

Abstract
The COVID19 pandemic globally and significantly has affected the life and health of many communities. The early detection of infected patients is effective in fighting COVID19. Using radiology (X-Ray) images is, perhaps, the fastest way to diagnose the patients. Thereby, deep Convolutional Neural Networks (CNNs) can be considered as applicable tools to diagnose COVID19 positive cases. Due to the complicated architecture of a deep CNN, its real-time training and testing become a challenging problem. This paper proposes using the Extreme Learning Machine (ELM) instead of the last fully connected layer to address this deficiency. However, the parameters’ stochastic tuning of ELM’s supervised section causes the final model unreliability. Therefore, to cope with this problem and maintain network reliability, the sine–cosine algorithm was utilized to tune the ELM’s parameters. The designed network is then benchmarked on the COVID-Xray-5k dataset, and the results are verified by a comparative study with canonical deep CNN, ELM optimized by cuckoo search, ELM optimized by genetic algorithm, and ELM optimized by whale optimization algorithm. The proposed approach outperforms comparative benchmarks with a final accuracy of 98.83% on the COVID-Xray-5k dataset, leading to a relative error reduction of 2.33% compared to a canonical deep CNN. Even more critical, the designed network’s training time is only 0.9421 ms and the overall detection test time for 3100 images is 2.721 s.
Keywords: COVID19, Deep convolutional neural networks, Sine–cosine algorithm, Extreme learning machine, Chest X-ray images
Introduction
In recent decades, the detection and diagnosis of various diseases have been successfully investigated by scientists (Jiang (2017); Li 2020; Zhu et al. 2020a; b; Zou et al. 2019). However, the early diagnosis of coronavirus has become a challenge for scientists due to the limited treatments and vaccines (Al-Waisy et al. 2020; Ashraf et al. 2020; Dansana 2020; Selvakumar and Lokesh 2021; Yousri et al. 2021). The polymerase chain reaction (PCR) test has been introduced as one of the primary methods for detecting COVID19 (Bwire et al. 2020). However, the PCR test is a laborious, time-consuming, and complicated process with current kits in short supply (Wu et al. 2007). On the other hand, X-ray images are extensively accessible (Hu et al. 2020; Jiang 2020; Li et al. 2020), and scans are comparatively low-cost (Pan 2020; Zenggang et al. 2019; Zuo et al. 2017).
Therefore, a method based on chest X-ray imaging has become almost the most useful method to detect COVID19 positive cases (Alabool et al. 2020). However, this method suffers from the long-time needed by the radiologists to read and interpret X-ray images (Eken 2020). Besides, due to the increasing prevalence of the COVID19 virus, the number of patients, who need an X-ray image interpretation, is much higher than the number of radiologists leading to the radiologists overloaded, long-time diagnosis process, and a critical risk of other people’s infection. Thereby, the rapid and automated X-ray image interpretation for accurately diagnosing the COVID19 positive cases is necessary. In this regard, Computer-Aided Diagnostic (CAD) models have been recently utilized to help radiologists (Al-Waisy et al. 2020; Dansana 2020; Alabool et al. 2020; Al-Qaness et al. 2020).
Deep-Learning (DL) models have been widely utilized in various challenging image processing and classification tasks (He et al. 2020; Ma and Xu 2020; Yang et al. 2021) including the COVID19 positive cases’ early detection and diagnosis (Abudureheman and Nilupaer 2021). Deep-COVID (Minaee et al. 2020a) was almost the pioneer in COVID19 detection using DL models. In this research, four well-known DEEP CNNs, including SqueezeNet, ResNet18, ResNet50, and DenseNet-121 were proposed to identify COVID19 positive cases in the analyzed chest X-ray images. Aside from the results, this reference provides a unique dataset of 5000 Chest X-rays (called COVID-Xray-5k) that radiologists have validated. This distinctive feature of the provided dataset motivates us to use it as a benchmark dataset.
Ozturk et al. (2020), an automated DarkNet model was used to perform a binary and a multiclass classification task. This model has designed to achieve up to 98% accuracy, but it used seventeen convolutional layers and numerous filtering on each layer leading to a model with high complexity. A particular deep CNN named CoroNet (Khan et al. 2020) was proposed to recognize COVID19 positive cases from chest X-ray images automatically. CoroNet is based on Xception architecture pre-trained on ImageNet dataset and trained end-to-end on a dataset developed by gathering COVID19 and other chest pneumonia X-ray images from two separate publicly accessible databases. Although the proposed model was fast and straightforward, the results were highly tolerable in accuracy and reliability. A customized deep CNN for detecting COVID19 positive cases, named COVID-Net, was proposed by Wang et al. (2020a). This model was utilized to divide the chest X-ray image into normal and COVID19 classes. The performance of the COVID-Net model was evaluated using two publicly available datasets. It is noted that the highest accuracy rate of 92.4% was obtained by COVID-Net, which is not very interesting. COVIDX-Net (Hemdan et al. 2020) is another DL model utilized to diagnose the COVID19 positive cases by chest X-ray images’ analysis. This model has been evaluated on seven well-known pre-trained models (e.g., DenseNet201, VGG19, ResNetV2, Inception, Xception, MobileNet, and V2InceptionV3) using a small dataset of fifty X-ray images. In this experiment, the highest accuracy rate of 91% was obtained using the DenseNet201. Reference (Mohammed 2020) proposed a novel model to select the best COVID19 detector using the TOPSIS and Entropy technique as well as 12 machine learning classifiers. The linear SVM classifier obtained the highest accuracy of 98.99%. Although the proposed represents a high classification accuracy, the model complexity was very high in time and space.
In another point of view, several deep CNNs were also utilized as feature descriptors to transfer the input image into lower-dimensional feature vectors (Kassani et al. 2020; Zhang et al. 2020a; Apostolopoulos and Mpesiana 2020; Abualigah et al. 2017). Afterward, these extracted feature vectors were fed into various classifiers to produce the final decision. Despite the reasonable classification accuracy (between 98 and 99%), these methods require manual parameter setting and matching feature extraction section with the classifier section. Also, the complexity of the final model is relatively high.
On the other hand, several methods have utilized preprocessing methods to improve the performance of classifiers. Heidari et al. (2021), Authors tried to use preprocessing methods to eliminate diaphragms, normalize X-ray image contrast-to-noise ratio, and produce three preprocessed images, which are then linked to a transfer learning-based deep CNN (i.e., VGG16) to categorize chest X-ray images into three classes of COVID-19, pneumonia, and normal cases. The classifier obtained the highest accuracy of 93.9%. A comparison study between VGG-19, Inception_V2, and the decision tree model was performed in Dansana (2020) to develop a binary classifier. In this work, first, the input images’ noise level was eliminated using a feature detection kernel to produce compact feature maps. These feature maps were fed into the DL models as input. The best accuracy rate of 91% was obtained using VGG-19 compared to 78%, and 60% were obtained by Inception_V2 and the decision tree method, in order. Heidari et al. (2020), after using a preprocessing model to detect and eliminate diaphragm areas showing on images, a histogram equalization algorithm and a bilateral filter are utilized to process the primary images to produce two sets of filtered images. Afterward, the primary image and the two filtered images are applied as inputs of three channels of the deep CNN to increase the model’s learning information. The designed model with two preprocessing stages generates a total accuracy of 94.5%, whereas without using two preprocessing steps, the designed model generates a lower classification accuracy of 88.0%. Although these methods increase the classifier’s accuracy, they will increase the overall complexity of the network.
Consequently, the necessity of designing an accurate (Liu et al. 2021; Yang and Sowmya 2015; Zhang et al. 2020b, c) and real-time detector (Ran et al. 2020; Wang 2020; Zuo et al. 2015) has become more prominent. Besides, this review on COVID19 detection systems shows that most of the existing deep learning-based systems have used deep CNN-based networks (Li et al. 2019a; Ma et al. 2019; Xu et al. 2020; Yang et al. 2020a,2021); thereby, we propose to employ the ability of deep CNN as a COVID 19 detector.
However, the aforementioned CNN-based methods are time-consuming, at least throughout the training phase. Therefore, before the user obtains feedback from the training phase, training and testing time can take hours even if the detector works well in the determined case. Besides, self-learning X-ray image detection, which trains progressively based on the user’s feedback, may not have an excellent user experience because it takes too long until the model converges while operating with it. In this case, the challenging point is having an appropriate model for X-ray image detection, which is efficient in both processing time and accuracy.
For the sake of having a real-time COVID19 recognizer, this paper proposes using ELM (Huang et al. 2006) instead of a fully connected layer to provide a real-time training process. In the proposed approach, we combine automatic feature learning of deep CNNs with efficient ELMs to address the mentioned shortcomings, i.e., manual feature extraction and extended training time, respectively. Consequently, the first phase is the deep CNN’s training, which is considered an automatic feature extractor. In the second phase, a fully connected layer will be replaced by ELM for designing a real-time classifier.
It is proven that the ELM’s origin is based on Random Vector Functional Link (RVLF) (Pao et al. 1994; Wang et al. 2021), leading to the ultra-fast learning and outstanding generalization capability (Zhang 2020; Niu 2020). Literature survey shows that ELM has been broadly utilized in many engineering applications (Li et al. 2019b; Liu 2020; Yang et al. 2020b). Although various kinds of ELMs are now accessible for image detection and classification tasks, it confronts serious issues such as the need for many hidden nodes for better generalization and determining the activation function type. Besides, ELM’s stochastic nature causes an additional uncertainty problem, particularly for high-dimensional image processing problems (Xie et al. 2012; Chen et al. 2012).
