

Abstract
The quantification of blood flow velocity in the human conjunctiva is clinically essential for assessing microvascular hemodynamics. Since the conjunctival microvessel is imaged in several seconds, eye motion during image acquisition causes motion artifacts limiting the accuracy of image segmentation performance and measurement of the blood flow velocity. In this paper, we introduce a novel customized optical imaging system for human conjunctiva with deep learning-based segmentation and motion correction. The image segmentation process is performed by the Attention-UNet structure to achieve high-performance segmentation results in conjunctiva images with motion blur. Motion correction processes with two steps—registration and template matching—are used to correct for large displacements and fine movements. The image displacement values decrease to 4–7 μm during registration (first step) and less than 1 μm during template matching (second step). With the corrected images, the blood flow velocity is calculated for selected vessels considering temporal signal variances and vessel lengths. These methods for resolving motion artifacts contribute insights into studies quantifying the hemodynamics of the conjunctiva, as well as other tissues.
Keywords: blood flow velocity quantification, conjunctival microvessel, deep learning, image processing, motion correction, optical imaging system, vessel segmentation
1. Introduction
The conjunctiva is a translucent and highly vascularized membrane covering the sclera of the human eye. These properties enable the conjunctiva to be the only tissue observing red blood cell (RBC) shift that can be utilized for measuring the blood flow velocity directly from the surface. Quantitative analysis of the blood flow velocity has been used to estimate the progression of eye diseases, including diabetic retinopathy [1] and dry eye syndrome [2,3,4]. The diabetic retinopathy patients group had slower blood flow velocities in the conjunctiva than the control group [1]. In the case of dry eye syndrome, the normal group had slow blood flow velocities in the conjunctiva [2,3,4]. Moreover, patients with unilateral ischemic stroke [5] and high cardiovascular disease risk [6] tend to have slower conjunctival blood flow velocities. These studies demonstrated that quantifying the conjunctival blood flow velocity can contribute to evaluate not only ophthalmic diseases but, also, systemic diseases in critical organs, especially the brain and cardiovascular system.
Conventional methods for quantifying the conjunctival blood flow velocity use functional slit-lamp biomicroscopy [7], a noninvasive optical imaging system (EyeFlow) [8], and orthogonal polarization spectral imaging [9]. These methods can be disturbed by motion artifacts inherited from the image acquisition process due to eye movements. The motion artifacts cause two distinct problems: (1) image displacement and (2) low-quality images.
First, the image displacement problem causes the vessel to be misaligned from the central point. Registration was performed by calculating the difference of the correlation coefficients from the reference frame [10,11,12]. In another method, the sharpness index of each image was measured by calculating pixel-to-pixel intensity variance, eliminating the inadequate frames below the threshold value [13]. These two methods can compensate for rapid eye movements but have difficulty correcting for fibrillation or respiratory eye movements.
Second, the segmentation, which is the essential step for quantifying the microcirculation, remains challenging for low-quality images of blurry structures and uneven light illumination by subject motions. Various segmentation methods [7,10,14,15] were applied to the conjunctiva images with motion artifacts. The Frangi filter [10,14] is the most commonly used segmentation algorithm and exploits multiscale information from the eigenvalues of the Hessian matrix. The supervised method [16], which uses the Gabor wavelet filter and the Gaussian mixture model (GMM) classifier, was suggested for conjunctiva vessel segmentation [7,15]. These two segmentation methods are efficient in identifying vessels but lack of the ability to identify low-quality vessels.
We solved the image displacement and low-quality image problems caused by motion artifacts by proposing a custom-built optical system with a two-step calibration method and a deep learning-based segmentation model. The custom-built optical system was optimized to acquire human bulbar conjunctival images. The two-step calibration method was motivated by the fact that image displacements can result from sudden eye movements and respiratory movements. The first step, registration, corrects the sudden eye movements. The second step, template matching, eliminates the respiratory movements. Since deep learning-based segmentation is effective with low-quality conjunctival images [17], a custom-built Attention-UNet model was constructed to extract accurate conjunctiva vascular information. The blood flow velocity was measured by generating a spatial–temporal analysis (STA) image from the corrected image sequence and vascular features. With this configured system, we can acquire a conjunctival vascular image set with minimal motion and accurately quantify conjunctival blood flow velocity.
2. Materials and Methods
2.1. Process of Quantifying Blood Flow Velocity
Quantification of the blood flow velocity is performed by the six steps shown in Figure 1. After acquiring image frames for 3 s with 25 fps, image processing, including image registration, feature extraction, and motion correction, provides motion-free image sequences for measuring the blood flow velocity through tracking the position of red blood cells. Detailed explanations of imaging acquisition, registration, and deep learning-based image segmentation and quantification are shown in following sections.
Figure 1.

The summary of experimental phase in this study.
2.2. Image Acquisition
The schematic of a customized optical imaging system is depicted in Figure 2. The conjunctival imaging system uses a green LED with a central wavelength of 525 nm and a spectral bandwidth of 5 nm, because hemoglobin and deoxyhemoglobin have high extinction coefficients at a wavelength of 530 nm. Accordingly, the image contrast between the blood vessels and the white sclera can be improved. We illuminate the uniform light using a diffuser (ED1-C50-MD, Thorlabs Inc., Newton, NJ, USA) forward to the LED. The power of the LED at the eye pupil is 300 μW/cm2, which is 0.3 times the laser safety standards (ANSI) limits under the condition of 10-min exposure [18].
