

Abstract
It is widely accepted that information derived from analyzing speech (the acoustic signal) and language production (words and sentences) serves as a useful window into the health of an individual’s cognitive ability. In fact, most neuropsychological testing batteries have a component related to speech and language where clinicians elicit speech from patients for subjective evaluation across a broad set of dimensions. With advances in speech signal processing and natural language processing, there has been recent interest in developing tools to detect more subtle changes in cognitive-linguistic function. This work relies on extracting a set of features from recorded and transcribed speech for objective assessments of speech and language, early diagnosis of neurological disease, and tracking of disease after diagnosis. With an emphasis on cognitive and thought disorders, in this paper we provide a review of existing speech and language features used in this domain, discuss their clinical application, and highlight their advantages and disadvantages. Broadly speaking, the review is split into two categories: language features based on natural language processing and speech features based on speech signal processing. Within each category, we consider features that aim to measure complementary dimensions of cognitive-linguistics, including language diversity, syntactic complexity, semantic coherence, and timing. We conclude the review with a proposal of new research directions to further advance the field.
Keywords: cognitive linguistics, vocal biomarkers, Alzheimer’s disease, schizophrenia, thought disorders, natural language processing
I. Introduction
EARLY detection of neurodegenerative disease and episodes of mental illness that impact cognitive function (henceforth, cognitive disorder and thought disorder, respectively) is a major goal of current research trends in speech and language processing. These afflictions have both significant societal and economic impacts on affected individuals. It is estimated that approximately one in six adults in the United States lives with some form of mental illness, according to the National Institute of Mental Health (NIMH), totaling 44.6 million people in 2016 [1]. In the United States alone, some estimate that the economic burden of mental illness is approximately $1 trillion annually [2]. The World Health Organization estimates that, in 2015, the global burden of Alzheimer’s disease and dementia equaled 1.1% of the global gross domestic product [3]. The ability to identify early signs and symptoms is critical for the development of interventions to impact progression or episodes.
Many aspects of cognitive and thought disorders are manifest in the way speech is produced and what is said. Irrespective of the underlying disease or condition, the analysis of speech and language can provide insight to the underlying neural function. This has motivated current research trends in quantitative speech and language analytics, with the hope of eventually developing clinically-validated algorithms for better diagnosis, prediction, and characterization of these conditions. This has both long-term and nearer-term potential for impact. In the long term, there is the potential for new diagnostics and early intervention for improved treatment outcomes and reduced economic burden. In the nearer term, there is the potential for improving the efficiency of clinical trials evaluating new drugs. It is generally accepted that early enrollment in clinical trials for evaluation of new drugs maximizes the chances of showing that a drug is successful [49], [50]. In addition, adopting endpoints that are more sensitive to change means that these studies can be powered with fewer participants. Digital endpoints collected frequently have recently garnered interest in this domain [51].
In this review, we limit our focus to speech and language analysis for cognitive and thought disorders in the context of neurodegenerative disease and mental illness. In keeping with the Diagnostic and Statistical Manual of Mental Disorders (DSM-5) [52] classification system, “cognitive disorders” refer to disturbances in memory and cognition, whereas “thought disorders” refer to the inability to produce and sustain coherent communication. Thus, Alzheimer’s disease (the most common form of dementia) is an example of a cognitive disorder, while schizophrenia is an example of a mental illness that presents as a thought disorder.
With access to clinical speech and language databases along with recent developments in the fields of speech signal processing, computational linguistics, and machine learning, there is an increased potential for using computational methods to automate the analysis of speech and language datasets for clinical applications [2]. Objective analysis of this sort has the potential to overcome some of the limitations associated with the current state-of-the-art for improved diagnosis, prediction, and characterization of cognitive and thought disorders. A high-level block diagram of existing methods in clinical-speech analytics is shown in Figure 1. Patients provide speech samples via a speech elicitation task. This could be passively collected speech, patient interviews, or recorded neuropsychological batteries. The resulting speech is transcribed, using either automatic speech recognition (ASR) or manual transcription, and a set of speech and language features are extracted that aim to measure different aspects of cognitive-linguistic change. These features become the input of a machine learning model that aims to predict a dependent variable of interest, e.g. detection of clinical conditions or assessment of social skills [53], [14], [13].
Fig. 1:

Overview of the process of using natural language processing and speech signal processing for extraction of speech and language features for clinical decision-making. Example language features include lexical complexity, syntactic complexity, semantic coherence, etc. Example of acoustic speech features include pause rate, prosody, articulation, etc.
Perhaps the most important parts of the analysis framework in Figure 1 are the analytical methods used to extract clinically-relevant features from the samples. With a focus on cognitive and thought disorders, we provide a survey of the existing literature and common speech and language features used in this context. The review is not focused on a particular disease, but rather on the methods for extracting clinically-relevant measures from the resultant speech.
A summary of the work reviewed in this paper can be seen in Table I and will be discussed in the subsequent sections. In the next section, we aim to place our review in context. We provide an overview of speech and language production, highlight the existing neuropsychological assessments used to evaluate speech and language, and provide an overview of the the speech and language dimensions that we focus on in this review.
TABLE I:
Summary of work covered in this review, including textual and acoustic features to assess cognitive and thought disorders that are automatically extracted from speech and language samples using NLP and speech signal processing. Note that in the abbreviations in the table, “Sz” refers to schizophrenia and “Sza” refers to the related schizoaffective disorder, which are considered together for simplicity in this summary.
| Category | Subcategory | Features or Methods Used | Cognitive & Thought Disorder(s) Assessed |
|---|---|---|---|
| Text-based | Lexical features | Bag of words vocabulary analysis Linguistic Inquiry & Word Count (LIWC) [6] Lexical Diversity (TTR, MATTR, BI, HS, etc.) Lexical Density (content density, idea density, P-density) Part-of-speech (POS) tagging |
Semantic dementia (SD) [4]; Alzheimer’s disease (AD) [5] Mild cognitive impairment (MCI) [7], schizophrenia (Sz/Sza) [8]; AD [9] AD [5], [10], [11]; primary progressive aphasia (PPA) [12], Sz/Sza [13], bipolar disorder (BPD) [13] MCI [14]; AD [5], [11], [9]; PPA [12]; chronic traumatic encephalopathy (CTE) [15]; Sz/Sza [13], BPD [13] MCI [14]; PPA [12]; AD [5], [9]; Sz/Sza [16], [17], [18] |
| Syntactical features | Constituency-based parse tree scores (Yngve [19], Frazier [20]) Dependency-based parse tree scores Speech graphs and attributes |
AD [5], [9]; MCI [14]; PPA [12] MCI [14] Sz/Sza [21], [22]; BPD [21], [22]; MCI [23] |
|
| Semantic features | Word & sentence embeddings: - LSA [24] - Neural word embeddings (word2vec [26], GloVe [27], etc.) - Neural sentence embeddings (SIF [29], InferSent [30], etc.) Topic modeling: - LDA [31] - Vector-space topic modeling with neural networks Semantic role labeling [34] |
Sz/Sza [25], [16], [17] Sz/Sza [28], [18], [13]; BPD [13] Sz/Sza [18], [13]; BPD [13] Sz/Sza [28], [8] AD [32], [33]; MCI [33] Sz/Sza [28] |
|
| Pragmatics | Sentiment analysis | Sz/Sza [28] | |
| Acoustic | Prosodic features | Temporal (pause rate, phonation rate, voiced durations, etc.) Fundamental frequency (F0) and trajectory Loudness and energy Emotional content |
MCI [14], [35], [36], [37]; AD [35], [38]; Sz/Sza [39] Frontotemporal lobal degeneration (FTLD) [40] AD [38]; BPD [41] AD [38] AD [38] |
| Spectral features | Formant trajectories (F1, F2, F3, etc.) Spectral centroid [43] MFCC statistics [44] |
PPA [42]; AD [5] AD [38] PPA [42]; AD [5] |
|
| Vocal quality | Jitter, shimmer, harmonic-to-noise ratio (HNR) | PPA [42]; AD [5], [38] | |
| ASR-related | Phone-level detection of filled pauses & temporal features Improving WER for clinical data | MCI [36], [37] AD [45], [9]; neurodegenerative dementia (ND) [46], [47], [48] |
Following that section, the review is split into two parts: natural language processing (NLP) features and speech signal processing features. With NLP, we can measure the complexity and coherence of language and with speech signal processing, we can measure acoustic proxies related to cognitive processing.
Finally, in Section V we discuss gaps in current research, propose future directions, and end with concluding remarks.
II. Background
A. Spoken Language Production
The production of spoken language in humans is a complex, multi-stage process that involves high levels of memory, cognition, and sensorimotor function. There are three distinct stages [55]:
Conceptualization: involves the formation of abstract ideas about the intended message to be communicated
Formulation: involves forming the exact linguistic construction of the utterance to be spoken
Articulation: involves actually producing sounds using the various components of the speech production system, i.e. lungs, glottis, larynx, vocal tract, etc.
These stages are visually represented in the block diagram in Figure 2. In the conceptualization stage, pre-verbal ideas are formed to link a desired concept to be expressed to the spoken language that is eventually formed. The formulation stage consists of several distinct components: (a) lexical, syntactical, & grammatical formulations, (b) morpho-phonological encoding, and (c) phonetic encoding. This involves forming the linguistic structure of a spoken utterance, determining which syllables are needed to articulate the utterance, and the creation of an articulatory score containing instructions that are to be executed by the vocal apparatus in the articulation stage [55].
Fig. 2:

Speech production block diagram model, adapted and modified from [54]. In this review, we focus primarily on the additional box we termed “Linguistic Formulation” within the formulation stage of speech production. Cognitive and thought disorders that affect this area have direct measurable outputs on the actual language content which can be studied by statistical text-based analysis. Additionally, they also have indirect downstream effects on the vocalized and articulated speech acoustics. Both of these areas are covered in our review.
Cognitive and thought disorders have the ability to affect any of these stages, but broadly, they can be captured through analysis of “content” (what is said) and “form” (how it is said). Indeed, the tools used to characterize content and form of speech are agnostic to the underlying condition. It is the constellation of features shown to be affected that converge on the locus of deficit for an individual. For example, speech that lacks coherence of ideas and jumps from topic to topic (impaired content), and is produced very rapidly and without pauses (impaired form), would point toward a thought or mood disorder, such as schizophrenia or mania. A person with dementia may present with reduced vocabulary size (impaired content), and with increased number and duration of pauses (impaired form). To reiterate, the speech and language measures are, themselves, agnostic to the underlying disorder. Rather, it is the constellation of deficit patterns that associate with different etiologies. Our aim here is to provide an overview of the methods used to extract these constellations without focusing on a particular disease area. We refer to clinical applications in each section to highlight existing work that uses these features in clinical applications.
B. Clinical Assessment of Speech & Language for Cognitive & Thought Disorders
A variety of clinical protocols exist for the evaluation and diagnosis of disorders affecting cognitive function in psychiatry and neurology. The DSM-5 [52], published by the American Psychiatric Association (APA), provides the standard diagnostic criteria for psychiatric and neurocognitive disorders, and it is updated as knowledge in the field evolves. The DSM-5 covers a large spectrum of psychiatric and cognitive disorders, such as depression, anxiety, schizophrenia, bipolar disorder, dementia, and several more.
Based on these criteria, many evaluation methodologies have been developed in clinical practice for diagnosing and evaluating these cognitive disorders. The mental status examination (MSE) is a commonly utilized and multi-faceted tool for screening an individual at a given point in time for signs of neurological and psychiatric disorders [56]. Components of the MSE evaluate affect, mood, appearance, judgment, speech, thought process, and overall cognitive ability through a variety of tasks and surveys. Related screenings include the mini-mental state examination (MMSE) [57], Addenbrooke’s Cognitive Examination (ACE) [58], and the Montreal Cognitive Assessment (MoCA) [59] for evaluating conditions like mild cognitive impairment (MCI), dementia, and Alzheimer’s disease (AD). Other forms of disorders, i.e. schizophrenia and bipolar disorder, can be evaluated with screenings such as the Clinical Assessment Interview for Negative Symptoms (CAINS) [60], Brief Negative Symptom Scale (BNSS) [61], the Social Skills Performance Assessment (SSPA) [53], and several others that measure the effects of thought and mood disorders.
