

Abstract
It is intriguing how the Hammett equation enables control of chemical reactivity throughout chemical space by separating the effect of substituents from chemical process variables, such as reaction mechanism, solvent, or temperature. We generalize Hammett's original approach to predict potential energies of activation in non aromatic molecular scaffolds with multiple substituents. We use global regression to optimize Hammett parameters ρ and σ in two experimental datasets (rate constants for benzylbromides reacting with thiols and ammonium salt decomposition), as well as in a synthetic dataset consisting of computational activation energies of ∼2400 SN2 reactions, with various nucleophiles and leaving groups (–H, –F, –Cl, –Br) and functional groups (–H, –NO2, –CN, –NH3, –CH3). Individual substituents contribute additively to molecular σ with a unique regression term, which quantifies the inductive effect. The position dependence of substituents can be modeled by a distance decaying factor for SN2. Use of the Hammett equation as a base-line model for Δ-machine learning models of the activation energy in chemical space results in substantially improved learning curves reaching low prediction errors for small training sets.
We generalize Hammett's original approach to predict potential energies of activation in non aromatic molecular scaffolds with multiple substituents.
1. Introduction
Chemical reactions are difficult to study and model from a theoretical point of view. In 1935, Hammett proposed a quantitative model for free energy differences in benzyl derivatives1,2 that assumes that the substituent and reaction effects can be separated by a product ansatz:
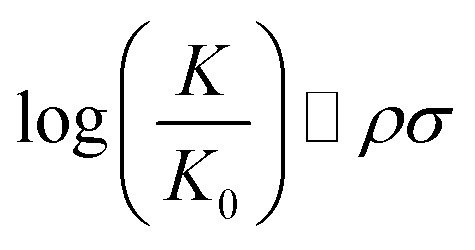 |
1 |
Here, K is either the equilibrium or rate constant for a substituted reactant, K0 refers to the unsubstituted reactant, ρ is a constant that depends only on the reaction, taking into account also conditions such as temperature and solvent and σ depends only on the type of substituent and its position on the molecule.
This model is compelling since it gives an intuitive concept of electron donating and electron withdrawing effects3–6 in the context of free energy differences. The model quickly became quite successful and has been applied to problems ranging from its original purpose, quantifying substituent effects,3 to redox potentials,7 dipole moments,8 orbital energies of metallorganic complexes,9 aromaticity,10–21 ion stabilization,22 mechanicistic investigation,23,24 catalyst activity of nanoparticles,25 proton–electron coupling in radicals,26 molecular conductance,27 excited singlet state,28 and even toxicities.29 More recent approaches have also tried to apply the models to non-benzyl systems.9,30–32 It is, however, less satisfying because the linear relationship postulated by Hammett lacks a motivation based on physical effects. Early attempts to explain the theory by electrostatic considerations33,34 were successful for special cases only. Nevertheless, Hammett's model has demonstrated remarkable predictive power and accuracy for many cases given the model's simplicity.3 Over time the equation has been expanded to also encompass, solvent effect,35–38 resonance and field effect,39 steric effects,40–43 nucleophilicity44 and oxidation potential.45 These models trade off transferability for accuracy; for this reason, in the majority of applications, the original equation is the one being used.
Hammett's model assumes that substituent effects can indeed be separated from other contributions and are perfectly transferable between environments by virtue of changing ρ only, leaving σ unchanged. In some sense, Hammett's model therefore captures the part of reality that is directly transferable across chemical environments. Since this assumption is of approximate nature, it is hard to assign unambiguous values of σ to functional groups, as they often lack transferability, such that the reference reaction and compound becomes of utmost importance.46 Similarly, ρ has shown to be hardly transferable and even exhibit an inconsistent temperature dependence.3
Interestingly, Hammett parameters can be inferred from experiments: either by OH vibrational frequencies related to the electron density at the point of bonding,47 by assessing NMR shifts48–51 or quadrupole resonance,52,53 by relation to electron binding energies,54,55 IR spectroscopy,56 electrochemical polarization,57 or charge transfer.58 Extensive comparison to experiment however, uncovered special cases in which Hammett's model struggles to adequately model reality, partially leading to the introduction of several σ values for the same functional group to be used in different molecular environments.59 Some limitations subsequently could be surpassed by extending the model, e.g. to include concentration dependence.60
From a computational perspective, atomic charges were quickly found to correlate with σ values for a given functional group,61–63 so the few available experimental data points that otherwise would be tedious to extend could be used to calibrate a linear regression while the functional groups were quickly screened by simple charge fitting methods or electron density self-similarity measures.64 Still, the resulting σ values lack transferability65 and computational studies were not successful for reactions involving excited states.66 More recently, energy decomposition approaches have been evaluated,67 connecting to the idea of electrostatic contributions as a dominating contribution to the validity of Hammett's model.
The use of Hammett's approach as a guide in chemical space to find molecules of desired energy differences has been hampered by three issues: the focus on single substituents, the difficulty to obtain a consistent set of Hammett coefficients3,68,69 and the restriction to free energy differences. While multiple substituents have been cautiously explored,70 experimental evidence was found that σ values of multiple substituents are additive, as long as no resonance is involved.6,71,72 In this work, we focus on addressing these three main limitations of Hammett's approach.
2. Method
2.1. The Hammett equation
The original formulation of the Hammett equation is shown at the beginning of the previous section. Here the only observables are the reaction constants K and K0, so it is not possible to calculate a unique set of {ρ} and {σ}, as there will always be an arbitrary constant that can be moved between the two. In order to remove this degree of freedom, Hammett proposed the following procedure:1 (i) pick a reference reaction i for which ρi = 1, (ii) use it to assign a value of σ to the substituents for which there is data for the reference reaction, (iii) use this set {σ} to evaluate ρj for another reaction j using a least squares regression, (iv) expand the set {σ} using the new ρj, (v) repeat steps (iii) and (iv) until each reaction and substituent has a value assigned.
