

Abstract
Meditation practice is believed to foster states of mindful awareness and mental quiescence in everyday life. If so, then the cultivation of these qualities with training ought to leave its imprint on the activity of intrinsic functional brain networks. In an intensive longitudinal study, we investigated associations between meditation practitioners' experiences of felt mindful awareness and changes in the spontaneous electrophysiological dynamics of functional brain networks. Experienced meditators were randomly assigned to complete 3 months of full‐time training in focused‐attention meditation (during an initial intervention) or to serve as waiting‐list controls and receive training second (during a later intervention). We collected broadband electroencephalogram (EEG) during rest at the beginning, middle, and end of the two training periods. Using a data‐driven approach, we segmented the EEG into a time series of transient microstate intervals based on clustering of topographic voltage patterns. Participants also provided daily reports of felt mindful awareness and mental quiescence, and reported daily on four experiential qualities of their meditation practice during training. We found that meditation training led to increases in mindful qualities of awareness, which corroborate contemplative accounts of deepening mental calm and attentional focus. We also observed reductions in the strength and duration of EEG microstates across both interventions. Importantly, changes in the dynamic sequencing of microstates were associated with daily increases in felt attentiveness and serenity during training. Our results connect shifts in subjective qualities of meditative experience with the large‐scale dynamics of whole brain functional EEG networks at rest.
Keywords: EEG, meditation, microstates, mindful awareness, resting state
We identified sequences of brain electric microstates across 3 months of residential training in meditation. Training‐related changes in the dynamic sequencing of microstates were associated with daily changes in self‐reported states of mindful awareness. These results connect subjective qualities of meditative experience with the dynamics of functional brain networks at rest.
1. INTRODUCTION
The large‐scale functional organization of the brain is reflected in the synchronized activity of widely distributed neural populations (Varela, Lachaux, Rodriguez, & Martinerie, 2001). These distributed brain networks fluctuate spontaneously according to dynamical patterns in their activity, which are observable even in the absence of external stimulation (Damoiseaux et al., 2006; Fox et al., 2005; Mantini, Perucci, del Gratta, Romani, & Corbetta, 2007). This spontaneous activity provides a window into the functional organization of intrinsic neurocognitive networks and their coordinated temporal dynamics. However, the functional architectures of these networks are not static over time: they reconfigure dynamically to support ongoing cognition and behavior, and may demonstrate experience‐dependent plasticity in response to changing behavioral patterns and habits—including engagement in meditation or mindfulness practice (e.g., Garrison, Zeffiro, Scheinost, Constable, & Brewer, 2015; Hasenkamp & Barsalou, 2012; Taren et al., 2017).
The activity and dynamics of functionally defined brain networks can provide insights into how long‐term psychological changes accompanying formal meditation practices are instantiated in the brain. Shamatha (transl. calm abiding) is one such foundational meditation practice of Buddhist contemplative traditions (Gethin, 1998; Wallace, 1999). Shamatha practice is thought to strengthen attentional capacities and calm the mind. During shamatha meditation, practitioners selectively attend to an object of concentration, such as the sensations of the breath or body, while monitoring and regulating the quality of their ongoing awareness and states of arousal (e.g., focused or distracted, alert or dull). With continued training, shamatha meditation is thought to bring about lasting changes in awareness and psychological functioning (Wallace, 1999, 2006; Wallace & Shapiro, 2006).
Shamatha meditation is also thought to lead to deepening levels of physical and mental relaxation with continued training. These qualities, in turn, accompany increases in the felt stability and vividness of one's attention (Wallace, 1999, 2006). Modern treatments of mindfulness frame this kind of mental stability as the degree to which one's focus persists over time; and vividness as the phenomenal clarity or salience of one's perceptual and mental experiences (Lutz, Jha, Dunne, & Saron, 2015). As expertise in meditation grows, these qualities are believed to pervade daily life and acquire a more trait‐like consistency, shaping one's ongoing experience in the world. A recent phenomenological study supports the idea that practitioners experience their mind as being more focused and clear when actively meditating than when at rest (Abdoun, Zorn, Poletti, Fucci, & Lutz, 2019). However, few studies have examined how these mental qualities develop over time with training, or whether they reflect stable cognitive traits that generalize to situations outside of formal meditation practice.
The spontaneous dynamics of the brain offer a framework for investigating how the organization and activity of functional brain networks support these developing states of awareness. Correlational and cross‐sectional studies have used magnetic resonance imaging (MRI) to describe patterns of functional connectivity during meditation and rest. One goal of this work has been to characterize the activity and connectivity of intrinsic brain networks that contribute to meditation‐related differences in cognitive function (Bauer, Whitfield‐Gabrieli, Diaz, Pasaye, & Barrios, 2019; Brewer et al., 2011; Garrison et al., 2015; Hasenkamp & Barsalou, 2012; Taylor et al., 2013). Several recent studies have also examined longitudinal changes in the organization and activity of structural and functional brain networks during periods of quiet rest following weeks or months of mindfulness training or meditation practice (Bauer et al., 2020; Kral et al., 2019; Taren et al., 2017; Valk et al., 2017).
By contrast, few studies of meditation have emphasized the time‐varying dynamics of functional brain networks, or their associations with the psychological transformations that accompany meditation‐based training (cf. Mooneyham et al., 2017). Instead, resting‐state studies of meditation have commonly employed functional MRI (fMRI) to characterize so‐called static functional network connectivity averaged over minutes of recording. However, the synchronized activity of the brain varies at much faster temporal scales; and importantly, moments of conscious experience that form the basis of meditative inquiry—such as fleeting perceptions, memories, and passing thoughts—are presumed to transpire within fractions of a second (Varela, 1999). Fortunately, the examination of these neurocognitive events and their supporting cortical systems is well‐suited to the millisecond time scale of the scalp‐recorded electroencephalogram (EEG).
One method for characterizing the spontaneous dynamics of electrophysiological functional brain networks involves the segmentation of EEG time series into brain electric microstates. Topographic patterns of EEG scalp voltage are known to vary over time in a dynamic but organized manner. Over brief timescales, the spatial distributions of particular head‐surface voltage topographies remain quasi‐stable for about 40–120 ms, before rapidly transitioning to other momentary configurations (Lehmann, 1971). These moments of topographic stability are known as microstates, and reflect topographically defined brain states of synchronized neuronal activity (for a review, see Michel & Koenig, 2018). Any change in the strength‐normalized topographic configuration of the scalp electric field suggests a change in the spatial distribution of active neural generators in the brain (Murray, Brunet, & Michel, 2008; Vaughan, 1982). Consequently, distinct topographic configurations of microstates reflect the activity of different neuronal networks. This makes characterizing moments of stability and change in scalp topography valuable because it enables the activity of distinct functional brain networks to be described in terms of their alternating temporal dynamics.
The decomposition of EEG time series into microstates has shown that a substantial portion of the observed topographic variance during periods of rest can be accounted for by four to seven data‐driven clusters, or configurations of distinct spatial topography. Indeed, the relative homogeneity of microstate configurations across studies of resting EEG is striking (Michel & Koenig, 2018), and is suggestive of a common electrophysiological functional network architecture in humans. Source localization and EEG‐informed fMRI methods have provided some indication of the brain generators that likely drive the voltage topographies of resting EEG microstates (Brechet et al., 2019; Britz, Van De Ville, & Michel, 2010; Custo et al., 2017; Yuan, Zotev, Phillips, Drevets, & Bodurka, 2012), which broadly align with the main hubs of fMRI‐derived resting‐state functional networks.
Microstate analysis affords a rich set of parameters for characterizing the dynamics of these electrophysiological brain states. These include the average activation strength, duration, and frequency with which microstates occur, among others. Past studies have associated these measures of microstate activity with information processing functions (e.g., Britz, Hernandez, Ro, & Michel, 2014), conscious cognitive acts (e.g., Brechet et al., 2019; Milz et al., 2016; Seitzman et al., 2017), states of alertness, arousal, perception, and meditation (e.g., Brodbeck et al., 2012; Comsa, Bekinschtein, & Chennu, 2019; Faber, Travis, Milz, & Parim, 2017; Zanesco, King, Skwara, & Saron, 2020), and spontaneous phenomenal experiences (e.g., Lehmann, Pascual‐Marqui, Strik, & Koenig, 2010; Lehmann, Strik, Henggeler, Koenig, & Koukkou, 1998; Pipinis et al., 2017). Importantly, one recent study found that 6 weeks of daily meditation practice led to clusters of optimal microstates with different topographic configurations in EEG collected at rest (Brechet et al., 2021).
The examination of microstates at rest may therefore provide insights into experience‐dependent changes in the dynamics of functional brain networks. More broadly, the complex succession of global brain states over time is thought to reflect how the brain and cognition are dynamically coupled with the world (Bressler & Kelso, 2016; Bressler & Menon, 2010; Rabinovich, Afraimovich, Bick, & Varona, 2012; Varela et al., 2001). Thus, ongoing cognitive function and the functional organization of brain networks should also be reflected in time series of microstates as brain states dynamically evolve over successive moments. In addition to metrics of averaged microstate dynamics, sequence analytic methods can quantify differences in sequences of microstate as they unfold over time.
In the present study, we examined the longitudinal effects of shamatha meditation training on felt states of awareness and the spontaneous dynamics of electrophysiological functional brain networks. We conducted two full‐time residential retreat interventions. During the first intervention, meditation practitioners were randomly assigned to engage in 3 months of training (6–10 hr daily) or to serve as waiting‐list controls. A second intervention was then held, in which wait‐list participants received their own training intervention. In both interventions, participants reported on their feelings of mindful attentiveness and serenity using a daily experience survey. In addition, training participants reported daily on four experiential dimensions of their meditation practice, which are commonly ascribed to focused‐attention (shamatha) meditation practices (Lutz et al., 2015): physical relaxation, mental relaxation, attentional stability, and attentional vividness. We expected meditation training to gradually increase these phenomenal aspects of meditation in practitioners' daily felt experience, coincident with their developing meditative expertise.
The fingerprints of practitioners' changing states of awareness may also be reflected in resting‐state electrophysiological dynamics. We collected resting broadband EEG at the beginning, middle, and end of each intervention, and segmented the EEG into microstates to estimate the activation strength of whole brain neuronal networks and their millisecond temporal dynamics. Relative to wait‐list controls, we expected differences to emerge in the strength, occurrence rate, and duration of microstates over the course of both interventions. However, due to limited prior research in this area, we had no hypotheses about whether such changes would be specific to a given microstate configuration or reflect more global changes to the dynamics of interacting microstates. As such, we also examined changes in the temporal patterning of microstates across the entire resting time series, and whether this patterning evolved differently for each group as a function of training. Finally, we explored whether longitudinal changes in experiential qualities of awareness were directly associated with the large‐scale neuronal dynamics of brain electric microstates. For all our analyses, we expected effects to replicate across both independent training interventions; results that do not replicate require corroboration from future research.
2. METHODS
2.1. Participants
Sixty individuals with prior meditation experience were recruited through advertisements in various Buddhist meditation centers and print and online publications. Participants were assigned to an initial training group (n = 30) or a waiting‐list control group (n = 30) through stratified random assignment. In the first of two 3‐month‐long interventions (Retreat 1), the initial training group lived onsite and practiced meditation at Shambhala Mountain Center in Red Feather Lakes, Colorado. During Retreat 1, the wait‐list participants traveled to the retreat center for week‐long assessments, but returned to their normal daily lives at home between assessments. Approximately 3 months after Retreat 1, these same control participants (n = 29) 1 received formally identical training during a second 3‐month intervention (Retreat 2) held at the same location. Group assignment occurred roughly 3 months prior to the beginning of Retreat 1.
The training and wait‐list participants were matched and assigned to groups on basic demographics (age, sex, handedness, and education) and prior meditation experience (see MacLean et al., 2010; Sahdra et al., 2011, for additional recruitment and participant details). The mean age was 48 years (range = 22–69), there were 28 males and 32 females, and 57 right‐handed (3 left‐handed) participants. All participants were required to have some prior meditation experience, including having previously attended a retreat by B. Alan Wallace, the meditation teacher who led the training in the present study. On average, participants had attended 14 prior meditation retreats and reported 2,610 total hours of estimated lifetime meditation experience (range = 200–15,000). All participants had normal or corrected‐to‐normal vision and hearing, and no known neurological or Axis I psychiatric diagnoses (based on the Mini International Neuropsychiatric Interview screen; Sheehan et al., 1998). We also confirmed that the groups did not differ on baseline measures of personality, cognitive control performance, or self‐reported anxiety, depression symptomology, and well‐being (see MacLean et al., 2010; Shields et al., 2020). Study procedures were approved by the Institutional Review Board of the University of California, Davis. All participants gave full informed consent and were compensated $20 per hour of data collection.
2.2. Meditation training
Participants received meditation training from B. Alan Wallace, an established Buddhist teacher and scholar. The training emphasized three shamatha techniques, which aim to foster calm sustained attention on a chosen object: (a) mindfulness of breathing, in which attention is drawn to the tactile sensations of the breath; (b) attending to the arising of mental content (e.g., thoughts, perceptions, sensations)—a technique known as settling the mind into its natural state; and (c) focusing attention on the sense of awareness itself, known as shamatha without a sign (Wallace, 2006). Participants also practiced complementary techniques, known collectively as the Four Immeasurables, which aim at generating compassion and benevolent aspirations for oneself and others.
While on retreat, participants were encouraged to maintain mindful awareness of their actions and surroundings throughout the day; met twice daily for group practice and discussion; and devoted an average of about 6 hr (SD = 1.5) of their remaining daily time to solitary shamatha meditation over the course of the entire retreat, based on estimates from daily experience surveys. Further details regarding the techniques employed and training time dedicated to different techniques can be found in Sahdra et al. (2011). B. Alan Wallace designed the structure of the training intervention but was not involved in data collection or analysis.
2.3. Procedure
All participants were assessed at the beginning, middle, and end of their respective training or wait‐list periods with a battery of self‐report, behavioral, and physiological laboratory measures (the results of which have been reported on elsewhere, e.g., MacLean et al., 2010; Sahdra et al., 2011; Saggar et al., 2012, 2015; Shields et al., 2020; Zanesco, King, MacLean, & Saron, 2018; Zanesco et al., 2019). At each assessment, testing took place across a 2‐day period, in two sound‐attenuated and darkened testing rooms located in the building where training participants lived and meditated. In addition, all participants were asked to complete a daily experience survey each evening for the duration of their training or wait‐list periods. Daily experience reports were included for a time period spanning from the end of the preassessment laboratory session (Day 5 after arrival) to the beginning of the postassessment laboratory session (Day 72 after arrival). During Retreat 1, the wait‐list control participants arrived 3 days (range = 65–75 hr) before each laboratory assessment to acclimatize to the moderate altitude (~2,400 m), diet, and natural surroundings of the retreat center.
Participants engaged in 4 min of silent rest at the start of each laboratory session. Participants were asked to sit quietly and comfortably with their eyes open or closed, with their hands on their lap, during four 1‐min epochs. A digital audio chime signaled the beginning and end of each epoch, presented in fixed order: eyes open, eyes closed, eyes closed, eyes open. To allow participants to settle into quiet rest—and to avoid confounds due to the temporal ordering of conditions—we limited our analyses to the two contiguous minutes of eyes closed rest. The eyes open epochs were not submitted to microstate clustering or analysis.
2.4. Daily experience questionnaire
The daily experience questionnaire included a modified list of 42 affect labels from the expanded Positive and Negative Affect Schedule (PANAS‐X; Watson & Clark, 1994). Participants rated how strongly each affect label described how they generally felt that day, from 1 (disagree strongly) to 7 (agree strongly). For the present analyses, we selected three items reflecting feelings of attentiveness (alert, attentive, focused) and three items reflecting feelings of serenity (at ease, calm, and serene). We then created daily composite scores for attentiveness and serenity by averaging items within these dimensions. 2 Active training participants were also asked to judge the quality of their meditation practice each day along four experiential dimensions: physical relaxation or comfort, mental relaxation or comfort, attentional stability, and attentional vividness. Ratings were made on a scale ranging from 1 (very poor) to 5 (very good).
