

Abstract
Objective: To introduce an MRI in-plane resolution enhancement method that estimates High-Resolution (HR) MRIs from Low-Resolution (LR) MRIs. Method & Materials: Previous CNN-based MRI super-resolution methods cause loss of input image information due to the pooling layer. An Autoencoder-inspired Convolutional Network-based Super-resolution (ACNS) method was developed with the deconvolution layer that extrapolates the missing spatial information by the convolutional neural network-based nonlinear mapping between LR and HR features of MRI. Simulation experiments were conducted with virtual phantom images and thoracic MRIs from four volunteers. The Peak Signal-to-Noise Ratio (PSNR), Structure SIMilarity index (SSIM), Information Fidelity Criterion (IFC), and computational time were compared among: ACNS; Super-Resolution Convolutional Neural Network (SRCNN); Fast Super-Resolution Convolutional Neural Network (FSRCNN); Deeply-Recursive Convolutional Network (DRCN). Results: ACNS achieved comparable PSNR, SSIM, and IFC results to SRCNN, FSRCNN, and DRCN. However, the average computation speed of ACNS was 6, 4, and 35 times faster than SRCNN, FSRCNN, and DRCN, respectively under the computer setup used with the actual average computation time of 0.15 s per 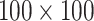
Keywords: Autoencoder, convolution neural network, deep learning, MRI, super resolution
I. Introduction
Magnetic Resonance Imaging (MRI) has superior soft tissue contrast versus x-ray-based imaging techniques such as Computed Tomography (CT) and cone beam CT [1]. MRIs can be acquired continuously without the risks of ionizing radiation. Therefore, MRI-guided Radiation Therapy (MRIgRT) is preferred for treating tumors that are affected by motion, including lung tumors located near critical or radiosensitive organs i.e. organs at risk (OARs) such as the esophagus, heart, or major vessels [1]. Currently, a cine of a single image plane containing the tumor is acquired to gate radiation dose delivery in MRIgRT. However, treatment gating is desired using the entire tumor volume and neighboring OARs to minimize errors associated with through-plane tumor motion. Thus, real-time four-dimensional (4D) MRI is being developed for MRIgRT. 4D MRI typically suffers from low spatial resolution (e.g., ≥ 3.5 mm in-plane resolution) due to the constraints of k-space acquisition, temporal resolution, and system latency [2]. Therefore, new techniques are required to optimize the spatial and temporal resolution of 4D MRI in MRIgRT.
Real-time 4D acquisitions are being accelerated using under-sampled non-Cartesian k-space trajectories and compressed sensing or iterative image reconstruction methods [3], [4]. Unfortunately, these techniques require computationally intensive and time-consuming image reconstruction algorithms [3]. Super-Resolution (SR) is a potential solution for the Low spatial Resolution (LR) problem [5]–[12]. Specifically, there is a demand for recovery of missing resolution information on each slice of MRI, which is considered an in-plane resolution problem [8].
Deep learning-based single image SR methods have been recently introduced in computer vision [9]–[12]. Deep learning is a new breakthrough technology that is a branch of machine learning [13], [14]. Many existing deep learning studies have addressed various applications such as classification, detection, tracking, pattern recognition, image segmentation, and parsing. They have also demonstrated robust performance of deep learning compared to other machine learning tools. In medical imaging, many deep learning-based frameworks have been introduced for feature extraction, anatomical landmark detection, and segmentation [15]–[17]. Recently, deep learning-based single image SR methods for medical imaging have been actively explored [18]–[28].
In this paper, we propose an in-plane SR method for MRI, called Autoencoder-inspired Convolutional Network-based SR (ACNS) and investigate the relationship between the network architecture, i.e., intra-layer structure and depth, and its performance. The proposed method estimates High-Resolution (HR) MRI slices from the LR MRI slices according to a scaling factor. ACNS is composed of three steps: feature extraction, multi-layered nonlinear mapping, and reconstruction, where multiple nonlinear mapping layers have less nodes than the feature extraction and reconstruction layers. The intra-layer structure and depth of ACNS are empirically determined as a compromise between its qualitative performance and computational time.
The contributions of this paper are twofold. First, this study not only achieves high image quality of MRI but also significantly reduces SR computational time. Spatial resolution enhancement of MRI needs to be performed with minimal latency during MRIgRT. Thus, the most important problem in the use of the deep learning-based SR methods is overcoming their long computational time. This paper demonstrates potential application of the proposed method for in-plane SR of real-time 4D MRI in MRIgRT. Second, this study provides a detailed analysis of the relationship between the deep learning network architecture, i.e., intra-layer structure and depth, and its performance based on our experimental outcomes. The results suggest a developmental direction to forthcoming deep learning-based SR methods for the medical imaging.
II. Related Works
A. MRI Super-Resolution Methods
SR studies for MRI have been proceeding since 1997 [29]. There are two primary goals that the SR research has pursued: the in-plane resolution improvement [30]–[35] and the through-plane resolution improvement [36]–[42]. The in-plane resolution improvement is to remedy missing resolution information on 2D MRI, or a slice of 3D or 4D MRI. The through-plane resolution improvement is to reduce the slice thickness and remove aliasing between multiple slices of 3D or 4D MRI. The through-plane resolution for 3D acquisitions may be lower than the in-plane resolution for multi-slice 2D acquisitions [8]. Most studies have focused on through-plane resolution improvements. Recently, the in-plane resolution improvement methods for 4D MRI have been actively studied [20]–[28].
As shown in Table 1, the existing in-plane resolution improvement methods include an Iterative Back-Projection (IBP) [30], simple bilinear INTerpolation (INT), LASR, TIKhonov (TIK), Direct Acquisition (DAC), THEOretical curves (THEO) [32], Conjugated Gradients (CG) [33], Low-Rank Total-Variation (LRTV) [34], wavelet-based Projection-Onto-Convex-Set (POCS) SR [31], and Toeplitz-based iterative SR for improving Periodically Rotated Overlapping ParallEL Lines with Enhanced Reconstruction (PROPELLER) MRI [35], [43]. IBP is simple and fast, but is vulnerable to noise. Additionally, IBP has no unique solution for the SR problem due to the ill-posed nature of the inverse problem. Deterministic regularization-based methods, such as INT, LASR, TIK, DAC, THEO, CG, and LRTV, convert a LR observation model into the well-posed problem by using a priori information. However, the deterministic regularization-based methods are also vulnerable to noise. POCS methods (the wavelet-based SR and Toeplitz-based iterative SR) are robust for noisy and dynamic images, but their convergence speeds are slow and computational costs are high.
TABLE 1. In-Plane Super-Resolution of MRI.
| Category | Method | Limitation |
|---|---|---|
| Back-projection | Iterative Back-Projection (IBP) | Vulnerable to noise |
| Deterministic regularization | Simple bilinear INTerpolation (INT), LASR, TIKhonov (TIK), Direct Acquisition (DAC), THEOretical curves (THEO), conjugated gradients, and Low-Rank Total-Variation (LRTV) | Vulnerable to noise |
| Projection Onto Convex Sets (POCS) | Wavelet-based POCS SR and Toeplitz-based iterative SR | Slow convergence speed High computational cost |
B. CNN-Based Super-Resolution Methods
Various SR approaches have been introduced in computer vision. They can be categorized as reconstruction-based and learning-based SR methods. The reconstruction-based super resolution methods contain steering kernel regression [44] and nonlocal mean [45] algorithms. These approaches depend on prior knowledge such as total variation, edge, gradient profile, generic distribution, and geometric duality priors [46]–[50]. The learning-based SR methods include nearest neighbor [51], sparse coding [52], [53], Support Vector Regression (SVR) [54], random forest [55], joint [56], nonlinear reaction diffusion [57], conditional regression [58], Fourier burst accumulation-based method [59], and Convolutional Neural Network (CNN)-based methods [7]–[12], [60]. The learning-based methods map the relationship between the LR image and HR image so they can accurately recover missing details on the image. CNN-based SR methods in particular are state of the art [9], as they have shown superior image quality improvements, albeit at high computational cost.
The rapid advance of deep learning methods made a variety of the CNN-based SR methods applicable in medical images such as retinal images [8], [62] and MRIs [21]–[28]. Pham et al. [21], [22] applied the Super-Resolution Convolutional Neural Network (SRCNN) [9], [10] for brain MRIs. Chen et al. proposed a densely connected super-resolution network for brain MRIs in [23] that was inspired by a densely connected network [63]. Zhang et al. and Qui et al. proposed fast medical image SR for retina images [62] and efficient medical image SR for knee MRIs [24]. Both methods use an identical network structure with three hidden layers of SRCNN [9], [10] and a sub-pixel convolution layer proposed by Shi et al. [64]. Chaudhari et al. [25] [26] proposed DeepResolve for knee MRIs that consists of 20 layers of paired 3D convolution operator and a rectified linear unit. Zhao et al. [27] proposed a synthetic multi-orientation resolution enhancement method for brain MRIs using an Enhanced Deep Residual Network (EDRN) [65]. In [61], a SR Generative Adversarial Network (SRGAN) [66] was employed for the retinal images. For 4D MRI, Chun et al. proposed a cascaded deep learning method that consists of a denoising autoencoder [67], downsampling network, and SRGAN [66]. Most of the proposed methods of natural images have been adopted for the medical images with or without minor modifications in the network architecture or a combination of several methods [21], [23], [24], [28] [61], [62].
We compare our method to well-known CNN-based SR methods with a single network structure that are expected to provide fast computation speed for 4D MRI. Table 2 shows three major methods in CNN-based SR methods: SRCNN [9], [10]; Deeply-Recursive Convolutional Network (DRCN) [12]; and Fast SRCNN (FSRCNN) [11]. SRCNN is a basic form of CNN excluding a pooling process that was reformulated from the conventional sparse coding-based SR methods. SRCNN was used for brain MRI in [21], [22], [24], [62]. The test time of SRCNN was 0.39 s per image in dataset Set14 [53] at the magnification power of 3. FSRCNN was redesigned from SRCNN with the additional process of shrinking and expanding to reduce its computational cost. The test time of FSRCNN was 0.061 s per image in dataset Set14 at the magnification power of 3. DRCN has a partially recursive structure with an exceptionally connected component, called a ‘skip connection’ that is considered a form of ResNet [23], [61], [68]. The skip connection directly feeds input data into a reconstruction network. The computation time of DRCN was not measured in [12].
TABLE 2. Convolutional Neural Network-Based Super-Resolution.
| Method | Featured structure | Average Computation time |
|---|---|---|
| Super-Resolution Convolutional Neural Network (SRCNN) | No pooling process | 0.39 s per image in dataset 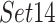 at magnification power of 3 [9] at magnification power of 3 [9]
|
| Fast Super-Resolution Convolutional Neural Network (FSRCNN) | No pooling process and additional process of shrinking and expanding | 0.061 s per image in dataset 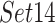 at magnification power of 3 [11] at magnification power of 3 [11]
|
| Deeply-Recursive Convolutional Network (DRCN) | No pooling process, partially recursive layers, and skip connection | Not measured in [12] |
III. Methods & Materials
The aim of this study is to produce an HR MRI slice, i.e., larger matrix size with extrapolated signals, from an original MRI of 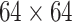 pixels or
pixels or 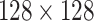 pixels, according to a specified magnification power called the ‘scaling factor.’ For instance, the MRI generated by the scaling factor of ‘3’ would have a spatial resolution 3 times higher than the original MRI. When enlarging, i.e., upsampling, the original MRI, the image quality of the original MRI slice will naturally decrease without compensation for the absent resolution information. Although the original MRI has inadequate spatial resolution for use in anatomical MRI, edges shown in the MRI are sufficiently sharp. Blurring should not be neglected in LR images. Among downsampling methods, a bicubic interpolation results in blurry images rather than pixelated ones by calculating a weighted average of the nearest pixels. The result of the bicubic downsampling is highly analogous to the result from blurring with a
pixels, according to a specified magnification power called the ‘scaling factor.’ For instance, the MRI generated by the scaling factor of ‘3’ would have a spatial resolution 3 times higher than the original MRI. When enlarging, i.e., upsampling, the original MRI, the image quality of the original MRI slice will naturally decrease without compensation for the absent resolution information. Although the original MRI has inadequate spatial resolution for use in anatomical MRI, edges shown in the MRI are sufficiently sharp. Blurring should not be neglected in LR images. Among downsampling methods, a bicubic interpolation results in blurry images rather than pixelated ones by calculating a weighted average of the nearest pixels. The result of the bicubic downsampling is highly analogous to the result from blurring with a 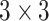 average filter in addition to downsampling with a nearest-neighbor interpolation with the scaling factor of ‘2’. Thus, we model both pixel information loss and blurring caused by the bicubic downsampling as ACNS:
average filter in addition to downsampling with a nearest-neighbor interpolation with the scaling factor of ‘2’. Thus, we model both pixel information loss and blurring caused by the bicubic downsampling as ACNS:
 |
where Y denotes an LR MRI corresponding to the original MRI, 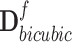 indicates the bicubic downsampling operator with a scaling factor
indicates the bicubic downsampling operator with a scaling factor 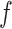 , and X is an HR MRI corresponding to the enlarged MRI that we desire to obtain. The proposed algorithm produces HR MRI from the original MRI Y with a scaling factor
, and X is an HR MRI corresponding to the enlarged MRI that we desire to obtain. The proposed algorithm produces HR MRI from the original MRI Y with a scaling factor 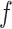 and a parameter set
and a parameter set 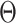 . We define an outcome of ACNS as the symbol Z. The lose function for the bicubic downsampling is produced from Eq. (1), as follows:
. We define an outcome of ACNS as the symbol Z. The lose function for the bicubic downsampling is produced from Eq. (1), as follows:
 |
The observation model is used to generate a training input dataset and the LR MRIs in our experiments.