The choice of the reference reaction, as well as the sequence used to expand the set {σ}, greatly influences the final result: for a set of NR reactions there are up to NR! possible sets of {ρ} and {σ}. Overall, with NR reactions and NS set of substituents there are NRNS different Hammett equations with only NR + NS parameters to determine. The system is greatly overdetermined, making it easy to overfit the model. Overfitting towards one reference reaction directly reduces transferability of the substituent parameter σ across reactions, as Hammett's model reproduces the reference reaction alone. To achieve maximum transferability, a method that is less biased towards one reference reaction is required. In the context of regression, this calls for robust regressors which are less prone to be impacted by observations that do not satisfy the linearity assumptions of Hammett's approach. These observations would constitute outliers for the Hammett regression.
In our model, we use the more robust Theil–Sen regressor,73 which evaluates the linear coefficient as the median of the slopes of all lines that pass through each pair of points, and we calculate the entire set of reaction constants {ρ} at once. This two additions make the model respectively more robust towards outliers, that could skew the values of the parameters, and remove the dependence on the choice of the reference reaction, which makes the final set of parameters more univoque. The substituent constants {σ} are then evaluated by inverting the Hammett equation and averaging the results over all reactions. For numerical reasons, it might be necessary to initially fix one arbitrary reaction constant to 1 to avoid trivial solutions. This is the only source of bias in the model, meaning that the number of possible set of reaction and substituent constant scales only linearly with the number of reactions, and not factorially like in the original model. This procedure allows to affordably identify the best set of parameters. The derivation of the model is explained in details in the ESI.†
For reactants with multiple substituents, σ describes the combined effect of all of them. To identify individual contributions, we propose a linear model where the molecular σ is given by the sum of single substituent parameters , obtained by a categorical regression using a dummy encoding. These term depend on the chemical composition of the substituent and on its position on the molecule. In order to separate these two contributions, we modelled each single substituent constant as a product between a term α, which depends only the chemical composition, and a distance decaying function (exponential or power law), which encodes the distance of the substituent from the reaction center.
To distinguish the two methods of calculating the substituent constants, i.e. by reversing the Hammett equation and by summing single substituents contributions, we named the first one σ-Hammett and the latter α-Hammett.
Non-linear functions, which can model many body contributions, have also been studied by including three body terms such as the Axilrod–Teller–Muto potential.74 This increases the number of parameters needed but allows to include the interactions between substituents.
2.2. Machine learning
We trained a Kernel Ridge Regression (KRR) machine to learn the kinetic constant and activation energies for different reactions. Molecules were described with a one-hot encoding representation, which maps every fragment into a fingerprint-like string of zeroes and ones. Our Hammett model was then used as a baseline for Delta Machine Learning75 (Δ-ML), where a machine was trained to learn the residuals of the method. This approach can give a faster learning, since the hypersurface of the residuals is usually smoother, thus easier to learn.
These models were programmed in Python using the QML76 and scikit-learn77 packages. Hyper-parameters were determined with a 5-fold validated grid search, final results obtained with a 15-fold cross validation.
3. Results
3.1. Experimental analysis
To test the effectiveness of our method, we apply it to two different set of experimental results and compare our predictions with the one from the original Hammett model.1 The two reactions are shown in Fig. 1, panels (a) and (b). The first data set78 studies the substituent effect on the nucleophilic reactivity between thiophenols and benzylbromides. We use a different ρ to describe each reaction with a different thiophenol and a different σ for each substituent R1 on the benzylbromide. The second data set79 reports the rate constants of the decomposition of tetra-alkylammonium salts in solution at different temperatures. According to the original formulation of Hammett, the temperature dependence is included in eqn (1) through the reaction constant, meaning that each temperature is described by a different ρ. Each set of substituents on the ammonium salt is then described by a different σ.
Fig. 1. Reactions studied in this paper: (a) nucleophilic reaction between thiophenols and benzylbromides, (b) decomposition of tetra-alkylammonium and (c) SN2. Data from reaction (a) and (b) are experimental values while for reaction (c) are computational.

The kinetic constants have been evaluated through the Hammett equation using three different set of parameters {ρ} and {σ}: the first one obtained with our model, the second one by applying the original Hammett method, as described in the beginning of the Method section, and the third one using the values of σ calculated by Hammett himself in the original paper.1 This last method could be used only for the first of the two experimental data set, since the molecules used in the second one where not included in the original paper.
The results are shown in Fig. 2. The upper half (subplots (a) to (d)) shows the results on nucleophilic substitution of benzylbromides,78 while the bottom half ((e) to (i)) the ones on the ammonium salts decomposition.79
Fig. 2. Prediction of kinetic constants on two experimental reaction data set: nucleophilic substitution between benzylbromides and thiols78 (top half) and decomposition of ammonium salts (bottom half).79 The picture compares results from our model (blue circles), from the original Hammett procedure (orange crosses) and from the tabulated parameters of the original paper (green diamonds).1 The correlation plots (a) and (e) show the higher reliability of our method for the prediction of the rate constants when compared to the others. The error bars display the dependence on the reference reaction. The Hammett plots on the right ((b), (c), (d), (f) and (g)) show the increased robustness of our method with respect to outliers and the preservation of the relative ordering of the substituent constants σ. The inset (h) reports the temperature dependence of the rate constants for the decomposition of two different ammonium salts, highlighting how the outliers correspond to unphysical behaviour.

The scatter plots (a) and (e) present the correlation between the experimental kinetic constants and the estimated ones. The blue dots are obtained by our model, the orange cross by the original approach1 and the green diamond are calculated using the {σ} from the original paper.1 The error bars show the range of results spanned by changing the reference reaction. For nucleophilic substitution of thiols (upper half), the reference uses the un-substituted thiol, while for the thermal decomposition of ammonium salts (bottom half), the reference is the reaction at 35 °C.
