

Abstract
Covariance estimation is essential yet underdeveloped for analysing multivariate functional data. We propose a fast covariance estimation method for multivariate sparse functional data using bivariate penalized splines. The tensor‐product B‐spline formulation of the proposed method enables a simple spectral decomposition of the associated covariance operator and explicit expressions of the resulting eigenfunctions as linear combinations of B‐spline bases, thereby dramatically facilitating subsequent principal component analysis. We derive a fast algorithm for selecting the smoothing parameters in covariance smoothing using leave‐one‐subject‐out cross‐validation. The method is evaluated with extensive numerical studies and applied to an Alzheimer's disease study with multiple longitudinal outcomes.
Keywords: bivariate smoothing, covariance function, functional principal component analysis, longitudinal data, multivariate functional data, prediction
1. INTRODUCTION
Functional data analysis (FDA) has been enjoying great successes in many applied fields, for example, neuroimaging (Reiss & Ogden, 2010; Lindquist, 2012; Goldsmith, Crainiceanu, Caffo, & Reich, 2012; Zhu, Li, & Kong, 2012), genetics (Leng & Müller, 2006; Reimherr & Nicolae, 2014; 2016), and wearable computing (Morris et al., 2006; Xiao et al., 2015). Functional principal component analysis (FPCA) conducts dimension reduction on the inherently infinite‐dimensional functional data and thus facilitates subsequent modelling and analysis. Traditionally, functional data are densely observed on a common grid and can be easily connected to multivariate data, although the notion of smoothness distinguishes the former from the latter. In recent years, covariance‐based FPCA (Yao, Müller, & Wang, 2005) has become a standard approach and has greatly expanded the applicability of functional data methods to irregularly spaced data such as longitudinal data. Various nonparametric methods have now been proposed to estimate the smooth covariance function, for example, Peng and Paul (2009), Cai and Yuan (2010), Goldsmith et al. (2012), Xiao, Li, Checkley, and Crainiceanu (2018), and Wong and Zhang (2019).
There has been growing interest in multivariate functional data where multiple functions are observed for each subject. For dense functional data, Ramsay and Silverman (2005, Chapter 8.5) proposed to concatenate multivariate functional data as a single vector and conduct multivariate PCA on the long vectors, and Berrendero, Justel, and Svarc (2011) repeatedly applied point‐wise univariate PCA. For sparse and paired functional data, Zhou, Huang, and Carroll (2008) extended the low‐rank mixed effects model in James, Hastie, and Sugar (2000). Chiou, Chen, and Yang (2014) considered normalized multivariate FPCA through standardizing the covariance operator. Petersen and Müller (2016) proposed various metrics for studying cross‐covariance between multivariate functional data. More recently, Happ and Greven (2018) introduced a FPCA framework for multivariate functional data defined on different domains.
The interest of the paper is FPCA for multivariate sparse functional data, where multiple responses are observed at time points that vary from subject to subject and may even vary between responses within subjects. There are much fewer works to handle such data. The approach in Zhou et al. (2008) focuses on bivariate functional data and can be extended to more than two‐dimensional functional data, although model selection (e.g., selection of smoothing parameters) can be computationally difficult and convergence of the expectation–maximization estimation algorithm could also be an issue. The local polynomial method in Chiou et al. (2014) can be applied to multivariate sparse functional data, although a major drawback is the selection of multiple bandwidths. Moreover, because the local polynomial method is a local approach, there is no guarantee that the resulting estimates of covariance functions will lead to a properly defined covariance operator. The approach in Happ and Greven (2018) (denoted by mFPCA hereafter) estimates cross‐covariances via scores from univariate FPCA and hence can be applied to multivariate sparse functional data. Although mFPCA is theoretically sound for dense functional data, it may not capture cross‐correlations between functions because scores from univariate FPCA for sparse functional data are shrunk towards zero.
We propose a novel and fast covariance‐based FPCA method for multivariate sparse functional data. Note that multiple auto‐covariance functions for within‐function correlations and cross‐covariance functions for between‐function correlations have to be estimated. Tensor‐product B‐splines are employed to approximate the covariance functions, and a smoothness penalty as in bivariate penalized splines (Eilers & Marx, 2003) is adopted to avoid overfit. Then, the individual estimates of covariance functions will be pooled and refined. The advantages of the new method are multifold. First, the tensor‐product B‐spline formulation is computationally efficient to handle multivariate sparse functional data. Second, a fast fitting algorithm for selecting the smoothing parameters will be derived, which alleviates the computational burden of conducting leave‐one‐subject‐out cross‐validation. Third, the tensor‐product B‐spline representation of the covariance functions enables a straightforward spectral decomposition of the covariance operator for the multivariate functional data; see Proposition 1. In particular, the eigenfunctions associated with the covariance operator are explicit functions of the B‐spline bases. Last but not the least, via a simple truncation step, the refined estimates of the covariance functions lead to a properly defined covariance operator.
Compared with mFPCA, the proposed method does not rely on scores from univariate FPCA, which could be a severe problem for sparse functional data and hence could better capture the correlations between functions. And an improved correlation estimation will lead to improved subsequent FPCA analysis and curve prediction. The proposed method also compares favourably with the local polynomial method in Chiou et al. (2014) because of the computationally efficient tensor‐product spline formulation of the covariance functions and the derived fast algorithm for selecting the smoothing parameters. Moreover, as mentioned above, there exists an explicit and easy‐to‐calculate relationship between the tensor‐product spline representation of covariance functions and the associated eigenfunctions/eigenvalues, which greatly facilitate subsequent FPCA analysis.
In addition to FPCA, there are also abundant literatures on models for multivariate functional data with most focusing on dense functional data. For clustering of multivariate functional data, see Zhu, Brown, and Morris (2012), Jacques and Preda (2014), Huang, Li, and Guan (2014), and Park and Ahn (2017). For regression with multivariate functional responses, see Zhu et al. (2012), Luo and Qi (2017), Li, Huang, and Zhu, (2017), Wong, Li, and Zhu (2019), Zhu, Morris, Wei, and Cox (2017), Kowal, Matteson, and Ruppert (2017), and Qi and Luo (2018). Graphical models for multivariate functional data are studied in (Zhu, Strawn, & Dunson, 2016) and Qiao, Guo, and James (2019). Works on multivariate functional data include also Chiou and Müller (2014, 2016).
The remainder of the paper proceeds as follows. In Section 2, we present our proposed method. We conduct extensive simulation studies in Section 3 and apply the proposed method to an Alzheimer's disease (AD) study in Section 4. A discussion is given in Section 5. All technical details are enclosed in the Appendix.