The ELM-based models randomly select the input weights and hidden biases from which the output weights are calculated. During this procedure, ELMs try to minimize the training error and identify the smallest output weights’ norm. Due to the stochastic choice of the input weights and biases in ELM, the output matrix may not indicate full column rank, leading to the system’s ill-conditioned matrices that produce non-optimal solutions (Xiong et al. 2016; Niu et al. 2020). Consequently, we apply a novel metaheuristic algorithm called SCA (Mirjalili 2016) to improve ELM conditioning and ensure optimal solutions.
For the rest of this research paper, the organization is as follows. In Sect. 2, some background resources are reviewed. Section 3 introduces the proposed scheme. Section 4 presents the simulation and discussion results, and finally, conclusions are presented in Sect. 5.
Background and materials
This section will represent the background knowledge, including the deep CNN, ELM, SCA, and COVID-Xray-5k dataset.
Deep convolution neural network
Generally, deep CNN is a conventional Multi-layer perceptron (MLP) based on three concepts: connection weights sharing, local receive fields, and temporal/spatial sub-sampling (Al-Saffar et al. 2017). These concepts can be arranged into two classes of layers, including sub-sampling layers and convolution layers. As shown in Fig. 1, the processing layers include three convolution layers C1, C3, and C5, located between layers S2 and S4, and final output layer F6. These sub-sampling and convolution layers are organized as feature maps. Neurons in the convolution layer are linked to a local receptive field in the prior layer. Consequently, neurons with identical feature maps (FMs) receive data from various input regions until the input is completely skimmed. However, the same weights are shared.
Fig. 1.

The architecture of LeNet-5 deep CNN
In the sub-sampling layer, the FMs are spatially by a factor of 2. As an illustration, in layer C3, the FM of size 10 × 10 is sub-sampled to conforming FM of size 5 × 5 in the next layer, S4. The classification process is the final layer (F6). Each FMs are the outcome of a convolution from the previous layer’s maps by their corresponding kernel and a linear filter in this structure. The weights and adding bias bk generate the kth (FM) using the tanh function as Eq. (1).
| 1 |
By reducing the resolution of FMs, the sub-sampling layer leads to spatial invariance, in which each pooled FM refers to one FM of the prior layer. The sub-sampling function is defined as Eq. (2).
| 2 |
where are the inputs, and b are trainable scalar and bias, respectively, after various convolution and sub-sampling layers. The last layer is a fully connected structure that carries out the classification task. There is one neuron for each output class. Thereby, in the case of the COVID19 dataset, this layer contains two neurons for their classes.
Extreme learning machine
ELM is one of the most widely used single-hidden layer neural network (SLNN) learning algorithms (Huang et al. 2006). ELM first randomly sets the input layer’s weights and biases and then calculates the output layer’s weights using these random values. This algorithm has a faster learning rate and better performance than traditional NN algorithms. Figure 2 indicates a typical SLNN, in which n denotes the number of input layer neurons, L indicates the number of hidden layer neurons, and m shows the number of output layer neurons.
Fig. 2.
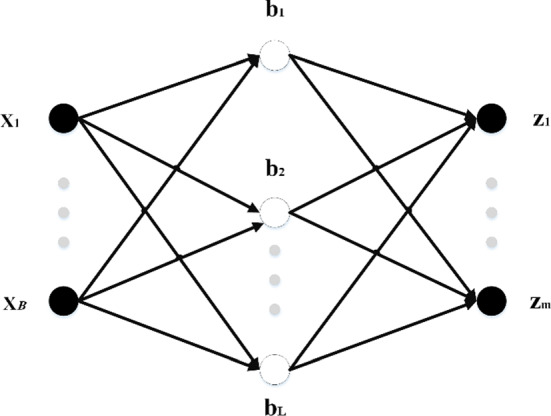
A single-hidden layer neural network
As indicated in Huang et al. (2006), the activation function can be shown as Eq. (3).
| 3 |
where wi denotes the input weight, bi shows the ith hidden neuron’s bias, xj represents the output weight, and Zjis the SLNN output. The matrix representation of Eq. (3) is shown in Eq. (4).
| 4 |
where , is the transpose of matrix Z, H is a matrix named hidden layer output matrix, which is calculated in Eq. (5).
| 5 |
Minimizing the training error is the primary training goal of ELM. In the conventional ELM, input biases and weights must be stochastically chosen, and the activation function must be infinitely differentiable. In this regard, the training of ELM leads to obtaining the output weight (Q) by optimizing the least-squares function indicated in Eq. (6), and the result can also be calculated as Eq. (7)
| 6 |
| 7 |
In this equation, H+ denotes the generalized Moore–Penrose inverse of the H matrix.
Sine–Cosine algorithm
Generally speaking, the optimization process in population-based methods begins with a series of responses that are randomly selected. The output function continually evaluates these random responses. Finally, the result of the output function gets optimized by the intended optimization method. If the number of selected responses and the iterations are appropriately considered, the probability of getting the best answer is also increased (Khishe and Mosavi 2020a; Abualigah and Diabat 2021).
Despite the differences between existing algorithms for population-based random optimization, in all of them, the optimization process is performed in two stages: exploration and exploitation (Mosavi et al. 2016b; Khishe and Mosavi 2020b; Khishe and Safari 2019). A randomized algorithm combines stochastic responses at a high rate in the search stage to find possible areas in search space. At the identification stage, slight changes are made to random responses, and outputs are recalculated. The method to calculate these outputs after applying changes to random responses is shown in Eqs. (8) and (9) (Mirjalili 2016).
| 8 |
| 9 |
In which is the location of current response in i-th dimension and t-th iteration. Also, are random numbers, pi is the location of a destination in the i-th dimension and represents absolute value. Equations (8) and (9) can be combined to generate Eq. (10).
| 10 |
In which r4 is a random number in a range of [0, 1]. As shown in Eq. (10), there are four main parameters in the algorithm. The parameter r1 shows the next location area (or direction of motion) that can be between the source and destination (or outside of it). The parameter r2 defines the amount of movement toward the destination or in the opposite direction. The parameter r3 determines the size of random weight to reach the destination (which may have a value as r3 > 3 or r3 < 3). Eventually, r4 changes equally between the components of the sinus and cosine as shown in Eq. (8). Figure 3 shows the effect of the sinus and cosine functions on Eqs. (8) and (9). This figure shows how the proposed equation defines the area between two responses in the search area (of course, this figure is plotted for the two-dimensional space).
Fig. 3.
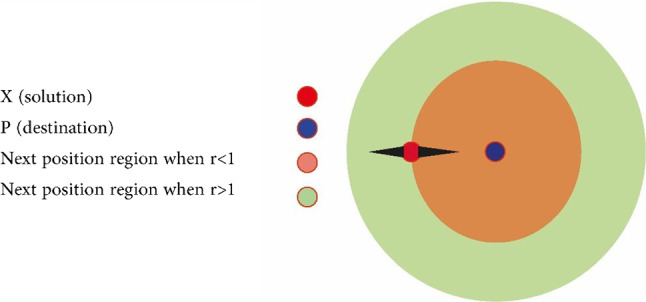
It should be noted, however, that Eqs. (8) and (9) can be extended to higher dimensions. The periodic form of the sinus and cosine functions allows a response to accumulating around another response. Therefore, identifying the defined space between the two responses is guaranteed. In order to find the destination (target) in the search area, the solution should search the space between similar responses (targets) comprehensively (Wang et al. 2020b). As shown in Fig. 4, this ability is achievable by changing the range of the sinus and cosine functions.
Fig. 4.
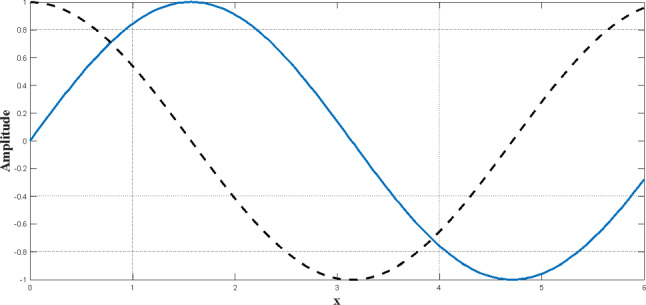
Changes in sinus and cosine functions in a specified interval
A conceptual model is shown in Fig. 5 to indicate the effectiveness of the sinus and cosine functions. This figure shows how the range of sine and cosine changes in order to update the location of a response.
Fig. 5.

Changes in the sinus and cosine functions within the range of [−2, 2] causes to get closer or more distant from the desired response
If the parameter r2 in Eq. (10) is defined as a random number in the range [0, 2π], then the existing mechanism guarantees to explore the search area. An appropriate algorithm should balance the exploration and exploitation operations, identify possible search areas, and ultimately converge to a general optimum. To achieve a balance between the exploitation and exploration phases, the domain of the sinus and cosine functions in Eqs. (8), (9), and (10) varies by Eq. (11).
| 11 |
where t is the current step, T is the maximum number of steps, and a is also a fixed number. Figure 6 shows the reduction in the range of the sinus and cosine functions during iterations.
Fig. 6.
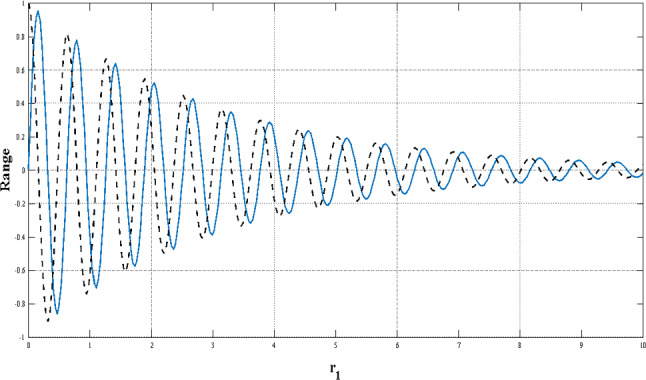
Reduction in the range of sine and cosine functions during iterations
According to Figs. 3 and 4, when the sinus and cosine functions are in the range of [−2, −1) and (1, 2], the algorithm will explore the search area. On the contrary, when they are in the range of [−1, 1], the algorithm detects the search area. This figure shows that the algorithm starts the optimization process using a set of random answers. Then the algorithm reserves the best answers (solutions) that have been obtained so far. The reserved answers are set as targets, and the rest of the responses are updated according to these targets. Besides, the range of the sinus and cosine functions are updated to enhance the search space identification and increase the number of steps.
