

Abstract
Clinical trial simulation (CTS) is a valuable tool in drug development. To obtain realistic scenarios, the subjects included in the CTS must be representative of the target population. Common ways of generating virtual subjects are based upon bootstrap (BS) procedures or multivariate normal distributions (MVNDs). Here, we investigated the performance of an alternative method based on conditional distributions (CDs). Covariate data from a hypertension drug development program were used. The methods were evaluated based on the original data set (internal evaluation) and on their ability to reproduce an older, unobserved population (extrapolation). Similar results were obtained in the internal evaluation for summary statistics, yet BS was able to preserve the correlation structure of the empirical distribution, which was not adequately reproduced by MVND; CD was in between BS and MVND. BS does not allow to extrapolate to an unobserved population. When the data set used to inform the extrapolation was well approximated by an MVND, the results from CD and MVND were comparable. However, improved extrapolation performance was observed for CD when deviations from normality assumptions occurred. If CTS is used to simulate within the observed distribution, BS is the preferred method. When extrapolating to new populations, a parametric method like CD/MVND is needed. In case the empirical multivariate distribution is characterized by linearly related covariates and unimodal marginal distributions, MVND can be used because of the simpler statistical framework and well‐established use; however, if uncertainty about the MVND assumptions exists, CD will increase the confidence in the simulations compared to MVND.
Study Highlights.
-
WHAT IS THE CURRENT KNOWLEDGE ON THE TOPIC?
Common ways of generating virtual subjects to be used in clinical trial simulation (CTS) tasks are based upon bootstrap (BS) procedures or multivariate normal distributions (MVNDs).
-
WHAT QUESTION DID THIS STUDY ADDRESS?
What is the performance of an alternative method based on conditional distributions (CDs) compared with BS and MVND?
-
WHAT DOES THIS STUDY ADD TO OUR KNOWLEDGE?
If CTS is used to simulate within the range of the observed distribution, BS is the preferred method for covariates simulation. When the CTS objectives involve extrapolations to new populations, a parametric method like CD or MVND is needed. As the MVND approach rests on relatively strong assumptions (i.e., linearly related covariates and unimodal distributions), CD is more robust when deviations from these assumptions occur.
-
HOW MIGHT THIS CHANGE DRUG DISCOVERY, DEVELOPMENT, AND/OR THERAPEUTICS?
Pharmacometricians will have at their disposal a new method for covariates simulation, which is particularly favorable when the empirical covariate distribution cannot be approximated by an MVND.
INTRODUCTION
In several research fields that aim to study complex systems, mathematical modeling is routinely used to quantitatively describe the system, generate or test hypotheses, and explore system behavior by means of model simulations. Drug discovery and development is one such field that has seen the application of modeling and simulation—or pharmacometrics—growing at a fast pace in the last decades. 1 Arguably, the success of pharmacometrics lies in its ability to integrate and synthesize evidence collected from heterogenous sources throughout the drug development spectrum, ultimately providing a sound quantitative input to the decision making process in pharmaceutical research and development (R&D). 2 , 3 , 4
In the pharmacometrician’s toolkit, clinical trial simulation (CTS) offers the possibility to mitigate the risk of study failure by prospectively exploring the performance of a given study design and/or of the decision making criteria. 5 Among others, applications of CTS include proof‐of‐concept study design, 6 outcome prediction in phase III, 7 pediatric trial optimization, 8 , 9 evaluation of non‐adherence, 10 , 11 and guidance in dose titration decisions. 12 CTS can be broken down into three building blocks: a disease model, a drug model, and a trial model. 13 The trial model requires the definition of a patient population through a set of characteristics, often termed covariates; in order to obtain realistic simulation scenarios, the set of covariates included in the CTS must be representative of the target population.
Common ways of generating covariate distributions for CTS are based upon nonparametric bootstrap (BS) procedures or multivariate normal distributions (MVNDs). 14 , 15 While BS is a nonparametric method, MVND requires certain parametric assumptions to be met by the original data set at hand. The different nature of these two methods brings respective pros and cons: with BS it is not possible to extrapolate outside of the observed distribution, but it preserves the relationships between covariates, thereby returning simulated subjects that are physiologically plausible. Conversely, the parametric distribution underlying the MVND—under certain assumptions about the means and correlations for the simulated population—can be used to generate completely new individuals. However, even with appropriate assumptions, the unrestricted nature of the underlying multivariate distribution may still lead to unrealistic simulated subjects.
