

Abstract
A mathematical model of COVID-19 is presented where the decision to increase or decrease social distancing is modelled dynamically as a function of the measured active and total cases as well as the perceived cost of isolating. Along with the cost of isolation, we define an overburden healthcare cost and a total cost. We explore these costs by adjusting parameters that could change with policy decisions. We observe that two disease prevention practices, namely increasing isolation activity and increasing incentive to isolate do not always lead to optimal health outcomes. We demonstrate that this is due to the fatigue and cost of isolation. We further demonstrate that an increase in the number of lock-downs, each of shorter duration can lead to minimal costs. Our results are compared with case data in Ontario, Canada from March to August 2020 and details of expanding the results to other regions are presented.
Keywords: COVID-19, mathematical modelling, social distancing, healthcare burden, cost analysis, testing impact
1. Introduction
As of February 2021, there have been over 106 million cases of COVID-19 worldwide, over 808 000 cases in Canada, and over 284 000 cases in the province of Ontario. The early stages of the outbreak focused on mathematical modelling of disease dynamics such as transmission and the basic reproduction number [1,2].
It quickly became clear that asymptomatic spreading was important and that undetected infections were important to consider in models [3]. This caused a global policy shift towards travel restrictions, community closures and social distancing implementations. The impacts of mathematical modelling on policy are documented in [4].
The implementation of non-pharmaceutical intervention (NPI) such as social distancing quickly became an important mathematical modelling task (cf. [5–8]). The majority of these models focus on fixed policy implementations such as reducing contacts on a given date and reinstating them on another. There are two main issues with this, the first is that it requires knowledge of the implementation and relaxation times. While this can be explored in model simulations and optimized for best results, its independence from the model itself can make it hard to adapt to other diseases, strains, or important factors. A second problematic issue is that it assumes an instantaneous policy compliance, i.e. that people will immediately reduce contacts upon implementation and stop upon relaxation. While this can be impacted by an adherence parameter, it does not allow for a dynamic response which is more realistic of human choice. Therefore, a dynamical social distancing model that reacts to the disease dynamics is more realistic.
A dynamic intervention strategy where intervention was turned on and off based on the state of the epidemic was considered in [8] where a decrease in both total infections and social distancing duration was observed compared with a fixed-duration intervention which they also considered. However, modelling the dynamics of intervention entirely on the disease progression assumes that people will immediately distance or relax at some threshold. This suggests that a periodic solution will emerge centred around the critical disease threshold and this appears to happen in [8]. While it is quite realistic that disease dynamics drive people into isolation, it is a separate mechanism, namely the cost of staying home, that people consider when relaxing their isolation habits. Cost is seldom considered in models, with most of the focus on larger economic influence [9,10]. These economic factors certainly play a role in individual cost but psychological factors such as loneliness and habit displacement are important as well.
For this paper, we propose a differential equation model for the spread of COVID-19 with separate dynamics for isolation and relaxation dependent on disease progression and relaxation cost, respectively. The disease progression information typically comes from media reports and has been investigated in the context of infectious diseases such as influenza (cf. [11–14]) and is usually used to reduce the susceptibility of individuals who are positively influenced by media. The relaxation cost is less often considered and its inclusion recognizes that repeated lock-downs would have diminishing returns as the cost to stay home becomes too overwhelming. A dynamic response model allows for more realistic policy strategies for disease mitigation and mortality prevention. Our model focuses on the spread of the disease in Ontario, Canada, but could be adapted with other parameters to other regions.
Our study is outlined as follows. In §2, we introduce the model and the dynamic response functions for social distancing and relaxation. We also introduce the parameters including those which we fit to data from [15]. We define health, economic and total costs of the pandemic. The health cost is based on overloading existing healthcare resources while the economic cost is the personal or societal cost of social distancing. We show the excellence of fit to our data in §3 and present a series of results based on different scenarios where policy parameters that control distancing and relaxing are varied. We consider scenarios where both health and relaxation costs are equally weighted or where health cost is much more strongly influencing the total cost. We consider a modification to the relaxation rate so that it depends on both cost and cases and see that multiple outbreak peaks can occur. We discuss the implications and conclusions of our work in §4.
2. Model
We consider a mathematical model for COVID-19 consisting of classes of people with various exposure to the disease. These classes are listed in table 1 where we note that the removed groups include people who have died from the virus which we do not separately consider. For each of the population classes, we assume there are three levels of social distancing indicated by a variable subscript zero, one or two. If the subscript is 0 then there is no social distancing, subscript 1 indicates that there is social distancing which reduces the contact probability by some percentage while for subscript 2, the contact probability is zero, i.e. full isolation. We introduce a further subscript, M which represents the mitigation of spread due to individuals who have tested positive and are isolated. We assume that only P, IS and IA populations can test positive and that these people will immediately and completely isolate effectively placing them in the social distance two category for the duration of their disease.
Table 1.
Variable and parameter definitions
| definition | value | comment | |
|---|---|---|---|
| S | susceptibles, people who can catch the virus | 0.9998N | initial condition |
| E | exposed, people who have caught the disease but are not yet infectious | 0 | initial condition |
| P | pre-symptomatic, people who are infectious but have not had the disease long enough to show symptoms | 0 | initial condition |
| IS | infected-symptomatic, people who are infectious and have started showing symptoms | 2.00 × 10−4N | initial condition |
| IA | infected-asymptomatic, people who are infectious but never show symptoms | 0 | initial condition |
| RS | removed-symptomatic, people who were symptomatic and infectious, but are no longer infectious | 0 | initial condition |
| RA | removed-asymptomatic, people who were asymptomatic and infectious, but are no longer infectious | 0 | initial condition |
| N | population of Ontario | 13 448 494 | 2016 census |
| Ncrit | critical population at which healthcare resources are overwhelmed | 81 301 | chosen |
| R0 | basic reproduction number | 2.40 | [16,17] |
| β | transmission rate of disease after coming in contact with the infected class | 0.223 d−1 | see (2.10) |
| δ | reduction in transmission due to social distancing in class 1 | 0.250 | chosen |
| α | reduction in transmission due to being asymptomatic | 0.500 | chosen |
| σ | rate at which exposed class enter pre-symptomatic class | 2.00 d−1 | [16] |
| ϕ | rate at which pre-symptomatic class can begin showing symptoms | 4.60−1 d−1 | [16,18,19] |
| Q | proportion of infected individuals who show symptoms | 0.690 | median value |
| γ | rate at which an infected person is no longer infectious | 10.0−1 d−1 | [20] |
| μmax | maximal rate at which someone moves from a less socially distant class to a more socially distant class | 1.00 d−1 | chosen |
| νmax | maximal rate at which someone moves from a more socially distant class to a less socially distant class | 1.00 d−1 | chosen |
| μI | rate at which people showing symptoms choose to isolate | 0.010 d−1 | chosen |
| q0 | proportion of S0 socially distancing into S1 | 0.9 | chosen |
| q2 | proportion of S2 relaxing social distancing into S1 | 0.6 | chosen |
| qI | proprotion of symptomatic individuals IS0 who isolate into IS1 | 0.6 | chosen |
| ρA | testing rate for someone not showing symptoms to test positive | 8.70 × 10−3 d−1 | see appendix B |
| ρS | testing rate for someone showing symptoms to test positive | 3.48 × 10−2 d−1 | see appendix B |
| Mc | critical active cases to induce social distancing | 2.09 × 103/Ncrit | see appendix B |
| M0 | active cases that lead to half the maximal rate of social distancing | 4.18 × 103/Ncrit | see appendix B |
| kc | critical approximate disease doubling rate to induce social distancing | 16.2−1 d−1 | see appendix B |
| k0 | approximate disease doubling rate that leads to half the maximal rate of social distancing | 4.06−1 d−1 | see appendix B |
| Cc | critical cost to induce social relaxation | 50 d | chosen |
| C0 | cost that leads to half the maximal rate of social relaxation | 100 d | chosen |
We follow the usual SEIR model framework (cf. [21,22]) which we illustrate in figure 1 with equations detailed in appendix A.
