

Abstract
Chromatin dynamics are mediated by remodeling enzymes and play crucial roles in gene regulation, as established in a paradigmatic model, the Saccharomyces cerevisiae PHO5 promoter. However, effective nucleosome dynamics, that is, trajectories of promoter nucleosome configurations, remain elusive. Here, we infer such dynamics from the integration of published single-molecule data capturing multi-nucleosome configurations for repressed to fully active PHO5 promoter states with other existing histone turnover and new chromatin accessibility data. We devised and systematically investigated a new class of ‘regulated on-off-slide’ models simulating global and local nucleosome (dis)assembly and sliding. Only seven of 68,145 models agreed well with all data. All seven models involve sliding and the known central role of the N-2 nucleosome, but regulate promoter state transitions by modulating just one assembly rather than disassembly process. This is consistent with but challenges common interpretations of previous observations at the PHO5 promoter and suggests chromatin opening by binding competition.
Research organism: S. cerevisiae
Introduction
Eukaryotic DNA is packaged inside the nucleus with several layers of compaction. The most basic layer consists of nucleosomes, where 147 bp of DNA are wrapped around a histone protein octamer (Luger et al., 1997). Nucleosomes occupy most of the genome and hinder binding of other proteins to DNA, for example transcription factors (Venter et al., 1994; Bell et al., 2011; Lai and Pugh, 2017), replication machinery (Chang et al., 2016), and DNA repair enzymes (Hauer and Gasser, 2017). This hindrance can be overcome by chromatin remodeling enzymes. Such ‘remodelers’ bind to nucleosomes and convert the energy from ATP hydrolysis into sliding, ejection, (re-)assembly or restructuring of nucleosomes (Bartholomew, 2014; Zhou et al., 2016; Clapier et al., 2017). Hence, nucleosomes are not static but are constantly replaced to varying degrees throughout the genome by remodeling processes, for example, in the context of transcription (Dion et al., 2007). To decipher the resulting nucleosome dynamics, detailed measurements of both, steady state and dynamic quantities are key.
Nucleosome occupancy, a steady-state quantity, is measured in a cell-averaged way with different techniques (reviewed in Lieleg et al., 2015). For example, non-nucleosomal DNA is digested with an endonuclease, like MNase, followed by high-throughput sequencing of the nucleosome-protected DNA. Or, DNA is cleaved close to the nucleosome dyad (=midpoint) position by hydroxyl radicals generated in situ at cysteine residues artificially introduced into histones, and the resulting DNA fragments are sequenced (Brogaard et al., 2012). After paired-end sequencing, the latter method also gives the distances between neighboring nucleosomes on the same DNA molecule. While such data sets provide quite reliable information on population averaged individual nucleosome positions and nucleosome occupancy, they have two disadvantages: First, the nucleosome occupancy in absolute terms, that is, the fraction of molecules where a certain position falls within a nucleosome, cannot be determined as only nucleosomal DNA was scored and non-nucleosomal DNA lost from the analysis (for detailed discussion and genome-wide solution to this question see Oberbeckmann et al., 2019). Second, the information on the interactions or coupling between several nucleosomes along the same DNA molecule in genomic regions of interest is lost, that is, the obtained occupancy map corresponds only to the one-particle density.
These two disadvantages prevent a more detailed modeling of nucleosome dynamics. In this study, we use the PHO5 promoter in Saccharomyces cerevisiae for which, as a unique exception, single-molecule data for configurations of several adjacent nucleosomes is available. This overcomes both above disadvantages and enables our detailed nucleosome dynamics modeling approach, which integrates steady state and dynamic quantities from four different data sets.
The PHO5 promoter is a classical and extremely well-studied model system for the role of nucleosome remodeling during promoter activation (reviewed in Korber and Barbaric, 2014). It also serves as a paradigm for human promoters. The PHO5 gene is regulated via the intracellular availability of inorganic phosphate. If phosphate is amply provided, the PHO5 gene is lowly expressed as its promoter region is occupied by four well-positioned nucleosomes numbered N-1 to N-4 relative to the gene start. Especially nucleosomes N-1 and N-2 occlude transcription factor binding sites that are crucial for gene induction. N-1 occupies the core promoter and prevents access of the TATA-box binding protein (TBP) to the TATA-box. N-2 hinders the transactivator Pho4 from binding its cognate UASp2 element (Upstream Activating Sequence phosphate regulated 2), while the UASp1 element is constitutively accessible in-between N-3 and N-2 . Upon phosphate depletion, a signaling cascade leads to Pho4 activation by inhibition of its phosphorylation and by increasing its nuclear localization (O'Neill et al., 1996; Komeili and O'Shea, 1999). Pho4 triggers an intricate nucleosome remodeling process involving up to five different nucleosome remodeling enzymes, some with redundant and some with crucial roles (Musladin et al., 2014). It also involves histone acetylation, histone chaperones and probably other cofactors that in the end lead to more or less complete removal of nucleosomes N-1 to N-5 and transcription of the PHO5 gene (reviewed in Korber and Barbaric, 2014). Importantly, this chromatin transition was historically among the first shown to be a prerequisite and not consequence of transcription initiation (Almer and Hörz, 1986; Fascher et al., 1993; Venter et al., 1994). Thus, it strongly argued for the now widely accepted view that chromatin structure, positioned nucleosomes in particular, are not just scaffolds for packaging DNA and passive structures during genomic processes, but constitute an important level of regulation.
While the involved cofactors for this model system are known to an exceptional degree, it still remains to be understood which kind of nucleosome dynamics these cofactors bring about. To elucidate these, the full promoter nucleosome configurations in different states are needed. Indeed, for the PHO5 promoter this information was derived from an electron microscopy (EM) single-molecule scoring approach, at least for the subsystem of the N-1, N-2 and N-3 positions, in several states (activated, weakly activated, and repressed; Brown et al., 2013) and from single-molecule DNA methylation footprinting (Small et al., 2014). The N-1 to N-3 subsystem of PHO5 promoter chromatin has been validated before to faithfully recapitulate the regulation of the full-length promoter (Fascher et al., 1993). In the single-molecule PHO5 promoter EM study (Brown et al., 2013), simple biologically motivated network Markov models were used to describe the dynamics of promoter nucleosome configurations. As the variation in nucleosome configurations is intrinsically stochastic, that is, is not the result of other stochastic events in the nucleus (Brown and Boeger, 2014), the use of Markov models for promoter nucleosome configuration dynamics is valid. However, such models were not systematically investigated but rather several similar models that fit the data of different promoter states presented without further justification or consideration of alternative models. Other, more mechanistically detailed computational models of nucleosome remodeling with base-pair resolution using the data from Brown et al., 2013, needed a lot of assumptions to fit the data and therefore do not represent a fully unbiased approach (Kharerin et al., 2016).
Since it is yet impossible to observe changes in nucleosome configurations at the same promoter over time in vivo or in vitro, these dynamics have to be inferred by systematic and unbiased theoretical modeling. In theory, each steady state distribution of promoter configurations can be the results of many equilibrium as well as non-equilibrium models. In equilibrium models, the free energy values of each configuration determine the steady state distribution while the reaction rates of each pair of reverting reactions are variable, as long as the ratio of rates corresponds to the Boltzmann factor of the difference in free energy. This results in zero net fluxes between different configurations in steady state, that is, the average number of reactions in time between any two configurations is equal. In non-equilibrium models, the simple picture of an energy landscape breaks down and net fluxes in steady state are not always zero, which allows for much richer dynamics, for example cycles, trajectories over several configurations with same start and end, which are more likely to occur in one direction than in the other. The challenge in modeling the promoter nucleosome dynamics is to find well-motivated restrictions and assumptions to reduce the number of fitted parameters to a reasonable level, while still staying unbiased, modeling on a similar level as the available experimental data and combining as many different experimental data sets as possible within the same model.
In our study, we achieved this by compiling a large and unbiased collection of possible models, mostly non-equilibrium, within our class of ‘regulated on-off-slide models’ and selecting the models that are consistent with experimental data. Specifically, we integrate four different experimental data sets: the PHO5 promoter nucleosome configuration data from Brown et al., 2013 of repressed, weakly activated, and activated cells, data from our own restriction enzyme accessibility experiments of two different 'sticky (=lower accessibility) N-3' mutant promoters, to address the coupling between remodeling of the N-3 and N-2 nucleosome, and two data sets of Flag-/Myc-tagged histone exchange dynamics experiments (Dion et al., 2007; Rufiange et al., 2007) to obtain a time scale. Our regulated on-off-slide models include assembly and disassembly of N-1, N-2, and N-3 nucleosomes as well as nucleosome sliding from one occupied position to an unoccupied neighboring position. Additionally, they can mimic regulated transitions from repressed over weakly activated to fully activated promoter state dynamics without changing the network topology and, once fitted, provide likely trajectories of promoter nucleosome configurations, which are completely inaccessible by experiments so far. After systematic analysis of all possible regulated on-off-slide models up to a fixed number of fitted parameters, we found only very few models in agreement with all four data sets and were able to describe the effective dynamics of nucleosome configurations during chromatin remodeling at the PHO5 promoter in yeast.
Results
General modeling approach
Our goal was to (i) create an unbiased class of effective minimal models featuring assembly, disassembly and sliding processes, which describe promoter configurations with the same detail as the available data sets and then (ii) investigate all models within this class to look for the least complex models to explain the data. PHO5 promoter nucleosome dynamics can be viewed in two different levels of detail. The site-centric point of view focuses on the three positions N-1, N-2, and N-3 (in the following also referred to as N-1, N-2, and N-3 ‘sites’ for modeling purposes) and remodeling at these sites individually, that is, without considering the nucleosome occupancy of neighboring sites (Figure 1A). An experimental example are accessibility measurements by restriction enzymes at these positions, since the measurements are taken at each position separately. A more detailed point of view keeps track of all the eight promoter nucleosome configurations (‘promoter configurations’), that is, simultaneously tracks which of the three sites are occupied in each cell (Figure 1B). We used the configurational data for three cases corresponding to different states of the PHO5 promoter (‘promoter states’): repressed (wild-type), weakly activated (pho4[85-99] pho80tata mutant), and activated (pho80 mutant) (Brown et al., 2013). Each promoter state shows a different steady state distribution for the occurrences of promoter configurations (Figure 1C). It is possible to calculate the three absolute site accessibilities from the promoter configuration occurrences, but important information is lost and the calculation cannot be inverted. To make full use of the information of the data of Brown et al., 2013, we based our models on the eight promoter configurations. To further restrict our models, we also used other available site-centric data, like restriction enzyme accessibility at the N-2 and N-3 site for wild-type and two sticky N-3 mutants (this study), as well as published data for histone exchange dynamics at the N-1 and N-2 site (Dion et al., 2007; Rufiange et al., 2007).
Figure 1. Modeling approach and promoter configuration occurrences.

(A) Simplified nucleosome dynamics at the PHO5 promoter including assembly, disassembly and sliding from a site-centric point of view. Dashed circles indicate possible nucleosome positions. Pho4-binding sites (UASp elements) are represented by small circles. (B) Configuration-specific modeling approach with eight promoter configurations and 32 reactions. Arrow color code as in panel A. (C) Measured relative occurrences of the eight promoter configurations indicated at the bottom as in panel B but rotated by 90° and for three different ‘promoter states’: the repressed wild-type, a weakly activated mutant (pho4[85-99] pho80tata) and the activated mutant (pho80), using data from Brown et al., 2013.
Regulated on-off-slide models
Each regulated on-off-slide model consists of a set of processes for nucleosome assembly, disassembly and sometimes sliding that allow reactions from one configuration to another (colored arrows in Figure 1B). These processes, which will be explained in the following, are the possible building blocks that define each model, that is, determine the transition rate matrix in the Master equation of the underlying Markov process for all three promoter states (Materials and methods). To describe all three promoter states within the same model, at least one of its processes has to be regulated, that is, change its rate to achieve different configuration occurrences and dynamics between different promoter states. Invoking the principle of Occam’s razor, we started with global processes and then replaced these in some cases with more specific processes, making the simplest models more and more complex until we found agreement with the considered data. A conceptually similar framework was used to model combinatorial acetylation patterns on histones, but with fixed global disassembly and without the possibilities of sliding and regulation (Blasi et al., 2016). Our approach can be applied to any system that features assembly and disassembly reactions on a fixed number of position/sites. The most important input is the steady state distribution of system configurations which can be accompanied by other known steady state or dynamic properties.
Global processes
The starting point was a model only consisting of two processes, global (i.e. PHO5 promoter-wide) nucleosome assembly (‘A’) and disassembly (‘D’). Remodeling enzymes can bind nucleosomes and slide them along the DNA (Bartholomew, 2014; Zhou et al., 2016), so we also included optional sliding processes, which move nucleosomes to a neighboring empty site. This yields another global process, global sliding (‘S’) (Figure 2A).
Figure 2. Definition and evaluation workflow of regulated on-off-slide models.
On-off-slide models consist of processes from different hierarchies: (A) Global processes for assembly, disassembly and (optional) sliding. Global processes govern all reactions of the corresponding type with the same rate , or . To fit multiple promoter states simultaneously, some processes have to be regulated, that is, have different rate values depending on the promoter state. In this example, the global assembly process is regulated. (B) Optional site-specific processes for assembly and disassembly at each position (example here with rates and ) and for sliding between each neighboring pair of positions (here ). Reactions in gray have not been overruled by more specific processes (here: site-specific processes) and consequently are still determined by the rate parameters of processes on the less specific hierarchy level (here: global processes). (C) The last hierarchy level is given by optional configuration-specific processes governing only one reaction (here with rates and ). Here, only the promoter configurations 1 to 4 are shown. (D) Each regulated on-off-slide model is fitted and evaluated successively using the experimental data on the left-hand side (promoter states during the experiment given in parentheses). Models are discarded if they do not match the maximum likelihood threshold after each stage. With each additional experimental data set, the fit results in new optimal relative rate values of the model. Only the dynamic Flag-/Myc-tagged histone measurements enable us to also fit the time scale.

