

Abstract
The computation of genomic distances has been a very active field of computational comparative genomics over the past 25 years. Substantial results include the polynomial-time computability of the inversion distance by Hannenhalli and Pevzner in 1995 and the introduction of the double cut and join distance by Yancopoulos et al. in 2005. Both results, however, rely on the assumption that the genomes under comparison contain the same set of unique markers (syntenic genomic regions, sometimes also referred to as genes). In 2015, Shao et al. relax this condition by allowing for duplicate markers in the analysis. This generalized version of the genomic distance problem is NP-hard, and they give an integer linear programming (ILP) solution that is efficient enough to be applied to real-world datasets. A restriction of their approach is that it can be applied only to balanced genomes that have equal numbers of duplicates of any marker. Therefore, it still needs a delicate preprocessing of the input data in which excessive copies of unbalanced markers have to be removed. In this article, we present an algorithm solving the genomic distance problem for natural genomes, in which any marker may occur an arbitrary number of times. Our method is based on a new graph data structure, the multi-relational diagram, that allows an elegant extension of the ILP by Shao et al. to count runs of markers that are under- or over-represented in one genome with respect to the other and need to be inserted or deleted, respectively. With this extension, previous restrictions on the genome configurations are lifted, for the first time enabling an uncompromising rearrangement analysis. Any marker sequence can directly be used for the distance calculation. The evaluation of our approach shows that it can be used to analyze genomes with up to a few 10,000 markers, which we demonstrate on simulated and real data.
Keywords: comparative genomics, DCJ-indel distance, genome rearrangements
1. Introduction
The study of genome rearrangements has a long tradition in comparative genomics. A central question is how many (and what kind of) mutations have occurred between the genomic sequences of two individual genomes. To avoid disturbances due to minor local effects, often the basic units in such comparisons are syntenic regions identified between the genomes under study, much larger than the individual DNA bases. We refer to such regions as genomic markers, or simply markers, although often one also finds the term “genes.”
Following the initial statement as an edit distance problem (Sankoff, 1992), a comprehensive trail of literature has addressed the problem of computing the number of rearrangements between two genomes. In a seminal article in 1995, Hannenhalli and Pevzner (1999) introduced the first polynomial time algorithm for the computation of the inversion distance of transforming one chromosome into another one by means of segmental inversions. Later, the same authors generalized their results to the HP model (Hannenhalli and Pevzner, 1995), which is capable of handling multi-chromosomal genomes and accounts for additional genome rearrangements. Another breakthrough was the introduction of the double cut and join (DCJ) model (Yancopoulos et al., 2005; Bergeron et al., 2006), which is able to capture many genome rearrangements and whose genomic distance is computable in linear time. The model is based on a simple operation in which the genome sequence is cut twice between two consecutive markers and re-assembled by joining the resulting four loose cut-ends in a different combination.
A prerequisite for applying the DCJ model in practice is that their genomic marker sets must be identical and that any marker occurs exactly once in each genome. This severely limits its applicability in practice. Linear time extensions of the DCJ model allow markers to occur exclusively in one of the two genomes, computing a genomic DCJ-insertion/deletion (indel) distance that minimizes the sum of DCJ and indel events (Braga et al., 2011; Compeau, 2013). Still, markers are required to be singleton, that is, no duplicates can occur. When duplicates are allowed, the problem is more intricate and all approaches proposed so far are NP-hard (see for instance, Sankoff, 1999; Bryant, 2000; Bulteau and Jiang, 2013; Angibaud et al., 2009; Martinez et al., 2015; Shao et al., 2015; Yin et al., 2016). From the practical side, more recently, Shao et al. (2015) presented an integer linear programming (ILP) formulation for computing the DCJ distance in the presence of duplicates, but restricted to balanced genomes, where both genomes have equal numbers of duplicates. Yin et al. (2016) then developed a branch and bound approach to compute the DCJ-indel distance of quasi-balanced genomes, which have not only an equal number of duplicated common markers but also markers that occur exclusively in one of the two genomes. An ILP that computes the DCJ-indel distance of unbalanced genomes was later presented by Lyubetsky et al. (2017), but their approach does not seem to be applicable to real data sets; see Section 6.1.2 for details.
In this article, we present the first feasible exact algorithm for solving the NP-hard problem of computing the distance under a general genome model where any marker may occur an arbitrary number of times in any of the two genomes, called natural genomes. Specifically, we adopt the maximal matches model where only markers appearing more often in one genome than in the other can be deleted or inserted. Our ILP formulation is based on the one from Shao et al. (2015), but with an efficient extension that allows to count runs of markers that are under- or over-represented in one genome with respect to the other, so that the pre-existing model of minimizing the distance allowing DCJ and indel operations (Braga et al., 2011) can be adapted to our problem. With this extension, once we have the genome markers, no other restriction on the genome configurations is imposed.
The evaluation of our approach shows that it can be used to analyze genomes with up to a few 10,000 markers, provided the number of duplicates is not too large. The complete source code of our ILP implementation and the simulation software used for generating the benchmarking data in Section 6.2 are available from https://gitlab.ub.uni-bielefeld.de/gi/ding.
This article is an extended version of earlier work that was presented at RECOMB 2020 (Bohnenkämper et al., 2020).
2. Preliminaries
A genome is a set of chromosomes, and each chromosome can be linear or circular. Each marker in a chromosome is an oriented DNA fragment. The representation of a marker m in a chromosome can be the symbol m itself, if it is read in direct orientation, or the symbol , if it is read in reverse orientation. We represent a chromosome S of a genome A by a string s, obtained by the concatenation of all symbols in S, read in any of the two directions. If S is circular, we can start to read it at any marker and the string s is flanked by parentheses.
Given two genomes A and B, let be the set of all markers that occur in any of the two genomes. For each marker , let be the number of occurrences of m in genome A and be the number of occurrences of m in genome B. We can then define . If both and , m is called a common marker. We denote by the set of common markers of A and B. The markers in are called exclusive markers. For example, if we have two unichromosomal linear genomes A={1 3 2¯5 ¯4 3 5 4} and B={1623173413}, then and . Further, , , , , , and .
2.1. The DCJ-indel model
A genome can be transformed or sorted into another genome with the following types of mutations:
A DCJ is the operation that cuts a genome at two different positions (possibly in two different chromosomes), creating four open ends, and joins these open ends in a different way. This can represent many different rearrangements, such as inversions, translocations, fusions, and fissions. For example, a DCJ can cut linear chromosome 1 2 ¯4 ¯3 5 6 before and after ¯4 ¯3, creating the segments , ¯4 ¯3 and , where the symbol represents the open ends. By joining the first with the third and the second with the fourth open end, we invert ¯4 ¯3 and obtain .
Since the genomes can have distinct multiplicity of markers, we also need to consider insertions and deletions of segments of contiguous markers (Yancopoulos and Friedberg, 2009; Braga et al., 2011; Compeau, 2013). We refer to insertions and deletions collectively as indels. For example, the deletion of segment from linear chromosome results in . Indels have two restrictions: (1) only markers that have positive can be deleted; and (2) only markers that have negative can be inserted.
In this article, we are interested in computing the DCJ-indel distance between two genomes A and B, that is denoted by and corresponds to the minimum number of DCJs and indels required to sort A into B. We separate the instances of the problem in four types:
-
(1)
Singular genomes: The genomes contain no duplicate markers, that is, each common marker is singular in each genome. (The exclusive markers are not restricted to be singular, because it is mathematically trivial to transform them into singular markers when they occur in multiple copies.) Formally, we have that, for each , . The distance between singular genomes can be easily computed in linear time (Bergeron et al., 2006; Braga et al., 2011; Compeau, 2013).
-
(2)
Balanced genomes: The genomes contain no exclusive markers, but can have duplicates, and the number of duplicates in each genome is the same. Formally, we have and, for each , . Computing the distance for this set of instances is NP-hard, and an ILP formulation was given in Shao et al. (2015).
-
(3)
Quasi-balanced genomes: The genomes contain exclusive markers and can have duplicates, but still the number of duplicates in each genome is the same. Formally, we have and, for each , . Computing the distance for this set of instances is also NP-hard, and a branch and bound approach was given in Yin et al. (2016).
-
(4)
Natural genomes: These genomes can have exclusive markers and duplicates, with no restrictions on the number of copies. Since these are generalizations of balanced genomes, computing the distance for this set of instances is also NP-hard. In the present work, we present an efficient ILP formulation for computing the distance in this case.
3. DCJ-indel Distance of Singular Genomes
First, we recall the problem when common duplicates do not occur, that is, when we have singular genomes. We will summarize the linear time approach to compute the DCJ-indel distance in this case that was presented in Braga et al. (2011), already adapted to the notation required for presenting the new results of this article.
3.1. Relational diagram
For computing a genomic distance, it is useful to represent the relation between two genomes in some graph structure (Hannenhalli and Pevzner, 1995; Bergeron et al., 2006; Friedberg et al., 2008; Braga et al., 2011). Here, we adopt a variation of this structure, defined as follows. For each marker m, denote its two extremities by and . Given two singular genomes A and B, the relational diagram has a set of vertices , where has a vertex for each extremity of each marker of genome A and has a vertex for each extremity of each marker of genome B. Due to the 1-to-1 correspondence between the vertices of and the occurrences of marker extremities in A and B, we can identify each extremity with its corresponding vertex. It is convenient to represent vertices in in an upper line, respecting the order in which they appear in each chromosome of A, and the vertices in in a lower line, respecting the order in which they appear in each chromosome of B.
If the marker extremities and are adjacent in a chromosome of A, we have an adjacency edge connecting them. Similarly, if the marker extremities and are adjacent in a chromosome of B, we have an adjacency edge connecting them. Marker extremities located at chromosome ends are called telomeres and are not connected to any adjacency edge. In contrast, each extremity that is not a telomere is connected to exactly one adjacency edge. Denote by and by the adjacency edges in A and in B, respectively. In addition, for each common marker , we have two extremity edges, one connecting the vertex mh from to the vertex from and the other connecting the vertex from to the vertex mt from . Denote by the set of extremity edges. Finally, for each occurrence of an exclusive marker in , we have an indel edge connecting the vertices representing its two extremities. Denote by and by the indel edges in A and in B. Each vertex is then connected either to an extremity edge or to an indel edge.
All vertices have degree one or two, therefore is a simple collection of cycles and paths. A path that has one endpoint in genome A and the other in genome B is called an AB-path. In the same way, both endpoints of an AA-path are in A and both endpoints of a BB-path are in B. A cycle contains either zero or an even number of extremity edges. When a cycle has at least two extremity edges, it is called an AB-cycle. Moreover, a path (respectively cycle) of composed exclusively of indel and adjacency edges in one of the two genomes corresponds to a whole linear (respectively circular) chromosome and is called a linear (respectively circular) singleton in that genome. Actually, linear singletons are particular cases of AA-paths or BB-paths. An example of a relational diagram for singular is given in Figure 1.
FIG. 1.

