

Abstract
Assuming a homogeneous population, we apply the mass action law for rate of new infections and a second-order gamma distribution for removal probability to model spread of an epidemic. In numerical examinations of higher-order gamma distributions for removal probability, we discover an unexpected pattern in maximum fraction of population infected. We develop from first principles of probability an eighth-order system of ordinary differential equations to model effects of isolation and quarantine. We derive analytical expressions for reproduction numbers modeling isolation and quarantine when applied separately and together and verify them numerically. We quantify strength and speed required of these interventions to contain epidemics of varying severity and examine how their effectiveness depends on when they begin. We find that effectiveness is highly sensitive to small changes of intervention strength in a critical region. Finally, adding two more differential equations to capture natural population dynamics, we calculate endemic disease equilibria when affected by isolation and examine dynamics of coming to an equilibrium state.
Keywords: Probabilistic model, Epidemic, Isolation, Quarantine, Ordinary differential equations, Endemic equilibria
Introduction
Mathematical epidemiology has a long history. In 1760, Daniel Bernoulli analyzed inoculation against smallpox, where he developed what is usually described as the first model in the subject (Bernoulli 1766; Blower 2004; Heesterbeck and Roberts 2015).
On developments directly relevant to the matter at hand, in 1906 Hamer proposed a mass action law, in which rate of new infections in a disease outbreak is proportional to the product of the number of susceptible individuals and the number of infected individuals. This model has been widely used since that time (Hamer 1906; Brauer 2017).
Kermack and McKendrick (1927) introduced compartments to model spread of infectious diseases. A special case of their general model is referred to as the SIR model, with compartments S (susceptible but well), I (infected and able to transmit the disease) and R (removed by immunity, recovery, death or quarantine). In this model, people who recover are permanently immune. The SIR model incorporates the mass action law and has become the starting point for a wide variety of compartmental models to the present day. The SIR model is deterministic, meaning it incorporates no element of chance. We will discuss the SIR model more, later in this article.
Beginning in 1928 and continuing through the 1930s and 1940s, L. J. Reed and W. H. Frost lectured at what is now the Johns Hopkins Bloomberg School of Public Health and developed the stochastic Reed–Frost model, which has been widely used and from which many extensions have been formulated (Lessler and Cummings 2016; Brauer 2017). Their work was published by their students (Abbey 1952; De Maia 1952). Stochastic models include the element of chance. We will discuss the Reed-Frost model more, later in this article.
Isolation is removal of an infected person from public interaction. Quarantine is removal of a segment of the population, regardless of health condition, usually by government order. A deterministic study by Hethcote et al. (2002) modeled compartments SIQR and SIQS. In the latter, people who recover are not immune but rather return to susceptibility. The compartment labeled Q was for isolation, in that transitions to Q were from I only. The analysis found conditions under which disease can be endemic, i.e., have a permanent presence. In some cases, the presence was a stable, constant equilibrium. In others, it was eventually periodic.
Gumel et al. (2004) authored a study on strategies for controlling SARS (severe acute respiratory syndrome) outbreaks. They used a deterministic SEQIJR model, where Q and J were for quarantine and isolation and E labeled a compartment for the exposed but asymptomatic. In the Hethcote et al. study above, the Gumel et al. study and most compartment-based studies, transitions between compartments are modeled as first-order, linear, single-parameter rates except for rate of new infections, which is modeled by various versions of the mass action law. In the Gumel et al. study, transitions to the quarantine compartment were from the exposed compartment only, which implies they were based on contact tracing. The study compared model predictions to actual outcomes in a number of geographic areas and found good agreement. It also showed the benefit of fast response in both isolation and quarantine together.
The literature has many articles analyzing isolation and quarantine that are based on compartmental models. Many are deterministic (e.g., Castillo-Chavez et al. 2003; Sahu and Dhar 2015; Denes and Gumel 2019) and some are stochastic by virtue of adding Wiener processes (e.g., Li et al. 2018). The latter require multiple solutions of the equations to produce multiple realizations of an epidemic in order to yield reliable “expected value” results (Monte Carlo simulation).
All the isolation and quarantine models discussed above assume a homogeneous population. Other studies using the same assumption but not employing compartmental models include Day et al. (2006), which used a discrete time branching process, and Fraser et al. (2004), which utilized partial differential equations of the transport type.
Even if populations were homogeneous, compartmental models are inadequate for the very early dynamics of epidemics (Diekmann et al. 2013; Brauer 2017). Important fluctuations in initial spread are represented much better by network branching processes.
Spatial, age and demographic heterogeneity are real-life conditions that require additional model sophistication. The professional standard is set by immense computer programs that account for actions of millions of people individually: their age, demographic status and location, with real data on such matters as airline schedules from city to city. The programs are stochastic but so large that only a few realizations can feasibly be produced, even on supercomputers. Halloran et al. (2008), Ferguson et al. (2006), German et al. (2006) and Lewis et al. (2007) are examples.
In today’s world, the sophisticated technologies described above are essential. But simple models have a place. With minimal time and effort, simple models can enable preliminary assessment of a wide range of strategic policy options and point the way to more in-depth studies. They can be useful introductory educational tools for those entering the epidemiology profession. Furthermore, even for basic subjects such as isolation and quarantine, a simple model can quantify, with a broad brush, effort required to contain an epidemic and clearly demonstrate how deleterious delay and noncompliance can be. Finally, it can identify endemic equilibria, conditions portending a long-term struggle against the disease.
This article develops and employs such a model.