The correlation plots show how our method outperforms the original Hammett method in the vast majority of the case, often by a significant margin; using the original {σ} yields very inaccurate results. The error bars demonstrate how important the choice of the reference reaction is: for our method the effect is too small to be visible, while for the original method it can give results that vary by up to 25% for both the first (a) and the second (b) data set. The usage of tabulated sigma removes this dependence but introduces a significant error that can be up to 50%.
The improvement given by our method is in part due to the increased robustness towards outliers. This effect becomes evident from the Hammett plots on the right panels ((b) to (d) and (f) and (e)), which show the linear relationship between substituent constant σ and log(k/k0) for each approach. Our method (panels (b) and (f)) gives a better interpolation for the majority of the data. Additionally, the Hammett plots show how the ordering of the different σ for different substituents does not depend on the method, meaning that it is still possible to use them as a relative measure of the inductive effect without loss of generality. This comes at the cost of a worse evaluation of the cases that deviate from the linearity.
The tradeoff in accuracy on the outliers is especially evident from the scatter plot (e) for the decomposition of ammonium salts. The original model gives better predictions only for some specific cases, for example when considering the reaction involving a beta-naphtyl thiol. The dependence of the kinetic constant of this last case on the temperature is shown in the top panel of inset (h). The linear behaviour is in contrast with the typical exponential Arrhenius-like that can be observed for any other case in this data set, as presented in the bottom panel of (h) for a para-methoxy thiol. This shows that the robustness of the revised Hammett proves useful when dealing with noisy data and can be helpful in identifying unphysical features in the data set.
Overall, Fig. 2 highlights the improvement on the original method given by the application of the Theil–Sen regressor,73 which remove the impact of the outliers on the parameters, and by the averaging out of the reference reaction, which significantly reduces the variance for the possible values of the parameters.
3.2. Hammett revisited for SN2
In this work, we extended the Hammett equation to a chemical space that is outside the scope of the original model by working on a computational data set of SN2 reactions on small molecules with an ethylene scaffold. The reaction is shown on the bottom of Fig. 1, while the typical transition state is depicted in the top right inset of Fig. 3. These molecules have four sites where substituents can be placed, labelled R1 to R4, and undergo a nucleophilic substitution of the leaving group LG by the nucleophile Nu. The substituents considered for positions R1 to R4 are –H, –NO2, –CN, –NH3, –CH3, while the leaving groups and nucleophiles are: –H, –F, –Cl, –Br. In total, we consider 12 different SN2 reactions, one for each combination of Leaving Group LG and nucleophile Nu, shown on the axis of Fig. 2 and 3. The potential energies have been taken from the QMrxn20 data set.80
Fig. 3. Correlation of the activation energies between the reactions in the data set. The labels indicate the nucleophile-leaving group couple, in this order. The data show a linear trend, which is the underlying assumption for the Hammett model. These activation energies range linearly between 3 kcal mol−1 and 40 kcal mol−1. The inset in the top right corner shows the general scaffold of the molecules in the data set, where R1 to R4 are the substituents and Nu and LG are the nucleophile and leaving group respectively. The carbon atoms where the substituents are attached are labeled C1 and C2 for the one that undergoes the substitution and the α carbon, respectively.

For this data, we worked with activation energies instead of the kinetic constant. The two quantities are related by the transition state theory, which assumes a quasi-chemical equilibrium between reactants and transition state. Thus, the Hammett equation can be applied to potential energy differences without loss of generality. However, it should be noted that there is an inverse proportionality between kinetic constant and activation energies: a small barrier will be easier to overcome, thus giving a higher kinetic constant, while the opposite is true for a large barrier.
Activation energies for the different reactions correlate linearly with each other, as shown in the lower left part of Fig. 3. Here each scatter plot compares the energy barriers of any two reactions; the nucleophile and leaving group are indicated on the edges, in this order. If Hammett's model was no approximation, all such scatter plots would show perfect linear correlation. We find that the activation energies are strongly correlated meaning that the relative effect of different substituents is the same even across different reactions. Consequently, the ordering of the elements in {σ} is unique. The slope of each linear fit expresses the relative susceptibility of the two reactions to the substituents' effect.
The improvement obtained with our method can be easily seen in Fig. 4. Here we present the Mean Absolute Error (MAE) for the prediction of the activation energy across all the reactions considered. The red line shows the MAE of our model, while the gray dots show the ones of the original model. For each reaction there are eleven dots, one for every different reference reaction in our data set. The thin gray lines connect the results obtained by applying the original Hammett approach to the same reference reaction. The size of each dot is proportional to the number of common set of substituents between the reference reaction and the one being predicted. Finally, the dashed blue line shows the typical error of the MP2 method for nucleophilic reactions,81,82 estimated by comparison to W3.2//QCISD.83,84
Fig. 4. Accuracy of our model with the respect to the original Hammett approach. For each reaction, we show the mean absolute error (MAE) obtained with our model (red line) and with the original Hammett model (gray dots), where each dot represents a different choice for the reference reaction. The size of the dots is proportional to the size of the training set for that data point. The blue dotted line corresponds to the estimated MP2 error.81,82.

Our method outperforms the classic Hammett approach in the vast majority of the cases. For only a few reactions the original model can give better results but there is no single choice of reference that shows a consistently smaller MAE. Our method averages out the error obtained from the selection bias of the reference and gives a consistent prediction across all reactions, comparable in accuracy to the underlying MP2 method.82 Using a higher level of theory could potentially improve the quality of the prediction as long as the different activation energies become more linearly related. It is to be expected though that the dominating linear trend is well-reproduced with MP2 calculations already and that higher level results introduce non-linear corrections to the MP2 energies. In that case, higher level calculations would not improve the Hammett model, as it is only able to capture linear relations and averages out non-linearities. It should be noted that potential energy differences such as activation energies are less susceptible to changes in level of theory.
