

Abstract
This paper concerns statistical inference for longitudinal data with ultrahigh dimensional covariates. We first study the problem of constructing confidence intervals and hypothesis tests for a low dimensional parameter of interest. The major challenge is how to construct a powerful test statistic in the presence of high-dimensional nuisance parameters and sophisticated within-subject correlation of longitudinal data. To deal with the challenge, we propose a new quadratic decorrelated inference function approach, which simultaneously removes the impact of nuisance parameters and incorporates the correlation to enhance the efficiency of the estimation procedure. When the parameter of interest is of fixed dimension, we prove that the proposed estimator is asymptotically normal and attains the semiparametric information bound, based on which we can construct an optimal Wald test statistic. We further extend this result and establish the limiting distribution of the estimator under the setting with the dimension of the parameter of interest growing with the sample size at a polynomial rate. Finally, we study how to control the false discovery rate (FDR) when a vector of high-dimensional regression parameters is of interest. We prove that applying the Storey (2002)’s procedure to the proposed test statistics for each regression parameter controls FDR asymptotically in longitudinal data. We conduct simulation studies to assess the finite sample performance of the proposed procedures. Our simulation results imply that the newly proposed procedure can control both Type I error for testing a low dimensional parameter of interest and the FDR in the multiple testing problem. We also apply the proposed procedure to a real data example.
Keywords: False discovery rate, generalized estimating equation, quadratic inference function
1. Introduction.
Longitudinal data are ubiquitous in many scientific studies in biology, social science, economy, and medicine. The major challenge in traditional longitudinal data analysis is how to construct more accurate estimates for regression coefficients by incorporating the within-subject correlation. Liang and Zeger (1986) proposed generalized estimating equation (GEE) method to improve efficiency by using working correlation structure. Qu et al. (2000) proposed quadratic inference function (QIF) approach to further improve the GEE method. Theoretical results for GEE and QIF have been well established by these authors for longitudinal data with fixed dimensional covariates.
In many scientific studies such as genomic studies and neuroscience researches, the dimension of covariates d can far exceed the sample size n. Due to space limitation, we present two concrete motivating examples in the supplementary material, where d is comparable to n and d is much larger than n. Motivated by these applications, it is of great interest to develop statistical inference procedures for longitudinal data with ultra-high dimensional covariates. Variable selection and model selection for longitudinal data have been studied by Wang and Qu (2009); Xue et al. (2010) and Ma et al. (2013) under the finite dimensional setting. Wang et al. (2012) proposed penalized GEE methods under the setting of d = O(n). However, theories developed in the aforementioned works are not applicable for ultrahigh dimensional setting with log d = o(n).
Some statistical inference procedures have been developed for independent and identically distributed (i.i.d.) observations with log d = o(n). van de Geer et al. (2014); Javanmard and Montanari (2013) Zhang and Zhang (2014) developed a debiased estimator for i.i.d. data under linear and generalized linear models, and constructed confidence intervals for low-dimensional parameters. Ning and Liu (2017) proposed a hypothesis testing procedure based on a decorrelated score function method for i.i.d. data, and Fang et al. (2017) further extended the method to the partial-likelihood for survival data. These existing methods and theories are not applicable for longitudinal data under the high-dimensional setting, due to the following two challenges. First, the construction of the optimal QIF (or GEE) depends on the existence of the inverse of the sample covariance matrix of a set of high-dimensional estimating equations (Qu et al., 2000). When the number of features is greater than the sample size, the matrix is not invertible, and therefore the quadratic inference function is not well defined. Second, the existing estimation result (Wang et al., 2012) does not hold under the regime log d = o(n), so that their penalized estimator cannot be used as the initial estimator for asymptotic inference. Due to these difficulties, the existing debiased and decorrelation methods are not applicable to the quadratic inference function for ultra-high dimensional longitudinal data.
In this paper, we propose a new inference procedure for longitudinal data under the regime log d = o(n) by decorrelating the QIF. We first consider how to construct confidence intervals and hypothesis tests for a low-dimensional parameter of interest. Specifically, we start by constructing multiple decorrelated quasi-score functions following the generalized estimating equations (GEE) instead of the likelihood or partial-likelihood function developed in the literature. Each decorrelated quasi-score function aims to capture a particular correlation pattern of the repeated measurements, specified by a basis of correlation matrices. Unlike Wang et al. (2012) who estimated the nuisance parameters by penalized generalized estimating equations with unstructured correlation matrix, we estimate the nuisance parameter under the working independence assumption. This is crucial to guarantee the fast rate of convergence of a preliminary estimator under the regime log d = o(n). Then, we propose to optimally combine the multiple decorrelated quasi-score functions to improve the efficiency of the inference procedures using the generalized method of moment. The resulting loss function is a quadratic form of the decorrelated quasi-score functions and therefore we call it quadratic decorrelated inference function (QDIF). Since the dimensionality of the estimating equations is reduced by using the decorrelated quasi-score functions, its sample covariance matrix is invertible with high probability. Thus, the proposed QDIF is always well defined, whereas the QIF may not exist in high dimensions. In theory, the asymptotic properties of the estimator corresponding to QDIF are studied in the following two regimes. First, when the parameter of interest is of fixed dimension, we show that the proposed estimator is asymptotically normal and attains the semiparametric information bound, based on which we can construct an optimal Wald test statistic. Second, when the dimension of the parameter of interest grows with the sample size at a polynomial rate, we give the characterization of the limiting distribution of the proposed estimator and the associated test statistic.
To further broaden the applicability of the proposed method, we study the following multiple testing problem:
for j = 1,…, d, where β* = (β1, ⋯ , βd)T is regression coefficient vector. The null hypothesis H0j is rejected if our test statistic for is greater than a cutoff. To guarantee most of the rejected null hypothesis being real discoveries, we aim to control the false discovery rate (FDR) within a given significance level by choosing a suitable cutoff for our test statistics. Due to the correlation among repeated measurements, the test statistics for different null hypothesis H0j become correlated, which makes the FDR control challenging. While the Benjamini-Hochberg method can control FDR if the test statistics are independent or positively dependent (Benjamini and Hochberg, 1995; Benjamini and Yekutieli, 2001), unfortunately, these dependence structures do not hold for our test statistics. To control FDR, we apply the procedure in Storey (2002), which is known to be more powerful than the Benjamini-Hochberg method. Our main result shows that the proposed method can control FDR asymptotically under the dependent test statistics. The intuition is that, by decorrelating the quasi-score function, the correlation among different test statistics becomes weak so that the correlation only contributes to the higher order terms in the FDR approximation, which can be well controlled. The proof of this result relies on a moderate deviation lemma of Liu (2013), who apply the Benjamini-Hochberg procedure to control FDR under Gaussian graphical models. While the FDR control under linear models is recently studied by G’Sell et al. (2016); Barber and Candès (2015), the corresponding sequential procedure and the knockoff method cannot be directly extended to the longitudinal data, due to the dependence structure. To the best of our knowledge, how to control FDR in the analysis of longitudinal data under the generalized linear model remains an open problem. Finally, we note that the proposed method is a general recipe for correlated data which can be easily modified to handle family data and clustered data. To facilitate the presentation, we consider the longitudinal data throughout the paper.
Paper Organization.
The rest of this paper is organized as follows. In Section 2, we propose the QDIF method and the resulting estimator. We further derive the asymptotic distribution of the estimator and construct the test statistic and confidence interval. In Section 3, we consider the FDR control problem. In Section 4, we investigate the empirical performance of the proposed methods using simulation examples and real data example. The proof and technical details are deferred to Appendix. Proofs of technical lemmas are given in the supplementary material of this paper (Fang et al., 2018).
Notation.
