

Studies have found that anterior temporal lobe (ATL) is critical for detailed knowledge of object categories, suggesting that it has an important role in semantic memory. However, in addition to information about entities, such as people and objects, semantic memory also encompasses information about places.
Keywords: fMRI, machine learning, posterior medial, anterior temporal, RSA, semantic memory
Abstract
Studies have found that anterior temporal lobe (ATL) is critical for detailed knowledge of object categories, suggesting that it has an important role in semantic memory. However, in addition to information about entities, such as people and objects, semantic memory also encompasses information about places. We tested predictions stemming from the PMAT model, which proposes there are distinct systems that support different kinds of semantic knowledge: an anterior temporal (AT) network, which represents information about entities; and a posterior medial (PM) network, which represents information about places. We used representational similarity analysis to test for activation of semantic features when human participants viewed pictures of famous people and places, while controlling for visual similarity. We used machine learning techniques to quantify the semantic similarity of items based on encyclopedic knowledge in the Wikipedia page for each item and found that these similarity models accurately predict human similarity judgments. We found that regions within the AT network, including ATL and inferior frontal gyrus, represented detailed semantic knowledge of people. In contrast, semantic knowledge of places was represented within PM network areas, including precuneus, posterior cingulate cortex, angular gyrus, and parahippocampal cortex. Finally, we found that hippocampus, which has been proposed to serve as an interface between the AT and PM networks, represented fine-grained semantic similarity for both individual people and places. Our results provide evidence that semantic knowledge of people and places is represented separately in AT and PM areas, whereas hippocampus represents semantic knowledge of both categories.
SIGNIFICANCE STATEMENT Humans acquire detailed semantic knowledge about people (e.g., their occupation and personality) and places (e.g., their cultural or historical significance). While research has demonstrated that brain regions preferentially respond to pictures of people and places, less is known about whether these regions preferentially represent semantic knowledge about specific people and places. We used machine learning techniques to develop a model of semantic similarity based on information available from Wikipedia, validating the model against similarity ratings from human participants. Using our computational model, we found that semantic knowledge about people and places is represented in distinct anterior temporal and posterior medial brain networks, respectively. We further found that hippocampus, an important memory center, represented semantic knowledge for both types of stimuli.
Introduction
Navigating through daily life requires accessing knowledge about previously encountered people and places. For example, making plans to meet friends at a restaurant might involve retrieving information about the restaurant (e.g., its location, the type of food served there, whether the place is dog-friendly) and information about the people you are meeting there (e.g., their personalities, dietary restrictions, whether anyone might be bringing a dog). Detailed semantic knowledge, which contains information about common features that generalize across specific episodes (Tulving, 1972), enables decision-making based on both the features of the relevant location and personal characteristics.
Distinct brain regions are recruited during viewing (Kanwisher et al., 1997; Epstein and Kanwisher, 1998; Collins and Olson, 2014) and perceptual discrimination (Lee et al., 2008; Barense et al., 2010a; Mundy et al., 2013; Costigan et al., 2019) of people and places. However, it is unclear whether distinct or overlapping areas are involved in representing semantic knowledge of people (e.g., personality, occupation, relationships) and places (e.g., spatial layout, cultural and historical significance). Anterior temporal lobe (ATL) (Patterson et al., 2007; Martin et al., 2018) and inferior frontal gyrus (IFG) (Thompson-Schill et al., 1997; Simmons et al., 2010) have been shown to play domain-general roles in representing and retrieving semantic knowledge. ATL in particular is thought to be a semantic hub that connects the proper names of unique entities, including both famous people and places, with knowledge about those unique entities (Gorno-Tempini and Price, 2001; Schneider et al., 2018).
Other work suggests, however, that distinct networks support semantic knowledge for people and places. ATL is specifically recruited during processing of social stimuli (Simmons and Martin, 2009; Simmons et al., 2010), including faces (Lee et al., 2007; Harry et al., 2016). Such findings have led to the proposition that ATL functions as part of an anterior temporal (AT) network, including the amygdala, inferior temporal cortex (ITC), and orbitofrontal cortex, to process information about individual entities, such as people and objects (Barense et al., 2010b; Ranganath and Ritchey, 2012; Clarke and Tyler, 2014; Collins et al., 2016; Harry et al., 2016). IFG is functionally coupled with ATL (Libby et al., 2012), suggesting it may also be a component of the AT network. Conversely, a posterior medial (PM) network, including parahippocampal cortex (PHC), retrosplenial cortex (RSC), angular gyrus, and precuneus, has been proposed to represent situation models that reflect semantic knowledge about places (Walther et al., 2009; Baldassano et al., 2018). The AT and PM networks are anatomically and functionally connected with the hippocampus (Witter et al., 2000; Kahn et al., 2008; Ranganath and Ritchey, 2012), which may represent domain-general conceptual content (Quiroga et al., 2008; De Falco et al., 2016; Mack et al., 2016; Morton et al., 2017). Here, we tested whether hippocampus and the individual component regions of the AT and PM networks represent domain-general or domain-specific semantic knowledge of people and places.
To quantify neural representations of semantic knowledge, we collected fMRI data while participants viewed pictures of 60 famous people and 60 famous locations around the world (Fig. 1A). We used representational similarity analysis (RSA) (Kriegeskorte et al., 2008a) to isolate neural representations of semantic knowledge of people and places (Fig. 1B). We first used text from Wikipedia articles with natural language embedding methods to develop a model of semantic similarity that successfully predicts human similarity judgments. We then compared the observed neural dissimilarity patterns for pairs of items with the dissimilarity predicted by our computational model of semantic knowledge. For places, we also tested whether geographical distance, independent of overall semantic similarity, was represented in neural dissimilarity patterns. We controlled for visual similarity using a model of low-level visual processing (Mutch and Lowe, 2006). This approach allowed us to test whether AT and PM regions are specifically involved in representing detailed semantic features of people and places, respectively, with hippocampus representing domain-general semantic content.
Figure 1.

A, During scanning, participants viewed pictures and names of famous people and places while performing an incidental color-change detection task. B, To determine whether a given brain region represented semantic features, we estimated the dissimilarity of neural activation patterns of each pair of items to create a representational dissimilarity matrix (RDM). We then compared the neural RDM with the RDM predicted by a model of semantic similarity, after controlling for visual similarity. For places, we also tested for representation of physical location by comparing the neural RDM to an RDM based on geographical distance between locations, after controlling for the semantic and visual models. C, Model RDMs for the people and places according to semantic, visual, and geography models (semantic dissimilarity is taken from the wiki2USE model). Photographs illustrate the items being compared for each set of rows and columns. Dissimilarity is shown by rank.
Materials and Methods
Participants
Thirty-seven right-handed volunteers participated in the scanning study (19 women; ages 18-30 years; mean = 22.3 ± 3.6 years [SD]). Consent was obtained in accordance with an experimental protocol approved by the Institutional Review Board at the University of Texas at Austin. Participants received monetary compensation for their involvement in the study. Data from 4 participants were excluded for excessive movement (more than two runs with >30% censored volumes; for details, see Functional ROIs). Data from the remaining 33 participants were included in all analyses (18 women; ages 18-30 years; mean 22.3 ± 3.7 years).
One-hundred fifty volunteers participated in the online similarity judgment task (67 women; ages 22-34 years; mean = 29.3 ± 2.3 years [SD]). Participants were recruited and compensated through Amazon Mechanical Turk. Consent was obtained in accordance with an experimental protocol approved by the Institutional Review Board at the University of Texas at Austin. Participants received monetary compensation for their involvement in the study. Data from 48 participants were excluded because of low performance on the manipulation check test or catch trials (for details, see Similarity judgment task). Data from the remaining 102 participants (44 women; ages 22-34 years; mean 29.4 ± 3.3 years [SD]) were included in analysis of similarity ratings.
Materials
Stimuli consisted of 120 images of famous people and places (30 male, 30 female; 30 manmade, 30 natural; see Fig. 1C). Stimuli were selected to maximize average familiarity of the stimuli, based on familiarity ratings collected from a population with similar demographics to our participants. For the purposes of stimulus selection, we determined average familiarity of each stimulus based on ratings on a 4 point scale collected from participants (ages 18-30 years) at Vanderbilt University (Morton and Polyn, 2017). Photographs of famous person faces and famous locations were obtained from free sources on the Internet. Images of people were edited to remove the background. Location pictures were selected to be taken during the day and outside, with the exception of locations best known for their interior (Sistine Chapel, Carlsbad Cavern, and Mammoth Cave). An additional 18 images of common objects were used in the manipulation check test of the online similarity judgment study.
Experimental design and statistical analyses
Participants first completed a one-back task during fMRI scanning, which allowed us to define category-sensitive functional ROIs. The task was designed to measure brain activity related to people, places, objects, and rest. Participants were presented with blocks of color photographs of unfamiliar faces (36 female, 36 male), unfamiliar places (36 manmade, 36 natural), and 72 common objects. Each of four scanning runs included six 20 s blocks (one each of female faces, male faces, manmade places, and natural places as well as two object blocks), with 18 s of rest at the beginning and end. During each block, participants viewed 10 stimuli (1.6 s duration, 0.4 s interstimulus interval) while performing a one-back task. Participants indicated via button press whether each stimulus was new or a repeat (each block contained one repeat).
After the one-back task scans, participants completed a stimulus viewing task that allowed us to estimate the BOLD activity response for each stimulus. Participants were presented with images of the 120 famous people and places, with their names shown below, while completing an incidental color-change detection task (Fig. 1A). There were six runs of the viewing task; each run included 40 stimuli (10 from each subcategory of female, male, natural, and manmade) that were each presented twice. Presentation order was randomized within each run. Each stimulus was presented in two randomly selected runs, for a total of four presentations per stimulus. Each stimulus was presented for 2 s, with an interstimulus interval of 2-6 s. The frequencies of the different interstimulus intervals were exponentially distributed (durations of 2, 4, and 6 s were presented with a frequency ratio of 4:2:1, respectively). Participants performed a change-detection task during the presentation of the stimuli to ensure sustained attention. Participants pressed one button if a small black circle at the center of the image turned blue and another if the circle turned yellow; the color change occurred at 0.25-0.75 s after picture onset. There was no instruction regarding what to think about (i.e., physical characteristics or semantic properties) during the task. The change-detection task was chosen to follow prior work examining stimulus-specific representations (Kriegeskorte et al., 2008b) and to ensure that task demands did not vary for the different stimuli. After the one-back task and viewing task scans, participants completed a memory task that spanned 2 d, with additional scans on the second day. Results related to the memory task will be reported elsewhere; here, we focus on the one-back and viewing tasks, which take place before any learning for the memory task.
Statistical analysis of fMRI data used nonparametric permutation tests to control Type I error and correct for multiple comparisons. Details of individual statistical analyses are described in Partial correlation analysis, Functional coupling analysis, and Searchlight analysis.
Image acquisition
Imaging data were acquired on a 3.0 T Siemens Skyra MRI at the University of Texas at Austin Biomedical Imaging Center. A T1-weighted 3-D MPRAGE volume (TR: 1.9 s, TE: 2.43 ms, flip angle: 9°, FOV: 256 mm, 192 slices, 1 mm3 voxels) was acquired on each day for coregistration and parcellation. Two oblique coronal TSE T2-weighted volumes were acquired perpendicular to the main axis of the hippocampus (TR: 13.15 s, TE: 82 ms, flip angle: 150°, 384 × 384 matrix, 60 slices, 0.4 × 0.4 mm in-plane resolution, 1.5 mm through-plane resolution) to facilitate localization of activity in the medial temporal lobe. High-resolution whole-brain functional images were acquired using a T2*-weighted multiband accelerated EPI pulse sequence (TR: 2 s, TE: 31 ms, flip angle: 73°, FOV: 220 mm, 75 slices, matrix: 128 × 128, 1.7 mm3 voxels, multiband factor: 3, GRAPPA factor: 2, phase partial Fourier: 7/8). We acquired a field map on each day (TR: 589 mm, TE: 5 ms and 7.46 ms, flip angle: 5°, matrix: 128 × 128, 60 slices, 1.5 × 1.5 × 2 mm voxels) to allow for correction of magnetic field distortions.
Image processing
Data were preprocessed and analyzed using FSL 5.0.9 (FMRIB's Software Library; https://fsl.fmrib.ox.ac.uk/fsl) and Advanced Normalization Tools 2.1.0 (ANTS; http://stnava.github.io/ANTs). The T1 and coronal T2 scans for each participant were each corrected for bias field using N4BiasFieldCorrection, coregistered using antsRegistration and antsApplyTransforms, scaled using a single multiplicative value, and averaged. FreeSurfer 6.0.0 was used to automatically segment cortical and subcortical areas based on the averaged T1 scans and to automatically identify hippocampus based on the averaged coronal T2 scans. The buildtemplateparallel program from ANTS (Avants et al., 2010) was used to create a group-level T1 template from brain-extracted MPRAGE scans from 30 individual participants (rigid initial target, three affine iterations, 10 nonlinear iterations). The included 30 participants were a subset of the current sample of 33 that were also included in analysis of the memory task. The resulting template was registered to the FSL 1 mm MNI template brain using affine registration implemented in ANTs, to obtain a final template.
