

Abstract
Deep neural networks achieve stellar generalisation even when they have enough parameters to easily fit all their training data. We study this phenomenon by analysing the dynamics and the performance of over-parameterised two-layer neural networks in the teacher–student setup, where one network, the student, is trained on data generated by another network, called the teacher. We show how the dynamics of stochastic gradient descent (SGD) is captured by a set of differential equations and prove that this description is asymptotically exact in the limit of large inputs. Using this framework, we calculate the final generalisation error of student networks that have more parameters than their teachers. We find that the final generalisation error of the student increases with network size when training only the first layer, but stays constant or even decreases with size when training both layers. We show that these different behaviours have their root in the different solutions SGD finds for different activation functions. Our results indicate that achieving good generalisation in neural networks goes beyond the properties of SGD alone and depends on the interplay of at least the algorithm, the model architecture, and the data set.
Keywords: machine learning
Deep neural networks behind state-of-the-art results in image classification and other domains have one thing in common: their size. In many applications, the free parameters of these models outnumber the samples in their training set by up to two orders of magnitude [1, 2]. Statistical learning theory suggests that such heavily over-parameterised networks generalise poorly without further regularisation [3–9], yet empirical studies consistently find that increasing the size of networks to the point where they can easily fit their training data and beyond does not impede their ability to generalise well, even without any explicit regularisation [10–12]. Resolving this paradox is arguably one of the big challenges in the theory of deep learning.
One tentative explanation for the success of large networks has focussed on the properties of stochastic gradient descent (SGD), the algorithm routinely used to train these networks. In particular, it has been proposed that SGD has an implicit regularisation mechanism that ensures that solutions found by SGD generalise well irrespective of the number of parameters involved, for models as diverse as (over-parameterised) neural networks [10, 13], logistic regression [14] and matrix factorisation models [15, 16].
In this paper, we analyse the dynamics of one-pass (or online) SGD in two-layer neural networks. We focus in particular on the influence of over-parameterisation on the final generalisation error. We use the teacher–student framework [17, 18], where a training data set is generated by feeding random inputs through a two-layer neural network with M hidden units called the teacher. Another neural network, the student, is then trained using SGD on that data set. The generalisation error is defined as the mean squared error between teacher and student outputs, averaged over all of input space. We will focus on student networks that have a larger number of hidden units K ⩾ M than their teacher. This means that the student can express much more complex functions than the teacher function they have to learn; the students are thus over-parameterised with respect to the generative model of the training data in a way that is simple to quantify. We find this definition of over-parameterisation cleaner in our setting than the oft-used comparison of the number of parameters in the model with the number of samples in the training set, which is not well justified for non-linear functions. Furthermore, these two numbers surely cannot fully capture the complexity of the function learned in practical applications.
The teacher–student framework is also interesting in the wake of the need to understand the effectiveness of neural networks and the limitations of the classical approaches to generalisation [11]. Traditional approaches to learning and generalisation are data agnostic and seek worst-case type bounds [19]. On the other hand, there has been a considerable body of theoretical work calculating the generalisation ability of neural networks for data arising from a probabilistic model, particularly within the framework of statistical mechanics [17, 18, 20–22]. Revisiting and extending the results that have emerged from this perspective is currently experiencing a surge of interest [23–28].
In this work we consider two-layer networks with a large input layer and a finite, but arbitrary, number of hidden neurons. Other limits of two-layer neural networks have received a lot of attention recently. A series of papers [29–32] studied the mean-field limit of two-layer networks, where the number of neurons in the hidden layer is very large, and proved various general properties of SGD based on a description in terms of a limiting partial differential equation. Another set of works, operating in a different limit, have shown that infinitely wide over-parameterised neural networks trained with gradient-based methods effectively solve a kernel regression [33–38], without any feature learning. Both the mean-field and the kernel regime crucially rely on having an infinite number of nodes in the hidden layer, and the performance of the networks strongly depends on the detailed scaling used [38, 39]. Furthermore, a very wide hidden layer makes it hard to have a student that is larger than the teacher in a quantifiable way. This leads us to consider the opposite limit of large input dimension and finite number of hidden units.
Our main contributions are as follows:
-
(a)
The dynamics of SGD (online) learning by two-layer neural networks in the teacher–student setup was studied in a series of classic papers [40–44] from the statistical physics community, leading to a heuristic derivation of a set of coupled ordinary differential equations (ODE) that describe the typical time-evolution of the generalisation error. We provide a rigorous foundation of the ODE approach to analysing the generalisation dynamics in the limit of large input size by proving their correctness.
