

Abstract
The importance of allopolyploidy in plant evolution has been widely recognized. The genetic changes triggered by allopolyploidy, however, are not yet fully understood due to inconsistent phenomena reported across diverse species. The construction of synthetic polyploids offers a controlled approach to systematically reveal genomic changes that occur during the process of polyploidy. This study reports the first fully sequenced synthetic allopolyploid constructed from a cross between Cucumis sativus and C. hystrix, with high‐quality assembly. The two subgenomes are confidently partitioned and the C. sativus‐originated subgenome predominates over the C. hystrix‐originated subgenome, retaining more sequences and showing higher homeologous gene expression. Most of the genomic changes emerge immediately after interspecific hybridization. Analysis of a series of genome sequences from several generations (S0, S4–S13) of C. ×hytivus confirms that genomic changes occurred in the very first generations, subsequently slowing down as the process of diploidization is initiated. The duplicated genome of the allopolyploid with double genes from both parents broadens the genetic base of C. ×hytivus, resulting in enhanced phenotypic plasticity. This study provides novel insights into plant polyploid genome evolution and demonstrates a promising strategy for the development of a wide array of novel plant species and varieties through artificial polyploidization.
Keywords: allopolyploidy, Cucumis, diploidization, evolution, genomes
The first whole‐genome sequence of a synthetic allopolyploid in Cucumis demonstrates significant subgenome dominance. Comparative genomic analyses on interspecific hybrid and different generations of allopolyploids successfully differentiate the divergent roles of hybridization, genome duplication, and diploidization in shaping the genome. Moreover, the merger of two distinct genomes practically creates a novel allopolyploid species with higher fitness.
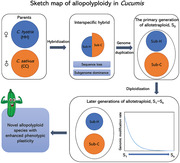
1. Introduction
Polyploids are organisms that contain three or more sets of chromosomes. They are mainly grouped into two types, autopolyploid and allopolyploid, depending on whether the multiple chromosome sets are identical or divergent. The prevalence of polyploids in nature demonstrates the evolutionary importance of polyploidy.[ 1 ] The success of allopolyploids suggests their evolutionary advantage owing to their increased diversity and plasticity.[ 2 ] However, allopolyploids face the challenge of coordinating distinct subgenomes with independent genetics and epigenetics into a single nucleus.[ 3 ] The merger of two or more divergent genomes is believed to cause “genomic shock” in the newly formed allopolyploid, resulting in genome‐wide changes of gene structure and expression.[ 4 ] One of the subgenomes may become dominant over other subgenome(s) experiencing less sequence loss and higher homeologous gene expression.[ 5 ] In other instances, allopolyploids do not show subgenome dominance, for example, Cucurbita.[ 6 ] Recent studies have suggested that the abundance and distribution of transposable elements (TEs) play a decisive role in this dominance.[ 6 , 7 ] These genomic changes are associated with phenotypic variation in allopolyploids,[ 8 ] which may ultimately contribute to their establishment and survival in nature.[ 9 ] Natural polyploids do not offer a system to study the mechanism by which cohabiting genomes are established. The exact parental genomes are often unknown or have evolved substantially since polyploid formation, and it is impossible to separately investigate changes resulting from the distinct events of interspecific hybridization and genome duplication. Efforts have been made for decades in different polyploid systems, yet the combined processes of hybridization and duplication when analyzed as snapshots seem to generate a range of possible responses that vary among genera. The examination of a synthetic allopolyploid with a defined genetic background and clear genetic history could reveal the underlying mechanisms for the distinct processes that occur during polyploidization.[ 10 ] Molecular genetics and genomic approaches applied to a synthetic allopolyploid and its derived genotypes allow a first glimpse at the process that accounts for the widespread radiation of allopolyploids in nature and agriculture.
During domestication, crops undergo evolutionary bottlenecks where genetic diversity is rapidly lost relative to wild populations; cucumber is a good example.[ 11 ] Cucumber (Cucumis sativus L.) (2n = 2x = 14), an economically important vegetable crop all over the world, is especially narrow in its genetic base.[ 11 , 12 ] Compared to other species, cucumber showed significantly fewer (61) nucleotide‐binding site (NBS) containing resistance genes,[ 13 ] highlighting the opportunity to test new approaches to enhance genetic diversity.
C. hystrix Chakr. (2n = 2x = 24) is a wild Asiatic species, rediscovered in an isolated forest in the early 1990s that is possible to cross with cucumber, although with great difficulty.[ 14 ] A synthetic allotetraploid species, C. × hytivus Chen and Kirkbride (2n = 4x = 38; containing both diploid genomes designated HHCC), was obtained via an interspecific hybridization between C. hystrix (2n = 2x = 24; HH) and C. sativus (2n = 2x = 14; CC) followed by genome duplication.[ 15 ] This interspecific amphidiploid defined a new species with fixed heterozygosity with the further possibility of introducing a wide array of novel and potentially useful genes into cucumber via sexual hybridization. Indeed, introgression lines derived from backcrossing the amphidiploid with cucumber showed increased genetic diversity, including vigorous vegetative growth, higher yield,[ 12b ] and improved resistance against several diseases, including powdery mildew,[ 16 ] downy mildew, and root‐knot nematode (RKN).[ 17 ]
Moreover, this amphidiploid, C. ×hytivus, can also be used as a model system to explore the process of allopolyploidization. Our previous studies have shown both genetic and epigenetic reprogramming in C. ×hytivus, which may contribute to the novel phenotypic variation found in amphidiploids, such as delayed leaf maturation.[ 18 ] However, understanding the underlying mechanisms has been limited by the lack of genomic information about this synthetic species. In the present study, several advanced technologies, including whole‐genome shotgun sequencing, single‐molecule real‐time (SMRT) sequencing, high‐throughput chromosome conformation capture (Hi‐C) technology, and BioNano optical genome mapping, were adopted to generate a high‐quality genome sequence of C. ×hytivus. Additionally, genome assembly of the unduplicated F1 homoploid hybrid and several early generations (S0, S4–S13) of C. ×hytivus were obtained through shotgun sequencing to differentiate the genomic consequences of interspecific hybridization from the genomic consequence of genome duplication. Furthermore, we systematically examined individuals drawn from repeated rounds of self‐pollination to reveal the genomic changes that occur after formation of the amphidiploid. By sequencing individuals that essentially define a time series through fourteen generations of inbreeding, we reveal the genomic basis for the phenomenon of “diploidization” observed in allotetraploid.
2. Results
2.1. Assembly and Annotation of the C. ×hytivus Synthetic Allotetraploid Genome
We developed a high‐quality reference genome assembly for C. ×hytivus Chen and Kirkbride (14th self‐pollinated generation, S14) (Figure S1, Supporting Information). The assembly of 69‐fold PacBio single‐molecule long reads yielded contigs totaling 530.78 Mb with an N50 of 6.9 Mb (Table 1 ). We also collected 730 970 BioNano DNA molecules over 100 kb, corresponding to 200 equivalents of the genome (Table S1, Supporting Information). The genome map assembled de novo consisted of 499 constituent genome maps with an average length of 1.66 Mb and N50 of 2.59 Mb. These assemblies were used to correct the PacBio genome assembly.[ 19 ] The final assembly via the BioNano approach contains 596 scaffolds, with a scaffold N50 of 8.09 Mb (Table 1). The total assembly size of 540.74 Mb was ≈67% and ≈77% of the genome size estimated via flow cytometry and K‐mer depth distribution of sequenced reads, respectively (Figure S2 and Table S2, Supporting Information). By aligning all the Illumina short reads of C. ×hytivus (S14) against each type of repeat, we estimated the proportion of repeats to be 62.68%, whereas the assembled repeat proportion is 39.54% of the estimated genome size (699.87 Mb) (Table S3, Supporting Information), suggesting that the remaining unassembled genome (≈23%) was mostly repeat sequences that were abnormally deeply covered by Illumina reads (Figure S3, Supporting Information). Of these repeats, 10.33% were tandem repeat sequences (i.e., types I, II, III, IV satellite DNAs, 5S, and 45S rDNA) and 12.81% were other repeats (i.e., microsatellites, minisatellites, and unassembled interspersed repeats). We further anchored the genome to chromosome scale using Hi‐C data (104‐fold coverage) (Table S4, Supporting Information). Finally, a total length of 525.78 Mb was distributed across 19 pseudomolecules (Figure S4 and Table S5, Supporting Information), representing 97.23% of the assembly above. Of this, 490.71 Mb (93.33%) can be ordered and orientated (Table S5, Supporting Information). We designated chromosomes as Chc01–Chc07 and Chh01–Chh12, corresponding to C01–C07 and H01–H12 of the diploid C. sativus (CC) and C. hystrix (HH) chromosomes, respectively (Figure 1 ).
Table 1.
C. ×hytivus (S14) reference genome assembly statistics
| PacBio | PaBio+BioNano | PaBio+BioNano+Hi‐C | |
|---|---|---|---|
| Total assembly size of contigs [bp] | 530 781 911 | 530 854 507 | 530 844 507 |
| Number of contigs | 716 | 716 | 771 |
| N50 contig length [bp] | 6 900 133 | 6 900 743 | 6 596 157 |
| N90 contig length [bp] | 756 312 | 756 360 | 657 835 |
| L50 contig count | 27 | 27 | 29 |
| L90 contig count | 112 | 112 | 121 |
| Longest contig [bp] | 26 058 674 | 26 071 117 | 26 071 117 |
| Total assembly size of scaffolds [bp] | – | 540 738 094 | 540 748 294 |
| Number of scaffolds | – | 596 | 562 |
| N50 scaffold length [bp] | – | 8 092 476 | 27 207 877 |
| N90 scaffold length [bp] | – | 1 500 330 | 15 854 818 |
| L50 scaffold count | – | 19 | 9 |
| L90 scaffold count | – | 74 | 19 |
| Gap length | – | 9 893 587 | 9 903 787 |
| Missing bases [%]A | – | 0.83% | 1.83% |
Missing bases (%) = gap length/total assembly size × 100.
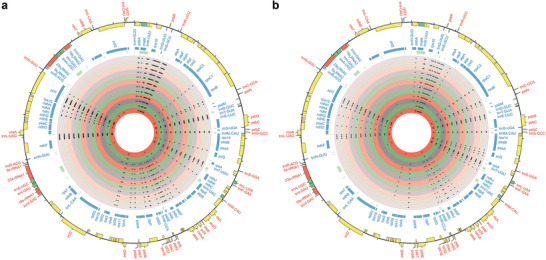
Figure 1.
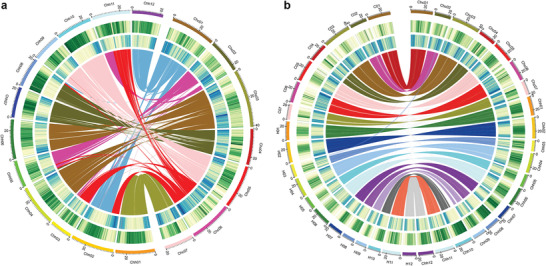
Characterization of the C. ×hytivus genome and chromosomes. a) Circos diagram showing relationships of Chc and Chh subgenome chromosomal pseudomolecules. The scale for the chromosomes (outer bars) is megabase; colors represent the density of transposon elements (blue) and genes (green). Homeologous blocks of ≥30 gene pairs between Chc01–Chc07 and Chh01–Chh12 are connected with lines. b) Syntenic comparisons between C. ×hytivus subgenomes and diploid HH and CC genomes. The outer three circles are chromosomes, density of genes, and density of transposon elements, respectively. Colored lines connect blocks with ≥30 orthologous gene pairs between the Chc and Chh subgenomes and CC and HH genomes, respectively, based on BLASP.
We identified 275.69 Mb of repetitive sequences in C. ×hytivus (S14), accounting for 50.98% of the assembly (Table S6, Supporting Information). Long terminal repeats comprise the majority of TEs, as in other sequenced Cucumis genomes.[ 13 , 20 , 21 ] By partitioning the TEs into two subgenomes, we would be able to reveal changes in repeats after allopolyploidization in these two subgenomes in comparison with their parental repeats (Figure S5, Supporting Information). In general, the Chc subgenome (SubC) of C. ×hytivus (S14) contained less TEs than the diploid C. sativus (CC) genome, while the Chh subgenome (SubH) maintained almost the same content and proportion of different types of TEs.