Figure 2—figure supplement 1. Occurrences of the different processes in the models with satisfactory likelihood at the different stages.
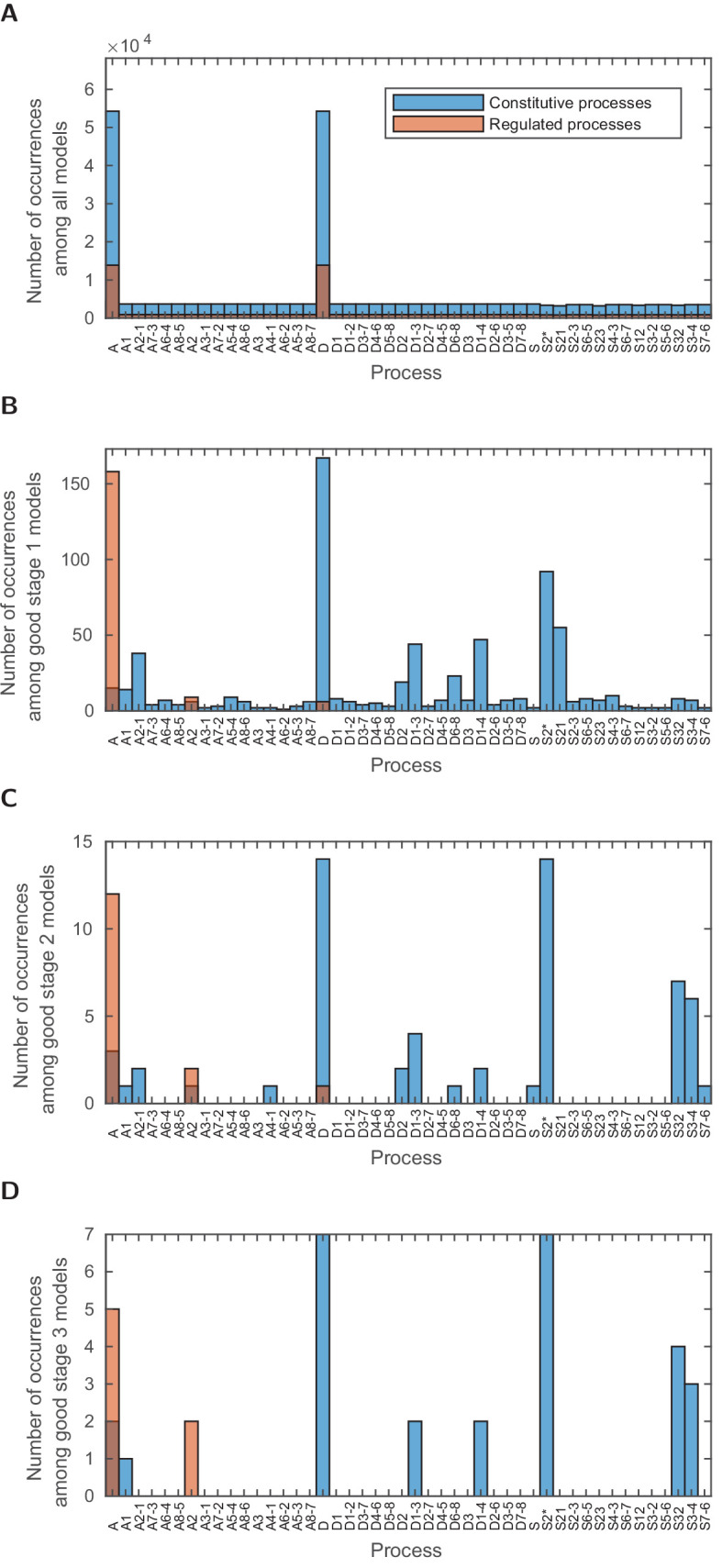
Figure 2—figure supplement 2. Stage 1: logarithmic likelihood ratio histograms.

Figure 2—figure supplement 3. Stage 1: top 30 models with likelihood above the threshold.

Figure 2—figure supplement 4. Stage 1: models with likelihood above the threshold and only six fitted parameters.

Figure 2—figure supplement 5. Reactions involving the sticky N-3 position.
Figure 2—figure supplement 6. Stage 2: logarithmic likelihood ratio histograms.

Figure 2—figure supplement 7. Stage 2: prefactor histograms.

Figure 2—figure supplement 8. Stage 2: models with likelihood above the threshold.

Regulation
We define a regulated on-off-sliding model by its set of processes combined with the information which of the processes are regulated. ‘Regulated’ processes may take on different rate values for different promoter states, whereas ‘constitutive’ processes have the same rate value for each promoter state. The changing rates of regulated processes are supposed to model the effects caused by transcription factors and/or other factors which influence the promoter state, such as recruited remodeling enzymes, in a coarse-grained fashion. The two simplest models have only the global assembly and global disassembly process, one being regulated and the other being constitutive. If a model is fitted to three different promoter states, one has to fit the three rate values for each regulated process, and one rate value for each constitutive process. Thus regulated processes have three fitted parameters, whereas constitutive processes have one, giving four fitted parameters for the two simplest models. One degree of freedom of the fit corresponds to the overall time scale of each model.
Site-specific assembly and disassembly processes
Brown et al., 2013 showed that only global processes are not sufficient to fit the measured occurrences of all eight configurations, even to describe only one promoter state (e.g. the activated promoter). There have to be local modifications of at least one global process (assembly, disassembly or sliding). In Brown et al., 2013, modifications were introduced by setting certain reaction rates in the configuration network to zero, effectively searching for a good network topology in the vast discrete space of all possible topologies. In contrast, our approach has the ability to continuously deviate from the global process rate values for a given set of reactions. Here, the simplest modification is given by site-specific processes (Figure 2B). Possible biological mechanisms could be sequence-dependent effects, recruitment or inhibition of remodeling factors in a site-specific way or local differences in the epigenetic marks of nucleosomes. To incorporate such possibilities, we added site-specific assembly, disassembly and sliding processes to the pool of optional processes (see example Figure 2B). All processes, except global assembly and global disassembly, are optional and the more optional processes are allowed, the larger the number of all possible models will become. To distinguish the processes at the three nucleosome positions N-1, N-2, and N-3, we named the three site-specific assembly processes ‘A1’, ‘A2’, and ‘A3’, and the three disassembly processes ‘D1’, ‘D2’, and ‘D3’, respectively.
Site-specific sliding processes
To allow directional sliding, as observed for example in vivo for ISW2 and suggested for RSC (Whitehouse et al., 2007; Krietenstein et al., 2016), we included five optional site-specific sliding processes. One process governs the rates for all sliding reactions leaving from the N-2 site to account for the possibility of start site-specific non-directional sliding (‘S2*'). Two processes enable directional sliding between N-1 and N-2 sites and two directional sliding between N-2 and N-3 sites, with the short name ‘Sxy’ for sliding from site x to site y. Note that these sliding processes actually are not only dependent on the state of one site, but two sites: the origin and the destination of the sliding process. The origin needs to be occupied and the destination to be empty. This already constitutes a correlation between neighboring sites. We still call these processes ‘site-specific’, since they do not take into account the full configuration.
Modulation by more specific processes
Site-specific processes govern a subset of reactions of all reactions of a given type (assembly, disassembly, or sliding) to allow deviations from the global process rate at a given position. To achieve this we invoke the following rule, which is also used for the even more specific processes of the following paragraph: If the reactions governed by any two processes in a given model overlap, as for example the global and any site-specific assembly process, the more specific process, that is, the one governing less reactions, determines the rate values of these reactions, 'overruling’ the more general process, which then only governs the left-over, non-overlapping reactions. Thus, a more specific process only overrules a more general process that contains the same reactions. This rule is the most general solution for overlapping processes, allowing an increased as well as a decreased rate value for the reactions of the more specific process, that is, the specific process to be enhanced or inhibited with respect to the general process. If all reactions of a process are overruled by more specific processes in a given model, that model is redundant and will be ignored.
Configuration-specific processes
To allow even more specific modulations, we also added configuration-specific processes which only govern a single reaction rate and overrule any more general process for this reaction (see example Figure 2C). Since there are in total 32 reactions, this gives another 32 optional processes. For instance, the disassembly process from configuration 1 to configuration 4, is denoted with ‘D1-4’, sliding from configuration 4 to configuration 3 with ‘S4-3’.
Resulting model set
With the simplest regulated on-off-slide models having four parameters, we increased the maximal parameter number up to seven to obtain the first models that simultaneously fit all data sets within the experimental error. This yielded models with one regulated process (having three fitted parameter), and 1–4 constitutive processes, as well as models with two regulated processes and one constitutive processes. Models with zero constitutive processes, that is, only regulated processes, are ignored since they decouple the time scales of the different promoter states and in this case the fit to steady state observables is not harmed by setting any single regulated process to a constitutive process. After taking into account all combinations of processes with up to seven parameters in total we ended up with 68,145 regulated on-off-slide models. Here, we ignored duplicate models with identical transition rate matrices constructed with different processes (e.g. rare models where all reactions of a process are overruled by other processes, making it identical to the model without the overruled process).
The relative occurrence of individual constitutive as well as regulated processes in this initial model set is the same for all assembly and disassembly processes except global assembly and disassembly and slightly lower for non-global sliding processes where the number of effectively identical, and thus ignored, models is higher (Figure 2—figure supplement 1A).
Staging
We used the models of this new class and a step by step (‘staged’) fitting procedure to determine which of them are capable to reproduce the four experimental data sets (Figure 2D). The benefit of this staging approach was that we could dissect the contributions of the different data sets to the model selection as well as reduce model count in the later, computationally more involved, stages. Each stage also fits again the data from the previous stages. Thus, models that drop out at an earlier stage cannot improve in a later fit to more data when using the same threshold in each stage, making the results independent of the exact staging order. Note that, even in a different order, the configuration statistics are needed in all stages to determine well-defined relative rates for the processes of each model, thus making it part of stage 1.
Promoter configuration statistics
First, in stage 1, the parameter values, that is, the rate values of the involved processes, of each model were determined by maximizing the likelihood to observe the measured PHO5 promoter configurations (see Materials and methods, Figure 1C). The global assembly parameter (for the activated state) was set to one to fix the time scale at first, which yielded relative rates for the remaining six parameter values. Since we will fit the time scale later as well, we always include it in the number of fitted parameters. As an example, consider the model with the processes and reaction network shown in Figure 3A. After the maximum likelihood fit, one can compare the different model nucleosome configuration distributions for the three promoter states with the configuration statistics data. Since also including the data sets discussed below into the fit did not worsen the deviations from the configuration statistics data for this specific model (data not shown), we already show here the final nucleosome configuration distributions (Figure 3B,C and D).
Figure 3. Best regulated on-off-slide model compatible with all the experimental data sets in stage 3.
All fits were done simultaneously (see Materials and methods). (A) Regulated on-off-slide model with the regulated process A (global assembly, thick arrows) and the constitutive processes D (global disassembly), D1-4 (disassembly from configuration 1 to 4, overrules D), S2* (sliding away from N-2) and S3-4 (sliding from configuration 3 to 4). (B, C, D) Combined fits to the steady-state promoter nucleosome configuration occurrences in repressed, weakly activated, and activated state. Only a change in the rate of the regulated global assembly process accounts for differences in the three distributions. The other processes (D, D1-4, S2*, and S3-4) are constitutive and their rates do not change. The model fits in stage 1 (ignoring all other data) and stage 2 (ignoring Flag-/Myc-tagged histone exchange data) are only slightly better (data not shown). (E) Fit to the sticky N-3 RE accessibility data of two mutants in the activated state (error bars with standard deviation of rescaled RE accessibility). Only reaction rates involving the N-3 were allowed to divert from the previously fitted parameter values. (F) Fit to the Rufiange et al., 2007 data of Flag amounts at N-1 over N-2 after 2 h of Flag expression (shifted by 0.25 h lag time determined in Dion et al., 2007). The error bar corresponds to the standard deviation of two measurements. (G) Fit to the Dion et al., 2007 data of Flag over Myc amounts at N-1 at four time points after Flag expression (shifted by 0.25 h lag time). y-axis points are normalized by their mean to account for a sloppy fitted parameter in the treatment of the data in Dion et al., 2007. Error bars are estimated experimental standard deviations used in the fit.

