

Abstract
Recent development in the data-driven decision science has seen great advances in individualized decision making. Given data with individual covariates, treatment assignments and outcomes, policy makers best individualized treatment rule (ITR) that maximizes the expected outcome, known as the value function. Many existing methods assume that the training and testing distributions are the same. However, the estimated optimal ITR may have poor generalizability when the training and testing distributions are not identical. In this paper, we consider the problem of finding an optimal ITR from a restricted ITR class where there is some unknown covariate changes between the training and testing distributions. We propose a novel distributionally robust ITR (DR-ITR) framework that maximizes the worst-case value function across the values under a set of underlying distributions that are “close” to the training distribution. The resulting DR-ITR can guarantee the performance among all such distributions reasonably well. We further propose a calibrating procedure that tunes the DR-ITR adaptively to a small amount of calibration data from a target population. In this way, the calibrated DR-ITR can be shown to enjoy better generalizability than the standard ITR based on our numerical studies.
Keywords: Covariate shifts, Distributionally robust optimization, Generalizability, Individualized treatment rules
1. Introduction
Data-driven individualized decision making problems are commonly seen in practice and have been studied intensively in the literature. In disease management, the physician may decide whether to introduce or switch a therapy for a patient based on his/her characteristics in order to achieve a better clinical outcome (Bertsimas et al., 2017). In public policy making, a policy that allocates the resource based on the characteristics of the targets can improve the overall resource allocation efficiency (Kube et al., 2019). In a context-based recommender system, the use of the contextual information such as time, location and social connection can increase the effectiveness of the recommendation process (Aggarwal, 2016). One common goal of these problems is to find the optimal individualized treatment rule (ITR) mapping from the individual characteristics or contextual information to the treatment assignment, that maximizes the expected outcome, known as the value function (Manski, 2004; Qian and Murphy, 2011).
One approach for estimating an optimal ITR is to first estimate the conditional mean outcome, known as the Q-function, given the individual characteristics and the treatment assignment, and then induce the ITR that prescribes the treatment by maximizing the estimated Q-function (Qian and Murphy, 2011). In the binary treatment case, such an approach can be reformulated as estimating the conditional treatment effect (CTE) as the difference of the conditional mean outcomes under two candidate treatments (Zhao et al., 2017; Chen et al., 2017; Qi et al., 2020). Another approach is to directly estimate the value function using the inverse-probability weighted estimator (IPWE), and then search for the ITR that maximizes the corresponding value function (Zhao et al., 2012; Kitagawa and Tetenov, 2018; Liu et al., 2018; Zhang et al., 2019). Since there are potential model misspecification issues of these approaches, the augmented IPWE (AIPWE) of the value function combines the estimates of the Q-function and the treatment propensity score. AIPWE is doubly robust in the sense that the consistency of the value function estimate is guaranteed as long as either the Q-function model or the propensity score model is correctly specified (Dudík et al., 2011; Zhang et al., 2012b; Athey and Wager, 2017; Zhao et al., 2019a). While the doubly robust property can protect against the violation of the model assumptions, one key assumption behind is that the training and testing distributions should be identical.
When the training and testing distributions are different, an estimated optimal ITR may not generalize well on the testing data (Zhao et al., 2019b). Similar phenomenon for causal inference in randomized controlled trials (RCTs) has also been pointed out by Muller (2014); Gatsonis and Morton (2017). Specifically, due to the inclusion and exclusion criteria of an RCT, the training sample can be unrepresentative of the testing population we are interested in. Therefore, the corresponding casual evidence may not be broadly applicable or relevant for the real-world practice. In causal inference literature, it is common to regard the training data as a selected sample from the pooled population of training and testing. The selection bias can be adjusted by reweighing or stratifying the training data according to the relationship between training and testing (O’Muircheartaigh and Hedges, 2014; Buchanan et al., 2018). However, it requires strong assumptions on completely measuring the selection confounders and correctly specifying the selection model, and thus can only work well on a prespecified testing population. There are many other practical scenarios where the difference between the training and testing distributions is unknown. One example is that the training data can be confounded by some unidentified effects such as batch effects, which may cause potential covariate shifts (Luo et al., 2010). Another possibility is that the testing distribution may evolve over time (Hand, 2006). There is also a widely studied scenario that multiple datasets are aggregated to perform combined analysis (Alyass et al., 2015; Shi et al., 2018; Li et al., 2020). Aggregating data from various sources can benefit from sharing common information, transferring knowledge from different but related samples, and maintaining certain privacy. However, due to the heterogeneity among data sources, standard approaches of finding pooled optimal ITRs may not generalize well on all these sources. One way of handling the heterogeneity is to formulate it as a problem of distributional changes, where we train on the mixture of subpopulations while testing on one of the subpopulations (Duchi et al., 2019). In all these applications, an optimal ITR that is robust to unattended distributional differences is of great interest.
Despite a vast literature in ITR, much less work has been done on the problem when the training and testing distributions are different. Imai and Ratkovic (2013) and Johansson et al. (2018) estimated the CTE function by reweighing the training loss to ensure the estimators generalizable on a prespecified testing distribution. Zhao et al. (2019b) aimed to find an ITR that optimizes the worst-case quality assessment among all testing covariate distributions satisfying some moment conditions. However, since their method only requires some moment conditions, the uncertainty set of the testing distributions can be very large. Recent developments in the distributionally robust optimization (DRO) literature provide the opportunities to quantify the difference between the training and testing distributions more precisely (Ben-Tal et al., 2013; Duchi and Namkoong, 2018; Rahimian and Mehrotra, 2019). Motivated by the DRO literature, we develop a new robust optimal ITR framework in this paper.
In this paper, we consider the problem of finding an optimal ITR from a restricted ITR class, where there is some unknown covariate changes between the training and testing distributions. We propose to use the distributionally robust ITR (DR-ITR) that maximizes the defined worst-case value function among value functions under a set of underlying distributions. More specifically, value functions are evaluated under all testing covariate distributions that are “close” to the training distribution, and the worst-case situation takes a minimal one. Our distributionally robust ITR framework is different from the existing doubly robust ITR framwork that uses an AIPWE. In particular, an AIPWE robustifies the model specification assumptions, while our DR-ITR robustifes the underlying distributions. The DR-ITR aims to guarantee reasonable performance across all testing distributions in an uncertainty set around the training distribution by optimizing the worst-case scenarios. In particular, we parameterize the amount of “closeness” by the distributional robustness-constant (DR-constant), where the smallest possible DR-constant corresponds to the standard ITR that maximizes the value function under the training distribution. To ensure the performance of the DR-ITR on a specific testing distribution, we fit a class of DR-ITRs for a spectrum of DR-constants at the training stage, and calibrate the DR-constant based on a small amount of the calibrating data from the testing distribution. In this way, the correctly calibrated DR-constant ensures that the DR-ITR performs at least as well as, often much better than, the standard ITR. Using our illustrative example, we show that the standard ITR can have very poor values on many testing distributions, while our calibrated DR-ITRs still maintain relatively good performance. In particular, our proposed calibrating procedures can tune DR-constants based on the small calibrating sample. To solve the worst-case optimization problem, we make use of the difference-of-convex (DC) relaxation of the nonsmooth indicator, and propose two algorithms to solve the related nonconvex optimization problems. We also provide the finite sample regret bound for the proposed DR-ITR.
The rest of this paper is organized as follows. In Section 2, we discuss an illustrative example that the optimality of an ITR can be sensitive to the underlying distribution, and introduce the DR-ITR that can generalize well across all testing distributions considered in this example. Then we propose the DR-ITR framework and the corresponding learning problem. In Section 3, we justify the theoretical guarantees of the finite sample approximations for the learning problem. In Section 4, we evaluate the generalizability of our proposed DR-ITR on two simulation studies: the problem of covariate shifts and the problem of mixture of multiple subgroups. We apply our proposed DR-ITR on the AIDS clinical dataset ACTG 175 and evaluate its generalizability on the subgroup of female patients in Section 5. Some related discussions and extensions are given in Section 6. The implementation details, technical proofs and some additional numerical results are all given in the Supplementary Material.
2. Methodology
In this section, we introduce the value maximization framework in the current literature, and discuss its limitation when the training and testing distributions are different. Then we propose the DR-value function that optimizes the worse-case value function across all distributions within an uncertainty set around the training distribution.
2.1. Maximizing the Value Function
Consider the training data , where denotes the covariates, is the binary treatment assignment, and is the observed outcome. We assume that the larger outcome is better. Let , be the potential outcomes. Consider a prespecified ITR class . For , denote as the potential outcome following the treatment assignment prescribed by the ITR d. Then the value function under the training distribution is defined as
Denote as the training propensity score function for treatment assignment. If we assume 1) the consistency of the observed outcome ; 2) the strict overlap for any ; and 3) the strong ignorability (Rubin, 1974), then we can identify in terms of the observed data by the IPWE of .
Instead of targeting the value function directly, we instead consider the CTE function as under the training distribution . Note that for an ITR d and all , the prescribed treatment assignment satisfies . Then we have . Based on this representation, we define another value function
| (1) |
Since , it can be observed that , where with probability and with probability . Therefore, can be interpreted as the value improvement of the ITR d upon the completely random treatment rule drand. In terms of the optimal ITR, the resulting rules by optimizing the value functions and over d are equivalent.
By the definition (1), we have with equality if almost surely. Such an ITR is the global optimal ITR when consists of all measurable functions from to . To obtain the global optimal ITR, we can estimate from data using flexible nonparametric techniques, such as the Bayesian additive regression tree (BART) (Hill, 2011), or the casual forest (Wager and Athey, 2018). However, in general, the global optimal ITR can take a very complicated functional form, while decision makers may want to have a simpler ITR (Kitagawa and Tetenov, 2018). Then the ITR class is often considered as a restricted subset of measurable functions from to . The following two-step procedure can be implemented to estimate the restricted optimal ITR on : first we estimate the CTE function using flexible nonparametric techniques; and then we estimate the ITR by solving on the restricted ITR class (Zhang et al., 2012a). Here, is the empirical average based on the training data.
2.2. Covariate Changes
It can be observed that the value functions defined in Section 2.1 depend on the underlying distribution. Suppose we are interested in a testing distribution that may be different from the training distribution to some extent. Then ITRs estimated by most existing methods may not be able to perform well on our target population. In order to address this problem, we first make the following assumption on the potential difference between and .
Assumption 1 (Covariate Changes). For every training distribution and testing distribution considered in this paper, we assume the followings:
There exists such that , and .