Only daily records with complete responses for all six affect labels were retained for analysis of attentiveness and serenity; and only records with complete responses on all four self‐reported meditation qualities were retained for analysis of these qualities. Daily records provided on days of the laboratory sessions were excluded from analyses. If participants mistakenly provided duplicate records for the same calendar date (<0.6% of useable records in Retreat 1 or Retreat 2), scores were averaged across records for that day. Fifty‐nine participants had available data in Retreat 1 for attentiveness and serenity scores (M = 55.8 days, SD = 14.3 range = 10–66), and 29 training participants had available data in Retreat 2 (M = 64.2 days, SD = 1.4, range = 60–65). One control participant did not complete any of the daily questionnaires in Retreat 1. Thirty active training participants had available data in Retreat 1 for ratings of their meditation quality (M = 62.7 days, SD = 4.8, range = 47–66), and 29 training participants had available data in Retreat 2 (M = 63.4 days, SD = 1.8, range = 59–65).
2.5. EEG data collection and processing
Continuous EEG was recorded from 88 electrodes (custom equidistant montage; http://www.easycap.de) using the Biosemi Active2 system (http://www.biosemi.com), sampled at 2,048 Hz with 24‐bit resolution. Individual electrodes were localized in three dimensions using a Polhemus Patriot digitizer (http://www.polhemus.com). The two 1‐min epochs of eyes‐closed EEG were concatenated, average referenced, and band‐pass filtered offline between 0.1 Hz (12 dB/octave zero‐phase) and 200 Hz (24 dB/octave zero phase). EEG were screened for poor signal quality, and channels with intermittent connectivity or periods of extreme amplitude were removed. Several recordings with poor overall signal quality were also excluded from further preprocessing. A total of 169 recordings (out of 180) from 59 participants were retained for Retreat 1, with 119.32 s (SD = 2.11) of retained EEG, on average. For Retreat 2, a total of 81 recordings (out of 87) from 29 participants were retained, with 119.34 s (SD = 1.95) of EEG, on average.
After initial data screening, second‐order blind source identification (SOBI; Belouchrani, Abed‐Meriam, Cardoso, & Moulines, 1997) was used to remove additional non‐neural signal contaminants, including 60 Hz noise, and ocular and muscle artifacts. Details regarding the SOBI procedure can be found in Saggar et al. (2012). The 2 min of 88‐channel EEG data were then reconstructed absent putative sources of noise and transformed into a standard 81‐channel montage (international 10–10 system) using spherical spline interpolation. This transformation was performed to ensure that the location and number of channels were consistent across participants following the removal of channels with poor signal quality. Initial data processing and interpolations were conducted using Brain Electrical Source Analysis software (BESA 5.3; www.besa.de). Finally, the EEG were down sampled to 102.4 Hz, low‐pass filtered (40.0 Hz, 12 dB/octave), and spatially smoothed to reduce the influence of signal outliers in the electrode montage (see Michel & Brunet, 2019, for a description of spatial smoothing). These final processing steps were done using the Cartool software toolbox version 3.7 (Brunet, Murray, & Michel, 2011).
2.6. Topographic segmentation and microstate parameter estimation
Topographic identification of microstates was achieved through an adapted k‐means clustering method, implemented in Cartool. This method determines the optimal number of clusters (k) that can account for the greatest global explained variance (GEV) in the spatial time series using the smallest number of representative topographic maps (Michel, Koenig, & Brandeis, 2009; Murray et al., 2008). A schematic summarizing steps of this procedure is depicted in Figure 1. See also Zanesco (2020) for a previous application of this technique to microstate analysis of resting EEG.
FIGURE 1.
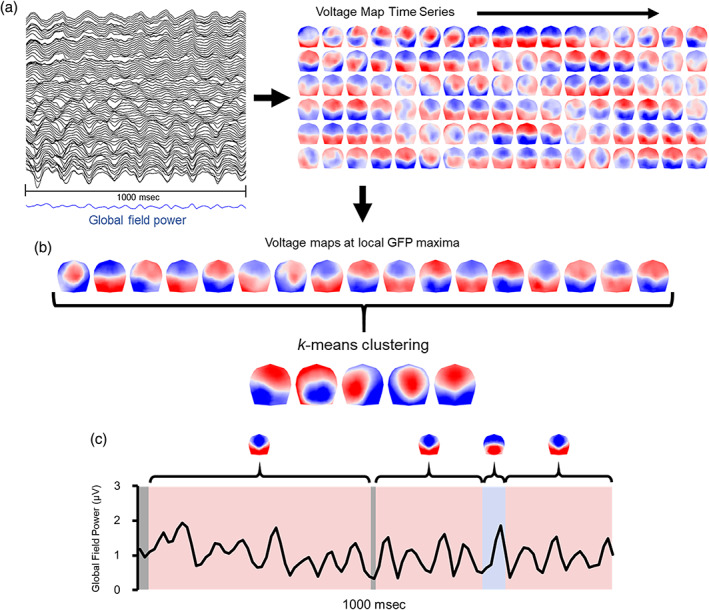
Schematic illustrating the method of topographic segmentation using 1 s of 81‐channel eyes‐closed rest taken from an individual electroencephalogram (EEG) recording at random. (a) The global field power (GFP) is calculated from the multichannel EEG and reflects a measure of the ongoing strength of the electric field. The time series succession of voltage maps is also derived from the EEG. Maps are 2D isometric projections with nasion upward. (b) Voltage maps at peaks of GFP are identified as periods of topographic quasi‐stability. k‐means clustering of maps at GFP peaks (polarity is ignored) identifies the optimal k clusters of voltage maps for that recording. The centroids of clusters from each recording are then submitted to a second k‐means clustering to identify the optimal k global clusters from among all recordings. (c) The original EEG time series is categorized according to which global cluster centroid best correlates with that instance in order to reexpress the multichannel EEG as a sequence of alternating microstates and derive measures of temporal dynamics from the categorized time series
To begin, topographic voltage maps were generated for each peak in the global field power (GFP) time series. This was done separately for each individual at each assessment. GFP is a reference‐independent measure of voltage potential (μV) that quantifies the strength of the scalp electric field at a given sample of the recording. The GFP is equivalent to the spatial SD of amplitude across the entire average‐referenced electrode montage (Skrandies, 1990). Maps were clustered at local GFP peaks because these moments provide optimal representations of the momentary quasi‐stable voltage topography (Zanesco, 2020).
2.6.1. Clustering of voltage maps
Each iteration of k‐means clustering proceeded as follows. A subset of 1–12 maps (k = [1:12]) was randomly selected from the total set of voltage maps for a given EEG recording, to use as initial centroids for clustering. The spatial correlation between the k centroid maps and the remaining voltage maps was then computed. Voltage maps were assigned to the centroid with which they had the highest spatial correlation, creating k clusters of maps. Maps were only assigned to a cluster if the spatial correlation with the centroid map exceeded 0.5; and correlation values were based on the relative topographical configuration but not the polarity of the maps by correcting the sign of the spatial correlation coefficients (Michel et al., 2009). After all correlations were calculated, k new centroids were created by averaging the constituent maps assigned to a given cluster. The process was repeated, such that each voltage map was compared to the recomputed (averaged) centroids and assigned again based on the correlation criterion. This process continued iteratively until the GEV between the average centroids and the maps converged to a limit.
This entire procedure was repeated 100 times for each value of k, with a new subset of k centroids selected for each iteration. After 100 iterations, the k set of centroids with maximal GEV was identified. This was repeated for each level of k = [1:12]. Across all levels of k (and for each individual and assessment), the optimal number of k clusters from the maximal GEV centroids was selected using a metacriterion defined by seven independent optimization criteria (see Brechet et al., 2019; Custo et al., 2017). This k‐means clustering revealed that four to seven topographies (M = 5.31, SD = 0.71) were the optimal number of k clusters for each individual EEG recording (totaling 1,327 topographies).
2.6.2. Clustering of subject‐level centroids
In a second step, we conducted k‐means clustering on the centroids identified through clustering of the subject‐level voltage maps. This was done to identify the optimal global clusters that best explain the subject‐level representative cluster centroids across all 250 recordings. A set of k = [1:15] maps were randomly selected from the set of subject‐level representative topographies and used as random centroids for clustering. For each level of k, 200 iterations were conducted, until the k centroids with the maximal GEV were selected. After all iterations, the optimal number of k global clusters was determined using the optimization metacriterion, resulting in a set of k global centroids that best represent the topographic configurations from all EEG recordings.
This second round of k‐means clustering identified six global clusters that together explained 82.14% of the GEV among the individual subject cluster centroids. These six clusters were selected as the optimal number based on the optimization metacriterion and appeared to be a good representation of the most common topographic patterns observed among participants across retreats. Figure 2 depicts the six global cluster centroids, which we named microstates A–F, along with the 1,321 individual subject cluster topographies grouped according to their global cluster membership. Six topographies went unassigned to a cluster.
FIGURE 2.
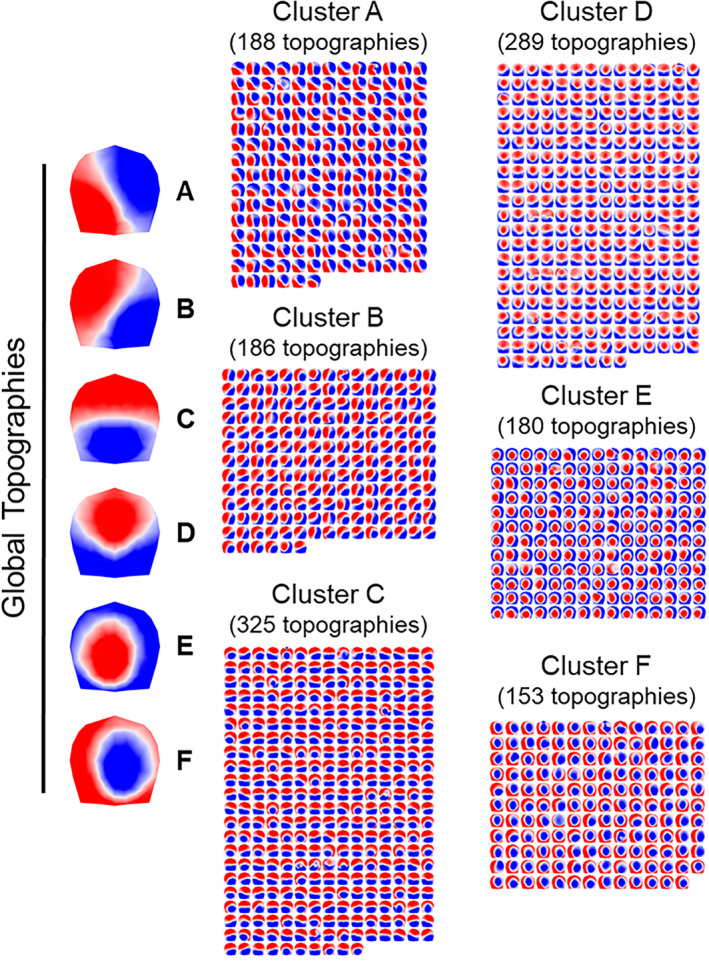
Six global cluster centroids were identified from k‐means clustering of 2 min of eyes‐closed rest from two retreat interventions. Here, 1,321 cluster centroids (A–F) derived from k‐means clustering of 250 separate recordings are shown grouped according to their global cluster membership. Each global topography is the centroid of respective clusters of maps. Maps are 2D isometric projections with nasion upward. Six cluster centroids went unassigned
2.6.3. Parameterization of the microstate time series
The six global centroids were then fit back to the original EEG recordings to derive time series sequences of microstates. All samples of a participant's continuous EEG were categorized by the global cluster topography that demonstrated the highest spatial correlation with a given sample‐wise voltage map. EEG samples that had low spatial correlations (<.5) with all global centroids were left unassigned; and polarity was again ignored during centroid assignment by correcting the sign of the correlation coefficient. Temporal smoothing was applied by ignoring assigned microstates that were present for less than three consecutive samples (30 ms), then splitting the time points between the preceding and subsequent microstates in the series. In addition to the continuous EEG, we also fit the six global centroids to the individual voltage maps associated with each peak of each participant's global field power.
We derived four microstate parameters from each subject‐level microstate time series. GEV is the percentage of observed variance in an individual's continuous EEG that is explained by a given global topographic centroid (i.e., microstate configuration). Mean microstate duration is the average duration (in ms) of contiguous samples categorized according to a specific global topography. Frequency of occurrence represents how many times per second, on average, a given microstate occurs in the continuous time series. Finally, mean global field power is the average of the fitted GFP peaks, and reflects the maximal field strength and degree of synchronization among the neural generators contributing to the voltage maps for each global topography. In prior work, mean microstate parameters calculated from 2 min of eyes closed EEG have demonstrated good reliability over two consecutive days (Liu et al., 2020). In the present study, reliabilities calculated over 3 months ranged from poor to excellent across measures and microstate configurations (see Supplementary Materials).
In Retreat 1, the six global cluster centroids were successfully assigned to 87.24% of samples from the continuous EEG time series (SD = 11.6%), and 96.9% of GFP peaks (SD = 6.2%), on average across participants. Of the 169 recordings, two were excluded from further analysis because a high percentage of voltage maps for the continuous time series (>69%) and GFP peaks (>42%) could not be assigned to a global cluster. For the remaining recordings, the six global microstate topographies explained an average total of 55.07% GEV for the continuous EEG time series (SD = 6.7%) and 71.84% GEV for the GFP peaks (SD = 6.8%). In Retreat 2, the centroids were successfully assigned to an average of 88.70% of continuous EEG samples (SD = 9.5%) and 97.81% of GFP peaks (SD = 3.0%). Additionally, the six global topographies explained an average of 56.3% GEV for the EEG time series (SD = 7.0%) and 73.0% GEV for the GFP peaks (SD = 6.4%).
2.7. Transition probabilities and microstate sequence analysis
In addition to the four global microstate parameters, we examined the dynamics of the microstate time series using Markov‐chain transition probabilities and sequence analysis.
2.7.1. Markov‐chain transition probabilities
First‐order Markov‐chain transition probabilities were calculated using the R package seqHMM (Helske & Helske, 2019). The probability that a given microstate transitions to another microstate was calculated for all 30 pairs of microstates. For these transition analyses, the microstate time series was transformed so that (a) the duration of each microstate was ignored by collapsing consecutive samples of the same microstate configuration into a single observation, (b) occurrences of consecutive microstate configurations were collapsed across unassigned epochs lasting for less than two consecutive samples (≤ 20 ms), and (c) unassigned epochs longer than two consecutive samples (≥30 ms) were included in the sequence time series, but transitions to these unassigned epochs were ignored.
2.7.2. Optimal matching and analyses of sequence dissimilarities
We employed a set of multivariate techniques to analyze time series sequences of microstates, accounting for both the frequency of occurrence of different microstates and their temporal ordering. Sequence analysis (Abbott & Tsay, 2000) enables the comparison of sets of multivariate symbolic data (e.g., a time series of symbolic states) by defining the dissimilarity between pairwise sets of sequences based on an edit distance. We calculated matrices of pairwise dissimilarities between entire (2 min) time series of microstates using the TraMineR package in R (Gabadinho, Ritschard, Müller, & Studer, 2011). Dissimilarities between sequences were determined using the optimal matching (OM) of spells algorithm (Studer & Ritschard, 2016). OM determines dissimilarity between pairs of sequences based on the minimal number of substitutions, insertions, and deletions required to transform one sequence into another. The Supplementary Materials provide a more detailed overview of OM methods applied to microstate sequences.
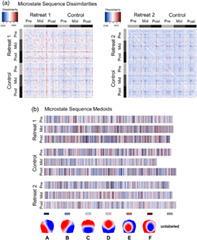
Figure 3 provides a schematic showing microstate sequences from a Retreat 1 training and control participant and their corresponding sequence dissimilarities. With sequence analysis, a descriptive measure of variance is calculated as the discrepancy among sequences. Discrepancy is calculated as the average dissimilarity of sequences from the distance center of a set of sequences. Greater discrepancy indicates that sequences are more heterogeneous on average between individuals. The sequence medoid can also be obtained to provide a visual representation of the most representative sequence for an entire grouping of sequences. The medoid in this instance refers to the least dissimilar sequence to all other sequences within its grouping. This makes the medoid similar to the median microstate sequence.