Figure 3—figure supplement 1. Stage 3: Flag amount ratios of tested models.

Figure 3—figure supplement 2. Stage 3: Flag over Myc amount ratios of tested models.
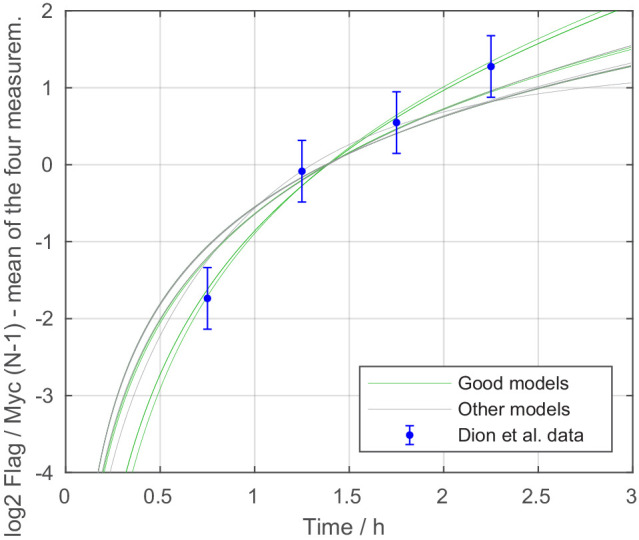
Figure 3—figure supplement 3. Stage 3: logarithmic likelihood ratio histograms.
For model selection, we used the logarithmic likelihood ratio with respect to the perfect fit, , where is the maximum log10 likelihood of a given model in stage 1 and the highest possible log10 likelihood to obtain the configuration data, corresponding to a perfect fit. The best model achieved (distribution of for all models in Figure 2—figure supplement 2A) and our example model in Figure 3 . We set an upper threshold to , , to define models that are in good agreement with the measured configuration statistics. We used the same in each stage and this threshold, which denotes a likelihood times lower than the current best model, gave enough room for fitting models to additional data later on. At this stage, we found 173 such models, with the top 30 models presented in Figure 2—figure supplement 3. Two of these 173 models used only 6 instead of the maximum of 7 fitted parameters (with and , Figure 2—figure supplement 2D and Figure 2—figure supplement 4).
For comparison, Brown et al., 2013 used different network topologies to fit the different promoter states with three parameters values per state (assembly, disassembly and sliding, with assembly set to 1). The corresponding logarithmic likelihood ratio of the combined model of the three states is , using seven fitted parameters, when also counting the time scale. This reveals the power of our systematic approach, since we found models with higher likelihood as well as models with one parameter less and not much worse likelihood.
Model heterogeneity
At this stage, the set of good candidate models, that is, models with below the threshold, was still quite heterogeneous, that is, there were models where all sliding reactions have positive rates, and models with no sliding at all (Figure 2—figure supplement 2C). In fact, this was already the case for the second best model (Figure 2—figure supplement 3). Some models with below the threshold did not use any configuration-specific processes (Figure 2—figure supplement 2B). The regulated processes were mostly global assembly, while some models showed regulated global disassembly or site-specific assembly at N-2 (Figure 2—figure supplement 1B). In the following stages, we further sorted out models by fitting to additional data sets.
Assembly-disassembly symmetry only for equilibrium models
Note that, except for a few cases, regulated on-off-slide models are non-equilibrium models. Equilibrium regulated on-off-slide models, that is, models where the net fluxes between all promoter configurations in steady state are zero in all states (also known as ‘detailed balance’ models), have an assembly-disassembly symmetry. That means, swapping all assembly processes to the equivalent disassembly process and vice versa (e.g. A to D, A1 to D1, D2 to A2), yields a model with equal maximum likelihood. Additionally, for each equilibrium model with a regulated assembly parameter there is a symmetric equilibrium model with the corresponding regulated disassembly parameter and equal maximum likelihood, and vice versa. Non-equilibrium models do not share this symmetry. Among the 68,145 investigated regulated on-off-slide models, there are 196 equilibrium models with zero net fluxes independent of their parameter values. These are models that only use global processes, where the symmetry is trivial, as well as models without any sliding or any configuration-specific processes. These equilibrium models did not fit the data well, with the best .
Integration of PHO5 promoter mutant data
Accessibility experiments for PHO5 promoter mutants
In the next stages, we eliminated the regulated on-off-slide models that did not agree with further data. Small et al., 2014 published two PHO5 promoter mutants where the DNA sequence underlying N-3 was mutated such as to increase certain dinucleotide periodicities that favor nucleosome formation and may increase intrinsic nucleosome stability (Satchwell et al., 1986). Using an at that time novel DNA methylation assay for probing nucleosome occupancies, these authors published that N-3 at these mutated PHO5 promoters was hardly removed upon PHO5 induction. These mutated PHO5 promoters offered an interesting parameter modulation and we could have used, in principle, these nucleosome occupancy data for further selection among our models. However, for reasons detailed in the Discussion section, we questioned the published data and wished to check them by classical and well-documented restriction enzyme (RE) accessibility assay (Gregory et al., 1999). Therefore, it was important that we obtained the exact same strains from Small et al., 2014 and measured N-2 and N-3 occupancies at the wild type and mutant PHO5 promoters (Table 1 and Table 1—source data 1). We confirmed that the sticky N-3 mutant promoters show reduced, relative to wild type, removal of both N-2 and N-3 upon PHO5 induction, but we did not confirm that these nucleosomes were hardly removed at all. Nonetheless, these data now provided additional constraints for our modeling approach as we needed to find the regulated on-off-slide models which show the same interdependence of N-2 and N-3 accessibility.
Table 1. Restriction enzyme (RE) accessibility of N-2 and N-3 sites in phosphate starved cells measured in this study and corresponding accessibility values of Brown et al., 2013 (RE accessibility with mean ± standard deviation of two independent biological replicates and the fold-change standard deviation calculated using standard error propagation).
The sticky N-3 mutants feature manipulated DNA sequences at the N-3 site, which decrease the RE accessibility at the N-3 site compared to the wild-type. In our study, this sticky N-3 also decreases the accessibility of the N-2 site. In stage 2, we tested which regulated on-off-slide models with compatible configuration distribution in stage 1 can at the same time reproduce the accessibility fold-changes at sites N-2 and N-3 for both sticky N-3 mutants.
| Wild type | Sticky N-3 mutant 1 | Sticky N-3 mutant 2 | |||
|---|---|---|---|---|---|
| accessibility | accessibility | wt fold-change | accessibility | wt fold-change | |
| N-2 RE (ClaI) | |||||
| N-2 Brown et al. | 82% | ||||
| N-3 RE (HhaI) | |||||
| N-3 Brown et al. | 55% | ||||
Accessibility fold-changes
The Small et al., 2014 strains included corresponding isogenic wild-type strains and we noted that our RE accessibilities for wild type in the activated state were lower than the accessibilities in the activated state of the wild type calculated from the data from Brown et al., 2013 (Table 1). This discrepancy likely stems from different experimental conditions. The Brown et al., 2013 study used a different strain background, YS18, and the pho80 allele in high phosphate conditions for induction, while we used the S288C background and over night phosphate starvation to achieve direct comparison with the data by Small et al., 2014. We saw repeatedly that S288C strains do not yield as high ClaI accessibility values in the induced state as the YS18 background, which was formerly used in classical PHO5 studies reporting such high degree of PHO5 promoter nucleosome remodeling (Ertel et al., 2010). Nonetheless, this discrepancy did not matter for our purposes as we could use the accessibility fold-changes of mutants compared to the wild-type to test our models in order to normalize the accessibility values coming from different experiments.
Modeling approach
In stage 2, we fitted the experimental fold-changes together with the data used in stage 1, minimizing with being the log likelihood to obtain the accessibility fold changes (see Materials and methods). We needed to systematically test for each model whether reasonably large changes in reaction rates involving the N-3 nucleosome could lead to the same behavior seen in the experiment. Since we did not know the exact consequences of the sticky N-3 mutation on the reaction rates or how to translate them within a given model, we had to consider all possibilities of changes in reactions where the N-3 nucleosome is involved. We achieved this by including prefactors for these 12 reaction rates (Figure 2—figure supplement 5), which were fitted together with the model parameters to the configuration statistics data and the accessibility fold changes of both sticky N-3 mutants and allowed each prefactor to vary between and 5 for each sticky N-3 mutant. For equilibrium models, the ratio of a pair of reverting reaction rates can be interpreted by , with denoting the energy difference between the two configurations. This leads to a maximal possible absolute change in N-3 nucleosome binding energy modeled by the prefactors of . We decided to use four prefactors per sticky N-3 mutant, one for each group of reactions, assembly at N-3, disassembly at N-3, sliding from N-3 to N-2 and from N-2 to N-3 (Figure 2—figure supplement 5), respectively.
Using the same likelihood threshold as in stage 1 left us with 15 models that fit both sticky N-3 mutants well (Figure 2—figure supplement 6A), with the best logarithmic likelihood ratio of for the model in Figure 3, with Figure 3E showing a perfect fit to the sticky N-3 fold changes (also including the following data sets). Out of these 15 models, only three models without configuration-specific processes remained (Figure 2—figure supplement 6B). With this fit we also excluded models without sliding processes (Figure 2—figure supplement 6C) as well as models with less than seven fitted parameters (Figure 2—figure supplement 6D).
Prefactor behavior
The fitted prefactor values show stable qualitative behavior for the models with below in both mutants (Figure 2—figure supplement 7): consistent with the reduced experimental accessibility at N-3, assembly at N-3 is increased by a prefactor greater than one while disassembly at N-3 is decreased by a prefactor smaller than 1. Furthermore, in these models the sliding from N-3 to N-2 is increased and the sliding from N-2 to N-3 decreased by the two sliding prefactors. While these favor the accessibility at N-3 again, they lead to the concomitant accessibility decrease at N-2.
Relative occurrence of sliding
Taking into account the sticky N-3 data has a strong impact on the relative occurrences of sliding processes, as it strongly favors models with either S32 or S3-4 processes, both of which enable the sliding from N-3 to N-2 (Figure 2—figure supplement 1C). All 15 good models in stage 2 include at least one sliding process (Figure 2—figure supplement 8).
Flag-/Myc-tagged nucleosome exchange simulation
In stage 3, we used histone dynamics measurements to further constrain our models and, for the first time, were able to determine the optimal time scale of each model. Histone dynamics measurements reflect the appearance/disappearance of nucleosomes regardless if via assembly/disassembly or sliding and is measured in cells that constitutively express Myc-tagged histones and are then induced to express also Flag-tagged histones, which, over time, are incorporated into nucleosomes (Schermer et al., 2005). We used the histone pool model as well as the measured average Flag over Myc amount ratio at the N-1 in MNase-ChIP-chip assays of Dion et al., 2007 and the measured Flag at N-1 over Flag at N-2 amount ratio in Flag-tagged H3 MNase-ChIP-qPCR assays of Rufiange et al., 2007 in the repressed promoter state. We investigated the nucleosome configuration dynamics of each model by keeping track which nucleosome contains a Flag- or Myc-tagged histone H3 (see Materials and methods). This enabled us to calculate the dynamics of the ratio of Flag at N-1 over Flag at N-2 amount (Figure 3F and Figure 3—figure supplement 1A) and the ratio of Flag over Myc amount at the N-1 (Figure 3G and Figure 3—figure supplement 2) for each model and determine the agreement with the two histone dynamics data sets. We obtained seven models in agreement with the data, with a best logarithmic likelihood ratio of , with being the summed log10 likelihoods of the third and fourth data set (Figure 3—figure supplement 3A). Thus, the threshold value of denotes a likelihood times lower as the best achieved value of . We also calculated the dynamics of the Flag amount ratios between the other sites (N-3 over N-2 and N-3 over N-1, see Figure 3—figure supplement 1B,C) and similarly the same ratios in the activated promoter state (Figure 3—figure supplement 1D,E,F).
Properties of satisfactory models
Processes and rate values
Out of the 68,145 models with at most seven fitted parameter values, seven models satisfied our threshold for the likelihood in the combined fit to the nucleosome configuration data, the sticky N-3 mutant accessibility data and the H3 exchange data. These ‘satisfactory’ models, their processes and rate values are presented in Figure 4, with the corresponding reaction rates shown in Figure 4—figure supplement 1.
Figure 4. The seven models that agree with all four data sets after stage 3.
The colored boxes in each row show the model processes and their rate values. White boxes denote the absence of a process in a model. Regulated processes are separated into two differently colored boxes for repressed (left half) and activated (right half) promoter state. Weakly activated rate values are not shown here. On the left side are the model number and the log10 ratio of the best possible likelihood and the model likelihood, . The models are grouped with respect to similarities in the site-centric net fluxes (Figure 5—figure supplement 5). The groups’ representatives are printed in bold with net fluxes compared in Figure 5.