The original method is highly susceptible to overfitting and numerical noise, as shown by the fact that small errors correspond mostly to medium size dots: few data points (small dots) lead to an unreliable fit, while too many (big dots) can make the model too rigid to be reliably transferable. This is especially evident for the two leftmost reactions (F–H and F–F), were the larger data set are described very poorly by the original model. This can give MAE of up to 5.2 kcal mol−1, while our model has an error of 3.8 kcal mol−1 at most.
As discussed in the Method section, the original Hammett approach can get up to NR! different set of parameters, which for the 12 reactions considered here is in the order of 108. The results shown in Fig. 4 are obtained from a regression that considers only the reference reaction and the one for the prediction, so stopping the procedure after only two ρ and a subset of σ have been assigned. The factorial scaling of the extensive search makes it prohibitively expensive to find the best set of parameters for the original Hammett approach. Since our improvement does not depend on the choice of a particular reference reaction anymore, there is a unique set of model parameters that can be obtained directly, without search.
3.3. Decomposition of σ for SN2
The non-aromatic molecules we considered have four substituents attached to two different carbons atoms: two on the one involved in the reaction, from now on denoted as C1, and two on a carbon atom connected to C1 by a single bond, from now on denoted as C2. The molecular σ for each set of substituents depends on all four groups and their position. Via categorical regression, described in the ESI,† it is possible to separate the individual contributions and express the overall σ as a linear combination.
The results of the decomposition are reported in Fig. 5. Each horizontal bar corresponds to one single-substituent and the colors are used to distinguish the four positions: red and orange for positions 1 and 2, on C1, and green and blue for positions 3 and 4, on C2 (cf.Fig. 3). The plot shows that the contributions given by positions 1 and 2 are almost identical. This makes sense chemically, since these two positions are nearly equivalent by symmetry (the molecule is chiral) and thus must have very similar effect on the reactivity of the molecule. The same is true for positions 3 and 4, although their absolute values of are much smaller with respect to positions 1 and 2. Again, this follows chemical intuition, as these positions are further away from the reacting centre and their effect is dampened. These two properties of are not imposed at any point during the procedure, but they emerge by themselves.
Fig. 5. Contribution of each pair of group g and position p to the molecular σ, as obtained from the dummy encoding. Positive contributions give larger σ, resulting in higher activation energies, while negative contributions lead to a lowered barrier.

The sign of the single substituent constants can be interpreted in the following way: if the reaction constant ρ is positive, a substituent with a negative substituent constant σ will give a lower activation energy than the reference substituent, and vice versa for positive σ. In our case, ρ > 0 for all reactions, so it is possible to correlate the single substituent constants with the inductive effect. The electron withdrawing power of the groups considered goes as–NO2 > –CN > –H > –CH3 > –NH2
Groups with negative values are electron withdrawing, while those with positive values are electron donating. This again make sense chemically since the transition state of an SN2 reaction is known to be negatively charged, and benefits more from a substituent that can remove electron density from the reacting centre. The discrepancy in the sign with respect to textbook values of σ emerges from the fact that here we are considering reaction barriers rather than kinetic constants, and the two properties are inversely related. The correlation with the inductive effect, as well as the magnitude of the substituents' effect depending on the position, is not imposed by the model but shows up naturally during the procedure.
Although the single substituents constant obtained by the categorical regression depend on both their position and chemical composition at the same time, the results of this model indicate that these two can be further separated. We expressed the position dependence as the spatial separation from the reaction center, using a distance decaying function – we tested an exponential and power law one – that scales the electron withdrawing/donating effect of the substituent. The latter is given by a constant which depends only the chemical composition.
The effects of interactions between different substituent on the molecular substituent constant can be modelled by a three-body term, as the Axilrod–Teller–Muto potential.
The results from these decompositions of the substituent constants are shown in Fig. 6. Here each scatter plot reports the correlation between the molecular σ and the single-substituent ones, obtained with four different prediction methods: (a) categorical regression via dummy encoding, (b) power law function, (c) exponential function and (d) Axilrod–Teller–Muto (ATM) function.74 Each panel shows the R2 of the relative fit.
Fig. 6. Correlation between the σ obtained from the revisited Hammett and the ones obtained from: (a) the dummy encoding, (b) the power law function, (c) the exponential function, (d) the three body Axilrod–Teller–Muto function. Each panel also shows the R2 of the correlation.

For each of these models, the number of parameters required depends on the number of substituent groups NG considered and the number of positions NG on the molecular backbone. For our SN2 dataset, NG = 5 (–H, –NO2, –CN, –NH3, –CH3) and NP = 4 (R1, R2, R3, R4) (cf.Fig. 3).
The dummy encoding shown in plot (a) requires a total of NPNG parameters, one for each group-position pair, so 20 for this data set. This approach has the great advantage of being independent from the backbone of the molecules, since it is sufficient to label each position and group. Including a new position or group in the data set would increase the number of parameters needed by NG (5) and NP (4) respectively.
For the exponential function and the power law in panels (b) and (c), the number of parameters required is NG + 1, one for each group plus an additional one to regulate the distance decay. For our data set, this means six parameters. In this case, it is necessary to know the geometry of the molecular skeleton, which can be easily obtained. In terms of scalability, adding one more group increases the number of parameters by one, while for a new position it is only necessary to evaluate its distance from the reaction centre. The results obtained by these two functions are very similar, correlate well with the one obtained with the revisited Hammett's algorithm and require less parameters than the categorical regression: in our case we go down from 20 to 6.
