

Abstract
To evaluate the rib fracture detection performance in computed tomography (CT) images using a software based on a deep convolutional neural network (DCNN) and compare it with the rib fracture diagnostic performance of doctors.
We included CT images from 39 patients with thoracic injuries who underwent CT scans. In these images, 256 rib fractures were detected by two radiologists. This result was defined as the gold standard. The performances of rib fracture detection by the software and two interns were compared via the McNemar test and the jackknife alternative free-response receiver operating characteristic (JAFROC) analysis.
The sensitivity of the DCNN software was significantly higher than those of both Intern A (0.645 vs 0.313; P < .001) and Intern B (0.645 vs 0.258; P < .001). Based on the JAFROC analysis, the differences in the figure-of-merits between the results obtained via the DCNN software and those by Interns A and B were 0.057 (95% confidence interval: −0.081, 0.195) and 0.071 (−0.082, 0.224), respectively. As the non-inferiority margin was set to −0.10, the DCNN software is non-inferior to the rib fracture detection performed by both interns.
In the detection of rib fractures, detection by the DCNN software could be an alternative to the interpretation performed by doctors who do not have intensive training experience in image interpretation.
Keywords: computed tomography, deep convolutional neural network, deep learning, external validation study, jackknife alternative free-response receiver operating characteristic analysis, rib fracture
1. Introduction
Rib fracture detection is an important task when interpreting the computed tomography (CT) images of patients with thoracic injuries. One of the reasons for this is that the presence of rib fractures could indicate large vessel injuries that lead to relatively high mortality rates.[1] Therefore, patients with such fractures require further medical investigation and detailed follow-up procedures.[2]
However, in recent years, the number of whole-body CT scans for trauma patients has rapidly increased.[3] Although the development of thin-slice CT images has improved the sensitivity of fracture detection, it has also increased the human effort required for CT image interpretation. It is difficult to prevent oversights during CT image interpretation considering the increasing number of CT images that radiologists have to interpret per day.[4] Previous results on the sensitivity of rib fracture detection using multi-planar reconstructions of CT images with an evaluation time of 30 s were found to be 77.5% even for experienced radiologists, and the sensitivity was even lower for radiology residents and interns.[5]
In contrast, significant progress has recently been made in clinical applications based on deep learning techniques for medical image interpretation; these applications have been useful for improving diagnostic accuracy and reducing human effort.[6–9]
Deep learning techniques have already been successfully applied to the detection of rib fractures.[10,11] However, to replace detection performed by doctors with deep learning techniques, researchers must verify statistically whether the detection performance of deep learning techniques is as good as or better than detection performed by doctors. This external validation has been lacking in previous studies.
Therefore, in this study, we evaluated the performance of rib fracture detection in CT images using a deep convolutional neural network (DCNN) and compared its diagnostic performance with those of doctors.
2. Materials and methods
Our institutional review board approved this retrospective study; accordingly, the requirement for informed consent from patients who were included in the study was waived.
2.1. Training dataset
We used a software (InferRead CT Bone: https://global.infervision.com/product/5/, Infervision, Beijing, China) based on a DCNN for the detection of rib fractures in CT images, which is commercially available. Chest CT images of 3644 examinations were used to train and validate the network of the DCNN software. The images were obtained from 19 hospitals in China between January 2014 and April 2019. These images were collected retrospectively. The locations of rib fractures in each case were interpreted by a minimum of three radiologists. Of these image datasets, 85% were randomly assigned to a training dataset, and the remaining to a validation dataset. The slice thickness of the input data is discussed in Supplemental Digital Content 1; further, information regarding the reconstruction kernels and the manufacturers of the CT scanner employed to obtain the images to train the network is described in Supplemental Digital Content 2.
2.2. Deep learning methods
In the developed detection software, an object detection algorithm called single shot multibox detector (SSD) was used.[12] Detection and classification of object candidate regions can be learned and performed simultaneously using this algorithm. In particular, this software relies on an algorithm based on DenseNet combined with SSD.[13] Because the original SSD only accepts one image as input data, a modified SSD, multichannel 2.5D convolutional neural network, was implemented. The modified SSD enabled inputting multiple images, including upper and lower slice images simultaneously.
