

Abstract
Purpose
Automatic segmentation and classification of surgical activity is crucial for providing advanced support in computer-assisted interventions and autonomous functionalities in robot-assisted surgeries. Prior works have focused on recognizing either coarse activities, such as phases, or fine-grained activities, such as gestures. This work aims at jointly recognizing two complementary levels of granularity directly from videos, namely phases and steps.
Methods
We introduce two correlated surgical activities, phases and steps, for the laparoscopic gastric bypass procedure. We propose a multi-task multi-stage temporal convolutional network (MTMS-TCN) along with a multi-task convolutional neural network (CNN) training setup to jointly predict the phases and steps and benefit from their complementarity to better evaluate the execution of the procedure. We evaluate the proposed method on a large video dataset consisting of 40 surgical procedures (Bypass40).
Results
We present experimental results from several baseline models for both phase and step recognition on the Bypass40. The proposed MTMS-TCN method outperforms single-task methods in both phase and step recognition by 1-2% in accuracy, precision and recall. Furthermore, for step recognition, MTMS-TCN achieves a superior performance of 3-6% compared to LSTM-based models on all metrics.
Conclusion
In this work, we present a multi-task multi-stage temporal convolutional network for surgical activity recognition, which shows improved results compared to single-task models on a gastric bypass dataset with multi-level annotations. The proposed method shows that the joint modeling of phases and steps is beneficial to improve the overall recognition of each type of activity.
Keywords: Surgical workflow analysis, deep learning, temporal modeling, multi-task learning, laparoscopic gastric bypass, endoscopic videos
Introduction
Recent works in computer-assisted interventions and robot-assisted minimally invasive surgery have seen significant progress in developing advanced support technologies for the demanding scenarios of a modern operating room (OR) [6, 21, 27]. Automatic surgical workflow analysis, i.e., reliable recognition of the current surgical activities, plays an important role in the OR by providing the semantic information needed to design assistance systems that can support clinical decision, report generation, and data annotation. This information is at the core of the cognitive understanding of the surgery and could help reduce surgical errors, increase patient safety, and establish efficient and effective communication protocols [5, 19, 21, 27].
A surgical procedure can be decomposed into activities at different levels of granularity, such as the whole procedure, phases, stages, steps, and actions [18]. Recent works have strongly focused on developing methods to recognize one specific level of granularity from video data. The visual detection of phases [7, 15, 16, 25, 30], robotic gestures [2, 10, 26, 29], and instruments [11, 14, 16, 22] has, for instance, seen a surge in research activities, due to their potential impact on developing intra- and postoperative tools for the purposes of monitoring safety, assessing skills, and reporting. Many of these previous works have focused on endoscopic cholecystectomy procedures, utilizing the publicly available large-scale Cholec80 dataset [25], and on cataract surgical procedures, utilizing the popular CATARACTS dataset [11, 30].
In this work, we target another type of high volume procedure, namely the gastric bypass. This procedure is particularly interesting for activity analysis as it exhibits a very complex workflow. Gastric bypass is a procedure to treat obesity, which is considered a global health epidemic by the World Health Organization [1], with approximately 500,000 laparoscopic bariatric procedures performed every year worldwide [3]. Laparoscopic Roux-En-Y gastric bypass (LRYGB), the most performed and gold standard bariatric surgical procedure [3], consists in the reduction of the stomach and the bypass of part of the small bowel. Various clinical groups have worked to find a consensus on the best workflow for this technically demanding surgical procedure in order to improve standardization and reproducibility [17]. A clear framework and shared nomenclature to segment surgical procedures are currently missing.
Similar to [17], we introduce a hierarchical representation of LRYGB procedure containing phases and steps representing the workflow performed in our hospital and focus our attention on the recognition of these two types of activities. Toward this end, we utilize a new large-scale dataset, called Bypass40, containing 40 endoscopic videos of gastric bypass surgical procedures annotated with phases and steps. Overall, 11 phases and 44 steps are annotated in all videos. This opens new possibilities for research in surgical knowledge modeling and recognition. To jointly learn the tasks of phase and step recognition, we introduce MTMS-TCN, a multi-task multi-stage temporal convolutional networks, extending MS-TCNs [9] proposed for action segmentation.