We adopt the following notation throughout this paper. For a vector and 1 ≤ q ≤ ∞, we define , and let ∥v∥0 = ∣supp(v)∣, where supp(v) = {j : vj ≠ 0}, and ∣A∣ is the cardinality of a set A. Denote ∥v∥∞ = max1≤i≤d ∣vi∣ and v⊗2 = vvT. For a matrix , let ∥M∥max = max1≤j,k≤d ∣Mjk∣, ∥M∥1 = ∑jk ∣Mjk∣ and ∥M∥∞ = maxj ∑k ∣Mjk∣. If the matrix M is symmetric, we let λmin(M) and λmax(M) be the minimal and maximal eigenvalues of M, respectively. We denote by Id the d × d identity matrix. For S ⊆ {1, …, d}, let vS = {vj : j ∈ S}, and let be the complement of S. The gradient and subgradient of a function f(x) are denoted by ∇f(x) and ∂f(x), respectively. Let ∇Sf(x) denote the gradient of f(x) with respect to xS. For two positive sequences an and bn, we write if C ≤ an/bn ≤ C′ for some constants C, C′ > 0. Similarly, we use a ≲ b to denote a ≤ Cb for some constant C > 0. For a sequence of random variables Xn, we write , for some random variable X, if Xn converges weakly to X, and we write Xn →p a, for some constant a, if Xn converges in probability to a. Given , let a ∨ b and a ∧ b denote the maximum and minimum of a and b, respectively. For notational simplicity, we use C, C′ to denote generic constants, and their values may change from line to line.
2. Inference in High-Dimensional Longitudinal Data.
Let Yij denote the response variable for the j-th observation of the i-th subject, where j = 1, …, mi and i = 1, …, n. Let denote the corresponding d-dimensional covariates. Our proposed procedure are still directly applicable for the setting in which mis are different from subject to subject, but the correlation structure such as the AR and compound symmetry retains the same. We refer to the supplementary material for further discussion. In most applications, m is relatively small comparing with n and d, and we assume throughout the paper that m is fixed.
Denote by and . We further assume that (Xi, Yi), i = 1, · · ·, n, are independent, while the within-subject observations are correlated.
2.1. Quadratic inference function in low-dimensional setting.
Under the framework of generalized linear models, we assume that the regression function follows , where μij(·) is a known function and with β* being the regression coefficient vector. Liang and Zeger (1986) proposed the GEE method to incorporate the within subject correlation to improve the estimation efficiency of β*. A brief description of this method is given in the Section S.2 of the supplementary material (Fang et al., 2018). The GEE yields consistent estimators for any working correlation structure, while the resulting estimator can be far less efficient when the working correlation structure is misspecified. To overcome this drawback, Qu et al. (2000) proposed an alternative approach called QIF, which avoids direct estimation of the correlation structure, and provides optimal estimator even if the working correlation structure is misspecified. Denote by , , and Vi = Cov(Yi∣Xi) is the true covariance matrix of Yi. We can decompose Vi as . Here, R is the corresponding correlation matrix and Ai(β) is a diagonal matrix in which the (j, j)-th entry is the variance of Yij given the covariates and can be written as [Ai(β)]jj = ϕVij(μij), where ϕ is the dispersion parameter and Vij(·) is a given variance function. We further assume that , which corresponds to the canonical link function under generalized linear models (while we do not impose the distributional assumptions as in GLMs). As seen later, the quasi-score function (2.1) is proportional to the dispersion parameter ϕ, and thus the root of the quasi-score function does not depend on ϕ. For simplicity, we assume ϕ = 1 in the rest of the paper.
In QIF, it is assumed that R−1 can be approximated by the linear space generated by some known basis matrices T1,…,TK, i.e., , where a1,…, aK are unknown parameters. Given these basis matrices, the quasi-score function of β is defined as
| (2.1) |
The QIF proposed by Qu et al. (2000) is
| (2.2) |
which combines the quasi-score function gn(β) using the generalized method of moment. Naturally, we estimate β by
| (2.3) |
Qu et al. (2000) showed that is -consistent and efficient under the classical fixed dimensional regime. The “large n, diverging d” asymptotics is studied under the generalized additive partial linear models by Wang et al. (2014) when d = o(n1/5). The variable selection consistency of the penalized QIF estimator is established under the same conditions.
While the estimation and variable selection properties of the penalized GEE and QIF methods have been investigated under the regime d = O(nα) for some α ≤ 1, how to perform optimal estimation and inference by incorporating the unknown correlation structure remains a challenging problem under the ultra-high dimensional regime, i.e., log d = o(nα) for some α > 0. In particular, to optimally combine the quasi-score function in QIF, one has to calculate in (2.2). However, does not exist when d > n. This is the main difficulty for extending the QIF method to high-dimensional data.
2.2. Optimal inference under high-dimensional setting.
In this section, we consider how to make inference on a low-dimensional component of the parameter β in longitudinal data. We focus on the high-dimensional regime, i.e., log d = o(nα) for some α > 0, which is a more challenging setting in comparison with existing works. For ease of presentation, we partition the vector β as β = (θT, γT)T, where θ is a d0-dimensional parameter of interest with d0 ≪ n, and γ is a high-dimensional nuisance parameter with dimension d−d0. Our goal is to construct the confidence region and test the hypotheses H0 : θ* = 0 versus H1 : θ* ≠ 0. Similarly, we denote the corresponding partition of Xi by Xi = (Zi, Ui), where and . In this section, we assume that there exists an initial estimator which converges to the true β* sufficiently fast. Section 2.3 presents a procedure to construct such an initial estimator .
Before we propose the new procedure, we note that inference in high-dimensional problems has been studied under the linear and generalized linear models with independent data (van de Geer et al., 2014; Zhang and Zhang, 2014; Javanmard and Montanari, 2013; Ning and Liu, 2017). Their methods require the existence of a (pseudo)-likelihood function and a penalized estimator such as Lasso. One may attempt to apply their methods to the associated quasi-likelihood of longitudinal data. However, this simple approach is only feasible under the working independence assumption and in general leads to sub-optimal results as the within-subject correlation is ignored (Liang and Zeger, 1986). To increase the efficiency, one may incorporate the within-subject correlation and apply their methods to the quadratic inference function Qn in (2.2). As explained above, the matrix Cn in (2.2) is not invertible in high dimensions, and the function Qn is not well-defined. Thus, we cannot directly apply the existing methods for efficient inference in high-dimensional longitudinal data.
To address the challenges, we propose a novel quadratic decorrelated inference function (QDIF) approach. Our proposed method relies on the generalized estimating equations and is distinguished from the methods that directly correct the bias of the Lasso type estimators. Instead, we modify the decorrelation idea in Ning and Liu (2017) to construct estimating equations that are insensitive to the impact of high-dimensional nuisance parameters. As aforementioned, how to design the decorrelation step is challenging in the setting of high-dimensional longitudinal data, as a (pseudo)-likelihood function is not available. Unlike the decorrelated score function constructed from the likelihood in Ning and Liu (2017), we construct a decorrelated quasi-score function directly from the generalized estimating equations in (2.1). Borrowing the idea from the QIF method, we replace the inverse of correlation matrix R−1 in GEE by , for some unknown parameters a1, …, aK and some pre-specified basis matrices T1, …,TK. For any 1 ≤ i ≤ n and 1 ≤ k ≤ K, we define the decorrelated quasi-score function for subject i with correlation basis Tk as
| (2.4) |
where , to be defined later, is an estimator of the decorrelation matrix for the k-th basis Tk, and is an initial estimator defined in Section 2.3. In comparison with the component of the standard quasi-score function gn(β) in (2.1), decorrelates the score functions for Zi and Ui by projection via . Denote
and Hkθθ is defined similarly. Then, we define the estimator in (2.4) as
| (2.5) |
where wkl is the (k, l)-th element of W, and λ′ is a tuning parameter. This estimator is introduced to estimate the true decorrelation matrix
| (2.6) |
Then, we define the decorrelated quasi-score function of θ by combining ‘s from the different basis matrices,
| (2.7) |
Note that the decorrelated quasi-score function is of dimension d0K instead of dimension dK as gn(β) in (2.1). As d0. K ≪ n in our setting, this decorrelated quasi-score function can be used to define the optimal quadratic inference function . In particular, given our initial estimator , we define our QDIF estimator as
| (2.8) |
Here is a neighborhood around the initial estimator for some small constant c > 0 and
| (2.9) |
Since is generally a nonconvex function of θ, there may exist multiple local solutions, especially when d0 is large. To alleviate these issues, we propose the above localized estimator by minimizing in a small neighborhood around the initial estimator . In the theoretical analysis, we show that is strongly convex for θ ∈ Θn with probability tending to one. Thus, any off-the-shelf convex optimization algorithm is applicable to solving the problem (2.8).
