

Abstract
Universal hitting sets (UHS) are sets of words that are unavoidable: every long enough sequence is hit by the set (i.e., it contains a word from the set). There is a tight relationship between UHS and minimizer schemes, where minimizer schemes with low density (i.e., efficient schemes) correspond to UHS of small size. Local schemes are a generalization of minimizer schemes that can be used as replacement for minimizer scheme with the possibility of being much more efficient. We establish the link between efficient local schemes and the minimum length of a string that must be hit by a UHS. We give bounds for the remaining path length of the Mykkeltveit UHS. In addition, we create a local scheme with the lowest known density that is only a log factor away from the theoretical lower bound.
Keywords: de Bruijn graph, depathing set, minimizers, sequence sketch, universal hitting set
1. Introduction
We study the problem of finding Universal Hitting Sets (UHS) (Orenstein et al., 2016). A UHS is a set of words, each of length k, such that every long enough string (say of length L or longer) contains as a substring element from the set. We call such a set a UHS for parameters k and L. They are sets of unavoidable words, that is, words that must be contained in any long strings, and we are interested in the relationship between the size of these sets and the length L.
More precisely, we say that a k-mer a (a string of length k) hits a string S if a appears as a substring of S. A set A of k-mers hits S if at least one k-mer of A hits S. A UHS for length L is a set of k-mers that hits every string of length L. Equivalently, the remaining path length of a universal set is the length of the longest string that is not hit by the set ( here).
The study of UHS is motivated, in part, by the link between UHS and the common method of minimizers (Schleimer et al., 2003; Roberts et al., 2004a,b). The minimizer method is a way to sample a string for representative k-mers in a deterministic way by breaking a string into windows, each window containing w k-mers, and selecting in each window a particular k-mer (the “minimum k-mer,” as defined by a preset order on the k-mers). This method is used in many bioinformatic software programs (Ye et al., 2012; Grabowski and Raniszewski, 2013; Chikhi et al., 2015; Deorowicz et al., 2015; Jain et al., 2017) to reduce the amount of computation and improve run time (see Marçais et al., 2019 for usage examples). The minimizer method is a family of methods parameterized by the order on the k-mers used to find the minimum. The density is defined as the expected number of sampled k-mers per unit length of sequence. Depending on the order used, the density varies.
In general, a lower density (i.e., fewer sampled k-mers) leads to greater computational improvements and is therefore desirable. For example, a read aligner such as Minimap2 (Li and Birol, 2018) stores all the locations of minimizers in the reference sequence in a database. It then finds all the minimizers in a read and searches in the database for these minimizers. The locations of these minimizers are used as seeds for the alignment. Using a minimizer scheme with a reduced density leads to a smaller database and fewer locations to consider, hence an increased efficiency, while preserving the accuracy.
There is a two-way correspondence between minimizer methods and UHS: each minimizer method has a corresponding UHS, and a UHS defines a family of compatible minimizer methods (Marçais et al., 2017, 2018). This correspondence also links the remaining path length of a UHS and the window size of a compatible minimizer scheme: the remaining path length of the UHS is upper bounded by the number of bases in each window in the minimizer scheme ().
Moreover, the relative size of the UHS, defined as the size of UHS over the number of possible k-mers, provides an upper bound on the density of the corresponding minimizer methods: the density is no more than the relative size of the UHS. Precisely, , where d is the density, U is the UHS, σk is the total number of k-mers on an alphabet of size σ, and w is the window length. In other words, the study of UHS with small size leads to the creation of minimizer methods with provably low density.
Local schemes (Mykkeltveit, 1972) and forward schemes are generalizations of minimizer schemes. These extensions are of interest because they can be used in place of minimizer schemes while sampling k-mers with lower density. In particular, minimizer schemes cannot have density close to the theoretical lower bound of when w becomes large, while local and forward schemes do not suffer from this limitation (Marçais et al., 2018). Understanding how to design local and forward schemes with low density will allow us to further improve the computation efficiency of many bioinformatic algorithms.
The previously known link between minimizer schemes and UHS relied on the definition of an ordering between k-mers, and therefore is not valid for local and forward schemes that are not based on any ordering. Nevertheless, UHS play a central role in understanding the density of local and forward schemes.
Our first contribution is to describe the connection between UHS, local and forward schemes. More precisely, there are two connections: first, between the density of the schemes and the relative size of the UHS, and second, between the window size w of the scheme and the remaining path length of the UHS (i.e., the maximum length L of a string that does not contain a word from the UHS). This motivates our study of the relationship between the size of a UHS U and the remaining path length of U.
There is a rich literature on unavoidable word sets (Lothaire, 2002). The setting for UHS is slightly different for two reasons. First, we impose that all the words in the set U have the same length k, as a k-mer is a natural unit in bioinformatic applications. Second, the set U must hit any string of a given finite length L, rather than being unavoidable only by infinitely long strings.
Mykkeltveit (1972) answered the question of what is the size of a minimum unavoidable set with k-mers by giving an explicit construction for such a set. The k-mers in the Mykkeltveit set are guaranteed to be present in any infinitely long sequence, and the size of the Mykkeltveit set is minimum in the sense that for any set with fewer k-mers, there is an infinitely long sequence that avoids . On the contrary, the construction gives no indication on the remaining path length.
