

Abstract
Fake COVID-19 tweets appear as legitimate and appealing to unsuspecting internet users because of lack of prior knowledge of the novel pandemic. Such news could be misleading, counterproductive, unethical, unprofessional, and sometimes, constitute a log in the wheel of global efforts toward flattening the virus spread curve. Therefore, aside the COVID-19 pandemic, dealing with fake news and myths about the virus constitute an infodemic issue which must be tackled to ensure that only valid information is consumed by the public. Following the research approach, this chapter aims at a predictive analytics of COVID-19 infodemic tweets that generates a classification rule and validates genuine information from verified accredited health institutions/sources. On deployment of classifier Vote ensembles formed by base classifiers SMO, Voted Perceptron, Liblinear, Reptree, and Decision Stump on dataset of tokenized 81,456 Bag of Words which encapsulate 2964 COVID-19 tweet instances and 3169 extracted numeric vector attributes, experimental result shows a novel 99.93% prediction accuracy on 10-fold cross validation while the information gain of each 3169 extracted attributes is ranked to ascertain the most significant COVID-19 tweet-words for the detection system. Other performance metrics including ROC area and Relief-F validates the reliability of the model and returns SMO as the most efficient base classifier. The thrust of the model centered more on the trustworthiness of COVID-19 tweet source than the truthfulness of the tweet which underscores the prominence of verified health institutions as well as it contributes to discourse on inhibition and impact of fake news especially on societal pandemics. The COVID-19 infodemic detection algorithm provides insight into new spin on fake news in the age of social media and era of pandemics.
Keywords: Bag of words, COVID-19, Ensemble, Fake news, Machine learning, Tweeter
1. Introduction
The emergence of the novel coronavirus in year 2019 (COVID-19), also refer to as 2019-nCov, came with divers challenges apart from the global health threats that nations and institutions are grappling with toward flattening the curve of the trend [1,2]. Chief of such attendant challenges is the issue of fake news, myths, and misguiding information that are daily propagated by disgruntled elements in the society, (and even innocent unknowing citizens) thereby constituting a cog in the wheel of progress of health institutions. The World Health Organization (WHO) in its attempt to trigger global efforts toward taming the trend of COVID-19 fake news across the world, noted that apart from the COVID-19 pandemic, the next most challenging problem is what it refers to and term as the infodemic nature of news daily circulated, most especially on online media [3], p. 3. Whereas the social networking sites are aids to ease communication and global interaction across nations of the world, they also pave ways for fake news which are seamlessly posted on web platforms including social media platforms to misguide unsuspecting citizens [4]. One of the most prominent social media platforms is Twitter. It enjoys patronage of both young and old who throng their twitter handles to post user-generated information popularly referred to as Tweets or simply join an ongoing hash-tag discussion which are arranged in threads amounting to millions of tweet posts in some cases. As at January 2020, internet users in Nigeria total 85.49 million, an increment of 2.2 million (+2.6%) from 2019 while internet penetration stands at 42% out of which a total of 27.00 million are social media users [5]. Aforementioned report shows an additional 3.4 million (+14%) more users were added between April 2019 till January 2020 alone while 99% out of the entire subscribers in Nigeria are active users who accesses their choice social media platforms through mobile phone with 3 h and 30 min as the average amount of time spent per day. Noteworthy from the report is the fact that Twitter enjoys 50% utilization preference out of the entire active users amidst other social media platforms, hence its huge traffic and coronavirus-related breaking news status. Traditional tabloids have also suddenly adopted Twitter where their breaking news are promptly posted before production of next issue the following day. With its wide acceptance, volatility, and user patronage, however, the major challenge that has continued to confront researchers is the most effective ways to curb the spread of fake news with its attendant threats to global peace and harmony. Fake news is one of the most prominent problems facing governments, institutions, cultures and societies, academia, and industry practitioners across the globe. This is attributed to the fact that communication of false and misleading information has greatly increased the trust deficit between government institutions, corporate organizations, and the societal populace [6].
Owing to the harmful societal implications of misleading news, detecting fake news, or in this case tweets, has attracted increasing attention globally. However, the detection models deployed using author's profile information, geographical location, handles, hash-tags, and or status of handle as either verified or unverified is generally not reliable as proponents and perpetrators of fake news had since learned to model and brand their social media accounts and handles in a responsible way and manner that will easily earn the trust of followers or visitors. Thus, there is need for efficient analysis of the news semantics not to just determine the truism of the post, as the target of most literature, but to ascertain the trustworthiness of the source by a way of placing emphasis on determining the source than the content of the news itself which is the main thrust of this research. Several methodologies have been adopted toward detecting fake news including the natural language processing (NLP), which is about the most applicable in text categorization efforts and since posts on social media and Twitter are texts, fake news detection naturally should fall under the purview of NLP [4].
Consequent upon the foregoing, the pandemic-nature of fake news and misguiding COVID-19 information cannot be overemphasized when there is dire need for a global consensus on international best practices to nosedive the ugly trend. Meanwhile most of the infodemic tweets are far counterproductive hence a desperate measure to develop a model that will identify sources of COVID-19 information before compliance with its dictate which is a motivating factor of this work coupled with the efficiency of machine learning algorithms for predictive analytics of big data mining, including text mining, as a reliable detective tool. Since a huge volume of data on social media is text data, most especially on Twitter with high limitations as to the number of words allowed for each tweet. Text mining and NLP which by design extract meaningful patterns and derive sense from text data is therefore apt for this work by way of detecting the source of twitter post and thereby ignore, report or reject a post as misguiding or comply with the dictate of the post as one from a verified institution.