Functional scans were corrected for motion through alignment to the center volume using MCFLIRT, with spline interpolation. Functional scans were unwarped using a modified version of epi_reg from FSL, which uses boundary-based registration implemented in FSL (Greve and Fischl, 2009), followed by ANTs to refine registration between functional scans and the T1. A brain mask derived from FreeSurfer was projected into native functional space and used to remove nonbrain tissue from the unwarped scans. Average brain-extracted unwarped functional scans were registered to a single reference scan (the first study-phase scan on the second day) using ANTS. After calculating all transformations, motion correction, unwarping, and registration to the reference functional scan were conducted using B-spline interpolation, in two steps to minimize interpolation. The bias field for the average image was estimated for each scan using N4 bias correction implemented in ANTS and removed by dividing the timeseries by a single estimated bias field image. Functional time series were high-pass filtered (128 s FWHM) and smoothed at 4 mm FWHM using FSL's SUSAN tool.
Anatomical ROIs
We examined anatomic regions within the PM and AT networks, which have been proposed to represent context and item information, respectively. Following a recent study examining these networks (Cooper and Ritchey, 2019), we used the Harvard-Oxford cortical atlas to define the PM network areas of angular gyrus, precuneus, and posterior cingulate cortex (PCC), and the AT network areas of amygdala, fusiform cortex, temporal pole, ITC, and orbitofrontal cortex. We also examined the pars opercularis and pars triangularis regions of IFG, which exhibits similar functional connectivity to AT regions (Libby et al., 2012), suggesting that IFG may also be part of the AT network. Regions were taken from the maximum probability atlas after thresholding at 50%. We further examined PHC and perirhinal cortex, which are thought to be critical regions within the PM and AT networks, respectively (Ranganath and Ritchey, 2012). PHC and perirhinal cortex were drawn manually on the FSL 1 mm MNI template and transformed to our custom template using ANTs. Finally, we interrogated anterior and posterior subdivisions of hippocampus, which is thought to be a zone of convergence between the PM and AT networks (Witter and Amaral, 1991; Witter et al., 2000; Ranganath and Ritchey, 2012; Cooper and Ritchey, 2019). Hippocampus was automatically labeled for individual subjects using FreeSurfer 6.0.0 (Iglesias et al., 2015), based on their high-resolution T2 coronal scans. The posterior hippocampus region was defined as the posterior two-thirds of hippocampus, along the longitudinal axis, and the anterior hippocampus region was defined as the anterior third.
Functional ROIs
Following prior studies of person and place processing, we defined a set of functional ROIs based on the one-back task scans (see Fig. 6A,B). We modeled the one-back task scans using a GLM implemented in FSL's FEAT tool (Woolrich et al., 2001). Task blocks, including images of faces, places, objects, and rest, were convolved with a canonical HRF. Additional regressors of no interest included six motion parameters and their temporal derivatives, framewise displacement, and DVARS (Power et al., 2012). Additional regressors were created to remove time points with excessive motion (defined as >0.5 mm of framewise displacement and >0.5% change in BOLD signal for DVARS), as well as one time point before and two time points after each high-motion frame. High-pass temporal filtering (128 s FWHM) was applied to the regressors. Parameter estimates were averaged across runs for each participant. Individual participant parameter estimates were transformed to our custom template space using ANTS, and voxel-level significance was assessed using FSL's FLAME 1 (Woolrich et al., 2004). Contrast z scores were thresholded to obtain each functional ROI on the group template (see Fig. 6A,B).
Figure 6.
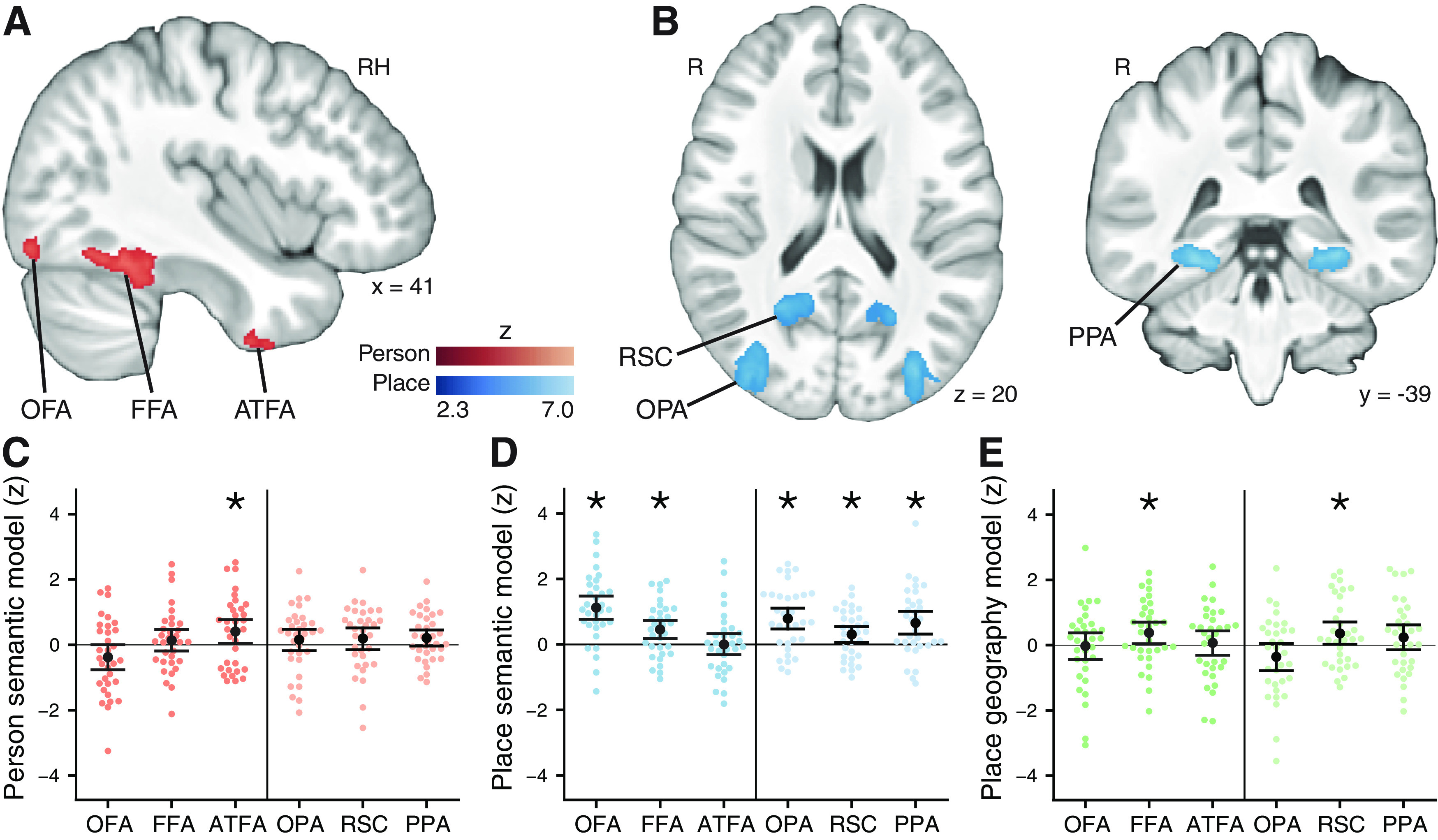
Representation of semantic relationships of famous people and places in category-sensitive functional ROIs defined from a separate one-back task. A, Person-sensitive ROIs showing a stronger response to faces than places and objects. B, Place-sensitive ROIs showing a stronger response to places than to faces and objects. C, RSA of person-sensitive regions was used to identify regions that represent the semantic similarity of famous people, after controlling for visual similarity. Only ATFA patterns showed a unique correlation with the semantic model. Left, Person-sensitive regions. Right, Place-sensitive regions. D, For famous places, similarity of activation patterns in OFA, FFA, OPA, PPA, and RSC correlated with semantic similarity after controlling for visual similarity. E, We tested whether any regions represented geographical distance between locations. RSC and FFA pattern dissimilarity correlated with the geographic distance between landmarks, after controlling for the other models. Points represent individual participant z statistics. Error bars indicate 95% CIs. *FDR q < 0.1.
Person-sensitive ROIs were defined based on a contrast of faces > places + common objects. We defined occipital face area (OFA), fusiform face area (FFA), and anterior temporal face area (ATFA) based on published definitions (Collins and Olson, 2014). OFA was only clearly defined in the right hemisphere, so only the right side was included; the other ROIs were defined bilaterally. Place-sensitive ROIs were defined based on a contrast of places > faces + common objects. Place-sensitive ROIs included occipital place area (OPA), RSC, and parahippocampal place area (PPA) (Kauffmann et al., 2015). Functional ROIs were reverse-normalized using ANTs to obtain ROIs in each participant's native functional space. Native-space ROIs were then dilated by 1 voxel.
Estimation of item-level activation patterns
Patterns of activation associated with individual items were estimated under the assumptions of the GLM using a least squares–separate approach (Mumford et al., 2012). Parameter estimate images were calculated for each of the 40 items presented in each scan. Each 2 s item presentation was convolved with a canonical (double Γ) HRF. Each item was estimated using a separate model; the two presentations of an item within each scan were modeled as a single regressor, with presentations of other items modeled as a separate regressor. As for the functional ROI analysis, additional regressors of no interest included six motion parameters and their temporal derivatives, framewise displacement, DVARS, and time points with excessive motion. High-pass temporal filtering (128 s FWHM) was applied to the regressors. Individual stimulus activity parameter estimates were calculated using a GLM implemented in custom Python routines. Each voxel's activity was z-scored across stimuli within run. Finally, normalized activity patterns for each item were averaged across the two scans in which that item appeared, resulting in 120 estimated item activity patterns.
Similarity judgment task
In a separate study, 150 participants completed an online similarity judgment task to measure semantic and visual similarity of the famous people and places. Participants were randomly assigned to one of four conditions: person semantic similarity, person visual similarity, place semantic similarity, or place visual similarity. Stimuli were presented and responses were collected using the Collector program for online data collection (https://github.com/gikeymarcia/Collector), which was hosted on a server running PHP. All trials were self-paced, and participants were given up to an hour to complete the task.
In each condition, participants first rated their familiarity with each of the 60 items on a scale from 1 to 4 (1 = very unfamiliar; 2 = somewhat unfamiliar; 3 = somewhat familiar; 4 = very familiar). Participants were then presented with a manipulation check test, in which they were instructed to rate the similarity of common objects based on either visual or semantic similarity, depending on the condition to which they were assigned. There were 6 manipulation check trials; each trial included three common objects. On each trial, participants were presented with an object in the center of the screen and asked to select the most similar item (Roads and Mozer, 2019) based on either visual or semantic similarity. Each trial was designed to have an item with high visual similarity and an item with high semantic similarity. For example, on one trial, the center item was a life preserver, the visually similar choice was a donut, and the semantically similar choice was a boat. Participants were excluded from further analysis if they answered <4 of the 6 questions correctly based on their instructions.
Finally, participants completed 84 trials of a similarity judgment task (Fig. 2C). Participants were shown a 3 × 3 array of 9 pictures with stimulus names below them and asked to click on the most similar item to the center picture, followed by the second most similar item (Roads and Mozer, 2019). After selecting a picture, a square appeared around it to indicate selection. In each block of 21 trials, there was one catch trial to assess whether participants were completing the task correctly. In each catch trial, one of the items was identical to the center item but shown with a left-right mirror image of the center image. Catch trials were scored as correct if participants selected the identical item as either of their two responses on that trial. Participants were not instructed about the catch trials ahead of time. Participants were excluded from further analysis if they responded incorrectly to >1 of the 4 catch trials. After applying exclusion criteria, there were at least 25 participants in each condition (person semantic: 26 participants; place semantic: 25; person visual: 25; place visual: 26).
Figure 2.

A, Semantic features of famous people and places were quantified through analysis of text from the Wikipedia article for each item. B, To develop the wiki2vec model, we first processed article text to extract a set of words and phrases for each item. We then converted each word or phrase to a 300-dimensional vector representation using the word2vec model of semantic similarity and summed all vectors to obtain the final wiki2vec vector for each item. The wiki2USE model was created by using the Universal Sentence Encoder (USE) to encode the text for each item as a 512-dimensional vector. C, We validated the Wikipedia-based models using a similarity judgment task. Participants were presented with a central item (e.g., Eiffel Tower) and asked to select the most similar (green) and second most similar (blue) items. Separate groups rated visual and semantic similarity. Similarity judgments were used to estimate separate psychological embeddings for each category based on visual and semantic similarity. D–F, Multidimensional scaling plots illustrating the semantic similarity of famous people according to the wiki2vec (D) and wiki2USE (E) models after Procrustes alignment to the semantic embedding model (F). Items that are closer together have more similar representations according to the model. G–I, Multidimensional scaling plots for the wiki2vec (G), wiki2USE (H), and semantic embedding (I) models for famous places.
Models of representational dissimilarity
wiki2vec model
To characterize the information contained in item-level activation patterns measured during the viewing task, we developed a model of the semantic features of our famous people and place stimuli. The model is derived from Wikipedia text, which is well suited to capture abstract general knowledge, as the articles are focused on encyclopedic descriptions. The wiki2vec model quantifies the semantic similarity of each pair of stimuli, allowing us to use RSA to measure neural representations of semantic knowledge about people and places (Fig. 1B). We first obtained text from the Wikipedia page of each famous person and place. The Wikipedia text for each item was then preprocessed using natural language processing and translated into a vector representation using Google word2vec, a publicly available model that was trained on text from Google News (Mikolov et al., 2013a).