The contributions of this paper are threefold: (1) we introduce new multi-level surgical activity annotations for the LRYGB procedure and utilize a novel dataset; (2) we propose a multi-task recognition model utilizing only visual features from the endoscopic video; and (3) we benchmark the proposed method with other state-of-the-art deep learning models on the new Bypass40 dataset for surgical activity recognition, demonstrating the effectiveness of the joint modeling of phases and steps.
Related work
EndoNet [25] and DeepPhase [30] belong to the early works that employed deep learning for surgical workflow analysis on cholecystectomy and cataract surgeries. EndoNet jointly performed phase and tool detection, and the model consisted of a CNN followed by a hierarchical hidden Markov model (HMM) for modeling temporal information, while DeepPhase used a CNN followed by recurrent neural network (RNN) temporal modeling. EndoNet was evolved to EndoLSTM [24] that consisted of a CNN for feature extraction and an LSTM, i.e., long short-term memory, for temporal refinement. Similarly, SV-RCNet [15] trained an end-to-end ResNet [12] and LSTM model incorporating a prior knowledge inference scheme for surgical phase recognition. MTRCNet-CL [16] proposed a multi-task model to detect tool presence and phase recognition. The features from the CNN were used to detect tool presence and also served as input to a LSTM model for phase prediction. Additionally, a correlation loss was introduced to enhance the synergy between the two tasks. Most of the previous methods use LSTMs, which retains memory for a limited sequence. Since the average duration of a surgery can range from less than half an hour to many hours, it makes it challenging for LSTM-based models to leverage the temporal information for surgical phase recognition.
Temporal convolutional networks (TCNs) [20] were introduced to hierarchically process videos for action segmentation. An encoder–decoder architecture was able to encode both high- and low-level features in contrast to RNNs. Furthermore, dilated convolutions [23] were utilized in TCNs for action segmentation that showed performance improvements due to a large receptive field for higher temporal resolution. MS-TCN [9] consisted of a multi-stage predictor architecture with each stage consisting of multi-layer TCN, which incrementally refined the prediction of the previous stage. Recently, TeCNO [7] adapted the MS-TCN architecture for online surgical phase prediction by implementing causal convolutions [23]. We build upon this architecture and confirm experimentally that it is superior to LSTM for multi-level activity recognition.
Hierarchical surgical activities: phases & steps
We introduce two hierarchically defined surgical activities called phases and steps for the LRYGB procedure. These two elements define the workflow of the surgery at two levels of granularity with the phases describing the surgical workflow at coarser level than the steps. Phases describe a set of fundamental surgical aims to accomplish in order to successfully complete the surgical procedure, while steps describe a set of surgical actions to perform in order to accomplish a surgical phase. The surgical procedure is segmented into 44 fine-grained steps, along with 11 coarser phases. All the phases and steps are presented in Fig. 2. These two types of activities are interesting for their inherent hierarchical relationship, which is shown in the figure. Additionally, the figure highlights all the critical phases, and corresponding critical steps, that are clinically known to be important for surgical outcomes [4].
Fig. 2.

List of all the phases and steps defined in the dataset with their hierarchical relationship. The surgically critical activities are highlighted in red
We make use of a new dataset, called Bypass40, consisting of 40 videos of LRYGB procedures with an average duration of 110 ± 30 minutes. This dataset is created from surgeries performed by 7 expert surgeons at IHU Strasbourg. The videos are captured at 25 frames-per-second (fps) with a resolution of or and annotated with phases and steps. Sample images with respective phase labels are shown in Fig. 1. The distribution of phases and steps in the Bypass40 dataset is shown in Fig. 3. As can be seen, there is a high imbalance in class distribution of both phases and steps. This is to be expected as all steps need not occur in all surgeries and also task completion time of the phases/steps may not be similar.
Fig. 1.

Sample images from the dataset with phase labels on top-left and step labels on top-right corner. The labels can be inferred from Fig. 2
Fig. 3.

Average duration of phases and steps across videos in the dataset
Methodology With the aim of joint online recognition of phases and steps, we propose an online surgical activity recognition pipeline consisting of the following steps: 1) A multi-task ResNet-50 is employed as a visual feature extractor. 2) A multi-task multi-stage causal TCN model refines the extracted feature of the current frame by encoding temporal information deduced by analyzing the history. We propose this two-step approach so that the temporal model training is independent of the backbone CNN feature extraction models. The overview of the model setup is depicted in Fig. 4.
Fig. 4.