The DOCKS (Orenstein et al., 2016) and ReMuVal (DeBlasio et al., 2019) algorithms are heuristics to generate unavoidable sets for parameters k and L. Both of these algorithms use the Mykkeltveit set as a starting point. In many practical cases, the longest sequence that does not contain any k-mer from the Mykkeltveit set is much larger than the parameter L of interest (which for a compatible minimizer scheme corresponds to the window length). Therefore, the two heuristics extend the Mykkeltveit set to cover every L-long sequence. These greedy heuristics do not provide any guarantee on the size of the unavoidable set generated compared with the theoretical minimum size and are only computationally tractable for limited ranges of k and L.
Our second contribution is to give upper and lower bounds on the remaining path length of the Mykkeltveit sets. These are the first bounds on the remaining path length for minimum size sets of unavoidable k-mers.
Defining local or forward schemes with a density of (i.e., within a constant factor of the theoretical lower bound) is not only of practical interest to improve the efficiency of existing algorithms, but it is also interesting for a historical reason. Both Roberts et al. (2004a) and Schleimer et al. (2003) used a probabilistic model to suggest that minimizer schemes have an expected density of . Unfortunately, this simple probabilistic model does not correctly model the minimizer schemes outside of a small range of values for parameters k and w, and minimizers do not have an density in general. Although the general question of whether a local scheme with exists is still open, our third contribution is an almost-optimal forward scheme with density of density. This is the lowest known density for a forward scheme, beating the previous best density of (Marçais et al., 2018), and hinting that might be achievable.
Understanding the properties of UHS and their many interactions with selection schemes (minimizer and forward and local schemes) is a crucial step toward designing schemes with lower density and improving the many algorithms using these schemes. In Section 2, we give an overview of the results, and in Section 3, we give detailed proofs. Further research directions are discussed in Section 4.
2. Results
2.1. Notation
2.1.1. Universal hitting sets
Consider a finite alphabet with elements. If , ak denotes the letter a repeated k times. We use to denote the set of strings of length k on alphabet Σ, and call them k-mers. If S is a string, denotes the substring starting at position n and of length l. For a k-mer and an l-long string , we say “a hits S” if a appears as substring of S [ for some i]. For a set of k-mers and , we say “A hits S” if there exists at least one k-mer in A that hits S. A set is a UHS for length L if A hits every string of length L.
2.1.2. de Bruijn graphs
Many questions regarding strings have an equivalent formulation with graph terminology using de Bruijn graphs. The de Bruijn graph on alphabet Σ and of order k has a node for every k-mer, and an edge (u, v) for every string of length with a prefix u and the suffix is v. There are σk vertices and edges in the de Bruijn graph of order k.
There is a one-to-one correspondence between strings and paths in : a path with w nodes corresponds to a string of characters. A UHS A corresponds to a depathing set of the de Bruijn graph: a UHS for k and L intersects with every path in the de Bruijn graph with vertices. We say “A is a -UHS” if A is a set of k-mers that is a UHS, with relative size and hits every walk of l vertices (and therefore every string of length ).
A de Bruijn sequence is a particular sequence of length that contains every possible k-mer once and only once. Every de Bruijn graph is Hamiltonian and the sequence spelled out by a Hamiltonian tour is a de Bruijn sequence.
2.1.3. Selection schemes
A local scheme (Schleimer et al., 2003) is a method to select positions in a string. A local scheme is parameterized by a selection function f. It works by looking at every w-mer of the input sequence S: , and selecting in each window a position according to the selection function f. The selection function selects a position in a window of length w, that is, it is a function . The output of a forward scheme is a set of selected positions: .
A forward scheme is a local scheme with a selection function such that the selected positions form a nondecreasing sequence. That is, if and are two consecutive windows in a sequence S, then .
A minimizer scheme is a scheme where the selection function takes in the sequence of w consecutive k-mers and returns the “minimum” k-mer in the window (hence the name minimizers). The minimum is defined by a predefined order on the k-mers (e.g., lexicographic order) and the selection function is .
See Figure 1 for examples of all three schemes. The local scheme concept is the most general as it imposes no constraint on the selection function, while a forward scheme must select positions in a nondecreasing way. A minimizer scheme is the least general and also selects positions in a nondecreasing way.
FIG. 1.

(a) Example of selecting minimizers with , , and the lexicographic order (i.e., ). The top line is the input sequence, each subsequent line is a 7-bases long window (the number of bases in a window is ) with the minimum 3-mer highlighted. The positions {1, 2, 5, 9, 10, 11} are selected for a density . (b) On the same sequence, an example of a selection scheme for (and because it is a selection scheme, hence the number of bases in a window is also w). The set of positions selected is {1, 6, 7, 8, 11, 13, 14}. This is not a forward scheme as the sequence of selected position is not decreasing. (c) A forward selection scheme for with selected positions {1, 7, 8, 12, 13}. Like the minimizer scheme, the sequence of selected positions is nondecreasing.
Local and forward schemes were originally defined with a function defined on a window of w k-mers, , similarly to minimizers. Selection schemes are schemes with , and have a single parameter w as the word length. While the notion of k-mer is central to the definition of the minimizer schemes, it has no particular meaning for a local or forward scheme: these schemes select positions within each window of a string S, and the sequence of the k-mers at these positions is no more relevant than a sequence elsewhere in the window to the selection function.
