

Summary
The development of ultrafast detectors for electron microscopy (EM) opens a new door to exploring dynamics of nanomaterials; however, it raises grand challenges for big data processing and storage. Here, we combine deep learning and temporal compressive sensing (TCS) to propose a novel EM big data compression strategy. Specifically, TCS is employed to compress sequential EM images into a single compressed measurement; an end-to-end deep learning network is leveraged to reconstruct the original images. Owing to the significantly improved compression efficiency and built-in denoising capability of the deep learning framework over conventional JPEG compression, compressed videos with a compression ratio of up to 30 can be reconstructed with high fidelity. Using this approach, considerable encoding power, memory, and transmission bandwidth can be saved, allowing it to be deployed to existing detectors. We anticipate the proposed technique will have far-reaching applications in edge computing for EM and other imaging techniques.
Keywords: electron microscopy, in situ, deep learning, compression, compressive sensing, TEM, big data, direct electron detection, direct detection device
Graphical abstract
Highlights
-
•
A novel framework, i.e., TCS-DL, has been proposed for big data compressing for EM
-
•
The proposed TCL-DL outperforms JPEG due to the built-in denoising capability
-
•
Considerable power, in situ memory, and transmission bandwidth could be saved
-
•
The proposed TCL-DL is a novel and promising way for EM data compressing
The bigger picture
The rapid development of electron microscopy (EM) opens a new door to exploring physical sciences; however, it raises grand challenges and urgent needs for big data processing. Therefore, it is crucial to compress the EM data. But existing compression methods developed for natural images do not perform well in EM images. In this paper, by combining deep learning and temporal compressive sensing, we propose a novel compression strategy specifically for EM data processing. Owing to the improved compression efficiency and built-in denoising capability of our framework over JPEG compression, compressed videos with compression ratio of 30 can be reconstructed with high fidelity. Therefore, considerable (encoding) power, in situ memory, and transmission bandwidth are expected to be saved. In the future, we will strive to increase the compression ratio without reducing the reconstruction quality. And we believe our proposed EM compression method has a wide application for the EM community.
We propose a novel framework, i.e., TCL-DL, for big data compressing for EM. Owing to the significantly improved compression efficiency and built-in denoising capability of our framework over conventional JPEG compression, compressed videos with compression ratio up to 30 can be successfully reconstructed with high fidelity. Therefore, considerable (encoding) power, in situ memory, and transmission bandwidth are expected to be saved.
Introduction
Electron microscopy (EM), as one of the most powerful tools nowadays in probing materials’ structure and chemistry, has extensive applications in biology, physics, chemistry, and materials science owing to its high spatial resolution and chemical sensitivity.1 EM provides rich, directly resolved information about the structure and dynamics of phenomena, spanning from the atomic scale to micrometer scale, which are of great fundamental and practical significance to society.2 Driven by the recent advances in computer science and electron microscopes, EM techniques, especially in situ transmission electron microscopy (TEM),3, 4, 5, 6, 7, 8, 9, 10 electron tomography,11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22 four-dimensional scanning transmission electron microscopy (4D-STEM),23, 24, 25 and EM image processing26, 27 become more and more dependent on big data processing and storage. In particular, due to the deployment of state-of-the-art direct electron detectors, sequential images could be generated with extraordinary frame rates up to thousands of frames per second. This, on the one hand, empowers researchers with the capability to acquire more data with an ultrahigh temporal resolution to discover new phenomena in nature. On the other hand, it poses great challenges to processing, storing, and transmitting large high-resolution EM videos or images. Compressive sensing (CS),28, 29, 30as an efficient signal processing technique, has been widely used in EM for data acquisition and reconstruction. It has been wildly used in capturing high-dimensional data, such as videos31, 32, 33, 34 and hyperspectral images.35, 36, 37, 38, 39, 40 As long as the data or signal are compressible or sparse in a certain transform domain, a measurement matrix that is not related to the transform base can be used to project the high-dimensional data obtained by the transformation onto a low-dimensional space, and, by solving an optimization problem, the original data can be reconstructed with high probability from few projections. Extensive attempts41, 42, 43, 44, 45, 46, 47 have been made to apply CS to meet the growing demand for efficient EM data acquisition and processing; however, challenges still remain, possibly due to the following drawbacks. On one hand, the iteration-based nature makes the conventional reconstruction algorithms time consuming. On the other hand, some tasks have a higher requirement for hardware, and even the performance could still be unsatisfactory when the compression ratio is higher. Here, by combining CS and deep learning, we propose a novel encoding-decoding strategy to tackle the challenge facing big data EM. Specifically, temporal compressive sensing is first used as an encoder to compress multiple frames into a single-frame measurement with significantly reduced (on the order of 10×) bandwidth and memory requirements for data transmission and storage. An end-to-end deep learning network is then constructed to reconstruct the original image series from the single-frame measurement with extremely high speed. Peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) evaluations show that the temporal compressive sensing-deep learning (TCS-DL) framework exhibits superior performance over the conventional JPEG compression method.
