

Abstract
Recent Transformer-based contextual word representations, including BERT and XLNet, have shown state-of-the-art performance in multiple disciplines within NLP. Fine-tuning the trained contextual models on task-specific datasets has been the key to achieving superior performance downstream. While fine-tuning these pre-trained models is straight-forward for lexical applications (applications with only language modality), it is not trivial for multimodal language (a growing area in NLP focused on modeling face-to-face communication). Pre-trained models don’t have the necessary components to accept two extra modalities of vision and acoustic. In this paper, we proposed an attachment to BERT and XLNet called Multimodal Adaptation Gate (MAG). MAG allows BERT and XLNet to accept multimodal nonverbal data during fine-tuning. It does so by generating a shift to internal representation of BERT and XLNet; a shift that is conditioned on the visual and acoustic modalities. In our experiments, we study the commonly used CMU-MOSI and CMU-MOSEI datasets for multimodal sentiment analysis. Fine-tuning MAG-BERT and MAG-XLNet significantly boosts the sentiment analysis performance over previous baselines as well as language-only fine-tuning of BERT and XLNet. On the CMU-MOSI dataset, MAG-XLNet achieves human-level multimodal sentiment analysis performance for the first time in the NLP community.
1. Introduction
Human face-to-face communication flows as a seamless integration of language, acoustic, and vision modalities. In ordinary everyday interactions, we utilize all these modalities jointly to convey our intentions and emotions. Understanding this face-to-face communication falls within an increasingly growing NLP research area called multimodal language analysis (Zadeh et al., 2018b). The biggest challenge in this area is to efficiently model the three pillars of communication together. This gives artificial intelligence systems the capability to comprehend the multi-sensory information without disregarding nonverbal factors. In many applications such as dialogue systems and virtual reality, this capability is crucial to maintain the high quality of user interaction.
The recent success of contextual word representations in NLP is largely credited to new Transformer-based (Vaswani et al., 2017) models such as BERT (Devlin et al., 2018) and XLNet (Yang et al., 2019). These Transformer-based models have shown performance improvement across downstream tasks (Devlin et al., 2018). However, their true downstream potential comes from fine-tuning their pre-trained models for particular tasks (Devlin et al., 2018). This is often done easily for lexical datasets which exhibit language modality only. However, this fine-tuning for multimodal language is neither trivial nor yet studied; simply because both BERT and XLNet only expect linguistic input. Therefore, in applying BERT and XLNet to multimodal language, one must either(a) forfeit the nonverbal information and fine-tune for language, or (b) simply extract word representations and proceed to use a state-of-the-art model for multimodal studies.
In this paper, we present a successful framework for fine-tuning BERT and XLNet for multimodal input. Our framework allows the BERT and XLNet core structures to remain intact, and only attaches a carefully designed Multimodal Adaptation Gate (MAG) to the models. Using an attention conditioned on the nonverbal behaviors, MAG essentially maps the informative visual and acoustic factors to a vector with a trajectory and magnitude. During fine-tuning, this adaptation vector modifies the internal state of the BERT and XLNet, allowing the models to seamlessly adapt to the multimodal input. In our experiments we use the CMU-MOSI (Zadeh et al., 2016) and CMU-MOSEI (Zadeh et al., 2018d) datasets of multimodal language, with a specific focus on the core NLP task of multimodal sentiment analysis. We compare the performance of MAG-BERT and MAG-XLNet to the above (a) and (b) scenarios in both classification and regression sentiment analysis. Our findings demonstrate that fine-tuning these advanced pre-trained Transformers using MAG yields consistent improvement, even though BERT and XLNet were never trained on multimodal data.
The contributions of this paper are therefore summarized as:
We propose an efficient framework for fine-tuning BERT and XLNet for multimodal language data. This framework uses a component called Multimodal Adaptation Gate (MAG) that introduces minimal overhead to both the models.
MAG-BERT and MAG-XLNet set new state of the art in both CMU-MOSI and CMU-MOSEI datasets, when compared to scenarios(a) and (b). For CMU-MOSI, MAG-XLNet achieves performance on par with reported human performance.
2. Related Works
The studies in this paper are related to the following research areas:
2.1. Multimodal Language Analyses
Multimodal language analyses is a recent research trend in natural language processing (Zadeh et al., 2018b) that helps us understand language from the modalities of text, vision and acoustic. These analyses have particularly focused on the tasks of sentiment analysis (Poria et al., 2018), emotion recognition (Zadeh et al., 2018d), and personality traits recognition (Park et al., 2014). Works in this area often focus on novel multimodal neural architectures (Pham et al., 2019; Hazarika et al., 2018) and multimodal fusion approaches (Liang et al., 2018; Tsai et al., 2018).
Related to content in this paper, we discuss some of the models in this domain including TFN, MARN, MFN, RMFN and MulT. Tensor Fusion Network (TFN) (Zadeh et al., 2017) creates a multi-dimensional tensor to explicitly capture all possible interactions between the three modalities: unimodal, bimodal and trimodal. Multi-attention Recurrent Network (MARN) (Zadeh et al., 2018c) uses three separate hybrid LSTM memories that have the ability to propagate the cross-modal interactions. Memory Fusion Network (Zadeh et al., 2018a) synchronizes the information from three separate LSTMs through a multi-view gated memory. Recurrent Memory Fusion Network (RMFN) (Liang et al., 2018) captures the nuanced interactions among the modalities in a multi-stage manner, giving each stage the ability to focus on a subset of signals. Multimodal Transformer for Unaligned Multimodal Language Sequences (MulT) (Tsai et al., 2019) deploys three Transformers – each for one modality – to capture the interactions with the other two modalities in a self-attentive manner. The information from the three Transformers are aggregated through late-fusion.
