

Abstract
Preterm birth (PTB) in a pregnant woman is the most serious issue in the field of Gynaecology and Obstetrics, especially in rural India. In recent years, various clinical prediction models for PTB have been developed to improve the accuracy of learning models. However, to the best of the authors' knowledge, most of them suffer from selecting the most accurate features from the medical dataset in linear time. The present paper attempts to design a machine learning model named as risk prediction conceptual model (RPCM) for the prediction of PTB. In this paper, a feature selection approach is proposed based on the notion of entropy. The novel approach is used to find the best maternal features (responsible for PTB) from the obstetrical dataset and aims to predict the classifier's accuracy at the highest level. The paper first deals with the review of PTB cases (which is neglected in many developing countries including India). Next, we collect obstetrical data from the Community Health Centre of rural areas (Kamdara, Jharkhand). The suggested approach is then applied on collected data to identify the excellent maternal features (text-based symptoms) present in pregnant women in order to classify all birth cases into term birth and PTB. The machine learning part of the model is implemented using three different classifiers, namely, decision tree (DT), logistic regression (LR), and support vector machine (SVM) for PTB prediction. The performance of the classifiers is measured in terms of accuracy, specificity, and sensitivity. Finally, the SVM classifier generates an accuracy of 90.9%, which is higher than other learning classifiers used in this study.
1. Introduction
Preterm birth (PTB) is a serious public health problem that adversely affects both families and the society [1]. It is a leading cause of neonatal mortality and morbidity across the world and also the second major cause of child deaths under the age of five years [2]. Over the past two decades, PTB has been a significant research study in healthcare domain. Pregnancy and childbirth unlocked the door for medical experts and researchers to explore various effective strategies to reduce preterm birth in women having pregnancy-related complications. These strategies include healthcare services given to all pregnant women to control PTB and any medical interventions aimed to enhance the knowledge of women on early indications of pregnancy complications [3, 4]. The maternal history of a pregnant woman is a key part of the neonatal studies for providing certain clinical treatments to newborn babies regarding their health, disease, care, and outcomes. Newborn babies are very special. They do not have any previous medical background, and their early neonatal path is directly connected to the maternal history of their mothers [5–7]. The healthcare services also incorporate the arrangements of essential social and economic support for women before, during, and after pregnancy including educational, medical, and other training programs that facilitate healthy motherhood.
In general, treatments of diseases (including PTB) are made by the physicians based upon their knowledge (experience). However, on the one hand, manual diagnosis may not be often right as physician's experience varies from expert to expert. On the other hand, manual treatment is a time-consuming job. Further, shortage of medical experts is increasing everyday with population explosion and developing countries like in India, large number of women belong to lower or middle income families. They do not get proper healthcare facilities or awareness regarding health education to know about any complication that arises during pregnancy, especially in rural area. Further, people often are afraid of doctors' prescription since doctors in most cases misguide the patients suggesting unnecessary tests (like double marker test, fetal echocardiography, urine test, and FT4 test which are used to determine any pregnancy complications) which are very expensive. Also, doctor's appointment fees are mostly on higher side. Besides, doctors could sometime diagnose the cases wrongly. After all, preterm delivery is the most critical issue in Gynaecology and Obstetrics and a major health concern for every pregnant woman. It may require several ultrasound sonography (USG) tests in addition to doctor's appointment fee for diagnosing high-risk patients, and these altogether may amount huge expense that may be beyond the income limit of many families. So, designing the computerized system (i.e., e-healthcare system) for birth prediction from past diagnosis data is the essential solution for quick and accurate decision to be taken for any adverse pregnancy outcome in order to save lives and cost.
Notably, a pioneering renovation is taking place in the Obstetrical community due to the advancement in technology and digitization of medical records. Data analytics is one of the most promising tool for research and development in the area of medicine [8–15]. Nowadays, machine learning techniques (e.g., neural networks, support vector machine, logistic regression, and Decision Trees) are playing important role in designing the disease predictive model to address the growing needs of human experts in the medical world [16–20]. However, medical datasets are highly imbalanced, conflicting in nature, and uncertain. So, designing the effective intelligent model for medical datasets is a challenging task. PTB dataset is one such clinical dataset. Numerous predictive models based on standard intelligent methods have been introduced by the researchers for prediction of PTB [21]. However, they usually suffer from several drawbacks like lack of understandability and inefficiency in making quick and correct decision. Further, early detection and diagnosis play important role in controlling such complications. Symptoms (text) based machine intelligent models may play vital role in early detection of such cases. The delay in receiving the clinical judgement for preterm delivery increases the risk of pregnancy complications which in turn increases the risk of prenatal mortality. Due to its direct association with prenatal mortality, neonatal health is also very important in the obstetrical community [7]. According to the UNICEF study released in 2015, 35% of neonatal death is due to PTB. The rate of PTB in rural areas of most developing countries is increasing due to lack of health facilities and insufficient number of healthcare workers.
In light of these considerations, the present study aims to design a novel conceptual model (by employing machine learning techniques) and its implementation for detection of PTB in pregnant women. In fact, the system can be used as a decision support system to assist the medical staff and healthcare workers for predicting premature delivery. More specifically, the present study focuses on novel feature selection (entropy-notion) approach to identify the most important maternal features (text-based symptoms) responsible for preterm delivery and aims to predict the classification accuracy.
The remaining sections of the paper are organized as follows. Section 2 describes the basic concept of PTB and feature selection. Section 3 elaborates the related work that has been carried out to predict PTB. Section 4 describes the methodology of this research. The experimental design and results are presented in Section 5. Finally, Section 6 deals with conclusion and future scopes.
2. Background of the Present Research
2.1. Preterm Birth (PTB): A Comprehensive Overview
Preterm or premature birth is defined as birth, for any reason, occurring before 37 completed weeks (or less than 259 days) of pregnancy. Every year, about fifteen million babies are born prematurely (before 37 completed weeks of gestation), and this is nearly equal to one-tenth of all babies around the world [22]. According to the WHO reports studied in 2005, 12.9 million births or 9.6% of all births across the world occurred prematurely [23]. The rate of preterm birth, however, significantly varies across the world. Preterm birth reflects the most prominent reason for neonatal morbidity and mortality [24].
2.1.1. Categorization of PTB
PTB can be classified into different categories based on gestational age at birth. The gestational age is defined as the time from the first day of the last menstrual period (LMP) of a woman to birth [21]. The four categories of PTB are as follows:
Extreme PTB (under 28 Weeks). It is the birth that takes place before 28 weeks of pregnancy
Very PTB (28 to 32 Weeks). It is the birth that takes place between 28 and 32 weeks of pregnancy
Moderate PTB (32 to 34 Weeks). It is the birth that takes place between 32 and 34 weeks of pregnancy
Late PTB (34 to 37 Weeks). It is the birth that takes place between 34 and 37 weeks of pregnancy
2.1.2. Medical Terminologies
For the purpose of clarity of the present study, the used terminologies are illustrated in Table 1.
