

Abstract
Detecting and controlling the diffusion of infectious diseases such as COVID-19 is crucial to managing epidemics. One common measure taken to contain or reduce diffusion is to detect infected individuals and trace their prior contacts so as to then selectively isolate any individuals likely to have been infected. These prior contacts can be traced using mobile devices such as smartphones or smartwatches, which can continuously collect the location and contacts of their owners by using their embedded localisation and communications technologies, such as GPS, Cellular networks, Wi-Fi, and Bluetooth. This paper evaluates the effectiveness of these technologies and determines the impact of contact tracing precision on the spread and control of infectious diseases. To this end, we have created an epidemic model that we used to evaluate the efficiency and cost (number of people quarantined) of the measures to be taken, depending on the smartphone contact tracing technologies used. Our results show that in order to be effective for the COVID-19 disease, the contact tracing technology must be precise, contacts must be traced quickly, and a significant percentage of the population must use the smartphone contact tracing application. These strict requirements make smartphone-based contact tracing rather ineffective at containing the spread of the infection during the first outbreak of the virus. However, considering a second wave, where a portion of the population will have gained immunity, or in combination with some other more lenient measures, smartphone-based contact tracing could be extremely useful.
Keywords: Mobile computing, opportunistic networking, epidemic models, social networks, digital epidemiology
I. Introduction
The recent COVID-19 pandemic poses a major threat to our society and way of life. To date, hundreds of thousands of people have died, and millions infected. Most countries have taken severe measures, such as quarantines, lockdowns and social distancing, which continue to impact the population dramatically. In addition, the impact on the world economy is still hard to predict.
Countries and regions have tried tackling the COVID-19 outbreak in different ways to varying results. Countries such as South Korea and Israel took action quickly just as the first infectious cases appeared. They started checking anyone with possible COVID-19 symptoms and, when a case of infection was detected, their contacts were traced in order to detect new cases. The use of mobility traces (mobile communication and GPS positions) was instrumental to accomplishing this task ([1]), and the epidemic was controlled without taking further severe measures. Other countries, however, despite taking some measures after the initial outbreak such as quarantining infected people or checking their direct contacts only, did not manage to control the outbreak and eventually had to take draconian measures, such as lockdowns and social distancing.
Recent studies based on mathematical models have shown that asymptomatic individuals have caused around 80% of infections ([2]). Detecting COVID-19 is especially challenging because most infected individuals only have mild or even no symptoms. An important lesson can be learnt from this experience: early detection and early response is key to containing the initial outbreak. Therefore, fast and accurate contact tracing is needed to aid in controlling epidemic diseases. Contact tracing is a more selective isolation measure targeting the subset of the population most likely to have the infection, that is, individuals that have been in contact with infected and detected individuals [3]. However, as has been seen with COVID-19, if the average number of neighbours and the basic reproductive rate are high, contact tracing has to be far more efficient and rapid.
The widespread presence of mobile phones and increased availability of data and computing power can provide a ubiquitous way of tracking infectious diseases. This is a new approach to dealing with epidemics, known as digital epidemiology, which uses data generated outside the public health system [4]. To be specific, smartphone contact tracing entails using smartphones to collect the location and contact details of their owners, so that when people do get infected, their mobile can be used to trace their prior contacts so as to locate anyone else who might have also potentially been infected. These people could then be isolated (quarantined) themselves, thus limiting the spread of infection. Recently, and with the urgent aim of dealing with COVID-19, several contact tracing mobile Apps have appeared, such as the Singapore Government’s TraceTogether [5], Europe’s PEPP-PT [6], and MIT’s SafePath [7]. Lastly, Google and Apple teamed up in April 2020 to develop and integrate into their mobile operating systems what seems to be a definitive solution for contact tracing and whose only potential Achilles’ heel lies in issues of privacy.
The technology of these mobile apps is based on the results of several years of research in Mobile Computing, and particularly Opportunistic Networking (OppNet). OppNet [8] is based on the opportunity of exchanging messages between nearby devices when some type of direct and localised communication link is established (e.g., through a Bluetooth or WiFi direct channel). In some way, their behaviour and dynamics are similar to an epidemic spread of messages. In fact, many of the models used to evaluate these networks are an adaptation of well-known epidemic population models [9]. The study of mobility models and social behaviour was also key to evaluating the spread of information [10]. We believe that all this research background can help in coping with the spread of infectious diseases. In particular, we have not only studied the dynamics of message spreading and human mobility but have also developed several mathematical models and simulations tools [11]–[14] in this field. While the main goal of these previous research efforts was to improve the spread of information, our primary goal now is to reduce and halt the spread of infectious diseases.
In this paper, we focus on evaluating how smartphone contact tracing impacts the control and spread of the COVID-19 disease. We first evaluate and compare several contact tracing technologies and the relative methods for obtaining contacts. We then use temporal network graphs to characterise both the temporal contacts and the resolution and accuracy of the different tracing technologies studied. On the basis of these temporal graphs, we introduce a stochastic epidemic model that considers the individual contacts and the tracing technology. This stochastic model is later transformed into a deterministic model using parameters obtained from the stochastic models, thus allowing contact tracing to be evaluated for large populations in a fast and accurate way. On the basis of these models, we evaluate several possible scenarios for smartphone-based contact tracing, including a real mobility scenario based on real traces.
We believe this paper contributes significantly to a better understanding of the potentials and pitfalls of mobile contact tracing applications, particularly when applied to such extreme scenarios as COVID-19. Some of the most important outcomes are:
-
•
Rapid contact tracing is extremely important for quickly isolating potentially infected individuals, particularly for a disease such as COVID-19, with a high reproduction rate and low detection rate. This result is in agreement with some recent results [15], [16], although our methodology differs substantially from the one used in these previous papers.
-
•
Smartphone contact tracing precision mainly impacts the number of quarantined persons, since it allows for greater selectivity when quarantining citizens, thereby reducing the personal inconveniences and economical costs of these drastic measures. However, this accuracy has no significant impact on reducing the final number of infected individuals.
-
•
Smartphone contact tracing, when adopted during a first outbreak, can only be effective when a fast and high-precision contact tracing technology is used, and when a significant proportion (more than 80%) of the population uses the smartphone application. These harsh requirements make it unlikely to be a feasible solution on its own.
-
•
Fortunately, for future outbreaks, and under the condition that at least 20% of individuals gain immunisation or that the reproductive rate gets reduced by some other more lenient social distancing measures, smartphone contact tracing can be very effective, even when only a portion of the population is willing to use it (less than 60%).
The outline of this paper is as follows: an overview of related works is presented in Section 2. Section 3 introduces the mobile tracing technologies and contact networks that are used in the stochastic and deterministic models developed in Section 4. Section 5 is devoted to evaluating these models and their precision, and Section 6 evaluates the efficiency of the quarantine measures and tracing technologies. Finally, Section 7 details the main conclusions and future work.
II. Related Work
Monitoring and controlling emerging infectious diseases is vital to public health. Through the use of new technologies such as internet-based surveillance, infectious disease modelling, remote sensing, telecommunications and mobile phones, these infectious diseases can be predicted, prevented and controlled [17]. This new approach for dealing with epidemics is usually categorised with a newly coined term: digital epidemiology [4].
Several works have evaluated the characterisation of human mobility patterns by using Call Detail Records (CDRs) for modelling and evaluating epidemic diseases [18]–[20]. Particularly, in [18], the authors explored the opportunity of using proxies of individual mobility to describe commuting flows and predict the diffusion of an influenza-like-illness epidemic. However, depending on the human mobility data source used, their predictive accuracy with regard to epidemic invasion timing and propagation patterns differed.
Another method for detecting and tracing contacts uses wireless sensor network technologies, such as Bluetooth or ZigBee. One of the first experiments using MOTES was performed by Salathé et al. [21]. They obtained high-resolution data of interpersonal contacts on one typical day at an American high school, which made it possible to reconstruct the relevant social network from an infectious disease transmission perspective. The paper also includes an SEIR (Susceptible, Exposed, Infectious, Recovered) model for evaluating disease diffusion and the impact of measures such as vaccination.
Mastrandrea and Barrat [22] also used wearable sensors to capture contacts between students and compared the results with contacts obtained from personal diaries. Furthermore, the authors compare how an epidemic disease was spread using two different contact networks (from sensors and diaries), which showed a notable difference in their dynamics.
Recent years have seen increasing interest in evaluating the efficiency and impact of contact tracing in epidemics. Contact tracing is a very useful measure focusing primarily on potential next-generation cases. Contact tracing has been proved to be a highly successful strategy when the number of infectious cases is low, or at the early stages of an outbreak, or especially when the disease may be asymptomatic (but still infectious), as it provides the only means by which such individuals can be easily identified [3]. Other studies evaluate the main factor in making an outbreak controllable [23], [24].
There are two main approaches for modelling contact tracing [25]: Population-based modelling is a top-down approach depicting disease dynamics on a system level that is typically used for analysing research matters from a macroscopic perspective; Agent-based modelling is a bottom-up approach dealing with each individual as an agent, each with their own movements and infection states, and is commonly used to evaluate heterogeneous and adaptive behaviours. In general, the latter method is more realistic, though it can be computationally demanding. Some papers, such as [26], [27], introduce a detailed stochastic model, which is reduced to a deterministic approach for obtaining the most fundamental dynamic of the epidemics and associated measures.
Most of these previous models only deal with generic networks. However, in order to evaluate the precision of trace contact models, we need to consider the network of contacts. For example, Huerta and Tsimring [27] introduced a stochastic model to evaluate the effect of contact tracing and random tracing as a part of the epidemic control strategy in complex networks. The paper shows that by tracing contacts, a major outbreak can be significantly reduced or even eliminated at low additional cost. This same stochastic model is also used by Farrahi et al. [28]. In this paper, the authors evaluate how communication traces can be obtained using mobile phones to estimate physical contacts, and thus help in selectively quarantining individuals. The results showed that contact tracing is only efficient at the beginning of the outbreak due to the rapidly increasing costs as the epidemic evolves. One of the main drawbacks of the stochastic model used in these two papers is its simplicity. For example, the model does not consider the possible quarantine of non-infected individuals or detected infected ones, as does the determinist model introduced by Keeling and Rohani [29]. Another approach is to model the spread of infectious diseases by considering the dynamic of the nodes using a temporal graph, as introduced by Yang et al. [30].
Some recent studies specifically deal with the COVID-19 pandemic. Ferretti et al. [15] claim that isolation and contact tracing as currently practised is not preventing the COVID-19 epidemic; this is mostly due to the high number of asymptomatic infected individuals that remain undetected, which contributes to the spread. Thus, they propose using mobile apps to trace the previous contacts, showing mathematically that epidemics can be contained even when not all the population uses the application (although the required portion is significantly high). Hellewell et al. [16] draw a similar conclusion through a simulated model. That is, in most scenarios, highly effective contact tracing and case isolation are enough to control a new outbreak of COVID-19 within 3 months, even when only 79% of the contacts are traced. Nevertheless, these conditions make smartphone-based contact tracing far from being a realistic solution.
One of the first attempts at using mobile phones to estimate contacts was the FluPhone application developed at Cambridge University [31]. That application used Bluetooth and other wireless signals as a proxy for estimating physical contacts and asked users to report flu-like symptoms in order to evaluate the risk of infections. For COVID-19, the Singapore Government developed and released the TraceTogether mobile App for tracing, which also relied upon Bluetooth contacts and had already been used to control disease spread [5]. Other similar proposals, also focusing on privacy issues, are the Pan-European Privacy-Preserving Proximity Tracing (PEPP-PT) [6] and SafePaths [7], [32]. Finally, Google and Apple have teamed up to develop and integrate similar solutions into the iOS and Android operating systems. As they are integrated into the operating system, the proposed solution is more efficient, and more importantly, will be ubiquitous for users.
