the observed data include n i.i.d. replicates of (X*, Y*, δ*, η*, L*, Z*), which follow the conditional distribution of (X, Y, δ, η, L, Z) given L < Y. Assume the cumulative incidence quantile regression model for T1, which is model (13) with k = 1. The basic estimation idea is to employ the IPCW technique with an inverse weight derived to properly account for both censoring by C and left truncation Y. Under the assumption of (L, C) is independent of (T1, T2, Z), an estimating equation is given by
| (19) |
where with
Here represents the Lynden-Bell estimator of , and is an adequate estimator of P(T2 > u|z). In practice, given T2 is only subject to random right censoring by C and random left truncation by L, may be obtained by using any existing regression method for left truncated and right censored data, such as the Cox proportional hazards model. After obtaining , equation (19) can be solved by an algorithm similar to that presented for equation (14). Desirable theoretical properties, including uniform consistency and weak convergence to a Gaussian process, can also be established for the resulting estimator.
When interests lie in net quantities related to the latent time to nonterminal event T1, utilizing the extra information in semi-competing risk data (beyond its competing risks portion) generally leads to better identifiability as well as improved statistical efficiency. Along this line, Li & Peng (2015) developed a quantile regression method tailored to study the conditional quantile of T1 in the semi-competing risks setting. Specifically, Li & Peng (2015) assumed the following models:
| (20) |
| (21) |
where is a subvector of Z or Z itself, C(·, ·; α) is a known copula function with a given copula parameter α, and g(·) is a known function. In copula model (20), the unknown parameter r0 depicts how covariates may influence the copula parameter, which is often closely linked to the association between T1 and T2. In (21), the non-intercept coefficients in β0(τ) and α0(τ) represent covariate effects on the τ-th quantile of T1 and T2 respectively, which are permitted to change with τ. When these coefficients are constant over τ, the models in (21) reduce to AFT models for T1 and T2.
To estimate models (20) and (21), a useful fact is that (20) implies
| (22) |
| (23) |
where KA(u, v, θ) = C(u, v; α)/v and KB(u, v, α) = {v – C(u, v; α)}/v. In addition, the model assumptions in (21) imply Pr(T1 ⩽ exp{ZTβ0(τ)} | Z) = τ and . Li & Peng (2015) utilized these results to construct the following estimating equations,
where is Peng & Huang (2008)’s estimator of α0(·) given T2 is only subject to random censoring by C, τU,2 is an upper bound of a τ-range where α0(τ) is identifiable, and
To compute Qi(β, , r, τ), one only needs to evaluate the integration over . Confining β(·) to be a cadlag step function, the integrand in Qi(β, , r, τ) is a piecewise constant function of τ, and hence Qi(β, , r, τ) can be calculated as a finite sum. Li & Peng (2015) presented an iterative algorithm to solve these estimating equations. Li & Peng (2015) showed that the resulting estimator of r0 is consistent and asymptotic normal. Desirable theoretical properties, including uniform consistency and weak convergence to a Gaussian process, were established for the resulting estimator of β0(τ) for τ ∈ [ν1, τU,1], where 0 < ν1 < τU,1 < 1.
4. Quantile Regression and Its Adaptations for Recurrent events data
Recurrent events data are frequently encountered in clinical or epidemiological studies when the event of interest, such as infection and hospitalization, can occur repeatedly over time. Consider a general recurrent events data setting, where the observation of recurrent events is subject to an observation window specified as a time interval (L, R] (Nelson 2003). The counting process for the observed recurrent events is given by , where T(j) denotes time to the jth recurrent event (j = 1, 2, …), and the at-risk process is given by Yre(t) = I(L < t ⩽ R). Let be a p×1 vector of covariates and . The observed recurrent events data include n i.i.d. replicates of Nre(·), Z, L, and R, denoted by . In this section, we introduce three different ways to apply or adapt quantile regression to recurrent events data.
4.1. Quantile regression of recurrent event gap time.
Luo et al. (2013) proposed to model the gap time between recurrent events, namely, . By this approach, it is assumed that conditioning on Zi and a nonnegative subject-specific frailty variable is a renewal process, and furthermore,
| (24) |
Consider the case where Li = 0 and Ri is independent of γi and given Zi. Let and Δi = I(mi > 1). Define Xi,j = Gi,j if j < mi and if j = mi. Define Ni,j(t) = I(Gi,j ⩽ t, Δi = 1), Ri,j(t) = I(Gi,j ⩾ t), H(x) = −log(1 – x). Note that uncensored gap times, {Xi,j, j = 1, …, mi − 1}, combined with the censored first gap time, Xi,1 with Δi = 0, can be viewed as clustered event times subject to random censoring. Under this view and by adapting the estimation framework of Peng & Huang (2008), Luo et al. (2013) proposed the following estimating equation for model (24):
| (25) |
where and . An efficient algorithm to solve equation (25) can be developed along the lines of Peng & Huang (2008).
4.2. Generalized accelerated recurrence time model.
Huang & Peng (2009) and Sun et al. (2016) adopted a different strategy to adapt quantile regression modeling to recurrence events data. The main idea is to utilize the concept of time to expected frequency, which is a generalized version of conditional quantile that fits the recurrent events setting. Specifically, time to expected frequency is defined as for u > 0, where and . It is easy to see that when the event of interest is not recurrent (i.e. T(j) = ∞ for j ⩾ 2), τZ(u) becomes the conditional quantile QT(1)(τ|Z). With recurrent events data, an adaptation of quantile regression modeling is to formulate covariate effects on τZ(u). This leads to the generalized accelerated recurrence time model, which is given by
| (26) |
where G(·) is a known positive increasing function, the non-intercept coefficients in β0(u) represent covariate effects on time to expected frequency G(u), and U > 0 is a prespecified constant.