Figure 2.

Custom-built optical imaging system for human bulbar conjunctiva.
The diffusely reflected light from the conjunctiva transmits to the complementary metal oxide semiconductor (CMOS) sensor-based camera (UI-3080CP Rev.2, IDS Inc., Obersulm, Germany) with an imaging sensor size of 8.473 mm × 7.086 mm to acquire a maximum resolution of 2456 2054 pixels. The pixel size on the camera sensor is 3.45 μm × 3.45 μm. The frame rate is set at 20 fps but is enhanced to 25 fps by binning the image size to 2208 × 1848 pixels for a more continuous blood flow assessment. The video data are recorded for approximately 3 s with 25 fps.
The magnification of the system is designed to achieve RBC flow imaging. An RBC with an average diameter of 7.5 μm [19] should be imaged by at least 2 pixels on the camera sensor to distinguish the individual RBC particles [20]. Moreover, the magnification for the reliable quantification of RBC flow velocity requires 4 to 5 pixels imaged per RBC [21], corresponding to 2 in our system. To achieve this magnification, we use a high-magnification zoom lens (MVL6 × 12Z, Thorlabs Inc., Newton, NJ, USA) with an adjustable magnification between 0.7 and 6. An extension tube (MVL20A, Thorlabs Inc., Newton, NJ, USA) with 2 magnification is connected for additional magnification, for a total range of 1.832 to 7.5. An optimized magnification is set at 3.798 for a field of view of 2.00 mm 1.68 mm, thereby sampling each RBC with 8.26 pixels.
2.3. Image Registration
Image registration is the process of eliminating the blurred frames caused by rapid eye motion or blinking. Image sequences are first examined with an image contrast index that can determine the quality of the images. To obtain the contrast index, we apply the Sobel edge algorithm [22,23], a method of quantitatively measuring the contrast of an image [24]. The contrast index is calculated with the Equation (1).
| (1) |
where are the dimensions of the image, are the pixel indices of each axis, and is the image pixel intensity. The overall image contrast is estimated by the average value of the edge intensity. The blurred frames with low-contrast indices are resolved by extracting only frames with a contrast index greater than 95% of the maximum value. A template frame is then designated based on the highest contrast index. The rest of the consecutive frames are automatically aligned to the template frame using the ImageJ plugin called motion corrector [25]. This algorithm corrects the image translation by maximizing the overlapping region between two images, thereby eliminating the significant displacement caused by rapid eye motions.
2.4. Deep Learning Vessel Segmentation
2.4.1. Dataset
A conjunctival vessel dataset and a high-resolution fundus (HRF) dataset are used to train and evaluate the deep learning model [26]. The HRF dataset has been established by the research team at the Friedrich-Alexander Universität and used to test the effectiveness of the deep learning-based segmentation algorithm [26]. The conjunctival vessel data are collected from the conjunctiva of five healthy human subjects (five males, age = 27 1) with the custom-built imaging system. This dataset contains 15 conjunctiva images with a size of 2208 1848 pixels. The conjunctiva images used for network learning are randomly selected in the frames extracted from image sequences without motion-blurred images. The HRF dataset comprises 45 color fundus images, equally distributed into three subsets (healthy, diabetic retinopathy, and glaucoma). Each image in the HRF dataset is 3304 2236 pixels. Both datasets have annotated vessel structures in the form of binary images.
2.4.2. Image Preprocessing and Preparation
Preprocessing enhances the contrast of the vessel in the image and removes uneven illuminations that occurred in the image acquisition step. We apply three preprocessing steps. In the first step, we crop the HRF images from the center point to the same size as the conjunctival images and resize both to 1104 924 pixels (0.5). Figure 3a,e illustrates the raw data of the conjunctival image and resized HRF image. In the second step, we extract the green channel from the HRF images. The green channel has a higher contrast and lower background noise than the other channels. Finally, contrast-limited adaptive histogram equalization (CLAHE) [27] is applied in the green channel of the HRF in Figure 3f and conjunctival images in Figure 3b to enhance the contrast of the images. After preprocessing, two datasets are combined into a single dataset to enhance the generalization ability of the model.
Figure 3.
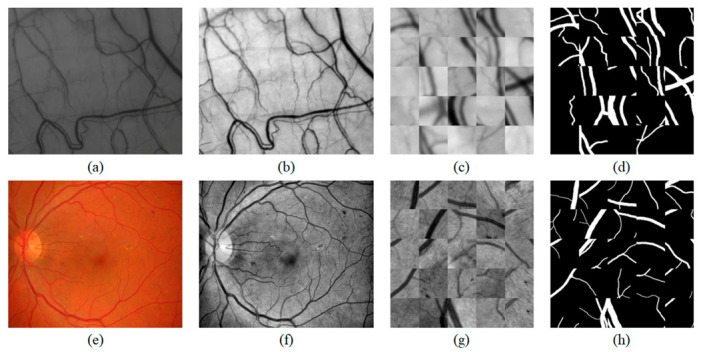
Preparation steps of the conjunctival dataset and the HRF dataset. The conjunctival data preparation step: (a) raw data of the conjunctival image, (b) CLAHE-adopted image, (c) conjunctiva patches, and (d) corresponding ground-truth of (c). The HRF data preparation step: (e) resized HRF image, (f) CLAHE-adopted image, (g) HRF patches, and the (h) corresponding ground-truth of (g).
