

Abstract
A listener’s interpretation of a given speech sound can vary probabilistically from moment to moment. Previous experience (i.e., the contexts in which one has previously encountered an ambiguous sound) can further influence the interpretation of speech, a phenomenon known as perceptual learning for speech. The present study used multi-voxel pattern analysis to query how neural patterns reflect perceptual learning, leveraging archival fMRI data from a lexically guided perceptual learning study conducted by Myers and Mesite (2014). In that study, participants first heard ambiguous /s/-/∫/ blends in either /s/-biased lexical contexts (epi_ode) or /∫/-biased contexts (refre_ing); subsequently, they performed a phonetic categorization task on tokens from an /asi/-/a∫i/ continuum. In the current work, a classifier was trained to distinguish between phonetic categorization trials in which participants heard unambiguous productions of /s/ and those in which they heard unambiguous productions of /∫/. The classifier was able to generalize this training to ambiguous tokens from the middle of the continuum on the basis of individual subjects’ trial-by-trial perception. We take these findings as evidence that perceptual learning for speech involves neural recalibration, such that the pattern of activation approximates the perceived category. Exploratory analyses showed that left parietal regions (supramarginal and angular gyri) and right temporal regions (superior, middle and transverse temporal gyri) were most informative for categorization. Overall, our results inform an understanding of how moment-to-moment variability in speech perception is encoded in the brain.
At its core, speech perception is a process of inferring a talker’s intended message from an acoustic signal. A challenge for the listener is the lack of a direct correspondence between the acoustic signal and the individual’s phonemic representations (i.e., the lack of invariance problem; Liberman, Cooper, Shankweiler, & Studdert-Kennedy, 1967). Rather, the same acoustic information may be interpreted in distinct ways depending on factors such as the preceding speech context (Ladefoged & Broadbent, 1957) and the overall rate of the speech (Summerfield, 1981). Further complication comes from the fact that different talkers produce speech sounds in distinct ways (Kleinschmidt, 2019; Peterson & Barney, 1952). Despite these challenges, listeners typically perceive speech with high accuracy and with relative ease.
One way that listeners may achieve robust speech perception is by exploiting contextual cues (Kleinschmidt & Jaeger, 2015). A listener’s interpretation of the speech signal is strongly informed by factors such as lexical knowledge (Ganong, 1980), lip movements (McGurk & MacDonald, 1976), and written text (Frost, Repp, & Katz, 1988). Critically, context does not just guide the interpretation of speech in the moment; context also influences the interpretation of subsequent speech from the same talker, even when later speech is encountered in the absence of informative context. In other words, initial context can guide a listener’s ability to learn how a particular talker produces their speech sounds – knowledge that can be applied later when context is no help to disambiguate the signal. Such perceptual learning for speech is often referred to as phonetic recalibration or phonetic retuning.
In a seminal study, Norris, McQueen and Cutler (2003) demonstrated how perceptual learning can be guided by a listener’s lexical knowledge. In that study, listeners were initially exposed to an ambiguous speech sound in contexts where lexical information consistently biased their interpretation toward one phoneme category. In a subsequent test phase, the ambiguous speech sound was embedded in contexts where lexical information could not be used to resolve phoneme identity. Participants generally interpreted the signal in a manner consistent with their previous exposure, indicating phonetic recalibration. Since then, a substantial body of research has provided evidence that lexical context can guide perceptual learning of speech sounds, with such learning shown to be relatively long-lasting (Kraljic & Samuel, 2005), talker-specific (at least for fricatives; Eisner & McQueen, 2005; Kraljic & Samuel, 2006, 2007), and robust to changes in the task used during exposure (Drouin & Theodore, 2018; Eisner & McQueen, 2006) and test (Sjerps & McQueen, 2010). Additionally, phonetic recalibration has been elicited using other forms of contextual cues during exposure, such as lip movements (Bertelson, Vroomen, & De Gelder, 2003) and written text (Keetels, Schakel, Bonte, & Vroomen, 2016).
Nonetheless, while context can bias a listener’s interpretation of a speech sound, it does not uniquely determine it, and there is a considerable amount of trial-by-trial variability in how a listener interprets the speech signal. In other words, the influence of contextual factors is probabilistic rather than deterministic. Hearing a sound that is intermediate between “s”-/s/ and “sh”-/∫/ in the context of epi_ode may bias the listener to the lexically congruent interpretation, /s/, (i.e., episode), but they may still sometimes interpret the phoneme in in the lexically incongruent way, epishode (Kleinschmidt & Jaeger, 2015). The same is true with regard to perceptual learning for speech: Having previously encountered an ambiguous /s/-/∫/ sound in /s/-biased contexts may make a listener more likely to later interpret similar ambiguous speech sounds as /s/, but a listener will still occasionally interpret these ambiguous sounds as /∫/.
The goal of the current study is to understand how variability in the interpretation of ambiguous speech sounds is reflected in patterns of brain activation, particularly following phonetic recalibration. Some insight into this question comes from two multi-voxel pattern analysis (MVPA) studies of perceptual learning for speech. In one such study, Kilian-Hütten, Valente, Vroomen, and Formisano (2011) used lip movements to guide phonetic recalibration, collecting fMRI data while participants alternated between exposure blocks (where disambiguating visual information guided interpretation of a stimulus ambiguous between ‘aba’ and ‘ada’) and test blocks (where participants categorized this ambiguous stimulus as well as two surrounding ambiguous tokens). Phonetic recalibration was observed in that participants categorized ambiguous stimuli as ‘aba’ more often after /b/-biased blocks than after /d/-biased blocks. To examine how trial-by-trial perception was reflected in the pattern of functional activation, the authors trained a support vector machine (SVM) on trial-by-trial patterns of activation from the bilateral temporal lobes, labeling trials based on perceptual identification data. When tested on activation patterns from held-out trials, the classifier was significantly above chance in its ability to correctly identify how the subject had perceived the stimulus on that trial. Furthermore, the most discriminative voxels tended to be left-lateralized and specifically located near primary auditory cortex. Similar results were obtained by Bonte, Correia, Keetels, Vroomen, and Formisano (2017), who used written text (aba or ada) to guide phonetic recalibration of ambiguous auditory stimuli (a?a). Using a similar SVM approach, Bonte and colleagues found that the subject’s trial-by-trial interpretation of an ambiguous stimulus could be identified based on the pattern of activity across the bilateral superior temporal cortex. Taken together, the results of these studies suggest that a listener’s ultimate percept of an ambiguous sound can be recovered from the pattern of activity in temporal cortex.
Because these previous studies were largely interested in whether perceptual information was encoded in early sensory regions, their analyses were restricted to bilateral temporal cortex. However, there are reasons to suspect that the pattern of neural activity in other regions may also provide information about the underlying percept, at least following lexically guided perceptual learning. Of particular relevance here is a lexically guided perceptual learning study by Myers and Mesite (2014). In that study, participants alternated between lexical decision blocks (during which they were exposed to an ambiguous /s/-/∫/ sound in lexically disambiguating contexts, such as epi_ode or refre_ing) and test blocks (wherein participants performed a phonetic categorization task with a continuum of stimuli from /asi/ to /a∫i/). Functional neuroimaging data collected during the phonetic categorization task implicated a broad set of neural regions in the process of lexically guided perceptual learning. In particular, the response of the right inferior frontal gyrus (IFG) to ambiguous tokens depended on whether the exposure blocks had biased subjects to interpret the ambiguous speech sound as /s/ or /∫/. The authors also reported several left hemisphere clusters – including ones in left parietal cortex (left supramarginal gyrus, or SMG) and in left IFG – that showed an emergence of talker-specific effects over the course of the experiment. Such findings suggest that a subject’s perceptual experience may be encoded in regions beyond temporal cortex, at least when lexical information guides phonetic retuning.
