

Abstract
COVID-19 has impacted all lives. To maintain social distancing and avoiding exposure, works and lives have gradually moved online. Under this trend, social media usage to obtain COVID-19 news has increased. Also, misinformation on COVID-19 is frequently spread on social media. In this work, we develop CHECKED, the first Chinese dataset on COVID-19 misinformation. CHECKED provides a total 2,104 verified microblogs related to COVID-19 from December 2019 to August 2020, identified by using a specific list of keywords. Correspondingly, CHECKED includes 1,868,175 reposts, 1,185,702 comments, and 56,852,736 likes that reveal how these verified microblogs are spread and reacted on Weibo. The dataset contains a rich set of multimedia information for each microblog including ground-truth label, textual, visual, temporal, and network information. Extensive experiments have been conducted to analyze CHECKED data and to provide benchmark results for well-established methods when predicting fake news using CHECKED. We hope that CHECKED can facilitate studies that target misinformation on coronavirus. The dataset is available at https://github.com/cyang03/CHECKED.
Keywords: Dataset, COVID-19, Infodemic, Information credibility, Fake news, Multimedia, Social media
Introduction
Starting from its first case, confirmed on December 31 in Sohrabi et al. (2020), the novel coronavirus has surged into a world phenomenon rapidly. On January 30, the World Health Organization (WHO) has declared its outbreak as a global emergency (Sohrabi et al. 2020). As of October 13, the COVID-19 outbreak has caused over 3.7 million confirmed cases and over 1 million deaths worldwide.1 To combat the epidemic, maintaining social distance has been considered effective. In turn, working and studying from home has become a new trend. With the decrease in physical social contacts and the rise of anxiety on the pandemic, the frequency of social media usage has increased. The COVID-19 outbreak as an international public health emergency is closely connected with individuals’ health and lives. Any news or information about the COVID-19 or a potential cure highly attracts public attention and influences social media. Therefore, it is of crucial importance to ensure information spread on COVID-19 is credible.
With more information on COVID-19, people gain a deeper understanding. To that end, a number of COVID-related datasets have been released and studied. Existing datasets have contributed to collecting either (i) Chinese COVID data without identifying news credibility (e.g., see Hu et al. 2020; Gao et al. 2020); or (ii) non-Chinese COVID data for news credibility (e.g., see Zhou et al. 2020a; Cui and Lee 2020; Li et al. 2020). Therefore, we are motivated to build a dataset which contains data from Chinese social media and includes ground-truth labels (i.e., true/false).
Weibo (weibo.com), as a platform for information sharing, dissemination, and acquisition based on user relations, is one of the most popular social media in China. According to Weibo’s first-quarter earnings report for 2020,2 Weibo passed 500 million monthly active users and 200 million daily active users in March. Due to the large number of active users, we consider Weibo as one of the most used Chinese social media for people to access information related to COVID-19. Furthermore, Weibo’s Community Management Center3, which timely provides fact-check results of suspected news information (microblogs) verified by experts, has been widely accepted for researching rumors and fake news (Jin et al. 2017; Wang et al. 2018). Therefore, we consider Weibo as a reliable source of collecting verified microblogs.
We develop CHECKED, the first Chinese COVID-19 social media dataset. CHECKED contains 344 “Fake” microblogs and 1760 “Real” microblogs from December 2019 to August 2020, along with 1,868,175 reposts and 1,185,702 comments that reveal how these verified microblogs were spread and reacted on Weibo. The main contributions of this work are:
We introduce the first fact-checked Chinese COVID-19 social media dataset, which enables more research on tracing the spread of microblogs misinformation and on analyzing content patterns in COVID-19 fake news.
We contribute the dataset with a rich set of features on microblogs related to COVID-19. We collect textual, visual, and video information as well as network and temporal information of a microblog.
We conduct comprehensive experiments to analyze CHECKED data. We provide benchmark results for well-established methods when identifying fake news using this data. Data and codes are all public (see https://github.com/cyang03/CHECKED).
The rest of the paper is organized as follows. Literature review is first conducted in Sect. 2. We explain how we collect data in Sect. 3. Data are then analyzed in Sect. 4, followed by benchmark results for well-established methods when applied to CHECKED in Sect. 5. Finally, we conclude in Sect. 6.