Section 2 develops the model from first principles of probability as it applies to unmitigated spread of an epidemic. Section 3 compares that model to the SIR equations and finds an interesting ratio in maximum fraction of population infected, which Sect. 4 explores further. Applying first principles of probability, Sect. 5 extends the model to include effects of isolation and quarantine. Section 6 employs the model to (a) determine requirements on isolation and quarantine to contain an epidemic, (b) quantify mitigation effectiveness as it depends on when intervention begins and (c) measure consequences of efforts falling short. It finds that intervention effectiveness is highly sensitive to small changes of effort in a critical region. Section 7 extends the model once more to examine endemic disease equilibria when affected by isolation. Finally Sect. 8 reviews main points of the article and summarizes advantages and disadvantages we perceive in this model with respect to others in the literature.
Developing the Basic Probabilistic Model
Let
conditional probability that individual in a population of people is susceptible to the disease but has not contracted it after time since its outbreak, given the sequence of contacts and times , .
probability that the person with whom individual interacted in his or her th interaction since disease outbreak was infected at time of interaction.
probability that the disease is transmitted in a single interaction between a susceptible-but-well person and an infected one.
number of interactions individual has had with other people by time .
Then, is given by the product of the probabilities of the individual not being infected on each of his or her interactions:
| 1 |
We are assuming for simplicity that no one is initially immune.
Equation (1) is a form of the Reed-Frost model. The variables , and are stochastic processes. The number takes on only integer values, increasing by one at randomly occurring interactions. Any realization of is constant between interactions, where it takes discontinuous steps down. From this, we form a deterministic, differentiable function by taking expected values.
Averaging over all possible interactions, the individuals involved and when,
We assume that interaction times follow a homogeneous Poisson process with growth rate , assumed constant. Let . Then is Poisson distributed with mean . We also assume that changes little in the small interval. Then we can approximate
| 2 |
Now
So
Assuming homogeneity of the population, this becomes
| 3 |
Then
Taking the limit as ,
| 4 |
This is the aforementioned mass action law. We have developed a well-known deterministic model from a well-known stochastic one. The fundamentals of this relationship are discussed in basic texts (e.g., Diekmann et al. 2013). We have included a bare sketch of the derivation to show the probabilistic underpinnings of our model. For a detailed rigorous proof, see Kurtz (1981). The product is often denoted , and we will follow that custom henceforth.
Next, we must derive an equation for . Let be the probability a given person has been infected at some time in the epidemic but has been removed via recovery or death by time . We assume that a person who recovers is permanently immune. To compute , we begin with the probability distribution
| 5 |
which has probability density . This says an infected person is more likely to be removed at a time after onset of infection than at any other time. Equation (5) is the second member of the Erlang family of distributions, which is the subset of the gamma family having integer order.
Let be the probability a given person was infected at some time prior to in the epidemic. Then
| 6 |
The state equation for is
| 7 |
Also,
| 8 |
if we assume that deaths due to the epidemic are not an appreciable fraction of the population. It is convenient to say here only that a nonconstant circulating population is a complication and to defer further explanation of the need for this assumption to Sect. 5.
From Eq. (5) and definition of :
| 9 |
Integrating by parts:
| 10 |
Numerical values for as given by Eq. (10) can be computed most readily by the following general process. Anticipating needs later in this paper, we consider an equation of the form
| 11 |
Differentiating:
| 12 |
Denote the second term on the right-hand side of Eq. (12) as . Then, Eq. (12) becomes
| 13 |
Differentiating :
| 14 |
Denote the second term on the right-hand side of Eq. (14) as . Continuing in this way
| 15 |
| 16 |
| 17 |
Numerically integrating the simultaneous ordinary differential Eqs. (13), (15), (16) and (17) gives numerical values to as given by Eq. (11).
Translating Eq. (10) into the general form in Eq. (11) results in the following equations for :
| 18 |
| 19 |
Equations (6), (7), (8), (18) and (19) constitute our basic model, applying to spread of an unmitigated epidemic. For simplicity and consistency, we will refer to it as the basic probabilistic model, although at this point, as we will see in the next section, it differs from the SIR model only in the equation for removal probability. The name probabilistic model will be more fitting when, using first principles of probability, we extend it to include isolation and quarantine in Sect. 5 and natural population dynamics in Sect. 7.
Comparison with the SIR Model
The SIR equations can be written
| 20 |
| 21 |
| 22 |
(See, e.g., Hethcote 2000.)
It is not difficult to show that the SIR model assumes
| 23 |
and for brevity we omit the proof. Equation (23) is the first member in the Erlang family of probability distributions. The probability density for the distribution in Eq. (23) is , which says that an infected person is more likely to recover immediately after infection than at any later time. This is unrealistic, as discussed, e.g., in Diekmann et al. (2013), so we prefer to use the probability distribution in Eq. (5).
The SIR equations are attractive for their simplicity and utility. Two important measures of epidemic severity are (a) , probability that a person chosen at random from the population is susceptible but well at the end of the epidemic and (b) , maximum probability of that person being infected (largest fraction of the population infected at any one time) during the epidemic. Derivations of the SIR model’s well-known equations for these measures are included here for convenience.
Setting in Eq. (21), we find that is the fraction of people susceptible but well when the number of people infected in the epidemic reaches its peak. Using Eqs. (20) and (21), we find that
Integrating:
| 24 |
Setting yields
| 25 |
Setting in Eq. (24), we have
| 26 |
Equation (26) applies beyond the SIR model, as we will discuss.
To compare the SIR and the basic probabilistic model quantitatively, we must find common ground, setting each model’s parameters so they represent the same severity of epidemic. Common ground is found in the basic reproduction number . can be defined as the expected number of cases directly generated by one infected person in a population where all other individuals are susceptible to infection. Mathematically,
| 27 |
For the SIR model, as is well-known and easy to prove:
For the basic probabilistic model:
contact (interaction) rate at time .
probability of transmitting infection on one interaction at time .
probability that infected person is in circulation at time
So for the basic probabilistic model,
| 28 |
Therefore, to compare the SIR and basic probabilistic models we set .
