

Graphical abstract

Keywords: Deep learning, Convolutional neural networks, COVID-19, Coronavirus, Radiology, CT scan, Medical image analysis, Automatic medical diagnosis, Lung CT scan dataset
Abstract
This paper aims to propose a high-speed and accurate fully-automated method to detect COVID-19 from the patient's chest CT scan images. We introduce a new dataset that contains 48,260 CT scan images from 282 normal persons and 15,589 images from 95 patients with COVID-19 infections. At the first stage, this system runs our proposed image processing algorithm that analyzes the view of the lung to discard those CT images that inside the lung is not properly visible in them. This action helps to reduce the processing time and false detections. At the next stage, we introduce a novel architecture for improving the classification accuracy of convolutional networks on images containing small important objects. Our architecture applies a new feature pyramid network designed for classification problems to the ResNet50V2 model so the model becomes able to investigate different resolutions of the image and do not lose the data of small objects. As the infections of COVID-19 exist in various scales, especially many of them are tiny, using our method helps to increase the classification performance remarkably. After running these two phases, the system determines the condition of the patient using a selected threshold. We are the first to evaluate our system in two different ways on Xception, ResNet50V2, and our model. In the single image classification stage, our model achieved 98.49% accuracy on more than 7996 test images. At the patient condition identification phase, the system correctly identified almost 234 of 245 patients with high speed. Our dataset is accessible at https://github.com/mr7495/COVID-CTset.
1. Introduction
On January 30, 2020, the World Health Organization (WHO) announced the outbreak of a new viral disease as an international concern for public health, and on February 11, 2020, WHO named the disease caused by the new coronavirus: COVID-19 [38]. The first patients with COVID-19 were observed in Wuhan, China. These people were associated with the local wild animal market, which indicates the possibility of transmitting the virus from animals to humans [33]. The severe outbreak of the new coronavirus spread rapidly throughout China and then spread to other countries. The virus disrupted many political, economic, and sporting events and affected the lives of many people worldwide.
The most important feature of the new coronavirus is its fast and wide-spreading capability. The virus is mainly transmitted directly from people with the disease to others; It is transmitted indirectly through the surfaces and air in the environment in which the infected people come in contact with it [38]. As a result, correctly identifying the symptoms of people with the disease and quarantining them plays a significant role in preventing the disease.
New coronavirus causes viral pneumonia in the lungs, which results in severe acute respiratory syndrome. The new coronavirus causes a variety of changes in the sufferer. The most common symptoms of new coronavirus are fever, dry cough, and tiredness [38]. The symptoms of this disease vary from person to person [21]. Other symptoms such as loss of sense of smell and taste, headache, and sore throat may occur in some patients, but severe symptoms that indicate the further progression of COVID-19 include shortness of breath, chest pain, and loss of ability to move or Talking [38].
There are several methods for the definitive diagnosis of COVID-19, including reverse transcriptase-polymerase chain reaction (RT-PCR), Isothermal nucleic amplification test, Antibody test, Serology tests, and medical imaging [39].
RT-PCR is the primary method of diagnosing COVID-19 and many viral diseases. However, the method is restricted for some of the assays as higher expertise and experimentation are required to develop new assays [10]. Besides, the lack of diagnostic kits in most contaminated areas around the world is leading researchers to come up with new and easier ways to diagnose the disease.
Due to the availability of medical imaging devices in most treatment centers, the researchers analyze CT scans and X-rays to detect COVID-19. In most patients with COVID-19, infections are found in the lungs of people with new coronavirus that can help diagnose the disease. Analysis of CT scans of patients with COVID-19 showed pneumonia caused by the new coronavirus [33]. With the approval of radiologists for the ability to use CT scans and X-rays to detect COVID-19, various methods have been proposed to use these images.
Most patients who have COVID-19 symptoms at least four days later have X-rays and CT scans of their lungs, showing infections that confirm the presence of a new coronavirus in their body [4]. Although medical imaging is not recommended for definitive diagnosis, it can be used for early COVID-19 diagnosis due to the limitations of other methods [3].
In [40], [4], some patients with early-onset COVID-19 symptoms were found to have new coronavirus infections on their CT scans. At the same time, their RT-PCR test results were negative, then both tests were repeated several days later, and RT-PCR confirmed the CT scan's diagnostic results. Although medical imaging is not recommended for the definitive diagnosis of COVID-19, it can be used as a primary diagnostic method for the COVID-19 to quarantine the Suspicious person and prevent the virus from being transmitted to others in the early stages of the disease.
The advantage of using medical imaging is the ability to visualize viral infections by machine vision. Machine vision has many different methods, one of the best of which is deep learning [12]. Machine vision and deep learning have many applications in medicine [31], agriculture [26], economics [11], etc., which have eliminated human errors and created automation in various fields.
The use of machine vision and deep learning is one of the best ways to diagnose tumors and infections caused by various diseases. This method has been used for various medical images, such as segmentation of lesions in the brain and skin [20], Applications to Breast Lesions, and Pulmonary Nodules [6], sperm detection and tracking [28] and state-of-the-art bone suppression in X-rays images [41].
On the other hand, diagnosing the disease by computer vision and deep learning is much more accurate than radiologists. For example, in [15], the accuracy of the method used is about 90%, while the accuracy of radiologists’ diagnosis is approximately 70%. Due to the effectiveness of machine vision and deep learning in medical imaging, especially CT scan and X-ray images, machine vision and deep learning have been used to diagnose COVID-19.
Convolutional neural networks made a great improvement in deep learning and computer vision tasks. Since the advent of convolutional layers some models like ResNet [12], DenseNet [14], EfficientNet [34] and Xception [7] were introduced and showed reliable results.
ResNet models [12] introduced residual layers which helped the models to reduce the effect of data corruption while feeding through layers.
Xception is the architecture that introduced separable convolutional layers. These layers are constructed of a depthwise convolutional layer and a pointwise convolutional layer consecutively. Separable convolutional layers proposed the idea that it is not necessary for the kernel of a convolution layer to be applied to each channel of the input data and separated the spatial and channel operations. Doing so, resulted in decreasing the number of weights and so made the authors capable of developing models with more layers.
Another model that we have inspired from, is the feature pyramid network [18]. Feature pyramid network (FPN) was developed for object detection tasks and helped the models to detect objects with various scales in the images. As COVID infections also exist in various scales especially in small scales, we designed a new classification architecture inspired by the FPN to improve classification accuracy of CT scan images.
In this paper, we introduce a fully-automated method for detecting COVID-19 cases from the output files (images) of the lung HRCT scan device. This system does not need any medical expert for system configuration and takes all the CT scans of a patient and clarifies if that patient is infected to COVID-19 or not.