Major problem with modeling of text however is the messy nature of words most especially user-generated social media posts which are stylishly crafted and posted with characteristic phone elements including emoticons, hash-tags, haphazard punctuations, abbreviations, deliberate misspellings, etc., which contravenes machine learning accepted standards of using well-defined fixed-length inputs and outputs. Since Twitter posts are not acceptable text words in machine learning metadata, there is need to convert tweets into vectors of numbers for a consequent classification phase of fake news detection model.
The rest of the paper is structured such that session II discusses existing-related works in the area of fake news detection and text classification data mining, while session III unveils the methodology deployed for the design of the proposed model. Session IV discusses the result of the predictive analytics and session V concluded this work with recommendations.
2. Related models
The motivation to checkmate fake news especially on social media is commonplace across different professional callings and research works with various approaches and methodologies deployed for an eventual accurate model of the goal in sight. In the work of [7], an in-depth analysis of the relationship between fake news and social media profile of perpetrators, and their cohorts were evaluated and established. Political bias, profile image, and location of users were features used to train random forest algorithm used for the classification analysis unlike [8] that developed a Check-it plug in that is aimed at taming misinformation on social media. The authors of Check-it conceptualized a web browser plug-in approach that put together variety of signals into a channel for identification of invalid news. In Ref. [6], data management and mining were the perspective of the survey conducted by the authors toward understudying approaches in literatures aimed at nose-diving effects of the scourge. Database and machine learning approaches were discussed as efficient ways of predicting beforehand the status of news items, while epidemiological approach and influence intensification models were established as mitigating choices in stemming the tide.
While identifying the towering usefulness of machine learning models in predictive analytics [9], emphasized the towering role of data mining toward solving classification problems as the author deploys academic data to predict future performance by assigning risk levels to current academic standing of students thereby returning a high-predictive accuracy which reechoes the efficiency of machine learning algorithms. In the work of Ref. [10], subjectivity of both legitimate and fake news was considered as of paramount importance in the predictive analytics of news categorization. A set of objectivity lexicons initiated by linguists was featured as input variables by calculating the Word Mover's Distance to build the feature vectors extracted from each of politics, sports, economy, and culture news domains for XGBoost and random forest classification, while Ref. [11] discusses the conventional bouts on junk news filters and attacks targets at text classification to detect the robustness of machine learning models using synthetic attacks often referred to as adversarial training. The essence is to generate synthetic data instances through the generative-adversarial network. In Ref. [12], detection of fake news on Twitter was the target of their weekly acquisition of tweets instances for a supervised classification approach. Tweets were labeled as trustworthy or untrustworthy and are trained by XGBoost with an F1 score of up to 0.9 by the binary classification of the training set. The dual classification approach of cross validation and training set deployed were to predict source of fake news and the text of fake news itself respectively with experimental result showing that labeled training set, of a large-scale dataset but with inexact labels returns good accuracies as well. The work of [13] is an approach to detect spam accounts on twitter through the deployment of classification algorithms including K-Nearest Neighbor, Decision Tree, Naive Bayesian, Random Forest, Logistic Regression, support vector machine (SVM), and XGBoost with numbers of followings and followers as independent input features while random forest returned the best classification accuracy result in detecting spammers.
The text mining of social media Facebook platform through Naïve Bayes was conducted by Ref. [14] to predict whether a post on Facebook is Real or Fake while convolutional neural networks and convolutional recurrent neural networks were used to extract features from Chinese texts in Ref. [15] before Chinese text predicative analytics. Automatic detection of racist news forms the essence of the work of [16] using SVM through the identification of indication words in texts of racists. Bag of words, bigram, and part of speech tags were concerted approaches deployed for the classification model in their work. Classification of demographic attributes to identify latent Twitter users was the thrust of the work of [17] through stacked-SVM model of single and ensemble approaches with gender, age, political affiliation, and ethnicity forming attributes of the predictive analytics.
In an attempt to automatically detect hoax on the internet, Ref. [18] deploys content analysis in the classification of fake news including mining the post diffusion pattern via social content feature returning 81.7% prediction accuracy. In Ref. [19], K-means clustering is deployed to count clusters in Twitter posts which is faster compared to methodologies in literatures despite the numbers of document vectors and their dimensions but there is a huge extension of time taken to perform task. A sentence-comment co-attention sub-network to exploit news content toward detection of fake news was the main aim of Ref. [20] in their model code-named defend. In the work, explainable detection of fake news was the approach which places emphasis on the rationale behind the decision to label a news item as fake while deploying explainable machine learning as well for the classification phase through intrinsic explainability and post-hoc explainability and is achieved through phases of content encodings. In Ref. [21], fake news detection in Twitter using hybrid CNN and RNN with an 82% performance accuracy was the main thrust of the research word on the twitter sub-domain of the social network.