A convolutional neural network (CNN) requires large amounts of training data to prevent overfitting of the network and improve the generalization ability. To train the dataset, we exploit a patch-wise strategy [17,28,29,30] and data augmentation. The patch-wise strategy is used to learn a small amount of data efficiently and overcome the memory limitations caused by high-image resolution. This strategy randomly extracts patches in the range of 64 to 128 pixels. The patch sizes from 65 65 pixels to 128 128 pixels are resized to 64 64-pixel patches. After resizing the extracted patches, overlapped regions of the conjunctiva in each different-sized patch are recognized as different regions in the network model.
A total of 300,000 patches are obtained by sampling 5000 patches from each image. Figure 3c,g are examples of patch-wise extractions. Figure 3d,h are the corresponding ground-truth images of the patches (Figure 3c,g) for the supervised learning of the convolutional neural network.
Data augmentation is applied to extract the patches with additional vascular features to improve the CNN generalization ability. We applied data augmentations such as geometrical distortions (rotation, shearing, and transformation) and motion blur. Geometrical distortions can increase the representation of the patches. Motion blur is used to learn the deformed vessel based on the movements that occurred in the image acquisition step. The patches are normalized to the zero mean and unit variance before the training process to reduce the effect of the large intensity variance.
2.4.3. Network Architecture
The Attention-UNet architecture [31] is adopted to learn the vascular features. We customize the Attention-UNet to optimize our datasets. The details of the architecture are described in Figure 4. The architecture is based on a layered CNN, consisting of an encoder–decoder structure with three stages and an attention mechanism.
Figure 4.

Customized Attention-UNet architecture.
The encoder gradually reduces the spatial dimension of the input to learn a low-resolution feature map. Each stage of the encoder consists of two convolution layers and one max-pooling layer. At the end of the encoder stage, a bottom layer exists without max-pooling. Whenever the stage progresses to the next stage, the filter size of the convolution layer doubles, and the dimensions of the input are halved. Each convolution layer comprises a 3 3 convolution filter with a stride of 1, batch normalization, and a rectified linear unit (ReLU).
The decoder enables precise localization by merging the low-resolution features from the previous layer and high-resolution features from the encoder of the same stage. When the low-resolution features are transported, the upsampling process, which is implemented by transposing a convolution kernel (kernel size = 3 3, stride = 2), reconstructs the salient features from the input. Before the encoder transfers the features, an attention gate is used to suppress the irrelevant background of the input and highlight the relevant foreground features. At the end of the 3-stage decoding, the last convolutional kernel (kernel size = 1 1) and SoftMax activation function are used for mapping the feature vector and classify the vessel.
2.4.4. Model Training and Testing
The deep learning model using Keras is trained and validated on a CPU (Xeon(R) silver 4112, Intel Corporation, Santa Clara, CA, USA) and a GPU (Quadro P4000, Nvidia Corporation, Santa Clara, CA, USA) operated by Ubuntu (16.04 LTS, Canonical Ltd, London, UK).
In the training process, the complete set of augmented patches is split into 240,000 for training the network and 60,000 for validation. The training process has 150 epochs with the strategy of reducing the learning rate on the plateau. A validation set is used to evaluate the performance of the model in each epoch. If the performance of the model in the validation set does not change in 15 epochs, the strategy will reduce the learning rate by 1/10. The training of the model is progressed by an adaptive moment estimation (Adam) optimizer (initial learning rate = 0.00005) and the Dice coefficient [32] as the loss function.
In conjunctival images, blood vessel information occupies a small portion of the entire image compared to the background region. Therefore, the Dice coefficient is used to solve the class imbalance problem. The Dice coefficient is defined in the Equation (2):
| (2) |
where is predicted segmentation map, and is the binary ground-truth image. denotes the number of pixels in each image, and is the position of the pixel in the image.
In the test phase, the CNN infers the test image, excluding the training dataset. The test image is generated by averaging 30 frames to distinguish the obscure vessel from the registered conjunctival images. By inferencing the test data using the optimal model for validation, a reference segmentation map is acquired.
2.5. Morphological Feature Extraction
The vessel length and diameter are measured from segmented conjunctival vessel images. Distinguishing the connected vessel segments is necessary to extract these morphological vessel features. The centerline and intersection points of the vessels are required to separate individual vessel segments. The centerline is obtained by a skeleton image using the pixel-wise thinning algorithm [33,34], a method of performing an iterative process until it remains one pixel wide in the segmented vessels. Skeleton segments lower than 20 pixels are removed, because these segments are not recognized as a connected vascular network. The intersection points at bifurcation and crossover are determined by the number of neighbors, a convolution result with a 3 3 unity kernel for each pixel of the centerline. The bifurcation points correspond to three in the convolution result, and the crossovers have a result greater than three. By removing these two points, each vessel segment is separated and given identification. We measure the vessel length and the diameter from the identified vessel segment. The length of the vessel is obtained by counting each pixel of the skeletonized vessel along its centerline. Moreover, the vessel diameters are measured in Euclidean distance by calculating the perpendicular distance from the centerline to the nearest background of the binary segmented vessels.