We also introduce and share a new dataset that we called COVID-CTset that contains 15,589 COVID-19 images from 95 patients and 48,260 normal images from 282 persons. At the first stage of our work, we apply an image processing algorithm for selecting those CT Scan images that inside the lung, and the possible infections are observable in them. In this way, we speed up the process because the network does not have to analyze all the images. Also, we improve the diagnosis accuracy by giving the network only the proper images.
After that, we will train and test three deep convolutional neural networks for classifying the selected images. One of them is our proposed enhanced convolutional model, which is designed to improve classification accuracy. At the final stage, we evaluate our model in two different ways. The first way is based on single-image classification, which was evaluated on more than 7996 images, and the second is evaluating the fully automated diagnosis system that was tested on almost 245 patients and 41,892 images.
We also investigate the infected areas of the COVID-19 classified images by segmenting the infections using a feature visualization algorithm.
The general view of our work in this paper is represented in Fig. 1 .
Fig. 1.

General view of our proposed method for automated patients classification.
In [23], [36], using existing deep learning networks, they have identified COVID-19 on chest X-ray images and reported high accuracy. In [27], by concatenating Xception and Resnet50v2 networks and using chest X-ray images, they were able to diagnose normal patients, pneumonia, and COVID-19, with an overall accuracy of 99.5, which was evaluated on 11,302 images.
In [17], 3322 eligible CT scans were selected from 3506 CT scans of different persons and used to learn and evaluate the proposed network, COVNet. In another study, CT scans of 120 people (2482 CT scans) were collected, half of which (60 people) were COVID-19, and they were classified by different networks, which the most accuracy was equal to 97.38% [32].
In [15], CT scans of 287 patients were collected, including three classes of COVID-19, Community-acquired pneumonia (CAP), or other viral diseases in the lungs, and healthy, and then, using the innovative algorithm called CovidCTNet, they classified the data with 90% accuracy.
In [37], CT scans of 5372 patients have been collected in several hospitals in China, which have been used in learning and evaluating the presented Innovative Deep Learning Network to classify data into three classes. In [35], CT scans have been used to segment infections caused by the new coronavirus. These papers [24], [25], [5], [2], [29] also worked on classifying CT Scan and X-ray images using machine learning techniques and deep convolutional models.
The rest of the paper is organized as follows: In Section 2, we will describe the dataset, neural networks, and proposed algorithms. In Section 3, the experimental results are presented, and in Section 4, the paper is discussed. In Section 5, we have concluded our paper, and in the end, the links to the shared codes and dataset are provided.
2. Materials and methods
2.1. COVID-CTset
COVID-CTset1 is our introduced dataset. It was gathered from Negin radiology located at Sari in Iran between March 5th to April 23rd, 2020. This medical center uses a SOMATOM Scope model and syngo CT VC30-easyIQ software version for capturing and visualizing the lung HRCT radiology images from the patients. The format of the exported radiology images was 16-bit grayscale DICOM format with 512*512 pixels resolution. As the patient's information was accessible via the DICOM files, we converted them to TIFF format, which holds the same 16-bit grayscale data but does not conclude the patients’ private information. Also, this format is easier to use with standard programming libraries. In the addressed link2 at the end of this paper, the general information (age, sex, time of radiology imaging) for each patient is available.
One of our novelties is using a 16-bit data format instead of converting it to 8bit data, which helps to improve classification results. Converting the DICOM files to 8bit data may cause losing some data, especially when few infections exist in the image that is hard to detect even for clinical experts. Also, original 16-bit CT scan images may contain information that human eyes can not distinguish, but the computers notice them while processing. The pixels’ values of the images differ from 0 to 5000, and the maximum pixel values of the images are considerably different. So scaling them through a consistent value or scaling each image based on the maximum pixel value of itself can cause the mentioned problems and reduce the network accuracy. So each image of COVID-CTset is a TIFF format, 16-bit grayscale image.
In some stages of our work, we used the help of clinical experts under the supervision of the third author, a radiology specialist, to separate those images that the COVID-19 infections are clear. To make these images visible with standard monitors, we converted them to float by dividing each image's pixel value by the maximum pixel value of that image. This way, the output images had 32-bit float type pixel values that could be visualized by standard monitors, and the quality of the images was good enough for analysis. Some of the images of our dataset are presented in Fig. 2 .
Fig. 2.

Some of the images in COVID-CTset.
COVID-CTset is made of 15,589 images that belong to 95 patients infected with COVID-19 and 48,260 images of 282 normal people (Table 1 ). Each patient has three folders that each folder includes the CT scans captured from the CT imaging device with a different thickness.3
Table 1.
COVID-CTset data distribution.
| COVID-19 patients | Normal patients | COVID-19 images | Normal images | |
|---|---|---|---|---|
| Number | 95 | 282 | 15,589 | 48,260 |
The distribution of the patients in COVID-CTset is shown in Fig. 3 .
Fig. 3.

This figure shows the number of patients based on age, gender, and infections.
2.2. CT scans selection algorithm
The lung HRCT scan device takes a sequence of consecutive images (we can call it a video or consecutive frames) from the chest of the patient that wants to check his infection to COVID-19. In an image sequence, the infection points may appear in some images and not be shown in other images.
The clinical expert analyzes these consecutive images and, if he finds the infections on some of them, indicates the patient as infected.
Many previous methods selected an image of each patient's lung HRCT images and then used them for training and validation. Here we decided to make the patient lung analysis fully automated. Consider we have a neural network that is trained for classifying CVOID-19 cases based on a selected data that inside the lung was obviously visible in them. If we test that network on each image of an image sequence that belongs to a patient, the network may fail. Because at the beginning and the end of each CT scan image sequence, the lung is closed as it is depicted in Fig. 4 . Hence, the network has not seen these cases while training; it may result in wrong detections, and so may not work well.
Fig. 4.

This figure presents some of the first, middle, and final images of a patient's CT scan sequence. It is obvious from the images that in the first and the last images, inside the lung is not observable.
To solve this, we can separate the dataset into three classes: infection-visible, no-infection, and lung-closed. Although this removes the problem but dividing the dataset into three classes has other costs like spending some time for making new labels, changing the network evaluating way. Also, it increases the processing time because the network shall see all the images of patient CT scans. But we propose some other techniques to discard the images that inside the lungs are not visible in them. Doing this also reduces performing time for good because, in the last method, the networks should have seen all the images, and now it only sees some selected images.
Fig. 6 shows the steps of the image-selection algorithm. As it is evident from Fig. 5 , the main difference between an open lung and a closed lung is that the open lung image has lower pixel values(near to black) in the middle of the lung. First, we set a region in the middle of the images for analyzing the pixel values in them. This region should be at the center of the lung in all the images, so open-lung and closed-lung show the differences in this area. Unfortunately, the images of the dataset were not on one scale, and the lung's position differed for different patients; so after experiments and analysis, as the images have 512*512 pixels resolution, we set the region in the area of 120 to 370 pixels in the x-axis and 240 to 340 pixels in the y-axis ([120,240] to [370,340]). This area shall justify containing the information of the middle of the lung in all the images. Fig. 7 shows the selected region in some different images.