Collecting personal mobility information, however, even for health application purposes, poses specific challenges when it comes to upholding ethical principles and issues of privacy [33]. Ultimately, the analysis of mobility data can be justified if it can yield benefits to public health.
This paper differs in that it specifically evaluates how smartphone contact tracing technology can reduce the spread of infectious diseases and the associated cost of the quarantine measures. To evaluate these contact tracing technologies, it is necessary to consider contacts individually and on a temporal basis. Additionally, as an example, we use a real scenario to evaluate these contact tracing technologies.
III. Contact Networks and Tracing
In this section, we model contacts obtained via smartphones by using contact network graphs. We first perform an evaluation of the different technologies that can be used to trace the location of a mobile phone. Then, we describe a network graph to model these contacts and how these previous contacts can be estimated. Finally, using a real mobility trace (NCCU trace), we describe how we obtained the different graphs that will be used in the epidemic models.
Traditionally, these contact graphs were usually obtained manually through personal interviews, during which the patient tried to remember prior contacts or any locations he/she had visited. This approach is widely used for some kinds of diseases (particularly sexually transmitted ones) where the contacts are clear and easy to remember. For most infectious diseases, however, personal interviews provide very poor tracing of prior contacts and locations.
A. Mobile Tracing Technologies
Mobile contact tracing applications are based on the idea of detecting contacts by using some of the latest localisation and communication technologies. For this paper in particular, we evaluate the ability of four different technologies to obtain a network of contacts.1 From lower to higher resolution and precision, we have:
-
1.
Cell. The mobile phone network is distributed over land areas called cells. Telecommunications providers can determine the rough location of connected phones depending on which cell the mobile phone is connected to. However, the precision of the obtained location can be very low since the area of any one cell can vary from hundreds to thousands of meters, making the process of determining contacts from these traces very inaccurate. On the other hand, a great advantage of this technology is that communication providers are already obtaining and storing this information (legally, they are obliged to do so in most countries), and so it could be used when necessary (meeting, naturally the legal requirements). Thus, the economic cost of using this technology can be considered negligible when compared to other technologies.
-
2.
Wi-Fi. Using local communication facilities, such as WiFi, we can determine the identity (MAC Address) of the surrounding devices. Thus, mobile nodes can periodically scan and store information about all these surrounding devices, which can also include the Received Signal Strength (RSSI) for estimating distance.
-
3.
GPS. Smartphones are equipped with GPS, which allows them to be used to trace the user location. The precision of this solution is about 10 to 15 meters outdoors, although indoors the precision is severely reduced, making this a significant restriction since most infectious contact takes place indoors.
-
4.
Bluetooth. Similar to Wi-Fi, although more precise. For example, using Bluetooth we can obtain a trace of the contacted devices with a resolution of 1–2 meters, making it ideal for determining close personal contact, which are the most likely to transmit infectious diseases.
Recent solutions using Wi-Fi and Bluetooth contact tracing are based on mobile apps that exchange anonymous key codes when a possible nearby contact is detected. This process generates data with the possible user contact information that must comply with each country’s regulations on data protection and privacy. This has led to two different models for managing and storing these data: centralised and distributed. In the centralised model, the anonymised data is uploaded from the users’ mobile phone to centralised servers. This way, the Health authorities can check and manage contacts. The decentralised model, on the other hand, stores these contacts locally and allow the users to voluntary check (or not) if they have been in contact with people who may have been infected. This approach is the one taken by the solution developed by Apple and Google. Both models (centralised and decentralised) can comply with most data protection and privacy regulations, but the decentralised approach may offer users a higher degree of privacy. However, the centralised model might provide Health authorities greater control and information about the spread of infections, and it may be faster at detecting new potentially infected individuals because it would not depend on the willingness of users to check their status.
In both cases, these technologies would require deployment not only of the mobile App but also of the required centralised servers to store and check the contacts, so the economical cost might be significant.
B. Characterising Contacts
One common way of representing the interactions between individuals is through the use of network graphs. These networks can be a very useful tool for understanding the transmission of infections in human populations [29], [34] where each individual is in contact with only a small proportion of the population. We consider a population of 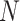 individuals (the nodes) whose contacts are defined as a temporal graph
individuals (the nodes) whose contacts are defined as a temporal graph 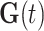 , where a link between nodes
, where a link between nodes 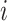 and
and 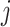 represents a contact between them at time
represents a contact between them at time 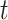 . In epidemic models, it is very common to use a day as the time unit, so contact graphs represent the contact between individuals in one day. That is,
. In epidemic models, it is very common to use a day as the time unit, so contact graphs represent the contact between individuals in one day. That is, 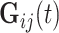 is 1 if the pair
is 1 if the pair 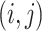 of individuals are in contact on day
of individuals are in contact on day 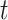 , and 0 otherwise. Usually, for infection applications, this graph is symmetric (
, and 0 otherwise. Usually, for infection applications, this graph is symmetric ( ), meaning that the infection can be passed in both directions. The temporal degree
), meaning that the infection can be passed in both directions. The temporal degree 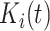 of an individual
of an individual 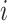 is the number of links (contacts) between this individual and the other individuals per unit time (days). From this temporal degree, we can obtain the average degree
is the number of links (contacts) between this individual and the other individuals per unit time (days). From this temporal degree, we can obtain the average degree 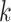 of a contact network over a given time
of a contact network over a given time 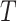 as:
as:
 |
To evaluate the diffusion of the infection, it is useful to obtain the number of contacts with individuals that can transmit the infection only, as:
 |
where 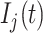 is 1 if individual
is 1 if individual 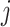 at time
at time 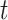 can infect others, and 0 otherwise. Note, that
can infect others, and 0 otherwise. Note, that  does not consider infected individuals that are isolated since they cannot transmit the infection.
does not consider infected individuals that are isolated since they cannot transmit the infection.
Using the contact network graph, we can also trace prior contacts when an infected individual is detected, i.e. trace back contacts in order to quarantine individuals who are more likely to have the infection. In this case, we consider all the contacts occurring in a given period 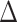 (the backward time window). The idea is to trace back only recent contacts, and this time window will depend on the dynamics of the disease (for example, the incubation time). Summing up, we want to check if an individual has had contact with at least one traced individual during the previous backward time. We therefore define a function
(the backward time window). The idea is to trace back only recent contacts, and this time window will depend on the dynamics of the disease (for example, the incubation time). Summing up, we want to check if an individual has had contact with at least one traced individual during the previous backward time. We therefore define a function 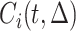 that checks it, returning 1 if it is true, and 0 otherwise:
that checks it, returning 1 if it is true, and 0 otherwise:
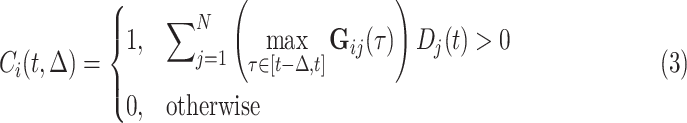 |
where 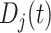 is 1 if individual
is 1 if individual 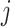 at time
at time 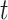 is detected and being traced, and 0 otherwise.
is detected and being traced, and 0 otherwise.
It is important to remember that the previous network graph 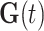 is the real contact network, that is, the one that reflects the real physical contacts and, therefore, the transmission of the disease. As when trying to model most real systems however, it is almost impossible to obtain this real network. For contact networks, in particular, it has been shown to be impossible to obtain the real close-encounter interactions of a population using wearable devices [35]. Therefore, by using some of the previous tracing methods, we can only estimate the real contact networks by obtaining a new graph
is the real contact network, that is, the one that reflects the real physical contacts and, therefore, the transmission of the disease. As when trying to model most real systems however, it is almost impossible to obtain this real network. For contact networks, in particular, it has been shown to be impossible to obtain the real close-encounter interactions of a population using wearable devices [35]. Therefore, by using some of the previous tracing methods, we can only estimate the real contact networks by obtaining a new graph 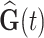 , which is an estimation of the real one.2 In other words, they are a noisy measure of the real network.
, which is an estimation of the real one.2 In other words, they are a noisy measure of the real network.
A method for measuring how noisy this estimation is was introduced in [28]. We extend this method to consider temporal networks. The method considers two main differences between the estimated and real networks: (i) removed links, when some of the real contacts may not have been captured using mobile traces, and so some links from the real graph do not appear in the estimated one; and (ii) added links, when smartphone contact tracing apps generate some incorrect contacts that do not occur in the real world, causing some links to be added to the estimated graph that do not appear in the real one. By making 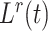 the number of removed links at time
the number of removed links at time 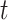 , and
, and 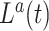 the added ones, and considering that
the added ones, and considering that 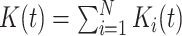 is the full number of links of the real network graph
is the full number of links of the real network graph 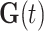 (that is, the daily contacts), we can define the error of the estimated network at time
(that is, the daily contacts), we can define the error of the estimated network at time 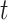 as:
as:
 |
which ranges from 0 (both networks have the same links) to 1 (the networks differ completely, not sharing any links). If we consider a measured interval from 0 to 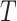 , we can obtain the average error as:
, we can obtain the average error as:
 |
which will provide a measure of the precision of the estimated contact trace.
C. NCCU Trace Analysis
To evaluate the different mechanisms that go into obtaining a network of contacts, we have used the NCCU Trace, a real-life mobility trace obtained at the NCCU University campus [36]. This NCCU Trace was collected using an Android app installed on the smartphones of 115 students attending the National Chengchi University, Taiwan. The trace was recorded over a period of 15 days and contains the GPS data, Wi-Fi access points, and Bluetooth devices in proximity. Time is specified with a resolution of one second, and the position information is rounded to meters.
It is important to remember that, in most real experiments, we cannot obtain the set of real physical contacts. Since we want to evaluate the precision of the different technologies (Mobile cells, GPS, Wi-Fi and Bluetooth), we consider that a real contact susceptible to producing an infection is one that is within the range of two meters and has a duration greater than 1 minute. Therefore, we processed the NCCU trace using these parameters to obtain the 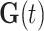 contact network graph. The result is a contact graph for 15 days with an average rank of 7.66 (i.e. the average number of contacts per day and individual). Figure 1 shows this contact graph for the first day and includes the first 40 individuals. For some experiments, 15 days may not be enough time to evaluate the spread of an infection. Thus, when required, the trace will be extended by repeating the previous weeks. It is assumed that mobility patterns are very similar over consecutive weeks. This fact is confirmed when analysing the contact time series, which show high auto-correlation for the same weekdays.
contact network graph. The result is a contact graph for 15 days with an average rank of 7.66 (i.e. the average number of contacts per day and individual). Figure 1 shows this contact graph for the first day and includes the first 40 individuals. For some experiments, 15 days may not be enough time to evaluate the spread of an infection. Thus, when required, the trace will be extended by repeating the previous weeks. It is assumed that mobility patterns are very similar over consecutive weeks. This fact is confirmed when analysing the contact time series, which show high auto-correlation for the same weekdays.
Figure 1.

Contact network graph for the first 40 nodes during the first day. a) Real contacts; b) Bluetooth contacts.
Since our goal is to evaluate different technologies for estimating contacts, we describe the different patterns and methods used to obtain these contacts. Note that most contact tracing applications only consider simple contact patterns, i.e. a contact occurs if two mobile devices are within a given distance for at least a predefined time. Thus, based on these technologies, we generated several estimated contact graphs 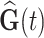 as follows:
as follows:
-
•
Cell: The evaluated area of the campus is
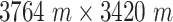 , and we consider here a mobile cell network with four towers and a resolution of 200 meters. Contacts are obtained with this range in consideration.
, and we consider here a mobile cell network with four towers and a resolution of 200 meters. Contacts are obtained with this range in consideration. -
•
Wi-Fi: The range of varies depending on whether it is an open space or not. We consider a range of 25m indoors, and 100m outdoors. Thus, for generating the contacts, we evaluated whether the individuals are indoors (or outdoors) by checking that the actual GPS locations are inside (or not) a building area.