Figure 4—figure supplement 1. Relative rate values for all 32 reactions of the seven satisfactory models.

Only one regulated process
All satisfactory models had one regulated process and four constitutive processes (Figure 4). Simultaneous regulation of two processes in combination with one constitutive process (also summing up to seven fitted parameters) did not fit the data well enough, probably because regulation with two processes leaves only one possible constitutive process slot and only three processes in total. Thus, the rather simple regulation of only one process is preferred over regulation of several processes, when keeping the total number of fitted parameter constantly at 7.
Regulation by assembly
Within the seven satisfactory models, the regulated processes are global assembly, A (5x) and assembly at N-2, A2 (2x) (Figure 4 and Figure 2—figure supplement 1D). The fact that regulation by assembly rather than disassembly is more likely to reproduce the data can already be observed after the maximum likelihood fit to the configuration data in stage 1 (Figure 2—figure supplement 1B). The rates of all regulated assembly processes decrease when going from the repressed over the weakly activated to the activated state. This is in agreement with the total nucleosome occupancy decrease on the promoter.
Sliding processes needed
Since all sliding processes are optional, we asked whether sliding is needed to fit all data sets. We found that sliding occurs in all seven models, and in each case with at least two different processes, that is, just global sliding with the same rate for each sliding reaction is not sufficient. Every satisfactory model employs the sliding process away from N-2 (S2*) and a process that allows sliding from N-3 to N-2 (Figure 4 and Figure 2—figure supplement 1D).
Use of site- and configuration-specific processes
On-off-slide models combine processes from different hierarchies. Each model has a global assembly and global disassembly process, but global sliding is optional and not used in any of the satisfactory models. Each of these models has one to three site-specific processes out of A1, A2, S2*, and S32, which overrule global processes. We found two models without configuration-specific processes, models 8166 and 27,443 (Figure 4). All other satisfactory models have one or two configuration-specific processes. Thus, configuration-specific processes are helpful, but not needed to achieve agreement with the data. However, that does not mean that the three nucleosome sites can be independent of each other, since the sliding reactions always introduce coupling between neighboring sites.
Fluxes
Knowing all reaction rates, it is easy to calculate the directional fluxes (Figure 5—figure supplement 1 and Figure 5—figure supplement 2) as well as the net fluxes (Figure 5—figure supplement 3 and Figure 5—figure supplement 4) between all configurations for each satisfactory model and for different promoter states. Since there are no methods available to measure these fluxes experimentally, modeling approaches provide the only view into possible internal promoter configuration dynamics. As stated before, the vast majority of all regulated on-off-slide models are non-equilibrium models, that is, have non-zero net fluxes. In the repressed promoter, the seven satisfactory models showed the highest fluxes as well as net fluxes occurring between the configurations with three or two nucleosomes (Figure 5—figure supplement 1 and Figure 5—figure supplement 3) and cyclic net fluxes from configuration 1 to 2 to 3 and back to 1. Despite qualitative similarities, the fluxes and net fluxes also show the different behavior of the seven models, for example only five of them showed cyclic net fluxes from configuration 1 to 4 to 3 and back to 1. In the activated promoter state, the higher fluxes and net fluxes between the first four configurations are lost and the differences between the seven models become more pronounced.
Site-centric net fluxes
Going back to the view point of nucleosome sites as in Figure 1A, we define effective ‘site-centric net fluxes’ by summing all assembly/disassembly net fluxes at each site and sliding net fluxes between N-1 and N-2 as well as N-2 and N-3 (Figure 5—figure supplement 5). The site-centric net fluxes give a simplified picture of the net paths of the nucleosomes on the promoter, but ignore the events on neighboring sites, which are only correctly depicted in the directional or net fluxes between the promoter configurations. While in all satisfactory models, the N-2 site had a central role with the strongest net nucleosome influx in all promoter states, we also found differences and divided the satisfactory models into three groups. Two models (group 1) have site-centric net influx only at N-2 and N-3 for the repressed state and only at N-2 for the activated state. The other models have site-centric net influx only at N-2 for all promoter states, but show very different flux amounts. Three models (group 2) show a repressed N-2 site-centric net influx of , while the last two models (group 3) have . The time scale parameters of group 3 are 10-fold lower than for the other two groups and have larger error bars (see Materials and methods and Figure 4—source data 1), allowing the time scale to increase by up to a factor of 10 as well as becoming arbitrarily small, while still meeting the fit threshold. Thus, the time scale parameter of this group is not properly determined by the given data. For each group, we picked a representative model (highest likelihood within the group) and show the net fluxes and the site-centric net fluxes in Figure 5.
Figure 5. Overview of net fluxes and site-centric net fluxes for the three group representatives.
First two rows: net fluxes in repressed and activated promoter state (arrows) with configuration probabilities as orange horizontal bars (a filled promoter rectangle corresponds to probability 1). Arrow length indicates the relative flux amount within a flux network with the maximum stated above. Third row: site-centric net fluxes in repressed (red) and activated (green) state, obtained by summing all assembly/disassembly net fluxes at each site and sliding net fluxes between N-1 and N-2 as well as N-2 and N-3. Here, the arrow thickness indicates the amount of flux with the maximum stated above.

Figure 5—figure supplement 1. Directional fluxes in repressed promoter state of all satisfactory models.

Figure 5—figure supplement 2. Directional fluxes in activated promoter state of all satisfactory models.

Figure 5—figure supplement 3. Net fluxes in repressed promoter state of all satisfactory models.

Figure 5—figure supplement 4. Net fluxes in activated promoter state for each satisfactory model in stage 3.

Figure 5—figure supplement 5. Site-centric net fluxes of all satisfactory models.

Figure 5—figure supplement 6. Configuration distribution dynamics during chromatin opening with instantaneous signal.

Figure 5—figure supplement 7. Configuration distribution dynamics during chromatin closing with instantaneous signal.