Fig. 6.
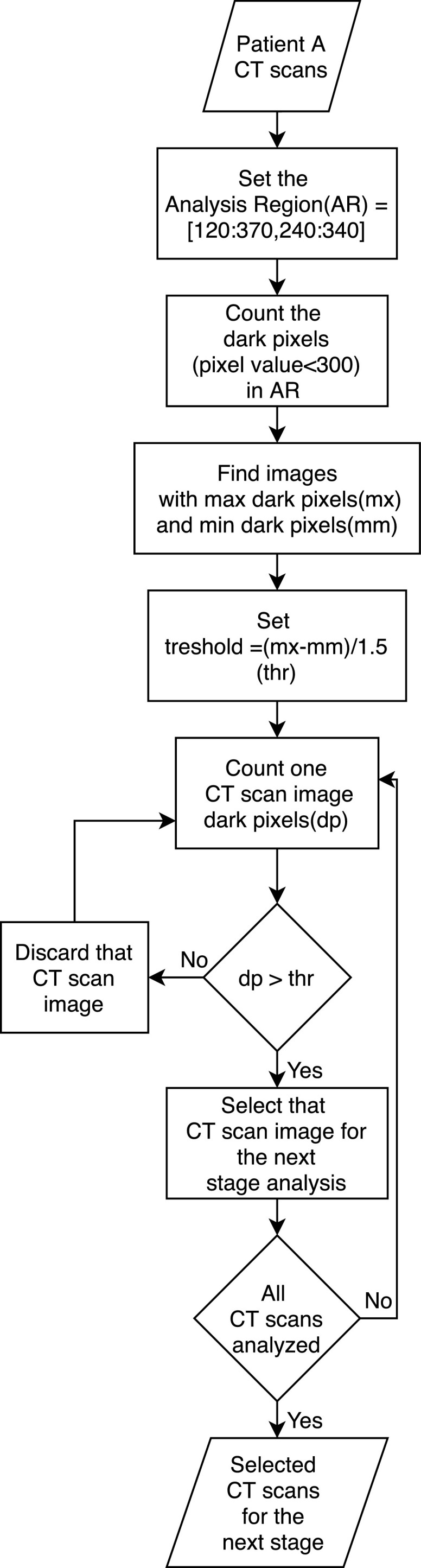
The flowchart of the proposed algorithm for selecting the efficient CT scan images of a sequence.
Fig. 5.

It can be visualized from this figure that a closed-lung has higher pixel values in the middle of the image.
Fig. 7.

The selected region in different images with different scales.
The images of our dataset are 16-bit grayscale images. The maximum pixel value between all the images is almost equal to 5000. This maximum value differs very much between different images. At the next step for discarding some images of a patient’s CT scans and selecting the rest of them for further analysis, we aim to measure the pixels of each image in the indicated region that have less value than 300, which we call dark pixels. This number was chosen out of our experiments.
For all the images in a sequence, we count the number of pixels in the selected region with less value than 300 (dark pixels). After that, we would divide the difference between the maximum counted number and the minimum counted number by 1.5. This calculated number is our threshold. For example, if an image in a CT scan image sequence has the most number of dark pixels equal to 3000, and another image has the minimum dark pixels equal to 30 pixels, then the threshold becomes 2000. The image with fewer dark pixels in the region than the threshold is the image that the lung is almost closed in that, and the image with more dark pixels than the threshold is the one that inside the lung is visible in it.
We calculated this threshold in this manner that the images in a sequence (CT scans of a patient) be analyzed together because, in one sequence, the imaging scale does not differ. Still, it may vary between different CT scans (of different patients). After that, we discard those images that have less counted dark pixels than the calculated threshold. So the images with more dark pixels than the computed threshold will be selected to be given to the network for classification.
In Fig. 8 , the image sequence of one patient is depicted, where it can be observed, which of the images the algorithm discards and which will be selected.
Fig. 8.

The CT scan images of a patient are shown in this figure. The highlighted images are the ones that the algorithm discards. It is observable that those images that clearly show inside the lung are selected to be classified at the next stage.
2.3. Enhanced deep convolutional neural network for classification
Machine vision has been a superior method for advancing many fields like Agriculture [26], biomedical engineering [28], [22], industry [16] and others. Implementing machine vision methods on deep neural networks, especially using the convolution layers, has resulted in extremely accurate performance. In this research, we used deep convolution networks to classify the selected CT scan images exported from the CT scan selecting algorithm into normal or COVID-19. We trained, evaluated, and compared three different deep convolutional networks: Xception [7], ResNet50V2 [13], and our proposed model.
Xception introduced new inception modules constructed of depth-wise, separable convolution layers (depth-wise convolutional layers followed by a point-wise convolution layer). Xception achieved one of the best results on ImageNet [9] dataset. ResNet50V2, is a upgraded version of ResNet50 [12]. In this neural network, the authors made some changes in the connections and skip-connections between blocks and increased network performance on the ImageNet dataset.
Feature pyramid network (FPN) was introduced by paper [18] and was utilized in RetinaNet [19] for enhancing object detection. FPN helps the network better learning and detecting objects at different scales that exist in an image. Some of the previous methods worked by giving an image pyramid (that includes different scales of the input image) to the network as the input. Doing this indeed improves the feature extraction process but also increases the processing time and is not efficient.
FPN solves this problem by generating a bottom-up and a top-down feature hierarchy with lateral connections from the network's generated features at different scales. This helps the network generate more semantic features, so using FPN helps increase detection accuracy when there are objects with various scales in the image while not changing detection speed.
Although FPN was developed for object detection networks, we propose a new model that utilizes FPN for image classification. COVID-19 infections exist in different scales, so using FPN helps to extract various semantic features of the input image. Our model can detect COVID infections even when they are tiny and, more importantly, detect COVID false positives fewer because it learns better about the infection points.
In Fig. 9 , the architecture of the proposed network can be observed. We used ResNet50V2 as the backbone network and compared our model with ResNet50V2 and Xception. Other researchers can also use other models as the backbone. The FPN we used is like the original version of FPN [18] with this difference that we used concatenation layers instead of adding layers inside the feature pyramid network due to the authors’ experience.
Fig. 9.

This figure shows our model, which uses ResNet50V2 as the backbone and applies the feature pyramid network and the designed layers for classification.
FPN extracts five final features that each one presents the input image features on a different scale. After that, we implemented dropout layers (to avoid overfitting), followed by the first classification layers. Note that we did not use SoftMax functions for the first classification layers because we wanted to feed them to the final classification layer, and as the SoftMax function computes each output neuron based on the ratio of other output neurons, it is not suitable for this place. Relu activation function is more proper.