Figure 1.
Graphical representation of the SEIR model used throughout the manuscript. We use fading to indicate a reduction in transmission which comes from distancing/isolation and also from the asymptomatic disease carriers being less infectious. These effects are quantified by δ and α respectively in the full model detailed in appendix A. For a condensed graphical representation, we have indicated a representative parameter on particular arrows; however, in general each parameter has a subscript (i, j) indicating the originating and terminal compartment respectively, details of which are in the main text. The parameter μ (red arrowhead in figure) indicates distancing to a higher category while ν (green arrowhead in figure) indicates relaxing down to a lower category. F(Ij) represents the force of infection indicating that susceptible people require interaction with one of the infected classes for successful disease transmission. The portion of the model in the green rectangle is the model when social distancing and testing is not considered.
For the model, we assume that vital statistics are not important on the time scales we consider so we take a fixed population N. We also normalize the model by another population Ncrit which is the amount of people needing healthcare resources that puts the system at full capacity. Figure 1 shows the various model parameters which are summarized in table 1. Each transition parameter has a subscript (i, j) with i the originating class and j the terminal class. The exception to this is βi,j, where i is the class of the susceptible person and j the class of the infected contact. We make the following assumptions about the model parameters:
-
(i)
the parameters δ, σ, ϕ, γ and Q are constant and the same for each social distancing class as the disease progression characteristics are unaffected by social distancing. The social distancing partition parameters q0, q2 and qI are also constant.
-
(ii)
a constant which incorporates both contact and disease transmission probability. We assume that people not showing symptoms shed a lower viral load and hence reduce transmission by a constant factor α and that those in social distancing class 1 reduce their contacts by a constant factor of δ, effectively also reducing their transmission. For example, , and .
-
(iii)
people in the infected symptomatic class choose to isolate at a constant rate μI with qI going into and (1 − qI) going into . They stay in the social distancing class until they have recovered from the disease, i.e. νI = 0. Furthermore, this means that someone already social distancing in state 1 or 2 who becomes symptomatic remains in that social distance class. We note that individuals in , and know that they are sick but have not tested positive for the disease. If they test positive, they transition to and are completely quarantined.
-
(iv)
there are two testing rates ρA and ρS for asymptomatic (including pre-symptomatic) and symptomatic individuals, respectively, with ρS > ρA as we assume that symptomatic people are more likely to seek out a test as they have symptoms. Asymptomatic people are likely to only seek a test out if they believe, through contact tracing or otherwise, they have come into contact with someone who has the virus, or through targeted testing initiatives. Despite the fact that testing numbers fluctuate with the progression of the disease, we take the testing rates to be constant which makes them an effective testing rate. This is consistent with studies estimating global infections per symptomatic test case (cf. [23,24]). To help restrict the model, we take ρS = 4ρA which is a similar value as observed in [24], which compared data from Germany, South Korea and the USA.
-
(v)
we assume that only people in the P, IS or IA classes will test positive if a test is administered. Therefore, we explicitly assume people in the E class do not have a high enough viral load to shed.
-
(vi)
people who have tested positive are isolated (effectively put in social class 2) until recovery and cannot transmit the disease. This ignores infections to family members living in a household with an isolated member or infections to healthcare workers who are conducting tests or treating COVID-19 patients. See [25] for considerations of a model with household structure included.
2.1. Social distancing and testing
Since people without symptoms are unaware of whether they have the virus or not, we assume that both social distancing and relaxing rates are independent of the disease class they are in. We therefore define μ as the rate of social distancing from state 0 with proportion q0 going to state 1 and (1 − q0) going to state 2. We similarly define ν as the rate of decreasing social distance from state 2 with proportion q2 going to state 1 and (1 − q2) going to state 0. We define those social distancing from state 1 to state 2 as μ/2 to account for the fact that anybody in state 1 has already undergone one transition and so they should be slower at making a secondary transition. For a similar reason, we define the social distancing relaxation from state 1 to state 0 as ν/2.
Testing provides two important quantities reported by the media that can help inform social distancing, the total number of cases M and the active cases MA (each also scaled by Ncrit) which are defined by
| 2.1a |
and
| 2.1b |
If the disease is in the exponential phase of spread then the doubling rate can be deduced from the cumulative case information, M, to yield
| 2.2 |
We assume that this can approximate the doubling rate at all times and is what locally drives social distancing. However, while the disease growth rate is important, it should be weighed against the number of active cases as well and therefore we propose a social distance transition function
| 2.3 |
where μmax is the maximal rate of social distancing, [ · ]+ is defined such that,
Social distancing is not something that people want to do and the parameters kc and Mc represent critical doubling rates and active case numbers, respectively, below which people will not social distance, which is the role of the maximum function. These parameters can be thought of as policy parameters since implementing lock-downs, closing businesses and halting social gatherings will impact these values. The parameters k0 and M0 represent doubling rates and case numbers where social distancing reaches its half-maximum.
