

Abstract
Digital experiences capture an increasingly large part of life, making them a preferred, if not required, method to describe and theorize about human behavior. Digital media also shape behavior by enabling people to switch between different content easily, and create unique threads of experiences that pass quickly through numerous information categories. Current methods of recording digital experiences provide only partial reconstructions of digital lives that weave – often within seconds – among multiple applications, locations, functions and media. We describe an end-to-end system for capturing and analyzing the “screenome” of life in media, i.e., the record of individual experiences represented as a sequence of screens that people view and interact with over time. The system includes software that collects screenshots, extracts text and images, and allows searching of a screenshot database. We discuss how the system can be used to elaborate current theories about psychological processing of technology, and suggest new theoretical questions that are enabled by multiple time scale analyses. Capabilities of the system are highlighted with eight research examples that analyze screens from adults who have generated data within the system. We end with a discussion of future uses, limitations, theory and privacy.
Keywords: Mobile, internet use, cognitive science, communication, visualization, software development, personal tools
Background.
This multi-year collaboration is designed to develop new methods and analytics to understand how people use digital media, and how they are affected by digital media. The collaboration combines expertise across a number of different areas, including media psychology, behavioral science, medicine, political communication, dynamic modeling of time series data, text extraction from images, database construction, and smartphone app development.
1. INTRODUCTION
The breadth of digitized experiences is impressive. Laptop computers and smartphones can be used for email and texting, shopping and finances, business and social relationships, work spreadsheets and writing, entertainment TV, news, movies and games, and monitoring personal information about health, activity, sleep, energy, appliances, driving and even home security, lighting and irrigation. The variety of human experiences available digitally will continue to grow as more artifacts of life – from refrigerators to shoes to food to car parts – become part of the so-called “internet of things.”
Although digital promises are decades old, the ubiquity and completeness of digitization is new and has crept up on us. Life now unfolds on and through digital media, not just in the familiar media categories of entertainment and work, but across multiple life domains including tasks and platforms related to social relationships, health, finance, work, shopping, politics, school, entertainment, parenting, and more. The merging of daily and digital life prompts consideration of how we study human behavior in its natural context. It is increasingly difficult to imagine any attempt to assess the course of individuals’ thinking, feeling or behavior without recourse to information obtained from digital media.
We propose consideration of the digital screenome, i.e., a unique individual record of experiences that constitute psychological and social life on digital devices with screens, the study of which we call screenomics. Like other “omes” from the biological and social sciences, the screenome has a standardized structure. It is composed of smartphone, laptop, and cable screens, with information sequences describing the temporal organization, content, functions and context of person-screen interactions. The screenome’s most important qualities are that it defines both the general structure of everyone’s screen experiences and the individual variants within that structure that are related to unique social, psychological, and behavioral characteristics and experiences. The screenome can be usefully linked to other levels of analysis showing, for example, how biological omics might affect or be affected by digital life experiences (Chen et al., 2012), and how cultural context might change or be changed by individual experiences (Jenkins, 2006).
This article first reviews how new digital technology has changed the ways people experience life. Then we define the screenome and its elements as a fundamental description of digital life, noting the benefits and differences of this approach relative to other logging and experience sampling methods. Next, we review how psychological theory can be extended by study of the screenome, including new theoretical questions that can be asked as a result of data that includes multiple time domains of experience. We then describe a specific system for recording and analyzing the screenome, followed by eight examples illustrating a variety of ways the screenome can be analyzed. We end with a discussion of limitations, future considerations, privacy and theory.
2. PSYCHOLOGICAL IMPLICATIONS OF DIGITIZATION
The breadth of digitization is reason enough to bend research methods toward recording life in media. There is an opportunity now to know more about human behavior via media than has ever been possible. We note three important changes in media that bolster this claim.
First, the digitization of life has produced a mediatization of life (Lundby, 2014), whereby societies experience psychological, social, and cultural transformations caused by media saturation. This means more than the simple fact that analog experiences are now digital. Mediatization means that life experiences now have all of the added features, for better and worse, of a symbolic experience. Interfaces, displays, visual effects, and device forms all add unique value to analog counterparts. Digitally mediated representations of life are now a primary means by which individuals evaluate life, and make decisions about themselves, their social partners and the world.
Second, while the amount of digital information has expanded, the number of different screen sources has consolidated. Twenty years ago, before smartphones and the rise of laptop computers, there were numerous separate screens that were specialized for different experiences (e.g., music players, work computers, home theaters). Now, smartphones and laptops are prominent devices, and especially for Millennials, a third of whom have cut the cords to other screens (GfK Research, 2017). The primary implication of screen consolidation is that numerous and radically different experiences, ones that in analog life would take significant time to arrange or reorder, can now be experienced in rapid succession on a single screen. Two recent studies of content switching on a digital device found that the median time devoted to any single activity was 10 to 20 seconds (Yeykelis, Cummings & Reeves, 2014; Yeykelis, Cummings & Reeves, 2018), and studies about technology use at work find only slightly longer segments (e.g., Mark, et al., 2012). Advances in media technology are providing both more flexibility in the types of experiences that can be engaged on any given screen and the pace at which we can switch among those experiences.
Third, digitization has influenced the fragmentation of experience (Yeykelis et al, 2018). Digital technology has freed individuals from the requirement that an activity be experienced whole and uninterrupted. Most digital experiences can now be paused and restarted without missing a thing. Thus, people are increasingly free to partition experiences into smaller bits and attend to those smaller pieces whenever they choose. Individuals have increased control over digital experiences, and are now able to create threads that weave in and out of larger life categories. Psychological research has long highlighted how temporal proximity strengthens the interdependence among different types of experiences (e.g., stimulus response pairings). Contextual differences in how information is presented are well-known to influence attitudes, decisions and behaviors (e.g., Kahneman, 2011; Ross & Nisbett, 2011). Users’ quick-switching between activities creates considerable opportunity for context effects; for example, for social relationships to influence work, for work to influence play, for money to influence health, and so on. The record of life now embedded in digital life provides new opportunity to study the complexities of context effects on real-world human behavior.
3. THE SCREENOME AS A MEASURE OF DIGITAL LIFE
Any system used to study personal experiences needs to record them at the new speed of life. Recording how individuals’ digital behavior weaves in and out of different content, actions, applications, platforms and commercial products requires assessment of moment-by-moment changes in the order in which they occur. General characterizations of daily life (e.g., “I use Facebook about one hour every day”) do not capture the reality of how quickly individuals are switching experiences or of how experiences are being altered by or are altering other parts of life. Study of individuals’ in situ behavior, and the fluid movement between and among digital content thus requires tracking or logging experiences as they unfold in real time.
3.1. Literature On Life Logging Methods
A range of different methods and goals characterize research that tracks individuals’ real-world media experiences. The literatures have names ranging from experience sampling to shadowing to url logging to lifelogging, and they are in disciplines as diverse as psychology, computer science, political science and health. We review each of the techniques, noting their strengths and weaknesses in relation to our goal of understanding the psychological experiences that individuals have with diverse media content and over extended periods of time.
Offline and experience sampling methods (e.g., diaries, post-hoc surveys) have been used frequently in psychology (e.g., Fraley & Hudson, 2014; Mehl & Connor, 2012) and communication (e.g., Kubey & Csikszentmihalyi, 2013). These methods allow people to provide subjective evaluations and reports of their momentary or recent experiences, and technology is often used to assist recording (e.g., text message surveys, photo sharing, and digital diaries). People are asked to make evaluations that summarize long time periods, often no shorter than one day and only rarely shorter than one hour (Fraley & Hudson, 2014; Csikszentmihalyi & Larson, 2014). Beyond concerns about intrusiveness and errors associated with recall and subjective judgments, it is difficult for people to reconstruct digital experiences at granularities that match the speed of behavior.
There have been attempts to closely shadow information workers while they use technology during the day (e.g., Su, Brdiczka, & Begole, 2013), and one study even had researchers shadowing people in their homes and recording media use every ten seconds (Taneja, Webster, Malthouse, & Ksiazek, 2012). Those studies provide rich context, but are not able to note fine-grained details of use that go beyond genre and software titles. The effort and expense required to arrange observations, take detailed notes, and debrief participants makes such methods difficult to scale.
Lab experiments, used often in psychology and media studies, create controlled environments where quick changes can be recorded. This allows researchers to examine, for example, television program changes (Wang & Lang, 2012), and the use of features that appear only momentarily, like swiping, hovering, sliding, and zooming (Sundar, Bellur, Oh, Xu, & Jia, 2014). The constraints of lab settings (e.g., provision of limited content, imposed instructions about the goals for making changes) provide for focused study of a specific digital experience or interface. In software usability studies, for example, screen captures or video recordings of a user’s interaction are used to understand how and when users discover and use particular design features (e.g., Kaufman et al, 2003). However, by design, these paradigms inhibit movement across the wide variety of content available to people outside of the lab, and thus are difficult to generalize to real-world behavior.
Researchers have long sought measures that use technology to sample natural experiences more often and without the requirement that people interrupt their experiences to cooperate. Studies that use computer and smartphone logging are plentiful, from political science to medicine to human-computer interaction. Search and toolbar plugins that provide precise records of websites visited and search terms used (e.g., Cockburn & McKenzie, 2001; Jansen & Spink, 2006; Kumar & Tomkins, 2010; Tossell, Kortum, Rahmati, Shepard, & Zhong, 2012; White & Huang, 2010) have been used to study diverse topics such as creation of online echo chambers (Dvir-Gvirsman, Tsfati, & Menchen-Trevino, 2016), and how health, diet, and food preparation are linked to medical problems (West, White, & Horvitz, 2013). In political science, several projects have focused on analysis of single platforms, notably Twitter (e.g., Colleoni, Rozza & Arvidsson, 2014). In the study of social networks, phone and text logs have been used to describe the variety and number of contacts in social networks (Battestini, Setlur, & Sohn, 2010), how and when people change locations (Deville, et al., 2014), and differences in communications within families, at work, and in social networks (Min, Wiese, Hong, & Zimmerman, 2013). Sophisticated sensors and recordings, from call and SMS logs to Bluetooth scans to app usage, have been used in psychology to describe personality (Chittaranjan, Blom, & Gatica-Perez, 2013), student mental health and progress in college (Wang et al., 2014), health interventions (Aharony, Pan, Ip, Khayal, & Pentland, 2011), and social networks (Eagle, Pentland, & Lazer, 2009). Typically, these approaches concentrate on tracking of very specific types of content or behavior. However, these data sets continue to grow, with significant new projects underway; for example, the Kavli Human Project that is collecting everything from the genome to smartphone usage from 10,000 New Yorkers over 20 years (Azmak et al., 2016).
In computer science, lifelogging describes efforts to record, as a form of pervasive computing, the totality of an individual’s experiences using multi-modal sensors, and then store those data permanently as a personal multimedia archive (Dodge & Kitchin, 2007; Gurrin, Smeaton, & Doherty, 2014; Jacquemard, Novitzky, O’Brolcháin, Smeaton, & Gordijn, 2014). There are proposals for storing the entirety of digital traces, including MyLifeBits (e.g., Gemmell, Bell, Lueder, Drucker, & Wong, 2002), recordings that track the focus of visual attention (Dingler, Agroudy, Matheis, & Schmidt, 2016), a smartphone application, LifeMap, that can identify and store precise locations (Chon & Cha, 2011), comprehensive platforms that allow developers to create original tools (Rawassizadeh, Tomitsch, Wac, & Tjoa 2013), and systems, like “Stuff I’ve Seen,” that emphasize recording for the purpose of information reuse (Dumais et al., 2016).
The goal of lifelogging is often to obtain information about oneself, similar to an automated biography, that can be summarized on a dashboard, and then used for reflection and self-improvement. Although that goal is different from our interest in studying psychological experiences, our framework is related to lifelogging. In particular, the ability to examine relations among different kinds of experiences in multiple domains is important in lifelogging and for screenomics. The proposed breadth of lifelogging data, however, from implanted physiological sensors to cameras that provide environmental context, is more ambitious than our own, especially with respect to enabling studies of human behavior at scale.
The most important limitation of many logging techniques is that they cannot easily capture threads of experience that span different applications, software, platforms and screens. Consider a user who switches from a Facebook post about the President to a CNN news story about the President, to a Saturday Night Live video that parodied the President, to the creation of a text message about the President – all within a single minute. It is conceivable that a researcher could obtain a record of that person’s Facebook activity using an API, install a browser plug-in that would record the CNN website visit, and obtain logs about phone calls and SMS activity that would contain time-stamped text messages. However, the management necessary to combine the information would be substantial, including negotiation to obtain individual passwords for each platform-specific API and creation of plug-ins for several browsers (or limiting subjects to the use of one). This is not an unusual example, but one that is increasingly typical of how people use a wide variety of media as they follow their own interests and create unique threads of experience. We propose an alternative framework based on the collection of high-density sequences of screenshots – screenomes – for obtaining accurate records of what people actually do with technology, within and across applications, software, platforms, and screens.
3.2. The Screenome and Psychological Theory
The goal of collecting screenomes is to obtain data that can be used both to test current theory about human behavior and digital life, and to generate new research questions that have not yet been studied. In this section, we briefly review established theories that could be elaborated with screenome analyses and indicate how the screenome might enable new theories of digital behavior. We organize comments about the screenome and theory around four key aspects of behavior: time, content, function and context.
Time.
Several reviews in psychology consider time to be a critical differentiator of psychological theories (e.g., Kahneman, 2011). Early conceptions of human-computer interaction (Newell & Card, 1985) also highlight the importance of time scales (from milliseconds to years) when theorizing about complex behaviors. Education, for example, can be defined with respect to numerous time scales, from neural firings and memory traces that occur over milliseconds, to the social dialogue between students and teachers that occur during a 3-hour seminar, or with respect to institutional policy changes that occur over decades (Lemke, 2000). Media and technology are similarly complex in that they can also be approached from many time scales (Reeves, 1989; Nass & Reeves, 1991). Psychological effects of media exposure, for instance, can be defined with respect to physiological arousal and dopaminergic rewards that occur over seconds, with respect to conditioned responses built over weeks, or with respect to use patterns that change over months or years. Each different time scale, from millisecond responses to processes unfolding over years, may require a separate theoretical approach. Certainly, each requires observation and measurement that is appropriately matched to the time-scale at which the processes work.
Many studies about psychological processing of technology have examined relatively long experiences; for example, the amount of time that people say they spend with online categories like news (e.g., Bakshy, Messing, & Adamic, 2015), social media (e.g., Allcott & Gentzkow, 2017) or computer and video games (e.g., Greitemeyer & Mügge, 2014). Media use, measured in units of days, weeks and months, is conceived as an accumulation of experiences that are thought to be influential as an aggregate. For example, greater time spent playing video games is associated with increases in aggressive tendencies, a finding that supports theory about how the accumulation of general learning about normative beliefs and behavioral scripts changes behavioral tendencies (Gentile, Li, Khoo, Prot, & Anderson, 2014). The general learning model applied to video games emphasizes repeated exposure over months and years – large time units – with the process of affective habituation (a desensitization to aggression) contributing to long-term development of personality characteristics that influence behavior over a lifetime. The assessment of general patterns of media experience over the longer time units (e.g., “How many hours did you spend playing a video game this month?”) is matched to the extended process of interest.
The fine granularity of behavior recorded in screenomes simultaneously supports investigation of individuals’ aggregate experience and their moment-by-moment experiences. The multiple time-scale nature of the screenome thus provides new opportunities to address areas where there is a mismatch between the theoretically implicated time scale and the time scale at which measurements are obtained. For example, current research on addiction to technology (e.g., Petry, et al., 2014; Kubey & Czikszentmihalyi, 2002), and particularly addiction to smartphones (Kwon et al., 2013; Lin et al., 2015), typically asks people to evaluate their own patterns of use, how they feel when interacting with different content, how much they miss their device when it is not with them or how addicted they feel to their phone – one time self-reports that apply to weeks or months of device use. The biology that explains addiction, however, operates at a much different time scale. If technology addiction is indeed similar to substance addiction, then the biobehavioral responses occur within seconds after the introduction of a pleasurable stimulus. These responses, marked by momentary changes in neurochemistry, become conditioned responses over multiple repetitions (Volkow, Koob, & McLellan, 2016). The time domain of the biological response is on the order of single-digit seconds. Most measures of addiction, however, consider use patterns that manifest at substantially longer units of time, usually days, weeks and months. The mismatch between the theory and the data occurs because of the difficulty in measuring individuals’ moment-by-moment technology use. Although it is possible to examine behavioral contingencies in the laboratory, those assessments could not easily, if ever, simulate the natural experience of the hundreds of smartphone sessions an individual might engage in during a typical day in their natural environment. The screenome allows observation of both how the moment-by-moment contingencies form in the natural environment and how those contingencies develop into or transform long-term behavior.