Results and discussion
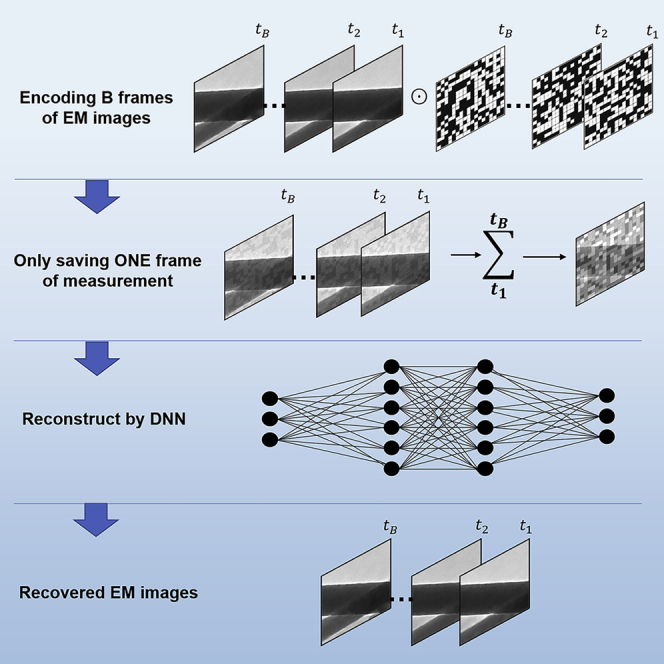
The workflow of the proposed TCS-DL approach is summarized (Figure 1). Firstly, for the TCS compression, we consider continuous video frames (B represents the number of EM images) captured at time slots . For each frame, we superimpose a random binary mask (coded masks) composed of and with the same probability. The coded images are then summed to form a single-frame measurement,31,48 denoted by compressed measurement in the top right of Figure 1. Until now, the encoder part of the TCS-DL is finished with EM images being compressed to a single-frame compressed measurement. Since the -coded masks can be pre-determined and stored, the data size is reduced by times. A multi-layer deep learning network is then constructed and employed as a decoder to reconstruct the original multi-frame images from the single-frame measurement. The deep neural network (DNN) is composed of a convolutional neural network (CNN) plus two recurrent neural networks (RNNs) (see details in the methods). During our experiments, the summing process in the encoder does not squeeze the dynamic range of the original image. It is purely a mathematical summation process. As we mentioned before about CS, the compressed process can be expressed as , where y is the measurement, is the compression matrix, and x are the original frames. Reconstructing x from y is an ill-conditioned problem. In this work, the optimization problem is solved by a DNN. It combines the CNN and RNN, which takes into account the correlation between adjacent frames; the learned correlation will help to reconstruct the result by maintaining the information included in the original images.
Figure 1.

Workflow of the TCS-DL for big data EM
The TCS-DL consists of two parts: an encoder compressing B frames of EM images using a B random binary mask into a single compressed measurement (upper part), and a decoder using a deep neural network to reconstruct the EM images (middle part). The masks used in the encoder and the compressed measurement are first sent into a CNN to generate the first video frame. Then a forward RNN is used to generate the consequent frames. After this, a backward RNN is used to refine the frames in a reverse order to output the final EM images.