Notably, Myers and Mesite (2014) employed only univariate statistics to investigate the neural basis of subjects’ perceptual experiences. By contrast, MVPA exploits potential interactions between voxels (focal and/or distributed) to uncover otherwise hidden cognitive states. MVPA also allows researchers to investigate the generalization of multi-voxel patterns across different cognitive states, which is crucial for studying invariance to specific experimental dimensions (Correia et al., 2014; Correia, Jansma, & Bonte, 2015).
In the current study, we used MVPA to analyze patterns of functional activation during the course of lexically guided perceptual learning, considering a broad set of regions implicated in language processing. To this end, we re-analyzed data originally collected by Myers and Mesite (2014). In the phonetic categorization task used by Myers and Mesite, participants were asked to categorize both ambiguous stimuli (i.e., stimuli near the phonetic category boundary) as well as unambiguous ones (i.e., stimuli near the endpoints of the phonetic continuum). This allowed us to ask whether the information needed to distinguish unambiguous stimuli can be generalized to distinguish between ambiguous stimuli on the basis of trial-by-trial perception. Hence, we trained SVM classifiers on multi-voxel patterns from the unambiguous tokens of the continuum; one unambiguous token had been created by averaging the waveforms of a clear /s/ and a clear /∫/ but weighting the mixture toward /∫/ (20% /s/ and 80% /∫/), and the other was a blend weighted toward /s/ (70% /s/ and 30% /∫/). Both training tokens were perceived unambiguously, and participants categorized them with near-perfect accuracy. We then examined whether the classification scheme that was useful for distinguishing unambiguous tokens could be used to distinguish ambiguous tokens in the middle of the continuum (a 40% /s/ token and a 50% /s/ token, for which subjects exhibited considerable variability in their phonetic categorization). Critically, we labeled test stimuli on the basis of how they were ultimately perceived on that individual trial. If functional activation patterns reflect variability in perception, then the patterns of activation should differ between trials where the same acoustic information (e.g., the 40% /s/ token) was interpreted as a /s/ or as a /∫/. In this way, we can glean insight into how a subject’s perceptual experience, which may vary from trial to trial even when acoustics are held constant, is reflected in the underlying neural patterns of activation. Furthermore, by training the classifier on unambiguous stimuli and testing it on ambiguous tokens, we can directly test how subjects’ neural encoding of ambiguous speech sounds compares to their encoding of unambiguous stimuli.
Methods
Data collection
Data were obtained from Myers and Mesite (2014), to which the reader is referred for full details regarding stimuli construction and data acquisition. We analyzed data from 24 adults (age range: 18–40 years, mean: 26), all of whom were right-handed native speakers of American English with no history of neurological or hearing impairments. Participants completed alternating runs of lexical decision and phonetic categorization, completing five runs of each. During lexical decision, participants encountered ambiguous /s/-/∫/ stimuli in contexts where lexical information biased their interpretation, with half of the participants receiving /s/-biased contexts (e.g., epi_ode) and half receiving /∫/-biased contexts (e.g., refre_ing). During phonetic categorization blocks, participants heard four tokens from an /asi/-/a∫i/ continuum – two tokens that were unambiguous (20% /s/ and 70% /s/) as well as two that were perceptually ambiguous (40% /s/ and 50% /s/). Participants made behavioral responses during the lexical decision and phonetic categorization tasks, and buttons were pressed using their right index and middle fingers; response mappings were counterbalanced across participants. Across all runs, participants received 160 phonetic categorization trials (8 per token during each of the 5 runs). The study implemented a fast event-related design with sparse sampling (Edmister, Talavage, Ledden, & Weisskoff, 1999), where each 2-second EPI acquisition was followed by 1 second of silence. Auditory stimuli were only presented during silent gaps.
Data analysis
Feature estimation.
For the present analyses, functional images were minimally preprocessed in AFNI (Cox, 1996) using an afni_proc.py script that simultaneously aligned functional images to their anatomy and registered functional volumes to the first image of each run. The remaining analyses were conducted using custom scripts in MATLAB (The Mathworks Inc., Natick, MA, USA). We next estimated the multi-voxel pattern of activation for each trial of the phonetic categorization task; note that lexical decision trials were not included in these analyses. Because data were obtained using a rapid event-related design, we used a least squares-separate approach to estimate a beta map for each trial (Mumford, Turner, Ashby, & Poldrack, 2012). In this approach, a separate general linear model is performed for every trial. In each model, the onset of the current trial is convolved with a basis function, and this is then used as the regressor of interest. A nuisance regressor is made from a vector of all other trial onsets convolved with the same basis function. This approach leads to more accurate and less variable estimates of single-trial activations in rapid event-related designs, thereby leading to more reliable MVPA analyses (Mumford et al., 2012). For our analyses, we used a double gamma function as the basis function, following the recommendation of Mumford and colleagues. We set the onset of the audio stimulus to be the onset of the response function but otherwise used the default parameters in the spm_hrf function.
ROI selection.
In contrast to previous studies that have only considered the activity of temporal cortex (Bonte et al., 2017; Kilian-Hütten et al., 2011), we considered the pattern of activity across a broad set of regions implicated in language processing. Specifically, we considered bilateral frontal cortex (inferior and middle frontal gyri), parietal cortex (supramarginal and angular gyri), temporal cortex (superior, middle and transverse temporal gyri) and insular cortex. Note that precentral and postcentral gyri were excluded from this mask because of the concern that classification accuracy in these areas could be driven by the motor requirements of making a behavioral response on every trial. Regions were defined anatomically using the Talairach and Tournoux (1988) atlas built into AFNI and are visualized in Figure 1A. Group-level masks were warped into each subject’s native brain space in AFNI using the 3dfractionize program so that classification analyses could be performed in each subject’s native brain space.
Figure 1.