Related work
Our related work can be organized into (I) social media datasets on COVID-19; (II) COVID-19 datasets for news credibility; and (III) Weibo data for news credibility research.
-
I. COVID-19 Social Media Datasets
Social media can provide a wealth of information, especially during the pandemic. Thus, a number of social media datasets on COVID-19 have emerged. Chen et al. (2020) released the first COVID-19 dataset collected from Twitter, tracking the information related to coronavirus from January 2020 till the present with continuous updates. There are a few social media COVID-19 datasets in Chinese (e.g., see Hu et al. 2020 and Gao et al. (2020)). Weibo-COV (Hu et al. 2020) is a large-scale COVID-19 dataset with 40 million microblogs in Chinese from December 2019 to April 2020. The dataset provides textual information, geographical information, and response information. NAIST-COVID (Gao et al. 2020) is a large-scale multilingual COVID-19 dataset which consists of English (16 million), Japanese (9 million), and Chinese (180 thousand) microblogs from Twitter and Weibo from January 20 to March 24.
While these datasets are large, they do not provide visual information or labels on news credibility.
-
II. COVID-19 News Credibility Datasets
With the spread of COVID-19, rumors and fake news related to it have also spread. Thus, constructing a COVID-19 dataset with labels on news credibility, which often relies on verification by domain experts, is invaluable for research. ReCOVery dataset (Zhou et al. 2020a) contains over 2,000 verified news articles on COVID-19 from extremely reliable and unreliable outlets. Both textual and visual information of news articles are collected, along with over 140 thousand tweets by tracking news URLs on Twitter. CoAID dataset (Cui and Lee 2020) includes verified 3,252 news articles and 851 microblogs on Twitter about COVID-19, which correspond to 296,000 related user engagements from December 2019 to July 2020. MM-COVID dataset (Li et al. 2020) provides multilingual fact-checked news statements in six languages (English, Spanish, Portuguese, Hindi, French and Italian) and the relevant social context. The Spanish dataset in MM-COVID dataset is the largest non-English COVID-19 dataset, containing 3,213 verified news articles and 28,824 related user engagements.
Nevertheless, few Chinese COVID-19 dataset has been constructed to support Chinese COVID-19 news credibility research, which motivates our work.
-
III. Weibo Data for News Credibility Research
Weibo’s Community Management Center, which timely provides fact-check results of suspected news information (microblogs) verified by experts, has been widely accepted for researching rumors and fake news. For example, the dataset constructed in Jin et al. (2017) and utilized in Wang et al. (2018) contains 4,749 fake news, collected from Weibo’s Community Management Center, and 4,779 real news, collected from Xinhua News Agency.
Though these Weibo data have greatly contributed to fake news and rumor research, they were collected before COVID-19 pandemic and would not be timely updated; hence can be hardly used, in particular, to combat COVID-19 infodemic.
Compared to the datasets mentioned above, CHECKED is the first Chinese COVID-19 dataset with ground truth labels. CHECKED includes both textual and visual information, as well as the label of news credibility and propagation information in terms of comments and reposts. CHECKED is comparable in to most non-English COVID-19 datasets for news credibility research.
Data collection
We detail the data collection method which answers the following questions: (I) Where can we obtain the ground-truth labels (real or fake) on news events?; (II) How can we identify whether a news event is relevant to the coronavirus or not?; (III) What time intervals should be considered to achieve an extensive yet efficient search coverage?; and (IV) How can the information on news events (meta-data and its spread on Weibo) be tracked and stored in the dataset.
I-1 Collecting Fake News. Weibo provides the Weibo Community Management Center, an official service where users can report either a microblog that (i) contains false information, (ii) releases user privacy without permission, (iii) has evidence of cyberbullying, and (iv) shows plagiarism; or belongs to a user who (v) impersonates as someone else. Experts in charge are then involved in verifying and ultimately, share their detailed evaluation of the reports at the platform publicly. This official service has helped verify over two million microblogs and remove tens of thousands of mis-/disinformation. Our fake news collection focuses on these microblogs, which having been reported and labeled as false information in the Weibo Community Management Center.