All of these neuropsychological batteries for evaluating cognitive health have a significant speech and language assessment, as cognitive-linguistic function is a strong biomarker for neuropsychological health in many dimensions. However, ratings for narrative, recall, conversational, or other spoken language tasks are often subjective in nature and of variable reliability, making the underlying diagnosis more challenging [62]. While the diagnosis for many common psychiatric conditions has become more consistent over time as they are better understood, others (e.g. schizoaffective disorder) are often evaluated inconsistently by different clinical assessors due to the subjective nature of the test batteries applied [63], [64]. The speech and language samples collected during these screenings serve as potentially valuable databases for objective and automatically computable measures of cognitive-linguistic ability. Recent research suggests that analysis of this rich data allows us to explore several new objective dimensions for evaluation, which has a largely untapped potential to improve clinical assessment and outcomes. These new tools have the potential to provide a finer-grained analysis of the resultant speech when compared against existing rating scales.
C. Speech & Language Dimensions of Interest
Natural spoken language contains several measurable dimensions that indicate various aspects of cognitive health. In this review, we are interested in the analysis of linguistic and acoustic speech features that are indicative of cognitive and thought disorders related to thought content and thought organization. These include a variety of neurological impairments (e.g. MCI, dementia, AD, chronic traumatic encephalopathy) and psychiatric conditions (e.g. schizophrenia, schizoaffective disorder, bipolar disorder).
Most of the work in this space exists in the context of textual language analysis, either by manual or automatic transcription of spoken utterances. Looking at Figure 2, we focus mainly on the “Linguistic formulation” area within the formulation stage. Neurological thought disorders all affect the ability of an individual to form complex thoughts and sentence structures, and may often have issues such as poverty of speech or disorganized speech. Therefore, we look at methods for examining thought content density, complexity of sentence syntax, semantic coherence, and sentiment analysis as they relate to these conditions.
Analysis of acoustic speech samples leads to additional insight for characterizing neurological and psychiatric thought disorders, as impairments in language formation in turn affect the articulation of the spoken output. As seen in Figure 2, the articulation pathway that leads to speech output depends upon the cognitive ability required for the conceptualization and formulation stages of speech production. Cognitive and working memory disorders can lead to impairments in neuromuscular motor coordination and proprioceptive feedback as well, affecting speech output [65]. Among the speech signal features considered are those related to temporal analysis and prosody (e.g. pause rate, phonation rate, periodicity of speech, etc.) and those related to frequency analysis (e.g. mean, variance, kurtosis of Mel frequency cepstral coefficients).
We note that the purpose of this review is to highlight recent research that identifies and characterizes automatically computed speech and language features related to neurological and psychiatric disorders of thought content and formulation. In each part, we will provide an overview of commonly used techniques for extracting various speech and language features, present examples of their clinical application, and discuss the advantages and disadvantages of the methods reviewed.
III. Measuring Cognitive and Thought Disorders with Natural Language Processing
In this section, we will provide a review of several families of natural language processing methods that range from simple lexical analysis to state-of-the-art language models that can be utilized for clinical assessment.
The sections below present families of approaches in order of increasing complexity. In the first section, we describe methods based on subjective evaluation of speech and language; then we discuss methods that rely on lexeme-level information, followed by methods that rely on sentence-level information, and end with methods that rely on semantics. For each section, we provide a description of representative approaches and a review of how these methods are used in clinical applications. We end each section with a discussion of the advantages and disadvantages of the approaches in that section.
A. Early Work
Simple analysis of written language samples has long been thought to provide valuable information regarding cognitive health. One of the best-known early examples of such work is the famous “nun study” by Snowdon et al. on linguistic ability as a predictor of Alzheimer’s disease (AD) [66]. In this work, manual evaluations of the linguistic abilities of 93 nuns were conducted by analysis of autobiographical essays they had written earlier in their lives. The researchers evaluated the linguistic structure of the essays by scoring the grammatical complexity and idea density in the writing samples. In particular, the study found that low idea density in early life was a particularly strong predictor of reduced cognitive ability or the presence of AD in later life. Roughly 80% of the participants that were determined to lack linguistic complexity in their writings developed AD or had mental and cognitive disabilities in their older age.
This work was groundbreaking in showing that linguistic structure and complexity can serve as a strong predictor for the onset of AD and potentially other forms of cognitive impairment. However, it required tedious manual analysis of writing samples and careful consideration that the scores given by different evaluators had a high correlation, due to the subjective nature of the scoring.
These factors make in-clinic use prohibitive; as a result, these methods have received limited attention in follow-on work. The development of automated and quantitative metrics to analyze language complexity can potentially save several hours of research time to conduct similar linguistic studies to understand neurodegenerative disease and mental illness. Several techniques devised in the NLP literature have been utilized to address the challenge of conducting quantitative analysis to replace traditionally subjective and task-dependent methods of measuring linguistic complexity.
B. First Order Lexeme-Level Analysis
1). Methods:
Automated first-order lexical analysis, i.e. at the lexeme-level or word-level, can generate objective language metrics to provide valuable insight into cognitive function. The most basic approaches treat a body of text as a bag of words, meaning the ordering of words within the text is not considered. This can be done by simply considering the frequency of usage of particular words and how they relate to a group of individuals. Specialized tools, such as Linguistic Inquiry and Word Count (LIWC) [6], are often used to analyze the content and categorize the vocabulary within a text. LIWC associates words in a text with categories associated with affective processes (i.e. positive/negative emotions, anxiety, sadness, etc.), cognitive processes (i.e. insight, certainty, causation, etc.), social processes (i.e. friends, family, humans), the presence of dysfluencies (pauses, filler words, etc.), and many others. The categorization of the lexicon allows for further tasks of interest, such as sentiment analysis based on the emotional categories. The frequency of usage and other statistics of words from particular categories can lend insight to overall language production.
The concept of lexical diversity refers to a measure of unique vocabulary usage. The type-to-token ratio (TTR), given in Equation (1), is a well-known measure of lexical diversity, in which the number of unique words (types, V) are compared against the total number of words (tokens, N).
| (1) |
However, TTR is negatively impacted for longer utterances, as the diversity of unique words typically plateaus as the number of total words increase. The moving average type-to-token ratio (MATTR) [67] is one method which aims to reduce the dependence on text length by considering TTR over a sliding window of the text. This approach does not have a length-based bias, but is considerably more variable as the parameters are estimated on smaller speech samples. Brunét’s Index (BI) [68], defined in Equation (2), is another measure of lexical diversity that has a weaker dependence on text length, with a smaller value indicating a greater degree of lexical diversity,
| (2) |
An alternative is also provided by Honoré’s Statistic (HS) [69], defined in Equation (3), which emphasizes the use of words that are spoken only once (denoted by V1),
| (3) |
The exponential and logarithm in the BI and the HS reduce the dependence on the text length, while still using all samples to estimate the diversity measure, unlike the MATTR.
Measures of lexical density, which quantify the degree of information packaging within an utterance, may also be useful for cognitive assessment. Content words1 (i.e. nouns, verbs, adjectives, adverbs) tend to carry more information than function words2 (e.g. prepositions, conjunctions, interjections, etc.). These can be used to compute notions of content density (CD) in written or spoken language, given in Equation (4),
| (4) |
Part-of-speech (POS) tagging of text samples is one way in which the word categories can be automatically determined; individual word tokens within a sentence are identified and labeled as the part-of-speech that they represent, typically from the Penn Treebank tagset [70]. Several automatic algorithms and available implementations exist for rule-based and statistical taggers, i.e. using a hidden Markov model (HMM) or maximum entropy Markov model (MEMM) implementation to determine POS tags with a statistical sequence model [71]. For example, the widely-used Stanford Tagger [72] uses a bidirectional MEMM model to assign POS tags to samples of text. Several notions of content density can be computed at the lexeme-level if POS tags can be automatically determined to reflect the role of each word in an utterance. Examples of these include: the propositional density (P-density), a measure of the number of expressed propositions (verbs, adjectives, adverbs, prepositions, and conjunctions) divided by the total number of words, and the content density, which is a measure of the ratio of content words to function words [14], [5].
2). Clinical Applications:
Several studies have utilized first order lexical features to assess cognitive health by automated linguistic analysis. The simplest bag-of-words analysis for vocabulary usage can often provide valuable insight in this regard. For example, the work by Garrard et al. computed vocabulary statistics for participants with left- (n = 21) and right-predominant (n = 11) varieties of semantic dementia (SD) and, and compared them with language samples from healthy controls (n = 10) [4]. Classification accuracy of over 90% was reached for categorizing the participants for two tasks: (1) participants with SD against the healthy control participants, and (2) classifying the left- and right-predominant variants of SD. They used the concept of information gain to determine which word types were most useful in each classification problem. Asgari et al. used the LIWC tool [6] to study the language of those with mild cognitive impairment (MCI), often a precursor to Alzheimer’s disease (AD) [7]. The transcripts of unstructured conversation with the study’s participants were analyzed with LIWC to generate a 68-dimensional vector of word counts that fall within each of the 68 subcategories in the LIWC lexicon. They were able to achieve over 80% classification accuracy by selecting LIWC categories that best represented the difference in the MCI and healthy control datasets.
Roark et al. considered a larger variety of speech and language features to detect MCI [14]. In this work, the authors compared the language of elderly healthy control participants and patients with MCI on the Wechsler Logical Memory I/II Test [73], in which participants are tested on their ability to retell a short narrative that has been told them at different time points3. Among the features considered included multiple measures of lexical density. POS tagging was performed on the transcripts of clinical interviews of patients with MCI and healthy control participants. Two measures of lexical density derived from the POS tags were the P-density and the content density. In particular, the content density was a strong indicator of group differences between healthy controls and patients with MCI. The automated language features were used in conjunction with speech features and clinical test scores to train a support vector machine (SVM) classifier that achieved good leave-pair-out cross validation results in classifying the two groups (AUC = 0.732, 0.703, 0.861 when trained on language features, language features + speech features, and language + speech features + test scores, respectively)4.
Bucks et al. [10] and Fraser et al. [5] both used several first-order lexical features in their analysis of patients with AD. In [10], the authors successfully discriminated between a small sample of healthy older control participants (n = 16) and patients with AD (n = 8) using TTR (Equation (1)), BI (Equation (2)), and HS (Equation (3)) as measures of lexical diversity or vocabulary richness. They additionally considered the usage rates of other parts of speech (i.e. nouns, pronouns, adjectives, verbs). In particular, TTR, BI, verb-rate, and adjective-rate all indicated strong group differences between the participants with AD and healthy controls; the groups could be classified with a cross-validation accuracy of 87.5%. In [5], Fraser et al. performed similar work using the DementiaBank5 database to obtain patient transcripts. They additionally used other vocabulary-related features, such as frequency, familiarity, and imageability values for words in the transcripts. This work was in turn based on a previous study [12] in which similar features were extracted to study the language of participants with two different subtypes6 of primary progressive aphasia (PPA) and healthy control subjects.
Berisha et al. performed a longitudinal analysis of non-scripted press conference transcripts from U.S. Presidents Ronald Reagan (who was diagnosed with AD late in life) and George H.W. Bush (no such diagnosis) [11]. Among the linguistic features that were tracked were the lexical diversity and lexical density for both presidents over several years worth of press conference transcripts. The study shows that the number of unique words used by Reagan over the period of his presidency steadily declined over time, while no such changes were seen for Bush. These declines predated his diagnosis of AD in 1994 by 6 years, suggesting that these computed lexical features may be useful in predicting the onset of AD pre-clinically. A related study examined the language in interview transcripts of professional American football players in the National Football League (NFL) [15], at high-risk for neurological damage in the form of chronic traumatic encephalopathy (CTE). The study longitudinally measured TTR (Equation 1) and CD7 (Equation 4) in interview transcripts of NFL players (n = 10) and NFL coaches/front office executives8 (n = 18). Previous work has shown that TTR and CD are expected to increase or remain constant as healthy individuals age [74], [75], [76]. However, this study demonstrated clear longitudinal declines in both variables for the NFL players while showing the expected increase in both variables for coaches and executives in similar contexts.
3). Advantages & Disadvantages:
It is clear from the literature that first-order lexeme-level features, i.e. those related to lexical diversity and density, are useful biomarkers for detecting the presence or predicting the onset of a variety of conditions, such as MCI, AD, CTE, and potentially several others. POS tagging has several reliable and accurate implementations, and these features are simple and easy to compute. Additionally, these linguistic measures are easily clinically interpretable for measuring cognitive-linguistic ability.
However, lexeme-level features are limited in what information they provide alone, and many of the previously discussed works used these features in conjunction with several other speech and language features to build their models for classification and prediction of disease onset. Since these measures are based on counting particular word types and tokens, they tell us little about how individual lexical units interact with each other in a full sentence or phrase. Additionally, measures of lexical diversity and lexical density provide little insight regarding semantic similarity between words within a sentence. For example, the words “car”, “vehicle”, and “automobile” are all counted as unique words, despite there being a clear semantic similarity between them9 In the following sections, we will discuss more complex language measures that aim to address these issues.