The optimization process by the algorithm ends when the number of steps exceeds the maximum defined by default. Of course, it should be noted that other conditions, such as the maximum number of function evaluations or overall optimization accuracy, can be considered as conditions to end the optimization process. By using the operators mentioned above, the proposed algorithm can solve optimization problems theoretically for the reasons given below.
The algorithm creates and optimizes a set of random answers for a particular problem. Therefore, its advantage compared to other algorithms that are based on one response is the high exploration ability and avoidance of trapping in local minima.
When the sinus and cosine functions have values greater than 1 or smaller than −1, different search space areas are explored to find the answer.
When the sinus and cosine functions have values between 1 and −1, the explored areas are likely to be part of the answer.
The algorithm alters slowly from exploration to exploitation mode based on changes in the range of the sinus and cosine functions.
The best optimum approximation is stored in a variable as the target (response) and maintained throughout the entire optimization process.
As responses constantly update their location around the best answer, they always tend to choose the best search area during the optimization process.
Since the proposed algorithm considers the problem as a black box, it can be easily used for well-formulated problems.
COVID-X-ray dataset
A dataset named COVID-X-ray-5 k dataset, including 2084 training and 3100 test images, was utilized (Minaee et al. 2020a). In this dataset, considering radiologist advice, only anterior–posterior COVID19 X-ray images are used because the lateral photos are not applicable for detection purposes. Expert radiologists evaluated those images, and those that did not have clear pieces of evidence of COVID19 were eliminated. In this way, 19 images out of the whole 203 images were removed, and 184 images remained, indicating clear pieces of evidence of COVID19. With this method, a group with a more clearly labeled dataset was introduced. Out of 184 photos, 100 images are considered for the test set, and 84 images are intended for the training set. For the sake of increasing the number of positive cases to 420, data augmentation is applied. Since the number of normal cases was small in the covid-chestxray-dataset (Wynants et al. 2020), the supplementary ChexPert dataset (Irvin 2019) was employed. This dataset includes 224,316 chest X-ray images from 65,240 patients. Two thousand and 3000 non-COVID images were chosen from this dataset for the training and test sets, respectively. The final number of images related to various classes is reported in Table 1. Figure 7 indicates six stochastic sample cases from the COVID-X-ray-5 k dataset, including two positive and four normal samples.
Table 1.
The categories of images per class in the COVID dataset
| Category | COVID-19 | Normal |
|---|---|---|
| Training Set | 420 (84 before augmentation) | 2000 |
| Test Set | 100 | 3000 |
Fig. 7.

Six stochastic sample images from the COVID-X-ray-5k dataset
Methodology
As previously stated, this paper uses the LetNet-5 structure as a COVID19 positive cases detector. It consists of three convolutional layers, two pooling layers followed by a Fully Connected (FC) layer, which uses Gradient Descent-based Back Propagation (GDBP) algorithm for learning. Considering the aforementioned GDBP deficiencies, we propose to use a single-layer ELM instead of FC layers to classify the extracted features, as shown in Fig. 8.
Fig. 8.

The conventional vs. proposed architecture
The convolutional layers’ weights are pre-trained on a large dataset as a complete LetNet-5 with a standard GDBP learning algorithm. After the pre-training phase, the FC layers are removed, and the remaining layers are frozen to exploit as a feature extractor. The features generated by the stub-CNN will provide the ELM network’s input values. In the proposed structure, ELM has 120 hidden layer neurons and two output neurons. Noted that the sigmoid function is used as an activation function.
Stabilizing ELM using SCA
Despite the reduction of training time in ELMs compared to the standard FC layer, ELMs are not stable and reliable in real-world engineering problems due to the random determination of the input layer’s weights and biases. Thereby, we apply the SCA for tuning the input layer weights and biases of ELM to increase the network stabilization (SCA-ELM) and reliability while keeping the real-time operation. Generally, there are two main issues in tuning a deep network using a meta-heuristic optimization algorithm. First, the structure’s parameters must be represented by the searching agents (candid solution) of the meta-heuristic algorithm; next, the fitness function must be defined based on the considered problem’s interest.
The presentation of network parameters is a distinct phase in tuning a Deep Convolutional ELM using SCA (DCELM-SCA) algorithm. Thereby, ELM’s input layer weights and biases should be determined to provide the best diagnosis accuracy. To sum up, SCA optimizes the input layer weights and biases of ELM, which are used to calculate the loss function as a fitness function. In fact, the values of weight and bias are used as searching agents in the SCA. Generally speaking, three schemes are used to present weights and biases of a DCELM as candid solutions of the meta-heuristic algorithm: vector-based, matrix-based, and binary state (Mosavi et al. 2017a, b, 2019). Because the SCA needs the parameters in a vector-based model, in this paper, the candid solution is shown as Eq. (12) and Fig. 9.
| 12 |
where n is the number of the input nodes, Wij indicates the connection weight between the ith feature node and the jth ELM’s input neuron, and bj is the bias of the jth input neuron. As previously stated, the proposed architecture is a simple LeNet-5 structure (LeCun 2015). In this section, two structures, namely in_6c_2p_12c_2p and in_8c_2p_16c_2p, are used where c and p, are convolution and pooling layers, respectively. The kernel size of all convolution layers is 5 × 5, and the scale of pooling is down-sampled by a factor of 2.
Fig. 9.
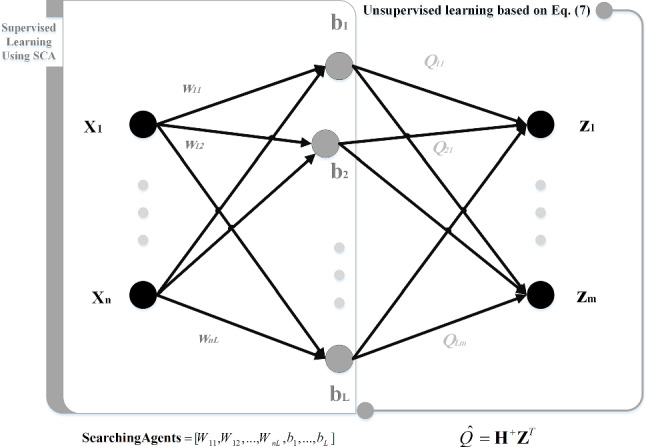
Assigning the deep CNN’s parameters as the candid solution (searching agents) of SCA
Loss function
In the proposed meta-heuristic method, the SCA algorithm trains DCELM to obtain the best accuracy and minimize evaluated classification error. This objective can be computed by the loss function of the metaheuristic searching agent or the mean square error (MSE) of the classification procedure. However, the loss function used in this method is as follows (Mosavi et al. 2016a):
| 13 |
where o shows the supposed output, u indicates the desired result, and N indicates the number of training samples. Two termination criteria include reaching maximum iteration or predefined loss function are utilized by the proposed SCA algorithm. Consequently, the pseudo-code of DCELM-SCA is shown in Fig. 10. Also, a schematic workflow explaining the proposed method is shown in Fig. 11.
Fig. 10.

The pseudo-code for DCELM-SCA model
Fig. 11.

The flowchart of the designed model
Simulation results and discussion
As previously stated, the hybrid method’s primary target is to enhance the diagnosis rate of classic deep CNN by using the ELM and SCA learning algorithms. In the DCELM-SCA simulation, the population is equal to 50, and the maximum iteration is equal to 10. The parameter of deep CNN, i.e., the learning rate and the batch size, are equal to 0.0001 and 12, respectively. Also, the number of epochs is considered between 1 and 10 for every evaluation. We down-sample all input images to 31 × 31 before applying them to deep CNNs. The assessment was carried out in MATLAB-R2019a on a PC with Intel Core i7-4500u processor, 16 GB RAM, in Windows 10, with ten individual runtimes. The performance of DCELM-SCA is compared with DCELM (Kölsch et al. 2017), DCELM-GA (Sun et al. 2020), DCELM-CS (Mohapatra et al. 2015), and DCELM-WOA (Li et al. 2019c) on the COVID-Xray-5k dataset. The parameters of the SCA, GA, CS, and WOA are shown in Table 2.
Table 2.
The parameters of benchmark algorithms
| Algorithm | Parameters | Values |
|---|---|---|
| GA | Cross-over probability | 0.7 |
| Mutation probability | 0.1 | |
| Population size | 50 | |
| CS | Discovery rate of alien eggs | 0.25 |
| Population size | 50 | |
| WOA | Linearly decreased from 2 to 0 | |
| Population size | 50 | |
| SCA | 2 | |
| r1, r2, r3, r4 | Random in the range of [0, 1] | |
| Population size | 50 |
Evaluation metrics
Various metrics can be remarkably used to measure classification models’ efficiency, such as sensitivity, classification accuracy, specificity, precision, Gmean, Norm, and F1-score. Since the dataset is significantly imbalanced (100 COVID19 images, 3000 Non-COVID images), we utilize specificity (true negative rate) and sensitivity to correctly reporting the performance of designed models, as following equations (true positive rate).
| 14 |
| 15 |
where TP denotes the number of true positive cases, FN is the number of false-negative cases, TN indicates the number of true negative cases, and FP represents the number of false-positive cases.