There are multiple reasons to consider selection schemes. First, they are slightly simpler as they have only one parameter, namely the window length w. Second, in our analysis, we consider the case where w is asymptotically large, therefore and the setting is similar to having . Finally, this simplified problem still provides information about the general problem of local schemes. Suppose that f is the selection function of a selection scheme, for any we can define as . That is, gk is defined from the function f by ignoring the last characters in a window. The functions gk define proper selection functions for local schemes with parameters w and k, and because exactly the same positions are selected, the density of gk is equal to the density of f. In the following sections, unless noted otherwise, we use forward and local schemes to denote forward and local selection schemes.
2.1.4. Density
Because a local scheme on string S may pick the same location in two different windows, the number of selected positions is usually less than . The particular density of a scheme is defined as the number of distinct selected positions divided by (Fig. 1). The expected density, or simply the density, of a scheme is the expected density on an infinitely long random sequence. Alternatively, the expected density is computed exactly by computing the particular density on any de Bruijn sequence of order . In other words, a de Bruijn sequence of large enough order “looks like” a random infinite sequence with respect to a local scheme (see Marçais et al., 2017 and Section 3.1).
2.2. Main results
The density of a local scheme is in the range , as corresponds to selecting exactly one position per window, and 1 corresponds to selecting every position. Therefore, the density goes from a low value with a constant number of positions per window [density is , which goes to 0 when w gets large], to a high with constant value [density is ] where the number of positions per window is proportional to w. When the minimizers and winnowing schemes were introduced, both articles used a simple probabilistic model to estimate the expected density to , or about 2 positions per window. Under this model, this estimate is within a constant factor of the optimal, .
Unfortunately, this simple model properly accounts for the minimizer behavior only when k and w are small. For large k—that is, —it is possible to create an almost-optimal minimizer scheme with a density . More problematic, for large w—that is, —and for all minimizer schemes, the density becomes constant [] (Marçais et al., 2018). In other words, minimizer schemes cannot be optimal or within a constant factor of optimal for large w, and the estimate of is very inaccurate in this regime.
This motivates the study of forward schemes and local schemes. It is known that there exist forward schemes with a density of (Marçais et al., 2018). This density is not within a constant factor of the optimal density but at least shows that forward and local schemes do not have constant density such as minimizer schemes for large w and that they can have much lower density.
2.2.1. Connection between UHS and selection schemes
In the study of selection schemes, as for minimizer schemes, UHS play a central role. We describe the link between selection schemes and UHS, and show that the existence of a selection scheme with low density implies the existence of a UHS with a small relative size.
Theorem 1. Given a local scheme f on w-mers with density df, we can construct a on -mers. If f is a forward scheme, we can construct a on -mers.
2.2.2. Almost-optimal relative size UHS for linear path length
Conversely, because of their link to forward and local selection schemes, we are interested in UHS with remaining path length . Necessarily a universal hitting hits any infinitely long sequences. On de Bruijn graphs, a set hitting every infinitely long sequence is a decycling set: a set that intersects with every cycle in the graph. In particular, a decycling set must contain an element in each of the cycles obtained by the rotation of the w-mers (e.g., cycle of the type ). The number of these rotation cycles is known as the “necklace number” (Golomb, 2014), where is the Euler's totient function.
Consequently, the relative size of a UHS, which contains at least one element from each of these cycles, is lower bounded by . The smallest previously known UHS with remaining path length has a relative size of (Marçais et al., 2018). We construct a smaller UHS with relative size :
Theorem 2. For every sufficiently large w, there is a forward scheme with density of and a corresponding -UHS.
2.2.3. Remaining path length bounds for the Mykkeltveit sets
Mykkeltveit (1972) gave an explicit construction for a decycling set with exactly one element from each of the rotation cycles, and thereby proved a long-standing conjecture (Golomb, 2014) that the minimal size of decycling sets is equal to the necklace number. Under the UHS framework, it is natural to ask what the remaining path length for Mykkeltveit sets is. Given that the de Bruijn graph is Hamiltonian, there exist paths of length exponential in w: the Hamiltonian tours have σw vertices. Nevertheless, we show that the remaining path length for Mykkeltveit sets is upper and lower bounded by polynomials of w:
Theorem 3. For sufficiently large w, the Mykkeltveit set is a -UHS, having the same size as minimal decycling sets, while for some constants c1 and c2.
3. METHODS AND PROOFS
For length reasons, several parts of the proof are found in the Supplementary Material.
3.1. UHS from selection schemes
3.1.1. Contexts and densities of selection schemes
We derive another way of calculating densities of selection schemes based on the idea of contexts.
Recall a local scheme is defined as a function . For any sequence S and scheme f, the set of selected locations is and the density of f on the sequence is the number of selected locations divided by . Counting the number of distinct selected locations is the same as counting the number of w-mers such that f picks a new location from all previous w-mers. f can pick identical locations on two w-mers only if they overlap, so intuitively, we only need to look back windows to check if the position is already picked. Formally, f picks a new position in window if and only if for all .
For a location i in sequence S, the context at this location is defined as , a -mer whose last w-mer starts at i. Whether f picks a new position in is entirely determined by its context, as the conditions only involve w-mers as far back as , which are all included in the context. This means that instead of counting selected positions in S, we can count the contexts c satisfying for all , which are the contexts such that f on the last w-mer of c picks a new location. We denote by the set of contexts that satisfy this condition.