2. METHODS
2.1. Fundamentals of multivariate functional principal component analysis
Let p be a positive integer and denote by a continuous and bounded domain in the real line . Consider the Hilbert space equipped with the inner product and norm such that for arbitrary functions and in with each element in , and . Let be a set of p random functions with each function in . Assume that the p‐dimensional vector has a p‐dimensional smooth mean function, . Define the covariance function as and . Then, the covariance operator associated with the kernel C(s,t) can be defined such that for any , the kth element of Γf is given by
where C k (s,t)=(C k1(s,t),…,C kp (s,t))⊤. Note that Γ is a linear, self‐adjoint, compact, and non‐negative integral operator. By the Hilbert–Schmidt theorem, there exists a set of orthonormal bases , , and , such that
| (1) |
where d ℓ is the ℓth largest eigenvalue corresponding to Ψ ℓ . Then, the multivariate Mercer's theorem gives
| (2) |
where . As shown in Saporta (1981), x(t) has the multivariate Karhunen–Loève representation, , where are the scores with and . The covariance operator Γ has the positive semidefiniteness property; that is, for any , the covariance function of a ⊤ x, denoted by C a (s,t), satisfies that for any sets of time points with an arbitrary positive integer q, the square matrix is positive semidefinite.
2.2. Covariance estimation by bivariate penalized splines
Suppose that the observed data take the form , where is the observed time point, is the observed kth response, n is the number of subjects, and m ik is the number of observations for subject i's kth response. The model is
| (3) |
where , are random noises with zero means and variances and are independent across i,j, and k.
The goal is to estimate the covariance functions C kk ′ . We adopt a three‐step procedure. In the first step, empirical estimates of the covariance functions are constructed. Let be the residuals and be the auxiliary variables. Note that for 1 ≤ j 1 ≤ m ik ,1 ≤ j 2 ≤ m ik ′ . Thus, is an unbiased estimate of whenever k≠k ′ or j 1≠j 2. In the second step, the noisy auxiliary variables are smoothed to obtain smooth estimates of the covariance functions. For smoothing, we use bivariate P‐splines (Eilers & Marx, 2003) because it is an automatic smoother and is computationally simple. In the final step, we pool all estimates of the individual covariance functions and use an extra step of eigendecomposition to obtain refined estimates of covariance functions. The refined estimates lead to a covariance operator that is properly defined, that is, positive semidefinite. In practice, the mean functions μ (k)s are unknown, and we estimate them using P‐splines (Eilers & Marx, 1996) with the smoothing parameters selected by leave‐one‐subject‐out cross‐validation; see the Supporting Information for details. Denote the estimates by . Let and , the actual auxiliary variables.
The bivariate P‐splines model uses tensor‐product splines for 1 ≤ k,k ′ ≤ p. Specifically, , where is a coefficient matrix, {B 1(·),…,B c (·)} is the collection of B‐spline basis functions in , and c is the number of equally spaced interior knots plus the order (degree plus 1) of the B‐splines. Because , it is reasonable to impose the assumption that
so that G kk ′ (s,t)=G k ′ k (t,s). Therefore, in the rest of the section, we consider only k ≤ k ′.
Let denote a second‐order differencing matrix such that for a vector , . Also let ‖·‖ F be the Frobenius norm. For the cross‐covariance function with k<k ′, the bivariate P‐splines estimate the coefficient matrix Θ kk ′ by , which minimizes the penalized least squares
| (4) |
where and are two non‐negative smoothing parameters that balance the model fit and smoothness of the estimate and will be determined later. Indeed, the column penalty penalizes the second‐order consecutive differences of the columns of Θ kk ′ and similarly, the row penalty penalizes the second‐order consecutive differences of the rows of Θ kk ′ . The two penalty terms are essentially penalizing the second‐order partial derivatives of G kk ′ (s,t) along the s and t directions. The two smoothing parameters are allowed to differ to accommodate different levels of smoothing along the two directions.
For the auto‐covariance functions C kk (s,t) with k=1,…,p, we conduct bivariate covariance smoothing by enforcing the following constraint on the coefficient matrix Θ kk (Xiao et al., 2018):
| (5) |
It follows that G kk (s,t) is a symmetric function. Then, the coefficient matrix Θ kk and the error variance are jointly estimated by and , which minimize the penalized least squares
| (6) |
over all symmetric Θ kk and λ k is a smoothing parameter. Note that the two penalty terms in Equation (4) become the same when Θ kk is symmetric, and thus, only one smoothing parameter is needed for auto‐covariance estimation.
2.2.1. Estimation
We first introduce the notation. Let vec(·) be an operator that stacks the columns of a matrix into a column vector and denote by ⊗ the Kronecker product. Fix k and k ′ with k ≤ k ′. Let be a vector of the coefficients and denotes the B‐spline base. Then,
We now organize the auxiliary responses for each pair of k and k ′. Let , and , where is the total number of auxiliary responses for the pair of k and k ′. As for the B‐splines, let , , and .
For estimation of the cross‐covariance functions C kk ′ with k<k ′, the penalized least squares in Equation (4) can be rewritten as
| (7) |
where and . The expression in Equation (7) is a quadratic function of the coefficient vector θ kk ′ . Therefore, we derive that
and the estimate of the cross‐covariance function C kk ′ (s,t) is .
For estimation of the auto‐covariance functions, because of the constraint on the coefficient matrix in Equation (5), let be a vector obtained by stacking the columns of the lower triangle of Θ kk , and let be a duplication matrix such that θ kk =G c η k (Seber, 2008, p. 246).
Let and . Finally, let with . It follows that the penalized least squares in Equation (6) can be rewritten as
where and . Therefore, we obtain
It follows that , and the estimate of the auto‐covariance function C kk (s,t) is .
The above estimates of covariance functions may not lead to a positive semidefinite covariance operator and thus have to be refined. We pool all estimates together, and we shall use the following proposition.
Proposition 1
Assume that . Let and assume that G is positive definite (Zhou, Shen, & Wolfe, 1998). Then, admits the spectral decomposition, , where d ℓ is the ℓth largest eigenvalue of the covariance operator Γ, and is the associated eigenvector with and such that .
The proof is provided in Appendix A. Proposition 1 implies that, with the tensor‐product B‐spline representation of the covariance functions, one spectral decomposition gives us the eigenvalues and eigenfunctions. In particular, the eigenfunctions are linear combinations of the B‐spline basis functions, which means that they can be straightforwardly evaluated, an advantage of spline‐based methods compared with other smoothing methods for which eigenfunctions are approximated by spectral decompositions of the covariance functions evaluated at a grid of time points.
Once we have , the estimate of the coefficient matrix Θ kk ′ , the spectral decomposition of gives us estimates and . We discard negative to ensure that the multivariate covariance operator is positive semidefinite, and this leads to a refined estimate of the coefficient matrix Θ kk ′ , . Then, the refined estimate of the covariance functions is . Proposition 1 also suggests that the eigenfunctions can be estimated by .
For principal component analysis or curve prediction in practice, one may select further the number of principal components by either the proportion of variance explained (PVE) (Greven, Crainiceanu, Caffo, & Reich, 2010) or an Akaike information criterion‐type criterion (Li, Wang, & Carroll, 2013). Here, we follow Greven et al. (2010) using PVE with a value of 0.99.