C. Sentence-Level Syntactical Analysis
Generating free-flowing speech requires that we not only determine which words best convey an idea, but also to determine the order in which to sequence the words in forming sentences. The complexity of the sentences we structure provides a great deal of insight into cognitive-linguistic health. In this section we provide an overview of various methods used to measure syntactic complexity as a proxy for cognitive health.
1). Methods:
The ordering of words in sentences and sentences in paragraphs can also provide important insight into cognitive function. Many easy-to-compute and common structural metrics of language include the mean length of a clause, mean length of sentence, ratio of number of clauses to number of sentences, and other related statistics [5]. Additionally, several more complicated methods for syntactical analysis of natural language can also be used to gain better insight for assessing linguistic complexity and cognitive health.
A commonly used technique involves the parsing of naturally produced language based on language-dependent syntactical and grammatical rules. A constituency-based parse tree is generated to decompose a sentence or phrase into lexical units or tokens. In English, for example, sentences are read left to right and are often parsed this way. An example of a common constituency-based left to right parse tree can be seen in Figure 3a for the sentence “She was a cook in a school cafeteria”, adapted from [14]. At the root node, the sentence is split into a noun phrase (“she”) and a verb phrase (“was a cook in a school cafeteria”). Then, the phrases are further parsed into individual tokens with a grammatical assignment (nouns, verbs, determiners, etc.). Simple sentences in the English language are often right-branching when using constituency-based parse trees. This means that the subject typically appears first and is followed by the verb, object, and other modifiers. This is primarily the case for the sentence in Figure 3a. By contrast, left-branching sentences place verbs, objects, or modifiers before the main subject of a sentence [77]. Left-branching sentences are often cognitively more taxing as they involve more complex constructions that require a speaker to remember more information about the subject before the subject is explicitly mentioned. As a result, in English, the degree of left-branching within a particular parsing of a sentence can be used as a proxy for syntactic complexity.
Fig. 3:


(a) A constituency-based and (b) dependency-based parsing of a simple sentence. Both adapted from [14].
(a) Constituency-based parsing of sample sentence (i.e. top-down and left to right). In the diagram, S = sentence, NP = noun phrase, VP = verb phrase, PP = prepositional phrase, PRP = personal pronoun, AUX = auxiliary verb, DT = determiner, NN = noun, and IN = preposition. The figure contains examples of both Yngve scoring (Y) [19], Frazier scoring (F) [20] for each branch of the tree. At the bottom is the total score of each type for each word token in the sentence summed up to the root of the tree.
(b) Dependency-based parsing of the same sample sentence. Lexical dependency distances can be computed.In this example, there are 7 total links, a total lexical dependency distance of 11, and an average distance of . Longer distances indicate greater linguistic complexity.
Once a parsing method has been implemented, various measures of lexical and syntactical complexity can be computed for each sentence or phrase. Yngve proposes one such method in [19]. Given the right-branching nature of simple English sentences, he proposes a measure of complexity based on the amount of left-branching in a given sentence. At each node in the parse tree, the rightmost branch is given a score of 0. Then, each branch to the left of it is given a score that is incremented by 1 when moving from right to left at a given node. The score for each token is the sum of scores up all branches to the root of the tree. An alternative scoring scheme for the same parse tree structure was proposed by Frazier [20]. He notes that embedded clauses within a sentence are an additional modifier that can increase the complexity of the syntactical construction of that sentence. Therefore, just as with left-branching language, the speaker or listener would need to retain more information in order to properly convey or interpret the full sentence, respectively. Frazier’s scoring method emphasizes the use of embedded clauses when evaluating the syntactic complexity. The scores are assigned to each lexeme as in Yngve’s scoring, but they are summed up to the root of the tree or the lowest node that is not the leftmost child of its parent node. Examples of both Yngve and Frazier scoring can be seen in Figure 3a.
Another type of syntactical parsing of a sentence is known as dependency parsing, in which all nodes are treated as terminal nodes (no phrase categories such as verb phrase or noun phrase) [78]. A dependency-based parse tree aims to map the dependency of each word in a sentence or phrase to another within the same utterance. Methods proposed by Lin [79] and Gibson [80] provide some ways by which the lexical dependency distances can be determined. The general idea behind these methods is that longer lexical dependency distances within a sentence indicate a more complex linguistic structure, as the speaker and listener must remember more information about the dependencies between words in a sentence. An example of the same sentence is shown with a dependency-based parse tree in Figure 3b, also adapted from [14].
Mota et al. also propose a graph-theoretic approach for analyzing language structure as a marker of cognitive-linguistic ability with the construction of speech graphs [21], [22]. In this representation, the nodes are words that are connected to consecutive nodes in the sample text by edges representing lexical, grammatical, or semantic relationships between words in the text. As an examples, for a speech graph based on words in an utterance, the spoken language is first transcribed and tokenized into individual lexemes, with each unique word by a graph node. Directed edges then connect consecutive words10. The researchers in this work suggest that structural graph features, i.e. loop density, distance (number of nodes) between words of interest, etc.) serve as clinically relevant objective language measures that give insight into cognitive function. An example speech-graph representation structure of an arbitrary utterance is seen in Figure 4a. The computed speech graph attributes (SGAs) are the features which are extracted from these graphs, and some common ones visualized in Figure 4b. The SGAs provide indirect measures of lexical diversity and syntactic complexity. For example, N is the number of unique words, E is the total number of words, and repeated edges represent repeated words or phrases in text.
Fig. 4:


(a) A sample speech-graph for a complete spoken utterance. (b) Example speech-graph attributes (SGAs). Both adapted from [22].
(a) Sample speech-graph representation of a spoken utterance. Each of the circular nodes represents a lexical unit (e.g. a single word) and the curved arrows represent edges which connect the relevant lexemes in the utterance. Attributes can be computed using the graph.
(b) Examples of speech graph attributes (SGAs). Examples include Nodes (N), Edges (E), Repeated Edges (RE) in same direction, Parallel Edges (PE), loops with 1, 2 and 3 nodes (L1, L2, L3), and the largest strongly connected component (LSC), i.e. the portion of the total graph that can be reached from all others when considering the directionality of edges.
2). Clinical Applications:
The structural aspects of spoken language have been shown to have clinical relevance for understanding medical conditions that affect cognitive-linguistic ability. The previously mentioned work by Roark et al. also utilized several of the aforementioned methods to analyze the language of individuals with MCI and healthy control participants [14]. In addition to the lexeme-level features described in Section III-B, they also considered Yngve [19] and Frazier [20] scoring measures from constituency-based parsing of the transcripts of participant responses11. Mean, maximum, and average Yngve and Frazier scores were computed for each participant’s language samples. Roark et al. also used dependency parsing and computed lexical dependency distances, similar to the example in Figure 3b. Along with the lexical features and speech features, participants with MCI and healthy elderly control participants were classified successfully, as previously described in Section III-B.
The speech-graph approach is used by Mota et al. to study the language of patients with schizophrenia and bipolar disorder (mania) [21], [22]. The researchers were able to identify structural features of the generated graphs (such as loop density, distance between words of interest, etc.) that serve as objective language measures containing clinically relevant information (e.g. flight of thoughts, poverty of speech, etc.). Using these features, the researchers were able to visualize and quantify concepts such as the logorrhea (excessive wordiness and incoherence) associated with mania, evidenced by denser networks. Similarly, the alogia (poverty of speech) typical of schizophrenia was also visible in the generated speech-graph networks, as evidenced by a greater number of nodes per word and average total degree per node. Control participants, participants with schizophrenia, and participants with mania were classified with over 90% accuracy, significantly improving over traditional clinical measures, such as the Positive and Negative Syndrome Scale (PANSS) and Brief Psychiatric Rating Scale (BPRS) [21].
3). Advantages & Disadvantages:
Consideration of sentence-level syntactical complexity offers several advantages that address some of the drawbacks of lexeme-level analysis. As the work discussed here reveals, sentence structure metrics via syntactic parsing or speech-graph analysis offer powerful information in distinguishing healthy and clinical participants with schizophrenia, bipolar disorder/mania, mild cognitive impairment, and potentially several other conditions. Since sentence construction further taxes the cognitive-linguistic system beyond word finding, methods that capture sentence complexity provide more insight into the neurological health of the individual producing these utterances. This provides a multi-dimensional representation of cognitive-linguistics and allows for better characterization of different clinical conditions, as Mota et al. did with patients with schizophrenia and those with bipolar disorder/mania [21].
However, while offering the ability to analyze more complex sentence structures, sentence-level syntactical analysis is also prone to increased complexity due to large range of implementation methodologies. For example, there are countless methods developed over the years for parsing language with different tools for measuring complexity relying on different algorithmic implementations of the language parsers, a widely studied topic in linguistic theory. A thorough empirical evaluation of the various parsing methods is required to better characterize the performance of these methods in the context of clinical applications.
D. Semantic Analysis
Cognitive function is also characterized by one’s ability to convey organized and coherent thoughts through spoken or written language. Here, we will cover some of the fundamental methods in NLP for measuring semantic coherence that have been used in clinical applications.
1). Methods:
Semantic similarity in natural language is typically measured computationally by embedding text into a high-dimensional vector space that represents its semantic content. Then, a notion of distance between vectors can be used to quantify semantic similarity or difference between the words or sentences represented by the vector embeddings.
Word embeddings are motivated by the distributional hypothesis in linguistics, a concept proposed by English linguist John R. Firth who famously stated “You shall know a word by the company it keeps” [83], i.e. that the inherent meaning of words is derived from their contextual usage in natural language. One of the earliest developed word embedding methods is latent semantic analysis (LSA) [24], in which word embeddings are determined by co-occurrence. In LSA, each unit of text (such as a sentence, paragraph, document, etc.) within a corpus is modeled as a bag of words.
As per Firth’s hypothesis, the principal assumption of LSA is that words which occur together within a group of words will be semantically similar. As seen in Figure 5, a matrix (A) is generated in which each row is a unique word in the text (w1, . . . , wn) and each column represents a document or collection of text as described above (d1, . . . dd). The matrix entry values simply consist of the count of co-occurrence statistics, that is the number of times each word appears in each document. Then a singular value decomposition (SVD) is performed on A, such that A = UΣVT. Here, U and V are orthogonal matrices consisting of the left-singular and right-singular vectors (respectively) and Σ is a rectangular diagonal matrix of singular values. The diagonal elements of Σ can be thought to represent semantic categories, the matrix U represents a mapping from the words to the categories, and the matrix V represents a mapping of documents to the same categories. A subset of the r most significant singular values is typically chosen, as shown by the matrix in Figure 5. This determines the dimension of the desired word embeddings (typically in the range of ~100-500). Similarly, the first r columns of U form the matrix and the first r rows of VT form the matrix . The r-dimensional word embeddings for the n unique words in the corpus are given by the resulting rows of the product . Similarly, r-dimensional document embeddings can be generated by taking the d columns of the product .
Fig. 5:

A visual representation of latent semantic analysis (LSA) by singular value decomposition (SVD).
In recent years, several new word embedding methods based on neural networks have gained popularity, such as word2vec [26] or GloVe [27], which have shown improved performance over LSA for semantic modeling when sufficient training data is available [84]. As an example, we take a more detailed look at word2vec, proposed by Mikolov et al., in which they present an efficient method for predicting word vectors based on very large corpora of text. They present two versions of the word2vec algorithm, a continuous bag-of-words (CBOW) model and continuous skip-gram model, seen in Figure 6. At the input in both implementations, every word in a corpus of text is uniquely one-hot encoded; i.e. in a corpus of V unique words, each word is uniquely encoded as a V-dimensional vector in which all elements are 0 except for a single 1. In the CBOW implementation (Figure 6a), the inputs are the context words in the particular neighborhood of a target center word, wt. In the skip-gram implementation (Figure 6b), the input is the center word and the objective is to predict the context words at the output. In both models, the latent hidden representation of dimension N gives an embedding for the word represented by the one-hot encoded input word. The training objective is to minimize the cross-entropy loss for the prediction outcomes.
