

Abstract
Background
Prior to the COVID-19 pandemic, US hospitals relied on static projections of future trends for long-term planning and were only beginning to consider forecasting methods for short-term planning of staffing and other resources. With the overwhelming burden imposed by COVID-19 on the health care system, an emergent need exists to accurately forecast hospitalization needs within an actionable timeframe.
Objective
Our goal was to leverage an existing COVID-19 case and death forecasting tool to generate the expected number of concurrent hospitalizations, occupied intensive care unit (ICU) beds, and in-use ventilators 1 day to 4 weeks in the future for New Mexico and each of its five health regions.
Methods
We developed a probabilistic model that took as input the number of new COVID-19 cases for New Mexico from Los Alamos National Laboratory’s COVID-19 Forecasts Using Fast Evaluations and Estimation tool, and we used the model to estimate the number of new daily hospital admissions 4 weeks into the future based on current statewide hospitalization rates. The model estimated the number of new admissions that would require an ICU bed or use of a ventilator and then projected the individual lengths of hospital stays based on the resource need. By tracking the lengths of stay through time, we captured the projected simultaneous need for inpatient beds, ICU beds, and ventilators. We used a postprocessing method to adjust the forecasts based on the differences between prior forecasts and the subsequent observed data. Thus, we ensured that our forecasts could reflect a dynamically changing situation on the ground.
Results
Forecasts made between September 1 and December 9, 2020, showed variable accuracy across time, health care resource needs, and forecast horizon. Forecasts made in October, when new COVID-19 cases were steadily increasing, had an average accuracy error of 20.0%, while the error in forecasts made in September, a month with low COVID-19 activity, was 39.7%. Across health care use categories, state-level forecasts were more accurate than those at the regional level. Although the accuracy declined as the forecast was projected further into the future, the stated uncertainty of the prediction improved. Forecasts were within 5% of their stated uncertainty at the 50% and 90% prediction intervals at the 3- to 4-week forecast horizon for state-level inpatient and ICU needs. However, uncertainty intervals were too narrow for forecasts of state-level ventilator need and all regional health care resource needs.
Conclusions
Real-time forecasting of the burden imposed by a spreading infectious disease is a crucial component of decision support during a public health emergency. Our proposed methodology demonstrated utility in providing near-term forecasts, particularly at the state level. This tool can aid other stakeholders as they face COVID-19 population impacts now and in the future.
Keywords: COVID-19, forecasting, health care, prediction, forecast, model, quantitative, hospital, ICU, ventilator, intensive care unit, probability, trend, plan
Introduction
Since the novel coronavirus SARS-CoV-2 was identified and declared a global pandemic on March 11, 2020 [1], a key concern has been whether the demand for health care will exceed available resources. Early case reports clearly demonstrated that a large number of infections resulted in hospitalization, intensive care unit (ICU) admission, and breathing assistance via mechanical ventilation [2]. Further projection studies, which show plausible outcomes under defined scenarios [3], showed that COVID-19, the disease caused by SARS-CoV-2, had the potential to overwhelm existing capacity, especially given its limited treatment options [4-7]. In areas with limited resources and high rates of transmission, health care capacity has indeed been exceeded [8]. This threat has highlighted the need for continuous monitoring of hospital resources and for forecasting the impact of real-time changes in new cases on future strain of the health care system.
Real-time forecasting of infectious diseases has become a crucial component of decision support during public health emergencies. Since 2013, when the US Centers for Disease Control and Prevention (CDC) began hosting an annual influenza forecasting challenge [9], the field of infectious disease forecasting has grown. In the context of influenza, the task is for modelers to supply probabilistic forecasts of influenza-like illness for short-term targets, such as week-ahead incidence, at multiple geographical scales, using a variety of models and methods. From this effort, forecasting attempts for other diseases, such as chikungunya [10], Ebola [11], and West Nile [12], have proliferated in recent years, laying the groundwork for a rapid pivot to forecasting COVID-19 incident cases, deaths, and hospitalizations [13].
However, in the context of predicting impact on the health care system, the stress resulting from COVID-19 cases depends not only on the number of new hospitalized individuals but also on their overlapping periods of hospitalization. To the best of our knowledge, health care use forecasting in a probabilistic sense had not existed prior to the current COVID-19 pandemic. Hospitals had used historical data to make time series– and regression-based projections for long-term planning (ie, planning for the next 1 to 10 years). Generally, these projections examined a single relevant metric, such as average length of stay (ALOS) [14], discharges [15], demand for specific hospital specialties [16], or occupancy/bed need [17,18], and considered the impact of external trends, such as anticipated sociodemographic changes, through consideration of multiple scenarios [18]. Hospitals were also developing short-term forecasting tools of total occupancy or bed use [19-21], total occupancy as predicted by emergency department visits [22], and various emergency department metrics [23-26]. These short-term prediction efforts tended to approach the problem either from a hospital administration perspective, by focusing on operational measures informed by a single hospital’s [19-22] or department’s [23-26] historic data or surgery schedule [27], or from a research perspective by using hospital time series data as a use case for the development and assessment of novel statistical models [28-31] without regard to hospitals as complex systems in response to a burgeoning pandemic.
In response to the overwhelming demand from government agencies at the federal, state, and local levels to predict the immediate future burden of COVID-19, Los Alamos National Laboratory (LANL) first developed the COVID-19 Forecasts Using Fast Evaluations and Estimation (COFFEE) tool [32]. COFFEE generates short-term (1 day to 6 weeks ahead) forecasts of cumulative and incident confirmed cases and deaths for all US counties and states, as well as all countries with at least 100 confirmed cases and 20 deaths as reported by the Center of Systems Science and Engineering (CSSE) at the Johns Hopkins University (JHU) Coronavirus Resource Center dashboard [33]. To forecast the health care needs expected to arise from predicted cases, we additionally created the COVID-19 Hospitalization, Intensive Care, and Ventilator Estimator (CHIVE) forecasting tool, which combines forecasts every Monday and Thursday from COFFEE for the state of New Mexico, with current state-level data on hospitalizations, ICU bed use, and mechanical ventilator use. CHIVE is most useful as an actionable mid-term (ie, 2 to 4 weeks ahead) predictor of hospital resource use, enabling hospitals to order additional supplies and allocate existing staff and resources to best serve an expected influx of patients.
The aim of this modeling effort was to create a flexible forecasting tool to predict COVID-19–related health care use needs 2 to 4 weeks ahead, a time period identified by state and local stakeholders as being most useful for future planning. Here, we present the CHIVE methodology and characterize its performance over 29 forecasts made between September 1 and December 9, 2020, for New Mexico. This performance period includes both retrospective forecasts, as in, what the forecast would have been if the data were available, and those submitted in real time to the New Mexico Department of Health (NMDOH). The results of this study can provide a platform for other research groups or health departments to estimate health care needs and support decisions regarding resource planning and allocation.