Definition 1. For given w and local selection scheme , is a subset of .
The expected density of f is computed as the number of selected positions over the length of the sequence for a random sequence, as the sequence becomes infinitely long. For a sufficiently long random sequence (), the distribution of its contexts converges to a uniform random distribution over -mers. Because the distribution of these contexts is exactly equal to the uniform distribution on a circular de Bruijn S sequence of order at least , we can calculate the expected density of f as the density of f on S, or as .
3.1.2. UHS from selection schemes
The set over -mers is the UHS needed for Theorem 1. Intuitively, it is a UHS with remaining path length of at most , because one location must be picked every w window, meaning there is a window that picked a new location. The context that is prefix of this window is in by definition.
Lemma 1. is a UHS with remaining path length of at most .
Proof. By contradiction, assume there is a path of length w in the de Bruijn graph of order , say , that avoids . We construct the sequence S′ corresponding to the path: such that .
Since and include , it means f on the last w-mer of (which is ) picks a location that has been picked before on . The coordinate l of this selection in satisfies . As , the first w-mer in such that f picks (i.e., ) satisfies . The context then satisfies that a new location l is picked when f is applied to its last w-mer, and by definition , contradiction.
This results is also a direct consequence of the definition of . An alternative direct proof is available in Supplementary Section S1.
When f is a forward scheme, to determine if a new location is picked in a window, looking back one window is sufficient. This is because if we do not pick a new location, we have to pick the same location as in the last window. This means the context with two w-mers, or as a (w + 1)-mer, is sufficient, and our other arguments involving contexts still hold. Combining the pieces, we prove the following theorem:
Theorem 4. Given a local scheme f on w-mers with density df, we can construct a (df, w) − UHS on (2w − 1)-mers. If f is a forward scheme, we can construct a (df, w) − UHS on (w + 1)-mers.
3.2. Forbidden word depathing set
3.2.1. Construction and path length
In this section, we construct a set that is .
Definition 2 (Forbidden Word UHS). Let . Define as the set of w-mers that satisfies either of the following clauses: (1) 0d is the prefix of x (2) 0d is not a substring of x.
We assume that w is sufficiently large such that .
Lemma 2. The longest remaining path in the de Bruijn graph of order w after removing is .
Proof. Let be a path of length in the de Bruijn graph. If x0 does not have a substring equal to 0d, it is in . Otherwise, let c be the index such that . Since , and xc is in .
On the contrary, let and for . None of is in , meaning there is a path of length in the remaining graph.
The number of w-mer satisfying clause 1 is . For the rest of this section, we focus on counting w-mers satisfying clause 2 in Definition 2, that is, the number of w-mers not containing 0d.
3.2.2. Number of w-mers not containing 0d
We construct a finite state machine (FSM) that recognizes 0d as follows. The FSM consists of states labeled “0” to “d,” where “0” is the initial state and “d” is the terminal state. The state “i” with means that the last i characters were 0 and more zeroes are needed to match 0d. The terminal state “d” means that we have seen a substring of d consecutive zeroes. If the machine is at nonterminal state “i” and receives the character 0, it moves to state “,” otherwise it moves to state “0”; once the machine reaches state “d,” it remains in that state forever.
Now, assume we feed a random w-mer to the FSM. The probability that the machine does not reach state “d” for the input w-mer is the relative size of the set of w-mer satisfying clause 2. Denote such that is the probability of feeding a random k-mer to the machine and ending up in state “j,” for (note that the vector does not contain the probability for the terminal state “d”). The answer to our problem is then , that is, the sum of the probabilities of ending at a nonterminal state.
Define . Given that a randomly chosen w-mer is fed into the FSM, that is, each base is chosen independently and uniformly from Σ, the probabilities of transition in the FSM are: “i” “i + 1” with probability μ, “i” “0” with probability . The probability matrix to not recognize 0d is a matrix, as we discard the row and column associated with terminal state “d”:
Starting with as initially no sequence has been parsed and the machine is at state “0” with probability 1, we can compute the probability vector pw as .
3.2.3. Bounding
We start by deriving the characteristic polynomial of Ad and its roots, which are the eigenvalues of Ad:
Lemma 3.
Proof. The characteristic polynomial of Ad satisfies the following recursive formula, obtained by expanding the determinant over the first column and using the linearity of the determinant:
For , we have . Assuming for now, we repeatedly expand the recursive formula to obtain a closed-form formula for :
.
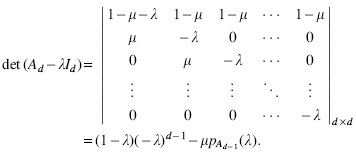
Now we fix d and focus on the polynomial . Since this is a polynomial of degree , it has roots and except for μ, which is a root of fd but not of , fd and have the same roots.
Lemma 4. For sufficiently large d, has a real root λ0 satisfying .
Proof. We show fd has opposite signs on the lower and upper bound of this inequality for sufficiently large d.
For the last line, if the first two terms cancel out and becomes dominant and positive, otherwise . Since fd is polynomial, fd is continuous and thus has a root between and .
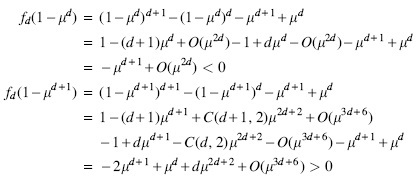
Lemma 5. Let . is the right eigenvector of Ad corresponding to eigenvalue , and for sufficiently large d.