-
(b)
These works focussed on training only the first layer, mainly in the case where the teacher network has the same number of hidden units and the student network, K = M. We generalise their analysis to the case where the student’s expressivity is considerably larger than that of the teacher in order to investigate the over-parameterised regime K > M.
-
(c)
We provide a detailed analysis of the dynamics of learning and of the generalisation when only the first layer is trained. We derive a reduced set of coupled ODE that describes the generalisation dynamics for any K ⩾ M and obtain analytical expressions for the asymptotic generalisation error of networks with linear and sigmoidal activation functions. Crucially, we find that with all other parameters equal, the final generalisation error increases with the size of the student network. In this case, SGD alone thus does not seem to be enough to regularise larger student networks.
-
(d)
We finally analyse the dynamics when learning both layers. We give an analytical expression for the final generalisation error of sigmoidal networks and find evidence that suggests that SGD finds solutions which amount to performing an effective model average, thus improving the generalisation error upon over-parameterisation. In linear and ReLU networks, we experimentally find that the generalisation error does change as a function of K when training both layers. However, there exist student networks with better performance that are fixed points of the SGD dynamics, but are not reached when starting SGD from initial conditions with small, random weights.
Crucially, we find this range of different behaviours while keeping the training algorithm (SGD) the same, changing only the activation functions of the networks and the parts of the network that are trained. Our results clearly indicate that the implicit regularisation of neural networks in our setting goes beyond the properties of SGD alone. Instead, a full understanding of the generalisation properties of even very simple neural networks requires taking into account the interplay of at least the algorithm, the network architecture, and the data set used for training, setting up a formidable research programme for the future.
Reproducibility—We have packaged the implementation of our experiments and our ODE integrator into a user-friendly library with example programs at https://github.com/sgoldt/nn2pp. All plots were generated with these programs, and we give the necessary parameter values beneath each plot.
1. Online learning in teacher–student neural networks
We consider a supervised regression problem with training set with μ = 1, …, P. The components of the inputs are i.i.d. draws from the standard normal distribution . The scalar labels y μ are given by the output of a network with M hidden units, a non-linear activation function and fixed weights with an additive output noise , called the teacher (see also figure 1(a)):
where is the mth row of w*, and the local field of the mth teacher node is . We will analyse three different network types: sigmoidal with , ReLU with g(x) = max(x, 0), and linear networks where g(x) = x.
Figure 1.

The analytical description of the generalisation dynamics of sigmoidal networks matches experiments. (a) We consider two-layer neural networks with a very large input layer. (b) We plot the learning dynamics ϵ g(α) obtained by integration of the ODEs (9) (solid) and from a single run of SGD (2) (crosses) for students with different numbers of hidden units K. The insets show the values of the teacher–student overlaps R in (5) for a student with K = 4 at the two times indicated by the arrows. N = 784, M = 4, η = 0.2.
A second two-layer network with K hidden units and weights , called the student, is then trained using SGD on the quadratic training loss . We emphasise that the student network may have a larger number of hidden units K ⩾ M than the teacher and thus be over-parameterised with respect to the generative model of its training data.
The SGD algorithm defines a Markov process with update rule given by the coupled SGD recursion relations
We can choose different learning rates η v and η w for the two layers and denote by the derivative of the activation function evaluated at the local field of the student’s kth hidden unit , and we defined the error term . We will use the indices i, j, k, … to refer to student nodes, and n, m, … to denote teacher nodes. We take initial weights at random from for sigmoidal networks, while initial weights have variance for ReLU and linear networks.
The key quantity in our approach is the generalisation error of the student with respect to the teacher:
where the angled brackets ⟨⋅⟩ denote an average over the input distribution. We can make progress by realising that ϵ g(θ*, θ) can be expressed as a function of a set of macroscopic variables, called order parameters in statistical physics [21, 40, 41],
together with the second-layer weights v* and v μ. Intuitively, the teacher–student overlaps measure the similarity between the weights of the ith student node and the nth teacher node. The matrix Q ik quantifies the overlap of the weights of different student nodes with each other, and the corresponding overlap of the teacher nodes are collected in the matrix T nm. We will find it convenient to collect all order parameters in a single vector
and we write the full expression for ϵ g(m μ) in equation (S31) (see the online supplementary material, available at (https://stacks.iop.org/JSTAT/12/124010/mmedia)).