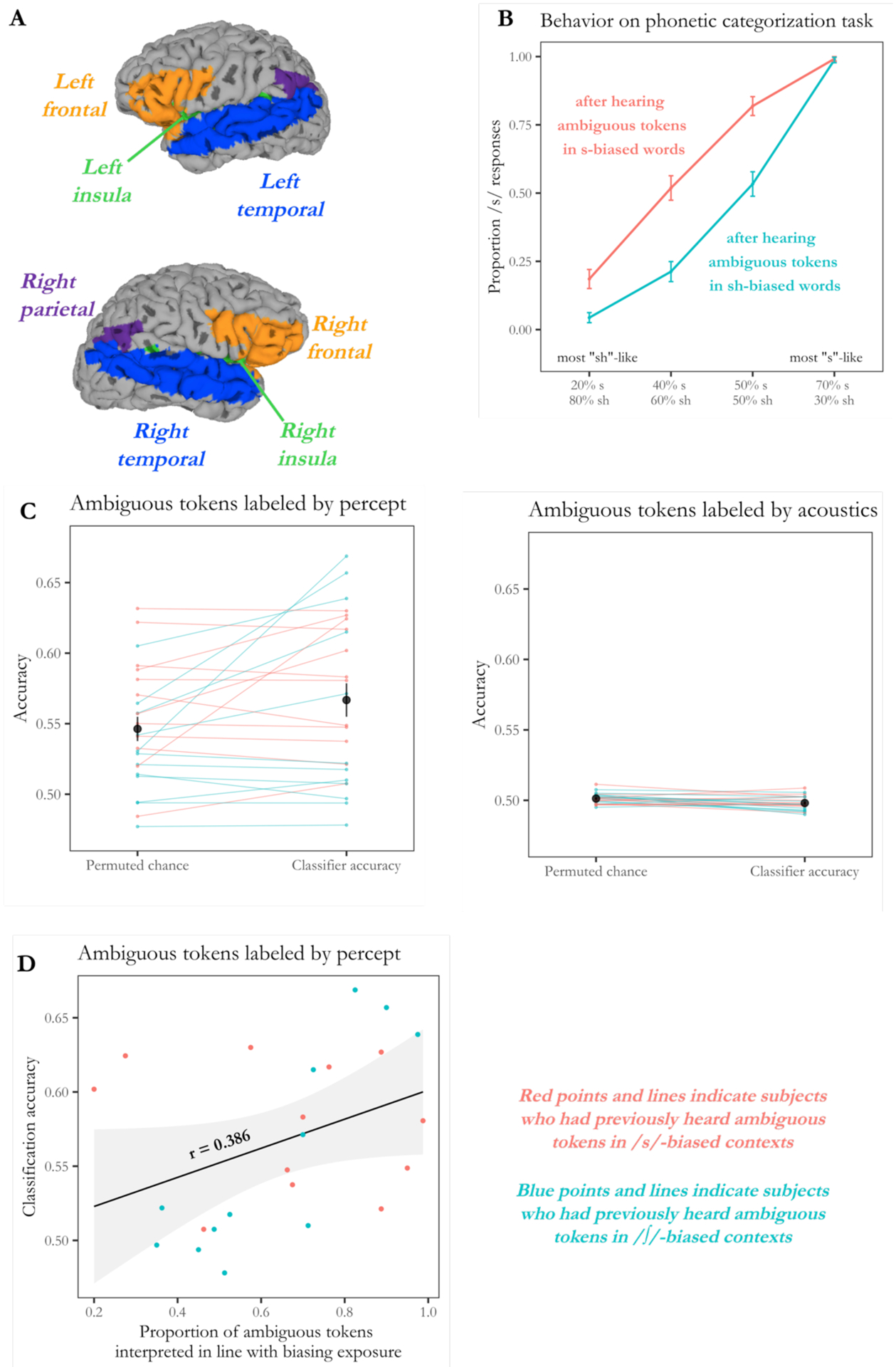
(A) Analyses considered the pattern of activation across several regions associated with language processing: bilateral frontal regions (inferior and middle frontal gyri), insular cortex, temporal regions (superior, middle, and transverse temporal gyri), and parietal regions (supramarginal and angular gyri). The analyses in this figure considered the classification ability of voxels in all these regions, irrespective of specific location.
(B) Behavioral performance on the phonetic categorization task, previously reported by Myers and Mesite (2014). Subjects made more /s/ responses as stimuli became more /s/-like, and their overall rate of /s/ responses was higher if they had previously encountered ambiguous stimuli in contexts where lexical information guided them to interpret the ambiguous stimulus as ‘s.’ Critically, there is still a considerable amount of trial-to-trial variability in classification of ambiguous tokens; for instance, subjects in the /s/-biased group interpreted the 40% /s/ token as /s/ approximately half the time and as /∫/ half the time.
(C) A classifier was trained to classify unambiguous stimuli as /s/ or /∫/ and was able to successfully generalize to ambiguous stimuli near the phonetic category boundary, with significantly above-chance accuracy in determining how subjects perceived an ambiguous stimulus on each particular trial (left panel). However, the classifier did not reach above-chance accuracy when ambiguous stimuli were labeled with respect to acoustics (right panel). Dark points indicate mean accuracy, and error bars indicate standard error. Light lines indicate classification accuracy by subject, with light red lines indicating subjects who had previously heard ambiguous tokens in /s/-biased contexts and light blue lines indicating those who had previously received /∫/-biased contexts.
(D) A follow-up analysis indicated that the classifier’s ability to recover trial-by-trial perceptual experiences was numerically related to individual differences in phonetic recalibration. In particular, the classifier was most accurate in classifying ambiguous tokens for subjects who showed large behavioral effects (measured as the proportion of bias-consistent responses made on ambiguous trials). Red points indicate subjects who had previously heard ambiguous tokens in /s/-biased lexical frames, while blue points indicate those who had heard ambiguous tokens in /∫/-biased contexts.
Classification and cross-validation approach.
Multi-voxel patterns were analyzed using support vector machines (SVMs) that were trained on beta maps from trials in which participants heard unambiguous tokens (20% /s/ and 70% /s/). These unambiguous trials were labeled as /s/ or /∫/ depending on their acoustics, not subjects’ trial-by-trial perception, though subjects had near-ceiling (94%) accuracy in classifying these stimuli. This ensured that training sets were balanced (i.e., there were an equal number of /s/ trials and /∫/ trials). After training on the unambiguous endpoint stimuli, SVMs were tested in their ability to classify ambiguous stimuli from the middle of the continuum (the 40% /s/ and 50% /s/ tokens).
If functional activation patterns reflect a subject’s perceptual experience (which results in part from the biasing effects of lexical context), then the pattern of activation should depend on how a subject ultimately perceived a trial; thus, patterns corresponding to a single stimulus (e.g., 40% /s/) may differ depending on how the acoustics were ultimately interpreted on that trial. Notably, for ambiguous tokens, the lexically-biasing context shifted the phonetic category boundary and significantly increased the probability that individuals who heard /s/-biased lexical contexts would assign the /s/ label to ambiguous tokens (and the opposite for the /∫/-biased group). As such, for one SVM, the ambiguous stimuli used for testing were labeled based on each subject’s trial-by-trial behavioral classification and thus reflected not only the stochasticity of perception of ambiguous tokens but also the effects of biasing context on those tokens. Alternatively, functional activation patterns may instead reflect only acoustic information. In this case, patterns for the 40% /s/ token may more closely resemble patterns from 20% /s/ trials than patterns from 70% /s/ trials. Therefore, for a second SVM, ambiguous stimuli were labeled based on which unambiguous token they more closely resembled acoustically (i.e., the 40% /s/ token labeled as /∫/ and the 50% /s/ token as /s/).
To ensure that no individual run biased results, the training set was divided into five folds using a leave-one-run-out approach for further cross-validation. That is, in each fold, the SVM was trained on the unambiguous patterns from only four of the five runs; it was then tested in its ability to classify the ambiguous boundary patterns from all five runs. By-subject classification accuracies were computed by averaging across folds. Note that because our classification procedure involved training on patterns from unambiguous trials and testing on patterns from ambiguous trials, the training and test sets were entirely non-overlapping.