FIGURE 3.
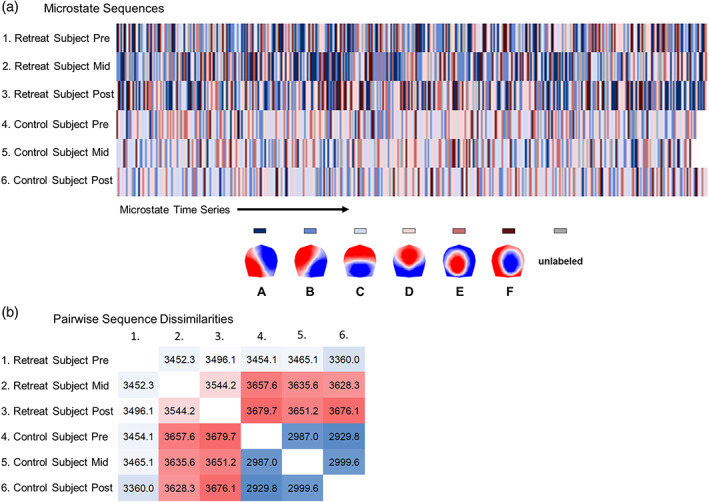
Schematic summarizing the calculation of pairwise dissimilarities between microstate sequences using optimal matching (OM) of spells. (a) Time series sequences of microstates are visualized on separate rows for two individuals at pre‐, mid‐, and postassessment. (b) Pairwise dissimilarities are shown for these six sequences based on OM. Sequences from mid‐ and postassessment for the Retreat 1 training participants are highly dissimilar from other sequences, and more heterogeneous overall (discrepancy = 1,165.85). Sequences from the control participants are less dissimilar from one another (discrepancy = 990.71), suggesting more homogeneous microstate sequences across assessments
Microstate sequence dissimilarities were compared between groups and assessments using multivariate distance matrix regression (MDMR; McArdle & Anderson, 2001; McArtor, Lubke, & Bergeman, 2017; Zapala & Schork, 2012) with the MDMR package in R (McArtor, 2018). MDMR is a person‐centered regression method that allows for the estimation of statistical associations between multivariate outcomes and categorical or continuous predictors based on dissimilarities among sets of data (McArtor et al., 2017). Dissimilarity in MDMR can be quantified from various distance measures (e.g., Euclidean distance or OM edit distance). When partitioning the sums of squares of dissimilarities in MDMR, dissimilarities were not squared because this is preferred when dissimilarity is based on edit distances (Studer, Ritschard, Gabadinho, & Müller, 2011). Mixed effects MDMR can also be used to account for hierarchical or dependent data (McArtor, 2018; McArtor et al., 2017).
2.8. Statistical analysis
We modeled linear changes in mean attentiveness, mean serenity, and the four experiential meditation qualities across sequential days of each intervention. Multilevel mixed effects models were implemented using PROC Mixed in SAS 9.4. Linear trajectories of change were described in terms of an intercept (i.e., starting point) and linear slope (i.e., rate of change). Fixed effects of day reflect the linear rate of change per day of retreat, and random effects of day were included to represent between‐person variability in slopes of daily change and covariance between slopes and the intercept. Model parameters were estimated using restricted maximum likelihood, and degrees of freedom were approximated by dividing the residual degrees of freedom into between‐person and within‐person components. For Retreat 1, fixed effects were referenced to the control group at the first day of the retreat.
Longitudinal changes in microstate parameters (GEV, GFP, duration, and occurrence) were also described using mixed effects models. Retreat 1 models included the between‐subjects fixed effect of group (training and control), and the within‐subjects effects of assessment (pre‐, mid‐, and postassessment) and microstate configuration (A, B, C, D, E, and F). For Retreat 2, we compared longitudinal changes in training participants to their own patterns of change as wait‐list controls (as a within‐subjects effect). We also compared transition probabilities between conditions for each microstate transition‐pair. Random subject intercepts were included to represent between‐person variability, and effects were referenced to the wait‐list control group at preassessment. Type III tests of fixed effects are reported for omnibus tests, and parameter estimates are given for simplified models of significant fixed effects. Because multilevel mixed models can accommodate missing data, we included all participants in our analyses who contributed data for any day or assessment of a given dependent measure.
We also assessed associations between longitudinal changes in daily experience (attentiveness and serenity) and changes in microstate parameters. For use as outcome measures, we calculated residualized changes in microstate parameters by regressing postassessment values on preassessment values and retained the unstandardized least squares residual estimates. We also obtained linear estimates of each participants' change in attentiveness and serenity across days of retreat from our longitudinal mixed models. These estimates reflect the empirical best linear unbiased predictors of the random effects solution (West, Welch, & Galecki, 2014), and were used to quantify person‐specific model‐estimated slopes. Bivariate correlations were then examined between these slope estimates and residual changes in microstate parameters for all individuals in each retreat.
For sequence analysis, we compared the fixed effects of group and assessment in Retreat 1 using mixed effects MDMR. Specifically, we examined the interaction terms that indicate whether the two groups changed differently in sequence dissimilarities from pre‐ to midassessment, and from pre‐ to postassessment. In Retreat 2, we compared changes in dissimilarities across assessments to participants' prior patterns of change as wait‐list controls. We followed up interaction terms with directed MDMR comparisons within each group separately, because: (a) the calculation of dissimilarities is potentially affected by group differences in edit costs, and (b) the partitions of sums of squares of dissimilarities are affected by the overall dissimilarity of sequences included in a given analysis. Finally, we assessed whether changes in sequence dissimilarities were moderated by longitudinal changes in attentiveness and serenity in Retreat 1 and Retreat 2.
3. RESULTS
3.1. Attentiveness, serenity, and qualities of meditation practice
We first examined longitudinal changes in self‐reported attentiveness and serenity, and qualities of meditation practice, across days of retreat. Figure 4 depicts longitudinal changes in attentiveness, serenity, and meditation qualities over days of Retreat 1. Figure 5 depicts similar changes over days of Retreat 2.
FIGURE 4.
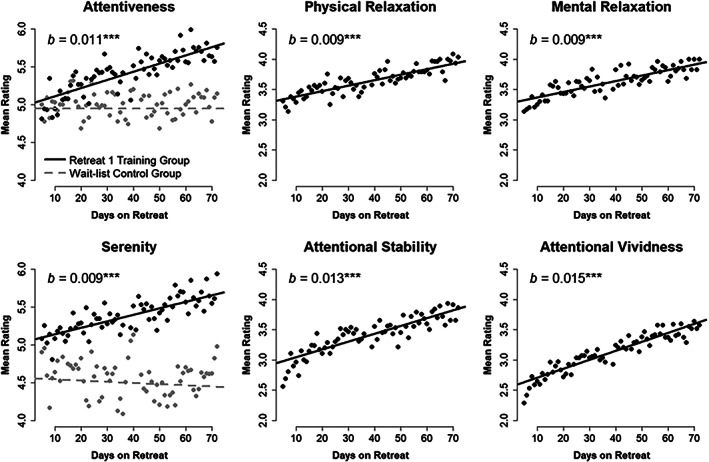
Mean self‐reported attentiveness and serenity for Retreat 1 training (n = 30) and wait‐list control (n = 29) groups across each day of retreat. Model estimated trajectories are plotted atop observed mean daily ratings. Estimates of daily linear change (b) are provided for retreat training participants. Four self‐reported qualities of meditation practice (physical relaxation, mental relaxation, attentional stability, and attentional vividness) are also shown for the training group. ***p < .001
FIGURE 5.
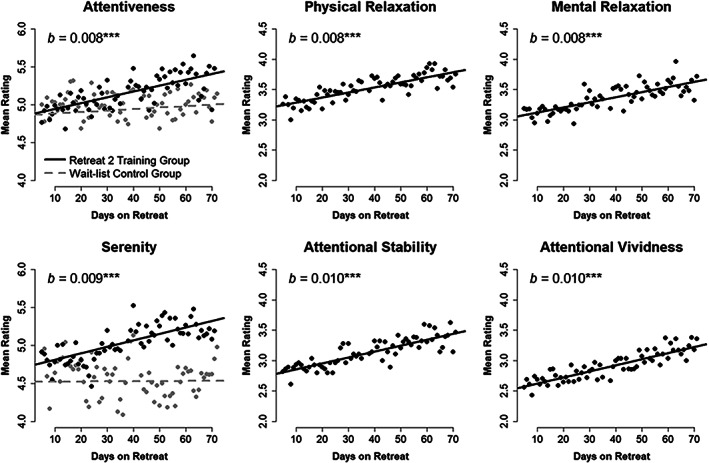
Mean self‐reported attentiveness and serenity for Retreat 2 training (n = 29) and Retreat 1 wait‐list control (n = 29) groups across each day of retreat. Model estimated trajectories are plotted atop observed mean daily ratings. Estimates of daily linear change (b) are provided for retreat training participants. Four self‐reported qualities of meditation practice (physical relaxation, mental relaxation, attentional stability, and attentional vividness) are also shown for the training group. ***p < .001
3.1.1. Felt attentiveness
In Retreat 1, the training (M = 5.413, SD = 0.653) and control (M = 4.942, SD = 0.700) groups differed significantly in observed mean attentiveness based on an independent‐samples t test, t(56.39) = 2.673, p = .010, d = 0.697, when averaged across the full intervention. A longitudinal mixed model showed that the intercept for wait‐list controls (b = 4.945, 95% CI [4.652, 5.238]) did not differ from the intercept for training participants (b = 0.058, p = .775, 95% CI [−0.349, 0.465]), and that controls did not change linearly over days of the intervention (b = 0.000, p = .983, 95% CI [−0.003, 0.003]). We did observe a significant interaction between linear change and group, suggesting that the training group increased significantly more over days of retreat than did the controls (b = 0.011, p < .001, 95% CI [0.006, 0.015]). Specifically, the training group was expected to linearly increase by 0.011 units of attentiveness each day (p < .001, 95% CI [0.008, 0.014]; see Figure 4). Subsequent estimates of each participants' linear daily change in attentiveness were obtained based on the random effects solution from this model.
In Retreat 2, participants increased linearly from an intercept of 4.857 (95% CI [4.540, 5.174]) by 0.008 units of attentiveness each day (p = .003, 95% CI [0.003, 0.013]). This model served as the basis for subsequent estimates of participant‐level slope outcomes. A separate model was used to contrast training participants in Retreat 2 with their experiences as wait‐list controls. This model showed that the intercept at the beginning of Retreat 1 (b = 4.861, 95% CI [4.570, 5.152]) did not differ from the intercept of Retreat 2 (b = 0.008, p = .906, 95% CI [−0.123, 0.138]), and confirmed that wait‐list controls did not change over days of Retreat 1 (b = 0.002, p = .297, 95% CI [−0.002, 0.006]). Importantly, we observed a significant interaction between linear change and retreat, indicating that participants increased significantly more over the course of Retreat 2 than when they acted as controls in Retreat 1 (b = 0.006, p < .001, 95% CI [0.003, 0.009]; see Figure 5). Retreat 2 participants therefore increased by 0.008 units of attentiveness each day (p < .001, 95% CI [0.004, 0.011]).
3.1.2. Felt serenity
The training (M = 5.383, SD = 0.649) and control (M = 4.485, SD = 0.927) groups differed significantly on mean serenity in Retreat 1 based on an independent‐samples t test, t(50.01) = 4.300, p < .001, d = 1.126. Moreover, a longitudinal model demonstrated that the intercept for controls (b = 4.559, 95% CI [4.202, 4.916]) did not differ from that of active training participants (b = 0.497, p = .050, 95% CI [0.001, 0.994]). As with attentiveness, controls did not change linearly over days (b = −0.002, p = .461, 95% CI [−0.006, 0.003]), and there was a significant interaction between linear change and group (b = 0.010, p < .001, 95% CI [0.004, 0.016]). The training group was expected to linearly increase by 0.009 units of serenity each day (p < .001, 95% CI [0.005, 0.012]; see Figure 4). Estimates of individuals' trajectory of change in serenity over days were based on this model.
In Retreat 2, training participants linearly increased by 0.009 units of serenity each day (p = .002, 95% CI [0.003, 0.014]). We obtained estimates of individuals' trajectory of change from this model. A separate model contrasting Retreat 2 training participants with their experiences during Retreat 1 showed that the intercept at the beginning of Retreat 1 (b = 4.521, 95% CI [4.187, 4.855]) differed from Retreat 2 (b = 0.203, p = .009, 95% CI [0.056, 0.350]), and that wait‐list controls did not change over days of Retreat 1 (b = 0.000, p = .953, 95% CI [−0.004, 0.004]). Again, we observed a significant interaction between linear change and retreat: training participants increased significantly more over the course of Retreat 2 than when they acted as controls in the first retreat (b = 0.008, p < .001, 95% CI [0.005, 0.012]; see Figure 5). Retreat 2 participants therefore increased by 0.009 units of attentiveness each day (p < .001, 95% CI [0.005, 0.013]).
3.1.3. Qualities of meditation practice
Mean values for self‐reported meditation qualities are presented in Table 1, separately by retreat group. For Retreat 1, longitudinal models indicated that the training group increased daily on each of the four self‐reported meditation qualities (see also Figure 4). Physical relaxation increased from an intercept of 3.294 (95% CI [3.023, 3.565]) by 0.009 units each day (p < .001, 95% CI [0.006, 0.012]). Mental relaxation increased from 3.282 (95% CI [2.997, 3.567]) by 0.009 units each day (p < .001, 95% CI [0.006, 0.012]). Attentional stability increased from 2.915 (95% CI [2.597, 3.234]) by 0.013 units each day (p < .001, 95% CI [0.009, 0.017]). And finally, attentional vividness increased from 2.560 (95% CI [2.239, 2.881]) by 0.015 units each day (p < .001, 95% CI [0.010, 0.019]).
TABLE 1.
Descriptive statistics and correlations for self‐reported states of awareness and meditation quality
| Correlations | ||||||
|---|---|---|---|---|---|---|
| Measure | Mean (SD) | 1 | 2 | 3 | 4 | 5 |
| Retreat 1 | ||||||
| 1. Attentiveness | 5.413 (0.653) | |||||
| 2. Serenity | 5.383 (0.649) | 0.677*** | ||||
| 3. Physical relaxation | 3.640 (0.530) | 0.728*** | 0.675*** | |||
| 4. Mental relaxation | 3.626 (0.574) | 0.795*** | 0.668*** | 0.927*** | ||
| 5. Attentional stability | 3.413 (0.596) | 0.853*** | 0.498** | 0.798*** | 0.871*** | |
| 6. Attentional vividness | 3.128 (0.688) | 0.617*** | 0.475** | 0.585*** | 0.694*** | 0.775*** |
| Retreat 2 | ||||||
| 1. Attentiveness | 5.156 (0.658) | |||||
| 2. Serenity | 5.036 (0.714) | 0.787*** | ||||
| 3. Physical relaxation | 3.520 (0.368) | 0.400* | 0.362 | |||
| 4. Mental relaxation | 3.356 (0.453) | 0.626*** | 0.585*** | 0.902*** | ||
| 5. Attentional stability | 3.128 (0.502) | 0.761*** | 0.631*** | 0.740*** | 0.896*** | |
| 6. Attentional vividness | 2.903 (0.641) | 0.540** | 0.515** | 0.594*** | 0.675*** | 0.803*** |
Note: Means and SDs (SD) for self‐reported attentiveness, serenity, and four qualities of meditation practice averaged across days of retreat for Retreat 1 (n = 30) and Retreat 2 (n = 29) training participants. Attentiveness and serenity were measured on a scale from 1 (disagree strongly) to 7 (agree strongly). Qualities of meditation practice were measured on a scale from 1 (very poor) to 5 (very good). Correlations are provided between measures.
p < .05.
p < .01.
p < .001.