At the end of the architecture, we concatenated the five classified layers (each consisting of two neurons) and made a ten neurons dense layer. Then we connected this layer to the final classification layer, which applies the SoftMax function. With running this procedure, the network utilizes different classification results based on various scale features. As a result, the network would become able to classify the images better.
Researchers can use our proposed model for running classification in similar cases and datasets to improve classification results.
2.4. Training phase
Our dataset is constructed of two sections. The first section is the raw data for each person that is described in Section 2.1. The second section includes training, validation, and testing data. We converted the images to 32-bit float types on the TIFF format so that we could visualize them with standard monitors. Then we took the help of the clinical experts under the supervision of the third author (Radiology Specialist) in the Negin radiology center to select the infected patients’ images that the infections were clear on them. We used these data for training and testing the trained networks.
To report more real and accurate results, we separated the dataset into five folds for training, validation, and testing. Almost 20 percent of the patients with COVID19 were allocated for testing in each fold. The rest were considered for training, and part of the testing data has been considered for validating the network after each epoch while training. Because the number of normal patients and images was more than the infected ones, we almost chose the number of normal images equal to the COVID-19 images to make the dataset balanced. Therefore the number of normal images that were considered for network testing was higher than the training images. The details of the training and testing data are reported in Table 2 .
Table 2.
Training and testing details of COVID-CTset.
| Training set |
Testing set |
|||||||
|---|---|---|---|---|---|---|---|---|
| COVID-19 patients | COVID-19 images | Normal patients | Normal images | COVID-19 patients | COVID-19 images | Normal patients | Normal images | |
| Fold1 | 77 | 1820 | 45 | 1916 | 18 | 462 | 237 | 7860 |
| Fold2 | 72 | 1817 | 37 | 1898 | 23 | 465 | 245 | 7878 |
| Fold3 | 77 | 1836 | 53 | 1893 | 18 | 446 | 229 | 7883 |
| Fold4 | 81 | 1823 | 76 | 1920 | 14 | 459 | 206 | 7856 |
| Fold5 | 73 | 1832 | 71 | 1921 | 22 | 450 | 211 | 7785 |
From the information in Table 2, the question may arise as to why the number of normal persons in the training set is less than the number of COVID-19 patients. Because in each image sequence of a patient with COVID-19, we allocated some of them with observable infections for training and testing. So the number of images for a COVID-19 patient is less than the number of images for a normal person.
We selected enough number of normal patients somehow that the number of normal images becomes almost equal to the number of COVID-19 class images. This number was enough for the network to learn to classify the images correctly, and the achieved results were high. As we had more normal images left, we selected a large number of normal data for testing so that the actual performance of our trained networks be more clear.
We trained our dataset on Xception [7], Resnet50V2 [13] and our model until 50 epochs. For training the networks, we used transfer learning from the ImageNet [9] pre-trained weights to make the networks’ convergence faster. We chose the Nadam optimizer and the Categorical Cross-entropy loss function. We also used data augmentation methods to make learning more efficient and stop the network from overfitting.
It is noteworthy that we did not resize the images for training or testing so as not to lose the small data of the infections. Our training parameters are listed in Table 3 .
Table 3.
Training parameters.
| Training parameters | Xception | ResNet50V2 | Our model |
| Learning Rate | 1e−4 | 1e−4 | 1e−4 |
| Batch size | 14 | 14 | 14 |
| Optimizer | Nadam | Nadam | Nadam |
| Loss function | Categorical Crossentopy | Categorical Crossentopy | Categorical Crossentopy |
| Epochs | 50 | 50 | 50 |
| Horizontal/vertical flipping | Yes | Yes | Yes |
| Zoom range | 5% | 5% | 5% |
| Rotation range | 0–360 degree | 0–360 degree | 0–360 degree |
| Width/height shifting | 5% | 5% | 5% |
| Shift range | 5% | 5% | 5% |
As is evident from Table 3, we used the same parameters for all the networks.
3. Experimental results
In this section, we report the results into two sections. The Image classification results section includes the results of the trained networks on the test set images. The Patient condition identification section reports the results of the automated system for identifying each person as normal or COVID-19.
We implemented our algorithms and networks on Google Colaboratory Notebooks, which allocated a Tesla P100 GPU, 2.00 GHz Intel Xeon CPU, and 12 GB RAM on Linux to us. We used Keras library [8] on Tensorflow backend [1] for developing and running the deep networks.
3.1. Image classification results
We trained each network on the training set with the explained parameters in Section 2.4. We also used the accuracy metric while training for monitoring the network validation result after each epoch to find the training network's best-converged version.
We evaluated the trained networks using four different metrics for each of the classes and the overall accuracy for all the classes as follows:
| (1) |
| (2) |
| (3) |
| (4) |
| (5) |
In these equations, for each class, TP (True Positive) is the number of correctly classified images, FP (False Positive) is the number of the wrong classified images, FN (False Negative) is the number of images that have been detected as a wrong class, and TN (True Negative) is the number of images that do not belong to another class and have not been classified as that class.
The results for each fold are reported in Table 9. We also showed the average results between five folds in confusion matrices in Fig. 10 .
Table 9.
Evaluation results for each network in each fold.