Methods
Data
From November 4, 2020, to January 5, 2021, as a result of our partnership with NMDOH and Presbyterian Healthcare Services, we received access to the statewide number of COVID-19 confirmed/suspected inpatient hospitalizations, the number of patients in ICUs, and the number of patients on mechanical ventilation as reported in EMResource, a web-based tool for hospital resource reporting [34]. This data set contained retrospective data beginning from July 20, 2020. We also received individual hospital data on COVID-19 hospitalizations. For each day of data, we created regional level time series by summing the numbers of confirmed COVID-19 inpatient hospitalizations, patients in ICUs, and patients on mechanical ventilation across the hospitals within the counties assigned to each of NMDOH’s five health regions (Figure 1A, Figure S1 in Multimedia Appendix 1).
Figure 1.
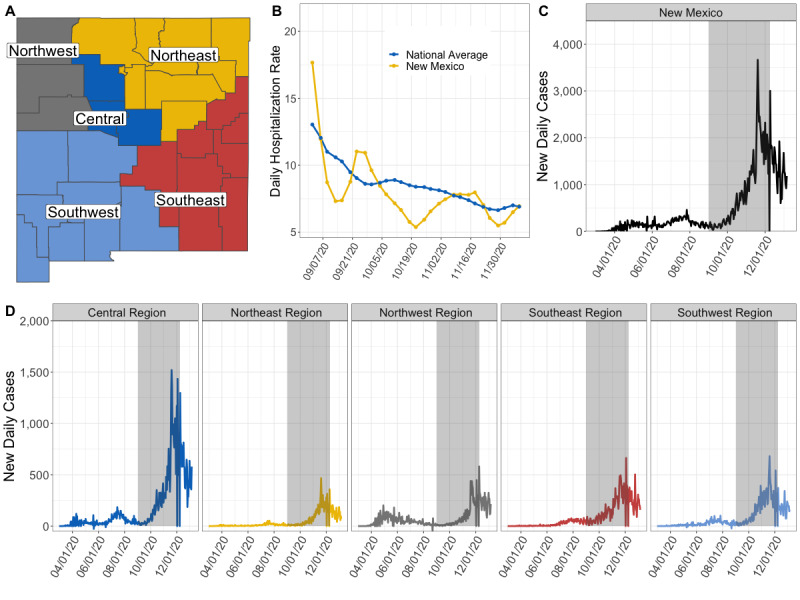
New Mexico health regions, COVID-19 confirmed case time series from March 2020 to January 2021, and daily hospitalization rates from September to December 2020. (A) Division of New Mexico’s 33 counties into five health regions. (B) The 2-week weighted daily hospitalization rate for New Mexico (yellow) compared to the national average (blue) (C). The number of new daily cases at the state level, with the grey box denoting the period of forecast performance evaluation. (D) The number of new daily COVID-19 cases for each of the five regions.
Daily Hospitalization Rate
Starting November 3, 2020, the United States Department of Health and Human Services began publishing a time series format of daily numbers of new hospitalizations by state [35], hereafter referred to as the HealthData.gov time series, with retrospective data for New Mexico going back to July 14, 2020. These data were released weekly.
We defined the daily hospitalization rate (DHR) as the ratio of new confirmed COVID-19 hospitalizations to new confirmed COVID-19 cases on the same day. To obtain the number of new confirmed COVID-19 hospitalizations from the HealthData.gov time series, we summed the previous day’s admissions of adults and pediatric COVID-19 cases. We used the number of new cases as reported by the CSSE JHU Coronavirus Resource Dashboard [33] as the number of new confirmed individuals with COVID-19. We aligned the HealthData.gov admission data for day t with the JHU data of t – 1 because the admission data are listed as the previous day. To account for data reporting anomalies (eg, “data dumps,” days with zero reported hospitalizations or new cases), we calculated a 7-day rolling average of each quantity. The DHR on day t, therefore, is the 7-day rolling average of hospitalizations divided by the 7-day rolling average of new COVID-19 cases. Because the HealthData.gov time series only provides state-level numbers, we applied the same DHR(t) to the regional forecasts.
The daily number of new hospitalizations in the future will impact the degree to which overlapping lengths of stay strain hospital resource capacity. To forecast the DHR into the future, DHR(t)', we calculated a 2-week time-weighted average of the DHR and then assumed this DHR would persist throughout the forecast duration. Where t= 0 is the last day of the observed data, the weight of each DHR (t – n) for n = 0: 13 was determined as
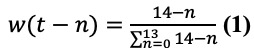 |
The DHR is a convenient ratio that is obtainable from available data. However, this metric is incorrectly defined because the denominator population is not included in the numerator population; thus, we used a 2-step modeling process to remove this inherent bias. Our goal was to create the most accurate forecast possible and not necessarily to maintain direct interpretation of the variables used in the model. A more traditional metric, such as case hospitalization rate, would require further inference about the lag between new cases and hospitalizations of those same cases, which is not necessary to achieve an accurate forecast.
Baseline Parameters of Health Care Use
The stress that COVID-19 places on New Mexico’s health care capacity depends not only on the rate of new hospitalizations but also on the amount of overlapping time during which individuals are hospitalized, which itself is dependent on the individual illness severity and length of stay for each patient. Therefore, we structured CHIVE around the probabilities that certain hospital events would occur (ie, ICU need) given hospitalization and the length of hospitalization given illness severity. Specifically, our model depended on four parameters: ALOS, ALOS for those admitted to the ICU or requiring mechanical ventilation, and percentages of those hospitalized and later admitted to the ICU and those hospitalized who were later placed on mechanical ventilation (Table 1). Early evidence showed that these parameters varied across age groups, and later evidence showed that they varied temporally as new treatment protocols were established [36]. For example, early in the pandemic, individuals were frequently placed on ventilators, leading to high percentages of hospitalized individuals on mechanical ventilation. In addition, it is uncertain how spatial variation in underlying health conditions and transmission intensity impact health care patterns.
Table 1.
New Mexico baseline parameters for COVID-19 health care use needs based on data from March to June 2020.
| Parameter | New Mexico baseline | US rangea |
| Average length of inpatient stay, days | 5 | 4-6 |
| Average length of stay for those admitted to the ICUb or on mechanical ventilator, days | 14 | 11-14 |
| Patients admitted to ICU among those hospitalized, % | 42.8 | 23.8-36.1 |
| Patients on mechanical ventilation among those hospitalized, % | 28.2 | 12.0-22.1 |
aFor comparison, we provide the best median estimate across age groups in the United States collected by the US Centers for Disease Control through August 8, 2020 [36].
bICU: intensive care unit.
Baseline parameters were estimated from data on New Mexico’s hospitalized COVID-19 cases from April 16 to June 15, 2020 [37]. In this time period, the ICU percentage of hospitalizations ranged from 37% to 53% and the percentage of patients on ventilation ranged from 22% to 36%. Rather than dynamically inferring the parameters with limited noisy data going forward, we used parameters that reflected these initial health care use trends in New Mexico, and we developed a postprocessing procedure (described in Step 2: Postprocessing Based on Back-Fitting) that adjusted the forecasts to time-varying trends without the need to determine new input values.