Assumption 1 (I) requires that the support of the testing distribution cannot go beyond the training distribution. Assumption 1 (II) is mathematically equivalent to assuming that the differences between and only appear in the covariate distributions. The treatment-response relationship conditional on covariates remains unchanged across training and testing distributions. Specifically, let and be the training and testing densities of the data . Then the density ratio becomes
If , i.e., the conditional distributions are identical under and , then , which is the weighting function in Assumption 1 (II).
The assumption of covariate changes is commonly seen in the setting of randomized trial. Consider the training and testing populations together as a pooled population with finite subjects. For each subject , let be a selection random variable such that if i is a training sample point, and if i is a testing sample point. Let the distributions of and be the training distribution and the testing distribution respectively. Denote as the joint distribution of . Then conditions in Assumption 1 can correspond to the following (Hotz et al., 2005; Stuart et al., 2011):
(Overlapping Support) ;
(Selection Unconfoundedness) .
In particular, under this finite population setting, the overlapping support condition is equivalent to that and , and the selection unconfoundedness condition is equivalent to Assumption 1 (II). Such a correspondence can bring more intuitive implications of Assumption 1 under the randomized trial setting. Specifically, the overlapping support requires the chances of each subject being selected into the training and testing populations to be both positive. The selection unconfoundnedness requires that the selection mechanism is independent of the potential outcomes given the covariates. Both conditions can be satisfied by a successful trial design (Pearl and Bareinboim, 2014). The phenomenon of covariate changes between and can exist if with a positive probability. This can be often the case if the subject needs to satisfy certain requirements before enrolling a trial.
As a consequence from Assumption 1, the CTE function remains unchanged under and . Then it can be convenient to consider the value functions and defined in (1). When the testing value function is of interest, maximizing the training value function may not be optimal. Alternatively, we can rewrite the testing value function where . Then based on the training data from , we can maximize that targets the correct objective. It amounts to determine the weighting function w that captures the differences between and .
Remark 1. Notice that for any weighting function , we have with equality if . That is, if consists of all measurable functions from to , then the global optimal ITR is not sensitive to any covariate changes in the testing distribution. However, the problem of covariate changes induces a challenge if is a restricted ITR class.
Remark 2. Our methodology only relies on the fact that remains unchanged under and . Therefore, it can be possible to relax Assumption 1 to allowing distributional changes in , while assuming that the CTE function remains identical across and . Furthermore, our methodology can also be meaningful if the testing CTE function can be different from training, but the optimal treatment assignment remains unchanged. We will discuss this extension in Remark 5.
2.3. An Illustrative Example
In this section, we begin with an example as in Figure 1 that the optimality of an ITR depends on the underlying distribution. There are two underlying bivariate normal distributions of means ; (training) and ; (testing) respectively. We obtain the standard ITR by maximizing the value function under the training distribution over the linear ITR class. We also obtain the DR-ITR by maximizing the DR-value function to be introduced in Section 2.4 over the linear ITR class. Then the DR-ITR is compared with the standard ITR through the value functions under the training distribution and under the testing distribution as in Table 1. Since the values can be comparable only through the same value function but not across different value functions, we further define the criteria relative regret of an ITR as , where “value” can be or , and the LB-ITR maximizes the corresponding value function over the linear ITR class. In this sense, value(LB-ITR) is the best achievable value among the linear ITR class for the corresponding value function, and becomes the benchmark reference for the relative regret criteria.
Figure 1:
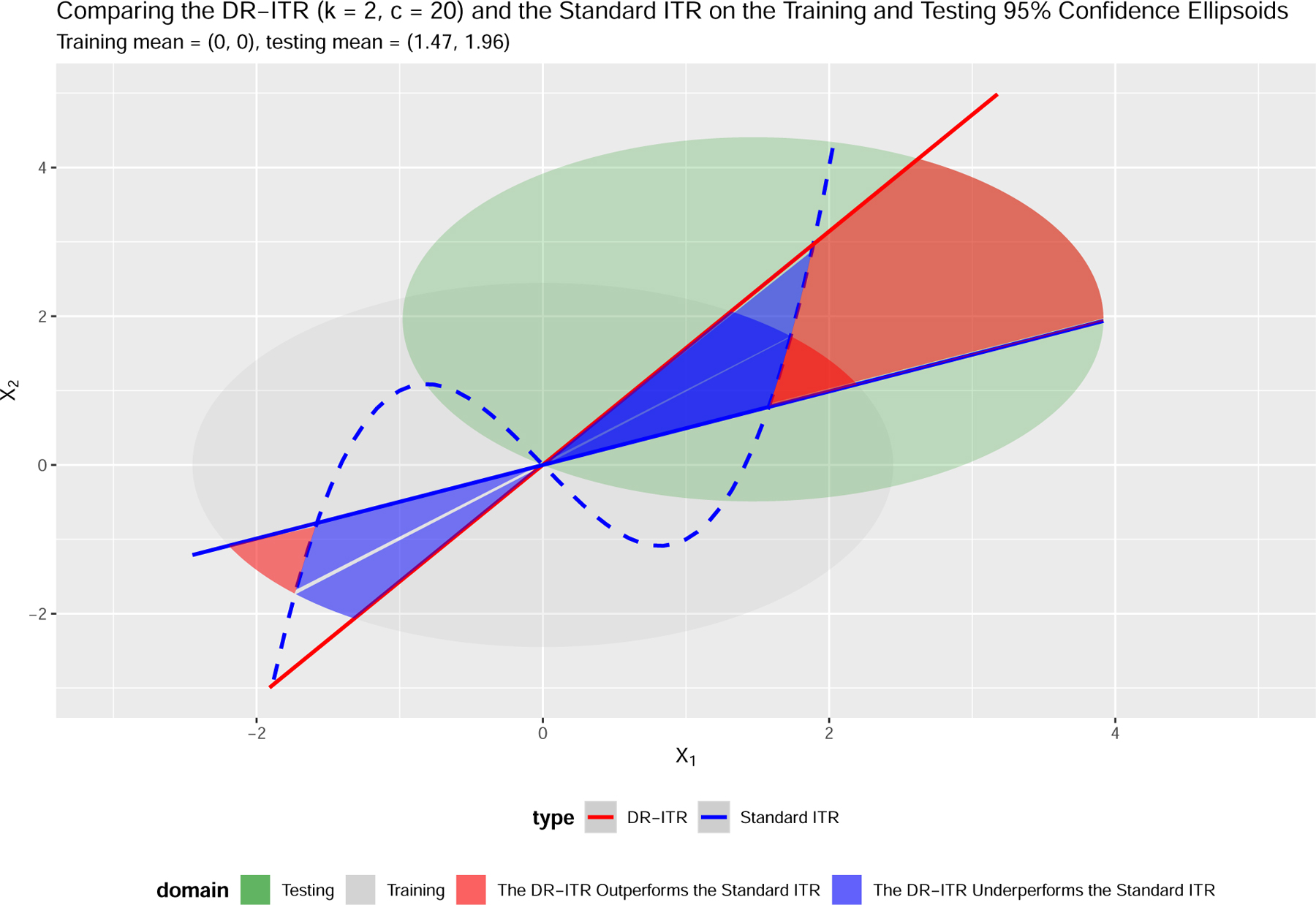
ITRs and the 95% confidence ellipsoids of the training distribution and the testing distribution . The blue dashed curve is the underlying CTE boundary .
Table 1:
Testing Values (Relative Regrets) Comparisons of ITRs
| Value ╲ ITR | DR-ITR | Standard ITR | LB-ITR |
|---|---|---|---|
| Training | 0.6253 (37.36%) | 0.9982 (0%) | 0.9982 |
| Testing | 4.8230 (9.16%) | 0.2927 (94.49%) | 5.3096 |
DR-ITR maximizes defined in (4) with and over the linear ITR class.
Standard ITR maximizes over the linear ITR class.
LB-ITR maximizes or over the linear ITR class.
Values (larger the better) can be comparable within rows but incomparable between rows.
Relative (smaller the better)
A size-10,000 sample is generated for fitting DR-ITR and LB-ITRs, and an independent size-100,000 sample is generated for evaluation under and .
Two facts can be concluded from Table 1: 1) the optimality of an ITR can be different across different distributions; and 2) maximizing the training value function may have poor testing performance when covariate changes exist. In Table 1, even though the standard ITR is optimal under the training distribution, it can be far from optimal (94.49% off in terms of relative regret) under the testing distribution. In contrast, the DR-ITR may not enjoy high training value, but can have much better testing performance (only 9.16% off in terms of relative regret).
Remark 3. Figure 1 also illustrates how the covariate changes affect the optimality of ITRs. Specifically, we can divide the covariate domain into two types of subdomains, annotated in blue and red, on which the DR-ITR and standard ITR have different treatment assignments. On the blue subdomain, the standard ITR assignment shares the same sign with the CTE function, while the DR-ITR does not. In this case, the standard ITR outperforms the DR-ITR with the difference of value at the individual level. The case reverses on the red subdomain on which the DR-ITR outperforms the standard ITR. The overall difference of values integrates the individual difference with respect to the training or testing density.
The overall outperformance of the DR-ITR under the testing distribution can be explained from the following three perspectives: 1) the 95% confidence ellipsoid of the training domain only covers a small area of the red subdomain, while that of the testing domain covers a much larger area; 2) the distance of the red subdomain from the testing centroid is much closer than its distance from the training centroid. Then the red subdomain concentrates higher testing density than training; and 3) the individual value differences are generally larger on the red subdomain intersected with the testing domain than that intersected with the training domain. Therefore, the DR-ITR performs much better than the standard ITR on the testing distribution.
2.4. Maximizing the Distributionally Robust Value (DR-Value) Function
We begin to introduce our DR-ITR that can show strong generalizability as in Figure 1. As discussed in Section 1, our goal in this paper is not to find an ITR that is generalizable on a specific testing distribution, but rather, to find an ITR that guarantees reasonable performance across an uncertain set of testing distributions. We first define the k-th power uncertainty set in two equivalent ways under Assumption 1:
| (2) |
| (3) |
The set consists of the probability distributions such that the -norm of the density ratio is bounded above by the DR-constant c. The definition (3) highlights that the density ratio is a weighting function w of X, and the distribution in can be characterized by the weighting function w satisfying the conditions in (3). Here the DR-constant controls the degree of the distributional robustness that measures how “close” is from . In particular, reduces the power uncertainty set to the singleton . The power order parametrizes the measurement of the distance of from . In particular, the power uncertainty set increases in c as k is fixed, and decreases in k as c is fixed. The latter one is due to the Lyapunov’s inequality: whenever . In the Supplementary Material, we will discuss the explicit form of in the context of specific parametric families of distributions, and how it depends on the DR-constant c and the power k. One important conclusion from Example S.2 in the Supplementary Material for the mean-shifted p-dimensional normal distribution is that if and only if .