Table 1.
Definitions used in the present study.
| Terminology | Description |
|---|---|
| Antenatal care | Antenatal care (ANC) refers to the fundamental, clinical, and nursing care suggested for ladies during pregnancy |
| Neonate | A neonate or a newborn infant is a child under 28 days of age |
| Neonatal death | A death during the first 28 days of life (0–27 days) is termed as a neonatal death |
| Live birth | A birth at which a child is born alive is termed as live birth |
| Term birth | A birth at the end of a normal duration of pregnancy between 37 and 40 weeks of gestation is termed as term birth |
| Maternal death | A maternal death is the death of a woman while pregnant or within 42 days of termination of pregnancy |
| Stillbirth | Stillbirth is the delivery, after the 20th week of pregnancy, of a baby who has died |
| Abortion | Termination of a pregnancy either medically or induced |
| Miscarriage | Natural loss of pregnancy during first trimester |
| Gestational age | Gestational age (GA) refers to the time from the first day of a woman's last menstrual period to birth |
2.1.3. Health Impact of PTB
PTB is the main risk factor for newborn mortality and morbidity. It is a leading cause of neonatal mortality and morbidity across the world and also the second major cause of child deaths under the age of five years [25]. It arises between 5 and 10% of all deliveries and involves 70% of neonatal mortality and up to 75% of neonatal morbidity [26]. Premature infants are more likely to suffer than normal birth and are at higher risk of brain paralysis, sensory impairment, respiratory failure, and so on. More than $13 billon of premature cost for maternity service is anticipated only in the USA [27, 28]. Most survivors of PTB face serious problems, often a lifetime of disability, including learning disabilities, visual, and hearing problems. In fact, babies born premature have more health problems compared with babies born at term birth. Term birth refers to babies that are born at 37 to 40 weeks of gestation. Furthermore, babies born at preterm are reported to be at an elevated risk of long-term health problems [29]. Unfortunately, after many years of research in obstetrics, yet the rate of PTB has not decreased [30]. Birth weight is generally associated with PTB and results in its own categorization. Usually, birth weight is simpler to measure precisely and is a first estimation of gestational age. Obviously, the most challenging issue in Gynaecology and Obstetrics is how to control the preterm delivery in pregnant women.
2.2. Feature Selection (FS)
The term feature selection in the machine learning, also known as feature subset selection, refers to the process of selecting a subset of excellent features during construction of the predictive model. The presence of redundant and irrelevant features in any datasets (especially in medical datasets) can reduce the accuracy of the model's prediction and also have the negative impact on the performance of the model. The main goal of any feature selection method is to select the best subset of features by removing redundant and irrelevant features from the datasets in order to reduce the training time and enhance the classifier's predictive performance. In fact, feature selection is typically used as a preprocessing step in data mining. There are three standard approaches of the feature selection algorithm, namely, filter method, wrapper method, and embedded method. For more details about feature selection, one may refer to [31–33].
Filter Method. The filter method measures the relevance of features based on the nature of data. The selection of features is independent of the classifiers used. The filter method is much faster compared with the wrapper method and provides an average accuracy for all the classifiers used. Some of the examples of filter methods are information gain, chi-square test, variance threshold, and so on.
Wrapper Method. The wrapper method finds the best subset of features based on a specific machine learning algorithm that we are trying to fit on a given dataset. The evaluation criteria are simply the predictive power of the particular classifier. The wrapper method has higher performance accuracy compared with the filter method but requires more computational time to find best features for a dataset with high-dimensional features. Some of the examples of wrapper methods are forward selection, backward elimination, genetic algorithms, and so on.
Embedded Method. The embedded method incorporates the advantages of both filter and wrapper methods. In this approach, feature selection is done during the process of model training and is usually unique to particular learning classifiers. This approach basically determines the importance of feature, i.e., which features to accept and which to reject, while making a prediction. The most typical embedded technique is the decision tree algorithm. This method typically falls somewhere between the filter method and wrapper method in terms of time complexity. Some of the examples of embedded methods are lasso regression, ridge regression, elastic net, and so on.
3. Related Works
This section focuses mainly on the existing methodologies related to prediction of PTB using machine learning, statistical analysis, and data mining techniques. Some of them are discussed in this section. The study of Mercer et al. [34] was designed to develop a risk-score-based model for predicting PTB. The model can be trained using a multivariate logistic regression technique to explore various risk factors using clinical data available between 23 and 24 weeks' gestation. Goodwin et al. employed the machine learning model to generate 520 predictive rules for PTB with the application of data mining techniques [35]. The study in [36] discussed the deep learning models for predicting preterm delivery using existing electronic medical records (EMRs) of mothers available in healthcare centres.
Weber et al. [37] performed a cohort study to predict spontaneous preterm. The prediction of PTB was performed using numerous classifiers, namely, K-nearest neighbours, lasso regression, and random forests. This study has taken into the consideration of demographic, race-ethnicity, and maternal characteristics. Mailath-Pokorny et al. [38] explored the predictive features for preterm delivery that occurs within 2 days after admission and before 224 days of gestation using the multivariate logistic regression model. The predictive features considered are age of the mother, gestational age during admission, maternal history, vaginal bleeding, cervical length, preterm history, and preterm premature rupture of membranes (PPROM) in their study. Son and Miller presented a prediction model for PTB using cervical length measurement in women with a singleton gestation. To accomplish better predictive performance, they attempted to determine the best cut points of cervical length [39].
Elaveyini et al. [40] explored the major risk factors of preterm birth using artificial neural networks. PTB prediction was based on the feed-forward backpropagation algorithm. Over the past decades, majority of research studies have been done to enhance the accuracy of prediction of PTB [41]. Researchers are continually making their best efforts to analyse and explore the principal risk factors for preterm delivery [42–44]. The present article focuses on the machine learning approaches for prediction of birth cases in rural community.
3.1. Shortcomings in the Existing Clinical Models
In recent years, using feature selection approach, a significant number of clinical prediction model have been developed to improve the accuracy of learning models. However, to the best of authors' knowledge, most of them suffer from selecting the most accurate features from the medical dataset in linear time. Hence, there is a scope for improving the performance of machine learning classifiers and reducing learning time.
3.2. Novel Contribution
A novel feature selection approach based on the notion of entropy is introduced in this study to address the identified issues of the existing models. The key role of the novel approach is to find the subset of optimal features from the medical dataset in order to improve the prediction's accuracy and ultimately reduce the machine learning time.