CHIVE Forecasting Model
To capture the heterogeneity in the severity of individual infections, we used probabilistic simulation. CHIVE works in two steps. In the first step, 4-week-ahead daily forecasts, θt=1:28, of new confirmed cases from COFFEE [32] were used as input data to simulate 4 weeks of health care use. We simulated health care use based on the forecasted number of new cases, θt=1:28, the weighted two-week average DHR(t)', and the baseline parameters. The output of the simulation is a forecast for the numbers of occupied inpatient beds (H1,..., H28), ICU beds (IC1,..., IC28) and in-use ventilators (V1,..., V28) due to COVID-19. After simulating 1000 independent iterations of Ht=1:28, ICt=1:28, and Vt=1:28, the second step adjusts the magnitudes of summary quantiles q of Ht=1:28, ICt=1:28, and Vt=1:28, based on observed differences between the prior weeks’ baseline forecasts and the subsequently observed data.
Step 1: Model Baseline Simulations
For an independent iteration i of the simulator, we first sampled a trajectory of new COVID-19 cases, θt=1:28, from the distribution specified by the 23 quantiles of θt=1:28 in the COFFEE output. Let pi~Uniform(0,1) be the percentile of θt=1:28 sampled. We drew θt=1:28 such that pi was the same for all t within iteration i.
For a day-ahead forecast t + n where t= 0 is the last day of observed data, we generated our forecasts as follows:
Using a binomial distribution with the success probability equal to DHR(t)', we sampled the number of new hospital admissions yt+n,i using the forecasted number of new confirmed cases θt+n,i on day t+n as the number of trials.
We next sampled the number of new individuals admitted to the ICU, ut+n,i, from a binomial distribution with yt+n,i trials and success probability equal to the ICU admission percentage among those hospitalized. Similarly, we sampled the number of new individuals needing mechanical ventilation wt+n,i from a binomial distribution with yt+n,i trials and probability equal to the percent of all hospital admissions that require mechanical ventilation. We assumed that if wt+n,i≤ut+n,i, all individuals requiring mechanical ventilation were also in an ICU; otherwise, we assumed that some non-ICU admissions also required mechanical ventilation. Thus, we calculated the number of new non-ICU or ventilator admissions (ie, general inpatient bed admissions), as y't+n,i = yt+n,i – max (ut+n,i, wt+n,i).
We next simulated the lengths of stay S for each new admission z. For admissions in an inpatient bed, we drew the lengths of stay from a Poisson distribution such that
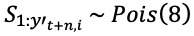 .
.Because we assumed that the length of stay was similar between ICU patients and those on mechanical ventilation, we drew the lengths of stay for these critical care individuals from a Poisson distribution where
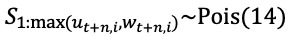 . To obtain the lengths of stay for individuals in the group min (ut+n,i, wt+n,i), we sampled a subset without replacement from
. To obtain the lengths of stay for individuals in the group min (ut+n,i, wt+n,i), we sampled a subset without replacement from 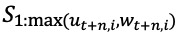 .
.For all admissions observed up through t+n, we decreased the remaining length of stay for each individual by 1. The number of needed inpatient beds Ht+n,i on t+n was then the number of individuals who have a positive length of stay remaining. Similarly, we tracked ICt+n,i and Vt+n,i.
We repeated this process for 1000 random samples of θt=1:28 and summarized the forecasts for day t + n by a set of 23 quantiles q at levels 0.01, 0.025, 0.05, 0.10, … , 0.95, 0.975, and 0.99, such that we obtained Ht=1:28,q=1:23, ICt=1:28,q=1:23 and Vt=1:28,q=1:23.
This method makes several simplifying assumptions. First, it assumes instantaneous movement from confirmation of COVID-19 to hospitalization. Second, it assumes that a hospitalized individual requires the same category of health care for the duration of their stay. We argue that because the forecasting model is not meant to infer epidemiologic parameters, these simplifications reduce the need for introducing additional parameters when data may not exist to sufficiently estimate them.
Step 2: Postprocessing Based on Back-Fitting
After generating the baseline 4-week forecasts Ht=1:28,q=1:23, ICt=1:28,q=1:23, and Vt=1:28,q=1:23, we adjust their magnitudes by finding scaling factors that bring the past week’s baseline forecasts into alignment with the observed data (Table S1, Multimedia Appendix 1). In this way, we do not need to adjust the baseline parameters.
We fitted linear regression models from the forecasts generated over the past week to the observed data as follows for variable X, where X is either H, IC, or V (Figure 2):
Figure 2.
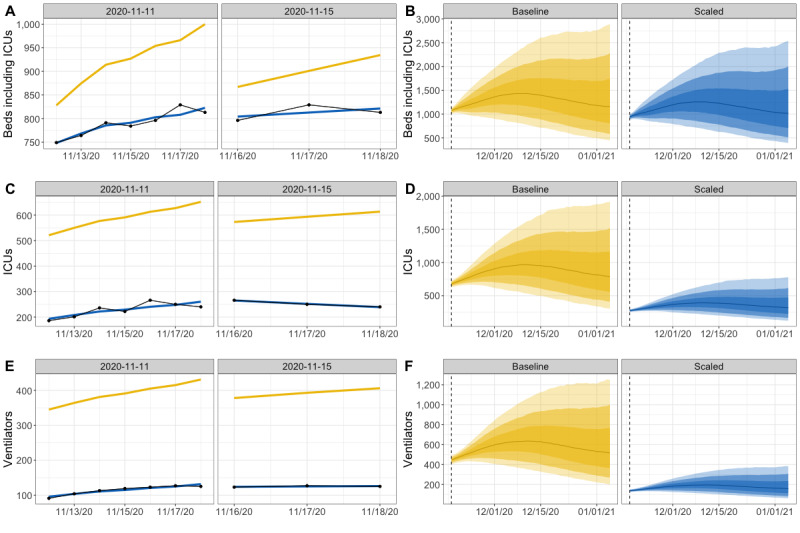
Back-fitting procedure for the November 18, 2020, forecast for New Mexico. (A, C, E) For each forecast from over the week (the panels), a regression was fit (blue line) from the 50th percentile of the baseline forecasts (yellow line) to the observed data (black dots). A time-weighted average of the 2 regression coefficients from each panel was calculated separately for inpatient beds (A), ICU beds (C), and ventilators (E). (B, D, F) For the November 18 forecast, the Baseline forecast was multiplied by the time-weighted average of the regression coefficients to produce the Scaled forecast for the next four weeks. ICU: intensive care unit.
Let t=0 be the day of the last observed data. For each forecast Xt–n, n=1,..., 7, we fit a linear regression model from the 50th percentile Xt–n, q=50 baseline trajectory to the eventually observed data Yt–n:t, in the form Yt–n = βt–nXt–n,q=50.
Across the forecasts, we take a time-weighted mean of the regression coefficients βt–n:t, assigning weights as in Equation 1.
We multiply all baseline forecast quantiles by the weighted mean
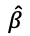 to obtain X't=1:28,q=1:23.
to obtain X't=1:28,q=1:23.
We found separately for inpatient beds, ICU beds, and in-use ventilators. All simulations and analyses were conducted using R, version 3.6.1 (R Foundation for Statistical Computing) [38].