Multiple imputation 16 , 17 is a technique used to handle complex missing data problems in statistical analysis, where multiple imputed data sets are analyzed separately, and inference is made on the pooled results. Missing data are imputed by sampling from conditional distributions using a prespecified imputation model. 18 A commonly used imputation model is predictive mean matching (PMM). 19 For each missing entry, PMM forms a small set of candidate donors from all complete cases that have predicted values closest to the predicted value for the missing entry. One donor is randomly drawn from the candidates, and the observed value of the donor is taken to replace the missing value. It follows that missing data are imputed with real values observed elsewhere in the data set, so imputations outside the observed data range will not occur. This feature makes sampling from conditional distributions (CDs) using PMM an appealing method for covariate simulations, because in principle it embraces the advantages of MVND and BS (i.e., it can retain physiological plausibility while allowing to extrapolate outside of the observed multivariate distribution).
The objectives of this analysis were to investigate the operating characteristics of CD when used to simulate covariates distributions, and to compare them with those of BS and MVND.
METHODS
Data
The data set used to build the simulations, hereafter referred to as the original data set, was obtained from a hypertension drug development program with data in 233 healthy subjects (HSs) and 706 patients. The original data set contained the baseline values of the following covariates: age, weight (WT), serum creatinine (SCR), creatinine clearance (CRCL), sex, and race. The summary statistics of the covariates in the original data set are reported in Table 1. The histograms of the continuous covariates stratified by HSs versus patients and the scatterplot matrix of the log‐transformed continuous covariates are shown in Figure 1a,b.
TABLE 1.
Summary statistics of the covariates in the original data set
| Total number of subjects | 939 |
| Continuous covariates | |
| Age (years) | |
| Mean | 46.4 |
| SD | 12.4 |
| Median | 47.0 |
| Range | 18.0–77.0 |
| Weight, kg | |
| Mean | 88.5 |
| SD | 20.1 |
| Median | 86.6 |
| Range | 46.3–172 |
| Serum creatinine, µmol/L | |
| Mean | 78.5 |
| SD | 16.2 |
| Median | 78.7 |
| Range | 41.5–133 |
| Creatinine clearance, ml/min | |
| Mean | 124 |
| SD | 34.3 |
| Median | 120 |
| Range | 47.0–282 |
| Categorical covariates | |
| Population, n (%) | |
| Patients | 706 (75.2) |
| Healthy subjects | 233 (24.8) |
| Sex, n (%) | |
| Males | 534 (56.9) |
| Females | 405 (43.1) |
| Race, n (%) | |
| White | 737 (78.5) |
| Black | 179 (19.1) |
| Asian | 19 (2.0) |
| American Indian | 2 (0.2) |
| Other | 2 (0.2) |
FIGURE 1.
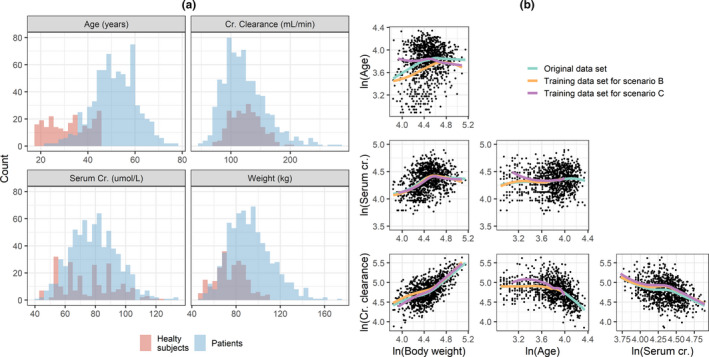
Histograms of continuous covariates colored by patients versus healthy subjects (a) and correlation between pairs of log‐transformed continuous covariates (b). The solid line is a loess regressor. Cr, creatinine
Covariate simulation methods
Bootstrap
The BS method consisted of sampling, with replacement, covariate vectors from the original data set.