To obtain text reflecting general knowledge of each item around the time of the experiment, we downloaded a Wikipedia Extensible Markup Language dump (https://dumps.wikimedia.org) archived on February 19, 2015, 3 months before the start of the experiment. These files were converted to plain text using Wikipedia Extractor (https://github.com/bwbaugh/wikipedia-extractor). We searched for the closest match of each item to a Wikipedia article and extracted the text for that article (Fig. 2A). The text was then processed using the Python-based Natural Language Toolkit (Bird et al., 2009) to generate a set of terms related to that item. To obtain a reduced set of terms related to item meaning, we first extracted the nouns, verbs, and adjectives. Named entities detected using NLTK, such as “Eiffel Tower,” were treated as a single unit. This unitization of named entities is useful for capturing the distinct meaning of phrases from their individual component words; for example, “Eiffel Tower” has a distinct meaning from “Eiffel” and “Tower” separately. To further reduce the set of unique terms, each noun and verb was then replaced with its lemma, or root word (for example, “acting” and “acts” would both be replaced with “act”). This process produced a set of terms (and their frequency of occurrence) for each of the 120 items.
To translate the set of terms for each Wikipedia article into a quantitative representation, we used Google's publicly available word2vec vectors dataset, which contains 300-dimensional vectors for 3 million words and phrases (Mikolov et al., 2013a,b). Phrases included combinations of words that appeared more frequently than would be expected based on the frequency of the constituent words (e.g., “global warming”). This set of vectors reflects the co-occurrence of words within the Google News corpus, with words that tend to occur in similar contexts being represented with similar vectors. These vectors provide a quantitative representation of a large set of terms, which can be used to correctly solve analogies (e.g., what is the word that is similar to “small” in the same sense as “biggest” is similar to “big”?) through simple addition and subtraction of individual vectors (Mikolov et al., 2013a). Code for word2vec and trained vectors can be found at https://code.google.com/archive/p/word2vec/.
We first searched for word2vec vectors corresponding to each term that appeared in any of the item term sets. We found matches for 26,222 of the 37,314 unique terms (the terms without matches were often unusual phrases or hyphenated terms, e.g., “then-husband”). We then generated a vector for each item by summing word2vec vectors corresponding to the terms derived from that item's Wikipedia article (Fig. 2B). Vectors were weighted by the number of times they appeared in the article. Finally, the estimated semantic dissimilarity between each item was calculated as 1 minus the correlation between each pair of item vectors to generate a semantic representational dissimilarity matrix (RDM) based on our wiki2vec model, for both people and places (see Fig. 4).
Figure 4.

Model validation analysis. A, Models of dissimilarity between pairs of people. Stimulus order is the same as in Figure 1. Dissimilarity is shown by percentile. Behavioral similarity ratings were used to estimate separate embedding models reflecting visual dissimilarity and semantic dissimilarity. We then evaluated our models of semantic dissimilarity by comparing them with the behaviorally derived embedding models and stimulus feature models representing gender, occupation, and age. Both the wiki2vec and wiki2USE models were correlated with each of these stimulus features. Furthermore, both the wiki2vec and wiki2USE models explained unique variance in the semantic embedding model after controlling for the visual embedding model, even after also controlling for gender, occupation, and age. These results suggest that the semantic dissimilarity models predict both objective stimulus features and fine-grained variation in psychological dissimilarity between pairs of people. B, Models of dissimilarity between pairs of places. Both the wiki2vec and wiki2USE models of semantic dissimilarity were correlated with stimulus feature models representing category (natural vs manmade), subcategory (e.g., river, mountain), and continent. The wiki2USE model was also correlated with a stimulus feature model representing the age of manmade locations. Furthermore, both semantic models explained unique variance in the semantic embedding model after controlling for the visual embedding, even after also controlling for category, subcategory, age, and continent.
We used nonmetric multidimensional scaling (Kruskal, 1964) to visualize the relative distances of items within each category according to the wiki2vec model and found that it captures detailed item features, such as a person's occupation and the different subtypes of locations (Fig. 2D,G). The wiki2vec model quantifies features of both people and places within a common high-dimensional space, allowing us to use RSA to probe neural representations of semantic knowledge for both categories using the same model.
wiki2USE model
We also developed an alternate model based on the Wikipedia text using the recently developed Universal Sentence Encoder (USE) version 4 (Cer et al., 2018). USE encodes text input sentences or paragraphs as 512-dimensional vectors, which may be used as embeddings for multiple natural language processing tasks. USE was trained on a set of different tasks, including unsupervised learning from arbitrary running text, conversational input-response, and classification (Cer et al., 2018). We used the Deep Averaging Network version (available at https://tfhub.dev/google/universal-sentence-encoder/4) with TensorFlow 2.1 to encode the Wikipedia text for each article as a vector. The Deep Averaging Network aggregates vector representations of individual words in the article to form a single vector summarizing the text. We then calculated semantic dissimilarity as 1 minus the correlation between each pair of item vectors (Fig. 1C; see also Fig. 4). We used nonmetric multidimensional scaling to visualize relative distances between items according to the model (Fig. 2E,H).
Geography model
A key semantic feature of familiar places is their geographical location. While the wiki2vec and wiki2USE models are based on Wikipedia text that includes location information, they emphasize other semantic features, such as location subtype (Fig. 2G,H). Therefore, to measure neural representations of relative spatial distance, we also defined a geography model based on each landmark's location on the Earth (Fig. 3). We used Google Maps to search for each item and recorded the longitude and latitude. We then calculated the pairwise distance between each pair of locations, using the haversine formula to calculate distance along the Earth's surface in killimeters. These pairwise distances together form the geography model RDM (Fig. 1C). We used this model with RSA to identify neural patterns that reflect the physical distance between places. For regions that correlated with the geography model, we visualized distance coding by dividing pairwise distances between places into equally spaced bins. We used non-negative least squares fitting (Jozwik et al., 2016) to control for effects of semantic similarity and visual similarity on neural dissimilarity between places. We then normalized neural dissimilarity across all stimulus pairs to obtain a z score of neural dissimilarity for each pair. Finally, for each subject, we calculated an average neural dissimilarity z score for each geographical distance bin.
Figure 3.

Geographic location of each famous place presented in the study. The geographic model reflects the shortest path between each pair of locations, based on their latitude and longitude. Inset, Locations in North America.
Visual model
Visual similarity is sometimes correlated with semantic similarity. For example, Carlsbad Caverns National Park and Mammoth Cave National Park are both more visually similar and semantically similar to one another than either are to the Great Barrier Reef. To control for visual similarity, we used a model of early visual processing, the Hierarchical Max-pooling (HMAX) model (Mutch and Lowe, 2006). While more sophisticated supervised models of visual processing have been developed recently (Khaligh-Razavi and Kriegeskorte, 2014), we selected HMAX as a simple, well-studied model that could be used to control for low-level processing. We used the HMAX package of the Cortical Network Simulator framework (Mutch et al., 2010), with the parameters of the full model described by Mutch and Lowe (2006), to process grayscale versions of each image (http://cbcl.mit.edu/jmutch/cns). Response vectors from the C1 layer of the model, which is proposed to reflect properties of early visual cortex, were extracted for each image (Clarke and Tyler, 2014). We calculated 1 minus the correlation between each pair of vectors to generate the visual model RDM for each category (Fig. 1C).
Embedding models
To validate our models of semantic similarity, we used a model of similarity judgments to estimate a psychological embedding for each of the four conditions in the similarity judgment task (Fig. 2C). The model assumes that items are represented within a multidimensional embedding and that similarity judgments are made based on the Minkowski distance between items in the embedding (Roads and Mozer, 2019). We fit the model to the data from our similarity judgment task to estimate a separate embedding for each condition (person visual, person semantic, place visual, and place semantic). We then used the embeddings to calculate the dissimilarity between each pair of items in each condition, resulting in four RDMs. In contrast to other methods that require collecting behavioral similarity judgments for each pair of items (e.g., Martin et al., 2018), this method is efficient for estimating item dissimilarity for large sets of items. If is the number of items, is the number of estimated dimensions in the embedding, and is a fixed number of parameters that determine how similarity judgments are made, fitting an embedding model involves estimating parameters. In contrast, estimating pairwise dissimilarity using similarity judgments requires estimating parameters. As a result, the embedding method can estimate pairwise dissimilarity more efficiently for large datasets.
We estimated the embeddings in Python 3.7.7 using PsiZ 0.2.2 (https://github.com/roads/psiz), TensorFlow 1.14.0, and TensorFlow Probability 0.7.0. Similarity judgment trials were excluded if the cue item was rated as “very unfamiliar” by the participant in the familiarity rating task. There was a mean of 72.7 ± 11.0 (SD) included trials for each participant (total included trials by condition: people semantic, 1999 trials; places semantic, 1783; people visual, 1824; places visual, 1808). Each embedding was estimated by inferring a 6-dimensional latent psychological space underlying the similarity judgments. Similarity judgments were assumed to be made based on an exponential similarity function of the psychological distances between the cue item in the center and the eight probe items surrounding it (Shepard, 1987; Roads and Mozer, 2019). The similarity between items and in the latent embedding was defined as follows:
Where is a free parameter that controls the type of distance (e.g., results in Euclidean distance) and , , and are free parameters that control the gradient of generalization.
The item locations in the embedding were estimated using maximum likelihood estimation. The Minkowski distance between each pair of items was calculated based on the estimated embedding space and distance parameter to generate a dissimilarity matrix for each embedding model (Fig. 4). We visualized the relative distances between items using nonmetric multidimensional scaling (Fig. 2F,I).
Model validation
We assessed each semantic model by comparing it with the semantic embedding model and with RDMs based on features of the stimuli (Fig. 4). Feature RDMs for people represented gender, main occupation, and age in years. All categorical feature RDMs, such as gender and occupation, were defined as 0 for item pairs in the same category and 1 for item pairs in different categories. Main occupation was determined based on the summary description of each person on Wikipedia. Occupations were actor, athlete, politician, rapper, singer, and television personality. The age RDM was computed based on age difference in years. Feature RDMs for places represented category (natural vs manmade), subcategory, age, and continent. Location subcategory was defined based on the summary description from Wikipedia. Manmade subcategories were amphitheater, bridge, church, dam, fortress, headquarters, mausoleum, museum, neighborhood, performing arts center, prison, theme park, and tower. Natural subcategories were archipelago, cave, desert, forest, island, lake, mountain, ocean, river, savanna, sea, valley, and waterfall. Age was defined for manmade locations as the date of construction. Dissimilarity of manmade locations in the age RDM was defined as the difference in construction date in years. Dissimilarity of natural locations was defined as 0, and dissimilarity between natural and manmade locations was defined as a constant value that was greater than the dissimilarity between any two manmade locations. In the continent RDM, items on the same continent were defined as having a distance of 0, and items on different continents were defined as having a distance of 1.
We first tested whether each semantic model was related to the feature RDMs. We used partial correlation analysis with non-negative least squares to assess whether each feature explained unique variance in the semantic model after controlling for the other features. First, the semantic model RDM, the feature RDM of interest, and control RDMs were converted to rank values (i.e., each dissimilarity value was replaced by the rank of that value within the whole RDM, excluding the diagonal). We then used non-negative least squares regression (Jozwik et al., 2016) to fit both the semantic model and the feature model of interest using the other models, and took the residuals from these fits. We then calculated the Spearman correlation between the semantic model and feature model of interest residuals. This correlation was compared with a baseline estimated by permuting the rows and columns of the RDM for the feature model of interest and calculating the partial correlation for that scrambled model; this process was repeated 100,000 times to generate a permutation distribution. The actual correlation was compared with this permutation distribution to calculate a p value for each feature model.
Next, we examined whether each semantic model predicted the dissimilarity of the semantic embedding model that we derived from behavioral similarity ratings. We used the same partial correlation analysis to test whether each model of semantic similarity explained unique variance in the semantic embedding model after controlling for the visual embedding model. We then tested whether the semantic models capture detailed relationships between items observed in the semantic embedding model. We tested whether each semantic model explained unique variance in the semantic embedding model after controlling for the visual embedding model and all feature models. Finally, we compared the wiki2vec and wiki2USE models in their ability to predict the semantic embedding model after controlling for the visual embedding model. We regressed the visual embedding model from the semantic embedding model, the wiki2vec model, and the wiki2USE model to obtain residuals for each model. We then used a test of dependent correlations (Williams, 1959; Steiger, 1980) to determine whether either model was significantly more correlated with the semantic embedding model after controlling for the visual embedding model.
Partial correlation analysis
To test our hypothesis that semantic knowledge of people and places is represented in distinct networks, we used RSA to measure neural representations of semantic knowledge while controlling for visual similarity (Fig. 5). Within a given region, we first calculated the average pattern of activity for each item. We then created a neural RDM by calculating 1 minus the correlation between the activation patterns observed for each pair of items (Kriegeskorte et al., 2008a). We used partial correlation to determine whether the semantic model explained variance in the observed neural dissimilarity matrix that was not explained by the visual model. We used MindStorm 0.2.0 to implement the partial correlation analysis (Morton, 2020). First, the neural RDM, model RDM of interest, and control RDM were converted to rank values (i.e., each dissimilarity value was replaced by the rank of that value within the whole RDM, excluding the diagonal). We then used non-negative least squares regression (Jozwik et al., 2016) to fit both the data and the model of interest using the other models, and took the residuals from these fits. We then calculated the Spearman correlation between the data and model of interest residuals.