Maximal reaction rates
After setting the time scale for each model, we investigated the rate values for each reaction (Figure 4—source data 1 and Figure 4—source data 2). Within all satisfactory models, the highest rate of assembly and disassembly processes were and , respectively. Sliding rate values had a maximum of , corresponding to translocation speeds of at least assuming an unidirectional travel of with constant speed between two sites and instantaneous binding of remodeler enzymes needed for sliding. Experimentally measured translocation speeds of up to of yeast SWI/SNF or RSC remodeling complexes in vitro (Zhang et al., 2006) leave enough room to account for a delay due to binding of sliding remodelers, possibly making it the limiting factor in the sliding rate of , which would in turn lead to corresponding translocation speeds closer to the experimentally measured value.
Bounds for chromatin opening and closing times
PHO5 induction results from consecutive signal transduction, promoter chromatin opening, transcription initiation and downstream processes that lead to functional Pho5 acid phosphatase gene product. On the level of PHO5 mRNA or acid phosphatase activity, induction starts about two hours after phosphate starvation of the cells (Rajkumar et al., 2013; Barbaric et al., 2001), while after the same time chromatin opening in terms of chromatin accessibility is usually complete, that is, the kinetics of PHO5 promoter chromatin opening are faster (Schmid et al., 1992; Barbaric et al., 2001; Korber et al., 2006; Barbaric et al., 2007). We modeled here PHO5 promoter chromatin remodeling and can give approximate upper bounds for the chromatin opening rates for each regulated on-off-slide model (‘effective chromatin opening rate’, see Materials and methods).
Models in group 1 had an effective chromatin opening rate close to . Group 2 showed a faster effective chromatin opening rate of , while group 3 yielded . Since these values are proportional to the time scale, they inherit its uncertainty. The effective chromatin opening rate of group 2 was high enough to reflect the experimentally measured kinetics. The other two groups could also match these kinetics, although just barely, if the maximum time scale uncertainty was considered (approximately an additional factor of 2 for group 1 and a factor of 10 for group 3, see Figure 4—source data 1).
Conversely, we did the same calculations for the ‘effective chromatin closing rate’, which is an upper bound of how fast a given model can switch to the repressed state. The ratio of the effective chromatin closing rate over the opening rate was between 2.9 and 3.5 for all satisfactory models. Even just after the first fit in stage 1, all investigated assembly-regulated models in agreement with the configurational data had a ratio ranging from 1.5 to 4.5. The few disassembly-regulated models after stage 1 had a ratio ranging from 0.25 to 0.65. This further supports the assembly-regulated models as promoter chromatin closing and repression of PHO5 transcription were experimentally shown to be faster than chromatin opening and transcription activation. After the shift from phosphate-free to phosphate-containing medium, repression of PHO5 transcription was almost complete within 20 min (Schermer et al., 2005) and 65% of chromatin closing was achieved within 45 min (Schmid et al., 1992).
We also used our models to directly calculate the dynamics of the nucleosome configuration distributions during chromatin opening and closing. Similar to the calculation of the effective chromatin opening/closing rates, we assumed an instantaneous signal, that is, an abrupt change of the regulated process rates from repressed to activated and vice versa. Interestingly, our models predict a probability maximum after leaving the initial repressed steady state and before arriving in the activated steady state for configuration three and some models also for configurations 2 and 4 (Figure 5—figure supplement 6). This behavior should translate into a scenario with a continuous regulation change as well. Similarly for closing, our models predict a non-monotonic probability dynamics for configurations 3, 4, and 6 and some models also for configurations 2 and 7 (Figure 5—figure supplement 7).
Extending the threshold
The properties of satisfactory models remained stable upon increasing the logarithmic likelihood ratio threshold from 6 to 7. This yielded 28 models with (data not shown). A notable exception was the appearance of models with both, global sliding and sliding away from N-2 (S2*) and the first model with only one sliding process (S2*). Otherwise, they all showed very similar properties as the models selected with .
Discussion
The following discussion is structured into five parts. We begin by reviewing our new modeling framework, which has broader applicability, beyond the analysis presented here. We then discuss our unexpected finding of nucleosome assembly playing a role in chromatin regulation, and consider the experimentally testable predictions of our satisfactory models. Lastly we propose further applications of our modeling framework, and clarify the effects of the sticky N-3 mutation on different measurements.
Establishment of a new effective modeling approach for nucleosome dynamics
We present a new approach for modeling nucleosome dynamics at promoters: regulated on-off-slide models. They include nucleosome assembly, disassembly and sliding and enable a combined fit of data for different promoter activation states. The hierarchical approach of global, site-specific and configuration-specific processes allowed us to represent different network topologies, that is, switching ‘off’ reactions by using a very low rate of a non-global process, and continuous variations among network topologies (Figure 2A–C). We investigated all regulated on-off-slide models with up to seven fitted parameters, establishing an unbiased modeling approach that can provide insight into aspects of nucleosome dynamics that are so far not directly accessible to experiments.
Using the PHO5 promoter as example, regulated on-off-slide models provided a unique integration of four different data sets in nucleosome resolution: nucleosome configuration measurements, our own nucleosome accessibility experiments in sticky N-3 mutants and two Flag/Myc-tagged histone H3 exchange experiments (Figure 2D). Only using the configuration measurements of Brown et al., 2013 was not enough to restrict our model set. For instance, the best and second best models after stage 1 had almost identical likelihood to reproduce the data, but very different properties (see 'Promoter configuration statistics - Model heterogeneity’).
Keeping these four data sets in mind, we designed our models to consider full nucleosomes, not individual histones, during assembly and disassembly and used an effective description rather than a more detailed approach with base-pair resolution and transcription factor dynamics (Kharerin et al., 2016). In this way, steady state data combined with dynamical data provided new insights into the nucleosome configuration dynamics, for example net fluxes between nucleosome configurations (Figure 5). We arranged our regulated on-off-slide models such that at least one process was regulated, that is, its rate value varied depending on the promoter state. This gave us the opportunity to examine how regulation between different promoter states was most likely achieved. We found that regulation from repressed over weakly activated to activated promoter states can be surprisingly simple, only using one regulated process, while the rates of all other processes remain constant.
Out of 68,145 tested models only seven models satisfied our threshold criterion after fitting all four data sets. All seven satisfactory models enabled sliding away from the N-2 position, but towards the N-2 only from the N-3 position. Equilibrium models and models without any sliding within the tested class could not simultaneously fit all four data sets. As we made all sliding processes optional, this showed that sliding is essential and has a net directionality. Configuration-specific processes, that is, processes governing only a single reaction, were used in all but two of the seven models, and could increase the likelihood. In these two cases, the necessary coupling between nucleosomal positions needed to find agreement with the experiments was introduced only by sliding.
By incorporating dynamical Flag-/Myc-tagged histone exchange data sets we were able to set the time scale for each model, which can not be done by using steady state data only. This is a completely new use case for these data sets and we took care not to over-interpret them. We found that some models had a rather ‘sloppy’ time scale, that is, the time scale could vary strongly without notably decreasing the fit quality. One reason was that the ratios at different times of Flag over Myc amount at N-1 needed to be shifted by their mean to take into account the high fit error of the absolute values in Dion et al., 2007. The method of Rufiange et al., 2007 did not have this problem, but unfortunately gave us measurements at only one time point, not restricting the slope of the dynamics of the ratio of N-1 and N-2 Flag amounts (Figure 3—figure supplement 1A).
Our models were selected according to four independent data sets derived from three orthogonal experimental approaches. Importantly, given the time scales, we could estimate lower bounds on how quickly the satisfactory models could switch from a closed state to an open state and vice versa. Taking into account the time scale errors, these effective chromatin opening rates were compatible with additional independent experimental values (see 'Properties of satisfactory models - Bounds for chromatin opening and closing times’). Furthermore, the ratios between effective chromatin opening versus closing rates were only compatible with the regulated assembly rather than disassembly models, even already after stage 1 just using the data from Brown et al., 2013. This amounts to confirmation by an additional fourth type of orthogonal data that was not used in the fitting procedure.
Before considering possible tests of predictions regarding Flag/Myc dynamics as well as chromatin opening and closing dynamics and further applications of our approach, we discuss the surprising role of nucleosome assembly in chromatin regulation within the satisfactory models.
Unexpected role of nucleosome assembly in chromatin regulation
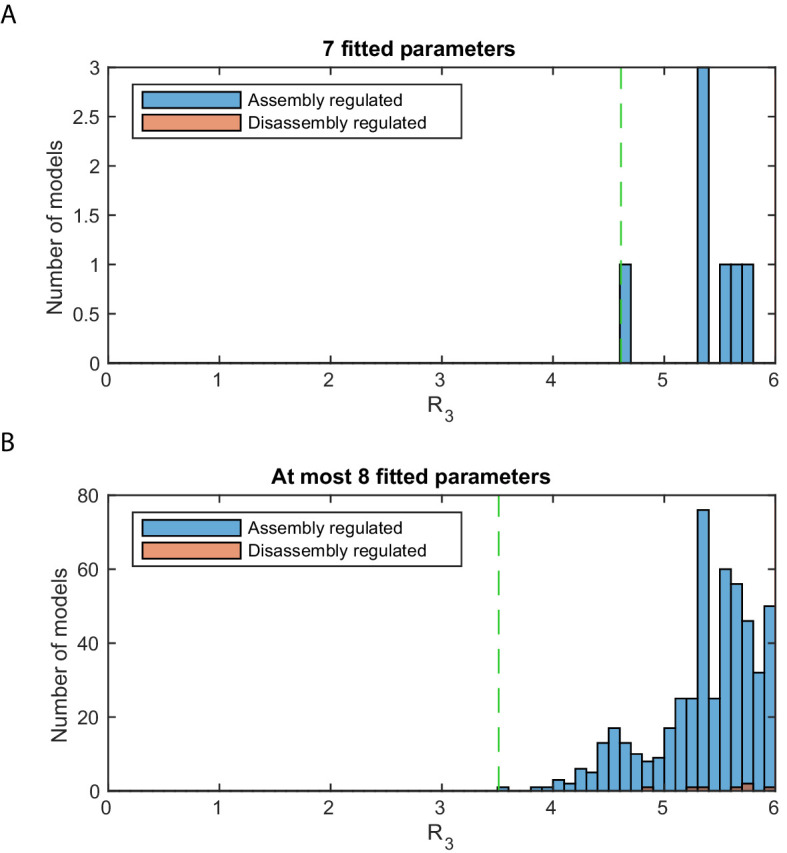
The identification of essential and directional sliding during PHO5 promoter chromatin opening, the estimated time scales and the central role for the N-2 nucleosome in all seven models matched expectations based on earlier studies. However, we were surprised that only a regulated assembly process was compatible with the data, but not a regulated disassembly process, as the latter would be commonly expected. In case of an equilibrium system, the same chromatin opening could result from more disassembly or from less assembly, but, as mentioned above, our selected models are non-equilibrium models and the tested equilibrium models did not fit the data at all. Therefore, the selection of regulated assembly does not just represent the flip side of the common view but seems indeed surprising. We note that models with regulated disassembly could result in satisfactory fits to all data sets after we allowed one additional fitted parameter, but were still a very small minority among all satisfactory models, with best maximum likelihood drastically lower (less than ) than the best assembly regulated models (Figure 3—figure supplement 3B).
At first sight, regulated assembly counters the common view on promoter chromatin opening mechanisms as derived from pioneering studies at the yeast PHO5 (Korber and Barbaric, 2014) or other, like the HO (Cosma et al., 1999) promoter, but also at mammalian promoters like the glucocorticoid-regulated MMTV promoter (Deroo and Archer, 2001; Johnson et al., 2008). According to this view, chromatin opening is triggered by binding of a (transcription) factor that locally recruits, either directly or via histone modifications like acetylation (Hassan et al., 2001), a chromatin remodeler, which in turn mediates nucleosome removal either by sliding and/or by disassembly (Sudarsanam and Winston, 2000; Vignali et al., 2000; Workman, 2006; Becker and Hörz, 2002; Narlikar et al., 2002). It is mainly based on (i) experiments showing physical interactions between transcription factors and remodelers (Neely et al., 1999; Yudkovsky et al., 1999; Natarajan et al., 1999) or between remodelers and modified chromatin (Hassan et al., 2001), (ii) on chromatin immunoprecipitation or microscopy data showing transcription factor or histone modifier recruitment to the promoter upon promoter activation (Cosma et al., 1999; Kowenz-Leutz and Leutz, 1999; Barbaric et al., 2003; Dhasarathy and Kladde, 2005; Johnson et al., 2008), and (iii) on in vitro assays demonstrating nucleosome sliding and disassembly activities for chromatin remodelers (Tsukiyama et al., 1994; Lorch et al., 1999; Längst et al., 1999; Hamiche et al., 1999). As chromatin opening amounts to the net removal of nucleosomes it was always intuitive to see nucleosome disassembly as the regulated process. Nonetheless, we note that remodelers were equally shown to mediate nucleosome assembly in vitro (Lorch et al., 1999; Haushalter and Kadonaga, 2003) and wonder if the well-documented remodeler recruitment at promoters upon promoter activation may also result in downregulation of nucleosome assembly rather than upregulation of disassembly.
Before ATP dependent remodeling enzymes and their active nucleosome displacement activities were fully recognized, it was proposed that binding competition between sequence specific DNA binders like transcription factors and the histone octamer, that is, mass action principles, was a major mechanism for nucleosome removal. For example, if a nucleosome was positioned over Gal4 binding sites in the absence of Gal4 it could be displaced by adding Gal4 in vitro (Workman and Kingston, 1992) or inducing Gal4 in vivo (Morse, 1993). Recently, the class of pioneer factors and general regulatory factors that have important roles in opening chromatin or keeping chromatin open, for example in the context of cellular reprogramming, were also suggested to displace nucleosomes by binding competition (Yan et al., 2018; Donovan et al., 2019; Iwafuchi et al., 2020). For the PHO5 promoter, this mechanism seemed attractive as its transactivator Pho4 indeed competes with nucleosome N-2 during binding to the intranucleosomal UASp2. Further, a PHO5 promoter lacking UASp2, that is, left only with the constitutively accessible UASp1 in-between N-2 and N-3, was not induced during phosphate starvation in vivo (Ertel et al., 2010).
However, early studies dismissed an essential role for binding competition at the PHO5 promoter as (i) the coregulated PHO8 promoter was opened without an intranucleosomal UASp (Barbarić et al., 1992), (ii) even the ΔUASp2 PHO5 promoter mutant could be opened if PHO4 was overexpressed (Ertel et al., 2010) and (iii) even an overexpressed Pho4 version containing a functional DNA-binding but no transactivation domain could not displace N-2 and trigger chromatin opening (Svaren et al., 1994) although just the Gal4 DNA binding domain could displace nucleosomes in other contexts (Workman and Kingston, 1992; Morse, 1993). However again, binding competition at UASp2 in N-2, while not essential if binding to UASp1 was boosted by increasing its affinity or by PHO4 overexpression, did have a supportive role in PHO5 promoter chromatin remodeling for wild type UASp1 and PHO4 expression levels (Ertel et al., 2010).