Similar opportunities exist in other research areas. Laboratory research on emotion management, for example, examines how individuals’ switching between different kinds of media content (e.g., news, entertainment) facilitates their goals to balance or equalize their emotional experience (e.g., Bartsch, Vorderer, Mangold, & Viehoff, 2008). Highly negative experiences, or highly arousing ones, are balanced by seeking ones that are positive or calming. The balancing occurs at time scales that range from days and hours to the length of time it takes to experience intact programs that last several minutes or hours and that correspond to the units of media and time scales that researchers have been able to access. Consequently, the theories that come from the research are necessarily about the units of media that could be measured. The screenome allows observation of how individuals switch between different kinds of media content at the time scale of seconds, and thus facilitates examination of how emotion management might occur within seconds, allowing for development of new theories that account for the micro-management of emotion. New research using the screenome (some of which will be described in Section 5) has found, for example, that when technology offers the ability to easily make quick switches, arousal management may occur within seconds (i.e., seeking calm in the face of too much excitement) (Yeykelis et al., 2014). The microscopic view provided by this new data stream changes explanations for why and how individuals use technology to manage emotions. In principle, balancing emotions at the second-to-second time scale may be more reactive and less thoughtful, while balancing emotions at the hour-to-hour or day-to-day time scale may be more reflective and purposive. The screenome thus can inform existing and new theory about how “bottom-up” regulation processes and “top-down” processes combine to drive emotional experience in the natural digital environment.
The temporal density of information in the screenome means that researchers can zoom in and out across time scales, examining time segments and sequences that span seconds and months and (eventually) years. The temporal density of the behavioral observations can foster discovery of the actual and multiple time scales that govern processing of media (Ram & Diehl, 2015). Researchers can simultaneously consider the biological, psychological and social theories relevant to a single process, and note both what is unique about each level of influence and how processes that manifest at different time scales (or levels of analysis) afford or constrain processes at other time scales. For example, when considering technology effects on cognition among different aged people, multiple time domain studies can simultaneously account for micro-time changes, for example in attentional focus, and macro-time changes related to longer-term development, for example in cognitive aging (Charness, Fox, & Mitchum, 2010). Integration across multiple levels of analysis and time scales has long been advocated in developmental psychology (e.g., Gottlieb, 1996; Nesselroade, 1991), even though most research remains focused on a single time domain (Ram & Diehl, 2015). The screenome facilitates integration across levels of analysis. For example, the flexible zoom afforded by temporally dense data allows examination of the bidirectional interplay between short-term stressors that manifest at a fast time scale during digital interactions and longer-term changes in well-being that manifest across weeks or months (Charles, Piazza, Mogle, Sliwinski, & Almeida, 2013). In sum, the inherent facility for combining multiple time scales in the same inquiry by simply zooming in and out of the temporal sequences embedded in the screenome creates new opportunities to examine how processes or content in one domain (and its corresponding time scale) influence and are influenced by processes and content in another domain (and at a different time scale).
Many areas of inquiry can benefit from the multiple time scale inquiry. Theories about individuals’ information processing, for example, all consider the sequencing of information. At fast time scales, perception and interpretation of any given piece of information may be influenced by what precedes and follows, through processes like priming (Hermans, De Houwer, & Eelen, 2001; Vorberg, Mattler, Heinecke, Schmidt, & Schwarzbach, 2003), framing (Seo, Goldfarb, & Barrett, 2010; Tversky & Kahneman, 1981), and primacy and recency effects (Murphy, Hofacker, & Mizerski, 2006). At slightly slower time scales, circadian, attentional, and interpersonal rhythms are reflected in, for example, the curation of media content (Cutting, Brunick, & Candan, 2012; Zacks & Swallow, 2007), the interactive cadence between consuming and producing information in dyadic communication (Beebe, Jaffe, & Lachmann, 2005; Burgoon, Stern, & Dillman, 2007), and daily cycles in sentiment of social media posts (Golder & Macy, 2011; Yin et al., 2014). The longitudinal sequences captured in the screenome provide new data about how all such rhythms manifest (or not) in media use, and they provide the temporal precision necessary for discovering the specific and often unknown time-scales at which individual behavior is actually organized. In the addiction example mentioned earlier, it would be possible to locate the specific, and likely idiosyncratic, cadence at which individuals respond to addictive features like notifications. Given that much psychological theory has not yet considered the time scale at which specific processes operate, the temporal component of the screenome can facilitate discovery of when and how often specific kinds of behavioral sequences manifest in everyday life.
A final point about the time information in the screenome is that the longitudinal data highlight and afford analysis of intraindividual change, as opposed to analysis of interindividual, cross-sectional differences. That is, the screenome is particularly relevant to theories about how one individual changes over time rather than about how groups of people are different at any given point in time. Much of the research in psychology and media has taken a nomothetic approach, examining between-subject differences in specific digital domains (e.g., health, social relationships, business collaboration). For example, active social media users have different friendship networks than inactive users. Findings based on interindividual differences, however, do not show how any given individual moves in and out of those networks, which is something that most people do every day (Estes, 1956; Robinson, 1950). Study of behavioral and psychological processes requires an idiographic approach (Magnusson & Cairns, 1996) that examines intraindividual variation to understand behavioral sequences (Molenaar, 2004). Given that most psychological theory is about within-person processes, intensive longitudinal data, like that included in the screenome, are required (Molenaar & Campbell, 2009; Ram & Gerstorf, 2009). The ability to track intraindividual change can enable discovery and testing of person-specific theories, detailed descriptions of individual-level processes that may be subsequently aggregated across people and groups. We show examples of intraindividual changes in the last section.
Content.
Theory in media psychology is often organized around categories of media. Media are described with respect to software applications (e.g., Facebook, Twitter), companies that produce or aggregate information (e.g., CNN, YouTube), or market segments (e.g., politics, health, relationships, finances). Cross-cutting themes organize content by domain (e.g., games, retail, finance, health, and social relationships), type of problems addressed (e.g., social issues, public policy or private problems), modality (e.g., text, image, video), or whether the content that is user generated versus sent from others (Kietzmann, Hermkens, McCarthy, & Silvestre, 2011). Within any given modality, text can be described in terms of sentiment (Kramer, Guillory, & Hancock, 2014), sentence complexity (e.g., number of words, sentence logic)(Schwartz et al., 2013) or vocabulary sophistication (Agichtein et al., 2008). Pictorial content is described with respect to presence and characteristics of faces (both particular people and strangers)(Krämer & Winter, 2008), the type of activity or action depicted (e.g., illegal behavior, social gatherings)(Morgan, Snelson, & Elison-Bowers, 2010). Forms of content are mapped to information content (Thorson, Reeves, & Schleuder, 1985; Lang, 2000), for example, through quantification of visual complexity or color spectrum qualities. And this list could easily be extended.
Any media experience, even a short one, is infinitely describable, never a “pure” stimulus, one thing and nothing else (Reeves, Yeykelis & Cummings, 2016). The inherent complexity of the stimuli complicates theory, especially when the units of media chosen for study are not necessarily consistent with the units of experience that a theory is about. Most studies about media and psychology begin by looking at a “big” (often commercially defined) category of content that is accessible to researchers (e.g., Facebook use, Amazon retail purchases, Outlook email use). That content, however, is incredibly complex. For example, social media messages may contain specific words that are shared by others or that reveal personal secrets, retail purchases may include the time when prices are compared, and email software shows whether information processed is incoming or outgoing, and so on. The screenome offers a more flexible method to pinpoint specific content of theoretical interest. In the study of news consumed online, for example, researchers can observe the exact screenshots related to a particular event (e.g., what the President said about an event at a specific time) regardless of whether the screen containing the information appeared in a formal news site, a social media post, a text message or anywhere else (we will show an example of these different placements in the last section). This has advantages for both confirmatory testing of theory and inductive generation of new theory.
The screenome can contribute to deductive, confirmatory testing of theory by providing stimulus specificity and by allowing for stimulus sampling. First, the screenome can be used to examine how a particular stimulus of interest is presented, engaged, and responded to in the real world. Studies can focus on the exact stimuli of interest without having to make assumptions about whether or not that content fits within a particular commercial container (or not). Second, the screenome provides the possibility to collect a representative sample of stimuli, without having to depend (as in the case of most media psychology experiments) on researcher selected examples of content that often inadequately represent a theoretically defined type of stimulus. Stimulus sampling is a problem in all social research (Judd, Westfall, & Kenny 2012), and media psychology in particular has suffered from use of paradigms where only one or a few prototypic stimuli are used to infer how a larger and more complex class of stimuli influences behavior (Reeves, et al., 2016). Media researchers can use the detailed record embedded in the screenome to examine all instances of a stimulus category for an individual, wherever and however those stimuli present themselves in the natural environment. The screenome thus simultaneously provides for both greater specificity and generalizability when testing relations between content and behavior.
The screenome can also be used to identify and define new types of content. The data stream is well suited to inductive research strategies and machine learning approaches to studying psychological responses (Shah, Cappella, & Neuman, 2015; Cappella, 2017). In those approaches, large numbers of stimuli are clustered based on stimulus qualities that are identified by computer algorithm rather than a priori definition of the exact material that may cause any specific effect of interest. The screenome is also suited to exploratory research that attempts to uncover theoretically useful definitions of digital content, definitions that can be substantially different than the commercial categories used in most research. For example, a database of millions of screenshots that are each tagged with respect to an effect of interest (e.g., arousal potential, visual complexity, relevance to social interaction) could be clustered in an attempt to identify the similarities and differences between screenshots that are different from and perhaps orthogonal to categories suggested by current theory. The screenome thus provides the raw material needed for inductive explorations into how individuals define and organize media content.
Function.
Functional theories in media psychology have been important for decades, including recent applications to the study of online behavior (Kaye & Johnson, 2002; Quan-Haase & Young, 2010; Raacke & Bonds-Raacke, 2008). These theories assume that the reasons people attend to media significantly influence what is attended to and how that information is perceived, remembered or used. Past research in this area of media psychology has focused on analysis of very large blocks of content by examining, for example, whether online and traditional media have different functions, or how different functions (e.g., social interaction, information seeking, passing time, entertainment, and relaxation) are served by different media modalities (e.g., text, image, video) (Sundar, 2012). The screenome provides for precise identification and study of how specific kinds of content serve different psychological functions.
In the laboratory, studies show that processing can be altered by precise manipulation of the motivations to process information (Sundar, Kalyanaraman, & Brown, 2003). For example, people who are asked to view political information with a motivation to learn how candidates stand on issues are more likely to become informed but have lower confidence in their knowledge, while people asked to view the same information with a motivation to find out what candidates are like as people pay greater attention to the pictorial content and have greater confidence in their knowledge. The point being that individuals differ in how they approach and use the media they encounter. The screenome offers information about how individuals interact with and use media content in the real world at the same level of specificity obtained in the laboratory. Information about the time that individuals dwell on different elements of content or how they focus on and follow different threads of information is all embedded in the screenome.
There is also need to understand if and how other laboratory results generalize to natural settings. For example, promising new work in neuroscience examines how differences in biologically constrained motivations to share information with others are related to how individuals receive and send media information (Meshi, Tamir, & Heekeen, 2015; Tamir, Zaki, & Mitchell, 2015). Neural activity in brain regions associated with motivation and reward are related to both subjective reports on sharing of information and on sharing actions in artificially constructed behavioral games. This work is by necessity done in the laboratory. Outside the laboratory, knowledge about individuals’ motivations has typically been studied through use of large-scale questionnaires (see Nadkarni & Hoffman, 2012 for a summary). This research notes very generally that individuals’ primary motivations to share through social media include connecting with others and managing the impressions that one can make of other people. Further, beyond some knowledge about how many texts or pictures individuals share in aggregate, little is known about the temporal organization of sharing, particularly with respect to what content was engaged immediately before or after sharing. Here the screenome provides a new microscope to examine what, when, and how often an individual shares material in real-world settings, as well as preferences for particular kinds of activities (e.g., reward-based games). This new record of screen activity can inform research about how functions of media in the laboratory, and the motivations individuals report in surveys, combine in everyday digital lives. In sum, the screenome provides data about how functions of media influence real-world behavior, and inductively, about new functions that have not yet been described.
Context.
A truism acknowledged by most psychological theory is that psychological contexts are inextricably linked to individual thinking, emotions and behavior (summarized by Rauthmann, Sherman, & Funder, 2015). Most psychologists agree that they have done a better job of understanding people than they have in understanding the situations in which they exist, and particularly the interaction between persons and situations. A forceful argument about the effects of the imbalance in attention to persons vs. situations was given by Ross and Nisbett (2011) when they questioned the relevance of the entirety of social and personality psychology, noting that much of what was “known” about behavior changed when the same phenomena were examined in a different context. Admonitions to examine situations are plentiful in many areas of psychology. In developmental psychology, for example, there has been strong evidence showing how the person-context “transactions” embedded, for example, in parent-child interactions (e.g., attachment theory) or epigenetic signaling (e.g., diathesis stress model) influence long-term development (Meaney, 2010). Dynamic systems theory, in particular, promotes the idea that all change, both long-term and short-term, is driven through a bidirectional interplay of biological and environmental “co-action” (Thelen & Smith, 2006).
The easy summary is that context is an important component of psychological theory. An advantage for research that hopes to include contextual detail is that increasingly complete descriptions of situations can now be obtained outside the laboratory. Many of the logging methods reviewed in the previous section can be used to obtain information about the “situation” surrounding any given behavior or sequence of behaviors. The added theoretical opportunity for the screenome is that much of the contextual information deemed important for understanding the situation is now embedded in digital records. Much of what is believed to be important outside of a media experience is now actually embedded in the media experience itself.
To illustrate, we highlight how specific aspects of psychological situations used to define contextual information across a range of theories (see Rauthmann et al., 2014) may be seen, at least partially, in the screenome. First, the cues that compose situations include objectively quantifiable information about persons, relationships, objects, events, activities, locations and time. These cues define “who, what, where, when and why” and are the environmental structures that help individuals define a particular experience, even a short one. All of these attributes can be extracted from the screenome and associated metadata (e.g., GPS). Second, the characteristics that give situations psychological meaning include, according to recent taxonomies (e.g., Rauthmann & Sherman, 2015), information about duty (is action required), intellect (is deep processing required), adversity (are there threats), positivity (is the situation pleasant), negativity (is the situation unpleasant), deception (is there dishonesty or duplicity), and socialability (are connections with other people possible, desirable or necessary). These characteristics can often be inferred from the screenome based on identification of textual and visual content. Third, situations are grouped or clustered into classes of situations that are based on the purpose of a situation. For example, in a taxonomy proposed by Van Heck (1984) that still guides much of the literature, situations are distinguished by conflict, joint working, intimacy, recreation, traveling, rituals, sport, excesses, and trading. A newer taxonomy based on evolutionary theory distinguishes situations with respect to self-protection, disease avoidance, affiliation, kin care, mate seeking, mate retention and group status (Morse, Neel, Todd, & Funder, 2015).
Each of these context characteristics can change the impact of any given digital experience and the screenome can provide information, otherwise difficult to uncover, that is relevant to determining the class to which a digital experience belongs. It is also worth noting that the screenome provides rich data for both quantitative and qualitative inductions. For qualitative researchers, and especially those who study uses of technology, the necessity of theorizing about the situations in which people use media is essential. The screenome may be particularly useful for ethnography because it allows researchers to engage in the “deep hanging out” that “gives voice” to the breadth of particulars that define the meaningfulness of individuals’ media practices (boyd, 2015; Carey, 1992; Geertz, 1998; Turkle, 1994). While screenshots do not follow people off-line, they do offer a sense of “over the shoulder” examination that facilitates discovery.
4. A FRAMEWORK FOR SCREENSHOT COLLECTION AND PROCESSING
In this section we outline the framework for collecting, processing, storing, examining, and analyzing individual screenomes. The overall architecture of our system is shown in Figure 1, with each module described below. In brief, each component of the architecture considers a separate task: recording experiences via device screenshots, extracting text and graphics from screenshots, and data from laptop and smartphone services, analyzing textual and graphical content with respect to important psychological features (e.g., sentiment, subjects covered), fusing the raw and processed data into a spatiotemporal database, visualizing data via interactive dashboards, and analyzing data using search engines, machine learning and statistical models.
Figure 1.
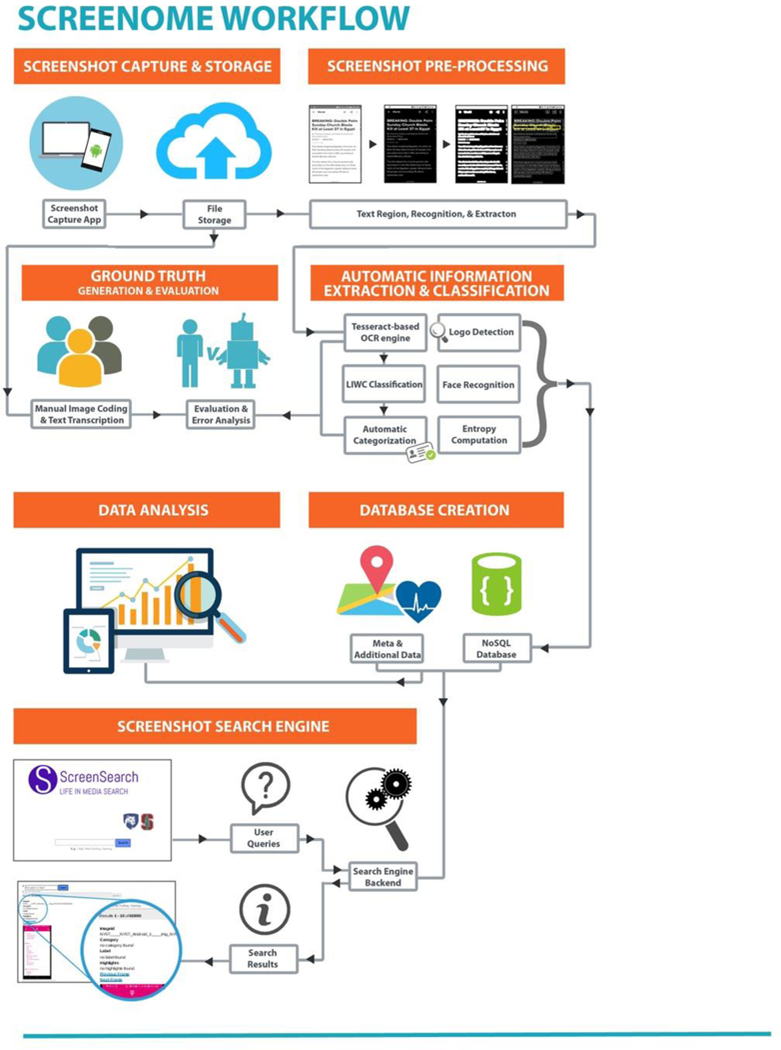
Diagram illustrating screenome workflow.