In the absence of an effective cross-validation scheme, the use of a large ROI can lead to overfitting (i.e., finding a multivariate solution in the training data that does not generalize to the test data). As such, for each fold, feature selection and classification were performed using Recursive Feature Elimination (RFE). RFE entails iteratively identifying and eliminating the voxels that are least informative to classification, therefore reducing the dimensionality of the data and preventing against overfitting. RFE in particular has been identified as an optimal method for recovering cognitive and perceptual states from auditory fMRI data (De Martino et al., 2008). To this end, 90% of the training trials were randomly selected on each iteration of the RFE procedure; this “split” of the training data was used to train the classifier and to identify the most discriminative voxels. This procedure was repeated, and after four splits, the classification outcomes were averaged. The voxels that ranked in the 30% least discriminative voxels (averaged across the four splits) were eliminated, and only the voxels that survived this feature selection step were considered in the next iteration. 10 iterations were performed per fold, meaning that feature selection occurred 10 times per fold (and that there was a total of 40 splits for each fold).
Because the RFE procedure entails discarding the least informative voxels, chance-level accuracy may be greater than 50% when RFE is used. Therefore, to evaluate the performance of the classifier against chance, we repeated the above procedure with randomly shuffled training labels; 100 permutations were conducted for each subject. Permuted accuracy values were averaged across folds and permutations in order to generate by-subject estimates of chance. To assess whether the classifier performed significantly above chance, we conducted a one-tailed paired samples t-test that compared each observed classification accuracy to the accuracy value that would have been expected by chance. Note that because our goal was to leverage decoding techniques to provide insight into brain function (rather than to predict behavioral performance on future trials), we do not require high classification accuracy; instead, the goal is only to assess whether classification accuracy is significantly above chance in order to assess whether particular brain regions can discriminate between two categories of interest (Hebart & Baker, 2018).
Results
As reported by Myers and Mesite (2014), participants’ performance on the phonetic categorization task was influenced by the contexts in which they had previously encountered the ambiguous sounds (Figure 1B). Notably, however, the influence of previous context is not deterministic; that is, it is not the case that participants always classified ambiguous /s/-/∫/ sounds as /s/ after hearing ambiguous tokens in /s/-biased lexical frames. Rather, context had a probabilistic influence on phonetic categorization responses, and critically, there was considerable trial-to-trial variability in behavioral responses, particularly in subjects’ classification of ambiguous tokens. In this study, we examined the trial-to-trial variability in the multi-voxel patterns of functional activation when participants heard ambiguous tokens.
Our approach was to train a support vector machine to classify unambiguous trials as /s/ trials or /∫/ trials. We then assessed whether the learned classification scheme yielded above-chance accuracy when the SVM was tested on held-out trials in which participants heard ambiguous tokens near the phonetic category boundary. As shown in Figure 1C, classification of ambiguous tokens was significantly above chance when the ambiguous tokens were labeled based on subjects’ trial-by-trial behavioral percepts, as evidenced by a one-tailed t-test against the permuted chance values, t(23) = 2.43, p = 0.012. However, classification was not above chance when ambiguous tokens were labeled based on which unambiguous token they were acoustically closer to (i.e., the 40% /s/ token was labeled as /∫/ and the 50% /s/ token labeled as /s/), t(23) = −3.14, p = 0.998. In other words, the features that could be used to classify multi-voxel patterns for unambiguous trials as /s/ or /∫/ could be used to classify ambiguous trials based on how they were ultimately perceived, but not based on their acoustic similarity to those unambiguous tokens.
These results indicate that a subject’s ultimate perception of an ambiguous stimulus can be recovered from the multi-voxel pattern across a broad set of regions involved in language processing. Notably, however, there was a considerable degree of variability in how accurately the classifier was able to recover subjects’ perceptual interpretation of the ambiguous stimuli. To probe the nature of this variability, we considered whether classification accuracy was related to subjects’ behavioral performance on the phonetic categorization task. In particular, we measured the extent to which subjects labeled ambiguous tokens in line with their biasing condition (e.g., how often subjects labeled ambiguous tokens as ‘s’ if they had previously heard ambiguous tokens in /s/-biased lexical frames). As shown in Figure 1D, there was a marginal relationship between classification accuracy and the proportion of bias-consistent responses made by each subject, r = 0.386, t(22) = 1.961, p = 0.062. Taken together, the present results indicate that as phonetic recalibration occurs, there is also some degree of neural retuning such that functional activation patterns reflect the subject’s ultimate percept. Further, the extent of neural returning may be related to the degree of phonetic recalibration observed behaviorally.
Because we considered a broad set of language regions in our primary analyses, we are limited in our ability to make strong claims about which regions are involved in this neural retuning process. To pursue this question of which regions contain more discriminative patterns, we also conducted a series of exploratory region-of-interest (ROI) analyses, examining the classifier’s performance when it was only given information about voxels in certain anatomically-defined regions. In particular, we parcellated our initial set of voxels into the eight regions shown in Figure 1A: left frontal, left insula, left temporal, left parietal, and the corresponding regions on the right.
Figure 2A shows the performance of the classifier when considering only the voxels in a particular region; results from one-tailed paired samples t tests are provided in Table 1. Because our primary analyses only found above-chance accuracy when the SVM classified ambiguous tokens with respect to subjects’ trial-by-trial percepts, these exploratory ROI analyses also labeled test trials based on trial-level behavioral responses.1 Results indicated that subjects’ behavioral responses could be successfully recovered when the classifier only considered the voxels in left parietal cortex, t(23) = 2.002, p = 0.029 (uncorrected). Above-chance accuracy was also achieved in right temporal cortex, t(23) = 1.734, p = 0.048 (uncorrected). No other regions yielded classification accuracy levels that were significantly above chance, all p > 0.05.
Figure 2.