The use of n-grams for lie detection was the aim of Ref. [22] that established datasets using crowd-sourcing which contain statements of people lying about their beliefs on issues that centered on abortion, friendship, and death penalty in an attempt to decipher dissimilarities in the texts while evaluating the efficiency of n-grams in classifying lies from the truth. Naive Bayes and SVM algorithms were trained deploying term frequency vectors of n-grams in the texts as inputs. A 70% classification accuracy was achieved in identifying lies as expressed in their beliefs and an accuracy of 75% in identifying lies about their feelings. A linguistic analysis-based method is likewise proposed in Refs. [23,24] with same n-gram classification approach for pretended appraisals through crowd-sourced workers who were enjoined to create false positive assessments about hotels [23] and false negative reviews on hotels [24]. Their work revealed that fake assessments contained fewer spatial words including floor, small, and location expectedly because the worker is alien to the hotel hence little or no availability of spatial detail for the assessment together with the discovery that positive sentimental words were overstated in the positive false assessments when comparison with their true counterparts. Related exaggeration was observed in negative sentimental words in false negative assessments.
A variant work proposed by Ref. [25] is specifically on the textual features extracted by adding an attention apparatus into an LSTM design to reflect resemblance of fake news words to depict portions of the text which are pointers to fact or sham such that words indicated with darker red seemed to be germane to fake news detection task. Whereas adding attention does not specifically improve detection performance but thus provide some interpretability from the extracted features by shedding more lights toward tagging significant words which can be deployed for qualitative fake news studies instead of detection which is a different approach to the work of Ref. [26] that features multitask knowledge approaches to mutually provide stand detection and truth classification to enhance accuracy by employing the interdependence in the two tasks. The proposed model is based on recurrent neural networks with shared and task-definite parameters by combining the task of opinion detection and truth classification where each task is tagged with a shared GRU and task-definite GRU layers. The intention of the shared GRU layer is to detect patterns similar to both tasks whereas task-definite GRU aids the detention of patterns that are paramount to one task than to the other. An ensemble classification of tweet sentiment was the thrust of the work of Ref. [27] which proposes an approach that uniquely classifies tweet sentiments by using ensembles classifier and lexicons with a binary classification of either positive or negative class output. The model is conceptualized for consumers who can search for products with sentiment analysis and for manufacturers who needs to monitor the public sentiments of their brands. A public tweet sentiment dataset is deployed on a formed ensemble with base classifiers of logistic regression, SVM, Multinomial Naïve Bayes, and Random Forest which significantly improved the predictive analytics of the classification.
The work of Ref. [28] is a systematic literature review on combating fake news through by analyzing the nitty-gritty of modern-day fake news problem including highlighting the technical tests associated therewith by discussing existing methodologies and techniques deployed for both detection and inhibition. The inherent characteristic features of public datasets in particular were discovered to have a significant influence on the eventual accuracy of any detection system designed purposely for preventive measures. Categorization of existing detection methods in the survey reveals three major approaches including content-based identification which comprises of cue and feature methods, deep learning content-based and linguistic analysis methods in no particular order. Feedback-based identification comprises of hand-crafted attributes, broadcast pattern study, temporal shape analysis, and response text and response user analysis. The third approach is referred to as the intervention-based solutions which comprises of identification and mitigation strategies. The survey recommended three germane factors and among which include the adoption of a dynamic knowledge base dataset which could reflect the changes occurring in a fast-paced world which influences the status of a news item along timeline between being truthful or otherwise and the deployment of datasets for news intent detection as against the usual “true” or “false” binary output class discovered in all the 23 public datasets surveyed in the systematic literature review.
The level of fake news associated with global outpour of impression and opinions about COVID-19 has resulted into a somewhat xenophobic attack toward those who have tested positive and especially on Chinese tourists as observed by Ref. [29] asserting that with the avalanche of misconceptions being spread through social media, discrimination against Chinese nationals has become extensive in some parts of the world resulting to more havoc than the virus itself. A trending #ChineseDon'tComeToJapan twitter hashtag is noted as referring to Chinese as insensitive, and even bioterrorists which is counterproductive to global concerted efforts toward finding an antidote to the menace and furthermore, an evolution tree study in a computational approach for probing the roots and spreading forms of fake news was carried out in the work of Ref. [30]. The work uses a recent progress in the field of evolution tree analysis by analyzing issues in the scope of the presidential election of the United States in 2016 by accessing 307,738 tweets about 30 fake and 30 real news items. Results show that root tweets about fake news are mostly authored by twitter handles of ordinary users with a link to noncredible news platforms while observing a significant variance between real and fake news items in terms of evolution patterns. In a deception detection research endeavor, Ref. [31] designed LIAR: a publicly dataset for false news detection by collecting a manually labeled 12,800 decade-long small statements in numerous situations from POLITIFACT.COM which provides exposition and links to source documents for each case. An automated fake news detection system was then investigated on LIAR based on surface-level linguistic patterns resulting into a novel, hybrid convolutional neural network which integrates metadata with text and consequently shows that the hybrid approach improves text-only deep learning model while a twitter bot detection through one-class classification approach was proposed by Ref. [32] to detect malicious posts and the proposal is reported to steadily identify different kinds of bots with a 0.89+ performance measured using AUC requiring little or no previous evidence about them. Ten classifiers were deployed for the work using the ROC curves to ascertain performance of classifiers on diverse thresholds. The AUC of the ROC curve was adopted as it reviews the accuracy of a classifier into a single metric.