| Fold | Network | Correct classified images | Wrong classified images | COVID correct classified | COVID not classified | Wrong classified as COVID | Normal correct classified | Normal not classified | Wrong classified as normal | Overall accuracy | COVID accuracy | Normal accuracy | COVID sensitivity | Normal sensitivity | COVID specificity | Normal specificity | COVID precision | Normal precision |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Our model | 8214 | 108 | 436 | 26 | 82 | 7778 | 82 | 26 | 0.987 | 0.987 | 0.987 | 0.9437 | 0.9896 | 0.9896 | 0.9437 | 0.8417 | 0.9967 | |
| 1 | Xception | 8165 | 157 | 456 | 6 | 151 | 7709 | 151 | 6 | 0.9811 | 0.9811 | 0.9811 | 0.987 | 0.9808 | 0.9808 | 0.987 | 0.7512 | 0.9992 |
| ResNet50V2 | 8169 | 153 | 453 | 9 | 144 | 7716 | 144 | 9 | 0.9816 | 0.9816 | 0.9816 | 0.9805 | 0.9817 | 0.9817 | 0.9805 | 0.7588 | 0.9988 | |
| Our model | 8215 | 128 | 443 | 22 | 106 | 7772 | 106 | 22 | 0.9847 | 0.9847 | 0.9847 | 0.9527 | 0.9865 | 0.9865 | 0.9527 | 0.8069 | 0.9972 | |
| 2 | Xception | 7921 | 422 | 458 | 7 | 415 | 7463 | 415 | 7 | 0.9494 | 0.9494 | 0.9494 | 0.9849 | 0.9473 | 0.9473 | 0.9849 | 0.5246 | 0.9991 |
| ResNet50V2 | 8109 | 234 | 456 | 9 | 225 | 7653 | 225 | 9 | 0.972 | 0.972 | 0.972 | 0.9806 | 0.9714 | 0.9714 | 0.9806 | 0.6696 | 0.9988 | |
| Our model | 8143 | 186 | 427 | 19 | 167 | 7716 | 167 | 19 | 0.9777 | 0.9777 | 0.9777 | 0.9574 | 0.9788 | 0.9788 | 0.9574 | 0.7189 | 0.9975 | |
| 3 | Xception | 8113 | 216 | 434 | 12 | 204 | 7679 | 204 | 12 | 0.9741 | 0.9741 | 0.9741 | 0.9731 | 0.9741 | 0.9741 | 0.9731 | 0.6803 | 0.9984 |
| ResNet50V2 | 8079 | 250 | 439 | 7 | 243 | 7640 | 243 | 7 | 0.97 | 0.97 | 0.97 | 0.9843 | 0.9692 | 0.9692 | 0.9843 | 0.6437 | 0.9991 | |
| Our model | 8205 | 110 | 442 | 17 | 93 | 7763 | 93 | 17 | 0.9868 | 0.9868 | 0.9868 | 0.963 | 0.9882 | 0.9882 | 0.963 | 0.8262 | 0.9978 | |
| 4 | Xception | 7854 | 461 | 449 | 10 | 451 | 7405 | 451 | 10 | 0.9446 | 0.9446 | 0.9446 | 0.9782 | 0.9426 | 0.9426 | 0.9782 | 0.4989 | 0.9987 |
| ResNet50V2 | 8166 | 149 | 439 | 20 | 129 | 7727 | 129 | 20 | 0.9821 | 0.9821 | 0.9821 | 0.9564 | 0.9836 | 0.9836 | 0.9564 | 0.7729 | 0.9974 | |
| Our model | 8141 | 94 | 419 | 31 | 63 | 7722 | 63 | 31 | 0.9886 | 0.9886 | 0.9886 | 0.9311 | 0.9919 | 0.9919 | 0.9311 | 0.8693 | 0.996 | |
| 5 | Xception | 8058 | 177 | 440 | 10 | 167 | 7618 | 167 | 10 | 0.9785 | 0.9785 | 0.9785 | 0.9778 | 0.9785 | 0.9785 | 0.9778 | 0.7249 | 0.9987 |
| ResNet50V2 | 7991 | 244 | 449 | 1 | 243 | 7542 | 243 | 1 | 0.9704 | 0.9704 | 0.9704 | 0.9978 | 0.9688 | 0.9688 | 0.9978 | 0.6488 | 0.9999 | |
| Our model | 8183.6 | 125.2 | 433.4 | 23 | 102.2 | 7750.2 | 102.2 | 23 | 0.9849 | 0.9849 | 0.9849 | 0.9496 | 0.987 | 0.987 | 0.9496 | 0.8126 | 0.997 | |
| Avg | Xception | 8022.2 | 286.6 | 447.4 | 9 | 277.6 | 7574.8 | 277.6 | 9 | 0.9655 | 0.9655 | 0.9655 | 0.9802 | 0.9647 | 0.9647 | 0.9802 | 0.636 | 0.9988 |
| ResNet50V2 | 8102.8 | 206 | 447.2 | 9.2 | 196.8 | 7655.6 | 196.8 | 9.2 | 0.9752 | 0.9752 | 0.9752 | 0.9799 | 0.9749 | 0.9749 | 0.9799 | 0.6988 | 0.9988 | |
The bold values show the maximum value in a column.
Fig. 10.

The average data between five folds are shown on these confusion matrices.
Fig. 11 shows the training and validation accuracy in 20 epochs of the training procedure. Our model converges faster to higher accuracy. This is the ability of our model, which enhances the base model.
Fig. 11.

These plots show training and validation accuracy in 20 epochs. It is clear that our model is converging faster and reaches to higher values of accuracy.
3.2. Patient condition identification
In this section, we present the main results of our work. CT scan data is not like many other data like X-ray images, which can be evaluated by investigating one single image. CT scans are sequences of consecutive images (like videos), so for medical diagnosis, the system or the expert person must analyze more than one image.
Based on this condition, for proposing an automatic diagnosis system, the developers must evaluate their system differently than single image classification. As we know, until today, we are the first that have evaluated our model in this way.
If our proposed fully-automated system wants to check the infection of COVID-19 for a patient, it takes all the images of the patient CT scans as input. Then it processes them with the proposed CT scan selection algorithm to select the CT scans that the lung is visible in them. Those chosen images will be fed to the deep neural network to be classified as COVID-19 or normal.
For indicating the condition of a patient, we must set a threshold. For each patient, if the number of CT scan images, which are identified as COVID-19, be more than the threshold, that patient would be considered as infected; otherwise, his condition would be normal. This threshold value depends on the precision of the model. In trained models with high accuracy, the threshold can be set to zero, meaning if at least one CT scan image of a patient (between the filtered CT scans by the selection algorithm) is detected as COVID-19, that patient would be considered being infected.
The number of data used for evaluating our system in this section is listed in Table 4 .
Table 4.
Details of the dataset used for the patient condition identification evaluation stage.
| Fold | Number of images belonging to patients with COVID | Number of patients with COVID | Number of images belonging to normal persons | Number of normal patients |
|---|---|---|---|---|
| Fold1 | 2858 | 18 | 40,094 | 237 |
| Fold2 | 3540 | 23 | 39,302 | 245 |
| Fold3 | 3640 | 18 | 39,391 | 229 |
| Fold4 | 2769 | 14 | 37,323 | 206 |
| Fold5 | 2783 | 22 | 37,758 | 211 |
Table 5 shows an interesting result. In this table, threshold 1 is zero, and threshold 2 is one-tenth of the number of the filtered CT scan images. It means that after filtering the CT scan images by the selection algorithm, in threshold1, if at least one CT scan image be identified as COVID, the patient would be selected as infected. In threshold 2, if at least one-tenth of the number of the filtered CT scan images are detected as COVID, then the system determines that patient, infected to COVID-19.
Table 5.
Comparison between different patient condition identification thresholds for each of the trained networks in fold1. Threshold 1 is zero and Threshold2 is equal to 0.1 of the CT images.
| Our model |
ResNet50V2 |
Xception |
||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| COVID correct detected | Wrong detected as Normal | Normal correct detected | Wrong detected as COVID | COVID correct detected | Wrong detected as Normal | Normal correct detected | Wrong detected as COVID | COVID correct detected | Wrong detected as Normal | Normal correct detected | Wrong detected as COVID | |
| Threshold1 | 17 | 1 | 231 | 6 | 17 | 1 | 205 | 32 | 17 | 1 | 195 | 42 |
| Threshold2 | 16 | 2 | 232 | 5 | 17 | 1 | 222 | 15 | 17 | 1 | 221 | 16 |
With these circumstances, in Table 5, we can see that our model performs very well in threshold 1, and this shows the high performance of this network. But other networks do not execute well in threshold 1, which indicates that these networks’ accuracy is lower than our model. This remarkable result is caused by the feature pyramid network that gives a high ability to detect the infections correctly and not to detect false points as infections.