-
•
GPS: In this case, we assume an outdoor accuracy of 5 meters, which increases to 25 meters indoors.
-
•
Bluetooth: In this case, we consider a direct detection between mobile phones with a range of eight meters, in both indoor and outdoor locations.
-
•
Exact: This would be the desired goal, to obtain a contact graph as close to the real physical contacts. It is included in our experiments for comparison purposes.
In all cases, the minimal contact duration considered is one minute. From top to bottom, the average rank of the above list of estimated contact networks is as follows: { Cell 89.31, Wi-Fi 69.18, GPS 41.00, Bluetooth 27.48, Exact 7.66}, clearly showing that the range used is decisive when estimating the number of contacts. With more detail, we can see the Bluetooth contact graph in Figure 1b. When it is compared to the real graph, we clearly observe an increase in the number of edges (contacts) obtaining an error, as defined in Equation 5, of 0.73. Figure 2 shows the temporal error between the two graphs, with small variations between days (always in the range [0.65, 0.75]. This figure also shows the average rank per day, where we can see that the Bluetooth contacts are much higher than the real ones due to the higher range used to detect contacts.
Figure 2.

Temporal error and rank of the real and Bluetooth contact networks. The error is plotted against the right y-axis, and the average rank against the left y-axis.
IV. Epidemic Model for Evaluating Contact Tracing Efficiency
In this section, we introduce our model for describing the individual contacts and tracing mechanism. We consider a SIR (Susceptible, Infected, Recovered) epidemic model with quarantine in a fixed population of 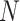 individuals.3 We first create a stochastic model using the event-driven approach and considering each node independently. The contacts in this model are driven by the real contact network defined by
individuals.3 We first create a stochastic model using the event-driven approach and considering each node independently. The contacts in this model are driven by the real contact network defined by 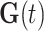 and the estimated contact network
and the estimated contact network 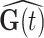 .
.
When considering an average number of contacts and tracing intensity, this stochastic model can be transformed into a deterministic model (that is, a mean-field approximation), which results in an extended model of the contact tracing quarantine model introduced by Keeling and Rohani ([29], pp. 314-316). This continuous model is useful for evaluating the dynamics of the epidemic and the impact of the different quarantine methods in greater populations.
A. The Stochastic Model
We consider a population of 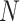 individuals whose real temporal contacts are determined by
individuals whose real temporal contacts are determined by 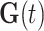 . Individuals have six states:
. Individuals have six states: 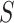 , susceptible individual (not infected);
, susceptible individual (not infected); 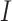 , infected individual;
, infected individual; 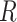 , individual recovered from the infection;
, individual recovered from the infection; 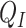 infected individual that has been detected (or traced) and therefore quarantined;
infected individual that has been detected (or traced) and therefore quarantined; 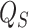 , a susceptible individual that is quarantined after being traced; and
, a susceptible individual that is quarantined after being traced; and 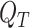 , an infected individual that has been detected and is being traced.
, an infected individual that has been detected and is being traced.
The model has for each individual eight possible events that imply a change of state that can occur at a defined rate.4 Formally speaking, the number of possible events is 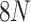 , since these events are for each individual. So, for example, an event from
, since these events are for each individual. So, for example, an event from  for an individual will imply a change of state in this node. As a reference of these events, see Table 1, and also the notation in Table 2.
for an individual will imply a change of state in this node. As a reference of these events, see Table 1, and also the notation in Table 2.
TABLE 1. Events of the Stochastic Model.
| Event | Rate | Description |
|---|---|---|
 |
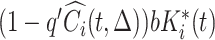 |
Infected individuals that are not traced. |
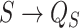 |
 |
Non-infected individual traced and quarantined. |
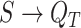 |
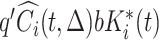 |
Infected individuals that are being traced and go directly to the tracing state. |
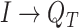 |
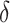 |
Detection of infected individuals, going to tracing. |
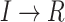 |
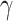 |
Infected individual recovered from disease. |
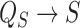 |
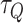 |
End of quarantine for susceptible individual. |
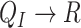 |
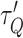 |
End of quarantine and infection. |
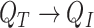 |
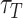 |
End of tracing, goes to the rest of their quarantine. |
TABLE 2. Notation Table.
| Symbol | Definition |
|---|---|
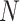 |
Population |
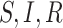 |
Susceptible, Infected and Recovered individuals states |
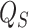 |
Susceptibles in quarantine by tracing |
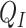 |
Infected detected and quarantined. |
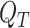 |
Infected detected and being traced. |
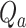 |
Accumulated individuals being quarantined by tracing. |
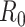 |
Basic reproductive ratio (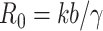 ) ) |
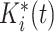 |
Contacts per time unit with infected individuals, for node 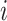 . . |
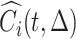 |
Check if an individual has contacted with a traced one. |
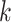 |
Average degree (i.e. average contacts per time unit and ind.). |
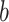 |
Probability of transmitting the disease. |
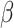 |
Transmission rate (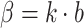 ) ) |
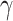 |
Recovery rate (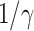 = days to recover) = days to recover) |
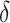 |
Detection rate of infected individuals |
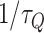 |
Average quarantine time |
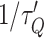 |
Average quarantine time minus 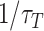
|
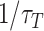 |
Average tracing time |
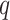 , , 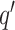
|
Fraction of traced contacts quarantined (normalised 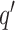 ) ) |
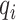 , , 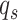
|
Estimated fraction of traced contacts (deterministic model). |
| CFR | Case Fatality Rate. |
The transmission rate, that is the rate at which the infection is transmitted from an infected individual to a susceptible one, can be obtained as the number of contacts at time 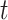 with infected individuals
with infected individuals 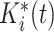 , and the probability of transmitting the disease,
, and the probability of transmitting the disease, 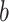 . The latter value depends on the type of disease. The infected individuals recover after
. The latter value depends on the type of disease. The infected individuals recover after 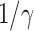 days, where
days, where 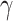 is the recovery rate. All these values are related to the basic reproductive ratio as
is the recovery rate. All these values are related to the basic reproductive ratio as 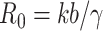 , where
, where 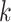 is the average degree of all individuals (see Equation 1). Thus, knowing some basic parameters of the disease (
is the average degree of all individuals (see Equation 1). Thus, knowing some basic parameters of the disease (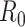 ,
, 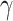 ) and the contact network
) and the contact network 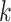 , we can obtain
, we can obtain 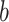 .
. 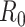 is one of the most important figures in epidemiology and represents the expected number of cases directly generated by a single case. Therefore, when
is one of the most important figures in epidemiology and represents the expected number of cases directly generated by a single case. Therefore, when 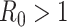 , the infection will start spreading in a population, but not if
, the infection will start spreading in a population, but not if 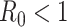 . Generally speaking, the larger the value of
. Generally speaking, the larger the value of 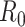 , the harder it is to control the epidemic. Finally, the most common measure for the mortality rate is the Case Fatality Ratio (CFR), which is the number of deaths divided by the number of cases (infected). This value is not usually used in SIR epidemic models since their behaviour is the same as that of a recovered individual: they cannot infect other individuals. In Table 3 we can see several estimated values of these values for COVID-19.5
, the harder it is to control the epidemic. Finally, the most common measure for the mortality rate is the Case Fatality Ratio (CFR), which is the number of deaths divided by the number of cases (infected). This value is not usually used in SIR epidemic models since their behaviour is the same as that of a recovered individual: they cannot infect other individuals. In Table 3 we can see several estimated values of these values for COVID-19.5
TABLE 3. Some Estimated Infectious Diseases Parameters (Time Unit Days). From [2], [15], [16].
| Parameter | Estimated value |
|---|---|
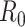 |
3 (1.5–6) |
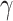 |
1/15 |
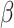 |
0.52 |
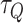 |
1/14 |
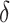 |
0.1 (0.05–0.1) |
In our model, we suppose that when an infected individual is detected, he/she is immediately isolated. Then, his/her contact network is evaluated in order to find any individuals with a high probability of having been infected. These individuals are also quarantining. We consider two quarantine strategies in our model, namely the Infected-Detected Quarantine and the Tracing Quarantine.
The first strategy, the Infected-Detected Quarantine is the most common quarantine measure, where the infected and detected individuals are isolated. In our model, infected individuals are detected, traced and quarantined with a rate 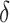 (event
(event 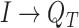 ), and stay in quarantine for an average time of
), and stay in quarantine for an average time of  days. Before going into the final quarantine state
days. Before going into the final quarantine state 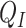 , these individuals stay for a short time
, these individuals stay for a short time 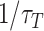 in state
in state 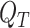 , where their previous contacts are traced. The time
, where their previous contacts are traced. The time 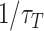 can model, for example, how long it takes to trace the contacts, allowing for a comparison of fast-tracing methods using mobiles phones versus traditional and slow-tracing methods. After this time
can model, for example, how long it takes to trace the contacts, allowing for a comparison of fast-tracing methods using mobiles phones versus traditional and slow-tracing methods. After this time 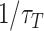 , they change to the
, they change to the 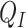 state, where they stay more time, which is the remaining average quarantine time:
state, where they stay more time, which is the remaining average quarantine time: 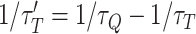 . After that time, they recover and change to the
. After that time, they recover and change to the 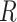 state (event
state (event 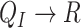 ). Also note that as with real epidemic spread, not all infected individuals are detected (for example, those having no symptoms or mild symptoms), and so they can still infect susceptible individuals. For those infected and not detected, they recover from the disease with a rate of
). Also note that as with real epidemic spread, not all infected individuals are detected (for example, those having no symptoms or mild symptoms), and so they can still infect susceptible individuals. For those infected and not detected, they recover from the disease with a rate of 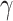 (event
(event 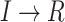 ).
).
In the second quarantine strategy, the Tracing Quarantine, when infected individuals are detected (that is, when they are in state 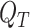 ), their prior contacts in the susceptible state are traced using the estimated contact network
), their prior contacts in the susceptible state are traced using the estimated contact network 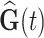 , and some of them are quarantined. Using Equation 3, an individual
, and some of them are quarantined. Using Equation 3, an individual 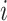 is a candidate for quarantine if
is a candidate for quarantine if 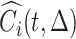 is one, where
is one, where 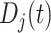 refers to the nodes that are in the
refers to the nodes that are in the 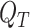 state. However, not all the traced individuals will be quarantined, so we define
state. However, not all the traced individuals will be quarantined, so we define 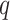 as the fraction of traced individuals being quarantined. For example, this value can reflect the number of individuals that use the mobile contact tracing app. In the case where the tracing time is greater than 1, the
as the fraction of traced individuals being quarantined. For example, this value can reflect the number of individuals that use the mobile contact tracing app. In the case where the tracing time is greater than 1, the 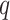 value must be normalised by the average tracing time, as
value must be normalised by the average tracing time, as 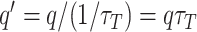 in order to distribute the tracing quarantine over the days. The idea is that if the tracing time is long (for example, by using interviews), it is precisely because it takes time to trace back the prior contacts, so the whole number of traced individuals during this tracing time is equally distributed over these days.
in order to distribute the tracing quarantine over the days. The idea is that if the tracing time is long (for example, by using interviews), it is precisely because it takes time to trace back the prior contacts, so the whole number of traced individuals during this tracing time is equally distributed over these days.
The rate at which all the susceptible individuals are traced is 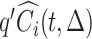 . Furthermore, a portion of these individuals may have been infected during the period corresponding to one time unit (that is, during the day). Thus, infected people have a rate of
. Furthermore, a portion of these individuals may have been infected during the period corresponding to one time unit (that is, during the day). Thus, infected people have a rate of 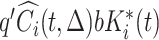 , changing also to state
, changing also to state 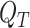 , and consequently starting a new tracing. On the other hand, non-infected people change to class
, and consequently starting a new tracing. On the other hand, non-infected people change to class 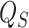 with rate
with rate 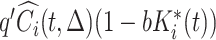 . After being quarantined, individuals in
. After being quarantined, individuals in 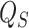 state go back to the susceptible state (event
state go back to the susceptible state (event 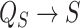 ), and individuals in
), and individuals in 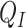 state change to the recovered state (event
state change to the recovered state (event 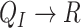 ).