I-2 Collecting Real News. To collect credible COVID-19 microblogs, we rely on two official reports, the (I) “2019 White Paper on the Social Value of Chinese Online Medium”4 and the (II) “Research Report on the Public Awareness and Information Dissemination of COVID-19”5, provided by the State Information Center in (Administration Center of China E-government Network), the public institution directly affiliated to the National Development and Reform Commission (NDRC). Both reports provide rankings based on different criteria for Chinese online media. Specifically,
In the white paper, domain experts evaluate 24 Chinese major online media based on eight primary criteria and 28 secondary criteria. The evaluation covers aspects of the (i) quality and diversity in platform construction; (ii) social influence including the platform popularity; (iii) activity; (v) reputation in the field and among online users; and (vi) how the medium contributes to charity.
The COVID-19 research report ranks the performance of online media during the pandemic. The ranking data is obtained through 3,000 valid surveys taken by online users, which focuses on the platform content trustworthiness, communication capacity, and social responsibility.
We select the Weibo account, People’s Daily,6 to collect real news. As China’s largest newspaper group, People’s Daily is ranked first in both reports, with over 120 million followers and over 120,000 microblogs on Weibo.
II. Identifying Microblog Topics. After a broad investigation, we finally select a total of 39 keywords to determine whether a microblog is relevant to COVID-19 or not. All the identified keywords are listed in Table 1, which relate to (i) the name of the virus and disease, (ii) pandemic, (iii) the figures and organizations playing a pivotal role in combating the pandemic, (iv) medical supplies, and (v) policies. Most keywords are in Chinese (33 keywords) and a few, as commonly used professional terms (e.g., N95), are in English (6 keywords). English keywords are case-insensitive. A microblog containing any of the keywords in our list is regarded as relevant to COVID-19. To guarantee the data quality and news relevance, we also manually checked all fetched news articles and removed those irrelevant to COVID-19.
Table 1.
List of Keywords Relevant to COVID-19

III. Collection Interval. For an unbiased data collection, we collected both real and fake microblogs (news events) from December 2019, when the coronavirus was first identified in Wuhan, Heibei, China (Huang et al. 2020), to August 2020 (nine months).
IV. Collecting News Events and Tracking their Spread on Weibo. Given sources for real and fake news, keywords, and data collection time interval for coronavirus pandemic, we collect microblogs, each with the following components:
: Each microblog is identified by a unique 16-digit ID number assigned by Weibo. To protect users’ privacy, we have hashed each ID to 32 digits in the CHECKED dataset.
: is either “real” or “fake,” as the label of each microblog.
: It is an official report including detailed analysis and a result on detecting fake news from Weibo experts.
: is the time each microblog is posted in -- : format.
: is a unique 10-digit ID number assigned to the user by Weibo. Each user can change his or her ID only once to a string formed by 4 to 20 characters, in which letters are allowed. To protect users’ privacy, we have also hashed each user’s ID to 32 digits in the CHECKED dataset.
: It contains the textual information of a microblog.
: the URL for the visual information of the microblog; Users are allowed to attach no more than 18 images to each microblog. Such visual information has been recently developed for multimodal fake news detection (Zhou et al. 2020b; Wang et al. 2018; Jin et al. 2017)
: this URL for the video information of the microblog. Each microblog (i) can only include at most one video; and (ii) cannot contain both a video and an image.
, , and : the numbers of comments, forwards, and likes for a microblog, respectively.
: detailed information on user comments for each microblog. The information includes the hashed ID, date, and content of comments (microblogs), and the hashed ID of commenters (users). For each comment, no more than one image and no video are allowed.
: detailed information on user forwards for each microblog: the hashed ID, date, content of forwards (microblogs), and the hashed ID of forwarders (users). Similar to comments, each forward has at most one image and no video information. If a user forwards a repost with an image, the of the new forward will also include this image along with the original image.
We illustrate a real and fake microblog collected in our dataset in Fig. 1. Meanwhile, we point out that, due to Weibo’s access restriction and editable visibility, it is possible that, for a few microblogs, their number of comments (forwards) in (), which indicates the number visible on Weibo, is less than that of comments (forwards) in (), which captures the actual number.
Fig. 1.

Illustrations of Collected Microblogs
Data analysis
The statistics of CHECKED dataset is presented in Table 2. Next, we analyze the collected data in terms of (I) textual information, (II) visual information, (III) propagation and responses of collected microblogs.
Table 2.