Overview of our model setup. Multi-task architecture of the ResNet-50 feature extractor backbone on the left and the multi-task setup of the TCN temporal model on the right
Feature Extraction Architecture ResNet-50 [13] has been successfully employed in many works for phase segmentation [7, 15, 16, 28]. In this work, we utilize the same architecture as our backbone visual feature extraction model. The model maps RGB images to a feature space of size . The model is trained on frames extracted from the videos, without any temporal context, in a multi-task setup to predict both phase and step as shown in Fig. 1 (a). Since both activities are multi-class classification problems that exhibit imbalance in the class distribution, softmax activations and class-weighted cross-entropy loss are utilized. The class weights for both activities are calculated using the median frequency balancing [8]. The total loss, , is obtained by combining equally weighted contributions of class-weighted cross-entropy loss for phases and steps .
Temporal Modeling
For joint temporal surgical activity recognition task, we propose MTMS-TCN, a multi-task extension of a multi-stage temporal convolutional network. The model takes an input video consisting of , frames, where T is the total number of frames, and predicts where is the class label for the current timestamp t. Following the design of MS-TCN, MTMS-TCN contains neither pooling layers nor fully connected layers and it is only constructed with temporal convolutional layers. Our temporal model consists of only temporal convolutional layers; in particular, they are dilated residual layers performing dilated convolutions. Since our aim is to segment surgical activities online, similar to TeCNO [7], we perform causal convolutions [23] at each layer which depends only on n past frames and does not rely on any future frames. The dilation factor is increased by a factor of 2 for each consecutive layer which increases exponentially the temporal receptive field of the network without introducing any pooling layer. Additionally, the multi-stage model recursively refines the output of the previous stage.
Similar to our setup for CNN, we train our MTMS-TCN in a multi-task fashion to jointly predict the two activities by attaching two heads at the end of a stage. Softmax activations with cross-entropy loss for phase and step are applied, and the total loss is similar to the loss utilized for training the backbone CNN (Eq. 3). Please note that the cross-entropy loss is not class-weighted. This is done to allow the temporal model to learn implicitly the duration and occurrence of each class in both phases and steps.
Experimental setup
Dataset We evaluate our method on the Bypass40 dataset described in Section 3. We split the 40 videos in the dataset into 4 subsets of 10 videos each to perform 4-fold cross-validation. Each subset was used as test set, while the other subsets were combined together and divided into training and validation tests consisting of 24 and 6 videos, respectively. The dataset was subsampled at 1 fps amounting to approximately 149,000 frames for training, 41,000 frames for validation, and 66,000 frames for testing in each fold. The frames are resized to ResNet-50’s input dimension of , and the training dataset is augmented by applying horizontal flip, saturation, and rotation.
Model Training The ResNet-50 model is initialized with weights pre-trained on ImageNet. The model is then trained for the task of phase and step recognition in a single-task setup, called ResNet, and jointly in a multi-task setup, called MT-ResNet, described in Section 3. In all the experiments, the model is trained for 30 epochs with a learning rate of 1e-5, weight regularization of 5e-5, and a batch size of 32. The test results presented are from the best performing model on the validation set. The baseline TCN model is trained in a single-task setup utilizing the features extracted from backbone ResNet (Fig. 5). This is effectively achieved by training TeCNO separately for the two activity recognition tasks. The MTMS-TCN model is trained in a multi-task setup utilizing the backbone MT-ResNet trained in a similar fashion. All models are trained with a different number of TCN stages to identify the effect of the number of stages on long temporal associations. In all the experiments, the model is trained for 200 epochs with a learning rate of 3e-4. The features representations of augmented data for CNN are also utilized for training the TCN model (Fig. 5). Our CNN backbone was implemented in TensorFlow, while the temporal models (TCN and LSTM) were implemented in Pytorch. Our models were trained on NVIDIA GeForce RTX 2080 Ti GPUs.
Fig. 5.

Overview of all the models used for evaluation. All the models trained in a single-task setup are shown on the left, while all the models trained in multi-task setup are shown on the right
Evaluation Metrics We follow the same evaluation metrics used in other related publications [7, 15, 16], where accuracy (ACC), precision (PR), recall (RE), and F1 score (F1) are used to effectively compare the results. Accuracy quantifies the total correct classification of activity in the whole video. PR, RE, and F1 are computed class-wise, defined as:
| 1 |
where GT and P represent the ground truth and prediction for one class, respectively. These values are averaged across all the classes to obtain PR, RE, and F1 for the entire test set. We perform 4-fold cross-validation and report the results as mean and standard deviation across all the folds.