The estimation of model (26) is facilitated by the counting process representation of model (26) justified in Sun et al. (2016). That is, model (26) is equivalent to
| (27) |
where g(u) = dG(u)/du. This motivates a stochastic integral equation taking the form,
| (28) |
As commented in Sun et al. (2016), the theoretical and computational framework of Peng & Huang (2008) can be readily extended to study the recurrent events model (26). The algorithm to solve equation (28) is very similar to that for Peng & Huang (2008)’s martingale-based estimator (see section 2). The key modifications include adopting a grid on the frequency scale (instead of the τ-scale), {0 = u0 < u1 < ⋯ < uL(n) = U}, and replace the objective function in Step 2 by
where R* is an extremely large number. Theoretical arguments for Peng & Huang (2008)’ estimator can also be generalized to establish the asymptotic properties of the estimator derived based on equation (28), including the uniform consistency for u ∈ [v, U], where 0 < v < U, and weak convergence to a Gaussian process at the root n rate.
4.3. Quantile regression of individual recurrent risk measure.
More recently, Ma et al. (2020) proposed quantile regression of a sensible individual risk measure formulated upon the intensity process of recurrent events. Let denote the underlying recurrent event process. Ma et al. (2020) assumed that given a nonnegative random variable γi, is a nonstationary Poisson process with the intensity function,
| (29) |
Here λ0(t) stands for an unknown baseline intensity function, which is nonnegative and continuous, and is subject to the constraint, , with a predetermined constant ν*. This constraint is necessary for the purpose of model identifiability.
Under model (29), γi captures the scale shift of subject i’s intensity process from the unknown baseline intensity λ0(t). A special case of model (29) is Wang et al. (2001)’s semi-parametric multiplicative intensity model, where , and ξi is an unobservable frailty. This connection suggests that γi can serve as a sensible measure of the latent subject-specific risk of recurrent events, which may naturally account for both observed covariates and unobservable frailty.
Ma et al. (2020) proposed to use quantile regression to explore the heterogeneity in γi which quantifies the subject-specific risk of recurrent events. Specifically, it is assumed that
| (30) |
The non-intercept coefficients in β0(τ) represent covariate effects on the τ-th quantiles of γi.
A main challenge to estimate model (30) is that γi’s are not observed. Considering the setting with Li = 0 and assuming Ri is independent of given γi, and Ri is independent of γi given Zi, Ma et al. (2020) employed the principle of conditional score (Stefanski & Carroll 1987) and proposed the estimating equation,
| (31) |
where and with . Here ψτ(v) = τ – I(v < 0), and
where and , with τγ = {τ ∈ (0, 1) : exp{XTβ(τ) = γ}. It can be shown that f{γ|m, C, X; β0(·), μ0(·)} denotes the conditional density of γ given m, C and X under the assumed models, and hence E[Sn(β0, μ0, τ)] = 0.
To solve equation (31), Ma et al. (2020) approximated β(τ) by using splines with K(n) knots, and developed an iterative algorithm to find an estimate for the β0(τ) in model (30) based on equation (31). The details are omitted here. Under certain regularity conditions, the resulting estimator was shown to be uniformly consistent for τ ∈ [ζ1, ζ2], where 0 < ζ1 < ζ2 < 1. Weak convergence to a Gaussian process was also established.
5. Illustrations of quantile regression for survival data
5.1. An example of quantile regression analysis with randomly censored data
We use a dataset from a dialysis study that investigated predictors of mortality in a cohort of 191 incident dialysis patients with chronic renal failure, aged 20 years and older, who started on chronic hemodialysis or peritoneal dialysis therapy between July 1996 and August 1997, recruited from metro-Atlanta area (Kutner et al. 2002). Of particular interest is a risk factor on symptoms of restless legs syndrome (RLS), which negatively affect quality of life and mortality risk as evidenced by prior studies. In this study, baseline measures were collected between 1996 and 1997 and vital status was monitored to December, 2005. In this dataset, the survival time T of 35% dialysis patients were censored due to renal transplant or end of study.
Figure 1 plots the Kaplan-Merier curves for survival time stratified by the binary variable indicating moderate to severe RLS symptoms versus mild RLS symptoms (denoted by BLEGS). It is noted that the 25th percentiles of survival time for the the severe RLS group and the mild RLS groups are 0.95 versus 2.45 years, which are statistically significantly different. The 75th survival time percentiles for these two groups are rather similar, both between 7 and 8 years. This observation suggests that BLEGS may have an inhomogeneous effect on the distribution or quantile function of T. We next consider BLEGS, along with other potential predictors including patient’s age (AGE), the indicator of fish consumption over the first year of dialysis (FISHH), the indicator of baseline HD dialysis modality (BHDPD), the indicator of eduction equal or higher than college (HIEDU), and the indicator of being black (BLACK). We fit the data with the standard Cox PH model and AFT model. In Table 1, we present the estimation results including the estimated coefficients and the associated p values. It is shown that both Cox PH model and AFT model do not suggest a significant effect of BLEGS on dialysis survival, though Figure 1 demonstrates its potential influence on the lower part of the survival distribution.
Figure 1.