Therefore, we find it plausible that the downregulation of nucleosome assembly implicated by our models could result from the competition between Pho4 binding to the promoter and nucleosome assembly at the promoter. This pertains only to the wild type version of the PHO5 promoter, with Pho4 binding to UASp elements, which we exclusively studied here. Impeding the assembly of N-2 by Pho4 binding at UASp2 could directly correspond to the downregulated N-2 assembly processes in our models 27,443 and 27,448 (Figure 4). Pho4 binding to both UASp2 and UASp1 may correspond to impaired global assembly in the other models.
The emphasis on regulation of nucleosome assembly rather than disassembly within our models thus suggests a new perspective on the effective dynamics of chromatin remodeling during promoter opening and calls for experimental assessment in future studies. These may address the recently revived debate about the role of binding competition in nucleosome remodeling.
Experimentally testable predictions
To further assess the validity of our satisfactory models, we suggest several lines of studies to investigate predictions regarding the nucleosome dynamics in the steady states as well as during chromatin opening and closing. Firstly, to obtain more information about the dynamics within the steady states, more Flag-/Myc-tagged histone exchange experiments would be most helpful. Measured Flag amount ratios between N-3 and N-2 or N-3 and N-1 and more time points for each ratio would allow further discrimination between our models. Six of our seven satisfactory models predict a similar Flag amount between N-3 and N-1 (Figure 3—figure supplement 1B), while the satisfactory models exhibit very different behavior for the ratio between N-3 and N-2 (Figure 3—figure supplement 1C). Additionally these measurements could in principle also be taken in the activated promoter state, where our remaining models also show diverse behavior (Figure 3—figure supplement 1D,E,F).
A second line of studies may investigate the opening and closing dynamics in the wild-type scenario in more detail. We argued that the experimentally observed faster closing than opening is consistent with regulation by assembly and inconsistent with regulation by disassembly (see 'Properties of satisfactory models - Bounds for chromatin opening and closing times’). The underlying reason for the faster closing, however, remains unclear. It might be due to faster nucleosome closing dynamics, as our models suggest, but possibly also due to faster signaling speed in closing and a delayed signaling in opening. To address this question and also obtain further detailed information we suggest a time series of configuration measurements for chromatin opening and closing. The measured distributions of configurations at different times can then be compared with our models’ predictions, especially the non-monotonic dynamics of certain configurations (Figure 5—figure supplement 6 and Figure 5—figure supplement 7). Prerequisite for these studies will be the generation of single molecule nucleosome configuration data as in Brown et al., 2013 at different time points of chromatin opening. It should be noted that such data are nowadays much easier to obtain than by the psoralen-TEM approach of Brown et al., 2013 due to the recent development of single molecule long-read sequencing of DNA methylation footprints (Shipony et al., 2020; Stergachis et al., 2020; Lee et al., 2020; Oberbeckmann et al., 2019).
Future applications of our newly established approach
In the following, we propose further applications of our modeling approach in studies with manipulations which possibly lead to dynamics diverging from the wild-type behavior. Indeed, a major outcome of our study is that our approach allows to derive which kind of effective dynamics underlie different chromatin states and the transition between states. This was so far hardly accessible as mostly only the occupancy at sites at certain conditions was determined and compared. It may well be that seemingly the same 'open PHO5 promoter’ as judged by chromatin accessibility in nuclease-based or by chromatin bound factors in chromatin immunoprecipitation assays does correspond to different configuration dynamics or was generated along different trajectories. While former studies concluded that the PHO5 promoter 'could still be opened’ despite certain manipulations, for example, lack of replication, lack of USAp2, lack of Snf2, Gcn5 or other chromatin cofactors, our approach may reveal that the remodeling pathways and initial or final chromatin states were affected and quite different nonetheless.
Manipulations that are likely to change the dynamics and the underlying biological processes give us no information on the wild type dynamics unless we already know the effect of the manipulation and are able to model it within our modeling approach (as we assume for instance for the sticky N-3 mutants in 'Integration of PHO5 promoter mutant data’). If the effect of the manipulation cannot be incorporated within our models, the resulting datasets cannot be used for a combined fit with the existing wild-type data. Nevertheless, manipulated promoter datasets can be fitted from scratch with our regulated on-off-slide models, if the needed data is obtained (configurations under repressed and activating conditions, Flag-/Myc-tagged histone exchange measurements and possibly also effects of further sticky mutations on configurations or occupancies). We then obtain a picture of the effective dynamics in the manipulated strains which then can be compared to the wild type. In this way, manipulations that earlier were found to also allow chromatin opening and thus were deemed unimportant, might still reveal different steady state configuration distributions and effective nucleosome dynamics.
A first manipulation study might employ Pho4 binding site mutations with possibly altered positions to affect the hypothesized binding competition, for example a ΔUASp2 PHO5 promoter mutant without intranucleosomal Pho4 site under PHO4 overexpression. In hindsight, even though PHO5 promoter opening by PHO4 overexpression in the absence of UASp2 led to the same open promoter state as judged by DNAseI indirect endlabeling and restriction enzyme accessibilities (Ertel et al., 2010), different effective nucleosome dynamics may underlie this mutant compared to the wild type promoter. If single molecule nucleosome configurations were available for this ΔUASp2 PHO5 promoter chromatin transition, our modeling approach could test this. Another approach is moving the intranucleosomal Pho4 site to the N-1 or N-3 nucleosome, either instead or in combination with the native site in the N-2 nucleosome to investigate the effects of the positions of the intranucleosomal Pho4 site on the regulated processes of the fitted models.
A second manipulation study might investigate remodeler deletion strains to shed light on the influence of remodeler actions on the effective nucleosome dynamics. Nucleosome movement in vivo is mediated by ATP dependent remodelers and histone modifying enzymes. Five different remodelers (SWI/SNF, RSC, INO80, Isw1, Chd1) (Barbaric et al., 2007; Musladin et al., 2014) and at least three histone modifiers (Gcn5, Rtt109, Set1) (Barbaric et al., 2001; Korber et al., 2006; Carvin and Kladde, 2004) are involved in opening PHO5 promoter chromatin. These cofactors are redundant, that is, single-deletion mutants are still inducible (Barbaric et al., 2007). However, comparing the effective nucleosome dynamics at the PHO5 promoter as determined by our approach in mutant backgrounds where one or several of these factors are missing should reveal different fluxes and net fluxes. Furthermore one could test if a lack of Gcn5, the main histone acetyltransferase that generates the acetylated lysine residues involved in recruiting SWI/SNF and RSC via their bromodomains, has a similar effect as removing these remodeling enzymes (Hassan et al., 2002; VanDemark et al., 2007).
A third manipulation study could explore the effective dynamics without the influence of replication and investigate the role of replication during PHO5 promoter opening. Induction via phosphate starvation or via the pho80 allele occurs during ongoing cell cycle with intermittent S phases where nucleosomes are globally disassembled and reassembled. Induction via phosphate starvation or via the pho80 allele occurs during the ongoing cell cycle with intermittent S phases which include global nucleosome disassembly and reassembly. It was shown that PHO5 promoter chromatin can be opened without replication in arrested cells (Schmid et al., 1992), but our approach can now assess if this changes the effective nucleosome configuration dynamics.
Clarification of effects of the sticky N-3 mutation
While we obtained and used the same two sticky N-3 mutant strains as published (Small et al., 2014), we did not use their published chromatin data. These were generated by an at that time novel single molecule DNA methylase footprinting approach and seemed less trustworthy for the following reasons. First, it was not clear if the DNA methylation reactions were saturated (for a detailed discussion see Oberbeckmann et al., 2019). Second, accessibility at the N-3 position in wild-type cells was lower (7%) in the activated compared to the repressed (28%) state, which is in contrast to chromatin opening upon activation and the data by Brown et al., 2013 with 55% accessibility at N-3 in the activated promoter state. Third, the authors did not detect any case where all three N-1 to N-3 nucleosomes were removed upon activation, although this configuration was among the most populated in the study by Brown et al., 2013. Both the second and third point may be due to incomplete methylation and/or to erroneous interpretation of methylation footprint patterns, as not only nucleosomes but also other factors like the transcription initiation machinery could obstruct methylation. Fourth, we found it hard to believe that the point mutations introduced in the sticky N-3 PHO5 promoter mutant versions would completely abolish chromatin opening not only at the N-3 but also at the N-2 nucleosome as claimed by the authors (Small et al., 2014).
Therefore, we rather employed the classical and well-documented restriction enzyme accessibility assay (Almer et al., 1986; Gregory et al., 1999) to monitor PHO5 chromatin opening in the sticky N-3 mutants. In this assay, both sticky N-3 mutants still showed considerable chromatin opening but we confirmed the general conclusion by Small et al., 2014 that opening of both the N-2 and N-3 nucleosomes was less extensive than for the wild type promoter. Even though the effect was less pronounced than claimed originally, it is remarkable how it substantiates earlier observations at the yeast PHO8 and PHO84 promoters (Wippo et al., 2009), which are co-regulated with the PHO5 promoter, about the role of underlying DNA sequence in stabilizing nucleosomes against remodeling. Recent in vitro experiments started to reveal how chromatin remodeling enzymes are regulated by nucleosomal DNA sequences (Lorch et al., 2014; Winger and Bowman, 2017; Krietenstein et al., 2016). The PHO5 promoter periodicity mutants pioneered by Small et al., 2014 may provide an impressive case how this is relevant in vivo.
Materials and methods
The maximum likelihood fit procedure (Figure 2D) was implemented in MATLAB and the source code is available at https://github.com/gerland-group/PHO5_on-off-slide_models.
Maximum likelihood fits
Depending on the stage of the analysis, we optimized the parameter values, that is, the rate values of the processes within a given model, , by maximizing the sum of log10 likelihood values: in stage 1, in stage 2 and in stage 3. Note that the optimal can differ between different stages. We ignored additive constants to the log likelihood, so that after including the next data set into the fit, a perfect agreement between model and the additional data set, already with the values from the previous stage, would lead to the same log likelihood value as before. In all stages we used the MATLAB fmincon function to find the parameter values that maximize the likelihood.
With the rate parameter notation introduced in Figure 2, we have for the example of Figure 3A:
| (1) |
Let be the transition rate matrix of the Markov process defined by the model for promoter state , where denotes the vector containing the regulated parameter value(s) of promoter state and all constitutive parameter values. A non-diagonal entry is the rate to go from configuration to configuration and is non-zero only for valid assembly, disassembly and sliding reactions and then given by the entry of which holds the parameter value of the process that governs this reaction in the given model. If sliding reactions are not governed by any sliding process within the model, their rate is set to zero. Diagonal entries are given by . In the example of Figure 3A, the transition rate matrix in the activated state is given by (with '' representing the diagonal entries)
| (2) |
The steady state distribution of is the solution of .
Then can be calculated using the multinomial distribution,
| (3) |
with being the number of observations of the corresponding promoter configurations (Figure 1—source data 1).
For each model, we used 100 different sets of initial parameter values to ensure a robust maximum. To calculate the steady state distribution of a given model for fixed parameter values, we used the state reduction algorithm (Sheskin, 1985; Grassmann et al., 1985; Shanbhag and Rao, 2003). Alternatively, the Matrix-Tree theorem can be used to find the steady state distributions of Markov processes (Wong and Gunawardena, 2020). We limited the range of parameter values to , with one being the rate value of the global assembly process for the activated state. A wider range of did not affect the results. In 3.6% of all models the 100 tries found at least two different maximal likelihood values, which were always extremely low. In 2.4% of all models, the found maximum likelihood parameter values were not unique. In both cases, none of these problematic models were among models with relatively high maximal likelihoods.
In stage 2, the sum of and is optimized. Assuming the experimental fold changes are normally distributed the log10 likelihood of a model to reproduce the new data up to an additive constant is given by
| (4) |
with and being mean and variance, respectively, of the measured accessibility fold changes in active state of sticky N-3 mutant at nucleosome site (two for N-2 and 3 for N-3), being the corresponding model fold change, and being the values of the rate prefactors of sticky mutant .
To obtain for each model, we calculated a modified transition rate matrix for each mutant using the non-diagonal part of the transition rate matrix and multiplied it component-wise with the matrix containing the prefactor values for the affected reactions for mutant (and one otherwise). Using the modified transition rate matrices, we calculated the mutant steady state distributions and finally the corresponding fold ratios of accessibilities at N-2 and N-3.
