

Abstract
Autosomal genetic analyses of blood lipids have yielded key insights for coronary heart disease (CHD). However, X chromosome genetic variation is understudied for blood lipids in large sample sizes. We now analyze genetic and blood lipid data in a high-coverage whole X chromosome sequencing study of 65,322 multi-ancestry participants and perform replication among 456,893 European participants. Common alleles on chromosome Xq23 are strongly associated with reduced total cholesterol, LDL cholesterol, and triglycerides (min P = 8.5 × 10−72), with similar effects for males and females. Chromosome Xq23 lipid-lowering alleles are associated with reduced odds for CHD among 42,545 cases and 591,247 controls (P = 1.7 × 10−4), and reduced odds for diabetes mellitus type 2 among 54,095 cases and 573,885 controls (P = 1.4 × 10−5). Although we observe an association with increased BMI, waist-to-hip ratio adjusted for BMI is reduced, bioimpedance analyses indicate increased gluteofemoral fat, and abdominal MRI analyses indicate reduced visceral adiposity. Co-localization analyses strongly correlate increased CHRDL1 gene expression, particularly in adipose tissue, with reduced concentrations of blood lipids.
Subject terms: Genome-wide association studies, Cardiovascular genetics
The influence of X chromosome genetic variation on blood lipids and coronary heart disease (CHD) is not well understood. Here, the authors analyse X chromosome sequencing data across 65,322 multi-ancestry individuals, identifying associations of the Xq23 locus with lipid changes and reduced risk of CHD and diabetes mellitus.
Introduction
Mendelian, population, and functional genetic analyses of blood lipids (total cholesterol, low-density lipoprotein cholesterol [LDL-C], high-density lipoprotein cholesterol [HDL-C], and triglycerides) have yielded important fundamental insights regarding the root causes of coronary heart disease (CHD)1,2. For example, rare and common autosomal genomic variation influencing LDL-C, correspondingly influence CHD risk3–6. Such observations buttress clinical recommendations and bolster efforts to discover and validate lipid-related drug targets for CHD risk reduction7–9.
Although the X chromosome comprises 5% of the genome, it has only been studied in a few genome-wide association analyses for blood lipids and coronary disease10–13. Major reasons for exclusion include incomplete coverage on genotyping arrays, potential discrepancies in genotyping quality on arrays due to haploinsufficiency in men, imputation and analytic challenges, and somatic X inactivation across tissues in women. Deep-coverage whole-genome sequencing (WGS) and analysis of the X chromosome now offers the promise for uniform coverage and high-fidelity genotyping for both sexes14.
While differences in lipid levels and CHD risk by sex are well established15,16, X chromosome dosage is also linked to lipid differences. Monosomy X (45X, Turner syndrome) is linked to dyslipidemia and premature CHD17–19. While obesity and gonadal deficiency was long believed to be the primary contributor to these phenotypes, women with Turner syndrome have higher total cholesterol, LDL-C, and triglyceride concentrations than age- and body composition-matched 46XX women with premature ovarian failure19,20. Men with an additional X chromosome (47XXY, Klinefelter syndrome) also suffer from infertility with higher rates of obesity, dyslipidemia, and CHD21,22. Furthermore, adult gonadectomized mice with XY, XX, and XXY chromosomes, regardless of gonadal sex, demonstrate dose-dependent changes in lipid levels23. Such observations, suggest that apparent sexual dimorphism in lipid levels may be explained by the sex chromosomes themselves.
Our study aims to discover X chromosome genomic variation associated with blood lipid levels among 65,322 multi-ancestry individuals with high-coverage whole X chromosome sequencing and available lipids in the NHLBI Trans-Omics for Precision Medicine (TOPMed) program24. Independent serial replication is performed in up to 390,606 and 66,287 individuals with GWAS array and lipids available in the UK Biobank and Nord-Trøndelag Health (HUNT) study, respectively25,26. We further evaluate the phenotypic consequences of lipid-associated variation in the UK Biobank, HUNT, and 176,899 additional participants of FinnGen27. Lastly, we perform colocalization analyses to pinpoint the possible causal gene in association regions. Here, we characterize an X chromosome locus associated with lipids and related cardiometabolic traits and prioritize CHRDL1 as the causal gene.
Results
Baseline characteristics, blood lipids, and chromosome X genotypes
TOPMed sequences were aggregated and aligned, and variants were called by the TOPMed Informatics Research Center. A total of 65,367 out of 140,000 individuals in TOPMed freeze 8 with WGS data, including X chromosome sequence data had harmonized lipid levels available (Supplementary Fig. 1). Forty-five individuals with anomalous X chromosome copy number were excluded, leaving 65,322 individuals for analysis. 40,577 (62.1%) individuals were female and mean (standard deviation [SD]) age was 52.4 (14.9) years. Across all 21 included cohorts, 29,513 (45.2%) were white, 16,431 (25.2%) black, 13,432 (20.6%) Hispanic, 4714 (7.2%) Asian, 1182 (1.8%) Samoan, and 50 (0.1%) Native American (Supplementary Table 1; Supplementary Fig. 2). The included studies were largely observational cohorts with some variations in ascertainment schemes as described in the Supplementary Note. Blood lipid distributions were generally similar across cohorts with some differences due to differences in study design and ancestry (Supplementary Table 2 and Supplementary Fig. 3). After adjusting for lipid-lowering medicines within each cohort and ancestry, we generated residuals within each cohort and race group adjusted for age, age2, sex, 11 principal components of ancestry, and cohort-specific covariates. These residuals were inverse rank normalized and multiplied by the standard deviation within each cohort and race group to obtain effects in mg/dl units (see Methods) (Supplementary Fig. 4).
Among 65,322 TOPMed participants with lipid levels and WGS, we identified 19,898,222 total variants on the X chromosome by WGS. Of these variants, 88,008 (0.4%) were nonsynonymous variants and 4632 (0.02%) were rare (MAF < 1%) predicted protein-truncating variants. As expected, participants of African ancestry had the most X chromosome variants (Fig. 1a). Likely due to sample size differences, there were overall more total variants observed in our dataset among white participants compared to other ancestries (Fig. 1b). Within the X chromosome, females had a greater average [SD] number of variants per individual (133,255 [22,455]) than males (90,117 [12,166]), as expected (Supplementary Table 3). Generally, most of the variation observed across individuals was uncommon (i.e., 98.8% of variants had MAF < 5%) (Supplementary Table 4).
Fig. 1. Distribution of X chromosome variants detected by whole-genome sequencing in TOPMed.

a Violin plots of the distributions of total X chromosome variants detected by whole-genome sequencing per sample by ancestry are depicted. Within each ancestry, distributions are shown by sex (orange: female; turquoise: male). Only discovery samples from TOPMed freeze 8 with lipids are included. b Across all TOPMed freeze eight samples with lipids, total X chromosome variants by ancestry are tabulated by allele count/frequency bins (dark green: AC 1; green: AC 2; light green: AC 3; lightest purple: AC 4—MAF 0.001; light purple: MAF 0.001–0.01; purple: MAF 0.01–0.05; dark purple: MAF 0.05–0.50). AC allele count, AI_AN American Indian / Native American / Alaskan Native, AFR African, ASN East Asian, EUR European, HIS Hispanic, MAF minor allele frequency, SAM Samoan, TOPMed Trans-Omics for Precision Medicine.
X chromosome single-variant association with lipid levels
In single-variant discovery analyses in TOPMed, we performed X chromosome-wide association analyses for genetic variants with minor allele count >20 that are not in the pseudoautosomal region, yielding 2.2 million analyzed of the 19.8 million detected. To maximize power, all samples (i.e., males and females) were included in the linear mixed model association analyses with SD-adjusted residuals of lipid levels as the outcome, where adjustments included sex (Supplementary Fig. 5).
Across variants assessed, we found 21 variants showing suggestive evidence (P < 1 × 10−6) of association with lipids in TOPMed (Supplementary Table 5 and Supplementary Fig. 6). We evaluated these associations for replication, serially, in the UK Biobank (N = 390,606) (Supplementary Table 6) and HUNT (66,635) (Supplementary Table 7). Three variants showed evidence of replication (P < 0.05/21 = 0.002) in UK Biobank and in HUNT and additionally met a stringent threshold for statistical significance in the meta-analysis (alpha = 0.05/2.2 M variants/4 traits = 5.7 × 10−9) (Table 1).
Table 1.
Discovery and replication of chromosome Xq23 variants associated with lipid levels in TOPMed, UK Biobank, and HUNT.