With Eq. (2), we can translate the given image SR problem of MRI into an optimization problem:
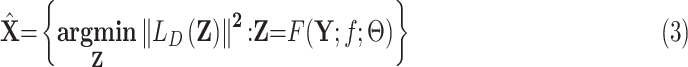 |
where 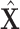 indicates an estimated HR MRI, Z is an outcome of ACNS,
indicates an estimated HR MRI, Z is an outcome of ACNS, 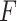 (
( ) denotes the proposed method as a function, and
) denotes the proposed method as a function, and 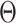 is a parameter set for
is a parameter set for 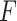 (
( ). The parameter set
). The parameter set 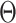 includes filters (weights) and biases of each layer in ACNS.
includes filters (weights) and biases of each layer in ACNS.
ACNS consists of convolution layers, activation function layers, and a deconvolution layer as illustrated in Fig. 1. Convolution layers and activation function layers are primary components of typical CNN. The other prime component of CNN is a pooling layer—also called a subsampling layer. The pooling layer chooses featured values from the image for progressive reduction of the number of parameters and the computational cost in the network, but it causes loss of input image information. In order to keep the feature values, the proposed method excluded the pooling layer in its architecture and designed ACNS with the deconvolution layer to upsample the LR MRI. We also determined the network structure of ACNS based on the experimental results.
FIGURE 1.
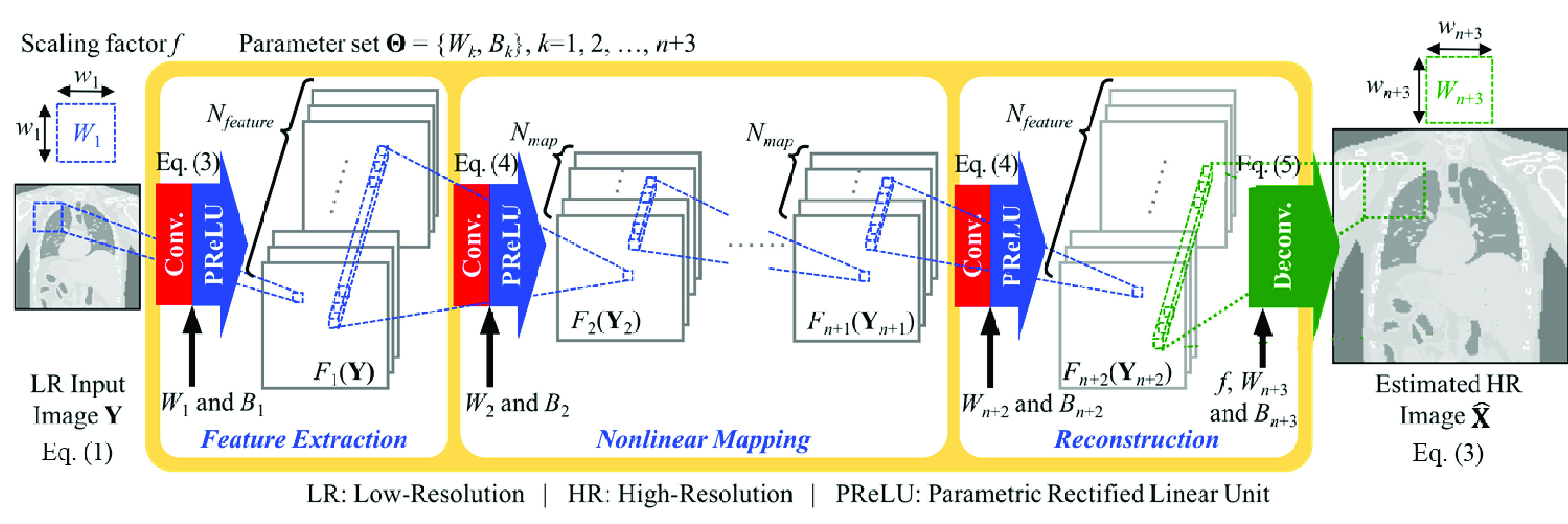
Autoencoder-inspired convolutional network-based super-resolution.
ACNS was inspired by the autoencoder [69], one of the well-known artificial neural networks. The autoencoder achieves dimensionality reduction with less nodes in its hidden layers than those in the input and output layers. We hypothesized that critical features to be preserved through the network would be limited even though their exact number is unknown. Under this hypothesis, the structure of the autoencoder would perform well for the given SR problem if parameters are appropriately set for the network. Moreover, this structure would largely contribute to a decrease in test time by reducing the computation in the hidden layers of the network.
As shown in Fig. 1, ACNS is described as the three steps: feature extraction, nonlinear mapping, and reconstruction. In feature extraction, local features of Y are extracted depending on receptive fields as follows:
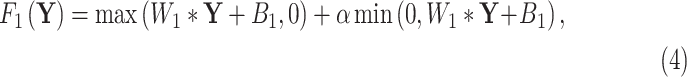 |
where an operator ‘*’ denotes a convolution, max(0,  ) +
) + 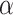 min(
min( , 0) is an activation function, i.e., Parametric Rectified Linear Unit (PReLU) function [70], and
, 0) is an activation function, i.e., Parametric Rectified Linear Unit (PReLU) function [70], and 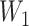 and
and 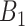 represent filters and biases of feature extraction operation, respectively. The size of
represent filters and biases of feature extraction operation, respectively. The size of 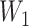 is
is 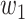 , which restricts a unit range to extract the local features on Y. The number of
, which restricts a unit range to extract the local features on Y. The number of 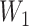 , i.e.,
, i.e., 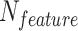 , equals the number of the extracted features.
, equals the number of the extracted features.
As existing studies proved, nonlinearity of mapping is a highly important process in CNN-based SR to enhance image quality performance [12]. Therefore, we iterate the nonlinear mapping between the Y and X:
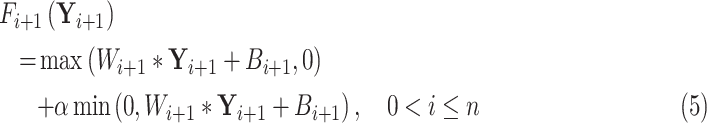 |
where 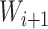 indicates filters and
indicates filters and 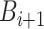 represents biases of the
represents biases of the 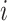 th recurrence of the nonlinear mapping operation. The number of
th recurrence of the nonlinear mapping operation. The number of 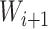 is
is 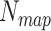 . In Eq. (5), Y2 equals
. In Eq. (5), Y2 equals 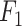 (Y), i.e., the output of the feature extraction operation. After
(Y), i.e., the output of the feature extraction operation. After 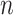 times of recurring nonlinearity mapping, the output is defined as
times of recurring nonlinearity mapping, the output is defined as 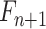 (Y
(Y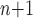 ).
).
In nonlinear mapping, the size of 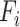 (Y
(Y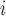 ) must be identical with that of
) must be identical with that of 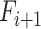 (Y
(Y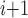 ) because
) because 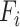 (Y
(Y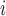 ) is the output of the
) is the output of the 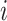 th iteration and the input of the (
th iteration and the input of the (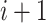 )th iteration. The output size of the convolution operation is calculated as ‘output size = (input size −
)th iteration. The output size of the convolution operation is calculated as ‘output size = (input size − 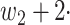 zero-padding size)/stride + 1.’ Here,
zero-padding size)/stride + 1.’ Here, 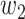 is the size of
is the size of 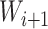 , and we set ‘stride’ to ‘1’ to fully utilize the extracted features. For this, the nonlinear mapping must have
, and we set ‘stride’ to ‘1’ to fully utilize the extracted features. For this, the nonlinear mapping must have 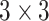 pixels
pixels 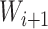 with 1 pixel zero-padding. Obviously, more iterations lead to higher computational complexity. Accordingly, the time to process the resolution-enhanced MRI slices would be longer. Thus, selecting the appropriate
with 1 pixel zero-padding. Obviously, more iterations lead to higher computational complexity. Accordingly, the time to process the resolution-enhanced MRI slices would be longer. Thus, selecting the appropriate 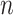 is important to compromise between image quality and processing time.
is important to compromise between image quality and processing time.
After the nonlinear mapping, we obtain HR features using the convolution operation as Eq. (5) where 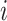 equals
equals 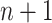 . The number of
. The number of 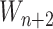 is set to
is set to 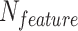 . Then, we use a deconvolution operation to upscale and aggregate the HR features depending on
. Then, we use a deconvolution operation to upscale and aggregate the HR features depending on 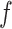 as follows:
as follows:
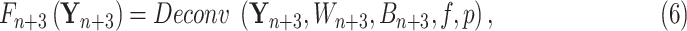 |
where Deconv ( ) denotes the deconvolution function,
) denotes the deconvolution function, 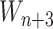 indicates filters,
indicates filters, 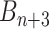 represents biases of the reconstruction operation, and
represents biases of the reconstruction operation, and 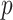 denotes zero-padding size. Here, the size of
denotes zero-padding size. Here, the size of 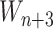 , is
, is 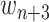 . In Eq. (6), Y
. In Eq. (6), Y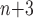 equals
equals 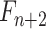 (Y
(Y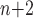 ), i.e., the obtained HR features after the nonlinearity mapping operation. We summarize the proposed ACNS as the following pseudocode.
), i.e., the obtained HR features after the nonlinearity mapping operation. We summarize the proposed ACNS as the following pseudocode.
Autoencoder-Inspired Convolutional Network-Based Super-Resolution (ACNS)
-
Input:
Y: Low-Resolution (LR) MRI
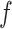 : Scaling factor
: Scaling factor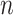 : Calculation iteration number of nonlinear mapping
: Calculation iteration number of nonlinear mapping 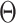 = {
= {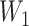 ,
, 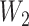 ,
, 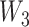 ,
, 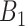 ,
, 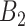 ,
, 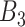 }: Convolutional network parameters
}: Convolutional network parameters-
Output:
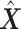 : estimated High-Resolution (HR) MRI
: estimated High-Resolution (HR) MRI -
1)
Extract features from Y with
 by Eq. (4)
by Eq. (4) for
 to
to  do
do-
2)
Map the extracted features of
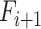 (
(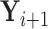 ) nonlinearly with
) nonlinearly with 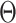 by Eq. (5)
by Eq. (5) end for
-
3)
Acquire HR feature with
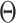 by Eq. (5)
by Eq. (5) -
4)
Compute
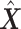 by up-scaling and aggregating HR features of
by up-scaling and aggregating HR features of 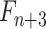 (
(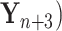 with
with 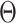 by Eq. (6)
by Eq. (6)
Training of ACNS is designed to find the optimal 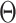 that minimizes the loss between the estimated HR MRI slice
that minimizes the loss between the estimated HR MRI slice 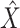 , i.e.,
, i.e., 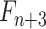 (Y
(Y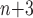 ), and the HR MRI slice X. We use Mean Squared Error (MSE) as the loss function
), and the HR MRI slice X. We use Mean Squared Error (MSE) as the loss function
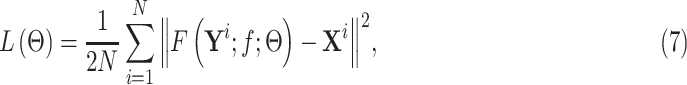 |
where 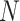 indicates the number of the training samples. The loss function in Eq. (7) is minimized by the stochastic gradient descent algorithm based on backpropagation [71]. The weights are updated as follows:
indicates the number of the training samples. The loss function in Eq. (7) is minimized by the stochastic gradient descent algorithm based on backpropagation [71]. The weights are updated as follows:
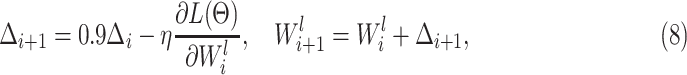 |
where 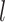 denotes a layer number,
denotes a layer number, 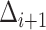 is a current update value,
is a current update value, 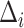 is a previous update value,
is a previous update value, 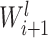 is a current weight,
is a current weight, 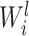 is a previous weight,
is a previous weight, 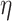 indicates a learning rate, and
indicates a learning rate, and 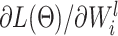 is a derivative of
is a derivative of 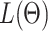 . ACNS uses a Xavier algorithm for weight initialization to automatically determine initialization scale according to the network structure [71]. In [70], the authors showed that a combination of Xavier algorithm and PReLU function would either converge slowly or not converge when the network was very deep (i.e. 22 layers or deeper). However, the initialization method was empirically chosen considering the structure of ACNS that compromises image quality with computation time. In training, multiple local images were extracted as patches from both the HR and LR MRIs, and these patches were applied as the training input images.