).
Finally, an alternative and more draconian measure can be taken: a lockdown or full quarantine. That is, when the outbreak starts, the entire population is forced to isolate in their homes, and all public spaces are closed in order to drastically reduce the number of contacts as a way of stopping or slowing down the spread of the infection. This implies a change in the contact network, where the number of contacts is drastically reduced in order to reduce the reproductive ratio (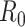 ).
).
This event-driven stochastic model, as described in Table 1, can be solved using the Gillispie method [37]. This iterative method is based on estimating the time until the next event occurs by using the cumulative rates of all possible events. Considering 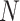 individuals and an initial number of infected individuals (
individuals and an initial number of infected individuals (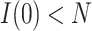 ), we set
), we set 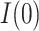 individuals in the Infected state,
individuals in the Infected state, 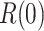 individuals in the Recovered state,6 and the rest in the Susceptible state. This procedure is repeated for a given evaluation time
individuals in the Recovered state,6 and the rest in the Susceptible state. This procedure is repeated for a given evaluation time 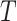 , or until the number of infected individuals is 0. We consider that these individuals have a physical contact network determined by graph
, or until the number of infected individuals is 0. We consider that these individuals have a physical contact network determined by graph 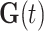 , and an estimated one defined by
, and an estimated one defined by 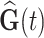 . These graphs are obtained on a daily basis; thus, if we want to evaluate
. These graphs are obtained on a daily basis; thus, if we want to evaluate 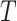 days, we will have
days, we will have 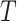 different graphs, and the event times need to be rounded to a day.
different graphs, and the event times need to be rounded to a day.
To evaluate the efficiency of the different isolation methods, we also compute the accumulated number of individuals quarantined using tracing methods (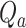 ). To account for the individuals quarantined,
). To account for the individuals quarantined, 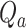 is initially set to zero, and it is incremented by one whenever an individual is quarantined by tracing (events
is initially set to zero, and it is incremented by one whenever an individual is quarantined by tracing (events 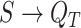 and
and 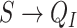 in Table 1). Note that sometimes, if the duration of the infection is long, individuals can be quarantined several times; that is, when they leave the quarantine they return to the susceptible class so they can be quarantined again.
in Table 1). Note that sometimes, if the duration of the infection is long, individuals can be quarantined several times; that is, when they leave the quarantine they return to the susceptible class so they can be quarantined again.
The computational cost of this model depends on the number of individuals 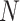 and on the average degree
and on the average degree 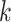 of the contact networks. The performed experiments show that its computational cost is exponential with
of the contact networks. The performed experiments show that its computational cost is exponential with 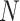 . Therefore, we need an alternative method when considering large populations, like the deterministic model we introduce in the next subsection.
. Therefore, we need an alternative method when considering large populations, like the deterministic model we introduce in the next subsection.
B. Deterministic Model
The stochastic model described above can be converted into a deterministic model, assuming a degree of homogeneity in the contact network. Thus, the precision of this model will depend not only on the homogeneity of the contacts but also on the number of nodes (individuals), where accuracy is greater when the number of nodes is high. In this deterministic model, the previously considered six states of an individual are now transformed into six classes, which represent the number of individuals in each state. Furthermore, to model the transmission, we use the number of average contacts (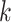 ) of the contact network.
) of the contact network.
To model the contact tracing methods, we use two different fractions of quarantined contacts, one for infected nodes, 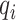 and another for susceptible ones,
and another for susceptible ones, 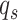 . The reason for having these two fractions is to consider the effect that the real and estimated contact networks have on the tracing of contacts. The goal is to measure the precision of the technology used to retrieve the infected individuals when tracing. If the estimated contact network used for tracing has many more contacts than the real one (for example, when using the Cell one), it will trace more susceptible nodes than a more accurate one.
. The reason for having these two fractions is to consider the effect that the real and estimated contact networks have on the tracing of contacts. The goal is to measure the precision of the technology used to retrieve the infected individuals when tracing. If the estimated contact network used for tracing has many more contacts than the real one (for example, when using the Cell one), it will trace more susceptible nodes than a more accurate one.
The first value, 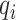 is obtained from the stochastic model as the average value of
is obtained from the stochastic model as the average value of 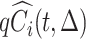 for all
for all 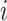 using the real contact network as the estimated one (that is, considering perfect contact tracing). To obtain this value
using the real contact network as the estimated one (that is, considering perfect contact tracing). To obtain this value 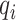 , it is necessary to perform several realisations of the stochastic model, for example by using the Gillespie method. The second value,
, it is necessary to perform several realisations of the stochastic model, for example by using the Gillespie method. The second value, 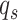 is obtained in a similar way but using the estimated contact network. In other words, the value
is obtained in a similar way but using the estimated contact network. In other words, the value 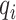 determines the fraction of contacts with infected individuals being traced and potentially infected, and
determines the fraction of contacts with infected individuals being traced and potentially infected, and 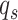 the equivalent for the ones not infected.7 In general, we can see that
the equivalent for the ones not infected.7 In general, we can see that 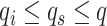 , since the estimated contact network has more contacts than the real one, and both of them refer to the whole set of infected individuals, whereas
, since the estimated contact network has more contacts than the real one, and both of them refer to the whole set of infected individuals, whereas 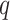 only refers to a subset of the infected individuals being traced.
only refers to a subset of the infected individuals being traced.
The transmission rate 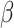 , that is, the rate at which the infection is transmitted from one infected individual to one susceptible individual, is formed by the product of the number of contacts per time unit
, that is, the rate at which the infection is transmitted from one infected individual to one susceptible individual, is formed by the product of the number of contacts per time unit 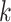 , and the probability of transmitting the disease
, and the probability of transmitting the disease 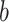 ; hence, newly infected individuals are generated with a rate
; hence, newly infected individuals are generated with a rate 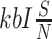 . Regarding the tracing quarantine, the previously mentioned
. Regarding the tracing quarantine, the previously mentioned 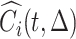 term will depend on the average rank of the estimated graph, considering only the fraction
term will depend on the average rank of the estimated graph, considering only the fraction 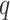 of contacted individuals. Taking into account the rates in Table 1 as well, the equations of the continuous model are as follows:
of contacted individuals. Taking into account the rates in Table 1 as well, the equations of the continuous model are as follows:
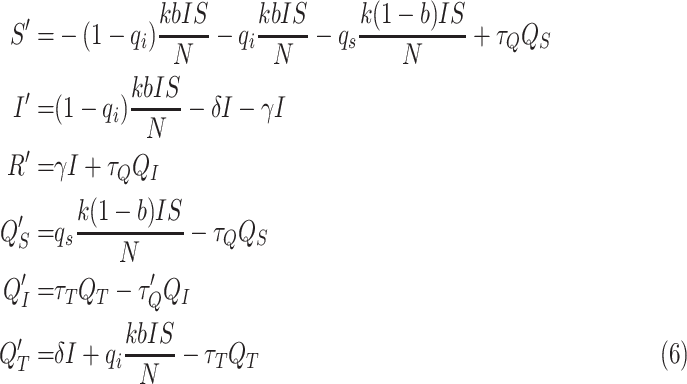 |
In all equations, we have omitted the time in the classes (e.g. for class 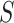 ,
, 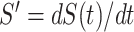 and
and 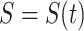 ). Also, note that we have opted for not simplifying some expressions in order to clearly differentiate the different transition terms.
). Also, note that we have opted for not simplifying some expressions in order to clearly differentiate the different transition terms.
A key issue in epidemic control is reducing the number of infected individuals that remain undetected and who can contribute to the fast spread of the infection (this fact has been one of the main causes for the fast spread of COVID-19). This can be achieved by increasing the detection ratio, for example by increasing the number of tests, even for asymptomatic individuals, and also by increasing the traced individuals. From the previous model, we can obtain the conditions for an outbreak to be controlled, that is, when 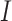 decreases. Thus, working out when the second equation in 6 is negative, we have:
decreases. Thus, working out when the second equation in 6 is negative, we have:
 |
This expression is similar to the one obtained by Keeling and Rohani [29] (pp. 315-316). Considering that 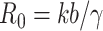 , we can obtain the threshold for an epidemic outbreak depending on the basic reproductive ratio
, we can obtain the threshold for an epidemic outbreak depending on the basic reproductive ratio 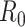 and the proportion of susceptible people (
and the proportion of susceptible people (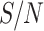 ). Note that this expression depends on
). Note that this expression depends on 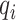 and not on
and not on 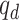 . This makes sense since only the detection and quarantine of infected individuals can stop the spread of the infection. This also means that less precise contact tracing will increase the number of susceptible quarantined individuals. In other words, for the same number of traced quarantined people, a less precise tracing will be less effective.
. This makes sense since only the detection and quarantine of infected individuals can stop the spread of the infection. This also means that less precise contact tracing will increase the number of susceptible quarantined individuals. In other words, for the same number of traced quarantined people, a less precise tracing will be less effective.
The set of Equations 6 do not have an analytical solution, so we have to use a numerical solution such as the Euler method, or even more efficient algorithms such as the built-in Matlab function ode45 used in this paper. Initially, we assume a number of infected individuals 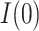 and recovered individuals
and recovered individuals 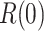 , meaning that
, meaning that 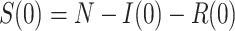 , and the other classes are zero. Then, the model is solved for a given time (one year, for example) or until the number of infected individuals (the sum of classes
, and the other classes are zero. Then, the model is solved for a given time (one year, for example) or until the number of infected individuals (the sum of classes 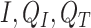 ) is less than one. The latter means that the infection has finished and the duration of the epidemic can be obtained as the time when
) is less than one. The latter means that the infection has finished and the duration of the epidemic can be obtained as the time when 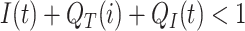 .
.
As in the stochastic model, we can also obtain the accumulated number of individuals that have been quarantined by tracing as:
 |
Thus, 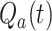 is the total number of individuals quarantined by tracing up to time
is the total number of individuals quarantined by tracing up to time  .
.
V. Evaluation of the Models
This section evaluates the previous models, their precision and applicability. It also shows the dynamics of the epidemic when considering different quarantine measures.
A. Comparison of Stochastic and Deterministic Models
In order to use the deterministic model, it is necessary to evaluate how the results of both the stochastic and deterministic models match. To evaluate both models, we used the estimated COVID-19 parameters shown in Table 3. In the following experiments, we evaluate the spread of the infection using the NCCU trace, assuming an initial outbreak at day one with five infected individuals (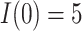 ), with no recovered individuals (
), with no recovered individuals (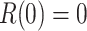 ), and the tracing time was set to one day (
), and the tracing time was set to one day (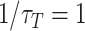 ), reflecting fast mobile tracing. For the estimated contact network
), reflecting fast mobile tracing. For the estimated contact network 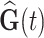 , we used the one obtained using Bluetooth technology. For the stochastic model, we performed 30 realisations, selecting the initially infected individuals for each realisation randomly. Using all these realisations, we also obtained the averages of the main curves, i.e., the number of Susceptible, Infected, and Recovered individuals. From these realisations, we also obtained the value of
, we used the one obtained using Bluetooth technology. For the stochastic model, we performed 30 realisations, selecting the initially infected individuals for each realisation randomly. Using all these realisations, we also obtained the averages of the main curves, i.e., the number of Susceptible, Infected, and Recovered individuals. From these realisations, we also obtained the value of 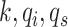 to be used in the deterministic model.
to be used in the deterministic model.