| rsID | Minor allele | Trait | Discovery | Replication | Meta-analysis | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TOPMed (N = 65,322) | UK Biobank Whites (N = 390,606) | UK Biobank non-Whites (N = 51,168) | HUNT (N = 66,287) | |||||||||||||||||
| MAF | Beta | SE | P | Beta | SE | P | Beta | SE | P | Beta | SE | P | Beta | SE | P | I2 | Pmeta | |||
| rs5942634 | T | TC | 34.4% | −1.95 | 0.24 | 2.0 × 10−16 | −1.17 | 0.077 | 1.17 × 10−52 | −1.043 | 0.23 | 6.47 × 10−6 | −1.24 | 0.20 | 3.4 × 10−10 | −1.23 | 0.066 | 3.78 × 10−77 | 71% | 0.016 |
| log(TG) | −0.017 | 0.0028 | 5.0 × 10−9 | −0.025 | 0.0018 | 1.18 × 10−44 | −0.027 | 0.0054 | 7.24 × 10−7 | −0.011 | 0.0024 | 3.8 × 10−6 | −0.020 | 0.0012 | 1.42 × 10−56 | 88% | 1.90 × 10−05 | |||
| HDL-C | 0.14 | 0.084 | 0.09 | 0.12 | 0.026 | 8.99 × 10−6 | 0.27 | 0.077 | 4.82 × 10−4 | 0.068 | 0.062 | 0.27 | 0.13 | 0.022 | 8.63 × 10−09 | 33% | 0.22 | |||
| LDL-C | −1.53 | 0.22 | 2.0 × 10−12 | −1.00 | 0.061 | 1.67 × 10−60 | −1.028 | 0.18 | 2.39 × 10−8 | −0.93 | 0.18 | 3.7 × 10−7 | −1.028 | 0.053 | 1.31 × 10−82 | 47% | 0.13 | |||
| rs5985504 | T | TC | 43.3% | −1.82 | 0.24 | 1.9 × 10−14 | −1.18 | 0.077 | 5.37 × 10−53 | −1.081 | 0.23 | 3.77 × 10−6 | −1.30 | 0.20 | 3.3 × 10−11 | −1.23 | 0.066 | 4.96 × 10−78 | 57% | 0.072 |
| log(TG) | −0.019 | 0.0029 | 4.2 × 10−11 | −0.024 | 0.0018 | 2.36 × 10−40 | −0.030 | 0.0055 | 3.39 × 10−8 | −0.012 | 0.0024 | 4.3 × 10−7 | −0.02 | 0.0013 | 1.29 × 10−57 | 85% | 0.00022 | |||
| HDL-C | 0.088 | 0.084 | 0.30 | 0.095 | 0.026 | 3.1 × 10−4 | 0.25 | 0.078 | 1.13 × 10−3 | 0.12 | 0.063 | 0.051 | 0.11 | 0.022 | 6.70 × 10−07 | 18% | 0.30 | |||
| LDL-C | −1.26 | 0.22 | 8.7 × 10−9 | −0.99 | 0.061 | 3.87 × 10−60 | −1.043 | 0.19 | 2.05 × 10−8 | −1.00 | 0.18 | 3.0 × 10−8 | −1.011 | 0.054 | 2.35 × 10−79 | 0% | 0.70 | |||
| rs5942648 | A | TC | 38.3% | −1.88 | 0.24 | 8.2 × 10−16 | −1.19 | 0.077 | 1.23 × 10−53 | −1.13 | 0.23 | 8.21 × 10−7 | −1.20 | 0.19 | 9.2 × 10−10 | −1.24 | 0.066 | 1.69 × 10−79 | 62% | 0.050 |
| log(TG) | −0.016 | 0.0028 | 7.6 × 10−9 | −0.025 | 0.0018 | 6.31 × 10−45 | −0.030 | 0.0054 | 3.59 × 10−8 | −0.012 | 0.0024 | 2.0 × 10−6 | −0.02 | 0.0012 | 7.28 × 10−58 | 88% | 2.17 × 10−05 | |||
| HDL-C | 0.14 | 0.083 | 0.094 | 0.11 | 0.026 | 2.77 × 10−05 | 0.24 | 0.076 | 2.0 × 10−3 | 0.090 | 0.063 | 0.15 | 0.12 | 0.022 | 4.71 × 10−08 | 0% | 0.40 | |||
| LDL-C | −1.53 | 0.22 | 1.2 × 10−12 | −1.00 | 0.061 | 5.79 × 10−61 | −1.076 | 0.18 | 3.47 × 10−9 | −0.89 | 0.18 | 7.4 × 10−7 | −1.028 | 0.053 | 1.02 × 10−82 | 51% | 0.101 | |||
Variants attaining P < 1 × 10−6 in TOPMed (discovery) and P < 0.002 in UK Biobank and HUNT (replication studies). Effect estimates for the minor alleles are presented from linear regression, adjusted for age, age2, sex, batch, and principal components of ancestry, as well as cohort-specific covariates where appropriate. Two-sided p-values are presented; accounting for multiple-hypothesis testing, p-values < 5.7 × 10−9 are considered significant. rs5942634 was the top association for total cholesterol, rs5985504 for triglycerides, and rs5942648 for LDL-C. Since the variants were in at least moderate linkage disequilibrium (minimum pairwise r2 = 0.61), there was evidence of association across all three of the aforementioned lipid traits for these three variants.
MAF minor allele frequency.
The three variants occurred on chrXq23 and were all in at least moderate linkage disequilibrium across all included TOPMed participants (Supplementary Fig. 7 and Supplementary Table 8). They were also in moderate linkage disequilibrium with a previously described nearby variant, rs598547112, (r2 0.61–0.76). All three associated variants in our dataset have similar nonreference allele frequency (0.34–0.43), which was also similar between males and females. We observed similar associations for both males and females within TOPMed except male rs5985504-T carriers had greater decrease in triglycerides compared to female rs5985504-T carriers (Pinteraction = 0.001) (Supplementary Table 9).
The minor alleles for these variants are common in all TOPMed ancestries except for Asian Americans (MAF 0.02) and Samoans (MAF 0.01). Nevertheless, effect estimates were largely of similar magnitude across ancestries in TOPMed for total cholesterol (Supplementary Table 10) with no evidence of heterogeneity (Pheterogeneity > 0.05).
The three chrXq23 variants were associated with reduced atherogenic lipoproteins (i.e., total cholesterol, triglycerides, and LDL-C) (Table 1). The rs5942634-T allele is an intergenic variant and is 8 kb downstream from RTL9 (also referred to as RGAG1 in the literature), and was the top variant for total cholesterol, associated with 1.95 mg/dl lower concentration (P = 2 × 10−16). The rs5942648-A allele occurs 81 kb downstream, is intergenic between RTL9 and CHRDL1, and was the top variant for LDL-C, associated with 1.53 mg/dl lower concentration (P = 1 × 10−12). The rs5985504-T allele resides 60 kb further downstream and is 68 kb from CHRDL1 and was the top variant for log(triglycerides) leading to 2% lower triglycerides concentration (P = 4 × 10−11). Overall, the associated variants reside within a ~0.22 Mb linkage disequilibrium block spanning RTL9 and CHRDL1 (Supplementary Fig. 7). Within this block, variants within predicted active adult liver enhancers are in proximity to both the RTL9 and CHRDL1 genes (Supplementary Fig. 8). Only two variants reside within both an adult liver enhancer and DNase hypersensitivity site—rs2883091 in an intron of RTL9, and rs2143760 residing 4 kb from CHRDL1 but 214 kb from RTL9. These variants are in at least moderate linkage disequilibrium (r2 > 0.60) with the top associated variants in the locus. Virtual 4 C data additionally demonstrate a contact between the rs5985504 site and upstream of CHRDL1 (Supplementary Fig. 9).
To determine whether our signal was independent of previously reported variants in the region, we performed conditional analysis for the associated between total cholesterol and rs5942634 with rs594305711, rs598547112, and rs594293713 (Supplementary Table 11). Previously reported SNPs were highly associated with total cholesterol when the variants were individually modeled. However, after adjusting for our reported total cholesterol variant (rs5942634), the known variants have dramatically lower effect estimates and are no longer associated with total cholesterol. On the other hand, rs5942634 remains marginally associated with total cholesterol and with a less of a change in effect size after adjusting for the three known variants. Similar results were obtained when adjusting the association between total cholesterol and rs5942634 for the individual previously reported variants in the region (results not shown). This indicates that rs5942634 is only partially explained by the three reported variants.
Phenome-wide association Of Chrxq23 variants
Given prior genetic associations of LDL-C-lowering and triglyceride-lowering autosomal variants with lower risk for CHD, we hypothesized that sex chromosome variants lowering LDL-C or triglycerides would also lower risk for CHD. In HUNT, UK Biobank, and FinnGen (Supplementary Table 12), we observed that the top lipid-lowering alleles at this locus showed a reduced risk for CHD (Fig. 2). We found a 0.98 (95% CI 0.96, 0.99; P = 1.7 × 10−4) odds of CHD for each rs5942634-T allele, the lead cholesterol-lowering variant (alpha = 0.05 for the single haplotype assessment), and a correlation between the effect sizes of variants on total cholesterol in the chrXq23 locus and the effect sizes of these variants on CAD (r = 0.25), T2D (r = 0.33), and BMI (r = −0.34) (Supplementary Fig. 10).
Fig. 2. Association of lead cholesterol-lowering chrXq23 variant rs5942634-T with reduced odds of coronary heart disease and diabetes mellitus type 2.

The lead cholesterol-lowering allele at chrXq23 (i.e., rs5942634-T) and evidence of association with coronary heart disease and diabetes mellitus type 2 in each of three datasets in black, UK Biobank, HUNT, and FinnGEN, as well as meta-analysis in blue are shown. Odds ratios (OR) and 95% confidence intervals around the odds ratios are displayed.
To explore the range of phenotypes associated with the chrXq23 locus, we evaluated the associations of each of these three variants with 80 manually curated diverse clinical traits and conditions in the UK Biobank (Supplementary Table 13). Given the high degree of correlation among these variants, phenome-wide association results were similar (Supplementary Tables 14-16). As expected, the strongest associations were for reduced odds of hypercholesterolemia. Associations reaching a P < 6.3 × 10−4 (P < 0.05/80 traits) included reduced odds for diabetes mellitus type 2 (T2D), hypertension, and glaucoma, but increased odds for ever smoking as well as increased body-mass index (BMI) and body fat percentage. Notably, we observed lower odds of T2D for rs5942648 (OR = 0.97; 95% CI 0.96, 0.99; P = 1.4 × 10−5) (Fig. 2).
We additionally explored the association between each of these three variants with lipoprotein subspecies identified through nuclear magnetic resonance spectroscopy (NMR) within the Framingham Heart Study and Multi-Ethnic Study of Atherosclerosis cohorts (up to 6356 individuals). While we did not find any associations that passed a Bonferroni-corrected significance threshold (0.05/(3 SNPs × 16 lipoprotein subspecies) = 0.001; Supplementary Table 17), we found two lipoprotein subspecies associated with suggestive evidence (p < 0.05), including greater concentration of medium HDL particles (but no effect on small or large HDL particles) and greater LDL size. We assessed for evidence of replication for indices related to LDL size (alpha 0.05) since the chrX variants associated with LDL-C. Among 6443 participants of the Atherosclerosis Risk in Communities cohort, we concordantly observed a −0.034 SD (P = 0.022) lower concentration of small dense LDL for rs5942648-A. Among 365,365 participants of the UK Biobank, when using LDL-C/apolipoprotein B ratio as a proxy for LDL particle size, we observed a nominal increase in LDL size even with adjusting for both LDL-C and apolipoprotein B (Beta = 1.1 × 10−5, P = 0.048).
To better characterize effects on adiposity given the aforementioned clinical phenotype associations, we evaluated the association between rs5942634-T and body composition measurements in the UK Biobank. Although rs5942634-T was associated with increased BMI, it was associated with slightly reduced waist-to-hip ratio adjusted for BMI (Beta = −6.3 × 10−4, SE = 1.1 × 10−4, P = 1.3 × 10−8). rs5942634-T is associated with both increased truncal fat mass (Beta = 63 g, SE = 10 g, P = 4.0 × 10−10) as well as increased total peripheral fat mass, with increase of 21 g (P = 3.6 × 10−12) of the right leg, 20 g (P = 3.4 × 10−12) of the left leg, 7 g (P = 4.1 × 10−7) of the right arm, and 8 g (P = 1.7 × 10−9) of the left arm (Supplementary Table 18). Additionally, among 4750 unrelated UK Biobank participants with abdominal MRI measures available, rs5942634-T was associated with log-transformed inverse rank standardized increased abdominal subcutaneous adipose tissue (Beta = +0.43, SE = 0.15, P = 5.9 × 10−3) but decreased visceral adipose fat (Beta = −1.12, SE = 0.14, P = 1.1 × 10−15) to a greater degree. Given nine adiposity traits assessed, Bonferroni-corrected significance was assigned at 0.05/9 = 5.6 × 10−3.
Rare pathogenic variants in CHRDL1 were previously linked to X-linked recessive megalocornea, a condition characterized by enlarged corneal diameters with associated complications, including reduced visual acuity. Given these prior observations, we asked whether common variants associated with cholesterol at the CHRDL1 locus were associated with differences in visual acuity. Among 112,842 UK Biobank participants (46.5% women; median age at assessment 58.5 years), we observed no association of lipid-associated chrXq23 alleles with altered visual acuity (P > 0.05; Supplementary Table 19). Given our sample size of 112,842 and SNP frequency of 34.4%, we had >99% power to detect effects >1/10th of a standard deviation unit of visual acuity at an alpha of 0.05.