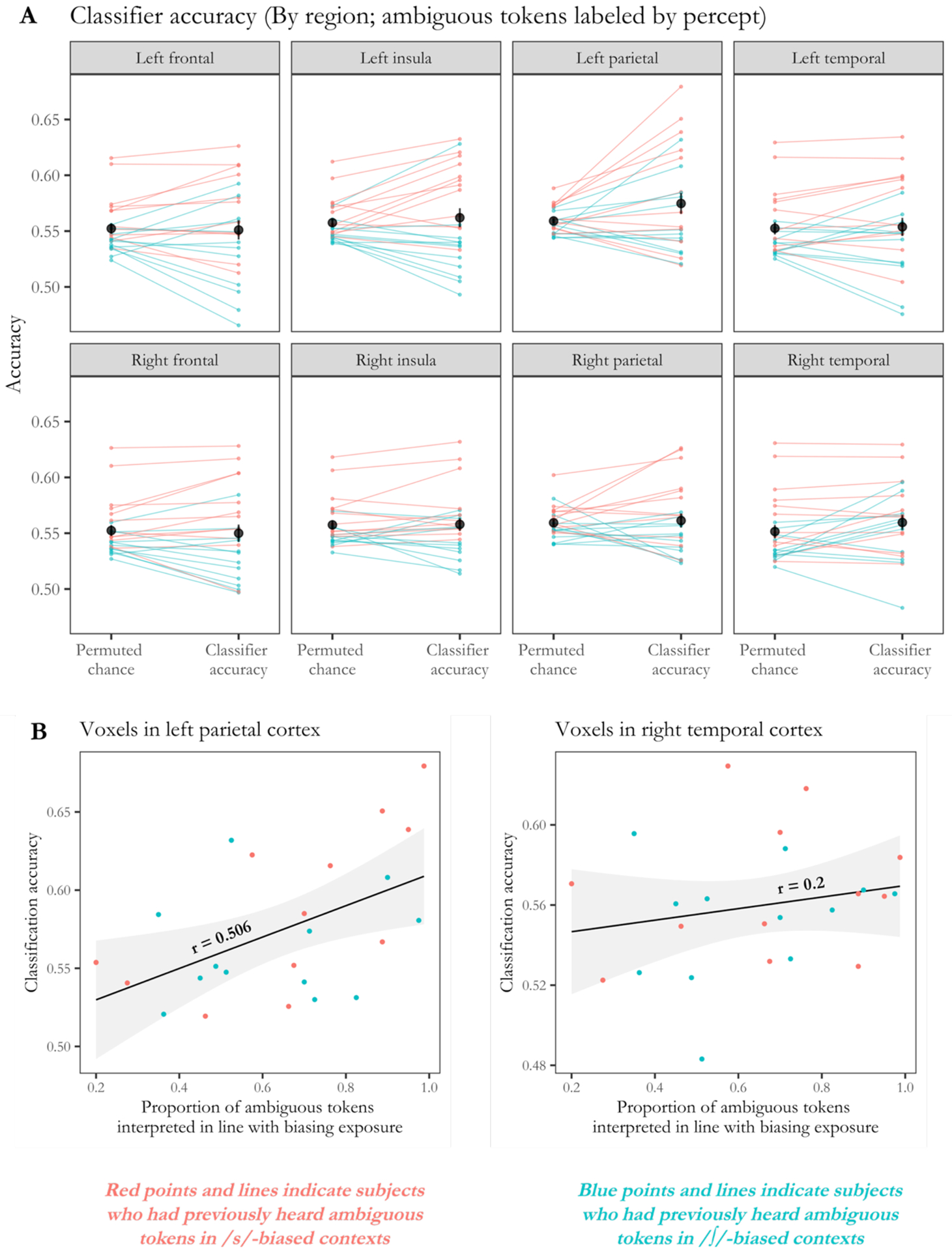
(A) Exploratory analyses considered the classifier’s ability to determine by-trial perceptual interpretations, considering each brain region separately. Above-chance accuracy was achieved in left parietal cortex and right temporal cortex, uncorrected for multiple comparisons. Dark points indicate mean accuracy, and error bars indicate standard error. Light lines indicate classification accuracy by subject, with light red lines indicating subjects who had previously heard ambiguous tokens in /s/-biased contexts and light blue lines indicating those who had previously received /∫/-biased contexts.
(B) Follow-up analyses tested whether classification accuracy in these ROIs was related to the behavioral extent of perceptual learning. This relationship was significant when considering only the voxels in left parietal cortex (left panel) but not when considering the voxels in right temporal cortex (right panel). Red points indicate subjects who had previously heard ambiguous tokens in /s/-biased contexts, while blue points indicate those who had heard ambiguous tokens in /∫/-biased contexts.
Table 1.
Results from exploratory classification analyses testing whether subjects’ trial-by-trial interpretations of ambiguous stimuli could be recovered from the pattern of activation in particular sets of brain regions.
| Regions | Left | Right |
|---|---|---|
| Frontal | t(23) = −0.229, p = 0.590, n.s. | t(23) = −0.566, p = 0.711, n.s. |
| Insula | t(23) = 0.732, p = 0.236, n.s. | t(23) = 0.115, p = 0.455, n.s. |
| Temporal | t(23) = 0.261, p = 0.398, n.s. | t(23) = 1.734, p = 0.048, * |
| Parietal | t(23) = 2.002, p = 0.029, * | t(23) = 0.343, p = 0.367, n.s. |
indicates classification accuracy that was significantly above chance at p < 0.05, uncorrected for multiple comparisons.
As before, we also examined whether classification accuracy was related to subjects’ behavioral performance on the phonetic categorization task. We found that the proportion of bias-consistent responses subjects made on ambiguous trials was a significant predictor of classification accuracy when the classifier only considered voxels from left parietal cortex, r = 0.506, t(22) = 2.751, p = 0.012, but not when the classifier only considered voxels from right temporal cortex, r = 0.200, t(22) = 0.960, p = 0.348 (Figure 2B).
General Discussion
Speech perception is a nondeterministic process, wherein the same acoustic signal can be interpreted differently from instance to instance. Such moment-to-moment variability is particularly pronounced near phonetic category boundaries, where phoneme identity is decidedly ambiguous (Liberman, Harris, Hoffman, & Griffith, 1957).2 Additional variability in the interpretation of the speech signal is driven by listeners’ perceptual histories, as in the case of lexically guided perceptual learning (Norris et al., 2003). More generally, the challenge of speech perception may be characterized as one of inference under uncertainty, in which different perceptual outcomes are associated with varying degrees of probability, and the probability of any single outcome need not be 100% (Kleinschmidt & Jaeger, 2015). In the current investigation, we examined archival data from a lexically guided perceptual learning study by Myers and Mesite (2014) in which participants completed alternating blocks of lexical decision and phonetic categorization. We considered how trial-level variability in phonetic categorization of ambiguous speech (specifically, speech ambiguous between /s/ and /∫/) was reflected in patterns of functional activation across the brain.
We observed that the pattern of functional activation across the brain reflects a subject’s ultimate interpretation of an ambiguous speech sound, even as this interpretation may vary from trial to trial. In particular, multi-voxel pattern analyses indicated that the information that was useful for classifying unambiguous stimuli (i.e., those near the endpoints of the phonetic continuum) could also be used to classify ambiguous stimuli (i.e., those near the phonetic category boundary) on the basis of subjects’ trial-level perceptual interpretations. That is, when a listener interpreted an ambiguous stimulus as /s/, the pattern of activation better resembled a canonical (unambiguous) /s/ pattern than a canonical /∫/ pattern. Note that our analyses did not include precentral and postcentral gyri; as such, it is unlikely that our results reflect the motor requirements of making a behavioral response on every trial. Strikingly, the more that subjects’ behavioral responses to ambiguous stimuli were influenced by the lexical contexts they had previously encountered, the greater the classifier’s ability to classify ambiguous stimuli, although this correlation did not reach significance. Taken together, these results suggest that the phonetic retuning observed in lexically guided perceptual learning studies may be accompanied by a comparable degree of neural retuning.
We also attempted to classify ambiguous stimuli based on which unambiguous stimulus they better resembled acoustically. However, we found that even across a broad set of regions involved in language processing, the classification boundary that separated unambiguous stimuli into /s/ and /∫/ categories could not be used to classify ambiguous tokens based on acoustic proximity (i.e., to label a 40% /s/ token as a /∫/ and a 50% /s/ token as a /s/). One possibility is that the fine-grained acoustic detail needed to make such a distinction is not preserved in cortical representations, or at least in the BOLD signal measured in functional MRI studies. Data from a categorical perception study by Bidelman, Moreno and Alain (2013) are consistent with this view. In that study, the authors found that the functional activity of the brainstem varied continuously with changes in the spectral content of the speech signal, but the activity of cortex mostly reflected subjects’ ultimate interpretation of the signal, with only very early cortical waves (i.e., those before 175 ms) showing fine-grained sensitivity to the speech sound. We suggest that additional studies focusing on the functional responses of earlier auditory regions might inform our understanding of how the fine-grained auditory details of ambiguous speech are mapped onto perceptual interpretations in the wake of perceptual learning.