Fig. 6:
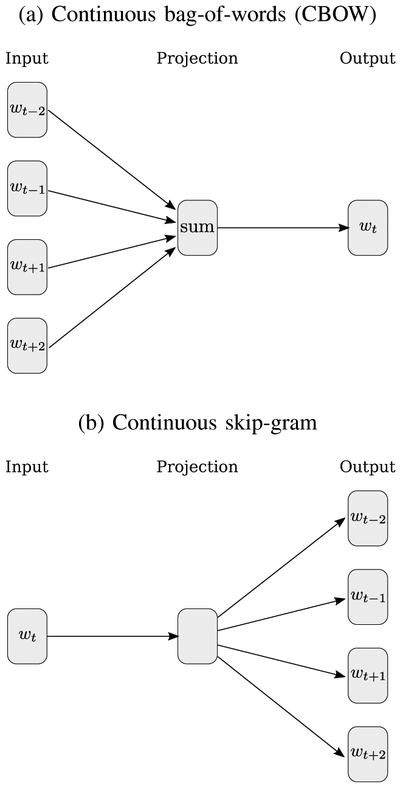
word2vec model architectures proposed in [26]. (a) In the CBOW model, the context words are inputs used to predict the center word. (b) In the skip-gram model, the center word is used to predict the context words.
There are several other methods for word embeddings, each relying on the distributional hypothesis and each with various advantages and disadvantages. For example, LSA, word2vec and GloVe are simple to train and effective, but a major disadvantage is that they do not handle out-of-vocabulary (OOV) words or consider words with multiple unrelated meanings. For example, the English word “bark” can refer to the bark of a dog or to the bark of a tree, but its vector representation would be an average representation, despite the drastically different usage in each context. Some methods based on deep neural networks (DNNs), such as recurrent neural network (RNN) / long-short term memory (LSTM) networks (e.g. ELMo [85]) or transformer architectures (e.g. BERT [86]) utilize contextual information to generate embeddings for OOV words.
In addition to individual words, embeddings can also be learned at the sentence level. The simplest forms of sentence embeddings involve unweighted averaging of LSA, word2vec, GloVe, or other embeddings. Weighted averages can also be computed, such as by using term frequency-inverse document frequency (tf-idf) generated weights or Smooth Inverse Frequency (SIF) [29]. Others have found success learning sentence representations directly, such as in sent2vec [87]. Whole sentence encoders, such as InferSent [30] and the Universal Sentence Encoder (USE) [88] offer the advantage of learning a full sentence encoding that considers word order within a sentence; e.g. the sentences “The man bites the dog” and the “The dog bites the man” will each have different encodings though they contain the same words.
Once an embedding has been defined, a notion of semantic similarity or difference must also be defined. Several notions of distance can be computed for vectors in high-dimensional space, such as Manhattan distance (ℓ1 norm), Euclidean distance (ℓ2 norm), or many others. Empirically, the cosine similarity (cosine of the angle, θ, between vectors) has been found to work well in defining semantic similarity between word and sentence vectors of many types. Cosine similarity can be computed using Equation (5) for vectors w1 and w2.
| (5) |
In addition to word and sentence embedding semantic similarity measures, techniques such as topic modeling and semantic role labeling have also gained recently popularity in NLP and its applications to clinical language samples. Latent dirichlet analysis (LDA) is one such statistical topic modeling method which can be used to identify overarching themes in samples of text [31]. Other studies have utilized semantic role labeling, a probabilistic technique which automatically attempts to identify the semantic role a particularly entity plays in a sentence [34].
2). Clinical Application:
Many forms of mental illness can result in a condition known as formal thought disorder (FTD), which impairs an individual’s ability to produce semantically coherent language. FTD is most commonly associated with schizophrenia but is often present in other forms of mental illness such as mania, depression, and several others [89], [90]. Some common symptoms include poverty of speech (alogia), derailment of speech, and semantically incoherent speech (word salad) [90], [91]. Language metrics that track semantic coherence are potentially useful in clinical applications, such as measuring the coherence of language as it relates to FTD in schizophrenia. One of the first studies to demonstrate this was conducted by Elvevåg et al. [25]. The language of patients with varying degrees of FTD (rated by standard clinical scales) was compared with a group of healthy control participants. The experimental tasks consisted of single word associations, verbal fluency (naming as many words as possible within a specific category), long interview responses (~1-2 minutes per response), and storytelling. LSA was utilized to embed the word tokens in the transcripts. The semantic coherence in each task was computed as follows:
Word Associations: Cosine similarity between cue word and response word, with an average coherence score for each participant
Verbal Fluency: Cosine similarity between first and second word, second and third word, etc. were computed, with an average coherence score computed per participant
Interviews: Cosine similarity was computed between the question and participant responses. An average word vector was computed for the prompt question from the interviewer. Then a moving window (of size 2-6 words) for the participant response was used to average all the word vectors within the window and compute a cosine similarity between the question and response. The window was moved over the entire participant response and a new cosine similarity was computed between the question and response window until reaching the end of the response. This method tracks how the cosine similarity behaves as the participant response goes farther from the question, with the expectation that the response would be more tangential over time with decreased coherence as the participant moves farther from the question. A regression line was fit for each participant to measure the change in cosine similarity coherence over time, and the slope of the line was computed to measure the tangentiality of the response per participant.
Storytelling: Cosine similarity of the participant’s response was compared to the centroid participant response for all narrative utterances of the same story. This was used to predict the clinical rating for thought disordered language samples when asked to tell the same story.
They demonstrated that the control participants had higher coherence scores compared to the FTD groups across all tasks.
In a more recent study, predictive features of language for the onset of psychosis were studied by Bedi et al. [16]. Open-ended narrative-like interview transcripts of young individuals who were determined to be at clinical high-risk (CHR) for psychosis were collected and analyzed to predict which individuals would eventually develop psychosis. Participants were tracked and interviewed over a period of two and a half years. In this study, LSA was again used to generate word embeddings. An average vector for each phrase was computed, and a cosine-similarity measure was computed to measure the semantic coherence between consecutive phrases (first-order coherence) and every other phrase (second-order coherence).
A distribution of the first and second-order coherence scores (cosine similarities) was compiled for each participant, and several statistics were computed based on the distribution of coherence scores, e.g. maximum, minimum, standard deviation, mean, median, 10th percentile, and 90th percentile. Each of these statistics was considered as a separating feature between the clinical and control samples. In addition to the semantic analysis, POS-tagging was performed to compute the frequency of use of each part-of-speech to obtain information about the structure of each participant’s naturally-produced language. The language features with the best predictive power in the classifier were the minimum coherence between consecutive phrases for each participant (maximum discontinuity) and the frequency of use of determiners (normalized by sentence length). This initial study only had 34 participants total (only 5 CHR+ participants) and was intended as a proof-of-principle exploration. In an expansion of this work, Corcoran et al. trained their classifier using two larger datasets, in which one group of participants was questioned with a prompt-based protocol and another group of participants was given a narrative protocol in which they were required to provide longer answers (similar to the previous work) [17]. They note that the first and second-order coherence metrics collected in the previous study were useful for determining semantic coherence with the narrative-style interview transcripts with longer responses. However, for the shorter prompt-based responses (often under 20 words), it is often difficult to obtain these metrics. Therefore, coherence was-computed on the word-level rather than phrase-level by computing the cosine similarity between word embeddings within a response with an inter-word distance of k, with k ranging from 5 to 8. As before, typical statistics were computed on the coherence values obtained for each participant response (maximum, minimum, mean, median, 90th percentile, 10th percentile, etc.). They were able to successfully predict the onset of schizophrenia by discriminating the speech of healthy controls and those with early onset schizophrenia with ~ 80% accuracy.
Other studies make use of a variety of linguistic features to predict the presence of clinical conditions. For example, Kayi et al. identified predictive linguistic features of schizophrenia by analyzing laboratory writing samples of patients and controls for their semantic, syntactic, and pragmatic (sentimental) content [28]. A second dataset of social media messages from self-reporting individuals with schizophrenia over the Twitter API was also evaluated for the same types of content. The semantic content of the language was quantified by three methods: First, semantic role labeling was performed using the Semafor tool [34] to identify the role of individual words within a sentence or phrase Then, LDA was used to identify overarching themes that separated the clinical and control writing samples [31]. LDA identifies topics in the text and also identifies the top vocabulary used in each topic. Finally, clusters of word embeddings within the writing were generated using the k-means algorithm and GloVe word vector embeddings [27]. The frequency of each cluster was computed per document by checking the use of each word of the document in each cluster. The syntactic features used in this study again were obtained by computing the frequency of use of parts of speech (found by POS tagging) and by generating parse trees, using tools optimized for the corpus. Lastly, pragmatic features were found by performing sentiment analysis to classify the sentiment of the writing samples into distinct groups (very negative, negative, neutral, positive, very positive). They successfully showed a distinct set of predictive features that could accurately separate participants with schizophrenia from healthy controls in all of the language analysis categories. However, when using a combination of features and various machine learning classifiers (random forest and support vector machine), they found that utilizing a combination of the semantic and pragmatic features led to the most promising accuracy (81.7%) in classification of control participants and those with schizophrenia. The limited availability of language data in schizophrenia is always a difficult challenge, so another study by Mitchell et al. analyzed publicly available social media (Twitter) posts by self-identifying individuals with schizophrenia using LDA, LIWC generated-vectors, and various clustering techniques to show statistically significant differences in their language patterns when compared to general users [8].
Another vector-space topic modeling approach was developed by Yancheva and Rudzicz for analyzing transcripts of picture description tasks for participants with AD and healthy controls [32]. They propose a general method for generating information content units (ICUs), or topics of interest, from common images used in clinical description task evaluations, i.e. the famous Cookie Theft picture with reference speech samples [92]. The generated ICUs were compared with human-supplied ICUs from common usage in clinical practice, and most of the categories exhibited a close match. The study found that participants with AD and healthy controls were likely to discuss the same topics, but those with AD had wider topic clusters with more irrelevant directions. Additionally, they were able to find a small set of generated ICUs that had slightly better classification performance than a much larger set of human selected ICUs for the same task, with ~ 80% accuracy. Related work by Hernández-Domínguez et al. took a similar approach to generate a population-specific set of categories for participants with AD (n = 257), MCI (n = 43), and healthy controls (n = 217) [33]. The resulting features were significantly correlated with severity as assessed by the MMSE, and classification performance was characterized by the receiver operating characteristic (ROC) area under curve (AUC) performance of AUC ≈ 0.76 for all three groups.
3). Advantages and Disadvantages:
While these studies have been successful in measuring the semantic coherence of language as it relates to thought disorders, there are several limitations. Recent work by Iter et al. identifies and attempts to address some of these shortcomings when measuring semantic coherence for FTD in schizophrenia [18]. Interviews with a small sample of patients were collected and just the participant responses (of ~300 words each) were analyzed for their semantic content. They noted that when using the tangentiality model of semantic coherence (i.e. regression of the coherence over time with the sliding window) of Elvevåg et al. [25] and the incoherence model of semantic coherence of Bedi et al. [16], they were unable to convincingly separate their clinical and control participants based on language analysis. One reason for this was due to the presence of verbal fillers, such as "um" or "uh" and many stop words without meaningful semantic content. Another reason is that longer sentences (or long moving windows) tend to be scored as more coherent due to a larger overlap of words. The third reason they identified (but did not address) is that repetitive sentences and phrases would be scored as highly coherent, even though repetition of ideas is common in FTD and should be scored negatively. The authors proposed a series of improvements to address some of these limitations. However, the sample sizes in this study were small (9 clinical participants and 5 control participants).
Another issue with semantic coherence computation in clinical practice is difficulty with interpretability of computed metrics; for example, the cosine similarity between high dimensional word vectors is a somewhat abstract concept which is difficult for most to visualize. Recent work [13] attempted to address this issue by computing semantic coherence measures (using word2vec, InferSent, and SIF embeddings), lexical density and diversity measures, and syntactic complexity measures as they relate to the language of patients with schizophrenia, patients with bipolar disorder, and healthy controls undergoing a validated clinical social skills assessment [53]. Linear regression was used to determine a subset of language features across all categories that could effectively model the scores assigned by clinicians during the social skills performance assessment, in which participants were required to act out various role-playing conversational scenes with clinical assessors scored for cognitive performance. Then, these features were used to train simple binary classifiers (both naïve Bayes and logistic regression), for which leave-one-out cross-validation was used to determine their effectiveness at classifying groups of interest. For classifying clinical (patients with schizophrenia and bipolar I disorder) participants and healthy control participants, the selected feature subset achieved ROC curve AUC performance of AUC ≈ 0.90; for classifying within the clinical group (to separate participants with schizophrenia and bipolar disorder), the classifier performance achieved AUC ≈ 0.80.