. ACNS uses a Xavier algorithm for weight initialization to automatically determine initialization scale according to the network structure [71]. In [70], the authors showed that a combination of Xavier algorithm and PReLU function would either converge slowly or not converge when the network was very deep (i.e. 22 layers or deeper). However, the initialization method was empirically chosen considering the structure of ACNS that compromises image quality with computation time. In training, multiple local images were extracted as patches from both the HR and LR MRIs, and these patches were applied as the training input images.
The computation time of ACNS is determined by 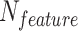 ,
, 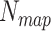 ,
, 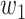 ,
, 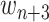 , and
, and 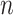 . Obviously, the computational complexity increases with the number and size of the filters (i.e.
. Obviously, the computational complexity increases with the number and size of the filters (i.e. 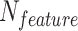 ,
, 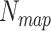 ,
, 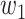 and
and 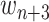 ,) as well as the number of network layers (i.e.
,) as well as the number of network layers (i.e. 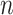 ). Furthermore, the selection of
). Furthermore, the selection of 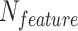 ,
, 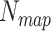 ,
, 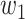 ,
, 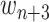 ,
, 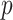 , and
, and 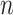 affects the image quality performance in addition to how well
affects the image quality performance in addition to how well 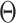 (i.e.
(i.e. 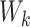 and
and 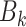 where
where 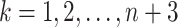 ) is trained. Unlike computation time, it is impossible to grasp the explicit relationship between the network structure and its performance without validation. Therefore, the selection of
) is trained. Unlike computation time, it is impossible to grasp the explicit relationship between the network structure and its performance without validation. Therefore, the selection of 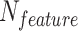 ,
, 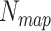 ,
, 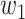 ,
, 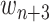 ,
, 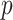 , and
, and 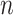 is significant, and we define them as network parameters of ACNS. In designing ACNS, there is no restriction on choosing
is significant, and we define them as network parameters of ACNS. In designing ACNS, there is no restriction on choosing 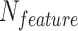 ,
, 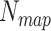 , and
, and 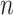 . However, we selected
. However, we selected 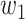 ,
, 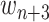 , and
, and 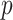 to satisfy the following four conditions:
to satisfy the following four conditions:
-
1)
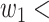 LR patch size,
LR patch size, -
2)
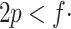 (LR patch size -
(LR patch size - 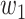 ),
), -
3)
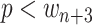 , and
, and -
4)
LR patch size
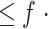 (LR patch size −
(LR patch size − 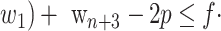 LR patch size + mod(LR patch size, 2),
LR patch size + mod(LR patch size, 2),
where Condition2 and Condition4 are derived by constraints on the output size of the deconvolution operation: ‘output size = stride
 (input size − 1)
(input size − 1) 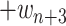 −
− 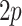 ).’ Here,
).’ Here, 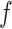 is assigned as ‘stride’, and ‘input size’ corresponds to ‘output size’ of the non-linear mapping layer, i.e., ‘LR patch size −
is assigned as ‘stride’, and ‘input size’ corresponds to ‘output size’ of the non-linear mapping layer, i.e., ‘LR patch size − 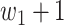 .’ Evaluation of image quality and processing time according to the network parameters is given in Section IV.
.’ Evaluation of image quality and processing time according to the network parameters is given in Section IV.
For the image quality evaluation, we used typical metrics in SR studies: Peak Signal-to-Noise Ratio (PSNR), Structure SIMilarity index (SSIM), and Information Fidelity Criterion (IFC) [9], [72]. PSNR was computed as
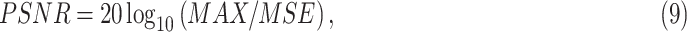 |
where MAX is the maximum intensity value.
SSIM was calculated as
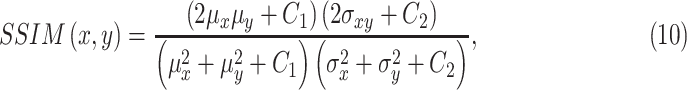 |
where 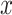 corresponds to the MRIs enlarged by ACNS,
corresponds to the MRIs enlarged by ACNS, 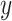 indicates the ground truth MRIs, and
indicates the ground truth MRIs, and 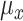 ,
, 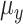 ,
, 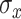 ,
, 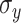 , and
, and 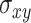 are means, variances, and covariance of
are means, variances, and covariance of 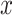 and
and 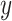 , respectively. In SSIM,
, respectively. In SSIM, 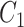 and
and 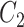 denote stabilization constants calculated as
denote stabilization constants calculated as 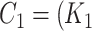 MAX)2 and
MAX)2 and 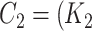 MAX)2, where
MAX)2, where 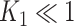 and
and 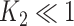 . Here, we set
. Here, we set 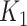 as 0.1 and
as 0.1 and 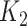 as 0.3 according to the Image Processing Toolbox of MATLAB.
as 0.3 according to the Image Processing Toolbox of MATLAB.
IFC was calculated as
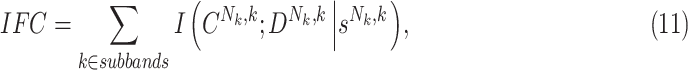 |
where 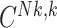 ,
, 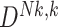 , and
, and 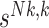 denote
denote 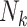 coefficient from the reference image
coefficient from the reference image 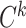 , the test image
, the test image 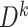 , and the random field of positive scalars
, and the random field of positive scalars 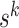 of the
of the 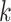 th sub-band, respectively.
th sub-band, respectively.
IV. Results
A. Experimental Data
Virtual phantom and MRI data were used in the experiments. We obtained 200 images from a virtual model of the human torso with cardiac and respiratory motions, the 4D extended Cardiac-Torso (XCAT) Phantom [73]. The size of the virtual phantom model is 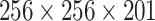 voxels, and the size of the acquired virtual phantom images were
voxels, and the size of the acquired virtual phantom images were 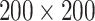 pixels. Out of 713 slices, i.e. 256 coronal, 256 sagittal, and 201 transverse slices, we selected the slices containing a lung region only. Dataset1 contains 60 coronal slices. Dataset2 contains 60 sagittal slices. Dataset3 contains 60 transverse slices.
pixels. Out of 713 slices, i.e. 256 coronal, 256 sagittal, and 201 transverse slices, we selected the slices containing a lung region only. Dataset1 contains 60 coronal slices. Dataset2 contains 60 sagittal slices. Dataset3 contains 60 transverse slices.
Dynamic multislice 2D True Fast Imaging with Steady state Precession (TrueFISP) and GRadient And Spin Echo (GRASE) images were collected from four volunteers using a ViewRay 0.35 T MRIgRT at the Washington University in St. Louis after volunteers provided informed consent. Table 3 describes the MRI data of the four volunteers used for performance verification of the proposed image SR method.
TABLE 3. MRI Data of Four Subjects for Performance Validation.
| Volunteer ID | Data # | View | Field of view (mm) | Slice thickness (mm) | # of images (slices  sets) sets) |
Slice size (pixel2) | Image protocol | Acquisition Type | Acquisition Time | BW |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | Sagittal | 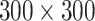 |
5 | 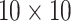 |
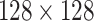 |
TrueFISP | 2D | 289 ms/image | 501 Hz/pixel |
| 2 | Sagittal | 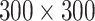 |
5 | 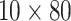 |
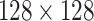 |
TrueFISP | 2D | 289 ms/image | 501 Hz/pixel | |
| 2 | 3 | Transverse |  |
5 |  |
 |
TrueFISP | 2D | 438 ms/image | 558 Hz/pixel |
| 4 | Transverse |  |
5 |  |
 |
TrueFISP | 2D | 173 ms/image | 1002 Hz/pixel | |
| 3 | 5 to 8 | Transverse | 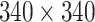 |
6 | 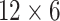 |
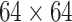 |
GRASE | 3D | 600 ms/volume | 2003 Hz/pixel |
| 9 & 10 | Transverse | 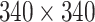 |
6 |  |
 |
GRASE | 3D | 600 ms/volume | 2003 Hz/pixel | |
| 4 | 11 to 13 | Coronal |  |
5 |  |
 |
TrueFISP | 3D | 0.7 s/volume | 898 Hz/pixel |
| 14 to 18 | Sagittal |  |
5 |  |
 |
TrueFISP | 3D | 0.7 s/volume | 898 Hz/pixel | |
| 19 & 20 | Sagittal |  |
5 |  |
 |
TrueFISP | 3D | 1.27 s/volume | 898 Hz/pixel | |
| 21 & 22 | Coronal |  |
5 | 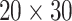 |
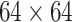 |
TrueFISP | 3D | 1.27 s/volume | 898 Hz/pixel |
Data1 and 2 are the sagittal MRIs from Volunteer1 and their image size is 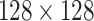 pixels. Data3 and 4 are from the transverse MRIs from Volunteer2 and their image sizes are
pixels. Data3 and 4 are from the transverse MRIs from Volunteer2 and their image sizes are 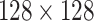 pixels and
pixels and 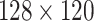 pixels, respectively. Data5 to 10 are the transverse MRIs from Volunteer3 and the image size is
pixels, respectively. Data5 to 10 are the transverse MRIs from Volunteer3 and the image size is 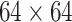 pixels. Data11 to 22 are the coronal and sagittal MRIs from Volunteer4 with the size of
pixels. Data11 to 22 are the coronal and sagittal MRIs from Volunteer4 with the size of 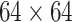 pixels. We additionally used 42 slices—14 coronal, 14 sagittal, and 14 transverse images—of
pixels. We additionally used 42 slices—14 coronal, 14 sagittal, and 14 transverse images—of 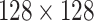 pixels from Volunteer3 and 5 slices—2 coronal, 2 sagittal, and 1 transverse images—of
pixels from Volunteer3 and 5 slices—2 coronal, 2 sagittal, and 1 transverse images—of 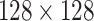 pixels from Volunteer4 for the purpose of training the ACNS.
pixels from Volunteer4 for the purpose of training the ACNS.
B. Training
The original images were used as the ground truth in the training step. LR images were generated from the original images following the observation model of Eq. (1). The training datasets included 91 non-medical images [52], 50 XCAT images, and 42 MRIs.
There are two main reasons why we included non-medical images and XCAT images. First, ACNS estimates pixel loss from HR image to LR image, independent of MRI contrast properties. ACNS’s learning, i.e., mapping between LR and HR images in the image domain, depends on the observation model of (1). In this paper, we focus on the LR problem only. Other problems of MRI were not considered when defining our observation model. For example, ACNS does not address MRI distortion. Therefore, all the training datasets do not need to be MRI as long as the image pairs satisfy the relationship of (1). Second, the use of higher-resolution images in training leads to better image quality. The SR result would be able to reach the ground truth in an ideal case. Therefore, the resultant image quality is limited by the ground truth employed in training. The deep learning network trained by higher-resolution image sets can learn more details of the pixel information to be recovered. Accordingly, it is beneficial to include non-medical images, commonly used in computer vision studies, and pixelated XCAT images with highly clear boundaries in the training dataset because their resolution is higher than that of MRIs.
Since our maximum scaling factor 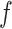 is ‘4,’ the LR image size would be extremely small, only
is ‘4,’ the LR image size would be extremely small, only 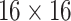 pixels, if we selected the MRIs of
pixels, if we selected the MRIs of 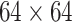 pixels for the training samples. Thus, we chose relatively larger matrix sizes among the TrueFISP images we collected: 42 MRIs of
pixels for the training samples. Thus, we chose relatively larger matrix sizes among the TrueFISP images we collected: 42 MRIs of 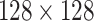 pixels for training and 5 MRIs of
pixels for training and 5 MRIs of 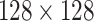 pixels for testing the training step. We produced the training images by splitting the training images into patches of
pixels for testing the training step. We produced the training images by splitting the training images into patches of 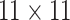 pixels with stride 4. The number of the patches was calculated as floor ((LR image size − patch size + 1)/ stride). For example, the LR MRIs of
pixels with stride 4. The number of the patches was calculated as floor ((LR image size − patch size + 1)/ stride). For example, the LR MRIs of 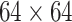 pixels are generated by Eq. (1) when
pixels are generated by Eq. (1) when 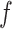 is 2 and 196 patches were created. Similarly, the ground truth images, i.e. the original MRIs, were also separated into local patches. Their patch size depends on the network parameters and the details are given in the following Section IV-C.
is 2 and 196 patches were created. Similarly, the ground truth images, i.e. the original MRIs, were also separated into local patches. Their patch size depends on the network parameters and the details are given in the following Section IV-C.
Our experiments were conducted on a PC with Intel®Xeon®CPU (ES-2637 3.50 GHz), NVIDIA Quadro M6000 24GB GPU, and 128 GB RAM. The ACNS model was trained using the Caffe package [74]. We set 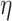 of feature extraction and nonlinear mapping layers to 0.001 and
of feature extraction and nonlinear mapping layers to 0.001 and 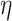 for the ACNS reconstruction layer to 0.0001. We denote the ACNS according to the network parameters, such as ACNS(
for the ACNS reconstruction layer to 0.0001. We denote the ACNS according to the network parameters, such as ACNS(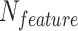 ,
, 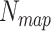 ,
, 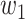 ,
, 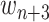 ,
, 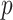 ,
, 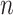 ). For ACNS(16, 8, 5, 9, 5, 4), it took approximately 6 hours and 30 mins for training 183 images (91 non-medical images, 50 XCAT images, and 42 MRIs) with 1,000,000 training iterations.