The present investigation follows other MVPA studies (Bonte et al., 2017; Kilian-Hütten et al., 2011) that have considered how context can guide perceptual learning for speech. In these studies, trial-by-trial interpretations of ambiguous speech sounds were recoverable from the activation of bilateral temporal regions. Critically, the present study differed from previous ones in three notable ways. First, our analyses examined whether the distinctions that matter for classifying unambiguous tokens can be generalized to also classify ambiguous tokens; by contrast, the classification approach used in these previous studies was to consider only whether ambiguous tokens could be distinguished from each other according to the reported percept. As such, the present study shows that sounds that are perceptually grouped in the same phonetic category are also more similar to one another in terms of the evoked neural response, as the classification boundary between unambiguous tokens can be used to distinguish ambiguous tokens based on perception. Second, the present study considered phonetic recalibration that was driven by lexical information specifically, whereas previous studies considered aftereffects of written text and of lip movements. Some researchers have noted that while lipread and lexical information seem to influence phonetic recalibration similarly, there may be important differences between them – and potentially differences in the underlying mechanism (van Linden & Vroomen, 2007). Lip movements influence the perception of speech even at early stages of development and themselves constitute a source of bottom-up information; lexical information, by contrast, exerts its influence only at developmentally later stages and potentially guides recalibration in a top-down fashion. As such, the mechanisms underlying different forms of phonetic recalibration may vary, at least when context is provided by lexical information versus by lip movements. For instance, if we consider visual information from the face during speech to be a bottom-up signal, it may have a more central effect on phonetic recalibration, and thus be found earlier in the processing stream in the temporal lobe. By contrast, lexical information can only be brought to bear after the word is accessed, and as such recalibration may be more apparent in parietal regions more distal from first-stage acoustic-phonetic processing. Finally, the present study considered a large set of regions that have been implicated in language processing, not only the STG.
Exploratory analyses of the current data set further examined classification ability within anatomically-defined regions of interest when the support vector machine was trained on unambiguous tokens and tested on its ability to classify ambiguous tokens based on trial-level perception. These follow-up analyses indicated that above-chance classification of ambiguous stimuli could also be achieved when considering only voxels in left parietal cortex (supramarginal and angular gyri) or, alternatively, when only considering right temporal cortex (superior, middle and transverse temporal gyri).
The suggestion that left parietal regions are important for encoding trial-by-trial perceptual interpretations of speech sounds is particularly striking. Left parietal regions have been implicated in the interface between phonological and lexical information (e.g., Prabhakaran, Blumstein, Myers, Hutchison, & Britton, 2006), and neuroimaging studies have suggested that top-down lexical effects on phonetic processing may manifest through top-down influences of left parietal cortex on posterior temporal regions (Gow, Segawa, Ahlfors, & Lin, 2008; Myers & Blumstein, 2008). Consistent with this view, we observed a significant relationship between the degree to which lexical context influenced behavior (measured in terms of the proportion of bias-consistent behavioral responses) and the degree of neural retuning (as reflected by classification accuracy). However, because previous MVPA studies of phonetic recalibration (Bonte et al., 2017; Kilian-Hütten et al., 2011) have restricted their analyses to the temporal lobes, it is an open question whether the involvement of left parietal regions is specific to phonetic recalibration guided by lexical context. It may be the case that perceptual learning of speech always entails neural retuning observable in left parietal cortex; indeed, the supramarginal and angular gyri have been implicated in discriminating between phonemes across a range of behavioral tasks (Turkeltaub & Branch Coslett, 2010) and in sensitivity to phonetic category structure (Joanisse, Zevin, & McCandliss, 2007; Raizada & Poldrack, 2007). We therefore suggest that future work carefully consider the involvement of parietal cortex in encoding details about subjects’ trial-by-trial perception of speech, particularly when perception is guided by lexical information.
In addition to the findings in left parietal cortex, we found that the perception of ambiguous speech sounds could be recovered from temporal cortex, though notably, we observed above-chance classification in right temporal cortex, not left. Prominent neurobiological models of speech perception posit that the early analysis of speech sounds is accomplished by bilateral temporal regions, though the specific role of right temporal regions in speech perception is not as well understood as compared to left temporal regions (Binder et al., 1997; Hickok & Poeppel, 2000, 2004, 2007; Yi, Leonard, & Chang, 2019). Notably, right posterior temporal cortex has been implicated in discriminating between different talkers’ voices (Belin, Zatorre, Lafaille, Ahad, & Pike, 2000; Formisano, De Martino, Bonte, & Goebel, 2008; von Kriegstein & Giraud, 2004) and in recognizing talker differences in how acoustic detail maps onto phonetic categories (Myers & Theodore, 2017), while right anterior temporal regions are thought to be involved in voice identification based on talker-specific acoustic details (Belin, Fecteau, & Bédard, 2004; Schall, Kiebel, Maess, & von Kriegstein, 2014). Given that lexically guided perceptual learning has been characterized as a process in which listeners make inferences about how a particular talker produces their speech (Kraljic, Brennan, & Samuel, 2008; Kraljic & Samuel, 2011; Kraljic, Samuel, & Brennan, 2008; Liu & Jaeger, 2018), the importance of right temporal regions in the present results may reflect the talker specificity of perceptual learning for speech. Alternatively, the engagement of the right hemisphere may reflect its purported role in analyzing spectral or longer-duration cues (e.g., Poeppel, 2003), as the current study used fricative stimuli (/s/ and /∫/) that are differentiated by such cues.
Notably, we observed a significant relationship between the size of the lexical effect on behavior (i.e., how often subjects labeled an ambiguous token as ‘s’ after previously hearing ambiguous tokens in /s/-biased lexical contexts) and classification accuracy when our analysis was limited to left parietal cortex, but we did not observe such a relationship when our analysis was limited to right temporal cortex. Such a pattern of results might be understood through a framework in which left parietal cortex is involved in lexical-phonetic interactions and the right temporal cortex is involved in conditioning phonetic identity on talker identity. Under such a framework, we might expect the degree of neural retuning in left parietal cortex to reflect the influence of lexical context on phonetic processing, whereas we might expect the degree of neural retuning in right temporal cortex to reflect the talker specificity of phonetic recalibration. Because the current study did not manipulate talker identity (i.e., listeners only heard one voice throughout the experiment), we defer a serious treatment of this hypothesis to future work.
The view that trial-by-trial perceptual experiences are reflected in the activation of temporal cortex is also supported by several electrophysiological studies. In an electrocorticography study conducted by Leonard, Baud, Sjerps, and Chang (2016), for instance, participants listened to clear productions of minimally contrastive words, such as /fæstr/ (faster) and /fæktr/ (factor), as well as a stimulus in which in the critical segment (here, either /s/ or /k/) was replaced by noise (e.g., /fæ#tr/). Meanwhile, neural activity was recorded through electrodes placed directly on the surface of the left or right hemisphere. As in previous phoneme restoration studies (Warren, 1970), participants subconsciously “filled in” the missing sound, and here, their perception was bi-stable, with participants sometimes interpreting the ambiguous stimulus as faster and sometimes as factor. Critically, when participants encountered an ambiguous stimulus, the activity of bilateral STG reflected their ultimate perception: When they interpreted the ambiguous stimulus as faster, STG activity approximated the STG response to a clear production of faster, and when they interpreted the ambiguous stimulus as factor, STG activity resembled the response to a clear production of factor. Similar results come from an electroencephalography study by Bidelman et al. (2013), who found that the event-related responses to ambiguous vowel stimuli – specifically, the amplitude of the cortical P2 wave – depended on how the signal was perceived on a particular trial; consistent with the findings of Leonard et al., the P2 wave is thought to originate from temporal cortex. In the present study, we observed a similar pattern of results in that (right) temporal lobe responses to ambiguous stimuli differed depending on subjects’ perceptual experiences, with the activation pattern on an ambiguous trial approximating the pattern for the clear version of the perceived stimulus.