Figure 1 graphs and Fig. 2 graphs for the two models as a function of basic reproduction number. Numerical integration was accomplished with the Adams–Moulton algorithm.
Fig. 1.

Computing as a function of basic reproduction number . The SIR model and basic probabilistic model give the same result
Fig. 2.

Comparing the basic probabilistic model to the SIR model in computation of as a function of basic reproduction number
There has been interest in the generality of the final size formula, which is Eq. (26) with replaced by . (Final size is defined as .) For example, Ma and Earn (2006) demonstrate that the formula applies to three SIR variations. Figure 1 shows that the final size formula applies as well to the basic probabilistic model. In fact, Anderson and Watson (1980) proved that, for SIR-like models, removal probabilities given by gamma distributions of any order yield the same final size.
Figure 2 shows that for the probabilistic model can be considerably larger than that for the SIR model. Interestingly, to the accuracy of our numerical integration, the ratio of for the second-order removal distribution is 4/3 that for the SIR model as approaches one. This curious result will divert us temporarily to a mathematical sidebar in the next section. The ratio is not greatly different from 4/3 when is much larger; e.g., the ratio is 1.300 when is 2.75.
Mathematical Sidebar
We consider the SIR model with higher-order members of the Erlang family of probability distributions for the removal process. That is, we consider equation sets of the form
| 29 |
which produce a SIR-like model with removal probability density
| 30 |
where is time since onset of infection and the average time from infection to removal.
We have computed results for up to and including 5 and found that within the accuracy of our numerical integration:
The limit of the ratio of produced by the gamma distribution of order to that given by Eq. (25) is as goes to one.
We conjecture that this is mathematically true for all integer orders.
Introducing Quarantine and Isolation in the Probabilistic Model
Our objective here is to develop a probabilistic model of quarantine and isolation in an epidemic. Section 6 will employ the model to quantify important aspects of their effectiveness.
We are modeling a homogeneous population but ought to take into account that governments differ and orders to quarantine can come from anywhere within the hierarchy of nation, state, county and city. We can do this by assuming that the order comes with a probability distribution. Compliance to the order will also be distributed and we combine the two events into one process modeled by.
| 31 |
where is the probability the person will eventually be quarantined and the most probable time after epidemic outbreak that he or she enters quarantine. We believe that modeling both strength and speed of the process is framework for more realistic representation.
Let denote the probability a randomly drawn person is susceptible but well and quarantined. Using Eq. (6), we can compute by
| 32 |
We implement Eq. (32) in the ODEs, using Eq. (31), by
| 33 |
Equation (33) assumes a susceptible-but-well person once quarantined remains so for the duration of the epidemic.
Let denote the probability a person drawn at random from the population at time from start of the epidemic is susceptible but well and not quarantined. From Eqs. (6) and (32)
| 34 |
Integrating Eq. (32) by parts, Eq. (34) can be rewritten as
| 35 |
which will be useful later on.
In addition to responding to an order, a person may also be removed by the process of isolation after becoming infected at time and recognizing that fact through testing or onset of symptoms. Denote by the probability of removal by time via this second process, given infection at time and that the person has not been removed by recovery, death or quarantine. We model as:
| 36 |
where is the (conditional) probability of a person eventually going into isolation on learning of his or her infection and is the (conditionally) most probable time the person enters isolation after the infection has occurred. Introducing this process will later cause us to amend the definition of .
Let denote the probability that a person drawn at random from the population has been infected but at time has not been removed by recovery, death, quarantine or isolation. Putting quarantine aside for a moment and recalling Eq. (5),
| 37 |
Integrating by parts
Substituting Eqs. (5) and (36) into the above and doing a little work lead to
| 38 |
where
| 39 |
Translating Eq. (39) into the general form in Eq. (11) results in the following equations for :
| 40 |
We will need to determine the probability a person drawn at random from the population is in isolation at time . We assume that only a person who is currently infectious is subject to isolation. A person goes into isolation based on testing and/or obvious symptoms. Testing and/or disappearance of symptoms should also prove recovery. It is undesirable from both public health and individual liberty points of view for a recovered (and by assumption therefore immune) person to be isolated. Hence, we can describe as
| 41 |
where is given by Eq. (5), by Eq. (36), and we will reconsider shortly. Equation (41) can be rewritten as
Integrating by parts, we find that the probability of being put into isolation can be written
| 42 |
where is given by Eqs. (40) and by Eqs. (18) and (19). Note that substituting Eq. (42) into Eq. (38) leads to the simpler and more intuitive
| 43 |
Equation (43) applies when isolation is implemented alone. When quarantine and isolation are applied together, denoting the probability of a randomly drawn person being infected and in quarantine as :
| 44 |
where, using Eq. (43),
| 45 |
We implement Eq. (45) in the ODEs as
| 46 |
Integrating by parts in Eq. (45), Eq. (44) can be rewritten as
| 47 |
which, together with Eq. (35), will be useful later on.
There are two comments we need to make at this point. First, Eq. (44) must be followed by a check: If then end the integration; the epidemic is over. Without this check, computations can run away nonsensically. Second, Eq. (46) informs us that we must amend the definition of alongside Eq. (31). It is not the probability of a given person being in quarantine at time ; it is the conditional probability given that the person has not previously been isolated.