Figure 5.

We used a partial RSA to test for neural representations of semantic knowledge. For a given brain region, we compared the neural RDM with the semantic model RDM. We first used non-negative least squares to fit the visual model to both the neural and semantic RDMs. Middle row represents the visual model after fitting to the neural and semantic RDMs. We then subtracted these fitted RDMs to obtain residuals. We then used these residuals to test whether the neural RDM was correlated with the semantic RDM after controlling for the visual RDMs.
This correlation was compared with a baseline estimated by permuting the rows and columns of the RDM for the model of interest and calculating the partial correlation for that scrambled model; this process was repeated 100,000 times to generate a permutation distribution. The actual correlation was compared with this permutation distribution to calculate a p value for each participant, which was transformed to a z statistic. Finally, a one-sided nonparametric test was used to assess whether partial correlation for a given model was significantly greater than chance across subjects. We corrected for multiple comparisons using a resampling-based method for controlling false discovery rate (FDR) (Yekutieli and Benjamini, 1999). The sign of each z statistic was randomly flipped 100,000 times, and a one-sample t test was run for each comparison and permutation to estimate a null value distribution. To account for correlations between ROIs, the same random sign flips were used across all ROIs. Using the null distribution and the observed values, we calculated an estimate, , of the FDR for each comparison (Yekutieli and Benjamini, 1999). We thresholded the FDR at , thereby controlling the expected fraction of false discoveries out of the rejected null hypotheses at 0.1.
For both people and places, we tested the semantic model while controlling for the visual model. For places, we also tested the geography model while controlling for the visual and semantic models. This analysis allowed us to measure representation of spatial location while controlling for semantic relationships between places that may covary with geographical location. While the visual model accounts for low-level similarity, stimuli may also be divided into categories based on visual features; for example, mountains and rivers may be discriminated based on visual characteristics of the images. To account for visual categories, a follow-up analysis tested for partial correlation between neural dissimilarity and the wiki2USE semantic model while controlling for both the visual model and visual categories. For people, we included gender as a visual category control model (Fig. 4A). Place visual categories included category (natural vs. manmade) and subcategory (e.g., river, mountain; see Fig. 4B). To test our main hypothesis that the PM network would represent semantic similarity of places while the AT network would represent semantic similarity of people, we averaged partial correlation z statistics across all ROIs within each network, separately for people and places. We then tested for an interaction between network (AT or PM) and stimulus category (person or place).
Controlling for familiarity
The similarity judgment task included ratings of familiarity on a 4 point scale, with 4 being highest. Based on the ratings of the 102 participants included in the similarity judgment task, mean familiarity was similar for the two categories (people: mean 3.14, SEM: 0.08; places: mean 2.84, SEM: 0.07), although places were less familiar on average (t(100) = 2.88, , Cohen's ). The mean famililiarity was higher for male celebrities than for female celebrities (female: mean 3.07, SEM: 0.09; male: mean 3.22, SEM: 0.08; t(50) = 3.68, , ). Mean familiarity was higher for manmade places than natural places (manmade: mean 3.01, SEM: 0.07; natural: mean 2.68, SEM: 0.06; t(50) = 9.17, , ).
To control for the difference in familiarity between the subcategories (female, male, manmade, natural), a follow-up partial correlation analysis used a subset of stimuli with matched familiarity. First, for each item, we calculated the average familiarity across participants based on the similarity judgment task data. We then calculated the minimum and maximum familiarity for each subcategory and excluded any item that was outside the range of any other subcategory. We next subsampled each subcategory to match the distribution of familiarity values in the natural category, which had the lowest familiarity on average. We estimated the density of the distribution of familiarity values for each subcategory using Gaussian kernel density estimation. We then randomly sampled items from each subcategory, without replacement, to obtain a matched subsample. The probability of each item being sampled was proportional to the target density (estimated from the natural distribution) divided by the original density. After subsampling, there were 19 items in each subcategory. There was no significant difference in familiarity between people and places for the subsampled stimuli (people: mean 3.04, SEM: 0.09; places: mean 2.94, SEM: 0.07; t(100) = 0.84, , ). We used the subsampled stimuli to test whether there was an interaction between network (AT or PM) and stimulus category (person or place) after controlling for stimulus familiarity.
Functional coupling analysis
We hypothesized that hippocampus, which shares anatomic connections with both the AT and PM networks (Witter and Amaral, 1991; Witter et al., 2000; Ranganath and Ritchey, 2012), would be differentially coupled with person- and place-sensitive ROIs during person and place trials. We used a functional coupling analysis to test whether functional ROIs evincing semantic representations of people or places were differentially coupled with hippocampus during person or place trials. Prior work has found evidence of differences in anatomic connections and functional coupling between anterior and posterior hippocampus (Witter and Amaral, 1991; Witter et al., 2000; Libby et al., 2012), with PHC connected primarily to posterior hippocampus and perirhinal cortex connected primarily to anterior hippocampus. This pattern of connectivity suggests that person-sensitive ROIs may primarily functionally couple with anterior hippocampus, and place-sensitive ROIs may primarily couple with posterior hippocampus.
However, other models differentiate anterior and posterior hippocampus function based on the granularity of representation; such models suggest that posterior hippocampus represents fine-grained, local information, whereas anterior hippocampus represents coarse, global associations reflecting commonalities (Poppenk et al., 2013; Morton et al., 2017; Brunec et al., 2018), including conceptual learning of stimulus categories (Mack et al., 2016). This representational account raises the possibility that both person- and place-sensitive ROIs will functionally couple with anterior hippocampus during processing of familiar stimuli. Thus, we tested functional coupling of person- and place-sensitive ROIs with posterior and anterior hippocampus separately. We first calculated the mean activation within each region for each item. We then calculated the correlation of hippocampus activation for each item with item activation in each ROI, separately for people and place trials, and calculated the difference between people and place trials. We then tested whether the correlation between regions differed between person and place trials using a nonparametric sign-flipping test. A threshold was set based on the permutation distribution to control familywise error across hippocampal subregions at .
Searchlight analysis
Searchlight analysis was used to examine representations within hippocampus with greater spatial precision. Each searchlight was conducted within each subject's native functional space with a radius of 3 voxels, using the PyMVPA toolbox (Hanke et al., 2009) and custom Python routines (Morton et al., 2021a). As described in Partial correlation analysis, we used partial correlation to examine whether the semantic model explained unique variance in the patterns of activity observed in each region, after controlling for the visual model. For places, we also tested whether the geography model explained unique variance after controlling for the visual and semantic models.
To account for error in registering individual participants to the group template, the searchlight was run at all voxels within 3 voxels of the participant's individual defined mask defined by FreeSurfer. For each searchlight sphere, only voxels within the individually defined hippocampus mask were included. Spheres with <10 included voxels were excluded from the analysis. The center voxel of each searchlight sphere was set to the z statistic based on a permutation test with 10,000 permutations. Participant z statistic maps were transformed to the group-level template using antsApplyTransforms. A group-level nonparametric test was implemented using FSL's randomise tool with 10,000 permutations. Voxelwise significance was thresholded at p < 0.01.
To determine cluster-level significance, we estimated spatial smoothness of the data based on residuals from the trial-level GLM of the viewing task (in this case, we used a single LSA model) (Mumford et al., 2012). Residuals from the native-space GLM models for each run were transformed to template space using ANTs. For small-volume correction, we generated a group-level hippocampus mask that included all voxels that were within 1 mm of hippocampus for at least 10% of participants. Within the group-level ROI, smoothness was estimated using AFNI 3dFWHMx using the autocorrelation function method, and averaged across all volumes, runs, and subjects. Finally, a cluster size threshold was determined based on this estimated smoothness, using 3dClustSim with 10,000 iterations, one-sided thresholding at p < 0.01, and familywise α of 0.05.
Software accessibility
Code for running partial RSA with non-negative least squares (Morton, 2020) and for running other reported analyses (Morton et al., 2021a) is publicly available. Code and instructions for generating the wiki2vec and wiki2USE models for an arbitrary set of commonly known people, places, or things are also publicly available (Zippi et al., 2020; Morton et al., 2021b).
Results
Wikipedia-based models reflect stimulus features and predict behavioral measures of similarity
To validate our models of semantic similarity, we used data from the similarity judgment task to create a behavior-based model of semantic similarity. Separately for each condition (people semantic, place semantic, people visual, and place visual), we used the similarity judgment responses to estimate the latent psychological embeddings of the items underlying those judgments. We assessed convergence of each embedding model by comparing the embedding based on the full dataset with an embedding based on 90% of the data. We found that between the full and restricted embeddings was at least 86% for each of the conditions (people semantic: ; place semantic: ; people visual: ; place visual: ), suggesting that we had sufficient similarity data to obtain convergence. Best-fitting parameters for the embedding models were similar for each condition (person semantic: , , , ; place semantic: , , , ; person visual: , , , ; place visual: , , , ). These parameters were used to calculate pairwise distances for items in each condition based on the embeddings (Figs. 2F,I, 4).
We used the feature RDMs and embedding models to evaluate our two Wikipedia-based models of semantic dissimilarity (Fig. 4). First, to examine what information is present in the semantic dissimilarity models, we tested whether each semantic model was correlated with specific stimulus features. For people, we found that each of the stimulus features we tested explained unique variance in both the wiki2vec model (occupation: , ; gender: , ; age: , ) and the wiki2USE model (occupation: , ; gender: , ; age: , ). For places, we found that multiple stimulus features explained unique variance for the wiki2vec model (category: , ; subcategory: , ; continent: , ), although building age did not explain unique variance (, ). Each of the place features we tested explained unique variance in the wiki2USE model (category: , ; subcategory: , ; age: , ; continent: , ). Our results demonstrate that both models are sensitive to multiple semantic features of the people and place stimuli.
We next compared the Wikipedia-based models to the behaviorally derived embedding models. To control for any influence of visual similarity on the semantic similarity judgments, we tested whether the Wikipedia-based models correlated with the semantic embedding model after controlling for the visual embedding model. We found that both wiki2vec and wiki2USE explained unique variance in the semantic embedding model, for both people (wiki2vec: , ; wiki2USE: , ) and places (wiki2vec: , ; wiki2USE: , ). Importantly, the Wikipedia-based models still explained unique variance in the semantic embedding model after controlling for the stimulus feature models, both for people (wiki2vec: , ; wiki2USE: , ) and places (wiki2vec: , ; wiki2use: , ). Together, our results demonstrate that wiki2vec and wiki2USE reflect objective stimulus features and predict nuanced patterns in behavioral measures of semantic similarity.
Finally, we tested whether wiki2vec or wiki2USE were significantly more predictive of the semantic embedding model after controlling for the visual embedding model. For people, we found that the wiki2USE model was numerically more correlated with the semantic embedding model than the wiki2vec model (t(1767) = 1.58, ). For places, the wiki2USE model was significantly more correlated with the semantic embedding model (t(1767) = 4.72, ). While both models were correlated with both stimulus features and the behaviorally derived semantic embedding model, wiki2USE was more predictive of the semantic embedding model overall. Therefore, we use the wiki2USE model for all subsequent analysis. The wiki2USE model had a similar partial correlation with the semantic embedding model for people () and places (), demonstrating that it provides a reasonable model of semantic similarity for both categories.
Category-sensitive regions represent semantic similarity of famous people and places
Research on visual processing has identified regions that show preferential activation toward face (Kanwisher et al., 1997; Collins and Olson, 2014; Harry et al., 2016) or place (Epstein and Kanwisher, 1998; Hodgetts et al., 2017) stimuli. Neuropsychological work has also demonstrated that category-sensitive regions in the medial temporal lobe are necessary for discrimination and naming of individual faces or places (Lee et al., 2007; Ahmed et al., 2008). Furthermore, there is evidence from recent work that patterns of activation in category-sensitive regions reflect visual place category (Walther et al., 2009) and learned features of fictional people (Collins et al., 2016). Here, we test whether patterns of activation in category-sensitive regions represent semantic knowledge about real-world famous people and places. We examined the person-sensitive regions OFA, FFA, and ATFA (Collins et al., 2016), and the place-sensitive regions OPA, RSC, and PPA (Kauffmann et al., 2015). We defined the functional ROIs based on data from the one-back task (Fig. 6A,B) and then examined activity in those ROIs during the viewing task. In each ROI, we first used RSA to test for semantic representations of people and places (using the wiki2USE model) after controlling for low-level visual similarity based on the HMAX model (Fig. 5). Follow-up analyses then examined these representations while controlling for high-level visual categories.
We hypothesized that ATFA, a region within ATL near perirhinal cortex, would represent semantic knowledge about famous people. ATFA is sensitive to faces (Harry et al., 2016), distinguishes between individual faces (Kriegeskorte et al., 2007), and has been proposed to form a view-invariant representation of individual faces that connects to knowledge about individual people (Collins and Olson, 2014). We compared ATFA with OFA and FFA, which are thought to be involved in more intermediate perceptual processing of faces (Collins and Olson, 2014). Consistent with our predictions, we found that activation patterns in ATFA were consistent with the semantic similarity model, after controlling for the visual similarity model (Fig. 6C; z statistic mean: 0.41, SEM: 0.19, t(32) = 2.18, , Cohen's ). All other ROIs, including OFA, FFA, and the place-sensitive regions, did not correlate with the semantic model after controlling for the visual similarity model (FDR ).