2.3. An initial estimator based on working independence structure.
As seen in the previous section, the decorrelated quasi-score function (2.4) requires the knowledge of an initial estimator of β. In this subsection, we shall construct such an initial estimator in the ultra-high dimensional regime, i.e., log d = o(nα) for some α > 0.
Since the initial estimator is only used to estimate the nuisance parameter in (2.4), we allow the estimator to be less efficient in terms of incorporating the within-subject dependence. The following penalized maximum quasi-loglikelihood estimator under the working independence structure serves this purpose,
| (2.10) |
where
Here is known as the negative quasi-loglikelihood under the working independence assumption, and is a penalization term encouraging sparsity of with some tuning parameter λ > 0. The penalization term can be either convex such as Lasso (Tibshirani, 1996) or nonconvex (e.g., SCAD (Fan and Li, 2001)). Before we pursue the statistical properties of further, let us introduce some definitions.
Definition 2.1 (Sub-exponential variable and sub-exponential norm). A random variable X is called sub-exponential if there exists some positive constant K1 such that for all t ≥ 0. The sub-exponential norm of X is defined as .
Furthermore, denoting by s = ∥β*∥0 the sparsity of β*, we impose the following assumptions.
Assumption 2.1. Assume that the error is sub-exponential, i.e., ∥ϵij∥ψ1 ≤ C for some constant C > 0. The covariates are uniformly bounded, .
Note that the sub-exponential and bounded covariate assumptions are technical assumptions in concentration inequalities and hold in most applications. Similar assumptions are widely used in the literature, e.g., van de Geer et al. (2014) and Ning and Liu (2017), for analyzing high-dimensional generalized linear models.
Assumption 2.2. For any set where and any vector v belonging to the cone , it holds that
This assumption is known as the restricted eigenvalue condition (Bühlmann and Van De Geer, 2011), and provides the necessary curvature of the loss function within a cone. Specifically, it bounds the minimal eigenvalue of the Hessian matrix from below within the cone . Under Assumptions 2.1 and 2.2 and the technical conditions in Section 2.4, if and , a simple modification of Theorem 5.2 in van de Geer and Müller (2012) implies
| (2.11) |
| (2.12) |
The rate in (2.11) shows that even if we ignore the correlation structure, the penalized maximum quasi-loglikelihood estimator still converges to β* with the optimal rate in the high-dimensional regime. Assumption 2.2 can be further relaxed by using nonconvex penalties and more tailored statistical optimization algorithms as discussed in Loh and Wainwright (2013); Wang et al. (2013); Fan et al. (2015); Zhao et al. (2018). It can be easily verified that, Assumption 2.2 holds under the conditions in the next subsection and the minimum eigenvalue condition on the population matrix . For ease of presentation, we assume that Assumptions 2.1 and 2.2 hold throughout our later discussion, and therefore the rate of convergence (2.11) and (2.12) is achieved.
2.4. Theoretical properties.
In this subsection, we establish the asymptotic distribution of in (2.8). In the analysis, we assume m, K are fixed, and n, d increase to infinity with log d = o(nα) for some α > 0. To make the proposed framework more flexible, we allow d0 to diverge together with n and d. We note that the theoretical results also hold for fixed d0.
To facilitate our discussion, we impose some technical assumptions. Let
| (2.13) |
| (2.14) |
be the “ideal” versions of and , respectively. Also, we let
| (2.15) |
denote the population version of the gradient of S*(θ) at θ*, and let
| (2.16) |
denote the population version of the matrix .
Assumption 2.3. The decorrelation matrix is column-wise sparse, i.e., , for 1 ≤ k ≤ K. and .
Assumption 2.4. The mean function μij(·) is third order continuously differentiable and satisfies
Assumption 2.5. The eigenvalues of Tk and C* are bounded, i.e., C−1 ≤ λmin(Tk) ≤ λmax(Tk) ≤ C for any 1 ≤ k ≤ K, C−1 ≤ λmin(C*) ≤ λmax(C*) ≤ C. In addition, the following eigenvalue conditions on the design matrix hold, and for some constant C > 0.
Assumption 2.3 specifies the sparsity of and the bounded covariate effect, which ensure the fast rate of convergence of the estimators . To understand the sparsity assumption on , let us consider d0 = 1. Denote and . If there exists such that
| (2.17) |
we can verify that for any 1 ≤ k ≤ K. For instance, if μij(ηij) is a quadratic function (corresponding to the Gaussian response) and for 1 ≤ j ≤ m follows the Gaussian design, then (2.17) holds and the sparsity assumption on (and W* in (2.17)) is implied by the sparsity of Σ−1, which is a standard condition for high-dimensional inference in the generalized linear model (van de Geer et al., 2014).
Assumption 2.4 provides some local smoothness conditions of μi(·)’s around ‘s, and it is easy to verify that this assumption is satisfied for many commonly used regression functions μij(·). In Assumption 2.5, we require the basis matrices Tk to be positive definite. In practice, we usually choose the following matrices as the bases: T1 an identity matrix Im, a matrix of diagonal elements set to be 0’s and off-diagonal elements set to be 1’s, a matrix with two main diagonals set to be 1’s and 0’s elsewhere, and with 1’s on the corners (1, 1) and (m, m) and 0 elsewhere. As shown by Qu et al. (2000), the commonly used equal-correlation and AR(1) models can be written as the linear combination of the above four basis matrices. However, the matrices , and are not positive definite. To meet Assumption 2.5, we can add an identity matrix to and define for some constant λ > 0. The eigenvalue condition on C* in Assumption 2.5, as we shall see later, guarantees the existence of the asymptotic variance, which is even essential in the low-dimensional setting. Finally, the minimum eigenvalue condition on is used to verify the restricted eigenvalue condition for and the maximum eigenvalue condition on is used to control ∥Hkθθ∥2, especially when d0 diverges.
Denote to be the maximum absolute column sum of the matrix A. The following lemma shows the rate of convergence of the estimation and prediction errors of .
Lemma 2.6. Under Assumptions 2.1, 2.2, 2.3, 2.4 and 2.5, if and , we have
where .
Based on Lemma 2.6, we first establish the rate of convergence of the decorrelated estimator in (2.8).
Theorem 2.7. Under Assumptions 2.1, 2.2, 2.3, 2.4 and 2.5, if , and as n, d → ∞,
| (2.18) |
then the rate of convergence of the estimator is
| (2.19) |
When the dimension of θ* diverges, the convergence rate (2.19) is comparable to Theorem 3.6 of Wang (2011), in which the author showed that the convergence rate of the GEE estimator is with diverging number of covariates d = o(n1/2). This also agrees with our condition d0 = o(n1/2) in (2.18). When d0 is fixed, (2.19) implies that the estimator has the standard root-n rate under the sparsity condition (s ∨ s′) log d log n = o(n1/2), which agrees with the weakest possible assumption in the literature for generalized linear models up to logarithmic factors in d and n (van de Geer et al., 2014).
In order to conduct valid inference, we need to understand the asymptotic distribution of the estimator. The following main theorem of this section establishes the asymptotic normality of our estimator .