Gene expression analyses at chromosome Xq23
We leveraged the GTEx eQTL data to better understand the gene or genes in the region that are influencing atherogenic lipid levels. Our most significant SNP, rs5942634, was associated with reduced expression of CHRDL1 in skeletal muscle (beta = −0.17, P = 1.2 × 10−11), subcutaneous adipose (beta = −0.16, P = 8.6 × 10−8), visceral adipose (beta = −0.17, P = 4.3 × 10−6), and liver (beta = −0.25, P = 5.9 × 10−5). Additionally, rs5942634 was associated with increased expression of RTL9 in skeletal muscle (beta = 0.18, P = 2.7 × 10−5; Supplementary Table 20).
Interrogating eQTL data for a single variant may lead to biased interpretations for causal gene inference. Therefore, we colocalized eQTL results for 8 genes (i.e., ACSL4, TMEM164, AMMECR1, RTL9, CHRDL1, PAK3, CAPN6, DCX) within the ChrXq23 region across prespecified lipid-related tissues (i.e., subcutaneous adipose, terminal ileum, visceral omentum adipose, whole blood, liver, and skeletal muscle) to relate aggregate blood lipid-association data with gene expression data. We observe that increased gene expression of CHRDL1 shows consistent colocalization with decreased cholesterol across tissues, indicating that CHRDL1 is the likely causal gene in the region (Fig. 3, Supplementary Fig. 11, and Supplementary Table 21).
Fig. 3. Colocalization of expression of genes at chrXq23 in subcutaneous adipose tissue with blood cholesterol effects strongly implicates CHRDL1.
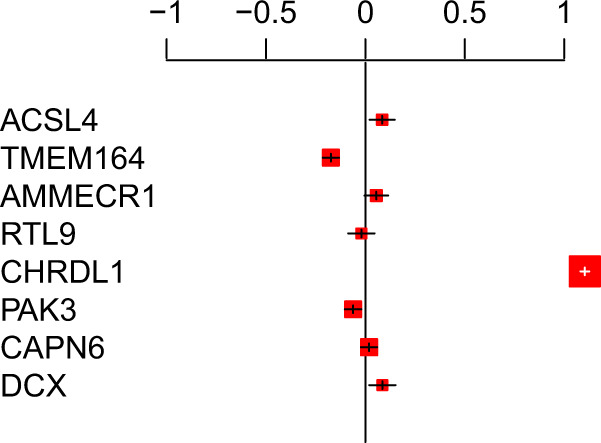
The x-axis represents eight genes in the chrXq23 locus and y-axis represents standardized gene expression effect estimates in subcutaneous adipose tissues with 95% confidence intervals. Accounting for linkage disequilibrium, standardized effects and evidence of associations of cholesterol-lowering alleles were correlated with gene expression of genes at chrXq23 (ACSL4, TMEM164, AMMECR1, RTL9, CHRDL1, PAK3, CAPN6, and DCX).
Rare chromosome X variant association analyses
We performed SKAT gene-based tests of rare variants (MAF < 1%) across the X chromosome implemented by the GENESIS package within the TOPMed samples. We tested a maximum of 746 genes with more than 1 rare variant and at least 10 individuals carrying a minor allele with each lipid trait. No genes reached a Bonferroni-corrected significance threshold (0.05/746 = 6.7 × 10−5; Supplementary Table 22).
Discussion
Using deep-coverage next-generation sequencing of the X chromosome in the NHLBI TOPMed program, we identified a locus that was previously associated with lipids in primarily European ancestry datasets, which we now extend to diverse ancestries along with strong replication in two independent studies. In addition to replicating the associations of chrXq23 lipid-lowering alleles with reduced odds for CHD, we also observe associations with reduced T2D odds and favorable adiposity indices. These observations allow us to draw several conclusions about X chromosome genetic variation with blood lipid levels, as well as related cardiometabolic effects.
First, bioinformatic analyses implicate CHRDL1 as a candidate causal gene for the association of chrXq23 variants with lipids. Based on genomic proximity of the strongest signal, RTL9 was assigned as the likely causal gene in prior work12. However, colocalization analyses strongly prioritize increased CHRDL1 gene expression in lipid-related, particularly adipose, tissues with reduced lipoprotein measures over other genes in the region. CHRDL1 is not a previously known Mendelian lipid gene. In our study, disruptive rare coding variants in CHRDL1 were not significantly associated with lipids, nor was any gene in the region.
Second, despite observing an association with increased BMI, chrXq23 lipid-associated alleles may lead to favorable effects on adiposity. We observed that chrXq23 lipid-lowering alleles were associated with increased gluteofemoral adipose tissue. Autosomal alleles similarly linked to expansion of gluteofemoral adipose tissue are associated with favorable risk for CHD and T2D28,29. Autosomal alleles associated with body fat distribution are also associated with various functional adipose measures, including morphology, lipolysis, and lipogenesis30. Recent gene expression analyses of human adipose-derived stromal cells showed persistent upregulation of CHRDL1 after inducing adipogenesis31. CHRDL1 is believed to influence adipogenic differentiation in human isolated preadipocytes32. Comparative gene expression analyses suggest relatively greater CHRDL1 expression in subcutaneous versus visceral fat32,33. In our analyses, the chrXq23 lipid-lowering alleles were associated with an increase in abdominal subcutaneous adipose tissue but a decrease in visceral adipose tissue. A proteomic discovery analysis showed that increasing circulating CHRDL1 concentrations were associated with increased birth weight but decreased triglycerides and homeostatic model assessment of insulin resistance34.
Third, chrXq23 lipid-lowering alleles have favorable cardiometabolic effects that appear to reduce risk for CHD and T2D. Our results for CHD at chrXq23 are consistent with prior work at this locus12, and extend to prior observational epidemiology, genetic, functional, and clinical trial evidence implying a causal relationship between reduced LDL-C and reduced CHD risk35. In aggregate, autosomal LDL-C-reducing alleles are associated with increased T2D risk but the effects are inconsistent across individual variants7,36,37. In meta-analyses of randomized controlled trials, statins are associated with a modestly increased risk of incident T2D38,39. The effects of triglyceride-lowering alleles and T2D risk are generally inconsistent40–42. Common triglyceride-lowering variants at LPL and ANGPTL4 p.E40K in the lipoprotein lipase pathway are associated with reduced triglyceride concentrations, CHD odds, and T2D risk40,43,44. Rare loss-of-function variants in ANGPTL3, also implicated in the lipoprotein lipase pathway, are associated with reduced LDL-C and triglyceride concentrations as well as reduced CHD odds but favorable effects on T2D risk have not yet been observed40,45,46. However, we uniquely describe a genetic locus associated with reduced LDL-C concentrations, reduced triglyceride concentrations, lower CHD risk, and lower T2D risk. Similarly, we observed that lipid-lowering chrXq23 alleles were independently associated with increased LDL-C/apoB ratio, which has been independently associated with reduced CHD and T2D risk in observational epidemiologic studies47–50. These data imply that therapeutic modulation of the causal pathway may lead diverse favorable cardiometabolic indices. Whether implicated variants influence the lipoprotein lipase pathway or represent a novel lipid-related pathway for combined CHD and T2D should be addressed by future research.
Fourth, common lipid-associated variants linked to increased CHRDL1 expression are not associated with visual acuity measures. Ventropin, the product of CHRDL1, was first described as a bone morphogenic protein 4 inhibitor and a regulator of retinal development51. Pathogenic disruptive variants in CHRDL1 are implied in X-linked megalocornea52. However, common lipid-associated variants linked to increased CHRDL1 expression in the present study do not associate with measures of visual acuity in the UK Biobank. These data imply that therapeutic modulation to recapitulate the protective effects associated with chrXq23 lipid-lowering alleles is not anticipated to lead to on-target adverse visual acuity effects.
Important limitations should be considered in the interpretation of our findings. First, our genetic association analyses of the X chromosome do not account for random X inactivation. Accounting for random X inactivation is expected to modestly improve power and thus our approach biases our findings toward the null53,54. We found that there was slightly higher variance of total cholesterol in heterozygous females (sd = 44.1 mg/dl) compared to homozygous females (homozygous ref sd = 43.0, homozygous alt sd = 43.9) of rs5942634 using the Levene’s Test for Homogeneity of variance (P = 0.002), indicating this locus may be subject to random X inactivation. Second, while our in silico analyses and prior literature strongly implicate CHRDL1 as the causal gene, additional analyses including perturbational experiments in model systems are necessary to confirm our hypotheses. Furthermore, whether additional cis-acting or trans-acting gene expression for other genes are additionally relevant for the observed effects on blood lipids are currently unknown. Third, chrXq23 lipid-lowering alleles were associated with both increased truncal and gluteofemoral adiposity indices, and whether the former associations result in adverse clinical consequences is not known. Nevertheless, phenome-wide association analyses did not reveal concerning clinical phenotype associations related to modest increases in BMI. Notably, chrXq23 lipid-lowering alleles were associated with decreased visceral adipose tissue.
In conclusion, we observe a consistent association of chrXq23 alleles with reduced total cholesterol, LDL-C, triglycerides, CHD, and T2D. Despite an increase in BMI, these alleles were favorably associated with increased gluteofemoral and abdominal subcutaneous adiposity, decreased visceral adiposity, and increased LDL-C/apolipoprotein B ratio. Colocalization analyses strongly implicate increased CHRDL1 expression in adipose tissues with these favorable cardiometabolic indices, pointing to CHRDL1 as the leading candidate gene in the region.
Methods
Study participants
For discovery, 65,322 individuals from 21 studies in the freeze 8 release of the NHLBI TOPMed Program with WGS passing central quality control by the TOPMed Informatics Research Core and blood lipid data available were included for analysis (Supplementary Fig. 1). The included studies are Atherosclerosis Risk in Communities study (ARIC, 7991), Old Order Amish (Amish, 1083), Mt Sinai BioMe Biobank (BioMe, 9857), Coronary Artery Risk Development in Young Adults (CARDIA, 3054), Cleveland Family Study (CFS, 577), Cardiovascular Health Study (CHS, 2773), Diabetes Heart Study (DHS, 365), Framingham Heart Study (FHS, 3990), Genetic Epidemiology Network of Arteriopathy (GENOA, 1,044), Genetics of Lipid-Lowering Drugs and Diet Network (GOLDN, 924), Genetic Epidemiology Network of Salt Sensitivity (GenSalt, 1770), Genetic Studies of Atherosclerosis Risk (GeneSTAR, 1755), Hispanic Community Health Study—Study of Latinos (HCHS/SOL, 7391), Hypertension Genetic Epidemiology Network and Genetic Epidemiology Network of Arteriopathy (HyperGEN, 1853), Jackson Heart Study (JHS, 2846), Multi-Ethnic Study of Atherosclerosis (MESA, 5283), Massachusetts General Hospital Atrial Fibrillation Study (MGH_AF, 683), San Antonio Family Study (SAFS, 617), Samoan Adiposity Study (Samoan, 1182), Taiwan Study of Hypertension using Rare Variants (THRV, 1976), and Women’s Health Initiative (WHI, 8305) (Please refer to the Supplementary Note for additional details). Study participants provided consent per each study’s IRB approved protocol. These data were secondarily analyzed through a protocol approved by the Partners Healthcare IRB and Boston University IRB.