While our initial analysis controlled for low-level visual similarity, the people stimuli include a salient visual category of gender that is not perfectly captured by the visual similarity model. We found that ATFA similarity correlated with the semantic similarity model, even after controlling for gender in addition to the visual similarity model (mean: 0.39, SEM: 0.18, t(32) = 2.16, , ). Finally, we tested whether the semantic model explained variance in ATFA similarity beyond occupation. The semantic model did not explain unique variance in ATFA after controlling for visual similarity, gender, and occupation (mean: 0.0062, SEM: 0.221, t(32) = 0.028, , ). Thus, we did not find evidence that ATFA is sensitive to more detailed variation in semantic similarity that is not explained by gender and occupation; however, this null result might be because of a lack of statistical power to detect nuances in pattern similarity within ATFA. Overall, our results suggest that activation patterns in ATFA reflect semantic knowledge of famous people, while more posterior regions (OFA and FFA) do not.
We hypothesized that place knowledge would be represented in RSC and PPA, which have been proposed to be core components of the PM network that is thought to represent knowledge about spatial contexts (Ranganath and Ritchey, 2012). We also examined OPA, which has been proposed to process the local elements of places (Kamps et al., 2016); we predicted that OPA would not be sensitive to the global semantic similarity of places. First, we observed significant correlations with semantic similarity after controlling for visual similarity (Fig. 6D), in both RSC (mean: 0.31, SEM: 0.13, t(32) = 2.41, , ) and PPA (mean: 0.66, SEM: 0.18, t(32) = 3.63, , ). We next examined whether the other category-sensitive regions represented the semantic similarity of places. OPA was correlated with the semantic similarity model (mean: 0.79, SEM: 0.17, t(32) = 4.77, , ), as were OFA (mean: 1.12, SEM: 0.18, t(32) = 6.14, , ) and FFA (mean: 0.46, SEM: 0.14, t(32) = 3.21, , ). ATFA activation during place presentation did not correlate with the semantic similarity model (FDR ).
However, while the above analysis controlled for low-level visual similarity using the HMAX model, the places may be separated into distinct categories based on high-level visual information. Thus, we tested whether each region that correlated with the semantic similarity model was still correlated after controlling for the visual similarity model, category (manmade vs natural), and subcategory (e.g., river, mountain). We found that OPA and PPA were still correlated with the semantic model after controlling for low-level visual similarity and visual categories (OPA: mean: 0.38, SEM: 0.19, t(32) = 1.95, , ; PPA: mean: 0.35, SEM: 0.21, t(32) = 1.67, , ). These results suggest that the place-sensitive PPA and OPA regions are sensitive to the detailed semantic relationships between famous places. We also found that OFA was still correlated with the semantic model after controlling for low-level visual similarity and visual categories (mean: 0.68, SEM: 0.19, t(32) = 3.60, , ). We did not observe correlation with the semantic model after controlling for visual categories in RSC or FFA (FDR ). While we did not see evidence for significant coding of semantic relationships in RSC after controlling for visual scene category, we did observe representation of detailed place semantics in PPA, as well as lateral occipital areas, including OPA and OFA.
We next examined representation of the spatial distance between famous places. We hypothesized that spatial distance might be represented independently from the semantic activation patterns that we observed in PPA, OPA, and OFA. To measure spatial distance coding, we tested whether the neural pattern dissimilarity between different places was correlated with the geographical distance between them, after controlling for the visual similarity model and the semantic similarity model. This analysis allowed us to measure distance coding independent of semantic similarity, which was correlated with coarse geographical distance (i.e., places in the same continent were more similar according to the semantic model). We hypothesized that RSC, which has previously been shown to be sensitive to distance to a goal during navigation in a familiar environment (Patai et al., 2019), would represent spatial distance between familiar places. Consistent with this hypothesis, we found evidence of geographical coding within RSC (Fig. 6E; mean: 0.36, SEM: 0.18, t(32) = 2.03, , ). We next tested for geographical coding in the other regions, and observed sensitivity to geographical distance in FFA (mean: 0.38, SEM: 0.17, t(32) = 2.20, , ) but not in other regions (FDR ). Sensitivity to geographical distance may reflect either a detailed representation of distances between locations or coarser sensitivity to general spatial location, which we operationalized here as coding of the continent in which the places are located. We found that neither RSC (mean: 0.26, SEM: 0.17, t(32) = 1.54, , ) nor FFA (mean: −0.033, SEM: 0.171, t(32) = 0.19, , ) was significantly correlated with the geographical model after controlling for visual similarity, semantic similarity, and continent. When considered together, these results suggest that RSC may represent coarse geographical features of places, such as the continent on which they are located, but may not be sensitive to finer levels of geographic distance.
We hypothesized that hippocampus, which is anatomically connected to both PHC and AT cortex (Witter et al., 2000; Mohedano-Moriano et al., 2007) and is sensitive to individual person and place stimuli (Quiroga et al., 2005), would represent semantic features of both people and places. We predicted that hippocampus would be differentially functionally coupled to person-sensitive and place-sensitive regions during person and place trials, respectively. Specifically, we predicted that activity in ATFA, which represented semantic features of people, would be functionally coupled with hippocampus during person trials, whereas activation in PPA and RSC would be functionally coupled with hippocampus during place trials. We also tested whether OFA and OPA, which also represented semantic similarity among places, were functionally coupled with hippocampus. We tested functional coupling with posterior and anterior hippocampus separately. Prior work has found evidence that anterior and posterior hippocampus differ in their coupling with medial temporal lobe, with anterior hippocampus coupling more strongly with perirhinal cortex and posterior hippocampus coupling with PHC (Libby et al., 2012). These prior functional coupling results suggest that place-sensitive regions, which include PHC, may be more functionally coupled with posterior hippocampus. However, recent work suggests that anterior hippocampus may play a domain-general role in forming representations that reflect global properties of stimuli (Poppenk et al., 2013; Morton et al., 2017; Brunec et al., 2019), suggesting that anterior hippocampus may be functionally coupled with both person- and place-sensitive regions during processing of familiar person and place stimuli.
To examine functional coupling with hippocampus, we calculated the mean activation within each region for each item. We then calculated the correlation of hippocampal activation for each item with item activation in ATFA, OFA, OPA, PPA, and RSC, separately for people and places. We tested whether the correlation between regions differed between person and place trials. We found that ATFA activation was more correlated with anterior hippocampus activation on person trials than on place trials (mean difference in correlation: 0.0689, SEM: 0.0243, , , permutation test, corrected across hippocampal regions), but there was no significant difference in correlation with posterior hippocampus (mean difference: 0.0309, SEM: 0.0340, , corrected, ). In contrast, activation in both RSC (mean difference: 0.0906, SEM: 0.0294, , corrected, ) and PPA (mean difference: 0.0659, SEM: 0.0313, , corrected, ) was more correlated with anterior hippocampal activation on place trials than on person trials. There was no difference in correlation with posterior hippocampus for either RSC (mean place-person difference: 0.0171, SEM: 0.0291, , corrected, ) or PPA (mean difference: −0.0137, SEM: 0.0271, , corrected, ). We did not observe category-specific correlations with either hippocampal region for OFA or OPA (all ). While these results are correlational rather than indexing connectivity directly, these results suggest that anterior hippocampus may be more functionally connected with high-level place areas PPA and RSC during viewing of famous places, and more connected with the high-level face area ATFA during viewing of famous people.
PM and AT networks represent distinct semantic knowledge
While many investigations of category-specific brain activity have focused on regions that differ in activation between categories, recent work based on functional connectivity findings suggests that these regions are embedded within large-scale networks that process distinct item and context information (Libby et al., 2012). We examined two proposed networks, AT and PM, that have been proposed to be optimized for distinct forms of memory-guided processing (Ranganath and Ritchey, 2012). The AT network is thought to process information about entities (people and objects), whereas the PM network processes contexts (places and locations). We examined a range of anatomic ROIs included in the AT and PM networks. Within each ROI, we tested whether the semantic model accounted for unique variance after controlling for visual similarity. We used a permutation test to correct for FDR over ROIs within each network. We predicted that the AT network would selectively represent semantic features of people, whereas the PM network would represent semantic features of places. While the semantic model focuses on conceptual features of individual people and places, we also tested for geographical information about places, which we predicted would be represented in the PM network.
Consistent with our predictions, we found that semantic features of people and places were selectively represented in the AT and PM networks, respectively (Fig. 7A,B). Multiple regions in the AT network showed evidence of representing semantic similarity of people, after controlling for visual similarity. We observed significant correlation with the semantic similarity model in fusiform gyrus (z statistic mean: 0.31, SEM: 0.16, t(32) = 1.95, , Cohen's ). We also observed significant correlations in the IFG pars opercularis (mean 0.38, SEM: 0.17, t(32) = 2.17, , ) and pars triangularis (mean: 0.67, SEM: 0.17, t(32) = 3.82, , ) as well as orbitofrontal cortex (mean: 0.36, SEM: 0.16, t(32) = 2.21, , ). No regions in the PM network were correlated with the semantic similarity model for people (FDR ). While perirhinal cortex has been shown to represent the semantic features of common objects (Clarke and Tyler, 2014; Martin et al., 2018), here we do not find evidence that perirhinal cortex represents semantic features of famous people (, uncorrected), suggesting that the semantic representations of people may differ from the semantic representations of objects.
Figure 7.

Semantic representations of people and places within the PM and AT networks. A, Semantic information about people was represented within multiple regions within the AT network. These regions correlated with the semantic model after controlling for visual similarity. B, Semantic information about famous places was observed in each region within the PM network after controlling for visual similarity. C, Activity patterns in the precuneus (PREC) and PHC correlated with the geographical distance between famous places, after controlling for the semantic and visual models. Points represent individual participant z statistics. Error bars indicate 95% CIs. *FDR , corrected within each network. ANG, Angular gyrus; PRC, perirhinal cortex; AMYG, amygdala; FUS, fusiform gyrus; TPO, temporal pole; OPER, pars opercularis; TRIA, pars triangularis; OFC, orbitofrontal cortex.
While our initial analysis controlled for low-level visual similarity, the people stimuli also include a high-level visual category of gender that may not be perfectly captured by the low-level visual similarity model. To control for these high-level visual differences, we tested whether activation patterns in AT network regions that correlated with the wiki2USE model are still correlated with semantic similarity after controlling for gender. We found evidence of significant correlation after controlling for gender in each region, including fusiform gyrus (mean: 0.30, SEM: 0.16, t(32) = 1.89, , ), the IFG pars opercularis (mean: 0.32, SEM: 0.18, t(32) = 1.84, , ) and pars triangularis (mean: 0.62, SEM: 0.18, t(32) = 3.49, , ), and orbitofrontal cortex (mean: 0.33, SEM: 0.16, t(32) = 2.06, , ). Finally, we tested whether any regions demonstrated evidence of correlation with the semantic similarity model after controlling for visual similarity, gender, and occupation. We did not observe a significant correlation in any region (FDR ). Thus, we did not find evidence that AT regions are sensitive to more detailed variation in semantic similarity that is not explained by gender and occupation; however, this null result may reflect a lack of statistical power to detect nuanced differences in pattern similarity. Overall, our results demonstrate that multiple regions in the AT network are sensitive to semantic similarity of famous people.
In contrast, we found that semantic similarity of places was represented in the PM network, in each of the regions we examined (Fig. 7B). We observed significant correlation with the semantic similarity model in angular gyrus (z statistic mean: 0.37, SEM: 0.18, t(32) = 2.02, , ), precuneus (mean: 0.47, SEM: 0.12, t(32) = 3.72, , ), PCC (mean: 0.50, SEM: 0.13, t(32) = 3.84, , ), and PHC (mean: 0.49, SEM: 0.19, t(32) = 2.61, , ). Within the AT network, we observed a significant correlation in fusiform gyrus (mean: 0.41, SEM: 0.15, t(32) = 2.77, , ). No other AT regions were significantly correlated with the wiki2USE model (FDR ). We next tested, for each region that correlated with semantic similarity, whether sensitivity to semantic similarity was related to high-level visual place categories. We found that PCC was still significantly correlated with the wiki2USE model after controlling for category (natural vs manmade) and subcategory (e.g., river, mountain; mean: 0.43, SEM: 0.16, t(32) = 2.77, , ). The other regions were not correlated with the wiki2USE model after controlling for category and subcategory (FDR ).
We also found evidence of sensitivity to geographical distance in the PM network, in precuneus (z statistic mean: 0.39, SEM: 0.17, t(32) = 2.25, , ) and PHC (mean: 0.34, SEM: 0.19, t(32) = 1.79, , ) after controlling for visual similarity and the semantic similarity model (Fig. 7C). The other PM network regions did not correlate with the geographical distance model (FDR ). The anatomic precuneus ROI partially overlaps with the functional RSC ROI, which we previously found to be sensitive to geographical distance. None of the AT regions showed a significant relationship with geographical distance (FDR ). We next tested whether the regions that correlated with geographical distance were still correlated after controlling for the continent in which each place is located (Fig. 4B). We found that precuneus was significantly correlated with geographical distance after controlling for visual similarity, semantic similarity, and continent (mean: 0.31, SEM: 0.17, t(32) = 1.85, , ), but PHC was not (mean: 0.011, SEM: 0.194, t(32) = 0.056, , ). These results suggest that PHC and precuneus are sensitive to geographical distance between places, and that precuneus is sensitive to geographical distances that are finer than the level of continents. To visualize the relationship between geographical distance and precuneus pattern similarity, we calculated mean pattern similarity (after controlling for visual similarity and semantic similarity) for different geographical distance bins (Fig. 8).