2.2.2. Selection of smoothing parameters
We select the smoothing parameters in each auto‐covariance/cross‐covariance estimation using leave‐one‐subject‐out cross‐validation; see, for example, Yao et al. (2005) and Xiao et al. (2018). A fast approximate algorithm for the auto‐covariance has been derived in Xiao et al. (2018). So we focus on the cross‐covariance and use the notation in Equation (7). Note that there are two smoothing parameters for each cross‐covariance estimation.
For simplicity, we suppress the superscript and subscript kk ′ in Equation (7) for both and B. Let be the prediction of the auxiliary responses from the estimate using data without the ith subject. Let ‖·‖ be the Euclidean norm, and the cross‐validation error is
| (8) |
We shall also now suppress the subscript k from m ik and kk ′ from N kk ′ . Let , , and .
Then, a shortcut formula for Equation (8) is
Similar to Xu and Huang (2012) and Xiao et al. (2018), the iCV can be further simplified by adopting the approximation , which results in the generalized cross‐validation, denoted by iGCV,
| (9) |
Although iGCV is much easier to compute than iCV, the formula in Equation (9) is still computationally expensive to compute. Indeed, the smoother matrix S is of dimension 2,500×2,500 if n=100 and m i =m=5 for all i. Thus, we need to further simplify the formula.
Let , , , , , and . Also let , , and . Then, Equation (9) can be simplified as
| (10) |
Note that Σ has two smoothing parameters. Following Wood (2000), we use an equivalent parameterization , where ρ=λ 1+λ 2 represents the overall smoothing level and w=λ 1 ρ −1∈[0,1] is the relative weight of λ 1. We conduct a two‐dimensional grid search of (ρ,w), as follows. For a given w, let Udiag(s)U ⊤ be the eigendecompsition of , where is an orthonormal matrix and is the vector of eigenvalues. Then, with .
Proposition 2
Let ⊙ stand for the point‐wise multiplication. Then,
where , , , , and .
The proof is provided in Appendix A. For each w, note that only depends on ρ and needs to be calculated repeatedly, and all other terms need to be calculated only once. The entire algorithm is presented in Algorithm 1. We give an evaluation of the complexity of the proposed algorithm. Assume that m i =m for all i. The first initialization (Step 1) requires O(nm 2 c 2+nc 4+c 6) computations. For each w, the second initialization (Step 2) also requires computations. For each ρ, Steps 3–8 require O(nc 4) computations. Therefore, the formula in Proposition 2 is most efficient to calculate for sparse data with small numbers of observations per subject; that is, m i s are small.

2.3. Prediction
For prediction, assume that the smooth curve x i (t) is generated from a multivariate Gaussian process. Suppose that we want to predict the ith multivariate response x i (t) at {s i1,…,s im } for m ≥ 1. Let be the vector of observations at for the kth response. Let be the vector of the kth mean function at the observed time points. Let and . Let be the vector of mean functions at the time points for prediction.
It follows that
Thus, we obtain
Let and . Next, let and . Then, Cov(y i ) given by , and Cov(x i ) and Cov(y i ,x i ) are given by and , respectively. Let . Plugging in the estimates, we predict x i by
where is the estimate of , is the estimate of , . An approximate covariance matrix for is
Therefore, a 95% point‐wise confidence interval for the kth response is given by
where can be extracted from the diagonal of .
Finally, we predict the first L ≥ 1 scores ξ i =(ξ i1,…,ξ iL )⊤ for the ith subject. Note that . With a similar derivation as above, x i (t)− μ (t) can be predicted by . By Proposition 1, the eigenfunctions are estimated by , and thus, . It follows that
3. SIMULATIONS
We evaluate the finite sample performance of the proposed method (denoted by mFACEs) against mFPCA via a synthetic simulation study and a simulation study mimicking the Alzheimer's Disease Neuroimaging Initiative (ADNI) data in the real data example. Here, we report the details and results of the former as the conclusions remain the same for the latter, and details are provided in the Supporting Information.
3.1. Simulation settings and evaluation criteria
We generate data by model (3) with p=3 responses. The mean functions are . We first specify the auto‐covariance functions. Let , , and . Also let
Then, the auto‐covariance functions are . For the cross‐covariance functions, let for k≠k ′, where ρ∈[0,1] is a parameter to be specified. The induced covariance operator from the above specifications is proper; see Lemma 1 in Appendix B. It is easy to derive that the absolute value of cross‐correlation is bounded by ρ. Hence, ρ controls the overall level of correlation between responses: if ρ=0, then the responses are uncorrelated from each other.
The eigendecomposition of the multivariate covariance function gives nine nonzero eigenvalues with associated multivariate eigenfunctions; hence, for ℓ=1,…,9, we simulate the scores ξ iℓ from , where d ℓ are the induced eigenvalues. Next, we simulate the white noises from , where is determined according to the signal‐to‐noise ratio . Here, we let SNR=2. For each response, the sampling time points are drawn from a uniform distribution in the unit interval, and the number of observations for each subject, m ik , is generated from a uniform discrete distribution on {3,4,5,6,7}. Thus, the sampling points vary not only from subject to subject but also across responses within each subject.
We use a factorial design with two factors: the number of subjects n and the correlation parameter ρ. We let n=100,200, or 400. We let ρ=0.5, which corresponds to a weak correlation between responses as the average absolute correlation between responses is only 0.36. Another value of ρ is 0.9, which corresponds to a moderate correlation between responses as the average absolute correlation between responses is about 0.50.
In total, we have six model conditions, and for each model condition, we generate 200 datasets. To evaluate the prediction accuracy of the various methods, we draw 200 additional subjects as testing data. The true correlation functions and a sample of the simulated data are shown in the Supporting Information.
We compare mFACEs and mFPCA in terms of estimation accuracy of the covariance functions, the eigenfunctions and eigenvalues, and prediction of new subjects. For covariance function estimation, we use the relative integrated square errors (RISE). Let be an estimate of , and then RISE are given by
For estimating the ℓth eigenfunction, we use the integrated square errors (ISE), which are defined as
Note that the range of ISE is [0,2]. For estimating the eigenvalues, we use the ratio of the estimate against the truth; that is, .
For predicting new curves, we use the mean integrated square errors (MISE), which are given by
For the curve prediction using mFPCA, we truncate the number of principal components using a PVE of 0.99. It is worth noting that if no truncation is adopted, then the curve prediction using mFPCA reduces to curve prediction using univariate FPCA. We shall also consider the conditional expectation method based on the estimates of covariance functions from mFPCA. The method is denoted by mFPCA(CE), and its difference with mFACEs is that different estimates of covariance functions are used.
3.2. Simulation results
Figure 1 gives boxplots of RISEs of mFACEs and mFPCA for estimating covariance functions. Under all model conditions, mFACES outperforms mFPCA, and the improvement in RISEs as the sample size increases is much more pronounced for mFACEs. Under the model conditions with moderate correlations (ρ=0.9), the advantage of mFACEs is substantial even for the small sample size n=100.
Figure 1.