The performance of TCS-DL is tested on sequential atomic-resolution images of Au nanocrystals with complicated structures. These images, captured at full resolution (4k × 4k), show the in-situ-sintering process of Au nanocrystals during high-resolution TEM imaging (Figure 2). The raw images are processed using the TCS-DL framework with a compression rate B = 30, that is, 30 sequential EM images are compressed into a single frame measurement (Figure 2A) and then reconstructed (Figure 2B). As a comparison, JPEG compression is also performed on the raw images (Figure 2C). Note that, to keep the memory consumption to store the images the same as that using TCS-DL, the size of the JPEG-compressed image is kept as 1/B of the original image size. The results show that obvious artifacts and noises are observed in the JPEG-compressed images. In sharp contrast, the reconstructed EM images using TCS-DL show a clean background, fine details, and sharp edges. To quantitatively evaluate the performances of TCS-DL and JPEG, we calculate the PSNR and SSIM of both JPEG-compressed images and TCS-DL reconstructed images compared with denoised raw images. Note that these raw images are usually noisy and a denoising algorithm49,50 can be applied. In this paper, we use BM3D for denoising. However, this will incurs power and computation costs. Therefore, in this work, both JPEG and TCS-DL are performed directly on the raw images. The average PSNR for JPEG compression and TCS-DL is 23.98 and 25.91 dB, respectively. The PSNR improvement of 1.93 dB indicates an evidently improved performance of TCS-DL over JPEG, which is in good agreement with the enhanced image quality using TCS-DL (Figure 2B) compared with JPEG compression (Figure 2C).
Figure 2.

Performance of TCS-DL framework on in situ atomic-resolution EM images
(A) The single-frame compressed measurement obtained from 30 sequential images using TCS-DL.
(B) Reconstructed sequential images obtained from the compressed measurement in (A) using TCS-DL. The average PSNR is 25.91 dB compared with the denoised raw EM images.
(C) JPEG-compressed images with the total image size equal to the compressed measurement in TCS-DL. The average PSNR is 23.98 dB. Insets show magnified images of local regions (raw images in Figure S6).
A more detailed comparison is made on representative selected frames as shown in Figure 3. The reconstructed images show enhanced surface atomic details (indicated by the arrows in Figures 3B and 3H) compared with that in the raw image (Figure 3A). However, in sharp contrast, the JPEG-compressed image shows severely deteriorated atomic details, especially at the crystal surface, e.g., the edge blurring as indicated by the arrows (Figures 3C and 3I). Fast Fourier transform (FFT) is further performed on the raw image as well as that processed using TCS-DL and JPEG compression (Figures 3D and 3F). The result shows that the high-frequency information (e.g., the (004) plane of the Au nanocrystal) in the raw image is well retained in the reconstructed image using TCS-DL. In contrast, the FFT of the JPEG-compressed image shows deteriorated resolution (indicated by the unresolved (004) plane of the Au nanocrystal) compared with the raw image and reconstructed image using the TCS-DL framework. The above results reveal that, distinct from the conventional JPEG, which introduces information loss during compression, the TCS-DL framework is capable of recovering the detailed information in the raw data. In addition, the built-in denoising capability of TCS-DL could further slightly improve the quality of raw images.
Figure 3.

Comparison of selected atomic-resolution images obtained using TCS-DL and JPEG compression in Figure 2
(A–C) 5th raw images, reconstructed images using TCS-DL and JPEG compression.
(D–F) Fast Fourier transforms of the images in (A–C). Bragg spots corresponding to the (004) planes are indicated by the arrows in (D and E). Information loss is identified in the JPEG-compressed image (F) as the Bragg spots corresponding to (004) planes are not resolved.
(G–I) 25th raw images, reconstructed images using TCS-DL and JPEG compression. Compared to the raw image (G), more surface details are observed in the TCS-DL-processed image (H) due to the edge enhancement. In contrast, deteriorated image quality such as edge blurring is identified in the JPEG-compressed image (I).
Aside from atomic-resolution images of ultrasmall nano-objects, we further tested the performance of the TCS-DL framework on objects with a much larger feature size in a large field of view. Figure 4 shows sequential EM images of two carbon fibers during in situ deformation. The raw images are processed using TCS-DL and JPEG compression, respectively. The TCS-DL reconstructed images show a clean background as well as a sharp edge, which thereby enables accurate tracking of the motions of the fibers (Figure 4C). In contrast, the JPEG-compressed images inherit the noises in the raw images, similar to that in atomic-resolution images as shown in Figures 2 and 3. It is worth noting that, due to the relatively simple morphology of the carbon fibers compared with Au nanocrystals, the PSNR of both JPEG compression and TCS-DL framework are evidently higher than that of the atomic-resolution images, as shown in Figures 2 and 3. Yet, the TCS-DL framework still outperforms JPEG compression with a considerable PSNR improvement of approximately 3 dB, from 32.38 dB (JPEG compression) to 35.41 dB (TCS-DL). Similar performance improvement is also obtained for EM images reconstructed from TCS-DL at B = 20 (Figure S1). Results of different compression ratios are shown in Video S1. We also present the results of different video compression algorithms in Videos S2 and S3.
