

Abstract
Humankind is generating digital data at an exponential rate. These data are typically stored using electronic, magnetic or optical devices, which require large physical spaces and cannot last for a very long time. Here we report the use of peptide sequences for data storage, which can be durable and of high storage density. With the selection of suitable constitutive amino acids, designs of address codes and error-correction schemes to protect the order and integrity of the stored data, optimization of the analytical protocol and development of a software to effectively recover peptide sequences from the tandem mass spectra, we demonstrated the feasibility of this method by successfully storing and retrieving a text file and the music file Silent Night with 40 and 511 18-mer peptides respectively. This method for the first time links data storage with the peptide synthesis industry and proteomics techniques, and is expected to stimulate the development of relevant fields.
Subject terms: Proteomics, Biotechnology, Computational biology and bioinformatics, Mass spectrometry
Finding durable, high-density media for data storage is necessary to support the ever-expanding generation of digital data. Here, the authors use peptide sequences to store digital data and retrieve them using tandem mass spectrometry, proving that peptides can be used as a storage medium.
Introduction
From the beginning of civilization, the media for storing data have been continuously evolving from such as stone tablets, animal bones, and bamboo tablets to paper, with improvements on data density over time. Since the invention of electronics in the last century, the percentage of data stored in digital form has been increasing rapidly to almost 100% recently1. Moreover, the amount of data generated has been increasing exponentially, from several ZB in 2008 to expected 74 ZB in 2021, causing a much increased demand for data storage correspondingly2. Most of the digital data are stored in physical media such as hard drives. In addition, many of the data are rarely accessed and are archived on reels of magnetic tapes. However, the physical thickness of the tapes and the size of magnetic domains limit the maximum data density, which is expected to reach a plateau soon. Furthermore, data in old tapes need to be copied onto new tapes regularly, as the magnetic tapes can normally last for 10 to 20 years only. This process is time-consuming and expensive. Hence, next-generation media that can store digital data with a much higher data density and durability are needed.
One of the emerging technologies to fulfill this need is storing digital data in molecules. A widely reported technique is data storage with deoxyribonucleic acid (DNA), where the capability of DNA data storage had advanced from several bytes decades ago3 to hundreds-MB-scale recently4–6. While early examples did not achieve complete data recovery7, the data integrity has been improving by incorporating error-correction schemes in DNA data storage, from simple repetitions8 towards more complex and efficient schemes such as Reed–Solomon (RS) code9 and fountain code10. DNA could offer much higher data density than magnetic tapes11 and store information for thousands of years9.
In addition to DNA, other molecules were investigated for storing digital data. For example, Roy et al. encoded data in synthetic polymers such as poly(alkoxyamine amide)s12, and Huang et al. transformed the data into binary trees and encoded the transformed data in dendrimers13. Very recently, Cafferty et al. encoded data in organic molecules using a set of molecules with different masses representing the 0 and 1 in digital data and read out using matrix-assisted laser desorption/ionization mass spectrometry14.
Here we report the use of peptide sequences for digital data storage, a method that has not been reported before15. Compared to DNA and other types of polymers, peptides offer several advantages for data storage. Firstly, in DNA, typically only four natural nucleotides are used as monomers due to the requirement of enzyme recognition for PCR amplification and high-throughput sequencing. In synthetic peptides, a much greater variety of monomers (amino acids) can be incorporated because enzyme recognition is not mandatory in the synthesis and sequencing of peptides. In addition to the 20 natural amino acids, many unnatural amino acids can be used. The increased set of possible monomers and lower masses than those of nucleotides could in principle allow peptides to have a higher density than DNA for data storage. Secondly, peptides can be more stable than DNA. It has been shown that after millions of years, peptides or proteins could still be detected and sequenced but DNA had already degraded16,17. Comparing to DNA, peptides cannot be amplified with techniques such as polymerase chain reaction (PCR). However, using tandem mass spectrometry (MS/MS)-based techniques, peptides can be detected and sequenced with good sensitivity and direct data readout without PCR-like preprocessing18–20. Moreover, the field of proteomics has been developing rapidly with constantly improving methods, hardware and software to allow sequencing of thousands of peptides within a very short time;21,22 the peptide synthesis industry has been established, and the price for peptide synthesis continues to decrease. Thus comparing to other polymers or small molecules, peptides could better leverage the established methodologies and industry for design and sequencing.