Figure 8.

Geographical distance coding in precuneus. Average neural distance between activation patterns observed during presentation of places increased as a function of the geographical distance between them. The neural distance measure controls for visual similarity and semantic similarity. Error bars indicate 95% CIs. The analysis used to select this region is not independent from the relationship plotted here, so effect sizes may be inflated.
We next directly tested our overall hypothesis that place semantic similarity would be represented in the PM network while person semantic similarity would be represented in the AT network. For each participant, we calculated the mean z statistic of the test of correlation with the semantic similarity model after controlling for visual similarity, averaged over regions within each network. During viewing of people, we found that AT regions were more correlated with the semantic similarity model than PM regions were (mean difference: 0.29, SEM: 0.11, , permutation test, ). During viewing of places, PM regions were more sensitive to semantic similarity than AT regions (mean difference: 0.38, SEM: 0.11, , permutation test, ). Finally, there was a significant interaction between stimulus category (person or place) and network (AT or PM; mean difference: 0.67, SEM: 0.14, , ). This interaction was still significant when controlling for both low-level visual similarity and high-level visual categories (mean difference: 0.50, SEM: 0.15, , ). These results provide evidence that semantic similarity of famous people and places is represented in distinct networks.
Data from the similarity judgment task indicated that the famous places were, on average, less familiar than the famous people (see Materials and Methods). To control for this difference in familiarity, we used a follow-up analysis that matched familiarity of people and places. We restricted the analysis to a set of 19 items from each subcategory (female, male, manmade, and natural) that had matched familiarity. In each region, we calculated a permutation z statistic of correlation with the semantic similarity model after controlling for low-level visual similarity. We found that there was a significant interaction between stimulus category (person or place) and network (AT or PM; mean difference: 0.49, SEM: 0.16, , ), even after controlling for stimulus familiarity. These results provide evidence that the representational differences we observed between the AT and PM networks are not because of differences in familiarity between famous people and places.
Searchlight analysis reveals semantic features of both people and places in hippocampus
The hippocampus is anatomically connected with perirhinal cortex, PHC, and RSC (Wyss and Groen, 1992; Witter et al., 2000) and has been proposed to be involved in domain-general processing (Ranganath and Ritchey, 2012; Morton et al., 2017). As research suggests that hippocampus contains a number of important functional subdivisions (Blessing et al., 2016), we used a searchlight analysis to examine spatially localized representations in hippocampus. The searchlight was restricted to hippocampus, as defined for each participant based on automatic segmentation of their high-resolution T2 coronal scan. For both people and places, we tested for correlation with the semantic model while controlling for visual similarity. For places, we also tested for coding of geographical distance while controlling for visual similarity and semantic similarity. Searchlight results were transformed to our common template space and tested for significant partial correlation with cluster correction within hippocampus.
Consistent with our hypothesis that hippocampus would represent semantic knowledge of both people and places, we found that the semantic similarity model explained unique variance in activation patterns within right hippocampus, for both people and places (Fig. 9A). We did not observe any significant clusters exhibiting geographical distance coding. We next tested whether the person and place semantics clusters were correlated with the semantic similarity model after controlling for stimulus subcategories. In the person cluster, we found that person activation patterns were still significantly correlated with the semantic similarity model after controlling for visual similarity and gender (Fig. 9B; z statistic mean: 0.51, SEM: 0.16, , Cohen's ). Furthermore, this cluster was still significantly correlated with the semantic similarity model after also controlling for occupation (mean: 0.52, SEM: 0.12, , ). In the place cluster, we found that place activation patterns were still significantly correlated with the semantic similarity model after controlling for visual similarity, place category (manmade vs natural), and subcategory (e.g., river, mountain; Fig. 9C; mean: 0.40, SEM: 0.15, , ). Our findings suggest that hippocampus represents conceptual distance between items, both for famous people and places, and is sensitive to fine-grained differences rather than purely reflecting stimulus subcategories.
Figure 9.

A, We used a searchlight analysis to examine whether hippocampus is sensitive to the semantic similarity of individual people and places. A cluster in hippocampus exhibited activation patterns whose similarity was correlated with semantic similarity between people after controlling for visual similarity. Another cluster showed evidence of representing semantic similarity of places after controlling for visual similarity. Lines in the sagittal view illustrate cutting planes for the coronal sections. Outline indicates searchlight volume. B, Pattern similarity in the people cluster was still significantly correlated with the semantic model after controlling for gender and occupation, suggesting that hippocampal patterns reflect detailed semantic features. C, Pattern similarity in the places cluster was still significantly correlated with the semantic model after controlling for category (manmade vs natural) and subcategory (e.g., river, mountain). Error bars indicate 95% CIs. *p < 0.05.
Discussion
While visual perception of people and places involves distinct brain regions (Kanwisher et al., 1997; Epstein and Kanwisher, 1998; Lee et al., 2008; Harry et al., 2016), it is unclear whether semantic knowledge of people and places is represented within the same (Thompson-Schill et al., 1997; Gorno-Tempini and Price, 2001; Damasio et al., 2004; Patterson et al., 2007; Binder and Desai, 2011; Ross and Olson, 2012) or distinct regions (Simmons and Martin, 2009; Ranganath and Ritchey, 2012; Olson et al., 2013). Using a novel method to identify semantic knowledge representation, we found that knowledge about famous people is represented within the AT network, while knowledge of famous places is represented in the separate PM network. Furthermore, hippocampus represented semantic knowledge of both people and places, consistent with proposals that hippocampus supports domain-general processing via connections with AT and PM areas (Staresina et al., 2011; Ranganath and Ritchey, 2012).
Quantitative measures of semantic similarity can be used to identify neural representations of semantic knowledge (Bruffaerts et al., 2019). Existing methods for quantifying semantic knowledge require large text corpuses or relational databases (Huth et al., 2012; Carlson et al., 2014), which are difficult to obtain for contemporary famous people and places. To address this issue, we used recently developed natural language models that can quantify semantic meaning using smaller text samples. We applied these models to text from Wikipedia to generate two semantic similarity models, wiki2vec and wiki2USE. Both models compress information in a given article into a single vector representation that summarizes information about each person or place. Our models are sensitive to multiple features of both people and places and predict human judgments of semantic similarity. The wiki2USE model performed best for both people and places, suggesting that it may be useful for model-based neuroimaging (Bruffaerts et al., 2019) using a range of different stimuli.
Using the wiki2USE model to interrogate our neural data, we found that the ATL was sensitive to the semantic similarity of famous people, consistent with its proposed role in social cognition (Simmons and Martin, 2009; Ranganath and Ritchey, 2012; Olson et al., 2013). Prior work found evidence that ATFA represents recently acquired semantic knowledge of fictional people (Collins et al., 2016); our results extend this study by showing that ATFA also represents knowledge about famous people learned over the course of years. We did not find evidence for semantic representation of people in perirhinal cortex, despite prior work demonstrating its involvement in face perception (Barense et al., 2010a; Mundy et al., 2013) and representation of both visual and semantic similarity of objects (Martin et al., 2018). Our results provide empirical support for a recent theoretical account suggesting that ATFA function may parallel that of perirhinal cortex in object representation by integrating both perceptual and semantic features of individual people (Collins and Olson, 2014). Prior work has proposed that ATL represents domain-general semantic knowledge (Patterson et al., 2007; Ralph et al., 2017; Rice et al., 2018) and facilitates processing of unique people and places by connecting semantic knowledge of unique entities with their proper names (Gorno-Tempini and Price, 2001; Damasio et al., 2004; Tranel, 2006; Ross and Olson, 2012; Schneider et al., 2018). However, we did not find evidence for semantic representation of places within ATFA or a larger temporal pole ROI. Null findings in ATL, however, must be interpreted with caution given the increased signal dropout and distortion in this region. While we used multiband imaging to improve image quality in ATL, other techniques, such as multiecho EPI (Poser et al., 2006; Halai et al., 2014), may improve signal in future studies.
We found that IFG, which is connected with the ATL (Thiebaut de Schotten et al., 2012; Hsu et al., 2020), also represents semantic similarity among people. IFG has been proposed to have a domain-general role in retrieval of semantic knowledge (Thompson-Schill et al., 1997; Binder et al., 2009) and has been found to be activated during encoding (Simmons and Martin, 2009) or retrieval (Rice et al., 2018) of semantic knowledge about places. However, we did not observe semantic knowledge representation of places in IFG. IFG is thought to resolve interference during semantic retrieval (Thompson-Schill et al., 1997; Badre and Wagner, 2007). For instance, IFG is engaged when reading words with ambiguous meaning and may guide selection of relevant semantic representations in ATL (Musz and Thompson-Schill, 2017). IFG may serve a similar role when recognizing familiar people (e.g., when disambiguating two similar-looking acquaintances), by selecting relevant semantic knowledge about a specific person.
We found that place semantics were represented distinctly from person semantics in a PM network, comprising PHC (including PPA), precuneus, PCC, and angular gyrus. PHC, precuneus, and PCC have previously been implicated in perception and discrimination of places (Epstein and Kanwisher, 1998; Lee et al., 2008; Costigan et al., 2019), and PHC is sensitive to natural scene categories (Walther et al., 2009). Our results suggest that these regions may also represent the semantic relatedness of unique famous places. However, place-sensitive regions have previously been shown to represent high-level visual features that discriminate between place categories (Kravitz et al., 2011). Critically, we found that PPA and PCC were still correlated with the place semantic similarity model after controlling for place category, suggesting that they represent semantic knowledge above and beyond high-level visual information. We also found that precuneus and RSC were sensitive to the geographical distance between places, consistent with prior work implicating these regions in spatial memory and navigation (Epstein, 2008; Vann et al., 2009; Hebscher et al., 2018). While RSC reflected only coarse distance coding, we observed finer distance coding in precuneus. This finding is consistent with evidence that precuneus represents detailed features of memories during vivid recall (Sreekumar et al., 2018).
While the AT and PM networks are both involved in episodic memory (Ranganath, 2010; Staresina et al., 2011; Cooper and Ritchey, 2019; Renoult et al., 2019), the PM network in particular has long been linked to episodic memory processes that support retrieval of unique events (Vincent et al., 2006; Rugg and Vilberg, 2013; Ritchey and Cooper, 2020). However, other recent data indicate that the PM network is activated during retrieval of abstract knowledge (Gilboa and Marlatte, 2017) and forms general knowledge representations of places that are derived from many unique, real-world events (Ranganath and Ritchey, 2012; Baldassano et al., 2018); consistent with these findings, we found that PM regions represent the general knowledge encoded in the wiki2USE model. PM network representation of place knowledge in the present study may thus reflect retrieval of abstract knowledge rather than conscious recollection of personally experienced events (Tulving, 1972, 2005). Abstract representations of places in the PM network may contribute to episodic memory, however, by providing a framework through which future events are processed, encoded, and retrieved (Ranganath and Ritchey, 2012; Robin et al., 2016, 2018; Ritchey and Cooper, 2020).
The hippocampus is anatomically and functionally connected with both the AT and PM networks (Witter et al., 2000; Libby et al., 2012) and is thought to guide memory reactivation in both networks (Ranganath and Ritchey, 2012; Ritchey et al., 2015; Cooper and Ritchey, 2019). Consistent with this hypothesis, we found that ATFA is functionally coupled with hippocampus during viewing of familiar people, whereas PPA and RSC are functionally coupled with hippocampus during viewing of familiar places. Furthermore, we found evidence that hippocampus represents detailed semantic similarity of both people and places. Hippocampal activation patterns correlated with semantic similarity even after controlling for the gender and occupation of people or the category (e.g., river, mountain) of places. This finding converges with prior results demonstrating single-unit responses in human hippocampus that are specific to individual people and places (Quiroga et al., 2005). These responses are abstract, responding similarly to different pictures or the written name of that person or place. Semantic representations in hippocampus may facilitate reasoning about high-level item properties, such as conceptual categories (Mack et al., 2016) and social status (Tavares et al., 2015), while also serving as building blocks for representing new memories (Quiroga, 2012).
Collectively, our results indicate that semantic knowledge for people and places is distributed across distinct AT and PM networks. These networks may group together individual items based on relevant features for each category. For example, places with similar properties, such as airports, are represented similarly in the PM network (Baldassano et al., 2018), while people with the same occupation may be represented similarly within the AT network. These separate networks may help guide domain-specific behavior; for example, AT network representations may facilitate accounting for a person's occupation and social status when interacting with them. Our results indicate that hippocampus may further guide reactivation of distinct PM and AT representations when decisions rely on both place and social information. Broadly, our findings suggest that semantic representation may be hierarchical; distinct large-scale networks represent person and place knowledge, whereas finer distinctions within each category are represented within each network.
Footnotes
This work was supported by National Institutes of Health-National Institute of Mental Health R01 MH100121 to A.R.P., and National Institutes of Health-National Institute of Mental Health National Research Service Award F32-MH114869 to N.W.M. We thank Bernie Gelman and Robert Molitor for help with data collection; Dasa Zeithamova for help with experimental design and analysis; Jackson Liang and Katie Guarino for help with defining anatomical masks; Garima Shukla for help with a literature search; Meghana Potturu for help with model evaluation; and Sean Polyn, Michael Mack, Katherine Sherrill, Christine Coughlin, Mark Hollenbeck, and Evan Roche for valuable discussions.