With the power uncertainty set , we propose to robustly maximize the following worst-case value function among the values under :
| (4) |
which we term as the DR-value function. In particular, reduces the DR-value function to the standard value function in the definition (1).
Remark 4 (Optimality). The “optimality” of the DR-ITR is with respect to the DR-value function , which highlights its difference from the traditional “optimal” ITR with respect to the standard value function .
In the example in Section 2.3, the standard ITR maximizes the value function under the training distribution over the linear ITR class, while the DR-ITR maximizes the DR-value function of and over the linear ITR class. In particular, the randomness of comes from the training covariate distribution . Such a choice of contains the mean-shifted normal distributions for all . In Figure 2a, we enumerate such mean-shifted normal distributions as the testing distributions, and evaluate the relative improvement of the DR-ITR over the standard ITR as the difference of their relative regrets. Among all testing distributions, the relative improvements of the DR-ITR span from −37.4% to 85.3%, suggesting that the potential of improvement can be large. Besides the DR-constant , we also consider the case in the Supplementary Material. As c increases, the range of relative improvements becomes wider. The increase in the relative improvement upper bound is in general much larger than the decrease in the lower bound.
Figure 2:
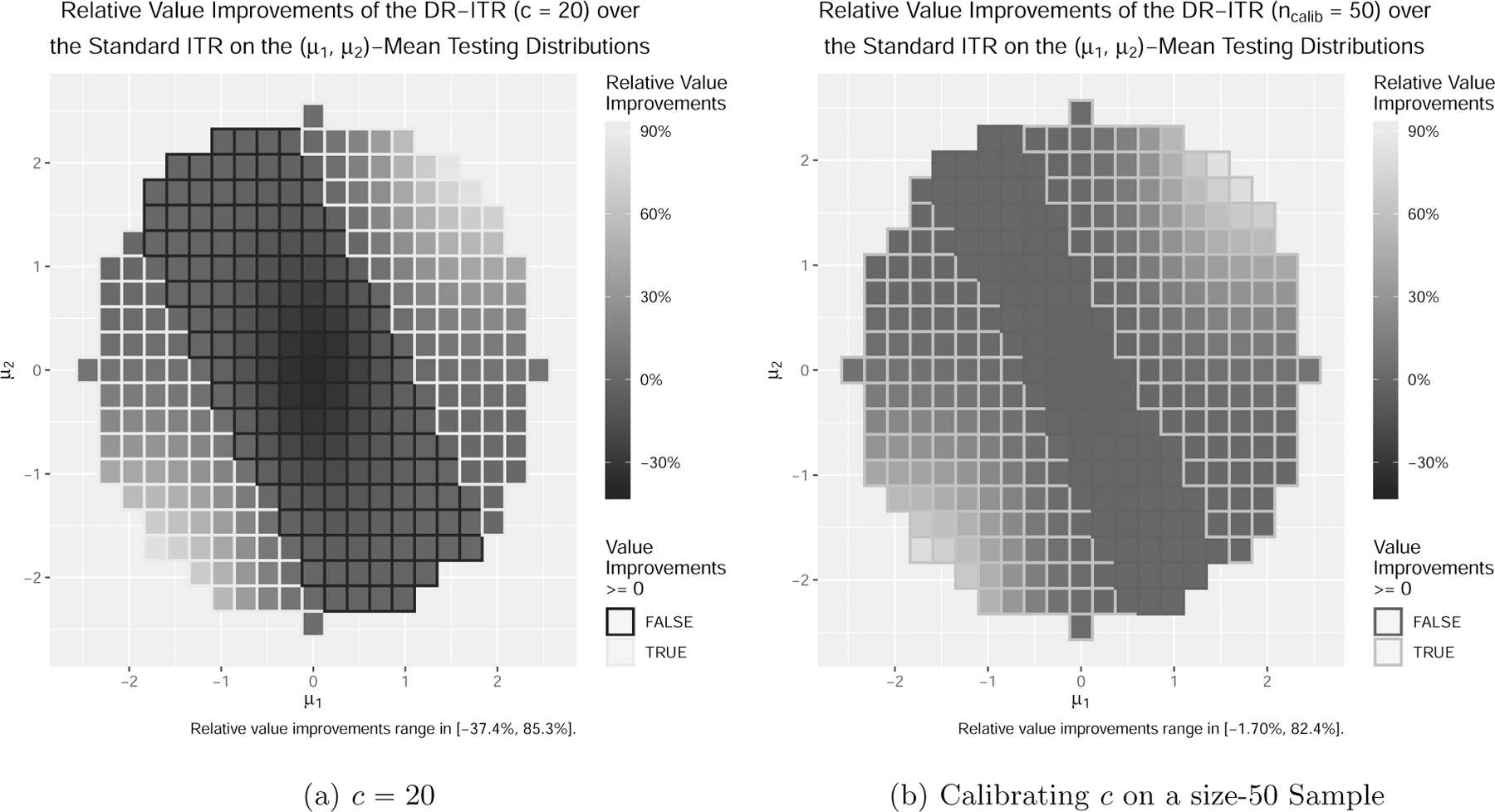
Relative improvements of the DR-ITR over the standard ITR as the difference of relative regrets on testing distributions of (lighter the better).
Based on these observations, the DR-constant c should be carefully chosen. On one hand, as can be seen from Figure 2a, the DR-ITR for a fixed DR-constant c may or may not improve over the standard ITR on a specific testing distribution within . When the DR-constant c can be tuned adaptive to the specific testing distribution, then the DR-ITR can perform at least as well as the standard ITR. On the other hand, we may not even have any prior information on c to ensure that the power uncertainty set contains the testing distribution of interest. Both cases ask for additional information to calibrate the choice of c so that the DR-ITR performs well on a specific testing distribution. Suppose we are able to obtain a small size of calibrating sample from the testing distribution. We propose the following training-calibrating procedure to choose c: 1) at the training stage, we estimate DR-ITRs where c is the DR-constant to compute , and C is a set of candidate DR-constants; 2) we obtain a calibrating sample from the testing distribution, on which we estimate the testing values of ; 3) we select the that maximizes the value of among .
In order to estimate the value function under the testing distribution, we consider the following two possible calibration scenarios: 1) the calibrating sample is a randomized controlled trial (RCT) dataset from the testing distribution; and 2) the calibrating sample only consists of the covariates X from the testing distribution. Scenario 1 will be more ideal than Scenario 2 since we have the testing information of both the treatment and the outcome. We can evaluate an ITR d using the IPWE , where is the empirical average over the calibrating sample, πcalib is the corresponding propensity score function, and πcalib is known or estimable from the calibrating data. We call the corresponding calibrate DR-ITR as RCT-DR-ITR. In Scenario 2, we do not have the treatment-response information from the testing distribution. We can instead use the value function estimate to evaluate d, where is estimated at the training stage. However, the CTE estimate may also suffer from a potential generalizability problem on the testing distribution. Practitioners need to be careful of the generalizability of the CTE estimate when performing the calibration. We call the corresponding DR-ITR as CTE-DR-ITR.
RCT-DR-ITR and CTE-DR-ITR are different in their use of information for calibration. Specifically, the RCT-DR-ITR makes use of from the testing distribution, while the CTE-DR-ITR only makes use of X from the testing distribution, and the underlying CTE function . In practice, is estimated from training data. It requires Assumption 1 to generalize the CTE estimate from training to testing. If Assumption 1 holds, then CTE-DR-ITR can have better performance than RCT-DR-ITR, since CTE-DR-ITR captures less variance from calibrated data. If Assumption 1 is violated, which will be illustrated in Section 4.2, then CTE-DR-ITR can have poorer performance than RCT-DR-ITR, since the testing value function estimate of CTE-DR-ITR can be biased.
In Figure 2b, we generate a calibrating RCT sample from of size 50. It shows that across the mean-shifted testing distributions, the relative improvements of the calibrated DR-ITRs range from −1.70% to 82.4%. It suggests that the small sample size 50 is sufficient for a reasonably good calibration, with the positive relative improvements being maintained.
Remark 5 (Extending Covariate Changes). Consider the case that Assumption 1 is violated. Let Ctest be the testing CTE function that can be different from the training CTE function C. We use the notations and to refer to the training and testing covariate distributions. Assume that almost surely. Then we can still represent the value function under the testing distribution as follows:
The definition of the DR-value function (4) can be robust with respect to the change of (, ) from (, C), such that satisfies and .
Remark 6. The calibration procedure ensures that among the DR-ITRs of various DR-constants, the best one is chosen to maximize the testing value function. In this sense, the calibrated DR-ITR can have potential of improving the generalizability from training to testing. However, if the testing distribution is very far from the training distribution, one cannot expect that an ITR estimated by any method from the training data can perform well on the test data, even though our proposed method may be able to protect against such a distributional change to some extent. Therefore, in practice, we suggest to use our method when training and testing distributions are relatively close.
2.5. Distributionally Robust Expectation
In this section, we first discuss the rationale of considering the Lk-norm of the density ratio as the measurement of distributional distance. We show that the k-th power uncertainty set is equivalent to the distributional ball induced by the ϕ-divergence (Pardo, 2005) for some specific divergence ϕ. Then we derive the dual form of the worst-case expectation over , which provides a more tractable optimization problem.
2.5.1. Equivalence to the Divergence-Based Distributional Ball
As a generalization of the conventional likelihood-based framework which corresponds to the Kullback-Leibler (KL) divergence, the framework of general ϕ-divergence between distributions has been well studied in the context of parameter estimation and hypothesis testing (Pardo, 2005). The ϕ-divergence between two probability distributions and such that is defined as follows:
where Φ is a class of convex functions on that satisfies the regularity conditions: for , , and for . The definition with various choices of ϕ’s includes the empirical likelihood , the KL divergence , and the χ2-divergence . There is another important special case that relates to the power uncertainty set of . Consider the optimization indicator for if and otherwise, for which if , and otherwise. Then if and only if .