We assume that social relaxation, ν, is proportional to the cost of social distancing, c, in dollars, which we model as
| 2.4 |
The parameter κ is the cost per person per day of being in social distancing class 2. Those in social distance state 1 effect their transmissibility by a factor δ and we assume this comes at a reciprocal burden cost of (1 − δ) relative to κ. For example, if δ = 1 then the 1 and 2 states are both fully isolated and contribute an equal maximal cost. The parameter Ncrit appears in (2.4) because of the scaling on the populations. We only include susceptible and exposed classes in (2.4) because we assume there is a greater benefit to having transmitting classes (Pi, Ii) stay home. Arguably, exposed people who will soon become infectious should stay home too, but as they would test negative, they would think they are healthy and therefore we assume they contribute to the cost. For simplicity, we ignore the cost of recovered people social distancing which will be invalid if many people have recovered but policy prevents them from returning to their workplaces etc. As written, the cost accumulates with time. We could remedy this by including a decay factor −μcc in (2.5) but we assume that the time scale of recovery is much longer than that of the pandemic. Since c does not factor in day-to-day economic costs in non-pandemic times, it is normalized so that zero cost represents the cost of society pre-pandemic. Similarly, then the maximum additional costs come from those isolating completely in social distance state 2.
Defining cost as we have in (2.4) attributes a single dollar amount, κ to social distancing. This is a general opportunity cost which will vary from person to person and include direct economic costs in the form of people staying home from their jobs, but also indirect economic costs such as the psychological tolls of being isolated for a long period of time. As we have not stratified our model by demographics such as age and poverty level, we are not able to capture demographic effects on the cost. This generality in the model means that identifying an actual dollar amount per day, κ, is difficult. Instead, we define
allowing us to eliminate κ in (2.4) to yield,
| 2.5 |
With this definition, C is measured in days. Since κN represents the cost per day of every person in the population being full isolated then C represents the equivalent cost in days of the entire province isolating. Interpreting a reasonable value of κ will allow governments and policy makers to transform the cost into a daily total in dollars.
Defining the relaxation cost using (2.5), we propose ν be modelled by
| 2.6 |
where νmax is the maximal rate at which social distancing can be relaxed, C0 is the cost which triggers the half-maximal rate, and Cc is the cost required to trigger social relaxation. Cc is also a policy parameter as mental health promotion, economic stimulus, and wage subsidy programs can influence the cost people can endure before social relaxation.
To understand the true cost of the pandemic, we must balance the relaxation cost, C, with the overburden healthcare cost, H, which we define as
| 2.7 |
where t0 is the time where active cases exceed Ncrit/2 and t1 is the time they return below Ncrit/2. We choose this value as many provinces use this as an indicator of overload since by the time cases reach Ncrit resources are completely overwhelmed. An alternative definition of the healthcare cost could be to integrate over the whole duration of the pandemic. In this formulation, zero health cost could only come from having no cases at all. Additionally, it means that a very small daily active caseload sustained over several years could be equivalent to or worse than an extreme overload of the system over a couple of weeks. By defining (2.7), we are assuming that the healthcare system has measures in place to manage caseloads below Ncrit/2. Even small case numbers will contribute to death and chronic illness, but we assume that below Ncrit/2 these are solely a function of the disease, while above the threshold, the impact on healthcare strain is likely to be a contributing factor.
The choice of integrating H in (2.7) balances intensity of the outbreak along with duration. The sum allows for multiple outbreaks where the hospital resources are exceeded. The reason we measure active cases is that we assume all COVID-19 cases entering the hospital will be tested. Realistically a portion of the untested symptomatic cases will also impact the healthcare system and therefore this can be considered an underestimated cost. Having defined the overburden healthcare cost, we can then define the total cost as
| 2.8 |
where H∞ is the overburden healthcare cost with no social distancing intervention (μmax = 0) and C∞ is the largest isolation cost allowable. We define ω as a weighting factor between the two cost contributions.
2.2. Parameter determination
We first consider a variant of the full model that does not include social distancing or testing (green-dash rectangle of figure 1) which is given by,
| 2.9 |
This reduced model represents the disease transmission dynamics prior to widespread knowledge of COVID-19. Following [16], we assume that people without symptoms are half as infectious as those with symptoms and therefore take α = 1/2.
The disease free state is [S, E, P, IS, IA, RS, RA] = [N/Ncrit, 0, 0, 0, 0, 0, 0] and we identify the basic reproduction number R0 as the non-zero eigenvalue of the next generation matrix produced from (2.9) (cf. [26,27]),
| 2.10 |
Taking R0 from measurements such as the studies in [16,17] which estimate R0 = 2.4 we can rearrange (2.10) to determine a value for β.
We assume that this base transmission rate between the susceptible and symptomatic populations is the same as that between S0 and in the social distancing model (A 1), i.e. . The parameters considered for the base model are presented in table 1 and we comment on some of the assumptions made.
As of 16 July 2020, the hospitalization rate of COVID-19 in Ontario, Canada was 12.3% and there were approximately 10 000 hospital beds available for people which together define Ncrit = 81 301. We choose μmax = νmax = 1 under the assumption that people generally need at least 1 day to change their routines. We arbitrarily assume that C0 = 2Cc and that k0 = 4kc to help constrain the model. This means that the relaxation cost needed to initiate the half-maximum rate is twice as many days as the onset of social relaxation while the disease needs to double twice for the half-maximal social distancing rate to occur. We chose Cc = 50 based on Ontario imposing a stage-one lock-down in March 2020 that lasted almost 100 days coupled with the fact that it did not impact the entire province.
We predicted the values of kc, Mc and ρA (recalling that ρS = 4ρA) by fitting our model to active and total case data from [15] between 10 March and 18 August 2020 inclusive. We used a nonlinear least-squares method for the fitting, the details of which are in appendix B. Using the Ncrit scale, we can convert the values of Mc and M0 from table 1 to 2090 and 4180 people, respectively. The values of μI, q0, q2 and qI are arbitrarily chosen. However, as is seen in appendix B where a sensitivity analysis is performed, these parameters are not very influential on model results. The most influencing parameter is μI. Considering that at the half-maximal rates, the social distancing rate is μ = 1/4 and that a recent study from [28] suggested that up to 90% of Americans go into work sick then a further 90% reduction would yield μI ≈ 0.025 which is the same order of magnitude as the chosen value.
We took a median value for the symptomatic rate, Q, of 69% following a variety of studies (see [29–34]).
3. Results
We simulated (A 1) using Matlab 2020a with parameters in table 1. We took 10 March 2020 as the initial time with an initial condition that 0.02% of the population was infected with symptoms and placed the remaining 99.98% of the population in the susceptible class.