The use of the framework for a single subject proceeds as follows. First, screenshot capture software is installed on a subject’s smartphone and/or laptop. There is a separate application for Windows and Mac laptops, and an application for Android smartphones (iPhones are currently not supported). The installation of the software can be done during a visit to the research lab or the software can be downloaded from a research website. Screenshots are then automatically encrypted, compressed and transmitted on a daily basis to secure university servers while the subject uses the devices over the course of days, weeks or months. After data collection, preprocessing of the screenshots is accomplished using the procedures described below to extract text and images, and a database is then created that synchronizes all material in time. Statistical analyses are conducted using that database. Qualitative descriptions and coding of material is facilitated by a screenshot search engine (described below).
4.1. Collection of Screenshots
The data collection module includes software that captures screenshots at researcher-chosen intervals, stores them on local devices, and encrypts and transmits bundles of screenshots to research servers at intervals that accommodate constraints in bandwidth and device memory. In-house applications take screenshots at periodic intervals (e.g., every five seconds that the device is in use), and store those images in a local folder. Once or twice per day the folder is encrypted, transmitted and then deleted from the laptop or smartphone. Data collection on Android devices (Lollipop OS) is done with a two-component application that uses functions in the Media Projection Library to capture a short three-frame video of the screen action at a regular interval set by the researcher. One frame from each video is retained and stored in a local folder. AlarmManager functions are used to invoke periodic transfer of bundled and encrypted screenshots to the research server when the device has a wireless connection, is plugged in or has reached a pre-determined memory limit. Helper functions ensure that the application starts automatically on device reboot, and allow for remote updating. The application enables capture of a continuous stream of screenshots without any participant intervention, without excessive battery drain, and (based on participant debriefing) without undue influence on individuals’ normal device use (also see notes in Section 6.0). Applications for Mac and PC work similarly, but retain screenshots directly (rather than retain a video image). The Mac application, coded in AppleScript and shell script, takes screenshots at researcher-specified intervals, and saves to a local folder that is then periodically encrypted and sent to the research server. Application startup is managed through placement in the operating system’s launch daemon. For Windows computers, we used a commercial application, TimeSnapper (version 3.9.0.3), to take the screenshots. The software was set to launch automatically at computer startup and take screenshots every five seconds. A separate application periodically encrypts the data and sends it to the research server. New versions of the applications for each platform are further optimizing functionality, including a subject enrollment interface and researcher data collection management tools.
The screenshot data stream is supplemented with other data already available from individuals’ smartphones and wearables. We make use of commercial location tracking apps that can identify locations and modes of transportation. Screenome data can be supplemented with surveys (e.g., online questionnaires), laboratory assessments (e.g., blood assays, cognitive tasks), or concurrent ambulatory monitoring (e.g., actigraphy, physiological monitoring, experience sampling). Synchronization of streams is currently done using time-stamps that are encoded from each device’s internet-updated clock.
4.2. Information Extraction
Screenshots represent the exact information that people consume and produce; however, extraction of behaviorally and psychologically relevant data from the digital record is required prior to analysis. The extraction techniques that follow were used to produce the example analytics reported in the next section, and are being updated as screenomics research develops.
Optical character recognition (OCR).
A major component of screenshot content is text. Some of the challenges typically associated with text extraction from degraded or natural images (e.g., diverse text orientation, heterogeneous background luminance) are not problematic with screenshots. But some are including inconsistency in fonts, screen layouts, and presence of multiple overlapping windows and these problems complicate identification, extraction, and organization of textual content. Our current text extraction module (Chiatti et al., 2017) makes use of open-source tools: OpenCV for image pre-processing (Culjak, Abram, Pribanic, Dzapo, & Cifrek, 2012), and Tesseract for OCR (Smith, 2007).
As shown in Figure 1, each screenshot is first converted from RGB to grayscale and then binarized to discriminate the textual foreground from surrounding background. Simple inverse thresholding combined with Otsu’s global binarization technique (Otsu, 1979) has been sufficient, given that most screenshots have consistent illumination across the image. Candidate blocks of text are then identified using a connected component approach (Talukder & Mallick, 2014) where white pixels are dilated, and a rectangular contour (i.e. bounding box) is wrapped around each region of text. Given the predominantly horizontal orientation of screenshot text, processing efficiency is maintained by skipping the skew estimation step. Each candidate block of text is then fed to a Tesseract-based OCR module to obtain a collection of text snippets that are compiled into Unicode text files, one for each screenshot. Our published studies, wherein we compared OCR results against ground-truth transcriptions of 2,000 images, show the accuracy of the text extraction procedures at 74% at the individual character level (Chiatti et al., 2017). On-going experiments support further improvements through integration of neural net-based line recognition that is trained and tuned specifically on the expanding screenshot repository, similar to the approach used in the OCRopus framework (Breuel, 2008), and included in the alpha version of Tesseract 4.0. Improvements in image segmentation, in particular, are expanding further opportunities for natural language processing analyses (e.g., LIWC; Pennebaker, Booth, Boyd, & Francis, 2015) that are then used to identify meaningful content from the extracted text.
Image analysis.
Parallel to text extraction, the pictures and images nested within each screenshot can be cataloged. This is done with open-source computer vision tools in the OpenCV library (Culjak et al., 2012) that provide for face detection, template matching, and quantification of color distributions and other image attributes. For example, identification of the screenshots that contain specific logos (e.g., ABC News, Facebook, Twitter) or screen pop-ups (e.g., keyboards, notification banners) can be accomplished through researcher selection of a reference template of interest and automated identification of edges that have the best match to the template (using Canny edge detection; Canny, 1986). Probability distributions can be examined for viable threshold values and probable matches confirmed through human tagging. Similar procedures provide for identification of faces and other common images using Haar cascades (Lienhart & Maydt, 2002; Viola & Jones, 2001) and lightweight convolutional neural nets and pre-trained detection models (Szegedy et al., 2015). Pixel-level information is also used to quantify screenshots with respect to image complexity (e.g., color entropy, Sethna, 2006.), and image velocity and flow (e.g., sum difference of RGB values for all pixels in successive screenshots, Richardson, 2003). These features are then used, in conjunction with labeled data, to identify the specific applications being used, type of content and so on. For example, smartphone screens where the user is producing textual content are identified with 98% accuracy using prediction models based on a collection of color entropy, face count, text, and logo features.
Labeling (Human Tagging).
There are some features of screenshots that are of theoretical interest but for which there are not yet automated methods for obtaining labels. Consequently, we facilitate labeling of individual screenshots with tools for human tagging. Human labeling of big data often uses public crowd-sourcing platforms (e.g., Amazon Mechanical Turk; Buhrmester, Kwang, & Gosling, 2011; Berinsky, Quek, & Sances, 2012; Bohannon, 2011; Horton, Rand, & Zeckhauser, 2011). Confidentiality and privacy protocols for the screenome require that labeling be done only by members of the research team that are authorized to see the raw data. Manual labeling and text transcription is done using a custom module built on top of the localturk opensource API (Vanderkam, 2017) and for some tasks the opensource Datavyu (2014) software. Through a secure server, screenshot coders (human subject approved university students) are presented screenshots to categorize using pre-defined response scales related to the specific features of content and function depicted in the image. For each particular project, research question or analysis, manual annotations for randomly or purposively selected subsets of screenshots are used as ground truth data to train and evaluate the performance of machine learning algorithms that are then used to propagate informative labels to the remaining data. For example, in a project focused on smartphone switching behaviors, the random forests currently used to propagate labels indicating the specific application that appears in a given screenshot currently run at greater than 85% accuracy, with misclassifications of any specific category running less than 1 percent (browsing in Facebook, 0.9% error; lock screen, 0.8%; home screen, 0.7%; browsing in Chrome, 0.6%; browsing in Instagram, 0.6%). Inaccuracies appear to be mostly in distinguishing very similar activities (e.g., browsing in Instagram vs Facebook) that are often considered together (e.g., both are social applications that serve similar functions).
4.3. Master Database
The output of information extraction and manual classification modules supplement the raw screenshots with a collection of additional “metadata.” Heterogeneity of data types is accommodated using a secure, limited access NoSQL database deployed in accordance with human subjects protocols for protection of privacy. Text, image, numeric, string, spatial, and temporal data are fused (by subject and time) within a schema-less NoSQL framework that supports flexible query and analysis. We use the open source MongoDB document-oriented framework that facilitates expansion of the metadata associated with subsets of the collection as different researchers in our group develop, refine, and add new fields and corresponding metrics to the feature set. The framework is specifically constructed to facilitate scaling, including repository expansion, parallelization, flexible workload distribution, and smooth integration with search, retrieval, and data analysis technologies.
4.4. Screenshot and Content Search
Examination of the document store is facilitated by a custom search engine that allows a user to enter a textual query (e.g., “president AND New York Times”) that returns a ranked list of screenshot thumbnails related to the input query. Indexing and search is done using a tailored vertical search engine built using Apache Solr Lucene. In brief, an xml-based document associated with each screenshot is indexed with respect to its enclosed text (with stemming and ignoring stop words) and content fields (e.g., geohash, content categories). When a researcher enters a query into the web-based user interface, all images with the exact text or content similar to the query are drawn from the document store, ranked based on relevance (e.g., using Okapi B25 metric; Robertson, Walker, Jones, Hancock-Beaulieu, & Gatford, 1995), and displayed to the researcher as a list of relevant screenshots. Summaries and links accompanying each search hit provide additional information (e.g., content category, geographic location, links to temporally adjacent screenshots). The search engine is critical for understanding the range of screen behaviors that pertain to specific content areas (e.g., health, politics), and for generating hypotheses about how screenome content is related to a wide range of thoughts, actions, and feelings.
5. RESEARCH EXAMPLES
This section presents eight examples of how the screenome framework can be used to study digital life experiences. Section 3.0 outlined advantages of theorizing with screenome data across several different literatures. The purpose of this section is not to test the range of theoretical potential but rather to offer exemplary analyses that different researchers might engage. Some of the examples follow only a single individual over the course of one day; others analyze larger samples and longer durations. All of the examples were chosen to highlight new ways to analyze technology experiences that are enabled by examination of individual screenomes.
All of the data collection followed the same general procedure. Participants were screened during short phone calls about their devices, and willingness and ability to participate. They then either visited our university lab or a central research facility. Once there, participants read and signed human subjects consent forms and filled out background questionnaires about demographics (e.g., race, sex), media use, and questions about psychological motivations and information searching. Software was then installed on their laptop computer and Android smartphone, and linked to the computational infrastructure described above. Participants then left the laboratory and went about their daily lives while the system unobtrusively recorded their device use and (in some cases) movement in physical space. The exact data associated with each example is listed in the endnotes. Figures 2 to 9 display the results of each analysis and were produced during analysis. They are not inherent to the screenome pipeline itself.
Figure 2.
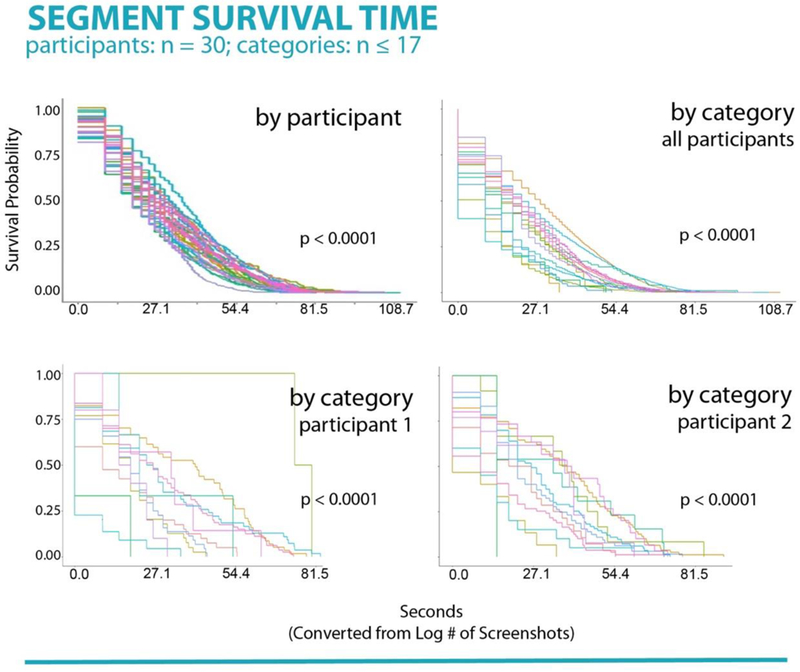
Top left panel. Survival analysis for each participant in the study. Each curve represents an individual’s likelihood of switching screens at a given point in time. Individual differences in survival rates (i.e., rate of switching behaviors) were found. Top right panel. Survival analysis for each of 17 screen segment categories in the study, aggregated across the sample. Each curve represents the sample’s likelihood of switching screens given a particular screen category at each time point. Differences in survival rates (i.e., rate of switching behaviors) were found. Bottom panels. Survival analysis for each of 17 screen segment categories in the study for two individuals. Individual differences between switching behaviors given a certain screen category can be seen.
Figure 9.
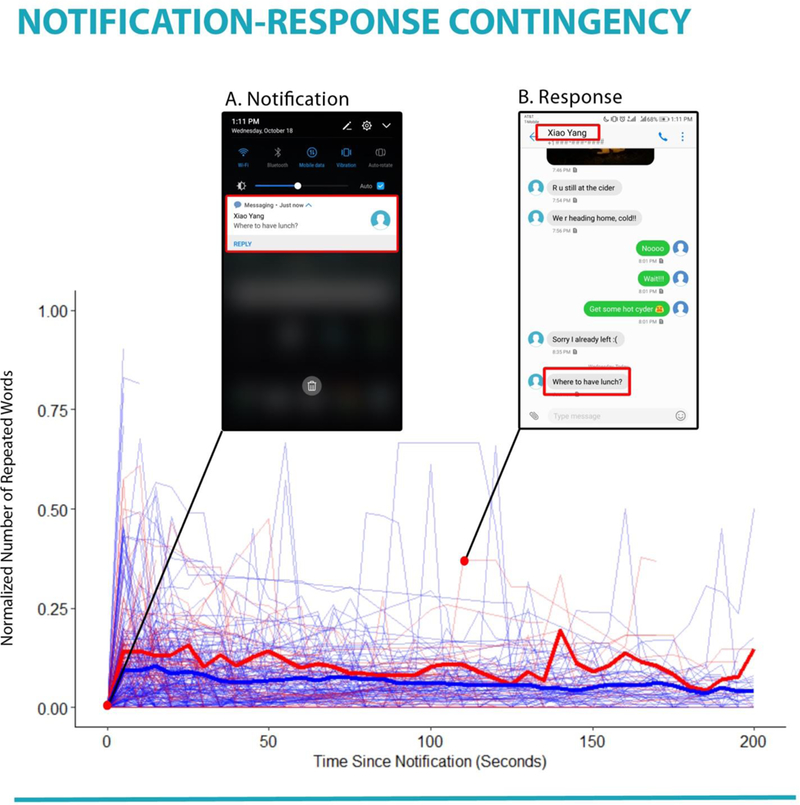
The graph shows how the content of specific notification stimuli manifested in the screenshots following that notification. Red lines indicate notifications characterized as social cues, and blue lines indicate notifications with non-social cues. Bold lines provide the response profile for each type of cue, as averaged across all notifications in the two cue types. Inserts highlight a specific notification cue, and the moment, 115 s later, that the content of the cue returned (i.e., the response).
5.1. Example 1: Serial Switching Between Tasks
This example shows how time structure can be defined in the screenome with respect to the speed of switching between different content. This is of great interest in media psychology because quick switching may contribute to short attention spans (Anderson & Rainie, 2012; Brown, 2000; Rosen, Carrier, & Cheever, 2013), information overload (Bawden & Robison, 2009; DeStefano & LeFevre, 2007), and divided attention (Brasel & Gips, 2011; Hembrooke & Gay, 2003). Descriptions of switching, however, have been almost impossible, at least in natural environments, because tracking methods have not been able to follow threads of attention over time and across platforms and screens.