2.2. Pre-trained Language Representations
Learning word representations from large corpora has been an active research area in NLP community (Mikolov et al., 2013; Pennington et al., 2014). Glove (Pennington et al., 2014) and Word2Vec (Mikolov et al., 2013) contributed to advancing the state-of-the-art of many NLP tasks. A major setback of these word representations is their non-contextual nature. Recently, contextual language representation models trained on large text corpora have achieved state of the art results on several NLP tasks including question answering, sentiment classification, part-of-speech (POS) tagging and similarity modeling (Peters et al., 2018; Devlin et al., 2018). The first two notable contextual representation based models were ELMO (Peters et al., 2018) and GPT (Radford et al., 2018). However, they only captured unidirectional context and therefore, missed more nuanced interactions among words of a sentence. BERT (Bidirectional Encoder Representations from Transformers) (Devlin et al., 2018) outperforms both ELMO and GPT since it can provide better representation through capturing bi-directional context using Transformers. XLNet (Dai et al., 2019) gives new contextual representations through building an auto-regressive model capable of capturing all possible factorizations of the input. Fine-tuning pretrained models for BERT and XLNet has been a key factor in achieving state of the art performance for downstream tasks. Even though previous works have explored using BERT to model multimodal data (Sun et al., 2019), to the best of our knowledge, directly fine-tuning BERT or XLNet for multimodal data has not been explored in previous works.
3. BERT and XLNet
To better understand the proposed multimodal framework in this paper, we first present an overview of both the BERT and XLNet models. We start by quickly formalizing the operations within Transformer and Transformer-XL models, followed by an overview of BERT and XLNet.
3.1. Transformer
Transformer is a non-recurrent neural architecture designed for modeling sequential data (Vaswani et al., 2017). The superior performance of Transformer model is largely credited to a Multi-head Self-Attention module. Using this module, each element of a sequence is attended by conditioning on all the other sequence elements. Figure 2 summarizes internal operations of a Transformer layer (for M such layers). Commonly, a Transformer uses an encoder-decoder paradigm. A stack of encoders is followed by a stack of decoders to map an input sequence to an output sequence. An additional embedding step with Positional Input Embedding is applied before the input goes through the stack of encoders and decoders.
Figure 2:
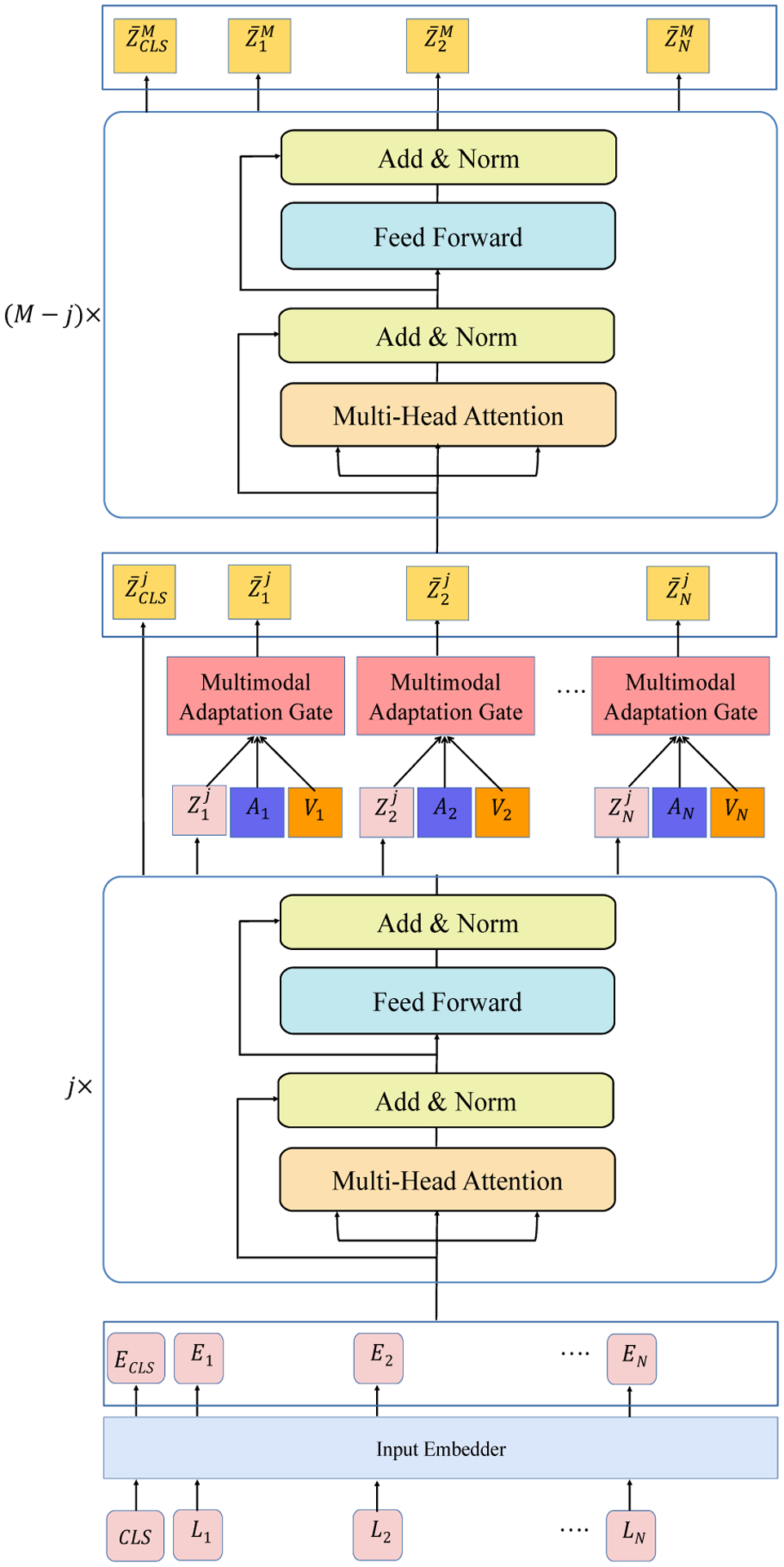
Best viewed zoomed in and in color. The Transformer architecture of BERT/XLNet with MAG applied at jth layer. We consider a total of M layers within the pretrained Transformer. MAG can be applied at different layers of the pretrained Transformers.