What effect do quarantine and isolation have on the equation for rate of new infections, i.e., on the equation for given by Eq. (7) when quarantine and isolation are absent? First, it is clear we must replace with where is the probability a person drawn at random from the population is in either isolation or quarantine. (We have not written an equation for here and will not do so. It would require three more ODEs and in the end we will not need to calculate it.) To motivate the replacement, consider again the person-to-person interactions Sect. 2 analyzed. There, denoted the probability a person one interacts with is infected, but it also represented the probability a person drawn from the population as a whole is infected. In Sect. 2, . Here, in Sect. 5, and include the condition that the person is not in isolation or quarantine. What is important is the probability of interacting with an infected person within the circulating population. Our analysis has not required us to determine the probability a person was removed and not in isolation or quarantine, but if it had, and calling that probability , we would find . To make the probabilities of compartments of people one interacts with sum to unity, we must divide them by . Hence, the probability that a person one interacts with is infected is . Hethcote et al. (2002) and Li et al. (2018) applied this also in SIR-like analyses, with the premise of a constant contact rate, and called quarantine-adjusted incidence. Similar reasoning explains the assumption in Sect. 2 that deaths due to the epidemic are not an appreciable fraction of the population. Without the assumption, Eq. (8) is inconsistent with Eq. (1).
It is also clear that no adjustment need be made to . The equation for rate of new infections needs the probability a person is susceptible but well and not in isolation or quarantine.
Does the average rate of contacts , and therefore , require an adjustment? Here the answer is not so clear. We believe there is basis for decision in neither probability theory nor biology of disease and we must make a judgment based on common sense, which is not easy. What, e.g., is the effect of social distancing orders? Hethcote et al. (2002) considered two alternatives. The first, as mentioned above, was to leave contact rate unchanged from its value in an unmitigated epidemic. The second assumed contact rate is reduced in proportion to density of circulating population. We believe that to analyze both here would be unwieldy. Either choice could be defended. Leaving contact rate unchanged leads to simpler equations and provides bounds on performance. However, it leads to equations that we believe undervalue quarantine. Assuming contact rate is reduced in proportion to density of circulating population ascribes, we believe, more appropriate value to quarantine. We reduce contact rate to , which modifies to .
In conclusion, the probabilistic model’s equation for rate of new infections in an epidemic controlled by isolation and quarantine is
| 48 |
Equations (18), (19), (33), (34), (40), (42), (44), (46) and (48) suffice to compute and . Then the measures of epidemic severity, recognizing that we are unconcerned here whether the person is “on the street” or not, are computed by taking the final value of
| 49 |
and the largest in the time history of
| 50 |
To complete the probabilistic model for quarantine and isolation, we derive formulas for reproduction numbers applicable to isolation alone, quarantine alone, and isolation and quarantine together. These expressions are an efficient means of determining minimum effort needed to contain an epidemic, although we will find that containment is achieved only if the processes are begun early enough.
For isolation alone, we return to the definition: expected number of cases directly generated by one infected person in a population where all others are susceptible to infection. The infected individual’s interaction with others is unaffected but his or her time in circulation is reduced. Given that the individual was infected at time , the probability he or she is still infectious and circulating at time is . From Eqs. (5), (27) and (36),
| 51 |
We arrive at
| 52 |
where
Recalling
we find
| 53 |
Now is the basic reproduction number for the unmitigated epidemic. Hence, Eq. (52) can be written
| 54 |
In the next section, ODE results show that setting in Eq. (54) is remarkably consistent in predicting the strength () and speed () required to contain an epidemic, provided isolation is begun early enough. Section 7 further confirms its validity.
Quarantine is much less likely to be applied alone than is isolation, because of its impact on the public, but we consider the possibility here nevertheless.
It is worthwhile to let quarantine reproduction number depend on when quarantine is initiated. In the following discussion, we will be anticipating some of the numerical results of the next section. If quarantine starts early enough, the process can essentially be completed by the time the fraction of infected people becomes appreciable and, using Eq. (35), we can write
But , so
| 55 |
Similarly, using Eq. (47), with ,
| 56 |
Then Eq. (48) becomes
| 57 |
which is just the constant times the equation for initial moments of the unmitigated epidemic. Hence, the effect of quarantine with an early start is to reduce to . There being no dynamic remaining other than infection and recovery, we know that an epidemic will occur in this case if . Hence, denoting the reproduction number of quarantine started early as :
| 58 |
The next section will show that this simple equation is useful when quarantine starts early enough.
If quarantine starts late, and we will quantify “early” and “late” in the next section, dynamics of quarantine are simultaneous with those of infection and removal. In this case, we turn once more to the definition of reproduction number based on one infected individual in a population of susceptible but well people. Using Eq. (27), we find
| 59 |
A straightforward calculation leads to
| 60 |
where
| 61 |
When isolation and quarantine are combined, we again have different formulas for early and late start of quarantine. In an early start, A and B processes are uncoupled in time and it is easy to see that the reproduction number for isolation and quarantine combined is
| 62 |
For the late start, given the forms of and above we might expect the combined reproduction number to be in the form
| 63 |
where is given by Eq. (53), and by Eqs. (61), and and are to be determined. A tedious calculation starting with
| 64 |
confirms the form in Eq. (63) and determines that
| 65 |
For convenience of the reader, we collect and display below the probabilistic model for control of an epidemic by isolation and quarantine, with exception of the long equations for above.
| 66 |
Computing the Effects of Isolation and Quarantine on Epidemic Severity
We gauge the effectiveness of control efforts by measuring the improvement in , the fraction of population not infected during the epidemic, and , the largest fraction of population infected at any one time. We conduct analysis at four levels of epidemic severity, for which the probabilistic model predicts and as shown in Table 1 when the epidemic is unmitigated. We base the four epidemic cases on specific values of . The unit of time throughout is , the average time of removal in an unmitigated epidemic. For numerical integration, we employ the Adams–Moulton algorithm.
Table 1.