We used four gene‐prediction methods (RNA‐Seq, PacBio isoform sequencing (Iso‐Seq, Table S7, Supporting Information), homology‐based, and ab initio) to identify protein‐coding genes. A consensus gene set was constructed by merging all the results (Figure S6 and Table S8, Supporting Information). A total of 45 687 genes were predicted, with an average gene length of 3846 bp and 5.26 exons per gene (Table S9, Supporting Information). Approximately 97.53% of predicted genes could be annotated by matches with non‐redundant nucleotide and protein sequences in the The National Center for Biotechnology Information (NCBI), Cluster of Orthologous Groups, Gene Ontology (GO), Swiss‐Prot, and Kyoto Encyclopedia of Genes and Genomes (KEGG) databases (Table S10, Supporting Information). Genes are sparse near centromeric heterochromatin and abundant in distal euchromatin (Figure 1a). Identification of 90.90% of the 1440 genes in the Plantae Benchmarking Universal Single‐Copy Orthologs (BUSCO) dataset[ 22 ] and 97.82% of 458 core eukaryotic genes (Cluster of Essential Genes database)[ 23 ] indicated high‐quality genome assembly and annotation (Table S11, Supporting Information). Of the 18 882 orthologous gene families identified in CC and HH diploid genomes, 18 428 (97.60%) were also identified in the C. ×hytivus (S14) allotetraploid (Figure 2 ). Additionally, we identified noncoding RNAs, including 134 microRNAs, 1274 tRNAs, 2125 rRNAs, and 573 small nuclear RNAs from the C. ×hytivus (S14) genome (Table S12, Supporting Information).
Figure 2.
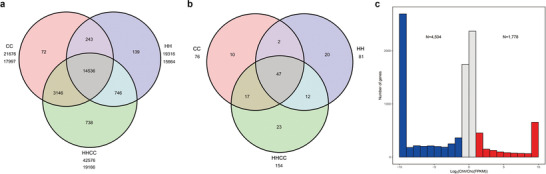
Changes of genes after allotetraploidization. a) Numbers of shared and unique orthologous protein‐coding gene clusters in C. ×hytivus, C. hystrix, and C. sativus. b) Numbers of shared and unique orthologous NBS‐encoding genes in C. ×hytivus, C. hystrix, and C. sativus. c) Histograms of genome‐wide expression of syntenic homeologous genes in C. ×hytivus (S14) leaves. N values indicate the total number of CC‐dominant (blue) and HH‐dominant (red) genes.
2.2. Subgenome Dominance
We divided the assembly of C. ×hytivus (S14) genome into Chc (203.36 Mb) and Chh (287.37 Mb) subgenomes, both of which are smaller than the corresponding CC genome (226.21 Mb)[ 20 ] and the HH genome (297.49 Mb). Similarly, the Chc and Chh subgenomes contain 23 108 and 22 535 genes, respectively, which are less than the corresponding parental species, C. sativus (24 317) and C. hystrix (23 864) (Table S9, Supporting Information). This observation contrasts with previously published work in peanut,[ 24 ] and suggests that the reported gene expansion after polyploidization in that species is not an inevitable result of polyploidization but could have occurred later in the process of diploidization. Nevertheless, the Chc and Chh subgenomes are largely colinear with the corresponding diploid parent HH and CC genomes, as shown by syntenic comparisons, which are mostly collinear (Figure 1b; Figure S7, Supporting Information). The colinearity of Chc04 with Chh07 and Chh08 was confirmed by cytological observation (Figure S8, Supporting Information). We used a previously synthesized oligo library of CC chromosome C04, which contains all oligos selected based on single copy sequences, to paint the pachytene chromosomes of C. ×hytivus (S14) by fluorescence in situ hybridization (FISH), employing a recently developed multiplex PCR‐based chromosome segmentation painting strategy[ 25 ] with the caveat that oligo‐painting cannot detect repeated sequence changes and gene loss.
Although the differences in the accuracy of the parental genome assemblies may lead to biased results, analysis of gene colinearity in C. ×hytivus (S14) revealed that the CC genome was less fractionated than the HH genome (Figure S7a, Supporting Information). In addition, structural variant (SV) analysis using the actual parental genome reads also showed that more SVs were detected in the Chh subgenome than in the Chc subgenome (Table S13, Supporting Information). We also detected parental gene loss in C. ×hytivus (S14). We identified 21 382 (88% of CC genes) orthologous gene pairs between the Chc subgenome and CC parental genome, and 18 105 (76% of HH genes) orthologous gene pairs between Chh subgenome and HH parental genome (Tables S14 and S15, Supporting Information). Compared with CC, more HH genes appeared to be lost in C. ×hytivus (S14), although most of the orthologous gene pairs in CC and HH remained as homeologous pairs in C. ×hytivus (S14). Validation via sequence depth analysis confirmed the absence of 11 CC and 146 HH genes in the C. ×hytivus (S14) genome (Tables S16 and S17, Supporting Information). These observations indicate that the Chc subgenome may be dominant over that of the Chh subgenome.
Homoeologous exchange (HE) analysis demonstrated that more HH sequences were converted by CC sequences, consistent with the dominance of the CC genome (Tables S18 and S19, Supporting Information). Moreover, we investigated the expression of syntenic gene pairs in the subgenomes of C. ×hytivus (S14). The results revealed that CC‐dominant genes were expressed significantly more than HH‐dominant genes (Figure 2c; Table S20, Supporting Information), which again proved the dominance of the Chc subgenome. Our results reinforce the phenomenon of fractionation bias[ 26 ] in allopolyploids. Fractionation bias is hypothesized to be driven by differential density of TE insertions in the progenitor genomes.[ 27 ] In this model, inactivation of TEs spreads to nearby genes, such that, on average, the homoeologous genome with the greatest density of TEs has overall weaker expression, leading to a greater probability of gene inactivation and eventual loss.[ 28 ] The genomes of the CC and Chc subgenomes contain fewer TEs than the HH genome and Chh subgenome (Figure S5, Supporting Information). Our study proved this hypothesis, showing that the overall TE densities near genes were lower for the Chc subgenome than for the other parental subgenome (Figure S9, Supporting Information).
2.3. Changes in Hybridization, Duplication, and Diploidization
To distinguish the effect of hybridization, duplication, and diploidization, we further identified 157 confirmed missing genes in the F1, S0, and other subsequent generations (S4–S13) using clean sequence read coverage analysis (Table S21, Supporting Information). The results showed that 102 genes were absent in F1 (Figure 3b, Tables S22 and S23, Supporting Information), suggesting that nuclear sequence elimination occurred immediately after the interspecific hybridization event. More interestingly, few missing genes in F1 reappeared in S0 (Tables S22 and S23, Supporting Information), suggesting a distinct role of genome duplication from genome merger in allopolyploidy. The chloroplast (cp) genome is maternally inherited in Cucumis species.[ 29 ] Comparative DNA sequence analyses revealed a total of 195 single nucleotide polymorphisms (SNPs) and 100 insertion–deletion polymorphisms (indels) in the cp genome in the F1 homoploid hybrid and early generations (S0, S4–S13) of C. ×hytivus relative to the cp genome of HH (Figure 4 ; Tables S24 and S25, Supporting Information). Of these, the majority of SNPs (73.85%) and indels (73%) were detected in F1, indicating a significantly larger effect of hybridization on the cp genome than as a result of duplication and diploidization during the process of allopolyploidization in Cucumis.
Figure 3.
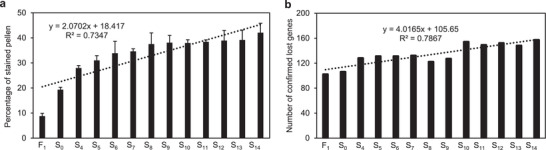
a) Pollen stainability of F1 homoploid hybrid and early generations of C. ×hytivus. Five biological replicates of 15 male flowers randomly collected from each generation of allotetraploid C. ×hytivus were assayed for pollen stainability (mean ± 5 SD). A minimum of 2000 pollen grains were collected for each biological replicate. b) Number of missing genes in F1 homoploid hybrid and early generations of C. ×hytivus.
Figure 4.
a) SNPs (closed circles) and b) indels (closed triangles) distribution of the cp genome of F1 homoploid hybrid and early generations of C. ×hytivus (from inner to outer circles) along the cp genome of C. hystrix.
According to our results, the process of diploidization can be resolved into two distinct stages. The first stage is the first three generations (S0–S4), during which the changes are dramatic. Most nuclear and cp genomic changes that occurred after allopolyploidization were detected in S4 and inherited in later generations of C. ×hytivus (Figures 3b and 4; Tables S22–S25, Supporting Information), providing direct evidence that rapid genomic changes occurred in the first few generations after allopolyploidization. Accordingly, pollen viability increased by 9% (Figure 3a).
The second stage begins with the fourth and subsequent generation (S4–S14) where we observed only sporadic nuclear sequence loss (gene loss), and no new SNPs or indels in cp genomes were identified. Occasionally, anomalies of sequence loss (gene loss), SNPs, and indels were observed in different generations (Tables S22–S25, Supporting Information), which can be explained by the individual differences within each generation as only one plant was randomly chosen for sequencing. To investigate the meiotic behavior between two subgenomes during the process of diploidization, we performed genomic in situ hybridization (GISH) experiments on pollen mother cells (PMCs) at metaphase I (MI) and anaphase I (AI) of different generations of C. ×hytivus. Abnormal meiotic chromosome behaviors were frequently observed, including asynchronous meiosis at MI (Figure S10b, Supporting Information, white and red arrows), univalents (Figure S10c, Supporting Information), intergenomic pairings (Figure S10d,e, Supporting Information), and lagging chromosomes (Figure S10f, Supporting Information). Meiotic chromosome behaviors of six generations of plants (S4, S6, S8, S10, S12, and S14) showed that the number of univalents and lagging frequency of the Chc subgenome was significantly lower than that of the Chh subgenome (Table 2 ). This suggests some instability of the Chh subgenome in this allotetraploid, which could potentially exhibit higher rates of lost sequence through inbreeding.
Table 2.
Meiotic chromosome behavior in six different generations of the synthetic allotetraploid C. ×hytivus. Different lower case letters indicate significant difference between the values in each column by Duncan's test, p < 0.05
| Generation | No. of PMCsA at MIB | No. [%] of PMCs with 19 homologous bivalents | Bivalents [mean ± SD] | No. [%] of PMCs with univalent | No. [%] of PMCs with intergenomic pairings | No. of PMCs at AIC | No. [%] of PMCs with lagging chromosome | |||
|---|---|---|---|---|---|---|---|---|---|---|
| Chc | Chh | Chc | Chh | Chc | Chh | |||||
| S4 | 143 | 49 (34.2)e | 6.69 ± 0.5 | 10.81 ± 1.1 | 34 (23.5) a | 93 (65.2) a | 35 (24.4) a | 95 | 26 (26.6) a | 75 (79.0) a |
| S6 | 122 | 45 (36.9)e | 6.71 ± 0.5 | 10.94 ± 1.0 | 24 (19.6) b | 76 (62.5) a | 24 (19.8) b | 102 | 25 (24.3)a,b | 74 (72.2)a,b |
| S8 | 104 | 44 (42.2)d | 6.76 ± 0.5 | 11.13 ± 0.9 | 17 (16.6) b | 57 (55.3) b | 18 (17.1)b,c | 89 | 18 (20.6)a,b,c | 60 (67.4)b,c |
| S10 | 113 | 54 (48.01) c | 6.77 ± 0.4 | 11.17 ± 1.0 | 13 (11.7) c | 57 (50.4) b | 17 (15.0)c,d | 117 | 22 (19.6)b,c | 74 (62.7)c |
| S12 | 128 | 76 (59.1) b | 6.87 ± 0.3 | 11.5 ± 0.7 | 12 (9.6)c,d | 52 (40.9) c | 15 (11.7)d,e | 102 | 15 (14.7)c,d | 61 (59.5)c,d |
| S14 | 131 | 98 (74.0) a | 6.88 ± 0.4 | 11.7 ± 0.6 | 9 (6.9)d | 31 (24.6)d | 13 (10.0)e | 113 | 11 (10.1)d | 63 (55.8)d |
Pollen mother cells
Metaphase I
Anaphase I.
We hypothesized that genome instability of Chh could be primarily responsible for the reduced fertility of C. ×hytivus. Nevertheless, the frequency of PMCs with 19 homologous bivalents increased significantly with generations. Correspondingly, the frequency of meiotic abnormalities, including univalents, intergenomic pairing, and lagging chromosomes, decreased significantly (Table 2). In line with this, pollen stainability increased steadily by generation, suggesting the recovery of fertility (Figure 3a).