The authors declare no competing financial interests.
References
- Ahmed S, Arnold R, Thompson SA, Graham KS, Hodges JR (2008) Naming of objects, faces and buildings in mild cognitive impairment. Cortex 44:746–752. 10.1016/j.cortex.2007.02.002 [DOI] [PubMed] [Google Scholar]
- Avants BB, Yushkevich P, Pluta J, Minkoff D, Korczykowski M, Detre J, Gee JC (2010) The optimal template effect in hippocampus studies of diseased populations. Neuroimage 49:2457–2466. 10.1016/j.neuroimage.2009.09.062 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Badre D, Wagner AD (2007) Left ventrolateral prefrontal cortex and the cognitive control of memory. Neuropsychologia 45:2883–2901. 10.1016/j.neuropsychologia.2007.06.015 [DOI] [PubMed] [Google Scholar]
- Baldassano C, Hasson U, Norman KA (2018) Representation of real-world event schemas during narrative perception. J Neurosci 38:9689–9699. 10.1523/JNEUROSCI.0251-18.2018 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Barense MD, Henson RN, Lee AC, Graham KS (2010a) Medial temporal lobe activity during complex discrimination of faces, objects, and scenes: effects of viewpoint. Hippocampus 20:389–401. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Barense MD, Rogers TT, Bussey TJ, Saksida LM, Graham KS (2010b) Influence of conceptual knowledge on visual object discrimination: insights from semantic dementia and MTL amnesia. Cereb Cortex 20:2568–2582. 10.1093/cercor/bhq004 [DOI] [PubMed] [Google Scholar]
- Binder JR, Desai RH (2011) The neurobiology of semantic memory. Trends Cogn Sci 15:527–536. 10.1016/j.tics.2011.10.001 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Binder JR, Desai RH, Graves WW, Conant LL (2009) Where is the semantic system? A critical review and meta-analysis of 120 functional neuroimaging studies. Cereb Cortex 19:2767–2796. 10.1093/cercor/bhp055 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bird S, Klein E, Loper E (2009) Natural language processing with Python. Sebastopol, CA: O'Reilly Media. [Google Scholar]
- Blessing EM, Beissner F, Schumann A, Brünner F, Bär KJ (2016) A data-driven approach to mapping cortical and subcortical intrinsic functional connectivity along the longitudinal hippocampal axis. Hum Brain Mapp 37:462–476. 10.1002/hbm.23042 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bruffaerts R, Deyne SD, Meersmans K, Liuzzi AG, Storms G, Vandenberghe R (2019) Redefining the resolution of semantic knowledge in the brain: advances made by the introduction of models of semantics in neuroimaging. Neurosci Biobehav Rev 103:3–13. 10.1016/j.neubiorev.2019.05.015 [DOI] [PubMed] [Google Scholar]
- Brunec IK, Bellana B, Ozubko JD, Man V, Robin J, Liu ZX, Grady C, Rosenbaum RS, Winocur G, Barense MD, Moscovitch M (2018) Multiple scales of representation along the hippocampal anteroposterior axis in humans. Curr Biol 28:2129–2135.e6. 10.1016/j.cub.2018.05.016 [DOI] [PubMed] [Google Scholar]
- Brunec IK, Robin J, Patai EZ, Ozubko JD, Javadi AH, Barense MD, Spiers HJ, Moscovitch M (2019) Cognitive mapping style relates to posterior–anterior hippocampal volume ratio. Hippocampus 29:748–754. 10.1002/hipo.23072 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carlson TA, Simmons RA, Kriegeskorte N, Slevc LR (2014) The emergence of semantic meaning in the ventral temporal pathway. J Cogn Neurosci 26:120–131. 10.1162/jocn_a_00458 [DOI] [PubMed] [Google Scholar]
- Cer D, Yang Y, Kong S, Hua N, Limtiaco N, John RS, Constant N, Guajardo-Cespedes M, Yuan S, Tar C, Sung YH, Strope B, Kurzweil R (2018) Universal sentence encoder. arXiv 1803.11175. [Google Scholar]
- Clarke A, Tyler LK (2014) Object-specific semantic coding in human perirhinal cortex. J Neurosci 34:4766–4775. 10.1523/JNEUROSCI.2828-13.2014 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Collins JA, Olson IR (2014) Beyond the FFA: the role of the ventral anterior temporal lobes in face processing. Neuropsychologia 61:65–79. 10.1016/j.neuropsychologia.2014.06.005 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Collins JA, Koski JE, Olson IR (2016) More than meets the eye: the merging of perceptual and conceptual knowledge in the anterior temporal face area. Front Hum Neurosci 10:189. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cooper RA, Ritchey M (2019) Cortico-hippocampal network connections support the multidimensional quality of episodic memory. eLife 8:e45591. 10.7554/eLife.45591 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Costigan AG, Umla-Runge K, Evans CJ, Hodgetts CJ, Lawrence AD, Graham KS (2019) Neurochemical correlates of scene processing in the precuneus/posterior cingulate cortex: a multimodal fMRI and 1H-MRS study. Hum Brain Mapp 40:2884–2898. 10.1002/hbm.24566 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Damasio H, Tranel D, Grabowski T, Adolphs R, Damasio A (2004) Neural systems behind word and concept retrieval. Cognition 92:179–229. 10.1016/j.cognition.2002.07.001 [DOI] [PubMed] [Google Scholar]
- De Falco E, Ison MJ, Fried I, Quian Quiroga R (2016) Long-term coding of personal and universal associations underlying the memory web in the human brain. Nat Commun 7:13408. 10.1038/ncomms13408 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Epstein RA (2008) Parahippocampal and retrosplenial contributions to human spatial navigation. Trends Cogn Sci 12:388–396. 10.1016/j.tics.2008.07.004 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Epstein RA, Kanwisher NG (1998) A cortical representation of the local visual environment. Nature 392:598–601. 10.1038/33402 [DOI] [PubMed] [Google Scholar]
- Gilboa A, Marlatte H (2017) Neurobiology of schemas and schema-mediated memory. Trends Cogn Sci 21:618–631. 10.1016/j.tics.2017.04.013 [DOI] [PubMed] [Google Scholar]
- Gorno-Tempini ML, Price CJ (2001) Identification of famous faces and buildings: a functional neuroimaging study of semantically unique items. Brain 124:2087–2097. 10.1093/brain/124.10.2087 [DOI] [PubMed] [Google Scholar]
- Greve DN, Fischl B (2009) Accurate and robust brain image alignment using boundary-based registration. Neuroimage 48:63–72. 10.1016/j.neuroimage.2009.06.060 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Halai AD, Welbourne SR, Embleton K, Parkes LM (2014) A comparison of dual gradient-echo and spin-echo fMRI of the inferior temporal lobe. Hum Brain Mapp 35:4118–4128. 10.1002/hbm.22463 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hanke M, Halchenko YO, Sederberg PB, Hanson SJ, Haxby JV, Pollmann S (2009) PyMVPA: a Python toolbox for multivariate pattern analysis of fMRI data. Neuroinformatics 7:37–53. 10.1007/s12021-008-9041-y [DOI] [PMC free article] [PubMed] [Google Scholar]
- Harry BB, Umla-Runge K, Lawrence AD, Graham KS, Downing PE (2016) Evidence for integrated visual face and body representations in the anterior temporal lobes. J Cogn Neurosci 28:1178–1193. 10.1162/jocn_a_00966 [DOI] [PubMed] [Google Scholar]
- Hebscher M, Levine B, Gilboa A (2018) The precuneus and hippocampus contribute to individual differences in the unfolding of spatial representations during episodic autobiographical memory. Neuropsychologia 110:123–133. 10.1016/j.neuropsychologia.2017.03.029 [DOI] [PubMed] [Google Scholar]
- Hodgetts CJ, Voets NL, Thomas AG, Clare S, Lawrence AD, Graham KS (2017) Ultra-high-field fMRI reveals a role for the subiculum in scene perceptual discrimination. J Neurosci 37:3150–3159. 10.1523/JNEUROSCI.3225-16.2017 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hsu CC, Rolls ET, Huang CC, Chong ST, Lo CY, Feng J, Lin CP (2020) Connections of the human orbitofrontal cortex and inferior frontal gyrus. Cereb Cortex 30:5830–5843. [DOI] [PubMed] [Google Scholar]
- Huth AG, Nishimoto S, Vu AT, Gallant JL (2012) A continuous semantic space describes the representation of thousands of object and action categories across the human brain. Neuron 76:1210–1224. 10.1016/j.neuron.2012.10.014 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Iglesias JE, Augustinack JC, Nguyen K, Player CM, Player A, Wright M, Roy N, Frosch MP, McKee AC, Wald LL, Fischl B, Van Leemput K, Alzheimer's Disease Neuroimaging Initiative (2015) A computational atlas of the hippocampal formation using ex vivo, ultra-high resolution MRI: application to adaptive segmentation of in vivo MRI. Neuroimage 115:117–137. 10.1016/j.neuroimage.2015.04.042 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jozwik KM, Kriegeskorte N, Mur M (2016) Visual features as stepping stones toward semantics: explaining object similarity in IT and perception with non-negative least squares. Neuropsychologia 83:201–226. 10.1016/j.neuropsychologia.2015.10.023 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kahn I, Andrews-Hanna JR, Vincent JL, Snyder AZ, Buckner RL (2008) Distinct cortical anatomy linked to subregions of the medial temporal lobe revealed by intrinsic functional connectivity. J Neurophysiol 100:129–139. 10.1152/jn.00077.2008 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kamps FS, Julian JB, Kubilius J, Kanwisher N, Dilks DD (2016) The occipital place area represents the local elements of scenes. Neuroimage 132:417–424. 10.1016/j.neuroimage.2016.02.062 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kanwisher N, McDermott J, Chun MM (1997) The fusiform face area: a module in human extrastriate cortex specialized for face perception. J Neurosci 17:4302–4311. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kauffmann L, Ramanoël S, Guyader N, Chauvin A, Peyrin C (2015) Spatial frequency processing in scene-selective cortical regions. Neuroimage 112:86–95. 10.1016/j.neuroimage.2015.02.058 [DOI] [PubMed] [Google Scholar]
- Khaligh-Razavi SM, Kriegeskorte N (2014) Deep supervised, but not unsupervised, models may explain IT cortical representation. PLoS Comput Biol 10:e1003915. 10.1371/journal.pcbi.1003915 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kravitz DJ, Peng CS, Baker CI (2011) Real-world scene representations in high-level visual cortex: it's the spaces more than the places. J Neurosci 31:7322–7333. 10.1523/JNEUROSCI.4588-10.2011 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kriegeskorte N, Formisano E, Sorger B, Goebel R (2007) Individual faces elicit distinct response patterns in human anterior temporal cortex. Proc Natl Acad Sci USA 104:20600–20605. 10.1073/pnas.0705654104 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kriegeskorte N, Mur M, Bandettini P (2008a) Representational similarity analysis: connecting the branches of systems neuroscience. Front Syst Neurosci 2:4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kriegeskorte N, Mur M, Ruff DA, Kiani R, Bodurka J, Esteky H, Tanaka K, Bandettini PA (2008b) Matching categorical object representations in inferior temporal cortex of man and monkey. Neuron 60:1126–1141. 10.1016/j.neuron.2008.10.043 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kruskal JB (1964) Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis. Psychometrika 29:1–27. 10.1007/BF02289565 [DOI] [Google Scholar]
- Lee AC, Levi N, Davies RR, Hodges JR, Graham KS (2007) Differing profiles of face and scene discrimination deficits in semantic dementia and Alzheimer's disease. Neuropsychologia 45:2135–2146. 10.1016/j.neuropsychologia.2007.01.010 [DOI] [PubMed] [Google Scholar]
- Lee AC, Scahill VL, Graham KS (2008) Activating the medial temporal lobe during oddity judgment for faces and scenes. Cereb Cortex 18:683–696. 10.1093/cercor/bhm104 [DOI] [PubMed] [Google Scholar]
- Libby LA, Ekstrom AD, Ragland JD, Ranganath C (2012) Differential connectivity of perirhinal and parahippocampal cortices within human hippocampal subregions revealed by high-resolution functional imaging. J Neurosci 32:6550–6560. 10.1523/JNEUROSCI.3711-11.2012 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mack ML, Love BC, Preston AR (2016) Dynamic updating of hippocampal object representations reflects new conceptual knowledge. Proc Natl Acad Sci USA 113:13203–13208. 10.1073/pnas.1614048113 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Martin CB, Douglas D, Newsome RN, Man LL, Barense MD (2018) Integrative and distinctive coding of visual and conceptual object features in the ventral visual stream. eLife 7:e31873. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mikolov T, Chen K, Corrado G, Dean J (2013a) Efficient estimation of word representations in vector space. arXiv 13013781v3. [Google Scholar]