3.2. Transformer-XL
Transformer-XL (Dai et al., 2019) is an extension of the Transformer which offers two improvements: a) it enhances the capability of the Transformer to capture long-range dependencies (specifically for the case of context fragmentation), and b) it improves the capability to better predict first few symbols (which are often crucial for the rest of the sequence). It does so with a recurrence mechanism designed to pass context information from one segment to the next and a relative positional encoding mechanism to enable state reuse without causing temporal confusion.
3.3. BERT
BERT is a successful language model that provides rich contextual word representation (Devlin et al., 2018). It follows an auto-encoding approach – masking out a portion of input tokens and predicting those tokens based on all other non-masked tokens – and thus learning a vector representation for the masked out tokens in that process. We use the variant of BERT used for Single Sentence Classification Tasks. First, input embeddings are generated from a sequence of word-piece tokens by adding token embeddings, segment embeddings and position embeddings. Then multiple Encoder layers are applied on top of these input embeddings. Each Encoder has a Multi-Head Attention layer and a Feed Forward layer, each followed by a residual connection with layer normalization. A special [CLS] token is appended in front of the input token sequence. So, for a N length input sequence, we get N + 1 vectors from the last Encoder layer – the first of those vectors is used to predict the label of the input after that vector undergoes an affine transformation.
3.4. XLNet
XLNet (Yang et al., 2019) sets out to improve two critical aspects of the BERT model: a) independence among the masked out tokens and b) pretrain-finetune discrepancy in training vs inference, since inference inputs do not have masked out tokens. XLNet is an auto-regressive model and therefore, is free from the need of masking out certain tokens. However, auto-regressive models usually capture the unidirectional context (either forward or backward). XLNet can learn bidirectional context by maximizing likelihood over all possible permutations of factorization order. In essence, it randomly samples multiple factorization orders and trains the model on each of those orders. Therefore, it can model input by taking all possible permutations into consideration (in expectation).
XLNet utilizes two key ideas from Transformer-XL (Dai et al., 2019): relative positioning and segment recurrence mechanism. Like BERT, it also has a Input Embedder followed by multiple Encoders. The Embedder converts the input tokens into vectors after adding token embedding, segment embedding and relative positional embedding information. Each encoder consists of a Multi-Head attention layer and a feed forward layer – each followed by a residual addition and normalization layer. The embedder output is fed into the encoders to get a contextual representation of input.
4. Multimodal Adaptation Gate (MAG)
In multimodal language, a lexical input is accompanied by visual and acoustic information - simply gestures and prosody co-occurring with language. Consider a semantic space that captures latent concepts (positions in the latent space) for individual words. In absence of multimodal accompaniments, the semantic space is directly conditioned on the language manifold. Simply put, each word falls within some part of this semantic space, depending only on the meaning of the word in a linguistic structure (i.e. sentence). Nonverbal behaviors can have an impact on the meaning of words, and therefore on the position of words in this semantic space. Together, language and nonverbal accompaniments decide on the new position of the word in the semantic space. In this paper, we regard to this new position as addition of the language-only position with a displacement vector; a vector with trajectory and magnitude that shifts the language-only position of the word to the new position in light of nonverbal behaviors. This is the core philosophy behind the Multimodal Adaptation Gate (MAG).
A particularly appealing implementation of such displacement is studied in RAVEN (Wang et al., 2018), where displacements are calculated using cross-modal self-attention to highlight relevant non-verbal information. Figure 1 shows the studied MAG in this paper. Essentially, a MAG unit receives three inputs, one is purely lexical, one is visual, and the last one is acoustic. Let the triplet (Zi, Ai, Vi) denote these inputs for ith word in a sequence. We break this displacement into bimodal factors [Zi;Ai] and [Zi; Vi] by concatenating lexical vector with acoustic and visual information respectively and use them to produce two gating vectors and :
| (1) |
| (2) |
where Wgv, Wga are weight matrices for visual and acoustic modality and bv and ba are scalar biases. R(x) is a non-linear activation function. These gates highlight the relevant information in visual and acoustic modality conditioned on the lexical vector.