Parameters of epidemics for case study and their unmitigated measures of severity
| Epidemic case number | ||||
|---|---|---|---|---|
| I | 1.1886 | 2 | 0.7 | 0.01784 |
| II | 1.3861 | 2 | 0.5 | 0.05729 |
| III | 1.7198 | 2 | 0.3 | 0.13674 |
| IV | 2.5582 | 2 | 0.1 | 0.31578 |
Figure 3 describes minimum requirements on and to contain an epidemic with isolation alone, on condition that the process is initiated sufficiently early.
Fig. 3.
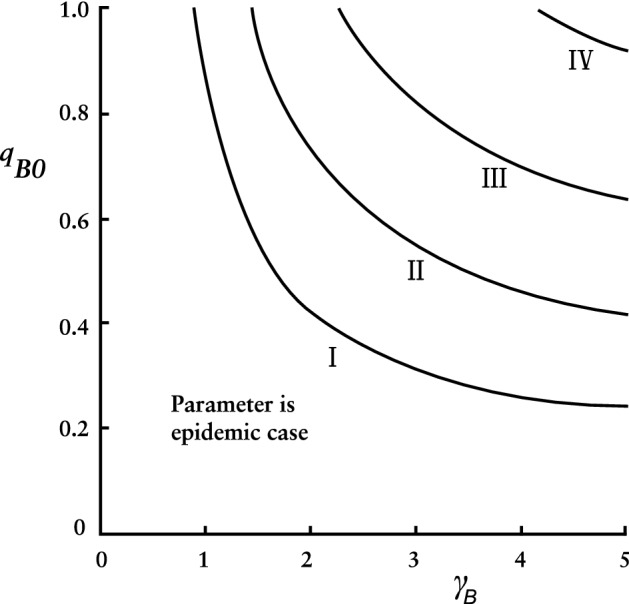
Conditional requirements to contain an epidemic by isolation alone
Figure 3 is based on setting the reproduction number in Eq. (56) equal to unity. When values for strength () and speed () from Fig. 3 were input to the ODEs and initial condition set at the resulting values were always between 0.99953 and 0.99959. When , those same and values produced ’s varying between 0.95535 and 0.95576, again remarkably consistent but a low bar for containment.
All the intervention reproduction numbers we consider here have this property: If we (a) find strength and speed combinations that yield the reproduction number equal to one and (b) input those strength and speed values into the ODEs, the resulting values cluster closely about one point. For some that cluster point is close enough to unity that the epidemic can be considered contained. As increases, the cluster point decreases.
We can measure the dependence of the cluster point, call it degree of mitigation (), on . Again, in short, is the average achieved by intervention effort that yields its reproduction number equal to one. Figure 4 graphs as a function of for each of the intervention reproduction numbers considered here. The ceiling, , is also plotted.
Fig. 4.

Degree of mitigation for various intervention reproduction numbers as a function of initial condition
The particular numbers one calculates to create Fig. 4 depend to a degree on parameter ranges one considers: on basic reproduction number , speeds and , and initial condition . In this study, we arbitrarily selected (as shown in Table 1), , and . Within this set, for each intervention reproduction number in Fig. 4 except , we can state the following: For each and each specific effort satisfying , there exists a such that, with these inputs, the ODEs produce
| 67 |
and is nearly independent of Hence, for each but ,
| 68 |
Table 2 lists for each other than . Furthermore, our numerical analysis shows that, for ,
| 69 |
where, if expressed as , to better than one part in a thousand.
Table 2.
Coefficient in the equation , as it depends on intervention measure
| 3.60 | |
| 4.38 | |
| 7.14 | |
| 8.96 |
Returning to discussion of requirements, it is simpler to state than to graph requirements to contain an epidemic with quarantine alone when the process starts early. Setting in Eq. (58), the minimum to contain an epidemic is then
| 70 |
says quarantine performance is invariant to , while compares to removal rate . The growing dependence on is gradual. What is an “early” quarantine start?
Equation (68) means that both (Eq. 58) and (Eqs. 60 and 61) are consistent throughout the stated range. The key factor in deciding which to use is how much their scatter about their . For each intervention reproduction number , call
| 71 |
where extrema are again taken over the above-defined set at a particular . We find that
| 72 |
is much more accurate everywhere, but we would prefer, if possible, to use the much simpler . Scatter in on the order of () is, when viewed in the absolute, not a problem for practical purposes. Scatter on the order of () certainly is.
Acknowledging its subjective elements, we offer our opinion that “early” quarantine start ends and “late” start begins at about .
Figure 5 graphs minimum requirements on and to contain an epidemic with quarantine alone, based on setting the “late start” reproduction number in Eq. (60) equal to unity. Comparing Fig. 5 to Fig. 3, we see that, to contain an epidemic of a given severity, quarantine requires less strength and less speed than does isolation. (Of course, quarantine has a much greater impact on the public.)
Fig. 5.

Conditional requirements to contain an epidemic by quarantine alone
When isolation and quarantine are combined, a pertinent issue is allocation of effort between the two. How is burden of performance to be divided? We will lay out examples of choices.
Simplicity of the reproduction number formula for isolation combined with quarantine started early makes allocation for this case an easy task. Allocation is more complicated for late quarantine start, and it is perhaps a more realistic scenario, so we devote our attention to this case.
Figures 6 and 7 quantify strength and speed of the two processes needed to contain an epidemic, on condition that the processes start early enough. For brevity, we show only results for cases II and III. Figures 6 and 7 are based on setting , using Eqs. (63) and (65).
Fig. 6.

Conditional requirements on isolation and quarantine combined to contain epidemic case II
Fig. 7.