Multivariate normal distribution
The MVND was implemented based on the framework presented in Tannenbaum et al 15 that is briefly described. Before estimating the parameters of the MVND from the original data set, continuous covariates are log‐transformed to constrain them to be positive; the covariate vectors simulated with the MVND are then exponentiated back to obtain the actual covariate values. As to categorical covariates, no pretransformation is used, and they are treated as if they were continuous variables. This implies that the MVND can generate nondiscrete values for categorical covariates, which then must be mapped back to their respective category based on a continuous critical value (see ref. 15 for more details). Two important assumptions of the MVND are that the covariates in the original data set follow the same known distribution, and that they are linearly related to each other. A third assumption is that all the marginal distributions should not display clear multimodal trends. No truncation was applied to the covariates simulated with the MVND.
Conditional distribution
Simulations with CD were performed using the fully conditional specification (FCS) algorithm (also known as multivariate imputation by chained equations) as implemented in the R package mice version 3.6.0. 19 FCS is an iterative method in which missing data are imputed on a variable‐by‐variable basis. Let the covariate data set be represented by the matrix Y, FCS specifies a group of conditional densities P(Yj mis | Yj obs, Y‐ j, ϕ), where Yj mis and Yj obs are the set of missing and observed values for the j‐th covariate, respectively, Y‐ j are the values of all covariates in Y that are not the j‐th one, and ϕ is the imputation model. Starting from simple random draws from the marginal distribution, imputation under FCS is done by iterating over the conditionally specified imputation models (an illustrative example using standard linear regression as imputation model is shown in Figure S1). The complete FCS algorithm as implemented in the mice package is reported in Supporting information S1, further details can be found in refs. 16, 18
The mice package offers the opportunity to choose from a selection of linear imputation models; here, the default methods were used, namely PMM 19 and multinomial logistic regression for continuous and categorical covariates, respectively. PMM first calculates the predicted value of the target covariate according to the specified linear regression model, secondly forms a set of donors/neighbors from the original data set constituted by the K closest values to the predicted one (K = 5 in the present analysis), and finally makes the actual prediction by randomly drawing one value from the set of donors. Thus, the value of the simulated covariate is ultimately drawn from the original data set.
The CD simulations were performed as imputation of data sets where all covariates were assumed to be missing, leveraging the original data to train each univariate imputation model (Figure S1). By doing so, the probability of a certain covariate being missing does not depend on the unobserved values of that (or other) covariate(s), that is, the missing covariates are said to be missing at random (MAR); this in turn implies that the missing data mechanism is ignorable, a condition that can be handled by the FCS algorithm. 16 , 18 An ad hoc R function was developed and used to automate covariates simulation with CD (Supporting information S2).
Simulations set up and methods comparison
Thirty replicates of the same size as the original data set were simulated using BS, MVND, and CD. CRCL was not directly simulated but derived from the simulated values of WT, SCR, and sex using the Cockcroft‐Gault 20 formula, similarly to what was done in the original data set.
In a first step, mean, standard deviation (SD), median, range, and variance‐covariance matrix for continuous covariates and proportions for categorical covariates were calculated for each of the 30 simulated replicates. Second, for each replicate r, the relative prediction error between the statistic of the simulated data set (P sim,r) and the original statistic (P org) was computed as rPEr (%) = (P sim,r – P org)/P org*100. Finally, relative bias (rBias) and root mean squared error (rRMSE) were derived as and , respectively.
The comparisons described above were carried out under three different scenarios. Scenario A used the entire original data set to inform the BS, MVND, and CD simulations (internal evaluation). In scenario B, with the aim of investigating the extrapolation performance of the methods, the original data set was divided into a training and a test data set, where only the training data set was used to inform the simulations, whereas the test data set was used to assess the predictive performance of the methods (external evaluation, P org in this case is the statistics computed in the test data set). The training data set was defined as all subjects in the original data set younger than 55 years of age, mimicking a CTS exercise executed to investigate the features of a clinical trial performed in an older, unobserved population. Scenario C was the same as scenario B but excluding HS from the training data set (the histograms of the continuous covariates stratified by sex in the training and test data sets for scenarios B and C are displayed in Figure S2). By definition, the BS does not allow to extrapolate outside of the empirical distribution, hence scenarios B and C were tested for CD and MVND only. In Scenarios B and C, the MVND simulations for age were obtained by truncating the distribution in the range 55–77 years. The age values simulated by the MVND were then used to seed the CD simulations, that is, the age values were not imputed but assumed to be known (see example C in Supporting information S2). Accordingly, only the covariance terms for age were included in the evaluation, whereas the other age statistics were not. It should be noted that in the CD simulations under scenarios B and C the MAR assumption still holds true, as the probability of the missing data depends on the observed data (i.e., the probability of a covariate being missing is higher in older subjects compared with younger ones).