We demonstrate the results from data-fitting the parameters kc, Mc and ρA in figure 2a,b. Comparing data with simulation, we observe a difference in the early peak-time of 4.7 days and a difference in peak active cases of 359 people. We extend our simulation beyond 18 August 2020 and compare with data up to 6 January 2021 in figure 2c,d. We see that the fit is good until around the end of September 2020. We discuss how to improve this fit in appendix B where we also discuss comparisons with social mobility data. We observe the impact of the disease on total cost (2.8) by simulating the full model (A 1) and varying the critical threshold at which people social distance (Mc) and the critical cost before social relaxation begins (Cc). We consider 1/4, 1/2, 2 and 4 times the base values given in table 1. The value for kc from data fitting is already quite extreme and we do not vary this. We plot heat maps for the total cost CT in figure 3 for different weights ω with the maps coloured relative to the maximal and minimal costs. We compute H∞ by simulating the model with parameters in table 1 and taking μmax = 0. We take C∞ as the highest cost that emerges from all of the simulations. We note that ω = 0 is just the relaxation cost C given by (2.5) scaled by C∞ while ω = 1 is just the overburden health cost H given by (2.7) scaled by H∞. Reducing Mc means that people require less active cases before triggering their social distance behaviour. If we denote this behaviour as vigilance then smaller values of Mc lead to increased vigilance. Therefore, in figure 3, vigilance increases from bottom to top as Mc decreases. Cc increases from left to right, which corresponds to a higher tolerance for social distancing meaning that people delay their relaxation behaviour. We associate this to increased spending as people can absorb more cost.
Figure 2.

Comparison between simulation and data from [15]. Data are fitted from 10 March to 18 August 2020 (a,b) and then projected (c,d) with unfitted data from 19 August 2020 to 6 January 2021. Improvements to fit are discussed in appendix B.
Figure 3.

Total cost (2.8) from varying Mc and Cc in the model (A 1) with other parameters fixed from table 1 (excluding C0 and M0 which are appropriately updated). and refer to the base values in table 1. In these simulations, H∞ = 292.7 and C∞ = 230 days. Ascending the vertical axis corresponds to increased vigilance (lower required active cases before social distancing) while moving left-to-right on the horizontal axis corresponds to increased spending (longer tolerance before relaxing). (a) ω = 0. CT = C/C∞ with C given by (2.5), (b) ω = 0.2, (c) ω = 0.4, (d) ω = 0.6, (e) ω = 0.8, (f) ω = 1. CT = H/H∞ with H given by (2.7).
When ω is small, corresponding to more weight being put on relaxation cost, figure 3 intuitively shows that increasing Cc increases the total cost. This changes when ω approaches 1, where increasing Cc can decrease total cost. This is also intuitive because when ω = 1 there is no contribution of social distancing to the total cost, but the advantage that people are staying home and not getting sick. Therefore, encouraging that behaviour only leads to better outcomes. These two different behaviours suggest that there is a value of ω where both increasing and decreasing Cc may lead to increased total costs. Indeed this phenomenon can be observed in figure 3a where the optimal spending occurs at and .
A very non-intuitive trend occurs in figure 3 which is that increasing vigilance (smaller Mc) increases total cost. The only exception to this is in figure 3f when and the minimum total cost occurs when . To understand this result, we focus on the case ω = 1 where only the overburden health cost is considered. First consider and . As vigilance increases, we expect that maximum active case load to decrease as people are social distancing with greater frequency. We see that this is indeed the case in figure 4a as we change from to . However, we also see that the duration of the epidemic straining healthcare resources is longer and the small decrease in peak is not enough to overcome this duration. We contrast this case to when and a minimum overburden healthcare cost is observed at . The active case load is plotted in figure 4b for , , and . Increasing vigilance from to decreases the peak and increases the duration. However, unlike the case in figure 4b, the depression is significant enough to cause an overall decrease in total cost. However, as vigilance is increased further to , the peak increases and duration decreases leading to an increase in cost. The non-intuitive result that higher vigilance leads to worse outcomes can be explained by isolation fatigue. A higher vigilance causes people to enter isolation too early. Once they hit a certain cost threshold they relax back to their regular social habits and then cannot sustain further isolation when the second wave of the pandemic arrives.
Figure 4.

Comparison of active cases corresponding to figure 3f for different parameter values. (a) ω = 1, and (b) ω = 1, .
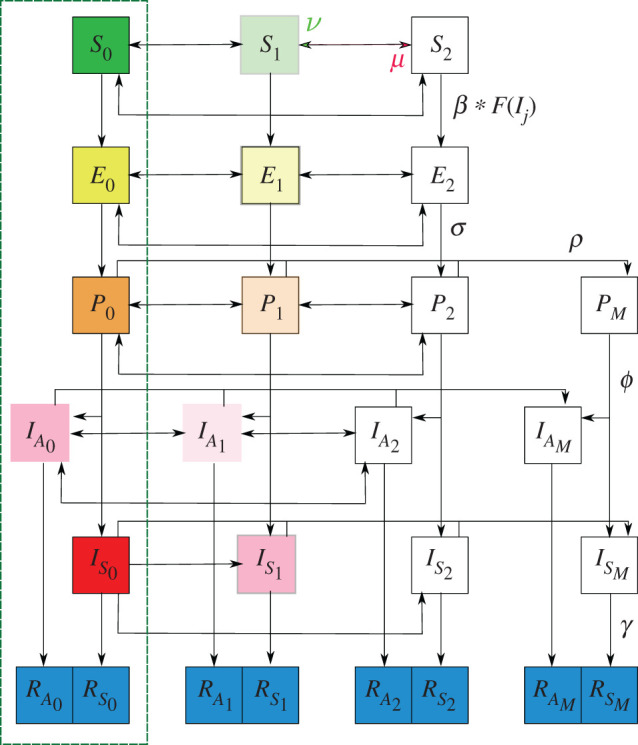
We define H∞ in the case when no social distancing occurs and therefore the relative overburden healthcare cost H/H∞ tends to its maximum value of one as social distancing is relaxed. However, as demonstrated in figure 3, increasing vigilance can also lead to H/H∞ tending to 1. This suggests that for every spending level, Cc, there is an optimal social distancing Mc to minimize the overburden health cost. Indeed, this is the case as demonstrated in figure 5 for the case ω = 1 and where we report the critical number of active cases to isolate, Mc as a percentage of the population N. The value is indicated by the black line and demonstrates that based on the data from Ontario, social distancing vigilance was initially too severe. This is a very important policy result since if isolation is too vigilant then the fatigue from isolation cost has a very negative impact long term. This result can easily be extended to other regions by using different parameters.
Figure 5.
Overburden health cost, H, given by (2.7) (equivalent to total cost (2.8) when ω = 1) when and Mc is varied as a percentage of the total population N. The dashed black line indicates the value fitted from Ontario Public Health data [15].
Plots of all of the active cases and costs for the scenarios in figure 3 can be found in the electronic supplementary material along with the populations of each isolation class to visualize the impact of social distancing and relaxation. The cumulative number of symptomatic-infected people for each scenario is plotted in figure 6. It can be seen that decreasing vigilance causes a more uniform accumulation of cases while increasing relaxation cost delays the peak of infection. In all cases, the same number of total people are infected as in the baseline case where testing occurs but no social distancing happens. This is expected as complacency and fatigue from NPIs eventually force the cost of social distancing to be too high for people to remain away from others. However, these delays can provide time for vaccination and other medical efforts to minimize the impact of the disease.