Figure 4.

Performance of the TCS-DL framework on carbon fibers with relatively simple morphology (B = 10)
(A) Raw images of the carbon fibers during in situ deformation.
(B) JPEG-compressed images with the total image size equal to the compressed measurement in TCS-DL. The average PSNR is 32.38 dB compared with the denoised raw images.
(C) Reconstructed images using the TCS-DL framework. The average PSNR is 35.41 dB. Note that the JPEG-compressed images preserve the noise in the raw images (additional results in Figures S3–S5).
PSNR and SSIM are calculated and summarized to quantitatively compare the performance of the TCS-DL framework and JPEG compression. As shown in Figure 5, we conduct both TCS-DL and JPEG compression at different compression ratios from B = 10 to B = 30. PSNR, which is a ratio between the maximum possible power of a signal and the power of corrupting noise that affects the fidelity of its representation, is mainly used to evaluate the performance of reconstructed EM images using different compression methods. SSIM is used for measuring the similarity between the reconstructed EM images and the corresponding ground truth. Clearly, TCS-DL has higher PSNR and SSIM, which means that it can get better performance, especially when the raw images are noisier (Figures 2 and 4) and the compression ratio (Figure 2) is high, because our framework can reduce the background noise while JPEG produces obvious artifacts when the compression ratio is high. What needs to be mentioned is that the reconstruction process in this work utilizes both CNN and RNN structures, where RNN is mainly used to learn the correlation between adjacent frames. If the frames are obviously incoherent, the reconstruction result would be vulnerable. In most instances, the frames in the in situ TEM movie are coherent. We can utilize our compression method under the condition just mentioned. But at the edge, when the content in the receptive field changes suddenly, we do not use this method to compress the incoherent frames. In future work, we can automatically detect the sudden change and choose the corresponding compression method. If the receptive field does not change frequently, which means that the coherent frame number is sufficiently greater than the compression ratio B, TCS-DL can achieve a generally impressive result.
Figure 5.

Average PSNR (in dB), SSIM of TCS-DL and JPEG at different compression ratios
Denoised raw EM images are used as a baseline for calculation of the PSNR and SSIM. The results are based on the data in Figures 3, 4, and S2.
The training loss and validation loss during the learning process with B = 10 are shown in Figure 6. As we can see, the validation loss gradually converges as the training process progresses. Because we have sufficient data and we stop the training at the appropriate epoch, the validation loss curve does not show a V-shaped trend,which means it is not overfitted.
Figure 6.

The training loss and validation loss during the learning process with B = 10
The validation loss gradually converges as the training process progresses.
Conclusion
In conclusion, by combining deep learning and temporal compressive sensing, a novel encoding-decoding framework, i.e., TCS-DL, has been proposed for big data compression/decompression for EM. Owing to the significantly improved compression efficiency and built-in denoising capability of the TCS-DL framework over the conventional JPEG compression method, compressed EM time series with a high compression ratio can be successfully reconstructed with high fidelity by the TCS-DL framework from a single measurement. Our work, by offering a universally applicable super-compression strategy for EM data compression, opens the possibility for EM big data storage, processing, and transmission at the expense of significantly reduced power, in situ memory, and transmission bandwidth.
Experimental procedures
Resource availability
Lead contact
Further information and requests for resources and reagents should be directed to and will be fulfilled by the lead contact, Huolin L. Xin (huolinx@uci.edu).
Materials availability
This study did not generate new unique reagents.
Data and code availability
The original data within this paperis available from our website http://temimagenet.ps.uci.edu/. The code used in this work is available at https://github.com/xinhuolin/TCS-DL.
Methods
We first derive the mathematical model of TCS-DL and then present the details of the DNN for reconstruction.
Let denote the frames of the EM images being coded with masks . Each frame is of spatial size pixels. From Figure 1, the coded measurement can be expressed as
| (Equation 1) |
Here, denotes the element-wise product. Note that since the masks are composed of 0 and 1, there is no multiplication in Equation 1. We only need to index the “1” elements in the corresponding frames and sum across the frames to get the compressed measurement Y. Therefore, our proposed encoder is ultra-simple. Indeed, only Equation 1 will finish the encoder and the complexity is of .