For genomes A={1 ¯6 5 3, 4 2} and B={1 7 2 3 4 5, 7 ¯8}, the relational diagram contains one cycle, two AB-paths (represented in blue), one AA-path, and one BB-path (both represented in red). Short dotted horizontal edges are adjacency edges, long horizontal edges are indel edges, and top–down edges are extremity edges.
The numbers of telomeres and of AB-paths in are even. The DCJ-cost (Braga et al., 2011) of a DCJ operation , denoted by , is defined as follows. If it increases either the number of AB-cycles by one, or the number of AB-paths by two, is optimal and has = 0. If it does not affect the number of AB-cycles and AB-paths in the diagram, is neutral and has = 1. If it decreases either the number of AB-cycles by one, or the number of AB-paths by two, is counter-optimal and has = 2.
3.2. Runs and indel-potential
The approach that uses DCJ operations to group exclusive markers for minimizing indels depends on the following concepts.
Given two genomes A and B and a component C of , a run (Braga et al., 2011) is a maximal subpath of C in which the first and the last edges are indel edges and all indel edges belong to the same genome. It can be an -run when its indel edges are in genome A, or a -run when its indel edges are in genome B. We denote by the number of runs in component C. If , the component C is said to be indel-enclosing; otherwise, if , C is said to be indel-free.
While sorting components separately with optimal DCJs only, runs can be merged (when two runs become a single one), and also accumulated together (when all its indel edges alternate with adjacency edges only and the run can be inserted or deleted at once) (Braga et al., 2011). The indel-potential of a component C, denoted by , is the minimum number of indels derived from C after this process and can be directly computed from :
Figure 2 shows a BB-path with 4 runs, and how its indel-potential can be achieved.
FIG. 2.

(i) A BB-path with four runs. (ii) After an optimal DCJ that creates a new cycle, one -run is accumulated (between edges e4 and e3 there is only an adjacency edge) and two -runs are merged (e2 is in the same run with e5 and e6). Indeed, the indel-potential of the original BB-path is three.
The indel-potential allows to state an upper bound for the DCJ-indel distance.
Lemma 1 (from Bergeron et al., 2006; Braga et al., 2011): Given two singular genomes A and B, whose relational diagram has c AB-cycles and i AB-paths, we have:
Let and be, respectively, the sum of the indel-potentials for the components of the relational diagram before and after a DCJ . The indel-cost of is then , and the DCJ-indel cost of is defined as . While sorting components separately, it has been shown that by using neutral or counter-optimal DCJs one can never achieve ; therefore, we cannot decrease the upper bound stated earlier with DCJ operations that act on a single component of the diagram (Braga et al., 2011).
3.3. Distance of circular genomes
For singular circular genomes, the diagram is composed of cycles only. In this case, the upper bound given by Lemma 1 is tight and leads to a simplified formula (Braga et al., 2011):
3.4. Recombinations and linear genomes
For singular linear genomes, the upper bound given by Lemma 1 is achieved when the components of are sorted separately. However, there is another type of DCJ operation, called recombination, whose cuts are applied on two distinct components. These two components are called sources, whereas the components obtained after the joinings are called resultants. In particular, some recombinations whose both sources are paths have and are then said to be deducting. The total number of types of deducting recombinations is relatively small. By exhaustively exploring the space of recombination types, it is possible to identify groups of chained recombinations, so that the sources of each group are the original paths of the diagram. In other words, a path that is a resultant of a group is never a source of another group. This results in a greedy approach that optimally finds the value to be deducted, as we will describe in the following.
3.4.1. Deducting recombinations
Any recombination whose sources are an AA-path and a BB-path is optimal. A recombination whose sources are two different AB-paths can be either neutral, when the resultants are also AB-paths, or counter-optimal, when the resultants are an AA-path and a BB-path. Any recombination whose sources are an AB-path and an AA- or a BB-path is neutral (Braga and Stoye, 2010; Braga et al., 2011).
Let (respectively ) be a sequence with an odd () number of runs, starting and ending with an -run (respectively -run). We can then make any combination of and , such as , that is a sequence with an even () number of runs, starting with an -run and ending with a -run. An empty sequence (with no run) is represented by . Then each one of the notations , , , , , , , , , , , , and represents a particular type of path (AA, BB, or AB) with a particular structure of runs (, , , , or ). By convention, an AB-path is always read from A to B. These notations were adopted due to the observation that, besides the DCJ type of the recombination (optimal, neutral, or counter-optimal), the only properties that matter are whether the paths have an odd or an even number of runs and whether the first run is in genome A or in genome B (Braga et al., 2011). An example of a deducting recombination is given in Figure 3.
FIG. 3.