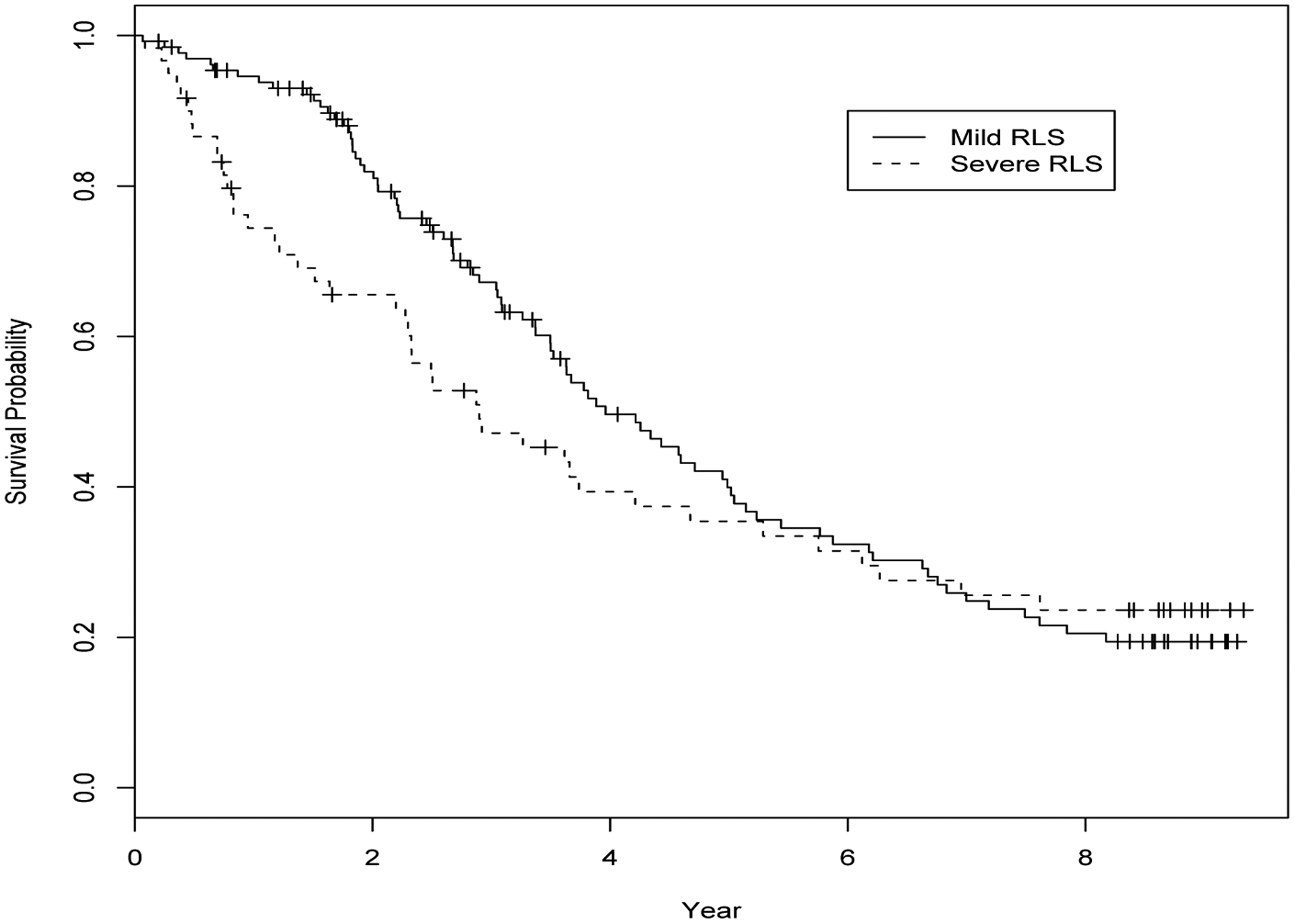
The dialysis example: Kaplan Meier curves of survival time stratified by the status of RLS symptoms
Table 1.
Results from fitting the Cox PH model and AFT model to the dialysis dataset.
| Cox Model | AFT Model | |||
|---|---|---|---|---|
| Coef | p value | Coef | p value | |
| AGE | 0.059 | <0.001 | −0.035 | <0.001 |
| FISHH | −0.831 | <0.001 | 0.485 | <0.001 |
| BHDPD | 0.837 | <0.001 | −0.473 | <0.001 |
| BLEGS | 0.264 | 0.197 | −0.173 | 0.232 |
| HIEDU | 0.625 | 0.009 | 0.364 | 0.024 |
| BLACK | −1.014 | <0.001 | 0.591 | <0.001 |
Coef: coefficient estimate; SE: standard error
We next conduct quantile regression based on model (4) using Peng & Huang (2008)’s method for the same dataset. Figure 2 displays Peng & Huang (2008)’s estimator of β0(τ) along with 95% pointwise confidence intervals. In Figure 2, we observe that the coefficient for BLEGS diminishes gradually with τ whereas estimates for the other coefficients seem to be fairly constant. We apply the second-stage inference to formally investigate the constancy of each coefficient. The results confirm our observation from Figure 1, suggesting a varying effect of BLEGS and constant effects of the other covariates. This may lead to an interesting scientific implication that BLEGS may affect the survival experience of dialysis patients with short survival times but may have little impact on that of long-term survivors. The confirmed nonconstancy of the BLEGS coefficients further indicates the lack-of-fit of an AFT model for this dialysis data.
Figure 2.