Results
Back-Fit Coefficients Are Dynamic by Time and Geography
At the state level, the 1-week weighted coefficients fluctuated through time (Figure 3A). All three health care use coefficients showed three peaks: one in early September, a second in late October, and a third in early December. During the first two peaks, the baseline forecasted number of inpatient beds was underestimated (coefficients greater than 1.0), while the baseline forecasts of ICU beds and individuals on ventilators were consistently overestimated (coefficients less than 1.0).
Figure 3.
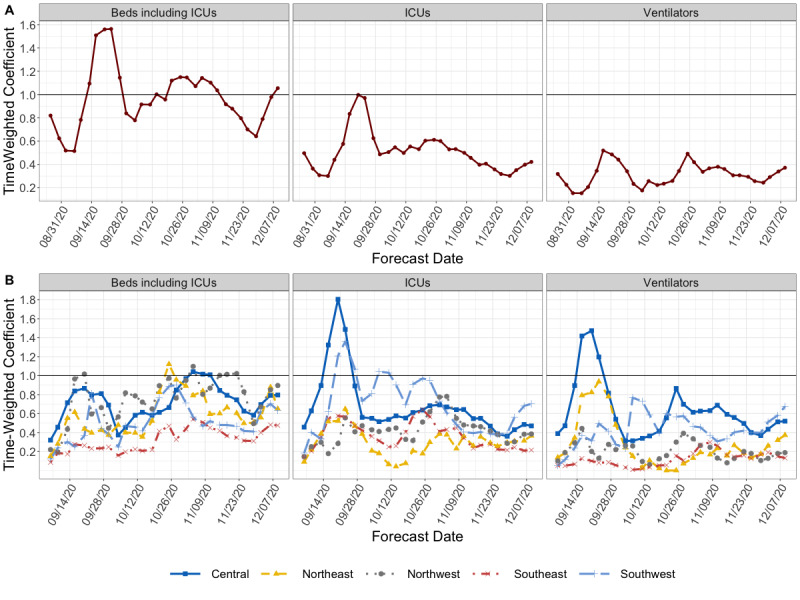
The fitted scaling coefficients from September to December, 2020, for hospital inpatient beds, ICU beds, and ventilators at the state level (A) and regional level (B). The solid black line represents a coefficient of 1.0, where the original 50th percentile forecast would be a good match for the eventual observed data. ICU: intensive care unit.
At the regional level, the baseline parameters most often produced forecasts that were overestimates for each of the five New Mexico regions (Figure 3B). In contrast to the state level, baseline forecasts of needed ICU beds and ventilators were underestimated for the Central region during mid-September. Across health care use categories, the coefficients for the Central region were closest to 1.0, indicating that the baseline parameters were the best match for this region. The coefficients for the Southeast region were consistently the smallest, indicating that the baseline parameters did not reflect health care trends in this region.
Forecasts Showed Higher Error at the Regional Level and for Ventilators
Using validation data through January 5, 2021, we compared the accuracy of the 4-week forecast horizons for the 29 forecasts made between September 1 and December 9, 2020 (Figure 4). To compare accuracy across health care use categories, regions, and time—where the observed magnitude varies widely—we looked at the weighted absolute percentage error (WAPE) while providing the mean absolute error (MAE) for context. The MAE is the difference between the median forecast (50th percentile) and the observed value. The WAPE is the sum of the absolute differences divided by the sum of the observed values over the 4-week forecast horizon. The WAPE can accommodate observed zero values, which occurred in our data at the regional level.
Figure 4.
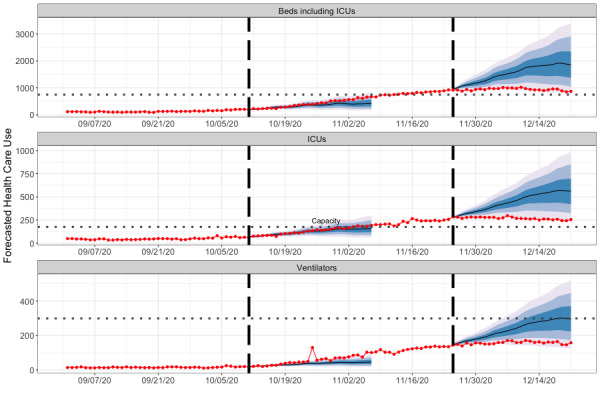
Reported health care use and example forecasts for New Mexico from October and November 2020. The numbers of concurrent hospitalization beds, ICU beds, and ventilators needed throughout hospitals in New Mexico from September 1 to December 29, 2020 (red points and line). Forecasts are day-ahead predicted medians (black line), and the 50%, 80% and 95% prediction intervals for 28 days (4 weeks). We show two examples, the first beginning on October 11, 2020, and the second beginning on November 25, 2020. ICU: intensive care unit.
At the state level, the median forecasts were consistently 15% to 25% off for all three health care use categories for the 1- to 2-week horizon, and they showed an increase in error up through 4 weeks ahead (Table 2). Looking at the completed months during which a forecast was made, the October forecasts had the lowest overall mean WAPE of 20.0%, while the September forecasts had the highest WAPE of 39.7%. Of the three health care use categories, inpatient bed forecasts had the lowest overall WAPE (27.3%), while ICU beds had the highest (29.2%).
Table 2.
The WAPEs and MAEs of the predicted forecasted median for COVID-19 health care use numbers reported for September 1 to January 5, 2020, in New Mexico.