An optimal recombination with .
The complete set of path recombinations with is given in Table 1. In Table 2, we also list recombinations with that create at least one source of recombinations of Table 1. We denote by an AB-path that cannot be a source of a recombination in Tables 1 and 2, such as , , and .
Table 1.
Path Recombinations That Have and Allow the Best Reuse of the Resultants
| Sources | Resultants | Sources | Resultants | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | |||||||||
| 0 | |||||||||
| 0 | |||||||||
| 0 | |||||||||
| 0 | |||||||||
| 0 | |||||||||
| 0 |
Table 2.
Path Recombinations with Creating Resultants That Can Be Used in Recombinations with
| Sources | Resultants | Sources | Resultants | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | ||||||
| 0 | 0 | 0 | 0 | ||||||
| 0 | 0 | ||||||||
| 0 | 0 |
The two sources of a recombination can also be called partners. Looking at Table 1, we observe that all partners of - and -paths are also partners of - and -paths, all partners of - and -paths are also partners of -paths, and all partners of - and -paths are also partners of -paths. Moreover, in some cases deducting recombinations are chained, that is, resultants from deducting recombinations in Tables 1 and 2 are sources of other deducting recombinations, as shown in Figure 4. These observations allow the identification of groups of chained recombinations, as listed in Table 3.
FIG. 4.

Chained recombinations transforming four paths () into four other paths () with overall .
Table 3.

Each group is represented by a combination of letters, where:
represents an , ¯W represents an , and _W represents an ;
represents a , ¯M represents a , and _M represents a ;
represents an , and represents an .
Although some groups have reusable resultants, those are actually never reused. (If groups that are lower in the table use as sources resultants from higher groups, the sources of all referred groups would be previously consumed in groups that occupy even higher positions in the table.) Due to this fact, the number of occurrences in each group depends only on the initial number of each type of component.
The deductions shown in Table 3 can be computed with an approach that greedily maximizes the groups in P, Q, T, S, M, and M in this order. The P part contains only one operation and is, thus, very simple. The same happens with Q, since the two groups in this part are exclusive after applying P. The four subparts of T are also exclusive after applying Q. (Note that groups WW¯M, WW_M, MM¯W, and MM_W of T are simply subgroups of Q.) The groups in S correspond to the simple application of all possible remaining operations with . After applying operations of type , ¯W¯M, and _W_M, the remaining operations in S are all exclusive. After S, the two groups in are exclusive and then the same happens to the six groups in N (that are simply subgroups of ).
We can now write the theorem that gives the exact formula for the DCJ-indel distance of linear singular genomes.
Theorem 1 (from Braga et al., 2011):
Given two singular linear genomes A and B, whose relational diagram has c AB-cycles and i AB-paths, we have:
where and P, Q, T, S, , and N here refer to the number of deductions in the corresponding chained recombination groups.
4. DCJ-indel Distance of Natural Genomes
Based on the results presented so far, we develop an approach for computing the DCJ-indel distance of natural genomes A and B. First, we note that it is possible to transform A and B into matched singular genomes and as follows. For each common marker , if , we should determine which occurrence of m in B matches each occurrence of m in A, or if , which occurrence of m in A matches each occurrence of m in B. The matched occurrences receive the same identifier (e.g., by adding the same index) in and in . Examples are given in Figure 5 (top and center). Observe that, after this procedure, the number of common markers between any pair of matched genomes and is:
FIG. 5.