2.4. Broadened Genetic‐Based and ‐Enhanced Heat Resilience
The initial gene prediction identified 72 and 82 NBS‐LRR‐encoding genes in the Chc and Chh subgenomes of C. ×hytivus, respectively (Tables S26 and S27, Supporting Information). Of these, 79.87% (64 Chc and 59 Chh) were colinear with those of CC and HH (Figure 2b; Table S27, Supporting Information). The retention of the most duplicated NBS‐LRR encoding genes from both parents could provide C. ×hytivus with more resilience to diseases, increasing its chance to survive where the parent species cannot.[ 30 ] Indeed, C. ×hytivus (S14) showed resistance to RKN (Meloidogyne spp.) comparable to that of HH,[ 31 ] and higher than that of CC (Figure S11, Supporting Information).
In addition, polyploidy confers resistance to abiotic stresses not tolerated by diploid progenitors.[ 32 ] We compared the growth, physiological response, and transcriptomic expression levels in the leaves of C. ×hytivus compared with its two diploid parental species exposed to elevated temperature and control conditions. The relative growth rates (RGR) of plant height were significantly increased in C. ×hytivus under heat treatment for 5 days, while the RGR of leaf size was significantly decreased (Figure 5a–c). The chlorophyll (Chl) content and net photosynthesis rate (Pn) of C. ×hytivus significantly increased after 2 days and 1 day of heat treatment, respectively (Figures 5e and 5h). Gene expression analysis showed that the expression of 2135 genes was significantly changed after heat treatment in C. ×hytivus, but not in the parents (Figure S12a, Supporting Information). These genes were mainly involved in carbon fixation in photosynthetic organisms, carbon metabolism, and glyoxylate and dicarboxylate metabolism, which confirmed the observed enhanced Chl accumulation and photosynthesis of C. ×hytivus in response to heat stress (Figure S12b, Supporting Information).
Figure 5.
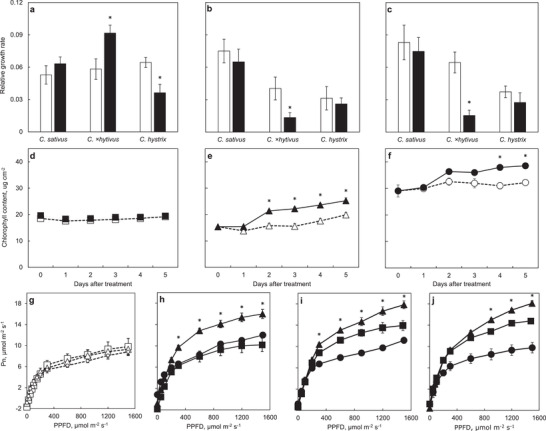
a–c) RGR of C. ×hytivus and diploid parents under control (white bars) and high temperature (black bars) for 5 days: a) plant height, b) leaf length, and c) leaf width. d–f) Chl content of developing leaf in the three species measured by Dualex 4 from day 0 to day 5: d) C. sativus (CC), e) C. ×hytivus, and f) C. hystrix (HH). g–j) Light response curves of Pn of the three species g) before the treatments, h) on day 1, i) day 2, and j) day 5 of the treatments: C. sativus (CC) (square); C. ×hytivus (HHCC) (triangle), and C. hystrix (HH) (circular). Control (white dotted line) and HT treatment (black solid line). Vertical bars represent the mean values ± SD (n = 3). An ANOVA was performed to test the differences between the control and HT treatment. Mean separations were done using the Duncan multiple range test of p < 0.05.
3. Discussion
In this study, we present the first chromosome‐scale genome assembly of a synthesized allotetraploid. Thereafter, by systematic sampling through generations of inbreeding after the initial polyploidization, we were able to precisely identify the nature of genomic changes that emerged through successive rounds of inbreeding, and tested for changes in underlying adaptability to stress. Our results reveal a detailed set of mechanisms that likely account for the phenomenon of subgenome dominance, which has been described in many allopolyploid species,[ 26 ] including Arabidopsis thaliana,[ 7 ] Zea mays,[ 33 ] Brassica rapa,[ 30b ] B. juncea,[ 19 ] Triticum aestivum,[ 34 ] and Arachis hypogaea.[ 24 ] Some allopolyploids such as Capsella bursa‐pastoris do not exhibit subgenome dominance.[ 35 ] Pumpkin or squash (Cucurbita spp.), belonging to the same Cucurbitaceae family as Cucumis, is a paleo‐allotetraploid. No significant dominance was found between the two ancient subgenomes of Cucurbita, perhaps due to their similar TE numbers and distributions.[ 8 ] In a previous study on C. ×hytivus, preliminary amplified fragment length polymorphism (AFLP) analysis showed that the frequency of sequence loss from the CC genome was higher than that from the HH genome in both the initial F1 hybrid and S0 generation.[ 18d ] It should be noted, however, that AFLPs are dominant markers; therefore, it is difficult to infer genome‐wide conclusions from them. In contrast to the previous study, in the present work, genome‐wide analysis was carried out via sequencing that demonstrated that the CC‐derived Chc subgenome experienced significantly less fractionation and was more highly expressed than the HH‐derived Chh subgenome following the experimental allopolyploidization that synthesized C. ×hytivus. This bias (“dominance”) begins to manifest immediately after interspecific hybridization, consistent with the results from a recent report on monkeyflowers.[ 9 ]
Allopolyploidization involves two processes: genome merger (e.g., hybridization of different genotypes, typically from different species) and genome duplication. Synthetic allopolyploid systems allow direct comparison of the unduplicated F1 hybrid with its doubled offspring, and thus represent an important tool for understanding the early stages of allopolyploid formation,[ 5 , 14 ] and for assessing the relative contributions of genome merger and genome doubling.[ 14 ] Given the importance and prevalence of allopolyploidy in plants,[ 36 ] relatively few studies have been conducted to date, and even among these, results among distinct genera differ.[ 37 ] In Arabidopsis allotetraploids, changes in gene expression were primarily attributed to interspecific hybridization rather than polyploidization.[ 38 ] Similarly, hybridization rather than genome doubling is reported to trigger the majority of genetic and epigenetic changes in Spartina.[ 39 ] In contrast, although most sequence elimination was attributed to hybridization in one cross between two species of wheat (Aegilops sharonensis × A. umbellulata), it was a chromosome duplication that led to more sequence loss in another cross of two wheat species (A. longissima × T. urartu).[ 40 ] Furthermore, a study of a Senecio allohexaploid suggested that the two events could have distinct effects on gene expression: changes in gene expression induced by hybridization may have been ameliorated by genome duplication.[ 41 ] Our results suggest that genome duplication may also have a recovery effect on genome structure, and many missing genes in the F1 diploid hybrid reappeared in the duplicated allotetraploid (Figure 3b). It also supports our earlier AFLP analysis that some of the parental fragments lost at the hybrid stage reappeared after allopolyploid formation.[ 18d ] However, the underlying mechanism of regaining the lost gene needs to be further uncovered. Although bioinformatic inference of gene loss is widely applied in polyploid studies, it should also be noted that statistical false results, for example, false read alignment, are also possible, since the definition of gene loss is based on the artificially calculated threshold value.[ 19 , 42 ] Nevertheless, all these observations lead to the conclusion that the effects of interspecific hybridization and genome duplication on shaping the genome of allopolyploids are species dependent, and it is more common that hybridization has a larger impact than duplication, as is the case in our Cucumis allotetraploid. More genome‐wide analysis taking advantage of sequencing technology of different synthetic allopolyploids and their F1 progenitors in the future would help to discover which of the two processes is generally more important in the genomic shock phenomenon.
Changes occurred not only during the process of allopolyploidization, but also in subsequent generations (post‐allopolyploidy). Rapid genomic reshaping is frequently observed in many synthetic allopolyploids, such as wheat (T. aestivum),[ 43 ] Brassica,[ 44 ] and Tragopogon.[ 45 ] Analyses of the Aegilops–Triticum complex (wheat and its relatives) revealed that changes in DNA sequence accumulated throughout the first three generations after allopolyploidization.[ 46 ] In contrast to these observations, no rapid genomic changes were observed after polyploidization in cotton.[ 47 ] Our previous study using AFLP markers indicated that sequence elimination occurred in the first few generations after polyploid formation, and then slowed down during diploidization.[ 18d,e ] These findings were further validated by the present study, which showed that genome‐wide changes happened quickly in the first few generations after allopolyploidization, with fewer changes afterwards. In nature, this diploidization process could last for millions of years, which is still considered “rapid” in plant evolution, for an interspecific hybridization event followed by genome duplication to return to disomic inheritance and become established as a new species.[ 48 ] According to estimates, the percentage of stained pollen of C. ×hytivus recovered to over 80% after 14 more generations. Compared to the natural evolutionary time scale, our results showed that relatively stable (recovered fertility and diploid‐like meiotic behavior) allopolyploids could be obtained relatively rapidly through diploidization following artificial polyploidization, which is promising for crop improvement via polyploidy.
Given the widespread distribution and evolutionary and ecological success of allopolyploid species, it has been inferred that this genomic structure may be advantageous, owing to various attributes, notably fixed heterozygosity.[ 49 ] The retention and persistence of duplicate versions of expressed genes in allopolyploids may facilitate genetic robustness and adaptation to environmental changes.[ 38a ] For instance, most of the resistance genes from both parents were retained in C. ×hytivus, including those genes from HH that were absent in CC. Increased disease resistance of C. ×hytivus relative to CC indicates the feasibility and potential utility of transferring useful resistance genes from wild relative species to cultivated species by artificial polyploidization. Enhanced abiotic stress tolerance has been observed in some allopolyploids.[ 32 , 50 ] Allopolyploids may reach a new transcriptional homeostasis under stress by regulating duplicate gene expression to accelerate phenotypic adaptation,[ 51 ] as is indicated by our results. Studies on hexaploid wheat suggested that condition‐dependent functionalization of the duplicated genes from subgenomes might have contributed to the improved adaptability.[ 52 ] In addition, our SV analysis showed that polyploidization‐induced SV was involved with a various of biological processes, including plant hormone signal transduction, plant–pathogen interaction, and photosynthesis (Table S28, Supporting Information), suggesting that de novo mutations accumulated after polyploidization may also contribute to its wide‐ranging adaptability. Therefore, the factors that cause the increased tolerance of polyploids could vary, such as de novo mutations, transcriptomic regulation of duplicated genes, new gene interactions, and so on. Studies on different polyploid experimental systems may also result in various outputs. More evidence is needed to fully reveal the underlying mechanism of polyploidization‐driven tolerance to harsh environmental conditions. Nevertheless, considering predicted global warming and rising frequency of extreme climate events, possible advantageous adaptability resulting from artificial allopolyploidization has implications for developing tolerant species/varieties to feed the world's growing population in a challenging climate.
4. Conclusion
In this study, we report the high‐quality genome of a synthetic allotetraploid obtained using interspecific hybridization between cucumber (C. sativus) and its wild relative species (C. hystrix) and subsequent chromosome duplication, which is the first fully sequenced synthetic allopolyploid. By precise comparative analysis with parental genomes, we demonstrated the dominance of the C. sativus‐originated subgenome, although both subgenomes largely maintained the chromosome structure of their diploid parents. We also sequenced the genomes of the F1 homoploid hybrid, the original duplicated allotetraploid (S0), and the subsequent generation individuals (S4–S13). Our results indicate that hybridization, rather than genome duplication, causes the majority of genomic changes in both nuclear and cp genomes. Moreover, post‐polyploidy genomic changes occurred mainly in the first few generations and slowed down afterwards. By testing the RKN resistance and heat tolerance, we suggested that the fixed heterozygosity provides C. ×hytivus with increased stress adaptation. Our results provide new insights into plant polyploidy evolution and offer a prospective breeding strategy for future crops.
5. Experimental Section
Plant Materials
Inbred lines of the two diploid parents (C. sativus L. var “Beijingjietou” and C. hystrix Chakr.), their interspecific F1 homoploid hybrid, and synthetic allotetraploid C. ×hytivus were used. Different generations (S4–S14) of C. ×hytivus were obtained by continuing self‐pollination with the original duplicated F1, named S0. In each generation, individual self‐pollination was performed, seeds obtained were mixed, and several seeds were randomly chosen and planted to generate the next generation. The original F1 homoploid hybrid and S0 were preserved via tissue culture. The highly inbred synthetic allotetraploid, C. ×hytivus (S14), was chosen as the reference for genome sequencing using SMRT sequencing technology (Pacific Biosciences). The original F1 homoploid hybrid, S0, and one individual from each generation (S4–S13) of C. ×hytivus were also used for genome sequencing using Illumina short‐read technology for comparative genomics analysis. Six generation plants of C. ×hytivus (S4, S6, S8, S10, S12, and S14) were chosen for meiotic analysis. All the materials were grown in a greenhouse at Baima Teaching and Research Base of Nanjing Agricultural University, Nanjing, China, unless special conditions are mentioned. It should be noted that the individual C. hystrix used for genome sequencing is not the one for interspecific hybridization, but its self‐crossed progeny. The male parent C. sativus L. var “Beijingjietou” is a close cucumber cultivar to the sequenced cucumber “Chinese long” inbred line 9930.