4. Research Methodology
4.1. Objective
The finding of this research study can be utilized to fulfill the three following main objectives:
A machine learning-based risk prediction conceptual model (RPCM) for PTB can be introduced with the help of novel feature selection approach using entropy-notion to predict the birth cases (TB and PTB) from the obstetrical records.
The suggested approach is used to identify the excellent (text-based symptoms) features responsible for PTB. Furthermore, medical experts' (physicians and obstetricians) opinions are also considered through review of medical records of patients and survey analysis. The model can be extended to select the regions for pregnancy consultation.
The predictive model can be beneficial for rural India to identify the important maternal features in order to predict the possibility of PTB in the gestation of women. This information can support rural medical staff for taking effective decisions for adverse pregnancy outcome—that aim to reduce the diagnosis cost.
4.2. The Proposed Feature Selection Approach Based on the Notion of Entropy
According to the study in [45], attributes having strong correlation cannot be the part of feature subset. Besides, more the attributes are independent among themselves and more information gain they will have which would eventually give better outcomes over unseen data. The present research focuses on medical (obstetrical) datasets which are more sensitive in nature, so feature selection approach is more effective for such datasets. In light of this point, a feature selection (entropy-notion) approach is presented here to extract the most relevant features from obstetrical (term-preterm) dataset. These features are utilized to classify all birth cases into term birth and PTB. A conceptual model of the proposed approach is shown in Figure 1.
Figure 1.
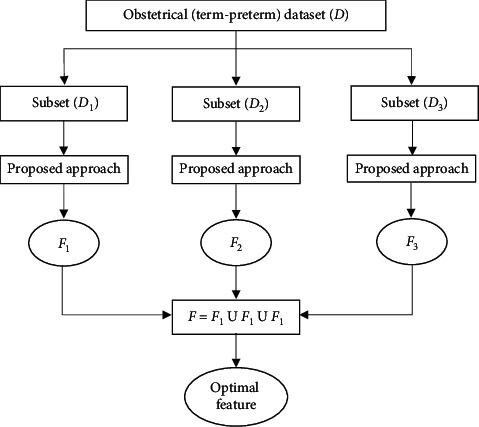
Conceptual model for feature selection approach.
The proposed approach is stated as follows:
Suppose that D is a medical dataset having n attributes, say Ai for i = 1, 2, 3,…, n.
Let F0 denote a set of features in the original dataset D.
Initially, F0 = {A1, A2, A3,…, An}.
Since D is divided into three distinct subsets as D1, D2, and D3, so after applying the proposed approach, we get three feature subsets, namely, F1, F2, and F3 from these data subsets.
F is considered as a resultant feature set derived from F1, F2, and F3. Initially, Fk = F0 for k = 1, 2, 3.
Let P be a classification problem described by a set of n attributes, say Ai for i = 1, 2, 3,…, n and also consider that F represents the set of features derived from the original dataset.
Initialize, F = F0 = {A1, A2, A3,…, An}.
for each data subset Di ∈ D; where i = 1, 2, 3
do
for each attribute Ai ∈ F0
do
Calculate Gain (S, Ai)//information gain for Ai
Using formula stated below,
Gain(S, Ai)=Entropy(S) − Σvj∈Ai(|Svj|/|s|)Entropy(Svj), where vj denotes values of attribute Ai and Entropy(S)= Σpmlog2pm, where S represents the number of instances in P and pm is the nonzero probability of sm instances (out of S) belonging to class m, out of c classes.
end for
Compute r=(Max_Gain(S, Ai) − Min_Gain(S, Ai)/n), where i = 1, 2, 3,…, n.
//Here, r is considered as a threshold value for selecting features
for each attribute Ai ∈ F0
do
if Gain(S, Ai) < r
then
update Fk = Fk─{Ai}//removing Ai from Fk
end if
end for
end for
F = F1 U F2 U F3//including all attributes of F1, F2, and F3.
Note. The proposed feature selection approach in this study is a form of the filter method and is implemented in Java-1.4.
Time Complexity. The algorithm is simple and easy to understand. The running time of an algorithm is O(n), where n is the number of attributes in the dataset.
4.3. The Proposed Framework: Risk Prediction Conceptual Model (RPCM)
Based on novel feature selection (entropy-notion) approach and several studies in [46–49], RPCM is carefully designed to predict the risk of PTB in pregnant women. The workflow of the framework consisting of three stages (Stage-I, Stage-II, and Stage-III) is depicted in Figure 2, and then its each component is detailed.
Figure 2.
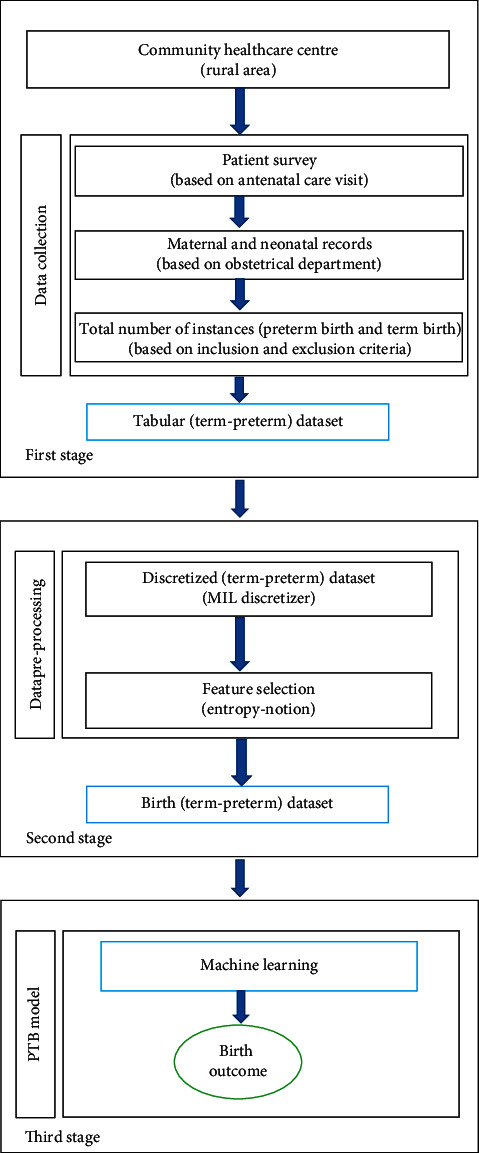
Framework of the proposed model.