The users can select this threshold based on their model accuracy. In the following (6), we used the second threshold (equal to one-tenth) for reporting the full results. But we recommend using the first threshold for accurate models like our model.
Table 6.
Patients condition identification results with the second threshold (0.1).
| Fold | Network | Correct identified patients | Wrong identified patients | COVID correct identified | Wrong identified as normal | Normal correct identified | Wrong identified as COVID |
|---|---|---|---|---|---|---|---|
| Our model | 248 | 7 | 16 | 2 | 232 | 5 | |
| 1 | Xception | 238 | 17 | 17 | 1 | 221 | 16 |
| ResNet50V2 | 239 | 16 | 17 | 1 | 222 | 15 | |
| Our model | 254 | 14 | 21 | 2 | 233 | 12 | |
| 2 | Xception | 234 | 34 | 23 | 0 | 211 | 34 |
| ResNet50V2 | 245 | 23 | 22 | 1 | 223 | 22 | |
| Our model | 232 | 15 | 17 | 1 | 215 | 14 | |
| 3 | Xception | 227 | 20 | 18 | 0 | 209 | 20 |
| ResNet50V2 | 223 | 24 | 17 | 1 | 206 | 23 | |
| Our model | 213 | 7 | 13 | 1 | 200 | 6 | |
| 4 | Xception | 183 | 37 | 14 | 0 | 169 | 37 |
| ResNet50V2 | 203 | 17 | 13 | 1 | 190 | 16 | |
| Our model | 222 | 11 | 21 | 1 | 201 | 10 | |
| 5 | Xception | 212 | 21 | 22 | 0 | 190 | 21 |
| ResNet50V2 | 216 | 17 | 22 | 0 | 194 | 17 | |
| Our model | 233.8 | 10.8 | 17.6 | 1.4 | 216.2 | 9.4 | |
| Avg | Xception | 218.8 | 25.8 | 18.8 | 0.2 | 200 | 25.6 |
| ResNet50V2 | 225.2 | 19.4 | 18.2 | 0.8 | 207 | 18.6 | |
The bold values show the maximum value in a column.
The results of Patient condition identification for each of the trained networks in each fold are available in Table 6 . The speed of the fully automated system is reported in Table 7 and the training and inference time of each model is available at Table 8 .
Table 7.
This table shows the fully automated system's speed based on our model, for CT scans of different patients with various CT scan slices.
| Number of CT scan slices | Time (s) |
|---|---|
| 35 | 2.3039 |
| 52 | 3.1504 |
| 56 | 3.3080 |
| 65 | 3.56452 |
| 130 | 9.8845 |
| 198 | 12.4371 |
| 355 | 13.2398 |
| 406 | 23.6463 |
Table 8.
Training and inference time of the models on Tesla P100 GPU.
| Model name | Training time per epoch | Inference time per image |
|---|---|---|
| Xception | 356 s | 65.4 ms |
| ResNet50V2 | 195 s | 52.6 ms |
| Our Model | 198 s | 66.1 ms |
3.3. Feature visualization
In this section, we aim to use the Grad-CAM algorithm [30] to visualize the extracted features of the network to determine the areas of infections and investigate the network's correct performance.
By looking at Fig. 12 and comparing the normal and COVID images; it is visible that the network is classifying the images based on the infected areas. In the COVID-19 images, the highlighted features are around the infection areas, and in the normal images, as the network does not see any infections, the highlighted features are at the center showing the no infections have been found. Therefore the results can be trusted for medical diagnosis. Using the Grad-CAM algorithm can help the medical expert distinguish the CT scan images better and find the infections.
Fig. 12.

Visualized features by the Grad-CAM algorithm to show that the network is operating correctly and indicate the infection regions in the COVID-19 CT scan images.
4. Discussion
In the single image evaluating phase (Table 9 ), the average results between five-folds show that our model achieved 98.49% overall accuracy and 94.96% sensitivity for the COVID-19 class. Xception evaluation results show 96.55% overall accuracy and 98.02% COVID-19 sensitivity. Our investigations indicate that our model detects infection points very carefully but normal models like Xception and ResNet50V2 determine any similar points as infections and mistakenly identifies more normal images as COVID so this is the reason our model achieves higher overall accuracy.
At the fully automated patient condition identification phase, we evaluated our model on almost 245 patients and 41,892 images with different thicknesses. The average results between five folds in Table 6 show that our model achieved the best results and approximately correctly classifies 234 persons from 245 persons, which is an acceptable value.
By referring to Table 5, it can be seen that our model performs patient condition identification more precisely than other networks especially when the COVID threshold is very low. This means our model has learned the COVID infections very well so its false detections as COVID are much fewer than simple models.
Fig. 12 also presents some of the classified images processed by the Grad-CAM algorithm to visualize the sensitive extracted features. Based on this figure, the system classifies the images by looking to correct points, and the results are trustworthy.
From Table 7, and 8 it can be understood that our model runs almost as fast as other models and the processing speed is good. As one CT scan image sequence has less than 100 images in most cases (when imaging thickness is between 2 to 6), this system can process them in near 4 to 6 s. It can be seen from Table 7 that some of the CT scan slices with a close difference differ in speed more than what is expected. The reason is that the CT scan selection algorithm may select different proper CT scan images from each of the CT image sequences. So, the processing speed changes more than expected.
Another thing that worth noting is that the reason COVID class precision is not very high, like accuracy or sensitivity, is because of having an unbalanced test dataset. We had around 450 COVID-19 images and 7800 normal images for testing the network performance. Our model averagely classified 102 images from 7852 normal images as CODIV-19 wrongly, which is a good value, but because the number of COVID-19 images in the test-set is much lower than normal test images, it made the COVID-19 precision around 81 percent. So, this value of precision does not mean the network is performing poorly.
What makes this work reliable is that it is designed and tested in real circumstances like considering the input data as an image-sequence or video (not just a single image), being evaluated on a large dataset, showing high accuracy and low false positives, and good inference speed. We hope that our shared dataset and codes can help other researchers improve AI models and use them for advanced medical diagnosis.