Although Dϕ is not a proper metric between probability distributions since it is asymmetric, we can still define a Dϕ-distributional ball as , where is the center and is the radius. Then for any , the -distributional ball , which coincides with the power uncertainty set defined in (2) for . Such an equivalence can be extended to all finite when a Cressie-Read (CR) family (Cressie and Read, 1984) of divergence functions is taken into consideration. For , the corresponding is defined as
Here, ϕk effectively measures the probability-distributional distance by the k-th moment of the density ratio, since as long as is a probability distribution. Then it can be inferred that the -distributional ball is actually equivalent to the power uncertainty set in (2). Here, there is a one-to-one correspondence between the DR-constant c and the radius ρ of the -distributional ball with . We conclude the case and with the following:
| (5) |
2.5.2. Dual Representation
We begin with a general result on the dual representation of the ϕ-divergence-based distributionally robust expectation. We state the following lemma and refer readers to Duchi and Namkoong (2018, Proposition 1).
Lemma 1. Fix a random variable Z on with distribution . Let be a legitimate divergence function. Define the convex conjugate of ϕ as
Then for ρ > 0,
| (6) |
Let . Lemma 1 can be directly applied to the optimization indicator: if and otherwise, whose convex conjugate is given by . Then λ in (6) attains the infimum at λ = 0, so that
| (7) |
In particular, the right hand side of (7) is solved by the -value-at-risk in finance, or equivalently, the -quantile of Z under the center distribution . The right hand side of (7) itself is defined as the -conditional value-at-risk (Rockafellar and Uryasev, 2000). Next, we apply Lemma 1 to the k-th power divergence ϕk to derive the dual problem of the worst-case expectation over .
Lemma 2. Let ΦCR be the Cressie-Read family of divergence functions, k, be conjugate numbers, i.e., , and . Then we have following conclusions:
- The convex conjugate of ϕk is given by
- Fix a probability measure and a random variable Z on . Then for ,
where .(8)
Note that the right hand side of (8) and its optimizer η are both coherent risk measures as the higher-order generalizations of the CVaR and VaR (Krokhmal, 2007).
Using the equivalence in (5), the worst-case expectation over the power uncertainty set for and (in particular,) unifies (7) and (8) as follows:
| (9) |
By inspecting the dual problem (9), the right hand side is computationally more tractable than the left hand side, since instead of optimizing over an infinite-dimensional probability measure , we only need to optimize over a univariate variable η.
In order to apply the duality result to the DR-ITR problem, we negate the DR-value maximization to a risk minimization problem. Denote the risk function under the training distribution as . Then for and , the DR-risk function is defined as
Using the fact , the dual representation (9) can be expressed in the following particular form (10).
Corollary 3 (Dual Representation of the DR-Risk Function). Let , if and if , . Then the DR-risk function has the following dual representation:
| (10) |
2.6. Implementation
In this section, we introduce the implementation of DR-risk minimization based on the empirical data. We cast the learning problem as finding a decision function that induces an ITR based on its sign: . The ITR class can correspond to a prespecified decision function class . The DR-risk function as a functional of the decision function becomes . However, directly optimizing the risk is challenging, since the operation is nonconvex and nonsmooth. We consider a specific difference-of-convex (DC) relaxation of the sign operator.
We propose to relax the indicators in the dual form (10) by the following robust smoothed ramp loss (Zhou et al., 2017): . The DC representation is given by , where , . The advantages of using the symmetric nonconvex loss can be: 1) to protect from outliers in X and improve generalizability (Shen et al., 2003; Wu and Liu, 2007), and 2) to equally indicate and . We would like to point out that will be preserved to in this surrogate loss. Then we define the DR-ψ-risk function as
| (11) |
Algebraically, we can invert (11) to its primal representation by introducing a sign random variable with . That is, given the covariate X, the original deterministic sign is relaxed to the random sign with probability . In particular, if , then is a hard sign while is a soft sign with . When c = 1, the DR-risk function reduces to the risk function under the training distribution, and the DC relaxation here is equivalent to the relaxation in Zhou et al. (2017).
The DR-ψ-risk function provides the learning objective based on the empirical data. In particular, the population expectation is replaced by the empirical average , and the CTE function is replaced by a plug-in estimate . The corresponding empirical objective is minimized over the decision function f and the auxiliary variables (, ) jointly:
The objective function is a summation of multiple products of DC functions. For , we consider a block successive upper-bound minimization algorithm (Razaviyayn et al., 2013) to alternatively minimize the convex upper bounds over the decision function f and the auxiliary variables (, ) respectively. For , it requires a further probabilistic enhancement to break ties at argmin and ensure the convergence to stationarity (Qi et al., 2019a,b). The implementation details are given in the Supplementary Material.
3. Theoretical Properties
In this section, we justify the validity of the DC relaxation and the empirical substitution. First of all, we introduce the following joint stochastic objectives:
Here, can be the plug-in estimate or the underlying true CTE C. Denote , . Then by Corollary 3, we have , . In the following proposition, we show the validity of the DC re-laxation.
Proposition 4 (Fisher Consistency and Excess Risk). Suppose , , and are defined as above. Fix , , , , . Then the following results hold:
- (Fisher Consistency)
- (Excess Risk) Denote . Then for , we have
Denote . Then for , we have
Suppose is a functional class on with norm that characterizes the complexity of function. Motivated by Steinwart and Scovel (2007, (6)), we define for the constrained version of the approximation error
Similarly to that in Steinwart and Scovel (2007), with the appropriately chosen tuning parameter γ can trade off the learnability and the approximatability of towards the population Bayes rule . Specifically, as γ increases, the population approximation error (“bias”) decreases with γ, while the empirical complexity (“variance”) increases with γ. The trade-off will be stated more explicitly in the following Assumption 5.
Next, we make the following assumptions to show the regret bound for the empirical minimization of the ψ-risk . Without loss of generality, we restrict to consider the functional class as the Reproducing Kernel Hilbert Space (RKHS) with the Gaussian radial basis function kernels, where is the RKHS-norm. General results can be established by adopting the covering number argument as in Zhao et al. (2019a, Theorem 3.1).
Assumption 2 (Boundedness). There exists such that almost surely.
Assumption 3 (Diffuse Property). The distribution of has a uniformly bounded density with respect to the Lebesgue measure.
Assumption 4 (Convergence of the Plug-in CTE). For the CTE estimate , we assume that .
Assumption 5 (Approximation Error Rate). There exists and such that for all small enough , we have .
As a remark, we note that Assumption 2 can hold if the difference of potential outcomes is uniformly bounded, or is compact and is continuous. Assumption 3 holds if X has a diffuse distribution, i.e., X doesn’t contain points with positive mass; and is injective. Assumption 3 is the key assumption to bound λ away from 0. This assumption will not be necessary if and . Assumption 4 can be met if is compact and is a random forest estimate (Wager and Walther, 2015). Following Steinwart and Scovel (2007, Theorem 2.7), Assumption 5 can be shown valid if the Tsybakov’s noise assumption on the population margin is met and the kernel bandwidth parameter is chosen appropriately. In the following proposition, we establish the regret bound.
Proposition 5 (Regret Bound). Suppose , , and , are defined as above. Fix , , . Assume that Assumptions 2–5 hold. Let
with the tuning parameter satisfying as . Then there exists constants and such that for , with probability at least , we have
In particular, there exists , , , not depending on c, M, such that
In Proposition 5, it can be of theoretical interest to understand how the regret bound depends on the DR-constant c and the power order k. Specifically, as , η approaches to the essential supremum of (Krokhmal, 2007, Example 2.3). Then λ vanishes to 0 so that tends to . Since the Lipschitz constant of with respect to λ scales with , the universal constants K0 and K1 grow to as well.
Another important fact is that the conjugate number k* of k appears in the polynomial orders of c and M respectively in the universal constants K0 and K1. In particular, for a large conjugate order k*, the universal constants K0 and K1 increase with the DR-constant c and the CTE bound M more rapidly. In order to achieve a tighter finite sample regret bound, a smaller k* and hence a larger k is preferred. Such a phenomenon complements the fact that the power uncertainty set decreases in k. Specifically, as the power order k increases, its conjugate order k* decreases, and the regret bound in Proposition 5 becomes tighter. On the contrary, the power uncertainty set gets smaller, and the worst-case objective is less distributionally robust. Therefore, the power order k trades off between the distributional robustness in terms of the size of , and the finite sample regret bound.
4. Simulation Studies
In this section, we carry out two simulation studies to evaluate the generalizability of the DR-ITR on the testing distributions that are different from the training distribution. The first simulation considers the covariat shifts. The second simulation considers the mixture of subgroups.
4.1. Covariate Shifts
In this section, we extend the motivating example in Section 2.3 to a more practical simulation setting. Consider the training data generating process: n = 1,000, p =10, , and , where , .
At the training stage, we first obtain a CTE function estimate by fitting a casual forest (Wager and Athey, 2018) on the training data. Then we obtain the out-of-bag prediction at the training covariates . Next we fit the standard ITR by empirically minimizing as the ψ-relaxation of the empirical risk function , over the linear function class . The tuning parameter is determined by 10-fold cross-validation among {0.1, 0.5, 1, 2, 4}. Finally, we fit the DR-ITRs for and from the function class , where γ is the same as that of the standard ITR.
We consider the mean-shifted testing distribution for various covariate centroids µ’s. In order to calibrate the DR-constant c for every fixed µ, we generate a calibrating dataset of size from the testing distribution. The following two scenarios for the calibrating data are considered here: 1) a randomized controlled trial (RCT) dataset is generated, with and as before; and 2) only the covariate vector is generated. In Scenario 1, we use the IPWE of the calibrating value function to evaulate the DR-constant c, while in Scenario 2, we use the CTE-based calibrating value function instead. Here, the estimated CTE function is obtained from the training stage.
For comparison, we consider the following: 1) the LB-ITR that maximizes the value function under the testing distribution; 2) the -penalized least-square (-PLS) (Qian and Murphy, 2011) of on and the corresponding estimated ITR ; 3) the standard ITR; 4) the RCT-DR-ITR for the calibrating Scenario 1; and 5) the CTE-DR-ITR for the calibrating Scenario 2. We compare the testing values based on an independent testing dataset of size for every testing distribution. The testing values across different testing distributions are not comparable. For a specific testing distribution, the LB-ITR can be a benchmark to be compared to, since its testing value is the best achievable in theory among the linear ITR class. The training-calibrating-testing procedure is replicated for 500 times. The testing values (standard errors) for are reported in Table 2.