The overview of all evaluated models is depicted in Fig. 5. MTMS-TCN is evaluated against popular surgical phase recognition networks, ResNetLSTM [15], and TeCNO [7]. Both these networks are trained in a two-step process for the single-task of phase and step separately. Furthermore, ResNetLSTM is extended to get MT-ResNetLSTM where the ResNetLSTM model is trained in a multi-task setup. Since causal convolutions are used in the model for online recognition of activities, for fair comparison unidirectional LSTM is utilized. The LSTM, with 64 hidden units, is trained using the video features extracted from the CNN backbone with a sequence length equal to the length of the videos for 200 epochs with a learning rate of 3e-4.
Results and discussions
Comparison of MTMS-TCN (Stage I) with other state-of-the-art methods, utilizing both LSTMs and TCNs, is presented in Table 1 and Table 2 on both phase and step recognition tasks. TeCNO which utilizes TCNs outperforms both ResNetLSTM and MT-ResNetLSTM models by 1% and 3% in terms of accuracy. MTMS-TCN outperforms TeCNO, ResNetLSTM, and MT-ResNetLSTM models for by 2% the phase recognition.
Table 1.
Baseline comparison on the dataset for phase recognition. Accuracy (ACC), precision (PR), recall (RE), and F1-score (F1) (%) are reported across all the 4-fold cross-validation
| Phase | |||||
|---|---|---|---|---|---|
| ACC | PR | RE | F1 | ||
| No TCN | ResNet | 82.1 ± 3.3 | 73.9 ± 3.3 | 72.2 ± 3.4 | 72.5 ± 3.6 |
| MT-ResNet | 81.7 ± 2.7 | 73.1 ± 2.8 | 72.1 ± 2.3 | 72.1 ± 2.6 | |
| ResNetLSTM | 89.1 ± 2.8 | 82.1 ± 3.6 | 82.3 ± 3.5 | 81.7 ± 3.5 | |
| MT-ResNetLSTM | 88.6 ± 2.7 | 81.4 ± 3.9 | 81.1 ± 3.5 | 80.7 ± 3.8 | |
| Stage I | TeCNO | 89.8 ±3.5 | 85.4 ± 4.0 | 82.3 ± 4.5 | 83.0 ± 4.1 |
| MTMS-TCN | 91.2 ± 2.9 | 86.1 ± 3.7 | 83.8 ± 4.0 | 84.4 ± 3.5 | |
| Stage II | TeCNO | 89.9 ± 3.3 | 84.4 ± 4.3 | 83.3 ± 3.9 | 83.5 ± 4.0 |
| MTMS-TCN | 90.9 ± 3.2 | 85.6 ± 4.5 | 84.0 ± 4.2 | 84.2 ± 4.2 | |
Bold numbers denote best performance for each metric
Table 2.
Baseline comparison on the dataset for step recognition. Accuracy (ACC), precision (PR), recall (RE), and F1-score (F1) (%) are reported across all the 4-fold cross-validation
| Step | |||||
|---|---|---|---|---|---|
| ACC | PR | RE | F1 | ||
| No TCN | ResNet | 65.5 ± 2.0 | 45.3 ± 3.0 | 43.2 ± 2.7 | 42.6 ± 2.3 |
| MT-ResNet | 66.6 ± 2.4 | 46.0 ± 3.1 | 44.7 ± 3.1 | 43.8 ± 2.9 | |
| ResNetLSTM | 71.3 ± 2.3 | 47.8 ± 4.1 | 47.7 ± 2.8 | 45.8 ± 2.7 | |
| MT-ResNetLSTM | 72.2 ± 2.0 | 51.0 ± 3.3 | 49.3 ± 1.8 | 47.9 ± 2.1 | |
| Stage I | TeCNO | 75.1 ± 2.4 | 54.7 ± 2.6 | 50.9 ± 2.4 | 49.9 ± 1.8 |
| MTMS-TCN | 76.1 ± 2.7 | 56.4 ± 3.6 | 52.5 ± 3.3 | 51.9 ± 2.9 | |
| Stage II | TeCNO | 74.8 ± 2.5 | 53.2 ± 2.5 | 50.8 ± 3.3 | 49.9 ± 3.7 |
| MTMS-TCN | 75.5 ± 3.1 | 54.9 ± 4.4 | 52.6 ± 4.2 | 51.8 ± 4.1 | |
Bold numbers denote best performance for each metric
Similarly, for step recognition, TeCNO outperforms both LSTM-based models by 3-4% with respect to accuracy and 3-6% in terms of precision. MTMS-TCN improves over TeCNO by 1% in accuracy and outperforms it by 2% and 1.5% in terms of precision and recall, respectively. In turn, MTMS-TCN outperforms LSTM-based models by 4-5% in terms of accuracy and 3-8% in terms of precision and recall.