Figure 1:
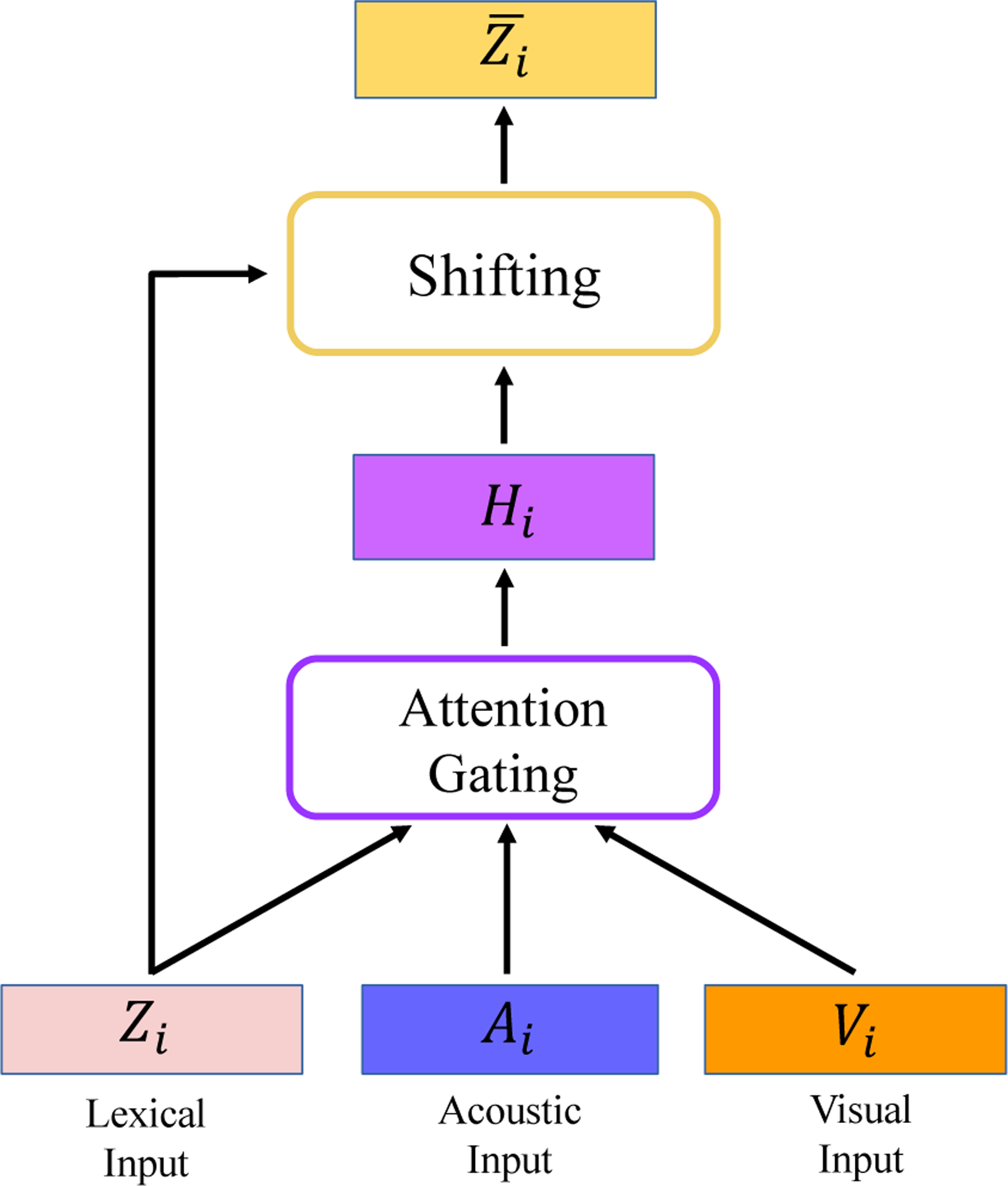
Multimodal Adaptation Gate (MAG) takes as input a lexical input vector, as well as its visual and acoustic accompaniments. Subsequently, an attention over lexical and nonverbal dimensions is used to fuse the multimodal data into another vector, which is subsequently added to the input lexical vector (shifting).
We then create a non-verbal displacement vector Hi by fusing together Ai and Vi multiplied by their respective gating vectors:
| (3) |
where Wa and Wv are weight matrices for acoustic and visual information respectively and bH is the bias vector.
Subsequently, we use a weighted summation between Zi and its nonverbal displacement Hi to create a multimodal vector :
| (4) |
| (5) |
where β is a hyper-parameter selected through the cross-validation process. ∥Zi∥2 and ∥Hi∥2 denote the L2 norm of the Zi and Hi vectors respectively. We use the scaling factor α so that the effect of nonverbal shift Hi remains within a desirable range. Finally, we apply a layer normalization and dropout layer to .
4.1. MAG-BERT
MAG-BERT is a combination of MAG applied to a certain layer of BERT network (Figure 2 demonstrates the structure of MAG-BERT as well as MAG-XLNet). Essentially, at each layer, BERT contains lexical vectors for ith word in the sequence. For the same word, nonverbal accompaniments are also available in multimodal language setup. MAG essentially forms an attachment to the desired layer in BERT; an attachment that allows for multimodal information to leak into the BERT model and displace the lexical vectors. The operations within MAG allows for the lexical vectors within BERT to adapt to multimodal information by changing their positions within the semantic space. Aside from the attachment of MAG, no change is made to the BERT structure.
Given an N length language sequence L = [L1, L2, … LN] carrying word-piece tokens, a [CLS] token is appended to L so that we can use it later for class label prediction. Then, we input L to the Input Embedder which outputs E = [ECLS, E1, E2, … EN] after adding token, segment and position embeddings. Then, we input E to the first Encoding layer and then apply j Encoders on it successively. After that encoding process, we get the output which denotes the Lexical Embeddings after j layers of Encoding.