The first experiment considers no tracing quarantine measures are taken, that is, when 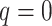 . Figure 3b shows the number of individuals in the
. Figure 3b shows the number of individuals in the 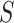 ,
, 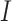 and
and 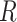 states (classes). Considering the average curves of the stochastic model (solid lines), we can see that the number of infected individuals initially increases, but after fifteen days (peak of infections) the infection diminishes, and it ends around the eightieth day. Figure 3b shows the number of individuals quarantined, so we can see the peak of quarantined individuals takes place on about day twenty-five. Regarding the differences between the two models, we can see that, in general, the deterministic model (dashed lines), when compared with the average of the stochastic model (solid lines), slightly overestimates the number of infections.
states (classes). Considering the average curves of the stochastic model (solid lines), we can see that the number of infected individuals initially increases, but after fifteen days (peak of infections) the infection diminishes, and it ends around the eightieth day. Figure 3b shows the number of individuals quarantined, so we can see the peak of quarantined individuals takes place on about day twenty-five. Regarding the differences between the two models, we can see that, in general, the deterministic model (dashed lines), when compared with the average of the stochastic model (solid lines), slightly overestimates the number of infections.
Figure 3.
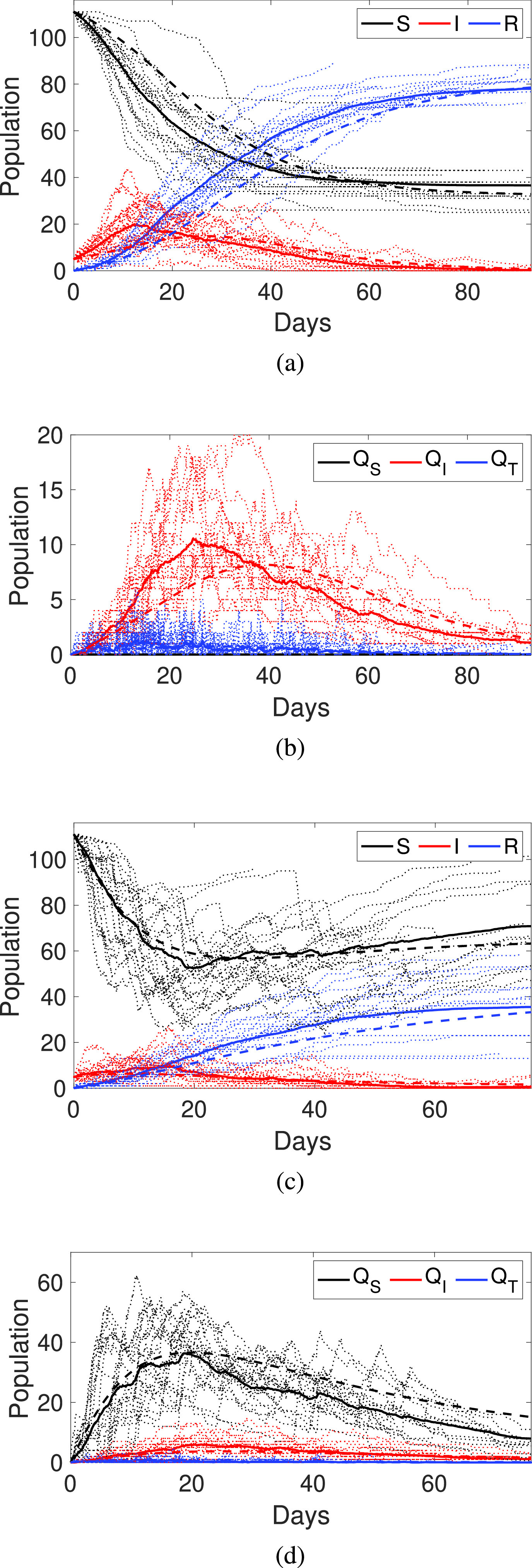
Dynamics of the COVID-19 epidemics in the NCCU trace. a) and b) without tracing quarantine; c) and d) using tracing quarantine with 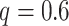 . Dotted lines are the results of 30 realisations using the stochastic model; Solid lines are the average of these stochastic realisations, and dashed lines are the results using the deterministic model.
. Dotted lines are the results of 30 realisations using the stochastic model; Solid lines are the average of these stochastic realisations, and dashed lines are the results using the deterministic model.
The second experiment considers a tracing quarantine with 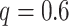 . With this value, the estimated fractions of traced contacts quarantined for the deterministic model are
. With this value, the estimated fractions of traced contacts quarantined for the deterministic model are 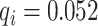 and
and 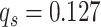 . In this case, we can see in Figure 3c that the number of infected individuals has been reduced when compared to the no-tracing quarantine results but at the cost of increasing the number of individuals quarantined, as shown in Figure 3d. The duration of the infection is slightly shorter, showing the effect of the quarantine. The most significant difference between the average stochastic and deterministic curves is the traced susceptible quarantined (
. In this case, we can see in Figure 3c that the number of infected individuals has been reduced when compared to the no-tracing quarantine results but at the cost of increasing the number of individuals quarantined, as shown in Figure 3d. The duration of the infection is slightly shorter, showing the effect of the quarantine. The most significant difference between the average stochastic and deterministic curves is the traced susceptible quarantined (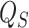 ). The reason for this difference is that, in the stochastic model, it is more likely for an individual being traced to get infected (she/he has been in contact with an infected person). This implies that transition
). The reason for this difference is that, in the stochastic model, it is more likely for an individual being traced to get infected (she/he has been in contact with an infected person). This implies that transition 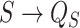 is less probable than in the deterministic model, in which all traced nodes are evaluated homogeneously.
is less probable than in the deterministic model, in which all traced nodes are evaluated homogeneously.
We repeated the previous experiments using other tracing contact networks 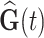 (that is, considering GPS, Wi-Fi and Cell technologies for contact tracing) and the results were quite similar. The effect of the tracing mechanism is measured in the obtained values of
(that is, considering GPS, Wi-Fi and Cell technologies for contact tracing) and the results were quite similar. The effect of the tracing mechanism is measured in the obtained values of 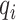 and
and 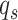 . These values not only depend on
. These values not only depend on 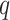 , but also on the detection rate
, but also on the detection rate 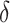 (and, of course, the contact network studied). Thus, to use the deterministic model, we can estimate
(and, of course, the contact network studied). Thus, to use the deterministic model, we can estimate 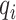 and
and 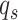 for any given
for any given 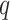 and
and 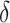 values. Depending on these values, there is an upper limit range on
values. Depending on these values, there is an upper limit range on 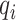 and
and 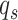 , as shown in Figure 4. We can see that due to a lack of precision for detecting true contacts, some technologies can trace up to 60% of the susceptible individuals that have been in contact with infected individuals, meaning most of them would be false positives (individuals traced and quarantined, but not likely to have been infected). Additionally, these results restrain the study of the deterministic model to these limit values. Considering these issues, we can use the deterministic model to evaluate large populations, which is not computationally amenable using the stochastic model.
, as shown in Figure 4. We can see that due to a lack of precision for detecting true contacts, some technologies can trace up to 60% of the susceptible individuals that have been in contact with infected individuals, meaning most of them would be false positives (individuals traced and quarantined, but not likely to have been infected). Additionally, these results restrain the study of the deterministic model to these limit values. Considering these issues, we can use the deterministic model to evaluate large populations, which is not computationally amenable using the stochastic model.
Figure 4.

Estimated maximum values for the fraction of tracing quarantine (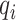 ,
, 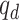 ) to use in the deterministic model depending on the detection ratio
) to use in the deterministic model depending on the detection ratio 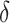 .
.
B. Epidemic Dynamics
In this subsection, we study the epidemic dynamics using the deterministic model described by Equations 6 depending on the different quarantine strategies. The idea is to provide a better understanding of the dynamics of quarantining using contact tracing. We again use the COVID-19 disease estimated parameters shown in TABLE 3 with a population of 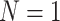 million, and an initial number of infected individuals set at 10 (
million, and an initial number of infected individuals set at 10 (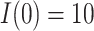 ), with no immunised individuals (
), with no immunised individuals (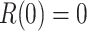 ) and an average of eight contacts per day (
) and an average of eight contacts per day (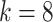 ).
).
We start by considering the case when no measures are taken, that is, individuals are neither detected nor quarantined (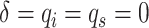 ). The results are shown in Figure 5a, which clearly represents a typical simple SIR model where most of the population gets infected due to the high reproductive ratio (
). The results are shown in Figure 5a, which clearly represents a typical simple SIR model where most of the population gets infected due to the high reproductive ratio (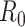 ). In the second Figure 5b, we consider that some of the infected individuals are detected and isolated (that is, the detection rate is
). In the second Figure 5b, we consider that some of the infected individuals are detected and isolated (that is, the detection rate is 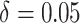 ). We can see that this simple measure reduces the number of individuals that get infected, although the duration of the infection is slightly increased due to a small number of remaining infected individuals, which slowly drops off after day 150. If we increase the detection ratio to
). We can see that this simple measure reduces the number of individuals that get infected, although the duration of the infection is slightly increased due to a small number of remaining infected individuals, which slowly drops off after day 150. If we increase the detection ratio to 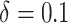 , for example by increasing the number of tests performed, the infected curve is flattened, as shown in Figure 5c, significantly reducing the final number of infected individuals. Flattening the curve of infected individuals also implies that the duration of the infection increases.
, for example by increasing the number of tests performed, the infected curve is flattened, as shown in Figure 5c, significantly reducing the final number of infected individuals. Flattening the curve of infected individuals also implies that the duration of the infection increases.
Figure 5.
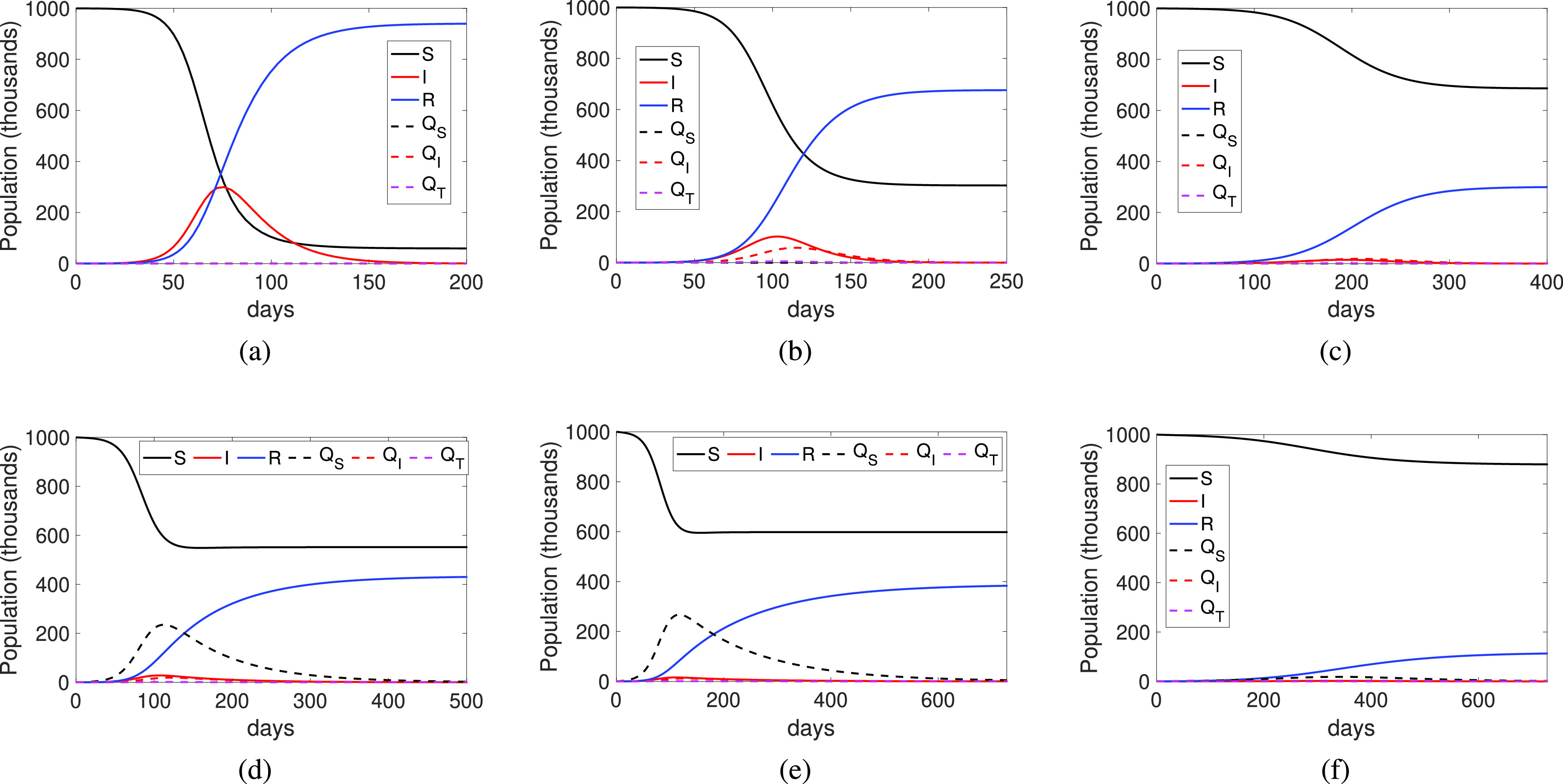
Epidemic Dynamics under different quarantine methods for the COVID-19 infection. a) No measures (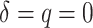 ); b) Detection and isolation of individuals. (
); b) Detection and isolation of individuals. (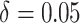 ,
, 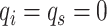 ) c) Increasing detection ratio (
) c) Increasing detection ratio (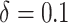 ,
, 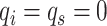 ); d) Adding tracing quarantine (
); d) Adding tracing quarantine (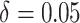 ,
, 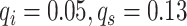 ); f) Increasing tracing quarantine (
); f) Increasing tracing quarantine (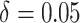 ,
, 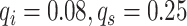 ); g) Increasing also the detection ratio (
); g) Increasing also the detection ratio (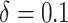 ,
, 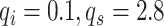 ).