The Retreat 2 training group replicated the patterns of self‐reported meditation qualities seen in Retreat 1 (see Figure 5). Physical relaxation increased from 3.200 (95% CI [3.000, 3.401]) at the intercept by 0.008 units each day (p < .001, 95% CI [0.005, 0.012]). Mental relaxation increased from 3.037 (95% CI [2.778, 3.296]) by 0.008 units each day (p < .001, 95% CI [0.004, 0.013]). Attentional stability increased from 2.761 (95% CI [2.503, 3.019]) by 0.010 units per day (p < .001, 95% CI [0.005, 0.014]). And attentional vividness increased from 2.520 (95% CI [2.226, 2.813]) by 0.010 units each day (p < .001, 95% CI [0.005, 0.015]).
Meditation qualities were themselves significant predictors of average self‐reported attentiveness and serenity in each training group. Correlations among individuals' means of these measures, averaged across days of retreat, are reported in Table 1. Meditation qualities were moderately to strongly correlated (r range = .36–.85) with mean attentiveness and serenity. Importantly, a series of bivariate growth curve models demonstrated that daily linear changes among attentiveness, serenity, and qualities of meditation were also highly correlated in their change over time for both training groups (r range = .46–.99; see Supplementary Materials). Together, these findings suggest that self‐reported meditation practice quality was related to attentiveness and serenity felt generally throughout one's day during retreat. Moreover, all patterns of change in daily experience appeared to replicate across the independent training interventions.
3.2. Microstate strength and temporal dynamics
Global parameters of GEV, mean GFP, mean duration, and frequency of occurrence were derived for microstates in Retreat 1 and then compared between groups and across assessments. We then attempted to replicate patterns of results from the first retreat when the wait‐list control group entered training in Retreat 2. Table 2 reports descriptive statistics for these microstate parameters and the number of participants contributing data at each assessment for Retreat 1. Table 3 reports comparable values for Retreat 2.
TABLE 2.
Descriptive statistics of microstate parameters in Retreat 1
| Training group | Control group | |||||
|---|---|---|---|---|---|---|
| Pre | Mid | Post | Pre | Mid | Post | |
| N | 26 | 28 | 28 | 29 | 28 | 28 |
| GEV (%) | ||||||
| A | 5.29 (2.6) | 5.77 (3.5) | 5.22 (3.2) | 4.64 (3.7) | 4.60 (2.6) | 5.12 (3.5) |
| B | 5.77 (2.6) | 6.56 (3.8) | 6.39 (3.5) | 5.61 (3.7) | 6.17 (3.3) | 5.99 (3.2) |
| C | 17.96 (12.5) | 16.35 (11.0) | 16.01 (10.9) | 19.98 (10.6) | 19.56 (12.0) | 20.74 (13.7) |
| D | 15.90 (8.6) | 16.55 (10.9) | 16.17 (10.5) | 16.56 (7.7) | 16.82 (7.0) | 14.93 (7.3) |
| E | 4.97 (2.4) | 4.61 (2.1) | 5.20 (3.0) | 4.53 (3.1) | 4.37 (3.4) | 4.54 (3.3) |
| F | 4.20 (2.1) | 4.60 (2.3) | 4.58 (2.5) | 4.56 (3.2) | 5.06 (3.9) | 4.46 (2.5) |
| Total | 54.08 (6.7) | 54.43 (6.2) | 53.56 (5.7) | 55.87 (6.3) | 56.57 (7.0) | 55.77 (7.9) |
| GFP (μV) | ||||||
| A | 5.25 (1.6) | 4.98 (1.4) | 4.83 (1.4) | 5.95 (2.0) | 6.08 (1.9) | 6.01 (1.7) |
| B | 5.35 (1.6) | 5.02 (1.5) | 4.96 (1.5) | 6.21 (2.1) | 6.32 (1.9) | 6.24 (1.8) |
| C | 6.12 (2.2) | 5.71 (1.9) | 5.60 (1.9) | 7.32 (2.7) | 7.31 (2.5) | 7.29 (2.5) |
| D | 6.00 (2.0) | 5.61 (1.8) | 5.56 (1.8) | 7.07 (2.3) | 7.15 (2.2) | 6.95 (2.2) |
| E | 5.11 (1.5) | 4.81 (1.4) | 4.82 (1.4) | 5.97 (1.9) | 5.84 (1.8) | 5.80 (1.6) |
| F | 5.14 (1.6) | 4.82 (1.4) | 4.84 (1.4) | 5.95 (1.9) | 6.01 (1.8) | 5.91 (1.6) |
| Average | 5.50 (1.7) | 5.16 (1.5) | 5.10 (1.5) | 6.41 (2.1) | 6.45 (2.0) | 6.37 (1.8) |
| Duration (ms) | ||||||
| A | 82.92 (9.1) | 79.22 (9.5) | 76.88 (11.4) | 85.73 (13.9) | 86.01 (11.6) | 85.20 (10.6) |
| B | 85.08 (8.5) | 79.91 (9.7) | 78.10 (11.6) | 88.05 (17.1) | 87.77 (13.2) | 85.83 (13.7) |
| C | 100.98 (22.8) | 91.48 (20.6) | 91.68 (23.0) | 107.73 (22.8) | 103.75 (21.0) | 106.77 (24.7) |
| D | 96.41 (14.2) | 91.60 (15.8) | 88.85 (13.2) | 98.95 (12.5) | 101.08 (11.4) | 97.89 (12.0) |
| E | 84.42 (8.3) | 79.34 (8.7) | 80.17 (11.6) | 85.91 (12.6) | 85.22 (13.4) | 85.25 (11.6) |
| F | 82.85 (8.4) | 79.94 (8.6) | 77.48 (11.7) | 86.01 (10.8) | 85.19 (12.9) | 85.09 (9.2) |
| Average | 88.78 (8.6) | 83.58 (9.7) | 81.19 (11.6) | 92.06 (12.3) | 91.50 (10.4) | 91.01 (9.2) |
| Occurrence (Hz) | ||||||
| A | 1.09 (0.4) | 1.23 (0.5) | 1.17 (0.5) | 0.92 (0.5) | 0.96 (0.3) | 1.03 (0.5) |
| B | 1.17 (0.4) | 1.32 (0.6) | 1.29 (0.5) | 1.03 (0.4) | 1.17 (0.4) | 1.13 (0.4) |
| C | 1.90 (0.6) | 1.93 (0.7) | 1.88 (0.6) | 1.98 (0.6) | 1.99 (0.7) | 1.95 (0.6) |
| D | 1.94 (0.5) | 2.01 (0.7) | 2.14 (1.1) | 2.01 (0.8) | 1.99 (0.6) | 1.81 (0.6) |
| E | 1.11 (0.4) | 1.14 (0.4) | 1.20 (0.4) | 0.95 (0.4) | 0.96 (0.4) | 0.99 (0.4) |
| F | 0.93 (0.3) | 1.07 (0.4) | 1.05 (0.4) | 0.97 (0.4) | 0.99 (0.5) | 0.97 (0.3) |
| Total | 8.14 (0.9) | 8.69 (1.2) | 8.73 (1.3) | 7.86 (0.9) | 8.05 (1.2) | 7.89 (1.2) |
Note: Means and SDs are provided for global explained variance (GEV %), global field power (GFP μV), microstate duration (in ms), and per‐second rate of microstate occurrence (Hz) for each microstate configuration (A–F). The sum of microstates is indicated by the total, and the mean of microstates is indicated by the average. N denotes the available sample size for Retreat 1 participants at each assessment.
TABLE 3.
Descriptive statistics of microstate parameters in Retreat 2
| Pre | Mid | Post | |
|---|---|---|---|
| N | 28 | 28 | 25 |
| GEV (%) | |||
| A | 4.27 (2.4) | 4.78 (2.5) | 4.85 (2.6) |
| B | 6.50 (3.4) | 6.52 (3.3) | 6.89 (3.7) |
| C | 19.41 (10.3) | 20.24 (10.6) | 19.56 (10.9) |
| D | 17.13 (7.9) | 16.26 (8.7) | 15.78 (5.6) |
| E | 4.67 (2.9) | 4.51 (3.4) | 4.44 (2.3) |
| F | 4.14 (2.9) | 4.21 (2.7) | 4.69 (3.0) |
| Total | 56.13 (7.2) | 56.52 (6.9) | 56.21 (7.2) |
| GFP (μV) | |||
| A | 5.82 (1.8) | 5.65 (1.7) | 5.90 (2.0) |
| B | 6.20 (1.9) | 5.94 (1.7) | 6.10 (2.0) |
| C | 7.16 (2.5) | 6.88 (2.3) | 7.03 (2.6) |
| D | 6.99 (2.3) | 6.58 (2.1) | 6.80 (2.3) |
| E | 5.77 (1.5) | 5.49 (1.6) | 5.81 (1.9) |
| F | 5.71 (1.6) | 5.54 (1.5) | 5.76 (1.7) |
| Average | 6.28 (1.9) | 6.01 (1.8) | 6.23 (2.0) |
| Duration (ms) | |||
| A | 84.64 (12.6) | 79.79 (10.8) | 80.00 (9.6) |
| B | 87.67 (10.1) | 81.89 (10.0) | 82.54 (8.9) |
| C | 102.13 (17.6) | 98.32 (17.3) | 96.65 (16.9) |
| D | 98.44 (13.3) | 92.23 (14.9) | 90.55 (11.1) |
| E | 84.90 (12.2) | 80.56 (10.2) | 79.07 (7.1) |
| F | 84.83 (12.5) | 78.69 (10.3) | 79.77 (8.1) |
| Average | 90.43 (10.2) | 85.25 (9.5) | 84.76 (7.6) |
| Occurrence (Hz) | |||
| A | 0.94 (0.4) | 1.06 (0.4) | 1.04 (0.4) |
| B | 1.17 (0.5) | 1.26 (0.4) | 1.33 (0.5) |
| C | 2.05 (0.6) | 2.14 (0.7) | 2.10 (0.7) |
| D | 2.00 (0.6) | 2.01 (0.7) | 2.11 (0.5) |
| E | 1.02 (0.4) | 1.07 (0.5) | 1.07 (0.3) |
| F | 0.90 (0.4) | 0.98 (0.4) | 1.01 (0.4) |
| Total | 8.08 (1.1) | 8.52 (0.9) | 8.66 (1.0) |
Note: Means and SDs are provided for global explained variance (GEV %), global field power (GFP μV), microstate duration (in ms), and per‐second rate of microstate occurrence (Hz) for each microstate configuration (A–F). The sum of microstates is indicated by the total, and the mean of microstates is indicated by average. N denotes the available sample size for Retreat 2 training participants at each assessment.
3.2.1. Global explained variance
We first compared the mean GEV of the global topographies for Retreat 1. We observed no significant effect of group, F(1, 57) = 0.68, p = .412, no significant effect of assessment, F(2, 104) = 0.04, p = .962, and a significant effect of microstate configuration, F(5, 285) = 158.18, p < .001. There was no significant interaction between group and assessment, F(2, 104) = 0.00, p = .997, and no other significant interactions between group, assessment, or microstate (all ps >.056). Accordingly, we report parameter estimates and mean comparisons from a simplified model based on the significant effects of microstate alone. These parameter estimates are reported in Table 4.
TABLE 4.
Model parameter estimates from analyses of microstate parameters in Retreat 1
| Estimate (SE) | ||||
|---|---|---|---|---|
| Model effects | GEV (%) | GFP (μV) | Duration (ms) | Occurrence (Hz) |
| Fixed effects | ||||
| Intercept | 18.449 (0.501)*** | 7.096 (0.322)*** | 103.900 (1.976)*** | 1.894 (0.049)*** |
| Microstate A | −13.350 (0.709)*** | −1.043 (0.076)*** | −17.758 (1.224)*** | −0.874 (0.056)*** |
| Microstate B | −12.368 (0.709)*** | −0.875 (0.076)*** | −16.299 (1.224)*** | −0.757 (0.056)*** |
| Microstate D | −2.290 (0.709)** | −0.168 (0.076)* | −4.626 (1.224)*** | 0.043 (0.056) |
| Microstate E | −13.752 (0.709)*** | −1.167 (0.076)*** | −17.048 (1.224)*** | −0.882 (0.056)*** |
| Microstate F | −13.870 (0.709)*** | −1.114 (0.076)*** | −17.656 (1.224)*** | −0.943 (0.056)*** |
| Group | — | −0.781 (0.454) | −2.630 (2.600) | 0.098 (0.047)* |
| Midassessment | — | −0.077 (0.077) | −0.878 (1.228) | — |
| Postassessment | — | −0.123 (0.076) | −0.974 (1.214) | — |
| Group × midassessment | — | −0.322 (0.110)** | −4.694 (1.754)** | — |
| Group × postassessment | — | −0.427 (0.110)*** | −6.322 (1.755)*** | — |
| Random effects | ||||
| Intercept variance | 0 | 2.949 (0.558) | 76.297 (15.777) | 0.017 (0.006) |
| Residual variance | 41.961 (1.880) | 0.487 (0.023) | 124.990 (5.785) | 0.259 (0.012) |
| −2 log‐likelihood | 6,579.0 | 2,416.5 | 7,789.1 | 1,557.1 |
Note: Maximum likelihood estimates are reported for Retreat 1 models of global explained variance (GEV %), global field power (GFP μV), microstate duration (in ms), and per‐second rate of microstate occurrence (Hz) for the fixed effects of group (training vs. wait‐list control), assessment (pre‐, mid‐, and postassessment), and microstate configuration (microstates A–F). The reference condition was microstate C in wait‐list participants at the preassessment. Then, 59 participants were included with a total of 1,002 observations contributing to the analyses. SEs are reported in parentheses.
p < .05.
p < .01.
p < .001.
We then compared the GEV for wait‐list control participants to their values as training participants in Retreat 2. We observed no significant effect of retreat, F(1, 28) = 0.01, p = .925, no significant effect of assessment, F(2, 58) = 0.02, p = .977, and a significant effect of microstate configuration, F(5, 145) = 209.38, p < .001. There was no significant interaction between retreat and assessment, F(2, 45) = 0.00, p = .997, and no other significant interactions between retreat, assessment, and microstate (all ps >.965). Parameter estimates are reported in Table 5 for the simplified model.
TABLE 5.
Model parameter estimates from analyses of microstate parameters in Retreat 2
| Estimate (SE) | ||||
|---|---|---|---|---|
| Model effects | GEV (%) | GFP (μV) | Duration (ms) | Occurrence (Hz) |
| Fixed effects | ||||
| Intercept | 19.918 (0.474)*** | 7.245 (0.352)*** | 104.970 (1.857)*** | 2.000 (0.048)*** |
| Microstate A | −15.217 (0.663)*** | −1.263 (0.085)*** | −19.059 (1.221)*** | −1.045 (0.053)*** |
| Microstate B | −13.657 (0.663)*** | −0.996 (0.085)*** | −17.004 (1.221)*** | −0.858 (0.053)*** |
| Microstate D | −3.666 (0.663)*** | −0.241 (0.085)*** | −6.051 (1.221)*** | −0.048 (0.053) |
| Microstate E | −15.412 (0.663)*** | −1.387 (0.085)*** | −19.119 (1.221)*** | −1.026 (0.053)*** |
| Microstate F | −15.406 (0.663)*** | −1.351 (0.085)*** | −19.355 (1.221)*** | −1.065 (0.053)*** |
| Retreat | — | −0.175 (0.084)* | −0.884 (1.211) | 0.077 (0.031)* |
| Midassessment | — | −0.083 (0.084) | −0.488 (1.210) | — |
| Postassessment | — | −0.110 (0.083) | −1.056 (1.205) | — |
| Retreat × midassessment | — | −0.275 (0.119)* | −5.469 (1.717)** | — |
| Retreat × postassessment | — | −0.007 (0.121) | −5.275 (1.745)** | — |
| Random effects | ||||
| Intercept variance | 0.130 (0.319) | 3.521 (0.930) | 63.330 (17.679) | 0.019 (0.007) |
| Residual variance | 36.505 (1.664) | 0.593 (0.027) | 123.730 (5.660) | 0.236 (0.011) |
| −2 log‐likelihood | 6,404.9 | 2,488.6 | 7,679.0 | 1,450.7 |
Note: Maximum likelihood estimates are reported for Retreat 2 models of global explained variance (GEV %), global field power (GFP μV), microstate duration (in ms), and per‐second rate of microstate occurrence (Hz) for the fixed effects of retreat (Retreat 2 training vs. Retreat 1 wait‐list control), assessment (pre‐, mid‐, and postassessment), and microstate configuration (microstates A–F). The reference condition was microstate C in wait‐list participants at the preassessment. Then, 30 participants were included with a total of 996 observations contributing to the analyses. SEs are reported in parentheses.
p < .05.
p < .01.
p < .001.