). For ACNS(16, 8, 5, 9, 5, 4), it took approximately 6 hours and 30 mins for training 183 images (91 non-medical images, 50 XCAT images, and 42 MRIs) with 1,000,000 training iterations.
We compared the performance of ACNS with existing CNN-based image SR methods—SRCNN, FSRCNN, and DRCN—their codes are available at [75], [76], and [77], respectively. Whereas SRCNN and FSRCNN codes are public, the authors of DRCN provided the trained network code only. In addition, we speculate that the authors of SRCNN and FSRCNN did not disclose all the details about how they trained and tuned the algorithm. Therefore, we used SRCNN and FSRCNN trained by its authors with superior performance than the ones trained by us.
The SRCNN model was trained by C. Dong et al. with 395,909 images from the ILSVRC 2013 ImageNet detection training partition, using cuda-convnet package [78]. According to [9], C. Dong et al. required three days on a machine with GTX 770 GPU, Intel CPU 3.10 GHz, and 16 GB memory to train the SRCNN model with 91 images. For tests, they took 0.14 s to process an image of 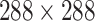 pixels. The FSRCNN model was also trained by C. Dong et al. with the Caffe package. They trained the FSRCNN model based on 91 images first, then fine-tuned it with 100 images. The training image sizes were from
pixels. The FSRCNN model was also trained by C. Dong et al. with the Caffe package. They trained the FSRCNN model based on 91 images first, then fine-tuned it with 100 images. The training image sizes were from 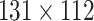 pixels to
pixels to 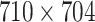 pixels. The DRCN model was trained by J. Kim et al. using the MathConvNet package [79]. The maximum number of recursions of the inference network was 16. Their training time was six days on a machine with a Titan X GPU, and it took 1 s to process an image of
pixels. The DRCN model was trained by J. Kim et al. using the MathConvNet package [79]. The maximum number of recursions of the inference network was 16. Their training time was six days on a machine with a Titan X GPU, and it took 1 s to process an image of 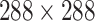 pixels.
pixels.
C. Network Parameter Selection
The network parameters—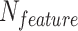 ,
, 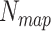 ,
, 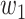 ,
, 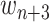 ,
, 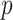 , and
, and 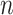 —decide not only the network architecture, but also the image quality performance and computation speed of ACNS. To find optimal network parameters, we created various ACNS models for
—decide not only the network architecture, but also the image quality performance and computation speed of ACNS. To find optimal network parameters, we created various ACNS models for 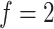 with different network parameter values and trained them on the training settings described in Section IV-B.
with different network parameter values and trained them on the training settings described in Section IV-B.
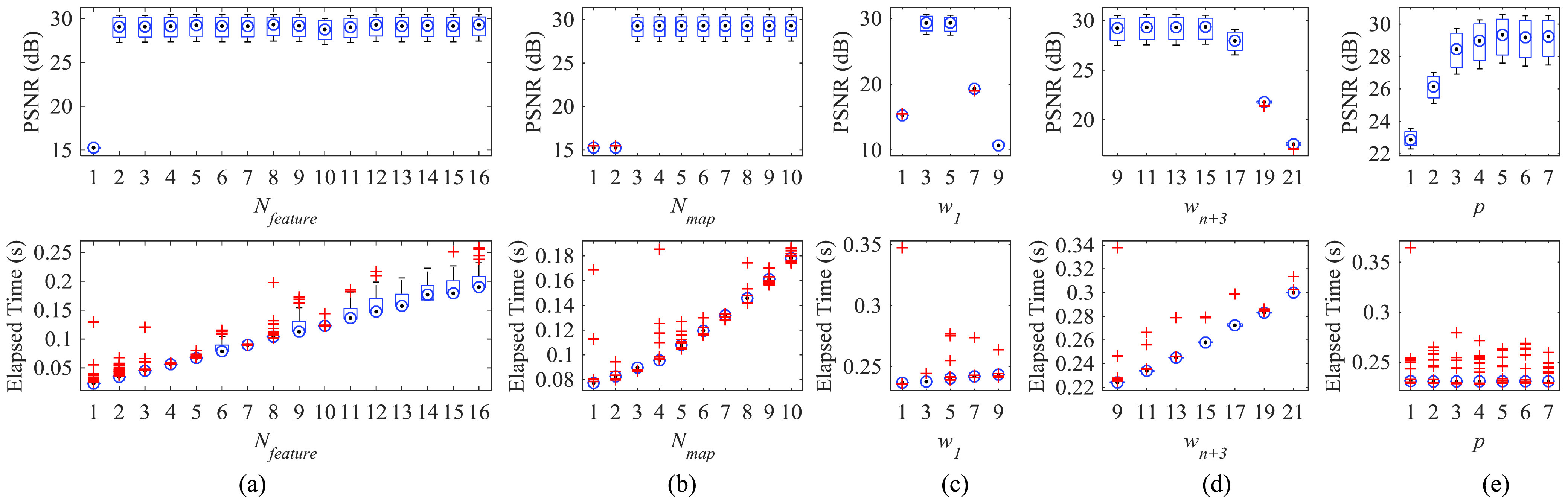
Figs. 2 (a)-(e) show the comparison of the box plot results from tests by ACNS(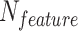 , 4, 5, 11, 5, 4), ACNS(7,
, 4, 5, 11, 5, 4), ACNS(7, 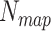 , 3, 11, 7, 4), ACNS(20, 4,
, 3, 11, 7, 4), ACNS(20, 4, 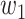 , 11, 10-
, 11, 10-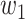 , 4), ACNS(20, 4, 3,
, 4), ACNS(20, 4, 3, 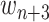 , 7, 4), and RDLS(20, 4, 3, 9,
, 7, 4), and RDLS(20, 4, 3, 9, 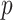 , 4) for 100 MRIs from Dataset1, respectively. The red ‘+’ symbols in Fig. 2 represent outliers. The first row is PSNR and the second row is elapsed time results in Fig. 2. Whereas the ranges of
, 4) for 100 MRIs from Dataset1, respectively. The red ‘+’ symbols in Fig. 2 represent outliers. The first row is PSNR and the second row is elapsed time results in Fig. 2. Whereas the ranges of 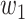 ,
, 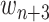 , and
, and 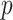 are dependent on the LR and HR patch sizes,
are dependent on the LR and HR patch sizes, 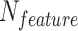 ,
, 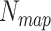 , and
, and 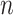 can be any natural number. We first compared the ACNS models with different
can be any natural number. We first compared the ACNS models with different 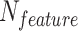 and
and 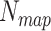 values. As shown in Figs. 2 (a) and (b), PSNR results were relatively high and stable when
values. As shown in Figs. 2 (a) and (b), PSNR results were relatively high and stable when 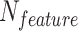 was ≥2 and
was ≥2 and 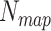 was ≥3. In addition, the larger
was ≥3. In addition, the larger 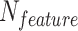 and
and 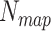 took longer to process the SR image.
took longer to process the SR image.
FIGURE 2.
PSNR and elapsed time according to: (a) the number of filters in feature extraction 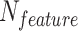 , (b) the number of filters in the nonlinear mapping
, (b) the number of filters in the nonlinear mapping 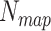 , (c) the filter size in the feature extraction
, (c) the filter size in the feature extraction 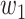 , (d) the filter size in reconstruction
, (d) the filter size in reconstruction 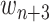 , and (e) the zero-padding size
, and (e) the zero-padding size 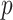 , when
, when 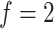 .
.
Candidate values of 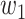 ,
, 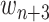 , and
, and 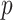 must satisfy the ACNS design conditions explained in Section III. With the LR patch size of 11, the conditions are simplified: Condition1:
must satisfy the ACNS design conditions explained in Section III. With the LR patch size of 11, the conditions are simplified: Condition1: 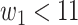 ; Condition2:
; Condition2: 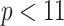 -
- 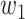 ; Condition3:
; Condition3: 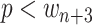 ; and Condition4:
; and Condition4: 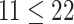 -
- 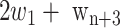 -
- 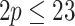 . Specifically, the candidate set for
. Specifically, the candidate set for 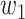 is {1, 3, 5, 7, 9} by Condition1,
is {1, 3, 5, 7, 9} by Condition1, 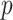 is {0, 1,
is {0, 1, 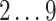 } by Condition2, and
} by Condition2, and 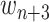 is {1, 3,
is {1, 3, 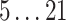 } by Condition4. Any candidate for
} by Condition4. Any candidate for 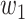 can be selected regardless of any given
can be selected regardless of any given 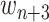 and
and 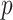 since
since 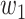 is an independent variable. However, selection of
is an independent variable. However, selection of 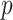 and
and 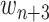 relies on
relies on 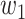 . A total of 167 networks are satisfied with the ACNS design conditions. As shown in Figs. 2 (c)-(e), larger
. A total of 167 networks are satisfied with the ACNS design conditions. As shown in Figs. 2 (c)-(e), larger 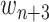 , and
, and 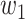 had a subtle increment in the elapsed time, but there was no elapsed time change according to
had a subtle increment in the elapsed time, but there was no elapsed time change according to 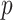 on average. On the other hand, PSNR was above 29 dB when
on average. On the other hand, PSNR was above 29 dB when 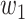 was 3 and 5, and
was 3 and 5, and 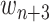 was less than 17. Besides, PSNR was over 29 dB at
was less than 17. Besides, PSNR was over 29 dB at 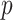 closer to its maximum value, i.e. 10 -
closer to its maximum value, i.e. 10 - 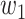 , as shown in Figs. 2 (c)-(e). As a result, we chose a
, as shown in Figs. 2 (c)-(e). As a result, we chose a 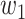 of 5,
of 5, 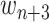 of 9, and
of 9, and 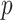 of 10 -
of 10 - 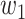 (i.e. 5) based on the results in Fig. 2.
(i.e. 5) based on the results in Fig. 2.
Fig. 3 shows the image quality performance of ACNS according to the number of nonlinear mapping recursion 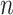 . The PSNR and SSIM results are shown in Fig. 3. ACNS did not produce a distinct difference according to
. The PSNR and SSIM results are shown in Fig. 3. ACNS did not produce a distinct difference according to 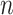 . Interestingly, both PSNR and SSIM were not improved with more recursion of the nonlinear mapping, whereas elapsed time increased from 0.22s to 0.45s. From the results in Fig. 3, we determined
. Interestingly, both PSNR and SSIM were not improved with more recursion of the nonlinear mapping, whereas elapsed time increased from 0.22s to 0.45s. From the results in Fig. 3, we determined 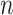 as 4. The cyclic shape of the results in Fig. 3 represent physiologic motion sampled during the test dataset acquisition. The dataset consisted of multislice single-shot TrueFISP 2D acquisitions with 10 slices/volume. Each slice was acquired in 0.3 s and sampled at 0.33 Hz (i.e. 3 s/volume).
as 4. The cyclic shape of the results in Fig. 3 represent physiologic motion sampled during the test dataset acquisition. The dataset consisted of multislice single-shot TrueFISP 2D acquisitions with 10 slices/volume. Each slice was acquired in 0.3 s and sampled at 0.33 Hz (i.e. 3 s/volume).
FIGURE 3.

Image quality performance of ACNS according to the number of nonlinear mapping layers 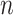 : (a) PSNR and (b) SSIM results. A cyan dashed, cyan dotted, red dashed, red solid, green dashed, green dotted, blue dashed, and blue dotted lines correspond to
: (a) PSNR and (b) SSIM results. A cyan dashed, cyan dotted, red dashed, red solid, green dashed, green dotted, blue dashed, and blue dotted lines correspond to 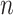 of 1, 2, 3, 4, 5, 8, 12, and 16, respectively. For visibility, we magnified a region with a red rectangle.
of 1, 2, 3, 4, 5, 8, 12, and 16, respectively. For visibility, we magnified a region with a red rectangle.
Although we found appropriate ranges of 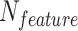 and
and 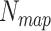 from Figs. 2 (a) and (b), we conducted further experiments to investigate a relationship between a combination of
from Figs. 2 (a) and (b), we conducted further experiments to investigate a relationship between a combination of 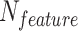 and
and 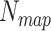 and the image quality performance. Because the training in ACNS strains to minimize the loss of the ACNS, i.e. Eq. (7), training loss can be translated as image quality performance. Fig. 4 illustrates the training loss of ACNS with various combinations of
and the image quality performance. Because the training in ACNS strains to minimize the loss of the ACNS, i.e. Eq. (7), training loss can be translated as image quality performance. Fig. 4 illustrates the training loss of ACNS with various combinations of 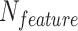 and
and 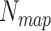 ; the designated
; the designated 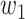 ,
, 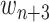 , and
, and 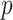 ; and
; and 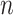 of 4. We presented Fig. 4 with a log scale for loss on the y-axis, to show delicate loss differences between the ACNS networks according to the combination of
of 4. We presented Fig. 4 with a log scale for loss on the y-axis, to show delicate loss differences between the ACNS networks according to the combination of 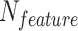 and
and 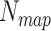 .