Structure expected probability grades
As previously stated, as the importance of time complexity, we utilize two simple LetNet-5 convolutional structures, i. e., in_6c_2p_12c_2p and in_8c_2p_16c_2p. The probability grade for each image is predicted by these structures, which indicates the possibility of the image being identified as COVID19. Comparing this likelihood with a threshold, we can extract a binary label indicating whether the specified image is COVID19 or not. A perfect structure must identify all COVID19 cases’ likelihood close to one and Non-Covid cases close to zero.
Figures 12 and 13 indicate the distribution of Expected Probability Grades (EPG) for the images in the test dataset, by in_6c_2p_12c_2p and in_8c_2p_16c_2p models, respectively. Because the Non-Covid category in covid-chestxray-dataset includes general cases and other kinds of infections, the distribution of EPG is presented for three categories, i.e., Covid19, Non-Covid other infections, and Non-Covid general cases. As shown in Figs. 12 and 13, the Non-Covid images with other kinds of infections have slightly larger grades than the Non-Covid general samples. It is logical since Non-Covid other infection images are more complicated to recognize from COVID19 than general cases. Positive COVID19 cases are expected to have much higher probabilities than the Non-Covid cases, which is certainly stimulating, as it indicates the structure is learning to recognize COVID19 from Non-Covid samples. The confusion matrices for these two structures on COVID-Xray-5k are shown in Figs. 14 and 15.
Fig. 12.
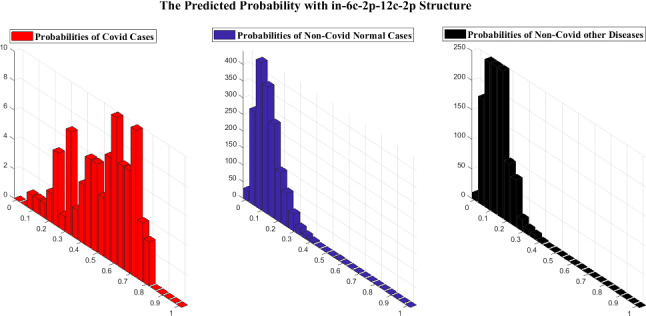
The EPG produced by in_6c_2p_12c_2p structure
Fig. 13.
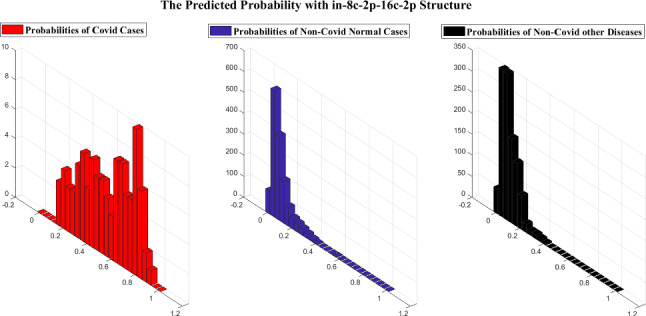
The EPG produced by in_8c_2p_16c_2p structure
Fig. 14.
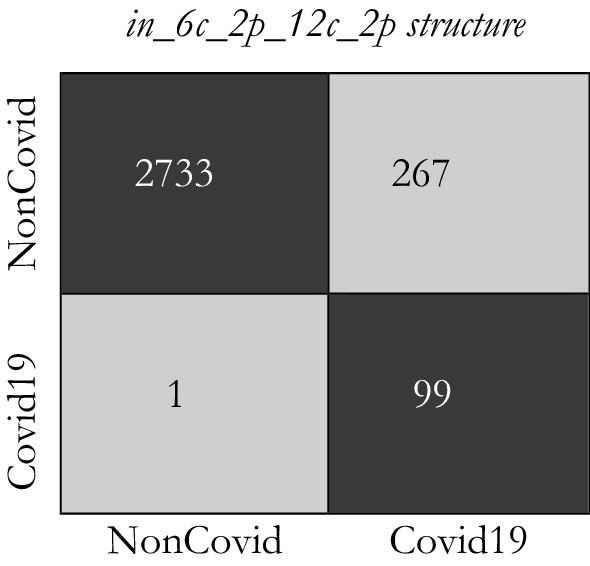
The confusion matrix for in_6c_2p_12c_2p model
Fig. 15.
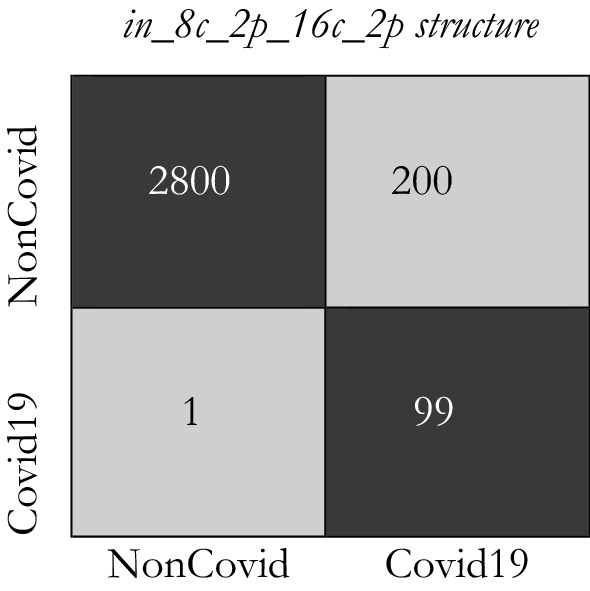
The confusion matrix for in_8c_2p_16c_2p model
Considering the calculated result, we choose the in_8c_2p_16c_2p structure as a benchmark structure named conventional deep CNN.
The comparison of specificity and sensitivity
Each structure EPG is indicating the possibility of the image being COVID19. These EPGs can be compared with a cut-off threshold to deduce whether the image is a positive COVID19 case or not. We use calculated labels to evaluate the specificity and sensitivity of each detector. Various specificity and sensitivity rates can be calculated based on the value of the cut-off threshold. The specificity and sensitivity rates based on conventional deep CNN, DCELM, DCELM-GA, DCELM-CS, DCELM-WOA, and DCELM-SCA models for various thresholds are represented in Table 3.
Table 3.
Specificity and sensitivity rates of benchmark models for various threshold values
| Model | Threshold | Sensitivity (%) | Specificity (%) | P-value |
|---|---|---|---|---|
| deep CNN | 0.1 | 98.22 ± 0.002 | 84.47 ± 0.003 | 0.0047 |
| 0.2 | 95.35 ± 0.002 | 85.73 ± 0.002 | 0.0025 | |
| 0.3 | 90.56 ± 0.005 | 87.42 ± 0.002 | 0.0047 | |
| 0.4 | 84.54 ± 0.006 | 90.82 ± 0.002 | 0.0085 | |
| DCELM | 0.1 | 98.11 ± 0.052 | 83.37 ± 0.082 | 0.041 |
| 0.2 | 94.56 ± 0.056 | 86.21 ± 0.022 | 0.0056 | |
| 0.3 | 89.96 ± 0.085 | 88.12 ± 0.013 | 0.0056 | |
| 0.4 | 83.22 ± 0.101 | 89.52 ± 0.011 | 3.12E−06 | |
| DCELM-GA | 0.1 | 98.33 ± 0.002 | 92.26 ± 0.002 | 0.0005 |
| 0.2 | 97.21 ± 0.003 | 93.85 ± 0.002 | 0.002 | |
| 0.3 | 92.36 ± 0.005 | 94.85 ± 0.001 | 1.11E−11 | |
| 0.4 | 89.24 ± 0.005 | 96.85 ± 0.001 | 0.0004 | |
| DCELM-CS | 0.1 | 99.23 ± 0.001 | 89.91 ± 0.002 | 0.0012 |
| 0.2 | 97.63 ± 0.001 | 92.85 ± 0.002 | 0.0032 | |
| 0.3 | 95.32 ± 0.002 | 96.33 ± 0.001 | 2.79E−06 | |
| 0.4 | 91.11 ± 0.002 | 97.33 ± 0.001 | 0.003 | |
| DCELM-WOA | 0.1 | 99.01 ± 0.002 | 85.12 ± 0.004 | 0.25 |
| 0.2 | 96.65 ± 0.003 | 92.98 ± 0.004 | 0.041 | |
| 0.3 | 91.21 ± 0.003 | 96.60 ± 0.003 | 0.045 | |
| 0.4 | 80.32 ± 0.004 | 97.90 ± 0.002 | 0.025 | |
| DCELM-SCA | 0.1 | 100 ± 0.000 | 84.34 ± 0.002 | N/A |
| 0.2 | 98.12 ± 0.001 | 93.32 ± 0.001 | N/A | |
| 0.3 | 97.56 ± 0.001 | 95.33 ± 0.001 | N/A | |
| 0.4 | 92.99 ± 0.002 | 98.66 ± 0.001 | N/A |
Given that the results are provided for ten individual runs, Table 3 shows the Average (Ave) and Standard deviation (Std) of the results. Besides, Wilcoxon’s rank-sum test (Wilcoxon et al. 1970), a non-parametric statistical test, was carried out to investigate whether the results of the DCELM-SCA differ from other compared models in a statistically significant way. It must be noted that a significance level of 5% was achieved in this case. In addition to AVE and STD, the rank-sum’s p values are reported in Table 3. It is worth noting that the N/A in the tables of results shortened form of “Not Applicable,” which indicates that the relating algorithm cannot be compared with itself in Wilcoxon’s test. Values greater than 0.05 indicate that the two comparison algorithms are not significantly different from each other; it should be noted that these numbers have been marked with an underline.
