

Abstract
Multilabel recognition of morphological images and detection of cancerous areas are difficult to locate in the scenario of the image redundancy and less resolution. Cancerous tissues are incredibly tiny in various scenarios. Therefore, for automatic classification, the characteristics of cancer patches in the X-ray image are of critical importance. Due to the slight variation between the textures, using just one feature or using a few features contributes to inaccurate classification outcomes. The present study focuses on five different algorithms for extracting features that can extract further different features. The algorithms are GLCM, LBGLCM, LBP, GLRLM, and SFTA from 8 image groups, and then, the extracted feature spaces are combined. The dataset used for classification is most probably imbalanced. Additionally, another focal point is to eradicate the unbalanced data problem by creating more samples using the ADASYN algorithm so that the error rate is minimized and the accuracy is increased. By using the ReliefF algorithm, it skips less contributing features that relieve the burden on the process. Finally, the feedforward neural network is used for the classification of data. The proposed method showed 99.5% micro, 99.5% macro, 0.5% misclassification, 99.5% recall rats, specificity 99.4%, precision 99.5%, and accuracy 99.5%, showing its robustness in these results. To assess the feasibility of the new system, the INbreast database was used.
1. Introduction
Breast cancer is considered a key health issue in women which is causing a high rate of casualty. The initial diagnosis of breast cancer with mammographic screening and appropriate pharmacological treatments has steadily increased the prognosis of breast cancer [1]. These include mammography, biopsy, ultrasound image, and thermography [2]. The biopsy is painful procedure and rather expensive. Chemotherapy is usually frailty associated with a psychiatric condition defined as the accumulation of several interactive diseases, impairs, and disability: exhaustion, nausea, inadequate, relatively slow walking speed and physical exercise, and unintended weight loss [3, 4]. So, some doctors recommended dispensing low-dose aspirin before and after the detection of breast cancer [5]. But today's world image recognition methods have an important role to play in the analysis of tumor images by using a machine learning methodology. It uses a random generator, a function extractor, and a classifier to model a doctor's enquiry and construct a personalized questionnaire [6]. Also microwave-based imaging techniques were developed for breast cancer detection [7]. The data mining as well as classification techniques is a well-organized approach of classifying data. Particularly in the medical field, these approaches are commonly useable diagnostics research for decision making. Many classification methods are used in the algorithms of machine learning like decision tree (C45), support vector machine (SVM), and naive Bayes algorithm [8]. Support vector machine (SVM) discriminatory classifier is used to classify hyperplanes for binary groups. But, in particular case, the major drawback is low results for a greater number of characteristics than the number of samples [9]. The decision tree (C4.5) is a hierarchical decision support technique, but its downside is that it is highly unreliable and data-based. A minor shift in data leads to a completely different tree being created [9]. Naive Bayes (NB) and linear discriminant analysis (LDA) are unable to locate a nonlinear structure concealed in high-dimensional results. Secondly, the singularity of inherent matrix is a problem in which the determinant value is zero which leads to nonclassification of matrix [9]. A fuzzy support vector machine (FSVM) was implemented by Nedeljkovic to define and characterize the amount of breast ultrasound [10]. In order to eradicate such errors, algorithms were developed to assist radiologists. Therefore, this distinctive attribute of the tissue patches in the image played an important role in classification. The machine can extract five unique features [11]. Balance them by ADASYN [12] and classification is by multilayer perceptron neural network. The advantage multilayer perceptron neural networks (MLPNNs) MLP is an artificial neural network feedforward architecture that is used to design recognition schemes to identify particular patterns. It is nonparametric learning and is enforceable on a noisy input. It is able to model complex nonlinear and high-dimensional problems. You can pick different kernel functions [9]. Finally, classification is used in the doubtful areas into abnormal or normal detection.
2. Related Work
For several years, the community of medical imaging has made attempts to develop CAD framework. With its arrival, novel challenges started emerging, which now require proper knowledge as well as thorough research.
Research has been done on some key modules of CAD. This created a need to develop the computer-aided diagnosis system. It has three aims. First is the detection of the abnormal breast from mammography. The second involves masses' detection, while the third one is meant to differentiate benign from malevolent masses. In this study, the former is focused while it is the essential process of further two attempts. In the previous 10 years, various approaches have been recommended. Milosevic et al. [13] utilized the 20 GLCM features. They used naive Bayes classifier for sorting, keeping up vector machines as well as k-nearest neighbors. Petrosian et al. [14] investigated the utility of texture characteristics for mass and normal tissue classification based on spatial gray-level dependency (SGLD) matrices. Iseri and Oz [15] developed a new method of extraction of features, i.e., statistical analysis based on multiwindow, in order to detect microcalcification clusters. Nababan et al. [16] use three layers of SECoS with 16 features as proposed for classifying benign and malignant masses. Sigh et al. [17] utilized a support vector device that had texture, shape features, and hierarchical technique for categorizing both malignant and compassionate stacks. Perez et al. [18] talked about experimental evaluation and the theoretical description of an innovative attribute collection method that is called uFilter. Via the integrated mammography data as well as MRI, Yang and Li recognized breast cancer. They performed information integration by two techniques, i.e., MIP and TPS. In Kinoshita et al. [19], the mixture of form and texture used provides space for the classification of regular and infected breast lesions based on gray-level cooccurrence matrices (GLCM). Anita and Peter [20] proposed an automated segmentation technique to classify and segment abnormal mass regions on the basis of the maximum cell intensity update. In Peng et al. [21], for initial breast cancer diagnosis in patients with breast microcalcification lesions, FDG-PET/CT was used. Molloi et al. [22] evaluated the breast density through spectral mammography. Kegelmeyer [23] constructed a tool to identify satellite lesions in mammograms and texture characteristics of computed laws from a chart of the local edge orientations. Gorgel et al. [24] suggested spherical wavelet transform. Mohanty et al. [25] recommended a technique that gets ROI by cropping operation. After ROI was extracted, 2D discrete wavelet transform was combined with GLCM in order to obtain texture-based features. There are a total of 65 features that were calculated by this combination. Moreover, PCA was also implemented to eradicate redundant features. At the last step, forest optimization algorithm was implemented to get classification results.
Abdel-Nasser et al. [26] invented technique for change in temperature on normal and abnormal breast cancer detection by extracting GLCM and 22 features and used learning-to-rank and texture analysis methods. Wang et al. [27] developed an algorithm for classifying benign and malignant masses into their appropriate classes. In their work, there were 16 spectrums that contained 16,777,216 features which were further reduced to 18 features by using PCA. The FD was combined with Jaya for training weights and biases of FNN. The projected method was later named Jaya-FNN. Welch et al. [28] did contrast enhancement and also performed dimensioning by CLAHE based adaptive method as well as histogram equalization. The ROI was extracted by using a bimodel processing algorithm in two levels. Firstly, extraction of normal breast boundary was done and then the abnormal breast boundary was extracted. GLCM method was utilized to get the second level statistical texture features. Shape features included eccentricity, LBP, circularity, and Hog. Intensity features included mean kurtoses and skewness. So the feature's space was reduced by a recursive approach. KNN, support vector machine, and decision tree were used for the classification of desirable functions. From the above literature research, segmentation, feature extraction, and feature selection as well as classification are considered as the major factors for categorizing to get better effectiveness of discovery of breast stacks. Mohanty et al. [29] used 19 (GLCM + GLRLM) features of extraction to classify detection of benign and malignant masses. The category imbalance problem [16,30–34] is heavily influenced by machine learning and statistical algorithms. The Heuristic Cover-Sampling Algorithm is a Synthetic Minority Over-sampling Technique (SMOTE). It produces artificial samples from the minority class by parsing existing instances that lie close together. It has been one of the most common methods used for data sample selection for a few weeks [35].
Sampling data approaches are such as Random Over-Sampling (ROS), which replicates extracted features, and Random Under-Sampling (RUS), which removes majority-class samples. In order to adapt to the binary classifier ratio, these methods distort individual counseling [12]. Sampling learning is an active process from datasets through Adaptive Synthetic (ADASYN) algorithm. ADASYN's guiding theory is the use of weighted consideration for the different ethnic groups. The ADASYN approach improves learning in two ways with respect to data distribution: (1) the bias created by the inequality of the class and (2) dynamically altering the boundary of the classification decision to reflect on those samples that are difficult to understand [12].
While each tissue type has its own characteristics for the proposed work, it often hardly differentiates between normal and abnormal cancers. Commonly, cells begin to expand in abnormal cancers and their tissues coloring is visible. Indiscretions have been brought to completion in cell arrays. The cell shows more common in natural tissue and its color is darker. However, there is also a low description of only some low-level dimensions of certain complex systems. In this research, different algorithms were tested to extract features at higher levels on morphological images. So, with extraction algorithms for GLCM features, LBP features, LBGLCM features, GLRLM features, and SFTA features, optimization methods have been attempted in the literature. As an appropriate method to extract features from individual image, each algorithm is applied to the entire dataset.
Unbalancing of dataset, therefore, using hand-crafted features will trigger poor performance from the dataset. The unbalanced data problem is eliminated with the ADASYN algorithm [12], which then deletes irrelevant features by ReliefF that improves training time. Finally, for the classification of data, the feedforward neural network is used.
3. Proposed Method
The methodology is adopted to distinguish among eight classes (benign to malignant) according to Breast Imaging-Reporting and Data System (BI-RADS). For such a purpose, preprocessing and segmentation are skipped in this algorithm and restrict the algorithm to four stages, i.e., features extraction, features margin, oversampling, and feature selection and reduction; finally classification is shown in Figure 1.
Figure 1.