IV. Measuring Cognitive and Thought Disorders with Speech Signal Processing
While cognitive-linguistic health is more directly observed through analysis of complex language production, additional information can be derived by speech signal analysis of individuals with cognitive impairments or thought disorders. This is because the acoustic stream is the physical manifestation of the cognitive-linguistic processing that has gone into creating the message being conveyed, in near real-time. In this way, pauses during speech can be associated with difficulty in lexical retrieval (word-finding difficulties) or with extra processing time needed for message formulation. Pressed speech, that which is rapidly produced without insertions of natural pauses, can be associated with mania and “flight of thoughts”. Conversely, reductions in the rhythmic and melodic variations in speech may be indicative of changes in mood.
The information derived from the speech signal is used alone or in conjunction with many of the previously described methods to assess cognitive-linguistic health. This is either done directly by measuring different aspects of speech production including prosody, articulation, or vocal quality; or is done as a pre-processing step by using automatic speech recognition (ASR) for transcription of speech samples for follow-on linguistic analysis.
In this section, we will review how various signal processing methods are used to extract clinically-relevant insight from an individual’s speech samples for additional insight into detection of disorders that affect cognition and thought. Referring back to Fig. 2, these include features extracted from vocal fold vibration (source), movement of the articulators (filter), and the overall rhythm of the speech signal (prosody).
A. Methods
1). Prosodic features:
Prosody refers to the rhythm and melody of speech. Examples of computable temporal prosodic features from recorded speech signals include the duration of voiced segments, duration of silent segments, loudness, measures of periodicity, fundamental frequency (F0), and many other similar features [14], [35]. These measures can indicate irregularities in the rhythm and timing of speech. Additionally, nonverbal speech cues, e.g. counting the number of interruptions, interjections, natural turns, and response times can also indicate identifying features of irregular speech patterns [39].
2). Articulation features:
Several spectral features that capture movement of the articulators have been used in the clinical speech literature to measure the acoustic manifestation of the cognitive-linguistic deficits discussed in Section 2. These include computing statistics related to the presence of additional formant harmonic frequencies, i.e. F1, F2, and F3, computing formant trajectories over time [93], or computing the vowel space area [94]. The spectral centroid can also be computed for each frame of speech signal that is analyzed [43]. The spectral centroid is essentially the center of mass for the frequency spectrum of a signal, and relates to the “brightness” or timbre of the perceived sound for audio.
Time-frequency signal processing techniques are also commonly used since acoustic speech signals are highly non-stationary. For example, computation of the mel-frequency cepstral coefficients (MFCC) with the mel scale filterbank provides a compressed and whitened spectral representation of the speech [44]. These features are often used as inputs into an automatic speech recognition (ASR) system, but can also be monitored over time to identify irregularities in speech due to cognitive or thought disorders. As an example, common statistical features such as the mean, variance, skewness, and kurtosis of the MFCCs over time can be tracked for identification of irregularities between healthy individuals and those with some cognitive or thought disorders [5].
3). Vocal quality features:
There is evidence that there are vocal quality changes associated with cognitive disorders [95]. These can be measured from the speech signal by isolating the source of speech production, involving the flow of air through the lungs and glottis and affecting perceptible voice quality. Voice quality measures that have previously been used in the context of cognitive and thought disorders include:
jitter: small variations in glottal pulse timing during voiced speech
shimmer: small variations in glottal pulse amplitude during voiced speech
harmonic-to-noise ratio (HNR): the ratio of formant harmonics to inharmonic spectral peaks, i.e. those that are not whole number multiples of F0
These features alone are often difficult to consistently compute and interpret, but can provide insight for the diagnosis and characterization of certain clinical conditions.
4). Automatic Speech Recognition:
Recent improvements in ASR and in tools for easily implementing ASR systems have made possible the use of these systems in clinical speech analysis. This is most commonly done by using ASR in place of manual transcription for the extraction of linguistic features (i.e. features covered in Section III); however, this is often more error prone with regard to incorrect word substitutions, unintended insertions, or unintended deletions in the automatically generated transcript. The word error rate (WER) for an utterance of N words is given in Equation (6),
| (6) |
and is a typical statistic used to evaluate the performance of an ASR system. It is often more difficult to maintain high accuracy (low WER) for ASR with pathological speech samples, as the relative dearth of this data makes it difficult to train reliable ASR models optimized for this task. Other studies have also made use of ASR for paralinguistic feature extraction, such as the automated detection of filled pauses, natural turns, interjections, etc. Understanding the effects of ASR errors on downstream NLP tasks is an important area to address in which the current work is limited. Some recent attempts have been made to simulate ASR errors on text datasets and evaluate their effects on downstream tasks [96], [97], [98]. These potentially have future applications in language models that can analyze noisy datasets with ASR errors in clinical practice.
B. Clinical Applications
1). Acoustic analysis:
Disorders such as PPA, MCI, AD, and other forms of dementia are associated with a general slowing of thoughts in affected individuals. This has been shown to have detectable effects on speech production through acoustic analysis. In a study by König et al., healthy controls and participants with MCI and AD were recorded as they were asked to perform various tasks, such as counting backwards, image description, sentence repeating, and verbal fluency testing [35]. Temporal prosodic features such as the duration of voiced segments, silent segments, periodic segments, and aperiodic segments were all computed. Then, the ratio of the mean durations of voiced segments to silent segments were also computed as features to express the continuity of speech in the study’s participants. As expected, it was shown that healthy control participants showed greater continuity in these metrics when compared to those with MCI or AD. These quantifiable alterations of speech in individuals with MCI and AD allowed the researchers to successfully separate patients with AD from healthy controls (approx. 87% accuracy), patients with MCI from controls (approx. 80% accuracy), and patients with MCI from patients with AD (approx. 80% accuracy). López-de-Ipiña et al. conducted another study in which acoustic features (related to prosody, spectral analysis, and features with emotional content) were extracted from spontaneous speech samples to classify participants with AD at different stages (early, intermediate, and advanced) [38]. Among the computed prosodic features were the mean, median, and variance for durations of voiced and voiceless segments. Short-time energy computations were also computed for the collected samples in the time-domain. In the frequency-domain, the spectral centroid was determined for each speech sample. The authors also claim that features such as the contour of F0 and source features like shimmer, jitter, and noise-harmonics ratio contain emotional content that can be useful in the automatic AD diagnosis. Lastly, they propose a new feature, which they term emotional temperature (ET), which is a normalized (independent of participant) measure ranging from 0-100 based on several of prosodic and paralanguistic features that were previously mentioned12. The study revealed several interesting findings. First, the spontaneous speech analysis indicated that participants with AD exhibited higher proportions of voiceless speech and lower proportions of voiced speech, indicating a loss of fluency and shortening of fluent speech segments for those with AD. While classification accuracy was good when using a set of prosodic speech features, they noted that accuracy improved when the emotional features (i.e. the proposed ET metric) were used13.
Acoustic analysis of speech can make use of ASR to count dysfluencies in spoken language that are often associated with neurodegenerative decline. Pakhomov et al. made an early attempt to use ASR to extract many such prosodic features (pause-to-word ratio, normalized pause length, etc.) on picture-description task transcripts for participants with three variants of Frontotemporal Lobar Degeneration (FTLD) [40]. A more recent pair of studies by Tóth et al. explored using ASR for detection of MCI [36], [37]. However, in their work, only acoustic features were considered, and precise word transcripts were not required, mitigating the effect of the typically high WER for clinical speech samples. Instead, the authors trained a new ASR model with a focus of detecting individual phonemes. The features considered in this study were mostly prosodic (articulation rate, speech tempo, length of utterance, duration of silent and filled pauses, the number of silent and filled pauses). The focus of the study was to compare the effects of manually annotating transcripts with the faster ASR method. Since most ASR models cannot differentiate between filled pauses and meaningful voiced speech, their detection was a major focus of this work for automated MCI detection. The ASR model was trained with annotated filled pause samples to learn to detect them in spontaneous speech. The authors were able to show comparable results between the ASR and manual methods for MCI detection with the same feature set (82% accuracy for manual vs. 78% for ASR) [36].
While acoustic speech processing on its own has been less explored in detecting thought-disorder related mental illness, some researchers have found ways in which useful information can be derived solely from speech signals for this purpose. One example is seen in work by Tahir et al. [39]. In this study, patients with severe schizophrenia, receiving Cognitive Remediation Therapy (CRT), were differentiated from control participants with less severe schizophrenia (no CRT recommended) by non-verbal speech analysis. They note that nonverbal and conversational cues in speech often play a crucial role in communication, and that it is expected that individuals with schizophrenia would have a muted display of these features of speech. Cues used as inputs to a classifier included interruptions, interjections, natural turns, response time, speaking rate, among others. Preliminary results from this study with participants with severe schizophrenia (n = 8) and less-severe forms of the disease (n = 7) indicate that these nonverbal cues show approximately 90% accuracy in classifying control participants from those with more severe forms of schizophrenia. They also attempted to validate the computed features by examining their correlation with traditional subjective clinical assessments. Some of the computed objective nonverbal speech cue features had high correlation with subjective assessments; e.g. “poor rapport with interviewer” has a strong correlation with longer participant response times. The acoustics of bipolar disorder have also been studied, for example by Guidi et al. [41]. In this study, the authors propose an automated method for estimating the contour of F0 over time with a moving window approach as a proxy for mood changes. In particular, they study local rising and falling events of the F0 contour, including positive and negative slopes, amplitude, duration, and tilt to indicate different emotional states. The features were first validated on a standard emotional speech database and then used to classify bipolar patients (n = 11) and healthy control subjects (n = 18). They noted that intra-subject analysis showed good specificity in classifying bipolar subjects and healthy controls across all contour features, but that directions of most were not consistent across different subjects. Due to limited data, they propose a study with a larger number of subjects including glottal, spectral, and energy features.
2). Combination of acoustic and textual features:
Many dementia studies also use both acoustic and textual data with promising results. As an example, the previously mentioned work by Roark et al. (in Section III) also made use of acoustic speech samples to aid in the detection of MCI from naturally-produced spoken language. The researchers used manual and automated methods to estimate features related to the duration of speech during each utterance, including the quantity and duration of pause segments. Some of the features that were computed include fundamental frequency, total phonation time, total pause time, pauses per sample, total locution time (both phonation and pauses), verbal rate, and several others [14]. They conclude that automated speech analysis produces very similar results to manually computing these metrics from the speech samples, demonstrating the potential of automated speech signal processing for detecting MCI. Additionally, they found that a combination of linguistic complexity metrics and speech duration metrics lead to improved classification results. The previously described work on PPA subtypes in [12] was expanded by Fraser et al. in [42]. Acoustic features were also extracted and added to the previous set of linguistic features to improve the classification results of PPA subtypes (PNFA and semantic dementia) and healthy control participants. The added acoustic features included temporal prosodic features (i.e. speech duration, pause duration,pause to word ratio, etc.), mean and variance of F0 and first three formants (F1, F2, F3), mean instantaneous power, mean and maximum first autocorrelation function, instantaneous power, and vocal quality features, i.e. jitter and shimmer. The authors tested the relative significance of all features using different feature reduction techniques and noted that more textual features were usually selected in each case. However, the addition of acoustic features had the greatest positive impact when attempting to differentiate between healthy control participants and those with one of the PPA subtypes, but proved less useful in distinguishing the subtypes. Their later study on AD [5] also used a similar hybrid approach with speech and language metrics to show good classification separating AD participants from healthy controls [5]. The DementiaBank14 corpus was used to collect the data for this analysis. The study considered 370 distinctive features; linguistic features included grammatical features (from part-of-speech tagging), syntactic complexity (e.g. mean length of sentences, T-units, clauses, and maximum Yngve depth scoring for the parse tree, as described above), information content (specific and nonspecific word use), repetitiveness of meaningful words, and many more. Acoustic features associated with pathological speech were also identified by computation of MFCCs, their derivatives, and their second derivatives. To differentiate the clinical and control group, they considered mean, variance, skewness, and kurtosis of the MFCCs over time. After performing factor analysis on these features, they showed that most of the variance between controls and those with AD could be explained by semantic impairment, acoustic abnormalities, syntactic impairment, and information impairment.
3). Impact of ASR on textual features:
Several studies have also used ASR to generate transcripts of spoken language tasks for textual feature extraction for dementia detection. However, unlike the phone-level ASR model built in [36] and [37], this use case does require accurate word-level transcripts (i.e. a low WER). Previous work has shown that ASR accuracy is reduced for both elderly patients and those with dementia [99], [100], [101]. To address this, Zhou et al. performed a study in which the DementiaBank14 corpus was used to train an ASR model on domain data with elderly patients, both with and without AD [45]. They were able to show that an ASR model trained with a smaller in-domain dataset could improve WER-based accuracy than one trained with a larger out-of-domain dataset. Additionally, they were able to confirm that even with their model, diagnostic accuracy decreases with increasing WER, as expected, but the correlation between the two is relatively weak when selecting certain features that are more robust to ASR errors (such as word frequency and word length related features)15.