The decoder aims to estimate the EM images, which can be denoised based on the previous analysis, from Y, given masks. As shown in Figure 1, we use a CNN and two RNNs to perform the reconstruction.51,52
The more information RNN takes as input, the better results we get. Therefore, the first frame for RNN with as much visual information as possible is required. To this purpose, we utilize a CNN with 12 layers to reconstruct the first input frame. We introduce normalized measurement
| (Equation 2) |
as input component of CNN. Where denotes the matrix division. We concatenate along the third dimension. The concatenation result is then fed into the CNN which consists of two four-layer CNNs, one three-layer residual block,53 and one self-attention block.54 Then, the first frame for RNN is generated. It is worth noting that is to approximate the real coded frames.
After getting , we introduce two RNNs with different directions to reconstruct the frames. As shown in Figure 1, the input of each RNN cell consists of three different parts. The first part is got from the former RNN cell's output except the first , which is obtained from the CNN. The second part is acquired by
| (Equation 3) |
where denotes concatenation along the third dimension which has the same meaning in Figure 1. The second item in the right part of Equation 3 could be considered to be an approximation of to some extent. The third part is hidden units obtained by former RNN cell except the first one initialized by zero. The three input parts are separately fed into three sub-CNNs. After the process of concatenation, there are two residual blocks, which outputs the new hidden unit fed to another sub-CNN. Then, each cell outputs the reconstructed frame. Noting that forward and backward RNNs have the same structure, but they do not share the parameters. Besides, the second input part of the backward RNN cell is different from the forward RNN cell
| (Equation 4) |
which uses reconstruction from forward RNN instead of . Another difference is that the initial hidden unit for backward RNN is not set to zero but which contains more information.
Acknowledgments
This material is based on work supported by the Early Career Research Program, Materials Science and Engineering Divisions, Office of Basic Energy Sciences of the U.S. Department of Energy, under award no. DE-SC0021204 (program manager Dr. Jane Zhu). S.Z.’s effort on this project was supported by H.L.X.'s startup funding.
Author contributions
H.L.X. and X.Y. conceived the idea. All authors designed and conducted the study. All authors wrote the manuscript.
Declaration of interests
The authors declare no competing interests. The third author, Xin Yuan, is an employee of Nokia.
Published: June 24, 2021
Footnotes
Supplemental information can be found online at https://doi.org/10.1016/j.patter.2021.100292.
Contributor Information
Xin Yuan, Email: xyuan@bell-labs.com.
Huolin L. Xin, Email: huolinx@uci.edu.
Supplemental information
References
- 1.Ruska E. The development of the electron microscope and of electron microscopy. Rev. Mod. Phys. 1987;59:627–638. doi: 10.1103/RevModPhys.59.627. [DOI] [Google Scholar]
- 2.Spurgeon S.R., Ophus C., Jones L., Petford-Long A., Kalinin S.V., Olszta M.J., Dunin-Borkowski R.E., Salmon N., Hattar K., Yang W.D. Towards data-driven next-generation transmission electron microscopy. Nat. Mater. 2020 doi: 10.1038/s41563-020-00833-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Wang C., Han L., Zhang R., Cheng H., Mu L., Kisslinger K. Resolving atomic-scale phase transformation and oxygen loss mechanism in ultrahigh-nickel layered cathodes for cobalt-free lithium-ion batteries. Matter. 2021;4(6):2013–2026. doi: 10.1016/j.matt.2021.03.012. [DOI] [Google Scholar]