RESULTS
Scenario A
Accuracy (rBias) and precision (rRMSE) of the continuous statistics are shown in Figure 2a,b. The mean and median of the original data set were maintained in the simulated population for all the methods. Likewise, SD and range were well‐estimated by BS and CD, whereas MVND resulted in larger rBias and rRMSE for the range of all covariates and for the SD of age. Figure 2c shows that the overall operating characteristics for the simulation of categorical covariates were similar across the three methods. BS was able to preserve the correlation structure of the empirical distribution, which was instead not adequately reproduced by MVND; CD was in between BS and MVND (Figure 3a). This in turn resulted in the lowest (BS) and highest (MVND) rBias and rRMSE in the elements of the variance‐covariance matrix (Figure 3b,c).
FIGURE 2.
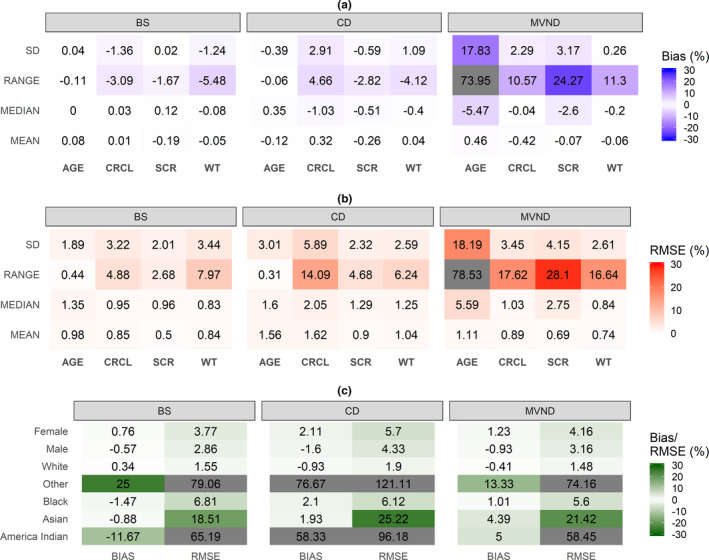
Relative bias and RMSE for summary statistics of continuous (a and b) and categorical (c) covariates in scenario A (cells where the absolute value of relative Bias/RMSE is greater than 30% are grayed out). BS, bootstrap; CD, conditional distribution; CRCL, creatinine clearance; MVND, multivariate normal distribution; RMSE, root mean squared error; SCR, serum creatinine; WT, weight
FIGURE 3.
Visual predictive check of the relationship between pairs of continuous covariates (a): the black line represents a loess regressor through the original data set, whereas the shaded area depicts the 80% confidence interval of the loess regressor fitted to each of the 30 replicates. Relative Bias (b) and RMSE (c) for the variance‐covariance matrix of the continuous covariates (cells where the absolute value of relative Bias/RMSE is greater than 30% are grayed out). Scenario A. BS, bootstrap; CD, conditional distribution; CRCL, creatinine clearance; MVND, multivariate normal distribution; RMSE, root mean squared error; SCR, serum creatinine; WT, weight
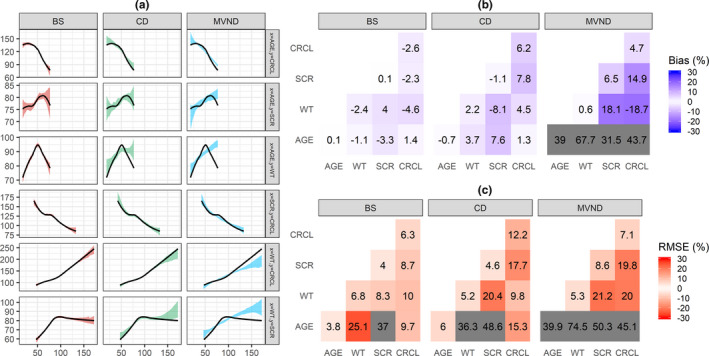
Scenario B
Using CD for the simulation of an older patient population led to lower rBias and rRMSE in the summary statistics of the continuous covariates, compared to MVND (Figure 4a,b). Figure 4c shows that the prediction of the proportion of men and women in the extrapolated data set was more accurate and precise for MVND versus CD, whereas similar performance was obtained for race.