Theorem 2.8. Under Assumptions 2.1, 2.2, 2.3, 2.4 and 2.5, if , and as n, d → ∞,
| (2.20) |
then the estimator satisfies, as d0 → ∞,
| (2.21) |
where and g0(θ) is defined in (2.15). If d0 is fixed, we have
| (2.22) |
Theorem 2.8 characterizes the asymptotic distribution of the decorrelated estimator. In particular, we note that Theorem 2.8 holds whether or not the inverse of the within-subject correlation matrix R−1 is correctly specified via the basis matrices {Tk}. Thus, similar to the classical QIF and GEE methods, our estimator is robust to the specification of the within-subject dependence structure.
When d0 diverges, (2.21) can be interpreted as , and one can further approximate by N(d0, 2d0). To justify the normal approximation of the decorrelated estimator, the required condition d0 = o(n1/3) in (2.20) is stronger than that in Theorem 2.7, and again it is comparable to the condition in Theorem 3.8 of Wang (2011). When d0 is fixed, (2.22) implies that the estimator is asymptotically normal under the same sparsity condition (s ∨ s′) log d log n = o(n1/2) as in Theorem 2.7. Moreover, if is correctly specified, as shown in Corollary 2.10, our estimator is semiparametrically efficient.
In order to use the above result to construct confidence regions and statistical tests, we need to estimate the asymptotic variance Σθ in (2.21). This can be accomplished by using the plug-in estimator
| (2.23) |
Lemma 2.9. Under the same assumptions as in Theorem 2.8, we have as d0 → ∞,
where Σθ and are defined in (2.21) and (2.23), respectively. If d0 is fixed,
where denotes the chi-square distribution with d0 degrees of freedom.
Consider the following hypothesis testing problem
Based on the above result, we define the Wald-type test statistic as follows,
| (2.24) |
Lemma 2.9 implies that the distribution of the test statistic can be approximated by a chi-squared distribution with d0 degrees of freedom under H0. In addition, we can obtain an asymptotic (1 − α) × 100% confidence region of θ*:
where denotes the (1 − α) × 100%-th percentile of a chi-square distribution with d0 degrees of freedom.
To conclude this section, we compare the efficiency of the proposed estimator with the decorrelated estimator based on the quasi-likelihood. The latter corresponds to the special case of the estimator (2.8) with K = 1 and T1 = I. Consider the case d0 = 1. We denote the estimator by . The following corollary shows that our estimator is more efficient than and attains the semiparametric information bound. Thus, the proposed QDIF method provides the optimal inference for high-dimensional longitudinal data.
Corollary 2.10. Assume that the assumptions in Theorem 2.8 hold. By taking T1 = I, we obtain , where Avar denotes the asymptotic variance of the estimator. Moreover, if the true correlation matrix R satisfies for some constants a1, …, aK and (2.17) holds, then the proposed estimator is semiparametrically efficient.
3. False Discovery Rate Control.
In the previous section, we develop valid inferential methods to test a low-dimensional parameter of interest in high-dimensional longitudinal data. However, in many practical applications, the parameter of interest may not be pre-specified. Instead, we are interested in simultaneously testing all d hypotheses with θ = βj, i.e., versus for all j = 1, …, d. The knowledge of which null hypotheses are rejected can help us identify important features in the longitudinal data. When conducting multiple hypothesis tests, it is a common practice to control the false discovery rate (FDR) to avoid spurious discoveries. Under the high-dimensional setting, due to the potential dependence among test statistics, how to control FDR is a challenging problem. In this direction, Liu (2013) and Barber and Candès (2015) applied the Benjamini-Hochberg procedure and the knockoff procedure to control the FDR under the Gaussian graphical model and linear model, respectively. Both of their methods crucially depend on the linearity structure and are not directly applicable to the generalized linear model, let alone generalized estimating equations for longitudinal data. Thus, the FDR control for high-dimensional longitudinal data is still largely unexplored, while is of substantial practical importance.
In this section, we extend the procedure discussed in the previous section to control the FDR in multiple hypothesis testing for versus where j = 1, …, d. We first construct the test statistic for hypothesis H0j, where is defined as in (2.23). Then we obtain the asymptotic p-value , where is the cumulative distribution function of a chi-squared random variable with degree of freedom 1. Given a decision rule that rejects H0j if and only if Pj ≤ u for some cutoff u, we define the false discovery proportion (FDP) and false discovery rate (FDR) as
where denotes the set of true null hypotheses. Given the desired FDR level α, we aim to find the cutoff such that . However, in practice we cannot directly compute FDP(u) and FDR(u) as the set is unknown. To approximate FDP(u), we utilize the following procedure proposed by Storey (2002), which is known to be more powerful than the Benjamini-Hochberg procedure. Let t ∈ (0, 1) be a tuning parameter. For any u ∈ (0, 1), we define
| (3.1) |
as an approximation of FDP(u), where
Comparing (3.1) with FDP(u), the denominators are identical. For the numerator, by taking expectation, we have that , as Pj ~ Uniform(0, 1) asymptotically for all . It turns out the quantity π(t) in (3.1) tends to slightly overestimate , the proportion of null hypotheses among all hypotheses. To see this, we have , where is usually small as Pj are close to 0 if . This leads to a slightly conservative cutoff. However, we show in the proof that this overestimation is asymptotically negligible, i.e., in probability as in the setting of sparse high-dimensional model. Since , we force π(t) ≤ 1 by taking the minimum with 1 in the definition of π(t).
Given , we define to be the largest value of u such that is controlled at level α:
Then, we reject all the null hypotheses of which the corresponding p-values are below .. It is easily seen that the well known Benjamini-Hochberg procedure corresponds to choosing π(t) = 1 in . By introducing π(t) ≤ 1, the cutoff of p-values is no smaller than that in the Benjamini-Hochberg procedure, and therefore leads to more discoveries. Thus, the method is more powerful than the Benjamini-Hochberg procedure. In the literature, the theoretical justification of Storey (2002)’ procedure requires that the p-values are independent and uniformly distributed under the null hypothesis. To prove the validity of the procedure, the main technical difficulty is that the p-values from the proposed test statistics are not independent and their distribution holds only asymptotically. For 1 ≤ j ≤ d, we define
where , and denote the corresponding g0, C* and in the previous section for , and is defined in (2.21) with d0 = 1. Denote , where Ωjk is the correlation between Aij and Aik. For some constant C > 0, let denote the set of strong signals. As the main result in this section, the following theorem shows that our procedure controls the FDR and FDP asymptotically.
Theorem 3.1. Assume that Assumptions 2.1, 2.2, 2.3, 2.4 and 2.5 hold for all βj and . In addition, assume n−1/2s(log d)(log n) = o(1/log d), s/d = o(1), for some constant C > 0, and
| (3.2) |
Let c > 0 be a small constant. For any t ∈ [c, 1), we have as n, d → ∞,
In the following, we comment on the conditions in the theorem. First, we require n−1/2s(log d)(log n) = o(1/log d), which is identical to the condition in Theorem 2.8 for fixed d0 up to a logarithmic factor of d. This guarantees the validity of the p-values under the null asymptotically. Since we consider the sparse model, most βj’s are 0 implying s/d = o(1). We also require the number of strong signals tends to infinity, , which is needed to control FDP. We require to apply the moderate deviation lemma of Liu (2013). While we cannot allow d to grow exponentially fast in n as in Theorem 2.8, by choosing C > 1, d can still be much larger than n. Finally, (3.2) imposes conditions on the correlation of the test statistics. Recall that Ωjk is the correlation between Aij and Aik. Denote . If ∣Ωjk∣ ≤ a for some constant a < 1, then (3.2) holds under the assumption for some small δ > 0. In particular, under (2.17) and Assumption 2.3, we can show that and therefore (3.2) is true provided d is sufficiently large. Thus, the FDR and FDP control is still feasible under dependent test statistics provided their correlation satisfies (3.2).
4. Numerical Studies.
In this section, we evaluate the numerical performance of our proposed method by Monte Carlo simulation and a real data example. We further provide more simulation results in Supplementary Material Section S.4.
