

Abstract
Many neurological diseases are characterized by gradual deterioration of brain structure and function. Large longitudinal MRI datasets have revealed such deterioration, in part, by applying machine and deep learning to predict diagnosis. A popular approach is to apply Convolutional Neural Networks (CNN) to extract informative features from each visit of the longitudinal MRI and then use those features to classify each visit via Recurrent Neural Networks (RNNs). Such modeling neglects the progressive nature of the disease, which may result in clinically implausible classifications across visits. To avoid this issue, we propose to combine features across visits by coupling feature extraction with a novel longitudinal pooling layer and enforce consistency of the classification across visits in line with disease progression. We evaluate the proposed method on the longitudinal structural MRIs from three neuroimaging datasets: Alzheimer’s Disease Neuroimaging Initiative (ADNI, N = 404), a dataset composed of 274 normal controls and 329 patients with Alcohol Use Disorder (AUD), and 255 youths from the National Consortium on Alcohol and NeuroDevelopment in Adolescence (NCANDA). In all three experiments our method is superior to other widely used approaches for longitudinal classification thus making a unique contribution towards more accurate tracking of the impact of conditions on the brain. The code is available at https://github.com/ouyangjiahong/longitudinal-pooling.
Index Terms—: Longitudinal Analysis, Disease Progression, Recurrent Neural Networks
I. Introduction
Longitudinal neuroimaging studies enable scientists to track the gradual effect of neurological diseases and environmental influences on the brain over time [1]. Compared to cross-sectional studies, modeling temporal dependency captured by longitudinal MRIs is crucial to accurately quantify the aging trajectories of anatomical and functional brain organization [2]–[4] and monitoring the progression of neurological disorders in individuals [5]–[7].
Analysis of longitudinal MRIs is traditionally based on statistical approaches testing hypotheses [8]. In this scenario, each image is first reduced to a set of brain measurements (e.g., volumes of regions of interest (ROIs)) [9]. The effect of a condition (such as Alzheimer’s Disease (AD)) on the longitudinal trajectory of each brain measurement is then tested by statistical approaches [10]. For example, general linear models (GLM) are often used to compute the average developmental trajectories for each cohort of interest (e.g., normal controls or AD patients) [11]–[13]. The heterogeniety within each cohort can be captured by computing subject-specific trajectories via linear mixed effect (LME) models [5], [14]. Transitional methods, such as Markov models [15], [16], can then further refine the modeling of temporal dependency underlying these trajectories. However, these univariate statistical approaches underestimate group differences as they cannot model the multivariate relations within the high-dimensional MRI [17]. Even for multi-variate models, analyses typically rely on a priori selection of MRI measurements [18] that sub-optimally reflect the complex brain structure and function encoded by MRIs. Furthermore, inference of the findings is also limited to a cohort as they do not apply to individuals [19].
With recent advances in machine learning, inferences on an individual level are accomplished by training classifiers to distinguish longitudinal MRIs of normal controls from those of a cohort of interest. These classifiers can predict group assignment for each subject based on measurements of all brain regions thus avoiding the need of selecting measurements a priori. The most commonly used approach is to apply support vector machine (SVM) [20]–[22] to features encoding information of longitudinal trajectories. For example, Gray and colleagues [20] concatenated ROI features from different time points with the assumption that the number of time points is the same across all subjects. Dropping this assumption, automatic longitudinal feature selection approaches [21] first remove unrelated ROI features by cross-sectional analysis and then fit a linear regression model to estimate the changing rate of the selected features over time. Beyond using hand-crafted features from pre-defined ROIs, Zhang et al. [22] proposed a landmark-based feature extraction method that directly estimates data-driven features from images. Other feature selection methods are based on sparse learning (such as a multi-task sparse representation classifier [23] and a sparse Bayesian LME learner [24]), which can select a sparse subset of measurements that significantly contribute to the model prediction. The subset of measurements is then viewed as biomarkers associated with the disease [25].
State-of-the-art learning models are based on deep learning. Instead of using hand-crafted measurements, these models often reduce each MRI of the longitudinal sequence to informative features via Convolutional Neural Networks (CNN) and use the features to predict cohort assignment at each visit via Recurrent Neural Networks (RNN) [7], [26]–[29]. This architecture has advanced the analysis of longitudinal medical images, such as diagnosis [7], tissue segmentation [30], and predicting disease progression [31]. For example, Gao et al. [32] extracted features separately from each slice of a MRI via 2D CNN and then grouped features by Bag-of-Words before feeding them into the RNN layer. The RNNs themselves commonly consist of Long Short-Term Memory (LSTM) [33] and Gated Recurrent Units (GRU) [34]. For example, Cui et al. [7] captured the temporal dependencies through a bidirectional GRU correlating information at each visit with pre- and proceeding visits. Others explicitly modeled the time interval between visits by injecting that information into the LSTM [27], [28]. After each RNN classification, the corresponding visit-specific assignments can be reduced to a single label by, for example, simply relying on the assignment of the last visit [7], [27], [28], averaging across all visits [35], or adding a linear layer on top of the RNN [36] that weighs the importance of each visit for the final decision making [37].
Shortcomings of these deep learning approaches arise from their implementations of RNN, which, for example, analyze the longitudinal MRI in one temporal direction by performing inference at a visit only considering that and prior visits [38], [39]. Such unidirectional assumption is suitable for applications related to real-time computer-aided diagnosis, which aim to assess the current visit without observing the future. In many neuroscience applications, however, the goal is to quantify group differences by accounting for all visits in the longitudinal sequence such as in longitudinally consistent segmentation [40], registration [41], and network estimation [42]. While bidirectional RNNs could potentially alleviate this problem, they suffer from the ‘vanishing gradient’ problem [43]. Another critical issue overlooked by current implementations of RNN models is that they do not explicitly model progression of a condition, such as neurocognitive decline. The RNN classifications across visits can thus be clinically implausible such as predicting a transition from the irreversible AD to Mild Cognitive Impairment (MCI). To produce longitudinally and clinically consistent labelling, we propose to add two novel components to the CNN and RNN framework: a longitudinal pooling layer before the RNN to account for the features of all visits and a consistency loss function to regularize the RNN classifications through explicitly modelling irreversible conditions, such as in the case of AD. Both these two components can be generalized and plugged into models including but not limited to the combination of CNN and RNN. Specifically, longitudinal pooling layer can be adopted when the model needs to exploit the temporal dependency in features from multiple time points, while the consistency loss can be utilized when the trend in the longitudinal predictions are needed.
Common approaches to account for the information across visits are feature concatenation [44] and fully connected networks [45]. However, these models require the number of visits to be the same for each longitudinal scan, which is generally not the case for neuroscience studies [46]. A potential approach for modelling varying number of visits across subjects is social pooling [47], which was originally created to predict the spatial trajectories of pedestrian. Inspired by this model, our design of the longitudinal pooling layer generates (for each visit) a compact representation of MRI features of the current and proceeding visits before feeding them into the RNN. The classifications produced by the RNN are then regularized by a consistency loss function, which strongly discourages changes in cohort assignment of subjects with irreversible conditions, such as AD. For example, the function penalizes a decrease in confidence in labelling AD at a visit if the subject was labelled as such in prior ones. By doing so, the sequence of scalar confidence values (across visits) has the potential to refine categorical modelling of disease progression, such as healthy, MCI, and AD.
We evaluate our method on three longitudinal T1-weighted MRI datasets: 404 subjects from ADNI to analyze the progression of Alzheimer’s disease (AD), 603 subjects to distinguish healthy subjects from those diagnosed with Alcohol Use Disorder (AUD), and 255 no-to-low drinking youths (ages 14 to 16 at baseline) of the National Consortium on Alcohol and NeuroDevelopment in Adolescence (NCANDA) to identify the ones that transition to heavy drinkers during early adulthood (i.e., age 18 years or older). On these data sets, the accuracy of our proposed architecture is higher than alternative models without the longitudinal pooling and consistency layers. Finally, we derive voxel-wise saliency maps for the learned models to identify critical brain regions contributing to the classification. These regions converge with current understanding in neuroscience literature regarding the specific brain disorders or conditions under investigation.
II. Method
Let be the sequence of structural MRIs of subject s acquired over ms visits. Our deep learning model learns to predict binary labels , which classify a subject s at each visit t being a control or belonging to the cohort of interest (e.g., AD). The total number of visits ms may vary across subjects. We make the simplifying assumption that the interval between visits is the same and that the same acquisition protocol is used throughout the study. We denote the entire dataset with .
To predict the label from , our method is based on a 3D-CNN coupled with a sequence-to-sequence RNN (gray components in Fig. 1). Specifically, a 3D-CNN is independently applied to the MRI of each visit t of the longitudinal sequence in order to extract informative features1
| (1) |
The specific design of our 3D-CNN is shown in Fig. 2. Note, the same 3D-CNN (i.e., set of weights) is used across visits in order for the model to accurately track the trajectories of features. This tracking is done by a RNN based on Gate Recurrent Unit (GRU) [48]. GRU consists of an update gate and a reset gate that respectively determine how much of the past information needs to be passed on or forgotten. Let be the input, be the update gate vector, the reset gate vector, and be the output of the RNN unit, then the network is defined as
| (2) |
where Wrz, Wrr, Wrh, Urz, Urr, Urh form the parameters Wr of the GRU cell. To turn the output of each RNN cell into a binary label, is fed into a fully connected (FC) layer followed by a sigmoid activation layer. We propose to extend this framework by adding a Longitudinal Pooling layer between the CNN and RNN, and feeding the binary label into a Consistency Loss function. The remainder of this section describes these layers and the training of the method in detail.
Fig. 1.