3.2.2. Mean global field power
We next compared the mean GFP of all local GFP maxima that were categorized according to different microstate configurations. In Retreat 1, we observed a significant effect of group, F(1, 57) = 5.26, p = .026, a significant effect of assessment, F(2, 104) = 19.84, p < .001, and a significant effect of microstate configuration, F(5, 285) = 88.91, p < .001. Importantly, we observed a significant interaction between group and assessment, F(2, 104) = 8.21, p < .001. We also observed a significant interaction between group and microstate, F(5, 285) = 3.92, p = .002. There were no other significant interactions (all ps >.996). Parameter estimates from a simplified model based on these significant effects are presented below and in Table 4.
Across Retreat 1 microstates, the groups showed no differences in mean GFP at the preassessment (b = −0.781 μV, p = .091, 95% CI [−1.691, 0.128]), and the control group did not significantly change from pre‐ to midassessment (b = −0.077 μV, p = .317, 95% CI [−0.230, 0.075]) or from pre‐ to postassessment (b = −0.123 μV, p = .108, 95% CI [−0.273, 0.027]). However, the training group decreased in GFP amplitude significantly more than controls from pre‐ to midassessment (b = −0.322 μV, p = .004, 95% CI [−0.539, −0.104]), and from pre‐ to postassessment (b = −0.427 μV, p < .001, 95% CI [−0.645, −0.210]). The mean microstate GFP of the training group was estimated to decrease by −0.399 μV from pre‐ to midassessment (p < .001, 95% CI [−0.554, −0.244]), and decrease by −0.550 μV from pre‐ to postassessment (p < .001, 95% CI [−0.707, −0.393]). In addition, the training group had significantly lower GFP at the midassessment (b = −1.103 μV, p = .017, 95% CI [−2.003, −0.203]), and at the postassessment (b = −1.209 μV, p = .009, 95% CI [−2.109, −0.309]), than controls. These findings can be interpreted as showing global reductions in the strength of the electric field at the GFP peaks of microstate intervals for training participants. Model estimated means and observed subject averages for these effects are depicted in Figure 6.
FIGURE 6.
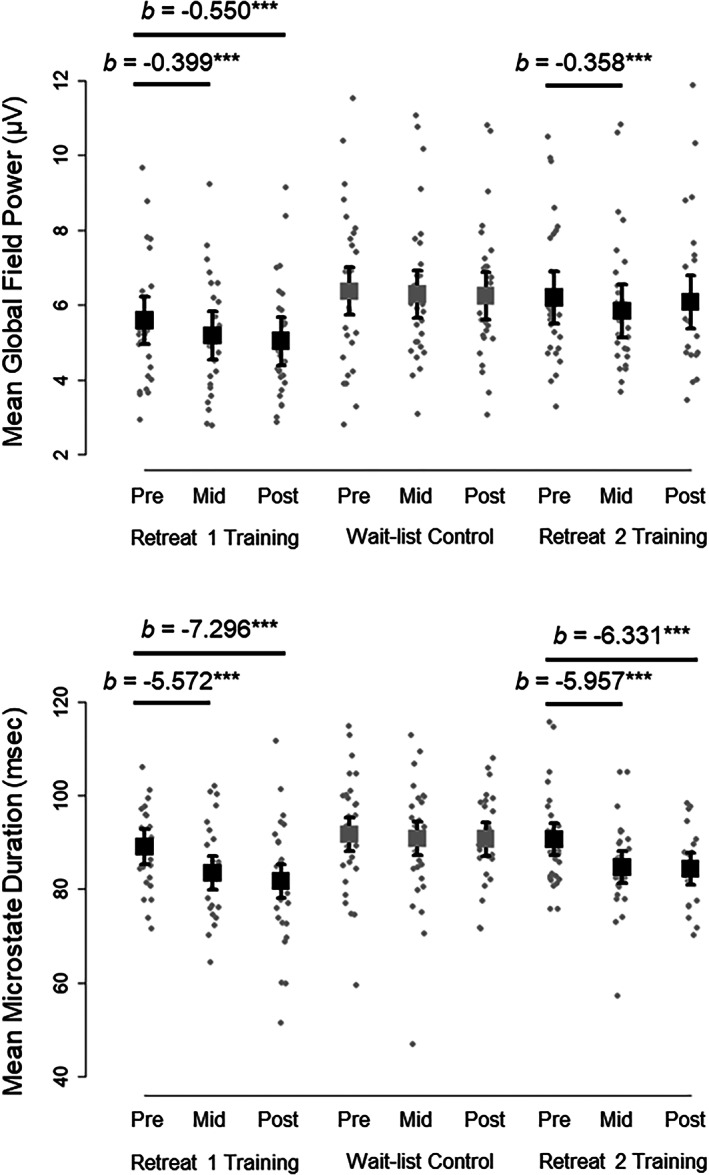
Model estimated means from multilevel mixed effects models are plotted for global field power for microstate peaks (top) and microstate interval duration (bottom) across assessments (pre‐, mid‐, and postassessment) and groups (training and control) in Retreat 1 and Retreat 2. Boxes are model estimates for the mean across microstate configuration. Errors bars are 95% confidence intervals around each model estimate. Observed subject averages are plotted as dots for each condition. Model estimates (b) for significant changes from pre‐ to midassessment and from pre‐to postassessment are provided above the observed data. ***p < .001
For the Retreat 2 participants, we observed a significant effect of retreat, F(1, 28) = 28.36, p < .001, a significant effect of assessment, F(2, 58) = 6.73, p = .002, and a significant effect of microstate configuration, F(5, 145) = 99.11, p < .001. Importantly, we observed a significant interaction between retreat and assessment, F(2, 45) = 3.34, p = .044. There were no other significant interactions (all ps >.975). We simplified the model and report parameter estimates below and in Table 5.
Retreat 2 participants showed significantly lower mean GFP amplitude (across all microstates) at the beginning of Retreat 2 than when they were wait‐list controls at the beginning of Retreat 1 (b = −0.175 μV, p = .047, 95% CI [−0.346, −0.003]). They also decreased in GFP amplitude from pre‐ to midassessment significantly more in Retreat 2 than they did as controls (b = −0.275 μV, p = .026, 95% CI [−0.514, −0.035]); but they did not decrease more from pre‐ to postassessment (b = −0.007 μV, p = .954, 95% CI [−0.250, 0.237]). The mean microstate GFP of the Retreat 2 training participants was estimated to decrease by −0.358 μV from pre‐ to midassessment (p < .001, 95% CI [−0.527, −0.189]), but not significantly decrease from pre‐ to postassessment (b = −0.117 μV, p = .187, 95% CI [−0.292, 0.058]). Nevertheless, they had significantly lower GFP at both the midassessment (b = −0.449 μV, p < .001, 95% CI [−0.620, −0.278]), and postassessment (b = −0.182 μV, p = .045, 95% CI [−0.359, −0.004]) of Retreat 2, compared to their prior measurements in the first retreat. Thus, global reductions in the strength of microstates at GFP peaks were observed in Retreat 2, replicating patterns observed in training participants from the first retreat (see Figure 6).
3.2.3. Mean duration
In Retreat 1, we observed a significant effect of group, F(1, 57) = 6.97, p = .011, a significant effect of assessment, F(2, 104) = 12.15, p < .001, and a significant effect of microstate configuration, F(5, 285) = 81.19, p < .001, on mean microstate duration. We also observed a significant interaction between group and assessment, F(2, 104) = 6.93, p = .002. There were no other no significant interactions (all ps >.071). Table 4 reports parameter estimates from a simplified model based on significant effects.
Considered across all microstates, the two groups showed no differences in mean duration at the preassessment in Retreat 1 (b = −2.630 ms, p = .316, 95% CI [−7.836, 2.576]), and the control group did not significantly change from pre‐ to midassessment (b = −0.878 ms, p = .476, 95% CI [−3.312, 1.557]), or from pre‐ to postassessment (b = −0.974 ms, p = .424, 95% CI [−3.381, 1.433]). In contrast, the training group decreased in mean microstate duration significantly more than controls from pre‐ to midassessment (b = −4.694 ms, p = .009, 95% CI [−8.173, −1.216]), and from pre‐ to postassessment (b = −6.322 ms, p < .001, 95% CI [−9.802, −2.841]). The mean microstate duration of the training group was estimated to decrease by −5.572 ms from pre‐ to midassessment (p < .001, 95% CI [−8.057, −3.087]), and decrease by −7.296 ms from pre‐ to postassessment (p < .001, 95% CI [−9.809, −4.782]). They also had significantly lower duration at the mid‐ (b = −7.324 ms, p = .006, 95% CI [−12.459, −2.190]), and postassessment (b = −8.951 ms, p < .001, 95% CI [−14.086, −3.817]), compared to controls. These findings suggest global reductions in the duration of microstate intervals on average for retreat training participants. Model estimated means and observed subject averages are depicted in Figure 6.
For Retreat 2, we observed a significant effect of retreat, F(1, 28) = 37.92 p < .001, a significant effect of assessment, F(2, 58) = 10.65, p < .001, and a significant effect of microstate configuration, F(5, 145) = 90.61, p < .001. We also observed a significant interaction between retreat and assessment, F(2, 45) = 6.37, p = .004. There were no other no significant interactions (all ps >.679). Parameter estimates from the simplified model are presented in Table 5.
Retreat 2 participants did not differ on average duration (across microstates) at the preassessment as a function of retreat (b = −0.884 ms, p = .472, 95% CI [−3.364, 1.597]). However, these individuals decreased in mean microstate duration significantly more from pre‐ to midassessment (b = −5.469 ms, p = .003, 95% CI [−8.927, −2.011]), and from pre‐ to postassessment (b = −5.275 ms, p = .004, 95% CI [−8.789, −1.761]) as active training participants than as wait‐list controls. The mean microstate duration of Retreat 2 training participants was estimated to decrease by −5.957 ms from pre‐ to midassessment (p < .001, 95% CI [−8.396, −3.518]), and decrease by −6.331 ms from pre‐ to postassessment (p < .001, 95% CI [−8.855, −3.806]). They had significantly lower mean duration at the midassessment (b = −6.353 ms, p < .001, 95% CI [−8.817, −3.888]), and postassessment (b = −6.159 ms, p < .001, 95% CI [−8.712, −3.605]) in Retreat 2, compared to themselves in Retreat 1. Thus, global reductions in the duration of microstates were also observed in Retreat 2, replicating patterns observed in the first retreat (see Figure 6).
3.2.4. Occurrence frequency
For Retreat 1, we observed a significant effect of group, F(1, 57) = 4.18, p = .046, no significant effect of assessment, F(2, 104) = 1.32, p = .271, and a significant effect of microstate configuration, F(5, 285) = 135.24, p < .001, on the mean rate of microstate occurrence. There was no significant interaction between group and assessment, F(2, 104) = 0.64, p = .527, and no other significant interactions (all ps >.149). Parameter estimates are reported in Table 4. Across all assessments, microstates occurred more frequently on average for training group participants than for controls (b = 0.098 Hz, p = .042, 95% CI [0.004, 0.191]).
Global reductions in microstate duration (as we showed in Retreat 1) ought to be accompanied by increases in the total occurrence of microstates overall, irrespective of particular microstate configuration. Therefore, for Retreat 1 participants, we also investigated the total rate of occurrence, summed across all microstates (see Table 2). We observed no significant effect of group, F(1, 57) = 3.99, p = .051, a significant effect of assessment, F(2, 104) = 8.48, p < .001, and a significant interaction between group and assessment, F(2, 104) = 4.13, p = .019. Groups did not differ at the preassessment on total occurrence rate (b = 0.266 Hz, p = .375, 95% CI [−0.330, 0.862]), and the control group did not significantly change from pre‐ to midassessment (b = 0.176 Hz, p = .169, 95% CI [−0.076, 0.429]), or from pre‐ to postassessment (b = 0.027 Hz, p = .829, 95% CI [−0.222, 0.277]). In contrast, the training group increased in total microstate occurrences more than controls from pre‐ to postassessment (b = 0.510 Hz, p = .006, 95% CI [0.149, 0.871]), but not from pre‐ to midassessment (b = 0.357 Hz, p = .052, 95% CI [−0.004, 0.718]). The total microstate occurrence rate of the training group was estimated to increase by 0.533 microstates per second from pre‐ to midassessment (p < .001, 95% CI [0.278, 0.791]), and increase by 0.537 from pre‐ to postassessment (p < .001, 95% CI [0.276, 0.798]). The training group also had significantly greater total occurrence at the midassessment (b = 0.623 Hz, p = .038, 95% CI [0.346, 1.212]), and postassessment (b = 0.776 Hz, p = .010, 95% CI [0.187, 1.364]), than controls.
We next compared the mean occurrence rate of microstates for wait‐list control participants across the two retreat interventions. We observed a significant effect of retreat, F(1, 28) = 6.29, p = .018, no significant effect of assessment, F(2, 58) = 1.37, p = .263, and a significant effect of microstate configuration, F(5, 145) = 178.94, p < .001. There was no significant interaction between retreat and assessment, F(2, 45) = 0.82, p = .447, and no other significant interactions (all ps >.720; see Table 5 for parameter estimates from the simplified model). On average, microstates occurred more frequently for individuals when they participated as Retreat 2 training participants than as wait‐list controls (b = 0.077 Hz, p = .020, 95% CI [0.013, 0.141]).
Finally, we also investigated the total rate of occurrence summed across all microstates for Retreat 2 participants. We observed a significant effect of retreat, F(1, 28) = 33.27, p < .001, a significant effect of assessment, F(2, 58) = 7.67, p = .001, and a significant interaction between group and assessment, F(2, 45) = 4.73, p = .014. Participants did not differ at the preassessment as a function of retreat (b = 0.151 Hz, p = .281, 95% CI [−0.130, 0.432]). Importantly, they increased in total microstate occurrence significantly more from pre‐ to postassessment when in training in Retreat 2 (b = 0.604 Hz, p = .004, 95% CI [0.206, 1.001]), but not from pre‐ to midassessment (b = 0.352 Hz, p = .077, 95% CI [−0.040, 0.744]). The total microstate occurrence rate of Retreat 2 training participants was estimated to increase by 0.604 microstates per second from pre‐ to postassessment (p = .004, 95% CI [0.206, 1.001]), but not significantly change from pre‐ to midassessment (b = 0.352 Hz, p = .077, 95% CI [−0.040, 0.744]). In addition, they had significantly greater total occurrence at the midassessment (b = 0.503 Hz, p < .001, 95% CI [0.224, 0.782]), and postassessment (b = 0.754 Hz, p < .001, 95% CI [0.465, 1.044]). Thus, the pattern observed in Retreat 2 again replicated that of the first retreat.
3.3. Experiential correlates of changes in microstate parameters
We correlated residualized changes in microstate mean GFP and duration (from pre‐ to postassessment) with individual estimates of daily linear changes in attentiveness and serenity obtained from random effects of mixed models. We focused on mean GFP and duration, since these were the parameters that showed consistent change across both retreat interventions. In Retreat 1 (n = 52), daily changes in attentiveness were not significantly correlated with change in mean microstate GFP (r = −.248, p = .076, 95% CI [−0.488, 0.026]) or change in mean microstate duration (r = −.272, p = .051, 95% CI [−0.507, 0.001]). Daily change in serenity, however, was significantly correlated with reductions in GFP (r = −.445, p < .001, 95% CI [−0.640, −0.195]) and duration (r = −.341, p = .013, 95% CI [−0.562, −0.075]). Scatterplots of these correlations are shown in Figure 7.
FIGURE 7.