Table 2:
Testing Values (Standard Errors) on the Mean-Shifted Covariate Domains (ncalib = 50)
| µ2 ╲ µ1 | Type | 0 | 0.734 | 1.469 | 1.958 |
|---|---|---|---|---|---|
| 1.958 | LB-ITR | 2.333 (0.00244) | 2.907 (0.011) | 5.334 (0.0362) | 9.27 (0.0154) |
| ℓ1-PLS | 2.124 (0.0022) | 2.235 (0.011) | 3.613 (0.0505) | 6.32 (0.103) | |
| Standard ITR | 2.089 (0.00158) | 1.735 (0.013) | 1.348 (0.0595) | 1.567 (0.13) | |
| RCT-DR-ITR | 2.085 (0.00444) | 2.286 (0.0114) | 4.545 (0.0255) | 8.371 (0.0451) | |
| CTE-DR-ITR | 2.098 (0.00348) | 2.304 (0.0106) | 4.551 (0.0238) | 8.459 (0.0424) | |
| 1.469 | LB-ITR | 1.893 (0.00712) | 2.627 (0.00656) | 5.28 (0.0213) | 9.379 (0.0128) |
| ℓ1-PLS | 1.667 (0.00307) | 2.021 (0.0076) | 4.095 (0.0342) | 7.573 (0.0706) | |
| Standard ITR | 1.674 (0.00152) | 1.645 (0.0127) | 2.377 (0.0553) | 4.011 (0.119) | |
| RCT-DR-ITR | 1.627 (0.00688) | 1.987 (0.00997) | 4.484 (0.0192) | 8.611 (0.0285) | |
| CTE-DR-ITR | 1.663 (0.00326) | 1.997 (0.00992) | 4.55 (0.0163) | 8.686 (0.0269) | |
| 0.734 | LB-ITR | 1.227 (0.00244) | 2.144 (0.00609) | 5.269 (0.00931) | 9.608 (0.00898) |
| ℓ1-PLS | 1.094 (0.00418) | 1.676 (0.00442) | 4.587 (0.0151) | 8.8 (0.0314) | |
| Standard ITR | 1.174 (0.00149) | 1.553 (0.00806) | 3.739 (0.0379) | 7.06 (0.0763) | |
| RCT-DR-ITR | 1.094 (0.00753) | 1.651 (0.00675) | 4.622 (0.0109) | 9.036 (0.015) | |
| CTE-DR-ITR | 1.152 (0.00292) | 1.667 (0.00588) | 4.648 (0.0113) | 9.06 (0.0161) | |
| 0.000 | LB-ITR | 0.9942 (0.00202) | 1.774 (0.0034) | 5.232 (0.00559) | 9.767 (0.0068) |
| ℓ1-PLS | 0.8296 (0.00454) | 1.648 (0.0036) | 4.914 (0.00501) | 9.476 (0.0103) | |
| Standard ITR | 0.9437 (0.00153) | 1.679 (0.00336) | 4.654 (0.017) | 8.895 (0.0342) | |
| RCT-DR-ITR | 0.8374 (0.00821) | 1.647 (0.00574) | 4.868 (0.00797) | 9.444 (0.00841) | |
| CTE-DR-ITR | 0.9206 (0.00272) | 1.688 (0.00289) | 4.888 (0.00698) | 9.442 (0.00999) | |
with µ1 in column and µ2 in row is the testing covariate centroid.
Values (larger the better) can be comparable for the same but incomparable across different .
LB-ITR maximizes the testing value function at over the linear ITR class. The corresponding testing value is the best achievable among the linear ITR class.
When the testing distribution is the same as training , the calibration procedures for the DR-ITRs are expected to choose c = 1, which corresponds to the standard ITR. With the finite calibrating sample, some DR-constant c greater than 1 can be possibly chosen, leading to smaller testing values for the DR-ITRs in Table 2. In particular, the testing value of the CTE-DR-ITR is higher than that of the RCT-DR-ITR, and is closer to the testing value of the standard ITR in this case. The reason is that, the RCT-based calibrating value function estimate depends on in the calibrating data, while the CTE-based one depends on X only. As a consequence, the CTE-based calibration can be more accurate than the RCT-based one.
When , the testing distribution is different from training, and the performance of the standard ITR deteriorates while the DR-ITRs still maintain reasonably good performance. The phenomenon is more evident when . In particular at , the value of the standard ITR can be as low as 17% of the best achievable value among the linear ITR class, while the DR-ITRs can maintain more than 90%. In fact, such a phenomenon is general. In Figure 3a, we further enumerate the testing covariate centroid for and compute the relative regrets of the standard ITR and the RCT-DR-ITR. Across all mean-shifted testing distributions, the relative regrets of the standard ITRs can be as high as 108%, in which case the standard ITR value is negative, and hence even worse than the completely random treatment rule drand. On the contrary, the relative regrets for the RCT-DR-ITR (ncalib = 50) shown in Figure 3b are at most 24% across all testing centroids. This suggests that the RCT-DR-ITR maintains relatively good performance on all such testing distributions, while the standard ITR fails. Figure 4 further shows that the DR-ITR provides substantial testing value improvements over the standard ITR. This demonstrates that the small sample size ncalib = 50 is sufficient for calibrating the DR-ITR with significant testing improvement.
Figure 3:
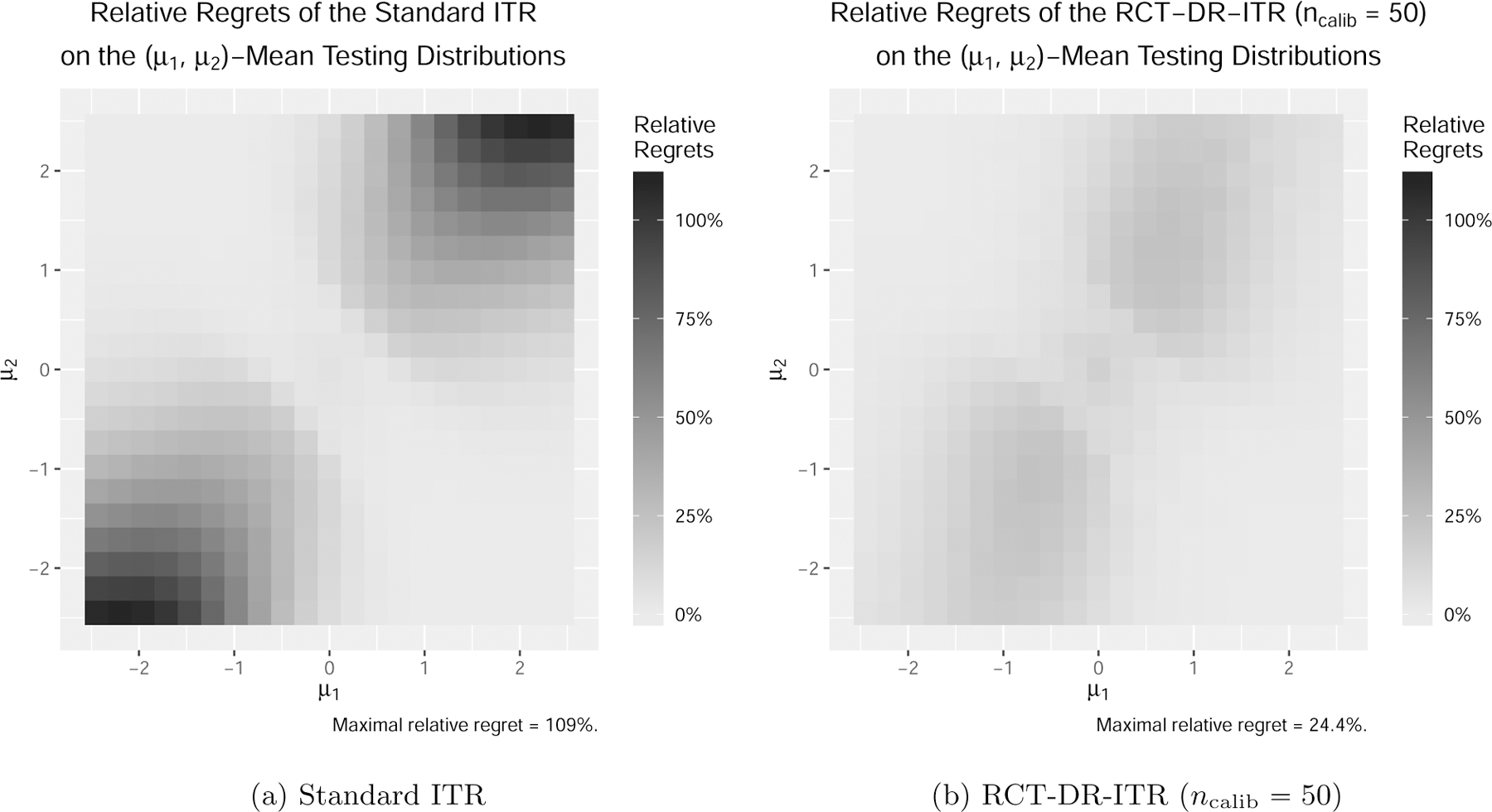
Relative Regrets on the Mean-Shifted Covariate Domains (lighter the better).