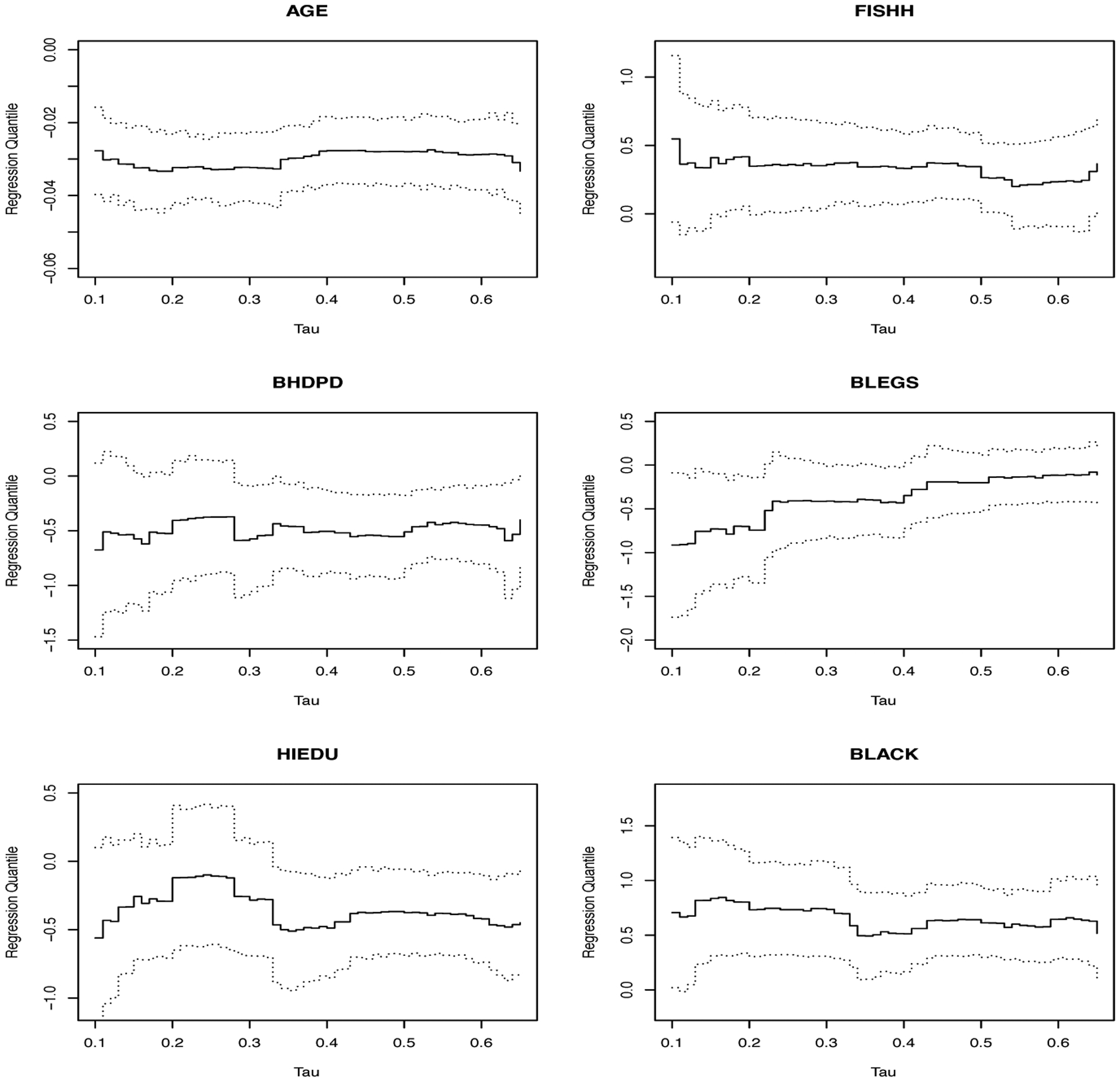
The dialysis example: Peng and Huang’s estimator (solid lines) and 95% pointwise confidence intervals (dotted lines) of regression quantiles.
We also estimate the average quantile effects defined as . The results are given in Table 2. We observe that the estimated average effect of BLEGS based on quantile regression has a larger magnitude compared to that based on the AFT model. The associated p value is less than 0.05, providing some evidence for the association between RLS and dialysis survival. This example suggests that naively treating varying effects as constant ones may lead to attenuated covariate effect estimates and consequently result in biased conclusions.
Table 2.
Estimation of average covariate effects based on quantile regression.
| AveEff | SE | p value | |
|---|---|---|---|
| AGE | −0.030 | 0.003 | < 0.001 |
| FISHH | 0.327 | 0.116 | 0.005 |
| BHDPD | −0.489 | 0.162 | 0.003 |
| BLEGS | −0.369 | 0.161 | 0.022 |
| HIEDU | −0.350 | 0.137 | 0.011 |
| BLACK | 0.654 | 0.144 | < 0.001 |
AveEff: Estimated average effect; SE: standard error
5.2. An example of quantile regression analysis with competing risks data
We use the dataset from the breast cancer trial E1178 by the Eastern Cooperative Oncology Group (Cummings et al. 1993). In this study, patients were followed-up until breast cancer recurrence (BCR) or non-recurrence related death (NRD), whichever occurred first. This dataset includes 82 patients assigned to placebo and 85 patients assigned to tamoxifen. In the tamoxifen group, 42 patients experienced breast cancer recurrence and 23 died without recurrence; in the placebo group, 59 patients had breast cancer recurrence and 19 died without recurrence.