3. Research methodology
In this NLP predictive analytics research, numeric word vectors are derived from the corpus of 81,456 COVID-19 twitter word-posts to reflect various linguistic properties of posted COVID-19 texts acquired from verified twitter handles of national and global health institutions and handles of unverified and random Twitter users in an attempt to detect fake COVID-19 news which forms the new global infodemic menace. With the execution of this model, Twitter users who post unsubstantiated, unauthorized, unverifiable, misleading, counterproductive, and misguiding COVID-19 tweets can be identified and their tweet disregarded or reported accordingly as people who circulate fake news or are not authorized to issue classified statements to the public. Hence, vocabulary of known words through Bag of Words is deployed in this work as dataset inputs encapsulating 2964 COVID-19 tweet instances for preprocessing and tokenization and subsequently for the supervised dual classification phase of ensemble and singly predictive analytics with the aim of isolating fake COVID-19 tweets from valid ones which has affected government spirited efforts in no small way. The Waikato Environment for Knowledge Analysis (WEKA) tool was used for the preprocessing, tokenization, and machine learning phases of this work.
The research work followed the research approach in Ref. [32] as outlined in Fig. 19.1 as it deploys NLP of user-generated COVID-19 tweets to ascertain the validity of the information being passed across the Twitter medium. Semantic features of Tweet texts are tokenized through the Word-to-Vector filter in the WEKA application tool. The pipeline of this infodemic predictive analytics is in four phases of Tweet Acquisition phase, Tweet Tokenization phase, Ensemble Classification and Rules generation phase. The proposed infodemic COVID-19 tweet detection model framework is as represented in Fig. 19.1.
Figure 19.1.

The proposed framework for COVID-19 infodemic detection model.
3.1. Tweet-data acquisition phase
A total of 81,456 corpus of tweet-texts from 2964 COVID-19–related tweets forms the training and testing dataset which are tweets from either verified authorized institutions or from individual twitter users hence a binary classification task ahead. A total of 1602 tweets from verified institutions amounting to 54.048% are labeled as valid or trusted COVID-19 tweets, while 1362 tweets from individuals amounting to 45.95% are labeled as invalid COVID-19 tweets. Table 19.1 shows the labeling of tweets depending on the source. The tweets, in their dirty and raw form, were subjected to cleaning to remove stop words, invalid icons, and emoticons that are the characteristic nature of tweets across demography of the world. Upon cleaning, the 81,456 tweet texts are prepared as arff file before filtering in the second stage of this machine learning pipeline.
Table 19.1.
News sources and sample size between valid and invalid COVID-19 tweets as manually harvested from respective handles, threads, and hashtags.
| S/N | Source | Sample COVID-19 tweet [source] | Status | Tweet sampling (%) |
|---|---|---|---|---|
| 1. | Nigeria Center for Disease Control | “As at 11:30pm tonight, 176 new cases of COVID-19 cases have been reported in Nigeria” [@ncdcgov; #TakeResponsibiklity] | Valid | 54.048 |
| 2. | Federal Ministry of Health | “Contrary to news in circulation, fact finding team that was deployed to Kano state by @Fmohnigeria was well received by @GovUmarGanduje to conduct an appraisal of the situation and are currently looking for outlines to provide technical support.” [@Fmohnigeria] | ||
| 3. | Lagos State Government |
“N95 and surgical masks help our medical workers stay safe while cloth masks made to specifications that will be released by @LSMOH combined with other guidelines will help protect our residents from #COVID19” [@followlasg; #CovidLASG] |
||
| 4. | Ogun State Ministry of Health | “COVID-19 can infect all ages and hence the need to adhere strictly to medical advices” [@HealthOgun; @OGSG_Official] |
||
| 5. | World Health Organization-Nigeria |
“Exposing yourself to the sun or to temperature higher than 25C degr3ees DOES NOT prevent nor cure #Covid19” [@WHONigeria] |
||
| 6. | World Health Organization-Africa |
“#Covid19 IS NOT transmitted through houseflies” [@WHOAfrica; #coronavirus] |
||
| 7. | World Health Organization-Global | “Spraying or introducing bleach or another disinfectant into your body WILL NOT protect you against #COVID19 and can be dangerous.” [@WHO; #KnowTheFacts; #coronavirus] | ||
| 8. | Unverified individual twitter handles, hashtags, and threads |
“Coronavirus cannot thrive in hot regions like Nigeria,” “There are no COVID-19 cases in Nigeria. Government is only playing alongside western countries,” “If you read your Quran or Bible, your COVID-19 positive case will turn negative,” “5G mobile network can transmit COVID-19,″ “Ignore lockdown. It's better to die of a virus than let hunger virus kill you” [#Covid19; #Covid19Nigeria; #threads; random individual twitter handles] |
Invalid | 45.95 |
3.2. Tweet Tokenization and information gain evaluation
To acquire useful classification elements embedded within texts of tweets for a syntactic representation, StringToWordVector filter is applied in this stage of the activity flow to make the text file classifiable by a way of text extraction. By a way of word count, a Bag of Words emerges from this stage which forms input, as an arff file, into the next stage of ensemble machine learning phase. The StringToWordVector filter converts the string of tweets to a set of numeric attributes representing frequency of word appearance from the tweet corpus. Features extracted from the tweets serve as attributes from the 2964 collected valid and invalid tweeter posts. The word-count frequency of these attributes serves as independent attributes that point to the pandemic status of each post which are tagged as either valid or invalid in the class output labeling. The array of the resulting attributes is referred to as the Bag of Words in arff file format which is the representation of the 8,1456 COVID-19 Twitter texts. With Bag of Words, the trustworthiness of the tweet source takes prominence over the truth of the tweet itself which underscores the prominence of constituted authorities in COVID-19 information dissemination efforts.