Proof. For the first part, we need to verify . For indices ,(Adν0)i=μ(ν0)i-1=μsi-1=λ0si=(λ0ν0)i. For the first element in the vector, we have:
This verifies . For the second part, note that for sufficiently large d we have and since , we have . Every element of is positive, so .
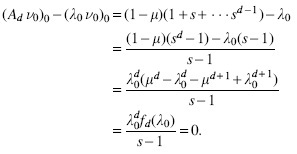
Lemma 6. .
Proof. Let , where from last lemma. Because , the elements of and Ad are all non-negative, then the elements of and are also non-negative. Now, recall that , which implies that .
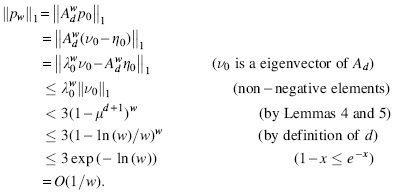
This lemma implies that the relative size for the set is dominated by the w-mers satisfying clause 1 of Definition 2 and is of relative size . This completes the proof that is .
3.3. Construction of the Mykkeltveit sets
In this section, we construct the Mykkeltveit set and prove some important properties of the set. We start with the definition of the Mykkeltveit embedding of the de Bruijn graph.
Definition 3 (Modified Mykkeltveit Embedding). For a w-mer x, its embedding in the complex plane is defined as , where rw is a wth root of unity, .
Intuitively, the position of a w-mer x is defined as the following center of mass. The w roots of unity form a circle in the complex plane, and a weight equal to the value of the base xi is set at the root . The position of x is the center of mass of these w points and associated weights. Originally, Mykkeltveit defined the embedding with weight (Mykkeltveit, 1972). This extra factor of rw in our modified embedding rotates the coordinate and is instrumental in the proof.
Define the successor function , where . The successor function gives all the neighbors of x in the de Bruijn graph. A pure rotation of x is the particular neighbor , that is, the sequence of is a left rotation of x.
We focus on a particular kind of cycle in the de Bruijn graph. A pure cycle in the de Bruijn graph, also known as conjugacy class, is the sequence of w-mers obtained by repeated rotation: . Each pure cycle consists of w distinct w-mer s, unless is periodic, and in this case, the size of the cycle is equal to its shortest period.
The embeddings from pure rotations satisfy a curious property:
Lemma 7 (Rotations and Embeddings). on the complex plane is rotated clockwise around origin by . is shifted by on the real part, with the imaginary part unchanged.
Proof. By Definition 3 and the definition of successor function :
Note that for pure rotations , and is exactly rotated clockwise by .
The range for is . In particular, can be negative. In a pure cycle, either all w-mers satisfy , or they lie equidistant on a circle centered at origin. Figure 2a shows the embeddings and pure cycles of 5-mers. It is known that we can partition the set of all w-mers into disjoint pure cycles. This means any decycling set that breaks every cycle of the de Bruijn graph will be at least this large. We now construct our proposed depathing set with this idea in mind.
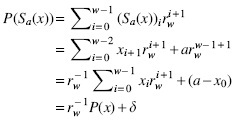
FIG. 2.

(a) Mykkeltveit embedding of the de Bruijn graph of order 5 on the binary alphabet. The nodes of a conjugacy class have the same color and form a circle (there is more than one class per circle). The pure rotations are represented by the red edges. A nonpure rotation is a red edge followed by a horizontal shift (blue edge). The set of nodes circled in gray is the Mykkeltveit set. (b) Weight-in embedding of the same graph. Multiple w-mers map to the same position in this embedding and each circle represents a conjugacy class. The gray dots on the horizontal axis are the w centers of rotations and the vertical gray lines going through the centers separate the space in subregions of interest.
Definition 4 (Mykkeltveit set). We construct the Mykkeltveit set as follows. Consider each conjugacy class, we will pick one w-mer from each of them by the following rule:
-
1.
If every w-mer in the class embeds to the origin, pick an arbitrary one.
-
2.
If there is one w-mer x in the class such that Re(P(x)) <0 and Im(p(x) = 0) (on the negative real axis), pick that one.
-
3.
Otherwise, pick the unique w-mer x such that Im(p(x) < 0) and Im(P(R(x))) >0. Intuitively, this is the w-mer in the cycle right below the negative real axis.
This set breaks every pure cycle in the de Bruijn graph by its construction, with an interesting property:
Lemma 8. Let {xi} be a path on the de Bruijn graph that avoids . If Im(P(xi)) ≤0, then for all j ≥ 1, Im(P(xj)) ≤0.
Proof. It suffices to show that in the remaining de Bruijn graph after removing , there are no edges x → y such that Im(P(x)) ≤0 and Im(P(y)) >0. The edge x → y means that y = Sa(x) for some a. By Lemma 7, Im(P(R(x))) = Im(P(Sa(x))) = Im(P(y)) >0.
If we have Im(P(x)) <0, by clause 3 of Definition 4, .
If we have Im(P(x)) = 0 and Re(P(x)) <0, by clause 2 of Definition 4, we have .
If we have Im(P(x)) = Re(P(x)) = 0, we would have Im(P(y)) = Im(P(R(x))) = 0, a contradiction.