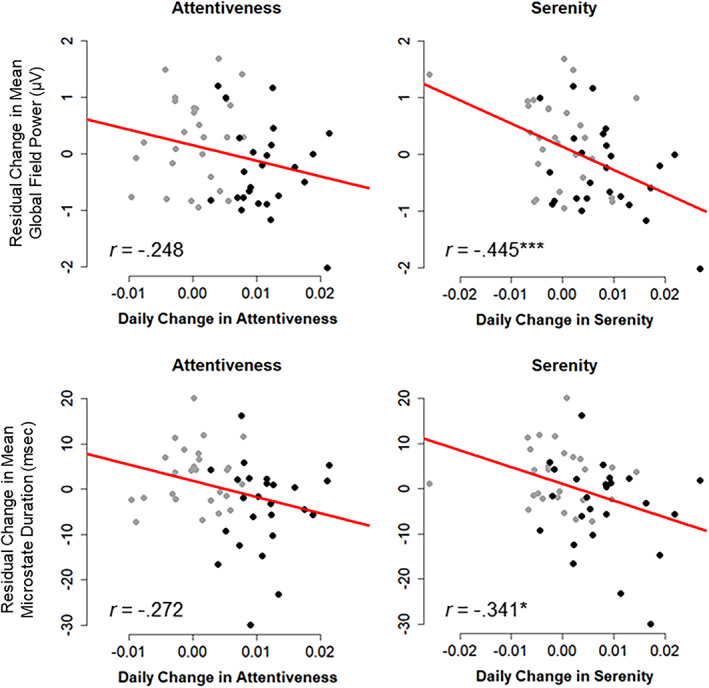
Scatterplots of residualized change (pre‐ to postassessment) in global field power for microstate peaks (top) and microstate interval duration (bottom) in Retreat 1 (n = 52), plotted against trajectories of linear daily change in attentiveness and serenity. Bivariate correlation coefficients (r) are provided. Training participants are depicted as black points and control participants as gray points. *p < .05, ***p < .001
In Retreat 2 (n = 24), attentiveness (r = −.028, p = .898, 95% CI [−0.426, 0.380]) and serenity (r = −.275, p = .194, 95% CI [−0.610, 0.145]) were not significantly correlated with reductions in GFP from pre‐ to postassessment. Nor were attentiveness (r = −.025, p = .908, 95% CI [−0.424, 0.382]) and serenity (r = −.205, p = .336, 95% CI [−0.562, 0.216]) significantly correlated with reductions in duration. Thus, these correlations did not replicate across retreats, although their magnitude and 95% CIs generally overlapped with those observed in the first retreat.
3.4. Microstate transition dynamics
3.4.1. Transition probabilities
Figure 8 depicts the mean Markov‐chain transition probabilities calculated from sets of microstate sequences for each group and retreat. Rows of the transition probability matrix reflect the total probability (i.e., each row sums to 1) of a transition from one microstate to every other microstate. We examined fixed effects of group, assessment, and the interaction between group and assessment for all 30 pairs of these Markov‐chain transition probabilities. For Retreat 1, we observed no significant main effects or interactions (all ps >.050) for any transition‐pair. In Retreat 2, we observed no significant effect of assessment (ps >.054), and no significant interactions between retreat and assessment (ps >.286) for any transition pair. There were, however, several significant differences between Retreat 1 and Retreat 2 for the wait‐list participant group (ps < .047). Compared to Retreat 1, these participants had fewer transitions from B → A (b = −0.015, p = .047, 95% CI [−0.029, −0.000]), F → A (b = −0.025, p = .005, 95% CI [−0.041, −0.008]), and C → F (b = −0.015, p = .038, 95% CI [−0.029, −0.001])—and more transitions from F → B (b = 0.023, p = .016, 95% CI [0.005, 0.041])—than they did in Retreat 2. Importantly, however, these findings did not replicate across both retreats.
FIGURE 8.
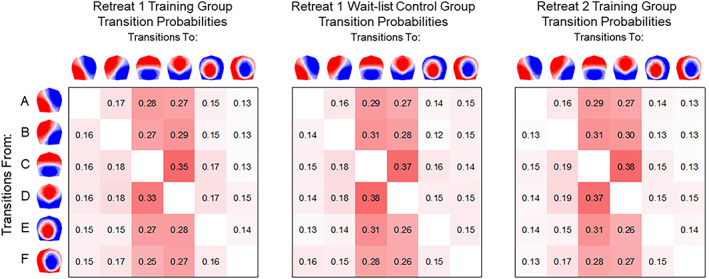
Mean Markov‐chain transition probabilities resting‐state microstates based on 167 sets of microstate sequences. Transition probabilities are shown from each microstate on the vertical axis to each corresponding microstate on the horizontal axis. Maps are 2D isometric projections with nasion upward
3.4.2. MDMR of microstate sequences
Figure 9 presents the observed microstate sequences for all participants as a function of condition. Brief occurrences of microstates and the complexity of their alternating dynamics are evident in the time series. Some sequences appear more homogeneous than others; but no obvious visual pattern differentiates assessments or groups overall. Figure 10 depicts pairwise sequence dissimilarities calculated between participants in each retreat, and the corresponding sequence medoid for each intervention group and assessment. The matrices were based on the OM of spells algorithm, with OM edit costs derived from the log of inverse state frequencies (see Supplementary Materials).
FIGURE 9.

Sequences of microstates are represented on individual rows for each participant as a function of the intervention groups and assessments. Each row represents the roughly 2‐min continuous microstate time series
FIGURE 10.
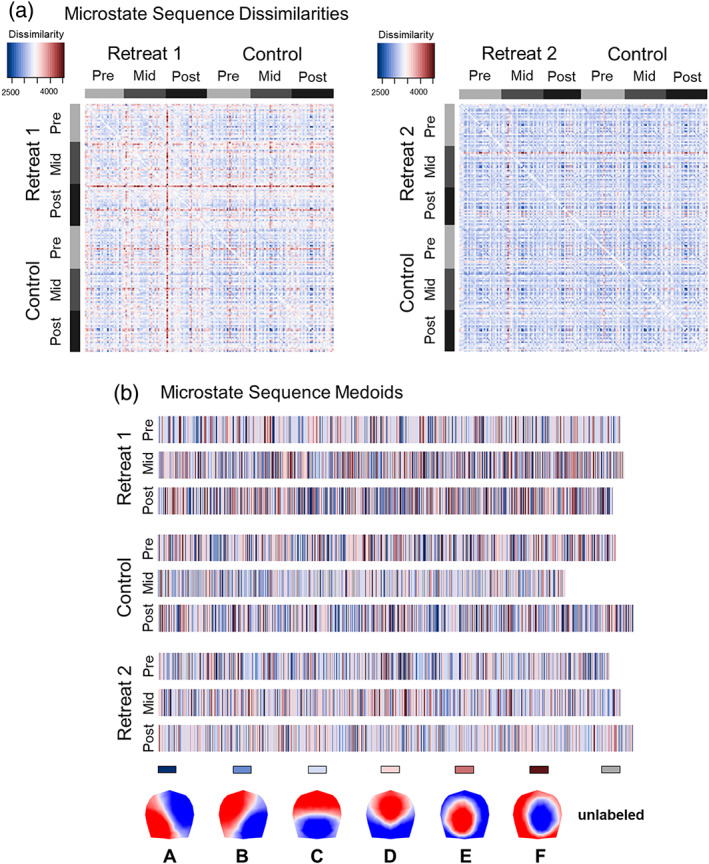
(a) Symmetrical matrices depict the pairwise dissimilarities between individuals' microstate sequences calculated based on optimal matching (OM) of spells. Dissimilarity matrices are organized according to study group and assessment. The matrix of dissimilarities for Retreat 1 are on the left and Retreat 2 on the right. (b) Microstate sequence medoids are shown for groupings of microstate sequences by intervention groups and assessments. The medoid is the actual sequence that is least dissimilar to all other sequences in its grouping and is therefore the most representative sequence of its group
MDMR analysis of sequence dissimilarities demonstrated significant interactions between Retreat 1 groups and assessments. Compared to controls, the training group showed a different pattern of change in dissimilarities from pre‐ to postassessment (p = .046), but not from pre‐ to midassessment (p = .279). Directed comparisons in the training group (with edit costs calculated independent of the control group) revealed that sequences significantly differed from pre‐ to postassessment (p < .001), but not from pre‐ to midassessment (p = .051). As such, the dissimilarity between multivariate distance centers was greater from pre‐ to postassessment (dissimilarity = 662.74) than from pre‐ to midassessment (633.78) or mid‐ to postassessment (607.21). In general, there was more overall discrepancy (i.e., dispersion around the distance center) between sequences at postassessment (discrepancy = 1,688.85) and midassessment (1,681.70), relative to the preassessment (1,636.73). In contrast, dissimilarities did not significantly differ from pre‐ to midassessment (p = .332) or pre‐ to postassessment for the control group (p = .300), and sequence discrepancy was comparable at the pre‐ (discrepancy = 1,628.28), mid‐ (1,609.76), and postassessment (1,640.61).
In contrast, Retreat 2 participants did not significantly differ in their change in dissimilarities from pre‐ to midassessment (p = .350) or from pre‐ to postassessment (p = .258), when compared to their status as wait‐list controls. Nevertheless, directed comparisons in Retreat 2 (with edit costs calculated independent of controls from Retreat 1) showed that dissimilarities significantly differed from pre‐ to postassessment in Retreat 2 (p = .026), but not from pre‐ to midassessment (p = .119). Dissimilarity between multivariate distance centers was greater from pre‐ to postassessment (dissimilarity = 635.75) than from pre‐ to midassessment (606.22) or mid‐ to postassessment (625.37). There was more overall discrepancy between sequences at postassessment (discrepancy = 1,651.63) and midassessment (1,647.05), relative to the preassessment (1,630.89). Thus, change from pre‐ to postassessment in the retreat training groups replicated across both retreats, and sequences appeared more heterogeneous (i.e., had more discrepancy) after retreat.
3.4.3. Experiential correlates of microstate sequences
Estimates of daily linear change in attentiveness and serenity were included as moderators of the effects of assessment on sequence dissimilarities in mixed effects MDMR. For Retreat 1 training participants, we observed significant interactions between serenity and differences in dissimilarities from pre‐ to midassessment (p = .042), as well as pre‐ to postassessment (p = .011). This suggests that daily changes in serenity moderated differences in dissimilarity between sequences. The interactions for attentiveness, however, did not reach significance for either pre‐ to midassessment (p = .081) or pre‐ to postassessment (p = .079). Retreat 1 training participants who increased an average amount in daily attentiveness (centered at b = 0.011) and serenity (b = 0.009) differed significantly in their sequence dissimilarities from pre‐ to midassessment (p = .014) and from pre‐ to postassessment (p < .001). In contrast, training participants who did not show daily change (bs centered at 0) differed from pre‐ to postassessment only (p = .028), but not from pre‐ to midassessment (p = .085).
For Retreat 2 training participants, we observed significant interactions between serenity and differences in dissimilarities from pre‐ to postassessment (p = .007) but not pre‐ to midassessment (p = .058). We also observed interactions between attentiveness and differences from pre‐ to postassessment (p = .027) but not pre‐ to midassessment (p = .091). Retreat 2 training participants who increased an average amount in daily attentiveness and serenity (bs centered at 0.008) differed significantly in their sequence dissimilarities from pre‐ to postassessment (p = .015) but not from pre‐ to midassessment (p = .059). Training participants who did not change (bs centered at 0) also differed from pre‐ to postassessment (p = .040) but not pre‐ to midassessment (p = .070). Across both retreats, these findings suggest that changes in the multivariate microstate sequence time series were different for training group participants who experienced greater levels of daily change in attentiveness and serenity over the course of their retreat.
4. DISCUSSION
In an intensive longitudinal study, we found that full‐time residential training in shamatha meditation reduced the strength and duration of brain electric microstates and differentiated their temporal patterning during periods of quiet rest. Microstates were derived by segmenting ongoing neuroelectric activity into a time series of transient intervals reflecting the spontaneous phase‐synchronized activity of whole‐brain neuronal networks. In addition, we observed changes in felt qualities of awareness that appear to corroborate phenomenological accounts of deepening mental calm and mindful attentiveness with contemplative training over time (Wallace, 1999, 2006). These increases in felt attentiveness and serenity were in turn associated with changes in the multivariate sequencing of entire time series of microstates. Critically, these patterns were replicated in a second 3‐month retreat in which wait‐list control participants received training of their own. Our findings provide robust evidence that dedicated meditation practice changes the felt experiences of meditation practitioners and leaves its imprint in the dynamic activity of functional brain networks.
Practitioners' daily attentiveness and serenity increased systematically during both retreats relative to wait‐list controls. Similar, correlated, increases were observed in the reported quality of participants' meditation practice each day. Together, these findings corroborate traditional perspectives on shamatha meditation, which hold that shamatha enhances the stability and vividness of an individual's concentration and cultivates states of physical and mental relaxation as expertise develops (Wallace, 2006). Participants who reported greater attentional stability and vividness—and who indicated greater self‐reported physical and mental relaxation during meditation practice—also reported greater levels of daily attentiveness and serenity during the retreat. Thus, during intensive practice, the qualities of one's meditation practice develop systematically over time and appear to generalize into dispositional experiences felt more generally throughout one's day. These increases in attentional stability, vividness, and felt daily attentiveness, are compatible with retreat‐related improvements in attention and perceptual sensitivity that have previously been reported in these same study participants using behavioral and event‐related potential methods (MacLean et al., 2010; Sahdra et al., 2011; Shields et al., 2020; Zanesco et al., 2018, 2019). Our findings also inform emerging phenomenological models that profile the distinctive feeling qualities associated with different meditation practices (Lutz et al., 2015), and join other recent studies investigating experiential qualities of meditation (Abdoun et al., 2019; Kok & Singer, 2017; Petitmengin, van Beek, Bitbol, Nissou, & Roepstorff, 2019; Przyrembel & Singer, 2018).
Consistent with prior work, we found that six data‐driven global topographic centroids explained the preponderance of variance in the resting topographic voltage patterns obtained from our 250 EEG recordings (for a review, see Michel & Koenig, 2018). Microstate clusters A through D match canonical patterns observed in prior research, while microstates E and F appear to reflect two distinct lateralized configurations, which share similarity to those identified in recent studies utilizing data‐driven approaches to determine the optimal number of clusters (cf. Brechet et al., 2019; Custo et al., 2017; Zanesco et al., 2020). However, there remained an appreciable amount of unexplained variance in the EEG in our study. This raises the possibility that other microstate configurations, not included among our data‐derived global clusters, may have further explained meaningful EEG patterns or demonstrated sensitivity to meditation training.
We observed global reductions in the strength and duration of microstate intervals following meditation training, irrespective of the configurations considered. The shorter duration of microstates was mirrored by an increase in their total occurrence. Reductions in the global field power at the peaks of microstate intervals can be interpreted as resulting from fewer phase‐synchronized neurons contributing (on average) to the strength of a given microstate as it predominates at that moment in time. Moreover, reductions in the average duration of microstates can be interpreted as reflecting less momentary temporal stability in the neural ensemble underlying the generation of each microstate (Khanna, Pascual‐Leone, Michel, & Farzan, 2015). Together, these findings imply that the brain generators responsible for the formation of brain electric microstates are less stable following 3 months of intensive meditation, manifesting as an increase in the frequency with which microstates precariously cycle between different configurations.
One interpretation of our findings is that meditation practitioners' tendency to calmly rest their awareness in the present moment might be realized in the increased lability of resting‐state microstate dynamics. It has been suggested that an increased lability might be an optimal condition for metastable brain dynamics, reflecting a continual state of inner exploration in which neural systems are readied for unpredictable external input (Deco, Jirsa, & McIntosh, 2011). This affords cortical function a flexibility that allows the brain to accommodate the contingencies of the present moment (Bressler & Kelso, 2001, 2016). Indeed, this flexibility appears to be meaningfully associated with states of awareness and cognitive function. More frequent switching among fMRI‐derived functional networks has been found to be associated with self‐reported states of attentiveness and arousal (Betzel, Satterthwaite, Gold, & Bassett, 2017) and better cognitive performance (Pedersen, Zalesky, Omidvarnia, & Jackson, 2018). Practitioners reporting greater levels of attentional absorption have also demonstrated reduced long‐range temporal dependencies (i.e., more random fluctuations) in EEG oscillations during meditation (Irrmischer et al., 2018).