Methodology of the proposed model.
The model that was mentioned was checked on the INbreast database [36]. For each object, five hand-crafted features (GLCM, GLRLM, LBP, LBGLCM, and SFTA) were extracted from 8 groups of images and their values are stored in a file. For each image, 88 features are obtained by combining these feature vectors. Then, with the ADASYN procedure, the feature vectors of 411 images consisting of 88 functions are oversampled. After this step, 1773 function vectors are generated. Using the ReliefF algorithm, these features were layered down to ten subset functions. In the end, feedforward neural network was modified to multilayer and trained on a selected subset to get a result.
3.1. Feature Extraction Method
3.1.1. The Gray Level Cooccurrence Matrix (GLCM)
GLCM is a common method of extraction of texture-based features. By performing an operation in the images due to the second-order statistics, the GLCM decides the textural relationship between pixels. For this procedure, two pixels are normally used [37]. The frequency of variations in these measured pixel brightness values is specified by the GLCM. Namely, it reflects the pixel pairs' frequency creation [38]. As seen in Figure 2, there are several statistical characteristics from a GLCM grey level picture type. The square matrix of features can be denoted by G (i, j). Four distinct forms are used to segment the G matrix into regularized typical forming modes. Such patterns are referred to as crossed directions: vertical, lateral, right, and left paths. This can be determined for both neighboring paths.
Figure 2.

ADASYN oversampling for multiple classes.
The Grey Level Cooccurrence Matrix was utilized to extract 22 texture characteristics I-e dissimilarity, association, homogeneity, liveliness dissimilarity, entropy, cluster hue, square variance number, energy, sum variance, sum average, entropy, sum entropy, entropy difference, maximum likelihood, cluster prominence, variance difference, normalized autocorrelation inverse difference moment and measurement details. [39].
3.1.2. Local Binary Pattern (LBP) Feature
A quite effective technique that is responsive to light variations is the extraction algorithm. The LBP method can simply be defined as follows; the image is crossed through a window with a given neighborhood value. And an assignment of an image pixels mark is made. In this step, the threshold is applied according to pixel values adjacent to the middle pixel. The LBP matric is then determined according to clockwise or counter clockwise values in the surrounding neighborhood. Thus, it comprehensively defined the systemic and statistical pattern of the textural system [40]. The LBP algorithm's most key qualities are resistant to changes in the grey level and statistical versatility in real-time applications, which could be used [41].
3.1.3. Local Binary Grey Level Cooccurrence Matrix (LBGLCM)
A combined approach applied along with Local Binary Pattern (LBP) and GLCM is the LBGLCM feature extraction process. The grey level picture is related to the LBP methodology. Instead, since the acquired LBP texture image, GLCM features are removed. At the feature extraction point, the GLCM technique takes adjacent pixels into consideration. It does not execute any procedure in the picture on other local patterns. Textural and spatial knowledge in the picture is collected in accordance with the LBGLCM process. The availability of the LBGLCM algorithm in image processing applications is improved by the simultaneous acquisition of this information [42].
3.1.4. Grey Level Run Length Matrix (GLRLM)
In extracting the spatial properties of gray level pixels, GLRLM uses higher-level statistical techniques. The structure of the features obtained is two-dimensional.
Each value in the matrix reflects the maximum value of the grey level. The characteristics of GLRLM are seven in total. Short-term concentration, long-term focus, and gray-level semi, run-long nonuniformity, take, low gray-level running focus, and overall organization running focus are such high statistical characteristics [43].
| (1) |
3.1.5. Segmentation-Based Fractal Texture Analysis
Limited computation time and successful attribute extraction are important in texture analysis. The SFTA solution is a methodology that can be tested in this theory. Throughout the SFTA process, multiple thresholding techniques transform the image into a binary form. Thresholds of t1, t2, t3,…, tn are rendered. Interclass and in-class variance values are used to determine the threshold sets. The optimal threshold number is added to the representation regions to minimize the in-class variance value.
Figure 3 demonstrates the extraction steps of the pseudocode SFTA algorithm. The obtained function vector represents VSFTA. Initially, different threshold values (T), all pairs of contiguous thresholds (TA), and threshold values (TB) corresponding to the maximum grey level are determined. Then, for all threshold values in the loop, segmented image pixels, boundaries, and VSFTA are modified. The obtained VSFTA vector's asymptotic complexity is O (N•|T|). Although N indicates the number of pixels, |T| indicates the number of different thresholds arising from the Otsu multilevel algorithm [44].
Figure 3.