Heat Treatment
Seeds of C. ×hytivus (S14) and inbred lines of diploid parents, C. sativus L. var. “BeijingJietou” and C. hystrix Chakr., were sown in plastic pots of 11 × 11 × 6 cm (length × width × height) filled with peat‐based potting mix (Pindstrup 2, Pindstrup Mosebrug A/S, Ryomgaard, Denmark). Uniform seedlings with three true leaves were transferred to controlled climate chambers. Temperature treatment was conducted in these controlled climate chambers with heat treatment defined as (38 °C/30 °C day/night) contrasted with control conditions that were not heat stressed (28 °C/20 °C day/night), respectively. The photoperiod was set to 14/10 h day/night, light intensity was 500 µmol m−2 s−1, and air humidity (AH) was ≈75%. Irrigation was done every morning by flooding the seedling for 10 min with nutrient solution containing N (196 mg L−1), P (31 mg L−1), K (234 mg L−1), and Mg (43.2 mg L−1) along with micronutrients.
Physiological Measurements and Data Analysis
RGR was calculated from plant height, stem diameter, leaf length, and leaf width from the control and HT treatments using the formula: RGR = [ln (M2) − ln (M1)]/(T2 − T1) (M1: measurement 1, M2: measurement 2, T1: measurement time 1, and T2: measurement time 2).
During the experiment, the change in Chl content was noninvasively monitored via Dualex 4 (FORCE‐A, Orsay, France).[ 53 ] Dualex 4 measures Chl contents in micrograms per square centimeter. The mean value of each leaf was calculated from three sections on both sides. On day 0, the first unfolded leaf was measured, and the same leaf was used throughout the treatment.
Pn, stomatal conductance (Gs), internal CO2 concentration (Ci), and transpiration rate (Tr) were measured using a Li‐6400 portable photosynthesis assay apparatus (LI‐COR Biosciences, Inc., USA). The light response curves were measured using a 6400‐02B red and blue light source of the LI‐6400 photosynthesis system. The leaf photosynthetically active radiation (PAR) was controlled at 12 levels from 0 to 1500 µmol m−2 s−1 (0, 25, 50, 75, 100, 150, 200, 300, 600, 900, 1200, and 1500). During the measurement, the ambient leaf temperature, humidity, and CO2 concentration were controlled to a steady state.
Genome Sequencing
Fresh young leaves were collected from a single plant for each sample and immediately frozen in liquid nitrogen for 24 h. Genomic DNA for PacBio and Illumina sequencing was extracted using the CTAB method. The PacBio sequencing library was prepared according to the recommendations of Pacific Biosciences. Genomic DNA was fragmented to ≈20 kb targeted size by g‐TUBE centrifuged at 2000 rpm for 2 min, then treated with end‐repair, adapter ligation, and exonuclease digestion. DNA fragments of ≈20 kb in length were collected via BluePippin electrophoresis (Sage Sciences). DNA libraries were sequenced on the PacBio Sequel platform (Pacific Biosciences) using P6‐C4 chemistry. A total of 53.92 G raw data were obtained.
For genome sequencing of 12 samples including F1 and early generations (S0, S4–S13), two mate‐pairs (3 and 4 kb), and one paired‐end (270 bp) Illumina libraries were constructed and sequenced according to the standard protocol of the Illumina X‐TEN platform (Illumina, San Diego, CA, USA) for each sample.
BioNano Sequencing
Cuttings from the C. ×hytivus (S14) plant used for genome sequencing were planted in plastic pots (11 cm diameter, 0.5 L) filled with a peat‐based potting mix (Pindstrup 2, Pindstrup Mosebrug A/S, Ryomgaard, Denmark) and irrigated and fertilized regularly with a nutrient solution with N/P/K of 160:35:190, pH 5.8, and electric conductivity of 1.8. They were cultivated in a growth chamber at Nanjing Agricultural University. Young leaves were treated in the dark for 2 days before sampling. High‐molecular‐weight DNA was isolated and labeled with the single‐stranded nicking endonuclease Nt. BssSI following standard BioNano protocols. The labeled DNA sample was subsequently loaded onto the IrysChip nanochannel array, and the stretched DNA molecules were imaged with the BioNano Irys system. Basic labeling and DNA length information were retrieved from bnx files converted from raw image data using AutoDetect software.[ 54 ]
Hi‐C Sequencing
Hi‐C libraries were prepared from leaves as described previously.[ 55 ] Briefly, nuclear DNA was fixed with formaldehyde and then digested with Hind III. Sticky ends were biotinylated, and then diluted and ligated. Biotinylated DNA was enriched and then sheared to ≈350 bp fragment size. The Hi‐C fragment library was constructed and sequenced using the Illumina X‐TEN platform (Illumina, San Diego, CA, USA, 2 × 150 bp) for pseudomolecules construction.
RNA‐Seq and PacBio Iso‐Seq
On the sixth day of the chamber heat treatments, the same leaves that were used for physiological measurements were sampled for RNA extraction. Samples were stored in liquid nitrogen until RNA extraction. After RNA extraction, the purity, concentration, and integrity of RNA were tested using Nanodrop, Qubit 2.0, and Agilent 2100, respectively. mRNA‐Seq library construction was performed after obtaining quality samples that were subjected to high‐throughput sequencing using Illumina HiSeq.
For Iso‐Seq, high‐quality RNA was extracted from eight tissues of C. ×hytivus (S14), including root, stem, leaf, seed, female, and male flowers and fruits (2 and 6 days post‐anthesis), and reverse transcribed. The cDNA was normalized using the Evrogen‐Trimmer‐2 Kit (Evrogen, Moscow, Russia, catalog no. NK003). Tissue‐specific barcodes were added before pooling for subsequent amplification. To avoid loading bias, which favors sequencing of shorter transcripts, multiple size‐fractionated libraries (≈0.5 and ≈2 kb) were constructed using a SageELF device.
Genome In Situ Hybridization and Oligo‐Fluorescent In Situ Hybridization
Root tips and young male flower buds of plant materials were collected and fixed in Carnoy's solution at 4 °C for 1 day. The young male flower buds of six different generations were randomly collected and divided into three groups for meiotic behavior analysis. The procedure to prepare samples for analysis was performed as described previously, with some modifications as follows.[ 56 ] The fixed root tips were digested with an enzyme mixture containing 4% cellulose R‐10 (Yakult), 2% pectinase (Sigma‐Aldrich), and 0.1% pectolase (Yakult) in 0.01 m citrate buffer (pH = 4.8), at 37 °C for 40–60 min. The anthers were collected and digested using enzyme mixtures, including 4% cellulose R‐10 (Yakult), 4% pectinase (Sigma‐Aldrich), and 2% pectolase (Yakult) at 37 °C for 50–70 min (meiotic pachytene) and 2–3 h (meiotic metaphase and anaphase). Finally, the digested root tips and anthers were smeared onto slides. The slides that showed adequately spread chromosomes were prepared for FISH and GISH experiments.
An oligo library developed from C. sativus chromosome C04 was designed using Chorus software (https://github.com/forrestzhang/Chorus). The repeat sequences in cucumber genome sequences were filtered using RepeatMasker (http://www.repeatmasker.org/). The oligos (50 nt) specific to “the Chinese long cucumber” genome (http://cucurbitgenomics.org/organism/20, v3 Genome) were selected throughout filtered sequences of chromosome C04 with a step size of 25 nt. The oligos located at CDS and single‐copy regions were selected preferentially to ensure utility for cross‐species FISH painting. A total of 93 396 oligos were generated for cucumber chromosome C04. As previously described, the oligo library was divided into eight sub‐pools to perform chromosomal segmentation painting to illustrate the syntenic relationship of chromosomes involved, and synthesized by Synbio Technologies (Suzhou, China, http://www.synbio-tech.com.cn). The oligo probes were synthesized using a published protocol as follows.[ 26 ] Briefly, 50 µL of PCR mixture consisted of ≈0.14 ng DNA from the oligo library, 2 µL of 1 × 10−3 m fluorophore‐tagged F primer, 2 µL of 1 × 10−3 m fluorophore‐tagged R primer, 25 µL of HiFi HotStart ReadyMix (KAPA, Kit Code, KK2601), and 18 µL of nuclease‐free water. The PCR mixture was incubated at 95 °C for 3 min, followed by 15 cycles of 98 °C for 20 s, 60 °C for 30 s, 72 °C for 30 s, then 25 cycles of 98 °C for 20 s, 55 °C for 30 s, 72 °C for 30 s, with a final extension at 72 °C for 1 min. The PCR reaction was cleaned with the GeneJET PCR Purification kit (Thermo Fisher Scientific, Kit Code, K0702) and eluted with 40 µL solution buffer to obtain labeled oligo probes for chromosome painting.
FISH was performed essentially as described previously.[ 57 ] The hybridization mixture containing 10 µL of 100% formamide, 2 µL of 20× SSC, 4 µL of 50% dextran sulfate, and 3 µL oligo probes (>500 ng) was denatured at 90 °C for 6 min, then transferred to ice and incubated for at least 5 min. The hybridization mixture was then applied to denatured chromosome slides and incubated overnight at 37 °C. Slides were washed for 5 min in 2× SSC at room temperature (RT), then for 10 min in 2× SSC at 42 °C, and then for 5 min in 2× SSC at RT for 5 min in 1× PBS at RT. The washed slides were air‐dried in the dark, and then counterstained with DAPI in VECTASHIELD Antifade solution (Vector Laboratories).
For GISH treatments, genomic DNA was extracted from cucumber and C. hystrix using the CTAB method, and then labeled as GISH probes for distinguishing the two subgenomes of allotetraploid C. ×hytivus during meiosis.[ 57 ] All experimental procedures for GISH were performed as previously described.[ 56 ] FISH and GISH images were captured using a SENSYS (http://www.photometrics.com) CCD camera attached to an Olympus (http://www.olympus-global.com) BX51 microscope. The CCD camera was controlled using FISH view 5.5 software (Applied Spectral Imaging, Inc., http://www.spectral-imaging.com). Images were processed using Adobe Photoshop CC (Adobe Systems, http://www.adobe.com). Pachytene chromosomes were straightened using ImageJ software (https://imagej.nih.gov/ij/).
Chloroplast DNA Isolation and Sequencing
About 10 g fresh leaves were sampled from adult plants of C. hystrix. An improved sucrose gradient centrifugation method was used to isolate the total cp DNA.[ 58 ] The quality of genomic DNA was checked by monitoring A260/A280 ratios (DU800, Beckman Coulter, USA) and Tris‐borate‐EDTA polyacrylamide gel electrophoresis. DNA was randomly fragmented by sonication. The resulting fragments were subsequently subjected to end‐repair and phosphorylation using T4 DNA polymerase, Klenow DNA polymerase, and T4 Polynucleotide Kinase. Thereafter, an “A” base was inserted as an overhang at the 3ʹ ends of the repaired DNA fragments and Illumina paired‐end adaptors were subsequently ligated to these DNA fragments to distinguish the different sequencing samples. Finally, the library was sequenced using an Illumina HiSeq 2000 instrument according to the manufacturer's instructions (Illumina, San Diego, CA).