For lipid replication, 69,635 participants from the Nord-Trøndelag Health (HUNT) study and 390,606 participants of the UK Biobank with genome-wide array data and lipid data were included. The HUNT study is a longitudinal, repetitive population-based health survey conducted in the county of Nord-Trøndelag, Norway26. Since 1984, the adult population in the county has been examined three times, through HUNT1 (1984–86), HUNT2 (1995–97), and HUNT3 (2006–08). A fourth survey, HUNT4 (2017–2019), is ongoing. HUNT was approved by the Data Inspectorate and the Regional Ethics Committee for Medical Research in Norway (REK: 2014/144). All HUNT participants gave informed consent. Approximately 120,000 individuals have participated in HUNT1–HUNT3 with extensive phenotypic measurements and biological samples. The subset of these participants that have been genotyped (~70,000) using Illumina HumanCoreExome v1.0 and 1.1 and imputed with Minimac3 using a combined HRC and HUNT-specific WGS reference panel are included in the current study. The UK Biobank is a large, prospective cohort of ~500,000 United Kingdom residents aged 40–69 years25,55. Patients provided answers to questions regarding socio-demographic, lifestyle, and health-related factors; additionally, participants provided blood, urine, and saliva for genetic and other future assays. Genotyping was performed on a custom Affymetrix array followed by imputation. Various additional measurements were performed on all recruited participants (e.g., electrocardiography, etc) and some measurements in subsets (e.g., cardiac magnetic resonance imaging, etc). Study participants provided consent per the UK Biobank’s IRB approved protocol. We excluded UK Biobank individuals that met the following criteria: (1) Individuals whose submitted gender is not same as inferred gender; (2) Individuals with putative sex chromosome aneuploidy; (3) Individuals with second degree or higher degree relatives; and (4) Individuals who withdrawn consent. We analyzed individuals who were British white separately from those that were not considered British White. These data were secondarily analyzed through a protocol approved by the Partners Healthcare IRB.
The effects of lipid-associated X chromosome variants on CHD risk were estimated in 69,635 participants of HUNT, 390,606 British White participants of UK Biobank, and 176,899 participants of FinnGen. The effects on risk of diabetes mellitus were estimated in 69,635 participants of HUNT, 390,606 participants of UK Biobank, and 171,087 participants of FinnGen. FinnGen (https://www.finngen.fi/en) is a large biobank study that aims to genotype 500,000 Finns on a FinnGen ThermoFisher Axiom custom array, with the current data freeze comprising 181,820 Finnish individuals27. FinnGen includes prospective epidemiological and disease-based cohorts, and hospital biobank samples. The data were linked by the unique national personal identification numbers to national hospital discharge (available from 1968), death (1969-), cancer (1953-), and medication reimbursement (1995-) registries and disease endpoints were defined by harmonizing the International Classification of Diseases (ICD) revisions 8, 9, and 10, cancer-specific ICD-O-3 and ATC-codes. The FinnGen project is approved by Finnish Institute for Health and Welfare (THL).
Sequencing, genotyping, and quality control of TOPmed
Whole-genome sequencing of at least 30× was performed across six sequencing centers using PCR-free library preparation kits for TOPMed samples24. In most cases, all samples for a given study were sequenced at the same center. Samples were excluded if estimated contamination by verifyBamId was >3%{Jun, 2012 #278} or <95% of the genome attained >10× coverage. The reads were centrally realigned at the TOPMed Informatics Research Center (IRC) to human genome build GRCh38 at each center using BWA-MEM56,57. Joint variant discovery was subsequently performed with the ‘GotCloud’ pipeline by the IRC58. The variant calling software tools are under active development; updated versions can be accessed at http://github.com/atks/vt, http://github.com/hyunminkang/apigenome, and https://github.com/statgen/topmed_variant_calling. Using sequencing quality metrics, a catalogue of previously discovered variants, and variants with Mendelian inconsistencies from included families, variant-level quality controlled was performed using a support vector machine algorithm. Sample-level quality control was performed by the TOPMed IRC and Data Coordinating Center (DCC) to remove samples genotypic/reported inconsistencies for pedigree and sex, and substantial discordance with prior genome-wide array genotyping. Only variants and samples that passed quality control were included in the call set.
One individual from duplicate pairs identified by the DCC was removed, retaining the individual with lipid levels available when one did not have lipid levels. If both individuals had lipid levels, one individual was randomly selected. Individuals were excluded when their genotype determine sex did not match phenotype reported sex (n = 6) and individuals <18 years old where excluded (n = 865).
Blood lipid measurements and phenotypic modeling
Conventionally measured fasting blood lipids, including total cholesterol, LDL-C, HDL-C, and triglycerides, were included for analysis. Harmonization of the lipid values, lipid-lowering medication status, and fasting status at lipid blood draw was performed by the TOPMed Data Coordinating Center. LDL-C was either calculated by the Friedewald equation when triglycerides were <400 mg/dl or directly measured. Given the average effect of lipid-lowering medicines, when lipid-lowering medicines (largely statins) were present, total cholesterol was adjusted by dividing by 0.8 and LDL-C by dividing by 0.7, as previously done2. Triglycerides were natural log transformed for analysis. Standard deviation scaled inverse-normalized residuals adjusting for age, age2, sex, the first 11 PCs of ancestry (as recommended by the TOPMed DCC), as well as cohort-specific covariates (study site or known founder mutations), where created within each study by self-reported race. Effect sizes are reported in mg/dl or log(mg/dl) for TG.
Coronary heart disease and diabetes mellitus type 2 phenotyping
In the UK Biobank, we used National Health System OPCS-4 (Office of Population, Census and Surveys: Classification of Interventions and Procedures, version 4) codes K40.1-40.4, K41.1-41.4, K45.1-45.5, K49.1-49.2, K49.8-49.9, K50.2, K75.1-75.4, or K75.8-75.9 to indicate the presence of coronary heart disease. For diabetes mellitus type 2 classification in the UK Biobank, we used the presence of OPCS-4 codes E11.0-E11.9 or ICD9 code 1223.
Coronary heart disease (CHD) in HUNT was defined as individuals with self-reported coronary artery bypass, angioplasty, or stent placement or with diagnosis of myocardial infarction or chronic ischemic heart disease based on at least one occurrence of the following codes: ICD9: 410, 411, 412, 414.0, 414.8, 414.9 or ICD10: I21, I22, I23, I24, I25.1, I25.2, I25.5, I25.6, I25.7, I25.8, I25.9. Individuals with angina were excluded from controls. Type II diabetes was defined based on at least 1 occurrence of the following diagnosis codes: ICD9: 250.00, 250.02, 250.10, 250.12, 250.20, 250.22, 250.30, 250.32, 250.40, 250.42, 250.50, 250.52, 250.60, 250.62, 250.70, 250.72, 250.80, 250.82, 250.90, 250.92 ICD10: E11 or by diagnosis of diabetes during HUNT clinical examinations (nonfasting serum or blood glucose > 11.1 mmol/L or Hemoglobin A1C > 6.5%).
In FinnGen, CHD cases were defined as subjects with either an underlying or direct cause of death with ICD codes I20-I25, I46, R96 or R98 (ICD10) or 410–414 or 798 (ICD9/8), a hospital discharge diagnosis with ICD codes I200, I21-I22 (ICD10) or 410, 4110 (ICD9/8) and/or a coronary revascularization procedure (coronary artery bypass surgery procedure or coronary angioplasty, or an entry of invasive cardiac procedures in the country-wide register. Type 2 diabetes was defined as subjects with an underlying or direct cause of death or as the main or side diagnosis at hospital discharge with ICD codes E11 (ICD10)/250(0–9)A (ICD9) with ICD codes E11 (ICD10); 250(0–9)A (ICD-8/9) or at least three prescription medicine purchases with ATC class A10B, or as the specially reimbursed medication for diabetes. Cases with both type 2 and type 1 diabetes mellitus were excluded. In these definitions, the ICD10, ICD9 and ICD-8 below refer to the Finnish versions of the ICD codes.
UK Biobank phenotype ascertainment
Our approach to phenome-wide association analyses are similar to prior efforts59,60. Briefly, a phenome-wide association analysis was performed to evaluate the associations of X chromosome lipid-associated variants with a broad range of clinical phenotypes61. A total of 80 manually curated traits were classified according to a combination of self-report and billing codes, except for the following which were based on corresponding UK Biobank data fields: death (40000), ever smoked (20610), BMI (23104), and percentage body fat (23099) (Supplementary Table 13). Lipid-associated variants were associated with each trait, using linear regression for continuous traits and logistic regression for dichotomous traits, adjusting for age, sex, array type, and the first five PCs in the model.
For adiposity analyses, body composition values were obtained using bioelectrical impedance measurement (Category 100009) with a Tanita BC418MA body composition analyzer. Separate readings for fat percentage, mass, and free mass as well as predicted muscle mass are generated for the whole body, trunk, each leg, and each arm. In linear regression analyses, lipid-associated variants were associated with fat mass (in kilograms) for each of the aforementioned components adjusting for age, sex, and the first five PCs in the model. We also separately analyzed the association of lipid-associated variants with abdominal subcutaneous adipose fat (22408) and visceral adipose fat (22407) among unrelated UK Biobank participants with abdominal MRI measures available62. Each of these phenotypes was natural log-transformed and inverse rank standardized; linear regression models were then adjusted for age, sex, array type, and the first 11 PCs.
For visual acuity analyses, we included data where baseline visual acuity was available for at least one eye and genotyping data was available in the UKBB63. Methods from visual acuity assessment in UKBB were previously described. Briefly, visual acuity was measured using the logarithm of the minimum angle of resolution (“LogMAR”) chart (Precision Vision, LaSalle, Illinois, USA) at a distance of four meters. Using one eye at a time, participants were tasked with identifying the five letters displayed at the top row; they proceeded to read letters from successive rows, which had progressively smaller text. The test was terminated when two or more of the five letters on a given row were read incorrectly. Visual acuity was computed based on the number of successfully read rows; the visual acuity result was provided by the UK Biobank as Field ID 5208 (left eye) and Field ID 5201 (right eye). Data from the right eye was available in 60,421 women and 51,245 men, while data from the left eye was available in 60,402 women and 51,280 men. Linear mixed models from the lme4 package in R (v3.6.1) were used to estimate the association if each of the three variants with visual acuity, adjusting for age, sex, the first five PCs in the model, as well as a random effect accounting for which eye was tested (left or right).