Conditional requirements on isolation and quarantine combined to contain epidemic case III
It goes without saying that on-the-ground realities drive what can be done; practicalities of implementation are primary. For instance, are means in place for testing and contact tracing necessary for isolation? What is the public’s commitment to quarantine? Figures 6 and 7 provide broad-brush quantitative insight into potential of the combined measures.
Figures 8 and 9 address consequences of efforts falling short. In these figures, we arbitrarily set and and called the common values and .
Fig. 8.

as a function of for various epidemic severities, with as parameter
Fig. 9.

as a function of for various epidemic severities, with as parameter
Figure 8 plots as a function of with as parameter for each of the epidemic cases considered, at . Figure 8 shows that mitigation achieved by strength just above a critical value is much greater, though short of containment, than that achieved by strength just below it. The critical strength is roughly two-thirds of the containment requirement derived from , which we denote as . Table 3 compares to for the four epidemic cases, for and .
Table 3.
Comparing critical value of combined strength to that derived from , when and
| Case I | Case II | Case III | Case IV | |
|---|---|---|---|---|
| 0.066522 | 0.124518 | 0.202420 | 0.338233 | |
| 0.0964 | 0.1813 | 0.3008 | 0.5329 | |
| Ratio | 0.6900 | 0.6868 | 0.6729 | 0.6347 |
In Fig. 8 are bold circles marking points where a curve’s abscissa meets a containment requirement . Notice that the circles cluster at about 0.9995. These are but a few of the points that went into calculation of for .
For brevity, we omit graphs of quarantine alone and isolation alone in the format of Fig. 8. We can summarize important aspects of them: The graph for quarantine alone shows discontinuities similar to those in Fig. 8. The graph for isolation alone, on the other hand, has smooth, gently sloping curves. The graph of isolation alone also shows that, while is only 0.98590 at , plausibly achievable increases in from values can raise to much higher levels for epidemic cases I and II. In case I, e.g., with 4, increases in from the value of 0.2678 to 0.320 and 0.420 raise to 0.997 and 0.999, respectively. Creating graphs in the format of Fig. 8 is probably the best way to find levels of intervention effort that achieve desired values when is too low, i.e., when intervention has begun too late.
In Fig. 8, is highly sensitive to small changes in . If is a continuous function of , then for every there exists a such that if then . We conducted numerical experiments at the critical points to quantify this. An example result: for Case III and , as decreased from to decreased only from 0.24620 to 0.23521. But despite the extremely slow convergence, we believe the function is continuous and, in fact, differentiable.
As mentioned earlier, we used the Adams–Moulton (A–M) numerical integration algorithm for this study. To verify that the high sensitivity of to changes in we see in Fig. 8 is not an artifact of the algorithm, we also used the Runge–Kutta (R–K) and backward differentiation formula (BDF) algorithms to integrate the ODEs and recreate Fig. 8. We found the same high sensitivity with all three algorithms. Furthermore, the difference between values computed by the A–M algorithm and R–K algorithm was less than , and difference between values computed by A–M algorithm and BDF algorithm was less than . Differences in computed were also minimal.
Figure 9 plots as a function of with as parameter for epidemic cases III and IV. Discontinuities are again evident, at the same critical values of . The figure shows that half measures leave the public facing a still-serious epidemic.
Expanding the Model to Examine Endemic Equilibrium States
Our final objective is to examine endemic equilibrium states. We will calculate equilibrium values for the important state variables and examine dynamics of a disease coming to equilibrium. We assume that isolation, but not quarantine, is in effect. Maintaining quarantine over a significant portion of the population for a very extended period is unlikely.
For a model to exhibit an endemic state, it must include the population’s natural dynamics: births, deaths and net immigration. It then becomes necessary for us to use, instead of probabilities, state variables , the expected number of people in the population susceptible but well at time ; , the expected number of people infected and not in isolation at time ; and , the expected number of people in the population who have been infected but have recovered at time . We continue to assume that the number of people who die from the disease is not an appreciable fraction of the population. Denote the number of births and net immigrants per unit time, assumed constant, as . Let the probability a person drawn at random from the population is dead of natural causes by time given he or she is alive at time be
| 73 |
Let the rate of new infections be given by
| 74 |
Then
| 75 |
| 76 |
It is convenient to consider next:
| 77 |
which leads, via Eqs. (11) to (17), to
| 78 |
Next, modifying Eq. (37):
| 79 |
which can be written, in fashion similar to Eq. (38),
| 80 |
where, after again using Eqs. (11) to (17),
| 81 |
With these equations in hand, we can proceed. If the variables , and are all constant, then
| 82 |
where is a constant. Then, Eqs. (76), (78) and (81) all take the form
which has solution
| 83 |
Using Eqs. (74), (76), (78), (80) and (81), we eventually find the steady-state values
| 84 |
Given numerical values for the parameters, one could solve for via Eq. (74). However, it is of more interest to assume , so Eqs. (84) become
| 85 |
and Eq. (74) becomes
| 86 |
We can then solve for in closed form and find, with ,
| 87 |
where is the isolation reproduction number given by Eq. (54). Note that the threshold for an endemic state in an epidemic with isolation is . Although the probabilistic model has the added complexities of a second-order removal probability and an isolation process, it has led to the well-known SIR equations for the equilibrium state, with replacing . (See, e.g., Diekmann et al. 2013.)
How does a disease become endemic? Only under special conditions, it appears. The disease must first have been epidemic, to drive the number of susceptible people below . The equilibrium position is at the threshold for herd immunity, when the portion of the population immune to the disease suffices to negate an epidemic. (See, e.g., Hethcote 2000.) If an incursion of infected people occurs when and mitigation is inadequate, an epidemic inevitably follows, driving past to the concomitant with the starting point and to zero. Then begins a disease-free course to the natural capacity .