RKN (Meloidogyne spp.) Resistance Determination
Before germination, seeds of C. sativus, C. hystrix, and C. ×hytivus (S14) were surface sterilized with 5% sodium hypochlorite solution for 10 min, and rinsed with distilled water three times. Sterilized seeds were placed on wet filter paper in Petri dishes, and incubated in a growth chamber at 28 °C. Seedlings were then sown individually into 11 × 11 × 6 cm (length × width × height) plastic pots filled with steam‐sterilized sand. Air temperatures in the greenhouse were maintained at ≈30 °C during the day and 24 °C at night. A randomized complete block experimental design with four biological replications was used. Two‐week‐old plantlets were inoculated with ≈400 second‐stage juveniles (J2 s) of Meloidogyne incognita race 1 at the root tip using a pipette tip. Thirty days after inoculation, each plant was uprooted, the roots were washed free of soil, and the M. incognita galls were counted. The reproduction rate of M. incognita was determined according to a published protocol.[ 59 ]
Data Availability
Raw genome sequence reads of C. ×hytivus have been deposited at DDBJ/ENA/GenBank under the accessions number PRJNA594754. The genomic data of C. hystrix are available at Figshare (https://doi.org/10.6084/m9.figshare.13377671). The raw PacBio Iso‐Seq reads and transcriptome sequence reads were deposited at the NCBI sequence read archive under accessions SRP262554 and SRP155470, respectively. The clean Illumina sequencing reads of actual male parent, C. sativus L. var. “Beijingjietou,” was deposited at the NCBI sequence read archive under accession SRP284803. The genome sequences and annotations of C. sativus, C. hystrix, and C. ×hytivus are also available in the Cucumis Genome Database (http://www.cucumisgdb.cn/). All materials and other data in this study are available upon reasonable request.
Statistical Analysis—Physiological Data Analysis
For Chl content measurement, three random plants from each species were selected from each treatment and measured (n = 3), and the standard deviations (SD) were considered as the error line. A two‐way analysis of variance (ANOVA) was performed to test the differences between the control and HT treatment over a 5 day period of measurements. The software R (i3862.15.0, www.r-project.org/) was used for statistical analysis. Mean separations were performed using Duncan's multiple range test of p < 0.05.
Genome Assembly
The raw polymerase reads were processed using the PacBio SMRT‐Analysis package (https://www.pacb.com/products-and-services/analytical-software/smrt-analysis/) to remove sequencing adapters and filter low quality and short length reads (parameters: readScore, 0.75; minSubReadLength, 500). Considering the high error rate of PacBio reads, an error correction module embedded in Canu (correctedErrorRate: 0.045) was first used to correct the reads.[ 60 ] Next, the resulting high‐quality PacBio sub‐reads were used for genome assembly with Canu software (Table S29, Supporting Information).[ 60 ] The assembled contigs were supported by mapping 96.79% of clean sub‐reads (with sequence length >10 kb) for C. ×hytivus (S14) using BLASR.[ 61 ] Finally, consensus sequences of assembly were subjected to mapping of ≈50‐fold coverage of Illumina pair‐end reads using BWA[ 62 ] and were polished using Pilon software (parameters: –mindepth 10 –changes –fix bases). An independent whole‐genome sequence assembly was executed using SOAPdenovo2 packages for each sample of the F1 and early generations (S0, S4–S13). From over 80‐fold coverage reads (≈60 Gb), 469–491 Mb results were assembled with scaffold N50 and contig N50 of 134–226 kb and 47–73 kb, respectively (Table S30, Supporting Information). To decrease the chimeric sequences in initial assembly results, different fragment mate‐paired data were mapped to the contigs using BWA,[ 62 ] considering only unique mapping reads for further scaffold construction. Scaffolding was performed via SSPACE[ 63 ] using two mate‐pair data and estimating gaps between the contigs according to the distance of MP links. Two contigs supported by at least five reasonable MP links in each fragment library (insert size ±5 SD) were joined as a scaffold.
Scaffolding Using Optical Maps of the BioNano System
In total, 163.4 Gb single molecule data for C. ×hytivus (S14) were obtained after filtration by a molecule length ≥150 kb with a signal‐to‐noise ratio (SNR) ≥3.0, average molecule intensity <0.6, and labels ≥8 per molecule. High‐quality labeled molecules were pairwise aligned, clustered, and de novo assembled into a consensus map following the Assembler software developed by BioNano Genomics (http://www.bionanogenomics.com/). A physical map was assembled with a total length of 499.04 Mb (Table S1, Supporting Information). The in silico map from contigs assembled from PacBio subreads was aligned with the optical consensus map using RefAligner. Anomalies in the PacBio‐based assembly and consensus map were corrected, and then PacBio‐based contigs were extended using Irys‐scaffolding with default parameters. The hybrid assembly was obtained with a length of 540.74 Mb and scaffold N50 8.09 Mb. Thereafter, the clean Illumina short reads were mapped back to the assembly for SNP calling and 1067 homozygous SNPs were obtained, and the single base error rate was 0.0001973192%.
Chromosome‐Scale Assembly Using Hi‐C
Raw Hi‐C data were processed to filter low‐quality reads, and adapters were trimmed with cutadapt (RRID: SCR 011841).[ 64 ] The clean Hi‐C reads were then mapped to the assembly results genome of C. ×hytivus (S14) with BWA (mapping method: aln).[ 62 ] Only unique mapped read pairs (58.13%) were considered for further analysis (Table S4, Supporting Information). Duplicate removal, sorting, and quality assessment were carried out using HiC‐Pro.[ 65 ] Of the Hi‐C data, 59.00% were valid interaction pairs. Next, the uniquely mapped data were retained for assembly using LACHESIS.[ 66 ] Hi‐C data were used to correct mis‐joins in contigs, and then to order and orient contigs. Pre‐assembly was performed for contig correction by splitting contigs into segments with an average length of 50 kb, and then the segments were pre‐assembled with Hi‐C data. Misassembled points were identified and broken at the likely point of misassembly when split segments could not be placed in the original position. Next, the corrected contigs were assembled using LACHESIS with parameters CLUSTER_MIN_RE_SITES = 225, CLUSTER_MAX_LINK_DENSITY = 2; ORDER_MIN_N_RES_IN_TRUN = 105; ORDER_MIN_N_RES_IN_SHREDS = 105 with Hi‐C valid pairs. Gaps between ordered contigs were filled with 100 N's. Based on 104‐fold coverage of Hi‐C data, the vast majority (97.23%) of the assembled sequence was anchored onto the 19 pseudo‐chromosomes via frequency distribution of valid interaction pairs (Table S5, Supporting Information). To assess the quality of assembly, Hi‐C data were mapped to chromosomes using HiC‐Pro.[ 65 ] The interaction matrix was visualized with a heatmap at the 100 kb resolution (Figure S4, Supporting Information).
RNA‐Seq and Iso‐Seq
Three biological replicates were used for RNA‐seq. Empty reads, adapter sequences and low‐quality sequences were removed from raw reads to obtain clean reads. A total of 135.86 Gb clean data were obtained. The clean data of each sample reached 6.10 Gb and a Q30 base percentage of 91.37% or higher. For Iso‐Seq, although PacBio single molecule sequencing yields long reads, it has a high error rate. Using the Iso‐Seq protocol, the error rate is lower because multiple subreads in the same zero‐mode waveguides produce a read of insert (ROI) (also known as circular consensus sequence) with higher accuracy. Consequently, 329 978 ROIs were obtained, of which 203 354 were full‐length ROIs (containing 5ʹ primer, 3ʹ primer, and poly (A) tail). The rest were non‐full‐length ROIs (Table S7, Supporting Information).
Repeat Analyses
Tandem repeat composition analysis was performed according to previous method.[ 67 ] All Illumina reads of C. ×hytivus (S14) were aligned against each type of tandem repeat using BLASTN with an e‐value of 1e‐10. The reads were considered as repeat if the length of alignment was over 100 bp or the coverage of the read was over 70%. Type I/II, III, and IV repeats in cucumber were retrieved from GenBank. Two rDNA (45S and 5S) sequences were obtained previously.[ 68 ]
The repeat sequences of C. ×hytivus (S14) and the parent species (C. hystrix and C. sativus L. var. 9930) were distinguished using a combination of de novo and homolog strategies. Four de novo programs, including RepeatScout,[ 69 ] LTR‐FINDER,[ 70 ] MITE‐Hunter,[ 71 ] and PILER,[ 72 ] were used to construct the initial repeat library. The initial repeat database was classified using PASTEClassifier,[ 73 ] and three de novo libraries from C. sativus, C. hystrix, and C. ×hytivus were then merged with the known Repbase database.[ 74 ] Finally, the merged repeat database was used to distinguish the genome assembly repeat sequences using RepeatMasker (Table S6, Supporting Information).[ 75 ]
Gene Annotation
Genes were annotated using a combined strategy of three approaches: de novo, homology‐based, and transcript‐based. These results were finally merged with evidence modeler (EVM) (Figure S6 and Table S8, Supporting Information).[ 76 ] For de novo prediction, Genscan,[ 77 ] Augustus,[ 78 ] GlimmerHMM,[ 79 ] GeneID,[ 80 ] and SNAP[ 81 ] were used to scan the repeat‐masked genome. The protein sequences from five sequenced eudicot species, including A. thaliana (TAIR10), Oryza sativa (MUSv7.0), Citrullus lanatus (watermelon (97103) genome v2), C. melo (melon (DHL92) genome 3.5.1) and C. sativus (cucumber (Chinese Long) genome v3), were used for homology‐based prediction through GeMoMa.[ 82 ] In the third approach, the Hisat[ 83 ] and Stringtie[ 84 ] programs were used to carry out reference‐based transcriptome assembly. GeneMarkS‐T[ 85 ] was used to predict genes based on transcripts. PASA software was used to predict genes based on unigenes and full‐length transcripts from PacBio sequencing.[ 86 ] The gene annotation result was evaluated by identifying 448 (97.82%) conserved eukaryotic genes and 1309 (90.90%) complete BUSCO hits (Table S11, Supporting Information). All the predicted genes were annotated by searching the GenBank Non‐Redundant (NR, 20150226), TrEMBL (20151014), Pfam (30.0), Swiss‐Prot (20151014), eukaryotic orthologous groups (KOG, 20110125), GO (20160907), and KEGG (20170310) databases (Table S10, Supporting Information).
Pseudogene Prediction and Non‐Coding RNA Annotation
The whole genome was scanned with GenBlastA after masking predicted functional genes.[ 87 ] Pseudogenes were confirmed by searching for internal stop codons and frame‐shift mutations using GeneWise.[ 88 ] Non‐coding RNAs (ncRNAs) were predicted using the software Infernal[ 89 ] based on the Rfam database and miRBase database for rRNA and microRNA, respectively. The tRNAscan‐SE program was applied to detect reliable tRNA positions.[ 90 ] Summary of non‐coding RNAs and pseudogenes are presented in Table S12, Supporting Information.
Syntenic Orthologous Gene Pair Identification and Gene Loss Analyses
The previous assemblies of the C. hystrix genome (https://doi.org/10.6084/m9.figshare.13377671) and C. sativus L. var. 9930 (v3) were used for comparative analysis.[ 20 ] Syntenic orthologous gene pairs and syntenic blocks were identified using the QUOTA‐ALIGN package.[ 91 ] The two diploid parents (C. sativus and C. hystrix) were mapped to the corresponding subgenomes (Chc and Chh) of C. ×hytivus (S14), to allow calling of syntenic blocks. First, all‐against‐all BLASP[ 92 ] alignment was performed with parameters ‐v = 5 ‐b = 5 ‐e = 1e‐5 between C. sativus and Chc subgenome and then chained the BLASP hits using QUOTA‐ALIGN (cscore = 0.9)[ 91 ] with “1:1 synteny screen.” The distance cut‐off of 20 genes was adopted for syntenic block identification. At least four gene pairs were required for individual synteny blocks. Similarly, four pairwise comparisons were performed including Chc to CC (orthologs), Chc to HH (orthologs), HH to CC (orthologs), and Chc to Chh (homeologs) to generate the syntenic relationship and syntenic homologous gene pairs set between two subgenomes (Tables S14 and S15, Supporting Information).
For genes within syntenic blocks, potential gene loss in the Chc subgenome was defined using the following metrics: 1) gene located in CC‐Chc synteny block and 2) gene present in syntenic block of its ancestral genome CC but unable to find homologs within five syntenic gene pairs of corresponding Chc syntenic blocks. These candidate genes missing from the derived subgenome were then considered “potential lost genes.” These genes were first checked in unanchored scaffolds or contigs to exclude false gene loss due to the assembly. Further, to avoid false positives in calling genes because of misassembly and/or mis‐annotation, the protein of the potential lost gene was further mapped in CC to the corresponding syntenic DNA sequences in Chc and identified the potentially miss‐annotated gene (Table S16, Supporting Information). GeMoMa[ 93 ] was used to identify the miss‐annotated gene using a homolog‐based strategy in Chc. The coding sequence of newly predicted genes from the results of GeMoMa packages in Chc were aligned to the reference genes of “potential lost genes” in CC using BLASTP. If the newly predicted gene was homologous to the reference gene at an identity ≥95% with coverage (alignment length/query, subject) ≥90% and the gene locus was within five adjacent syntenic gene pairs, a candidate lost gene was considered a false positive. In the second step, high‐confidence partially lost genes were removed. If the candidate genes lacked a start or stop codon, they were defined as “partial loss.” If the candidate gene had pseudogenes with frameshift mutations in the homologous region of Chc, they were defined as “pseudogenes.” GeneWise[ 88 ] was used to predict pseudogenes. After the above filtering, the remaining “potential lost genes” were considered to be “DNA loss” and further validated using Illumina short reads generated from the same accession. To validate the lost gene by short reads, ≈50× clean Illumina reads from C. ×hytivus (S14) were mapped to the artificial tetraploid genome synthesized from the two parents using BWA with parameters ‐k35 ‐O11. For each “DNA loss” gene, the depth was calculated using command “bedtools coverage ‐counts.” Only genes with depth <1× and coverage of gene body <5% were considered as true lost genes.