An example research question is: How long does one particular segment of experience last before another takes its place? To illustrate how such a question can be answered, we applied a proportional hazards model (Cox, 1972) to screenomes from 30 student laptop computers (see Yeykelis et al., 2018).i We identified median task switching time between segments at 20 seconds (e.g., switching from reading an email to conducting a Google search to texting a friend to liking a Facebook post). We were also able to consider individual and contextual differences. As shown in Figure 2 there were substantial differences in median switch-times (a) between individuals (χ2(29, N = 30) = 548, p <.01; top left panel) that were indicative of individual differences in attention, (b) between content categories such as email, information, news, pornography, shopping, social media and work (χ2(16, N = 17) = 1646, p <.01; top right panel) that were indicative of differential pull of attention across stimuli, and (c) in how different people approached the different categories (bottom panels), i.e., as indicative of person x stimuli interactions.
This analysis represents the first look at the rapid pacing of digital life in a way that considers switching between applications and platforms, between consumption and production of content, and between work and leisure domains. The results also highlight the importance of information embedded in the screenome, and the possibility of discovering behavioral “fingerprints” that represent the unique rates of switching and ordering of content that indicate how an individual seeks, learns, and organizes information. In sum, screenshots collected at five-second intervals provided a new opportunity to identify the time-invariant (e.g., age, gender, motivational style) or time-varying (e.g., sentiment, topic) characteristics of people and content that can influence how and when switching occurs.
5.2. Example 2: Quick Switching Between and Within Screens
This example shows how the screenome allows content to be tracked within and between screens. Studies in media psychology and human-computer interaction often examine user interactions with a specific kind of content on a single device; for example, playing games on a computer, reading political news using a tablet app or posting on social media with a smartphone. Such research interests are limited to particular content categories and devices. Digitization, consolidation and fragmentation of media, however, increases the probability of switching between different categories of content and thus changes how content is sequenced.
Tracking the sequence of digital experiences across traditional boundaries of commercial content and devices is important theoretically. Priming studies, for example, show how the sequencing of news and political information can change perceptions of content (Cacciatore, Scheufele, & Iyengar, 2016). Studies of excitation transfer show that there is temporal generalization of highly arousing content forward to new material that itself might be arousing (Lang, Sanders-Jackson, Wang, & Rubenking, 2013). Persuasive messages that are humorous or serious have different effects if they follow humorous or serious program segments (Bellman, Wooley, & Varan, 2016). These studies, however, have studied sequence effects using long blocks of homogeneous content (e.g., examining the influence of a TV program on a 30-second ad that follows it) or single transitions observed in a lab (e.g., examining how arousal during one experience influences arousal for content that follows). Our screenome sequences suggest that digital life is better characterized by hundreds or thousands of transitions, and often many per minute. An example research question is: How does an individual transition between content categories and devices?
To illustrate how such a question can be answered, we examined how one individual moved between devices (laptop and smartphone) and among content categories (e.g., calendar, call, chat) during one day (Figure 3).ii Transitions in the example are shown as arcs, colored by the category being used when the switch occurred. On this day, there were 312 transitions with the majority (57%) of those transitions characterized by exit from one device and entry to the other device. Some transitions were consistent: the phone calls were each followed by web surfing on the laptop; engagement with transportation content on the laptop (e.g., Google Maps) was followed by engagement with transportation (n=24, 27.9%), news (n=20, 23.3%) or web surfing (n=18, 20.9%) on the smartphone, with five other categories (n=24, 27.9%) constituting the remainder of switches. In contrast, some category transitions were more heterogeneous: chatting on the laptop was followed by instances of web surfing (n=3, 30%), gaming (n=2, 20%), checking a calendar (n=1, 10%), mail apps (10%), text editing (10%), and other (10%), all on the laptop. Notably, almost all types of content were represented on both laptop and smartphone, and only a few activities were device-specific; for example, this person used only the laptop to look at calendar and video content. In summary, this person’s screenome illustrated both simultaneous and serial engagement with multiple and overlapping content on two digital devices, sequences that would be difficult to observe with other records and methods.
Figure 3.
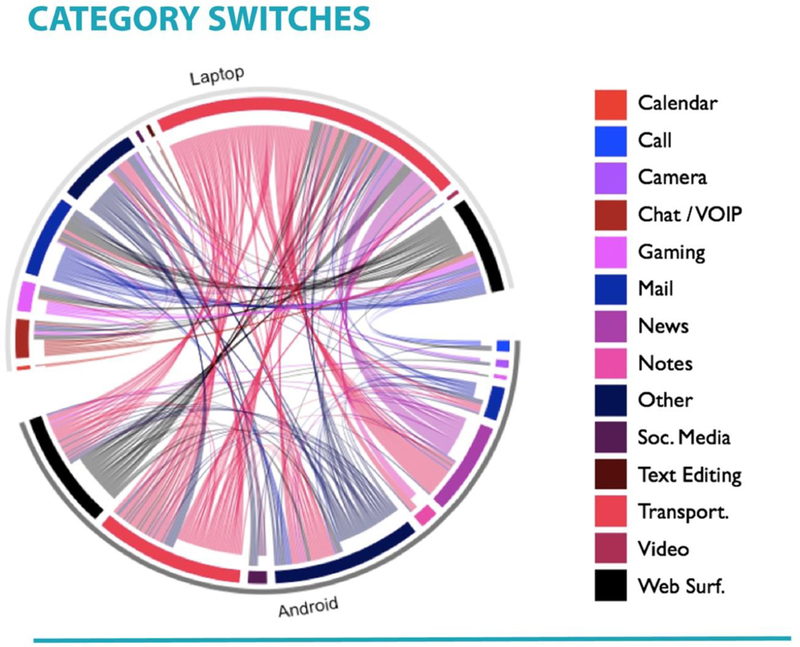
Visualization of within- and between- device switches by category for one person for one day.
Screenome sequences also have a time structure that allows examination of changes at different timescales. An example research question is: How is device and content switching organized across the day? Zooming out to 30-minute segments, the larger temporal structure can be examined (Figure 4). The day for this person began with a half-hour of switches among content on the phone (dark green). After actively switching between devices (light green and light purple) in the period from 8am and 1pm, this person did not use either device, and she used only the phone between 4:30pm and 7pm. The day ended with 3.5 hours of switches among content only on the laptop (dark purple). Together, Figures 3 and 4 illustrate how high-density data from the screenome can show moment-to-moment (temporal zoom-in) and hour-to-hour (temporal zoom-out) transition and patterns. This example illustrates how the screenome can be used to study technology use occurring at multiple time-scales.
Figure 4.
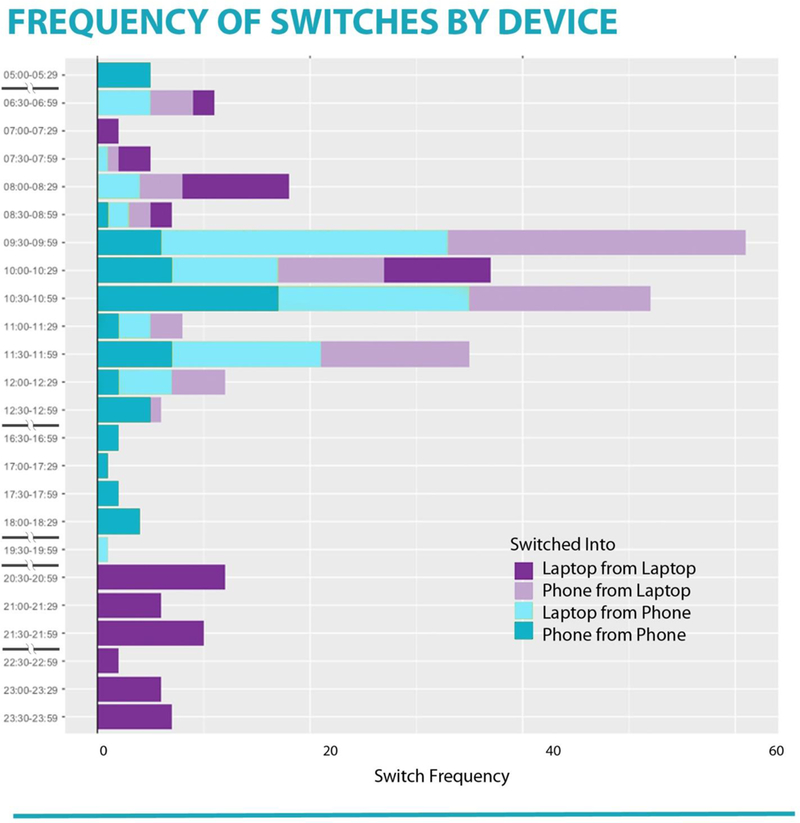
Transitions between and within devices for one person over the course for one day.
5.3. Example 3: Threads of Experience
As the variance in material available on digital devices grows, and as affordances for switching quickly between the material increase, technology use can be described as threads of experience that connect contiguous but different content. This next example, in the area of political communication, illustrates how following those threads can uncover previously invisible influences, and how theory about the processing of content might change as a result of tracking the connections.
An example research question is: How and when do people engage with political news and information? In studies of voting behavior, research has typically collected self-reports about the quantity and quality of news exposure, usually assessed by asking people about exposure to specific news outlets over long periods of time. Recently, more accurate measurements of exposure to political news have used web-browsing logs and posts on social media (e.g., Dilliplane, Goldman, & Mutz, 2013). In these cases, however, tracking of exposure to political information is restricted to individual platforms, either by researchers when they examine logs or by participants when they answer survey questions about use of the material (Romantan, Hornik, Price, Cappella, & Viswanath, 2008).
In contrast, the screenome provides a record of how political topics are ‘threaded’ through a variety of media experiences, across content categories and across platforms. Screenshots capture both individuals’ incidental exposure to political information, material about politics that is influential in civic learning but encountered while engaged in other functional tasks such as communicating with friends (Kim, Chen, & de Zúñiga, 2013; Wells & Thorson, 2017), and individuals’ intentional exposure through focused directed surveillance of political information for the purpose of political reinforcement or change (Eveland, Hutchens, & Shen, 2009; Ksiazek, Malthouse, & Webster, 2010; Valentino, Hutchings, Banks, & Davis, 2008). Viewing the screenome through the same lens used in the prior research, we can observe the temporal organization of individuals’ incidental and intentional exposures to political information at a level of detail that has not been measured previously and that is missing from the political communication literature.
To illustrate how threads of engagement with political news manifest in the screenome, we describe how information related to the presidency, defined as presence of relevant key words, including Clinton, Donald, election, Hillary, president, Trump, White House, and information about the Syrian crisis, defined as presence of key words Assad, Iraq, Middle East, refugee, Saudi, Syria, war manifest in the 36-hour screenome obtained from one individual during mid-April 2017 and shown in Figure 7.iii Screenshots are shown as 3,700 colored vertical bars: red and yellow bars on the lower timeline (n = 171) indicating presence of information related to the presidency, and on the upper timeline (n = 42) indicating presence of information related to the Syrian crisis. Gray bars are for all other content. Most of the presidency and Syrian crisis content was encountered incidentally (in yellow, 162 of 213 screenshots, 76%) in informal settings (e.g., while browsing Twitter or Reddit). Of the 11 instances of active news-seeking, as indicated by sustained reading, active conversation, or a traditional news source, 7 were click-throughs from incidental encounters. Information related to the presidency stayed on screen for up to 50 seconds (M = 12.0, SD = 11.2) while information related to the Syrian crisis stayed on the screen for up to 60 seconds (M = 15.8, SD = 16.1), in this case through a podcast application (total listening time was 32.65 minutes). The screenome provided a record of the precise content that was engaged and the context surrounding that engagement. Expanded analysis of larger samples can provide new understanding of how and when individuals are exposed to politics, and how they formally or informally engage with politically relevant information.
Figure 7.
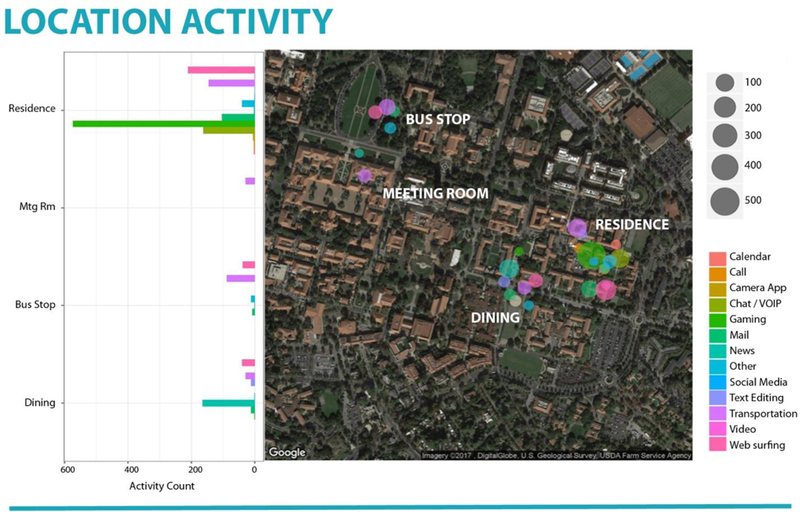
Barplot and map of a person’s screen activity for one day within one city. Locations visited include (from top to bottom of barplot): residence, meeting room, bus stop, and dining establishment.
5.4. Example 4: Screenome Variance Between Groups versus Within Persons
This example illustrates the value of the screenome in assessing intraindividual as opposed to interindividual variation. The vast majority of media and life experience studies seek to differentiate groups of people from one another – interindividual differences. There are many definitions for the groups – demographics, personality, geography, viewing levels. For example, people who are sensation seekers are more likely to switch quickly between different types of content (Yeykelis et al., 2018). Extroverted personalities are more likely users of social media (Correa, Hinsely, & de Zúñiga, 2010). High media multi-taskers are better at certain visual acuity tasks (Ophir, Nass, & Wagner, 2009). Such studies seek results that generalize across persons to describe prototypical behavior. While these are worthy goals, it is also a mathematical reality that group-level averages do not indicate how any given individual behaves (i.e., the ecological fallacy), and significant errors are made by generalizing cross-sectional results to individuals (Estes, 1956; Robinson, 1950).
Questions about intraindividual variation ask: What is one individual’s media experience over time? To illustrate the issue and possibilities, Figure 6 shows four-day screenomes compiled from laptop computers for 30 undergraduate students.iv Each person is shown in a separate panel. Differences in the quantity and sequencing of engagement with five different types of content (email, entertainment, news, work, and a miscellaneous category including search) are shown by the order of colors seen in each panel. For example, the person shown on the bottom row, third from the left, has a considerable number of email interruptions, shown with orange lines. People with predominantly blue lines (e.g., the person on the far right in row three) are oriented toward entertainment (e.g., YouTube videos, movie segments, games). But even though it is possible to average across the four days for each screenome and cluster people into groups (e.g., those who work more than play), a substantial amount of the variance within each screenome would remain unexplained by the between-group difference. The screenomes in the figure show that no individual is “average.” The screenome allows consideration of each individual’s unique experience and provides rich time-series data needed to identify the patterns and irregularities embedded in experiences. Intraindividual variations are visually evident within a day and between days. Particularly with regard to interventions focused on behavioral change, the screenome may support more accurate, personalized prediction and delivery of real-time and context-sensitive services than would be possible with cross-sectional or aggregated data.
Figure 6.
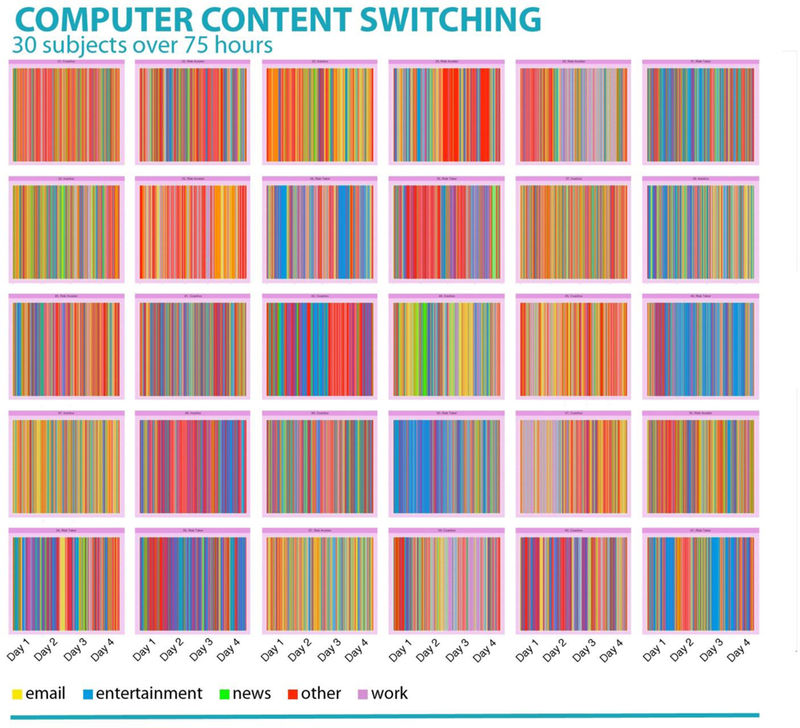
Intraindividual variation in laptop screenshot content categories over the course of four days for 30 people. Each panel of vertical colored lines represents a unique person and each vertical line represents time spent in five different categories of content. Both within-person and between-person differences are evident across panels.