Table 3 presents performance of all the models on joint recognition of phase and step. We present joint phase-step prediction accuracy which is computed as the average number of instances where both the phase and step are correctly recognized by the model. All the multi-task models outperform their single-task counterpart. In particular, MTMS-TCN outperforms TeCNO by 3%. Moreover, the joint-recognition accuracy of MTMS-TCN is very close to its step recognition accuracy which indicated that the model has implicitly learned the hierarchical relationship and benefited from it.
Table 3.
Baseline comparison on the dataset for joint phase and step recognition. Accuracy (ACC) is reported after 4-fold cross-validation
| Phase ACC | Step ACC | Phase-Step ACC | ||
|---|---|---|---|---|
| No TCN | ResNet | 82.1 ± 2.9 | 65.5 ± 1.8 | 54.9 ± 2.6 |
| MT-ResNet | 81.7 ± 2.3 | 66.6 ± 2.1 | 64.8 ± 2.0 | |
| ResNetLSTM | 89.1 ± 2.4 | 71.3 ± 2.0 | 68.5 ± 2.3 | |
| MT-ResNetLSTM | 88.6 ± 2.3 | 72.2 ± 1.8 | 70.7 ± 1.9 | |
| Stage I | TeCNO | 89.8 ± 3.0 | 75.1 ± 2.1 | 72.3 ± 3.0 |
| MTMS-TCN | 91.2 ± 2.5 | 76.1 ± 2.3 | 75.1 ± 2.8 | |
| Stage II | TeCNO | 89.9 ± 2.8 | 74.8 ± 2.2 | 71.9 ± 2.7 |
| MTMS-TCN | 90.9 ± 2.8 | 75.5 ± 2.7 | 75.1 ± 2.8 |
Bold numbers denote best performance for each metric
The improvement achieved by both MTMS-TCN and TeCNO in both the recognition tasks over LSTM-based models is attributed to the higher temporal resolution and large receptive field of the underlying TCN module. On the other hand, improvement of MTMS-TCN over TeCNO is attributed to the multi-task setup. Additionally, MT-ResNet, the backbone of our MTMS-TCN, achieves improved performance in steps with a small decrease in performance for phase recognition compared to ResNet, the backbone of TeCNO.
A set of surgically critical steps along with their average precision, recall, and F1-score is presented in Table 4. MTMS-TCN performs better than TeCNO in recognizing many of the steps. Moreover, short duration steps such as S25, S30, and S39 that are harder to recognize are significantly better recognized by our MTMS-TCN over TeCNO. All these results validate our model trained in a multi-task setup for joint recognition of phases and steps.
Table 4.
TeCNO vs MTMS-TCN: 4-fold cross-validation average precision, recall, and F1-score (%) reported for the critical steps
| TeCNO | MTMS-TCN | |||||
|---|---|---|---|---|---|---|
| ID | PR | RE | F1 | PR | RE | F1 |
| S4 | 84.2±5.7 | 90.0±3.8 | 85.6±4.1 | 86.4±10.8 | 88.3±3.9 | 86.1±6.6 |
| S5 | 87.7±1.7 | 80.4±9.4 | 80.8±7.6 | 87.5±4.3 | 77.4±6.7 | 79.2±6.8 |
| S6 | 77.4±7.8 | 64.7±22.3 | 63.0±16.3 | 76.4±15.8 | 66.9±22.5 | 62.5±13.6 |
| S7 | 77.2±10.1 | 64.7±11.8 | 67.8±9.3 | 72.1±8.0 | 64.0±10.7 | 66.4±9.8 |
| S8 | 78.0±8.3 | 77.1±10.5 | 72.8±4.0 | 75.6±7.0 | 77.1±9.8 | 72.7±3.4 |
| S16 | 76.4±7.1 | 69.1±6.5 | 68.7±4.2 | 79.1±3.2 | 67.7±4.0 | 68.6±4.4 |
| S18 | 92.4±2.3 | 83.1±5.3 | 86.6±2.3 | 89.8±4.9 | 80.5±3.1 | 83.4±3.6 |
| S25 | 55.1±12.4 | 39.4±18.6 | 40.6±16.1 | 47.6±6.6 | 49.5±18.3 | 45.2±10.7 |
| S30 | 62.3±4.8 | 62.0±13.5 | 57.5±10.3 | 65.3±6.7 | 71.2±5.2 | 64.8±5.6 |
| S32 | 87.9±3.8 | 85.4±4.4 | 84.0±6.6 | 85.1±5.4 | 86.3±3.3 | 83.7±2.9 |
| S39 | 46.2±27.1 | 47.8±25.4 | 39.0±22.2 | 49.6±33.9 | 42.9±27.2 | 40.6±25.5 |
Bold numbers denote best performance per step per metric
Fig. 6 visualizes a video set of 3 best and 3 worst performances of MTMS-TCN for phase recognition. The MTMS-TCN, in some cases, performs better than TeCNO in recognizing smaller phases, such as P5, P7, P9, and P10. MTMS-TCN is also able to recognize phase transitions better than TeCNO in some instances (e.g., P3, P4, and P9). Additionally, both the methods outperform ResNet and ResNetLSTM models.