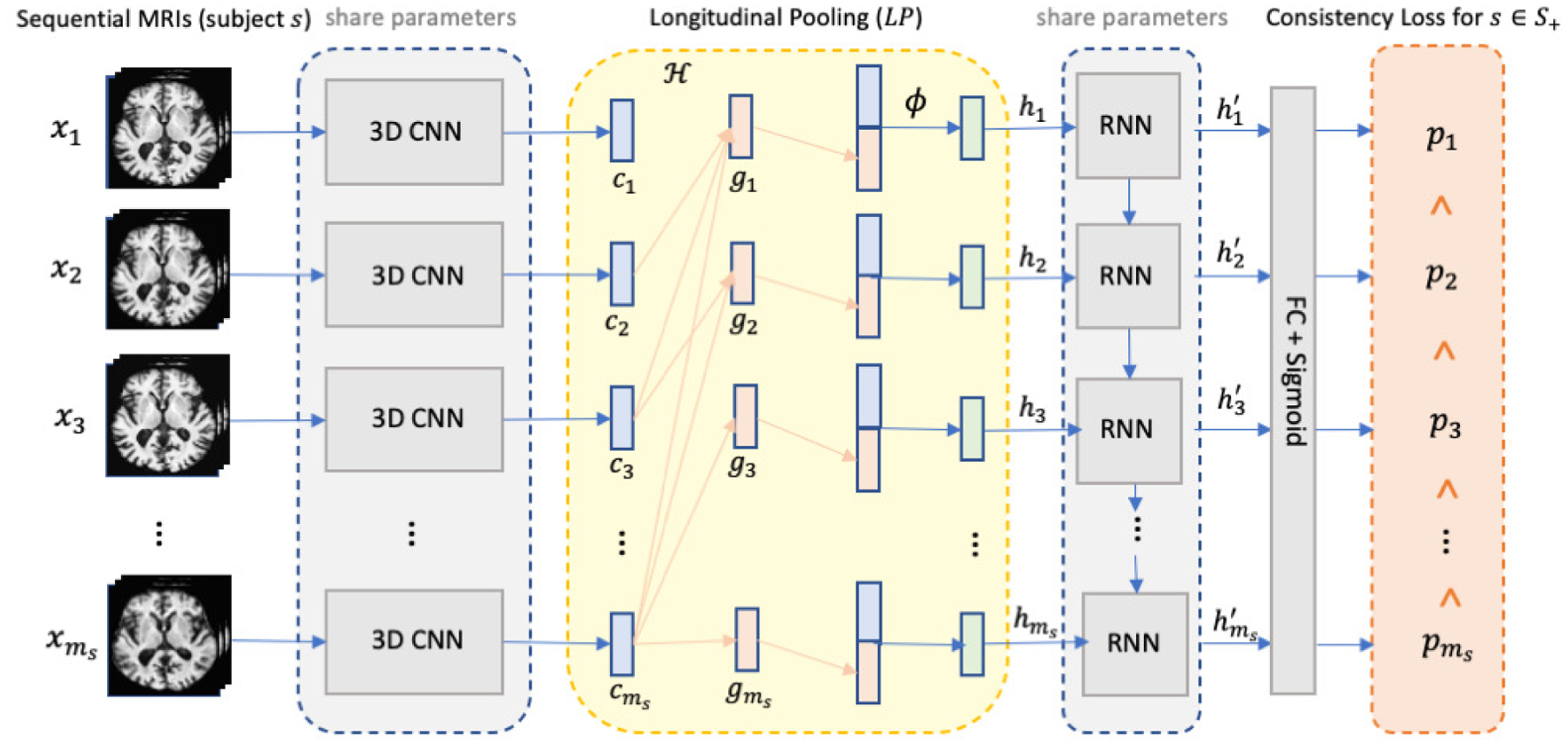
The overview of the proposed method with the CNN+RNN backbone highlighted in gray. The CNN and RNN components share the same set of network parameters across time points. We introduce two innovative layers to the backbone: the longitudinal pooling layer (yellow component) augments the features derived by the 3D CNN at a visit with those of future visits and the consistency loss (orange) encourages higher prediction confidence as time progresses for the subjects from the cohort of interest (e.g., AD).
Fig. 2.
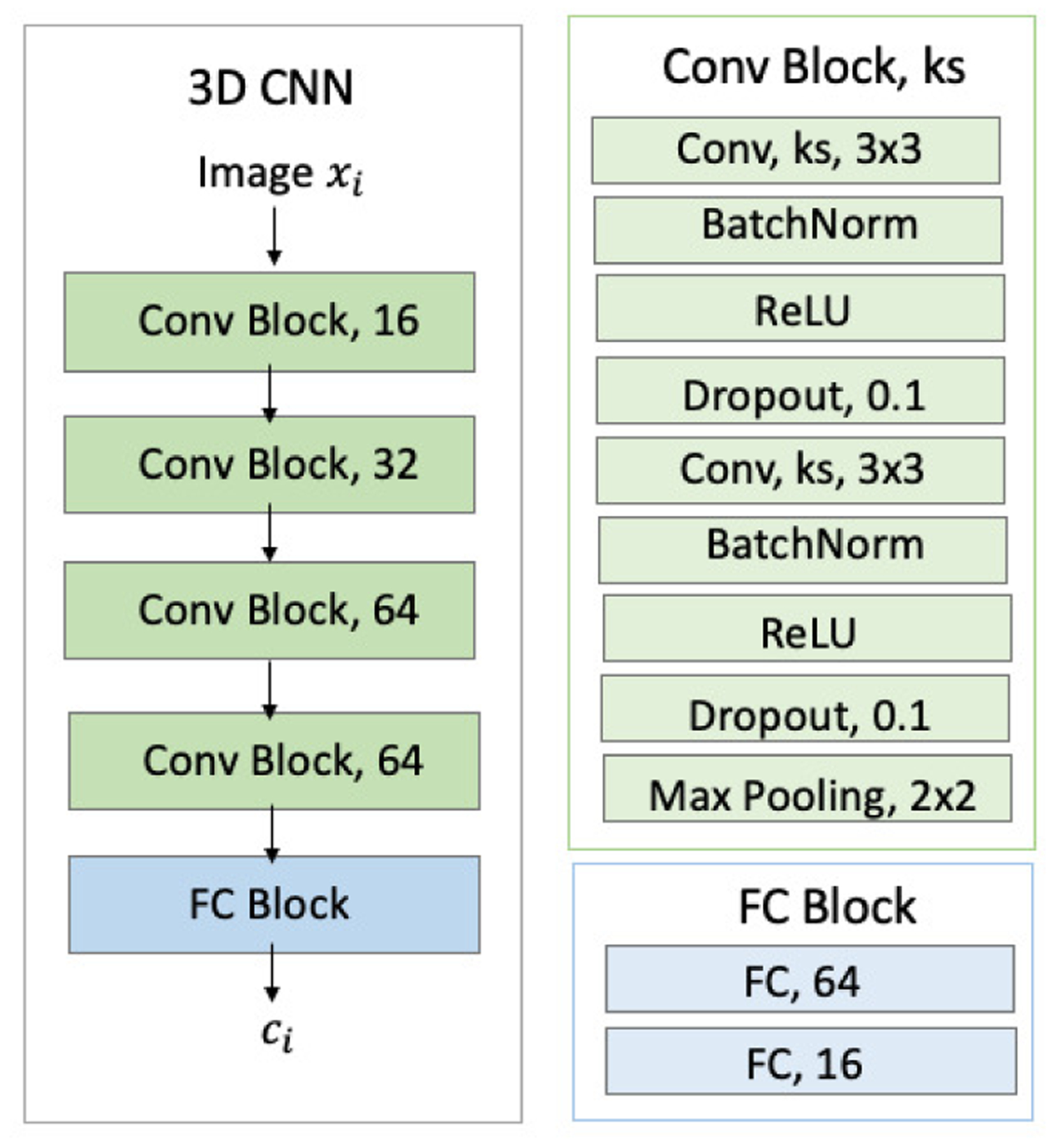
Detailed structures of 3D-CNN. Green blocks denote convolutional (Conv) layers. Blue blocks denote fully connected (FC) layers. ‘ks’ denotes kernel size.
A. Longitudinal Pooling (LP)
Inspired by social pooling [47], the LP layer augments the features derived by the 3D CNN for subject s at visit t with those of future visits via a pooling operation , i.e.,
| (3) |
For simplicity, computes the average. The last visit does not have proceeding visits to pool from, so we use itself.
For each visit, the features of the current visit are concatenated with the pooling embedding , which are then applied to a fully connected layer ϕ(·) (i.e, a linear function with tanh activation and weights Wf) to determine the augmented hidden state . Lastly, becomes the new input to the RNN layer. Note, LP can be easily generalized to the scenario of multiple RNN layers. In this case, the pooling operation defined with respect to Eq. (3) and is performed on instead of .
B. Consistency Loss
To explicitly model irreversible conditions, such as in the case of AD, we encourage our approach to predict with higher confidence for subjects assigned to the cohort of interest (e.g., AD) as time progresses. In other words, the consistency loss function expects for and penalizes classifications violating this rule:
| (4) |
where ⌊·⌋+ sets negative values to 0. Note, this consistency loss is a soft restriction, which only encourages but does not strictly enforce the monotonicity of . This practice is more computationally stable than enforcing the hard inequality constraint in general deep learning frameworks [49]. Lastly, the consistency loss ignores subjects not belonging to (e.g., health controls) as the condition does not apply to them.
C. Objective Function and Training Strategy
The final training stage aims to minimize an objective function consisting of the consistency loss Lcons of Eq. (4), a weighted binary cross entropy, and a term regularizing the weights W = {Wr, Wf} of all recurrent and linear layers. Let ∥ · ∥2 be the L2-norm and the binary entropy be
| (5) |
with the parameters wpos balancing the influence of the cohort of interest S+ over the controls (S\S+). Then the objective function is defined as
| (6) |
where λcons and λreg weigh the importance of the consistency loss and regularization loss over the weighted binary entropy.
As jointly training CNN and RNN from scratch can easily lead to overfitting due to the large number of parameters, we first pre-train the convolutional blocks (green blocks in Fig. 2) of the 3D-CNN as proposed in [7]. We do so by training a cross-sectional CNN-based classifier (i.e. applying a linear classifier to ) on all available training images while discarding their longitudinal dependencies. Based on the pretrained network parameters in the convolutional blocks, we reinitialize the parameters in the FC blocks and jointly train our CNN+RNN model with the recurrent and longitudinal pooling layers. Alternative approaches for pre-training the CNN (not explored here) are to apply unsupervised representation learning frameworks (such as auto-encoders [50]) or self-supervised learning frameworks, such as patch-based [51], [52] and distortion-based approaches [53].