In a series of classic papers, Biehl, Schwarze, Saad, Solla and Riegler [40–44] derived a closed set of ODE for the time evolution of the order parameters m (see SM section B). Together with the expression for the generalisation error ϵ g(m μ), these equations give a complete description of the generalisation dynamics of the student, which they analysed for the special case K = M when only the first layer is trained [42, 44]. Our first contribution is to provide a rigorous foundation for these results under the following assumptions:
-
(A1)
Both the sequences x μ and ζ μ, μ = 1, 2, …, are i.i.d. random variables; x μ is drawn from a normal distribution with mean 0 and covariance matrix , while ζ μ is a Gaussian random variable with mean zero and unity variance;
-
(A2)
The function g(x) is bounded and its derivatives up to and including the second order exist and are bounded, too;
-
(A3)
The initial macroscopic state m 0 is deterministic and bounded by a constant;
-
(A4)
The constants σ, K, M, η w and η v are all finite.
The correctness of the ODE description is then established by the following theorem:
Theorem 1
Choose T > 0 and define α ≡ μ/N. Under assumptions (A1)–(A4), and for any α > 0, the macroscopic state m μ satisfies
where C(T) is a constant depending on T, but not on N, and m(α) is the unique solution of the ODE
with initial condition m*. In particular, we have
where all f(m(α)) are uniformly Lipschitz continuous in m(α). We are able to close the equations because we can express averages in equation (9) in terms of only m(α).
We prove theorem 1 using the theory of convergence of stochastic processes and a coupling trick introduced recently by Wang et al [45] in section A of the SM. The content of the theorem is illustrated in figure 1(b), where we plot ϵ g(α) obtained by numerically integrating (9) (solid) and from a single run of SGD (2) (crosses) for sigmoidal students and varying K, which are in very good agreement.
Given a set of non-linear, coupled ODE such as equation (9), finding the asymptotic fixed points analytically to compute the generalisation error would seem to be impossible. In the following, we will therefore focus on analysing the asymptotic fixed points found by numerically integrating the equations of motion. The form of these fixed points will reveal a drastically different dependence of the test error on the over-parameterisation of neural networks with different activation functions in the different setups we consider, despite them all being trained by SGD. This highlights the fact that good generalisation goes beyond the properties of just the algorithm. Second, knowledge of these fixed points allows us to make analytical and quantitative predictions for the asymptotic performance of the networks which agree well with experiments. We also note that several recent theorems [29–31] about the global convergence of SGD do not apply in our setting because we have a finite number of hidden units.
2. Asymptotic generalisation error of soft committee machines
We will first study networks where the second layer weights are fixed at . These networks are called a soft committee machine (SCM) in the statistical physics literature [18, 27, 40–42, 44]. One notable feature of ϵ g(α) in SCMs is the existence of a long plateau with sub-optimal generalisation error during training. During this period, all student nodes have roughly the same overlap with all the teacher nodes, R in = const. (left inset in figure 1(b)). As training continues, the student nodes ‘specialise’ and each of them becomes strongly correlated with a single teacher node (right inset), leading to a sharp decrease in ϵ g. This effect is well-known for both batch and online learning [18] and will be key for our analysis.
Let us now use the equations of motion (9) to analyse the asymptotic generalisation error of neural networks after training has converged and in particular its scaling with L = K − M. Our first contribution is to reduce the remaining K(K + M) equations of motion to a set of eight coupled differential equations for any combination of K and M in section C. This enables us to obtain a closed-form expression for as follows.
In the absence of output noise (σ = 0), the generalisation error of a student with K ⩾ M will asymptotically tend to zero as α → ∞. On the level of the order parameters, this corresponds to reaching a stable fixed point of (9) with ϵ g = 0. In the presence of small output noise σ > 0, this fixed point becomes unstable and the order parameters instead converge to another, nearby fixed point m* with ϵ g(m*) > 0. The values of the order parameters at that fixed point can be obtained by perturbing equation (9) to first order in σ, and the corresponding generalisation error ϵ g(m*) turns out to be in excellent agreement with the generalisation error obtained when training a neural network using (2) from random initial conditions, which we show in figure 2(a).
Figure 2.