FIGURE 4.

Relative Bias and RMSE for summary statistics of continuous (a) and categorical (c) covariates in scenario B (cells where the absolute value of relative Bias/RMSE is greater than 30% are grayed out). Relative Bias and RMSE for the variance‐covariance matrix of the continuous covariates (b) in scenario B (cells where the absolute value of relative Bias/RMSE is greater than 100% are grayed out). There were no subjects with “race = other” in the training data set, therefore in subfigure C rBias and rRMSE were computed using the absolute difference instead of the relative one for this category. CD, conditional distribution; CRCL, creatinine clearance; MVND, multivariate normal distribution; RMSE, root mean squared error; SCR, serum creatinine; WT, weight
Scenario C
When the HS data were removed from the training data set, no clear differences were observed between CD and MVND: some continuous covariates were better predicted by MVND (e.g., serum creatinine) and some others by CD (e.g., WT; Figure 5a,b). As displayed in Figure 5c, sex was still more accurate and precise for MVND versus CD.
FIGURE 5.
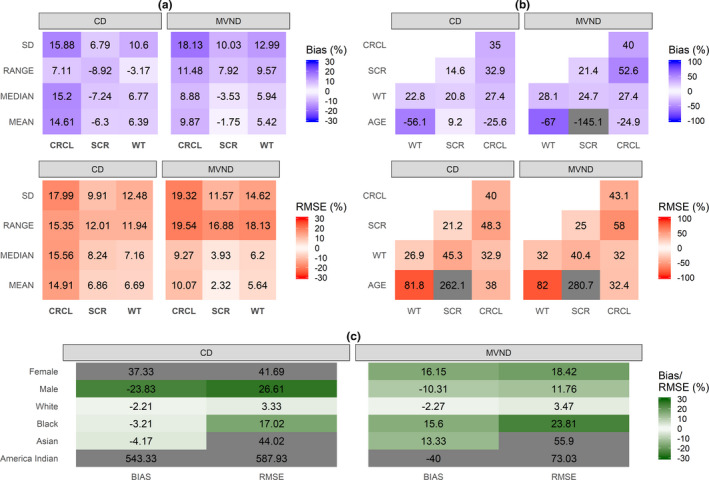
Relative Bias and RMSE for summary statistics of continuous (a) and categorical (c) covariates in scenario C (cells where the absolute value of relative Bias/RMSE is greater than 30% are grayed out). Relative Bias and RMSE for the variance‐covariance matrix of the continuous covariates (b) in scenario C (cells where the absolute value of relative Bias/RMSE is greater than 100% are grayed out). CD, conditional distribution; CRCL, creatinine clearance; MVND, multivariate normal distribution; RMSE, root mean squared error; SCR, serum creatinine; WT, weight
DISCUSSION
To maximize the predictability of a CTS exercise, plausible covariate values—representative of the target patient population—must be included in the trial model. Previous studies have investigated the operating characteristics of MVND as a tool to generate virtual populations, 15 and compared them with BS techniques. 14 In the present work, we introduced an alternative approach to covariate simulations that borrow from the methodology used in multiple imputation of incomplete data sets in statistical analysis. 16 , 17 In addition, we have also explored the extrapolation performance of the methods in predicting the summary statistics of an older, unobserved patient population.
In the internal evaluation (scenario A), the three methods adequately reproduced the summary statistics of the continuous covariates present in the original data set (Figure 2a,b). The results indicated that, for some covariates like age and SCR, dispersion parameters were not well‐predicted by MVND, which in turn led to the generation of implausible virtual subjects (e.g., 150 years old). Truncating the simulated covariates to more realistic values can help mitigate this problem; however, this was not assessed in the present analysis primarily because the cutoff values should be selected on a case‐by‐case basis, whereas the present work aimed at maximizing the generalizability of the results. In terms of categorical covariates, no clear differences among the operating characteristics of the three methods stood out; poorly represented categories, like “other” and “American Indian” for race, were characterized by large rBias and rRMSE (Figure 2c).
Because the relationship between some pairs of log‐transformed covariates deviated significantly from linearity (see for example age~WT correlation in Figure 1b), MVND provided more inaccurate and imprecise predictions of the covariance terms compared with BS and CD (Figure 3b,c). As expected, BS could reproduce the original relationship between covariates regardless of its shape (Figure 3a), whereas CD appeared to be more robust than MVND to deviations from the linearity assumptions. It should be noted that the original data set was characterized by a substantial overlap in the covariate distributions between HSs and patients (Figure 1); in case relevant differences between these distributions are observed, BS and MVND should account for that by using stratification and mixture modeling, respectively.