- 4.Song M., Zhou G., Lu N., Lee J., Nakouzi E., Wang H., Li D. Oriented attachment induces fivefold twins by forming and decomposing high-energy grain boundaries. Science. 2020;367:40–45. doi: 10.1126/science.aax6511. [DOI] [PubMed] [Google Scholar]
- 5.Chen Y., Wang Z., Li X., Yao X., Wang C., Li Y., Xue W., Yu D., Kim S.Y., Yang F. Li metal deposition and stripping in a solid-state battery via Coble creep. Nature. 2020;578:251–255. doi: 10.1038/s41586-020-1972-y. [DOI] [PubMed] [Google Scholar]
- 6.He S., Wang C., Qi L., Ye H., Du K. In situ observation of twin-assisted grain growth in nanometer-scaled metal. Micron. 2020;131:102825. doi: 10.1016/j.micron.2020.102825. [DOI] [PubMed] [Google Scholar]
- 7.Sang X., Xie Y., Yilmaz D.E., Lotfi R., Alhabeb M., Ostadhossein A., Anasori B., Sun W., Li X., Xiao K. In situ atomistic insight into the growth mechanisms of single layer 2D transition metal carbides. Nat. Commun. 2018;9:2266. doi: 10.1038/s41467-018-04610-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Liao H.-G., Zherebetskyy D., Xin H., Czarnik C., Ercius P., Elmlund H., Pan M., Wang L.-W., Zheng H. Facet development during platinum nanocube growth. Science. 2014;345:916–919. doi: 10.1126/science.1253149. [DOI] [PubMed] [Google Scholar]
- 9.Wang X., Wang C., Chen C., Duan H., Du K. Free-standing monatomic thick two-dimensional gold. Nano Lett. 2019;19:4560–4566. doi: 10.1021/acs.nanolett.9b01494. [DOI] [PubMed] [Google Scholar]
- 10.Wang C., Du K., Song K., Ye X., Qi L., He S., Tang D., Lu N., Jin H., Li F., Ye H. Size-dependent grain-boundary structure with improved conductive and mechanical stabilities in sub-10-nm gold crystals. Phys. Rev. Lett. 2018;120:186102. doi: 10.1103/PhysRevLett.120.186102. [DOI] [PubMed] [Google Scholar]
- 11.Zhou J., Yang Y., Yang Y., Kim D.S., Yuan A., Tian X., Ophus C., Sun F., Schmid A.K., Nathanson M. Observing crystal nucleation in four dimensions using atomic electron tomography. Nature. 2019;570:500–503. doi: 10.1038/s41586-019-1317-x. [DOI] [PubMed] [Google Scholar]
- 12.Wang C., Duan H., Chen C., Wu P., Qi D., Ye H., Jin H.-J., Xin H.L., Du K. Three-dimensional atomic structure of grain boundaries resolved by atomic-resolution electron tomography. Matter. 2020;3:1999–2011. doi: 10.1016/j.matt.2020.09.003. [DOI] [Google Scholar]
- 13.Miao J., Ercius P., Billinge S.J. Atomic electron tomography: 3D structures without crystals. Science. 2016;353 doi: 10.1126/science.aaf2157. [DOI] [PubMed] [Google Scholar]
- 14.Eggeman A.S., Krakow R., Midgley P.A. Scanning precession electron tomography for three-dimensional nanoscale orientation imaging and crystallographic analysis. Nat. Commun. 2015;6:7267. doi: 10.1038/ncomms8267. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Albrecht W., Bals S. Fast electron tomography for nanomaterials. J. Phys. Chem. C. 2020;124:27276–27286. doi: 10.1021/acs.jpcc.0c08939. [DOI] [Google Scholar]
- 16.Kim B.H., Heo J., Kim S., Reboul C.F., Chun H., Kang D., Bae H., Hyun H., Lim J., Lee H. Critical differences in 3D atomic structure of individual ligand-protected nanocrystals in solution. Science. 2020;368:60–67. doi: 10.1126/science.aax3233. [DOI] [PubMed] [Google Scholar]
- 17.Liao M., Cao E., Julius D., Cheng Y. Structure of the TRPV1 ion channel determined by electron cryo-microscopy. Nature. 2013;504:107. doi: 10.1038/nature12822. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Ding G., Liu Y., Zhang R., Xin H.L. A joint deep learning model to recover information and reduce artifacts in missing-wedge sinograms for electron tomography and beyond. Sci. Rep. 2019;9:12803. doi: 10.1038/s41598-019-49267-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Wang C., Ding G., Liu Y., Xin H.L. 0.7 Å resolution electron tomography enabled by deep-learning-aided information recovery. Adv. Intell. Syst. 2020;2:2000152. doi: 10.1002/aisy.202000152. [DOI] [Google Scholar]