We used four prefactors per sticky N-3 mutant, one for each group of reactions, assembly at N-3, disassembly at N-3, sliding from N-3 to N-2 and from N-2 to N-3 (Figure 2—figure supplement 5), respectively, leading to . The off-diagonal part of is then given by
| (5) |
where the diagonal does not matter due the component-wise multiplication with the non-diagonal part of in order to obtain the non-diagonal part of the mutant rate transition matrices. Thus, depends only on . Note that the exact values of prefactors found during optimization depended on their initial condition, as their best values were often sloppy or not unique, but still resulted in the maximum likelihood.
For stage 3, has two contributions, one for each histone H3 exchange experiment:
| (6) |
Strictly speaking depends only on , since all the histone H3 exchange experiments were done in the repressed state. For the first contribution, to fit the data from Rufiange et al., 2007, we used
| (7) |
with and being the mean and variance, respectively, of the measured log2 ratios of Flag amounts at N-1 over N-2 (Flag-H3 MNase-ChIP in Rufiange et al., 2007, ratio values 0.591 and 0.483 for replicate 1 and 2, respectively) and the corresponding log2 ratio of the model (see Materials and methods section: H3 histone exchange model) for measurement time (not corrected for the lag time).
For the second contribution, let denote the measured normalized mean log2 ratios of Flag amount over Myc amount at N-1, with indicating the four different time points. We obtained from Dion et al., 2007 as follows: we recalculated the normalization constant of each time point using the measured mean log2 Myc/Flag signal ratios as described (supplementary material of Dion et al., 2007 using the whole-genome commercial microarrays (Agilent) data with the nucleosome pool parameters as in the section above) and then took the normalized results of the probe at the N-1 position of the PHO5 promoter (chr2:431049–431108). Unfortunately, neighboring probes were only in linker regions between promoter nucleosome positions. As mentioned in Dion et al., 2007 and corroborated by our own calculations, the values have large uncertainties, mostly due to an additive sloppy global normalization constant leading to systematic errors, while the differences between time points were determined with reasonable accuracy. Thus, we decided to fit the measured values only after a transformation that eliminates the sloppy global normalization constant by choosing the average over the four time points as a reference: . Let be the resulting covariance matrix after this linear transformation, assuming an independent estimated experimental standard deviation of 0.4 before the transformation. This estimate was informed by the standard deviation of the Rufiange et al., 2007 data as well as from perturbations of the nucleosome pool parameters when recalculating the normalization constants. The corresponding normalized values of the model are denoted by , calculated from the log2 ratios of Flag amount over Myc amount at N-1, (see Materials and methods section: H3 histone exchange model), using the same transformation, with denoting the measurement time points. Since the four measurements at different time points were linearly mapped to always have an average of zero, the estimated density follows a degenerate multivariate normal distribution with the covariance matrix . Thus the log10 likelihood can be calculated with
| (8) |
where is the Moore-Penrose inverse (pseudoinverse) of .
H3 histone exchange model
To obtain the Flag and Myc amounts in a given model with given parameter values and then determine and , we used the histone pool and nucleosome turnover models in Dion et al., 2007 and assumed that the Myc H3 and Flag H3 amounts in the histone pool are given by and
| (9) |
where we used the production rates , , the degradation rates , and the lag time which were fitted in Dion et al., 2007. For , the probability that a newly assembled nucleosome contains a Flag H3 is given by
| (10) |
In Dion et al., 2007, the conditional probability that a given nucleosome at site l at time t contains a Flag H3 then fulfills the ordinary differential equation
| (11) |
with being an effective turnover rate at probe position . In our case, the dynamics of the three promoter nucleosomes are coupled, determined by the transition rate matrix of a given regulated on-off-slide model. At this stage, we included different nucleosome types (i.e. Flag and Myc) into the model, replacing the eight promoter configurations by all 27 possibilities to arrange no, a Flag or a Myc nucleosome at each of the three sites. Based on and , we define an extended Flag/Myc transition rate matrix . Each ‘new’ assembly reaction rate in is given by the corresponding ‘old’ assembly rate in times either or , for a new Flag or Myc nucleosome, respectively. To find the corresponding ‘old’ reaction any extended Flag/Myc configuration is projected to one of the eight normal nucleosome configurations simply by ignoring the Flag/Myc tag information. For example, denoting Flag- and Myc-tagged nucleosomes with ‘F’ and ‘M’, respectively, an assembly reaction from the state (F, M, 0) to the state (F, M, M) in the extended model corresponds to an assembly reaction from state (1, 1, 0) to the state (1, 1, 1) in the normal model, and its reaction rate is multiplied by in the extended model, since the new nucleosome is Myc-tagged. The rates of sliding and disassembly of Flag or Myc nucleosomes are assumed to be equal to the corresponding normal sliding and disassembly rates. The probability of extended configuration at time is the -th entry of , the solution of
| (12) |
where is fixed in the repressed state, in which all histone exchange experiments took place. The log2 ratios of Flag at N-1 over Flag at N-2 amount, , and Flag over Myc amounts at N-1, , of each model then correspond to log2 ratios of sums of over suitable configurations with Flag or Myc nucleosomes at the wanted sites.
Sensitivity analysis
In order to determine how sloppy the found best parameter values for a given model are, we performed a simple sensitivity analysis, by calculating the log10 likelihood along certain directions from the best fit point in logarithmic parameter space. We found that an approximation of the real likelihood function by a second-order Taylor expansion at the best fit point worked only in a small area, as expected in a highly non-linear setting, but too small to determine parameter sloppiness properly.
As a compromise between properly scanning the parameter space and computational feasibility, we chose a small number of test directions: each fitted parameter value individually, the eigenvectors of the numerical Hessian of the likelihood function at the best fit, as well as the numerical gradient, which can be non-zero if the best fit point lies on the boundary. We ignored the boundary during the sensitivity analysis, to also take into account sloppiness that 'reaches over’ the boundary. Along these directions, we tested in exponentially increasing steps from the best fit position which positions in parameter space lead to a decrease of the likelihood by , that is, a log10 likelihood ratio change of , which is of similar order as the log10 likelihood differences within our group of satisfactory models. We then obtained 'error bars’ for each parameter by taking the largest deviation of the log10 parameter value at the 50% likelihood level from the best value found in all tested directions (Figure 4—source data 1 and Figure 4—source data 2).
Effective chromatin opening and closing rates
The effective trajectory in time of the regulated process rate from the value of the repressed state to the value of the activated state depends on how fast the cell senses the phosphate starvation and subsequent signal processes. To obtain a reasonable upper bound for the chromatin opening rate, we assumed the regulation happens instantaneously, that is, the activated rate value of the regulated processes applies immediately at the change of the medium for a population in repressed state. Then the promoter configuration distribution decays exponentially toward the activated steady state with a rate well approximated by the negative eigenvalue of the transition rate matrix closest (but not equal) to zero, taking into account the fitted time scale. This ‘effective chromatin opening rate’ is an upper bound of how fast a given model can switch to the activated state. Conversely, we did the same calculations for the ‘effective chromatin closing rate’, which is an upper bound of how fast a given model can switch to the repressed state.
Sticky N-3 experiments
Strains 'sticky N-3 mutant 1’ and 'sticky N-3 mutant 2’ used for restriction enzyme accessibility assays were generated by transformation of linear fragments of plasmids ECS53 and ECS56, respectively, into the wild type strain BY4741 as described for the 'periodicity mutants’ in Small et al., 2014. For the sticky N-3 mutant 1, the sequence GTTTTCTCATGTAAGCGGACGTCGTC inside the PHO5 promoter was replaced with GTTTTCTTATGTAAGCTTACGTCGTC. For sticky N-3 mutant 2, GCGCAAATATGTCAACGTATTTGGAAG was replaced with GCGCAAATATGTCAAAGTATTTGGAAG. Strains were grown in YPDA medium to logarithmic phase for repressive (+Pi) and shifted from logarithmic phase to phosphate-free YNB medium (Formedia) over night for inducing (-Pi) conditions. Nuclei preparation, restriction enzyme digestion, DNA purification, secondary digest, agarose gel electrophoresis, Southern blotting, hybridization, and Phosphorimager analysis were as in Musladin et al., 2014. Secondary digest was with HaeIII for both ClaI and HhaI digests probing N-2 or N-3, respectively. The probe for both ClaI and HhaI digests corresponded to the ApaI-BamHI restriction fragment upstream of N-3.
Acknowledgements
We thank Eliza Small (Northwestern University Feinberg School of Medicine, Chicago, USA) for providing the plasmids ECS53 and ECS56. Furthermore we thank Oliver J Rando and his group for providing the fitted nucleosome pool parameters used in Dion et al., 2007 and Amine Nourani and his group for providing the Flag-H3 MNase-ChIP values for the N-1 and N-2 sites of the two replicates in Rufiange et al., 2007. MRW is a member of the Graduate School of Quantitative Biosciences Munich (QBM).
Funding Statement
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Contributor Information
Philipp Korber, Email: pkorber@lmu.de.
Ulrich Gerland, Email: gerland@tum.de.
Naama Barkai, Weizmann Institute of Science, Israel.
Naama Barkai, Weizmann Institute of Science, Israel.
Funding Information
This paper was supported by the following grants:
Deutsche Forschungsgemeinschaft SFB863 to Ulrich Gerland.
Deutsche Forschungsgemeinschaft SFB1064 to Philipp Korber.
Additional information
Competing interests
No competing interests declared.
Author contributions
Conceptualization, Software, Formal analysis, Validation, Investigation, Visualization, Methodology, Writing - original draft, Writing - review and editing.
Validation, Investigation.
Conceptualization, Resources, Supervision, Funding acquisition, Validation, Investigation, Methodology, Writing - review and editing.
Conceptualization, Resources, Supervision, Funding acquisition, Methodology, Project administration, Writing - review and editing.
Additional files
Data availability
All data generated or analysed during this study are included in the manuscript and supporting files. Source data files have been provided for Figure 1, Table 1 and Figure 4. Program code has been uploaded to github (see Materials and methods).
The following previously published datasets were used:
Dion MF, Kaplan T, Kim M, Buratowski S, Friedman N, Rando OJ. 2007. Dynamics of Replication-Independent Histone Turnover in Budding Yeast. NCBI Gene Expression Omnibus. GSE6666
Rufiange A, Jacques PÉ, Bhat W, Robert F, Nourani A. 2007. Genome-Wide Replication-Independent Histone H3 Exchange Occurs Predominantly at Promoters and Implicates H3 K56 Acetylation and Asf1. NCBI Gene Expression Omnibus. GSE8299
References
- Almer A, Rudolph H, Hinnen A, Hörz W. Removal of positioned nucleosomes from the yeast PHO5 promoter upon PHO5 induction releases additional upstream activating DNA elements. The EMBO Journal. 1986;5:2689–2696. doi: 10.1002/j.1460-2075.1986.tb04552.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Almer A, Hörz W. Nuclease hypersensitive regions with adjacent positioned nucleosomes mark the gene boundaries of the PHO5/PHO3 locus in yeast. The EMBO Journal. 1986;5:2681–2687. doi: 10.1002/j.1460-2075.1986.tb04551.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Barbarić S, Fascher KD, Hörz W. Activation of the weakly regulated PHO8 promoter in S. cerevisiae: chromatin transition and binding sites for the positive regulatory protein PHO4. Nucleic Acids Research. 1992;20:1031–1038. doi: 10.1093/nar/20.5.1031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Barbaric S, Walker J, Schmid A, Svejstrup JQ, Hörz W. Increasing the rate of chromatin remodeling and gene activation--a novel role for the histone acetyltransferase Gcn5. The EMBO Journal. 2001;20:4944–4951. doi: 10.1093/emboj/20.17.4944. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Barbaric S, Reinke H, Hörz W. Multiple mechanistically distinct functions of SAGA at the PHO5 promoter. Molecular and Cellular Biology. 2003;23:3468–3476. doi: 10.1128/MCB.23.10.3468-3476.2003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Barbaric S, Luckenbach T, Schmid A, Blaschke D, Hörz W, Korber P. Redundancy of chromatin remodeling pathways for the induction of the yeast PHO5 promoter in vivo. Journal of Biological Chemistry. 2007;282:27610–27621. doi: 10.1074/jbc.M700623200. [DOI] [PubMed] [Google Scholar]
- Bartholomew B. Regulating the chromatin landscape: structural and mechanistic perspectives. Annual Review of Biochemistry. 2014;83:671–696. doi: 10.1146/annurev-biochem-051810-093157. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Becker PB, Hörz W. ATP-dependent nucleosome remodeling. Annual Review of Biochemistry. 2002;71:247–273. doi: 10.1146/annurev.biochem.71.110601.135400. [DOI] [PubMed] [Google Scholar]
- Bell O, Tiwari VK, Thomä NH, Schübeler D. Determinants and dynamics of genome accessibility. Nature Reviews Genetics. 2011;12:554–564. doi: 10.1038/nrg3017. [DOI] [PubMed] [Google Scholar]
- Blasi T, Feller C, Feigelman J, Hasenauer J, Imhof A, Theis FJ, Becker PB, Marr C. Combinatorial histone acetylation patterns are generated by Motif-Specific reactions. Cell Systems. 2016;2:49–58. doi: 10.1016/j.cels.2016.01.002. [DOI] [PubMed] [Google Scholar]