We apply the quantile regression strategy to evaluate the difference between two-year tamoxifen therapy versus placebo, while adjusting for other potential risk factors, including age, tumor size, number of positive nodes. Since it is more clinically relevant to evaluate BCR in the presence of NRD than with the unrealistic exclusion of NRD, we choose to use the cumulative incidence quantile regression method (Peng & Fine 2009) to analyze this competing risks dataset.
In Figure 3, we plot the BCR and NRD cumulative incidence functions separately for patient groups stratified by treatment, or age, number of positive nodes, and tumor size dichotomized at their median values, which are 71 years, 3, and 25mm, respectively. From Figure 3, we observe that all BCR cumulative incidence curves exceed 0.45 in the right tails. In contrast, the cumulative incidence curves for NRD are below 0.20. A visual impression from Figure 3 is that tamoxifen, number of positive nodes and tumor size may impact the cumulative incidence of BCR but not NRD, and their effects on BCR may not be constant.
Figure 3.
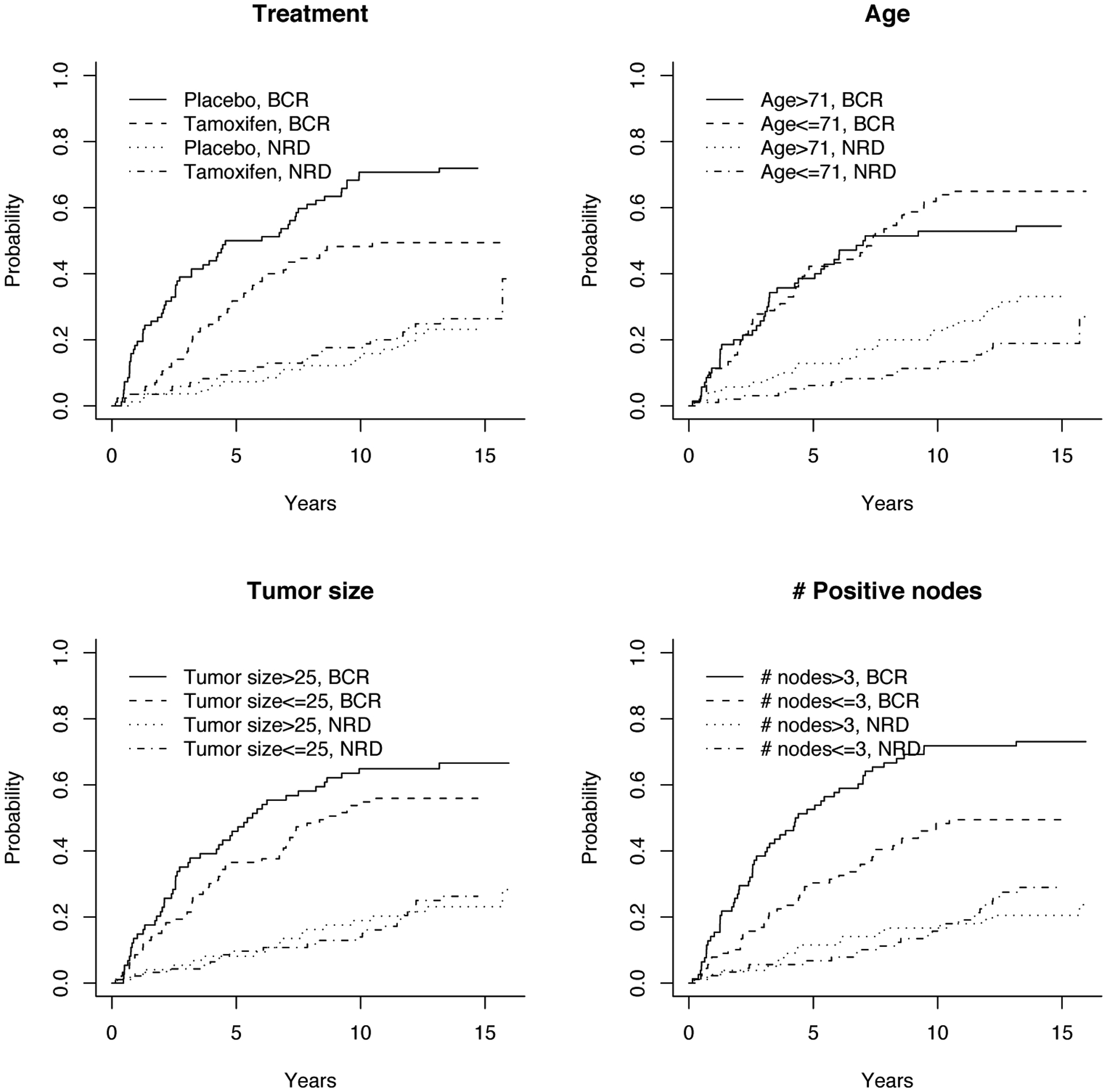
E1178 Trial Example: Estimated Cumulative Incidence Functions.