Statistics of CHECKED Data
| Real | Fake | All | |
|---|---|---|---|
| # Microblogs | 1,760 | 344 | 2,104 |
| with images | 1,149 | 53 | 1,202 |
| with video | 563 | 106 | 669 |
| with reposts | 1,151 | 229 | 1,380 |
| with comments | 1,151 | 292 | 1,443 |
| # Reposts of microblogs | 1,827,817 | 40,358 | 1,868,175 |
| # Comments of microblogs | 1,169,246 | 16,456 | 1,185,702 |
| # Likes of microblogs | 56,407,610 | 445,116 | 56,852,726 |
| # Weibo users | 686,077 | 51,674 | 737,751 |
I. Textual Information of Microblogs We first present the distribution of our keywords within the collected microblogs in Fig. 2; the keywords help identify if a microblog is relevant to COVID-19. We observe that the Chinese keywords are more frequently used than the English ones; this is reasonable as Weibo mostly targets Chinese users who might be multilingual.
Fig. 2.

Distribution of Selected Keywords in Collected Microblogs
On the other hand, Fig. 3 presents the word cloud of collected microblogs for all words in addition to the keywords. The top-ten vocabularies with the highest frequencies are “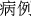 (case)” (#=2919), “
(case)” (#=2919), “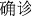 (confirmed case)” (#=2158), “
(confirmed case)” (#=2158), “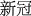 ((abbr.) COVID-19)” (#=1827), “
((abbr.) COVID-19)” (#=1827), “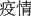 (pandemic/epidemic)” (#=1701), “
(pandemic/epidemic)” (#=1701), “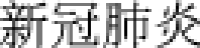 (COVID-19)” (#=1649), “
(COVID-19)” (#=1649), “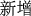 (new case)” (#=1331), “
(new case)” (#=1331), “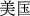 (United State)” (#=1227), “
(United State)” (#=1227), “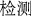 (test)” (#=923), and “
(test)” (#=923), and “ (China)” (#=866). We observe that most of these vocabularies are included in our keyword list, while a few are not. These are not directly related to COVID-19, e.g., United States and China.
(China)” (#=866). We observe that most of these vocabularies are included in our keyword list, while a few are not. These are not directly related to COVID-19, e.g., United States and China.
Fig. 3.

Word Cloud
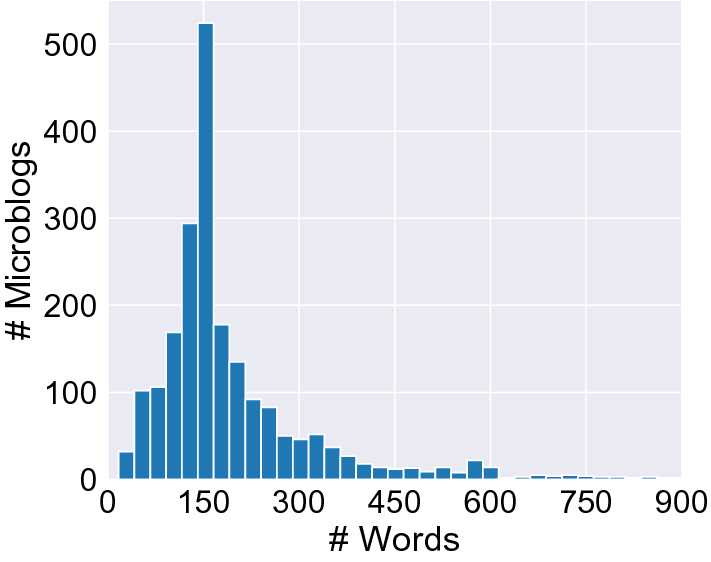
Finally, in Fig. 4, we plot the distribution of the number of words within collected microblogs, which share an average (median) number of 216 (154). We point out that each microblog is restricted to up to 140 words for all Weibo users before version 6.0.0, after which the restriction has been lifted for VIP users, e.g., People’s Daily; it explains why some microblogs in our data have over 140 words.
Fig. 4.