- 20.Han L., Meng Q., Wang D., Zhu Y., Wang J., Du X., Stach E.A., Xin H.L. Interrogation of bimetallic particle oxidation in three dimensions at the nanoscale. Nat. Commun. 2016;7:13335. doi: 10.1038/ncomms13335. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Wang D., He H., Han L., Lin R., Wang J., Wu Z., Liu H., Xin H.L. Three-dimensional hollow-structured binary oxide particles as an advanced anode material for high-rate and long cycle life lithium-ion batteries. Nano Energy. 2016;20:212–220. doi: 10.1016/j.nanoen.2015.12.019. [DOI] [Google Scholar]
- 22.Lin R., Bak S.M., Shin Y., Zhang R., Wang C., Kisslinger K., Ge M., Huang X., Shadike Z., Pattammattel A. Hierarchical nickel valence gradient stabilizes high-nickel content layered cathode materials. Nat. Commun. 2021;12:2350. doi: 10.1038/s41467-021-22635-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Jiang Y., Chen Z., Han Y., Deb P., Gao H., Xie S., Purohit P., Tate M.W., Park J., Gruner S.M. Electron ptychography of 2D materials to deep sub-angstrom resolution. Nature. 2018;559:343–349. doi: 10.1038/s41586-018-0298-5. [DOI] [PubMed] [Google Scholar]
- 24.Ophus C., Ercius P., Sarahan M., Czarnik C., Ciston J. Recording and using 4D-STEM datasets in materials science. Microsc. Microanalysis. 2014;20:62–63. doi: 10.1017/s1431927614002037. [DOI] [Google Scholar]
- 25.Gao W., Addiego C., Wang H., Yan X., Hou Y., Ji D., Heikes C., Zhang Y., Li L., Huyan H. Real-space charge-density imaging with sub-angstrom resolution by four-dimensional electron microscopy. Nature. 2019;575:480–484. doi: 10.1038/s41586-019-1649-6. [DOI] [PubMed] [Google Scholar]
- 26.Lin R., Zhang R., Wang C., Yang X.Q., Xin H.L. TEMImageNet training library and AtomSegNet deep-learning models for high-precision atom segmentation, localization, denoising, and deblurring of atomic-resolution images. Sci. Rep. 2021;11:5386. doi: 10.1038/s41598-021-84499-w. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Wang Chunyang, Zhang Rui, Kisslinger Kim, Xin Huolin L. Atomic-Scale Observation of O1 Faulted Phase-Induced Deactivation of LiNiO2 at High Voltage. Nano Letters. 2021;21:3657–3663. doi: 10.1021/acs.nanolett.1c00862. [DOI] [PubMed] [Google Scholar]
- 28.Candès E.J., Romberg J., Tao T. Robust uncertainty principles: exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inf. Theor. 2006;52:489–509. [Google Scholar]
- 29.Candès E.J., Wakin M.B. An introduction to compressive sampling. IEEE Signal. Process. Mag. 2008;25:21–30. [Google Scholar]
- 30.Donoho D.L. Compressed sensing. IEEE Trans. Inf. Theor. 2006;52:1289–1306. [Google Scholar]
- 31.Hitomi Y., Gu J., Gupta M., Mitsunaga T., Nayar S.K. IEEE; 2011. Video from a Single Coded Exposure Photograph Using a Learned Over-complete Dictionary; pp. 287–294. [Google Scholar]
- 32.Reddy D., Veeraraghavan A., Chellappa R. IEEE; 2011. P2C2: Programmable Pixel Compressive Camera for High Speed Imaging; pp. 329–336. [Google Scholar]
- 33.Yuan X., Pang S. IEEE; 2016. Compressive Video Microscope via Structured Illumination; pp. 1589–1593. [Google Scholar]
- 34.Yuan X., Pang S. Structured illumination temporal compressive microscopy. Biomed. Opt. Express. 2016;7:746–758. doi: 10.1364/BOE.7.000746. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Gehm M.E., John R., Brady D.J., Willett R.M., Schulz T.J. Single-shot compressive spectral imaging with a dual-disperser architecture. Opt. Express. 2007;15:14013–14027. doi: 10.1364/oe.15.014013. [DOI] [PubMed] [Google Scholar]
- 36.Wagadarikar A., John R., Willett R., Brady D. Single disperser design for coded aperture snapshot spectral imaging. Appl. Opt. 2008;47:B44–B51. doi: 10.1364/ao.47.000b44. [DOI] [PubMed] [Google Scholar]
- 37.Wagadarikar A.A., Pitsianis N.P., Sun X., Brady D.J. Video rate spectral imaging using a coded aperture snapshot spectral imager. Opt. Express. 2009;17:6368–6388. doi: 10.1364/oe.17.006368. [DOI] [PubMed] [Google Scholar]