The asymptotic generalisation error of SCMs increases with the network size. N = 784, η = 0.05, σ = 0.01. (a) Our theoretical prediction for for sigmoidal (solid) and linear (dashed), equations (10) and (12), agree perfectly with the result obtained from a single run of SGD (2) starting from random initial weights (crosses). (b) The final overlap matrices Q and R (5) at the end of an experiment with M = 2, K = 5. Networks with sigmoidal activation function (top) show clear signs of specialisation as described in section 2. ReLU networks (bottom) instead converge to solutions where all of the student’s nodes have finite overlap with teacher nodes.
Sigmoidal networks
We have performed this calculation for teacher and student networks with . We relegate the details to section C.2, and content us here to state the asymptotic value of the generalisation error to first order in σ 2,
where f(M, L, η) is a lengthy rational function of its variables. We plot our result in figure 2(a) together with the final generalisation error obtained in a single run of SGD (2) for a neural network with initial weights drawn i.i.d. from and find excellent agreement, which we confirmed for a range of values for η, σ, and L.
One notable feature of figure 2(a) is that with all else being equal, SGD alone fails to regularise the student networks of increasing size in our setup, instead yielding students whose generalisation error increases linearly with L. One might be tempted to mitigate this effect by simultaneously decreasing the learning rate η for larger students. However, lowering the learning rate incurs longer training times, which requires more data for online learning. This trade-off is also found in statistical learning theory, where models with more parameters (higher L) and thus a higher complexity class (e.g. VC dimension or Rademacher complexity [4]) generalise just as well as smaller ones when given more data. In practice, however, more data might not be readily available, and we show in figure S2 of the SM that even when choosing η = 1/K, the generalisation error still increases with L before plateauing at a constant value.
We can gain some intuition for the scaling of by considering the asymptotic overlap matrices Q and R shown in the left half of figure 2(b). In the over-parameterised case, L = K − M student nodes are effectively trying to specialise to teacher nodes which do not exist, or equivalently, have weights zero. These L student nodes do not carry any information about the teachers output, but they pick up fluctuations from output noise and thus increase . This intuition is borne out by an expansion of in the limit of small learning rate η, which yields
which is indeed the sum of the error of M independent hidden units that are specialised to a single teacher hidden unit, and L = K − M superfluous units contributing each the error of a hidden unit that is ‘learning’ from a hidden unit with zero weights (see also section D of the SM).
Linear networks
Two possible explanations for the scaling in sigmoidal networks may be the specialisation of the hidden units or the fact that teacher and student network can implement functions of different range if K ≠ M. To test these hypotheses, we calculated for linear neural networks [46, 47] with g(x) = x. Linear networks lack a specialisation transition [27] and their output range is set by the magnitude of their weights, rather than their number of hidden units. Following the same steps as before, a perturbative calculation in the limit of small noise variance σ 2 yields
This result is again in perfect agreement with experiments, as we demonstrate in figure 2(a). In the limit of small learning rates η, equation (10) simplifies to yield the same scaling as for sigmoidal networks,
This shows that the scaling is not just a consequence of either specialisation or the mismatched range of the networks’ output functions. The optimal number of hidden units for linear networks is K = 1 for all M, because linear networks implement an effective linear transformation with an effective matrix W = ∑k w k. Adding hidden units to a linear network hence does not augment the class of functions it can implement, but it adds redundant parameters which pick up fluctuations from the teacher’s output noise, increasing ϵ g.
ReLU networks
The analytical calculation of , described above, for ReLU networks poses some additional technical challenges, so we resort to experiments to investigate this case. We found that the asymptotic generalisation error of a ReLU student learning from a ReLU teacher has the same scaling as the one we found analytically for networks with sigmoidal and linear activation functions: (see figure S3). Looking at the final overlap matrices Q and R for ReLU networks in the bottom half of figure 2(b), we see that instead of the one-to-one specialisation of sigmoidal networks, all student nodes have a finite overlap with some teacher node. This is a consequence of the fact that it is much simpler to re-express the sum of M ReLU units with K ≠ M ReLU units. However, there are still a lot of redundant degrees of freedom in the student, which all pick up fluctuations from the teacher’s output noise and increase .
Discussion
The key result of this section has been that the generalisation error of SCMs scales as
Before moving on the full two-layer network, we discuss a number of experiments that we performed to check the robustness of this result (details can be found in section G of the SM). A standard regularisation method is adding weight decay to the SGD updates (2). However, we did not find a scenario in our experiments where weight decay improved the performance of a student with L > 0. We also made sure that our results persist when performing SGD with mini-batches. We investigated the impact of higher-order correlations in the inputs by replacing Gaussian inputs with MNIST images, with all other aspects of our setup the same, and the same ϵ g–L curve as for Gaussian inputs. Finally, we analysed the impact of having a finite training set. The behaviour of linear networks and of non-linear networks with large but finite training sets did not change qualitatively. However, as we reduce the size of the training set, we found that the lowest asymptotic generalisation error was obtained with networks that have K > M.
