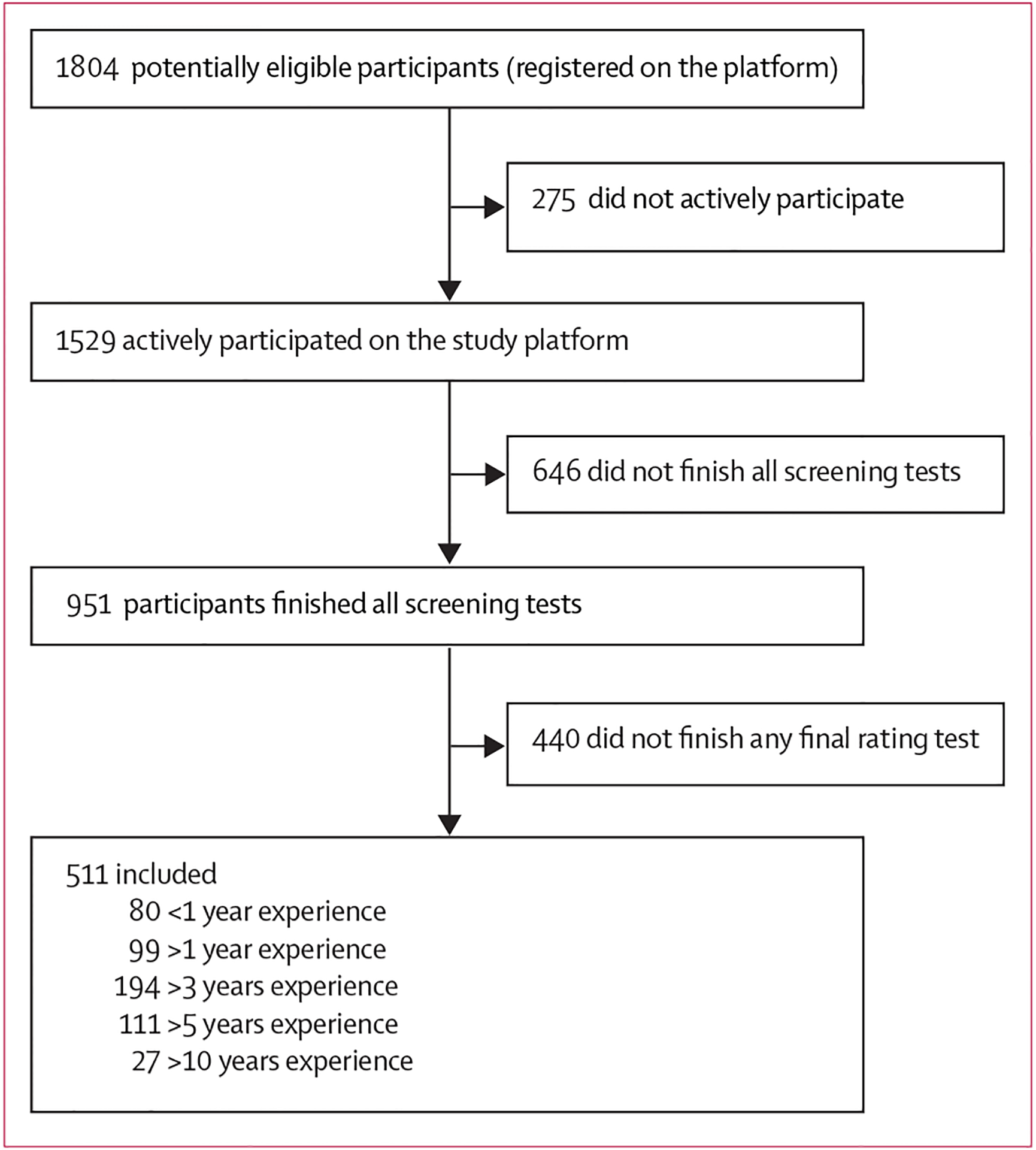
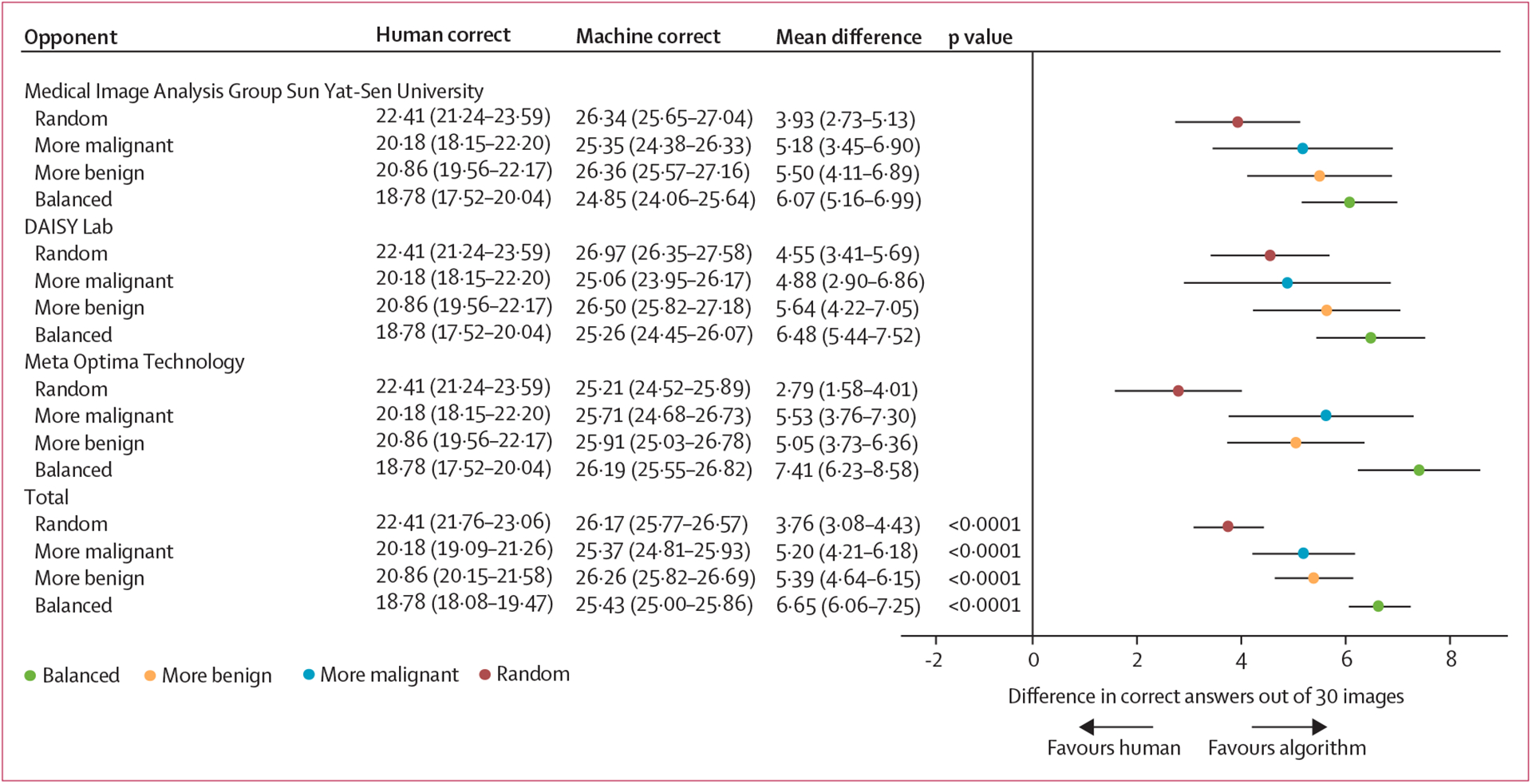
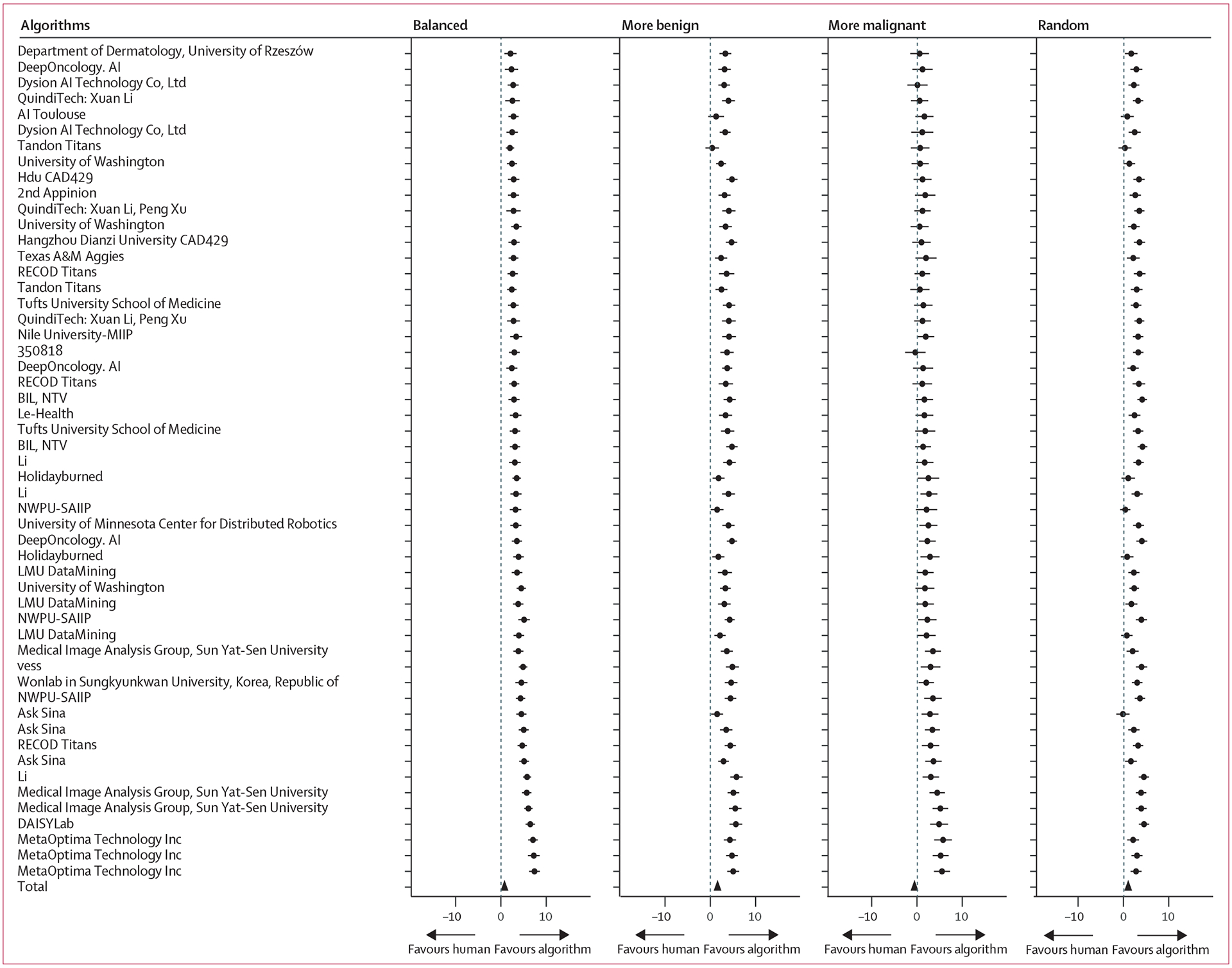
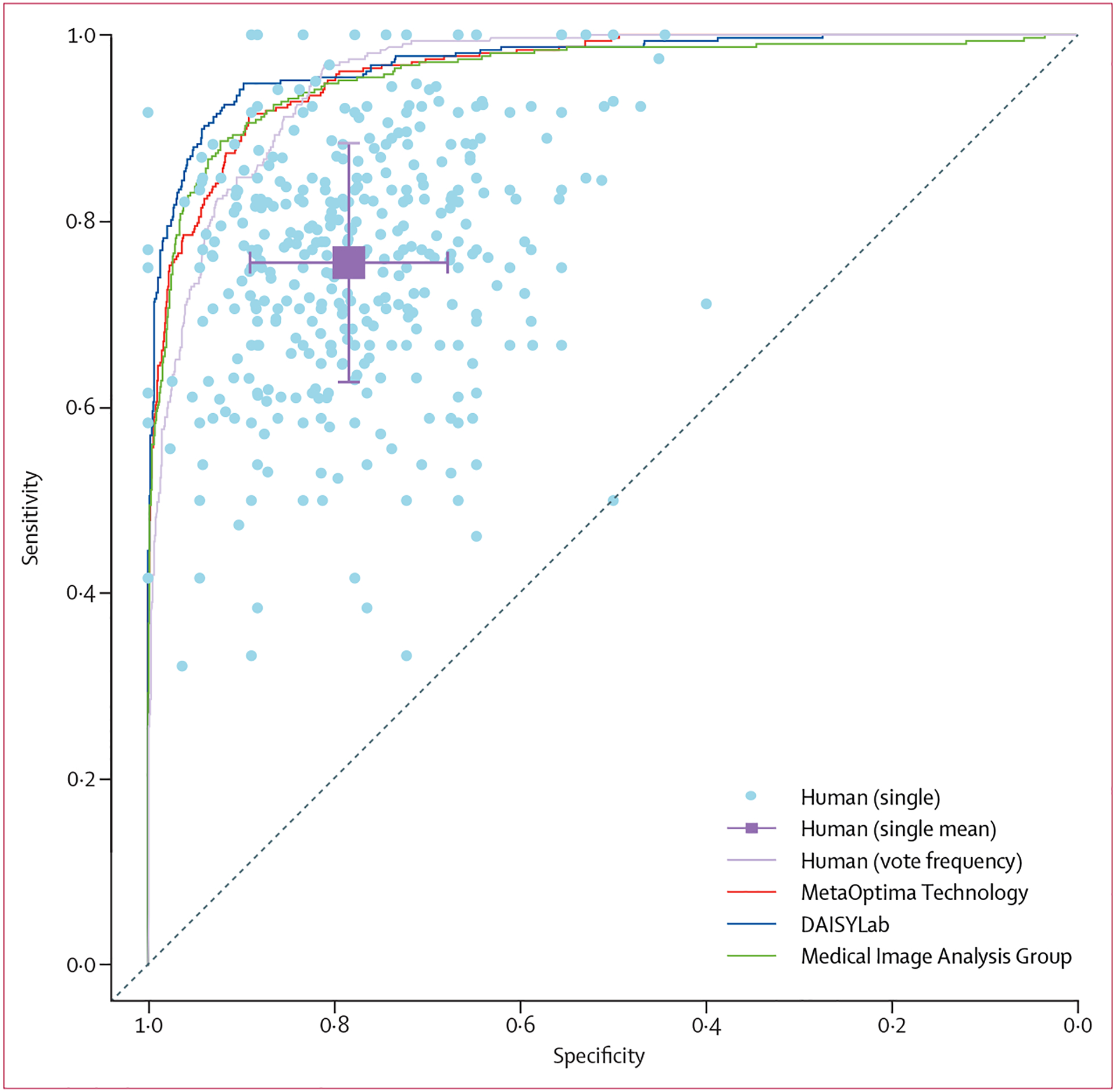
Philipp Tschandl
Philipp Tschandl
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Noel Codella
Noel Codella
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Bengü Nisa Akay
Bengü Nisa Akay
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Giuseppe Argenziano
Giuseppe Argenziano
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Ralph P Braun
Ralph P Braun
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Horacio Cabo
Horacio Cabo
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
David Gutman
David Gutman
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Allan Halpern
Allan Halpern
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Brian Helba
Brian Helba
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Rainer Hofmann-Wellenhof
Rainer Hofmann-Wellenhof
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Aimilios Lallas
Aimilios Lallas
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Jan Lapins