The data presented in Table 3 shows that all benchmark networks obtain very encouraging outcomes, and the best performing structure (DCELM-SCA) achieves a sensitivity rate of 100% and a specificity rate of 99.11%. In second and third place, DCELM-CS and DCELM-WOA get slightly better efficiency than other benchmark structures.
The Reliability analysis of imbalance dataset
Considering the limitation of the number of approved labeled positive COVID19 cases, we just have 100 positive COVID19 cases in the COVID-Xray-5k dataset. Therefore, the reported sensitivity and specificity rates in Table 3 may not be completely reliable. Theoretically, more numbers of positive COVID19 cases are needed to carry out a more reliable assessment of sensitivity rates. However, the 95% confidence interval of the obtained specificity and sensitivity rates can be evaluated to examine what is the feasible interval of calculated values for the current number of test cases in each category. We can calculate the accuracy rate’s confidence interval as Eq. (16) (Hosmer and Lemeshow 1992).
| 16 |
where p indicates the confidence interval’s significance level, i.e., the Gaussian distribution’s standard deviation, N represents the number of cases for each class, Accuracy · Rate is the evaluated accuracy, which is sensitivity and specificity in this example. The 95% confidence interval is utilized to lead to the corresponding value of 1.96 for p. Because a sensitive network is essential for the COVID19 detection problem, the particular threshold levels are selected, which corresponds to a sensitivity rate of 98% for each benchmark network, and their specificity rates are then examined. The comparison of the six model’s performance is presented in Table 4. The data presented in Table 4 show that the specificity rates’ confidence interval is about 1%. In comparison, it is equal to around 2.8% for sensitivity because there are 3000 images for the Non-Covid class, whereas 100 images for the sensitivity rate in the test set.
Table 4.
The reliability analysis of sensitivity and specificity of four evolutionary benchmark DCELM and deep CNN
| Model | Sensitivity (%) | Specificity (%) |
|---|---|---|
| deep CNN | 98 ± 2.8 | 84.47 ± 1.31 |
| DCELM | 98 ± 2.8 | 83.37 ± 1.32 |
| DCELM-GA | 98 ± 2.8 | 92.26 ± 0.90 |
| DCELM-CS | 98 ± 2.8 | 91.85 ± 0.91 |
| DCELM-WOA | 98 ± 2.8 | 91.33 ± 0.91 |
| DCELM-SCA | 98 ± 2.8 | 93.22 ± 0.82 |
As can be seen in Table 4, the specificity of canonical deep CNN was reduced when the ELM network was applied, i.e., the specificity of DCELM is lower than deep CNN. However, the specificity of DCELM-SCA is higher than canonical deep CNN and DCELM because of applying the SCA algorithm to improve the whole network’s stability.
The comparison of various structures just based on their specificity and sensitivity rates does not represent enough information about the detector’s performance because various threshold levels cause different specificity and sensitivity rates. The precision-recall curve is a good presentation that can be utilized to see the comprehensive comparison between these networks for all feasible cut-off threshold levels. This presentation indicates the precision rate as a function of recall rate. Precision is defined as the TPR divided by the TP [i.e., Eq. (14)], and the recall is the same as TNR [i.e., Eq. (15)]. Figure 16 shows the precision-recall plot of these six benchmark models. The Receiver Operating Characteristic (ROC) plot is another appropriate tool representing the TPR as a function of FPR. Therefore, Fig. 16 also shows the ROC curve of these six benchmark structures. The ROC curves show that DCELM-SCA significantly outperforms other DCELM-based networks as well as conventional deep CNN on the test dataset. However, it should be noted that the area under curve (AUC) of ROC curves may not right indicate the model efficiency since it can be very high for broadly imbalanced test sets like the COVID-Xray-5k dataset.
Fig. 16.

The ROC curves and precision-recall curves for DCELM-SCA and other benchmarks
The analysis of time complexity
Measuring the time complexity is necessary for the sake of analyzing a real-time detector. In this regard, besides the benchmark networks, we implement the designed COVID19 detector using NVidia Tesla K20 as the GPU and an Intel Core i7-4500u processor as the CPU. The testing time is the time required to process the whole test set of 3100 images. As shown from Fig. 16, the DCELM-SCA detector indicates outstanding COVID19 detection results compared with other benchmark models. For the sake of comparison, the proposed DCELM-SCA provides over 99.11% correct COVID19 sample detection for less than a 0.89% false alarm detection rate, which shows the SCA algorithm’s capability to increase the performance of the deep CNN model.
Generally, the precision-recall plot shows the tradeoff between recall and precision for various threshold levels. A high area under the precision-recall curve represents both high precision and recall, where high precision indicates a low false-positive rate, and high-recall indicates a low false-negative rate. As can be observed from the curves in Fig. 16, DCELM-SCA has a higher area under the precision-recall curves. Therefore, it means a lower false-positive and false-negative rate than other benchmark detectors. The simulation results indicate that DCELM-SCA represents the best accuracy for all epochs.
As shown from the ROC and precision-recall curves, the area under curve (AUC) of DCELM (deep CNN with ELM) is reduced compared to conventional deep CNN. It means that deep CNN’s performance decreases when we replace the fully connected layer with ELM because the advantages of supervised learning are neglected. However, it is pronounced that other evolutionary deep CNNs have better performance compared to standard deep CNN. We benefit from the stochastic supervised nature of the evolutionary learning algorithm and the unsupervised nature of ELM. Consequently, the result detector’s performance is improved by combining the advantages of these hybrid supervised-unsupervised learning algorithms.
From another point of view, when considering the result of Table 5, it is apparent the training and testing time of DCELMs is remarkably lower than classic deep CNN. Notably, in GPU accelerated training, the proposed approach is more than 538 times faster than the current deep CNN. Considering the number of testing and training images in Table 1 and also the entire test and training processing time in Table 5, we can easily conclude that DCELMs require less than one millisecond per image for both training and testing, thus making DCELMs real-time in both phases. Because more than 90% of the processing time is related to the feature extraction part, using other deep-learning models can reduce the processing time even further. Note that the best results are highlighted in bold type.
Table 5.
The comparison of test and training time of benchmark network implemented on GPU and CPU
| Model | CPU vs. GPU | Training time | Testing time | P-value |
|---|---|---|---|---|
| deep CNN | GPU | 10 min, 34 s | 3180 ms | 1.53E−07 |
| CPU | 6 h, 44 min, 8 s | 4 min, 30 s | 1.37E−03 | |
| DCELM | GPU | 1176 ms | 2936 ms | N/A |
| CPU | 1 min, 26 s | 4 min, 19 s | N/A | |
| DCELM-GA | GPU | 3645.6 ms | 3102 ms | 1.13E−03 |
| CPU | 4 min, 26.6 s | 4 min, 22 s | 1.05E−04 | |
| DCELM-CS | GPU | 2578.2 ms | 3101 ms | 1.62E−05 |
| CPU | 3 min, 9.2 s | 4 min, 27 s | 1.32E−03 | |
| DCELM-WOA | GPU | 1299.2 ms | 3015 ms | 0.57 |
| CPU | 2 min, 9 s | 4 min, 21 sec | 1.45E−09 | |
| DCELM-SCA | GPU | 1287 ms | 2985 ms | 0.604 |
| CPU | 2 min, 01 s | 4 min, 20 sec | 0.611 |
Sensitivity analysis of designed model
This subsection evaluates the sensitivity analysis of three control parameters employed in the designed model. The first parameter is a, which controls the reduction rate in the range of the sinus and cosine functions during the execution of iterations and its contribution to the optimization process, and the second and third ones are related to the network structure, i.e., the number of layers and batches. The analysis indicates which parameters are sensitive to various inputs and which ones are robust. Considering the references (Chai et al. 2019, 2020), experiments were conducted by defining four-parameter levels, as represented in Table 6. Afterward, an orthogonal array can be generated to characterize various parameter combinations (as represented in Table 7). The designed model is trained for each parameter combination. The calculated MSEs for various experiments are also represented in Table 7. Considering the results from Table 7, the level trends of parameters are indicated in Fig. 17. As shown in this figure, the best performance is obtained if these three parameters are set as NL = 5, a = 1, and Nb = 10.
Table 6.
The specification of parameters
| Parameters | Level | |||
|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |
| Nl | 3 | 4 | 5 | 6 |
| 2.5 | 0.5 | 0.75 | 1 | |
| Nb | 6 | 8 | 10 | 12 |
Table 7.
Results of various parameter combinations
| Test number | Parameters | Result (MSE) | ||
|---|---|---|---|---|
| Nl | Nb | |||
| Ex. #1 | 3 | 0.25 | 6 | 0.1984 |
| Ex. #2 | 3 | 0.5 | 8 | 0.1652 |
| Ex. #3 | 3 | 0.75 | 10 | 0.1655 |
| Ex. #4 | 3 | 1 | 12 | 0.0952 |
| Ex. #5 | 4 | 0.25 | 8 | 0.1821 |
| Ex. #6 | 4 | 0.5 | 6 | 0.1852 |
| Ex. #7 | 4 | 0.75 | 12 | 0.1123 |
| Ex. #8 | 4 | 1 | 10 | 0.0852 |
| Ex. #9 | 5 | 0.25 | 6 | 0.0923 |
| Ex. #10 | 5 | 0.5 | 12 | 0.0601 |
| Ex. #11 | 5 | 0.75 | 8 | 0.0532 |
| Ex. #12 | 5 | 1 | 10 | 0.0423 |
| Ex. #13 | 6 | 0.25 | 12 | 0.0977 |
| Ex. #14 | 6 | 0.5 | 10 | 0.0887 |
| Ex. #15 | 6 | 0.75 | 8 | 0.0731 |
| Ex. #16 | 6 | 1 | 6 | 0.0511 |
Fig. 17.