In scenario B, the aim was to evaluate the extrapolation capabilities of MVND and CD by assessing their predictive performance on a test data set composed by subjects older than 55 years of age, when the simulations were informed by a training data set from younger subjects. Similar to scenario A, the results suggested that, in general, CD achieved higher accuracy and precision levels than MVND for continuous covariates (Figure 4a,b). Although comparable performance was observed for the prediction of the race categories, the predicted proportion of men and women was more biased and imprecise for CD compared to MVND. However, a previous study comparing MVND and CD approaches for multiple imputations found that CD is more accurate than MVND whenever the data include categorical variables. 21 Figure S2 indicates that—in the training data set—women have a generally lower WT than men, whereas in the test data set the WT distribution in male subjects is shifted toward that of female subjects, and the two overlap into a unimodal distribution. It is reasonable to assume that, because WT is a relatively strong predictor for sex in the training data set, CD predicted a higher proportion of women (and lower proportion of men) because the mean WT in the test data set is lower than the one in the training data set. Instead, MVND led to better performance because the sex proportion is similar between the two data sets, although it should be noted that MVND can poorly perform when the marginal distributions are characterized by strong bimodalities. 15
When the HS data were removed from the training data set (scenario C), the nonlinearities in the correlation between age and other covariates were diminished (purple line in Figure 1b). As a result, the extrapolation performance of MVND improved compared to scenario B and, although the CD operating characteristics also did, no large differences were observed between the two methods in terms of continuous covariates (Figure 4a,b). The rBias and rRMSE in the sex covariate were still lower for MVND versus CD, yet the aforementioned discussion on scenario B concerning the different WT distribution between men and women applies to scenario C as well (Figure S2).
In general, CD was more robust to departures of the data from normality assumptions. The reason seems to lie more on the PMM method used to predict the new covariate value rather than in the different statistical background between the two methods (in MVND the data are modeled as a sample from a joint multivariate normal distribution, whereas in CD each variable is modeled conditionally on all the others). In fact, PMM slightly downweighs the model prediction by picking up a covariate value in the original data set that is very close to the predicted one; nevertheless, it should be noted that if strong nonlinear relations exist in the original data set, the consequent misspecification in the underlying predictive model could result in poor CD performance. 22 Tannenbaum et al. 15 suggest to carry out additional methods prior to creating the MVND in order to correct for nonlinear relations between continuous covariates, but this was not performed in the present implementation (apart from log‐transformation). Although this could have improved the MVND results, especially in terms of the variance‐covariance matrix, it is likely that CD would have also benefitted from such pretransformations given that it is still based on linear prediction models. Likewise, truncation of MVND simulations to plausible values might also have positively impacted the MVND operating characteristics. On the other hand, it can be noticed that whereas CD simulates ready‐to‐use covariates (Supporting information S2), MVND can require additional postprocessing of its input as well as output data, which, in turn, requires extra efforts and assumptions to be made.
The different results of the MVND between scenarios B and C can be attributed primarily to the distribution of age in HS, which is approximately uniform between 18 and 45 years. As shown in Figure 1a, the HS data distort the overall distribution of age, which is instead well approximated by a normal distribution in patients alone. Presumably, this is also the reason for the MVND issues in reproducing dispersion metrics under scenario A. This suggests that study‐specific nuisance covariates, such as HS versus patients, should be handled carefully before embarking in a CTS effort. For example, in order to mimic the data generation process, the MVND approach could have been applied separately for patients and HSs; however, attention needs to be paid when applying such stratification as it may decrease the precision in the means and covariances of the two MVNDs, thereby increasing the uncertainty in the corresponding predictions.
BS was excluded from scenarios B and C because, by definition, it does not allow to extrapolate outside of the empirical distribution. This limitation can be overcome if observational data on the target indication are available, for example, from routine care databases used to identify patients for enrollment in clinical trials. However, whereas for common indications like hypertension this might easily be achieved, large patient registries for less frequent diseases are often not available.