The intuition is that some particular COVID-19 tweets are similar and from same source if they have similar content in terms of some specific known words, hence, the creation of a vector document of Boolean representation such that the presence of specific words are marked 1 and 0 for their absence. These words constitute the independent attributes of the dataset, and the following pseudocode generates the Bag of Words.
-
1.
bow feature = [0,0,…,0]
-
2.
forword in text.tokenize() do
-
3.
ifword in dict then
-
4.
word id = getindex(dict, word)
-
5.
bow feature[word id]++
-
6.
else
-
7.
continue
-
8.
end if
-
9.
end for
-
10.
return bow feature
From the generated arff Bag of Words, a preprocessing of the dataset is implemented by an Information Gain (I.G) evaluator filter to rank the entire 3169 word attributes to ascertain the relevance of each word in the determination of the valid or invalid status of each COVID-19 tweeter post. To achieve this, Ranker calculates the entropy for each attribute which varies from 0 (no information) to 1 (maximum information) and then assigns high I.G value to attributes that contributes more information toward the categorization task as shown in Eq. (19.1) thus:
| (19.1) |
where C is the output class, and Bi and E as the entropy.
3.3. Singly and ensemble classification stage
Three ensemble of classifiers including ADABOOST, BAGGING, and VOTE are separately deployed for the classification stage in 10-fold cross validation each and then followed by singly classification by Decision Stump and Reptree of the tree subcategory and SMO, Liblinear and Voted perceptron of the function subcategory which are all of supervised learning all in a bid to increase the reliability of the study. Dual training is done on the ADABOOST with SMO and Decision Stump base learners over 10 iterations and likewise for BAGGING deploying SMO and Reptree base learners, respectively, conducted in 10 iterations as well. The VOTE ensemble classification was achieved on SMO, Liblinear, voted perceptron, and Reptree base learners to derive the weighted average performance metrics.
BAGGING is often referred to as BOOTSRAP combining bootstrapping and aggregation to form one ensemble model. Given our dataset of numeric bag of words, multiple bootstrapped sub-data are pulled which then forms a decision tree on each data sample. Each subsample decision tree is then aggregated through averaging process to form the most efficient predictor.
ADABOOST considers homogenous weak base learners by learning sequentially in an adaptive manner such that a base model depends on the previous ones preceding it and then combines them following a deterministic strategy. The Reptree machine learning algorithm is of the supervised tree family and is deployed for the purpose of rule generation to aid fake COVID-19 tweets identification with the Bag of Words input. It simply identifies word attributes that are significant to the unique identification of invalid tweets through word frequency occurrence ratio in both valid and invalid tweet texts relating to COVID-19.
In VOTING, multiple classification models are initially created using training dataset as each base models are created using same training set with different algorithms. Each base models then forwards its prediction (votes) for respective test instance using 10-fold cross validation hence the final output prediction which takes into cognizance the prediction of the better models multiple times.
4. Results and discussion
Filtering of the total number of 8,1456 tweet corpus extracted from 2964 COVID-19 news-item Tweets, through the use of String to Word Filter, returns a total of 3169 Bag of Words independent numeric attributes which serves as the dictionary of words for the subsequent I.G evaluation, ensemble and singly classification stages, and subsequent rule generation phase. 10 fold cross validation was used to validate the results and as observed from the performance accuracy graph of Fig. 19.2 , BAGGING, with the Reptree base model, outperforms ADABOOST, with Decision Stump base model, with a percentage difference of 10.29 while both trailed VOTE ensemble classifier which records a novel 99.93% accuracy. Consecutively replacing ADABOOST and BAGGING weak learners with SMO classification model however resulted in a significant accuracy boost for the duo recording a significant accuracy improvement tallying with the Voted model as is presented on Table 19.2 . The singly classifiers with its performance metrics presented on Table 19.3 shows SMO, Reptree, Liblinear, and Voted perceptron individually outperforms ADABOOST (Decision stump base learner) ensemble classifier with 99.93%, 94.93%, 99.93%, and 98.48%, respectively. However, Decision stump singly learner returns 81.1066% accuracy lower than the 86.17% recorded with ADABOOST ensemble. The error metrics for the dual classification approaches of ensemble and singly are as presented on Table 19.4, Table 19.5 while the attribute ranking feature of our model as presented on Table 19.6 shows the first 21 attributes with the highest I.G thereby contributing most information toward the determination of the endemic nature of the COVID-19 post determination. Their average rank and merit altogether returns the popular hash-tag #Covid19 as the attribute with the most I.G and the @ncdcgov as the first most significant twitter handle while the world health organization abbreviation, WHO, is the eighth most significant attribute and the coronavirus returns as the 18th most significant word. Table 19.7 encapsulates our model-generated rules to detect COVID-19 infodemic tweets, which is the output from the Reptree supervised learning model. This uniquely identifies fake COVID-19 tweets which are not only misguiding but forms various myths that impede government efforts toward engaging the citizenry toward taming the COVID-19 trend in the country in an attempt to flatten its curve.
Figure 19.2.
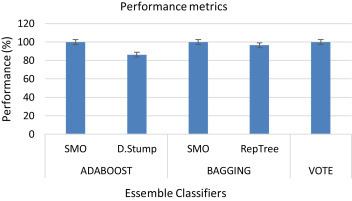
Classification accuracy graph of ensemble classifiers.
Table 19.2.