Fig. 6.
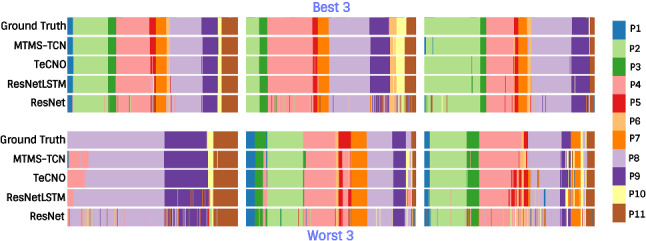
Phase recognition on complete videos in Bypass40 for quality assessment. The top row shows 3 videos on which our model performs best, and the bottom row shows 3 videos with worst performance
Fig. 7 visualizes the complete video set of one best and one worst performance of MTMS-TCN for step recognition. Since there are 44 steps, visualizing all of them is quite challenging and clutters the plot. To effectively show the results, we look at one videos instead of 3 in each best and worst category. Furthermore, for better visualization we use a 20 categorical colormap and all 44 steps are mapped onto this colormap. The results clearly show that MTMS-TCN is able to better capture smaller steps and step transitions in comparison to TeCNO and ResNetLSTM.
Fig. 7.
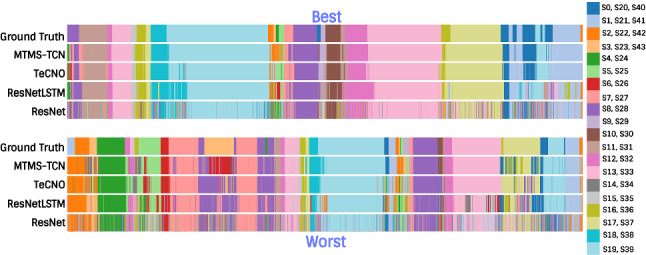
Step recognition on complete videos in Bypass40 for quality assessment. The figure shows best (top) and worst (bottom) performance of our model. The 44 distinct steps are mapped to the same 20 categorical colormap
Conclusion
In this paper, we introduce a new multi-level surgical activity annotations for the LRYGB procedures, namely phases and steps. We proposed MTMS-TCN, a multi-task multi-stage temporal convolutional network that was successfully deployed for joint online phase and step recognition. The model is evaluated on a new dataset and compared to state-of-the-art methods in both single-task and multi-task setups and demonstrates the benefits of modeling jointly the phases and steps for surgical workflow recognition.
Acknowledgements
This work has received funding from the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No. 813782 - project ATLAS. This work was also supported by French state funds managed within the Investissements d’Avenir program by BPI France (project CONDOR) and by the ANR (ANR-16-CE33-0009, ANR-10-IAHU-02). The authors would also like to thank the IHU and IRCAD research teams for their help with the data annotation during the CONDOR project.
Funding
Open access funding provided by Università degli Studi di Verona within the CRUI-CARE Agreement.
Declarations
Conflict of Interest
The authors declare that they have no conflict of interest.
Ethical approval
The research was conducted in accordance with the 1964 Helsinki Declaration. The surgical videos were recorded and collected in an anonymized manner following informed consent of patients. The local medical research and ethical committee cleared the present study from the Research Involving Human Subjects Act since the study did not imply any deviation from standard of care.