Figure 4:
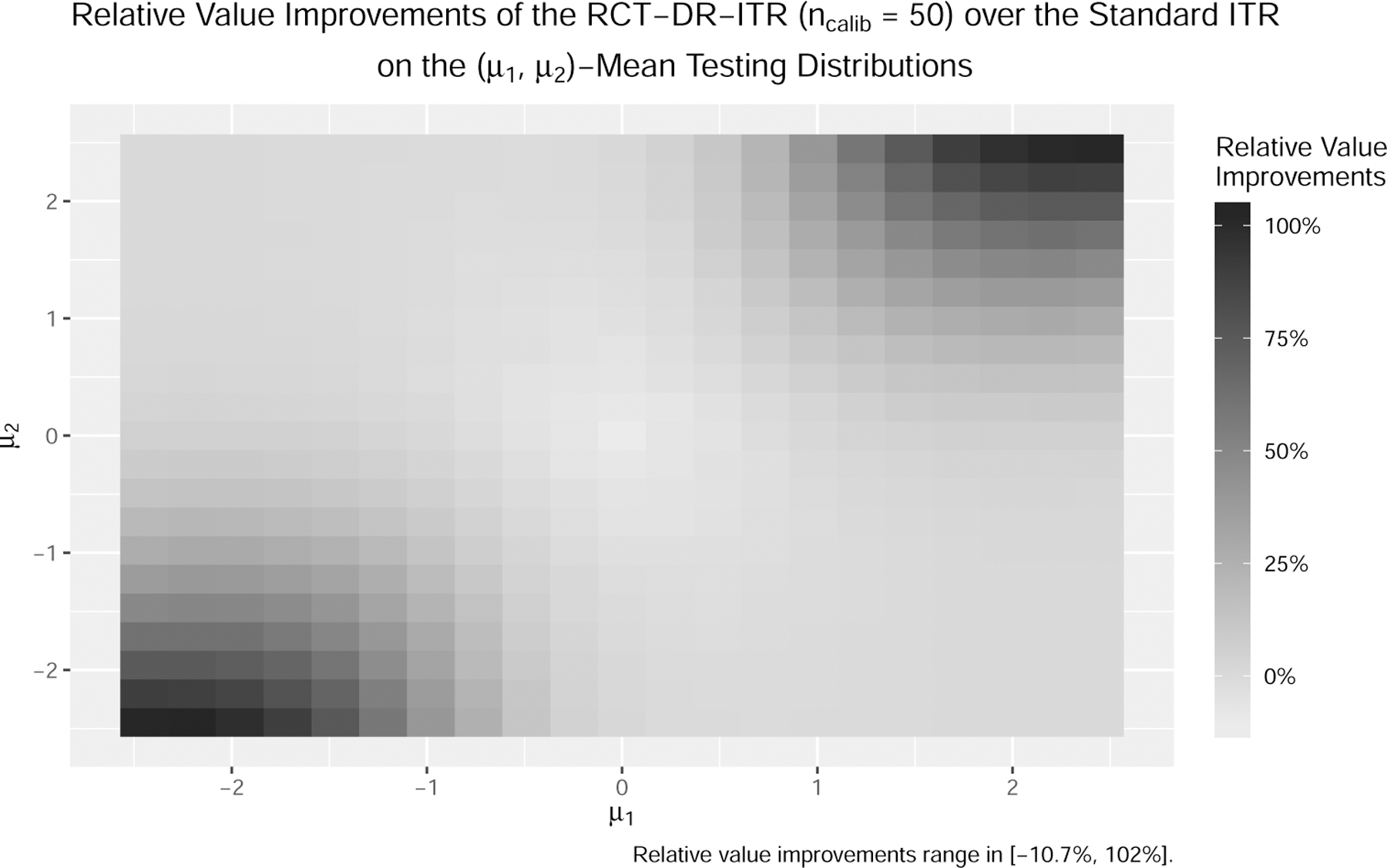
Relative improvements of the RCT-DR-ITR over the standard ITR as the difference of their relative regrets on the mean-shifted covariate domains (ncalib = 50, darker the better).
From Table 2, it can be also observed that -PLS can have better performance than the standard ITR when training and testing distributions are different. The reason is that, the objective of -PLS does not target the value function under the training distribution directly, but rather, the mean squared error of the linear approximation to under the training distribution. Such a linear approximation can perform well when the testing distribution is not far from the training distribution. However, in the case in the sense that the testing distribution deviates more from the training one, the DR-ITRs enjoy notably higher testing values than -PLS.
In the Supplementary Material, we provide more detailed results for other comparisons including the relative regrets/improvements on all mean-shifted covariate domains of all centroids, the misclassification rates on all mean-shifted covariate domains of all centroids, the comparison with some other methods in relative regrets and misclassification rates, and the case of . In particular, the misclassification rates inform similar conclusions as the relative regrets/improvements. If we increase the calibrating sample size from 50 to 100, then the testing values of DR-ITRs can be further improved. We also find that among our simulation scenarios, the testing values of the DR-ITR are not very sensitive to difference choices of k.
4.2. Performance on the Mixture of Subgroups
In this section, we consider a population that consists of two subgroups, with each following a distinct CTE function. We aim to find an ITR that can generalize well on different mixtures of subgroups.
We modify the simulation setup in Section 4.1 as follows: , where is the unobservable mixture/subgroup indicator with subgroup 1 probability pmix and subgroup 0 probability 1−pmix, and the subgroup means and . We consider the CTE function that is linear in the covariate vector, but with a subgroup-dependent intercept , and . The unconditional CTE function is nonlinear:
In particular, the unconditional CTE function depends on the subgroup 1 probability pmix. The distributional changes are due to the subgroup 1 probability. Specifically, the training subgroup 1 probability is 0.75, while the testing subgroup 1 probability varies in {0.1, 0.25, 0.5, 0.75, 0.9}. Since the training and testing CTE functions can be different, Assumption 1 cannot be fully met. Therefore, our proposed DR-ITR can be robust to such distributional changes only to some extent.
We consider the same training-calibrating-testing procedure as that in Section 4.1, except that the DR-constant c ranges in . The testing values of the ITRs are reported in Table 3. When the training and testing distributions are the same at , all ITRs have similar testing performance. The standard ITRs have higher testing values than the DR-ITRs in this case. When the testing pmix becomes smaller, the DR-ITRs show better testing performance than the standard ITR. When the testing pmix = 0.25 or 0.1, the RCT-DR-ITR has the highest testing values among all. Since the true testing CTE function changes along with the testing pmix, the corresponding estimate based on the training data can suffer from the generalizability problem. Therefore, the CTE-based calibration performs slightly worse than the RCT-based calibration in this case. However, the CTE-based DR-ITR is superior to the standard ITR, and is comparable to the -PLS. More detailed comparisons and the case ncalib = 100 are provided in the Supplementary Material.
Table 3:
Testing Values (Standard Errors) on the Mixture of Subgroups (ncalib = 50)
| Testing Subgroup 1 Probability |
|||||
|---|---|---|---|---|---|
| type | 0.1 | 0.25 | 0.5 | 0.75 | 0.9 |
| LB-ITR | 1.665 (0.0067) | 1.537 (0.00618) | 1.444 (0.00412) | 1.545 (0.00537) | 1.679 (0.00585) |
| ℓ1-PLS | 1.182 (0.00191) | 1.264 (0.0014) | 1.399 (0.000591) | 1.537 (0.000333) | 1.624 (0.000781) |
| Standard ITR | 1.143 (0.00434) | 1.232 (0.00329) | 1.383 (0.0015) | 1.535 (0.000543) | 1.632 (0.00142) |
| RCT-DR-ITR | 1.267 (0.0066) | 1.305 (0.00423) | 1.395 (0.00256) | 1.52 (0.00212) | 1.614 (0.00234) |
| CTE-DR-ITR | 1.16 (0.00409) | 1.247 (0.00323) | 1.388 (0.00137) | 1.534 (0.00055) | 1.628 (0.00149) |
Testing subgroup 1 probability = 0.75 is the same as the training one.
Values (larger the better) can be comparable for the same subgroup 1 probability but incomparable across different subgroup 1 probabilities
LB-ITR maximizes the testing value function over the linear ITR class. The corresponding testing value is the best achievable among the linear ITR class.
5. Application to the ACTG 175 Trial Data
In this section, we evaluate the generalizability of our proposed DR-ITR on a clinical trial dataset from the “AIDS clinical trial group study 175” (Hammer et al., 1996). The goal of this study was to compare four treatment arms among 2,139 randomly assigned subjects with human immunodeficiency virus type 1 (HIV-1), whose CD4 counts were 200–500 cells/mm3. The four treatments are the zidovudine (ZDV) monotherapy, the didanosine (ddI) monotherapy, the ZDV combined with ddI, and the ZDV combined with zalcitabine (ZAL).
The evidence found from the AIDS trial data can have some generalizability problems. When studying women living with HIV and women at risk for HIV infection in the USA cohort, the Women’s Interagency HIV Study (WIHS) (Bacon et al., 2005) has been considered to be representative. However, it was reported in Gandhi et al. (2005) that 28–68% of the HIV positive women in WIHS were excluded from the eligibility criteria of many ACTG studies. In the ACTG 175 dataset, the number of female patients is only 368 out of 2139. Thus we suspect that the female patients may be underrepresented in this dataset, and the ITR based on the dataset may not generalize well on the women subgroup. In this section, we study the generalizability of DR-ITR when the testing dataset consists of female patients only. Specifically, the training dataset is a subsample from ACTG 175 with original male/female proportion, while the testing dataset is a subsample from the female patients of ACTG 175, and there is no overlap across training and testing. We try to resemble the ideal world that we can have independent testing data from the female population.
We consider the outcome Y as the difference between the early stage (at 20±5 weeks from baseline) CD4 cell counts and the CD4 counts at baseline. We focus on the treatment comparison between the ZDV + ZAL (A = 1) and the ddI (A = −1), and the corresponding patients from the dataset. In particular, only 180 of them are women. The average treatment effects on the male and female subgroups are −8.97 and −1.39 respectively, which suggests that there is treatment effect discrepancy between these subgroups. We sample the training data from the ACTG 175 dataset in the ZDV + ZAL or ddI arm of sample size 1, 085 × 60% = 651 stratified to the gender. In particular, the training dataset includes 180 × 60% = 108 female patients. The remaining female data (180 − 108 = 72) are used for testing. We only consider female patients in testing. We further sample 50 from the testing female data for calibration, and the remaining (72 − 50 = 22) are the testing dataset. We also consider 12 selected baseline covariates X as was studied in Lu et al. (2013). There are 5 continuous covariates: age (year), weight (kg, coded as wtkg), CD4 count (cells/mm3) at baseline, Karnofsky score (scale of 0–100, coded as karnof), CD8 count (cells/mm3) at baseline. They are centered and scaled before further analysis. In addition, there are 7 binary variables: gender (1 = male, 0 = female), homosexual activity (homo, 1 = yes, 0 = no), race (1 = nonwhite, 0 = white), history of intravenous drug use (drug, 1 = yes, 0 = no), symptomatic status (symptom, 1 = symptomatic, 0 = asymptomatic), antiretroviral history (str2, 1 = experienced, 0 = naive) and hemophilia (hemo, 1 = yes, 0 = no).
Before fitting ITRs, we estimate the CTE function by the following regress-and-subtract procedure: first we fit two separate random forests by regressing Y on X restricted on A = 1 and A = −1 respectively; then we subtract two regression models to obtain the CTE function estimate . We follow the same implementation as in Section 4.1 to fit the standard ITR and DR-ITRs over a constrained linear function class on the training data. The testing performance is evaluated by the IPWE of the value function on the testing data. The training-calibrating-testing procedure is repeated for 1,500 times. The testing values are reported in Table 4, where the value can be interpreted as the expected CD4 count improvement from baseline at the early stage (20 ± 5 weeks). In addition to the calibrated DR-ITRs, we also include the value of the best DR-ITR that enjoys the highest testing performance among all DR-constants. For comparison, we include the results of residual weighted learning (RWL) (Zhou et al., 2017) with linear kernel. Both RWL and the standard ITR share similar implementation, except that RWL can be shown equivalently using as a plug-in CTE estimate.