Pseudocode of SFTA algorithm.
3.2. Oversampling with Adaptive Synthetic (ADASYN) Algorithm
To address unbalanced class allocation issues for classification activities, the ADAYSN approach is useful. This method is applied to all minority classes. In general, ADASYN bases its operation on weighting the examples of the minority classes according to their difficulty of being learned; therefore more synthetic data will be generated from the more difficult samples, and fewer samples in the case of the easier to learn [12]. This sampling method aims to help the classifier in two ways: first, reducing the error produced by the imbalance of the classes and then focusing the synthetic samples only on the difficult samples to learn [45, 46]. To apply the oversampling method in a multiclass problem, all of the sampled minority classes will be nearer to 1 until the imbalanced rate is nearer to 1. For example, the second is the majority class, with 220 samples, and the first class is with 67 samples; the imbalance rate of these classes is 0.3045. The ADASYN process generates synthetic samples before the rate equal to or nearest to 1 in the method generates 154 samples, generating an imbalanced rate = ∼1.3rd class of 24 samples, the imbalance rate is 0.1090, the method generates 192 samples, the fourth class of 13 samples generates an imbalance rate of 0.05909, and the method generates 209 samples.
In the fifth class of 8 samples, the imbalance rate is 0.0363 and the method generates 208 samples; in the sixth class of 21 samples, the imbalance rate is 0.0954 and the method generates 207 samples; in the seventh class of 50 samples, the imbalance rate is 0.2272 and the method generates 181 samples, and in the last class of 8 samples, the imbalance rate is 0.0363 and the method generates 211 samples of the minority class. ADASY displays the balance of eight groups in Figure 3. The multiple classes' classification problem is described. The algorithm representation is shown in Algorithm 1.
Algorithm 1.

ADASYN.
3.3. Feature Selection Method
This stage is of significant importance as rarely distinguishable features are discarded, which increases the computational burden on the modeling process. In the present study, ReliefF algorithm was used for dimensional reduction as ReliefF is proved to be computationally efficient and has been proved to be sensitive to complex patterns of association [47–50]. It was used to estimate attributes based upon how their values reflect variations between instances close to each other. By using the abovementioned method, 88 raw features were selected and reduced to 10 optimal features because of their participation topmost according to the weightage to get maximum accuracy. The graph shows 99.5%.
Accuracy at 10 features and 12 features is 100%. This is shown in Figure 4. So that is why we select 10 features. There is not much difference in output, so we skip the remaining ones because that elevates the computational burden of a model. The graph in Figure 4 shows cumulative accuracy against feature numbers which are selected as 10 features that can participate more than total variances.
Figure 4.

Cumulative accuracy against feature numbers.
3.3.1. ReliefF Algorithm
ReliefF is capable of accurately evaluating the quality of attributes with heavy correlations between attributes in classification problems. They have a global perspective by leveraging local knowledge generated by distinct contexts. ReliefF makes a ranking of features according to weight-age and the ones who are participating the most come in the first predictor rank. Other features contain nearly less contribution toward the last as shown in Figure 5. So we can select the 10 most powerful features according to their weight-age and skip irrelevant features that elevate the computational burden of the model [47–49].
Figure 5.

Weight ranking of features.
Original ReliefF is work done with two classes: difficulties and a stronger class, which deal with noisy data and imperfect data. It is used to calculate feature usability for every feature which can later be applied in order to select features that contain top scores for feature selection. Likewise, ReliefF selects an instance T randomly (Step 3), but later, k observes the closest neighbors of the same class called the nearest hit values of H. So we use the number of nearest neighbors as 3 to mean a positive integer scalar (Step 4), and in the same manner, k-nearest neighbors are the value of one to one of the various classes, called nearest misses M(T) values (Steps 5 and 6). It also updates the accuracy of the W[A] class estimate for each attribute A, based on their values for T, hits H, and misses M(T) (Steps 7 and 8) as in Algorithm 2.
Algorithm 2.