We apply Peng & Fine (2009)’s method to fit the data with the competing risks quantile regression model (13), where the failure type corresponds to BCR and the exponential link function is replaced by the identify function. The number of positive nodes is incorporated into the model after log-transformation. Based on the results in Figure 3, we let [τL, τU] = [0.10, 0.45]. The analysis results displayed in Figure 4 suggest that patients who received placebo tend to experience breast cancer recurrence sooner than those on tamoxifen. In this example, age does not show a significant effect on the timing of breast cancer recurrence in the presence of nonrecurrence death. The effects of tumor size and number of nodes demonstrate some interesting increasing trend. The coefficient estimates, coupled with the 95% confidence intervals, suggest that tumor size and node number may only have a significant influence on the BCR cumulative incidence quantiles with relatively larger τ’s, such as τ = 0.35 or 0.4. The changing trend of the effects of tumor size and node number over τ is confirmed by second-stage constancy tests. The clinical implication may be that either tumor size or number of positive nodes may significantly shorten the time to BCR for patients with moderate or low risk of BCR (corresponding to large τ’s), while such an impact may vanish when patients are subject to high risk of BCR (corresponding to small τ’s) possibly due to worse pre-existing health condition or other unknown factors. The treatment coefficients are rather constant, and are significantly above zero for many τ’s. This reflects the beneficial effect of Tamoxifen treatment in term of prolonging the progression to BCR.
Figure 4.
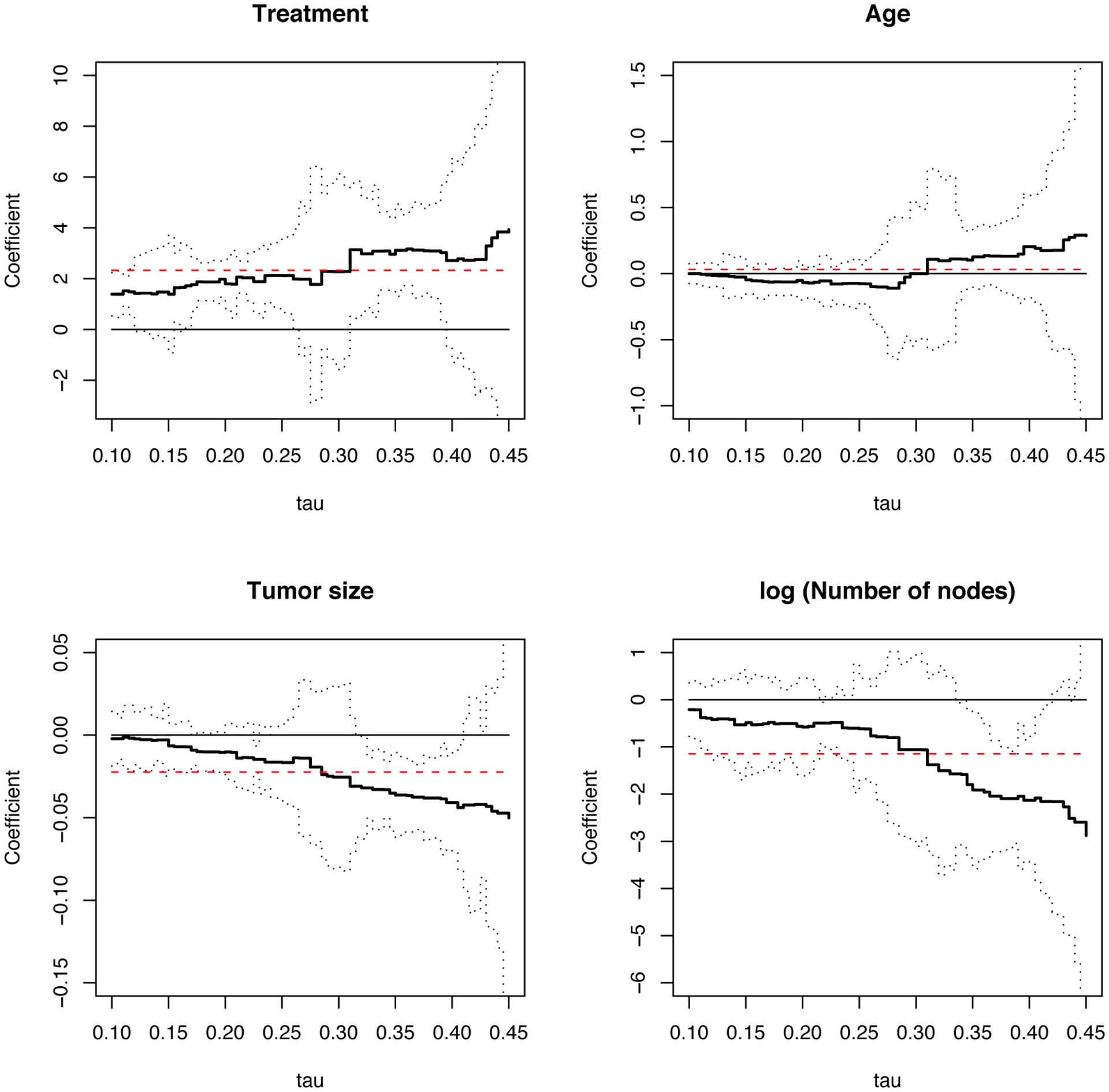
E1178 Trial Example: Estimated Regression Coefficients for the Breast Cancer Recurrence Endpoint. Bold Solid Lines Represent Coefficient Estimates; Dotted Lines Represent 95% Pointwise Confidence Intervals; Dashed Lines Represent Estimates for Trimmed Mean Covariate Effects.
6. Remarks
Applying quantile regression to analyze survival data can provide robust and dynamic insight about the association between covariates and survival outcomes, which may not be offered by traditional survival regression methods. There have been rich developments of quantile regression methods for survival data in the last two decades. In this paper, we provide a selective review of approaches available to handle various types of survival data, including randomly censored data, competing and semi-competing risks data, truncated data, recurrent events data. Most of these methods are easy and stable to implement. This feature can help foster the applications of quantile regression in survival analysis.