Single-variant association analyses
For discovery, each single variant on the X chromosome with at least 20 copies of the minor allele was analyzed for association with each adjusted blood lipid residual across all TOPMed samples with lipid levels available (see Blood lipids measurements and phenotypic modeling) using a fast linear mixed model with kinship adjustment (SAIGE-QT, version 0.29.4.464) since a large proportion of TOPMed participants are related in ENCORE (https://encore.sph.umich.edu) additionally adjusting for the first 11 PCs in the model. SAIGE-QT was specifically used to maximize computational efficiency given hosting and kinship precomputation by the TOPMed Informatics Research Core. Heterozygous and homozygous women were coded as having 1 or 2 nonreference alleles, respectively. Hemizygous males were coded as having two reference alleles. This modeling is consistent with random X inactivation of one of two X chromosomes in females yet consistent expression of the single X chromosome in males.
For SNPs with suggestive evidence of association in TOPMed (P < 1 × 10−6), we sought replication in UKBB. For replication in UKBB unrelated individuals, we performed linear regression associations using R version 3.6.0. Covariates included age, age2, sex, the first 10 PCs in the model, and genotyping array.
For replication in HUNT, a cohort within a founder population, plasma lipids were analyzed using efficient linear mixed models implemented by BOLT-LMM v2.3.165 with covariates for sex, age, age2, batch, and principle components 1–4. CAD was analyzed using SAIGE with birth year, batch, sex, and principle components 1–4 as covariates.
Covariates included in the models of association for each contributing study were based on study characteristics and recommendations from study investigators. We took loci reaching a suggestive association with lipid levels (P < 1 × 10−6) in TOPMed onto replication in UKBB and HUNT. For replication, we used a significance level of 0.002 (Bonferroni correction for 21 loci) that met a suggestive level of association in TOPMed. We used a fixed effects meta-analysis to combine the association results from TOPMed, UKBB, and HUNT. We set the statistical significance for our meta-analysis to be alpha = 5.7 × 10−9 (0.05/2.2 M variants/4 traits = 5.7 × 10−9), which is more stringent than a standard genome-wide significance threshold of 5 × 10−8. Heterogeneity of effect sizes in the meta-analysis was determined through Cochran’s Q and I2 is reported. Additionally, we tested for the interaction between rs5985504-T and sex on log triglycerides adjusting for the same covariates as the main analysis.
To determine the correlation of the effect sizes of variants on total cholesterol in the chrXq23 locus and the effect sizes of these variants on CAD, T2D, and BMI, we performed analysis of chrXq23 variation on these three outcomes adjusting for age, age2, sex, genotyping array, and PCs in the UK Biobank, using the main effects model assuming X inactivation. We correlated effect sizes of total cholesterol–variants with effect sizes of variants on CAD, T2D, or BMI limiting to total cholesterol–variants with a MAF > 0.05 and P < 0.05.
Expression quantitative trait analyses
We downloaded the v7 SNP gene association results in tissue-specific files from the GTEx portal (https://gtexportal.org/home/datasets). We limited to six tissues that have been implicated in lipid biology or CHD (Adipose_Subcutaneous, Small_Intestine_Terminal_Ileum, Adipose_Visceral_Omentum, Whole_Blood, Liver, Muscle_Skeletal) and looked at expression of eight genes within the ChrXq23 region (ACSL4, TMEM164, AMMECR1, RTL9, CHRDL1, PAK3, CAPN6, DCX). We set our significance threshold to 0.001 (0.05/[6 tissues × 8 genes]). First, we determined eQTLs of our top association with lipids. Second, we performed correlation of our lipid–variant associations with the association of each of the eight genes expression on the variants using the gene transcripts ± 100 KB. Lastly, we used the lmekin function in the R package kinship2 to run linear mixed effects models and predict the lipid–variant test statistic (Z = beta/SE) from the expression–variant test statistic to adjust for the correlation between the variants.
Lipid subfractions association analyses
Concentrations of lipoprotein particles were measured at LipoScience, Inc. (Raleigh, NC) using NMR spectroscopy on plasma EDTA specimens. LipoScience has developed validated software for analysis of NMR measured LipoProfile spectra that uses an optimized deconvolution algorithm to quantify lipoprotein subspecies66,67. MESA was measured with the LipoProfile-III assay while FHS samples were measured with the LipoProfile-I assay, which provides less accuracy for some measurements but is similar to LipoProtein-III. We associated lipoprotein profiles with top associated SNPs within up to 1,802 FHS and 4551 MESA participants adjusting for age, sex, and lipid-lowering therapy.
For individuals who participated in ARIC study visit 4 (1996–1998), a homogeneous assay method was used for the direct measurement of sdLDL-C in plasma (sd-LDL-EX “Seiken”, Denka Seiken, Tokyo, Japan) on a Hitachi 917 automated chemistry analyzer68. We associated top associated SNPs with ARIC participants adjusting for age, sex, lipid-lowering therapy, race, study center, and the first 11 principal components of ancestry.
Rare variant association analyses
We performed the SKAT test to associate aggregates of rare coding variants with blood lipid levels within TOPMed as implemented by GENESIS v2.14.4 in the CHARGE Analysis Commons69,70. For this gene-based test, high confidence loss-of-function (HC LOF by LOFTEE71) and missense metaSVM72 damaging variants with MAF < 1% were collapsed into regions based on the gene annotations generated by snpEff 4.3t (http://snpeff.sourceforge.net/) using the GRCh38.86 database73.
Reporting summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Supplementary information
Acknowledgements
This work was supported by grants from the National Heart, Lung, and Blood Institute (NHLBI): R01HL142711 (to P.N. and G.M.P.), K08HL140203 (to P.N.), R03HL141439 and K01HL125751 (to G.M.P.). P.N. is also supported by a Hassenfeld Scholar Award from the Massachusetts General Hospital, Fondation Leducq (TNE-18CVD04), and additional grants from the National Heart, Lung, and Blood Institute (R01HL148565 and R01HL148050). P.S.de.V. is supported by American Heart Association grant number 18CDA34110116. B.E.C. and J.L. are supported by R35HL135818, HL113338, and HL46380. B.E.C. is also supported by K01HL135405. S.L. is supported by NIH grant 1R01HL139731 and American Heart Association 18SFRN34250007. Whole-genome sequencing (WGS) for the Trans-Omics in Precision Medicine (TOPMed) program was supported by the National Heart, Lung, and Blood Institute (NHLBI). Centralized read mapping and genotype calling, along with variant quality metrics and filtering were provided by the TOPMed Informatics Research Center (3R01HL-117626-02S1; contract HHSN268201800002I). Phenotype harmonization, data management, sample-identity QC, and general study coordination were provided by the TOPMed Data Coordinating Center (3R01HL-120393-02S1; contract HHSN268201800001I). We gratefully acknowledge the studies and participants who provided biological samples and data for TOPMed. Please refer to Supplementary Notes 1–4 for study-specific acknowledgements. The views expressed in this manuscript are those of the authors and do not necessarily represent the views of the National Heart, Lung, and Blood Institute; the National Institutes of Health; or the U.S. Department of Health and Human Services.
Source data
Author contributions
Conceptualization of work and wrote original draft of manuscript: P.N. and G.M.P. Data curation and provided resources for study: P.N., A.Pampana, S.E.G., S.E.R., P.S.d.V., J.G.B., B.W., J.A.B., L.A.-F., K.A., M.C.H., J.P.P., M.A., S.A., T.L.A., C.M.B., L.F.B., J.C.B., B.E.C., R.D., H.D., L.S.E., Y.-.J.H., A.T.K., L.A.L., J.L., R.N.L., L.W.M., G.M., J.-Y.M., J.R.O., N.D.P., J.M.P., A.M.S., M.T., F.F.W., D.E.W., L.R.Y., J.B., E.B., D.W.B., D.M.L.-J., Y.-C.C., Y.I.C., W.J.C., J.E.C., M.J.D., S.K.D., P.T.E., S.A.L., M.F., B.I.F., S.G., R.A.G., J.H., G.P.J., R.C.K., S.L.K., S.K., C.K., L.A.C., C.C.L., D.M.L., S.A.L., K.A.V.M., S.T.M., A.C.M., K.E.N., A.Palotie, C.J.P., B.M.P., D.C.R., S.Redline, A.P.R., D.S., J.-.S.S., R.S.V., J.I.R., S.S.R., S.Ripatti, and G.M.P. Statistical Analyses: P.N., A.Pampana, S.E.G., J.A.P., B.W., J.A.B., and G.M.P. Acquired funding and supervision of contributing studies: P.N., S.E.R., T.L.A., J.C.B., Y.-J.H., R.N.L., M.E.M., J.R.O., P.A.P., J.G.W., G.A., D.K.A., L.C.B., J.B., E.B., Y.-C.C., A.C., J.E.C., K.H., S.L.K., E.K., R.W.K., R.J.L., R.A.M., B.D.M., D.A.N., K.E.N., B.M.P., A.V.S., C.W., and G.M.P. Critically revised manuscript: P.N., A.Pampana, S.E.G., S.E.R., P.S.d.V., M.A., L.F.B., R.D., L.S.E., M.R.I., L.A.L., R.N.L., N.D.P., P.A.P., L.R.Y., J.G.W., L.C.B., J.B., A.C., J.E.C., M.F., S.L.K., E.K., R.J.L., R.A.M., A.C.M., K.E.N., R.P.T., and G.M.P. All authors approved the final manuscript.
Data availability
Controlled access of the individual-level TOPMed data is available through dbGaP, and the individual-level UK Biobank data are available upon application to the UK Biobank (https://www.ukbiobank.ac.uk/). FinnGen summary-level data are fully freely available at https://www.finngen.fi/en/access_results. Individual-level access to FinnGen and HUNT cohorts may be obtained through reasonable request and suitable institutional review board approvals. The dbGaP accessions for TOPMed cohorts are as follows: Atherosclerosis Risk in Communities (ARIC) phs001211 and phs000280; Old Order Amish phs000956 and phs000391; Mt Sinai BioMe Biobank phs001644 and phs000925; Coronary Artery Risk Development in Young Adults (CARDIA) phs001612 and phs000285; Cleveland Family Study (CFS) phs000954 and phs000284; Cardiovascular Health Study (CHS) phs001368; Diabetes Heart Study (DHS) phs001412 and phs001012; Framingham Heart Study (FHS) phs000974 and phs000007; Genetic Epidemiology Network of Arteriopathy (GENOA) phs001345 and phs001238; Genetics of Lipid-Lowering Drugs and Diet Network (GOLDN) phs001359 and phs000741; Genetic Epidemiology Network of Salt Sensitivity (GenSalt) phs001217 and phs000784; Genetic Studies of Atherosclerosis Risk (GeneSTAR) phs001218 and phs000375; Hispanic Community Health Study—Study of Latinos (HCHS/SOL) phs001395 and phs000810; Hypertension Genetic Epidemiology Network and Genetic Epidemiology Network of Arteriopathy (HyperGEN) phs001293; Jackson Heart Study (JHS) phs000964 and phs000286; Multi-Ethnic Study of Atherosclerosis (MESA) phs001416 and phs000209; Massachusetts General Hospital Atrial Fibrillation Study (MGH_AF) phs001062 and phs001001; San Antonio Family Study (SAFS) phs001215 and phs000462; Samoan Adiposity Study phs000972 and phs000914; Taiwan Study of Hypertension using Rare Variants (THRV) phs001387; Women’s Health Initiative (WHI) phs001237 and phs000200. Source data are provided with this paper.