For injecting audio-visual information into these embeddings, we prepare a sequence of triplets by pairing with the corresponding (Ai, Vi). Each of these triplets are passed through the Multimodal Adaptation Gate which transforms the ith triplet into – a unified multimodal representation of the corresponding Lexical Embedding.
As there exists M = 12 Encoder layers in our BERT model, we input to the next Encoder and apply M – j Encoder layers on it successively. At the end, we get from the Mth Encoder layer. As the first element represents the [CLS] token, it has the information necessary to make a class label prediction. Therefore, goes through an affine transformation to produce a single real-value which can be used to predict a class label.
4.2. MAG-XLNet
Like MAG-BERT, MAG-XLNet also has the capability of injecting audio-visual information at any of its layers using MAG. At each position j of any of its layer, it holds the lexical vector corresponding to that position. Utilizing the audio-visual information available for that position, it can invoke MAG to get an appropriately shifted lexical vector in multimodal space. Although it mostly follows the general paradigm presented in Figure 2 verbatim, it uses the XLNet specific Embedder and Encoders. One other key difference is the position of the [CLS] token. Unlike BERT, the [CLS] token is appended at the right end of the input token sequence, and therefore in all the intermediate representations, the vector corresponding to the [CLS] will be the rightmost one. Following the same logic, the output from the final Encoding layer will be The last item, can be used for class label prediction after it goes through an affine transformation.
5. Experiments
In this section we outline the experiments in this paper. We first start by describing the datasets, followed by description of extracted features, baselines, and experimental setup.
5.1. CMU-MOSI Dataset
CMU-MOSI (CMU Multimodal Opinion Sentiment Intensity) is a dataset of multimodal language specifically focused on multimodal sentiment analysis (Zadeh et al., 2016). CMU-MOSI contains 2199 video segments taken from 93 Youtube movie review videos. The dataset has real-valued high-agreement sentiment intensity annotations in the range [−3, +3]
5.2. Computational Descriptors
For each modality, the following computational descriptors are available:
Language: We transcribe the videos using Youtube API followed by manual correction.
Acoustic: COVAREP (Degottex et al., 2014) is used to extract the following relevant features: fundamental frequency, quasi open quotient, normalized amplitude quotient, glottal source parameters (H1H2, Rd, Rd conf), VUV, MDQ, the first 3 formants, PSP, HMPDM 0–24 and HM-PDD 0–12, spectral tilt/slope of wavelet responses (peak/slope), MCEP 0–24.
Visual: For the visual modality, the Facet library (iMotions, 2017) is used to extract a set of visual features including facial action units, facial landmarks, head pose, gaze tracking and HOG features.
For each word, we align all three modalities following the convention established in (Chen et al., 2017). Firstly, the word alignment between language and audio is obtained using forced alignment (Yuan and Liberman, 2008). Afterwards, the boundary of each word denotes the co-occurring visual and acoustic features (FACET and COVAREP). Subsequently, for each word, the co-occurring acoustic and visual features are averaged across each feature – thus achieving Ai and Vi vectors corresponding to word i.
5.3. Baseline Models
We compare the performance of MAG-BERT and MAG-XLNet to a variety of state-of-the-art models for multimodal language analysis. These models are trained using extracted BERT and XLNet word embeddings as their language input:
TFN (Tensor Fusion Network) explicitly models both intra-modality and inter-modality dynamics (Zadeh et al., 2017) by creating a multi-dimensional tensor that captures unimodal, bimodal and trimodal interactions across three modalities.
MARN (Multi-attention Recurrent Network) models view-specific interactions using hybrid LSTM memories and cross-modal interactions using a Multi-Attention Block (MAB) (Zadeh et al., 2018c).
MFN (Memory Fusion Network) has three separate LSTMs to model each modality separately and a multi-view gated memory to synchronize among them (Zadeh et al., 2018a).
RMFN (Recurrent Memory Fusion Network) captures intra-modal and inter-modal information through recurrent multi-stage fashion (Liang et al., 2018).
MulT (Multimodal Transformer for Unaligned Multimodal Language Sequence) uses three sets of Transformers and combines their output in a late fusion manner to model a multimodal sequence (Tsai et al., 2019). We use the aligned variant of the originally proposed model, which achieves superior performance over the unaligned variant.
We also compare our model to fine-tuned BERT and XLNet using language modality only to measure the success of the MAG framework.
5.4. Experimental Design
All the models in this paper are trained using Adam (Kingma and Ba, 2014) optimizer with learning rates between {0.001, 0.0001, 0.00001}. We use dropouts of {0.1, 0.2, 0.3, 0.4, 0.5} for training each model. LSTMs in TFN, MARN, MFN, RMFN, LFN use latent size of {16, 32, 64, 128}. For MulT, we use {3, 5, 7} layers in the network and {1, 3, 5} attention heads. All models use the designated validation set of CMU-MOSI for finding best hyper-parameters.
We perform two different evaluation tasks on CMU-MOSI datset: i) Binary Classification, and ii) Regression. We formulate it as a regression problem and report Mean-absolute Error (MAE) and the correlation of model predictions with true labels. Besides, we convert the regression outputs into categorical values to obtain binary classification accuracy (BA) and F1 score. Higher value means better performance for all the metrics except MAE. We use two evaluation metrics for BA and F1, one used in (Zadeh et al., 2018d) and one used in (Tsai et al., 2019).