III. Experiments
We applied this method to three longitudinal neuroimaging datasets: a subset of ADNI consisting of 214 normal controls and 190 AD patients, a dataset acquired by us (AP and EVS) of 274 normal controls and 329 AUD patients, and 255 no-to-low drinking youths (ages 14 to 16 at baseline) of NCANDA, of which 69 transitioned to heavy drinkers once they became adults. For each dataset, we compared the classification accuracy of the proposed model with several other widely used baselines and visualized the saliency of our model to identify brain regions critically contributing to the classification. The remainder of this section describes the experimental setup and findings on the three datasets in detail.
A. Experiment Setting
1). Data Preprocessing:
In line with our prior cross-sectional study [54], [55], all longitudinal MRIs in the following experiments were first preprocessed by a pipeline composed of denoising, bias field correction, skull striping, affine registration to a template, and re-scaling to a 64 × 64 × 64 volume [54]. At the sacrifice of image resolution, the downsampling enables the design of a compact CNN model with a relatively small number of network parameters, which can effectively boost training speed and avoid the vanishing gradient problem in training RNN models [43]. Note, while theoretically not required for the training of CNN-based methods, these processing steps generally result in faster convergence, less overfitting, and more accurate classification [56].
Next, we split the data set into training, validation, and testing sets. After randomly selecting 10% subjects as the validation set, the remaining subjects were split into 5 folds for cross-validation while keeping the proportion of the same in each fold. For each testing run, the corresponding training data were augmented by applying random 3D poses (rotation and shifting) to the longitudinal MRIs, where the same pose was applied to each MRI of the longitudinal sequence. Furthermore, we flipped hemispheres based on the assumption that the studied condition effected the brain bilaterally, which is the case for most neurological diseases. This process increased the size of the training set by a factor of 10. Based on this augmented data set from the training folds, we performed the pre-training of CNN and the joint training of CNN+RNN.
2). Model Architecture & Hyperparameters:
As shown in Fig. 2, the 3D CNN contained 4 convolutional blocks connected by 2 × 2 × 2 3D MaxPooling. Each block consisted of two stacks of 3 × 3 × 3 3D convolution (16/32/64/64 as number of channels for the 4 blocks), Batch Normalization, ReLU, and dropout layers. The resulting 512-D features were connected to two fully connected layers (FC) with tanh activation producing a 16-D feature (ct) as the input of RNN. To reduce the risk of overfitting, the RNN implementation was constructed by a GRU layer with 16 hidden units. In comparison to the commonly used LSTM [33], GRU not only requires training of fewer network parameters but also trains faster [48]. We set λreg = 0.02 and λcons = 2.0 as they resulted in the highest accuracy score on the validation set.
3). Evaluation Metrics & Visualization Method:
While the 5 folds were split based on subjects (or longitudinal MRIs), we measured the accuracy of our proposed method (CNN+RNN+LP+CL) with respect to each individual MRI of the longitudinal sequence in the testing fold. Specifically, we measured the sensitivity (SEN), specificity (SPE), Area Under the Curve (AUC) in percent, and the balanced accuracy (BACC) [57], where the classification accuracy for each cohort was balanced with respect to the total number of visits (or MRIs) across all subjects of the cohort. The standard deviation of BACC was computed across 5 folds for each method. To put those accuracy scores in perspective, we repeated the experiment for alternative classification models. First, we applied a cross-sectional CNN to each MRI of a longitudinal scan [58] (i.e., discarding the temporal relationship). The CNN baseline was also used in [59], [60] for normal control vs. AD classification on the ADNI dataset. Next, we added an average pooling layer to the CNN baseline by concatenating the CNN features of a visit with the average of the CNN features across all the other visits (CNN+AP). The basic longitudinal approach was the standard CNN+RNN that was previously applied to the ADNI dataset in [7], [32]. On top of this baseline, we also added the LP layer (CNN+RNN+LP). In addition, we also applied two state-of-the-art longitudinal models: CNN+biRNN [7] and CNN+tRNN [27]. biRNN captured information from all visits based on a bidirectional GRU layer and tRNN modelled the potentially imbalanced time interval between successive visits within a LSTM cell. To make the results comparable across methods, each approach used the same CNN architecture and training strategy.
In addition to reporting accuracy scores, we visualized brain regions for driving the model decision by computing the saliency maps for each subject and visit. Extending the original visualization approach [61] to a longitudinal setting, we computed voxel-wise partial derivatives (measure of saliency values) of the classification at each visit with respect to each MRI in the longitudinal series. For example, a subject with 5 visits will have 5 × 5 saliency maps, where the map at the ith row and jth column shows the important brain regions of the MRI at the jth visit with respect to the classification at ith visit. Thus, the lower triangular of the 5 × 5 matrix represents how the classification at each visit depends on prior ones, the diagonal represents the current visit, and the upper triangular reveals the relevance of proceeding visits. The saliency values were re-normalized by 98% of the maximum value within each subject to account for potential outliers in estimating partial-derivatives. The mean across the saliency maps of all subjects was overlaid with the SRI24 atlas [62] to relate brain areas most relevant to the specific brain disorder (or condition).
B. Application to the ADNI Data Set
Based on all successfully processed T1-weighted MRIs of the ADNI data set, we applied the proposed method to distinguish 214 normal controls (NC; age: 75.57 ± 5.06 years, 108 male / 106 female) from 190 patients diagnosed with Alzheimer’s disease (AD; age: 75.17 ± 7.57 years, 104 male/86 female). There was no significant age difference between the NC and AD cohorts (p=0.55, two-sample t-test). The number of visits ms varied from 1 to 5 covering the first two years of the ADNI study with 6-month intervals.
According to the accuracy scores listed in Table I (top), each implementation recorded a sensitivity that was similar to its specificity indicating that the classification accuracy was fairly balanced across the two cohorts. However, the accuracy scores were quite different across implementations with CNN recording the lowest BACC of 86.1%. The accuracy slightly improved when adding subject-level average pooling to the model (CNN+AP) but was still lower than that of the longitudinal models. This indicates that omitting the temporal information when performing classification on longitudinal MRIs might result in suboptimal results. Of those longitudinal models, CNN+RNN recorded the lowest accuracy and AUC, implementations including LP achieved the highest AUC (91.5%), and the highest BACC of 90.4% was recorded for the model with both LP and consistency loss (CL). This accuracy score was also higher than the two alternative longitudinal models CNN+tRNN (89.7%) and CNN+biRNN (89.6%). The score for CNN+biRNN was also confirmed by the original publication of biRNN [7] (i.e, 89.4% when applied to a similar subset of the ADNI data), which suggests that the proposed longitudinal pooling might be more suitable than biRNN in extracting information from proceeding visits. Only our proposed model was significantly more accurate than the CNN baseline (p<0.005 according to DeLong’s test [63]).
TABLE I.
ADNI Dataset. Top: Comparison across methods on NC vs. AD classification; Bottom: Balanced Classification Accuracy of the proposed method dependent on the number of visits
| Method | BACC ± std | SEN | SPE | AUC |
|---|---|---|---|---|
| CNN | 86.1 ± 1.83 | 86.8 | 85.4 | 91.3 |
| CNN+AP | 87.8 ± 2.55 | 88.2 | 87.4 | 91.3 |
| CNN+RNN | 89.5 ± 1.41 | 88.7 | 90.3 | 91.4 |
| CNN+RNN+LP | 90.0 ± 1.44 | 89.2 | 90.8 | 91.5 |
| CNN+RNN+LP+CL | 90.4 ±1.51 | 88.9 | 91.9 | 91.5 |
| CNN+biRNN [7] | 89.6 ± 1.48 | 86.8 | 92.4 | 91.5 |
| CNN+tRNN [27] | 89.7 ± 1.67 | 88.8 | 90.6 | 91.4 |
| Visits | NC/AD | BACC ± std | |
|---|---|---|---|
| CNN+RNN+LP+CL | 1+ visit | 188/169 | 89.8 ± 1.48 |
| 2+ visits | 163/103 | 90.1 ± 1.53 | |
| 3+ visits | 138/78 | 90.6 ± 1.59 | |
| 4+ visits | 109/52 | 90.6 ± 1.46 | |
| 5+ visits | 73/0 | 91.8 ± 1.49 |
To further show the impact of the consistency regularization, we added 137 ADNI subjects labelled as progressive MCI (pMCI) to the training data set; pMCIs transitioned from MCI to AD during the study, so they potentially exhibit more pronounced progression of cognitive decline than the patients diagnosed as AD since the beginning. Correctly capturing disease progression can guide the model to focus on cognitive decline, which in turn improves the NC/AD classification. Therefore, our novel consistency loss was defined on all three cohorts including the pMCI subjects while the classification loss was confined to NC and AD subjects. Incorporating the pMCI subjects increased the BACC of NC and AD classification to 90.8%. This result suggests that including the pMCI subjects in the consistency loss component regularizes the model such that the prediction scores for each time point are related to the state of cognitive decline among subjects and reflect the progressive nature of the disease.
To put the above accuracy scores in perspective, we compared our results with those reported by prior studies using traditional machine learning and deep learning (Table II). In general, deep-learning-based methods tend to have higher or comparable prediction accuracy than traditional machine learning methods, suggesting that the data-driven feature extraction is more sensitive in revealing group differences compared to hand-crafted measurements. Among the three longitudinal studies that use CNN+RNN, the number of training samples may become a factor impacting the classification accuracy as the BACC increases with the size of the training set. Despite the discrepancy in experimental setups (e.g., number of samples and imaging modalities) across these studies, our proposed method still achieved relatively good performance among all the reported scores.
TABLE II.
Comparison of the proposed method with other traditional methods and deep learning based methods on ADNI dataset. ‘C’ denoted CNN, ‘R’ denoted RNN, and ‘N’ denoted non-deep-learning methods.
In Table I (bottom), we also recorded testing accuracy on sub-groups confined to the number of visits greater or equal to a certain threshold. We observed that subjects with more visits tend to have better accuracy. CNN+RNN+LP+CL achieved the highest accuracy of 91.8% when basing classifications on the longitudinal MRIs of subjects with 5 visits. This indicates that our model was effectively capturing the changes within the longitudinal MRI. In addition, for subjects that have fewer number of visits, the proposed method still outperformed CNN+AP, suggesting the superiority of the proposed longitudinal pooling over average pooling.