2.6. Template Matching for Motion Correction
The template matching algorithm is used for correcting the fine movements in image sequences caused by respiratory movement. First, the template image is assigned by selecting a template vessel considering the morphological features, including the vessel length and diameter. The template vessel must be contained in all frames and distinguished from other blood vessels. Equation (3) is applied to each vessel segment to select a vessel of the template image with a long length and large diameter.
| (3) |
is the function for selecting the template vessel, are the weight factors, is the length of the vessel segment, and is the diameter of the vessel. The vessel length and diameter are normalized to equalize the scales of each parameter. The vessel segment with the highest value of the function is determined as the template vessel.
We generate the template image by cropping the selected template vessel to the minimum bounding box. The template-matching algorithm based on the assigned template image is applied to the target frames, and this algorithm is implemented with the cvMatchTemplate function in the OpenCV library [35]. This function calculates the normalized correlation coefficient at each pixel to search the most similar region with the template image, as shown in the Equation (4):
| (4) |
where is the template image, is a source image to find a match with the template image, is the pixel location of the source image, and indicates the pixel location of the template image. After finding the most similar region to the template image with the source images, the displacement value is obtained from the center point of the source image. We shift the source images as much as the displacement value, thereby successfully correcting the fine movements.
2.7. Blood Flow Velocity Measurements
Several blood vessels can be observed in motion-corrected conjunctival images, but a RBC shift is not detectable in all blood vessels. Measuring the blood flow velocity requires distinguishing the blood vessels capable of detecting the RBC shift. Generally, vessels with measurable blood flow have high temporal variance in the centerline due to the RBC shifts. Moreover, vessels with longer lengths are more conducive to measuring the blood flow velocity, because the movements of RBC can be observed continuously for a long duration. Considering the temporal variance and vessel length, an index of observability is defined as shown in the Equation (5):
| (5) |
where is the weighting factor, is the temporal variance, and is the length of the vessel segments. Vessels with a high index are considered to be capable of measuring the blood flow velocity. We choose 15 vessel segments with the highest observability index to analyze the blood flow velocity.
The blood flow velocity is measured by tracking the RBC movements in the selected vessels centerline, as depicted in Figure 5a. Tracking is performed using the spatial–temporal analysis (STA) method, which demonstrates an alteration of the pixel intensity of the centerline due to the RBC movements. Figure 5b displays an example of an alteration in the pixel intensity of the vessel centerlines as a function of time. We generate the STA image by stacking the centerlines to each column, as depicted in Figure 5c. Frames corresponding to 3.7 s are stacked to form 70 columns. Consequently, the flow of the RBC cluster forms lines consistent with the yellow line in Figure 5c, with the slope on the STA image. The blood flow velocities are measured by calculating the average values of the slopes.
Figure 5.

(a) The RBC cluster shifts over time in the vessel centerline. (b) Pixel intensity of the vessel centerline changes due to the RBC cluster shift. (c) Spatial–temporal analysis (STA) image generated by the pixel intensity from the vessel centerline as stacking at each column. The x and y axes indicate the frame time and vessel length, respectively. The yellow line shown in the STA image displays the slope, indicating the blood flow velocity.
3. Results
3.1. Segmentation
We identified blurry, low-contrast conjunctival vessels by constructing a dataset mixed with conjunctiva images and HRF to train the custom-built Attention-UNet model. The segmentation map was obtained using model prediction on the averaged image. Figure 6 illustrates the results of the model prediction. The conjunctival image of Figure 6a is unseen data obtained from healthy subjects. Figure 6b,e,h are additional processed images to show the unseen data of Figure 6a,d,g for readers. Figure 6c results from the model prediction in Figure 6a. Each box with a color boundary in Figure 6a–c represents regions of interest for the low-contrast, blurry vessels. These results demonstrate that Attention-UNet trained with mixed datasets is accurate for low-contrast vascular structures without additional postprocessing.
Figure 6.

(a) Averaged conjunctival image. (b) Brightness and contrast-adjusted (a) by Image J (set display range: 25–115). (c) Attention-UNet segmentation results. (d,g) Cropped images from the low-contrast, blurry areas of (a). (e,h) Cropped images from (b). (f,i) Corresponding to the prediction results of (d,g). Brightness and contrast-adjusted images (b,e,h) were placed to provide easier visibility for the reader.
3.2. Motion Correction
To evaluate the performance of the motion correction processes, we compare the displacement values of 70 frames of the conjunctival microvessels. Figure 7 illustrates the horizontal and vertical axial displacement values of the source images from the first frame. In the uncorrected case (black line), the intense axial motions of the frames are visible. After the correction process, the axial motions are noticeably reduced (red and blue lines). For the horizontal axis depicted in Figure 7a, the mean axial displacement decreased to 2.69 μm from 16.84 μm after the first registration process. After the second process of motion correction, it decreased to 0.9 μm. For the vertical axis depicted in Figure 7b, it also decreased to 0.81 μm from 14 μm. Consequently, most of the displacement values decreased, except for the movements smaller than 1 μm.