3. Training both layers: asymptotic generalisation error of a neural network
We now study the performance of two-layer neural networks when both layers are trained according to the SGD updates (2) and (3). We set all the teacher weights equal to a constant value, , to ensure comparability between experiments. However, we train all K second-layer weights of the student independently and do not rely on the fact that all second-layer teacher weights have the same value. Note that learning the second layer is not needed from the point of view of statistical learning: the networks from the previous section are already expressive enough to capture the students, and we are thus slightly increasing the over-parameterisation even further. Yet, we will see that the generalisation properties will be significantly enhanced.
Sigmoidal networks
We plot the generalisation dynamics of students with increasing K trained on a teacher with M = 2 in figure 3(a). Our first observation is that increasing the student size K ⩾ M decreases the asymptotic generalisation error , with all other parameters being equal, in stark contrast to the SCMs of the previous section.
Figure 3.

The performance of sigmoidal networks improves with network size when training both layers with SGD. (a) Generalisation dynamics observed experimentally for students with increasing K, with all other parameters being equal. (N = 500, M = 2, η = 0.05, σ = 0.01, v* = 4). (b) Overlap matrices Q, R, and second layer weights v k of the student at the end of the run with K = 5 shown in (a). (c) Theoretical prediction for (solid) against observed after integration of the ODE until convergence (crosses) (9) (σ = 0.01, η = 0.2, v* = 2).
A look at the order parameters after convergence in the experiments from figure 3(a) reveals the intriguing pattern of specialisation of the student’s hidden units behind this behaviour, shown for K = 5 in figure 3(b). First, note that all the hidden units of the student have non-negligible weights (Q ii > 0). Two student nodes (k = 1, 2) have specialised to the first teacher node, i.e. their weights are very close to the weights of the first teacher node (R 10 ≈ R 20 ≈ 0.85). The corresponding second-layer weights approximately fulfill v 1 + v 3 ≈ v*. Summing the output of these two student hidden units is thus approximately equivalent to an empirical average of two estimates of the output of the teacher node. The remaining three student nodes all specialised to the second teacher node, and their outgoing weights approximately sum to v*. This pattern suggests that SGD has found a set of weights for both layers where the student’s output is a weighted average of several estimates of the output of the teacher’s nodes. We call this the denoising solution and note that it resembles the solutions found in the mean-field limit of an infinite hidden layer [29, 31] where the neurons become redundant and follow a distribution dynamics (in our case, a simple one with few peaks, as e.g. figure 1 in [31]).
We confirmed this intuition by using an ansatz for the order parameters that corresponds to a denoising solution to solve the equations of motion (9) perturbatively in the limit of small noise to calculate for sigmoidal networks after training both layers, similarly to the approach in section 2. While this approach can be extended to any K and M, we focussed on the case where K = ZM to obtain manageable expressions; see section E of the SM for details on the derivation. While the final expression is again too long to be given here, we plot it with solid lines in figure 3(c). The crosses in the same plot are the asymptotic generalisation error obtained by integration of the ODE (9) starting from random initial conditions, and show very good agreement.
While our result holds for any M, we note from figure 3(c) that the curves for different M are qualitatively similar. We find a particular simple result for M = 1 in the limit of small learning rates, where:
This result should be contrasted with the ϵ g ∼ K behaviour found for SCM.
Experimentally, we robustly observed that training both layers of the network yields better performance than training only the first layer with the second layer weights fixed to v*. However, convergence to the denoising solution can be difficult for large students which might get stuck on a long plateau where their nodes are not evenly distributed among the teacher nodes. While it is easy to check that such a network has a higher value of ϵ g than the denoising solution, the difference is small, and hence the driving force that pushes the student out of the corresponding plateaus is small, too. These observations demonstrate that in our setup, SGD does not always find the solution with the lowest generalisation error in finite time.