5.5. Example 5: Personal and Social Context Surrounding Media Use
This example illustrates the context that is available in the screenome and how the screenshot sequences facilitate rich description and theorizing about individual media use. The screenome is useful for ethnography because the detailed record “gives voice” to the breadth of particulars that define the meaningfulness of individuals’ media practices (Carey, 1992). The temporal sequencing, in particular, allows researchers to engage in the “deep hanging out” that makes for good ethnography (Geertz, 1998; Turkle, 1994; boyd, 2015). While screenshots do not follow people off-line, they do offer a sense of “over the shoulder” examination of the interdependencies among different content and contexts. Consider these two examples based on a qualitative analysis of one-day screenomes of two individuals.v
Story 1 – “News You Can Use”.
“Frank” lives outside of a large US city and spends hours on his phone doing everything from checking Facebook to talking to his partner to searching for repair shops for his broken-down truck to watching hours of live musical performances on YouTube and catching up on the news. One mid-April morning, at 6:15 AM, he woke up and checked the headlines. He opened the Fox News app and started reading. He scrolled quickly past the top stories (“‘STRATEGIC PATIENCE IS OVER’ Pence fires warning shots across DMZ in message to North Korea,” and “MANHUNT WIDENS 4 more states on alert for Facebook murder suspect”).
The story that caught his attention came just after the first scroll (“ANOTHER NIGHTMARE? Couple booted from United flight over seat switch”). He read the entire article, focusing for 10 seconds on the subtitle “Bride and groom on way to wedding booted off United flight.” Total time spent on the article was one minute and 55 seconds, longer than any other story that day. In isolation, we might assume that this was a salient topic within the public at large. The story came on the heels of a highly-publicized incident and widely-distributed videos and photos of a passenger being dragged from an overbooked flight. By looking at the broader context of Frank’s media day, there is a different story unique to Frank and with implications for media behavior more broadly.
Immediately after reading the article, Frank opened his e-mail and began searching for a reservation confirmation for an up-coming flight to Hawaii – on United Airlines. Frank opened the reservation details and struggled (meaning he went back and forth between steps) with online check-in for himself, his partner, and his pre-teen daughter. After the United news story, thoughts about the pending family trip make more sense.
Several hours passed as Frank struggled to figure out why his truck would not start, discussed the truck with his partner, and looked up towing and repair companies and their Google reviews. Finally, in the mid-afternoon, the truck problem unresolved and Frank immobile, he again opened the Fox News app. He briefly opened the breaking news notifications, as a red number six blinked in the upper right corner of the app next to a red gumball machine police light. After briefly looking at the top headlines (“REWARD FOR KILLER: Cleveland police announce $50,000 reward for so-called ‘Facebook killer’ Steve Stevens” and “Cleveland Police deliver update on search for Facebook Killer” were in the top two spots), he re-entered the main app and clicked on the third headline. The headline was about Hawaii (“HAWAII HUNKERS DOWN: Islands prep for possible attack by North Korea”), with an in-story subhead (“North Korea tensions have Hawaii pols revisiting emergency attack plans”). It is understandable, once the different components of Frank’s media thread are combined, why he felt compelled to read through this whole article. If Hawaii is in danger, his family could be affected.
Without access to Frank’s screens, across apps and across contexts, and without the ability to weave together seemingly unrelated bits and pieces of information, the personal meaning of his media experience would be lost.
Story 2: “It’s who you know.”
“Aung” lives in Yangon, Myanmar and spends hours on his phone every day. On a Saturday this past summer, he woke up 15 seconds past 11:52am. At 12:00pm, he glanced at his missed calls, spent five minutes checking two separate group chats on Facebook Messenger, and returned a phone call. Much of his morning was rapid switches between group text-chats, phone calls, and video-chats all facilitated by Facebook and Facebook Messenger. At 12:27pm, Aung checked his Facebook notifications for the first time that day, revealing 17 unread notifications ranging from a news alert (“Mizzima – News in Burmese is live now: 4R Health Talk…”) to friends’ reactions (“[name] and 12 other people like your post:…”) to updates on membership in ten separate Groups and Pages, many that he administers.
In terms of topical content, there is not much continuity in Aung’s information diet. In terms of format, however, there are trends. Out of 637 screenshots captured from 11:52am until 11:44pm, only 156 were on non-Facebook platforms, and those were mainly of home screen views and phone calls. A Facebook chat or group-chat icon was always present on screen regardless of the app open. Aung’s screenome sounds typical of many Western digital cultures. What is perhaps most significant, however, is that Aung’s story would have been impossible in Myanmar only seven years ago. Myanmar has leapfrogged from having virtually no phone connections in 2011 to a Facebook-dominant, smartphone-only app culture, powered by Chinese devices (Leong, 2017).
The screenomes provide an opportunity to study a fast-paced digital revolution in a developing country, and one different from the comparatively slower changes in Western countries. “Over-the-shoulder” observation of Aung’s media use, and how Facebook sits within that use, provides new opportunity to study differences in cultural context. In the US, studies show multiple motivations for Facebook use, including a connection to greater civic participation (Conroy, Feezell, & Guerrero, 2012; Nadkarni & Hoffman, 2012; Wells & Thorson, 2017). In Myanmar, the reverse may be true. Whereas much of the world adopted the Internet in the age of search engines, Aung’s day reflects a Facebook-first community connection network. Aung very rarely used the Facebook search bar tool, and never used any other Internet search engine. Rather, information was sought from and provided through his social network. The rich temporal, content, function, and context provided by the screenome allows for such observations and the generation of new research questions about international differences in media use.
5.6. Example 6: Geolocation and Digital Life
This example shows how the screenome can be tied to location and used to theorize about how places might influence psychological processing. Digital devices invite use in locations far beyond dedicated spaces for traditional media. While geolocation data have been used to understand how people move from place to place (e.g., Do & Gatica-Perez, 2014), there are no studies that tightly couple the influence of place on what people consume and produce in their digital interactions. The screenome fuses geolocation data to each screenshot so that the experiences can be placed in physical context.
An example research question is: How does media use differ across locations? To illustrate how the screenome facilitates such an inquiry, Figure 7 shows one individual’s activity for one day within one city.vi The locations this person visited included a residence, dining establishment, bus stop and meeting room. The size of the circles in the figure indicate the number of screenshots in each location, which approximates duration in minutes and seconds. The location data highlight that most time on her devices was spent in her residence, followed by the dining establishment, bus stop and meeting room respectively. Very little activity, 2.5 minutes of engagement with a transportation app, occurred in the meeting room. The participant spent roughly 12 minutes on her mobile phone while waiting for a bus, with 60% of that time (n=88 screenshots) spent looking up her transportation route and 26% of her time (n=38 screenshots) web-surfing. Gaming contributed a significant number of screenshots in the subject’s residence (n=574 screenshots; about 50 minutes and 34% of in-residence screen-time); although we could see that the participant was not actually playing the game but rather watching a shared screen of her friend’s gameplay while they were located elsewhere. News contributed a significant number of screenshots in the dining establishment (n=165 screenshots, about 15 minutes and 62.5% of in-dining screen-time).
Knowledge about situational context has long been recognized as critical to understanding most social and psychological experiences (e.g., Ross & Nisbett, 2011). Physical location is a rich source of information about context, and one that has been largely absent in consideration of media and technology. Further, although study of “activity space” considers the types of activities individuals can and do engage in their daily life (Sherman, Spencer, Preisser, Gesler, & Arcury, 2005), there is little knowledge about how physical and virtual activity spaces overlap or blend. The geolocation information embedded in the screenome provides insight into how context influences people’s use and processing of technology.
5.7. Example 7: Interactivity and Social Media
Many technology platforms support social interactions. Studies of computer mediated interactions mostly look at communication between people within specific platforms. These within-platform observations, however, may miss substantial pieces of interactions for a single person and for an established dyad. The screenome provides for cross-platform inquiries, including input for new definitions of media content.
An example research question is: What is the temporal structure of communication in a relationship via technology? To illustrate how the screenome facilitates such an inquiry, we examined a 29-hour segment of the screenomes obtained from two undergraduate students who were in an established romantic relationship and were living together.vii As seen in Figure 8, differences between the two people are apparent in device use and the range of social media applications used. Person A’s 17,430 screenshots included 16 minutes of smartphone use and ~4.5 hours of laptop use, with 39% of total use identified as social media. Person B’s 18,630 screenshots included ~4.5 hours of smartphone use and 41 minutes of laptop use, with 65% of total use identified as engagement with social media.
Figure 8.
Panels depicts two individuals’ social media use during a 29-hour period on both laptops and smartphones. Each color represents a different interpersonal media platform, with black indicating device use that was not on a social media platform, and gray indicating that the device was off. Zoomed panel shows detail of asynchronous and synchronous communication during a specific 3-hour period.
How these two individuals engaged with social media differed substantially. Over 29 hours, Person B used 13 different interpersonal media platforms for interactions that lasted a total of 21 minutes, switching among multiple platforms (e.g., Messenger, GroupMe, Instagram, Snapchat), and switching frequently while interacting with friends (47%), groups (39%), and his partner (12%). In contrast, Person A used only six different platforms during 43 minutes of interaction with friends (69%), family members (20%), groups (4%) and her partner (6%).
The upper panel of Figure 8 zooms into a 3-hour period when Person A was using social media. The range and sequencing of colors indicates substantial moment-by-moment switching among platforms. During the same period, Person A used seven different platforms (Facebook, email, GroupMe, Messenger, default instant messaging, WhatsApp, YouTube), often choosing specific platforms for specific relationships (e.g., interaction with family members only used WhatsApp). We were also able to see that 33 of 56 (59%) of Person A’s social interactions were asynchronous (71% for Person B, not shown). This suggests that during most interactions other material is viewed between the sending and receiving of messages. The screenome, and the temporal sequences embedded in it, provide a detail that has been difficult to consider in technology-mediated communication research.
5.8. Example 8: Response Contingencies
People respond to information cues at different speeds and to achieve different kinds of goals. The screenome provides a venue for conducting natural experiments to test whether and how people respond under different interaction goals, between-person differences in responses, and intraindividual change in responses. This example illustrates how the screenome can be used to study responses to specific cues.
A sample research question is: Do people respond more quickly to social cues than information cues? To illustrate how the screenome facilitates testing of a hypothesis, we conducted a natural experiment about notifications.viii Specifically, we examined an information processing difference suggested in the literature about how people respond to social versus non-social cues (e.g., Carstensen, Isaacowitz, & Charles, 1999). First, we identified all of the screenshots that contained a notification (n = 394 notifications). Following the designs used in many psychophysiology and neuro-imaging studies, responses to these cues were examined as an event related potential (ERP). As shown in Figure 9, we derived a profile of how long it took for the information presented in the cue to reappear (i.e., get processed). Making use of the text extraction tool, we evaluated the similarity between the specific information presented in the cue and the subsequent screenshots. Averaging across the response profiles of individual “trials” characterized by different types of cues (categorized based on presence of “social” words, as defined by LIWC, Pennebaker et al., 2015), the bold red and blue lines depict this person’s typical response profile for social content (thin red lines) and non-social content (thin blue lines). We found that this individual had a higher chance of responding to social cues, indicated by the bold red line that is higher across time compared to the bold blue line. Expansion to multiple individuals’ screenomes, to other types of cues, and to other types of response profiles should open a new way to study intraindividual changes in information processing in real-world settings.
6. SUMMARY, LIMITATIONS AND FUTURE USES OF SCREENOMES
Our summary conclusion is that the screenome, the collection of screenshots that capture the exact words and images that people view on their digital devices and the order and timeframe in which they view them, can best represent threads of experience that cut between radically different content and screens. Recordings of technology use now capture an increasingly complete record of life experiences. As we illustrated through the examples, the nature of the technology also changes the experiences by allowing them to be more rapid, fragmented, distributed, and interdependent. Having a record of actual screens that people see minimizes the need to make inferences about information uses and effects from knowledge of website addresses or media use logs, and it provides a direct means to unobtrusively assess individuals’ digital experiences. Some of the most important information for theorizing about human behavior is the actual stimuli that people view, and the screenome provides that record, as well as a measure of their actions in response to those stimuli.
6.1. Limitations of the Screenome
Although the screenome offers an increasingly complete record of personal digital experiences, there are limitations, discussed in this section. They include the following.
Missing screens.
Our current data are from laptop computers and smartphones. There are other important screens. In particular, future work mmight also integrate content from tablet and television screens. Multi-screen implementations would capture additional details of how individuals transition among content and how and when they engage in dual-screen activity (e.g., texting while watching a television program). Capturing the television screenome is technically easier than capturing mobile device screenomes because the point of collection is stable (e.g., interface with cable boxes, Apple TV, Roku) and it is usually always connected to power and Wi-Fi. For those screens it may be additionally useful to supplement the data with eye-tracking data that informs more specifically about how individuals attention moves on and off of each of their active screens.
Non-screen behavior.
Although an increasingly large portion of life is digital and gets coded into the screenome, far from all of human experience is represented. Although off-screen life is missed, there are ways in which additional data about that portion of life can be combined with the screenome. We are already integrating GPS and physiology data into the screenome and bundling screenomes with other meta-data (e.g., demographics, personality). Combining data streams provides new opportunities to examine the interplay between screen-based and non-screen aspects of life. Adding the screenome to large panel studies could provide new and rich opportunities to discover how previously unobserved aspects of behavior influence and are influenced by processes that operate at multiple levels of analysis (e.g., biological or community-level processes).
Onboarding.
A logistical hurdle in collecting screenome data is the onboarding of participants. In addition to completing screening questionnaires and obtaining informed consent, participants need to load software onto their personal devices and test the connections with research servers. While this report was being prepared, we have built an online system for onboarding. Participants are directed to a website to answer screening questions and complete informed consent documentation, answer preliminary survey questionnaires (e.g., media habits, personality), download and test software, and, if indicated, provide information that will enable payment for participation.
System optimization.
The data collection and processing system described in Section 4 has been deployed successfully in a variety of studies. Generally, researchers (end users of the system) have found the data useful for reflection on their own digital lives; however, formal usability studies are needed to add user feedback as a benefit of the system. For example, different ranking algorithms might be tested and used to optimize the search engine module so that users could locate and evaluate their own activity. Other parts of the system also might be optimized, including the data collection modules (e.g., battery limitations, data transfer time), the data processing modules (OCR quality, image recognition), and database alignment (e.g., temporal alignment of data from multiple devices). Also, as more is learned about data visualizations, the most useful analytics (which are currently developed outside the system) could be incorporated into the main work flow.
6.2. Extensions of the Screenome
Possible extensions of the screenome may help address challenges in the current work. They include the following.
Structured vs. unstructured data.
We have noted the limitations of current logging techniques that use APIs, plugins, and apps, as often complex and incomplete representations of what people actually view. While that is true, those techniques do provide structured data. The data in the screenome are unstructured, a matrix of pixels with RGB values. Conversion to structured forms and extraction of behaviorally meaningful features is difficult. Although errors in conversion are conservative penalties in statistical analysis (i.e., they are likely to hide rather than accent findings), it will be important to continue to improve the conversion methods and to validate them against ground truth data so that errors can be minimized and precision can be improved.
Creating behavioral indices from screenome data.
The screenome provides an opportunity to ask many new research questions. For example, what might be the pace of screen switching for different personalities? How is voting behavior or political activity related to exposure to civic information? How does the fragmentation of social interaction influence satisfaction with an intimate relationship? For each of these questions, we can now obtain the record of digital experiences needed for an answer. Some of the answers will come from inside the screenome; for example, the pace and frequency of quick-switching between screens may be used to diagnose mental conditions such as “hyperactivity.” Other indicators will be found at the interface between the screenome and other information; for example, metrics that combine information in the screenome with objective observations of behaviors, medical testing or face-to-face encounters. There is considerable discovery work to be done on metrics hidden in the screenome, and on how to extract those markers reliably, both within-person over time and across people. A key challenge is generating enough ground-truth data to support training of machine learning algorithms that facilitate feature extraction and propagation of tags to new and larger data.
Internal and external validity.
All of our data so far have been generated by adult volunteers recruited for their willingness to participate in new research. We have purposively recruited digitally active younger adults, and although the samples are balanced by gender and geography, they are not randomly selected or representative of national populations or subgroups in terms of race, income, and other important characteristics that may influence technology use. Consequently, we have prioritized internal validity and demonstrations of the value of screenome data. Going forward, the samples will need to be more representative. There are significant known differences in how individuals use digital media (Correa et al., 2010; Jackson et al., 2008), and those differences must be reflected in future samples.
Between-person differences and within-person change.
The research examples demonstrate both between-person differences (e.g., the different groups of people that switch tasks in similar ways) and within-person change (e.g., following a single person over time through different changes in content selection). We note, however, that the bias in media psychology research, and indeed in psychology more generally, is to focus on differences between groups. While the screenome can answer questions about those differences, for example, with respect to personality, socioeconomic status, gender, geography, politics, religion, and so on, the high-resolution longitudinal sequences that make up the screenome are particularly well suited to studying within-individual changes over time. As noted in the empirical examples, the temporal precision provided by the screenome means that we can see large between-person differences. No two individuals’ screenomes are alike. This suggests more focus on within-person dynamics and elaboration of theories about how single individuals change. As highlighted in many areas of social science, inference about individual-level behavior from group-level averages risks ecological fallacy (Estes, 1956; Molenaar, 2004; Robinson, 1950). There is a push for more precise characterization of individual-level processes that avoid ecological fallacy (Ram, Brinberg, Pincus, & Conroy, 2017; Ram, Brose, & Molenaar, 2013), and an analogous movement in the medical sciences for personalized characterizations (Chen et al, 2012). The screenome is a good candidate to provide that precision.