Code availability
The variant calling software tools are under active development; updated versions can be accessed at http://github.com/atks/vt, http://github.com/hyunminkang/apigenome, and https://github.com/statgen/topmed_variant_calling.
Competing interests
P.N. reports grants from Amgen, Apple, Boston Scientific, and Novartis, and consulting income from Apple, Blackstone Life Sciences, Genentech, and Novartis. S.L. reports grants from Bristol Myers Squibb / Pfizer, Bayer AG, and Boehringer Ingelheim, and consulting income from Bristol Myers Squibb / Pfizer and Bayer AG. P.E. is supported by a grant from Bayer AG to the Broad Institute focused on the genetics and therapeutics of cardiovascular diseases. P.E. reports consulting income from Bayer AG, Quest Diagnostics, and Novartis. All others declare no competing interests for the present work.
Footnotes
Peer review information Nature Communications thanks Christopher Nelson and the other, anonymous, reviewers for their contribution to the peer review of this work. Peer reviewer reports are available.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Lists of authors and their affiliations appear at the end of the paper.
Contributor Information
Pradeep Natarajan, Email: pnatarajan@mgh.harvard.edu.
Gina M. Peloso, Email: gpeloso@bu.edu
NHLBI Trans-Omics for Precision Medicine (TOPMed) Consortium:
Namiko Abe, Christine Albert, Laura Almasy, Alvaro Alonso, Seth Ament, Peter Anderson, Pramod Anugu, Deborah Applebaum-Bowden, Dan Arking, Allison Ashley-Koch, Paul Auer, Dimitrios Avramopoulos, John Barnard, Kathleen Barnes, R. Graham Barr, Emily Barron-Casella, Terri Beaty, Diane Becker, Rebecca Beer, Ferdouse Begum, Amber Beitelshees, Emelia Benjamin, Marcos Bezerra, Larry Bielak, Thomas Blackwell, Russell Bowler, Ulrich Broeckel, Karen Bunting, Esteban Burchard, Erin Buth, Jonathan Cardwell, Cara Carty, Richard Casaburi, James Casella, Mark Chaffin, Christy Chang, Daniel Chasman, Sameer Chavan, Bo-Juen Chen, Wei-Min Chen, Michael Cho, Seung Hoan Choi, Lee-Ming Chuang, Mina Chung, Matthew P. Conomos, Elaine Cornell, Carolyn Crandall, James Crapo, Jeffrey Curtis, Brian Custer, Coleen Damcott, Dawood Darbar, Sayantan Das, Sean David, Colleen Davis, Michelle Daya, Mariza de Andrade, Michael DeBaun, Ranjan Deka, Dawn DeMeo, Scott Devine, Qing Duan, Ravi Duggirala, Jon Peter Durda, Susan Dutcher, Charles Eaton, Lynette Ekunwe, Charles Farber, Leanna Farnam, Tasha Fingerlin, Matthew Flickinger, Nora Franceschini, Mao Fu, Stephanie M. Fullerton, Lucinda Fulton, Weiniu Gan, Yan Gao, Margery Gass, Bruce Gelb, Xiaoqi (Priscilla) Geng, Chris Gignoux, Mark Gladwin, David Glahn, Stephanie Gogarten, Da-Wei Gong, Harald Goring, C. Charles Gu, Yue Guan, Xiuqing Guo, Jeff Haessler, Michael Hall, Daniel Harris, Nicola Hawley, Ben Heavner, Susan Heckbert, Ryan Hernandez, David Herrington, Craig Hersh, Bertha Hidalgo, James Hixson, John Hokanson, Elliott Hong, Karin Hoth, Chao (Agnes) Hsiung, Haley Huston, Chii Min Hwu, Rebecca Jackson, Deepti Jain, Cashell Jaquish, Min A. Jhun, Jill Johnsen, Andrew Johnson, Craig Johnson, Rich Johnston, Kimberly Jones, Hyun Min Kang, Laura Kaufman, Shannon Kelly, Michael Kessler, Greg Kinney, Barbara Konkle, Holly Kramer, Stephanie Krauter, Christoph Lange, Ethan Lange, Cecelia Laurie, Meryl LeBoff, Seunggeun Shawn Lee, Wen-Jane Lee, Jonathon LeFaive, David Levine, Dan Levy, Joshua Lewis, Yun Li, Honghuang Lin, Keng Han Lin, Xihong Lin, Simin Liu, Yongmei Liu, Kathryn Lunetta, James Luo, Michael Mahaney, Barry Make, Ani Manichaikul, JoAnn Manson, Lauren Margolin, Susan Mathai, Patrick McArdle, Merry-Lynn McDonald, Sean McFarland, Caitlin McHugh, Hao Mei, Deborah A. Meyers, Julie Mikulla, Nancy Min, Mollie Minear, Ryan L. Minster, Solomon Musani, Stanford Mwasongwe, Josyf C. Mychaleckyj, Girish Nadkarni, Rakhi Naik, Take Naseri, Sergei Nekhai, Sarah C. Nelson, Deborah Nickerson, Jeff O’Connell, Tim O’Connor, Heather Ochs-Balcom, James Pankow, George Papanicolaou, Margaret Parker, Afshin Parsa, Sara Penchev, Marco Perez, Ulrike Peters, Lawrence S. Phillips, Sam Phillips, Toni Pollin, Wendy Post, Julia Powers Becker, Meher Preethi Boorgula, Michael Preuss, Dmitry Prokopenko, Pankaj Qasba, Dandi Qiao, Zhaohui Qin, Nicholas Rafaels, Laura Raffield, Laura Rasmussen-Torvik, Aakrosh Ratan, Robert Reed, Elizabeth Regan, Muagututi‘a Sefuiva Reupena, Ken Rice, Dan Roden, Carolina Roselli, Ingo Ruczinski, Pamela Russell, Sarah Ruuska, Kathleen Ryan, Ester Cerdeira Sabino, Phuwanat Sakornsakolpat, Shabnam Salimi, Steven Salzberg, Kevin Sandow, Vijay G. Sankaran, Christopher Scheller, Ellen Schmidt, Karen Schwander, David Schwartz, Frank Sciurba, Christine Seidman, Jonathan Seidman, Vivien Sheehan, Amol Shetty, Aniket Shetty, Wayne Hui-Heng Sheu, M. Benjamin Shoemaker, Brian Silver, Edwin Silverman, Jennifer Smith, Josh Smith, Nicholas Smith, Tanja Smith, Sylvia Smoller, Beverly Snively, Tamar Sofer, Nona Sotoodehnia, Elizabeth Streeten, Jessica Lasky Su, Yun Ju Sung, Jody Sylvia, Adam Szpiro, Carole Sztalryd, Daniel Taliun, Hua Tang, Margaret Taub, Kent D. Taylor, Simeon Taylor, Marilyn Telen, Timothy A. Thornton, Lesley Tinker, David Tirschwell, Hemant Tiwari, Dhananjay Vaidya, Peter VandeHaar, Scott Vrieze, Tarik Walker, Robert Wallace, Avram Walts, Emily Wan, Heming Wang, Karol Watson, Bruce Weir, Scott Weiss, Lu-Chen Weng, Kayleen Williams, L. Keoki Williams, Carla Wilson, Quenna Wong, Huichun Xu, Ivana Yang, Rongze Yang, Norann Zaghloul, Maryam Zekavat, Yingze Zhang, Snow Xueyan Zhao, Wei Zhao, Degui Zhi, Xiang Zhou, Xiaofeng Zhu, Michael Zody, and Sebastian Zoellner
FinnGen:
Aarno Palotie, Mark Daly, Howard Jacob, Athena Matakidou, Heiko Runz, Sally John, Robert Plenge, Mark McCarthy, Julie Hunkapiller, Meg Ehm, Dawn Waterworth, Caroline Fox, Anders Malarstig, Kathy Klinger, Kathy Call, Tomi Mkel, Jaakko Kaprio, Petri Virolainen, Kari Pulkki, Terhi Kilpi, Markus Perola, Jukka Partanen, Anne Pitkranta, Riitta Kaarteenaho, Seppo Vainio, Kimmo Savinainen, Veli-Matti Kosma, Urho Kujala, Outi Tuovila, Minna Hendolin, Raimo Pakkanen, Jeff Waring, Bridget Riley-Gillis, Jimmy Liu, Shameek Biswas, Dorothee Diogo, Catherine Marshall, Xinli Hu, Matthias Gossel, Samuli Ripatti, Johanna Schleutker, Mikko Arvas, Olli Carpen, Reetta Hinttala, Johannes Kettunen, Reijo Laaksonen, Arto Mannermaa, Juha Paloneva, Hilkka Soininen, Valtteri Julkunen, Anne Remes, Reetta Klviinen, Mikko Hiltunen, Jukka Peltola, Pentti Tienari, Juha Rinne, Adam Ziemann, Jeffrey Waring, Sahar Esmaeeli, Nizar Smaoui, Anne Lehtonen, Susan Eaton, Sanni Lahdenper, John Michon, Geoff Kerchner, Natalie Bowers, Edmond Teng, John Eicher, Vinay Mehta, Padhraig Gormley, Kari Linden, Christopher Whelan, Fanli Xu, David Pulford, Martti Frkkil, Sampsa Pikkarainen, Airi Jussila, Timo Blomster, Mikko Kiviniemi, Markku Voutilainen, Bob Georgantas, Graham Heap, Fedik Rahimov, Keith Usiskin, Joseph Maranville, Tim Lu, Danny Oh, Kirsi Kalpala, Melissa Miller, Linda McCarthy, Kari Eklund, Antti Palomki, Pia Isomki, Laura Piril, Oili Kaipiainen-Seppnen, Johanna Huhtakangas, Apinya Lertratanakul, David Close, Marla Hochfeld, Nan Bing, Jorge Esparza Gordillo, Nina Mars, Tarja Laitinen, Margit Pelkonen, Paula Kauppi, Hannu Kankaanranta, Terttu Harju, Steven Greenberg, Hubert Chen, Jo Betts, Soumitra Ghosh, Veikko Salomaa, Teemu Niiranen, Markus Juonala, Kaj Metsrinne, Mika Khnen, Juhani Junttila, Markku Laakso, Jussi Pihlajamki, Juha Sinisalo, Marja-Riitta Taskinen, Tiinamaija Tuomi, Jari Laukkanen, Ben Challis, Andrew Peterson, Audrey Chu, Jaakko Parkkinen, Anthony Muslin, Heikki Joensuu, Tuomo Meretoja, Lauri Aaltonen, Annika Auranen, Peeter Karihtala, Saila Kauppila, Pivi Auvinen, Klaus Elenius, Relja Popovic, Jennifer Schutzman, Andrey Loboda, Aparna Chhibber, Heli Lehtonen, Stefan McDonough, Marika Crohns, Diptee Kulkarni, Kai Kaarniranta, Joni Turunen, Terhi Ollila, Sanna Seitsonen, Hannu Uusitalo, Vesa Aaltonen, Hannele Uusitalo-Jrvinen, Marja Luodonp, Nina Hautala, Erich Strauss, Hao Chen, Anna Podgornaia, Joshua Hoffman, Kaisa Tasanen, Laura Huilaja, Katariina Hannula-Jouppi, Teea Salmi, Sirkku Peltonen, Leena Koulu, Ilkka Harvima, Ying Wu, David Choy, Anu Jalanko, Risto Kajanne, Ulrike Lyhs, Mari Kaunisto, Justin Wade Davis, Danjuma Quarless, Slav Petrovski, Chia-Yen Chen, Paola Bronson, Robert Yang, Diana Chang, Tushar Bhangale, Emily Holzinger, Xulong Wang, Xing Chen, sa Hedman, Kirsi Auro, Clarence Wang, Ethan Xu, Franck Auge, Clement Chatelain, Mitja Kurki, Juha Karjalainen, Aki Havulinna, Kimmo Palin, Priit Palta, Pietro Della Briotta Parolo, Wei Zhou, Susanna Lemmel, Manuel Rivas, Jarmo Harju, Arto Lehisto, Andrea Ganna, Vincent Llorens, Antti Karlsson, Kati Kristiansson, Kati Hyvrinen, Jarmo Ritari, Tiina Wahlfors, Miika Koskinen, Katri Pylks, Marita Kalaoja, Minna Karjalainen, Tuomo Mantere, Eeva Kangasniemi, Sami Heikkinen, Eija Laakkonen, Juha Kononen, Anu Loukola, Pivi Laiho, Tuuli Sistonen, Essi Kaiharju, Markku Laukkanen, Elina Jrvensivu, Sini Lhteenmki, Lotta Mnnikk, Regis Wong, Hannele Mattsson, Tero Hiekkalinna, Manuel Gonzlez Jimnez, Kati Donner, Kalle Prn, Javier Nunez-Fontarnau, Elina Kilpelinen, Timo P. Sipil, Georg Brein, Alexander Dada, Ghazal Awaisa, Anastasia Shcherban, Tuomas Sipil, Hannele Laivuori, Tuomo Kiiskinen, Harri Siirtola, Javier Gracia Tabuenca, Lila Kallio, Sirpa Soini, Kimmo Pitknen, and Teijo Kuopio
Supplementary information
The online version contains supplementary material available at 10.1038/s41467-021-22339-1.