Fig. 3 qualitatively confirms this finding. Many of the classifications generated by the cross-sectional CNN fluctuate between NC and AD as the lines (which connect classifications of the same subject) frequently cross 0.5 (dotted blue line). These clinically impossible transitions rarely happened for the classifications of our approach. The intra-subject classification scores for most AD patients increased with each visit suggesting that one might be able to use the scores for tracking disease progression. Although only applied to the AD patients, the consistency loss seemed to also regularize the prediction of NC subjects, which generally decreased with time and resulted in a clear separation between NC and AD cohorts.
Fig. 3.
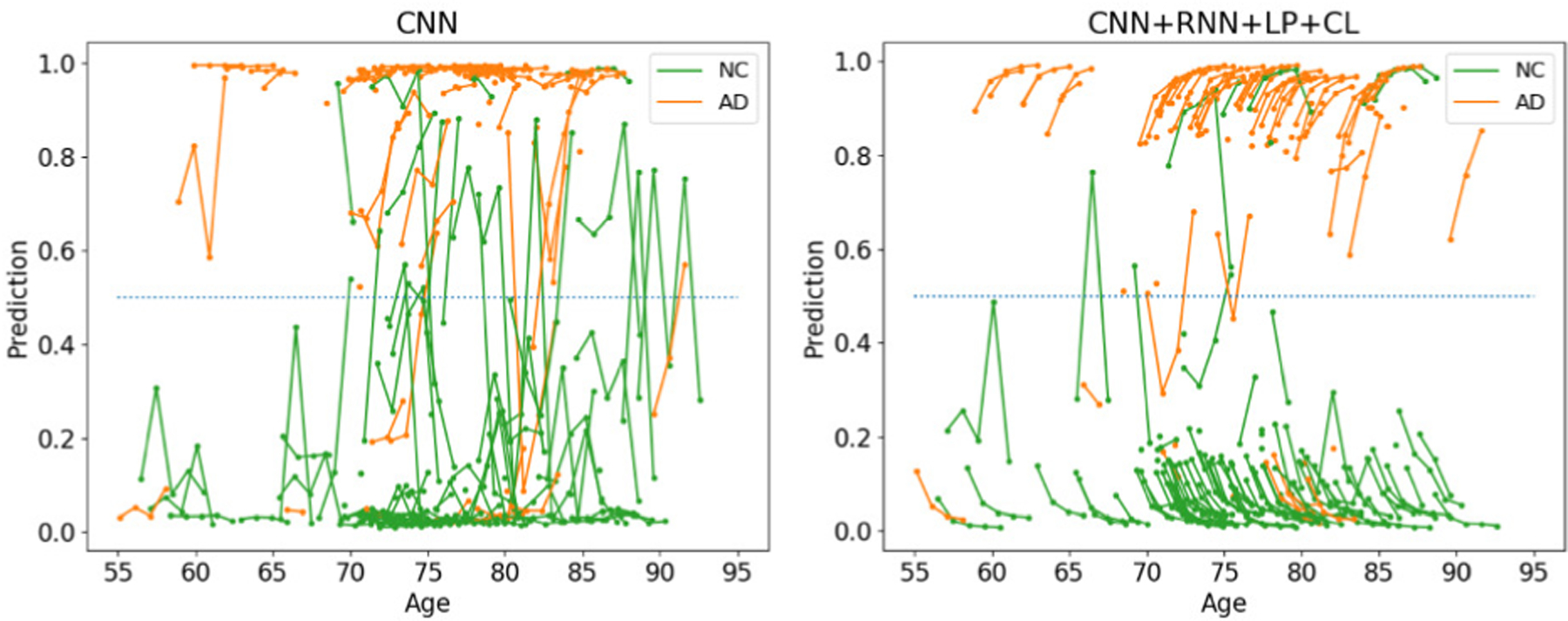
Classifications by CNN and the proposed method on ADNI
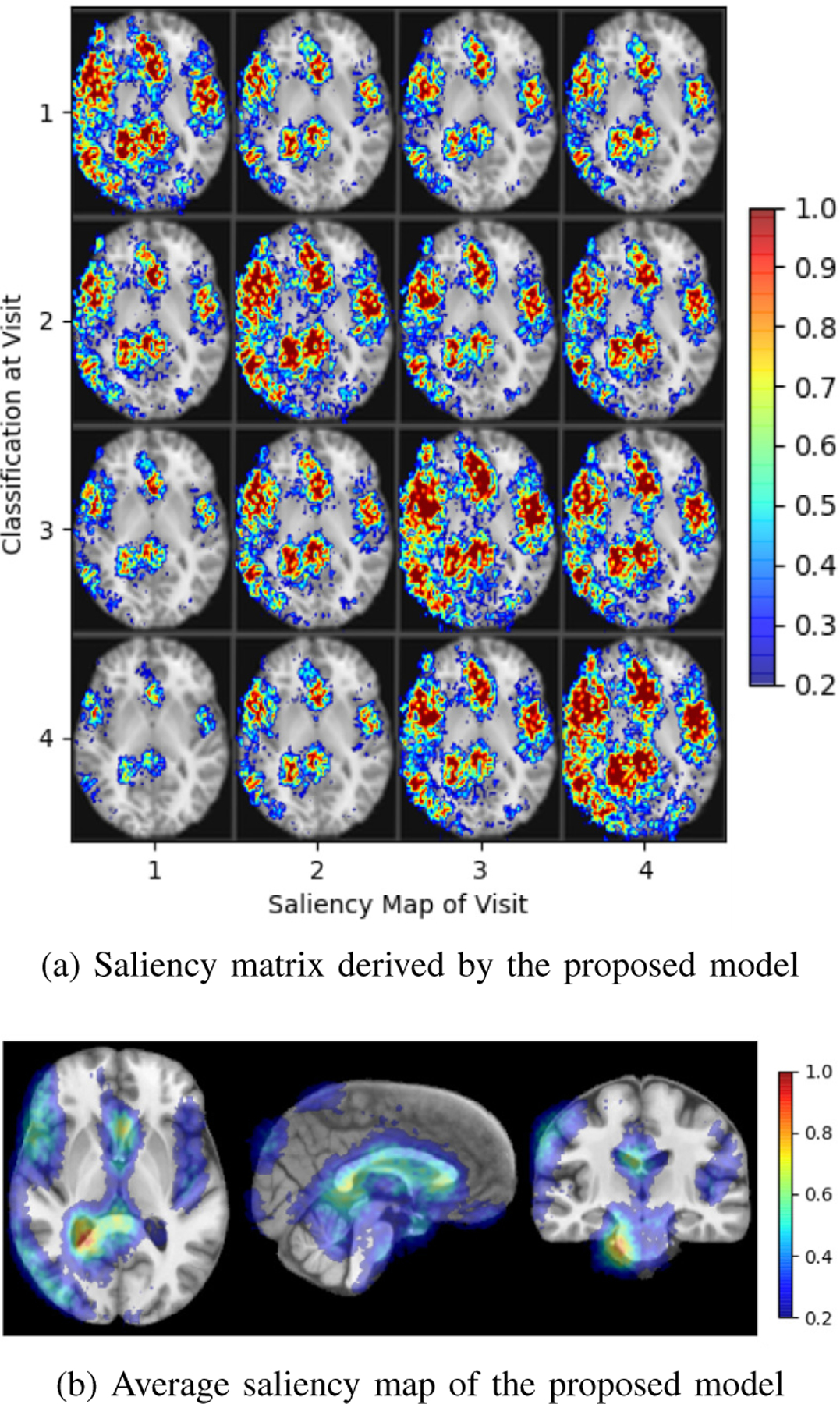
The salience maps of this classification model are shown in Fig. 4. The example of the salience matrix derived by CNN+RNN (see Fig. 4a) reveals that most salient regions are in the maps located at the diagonal, which indicates that the classification decision for each visit was mainly driven by the MRI of that visit alone. In comparison, the saliency matrix of the proposed model (Fig. 4b) highlights salient regions across all visits slightly favoring proceeding visits for classifications at later visits (i.e., upper triangle). Lastly, Fig. 4c shows the average saliency map for the proposed model across all subjects. Areas of high saliency are the hippocampus and lateral ventricles, which are known to subserve memory consolidation and affected in early stages of AD [64]. High saliency was also found in the cerebral cortex potentially corresponding to brain atrophy and loss of brain mass [65].
Fig. 4.

Saliency of controls versus AD
C. Identifying AUD based on Longitudinal MRIs
AUD often causes gradual deterioration in the gray and white matter tissue [66], [67]. In this experiment, we applied the proposed method to distinguish longitudinal T1-weighted MRIs (up to 4 visits) of 274 normal controls (NC; age: 47.3 ± 17.6, 136 male / 138 female) from those of 329 patients diagnosed with Alcohol Use Disorder (AUD; age: 49.3 ± 10.5, 100 male / 229 female). The study was approved by the institutional review boards of Stanford University School of Medicine and SRI International.
As it was the case in the ADNI experiment, all implementations (except CNN) recorded a sensitivity that was similar to its specificity and achieved accuracy scores significantly more accurate than chance (p<1e-5; Fisher Exact test [68]); the longitudinal approaches were more accurate than the cross-sectional ones, and the accuracy of CNN+RNN+LP+CL improved with the number of available visits for classification (according to Table III). However, the accuracy scores were much lower than recorded for ADNI and the consistency loss did not improve the accuracy as CNN+RNN+LP and CNN+RNN+LP+CL had similar scores. One reason could be that even the cross-sectional CNN produced classifications that were relatively stable across visits (see Fig. 5) so that the benefit of the consistency loss function was limited for this dataset. Another reason could be the relatively small number of subjects with more than two visits (Table III). Nevertheless, our proposed method was more accurate for subjects with more visits and achieved a BACC of 79.5% for subjects with four visits. This result supported the advantage of longitudinal modeling proposed herein.
TABLE III.