2.3. Patient selection
We searched our CT database to identify patients who underwent CT scans using the revolution CT (GE Healthcare, Waukesha, WI) system for thoracic injuries between November 2018 and July 2019; our search revealed 47 such consecutive patients. The following exclusion criteria were applied for these patients:
-
(i)
Younger than 20 years of age (5 out of 47 cases) and
-
(ii)
Postmortem imaging (3 out of 47 cases).
Consequently, 8 patients were excluded, while the remaining 39 patients were included in our study. The flowchart for the patient selection procedure is shown in Figure 1, while the characteristics of the selected patients are listed in Table 1.
Figure 1.
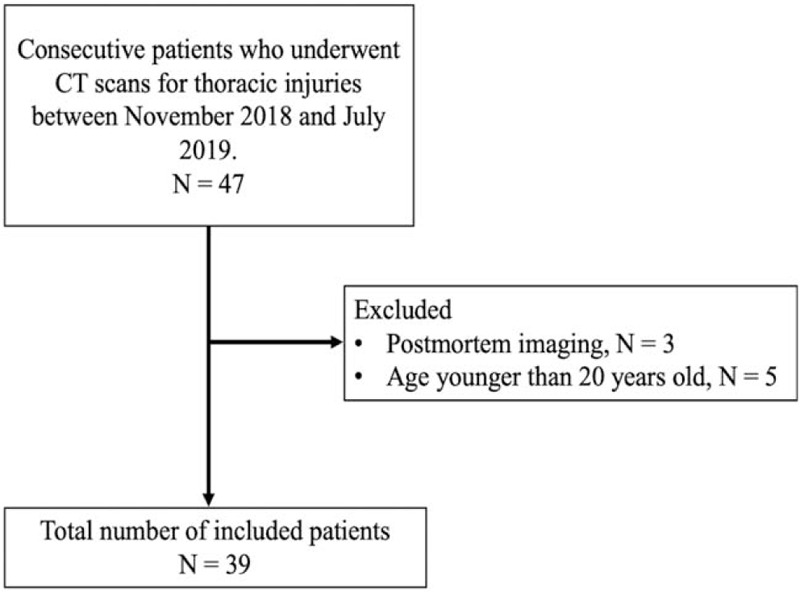
Flowchart for the patient selection procedure used in this study. CT = computed tomography.
Table 1.
Characteristics of included patients.
| Number of Patients | |
| All patients | 39 |
| Male patients | 28 |
| Female patients | 11 |
| Age (yr) | |
| All patients | 58 ± 21 (20–91)∗ |
| Male patients | 59 ± 20 (20–84)∗ |
| Female patients | 53 ± 23 (22–91)∗ |
| With or without contrast agent | |
| Without contrast agent | 6 |
| With intravenous contrast agent | 33 |
| Iohexol 600 mg Iodine/kg | 19 |
| Iopamidol 600 mg Iodine/kg | 14 |
2.4. CT scanning and image reconstruction
The scanning parameters were as follows: beam collation, 80 mm; detector collection, 0.625 mm; detector pitch, 1.53; gantry rotation period, 0.28 s; scan field of view, 50 × 50 cm; tube voltage, 120 kilovoltage peak; tube current, automatically adjusted using automated exposure control software.
We generated the gapless axial images (slice thickness, 0.625 mm; reconstruction kernel, BONE) for each case with the filtered back-projection reconstruction.
2.5. Gold standard
Two radiologists, namely Radiologist A and Radiologist B with 26 and 6 years of image interpretation experience, respectively, independently interpreted the CT images to detect rib fractures; in addition, they did not refer to the corresponding medical records before interpretation. Subsequently, the locations of rib fractures were defined after discussion between the two radiologists. These identified locations were used as the gold standard in our study.
2.6. CT image interpretation and scoring
We evaluated the CT images using the DCNN software. A screenshot of the user interface of the software is shown in Figure 2. This software automatically detected every point in the input images that could be a rib fracture. It also generated a confidence score for each of the detected points as continuous values in a range from 0% to 100%.
Figure 2.