ReLU and linear networks
We found experimentally that remains constant with increasing K in ReLU and in linear networks when training both layers. We plot a typical learning curve in green for linear networks in figure 4, but note that the figure shows qualitatively similar features for ReLU networks (figure S4). This behaviour was also observed in linear networks trained by batch gradient descent, starting from small initial weights [48]. While this scaling of with K is an improvement over its increase with K for the SCM, (blue curve), this is not the 1/K decay that we observed for sigmoidal networks. A possible explanation is the lack of specialisation in linear and ReLU networks (see section 2), without which the denoising solution found in sigmoidal networks is not possible. We also considered normalised SCM, where we train only the first layer and fix the second-layer weights at and v k = 1/K. The asymptotic error of normalised SCM decreases with K (orange curve in figure 4), because the second-layer weights v k = 1/K effectively reduce the learning rate, as can be easily seen from the SGD updates (2), and we know from our analysis of linear SCM in section 2 that ϵ g ∼ η. In SM section F we show analytically how imbalance in the norms of the first and second layer weights can lead to a larger effective learning rate. Normalised SCM also beat the performance students where we trained both layers, starting from small initial weights in both cases. This is surprising because we checked experimentally that the weights of a normalised SCM after training are a fixed point of the SGD dynamics when training both layers. However, we confirmed experimentally that SGD does not find this fixed point when starting with random initial weights.
Figure 4.
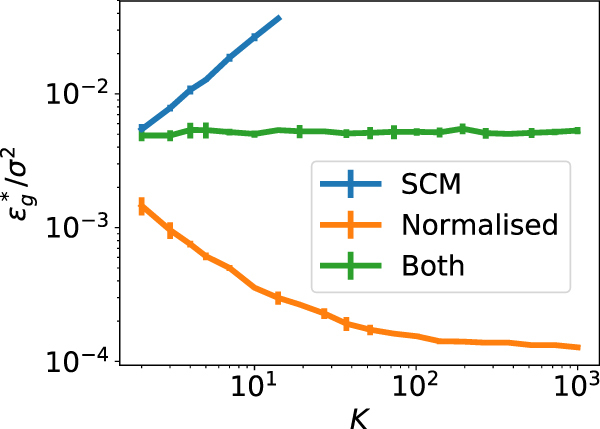
Asymptotic performance of linear two layer network. Error bars indicate one standard deviation over five runs. Parameters: N = 100, M = 4, v* = 1, η = 0.01, σ = 0.01.
Discussion
The qualitative difference between training both or only the first layer of neural networks is particularly striking for linear networks, where fixing one layer does not change the class of functions the model can implement, but makes a dramatic difference for their asymptotic performance. This observation highlights two important points: first, the performance of a network is not just determined by the number of additional parameters, but also by how the additional parameters are arranged in the model. Second, the non-linear dynamics of SGD means that changing which weights are trainable can alter the training dynamics in unexpected ways. We saw this for two-layer linear networks, where SGD did not find the optimal fixed point, and in the non-linear sigmoidal networks, where training the second layer allowed the student to decrease its final error with every additional hidden unit instead of increasing it like in the SCM.
Acknowledgments
S G and L Z acknowledge funding from the ERC under the European Union’s Horizon 2020 Research and Innovation Programme Grant Agreement 714608-SMiLe. M A thanks the Swartz Programme in Theoretical Neuroscience at Harvard University for support. A S acknowledges funding by the European Research Council, Grant 725937 NEUROABSTRACTION. F K acknowledges support from ‘Chaire de recherche sur les modèles et sciences des données’, Fondation CFM pour la Recherche-ENS, and from the French National Research Agency (ANR) grant PAIL.
Footnotes
This article is an updated version of: Goldt S, Advani M S, Saxe A M, Krzakala F and Zdeborova L 2019 Dynamics of stochastic gradient descent for two-layer neural networks in the teacher-student setup Advances in Neural Information Processing Systems pp 6981–91.