Natural genomes A=1 3 2 ¯5 ¯4 3 5 4 and can give rise to many distinct pairs of matched singular genomes. The relational diagrams of two of these pairs are represented here, in the top and center. In the bottom, we show the multi-relational diagram . The decomposition that gives the diagram in the top is represented in red/orange. Similarly, the decomposition that gives the diagram in the center is represented in blue/cyan. Edges that are in both decompositions have two colors.
Let be the set of all possible pairs of matched singular genomes obtained from natural genomes A and B. The DCJ-indel distance of A and B is then defined as:
4.1. Multi-relational diagram
Although the original relational diagram clearly depends on the singularity of common markers, when they appear in multiple copies we can obtain a data structure that integrates the properties of all possible relational diagrams of matched genomes. The multi-relational diagram of two natural genomes A and B also has a set with a vertex for each of the two extremities of each marker occurrence of genome A and a set with a vertex for each of the two extremities of each marker occurrence of genome B.
Again, sets and contain adjacency edges connecting adjacent extremities of markers in A and in B. But here the set contains, for each marker , an extremity edge connecting each vertex in that represents an occurrence of to each vertex in that represents an occurrence of , and an extremity edge connecting each vertex in that represents an occurrence of to each vertex in that represents an occurrence of mh. Further, for each marker with , the set contains one indel edge connecting the vertices representing the two extremities of the same occurrence of m in A. Similarly, for each marker with , the set contains one indel edge connecting the vertices representing the two extremities of the same occurrence of in B. An example of a multi-relational diagram is given in Figure 5 (bottom).
4.1.1. Consistent decompositions
Note that if A and B are singular genomes, reduces to the ordinary . On the other hand, in the presence of duplicate common markers, may contain vertices of a degree larger than two. A decomposition is a collection of vertex-disjoint components, which can be cycles and/or paths, covering all vertices of . There can be multiple ways of selecting a decomposition, and we need to find one that allows to match occurrences of a marker in genome A with occurrences of the same marker in genome B.
Let and be, respectively, occurrences of the same marker m in genomes A and B. The extremity edge that connects to and the extremity edge that connects to are called siblings. A set is a sibling set if it is exclusively composed of pairs of siblings and does not contain any pair of incident edges. In other words, there is a clear bijection between matchings of occurrences and sibling sets of . In particular, a maximal sibling set S corresponds to a maximal matching of occurrences of common markers in both genomes and we denote by and the matched singular genomes corresponding to the sibling set S.
The set of edges induced by a maximal sibling set S is said to be a consistent decomposition of and can be obtained by the following two steps: (i) In the beginning, is the union of S with the sets of adjacency edges and ; (ii) for each indel edge e, if its two endpoints have degree one or zero in , then e is added to . Note that the consistent decomposition covers all vertices of and is composed of cycles and paths, allowing us to compute the value:
where cD and iD are the numbers of AB-cycles and AB-paths in , respectively, and is the optimal deduction of recombinations of paths from . Since is constant for any consistent decomposition, we can separate the part of the formula that depends on , called weight of :
Given two natural genomes A and B, the DCJ-indel distance of A and B can then be computed by the following equation:
where is the set of all maximal sibling sets of .
A consistent decomposition such that is said to be optimal. Computing the DCJ-indel distance between two natural genomes A and B, or, equivalently, finding an optimal consistent decomposition of is an NP-hard problem. In Section 6, we will describe an efficient ILP formulation to solve it. Before that, we need to introduce a transformation of that is necessary for our ILP.
5. Capping
The ends of linear chromosomes produce some difficulties for the decomposition. Fortunately there is an elegant technique to overcome this problem, called capping (Hannenhalli and Pevzner, 1995). It consists of modifying the genomes by adding artificial singular common markers, called caps, that circularize all linear chromosomes, so that their relational diagram is composed of cycles only, but, if the capping is optimal, the genomic distance is preserved.
5.1. Capping of canonical genomes
When two singular genomes A and B have no exclusive markers, they are called canonical genomes.
The diagram of canonical genomes A and B has no indel edges, and the indel-potential of any component C is . In this case, the upper bound given by Lemma 1 is tight, and the distance formula can be simplified to , as already shown in Bergeron et al. (2006).
Also, obtaining an optimal capping of canonical genomes is quite straightforward (Hannenhalli and Pevzner, 1995; Yancopoulos et al., 2005; Braga and Stoye, 2010), as shown in Table 4: The caps should guarantee that each AB-path is closed into a separate AB-cycle, and each pair composed of an AA- and a BB-path is closed into an AB-cycle by linking each extremity of the AA-path to one of the two extremities of the BB-path (there are two possibilities of linking, and any of the two is optimal). If the numbers of linear chromosomes in A and in B are different, there will be some AA- or BB-paths remaining. For each of these, an artificial adjacency between caps is created in the genome with less linear chromosomes, and each artificial adjacency closes each remaining AA- or BB-path into a separate AB-cycle.
Table 4.
Linking Paths from of Canonical Genomes
| Linking AB-cycle | |||||
|---|---|---|---|---|---|
| Paths | |||||
| AB | 0 | ||||
| 0 | 0 | ||||
| Remaining paths | |||||
| AA | 0 | 0 | |||
| BB | 0 | 0 | |||
The symbol represents an artificial adjacency in A, and the symbol represents an artificial adjacency in B. The value corresponds to .
Let be the total number of linear chromosomes in A and be the total number of linear chromosomes in B. The difference between the number of AA- or BB-paths is equal to the difference between and . In other words, if has a AA-paths, b BB-paths, and i AB-paths, the number of artificial adjacencies in such an optimal capping is exactly . Moreover, the number of caps to be added is:
We can show that the capping described earlier is optimal by verifying the corresponding DCJ-indel distances. Let the original genomes A and B have n markers and have c AB-cycles, besides the paths. Then, after capping, the circular genomes and have markers and has AB-cycles and no path, so that:
An example of an optimal capping of two canonical linear genomes is given in Figure 6.
FIG. 6.

Optimal capping of canonical genomes and into , and . Each pair of AA-+BB-path is linked into a separate AB-cycle.
5.2. Singular genomes: correspondence between recombinations and capping
When exclusive markers occur, we can obtain an optimal capping by simply finding caps that properly link the sources of each recombination group (listed in Table 3) into a single AB-cycle. Indeed, in Table 5 we give a linking that achieves the optimal for each recombination group, followed by the optimal linking of remaining paths. The remaining paths are treated exactly as the linking of paths in canonical genomes. By greedily linking the paths following a top–down order of the referred Table 5, we clearly obtain an optimal capping that transforms A and B into circular genomes and with . See an example in Figure 7.
Table 5.
Linking Sources of Chained Recombination Groups from Table 3

FIG. 7.

Optimal capping of singular genomes and into 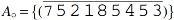 and . This capping shows how to optimally link the four sources of the chained recombinations of Figure 4 into a single AB-cycle.
and . This capping shows how to optimally link the four sources of the chained recombinations of Figure 4 into a single AB-cycle.
Further, similar to the case of canonical genomes, the numbers of artificial adjacencies and caps in such a capping are, respectively, and as we will show in the following.
In Table 5, we can observe that there are two types of groups: (1) balanced, which contain the same number of AA- and BB-paths, and (2) unbalanced, in which the numbers of AA- and BB-paths are distinct. Unbalanced groups require some extra elements to link the cycle. These elements can be indel-free AA- or BB-paths (of the type, i.e., under-represented in the group) or, if these paths do not exist, artificial adjacencies either in genome A or in genome B (again, of the genome, i.e., under-represented in the group). We then need to examine these unbalanced groups to determine the number of caps and of artificial adjacencies that are required for an optimal capping.
Proposition 1: After identifying the recombination groups, either we have only unbalanced groups that are over-represented in genome A or we have only unbalanced groups that are over-represented in genome B.
Proof: It is clear that, after P and until N, we have either only groups (over-represented in A) or only groups (over-represented in B). The question is whether groups in N that are over-represented in B are compatible with previous groups of type and, symmetrically, whether groups in N that are over-represented in A are compatible with previous groups of type .
Let us examine the case of group ZZ_W. (1) At a first glance, one could think that this group is compatible with MM_W. However, if all components of these two unbalanced groups would be in the diagram, we would instead have two times the group MZ_W, which is balanced and located before the two other groups in the table (observe that MZ_W has a smaller than ZZ_W + MM_W). (2) When we test the compatibility of ZZ_W with MM¯W, we see that with the same components we would get MM¯W_W, which is balanced and located before the two other groups in the table (observe that MM¯W_W has the same as ZZ_W + MM¯W).
With a similar analysis we can show that for all cases either we have only unbalanced groups that are over-represented in genome A or we have only unbalanced groups that are over-represented in genome B.
Proposition 2: When an unbalanced group is being linked, either there is a remaining AA- or BB-path (of the genome that is under-represented), which is then used to link the group, or there is no remaining AA- or BB-path (of the genome, i.e., under-represented) and an artificial adjacency links the group.
Proof: First we observe that, after distributing all paths of the relational diagram among the recombination groups, following the top–down greedy approach, there could be AA- and/or BB-paths remaining, which were not assigned to any group, and they might be useful to link unbalanced groups. We will now examine the procedure of linking the unbalanced groups either with those remaining paths or with artificial adjacencies.
A particular case are the unbalanced groups from T. Since all unbalanced groups in T have analogous compositions, without loss of generality, suppose a group over-represented in genome A of type WW¯M is being linked. If, at this point, there is a remaining indel-enclosing BB-path, it cannot be or ; otherwise with the components of the group being linked and the existing remaining path we could form a balanced group that appears in a higher position of the table, with at least the same , which is a contradiction. We could, however, have an extra -path. In this case, we would take the alternative solution of linking each pair + into a separate cycle, which is twice group W¯M of S, achieving the same . If no -path remains, we would have the standard linking of the three paths into a single cycle, including either an indel-free BB-path or an artificial adjacency in B.
The unbalanced groups from S or N are easier to analyze: If one of these groups, over-represented in genome A (respectively in genome B), is being linked, there cannot be any remaining indel-enclosing BB-path (respectively AA-path). We can verify this by supposing, without loss of generality, that an unbalanced group over-represented in genome A is being linked. If, at this point, there is a remaining indel-enclosing BB-path, then with the components of the group being linked and the existing remaining path we could form a balanced group that appears in a higher position of the table, with at least the same , which is a contradiction.
Propositions 1 and 2 prove the following result.
Theorem 2: Let and be, respectively, the total numbers of linear chromosomes in singular genomes A and B. We can obtain an optimal capping of A and B with exactly
caps and artificial adjacencies between caps.
5.3. Capped multi-relational diagram
We can transform into the capped multi-relational diagram as follows. First, we need to create new vertices, named and , with each one representing a cap extremity. Each of the telomeres of A is connected by an adjacency edge to a distinct cap extremity among . Similarly, each of the telomeres of B is connected by an adjacency edge to a distinct cap extremity among . Moreover, if , for , connect to by an artificial adjacency edge. Otherwise, if , for , connect to by an artificial adjacency edge. All these new adjacency edges and artificial adjacency edges are added to and , respectively. We also connect each , , by a cap extremity edge to each , , and denote by the set of cap extremity edges. An example of a capped multi-relational diagram is given in Figure 8.
FIG. 8.