4.3.1. Key Components of the Proposed Model
The proposed model consists of some key components, namely, healthcare centre, patient survey, maternal and neonatal records, data preprocessing, machine learning, and birth outcome. Each of these is discussed as follows:
Healthcare Centre. A healthcare centre is a part of a network of hospitals employed by a group of general physicians, nurses, and healthcare professionals that provide healthcare facilities to people in a certain area. In addition to standard medical treatments, one of the main goals of the primary healthcare centre is maternal care during pregnancy especially in rural India. This is because people from rural India avoid contacting healthcare professionals and practitioners for pregnancy care which increases the cases of maternal and neonatal deaths.
Patient Survey. A comprehensive care to mother and child is primarily concerned to all healthcare systems in India. The term survey describes any study that consists of requesting people to respond queries. This entails researcher-developed questionnaires and personal interviews with pregnant women during their antenatal care visits.
Maternal and Neonatal Records. Maternal and neonatal records play a vital role in deciding the way healthcare services are provided, accessed, and affected by health outcomes. It stores the statistical reports describing the use of prenatal services, maternal risk factors, and birth outcomes for all patients residing in rural area. PTB is one of the most frequent complication of pregnancy. It occurs due to several medical reasons and is affected by some of the important maternal features based on human experts (experience) and several research studies [50–53]. These maternal features are critical in nature to predict cases of PTB. The total number of birth instances is taken from the obstetrical data.
Data Discretization. A technique of converting continuous values of attribute into a finite set of intervals and associating a new discrete value with each interval is known as data discretization. Since any classifiers prefer to handle discrete values rather than continuous values for the learning process, data discretization plays a crucial role in the process of machine learning. The study in [54] suggests that data discretization improves the quality of discovered knowledge, and it is based on the concept of information theory.
Feature Selection. One of the core concepts in machine learning is the feature selection. Feature selection is the process of selecting those features from the input datasets which highly impact the performance of the predictive model. The present study focuses on feature selection approach based on entropy notion as already discussed in Section 4.2.
Data Preprocessing. The tabular dataset collected from obstetrical data is preprocessed and converted into a normalized form with the help of MIL discretizer [55, 56].
Machine Learning (ML). The present study focuses on applying machine learning algorithms [46, 49] for PTB prediction. ML is a method of data analysis that automates analytical model building. Classification is one of the most popular approaches for applying ML methods (e.g., DT, LR, and SVM). These techniques are used to in medical domain for classification, prediction, and diagnosis purposes.
Birth Outcome. This component is very crucial in preventing preterm delivery in pregnant women during antenatal care clinics. The predicted birth outcome can also be used to properly analyse the key maternal features responsible for PTB.
4.4. Details of Stage-I
The main role of the first stage of framework is to collect obstetrical data from the Community Healthcare Centre, and it is detailed in this section.
4.4.1. Study Design
The study was conducted in the Community Health Centre, Kamdara (Gumla), situated in rural area of Jharkhand, during a period from July 2018 to September 2020. The hospital provides obstetric and gynaecological services to all categories of women, whether registered for antenatal care or referred. The approval for the study was taken from the Institutional Ethics Committee.
Selection Criteria. The selection of patients (women) depends on the following inclusion-exclusion criteria:
- Inclusion criteria include the following:
- Women registered for ANC and having birth at the Community Health Centre
- Women having birth occurring at the gestational age of 28 weeks or more
- Women who delivered a live birth
- Exclusion criteria include the following:
- Women having still birth
- Women having birth of twins
- Women referred to other hospitals
4.4.2. Data Collection
The basic step of Stage-I is to collect data based on patient survey and maternal records available in the obstetrics department. Initially, 1800 records were collected during a research period. Then, 1300 records were selected for further study based upon inclusion-exclusion criteria. The collected records include all instances of term birth and PTB. A manual analysis is performed to select all maternal features which are involved during pregnancy (based on medical experts' opinion and several research studies) [51, 52, 57, 58]. The description of the obstetrical dataset (original) after data collection is summarized in Table 2.
Table 2.
Summary of the obstetrical (term-preterm) dataset.
| Problem name | Number of features | Number of classes | Number of instances |
|---|---|---|---|
| Birth case | 36 | 2 | 1300 |
Initially, all instances are in a raw-form which are compiled into a tabular-form using MS Excel program. As a result, a tabular (term-preterm) dataset is prepared for the research purpose. The tabular (term-preterm) dataset used in this work is a binary class dataset.
The feature values in this dataset are of the form-string, integer, and continuous. The tabular (term-preterm) dataset consists of 1300 instances, composed of thirty-six different features which are taken into consideration before, during, and after pregnancy. These features are listed in Table 3. The questionnaire used for data entry during patient survey was mainly focused on their background details, medical history, previous pregnancy details, current pregnancy details, baby details, and medical disorders in current pregnancy.
Table 3.
Maternal features associated with PTB.
| S. no. | Feature ID | Feature name |
|---|---|---|
| 1 | PID | Patient identification |
| 2 | WA | Woman age |
| 3 | LMP | Last menstrual period |
| 4 | EDD | Estimated delivery date |
| 5 | G | Gravida |
| 6 | P | Parity |
| 7 | A | Abortion |
| 8 | L | Living |
| 9 | EL | Educational level |
| 10 | H | Height |
| 11 | W | Weight |
| 12 | BMI | Body mass index |
| 13 | BP | Blood pressure |
| 14 | HB | Hemoglobin |
| 15 | ANC | Antenatal care visit |
| 16 | ADD | Actual delivery date |
| 17 | OH | Obstetric history |
| 18 | PCS | Previous caesarean section |
| 19 | GA | Gestational age |
| 20 | BW | Birth weight |
| 21 | GDM | Gestational diabetes mellitus |
| 22 | FHR | Fetal heart rate |
| 23 | MG | Multiple gestation |
| 24 | ND | Normal delivery |
| 25 | MH | Previous medical history |
| 26 | LBW | Low birth weight |
| 27 | ASPX | Asphyxia |
| 28 | HT | Hypertension |
| 29 | PE | Preeclampsia |
| 30 | LV | Live birth |
| 31 | SB | Still birth |
| 32 | OB | Obesity |
| 33 | AN | Anemia |
| 34 | TH | Thyroid |
| 35 | NS | Neonatal status |
| 36 | PTB | Preterm birth |
4.5. Description of Stage-II
The collected data from tabular (term-preterm) dataset are preprocessed at the second stage of the framework. This stage deals with two main operations, namely, data discretization and feature selection.
4.5.1. Data Discretization
During data preprocessing, tabular (term-preterm) dataset is converted into a normalized form with the help of data discretization process. This gives a discretized (term-preterm) dataset. This dataset is utilized to select most accurate features by applying suggested feature selection approach based on the notion of entropy. The initial statistics of discretized (term-preterm) dataset is shown in Table 4.
Table 4.