Dist. of Words
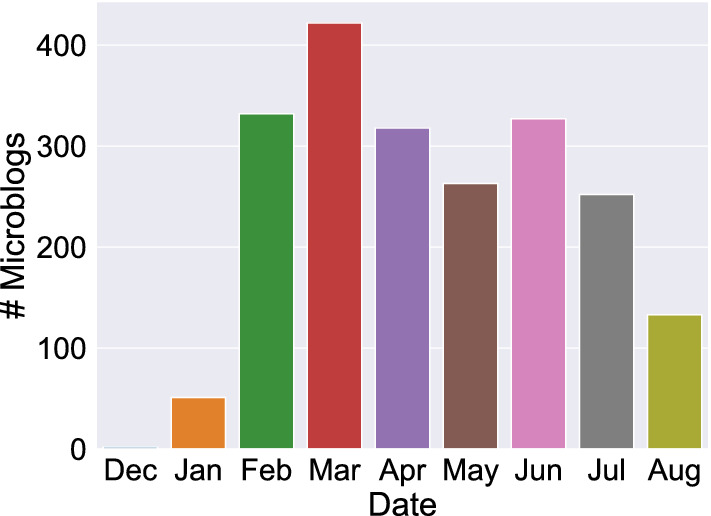
II. Temporal and Visual Information of Microblogs Figure 5 presents the distribution of the posting time of our collected microblogs. We observe that a very few microblogs related to COVID-19 were posted in December 2019 as the first case of the coronavirus was confirmed at the end of this month (Sohrabi et al. 2020). We notice that the number of COVID-19 microblogs (or say, online discussion) significantly increases since February 2020, which is also the month with the highest number of confirmed cases of the coronavirus.
Fig. 5.
Dist. of Dates Posted
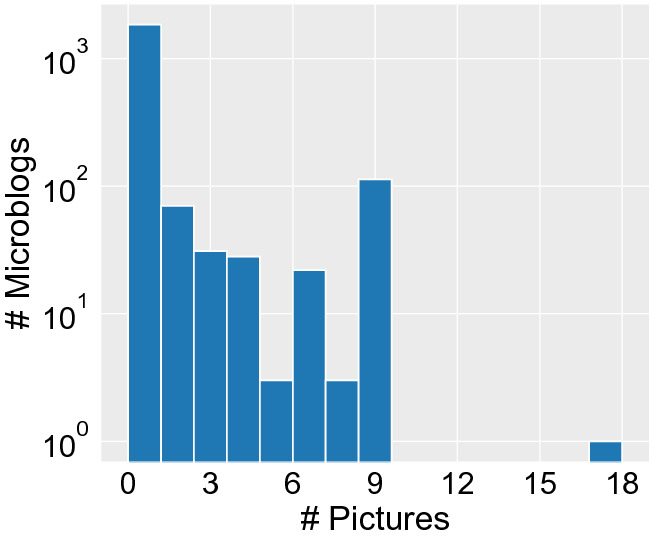
As for images attached within microblogs, we observe from Fig. 6 that most collected microblogs contain no more than 9 images. A few microblogs have more than nine images, because posting over 9 images within a microblog has been allowed recently, as a new version 9.9.3 of Weibo.
Fig. 6.
Dist. of Images
III. Propagation and Responses of Microblogs We track the influence of [real and fake] microblogs on the coronavirus, as well as how they propagate on Weibo from three perspectives: (i) comments, (ii) forwards, and (iii) likes; their corresponding distributions for our data are provided in Figs. 7, 8, 9, which all follow a power-law-like distribution with a long tail. We observe that (i) in general, 80% microblogs have less than 2,000 comments, 2,000 forwards, and/or 20,000 likes; (ii) the most influential microblog can have over 20,000 comments, one million forwards, and/or one million likes; and (iii) all collected microblogs share an average (median) frequencies of being commented, forwarded, and liked of 1,785 (744), 3,482 (586), and 26,851 (6,179).
Fig. 7.
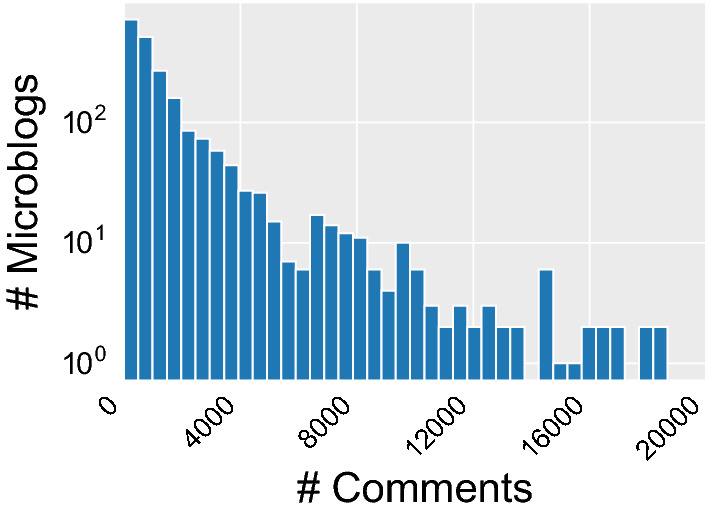
Dist. of Comments
Fig. 8.