If the disease incursion occurs when is well below , the outbreak is relatively quickly extinguished and continues its path to . Only if the incursion happens as nears from below, as in Fig. 10, can the S trajectory be forced into transition to its equilibrium value.
Fig. 10.
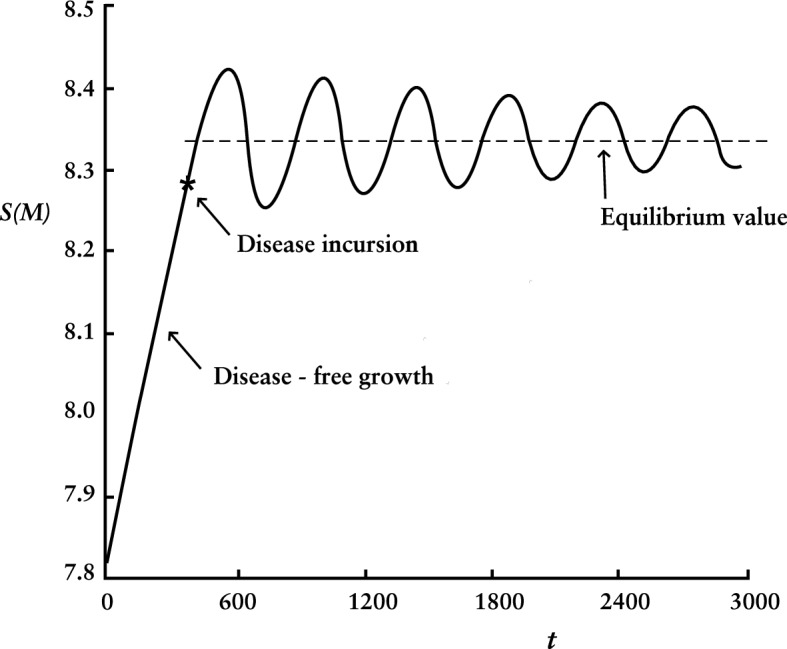
Expected number of people susceptible but well as a function of time as disease settles into endemic equilibrium state
Figure 10 pictures dynamics of settling into equilibrium. Here, the natural capacity , , , and other values are as in Sect. 6. If the average recovery period is 2.6 weeks, then 20 time units equal one year.
Compared to duration of an epidemic, dynamics of settling into equilibrium are slow, as is well known. (See, e.g., analysis of the linearized SIR model in Diekmann et al. 2013.) For , as in Fig. 10, the oscillation period is about 21 years and decay time constant about 140 years. For , they are about 9 and 90 years.
The equilibrium is small compared to the epidemic : 78 people for and 235 for . Transitioning as in Fig. 10, amplitude of oscillations in and depends on and imperceptibly (if at all, given numerical uncertainty) on size of the small incursion or its timing (within limits described earlier).
Computed values agree with Eq. (87) to within small fractions of a percent.
Concluding Remarks
We review here main points of this article, summarize how the probabilistic model differs from other models in the literature and opine on advantages and disadvantages these differences confer.
Beginning with a small but nontrivial difference, the probabilistic model adopts a second-order gamma distribution for removal probability while most other models employ one of first order. The first-order distribution is attractive for its simplicity but is unrealistic in its time profile. In concert with the mass action law, the second-order removal distribution predicts an expected maximum fraction of population infected at any one time, , significantly greater than does the first order, e.g., more than 30% for . This is consequential for predicting peak stress on medical facilities.
Our numerical studies indicate that the limit of the ratio of produced by the gamma distribution of order to that of order one is as goes to one.
Moving to a more significant difference, the probabilistic model incorporates two parameters versus one in both isolation and quarantine. We believe that modeling both strength ( and ) and speed ( and ) of these processes is framework for more realistic representation. These parameters are easy to interpret and potentially measurable, which should make the model useful in empirical research. When quarantine or combined intervention strength is modeled, we discover that intervention effectiveness, as measured by either or , is highly sensitive to small changes at a critical value of that strength. The critical value is about two-thirds of the containment requirement derived from reproduction number. Does this accurately model the natural world? If so, knowledge of the phenomenon should be valuable.
Another major difference is that our model is founded on first principles of probability rather than mathematical simplicity. Coefficients such as that arise naturally in the probabilistic model have no counterpart in typical SIR-like models. Note that the coefficient combines parameters from different processes. The typical SIR-like model describes transitions with pairs of equations like and , where the rate common to the pair is a parameter set by the analyst. Whether basis in probability is an advantage remains to be seen. We expect it to represent reality more accurately, but comparison with field data is required.
A disadvantage: the ODE equations modeling quarantine are not time-invariant, which can be a hindrance, e.g., in stability analysis. We have modeled quarantine as time-driven, which we believe is more realistic than event-driven, e.g., removal only after tracing from contact with an infectious person.
We used reproduction numbers to determine requirements on , , and to contain epidemics of varying severity, confirmed them with ODE results and quantified dependence of intervention effectiveness on when interventions begin. We derived expressions for endemic disease equilibria when affected by isolation and found familiar formulas, with replacing . We examined dynamics of coming to an equilibrium and found that only special conditions permit it.
In sum, assuming a homogeneous population we developed a model based on first principles of probability, with eight differential equations, six parameters and five reproduction numbers, and quantified important aspects of isolation and quarantine effectiveness in controlling an epidemic.
Acknowledgement
I thank reviewers for their constructive comments, and especially the reviewer who saved me from several mistakes in derivations and pointed me to an important reference.
Funding
Not applicable.
Declarations
Conflict of interest
The author declares no conflict of interest.