| Regiona and type | Forecast horizonb | |||||||||||||||
|
|
1 week ahead | 2 weeks ahead | 3 weeks ahead | 4 weeks ahead | ||||||||||||
|
|
WAPEc | MAEd (SD) | WAPE | MAE (SD) | WAPE | MAE (SD) | WAPE | MAE (SD) | ||||||||
| State | ||||||||||||||||
|
|
Beds including ICUse | 0.170 | 81.8 (91.9) | 0.244 | 130 (141) | 0.307 | 179 (206) | 0.334 | 210 (249) | |||||||
|
|
ICUs | 0.163 | 23.6 (22.4) | 0.244 | 38.8 (39.4) | 0.338 | 58.3 (64.1) | 0.380 | 69.6 (81.0) | |||||||
|
|
Ventilators | 0.188 | 13.5 (13.6) | 0.261 | 21.2 (21.9) | 0.324 | 29.2 (31.4) | 0.349 | 34.2 (40.3) | |||||||
| Central | ||||||||||||||||
|
|
Beds including ICUs | 0.175 | 27.3 (33.9) | 0.267 | 46.9 (60.9) | 0.381 | 74.0 (97.9) | 0.486 | 103 (113) | |||||||
|
|
ICUs | 0.177 | 12.1 (13.7) | 0.257 | 19.5 (23.4) | 0.385 | 31.8 (39.7) | 0.485 | 42.8 (50.6) | |||||||
|
|
Ventilators | 0.204 | 9.43 (10.7) | 0.281 | 14.7 (17.3) | 0.358 | 20.9 (26.2) | 0.406 | 25.9 (32.6) | |||||||
| Northwest | ||||||||||||||||
|
|
Beds including ICUs | 0.283 | 12.8 (19.5) | 0.335 | 17.9 (27.6) | 0.425 | 26.5 (39.7) | 0.480 | 34.0 (44.2) | |||||||
|
|
ICUs | 0.261 | 3.62 (4.09) | 0.368 | 5.81 (7.07) | 0.482 | 8.82 (11.3) | 0.516 | 10.6 (14.2) | |||||||
|
|
Ventilators | 0.557 | 2.06 (2.17) | 0.673 | 2.76 (2.80) | 0.757 | 3.53 (4.30) | 0.729 | 3.73 (5.44) | |||||||
| Southeast | ||||||||||||||||
|
|
Beds including ICUs | 0.240 | 8.89 (7.59) | 0.310 | 12.5 (12.9) | 0.394 | 17.1 (16.4) | 0.468 | 21.9 (19.5) | |||||||
|
|
ICUs | 0.271 | 5.49 (4.55) | 0.367 | 7.98 (7.64) | 0.446 | 10.1 (10.2) | 0.425 | 9.90 (10.1) | |||||||
|
|
Ventilators | 0.346 | 2.17 (2.21) | 0.468 | 3.34 (3.43) | 0.547 | 4.21 (4.55) | 0.605 | 5.03 (4.86) | |||||||
| Southwest | ||||||||||||||||
|
|
Beds including ICUs | 0.251 | 15.1 (14.4) | 0.413 | 26.9 (30.0) | 0.595 | 41.0 (44.2) | 0.618 | 45.0 (43.0) | |||||||
|
|
ICUs | 0.249 | 10.1 (9.47) | 0.410 | 18.2 (21.1) | 0.562 | 26.6 (33.5) | 0.601 | 30.0 (34.4) | |||||||
|
|
Ventilators | 0.240 | 5.32 (5.04) | 0.366 | 9.06 (9.40) | 0.412 | 11.4 (10.6) | 0.428 | 12.9 (9.95) | |||||||
| Northeast | ||||||||||||||||
|
|
Beds including ICUs | 0.306 | 10.4 (13.3) | 0.417 | 15.7 (20.1) | 0.584 | 24.6 (30.4) | 0.672 | 30.8 (34.8) | |||||||
|
|
ICUs | 0.311 | 3.25 (3.64) | 0.434 | 5.27 (6.16) | 0.570 | 7.63 (9.51) | 0.650 | 9.46 (10.3) | |||||||
|
|
Ventilators | 0.408 | 2.21 (2.34) | 0.514 | 3.33 (3.15) | 0.582 | 4.20 (3.83) | 0.609 | 4.69 (4.11) | |||||||
aRegions are listed in increasing order of overall WAPE across both the forecast horizon and health care categories.
bFor each forecast horizon, we considered all daily forecasts within that week.
cWAPE: weighted absolute percentage error.
dMAE: mean absolute error.
eICUs: intensive care units.
The regional level WAPEs similarly increased though the 3-week forecast horizon; however, for each forecast horizon, the regional WAPEs often exceeded their corresponding state-level WAPEs. Aggregated across forecast horizons and regions, the regional-level WAPE was 40.0% for inpatient hospitalizations, 40.4% for ICU units, and 40.0% for ventilators. However, because of smaller quantities, these errors translate to smaller absolute errors. For example, in the Northwest region, ventilator median forecasts were off by between 55% and 75% on average, corresponding to a raw difference of approximately 3 ventilators.
At the regional level, forecast error varied by location, month, and health care use category. All three health care use categories in the Central region had the lowest forecast WAPEs in October (hospital beds: 33.7%, ICU beds: 25.0%, ventilators: 28.6%), while the lowest forecast WAPEs for the Southwest regions all occurred in November (hospital beds: 39.8%, ICU beds: 42.7%, ventilators: 35.3%). For the remaining combinations of regions and health care needs, the results were split, with 66% of the lowest WAPEs occurring in November.
To understand how time series properties may have impacted the accuracy of the forecasts, we compared the monthly WAPE against the monthly volatility of the time series. The volatility, calculated as 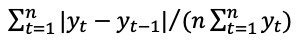 , is a measure that captures the noisiness of the observed time series data. We found no relationship between the volatility of a monthly time series and the WAPE. We also did not find a relationship between the WAPE and the total number of each health care use need in a particular month.
, is a measure that captures the noisiness of the observed time series data. We found no relationship between the volatility of a monthly time series and the WAPE. We also did not find a relationship between the WAPE and the total number of each health care use need in a particular month.
Prediction Intervals Start Off Narrow and Increase With Time
We assessed how well the forecasts were calibrated by measuring how often the observed data fell within a range of prediction intervals. If a forecasting model is well calibrated (ie, the prediction intervals are the correct width), the observed data should fall into the nominal prediction interval of the model with the expected frequency. For example, the observed data should fall into the 50% nominal prediction interval 50% of the time. Across the two geographic regions, prediction intervals were conservative (overconfident) at both the 50% and 90% prediction intervals. At the state level, the empirical coverage approached the nominal coverage by the 3- and 4-week-ahead forecast horizons (Figure 5, Table 3) for inpatient beds and needed ICU beds. However, across the regional levels and health care categories, the prediction intervals remained consistently narrow.
Figure 5.
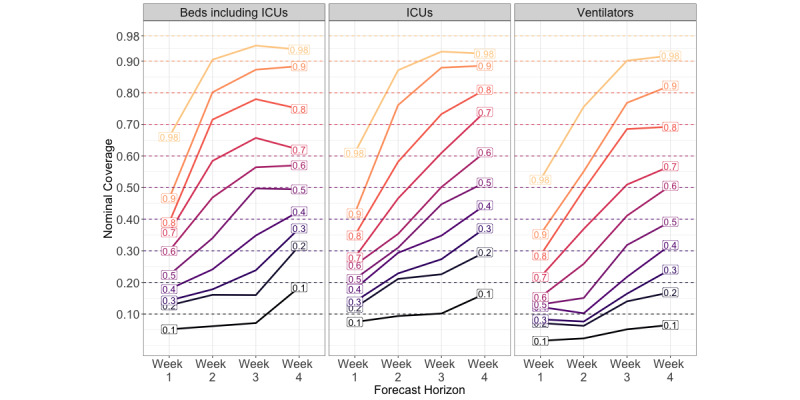
Coverage plot for New Mexico state-level forecasts at 4-week ahead horizons made between September 1 and December 9, 2020. Colored lines are labeled by their nominal coverage, while the position on the y-axis indicates its empirical coverage. If a forecast is well-calibrated, the empirical coverage should fall along the y-axis at its corresponding nominal coverage. ICU: intensive care unit.
Table 3.