Summary of discretized (term-preterm) dataset.
| Outcome | N |
|---|---|
| Number of features | 36 |
| Number of classes | 2 |
| Total instances | 1300 |
| Term birth | 991 |
| Preterm birth | 309 |
In reality, attributes of any medical dataset may contain mixture of string, continuous, outliers, and missing data. Many classifiers cannot handle continuous attributes but each of them can operate on discretized attributes [55]. Besides, performance of classifiers can be significantly improved by replacing continuous attributes with its discretized values. Depending upon the amount of missing data and the criticality of the feature in which the data is missing, it may impact the accuracy of prediction. In this study, the missing value in any feature is replaced with the mean value of that feature, and minimum information loss (MIL) data discretizer [12, 54, 59] is employed here for data processing, which make data compatible with the machine learning algorithm.
4.5.2. Feature Selection
After that, the proposed feature selection approach is taken into consideration to select the most probable features (responsible for PTB) from the discretized (term-preterm) dataset. As a result, seventeen different features are selected from this dataset. These maternal features (listed in Table 5) are also considered as major risk factors for PTB as suggested by medical experts and several research studies. Then, a final birth (term-preterm) dataset, consisting of these selected features, is prepared for the last stage of framework. The birth dataset also contains 1300 instances of term birth and PTB.
Table 5.
List of excellent features in discretized (term-preterm) dataset.
| Feature code | Feature name | Feature type |
|---|---|---|
| WA | Woman age | Numeric |
| PT | Parity | Numeric |
| GD | Gravida | Numeric |
| BMI | Body mass index | Ordinal |
| ANC | Antenatal care visit | Numeric |
| GA | Gestational age | Numeric |
| FHR | Fetal heart rate | Numeric |
| BP | Blood pressure | Ordinal |
| HB | Hemoglobin | Numeric |
| GDM | Gestational diabetes mellitus | Binary |
| PE | Preeclampsia | Binary |
| HT | Hypertension | Binary |
| OH | Obstetric history | Binary |
| EL | Education level | Ordinal |
| CS | Previous caesarean section | Binary |
| MH | Previous medical history | Binary |
| PTB | Preterm birth (target variable) | Binary |
4.6. Description of Stage-III
Finally, a machine learning-based prediction model for PTB is built at this stage. This section describes the actual construction of the suggested system.
4.6.1. Machine Learning PTB Model
The aim of this research is to find a suitable classifier which can predict the PTB with more accuracy. The three classifiers, namely, decision tree (DT), logistic regression (LR), and support vector machine (SVM) are used in this analysis. The method of selecting classifier in this study is illustrated in Figure 3. Model fitting was carried out by dividing the input dataset into training dataset and test dataset at a ratio of 70% and 30%, respectively. The training set is used in learning phase and test set is used in prediction phase, to determine the best model. Researchers may find ample information about several machine learning classifiers from the articles [60–63].
Figure 3.
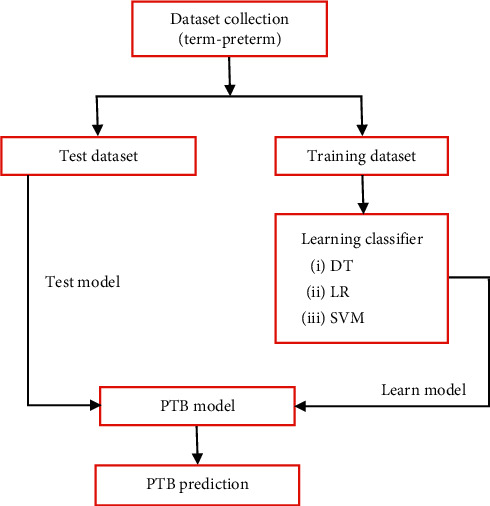
A conceptual PTB prediction model.
4.6.2. Evaluation of Machine Learning Classifiers
The empirical measures can be extracted from the confusion matrix in order to evaluate the performance of the learning classifier [64]. A confusion matrix shows the accuracy of the solution to a classification problem. Table 6 depicts the confusion matrix, which summarizes the number of instances predicted correctly or incorrectly by a classification model.
Table 6.
Confusion matrix.
| Predictive positive | Predictive negative | |
|---|---|---|
| Actual positive | True Positive (TP) | False Negative (FN) |
| Actual negative | False Positive (FP) | True Negative (TN) |
Furthermore, the other parameters used to measure the classifier's performance are correct classification rate (CCR) or accuracy, true positive rate (TPR) or sensitivity, true negative rate (TNR) or specificity, false positive rate (FPR), false negative rate (FNR), precision, recall, and F1 score. A formal definition of these performance metrics is shown in Table 7.
Table 7.
Performance metrics for machine learning classifiers.
| Metrics | Formula |
|---|---|
| CCR | ((TP+TN)/(TP+FP+FN+TN))% |
| TPR | TP/(TP+FN) |
| TNR | TN/(TN+FP) |
| FPR | FP/(TN+FP) |
| FNR | FN/(TP+FN) |
| Precision | TP/(TP+FP) |
| Recall | TP/(TN+FN) |
| F 1 score | 2∗TP/(2∗TP+Fp+FN) |
5. Experimental Design and Results
5.1. Experimental Design
A birth (term-preterm) dataset with 1300 patients' observations is obtained in order to perform the experiment. The experiment is carried out with the help of Python and Scikit-Learn library or under WEKA toolbox (http://www.cs.waikato.ac.nz/ml/weka). The observations in the birth dataset are carefully reviewed for prediction of birth cases. This is in fact a binary class dataset in which all births occurring between 28th to 37th weeks are termed as PTB class with label “1” whereas all births after 37th weeks are termed as term birth (TB) class with label “0.” According to the study, around 24% of the findings in the dataset are of PTB with label “1” and remaining 76% are of TB with label “0.” Hence, PTB class is dominated by TB class, and we can say that PTB is the minority class and TB is the majority class. Therefore, there is a need of a good sampling technique for medical datasets [24, 52]. In this context, synthetic minority oversampling technique (SMOTE) is used to balance the target dataset [65]. This can be achieved by replicating the PTB cases until it reaches approximately 50% of the dataset. This gives a new balanced (term-preterm) dataset.
5.2. Results and Discussion
A total of 1300 patients (women) were selected in this study based on inclusion-exclusion criteria. Out of 1300 pregnant women, 309 women were having preterm birth and rest 991 women were having term birth. Thus, the incidence of PTB is 23.78% of total pregnant women. In this work, the performance of DT, LR, and SVM classifiers is evaluated in terms of accuracy, specificity, and sensitivity [66]. With these indicators, it is possible to compare the proposed model performance with three classifiers. Tables 8 and 9 present the performance metrics of classifiers for the original dataset and balanced dataset, respectively.
Table 8.