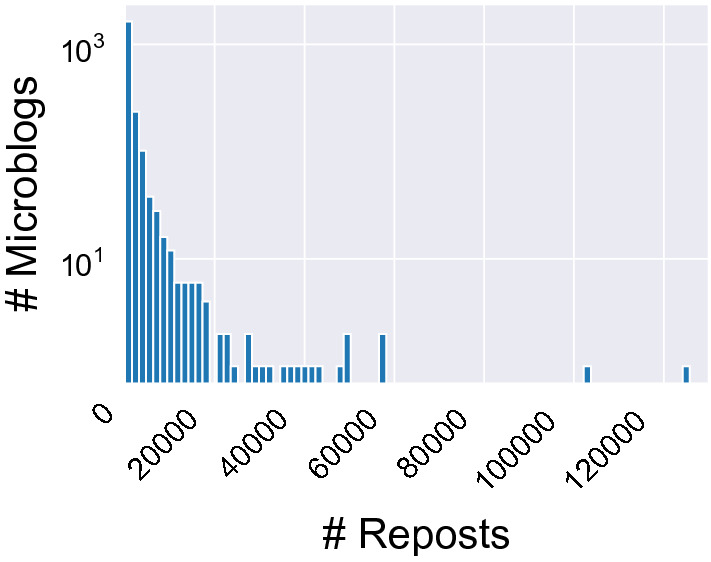
Dist. of Reposts
Fig. 9.
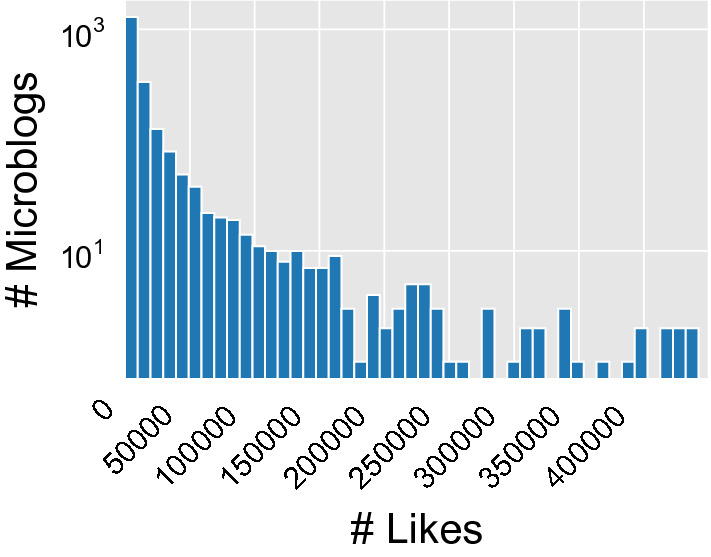
Dist. of Likes
Benchmark results using CHECKED data for fake news detection
In this section, we provide the benchmark result using CHECKED data when utilizing various methods to predict fake news. These neural-network-based methods have been well-established and widely accepted for text-classification, including (i) FastText (Joulin et al. 2017), (ii) TextCNN (Kim 2014), (iii) TextRNN (Liu et al. 2016), (iv) Attention-based TextRNN (Att-TextRNN) (Zhou et al. 2016), and the (v) Transformer (Vaswani et al. 2017). We first separate the data, based on their posting time order, for training, validation, and testing with a proportion of 70%:10%:20%. Due to the class imbalance in data, we use macro to evaluate the method performance. For all baseline methods, we set the padding size as 150, batch size as 16, and dropout ratio as 0.5. Final results are provided in Table 3.
Table 3.