For genes outside the syntenic blocks, all of them were regarded as “potential gene losses.” These “potential gene losses” were also further validated in the same way as those potential lost genes within the syntenic blocks.
A similar strategy was used to identify gene loss in the other subgenome, Chh. In addition, to eliminate the possible effect of genetic differences between genotypes, the lost genes were further validated from the CC genome by resequencing Illumina reads of C. sativus L. var. “Beijingjietou.”
The status of the confirmed deleted genes in C. ×hytivus (S14) in the unduplicated F1 homoploid hybrid and several early generations (S0, S4–S13) of C. ×hytivus (Tables S20 and S21, Supporting Information) was further checked by analyzing their Illumina short read coverage as described above. Clean Illumina reads from the F1 homoploid hybrid and several early generations (S0, S4–S13) of C. ×hytivus were mapped to two parental genomes of C. sativus (CC) and C. hystrix (HH). All mapping was performed using BWA with parameters ‐k35 ‐O11 to guarantee high‐quality mapping results. The depth and breadth of coverage for each gene were calculated as described above. Genes with a depth of less than onefold coverage and 5% of gene body coverage were inferred to be deletions.
Analysis of HE
This study assayed for HE between the Chc and Chh subgenomes in the C. ×hytivus (S14) by assessing the read depth coverage and sequence identity. The read depth of coverage analysis was performed as follows. The average depth for the whole genome was ≈50×. Regions with double read coverage (75–150×) were considered duplicated, and those with low or no coverage (0–25×) indicated deletions. The high‐quality PacBio sub‐reads of C. ×hytivus (S14) were mapped to parental C. hystrix and C. sativus genomes using BLASR with parameters ‐bestn 1 ‐nCandidates 10 ‐minPctIdentity 70 to guarantee that each subread would uniquely align to the parental genome. The average depth was calculated on 5 kb windows. Adjacent duplicated windows with depths greater than the threshold and within ten distant windows were linked together, as well as adjacent deleted windows. A double‐depth region was considered a candidate HE when the mapping length was more than 30% of the query window. Identity analysis using BLASTN with default parameters was performed between corresponding duplicated and deleted homologous regions of two ancestral genomes. Sequence identity analysis was carried out as follows. First, syntenic analysis between both parents was performed using MUMmer with parameter –mum.[ 94 ] Adjacent syntenic blocks with distance less than 20 kb were linked together to generate more continuous collinear blocks. For each candidate HE, BLASTN alignment between corresponding HE regions within syntenic blocks of two parents was performed to assess the sequence identity between genomic homeologous exchange sequences. Integrating the evidence of read coverage results and homolog between parental subgenomes, HE could be detected with confidence (Tables S18 and S19, Supporting Information).
Analysis of SV
The corrected PacBio reads of C. ×hytivus (S14) were aligned to the genomes of the parental species (C. hystrix and C. sativus L. var. 9930), respectively, using NanoVar for SV (insertion, deletion, inversion, translocation, and transposition) calling.[ 95 ] Since small insertions and deletions can be detected with SNP and indel calling, only large SVs (>25 bp) were considered. Subsequently, these initial SVs were verified with Illumina reads by mapping the short reads of C. ×hytivus (S14) to its ancestral genomes and checked the breakpoint around the SV locus, as supported by soft‐clip alignment reads. Notably, different from the donor C. hystrix of the HH subgenome, C. sativus L. var. 9930 used as an ancestral species is not the direct donor of the CC subgenome in C. ×hytivus (S14). Therefore, the Illumina reads of the actual parent line C. sativus L. var “Beijingjietou” of C. ×hytivus (S14) was mapped onto the genome of C. sativus L. var. 9930 using BWA‐MEM with default settings to exclude false SVs resulting from different genotypes. The SVs supported by reads of the actual parent line C. sativus L. var. “Beijingjietou” may result from the different genotypes of C. sativus L. var. 9930 and C. sativus L. var. “Beijingjietou.” The remaining SVs were considered as true SVs accumulated after allotetraploid events. Genes related to these true SVs were retrieved and enriched for functional annotation.
Analysis of Gene Expression
The clean reads filtered from the raw reads were mapped onto C. hystrix, C. sativus, and C. ×hytivus (S14) genome sequences using Hisat.[ 83 ] The fragments per kilobase per million mapped read values of expression genes were calculated using StringTie.[ 84 ] Differentially expressed genes between the control and high‐temperature treatments in the three species were screened using DESeq.[ 96 ] The Benjamini–Hochberg method was used for differential expression analysis, with the p‐value corrected, and false discovery rate <0.01, fold change >2. Analysis of homeologous gene expression bias was performed within syntenic gene pairs according to published protocols.[ 19 ] Differentially expressed gene pairs that passed the twofold change threshold were regarded as biased gene pairs, and classified as either C‐dominant or H‐dominant. The homeologous copy that showed relatively higher levels of gene expression for each of the biased gene pairs was considered dominant; thus, the more weakly expressed homeologue was determined to be subordinate with respect to the expression level in the particular treatment. The remaining syntenic gene pairs that showed no dominance relationship between the homeologues in a designated gene pair were classified as neutral gene pairs. The number of C‐dominant gene pairs, H‐dominant gene pairs, and neutral gene pairs are shown in Table S20, Supporting Information.
Analysis of Pollen Viability
Five biological replicates of 15 male flowers randomly collected from each generation of allotetraploid C. ×hytivus were assayed for pollen stainability. A minimum of 2000 pollen grains per biological replicate were collected, stained with 1% acetocarmine solution, and counted under a stereomicroscope. The percentage of plump, deeply stained pollen grains was calculated to represent the pollen stainability.
Chloroplast Assembly and Annotation
Raw data were cleaned in several steps, including removing reads with unknown bases call (N) more than 10%, removing reads with 20 bp of low quality (≤Q20) bases, removing adapter contamination, and removing duplicated reads. The filtered reads were assembled de novo using the SOAPdenovo,[ 97 ] and the GapCloser[ 98 ] software was used to close gaps and finally remove the redundant segment sequence to obtain the final assembly results.
Functional annotations were made using several homologous alignment methods; thus, for a particular sequence, multiple alignment results could be obtained. To ensure biological significance, the annotation retained the optimal match result as a comment for the gene. The assembled sequences were compared with the GenBank Non‐Redundant (NR, 20150226), TrEMBL (20151014), Pfam (30.0), Swiss‐Prot (20151014), eukaryotic orthologous groups (KOG, 20110125), GO (20160907), and KEGG (20170310) databases using the Basic Local Alignment Search Tool (BLAST) to obtain functional annotation information for the encoded gene. The genome of the samples was displayed using Circos (http://www.circos.ca/) software for the assembled genomic sequence of the sequenced sample, combined with the predicted results of the coding gene.
SNP and Indel Analysis for Chloroplast Genome
Qualified reads were aligned against the C. hystrix cp reference genome with BWA.[ 62 ] Single nucleotide variants and small insertions and deletions (indels, 2–50 bp) were called by the HaplotypeCaller module of GATK3.4.[ 99 ] The distribution of SNPs and indels in the C. hystrix cp genome was visualized using Circos.[ 100 ]
Conflict of Interest
The authors declare no conflict of interest.
Supporting information
Supporting Information
Supporting Table
Acknowledgements
X.Y., P.W., J.L., Q.Z., and C.J. contributed equally to this work. This work was supported by the National Key Research and Development Program of China (2018YFD1000804), the National Natural Science Foundation of China (nos. 31902006, 31902007), the 111 Project (B18029), the Natural Science Foundation of Jiangsu Province, China (BK20180536), National Key Research and Development Program of China (nos. 2016YFD0101705‐5, 2016YFD0100204‐25), and the Priority Academic Program Development of Jiangsu Higher Education Institutions. The authors gratefully acknowledge the contribution of the late Prof. Jack Staub to this study and a Tang Fellowship awarded to J.C. at Cornell University.
Yu X., Wang P., Li J., Zhao Q., Ji C., Zhu Z., Zhai Y., Qin X., Zhou J., Yu H., Cheng X., Isshiki S., Jahn M., Doyle J. J., Ottosen C.‐O., Bai Y., Cai Q., Cheng C., Lou Q., Huang S., Chen J., Whole‐Genome Sequence of Synthesized Allopolyploids in Cucumis Reveals Insights into the Genome Evolution of Allopolyploidization. Adv. Sci. 2021, 8, 2004222. 10.1002/advs.202004222
Data Availability Statement
The data that support the findings of this study are openly available in DDBJ/ENA/GenBank under the accessions number PRJNA594754, SRP262554, SRP155470 and SRP284803, and in figshare at https://doi.org/10.6084/m9.figshare.13377671.