Performance metrics of the classifiers—original dataset.
| Classifiers | Accuracy | Sensitivity | Specificity |
|---|---|---|---|
| DT | 0.777 | 0.702 | 0.930 |
| LR | 0.841 | 0.863 | 0.971 |
| SVM | 0.861 | 0.801 | 0.702 |
Table 9.
Performance metrics of the classifiers—balanced dataset.
| Classifiers | Accuracy | Sensitivity | Specificity |
|---|---|---|---|
| DT | 0.796 | 0.713 | 0.972 |
| LR | 0.872 | 0.832 | 0.954 |
| SVM | 0.909 | 0.891 | 0.783 |
Based on the results shown in Tables 8 and 9, we can observe that the accuracy of three different classifiers is roughly around 85%. With respect to the original dataset, the accuracy of SVM is 86.1% which is highest, followed by LR and DT. The results were additionally improved (after applying SMOTE) with the balanced dataset. The accuracy of SVM classifier in the balance dataset increases from 86.1% to 90.9% compared with original dataset. In summary, the SVM model is the best classifier in the experiment.
6. Conclusion and Future Scope
In this study, the proposed model (RPCM) can be used for prediction of PTB based on excellent features (text-based symptoms) available in obstetrical data. The work focuses on feature selection (entropy-notion) approach by applying machine learning classifiers (DT, LR, and SVM) in order to classify all birth cases into term birth and PTB. Comparing the performances of the classifiers, it is evident that SVM classifier is the most suitable classifier as it achieves an accuracy of 90.9%. According to the findings of this study, the identified risk factors (excellent features) will be helpful in the prediction of PTB, especially in rural community. The developed model supports the decision-making process in maternity care by identifying and alerting the pregnant women at risk of preterm delivery thereby preventing possible complications, reducing the diagnosis cost, and ultimately minimizing the risk of PTB. The present system can be regarded as a successful innovation in Obstetrics to give clinical support to patients during pregnancy consultations. In particular, RPCM claims to assist healthcare professionals to make effective and timely decisions without consulting specialists directly.
The limitation of the present research is that the risk factors for PTB are limited in size and dataset is small, which could be increased to improve the performance of the PTB prediction in the future studies. However, expert knowledge and clinical judgement may still be needed to interpret this risk and take appropriate action in individual cases.
Acknowledgments
The authors acknowledge the staff of Department of Gynaecology and Obstetrics at Community Health Centre (Kamdara, Jharkhand) for their efforts in the completion of this research work. The authors gratefully thank Dr. Ruchi Bhushan, MBBS, MS (OBG), for her valuable comments and helpful discussions. The authors would also like to convey their sincere gratitude to Mrs. Priyanka and Ms. Prerna for their neverending support and motivation.
Data Availability
The data used to support the finding of this study are available from the corresponding author upon reasonable request. The data are not publicly available due to privacy and ethical restrictions of Institutional Ethics Committee.
Disclosure
The content of this paper represents the views of the authors and do not necessarily reflect the views of the Community Health Centre.
Conflicts of Interest
The authors declare that they have no conflicts of interest.
References
- 1.Blencowe H., Cousens S., Chou D., et al. Born Too Soon: the global epidemiology of 15 million preterm births. Reproductive Health. 2013;10(1):p. S2. doi: 10.1186/1742-4755-10-S1-S2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Liu L., Oza S., Hogan D., et al. Global, regional, and national causes of child mortality in 2000-13, with projections to inform post-2015 priorities: an updated systematic analysis. The Lancet. 2015;385(9966):430–440. doi: 10.1016/S0140-6736(14)61698-6. [DOI] [PubMed] [Google Scholar]
- 3.Govindaswami B., Jegatheesan P., Nudelman M., Narasimhan S. R. Prevention of prematurity. Clinics in Perinatology. 2018;45(3):579–595. doi: 10.1016/j.clp.2018.05.013. [DOI] [PubMed] [Google Scholar]
- 4.Meertens L. J. E., van Montfort P., Scheepers H. C. J., et al. Prediction models for the risk of spontaneous preterm birth based on maternal characteristics: a systematic review and independent external validation. Acta obstetricia et gynecologica Scandinavica. 2018;97(8):907–920. doi: 10.1111/aogs.13358. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Perez M. J., Chang J. J., Temming L. A., et al. Driving factors of preterm birth risk in adolescents. American Journal of Perinatology Reports. 2020;10(3):e247–e252. doi: 10.1055/s-0040-1715164. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Shrestha S., Dangol S. S., Shrestha M., Shrestha R. P. B. Outcome of preterm babies and associated risk factors in a hospital. Journal of the Nepal Medical Association. 2010;50(180) doi: 10.31729/jnma.57. [DOI] [PubMed] [Google Scholar]
- 7.Catley C., Frize M., Walker R. C., Petriu D. C. Predicting preterm birth using artificial neural networks. In Proceedings of the 18th IEEE Symposium on Computer-Based Medical Systems (CBMS’05); June 2005; Dublin, Ireland. pp. 103–108. [DOI] [Google Scholar]
- 8.Belle A., Thiagarajan R., Soroushmehr S. M. R., Navidi F., Beard D. A., Najarian K. Big data analytics in healthcare. BioMed Research International. 2015;2015:16. doi: 10.1155/2015/370194.370194 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Raja R., Mukherjee I., Sarkar B. K. A systematic review of healthcare big data. Scientific Programming. 2020;2020:15. doi: 10.1155/2020/5471849.5471849 [DOI] [Google Scholar]
- 10.Chen M., Hao Y., Hwang K., Wang L., Wang L. Disease prediction by machine learning over big data from healthcare communities. IEEE Access. 2017;5:8869–8879. doi: 10.1109/access.2017.2694446. [DOI] [Google Scholar]
- 11.Mansoul A., Atmani B., Benbelkacem S. A hybrid decision support system: application on healthcare. 2013. http://arxiv.org/abs/1311.4086.