Figure 6.

Total cumulative symptomatic cases (plotted as a percentage of the total population). The baseline case refers to no social distancing, i.e. μmax = 0. (a) , (b) , (c) , (d) and (e) .
3.1. Multiple secondary waves
The model as derived only allows for one large secondary wave following the peak in Ontario around early May 2020. Since the relaxation rate, ν, is solely a function of relaxation cost (2.5) which is always increasing, isolation fatigue becomes too overwhelming that there is resistance for prolonged isolation. This model is likely to be appropriate for regions that have a strong aversion to social distancing. For other regions, it is likely that relaxation will be a function of cost and active cases as people will prioritize their health in a sustained outbreak and thus not want to relax if case numbers are sufficiently large. If we refer to the rate in (2.6) as ν0 then we propose modifying ν to
| 3.1 |
where η is a concern factor and is the number of critical cases Mc that stops social relaxation regardless of cost. Implementing this change allows for secondary infection peaks as evidenced in figure 7 where we use parameters in table 1 and arbitrarily take η = 1/2 for figure 7a and η = 1/5 for figure 7b. It is important to note that these changes do not impact the initial peak fitted to data in figure 2 and only alter future projections. Furthermore, as of January 2021, Ontario is still in the midst of its first secondary peak. For these reasons, it is difficult to estimate η as several peaks will need to have occurred.
Figure 7.

Comparison of true active cases (dashed blue), tested active cases (solid green) and cost (solid red) for two values of η. The black-dashed line is Ncrit/2 from which the health cost is measured. (a) and (b) .
We repeat the cost analysis as in figure 3 for the modified relaxation cost (3.1), however, we fix , the value from table 1 and instead modify η. The results are presented in figure 8.
Figure 8.

Total cost (2.8) using the relaxation cost (3.1) varying η and Cc in the model (A 1) with other parameters fixed from table 1 (excluding C0 which is appropriately updated). refers to the base value in table 1. In these simulations, H∞ = 292.7 and C∞ = 614 days. Ascending the vertical axis corresponds to increased concern (lower required active cases before social relaxation stops) while moving left-to-right on the horizontal axis corresponds to increased spending (longer tolerance before relaxing). (a) ω = 0. CT = C/C∞ with C given by (3.1), (b) ω = 0.2, (c) ω = 0.4, (d) ω = 0.6, (e) ω = 0.8. and (f ) ω = 1. CT = H/H∞ with H given by (2.7).
Figure 8 shows a different result compared with the case of figure 3, when (2.5) was used for the relaxation. In the latter case, there was a general trend upward in cost that had little difference between the value of Mc; however, in figure 8 there is a strong dependence in η. This is because the multi-secondary outbreaks caused by reducing relaxation with high active cases extends the duration of the epidemic which only increases the cumulative cost. The high impact of this is noticed as well with C∞ = 230 days for figure 3, while C∞ = 614 days for figure 8. H∞ remains the same in both cases since that is calculated with no social distancing at all (and therefore no social relaxation).
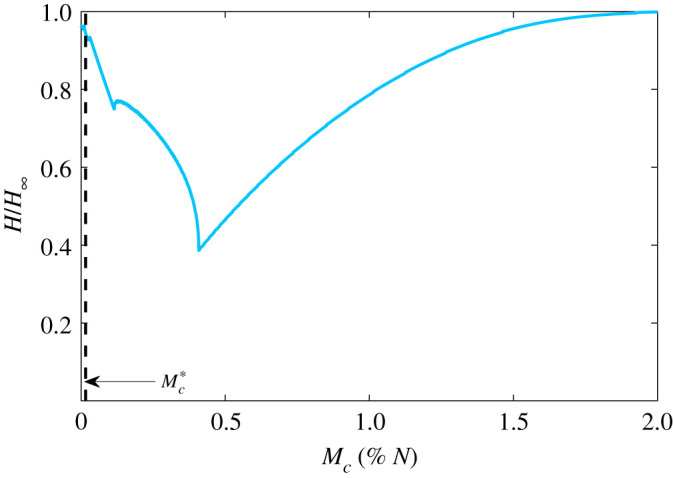
The introduction of the modified relaxation cost (3.1) has an impact on the health cost, as seen most dramatically in figure 8f where ω = 1. For small values of Cc when η = 1/4, there is no cost at all as the critical threshold is never reached. Non-intuitively, increasing spending (larger Cc) which provides incentive for people to stay home leads to worse health outcomes. The rationale for this is similar to what was observed in [8], where keeping people isolated for a longer duration increases their fatigue and resistance to staying isolated in future instances leading to large outbreaks. The impact of increased spending on active cases with η fixed is demonstrated in figure 9. It is important to note that for a given spending Cc, the minimum total cost is not necessarily with the smallest value of η (e.g. figure 8e when ). This is because there is a critical value of η below which no additional healthcare savings occur but increasing expenses occur for relaxation. These results suggest a careful policy direction with more isolation periods of shorter duration.
Figure 9.
Comparison of the active cases when η = 1/4 for two values of Cc. When then there is a long period of time with no cases. However, a large outbreak forms since there is too much fatigue to isolate again when cases get large. Conversely, when , a mild wave occurs early on because there is little incentive to isolate. However, since people were not isolating for very long, it is easier to endure further isolation when a second wave comes which leads to it also being mild. We note that when the critical threshold Ncrit is never exceeded so there is no overburden healthcare cost.
The plots of cases and total infections for each of the scenarios in figure 8 can be found in the electronic supplementary material along with plots of each isolation class to demonstrate the social distancing and relaxing behaviour. We plot the cumulative symptomatic-infected proportions for each scenario in figure 10.
Figure 10.

Total cumulative symptomatic cases (plotted as a percentage of the total population) with the modified cost function (3.1). The baseline case refers to no social distancing, i.e. μmax = 0. (a) η = 1/4, (b) η = 1/2, (c) η = 1, (d) η = 2 and (e) η = 4.
Unlike the scenarios in figure 6 associated with the relaxation cost (2.5), basing relaxation on active cases as well can impact the terminal number of cumulative infections. Continually reducing η decreases the total number of infected people which provides more evidence that increasing the relaxation cost threshold Cc can cause more people to become infected. However, similar to figure 6, increasing Cc leads to a longer delay before significant infection numbers occur.