References
- 1.a) Van De Peer Y., Mizrachi E., Marchal K., Nat. Rev. Genet. 2017, 18, 411; [DOI] [PubMed] [Google Scholar]; b) Wendel J. F., Jackson S. A., Meyers B. C., Wing R. A., Genome Biol. 2016, 17, 37. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.a) Leitch A. R., Leitch I. J., Science 2008, 320, 481; [DOI] [PubMed] [Google Scholar]; b) Jiao Y., Wickett N. J., Ayyampalayam S., Chanderbali A. S., Landherr L., Ralph P. E., Tomsho L. P., Hu Y., Liang H., Soltis P. S., Soltis D. E., Clifton S. W., Schlarbaum S. E., Schuster S. C., Ma H., Leebens‐Mack J., dePamphilis C. W., Nature 2011, 473, 97. [DOI] [PubMed] [Google Scholar]
- 3. Comai L., Nat. Rev. Genet. 2005, 6, 836. [DOI] [PubMed] [Google Scholar]
- 4. McClintock B., Science 1984, 226, 792. [DOI] [PubMed] [Google Scholar]
- 5. Thomas B. C., Pedersen B., Freeling M., Genome Res. 2006, 16, 934. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Sun H., Wu S., Zhang G., Jiao C., Guo S., Ren Y., Zhang J., Zhang H., Gong G., Jia Z., Zhang F., Tian J., Lucas W. J., Doyle J. J., Li H., Fei Z., Xu Y., Mol. Plant 2017, 10, 1293. [DOI] [PubMed] [Google Scholar]
- 7. Edger P. P., Smith R. D., McKain M. R., Cooley A. M., Vallejo‐Marin M., Yuan Y., Bewick A. J., Ji L., Platts A. E., Bowman M. J., Childs K. L., Washburn J. D., Schmitz R. J., Smith G. D., Pires J. C., Puzey J. R., Plant Cell 2017, 29, 2150. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.a) Madlung A., Masuelli R. W., Watson B., Reynolds S. H., Davison J., Comai L., Plant Physiol. 2002, 129, 733; [DOI] [PMC free article] [PubMed] [Google Scholar]; b) Gaeta R. T., Pires J. C., Iniguez‐Luy F., Leon E., Osborn T. C., Plant Cell 2007, 19, 3403. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.a) Kagale S., Koh C., Nixon J., Bollina V., Clarke W. E., Tuteja R., Spillane C., Robinson S. J., Links M. G., Clarke C., Higgins E. E., Huebert T., Sharpe A. G., Parkin I. A., Nat. Commun. 2014, 5, 3706; [DOI] [PMC free article] [PubMed] [Google Scholar]; b) Vanneste K., Baele G., Maere S., Van de Peer Y., Genome Res. 2014, 24, 1334. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Hegarty M., Coate J., Sherman‐Broyles S., Abbott R., Hiscock S., Doyle J., Cytogenet. Genome Res. 2013, 140, 204. [DOI] [PubMed] [Google Scholar]
- 11.a) Doebley J. F., Gaut B. S., Smith B. D., Cell 2006, 127, 1309; [DOI] [PubMed] [Google Scholar]; b) Qi J., Liu X., Shen D., Miao H., Xie B., Li X., Zeng P., Wang S., Shang Y., Gu X., Du Y., Li Y., Lin T., Yuan J., Yang X., Chen J., Chen H., Xiong X., Huang K., Fei Z., Mao L., Tian L., Städler T., Renner S. S., Kamoun S., Lucas W. J., Zhang Z., Huang S., Nat. Genet. 2013, 45, 1510; [DOI] [PubMed] [Google Scholar]; c) Tang H., Sezen U., Paterson A. H., Curr. Opin. Plant Biol. 2010, 13, 160; [DOI] [PubMed] [Google Scholar]; d) Gross B. L., Olsen K. M., Trends Plant Sci. 2010, 15, 529. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.a) Dijkhuizen A., Kennard W. C., Havey M. J., Staub J. E., Euphytica 1996, 90, 79; [Google Scholar]; b) Behera T. K., Staub J. E., Behera S., Delannay I. Y., Chen J. F., Euphytica 2011, 178, 261. [Google Scholar]
- 13. Huang S., Li R., Zhang Z., Li L., Gu X., Fan W., Lucas W. J., Wang X., Xie B., Ni P., Ren Y., Zhu H., Li J., Lin K., Jin W., Fei Z., Li G., Staub J., Kilian A., van der Vossen E. A., Wu Y., Guo J., He J., Jia Z., Ren Y., Tian G., Lu Y., Ruan J., Qian W., Wang M., Huang Q., Li B., Xuan Z., Cao J., Asan, Wu Z., Zhang J., Cai Q., Bai Y., Zhao B., Han Y., Li Y., Li X., Wang S., Shi Q., Liu S., Cho W. K., Kim J. Y., Xu Y., Heller‐Uszynska K., Miao H., Cheng Z., Zhang S., Wu J., Yang Y., Kang H., Li M., Liang H., Ren X., Shi Z., Wen M., Jian M., Yang H., Zhang G., Yang Z., Chen R., Liu S., Li J., Ma L., Liu H., Zhou Y., Zhao J., Fang X., Li G., Fang L., Li Y., Liu D., Zheng H., Zhang Y., Qin N., Li Z., Yang G., Yang S., Bolund L., Kristiansen K., Zheng H., Li S., Zhang X., Yang H., Wang J., Sun R., Zhang B., Jiang S., Wang J., Du Y., Li S., Nat. Genet. 2009, 41, 1275. [DOI] [PubMed] [Google Scholar]
- 14. Chen J., Staub J. E., Qian C., Jiang J., Luo X., Zhuang F., Theor. Appl. Genet. 2003, 106, 688. [DOI] [PubMed] [Google Scholar]
- 15. Chen J. F., Kirkbride J. H., Brittonia 2000, 52, 315. [Google Scholar]
- 16. Zhang K., Wang X., Zhu W., Qin X., Xu J., Cheng C., Lou Q., Li J., Chen J., Theor. Appl. Genet. 2018, 131, 2229. [DOI] [PubMed] [Google Scholar]
- 17. Wang X., Cheng C. Y., Zhang K. J., Tian Z., Xu J., Yang S. Q., Lou Q. F., Li J., Chen J. F., BMC Genomics 2018, 19, 583. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.a) Yu X., Wang X., Hyldgaard B., Zhu Z., Zhou R., Kjaer K. H., Ouzounis T., Lou Q., Li J., Cai Q., Rosenqvist E., Ottosen C. O., Chen J., Plant J. 2018, 94, 393; [DOI] [PubMed] [Google Scholar]; b) Zhuang Y., Chen J. F., Genet. Resour. Crop Evol. 2009, 56, 1071; [Google Scholar]; c) Zhuang Y., Chen J. F., Jahn M., Mol. Biol. Rep. 2009, 36, 1725; [DOI] [PubMed] [Google Scholar]; d) Chen L., Lou Q., Zhuang Y., Chen J., Zhang X., Wolukau J. N., Planta 2007, 225, 603; [DOI] [PubMed] [Google Scholar]; e) Chen L., Chen J., Genome 2008, 51, 789. [DOI] [PubMed] [Google Scholar]
- 19. Yang J., Liu D., Wang X., Ji C., Cheng F., Liu B., Hu Z., Chen S., Pental D., Ju Y., Yao P., Li X., Xie K., Zhang J., Wang J., Liu F., Ma W., Shopan J., Zheng H., Mackenzie S. A., Zhang M., Nat. Genet. 2016, 48, 1225. [DOI] [PubMed] [Google Scholar]
- 20. Li Q., Li H., Huang W., Xu Y., Zhou Q., Wang S., Ruan J., Huang S., Zhang Z., GigaScience 2019, 8, giz031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21. Garcia‐Mas J., Benjak A., Sanseverino W., Bourgeois M., Mir G., González V. M., Hénaff E., Câmara F., Cozzuto L., Lowy E., Alioto T., Capella‐Gutiérrez S., Blanca J., Cañizares J., Ziarsolo P., Gonzalez‐Ibeas D., Rodríguez‐Moreno L., Droege M., Du L., Alvarez‐Tejado M., Lorente‐Galdos B., Melé M., Yang L., Weng Y., Navarro A., Marques‐Bonet T., Aranda M. A., Nuez F., Picó B., Gabaldón T., Roma G., Guigó R., Casacuberta J. M., Arús P., Puigdomènech P., Proc. Natl. Acad. Sci. USA 2012, 109, 11872. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Simão F. A., Waterhouse R. M., Ioannidis P., Kriventseva E. V., Zdobnov E. M., Bioinformatics 2015, 31, 3210. [DOI] [PubMed] [Google Scholar]
- 23. Ye Y. N., Hua Z. G., Huang J., Rao N., Guo F. B., BMC Genomics 2013, 14, 769. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Zhuang W., Chen H., Yang M., Wang J., Pandey M. K., Zhang C., Chang W. C., Zhang L., Zhang X., Tang R., Garg V., Wang X., Tang H., Chow C. N., Wang J., Deng Y., Wang D., Khan A. W., Yang Q., Cai T., Bajaj P., Wu K., Guo B., Zhang X., Li J., Liang F., Hu J., Liao B., Liu S., Chitikineni A., Yan H., Zheng Y., Shan S., Liu Q., Xie D., Wang Z., Khan S. A., Ali N., Zhao C., Li X., Luo Z., Zhang S., Zhuang R., Peng Z., Wang S., Mamadou G., Zhuang Y., Zhao Z., Yu W., Xiong F., Quan W., Yuan M., Li Y., Zou H., Xia H., Zha L., Fan J., Yu J., Xie W., Yuan J., Chen K., Zhao S., Chu W., Chen Y., Sun P., Meng F., Zhuo T., Zhao Y., Li C., He G., Zhao Y., Wang C., Kavikishor P. B., Pan R. L., Paterson A. H., Wang X., Ming R., Varshney R. K., Nat. Genet. 2019, 51, 865. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. Bi Y., Zhao Q., Yan W., Li M., Liu Y., Cheng C., Zhang L., Yu X., Li J., Qian C., Wu Y., Chen J., Lou Q., Plant J. 2020, 102, 178. [DOI] [PubMed] [Google Scholar]
- 26. Liang Z., Schnable J. C., Mol. Plant 2018, 11, 388. [DOI] [PubMed] [Google Scholar]
- 27. Vicient C. M., Casacuberta J. M., Ann. Bot. 2017, 120, 195. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Woodhouse M. R., Cheng F., Pires J. C., Lisch D., Freeling M., Wang X., Proc. Natl. Acad. Sci. USA 2014, 111, 5283. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. Shen J., Kere M. G., Chen J. F., Sci. Hortic. 2013, 155, 39. [Google Scholar]
- 30.a) Fopa Fomeju B., Falentin C., Lassalle G., Manzanares‐Dauleux M. J., Delourme R., BMC Genomics 2014, 15, 498; [DOI] [PMC free article] [PubMed] [Google Scholar]; b) Wang X., Wang H., Wang J., Sun R., Wu J., Liu S., Bai Y., Mun J. H., Bancroft I., Cheng F., Huang S., Li X., Hua W., Wang J., Wang X., Freeling M., Pires J. C., Paterson A. H., Chalhoub B., Wang B., Hayward A., Sharpe A. G., Park B. S., Weisshaar B., Liu B., Li B., Liu B., Tong C., Song C., Duran C., Peng C., Geng C., Koh C., Lin C., Edwards D., Mu D., Shen D., Soumpourou E., Li F., Fraser F., Conant G., Lassalle G., King G. J., Bonnema G., Tang H., Wang H., Belcram H., Zhou H., Hirakawa H., Abe H., Guo H., Wang H., Jin H., Parkin I. A., Batley J., Kim J. S., Just J., Li J., Xu J., Deng J., Kim J. A., Li J., Yu J., Meng J., Wang J., Min J., Poulain J., Wang J., Hatakeyama K., Wu K., Wang L., Fang L., Trick M., Links M. G., Zhao M., Jin M., Ramchiary N., Drou N., Berkman P. J., Cai Q., Huang Q., Li R., Tabata S., Cheng S., Zhang S., Zhang S., Huang S., Sato S., Sun S., Kwon S. J., Choi S. R., Lee T. H., Fan W., Zhao X., Tan X., Xu X., Wang Y., Qiu Y., Yin Y., Li Y., Du Y., Liao Y., Lim Y., Narusaka Y., Wang Y., Wang Z., Li Z., Wang Z., Xiong Z., Zhang Z., Brassica rapa Genome Sequencing Project Consortium , Nat. Genet. 2011, 43, 1035. [DOI] [PubMed] [Google Scholar]
- 31. Chen J. F., Staub J., Adelberg J., Lewis S., Kunkle B., Euphytica 2002, 123, 315. [Google Scholar]
- 32.a) Otto S. P., Whitton J., Annu. Rev. Genet. 2000, 34, 401; [DOI] [PubMed] [Google Scholar]; b) Bertrand B., Bardil A., Baraille H., Dussert S., Doulbeau S., Dubois E., Severac D., Dereeper A., Etienne H., Plant Cell Physiol. 2015, 56, 2035. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33. Schnable J. C., Springer N. M., Freeling M., Proc. Natl. Acad. Sci. USA 2011, 108, 4069. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Eckardt N. A., Plant Cell 2014, 26, 1834. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35. Douglas G. M., Gos G., Steige K. A., Salcedo A., Holm K., Josephs E. B., Arunkumar R., Ågren J. A., Hazzouri K. M., Wang W., Platts A. E., Williamson R. J., Neuffer B., Lascoux M., Slotte T., Wright S. I., Proc. Natl. Acad. Sci. USA 2015, 112, 2806. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36. Leebens‐Mack H., Barker M. S., Carpenter E. J., Deyholos M. K., Gitzendanner M. A., Graham S. W., Grosse I., Li Z., Melkonian M., Mirarab S., Porsch M., Quint M., Rensing S. A., Soltis D. E., Soltis P. S., Stevenson D. W., Ullrich K. K., Wickett N. J., DeGironimo L., Edger P. P., Jordon‐Thaden I. E., Joya S., Liu T., Melkonian B., Miles N. W., Pokorny L., Quigley C., Thomas P., Villarreal J. C., Augustin M. M., et al., Nature 2019, 547, 679. [Google Scholar]
- 37.a) Doyle J. J., Flagel L. E., Paterson A. H., Rapp R. A., Soltis D. E., Soltis P. S., Wendel J. F., Annu. Rev. Genet. 2008, 42, 443; [DOI] [PubMed] [Google Scholar]; b) Yoo M. J., Liu X., Pires J. C., Soltis P. S., Soltis D. E., Annu. Rev. Genet. 2014, 48, 485. [DOI] [PubMed] [Google Scholar]
- 38.a) Chen Z. J., Annu. Rev. Plant Biol. 2007, 58, 377; [DOI] [PMC free article] [PubMed] [Google Scholar]; b) Wang J., Tian L., Lee H. S., Wei N. E., Jiang H., Watson B., Madlung A., Osborn T. C., Doerge R. W., Comai L., Chen Z. J., Genetics 2006, 172, 507. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39. Ainouche L., Baumel A., Salmon A., Yannic G., New Phytol. 2004, 161, 165. [Google Scholar]