Jan Lapins
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Caterina Longo
Caterina Longo
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Josep Malvehy
Josep Malvehy
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Michael A Marchetti
Michael A Marchetti
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Ashfaq Marghoob
Ashfaq Marghoob
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Scott Menzies
Scott Menzies
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Amanda Oakley
Amanda Oakley
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
John Paoli
John Paoli
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Susana Puig
Susana Puig
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Christoph Rinner
Christoph Rinner
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Cliff Rosendahl
Cliff Rosendahl
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Alon Scope
Alon Scope
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Christoph Sinz
Christoph Sinz
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
H Peter Soyer
H Peter Soyer
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Luc Thomas
Luc Thomas
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Iris Zalaudek
Iris Zalaudek
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1,
Harald Kittler
Harald Kittler
1ViDIR Group, Department of Dermatology (P Tschandl PhD, C Sinz MD, H Kittler MD) and Center for Medical Statistics, Informatics and Intelligent Systems (CeMSIIS) (C Rinner PhD), Medical University of Vienna, Vienna, Austria; IBM Research AI, T J Watson Research Center, Yorktown Heights, NY, USA (N Codella PhD); Department of Dermatology, Medicine Faculty, Ankara University, Ankara, Turkey (B N Akay MD); Dermatology Unit, University of Campania, Naples, Italy (Prof G Argenziano PhD); Skin Cancer Center, Department of Dermatology, University Hospital Zürich, Zürich, Switzerland (R P Braun MD); Department of Dermatology, Instituto de Investigaciones Médicas, Buenos Aires, Argentina (Prof H Cabo MD); Department of Neurology, Emory University School of Medicine, Atlanta, GA, USA (D Gutman PhD); Dermatology Service, Department of Medicine, Memorial