.
FIGURE 4.

Training loss of ACNS with various combinations of 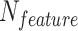 and
and 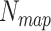 ; the designated
; the designated 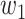 ,
, 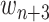 , and
, and 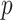 ; and
; and 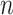 of 4. The area marked with a red rectangle in (a) is magnified as (b). A y-axis, i.e. loss, is in a log scale. A cyan dashed line is the result of ACNS(8, 4, 5, 9, 5, 4), a red dashed line is the result of ACNS(16, 4, 5, 9, 5, 4), a red solid line is the result of ACNS(16, 8, 5, 9, 5, 4), a red dotted line is the result of ACNS(16, 16, 5, 9, 5, 4), a green dashed line is the result of ACNS(32, 16, 5, 9, 5, 4), a green solid line is the result of ACNS(32, 32, 5, 9, 5, 4), a blue dashed line is the result of ACNS(48, 16, 5, 9, 5, 4), a blue solid line is the result of ACNS(48, 24, 5, 9, 5, 4), and a blue dotted line is the result of ACNS(48, 48, 5, 9, 5, 4).
of 4. The area marked with a red rectangle in (a) is magnified as (b). A y-axis, i.e. loss, is in a log scale. A cyan dashed line is the result of ACNS(8, 4, 5, 9, 5, 4), a red dashed line is the result of ACNS(16, 4, 5, 9, 5, 4), a red solid line is the result of ACNS(16, 8, 5, 9, 5, 4), a red dotted line is the result of ACNS(16, 16, 5, 9, 5, 4), a green dashed line is the result of ACNS(32, 16, 5, 9, 5, 4), a green solid line is the result of ACNS(32, 32, 5, 9, 5, 4), a blue dashed line is the result of ACNS(48, 16, 5, 9, 5, 4), a blue solid line is the result of ACNS(48, 24, 5, 9, 5, 4), and a blue dotted line is the result of ACNS(48, 48, 5, 9, 5, 4).
As shown in Fig. 4 (a), ACNS(8, 4, 5, 9, 5, 4) and ACNS(16, 4, 5, 9, 5, 4) had relatively large training losses compared to the other ACNS networks. In the results of Fig. 4 (b), ACNS(48, 48, 5, 9, 5, 4) showed the lowest training loss. However, the training loss of ACNS(16, 16, 5, 9, 4) was less than that of ACNS(16, 16, 5, 9, 5, 4), ACNS(32, 16, 5, 9, 5, 4), ACNS(32, 32, 5, 9, 5, 4), ACNS(48, 16, 5, 9, 5, 4), and ACNS(48, 24, 5, 9, 5, 4). This means that there is no significant difference of the image quality performance between the ACNS networks with 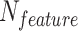 and
and 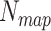 , above the values 8 and 4, respectively, according to the result of Fig. 4. Therefore, we selected
, above the values 8 and 4, respectively, according to the result of Fig. 4. Therefore, we selected 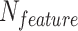 as 16 and
as 16 and 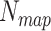 as 8 considering the computation speed of ACNS. In the remaining Section IV, we used ACNS(16, 8, 5, 9, 5, 4) for all
as 8 considering the computation speed of ACNS. In the remaining Section IV, we used ACNS(16, 8, 5, 9, 5, 4) for all 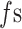 according to the results in this subsection. The HR patch size was determined as 11 for
according to the results in this subsection. The HR patch size was determined as 11 for 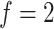 , 17 for
, 17 for 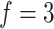 , and 23 for
, and 23 for 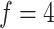 .
.
D. Image Quality Evaluation
We verified the image quality performance of ACNS by comparing it with SRCNN, FSRCNN, and DRCN. Unlike ACNS and FSRCNN, SRCNN and DRCN improve image resolution while maintaining the original image size, without image size expansion depending on 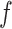 . For comparisons with the identical input images, we first enlarged the LR image using bicubic upsampling according to
. For comparisons with the identical input images, we first enlarged the LR image using bicubic upsampling according to 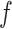 , then applied the upsampled LR image to SRCNN and DRCN, whereas the LR image was directly used as the input of ACNS and FSRCNN. We used the original images as the ground truth and the LR images produced by Eq. (1) to measure PSNR, SSIM, and IFC. The ground truth images need to be large enough for the maximum
, then applied the upsampled LR image to SRCNN and DRCN, whereas the LR image was directly used as the input of ACNS and FSRCNN. We used the original images as the ground truth and the LR images produced by Eq. (1) to measure PSNR, SSIM, and IFC. The ground truth images need to be large enough for the maximum 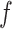 , as in training. Therefore, three XCAT datasets, and Volunteer1 and Volunteer2 datasets were used for PSNR, SSIM, and FIC comparison.
, as in training. Therefore, three XCAT datasets, and Volunteer1 and Volunteer2 datasets were used for PSNR, SSIM, and FIC comparison.
Fig. 5 shows a comparison of the resolution-enhanced XCAT image and MRIs. We randomly selected three resultant images from the XCAT dataset1, Volunteer1 and Volunteer2 datasets, shown in Figs. 5 (a), (b), and (c), respectively. As shown in Fig. 5, all resultant images were more detailed than the LR XCAT image and LR MRIs. SRCNN, FSRCNN, and ACNS maintained the image intensity values regardless of resolution improvement. However, DRCN increased the intensity contrast of the MRIs.
FIGURE 5.
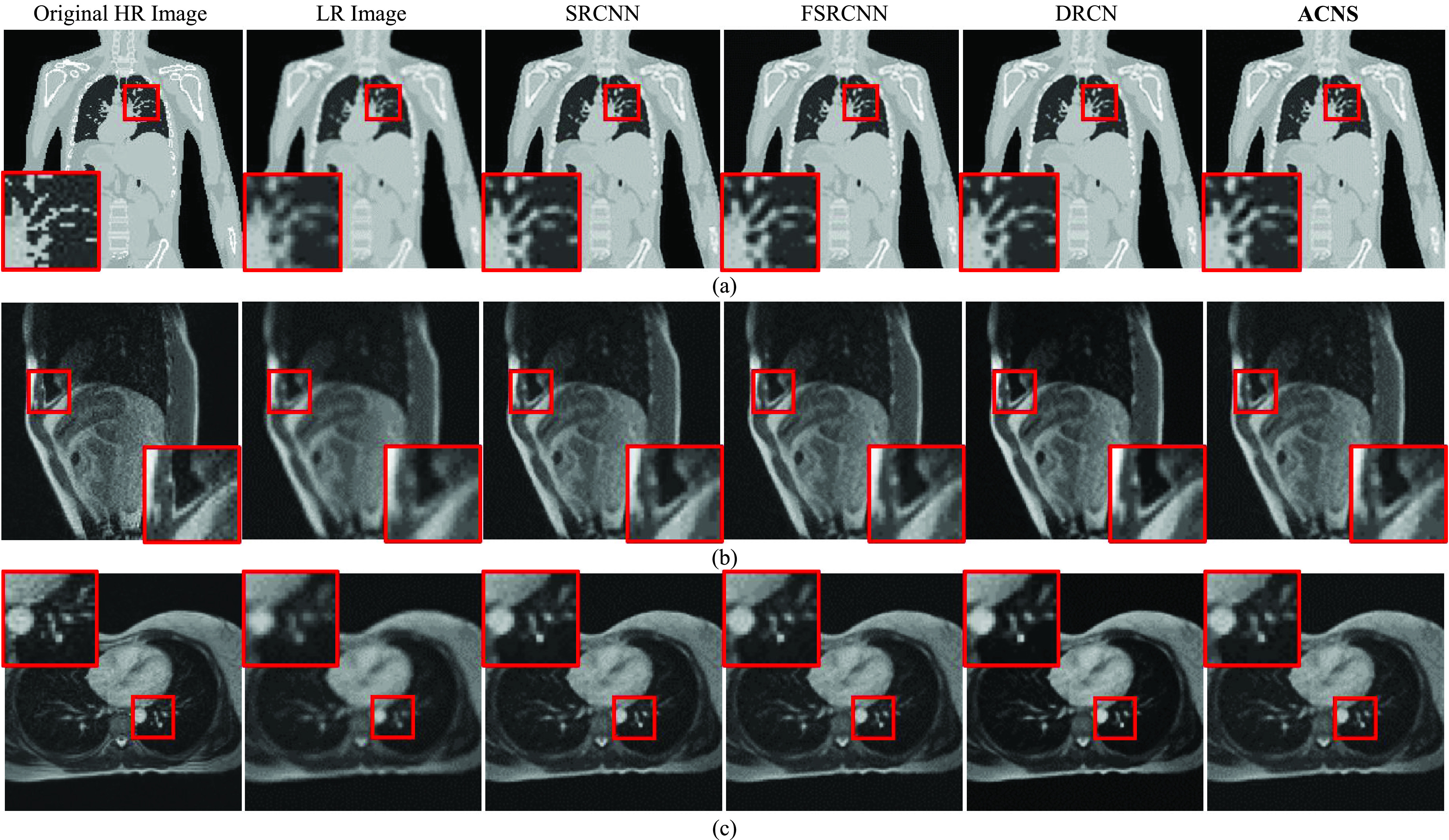
Comparison of resolution-enhanced XCAT image and MRIs using SRCNN, FSRCNN, DRCN, and ACNS: (a) XCAT dataset1, (b) Volunteer1, and (c) Volunteer2 datasets. The first and second columns present the original HR and LR images; and the third, fourth, and fifth columns indicate SR results from SRCNN, FSRCNN, and DRCN, respectively. The sixth column is the resolution-enhanced XCAT image and MRIs by ACNS. All results were at a 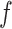 of 2. To provide visible comparison, the images were partially enlarged from the regions marked as red squares.
of 2. To provide visible comparison, the images were partially enlarged from the regions marked as red squares.
In Table 4, we provided the quantitative results, i.e., average PSNR, SSIM, and IFC of the resolution-enhanced virtual phantom images. The best results are highlighted in bold font. The average PSNRs of three XCAT datasets for three 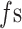 using SRCNN, FSRCNN, DRCN, and ACNS were 26.36 dB, 25.96 dB, 26.73 dB, and 26.53 dB, the average SSIMs were 0.86, 0.48, 0.93, and 0.84, and the average IFCs were 2.32, 2.38, 2.45, and 2.50, respectively. As shown in Table 4, ACNS showed the best IFC performance and the second best PSNR performance next to DRCN. In addition, ACNS had better performance than FSRCNN in terms of SSIM.
using SRCNN, FSRCNN, DRCN, and ACNS were 26.36 dB, 25.96 dB, 26.73 dB, and 26.53 dB, the average SSIMs were 0.86, 0.48, 0.93, and 0.84, and the average IFCs were 2.32, 2.38, 2.45, and 2.50, respectively. As shown in Table 4, ACNS showed the best IFC performance and the second best PSNR performance next to DRCN. In addition, ACNS had better performance than FSRCNN in terms of SSIM.