ReliefF algorithm representation.
4. Classification
4.1. Feedforward Neural Network
Classification of morphological images of each class and identifying cancerous conditions seem to be very complex. Feedforward neural network is used to classify tumors [41]. This algorithm is the fastest backpropagation algorithm and is strongly recommended to be used as a first choice supervised algorithm and does not need more memory than others. The network has used four hidden layers. Feedforward neural network was developed by using “newff,” command. The first hidden layer of the network contained 40 neurons having linear transfer function. The second secret layer held 20 hidden neurons. And the third and fourth secret layers contained 10 and 8 hidden neurons. The four-layer network shown (Layer-4) is the output layer and the remaining three layers are hidden layers (Layer-1, 2, 3). The problem under consideration was multilabel classification. For problems with more than two classes, the softmax function is used with multinomial cross-entropy as the cost function; it updated the weight as well as bias values conferring to Levenberg–Marquardt optimization. Data is classified into training, validation, and testing as 60 percent is for preparation, 20 percent is for validation, and the remaining 15 percent is for research. It is fastest for training a moderate-sized FNN. It has been deduced that this optimization is used for approaching second direction training speed without the Hessian matrix. On the other hand, training feedforward networks Hessian matrix can be as
| (2) |
Gradient will be
| (3) |
where J represents Jacobian matrix having network errors derivate regarding biases and weights and network errors represent vector by “e.” A network has four layers. Each layer has a matrix of “W” mass, a vector of ‘b' bias, and an output vector “a.” To differentiate between matrices of weight, vectors of output, etc., in our estimates for each one of these layers, we are adding the layer number as a superscript to the interest variable. In the four-layer network seen in Figure 6, you can see the use of this layer notation and in the calculations at the bottom of the diagram.
Figure 6.
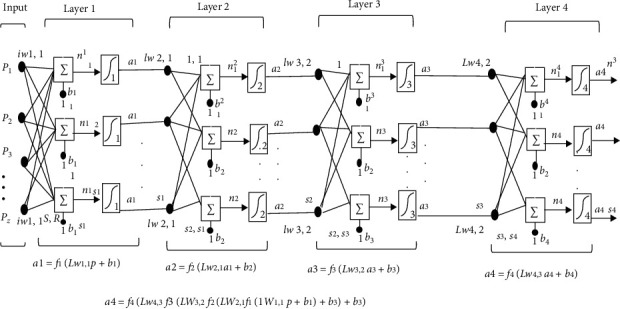
Multiple layers of FNN.
The network is shown in Figure 6, below R1 inputs, S1 neurons first layer, S2 neurons second layer, etc. For different layers, it is common to have different neuron numbers. For each neuron, the constant input 1 is fed to the biases.
Notice that each intermediate layer's outputs are the inputs to the following layer. It is also possible to evaluate layer 2 as a one-layer network with S1 inputs, S2 neurons, and a W2 weight matrix of S2 × S1. A1 is the input to layer 2; a2 is the output. Now that we have identified all the vectors and matrices of layer 2 and so on with other layers, the output layer of the network is the last layer. This approach can be adjusting weight as shown in Figure 7.
Figure 7.

Adjusting weight and comparing the output with the target.
5. Experimental Results and Discussion
The proposed model for MATLAB 2017a has been created. It was used on a Core-i7 processor personal computer with 8GB of RAM as well as 2GB of the graphics card. Mammographic photographs have been used for the study of the scheme proposed. These photographs were taken from the INbreast dataset [26], created by multiple University of Porto institutions, and made available to the public with the permission of the authors. The dataset had a total of 411 images. The matrix of the images was 3328 × 4084 or 2560 × 3328 pixels, while the images were processed in DICOM format. The present research used 411 mammogram images and was further divided into 6 classes according to the Breast Imaging-Reporting and Data System (BI-RADS) class [26] and the classification is shown in Figure 8. It is a risk management and quality assurance method developed by the American College of Radiology that offers a generally recognized lexicon and reporting scheme for breast imaging as shown in Table 1. This refers to mammography, ultrasound, and MRI.
Figure 8.

INbreast dataset of BI-RADS categories.
Table 1.
Classification of 8 categories with respective classes.
| Breast image categories | Classes | No. of images |
|---|---|---|
| BI-RADS 1 | Negative | 67 |
| BI-RADS 2 | Benign | 220 |
| BI-RADS 3 | Probably benign | 24 |
| BI-RADS 4A | Low suspicion for malignancy | 13 |
| BI-RADS 4B | Moderate suspicion for malignancy | 8 |
| BI-RADS 4C | High suspicion for malignancy | 21 |
| BI-RADS 5 | Highly suggestive of malignancy | 30 |
| BI-RADS 6 | Known biopsy-proven malignancy | 8 |
|
| ||
| Total | 411 | |
The archive is accessible on this web page.
http://medicalresearch.inescporto.pt/breastresearch/index.php/Get_INbreast_Database.
5.1. Performance Analysis of the Proposed Method
Multilabel classification and the closely related problem of multioutput classification are variations of the classification problem where several labels can be applied to each case. Multilabel classification is a generalization of multiclass classification [51], which is the single-label problem of categorizing instances into exactly one of more than two classes; there is no restriction on how many of the classes an instance may be allocated to in the multilabel problem. In our case of Multiclass Classification Issue to be an 8-Class Classification Issue since we have a dataset that has eight class names, sensitivity, precision, and consistency are very critical for the system. Sensitivity reflected the proportion of both positive and genuinely positive events [52]. Specificity showed the percentage of true negative classified cases.
Meanwhile, accuracy depicted the percentage of true positive and true negative correctly classified mammograms. The confusion matrix represented in Figure 8 shows the actual and predicted class count obtained by the classifier. But multiclass classification is an implementation of unlikely binary classification of mammograms. Since the classes here are not positive or negative, at first, it may be a little difficult to find TP, TN, FP, and FN because there are no positive or negative grades, but it is pretty simple. What we did here, for each person class, was to find TP, TN, FP, and FN. We take class BI-RADS 1 and then let us see the values of the metrics from the confusion matrix. Confusion matrix is represented in Figure 8, so we find about true positive (TP) of multiclass values in the diagonal form in green color. If we want to find an overall matrix of TP value, we should add all classes of TP values. For false positive (FP) sum of values in the corresponding column and excluding TP values and for overall, we can sum all classes of FP values. For the false negative (FN) number of values in the following row and except for the TP value, all groups of FN values can be summed overall. For the true negative (TN) class, it is not difficult to take the number of columns and rows and deduct the column and row class. The assessment metrics written below are those of the following.
Sensitivity is used to deal with positive cases only. The ratio of classified to the actual positive cases is shown by sensitivity. When sensitivity is high, the false negative rate is less.
| (4) |
Specificity deals with negative cases only. It is used to depict the ratio of actual negative cases to classified ones. When specificity is greater, the false positive rate is less.
| (5) |
Positive predictive value (PPV) is used to deal with positive predictive cases only. The ratio of classified to the actual positive predictive cases is shown by PPV.
| (6) |
Negative predictive value (NPV) deals with negative predictive cases only. It is used to depict the ratio of actual negative predictive cases to classified ones. When NPV is greater, the false positive predictive rate is less.
| (7) |
Accuracy deals with the correctness of classification results. The system is considered efficient when accuracy is more.
| (8) |
Data is classified into training, validation, and testing by using 10 global features, in which 60% is for training, 20% is considered for validation, and the remaining 20% is for testing.
5.1.1. Training on INbreast Dataset
For the training purpose without oversampling, 287 images out of 411 images are used in which 277 images are correctly classified and 10 of them are misclassified. And after using oversampling ADASYN, we used 1241 images out of 1773 images, in which 1233 images are correctly classified and 8 images are misclassified.
5.1.2. Validation on INbreast Dataset
For validation purpose without oversampling, 62 images out of 411 images are used for validation. 60 images are correctly classified for the validation process and 2 are misclassified, and after oversampling ADASYN, 266 images out of 1773 images are used for validation purpose. And all of the 266 images are correctly classified and no image is misclassified.
5.1.3. Testing on INbreast Dataset
For the testing purpose without oversampling, 62 images out of 411 images are used for testing. 59 images are correctly classified testing process and 3 are misclassified class, and after oversampling ADASYN, 266 images out of 1773 images are used for testing purpose, in which 265 images are correctly classified and 1 image is misclassified.
5.1.4. Overall on INbreast Dataset
For the overall talk about without oversampling, 411 images are used in which 396 are correctly classified and 15 images are misclassified.
After applying oversampling ADASYN, 1773 images are used, in which 1764 images are correctly classified and 6 images are misclassified.
5.2. Classification Results of Raw Samples
Three phases are included in the proposed framework: feature extraction, feature selection, and classification. Firstly, with 411 samples, the classification results are examined in raw form for 88 features [42]. And then the ReliefF algorithm chooses the 10 most contributory characteristics [50]. Through comparing the output of the classification processes by the FNN algorithm, the contribution of the oversampling system is explored. And there results of each class are shown in Table 2. And individual class accuracy is defined in Figure 9.
Table 2.
Classification with raw samples.
| Method | ReliefF optimal features with raw samples | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Breast image categories | True positive | True negative | False positive | False negative | Recall rate | Precision | F1-score | Misclassification rate | Accuracy |
| BI-RADS 1 | 67 | 334 | 0 | 0 | 100 | 100 | 100 | 0 | 100 |
| BI-RADS 2 | 220 | 191 | 0 | 0 | 100 | 100 | 100 | 0 | 100 |
| BI-RADS 3 | 20 | 386 | 1 | 4 | 83.3 | 95.2 | 88.9 | 1.2% | 98.5 |
| BI-RADS 4A | 8 | 395 | 3 | 5 | 61.5 | 72.7 | 66.7 | 1.9% | 98.05 |
| BI-RADS 4B | 5 | 40 | 2 | 3 | 62.5 | 71.4 | 66.7 | 10% | 90 |
| BI-RADS 4C | 21 | 382 | 8 | 0 | 100 | 72.4 | 84 | 1.9% | 98.05 |
| BI-RADS 5 | 50 | 360 | 1 | 0 | 100 | 98.0 | 99 | 0.2% | 99.75 |
| BI-RADS 6 | 5 | 403 | 0 | 3 | 62.5 | 100 | 76.92 | 0.7% | 99.3 |
Figure 9.