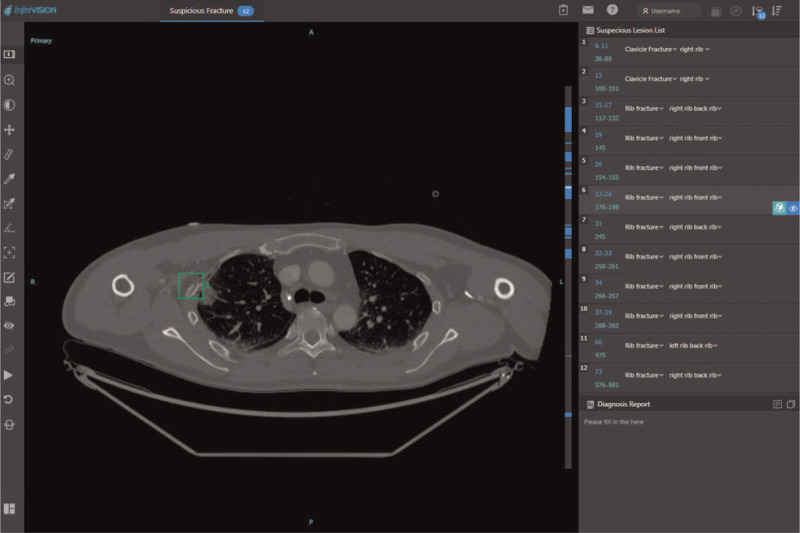
A screenshot of the user interface of the DCNN software displaying the list of suspected lesions on the right side of the screen. The square region of interest indicates where the fracture is presumed to be. DCNN = deep convolutional neural network.
Subsequently, two interns (Intern A and Intern B, both with 1 year and a half of clinical experience after completing medical school, but without intensive training experience in image interpretation) independently interpreted the CT images. Two readers noted the confidence score for all points that he/she recognized as fractures on a scale of 1% to 100%. Here, the confidence score is a numerical value that indicates how certain he/she is of the decision. The interns did not refer to the corresponding medical records or the interpretation result of the two radiologists before their evaluation. While no time limit was set for interpretation, the interns were asked to interpret the images in the time they generally take during daily clinical practice.
True–false judgments were made for the detection results obtained using the DCNN software and those by the interns, based on the defined gold standard for each detection point.
The cause of each false positive in the detection by the DCNN software was also analyzed.
2.7. Statistical analyses
We used a statistical software R version 3.6.3 (https://www.r-project.org/, The R Foundation, Vienna, Austria) for statistical analyses. We calculated the sensitivity and positive predictive values of rib fracture detection by the software and the two interns; for all the three sets of results (i.e., obtained by the software and by both interns), a threshold was set such that the resulting F1 score was maximum. In particular, the F1 score is the harmonic mean of precision (i.e., sensitivity) and recall (i.e., positive predictive value); this score helps assess the accuracy of detection. The F1 score is defined as follows:
Furthermore, we conducted a jackknife alternative free-response receiver operating characteristic (JAFROC) analysis using RJafroc version 1.3.1 (https://CRAN.R-project.org/package=RJafroc, Chakraborty DP, University of Pittsburgh, Pittsburgh, PA) and calculated the Figure-Of-Merits (FOMs) of the DCNN software and of the two interns.[14,15] The aim of the JAFROC analysis was to evaluate and compare the performance of the DCNN software and 2 interns quantitatively. We compared these FOMs based on the modeling assumption of fixed-reader random-case using the Dorfman–Berbaum–Metz–Hillis method.[16,17] Forest plots were used to represent the difference between each FOM with two-sided confidence intervals of 95%. A non-inferiority margin of −0.10 was determined before the initiation of the study.[18] To satisfy the non-inferiority condition, the lower 95% confidence interval for the difference in FOMs must be greater than −0.10. We performed an analysis of variance using F-statics and obtained a P value. We applied the Bonferroni correction for multi-group comparisons and a P value of less than .05 / (number of comparisons) was considered to be significant.
A receiver operating characteristics analysis is widely used to evaluate the performance of machine learning models; however, a disadvantage of this analysis is that it can be applied to only one signal (lesion) from one sample. In contrast, the free-response receiver operating characteristic (FROC) analysis method used in this study considers the coordinates and probability of each lesion. Thus, FROC analysis is suitable for cases where one sample contains multiple signals (lesions).[19–21]
3. Result
3.1. Gold standard for rib fracture detection
According to their independent interpretations of chest CT images of 39 patients, Radiologist A detected 224 fractures, whereas Radiologist B detected 215 fractures. Subsequently, after consultation with each other, the two radiologists defined 256 lesions in the chest CT images as rib fractures. We considered this result as the gold standard for our performance evaluation. Sensitivity and positive predictive values of each radiologist based on the gold standard are listed in Table 2.