- Mikolov T, Sutskever I, Chen K, Corrado G, Dean J (2013b) Distributed representations of words and phrases and their compositionality. In: Advances in neural information processing systems (Burges CJC, Bottou L, Welling M, Ghahramani Z, Weinberger KQ, eds), pp 3111–3119. Red Hook, NY: Curran. [Google Scholar]
- Mohedano-Moriano A, Pro-Sistiaga P, Arroyo-Jimenez MM, Artacho-Pérula E, Insausti AM, Marcos P, Cebada-Sánchez S, Martínez-Ruiz J, Muñoz M, Blaizot X, Martinez-Marcos A, Amaral DG, Insausti R (2007) Topographical and laminar distribution of cortical input to the monkey entorhinal cortex. J Anat 211:250–260. 10.1111/j.1469-7580.2007.00764.x [DOI] [PMC free article] [PubMed] [Google Scholar]
- Morton NW (2020) Mindstorm: advanced neuroimaging analysis. Available at 10.5281/zenodo.4248136. [DOI]
- Morton NW, Polyn SM (2017) Beta-band activity represents the recent past during episodic encoding. Neuroimage 147:692–702. 10.1016/j.neuroimage.2016.12.049 [DOI] [PubMed] [Google Scholar]
- Morton NW, Sherrill KR, Preston AR (2017) Memory integration constructs maps of space, time, and concepts. Curr Opin Behav Sci 17:161–168. 10.1016/j.cobeha.2017.08.007 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Morton NW, Zippi EL, Noh SM, Preston AR (2021a) WikiSim: Using Wikipedia to measure neural representations of semantic knowledge. Available at 10.5281/zenodo.4453790. [DOI]
- Morton NW, Zippi EL, Noh SM, Preston AR (2021b) WikiVector: Tools for encoding Wikipedia articles as vectors. Available at 10.5281/zenodo.4453879. [DOI]
- Mumford JA, Turner BO, Ashby FG, Poldrack RA (2012) Deconvolving BOLD activation in event-related designs for multivoxel pattern classification analyses. Neuroimage 59:2636–2643. 10.1016/j.neuroimage.2011.08.076 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mundy ME, Downing PE, Dwyer DM, Honey RC, Graham KS (2013) A critical role for the hippocampus and perirhinal cortex in perceptual learning of scenes and faces: complementary findings from amnesia and fMRI. J Neurosci 33:10490–10502. 10.1523/JNEUROSCI.2958-12.2013 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Musz E, Thompson-Schill SL (2017) Tracking competition and cognitive control during language comprehension with multi-voxel pattern analysis. Brain Lang 165:21–32. 10.1016/j.bandl.2016.11.002 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mutch J, Lowe DG (2006) Multiclass object recognition using sparse, localized features. Comput Vis Pattern Recognition, IEEE Conference, pp 11–18. [Google Scholar]
- Mutch J, Knoblich U, Poggio T (2010) CNS: a GPU-based framework for simulating cortically-organized networks. MIT-CSAIL-TR-2010-013/CBCL-286. Cambridge, MA: Massachusetts Institute of Technology. [Google Scholar]
- Olson IR, McCoy D, Klobusicky E, Ross LA (2013) Social cognition and the anterior temporal lobes: a review and theoretical framework. Soc Cogn Affect Neurosci 8:123–133. 10.1093/scan/nss119 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Patai EZ, Javadi AH, Ozubko JD, O'Callaghan A, Ji S, Robin J, Grady C, Winocur G, Rosenbaum RS, Moscovitch M, Spiers HJ (2019) Hippocampal and retrosplenial goal distance coding after long-term consolidation of a real-world environment. Cereb Cortex 29:2748–2758. 10.1093/cercor/bhz044 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Patterson K, Nestor PJ, Rogers TT (2007) Where do you know what you know? The representation of semantic knowledge in the human brain. Nat Rev Neurosci 8:976–987. 10.1038/nrn2277 [DOI] [PubMed] [Google Scholar]
- Poppenk J, Evensmoen HR, Moscovitch M, Nadel L (2013) Long-axis specialization of the human hippocampus. Trends Cogn Sci 17:230–240. 10.1016/j.tics.2013.03.005 [DOI] [PubMed] [Google Scholar]
- Poser BA, Versluis MJ, Hoogduin JM, Norris DG (2006) BOLD contrast sensitivity enhancement and artifact reduction with multiecho EPI: parallel-acquired inhomogeneity-desensitized fMRI. Magn Reson Med 55:1227–1235. 10.1002/mrm.20900 [DOI] [PubMed] [Google Scholar]
- Power JD, Barnes KA, Snyder AZ, Schlaggar BL, Petersen SE (2012) Spurious but systematic correlations in functional connectivity MRI networks arise from subject motion. Neuroimage 59:2142–2154. 10.1016/j.neuroimage.2011.10.018 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Quiroga RQ (2012) Concept cells: the building blocks of declarative memory functions. Nat Rev Neurosci 13:587–597. 10.1038/nrn3251 [DOI] [PubMed] [Google Scholar]
- Quiroga RQ, Reddy L, Kreiman G, Koch C, Fried I (2005) Invariant visual representation by single neurons in the human brain. Nature 435:1102–1107. 10.1038/nature03687 [DOI] [PubMed] [Google Scholar]
- Quiroga RQ, Kreiman G, Koch C, Fried I (2008) Sparse but not “Grandmother-cell” coding in the medial temporal lobe. Trends Cogn Sci 12:87–91. 10.1016/j.tics.2007.12.003 [DOI] [PubMed] [Google Scholar]
- Ralph MA, Jefferies E, Patterson K, Rogers TT (2017) The neural and computational bases of semantic cognition. Nat Rev Neurosci 18:42–55. 10.1038/nrn.2016.150 [DOI] [PubMed] [Google Scholar]
- Ranganath C (2010) Binding items and contexts: the cognitive neuroscience of episodic memory. Curr Dir Psychol Sci 19:131–137. 10.1177/0963721410368805 [DOI] [Google Scholar]
- Ranganath C, Ritchey M (2012) Two cortical systems for memory-guided behaviour. Nat Rev Neurosci 13:713–726. 10.1038/nrn3338 [DOI] [PubMed] [Google Scholar]
- Renoult L, Irish M, Moscovitch M, Rugg MD (2019) From knowing to remembering: the semantic–episodic distinction. Trends Cogn Sci 23:1041–1057. 10.1016/j.tics.2019.09.008 [DOI] [PubMed] [Google Scholar]
- Rice GE, Hoffman P, Binney RJ, Ralph MA (2018) Concrete versus abstract forms of social concept: an fMRI comparison of knowledge about people versus social terms. Philos Trans R Soc Lond B Biol Sci 373:20170136. 10.1098/rstb.2017.0136 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ritchey M, Cooper RA (2020) Deconstructing the posterior medial episodic network. Trends Cogn Sci 24:451–465. 10.1016/j.tics.2020.03.006 [DOI] [PubMed] [Google Scholar]
- Ritchey M, Libby LA, Ranganath C (2015) Cortico-hippocampal systems involved in memory and cognition: the PMAT framework. In: Progress in Brain Research (O'Mara S, Tsanov M, eds), Vol 219, pp 45–64. Waltham, MA: Elsevier. [DOI] [PubMed] [Google Scholar]
- Roads BD, Mozer MC (2019) Obtaining psychological embeddings through joint kernel and metric learning. Behav Res Methods 51:2180–2193. 10.3758/s13428-019-01285-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Robin J, Wynn J, Moscovitch M (2016) The spatial scaffold: the effects of spatial context on memory for events. J Exp Psychol Learn Mem Cogn 42:308–315. 10.1037/xlm0000167 [DOI] [PubMed] [Google Scholar]
- Robin J, Buchsbaum BR, Moscovitch M (2018) The primacy of spatial context in the neural representation of events. J Neurosci 38:2755–2765. 10.1523/JNEUROSCI.1638-17.2018 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ross LA, Olson IR (2012) What's unique about unique entities? An fMRI investigation of the semantics of famous faces and landmarks. Cereb Cortex 22:2005–2015. 10.1093/cercor/bhr274 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rugg MD, Vilberg KL (2013) Brain networks underlying episodic memory retrieval. Curr Opin Neurobiol 23:255–260. 10.1016/j.conb.2012.11.005 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schneider B, Heskje J, Bruss J, Tranel D, Belfi AM (2018) The left temporal pole is a convergence region mediating the relation between names and semantic knowledge for unique entities: further evidence from a “recognition-from-name” study in neurological patients. Cortex 109:14–24. 10.1016/j.cortex.2018.08.026 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thiebaut de Schotten M, Dell'Acqua F, Valabregue R, Catani M (2012) Monkey to human comparative anatomy of the frontal lobe association tracts. Cortex 48:82–96. 10.1016/j.cortex.2011.10.001 [DOI] [PubMed] [Google Scholar]
- Shepard RN (1987) Toward a universal law of generalization for psychological science. Science 237:1317–1323. 10.1126/science.3629243 [DOI] [PubMed] [Google Scholar]
- Simmons WK, Martin A (2009) The anterior temporal lobes and the functional architecture of semantic memory. J Int Neuropsychol Soc 15:645–649. 10.1017/S1355617709990348 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Simmons WK, Reddish M, Bellgowan PS, Martin A (2010) The selectivity and functional connectivity of the anterior temporal lobes. Cereb Cortex 20:813–825. 10.1093/cercor/bhp149 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sreekumar V, Nielson DM, Smith TA, Dennis SJ, Sederberg PB (2018) The experience of vivid autobiographical reminiscence is supported by subjective content representations in the precuneus. Sci Rep 8:14899. 10.1038/s41598-018-32879-0 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Staresina BP, Duncan KD, Davachi L (2011) Perirhinal and parahippocampal cortices differentially contribute to later recollection of object- and scene-related event details. J Neurosci 31:8739–8747. 10.1523/JNEUROSCI.4978-10.2011 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Steiger JH (1980) Tests for comparing elements of a correlation matrix. Psychol Bull 87:245–251. 10.1037/0033-2909.87.2.245 [DOI] [Google Scholar]
- Tavares RM, Mendelsohn A, Grossman Y, Williams CH, Shapiro M, Trope Y, Schiller D (2015) A map for social navigation in the human brain. Neuron 87:231–243. 10.1016/j.neuron.2015.06.011 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thompson-Schill SL, D'Esposito M, Aguirre GK, Farah MJ (1997) Role of left inferior prefrontal cortex in retrieval of semantic knowledge: a reevaluation. Proc Natl Acad Sci USA 94:14792–14797. 10.1073/pnas.94.26.14792 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tranel D (2006) Impaired naming of unique landmarks is associated with left temporal polar damage. Neuropsychology 20:1–10. 10.1037/0894-4105.20.1.1 [DOI] [PubMed] [Google Scholar]
- Tulving E (1972) Episodic and semantic memory. In: Organization of Memory (Tulving E, Donaldson W, eds), pp 381–402. New York, NY: Academic Press. [Google Scholar]
- Tulving E (2005) Episodic memory and autonoesis: uniquely human? In: The missing link in cognition: origins of self-reflective consciousness (Terrace HS, Metcalfe J, eds), pp 3–56. New York, NY: Oxford University Press. [Google Scholar]
- Vann SD, Aggleton JP, Maguire EA (2009) What does the retrosplenial cortex do? Nat Rev Neurosci 10:792–802. 10.1038/nrn2733 [DOI] [PubMed] [Google Scholar]
- Vincent JL, Snyder AZ, Fox MD, Shannon BJ, Andrews JR, Raichle ME, Buckner RL (2006) Coherent spontaneous activity identifies a hippocampal-parietal memory network. J Neurophysiol 96:3517–3531. 10.1152/jn.00048.2006 [DOI] [PubMed] [Google Scholar]
- Walther DB, Caddigan E, Fei-Fei L, Beck DM (2009) Natural scene categories revealed in distributed patterns of activity in the human brain. J Neurosci 29:10573–10581. 10.1523/JNEUROSCI.0559-09.2009 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Williams EJ (1959) The comparison of regression variables. J R Stat Soc B 21:396–399. 10.1111/j.2517-6161.1959.tb00346.x [DOI] [Google Scholar]
- Witter MP, Amaral DG (1991) Entorhinal cortex of the monkey: V. Projections to the dentate gyrus, hippocampus, and subicular complex. J Comp Neurol 307:437–459. [DOI] [PubMed] [Google Scholar]
- Witter MP, Naber PA, Van Haeften T, Machielsen WC, Rombouts SA, Barkhof F, Scheltens P, Lopes Da Silva FH (2000) Cortico-hippocampal communication by way of parallel parahippocampal-subicular pathways. Hippocampus 10:398–410. [DOI] [PubMed] [Google Scholar]
- Woolrich MW, Ripley BD, Brady M, Smith SM (2001) Temporal autocorrelation in univariate linear modeling of fMRI data. Neuroimage 14:1370–1386. 10.1006/nimg.2001.0931 [DOI] [PubMed] [Google Scholar]
- Woolrich MW, Behrens TE, Beckmann CF, Jenkinson M, Smith SM (2004) Multilevel linear modelling for FMRI group analysis using Bayesian inference. Neuroimage 21:1732–1747. 10.1016/j.neuroimage.2003.12.023 [DOI] [PubMed] [Google Scholar]
- Wyss JM, Groen TV (1992) Connections between the retrosplenial cortex and the hippocampal formation in the rat: a review. Hippocampus 2:1–11. 10.1002/hipo.450020102 [DOI] [PubMed] [Google Scholar]
- Yekutieli D, Benjamini Y (1999) Resampling-based false discovery rate controlling multiple test procedures for correlated test statistics. J Stat Plan Inference 82:171–196. 10.1016/S0378-3758(99)00041-5 [DOI] [Google Scholar]
- Zippi EL, Morton NW, Preston AR (2020) Modeling semantic similarity of well-known stimuli. Available at https://osf.io/72apm/.