Model shows multiclass samples and obtains each class accuracy.
Figure 9 shows individual accuracy of each class with samples of classes.
5.3. Classification Results Balance by ADASYN
The methods involve four steps: feature extraction, oversampling, feature selection, and classification. Here is the oversampling method ADASYN which helps balance all classes until the imbalanced rate will be closest to 1. And it also prevents overfit problem. ADASYN bases its operation on weighting the examples of the minority classes according to their difficulty of being learned; therefore more synthetic data will be generated from the more difficult samples, and fewer samples are in the case of the easier to learn [25]. The majority class only provides information to quantify the degree of class imbalance, and the number of synthetic data examples to be generated for the minority class in Table 3 shows the output parameters of the 10 most significant feature vectors consisting of 1773 samples of the ADAYSN algorithm. Accuracy of each class is shown in Figure 10. Growing the minority groups with synthetic samples is shown to have a beneficial impact on the accuracy of classification. And the results of each class are shown in Table 3.
Table 3.
Classification with ADASYN samples.
| Method | ReliefF optimal features with ADASYN samples | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Breast image categories | True positive | True negative | False positive | False negative | Recall rate | Precision | F1-score (%) | Misclassification rate | Accuracy |
| BI-RADS 1 | 220 | 1546 | 0 | 1 | 99.5 | 100 | 99.8 | 0.1 | 99.9 |
| BI-RADS 2 | 220 | 1552 | 1 | 0 | 100 | 99.5 | 99.8 | 0.1 | 99.9 |
| BI-RADS 3 | 214 | 1557 | 0 | 2 | 99.1 | 100 | 99.5 | 0.1 | 99.9 |
| BI-RADS 4A | 222 | 1549 | 0 | 0 | 100 | 100 | 100 | 0 | 100 |
| BI-RADS 4B | 215 | 1557 | 0 | 1 | 99.5 | 100 | 99.8 | 0.1 | 99.9 |
| BI-RADS 4C | 228 | 1317 | 2 | 0 | 100 | 99.1 | 99.6 | 0.1 | 99.9 |
| BI-RADS 5 | 226 | 1539 | 3 | 5 | 97.8 | 98.7 | 98.3 | 0.5 | 99.5 |
| BI-RADS 6 | 219 | 1551 | 3 | 0 | 100 | 98.6 | 99.3 | 0.2 | 99.8 |
Figure 10.

Model shows multiclass samples and obtains each class accuracy by ADASYN.
The definition made with the inclusion of synthetic samples is seen to generate a contribution of more. One of the most relevant factors is to eliminate the imbalance between classes shown in Table 4. After accuracy level improved, in the confusion matrix, the correctly classified cases are shown in Figure 11. Diagonal is within green color, while misclassified cases are shown in red color. The last column of the confusion matrix shows the sensitivity, precision, and accuracy of the model.
Table 4.
The comparative results between imbalance and balance samples.
| Method | Micro F1 (%) | Macro F1 (%) | Weight F1 (%) | Misclassification rate (%) | Recall rate (%) | Specificity (%) | Precision (%) | Accuracy (%) |
|---|---|---|---|---|---|---|---|---|
| ReliefF features with 411 samples | 96.35 | 85.23 | 96.3 | 3.54 | 96.35 | 98.98 | 96.35 | 96.46 |
| ReliefF features with 1773 samples | 99.5 | 99.5 | 99.5 | 0.5 | 99.5 | 99.4 | 99.5 | 99.5 |
Figure 11.

ReliefF optimal features with 1773 samples.
The training state is presented in Figure 12. The gradient is the value of the backpropagation gradient on every iteration. Epoch shows how many iterations should be shown for training purposes. And MU is momentum update which includes weight update expression to avoid the problem of a local minimum.
Figure 12.

Training state of the proposed model.
The performance plot for training is shown in Figure 13. Training mean square error (mse) is downloading which shows perfect training. Best training performance shows few errors determined in Figure 13, which shows 0.0012691 error estimates that are minimal error rate.
Figure 13.