5. Conclusion
In this paper, we have proposed a fully automated system for COVID-19 detection from lung HRCT scans. We also introduced a new dataset containing 15,589 images of normal persons and 48,260 images belonging to patients with COVID-19. At first, we proposed an image processing algorithm to filter the proper images of the patients’ CT scans, which show inside the lung perfectly. This algorithm helps increase network accuracy and speed. At the next stage, we introduced a novel deep convolutional neural network for improving classification. This network can be used in many classification problems to improve accuracy, especially for the images containing important objects in small scales.
We trained three different deep convolution networks for classifying the CT scan images into COVID-19 or normal. Our model, which utilizes ResNet50V2, a modified feature pyramid network, and the designed architecture, achieved the best results. After training, we used the trained networks for running the fully automated COVID-19 identifier system. We evaluated our system in two different ways: one on more than 7796 images and the other one on almost 245 patients and 41,892 images with different thicknesses. For single image classification (first evaluation way), our model showed 98.49% overall accuracy.
Our model obtained the best results at the patient condition identification stage (second evaluation way) and correctly identified approximately 234 patients from 245 patients. We also used the Grad-CAM algorithm to highlight the CT scan images’ infection areas and investigate the classification correctness. Based on the obtained results, it can be understood that the proposed methods can improve COVID-19 detection and run fast enough for implementation in medical centers.
Data availability
We have made our data available for public use in this address: (https://github.com/mr7495/COVID-CTset). The dataset is available in two parts: one is the raw data presented in three folders for each patient. The next part is the training, validation, and testing data in each fold. We hope that this dataset will be utilized for improving COVID-19 monitoring and detection in the coming researches.
Code availability
All the used codes for data analysis, training, validation, testing, and the trained networks are shared at (https://github.com/mr7495/COVID-CT-Code).
Ethics statement
We declare that this paper is original and has been read and approved by all named authors and that there are no other persons who satisfied the criteria for authorship but are not listed. We further confirm that all have approved the order of authors listed in the paper of us. All the patients’ shared data have been approved by Negin Radiology Medical Center located at Sari, Iran, under the supervision of its director (Dr.Sakhaei, radiology specialist). It must be mentioned that to protect patients’ privacy; all the DICOM files have been converted to TIFF format files to remove the patients’ information.
CRediT author statement
Mohammad Rahimzadeh: Conceptualization; Methodology; Data Curation; Writing – Original Draft; Writing – Review & Editing; Visualization; Supervision
Abolfazl Attar: Writing – Original Draft; Visualization
Seyed Mohammad Sakhaei: Resources; Data Curation
Acknowledgment
We wish like to thank Negin radiology experts that helped us in proving the dataset. We also like to appreciate Google for providing free and powerful GPU on Colab servers and free space on Google Drive.
Acknowledgments
Declaration of Competing Interest
The authors report no declarations of interest.
Footnotes
This dataset is shared at: https://github.com/mr7495/COVID-CTset.
The details of each patient in our dataset are available at: https://github.com/mr7495/COVID-CTset/blob/master/Patient_details.csv.
The thicknesses and other details of each patient in our dataset are available at https://github.com/mr7495/COVID-CTset/blob/master/Patient_details.csv.
References
- 1.Abadi M., Agarwal A., Barham P., Brevdo E., Chen Z., Citro C., Corrado G.S., Davis A., Dean J., Devin M., Ghemawat S., Goodfellow I., Harp A., Irving G., Isard M., Jia Y., Jozefowicz R., Kaiser L., Kudlur M., Levenberg J., Mané D., Monga R., Moore S., Murray D., Olah C., Schuster M., Shlens J., Steiner B., Sutskever I., Talwar K., Tucker P., Vanhoucke V., Vasudevan V., Viégas F., Vinyals O., Warden P., Wattenberg M., Wicke M., Yu Y., Zheng X. Software available from tensorflow.org; 2015. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. [Google Scholar]
- 2.Abdulmunem A.A., Abutiheen Z.A., Aleqabie H.J. Recognition of corona virus disease (covid-19) using deep learning network. Int. J. Electr. Comput. Eng. (IJECE) 2021;11(1):365–374. [Google Scholar]
- 3.ACR . 2020 05. ACR Recommendations for the Use of Chest Radiography and Computed Tomography (CT) for Suspected Covid-19 Infection | American College of Radiology. https://www.acr.org/Advocacy-and-Economics/ACR-Position-Statements/Recommendations-for-Chest-Radiography-and-CT-for-Suspected-COVID19-Infection (accessed on 31.05.20) [Google Scholar]
- 4.Ai T., Yang Z., Hou H., Zhan C., Chen C., Lv W., Tao Q., Sun Z., Xia L. Correlation of chest ct and rt-pcr testing in coronavirus disease 2019 (covid-19) in China: a report of 1014 cases. Radiology. 2020 doi: 10.1148/radiol.2020200642. page 200642. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Barstugan M., Ozkaya U., Ozturk S. 2020. Coronavirus (covid-19) Classification Using CT Images by Machine Learning Methods. [Google Scholar]
- 6.Cheng J.-Z., Ni D., Chou Y.-H., Qin J., Tiu C.-M., Chang Y.-C., Huang C.-S., Shen D., Chen C.-M. Computer-aided diagnosis with deep learning architecture: applications to breast lesions in us images and pulmonary nodules in ct scans. Sci. Rep. 2016;6(1):1–13. doi: 10.1038/srep24454. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Chollet F. Xception: deep learning with depthwise separable convolutions. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017:1251–1258. [Google Scholar]
- 8.Chollet F., et al. 2015. keras. [Google Scholar]
- 9.Deng J., Dong W., Socher R., Li L.-J., Li K., Fei-Fei L. Imagenet: a large-scale hierarchical image database. 2009 IEEE Conference on Computer Vision and Pattern Recognition; IEEE; 2009. pp. 248–255. [Google Scholar]
- 10.Geneticeducation . 2020. Reverse Transcription PCR: Principle, Procedure, Application, Advantages and Disadvantages. https://geneticeducation.co.in/reverse-transcription-pcr-principle-procedure-applications-advantages-and-disadvantages/#Disadvantages (accessed 31.05.20) [Google Scholar]
- 11.Green G.P., Bean J.C., Peterson D.J. Deep learning in intermediate microeconomics: using scaffolding assignments to teach theory and promote transfer. J. Econ. Educ. 2013;44(2):142–157. [Google Scholar]
- 12.He K., Zhang X., Ren S., Sun J. Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016:770–778. [Google Scholar]