Table 4:
Expected CD4 Count Improvement (cells/mm3) from Baseline at the Early Stage (20±5 weeks) and Standard Errors on the ACTG-175 Female Patients (higher the better).
| RWL | Standard ITR | Best DR-ITR | RCT-DR-ITR | CTE-DR-ITR |
|---|---|---|---|---|
| 10.7617 (0.8636) | 10.593 (0.8627) | 13.9423 (0.8378) | 11.8133 (0.8357) | 11.1563 (0.8514) |
Standard errors are computed based on 1,500 replications.
The testing results show that our proposed DR-ITRs can have better values than the standard ITR and RWL. In particular, the improvement of the best DR-ITR is substantial, while the improvements of the calibrated ITRs are not as strong. We plot the testing values of the DR-ITRs against the corresponding DR-constants in Figure 5. It suggests that the testing values generally increase with the DR-constant. In this analysis, the calibrated DR-constants are not close to the optimal DR-constant. As a result, the testing performance of the calibrated DR-ITRs is not as good as the best DR-ITR. One reason for this phenomenon can be that the outcome Y has a heavy tail distribution, as was highlighted in Qi et al. (2019b), so that the value function estimate is highly variable based on the small calibrating sample. Another reason can be that the random forest regress-and-subtract estimate of the CTE function does not generalize well on the testing distribution.
Figure 5:
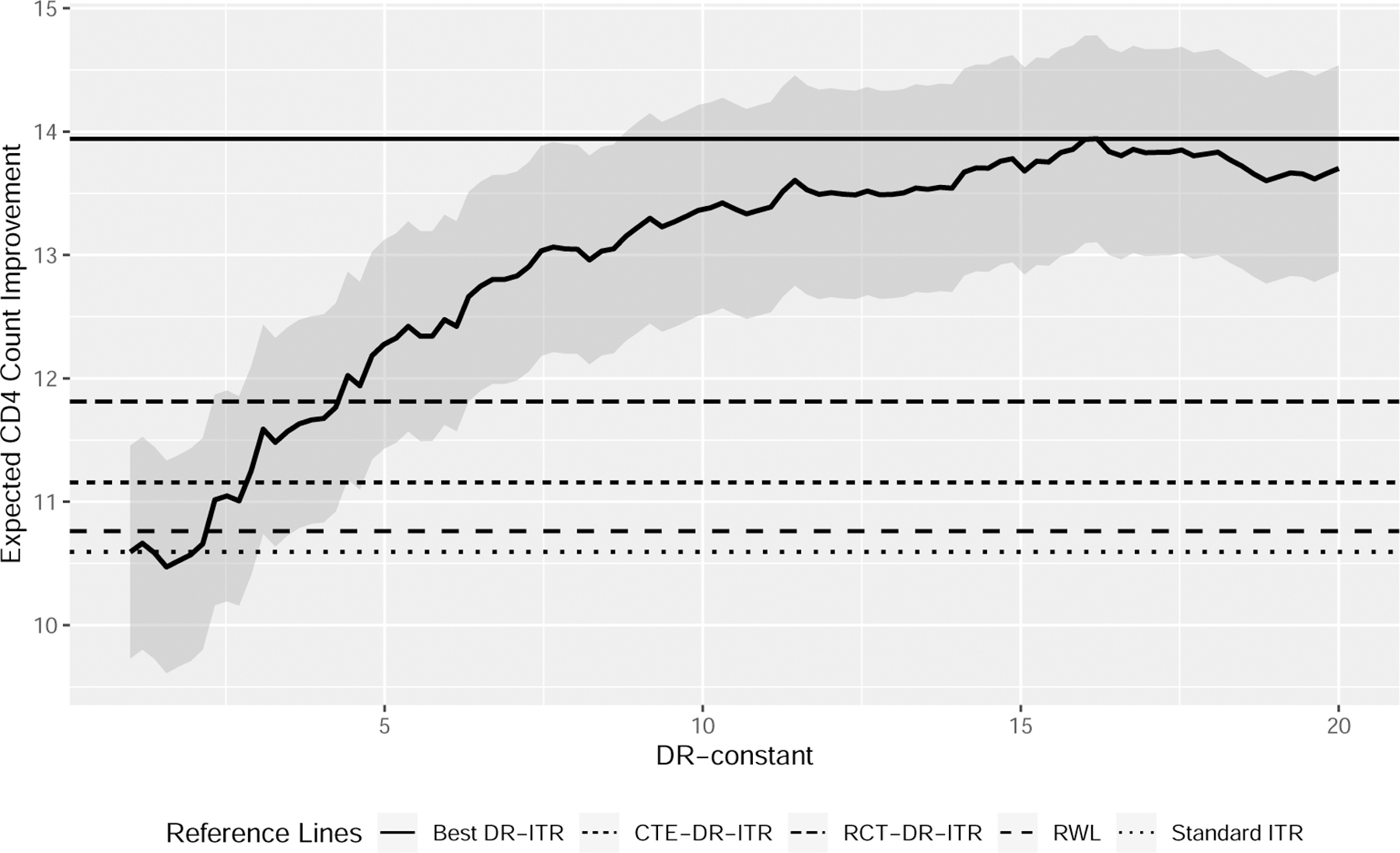
Expected CD4 Count Improvement (cells/mm3) from Baseline at the Early Stage (20±5 weeks) of the DR-ITRs of Various DR-Constants on the ACTG 175 Female Patients (higher the better)
On the overall dataset, we fit the DR-ITRs and report their fitted coefficients in Table 5 for selected DR-constants. To stabilize the randomness from the random forest estimate of the CTE function, we refit the random forest 20 times and average the corresponding DR-ITR coefficients. We find that there are noticeable changes in the coefficients of the intercept and the homosexual activity when the DR-constant gets large. Within the ACTG 175 dataset (ZDV + ZAL or ddI), we find that only 6 female patients have homosexual activity. Four of them are treated with ZDV + ZAL, and the change of their CD4 counts are 123, 34, −11 and 158 respectively. Two of them are treated with ddI, and the change of their CD4 counts are −41, −182. Therefore, the ZDV + ZAL (A = −1) may have more benefits compared to the ddI (A = −1) on these patients. This helps to explain why the larger coefficients in homosexual activity for the larger DR-constants can be beneficial for the female patients.
Table 5:
Linear Coefficients of the DR-ITRs Fitted on the ACTG 175 Dataset
| DR-constant | Intercept | age | wtkg | cd40 | karnof | cd80 | gender | homo | race | drugs | symptom | str2 | hemo |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | −0.02 | −0.25 | 0.06 | −0.58 | −0.06 | 0.53 | −0.16 | −0.4 | 0.16 | 0.16 | 0.16 | 0.16 | 0.09 |
| 4.8 | −0.31 | −0.23 | 0.12 | −0.67 | 0.11 | 0.55 | −0.12 | −0.21 | 0.2 | 0.12 | 0.1 | −0.06 | 0.09 |
| 8.6 | −0.43 | −0.23 | 0.11 | −0.64 | 0.16 | 0.54 | −0.11 | −0.05 | 0.12 | 0.04 | 0.07 | −0.24 | 0.01 |
| 12.4 | −0.54 | −0.22 | 0.1 | −0.64 | 0.19 | 0.51 | −0.04 | 0.01 | 0.08 | 0.05 | 0.04 | −0.27 | −0.02 |
| 16.2 | −0.61 | −0.23 | 0.1 | −0.64 | 0.2 | 0.51 | 0 | 0.03 | 0.06 | 0.05 | 0.02 | −0.27 | −0.02 |
| 20 | −0.64 | −0.24 | 0.09 | −0.63 | 0.22 | 0.5 | 0.01 | 0.03 | 0.05 | 0.07 | 0.01 | −0.26 | −0.01 |
DR-constant = 1 corresponds to the standard ITR; DR-constant = 16.2 has the highest testing value in Figure 5.
6. Discussion
In this paper, we propose a new framework for learning a distributionally robust ITR by maximizing the worst-case value function among values under distributions within the power uncertainty set. We introduce two possible calibration scenarios under which the DR-constant can be tuned adaptively to a small amount of the calibrating data from the target population. In this way, when the training and testing distributions are identical, the calibrated DR-ITRs can achieve similar performance as compared to the standard ITR. When the testing distribution deviates from the training distribution, we show that there are many possible scenarios that the standard ITR generalizes poorly, while the calibrated DR-ITRs maintain relatively good testing performance. Our simulation studies and an application to the ACTG 175 dataset demonstrate the competitive generalizability of our proposed DR-ITR.
The main assumption on the changes of covariates in our DR-ITR framework is equivalent to the selection unconfoundedness assumption in a randomized controlled trial. In practice, there may exist unmeasured selection confounding problems for the trial data, and the distributional changes affect both the covariates and the CTE function. One possible extension is to consider the simultaneous changes of the covariate distribution and the CTE function, and leverage more general robustness measure against these changes.
In our DR-ITR framework, we require an estimate of the CTE function based on the flexible nonparametric techniques. The performance of our DR-ITR can depend on the quality of the CTE function estimate. An alternative strategy is to avoid plugging in a CTE estimate. Instead, the dual representation (10) can be identified from directly using a variational representation of (Duchi et al., 2019). This can be a possible extension of our framework.
Another possible extension is to consider the problem of high-dimensional covariates. Our current formulation involves an -constraint to control the model complexity. It can be extended to obtain sparse solutions when a -constraint is used instead. Besides the high-dimensional extension, our current theoretical results assume that is uniformly bounded. It will be interesting to relax the assumption, such as sub-Gaussianity. Further investigations along these lines can be pursued.
Supplementary Material
Acknowledgments
The authors would like to thank the editor, the associate editor, and reviewers, whose helpful comments and suggestions led to a much improved presentation.
Funding
The authors were supported in part by NSF grants IIS-1632951, DMS-1821231, and NIH grants R01GM126550 and P01 CA-142538.
Contributor Information
Weibin Mo, Department of Statistics and Operations Research, University of North Carolina at Chapel Hill, Chapel Hill, NC 27599.
Zhengling Qi, Department of Decision Sciences, George Washington University, Washington, D.C. 20052, USA.
Yufeng Liu, Department of Statistics and Operations Research, Department of Genetics, Department of Biostatistics, Carolina Center for Genome Science, Lineberger Comprehensive Cancer Center, University of North Carolina at Chapel Hill, NC 27599, USA.