Results and discussion
We have developed a method for data storage using peptide sequences, with the precise ordering of amino acids encoding the order of digital bits. As shown in Fig. 1, in our method, amino acids are assigned as sequences of digital bits (Table 1). Raw data are first encoded as long strings of 0 s and 1 s, which correspond to sequences of amino acids, i.e., peptides, according to the assignments. The peptides are synthesized and hence the data are stored. To retrieve the data, the peptides are sequenced, and the obtained sequences are converted into bits of 0 and 1, which are then decoded as the raw data. The peptides can be commercially synthesized, and MS/MS is the state-of-the-art technique for peptide sequencing. Peptides must not be too long in order to ensure effective synthesis and sequencing. Therefore, the encoded strings are broken into smaller parts, and an address indicator is added into each part to ensure all the parts will be in their original order when they are read back. In this way, raw data will be stored in a mixture of peptides, which can be separated and sequenced using liquid chromatography coupled with MS/MS (LC-MS/MS). The keys of this method are the successful synthesis, detection and sequencing of all the peptides, which have been achieved by selecting suitable amino acids to comprise the peptides, designing suitable error-correction coding schemes, optimizing the protocol for LC-MS/MS analysis, and developing a software to effectively recover peptide sequences from the MS/MS spectra. These efforts are illustrated below, with more details available in Methods and Supplementary Information sections.
Fig. 1. Overview of the process of storing and retrieving data into and from peptides.

The direction in blue represents the data storing process, while the direction in red represents the data retrieving process.
Table 1.
The one-to-one mapping of bit sequences to amino acids.
In proteomics studies, thousands of proteins could be reliably identified in one LC-MS/MS analysis, even with low sequencing coverage of the peptides, since the peptides are originated from proteins with sequences available in databases for searching21,22. However, such a strategy cannot be used for sequencing data-bearing peptides, which requires nearly all the amino acids of each peptide to be correctly sequenced in order to recover all encoded information. De novo peptide sequencing, a technique based on high accuracy MS/MS23,24 and widely used for sequencing of monoclonal antibodies in industry25, was thus used to sequence the encoded peptides. Fortunately, different from proteomic peptides with totally random and unknown sequences, the peptide sequences used for data storage can be designed beforehand according to some rules such that the sequencing accuracy is optimized.
For the peptide design, we considered several parameters with an aim to increasing the success rate of complete sequencing. The first parameter is the peptide length. Shorter peptides are easier to be synthesized and sequenced with fewer missed fragmentation, while longer peptides could store more data per peptide, reducing the number of peptides required as well as the number of addresses and error correction overhead for the same amount of data. To balance these factors, the peptide length was fixed to 18-mer long in this study. The second parameter is the choice and positioning of amino acids. Among the 20 natural amino acids, proline (P) was eliminated as peptides containing P are difficult to synthesize26. Histidine (H), lysine (K), and arginine (R) were not used in the middle or at the N-terminus as they caused sharp decrease in peak intensity27,28. Methionine (M) and cysteine (C) were eliminated because they were prone to oxidization and formation of disulfide bridges, respectively. Asparagine (N) and glutamine (Q) were eliminated as they were prone to amine loss during fragmentation in MS/MS27. Isoleucine (I) was eliminated as it is isobaric with leucine (L). From the 11 remaining amino acids, eight amino acids, i.e., alanine (A), valine (V), leucine (L), serine (S), threonine (T), phenylalanine (F), tyrosine (Y) and glutamic acid (E), were selected to comprise the data storage peptides with 3 bits per amino acid (Table 1). (Note that it requires 16 amino acids in order to encode 4 bits per amino acid.) C-terminal arginine has been found to promote the signal intensity of the y-ion series and suppress the b-ion series28. As this would simplify spectral analysis, a non-data-bearing amino acid, R, was placed at the C-terminus for each peptide. As the first and second amino acids from the N-terminus were rarely fragmented in MS/MS29, another non-data-bearing amino acid, F, was fixed as the first amino acid from the N-terminus, so that the mass of the second amino acid could still be calculated when the first and second amino acids failed to be fragmented. Another reason for fixing F at the N-terminus was to balance the hydrophobicity of peptides, as F was hydrophobic, while R that was fixed at the C-terminus was hydrophilic. Peptides with medium hydrophobicity could facilitate peptide synthesis, as the solubility of hydrophobic peptides is low, and very hydrophilic peptides are difficult to be purified by HPLC. These choices would produce peptides that could be easily synthesized and chemically stable. They could also generate MS/MS spectra that easily allow correct peptide sequence recovery.