The Axilrod–Teller–Muto function shown in panel (d) takes into account the interaction between any two different groups in different positions on the molecule. This requires a total of NG + (NG2 + NG)/2 + 1 parameters: one for each group, one for every unique pair, and an additional one for the distance decay. For our data set, this brings us back to 20, as for the dummy encoding. For the ATM approach it is necessary to know the exact geometries of every molecule in order to calculate the distances and angles between different groups and positions. Extending the data set to a new group increases the parameters' cost by 1 + NG, i.e. 6. Including the interaction between groups and positions removes the simple additivity of single-substituents and actually worsens and the prediction.
Overall, Fig. 6 shows that the molecular substituent constants: (i) can be described quite well with only NG + 1, i.e. 6 parameters, and (ii) show physical additivity. This parametrization allows us to transfer the information gained on one set of substituent to another, making it possible to evaluate the σ for a new molecule.
3.4. Comparison with machine learning for SN2
We compared the performance of our method with a kernel ridge regression machine learning model. We used a one-hot encoding representation, where each molecule is described with fingerprint-like string that depends on the functional groups present. This representation was chosen because it contains no exact structural information, i.e. no cartesian coordinates, just like the categorical regression, making the comparison more fair as the two models work with the same information. The machine was trained on both the activation energies and the residuals of the prediction from our revisited Hammett. The latter approach is called delta-machine learning,75 and uses as a baseline the predictions obtained from our α-Hammett method, described in the Method section and in the ESI,† where the substituent constants are obtained from a linear combination of single substituent contributions that are scaled by a distance decaying function. We choose this method as a baseline because it gives better predictions starting from smaller training set and because its residuals are more consistent, thus easier to learn.
The comparison of different methods is shown in Fig. 7. Here we report different learning curves, which show how the performance of each method improves as the training set size increases.
Fig. 7. Learning curves for the activation energies with different methods. The circles are obtained by the Hammett model, where the σ are calculated globally for the blue line (σ-Hammett) and additively for the green line (α-Hammett). The diamonds and squares are given by machine learning and Δ-ML respectively, the baseline for the latter is α-Hammett.

For a small training set, only some reactions and set of substituents can be sampled, giving values of ρ that are highly influenced by random noise. For the σ-Hammett model, this generates a set {σ} that poorly reflects the true substituents' effect and gives very high prediction errors. This method shows significant improvement with the increase of the training set size, and using the complete data set recovers the accuracy shown in Fig. 4.
The α-Hammett method already gives errors below 5 kcal mol−1 for only 400 training points and quickly converges to an accuracy close to the underling level of theory. The flattening out of the learning curve is due to the difficulty of distinguishing similar substituent constants, as also shown by the patter of horizontal lines in Fig. 6.
The ML and Δ-ML methods converge towards the same error, however the latter's learning curve has a significantly lower offset. This means that our method can also be used to speed up the learning of the target property at the cost of a very quick and inexpensive initial treatment of the data. The two learning curves converge at around 1600 data points, where the baseline for the due Δ-ML flattens out. Beyond this point, both methods just learn the MP2 error.
Overall, machine learning consistently outperforms our models in terms of prediction errors. This, however, comes at the cost of a higher complexity of the model, which requires a significantly higher number of parameter and sacrifices chemical interpretability. Kernel ridge regression requires one parameter for each training point, while the Hammett model has only as many parameters as there are reactions and set of substituents. This number is further cut down when considering the α-Hammett approach, which for this application makes use of only 18 parameters in total (cf. Section 3.3). Each parameter of our model can be understood in terms of inductive effect or susceptibility to it.
The increased flexibility of KRR becomes relevant for deviations from linearity, which the Hammett equation cannot intrinsically handle, as reflected by the flatting out of the learning curves for our models. This occurs when the data in the training set samples the reaction and substituent spaces extensively enough to give stable values for σ and ρ, and the model cannot give a significant improvement beyond this point.
4. Conclusion
We generalized the calculation of Hammett parameters ρ and σ to account also for potential energy changes due to reactions of non-aromatic molecules with multiple substituents. Our results indicate that substituent effects are largely additive as long as no resonance occurs. For the SN2 reaction space, Hammett σ values can be explained by chemical composition and distance to the reaction center alone. This connects to the established view regarding the Hammett σ values as a measure of the inductive effect, reduces the number of parameters needed by our model and gives each of them a chemical meaning. The decomposition proposed makes it possible to transfer the chemical information gained from one set of substituents to a different one, allowing to estimate the values of σ for new molecules. This decomposition in principle would allow future work to extend our approach to resonance cases by assigning σ values to pairs (or n-tuples) of substituents while retaining the readily interpretable concept of Hammett's model.
Moreover, we present a method to compress quantum chemical reference energies from several reactions into one reliable set of Hammett parameters. This allows to reduce the number of calculations required for real-world applications of Hammett's empirical relationship. Additionally, it reduces the risk of over-fitting towards one specific reaction which we demonstrate to be a significant problem with the original formulation. The overall improvement in robustness over the original method is achieved by using the more robust Theil–Sen regressor for the linear interpolations and by averaging out the influence of the reference reaction.
Our approach builds on the original Hammett equation and it still belongs to the family of linear free energy relationships. The core assumption and main limitation of the model is that a significance variance of the data must be explainable in terms of linear trends. Using higher levels of theory can improved the quality of the prediction as long as this condition is met. Reaction barriers and potential energy differences however, are less susceptible to changes in computational accuracy.
We tested this method on two different experimental data sets and on a computational one and showed systematic and overall improvement in both, prediction quality and reliability. This method also provides an excellent baseline for Δ-ML approaches, effectively forming an valuable stepping stone for dramatically reducing the need for training data obtained from computationally expensive quantum chemistry calculations.
Given modest but sufficient experimental data, and based on the demonstrated improvement of Hammett's empirical formula for potential energies, one can now think of this approach as a more general guideline how to assist in chemical reaction design—without the need of extensive trial-and-error experiments. We rather advocate for diverse data from many different reactions but common molecular skeletons, which then can be combined into one model following our approach. We demonstrated on our data set that this model reaches accuracies similar to quantum chemical calculations. Accordingly, we believe that the promise of Hammett's original idea can now be delivered in order to uncover trends in reaction energetics throughout substantially larger chemical spaces. The code used in our work is freely available.85
Conflicts of interest
There are no conflicts to declare.