References
- Abbey H. An examination of the Reed-Frost theory of epidemics. Hum Biol. 1952;243:201. [PubMed] [Google Scholar]
- Anderson D, Watson R. On the spread of a disease with gamma distributed latent and infectious periods. Biometrika. 1980;67(1):191–198. doi: 10.1093/biomet/67.1.191. [DOI] [Google Scholar]
- Bernoulli D. An attempt at a new analysis of the mortality caused by smallpox and the advantages of inoculation to prevent it. Mem Math Phys Acad Roy Sci Paris. 2004;14:275. doi: 10.1002/rmv.443. [DOI] [PubMed] [Google Scholar]
- Blower S. An attempt at a new analysis of the mortality caused by smallpox and the advantages of inoculation to prevent it. Rev Med Virol. 2004;14:275. doi: 10.1002/rmv.443. [DOI] [PubMed] [Google Scholar]
- Brauer F. Mathematical epidemiology: past, present and future. Infect Dis Model. 2017;2(2):113–127. doi: 10.1016/j.idm.2017.02.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Castillo-Chavez C, Castillo-Garsow CW, Yakuba A. Mathematical models of isolation and quarantine. JAMA. 2003;290(21):2876–2877. doi: 10.1001/jama.290.21.2876. [DOI] [PubMed] [Google Scholar]
- Colizza V, Barrat A, Barthelemy M, Valleron A, Vespignani A. Modeling the worldwide spread of pandemic influenza: baseline case and containment interventions. PLoS Med. 2007;4:e13. doi: 10.1371/journal.pmed.0040013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Day T, Park A, Madras N, Gumel A, Wu J. When is quarantine a useful control strategy for emerging infectious diseases? Am J Epidemiol. 2006;163(5):479–485. doi: 10.1093/aje/kwj056. [DOI] [PMC free article] [PubMed] [Google Scholar]
- De Maia JO. Some mathematical developments on the epidemic theory developed by Reed and Frost. Hum Biol. 1952;24(3):167. [PubMed] [Google Scholar]
- Denes A, Gumel AB. Modeling the impact of quarantine during an outbreak of Ebola virus disease. Infect Dis Model. 2019;4:12–27. doi: 10.1016/j.idm.2019.01.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Diekmann O, Heesterbeek H, Britton T. Mathematical tools for understanding infectious disease dynamics. Princeton: Princeton University Press; 2013. [Google Scholar]
- Feng ZI, Thieme HR. Endemic models with arbitrarily distributed periods of infection. SIAM J Appl Math. 2000;61(3):803–833. doi: 10.1137/S0036139998347834. [DOI] [Google Scholar]
- Ferguson NM, Cummings DAT, Fraser C, Cajka JC, Cooley PC, Burke DS. Strategies for mitigating an influenza epidemic. Nature. 2006;442:448–452. doi: 10.1038/nature04795. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fraser C, Riley S, Anderson R, Ferguson N. Factors that make an infectious disease controllable. PNAS. 2004;101(16):6146–6151. doi: 10.1073/pnas.0307506101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- German TC, Kadau K, Longini IM, Macken CA. Mitigation strategies for pandemic influenza in the US. PNAS. 2006;103(15):5935–5940. doi: 10.1073/pnas.0601266103. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gumel AB, et al. Modeling strategies for controlling SARS outbreaks. Proc R Soc Lond B. 2004;271:2223–2232. doi: 10.1098/rspb.2004.2800. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hamer WH (1906) Epidemic disease in England—the evidence of viability and of persistence. Lancet 167
- Halloran ME, et al. Modeling target layered containment of an influenza epidemic in the US. PNAS. 2008;105(12):4639–4644. doi: 10.1073/pnas.0706849105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Heesterbeck JAP, Roberts MG. How mathematical epidemiology became a field of biology. Philos Trans R Soc. 2015;370:20140307. doi: 10.1098/rstb.2014.0307. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hethcote HW. The mathematics of infectious disease. SIAM Rev. 2000;42(4):599–653. doi: 10.1137/S0036144500371907. [DOI] [Google Scholar]
- Hethcote H, Zhein M, Shengbing I. Effects of quarantine in six endemic models for infectious diseases. Math Biosci. 2002;180:141–160. doi: 10.1016/S0025-5564(02)00111-6. [DOI] [PubMed] [Google Scholar]
- Kermack WO, McKendrick AG. A contribution to the mathematical theory of epidemics. Proc R Soc A. 1927;115(772):701–722. [Google Scholar]
- Kurtz TG. Approximation of population processes. New York: SIAM; 1981. [Google Scholar]
- Li F, Meng X, Wang X (2018) Analysis and numerical simulations of a stochastic SEIQR epidemic system with quarantine-adjusted incidence and imperfect vaccination. Special issue: Multiscale computational models for respiratory aerosol dynamics with medical applications. Comput Math Methods Med 2018 [DOI] [PMC free article] [PubMed]
- Lessler J, Cummings DA. Mechanistic models of infectious disease and their impact on public health. Am J Epidemiol. 2016;183(5):415–422. doi: 10.1093/aje/kww021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lewis B et al (2007) Simulated pandemic influenza outbreaks in Chicago. Virginia Bioinformatics Institute, Virginia Polytechnic Institute and State University, Tech Report NDSSL-TR-07-004
- Ma J, Earn DJD. Generality of the final size formula for an epidemic of a newly invading infectious disease. Bull Math Biol. 2006;68:679–702. doi: 10.1007/s11538-005-9047-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sahu GP, Dhar J. Dynamics of an SEQIHRS epidemic model with media coverage, quarantine and isolation in a community with pre-existing immunity. JAMA. 2015;421(2):1651–1672. doi: 10.1016/j.jmaa.2014.08.019. [DOI] [PMC free article] [PubMed] [Google Scholar]