6. Results and Discussion
Table 1 shows the results of the experiments in this paper. We summarize the observations from the results in this table as following:
Table 1:
Sentiment prediction results on CMU-MOSI dataset. Best results are highlighted in bold. MAG-BERT and MAG-XLNet achieve superior performance than the baselines and their language-only finetuned counterpart. BA denotes binary accuracy (higher is better, same for F1), MAE denotes Mean-absolute Error (lower is better), and Corr is Pearson Correlation (higher is better). For BA and F1, we report two numbers: the number on the left side of “/” is measures calculated based on (Zadeh et al., 2018c) and the right side is measures calculated based on (Tsai et al., 2019). Human performance for CMU-MOSI is reported as (Zadeh et al., 2018a).
| Task Metric | F1↑ | Corr↑ | ||
|---|---|---|---|---|
| Original (glove) | ||||
| TFN | 73.4/− | 0.633/− | ||
| MARN | 77.0/− | 0.625/− | ||
| MFN | 77.3/− | 0.632/− | ||
| RMFN | 78.0/− | 0.681/− | ||
| LFN | 75.7/− | 0.668/− | ||
| MulT | −/82.8 | −/0.698 | ||
| BERT | ||||
| TFN | 74.1/75.2 | 0.649 | ||
| MARN | 77.9/78.2 | 0.691 | ||
| MFN | 78.1/78.4 | 0.699 | ||
| RMFN | 78.9/79.1 | 0.712 | ||
| LFN | 77.3/78.1 | 0.701 | ||
| MulT | 80.6/83.9 | 0.711 | ||
| BERT | 83.4/85.2 | 0.782 | ||
| MAG-BERT | 84.1/86.0 | 0.796 | ||
| XLNet | ||||
| TFN | 78.2/78.8 | 0.713 | ||
| MARN | 78.8/79.6 | 0.707 | ||
| MFN | 78.4/79.1 | 0.713 | ||
| RMFN | 78.6/80.0 | 0.703 | ||
| LFN | 79.1/81.6 | 0.701 | ||
| MulT | 80.4/83.1 | 0.738 | ||
| XLNet | 84.6/86.7 | 0.812 | ||
| MAG-XLNet | 85.6/87.9 | 0.821 | ||
| Human | 87.5/− | 0.820 | ||
6.1. Performance of MAG-BERT
In all the metrics across the CMU-MOSI dataset, we observe that performance of MAG-BERT is superior to state-of-the-art multimodal models that use BERT word embeddings. Furthermore, MAG-BERT also performs superior to fine-tuned BERT. This essentially shows that the MAG component is allowing the BERT model to adapt to multimodal information during fine-tuning, thus achieving superior performance.
6.2. Performance of MAG-XLNet
A similar performance trend to MAG-BERT is also observed for MAG-XLNet. Besides superior performance than baselines and fine-tuned XLNet, MAG-XLNet achieves near-human level performance for CMU-MOSI dataset. Furthermore, we train MulT using the fine-tuned XLNet embeddings and get the following performance: 83.6/85.3, 82.6/84.2, 0.810, 0.759 which is lower than both MAG-XLNet and XLNet. It is notable that the p-value for student t-test between MAG-XLNet and XLNet in Table 1 is lower than 10e − 5 for all the metrics.
The motivation behind the experiments reported in Table 1 is as follows: we extracted word embeddings from pre-trained BERT and XLNet models and trained the baseline models using those embeddings. Since BERT and XLNet are often perceived to provide better word embeddings than Glove, it is not fair to compare MAG-BERT/MAG-XLNet with previous models trained with Glove embeddings. Therefore, we retrain previous works using BERT/XLNet embeddings to establish a more fair comparison between proposed approach in this paper, and previous work. Based on the information from Table 1, we observe that MAG-BERT/MAG-XLNet models outperforms various baseline models using BERT/XLNet/Glove models substantially.
6.3. Adaptation at Different Layers
We also study the effect of applying MAG at different encoder layers of the XLNet. Specifically, we first apply the MAG to the output of the embedding layer. Subsequently, we apply the MAG to the layer j ∈ {1, 4, 6, 8, 12} of the XLNet. Then, we apply MAG at all the XLNet layers. From Table 2, we observe that earlier layers are more suitable for application of MAG.
Table 2:
Results of variations of XLNet model: MAG applied at different layers of the XLNet model, input-level concatenation and addition of all modalities. “E” denotes application of MAG immediately after embedding layer of the XLNet and “A” denotes applying MAG after the embedding layer and all the subsequent Encoding layers. ⊕ and ⊙ denote input-level addition and concatenation of all modalities respectively. MAG applied at initial layers performs better overall.
| Model | E | 1 | 4 | 6 | 8 | 12 | A | ⊕ | ⊙ |
|---|---|---|---|---|---|---|---|---|---|
| MAG-XLNet | 80.1 | 85.6 | 84.1 | 84.1 | 83.8 | 83.6 | 64.0 | 60.0 | 55.8 |
We believe that earlier layers allow for better integration of the multimodal information, as they allow the word shifting to happen from the beginning of the network. If the semantics of words should change based on the nonverbal accompaniments, then initial layers should reflect the semantic shift, otherwise, those layers are only working unimodally. Besides, the higher layers of BERT learn more abstract and higher-level information about the syntactic and semantic structure of linguistic features (Coenen et al., 2019). Since, the acoustic and visual information present in our model corresponds to each word in the utterance, it will be more difficult for the MAG to shift the vector extracted from a later layer since that vector’s information will be very abstract in nature.
6.4. Input-level Concatenation and Addition
From Table 2, we see that both input-level concatenation and addition of modalities perform poorly. For Concatenation, we simply concatenate all the modalities. For Addition, we add the audio and visual information to the language embedding after mapping both of them to the language dimension. These results demonstrate the rationale behind using an advanced fusion mechanism like MAG.