In summary, the present work demonstrates that trial-by-trial variability in the perception of ambiguous speech is reflected in the pattern of activation across several brain regions, especially in left parietal and right temporal regions. In particular, the brain’s response to an ambiguous token depends on how the stimulus is interpreted in that moment, with the pattern of activation elicited on an ambiguous trial resembling the pattern elicited by an unambiguous production of the perceived category. These results ultimately contribute to an understanding of how the brain encodes the perceptual variability listeners experience during speech perception.
Acknowledgments
This work was supported by NSF IGERT DGE-1144399 (PI: Magnuson), NIH R03 DC009395 (PI: Myers), NIH R01 DC013064 (PI: Myers) and an NSF Graduate Research Fellowship to SL. The authors report no conflict of interest. We extend thanks to attendees of the 2019 meeting of the Society of Neurobiology of Language for helpful discussions on this project. Additional thanks are extended to two anonymous reviewers for helpful feedback on a previous draft of this paper. All analysis scripts are available at https://osf.io/fdbwn.
Footnotes
As described above, we did not achieve above-chance classification when our SVM considered whether ambiguous tokens could be distinguished based on which unambiguous token they more closely resembled acoustically. This is particularly striking because the RFE algorithm iteratively eliminates voxels that are least informative for the classification, allowing the more informative voxels to exert a relatively large influence over the ultimate multivariate solution. Thus, if an “acoustic similarity” classification could have been made from any of the voxels considered in the primary analyses, these voxels should, in principle, have been identified. We therefore refrain from conducting exploratory ROI analyses where ambiguous trials are labeled with respect to the underlying acoustics, especially since the risk of a Type I error increases with additional comparisons.
Such variability may emerge at a number of stages in processing, potentially being influenced by perceptual warping near the category boundary, the particular acoustic features that listeners happen to be attending at a given moment (Riecke, Esposito, Bonte, & Formisano, 2009), and/or decision-level inconsistency in labeling (Best & Goldstone, 2019; Hanley & Roberson, 2011). However, the current data cannot adjudicate between these different explanations, as participants made explicit behavioral responses on every trial.
Contributor Information
Sahil Luthra, University of Connecticut.
João M. Correia, Centre for Biomedical Research, University of Algarve, Portugal, Basque Center on Cognition, Brain and Language
Dave F. Kleinschmidt, Rutgers University
Laura Mesite, MGH Institute of Health Professions, Harvard Graduate School of Education.
Emily B. Myers, University of Connecticut
References
- Belin P, Fecteau S, & Bédard C (2004). Thinking the voice: Neural correlates of voice perception. Trends in Cognitive Sciences, 8(3), 129–135. [DOI] [PubMed] [Google Scholar]
- Belin P, Zatorre RJ, Lafaille P, Ahad P, & Pike B (2000). Voice-selective areas in human auditory cortex. Nature, 403(6767), 309–312. [DOI] [PubMed] [Google Scholar]
- Bertelson P, Vroomen J, & De Gelder B (2003). Visual recalibration of auditoryspeech identification: A McGurk aftereffect. Psychological Science, 14(6), 592–597. [DOI] [PubMed] [Google Scholar]
- Best RM, & Goldstone RL (2019). Bias to (and away from) the extreme: Comparing two models of categorical perception effects. Journal of Experimental Psychology: Learning, Memory, and Cognition, 45(7), 1166–1176. [DOI] [PubMed] [Google Scholar]
- Bidelman GM, Moreno S, & Alain C (2013). Tracing the emergence of categorical speech perception in the human auditory system. Neuroimage, 79, 201–212. [DOI] [PubMed] [Google Scholar]
- Binder JR, Frost JA, Hammeke TA, Cox RW, Rao SM, & Prieto T (1997). Human brain language areas identified by functional magnetic resonance imaging. The Journal of Neuroscience, 17(1), 353–362. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bonte M, Correia JM, Keetels M, Vroomen J, & Formisano E (2017). Reading-induced shifts of perceptual speech representations in auditory cortex. Scientific Reports, 7(1), 1–11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Correia J, Formisano E, Valente G, Hausfeld L, Jansma B, & Bonte M (2014). Brain-based translation: fMRI decoding of spoken words in bilinguals reveals language-independent semantic representations in anterior temporal lobe. Journal of Neuroscience, 34(1), 332–338. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Correia JM, Jansma BM, & Bonte M (2015). Decoding articulatory features from fMRI responses in dorsal speech regions. Journal of Neuroscience, 35(45), 15015–15025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cox RW (1996). AFNI: Software for analysis and visualization of functional magnetic resonance neuroimages. Computers and Biomedical Research, 29(3), 162–173. [DOI] [PubMed] [Google Scholar]
- De Martino F, Valente G, Staeren N, Ashburner J, Goebel R, & Formisano E (2008). Combining multivariate voxel selection and support vector machines for mapping and classification of fMRI spatial patterns. Neuroimage, 43(1), 44–58. [DOI] [PubMed] [Google Scholar]
- Drouin JR, & Theodore RM (2018). Lexically guided perceptual learning is robust to task-based changes in listening strategy. Journal of the Acoustical Society of America, 144(2), 1089–1099. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Edmister WB, Talavage TM, Ledden PJ, & Weisskoff RM (1999). Improved auditory cortex imaging using clustered volume acquisitions. Human Brain Mapping, 7(2), 89–97. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Eisner F, & McQueen JM (2005). The specificity of perceptual learning in speech processing. Perception & Psychophysics, 67(2), 224–238. [DOI] [PubMed] [Google Scholar]
- Eisner F, & McQueen JM (2006). Perceptual learning in speech: Stability over time. The Journal of the Acoustical Society of America, 119(4), 1950–1953. [DOI] [PubMed] [Google Scholar]
- Formisano E, De Martino F, Bonte M, & Goebel R (2008). “Who” is saying “what”? Brain-based decoding of human voice and speech. Science, 322(5903), 970–973. [DOI] [PubMed] [Google Scholar]
- Frost R, Repp BH, & Katz L (1988). Can speech perception be influenced by simultaneous presentation of print? Journal of Memory and Language, 27(6), 741–755. [Google Scholar]
- Gow DW, Segawa JA, Ahlfors SP, & Lin FH (2008). Lexical influences on speech perception: A Granger causality analysis of MEG and EEG source estimates. NeuroImage, 43(3), 614–623. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hanley JR, & Roberson D (2011). Categorical perception effects reflect differences in typicality on within-category trials. Psychonomic Bulletin & Review, 18(2), 355–363. [DOI] [PubMed] [Google Scholar]
- Hebart MN, & Baker CI (2018). Deconstructing multivariate decoding for the study of brain function. NeuroImage, 180, 4–18. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hickok G, & Poeppel D (2000). Towards a functional neuroanatomy of speech perception. Trends in Cognitive Sciences, 4(4), 131–138. [DOI] [PubMed] [Google Scholar]