References
- 1.Peloso GM, Natarajan P. Insights from population-based analyses of plasma lipids across the allele frequency spectrum. Curr. Opin. Genet. Dev. 2018;50:1–6. doi: 10.1016/j.gde.2018.01.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Natarajan P, et al. Deep-coverage whole genome sequences and blood lipids among 16,324 individuals. Nat. Commun. 2018;9:3391. doi: 10.1038/s41467-018-05747-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Abifadel M, et al. Mutations in PCSK9 cause autosomal dominant hypercholesterolemia. Nat. Genet. 2003;34:154–156. doi: 10.1038/ng1161. [DOI] [PubMed] [Google Scholar]
- 4.Brown MS, Goldstein JL. Familial hypercholesterolemia: defective binding of lipoproteins to cultured fibroblasts associated with impaired regulation of 3-hydroxy-3-methylglutaryl coenzyme A reductase activity. Proc. Natl Acad. Sci. USA. 1974;71:788–792. doi: 10.1073/pnas.71.3.788. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Cohen JC, Boerwinkle E, Mosley TH, Jr., Hobbs HH. Sequence variations in PCSK9, low LDL, and protection against coronary heart disease. N. Engl. J. Med. 2006;354:1264–1272. doi: 10.1056/NEJMoa054013. [DOI] [PubMed] [Google Scholar]
- 6.Holmes MV, et al. Mendelian randomization of blood lipids for coronary heart disease. Euro. Heart J. 2015;36:539–550. doi: 10.1093/eurheartj/eht571. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Ference BA, et al. Variation in PCSK9 and HMGCR and risk of cardiovascular disease and diabetes. N. Engl. J. Med. 2016;375:2144–2153. doi: 10.1056/NEJMoa1604304. [DOI] [PubMed] [Google Scholar]
- 8.Myocardial Infarction Genetics Consortium, I. et al. Inactivating mutations in NPC1L1 and protection from coronary heart disease. N. Engl. J. Med. 2014;371:2072–2082. doi: 10.1056/NEJMoa1405386. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Sabatine, M. S. et al. Evolocumab and clinical outcomes in patients with cardiovascular disease. N. Engl. J. Med.10.1056/NEJMoa1615664 (2017). [DOI] [PubMed]
- 10.Wise AL, Gyi L, Manolio TA. eXclusion: toward integrating the X chromosome in genome-wide association analyses. Am. J. Hum. Genet. 2013;92:643–647. doi: 10.1016/j.ajhg.2013.03.017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Coronary Artery Disease Genetics, C. A genome-wide association study in Europeans and South Asians identifies five new loci for coronary artery disease. Nat. Genet. 2011;43:339–344. doi: 10.1038/ng.782. [DOI] [PubMed] [Google Scholar]
- 12.Consortium UK, et al. The UK10K project identifies rare variants in health and disease. Nature. 2015;526:82–90. doi: 10.1038/nature14962. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Hoffmann TJ, et al. A large electronic-health-record-based genome-wide study of serum lipids. Nat. Genet. 2018;50:401–413. doi: 10.1038/s41588-018-0064-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Bonas-Guarch S, et al. Re-analysis of public genetic data reveals a rare X-chromosomal variant associated with type 2 diabetes. Nat. Commun. 2018;9:321. doi: 10.1038/s41467-017-02380-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.McNamara JR, et al. Effect of gender, age, and lipid status on low density lipoprotein subfraction distribution. Results from the Framingham Offspring Study. Arteriosclerosis. 1987;7:483–490. doi: 10.1161/01.ATV.7.5.483. [DOI] [PubMed] [Google Scholar]
- 16.Schaefer EJ, et al. Effects of age, gender, and menopausal status on plasma low density lipoprotein cholesterol and apolipoprotein B levels in the Framingham Offspring Study. J. Lipid Res. 1994;35:779–792. doi: 10.1016/S0022-2275(20)39173-2. [DOI] [PubMed] [Google Scholar]
- 17.Silberbach M, et al. Cardiovascular Health in Turner Syndrome: a scientific statement from the American Heart Association. Circ. Genom. Precis. Med. 2018;11:e000048. doi: 10.1161/HCG.0000000000000048. [DOI] [PubMed] [Google Scholar]
- 18.Stochholm K, Juul S, Juel K, Naeraa RW, Gravholt CH. Prevalence, incidence, diagnostic delay, and mortality in Turner syndrome. J. Clin. Endocrinol. Metab. 2006;91:3897–3902. doi: 10.1210/jc.2006-0558. [DOI] [PubMed] [Google Scholar]
- 19.Van PL, Bakalov VK, Bondy CA. Monosomy for the X-chromosome is associated with an atherogenic lipid profile. J. Clin. Endocrinol. Metab. 2006;91:2867–2870. doi: 10.1210/jc.2006-0503. [DOI] [PubMed] [Google Scholar]
- 20.Cooley M, Bakalov V, Bondy CA. Lipid profiles in women with 45,X vs 46,XX primary ovarian failure. JAMA. 2003;290:2127–2128. doi: 10.1001/jama.290.16.2127. [DOI] [PubMed] [Google Scholar]
- 21.Belling K, et al. Klinefelter syndrome comorbidities linked to increased X chromosome gene dosage and altered protein interactome activity. Hum. Mol. Genet. 2017;26:1219–1229. doi: 10.1093/hmg/ddx014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Zore T, Palafox M, Reue K. Sex differences in obesity, lipid metabolism, and inflammation-A role for the sex chromosomes? Mol. Metab. 2018;15:35–44. doi: 10.1016/j.molmet.2018.04.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Link JC, et al. Increased high-density lipoprotein cholesterol levels in mice with XX versus XY sex chromosomes. Arterioscler. Thromb. Vasc. Biol. 2015;35:1778–1786. doi: 10.1161/ATVBAHA.115.305460. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Taliun D, et al. Sequencing of 53,831 diverse genomes from the NHLBI TOPMed Program. Nature. 2021;590:290–299. doi: 10.1038/s41586-021-03205-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Bycroft C, et al. The UK Biobank resource with deep phenotyping and genomic data. Nature. 2018;562:203–209. doi: 10.1038/s41586-018-0579-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Krokstad S, et al. Cohort Profile: the HUNT Study, Norway. Int. J. Epidemiol. 2013;42:968–977. doi: 10.1093/ije/dys095. [DOI] [PubMed] [Google Scholar]
- 27.Tabassum R, et al. Genetic architecture of human plasma lipidome and its link to cardiovascular disease. Nat. Commun. 2019;10:4329. doi: 10.1038/s41467-019-11954-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Emdin CA, et al. Genetic association of waist-to-hip ratio with cardiometabolic traits, type 2 diabetes, and coronary heart disease. JAMA. 2017;317:626–634. doi: 10.1001/jama.2016.21042. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Lotta LA, et al. Association of genetic variants related to gluteofemoral vs abdominal fat distribution with type 2 diabetes, coronary disease, and cardiovascular risk factors. JAMA. 2018;320:2553–2563. doi: 10.1001/jama.2018.19329. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Dahlman I, et al. Numerous genes in loci associated with body fat distribution are linked to adipose function. Diabetes. 2016;65:433–437. doi: 10.2337/db15-0828. [DOI] [PubMed] [Google Scholar]
- 31.Ambele MA, Dessels C, Durandt C, Pepper MS. Genome-wide analysis of gene expression during adipogenesis in human adipose-derived stromal cells reveals novel patterns of gene expression during adipocyte differentiation. Stem Cell Res. 2016;16:725–734. doi: 10.1016/j.scr.2016.04.011. [DOI] [PubMed] [Google Scholar]
- 32.Gustafson B, et al. BMP4 and BMP antagonists regulate human white and beige adipogenesis. Diabetes. 2015;64:1670–1681. doi: 10.2337/db14-1127. [DOI] [PubMed] [Google Scholar]
- 33.Dahlman I, et al. Functional annotation of the human fat cell secretome. Arch Physiol. Biochem. 2012;118:84–91. doi: 10.3109/13813455.2012.685745. [DOI] [PubMed] [Google Scholar]
- 34.Menni C, et al. Circulating proteomic signatures of chronological age. J. Gerontol. A Biol. Sci. Med. Sci. 2015;70:809–816. doi: 10.1093/gerona/glu121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Ference BA, et al. Low-density lipoproteins cause atherosclerotic cardiovascular disease. 1. Evidence from genetic, epidemiologic, and clinical studies. A consensus statement from the European Atherosclerosis Society Consensus Panel. Euro. Heart J. 2017;38:2459–2472. doi: 10.1093/eurheartj/ehx144. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Liu DJ, et al. Exome-wide association study of plasma lipids in >300,000 individuals. Nat. Genet. 2017;49:1758–1766. doi: 10.1038/ng.3977. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Lotta LA, et al. Association between low-density lipoprotein cholesterol-lowering genetic variants and risk of type 2 diabetes: a meta-analysis. JAMA. 2016;316:1383–1391. doi: 10.1001/jama.2016.14568. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Sattar N, et al. Statins and risk of incident diabetes: a collaborative meta-analysis of randomised statin trials. Lancet. 2010;375:735–742. doi: 10.1016/S0140-6736(09)61965-6. [DOI] [PubMed] [Google Scholar]