Table 2.
Sensitivities and positive predictive values for rib fracture detection in chest computed tomography images by 2 radiologists.
| Sensitivity (95% CI) | Positive Predictive Value (95% CI) | |
| Radiologist A | 224/256 | 224/233 |
| 0.875 (0.834–0.916) | 0.961 (0.935–0.988) | |
| Radiologist B | 215/256 | 215/227 |
| 0.840 (0.795–0.885) | 0.947 (0.916–0.978) |
3.2. Sensitivity and positive predictive value
The sensitivities, positive predictive values, and highest F1 scores for the three results (obtained via the software, by Intern A, and by Intern B) are listed in Table 3. The thresholds of the confidence score for the highest F1 scores were 26%, 20%, and 53% for the software, Intern A, and Intern B, respectively. The sensitivities of the results made by the software and the two interns as well as the P-values between the software and each intern are shown as a forest plot in Figure 3. Based on these results, the software showed significantly higher sensitivity for rib fracture detection than both Intern A (0.645 vs 0.313; P < .001) and Intern B (0.645 vs 0.258; P < .001). However, the sensitivity of the software (0.645) was lower than those of both Radiologist A (0.875) and Radiologist B (0.840).
Table 3.
Sensitivities, positive predictive values, and highest F1 scores for rib fracture detection in chest computed tomography images via the DCNN software and by two interns.
| Sensitivity (95% CI) | Positive Predictive Value (95% CI) | F1 Score | |
| The DCNN software (confidence score from 26% to 100%) | 165/256 | 165/208 | 0.711 |
| 0.645 (0.586–0.703) | 0.793 (0.738–0.848) | ||
| Intern A (confidence score from 20% to 100%) | 80/256 | 80/94 | 0.457 |
| 0.313 (0.256–0.369) | 0.851 (0.778–0.924) | ||
| Intern B (confidence score from 53% to 100%) | 66/256 | 66/89 | 0.383 |
| 0.258 (0.204–0.311) | 0.742 (0.651–0.832) |
Figure 3.
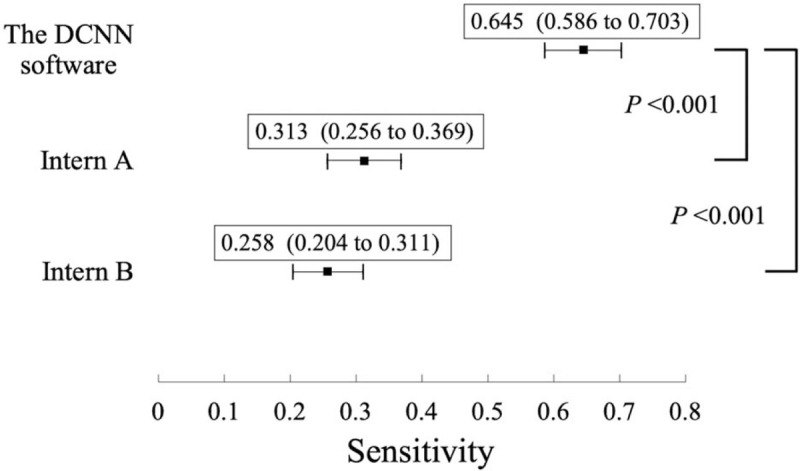
Sensitivities of the DCNN software and those of two interns (Intern A and Intern B), and P value between the software and each of the two interns. Forest plot showing the sensitivities of the DCNN software and those of two interns (Intern A and Intern B) with 95% confidence intervals for rib fracture detection. The P values between the sensitivities of the DCNN software and each of the two interns are also shown. The sensitivity of the software was significantly better than those of both Intern A (P < .001) and Intern B (P < .001). DCNN = deep convolutional neural network.
3.3. JAFROC analysis
The FOMs obtained based on JAFROC analysis are listed in Table 4. The FOMs for the detection results obtained via the DCNN software, by Intern A, and by Intern B are in a descending order. The differences between the FOMs were estimated using two-sided confidence intervals of 95%; these differences are depicted in Figure 4 as a forest plot. The DCNN software was non-inferior to the rib fracture detection performed by both interns. P values between two FOMs are also shown in Figure 4. Because we performed the test two times, the P value was corrected via the Bonferroni correction; a P value of .025 or less was considered to be statistically significant. There was no significant difference between the performance obtained via the DCNN software and that by each intern.