Figure 7.

Comparison of the displacement values between uncorrected (black line) and motion-corrected (red and blue lines) image sequence. Red line indicates the displacement values after the first registration step, and the blue line represents after the second motion correction step. (a) Horizontal displacement values. (b) Vertical displacement values.
Furthermore, we compared before and after the motion correction of the spatial–temporal analysis (STA) images, which are crucial to quantifying the blood flow velocity. The red line in Figure 8a displays a target vessel to analyze the blood flow velocity. Figure 8b illustrates an STA image before motion correction. In this STA image, the slope required to calculate the blood flow velocity cannot be verified because of the motion artifacts. In contrast, the clear edges of the slope displayed by the yellow line in Figure 8c are observed in the STA image after motion correction. Finally, the blood flow velocity obtained from the average values of the yellow slopes is 0.338 mm/s.
Figure 8.
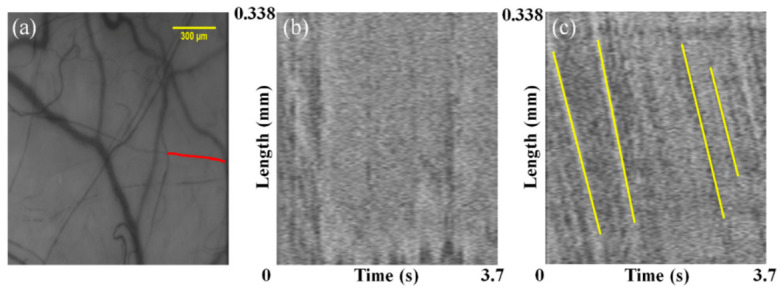
(a) Vessel used to generate the STA image (red line). (b) STA image before motion correction. (c) STA image after motion correction. Yellow lines represent slopes, which indicate blood flow velocity.
Table 1 illustrates the characteristics of conjunctival microvessels, including diameter, length, and blood flow velocity. These characteristics are measured in the selected vessel segments with the highest observability indices. Starting with V1, 10 blood vessels with a high observability index are sequentially arranged. The minimum and Table 1 illustrate the characteristics of the conjunctival microvessels, including diameter, length, and blood flow velocity. These characteristics are measured in the selected vessel segments with the highest observability indices. Starting with V1, 10 blood vessels with a high observability index are sequentially arranged. The minimum and maximum blood vessel diameters are 8.172 and 15.62 μm. The blood flow velocity ranges between 0.078 and 0.338 mm/s, similar to the values in a previous study, were measured with other equipment [36].
Table 1.
Diameter, length, and blood flow velocity of conjunctival microvessels.
| Vessel | Diameter (μm) | Length (mm) | Blood Flow Velocity (mm/s) |
|---|---|---|---|
| V1 | 13.158 | 0.414 | 0.086 |
| V2 | 15.282 | 0.356 | 0.097 |
| V3 | 8.172 | 0.338 | 0.338 |
| V4 | 9.878 | 0.330 | 0.090 |
| V5 | 10.170 | 0.318 | 0.270 |
| V6 | 8.682 | 0.220 | 0.141 |
| V7 | 9.574 | 0.250 | 0.078 |
| V8 | 15.422 | 0.246 | 0.137 |
| V9 | 15.620 | 0.128 | 0.114 |
| V10 | 9.934 | 0.214 | 0.153 |
4. Discussion
In this paper, we introduced a system that can accurately quantify the conjunctival blood flow velocity by overcoming motion artifacts. First, Attention-UNet was implemented to precisely segment the low-quality vessel images. The Attention-UNet trained with a retinal dataset was used to segment conjunctival vessels with low-contrast, blurry structures [17]. This study inferred that Attention-UNet has a high generalization ability to learn the vascular structure.
Second, we conducted a two-step correction process to solve the problem of changing local information. Fine movements are critical to high magnification imaging to track red blood cells (RBC) for measuring the blood flow. Although we corrected a large motion through the registration process, 4–7 μm of the displacement remained. An additional correction process was essential to obtain an accurate blood flow velocity by tracking RBC particles of approximately 7.5 μm in diameter [19]. Therefore, we implemented an additional motion correction algorithm, template matching, by considering the vessel features, including diameter and length. The displacements of the conjunctival microvasculature images are reduced to the order of 1 μm while minimizing the frame loss.
We construct a custom-built optical system to image the human conjunctiva and acquire the conjunctival images from five healthy subjects. Conjunctival datasets have a risk of overfitting due to a lack of images, which we avoided by adding a retinal dataset with a similar domain to the conjunctival images. The high-resolution fundus (HRF) dataset was selected as an additional dataset because of the vessel size similar to our conjunctival image. The model trained by the mixed dataset achieved more accurate segmentation results than the conjunctival dataset only.
Furthermore, our motion correction process can produce insights in observing blood flow velocity for an extended period by correcting their fine control movements. When the human eye gazes at a fixed object, the dwelling time ranges from 90 to 900 ms [37]. After the dwelling time, the fixated eyes start vibrating. Due to eye movements caused by the short dwelling time, conjunctival hemodynamics were observed for only 0.3 s in a previous study [10].