6.5. Results on Comparable Datasets
We also perform experiments on the CMU-MOSEI dataset (Zadeh et al., 2018d) to study the generalization of our approach to other multimodal language datasets. Unlike CMU-MOSI which has sentiment annotations at utterance level, CMU-MOSEI has sentiment annotations at sentence level. The experimental methodology for CMU-MOSEI is similar to the original paper. For the sake of comparison, we suffice1 to comparing the binary accuracy and f1 score for the top 3 models in Table 1. In BERT category, we compare the performance of MulT (with BERT embeddings), BERT and MAG-BERT which are respectively as follows: [83.5, 82.9] for MulT, [83.9, 83.9] for BERT, and [84.7, 84.5] for MAG-BERT. Similarly for XLNET category, the results for MulT (with XLNet embeddings), XLNet and MAG-XLNet are as follows: [84.1, 83.7] for MulT, [85.4, 85.2] for XLNet and [85.6, 85.7] for MAG-XLNet. Therefore, superior performance of MAG-BERT and MAG-XLNet also generalizes to CMU-MOSEI dataset.
6.6. Fine-tuning Effect
We study whether or not the superior performance of the MAG-BERT and MAG-XLNet is related to successful finetuning of the models, or related to other factors e.g. any transformer with architecture like BERT or XLNet would achieve superior performance regardless of being pretrained. By randomly initializing the weights of BERT and XLNet within MAG-BERT and MAG-XLNet, we get the following performance on BA for the CMU-MOSI:70.1 and 70.7 respectively. This indicates that the success of the MAG-BERT and MAG-XLNet is due to successful fine-tuning. Even on the larger CMU-MOSEI dataset we get BA of 76.8 and 78.4 for MAG-BERT and MAG-XLNet, which further substantiates the fact that fine-tuning is successful using MAG framework.
6.7. Qualitative Analysis
In Table 3, we present some examples where MAG-XLNet adjusted sentiment intensity properly by taking into account nonverbal information. The examples demonstrate that MAG-XLNET can successfully integrate the non-verbal modalities with textual information.
Table 3:
Examples from the CMU-MOSI dataset. The ground truth sentiment labels are between strongly negative (−3) and strongly positive (+3). For each example, we show the Ground Truth and prediction output of both the MAG-XLNet and XLNet. XLNet seems to be replicating language modality mostly while MAG-XLNet is integrating the non-verbal information successfully.

|
In both Example-1 and Example-2, XLNet correctly predicted the polarity of the displayed emotion. However, additional information was present in the acoustic and visual domain which XLNet could not utlize. Given those information, MAG-XLNet could better predict the magnitude of emotion displayed in both cases.
Although the emotion in the text of Example-3 can be portrayed as a bit positive, the tense voice and frown expression helps MAG-XLnet reverse the polarity of predicted emotion. Similarly, the text in Example-4 is mostly neutral, but MAG-XLNet can predict the negative emotion through the sarcastic vocal and frustrated facial expression.
7. Conclusion
In this paper, we introduced a method for efficiently finetuning large pre-trained Transformer models for multimodal language. Using a proposed Multimodal Adaptation Gate (MAG), BERT and XLNet were successfully fine-tuned in presence of vision and acoustic modalities. MAG essentially poses the nonverbal behavior as a vector with a trajectory and magnitude, which is subsequently used to shift lexical representations within the pre-trained Transformer model. A unique characteristic of MAG is that it makes no change to the original structure of BERT or XLNet, but rather comes as an attachment to both models. Our experiments demonstrated the superior performance of MAG-BERT and MAG-XLNet. The code for both MAG-BERT and MAG-XLNet are publicly available here2
Acknowledgement
This research was supported in part by grant W911NF-15-1-0542 and W911NF-19-1-0029 with the US Defense Advanced Research Projects Agency (DARPA) and the Army Research Office (ARO). Authors AZ and LM were supported by the National Science Foundation (Awards #1750439 #1722822) and National Institutes of Health. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of US Defense Advanced Research Projects Agency, Army Research Office, National Science Foundation or National Institutes of Health, and no official endorsement should be inferred.
Footnotes
Since Transformer based models take a long time to train for CMU-MOSEI
References
- Chen Minghai, Wang Sen, Liang Paul Pu, Baltrušaitis Tadas, Zadeh Amir, and Morency Louis-Philippe. 2017. Multimodal sentiment analysis with word-level fusion and reinforcement learning. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, pages 163–171. ACM. [Google Scholar]
- Coenen Andy, Reif Emily, Yuan Ann, Kim Been, Pearce Adam, Viégas Fernanda, and Wattenberg Martin. 2019. Visualizing and measuring the geometry of bert. arXiv preprint arXiv:1906.02715. [Google Scholar]
- Dai Zihang, Yang Zhilin, Yang Yiming, Cohen William W, Carbonell Jaime, Le Quoc V, and Salakhutdinov Ruslan. 2019. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860. [Google Scholar]
- Degottex Gilles, Kane John, Drugman Thomas, Raitio Tuomo, and Scherer Stefan. 2014. Covarep—a collaborative voice analysis repository for speech technologies. In 2014 ieee international conference on acoustics, speech and signal processing (icassp), pages 960–964. IEEE. [Google Scholar]
- Devlin Jacob, Chang Ming-Wei, Lee Kenton, and Toutanova Kristina. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805. [Google Scholar]
- Hazarika Devamanyu, Poria Soujanya, Zadeh Amir, Cambria Erik, Morency Louis-Philippe, and Zimmermann Roger. 2018. Conversational memory network for emotion recognition in dyadic dialogue videos. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), volume 1, pages 2122–2132. [DOI] [PMC free article] [PubMed] [Google Scholar]
- iMotions. 2017. Facial expression analysis.