Table 4.
Figure-of-merits for the DCNN software and the two interns.
| The DCNN software | Intern A | Intern B | |
| Figure-Of-Merit (95%CI) | 0.571 (0.454–0.689) | 0.514 (0.415–0.614) | 0.500 (0.393–0.607) |
Figure 4.
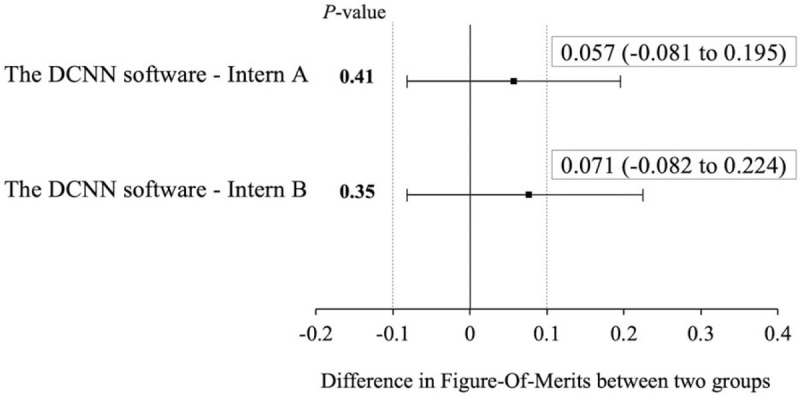
Estimated differences in Figure-Of-Merits between the software and each intern (Intern A and Intern B). Forest plot showing estimated differences in jackknife alternative free-response receiver operating characteristic Figure-Of-Merits between the observer performance of the software and each intern (Intern A and Intern B) for rib fracture detection. Since the non-inferiority margin was set to −0.10, the DCNN software is non-inferior to the rib fracture detection performed by both interns. The P-values between the performance of the software and each intern are also shown. There was no significant difference between the two groups. DCNN = deep convolutional neural network.
3.4. Cause of false positive
The causes of false positive results among the rib fractures detected by the DCNN software are as follows: contrast enhancement of intercostal artery, 5/43: costotransverse joint, 3/43; bone island, 2/43; costovertebral joint, 1/43; lung nodule, 1/43; unknown reason, 31/43.
4. Discussion
We designed an external validation study to evaluate the performance of the DCNN-based software for the detection of rib fractures in chest CT images. The performance of the software was then compared with those of actual doctors.
In general, for deep learning techniques, the greater is the amount of learning data, the higher the recognition accuracy tends to be. In particular, training with a small amount of data is a major cause of overfitting and does not lead to suitable generalization of performance (i.e., performance against unknown data).[22] According to the previous studies on fracture detection in other parts (vertebral and calcaneus fracture), CT images of 1000 to 2000 examinations were used to train and validate the network, and these studies reported good results.[23–25] In light of this, a considerable amount of training data was used to train and validate the DCNN software used in this study, which seems to be sufficient considering the amount of training data used in previous studies.
The sensitivity of the DCNN software for rib fracture detection was 0.645, which was less than those of Radiologist A (0.875) and Radiologist B (0.840). Based on these results, it would now be difficult to replace diagnostic imaging specialists with the DCNN software.
In contrast, the sensitivity of the DCNN software for rib fracture detection was significantly better than those of both interns; in addition, the FOM of the software indicated non-inferiority to detection by both interns in terms of 2-sided 95% confidence intervals. We consider the performance of the interns in this study for rib fracture detection to be reasonable. The mean sensitivity and positive predictive value of rib fracture detection for the 2 interns in this study were 28.9% and 79.4%, respectively. However, according to a previous study, the sensitivity and positive predictive value of rib fracture detection by interns using multi-planar reconstruction images (slice thickness: 0.75 mm) were 29.4% and 82.5%, respectively.[5] Thus, the performance of the interns obtained in this study match those reported in the above study. Based on the performances of the DCNN software and the interns obtained in this study and the validity of the performances of the interns, the detection performance of the DCNN software for rib fractures is expected to be equal to or exceed that of doctors who are not specialized in image interpretation. In general, the diagnosis and treatment of trauma patients are time sensitive. Thus, doctors who are not specialized in image interpretation often have to diagnose rib fractures using medical images when imaging specialists are absent; in such clinical settings, the DCNN detection software could prove useful.