Observed prediction interval coverage for COVID-19 health care use needs in New Mexico reported from September 1 to December 9, 2020.
| Model and type | Measure (% coverage) | Observed prediction interval coverage | ||||||
|
|
|
|
Forecast horizon | |||||
|
|
|
|
1 week ahead | 2 weeks ahead | 3 weeks ahead | 4 weeks ahead | ||
| State | ||||||||
|
|
Beds including ICUsb | 50 | 0.22 | 0.34 | 0.50 a | 0.50 | ||
|
|
|
90 | 0.47 | 0.80 | 0.87 | 0.88 | ||
|
|
ICU | 50 | 0.21 | 0.31 | 0.45 | 0.52 | ||
|
|
|
90 | 0.42 | 0.76 | 0.88 | 0.89 | ||
|
|
Ventilators | 50 | 0.13 | 0.15 | 0.32 | 0.39 | ||
|
|
|
90 | 0.35 | 0.55 | 0.77 | 0.82 | ||
| Regionalc | ||||||||
|
|
Beds including ICU | 50 | 0.27 | 0.33 | 0.36 | 0.30 | ||
|
|
|
90 | 0.54 | 0.69 | 0.70 | 0.60 | ||
|
|
ICU | 50 | 0.29 | 0.29 | 0.36 | 0.38 | ||
|
|
|
90 | 0.57 | 0.65 | 0.70 | 0.71 | ||
|
|
Ventilators | 50 | 0.20 | 0.23 | 0.27 | 0.33 | ||
|
|
|
90 | 0.49 | 0.51 | 0.62 | 0.67 | ||
aItalicized quantities are within 5% of their nominal coverage.
bICUs: intensive care units.
cRegional results are averaged across the five regions.
At the state level, we ranked the calibrations by comparing the relative absolute coverage error, as in, (nominal coverage – observed coverage)/nominal coverage. Between health care categories, the hospitalization forecasts were the best calibrated at both geographic scales, while the ventilator forecasts were the worst calibrated. At the regional scale, the Central region was the best calibrated model, while the Northeast region was the worst (Figure S3, Multimedia Appendix 1).
Discussion
Principal Findings
Given the uncertainty and unavailability of data regarding health care parameters associated with COVID-19, we chose to implement a naïve model and fitting procedure in which the main intent was to produce forecasts of the expected health care use levels up to 4 weeks into the future. Although COVID-19 case data have been widely available, hospitalization data have been consistently sparse and not always timely. Therefore, alternative approaches such as naive models may prove to be more robust in addressing these challenges. Our evaluations show that using a simple model and available forecasts of cases, one can forecast future health care use levels with sufficient accuracy for operational planning. During the pandemic, these data were used across local health care systems to determine staffing, equipment, and contingency plans, enabling superior preparation for surges in cases. Additionally, transport logistics were informed by our forecasts, ensuring that communities had the necessary capabilities to move patients to higher levels of care.
We found that CHIVE varied in its ability to accurately forecast across space, time, and health care needs. First, CHIVE was more accurate and better calibrated at the state level than for the five regions of New Mexico. We may have obtained this result because although CHIVE forecasts the expected needed number of beds, ICU beds, and ventilators, decision-making on the ground of individual treatment and new incoming patient diversions based on capacity, staffing resources, etc, will impact these numbers. These individual decisions will have more of an impact on the regional numbers than overall state numbers. Second, at both geographic scales, the forecasts of inpatient beds had the smallest error, possibly because of fewer unaccounted-for downstream effects that could impact the number of ICU beds and ventilators. Third, the forecasting model was most accurate at the 1-week forecast horizon but improved its uncertainty coverage at the 2-week forecast horizon. Finally, CHIVE performed well in October and November, when confirmed COVID-19 cases and new hospitalizations were rising. This finding suggests this method is flexible for different phases of the epidemic. Overall, our results suggest that the conditions for which CHIVE is most suited include forecasting the number of hospital inpatient beds at higher geographical scales in the 2-week horizon.
Both a strength and limitation of our method is that it is dependent on the LANL COFFEE model. First, the resolution of the case forecasts limits the resolution of the hospitalization forecasts. At the state and regional levels, the model is not resolved enough for individual hospital planning in its current form; however, it can still provide intuition about how rising case numbers translate to stresses on capacity. Real-time awareness of where cases are rising and the features of specific hospitals (ie, rural vs urban) by public health professionals can provide synergistic information that can translate to an indication of where capacity may be stressed and needs to be reinforced. Second, the coverage, or prediction interval widths, were consistently too small. Because the distribution of case forecasts was used as input, this may be a reflection of overconfident intervals of the COFFEE model. Finally, both COFFEE and CHIVE are agnostic to on-the-ground public health actions. For example, the Governor of New Mexico reimposed a strict lockdown on November 13, 2020, to curtail rising case numbers [39]. The forecast for November 25 (Figure 4) overpredicted the number of inpatient beds, ICU beds, and ventilators. This may be because the effects of the stay-at-home order had yet not been observed in the data, so neither COFFEE nor the postprocessing step of CHIVE anticipated the reduction in new cases at the start of December.
Separate from COFFEE, a limitation of our method is that new hospitalizations are assumed to be a fraction of newly confirmed cases; meanwhile, data have shown that there is a median of 6 days between symptom onset and hospitalization and of 3 days between symptom onset and administration of a SARS-CoV-2 test [36]. Future iterations of the model could consider identifying the correct lag. However, we assume that lag is also a dynamic parameter. Finally, ALOS and other average values used are poor representations of the underlying distributions of hospital stays, which are known to have very long tails [40].
Nonetheless, we believe that given the availability of COFFEE forecasts for many geographic regions, this simple method could be used as a situational awareness tool for many health care departments across the nation (and even worldwide), who would only need to have their locale’s health care occupancy data available to supplement the forecasts of confirmed cases from COFFEE. For quantities that prove to be well calibrated, individual hospitals can use prediction intervals rather than point forecasts for their own needs. For example, if a hospital consistently sees their own caseloads around the lower 5% prediction interval, they can use this estimate for their individual needs. Alternatively, individual hospitals can use prediction intervals to determine their own risk avoidance by balancing the cost of unused beds versus going over capacity. In addition, this type of model could be used in nonpandemic settings where forecasts of disease burden take place, such as seasonal influenza.
The COVID-19 pandemic has highlighted the need for continued development of health care use forecasting. Seasonal hospitalization rates of influenza-like illnesses will be altered for years to come, compromising previous methodology that relied on historical time series to predict seasonal demand. Short-term forecasting may help state health departments and hospitals gain key situational awareness about what is expected in the near future. In addition, forecasting at a finer resolution, such as regions, can provide the opportunity for coordination of necessary resources. These modeling techniques may also prove helpful in addressing emergent needs in special and diverse populations that may otherwise go unmet and recognized. We see a strong and urgent need for continued collaboration between infectious diseases modelers, public health officials, and hospital managers. Although modelers can provide an outlook on transmission activity in the general population and translate transmission forecasts to incoming numbers and resources needed, hospital operations subject matter experts are best able to understand the limits of hospital capacities and resources, while public health officials can aid policy.
Conclusions
Although there is uncertainty in our forecasts, the proposed methodology is intended to provide estimates to decision makers and public health officials regarding the potential need of health care resources resulting from a burgeoning pandemic. Specifically, the results of this study can help research groups, departments of health, and ministries of health estimate future health care needs and support decisions regarding resource planning and allocation to ultimately reduce negative health care outcomes and save lives.