).
Now, we evaluate the impact of the contact tracing quarantine. Figure 5d shows the result for 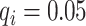 ,
, 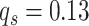 and
and 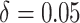 . These values correspond to
. These values correspond to 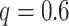 in the stochastic model. It can be observed that the number of infected nodes is reduced when compared to the results in Figure 5b, although the duration of the infection is increased. Note also that, as expected, the number of quarantined individuals (dashed lines) has also increased. If we increase
in the stochastic model. It can be observed that the number of infected nodes is reduced when compared to the results in Figure 5b, although the duration of the infection is increased. Note also that, as expected, the number of quarantined individuals (dashed lines) has also increased. If we increase 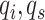 to the maximum allowed for
to the maximum allowed for 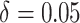 , which is
, which is 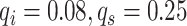 , the infected population is notably reduced, as shown in Figure 5e, and the quarantined individuals are also reduced. Finally, Figure 5f shows the effect of increasing the detection ratio to
, the infected population is notably reduced, as shown in Figure 5e, and the quarantined individuals are also reduced. Finally, Figure 5f shows the effect of increasing the detection ratio to 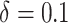 with
with 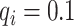 and
and 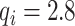 . In this case, the curve of those infected has been completely flattened, and the number of infected individuals is also reduced. If we increase these values, for example to
. In this case, the curve of those infected has been completely flattened, and the number of infected individuals is also reduced. If we increase these values, for example to 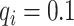 and
and 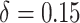 , the result (not shown here since they are flat curves) is a control of the outbreak, and the infection is not spread. These threshold values can be obtained using Equation 7, considering nearly all people to be susceptible
, the result (not shown here since they are flat curves) is a control of the outbreak, and the infection is not spread. These threshold values can be obtained using Equation 7, considering nearly all people to be susceptible 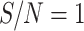 . We will study this issue in detail in the next section.
. We will study this issue in detail in the next section.
Summing up, the right selection of the detection rate along with quarantine measures has a huge impact on controlling the spread of the infection. In the next section, we will study in detail the best combination of these measures.
VI. Efficiency of Quarantine Measures and Tracing Technologies
This section extends the previous experiments to determine the effectiveness of each quarantine measure, and thus the optimal strategy. It also evaluates the precision of the different contact tracing technologies.
A. Efficiency of Quarantine Measures
First, we evaluate the threshold for controlling an outbreak (that is, when the number of infected individuals decreases) using Equation 7, depending on the proportion of susceptible people 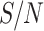 and the basic reproductive ratio
and the basic reproductive ratio 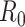 . We evaluate a first epidemic outbreak for not only when all individuals were susceptible (
. We evaluate a first epidemic outbreak for not only when all individuals were susceptible (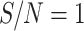 ), but also when some proportion of the population has gained immunity after having recovered. This fact is a key issue in controlling future and localised waves of infection since some population will be immunised. The results are shown in Figure 6. Note that only the values delimited by the black lines correspond to the possible values for the NCCU scenario.
), but also when some proportion of the population has gained immunity after having recovered. This fact is a key issue in controlling future and localised waves of infection since some population will be immunised. The results are shown in Figure 6. Note that only the values delimited by the black lines correspond to the possible values for the NCCU scenario.
Figure 6.

Threshold for infection control for different ratios of susceptible population. The pair of values above the dashed line results in a disease-free equilibrium. The area delimited by the black line corresponds to the possible values for the NCCU scenario.
The presented results are very significant, especially when considering that COVID-19 has an estimated average detection rate of 0.05 and a reproductive ratio 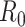 close to 3. We can see that, for the initial outbreak when
close to 3. We can see that, for the initial outbreak when 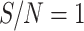 , even using efficient contact tracing, the disease cannot be controlled, as unfortunately has happened. On the contrary, when some fraction of people get immunised, outbreaks can be better controlled using smartphone contact tracing applications. For example, for
, even using efficient contact tracing, the disease cannot be controlled, as unfortunately has happened. On the contrary, when some fraction of people get immunised, outbreaks can be better controlled using smartphone contact tracing applications. For example, for 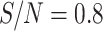 , we can obtain an outbreak control for
, we can obtain an outbreak control for 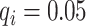 and
and 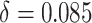 . Note that for the NCCU scenario, a value of
. Note that for the NCCU scenario, a value of 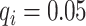 corresponds to approximately
corresponds to approximately 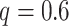 , that is, the required fraction of people using the contact tracing application. This means that the previous requirement of having a significant fraction of people using the contact tracing application is relaxed. We can also see that, if
, that is, the required fraction of people using the contact tracing application. This means that the previous requirement of having a significant fraction of people using the contact tracing application is relaxed. We can also see that, if 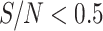 , the quarantine will not be necessary as the system will be close to herd immunity. Additionally, if we consider the concurrent application of future measures like relaxed social distancing (after the strict initial lockdowns), which can reduce the reproductive ratio
, the quarantine will not be necessary as the system will be close to herd immunity. Additionally, if we consider the concurrent application of future measures like relaxed social distancing (after the strict initial lockdowns), which can reduce the reproductive ratio 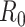 , we can also see in Figure 6 that for
, we can also see in Figure 6 that for 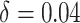 with relatively small values of
with relatively small values of 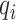 (between 0.01 and 0.04), the outbreak can be controlled. The consequence is that the required fraction of people that must be using the application is reduced to values of between 0.2 to 0.4, making it a feasible solution.
(between 0.01 and 0.04), the outbreak can be controlled. The consequence is that the required fraction of people that must be using the application is reduced to values of between 0.2 to 0.4, making it a feasible solution.
We now evaluate the case of when the infection has not been controlled, and thus many individuals get infected. This evaluation is performed using the deterministic model, but only showing the final results, that is, when the infection is over. Again, the same COVID-19 disease parameters are used with a population of 1 million and considering Bluetooth technology for tracing contacts. The infected and quarantine values are expressed as a fraction of the population (i.e. divided by 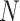 ). Figure 7a shows the fraction of the infected population depending on the detection rate (
). Figure 7a shows the fraction of the infected population depending on the detection rate (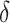 ), and the fraction of traced contacts quarantined (
), and the fraction of traced contacts quarantined (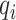 ). We can clearly see how the infection is reduced when both the detection rate and quarantine measures are considered. We can contrast these results with the fraction of population quarantined, as shown in Figure 7b, where for low values of detection rates, the quarantined population can be very high.8 Using a less precise tracing technology (GPS), we found that, as expected, the fraction of quarantined people increases, as shown in 7c. Finally, if we consider that part of the population is already immunised, with
). We can clearly see how the infection is reduced when both the detection rate and quarantine measures are considered. We can contrast these results with the fraction of population quarantined, as shown in Figure 7b, where for low values of detection rates, the quarantined population can be very high.8 Using a less precise tracing technology (GPS), we found that, as expected, the fraction of quarantined people increases, as shown in 7c. Finally, if we consider that part of the population is already immunised, with 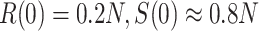 , the fraction of newly infected individuals is significantly reduced when considering contact tracing, and additionally, the number of quarantined people practically drops to half.
, the fraction of newly infected individuals is significantly reduced when considering contact tracing, and additionally, the number of quarantined people practically drops to half.
Figure 7.
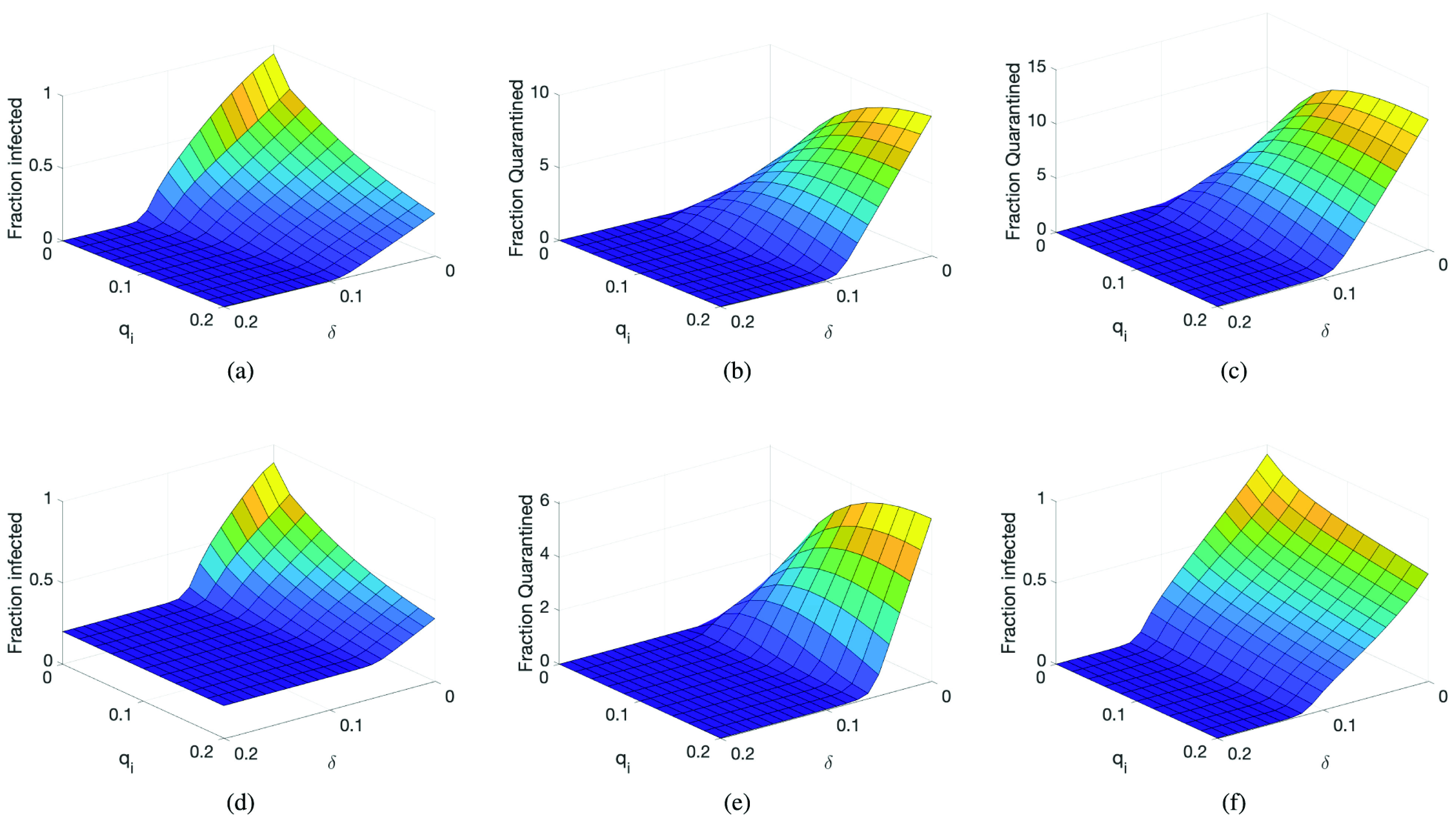
Quarantine measure effectiveness: a) Fraction of population infected using Bluetooth-based tracing contact technology (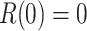 ); b) Fraction of population quarantined using Bluetooth-based tracing contact technology (
); b) Fraction of population quarantined using Bluetooth-based tracing contact technology (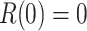 ); c) Fraction of population quarantined using GPS-based tracing contact technology (
); c) Fraction of population quarantined using GPS-based tracing contact technology (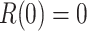 ); d) Fraction of population infected using Bluetooth-based tracing contact technology (
); d) Fraction of population infected using Bluetooth-based tracing contact technology (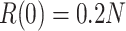 ); e) Fraction of population quarantined using Bluetooth-based tracing contact technology (
); e) Fraction of population quarantined using Bluetooth-based tracing contact technology (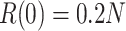 ).