4.1. Simulation studies.
We first assess the empirical performance of the proposed method using simulated data. In all settings, we randomly select s out of the d components to be nonzero. We consider two settings where the nonzero components are all 1’s (in what follows, we refer to this setting as Dirac), or each of the nonzero components are generated from a uniform distribution over [0, 2] independently. We consider linear model where each , and ϵij follows a normal distribution with variance equals 1. Note that the noise ϵij’s are correlated with other ϵij′’s as specified later. The cardinality s of the active set is set as 5, 10 or 20, and we let d = 200, 500, 1000, and n = 50, 100. In each simulation, we generate the covariate for each (i, j), where the -th element of Σ equals , and ρ = 0.25, 0.4, 0.6 or 0.75. We set m = 3 or 5, and we take the within-subject correlation to be either equal-correlation model or AR(1) model. In our method, we include a broad class of matrices as the basis for the inverse of the correlation matrix. Specifically, we generate data from either the equal-correlation model or AR(1) model, and include the basis matrices discussed in Section 2.4. For ease of presentation, we investigate Type I error, false discovery rate and power of our method.
We first consider the empirical Type I error. Specifically, we apply the proposed method to test the null hypothesis , which we assume to be true in our setting. The tuning parameters λ and λ′ are determined by the five-fold cross validation. The simulation is repeated 1,000 times. We report the empirical Type I error at 5% significance level in Tables 1 and 2. It is clearly seen that the proposed test can control the empirical Type I errors at the desired nominal level. This implies the asymptotic distribution of our test statistic is reasonably accurate in finite sample.
Table 1.
Empirical Type I error rate (%) under equal-correlation with correlation parameter being 0.5. The nominal level is set to be 5%.
| ρ = 0.25 | ρ = 0.4 | ρ = 0.6 | ρ = 0.75 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| (n, d) | s | Dirac | U[0, 2] | Dirac | U[0, 2] | Dirac | U[0, 2] | Dirac | U[0, 2] |
| m = 3 | |||||||||
| (50,200) | 5 | 5.9 | 5.5 | 5.5 | 5.3 | 5.8 | 4.7 | 4.4 | 4.6 |
| 10 | 5.9 | 5.9 | 5.2 | 4.8 | 4.8 | 5.8 | 5.1 | 4.9 | |
| 20 | 6.1 | 5.7 | 5.9 | 4.8 | 6.2 | 6.0 | 5.4 | 5.5 | |
| (100,500) | 5 | 5.6 | 5.4 | 5.7 | 5.2 | 6.0 | 5.9 | 4.7 | 5.1 |
| 10 | 5.8 | 5.2 | 5.5 | 5.3 | 5.8 | 5.3 | 3.9 | 5.4 | |
| 20 | 5.7 | 4.9 | 5.4 | 4.9 | 5.6 | 4.0 | 6.2 | 5.7 | |
| (100,1000) | 5 | 5.3 | 5.7 | 5.8 | 5.5 | 5.8 | 6.3 | 5.1 | 4.5 |
| 10 | 5.9 | 5.4 | 5.3 | 5.5 | 5.3 | 5.1 | 4.0 | 4.3 | |
| 20 | 6.1 | 5.8 | 5.6 | 5.7 | 5.5 | 4.3 | 6.8 | 6.2 | |
| m = 5 | |||||||||
| (50,200) | 5 | 5.5 | 5.2 | 5.3 | 5.2 | 5.4 | 5.1 | 5.0 | 4.8 |
| 10 | 5.3 | 5.2 | 5.3 | 5.1 | 4.9 | 5.5 | 5.3 | 5.0 | |
| 20 | 5.3 | 5.4 | 5.4 | 5.3 | 5.7 | 5.3 | 5.3 | 5.6 | |
| (100,500) | 5 | 5.3 | 5.3 | 5.5 | 5.3 | 5.4 | 5.6 | 4.9 | 5.2 |
| 10 | 5.5 | 5.4 | 5.4 | 5.1 | 5.6 | 5.5 | 4.7 | 4.8 | |
| 20 | 5.5 | 5.3 | 5.3 | 5.0 | 4.8 | 4.4 | 5.8 | 5.9 | |
| (100,1000) | 5 | 5.2 | 5.5 | 5.5 | 5.4 | 5.5 | 5.8 | 5.3 | 5.4 |
| 10 | 5.6 | 5.7 | 5.0 | 5.6 | 5.2 | 5.3 | 4.4 | 4.5 | |
| 20 | 5.9 | 5.6 | 5.3 | 5.5 | 5.4 | 4.8 | 5.7 | 6.0 | |
Table 2.
Empirical Type I error rate (%) under AR-correlation structure with correlation parameter being 0.6. The nominal level is set to be 5%.
| ρ = 0.25 | ρ = 0.4 | ρ = 0.6 | ρ = 0.75 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| (n, d) | s | Dirac | U[0, 2] | Dirac | U[0, 2] | Dirac | U[0, 2] | Dirac | U[0, 2] |
| m = 3 | |||||||||
| (50,200) | 5 | 5.4 | 5.3 | 5.4 | 5.5 | 5.2 | 5.0 | 5.3 | 5.1 |
| 10 | 4.6 | 5.1 | 5.4 | 4.8 | 5.1 | 5.3 | 5.1 | 5.2 | |
| 20 | 5.8 | 5.7 | 5.2 | 5.5 | 5.6 | 5.2 | 4.7 | 5.4 | |
| (100,500) | 5 | 5.4 | 5.1 | 5.6 | 5.3 | 5.5 | 5.3 | 5.2 | 5.3 |
| 10 | 5.5 | 5.6 | 5.7 | 5.4 | 5.8 | 5.6 | 5.3 | 5.5 | |
| 20 | 5.6 | 4.8 | 5.8 | 5.3 | 5.3 | 4.5 | 4.6 | 4.6 | |
| (100,1000) | 5 | 5.3 | 5.4 | 4.8 | 4.7 | 5.3 | 5.9 | 5.7 | 5.6 |
| 10 | 5.4 | 5.6 | 5.3 | 5.4 | 5.5 | 5.3 | 4.6 | 4.4 | |
| 20 | 6.1 | 5.8 | 5.6 | 5.7 | 5.5 | 5.3 | 5.9 | 5.7 | |
| m = 5 | |||||||||
| (50,200) | 5 | 5.2 | 5.2 | 5.3 | 5.6 | 5.1 | 5.2 | 5.4 | 5.0 |
| 10 | 5.1 | 5.3 | 5.2 | 5.1 | 5.3 | 5.2 | 5.2 | 5.3 | |
| 20 | 5.5 | 5.6 | 5.3 | 5.4 | 5.5 | 5.1 | 4.8 | 5.3 | |
| (100,500) | 5 | 5.3 | 5.3 | 5.4 | 5.5 | 5.4 | 5.2 | 5.1 | 5.2 |
| 10 | 5.2 | 5.7 | 5.6 | 5.5 | 4.8 | 4.9 | 5.2 | 5.6 | |
| 20 | 5.5 | 5.8 | 5.5 | 5.4 | 5.6 | 5.2 | 4.9 | 4.7 | |
| (100,1000) | 5 | 5.5 | 5.7 | 5.4 | 5.6 | 5.5 | 5.6 | 5.4 | 5.7 |
| 10 | 5.6 | 5.7 | 5.2 | 5.5 | 5.6 | 5.4 | 5.2 | 5.3 | |
| 20 | 5.8 | 6.1 | 5.8 | 5.7 | 6.0 | 5.9 | 4.5 | 4.3 | |
Next, we consider the empirical false discovery rate by applying the methods described in Section 3. In particular, we simultaneously test all d hypotheses that for all j = 1, …, d. After getting d different p-values, we apply the proposed method under the level α = 0.1 or 0.2. Under the same data generating schemes for investigating empirical Type I error, we repeat the simulation 1,000 times and report the averaged false discovery rate in Tables 3 and 4. We find that the empirical false discovery rates are well controlled under different settings. Furthermore, we plot the empirical false discovery rate against the nominal false discovery rate from 0 to 1 in Figure 1 under several settings. Our approach well controls the false discovery rate for different desired levels. It is worth noting that in the second subfigure, the empirical FDR deviates from the nominal one as the maximum possible false discovery rate is (d − s)/d = 90% when (s, d) = (20, 200).