- Kingma Diederik P and Ba Jimmy. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980. [Google Scholar]
- Liang Paul Pu, Liu Ziyin, Zadeh Amir, and Morency Louis-Philippe. 2018. Multimodal language analysis with recurrent multistage fusion. arXiv preprint arXiv:1808.03920. [Google Scholar]
- Mikolov Tomas, Sutskever Ilya, Chen Kai, Corrado Greg S, and Dean Jeff. 2013. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pages 3111–3119. [Google Scholar]
- Park Sunghyun, Shim Han Suk, Chatterjee Moitreya, Sagae Kenji, and Morency Louis-Philippe. 2014. Computational analysis of persuasiveness in social multimedia: A novel dataset and multimodal prediction approach. In Proceedings of the 16th International Conference on Multimodal Interaction, pages 50–57. ACM. [Google Scholar]
- Pennington Jeffrey, Socher Richard, and Manning Christopher. 2014. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1532–1543. [Google Scholar]
- Peters Matthew E, Neumann Mark, Iyyer Mohit, Gardner Matt, Clark Christopher, Lee Kenton, and Zettlemoyer Luke. 2018. Deep contextualized word representations. arXiv preprint arXiv:1802.05365. [Google Scholar]
- Pham Hai, Liang Paul Pu, Manzini Thomas, Morency Louis-Philippe, and Poczos Barnabas. 2019. Found in translation: Learning robust joint representations by cyclic translations between modalities. arXiv preprint arXiv:1812.07809. [Google Scholar]
- Poria Soujanya, Hussain Amir, and Cambria Erik. 2018. Multimodal Sentiment Analysis, volume 8. Springer. [Google Scholar]
- Radford Alec, Narasimhan Karthik, Salimans Tim, and Sutskever Ilya. 2018. Improving language understanding by generative pre-training. URL https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/languageunsupervised/languageunderstandingpaper.pdf.
- Sun Chen, Myers Austin, Vondrick Carl, Murphy Kevin, and Schmid Cordelia. 2019. Videobert: A joint model for video and language representation learning. arXiv preprint arXiv:1904.01766. [Google Scholar]
- Tsai Yao-Hung Hubert, Bai Shaojie, Liang Paul Pu, Kolter J Zico, Morency Louis-Philippe, and Salakhutdinov Ruslan. 2019. Multimodal transformer for unaligned multimodal language sequences. arXiv preprint arXiv:1906.00295. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tsai Yao-Hung Hubert, Liang Paul Pu, Zadeh Amir, Morency Louis-Philippe, and Salakhutdinov Ruslan. 2018. Learning factorized multimodal representations. arXiv preprint arXiv:1806.06176. [Google Scholar]
- Vaswani Ashish, Shazeer Noam, Parmar Niki, Uszkoreit Jakob, Jones Llion, Gomez Aidan N, Kaiser Łukasz, and Polosukhin Illia. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, pages 5998–6008. [Google Scholar]
- Wang Yansen, Shen Ying, Liu Zhun, Liang Paul Pu, Zadeh Amir, and Morency Louis-Philippe. 2018. Words can shift: Dynamically adjusting word representations using nonverbal behaviors. arXiv preprint arXiv:1811.09362. [PMC free article] [PubMed] [Google Scholar]
- Yang Zhilin, Dai Zihang, Yang Yiming, Carbonell Jaime, Salakhutdinov Ruslan, and Le Quoc V. 2019. Xlnet: Generalized autoregressive pretraining for language understanding. arXiv preprint arXiv:1906.08237. [Google Scholar]
- Yuan Jiahong and Liberman Mark. 2008. Speaker identification on the scotus corpus. Journal of the Acoustical Society of America, 123(5):3878. [Google Scholar]
- Zadeh Amir, Chen Minghai, Poria Soujanya, Cambria Erik, and Morency Louis-Philippe. 2017. Tensor fusion network for multimodal sentiment analysis. arXiv preprint arXiv:1707.07250. [Google Scholar]
- Zadeh Amir, Liang Paul Pu, Mazumder Navonil, Poria Soujanya, Cambria Erik, and Morency Louis-Philippe. 2018a. Memory fusion network for multi-view sequential learning. In Thirty-Second AAAI Conference on Artificial Intelligence. [PMC free article] [PubMed] [Google Scholar]
- Zadeh Amir, Liang Paul Pu, Morency Louis-Philippe, Poria Soujanya, Cambria Erik, and Scherer Stefan. 2018b. Proceedings of grand challenge and workshop on human multimodal language (challenge-hml). In Proceedings of Grand Challenge and Workshop on Human Multimodal Language (Challenge-HML). [Google Scholar]
- Zadeh Amir, Liang Paul Pu, Poria Soujanya, Vij Prateek, Cambria Erik, and Morency Louis-Philippe. 2018c. Multi-attention recurrent network for human communication comprehension. In Thirty-Second AAAI Conference on Artificial Intelligence. [PMC free article] [PubMed] [Google Scholar]
- Zadeh Amir, Zellers Rowan, Pincus Eli, and Morency Louis-Philippe. 2016. Mosi: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos. arXiv preprint arXiv:1606.06259. [Google Scholar]
- Zadeh AmirAli Bagher, Liang Paul Pu, Poria Soujanya, Cambria Erik, and Morency Louis-Philippe. 2018d. Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, pages 2236–2246. [Google Scholar]