Mirheidari et al. also used ASR with a combination of acoustic (temporal prosodic) and textual features (syntactical and semantic features) to diagnose and detect participants with neurodegenerative dementia (ND) and differentiate them from those with non-dementia related Functional Memory Disorder (FMD) with a conversational analysis dataset [46], [47]. With manual transcriptions, the classification accuracy was over 90% in classifying the two groups, but it dropped to 79% when ASR was used. As expected, they found that the significance of the syntactic and semantic textual features is diminished when transcriptions contain ASR errors. Sadeghian et al. attempted to improve the issue of transcription errors by training a custom ASR model using collected speech samples from participants with AD (n = 26) and healthy controls (n = 46) [9]. This was done by limiting the potential lexicon to the collected speech in their dataset as well as cleaning the audio files to reduce the WER. Their study used a combination of acoustic features (temporal prosodic features and F0 statistics) and textual features computed from both manual and ASR-generated transcripts (POS tags, syntactic complexity measures from [14], idea density, and LIWC features [6]). In their work, the best classification results (over 90%) were seen when feature selection was performed using both the MMSE scores and computed acoustic and textual features, but using the computed features alone was nearly comparable and outperformed the MMSE scores on their own. Weiner et al. [48] instead compared the difference in the analysis of manual and ASR-derived transcripts for a large range of acoustic (prosody and timing related) and textual features (lexical diversity with Brunet’s index and Honoré’s statistic) for comparing participants with dementia and healthy controls. The off-the-shelf ASR model used in this work had a relatively high WER, but they were interestingly able to show that the WER itself was a reliable feature for classifying the different types of subjects. Additionally, many of the features they selected showed robustness to transcription quality, possibly even taking advantage of the poor ASR performance to identify participants with dementia.
C. Advantages & Disadvantages
It is intuitive that fine-grained and discrete measures of “what is said” (language, in terms of lexical diversity, lexical density, semantic coherence, language complexity, etc.) may more directly capture early cognitive-linguistic changes in illness and disease than measures of “how it is said” (analysis of speech acoustics). However, emerging data shows that acoustic analysis offers converging and complementary information to several of the textual features discussed in Section III. Most interestingly, changes in the outward flow of speech may precede measurable language-based changes [39], [42].
A particular advantage of evaluating speech acoustics is that ASR or transcription is not necessarily a required step. Automated acoustic metrics can be extracted from non-labeled speech samples [35], [39], [38], [102]. Further, some of the metrics provide complementary and interpretable value that cannot be gleaned from transcripts (rate, pause metrics, speech prosody). These directly correspond with subjectively described clinical characteristics (e.g. pressed speech, halting speech, flat affect etc). A disadvantage is that not all acoustic metrics offer that level of transparency. This is a running theme in clinical speech analysis. Many of these features are not currently used in clinical diagnosis despite their powerful predictive power because they are difficult to directly interpret (e.g. MFCCs); this means that clinicians can see the output of a complicated model but not understand why the model came to that decision or if it is considering clinically-relevant dimensions. For this reason, some effort has been undertaken to map the information contained in high-dimensional data to be easily visualized and interpreted by clinicians, but this remains a significant challenge [103], [104].
V. Concluding Remarks and Future Work
An analysis of the existing literature reveals a set of future research directions to help advance the state of the art in this area. Here, we provide an overview of these directions and highlight some important open questions in this space.
A. Characterizing Inter and Intra-Speaker Variability in Healthy Populations
There is a great deal of variability to be expected in speech and language data. Extensive work on the language variables influencing inter- and intra-speaker variation suggest that any level of language (i.e. phonological, phonetics, semantics, syntax, morphology) is subject to both conscious/explicit and completely unconscious/subtle variation within a speaker. These conscious and unconscious sources of variability are conditioned by pragmatics, style-shifting, or register shifting [105], [106]. Similarly, speech acoustics are impacted by speaker identity, context, background noise, spoken language, etc. [107]. These individual sources of variability have yet to be fully characterized quantitatively for the features that we described in this paper. A more complete understanding of this variability in healthy populations helps to interpret changes observed in clinical populations. For example, this knowledge can help understand how typical or atypical is a particular semantic coherence score (e.g. in what percentile does the semantic coherence score fall?). Furthermore, this understanding can inform stratified sampling schemes that allow experimenters to match healthy and clinical cohorts on relevant aspects of speech/language production. This is critical for clinical trial design.
B. Joint Optimization of Speech Elicitation and Speech & Language Analytics
Algorithms published in the literature typically make use of previously-collected speech and language samples. These samples are often collected for other reasons and are only used by algorithm designers because they are available. A related challenge also arises in comparing the results of various analyses of speech and language analytics for cognitive assessment when the datasets used in each study are vastly different. This is evident in the large range of speech elicitation tasks used in many of the studies mentioned in this review. The lack of standardization in data collection for cognitive assessment therefore contributes to the problem of limited available data for any particular task.
As a result, published results are potentially biased because these data sets are small and collected on a limited set of elicitation tasks. Deeper collaborations between speech neuroscientists, neuropsychologists, and speech technologists are required to push the state-of-the-art forward. There is an extensive literature on how to efficiently and reliably elicit speech to exert pressure on the underlying cognitive-linguistic processing [108]. The algorithms for extracting clinically-relevant information from speech and audio have been developed independently from this work. We posit that joint exploration of the elicitation-analytics space has the potential to result in improved sensitivity in detecting cognitive-linguistic change. This analysis will reveal which elicitation tasks and analytics are maximally sensitive for a given problem.
The rate-limiting factor in being able to answer these questions is the lack of publicly-available data on a large scale. Unlike speech recognition research, data for clinical speech research is much more difficult to collect and share because it’s scarcer, requires experts to label, and there are privacy issues. Until these issues are resolved, it will be difficult to overcome some of the scientific challenges we highlight here.
C. Robustness to Noisy Data
The sensitivity of the features we describe herein and the follow-on models they drive are not well understood under noisy conditions. Our definition of noisy is rather loose here. For example, noise may arise from imperfect transcripts provided by an ASR engine, background noise that may corrupt the acoustics, or feature distribution mismatch between training and test data in supervised settings. Unimportant nuisance parameters for clinical applications (e.g. idiosyncratic features related to different speakers) are especially problematic in acoustic analysis [107]. A better characterization of the sensitivity of these nuisance features can inform the development of new representations that are robust to various sources of noise. These models can improve the algorithms’ ability to generalize and can help understand the fundamental limits of speech as a diagnostic.
D. Data-Driven and Interpretable Features
Many of the features described herein are readily interpretable and, given the existing literature, it is reasonable to posit that they have clinical utility. However, if clinical speech data becomes available on a large scale, we expect that data-driven artificially intelligence (AI) systems will replace some of the domain-expert features described herein. For example, it is reasonable to expect that features that are optimized for a specific application (e.g. diagnosing schizophrenia) would outperform the general-purpose features described here. This improved performance likely comes at the expense of reduced feature interpretability. An area ripe for further exploration in clinical speech analytics, and clinical analytics in general, is the development of AI models that provide interpretable outputs when interrogated, such as in [104]. This area has received some attention recently and will continue to become more important as AI systems are deployed in healthcare.
Biography

Rohit Voleti is a Ph.D. student in the School of Electrical, Computer, & Energy Engineering at Arizona State University (ASU) in Tempe, AZ, USA. Prior to his time at ASU, he obtained a B.S. and M.S. in Electrical Engineering from the University of California, Los Angeles (UCLA), and worked as a systems engineer in the medical device industry in Southern California.

Julie M. Liss is a Professor of Speech & Hearing Science and Associate Dean of the College of Health Solutions at Arizona State University (ASU) in Tempe, AZ, USA. Her research explores the ways in which speech and language change in the context of neurological damage or disease.

Visar Berisha is an Associate Professor in the College of Health Solutions and Fulton Entrepreneurial Professor in the School of Electrical Computer & Energy Engineering at Arizona State University (ASU) in Tempe, AZ, USA. His research interests include computational models of speech production and perception, clinical speech analytics, and statistical signal processing.
Footnotes
Content words are also referred to as “open-class”, meaning new words are often added and removed to this category of words as language changes over time.
Function words are also referred to as “closed-class” since words are rarely added to or removed from these categories.
Asked to retell the story immediately (LM1) and after approximately 30 minutes (LM2)
Additional language and speech features will be discussed later
https://dementia.talkbank.org/access/, Accessed August 20, 2019
Progressive nonfluent aphasia (PNFA) and semantic dementia (SD)
The authors in [15] refer to CD simply as “lexical density” (LD)
Coaches and executives were limited to those who were not former players experiencing similar head trauma to serve as a control in the language study.
Note: lexical diversity is still a potentially useful measure in this case, as a diverse word choice may indicate higher cognitive function.