Performance metrics of ensemble classification models.
| S/N | Ensembles | Base classifiers | Performance metrics (%) |
||||
|---|---|---|---|---|---|---|---|
| Precision | Recall | F-Measure | ROC | Accuracy | |||
| 1. | ADABOOST | SMO | 0.999 | 0.999 | 0.999 | 0.999 | 99.9325 |
| Decision Stump | 0.862 | 0.862 | 0.862 | 0.928 | 86.1673 | ||
| 2. | BAGGING | SMO | 0.999 | 0.999 | 0.999 | 1.000 | 99.9325 |
| Reptree | 0.965 | 0.965 | 0.965 | 0.992 | 96.4575 | ||
| 3. | VOTE | 0.999 | 0.999 | 0.999 | 1.000 | 99.9325 | |
Table 19.3.
Performance metrics of singly models.
| S/N | Classifiers | Performance metrics (%) |
||||
|---|---|---|---|---|---|---|
| Precision | Recall | F-Measure | ROC | Accuracy | ||
| 1. | Decision stump | 0.814 | 0.811 | 0.811 | 0.800 | 81.1066 |
| 2. | SMO | 0.999 | 0.999 | 0.999 | 0.999 | 99.9325 |
| 3. | Reptree | 0.949 | 0.949 | 0.949 | 0.979 | 94.9393 |
| 4. | Voted perceptron | 0.985 | 0.985 | 0.985 | 0.986 | 98.4818 |
| 5. | Liblinear | 0.999 | 1.000 | 1.000 | 1.000 | 99.9325 |
Table 19.4.
Error metrics of singly classification models.
| S/N | Classifiers | Error metrics |
||||
|---|---|---|---|---|---|---|
| Kappa statistic | Mean absolute error | Root mean squared error | Relative absolute error (%) | Root relative squared error (%) | ||
| 1. | Decision stump | 0.622 | 0.03034 | 0.3897 | 61.0759 | 78.1971 |
| 2. | SMO | 0.9986 | 0.0007 | 0.026 | 0.1358 | 5.2124 |
| 3. | Reptree | 0.8982 | 0.0658 | 0.2008 | 13.2463 | 40.2938 |
| 4. | Voted perceptron | 0.9694 | 0.0152 | 0.1232 | 3.0565 | 24.7244 |
| 5. | Liblinear | 0.9986 | 0.0007 | 0.026 | 0.1358 | 5.2124 |
Table 19.5.
Error metrics of ensemble classification models.
| S/N | Ensemble classifiers | Base classifiers | Error metrics |
||||
|---|---|---|---|---|---|---|---|
| Kappa statistic | Mean absolute error | Root mean squared error | Relative absolute error (%) | Root relative squared error (%) | |||
| 1. | ADABOOST | SMO | 0.9986 | 0.0007 | 0.026 | 0.1403 | 5.2179 |
| Decision stump | 0.7212 | 0.2211 | 0.3207 | 44.5045 | 64.3576 | ||
| 2. | BAGGING | SMO | 0.9986 | 0.0015 | 0.0253 | 0.2989 | 5.0804 |
| Reptree | 0.9287 | 0.0672 | 0.1678 | 13.521 | 33.6618 | ||
| 3. | VOTE | 0.9986 | 0.0166 | 0.0556 | 3.3421 | 11.1641 | |
Table 19.6.
Ranking of bag of words attributes by information gain evaluation.
| S/N | Average merit | Average rank | Attribute |
|---|---|---|---|
| 1. | 0.317 ± 0.006 | 1 ± 0 | #COVID19 |
| 2. | 0.192 ± 0.004 | 2 ± 0 | Transmitted |
| 3. | 0.185 ± 0.004 | 3 ± 0 | Through |
| 4. | 0.179 ± 0.004 | 4 ± 0 | Houseflies |
| 5. | 0.119 ± 0.005 | 5.1 ± 0.3 | With |
| 6. | 0.11 ± 0.002 | 6.5 ± 0.67 | Briefing |
| 7. | 0.107 ± 0.002 | 7.2 ± 1.6 | @NCDCgov |
| 8. | 0.107 ± 0.002 | 7.5 ± 0.5 | WHO |
| 9. | 0.102 ± 0.002 | 9.6 ± 0.66 | Joint |
| 10. | 0.102 ± 0.002 | 10 ± 0.89 | WEF |
| 11. | 0.099 ± 0.002 | 11 ± 1.1 | Replying |
| 12. | 0.098 ± 0.005 | 11.1 ± 1.22 | Of |
| 13. | 0.084 ± 0.002 | 13.5 ± 0.81 | Media |
| 14. | 0.082 ± 0.003 | 14.6 ± 0.92 | Watch |
| 15. | 0.08 ± 0.002 | 15.2 ± 1.78 | Not |
| 16. | 0.079 ± 0.002 | 16 ± 1.34 | @FMICNigeria |
| 17. | 0.078 ± 0.002 | 16.7 ± 1.1 | Others |
| 18. | 0.078 ± 0.002 | 17 ± 1 | #Coronavirus |
| 19. | 0.073 ± 0.001 | 19.6 ± 0.66 | Rubbish |
| 20. | 0.073 ± 0.001 | 19.6 ± 0.49 | Complete |
| 21. | 0.07 ± 0.001 | 21.4 ± 0.49 | Buharis |
Table 19.7.