- 40.a) Shaked H., Kashkush K., Ozkan H., Feldman M., Levy A. A., Plant Cell 2001, 13, 1749; [DOI] [PMC free article] [PubMed] [Google Scholar]; b) Salmon A., Ainouche M. L., Wendel J. F., Mol. Ecol. 2005, 14, 1163. [DOI] [PubMed] [Google Scholar]
- 41. Hegarty M. J., Barker G. L., Wilson I. D., Abbott R. J., Edwards K. J., Hiscock S. J., Curr. Biol. 2006, 16, 1652. [DOI] [PubMed] [Google Scholar]
- 42. Chalhoub B., Denoeud F., Liu S., Parkin I. A., Tang H., Wang X., Chiquet J., Belcram H., Tong C., Samans B., Corréa M., Da Silva C., Just J., Falentin C., Koh C. S., Le Clainche I., Bernard M., Bento P., Noel B., Labadie K., Alberti A., Charles M., Arnaud D., Guo H., Daviaud C., Alamery S., Jabbari K., Zhao M., Edger P. P., Chelaifa H., et al., Science 2014, 345, 950. [DOI] [PubMed] [Google Scholar]
- 43. Feldman M., Liu B., Segal G., Abbo S., Levy A. A., Vega J. M., Genetics 1997, 147, 1381. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44. Hurgobin B., Golicz A. A., Bayer P. E., Chan C.‐K. K., Tirnaz S., Dolatabadian A., Schiessl S. V., Samans B., Montenegro J. D., Parkin I. A. P., Pires J. C., Chalhoub B., King G. J., Snowdon R., Batley J., Edwards D., Plant Biotechol. J. 2018, 16, 1265. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45. Buggs R. J., Chamala S., Wu W., Tate J. A., Schnable P. S., Soltis D. E., Soltis P. S., Barbazuk W. B., Curr. Biol. 2012, 22, 248. [DOI] [PubMed] [Google Scholar]
- 46. Ozkan H., Levy A. A., Feldman M., Plant Cell 2001, 13, 1735. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47. Liu B., Brubaker C. L., Mergeai G., Cronn R. C., Wendel J. F., Genome 2001, 44, 321. [PubMed] [Google Scholar]
- 48. Lynch M., Conery J. S., Science 2000, 290, 1151. [DOI] [PubMed] [Google Scholar]
- 49.a) McLysaght A., Hokamp K., Wolfe K. H., Nat. Genet. 2002, 31, 200; [DOI] [PubMed] [Google Scholar]; b) Barker M. S., Arrigo N., Baniaga A. E., Li Z., Levin D. A., New Phytol. 2016, 210, 391; [DOI] [PubMed] [Google Scholar]; c) Rapp R. A., Udall J. A., Wendel J. F., BMC Biol. 2009, 7, 18. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.a) Cavé‐Radet A., Salmon A., Lima O., Ainouche M. L., Amrani A. E.l, Plant Sci. 2019, 280, 143; [DOI] [PubMed] [Google Scholar]; b) Ruiz M., Pensabene‐Bellavia G., Quiñones A., García‐Lor A., Morillon R., Ollitrault P., Primo‐Millo E., Navarro L., Aleza P., Front. Plant Sci. 2018, 9, 901. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51. Ha M., Li W. H., Chen Z. J., Trends Genet. 2007, 23, 162. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52. Yang C., Zhao L., Zhang H., Yang Z., Wang H., Wen S., Zhang C., Rustgi S., von Wettstein D., Liu B., Proc. Natl. Acad. Sci. USA 2014, 111, 11882. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.a) Goulas Y., Cerovic Z. G., Cartelat A., Moya I., Appl. Opt. 2004, 43, 4488; [DOI] [PubMed] [Google Scholar]; b) Cerovic Z. G., Masdoumier G., Ghozlen N. B., Latouche G., Physiol. Plant. 2012, 146, 251. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54. Lam E. T., Hastie A., Lin C., Ehrlich D., Das S. K., Austin M. D., Deshpande P., Cao H., Nagarajan N., Xiao M., Kwok P., Nat. Biotechol. 2012, 30, 771. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55. Xie T., Zheng J. F., Liu S., Peng C., Zhou Y. M., Yang Q. Y., Zhang H. Y., Mol. Plant 2015, 8, 489. [DOI] [PubMed] [Google Scholar]
- 56. Lou Q., Zhang Y. X., He Y. H., Li J., Jia L., Cheng C. Y., Guan W., Yang S. Q., Chen J. F., Plant J. 2014, 78, 169. [DOI] [PubMed] [Google Scholar]
- 57. Wang Y., Zhao Q., Qin X., Yang S., Li Z., Li J., Lou Q., Chen J., Chromosoma 2017, 126, 713. [DOI] [PubMed] [Google Scholar]
- 58. Diekmann K., Hodkinson T. R., Fricke E., Barth S., PLoS OneOne 2008, 3, e2813. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59. Bleve‐Zacheo T., Bongiovanni M., Melillo M. T., Castagnone‐Sereno P., Plant Sci. 1998, 133, 79. [Google Scholar]
- 60. Koren S., Walenz B. P., Berlin K., Miller J. R., Bergman N. H., Phillippy A. M., Genome Res. 2017, 27, 722. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61. Chaisson M. J., Tesler G., BMC BioinformaticsBioinf. 2012, 13, 238. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62. Li H., Durbin R., Bioinformatics 2009, 25, 1754. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63. Boetzer M., Henkel C. V., Jansen H. J., Butler D., Pirovano W., Bioinformatics 2011, 27, 578. [DOI] [PubMed] [Google Scholar]
- 64. Martin M., EMBnet J. 2011, 17, 3. [Google Scholar]
- 65. Servant N., Varoquaux N., Lajoie B. R., Viara E., Chen C. J., Vert J. P., Heard E., Dekker J., Barillot E., Genome Biol. 2015, 16, 259. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66. Xu Z., Wang H., Nucleic Acids Res. 2007, 35, W265. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67. Han Y., Wessler S. R., Nucleic Acids Res. 2010, 38, e199. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68. Edgar R. C., Myers E. W., Bioinformatics 2005, 21, i152. [DOI] [PubMed] [Google Scholar]
- 69. Wicker T., Sabot F., Hua‐Van A., Bennetzen J. L., Capy P., Chalhoub B., Flavell A., Leroy P., Morgante M., Panaud O., Paux E., SanMiguel P., Schulman A. H., Nat. Rev. Genet. 2007, 8, 973. [DOI] [PubMed] [Google Scholar]
- 70. Burton J. N., Adey A., Patwardhan R. P., Qiu R., Kitzman J. O., Shendure J., Nat. Biotechnol. 2013, 31, 1119. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71. Han Y. H., Zhang Z. H., Liu J. H., Lu J. Y., Huang S. W., Jin W. W., Cytogenet. Genome Res. 2008, 122, 80. [DOI] [PubMed] [Google Scholar]
- 72. Yang S., Cheng C., Qin X., Yu X., Lou Q., Li J., Qian C., Chen J., Hortic. Plant J. 2019, 5, 192. [Google Scholar]
- 73. Price A. L., Jones N. C., Pevzner P. A., Bioinformatics 2005, 21, i351. [DOI] [PubMed] [Google Scholar]
- 74. Jurka J., Kapitonov V. V., Pavlicek A., Klonowski P., Kohany O., Walichiewicz J., Cytogenet. Genome Res. 2005, 110, 462. [DOI] [PubMed] [Google Scholar]
- 75. Tarailo‐Graovac M., Chen N., Curr. Protoc. Bioinf. 2009, 4, 10. [DOI] [PubMed] [Google Scholar]
- 76. Haas B. J., Salzberg S. L., Zhu W., Pertea M., Allen J. E., Orvis J., White O., Buell C. R., Wortman J. R., Genome Biol. 2008, 9, R7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77. Burge C., Karlin S., J. Mol. Biol. 1997, 268, 78. [DOI] [PubMed] [Google Scholar]
- 78. Stanke M., Keller O., Gunduz I., Hayes A., Waack S., Morgenstern B., Nucleic Acids Res. 2006, 34, W435. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 79. Majoros W. H., Pertea M., Salzberg S. L., Bioinformatics 2004, 20, 2878. [DOI] [PubMed] [Google Scholar]
- 80. Alioto T., Blanco E., Parra G., Guigó R., Curr. Protoc. Bioinf. 2018, 64, e56. [DOI] [PubMed] [Google Scholar]
- 81. Korf I., BMC BioinformaticsBioinf. 2004, 5, 59. [Google Scholar]
- 82. Keilwagen J., Wenk M., Erickson J. L., Schattat M. H., Grau J., Hartung F., Nucleic Acids Res. 2016, 44, e89. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83. Kim D., Langmead B., Salzberg S. L., Nat. Methods 2015, 12, 357. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 84. Pertea M., Pertea G. M., Antonescu C. M., Chang T. C., Mendell J. T., Salzberg S. L., Nat. Biotechnol. 2015, 33, 290. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 85. Tang S., Lomsadze A., Borodovsky M., Nucleic Acids Res. 2015, 43, e78. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 86. Haas B. J., Delcher A. L., Mount S. M., Wortman J. R., R. K. Smith, Jr. , Hannick L. I., Maiti R., Ronning C. M., Rusch D. B., Town C. D., Salzberg S. L., White O., Nucleic Acids Res. 2003, 31, 5654. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 87. She R., Chu J. S., Wang K., Pei J., Chen N., Genome Res. 2009, 19, 143. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 88. Birney E., Clamp M., Durbin R., Genome Res. 2004, 14, 988. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 89. Nawrocki E. P., Eddy S. R., Bioinformatics 2013, 29, 2933. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 90. Lowe T. M., Eddy S. R., Nucleic Acids Res. 1997, 25, 955. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 91. Tang H., Lyons E., Pedersen B., Schnable J. C., Paterson A. H., Freeling M., BMC BioinformaticsBioinf. 2011, 12, 102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 92. Kielbasa S. M., Wan R., Sato K., Horton P., Frith M. C., Genome Res. 2011, 21, 487. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 93. Keilwagen J., Hartung F., Paulini M., Twardziok S. O., Grau J., BMC Bioinf. 2018, 19, 189. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 94. Marcais G., Delcher A. L., Phillippy A. M., Coston R., Salzberg S. L., Zimin A., PLoS Comput. Biol. 2018, 14, e1005944. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 95. Tham C. Y., Tirado‐Magallanes R., Goh Y., Fullwood M. J., Koh B. T. H., Wang W., Ng C. H., Chng W. J., Thiery A., Tenen D. G., Benoukraf T., Genome Biol. 2020, 21, 56. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 96. Anders S., Huber W., Genome Biol. 2010, 11, R106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 97. Luo R., Liu B., Xie Y., Li Z., Huang W., Yuan J., He G., Chen Y., Pan Q., Liu Y., Tang J., Wu G., Zhang H., Shi Y., Liu Y., Yu C., Wang B., Lu Y., Han C., Cheung D. W., Yiu S. M., Peng S., Xiaoqian Z., Liu G., Liao X., Li Y., Yang H., Wang J., Lam T. W., Wang J., GigaScience 2012, 1, 18. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 98. Li R., Li Y., Kristiansen K., Wang J., Bioinformatics 2008, 24, 713. [DOI] [PubMed] [Google Scholar]
- 99. Van der Auwera G. A., Carneiro M. O., Hartl C., Poplin R., Del A. G., Levy‐Moonshine A., Jordan T., Shakir K., Roazen D., Thibault J., Curr. Protoc. Bioinf. 2013, 43, 11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 100. Krzywinski M., Schein J. I., Birol I., Connors J., Gascoyne R., Horsman D., Jones S. J., Marra M. A., Genome Res. 2009, 19, 1639. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supporting Information
Supporting Table
Data Availability Statement
Raw genome sequence reads of C. ×hytivus have been deposited at DDBJ/ENA/GenBank under the accessions number PRJNA594754. The genomic data of C. hystrix are available at Figshare (https://doi.org/10.6084/m9.figshare.13377671). The raw PacBio Iso‐Seq reads and transcriptome sequence reads were deposited at the NCBI sequence read archive under accessions SRP262554 and SRP155470, respectively. The clean Illumina sequencing reads of actual male parent, C. sativus L. var. “Beijingjietou,” was deposited at the NCBI sequence read archive under accession SRP284803. The genome sequences and annotations of C. sativus, C. hystrix, and C. ×hytivus are also available in the Cucumis Genome Database (http://www.cucumisgdb.cn/). All materials and other data in this study are available upon reasonable request.
The data that support the findings of this study are openly available in DDBJ/ENA/GenBank under the accessions number PRJNA594754, SRP262554, SRP155470 and SRP284803, and in figshare at https://doi.org/10.6084/m9.figshare.13377671.