Time-scales.
All of the screenomes reported here were constructed using screenshots taken at five-second intervals. That interval, which is considerably faster than many experience sampling techniques used in research, was only a first attempt to define the best sampling frequency. The switching time results (Section 5.1) suggest using even shorter intervals. Indeed, with five-second intervals we are only able to model behaviors manifesting at a ten-second time-scale. Screenshots taken every one or two seconds could better characterize, for example, quick switches between sending and receipt of messages in a synchronous text exchange or observations of how swiping or pinching content accelerates and decelerates across context and time.
6.3. Use of the Screenome for Interventions
One promising future use of the system and approach presented here is the ability to “interact” with an individual’s screenome and to deliver interventions that alter how people think, learn, feel and behave. This may help realize the promise of precision interventions to preempt or treat unwanted thoughts, emotions or behaviors, and to promote desirable ones. Delivering the right intervention to the right person at the right time and in the right context with the lowest risks of adverse side effects could close the loop between feedback and optimization in real time. Some of the most exciting potentials for precision interventions are in health. Many health parameters are dynamic, in that they change and vary over time (e.g., blood pressure). The screenome may allow researchers to identify causal relations at a time scale that matches the speed at which symptoms and diseases actually vary.
6.4. Inductive vs. Deductive Approaches to Theory
Our first analyses of screenome data attempted to answer specific questions about how people use technology; for example, how arousal management prompts people to switch from familiar to new information (Yeykelis et al., 2014), and how people with different enduring motivational strategies biased toward positive or negative experiences create different information threads (Yeykelis et al., 2018). These deductive efforts started with theories about human motivation, and used screenome data to test hypotheses derived from those theories. The enthusiasm for new analyses, however, has been inductively centered. We have found it very useful to study individual screenomes without the constraints of any particular theoretical test, generating ideas about how and why individuals behave in various ways. The screenome may be particularly well suited for research that begins inductively, generates new theory, and then moves to testing hypotheses suggested by the theory.
6.5. Privacy
The screenome is an example of big data as defined within computational social science (Shah, et al., 2015). It uses complex data measured in tera- and petabytes from naturally occurring digital media sources; it depends on computational or algorithmic solutions to identify patterns; and it is applicable to a variety of information domains, from politics to health to social relationships. While the advantages of big data are clear, so too are the risks. Big data, including the screenome, raises a variety of ethical concerns (Butler, 2007; Lazer et al., 2009). The screenome contains substantial private information—perhaps as much or more than any other individual record.
All of the data for our screenome project were collected using a rigorous privacy protocol. The data are stored securely, they are never shared outside of the laboratory, data are viewed only by trained research staff and on selected computers that are permanently located in the lab. But even with these privacy standards, many people did not or could not participate. About one third of the people contacted about the research declined to continue after the study was explained. Some declined because they used work devices for both personal and professional interactions, and it was impossible for them to risk exposing employer material. Most of the declines, however, were concerns about privacy, and particularly the privacy of text messages. The acceptance rate for participation, about two-thirds, was higher than some previous research suggested for this type of disclosure (Harari et al., 2017), and higher than we expected given the sensitivity of the request. Although agreement to participate may reflect lowered concerns about privacy, especially among younger users (Acquisti, Brandimarte, & Loewenstein, 2015) or belief in the value of the university research enterprise, additional research is needed to address the privacy issues surrounding collection and analysis of the screenome. For example, as researchers identify the aspects of the screenome needed to answer specific questions, it will be possible to further reduce risks associated with data transfer by performing local analysis and only transferring summary results to the research team (e.g., Boker et al., 2015).
In summary, we forward the screenome as a new framework to study human behavior and the ways that technology changes behavior, one that is appropriately matched to the time-scales and ways in which actions, cognitions, emotions and social interactions emerge and change over time in the digital world.
Figure 5.
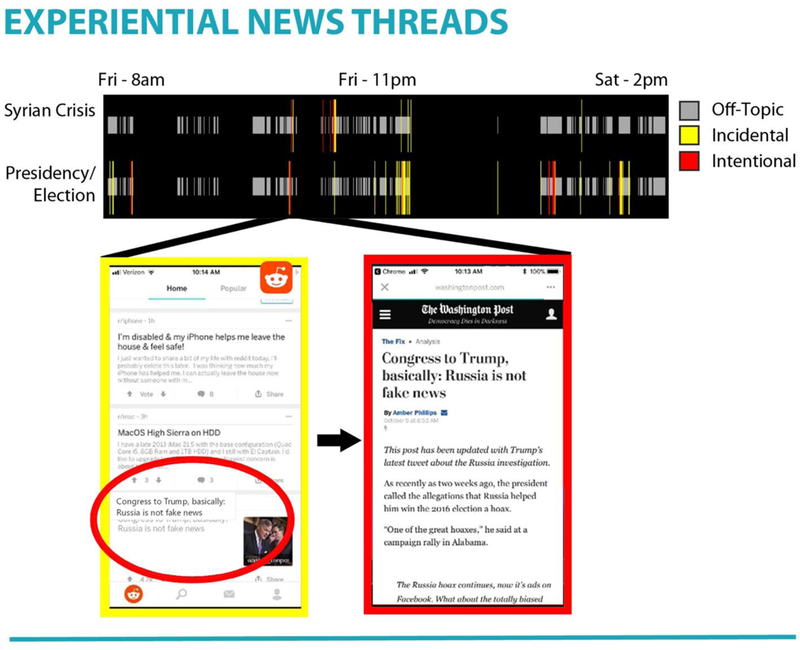
This 36-hour screenome shows how incidental exposure to political information can lead to intentional information-seeking. For instance, the magnified screenshots show that a headline on Reddit inspires click-through to a traditional news source.
Acknowledgments.
Several researchers working on digital recording advised our project at its onset. They included Deborah Estrin (Cornell Tech), Michael Bernstein (Stanford University), and Laura Carstensen (Stanford University).
Funding. The Screenomics Project was initially developed at the Center for Advanced Study of Behavioral Science at Stanford University, and is directly funded by grants from the Stanford University Cyber Social Initiative, the Knight Foundation, the Stanford Child Health Research Institute, the Stanford University PHIND Center (Precision Health and Integrated Diagnostics) and the Pennsylvania State University Colleges of Health & Human Development and Information Science & Technology.
Biographies
Byron Reeves (reeves@stanford.edu, https://comm.stanford.edu/faculty-reeves) studies the psychological processing of media in the Department of Communication at Stanford University.
Nilam Ram (nilam.ram@psu.edu, https://hhd.psu.edu/contact/nilam-ram) studies how intensive longitudinal data contributes to knowledge of psychological processes in the Department of Human Development & Family Studies at Pennsylvania State University.
Thomas N. Robinson (tom.robinson@stanford.edu, https://profiles.stanford.edu/thomas-robinson) studies behavior change interventions to promote health and prevent disease in the Departments of Pediatrics and Medicine at Stanford University.
James J. Cummings (cummingj@bu.edu, http://www.bu.edu/com/profile/jim-cummings/) studies the psychological processing and effects of media in the College of Communication’s Division of Emerging Media Studies at Boston University.
C. Lee Giles (giles@ist.psu.edu, https://clgiles.ist.psu.edu) studies information and knowledge extraction, data mining, and artificial intelligence in the College of Information Science & Technology at Pennsylvania State University.
Jennifer Pan (jp1@stanford.edu, http://jenpan.com/) studies political communication in authoritarian countries and computational methods in the Department of Communication at Stanford University.
Agnese Chiatti (azc76@ist.psu.edu) studies knowledge extraction, retrieval and discovery in the Department of Information Sciences and Technology at Pennsylvania State University.
MJ Cho (mujung.cho@stanford.edu, http://comm.stanford.edu/doctoral-cho/) studies people’s use of media technologies and social behavior in the Department of Communication at Stanford University.
Katie Roehrick (kroehr@stanford.edu, https://comm.stanford.edu/doctoral-roehrick) uses computational linguistic analyses to study human-computer interaction and digital media in the Department of Communication at Stanford University.
Xiao Yang (xfy5031@psu.edu, https://quantdev.ssri.psu.edu/people/xfy5031) studies quantitative methods and psychological dynamics in the Department of Human Development & Family Studies at Pennsylvania State University.
Anupriya Gagneja (anupriya.gagneja@gmail.com) is a Software Engineer at Apple Inc, working with the Machine Learning Platform Team.
Miriam Brinberg (mjb6504@psu.edu, https://quantdev.ssri.psu.edu/people/mjb6504) develops methods to examine interpersonal dynamics in the Department of Human Development & Family Studies at Pennsylvania State University.
Daniel Muise (dmuise@stanford.edu) studies the effects of Internet capacity on political information consumption & diffusion, trust, and development in the Department of Communication at Stanford University.
Yingdan Lu (yingdan@stanford.edu) studies political communication and social effects of digital media in the Chinese context in the Department of Communication at Stanford University.
Mufan Luo (mufanl@stanford.edu, https://comm.stanford.edu/doctoral-luo/) studies communication technology and psychological well-being, and is a PhD student in the Department of Communication at Stanford University.
Andrew Fitzgerald (afitzger@stanford.edu) studies the sociocultural and political economic impacts of digital media with a particular focus on national security and democracy in the Department of Communication at Stanford University.
Leo Yeykelis (yeyleo@gmail.com, www.yeyleo.com) studies how psychological processes and HCI affect product design, and he works in the self-driving car, consumer and enterprise application spaces.
Footnotes
N = 30 undergraduate students (22 women, 8 men) age 19 to 23 years from a medium-sized university in the western US; 4 days of screenshots.
N = 1, 24-hours of screenshots provided by a Hispanic, young adult female living in the United States.
N = 1, 36-hours of screenshots provided by a White, young adult male living in the United States.
N = 30 undergraduate students (22 women, 8 men) age 19 to 23 years from a medium-sized university in the western US; 4 days of screenshots.
Story 1 is based on analysis of 24-hours of screenshots provided by a White, middle-age adult male living in the United States; Story 2 is based on analysis of 24-hours of screenshots provided by a young adult male living in Myanmar
N = 1, 24-hours of screenshots provided by a White, young adult female college student living in the United States.
N = 2, 29-hours of screenshots provided by an Asian, young adult couple in a heterosexual relationship living in the United States.
N = 1, 24-hours of screenshots provided by a white, young adult male living in the United States.
References
- Acquisti A, Brandimarte L, & Loewenstein G (2015). Privacy and human behavior in the age of information. Science, 347(6221), 509–514. [DOI] [PubMed] [Google Scholar]
- Agichtein E, Castillo C, Donato D, Gionis A, & Mishne G (2008, February). Finding high-quality content in social media. In Proceedings of the 2008 international conference on web search and data mining (183–194). ACM. [Google Scholar]
- Aharony N, Pan W, Ip C, Khayal I, & Pentland A (2011). Social fMRI: Investigating and shaping social mechanisms in the real world. Pervasive and Mobile Computing, 7(6), 643–659. [Google Scholar]
- Allcott H, & Gentzkow M (2017). Social media and fake news in the 2016 election. Journal of Economic Perspectives, 31(2), 211–36. [Google Scholar]
- Anderson C (2008). The end of theory: The data deluge makes the scientific method obsolete. Wired Magazine, 16(7), 16–07. [Google Scholar]
- Anderson J, & Rainie L (2012, February 29). Millennials will benefit and suffer due to their hyperconnected lives. Pew Research Center. Retrieved from: https://s3.amazonaws.com/academia.edu.documents/30881000/PIP_Future_of_Internet_2012_Young_Brains_PDF.pdf?AWSAccessKeyId=AKIAIWOWYYGZ2Y53UL3A&Expires=1509479686&Signature=IJ4GkUTlR0SLCDllId4tM52xe8o%3D&response-content-disposition=inline%3B%20filename%3DMillennials_Will_Benefit_and_Suffer_Due.pdf [Google Scholar]
- AppAnnie. (2017). Spotlight on consumer app usage. Retrieved from http://files.appannie.com.s3.amazonaws.com/reports/1705_Report_Consumer_App_Usage_EN.pdf
- Azmak O, Bayer H, Caplin A, Chun M, Glimcher P, Koonin S, & Patrinos A (2015). Using Big data to understand the human condition: the Kavli HUMAN project. Big Data, 3(3), 173–188. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bakshy E, Messing S, & Adamic LA (2015). Exposure to ideologically diverse news and opinion on Facebook. Science, 348(6239), 1130–1132. [DOI] [PubMed] [Google Scholar]
- Bartsch A, Vorderer P, Mangold R, & Viehoff R (2008). Appraisal of emotions in media use: Toward a process model of meta-emotion and emotion regulation. Media Psychology, 11(1), 7–27. [Google Scholar]
- Battestini A, Setlur V, & Sohn T (2010, September). A large scale study of text-messaging use. In Proceedings of the 12th International Conference on Human Computer Interaction with Mobile Devices and Services (pp. 229–238). ACM. [Google Scholar]
- Bawden D, & Robinson L (2009). The dark side of information: overload, anxiety and other paradoxes and pathologies. Journal of Information Science, 35(2), 180–191. [Google Scholar]
- Beebe B, Jaffe J, & Lachmann F (2005). A dyadic systems view of communication. In Auerbach J, Levy K, Schaffer C, & Stein M (Eds.), Relatedness, self-definition and mental representation, (pp. 23–42). London: Routledge. [Google Scholar]
- Bellman S, Wooley B, & Varan D (2016). Program–Ad matching and television ad effectiveness: A reinquiry using facial tracking software. Journal of Advertising, 45(1), 72–77. [Google Scholar]
- Berinsky AJ, Quek K, and Sances M (2012). Conducting online experiments on mechanical turk. Newsletter of the APSA Experimental Section, 3(1):2–9. [Google Scholar]
- Blei DM, & Lafferty JD (2006, June). Dynamic topic models. In Proceedings of the 23rd International Conference on Machine Learning (pp. 113–120). ACM. [Google Scholar]
- Blei DM, Ng AY, & Jordan MI (2003). Latent dirichlet allocation. Journal of Machine Learning Research, 3(Jan), 993–1022. [Google Scholar]
- Bohannon J (2011). Social science for pennies. Science, 334(6054), 307–307. [DOI] [PubMed] [Google Scholar]
- Boker SM, Brick TR, Pritikin JN, Wang Y, Oertzen TV, Brown D, ... & Neale MC (2015). Maintained individual data distributed likelihood estimation (middle). Multivariate Behavioral Research, 50(6), 706–720. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bolger N, & Laurenceau JP (2013). Intensive longitudinal methods: An introduction to diary and experience sampling research. New York, NY: Guilford Press. [Google Scholar]
- boyd d. (2015). Making sense of teen life: Strategies for capturing ethnographic data in a networked era. In Digital Research Confidential: The Secrets of Studying Behavior Online. Cambridge: MIT Press. [Google Scholar]
- Brasel SA, & Gips J (2011). Media multitasking behavior: Concurrent television and computer usage. Cyberpsychology, Behavior, and Social Networking, 14(9), 527–534 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Breuel TM (2008). The OCRopus open source OCR system. In Proc. SPIE 6815, Document Recognition and Retrieval XV (Vol. 6815, pp. 68150F1–68150F15). SPIE. [Google Scholar]
- Brown JS (2000). Growing up: Digital: How the web changes work, education, and the ways people learn. Change: The Magazine of Higher Learning, 32(2), 11–20. [Google Scholar]
- Buhrmester M, Kwang T, & Gosling SD (2011). Amazon’s Mechanical Turk: A new source of inexpensive, yet high-quality, data?. Perspectives on Psychological Science, 6(1), 3–5. [DOI] [PubMed] [Google Scholar]
- Burgoon JK, Stern LA, & Dillman L (2007). Interpersonal adaptation: Dyadic interaction patterns. Cambridge University Press. [Google Scholar]
- Butler D (2007, October 10). Data sharing threatens privacy. Nature. Retrieved from https://www.nature.com/news/2007/071010/full/449644a.html [DOI] [PubMed] [Google Scholar]
- Cacciatore MA, Scheufele DA, & Iyengar S (2016). The end of framing as we know it… and the future of media effects. Mass Communication and Society, 19(1), 7–23. [Google Scholar]
- Canny J (1986). A computational approach to edge detection. IEEE Transaction on Pattern Analysis and Machine Intelligence, 8(6), 679–698. [PubMed] [Google Scholar]
- Cappella JN (2017). Vectors into the future of mass and interpersonal communication research: Big data, social media, and computational social science. Human Communication Research, 43(4), 545–558. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carey James. (1992). Communication as Culture, Revised Edition: Essays on Media and Society (Media and Popular Culture). New York, NY: Routledge. [Google Scholar]