Performance plot showing mse reduction while training.
The network's ability to estimate the model target is evaluated by showing the regression plot in Figure 14. Regression evaluation can support a model that links between a dependent variable (which you are seeking to forecast) and one or better independent variables (the input of the model). Regression evaluation can determine if there is a considerable link between the independent variables and the dependent variable and the weight of the impact—when the independent variables move, by how much you can predict the dependent variable to proceed. Here we use linear regression to achieve the number of outputs. Linear regression is suitable for dependent variables that are stable and can be fitted with a linear function (straight line). The plot shows that the linear regression of the targets relatively achieves the numbers of outputs.
Figure 14.

Regression plot for training, testing, and validation.
The plot shows that the linear regression of the training, validation, and testing and overall targets of comparison achieves the number of outputs.
5.4. Comparison with Work
Many researchers have worked on those key modules of CAD. This created a need to develop a computer-aided diagnosis system. It has two aims. First is the disclosure of abnormal breasts from mammographic images by an innovative approach. And the second is various classes' classification that uniquely explains all classes according to BI-RADS. For tumor identification, few features contribute to a poor classification due to a slight variation in textures. The present thesis focuses on 5 different algorithms for the extraction of features that can extract different features. Then, because of the overfitting problem, we purpose the oversampling technique by ADASYN that increases the number of samples which also increases algorithm complexity and train time. So for that, we apply feature selection techniques such as ReliefF. And for multiple class classification, we use FNN and the results are shown by a confusion matrix.
Table 5 shows that Abdel-Nasser et al. [2] used local database by extracting 20 optimal features and SVM classifier to obtain accuracy of 88.0%. Pérez et al. [18] in 2011 used DDSM dataset and extracted GLCM + GLCLM 19 features from a region of interest (ROI) to obtain accuracy of 94.9% and furthermore on second hand selected 12 most contribution features of GLCM + GLCLM and got 92.3% accuracy. For classifying tumor region, they used a Boolean vector algorithm. Nababan et al. [16] used Mini MIAS dataset and got 92.26% sensitivity, 92.28% specificity, and 92.27% accuracy. Wang's 16,777,216 features were further reduced to 18 features by using PCA and FFN. Frisk et al. [5] used INbreast dataset and extracting GLCM 16 features from ROI and for classification used SECoS techniques obtaining 82.98% accuracy. Alam and Faruqui [39] expanded the previous work in 2012 and classified by decision tree and obtained accuracy of 96.7% by extracting 19 features and also obtained accuracy of 93.3% by extracting 12 most contributed features. Ozturk et al. used shrunken features which includes GLCM + LBGLCM + GLRLM + SFTA, for oversampling by SMOTE algorithms and classification use and PCA after which they got 94% accuracy for a COVID-19 dataset. We purposed a model by using INbreast dataset; the proposed model focuses on four steps: global feature extraction, oversampling method, feature selection method, and lastly classification and we got 99.5% sensitivity, 99.4% specificity, and 99.5% accuracy.
Table 5.
Result of proposed system and comparison with methodology by using features.
| Existing solution | Methodology | Features | Accuracy (%) |
|---|---|---|---|
| Abdel-Nasser et al. [2] | Local database + GLCM + SVM | 20 | 88.0% |
| Pérez et al. [18] | DDSM + ROI + GLCM + GLCLM + Boolean vector | 19 12 | 94.9% 92.3% |
| Nababan et al. [16] | Mini MIAS + WFRFT + Jaya-FNN | 18 | 92.27% |
| Nababan [5] | INbreast + ROI + GLCM + SECoS | 16 | 82.98% |
| Mohanty et al. [49] | DDSM + ROI + GLCM + GLCLM + decision tree | 19 12 | 96.7% 93.6% |
| Ozturk et al. [42] | Shrunken features + SMOTE + PCA | 20 | 94.23% |
| Proposed system | INbreast + (GLCM, LBP, LBGLCM, GLRLM, and SFTA) + ADASYN + FNN | 10 | 99.5% |
6. Conclusion
Various investigations have been carried out in the field of medicine to study medical disorders and thus to find their correct diagnosis. For this purpose, in the present work, data mining techniques were considered. By utilizing fewer numbers of features, the computational time was reduced without dropping the accuracy of diagnosis. Instead of using complex systems to strengthen the classification accuracy, an effort was made to adopt a simple method to produce a significant result. The results showed 99.5% accuracy which proved the effectiveness as well as the robustness of the proposed system.
Acknowledgments
The authors thank their supervisor Mr. Shengjun Xu who gave consistent support, motivation, and expert guidance to complete the research work and also the Chinese Government who gave this support and funding. This research was done under the supervision of Shengjun Xu and funded by the National Natural Science Foundation of China (Nos. 51678470 and 61803293) and also supported by the National Natural Science Foundation of Shaanxi Province, China (2019JQ-760).
Contributor Information
Taha Muthar Khan, Email: tahakhan05@yahoo.com.
Shengjun Xu, Email: sjxu@xauat.edu.cn.
Data Availability
The archive is accessible on the web page http://medicalresearch.inescporto.pt/breastresearch/index.php/Get_INbreast_Database.
Conflicts of Interest
The authors declare no conflicts of interest in this research.
References
- 1.Giordano S. H., Buzdar A. U., Smith T. L., Kau S.-W., Yang Y., Hortobagyi G. N. Is breast cancer survival improving? Cancer. 2004;100(1):44–52. doi: 10.1002/cncr.11859. [DOI] [PubMed] [Google Scholar]
- 2.Abdel-Nasser M., Moreno A., Puig D. Temporal mammogram image registration using optimized curvilinear coordinates. Computer Methods and Programs in Biomedicine. 2016;127:1–14. doi: 10.1016/j.cmpb.2016.01.019. [DOI] [PubMed] [Google Scholar]