TABLE 4. Average PSNR, SSIM, and IFC of Resolution-enhanced Virtual Phantom Images.
| Metric | Data-set | Scale | SRCNN [10] | FSRCNN [11] | DRCN [12] | ACNS |
|---|---|---|---|---|---|---|
| PSNR (dB) | 1 | 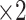 |
26.70 ± 1.55 | 26.54 ± 1.27 | 24.40 ± 1.38 | 27.01 ± 1.50 |
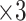 |
25.68 ± 2.25 | 24.56 ± 1.33 | 25.21 ± 1.34 | 24.80 ± 1.38 | ||
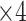 |
24.10 ± 1.97 | 23.29 ± 1.28 | 27.49 ± 1.23 | 23.86 ± 1.35 | ||
| 2 | 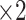 |
28.52 ± 0.82 | 28.03 ± 0.71 | 25.67 ± 1.07 | 28.84 ± 0.96 | |
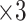 |
26.41 ± 0.88 | 26.17 ± 0.78 | 26.31 ± 1.10 | 26.73 ± 0.98 | ||
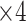 |
25.01 ± 0.92 | 24.97 ± 1.28 | 29.19 ± 0.93 | 25.85 ± 1.04 | ||
| 3 | 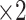 |
28.87 ± 1.55 | 28.36 ± 0.57 | 25.58 ± 0.88 | 29.10 ± 0.70 | |
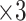 |
26.66 ± 2.25 | 26.53 ± 0.64 | 26.69 ± 0.66 | 26.74 ± 0.71 | ||
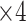 |
25.28 ± 1.97 | 25.15 ± 1.28 | 30.05 ± 0.84 | 25.88 ± 0.73 | ||
| SSIM | 1 | 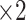 |
0.88 ± 0.04 | 0.63 ± 0.10 | 0.88 ± 0.03 | 0.83 ± 0.01 |
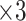 |
0.84 ± 0.07 | 0.59 ± 0.07 | 0.91 ± 0.03 | 0.82 ± 0.05 | ||
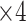 |
0.77 ± 0.09 | 0.54 ± 0.06 | 0.93 ± 0.01 | 0.76 ± 0.06 | ||
| 2 | 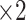 |
0.92 ± 0.01 | 0.47 ± 0.02 | 0.92 ± 0.01 | 0.84 ± 0.01 | |
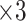 |
0.87 ± 0.02 | 0.46 ± 0.01 | 0.93 ± 0.01 | 0.88 ± 0.02 | ||
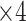 |
0.82 ± 0.02 | 0.43 ± 0.06 | 0.95 ± 0.01 | 0.85 ± 0.02 | ||
| 3 | 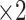 |
0.93 ± 0.04 | 0.42 ± 0.02 | 0.93 ± 0.01 | 0.84 ± 0.00 | |
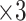 |
0.89 ± 0.07 | 0.42 ± 0.02 | 0.94 ± 0.01 | 0.89 ± 0.01 | ||
 |
0.85 ± 0.09 | 0.39 ± 0.06 | 0.96 ± 0.01 | 0.86 ± 0.01 | ||
| IFC | 1 |  |
4.34 ± 0.78 | 4.44 ± 0.81 | 3.37 ± 0.67 | 4.77 ± 0.89 |
 |
2.80 ± 0.40 | 2.92 ± 0.48 | 3.07 ± 0.75 | 3.01 ± 0.53 | ||
 |
1.89 ± 0.26 | 1.93 ± 0.30 | 3.00 ± 0.72 | 2.08 ± 0.34 | ||
| 2 | 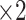 |
2.92 ± 0.23 | 2.93 ± 0.24 | 2.22 ± 0.18 | 3.19 ± 0.23 | |
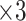 |
1.88 ± 0.13 | 1.98 ± 0.15 | 2.24 ± 0.19 | 2.07 ± 0.13 | ||
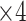 |
1.32 ± 0.09 | 1.33 ± 0.30 | 2.16 ± 0.15 | 1.46 ± 0.09 | ||
| 3 | 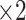 |
2.66 ± 0.78 | 2.67 ± 0.23 | 1.93 ± 0.20 | 2.76 ± 0.25 | |
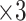 |
1.80 ± 0.40 | 1.89 ± 0.17 | 2.04 ± 0.21 | 1.81 ± 0.16 | ||
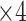 |
1.29 ± 0.26 | 1.30 ± 0.30 | 1.99 ± 0.19 | 1.32 ± 0.11 |
In the comparison of Table 4, there was an interesting finding that the average SSIM results by FSRCNN were exceedingly inferior to ACNS, DRCN, and even SRCNN with the simplest layer structure. The virtual phantom images contain the background along with the human torso. The background area is large relative to the virtual phantom image, and the background’s intensity value is ‘0.’ During the resolution improvement, FSRCNN failed to preserve the intensity values in the background while SRCNN, DRCN, and ACNS did. The intensity values of the background in the resolution-enhanced images by FSRCNN varied between ‘2’ and ‘7.’ The virtual phantom image was stored with 8 bits per pixel i.e., intensity ranges between ‘0’ and ‘255.’ The failure of FSRCNN in conserving the background intensity values degraded its SSIM results. The inferior SSIM results of FSRCNN were not observed in other studies using the natural images because the majority of natural images commonly used in computer vision do not include large background areas.
Table 5 compares average PSNR, SSIM, and IFC of the resolution-enhanced MRIs. The best results are highlighted using bold font. The average PSNR, SSIM, and IFC of the MRIs were greater at the smaller 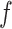 . The average PSNRs of two volunteer datasets for three
. The average PSNRs of two volunteer datasets for three 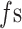 using SRCNN, FSRCNN, DRCN, and ACNS were 28.72 dB, 28.96 dB, 29.26 dB, and 29.25 dB, the average SSIMs were 0.76, 0.77, 0.77, and 0.80, and the average IFCs were 3.81, 4.09, 4.35, and 3.85, respectively.
using SRCNN, FSRCNN, DRCN, and ACNS were 28.72 dB, 28.96 dB, 29.26 dB, and 29.25 dB, the average SSIMs were 0.76, 0.77, 0.77, and 0.80, and the average IFCs were 3.81, 4.09, 4.35, and 3.85, respectively.
TABLE 5. Average PSNR, SSIM, and IFC of Resolution-Enhanced MRIs.
| Metric | Volunteer | Scale | SRCNN [10] | FSRCNN [11] | DRCN [12] | ACNS |
|---|---|---|---|---|---|---|
| PSNR (dB) | 1 | 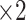 |
29.62 ± 0.76 | 29.79 ± 0.78 | 29.84 ± 0.75 | 29.58 ± 0.88 |
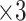 |
29.21 ± 2.50 | 29.40 ± 2.48 | 29.67 ± 2.59 | 27.88 ± 0.98 | ||
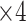 |
27.22 ± 2.10 | 27.54 ± 2.12 | 27.98 ± 1.95 | 26.38 ± 1.09 | ||
| 2 | 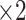 |
30.91 ± 2.27 | 31.10 ± 2.26 | 31.31 ± 2.54 | 33.12 ± 2.11 | |
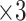 |
28.62 ± 1.78 | 28.86 ± 1.87 | 29.18 ± 1.78 | 30.37 ± 2.07 | ||
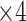 |
26.71 ± 1.58 | 27.05 ± 1.62 | 27.59 ± 1.49 | 28.15 ± 1.48 | ||
| SSIM | 1 | 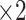 |
0.80 ± 0.02 | 0.81 ± 0.02 | 0.81 ± 0.02 | 0.82 ± 0.02 |
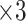 |
0.77 ± 0.07 | 0.78 ± 0.07 | 0.78 ± 0.07 | 0.75 ± 0.02 | ||
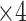 |
0.70 ± 0.07 | 0.71 ± 0.07 | 0.72 ± 0.07 | 0.71 ± 0.03 | ||
| 2 | 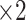 |
0.84 ± 0.05 | 0.84 ± 0.05 | 0.84 ± 0.05 | 0.91 ± 0.03 | |
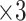 |
0.76 ± 0.06 | 0.76 ± 0.06 | 0.77 ± 0.06 | 0.84 ± 0.04 | ||
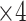 |
0.69 ± 0.06 | 0.70 ± 0.06 | 0.72 ± 0.06 | 0.79 ± 0.04 | ||
| IFC | 1 | 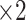 |
5.19 ± 0.15 | 5.56 ± 0.15 | 5.79 ± 0.17 | 5.58 ± 0.12 |
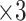 |
4.21 ± 1.05 | 4.53 ± 1.09 | 4.78 ± 1.14 | 3.48 ± 0.09 | ||
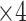 |
2.67 ± 0.62 | 2.86 ± 0.70 | 3.14 ± 0.64 | 2.32 ± 0.11 | ||
| 2 | 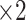 |
5.33 ± 0.30 | 5.70 ± 0.30 | 5.99 ± 0.40 | 5.94 ± 0.35 | |
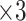 |
3.33 ± 0.13 | 3.62 ± 0.16 | 3.84 ± 0.14 | 3.52 ± 0.22 | ||
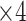 |
2.15 ± 0.11 | 2.24 ± 0.11 | 2.58 ± 0.12 | 2.27 ± 0.11 |
ACNS achieved the highest average PSNR of 33.12 dB and SSIM of 0.91 for the Volunteer2 dataset and 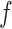 of 2 as shown in Table 5. ACNS mostly outperformed SRCNN, FSRCNN, and DRCN regarding PSNR and SSIM in the experiment using the Voluneer2 dataset. IFC results of ACNS was relatively low compared with FSRCNN and DRCN. For the Volunteer1 dataset, the performance of DRCN was slightly better than the other methods.
of 2 as shown in Table 5. ACNS mostly outperformed SRCNN, FSRCNN, and DRCN regarding PSNR and SSIM in the experiment using the Voluneer2 dataset. IFC results of ACNS was relatively low compared with FSRCNN and DRCN. For the Volunteer1 dataset, the performance of DRCN was slightly better than the other methods.
Fig. 6 shows MRIs of Volunteer1, Volunteer2, Volunteer3, and Volunteer4 datasets, enlarged by nearest-neighbor interpolation, bicubic interpolation, and ACNS. To obtain the enlarged MRIs as our ultimate goal, we used the original MRIs as the inputs of ACNS. As shown in Fig. 6, MRIs acquired by ACNS were less blurry than MRIs by bicubic upsampling and less pixelated than nearest-neighbor interpolation. In Fig. 6 (d), the MRIs enlarged by nearest-neighbor interpolation and bicubic upsampling lost pixel information of two bright lines at the center of the red square after its size changed while the ACNS images maintained it. However, ACNS accentuated artifacts as illustrated in Fig. 6 (a) and (c). This is because ACNS does not selectively remedy missing pixel information.
FIGURE 6.

MRIs enlarged by ACNS: (a) Volunteer1, (b) Volunteer2, (c) Volunteer3, and (d) Volunteer4 datasets. Each MRI was randomly selected. The first and second columns are the original MRIs magnified by nearest-neighbor interpolation and bicubic upsampling, and the third column is the resulting MRIs from ACNS, at a 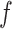 of 3. We magnified the area in the red square to show more details.
of 3. We magnified the area in the red square to show more details.
E. Computational Time Comparison
We compare the running times to produce resolution-enhanced images using SRCNN, FSRCNN, DRCN, and ACNS in Table 6. The best results are presented with bold font. For XCAT datasets, the input images of ACNS and FSRCNN were generated from the original images by Eq. (1) to obtain the resultant images of the identical size to the original images. For MRI datasets, we used the original images as the inputs of ACNS and FSRCNN, and upsampled the images with 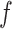 as the inputs of SRCNN and DRCN. The image size fed to the network varied and this caused a different level of computation for each method. ACNS and FSRCNN had
as the inputs of SRCNN and DRCN. The image size fed to the network varied and this caused a different level of computation for each method. ACNS and FSRCNN had 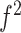 times smaller input images than SRCNN and DRCN. Thus, we can observe diminishing patterns with
times smaller input images than SRCNN and DRCN. Thus, we can observe diminishing patterns with 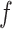 in ACNS and FSRCNN results with
in ACNS and FSRCNN results with 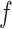 for XCAT datasets and increasing patterns with
for XCAT datasets and increasing patterns with  in SRCNN and DRCN for MRI datasets in Table 6.
in SRCNN and DRCN for MRI datasets in Table 6.
TABLE 6. Running Time.
| Dataset | Scale | SRCNN [10] (s) | FSRCNN [11] (s) | DRCN [12] (s) | ACNS(s) |
|---|---|---|---|---|---|
| XCAT 1 | 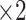 |
1.59 | 1.96 | 9.06 | 0.47 |
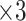 |
1.55 | 1.16 | 9.06 | 0.26 | |
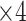 |
1.58 | 0.89 | 9.30 | 0.19 | |
| XCAT 2 |  |
1.53 | 1.97 | 9.16 | 0.47 |
 |
1.54 | 1.14 | 9.13 | 0.26 | |
 |
1.56 | 0.87 | 9.11 | 0.19 | |
| XCAT 3 |  |
1.55 | 1.97 | 9.22 | 0.47 |
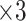 |
1.53 | 1.14 | 9.14 | 0.26 | |
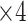 |
1.54 | 0.88 | 9.29 | 0.19 | |
| Volunteer1 | 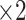 |
2.20 | 2.51 | 14.10 | 0.71 |
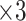 |
6.92 | 2.49 | 29.68 | 0.71 | |
 |
11.45 | 2.62 | 56.79 | 0.75 | |
| Volunteer2 |  |
2.20 | 2.41 | 14.95 | 0.69 |
 |
6.43 | 2.43 | 30.72 | 0.70 | |
 |
11.55 | 2.57 | 56.95 | 0.74 | |
| Volunteer3 | 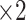 |
0.99 | 0.92 | 3.85 | 0.25 |
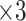 |
1.51 | 0.93 | 9.44 | 0.25 | |
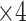 |
2.18 | 0.94 | 15.63 | 0.25 | |
| Volunteer4 | 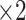 |
0.97 | 0.93 | 3.78 | 0.25 |
 |
1.48 | 0.92 | 8.98 | 0.25 | |
 |
2.18 | 0.94 | 15.50 | 0.25 |
As shown in Table 6, the average running time of ACNS was 0.71 s for the Volunteer1 and Volunteer2 datasets and 0.25 s for the Volunteer3 and Volunteer4 datasets. The test time measured in each method varied depending on the image size. The running time per 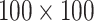 pixels of the resultant image was 0.89 s in SRCNN, 0.54 s in FSRCNN, 4.91 s in DRCN, and 0.14 s in ACNS. Accordingly, ACNS was 6, 4, and 35 times faster than SRCNN, FSRCNN, and DRCN, respectively. Although DRCN produced outstanding SR images, it required the longest computational time.
pixels of the resultant image was 0.89 s in SRCNN, 0.54 s in FSRCNN, 4.91 s in DRCN, and 0.14 s in ACNS. Accordingly, ACNS was 6, 4, and 35 times faster than SRCNN, FSRCNN, and DRCN, respectively. Although DRCN produced outstanding SR images, it required the longest computational time.