Level trends of the analyzed parameters
The analysis of convergence behavior
For more clarification, this subsection describes the experimental analyses of SCA’s searching agents’ convergence behavior. So, SCA’s searching agents’ convergence behavior is evaluated using qualitative metrics, including average fitness history and dynamic trajectories. Figure 18 represents the qualitative metrics for SCA’s searching agents’ convergence behavior in the four categories of benchmark optimization functions (i.e., unimodal, multimodal, fixed-dimension multimodal, and composition benchmark functions), which are described in Table 8. In Fig. 18, the first column indicates the two-dimensional view of benchmark functions. The second column shows the convergence curve, which is the best solution that has been updated by now. It can be observed from the figures in this column that each group of the function represents a particular downward behavior. SCA can initially encircle the optimum point in unimodal functions and then improve the solutions as iterations pass.
Fig. 18.


Search history, convergence curve, average fitness history, and trajectory of some functions
Table 8.
Benchmark functions
| Function | Dim | Range | fmin |
|---|---|---|---|
| Unimodal functions | |||
| 30 | 0 | ||
| 30 | 0 | ||
| Multimodal functions | |||
| 30 | |||
| 30 | 0 | ||
| 30 | [− 50, 50] | 0 | |
| Fixed-dimension multimodal functions | |||
| 2 | [− 65, 65] | 1 | |
| 2 | [− 2, 2] | 3 | |
| Composition function | |||
| 10 | [− 5, 5] | 0 | |
| 10 | [− 5, 5] | 0 | |
Contrary, the SCA’s searching agents attempt to globally discover the search space even in the final iterations to obtain superior solutions for other benchmark functions. This explorative behavior causes SCA’s searching agents to the step-like convergence curves. In other words, the convergence curve indicates the performance of the best SCA’s searching agents in obtaining the optimum point, whereas it does not represent any idea about the performance of the entire SCA’s searching agents. For this reason, we utilize another metric to investigate the entire SCA’s searching agents’ performance in the optimization process named average fitness history. This metric’s general pattern is almost similar to the convergence curve, while it focuses more on the total behavior and its impact on the results, improving from the initial stochastic population.
The trajectory of SCA’s searching agents is another metric, which is represented in column four. This trajectory indicates the topological amendments from the start to the end of the optimization task. Having many dimensions in the search space, only the first dimension is selected of an agent to show its trajectory. As shown in this column, the searching agents’ trajectory has high frequency and magnitude in the beginning iterations, vanishing in the last iterations. These figures verify the exploration phase in the beginning iterations while changing to the exploitation phase in the final iterations cause searching agents to converge to the global optimum finally.
The last column shows the search history as the fourth metric, indicating how searching agents’ diversity causes SCA to reach global optimum among various local optima. These figures indicate a more population density around the unimodal functions’ optimum points, contrary to multimodal and composition functions, in which there are more scattered SCA’s searching agents in the search space.
Identifying the region of interest
From the viewpoint of data science experts, the best result could be indicated in terms of the confusion matrix, overall accuracy, precision, recall, ROC curve, etc. However, these optimal results might not be sufficient for the medical specialists and radiologists if the results cannot be interpreted. Identifying the Region of Interest (ROI) that leads to the network’s decision making will enhance the understanding of both medical specialists and data science experts.
In this section, the results provided by designed networks for the COVID-Xray-5k dataset were investigated. The class activation mapping (CAM) (Fu et al. 2019) results were displayed for the COVID-Xray-5k dataset to localize the areas suspicious of the COVID19 virus. The probability predicted by the deep CNN model for each image class gets mapped back to the last convolutional layer of the corresponding model that is particular to each class to emphasize the discriminative regions. The CAM for a determined image class is the outcome of the activation map of the Rectified Linear Unit (ReLU) layer following the last convolutional layer. It is identified by how much each activation mapping contributes to the final grade of that particular class. The novelty of CAM is the total average pooling layer applied after the last convolutional layer based on the spatial location to produce the connection weights. Thereby, it permits identifying the desired regions within an X-ray image that differentiates the class specificity preceding the Softmax layer, which leads to better predictions. Demonstration using CAM for deep CNN models allows the medical specialists and radiology experts to localize the areas suspicious of the COVID19 virus, indicating Figs. 19 and 20.
Fig. 19.

ROI for positive COVID19 cases using ACM
Fig. 20.

ROI for Normal cases using ACM
Figures 19 and 20 indicate the results for COVID19 detection in X-ray images. Figure 19 shows the outcomes for the case marked as ‘COVID19’ by the radiologist, and the DCELM-SCA model predicts the same and indicates the discriminative area for its decision. Figure 20 shows the outcomes for a ‘normal’ case in X-ray images, and different regions are emphasized by both comparing models for their prediction of the ‘normal’ subset. Now, medical specialists and radiology experts can choose the network architecture based on these decisions. This kind of CAD visualization would provide a useful second opinion to the medical specialists and radiology experts and also improve their understanding of deep-learning models.
Conclusion
In this paper, the SCA and ELM were proposed to design an accurate and reliable deep CNN model for COVID19 positive cases from X-ray images. Numerical studies were carried out to evaluate the real-time capability of the proposed model. The 95% confidence interval of the obtained specificity and sensitivity rates was performed to confirm the proposed method’s reliability. According to the obtained results, we can conclude that the proposed model tends to be easier and more straightforward to implement compared to other benchmark models. Moreover, this design has the potential to be implemented in real-time COVID19 positive case detection. Consequently, we believe the proposed model and obtained numerical results are of practical interest to communities that are involved with deep neural network-based detectors and classifiers. The concept of class activation map was also applied to detect the virus’s regions potentially infected. It was found to correlate with clinical results, as confirmed by experts. A few research directions can be proposed for future work with the DCELM-SCA, such as underwater sonar target detection and classification. Also, changing SCA to tackle multi-objective optimization problems can be recommended as a potential contribution. The investigation of the chaotic maps’ effectiveness to improve the performance of the DCELM-SCA can be another research direction. Although the results were promising, further study is needed on a larger dataset of COVID19 images to have a more comprehensive evaluation of accuracy rates.
Availability of data and materials
The resource images can be downloaded using the following link and references (Minaee et al. 2020b). https://github.com/ieee8023/covid-chestxray-dataset, 2020.
Code availability
The source code of the models can be available by request.
Declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Footnotes
This article has been retracted. Please see the retraction notice for more detail: 10.1007/s00500-023-08595-x
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Change history
5/29/2023
This article has been retracted. Please see the Retraction Notice for more detail: 10.1007/s00500-023-08595-x
References
- Abualigah L, Diabat A (2021) Advances in sine cosine algorithm: a comprehensive survey. Artif Intell Rev 54:1–42. 10.1007/s10462-020-09909-3 [DOI] [PMC free article] [PubMed]
- Abualigah LM, Khader AT, Al-Betar MA, Alomari OA. Text feature selection with a robust weight scheme and dynamic dimension reduction to text document clustering. Expert Syst Appl. 2017;84:24–36. doi: 10.1016/j.eswa.2017.05.002. [DOI] [Google Scholar]
- Abualigah L, Diabat A, Mirjalili S, Abd Elaziz M, Gandomi AH. The arithmetic optimization algorithm. Comput Methods Appl Mech Eng. 2021;376:113609. doi: 10.1016/j.cma.2020.113609. [DOI] [Google Scholar]
- Abudureheman A, Nilupaer A (2021) Optimization model design of cross-border e-commerce transportation path under the background of prevention and control of COVID-19 pneumonia. Soft Comput 1–9. 10.1007/s00500-021-05685-6 [DOI] [PMC free article] [PubMed] [Retracted]
- Alabool H, Alarabiat D, Abualigah L et al (2020) Artificial intelligence techniques for containment COVID-19 pandemic: a systematic review. 10.21203/rs.3.rs-30432/v1