Informed consent
The patients consented to data recording
Code availability
The source code is public available at https://github.com/CAMMApublic/MTMS-TCN-Phase-Step-Bypass.
Footnotes
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Sanat Ramesh, Email: sanat.ramesh@univr.it.
Diego Dall’Alba, Email: diego.dallalba@univr.it.
Tong Yu, Email: tyu@unistra.fr.
Pietro Mascagni, Email: p.mascagni@unistra.fr.
Paolo Fiorini, Email: paolo.fiorini@univr.it.
Nicolas Padoy, Email: npadoy@unistra.fr.
References
- 1.Obesity: preventing and managing the global epidemic. Report of a WHO consultation. World Health Organ Tech Rep Ser 894, 1–253 (2000) [PubMed]
- 2.Ahmidi N, Tao L, Sefati S, Gao Y, Lea C, Haro BB, Zappella L, Khudanpur S, Vidal R, Hager GD. A dataset and benchmarks for segmentation and recognition of gestures in robotic surgery. IEEE Trans Biomed Eng. 2017;64(9):2025–2041. doi: 10.1109/TBME.2016.2647680. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Angrisani L, Santonicola A, Iovino P, Formisano G, Buchwald H, Scopinaro N (2015) Bariatric surgery worldwide 2013. Obes Surg 25(10):1822–1832 [DOI] [PubMed]
- 4.Birkmeyer JD, Finks JF, OReilly A, Oerline M, Carlin AM, Nunn AR, Dimick J, Banerjee M, Birkmeyer NJ, (2013) Surgical skill and complication rates after bariatric surgery. New Engl J Med 369(15):1434–1442. 10.1056/nejmsa1300625 [DOI] [PubMed]
- 5.Bricon-Souf N, Newman CR (2007) Context awareness in health care: A review. Int J Med Inf 76(1):2–12 [DOI] [PubMed]
- 6.Cleary K, Kinsella A. OR 2020: The operating room of the future - workshop report. J Laparoendosc Adv Surg Tech - Part A. 2005;15(5):495–573. doi: 10.1089/lap.2005.15.495. [DOI] [PubMed] [Google Scholar]
- 7.Czempiel T, Paschali M, Keicher M, Simson W, Feussner H, Kim ST, Navab N (2020) Tecno: Surgical phase recognition with multi-stage temporal convolutional networks. In: MICCAI
- 8.Eigen D, Fergus R (2015) Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In: 2015 IEEE International Conference on Computer Vision (ICCV), pp. 2650–2658. 10.1109/ICCV.2015.304
- 9.Farha YA, Gall J (2019) MS-TCN: Multi-stage temporal convolutional network for action segmentation. In: CVPR [DOI] [PubMed]
- 10.Funke I, Bodenstedt S, Oehme F, von Bechtolsheim F, Weitz J, Speidel S (2019) Using 3d convolutional neural networks to learn spatiotemporal features for automatic surgical gesture recognition in video. In: MICCAI
- 11.Hajj HA, Lamard M, Conze PH, Cochener B, Quellec G. Monitoring tool usage in surgery videos using boosted convolutional and recurrent neural networks. Med Image Anal. 2018;47:203–218. doi: 10.1016/j.media.2018.05.001. [DOI] [PubMed] [Google Scholar]
- 12.He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: CVPR
- 13.He K, Zhang X, Ren S, Sun J (2016) Identity mappings in deep residual networks. In: Computer Vision – ECCV 2016, pp. 630–645. Springer International Publishing
- 14.Jin A, Yeung S, Jopling J, Krause J, Azagury D, Milstein A, Fei-Fei L (2018) Tool detection and operative skill assessment in surgical videos using region-based convolutional neural networks. 2018 IEEE Winter Conference on Applications of Computer Vision (WACV) pp. 691–699
- 15.Jin Y, Dou Q, Chen H, Yu L, Qin J, Fu CW, Heng PA. SV-RCNet: Workflow recognition from surgical videos using recurrent convolutional network. IEEE Trans Med Imaging. 2018;37(5):1114–1126. doi: 10.1109/TMI.2017.2787657. [DOI] [PubMed] [Google Scholar]