Natural genomes A=1 3 2 ¯5 ¯4 3 5 4 and and their capped multi-relational diagram .
A set is a capping set if it does not contain any pair of incident edges. A capped consistent decomposition of is induced by a maximal sibling set and a maximal capping set and is composed of vertex disjoint cycles covering all vertices of . We then have , where the weight of can be computed by the simple formula:
Theorem 3: Let be the set of all maximal capping sets from . For each maximal sibling set S of and , we have:
Proof: Recall that each maximal sibling set S of corresponds to a pair of matched singular genomes and . Further, in , (1) each maximal capping set P corresponds to exactly caps, and (2) all adjacencies, including the artificial adjacencies between cap extremities, are part of each consistent decomposition . Theorem 2 states that the pair of matched singular genomes and can be optimally capped with caps and artificial adjacencies. Therefore, it is clear that at least one optimal capping of and corresponds to a consistent decomposition of , that is, .
As a consequence of Theorem 3, if is the set of all maximal sibling sets and is the set of all maximal caping sets, we have:
Each decomposition corresponds to several capped versions of singular genomes and , depending on how the cap extremities are paired. We do not need to identify the exact capped version we get, because all versions obtained with the same capping set P give the same DCJ-indel distance.
6. An Algorithm to Compute the DCJ-Indel Distance of Natural Genomes
An ILP formulation for computing the distance of two balanced genomes A and B was given by Shao et al. (2015). In this section, we describe an extension of that formulation for computing the DCJ-indel distance of natural genomes A and B, based on consistent cycle decompositions of . The main difference is that here we need to address the challenge of computing the indel-potential for each cycle C of each decomposition. Note that a cycle C of has either 0, or 1, or an even number of runs; therefore, its indel-potential can be computed as follows:
The formula cited earlier can be redesigned to a simpler one, which is easier to implement in the ILP. First, let a transition in a decomposition be an indel-free path that is flanked by an indel edge from and an indel edge from . Each transition is part of some cycle C of and we denote by the number of transitions in C. Observe that, if C is indel-free, then obviously . If C has a single run, then we also have . On the other hand, if C has at least 2 runs, then . Our new formula is then split into a part that simply tests whether C is indel-enclosing and a part that depends on the number of transitions .
Proposition 3: Given the function defined as if ; otherwise , the indel-potential can be computed from the number of transitions with the formula:
Note that , where and sQ are the number of indel-enclosing AB-cycles and the number of circular singletons in , respectively. Further, the number of transitions in , given by the sum does not really need to be computed per cycle, that is, we can directly count the number of transitions in without keeping trace of which cycle each transition belongs to. We then denote by the number of transitions in .
Now, we need to find a consistent decomposition of maximizing the weight:
where is the number of indel-free AB-cycles in .
6.1. ILP formulation
Our formulation (shown in Algorithm 1) searches for an optimal consistent cycle decomposition of , where the set of edges E is the union of all disjoint sets of the distinct types of edges, .
In the first part, we use the same strategy as Shao et al. (2015). A binary variable is introduced for every edge e, indicating whether e is part of the computed decomposition. Constraint C.01 ensures that adjacency edges are in all decompositions, Constraint C.02 ensures that each vertex of each decomposition has degree 2, and Constraint C.03 ensures that an extremity edge is selected only together with its sibling. Counting the number of cycles in each decomposition is achieved by assigning a unique identifier i to each vertex vi that is then used to label each cycle with the numerically smallest identifier of any contained vertex (see Constraint C.04, Domain D.02). A vertex vi is then marked by variable as representative of a cycle if its cycle label yi is equal to . However, unlike Shao et al., we permit each variable yi to take on value 0, which, by Constraint C.05, will be enforced whenever the corresponding cycle is indel-enclosing. Since the smallest label of any vertex is 1 (cf. Domain D.02), any cycle with label 0 will not be counted.
The second part is our extension for counting transitions. We introduce binary variables to label runs. To this end, Constraint C.07 ensures that each vertex v is labeled 0 if v is part of an -run and otherwise it is labeled 1, indicating its participation in a -run. Transitions between - and -runs in a cycle are then recorded by binary variable . If a label change occurs between any neighboring pair of vertices of a cycle, Constraint C.08 causes transition variable to be set to 1. We avoid an excess of co-optimal solutions by canonizing the locations in which transitions are observed. More specifically, Constraint C.09 prohibits label changes in adjacencies not directly connected to an indel and Constraint C.10 in edges other than adjacencies of genome A, resulting in the transition being observed as close to the A-run as possible.
In the third part we add a new constraint and a new domain to our ILP, so that we can count the number of circular singletons. Let K be the circular chromosomes in both genomes and be the set of indel edges of a circular chromosome . For each circular chromosome we introduce a decision variable , which is 1 if k is a circular singleton and 0 otherwise. A circular chromosome is then a singleton if all its indel edges are set (see Constraint C.11). Only in that case the left side of the inequality will take on value 1 and enforces sk to be set to 1 as well.
The objective of our ILP is to maximize the weight of a consistent decomposition, which is equivalent to maximizing the number of indel-free cycles, counted by the sum over variables zi, while simultaneously minimizing the number of transitions in indel-enclosing AB-cycles, calculated by half the sum over variables te, and the number of circular singletons, calculated by the sum over variables sk.