Due to space limit, we omit many important relevant method developments. These include, but are not limited to, cure rate quantile regression methods (Wu & Yin 2013, 2017b,a) and censored quantile regression methods attending to regression quantile monotonicity across quantile levels, such as semiparametric copula quantile regression (De Backer et al. 2017).
Some important problems not covered in this paper but worth attention are quantile regression for survival data with high-dimensional covariates, survival data with time-dependent covariates, and survival data with missing covariates. This paper also does not discuss scenarios where the collection of survival data is attached to a special epidemiologic design, such as case-cohort design, and nested case-cohort design. Another interesting direction for extending survival quantile regression is to integrate quantile regression with causal inference. Work has emerged along these directions and merits further research efforts.
ACKNOWLEDGMENTS
The author acknowledges the funding support from National Institutes of Health (grant number: R01HL113548).
LITERATURE CITED
- Andersen PK, Gill RD. 1982. Cox’s regression model for counting processes: a large sample study. The annals of statistics :1100–1120 [Google Scholar]
- Beran R. 1981. Nonparametric regression with randomly censored survival data
- Buchinsky M, Hahn J. 1998. A alternative estimator for censored quantile regression. Econometrica 66:653–671 [Google Scholar]
- Buckley J, James I. 1979. Linear regression with censored data. Biometrika 66:429–436 [Google Scholar]
- Chernozhukov V, Hong H. 2001. Three-step censored quantile regression and extramarital affairs. Journal of the American Statistical Association :872–882 [Google Scholar]
- Clayton D. 1978. A model for association in bivariate life tables and its application in epidemiological studies of familial tendency in chronic disease incidence 65:141–151 [Google Scholar]
- Cox DR. 1972. Regression models and life-tables. Journal of the Royal Statistical Society: Series B (Methodological) 34:187–202 [Google Scholar]
- Cummings F, Gray R, Tormey D, Davis T, Volk H, et al. 1993. Adjuvant tamoxifen versus placebo in elderly women with node-positive breast cancer: long-term follow-up and causes of death. Journal of clinical oncology 11:29–35 [DOI] [PubMed] [Google Scholar]
- De Backer M, El Ghouch A, Van Keilegom I. 2020. Linear censored quantile regression: A novel minimum-distance approach. Scandinavian Journal of Statistics [Google Scholar]
- De Backer M, El Ghouch A, Van Keilegom I, et al. 2017. Semiparametric copula quantile regression for complete or censored data. Electronic Journal of Statistics 11:1660–1698 [Google Scholar]
- De Backer M, Ghouch AE, Van Keilegom I. 2019. An adapted loss function for censored quantile regression. Journal of the American Statistical Association 114:1126–1137 [Google Scholar]
- Efron B. 1967. The two-sample problem with censored data. Proc fifth berkley symposium in mathematical statistics, IV :831–553 [Google Scholar]
- Fine JP, Jiang H, Chappell R. 2001. On semi-competing risks data. Biometrika 88:907–919 [Google Scholar]
- Fitzenberger B. 1997. A guide to censored quantile regressions. Handbooks of Statistics: Robust Inference 15:405–437 [Google Scholar]
- Fygenson M, Ritov Y. 1994. Monotone estimating equations for censored data. The Annals of Statistics 22:732–746 [Google Scholar]
- Genest C. 1987. Frank’s family of bivariate distributions 74:549–555 [Google Scholar]
- Huang Y. 2002. Calibration regression of censored lifetime medical cost. Journal of the American Statistical Association 98:318–327 [Google Scholar]
- Huang Y. 2010. Quantile Calculus and Censored Regression. The Annals of Statistics 38:1607–1637 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Huang Y, Peng L. 2009. Accelerated recurrence time models. Scandinavian Journal of Statistics 36:636–648 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ji S, Peng L, Cheng Y, Lai H. 2012. Quantile regression for doubly censored data. Biometrics :101–112 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ji S, Peng L, Li R, Lynn MJ. 2014. Analysis of dependently censored data based on quantile regression. Statistica Sinica 24:1411. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kalbfleisch JD, Prentice RL. 2002. The statistical analysis of failure time data (2nd ed.). New York: Wiley Koenker R. 2005. Quantile regression, no. 9780521845731 in cambridge books [Google Scholar]
- Koenker R. 2008. Censored quantile regression redux. Journal of Statistical Software 27:http://www.jstatsoft.com [Google Scholar]
- Koenker R. 2017. Quantile regression: 40 years on. Annual Review of Economics 9:155–176 [Google Scholar]
- Koenker R, Bassett G. 1978. Regression quantiles. Econometrica 46:33–50 [Google Scholar]
- Koenker R, Portnoy S, Ng PT, Zeileis A, Grosjean P, Ripley BD. 2019. Package ?quantreg?