4. Conclusion
We have presented a model for COVID-19 that allows for dynamic social distancing and relaxation based on the measured active cases and individual cost of isolating. The aim of this approach is that it more accurately reflects human behaviour and psychology unlike the modelling approach where behaviours are turned on and off at predetermined times. Understanding how people will react to a change in policy surrounding lock-downs or bans on social gatherings is essential in gauging the impact that COVID-19 and mitigation strategies will have on infections and mortality. Improving this modelling aspect can make sure that policies are put into place at the right time so people will react accordingly.
By modelling behaviour dynamically, we were able to produce non-intuitive results regarding the relative total cost of the disease, namely that increasing vigilance and relaxation cost does not necessarily lead to a decrease in total cost. This is because of the desire for people to socialize leading to isolation fatigue. We have demonstrated that in certain circumstances, however, the overburden healthcare cost can be eliminated entirely.
An advantage of the dynamic framework used in this model is that it is not restricted to Ontario nor is it even restricted to COVID-19. Changing the disease and behaviour parameters will allow this model to adapt to other scenarios. For COVID-19, policy makers would be advised to use data in the relatively early stages of a lock-down to fit behaviour parameters. Earlier time point data helps reduce the likelihood that the relaxation cost threshold has been exceeded so that the behaviour parameters are more accurate. Otherwise, and become stronger functions of the choice for . As discussed in appendix B, there are also issues of assuming static parameters when the duration of time series is taken too long. The limited data and types of data available should discourage too much parameter fitting. Having determined the parameters to a given set of data, cost analysis using (2.8) can be done leading to results similar to figures 3 and 8. Understanding the influence of tangible actions such as forced closures, wage subsidies, etc. on parameters such as Mc, Cc and η probably requires surveys and other follow-up studies.
It is important to acknowledge that this model does not take into account vaccination or other pharmaceutical interventions. These have an important role in not only limiting the healthcare impact but also in outbreak peak time and duration. The introduction of the modified cost in (3.1) causes significant delays between peaks at increased spending. The duration of the pandemic can then be several years longer than when fatigue is strong resulting in a single large outbreak peak. This additional duration may be significantly longer than the time for an effective vaccine to be developed and deployed and this needs to be considered in future work. Another important consideration is that social distancing is not truly discrete in that people do not suddenly reduce their contacts. In reality, it is a spectrum with fluid contact rates and this needs to be further explored. Finally, taking the testing rates constant should be relaxed and reflect that both the testing capacity and willingness for individuals to test is a function of disease progression.
Supplementary Material
Acknowledgements
The authors are grateful to members from the Centre for Disease Modelling for feedback on the model. We thank Suzan Sardroodi for a thorough review of the manuscript.
Appendix A. Differential equation model
The differential equation model visualized in figure 1 is given by
| A 1 |
where is the force of infection,
| A 2a |
and
| A 2b |
In deriving the model, we have normalized the population by Ncrit which represents the population that causes the healthcare system to be at capacity.
Appendix B. Parameter fitting and model sensitivity
Many of the parameters associated with the natural progression of the disease are unknown as are several of the intervention parameters such as social distancing and testing. We use data from [15] for the 161 days between 10 March and 18 August 2020 on active and total cases to elucidate some key parameters. To do this, we solve our model (A 1) with the parameters in table 1 excluding kc, k0, Mc, M0, ρA and ρS which we fit to the data. We run our model for 161 days using an initial condition that 0.02% of the population was initially infected with the remaining 99.98% being symptomatic. The actual number of people with COVID-19 is a matter of speculation and the arbitrary choice of the initial value will affect the fitting parameters, particularly the testing rates which are intimately linked. We do not partition any of the initial infected population into symptomatic or asymptomatic also due to the lack of clarity on true numbers. To help constrain the model, we take k0 = 4kc so that the doubling rate has to double twice to trigger the half-maximal social distancing. We also take M0 = 2Mc so that the number of active cases need to double to trigger the half-maximal social distancing rate. Finally, since we assume that symptomatic people are more likely to get tested than asymptomatic people we take ρS = 4ρA. These constraints should not be too restricting, probably impacting the fitted values of the remaining free variables kc, Mc and ρA.
We use a nonlinear least-squares iterative procedure to identify the parameters. This leads to the values kc=1/16.24 d−1, Mc = 2.57 × 10−2 and ρA = 8.7 × 10−3 d−1 as in table 1 with a residual norm of 9.5 × 10−3. A graphical representation of the fit between data and model is in figure 2.
B.1. Extended fitting
The parameter fittings for figure 2 lead to excellent agreement beyond the fitting time window up to around 30 September 2020. From there, the model begins to overestimate the case load. Observing the data points, we note a series of intermittent plateaus are reached with a general overall increasing trend. One possible explanation for slower growth than we initially anticipated is that we have assumed a static parameter set. In reality, there will be dynamic changes to behaviour if strategies fail or cases continue to climb. In particular, people will probably have an increased sensitivity to the rate of change of cases more so than the actual number.
To improve the fit, we consider two values of kc and k0, the one we have previously fitted in figure 2 and a second value associated with a panic in significant case increases. To fit the second set of values, we take the data from 6 September to 16 October 2020 and fit a new kc and k0 with all other parameters fixed and taken from table 1. Using the same nonlinear least square method as for the first fit, this leads to kc = 0 and k0 = 7.01 × 10−2. We note that this is very reflective of a panic type behaviour whereby no growth rate will prevent social distancing and the rate required to reach the half-maximal growth is significantly reduced.
Defining a base set and panic set for kc and k0 we simulate the model again. We assume that the base values hold until 6 September. From 6 September to 16 October, the panic values drive the model. Afterwards, we assume that behaviour alternates between base levels and panic levels, probably with fatigue so that panic cannot be sustained for very long. We plot a particular example of alternating behaviour in figure 11 where we take base values for 17 October to 10 November and then panic values for 10 days at which point we return to normalcy until 5 December 2020. We then take 10 more days of panic values before returning to normalcy for the remainder of the simulation.
Figure 11.

Modified data fitting to projected data taking account behavioural change due to large increases in active cases. (a) Active cases and (b) total cases.
We note that there are many ways to fit this data such as adjusting the time intervals for each behaviour or fitting a series of new parameters for each plateau region. Furthermore, the assumption of constant reporting rates probably does not reflect the day-to-day variability in testing, i.e. people opting for weekday tests over weekend tests. Therefore, we emphasize that the aim of figure 11 is to demonstrate that a poor fit to data in the second wave as seen in figure 2 does not necessarily mean that the underlying model has failed, but that behavioural assumptions have probably changed.