If we have Im(P(x)) = 0 and Re(P(x)) >0, P(x) lies on positive half of the real axis, so rotating it clockwise by degrees we would have Im(P(y)) = Im(P(R(x))) = 0, a contradiction.
3.4. Upper bounding the remaining path length in Mykkeltveit sets
In this section, we show that the remaining path after removing is at most long. This polynomial bound is a stark contrast to the number of remaining vertices after removing the Mykkeltveit set—that is, , which is exponential in w. Our main argument involves embedding a w-mer to point in the complex plane, similar to Mykkeltveit's construction.
3.4.1. From w-mers to embeddings
In this section, we formulate a relaxation that converts paths of w-mers to trajectories in a geometric space. Precisely, we model Sa in Lemma 7 as a rotation operating on a complex embedding with attached weights, where the weights restrict possible moves.
Formally, given a pair (z, t) where z is a complex number and t an integer, define the family of operations . When is the position of a w-mer x, is its weight, and when , . This means is equivalent to finding the position and weight of the successor .
We are now looking for the length of the longest path by repeated application of that satisfies , where is the maximum weight of any w-mer. This is a relaxation of the original problem of finding a longest path as some choices of and some pairs on these paths may not correspond to the actual transition or w-mer in the de Bruijn graph (when is negative or greater than , then it is not a valid transition). In some sense, the pair is a loose representation of a w-mer where the precise sequence of the w-mer is ignored and only its weight is considered. On the contrary, every valid path in the de Bruijn graph corresponds to a path in this relaxation, and an upper bound on the relaxed problem is an upper bound of the original problem.
3.4.2. Weight-in embedding and relaxation
The weight-in embedding maps the pair to the complex plane. This transforms the original longest remaining path problem into a geometric problem of bounding the length in the complex plane under some operation .
Definition 5 (Weight-In Embedding). The weight-in embedding of is . Accordingly, for a w-mer x, its embedding is .
The operations in this embedding correspond to a rotation, and, maybe surprisingly, this rotation is independent of the value .
Lemma 9. Let . For all , the point is the point rotated clockwise around the point .
Proof. By definition of weight-in embedding and the operation :
In the complex plane, the rotation formula around center c and of angle θ is . Therefore, the operations is a rotation around of angle .
Figure 2b shows the weight-in embedding of a de Bruijn graph. The set is the set of all the possible centers of rotation, and is shown by large gray dots on the x-axis of Figure 2b. Because all the w-mers in a given conjugacy class have the same weight, say t0, the conjugacy classes form a circle around a particular center . The image after application of is independent of the parameter , but dependent on the weight t of the underlying pair .
Multiple pairs of can share the same weight-in embedding . As seen in Figure 2b, every node belongs to two circles with different centers, meaning there are two embeddings with the same but different t.
Lemma 8 naturally divides any path in the de Bruijn graph avoiding into two parts, the first part with Im(P(x)) >0, and the second part with Im(P(x)) ≥0. Thanks to the symmetry of the problems, we focus on the upper half-plane, defined as the region with Im(P(x)) ≥0. With the weight-in embedding, as long as the path is contained in the upper half-plane, it is always traveling to the right (toward large real value) or stays unmoved, as stated below:
Lemma 10 (Monotonicity of Re(Q(·))). Assume and are both in the upper half-plane. If does not coincide with its associated rotation center , then , otherwise .
Proof. The operation is a clockwise rotation where the rotation center is on the x-axis and the two points are on the non-negative half-plane. Necessarily, the real part increased, unless the point is on the fix point of the rotation [which is when ].
We further relax the problem by allowing rotations from any of the centers in , not just from some corresponding to the weight in the weight-in embedding. Lemma 10 still applies in this case and the points in the upper half-plane move from left to right. We are now left with a purely geometric problem involving no w-mers or weights to track:
What is the longest path possible where is obtained from zi by a rotation of clockwise around a center from , while staying in the upper halfplane at all times ()?
We now break the problem into smaller stages as the weight-in embedding pass through rotation centers, defined as , the set of points that could possibly rotate around regardless of t. As there are rotation centers and the maximum for any w-mer is also , we define subregions, two between any adjacent pair. Formally:
Definition 6 (Half Subregions). A subregion is defined as the area called a left subregion or called a right subregion, for .
We now define the problem of finding the longest path, localized to one left subregion, as follows:
Definition 7 (Longest Local Trajectory Problem). Define the feasible region , and relaxed rotation centers . A feasible trajectory is a list of points such that each point is in the feasible region, and zi can be obtained by rotating around clockwise by degrees. The solution is the longest feasible trajectory.
Again, note that this new definition is a purely geometric problem involving no w-mers and no weights to track. zi might stagnate if it coincides with one of the rotation centers, so we do not allow in this geometric problem. Still, it suffices to solve this simpler problem, as indicated by the following lemma:
Lemma 11. For fixed w and σ, if the solution to the problem in Definition 7 is L, the longest path in the de Bruijn graph avoiding is upper bounded by .
We prove this lemma in Supplementary Section S2.
3.4.3. Backtracking, heights, and local potentials
In this section, we prove . We frequently switch between polar and Cartesian coordinates in this section and the next section. For simplicity, let and denote the radius and the polar angle of z written in polar coordinate.
Lemma 12. Any feasible trajectory within the region for is at most long.
Proof. The key observation is if a rotation is not around the origin, increases by .