References
- 1.LeCun Y, Bengio Y, Hinton G. Deep learning. Nature. 2015;521:436–44. doi: 10.1038/nature14539. [DOI] [PubMed] [Google Scholar]
- 2.Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. Int. Conf. on Learning Representations.2015. [Google Scholar]
- 3.Bartlett P L, Mendelson S. Rademacher and Gaussian complexities: risk bounds and structural results. J. Mach. Learn. Res. 2003;3:463–82. [Google Scholar]
- 4.Mohri M, Rostamizadeh A, Talwalkar A. Foundations of Machine Learning. Cambridge, MA: MIT Press; 2012. [Google Scholar]
- 5.Neyshabur B, Tomioka R, Srebro N. Norm-based capacity control neural networks. Conf. on Learning Theory.2015. [Google Scholar]
- 6.Golowich N, Rakhlin A, Shamir O. Size-independent sample complexity of neural networks. Proc. 31st Conf. on Learning Theory. 2018:297–9. [Google Scholar]
- 7.Dziugaite G, Roy D. Computing nonvacuous generalization bounds for deep (stochastic) neural networks with many more parameters than training data. Proc. 33rd Conf. on Uncertainty in Artificial Intelligence.2017. [Google Scholar]
- 8.Arora S, Ge R, Neyshabur B, Zhang Y. Stronger generalization bounds for deep nets via a compression approach. 35th Int. Conf. on Machine Learning, ICML 2018; 2018. pp. pp 390–418. [Google Scholar]
- 9.Allen-Zhu Z, Li Y, Liang Y. Learning and generalization in overparameterized neural networks, going beyond two layers. 2018 (arXiv: 1811.04918)
- 10.Neyshabur B, Tomioka R, Srebro N. In search of the real inductive bias: on the role of implicit regularization in deep learning. ICLR.2015. [Google Scholar]
- 11.Zhang C, Bengio S, Hardt M, Recht B, Vinyals O. Understanding deep learning requires rethinking generalization. ICLR.2017. [Google Scholar]
- 12.Arpit D, et al. A closer look at memorization in deep networks. Proc. 34th Int. Conf. on Machine Learning.2017. [Google Scholar]
- 13.Chaudhari P, Soatto S. On the inductive bias of stochastic gradient descent. Int. Conf. on Learning Representations.2018. [Google Scholar]
- 14.Soudry D, Hofer E, Srebro N. The implicit bias of gradient descent on separable data. Int. Conf. on Learning Representations.2018. [Google Scholar]
- 15.Gunasekar S, Woodworth B, Bhojanapalli S, Neyshabur B, Srebro N. Implicit regularization in matrix factorization. Advances in Neural Information Processing Systems; 2017. pp. pp 6151–9. [Google Scholar]
- 16.Li Y, Ma T, Zhang H. Algorithmic regularization in over-parameterized matrix sensing and neural networks with quadratic activations. Conf. on Learning Theory; 2018. pp. pp 2–47. [Google Scholar]
- 17.Seung H S, Sompolinsky H, Tishby N. Statistical mechanics of learning from examples. Phys. Rev. A. 1992;45:6056–91. doi: 10.1103/physreva.45.6056. [DOI] [PubMed] [Google Scholar]
- 18.Engel A, Van den Broeck C. Statistical Mechanics of Learning. Cambridge: Cambridge University Press; 2001. [Google Scholar]
- 19.Vapnik V. Statistical Learning Theory. New York: Springer: 1998. pp. pp 156–60. [Google Scholar]
- 20.Gardner E, Derrida B. Three unfinished works on the optimal storage capacity of networks. J. Phys. A: Math. Gen. 1989;22:1983–94. doi: 10.1088/0305-4470/22/12/004. [DOI] [Google Scholar]
- 21.Kinzel W, Ruján P, Rujan P. Improving a network generalization ability by selecting examples. Europhys. Lett. 1990;13:473–7. doi: 10.1209/0295-5075/13/5/016. [DOI] [Google Scholar]
- 22.Watkin T L H, Rau A, Biehl M. The statistical mechanics of learning a rule. Rev. Mod. Phys. 1993;65:499–556. doi: 10.1103/revmodphys.65.499. [DOI] [Google Scholar]
- 23.Zdeborová L, Krzakala F. Statistical physics of inference: thresholds and algorithms. Adv. Phys. 2016;65:453–552. doi: 10.1080/00018732.2016.1211393. [DOI] [Google Scholar]
- 24.Advani M, Ganguli S. Statistical mechanics of optimal convex inference in high dimensions. Phys. Rev. X. 2016;6:1–16. doi: 10.1103/physrevx.6.031034. [DOI] [Google Scholar]
- 25.Chaudhari P, et al. Entropy-SGD: biasing gradient descent into wide valleys. ICLR.2017. [Google Scholar]