- Hickok G, & Poeppel D (2004). Dorsal and ventral streams: A framework for understanding aspects of the functional anatomy of language. Cognition, 92(1–2), 67–99. [DOI] [PubMed] [Google Scholar]
- Hickok G, & Poeppel D (2007). The cortical organization of speech processing. Nature Reviews Neuroscience, 8(5), 393–402. [DOI] [PubMed] [Google Scholar]
- Joanisse MF, Zevin JD, & McCandliss BD (2007). Brain mechanisms implicated in the preattentive categorization of speech sounds revealed using fMRI and a short-interval habituation trial paradigm. Cerebral Cortex, 17(9), 2084–2093. [DOI] [PubMed] [Google Scholar]
- Keetels M, Schakel L, Bonte M, & Vroomen J (2016). Phonetic recalibration of speech by text. Attention, Perception, and Psychophysics, 78(3), 938–945. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kilian-Hütten N, Valente G, Vroomen J, & Formisano E (2011). Auditory cortex encodes the perceptual interpretation of ambiguous sound. Journal of Neuroscience, 31(5), 1715–1720. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kleinschmidt DF (2019). Structure in talker variability: How much is there and how much can it help? Language, Cognition and Neuroscience, 34(1), 43–68. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kleinschmidt DF, & Jaeger TF (2015). Robust speech perception: Recognize the familiar, generalize to the similar, and adapt to the novel. Psychological Review, 122(2), 148–203. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kraljic T, Brennan SE, & Samuel AG (2008). Accommodating variation: Dialects, idiolects, and speech processing. Cognition, 107(1), 54–81. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kraljic T, & Samuel AG (2005). Perceptual learning for speech: Is there a return to normal? Cognitive Psychology, 51(2), 141–178. [DOI] [PubMed] [Google Scholar]
- Kraljic T, & Samuel AG (2006). Generalization in perceptual learning for speech. Psychonomic Bulletin and Review, 13(2), 262–268. [DOI] [PubMed] [Google Scholar]
- Kraljic T, & Samuel AG (2007). Perceptual adjustments to multiple speakers. Journal of Memory and Language, 56(1), 1–15. [Google Scholar]
- Kraljic T, & Samuel AG (2011). Perceptual learning evidence for contextually-specific representations. Cognition, 121(3), 459–465. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kraljic T, Samuel AG, & Brennan SE (2008). First impressions and last resorts: How listeners adjust to speaker variability. Psychological Science, 19(4), 332–338. [DOI] [PubMed] [Google Scholar]
- Ladefoged P, & Broadbent DE (1957). Information conveyed by vowels. Journal of the Acoustical Society of America, 29(1), 98–104. [DOI] [PubMed] [Google Scholar]
- Leonard MK, Baud MO, Sjerps MJ, & Chang EF (2016). Perceptual restoration of masked speech in human cortex. Nature Communications, 7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liberman AM, Cooper FS, Shankweiler DP, & Studdert-Kennedy M (1967). Perception of the speech code. Psychological Review, 74(6), 431–461. [DOI] [PubMed] [Google Scholar]
- Liberman AM, Harris KS, Hoffman HS, & Griffith BC (1957). The discrimination of speech sounds within and across phoneme boundaries. Journal of Experimental Psychology, 54(5), 358–368. [DOI] [PubMed] [Google Scholar]
- Liu L, & Jaeger TF (2018). Inferring causes during speech perception. Cognition, 174, 55–70. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McGurk H, & MacDonald J (1976). Hearing lips and seeing voices. Nature, 264, 746–748. [DOI] [PubMed] [Google Scholar]
- Mumford JA, Turner BO, Ashby FG, & Poldrack RA (2012). Deconvolving BOLD activation in event-related designs for multivoxel pattern classification analyses. NeuroImage, 59(3), 2636–2643. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Myers EB, & Blumstein SE (2008). The neural bases of the lexical effect: An fMRI investigation. Cerebral Cortex, 18(2), 278–288. [DOI] [PubMed] [Google Scholar]
- Myers EB, & Mesite LM (2014). Neural systems underlying perceptual adjustment to non-standard speech tokens. Journal of Memory and Language, 76, 80–93. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Myers EB, & Theodore RM (2017). Voice-sensitive brain networks encode talker-specific phonetic detail. Brain and Language, 165, 33–44. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Norris D, McQueen JM, & Cutler A (2003). Perceptual learning in speech. Cognitive Psychology, 47(2), 204–238. [DOI] [PubMed] [Google Scholar]
- Peterson GE, & Barney HL (1952). Control methods used in a study of the vowels. The Journal of the Acoustical Society of America, 24(2), 175–184. [Google Scholar]
- Poeppel D (2003). The analysis of speech in different temporal integration windows: Cerebral lateralization as “asymmetric sampling in time.” Speech Communication, 41(1), 245–255. [Google Scholar]
- Prabhakaran R, Blumstein SE, Myers EB, Hutchison E, & Britton B (2006). An event-related fMRI investigation of phonological-lexical competition. Neuropsychologia, 44(12), 2209–2221. [DOI] [PubMed] [Google Scholar]
- Raizada RD, & Poldrack RA (2007). Selective amplification of stimulus differences during categorical processing of speech. Neuron, 56(4), 726–740. [DOI] [PubMed] [Google Scholar]
- Riecke L, Esposito F, Bonte M, & Formisano E (2009). Hearing illusory sounds in noise: the timing of sensory-perceptual transformations in auditory cortex. Neuron, 64(4), 550–561. [DOI] [PubMed] [Google Scholar]
- Schall S, Kiebel SJ, Maess B, & von Kriegstein K (2014). Voice identity recognition: Functional division of the right STS and its behavioral relevance. Journal of Cognitive Neuroscience, 27(2), 280–291. [DOI] [PubMed] [Google Scholar]
- Sjerps MJ, & McQueen JM (2010). The bounds on flexibility in speech perception. Journal of Experimental Psychology: Human Perception and Performance, 36(1), 195–211. [DOI] [PubMed] [Google Scholar]
- Summerfield Q (1981). Articulatory rate and perceptual constancy in phonetic perception. Journal of Experimental Psychology: Human Perception and Performance, 7(5), 1074–1095. [DOI] [PubMed] [Google Scholar]
- Talairach J, & Tournoux P (1988). Co-planar stereotaxic atlas of the human brain. 3-dimensional proportional system: An approach to cerebral imaging [Google Scholar]
- Turkeltaub PE, & Branch Coslett H (2010). Localization of sublexical speech perception components. Brain and Language, 114(1), 1–15. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van Linden S, & Vroomen J (2007). Recalibration of phonetic categories by lipread speech versus lexical information. Journal of Experimental Psychology: Human Perception and Performance, 33(6), 1483–1494. [DOI] [PubMed] [Google Scholar]
- von Kriegstein K, & Giraud AL (2004). Distinct functional substrates along the right superior temporal sulcus for the processing of voices. NeuroImage, 22(2), 948–955. [DOI] [PubMed] [Google Scholar]
- Warren RM (1970). Perceptual restoration of missing speech sounds. Science, 167(3917), 392–393. [DOI] [PubMed] [Google Scholar]
- Yi HG, Leonard MK, & Chang EF (2019). The encoding of speech sounds in the superior temporal gyrus. Neuron, 102(6), 1096–1110. [DOI] [PMC free article] [PubMed] [Google Scholar]