Benchmark Results using CHECKED data to Detect Fake News
| FastText | TextCNN | TextRNN | Att-TextRNN | Transformer | |
|---|---|---|---|---|---|
| Macro | 0.839 | 0.938 | 0.700 | 0.871 | 0.927 |
Conclusion
We present CHECKED, a Chinese COVID-19 dataset containing fact-checked microblogs from Weibo. The dataset includes a total of 2,104 microblogs from December 2019 to August 2020. Each microblog contains ground-truth labels, textual, visual, and propagation information that include 1,868,175 reposts, 1,185,702 comments, and 56,852,726 likes by 737,751 users. We emphasize that CHECKED can be only used for academic research. IDs of microblogs and users have been hashed in the dataset to protect users’ privacy. The dataset can be improved by (i) involving more COVID-19 microblogs from other sources of real news; (ii) including the data on COVID-19 news articles from other websites spreading on Weibo. We hope this dataset can promote research on COVID-19 fake news.
Footnotes
https://service.account.weibo.com/ (sign in required).
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Chen Yang, Email: cyang03@syr.edu.
Xinyi Zhou, Email: zhouxinyi@data.syr.edu.
Reza Zafarani, Email: reza@data.syr.edu.
References
- Chen E, Lerman K, Ferrara E. Tracking social media discourse about the COVID-19 pandemic: development of a public coronavirus Twitter data set. JMIR Public Health Surveill. 2020;6(2):e19273. doi: 10.2196/19273. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cui L, Lee D (2020) CoAID: COVID-19 healthcare misinformation dataset. arXiv preprint arXiv:2006.00885
- Gao Z, Yada S, Wakamiya S, Aramaki E (2020) NAIST COVID: multilingual COVID-19 Twitter and Weibo Dataset. arXiv preprint arXiv:2004.08145
- Hu Y, Huang H, Chen A, Mao XL (2020) Weibo-COV: a large-scale COVID-19 social media dataset from Weibo. arXiv pp. arXiv–2005
- Huang C, Wang Y, Li X, Ren L, Zhao J, Hu Y, Zhang L, Fan G, Xu J, Gu X, et al. Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. Lancet. 2020;395(10223):497–506. doi: 10.1016/S0140-6736(20)30183-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jin Z, Cao J, Guo H, Zhang Y, Luo J (2017) Multimodal fusion with recurrent neural networks for rumor detection on microblogs. In: Proceedings of the 2017 ACM on Multimedia Conference, ACM, pp. 795–816
- Joulin A, Grave É, Bojanowski P, Mikolov T (2017) Bag of tricks for efficient text classification. In: Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, pp. 427–431
- Kim Y (2014) Convolutional neural networks for sentence classification. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, pp. 1746–1751 [DOI] [PMC free article] [PubMed]
- Li Y, Jiang B, Shu K, Liu H (2020) MM-COVID: a multilingual and multidimensional data repository for combating COVID-19 fake new. arXiv preprint arXiv:2011.04088
- Liu P, Qiu X, Huang X (2016) Recurrent neural network for text classification with multi-task learning. In: Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, pp. 2873–2879
- Sohrabi C, Alsafi Z, O’Neill N, Khan M, Kerwan A, Al-Jabir A, Iosifidis C, Agha R. World Health Organization declares global emergency: a review of the 2019 novel coronavirus (COVID-19) Int J Surg. 2020;76:71–76. doi: 10.1016/j.ijsu.2020.02.034. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I (2017) Attention is all you need. In: Proceedings of the 31st international conference on neural information processing systems, pp 6000–6010
- Wang Y, Ma F, Jin Z, Yuan Y, Xun G, Jha K, Su L, Gao J (2018) EANN: Event adversarial neural networks for multi-modal fake news detection. In: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 849–857. ACM
- Zhou P, Shi W, Tian J, Qi Z, Li B, Hao H, Xu B (2016) Attention-based bidirectional long short-term memory networks for relation classification. In: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp. 207–212
- Zhou X, Mulay A, Ferrara E, Zafarani R (2020) ReCOVery: A Multimodal Repository for COVID-19 News Credibility Research. In: Proceedings of the 29th ACM International Conference on Information & Knowledge Management, pp. 3205–3212
- Zhou X, Wu J, Zafarani R (2020) SAFE: Similarity-Aware Multi-Modal Fake News detection. In: The 24th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD). Springer