Speech graphs in some studies, i.e. [81], may use POS tags or other node structures
Using the Charniak parser [82]
The example in [38] shows that a typical ET value is approx. 95 for healthy control participants and approx. 50 for those with AD
see Figure 9 in [38]
https://dementia.talkbank.org/access, accessed August 20, 2019
The authors identify features that provide best diagnostic ability for gold-standard manual transcripts and transcripts with varying WER and ASR to identify these robust features, but they do not claim to understand why certain features seem more robust than others
References
- [1].Center for Behavioral Health Statistics and Quality, “2016 national survey on drug use and health: Methodological summary and definitions,” Substance Abuse and Mental Health Services Administration, Rockville, MD, 2017. [Google Scholar]
- [2].Cecchi GA, Gurev V, Heisig SJ, Norel R, Rish I, and Schrecke SR, “Computing the structure of language for neuropsychiatric evaluation,” IBM Journal of Research and Development, vol. 61, no. 2/3, pp. 1:1–1:10, Mar. 2017.29200477 [Google Scholar]
- [3].Prince M, Wimo A, Guerchet M, Ali G-C, Wu Y-T, and Prina M, “The Global Impact of Dementia: An analysis of prevalence, incidence, cost and trends - Executive Summary,” Alzheimer’s Disease International, Tech. Rep, Sep. 2015. [Google Scholar]
- [4].Garrard P, Rentoumi V, Gesierich B, Miller B, and Gorno-Tempini ML, “Machine learning approaches to diagnosis and laterality effects in semantic dementia discourse,” Cortex, vol. 55, pp. 122–129, Jun. 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Fraser KC, Meltzer JA, and Rudzicz F, “Linguistic Features Identify Alzheimer’s Disease in Narrative Speech,” Journal of Alzheimer’s Disease, vol. 49, no. 2, pp. 407–422, Oct. 2015. [DOI] [PubMed] [Google Scholar]
- [6].Tausczik YR and Pennebaker JW, “The psychological meaning of words: LIWC and computerized text analysis methods,” Journal of language and social psychology, vol. 29, no. 1, pp. 24–54, 2010. [Google Scholar]
- [7].Asgari M, Kaye J, and Dodge H, “Predicting mild cognitive impairment from spontaneous spoken utterances,” Alzheimer’s & Dementia: Translational Research & Clinical Interventions, vol. 3, no. 2, pp. 219–228, Jun. 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [8].Mitchell M, Hollingshead K, and Coppersmith G, “Quantifying the language of schizophrenia in social media,” in Proc.of the 2nd Workshop on Computational Linguistics and Clinical Psychology: From Linguistic Signal to Clinical Reality, 2015, pp. 11–20. [Google Scholar]
- [9].Sadeghian R, Schaffer J, and Zahorian S, “Speech Processing Approach for Diagnosing Dementia in an Early Stage,” Interspeech 2017, pp. 2705–2709, Aug. 2017. [Google Scholar]
- [10].Bucks RS, Singh S, Cuerden JM, and Wilcock GK, “Analysis of spontaneous, conversational speech in dementia of Alzheimer type: Evaluation of an objective technique for analysing lexical performance,” Aphasiology, vol. 14, no. 1, pp. 71–91, Jan. 2000. [Google Scholar]
- [11].Berisha V, Wang S, LaCross A, and Liss J, “Tracking Discourse Complexity Preceding Alzheimer’s Disease Diagnosis: A Case Study Comparing the Press Conferences of Presidents Ronald Reagan and George Herbert Walker Bush,” Journal of Alzheimer’s Disease, vol. 45, no. 3, pp. 959–963, Mar. 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Fraser KC, Meltzer JA, Graham NL, Leonard C, Hirst G, Black SE, and Rochon E, “Automated classification of primary progressive aphasia subtypes from narrative speech transcripts,” Cortex, vol. 55, pp. 43–60, Dec. 2012. [DOI] [PubMed] [Google Scholar]
- [13].Voleti R, Woolridge S, Liss JM, Milanovic M, Bowie CR, and Berisha V, “Objective Assessment of Social Skills Using Automated Language Analysis for Identification of Schizophrenia and Bipolar Disorder,” in Proc. Interspeech 2019, 2019, pp. 1433–1437. [Google Scholar]
- [14].Roark B, Mitchell M, Hosom J-P, Hollingshead K, and Kaye J, “Spoken Language Derived Measures for Detecting Mild Cognitive Impairment,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 7, pp. 2081–2090, Sep. 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Berisha V, Wang S, LaCross A, Liss J, and Garcia-Filion P, “Longitudinal changes in linguistic complexity among professional football players,” Brain and Language, vol. 169, pp. 57–63, Jun. 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [16].Bedi G, Carrillo F, Cecchi GA, Slezak DF, Sigman M, Mota NB, Ribeiro S, Javitt DC, Copelli M, and Corcoran CM, “Automated analysis of free speech predicts psychosis onset in high-risk youths,” npj Schizophrenia, vol. 1, p. 15030, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [17].Corcoran CM, Carrillo F, Fernández-Slezak D, Bedi G, Klim C, Javitt DC, Bearden CE, and Cecchi GA, “Prediction of psychosis across protocols and risk cohorts using automated language analysis,” World Psychiatry, vol. 17, no. 1, pp. 67–75, Feb. 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Iter D, Yoon J, and Jurafsky D, “Automatic Detection of Incoherent Speech for Diagnosing Schizophrenia,” in Proceedings of the Fifth Workshop on Computational Linguistics and Clinical Psychology: From Keyboard to Clinic, 2018, pp. 136–146. [Google Scholar]
- [19].Yngve VH, “A Model and an Hypothesis for Language Structure,” Proceedings of the American Philosophical Society, vol. 104, no. 5, 1960. [Google Scholar]
- [20].Frazier L, “Syntactic Complexity,” in Natural Language Parsing. Cambridge, U.K.: Cambridge University Press, 1985. [Google Scholar]
- [21].Mota NB, Vasconcelos NAP, Lemos N, Pieretti AC, Kinouchi O, Cecchi GA, Copelli M, and Ribeiro S, “Speech Graphs Provide a Quantitative Measure of Thought Disorder in Psychosis,” PLoS ONE, vol. 7, no. 4, p. e34928, Apr. 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].Mota NB, Furtado R, Maia PPC, Copelli M, and Ribeiro S, “Graph analysis of dream reports is especially informative about psychosis,” Scientific Reports, vol. 4, no. 1, Jan. 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [23].Bertola L, Mota NB, Copelli M, Rivero T, Diniz BS, Romano-Silva MA, Ribeiro S, and Malloy-Diniz LF, “Graph analysis of verbal fluency test discriminate between patients with Alzheimer’s disease, mild cognitive impairment and normal elderly controls,” Frontiers in Aging Neuroscience, vol. 6, Jul. 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [24].Landauer TK and Dumais ST, “A solution to Plato’s problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge.” Psychological Review, vol. 104, no. 2, pp. 211–240, 1997. [Google Scholar]
- [25].Elvevåg B, Foltz PW, Weinberger DR, and Goldberg TE, “Quantifying incoherence in speech: An automated methodology and novel application to schizophrenia,” Schizophrenia Research, vol. 93, no. 1-3, pp. 304–316, Jul. 2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [26].Mikolov T, Chen K, Corrado G, and Dean J, “Efficient estimation of word representations in vector space,” arXiv preprint arXiv:1301.3781, 2013. [Google Scholar]
- [27].Pennington J, Socher R, and Manning C, “Glove: Global Vectors for Word Representation.” Association for Computational Linguistics, 2013. pp. 1532–1543. [Google Scholar]
- [28].Kayi ES, Diab M, Pauselli L, Compton M, and Coppersmith G, “Predictive Linguistic Features of Schizophrenia,” in Proceedings of the 6th Joint Conference on Lexical and Computational Semantics (*SEM 2017), 2017, pp. 241–250. [Google Scholar]
- [29].Arora S, Liang Y, and Ma T, “A Simple but Tough-to-Beat Baseline for Sentence Embeddings,” in Proc. of 5th International Conference on Learning Representations, Toulon, France, 2017, p. 16. [Google Scholar]
- [30].Conneau A, Kiela D, Schwenk H, Barrault L, and Bordes A, “Supervised Learning of Universal Sentence Representations from Natural Language Inference Data,” arXiv:1705.02364 [cs], May 2017. [Google Scholar]
- [31].Blei DM, Ng AY, and Jordan MI, “Latent dirichlet allocation,” Journal of Machine Learning Research, vol. 3, no. Jan, pp. 993–1022, 2003. [Google Scholar]
- [32].Yancheva M and Rudzicz F, “Vector-space topic models for detecting Alzheimer’s disease,” in Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), vol. 1, 2016, pp. 2337–2346. [Google Scholar]
- [33].Hernández-Domínguez L, Ratté S, Sierra-Martínez G, and Roche-Bergua A, “Computer-based evaluation of Alzheimer’s disease and mild cognitive impairment patients during a picture description task,” Alzheimer’s & Dementia: Diagnosis, Assessment & Disease Monitoring, vol. 10, pp. 260–268, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [34].Das D, Schneider N, Chen D, and Smith NA, “Probabilistic Frame-semantic Parsing,” in Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, ser. HLT ‘10. Stroudsburg, PA, USA: Association for Computational Linguistics, 2010, pp. 948–956. [Google Scholar]
- [35].König A, Satt A, Sorin A, Hoory R, Toledo-Ronen O, Derreumaux A, Manera V, Verhey F, Aalten P, Robert PH, and David R, “Automatic speech analysis for the assessment of patients with predementia and Alzheimer’s disease,” Alzheimer’s & Dementia: Diagnosis, Assessment & Disease Monitoring, vol. 1, no. 1, pp. 112–124, Mar. 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [36].Tóth L, Gosztolya G, Vincze V, Hoffmann I, Szatlóczki G, Gréta, Biró E, Zsura F, Pákáski M, and Kálmán J, “Automatic Detection of Mild Cognitive Impairment from Spontaneous Speech Using ASR,” in Proc. Interspeech 2015. Dresden, Germany: ISCA, Sep. 2015, pp. 2694–2698. [Google Scholar]
- [37].Tóth L, Hoffmann I, Gosztolya G, Vincze V, Szatlóczki G, Bánréti Z, Pákáski M, and Kálmán J, “A Speech Recognition-based Solution for the Automatic Detection of Mild Cognitive Impairment from Spontaneous Speech,” Current Alzheimer Research, vol. 15, no. 2, pp. 130–138, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [38].López-de-Ipiña K, Alonso JB, Solé-Casals J, Barroso N, Henriquez P, Faundez-Zanuy M, Travieso CM, Ecay-Torres M, Martínez-Lage P, and Eguiraun H, “On Automatic Diagnosis of Alzheimer’s Disease Based on Spontaneous Speech Analysis and Emotional Temperature,” Cognitive Computation, vol. 7, no. 1, pp. 44–55, Feb. 2015. [Google Scholar]
- [39].Tahir Y, Chakraborty D, Dauwels J, Thalmann N, Thalmann D, and Lee J, “Non-verbal speech analysis of interviews with schizophrenic patients,” in Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference On. IEEE, 2016, pp. 5810–5814. [Google Scholar]
- [40].Pakhomov SVS, Smith GE, Chacon D, Feliciano Y, Graff-Radford N, Caselli R, and Knopman DS, “Computerized analysis of speech and language to identify psycholinguistic correlates of frontotemporal lobar degeneration,” Cognitive and Behavioral Neurology: Official Journal of the Society for Behavioral and Cognitive Neurology, vol. 23, no. 3, pp. 165–177, Sep. 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [41].Guidi A, Vanello N, Bertschy G, Gentili C, Landini L, and Scilingo EP, “Automatic analysis of speech F0 contour for the characterization of mood changes in bipolar patients,” Biomedical Signal Processing and Control, vol. 17, pp. 29–37, Mar. 2015. [Google Scholar]
- [42].Fraser KC, Rudzicz F, and Rochon E, “Using Text and Acoustic Features to Diagnose Progressive Aphasia and its Subtypes,” in Proc. Interspeech 2013. Lyon, France: ISCA, Aug. 2013, pp. 2177–2181. [Google Scholar]
- [43].Peeters G, “A large set of audio features for sound description (similarity and classification) in the CUIDADO project,” CUIDADO IST Project Report, vol. 54, no. 0, pp. 1–25, 2004. [Google Scholar]
- [44].Davis S and Mermelstein P, “Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 28, no. 4, pp. 357–366, Aug. 1980. [Google Scholar]
- [45].Zhou L, Fraser KC, and Rudzicz F, “Speech Recognition in Alzheimer’s Disease and in its Assessment,” in Proc. Interspeech 2016. San Francisco, CA, USA: ISCA, Sep. 2016, pp. 1948–1952. [Google Scholar]
- [46].Mirheidari B, Blackburn D, Reuber M, Walker T, and Christensen H, “Diagnosing People with Dementia Using Automatic Conversation Analysis,” in Proc. Interspeech 2016, Sep. 2016, pp. 1220–1224. [Google Scholar]
- [47].Mirheidari B, Blackburn D, Harkness K, Walker T, Venneri A, Reuber M, and Christensen H, “Toward the Automation of Diagnostic Conversation Analysis in Patients with Memory Complaints,” Journal of Alzheimer’s Disease, vol. 58, no. 2, pp. 373–387, May 2017. [DOI] [PubMed] [Google Scholar]
- [48].Weiner J, Engelbart M, and Schultz T, “Manual and Automatic Transcriptions in Dementia Detection from Speech,” in Proc. Interspeech 2017. Stockholm, Sweden: ISCA, 2017, pp. 3117–3121. [Google Scholar]
- [49].Jeromin A and Bowser R, “Biomarkers in Neurodegenerative Diseases,” in Neurodegenerative Diseases, Beart P, Robinson M, Rattray M, and Maragakis NJ, Eds. Cham: Springer International Publishing, 2017, vol. 15, pp. 491–528. [DOI] [PubMed] [Google Scholar]