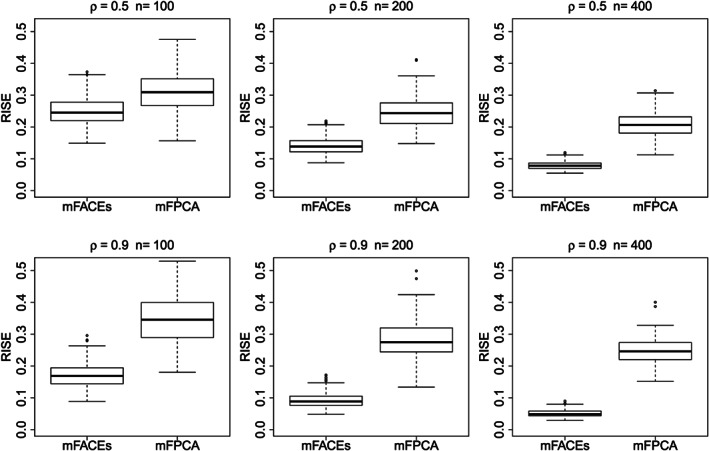
Boxplots of relative integrated square errors (RISEs) of mFACEs and mFPCA for estimating the covariance function
Figures 2 and 3 give boxplots of ISEs and violin plots of mFACEs and mFPCA for estimating the top two eigenfunctions and eigenvalues, respectively. The top two eigenvalues account for about 60% of the total variation in the functional data for ρ=0.5, and it is 80% for ρ=0.9. Figure 2 shows that although the two methods are overall comparable for estimating the first eigenfunction, mFACEs has a much better accuracy for estimating the second eigenfunction than mFPCA. The violin plots in Figure 3 show that mFACEs outperforms mFPCA substantially for estimating both eigenvalues under all model conditions. The mFPCA always underestimates the eigenvalues as the variation of scores from univariate FPCA is smaller than the true variation and hence leads to underestimates of eigenvalues.
Figure 2.
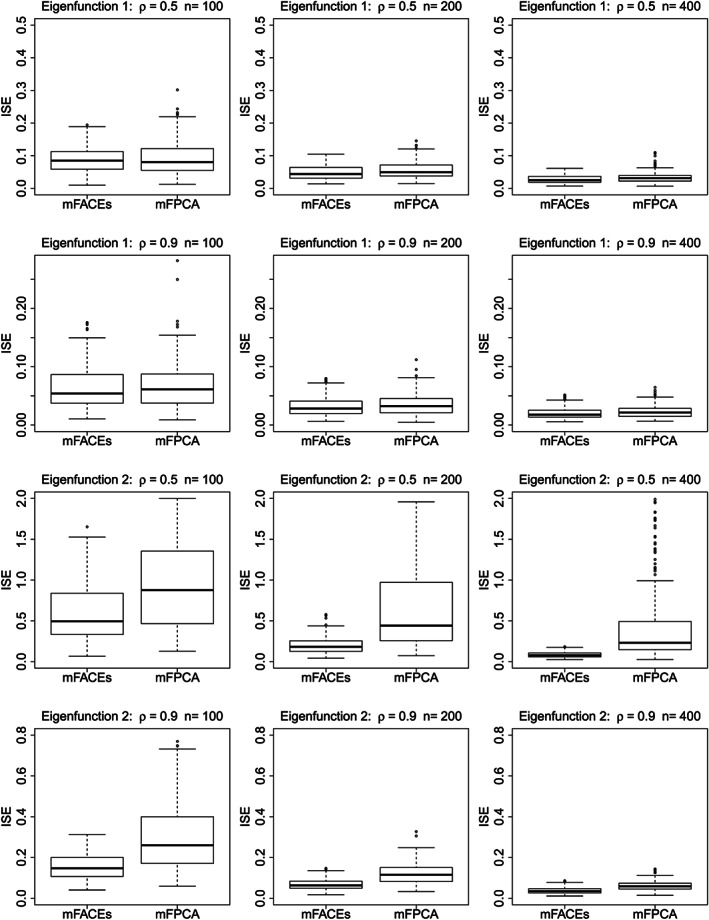
Boxplots of integrated square errors (ISEs) of mFACEs and mFPCA for estimating the top two eigenfunctions
Figure 3.
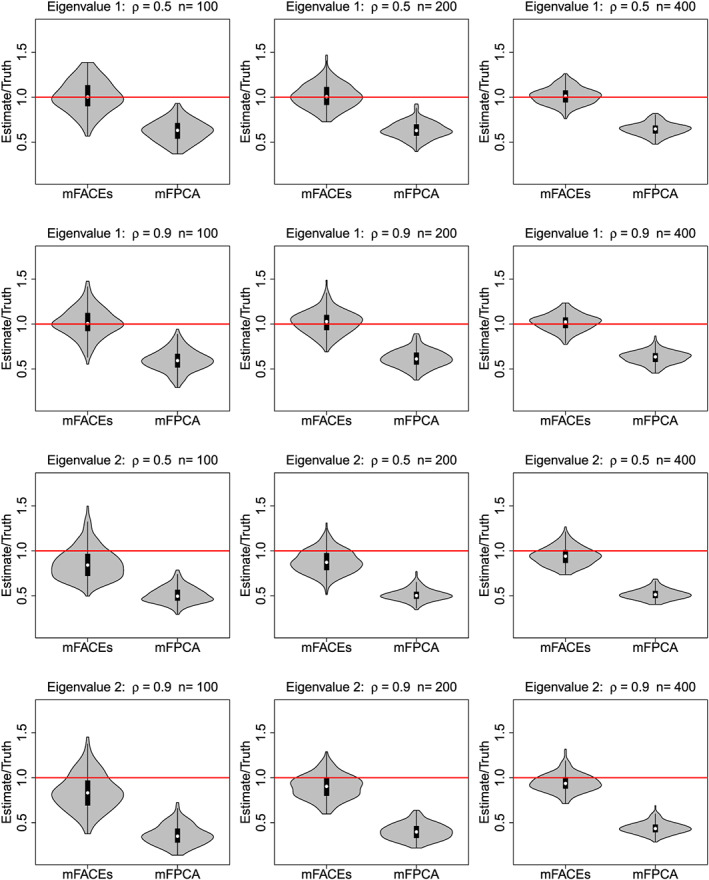
Violin plots of mFACEs and mFPCA for estimating the top two eigenvalues. The red horizontal lines indicate that the estimates are equal to the truth
Finally, we consider the prediction of new subjects by mFACEs, mFPCA, and mFPCA(CE). We define the relative efficiencies of different methods as the ratios of MISEs with respect to those of univariate FPCA; see Figure 4. Univariate FPCA is implemented in the R package face (Xiao, Li, Checkley, & Crainiceanu, 2018). We have the following findings. Under all model conditions, mFACEs has the smallest MISE, mFPCA(CE) has the second best performance, and mFPCA is close to univariate FPCA. Thus, on average, mFACEs provides the most accurate curve prediction. These results indicate that (a) mFACEs has better covariance estimation than mFPCA(CE) and so is the prediction based on it; (b) compared with mFPCA/univariate FPCA, mFPCA(CE) exploits the correlation information and hence results in better predictions.