- Kutner NG, Clow PW, Zhang R.and Aviles X. 2002. Association of fish intake and survival in a cohort of incident dialysis patients. American Journal of Kidney Diseases 39:1018–1024 [DOI] [PubMed] [Google Scholar]
- Li KC, Wang JL, Chen CH, et al. 1999. Dimension reduction for censored regression data. The Annals of Statistics 27:1–23 [Google Scholar]
- Li R, Peng L. 2011. Quantile regression for left-truncated semi-competing risks data. Biometrics 67:701–710 [DOI] [PubMed] [Google Scholar]
- Li R, Peng L. 2015. Quantile regression adjusting for dependent censoring from semicompeting risks. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 77:107–130 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Luo X, Huang CY, Wang L. 2013. Quantile regression for recurrent gap time data. Biometrics 69:375–385 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ma H, Peng L, Huang CY, Lai H. 2020. Heterogeneous individual risk modeling of recurrent events. Biometrika (Accepted) [DOI] [PMC free article] [PubMed] [Google Scholar]
- Miller RG. 1976. Least squares regression with censored data. Biometrika 63:449–464 [Google Scholar]
- Nelson W. 2003. Recurrent events data analysis for product repairs, disease recurrences and other applications. Philadelphia: ASA-SIAM [Google Scholar]
- Neocleous T, Vanden Branden K, Portnoy S. 2006. Correction to censored regression quantiles by s. portnoy, 98 (2003), 1001–1012. Journal of the American Statistical Association 101:860–861 [Google Scholar]
- Parzen MIWLJ, Ying Z. 1994. A resampling method based on pivotal estimating functions. Biometrika 81:341–350 [Google Scholar]
- Peng L. 2012. A note on self-consistent estimation of censored regression quantiles. Journal of Multivariate Analysis 105:368–379 [Google Scholar]
- Peng L, Fine J. 2009. Competing risks quantile regression. Journal of the American Statistical Association 104:1440–1453 [Google Scholar]
- Peng L, Huang Y. 2008. Survival analysis with quantile regression models. Journal of the American Statistical Association 103:637–649 [Google Scholar]
- Portnoy S. 2003. Censored regression quantiles. Journal of the American Statistical Association 98:1001–1012 [Google Scholar]
- Portnoy S, Lin G. 2010. Asymptotics for censored regression quantiles. Journal of Nonparametric Statistics 22:115–130 [Google Scholar]
- Powell J. 1984. Least absoluate deviations estimation for the censored regression model. Journal of Econometrics 25:303–325 [Google Scholar]
- Powell J. 1986. Censored regression quantiles. Journal of Econometrics 32:143–155 [Google Scholar]
- Prentice RL. 1978. Linear rank tests with right censored data. Biometrika 65:167–179 [Google Scholar]
- Reid N. 1994. A conversation with sir david cox. Statistical Science 9:439–455 [Google Scholar]
- Ritov Y. 1990. Estimation in a linear regression model with censored data. The Annals of Statistics :303–328 [Google Scholar]
- Robins J, Rotnitzky A. 1992. Recovery of information and adjustment for dependent censoring using surrogate markers. In AIDS Epidemiology-Methodological Issues, eds. Jewell N, Dietz K, Farewell V. Boston: Birkhauser, 24–33 [Google Scholar]
- Stefanski L, Carroll R. 1987. Conditional scores and optimal scores for generalized linear measurement-error models. Biometrika 74:703–716 [Google Scholar]
- Sun X, Peng L, Huang Y, Lai HJ. 2016. Generalizing quantile regression for counting processes with applications to recurrent events. Journal of the American Statistical Association 111:145–156 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sun Y, Wang HJ, Gilbert J. 2012. Quantile regression for competing risks data with missing cause of failure. Statistica Sinica 22 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tanner MA, Wong WH. 1987. The calculation of posterior distributions by data augmentation. Journal of the American statistical Association 82:528–540 [Google Scholar]
- Tsiatis A. 1975. A nonidentifiability aspect of the problem of competing risks. Proceedings of the National Academy of Sciences 72:20–22 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tsiatis AA. 1990. Estimating regression parameters using linear rank tests for censored data. The Annals of Statistics :354–372 [Google Scholar]
- Wang H, Wang L. 2009. Locally weighted censored quantile regression. Journal of the American Statistical Association 104:1117–1128 [Google Scholar]
- Wang MC, Qin J, Chiang CT. 2001. Analyzing recurrent event data with informative censoring. Journal of the American Statistical Association 96:1057–1065 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wei L, Gail M. 1983. Nonparametric estimation for a scale-change with censored observations. Journal of the American Statistical Association 78:382–388 [Google Scholar]
- Wei LJ, Ying Z, Lin D. 1990. Linear regression analysis of censored survival data based on rank tests. Biometrika 77:845–851 [Google Scholar]
- Wu Y, Yin G. 2013. Cure rate quantile regression for censored data with a survival fraction. Journal of the American Statistical Association 108:1517–1531 [Google Scholar]
- Wu Y, Yin G. 2017a. Cure rate quantile regression accommodating both finite and infinite survival times. Canadian Journal of Statistics 45:29–43 [Google Scholar]
- Wu Y, Yin G. 2017b. Multiple imputation for cure rate quantile regression with censored data. Biometrics 73:94–103 [DOI] [PubMed] [Google Scholar]
- Xia Y, Zhang D, Xu J. 2010. Dimension reduction and semiparametric estimation of survival models. Journal of the American Statistical Association 105:278–290 [Google Scholar]
- Yang X, Narisetty NN, He X. 2018. A new approach to censored quantile regression estimation. Journal of Computational and Graphical Statistics 27:417–425 [Google Scholar]
- Ying Z, Jung SH, Wei LJ. 1995. Survival analysis with median regression models. Journal of the American Statistical Association 90:178–184 [Google Scholar]
- Zhou L. 2006. A simple censored median regression estimator. Statistica Sinica 16:1043–1058 [Google Scholar]