Acknowledgments
We acknowledge the help of Amir Rahimi at Presbyterian Healthcare Services for assisting with the EMResource data. LAC gratefully acknowledges the support of the US Department of Energy through the LANL/Laboratory Directed Research and Development Program and the Center for Nonlinear Studies for this work. The research in this article was supported by the Laboratory Directed Research and Development program of LANL under grants 20200700ER, 20200698ER, and 20200697ER, and was partially funded by the National Institutes of Health/National Institute of General Medical Sciences under grant R01GM130668-01 awarded to SYD. This research was partially supported by the Department of Energy (DOE) Office of Science through the National Virtual Biotechnology Laboratory, a consortium of DOE national laboratories focused on the response to COVID-19, with funding provided by the Coronavirus CARES Act. Los Alamos National Laboratory is operated by Triad National Security, LLC, for the National Nuclear Security Administration of the US Department of Energy (89233218CNA000001). The content is solely the responsibility of the authors and does not represent the official views of the sponsors.
Abbreviations
- ALOS
average length of stay
- CDC
US Centers for Disease Control and Prevention
- CHIVE
COVID-19 Hospitalization, Intensive Care, and Ventilator Estimator
- COFFEE
COVID-19 Forecasts Using Fast Evaluations and Estimation
- CSSE
Center of Systems Science and Engineering
- DOE
Department of Energy
- DHR
daily hospitalization rate
- ICU
intensive care unit
- JHU
Johns Hopkins University
- LANL
Los Alamos National Laboratory
- MAE
mean absolute error
- NMDOH
New Mexico Department of Health
- WAPE
weighted absolute percentage error
Appendix
Supplemental figures and tables.
Footnotes
Conflicts of Interest: None declared.
References
- 1.Coronavirus disease 2019 (COVID-19) Situation Report - 51. World Health Organization. [2021-06-02]. https://www.who.int/emergencies/diseases/novel-coronavirus-2019/situation-reports/
- 2.CDC COVID-19 Response Team Severe outcomes among patients with coronavirus disease 2019 (COVID-19) - United States, February 12-March 16, 2020. MMWR Morb Mortal Wkly Rep. 2020 Mar 27;69(12):343–346. doi: 10.15585/mmwr.mm6912e2. doi: 10.15585/mmwr.mm6912e2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Massad E, Burattini M, Lopez L, Coutinho F. Forecasting versus projection models in epidemiology: the case of the SARS epidemics. Med Hypotheses. 2005;65(1):17–22. doi: 10.1016/j.mehy.2004.09.029. http://europepmc.org/abstract/MED/15893110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.IHME COVID-19 health service utilization forecasting team. Murray CJL. Forecasting the impact of the first wave of the COVID-19 pandemic on hospital demand and deaths for the USA and European Economic Area countries. medRxiv. doi: 10.1101/2020.04.21.20074732. Preprint posted online on April 26, 2020. [DOI] [Google Scholar]
- 5.Moghadas SM, Shoukat A, Fitzpatrick MC, Wells CR, Sah P, Pandey A, Sachs JD, Wang Z, Meyers LA, Singer BH, Galvani AP. Projecting hospital utilization during the COVID-19 outbreaks in the United States. Proc Natl Acad Sci U S A. 2020 Apr 21;117(16):9122–9126. doi: 10.1073/pnas.2004064117. http://www.pnas.org/cgi/pmidlookup?view=long&pmid=32245814. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Wang X, Pasco RF, Du Z, Petty M, Fox SJ, Galvani AP, Pignone M, Johnston SC, Meyers LA. Impact of social distancing measures on coronavirus disease healthcare demand, Central Texas, USA. Emerg Infect Dis. 2020 Oct;26(10):2361–2369. doi: 10.3201/eid2610.201702. doi: 10.3201/eid2610.201702. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Ferguson N, Laydon D, Nedjati GG, Imai N, Ainslie K, Baguelin M, Bhatia S, Boonyasiri A, Cucunuba Perez Z, Cuomo-Dannenburg G, Dighe A, Dorigatti I, Fu H, Gaythorpe K, Green W, Hamlet A, Hinsley W, Okell L, Van Elsland S, Thompson H, Verity R, Volz E, Wang H, Wang Y, Walker P, Walters C, Winskill P, Whittaker C, Donnelly C, Riley S, Ghani A. Impact of non-pharmaceutical interventions (NPIs) to reduce COVID-19 mortality and healthcare demand. Imperial College London. 2020. Mar 16, [2021-02-06]. [DOI]
- 8.Leatherby L, Keefe J, Tompkins L, Smart C, Conlen M. ‘There’s no place for them to go’: I.C.U. beds near capacity across U.S. New York Times. 2020. Dec 09, [2021-06-02]. https://www.nytimes.com/interactive/2020/12/09/us/covid-hospitals-icu-capacity.html.
- 9.Biggerstaff M, Alper D, Dredze M, Fox S, Fung I, Hickmann K, Lewis Bryan, Rosenfeld Roni, Shaman Jeffrey, Tsou Ming-Hsiang, Velardi Paola, Vespignani Alessandro, Finelli Lyn, Influenza Forecasting Contest Working Group Results from the centers for disease control and prevention's predict the 2013-2014 Influenza Season Challenge. BMC Infect Dis. 2016 Jul 22;16:357. doi: 10.1186/s12879-016-1669-x. https://bmcinfectdis.biomedcentral.com/articles/10.1186/s12879-016-1669-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Del Valle SY, McMahon BH, Asher J, Hatchett R, Lega JC, Brown HE, Leany ME, Pantazis Y, Roberts DJ, Moore S, Peterson AT, Escobar LE, Qiao H, Hengartner NW, Mukundan H. Summary results of the 2014-2015 DARPA Chikungunya challenge. BMC Infect Dis. 2018 May 30;18(1):245. doi: 10.1186/s12879-018-3124-7. https://bmcinfectdis.biomedcentral.com/articles/10.1186/s12879-018-3124-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Viboud C, Sun K, Gaffey R, Ajelli M, Fumanelli L, Merler S, Zhang Qian, Chowell Gerardo, Simonsen Lone, Vespignani Alessandro, RAPIDD Ebola Forecasting Challenge group The RAPIDD ebola forecasting challenge: synthesis and lessons learnt. Epidemics. 2018 Mar;22:13–21. doi: 10.1016/j.epidem.2017.08.002. https://linkinghub.elsevier.com/retrieve/pii/S1755-4365(17)30127-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.WNV Forecasting 2020. Epidemic Prediction Initiative. [2021-06-02]. https://predict.cdc.gov/post/5e18a08677851c0489cf10b8.