Figure 4.
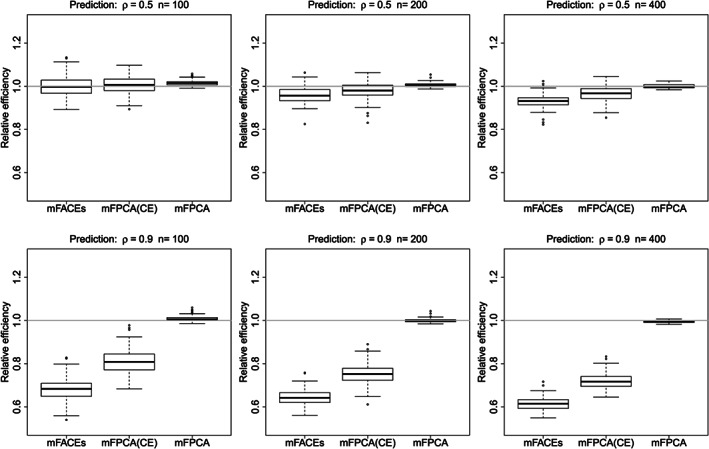
Boxplots of relative efficiency of three methods for curve prediction. The grey horizontal lines indicate the mean integrated square errors (MISEs) for univariate functional principal component analysis (FPCA)
In summary, mFACEs shows competing performance against alternative methods.
4. APPLICATION TO ALZHEIMER'S DISEASE STUDY
The ADNI is a two‐stage longitudinal observational study launched in year 2003 with the primary goal of investigating whether serial neuroimages, biological markers, clinical and neuropsychological assessments can be combined to measure the progression of AD (Weiner et al., 2017). The ADNI‐1 data from the first stage contain 379 patients with amnestic mild cognitive impairment (MCI, a risk state for AD) at baseline who had at least one follow‐up visit. Participants were assessed at baseline, 6, 12, 18, 24, and 36 months with additional annual follow‐ups included in the second stage of the study. At each visit, various neuropsychological assessments, clinical measures, and brain images were collected. The ADNI‐2 data include 424 additional patients suffering from MCI and significant memory concern, with at least one follow‐up visit and longitudinal data collected over 4 years. Thus, for the combined data, the total number of subjects is 803, and the average number of visits is 4.72. The data are publicly available at http://ida.loni.ucla.edu/.
We consider five longitudinal markers commonly measured in studies of AD with strong comparative predictive value (Li, Chan, Doody, Quinn, & Luo, 2017). Among the five markers, Disease Assessment Scale‐Cognitive 13 items (ADAS‐Cog 13), Rey Auditory Verbal Learning Test immediate recall (RAVLT.imme), Rey Auditory Verbal Learning Test learning curve (RAVLT.learn), and Mini‐Mental State Examination (MMSE) are neuropsychological assessments. Functional Assessment Questionnaire (FAQ) is a functional and behavioural assessment. High values of ADAS‐Cog 13 and FAQ indicate a high‐risk state for AD, whereas low values of RAVLT.imme, RAVLT.learn, and MMSE reflect severe cognitive impairment. The longitudinal trajectories in ADNI‐1 and ADNI‐2 are defined on the same time domain with the largest follow‐up time of 96 months from the start of ADNI‐1 (Time 0).
4.1. Multivariate FPCA via mFACEs
We analyse the five longitudinal biomarkers using mFACEs. For better visualization, we plot in Figure 5 the estimated correlation functions . The plot indicates two groups of biomarkers, ADAS‐Cog 13 and FAQ, in one group and RAVLT.imme, RAVLT.learn, and MMSE in another group. The biomarkers within the groups are positively correlated and negatively correlated between groups, which makes sense as high values of ADAS‐Cog 13 and FAQ and low values for the other biomarkers suggest of AD. Next, we display in Figure 6 the two estimated (multivariate) eigenfunctions associated with the top two estimated eigenvalues, which account for 69% and 11% of the total variance in the functional part of the data. The eigenfunctions reveal how the five biomarkers covary and how a subject's trajectories of biomarkers deviate from the population mean. Indeed, we see from Figure 6 that the first eigenfunction (solid curves) is below the zero line for ADAS‐Cog 13 and FAQ and above the zero line for the other three biomarkers. This means that the score corresponding to the first eigenfunction might be used as an indicator of AD. Indeed, a negative score for the first eigenfunction means higher‐than‐population‐mean values of the former whereas lower‐than‐population‐mean values of the latter, indicating more severe AD status. The second eigenfunction (dashed curves) for the five biomarkers is below the zero line at first and then above it or the other way around, potentially suggesting of a longitudinal pattern of the AD progression. Specifically, these subjects with a positive score for the second eigenfunction will have higher ADAS‐Cog 13/FAQ and lower RAVLT and MMSE over the months, suggesting of AD progression. Finally, we illustrate in Figure 7 the predicted curves along with the associated 95% point‐wise confidence bands for three subjects. We focus on predicting the trajectories over the first 4 years as there are more observations. We can see that the confidence bands are getting wider at the later time points because of fewer observations.
Figure 5.
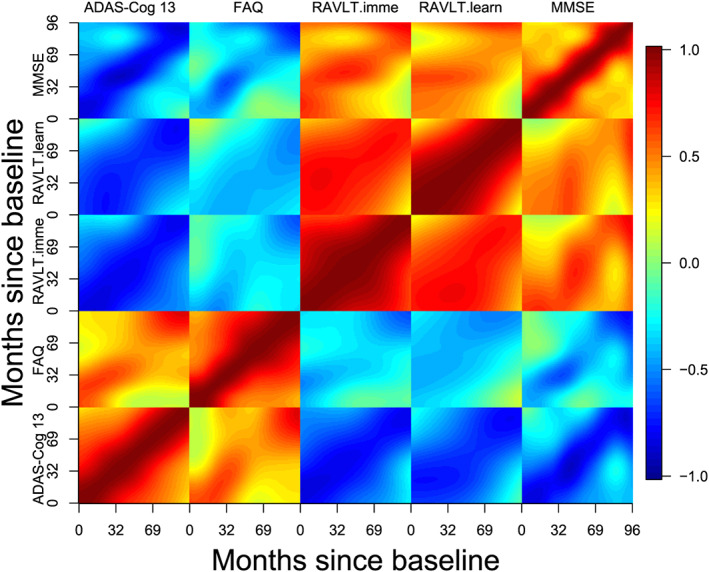
Estimated correlation functions for the longitudinal markers. ADAS‐Cog 13, Disease Assessment Scale‐Cognitive 13 items; FAQ, Functional Assessment Questionnaire; MMSE, Mini‐Mental State Examination; RAVLT.imme, Rey Auditory Verbal Learning Test immediate recall; RAVLT.learn, Rey Auditory Verbal Learning Test learning curve
Figure 6.