6.1.1. Implementation
We implemented the construction of the ILP as a python application, available at https://gitlab.ub.uni-bielefeld.de/gi/ding.
6.1.2. Comparison to the approach by Lyubetsky et al
As mentioned in Section 1, another ILP for the comparison of genomes with unequal content and paralogs was presented by Lyubetsky et al. (2017). To compare our method with theirs, we ran our ILP by using CPLEX on a single thread with the two small artificial examples given in that article on page 8. The results in terms of DCJ distance were the same. A comparison of running times is presented in Table 6.
Table 6.
Comparison of Running Times and Memory Usage to the Integer Linear Programming in Lyubetsky et al.
| Dataset | No. of markers | No. of marker occurrences | Running time as reported by Lyubetsky et al. (2017) | Our running time (seconds) | Our peak memory (kb) |
|---|---|---|---|---|---|
| Example 1 | 5/5 | 9/9 | “About 1.5 hours” | 0.16 | 13,200 |
| Example 2 | 10/10 | 11/11 | “About 3 hours” | 0.05 | 13,960 |
6.2. Performance benchmark
For benchmarking purposes, we used Gurobi 9.0 as a solver. In all our experiments, we ran Gurobi on a single thread.
6.2.1. Generation of simulated data
Here, we describe our simulation tool that is included in our software repository (https://gitlab.ub.uni-bielefeld.de/gi/ding) and used for evaluating the performance of our ILP implementation.
Our method samples marker order sequences over a user-defined phylogeny. However, here we restrict our simulations to pairwise comparisons generated over rooted, weighted trees of two leaves. Starting from an initial marker order sequence of user-defined length (i.e., number of markers), the simulator samples Poisson-distributed DCJ events with expectation equal to the corresponding edge weights. Likewise, insertion, deletion, and duplication events of one or more consecutive markers are sampled; however, their frequency is additionally dependent on a rate factor that can be adjusted by the user. The length of each segmental insertion, deletion, and duplication is drawn from a Zipfian distribution, whose parameters can also be adjusted by the user. At each internal node of the phylogeny, the succession of mutational operations is performed in the following order: DCJ operations, duplications, deletions, insertions. To this end, cut points, as well as locations for insertions, deletions, and duplications are uniformly drawn over the entire genome.
In our simulations, we used for Zipfian distributions of insertions and deletions, and for duplications. Unless specified otherwise, insertion and deletion rates were set to be and , respectively. We set the length of the root genome to 20,000 marker occurrences.
6.2.2. Evaluating the impact of the number of duplicate occurrences
To evaluate the impact of the number of duplicate occurrences on the running time, we first keep the number of simulated DCJ events fixed to and vary parameters that affect the number of duplicate occurrences.
Our ILP solves the decomposition problem efficiently for real-sized genomes under small to moderate numbers of duplicate occurrences: Solving times for genome pairs with <10,000 duplicate occurrences (50% of the genome size) shown in Figure 9(i) are with a few exceptions below 5 minutes and exhibit a linear increase, but solving time is expected to increase dramatically with higher numbers of duplicate occurrences. To further exploit the conditions under which the ILP is no longer solvable with reasonable compute resources, we continued the experiment with even higher amounts of duplicate occurrences and instructed Gurobi to terminate within 1 hour of computation. We then partitioned the simulated data set into 8 intervals of length 500 according to the observed number of duplicate occurrences. For each interval, we determined the average as well as the maximal multiplicity of any duplicate marker and examined the average optimality gap, that is, the difference in percentage between the best primal and the best dual solution computed within the time limit. The results are shown in Table 7 and emphasize the impact of duplicate occurrences in solving time: Below 14,000 duplicate occurrences, the optimality gap remains small and sometimes even the exact solution is computed, whereas above that threshold the gap widens very quickly.
FIG. 9.

Solving times for: (i) genomes with a varying number of duplicate occurrences, totaling 20,000 marker occurrences per genome; (ii) genome pairs with a varying number of linear chromosomes with 20,000 marker occurrences per genome; (iii) varying number of DCJs and indels applied by the simulation to genomes of 35,000 marker occurrences; and (iv) genome pairs with a varying total number of marker occurrences from both genomes.
Table 7.
Average Optimality Gap for Simulated Genome Pairs Grouped by Number of Duplicate Occurrences After 1 Hour of Running Time
| No. of duplicate occurrences | Average multiplicity of duplicate markers | Maximum multiplicity | Average optimality gap (%) |
|---|---|---|---|
| 11500..11999 | 2.206 | 8 | 0.000 |
| 12000..12499 | 2.219 | 8 | 0.031 |
| 12500..12999 | 2.217 | 7 | 0.025 |
| 13000..13499 | 2.233 | 9 | 0.108 |
| 13500..13999 | 2.247 | 8 | 0.812 |
| 14000..14499 | 2.260 | 8 | 1.177 |
| 14500..14999 | 2.274 | 8 | 81.865 |
| 15000..15499 | 2.276 | 9 | 33.102 |
6.2.3. Evaluating additional parameters
So far, we have examined only the impact of duplicates on solving times of our program. However, other parameters of our experiment are expected to have an effect on the solving times, too. We ran three experiments, in each varying one of the following parameters while keeping the others fixed: (1) genome size, (2) number of simulated DCJs and indels, and (3) number of chromosomes. The duplication rate was fixed at for these experiments, and the running time was limited to 1 hour.
The results, shown in Figure 9(ii)–(iv), indicate that the number of linear chromosomes plays a major factor in the solving time. At the same time, solving times vary more widely with increasing chromosome number. The latter has a simple explanation: Telomeres, represented as caps in the multi-relational diagram, behave in the same way as duplicate occurrences of the same marker do. Increasing their number (by increasing the number of linear chromosomes) increases exponentially the search space of matching possibilities.
Conversely, the number of simulated DCJs and indels has a minor impact on the solving times of our simulation runs. However, although initially exhibiting collinearity, the solving times for higher numbers of DCJs and indels divert super-linearly. Lastly, the genome size has a negligible effect on solving time within the tested range of to marker occurrences.
6.3. Real data analysis
To demonstrate the applicability to real datasets, we compared the genomes of six Drosophila species and reconstructed their phylogeny from pairwise DCJ-indel distances. The species names and the NCBI accession numbers of the assemblies are listed in Table 8.
Table 8.
List of Genome Assemblies Used in Our Experiments
| Species | NCBI assembly | No. of genes | No. of segments |
|---|---|---|---|
| Drosophila busckii | ASM1175060v1 | 11,371 | 23,285 |
| Drosophila melanogaster | Release 6 plus ISO1 MT | 13,048 | 62,415 |
| Drosophila pseudoobscura | UCI_Dpse_MV25 | 13,399 | 46,692 |
| Drosophila sechellia | ASM438219v1 | 13,037 | 60,855 |
| Drosophila simulans | ASM75419v2 | 13,023 | 59,520 |
| Drosophila yakuba | dyak_caf1 | 12,835 | 60,946 |
We used two types of markers. In our first experiment, markers correspond to the longest annotated coding sequences (CDSs) per locus obtained from the respective NCBI annotations. Their numbers are listed in Table 8 as well. Subsequently, we inferred hierarchical orthologous groups of these markers, with Drosophila busckii being the outgroup species running OMA standalone version 2.4.1 (Altenhoff et al., 2019) with default settings. As described earlier, we used Gurobi in computing pairwise DCJ-indel distances. As can be seen in Table 9, Gurobi was able to solve most instances within seconds with the exception of one pair, which took about 9 hours to compute, emphasizing again the sensitivity of the ILP's solving time to the number of duplicate occurrences.
Table 9.
Pairwise Comparisons of the Six Drosophila species (busckii [dbus], melanogaster [dmel], pseudoobscura [dpse], sechellia [dsec], simulans [dsim], and yakuba [dyak])
| Genome pair | Maximum multiplicity of duplicate marker | No. of duplicate markers | No. of duplicate occurrence. | Solving time (seconds) | |
|---|---|---|---|---|---|
| dbus-dmel | 23 | 303 | 832 | 4661 | 6.02 |
| dbus-dpse | 17 | 361 | 934 | 4688 | 5.29 |
| dbus-dsec | 15 | 295 | 766 | 4710 | 5.64 |
| dbus-dsim | 13 | 281 | 721 | 4767 | 5.05 |
| dbus-dyak | 19 | 318 | 785 | 4756 | 5.00 |
| dmel-dpse | 23 | 469 | 1319 | 3799 | 32,218.93 |
| dmel-dsec | 23 | 326 | 902 | 901 | 6.78 |
| dmel-dsim | 23 | 322 | 893 | 1093 | 5.73 |
| dmel-dyak | 23 | 362 | 972 | 1379 | 7.22 |
| dpse-dsec | 17 | 464 | 1227 | 3866 | 13.82 |
| dpse-dsim | 17 | 449 | 1198 | 3962 | 6.81 |
| dpse-dyak | 19 | 481 | 1259 | 3951 | 8.96 |
| dsec-dsim | 15 | 314 | 843 | 1138 | 5.67 |
| dsec-dyak | 19 | 354 | 903 | 1516 | 6.56 |
| dsim-dyak | 19 | 347 | 864 | 1661 | 23.07 |
Genomes were constructed by using genes as markers. All instances were solved by Gurobi on a single thread.
Using Neighbor Joining in MEGA X (Kumar et al., 2018), we constructed a phylogeny of the considered species. The tree rooted by D. busckii is shown in Figure 10(i). It is consistent with the knowledge on the Drosophila phylogeny so far, except for the resolution of the subtree containing the taxa melanogaster, sechellia, and simulans. Considering the corresponding Splits diagram constructed by NeighborNet in SplitsTree (Huson and Bryant, 2005) [Fig. 10(ii)], we observe that the distances in this subtree do not behave very tree-like. This suggests that, rather than an erroneous tree being computed, the resolution of the gene-based inference of markers simply does not provide distances for meaningfully clustering any two of the three taxa together.
FIG. 10.