AUD Dataset. Top: Comparison across methods on NC vs. AUD classification; Bottom: Balanced Classification Accuracy of the proposed method dependent on the number of visits
| Method | BACC ± std | SEN | SPE | AUC |
|---|---|---|---|---|
| CNN | 67.6 ± 3.54 | 62.9 | 72.2 | 70.9 |
| CNN+AP | 68.7 ± 3.68 | 66.7 | 70.7 | 71.5 |
| CNN+RNN | 69.0 ± 3.35 | 67.1 | 70.9 | 71.6 |
| CNN+RNN+LP | 69.5 ± 3.32 | 67.6 | 71.4 | 71.8 |
| CNN+RNN+LP+CL | 69.3 ± 3.31 | 67.9 | 70.8 | 71.8 |
| CNN+biRNN [7] | 68.9 ± 3.36 | 67.8 | 70.0 | 71.7 |
| CNN+tRNN [27] | 69.2 ± 3.42 | 68.6 | 69.8 | 71.8 |
| Visits | NC/AUD | BACC ± std | |
|---|---|---|---|
| CNN+RNN+LP+CL | 1+ visit | 244/293 | 65.0 ± 3.34 |
| 2+ visits | 124/150 | 70.6 ± 3.32 | |
| 3+ visits | 63/74 | 77.1 ± 3.28 | |
| 4+ visits | 30/29 | 79.5 ± 3.29 |
Fig. 5.
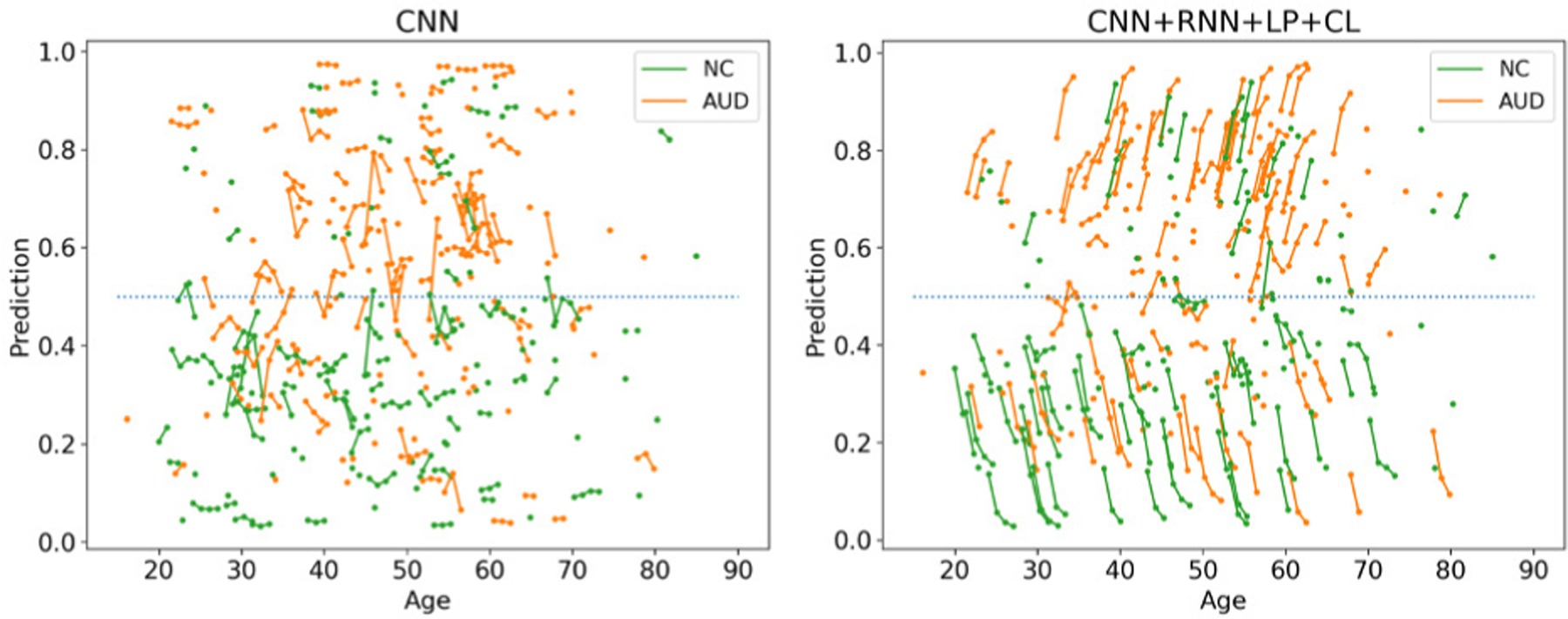
Classifications by CNN and the proposed method on AUD
Similar to the ADNI experiment, the example of a saliency matrix (Fig. 6a) derived by our model recorded high saliency in maps located at the off-diagonal implying that the proposed model utilized information from both preceding and proceeding visits. Unlike the ADNI experiment, the average saliency map (Fig. 6b) now concentrates on specific brain regions frequently linked to AUD, such as the calcarine and lingual regions of the occipital lobe [69], the orbitofrontal cortex [70], and the cerebellum [71].
Fig. 6.
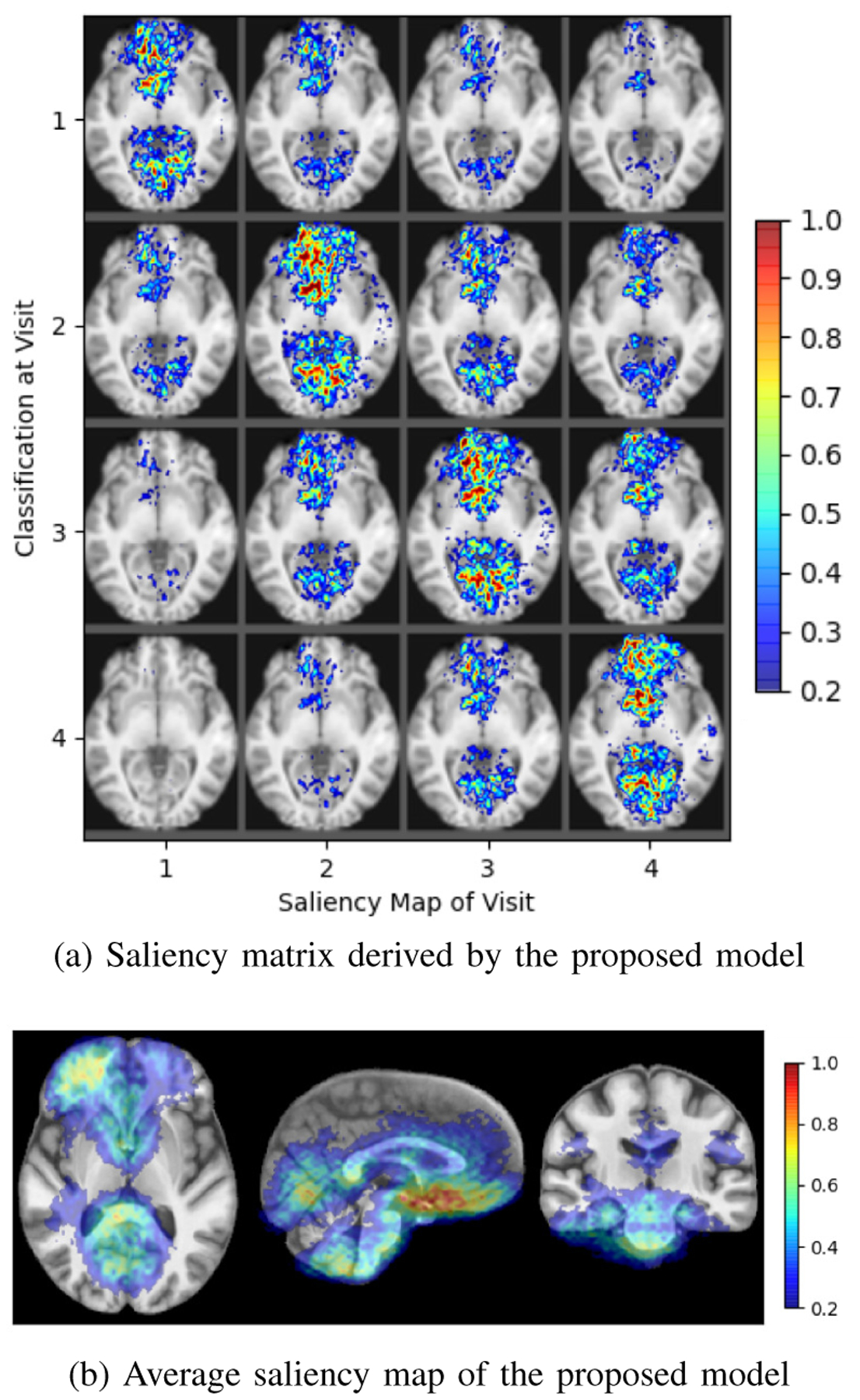
Saliency specific to AUD
D. Application to the NCANDA Data Set
One aim of NCANDA is to study the brains of adolescents before drinking appreciable levels of alcohol in order to identify predictive phenotypes associated with heavy drinking [72]. Based on the public data release NCANDA_PUBLIC_4Y_STRUCTURAL_V01 (DOI: 10.7303/syn22216457; distributed to the public according to the NCANDA Data Distribution agreement https://www.niaaa.nih.gov/research/major-initiatives/national-consortium-alcohol-and-neurodevelopment-adolescence/ncanda-data), we applied our implementations to the longitudinal MRIs (up to 5 visits) of the 255 no-to-low drinking adolescents (124 boys / 131 girls) of this study that were 14–16 years old at baseline. During late adolescence to young adulthood (i.e, age 18 or older), 115 subjects remained no-low drinkers, 71 subjects transitioned to moderate drinkers, and 69 were heavy drinkers according to the adjusted Cahalan criteria [73]. Our implementation now aimed to differentiate the heavy from no-to-low drinkers, while we reduced the risk of overfitting by adding the moderate drinkers to the heavy drinking cohort during training.
Again, findings of the previous experiments were largely confirmed. However, sensitivity and specificity were not as balanced as in previous experiments as all implementations favored the heavy drinking cohort. This resulted in the baseline CNN producing the highest AUC across all comparison methods. However, when using a non-informative operating point of 0.5 (threshold for class assignment), CNN+RNN+LP+CL achieved the highest accuracy with 72.7% and was significantly more accurate than the CNN baseline (p<0.001, DeLong’s test). Similar to the ADNI experiments, the consistency loss layer improved the accuracy of the classifications. Moreover, the classification scores of the cross-sectional CNN implementation greatly varied across time, while this was not the case for the proposed implementation (see Fig. 7). This underlines the importance of the pooling and consistency layer of our longitudinal CNN+RNN implementation, which produced classification scores that might be able to be used for tracking the impact of alcohol drinking on the adolescent brain. Unlike the previous two experiments, Table IV shows that the classification accuracy was less correlated with the number of visits used for classification despite that the highest BACC was associated with subjects with 5 or more visits. This indicates that risk factors for heavy alcohol drinking potentially precede the neurodevelopment before age 14 years [74]. This finding is also echoed by the relatively “flatter” classifications along age in Fig. 7 compared to previous plots for AD in Fig. 3 and AUD in Fig. 5.