However, the velocity pulse period (VPP), which is the time varying the blood flow velocity, due to the cardiac impulse is 940 ms [38], longer than the dwelling time. Consequently, it is necessary to observe the blood flow velocity for a more extended period than the VPP. Since we compensate for the motion above the VPP, the blood flow velocity is quantified above three seconds through the STA image. We created an opportunity for quantifying the long-term blood flow assessment, limited by a dwelling time shorter than the cardiac cycle time.
A limitation in the current configuration is that it can be difficult to compensate for the motion blur caused by movements that are faster than the frame rates. This type of image can be blurred, even if the location is not changed. One way to mitigate this problem is to reduce the exposure time and increase the frame rate. However, such an approach would inevitably decrease the contrast of the image. We overcame this limitation by comparing the contrast index assigned during registration, thereby removing the blurred frames with low-contrast values.
This study adopted several capabilities, including image registration, deep learning vessel segmentation, and template matching for motion correction, to quantify the microcirculation of the human conjunctiva. Using these methods, we acquired a blood flow velocity of 0.078 to 0.338 mm/s in the conjunctiva vessels. Although we could not perfectly control the factors affecting the blood flow velocity, we could confirm that our results partially corresponded to a previous study measuring the conjunctiva blood flow range as 0.19 to 0.33 mm/s [36].
As further works, our image processing method could provide blood flow velocity in the retina, wrists, lips, and fingernails. In addition, when significant correlations of conjunctival hemodynamics with cardiovascular diseases, as well as diabetes, are demonstrated, the developed imaging system and processing method can be used as one of the methods providing pre-diagnostic factors for systemic diseases [1,39].
5. Conclusions
We demonstrate a system that resolves motion artifacts to quantify the conjunctival blood flow velocity. Deep learning-based segmentation and motion correction techniques are used to solve the motion artifacts during image acquisition. We evaluated the system performance by analyzing conjunctival images from five healthy volunteers. The system segment low-contrast vessels reduced the image displacement to less than 1 to 2 μm. Pathways of red blood cells could be tracked free from the motion artifacts, resulting in quantifying the blood flow velocity. The range of quantifying the conjunctival blood flow velocity is 0.078~0.338 mm/s in a healthy subject. This conjunctival imaging instrument is applicable for imaging subjects with limited forward-looking capabilities or an unsteady fixation.
Author Contributions
Conceptualization, H.-C.J. and D.-Y.K.; methodology, H.-C.J., J.L. and D.-Y.K.; software, H.J.; resources, K.-S.N.; writing—original draft preparation, H.J. and J.L.; writing—review and editing, H.-C.J. and D.-Y.K.; supervision, D.-Y.K.; and project administration, D.-Y.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Research Foundation of Korea (NRF), the Ministry of Education, through the Basic Science Research Program under grant no. 2018R1A6A1A03025523, by the Ministry of Science and ICT under grant no. 2019R1A2C1006814, by the National Research Foundation of Korea (NRF) under grant no. 2019R1F1A1061421, and by the grant of the Catholic University Yeouido St.Mary′s Hospital made in the program year of 2020.
Institutional Review Board Statement
This study was conducted according to the guidelines of the Declaration of Helsinki and approved by the Institutional Review Board of Yeouido St. Mary’s Hospital (CMC IRB_SC19DESE0067, 23 September 2019).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study. Written informed consent was obtained from the patient(s) to publish this paper.
Data Availability Statement
In this paper, both publicly available datasets and custom datasets were used. Publicly available datasets were analyzed in this study. This data can be found here: https://www5.cs.fau.de/research/data/fundus-images/, accessed on 3 May 2021. The custom data presented in this study are available on request from the corresponding author. The data are not publicly available due to privacy.
Conflicts of Interest
The authors declare no conflict of interest.