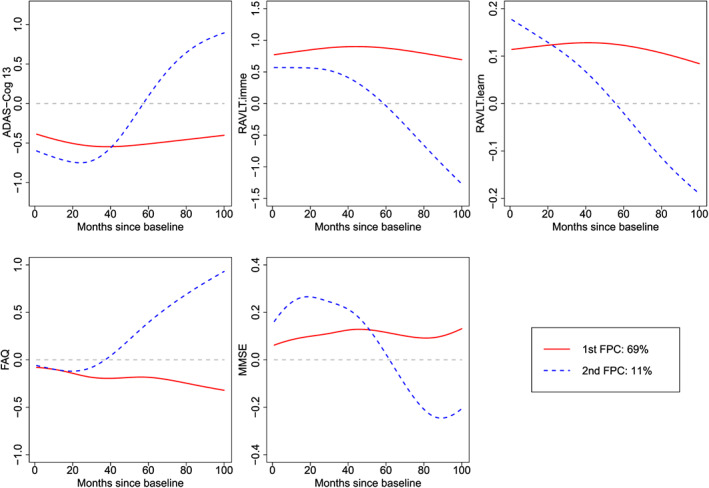
Estimated top two eigenfunctions for the longitudinal markers. ADAS‐Cog 13, Disease Assessment Scale‐Cognitive 13 items; FAQ, Functional Assessment Questionnaire; MMSE, Mini‐Mental State Examination; RAVLT.imme, Rey Auditory Verbal Learning Test immediate recall; RAVLT.learn, Rey Auditory Verbal Learning Test learning curve
Figure 7.
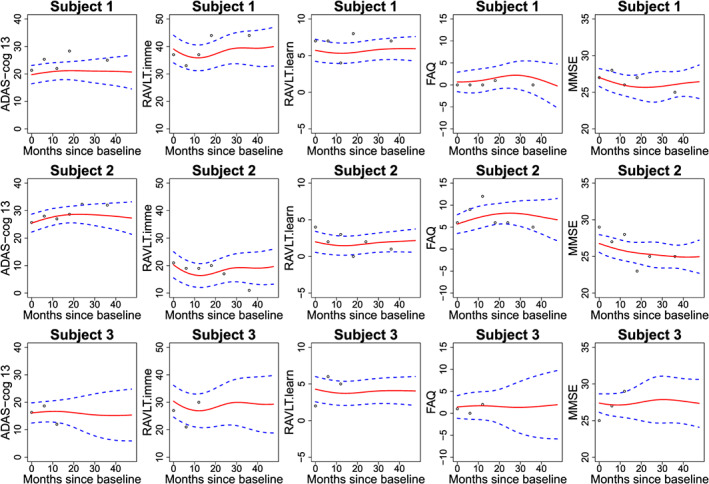
Predicted subject‐specific curves (red solid line) of the longitudinal markers and associated 95% point‐wise confidence bands (blue dashed line) for three subjects. ADAS‐Cog 13, Disease Assessment Scale‐Cognitive 13 items; FAQ, Functional Assessment Questionnaire; MMSE, Mini‐Mental State Examination; RAVLT.imme, Rey Auditory Verbal Learning Test immediate recall; RAVLT.learn, Rey Auditory Verbal Learning Test learning curve
4.2. Comparison of prediction performance of different methods
We compare the proposed mFACEs with mFPCA and mFPCA(CE) for predicting the five longitudinal biomarkers. The prediction performance is evaluated by the average squared prediction errors (APE),
where is the predicted value of the kth biomarker for the ith subject at time . We conduct two types of validation: an internal validation and an external validation. For the internal validation, we perform a 10‐fold cross‐validation to the combined data of ADNI‐1 and ADNI‐2. For the external validation, we fit the model using only the ADNI‐1 data and then predict ADNI‐2 data. Figure 8 summarizes the results. For simplicity, we present the relative efficiency of APE, which is the ratio of APEs of one method against the mFPCA. In both cases, mFACEs achieves better prediction accuracy than competing methods. Note that mFPCA(CE) outperforms mFPCA for predicting almost all biomarkers. The results suggest that (a) mFACEs is better than competing methods for analysing the longitudinal biomarkers. and (b) exploiting the correlations between the biomarkers improves prediction.
Figure 8.
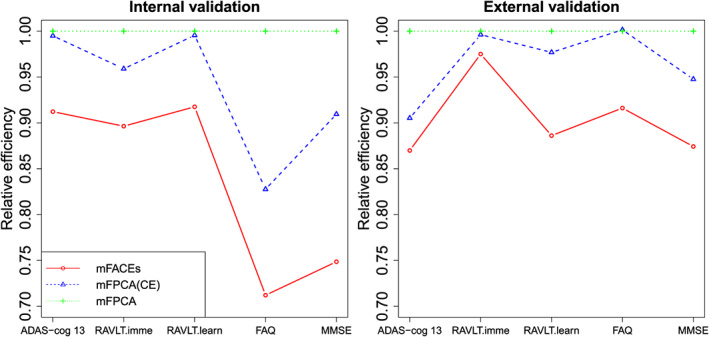
The internal and external prediction validations for the Alzheimer's Disease Neuroimaging Initiative longitudinal makers. ADAS‐Cog 13, Disease Assessment Scale‐Cognitive 13 items; FAQ, Functional Assessment Questionnaire; MMSE, Mini‐Mental State Examination; RAVLT.imme, Rey Auditory Verbal Learning Test immediate recall; RAVLT.learn, Rey Auditory Verbal Learning Test learning curve
5. DISCUSSION
The prevalence of multivariate functional data has sparked much research interests in recent years. However, covariance estimation for multivariate sparse functional data remains underdeveloped. We proposed a new method, mFACEs, and its features include the following: (a) A covariance smoothing framework is proposed to tackle multivariate sparse functional data; (b) an automatic and fast fitting algorithm is adopted to ensure the scalability of the method; (c) eigenfunctions and eigenvalues can be obtained through a one‐time spectral decomposition, and eigenfunctions can be easily evaluated at any sampling points; and (d) a multivariate extension of the conditional expectation approach (Yao et al., 2005) is derived to exploit correlations between outcomes. The simulation study and the data example showed that mFACEs could better capture between‐function correlations and thus gives improved principal component analysis and curve prediction.
When the magnitude of functional data are quite different, one may first normalize the functional data, as recommended by Chiou et al. (2014). One method of normalization is to rescale the functional data using the estimated variance function as in Chiou et al. (2014) and Jacques and Preda (2014). An alternative method is to use a global rescaling factor like as in Happ and Greven (2018). Both methods can be easily incorporated into our proposed method. In our data analysis, we find that the results with normalization are very close to those without normalization; thus, we present the results without normalization.
Because multivariate FPCA is more complex than univariate FPCA, weak correlations between the functions and small sample size may offset the benefit of conducting multivariate FPCA; see Section 7.3 in Wong et al. (2019). Thus, it is of future interest to develop practical tests to determine if correlations between multivariate functional data are different from 0.