- 12.Sarkar B. K. A two-step knowledge extraction framework for improving disease diagnosis. The Computer Journal. 2020;63(3):364–382. doi: 10.1093/comjnl/bxz034. [DOI] [Google Scholar]
- 13.Seera M., Lim C. P. A hybrid intelligent system for medical data classification. Expert Systems with Applications. 2014;41(5):2239–2249. doi: 10.1016/j.eswa.2013.09.022. [DOI] [Google Scholar]
- 14.Bhardwaj A., Tiwari A. Breast cancer diagnosis using genetically optimized neural network model. Expert Systems with Applications. 2015;42(10):4611–4620. doi: 10.1016/j.eswa.2015.01.065. [DOI] [Google Scholar]
- 15.Lisboa P. J., Taktak A. F. G. The use of artificial neural networks in decision support in cancer: a systematic review. Neural Networks. 2006;19(4):408–415. doi: 10.1016/j.neunet.2005.10.007. [DOI] [PubMed] [Google Scholar]
- 16.Mitchell T. M. Machine learning and data mining. Communications of the ACM. 1999;42(11):30–36. doi: 10.1145/319382.319388. [DOI] [Google Scholar]
- 17.Callahan A., Shah N. H. Key Advances in Clinical Informatics. Cambridge, MA, USA: Academic Press; 2017. Machine learning in healthcare; pp. 279–291. [DOI] [Google Scholar]
- 18.Fu L. Knowledge discovery based on neural networks. Communications of the ACM. 1999;42(11):47–50. doi: 10.1145/319382.319391. [DOI] [Google Scholar]
- 19.Zhang G. P. Neural networks for classification: a survey. IEEE Transactions on Systems, Man and Cybernetics, Part C (Applications and Reviews) 2000;30(4):451–462. doi: 10.1109/5326.897072. [DOI] [Google Scholar]
- 20.Klosgen W., Zytkow J. M. Handbook of Data Mining and Knowledge Discovery. Oxford, UK: Oxford University Press; 2002. [Google Scholar]
- 21.Pari R., Sandhya M., Sankar S. Risk factors based classification for accurate prediction of the Preterm Birth. Proceedings of the 2017 International Conference on Inventive Computing and Informatics (ICICI); November 2017; Coimbatore, India. IEEE; pp. 394–399. [Google Scholar]
- 22.The global burden of preterm birth. The Lancet. 2009;374 doi: 10.1016/S0140-6736(09)61762-1. [DOI] [PubMed] [Google Scholar]
- 23.Beck S., Wojdyla D., Say L., et al. The worldwide incidence of preterm birth: a systematic review of maternal mortality and morbidity. Bulletin of the World Health Organization. 2010;88(1):31–38. doi: 10.2471/blt.08.062554. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Saigal S., Doyle L. W. An overview of mortality and sequelae of preterm birth from infancy to adulthood. The Lancet. 2008;371(9608):261–269. doi: 10.1016/s0140-6736(08)60136-1. [DOI] [PubMed] [Google Scholar]
- 25.Rudan I., Chan K. Y., Zhang J. S., et al. Causes of deaths in children younger than 5 years in China in 2008. The Lancet. 2010;375(9720):1083–1089. doi: 10.1016/s0140-6736(10)60060-8. [DOI] [PubMed] [Google Scholar]
- 26.Hogan M. C., Foreman K. J., Naghavi M., et al. Maternal mortality for 181 countries, 19802008: a systematic analysis of progress towards Millennium Development Goal 5. The Lancet. 2010;375(9726):1609–1623. doi: 10.1016/s0140-6736(10)60518-1. [DOI] [PubMed] [Google Scholar]
- 27.World Health Organization (WHO) Commission on Information and Accountability for Women’s and Children’s Health. Keeping Promises, Measuring Results. Geneva, Switzerland: WHO; 2015. [Google Scholar]
- 28.Walani S. R., Biermann J. March of Dimes Foundation: leading the way to birth defects prevention. Public Health Reviews. 2017;38(1):1–7. doi: 10.1186/s40985-017-0058-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Dong Y., Yu J.-L. An overview of morbidity, mortality and long-term outcome of late preterm birth. World Journal of Pediatrics. 2011;7(3):199–204. doi: 10.1007/s12519-011-0290-8. [DOI] [PubMed] [Google Scholar]
- 30.Challis J. R. G., Lye S. J., Gibb W., Whittle W., Patel F., Alfaidy N. Understanding preterm labor. Annals of the New York Academy of Sciences. 2001;943(1):225–234. doi: 10.1111/j.1749-6632.2001.tb03804.x. [DOI] [PubMed] [Google Scholar]
- 31.Witten Ian H., Eibe F. Data Mining: Practical Machine Learning Tools and Techniques. 2nd. San Francisco, CA, USA: Morgan Kaufmann Publishers; 2005. [Google Scholar]
- 32.Li Y., Li T., Liu H. Recent advances in feature selection and its applications. Knowledge and Information Systems. 2017;53(3):551–577. doi: 10.1007/s10115-017-1059-8. [DOI] [Google Scholar]
- 33.Huan Liu H., Lei Yu L. Toward integrating feature selection algorithms for classification and clustering. IEEE Transactions on Knowledge and Data Engineering. 2005;17(4):491–502. doi: 10.1109/tkde.2005.66. [DOI] [Google Scholar]
- 34.Mercer B. M., Goldenberg R. L., Das A., et al. The preterm prediction study: a clinical risk assessment system. American Journal of Obstetrics and Gynecology. 1996;174(6):1885–1895. doi: 10.1016/s0002-9378(96)70225-9. [DOI] [PubMed] [Google Scholar]
- 35.Goodwin L. K., Iannacchione M. A., Hammond W. E., Crockett P., Maher S., Schlitz K. Data mining methods find demographic predictors of preterm birth. Nursing Research. 2001;50(6):340–345. doi: 10.1097/00006199-200111000-00003. [DOI] [PubMed] [Google Scholar]
- 36.Gao C., Osmundson S., Velez Edwards D. R., Jackson G. P., Malin B. A., Chen Y. Deep learning predicts extreme preterm birth from electronic health records. Journal of Biomedical Informatics. 2019;100:p. 103334. doi: 10.1016/j.jbi.2019.103334. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Weber A., Darmstadt G. L., Gruber S., et al. Application of machine-learning to predict early spontaneous preterm birth among nulliparous non-Hispanic black and white women. Annals of Epidemiology. 2018;28(11):783–789. doi: 10.1016/j.annepidem.2018.08.008. [DOI] [PubMed] [Google Scholar]
- 38.Mailath-Pokorny M., Polterauer S., Kohl M., et al. Individualized assessment of preterm birth risk using two modified prediction models. European Journal of Obstetrics & Gynecology and Reproductive Biology. 2015;186:42–48. doi: 10.1016/j.ejogrb.2014.12.010. [DOI] [PubMed] [Google Scholar]
- 39.Son M., Miller E. S. Predicting preterm birth: cervical length and fetal fibronectin. Seminars in Perinatology. 2017;41(8):445–451. doi: 10.1053/j.semperi.2017.08.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Elaveyini U., Devi S. P., Rao K. S. Neural networks prediction of preterm delivery with first trimester bleeding. Archives of Gynecology and Obstetrics. 2011;283(5):971–979. doi: 10.1007/s00404-010-1469-2. [DOI] [PubMed] [Google Scholar]