- 26.Advani M, Saxe A. High-dimensional dynamics of generalization error in neural networks. 2017 doi: 10.1016/j.neunet.2020.08.022. (arXiv: 1710.03667) [DOI] [PMC free article] [PubMed]
- 27.Aubin B, et al. The committee machine: computational to statistical gaps in learning a two-layers neural network. Advances in Neural Information Processing Systems; 2018. pp. pp 3227–38. [Google Scholar]
- 28.Baity-Jesi M, et al. Comparing dynamics: deep neural networks versus glassy systems. Proc. of the 35th Int. Conf. on Machine Learning.2018. [Google Scholar]
- 29.Mei S, Montanari A, Nguyen P-M. A mean field view of the landscape of two-layer neural networks. Proc. Natl Acad. Sci. 2018;115:E7665–71. doi: 10.1073/pnas.1806579115. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Rotskof G, Vanden-Eijnden E. Parameters as interacting particles: long time convergence and asymptotic error scaling of neural networks. Advances in Neural Information Processing Systems; 2018. pp. pp 7146–55. [Google Scholar]
- 31.Chizat L, Bach F. On the global convergence of gradient descent for over-parameterized models using optimal transport. Advances in Neural Information Processing Systems; 2018. pp. pp 3040–50. [Google Scholar]
- 32.Sirignano J, Spiliopoulos K. Mean field analysis of neural networks: a central limit theorem. Stoch. Process. Appl. 2019;130:1820–52. doi: 10.1016/j.spa.2019.06.003. [DOI] [Google Scholar]
- 33.Jacot A, Gabriel F, Hongler C. Neural tangent kernel: convergence and generalization in neural networks. Advances in Neural Information Processing Systems; 2018. pp. pp 8571–80. [Google Scholar]
- 34.Du S, Zhai X, Poczos B, Singh A. Gradient descent provably optimizes over-parameterized neural networks. Int. Conf. on Learning Representations; 2019. ( https://openreview.net/forum?id=S1eK3i09YQ) [Google Scholar]
- 35.Allen-Zhu Z, Li Y, Song Z. A convergence theory for deep learning via over-parameterization. 2018 (arXiv: 1811.03962)
- 36.Li Y, Liang Y. Learning overparameterized neural networks via stochastic gradient descent on structured data. Advances in Neural Information Processing Systems; 2018. [Google Scholar]
- 37.Zou D, Cao Y, Zhou D, Gu Q. Stochastic gradient descent optimizes over-parameterized deep ReLU networks. Mach. Learn. 2020;109:467–92. doi: 10.1007/s10994-019-05839-6. [DOI] [Google Scholar]
- 38.Chizat L, Oyallon E, Bach F. On lazy training in differentiable programming. Advances in Neural Information Processing Systems; 2019. [Google Scholar]
- 39.Mei S, Misiakiewicz T, Montanari A. Mean-field theory of two-layers neural networks: dimension-free bounds and kernel limit. 2019 (arXiv: 1902.06015)
- 40.Biehl M, Schwarze H. Learning by on-line gradient descent. J. Phys. A: Math. Gen. 1995;28:643–56. doi: 10.1088/0305-4470/28/3/018. [DOI] [Google Scholar]
- 41.Saad D, Solla S A. Exact solution for on-line learning in multilayer neural networks. Phys. Rev. Lett. 1995;74:4337–40. doi: 10.1103/physrevlett.74.4337. [DOI] [PubMed] [Google Scholar]
- 42.Saad D, Solla S A. On-line learning in soft committee machines. Phys. Rev. E. 1995;52:4225–43. doi: 10.1103/physreve.52.4225. [DOI] [PubMed] [Google Scholar]
- 43.Riegler P, Biehl M. On-line backpropagation in two-layered neural networks. J. Phys. A: Math. Gen. 1995;28 doi: 10.1088/0305-4470/28/20/002. [DOI] [Google Scholar]
- 44.Saad D, Solla S. Learning with noise and regularizers multilayer neural networks. Advances in Neural Information Processing Systems; 1997. pp. pp 260–6. [Google Scholar]
- 45.Wang C, Hu H, Lu Y M. A solvable high-dimensional model of GAN. 2018 (arXiv: 1805.08349)
- 46.Krogh A, Hertz J A. Generalization in a linear perceptron in the presence of noise. J. Phys. A: Math. Gen. 1992;25:1135–47. doi: 10.1088/0305-4470/25/5/020. [DOI] [Google Scholar]
- 47.Saxe A, McClelland J L, Ganguli S. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. ICLR.2014. [Google Scholar]
- 48.Lampinen A, Ganguli S. An analytic theory of generalization dynamics and transfer learning in deep linear networks. Int. Conf. on Learning Representations.2019. [Google Scholar]