References
- Aggarwal CC (2016), Recommender systems, Springer. [Google Scholar]
- Alyass A, Turcotte M, and Meyre D (2015), “From big data analysis to personalized medicine for all: challenges and opportunities,” BMC Medical Genomics, 8, 33. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Athey S and Wager S (2017), “Efficient policy learning,” arXiv preprint arXiv:1702.02896.
- Bacon MC, Von Wyl V, Alden C, Sharp G, Robison E, Hessol N, Gange S, Barranday Y, Holman S, and Weber K (2005), “The Women’s Interagency HIV Study: an observational cohort brings clinical sciences to the bench,” Clin. Diagn. Lab. Immunol, 12, 1013–1019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ben-Tal A, Den Hertog D, De Waegenaere A, Melenberg B, and Rennen G (2013), “Robust solutions of optimization problems affected by uncertain probabilities,” Management Science, 59, 341–357. [Google Scholar]
- Bertsimas D, Kallus N, Weinstein AM, and Zhuo YD (2017), “Personalized diabetes management using electronic medical records,” Diabetes Care, 40, 210–217. [DOI] [PubMed] [Google Scholar]
- Buchanan AL, Hudgens MG, Cole SR, Mollan KR, Sax PE, Daar ES, Adimora AA, Eron JJ, and Mugavero MJ (2018), “Generalizing evidence from randomized trials using inverse probability of sampling weights,” Journal of the Royal Statistical Society: Series A (Statistics in Society), 181, 1193–1209. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen S, Tian L, Cai T, and Yu M (2017), “A general statistical framework for subgroup identification and comparative treatment scoring,” Biometrics, 73, 1199–1209. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cressie N and Read TR (1984), “Multinomial goodness-of-fit tests,” Journal of the Royal Statistical Society: Series B (Methodological), 46, 440–464. [Google Scholar]
- Duchi JC, Hashimoto T, and Namkoong H (2019), “Distributionally robust losses against mixture covariate shifts,” Under Review.
- Duchi JC and Namkoong H (2018), “Learning Models with Uniform Performance via Distributionally Robust Optimization,” arXiv preprint arXiv:1810.08750.
- Dudík M, Langford J, and Li L (2011), “Doubly Robust Policy Evaluation and Learning,” in Proceedings of the 28th International Conference on International Conference on Machine Learning, Madison, WI, USA: Omnipress, ICML’11, p. 1097–1104. [Google Scholar]
- Gandhi M, Ameli N, Bacchetti P, Sharp GB, French AL, Young M, Gange SJ, Anastos K, Holman S, and Levine A (2005), “Eligibility criteria for HIV clinical trials and generalizability of results: the gap between published reports and study protocols,” Aids, 19, 1885–1896. [DOI] [PubMed] [Google Scholar]
- Gatsonis C and Morton SC (2017), Methods in Comparative Effectiveness Research, CRC Press. [Google Scholar]
- Hammer SM, Katzenstein DA, Hughes MD, Gundacker H, Schooley RT, Haubrich RH, Henry WK, Lederman MM, Phair JP, and Niu M (1996), “A trial comparing nucleoside monotherapy with combination therapy in HIV-infected adults with CD4 cell counts from 200 to 500 per cubic millimeter,” New England Journal of Medicine, 335, 1081–1090. [DOI] [PubMed] [Google Scholar]
- Hand DJ (2006), “Classifier Technology and the Illusion of Progress,” Statistical Science, 21, 1–14.17906740 [Google Scholar]
- Hill JL (2011), “Bayesian nonparametric modeling for causal inference,” Journal of Computational and Graphical Statistics, 20, 217–240. [Google Scholar]
- Hotz VJ, Imbens GW, and Mortimer JH (2005), “Predicting the efficacy of future training programs using past experiences at other locations,” Journal of Econometrics, 125, 241–270. [Google Scholar]
- Imai K and Ratkovic M (2013), “Estimating treatment effect heterogeneity in randomized program evaluation,” The Annals of Applied Statistics, 7, 443–470. [Google Scholar]
- Johansson FD, Kallus N, Shalit U, and Sontag D (2018), “Learning weighted representations for generalization across designs,” arXiv preprint arXiv:1802.08598.
- Kitagawa T and Tetenov A (2018), “Who should be treated? empirical welfare maximization methods for treatment choice,” Econometrica, 86, 591–616. [Google Scholar]
- Krokhmal PA (2007), “Higher moment coherent risk measures,” Quantitative Finance, 7, 373–387. [Google Scholar]
- Kube A, Das S, and Fowler PJ (2019), “Allocating interventions based on predicted outcomes: A case study on homelessness services,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 622–629. [Google Scholar]
- Li S, Cai TT, and Li H (2020), “Transfer Learning for High-dimensional Linear Regression: Prediction, Estimation, and Minimax Optimality,” arXiv preprint arXiv:2006.10593. [DOI] [PMC free article] [PubMed]
- Liu Y, Wang Y, Kosorok MR, Zhao Y, and Zeng D (2018), “Augmented outcome-weighted learning for estimating optimal dynamic treatment regimens,” Statistics in Medicine, 37, 3776–3788. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lu W, Zhang HH, and Zeng D (2013), “Variable selection for optimal treatment decision,” Statistical Methods in Medical Research, 22, 493–504. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Luo J, Schumacher M, Scherer A, Sanoudou D, Megherbi D, Davison T, Shi T, Tong W, Shi L, and Hong H (2010), “A comparison of batch effect removal methods for enhancement of prediction performance using MAQC-II microarray gene expression data,” The Pharmacogenomics Journal, 10, 278–291. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Manski CF (2004), “Statistical treatment rules for heterogeneous populations,” Econometrica, 72, 1221–1246. [Google Scholar]
- Muller S (2014), “Randomised trials for policy: a review of the external validity of treatment effects,” A Southern Africa Labour and Development Research Unit Working Paper Number 127. [Google Scholar]
- O’Muircheartaigh C and Hedges LV (2014), “Generalizing from unrepresentative experiments: a stratified propensity score approach,” Journal of the Royal Statistical Society: Series C: Applied Statistics, 195–210.
- Pardo L (2005), Statistical inference based on divergence measures, Chapman and Hall/CRC. [Google Scholar]
- Pearl J and Bareinboim E (2014), “External validity: From do-calculus to transportability across populations,” Statistical Science, 579–595.
- Qi Z, Cui Y, Liu Y, and Pang J-S (2019a), “Estimation of Individualized Decision Rules Based on an Optimized Covariate-Dependent Equivalent of Random Outcomes,” SIAM Journal on Optimization, 29, 2337–2362. [Google Scholar]
- Qi Z, Liu D, Fu H, and Liu Y (2020), “Multi-Armed Angle-Based Direct Learning for Estimating Optimal Individualized Treatment Rules With Various Outcomes,” Journal of the American Statistical Association, 115, 678–691. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Qi Z, Pang J-S, and Liu Y (2019b), “Estimating Individualized Decision Rules with Tail Controls,” arXiv preprint arXiv:1903.04367.
- Qian M and Murphy SA (2011), “Performance guarantees for individualized treatment rules,” Annals of Statistics, 39, 1180–1210. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rahimian H and Mehrotra S (2019), “Distributionally robust optimization: A review,” arXiv preprint arXiv:1908.05659.
- Razaviyayn M, Hong M, and Luo Z-Q (2013), “A unified convergence analysis of block successive minimization methods for nonsmooth optimization,” SIAM Journal on Optimization, 23, 1126–1153. [Google Scholar]
- Rockafellar RT and Uryasev S (2000), “Optimization of conditional value-at-risk,” Journal of Risk, 2, 21–42. [Google Scholar]
- Rubin DB (1974), “Estimating causal effects of treatments in randomized and nonrandomized studies,” Journal of Educational Psychology, 66, 688–701. [Google Scholar]
- Shen X, Tseng GC, Zhang X, and Wong WH (2003), “On ψ-learning,” Journal of the American Statistical Association, 98, 724–734. [Google Scholar]
- Shi C, Song R, Lu W, and Fu B (2018), “Maximin projection learning for optimal treatment decision with heterogeneous individualized treatment effects,” Journal of the Royal Statistical Society. Series B, Statistical methodology, 80, 681. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Steinwart I and Scovel C (2007), “Fast rates for support vector machines using Gaussian kernels,” The Annals of Statistics, 35, 575–607. [Google Scholar]
- Stuart EA, Cole SR, Bradshaw CP, and Leaf PJ (2011), “The use of propensity scores to assess the generalizability of results from randomized trials,” Journal of the Royal Statistical Society: Series A (Statistics in Society), 174, 369–386. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wager S and Athey S (2018), “Estimation and inference of heterogeneous treatment effects using random forests,” Journal of the American Statistical Association, 113, 1228–1242. [Google Scholar]
- Wager S and Walther G (2015), “Adaptive concentration of regression trees, with application to random forests,” arXiv preprint arXiv:1503.06388.
- Wu Y and Liu Y (2007), “Robust truncated hinge loss support vector machines,” Journal of the American Statistical Association, 102, 974–983. [Google Scholar]
- Zhang B, Tsiatis AA, Davidian M, Zhang M, and Laber E (2012a), “Estimating optimal treatment regimes from a classification perspective,” Stat, 1, 103–114. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang B, Tsiatis AA, Laber EB, and Davidian M (2012b), “A robust method for estimating optimal treatment regimes,” Biometrics, 68, 1010–1018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang C, Chen J, Fu H, He X, Zhao Y, and Liu Y (2019), “Multicategory outcome weighted margin-based learning for estimating individualized treatment rules,” Statistica Sinica. [DOI] [PMC free article] [PubMed]
- Zhao Q, Small DS, and Ertefaie A (2017), “Selective inference for effect modification via the lasso,” arXiv preprint arXiv:1705.08020. [DOI] [PMC free article] [PubMed]
- Zhao Y, Zeng D, Rush AJ, and Kosorok MR (2012), “Estimating individualized treatment rules using outcome weighted learning,” Journal of the American Statistical Association, 107, 1106–1118. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhao Y-Q, Laber EB, Ning Y, Saha S, and Sands BE (2019a), “Efficient augmentation and relaxation learning for individualized treatment rules using observational data.” Journal of Machine Learning Research, 20, 1–23. [PMC free article] [PubMed] [Google Scholar]
- Zhao Y-Q, Zeng D, Tangen CM, and Leblanc ML (2019b), “Robustifying trial-derived optimal treatment rules for a target population,” Electronic Journal of Statistics, 13, 1717–1743. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhou X, Mayer-Hamblett N, Khan U, and Kosorok MR (2017), “Residual weighted learning for estimating individualized treatment rules,” Journal of the American Statistical Association, 112, 169–187. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.