The mFACEs method has been implemented in an R package mfaces and will be submitted to CRAN for public access.
DATA AVAILABILITY STATEMENT
Data used in preparation of this article were obtained from the Alzheimer's Disease Neuroimaging Initiative (ADNI) database (http://adni.loni.usc.edu). As such, the investigators within the ADNI contributed to the design and implementation of ADNI and/or provided data but did not participate in analysis or writing of this paper. A complete listing of ADNI investigators can be found at: http://adni.loni.usc.edu/wp‐content/uploads/how_to_apply/ADNI_Acknowledgement_List.pdf.
Supporting information
The Supporting Information contains additional details and results of a simulation that mimics the ADNI data. R package mfaces (https://github.com/cli9/mfaces) contains an open‐source implementation of the proposed method described in the article. Demo zip file contains codes to demonstrate the proposed method with a simulated dataset in Section 3.
Supporting info item
ACKNOWLEDGEMENTS
This work was supported partly by National Institute of Neurological Disorders and StrokeR01NS091307. Data collection and sharing for this project was funded by the Alzheimer's Disease Neuroimaging Initiative (ADNI) (National Institutes of Health Grant U01 AG024904) and DOD ADNI (U.S. Department of Defense Award Number W81XWH‐12‐2‐0012). ADNI is funded by the National Institute on Aging, and the National Institute of Biomedical Imaging and Bioengineering, and through generous contributions from the following: AbbVie, Alzheimer's Association; Alzheimer's Drug Discovery Foundation; Araclon Biotech; BioClinica, Inc.; Biogen; Bristol‐Myers Squibb Company; CereSpir, Inc.; Cogstate; Eisai Inc.; Elan Pharmaceuticals, Inc.; Eli Lilly and Company; EuroImmun; F. Hoffmann‐La Roche Ltd and its affiliated company Genentech, Inc.; Fujirebio; GE Healthcare; IXICO Ltd.; Janssen Alzheimer Immunotherapy Research & Development, LLC.; Johnson & Johnson Pharmaceutical Research & Development LLC.; Lumosity; Lundbeck; Merck & Co., Inc.; Meso Scale Diagnostics, LLC.; NeuroRx Research; Neurotrack Technologies; Novartis Pharmaceuticals Corporation; Pfizer Inc.; Piramal Imaging; Servier; Takeda Pharmaceutical Company; and Transition Therapeutics. The Canadian Institutes of Health Research is providing funds to support ADNI clinical sites in Canada. Private sector contributions are facilitated by the Foundation for the National Institutes of Health (www.fnih.org). The grantee organization is the Northern California Institute for Research and Education, and the study is coordinated by the Alzheimer's Therapeutic Research Institute at the University of Southern California. ADNI data are disseminated by the Laboratory for Neuro Imaging at the University of Southern California.
APPENDIX A. PROOFS OF PROPOSITIONS 1 AND 2
Define , and then . Define . According to Equation (1),
Thus, with and . As , we derive that
(B1) By Equation (2),
which gives
As 1 ≤ k,k ′ ≤ p, the above is equivalent to
Because of Equation (B1), u ℓ s are orthonormal eigenvectors of with d ℓ s the corresponding eigenvalues. The proof is now complete.
By Equation (10),
(B2) Since , we have
(B3) Similarly,
(B4) Next we derive that
It follows that
(B5) By combining Equations (B2), (B3), (B4), and (B5), the proof is complete.
APPENDIX B. LEMMA
Lemma 1
The covariance operator with the covariance functions defined in Section 4.1 is positive semidefinite.
Let and , and then is a stochastic process with covariance function
where . Let . Then
which is always positive semidefinite, and the proof is complete.
Li C, Xiao L, Luo S. Fast covariance estimation for multivariate sparse functional data. Stat. 2019:9;e245. 10.1002/sta4.245
REFERENCES
- Berrendero, J. , Justel, A. , & Svarc, M. (2011). Principal components for multivariate functional data. Computational Statistics Data Analysis, 55(9), 2619–2634. [Google Scholar]
- Cai, T. , & Yuan, M. (2010). Nonparametric covariance function estimation for functional and longitudinal data. University of Pennsylvania and Georgia Institute of Technology.
- Chiou, J. M. , Chen, Y. T. , & Yang, Y. F. (2014). Multivariate functional principal component analysis: A normalization approach. Statistica Sinica, 24(4), 1571–1596. [Google Scholar]
- Chiou, J. M. , & Müller, H. G. (2014). Linear manifold modelling of multivariate functional data. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 76(3), 605–626. [Google Scholar]
- Chiou, J. M. , & Müller, H. G. (2016). A pairwise interaction model for multivariate functional and longitudinal data. Biometrika, 103(2), 377–396. [DOI] [PubMed] [Google Scholar]
- Eilers, P. , & Marx, B. (1996). Flexible smoothing with B‐splines and penalties (with discussion). Statistical Science, 11(2), 89–121. [Google Scholar]
- Eilers, P. , & Marx, B. (2003). Multivariate calibration with temperature interaction using two‐dimensional penalized signal regression. Chemometrics and Intelligent Laboratory Systems, 66, 159–174. [Google Scholar]
- Goldsmith, J. , Crainiceanu, C. M. , Caffo, B. , & Reich, D. (2012). Longitudinal penalized functional regression for cognitive outcomes on neuronal tract measurements. Journal of the Royal Statistical Society: Series C (Applied Statistics), 61(3), 453–469. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Greven, S. , Crainiceanu, C. M. , Caffo, B. , & Reich, D. (2010). Longitudinal functional principal component. Electronic Journal of Statistical, 4, 1022–1054. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Happ, C. , & Greven, S. (2018). Multivariate functional principal component analysis for data observed on different (dimensional) domains. Journal of the American Statistical Association, 113(522), 649–659. [Google Scholar]
- Huang, H. , Li, Y. , & Guan, Y. (2014). Joint modeling and clustering paired generalized longitudinal trajectories with application to cocaine abuse treatment data. Journal of the American Statistical Association, 109(508), 1412–1424. [Google Scholar]
- Jacques, J. , & Preda, C. (2014). Model‐based clustering for multivariate functional data. Computational Statistics & Data Analysis, 71, 92–106. [Google Scholar]
- James, G. , Hastie, T. , & Sugar, C. (2000). Principal component models for sparse functional data. Biometrika, 87(3), 587–602. [Google Scholar]
- Kowal, D. R. , Matteson, D. S. , & Ruppert, D. (2017). A Bayesian multivariate functional dynamic linear model. Journal of the American Statistical Association, 112(518), 733–744. [Google Scholar]
- Leng, X. , & Müller, H. (2006). Classification using functional data analysis for temporal gene expression data. Bioinformatics, 22(1), 68–76. [DOI] [PubMed] [Google Scholar]