- 41.Khatibi T., Kheyrikoochaksarayee N., Sepehri M. M. Analysis of big data for prediction of provider-initiated preterm birth and spontaneous premature deliveries and ranking the predictive features. Archives of Gynecology and Obstetrics. 2019;300(6):1565–1582. doi: 10.1007/s00404-019-05325-3. [DOI] [PubMed] [Google Scholar]
- 42.Colstrup M., Mathiesen E. R., Damm P., Jensen D. M., Ringholm L. Pregnancy in women with type 1 diabetes: have the goals of St. Vincent declaration been met concerning foetal and neonatal complications? The Journal of Maternal-Fetal & Neonatal Medicine. 2013;26(17):1682–1686. doi: 10.3109/14767058.2013.794214. [DOI] [PubMed] [Google Scholar]
- 43.Blencowe H., Cousens S., Oestergaard M. Z., et al. National, regional, and worldwide estimates of preterm birth rates in the year 2010 with time trends since 1990 for selected countries: a systematic analysis and implications. The Lancet. 2012;379(9832):2162–2172. doi: 10.1016/s0140-6736(12)60820-4. [DOI] [PubMed] [Google Scholar]
- 44.Liu L., Johnson H. L., Cousens S., et al. Global, regional, and national causes of child mortality: an updated systematic analysis for 2010 with time trends since 2000. The Lancet. 2012;379(9832):2151–2161. doi: 10.1016/s0140-6736(12)60560-1. [DOI] [PubMed] [Google Scholar]
- 45.Hall M. A. Correlation-based feature selection for discrete and numeric class machine learning. Proceedings of Seventeenth International Conference on Machine Learning; July 2000; Stanford, CA, USA. pp. 359–366. [Google Scholar]
- 46.Ngiam K. Y., Khor I. W. Big data and machine learning algorithms for health-care delivery. The Lancet Oncology. 2019;20(5):e262–e273. doi: 10.1016/s1470-2045(19)30149-4. [DOI] [PubMed] [Google Scholar]
- 47.Nam J. G., Park S., Hwang E. J., et al. Development and validation of deep learning-based automatic detection algorithm for malignant pulmonary nodules on chest radiographs. Radiology. 2019;290(1):218–228. doi: 10.1148/radiol.2018180237. [DOI] [PubMed] [Google Scholar]
- 48.Ahmed Z., Mohamed K., Zeeshan S., Dong X. Artificial Intelligence with Multi-Functional Machine Learning Platform Development for Better Healthcare and Precision Medicine. Database. 2020;2020 doi: 10.1093/database/baaa010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Rajkomar A., Dean J., Kohane I. Machine learning in medicine. New England Journal of Medicine. 2019;380(14):1347–1358. doi: 10.1056/nejmra1814259. [DOI] [PubMed] [Google Scholar]
- 50.Pereira S., Portela F., Santos M. F., Machado J., Abelha A. Portuguese Conference on Artificial Intelligence. Berlin, Germany: Springer; 2015. Predicting preterm birth in maternity care by means of data mining; pp. 116–121. [DOI] [Google Scholar]
- 51.Courtney K. L., Stewart S., Popescu M., Goodwin L. K. Predictors of preterm birth in birth certificate data. Studies in Health Technology and Informatics. 2008;136:555–60. [PubMed] [Google Scholar]
- 52.Prema N. S., Pushpalatha M. P. Emerging Research in Electronics, Computer Science and Technology. Berlin, Germany: Springer; 2019. Machine learning approach for preterm birth prediction based on maternal chronic conditions; pp. 581–588. [DOI] [Google Scholar]
- 53.Cunningham F., Leveno K., Bloom S., Spong C. Y., Dashe J. Williams Obstetrics, 24e. New York, NY, USA: McGraw-Hill; 2014. [Google Scholar]
- 54.Jin R., Breitbart Y., Muoh C. Data discretization unification. Knowledge and Information Systems. 2009;19(1):1–29. doi: 10.1007/s10115-008-0142-6. [DOI] [Google Scholar]
- 55.Sarkar B. K., Sana S. S., Chaudhuri K. MIL: a data discretisation approach. International Journal of Data Mining, Modelling and Management. 2011;3(3):303–318. doi: 10.1504/ijdmmm.2011.041811. [DOI] [Google Scholar]
- 56.Mitra G., Sundareisan S., Sarkar B. K. A simple data discretizer. 2017. http://arxiv.org/abs/1710.05091.
- 57.Kourou K., Exarchos T. P., Exarchos K. P., Karamouzis M. V., Fotiadis D. I. Machine learning applications in cancer prognosis and prediction. Computational and Structural Biotechnology Journal. 2015;13:8–17. doi: 10.1016/j.csbj.2014.11.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Jothi N., Rashid N. A. A., Husain W. Data mining in healthcare-a review. Procedia Computer Science. 2015;72:306–313. doi: 10.1016/j.procs.2015.12.145. [DOI] [Google Scholar]
- 59.Boulle M. Khiops: a statistical discretization method of continuous attributes. Machine Learning. 2004;55(1):53–69. doi: 10.1023/b:mach.0000019804.29836.05. [DOI] [Google Scholar]
- 60.Tan P. N., Steinbach M., Kumar V. Introduction to Data Mining. New Delhi, India: Pearson Education India; 2016. [Google Scholar]
- 61.Witten I. H., Frank E. Data mining. ACM Sigmod Record. 2002;31(1):76–77. doi: 10.1145/507338.507355. [DOI] [Google Scholar]
- 62.Dhillon A., Singh A. Machine learning in healthcare data analysis: a survey. Journal of Biology and Today’s World. 2019;8(6):1–10. [Google Scholar]
- 63.Ahmad M. A., Eckert C., Teredesai A. Interpretable machine learning in healthcare. Proceedings of the 2018 ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics; August 2018; Washington, DC, USA. pp. 559–560. [Google Scholar]
- 64.Gu Q., Zhu L., Cai Z. International Symposium on Intelligence Computation and Applications. Berlin, Germany: Springer; 2009. Evaluation measures of the classification performance of imbalanced data sets; pp. 461–471. [DOI] [Google Scholar]
- 65.Chawla N. V., Bowyer K. W., Hall L. O., Kegelmeyer W. P. SMOTE: synthetic minority over-sampling technique. Journal of Artificial Intelligence Research. 2002;16:321–357. doi: 10.1613/jair.953. [DOI] [Google Scholar]
- 66.Zhu W., Zeng N., Wang N. Sensitivity, specificity, accuracy, associated confidence interval and ROC analysis with practical SAS implementations. NESUG Proceedings: Health Care and Life Sciences. 2010;19 [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The data used to support the finding of this study are available from the corresponding author upon reasonable request. The data are not publicly available due to privacy and ethical restrictions of Institutional Ethics Committee.