Supplementary Material
Acknowledgments
We acknowledge support by the European Research Council (ERC-CoG grant QML) as well as by the Swiss National Science Foundation (No. PP00P2_138932, 407540_167186 NFP 75 Big Data, 200021_175747, NCCR MARVEL). This work was supported by a grant from the Swiss National Supercomputing Centre (CSCS) under project ID s848. Some calculations were performed at sciCORE (http://scicore.unibas.ch/) scientific computing core facility at University of Basel.
Electronic supplementary information (ESI) available. See DOI: 10.1039/d0sc04235h
Notes and references
- Hammett L. P. J. Am. Chem. Soc. 1937;59:96–103. doi: 10.1021/ja01280a022. [DOI] [Google Scholar]
- Hammett L. P. Chem. Rev. 1935;17:125–136. doi: 10.1021/cr60056a010. [DOI] [Google Scholar]
- Jaffe H. H. Chem. Rev. 1953;53:191–261. doi: 10.1021/cr60165a003. [DOI] [Google Scholar]
- Krygowski T. M. Stecpien B. T. Chem. Rev. 2005;105:3482–3512. doi: 10.1021/cr030081s. [DOI] [PubMed] [Google Scholar]
- Exner O. J. Phys. Org. Chem. 1999;12:265–274. doi: 10.1002/(SICI)1099-1395(199904)12:4<265::AID-POC124>3.0.CO;2-O. [DOI] [Google Scholar]
- Cherkasov A. Galkin V. Cherkasov R. J. Phys. Org. Chem. 1998;11:437–447. doi: 10.1002/(SICI)1099-1395(199807)11:7<437::AID-POC4>3.0.CO;2-C. [DOI] [Google Scholar]
- Masui H. Lever A. B. P. Inorg. Chem. 1993;32:2199–2201. doi: 10.1021/ic00062a052. [DOI] [Google Scholar]
- van Beek L. K. H. Recl. Trav. Chim. Pays-Bas. 1957;76:729–732. doi: 10.1002/recl.19570760908. [DOI] [Google Scholar]
- Chang A. M. Freeze J. G. Batista V. S. Chem. Sci. 2019;10:6844–6854. doi: 10.1039/C9SC02339A. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Szatylowicz H. Jezuita A. Ejsmont K. Krygowski T. M. Struct. Chem. 2017;28:1125–1132. doi: 10.1007/s11224-017-0922-2. [DOI] [Google Scholar]
- Stasyuk O. A. Szatylowicz H. Krygowski T. M. Fonseca Guerra C. Phys. Chem. Chem. Phys. 2016;18:11624–11633. doi: 10.1039/C5CP07483E. [DOI] [PubMed] [Google Scholar]
- Szatylowicz H. Jezuita A. Ejsmont K. Krygowski T. M. J. Phys. Chem. A. 2017;121:5196–5203. doi: 10.1021/acs.jpca.7b03418. [DOI] [PubMed] [Google Scholar]
- Szatylowicz H. Jezuita A. Siodła T. Varaksin K. S. Domanski M. A. Ejsmont K. Krygowski T. M. ACS Omega. 2017;2:7163–7171. doi: 10.1021/acsomega.7b01043. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gershoni-Poranne R. Rahalkar A. P. Stanger A. Phys. Chem. Chem. Phys. 2018;20:14808–14817. doi: 10.1039/C8CP02162G. [DOI] [PubMed] [Google Scholar]
- Hansch C. Leo A. Unger S. H. Kim K. H. Nikaitani D. Lien E. J. J. Med. Chem. 1973;16:1207–1216. doi: 10.1021/jm00269a003. [DOI] [PubMed] [Google Scholar]
- Katritzky A. R. Topsom R. D. Chem. Rev. 1977;77:639–658. doi: 10.1021/cr60309a001. [DOI] [Google Scholar]
- DiLabio G. Pratt D. Wright J. Chem. Phys. Lett. 1999;311:215–220. doi: 10.1016/S0009-2614(99)00786-1. [DOI] [Google Scholar]
- DiLabio G. A. Pratt D. A. Wright J. S. J. Org. Chem. 2000;65:2195–2203. doi: 10.1021/jo991833e. [DOI] [PubMed] [Google Scholar]
- Palát Jr K. Waisser K. Exner O. J. Phys. Org. Chem. 2001;14:677–683. doi: 10.1002/poc.416. [DOI] [Google Scholar]
- Krygowski T. M. Ejsmont K. Stepień B. T. Cyrański M. K. Poater J. Solà M. J. Org. Chem. 2004;69:6634–6640. doi: 10.1021/jo0492113. [DOI] [PubMed] [Google Scholar]
- Dey S. Manogaran D. Manogaran S. Schaefer H. F. J. Chem. Phys. 2019;150:214108. doi: 10.1063/1.5090588. [DOI] [PubMed] [Google Scholar]
- Buszta N. Depa W. J. Bajek A. Groszek G. Chem. Pap. 2019;73:2885–2888. doi: 10.1007/s11696-019-00837-3. [DOI] [Google Scholar]
- Cruz C. L. Nicewicz D. A. ACS Catal. 2019;9:3926–3935. doi: 10.1021/acscatal.9b00465. [DOI] [Google Scholar]
- Barbee M. H. Kouznetsova T. Barrett S. L. Gossweiler G. R. Lin Y. Rastogi S. K. Brittain W. J. Craig S. L. J. Am. Chem. Soc. 2018;140:12746–12750. doi: 10.1021/jacs.8b09263. [DOI] [PubMed] [Google Scholar]