).
Summing up, for the first outbreaks of COVID-19, smartphone-based contact tracing can only be effective when using fast and high-precision contact tracing technology and when considering that a significant proportion of the population uses the application. It is also shown that the number of people quarantined by contact tracing can be very high if the detection rate is low, as it is for COVID-19. Fortunately, for future outbreaks, and considering that at least 20% of individuals could be immunised, or that the reproductive ratio is reduced by some mild social distancing measures, smartphone contact tracing applications can be very effective.
B. Efficiency of Contact Tracing Technology
In this subsection, we evaluate two aspects related to smartphone contact tracing technology: its speed and contact detection precision, and how it impacts the control and spread of diseases.
One of the advantages of using smartphone-based contact tracing is its speed. When detecting an infected individual, tracing back his/her contacts is almost immediate. With traditional contact investigation it can take several days to obtain these prior contacts. Therefore, we evaluated the impact of this tracing time by increasing the value of 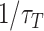 to 5 days, and repeating the experiment of Figure 7a. The results are shown in Figure 7f, evidencing a substantial increase in the fraction of infected individuals, and confirming how important tracing prior contacts is to having an effective quarantine.
to 5 days, and repeating the experiment of Figure 7a. The results are shown in Figure 7f, evidencing a substantial increase in the fraction of infected individuals, and confirming how important tracing prior contacts is to having an effective quarantine.
We shall now study the efficiency of the different contact tracing methodologies described in Section III. In previous experiments, we have shown that using a more precise contact network has no impact on reducing the number of infected individuals since this aspect mainly depends on the value of 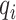 . However, using imprecise contact networks can increase the number of quarantined individuals, resulting in a similar number of infected individuals. Thus, using a more precise tracing technology will allow for greater selectivity of individuals who are more likely to have been infected, reducing the overall number of quarantined people.
. However, using imprecise contact networks can increase the number of quarantined individuals, resulting in a similar number of infected individuals. Thus, using a more precise tracing technology will allow for greater selectivity of individuals who are more likely to have been infected, reducing the overall number of quarantined people.
To confirm this, we performed the following experiment using the stochastic model and the NCCU mobility trace. The idea was to obtain the accumulated number of quarantined individuals (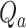 ) versus the final number of infected individuals. This way, we can compare the quarantine efforts required for each contact tracing technology. The results are shown in Figure 8a, which shows the average results of performing 500 stochastic realisations. We can clearly see that the more precise the technology is, the fewer people that get quarantined, with no increase in the number of infected individuals.
) versus the final number of infected individuals. This way, we can compare the quarantine efforts required for each contact tracing technology. The results are shown in Figure 8a, which shows the average results of performing 500 stochastic realisations. We can clearly see that the more precise the technology is, the fewer people that get quarantined, with no increase in the number of infected individuals.
Figure 8.
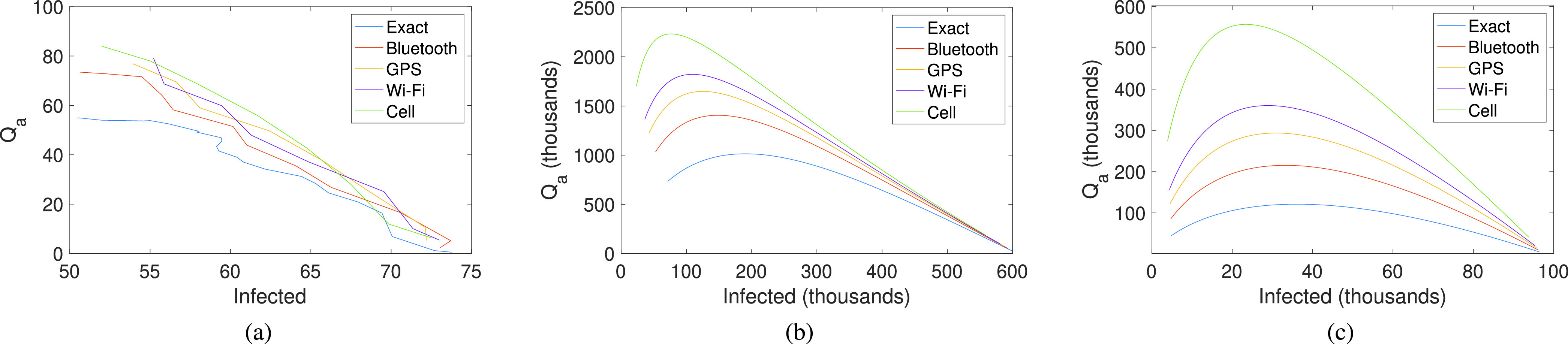
Evaluation of the contact tracing technology considering the final number of infected individual versus the required quarantine effort (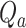 ). a) In the NCCU scenario using the Stochastic model; b) Using the deterministic model for
). a) In the NCCU scenario using the Stochastic model; b) Using the deterministic model for 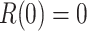 ; c) Using the deterministic model for
; c) Using the deterministic model for 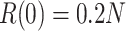 . Note that, in this case, infected people corresponds to the newly infected (not considering the previous ones).
. Note that, in this case, infected people corresponds to the newly infected (not considering the previous ones).
Using the values of 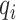 and
and 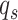 obtained from this experiment, we can evaluate the effect of tracing technology over a more extensive population using the deterministic model. For this experiment, we again consider, as in Subsection V-B, a population of
obtained from this experiment, we can evaluate the effect of tracing technology over a more extensive population using the deterministic model. For this experiment, we again consider, as in Subsection V-B, a population of 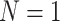 million, and an initial number of infected individuals of 10 (
million, and an initial number of infected individuals of 10 (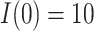 ), with no immunised individuals (
), with no immunised individuals (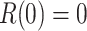 ), and an average of eight contacts per day (
), and an average of eight contacts per day (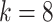 ). The results are shown in Figure 8b, which give a pattern similar to the results for the stochastic model. Finally, we evaluate the case when there is a fraction
). The results are shown in Figure 8b, which give a pattern similar to the results for the stochastic model. Finally, we evaluate the case when there is a fraction 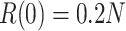 of the population already infected (that is, considering possible new outbreaks at second waves). The results (see Figure 8c) show that the number of quarantined citizens is reduced and that the number of newly infected individuals can be controlled with low quarantine efforts when highly accurate tracing technologies such as Bluetooth are adopted.
of the population already infected (that is, considering possible new outbreaks at second waves). The results (see Figure 8c) show that the number of quarantined citizens is reduced and that the number of newly infected individuals can be controlled with low quarantine efforts when highly accurate tracing technologies such as Bluetooth are adopted.
Summing up, as expected, mobile contact tracing technology exhibits a huge impact on the quarantine of individuals. Firstly, it is absolutely vital for it to be fast. Second, it must be precise when detecting real contacts.
VII. Conclusion
In general, accurate modelling and quantifying of human mobility is critical to improving control of epidemics, but it may be hindered by data incompleteness or unavailability [18]. Furthermore, depending on the technology used, we can obtain varying accuracy on the contact tracing.
In this paper, we focused on evaluating how smartphone contact tracing technology can impact the control and spread of infectious diseases. We have introduced a stochastic model that gets transformed into a deterministic model, while taking into consideration the effect of contact tracing and the quarantine measures. On the basis of these models, we evaluated and compared several possible scenarios for smartphone-based contact tracing. Although these models are generic for infectious diseases, we have studied the case of COVID-19 in particular.
With regard to contact tracing technology, our results show that the mobile technology used for detecting contacts has a great impact on the social and economic cost (measured as the number of people quarantined). Accurate technologies, such as Bluetooth, allow for greater selectivity when it comes to quarantining people.
Furthermore, the results also show that in order to be effective (and particularly for the COVID-19 infection), mobile contact tracing requires contacts be traced quickly and a very high percentage of the population must use the contact tracing App. Fortunately, our study also shows that for possible second waves of infection, mobile contact tracing can be effective in controlling the disease, assuming that some portion of the population will have gained immunity, or in combination with some other lenient measures, such as social distancing.
Biographies

Enrique Hernández-Orallo (Member, IEEE) received the M.Sc. and Ph.D. degrees in computer science from the Universitat Politècnica de València, Spain, in 1992 and 2001, respectively. From 1991 to 2005, he worked at several companies in real-time and computer networks projects. He is currently an Associate Professor with the Department of Computer Engineering, Universitat Politècnica de València. He is a member of the Computer Networks Research Group (GRC) and has participated in over ten Spanish and European research projects. He is the author of about 100 journal and conference papers and coauthor of two successful books of C++ in the Spanish language. His research interests include distributed systems, performance evaluation, mobile and pervasive computing, and real-time systems. He is mainly working in performance evaluation of MANET and opportunistic networks.

Pietro Manzoni (Senior Member, IEEE) received the master’s degree in computer science from the Università degli Studi of Milan, Italy, in 1989, and the Ph.D. degree in computer science from the Politecnico di Milano, Italy, in 1995. Between November 1992 and February 1993, he did an internship at Bellcore Laboratories, Red Bank, NJ, USA, and between February 1994 and November 1994, he was a Visiting Researcher with the International Computer Science Institute (ICSI), Berkeley, CA, USA. He is currently a Full Professor of computer engineering with the Universitat Politècnica de València, Spain. He is a Co-ordinator of the Computer Networks Research Group (GRC), Department of Computer Engineering (DISCA). His research interests include networking and mobile systems and applied to intelligent transport systems (ITSs), smart cities and the Internet of Things, and community networks (mesh).