The limitations of this study are as follows. First, in this study, images obtained using only one type of CT scanner were evaluated. The differences in images obtained using different types of CT scanners may affect the detection result. However, because images of various types of CT scanners were used in training and validation datasets, this effect is expected to be small. Second, minor rib fractures are sometimes identified at a later stage in diagnosis. Thus, such minor fractures might have been missed because the gold standard was defined only using the initial CT images in this study. However, many of these minor fractures might not be fatal and need no therapeutic intervention.
In conclusion, this study demonstrated that a software based on a DCNN had higher sensitivity and non-inferior FOM than interns for rib fracture detection; hence, such deep learning-based software might be useful in clinical practice, particularly when imaging specialists are unavailable.
Acknowledgments
The authors thank Hiroshi Imada, MD and Shunya Matsuo, MD for their support and assistance in image interpretation.
Author contributions
Conceptualization: Masafumi Kaiume, Shigeru Suzuki, Koichiro Yasaka, Yun Shen.
Data curation: Masafumi Kaiume, Shigeru Suzuki, Yoshiaki Katada, Rika Fukui.
Formal analysis: Masafumi Kaiume.
Methodology: Masafumi Kaiume.
Software: Yun Shen.
Supervision: Koichiro Yasaka, Osamu Abe.
Writing – original draft: Masafumi Kaiume.
Writing – review & editing: Shigeru Suzuki, Koichiro Yasaka, Haruto Sugawara, Takuya Ishikawa, Osamu Abe.
Supplementary Material
Supplementary Material
Footnotes
Abbreviations: CT = computed tomography, DCNN = deep convolutional neural network, FOM = figure-of-merit, FROC = free-response receiver operating characteristics, JAFROC = Jackknife alternative free-response receiver operating characteristic, SSD = single shot multibox detector.
How to cite this article: Kaiume M, Suzuki S, Yasaka K, Sugawara H, Shen Y, Katada Y, Ishikawa T, Fukui R, Abe O. Rib fracture detection in computed tomography images using deep convolutional neural networks. Medicine. 2021;100:20(e26024).
The authors have no funding and conflicts of interest to disclose.
The datasets generated during and/or analyzed during the current study are not publicly available, but are available from the corresponding author on reasonable request.
Supplemental digital content is available for this article.
Data are represented as the means ± standard deviations, with ranges in parentheses.
CI = confidence interval.
A threshold of confidence score is set such that the resulting F1 score is maximum.
CI = confidence interval, DCNN = deep convolutional neural network.
CI = confidence interval, DCNN = deep convolutional neural network.
References
- [1].Bankhead-Kendall B, Radpour S, Luftman K, et al. Rib fractures and mortality: breaking the causal relationship. Am Surg 2019;85:1224–7. [PubMed] [Google Scholar]
- [2].Murphy CE, Raja AS, Baumann BM, et al. Rib fracture diagnosis in the panscan era. Ann Emerg Med 2017;70:904–9. [DOI] [PubMed] [Google Scholar]
- [3].Broder J, Warshauer DM. Increasing utilization of computed tomography in the adult emergency department, 2000-2005. Emerg Radiol 2006;13:25–30. [DOI] [PubMed] [Google Scholar]
- [4].Cho SH, Sung YM, Kim MS. Missed rib fractures on evaluation of initial chest CT for trauma patients: pattern analysis and diagnostic value of coronal multiplanar reconstruction images with multidetector row CT. Br J Radiol 2012;85:845–50. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [5].Dankerl P, Seuss H, Ellmann S, Cavallaro A, Uder M, Hammon M. Evaluation of rib fractures on a single-in-plane image reformation of the rib cage in CT examinations. Acad Radiol 2017;24:153–9. [DOI] [PubMed] [Google Scholar]
- [6].Yasaka K, Akai H, Abe O, Kiryu S. Deep learning with convolutional neural network for differentiation of liver masses at dynamic contrast-enhanced CT: a preliminary study. Radiology 2018;286:887–96. [DOI] [PubMed] [Google Scholar]
- [7].Chilamkurthy S, Ghosh R, Tanamala S, et al. Deep learning algorithms for detection of critical findings in head CT scans: a retrospective study. Lancet 2018;392:2388–96. [DOI] [PubMed] [Google Scholar]