- 13.He K., Zhang X., Ren S., Sun J. Identity mappings in deep residual networks. Lect. Notes Comput. Sci. 2016:630–645. [Google Scholar]
- 14.Huang G., Liu Z., van der Maaten L., Weinberger K.Q. 2018. Densely Connected Convolutional Networks. [Google Scholar]
- 15.Javaheri T., Homayounfar M., Amoozgar Z., Reiazi R., Homayounieh F., Abbas E., Laali A., Radmard A.R., Gharib M.H., Mousavi S.A.J., et al. 2020. Covidctnet: An Open-Source Deep Learning Approach to Identify Covid-19 Using CT Image.arXiv:2005.03059 (arXiv preprint) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Li L., Ota K., Dong M. Deep learning for smart industry: efficient manufacture inspection system with fog computing. IEEE Trans. Ind. Inform. 2018;14(10):4665–4673. [Google Scholar]
- 17.Li L., Qin L., Xu Z., Yin Y., Wang X., Kong B., Bai J., Lu Y., Fang Z., Song Q., et al. Artificial intelligence distinguishes covid-19 from community acquired pneumonia on chest ct. Radiology. 2020 doi: 10.1148/radiol.2020200905. page 200905. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Lin T.-Y., Dollár P., Girshick R., He K., Hariharan B., Belongie S. Feature pyramid networks for object detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017:2117–2125. [Google Scholar]
- 19.Lin T.-Y., Goyal P., Girshick R., He K., Dollár P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018 doi: 10.1109/TPAMI.2018.2858826. [DOI] [PubMed] [Google Scholar]
- 20.Litjens G., Kooi T., Bejnordi B.E., Setio A.A.A., Ciompi F., Ghafoorian M., Van Der Laak J.A., Van Ginneken B., Sánchez C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017;42:60–88. doi: 10.1016/j.media.2017.07.005. [DOI] [PubMed] [Google Scholar]
- 21.Lybrate . 2020. Huntington’s Disease – Understanding the Stages of Symptoms! – by MS. Sadhana Ghaisas | Lybrate. https://www.lybrate.com/topic/huntington-s-disease-understanding-the-stages-of-symptoms/51a9194e8afa17a117aa5b8db364f2eb (accessed 31.05.20) [Google Scholar]
- 22.Mlynarski P., Delingette H., Alghamdi H., Bondiau P.-Y., Ayache N. Anatomically consistent cnn-based segmentation of organs-at-risk in cranial radiotherapy. J. Med. Imaging. 2020;7(1):014502. doi: 10.1117/1.JMI.7.1.014502. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Narin A., Kaya C., Pamuk Z. 2020. Automatic Detection of Coronavirus Disease (Covid-19) Using X-ray Images and Deep Convolutional Neural Networks.arXiv:2003.10849 (arXiv preprint) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Ozkaya U., Ozturk S., Barstugan M. 2020. Coronavirus (Covid-19) Classification Using Deep Features Fusion and Ranking Technique. [Google Scholar]
- 25.Öztürk Ş., Özkaya U., Barstuğan M. Classification of coronavirus (covid-19) from X-ray and ct images using shrunken features. Int. J. Imaging Syst. Technol. 2021;31(1):5–15. doi: 10.1002/ima.22469. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Rahimzadeh M., Attar A. 2020. Detecting and Counting Pistachios based on Deep Learning.arXiv:2005.03990 (arXiv preprint) [Google Scholar]
- 27.Rahimzadeh M., Attar A. A modified deep convolutional neural network for detecting covid-19 and pneumonia from chest x-ray images based on the concatenation of xception and resnet50v2. Inform. Med. Unlocked. 2020 doi: 10.1016/j.imu.2020.100360. page 100360. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Rahimzadeh M., Attar A., et al. 2020. Sperm Detection and Tracking in Phase-Contrast Microscopy Image Sequences Using Deep Learning and Modified csr-dcf.arXiv:2002.04034 (arXiv preprint) [Google Scholar]
- 29.Saha P., Sadi M.S., Islam M.M. Emcnet: automated covid-19 diagnosis from X-ray images using convolutional neural network and ensemble of machine learning classifiers. Inform. Med. Unlocked. 2021;22:100505. doi: 10.1016/j.imu.2020.100505. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Selvaraju R.R., Cogswell M., Das A., Vedantam R., Parikh D., Batra D. Grad-cam: visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vis. 2019;128(October (2)):336–359. [Google Scholar]
- 31.Shen D., Wu G., Suk H.-I. Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 2017;19:221–248. doi: 10.1146/annurev-bioeng-071516-044442. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Soares E., Angelov P., Biaso S., Froes M.H., Abe D.K. Sars-cov-2 CT-scan dataset: a large dataset of real patients CT scans for sars-cov-2 identification. medRxiv. 2020 [Google Scholar]
- 33.Song F., Shi N., Shan F., Zhang Z., Shen J., Lu H., Ling Y., Jiang Y., Shi Y. Emerging 2019 novel coronavirus (2019-ncov) pneumonia. Radiology. 2020;295(1):210–217. doi: 10.1148/radiol.2020200274. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Tan M., Le Q.V. 2020. Efficientnet: Rethinking Model Scaling for Convolutional Neural Networks. [Google Scholar]
- 35.Voulodimos A., Protopapadakis E., Katsamenis I., Doulamis A., Doulamis N. Deep learning models for Covid-19 infected area segmentation in CT images. medRxiv. 2020 doi: 10.3390/s21062215. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Wang L., Lin Z.Q., Wong A. Covid-net: a tailored deep convolutional neural network design for detection of covid-19 cases from chest X-ray images. Sci. Rep. 2020;10(1):1–12. doi: 10.1038/s41598-020-76550-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Wang S., Zha Y., Li W., Wu Q., Li X., Niu M., Wang M., Qiu X., Li H., Yu H., et al. A fully automatic deep learning system for covid-19 diagnostic and prognostic analysis. Eur. Respir. J. 2020 doi: 10.1183/13993003.00775-2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.WHO . 2020. Q&A on Coronaviruses (Covid-19) https://www.who.int/emergencies/diseases/novel-coronavirus-2019/question-and-answers-hub/q-a-detail/q-a-coronaviruses (accessed 31.05.20) [Google Scholar]
- 39.Wikipedia . 2020 05. Covid-19 Testing – Wikipedia. https://en.wikipedia.org/wiki/COVID-19_testing (accessed 31.05.20) [Google Scholar]
- 40.Xie X., Zhong Z., Zhao W., Zheng C., Wang F., Liu J. Chest ct for typical 2019-ncov pneumonia: relationship to negative rt-pcr testing. Radiology. 2020 doi: 10.1148/radiol.2020200343. page 200343. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Yang W., Chen Y., Liu Y., Zhong L., Qin G., Lu Z., Feng Q., Chen W. Cascade of multi-scale convolutional neural networks for bone suppression of chest radiographs in gradient domain. Med. Image Anal. 2017;35:421–433. doi: 10.1016/j.media.2016.08.004. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
We have made our data available for public use in this address: (https://github.com/mr7495/COVID-CTset). The dataset is available in two parts: one is the raw data presented in three folders for each patient. The next part is the training, validation, and testing data in each fold. We hope that this dataset will be utilized for improving COVID-19 monitoring and detection in the coming researches.