- Li, K. , Chan, W. , Doody, R. S. , Quinn, J. , & Luo, S. (2017). Prediction of conversion to Alzheimer's disease with longitudinal measures and time‐to‐event data. Journal of Alzheimer's Disease, 58(2), 361–371. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li, J. , Huang, C. , & Zhu, H. (2017). A functional varying‐coefficient single‐index model for functional response data. Journal of the American Statistical Association, 112(519), 1169–1181. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li, Y. , Wang, N. , & Carroll, R. J. (2013). Selecting the number of principal components in functional data. Journal of the American Statistical Association, 108(504), 1284–1294. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lindquist, M. (2012). Functional causal mediation analysis with an application to brain connectivity. Journal of the American Statistical Association, 107(500), 1297–1309. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Luo, R. , & Qi, X. (2017). Function‐on‐function linear regression by signal compression. Journal of the American Statistical Association, 112(518), 690–705. [Google Scholar]
- Morris, J. , Arroyo, C. , Coull, B. , Ryan, L. , Herrick, R. , & Gortmaker, S. (2006). Using wavelet‐based functional mixed models to characterize population heterogeneity in accelerometer profiles: A case study. Journal of the American Statistical Association, 101(476), 1352–1364. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Park, J. , & Ahn, J. (2017). Clustering multivariate functional data with phase variation. Biometrics, 73(1), 324–333. [DOI] [PubMed] [Google Scholar]
- Peng, J. , & Paul, D. (2009). A geometric approach to maximum likelihood estimation of functional principal components from sparse longitudinal data. Journal of Computational and Graphical Statistics, 18(4), 995–1015. [Google Scholar]
- Petersen, A. , & Müller, H. G. (2016). Fréchet integration and adaptive metric selection for interpretable covariances of multivariate functional data. Biometrika, 103(1), 103–120. [Google Scholar]
- Qi, X. , & Luo, R. (2018). Function‐on‐function regression with thousands of predictive curves. Journal of Multivariate Analysis, 163, 51–66. [Google Scholar]
- Qiao, X. , Guo, S. , & James, G. M. (2019). Functional graphical models. Journal of the American Statistical Association, 114(525), 211–222. [Google Scholar]
- Ramsay, J. , & Silverman, B. (2005). Functional data analysis. New York: Springer. [Google Scholar]
- Reimherr, M. , & Nicolae, D. (2014). A functional data analysis approach for genetic association studies. The Annals of Applied Statistics, 8(1), 406–429. [Google Scholar]
- Reimherr, M. , & Nicolae, D. (2016). Estimating variance components in functional linear models with applications to genetic heritability. Journal of the American Statistical Association, 111(513), 407–422. [Google Scholar]
- Reiss, P. , & Ogden, R. (2010). Functional generalized linear models with images as predictors. Biometrics, 66(1), 61–69. [DOI] [PubMed] [Google Scholar]
- Saporta, G. (1981). Méthodes exploratoires d'analyse de données temporelles. Cahiers du Bureau universitaire de recherche opérationnelle Série Recherche, 37, 7–194. [Google Scholar]
- Seber, G. (2008). A matrix handbook for statisticians. Hoboken, New Jersey: John Wiley & Sons. [Google Scholar]
- Weiner, M. W. , Veitch, D. P. , Aisen, P. S. , Beckett, L. A. , Cairns, N. J. , Green, R. C. , & Petersen, R. C. (2017). Recent publications from the Alzheimer's disease neuroimaging initiative: Reviewing progress toward improved ad clinical trials. Alzheimer's & Dementia: The Journal of the Alzheimer's Association, 13(4), e1–e85. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wong, R. K. , Li, Y. , & Zhu, Z. (2019). Partially linear functional additive models for multivariate functional data. Journal of the American Statistical Association, 114(525), 406–418. [Google Scholar]
- Wong, R. K. , & Zhang, X. (2019). Nonparametric operator‐regularized covariance function estimation for functional data. Computational Statistics & Data Analysis, 131, 131–144. [Google Scholar]
- Wood, S. N. (2000). Modelling and smoothing parameter estimation with multiple quadratic penalties. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 62(2), 413–428. [Google Scholar]
- Xiao, L. , Huang, L. , Schrack, J. , Ferrucci, L. , Zipunnikov, V. , & Crainiceanu, C. M. (2015). Quantifying the life‐time circadian rhythm of physical activity: A covariate‐dependent functional approach. Biostatistics, 16(2), 352–367. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xiao, L. , Li, C. , Checkley, W. , & Crainiceanu, C. M. (2018). R package face: Fast covariance estimation for sparse functional data (version 0.1‐4). http://cran.r‐project.org/web/packages/face/index.html. [DOI] [PMC free article] [PubMed]
- Xiao, L. , Li, C. , Checkley, W. , & Crainiceanu, C. M. (2018). Fast covariance estimation for sparse functional data. Statistics and Computing, 28(3), 511–522. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xu, G. , & Huang, J. (2012). Asymptotic optimality and efficient computation of the leave‐subject‐out cross‐validation. Annals of Statistics, 40(6), 3003–3030. [Google Scholar]
- Yao, F. , Müller, H. , & Wang, J. (2005). Functional data analysis for sparse longitudinal data. Journal of the American Statistical Association, 100(470), 577–590. [Google Scholar]
- Zhou, L. , Huang, J. Z. , & Carroll, R. J. (2008). Joint modelling of paired sparse functional data using principal components. Biometrika, 95(3), 601–619. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhou, S. , Shen, X. , & Wolfe, D. A. (1998). Local asymptotics for regression splines and confidence regions. Annals of Statistics, 26(5), 1760–1782. [Google Scholar]
- Zhu, H. , Brown, P. , & Morris, J. (2012). Robust classification of functional and quantitative image data using functional mixed models. Biometrics, 68(4), 1260–1268. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhu, H. , Li, R. , & Kong, L. (2012). Multivariate varying coefficient model for functional responses. Annals of Statistics, 40(5), 2634–2666. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhu, H. , Morris, J. S. , Wei, F. , & Cox, D. D. (2017). Multivariate functional response regression, with application to fluorescence spectroscopy in a cervical pre‐cancer study. Computational Statistics & Data Analysis, 111, 88–101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhu, H. , Strawn, N. , & Dunson, D. B. (2016). Bayesian graphical models for multivariate functional data. Journal of Machine Learning Research, 17(1), 7157–7183. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
The Supporting Information contains additional details and results of a simulation that mimics the ADNI data. R package mfaces (https://github.com/cli9/mfaces) contains an open‐source implementation of the proposed method described in the article. Demo zip file contains codes to demonstrate the proposed method with a simulated dataset in Section 3.
Supporting info item
Data Availability Statement
Data used in preparation of this article were obtained from the Alzheimer's Disease Neuroimaging Initiative (ADNI) database (http://adni.loni.usc.edu). As such, the investigators within the ADNI contributed to the design and implementation of ADNI and/or provided data but did not participate in analysis or writing of this paper. A complete listing of ADNI investigators can be found at: http://adni.loni.usc.edu/wp‐content/uploads/how_to_apply/ADNI_Acknowledgement_List.pdf.