The gene-based distances in Table 9 are used as input to reconstruct Drosophila-Phylogeny: (i) with Neighbor Joining; and (ii) as a Splits diagram.
To increase coverage and resolution, we also generated a second set of markers, directly from the genomic sequences and not restricted to genes or CDSs. We used GEESE (Rubert et al., 2020b) to construct genomic markers of length at least 500 bp. GEESE implements a heuristic for the genome segmentation problem (Visnovská et al., 2013) and takes as input local pairwise sequence alignments that we computed with LASTZ. The parameter settings used for both GEESE and LASTZ are detailed in our software repository. The number of markers in each genome is shown in Table 8. Again using Gurobi on a single thread, we were able to solve all corresponding instances of the ILP within a few minutes. The distances as well as data regarding duplicates and solving times can be found in Table 10.
Table 10.
Pairwise Comparisons of the Six Drosophila Species (busckii [dbus], melanogaster [dmel], pseudoobscura [dpse], sechellia [dsec], simulans [dsim], and yakuba [dyak])
| Genome pair | Maximum multiplicity of duplicate marker | No. of duplicate markers | No. of duplicate occurrences | Solving time (seconds) | |
|---|---|---|---|---|---|
| dbus-dmel | 15 | 582 | 1439 | 13,965 | 31.77 |
| dbus-dpse | 46 | 675 | 1882 | 14,329 | 29.94 |
| dbus-dsec | 15 | 578 | 1429 | 13,877 | 41.97 |
| dbus-dsim | 15 | 545 | 1349 | 13,822 | 23.69 |
| dbus-dyak | 15 | 615 | 1508 | 13,801 | 12.51 |
| dmel-dpse | 43 | 952 | 2480 | 18,660 | 20.38 |
| dmel-dsec | 43 | 1166 | 3126 | 5137 | 378.21 |
| dmel-dsim | 14 | 1045 | 2561 | 4791 | 23.85 |
| dmel-dyak | 34 | 1697 | 3896 | 7384 | 35.41 |
| dpse-dsec | 22 | 966 | 2511 | 18,469 | 22.72 |
| dpse-dsim | 14 | 897 | 2264 | 18,362 | 19.39 |
| dpse-dyak | 46 | 1174 | 3109 | 18,602 | 19.64 |
| dsec-dsim | 23 | 1228 | 3151 | 3403 | 29.61 |
| dsec-dyak | 23 | 1701 | 3908 | 7361 | 27.95 |
| dsim-dyak | 14 | 1562 | 3492 | 7141 | 30.20 |
Genomes were constructed by using segmentation. All instances were solved by Gurobi on a single thread.
Using the same procedure as described earlier to construct the Neighbor Joining tree and the Splits diagram (Fig. 11(i) and (ii), respectively), we find that the segmentation-based approach not only produces the correct topology of the tree, but also improves the strength of all correct splits in the previously problematic subtree, including those involving Drosophila yakuba. We notice, however, that the branch length of D. busckii is comparatively short. This is most likely due to the lack of markers, which could be inferred on the D. busckii genome (Table 8), thus leading to some rearrangements being missed. One might attribute the fact that the segmentation did not infer many homologies in this case to more rapid sequence evolution in non-coding regions.
FIG. 11.