- 3.Fried L. P., Tangen C. M., Walston J., et al. Frailty in older adults: evidence for a phenotype. The Journals of Gerontology Series A: Biological Sciences and Medical Sciences. 2001;56(3):M146–M157. doi: 10.1093/gerona/56.3.m146. [DOI] [PubMed] [Google Scholar]
- 4.Gilmore N., Mohile S., Lie L., et al. The longitudinal relationship between immune cell profiles and frailty in patients with breast cancer receiving chemotherapy. Breast Cancer Research. 2021;23(1):1–11. doi: 10.1186/s13058-021-01388-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Frisk G., Ekberg S., Lidbrink E., et al. No association between low-dose aspirin use and breast cancer outcomes overall: a Swedish population-based study. Breast Cancer Research. 2018;20(1):1–10. doi: 10.1186/s13058-018-1065-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Fan B., Li Y., Wen G., et al. Personalized body constitution inquiry based on machine learning. Journal of Healthcare Engineering. 2020;2020 doi: 10.1155/2020/8834465.8834465 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Aldhaeebi M. A., Alzoubi K., Almoneef T. S., Bamatraf S. M., Attia H., Ramahi O. M. Review of microwaves techniques for breast cancer detection. Sensors. 2020;20(8):p. 2390. doi: 10.3390/s20082390. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Asri H., Mousannif H., Moatassime H. A., Noel T. Using machine learning algorithms for breast cancer risk prediction and diagnosis. Procedia Computer Science. 2016;83:1064–1069. doi: 10.1016/j.procs.2016.04.224. [DOI] [Google Scholar]
- 9.Jalalian A., Mashohor S., Mahmud R., Karasfi B., Saripan M. I. B., Ramli A. R. B. Foundation and methodologies in computer-aided diagnosis systems for breast cancer detection. EXCLI Journal. 2017;16:p. 113. doi: 10.17179/excli2016-701. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Nedeljkovic I. Image classification based on fuzzy logic. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences. 2004;34(30):3–7. [Google Scholar]
- 11.Öztürk Ş., Akdemir B. Application of feature extraction and classification methods for histopathological image using GLCM, LBP, LBGLCM, GLRLM and SFTA. Procedia Computer Science. 2018;132:40–46. doi: 10.1016/j.procs.2018.05.057. [DOI] [Google Scholar]
- 12.He H., Bai Y., Garcia E. A., Li S. ADASYN: adaptive synthetic sampling approach for imbalanced learning. Proceedings of the 2008 IEEE international joint conference on neural networks (IEEE world congress on computational intelligence); June 2008; Hong Kong, China. IEEE; pp. 1322–1328. [Google Scholar]
- 13.Milosevic M., Jankovic D., Peulic A. Comparative analysis of breast cancer detection in mammograms and thermograms. Biomedical Engineering/Biomedizinische Technik. 2015;60(1):49–56. doi: 10.1515/bmt-2014-0047. [DOI] [PubMed] [Google Scholar]
- 14.Petrosian A., Chan H.-P., Helvie M. A., Goodsitt M. M., Adler D. D. Computer-aided diagnosis in mammography: classification of mass and normal tissue by texture analysis. Physics in Medicine and Biology. 1994;39(12):p. 2273. doi: 10.1088/0031-9155/39/12/010. [DOI] [PubMed] [Google Scholar]
- 15.Iseri I., Oz C. Computer aided detection of microcalcification clusters in mammogram images with machine learning approach. Optoelectronics and Advanced Materials. 2014;8:689–695. [Google Scholar]
- 16.Nababan E. B., Iqbal M., Rahmat R. F. Breast cancer identification on digital mammogram using evolving connectionist systems. Proceedings of the 2016 International Conference on Informatics and Computing (ICIC); October 2016; Mataram, Indonesia. IEEE; pp. 132–136. [Google Scholar]
- 17.Singh B., Jain V. K., Singh S. Mammogram mass classification using support vector machine with texture, shape features and hierarchical centroid method. Journal of Medical Imaging and Health Informatics. 2014;4(5):687–696. doi: 10.1166/jmihi.2014.1312. [DOI] [Google Scholar]
- 18.Pérez N. P., Guevara López M. A., Silva A., Ramos I. Improving the Mann-Whitney statistical test for feature selection: an approach in breast cancer diagnosis on mammography. Artificial Intelligence in Medicine. 2015;63(1):19–31. doi: 10.1016/j.artmed.2014.12.004. [DOI] [PubMed] [Google Scholar]
- 19.Kinoshita S., Marques P. A., Slaets A., Marana H. R., Ferrari R. J., Villela R. Digital Mammography. Berlin, Germany: Springer; 1998. Detection and characterization of mammographic masses by artificial neural network; pp. 489–490. [Google Scholar]
- 20.Anitha J., Peter J. D. Mammogram segmentation using maximal cell strength updation in cellular automata. Medical & Biological Engineering & Computing. 2015;53(8):737–749. doi: 10.1007/s11517-015-1280-0. [DOI] [PubMed] [Google Scholar]
- 21.Peng N. J., Chou C. P., Pan H. B., et al. FDG‐PET/CT detection of very early breast cancer in women with breast microcalcification lesions found in mammography screening. Journal of Medical Imaging and Radiation Oncology. 2015;59(4):445–452. doi: 10.1111/1754-9485.12309. [DOI] [PubMed] [Google Scholar]
- 22.Molloi S., Ding H., Feig S. Breast density evaluation using spectral mammography, radiologist reader assessment, and segmentation techniques. Academic Radiology. 2015;22(8):1052–1059. doi: 10.1016/j.acra.2015.03.017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Kegelmeyer W. P., Jr Evaluation of stellate lesion detection in a standard mammogram data set. International Journal of Pattern Recognition and Artificial Intelligence. 1993;07(06):1477–1492. doi: 10.1142/s0218001493000728. [DOI] [Google Scholar]
- 24.Görgel P., Sertbas A., Uçan O. N. Computer-aided classification of breast masses in mammogram images based on spherical wavelet transform and support vector machines. Expert Systems. 2015;32(1):155–164. doi: 10.1111/exsy.12073. [DOI] [Google Scholar]
- 25.Mohanty F., Rup S., Dash B., Majhi B., Swamy M. N. S. Mammogram classification using contourlet features with forest optimization-based feature selection approach. Multimedia Tools and Applications. 2019;78(10):12805–12834. doi: 10.1007/s11042-018-5804-0. [DOI] [Google Scholar]
- 26.Abdel-Nasser M., Moreno A., Puig D. Breast cancer detection in thermal infrared images using representation learning and texture analysis methods. Electronics. 2019;8(1):p. 100. doi: 10.3390/electronics8010100. [DOI] [Google Scholar]