- Al-Qaness MA, Ewees AA, Fan H, Abualigah L, Abd Elaziz M. Marine predators algorithm for forecasting confirmed cases of COVID-19 in Italy, USA, Iran and Korea. Int J Environ Res Public Health. 2020;17(10):3520. doi: 10.3390/ijerph17103520. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Al-Saffar AAM, Tao H, Talab MA (2017) Review of deep convolution neural network in image classification. In: 2017 international conference on radar, antenna, microwave, electronics, and telecommunications (ICRAMET). IEEE, pp 26–31
- Al-Waisy AS et al (2020) COVID-CheXNet: hybrid deep learning framework for identifying COVID-19 virus in chest X-rays images. Soft Comput 1–16. 10.1007/s00500-020-05424-3 [DOI] [PMC free article] [PubMed]
- Apostolopoulos ID, Mpesiana TA. Covid-19: automatic detection from x-ray images utilizing transfer learning with convolutional neural networks. Phys Eng Sci Med. 2020;43(2):635–640. doi: 10.1007/s13246-020-00865-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ashraf S, Abdullah S, Almagrabi AO (2020) A new emergency response of spherical intelligent fuzzy decision process to diagnose of COVID19. Soft Comput 1–17. 10.1007/s00500-020-05570-8 [DOI] [PMC free article] [PubMed]
- Bwire GM, Majigo MV, Njiro BJ, Mawazo A. Detection profile of SARS-CoV-2 using RT-PCR in different types of clinical specimens: a systematic review and meta-analysis. J Med Virol. 2020 doi: 10.1002/jmv.26349. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chai R, Tsourdos A, Savvaris A, Chai S, Xia Y, Chen CP. Six-DOF spacecraft optimal trajectory planning and real-time attitude control: a deep neural network-based approach. IEEE Trans Neural Netw Learn Syst. 2019;31(11):5005–5013. doi: 10.1109/TNNLS.2019.2955400. [DOI] [PubMed] [Google Scholar]
- Chai R, Tsourdos A, Savvaris A, Chai S, Xia Y, Chen CLP (2020) Design and implementation of deep neural network-based control for automatic parking maneuver process. IEEE Trans Neural Netw Learn Syst. 10.1109/TNNLS.2020.3042120 [DOI] [PubMed]
- Chen X, Liu W, Lai J, Li Z, Lu C. Face recognition via local preserving average neighborhood margin maximization and extreme learning machine. Soft Comput. 2012;16(9):1515–1523. doi: 10.1007/s00500-012-0818-4. [DOI] [Google Scholar]
- Dansana D et al (2020) Early diagnosis of COVID-19-affected patients based on X-ray and computed tomography images using deep learning algorithm. Soft Comput 1–9. 10.1007/s00500-020-05275-y [DOI] [PMC free article] [PubMed]
- Eken S (2020) A topic-based hierarchical publish/subscribe messaging middleware for COVID-19 detection in X-ray image and its metadata. Soft Comput 1–11. 10.1007/s00500-020-05387-5 [DOI] [PMC free article] [PubMed] [Retracted]
- Fu K, Dai W, Zhang Y, Wang Z, Yan M, Sun X. Multicam: Multiple class activation mapping for aircraft recognition in remote sensing images. Remote Sens. 2019;11(5):544. doi: 10.3390/rs11050544. [DOI] [Google Scholar]
- He S, Guo F, Zou Q. MRMD2. 0: a python tool for machine learning with feature ranking and reduction. Curr Bioinform. 2020;15(10):1213–1221. doi: 10.2174/2212392XMTA2bMjko1. [DOI] [Google Scholar]
- Heidari M, Mirniaharikandehei S, Khuzani AZ, Danala G, Qiu Y, Zheng B. Improving the performance of CNN to predict the likelihood of COVID-19 using chest X-ray images with preprocessing algorithms. Int J Med Inform. 2020;144:104284. doi: 10.1016/j.ijmedinf.2020.104284. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Heidari M, Mirniaharikandehei S, Khuzani AZ, Danala G, Qiu Y, Zheng B (2021) Detecting COVID-19 infected pneumonia from x-ray images using a deep learning model with image preprocessing algorithm. In: Medical imaging 2021: computer-aided diagnosis, vol 11597. International Society for Optics and Photonics, p 115970V
- Hemdan EE-D, Shouman MA, Karar ME (2020) Covidx-net: a framework of deep learning classifiers to diagnose covid-19 in x-ray images. arXiv preprint arXiv:2003.11055
- Hosmer DW, Lemeshow S (1992) Confidence interval estimation of interaction. Epidemiology 3(5):452–456. 10.1097/00001648-199209000-00012 [DOI] [PubMed]
- Hu Y, Chen Q, Feng S, Zuo C (2020) Microscopic fringe projection profilometry: a review. Opt Lasers Eng 106192. 10.1016/j.optlaseng.2020.106192
- Huang G-B, Zhu Q-Y, Siew C-K. Extreme learning machine: theory and applications. Neurocomputing. 2006;70(1–3):489–501. doi: 10.1016/j.neucom.2005.12.126. [DOI] [Google Scholar]
- Irvin J, et al. Chexpert: a large chest radiograph dataset with uncertainty labels and expert comparison. Proc AAAI Conf Artif Intell. 2019;33:590–597. [Google Scholar]
- Jiang Q, et al. Alzheimer’s disease variants with the genome-wide significance are significantly enriched in immune pathways and active in immune cells. Mol Neurobiol. 2017;54(1):594–600. doi: 10.1007/s12035-015-9670-8. [DOI] [PubMed] [Google Scholar]
- Jiang D, et al. Bioenergetic crosstalk between mesenchymal stem cells and various ocular cells through the intercellular trafficking of mitochondria. Theranostics. 2020;10(16):7260. doi: 10.7150/thno.46332. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kassani SH, Kassasni PH, Wesolowski MJ, Schneider KA, Deters R (2020) Automatic detection of coronavirus disease (covid-19) in x-ray and ct images: a machine learning-based approach. arXiv preprint arXiv:2004.10641 [DOI] [PMC free article] [PubMed]
- Khan AI, Shah JL, Bhat MM. CoroNet: a deep neural network for detection and diagnosis of COVID-19 from chest x-ray images. Comput Methods Progr Biomed. 2020;196:105581. doi: 10.1016/j.cmpb.2020.105581. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Khishe M, Mosavi M. Classification of underwater acoustical dataset using neural network trained by Chimp Optimization Algorithm. Appl Acoust. 2020;157:107005. doi: 10.1016/j.apacoust.2019.107005. [DOI] [Google Scholar]
- Khishe M, Mosavi MR. Chimp optimization algorithm. Expert Syst Appl. 2020;149:113338. doi: 10.1016/j.eswa.2020.113338. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Khishe M, Safari A. Classification of sonar targets using an MLP neural network trained by dragonfly algorithm. Wirel Pers Commun. 2019;108(4):2241–2260. doi: 10.1007/s11277-019-06520-w. [DOI] [Google Scholar]
- Kölsch A, Afzal MZ, Ebbecke M, Liwicki M (2017) Real-time document image classification using deep CNN and extreme learning machines. In: 2017 14th IAPR international conference on document analysis and recognition (ICDAR), vol 1. IEEE, pp 1318–1323
- LeCun Y (2015) LeNet-5, convolutional neural networks. URL: http://yann.lecun.com/exdb/lenet 20(5):14
- Li L-L, Sun J, Tseng M-L, Li Z-G. Extreme learning machine optimized by whale optimization algorithm using insulated gate bipolar transistor module aging degree evaluation. Expert Syst Appl. 2019;127:58–67. doi: 10.1016/j.eswa.2019.03.002. [DOI] [Google Scholar]
- Li T, Xu M, Zhu C, Yang R, Wang Z, Guan Z. A deep learning approach for multi-frame in-loop filter of HEVC. IEEE Trans Image Process. 2019;28(11):5663–5678. doi: 10.1109/TIP.2019.2921877. [DOI] [PubMed] [Google Scholar]
- Li G, Chen B, Qi X, Zhang L. Circular convolution parallel extreme learning machine for modeling boiler efficiency for a 300 MW CFBB. Soft Comput. 2019;23(15):6567–6577. doi: 10.1007/s00500-018-3305-8. [DOI] [Google Scholar]
- Li A, et al. A tutorial on interference exploitation via symbol-level precoding: Overview, state-of-the-art and future directions. IEEE Commun Surv Tutor. 2020;22(2):796–839. doi: 10.1109/COMST.2020.2980570. [DOI] [Google Scholar]
- Li B-H, Liu Y, Zhang A-M, Wang W-H, Wan S. A survey on blocking technology of entity resolution. J Comput Sci Technol. 2020;35(4):769–793. doi: 10.1007/s11390-020-0350-4. [DOI] [Google Scholar]
- Liu Y, et al. Development of 340-GHz transceiver front end based on GaAs monolithic integration technology for THz active imaging array. Appl Sci. 2020;10(21):7924. doi: 10.3390/app10217924. [DOI] [Google Scholar]
- Liu S, Yu W, Chan FT, Niu B. A variable weight-based hybrid approach for multi-attribute group decision making under interval-valued intuitionistic fuzzy sets. Int J Intell Syst. 2021;36(2):1015–1052. doi: 10.1002/int.22329. [DOI] [Google Scholar]
- Ma H-J, Xu L-X (2020) Decentralized adaptive fault-tolerant control for a class of strong interconnected nonlinear systems via graph theory. IEEE Trans Autom Control. 10.1109/TAC.2020.3014292
- Ma H-J, Xu L-X, Yang G-H (2019) Multiple environment integral reinforcement learning-based fault-tolerant control for affine nonlinear systems. IEEE Trans Cybern [DOI] [PubMed]
- Minaee S, Kafieh R, Sonka M, Yazdani S, Soufi GJ. Deep-covid: Predicting covid-19 from chest x-ray images using deep transfer learning. Med Image Anal. 2020;65:101794. doi: 10.1016/j.media.2020.101794. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Minaee S, Kafieh R, Sonka M, Yazdani S, Soufi GJ (2020b) Deep-covid: predicting covid-19 from chest x-ray images using deep transfer learning. arXiv preprint arXiv:2004.09363 [DOI] [PMC free article] [PubMed]
- Mirjalili S. SCA: a sine cosine algorithm for solving optimization problems. Knowl-Based Syst. 2016;96:120–133. doi: 10.1016/j.knosys.2015.12.022. [DOI] [Google Scholar]