Fig. 7.
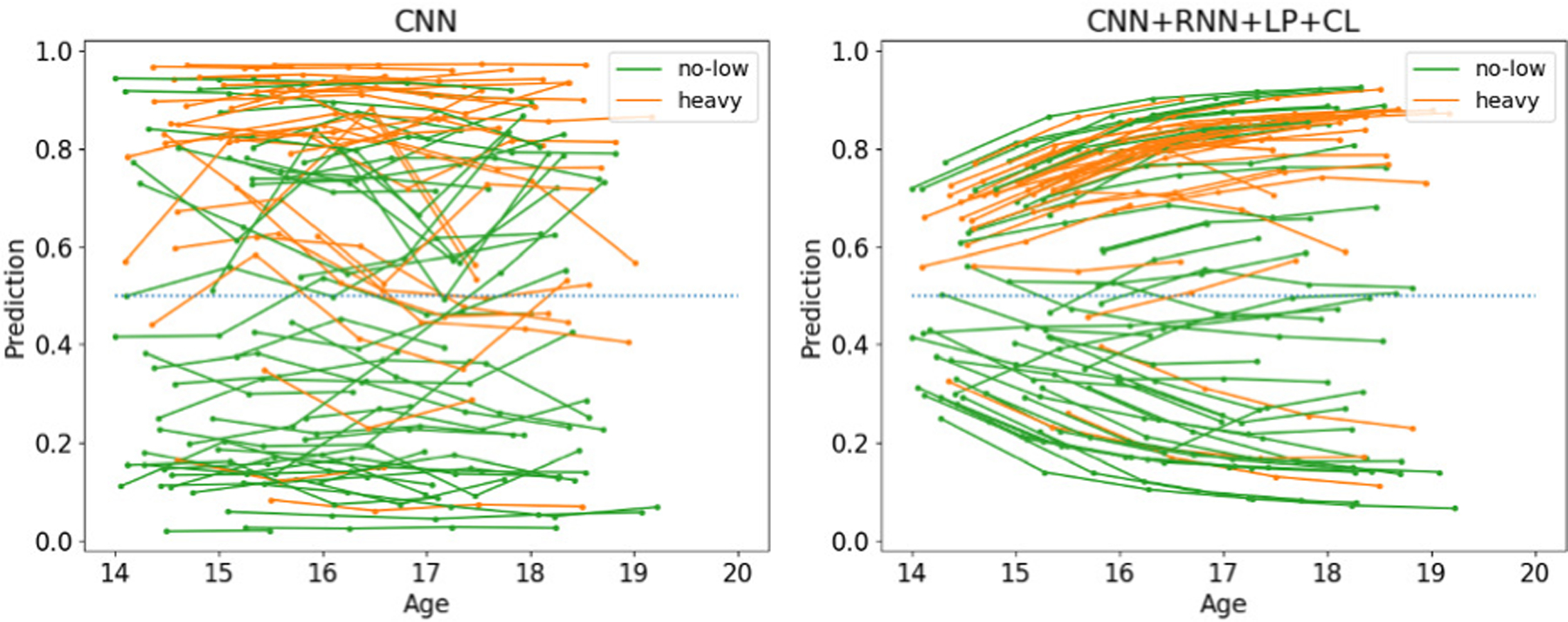
Classifications by CNN and the proposed method on NCANDA
TABLE IV.
NCANDA Dataset. Top: Comparison across methods on no-low vs. heavy drinking classification; Bottom: Balanced classification accuracy of the proposed method dependent on the number of visits
| Method | BACC ± std | SEN | SPE | AUC |
|---|---|---|---|---|
| CNN | 68.8 ± 2.81 | 75.5 | 62.1 | 74.5 |
| CNN+AP | 71.0 ± 3.67 | 77.3 | 64.7 | 74.2 |
| CNN+RNN | 70.8 ± 3.26 | 77.2 | 64.4 | 73.3 |
| CNN+RNN+LP | 72.1 ± 3.23 | 80.4 | 63.8 | 73.4 |
| CNN+RNN+LP+CL | 72.7 ± 3.21 | 81.3 | 64.1 | 73.4 |
| CNN+biRNN [7] | 71.4 ± 3.25 | 78.3 | 64.5 | 74.1 |
| CNN+tRNN [27] | 71.8 ± 3.30 | 76.8 | 66.8 | 73.8 |
| Visits | no-low/heavy | BACC ± std | |
|---|---|---|---|
| CNN+RNN+LP+CL | 1+ visit | 100/60 | 71.5 ± 3.23 |
| 2+ visit | 99/60 | 72.7 ± 3.26 | |
| 3+ visit | 93/56 | 72.3 ± 3.25 | |
| 4+ visit | 80/45 | 71.9 ± 3.18 | |
| 5+ visit | 37/20 | 79.0 ± 3.18 |
Fig. 8a and Fig. 8b both indicate that the classification was mainly driven by the inferior parietal lobule and the lateral and third ventricles. These findings comport with prior studies revealing the lateral and third ventricular are enlarged in adult with AUD [75], [76]. The saliency focuses more on the left hemisphere despite flipping the MRI during training. This potentially indicates that the deep model tended to discard redundant information to focus the learning on unilateral cues.
Fig. 8.
Saliency specific to youth transitioning to heavy drinking
IV. Discussion and Conclusion
We have proposed a generalized framework based on CNN and RNN to infer from longitudinal MRI the gradual deterioration of brain structure and function caused by neurological diseases and environmental influences. On the feature level, we proposed a novel longitudinal pooling layer that combined the features of a visit with a compact representation of information from proceeding visits. On the classification level, we included a consistency loss to characterize the gradual effect on brain structures across visits. The two proposed components can be easily plugged into any existing CNN-RNN architecture for improving the characterization of longitudinal trajectories. Our classification method was applied to three datasets: classifying Alzheimer’s disease vs. controls, alcohol use disorder vs. controls, and adolescents who remained no-to-low drinkers vs. those who transitioned to heavy alcohol drinking. On these datasets, the proposed method achieved higher accuracy scores compared with cross-sectional and longitudinal baseline methods. The classifications for most subjects were consistent across visits so that they potentially could be used for tracking the impact of diseases and environmental factors on the brain. Important for generating those classifications was leveraging information across visits revealed by the saliency matrices. The average across saliency matrices also highlighted regions that enhanced classification and comported with findings from prior studies.
The proposed longitudinal pooling and consistency regularization provide simple means of injecting temporal dependency in features and predictions across time points, so in principle they can be used to extend any existing cross-sectional CNN architectures into longitudinal settings. As these two components are vertical improvement directions to any specific design of the CNN and RNN, we refrained from optimizing classification accuracy by extensive exploration of network architectures. Instead, our implementation of the networks relied on some of the most fundamental network components used in deep learning and still recorded reasonable prediction accuracies. Therefore, it is conceivable that the findings discussed herein are likely to generalize to more advanced network architectures [77]–[79]. Other potential strategies for further improving the classification accuracy include fusing information from multi-modality inputs, using high-resolution input images, and utilizing pre-training strategies such as convolutional autoencoders [60].
While the ADNI experiment focused on classifying AD patients from the controls, the proposed longitudinal components may also have the potential to improve stratification of the differential progression patterns among MCI subjects, such as separating early stages of MCI from the controls [38], distinguishing progressive MCI from stable MCI [7], and predicting transition time from MCI to AD [80]. Lastly, although in this paper we focused the discussion on MRI and neuroimaging applications, the proposed method does not impose any assumptions on the input data type nor the total number of time points. Therefore, the method is likely to be generalizable to other imaging modalities or clinical applications in a longitudinal setting, such as radiological abnormality detection in chest X-rays [27] and lung nodule detection in CT [28].
Acknowledgments
Funding for this study was received from the U.S. National Institutes Health (NIH) grants AA010723, AA026762, AA021681, AA021690, AA021691, AA021692, AA021695, AA021696, AA021697, and MH113406. This study also benefited from Stanford Institute for Human-centered Artificial Intelligence (HAI) AWS Cloud Credit.
Footnotes
Functions are typeset in italics.
Contributor Information
Jiahong Ouyang, Department of Electrical Engineering, Stanford University, Stanford, CA 94305..
Qingyu Zhao, Department of Psychiatry and Behavioral Sciences, Stanford School of Medicine, Stanford, CA 94305..
Edith V. Sullivan, Department of Psychiatry and Behavioral Sciences, Stanford School of Medicine, Stanford, CA 94305.
Adolf Pfefferbaum, Department of Psychiatry and Behavioral Sciences, Stanford School of Medicine, Stanford, CA 94305.; Center for Biomedical Sciences, SRI International, Menlo Park CA, 94025.
Susan F. Tapert, Department of Psychiatry, University of California San Diego, La Jolla, CA 92093.
Ehsan Adeli, Department of Psychiatry and Behavioral Sciences, Stanford School of Medicine, Stanford, CA 94305.; Department of Computer Science, Stanford University, Stanford, CA 94305.
Kilian M. Pohl, Department of Psychiatry and Behavioral Sciences, Stanford School of Medicine, Stanford, CA 94305. Center for Biomedical Sciences, SRI International, Menlo Park CA, 94025.