V. Discussion
In the experiments, ACNS not only achieved comparable PSNR, SSIM, and IFC results to other CNN-based SR methods, but also substantially reduced the computational time compared to the methods currently considered state-of-the-art. The performance of ACNS results from its network structure. Given an identical training environment, the larger number of parameters, including the filters and layers, and bigger filter size caused longer computational time and did not lead to better image quality. This demonstrated that the common belief, “the deeper the better,” [22] is not always true. We determined the network structure of ACNS based on the experimental results in Section III-C. ACNS’s network structure is a compromise between image quality and computational time. ACNS consists of 6 layers and 5,728 parameters, whereas DRCN has 18 layers—when its recursive layers are unfolded—and 1,774,080 parameters. Thus, DRCN inevitably takes longer to calculate its outcome.
More complex and deeper networks require more painstaking and cumbersome training. Given two well-trained networks with different network depths, the deeper network (with higher nonlinearity) would be expected to achieve a greater improvement in image quality than the shallower network. Therefore, the well-trained DRCN yielded qualitatively better results than the other methods: SRCNN, FSRCNN, and ACNS.
SRCNN has only 3 layers, which is the shallowest layer structure. Therefore, SRCNN has less nonlinearity than FSRCNN, DRCN and ACNS, resulting in its inferior performance in image quality. Despite its simple layer structure, SRCNN generally demanded longer computational time than FSRCNN and ACNS due to its intra-layer design, i.e., the number and size of filters at each layer. Specifically, the number of the parameters was 8,032 for SRCNN and 12,464 for FSRCNN, i.e., 1.4 and 2.2 times greater than the number of the parameters in ACNS, respectively. We used the smallest practical number of the parameters in ACNS. We assume that the proposed framework can reduce the computational complexity and inference time due to fewer parameters and appropriate network structure than other methods.
The deconvolution operation also affected the computational time. Both ACNS and FSRCNN can produce an image of identical size with 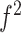 times less inputs than SRCNN and DRCN by using deconvolution for upsampling. Hence, the computation workload in ACNS and FSRCNN are
times less inputs than SRCNN and DRCN by using deconvolution for upsampling. Hence, the computation workload in ACNS and FSRCNN are 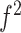 times less than SRCNN and DRCN. We can enhance the MRI resolution using SRCNN and DRCN before upsampling to preserve the identical size of the inputs and resultant images. This would prevent a computational time increase proportional to
times less than SRCNN and DRCN. We can enhance the MRI resolution using SRCNN and DRCN before upsampling to preserve the identical size of the inputs and resultant images. This would prevent a computational time increase proportional to 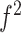 . However, the image quality would be appreciably deteriorated. The nearest-neighbor interpolation would unnaturally pixelate and the bicubic interpolation would blur the estimated HR MRI through upsampling. It is not practical to reduce computational time without a sacrifice in image quality.
. However, the image quality would be appreciably deteriorated. The nearest-neighbor interpolation would unnaturally pixelate and the bicubic interpolation would blur the estimated HR MRI through upsampling. It is not practical to reduce computational time without a sacrifice in image quality.
The biggest problem in applying the current CNN-based SR methods to 4D MRI for MRIgRT is their long computational time. Since 4D MRI needs to be promptly obtained and used during the treatment, it is necessary to accomplish both high image quality and fast processing. Ideally, reconstruction and resolution improvement of 4D MRI should be performed in real-time. According to [11], when FSRCNN was implemented in C++, the average computational time of FSRCNN was 0.061s at 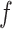 of 3 for dataset Set14, which includes 14 images in a range of
of 3 for dataset Set14, which includes 14 images in a range of 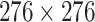 pixels to
pixels to 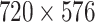 pixels. However, we implemented our method and FSRCNN in MATLAB, and the average test time of FSRCNN was 2.49 s at
pixels. However, we implemented our method and FSRCNN in MATLAB, and the average test time of FSRCNN was 2.49 s at 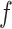 of 3, for Volunteer1 dataset with 900 MRIs of
of 3, for Volunteer1 dataset with 900 MRIs of 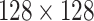 pixels. For the same dataset and
pixels. For the same dataset and 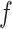 , ACNS was 3 times faster than FSRCNN. Accordingly, ACNS is expected to achieve real-time processing in C++. Moreover, GPU performance has become very fast. The GPU used in the experiment can process 7 trillion floating point operations per second (TFLOP) and the performance of the NVIDIA Quadro RTX 8000, one of the state-of-the-art GPUs, is 16.3 TFLOP. Thus, the real-time processing is feasible with high-performance GPUs in combination with implementation using C++.
, ACNS was 3 times faster than FSRCNN. Accordingly, ACNS is expected to achieve real-time processing in C++. Moreover, GPU performance has become very fast. The GPU used in the experiment can process 7 trillion floating point operations per second (TFLOP) and the performance of the NVIDIA Quadro RTX 8000, one of the state-of-the-art GPUs, is 16.3 TFLOP. Thus, the real-time processing is feasible with high-performance GPUs in combination with implementation using C++.
Additionally, our experiments showed the importance of network parameter selection in CNN-based SR. Based on the experimental results, the performance of ACNS did not rely on each network parameter, i.e., number and size of filters, zero-padding, and the number of layers, but their combination. Although more layers and filters led to longer computation time, they did not result in better image quality. We also observed that the training datasets affect the performance of ACNS. Therefore, there are no universal CNN-based SR methods. Instead, we need to customize the method for its purpose by empirically selecting optimal parameters and using appropriate training datasets. This evokes caution that when using deep learning methods for medical images, the performance with ensembles of the experimental data sets need to be continuously evaluated for their reliability because the deep learning methods are not transparent [20].
VI. Conclusion
In this study we demonstrated ACNS, an in-plane SR method for MRI that recovers missing image information of LR MRIs by CNN-based nonlinear mapping between LR and HR features. Our experiments showed that ACNS achieved comparable image quality improvement as well as outstanding processing speed, which was approximately 6, 4, and 35 times faster than SRCNN, FSRCNN, and DRCN, respectively. The result implies the potential application of ACNS to real-time resolution enhancement of 4D MRI in MRIgRT. Additionally, we presented experimental analysis regarding the relationship between deep learning network parameters and the network’s performance. According to the experimental results, the deep learning-based SR method needs to be customized for its purpose through empirical selection of the optimal parameters and the use of appropriate training datasets.
In this study, we focused on only the in-plane resolution enhancement for MRI. However, there is a clinical demand for the through-plane resolution enhancement in gating based on 3D or 4D MRI. Therefore, our future work aims to enhance the through-plane resolution of 3D and 4D MRI.
Funding Statement
This work was supported by Washington University in St. Louis Departments of Radiation Oncology and Radiology, National Institutes of Health grants NCI R01 CA159471 and NHLBI R01 HL101959, the National Science Foundation CAREER grant 1054333, the National Center for Advancing Clinical and Translational Science Awards (CTSA) Program under Grant UL1TR000058, the Center for Clinical and Translational Research Endowment Fund within Virginia Commonwealth University (VCU) through the Presidential Research Incentive Program, and a VCU Graduate School Dissertation Assistantship. This work involved human subjects or animals in its research. Approval of all ethical and experimental procedures and protocols was granted by the Institutional Review Board (IRB) Exempt Study HM20004559 MRI Breathing Prediction at Virginia Commonwealth University.
References
- [1].Menten M. J., Wetscherek A., and Fast M. F., “MRI-guided lung SBRT: Present and future developments,” Phys. Medica, vol. 44, pp. 139–149, Dec. 2017. [DOI] [PubMed] [Google Scholar]
- [2].Plenge E.et al. , “Super-resolution methods in MRI: Can they improve the trade-off between resolution, signal-to-noise ratio, and acquisition time?” Magn. Reson. Med., vol. 68, no. 6, pp. 1983–1993, Feb. 2012. [DOI] [PubMed] [Google Scholar]
- [3].Lustig M., Donoho D., and Pauly J. M., “Sparse MRI: The application of compressed sensing for rapid MR imaging,” Magn. Reson. Med., vol. 58, no. 6, pp. 1182–1195, Dec. 2007. [DOI] [PubMed] [Google Scholar]
- [4].Doneva M., Eggers H., Rahmer J., Börnert P., and Mertins A., “Highly undersampled 3D golden ratio radial imaging with iterative reconstruction,” in Proc. Int. Soc. Mag. Reson. Med., vol. 16, 2008, p. 336. [Google Scholar]
- [5].Zhang K., Gao X., Li X., and Tao D., “Partially supervised neighbor embedding for example-based image super-resolution,” IEEE J. Sel. Topics Signal Process., vol. 5, no. 2, pp. 230–239, Apr. 2011. [Google Scholar]
- [6].He C., Liu L., Xu L., Liu M., and Liao M., “Learning based compressed sensing for SAR image super-resolution,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 5, no. 4, pp. 1272–1281, Aug. 2012. [Google Scholar]
- [7].Farrugia R. A., Galea C., and Guillemot C., “Super resolution of light field images using linear subspace projection of patch-volumes,” IEEE J. Sel. Topics Signal Process., vol. 11, no. 7, pp. 1058–1071, Oct. 2017. [Google Scholar]
- [8].Reeth E. V., Tham I. W. K., Tan C. H., and Poh C. L., “Super-resolution in magnetic resonance imaging: A review,” Concepts Magn. Reson. A, vol. 40, no. 6, pp. 306–325, Nov. 2012. [Google Scholar]
- [9].Dong C., Loy C. C., He K., and Tang X., “Learning a deep convolutional network for image super-resolution,” in Proc. Eur. Conf. Comput. Vis. (ECCV), Sep. 2014, pp. 184–199. [Google Scholar]
- [10].Dong C., Loy C. C., He K., and Tang X., “Image super-resolution using deep convolutional networks,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 38, no. 2, pp. 295–307, Feb. 2016. [DOI] [PubMed] [Google Scholar]
- [11].Dong C., Loy C. C., and Tang X., “Accelerating the super-resolution convolutional neural network,” in Proc. Eur. Conf. Comput. Vis. (ECCV), Oct. 2016, pp. 391–407. [Google Scholar]
- [12].Kim J., Lee J. K., and Lee K. M., “Deeply-recursive convolutional network for image super-resolution,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 1637–1645. [Google Scholar]
- [13].Yang W., Zhang X., Tian Y., Wang W., Xue J.-H., and Liao Q., “Deep learning for single image super-resolution: A brief review,” IEEE Trans. Multimedia, vol. 21, no. 12, pp. 3106–3121, Dec. 2019. [Google Scholar]
- [14].Li K., Yang S., Dong R., Wang X., and Huang J., “Survey of single image super-resolution reconstruction,” IET Image Process., vol. 14, no. 11, pp. 2273–2290, 2020. [Google Scholar]
- [15].Xu Y., Mo T., Feng Q., Zhong P., Lai M., and Chang E. I.-C., “Deep learning of feature representation with multiple instance learning for medical image analysis,” in Proc. IEEE Int. Conf. Acoust., Speech Signal Process. (ICASSP), May 2014, pp. 1626–1630. [Google Scholar]
- [16].Yang D., Zhang S., Yan Z., Tan C., Li K., and Metaxas D., “Automated anatomical landmark detection on distal femur surface using convolutional neural network,” in Proc. IEEE Int. Symp. Biomed. Imag., Apr. 2015, pp. 17–21. [Google Scholar]
- [17].Bar Y., Diamant I., Wolf L., and Greenspan H., “Deep learning with non-medical training used for chest pathology identification,” Proc. SPIE, vol. 9414, Mar. 2015, Art. no. 94140V. [Google Scholar]
- [18].Lyu Q.et al. , “Multi-contrast super-resolution MRI through a progressive network,” IEEE Trans. Med. Imag., vol. 39, no. 9, pp. 2738–2749, Sep. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Du J., Wang L., Liu Y., Zhou Z., He Z., and Jia Y., “Brain MRI super-resolution using 3D dilated convolutional encoder–decoder network,” IEEE Access, vol. 8, pp. 18938–18950, 2020. [Google Scholar]
- [20].Chong J. J. R., “Deep-learning super-resolution MRI: Getting something from nothing,” J. Magn. Reson. Imag., vol. 51, no. 4, pp. 1140–1141, Apr. 2020. [DOI] [PubMed] [Google Scholar]
- [21].Pham C.-H., Ducournau A., Fablet R., and Rousseau F., “Brain MRI super-resolution using deep 3D convolutional networks,” in Proc. IEEE 14th Int. Symp. Biomed. Imag. (ISBI), Apr. 2017, pp. 197–200. [Google Scholar]
- [22].Pham C.-H.et al. , “Multiscale brain MRI super-resolution using deep 3D convolutional networks,” Comput. Med. Imag. Graph., vol. 77, Oct. 2019, Art. no. 101647. [DOI] [PubMed] [Google Scholar]
- [23].Chen Y., Xie Y., Zhou Z., Shi F., Christodoulou A. G., and Li D., “Brain MRI super resolution using 3D deep densely connected neural networks,” in Proc. IEEE 15th Int. Symp. Biomed. Imag. (ISBI), Apr. 2018, pp. 739–742. [Google Scholar]
- [24].Qiu D., Zhang S., Liu Y., Zhu J., and Zheng L., “Super-resolution reconstruction of knee magnetic resonance imaging based on deep learning,” Comput. Methods Programs Biomed., vol. 187, Apr. 2020, Art. no. 105059. [DOI] [PubMed] [Google Scholar]
- [25].Chaudhari A. S.et al. , “Utility of deep learning super-resolution in the context of osteoarthritis MRI biomarkers,” J. Magn. Reson. Imag., vol. 51, no. 3, pp. 768–779, Mar. 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [26].Chaudhari A. S.et al. , “Super-resolution musculoskeletal MRI using deep learning,” Magn. Reson. Med., vol. 80, no. 5, pp. 2139–2154, Nov. 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [27].Zhao C.et al. , “Applications of a deep learning method for anti-aliasing and super-resolution in MRI,” Magn. Reson. Imag., vol. 64, pp. 132–141, Dec. 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [28].Xue X., Wang Y., Li J., Jiao Z., Ren Z., and Gao X., “Progressive sub-band residual-learning network for MR image super resolution,” IEEE J. Biomed. Health Informat., vol. 24, no. 2, pp. 377–386, Feb. 2020. [DOI] [PubMed] [Google Scholar]
- [29].Fiat D., “Method of enhancing an MRI signal,” U.S. Patent 6 294 914 B1, Sep. 25, 2001.