Carlos Tavares Calafate received the degree (Hons.) in electrical and computer engineering from the University of Porto, Portugal, in 2001, and the Ph.D. degree in informatics from the Technical University of Valencia, Spain, in 2006. He has been working with the Technical University of Valencia, since 2002. He is currently a Full Professor with the Department of Computer Engineering, Technical University of Valencia (UPV). To date, he has published more than 300 articles, several of them in journals, including the IEEE Transactions on Vehicular Technology, the IEEE Transactions on Mobile Computing, the IEEE/ACM Transactions on Networking, Ad Hoc Networks, (Elsevier) and the IEEE Communications Magazine. He has participated in TPC of more than 150 international conferences. His research interests include ad hoc and vehicular networks, UAVs, smart cities and the Internet of Things, QoS, network protocols, video streaming, and network security. He is a Founding Member of the IEEE SIG on Big Data with Computational Intelligence.

Juan-Carlos Cano (Senior Member, IEEE) received the M.Sc. and Ph.D. degrees in computer science from the Polytechnic University of Valencia (UPV), Spain, in 1994 and 2002, respectively. From 1995 to 1997, he worked as a Programming Analyst at the IBM’s Manufacturing Division, Valencia. He is currently a Full Professor with the Department of Computer Engineering, UPV. His current research interests include vehicular networks, mobile ad hoc networks, and pervasive computing.
Funding Statement
This work was supported in part by the Ministerio de Ciencia, Innovación y Universidades, Spain, under Grant RTI2018-096384-B-I00.
Footnotes
We have focused our study on widely available current communication and localisation technologies that can be used for implementing real contact tracing applications (such as those under development for the COVID-19 disease). Technologies requiring additional infrastructure and services (i.e. BLE beacons) or those not supported by current mobile phones (such as LiFi or UWB) are not considered.
This is similar to the dual graph model used in [28], although we prefer here to use the dynamic system notation.
As a closed system, no natural births and deaths are considered. We consider that the time scale of the outbreak and the required tracing is small enough to allow for not taking into account this variation on the population.
In other notations, this rate is multiplied by a small 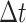 time interval in order to obtain the associated probability of the event.
time interval in order to obtain the associated probability of the event.
Note that these estimated values are drawn from very preliminary studies, and also depend on the location and country.
For evaluating a first outbreak, the value of 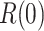 will be 0. Nevertheless, for possible subsequent outbreaks, part of the population may be considered to have recovered and thus have immunisation, meaning that
will be 0. Nevertheless, for possible subsequent outbreaks, part of the population may be considered to have recovered and thus have immunisation, meaning that 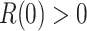 .
.
Note the difference between 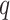 and
and 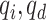 :
: 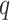 refers to the fraction of those individuals who have had contact with infected individuals being traced, whereas
refers to the fraction of those individuals who have had contact with infected individuals being traced, whereas 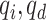 refers to the fraction of those individuals who have recently had contact with someone infected (not only someone traced).
refers to the fraction of those individuals who have recently had contact with someone infected (not only someone traced).
We again point out that a fraction of quarantined population greater than one means that individuals have been quarantined more than one time or for longer periods than the quarantine time used in the model.
References
- [1].Team K., “Contact transmission of COVID-19 in South Korea: Novel investigation techniques for tracing contacts,” Osong Public Health Res. Perspect., vol. 11, no. , pp. 60–63, Feb. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [2].Li R., Pei S., Chen B., Song Y., Zhang T., Yang W., and Shaman J., “Substantial undocumented infection facilitates the rapid dissemination of novel coronavirus (SARS-CoV-2),” Science, vol. 368, no. 6490, pp. 489–493, May 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [3].Eames K. and Keeling M., “Contact tracing and disease control,” Proc. Biol. Sci. Roy. Soc., vol. 270, pp. 2565–2571, Jan. 2004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Salathé M., “Digital epidemiology: What is it, and where is it going?” Life Sci., Soc. Policy, vol. 14, no. 1, p. 1, Dec. 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Singapore Government. (2020). Tracetogether. [Online]. Available: https://www.tracetogether.gov.sg
- [6].PePP-PT e.V. i.Gr. (2020). Pan-European Privacy-Preserving Proximity Tracing (PEPP-PT) [Online]. Available: https://www.pepp-pt.org
- [7].(2020). Safe Paths. [Online]. Available: http://safepaths.mit.edu
- [8].Pelusi L., Passarella A., and Conti M., “Opportunistic networking: Data forwarding in disconnected mobile ad hoc networks,” IEEE Commun. Mag., vol. 44, no. 11, pp. 134–141, Nov. 2006. [Google Scholar]
- [9].Zhang X., Neglia G., Kurose J., and Towsley D., “Performance modeling of epidemic routing,” Comput. Netw., vol. 51, no. 10, pp. 2867–2891, Jul. 2007. [Google Scholar]
- [10].Helgason O., Kouyoumdjieva S. T., and Karlsson G., “Opportunistic communication and human mobility,” IEEE Trans. Mobile Comput., vol. 13, no. 7, pp. 1597–1610, Jul. 2014. [Google Scholar]
- [11].Chancay-García L., Hernández-Orallo E., Manzoni P., Calafate C. T., and Cano J., “Evaluating and enhancing information dissemination in urban areas of interest using opportunistic networks,” IEEE Access, vol. 6, pp. 32514–32531, 2018. [Google Scholar]
- [12].Dede J., Forster A., Hernandez-Orallo E., Herrera-Tapia J., Kuladinithi K., Kuppusamy V., Manzoni P., bin Muslim A., Udugama A., and Vatandas Z., “Simulating opportunistic networks: Survey and future directions,” IEEE Commun. Surveys Tuts., vol. 20, no. 2, pp. 1547–1573, 2nd Quart., 2018. [Google Scholar]
- [13].Hernández-Orallo E., Murillo-Arcila M., Calafate C. T., Cano J. C., Conejero J. A., and Manzoni P., “Analytical evaluation of the performance of contact-based messaging applications,” Comput. Netw., vol. 111, pp. 45–54, Dec. 2016. [Google Scholar]
- [14].Hernandez-Orallo E., Olmos M. D. S., Cano J.-C., Calafate C. T., and Manzoni P., “CoCoWa: A collaborative contact-based watchdog for detecting selfish nodes,” IEEE Trans. Mobile Comput., vol. 14, no. 6, pp. 1162–1175, Jun. 2015. [Google Scholar]
- [15].Ferretti L., Wymant C., Kendall M., Zhao L., Nurtay A., Abeler-Dörner L., Parker M., Bonsall D., and Fraser C., “Quantifying SARS-CoV-2 transmission suggests epidemic control with digital contact tracing,” Science, vol. 368, no. 6491, May 2020, Art. no. eabb6936. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [16].Hellewell J., “Feasibility of controlling COVID-19 outbreaks by isolation of cases and contacts,” Lancet Global Health, vol. 8, no. 4, pp. e488–e496, Apr. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [17].Christaki E., “New technologies in predicting, preventing and controlling emerging infectious diseases,” Virulence, vol. 6, no. 6, pp. 558–565, Aug. 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Tizzoni M., Bajardi P., Decuyper A., Kon Kam King G., Schneider C. M., Blondel V., Smoreda Z., González M. C., and Colizza V., “On the use of human mobility proxies for modeling epidemics,” PLoS Comput. Biol., vol. 10, no. 7, Jul. 2014, Art. no. e1003716. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Lima A., Pejovic V., Rossi L., Musolesi M., and Gonzalez M., “Progmosis: Evaluating risky individual behavior during epidemics using mobile network data,” 2015, arXiv:1504.01316. [Online]. Available: https://arxiv.org/abs/1504.01316
- [20].Rubrichi S., Smoreda Z., and Musolesi M., “A comparison of spatial-based targeted disease mitigation strategies using mobile phone data,” EPJ Data Sci., vol. 7, no. 1, p. 17, Dec. 2018. [Google Scholar]
- [21].Salathé M., Kazandjieva M., Lee J. W., Levis P., Feldman M. W., and Jones J. H., “A high-resolution human contact network for infectious disease transmission,” Proc. Nat. Acad. Sci. USA, vol. 107, no. 51, pp. 22020–22025, 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].Mastrandrea R. and Barrat A., “How to estimate epidemic risk from incomplete contact diaries data?” PLOS Comput. Biol., vol. 12, no. 6, pp. 1–19, Jun. 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [23].Fraser C., Riley S., Anderson R. M., and Ferguson N. M., “Factors that make an infectious disease outbreak controllable,” Proc. Nat. Acad. Sci. USA, vol. 101, no. 16, pp. 6146–6151, Apr. 2004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [24].Klinkenberg D., Fraser C., and Heesterbeek H., “The effectiveness of contact tracing in emerging epidemics,” PLoS ONE, vol. 1, no. 1, pp. 1–7, Dec. 2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [25].Kwok K. O., Tang A., Wei V. W. I., Park W. H., Yeoh E. K., and Riley S., “Epidemic models of contact tracing: Systematic review of transmission studies of severe acute respiratory syndrome and middle east respiratory syndrome,” Comput. Struct. Biotechnol. J., vol. 17, pp. 186–194, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [26].Müller J., Kretzschmar M., and Dietz K., “Contact tracing in stochastic and deterministic epidemic models,” Math. Biosci., vol. 164, no. 1, pp. 39–64, Mar. 2000. [DOI] [PubMed] [Google Scholar]
- [27].Huerta R. and Tsimring L. S., “Contact tracing and epidemics control in social networks,” Phys. Rev. E, Stat. Phys. Plasmas Fluids Relat. Interdiscip. Top., vol. 66, no. 5, Nov. 2002, Art. no. 056115. [DOI] [PubMed] [Google Scholar]
- [28].Farrahi K., Emonet R., and Cebrian M., “Epidemic contact tracing via communication traces,” PLoS ONE, vol. 9, no. 5, May 2014, Art. no. e95133. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [29].Keeling M. J. and Rohani P., Model. Infectious Diseases Humans Animals. Princenton, NJ, USA: Princenton University Press, 2008. [Google Scholar]
- [30].Yang H.-X., Wang W.-X., Lai Y.-C., and Wang B.-H., “Traffic-driven epidemic spreading on networks of mobile agents,” EPL Europhys. Lett., vol. 98, no. 6, Jun. 2012, Art. no. 68003. [Google Scholar]
- [31].Computer Laboratory—University of Cambridge. (2010). The Fluphone Study. [Online]. Available: https://www.fluphone.org
- [32].Raskar R., “Apps gone rogue: Maintaining personal privacy in an epidemic,” 2020, arXiv:2003.08567. [Online]. Available: http://arxiv.org/abs/2003.08567
- [33].de Jong B. C., Gaye B. M., Luyten J., van Buitenen B., André E., Meehan C. J., O’Siochain C., Tomsu K., Urbain J., Grietens K. P., Njue M., Pinxten W., Gehre F., Nyan O., Buvé A., Roca A., Ravinetto R., and Antonio M., “Ethical considerations for movement mapping to identify disease transmission hotspots,” Emerg. Infectious Diseases, vol. 25, no. 7, Jul. 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [34].Barabási A.-L., Network Science. Cambridge, U.K.: Cambridge Univ. Press, 2016. [Google Scholar]
- [35].Isella L., Romano M., Barrat A., Cattuto C., Colizza V., Van den Broeck W., Gesualdo F., Pandolfi E., Ravá L., Rizzo C., and Tozzi A. E., “Close encounters in a pediatric ward: Measuring face-to-face proximity and mixing patterns with wearable sensors,” PLoS ONE, vol. 6, no. 2, pp. 1–10, Feb. 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [36].Tsai T.-C. and Chan H.-H., “NCCU trace: Social-network-aware mobility trace,” IEEE Commun. Mag., vol. 53, no. 10, pp. 144–149, Oct. 2015. [Google Scholar]
- [37].Gillespie D. T., “A general method for numerically simulating the stochastic time evolution of coupled chemical reactions,” J. Comput. Phys., vol. 22, no. 4, pp. 403–434, Dec. 1976. [Google Scholar]