Footnotes
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Khansari M.M., Wanek J., Tan M., Joslin C.E., Kresovich J.K., Camardo N., Blair N.P., Shahidi M. Assessment of conjunctival microvascular hemodynamics in stages of diabetic microvasculopathy. Sci. Rep. 2017;7:1–9. doi: 10.1038/srep45916. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Chen W., Batawi H.I.M., Alava J.R., Galor A., Yuan J., Sarantopoulos C.D., McClellan A.L., Feuer W.J., Levitt R.C., Wang J. Bulbar conjunctival microvascular responses in dry eye. Ocul. Surf. 2017;15:193–201. doi: 10.1016/j.jtos.2016.12.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Wang J., Jiang H., Tao A., DeBuc D., Shao Y., Zhong J., Pineda S. Limbal capillary perfusion and blood flow velocity as a potential biomarker for evaluating dry eye. Investig. Ophthalmol. Vis. Sci. 2013;54:4335. [Google Scholar]
- 4.Chen W., Deng Y., Jiang H., Wang J., Zhong J., Li S., Peng L., Wang B., Yang R., Zhang H. Microvascular abnormalities in dry eye patients. Microvasc. Res. 2018;118:155–161. doi: 10.1016/j.mvr.2018.03.015. [DOI] [PubMed] [Google Scholar]
- 5.Valeshabad A.K., Wanek J., Mukarram F., Zelkha R., Testai F.D., Shahidi M. Feasibility of assessment of conjunctival microvascular hemodynamics in unilateral ischemic stroke. Microvasc. Res. 2015;100:4–8. doi: 10.1016/j.mvr.2015.04.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Karanam V.C., Tamariz L., Batawi H., Wang J., Galor A. Functional slit lamp biomicroscopy metrics correlate with cardiovascular risk. Ocul. Surf. 2019;17:64–69. doi: 10.1016/j.jtos.2018.09.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Jiang H., Zhong J., DeBuc D.C., Tao A., Xu Z., Lam B.L., Liu C., Wang J. Functional slit lamp biomicroscopy for imaging bulbar conjunctival microvasculature in contact lens wearers. Microvasc. Res. 2014;92:62–71. doi: 10.1016/j.mvr.2014.01.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Shahidi M., Wanek J., Gaynes B., Wu T. Quantitative assessment of conjunctival microvascular circulation of the human eye. Microvasc. Res. 2010;79:109–113. doi: 10.1016/j.mvr.2009.12.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.van Zijderveld R., Ince C., Schlingemann R.O. Orthogonal polarization spectral imaging of conjunctival microcirculation. Graefe’s Arch. Clin. Exp. Ophthalmol. 2014;252:773–779. doi: 10.1007/s00417-014-2603-9. [DOI] [PubMed] [Google Scholar]
- 10.Khansari M.M., Wanek J., Felder A.E., Camardo N., Shahidi M. Automated assessment of hemodynamics in the conjunctival microvasculature network. IEEE Trans. Med Imaging. 2015;35:605–611. doi: 10.1109/TMI.2015.2486619. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Wang L., Yuan J., Jiang H., Yan W., Cintrón-Colón H.R., Perez V.L., DeBuc D.C., Feuer W.J., Wang J. Vessel sampling and blood flow velocity distribution with vessel diameter for characterizing the human bulbar conjunctival microvasculature. Eye Contact Lens. 2016;42:135. doi: 10.1097/ICL.0000000000000146. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Goobic A.P., Tang J., Acton S.T. Image stabilization and registration for tracking cells in the microvasculature. IEEE Trans. Biomed. Eng. 2005;52:287–299. doi: 10.1109/TBME.2004.840468. [DOI] [PubMed] [Google Scholar]
- 13.Brennan P.F., McNeil A.J., Jing M., Awuah A., Finlay D.D., Blighe K., McLaughlin J.A., Wang R., Moore J., Nesbit M.A. Quantitative assessment of the conjunctival microcirculation using a smartphone and slit-lamp biomicroscope. Microvasc. Res. 2019;126:103907. doi: 10.1016/j.mvr.2019.103907. [DOI] [PubMed] [Google Scholar]
- 14.Frangi A.F., Niessen W.J., Vincken K.L., Viergever M.A. Multiscale vessel enhancement filtering; Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, MICCAI 98; Cambridge, MA, USA. 11–13 October 1998; pp. 130–137. [Google Scholar]
- 15.Doubal F., MacGillivray T., Patton N., Dhillon B., Dennis M., Wardlaw J. Fractal analysis of retinal vessels suggests that a distinct vasculopathy causes lacunar stroke. Neurology. 2010;74:1102–1107. doi: 10.1212/WNL.0b013e3181d7d8b4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Soares J.V., Leandro J.J., Cesar R.M., Jelinek H.F., Cree M.J. Retinal vessel segmentation using the 2-D Gabor wavelet and supervised classification. IEEE Trans. Med. Imaging. 2006;25:1214–1222. doi: 10.1109/TMI.2006.879967. [DOI] [PubMed] [Google Scholar]
- 17.Luo Z., Zhang Y., Zhou L., Zhang B., Luo J., Wu H. Micro-vessel image segmentation based on the AD-UNet model. IEEE Access. 2019;7:143402–143411. doi: 10.1109/ACCESS.2019.2945556. [DOI] [Google Scholar]
- 18.Delori F.C., Webb R.H., Sliney D.H. Maximum permissible exposures for ocular safety (ANSI 2000), with emphasis on ophthalmic devices. JOSA A. 2007;24:1250–1265. doi: 10.1364/JOSAA.24.001250. [DOI] [PubMed] [Google Scholar]
- 19.Persons E.L. Studies on red blood cell diameter: III. The relative diameter of immature (reticulocytes) and adult red blood cells in health and anemia, especially in pernicious anemia. J. Clin. Investig. 1929;7:615–629. doi: 10.1172/JCI100246. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Webb R.H., Dorey C.K. Handbook of Biological Confocal Microscopy. Springer; Boston, MA, USA: 1995. The pixilated image; pp. 55–67. [Google Scholar]