- 39.Swerdlow DI, et al. HMG-coenzyme A reductase inhibition, type 2 diabetes, and bodyweight: evidence from genetic analysis and randomised trials. Lancet. 2015;385:351–361. doi: 10.1016/S0140-6736(14)61183-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Lotta LA, et al. Association of genetically enhanced lipoprotein lipase-mediated lipolysis and low-density lipoprotein cholesterol-lowering alleles with risk of coronary disease and type 2 diabetes. JAMA Cardiol. 2018;3:957–966. doi: 10.1001/jamacardio.2018.2866. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.White J, et al. Association of lipid fractions with risks for coronary artery disease and diabetes. JAMA Cardiol. 2016;1:692–699. doi: 10.1001/jamacardio.2016.1884. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Klimentidis YC, Chougule A, Arora A, Frazier-Wood AC, Hsu CH. Triglyceride-increasing alleles associated with protection against type-2 diabetes. PLoS Genet. 2015;11:e1005204. doi: 10.1371/journal.pgen.1005204. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Dewey FE, et al. Inactivating variants in ANGPTL4 and risk of coronary artery disease. N. Engl. J. Med. 2016;374:1123–1133. doi: 10.1056/NEJMoa1510926. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Stitziel NO, et al. Coding variation in ANGPTL4, LPL, and SVEP1 and the risk of coronary disease. N. Engl. J. Med. 2016;374:1134–1144. doi: 10.1056/NEJMoa1507652. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Dewey FE, et al. Genetic and pharmacologic inactivation of ANGPTL3 and cardiovascular disease. N. Engl. J. Med. 2017;377:211–221. doi: 10.1056/NEJMoa1612790. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Stitziel NO, et al. ANGPTL3 deficiency and protection against coronary artery disease. J. Am. College Cardiol. 2017;69:2054–2063. doi: 10.1016/j.jacc.2017.02.030. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Sniderman AD, et al. Concordance/discordance between plasma apolipoprotein B levels and the cholesterol indexes of atherosclerotic risk. Am. J. Cardiol. 2003;91:1173–1177. doi: 10.1016/S0002-9149(03)00262-5. [DOI] [PubMed] [Google Scholar]
- 48.Wilkins JT, Li RC, Sniderman A, Chan C, Lloyd-Jones DM. Discordance between apolipoprotein B and LDL-cholesterol in young adults predicts coronary artery calcification: The CARDIA Study. J. Am. College Cardiol. 2016;67:193–201. doi: 10.1016/j.jacc.2015.10.055. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Wagner AM, et al. LDL-cholesterol/apolipoprotein B ratio is a good predictor of LDL phenotype B in type 2 diabetes. Acta Diabetol. 2002;39:215–220. doi: 10.1007/s005920200037. [DOI] [PubMed] [Google Scholar]
- 50.Tani S, et al. Relation between low-density lipoprotein cholesterol/apolipoprotein B ratio and triglyceride-rich lipoproteins in patients with coronary artery disease and type 2 diabetes mellitus: a cross-sectional study. Cardiovasc. Diabetol. 2017;16:123. doi: 10.1186/s12933-017-0606-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Sakuta H, et al. Ventroptin: a BMP-4 antagonist expressed in a double-gradient pattern in the retina. Science. 2001;293:111–115. doi: 10.1126/science.1058379. [DOI] [PubMed] [Google Scholar]
- 52.Webb TR, et al. X-linked megalocornea caused by mutations in CHRDL1 identifies an essential role for ventroptin in anterior segment development. Am. J. Hum. Genet. 2012;90:247–259. doi: 10.1016/j.ajhg.2011.12.019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Gao F, et al. XWAS: A software toolset for genetic data analysis and association studies of the X chromosome. J. Hered. 2015;106:666–671. doi: 10.1093/jhered/esv059. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Ma L, Hoffman G, Keinan A. X-inactivation informs variance-based testing for X-linked association of a quantitative trait. BMC Genomics. 2015;16:241. doi: 10.1186/s12864-015-1463-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Sudlow C, et al. UK Biobank: an open access resource for identifying the causes of a wide range of complex diseases of middle and old age. PLoS Med. 2015;12:e1001779. doi: 10.1371/journal.pmed.1001779. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Regier AA, et al. Functional equivalence of genome sequencing analysis pipelines enables harmonized variant calling across human genetics projects. Nat. Commun. 2018;9:4038. doi: 10.1038/s41467-018-06159-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Li H, Durbin R. Fast and accurate short read alignment with Burrows-Wheeler transform. Bioinformatics. 2009;25:1754–1760. doi: 10.1093/bioinformatics/btp324. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Jun G, Wing MK, Abecasis GR, Kang HM. An efficient and scalable analysis framework for variant extraction and refinement from population-scale DNA sequence data. Genome Res. 2015;25:918–925. doi: 10.1101/gr.176552.114. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Emdin CA, et al. Analysis of predicted loss-of-function variants in UK Biobank identifies variants protective for disease. Nat. Commun. 2018;9:1613. doi: 10.1038/s41467-018-03911-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Klarin, D. et al. Genetic analysis in UK Biobank links insulin resistance and transendothelial migration pathways to coronary artery disease. Nat. Genet. 10.1038/ng.3914 (2017). [DOI] [PMC free article] [PubMed]
- 61.Denny JC, et al. Systematic comparison of phenome-wide association study of electronic medical record data and genome-wide association study data. Nat. Biotechnol. 2013;31:1102–1110. doi: 10.1038/nbt.2749. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.West J, et al. Feasibility of MR-based body composition analysis in large scale population studies. PloS ONE. 2016;11:e0163332. doi: 10.1371/journal.pone.0163332. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.Chua SYL, et al. Cohort profile: design and methods in the eye and vision consortium of UK Biobank. BMJ Open. 2019;9:e025077. doi: 10.1136/bmjopen-2018-025077. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Zhou W, et al. Efficiently controlling for case-control imbalance and sample relatedness in large-scale genetic association studies. Nat. Genet. 2018;50:1335–1341. doi: 10.1038/s41588-018-0184-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Loh PR, et al. Efficient Bayesian mixed-model analysis increases association power in large cohorts. Nat. Genet. 2015;47:284–290. doi: 10.1038/ng.3190. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Mackey RH, et al. Lipoprotein particles and incident type 2 diabetes in the multi-ethnic study of atherosclerosis. Diabetes Care. 2015;38:628–636. doi: 10.2337/dc14-0645. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Otvos JD, Jeyarajah EJ, Cromwell WC. Measurement issues related to lipoprotein heterogeneity. Am. J. Cardiol. 2002;90:22i–29i. doi: 10.1016/S0002-9149(02)02632-2. [DOI] [PubMed] [Google Scholar]
- 68.Hoogeveen RC, et al. Small dense low-density lipoprotein-cholesterol concentrations predict risk for coronary heart disease: the Atherosclerosis Risk In Communities (ARIC) study. Arterioscler. Thromb. Vasc. Biol. 2014;34:1069–1077. doi: 10.1161/ATVBAHA.114.303284. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Conomos MP, Miller MB, Thornton TA. Robust inference of population structure for ancestry prediction and correction of stratification in the presence of relatedness. Genet. Epidemiol. 2015;39:276–293. doi: 10.1002/gepi.21896. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 70.Brody JA, et al. Analysis commons, a team approach to discovery in a big-data environment for genetic epidemiology. Nat. Genet. 2017;49:1560–1563. doi: 10.1038/ng.3968. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71.Karczewski, K. J. LOFTEE (Loss-Of-Function Transcript Effect Estimator). https://github.com/konradjk/loftee (2015).
- 72.Liu X, Wu C, Li C, Boerwinkle E. dbNSFP v3.0: A one-stop database of functional predictions and annotations for human nonsynonymous and splice-site SNVs. Hum. Mutat. 2016;37:235–241. doi: 10.1002/humu.22932. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 73.Cingolani P, et al. A program for annotating and predicting the effects of single nucleotide polymorphisms, SnpEff: SNPs in the genome of Drosophila melanogaster strain w1118; iso-2; iso-3. Fly. 2012;6:80–92. doi: 10.4161/fly.19695. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
Controlled access of the individual-level TOPMed data is available through dbGaP, and the individual-level UK Biobank data are available upon application to the UK Biobank (https://www.ukbiobank.ac.uk/). FinnGen summary-level data are fully freely available at https://www.finngen.fi/en/access_results. Individual-level access to FinnGen and HUNT cohorts may be obtained through reasonable request and suitable institutional review board approvals. The dbGaP accessions for TOPMed cohorts are as follows: Atherosclerosis Risk in Communities (ARIC) phs001211 and phs000280; Old Order Amish phs000956 and phs000391; Mt Sinai BioMe Biobank phs001644 and phs000925; Coronary Artery Risk Development in Young Adults (CARDIA) phs001612 and phs000285; Cleveland Family Study (CFS) phs000954 and phs000284; Cardiovascular Health Study (CHS) phs001368; Diabetes Heart Study (DHS) phs001412 and phs001012; Framingham Heart Study (FHS) phs000974 and phs000007; Genetic Epidemiology Network of Arteriopathy (GENOA) phs001345 and phs001238; Genetics of Lipid-Lowering Drugs and Diet Network (GOLDN) phs001359 and phs000741; Genetic Epidemiology Network of Salt Sensitivity (GenSalt) phs001217 and phs000784; Genetic Studies of Atherosclerosis Risk (GeneSTAR) phs001218 and phs000375; Hispanic Community Health Study—Study of Latinos (HCHS/SOL) phs001395 and phs000810; Hypertension Genetic Epidemiology Network and Genetic Epidemiology Network of Arteriopathy (HyperGEN) phs001293; Jackson Heart Study (JHS) phs000964 and phs000286; Multi-Ethnic Study of Atherosclerosis (MESA) phs001416 and phs000209; Massachusetts General Hospital Atrial Fibrillation Study (MGH_AF) phs001062 and phs001001; San Antonio Family Study (SAFS) phs001215 and phs000462; Samoan Adiposity Study phs000972 and phs000914; Taiwan Study of Hypertension using Rare Variants (THRV) phs001387; Women’s Health Initiative (WHI) phs001237 and phs000200. Source data are provided with this paper.
The variant calling software tools are under active development; updated versions can be accessed at http://github.com/atks/vt, http://github.com/hyunminkang/apigenome, and https://github.com/statgen/topmed_variant_calling.