- Carstensen LL, Isaacowitz DM, & Charles ST (1999). Taking time seriously: A theory of socioemotional selectivity. American Psychologist, 54, 165–181. [DOI] [PubMed] [Google Scholar]
- Charles ST, Piazza JR, Mogle J, Sliwinski MJ, & Almeida DM (2013). The wear and tear of daily stressors on mental health. Psychological Science, 24(5), 733–741. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Charness N, Fox MC, & Mitchum AL (2011). Life-span cognition and information technology. In Fingerman KL, Berg CA, Smith J, & Antonucci TC (Eds.), Handbook of life-span development (pp. 331–361). New York, NY: Springer. [Google Scholar]
- Chen R, Mias GI, Li-Pook-Than J, Jiang L, Lam HY, Chen R, ... & Cheng Y (2012). Personal omics profiling reveals dynamic molecular and medical phenotypes. Cell, 148(6), 1293–1307. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chiatti A, Yang X, Brinberg M, Cho MJ, Gagneja A, Ram N, Reeves B and Giles CL (2017). Text Extraction from Smartphone Screenshots to Archive in situMedia Behavior. Proceedings of the Ninth International Conference on Knowledge Capture (K-CAP 2017). [Google Scholar]
- Chittaranjan G, Blom J, & Gatica-Perez D (2013). Mining large-scale smartphone data for personality studies. Personal and Ubiquitous Computing, 17(3), 433–450. [Google Scholar]
- Chon J, & Cha H (2011). Lifemap: A smartphone-based context provider for location-based services. IEEE Pervasive Computing, 10(2), 58–67. [Google Scholar]
- Cockburn A, & McKenzie B (2001). What do web users do? An empirical analysis of web use. International Journal of Human-Computer Studies, 54(6), 903–922. [Google Scholar]
- Colleoni E, Rozza A, & Arvidsson A (2014). Echo chamber or public sphere? Predicting political orientation and measuring political homophily in Twitter using big data. Journal of Communication, 64(2), 317–332. [Google Scholar]
- Conroy M, Feezell JT, & Guerrero M (2012). Facebook and political engagement: A study of online political group membership and offline political engagement. Computers in Human Behavior, 28(5), 1535–1546. [Google Scholar]
- Correa T, Hinsley AW, & de Zúñiga HG (2010). Who interacts on the Web?: The intersection of users’ personality and social media use. Computers in Human Behavior, 26(2), 247–253. [Google Scholar]
- Cox DR (1972). Regression models and life tables (with discussion). Journal of the Royal Statistical Society, 34, 187–220. [Google Scholar]
- Csikszentmihalyi M, & Larson R (2014). Validity and reliability of the experience-sampling method. In Flow and the Foundations of Positive Psychology (pp. 35–54). Springer; Netherlands. [Google Scholar]
- Culjak I, Abram D, Pribanic T, Dzapo H, & Cifrek M (2012, May). A brief introduction to OpenCV. In MIPRO, 2012 Proceedings of the 35th International Convention (pp. 1725–1730). IEEE. [Google Scholar]
- Cummings JJ, Yeykelis L, Reeves B (2016). Fragmentation of Media Tasks on a Laptop Computer: Moment-by-Moment Analysis of Task-Switching and Writing Performance. Manuscript submitted for publication. [Google Scholar]
- Cutting JE, Brunick KL, & Candan A (2012). Perceiving event dynamics and parsing Hollywood films. Journal of Experimental Psychology: Human Perception and Performance, 38(6), 1476. [DOI] [PubMed] [Google Scholar]
- Team Datavyu (2014). Datavyu: A video coding tool [Computer Software]. Retrieved from http://datavyu.org. [Google Scholar]
- DeStefano D, & LeFevre JA (2007). Cognitive load in hypertext reading: A review. Computers in Human Behavior, 23(3), 1616–1641. [Google Scholar]
- Deville P, Linard C, Martin S, Gilbert M, Stevens FR, Gaughan AE, ... & Tatem AJ. (2014). Dynamic population mapping using mobile phone data. Proceedings of the National Academy of Sciences, 111(45), 15888–15893. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Diehl M, Hooker K, & Sliwinski M (Eds.). (2015). Handbook of intraindividual variability across the lifespan. New York, NY: Routledge/Taylor & Francis. [Google Scholar]
- Dilliplane S, Goldman SK, & Mutz DC (2013). Televised exposure to politics: New measures for a fragmented media environment. American Journal of Political Science, 57(1), 236–248. [Google Scholar]
- Dingler T, Agroudy PE, Matheis G, & Schmidt A (2016, February). Reading-based screenshot summaries for supporting awareness of desktop activities. In Proceedings of the 7th Augmented Human International Conference 2016 (p. 27). ACM. [Google Scholar]
- Do TMT, & Gatica-Perez D (2014). The places of our lives: Visiting patterns and automatic labeling from longitudinal smartphone data. IEEE Transactions on Mobile Computing, 13(3), 638–648. [Google Scholar]
- Dodge M, & Kitchin R (2007). ‘Outlines of a world coming into existence’: pervasive computing and the ethics of forgetting. Environment and Planning B: Planning and Design, 34(3), 431–445. [Google Scholar]
- Doub AE, Small M, & Birch L (2016). An exploratory analysis of child feeding beliefs and behaviors included in food blogs written by mothers of preschool-aged children. Journal of Nutrition Education and Behavior, 48(2), 93–103. [DOI] [PubMed] [Google Scholar]
- Dumais S, Cutrell E, Cadiz JJ, Jancke G, Sarin R, & Robbins DC (2016, January). Stuff I’ve seen: a system for personal information retrieval and re-use. In ACM SIGIR Forum (Vol. 49, No. 2, pp. 28–35). ACM. [Google Scholar]
- Dvir-Gvirsman S, Tsfati Y, & Menchen-Trevino E (2016). The extent and nature of ideological selective exposure online: Combining survey responses with actual web log data from the 2013 Israeli Elections. New Media & Society, 18(5), 857–877. [Google Scholar]
- Eagle N, Pentland AS, & Lazer D (2009). Inferring friendship network structure by using mobile phone data. Proceedings of the National Academy of Sciences, 106(36), 15274–15278. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Elliott RJ, Aggoun L, & Moore JB (1995). Hidden Markov models: Estimation and control. New York, NY: Springer. [Google Scholar]
- Estes W (1956). The problem of inference from curves based on group data. Psychological Bulletin, 53, 134–140. [DOI] [PubMed] [Google Scholar]
- Estrin D, & Juels A (2016). Reassembling Our Digital Selves. Daedalus, 145(1), 43–53. [Google Scholar]
- Eveland WP Jr, Hutchens MJ, & Shen F (2009). Exposure, attention, or “use” of news? Assessing aspects of the reliability and validity of a central concept in political communication research. Communication Methods and Measures, 3(4), 223–244. [Google Scholar]
- Fraley RC, & Hudson NW (2014). Review of intensive longitudinal methods: An introduction to diary and experience sampling research. The Journal of Social Psychology, 154(1), 89–91. [Google Scholar]
- Geertz C (1973). The Interpretation of Cultures. New York, NY: Basic Books. [Google Scholar]
- Geertz C (1994). Thick description: Toward an interpretive theory of culture. In Martin M& McIntyre LC (Eds.), Readings in the philosophy of social science (pp. 213–231). Cambridge, MA: MIT Press. [Google Scholar]
- Geertz C (1998). Deep Hanging Out. The New York Review of Books, 45(16), 69–72. [Google Scholar]
- Gemmell J, Bell G, Lueder R, Drucker S, & Wong C (2002, December). MyLifeBits: fulfilling the Memex vision. In Proceedings of the tenth ACM international conference on Multimedia (pp. 235–238). ACM. [Google Scholar]
- Gentile DA, Li D, Khoo A, Prot S, & Anderson CA (2014). Mediators and moderators of long-term effects of violent video games on aggressive behavior: Practice, thinking, and action. JAMA Pediatrics, 168(5), 450–457. [DOI] [PubMed] [Google Scholar]
- Gentzkow M, & Shapiro JM (2011). Ideological segregation online and offline. The Quarterly Journal of Economics, 126(4), 1799–1839. [Google Scholar]
- Research GfK. (2017, January 23). Millennials account for nearly half of US cordless population. [Press Release]. Retrieved from: http://www.gfk.com/en-us/insights/press-release/millennials-account-for-nearly-half-of-us-cordless-population-gfk-mri/ [Google Scholar]
- Golder SA, & Macy MW (2011). Diurnal and seasonal mood vary with work, sleep, and daylength across diverse cultures. Science, 333(6051), 1878–1881. [DOI] [PubMed] [Google Scholar]
- Gottlieb G (1996). Developmental Psychobiological Theory. In Cairns R, Elder G, & Costello E (Eds.), Developmental Science (Cambridge Studies in Social and Emotional Development, pp. 63–77). Cambridge: Cambridge University Press. [Google Scholar]
- Greitemeyer T, & Mügge DO (2014). Video games do affect social outcomes: A meta-analytic review of the effects of violent and prosocial video game play. Personality and Social Psychology Bulletin, 40(5), 578–589. [DOI] [PubMed] [Google Scholar]
- Grossberg L (2008). Cultural Studies. In Donsbach W (Ed.), The International Encyclopedia of Communication. Hoboken, NJ: Wiley Publishing. [Google Scholar]
- Gurrin C, Smeaton AF, & Doherty AR (2014). Lifelogging: Personal big data. Foundations and Trends® in Information Retrieval, 8(1), 1–125. [Google Scholar]
- Harari GM, Müller SR, Mishra V, Wang R, Campbell AT, Rentfrow PJ, & Gosling SD (2017). An evaluation of students’ interest in and compliance with self-tracking methods: Recommendations for incentives based on three smartphone sensing studies. Social Psychological and Personality Science, 8(5), 479–492. [Google Scholar]
- Hembrooke H, & Gay G (2003). The laptop and the lecture: The effects of multitasking in learning environments. Journal of Computing in Higher Education, 15(1), 46–64. [Google Scholar]
- Hermans D, De Houwer J, & Eelen P (2001). A time course analysis of the affective priming effect. Cognition & Emotion, 15(2), 143–165. [Google Scholar]
- Hormes JM, Kearns B, & Timko CA (2014). Craving Facebook? Behavioral addiction to online social networking and its association with emotion regulation deficits. Addiction, 109(12), 2079–2088. [DOI] [PubMed] [Google Scholar]
- Horton JJ, Rand DG, and Zeckhauser RJ (2011). The online laboratory: Conducting experiments in a real labor market. Experimental Economics, 14(3), 399–425. [Google Scholar]
- Huff C, & Tingley D (2015). “Who are these people?” Evaluating the demographic characteristics and political preferences of MTurk survey respondents. Research & Politics, 2(3), 1–12. [Google Scholar]
- Jackson LA, Zhao Y, Kolenic III A, Fitzgerald HE, Harold R, & Von Eye A (2008). Race, gender, and information technology use: The new digital divide. CyberPsychology & Behavior, 11(4), 437–442. [DOI] [PubMed] [Google Scholar]
- Jacquemard T, Novitzky P, O’Brolcháin F, Smeaton AF, & Gordijn B (2014). Challenges and opportunities of lifelog technologies: A literature review and critical analysis. Science and Engineering Ethics, 20(2), 379–409. [DOI] [PubMed] [Google Scholar]
- Jansen BJ, & Spink A (2006). How are we searching the World Wide Web? A comparison of nine search engine transaction logs. Information Processing & Management, 42(1), 248–263. [Google Scholar]
- Jenkins H (2006). Convergence culture: Where old and new media collide. New York, NY: NYU Press. [Google Scholar]
- Jones NM, Wojcik SP, Sweeting J, & Silver RC (2016). Tweeting negative emotion: An investigation of Twitter data in the aftermath of violence on college campuses. Psychological Methods, 21(4), 526. [DOI] [PubMed] [Google Scholar]
- Judd T, & Kennedy G (2011). Measurement and evidence of computer-based task switching and multitasking by ‘Net Generation’ students. Computers & Education, 56(3), 625–631. [Google Scholar]
- Judd CM, Westfall J, & Kenny DA (2012). Treating stimuli as a random factor in social psychology: A new and comprehensive solution to a pervasive but largely ignored problem. Journal of Personality and Social Psychology, 103(1), 54. [DOI] [PubMed] [Google Scholar]
- Kahneman D (2011). Thinking, fast and slow. London: Macmillan. [Google Scholar]
- Kaufman DR, Patel VL, Hilliman C, Morin PC, Pevzner J, Weinstock RS, ... & Starren J (2003). Usability in the real world: assessing medical information technologies in patients’ homes. Journal of biomedical informatics, 36(1–2), 45–60. [DOI] [PubMed] [Google Scholar]
- Kaye BK, & Johnson TJ (2002). Online and in the know: Uses and gratifications of the web for political information. Journal of Broadcasting & Electronic Media, 46(1), 54–71. [Google Scholar]
- Kern ML, Park G, Eichstaedt JC, Schwartz HA, Sap M, Smith LK, & Ungar LH (2016). Gaining insights from social media language: Methodologies and challenges. Psychological Methods, 21(4), 507–525. [DOI] [PubMed] [Google Scholar]
- Kietzmann JH, Hermkens K, McCarthy IP, & Silvestre BS (2011). Social media? Get serious! Understanding the functional building blocks of social media. Business Horizons, 54(3), 241–251. [Google Scholar]
- Kim Y, Chen HT, & de Zúñiga HG (2013). Stumbling upon news on the Internet: Effects of incidental news exposure and relative entertainment use on political engagement. Computers in Human Behavior, 29(6), 2607–2614. [Google Scholar]
- Kooti F, Subbian K, Mason W, Adamic L, & Lerman K (2017, April). Understanding short-term changes in online activity sessions. In Proceedings of the 26th International Conference on World Wide Web Companion (pp. 555–563). International World Wide Web Conferences Steering Committee. [Google Scholar]
- Kramer AD, Guillory JE, & Hancock JT (2014). Experimental evidence of massive-scale emotional contagion through social networks. Proceedings of the National Academy of Sciences, 201320040. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Krämer NC, & Winter S (2008). Impression management 2.0: The relationship of self-esteem, extraversion, self-efficacy, and self-presentation within social networking sites. Journal of Media Psychology, 20(3), 106–116. [Google Scholar]
- Ksiazek TB, Malthouse EC, & Webster JG (2010). News-seekers and avoiders: Exploring patterns of total news consumption across media and the relationship to civic participation. Journal of Broadcasting & Electronic Media, 54(4), 551–568. [Google Scholar]
- Kubey R, & Csikszentmihalyi M (2002). Television addiction is no mere metaphor. Scientific American, 286(2), 74–80. [DOI] [PubMed] [Google Scholar]
- Kubey R, & Csikszentmihalyi M (2013). Television and the quality of life: How viewing shapes everyday experience. Routledge. [Google Scholar]
- Kumar R, & Tomkins A (2010, April). A characterization of online browsing behavior. In Proceedings of the 19th International Conference on World Wide Web (pp. 561–570). ACM. [Google Scholar]
- Kwon M, Lee JY, Won WY, Park JW, Min JA, Hahn C, ... & Kim DJ (2013). Development and validation of a smartphone addiction scale (SAS). PloS One, 8(2), e56936. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lang A (2000). The limited capacity model of mediated message processing. Journal of Communication, 50(1), 46–70. [Google Scholar]
- Lang A, Sanders-Jackson A, Wang Z, & Rubenking B (2013). Motivated message processing: How motivational activation influences resource allocation, encoding, and storage of TV messages. Motivation and Emotion, 37(3), 508–517. [Google Scholar]
- Lazer D, Pentland AS, Adamic L, Aral S, Barabasi AL, Brewer D, ... & Jebara T (2009). Life in the network: the coming age of computational social science. Science, 323(5915), 721. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lemke JL (2000). Across the scales of time: Artifacts, activities, and meanings in ecosocial systems. Mind, Culture, and Activity 7(4), 273–290. [Google Scholar]
- Leong L (2017). Mobile Myanmar: The development of a mobile app culture in Yangon. Mobile Media & Communication, 5(2), 139–160. [Google Scholar]
- Lienhart R & Maydt J (2002). An extended set of Haar-like features for rapid object detection. In Proceedings of the 2002 IEEE International Conference on Image Processing (Vol.1, pp. 900–903). IEEE. [Google Scholar]
- Lin YH, Lin YC, Lee YH, Lin PH, Lin SH, Chang LR, ... & Kuo TB (2015). Time distortion associated with smartphone addiction: Identifying smartphone addiction via a mobile application (App). Journal of Psychiatric Research, 65, 139–145. [DOI] [PubMed] [Google Scholar]
- Litman L, Robinson J, and Rosenzweig C (2015). The relationship between motiva-tion, monetary compensation, and data quality among US-and India-based workers on mechanical turk. Behavior Research Methods, 47(2):519–528. [DOI] [PubMed] [Google Scholar]
- Lundby K (Ed.). (2014). Mediatization of communication (Vol. 21). Berlin: Walter de Gruyter GmbH & Co KG. [Google Scholar]
- MacKillop J, Amlung MT, Few LR, Ray LA, Sweet LH, & Munafò MR (2011). Delayed reward discounting and addictive behavior: a meta-analysis. Psychopharmacology, 216(3), 305–321. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Magnusson D, & Cairns RB (1996). Developmental science: Toward a unified framework. In Cairns RB, Elder GH, & Costello EJ, (Eds.), Developmental science (pp. 7–30). New York, NY: Cambridge University Press. [Google Scholar]
- Manos D (Ed.). (2017). Rocking the baseline: Verily, Duke, and Stanford aim to make medicine more predictive with a new baseline study. Clinical OMICs, 4(3), 3–4. [Google Scholar]
- Mark G, Voida S, & Cardello A (2012, May). A pace not dictated by electrons: an empirical study of work without email. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (pp. 555–564). ACM. [Google Scholar]