Classification rule of COVID-19 infodemic tweet by reptree classifier.
|
#COVID19 < 0 | briefing < 0 | | State < 0 | | | Address < 0 | | | | of < 1 | | | | | on < 0.99 | | | | | | Ogun < 1 : 0 (683/9) [335/0] | | | | | | Ogun ≥ 1 : 1 (4/0) [1/0] | | | | | on ≥ 0.99 : 1 (15/8) [1/0] | | | | of ≥ 1 | | | | | @NCDCgov< 0.91 : 1 (58/28) [30/13] | | | | | @NCDCgov>= 0.91 : 0 (35/0) [22/1] | | | Address ≥ 0 : 1 (23/0) [12/0] | | State ≥ 0 | | | who < 0.05 | | | | Ondo < 0.27 : 1 (59/0) [23/0] | | | | Ondo ≥ 0.27 : 0 (6/0) [6/0] | | | who ≥ 0.05 : 0 (8/0) [4/0] | briefing ≥ 0 : 1 (107/0) [41/0] #COVID19 ≥ 0 | transmitted < 0 | | with < 0 | | | health < 0.01 | | | | for < 0.93 | | | | | of < 0.83 | | | | | | #coronavirus < 0.02 |
| | | | | | | Address < 0.03 | | | | | | | | including < 0.03 : 0 (98/2) [52/5] | | | | | | | | including ≥ 0.03 : 1 (3/0) [2/0] | | | | | | | Address ≥ 0.03 : 1 (8/0) [13/0] | | | | | | #Coronavirus ≥ 0.02 : 1 (9/0) [6/0] | | | | | of ≥ 0.83 | | | | | | to < 0.01 | | | | | | | and < 0.36 : 0 (12/0) [8/2] | | | | | | | and ≥ 0.36 | | | | | | | | one < 0.27 : 1 (5/0) [3/0] | | | | | | | | one ≥ 0.27 : 0 (4/0) [1/0] | | | | | | to ≥ 0.01 | | | | | | | some < 0.22 : 1 (37/3) [14/0] | | | | | | | some ≥ 0.22 : 0 (3/0) [1/0] | | | | for ≥ 0.93 : 1 (39/4) [18/4] | | | health ≥ 0.01 : 1 (51/0) [22/0] | | with ≥ 0 | | | Complete < 0.08 | | | | part < 0.14 | | | | | 323 < 0.29 : 1 (278/8) [158/8] | | | | | 323 ≥ 0.29 : 0 (5/0) [2/0] | | | | part ≥ 0.14 : 0 (7/1) [4/0] | | | Complete ≥ 0.08 : 0 (6/0) [2/0] | transmitted ≥ 0:1 (413/2) [207/0] |
5. Conclusion and recommendation
Twitter social media have turned veritable platforms for disgruntled elements in the society who are resolute in their determination to constitute a clog in the wheel of governments' efforts toward stemming the tide of the global COVID-19 pandemic ravaging nations of the world. This also holds true for citizens who are unintentional and/or inept with social media ethics. Their penchant for authoring and circulating fake news has resulted into another infodemic challenge for government and health institutions who battles the trend to further safeguard unsuspecting members of the public who digests fake news, COVID-19 myths, misguided and misleading information hook, line, and sinker. This study consequently deploys machine learning intelligence toward the classification of valid and invalid COVID-19 news items emanating from Twitter. Through NLP of Bag of Words and ensemble machine learning approach, VOTE ensemble classification model returns an efficient model toward detecting misguiding and fake COVID-19 tweets with cross validation satisfactory accuracy of 99.93% which serves the aim of this research by generating rules which uniquely identifies fake COVID-19 tweets. Future deployment of API is recommended for the acquisition of tweets for a robust and wider acquisition scope.
Acknowledgments
Authors appreciate the efforts of the reviewers toward the final and better outcome of this chapter.
References
- 1.WHO . World Health Organisation; Geneva: 2020. Coronavirus Disease 2019 (COVID-19) Situation Report.https://www.who.int/emergencies/diseases/novel-coronavirus-2019/situation-reports Accessed: April. 08, 2020. [Online]. Available: [Google Scholar]
- 2.Dong E., Du H., Gardner L. An interactive web-based dashboard to track COVID-19 in real time. Lancet Infect. Dis. 2020;20(5) doi: 10.1016/S1473-3099(20)30120-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Pulido C.M., Villarejo-Carballido B., Redondo-Sama G., Gómez A. COVID-19 infodemic: more retweets for science-based information on coronavirus than for false information. Int. Sociol. 2020;35(4):377–392. 0268580920914755. [Google Scholar]
- 4.Kroeze J.H., Matthee M.C., Bothma T.J. Proceedings of the 2003 Annual Research Conference of the South African Institute of Computer Scientists and Information Technologists on Enablement through Technology. South African Institute for Computer Scientists and Information Technologists; 2003. Differentiating data-and text-mining terminology; pp. 93–101. [Google Scholar]
- 5.Kemp S. 2020. Digital 2020: Nigeria.https://datareportal.com/reports/digital-2020-nigeria April. 30, 2020. [Online]. Available: [Google Scholar]
- 6.Lakshmanan L.V., Simpson M., Thirumuruganathan S. Combating fake news: a data management and mining perspective. Proc. VLDB Endow. 2019;12(12):1990–1993. [Google Scholar]
- 7.Shu K., Zhou X., Wang S., Zafarani R., Liu H. Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining. 2019. The role of user profiles for fake news detection; pp. 436–439. [Google Scholar]
- 8.Paschalides D., Christodoulou C., Andreou R., Pallis G., Dikaiakos M.D., Kornilakis A., Markatos E. 2019 IEEE/WIC/ACM International Conference on Web Intelligence (WI) IEEE; 2019. Check-it: a plugin for detecting and reducing the spread of fake news and misinformation on the web; pp. 298–302. [Google Scholar]