B.1.1. Sensitivity analysis
Having fit data to the model, we then performed a sensitivity analysis on the parameters ρS, ρA, qI, μI, q2, q0, q, γ, ϕ, σ and α. We used table 1 for the fixed parameters and as mean values for the varying parameters, each distributed uniformly between maximum and minimum values. We used the Latin hypercube sampling technique with 10 000 iterations and a Spearman partial rank correlation coefficient (PRCC) to measure monotonicity. We tested the sensitivity to the cumulative infected (symptomatic and asymptomatic), susceptibles, peak time for the outbreak, and the value at the peak of the outbreak. We plot the results in figure 12 The most significant parameter is the recovery rate γ (assumed the same for both classes) which seemingly has inverse behaviour to what is expected. That is, an increase in the recovery rate seems to cause more people to become sick. This is because the basic reproduction number is fixed at 2.4 and therefore changing γ effectively changes the transmission β making a higher recovery rate lead to a more transmissible disease. Aside from this, the most significant parameters unsurprisingly are the testing rates ρS and ρA as well as the symptomatic proportion q. This supports the importance of testing and social distancing. Interestingly, there is not much sensitivity to the peak time and value of the outbreak confirming the need for long-term planning regarding vaccination and hospital resource management.
Figure 12.

Sensitivity analysis of the model (A 1) using 10 000 iterations of a Latin hypercube sampling method with a Spearman partial rank correlation coefficient. Grey bars indicate a parameter with a p-value p > 0.05 dismissing their significance. If p < 0.05, the bar is blue unless it is strongly correlated (absolute PRCC greater than 0.5) in which case it is red.
We did not perform a sensitivity analysis on Cc or Mc as these are policy parameters. Their sensitivity is effectively measured by comparing costs in figures 3 and 8.
B.1.2. Mobility data
Google has provided a dataset of community mobility created from users with the location history active on their mobile devices [35]. The dataset has six categories which are retail and recreation, grocery and pharmacy, parks, transit stations, workplaces, and residential. Most categories compare a percentage change in visitors to a baseline which is the median activity in a five-week period encompassing 3 January to 6 February 2020. The exception to this is residential category which measures the change in duration.
It is hard to directly compare mobility data and social distancing/relaxation. For example, there could be no change in activity at a store in terms of visitors, but changes in policy such as enforced physical distancing or limited capacity shopping. This means that the number of visitors to a location may not change even though their social distancing behaviour has. This is evidenced in the Google mobility data for grocery and pharmacy where relatively little change is observed despite significant policy changes including mandatory masks. The residential category offers limited insight as there are only 24 h in a day so duration variability cannot be that high.
We considered the retail and recreation category to be the most reflective of distancing activity as it is generally a non-essential activity. For a baseline in our model, we assumed that without COVID-19, there would be no social distancing. If we define the social distancing population,
| B 1 |
i.e. it covers anyone who is isolating, then we consider the percentage change from baseline to be the fraction of the total population D/N that is social distancing. We take this percentage to be negative since social distancing is a reduction in their activity. A comparison between our simulation and Google’s community mobility data for Ontario from 10 March 2020 to 6 January 2021 is in figure 13. We emphasize the importance of qualitative trends. We note that our model predicts a similar uptake in isolation (about 55%). Our model reaches this level more gradually and then sustains it until a relaxation occurs whereas the data shows a steady increase to the relaxation point. Regional lock-downs probably contributed to the very sudden drop in retail usage. Furthermore, as previously stated, an increase in retail activity does not mean it was done while decreasing isolation. We note that our model sees a second decrease in activity which also qualitatively fits with the retail mobility data.
Figure 13.
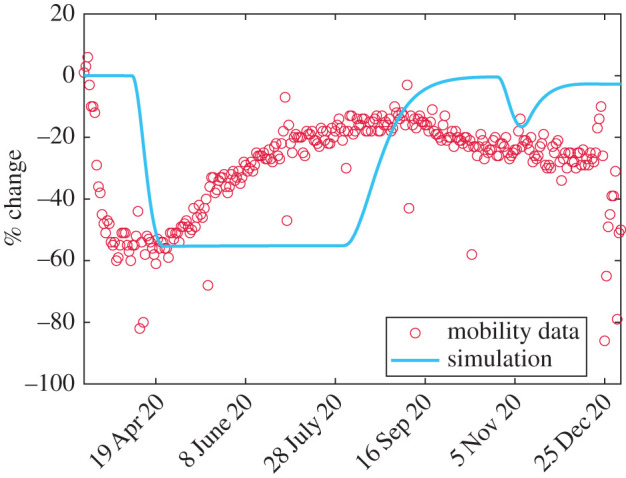
Comparison between simulation and mobility data from [35] for percentage change in retail activity from 10 March 2020 to 6 January 2021.
Data accessibility
The datasets and codes supporting this article have been uploaded as part of the electronic supplementary material. ‘Data.zip’ includes the data used ‘Code.zip’ includes all of the code used to run simulations and produce figures Inside ‘Code.zip’ is a README file with instructions on how to use codes and reproduce results.
Competing interests
We declare we have no competing interests.
Funding
I.R.M. acknowledges funding from an NSERC Discovery grant no. 2019-06337. J.M.H. acknowledges funding from an NSERC Discovery grant and Discovery Accelerator Supplement.
References
- 1.Kucharski AJ et al. 2020. Early dynamics of transmission and control of COVID-19: a mathematical modelling study. Lancet Infect. Dis. 20, 553-558. ( 10.1016/S1473-3099(20)30144-4) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Ndairou F, Area I, Nieto JJ, Torres DF. 2020. Mathematical modeling of COVID-19 transmission dynamics with a case study of Wuhan. Chaos, Solitons Fractals 135, 109846. ( 10.1016/j.chaos.2020.109846) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Ivorra B, Ferrández MR, Vela-Pérez M, Ramos A. 2020. Mathematical modeling of the spread of the coronavirus disease 2019 (COVID-19) taking into account the undetected infections. The case of China. Commun. Nonlinear Sci. Numer. Simul. 88, 105303. ( 10.1016/j.cnsns.2020.105303) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.McBryde ES, Meehan MT, Adegboye OA, Adekunle AI, Caldwell JM, Pak A, Rojas DP, Williams B, Trauer JM. 2020. Role of modelling in COVID-19 policy development. Paediatr. Respir. Rev. 35, 57-60. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Kissler SM, Tedijanto C, Lipsitch M, Grad Y. 2020. Social distancing strategies for curbing the COVID-19 epidemic. medRxiv, 1-21. [Google Scholar]
- 6.Kissler SM, Tedijanto C, Goldstein E, Grad YH, Lipsitch M. 2020. Projecting the transmission dynamics of SARS-CoV-2 through the postpandemic period. Science 368, 860-868. ( 10.1126/science.abb5793) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Matrajt L, Leung T. 2020. Evaluating the effectiveness of social distancing interventions to delay or flatten the epidemic curve of coronavirus disease. Emerg. Infect. Dis. 26, 1740. ( 10.3201/eid2608.201093) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Tuite AR, Fisman DN, Greer AL. 2020. Mathematical modelling of COVID-19 transmission and mitigation strategies in the population of Ontario, Canada. CMAJ 192, E497-E505. ( 10.1503/cmaj.200476) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Nicola M, Alsafi Z, Sohrabi C, Kerwan A, Al-Jabir A, Iosifidis C, Agha M, Agha R. 2020. The socio-economic implications of the coronavirus pandemic (COVID-19): a review. Int. J. Surg. (London, England) 78, 185. ( 10.1016/j.ijsu.2020.04.018) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Atkeson A. 2020. What will be the economic impact of COVID-19 in the US? Rough estimates of disease scenarios. Working Paper 26867. Cambridge, MA: National Bureau of Economic Research. ( 10.3386/w26867) [DOI]
- 11.Collinson S, Khan K, Heffernan JM. 2015. The effects of media reports on disease spread and important public health measurements. PLoS ONE 10, e0141423. ( 10.1371/journal.pone.0141423) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Xiao Y, Tang S, Wu J. 2015. Media impact switching surface during an infectious disease outbreak. Sci. Rep. 5, 7838. ( 10.1038/srep07838) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Cui J, Sun Y, Zhu H. 2008. The impact of media on the control of infectious diseases. J. Dyn. Differ. Equ. 20, 31-53. ( 10.1007/s10884-007-9075-0) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Tchuenche JM, Dube N, Bhunu CP, Smith RJ, Bauch CT. 2011. The impact of media coverage on the transmission dynamics of human influenza. BMC Public Health 11, S5. ( 10.1186/1471-2458-11-S1-S5) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Public Health Ontario. 2020 COVID-19 Data. Data retrieved on 18 August 2020 and 6 January 2021 from https://data.ontario.ca/dataset/status-of-covid-19-cases-in-ontario.