CD performed with the mice package requires the specification of some options, such as the number of donors K or the type of prediction model to use. All the default options were used in this analysis, yet the sensitivity of the results to the options choice should be further investigated. An interesting feature of mice that was not explored in the present work is that it potentially enables simulation of time‐varying covariates, which cannot be done with an MVND approach. Furthermore, extrapolation to other clinical contexts and generalizability of the results obtained in this work should be further explored.
The simulation of covariates, together with a disease and a drug model, represent the minimum working components that enable the generation of an in silico response to treatment for a group of patients. Thus, besides providing a tool for prospective investigations of study design features, CTS represents an appealing methodology for the creation of synthetic controls in clinical trials. Synthetic controls are formally defined as statistical methods that can be used to evaluate the comparative effectiveness of an intervention using external control data. 23 Although synthetic controls are usually based on collected real evidence, 24 the use of predictive statistical models to simulate virtual responses to standard‐of‐care treatments has recently been proposed as a way to generate synthetic controls. 25 In the case of rare diseases and small populations in general (e.g., pediatrics), where the use of control groups is often hampered by feasibility and ethical hurdles, simulated synthetic controls represent a promising alternative, as also indicated by their increased regulatory acceptance. 26
To conclude, the present analysis revealed that if CTS is used to simulate within the range of the observed distribution—for example, when studies in the target population are already available from other sources—BS can be considered as the preferred method for covariate simulation, particularly because it is able to guarantee the physiological plausibility of the simulated covariates. On the other hand, if the CTS objectives involve extrapolation to new populations, a parametric method like CD or MVND is needed. In case the empirical multivariate distribution used to inform the extrapolation is characterized by linearly related covariates and unimodal marginal distributions, CD and MVND have comparable performance, and the use of MVND may be favored in light of its simpler statistical framework and well‐established use. However, if uncertainty about the MVND hypotheses exists, CD allows to partly relax these hypotheses, thereby increasing the confidence in the simulation outcomes compared to MVND.
CONFLICT OF INTEREST
The authors declared no competing interests for this work.
AUTHOR CONTRIBUTIONS
G.S. and E.N.J. wrote the manuscript. E.N.J. designed the research. G.S. and E.N.J. performed the research. G.S. analyzed the data.
Supporting information
Fig S1
Fig S2
Supplementary Material
Supplementary Material
ACKNOWLEDGMENTS
The authors would like to thank all Pharmetheus’ colleagues for their valuable feedback on this work. Particular thanks go to Ola Caster, Sofia Friberg Hietala, and Peter Milligan, whose critical input improved the quality of the manuscript.
Funding information
This work was supported by Pharmetheus AB.
REFERENCES
- 1. EFPIA MID3 Workgroup , Marshall SF, Burghaus R, et al. Good practices in model‐informed drug discovery and development: practice, application, and documentation. CPT Pharmacometrics Syst Pharmacol. 2016;5(3):93‐122. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Milligan PA, Brown MJ, Marchant B, et al. Model‐based drug development: a rational approach to efficiently accelerate drug development. Clin Pharmacol Ther. 2013;93(6):502‐514. [DOI] [PubMed] [Google Scholar]
- 3. Gupta N, Bottino D, Simonsson USH, et al. Transforming translation through quantitative pharmacology for high‐impact decision making in drug discovery and development. Clin Pharmacol Ther. 2020;107(6):1285‐1289. [DOI] [PubMed] [Google Scholar]
- 4. Marshall S, Madabushi R, Manolis E, et al. Model‐informed drug discovery and development: current industry good practice and regulatory expectations and future perspectives. CPT Pharmacometrics Syst Pharmacol. 2019;8(2):87‐96. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Holford N, Ma SC, Ploeger BA. Clinical trial simulation: a review. Clin Pharmacol Ther. 2010;88(2):166‐182. [DOI] [PubMed] [Google Scholar]