The segmentation-based distances in Table 10 are used as input to reconstruct Drosophila-Phylogeny: (i) with Neighbor Joining; and (ii) as a Splits diagram.
7. Conclusion
By extending the DCJ-indel model to allow for duplicate markers, we introduced a rearrangement model that is capable of handling natural genomes, that is, genomes that contain shared, individual, and duplicated markers. In other words, under this model, genomes require no further processing nor manipulation once genomic markers and their homologies are inferred. The DCJ-indel distance of natural genomes being NP-hard, we presented a fast method for its calculation in the form of an integer linear program. Our program is capable of handling real-sized genomes, as evidenced in simulation and real data experiments. It can be applied universally in comparative genomics and enables uncompromising analyses of genome rearrangements.
Our experiments on real data show that our approach is easily applicable to real-world genomes, with markers generated by different methods. The power of the method, however, depends on the quality of the markers. Genes as markers proved reliable in resolving distances and relations between further related taxa while not being expressive enough to resolve some closer relations. In contrast, segmentation-based markers are better suited to resolve close distances, but they might underestimate larger distances due to lack of markers.
We hope that similar analyses will provide further insights into the underlying mutational mechanisms of other, less well-studied species. Conversely, we expect the model presented here to be extended and specialized in future to reflect the insights gained by these analyses. Follow-up work with a family-free version of our model has just appeared in the Proceedings of the Workshop on Algorithms in Bioinformatics (WABI 2020) (Rubert et al., 2020a).
Author Disclosure Statement
The authors declare they have no conflicting financial interests.
Funding Information
All funding for this work was provided by the authors' home institution, Bielefeld University.
References
- Altenhoff, A.M., Levy, J., Zarowiecki, M., et al. . 2019. OMA standalone: orthology inference among public and custom genomes and transcriptomes. Genome Res. 29, 1152–1163 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Angibaud, S., Fertin, G., Rusu, I., et al. . 2009. On the approximability of comparing genomes with duplicates. (A preliminary version appeared in Proc. of WALCOM 2008.) J. Graph Alg. Appl. 13, 19–53 [Google Scholar]
- Bergeron, A., Mixtacki, J., and Stoye, J.. 2006. A unifying view of genome rearrangements. In Proceedings of the 6th International Conference on Algorithms in Bioinformatics (WABI 2006). Volume 4175 of LNBI, Springer Verlag, Berlin-Heidelberg, pp. 163–173 [Google Scholar]
- Bohnenkämper, L., Braga, M.D.V., Doerr, D., et al. . 2020. Computing the rearrangement distance of natural genomes. In Schwartz, R., ed., Proceedings of the 24th International Conference on Research in Computational Molecular Biology, RECOMB 2020. Volume 12074 of LNCS, Springer Verlag, Cham, pp. 3–18 [Google Scholar]
- Braga, M.D.V., and Stoye, J.. 2010. The solution space of sorting by DCJ. (A preliminary version appeared in Proc. of RECOMB-CG 2009.) J. Comput. Biol. 17, 1145–1165 [DOI] [PubMed] [Google Scholar]
- Braga, M.D.V., Willing, E., and Stoye, J.. 2011. Double cut and join with insertions and deletions. (A preliminary version appeared in Proc. of WABI 2010.) J. Comput. Biol. 18, 1167–1184 [DOI] [PubMed] [Google Scholar]
- Bryant, D. 2000. The complexity of calculating exemplar distances. In Sankoff, D., and Nadeau, J.H., eds. Comparative Genomics. Kluwer Academic Publishers, Dordrecht, Boston, London. pp. 207–211 [Google Scholar]
- Bulteau, L., and M. Jiang. 2013. Inapproximability of (1,2)-exemplar distance. (A preliminary version appeared in Proc. of ISBRA 2012.) IEEE/ACM Trans. Comput. Biol. Bioinform. 10, 1384–1390 [DOI] [PubMed] [Google Scholar]
- Compeau, P.E.C. 2013. DCJ-indel sorting revisited. (A preliminary version appeared in Proc. of WABI 2012.) Alg. Mol. Biol. 8, 6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Friedberg, R., Darling, A.E., and Yancopoulos, S.. 2008. Genome rearrangement by the double cut and join operation. In Keith, J.M., ed. Bioinformatics, Volume I: Data, Sequence Analysis, and Evolution. Volume 452 of Methods in Molecular Biology, Humana Press, Totowa, New Jersey, USA, pp. 385–416 [DOI] [PubMed] [Google Scholar]
- Hannenhalli, S., and Pevzner, P.A.. 1995. Transforming men into mice (polynomial algorithm for genomic distance problem). In Proceedings of the 36th Annual Symposium of the Foundations of Computer Science (FOCS 1995). IEEE Press, Los Alamitos, California, USA, pp. 581–592 [Google Scholar]
- Hannenhalli, S., and Pevzner, P.A.. 1999. Transforming cabbage into turnip: polynomial algorithm for sorting signed permutations by reversals. (A preliminary version appeared in Proc. of STOC 1995.) J. ACM 46, 1–27 [Google Scholar]
- Huson, D.H., and Bryant, D.. 2005. Application of phylogenetic networks in evolutionary studies. Mol. Biol. Evol. 23, 254–267 [DOI] [PubMed] [Google Scholar]
- Kumar, S., Stecher, G., Li, M., et al. . 2018. MEGA X: molecular evolutionary genetics analysis across computing platforms. Mol. Biol. Evol. 35, 1547–1549 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lyubetsky, V., Gershgorin, R., and Gorbunov, K.. 2017. Chromosome structures: reduction of certain problems with unequal gene content and gene paralogs to integer linear programming. BMC Bioinform. 18, 537. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Martinez, F.V., Feijão, P., Braga, M.D.V., et al. 2015. On the family-free DCJ distance and similarity. (A preliminary version appeared in Proc. of WABI 2014.) Alg. Mol. Biol. 10, 13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rubert, D.P., Martinez, F.V., and Braga, M.D.V.. 2020. a. Natural family-free genomic distance. In Kingsford, C., and Pisanti, N., eds. Proceedings of the 20th International Workshop on Algorithms in Bioinformatics (WABI 2020), Volume 172 of Leibniz International Proceedings in Informatics (LIPIcs), Schloss Dagstuhl—Leibniz Center for Informatics, Dagstuhl, Germany, pp. 3:1–3:23 [Google Scholar]
- Rubert, D.P., Martinez, F.V., Stoye, J., et al. . 2020. b. Analysis of local genome rearrangement improves resolution of ancestral genomic maps in plants. BMC Genomics 21 (Suppl. 2): 273. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sankoff, D. 1992. Edit distance for genome comparison based on non-local operations. In Apostolico, A., Crochemore, M., Galil, Z., and Manber, U., eds. Proceedings of the Third Annual Symposium on Combinatorial Pattern Matching, CPM 1992. Volume 644 of LNCS, Springer Verlag, Berlin, pp. 121–135 [Google Scholar]
- Sankoff, D. 1999. Genome rearrangement with gene families. Bioinformatics 15, 909–917 [DOI] [PubMed] [Google Scholar]
- Shao, M., Lin, Y., and Moret, B.M.E.. 2015. An exact algorithm to compute the double-cut-and-join distance for genomes with duplicate genes. (A preliminary version appeared in Proc. of RECOMB 2014.) J. Comput. Biol. 22, 425–435 [DOI] [PubMed] [Google Scholar]
- Visnovská, M., Vinař, T., and Brejová, B.. 2013. DNA sequence segmentation based on local similarity. ITAT 1003, 36–43 [Google Scholar]
- Yancopoulos, S., Attie, O., and Friedberg, R.. 2005. Efficient sorting of genomic permutations by translocation, inversion and block interchange. Bioinformatics 21, 3340–3346 [DOI] [PubMed] [Google Scholar]
- Yancopoulos, S., and Friedberg, R.. 2009. DCJ path formulation for genome transformations which include insertions, deletions, and duplications. (A preliminary version appeared in Proc. of RECOMB-CG 2008.) J. Comput. Biol. 16, 1311–1338 [DOI] [PubMed] [Google Scholar]
- Yin, Z., Tang, J., Schaeffer, S.W., et al. . 2016. Exemplar or matching: modeling DCJ problems with unequal content genome data. J. Comb. Opt. 32, 1165–1181 [Google Scholar]