- 16.Jin Y, Li H, Dou Q, Chen H, Qin J, Fu C, Heng P. Multi-task recurrent convolutional network with correlation loss for surgical video analysis. Medical image analysis. 2020;59:101572. doi: 10.1016/j.media.2019.101572. [DOI] [PubMed] [Google Scholar]
- 17.Kaijser MA, van Ramshorst GH, Emous M, Veeger NJGM, van Wagensveld BA, Pierie JPEN. A delphi consensus of the crucial steps in gastric bypass and sleeve gastrectomy procedures in the netherlands. Obesity Surg. 2018;28(9):2634–2643. doi: 10.1007/s11695-018-3219-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Katić D, Julliard C, Wekerle AL, Kenngott H, Müller-Stich BP, Dillmann R, Speidel S, Jannin P, Gibaud B. LapOntoSPM: an ontology for laparoscopic surgeries and its application to surgical phase recognition. Int J Comput Assisted Radiol Surg. 2015;10(9):1427–1434. doi: 10.1007/s11548-015-1222-1. [DOI] [PubMed] [Google Scholar]
- 19.Kranzfelder M, Staub C, Fiolka A, Schneider A, Gillen S, Wilhelm D, Friess H, Knoll A, Feussner H. Toward increased autonomy in the surgical OR: needs, requests, and expectations. Surg Endoscopy. 2012;27(5):1681–1688. doi: 10.1007/s00464-012-2656-y. [DOI] [PubMed] [Google Scholar]
- 20.Lea C, Vidal R, Reiter A, Hager GD (2016) Temporal convolutional networks: A unified approach to action segmentation. In: Lecture Notes in Computer Science, pp. 47–54. Springer International Publishing
- 21.Maier-Hein L, Vedula SS, Speidel S, Navab N, Kikinis R, Park A, Eisenmann M, Feussner H, Forestier G, Giannarou S, Hashizume M, Katic D, Kenngott H, Kranzfelder M, Malpani A, März K, Neumuth T, Padoy N, Pugh C, Schoch N, Stoyanov D, Taylor R, Wagner M, Hager GD, Jannin P. Surgical data science for next-generation interventions. Nat Biomed Eng. 2017;1(9):691–696. doi: 10.1038/s41551-017-0132-7. [DOI] [PubMed] [Google Scholar]
- 22.Nwoye CI, Mutter D, Marescaux J, Padoy N. Weakly supervised convolutional lstm approach for tool tracking in laparoscopic videos. Int J Comput Assisted Radiol Surg. 2019;14:1059–1067. doi: 10.1007/s11548-019-01958-6. [DOI] [PubMed] [Google Scholar]
- 23.van den Oord A, Dieleman S, Zen H, Simonyan K, Vinyals O, Graves A, Kalchbrenner N, Senior A, Kavukcuoglu K (2016) WaveNet: A generative model for raw audio. In: Arxiv
- 24.Twinanda AP (2017) Vision-based approaches for surgical activity recognition using laparoscopic and rbgd videos. In: PhD thesis
- 25.Twinanda AP, Shehata S, Mutter D, Marescaux J, de Mathelin M, Padoy N. EndoNet: A deep architecture for recognition tasks on laparoscopic videos. IEEE Trans Med Imaging. 2017;36(1):86–97. doi: 10.1109/TMI.2016.2593957. [DOI] [PubMed] [Google Scholar]
- 26.Varadarajan B, Reiley C, Lin H, Khudanpur S, Hager G (2009) Data-derived models for segmentation with application to surgical assessment and training. In: G.Z. Yang, D. Hawkes, D. Rueckert, A. Noble, C. Taylor (eds.) MICCAI, pp. 426–434 [DOI] [PubMed]
- 27.Vercauteren T, Unberath M, Padoy N, Navab N. Cai4cai: The rise of contextual artificial intelligence in computer-assisted interventions. Proc IEEE. 2020;108(1):198–214. doi: 10.1109/JPROC.2019.2946993. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Yu T, Mutter D, Marescaux J, Padoy N (2019) Learning from a tiny dataset of manual annotations: a teacher/student approach for surgical phase recognition
- 29.Zappella L, Béjar B, Hager G, Vidal R. Surgical gesture classification from video and kinematic data. Med Image Anal. 2013;17(7):732–745. doi: 10.1016/j.media.2013.04.007. [DOI] [PubMed] [Google Scholar]
- 30.Zisimopoulos O, Flouty E, Luengo I, Giataganas P, Nehme J, Chow A, Stoyanov D (2018) DeepPhase: Surgical phase recognition in cataracts videos. In: MICCAI