- Kumar G. Tibbitts L. Newell J. Panthi B. Mukhopadhyay A. Rioux R. M. Pursell C. J. Janik M. Chandler B. D. Nat. Chem. 2018;10:268. doi: 10.1038/nchem.2911. [DOI] [PubMed] [Google Scholar]
- Kimura Y. Hayashi M. Yoshida Y. Kitagawa H. Inorg. Chem. 2019;58:3875–3880. doi: 10.1021/acs.inorgchem.8b03501. [DOI] [PubMed] [Google Scholar]
- Venkataraman L. Park Y. S. Whalley A. C. Nuckolls C. Hybertsen M. S. Steigerwald M. L. Nano Lett. 2007;7:502–506. doi: 10.1021/nl062923j. [DOI] [PubMed] [Google Scholar]
- Dobrowolski J. C. Lipiński P. F. J. Karpińska G. J. Phys. Chem. A. 2018;122:4609–4621. doi: 10.1021/acs.jpca.8b02209. [DOI] [PubMed] [Google Scholar]
- Song X. Zapata A. Eng G. J. Organomet. Chem. 2006;691:1756–1760. doi: 10.1016/j.jorganchem.2005.12.003. [DOI] [Google Scholar]
- Liveris M. Lutz P. G. Miller J. J. Am. Chem. Soc. 1956;78:3375–3378. doi: 10.1021/ja01595a031. [DOI] [Google Scholar]
- Ayoubi-Chianeh M. Kassaee M. Z. J. Phys. Org. Chem. 2019:e3988. [Google Scholar]
- Kilde M. D. Hansen M. H. Broman S. L. Mikkelsen K. V. Nielsen M. B. Eur. J. Org. Chem. 2017;2017:1052–1062. doi: 10.1002/ejoc.201601435. [DOI] [Google Scholar]
- Gallup G. A. Gilkerson W. R. Jones M. M. Trans. Kans. Acad. Sci. 1952;55:232. doi: 10.2307/3625881. [DOI] [Google Scholar]
- Price C. C. Chem. Rev. 1941;29:37–67. doi: 10.1021/cr60092a002. [DOI] [Google Scholar]
- Jahagirdar D. V. Arbad B. R. Kharwadkar R. M. Indian J. Chem. 1988;27A:601–605. [Google Scholar]
- Kondo Y. Matsui T. Tokura N. Bull. Chem. Soc. Jpn. 1969;42:1037–1047. doi: 10.1246/bcsj.42.1037. [DOI] [Google Scholar]
- Grunwald E. Winstein S. J. Am. Chem. Soc. 1948;70:846–854. doi: 10.1021/ja01182a117. [DOI] [PubMed] [Google Scholar]
- Winstein S. Grunwald E. Jones H. W. J. Am. Chem. Soc. 1951;73:2700–2707. doi: 10.1021/ja01150a078. [DOI] [Google Scholar]
- Swain C. G. Lupton E. C. J. Am. Chem. Soc. 1968;90:4328–4337. doi: 10.1021/ja01018a024. [DOI] [Google Scholar]
- Taft Jr R. W. J. Am. Chem. Soc. 1952;74:2729–2732. doi: 10.1021/ja01131a010. [DOI] [Google Scholar]
- Taft Jr R. W. J. Am. Chem. Soc. 1952;74:3120–3128. doi: 10.1021/ja01132a049. [DOI] [Google Scholar]
- Taft Jr R. W. J. Am. Chem. Soc. 1953;75:4538–4539. doi: 10.1021/ja01114a044. [DOI] [Google Scholar]
- Santiago C. B. Milo A. Sigman M. S. J. Am. Chem. Soc. 2016;138:13424–13430. doi: 10.1021/jacs.6b08799. [DOI] [PubMed] [Google Scholar]
- Swain C. G. Scott C. B. J. Am. Chem. Soc. 1953;75:141–147. doi: 10.1021/ja01097a041. [DOI] [Google Scholar]
- Edwards J. O. J. Am. Chem. Soc. 1954;76:1540–1547. doi: 10.1021/ja01635a021. [DOI] [Google Scholar]
- Pearson D. E. Baxter J. F. Martin J. C. J. Org. Chem. 1952;17:1511–1518. doi: 10.1021/jo50011a019. [DOI] [Google Scholar]
- Baker A. W. Shulgin A. T. J. Am. Chem. Soc. 1959;81:1523–1529. doi: 10.1021/ja01516a001. [DOI] [Google Scholar]
- Yoder C. H. Tuck R. H. Hess R. E. J. Am. Chem. Soc. 1969;91:539–543. doi: 10.1021/ja01031a001. [DOI] [Google Scholar]
- Axenrod T. Pregosin P. S. Wieder M. J. Milne G. W. A. J. Am. Chem. Soc. 1969;91:3681–3682. doi: 10.1021/ja01041a063. [DOI] [PubMed] [Google Scholar]
- Taft R. W. J. Phys. Chem. 1960;64:1805–1815. doi: 10.1021/j100841a003. [DOI] [Google Scholar]
- Thirunarayanan G. Gopalakrishnan M. Vanangamudi G. Spectrochim. Acta, Part A. 2007;67:1106–1112. doi: 10.1016/j.saa.2006.09.034. [DOI] [PubMed] [Google Scholar]
- Bray P. J. Barnes R. G. J. Chem. Phys. 1957;27:551–560. doi: 10.1063/1.1743767. [DOI] [Google Scholar]
- Bray P. J. J. Chem. Phys. 1954;22:1787–1788. doi: 10.1063/1.1739912. [DOI] [Google Scholar]
- Lindberg B. Svensson S. Malmquist P. Basilier E. Gelius U. Siegbahn K. Chem. Phys. Lett. 1976;40:175–179. doi: 10.1016/0009-2614(76)85053-1. [DOI] [Google Scholar]
- Takahata Y. Chong D. P. Int. J. Quantum Chem. 2005;103:509–515. doi: 10.1002/qua.20533. [DOI] [Google Scholar]