- Brogaard K, Xi L, Wang JP, Widom J. A map of nucleosome positions in yeast at base-pair resolution. Nature. 2012;486:496–501. doi: 10.1038/nature11142. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brown CR, Mao C, Falkovskaia E, Jurica MS, Boeger H. Linking stochastic fluctuations in chromatin structure and gene expression. PLOS Biology. 2013;11:e1001621. doi: 10.1371/journal.pbio.1001621. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brown CR, Boeger H. Nucleosomal promoter variation generates gene expression noise. PNAS. 2014;111:17893–17898. doi: 10.1073/pnas.1417527111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carvin CD, Kladde MP. Effectors of lysine 4 methylation of histone H3 in Saccharomyces cerevisiae are negative regulators of PHO5 and GAL1-10. Journal of Biological Chemistry. 2004;279:33057–33062. doi: 10.1074/jbc.M405033200. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chang HW, Pandey M, Kulaeva OI, Patel SS, Studitsky VM. Overcoming a nucleosomal barrier to replication. Science Advances. 2016;2:e1601865. doi: 10.1126/sciadv.1601865. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Clapier CR, Iwasa J, Cairns BR, Peterson CL. Mechanisms of action and regulation of ATP-dependent chromatin-remodelling complexes. Nature Reviews Molecular Cell Biology. 2017;18:407–422. doi: 10.1038/nrm.2017.26. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cosma MP, Tanaka T, Nasmyth K. Ordered recruitment of transcription and chromatin remodeling factors to a cell cycle- and developmentally regulated promoter. Cell. 1999;97:299–311. doi: 10.1016/S0092-8674(00)80740-0. [DOI] [PubMed] [Google Scholar]
- Deroo BJ, Archer TK. Glucocorticoid receptor-mediated chromatin remodeling in vivo. Oncogene. 2001;20:3039–3046. doi: 10.1038/sj.onc.1204328. [DOI] [PubMed] [Google Scholar]
- Dhasarathy A, Kladde MP. Promoter occupancy is a major determinant of chromatin remodeling enzyme requirements. Molecular and Cellular Biology. 2005;25:2698–2707. doi: 10.1128/MCB.25.7.2698-2707.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dion MF, Kaplan T, Kim M, Buratowski S, Friedman N, Rando OJ. Dynamics of replication-independent histone turnover in budding yeast. Science. 2007;315:1405–1408. doi: 10.1126/science.1134053. [DOI] [PubMed] [Google Scholar]
- Donovan BT, Chen H, Jipa C, Bai L, Poirier MG. Dissociation rate compensation mechanism for budding yeast pioneer transcription factors. eLife. 2019;8:e43008. doi: 10.7554/eLife.43008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ertel F, Dirac-Svejstrup AB, Hertel CB, Blaschke D, Svejstrup JQ, Korber P. In vitro reconstitution of PHO5 promoter chromatin remodeling points to a role for activator-nucleosome competition in vivo. Molecular and Cellular Biology. 2010;30:4060–4076. doi: 10.1128/MCB.01399-09. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fascher KD, Schmitz J, Hörz W. Structural and functional requirements for the chromatin transition at the PHO5 promoter in Saccharomyces cerevisiae upon PHO5 activation. Journal of Molecular Biology. 1993;231:658–667. doi: 10.1006/jmbi.1993.1317. [DOI] [PubMed] [Google Scholar]
- Grassmann WK, Taksar MI, Heyman DP. Regenerative analysis and steady state distributions for markov chains. Operations Research. 1985;33:1107–1116. doi: 10.1287/opre.33.5.1107. [DOI] [Google Scholar]
- Gregory PD, Barbaric S, Hörz W. Restriction nucleases as probes for chromatin structure. Methods in Molecular Biology. 1999;119:417–425. doi: 10.1385/1-59259-681-9:417. [DOI] [PubMed] [Google Scholar]
- Hamiche A, Sandaltzopoulos R, Gdula DA, Wu C. ATP-dependent histone octamer sliding mediated by the chromatin remodeling complex NURF. Cell. 1999;97:833–842. doi: 10.1016/S0092-8674(00)80796-5. [DOI] [PubMed] [Google Scholar]
- Hassan AH, Neely KE, Workman JL. Histone acetyltransferase complexes stabilize swi/snf binding to promoter nucleosomes. Cell. 2001;104:817–827. doi: 10.1016/S0092-8674(01)00279-3. [DOI] [PubMed] [Google Scholar]
- Hassan AH, Prochasson P, Neely KE, Galasinski SC, Chandy M, Carrozza MJ, Workman JL. Function and selectivity of bromodomains in anchoring chromatin-modifying complexes to promoter nucleosomes. Cell. 2002;111:369–379. doi: 10.1016/S0092-8674(02)01005-X. [DOI] [PubMed] [Google Scholar]
- Hauer MH, Gasser SM. Chromatin and nucleosome dynamics in DNA damage and repair. Genes & Development. 2017;31:2204–2221. doi: 10.1101/gad.307702.117. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Haushalter KA, Kadonaga JT. Chromatin assembly by DNA-translocating motors. Nature Reviews Molecular Cell Biology. 2003;4:613–620. doi: 10.1038/nrm1177. [DOI] [PubMed] [Google Scholar]
- Iwafuchi M, Cuesta I, Donahue G, Takenaka N, Osipovich AB, Magnuson MA, Roder H, Seeholzer SH, Santisteban P, Zaret KS. Gene network transitions in embryos depend upon interactions between a pioneer transcription factor and core histones. Nature Genetics. 2020;52:418–427. doi: 10.1038/s41588-020-0591-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Johnson TA, Elbi C, Parekh BS, Hager GL, John S. Chromatin remodeling complexes interact dynamically with a glucocorticoid receptor-regulated promoter. Molecular Biology of the Cell. 2008;19:3308–3322. doi: 10.1091/mbc.e08-02-0123. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kharerin H, Bhat PJ, Marko JF, Padinhateeri R. Role of transcription factor-mediated nucleosome disassembly in PHO5 gene expression. Scientific Reports. 2016;6:20319. doi: 10.1038/srep20319. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Komeili A, O'Shea EK. Roles of phosphorylation sites in regulating activity of the transcription factor Pho4. Science. 1999;284:977–980. doi: 10.1126/science.284.5416.977. [DOI] [PubMed] [Google Scholar]
- Korber P, Barbaric S, Luckenbach T, Schmid A, Schermer UJ, Blaschke D, Hörz W. The histone chaperone Asf1 increases the rate of histone eviction at the yeast PHO5 and PHO8 promoters. Journal of Biological Chemistry. 2006;281:5539–5545. doi: 10.1074/jbc.M513340200. [DOI] [PubMed] [Google Scholar]
- Korber P, Barbaric S. The yeast PHO5 promoter: from single locus to systems biology of a paradigm for gene regulation through chromatin. Nucleic Acids Research. 2014;42:10888–10902. doi: 10.1093/nar/gku784. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kowenz-Leutz E, Leutz A. A C/EBP beta isoform recruits the SWI/SNF complex to activate myeloid genes. Molecular Cell. 1999;4:735–743. doi: 10.1016/S1097-2765(00)80384-6. [DOI] [PubMed] [Google Scholar]
- Krietenstein N, Wal M, Watanabe S, Park B, Peterson CL, Pugh BF, Korber P. Genomic nucleosome organization reconstituted with pure proteins. Cell. 2016;167:709–721. doi: 10.1016/j.cell.2016.09.045. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lai WKM, Pugh BF. Understanding nucleosome dynamics and their links to gene expression and DNA replication. Nature Reviews. Molecular Cell Biology. 2017;18:548–562. doi: 10.1038/nrm.2017.47. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Längst G, Bonte EJ, Corona DF, Becker PB. Nucleosome movement by CHRAC and ISWI without disruption or trans-displacement of the histone octamer. Cell. 1999;97:843–852. doi: 10.1016/S0092-8674(00)80797-7. [DOI] [PubMed] [Google Scholar]
- Lee I, Razaghi R, Gilpatrick T, Molnar M, Gershman A, Sadowski N, Sedlazeck FJ, Hansen KD, Simpson JT, Timp W. Simultaneous profiling of chromatin accessibility and methylation on human cell lines with nanopore sequencing. Nature Methods. 2020;17:1191–1199. doi: 10.1038/s41592-020-01000-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lieleg C, Krietenstein N, Walker M, Korber P. Nucleosome positioning in yeasts: methods, maps, and mechanisms. Chromosoma. 2015;124:131–151. doi: 10.1007/s00412-014-0501-x. [DOI] [PubMed] [Google Scholar]
- Lorch Y, Zhang M, Kornberg RD. Histone octamer transfer by a chromatin-remodeling complex. Cell. 1999;96:389–392. doi: 10.1016/S0092-8674(00)80551-6. [DOI] [PubMed] [Google Scholar]
- Lorch Y, Maier-Davis B, Kornberg RD. Role of DNA sequence in chromatin remodeling and the formation of nucleosome-free regions. Genes & Development. 2014;28:2492–2497. doi: 10.1101/gad.250704.114. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Luger K, Mäder AW, Richmond RK, Sargent DF, Richmond TJ. Crystal structure of the nucleosome core particle at 2.8 A resolution. Nature. 1997;389:251–260. doi: 10.1038/38444. [DOI] [PubMed] [Google Scholar]
- Morse RH. Nucleosome disruption by transcription factor binding in yeast. Science. 1993;262:1563–1566. doi: 10.1126/science.8248805. [DOI] [PubMed] [Google Scholar]
- Musladin S, Krietenstein N, Korber P, Barbaric S. The RSC chromatin remodeling complex has a crucial role in the complete remodeler set for yeast PHO5 promoter opening. Nucleic Acids Research. 2014;42:4270–4282. doi: 10.1093/nar/gkt1395. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Narlikar GJ, Fan HY, Kingston RE. Cooperation between complexes that regulate chromatin structure and transcription. Cell. 2002;108:475–487. doi: 10.1016/S0092-8674(02)00654-2. [DOI] [PubMed] [Google Scholar]
- Natarajan K, Jackson BM, Zhou H, Winston F, Hinnebusch AG. Transcriptional activation by Gcn4p involves independent interactions with the SWI/SNF complex and the SRB/mediator. Molecular Cell. 1999;4:657–664. doi: 10.1016/S1097-2765(00)80217-8. [DOI] [PubMed] [Google Scholar]
- Neely KE, Hassan AH, Wallberg AE, Steger DJ, Cairns BR, Wright AP, Workman JL. Activation domain-mediated targeting of the SWI/SNF complex to promoters stimulates transcription from nucleosome arrays. Molecular Cell. 1999;4:649–655. doi: 10.1016/S1097-2765(00)80216-6. [DOI] [PubMed] [Google Scholar]
- O'Neill EM, Kaffman A, Jolly ER, O'Shea EK. Regulation of PHO4 nuclear localization by the PHO80-PHO85 cyclin-CDK complex. Science. 1996;271:209–212. doi: 10.1126/science.271.5246.209. [DOI] [PubMed] [Google Scholar]
- Oberbeckmann E, Wolff M, Krietenstein N, Heron M, Ellins JL, Schmid A, Krebs S, Blum H, Gerland U, Korber P. Absolute nucleosome occupancy map for the Saccharomyces cerevisiae genome. Genome Research. 2019;29:1996–2009. doi: 10.1101/gr.253419.119. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rajkumar AS, Dénervaud N, Maerkl SJ. Mapping the fine structure of a eukaryotic promoter input-output function. Nature Genetics. 2013;45:1207–1215. doi: 10.1038/ng.2729. [DOI] [PubMed] [Google Scholar]
- Rufiange A, Jacques PE, Bhat W, Robert F, Nourani A. Genome-wide replication-independent histone H3 exchange occurs predominantly at promoters and implicates H3 K56 acetylation and Asf1. Molecular Cell. 2007;27:393–405. doi: 10.1016/j.molcel.2007.07.011. [DOI] [PubMed] [Google Scholar]
- Satchwell SC, Drew HR, Travers AA. Sequence periodicities in chicken nucleosome core DNA. Journal of Molecular Biology. 1986;191:659–675. doi: 10.1016/0022-2836(86)90452-3. [DOI] [PubMed] [Google Scholar]
- Schermer UJ, Korber P, Hörz W. Histones are incorporated in trans during reassembly of the yeast PHO5 promoter. Molecular Cell. 2005;19:279–285. doi: 10.1016/j.molcel.2005.05.028. [DOI] [PubMed] [Google Scholar]
- Schmid A, Fascher KD, Hörz W. Nucleosome disruption at the yeast PHO5 promoter upon PHO5 induction occurs in the absence of DNA replication. Cell. 1992;71:853–864. doi: 10.1016/0092-8674(92)90560-Y. [DOI] [PubMed] [Google Scholar]
- Shanbhag DN, Rao CR. Stochastic Processes: Modelling and Simulation. In: Shanbhag D. N, editor. Handbook of Statistics. Elsevier; 2003. pp. 1–1000. [Google Scholar]
- Sheskin TJ. Technical Note—A Markov Chain Partitioning Algorithm for Computing Steady State Probabilities. Operations Research. 1985;33:228–235. doi: 10.1287/opre.33.1.228. [DOI] [Google Scholar]
- Shipony Z, Marinov GK, Swaffer MP, Sinnott-Armstrong NA, Skotheim JM, Kundaje A, Greenleaf WJ. Long-range single-molecule mapping of chromatin accessibility in eukaryotes. Nature Methods. 2020;17:319–327. doi: 10.1038/s41592-019-0730-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Small EC, Xi L, Wang JP, Widom J, Licht JD. Single-cell nucleosome mapping reveals the molecular basis of gene expression heterogeneity. PNAS. 2014;111:E2462–E2471. doi: 10.1073/pnas.1400517111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stergachis AB, Debo BM, Haugen E, Churchman LS, Stamatoyannopoulos JA. Single-molecule regulatory architectures captured by chromatin fiber sequencing. Science. 2020;368:1449–1454. doi: 10.1126/science.aaz1646. [DOI] [PubMed] [Google Scholar]
- Sudarsanam P, Winston F. The swi/Snf family nucleosome-remodeling complexes and transcriptional control. Trends in Genetics : TIG. 2000;16:345–351. doi: 10.1016/s0168-9525(00)02060-6. [DOI] [PubMed] [Google Scholar]
- Svaren J, Schmitz J, Hörz W. The transactivation domain of Pho4 is required for nucleosome disruption at the PHO5 promoter. The EMBO Journal. 1994;13:4856–4862. doi: 10.1002/j.1460-2075.1994.tb06812.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tsukiyama T, Becker PB, Wu C. ATP-dependent nucleosome disruption at a heat-shock promoter mediated by binding of GAGA transcription factor. Nature. 1994;367:525–532. doi: 10.1038/367525a0. [DOI] [PubMed] [Google Scholar]
- VanDemark AP, Kasten MM, Ferris E, Heroux A, Hill CP, Cairns BR. Autoregulation of the rsc4 tandem bromodomain by gcn5 acetylation. Molecular Cell. 2007;27:817–828. doi: 10.1016/j.molcel.2007.08.018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Venter U, Svaren J, Schmitz J, Schmid A, Hörz W. A nucleosome precludes binding of the transcription factor Pho4 in vivo to a critical target site in the PHO5 promoter. The EMBO Journal. 1994;13:4848–4855. doi: 10.1002/j.1460-2075.1994.tb06811.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vignali M, Hassan AH, Neely KE, Workman JL. ATP-dependent chromatin-remodeling complexes. Molecular and Cellular Biology. 2000;20:1899–1910. doi: 10.1128/MCB.20.6.1899-1910.2000. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Whitehouse I, Rando OJ, Delrow J, Tsukiyama T. Chromatin remodelling at promoters suppresses antisense transcription. Nature. 2007;450:1031–1035. doi: 10.1038/nature06391. [DOI] [PubMed] [Google Scholar]
- Winger J, Bowman GD. The sequence of nucleosomal DNA modulates sliding by the Chd1 chromatin remodeler. Journal of Molecular Biology. 2017;429:808–822. doi: 10.1016/j.jmb.2017.02.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wippo CJ, Krstulovic BS, Ertel F, Musladin S, Blaschke D, Stürzl S, Yuan GC, Hörz W, Korber P, Barbaric S. Differential cofactor requirements for histone eviction from two nucleosomes at the yeast PHO84 promoter are determined by intrinsic nucleosome stability. Molecular and Cellular Biology. 2009;29:2960–2981. doi: 10.1128/MCB.01054-08. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wong F, Gunawardena J. Gene regulation in and out of equilibrium. Annual Review of Biophysics. 2020;49:199–226. doi: 10.1146/annurev-biophys-121219-081542. [DOI] [PubMed] [Google Scholar]
- Workman JL. Nucleosome displacement in transcription. Genes & Development. 2006;20:2009–2017. doi: 10.1101/gad.1435706. [DOI] [PubMed] [Google Scholar]
- Workman JL, Kingston RE. Nucleosome core displacement in vitro via a metastable transcription factor-nucleosome complex. Science. 1992;258:1780–1784. doi: 10.1126/science.1465613. [DOI] [PubMed] [Google Scholar]
- Yan C, Chen H, Bai L. Systematic study of Nucleosome-Displacing factors in budding yeast. Molecular Cell. 2018;71:294–305. doi: 10.1016/j.molcel.2018.06.017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yudkovsky N, Logie C, Hahn S, Peterson CL. Recruitment of the SWI/SNF chromatin remodeling complex by transcriptional activators. Genes & Development. 1999;13:2369–2374. doi: 10.1101/gad.13.18.2369. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang Y, Smith CL, Saha A, Grill SW, Mihardja S, Smith SB, Cairns BR, Peterson CL, Bustamante C. DNA translocation and loop formation mechanism of chromatin remodeling by SWI/SNF and RSC. Molecular Cell. 2006;24:559–568. doi: 10.1016/j.molcel.2006.10.025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhou CY, Johnson SL, Gamarra NI, Narlikar GJ. Mechanisms of ATP-Dependent chromatin remodeling motors. Annual Review of Biophysics. 2016;45:153–181. doi: 10.1146/annurev-biophys-051013-022819. [DOI] [PMC free article] [PubMed] [Google Scholar]