References
- [1].Whitwell JL, “Longitudinal imaging: change and causality,” Current Opinion in Neurology, vol. 21, no. 4, pp. 410–416, 2008. [DOI] [PubMed] [Google Scholar]
- [2].Aubert-Broche B, Fonov VS, García-Lorenzo D, Mouiha A, Guizard N, Coupé P, Eskildsen SF, and Collins DL, “A new method for structural volume analysis of longitudinal brain MRI data and its application in studying the growth trajectories of anatomical brain structures in childhood,” NeuroImage, vol. 82, pp. 393–402, 2013. [DOI] [PubMed] [Google Scholar]
- [3].Herting MM, Johnson C, Mills KL, Vijayakumar N, Dennison M, Liu C, Goddings A-L, Dahl RE, Sowell ER, Whittle S, et al. , “Development of subcortical volumes across adolescence in males and females: A multisample study of longitudinal changes,” NeuroImage, vol. 172, pp. 194–205, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [4].Fraser MA, Shaw ME, and Cherbuin N, “A systematic review and meta-analysis of longitudinal hippocampal atrophy in healthy human ageing,” NeuroImage, vol. 112, pp. 364–374, 2015. [DOI] [PubMed] [Google Scholar]
- [5].Bernal-Rusiel JL, Greve DN, Reuter M, Fischl B, Sabuncu MR, and ADNI, “Statistical analysis of longitudinal neuroimage data with linear mixed effects models,” NeuroImage, vol. 66, pp. 249–260, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [6].Bilgel M, Prince JL, Wong DF, Resnick SM, and Jedynak BM, “A multivariate nonlinear mixed effects model for longitudinal image analysis: Application to amyloid imaging,” NeuroImage, vol. 134, pp. 658–670, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [7].Cui R, Liu M, and ADNI, “RNN-based longitudinal analysis for diagnosis of Alzheimer’s disease,” Computerized Medical Imaging and Graphics, vol. 73, pp. 1–10, 2019. [DOI] [PubMed] [Google Scholar]
- [8].Skup M, “Longitudinal fMRI analysis: A review of methods,” Statistics and Its Interface, vol. 3, no. 2, p. 235–252, 2010. [PMC free article] [PubMed] [Google Scholar]
- [9].Schwarz C, Gunter J, Wiste H, Przybelski S, Weigand S, Ward C, Senjem M, Vemuri P, Murray M, Dickson D, Parisi J, Kantarci K, Weiner M, Petersen R, and Jack C, “A large-scale comparison of cortical thickness and volume methods for measuring Alzheimer’s disease severity,” NeuroImage: Clinical, vol. 11, pp. 802–812, May 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [10].St L, Wold S, et al. , “Analysis of variance (ANOVA),” Chemometrics and Intelligent Laboratory Systems, vol. 6, no. 4, pp. 259–272, 1989. [Google Scholar]
- [11].Fjell AM, Walhovd KB, Fennema-Notestine C, McEvoy LK, Hagler DJ, Holland D, Brewer JB, and Dale AM, “One-year brain atrophy evident in healthy aging,” Journal of Neuroscience, vol. 29, no. 48, pp. 15223–15231, 2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [12].Sabuncu MR, Desikan RS, Sepulcre J, Yeo BTT, Liu H, Schmansky NJ, Reuter M, Weiner MW, Buckner RL, Sperling RA, et al. , “The dynamics of cortical and hippocampal atrophy in Alzheimer disease,” Archives of neurology, vol. 68, no. 8, pp. 1040–1048, 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [13].Frings L, Mader I, Landwehrmeyer BG, Weiller C, Hüll M, and Huppertz H-J, “Quantifying change in individual subjects affected by frontotemporal lobar degeneration using automated longitudinal MRI volumetry,” Human Brain Mapping, vol. 33, no. 7, pp. 1526–1535, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [14].Bernal-Rusiel JL, Reuter M, Greve DN, Fischl B, Sabuncu MR, and ADNI, “Spatiotemporal linear mixed effects modeling for the mass-univariate analysis of longitudinal neuroimage data,” NeuroImage, vol. 81, pp. 358–370, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [15].Salazar JC, Schmitt FA, Yu L, Mendiondo MM, and Kryscio RJ, “Shared random effects analysis of multi-state Markov models: application to a longitudinal study of transitions to dementia,” Statistics in Medicine, vol. 26, no. 3, pp. 568–580, 2007. [DOI] [PubMed] [Google Scholar]
- [16].Dwyer MG, Bergsland N, and Zivadinov R, “Improved longitudinal gray and white matter atrophy assessment via application of a 4-dimensional hidden Markov random field model,” NeuroImage, vol. 90, pp. 207–217, 2014. [DOI] [PubMed] [Google Scholar]
- [17].Habeck C and Stern Y, “Multivariate data analysis for neuroimaging data: Overview and application to Alzheimer’s disease,” Cell Biochemistry and Biophysics, vol. 58, pp. 53–67, November 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [18].Westman E, Aguilar C, Muehlboeck J-S, and Simmons A, “Regional magnetic resonance imaging measures for multivariate analysis in Alzheimer’s disease and mild cognitive impairment,” Brain topography, vol. 26, pp. 9–23, August 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [19].Rosenberg MD, Casey BJ, and Holmes AJ, “Prediction complements explanation in understanding the developing brain,” Nature Communications, vol. 9, no. 589, pp. 1–13, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [20].Gray KR, Wolz R, Heckemann RA, Aljabar P, Hammers A, Rueckert D, and ADNI, “Multi-region analysis of longitudinal FDG-PET for the classification of Alzheimer’s disease,” NeuroImage, vol. 60, no. 1, pp. 221–229, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].Zhang D, Shen D, and ADNI, “Predicting future clinical changes of MCI patients using longitudinal and multimodal biomarkers,” PloS one, vol. 7, no. 3, pp. 1–15, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].Zhang J, Liu M, An L, Gao Y, and Shen D, “Alzheimer’s disease diagnosis using landmark-based features from longitudinal structural MR images,” IEEE Journal of Biomedical and Health Informatics, vol. 21, no. 6, pp. 1607–1616, 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [23].Liu M, Suk H-I, and Shen D, “Multi-task sparse classifier for diagnosis of MCI conversion to AD with longitudinal MR images,” in International Workshop on Machine Learning in Medical Imaging, vol. 8184 of LNCS, pp. 243–250, Springer, 2013. [Google Scholar]
- [24].Sabuncu MR, “A sparse Bayesian learning algorithm for longitudinal image data,” in International Conference on Medical Image Computing and Computer-Assisted Intervention, vol. 9351 of LNCS, pp. 411–418, Springer, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [25].Adeli E, Kwon D, Zhao Q, Pfefferbaum A, Zahr NM, Sullivan EV, and Pohl KM, “Chained regularization for identifying brain patterns specific to HIV infection,” NeuroImage, vol. 183, pp. 425–437, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [26].Lipton ZC, Kale DC, Elkan C, and Wetzel R, “Learning to diagnose with LSTM recurrent neural networks,” arXiv preprint arXiv:1511.03677, 2015. [Google Scholar]
- [27].Santeramo R, Withey S, and Montana G, “Longitudinal detection of radiological abnormalities with time-modulated LSTM,” in Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, pp. 326–333, Springer, 2018. [Google Scholar]
- [28].Gao R, Huo Y, Bao S, Tang Y, Antic SL, Epstein ES, Balar AB, Deppen S, Paulson AB, Sandler KL, et al. , “Distanced LSTM: Time-distanced gates in long short-term memory models for lung cancer detection,” in International Workshop on Machine Learning in Medical Imaging, vol. 11861 of LNCS, pp. 310–318, Springer, 2019. [PMC free article] [PubMed] [Google Scholar]
- [29].Ghazi MM, Nielsen M, Pai A, Cardoso MJ, Modat M, Ourselin S, Sørensen L, et al. , “Training recurrent neural networks robust to incomplete data: Application to Alzheimer’s disease progression modeling,” Medical Image Analysis, vol. 53, pp. 39–46, 2019. [DOI] [PubMed] [Google Scholar]
- [30].Bai W, Suzuki H, Qin C, Tarroni G, Oktay O, Matthews PM, and Rueckert D, “Recurrent neural networks for aortic image sequence segmentation with sparse annotations,” in International Conference on Medical Image Computing and Computer-Assisted Intervention, vol. 11073 of LNCS, pp. 586–594, Springer, 2018. [Google Scholar]
- [31].Lee G, Nho K, Kang B, Sohn K-A, and Kim D, “Predicting Alzheimer’s disease progression using multi-modal deep learning approach,” Scientific Reports, vol. 9, no. 1, pp. 1–12, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [32].Gao L, Pan H, Liu F, Xie X, Zhang Z, Han J, and ADNI, “Brain disease diagnosis using deep learning features from longitudinal MR images,” in Asia-Pacific Web (APWeb) and Web-Age Information Management (WAIM) Joint International Conference on Web and Big Data, pp. 327–339, Springer, 2018. [Google Scholar]
- [33].Hochreiter S and Schmidhuber J, “Long short-term memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997. [DOI] [PubMed] [Google Scholar]
- [34].Cho K, van Merrienboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, and Bengio Y, “Learning phrase representations using RNN encoder-decoder for statistical machine translation,” 2014.