- 6. Lockwood P, Ewy W, Hermann D, Holford N. Application of clinical trial simulation to compare proof‐of‐concept study designs for drugs with a slow onset of effect; an example in Alzheimer's disease. Pharm Res. 2006;23(9):2050‐2059. [DOI] [PubMed] [Google Scholar]
- 7. De Ridder F. Predicting the outcome of phase III trials using phase II data: a case study of clinical trial simulation in late stage drug development. Basic Clin Pharmacol Toxicol. 2005;96(3):235‐241. [DOI] [PubMed] [Google Scholar]
- 8. Smania G, Baiardi P, Ceci A, Magni P, Cella M. Model‐based assessment of alternative study designs in pediatric trials. Part I: frequentist approaches. CPT Pharmacometrics Syst Pharmacol. 2016;5(6):305‐312. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Smania G, Baiardi P, Ceci A, Cella M, Magni P. Model‐based assessment of alternative study designs in pediatric trials. Part II: Bayesian approaches. CPT Pharmacometrics Syst Pharmacol. 2016;5(8):402‐410. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Pérez‐Ruixo C, Remmerie B, Peréz‐Ruixo JJ, Vermeulen A. A receiver operating characteristic framework for non‐adherence detection using drug concentration thresholds‐application to simulated risperidone data in schizophrenic patients. AAPS J. 2019;21(3):40. [DOI] [PubMed] [Google Scholar]
- 11. Piana C, Danhof M, Della Pasqua O. Impact of disease, drug and patient adherence on the effectiveness of antiviral therapy in pediatric HIV. Expert Opin Drug Metab Toxicol. 2017;13(5):497‐511. [DOI] [PubMed] [Google Scholar]
- 12. Clements JD, Perez Ruixo JJ, Gibbs JP, Doshi S, Perez Ruixo C, Melhem M. Receiver operating characteristic analysis and clinical trial simulation to inform dose titration decisions. CPT Pharmacometrics Syst Pharmacol. 2018;7(11):771‐779. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Gobburu JV, Lesko LJ. Quantitative disease, drug, and trial models. Annu Rev Pharmacol Toxicol. 2009;49:291‐301. [DOI] [PubMed] [Google Scholar]
- 14. Teutonico D, Musuamba F, Maas HJ, et al. Generating virtual patients by multivariate and discrete re‐sampling techniques. Pharm Res. 2015;32(10):3228‐3237. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15. Tannenbaum SJ, Holford NH, Lee H, Peck CC, Mould DR. Simulation of correlated continuous and categorical variables using a single multivariate distribution. J Pharmacokinet Pharmacodyn. 2006;33:773‐794. [DOI] [PubMed] [Google Scholar]
- 16. Van Buuren S. Flexible Imputation of Missing Data. Boca Raton, FL: CRC Press; 2018. [Google Scholar]
- 17. Rubin DB. Multiple Imputation for Nonresponse in Surveys. Hoboken, NJ: John Wiley & Sons; 1987. [Google Scholar]
- 18. van Buuren S, Groothuis‐Oudshoorn K. MICE: multivariate imputation by chained equations in R. J Stat Soft. 2011;45(3):1‐67. [Google Scholar]
- 19. Little RJA. Missing data adjustments in large surveys. Journal of Business & Economic Statistics. 1988;6:287‐301. [Google Scholar]
- 20. Cockcroft DW, Gault MH. Prediction of creatinine clearance from serum creatinine. Nephron. 1976;16(1):31‐41. [DOI] [PubMed] [Google Scholar]
- 21. Kropko J, Goodrich B, Gelman A, Hill J. Multiple imputation for continuous and categorical data: comparing joint multivariate normal and conditional approaches. Polit Anal. 2014;22(4):497‐519. [Google Scholar]
- 22. Morris TP, White IR, Royston P. Tuning multiple imputation by predictive mean matching and local residual draws. BMC Med Res Methodol. 2014;14:75. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Thorlund K, Dron L, Park JJH, Mills EJ. Synthetic and external controls in clinical trials ‐ a primer for researchers. Clin Epidemiol. 2020;12:457‐467. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Gökbuget N, Kelsh M, Chia V, et al. Blinatumomab vs historical standard therapy of adult relapsed/refractory acute lymphoblastic leukemia. Blood Cancer J. 2016;6(9):e473. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. Switchenko JM, Heeke AL, Pan TC, Read WL. The use of a predictive statistical model to make a virtual control arm for a clinical trial. PLoS One. 2019;14(9):e0221336. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. ENPR‐EMA Working Group on Trial Preparedness . Preparedness of medicines’ clinical trials in paediatrics. 2020. https://www.ema.europa.eu/en/documents/other/preparedness‐medicines‐clinical‐trials‐paediatrics‐recommendations‐enpr‐ema‐working‐group‐trial_en.pdf. Accessed October 25, 2020.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Fig S1
Fig S2
Supplementary Material
Supplementary Material