Table 3.
Empirical false discovery rate (%) at level α = 0.1 and 0.2 under equal-correlation structure with correlation parameter being 0.5.
| ρ = 0.25 | ρ = 0.4 | ρ = 0.6 | ρ = 0.75 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| α | 0.1 | 0.2 | 0.1 | 0.2 | 0.1 | 0.2 | 0.1 | 0.2 | |
| (n, d) | s | m = 3 | |||||||
| (50,200) | 5 | 9.3 | 19.1 | 9.6 | 19.6 | 8.9 | 18.9 | 10.6 | 20.8 |
| 10 | 8.8 | 19.3 | 9.2 | 18.9 | 9.3 | 20.7 | 10.4 | 21.0 | |
| 20 | 8.7 | 18.7 | 8.8 | 18.8 | 9.4 | 19.3 | 9.4 | 20.9 | |
| (100,500) | 5 | 9.6 | 19.2 | 10.3 | 20.2 | 11.0 | 20.9 | 10.9 | 21.3 |
| 10 | 9.7 | 20.1 | 9.5 | 21.1 | 8.7 | 20.8 | 8.8 | 20.8 | |
| 20 | 9.4 | 18.9 | 9.2 | 18.9 | 10.5 | 20.3 | 11.1 | 21.3 | |
| (100,1000) | 5 | 10.4 | 20.8 | 9.5 | 20.7 | 9.2 | 21.3 | 9.4 | 20.6 |
| 10 | 9.5 | 21.2 | 9.2 | 20.6 | 9.1 | 20.9 | 9.8 | 20.9 | |
| 20 | 9.3 | 21.8 | 8.9 | 21.5 | 8.7 | 22.0 | 12.1 | 21.4 | |
| m = 5 | |||||||||
| (50,200) | 5 | 9.5 | 19.7 | 9.4 | 19.5 | 9.2 | 19.3 | 10.0 | 20.5 |
| 10 | 9.1 | 19.5 | 9.6 | 19.2 | 9.1 | 21.3 | 10.7 | 20.4 | |
| 20 | 9.2 | 19.1 | 9.0 | 19.0 | 9.5 | 18.9 | 9.8 | 18.9 | |
| (100,500) | 5 | 9.3 | 20.5 | 9.7 | 21.0 | 10.6 | 20.3 | 10.2 | 20.7 |
| 10 | 9.5 | 19.7 | 9.6 | 21.3 | 9.8 | 20.4 | 9.5 | 21.3 | |
| 20 | 9.7 | 19.4 | 9.5 | 19.2 | 9.5 | 19.3 | 10.9 | 18.5 | |
| (100,1000) | 5 | 9.8 | 20.4 | 10.8 | 20.4 | 8.9 | 19.3 | 9.6 | 19.5 |
| 10 | 9.2 | 20.7 | 9.3 | 20.4 | 9.3 | 20.5 | 9.5 | 20.7 | |
| 20 | 9.1 | 21.0 | 10.5 | 19.2 | 9.2 | 21.7 | 11.3 | 20.6 | |
Table 4.
Empirical false discovery rate (%) at level α = 0.1 and 0.2 under AR-correlation structure with correlation parameter being 0.6
| ρ = 0.25 | ρ = 0.4 | ρ = 0.6 | ρ = 0.75 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| α | 0.1 | 0.2 | 0.1 | 0.2 | 0.1 | 0.2 | 0.1 | 0.2 | |
| (n, d) | s | m = 3 | |||||||
| (50,200) | 5 | 9.6 | 20.3 | 9.8 | 20.4 | 10.1 | 20.5 | 9.7 | 19.4 |
| 10 | 9.4 | 20.3 | 9.5 | 20.8 | 10.4 | 19.5 | 9.8 | 20.9 | |
| 20 | 10.8 | 19.5 | 10.6 | 21.2 | 10.0 | 19.3 | 9.6 | 18.8 | |
| (100,500) | 5 | 10.3 | 20.6 | 10.5 | 20.5 | 9.5 | 20.1 | 10.3 | 19.8 |
| 10 | 10.4 | 19.5 | 9.6 | 20.3 | 9.5 | 20.8 | 10.4 | 21.0 | |
| 20 | 8.9 | 20.8 | 9.3 | 19.2 | 8.8 | 21.0 | 8.7 | 20.9 | |
| (100,1000) | 5 | 10.5 | 20.6 | 10.6 | 20.7 | 9.3 | 19.2 | 9.2 | 20.3 |
| 10 | 10.5 | 20.7 | 10.8 | 19.5 | 10.2 | 19.4 | 9.7 | 20.4 | |
| 20 | 8.7 | 20.5 | 11.3 | 20.7 | 10.4 | 20.1 | 10.9 | 20.6 | |
| m = 5 | |||||||||
| (50,200) | 5 | 10.3 | 20.1 | 10.0 | 20.3 | 9.8 | 20.5 | 9.9 | 19.8 |
| 10 | 9.7 | 20.3 | 9.6 | 20.8 | 10.4 | 19.4 | 9.4 | 20.7 | |
| 20 | 9.6 | 19.5 | 9.5 | 19.3 | 10.5 | 20.9 | 10.8 | 20.8 | |
| (100,500) | 5 | 9.5 | 20.3 | 9.8 | 20.6 | 9.6 | 19.7 | 20.4 | 20.4 |
| 10 | 9.4 | 20.8 | 10.1 | 20.7 | 10.9 | 20.8 | 9.3 | 20.8 | |
| 20 | 10.3 | 20.5 | 9.2 | 21.1 | 10.5 | 20.9 | 9.1 | 19.5 | |
| (100,1000) | 5 | 10.7 | 20.8 | 10.5 | 19.5 | 9.8 | 20.0 | 9.6 | 19.5 |
| 10 | 10.6 | 20.5 | 10.8 | 20.9 | 9.2 | 20.8 | 8.9 | 21.1 | |
| 20 | 11.0 | 21.2 | 9.3 | 19.6 | 9.5 | 20.3 | 8.8 | 18.7 | |
Fig 1:
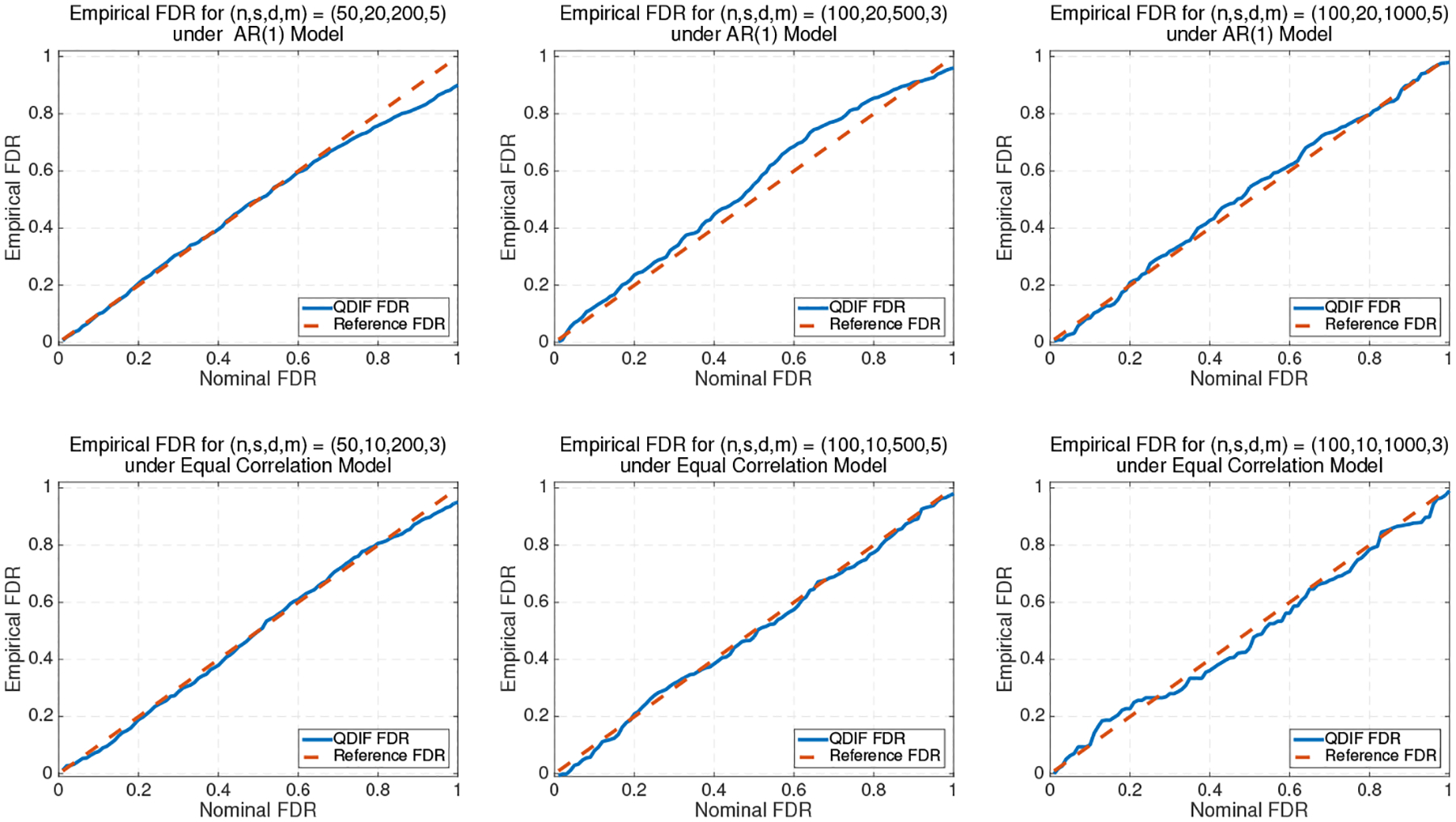
Empirical FDR of the proposed method in AR(1) and equal correlation models, where we take the correlation parameter as 0.75.
Finally, we investigate the empirical power of the proposed test, and compare it with some other high-dimensional inference procedures: the debiased Lasso method (Zhang and Zhang, 2014; van de Geer et al., 2014) and the decorrelation method (Ning and Liu, 2017) by pretending all observations are independent. In particular, we test H0 : β1 = 0, under the Dirac setting, where the signal of β1 gradually increase from 0 to 0.7, and we investigate the empirical rejection rate for different settings. The results are summarized in Figure 2. As expected, our QDIF approach achieves better empirical power, especially when the signal is weak and s is relatively large. This is in line with our theoretical results.
Fig 2:

Empirical power for quadratic decorrelated inference (QDIF), debiased Lasso and decorrelation methods under AR(1) and equal correlation models, where we take the correlation parameter as 0.75.
4.2. BMI dataset.