- [35].Xu Y, Hosny A, Zeleznik R, Parmar C, Coroller T, Franco I, Mak RH, and Aerts HJ, “Deep learning predicts lung cancer treatment response from serial medical imaging,” Clinical Cancer Research, vol. 25, no. 11, pp. 3266–3275, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [36].Che Z, Purushotham S, Cho K, Sontag D, and Liu Y, “Recurrent neural networks for multivariate time series with missing values,” Scientific Reports, vol. 8, no. 1, pp. 1–12, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [37].Wang C, Rimner A, Hu Y-C, Tyagi N, Jiang J, Yorke E, Riyahi S, Mageras G, Deasy JO, and Zhang P, “Toward predicting the evolution of lung tumors during radiotherapy observed on a longitudinal MR imaging study via a deep learning algorithm,” Medical Physics, vol. 46, no. 10, pp. 4699–4707, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [38].Aghili M, Tabarestani S, Adjouadi M, and Adeli E, “Predictive modeling of longitudinal data for Alzheimer’s disease diagnosis using RNNs,” in International Workshop on Predictive Intelligence in Medicine, vol. 11121 of LNCS, pp. 112–119, Springer, 2018. [Google Scholar]
- [39].Pham T, Tran T, Phung D, and Venkatesh S, “Predicting healthcare trajectories from medical records: A deep learning approach,” Journal of Biomedical Informatics, vol. 69, pp. 218–229, 2017. [DOI] [PubMed] [Google Scholar]
- [40].Reuter M, Schmansky N, Rosas H, and Fischl B, “Within-subject template estimation for unbiased longitudinal image analysis,” NeuroImage, vol. 61, pp. 1402–18, March 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [41].Wu G, Wang Q, and Shen D, “Registration of longitudinal brain image sequences with implicit template and spatial-temporal heuristics,” NeuroImage, vol. 59, pp. 404–21, July 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [42].Zhao Q, Kwon D, Müller-Oehring E, Le Berre A-P, Pfefferbaum A, Sullivan E, and Pohl K, “Longitudinally consistent estimates of intrinsic functional networks,” Human Brain Mapping, vol. 40, pp. 2511–2528, February 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [43].Pascanu R, Mikolov T, and Bengio Y, “On the difficulty of training recurrent neural networks,” in International Conference on Machine Learning, pp. 1310–1318, 2013. [Google Scholar]
- [44].Nie D, Zhang H, Adeli E, Liu L, and Shen D, “3D deep learning for multi-modal imaging-guided survival time prediction of brain tumor patients,” in International Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 212–220, Springer, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [45].Kamnitsas K, Ledig C, Newcombe V, Simpson J, Kane A, Menon D, Rueckert D, and Glocker B, “Efficient multi-scale 3d cnn with fully connected crf for accurate brain lesion segmentation,” Medical Image Analysis, vol. 36, pp. 61–78, March 2016. [DOI] [PubMed] [Google Scholar]
- [46].Matta TH, Flournoy JC, and Byrne ML, “Making an unknown unknown a known unknown: Missing data in longitudinal neuroimaging studies,” Developmental Cognitive Neuroscience, vol. 33, pp. 83–98, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [47].Alahi A, Goel K, Ramanathan V, Robicquet A, Fei-Fei L, and Savarese S, “Social LSTM: Human trajectory prediction in crowded spaces,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 961–971, 2016. [Google Scholar]
- [48].Chung J, Gulcehre C, Cho K, and Bengio Y, “Empirical evaluation of gated recurrent neural networks on sequence modeling,” arXiv preprint arXiv:1412.3555, 2014. [Google Scholar]
- [49].Márquez-Neila P, Salzmann M, and Fua P, “Imposing hard constraints on deep networks: Promises and limitations,” arXiv preprint arXiv:1706.02025, 2017. [Google Scholar]
- [50].Suk H-I, Lee S-W, Shen D, and ADNI, “Latent feature representation with stacked auto-encoder for AD/MCI diagnosis,” Brain Structure and Function, vol. 220, no. 2, pp. 841–859, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [51].Doersch C, Gupta A, and Efros AA, “Unsupervised visual representation learning by context prediction,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 1422–1430, 2015. [Google Scholar]
- [52].Noroozi M, Pirsiavash H, and Favaro P, “Representation learning by learning to count,” in Proceedings of the IEEE International Conference on Computer Vision, pp. 5898–5906, 2017. [Google Scholar]
- [53].Gidaris S, Singh P, and Komodakis N, “Unsupervised representation learning by predicting image rotations,” arXiv preprint arXiv:1803.07728, 2018. [Google Scholar]
- [54].Zhao Q, Adeli E, Pfefferbaum A, Sullivan EV, and Pohl KM, “Confounder-aware visualization of ConvNets,” in International Workshop on Machine Learning in Medical Imaging, vol. 11861 of LNCS, pp. 328–336, Springer, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [55].Adeli E, Zhao Q, Zahr NM, Goldstone A, Pfefferbaum A, Sullivan EV, and Pohl KM, “Deep learning identifies morphological determinants of sex differences in the pre-adolescent brain,” NeuroImage, vol. 223, pp. 1–13, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [56].Wen J, Thibeau-Sutre E, Diaz-Melo M, Samper-González J, Routier A, Bottani S, Dormont D, Durrleman S, Burgos N, Colliot O, et al. , “Convolutional neural networks for classification of Alzheimer’s disease: Overview and reproducible evaluation,” Medical Image Analysis, vol. 63, pp. 1–19, 2020. [DOI] [PubMed] [Google Scholar]
- [57].Park S, Zhang Y, Kwon D, Zhao Q, Zahr N, Pfefferbaum A, Sullivan E, and Pohl K, “Alcohol use effects on adolescent brain development revealed by simultaneously removing confounding factors, identifying morphometric patterns, and classifying individuals,” Scientific Reports, vol. 8, pp. 1–14, December 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [58].Esmaeilzadeh S, Belivanis DI, Pohl KM, and Adeli E, “End-to-end alzheimer’s disease diagnosis and biomarker identification,” in International Workshop on Machine Learning in Medical Imaging, vol. 11046 of LNCS, pp. 337–345, Springer, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [59].Liu S, Liu S, Cai W, Che H, Pujol S, Kikinis R, Feng D, Fulham MJ, et al. , “Multimodal neuroimaging feature learning for multiclass diagnosis of Alzheimer’s disease,” IEEE Transactions on Biomedical Engineering, vol. 62, no. 4, pp. 1132–1140, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [60].Hosseini-Asl E, Keynton R, and El-Baz A, “Alzheimer’s disease diagnostics by adaptation of 3D convolutional network,” in 2016 IEEE International Conference on Image Processing (ICIP), pp. 126–130, IEEE, 2016. [Google Scholar]
- [61].Simonyan K, Vedaldi A, and Zisserman A, “Deep inside convolutional networks: Visualising image classification models and saliency maps,” arXiv preprint arXiv:1312.6034, 2013. [Google Scholar]
- [62].Rohlfing T, Zahr NM, Sullivan EV, and Pfefferbaum A, “The SRI24 multichannel atlas of normal adult human brain structure,” Human Brain Mapping, vol. 31, no. 5, pp. 798–819, 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [63].DeLong ER, DeLong DM, and Clarke-Pearson DL, “Comparing the areas under two or more correlated receiver operating characteristic curves: a non-parametric approach,” Biometrics, pp. 837–845, 1988. [PubMed] [Google Scholar]
- [64].Association A et al. , “2017 Alzheimer’s disease facts and figures,” Alzheimer’s & Dementia, vol. 13, no. 4, pp. 325–373, 2017. [Google Scholar]
- [65].Leung K, Bartlett J, Barnes J, Manning E, Ourselin S, and Fox N, “Cerebral atrophy in mild cognitive impairment and alzheimer disease rates and acceleration,” Neurology, vol. 80, pp. 648–54, January 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [66].Pfefferbaum A, Rosenbloom M, Chu W, Sassoon S, Rohlfing T, Pohl K, Zahr N, and Sullivan E, “White matter microstructural recovery with abstinence and decline with relapse in alcohol dependence interacts with normal ageing: A controlled longitudinal DTI study,” The Lancet Psychiatry, vol. 1, pp. 202–212, August 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [67].Zahr NM and Pfefferbaum A, “Alcohol’s effects on the brain: Neuroimaging results in humans and animal models,” Alcohol Res, vol. 38, no. 2, p. 183–206, 2018. [PMC free article] [PubMed] [Google Scholar]
- [68].Fisher RA, “On the interpretation of χ 2 from contingency tables, and the calculation of p,” Journal of the Royal Statistical Society, vol. 85, no. 1, pp. 87–94, 1922. [Google Scholar]
- [69].Müller-Oehring E, Jung Y-C, Pfefferbaum A, Sullivan E, and Schulte T, “The resting brain of alcoholics,” Cerebral cortex, vol. 25, pp. 4155–68, June 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [70].Moorman D, “The role of the orbitofrontal cortex in alcohol use, abuse, and dependence,” Progress in Neuro-psychopharmacology Biological Psychiatry, vol. 87, pp. 85–107, January 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [71].Zhao Q, Pfefferbaum A, Podhajsky S, Pohl K, and Sullivan E, “Accelerated aging and motor control deficits are related to regional deformation of central cerebellar white matter in alcohol use disorder,” Addiction Biology, vol. 25, no. 3, pp. 1–12, 2020. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [72].Brown SA, Brumback T, Tomlinson K, Cummins K, Thompson WK, Nagel BJ, De Bellis MD, Hooper SR, Clark DB, Chung T, et al. , “The national consortium on alcohol and neurodevelopment in adolescence (NCANDA): a multisite study of adolescent development and substance use,” Journal of Studies on Alcohol and Drugs, vol. 76, no. 6, pp. 895–908, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [73].Pfefferbaum A, Kwon D, Brumback T, Thompson WK, Cummins K, Tapert SF, Brown SA, Colrain IM, Baker FC, Prouty D, et al. , “Altered brain developmental trajectories in adolescents after initiating drinking,” American Journal of Psychiatry, vol. 175, no. 4, pp. 370–380, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [74].Donovan JE and Molina BS, “Childhood risk factors for early-onset drinking,” Journal of Studies on Alcohol and Drugs, vol. 72, no. 5, pp. 741–751, 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [75].Wobrock T, Falkai P, Schneider-Axmann T, Frommann N, Wölwer W, and Gaebel W, “Effects of abstinence on brain morphology in alcoholism : AAA MRI study,” European Archives of Psychiatry and Clinical Neuroscience, vol. 259, pp. 143–50, February 2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [76].Sullivan E, Rosenbloom M, Lim K, and Pfefferbaum A, “Longitudinal changes in cognition, gait, and balance in abstinent and relapsed alcoholic men: Relationships to changes in brain structure,” Neuropsychology, vol. 14, pp. 178–88, May 2000. [PubMed] [Google Scholar]
- [77].Oh K, Chung Y-C, Kim KW, Kim W-S, and Oh I-S, “Classification and visualization of alzheimer’s disease using volumetric convolutional neural network and transfer learning,” Scientific Reports, vol. 9, no. 1, pp. 1–16, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [78].Spasov S, Passamonti L, Duggento A, Lió P, Toschi N, Initiative ADN, et al. , “A parameter-efficient deep learning approach to predict conversion from mild cognitive impairment to alzheimer’s disease,” Neuroimage, vol. 189, pp. 276–287, 2019. [DOI] [PubMed] [Google Scholar]
- [79].Ding Y, Sohn JH, Kawczynski MG, Trivedi H, Harnish R, Jenkins NW, Lituiev D, Copeland TP, Aboian MS, Mari Aparici C, et al. , “A deep learning model to predict a diagnosis of alzheimer disease by using 18f-fdg pet of the brain,” Radiology, vol. 290, no. 2, pp. 456–464, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [80].Thung K-H, Yap P-T, Adeli E, Lee S-W, Shen D, Initiative ADN, et al. , “Conversion and time-to-conversion predictions of mild cognitive impairment using low-rank affinity pursuit denoising and matrix completion,” Medical image analysis, vol. 45, pp. 68–82, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]