To see this, assume is the polar coordinate of with respect to the rotation center. The polar coordinate for is then . We note that as satisfies and is at least 0.5 away from any other rotation centers. The difference in real coordinate is . Now, we require and , so and the whole term is lower bounded by .
Only rotations not around origin are possible in the defined region, otherwise would increase by already. Between two rotations not around the origin, only rotations around the origin can happen, or the point would have rotated π degrees and cannot stay in the upper half-plane. This means the possible number of pure rotations is , which is also the asymptotic upper bound of path length.
This lemma is sufficient to prove and a total number of steps of . To obtain , we need a potential-based argument. Define , and let be the lowest point above the real axis of form where . We can show that a potential function of form is guaranteed to decrease by at least every rotation, and it can only decrease by total inside the feasible region, which would complete the proof. This proof can be found in Supplementary Section S3.
3.5. Lower bounding the remaining path length in Mykkeltveit sets
We provide here a constructive proof of the existence of a long path in the de Bruijn graph after removing . Since all w-mers in satisfy , a path satisfying at every step is guaranteed to avoid and our construction will satisfy this criterion. It suffices to prove the theorem for binary alphabet as the path constructed will also be a valid path in a graph with a larger alphabet. We present here the constructions for even values of w.
We need an alternative view of w-mers in this section, close to a shift register. Imagine a paper ring with w slots, labeled tag 0 to tag with content , and a pointer initially at 0. The w-mer from the ring is , assuming pointer is at tag j. A pure rotation on the ring is simply moving the pointer one base forward, and an impure one is to write a to yj before moving the pointer forward.
Let . We create ordered quadruples of tags taken modulo w: where , , and . In each quadruple Qj, the set of associated root of unity for the four tags is of form , adding up to 0. Consequently, changing yk for each k in Qj from 1 to 0 does not change the resulting embedding. The strategy consists of creating “pseudoloops”: start from a w-mer, rotate it a certain number of times, and switch the bit of the w-mer corresponding to the index in a quadruple to 0 to return to almost the starting position (the same position in the plane but a different w-mer with lower weight).
More precisely, the initial w-mer x is all ones but set to zero, with paper ring content y = x and pointer at tag 0. The resulting w-mer satisfies . The sequence of operations is as follows. First, do a pure rotation on x. Then, for each quadruple Qj from to , we perform the following actions on x: pure rotations until the pointer is at tag , impure rotation S0, pure rotations until the pointer is at tag , impure rotation S0, pure rotations until pointer is at tag , impure S0, pure rotations until pointer is at tag , impure S0.
Each round involves exactly w + 1 rotations since the last step is to an impure rotation S0 at tag , which increases by one between quadruples Qj and . The total length of the path over all Qi is at least for some constant c. Figure 3 shows an example of quadruples and a generated long path that fits in the upper half-plane.
FIG. 3.

(a) For w = 40, each set of four arrows of the same color represents a quadruple set of root of unity. There are a total of five sets. They were crafted so that the four vectors in each set cancel out. (b) The path generated by these quadruple sets. The top circle of radius 1 is traveled many times (between tags r1 and r2 in each quadruple), as after setting the 4 bits to 0, the w-mer has the same norm as the starting point.
The correctness proof for the construction is presented in Supplementary Section S4 and the construction for odd w is presented in Supplementary Section S5.
4. Discussion
4.1. Relationship between UHS and selection schemes
Our construction of a UHS of relative size and remaining path length w also implies the existence of a forward selection scheme with density , only a factor away from the lower bound on density achievable by forward and local schemes.
Unfortunately, this construction does not apply for an arbitrary UHS. In general, given a UHS with relative size d and remaining path length w, it is still unknown how to construct a forward or a local scheme with density . As described in Section 3.1, we can construct a UHS from a scheme by taking the set of contexts yielding new selections. However, it is not always possible to go the other way: there are UHS that are not equal to a set of contexts for any function f.
We are thus interested in the following questions. Given a UHS U with relative size d, is it possible to create another UHS from U that has the same relative size d and corresponds to a local scheme (i.e., there exists f such that )? If not, what is the smallest price to pay (extra density compared to relative size of the UHS) to derive a local scheme from UHS U?
4.2. Existence of “perfect” selection schemes
One of the goals in this research is to confirm or deny the existence of asymptotically “perfect” selection schemes with a density of , or at least . A study of UHS might shed light on this problem. If such a perfect selection scheme exists, asymptotic perfect UHS defined as -UHS would exist. On the contrary, if we denied the existence of an asymptotic perfect UHS, this would imply nonexistence of a “perfect” forward selection scheme with density .
4.3. Asymptotic results and practical uses of minimizer schemes
This line of research places more focus on asymptotic densities of minimizers (and naturally, asymptotic densities of local schemes, and asymptotic relative proportion and path length of UHS). That is, we focus on characterization of these quantities in the limit where w and k, the window length (number of k-mers in a window) and the length of a k-mer, go to infinity. On the contrary, for current practices, the values of w and k are relatively small, with w below 100 and k below 30 for the vast majority of use cases. While our results are not immediately useful to analyze these practical scenarios as we do not attempt to determine the constants behind the big-O notation, we believe that further refinement of our approaches can close the gap between theory and practice, and make rigorous analyses possible for practical minimizer and/or local schemes.