- 27.Wang S., Rao R. V., Chen P., Zhang Y., Liu A., Wei L. Abnormal breast detection in mammogram images by feed-forward neural network trained by Jaya algorithm. Fundamenta Informaticae. 2017;151(1-4):191–211. doi: 10.3233/fi-2017-1487. [DOI] [Google Scholar]
- 28.Welch H. G., Prorok P. C., O’Malley A. J., Kramer B. S. Breast-cancer tumor size, overdiagnosis, and mammography screening effectiveness. New England Journal of Medicine. 2016;375(15):1438–1447. doi: 10.1056/nejmoa1600249. [DOI] [PubMed] [Google Scholar]
- 29.Mohanty A. K., Beberta S., Lenka S. K. Classifying benign and malignant mass using GLCM and GLRLM based texture features from mammogram. International Journal of Engineering Research and Applications. 2011;1(3):687–693. [Google Scholar]
- 30.Lin T.-Y., Goyal P., Girshick R., He K., Dollár P. Focal loss for dense object detection. Proceedings of the IEEE international conference on computer vision; October 2017; Venice, Italy. pp. 2980–2988. [Google Scholar]
- 31.Khan S. H., Hayat M., Bennamoun M., Sohel F. A., Togneri R. Cost-sensitive learning of deep feature representations from imbalanced data. IEEE Transactions on Neural Networks and Learning Systems. 2017;29(8):3573–3587. doi: 10.1109/TNNLS.2017.2732482. [DOI] [PubMed] [Google Scholar]
- 32.Yang S.-N., Li F.-J., Liao Y.-H., Chen Y.-S., Shen W.-C., Huang T.-C. Identification of breast cancer using integrated information from MRI and mammography. PLoS One. 2015;10(6) doi: 10.1371/journal.pone.0128404. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Wong M. L., Seng K., Wong P. K. Cost-sensitive ensemble of stacked denoising autoencoders for class imbalance problems in business domain. Expert Systems with Applications. 2020;141 doi: 10.1016/j.eswa.2019.112918.112918 [DOI] [Google Scholar]
- 34.Basgall M. J., Hasperué W., Naiouf M., Fernández A., Herrera F. Conference on Cloud Computing and Big Data. Berlin, Germany: Springer; 2019. An analysis of local and global solutions to address big data imbalanced classification: a case study with SMOTE preprocessing; pp. 75–85. [Google Scholar]
- 35.González-Barcenas V., Rendón E., Alejo R., Granda-Gutiérrez E., Valdovinos R. M. Iberian Conference on Pattern Recognition and Image Analysis. Berlin, Germany: Springer; 2019. Addressing the big data multi-class imbalance problem with oversampling and deep learning neural networks; pp. 216–224. [Google Scholar]
- 36.Moreira I. C., Amaral I., Domingues I., Cardoso A., Cardoso M. J., Cardoso J. S. INbreast. Academic Radiology. 2012;19(2):236–248. doi: 10.1016/j.acra.2011.09.014. [DOI] [PubMed] [Google Scholar]
- 37.Albregtsen F., Nielsen B., Danielsen H. E. Adaptive gray level run length features from class distance matrices. Proceedings of the 15th International Conference on Pattern Recognition. ICPR-2000; September 2000; Barcelona, Spain. IEEE; pp. 738–741. [Google Scholar]
- 38.Sastry S. S., Kumari T. V., Rao C. N., Mallika K., Lakshminarayana S., Tiong H. S. Transition temperatures of thermotropic liquid crystals from the local binary gray level cooccurrence matrix. Advances in Condensed Matter Physics. 2012;2012 doi: 10.1155/2012/527065.527065 [DOI] [Google Scholar]
- 39.Alam F. I., Faruqui R. U. Optimized calculations of haralick texture features. European Journal of Scientific Research. 2011;50(4):543–553. [Google Scholar]
- 40.Heikkilä M., Pietikäinen M., Schmid C. Description of interest regions with local binary patterns. Pattern Recognition. 2009;42(3):425–436. doi: 10.1016/j.patcog.2008.08.014. [DOI] [Google Scholar]
- 41.Gunay A., Nabiyev V. V. Automatic age classification with LBP. Proceedings of the 2008 23rd International Symposium on Computer and Information Sciences; October 2008; Istanbul, Turkey. IEEE; pp. 1–4. [Google Scholar]
- 42.Ozturk S., Ozkaya U., Barstugan M. Classification of coronavirus images using shrunken features. 2020. [DOI] [PMC free article] [PubMed]
- 43.Sohail A. S. M., Bhattacharya P., Mudur S. P., Krishnamurthy S. Local relative GLRLM-based texture feature extraction for classifying ultrasound medical images. Proceedings of the 2011 24th Canadian Conference on Electrical and Computer Engineering (CCECE); May 2011; Niagara Falls, Canada. IEEE; pp. 001092–001095. [Google Scholar]
- 44.Traina C., Jr, Traina A., Wu L., Faloutsos C. Fast feature selection using fractal dimension. Journal of Information and Data Management. 2010;1(1):p. 3. [Google Scholar]
- 45.Gosain A., Sardana S. Computational Intelligence in Data Mining. Berlin, Germany: Springer; 2019. Farthest SMOTE: a modified SMOTE approach; pp. 309–320. [Google Scholar]
- 46.Gosain A., Sardana S. Handling class imbalance problem using oversampling techniques: a review. Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI); September 2017; Manipal, India. IEEE; pp. 79–85. [Google Scholar]
- 47.Kira K., Rendell L. A. Machine Learning Proceedings. Amsterdam, Netherlands: Elsevier; 1992. A practical approach to feature selection; pp. 249–256. [Google Scholar]
- 48.Urbanowicz R. J., Meeker M., La Cava W., Olson R. S., Moore J. H. Relief-based feature selection: introduction and review. Journal of Biomedical Informatics. 2018;85:189–203. doi: 10.1016/j.jbi.2018.07.014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Mohanty A. K., Senapati M. R., Beberta S., Lenka S. K. Texture-based features for classification of mammograms using decision tree. Neural Computing and Applications. 2013;23(3-4):1011–1017. doi: 10.1007/s00521-012-1025-z. [DOI] [Google Scholar]
- 50.Spolaôr N., Cherman E. A., Monard M. C., Lee H. D. ReliefF for multi-label feature selection. Proceedings of the 2013 Brazilian Conference on Intelligent Systems; October 2013; Fortaleza, Brazil. IEEE; pp. 6–11. [Google Scholar]
- 51.Ren D., Amershi S., Lee B., Suh J., Williams J. D. Squares: supporting interactive performance analysis for multiclass classifiers. IEEE Transactions on Visualization and Computer Graphics. 2016;23(1):61–70. doi: 10.1109/TVCG.2016.2598828. [DOI] [PubMed] [Google Scholar]
- 52.Panca V., Rustam Z. AIP Conference Proceedings. Vol. 1862. Melville, NY, USA: AIP Publishing LLC; 2017. Application of machine learning on brain cancer multiclass classification.030133 [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The archive is accessible on the web page http://medicalresearch.inescporto.pt/breastresearch/index.php/Get_INbreast_Database.