- Meaney MJ, & Ferguson-Smith AC (2010). Epigenetic regulation of the neural transcriptome: the meaning of the marks. Nature Neuroscience, 13(11), 1313. [DOI] [PubMed] [Google Scholar]
- Mehl MR, & Conner TS (Eds.). (2012). Handbook of research methods for studying daily life. New York, NY: Guilford Press. [Google Scholar]
- Meshi D, Tamir DI, & Heekeren HR (2015). The emerging neuroscience of social media. Trends in Cognitive Sciences, 19(12), 771–782. [DOI] [PubMed] [Google Scholar]
- Min JK, Wiese J, Hong JI, & Zimmerman J (2013, February). Mining smartphone data to classify life-facets of social relationships. In Proceedings of the 2013 Conference on Computer Supported Cooperative Work (pp. 285–294). ACM. [Google Scholar]
- Mischel W, Shoda Y, & Rodriguez ML (1989). Delay of gratification in children. Science, 244(4907), 933–938. [DOI] [PubMed] [Google Scholar]
- Molenaar PCM (2004). A manifesto on psychology as idiographic science: Bringing the person back into scientific psychology, this time forever. Measurement, 2(4), 201–218. [Google Scholar]
- Molenaar PCM, & Campbell CG (2009). The new person-specific paradigm in psychology. Current Directions in Psychology, 18, 112–117. [Google Scholar]
- Morgan EM, Snelson C, & Elison-Bowers P (2010). Image and video disclosure of substance use on social media websites. Computers in Human Behavior, 26(6), 1405–1411. [Google Scholar]
- Morse PJ, Neel R, Todd E, & Funder D (2015). Renovating situation taxonomies: Exploring the construction and content of fundamental motive situation types. Journal of Personality, 83(4), 389–403. [DOI] [PubMed] [Google Scholar]
- Murphy J, Hofacker C, & Mizerski R (2006). Primacy and recency effects on clicking behavior. Journal of Computer-Mediated Communication, 11(2), 522–535. [Google Scholar]
- Nadkarni A, & Hofmann SG (2012). Why do people use Facebook?. Personality and Individual Differences, 52(3), 243–249. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nass CI, & Reeves B (1991). Combining, distinguishing, and generating theories in communication: A domains of analysis framework. Communication Research, 18(2), 240–261. [Google Scholar]
- Nature. (2007, October 11). A matter of trust: Social scientists studying electronic interactions must take the lead on preserving data security. Retrieved from http://www.nature.com/nature/journal/v449/n7163/full/449637b.html
- Nesselroade JR (1991). The warp and the woof of the developmental fabric. In Downs RM, Liben LS, & Palermo DS (Eds.), Visions of aesthetics, the environment and development: The legacy of Joachim F. Wohlwill (pp. 213–240). Hillsdale, NJ: Erlbaum. [Google Scholar]
- Newell A and Card SK, 1985. The prospects for psychological science in human-computer interaction. Human-computer interaction, 1(3), pp.209–242. [Google Scholar]
- Norvig P (2012). Colorless green ideas learn furiously: Chomsky and the two cultures of statistical learning. Significance, 9(4), 30–33. [Google Scholar]
- Ofcom. (2017). Adults’ media use and attitudes report 2017. Retrieved from: https://www.ofcom.org.uk/__data/assets/pdf_file/0020/102755/adults-media-use-attitudes-2017.pdf
- Olken B (2009). Do television and radio destroy social capital. Evidence from Indonesian villages. American Economic Journal: Applied Economics, 1(4), 1–33. [Google Scholar]
- Ophir E, Nass C, & Wagner AD (2009). Cognitive control in media multitaskers. Proceedings of the National Academy of Sciences, 106(37), 15583–15587. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Otsu N (1979). A threshold selection method from gray-level histograms,” IEEE Trans. Systems, Man, and Cybernetics, 9(1), 62–66. [Google Scholar]
- Pea R, Nass C, Meheula L, Rance M, Kumar A, Bamford H, ... & Zhou M (2012). Media use, face-to-face communication, media multitasking, and social well-being among 8- to 12-year-old girls. Developmental Psychology, 48(2), 327. [DOI] [PubMed] [Google Scholar]
- Pennebaker JW, Booth RJ, Boyd RL, & Francis ME (2015). Linguistic Inquiry and Word Count: LIWC2015. Austin, TX: Pennebaker Conglomerates; (www.LIWC.net). [Google Scholar]
- Petry NM, Rehbein F, Gentile DA, Lemmens JS, Rumpf HJ, Mößle T, ... & Auriacombe M (2014). An international consensus for assessing internet gaming disorder using the new DSM‐5 approach. Addiction, 109(9), 1399–1406. [DOI] [PubMed] [Google Scholar]
- Pew Research Center. (2017, January 12). Mobile Fact Sheet. Retrieved from: http://www.pewinternet.org/fact-sheet/mobile/
- Putnam RD (1995). Bowling alone: America’s declining social capital. Journal of Democracy, 6(1), 65–78. [Google Scholar]
- Quan-Haase A, & Young AL (2010). Uses and gratifications of social media: A comparison of Facebook and instant messaging. Bulletin of Science, Technology & Society, 30(5), 350–361. [Google Scholar]
- Raacke J, & Bonds-Raacke J (2008). MySpace and Facebook: Applying the uses and gratifications theory to exploring friend-networking sites. Cyberpsychology & Behavior, 11(2), 169–174. [DOI] [PubMed] [Google Scholar]
- Ram N, Brinberg M, Pincus AL, & Conroy DE (2017). The questionable ecological validity of ecological momentary assessment designs: Prospects for unobtrusive monitoring and person-specific analysis. Research in Human Development, 14(3), 253–270. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ram N, Brose A & Molenaar PCM (2013). Dynamic factor analysis: Modeling person-specific process. In Little T (Ed.) Oxford handbook of quantitative methods Volume 2 Statistical Analysis (pp. 441–457). New York: Oxford University Press. [Google Scholar]
- Ram N & Diehl M (2015). Multiple time-scale design and analysis: Pushing towards real-time modeling of complex developmental processes. In Diehl M, Hooker K, & Sliwinski M (Eds). Handbook of intraindividual variability across the lifespan (pp. 308–323). NY: Routledge. [Google Scholar]
- Ram N & Gerstorf D (2009). Time structured and net intraindividual variability: Tools for examining the development of dynamic characteristics and processes. Psychology and Aging, 24(4), 778–791. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rauthmann JF, Gallardo-Pujol D, Guillaume EM, Todd E, Nave CS, Sherman RA, ... & Funder DC (2014). The Situational Eight DIAMONDS: A taxonomy of major dimensions of situation characteristics. Journal of Personality and Social Psychology, 107(4), 677. [DOI] [PubMed] [Google Scholar]
- Rauthmann JF, & Sherman RA (2015). Ultra-brief measures for the situational eight DIAMONDS domains. European Journal of Psychological Assessment, 32(2), 165–174. [Google Scholar]
- Rauthmann JF, Sherman RA, & Funder DC (2015). Principles of situation research: Towards a better understanding of psychological situations. European Journal of Personality, 29(3), 363–381. [Google Scholar]
- Rawassizadeh R, Tomitsch M, Wac K, & Tjoa AM (2013). UbiqLog: a generic mobile phone-based life-log framework. Personal and Ubiquitous Computing, 17(4), 621–637. [Google Scholar]
- Reeves B (1989). Theories about news and theories about cognition: Arguments for a more radical separation. American Behavioral Scientist, 33(2), 191–198. [Google Scholar]
- Reeves B, Yeykelis L, & Cummings JJ (2016). The use of media in media psychology. Media Psychology, 19(1), 49–71. [Google Scholar]
- Richardson IEG (2003). H.264 and MPEG-4 video compression: Video coding for next-generation multimedia. Chichester: John Wiley & Sons Ltd. [Google Scholar]
- Robertson SE, Walker S, Jones S, Hancock-Beaulieu MM & Gatford M (1995). Okapi at TREC-3. In Harmon DK (Ed.). Overview of the third text retrieval conference (Trec-3) (pp, 109–126). Darby, PA: DIANE Publishing Company. [Google Scholar]
- Robinson TN, Matheson D, Desai M, Wilson DM, Weintraub DL, Haskell WL, ... & Haydel KF (2013). Family, community and clinic collaboration to treat overweight and obese children: Stanford GOALS—a randomized controlled trial of a three-year, multi-component, multi-level, multi-setting intervention. Contemporary Clinical Trials, 36(2), 421–435. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Robinson WS (1950). Ecological correlations and the behavior of individuals. American Sociological Review, 15(3), 351–357. [Google Scholar]
- Romantan A, Hornik R, Price V, Cappella J, & Viswanath K (2008). A comparative analysis of the performance of alternative measures of exposure. Communication Methods and Measures, 2(1–2), 80–99. [Google Scholar]
- Rosen LD, Carrier LM, & Cheever NA (2013). Facebook and texting made me do it: Media-induced task-switching while studying. Computers in Human Behavior, 29(3), 948–958. [Google Scholar]
- Ross L, & Nisbett RE (2011). The person and the situation: Perspectives of social psychology. London: Pinter & Martin Publishers. [Google Scholar]
- Sankoff D & Kruskal JB (Eds.). (1983). Time warps, string edits, and macromolecules: The theory and practice of sequence comparison. Boston, MA: Addison-Wesley. [Google Scholar]
- Sarker A, Ginn R, Nikfarjam A, O’Connor K, Smith K, Jayaraman S, ... & Gonzalez G (2015). Utilizing social media data for pharmacovigilance: A review. Journal of Biomedical Informatics, 54, 202–212. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schwartz HA, Eichstaedt JC, Kern ML, Dziurzynski L, Ramones SM, Agrawal M, ... & Ungar LH (2013). Personality, gender, and age in the language of social media: The open-vocabulary approach. PloS One, 8(9), e73791. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Seo MG, Goldfarb B, & Barrett LF (2010). Affect and the framing effect within individuals over time: Risk taking in a dynamic investment simulation. Academy of Management Journal, 53(2), 411–431. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sethna JP (2006). Statistical mechanics: entropy, order parameters, and complexity. Oxford: Oxford University Press. [Google Scholar]
- Shah DV, Cappella JN, & Neuman WR (2015). Big data, digital media, and computational social science: Possibilities and perils. The ANNALS of the American Academy of Political and Social Science, 659(1), 6–13. [Google Scholar]
- Sherman JE, Spencer J, Preisser JS, Gesler WM, & Arcury TA (2005). A suite of methods for representing activity space in a healthcare accessibility study. International Journal of Health Geographics, 4(1), 24. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shiyko M, & Ram N (2011). Conceptualizing and estimating process speed in studies employing ecological momentary assessment designs: A multilevel variance decomposition approach. Multivariate Behavioral Research, 46(6), 875–899. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith A (2017, January 17). Record shares of Americans now own smartphone, have home broadband. Pew Research Center. Retrieved from: http://www.pewresearch.org/fact-tank/2017/01/12/evolution-of-technology/ [Google Scholar]
- Smith R (2007, September). An overview of the Tesseract OCR engine. In Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR 2007) (Vol. 2, pp. 629–633). IEEE. [Google Scholar]
- Su NM, Brdiczka O, & Begole B (2013). The routineness of routines: measuring rhythms of media interaction. Human–Computer Interaction, 28(4), 287–334. [Google Scholar]
- Sundar S (2009-02–12). Social psychology of interactivity in human-website interaction. In Joinson AN, McKenna KYA, Postmes T, and Reips U (Eds.), Oxford Handbook of Internet Psychology. Oxford University Press. Retrieved from http://www.oxfordhandbooks.com/view/10.1093/oxfordhb/9780199561803.001.0001/oxfordhb-9780199561803-e-007. [Google Scholar]
- Sundar SS, Bellur S, Oh J, Xu Q, & Jia H (2014). User experience of on-screen interaction techniques: An experimental investigation of clicking, sliding, zooming, hovering, dragging, and flipping. Human–Computer Interaction, 29(2), 109–152. [Google Scholar]
- Sundar SS, Kalyanaraman S, & Brown J (2003). Explicating web site interactivity: Impression formation effects in political campaign sites. Communication Research, 30(1), 30–59. [Google Scholar]
- Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, & Rabinovich A (2015). Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1–9). IEEE. [Google Scholar]
- Talukder KH & Mallick T (2014). Connected component based approach for text extraction from color image. In Proceedings of the 17th IEEE International Conference on Computer and Information Technology (ICCIT 2014) (pp. 204–209). IEEE. [Google Scholar]
- Tamir DI, Zaki J, & Mitchell JP (2015). Informing others is associated with behavioral and neural signatures of value. Journal of Experimental Psychology: General 144(6), 1114. [DOI] [PubMed] [Google Scholar]
- Taneja H, Webster JG, Malthouse EC, & Ksiazek TB (2012). Media consumption across platforms: Identifying user-defined repertoires. New Media & Society, 14(6), 951–968. [Google Scholar]
- Tewksbury D, Weaver AJ, & Maddex BD (2001). Accidentally informed: Incidental news exposure on the World Wide Web. Journalism & Mass Communication Quarterly, 78(3), 533–554. [Google Scholar]
- Thelen E, & Smith LB (2006). Dynamic systems theories. In Damon W & Lerner RM (Eds.), Handbook of Child Psychology. Hoboken, NJ: John Wiley & Sons. [Google Scholar]
- Thorson E, Reeves B, & Schleuder J (1985). Message complexity and attention to television. Communication Research, 12(4), 427–454. [Google Scholar]
- Tossell C, Kortum P, Rahmati A, Shepard C, & Zhong L (2012, May). Characterizing web use on smartphones. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (pp. 2769–2778). ACM. [Google Scholar]
- Turkle S (1994). Constructions and reconstructions of self in virtual reality: Playing in the MUDs. Mind, Culture, and Activity 1(3), 158–167. [Google Scholar]
- Tversky A, & Kahneman D (1981). The framing of decisions and the psychology of choice. Science, 211(4481), 453–458. [DOI] [PubMed] [Google Scholar]
- Valentino NA, Hutchings VL, Banks AJ, & Davis AK (2008). Is a worried citizen a good citizen? Emotions, political information seeking, and learning via the internet. Political Psychology, 29(2), 247–273. [Google Scholar]
- Van Heck GL (1984). The construction of a general taxonomy of situations. Personality psychology in Europe: Theoretical and empirical developments, 1, 149–164. [Google Scholar]
- Vanderkam D (2017). localturk [Computer Software]. Retrieved from https://github.com/danvk/localturk
- Viola P, & Jones M (2001). Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001) (Vol. 1, pp. I-I). IEEE. [Google Scholar]
- Volkow ND, Koob GF, & McLellan AT (2016). Neurobiologic advances from the brain disease model of addiction. New England Journal of Medicine, 374(4), 363–371. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vorberg D, Mattler U, Heinecke A, Schmidt T, & Schwarzbach J (2003). Different time courses for visual perception and action priming. Proceedings of the National Academy of Sciences, 100(10), 6275–6280. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang R, Chen F, Chen Z, Li T, Harari G, Tignor S, ... & Campbell AT (2014, September). StudentLife: assessing mental health, academic performance and behavioral trends of college students using smartphones. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing (pp. 3–14). ACM. [Google Scholar]
- Wang Z, & Lang A (2012). Reconceptualizing excitation transfer as motivational activation changes and a test of the television program context effects. Media Psychology, 15(1), 68–92. [Google Scholar]
- Wells C, & Thorson K (2017). Combining big data and survey techniques to model effects of political content flows in Facebook. Social Science Computer Review, 35(1), 33–52. [Google Scholar]
- West R, White RW, & Horvitz E (2013, May). From cookies to cooks: Insights on dietary patterns via analysis of web usage logs. In Proceedings of the 22nd international conference on World Wide Web (pp. 1399–1410). ACM. [Google Scholar]
- White RW, & Huang J (2010, July). Assessing the scenic route: measuring the value of search trails in web logs. In Proceedings of the 33rd international ACM SIGIR conference on Research and development in information retrieval (pp. 587–594). ACM. [Google Scholar]
- Yeykelis L, Cummings JJ, & Reeves B (2014). Multitasking on a single device: Arousal and the frequency, anticipation, and prediction of switching between media content on a computer. Journal of Communication, 64(1), 167–192. [Google Scholar]
- Yeykelis L, Cummings JJ, & Reeves B (2018). The Fragmentation of Work, Entertainment, E-Mail, and News on a Personal Computer: Motivational Predictors of Switching Between Media Content. Media Psychology, 21(3), 377–402. [Google Scholar]
- Yin P, Ram N, Lee WC, Tucker C, Khandelwal S, & Salathé M (2014, May). Two sides of a coin: Separating personal communication and public dissemination accounts in Twitter. In Pacific-Asia Conference on Knowledge Discovery and Data Mining (pp. 163–175). Springer, Cham. [Google Scholar]
- Zacks JM, & Swallow KM (2007). Event segmentation. Current Directions in Psychological Science, 16(2), 80–84. [DOI] [PMC free article] [PubMed] [Google Scholar]