- Liler M. Chem. Commun. 1965:244–245. doi: 10.1039/C19650000244. [DOI] [Google Scholar]
- Sarkar S. Patrow J. G. Voegtle M. J. Pennathur A. K. Dawlaty J. M. J. Phys. Chem. C. 2019;123:4926–4937. doi: 10.1021/acs.jpcc.8b12058. [DOI] [Google Scholar]
- Star A. Han T.-R. Gabriel J.-C. P. Bradley K. Grüner G. Nano Lett. 2003;3:1421–1423. doi: 10.1021/nl0346833. [DOI] [Google Scholar]
- Hünig S. Lehmann H. Grimmer G. Justus Liebigs Ann. Chem. 1953;579:87–96. doi: 10.1002/jlac.19535790203. [DOI] [Google Scholar]
- Hansch C. Maloney P. P. Fujita T. Muir R. M. Nature. 1962;194:178–180. doi: 10.1038/194178b0. [DOI] [Google Scholar]
- Ertl P. Quant. Struct.-Act. Relat. 1997;16:377–382. doi: 10.1002/qsar.19970160505. [DOI] [Google Scholar]
- Larsen J. W. Bouis P. A. J. Am. Chem. Soc. 1975;97:4418–4419. doi: 10.1021/ja00848a059. [DOI] [Google Scholar]
- Genix P. Jullien H. Goas R. L. J. Chemom. 1996;10:631–636. doi: 10.1002/(SICI)1099-128X(199609)10:5/6<631::AID-CEM451>3.0.CO;2-Z. [DOI] [Google Scholar]
- Gironés X. Ponec R. J. Chem. Inf. Model. 2006;46:1388–1393. doi: 10.1021/ci050061m. [DOI] [PubMed] [Google Scholar]
- Hine J. J. Am. Chem. Soc. 1959;81:1126–1129. doi: 10.1021/ja01514a028. [DOI] [Google Scholar]
- Wagner P. J. Thomas M. J. Harris E. J. Am. Chem. Soc. 1976;98:7675–7679. doi: 10.1021/ja00440a038. [DOI] [Google Scholar]
- Fernández I. Frenking G. J. Org. Chem. 2006;71:2251–2256. doi: 10.1021/jo052012e. [DOI] [PubMed] [Google Scholar]
- Lichtin N. N. Leftin H. P. J. Am. Chem. Soc. 1952;74:4207–4208. doi: 10.1021/ja01136a510. [DOI] [Google Scholar]
- White W. Schlitt R. Gwynn D. J. Org. Chem. 1961;26:3613–3615. doi: 10.1021/jo01067a669. [DOI] [Google Scholar]
- Shorter J. Stubbs F. J. Chem. Soc. 1949:1180–1183. doi: 10.1039/JR9490001180. [DOI] [Google Scholar]
- Yukawa Y. Tsuno Y. Bull. Chem. Soc. Jpn. 1959;32:965–971. doi: 10.1246/bcsj.32.965. [DOI] [Google Scholar]
- Taft R. W. J. Am. Chem. Soc. 1957;79:5075–5076. doi: 10.1021/ja01575a069. [DOI] [Google Scholar]
- Theil H. Math. Z. 1950;53:386–392. [Google Scholar]
- Axilrod B. M. Teller E. J. Chem. Phys. 1943;11:299–300. doi: 10.1063/1.1723844. [DOI] [Google Scholar]
- Ramakrishnan R. Dral P. O. Rupp M. von Lilienfeld O. A. J. Chem. Theory Comput. 2015;11:2087–2096. doi: 10.1021/acs.jctc.5b00099. [DOI] [PubMed] [Google Scholar]
- Christensen A., Faber F., Huang B., Bratholm L. A., Tkatchenko T. A., Muller K. and von Lilienfeld O. A., QML: A Python Toolkit for Quantum Machine Learning, 2017, https://github.com/qmlcode/qml
- Pedregosa F. Varoquaux G. Gramfort A. Michel V. Thirion B. Grisel O. Blondel M. Prettenhofer P. Weiss R. Dubourg V. Vanderplas J. Passos A. Cournapeau D. Brucher M. Perrot M. Duchesnay E. J. Mach. Learn. Res. 2011;12:2825–2830. [Google Scholar]
- Hudson R. F. Klopman G. J. Chem. Soc. 1962:1062–1067. doi: 10.1039/JR9620001062. [DOI] [Google Scholar]
- Burns J. T. Leffek K. T. Can. J. Chem. 1969;47:3725–3728. doi: 10.1139/v69-621. [DOI] [Google Scholar]
- von Rudorff G. F., Heinen S., Bragato M. and von Lilienfeld A., Machine Learning: Science and Technology, 2020 [Google Scholar]
- Møller C. Plesset M. S. Phys. Rev. 1934;46:618–622. doi: 10.1103/PhysRev.46.618. [DOI] [Google Scholar]
- Zheng J. Zhao Y. Truhlar D. G. J. Chem. Theory Comput. 2009;5:808–821. doi: 10.1021/ct800568m. [DOI] [PubMed] [Google Scholar]
- Karton A. Rabinovich E. Martin J. M. L. Ruscic B. J. Chem. Phys. 2006;125:144108. doi: 10.1063/1.2348881. [DOI] [PubMed] [Google Scholar]
- Pople J. A. Head-Gordon M. Raghavachari K. J. Chem. Phys. 1987;87:5968–5975. doi: 10.1063/1.453520. [DOI] [Google Scholar]
- Bragato M., von Rudorff G. and von Lilienfeld O. A., chemspacelab/Enhanced-Hammett: Enhanced_Hammett, 2020, 10.5281/zenodo.3952671 [DOI] [PMC free article] [PubMed]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.