- 21.Deneux T., Takerkart S., Grinvald A., Masson G.S., Vanzetta I. A processing work-flow for measuring erythrocytes velocity in extended vascular networks from wide field high-resolution optical imaging data. Neuroimage. 2012;59:2569–2588. doi: 10.1016/j.neuroimage.2011.08.081. [DOI] [PubMed] [Google Scholar]
- 22.Vincent O.R., Folorunso O. A descriptive algorithm for sobel image edge detection; Proceedings of the Informing Science & IT Education Conference (InSITE 2009); Macon, GA, USA. 12–15 June 2009; pp. 97–107. [Google Scholar]
- 23.Wang Z., Feng C., Ang W.T., Tan S.Y.M., Latt W.T. Autofocusing and polar body detection in automated cell manipulation. IEEE Trans. Biomed. Eng. 2016;64:1099–1105. doi: 10.1109/TBME.2016.2590995. [DOI] [PubMed] [Google Scholar]
- 24.Shih L. Autofocus survey: A comparison of algorithms; Proceedings of the Digital Photography III, Electronic Imaging 2007; San Jose, CA, USA. 28 January–1 February 2007; p. 65020B. [Google Scholar]
- 25.Dubbs A., Guevara J., Yuste R. moco: Fast motion correction for calcium imaging. Front. Neuroinformatics. 2016;10:6. doi: 10.3389/fninf.2016.00006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Odstrcilik J., Kolar R., Budai A., Hornegger J., Jan J., Gazarek J., Kubena T., Cernosek P., Svoboda O., Angelopoulou E. Retinal vessel segmentation by improved matched filtering: Evaluation on a new high-resolution fundus image database. IET Image Process. 2013;7:373–383. doi: 10.1049/iet-ipr.2012.0455. [DOI] [Google Scholar]
- 27.Pizer S.M., Amburn E.P., Austin J.D., Cromartie R., Geselowitz A., Greer T., ter Haar Romeny B., Zimmerman J.B., Zuiderveld K. Adaptive histogram equalization and its variations. Comput. Vis. Graph. Image Process. 1987;39:355–368. doi: 10.1016/S0734-189X(87)80186-X. [DOI] [Google Scholar]
- 28.Yamanakkanavar N., Lee B. Using a Patch-Wise M-Net Convolutional Neural Network for Tissue Segmentation in Brain MRI Images. IEEE Access. 2020;8:120946–120958. doi: 10.1109/ACCESS.2020.3006317. [DOI] [Google Scholar]
- 29.Wang C., Zhao Z., Ren Q., Xu Y., Yu Y. Dense U-net based on patch-based learning for retinal vessel segmentation. Entropy. 2019;21:168. doi: 10.3390/e21020168. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Yan Z., Yang X., Cheng K.-T. Joint segment-level and pixel-wise losses for deep learning based retinal vessel segmentation. IEEE Trans. Biomed. Eng. 2018;65:1912–1923. doi: 10.1109/TBME.2018.2828137. [DOI] [PubMed] [Google Scholar]
- 31.Oktay O., Schlemper J., Folgoc L.L., Lee M., Heinrich M., Misawa K., Mori K., McDonagh S., Hammerla N.Y., Kainz B. Attention u-net: Learning where to look for the pancreas. arXiv. 20181804.03999 [Google Scholar]
- 32.Zou K.H., Warfield S.K., Bharatha A., Tempany C.M., Kaus M.R., Haker S.J., Wells III W.M., Jolesz F.A., Kikinis R. Statistical validation of image segmentation quality based on a spatial overlap index1: Scientific reports. Acad. Radiol. 2004;11:178–189. doi: 10.1016/S1076-6332(03)00671-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Lee T.-C., Kashyap R.L., Chu C.-N. Building skeleton models via 3-D medial surface axis thinning algorithms. Cvgip Graph. Models Image Process. 1994;56:462–478. doi: 10.1006/cgip.1994.1042. [DOI] [Google Scholar]
- 34.Klingler J.W., Vaughan C.L., Fraker T., Andrews L.T. Segmentation of echocardiographic images using mathematical morphology. IEEE Trans. Biomed. Eng. 1988;35:925–934. doi: 10.1109/10.8672. [DOI] [PubMed] [Google Scholar]
- 35.Bradski G., Kaehler A. Learning OpenCV: Computer Vision with the OpenCV Library. O’Reilly Media, Inc.; Newton, MA, USA: 2008. [Google Scholar]
- 36.Xiao P., Duan Z., Wang G., Deng Y., Wang Q., Zhang J., Liang S., Yuan J. Multi-modal Anterior Eye Imager Combining Ultra-High Resolution OCT and Microvascular Imaging for Structural and Functional Evaluation of the Human Eye. Appl. Sci. 2020;10:2545. doi: 10.3390/app10072545. [DOI] [Google Scholar]
- 37.Duncan J., Ward R., Shapiro K. Direct measurement of attentional dwell time in human vision. Nature. 1994;369:313–315. doi: 10.1038/369313a0. [DOI] [PubMed] [Google Scholar]
- 38.Koutsiaris A.G., Tachmitzi S.V., Papavasileiou P., Batis N., Kotoula M.G., Giannoukas A.D., Tsironi E. Blood velocity pulse quantification in the human conjunctival pre-capillary arterioles. Microvasc. Res. 2010;80:202–208. doi: 10.1016/j.mvr.2010.05.001. [DOI] [PubMed] [Google Scholar]
- 39.Strain W.D., Paldánius P. Diabetes, cardiovascular disease and the microcirculation. Cardiovasc. Diabetol. 2018;17:1–10. doi: 10.1186/s12933-018-0703-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
In this paper, both publicly available datasets and custom datasets were used. Publicly available datasets were analyzed in this study. This data can be found here: https://www5.cs.fau.de/research/data/fundus-images/, accessed on 3 May 2021. The custom data presented in this study are available on request from the corresponding author. The data are not publicly available due to privacy.