Sloan Kettering Cancer Center, New York, NY, USA (Prof A Halpern MD, M A Marchetti MD); Kitware, Clifton Park, NY, USA (B Helba BS); Department of Dermatology, Medical University Graz, Graz, Austria (R Hofmann-Wellenhof MD); First Department of Dermatology, Aristotle University, Thessaloniki, Greece (A Lallas PhD); Department of Dermatology, Karolinska University Hospital and Karolinska Institutet, Stockholm, Sweden (J Lapins MD); Department of Dermatology, University of Modena and Reggio Emilia, Modena, Italy (C Longo PhD); Azienda Unità Sanitaria Locale—IRCCS di Reggio Emilia, Centro Oncologico ad Alta Tecnologia Diagnostica-Dermatologia, Reggio Emilia, Italy (C Longo); Melanoma Unit, Dermatology Department, Hospital Clínic Barcelona, Universitat de Barcelona, IDIBAPS, Barcelona, Spain (J Malvehy MD, S Puig MD); Centro de Investigación Biomédica en Red de Enfermedades Rarasd (CIBER ER), Instituto de Salud Carlos III, Barcelona, Spain (J Malvehy, S Puig); Memorial Sloan Kettering Cancer Center, Hauppauge, NY, USA (A Marghoob MD); Sydney Melanoma Diagnostic Centre & Sydney Medical School, Faculty of Medicine and Health, The University of Sydney, Sydney, NSW, Australia (Prof S Menzies MD); Department of Dermatology, Waikato District Health Board and Waikato Clinical Campus, University of Auckland, Hamilton, New Zealand (A Oakley MBChB); Department of Dermatology and Venereology, Institute of Clinical Sciences, Sahlgrenska Academy, University of Gothenburg, Gothenburg, Sweden (J Paoli MD); School of Clinical Medicine, University of Queensland (C Rosendahl PhD) and Dermatology Research Centre, The University of Queensland Diamantina Institute (Prof H P Soyer MD), University of Queensland, Brisbane, QLD, Australia; Medical Screening Institute, Sheba Medical Center and Sackler Faculty of Medicine, Tel Aviv University, Tel Aviv, Israel (A Scope MD); Department of Dermatology, Hospitalier Lyon Sud, Lyon, France (Prof L Thomas PhD); Lyon Cancer Research Center INSERM U1052—CNRS UMR5286, Lyon, France (Prof L Thomas); Lyon 1 University, Lyon, France (Prof L Thomas); and Dermatology Clinic, Maggiore Hospital, University of Trieste, Trieste, Italy (I Zalaudek MD)
1