Global changes in the strength, duration, and occurrence rate of microstates as a function of training replicated over two independent training interventions and did not depend on any specific microstate configuration.
Global changes such as these might reflect alterations in large‐scale brain processes that organize patterns of synchronization and neuronal excitability, as opposed to changes that are constrained to specific functional networks. This interpretation is also consistent with our results from multivariate sequence analyses of microstates, in which training participants from both retreats showed different temporal patterns in their microstate time series at the beginning of retreat than at the end of retreat. This demonstrates that dynamic temporal patterns in the whole sequence of categorically defined brain states differed in terms of their sequential evolution over successive moments. The microstate time series was more heterogeneous in retreat participants after training, in line with reduced duration and increased cycling between microstates overall. Microstate sequences (and their differences across training) were also found to be moderated by daily changes in serenity in both retreats, and by changes in attentiveness in the second retreat only. These findings suggest trait‐like increases in calm mindful attentiveness might moderate the rapidly fluctuating dynamics of microstate sequences at rest. Furthermore, they highlight the role that large‐scale dynamics of functional networks might play in practitioners' growing experience of attentiveness and serenity during retreat.
Although we observed differences in the multivariate sequencing of microstates, we did not find evidence for training‐related changes for any specific microstate transition probabilities. First‐order Markov transitions have been shown inadequate for describing the complex dynamics of microstate sequences, as microstate transitions are nonstationary, non‐Markovian, and display temporal dependencies at longer scales (von Wegner, Tagliazucchi, & Laufs, 2017). This suggests that our multivariate microstate sequence analysis differentiated sequences according to higher‐order dynamics that were invisible to a first‐order Markov process. Nevertheless, microstates C and D appeared to be important attractor states for ongoing brain network dynamics, since all other microstates were more likely to transition to these two configurations. This implies that these brain states may mediate interactions between other functional networks over temporal scales relevant to large‐scale neural integration.
We examined the consequences of an intensive bout or “dosage” of meditation practice on intrinsic brain network dynamics by investigating 3 months of full‐time residential retreat practice. However, the scenic retreat environment and the acute behavioral and social changes associated with participants' time in solitary meditation may have contributed to a number of nonspecific effects that could have influenced our outcomes. Residential retreat interventions provide a supportive and peaceful environment to help limit distraction and facilitate continued mindful awareness to ongoing experience (King, Conklin, Zanesco, & Saron, 2019). These elements might (indirectly) explain an unknown proportion of certain intervention outcomes, but they also directly support meditation‐related changes by facilitating continued practice, and calm, focused states of mind. One specific limitation of the present study in this regard is that the residential retreat took place at moderate altitude (~2,400 m). Altitude is a plausible environmental confound of neuroelectric measurements, as prior studies have demonstrated that the amplitude of EEG oscillations in various frequency bands are affected by rapid altitude ascent (e.g., Kaufman, Wesensten, Pearson, Kamimori, & Balkin, 1993) or prolonged exposure at more extreme altitudes (e.g., Zhao, Zhang, Qian, & Zhang, 2016). Yet, it is unclear how more moderate altitude might affect the temporal dynamics of microstates.
We attempted to reduce the influences of the quiet scenic environment and altitude on our study outcome measures by having wait‐list participants acclimatize for 3 days prior to each assessment. In addition, control participants were free to enjoy the natural scenery and interact with their control group peers during their week‐long stay at the retreat center. It is also likely that control participants shared many of the same expectations and motivations about meditation practice as those individuals who were assigned as active participants in the first retreat intervention. Wait‐list participants were stratified and randomly assigned to the control condition, but were also experienced meditators who continued their daily meditation practice at home in the interim between assessments. Wait‐list controls were matched with training participants on a number of demographic factors, including age, gender, education, handedness and prior meditation experience, and the groups did not differ along several major psychological dimensions (MacLean et al., 2010; Sahdra et al., 2011; Shields et al., 2020). Nevertheless, there was at least some evidence for an unexpected influence of retreat assignment on participants' felt experiences. In both retreats, we found higher initial levels of self‐reported serenity at the onset of training relative to wait‐list controls. GFP amplitude was also lower at the Retreat 2 preassessment, after wait‐list control participants began their own training. Future investigations of residential retreat interventions could better account for potential social, motivational, and environmental contributors by employing active (rather than passive) control conditions that are comparable in length and intensity to a residential intervention.
It is difficult to know what happens in a person's experience when they are asked to close their eyes and rest quietly. This inferential problem extends to the study of contemplative practice more broadly, where researchers have little recourse for corroborating experiential changes reported by practitioners. Moreover, most studies do not collect rich experiential data informed by meditative experiences. Methodological approaches that pair the phenomenological investigation (or manipulation) of conscious experiences with the analysis of microstate sequences hold promise for understanding how subjective experience unfolds at the millisecond temporal scale (Varela, 1996; Varela, Thompson, & Rosch, 2016). Contemplative practice itself might facilitate this scientific endeavor. Meditative expertise is thought to increase the veracity of introspective reports, as practitioners deepen their focus and familiarize themselves with a panoply of internal mental states (Abdoun et al., 2019; Lutz & Thompson, 2003; Varela et al., 2016). Our findings complicate this prospect, as states of awareness and properties of practitioners' brain network dynamics appear to change with training and differ at baseline from novices. Clearly, this is a rich area for future study, as the activity of microstates reflects neural integration at multiple temporal scales with many possible links to felt experiences and cognitive function.
Supporting information
Appendix S1. Supporting Information.
ACKNOWLEDGMENTS
We thank Stephen Aichele, David Bridwell, Tonya Jacobs, Baljinder Sahdra, and Katherine MacLean for their help collecting these data, and B. Alan Wallace for his many contributions to the study. Major support was provided by Fetzer Institute Grant #2191 and John Templeton Foundation Grant #39970; the Santa Barbara Institute for Consciousness Studies; and gifts from the Hershey Family, the Baumann, Tan Teo, Yoga Science, and Mental Insight Foundations, and anonymous and other donors all to C.D.S. We utilized the freely available Cartool software toolbox (cartoolcommunity.unige.ch) programmed by Denis Brunet, from the Functional Brain Mapping Laboratory, Geneva, Switzerland, and supported by the Center for Biomedical Imaging of Geneva and Lausanne.
Zanesco AP, Skwara AC, King BG, Powers C, Wineberg K, Saron CD. Meditation training modulates brain electric microstates and felt states of awareness. Hum Brain Mapp. 2021;42:3228–3252. 10.1002/hbm.25430
Funding information Fetzer Institute, Grant/Award Number: #2191; John Templeton Foundation, Grant/Award Number: #39970
ENDNOTES
One wait‐list control participant withdrew prior to participation in Retreat 2 for reasons unrelated to the intervention.
Our items overlapped with those from the original dimensions of the same name described in the PANAS‐X (Watson & Clark, 1994) for attentiveness (i.e., alert, attentive, concentrating, determined) and serenity (i.e., at ease, calm, and relaxed). We submitted our modified items to a confirmatory factor analysis (using the lavaan package in R; Rosseel, 2012), after averaging each item across days of retreat. Two latent factors representing attentiveness and serenity were a good fit of the data in Retreat 1 (n = 59), χ2(8) = 10.506, p = .231, CFI = .995, as well as in Retreat 2 (n = 29), χ2(8) = 14.97, p = .060, CFI = .968, and all indicators had strong positive loadings on their respective latent factor (R 2 range = .563–.975).
DATA AVAILABILITY STATEMENT
The data that support the findings of this study are available in the OSF repository and can be found at: https://osf.io/6j7at/
REFERENCES
- Abbott, A. , & Tsay, A. (2000). Sequence analysis and optimal matching methods in sociology: Review and prospect. Sociological Methods & Research, 29(1), 3–33. 10.1177/0049124100029001001 [DOI] [Google Scholar]
- Abdoun, O. , Zorn, J. , Poletti, S. , Fucci, E. , & Lutz, A. (2019). Training novice practitioners to reliably report their meditation experience using shared phenomenological dimensions. Consciousness and Cognition, 68, 57–72. 10.10106/j.concog.2019.01.004 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bauer, C. C. C. , Rosenkrantz, L. , Caballero, C. , Nieto‐Castanon, A. , Scherer, E. , West, M. R. , … Whitfield‐Gabrieli, S. (2020). Mindfulness training preserves sustained attention and resting state anticorrelation between default‐mode network and dorsolateral prefrontal cortex: A randomized controlled trial. Human Brain Mapping, 41, 5356–5369. 10.1002/hbm.25197 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bauer, C. C. C. , Whitfield‐Gabrieli, S. , Diaz, J. L. , Pasaye, E. H. , & Barrios, F. A. (2019). From state‐to‐trait meditation: Reconfiguration of central executive and default mode networks. eNeuro, 6(6), ENEURO.0335–ENEU18.2019. 10.1523/ENEURO.0335-18.2019 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Belouchrani, A. , Abed‐Meriam, K. , Cardoso, J. F. , & Moulines, E. (1997). A blind source separation technique using second‐order statistics. IEEE Transactions on Signal Processing, 45, 434–444. 10.1109/78.554307 [DOI] [Google Scholar]
- Betzel, R. F. , Satterthwaite, T. D. , Gold, J. I. , & Bassett, D. (2017). Positive affect, surprise, and fatigue are correlates of network flexibility. Scientific Reports, 7, 520. 10.1038/s41598-017-00425-z [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brechet, L. , Brunet, D. , Birot, G. , Gruetter, R. , Michel, C. M. , & Jorge, J. (2019). Capturing the spatiotemporal dynamics of task‐initiated thoughts with combined EEG and fMRI. NeuroImage, 194, 82–92. 10.1016/j.neuroimage.2019.03.029 [DOI] [PubMed] [Google Scholar]
- Brechet, L. , Ziegler, D. A. , Simon, A. J. , Brunet, D. , Gazzaley, A. , & Michel, C. M. (2021). Reconfiguration of electroencephalography microstate networks after breath‐focused, digital meditation training. Brain Connectivity. 11(2), 146–155. 10.1089/brain.2020.0848 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bressler, S. L. , & Kelso, J. A. S. (2001). Cortical coordination dynamics and cognition. Trends in Cognition Sciences, 5(1), 26–36. 10.1016/S1364-6613(00)01564-3 [DOI] [PubMed] [Google Scholar]
- Bressler, S. L. , & Kelso, J. A. S. (2016). Coordination dynamics in cognitive neuroscience. Frontiers in Neuroscience, 10, 397. 10.3389/fnins.2016.00397 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bressler, S. L. , & Menon, V. (2010). Large‐scale brain networks in cognition: emerging methods and principles. Trends in Cognitive Sciences, 14(6), 277‐290. 10.1016/j.tics.2010.04.004 [DOI] [PubMed] [Google Scholar]
- Brewer, J. A. , Worhunsky, P. D. , Gray, J. R. , Tang, Y. Y. , Weber, J. , & Kober, H. (2011). Meditation experience is associated with differences in default mode network activity and connectivity. Proceedings of the National Academy of Sciences of the United States of America, 108(50), 20254–20259. 10.1073/pnas.1112029108 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Britz, J. , Hernandez, L. D. , Ro, T. , & Michel, C. M. (2014). EEG‐microstate dependent emergence of perceptual awareness. Frontiers in Human Neuroscience, 8, 163. 10.3389/fnbeh.2014.00163 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Britz, J. , Van De Ville, D. , & Michel, C. M. (2010). BOLD correlates of EEG topography reveal rapid resting‐state network dynamics. NeuroImage, 52, 1162–1170. 10.1016/j.neuroimage.2010.02.052 [DOI] [PubMed] [Google Scholar]
- Brodbeck, V. , Kuhn, A. , von Wegner, F. , Morzelewski, A. , Tagliazucchi, E. , Borisov, S. , … Laufs, H. (2012). EEG microstates of wakefulness and NREM sleep. NeuroImage, 62(3), 2129–2139. 10.1016/j.neuroimage.2012.05.060 [DOI] [PubMed] [Google Scholar]
- Brunet, D. , Murray, M. M. , & Michel, C. M. (2011). Spatiotemporal analysis of multichannel EEG: CARTOOL. Computational Intelligence and Neuroscience, 2011, 2–15. 10.1155/2011/813870 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Comsa, I. M. , Bekinschtein, T. A. , & Chennu, S. (2019). Transient topographical dynamics of the electroencephalogram predict brain connectivity and behavioural responsiveness during drowsiness. Brain Topography, 32(2), 315–331. 10.1007/s10548-018-0689-9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Custo, A. , van de Ville, D. , Wells, W. M. , Tomescu, M. I. , Brunet, D. , & Michel, C. M. (2017). Electroencephalographic resting‐state networks: Source localization of microstates. Brain Connectivity, 7(10), 671–682. 10.1089/brain.2016.0476 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Damoiseaux, J. S. , Rombouts, S. A. R. B. , Barkhof, F. , Scheltens, P. , Stam, C. J. , Smith, S. M. , & Beckmann, C. F. (2006). Consistent resting‐state networks across healthy subjects. Proceedings of the National Academy of Sciences of the United States of America, 103(37), 13848–13853. 10.1073/pnas.0601417103 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Deco, G. , Jirsa, V. K. , & McIntosh, A. R. (2011). Emerging concepts for the dynamical organization of resting‐state activity in the brain. Nature Reviews Neuroscience, 12, 43–56. 10.1038/nrn2961 [DOI] [PubMed] [Google Scholar]
- Faber, P. L. , Travis, F. , Milz, P. , & Parim, N. (2017). EEG microstates during different phases of transcendental meditation practice. Cognitive Processing, 18(3), 307–314. 10.1007/s10339-017-0812-y [DOI] [PubMed] [Google Scholar]
- Fox, D. M. , Snyder, A. Z. , Vincent, J. L. , Corbetta, M. , Corbetta, M. , Van Essen, D. C. , & Raichle, M. E. (2005). The human brain is intrinsically organized into dynamic, anticorrelated functional networks. Proceedings of the National Academy of Sciences of the United States of America, 102(27), 9673–9678. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gabadinho, A. , Ritschard, G. , Müller, N. S. , & Studer, M. (2011). Analyzing and visualizing state sequences in R with TraMineR. Journal of Statistical Software, 40(4), 1–37. 10.18637/jss.v040.i04 [DOI] [Google Scholar]
- Garrison, K. A. , Zeffiro, T. A. , Scheinost, D. , Constable, R. T. , & Brewer, J. A. (2015). Meditation leads to reduced default mode network activity beyond an active task. Cognitive, Affective, & Behavioral Neuroscience, 15(3), 712–720. 10.3758/s13415-015-0358-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gethin, R. (1998). The foundations of Buddhism. Oxford, England: Oxford University Press. [Google Scholar]