We further evaluate our method using a BMI genomic dataset from the Framingham Heart Study (FHS). This is a long-term, ongoing cardiovascular study beginning in 1948 under the direction of the National Heart, Lung and Blood institute (NHLBI) on residents of the town of Framingham, Massachusetts. The objective is to identify the important characteristics that contribute to cardiovascular disease. We refer to Jaquish (2007) for more details of the study. Recently, 913,854 SNPs from 24 chromosomes have been genotyped from the Offspring Cohort study. We investigate the issue of obesity as the body mass index (BMI), where BMI = weight(kg)/height(m)2. Our dataset contains BMI of 977 samples, where each sample’s BMI value is collected at 26 times. Since there are some missing values presented in the response of different samples, we first adopt n = 234 samples with time points mi’s ranging from 3 to 7 where their BMI values are recorded. The nonrare SNPs genotypes from the twenty three chromosomes are also recorded. Taking the BMI values as response variables Y, we first screen the features by regressing the BMI values on each of the SNPs, and only keep the SNPs with marginal P-value less than 0.05. This reduces the dimension to d = 4,294. Then, for the jth SNP we treat this covariate as Z in Section 2 and the rest of the covariates as U. We apply the proposed QDIF method to test whether the jth SNP is associated with BMI, where we use the same basis matrices as in the simulations. The obtained p-value is recorded as Pj as in Section 3. We repeat this procedure for all the SNPs, which yields a sequence of p-values P1, …, Pd. When we select important SNPs based on these p-values, we need to account for the fact that we have been looking at a large number of candidate SNPs (the so called multiple testing effect). Failure to account for the multiple testing effect causes irreproducibility of the results and may yield misleading scientific conclusions. Given the practical importance of this problem, we developed a rigorous result on the FDR control. Applying our result to the data analysis, we find that the 12289th position of the 1st chromosome, 681st, 756th and 19880th SNPs of the 10th chromosome, and 1189th and 12075th SNPs of the 20th chromosome are the significant SNPs under the FDR at 10%. Interestingly, it is known that the 10th and 20th chromosomes are related to the obesity (Dong et al., 2003), which matches our results that the significant SNPs are mostly located at the 10th and 20th chromosomes.
5. Technical Lemmas and Proofs.
5.1. Technical lemmas.
In this subsection, we provide some technical lemmas used in our proofs in Sections 2 and 3. The proofs of these technical lemmas are given in the supplementary material Fang et al. (2018).
The first lemma on the rate of convergence of random matrices in the spectral norm is derived from the matrix Bernsteins inequality and is fundamental for the rest of the proof.
Lemma 5.1. Suppose that Assumptions 2.1 – 2.5 and hold. Then
| (5.1) |
and
| (5.2) |
Lemma 5.2. Recall that and . Under the conditions in Theorem 2.7, we have
Lemma 5.3. Recall that in (2.9), where , and in (2.16), where . Under the conditions in Theorem 2.7, we have
Lemma 5.4. Under the same conditions as in Theorem 2.7, we have,
Lemma 5.5. Recall that , where . Under the same conditions as in Theorem 2.7, we have
Lemma 5.6. Let c be a small constant. Under the conditions in Theorem 2.7, uniformly over it holds that with probability tending to one
for some positive constant C.
Lemma 5.7. Suppose Assumptions 2.1, 2.2, 2.3, 2.4 and 2.5 hold for all for j ∈ [d], and suppose that and n−1/2s(log d)(log n) = o(1/log d). Let the “ideal” version of be
| (5.3) |
where , and denote corresponding g0, C* and in the previous section for , and let the ideal version of be
where σj is defined in (2.21). We have that converges to such that as n → ∞,
and
Lemma 5.8. Suppose the conditions in Theorem 3.1 holds. Let rd be any sequence such that rd → ∞ as d → ∞, and . Then we have
in probability.
5.2. Proof of main results.
Proof of Theorem 2.7. Since under condition (2.18), we claim that θ* lies in Θn with probability tending to one. By the definition of , it holds that , which further implies
By Lemma 5.6, the left hand side is lower bounded by . Thus, by Cauchy-Schwartz inequality,
Together with Lemma 5.5, we have , which completes the proof.