- 9.Olaleye T.O., Vincent O.R. 2020 International Conference in Mathematics, Computer Engineering and Computer Science (ICMCECS) IEEE; 2020. A predictive model for students' performance and risk level indicators using machine learning; pp. 1–7. [Google Scholar]
- 10.Jeronimo C.L.M., Marinho L.B., Campelo C.E., Veloso A., da Costa Melo A.S. Proceedings of the 21st International Conference on Information Integration and Web-Based Applications & Services. 2019. Fake news classification based on subjective language; pp. 15–24. [Google Scholar]
- 11.Lee D., Verma R. Proceedings of the Sixth International Workshop on Security and Privacy Analytics. 2020. Adversarial machine learning for text; pp. 33–34. [Google Scholar]
- 12.Helmstetter S., Paulheim H. 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM) IEEE; 2018. Weakly supervised learning for fake news detection on Twitter; pp. 274–277. [Google Scholar]
- 13.Alom Z., Carminati B., Ferrari E. 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM) IEEE; 2018. Detecting spam accounts on Twitter; pp. 1191–1198. [Google Scholar]
- 14.Jain A., Kasbe A. 2018 IEEE International Students' Conference on Electrical, Electronics and Computer Science (SCEECS), Bhopal. 2018. Fake news detection; pp. 1–5. [Google Scholar]
- 15.Wang R., Li Z., Cao J., Chen T. Proceedings of the 3rd International Conference on Computer Science and Application Engineering. 2019. Chinese text feature extraction and classification based on deep learning; pp. 1–5. [Google Scholar]
- 16.Greevy E., Smeaton A.F. Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. 2004. Classifying racist texts using a support vector machine; pp. 468–469. [Google Scholar]
- 17.Rao D., Yarowsky D., Shreevats A., Gupta M. Proceedings of the 2nd International Workshop on Search and Mining User-Generated Contents. 2010. Classifying latent user attributes in twitter; pp. 37–44. [Google Scholar]
- 18.Della-Vedova M.L., Tacchini S.M., Ballarin G., DiPierro M., de Alfaro L. 2018 22nd Conference of Open Innovations Association ∗FRUCT, Jyvaskyla. 2018. Automatic online fake news detection combining content and social signals; pp. 272–279. [Google Scholar]
- 19.Bates A., Kalita J. Proceedings of the Second International Conference on Information and Communication Technology for Competitive Strategies. 2016. Counting clusters in twitter posts; pp. 1–9. [Google Scholar]
- 20.Dörre J., Gerstl P., Seiffert R. Proceedings of the Fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 1999. Text mining: finding nuggets in mountains of textual data; pp. 398–401. [Google Scholar]
- 21.Shu K., Cui L., Wang S., Lee D., Liu H. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019. Defend: explainable fake news detection; pp. 395–405. [Google Scholar]
- 22.Mihalcea R., Strapparava C. Proceedings of the ACL-IJCNLP 2009 Conference Short Papers. Association for Computational Linguistics; 2009. The lie detector: explorations in the automatic recognition of deceptive language; pp. 309–312. [Google Scholar]
- 23.Vanderwende L., Daumé H., III, Kirchhoff K. Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics: Human Language Technologies; 2013. [Google Scholar]
- 24.Ott M., Choi Y., Cardie C., Hancock J.T. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies-Volume 1. Association for Computational Linguistics; 2011. Finding deceptive opinion spam by any stretch of the imagination; pp. 309–319. [Google Scholar]
- 25.Chen T., Li X., Yin H., Zhang J. Pacific-Asia Conference on Knowledge Discovery and Data Mining. Springer; Cham: 2018. Call attention to rumors: deep attention based recurrent neural networks for early rumor detection; pp. 40–52. [Google Scholar]
- 26.Ma J., Gao W., Wong K.F. Companion Proceedings of the the Web Conference 2018. 2018. Detect rumor and stance jointly by neural multi-task learning; pp. 585–593. [Google Scholar]
- 27.Da Silva N.F., Hruschka E.R., Hruschka E.R., Jr. Tweet sentiment analysis with classifier ensembles. Decis. Support Syst. 2014;66:170–179. [Google Scholar]
- 28.Sharma K., Qian F., Jiang H., Ruchansky N., Zhang M., Liu Y. Combating fake news: a survey on identification and mitigation techniques. ACM Trans. Intell. Syst.Technol. 2019;10(3):1–42. [Google Scholar]
- 29.Shimizu K. 2019-nCoV, fake news, and racism. Lancet. 2020;395(10225):685–686. doi: 10.1016/S0140-6736(20)30357-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Jang S.M., Geng T., Li J.Y.Q., Xia R., Huang C.T., Kim H., Tang J. A computational approach for examining the roots and spreading patterns of fake news: evolution tree analysis. Comput. Hum. Behav. 2018;84:103–113. [Google Scholar]
- 31.Wang W.Y. 2017. Liar, Liar Pants on Fire": A New Benchmark Dataset for Fake News Detection. arXiv preprint arXiv:1705.00648. [Google Scholar]
- 32.Rodríguez-Ruiz J., Mata-Sánchez J.I., Monroy R., Loyola-González O., López-Cuevas A. Computers & Security; 2020. A One-Class Classification Approach for Bot Detection on Twitter; p. 101715. [Google Scholar]