- 38.Tsai T.-H., Llull P., Yuan X., Carin L., Brady D.J. Spectral-temporal compressive imaging. Opt. Lett. 2015;40:4054–4057. doi: 10.1364/OL.40.004054. [DOI] [PubMed] [Google Scholar]
- 39.Zheng S., Liu Y., Meng Z., Qiao M., Tong Z., Yang X., Han S., Yuan X. Deep plug-and-play priors for spectral snapshot compressive imaging. Photon. Res. 2021;9:B18–B29. [Google Scholar]
- 40.Yuan X., Brady D.J., Katsaggelos A.K. Snapshot compressive imaging: theory, algorithms, and applications. IEEE Signal. Process. Mag. 2021;38:65–88. [Google Scholar]
- 41.Foucart S., Rauhut H. A Mathematical Introduction to Compressive Sensing. Springer; 2013. An invitation to compressive sensing; pp. 1–39. [Google Scholar]
- 42.Saghi Z., Holland D.J., Leary R., Falqui A., Bertoni G., Sederman A.J., Gladden L.F., Midgley P.A. Three-dimensional morphology of iron oxide nanoparticles with reactive concave surfaces. A compressed sensing-electron tomography (CS-ET) approach. Nano Lett. 2011;11:4666–4673. doi: 10.1021/nl202253a. [DOI] [PubMed] [Google Scholar]
- 43.Stevens A., Yang H., Carin L., Arslan I., Browning N.D. The potential for Bayesian compressive sensing to significantly reduce electron dose in high-resolution STEM images. Microscopy. 2014;63:41–51. doi: 10.1093/jmicro/dft042. [DOI] [PubMed] [Google Scholar]
- 44.Stevens A., Luzi L., Yang H., Kovarik L., Mehdi B., Liyu A., Gehm M., Browning N. A sub-sampled approach to extremely low-dose STEM. Appl. Phys. Lett. 2018;112:043104. [Google Scholar]
- 45.Van den Broek W., Reed B.W., Béché A., Velazco A., Verbeeck J., Koch C.T. Various compressed sensing setups evaluated against Shannon sampling under constraint of constant illumination. IEEE Trans. Comput. Imaging. 2019;5:502–514. [Google Scholar]
- 46.Reed B.W., Moghadam A., Bloom R., Park S., Monterrosa A., Price P., Barr C., Briggs S., Hattar K., McKeown J. Electrostatic subframing and compressive-sensing video in transmission electron microscopy. Struct. Dyn. 2019;6:054303. doi: 10.1063/1.5115162. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Reed B.W., Park S.T., Bloom R.S., Masiel D.J. Compressively sensed video acquisition in transmission electron microscopy. Microsc. Microanalysis. 2017;23:84–85. [Google Scholar]
- 48.Liu Y., Yuan X., Suo J., Brady D.J., Dai Q. Rank minimization for snapshot compressive imaging. IEEE Trans. pattern Anal. Mach. Intellig. 2018;41:2990–3006. doi: 10.1109/TPAMI.2018.2873587. [DOI] [PubMed] [Google Scholar]
- 49.Yoshizawa T., Hirobayashi S., Misawa T. Noise reduction for periodic signals using high-resolution frequency analysis. EURASIP J. Audio Speech Music Process. 2011;2011:5. [Google Scholar]
- 50.Dabov K., Foi A., Katkovnik V., Egiazarian K. International Society for Optics and Photonics; 2006. Image Denoising with Block-Matching and 3D Filtering; p. 606414. [Google Scholar]
- 51.Cheng Z., Lu R., Wang Z., Zhang H., Chen B., Meng Z., Yuan X. Springer; 2020. BIRNAT: Bidirectional Recurrent Neural Networks with Adversarial Training for Video Snapshot Compressive Imaging; pp. 258–275. [Google Scholar]
- 52.Schuster M., Paliwal K.K. Bidirectional recurrent neural networks. IEEE Transactions Signal. Process. 1997;45:2673–2681. [Google Scholar]
- 53.He K., Zhang X., Ren S., Sun J. Deep residual learning for image recognition. Proceedings of the IEEE conference on computer vision and pattern recognition. 2016:770–778. https://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html. [Google Scholar]
- 54.Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., and Polosukhin, I. (2017). Attention Is All You Need. arXiv, 1706.03762. https://arxiv.org/abs/1706.03762.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The original data within this paperis available from our website http://temimagenet.ps.uci.edu/. The code used in this work is available at https://github.com/xinhuolin/TCS-DL.