- [50].Katsuno M, Sahashi K, Iguchi Y, and Hashizume A, “Preclinical progression of neurodegenerative diseases,” Nagoya Journal of Medical Science, vol. 80, no. 3, pp. 289–298, Aug. 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [51].Dodge HH, Zhu J, Mattek NC, Austin D, Kornfeld J, and Kaye JA, “Use of High-Frequency In-Home Monitoring Data May Reduce Sample Sizes Needed in Clinical Trials,” PLOS ONE, vol. 10, no. 9, p. e0138095, Sep. 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [52].A. P. Association and A. P. Association, Eds., Diagnostic and Statistical Manual of Mental Disorders: DSM-5, 5th ed. Washington, D.C: American Psychiatric Association, 2013. [Google Scholar]
- [53].Patterson TL, Moscona S, McKibbin CL, Davidson K, and Jeste DV, “Social skills performance assessment among older patients with schizophrenia,” Schizophrenia Research, vol. 48, no. 2-3, pp. 351–360, Mar. 2001. [DOI] [PubMed] [Google Scholar]
- [54].Cummins N, Scherer S, Krajewski J, Schnieder S, Epps J, and Quatieri TF, “A review of depression and suicide risk assessment using speech analysis,” Speech Communication, vol. 71, pp. 10–49, Jul. 2015. [Google Scholar]
- [55].Levelt WJ, “Producing spoken language: A blueprint of the speaker,” in The Neurocognition of Language, Brown CM and Hagoort P, Eds. Oxford: Oxford University Press, USA, 1999, ch. 4, pp. 83–122. [Google Scholar]
- [56].Trzepacz PT and Baker RW, The Psychiatric Mental Status Examination. New York: Oxford University Press, 1993. [Google Scholar]
- [57].Pangman VC, Sloan J, and Guse L, “An examination of psychometric properties of the Mini-Mental State Examination and the Standardized Mini-Mental State Examination: Implications for clinical practice,” Applied Nursing Research, vol. 13, no. 4, pp. 209–213, Nov. 2000. [DOI] [PubMed] [Google Scholar]
- [58].Mathuranath PS, Nestor PJ, Berrios GE, Rakowicz W, and Hodges JR, “A brief cognitive test battery to differentiate Alzheimer’s disease and frontotemporal dementia,” Neurology, vol. 55, no. 11, pp. 1613–1620, Dec. 2000. [DOI] [PubMed] [Google Scholar]
- [59].Nasreddine ZS, Phillips NA, Bédirian V, Charbonneau S, Whitehead V, Collin I, Cummings JL, and Chertkow H, “The Montreal Cognitive Assessment, MoCA: A Brief Screening Tool For Mild Cognitive Impairment,” Journal of the American Geriatrics Society, vol. 53, no. 4, pp. 695–699, Apr. 2005. [DOI] [PubMed] [Google Scholar]
- [60].Kring AM, Gur RE, Blanchard JJ, Horan WP, and Reise SP, “The Clinical Assessment Interview for Negative Symptoms (CAINS): Final Development and Validation,” American Journal of Psychiatry, vol. 170, no. 2, pp. 165–172, Feb. 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [61].Kirkpatrick B, Strauss GP, Nguyen L, Fischer BA, Daniel DG, Cienfuegos A, and Marder SR, “The Brief Negative Symptom Scale: Psychometric Properties,” Schizophrenia Bulletin, vol. 37, no. 2, pp. 300–305, Mar. 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [62].Tzur Bitan D, Grossman Giron A, Alon G, Mendlovic S, Bloch Y, and Segev A, “Attitudes of mental health clinicians toward perceived inaccuracy of a schizophrenia diagnosis in routine clinical practice,” BMC Psychiatry, vol. 18, no. 1, p. 317, Dec. 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [63].Harvey PD and Pinkham A, “Impaired self-assessment in schizophrenia: Why patients misjudge their cognition and functioning,” Current Psychiatry, vol. 14, no. 4, pp. 53–59, 2015. [Google Scholar]
- [64].Pies R, “How “Objective” Are Psychiatric Diagnoses?” Psychiatry (Edgmont), vol. 4, no. 10, pp. 18–22, Oct. 2007. [PMC free article] [PubMed] [Google Scholar]
- [65].Krajewski J, Schnieder S, Sommer D, Batliner A, and Schuller B, “Applying multiple classifiers and non-linear dynamics features for detecting sleepiness from speech,” Neurocomputing, vol. 84, pp. 65–75, May 2012. [Google Scholar]
- [66].Snowdon DA, Kemper SJ, Mortimer JA, Greiner LH, Wekstein DR, and Markesbery WR, “Linguistic Ability in Early Life and Cognitive Function and Alzheimer’s Disease in Late Life: Findings From the Nun Study,” JAMA, vol. 275, no. 7, pp. 528–532, Feb. 1996. [PubMed] [Google Scholar]
- [67].Covington MA and McFall JD, “Cutting the Gordian Knot: The Moving-Average Type-Token Ratio (MATTR),” Journal of Quantitative Linguistics, vol. 17, no. 2, pp. 94–100, May 2010. [Google Scholar]
- [68].Brunét E, Le Vocabulaire de Jean Giraudoux. Structure et Évolution. Slatkine, 1978, no. 1. [Google Scholar]
- [69].Honoré A, “Some Simple Measures of Richness of Vocabulary,” Association for Literary and Linguistic Computing Bulletin, vol. 7, no. 2, pp. 172–177, 1979. [Google Scholar]
- [70].Marcus MP, Santorini B, and Marcinkiewicz MA, “Building a Large Annotated Corpus of English: The Penn Treebank:,” Defense Technical Information Center, Fort Belvoir, VA, Tech. Rep, Apr. 1993. [Google Scholar]
- [71].Jurafsky D and Martin JH, Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition (DRAFT), 3rd ed., Aug. 2017. [Google Scholar]
- [72].Toutanova K, Klein D, Manning CD, and Singer Y, “Feature-rich part-of-speech tagging with a cyclic dependency network,” in Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology - NAACL ‘03, vol. 1. Edmonton, Canada: Association for Computational Linguistics, 2003, pp. 173–180. [Google Scholar]
- [73].Wechsler D, “Wechsler Memory Scale–Third Edition Manual,” San Antonio, TX: The Psychological Corp., 1997. [Google Scholar]
- [74].Kemper S, “Adults’ diaries: Changes made to written narratives across the life span,” Discourse Processes, vol. 13, no. 2, pp. 207–223, Apr. 1990. [Google Scholar]
- [75].Kemper S and Sumner A, “The structure of verbal abilities in young and older adults.” Psychology and Aging, vol. 16, no. 2, pp. 312–322, 2001. [PubMed] [Google Scholar]
- [76].Carlozzi NE, Kirsch NL, Kisala PA, and Tulsky DS, “An Examination of the Wechsler Adult Intelligence Scales, Fourth Edition (WAIS-IV) in Individuals with Complicated Mild, Moderate and Severe Traumatic Brain Injury (TBI),” The Clinical Neuropsychologist, vol. 29, no. 1, pp. 21–37, Jan. 2015. [DOI] [PubMed] [Google Scholar]
- [77].Berg T, Structure in Language: A Dynamic Perspective, 1st ed., ser. Routledge Studies in Linguistics. New York, NY: Routledge, 2009, no. 10, oCLC: 605351697. [Google Scholar]
- [78].Magerman DM, “Statistical decision-tree models for parsing,” in Proceedings of the 33rd Annual Meeting on Association for Computational Linguistics -. Cambridge, Massachusetts: Association for Computational Linguistics, 1995, pp. 276–283. [Google Scholar]
- [79].Lin D, “On the structural complexity of natural language sentences,” in Proceedings of the 16th Conference on Computational Linguistics -, vol. 2. Copenhagen, Denmark: Association for Computational Linguistics, 1996, p. 729. [Google Scholar]
- [80].Gibson E, “Linguistic complexity: Locality of syntactic dependencies,” Cognition, vol. 68, no. 1, pp. 1–76, Aug. 1998. [DOI] [PubMed] [Google Scholar]
- [81].Carrillo F, Mota N, Copelli M, Ribeiro S, Sigman M, Cecchi G, and Fernandez Slezak D, “Automated Speech Analysis for Psychosis Evaluation,” in Machine Learning and Interpretation in Neuroimaging, Rish I, Langs G, Wehbe L, Cecchi G, Chang K.-m. K., and Murphy A, Eds. Cham: Springer International Publishing, 2016, vol. 9444, pp. 31–39. [Google Scholar]
- [82].Charniak E, “A Maximum-entropy-inspired Parser,” in Proceedings of the 1st North American Chapter of the Association for Computational Linguistics Conference, ser. NAACL 2000. Association for Computational Linguistics, 2000, pp. 132–139. [Google Scholar]
- [83].Haugen E and Firth JR, “Papers in linguistics 1934-1951,” Language, vol. 34, no. 4, p. 498, Oct. 1958. [Google Scholar]
- [84].Altszyler E, Sigman M, Ribeiro S, and Slezak DF, “Comparative study of LSA vs Word2vec embeddings in small corpora: A case study in dreams database,” arXiv preprint arXiv:1610.01520, 2016. [Google Scholar]
- [85].Peters ME, Neumann M, Iyyer M, Gardner M, Clark C, Lee K, and Zettlemoyer L, “Deep contextualized word representations,” arXiv preprint arXiv:1802.05365, 2018. [Google Scholar]
- [86].Devlin J, Chang M-W, Lee K, and Toutanova K, “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” arXiv:1810.04805 [cs], Oct. 2018. [Google Scholar]
- [87].Pagliardini M, Gupta P, and Jaggi M, “Unsupervised Learning of Sentence Embeddings using Compositional n-Gram Features,” arXiv:1703.02507 [cs], Mar. 2017. [Google Scholar]
- [88].Cer D, Yang Y, Kong S.-y., Hua N, Limtiaco N, John RS, Constant N, Guajardo-Cespedes M, Yuan S, Tar C et al. , “Universal Sentence Encoder,” arXiv preprint arXiv:1803.11175, 2018. [Google Scholar]
- [89].Colman AM, A Dictionary of Psychology. Oxford University Press, 2015. [Google Scholar]
- [90].Yudofsky SC, Hales RE, and Publishing AP, Eds., The American Psychiatric Publishing Textbook of Neuropsychiatry and Clinical Neurosciences, 4th ed. Washington, DC: American Psychiatric Pub, 2002. [Google Scholar]
- [91].Videbeck SL, Psychiatric-Mental Health Nursing. Lippincott Williams & Wilkins, 2010. [Google Scholar]
- [92].Goodglass H and Kaplan E, “The assessment of aphasia and related disorders,” 1983. [Google Scholar]
- [93].Horwitz-Martin RL, Quatieri TF, Lammert AC, Williamson JR, Yunusova Y, Godoy E, Mehta DD, and Green JR, “Relation of Automatically Extracted Formant Trajectories with Intelligibility Loss and Speaking Rate Decline in Amyotrophic Lateral Sclerosis,” in Proc. Interspeech 2016. San Francisco, CA, USA: ISCA, 2016, pp. 1205–1209. [Google Scholar]
- [94].Sandoval S, Berisha V, Utianski RL, Liss JM, and Spanias A, “Automatic assessment of vowel space area,” The Journal of the Acoustical Society of America, vol. 134, no. 5, pp. EL477–EL483, Nov. 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [95].Hailstone JC, Ridgway GR, Bartlett JW, Goll JC, Buckley AH, Crutch SJ, and Warren JD, “Voice processing in dementia: A neuropsychological and neuroanatomical analysis,” Brain, vol. 134, no. 9, pp. 2535–2547, Sep. 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [96].Stuttle MN, Williams JD, and Young S, “A framework for dialogue data collection with a simulated ASR channel,” in Eighth International Conference on Spoken Language Processing, 2004. [Google Scholar]
- [97].Simonnet E, Ghannay S, Camelin N, and Estève Y, “Simulating ASR errors for training SLU systems,” in LREC 2018, Eleventh International Conference on Language Resources and Evaluation. Miyazaki, Japan: European Language Resources Association, May 2018, p. 7. [Google Scholar]
- [98].Voleti R, Liss JM, and Berisha V, “Investigating the Effects of Word Substitution Errors on Sentence Embeddings,” in ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), May 2019, pp. 7315–7319. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [99].Vipperla R, Renals S, and Frankel J, “Longitudinal study of ASR performance on ageing voices,” in Proc. Interspeech 2008. Brisbane, Australia: ISCA, Sep. 2008, pp. 2550–2553. [Google Scholar]
- [100].Young V and Mihailidis A, “Difficulties in Automatic Speech Recognition of Dysarthric Speakers and Implications for Speech-Based Applications Used by the Elderly: A Literature Review,” Assistive Technology, vol. 22, no. 2, pp. 99–112, 2010. [DOI] [PubMed] [Google Scholar]
- [101].Hakkani-Tür D, Vergyri D, and Tur G, “Speech-based automated cognitive status assessment,” in Proc. Interspeech 2010. Makuhari, Chiba, Japan: ISCA, Sep. 2010, pp. 258–261. [Google Scholar]
- [102].König A, Linz N, Tröger J, Wolters M, Alexandersson J, and Robert P, “Fully Automatic Speech-Based Analysis of the Semantic Verbal Fluency Task,” Dementia and Geriatric Cognitive Disorders, vol. 45, no. 3-4, pp. 198–209, 2018. [DOI] [PubMed] [Google Scholar]
- [103].Jiao Y, Berisha V, and Liss J, “Interpretable phonological features for clinical applications,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Mar. 2017, pp. 5045–5049. [Google Scholar]
- [104].Tu M, Berisha V, and Liss J, “Interpretable Objective Assessment of Dysarthric Speech Based on Deep Neural Networks,” in Proc. Interspeech 2017. Stockholm, Sweden: ISCA, Aug. 2017, pp. 1849–1853. [Google Scholar]
- [105].Coupland N, Style: Language Variation and Identity, ser. Key Topics in Sociolinguistics. Cambridge University Press, 2007. [Google Scholar]
- [106].Schilling N, “Investigating stylistic variation,” The handbook of language variation and change, pp. 325–349, 2013. [Google Scholar]
- [107].Benzeghiba M, De Mori R, Deroo O, Dupont S, Erbes T, Jouvet D, Fissore L, Laface P, Mertins A, Ris C, Rose R, Tyagi V, and Wellekens A, “Automatic speech recognition and speech variability: A review,” Speech Communication, vol. 49, no. 10-11, pp. 763–786, Oct. 2007. [Google Scholar]
- [108].Mueller KD, Koscik RL, Clark LR, Hermann BP, Johnson SC, and Turkstra LS, “The Latent Structure and Test–Retest Stability of Connected Language Measures in the Wisconsin Registry for Alzheimer’s Prevention (WRAP),” Archives of Clinical Neuropsychology, vol. 33, no. 8, pp. 993–1005, Dec. 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]