- Mohammed MA, et al. Benchmarking methodology for selection of optimal COVID-19 diagnostic model based on entropy and TOPSIS methods. IEEE Access. 2020;8:99115–99131. doi: 10.1109/ACCESS.2020.2995597. [DOI] [Google Scholar]
- Mohapatra P, Chakravarty S, Dash PK. An improved cuckoo search based extreme learning machine for medical data classification. Swarm Evol Comput. 2015;24:25–49. doi: 10.1016/j.swevo.2015.05.003. [DOI] [Google Scholar]
- Mosavi M, Kaveh M, Khishe M (2016a) Sonar data set classification using MLP neural network trained by non-linear migration rates BBO. In: The 4th Iranian conference on engineering electromagnetic (ICEEM 2016), pp 1–5
- Mosavi M, Kaveh M, Khishe M, Aghababaee M (2016b) Design and implementation a sonar data set classifier by using MLP NN trained by improved biogeography-based optimization. In: Proceedings of the 2nd national conference on marine technology, pp 1–6
- Mosavi MR, Khishe M, Akbarisani M. Neural network trained by biogeography-based optimizer with chaos for sonar data set classification. Wirel Pers Commun. 2017;95(4):4623–4642. doi: 10.1007/s11277-017-4110-x. [DOI] [Google Scholar]
- Mosavi M, Khishe M, Hatam Khani Y, Shabani M. Training radial basis function neural network using stochastic fractal search algorithm to classify sonar dataset. Iran J Electr Electron Eng. 2017;13(1):100–111. [Google Scholar]
- Mosavi MR, Khishe M, Naseri MJ, Parvizi GR, Mehdi A. Multi-layer perceptron neural network utilizing adaptive best-mass gravitational search algorithm to classify sonar dataset. Arch Acoust. 2019;44(1):137–151. [Google Scholar]
- Niu Z, Li D, Ji D, Liu Y, Feng Y, Zhou T, Zhang Y, Fan (2020) A mechanical reliability study of 3 dB waveguide hybrid couplers in the submillimeter and terahertz band. J Zhejiang Univ Sci C 1(1)
- Niu Z, et al. The research on 220GHz multicarrier high-speed communication system. China Commun. 2020;17(3):131–139. doi: 10.23919/JCC.2020.03.011. [DOI] [Google Scholar]
- Ozturk T, Talo M, Yildirim EA, Baloglu UB, Yildirim O, Acharya UR. Automated detection of COVID-19 cases using deep neural networks with X-ray images. Comput Biol Med. 2020;121:103792. doi: 10.1016/j.compbiomed.2020.103792. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pan D, et al. COCO enhances the efficiency of photoreceptor precursor differentiation in early human embryonic stem cell-derived retinal organoids. Stem Cell Res Ther. 2020;11(1):1–12. doi: 10.1186/s13287-020-01883-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pao Y-H, Park G-H, Sobajic DJ. Learning and generalization characteristics of the random vector functional-link net. Neurocomputing. 1994;6(2):163–180. doi: 10.1016/0925-2312(94)90053-1. [DOI] [Google Scholar]
- Ran W, Liu S, Zhang Z (2020) A polling-based dynamic order-picking system considering priority orders. Complexity 2020:1–15. 10.1016/j.optlaseng.2020.106192
- Selvakumar K, Lokesh S (2021) The prediction of the lifetime of the new coronavirus in the USA using mathematical models.Soft Comput 1–20. 10.1007/s00500-021-05643-2 [DOI] [PMC free article] [PubMed] [Retracted]
- Sun Y, Xue B, Zhang M, Yen GG, Lv J (2020) Automatically designing CNN architectures using the genetic algorithm for image classification. IEEE Trans Cybern 50(9):3840–3854. 10.1109/TCYB.2020.2983860 [DOI] [PubMed]
- Wang S, et al. Neurostructural correlates of hope: dispositional hope mediates the impact of the SMA gray matter volume on subjective well-being in late adolescence. Soc Cogn Affect Neurosci. 2020;15(4):395–404. doi: 10.1093/scan/nsaa046. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang L, Lin ZQ, Wong A. Covid-net: a tailored deep convolutional neural network design for detection of covid-19 cases from chest x-ray images. Sci Rep. 2020;10(1):1–12. doi: 10.1038/s41598-020-76550-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang Y, Yuan L, Khishe M, Moridi A, Mohammadzade F (2020b) Training RBF NN using sine-cosine algorithm for sonar target classification. Arch Acoust 45(4):753–764. 10.24425/aoa.2020.135281
- Wang B, Zhang B, Zou F, Xia Y (2021) A kind of improved quantum key distribution scheme. Optik
- Wilcoxon F, Katti S, Wilcox RA. Critical values and probability levels for the Wilcoxon rank sum test and the Wilcoxon signed rank test. Sel Tables Math Stat. 1970;1:171–259. [Google Scholar]
- Wu L-C, Horng J-T, Huang H-Y, Lin F-M, Huang H-D, Tsai M-F. Primer design for multiplex PCR using a genetic algorithm. Soft Comput. 2007;11(9):855–863. doi: 10.1007/s00500-006-0137-8. [DOI] [Google Scholar]
- Wynants L et al (2020) Prediction models for diagnosis and prognosis of covid-19: systematic review and critical appraisal. BMJ 369:1–16 [DOI] [PMC free article] [PubMed]
- Xie SJ, Yang J, Gong H, Yoon S, Park DS. Intelligent fingerprint quality analysis using online sequential extreme learning machine. Soft Comput. 2012;16(9):1555–1568. doi: 10.1007/s00500-012-0828-2. [DOI] [Google Scholar]
- Xiong L, Zhang H, Li Y, Liu Z. “Improved stability and H∞ performance for neutral systems with uncertain Markovian jump. Nonlinear Anal Hybrid Syst. 2016;19:13–25. doi: 10.1016/j.nahs.2015.07.005. [DOI] [Google Scholar]
- Xu S, Wang J, Shou W, Ngo T, Sadick A-M, Wang X (2020) Computer vision techniques in construction: a critical review. Arch Comput Methods Eng 1–15
- Yang S et al (2021) BiCoSS: toward large-scale cognition brain with multigranular neuromorphic architecture. IEEE Trans Neural Netw Learn Syst. 10.1109/TNNLS.2020.3045492 [DOI] [PubMed]
- Yang M, Sowmya A. An underwater color image quality evaluation metric. IEEE Trans Image Process. 2015;24(12):6062–6071. doi: 10.1109/TIP.2015.2491020. [DOI] [PubMed] [Google Scholar]
- Yang J, Li S, Wang Z, Dong H, Wang J, Tang S. using deep learning to detect defects in manufacturing: a comprehensive survey and current challenges. Materials. 2020;13(24):5755. doi: 10.3390/ma13245755. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yang Y, Hou M, Sun H, Zhang T, Weng F, Luo J. Neural network algorithm based on Legendre improved extreme learning machine for solving elliptic partial differential equations. Soft Comput. 2020;24(2):1083–1096. doi: 10.1007/s00500-019-03944-1. [DOI] [Google Scholar]
- Yang S, Gao T, Wang J, Deng B, Lansdell B, Linares-Barranco B. Efficient spike-driven learning with dendritic event-based processing. Front Neurosci. 2021;15:97. doi: 10.3389/fnins.2021.601109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yousri D, Abd Elaziz M, Abualigah L, Oliva D, Al-Qaness MA, Ewees AA. COVID-19 X-ray images classification based on enhanced fractional-order cuckoo search optimizer using heavy-tailed distributions. Appl Soft Comput. 2021;101:107052. doi: 10.1016/j.asoc.2020.107052. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zenggang X, Zhiwen T, Xiaowen C, Xue-Min Z, Kaibin Z, Conghuan Y (2019) Research on image retrieval algorithm based on combination of color and shape features. J Signal Process Syst 93:1–8
- Zhang J, Sun J, Chen Q, Zuo C. Resolution analysis in a lens-free on-chip digital holographic microscope. IEEE Trans Comput Imaging. 2020;6:697–710. doi: 10.1109/TCI.2020.2964247. [DOI] [Google Scholar]
- Zhang J, Chen Q, Sun J, Tian L, Zuo C. On a universal solution to the transport-of-intensity equation. Opt Lett. 2020;45(13):3649–3652. doi: 10.1364/OL.391823. [DOI] [PubMed] [Google Scholar]
- Zhang B, et al. Four-hundred gigahertz broadband multi-branch waveguide coupler. IET Microw Antennas Propag. 2020;14(11):1175–1179. doi: 10.1049/iet-map.2020.0090. [DOI] [Google Scholar]
- Zhang J, Xie Y, Li Y, Shen C, Xia Y (2020) Covid-19 screening on chest x-ray images using deep learning based anomaly detection. arXiv preprint arXiv:2003.12338
- Zhu S, Wang X, Zheng Z, Zhao X-E, Bai Y, Liu H. Synchronous measuring of triptolide changes in rat brain and blood and its application to a comparative pharmacokinetic study in normal and Alzheimer’s disease rats. J Pharm Biomed Anal. 2020;185:113263. doi: 10.1016/j.jpba.2020.113263. [DOI] [PubMed] [Google Scholar]
- Zhu S, Zheng Z, Peng H, Sun J, Zhao X-E, Liu H. Quadruplex stable isotope derivatization strategy for the determination of panaxadiol and panaxatriol in foodstuffs and medicinal materials using ultra high performance liquid chromatography tandem mass spectrometry. J Chromatogr A. 2020;1616:460794. doi: 10.1016/j.chroma.2019.460794. [DOI] [PubMed] [Google Scholar]
- Zou Q, Xing P, Wei L, Liu B. Gene2vec: gene subsequence embedding for prediction of mammalian N6-methyladenosine sites from mRNA. RNA. 2019;25(2):205–218. doi: 10.1261/rna.069112.118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zuo C, Chen Q, Tian L, Waller L, Asundi A. Transport of intensity phase retrieval and computational imaging for partially coherent fields: the phase space perspective. Opt Lasers Eng. 2015;71:20–32. doi: 10.1016/j.optlaseng.2015.03.006. [DOI] [Google Scholar]
- Zuo C, Sun J, Li J, Zhang J, Asundi A, Chen Q. High-resolution transport-of-intensity quantitative phase microscopy with annular illumination. Sci Rep. 2017;7(1):1–22. doi: 10.1038/s41598-017-06837-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The resource images can be downloaded using the following link and references (Minaee et al. 2020b). https://github.com/ieee8023/covid-chestxray-dataset, 2020.
The source code of the models can be available by request.