- 16.Ferguson N et al. 2020. Impact of non-pharmaceutical interventions (NPIs) to reduce COVID-19 mortality and healthcare demand. Report 9. London, UK: Imperial College COVID-19 Response Team.
- 17.Petersen E, Koopmans M, Go U, Hamer DH, Petrosillo N, Castelli F, Storgaard M, Al Khalili S, Simonsen L. 2020. Comparing SARS-CoV-2 with SARS-CoV and influenza pandemics. Lancet Infect. Dis. 20, e238-e244. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Böhmer MM et al. 2020. Investigation of a COVID-19 outbreak in Germany resulting from a single travel-associated primary case: a case series. Lancet Infect. Dis. 20, 920-928. ( 10.1016/S1473-3099(20)30314-5) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Ghinai I et al. 2020. Community transmission of SARS-CoV-2 at two family gatherings–Chicago, Illinois, February–March 2020. Technical report. Center for Disease Control.
- 20.Wölfel R et al. 2020. Virological assessment of hospitalized patients with COVID-2019. Nature 581, 465-469. ( 10.1038/s41586-020-2196-x) [DOI] [PubMed] [Google Scholar]
- 21.Kermack WO, McKendrick AG. 1927. A contribution to the mathematical theory of epidemics. Proc. R. Soc. A 115, 700-721. ( 10.1098/rspa.1927.0118) [DOI] [Google Scholar]
- 22.Hethcote HW. 2000. The mathematics of infectious diseases. SIAM Rev. 42, 599-653. ( 10.1137/S0036144500371907) [DOI] [Google Scholar]
- 23.Russell TW et al. 2020. Reconstructing the early global dynamics of under-ascertained COVID-19 cases and infections. BMC Med. 18, 1-9. ( 10.1186/s12916-020-01790-9) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Mahajan A, Solanki R, Sivadas N. 2020. Estimation of undetected symptomatic and asymptomatic cases of COVID-19 infection and prediction of its spread in USA. medRxiv, 1-15. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Yuan P et al. 2020. Efficacy of ‘stay-at-home’ policy and transmission of COVID-19 in Toronto, Canada: a mathematical modeling study. medRxiv. [Google Scholar]
- 26.Heffernan JM, Smith RJ, Wahl LM. 2005. Perspectives on the basic reproductive ratio. J. R. Soc. Interface 2, 281-293. ( 10.1098/rsif.2005.0042) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Diekmann O, Heesterbeek J, Roberts MG. 2010. The construction of next-generation matrices for compartmental epidemic models. J. R. Soc. Interface 7, 873-885. ( 10.1098/rsif.2009.0386) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Accounttemps. 2019 9 In 10 Employees Come To Work Sick, Survey Shows. Survey details retrieved on 29 September 2020 from http://rh-us.mediaroom.com/2019-10-24-9-In-10-Employees-Come-To-Work-Sick-Survey-Shows.
- 29.Steensels D, Oris E, Coninx L, Nuyens D, Delforge ML, Vermeersch P, Heylen L. 2020. Hospital-wide SARS-CoV-2 antibody screening in 3056 staff in a tertiary center in Belgium. Jama 324, 195-197. ( 10.1001/jama.2020.11160) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Sánchez-Álvarez JE et al. 2020. Status of SARS-CoV-2 infection in patients on renal replacement therapy: report of the COVID-19 Registry of the Spanish Society of Nephrology (SEN). Nefrología (English Edition). 40, 272-278. ( 10.1016/j.nefroe.2020.04.002) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Campbell KH, Tornatore JM, Lawrence KE, Illuzzi JL, Sussman LS, Lipkind HS, Pettker CM. 2020. Prevalence of SARS-CoV-2 among patients admitted for childbirth in Southern Connecticut. Jama 323, 2520-2522. ( 10.1001/jama.2020.8904) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Patel MC et al. 2020. Asymptomatic SARS-CoV-2 infection and COVID-19 mortality during an outbreak investigation in a skilled nursing facility. Clin. Infect. Dis. 71, 2920-2926. ( 10.1093/cid/ciaa763) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Sakurai A, Sasaki T, Kato S, Hayashi M, Tsuzuki Si, Ishihara T, Iwata M, Morise Z, Doi Y. 2020. Natural history of asymptomatic SARS-CoV-2 infection. N. Engl. J. Med. 383, 885-886. ( 10.1056/NEJMc2013020) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Mizumoto K, Chowell G. 2020. Transmission potential of the novel coronavirus (COVID-19) onboard the diamond Princess Cruises Ship, 2020. Infect. Dis. Model. 5, 264-270. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Google. 2021 COVID-19 Community Mobility Reports. Data retrieved on 6 January 2021 from https://www.google.com/covid19/mobility/.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The datasets and codes supporting this article have been uploaded as part of the electronic supplementary material. ‘Data.zip’ includes the data used ‘Code.zip’ includes all of the code used to run simulations and produce figures Inside ‘Code.zip’ is a README file with instructions on how to use codes and reproduce results.