4.4. Remaining path length of minimum decycling sets
There is more than one decycling set of minimum size (MDS) for given w. The Mykkeltveit set (Mykkeltveit, 1972) is one possible construction, and a construction based on very different ideas is given in Champarnaud et al. (2004). The number of MDSs is much larger than the two sets obtained by these two methods. Empirically, for small values of w, we can exhaustively search all the MDSs on the binary alphabet: for the number of MDSs is, respectively, 2, 4, 30, 28, 68 288, and 18 432.
While experiments suggest that the longest remaining path in a Mykkeltveit depathing set defined in the original article is around , matching our upper bound, we do not know if such bound is tight across all possible minimal decycling sets. The Champarnaud set seems to have a longer remaining path than the Mykkeltveit set, although it is unknown if it is within a constant factor, bounded by a polynomial of w of different degree, or is exponential. More generally, we would like to know what is the range of possible remaining path lengths as a function of w over the set of all MDSs.
Supplementary Material
Author Disclosure Statement
H.Z. declares no competing financial interests. C.K. is a cofounder of Ocean Genomics, Inc. G.M. is V.P. of software development at Ocean Genomics, Inc.
Funding Information
This work was partially supported, in part, by the Gordon and Betty Moore Foundation's Data-Driven Discovery Initiative through grant GBMF4554 to Carl Kingsford, by the U.S. National Science Foundation (CCF-1256087, CCF-1319998), and by the U.S. National Institutes of Health (R01GM122935).
Supplementary Material
References
- Champarnaud, J.-M., Hansel, G., and Perrin, D.. 2004. Unavoidable sets of constant length. Int. J. Algebra Comput. 14, 241–251 [Google Scholar]
- Chikhi, R., Limasset, A., and Medvedev, P.. 2015. Compacting de Bruijn graphs from sequencing data quickly and in low memory. Bioinformatics 32, i201–i208 [DOI] [PMC free article] [PubMed] [Google Scholar]
- DeBlasio, D., Gbosibo, F., Kingsford, C., et al. 2019. Practical universal K-mer sets for minimizer schemes, 167–176. In Proceedings of the 10th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, BCB’19. ACM, Niagara Falls, NY, New York, NY [Google Scholar]
- Deorowicz, S., Kokot, M., Grabowski, S., et al. 2015. KMC 2: Fast and resource-Frugal k-Mer counting. Bioinformatics 31, 1569–1576 [DOI] [PubMed] [Google Scholar]
- Golomb, S.W. 2014. Nonlinear shift register sequences, 110–168. In Shift Register Sequences. https://www.worldscientific.com/worldscibooks/10.1142/936. World Scientific. Singapore [Google Scholar]
- Grabowski, S., and Raniszewski, M.. 2013. Sampling the suffix array with minimizers, 287–298. In Iliopoulos, C., Puglisi, S., and Yilmaz, E, eds. String Processing and Information Retrieval. Lecture Notes in Computer Science 9309. Springer International Publishing. Switzerland [Google Scholar]
- Jain, C., Dilthey, A., Koren, S., et al. 2017. A fast approximate algorithm for mapping long reads to large reference databases, 66–81. In Sahinalp, S.C., ed. Research in Computational Molecular Biology. Lecture Notes in Computer Science. Springer International Publishing. Switzerland [DOI] [PMC free article] [PubMed]
- Li, H., and Birol, I.. 2018. Minimap2: Pairwise alignment for nucleotide sequences. Bioinformatics 34, 3094–3100 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lothaire, M. 2002. Algebraic Combinatorics on Words, vol. 90. Cambridge University Press. Cambridge, United Kingdom
- Marçais, G., DeBlasio, D., and Kingsford, C.. 2018. Asymptotically optimal minimizers schemes. Bioinformatics 34, i13–i22 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marçais, G., Pellow, D., Bork, D., et al. 2017. Improving the performance of minimizers and winnowing schemes. Bioinformatics 33, i110–i117 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marçais, G., Solomon, B., Patro, R., et al. 2019. Sketching and sublinear data structures in genomics. Annu. Rev. Biomed. Data Sci. 2, 93–118 [Google Scholar]
- Mykkeltveit, J. 1972. A proof of Golomb's conjecture for the de Bruijn graph. J. Comb. Theory Ser. B 13, 40–45 [Google Scholar]
- Orenstein, Y., Pellow, D., Marçais, G., et al. 2016. Compact universal K-mer hitting sets, 257–268. In Algorithms in Bioinformatics. Lecture Notes in Computer Science. Cham, Springer [Google Scholar]
- Roberts, M., Hayes, W., Hunt, B.R., et al. 2004. a. Reducing storage requirements for biological sequence comparison. Bioinformatics 20, 3363–3369 [DOI] [PubMed]
- Roberts, M., Hunt, B.R., Yorke, J.A., et al. 2004. b. A preprocessor for shotgun assembly of large genomes. J. Comput. Biol. 11, 734–752 [DOI] [PubMed] [Google Scholar]
- Schleimer, S., Wilkerson, D.S., and Aiken, A.. 2003. Winnowing: local algorithms for document fingerprinting, 76–85. In Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data. SIGMOD’03. ACM. New York, New York, USA [Google Scholar]
- Ye, C., Ma, Z.S., Cannon, C.H., et al. 2012. Exploiting sparseness in de novo genome assembly. BMC Bioinformatics 13, S1. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.