- Hasenkamp, W. , & Barsalou, L. W. (2012). Effects of meditation experience on functional connectivity of distributed brain networks. Frontiers in Human Neuroscience, 6, 38. 10.3389/fnhum.2012.0038 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Helske, S. , & Helske, J. (2019). Mixture hidden Markov models for sequence data: The seqHMM package in R. Journal of Statistical Software, 88(3), 1–32. 10.18637/jss.v088.i03 [DOI] [Google Scholar]
- Irrmischer, M. , Houtman, S. J. , Mansvelder, H. D. , Tremmel, M. , Ott, U. , & Linkenkaer‐Hansen, K. (2018). Controlling the temporal structure of brain oscillations by focused attention meditation. Human Brain Mapping, 39, 1825–1838. 10.1002/hbm.23971 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kaufman, D. , Wesensten, N. J. , Pearson, N. R. , Kamimori, G. H. , & Balkin, T. J. (1993). Altitude and time of day effects on EEG spectral parameters. Physiology & Behavior, 54(2), 283–287. 10.1016/0031-9384(93)90112-s [DOI] [PubMed] [Google Scholar]
- Khanna, A. , Pascual‐Leone, A. , Michel, C. M. , & Farzan, F. (2015). Microstates in resting‐state EEG: Current states and future directions. Neuroscience & Biobehavioral Reviews, 49, 105–113. 10.1016/j.neubiorev.2014.12.010 [DOI] [PMC free article] [PubMed] [Google Scholar]
- King, B. G. , Conklin, Q. A. , Zanesco, A. P. , & Saron, C. D. (2019). Residential meditation retreats: Their role in contemplative practice and significance for psychological research. Current Opinion in Psychology, 28, 238–244. 10.1016/j.copsyc.2018.12.021 [DOI] [PubMed] [Google Scholar]
- Kok, B. E. , & Singer, T. (2017). Phenomenological fingerprints of four meditations: Differential states changes in affect, mind‐wandering, meta‐cognition, and interoception before and after daily practice across 9 months of training. Mindfulness, 8(1), 218–231. 10.1007/s12671-016-0594-9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kral, T. R. A. , Imhoff‐Smith, T. , Dean, D. C. , Grupe, D. , Adluru, N. , Patsenko, E. , … Davidson, R. J. (2019). Mindfulness‐based stress reduction‐related changes in posterior cingulate resting brain connectivity. Social Cognitive and Affective Neuroscience, 14(7), 777–787. 10.1093/scan/nsz050 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lehmann, D. (1971). Multichannel topography of human alpha EEG fields. Electroencephalography and Clinical Neurophysiology, 31(5), 439–449. 10.1016/0013-4694(71)90165-9 [DOI] [PubMed] [Google Scholar]
- Lehmann, D. , Pascual‐Marqui, R. D. , Strik, W. K. , & Koenig, T. (2010). Core networks for visual‐concrete and abstract thought content: A brain electric microstate analysis. NeuroImage, 49(1), 1073–1079. 10.1016/j.neuroimage.2009.07.054 [DOI] [PubMed] [Google Scholar]
- Lehmann, D. , Strik, W. M. , Henggeler, B. , Koenig, T. , & Koukkou, M. (1998). Brain electric microstates and momentary conscious mind states as building blocks of spontaneous thinking: I. Visual imagery and abstract thoughts. International Journal of Psychophysiology, 29(1), 1–11. 10.1016/S0167-8760(97)00098-6 [DOI] [PubMed] [Google Scholar]
- Liu, J. , Xu, J. , Zou, G. , He, Y. , Zou, Q. , & Gao, J. (2020). Reliability and individual specificity of EEG microstate characteristics. Brain Topography, 33, 438–449. 10.1007/s10548-020-00777-2 [DOI] [PubMed] [Google Scholar]
- Lutz, A. , Jha, A. P. , Dunne, J. D. , & Saron, C. D. (2015). Investigating the phenomenological matrix of mindfulness‐related practices from a neurocognitive perspective. American Psychologist, 70(7), 632–658. 10.1037/a0039585 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lutz, A. , & Thompson, E. (2003). Neurophenomenology: Integrating subjective experience and brain dynamics in the neuroscience of consciousness. Journal of Consciousness Studies, 10(9–10), 31–52. [Google Scholar]
- MacLean, K. A. , Ferrer, E. , Aichele, S. R. , Bridwell, D. A. , Zanesco, A. P. , Jacobs, T. L. , … Saron, C. D. (2010). Intensive meditation training improves perceptual discrimination and sustained attention. Psychological Science, 21, 829–839. 10.1177/0956797610371339 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mantini, D. , Perucci, M. G. , del Gratta, C. , Romani, G. L. , & Corbetta, M. (2007). Electrophysiological signatures of resting state networks in the human brain. Proceedings of the National Academy of Sciences of the United States of America, 104(32), 13170–13175. 10.1073/pnas.0700668104 [DOI] [PMC free article] [PubMed] [Google Scholar]
- McArdle, B. H. , & Anderson, M. J. (2001). Fitting multivariate models to community data: A comment on distance‐based redundancy analysis. Ecology, 82(1), 290–297. 10.1890/0012-9658(2001)082[0290:FMMTCD]2.0.CO;2 [DOI] [Google Scholar]
- McArtor, D. B. (2018). MDMR: Multivariate distance matrix regression. R package version 0.5.1. Retrieved from https://CRAN.R-project.org/package=MDMR
- McArtor, D. B. , Lubke, G. H. , & Bergeman, C. S. (2017). Extending multivariate distance matrix regression with an effect size measure and the asymptotic null distribution of the test statistic. Psychometrika, 82(4), 1052–1077. 10.1007/s11336-016-9527-8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Michel, C. M. , & Brunet, D. (2019). EEG source imaging: A practical review of the analysis steps. Frontiers in Neurology, 10, 325. 10.3389/fneur.2019.00325 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Michel, C. M. , & Koenig, T. (2018). EEG microstates as a tool for studying the temporal dynamics of whole‐brain neuronal networks: A review. NeuroImage, 180, 577–593. 10.1016/j.neuroimage.2017.11.062 [DOI] [PubMed] [Google Scholar]
- Michel, C. M. , Koenig, T. , & Brandeis, D. (2009). Electric neuroimaging in the time domain. In Michel C. M., Koenig T., Brandeis D., Gianotti L. R. R., & Wackermann J. (Eds.), Electrical neuroimaging (pp. 111–144). Cambridge, England: Cambridge University Press. 10.1017/CBO9780511596889 [DOI] [Google Scholar]
- Milz, P. , Faber, P. L. , Lehmann, D. , Koenig, T. , Kochi, K. , & Pascual‐Marqui, R. D. (2016). The functional significance of EEG microstates—Associations with modalities of thinking. NeuroImage, 125, 643–656. 10.1016/j.neuroimage.2015.08.023 [DOI] [PubMed] [Google Scholar]
- Mooneyham, B. W. , Mrazek, M. D. , Mrazek, A. J. , Mrazek, K. L. , Phillips, D. T. , & Schooler, J. W. (2017). States of mind: Characterizing the neural bases of focus and mind‐wandering through dynamic functional connectivity. Journal of Cognitive Neuroscience, 29(3), 495–506. 10.1162/jocn_a_01066 [DOI] [PubMed] [Google Scholar]
- Murray, M. M. , Brunet, D. , & Michel, C. M. (2008). Topographic ERP analyses: A step‐by‐step tutorial review. Brain Topography, 20(4), 249–264. 10.1007/s10548-008-0054-5 [DOI] [PubMed] [Google Scholar]
- Pedersen, M. , Zalesky, A. , Omidvarnia, A. , & Jackson, G. D. (2018). Multilayer network switching rate predicts brain performance. Proceedings of the National Academy of Sciences of the United States of America, 115(52), 13376–13381. 10.1073/pnas.1814785115 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Petitmengin, C. , van Beek, M. , Bitbol, M. , Nissou, J. M. , & Roepstorff, A. (2019). Studying the experience of meditation through micro‐phenomenology. Current Opinion in Psychology, 28, 54–59. 10.1016/j.copsyc.2018.10.009 [DOI] [PubMed] [Google Scholar]
- Pipinis, E. , Melynyte, S. , Koenig, T. , Jarutyte, L. , Linkenkaer‐Hansen, K. , Ruksenas, O. , & Griskova‐Bulanova, I. (2017). Association between resting‐state microstates and ratings on the Amsterdam resting‐state questionnaire. Brain Topography, 30(2), 245–248. 10.1007/s10548-016-0522-2 [DOI] [PubMed] [Google Scholar]
- Przyrembel, M. , & Singer, T. (2018). Experiencing meditation—Evidence for differential effects of three contemplative mental practices in micro‐phenomenological interviews. Consciousness and Cognition, 62, 82–101. 10.1016/j.concog.2018.04.004 [DOI] [PubMed] [Google Scholar]
- Rabinovich, M. I. , Afraimovich, V. S. , Bick, C. , & Varona, P. (2012). Information flow dynamics in the brain. Physics of Life Reviews, 9(1), 51–73. 10.1016/j.plrev.2011.11.002 [DOI] [PubMed] [Google Scholar]
- Rosseel, Y. (2012). Lavaan: An R package for structural equation modeling and more. Journal of Statistical Software, 48(2), 1–36. 10.18637/jss.v048.i02 [DOI] [Google Scholar]
- Saggar, M. , King, B. G. , Zanesco, A. P. , MacLean, K. A. , Aichele, S. R. , Jacobs, T. L. , … Saron, C. D. (2012). Intensive training induces longitudinal changes in meditation state‐related EEG oscillatory activity. Frontiers in Human Neuroscience, 6, 256. 10.3389/fnhum.2012.00256 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Saggar, M. , Zanesco, A. P. , King, B. G. , Bridwell, D. A. , MacLean, K. A. , Aichele, S. R. , … Miikkulainen, R. (2015). Mean‐field thalamocortical modeling of longitudinal EEG acquired during intensive meditation training. NeuroImage, 114, 88–104. 10.1016/j.neuroimage.2015.03.073 [DOI] [PubMed] [Google Scholar]
- Sahdra, B. K. , MacLean, K. A. , Ferrer, E. , Shaver, P. R. , Rosenberg, E. L. , Jacobs, T. L. , … Saron, C. D. (2011). Enhanced response inhibition during intensive meditation training predicts improvements in self‐reported adaptive socioemotional functioning. Emotion, 11(2), 299–312. 10.1037/a0022764 [DOI] [PubMed] [Google Scholar]
- Seitzman, B. A. , Abell, M. , Bartley, S. C. , Erickson, M. A. , Bolbecker, A. R. , & Hetrick, W. P. (2017). Cognitive manipulation of brain electric microstates. NeuroImage, 146, 533–543. 10.1016/j.neuroimage.2016.10.002 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sheehan, D. V. , Lecruibier, Y. , Sheehan, K. H. , Amorim, P. , Janavs, J. , Weiller, E. , … Dunbar, G. C. (1998). The Mini‐International Neuropsychiatric Interview (M.I.N.I.): The development and validation of a structured diagnostic psychiatric interview for DSM‐IV and ICD‐10. Journal of Clinical Psychiatry, 59(Suppl 20), 22–33. [PubMed] [Google Scholar]
- Shields, G. S. , Skwara, A. C. , King, B. G. , Zanesco, A. P. , Dhabar, F. S. , & Saron, C. D. (2020). Deconstructing the effects of concentration meditation practice on interference control: The roles of controlled attention and inflammatory activity. Brain, Behavior, and Immunity, 89, 256–267. [DOI] [PubMed] [Google Scholar]
- Skrandies, W. (1990). Global field power and topographic similarity. Brain Topography, 3(1), 137–141. 10.1007/BF01128870 [DOI] [PubMed] [Google Scholar]
- Studer, M. , & Ritschard, G. (2016). What matters in differences between life trajectories: A comparative review of sequence dissimilarity measures. Journal of the Royal Statistical Society, 179(2), 481–511. 10.1111/rssa.12125 [DOI] [Google Scholar]
- Studer, M. , Ritschard, G. , Gabadinho, A. , & Müller, N. S. (2011). Discrepancy analysis of state sequences. Sociological Methods & Research, 40(3), 471–510. 10.1177/0049124111415372 [DOI] [Google Scholar]
- Taren, A. A. , Gianaros, P. J. , Greco, C. M. , Lindsay, E. K. , Fairgrieve, A. , Brown, K. W. , … Creswell, D. J. (2017). Mindfulness meditation training and executive control network resting state functional connectivity: A randomized controlled trial. Psychosomatic Medicine, 79(6), 674–683. 10.1097/PSY.0000000000000466 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Taylor, V. A. , Daneault, V. , Grant, J. , Scavone, G. , Breton, E. , Roffe‐Vidal, S. , … Beauregard, M. (2013). Impact of meditation training on the default mode network during a restful state. Social Cognitive and Affective Neuroscience, 8(1), 4–14. 10.1093/scan/nsr/087 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Valk, S. L. , Bernhardt, B. C. , Trautwein, F. M. , Böckler, A. , Kanske, P. , Guizard, N. , … Singer, T. (2017). Structural plasticity of the social brain: Differential change after socio‐affective and cognitive mental training. Science Advances, 3(19), e1700489. 10.1126/sciadv.1700489 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Varela, F. (1996). Neurophenomenology: A methodological remedy for the hard problem. Journal of Consciousness Studies, 3, 330–349. [Google Scholar]
- Varela, F. (1999). Present‐time consciousness. Journal of Consciousness Studies, 6, 111–140. [Google Scholar]
- Varela, F. , Lachaux, J. P. , Rodriguez, E. , & Martinerie, J. (2001). The brainweb: Phase synchronization and large‐scale integration. Nature Reviews Neuroscience, 2(4), 229–239. 10.1038/35067550 [DOI] [PubMed] [Google Scholar]
- Varela, F. , Thompson, E. , & Rosch, E. (2016). The embodied mind: Cognitive science and human experience. Cambridge, MA: MIT Press. [Google Scholar]
- Vaughan, H. G. (1982). The neural origins of human event‐related potentials. Annals of the New York Academy of Sciences, 388(1), 125–138. 10.1111/j.1749-6632.tb50788.x [DOI] [PubMed] [Google Scholar]
- von Wegner, F. , Tagliazucchi, E. , & Laufs, H. (2017). Information‐theoretical analysis of resting state EEG microstate sequences ‐non‐Markovianity, non‐stationarity and periodicities. NeuroImage, 158, 99–111. 10.1016/j.neuroimage.2017.06.062 [DOI] [PubMed] [Google Scholar]
- Wallace, B. A. (1999). The Buddhist tradition of Samatha: Methods for refining and examining consciousness. Journal of Consciousness Studies, 6, 175–187. [Google Scholar]
- Wallace, B. A. (2006). The attention revolution. Boston, MA: Wisdom Publications. [Google Scholar]
- Wallace, B. A. , & Shapiro, S. L. (2006). Mental balance and well‐being: Building bridges between Buddhism and Western psychology. American Psychologist, 61(7), 690–701. 10.1037/0003-066X.61.7.690 [DOI] [PubMed] [Google Scholar]
- Watson, D. , & Clark, L. A. (1994). The PANAS‐X: Manual for the positive and negative affect schedule‐expanded form. Ames, IA: The University of Iowa. [Google Scholar]
- West, B. T. , Welch, K. B. , & Galecki, A. T. (2014). Linear mixed models: A practical guide using statistical software (2nd ed.). New York, NY: CRC Press. [Google Scholar]
- Yuan, J. , Zotev, V. , Phillips, R. , Drevets, W. C. , & Bodurka, J. (2012). Spatiotemporal dynamics of the brain at rest—Exploring EEG microstates as electrophysiological signatures of BOLD resting state networks. NeuroImage, 4(1), 2062–2072. 10.1016/j.neuroimage.2012.02.031 [DOI] [PubMed] [Google Scholar]
- Zanesco, A. P. (2020). EEG electric field topography is stable during moments of high field strength. Brain Topography, 33, 430–460. 10.1007/s10548-020-00780-7 [DOI] [PubMed] [Google Scholar]
- Zanesco, A. P. , King, B. G. , MacLean, K. A. , & Saron, C. D. (2018). Cognitive aging and long‐term maintenance of attentional improvements following meditation training. Journal of Cognitive Enhancement, 2(3), 259–275. 10.1007/s41465-018-0068-1 [DOI] [Google Scholar]
- Zanesco, A. P. , King, B. G. , Powers, C. , de Meo, R. , Wineberg, K. , MacLean, K. A. , & Saron, C. D. (2019). Modulation of event‐related potentials of visual discrimination by meditation training and sustained attention. Journal of Cognitive Neuroscience, 31(8), 1184–1204. 10.1162/jocn_a_01419 [DOI] [PubMed] [Google Scholar]
- Zanesco, A. P. , King, B. G. , Skwara, A. C. , & Saron, C. D. (2020). Within and between‐person correlates of the temporal dynamics of resting EEG microstates. NeuroImage, 211(1), 116631. 10.1016/j.neuroimage.2020.116631 [DOI] [PubMed] [Google Scholar]
- Zapala, M. A. , & Schork, N. J. (2012). Statistical properties of multivariate distance matrix regression for high‐dimensional data analysis. Frontiers in Genetics, 3, 190. 10.3389/fgene.2012.00190 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao, J. P. , Zhang, R. , Qian, Y. , & Zhang, J. X. (2016). Characteristics of EEG activity during high altitude hypoxia and lowland reoxygenation. Brain Research, 1648, 243–249. 10.1016/j.brainres.2016.07.013 [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Appendix S1. Supporting Information.
Data Availability Statement
The data that support the findings of this study are available in the OSF repository and can be found at: https://osf.io/6j7at/