Proof of Theorem 2.8. We first note that
This implies belongs to the interior of Θn. By the first order optimality condition, satisfies
By the mean-value theorem for vector valued functions, for each component of , say there exists for some ζj ∈ [0, 1] such that . For notational simplicity, we suppress the subscript j in , and write it as
Thus, we have
Define
Then, it holds that . Putting together Lemmas 5.2, 5.3 and 5.4, we can show that
with some tedious algebraic manipulation similar to the proof of Lemma 5.6. In addition, we can show that
Combining the above results, we have
To show the limiting distribution of , we first note that
by Theorem 2.7 and the assumed conditions. Thus, it suffices to show the limiting distribution of . Note that . Theorem 1.1 in Bentkus (2003) implies
where is the set of all Euclidean balls in , C is a positive constant and are d0 independent N(0, 1). Finally, we obtain for any ,
where Φ(·) is the c.d.f. of a standard normal distribution and C′ is a absolute constant from the standard Berry-Esseen bound. The same probability can be lower bounded by using the same argument. Thus, as d0, n→ ∞, converges weakly to N(0, 1). When d0 is fixed, the Layponov condition for holds for any and thus . Finally, we obtain (2.22) by applying the Cramer-Wald device.
Proof of Theorem 3.1. For notational simplicity, we suppress the dependence of on t. By the definition of FDP(u) and , we have
| (5.5) |
We first show that in probability. We prove a moderate deviation result for this quantity. By assumption, we have . Let rd be a sequence such that rd → ∞ as d → ∞, and . We first prove that as n → ∞. Note that
Hence, for any , we have
| (5.6) |
Recall that . By extending the proof of Theorem 2.8, we get
| (5.7) |
For any , we have
Therefore, we have that
where in the last inequality we used the condition that for and . If , hence for large enough d. Moreover, by (5.7)
Hence we get . Therefore, by (5.6), we conclude that , uniformly over . Therefore, we have
which implies that in L1 and in probability. Hence, we have
As , we conclude that in probability, and hence by the definition of , we obtain
| (5.8) |
Hence, by (5.8) and Lemma 5.8, we conclude that in probability. Finally, by the definition of π(t), we have
If we have
We have , and in probability. Moreover, given any t ∈ [c, 1), for d large enough, we have t ≥ rd/d. Hence by Lemma (5.8), we have in probability. Hence we conclude that in probability. On the other hand, if , we have .
Putting together the above results and by (5.5), we get and similarly in probability, hence concluding the proof.
Supplementary Material
Acknowledgment.
The authors are grateful for the AE and reviewers for their constructive comments, which lead to a significant improvement of the earlier version of this paper. Li is the corresponding author, and he also received partial travel support from NNSFC grants 11690014 and 11690015 during his visit at Chinese Academy of Sciences and Nankai University.
* Supported by NIH grant P50 DA039838 and NSF grant DMS 1820702.
† Supported by NSF grant DMS 1854637.
‡ Supported by NSF grant DMS 1820702, NIH grants P50 DA039838 and T32 LM012415.
References.
- Barber RF and Candès EJ (2015). Controlling the false discovery rate via knockoffs. Ann. Statist, 43 2055–2085. [Google Scholar]
- Benjamini Y and Hochberg Y (1995). Controlling the false discovery rate: A practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. B 289–300. [Google Scholar]
- Benjamini Y and Yekutieli D (2001). The control of the false discovery rate in multiple testing under dependency. Ann. Statist 1165–1188. [Google Scholar]
- Bentkus V (2003). On the dependence of the Berry-Esseen bound on dimension. Journal of Statistical Planning and Inference, 113 385–402. [Google Scholar]
- Bühlmann P and Van De Geer S (2011). Statistics for High-Dimensional Data: Methods, Theory and Applications. Springer Science & Business Media. [Google Scholar]
- Dong C, Wang S, Li W-D, Li D, Zhao H and Price RA (2003). Interacting genetic loci on chromosomes 20 and 10 influence extreme human obesity. Amer. J. Hum. Genet, 72 115–124. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan J and Li R (2001). Variable selection via nonconcave penalized likelihood and its oracle properties. J. Amer. Statist. Asooc, 96 1348–1360. [Google Scholar]
- Fan J, Liu H, Sun Q and Zhang T (2015). TAC for sparse learning: Simultaneous control of algorithmic complexity and statistical error. arXiv preprint arXiv:1507.01037 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fang EX, Ning Y and Li R (2018). Supplement to “Test of significance for high-dimensional longitudinal data”. [DOI] [PMC free article] [PubMed]
- Fang EX, Ning Y and Liu H (2017). Testing and confidence intervals for high dimensional proportional hazards models. J. R. Stat. Soc. Ser. B, 79 1415–1437. [DOI] [PMC free article] [PubMed] [Google Scholar]
- G’Sell MG, Wager S, Chouldechova A and Tibshirani R (2016). Sequential selection procedures and false discovery rate control. J. R. Stat. Soc. Ser. B, 78 423–444. [Google Scholar]
- Jaquish CE (2007). The framingham heart study, on its way to becoming the gold standard for cardiovascular genetic epidemiology? BMC Med. Genet, 8 63. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Javanmard A and Montanari A (2013). Confidence intervals and hypothesis testing for high-dimensional statistical models. In Advances in Neural Information Processing Systems. 1187–1195. [Google Scholar]
- Liang K-Y and Zeger SL (1986). Longitudinal data analysis using generalized linear models. Biometrika, 73 13–22. [Google Scholar]
- Liu W (2013). Gaussian graphical model estimation with false discovery rate control. Ann. Statist, 41 2948–2978. [Google Scholar]
- Loh P-L and Wainwright MJ (2013). Regularized M-estimators with nonconvexity: Statistical and algorithmic theory for local optima. In Advances in Neural Information Processing Systems. 476–484. [Google Scholar]
- Ma S, Song Q and Wang L (2013). Simultaneous variable selection and estimation in semiparametric modeling of longitudinal/clustered data. Bernoulli, 19 252–274. [Google Scholar]
- Ning Y and Liu H (2017). A general theory of hypothesis tests and confidence regions for sparse high dimensional models. Ann. Statist, 45 158–195. [Google Scholar]
- Qu A, Lindsay BG and Li B (2000). Improving generalised estimating equations using quadratic inference functions. Biometrika, 87 823–836. [Google Scholar]
- Storey JD (2002). A direct approach to false discovery rates. J. R. Stat. Soc. Ser. B, 64 479–498. [Google Scholar]
- Tibshirani R (1996). Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B 267–288. [Google Scholar]
- van de Geer S, Bühlmann P, Ritov Y and Dezeure R (2014). On asymptotically optimal confidence regions and tests for high-dimensional models. Ann. Statist, 42 1166–1202. [Google Scholar]
- van de Geer S and Müller P (2012). Quasi-likelihood and/or robust estimation in high dimensions. Stat. Sci 469–480. [Google Scholar]
- Wang L (2011). GEE analysis of clustered binary data with diverging number of covariates. Ann. Statist, 39 389–417. [Google Scholar]
- Wang L, Kim Y and Li R (2013). Calibrating non-convex penalized regression in ultra-high dimension. Ann. Statist, 41 2505. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang L and Qu A (2009). Consistent model selection and data-driven smooth tests for longitudinal data in the estimating equations approach. J. R. Stat. Soc. Ser. B, 71 177–190. [Google Scholar]
- Wang L, Xue L, Qu A and Liang H (2014). Estimation and model selection in generalized additive partial linear models for correlated data with diverging number of covariates. Ann. Statist, 42 592–624. [Google Scholar]
- Wang L, Zhou J and Qu A (2012). Penalized generalized estimating equations for high-dimensional longitudinal data analysis. Biometrics, 68 353–360. [DOI] [PubMed] [Google Scholar]
- Xue L, Qu A and Zhou J (2010). Consistent model selection for marginal generalized additive model for correlated data. J. Amer. Statist. Assoc, 105 1518–1530. [Google Scholar]
- Zhang C-H and Zhang SS (2014). Confidence intervals for low dimensional parameters in high dimensional linear models. J. R. Stat. Soc. Ser. B, 76 217–242. [Google Scholar]
- Zhao T, Liu H and Zhang T (2018). Pathwise coordinate optimization for sparse learning: Algorithm and theory. Ann. Statist, 46 180–218. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.