- [8].Sim Y, Chung MJ, Kotter E, et al. Deep convolutional neural network-based software improves radiologist detection of malignant lung nodules on chest radiographs. Radiology 2020;294:199–209. [DOI] [PubMed] [Google Scholar]
- [9].Hua KL, Hsu CH, Hidayati SC, Cheng WH, Chen YJ. Computer-aided classification of lung nodules on computed tomography images via deep learning technique. Onco Targets Ther 2015;8:2015–22. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].Weikert T, Noordtzij LA, Bremerich J, et al. Assessment of a deep learning algorithm for the detection of rib fractures on whole-body trauma computed tomography. Korean J Radiol 2020;21:891–9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [11].Zhou QQ, Wang J, Tang W, et al. Automatic detection and classification of rib fractures on thoracic CT using convolutional neural network: accuracy and feasibility. Korean J Radiol 2020;21:869–79. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Liu W, Anguelov D, Erhan D, et al. SSD: Single Shot MultiBox Detector. [ArXiv preprint server cornell university library Web site]. December 8, 2015. Available at: https://arxiv.org/abs/1512.02325 [access date April 5, 2020]. [Google Scholar]
- [13].Huang G, Liu Z, van der Maaten L, Weinberger KQ. Densely Connected Convolutional Networks. [ArXiv preprint server cornell university library Web site]. August 25, 2016. Available at: https://arxiv.org/abs/1608.06993 [access date April 5, 2020]. [Google Scholar]
- [14].Chakraborty DP. Analysis of location specific observer performance data: validated extensions of the jackknife free-response (JAFROC) method. Acad Radiol 2006;13:1187–93. [DOI] [PubMed] [Google Scholar]
- [15].Chakraborty DP, Berbaum KS. Observer studies involving detection and localization: modeling, analysis, and validation. Med Phys 2004;31:2313–30. [DOI] [PubMed] [Google Scholar]
- [16].Dorfman DD, Berbaum KS, Metz CE. Receiver operating characteristic rating analysis. Generalization to the population of readers and patients with the jackknife method. Invest Radiol 1992;27:723–31. [PubMed] [Google Scholar]
- [17].Hillis SL. A comparison of denominator degrees of freedom methods for multiple observer ROC analysis. Stat Med 2007;26:596–619. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Fletcher JG, Fidler JL, Venkatesh SK, et al. Observer performance with varying radiation dose and reconstruction methods for detection of hepatic metastases. Radiology 2018;289:455–64. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Shiraishi J, Fukuoka D, Hara T, Abe H. Basic concepts and development of an all-purpose computer interface for ROC/FROC observer study. Radiol Phys Technol 2013;6:35–41. [DOI] [PubMed] [Google Scholar]
- [20].Hashida M, Kamezaki R, Goto M, Shiraishi J. Quantification of hazard prediction ability at hazard prediction training (Kiken-Yochi Training: KYT) by free-response receiver-operating characteristic (FROC) analysis. Radiol Phys Technol 2017;10:106–12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].Katsura M, Matsuda I, Akahane M, et al. Model-based iterative reconstruction technique for ultralow-dose chest CT: comparison of pulmonary nodule detectability with the adaptive statistical iterative reconstruction technique. Invest Radiol 2013;48:206–12. [DOI] [PubMed] [Google Scholar]
- [22].Lee MB, Kim YH, Park KR. Conditional generative adversarial network- based data augmentation for enhancement of iris recognition accuracy. IEEE Access 2019;7:122134–52. [Google Scholar]
- [23].Tomita N, Cheung YY, Hassanpour S. Deep neural networks for automatic detection of osteoporotic vertebral fractures on CT scans. Comput Biol Med 2018;98:08–15. [DOI] [PubMed] [Google Scholar]
- [24].Pranata YD, Wang KC, Wang JC, et al. Deep learning and SURF for automated classification and detection of calcaneus fractures in CT images. Comput Methods Programs Biomed 2019;171:27–37. [DOI] [PubMed] [Google Scholar]
- [25].Raghavendra U, Bhat NS, Gudigar A, et al. Automated system for the detection of thoracolumbar fractures using a CNN architecture. Future Gener Comput Syst 2018;85:184–9. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.