- [30].Holden J. E., Unal O., Peters D. C., and Oakes T. R., “Control of angular undersampling artifact in projection-based MR angiography by iterative reconstruction,” in Proc. 8th Annu. Meeting ISMRM, Denver, CO, USA, 2000, p. 1. [Google Scholar]
- [31].Hsu J. T., Yen C. C., Li C. C., Sun M., Tian B., and Kaygusuz M., “Application of wavelet-based POCS superresolution for cardiovascular MRI image enhancement,” in Proc. 3rd Int. Conf. Image Graph. (ICIG), Dec. 2004, pp. 572–575. [Google Scholar]
- [32].Plenge E.et al. , “Super-resolution reconstruction in MRI: Better images faster?” Proc. SPIE, vol. 8314, no. 3, pp. 1–8, Feb. 2012. [Google Scholar]
- [33].Poot D. H. J., Van Meir V., and Sijbers J., “General and efficient super-resolution method for multi-slice MRI,” in Proc. Int. Conf. Med. Image Comput. Comput. Assist. Intervent. Berlin, Germany: Springer, Sep. 2010, pp. 615–622. [DOI] [PubMed] [Google Scholar]
- [34].Shi F., Cheng J., Wang L., Yap P.-T., and Shen D., “LRTV: MR image super-resolution with low-rank and total variation regularizations,” IEEE Trans. Med. Imag., vol. 34, no. 12, pp. 2459–2466, Dec. 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [35].Malczewski K., “MRI image enhancement by PROPELLER data fusion,” in Proc. IEEE Int. Workshop Med. Meas. Appl., May 2008, pp. 29–32. [Google Scholar]
- [36].Jiang S., Xue H., Glover A., Rutherford M., Rueckert D., and Hajnal J. V., “MRI of moving subjects using multislice snapshot images with volume reconstruction (SVR): Application to fetal, neonatal, and adult brain studies,” IEEE Trans. Med. Imag., vol. 26, no. 7, pp. 967–980, Jul. 2007. [DOI] [PubMed] [Google Scholar]
- [37].Jiang S.et al. , “Diffusion tensor imaging (DTI) of the brain in moving subjects: Application to in-utero fetal and ex-utero studies,” Magn. Reson. Med., vol. 62, no. 3, pp. 645–655, Sep. 2009. [DOI] [PubMed] [Google Scholar]
- [38].Rousseau F.et al. , “A novel approach to high resolution fetal brain MR imaging,” in Proc. Int. Conf. Med. Image Comput. Comput. Assist. Intervent. (MICCAI), vol. 3749, Oct. 2005, pp. 548–555. [DOI] [PubMed] [Google Scholar]
- [39].Rousseau F.et al. , “Registration-based approach for reconstruction of high-resolution in utero fetal MR brain images,” Acad. Radiol., vol. 13, no. 9, pp. 1072–1081, Sep. 2006. [DOI] [PubMed] [Google Scholar]
- [40].Kim K., Habas P. A., Rousseau F., Glenn O. A., Barkovich A. J., and Studholme C., “Intersection based motion correction of multislice MRI for 3-D in utero fetal brain image formation,” IEEE Trans. Med. Imag., vol. 29, no. 1, pp. 145–158, Jan. 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [41].Gholipour A., Estroff J. A., and Warfield S. K., “Robust super-resolution volume reconstruction from slice acquisitions: Application to fetal brain MRI,” IEEE Trans. Med. Imag., vol. 29, no. 10, pp. 1739–1758, Oct. 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [42].Scherrer B., Gholipour A., and Warfield S. K., “Super-resolution reconstruction to increase the spatial resolution of diffusion weighted images from orthogonal anisotropic acquisitions,” Med. Image Anal., vol. 16, no. 7, pp. 1465–1676, Oct. 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [43].Pipe J. G., “Motion correction with PROPELLER MRI: Application to head motion and free-breathing cardiac imaging,” Magn. Reson. Med., vol. 42, no. 5, pp. 963–969, Nov. 1999. [DOI] [PubMed] [Google Scholar]
- [44].Takeda H., Farsiu S., and Milanfar P., “Kernel regression for image processing and reconstruction,” IEEE Trans. Image Process., vol. 16, no. 2, pp. 349–366, Feb. 2007. [DOI] [PubMed] [Google Scholar]
- [45].Buades A., Coll B., and Morel J.-M., “A non-local algorithm for image denoising,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2005, pp. 60–65. [Google Scholar]
- [46].Ren C., He X., Teng Q., Wu Y., and Nguyen T. Q., “Single image super-resolution using local geometric duality and non-local similarity,” IEEE Trans. Image Process., vol. 25, no. 5, pp. 2168–2183, May 2016. [DOI] [PubMed] [Google Scholar]
- [47].Sun J., Xu Z., and Shum H.-Y., “Image super-resolution using gradient profile prior,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2008, pp. 1–8. [Google Scholar]
- [48].Tai Y.-W., Liu S., Brown M. S., and Lin S., “Super resolution using edge prior and single image detail synthesis,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., Jun. 2010, pp. 2400–2407. [Google Scholar]
- [49].Liu C. and Sun D., “On Bayesian adaptive video super resolution,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 2, pp. 346–360, Feb. 2014. [DOI] [PubMed] [Google Scholar]
- [50].Pickup L. C., Capel D. P., Roberts S. J., and Zisserman A., “Bayesian image super-resolution, continued,” in Proc. Adv. Neural Inf. Process. Syst., 2006, pp. 1089–1096. [Google Scholar]
- [51].Chang H., Yeung D.-Y., and Xiong Y., “Super-resolution through neighbor embedding,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun./Jul. 2004, pp. 275–282. [Google Scholar]
- [52].Yang J., Wright J., Huang T. S., and Ma Y., “Image super-resolution via sparse representation,” IEEE Trans. Image Process., vol. 19, no. 11, pp. 2861–2873, Nov. 2010. [DOI] [PubMed] [Google Scholar]
- [53].Zeyde R., Elad M., and Protter M., “On single image scale-up using sparse-representations,” in Proc. Int. Conf. Curves Surf., Berlin, Germany, 2010, pp. 711–730. [Google Scholar]
- [54].Ni K. S. and Nguyen T. Q., “Image superresolution using support vector regression,” IEEE Trans. Image Process., vol. 16, no. 6, pp. 1596–1610, Jun. 2007. [DOI] [PubMed] [Google Scholar]
- [55].Schulter S., Leistner C., and Bischof H., “Fast and accurate image upscaling with super-resolution forests,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2015, pp. 3791–3799. [Google Scholar]
- [56].Wang Z., Yang Y., Wang Z., Chang S., Yang J., and Huang T. S., “Learning super-resolution jointly from external and internal examples,” IEEE Trans. Image Process., vol. 24, no. 11, pp. 4359–4371, Nov. 2015. [DOI] [PubMed] [Google Scholar]
- [57].Chen Y. and Pock T., “Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 6, pp. 1256–1272, Jun. 2017. [DOI] [PubMed] [Google Scholar]
- [58].Riegler G., Schulter S., Ruther M., and Bischof H., “Conditioned regression models for non-blind single image super-resolution,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Dec. 2015, pp. 522–530. [Google Scholar]
- [59].Jog A., Carass A., and Prince J. L., “Self super-resolution for magnetic resonance images,” in Proc. Int. Conf. Med. Image Comput. Comput.-Assist. Intervent., vol. 9902. Cham, Switzerland: Springer, 2016, pp. 553–560. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [60].Agustsson E. and Timofte R., “NTIRE 2017 challenge on single image super-resolution: Dataset and study,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), Jul. 2017, pp. 1110–1121. [Google Scholar]
- [61].Mahapatra D., Bozorgtabar B., Hewavitharanage S., and Garnavi R., “Image super resolution using generative adversarial networks and local saliency maps for retinal image analysis,” in Proc. Int. Conf. Med. Image Comput. Comput.-Assist. Intervent., vol. 10435. Cham, Switzerland: Springer, 2017, pp. 290–382. [Google Scholar]
- [62].Zhang S., Liang G., Pan S., and Zheng L., “A fast medical image super resolution method based on deep learning network,” IEEE Access, vol. 7, pp. 12319–12327, 2019. [Google Scholar]
- [63].Huang G., Liu Z., Van Der Maaten L., and Weinberger K. Q., “Densely connected convolutional networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 4700–4708. [Google Scholar]
- [64].Shi W.et al. , “Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 1874–1883. [Google Scholar]
- [65].Lim B., Son S., Kim H., Nah S., and Lee K. M., “Enhanced deep residual networks for single image super-resolution,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), Jul. 2017, pp. 136–144. [Google Scholar]
- [66].Ledig C.et al. , “Photo-realistic single image super-resolution using a generative adversarial network,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 105–114. [Google Scholar]
- [67].Vincent P., Larochelle H., Lajoie I., Bengio Y., and Manzagol P.-A., “Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion,” J. Mach. Learn. Res., vol. 11, no. 12, pp. 3371–3408, Dec. 2010. [Google Scholar]
- [68].He K., Zhang X., Ren S., and Sun J., “Deep residual learning for image recognition,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 770–778. [Google Scholar]
- [69].Goodfellow I., Bengio Y., and Courville A., Deep Learning. Cambridge, MA, USA: MIT Press, 2016. [Google Scholar]
- [70].He K., Zhang X., Ren S., and Sun J., “Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), Dec. 2015, pp. 1026–1034. [Google Scholar]
- [71].Lecun Y., Bottou L., Bengio Y., and Haffner P., “Gradient-based learning applied to document recognition,” Proc. IEEE, vol. 86, no. 11, pp. 2278–2324, Nov. 1998. [Google Scholar]
- [72].Sheikh H. R., Bovik A. C., and de Veciana G., “An information fidelity criterion for image quality assessment using natural scene statistics,” IEEE Trans. Image Process., vol. 14, no. 12, pp. 2117–2128, Dec. 2005. [DOI] [PubMed] [Google Scholar]
- [73].Segars W. P., Sturgeon G., Mendonca S., Grimes J., and Tsui B. M. W., “4D XCAT phantom for multimodality imaging research,” Med. Phys., vol. 37, no. 9, pp. 4902–4915, Sep. 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [74].Jia Y.et al. , “Caffe: Convolutional architecture for fast feature embedding,” in Proc. ACM Int. Conf. Multimedia, Nov. 2014, pp. 675–678. [Google Scholar]
- [75].Image Super-Resolution Using Deep Convolutional Networks. Accessed: Dec. 9, 2020. [Online]. Available: http://mmlab.ie.cuhk.edu.hk/projects/SRCNN.html
- [76].Accelerating the Super-Resolution Convolutional Neural Network. Accessed: Dec. 9, 2020. [Online]. Available: http://mmlab.ie.cuhk.edu.hk/projects/FSRCNN.html
- [77].Deeply-Recursive Convolutional Network for Image Super-Resolution. Accessed: Dec. 9, 2020. [Online]. Available: http://cv.snu.ac.kr/research/DRCN/
- [78].Krizhevsky A., Sutskever I., and Hinton G. E., “ImageNet classification with deep convolutional neural networks,” in Proc. Neural Inf. Process. Syst. (NIPS), 2012, pp. 1097–1105. [Google Scholar]
- [79].Vedaldi A. and Lenc K., “MatConvNet: Convolutional neural networks for MATLAB,” in Proc. ACM Int. Conf. Multimedia, Oct. 2015, pp. 689–692. [Google Scholar]