- 13.The COVID-19 Forecast Hub. [2020-12-01]. https://covid19forecasthub.org/
- 14.Tandberg D, Qualls C. Time series forecasts of emergency department patient volume, length of stay, and acuity. Ann Emerg Med. 1994 Feb;23(2):299–306. doi: 10.1016/s0196-0644(94)70044-3. [DOI] [PubMed] [Google Scholar]
- 15.McCoy TH, Pellegrini AM, Perlis RH. Assessment of time-series machine learning methods for forecasting hospital discharge volume. JAMA Netw Open. 2018 Nov 02;1(7):e184087. doi: 10.1001/jamanetworkopen.2018.4087. https://jamanetwork.com/journals/jamanetworkopen/fullarticle/10.1001/jamanetworkopen.2018.4087. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Ordu M, Demir E, Tofallis C. A comprehensive modelling framework to forecast the demand for all hospital services. Int J Health Plann Manage. 2019 Apr;34(2):e1257–e1271. doi: 10.1002/hpm.2771. https://onlinelibrary.wiley.com/doi/abs/10.1002/hpm.2771. [DOI] [PubMed] [Google Scholar]
- 17.Mackay M, Lee M. Choice of models for the analysis and forecasting of hospital beds. Health Care Manag Sci. 2005 Aug;8(3):221–30. doi: 10.1007/s10729-005-2013-y. [DOI] [PubMed] [Google Scholar]
- 18.Bouckaert N, Van den Heede K, Van de Voorde C. Improving the forecasting of hospital services: a comparison between projections and actual utilization of hospital services. Health Policy. 2018 Jul;122(7):728–736. doi: 10.1016/j.healthpol.2018.05.010. [DOI] [PubMed] [Google Scholar]
- 19.Littig SJ, Isken MW. Short term hospital occupancy prediction. Health Care Manag Sci. 2007 Feb;10(1):47–66. doi: 10.1007/s10729-006-9000-9. [DOI] [PubMed] [Google Scholar]
- 20.Earnest A, Chen MI, Ng D, Sin LY. Using autoregressive integrated moving average (ARIMA) models to predict and monitor the number of beds occupied during a SARS outbreak in a tertiary hospital in Singapore. BMC Health Serv Res. 2005 May 11;5(1):36. doi: 10.1186/1472-6963-5-36. https://bmchealthservres.biomedcentral.com/articles/10.1186/1472-6963-5-36. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Kumar A, Jiao R, Shim S. Predicting bed requirement for a hospital using regression models. 2008 IEEE International Conference on Industrial Engineering and Engineering Management; December 8-11, 2008; Singapore. 2008. pp. 665–669. [DOI] [Google Scholar]
- 22.Abraham G, Byrnes G, Bain C. Short-term forecasting of emergency inpatient flow. IEEE Trans Inform Technol Biomed. 2009 May;13(3):380–388. doi: 10.1109/titb.2009.2014565. [DOI] [PubMed] [Google Scholar]
- 23.Kadri F, Harrou F, Chaabane S, Tahon C. Time series modelling and forecasting of emergency department overcrowding. J Med Syst. 2014 Sep 23;38(9):107. doi: 10.1007/s10916-014-0107-0. [DOI] [PubMed] [Google Scholar]
- 24.Hoot NR, Zhou C, Jones I, Aronsky D. Measuring and forecasting emergency department crowding in real time. Ann Emerg Med. 2007 Jun;49(6):747–55. doi: 10.1016/j.annemergmed.2007.01.017. http://europepmc.org/abstract/MED/17391809. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Cochran JK, Broyles JR. Developing nonlinear queuing regressions to increase emergency department patient safety: approximating reneging with balking. Comput Ind Eng. 2010 Oct;59(3):378–386. doi: 10.1016/j.cie.2010.05.010. [DOI] [Google Scholar]
- 26.Peck J, Benneyan J, Nightingale D, Gaehde S. Predicting emergency department inpatient admissions to improve same-day patient flow. Acad Emerg Med. 2012 Sep;19(9):E1045–54. doi: 10.1111/j.1553-2712.2012.01435.x. doi: 10.1111/j.1553-2712.2012.01435.x. [DOI] [PubMed] [Google Scholar]
- 27.Davis S, Fard N. Theoretical bounds and approximation of the probability mass function of future hospital bed demand. Health Care Manag Sci. 2020 Mar 6;23(1):20–33. doi: 10.1007/s10729-018-9461-7. http://europepmc.org/abstract/MED/30397818. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Deng Y, Fan H, Wu S. A hybrid ARIMA-LSTM model optimized by BP in the forecast of outpatient visits. J Ambient Intell Human Comput. 2020 Oct 19; doi: 10.1007/s12652-020-02602-x. [DOI] [Google Scholar]
- 29.Jiao Y, Sharma A, Ben Abdallah Arbi, Maddox T, Kannampallil T. Probabilistic forecasting of surgical case duration using machine learning: model development and validation. J Am Med Inform Assoc. 2020 Dec 09;27(12):1885–1893. doi: 10.1093/jamia/ocaa140. https://academic.oup.com/jamia/article/27/12/1885/5919678. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Harrou F, Dairi A, Kadri F, Sun Y. Forecasting emergency department overcrowding: a deep learning framework. Chaos Solitons Fractals. 2020 Oct;139:110247. doi: 10.1016/j.chaos.2020.110247. http://europepmc.org/abstract/MED/32982079. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Yousefi M, Yousefi M, Fathi M, Fogliatto FS. Patient visit forecasting in an emergency department using a deep neural network approach. Kybernetes. 2019 Oct 16;49(9):2335–2348. doi: 10.1108/k-10-2018-0520. [DOI] [Google Scholar]
- 32.LANL COVID-19 cases and deaths forecasts. Los Alamos National Laboratory. [2021-06-02]. https://covid-19.bsvgateway.org/
- 33.Dong E, Du H, Gardner L. An interactive web-based dashboard to track COVID-19 in real time. Lancet Infect Dis. 2020 May;20(5):533–534. doi: 10.1016/s1473-3099(20)30120-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.EMResource. Juvare. [2020-12-30]. https://www.juvare.com/emresource/
- 35.COVID-19 estimated patient impact and hospital capacity by state. US Department of Health and Human Services. [2021-06-02]. https://healthdata.gov/dataset/COVID-19-Estimated-Patient-Impact-and-Hospital-Cap/vzfs-79pr.
- 36.COVID-19 pandemic planning scenarios. US Centers for Disease Control and Prevention. [2020-05-10]. https://www.cdc.gov/coronavirus/2019-ncov/hcp/planning-scenarios.html#five-scenarios.
- 37.COVID-19 modeling in New Mexico. New Mexico Department of Health. [2020-11-22]. https://cvmodeling.nmhealth.org/
- 38.R Core Team R: A language and environment for statistical computing. R Foundation for Statistical Computing. 2018. [2021-06-02]. http://www.r-project.org.
- 39.Public Health Emergency Order Clarifying that Current Guidance Documents, Advisories, and Emergency Public Health Orders Remain in Effect; and Amending Prior Public Health Emergency Orders to Provide Additional Temporary Restrictions Due to COVID-19. New Mexico Department of Health. 2020. Nov 16, [2021-06-02]. https://cv.nmhealth.org/wp-content/uploads/2020/11/111620-PHO.pdf.
- 40.Faddy M, Graves N, Pettitt A. Modeling length of stay in hospital and other right skewed data: comparison of phase-type, gamma and log-normal distributions. Value Health. 2009 Mar;12(2):309–14. doi: 10.1111/j.1524-4733.2008.00421.x. https://linkinghub.elsevier.com/retrieve/pii/S1098-3015(10)60709-7. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplemental figures and tables.