To further protect data integrity, error-correction schemes30 were incorporated during encoding, such that when peptides were not synthesized, detected, or sequenced well, the missing data could still be inferred from the appended redundant data9,10. In this study, we designed a concatenated error-correction code, assuming that 10% of amino acids were missing or incorrect during storage and retrieval, and the orders of the second and third amino acids counted from both N-terminus (Table 2, symbols S1 and S2) and C-terminus (Table 2, symbols S15 and S16) might be ambiguous because gap masses due to fragmentation were more common on these sites. The error of 10% missing amino acids was protected using an advanced low-density parity-check (LDPC)31 or RS32 code, while the error of ambiguous order of specific amino acids was protected by two bits, with each bit protecting the order of the second and third amino acids on each end of the peptide. From the design of the peptide structure, each amino acid represented one symbol, which contains 3 bits of information (Table 1, S1 and S2).
Table 2.
Structure of sequences with 16 3-bit symbols, where each 3-bit symbol can be translated to one amino acid according to Table 1.
The first 2 or 3 symbols are used to assign the address (“Add”, light red). The bit Qi,j is used to record the order of Si and Sj (white). The other symbols are used to store (i) the coded bits c (green) including the information and the parity bits; and (ii) some zero bits (blue) to ensure that at least three symbols are hydrophilic amino acids.
To retrieve the data from the stored peptides, the peptide mixtures were separated with LC and then subjected to fragmentation to produce MS/MS spectra that allowed recovery of the amino acid order based on the mass differences between the fragment ions (Fig. 2b, c). Currently available proteomics and de novo sequencing software21–25,29 were found not to work well for the sequence recovery since they were not developed for the specific peptides used in this project. An in-house software using a highest-intensity-tag-based method (Fig. 2d), tailored to the arrangements of amino acids of the designed peptides, was thus developed to recover peptide sequences from the MS/MS spectra (Table S3) in this project. The peptide sequences were then grouped by scoring and finally decoded to recover the original data.
Fig. 2. Overview of data retrieval from dataset A.

a The message of dataset A; b The chromatogram for analysis of the 40 peptides for dataset A; c A typical MS/MS spectrum for analysis of peptides in dataset A, and the sequence of one of the data-bearing peptide read out from the spectrum; d The highest-intensity-tag-based sequencing method used in the sequence recovery.
As proofs of concept, two datasets were stored and retrieved in this study. Dataset A was an 848 bits long BIG5-formatted text for “The Hong Kong Polytechnic University, 80th anniversary.” in both Chinese and English and the motto of The Hong Kong Polytechnic University in Chinese (Fig. 2a), while dataset B was 13,752 bits long, containing the music Silent Night in MIDI (Supplementary Audio 1) format and its title in ASCII format. Dataset A was encoded (Table 1 and S1) and translated into 40 18-mer peptides (Table S4), which were synthesized for data storage. For data retrieval, the peptide mixture was analyzed using LC-MS/MS (Fig. 2b), and the acquired MS/MS spectra (Fig. 2c) were processed with the in-house software for recovery of the peptide sequences, which were converted back to sequences of bits according to the previous assignments (Table 1) and then decoded back to the original raw data. The results showed that the sequences of all 40 peptides were correctly obtained, allowing complete retrieval of the original data. Similar procedures (Fig. 3 and Table 1 and S2) were employed for storage and retrieval of dataset B, which required 511 18-mer peptides for data storage. The results showed that 93.7% (7659/8176) of the amino acids were correctly recovered (Table S5). After the error-correction decoding procedure that could recover a maximum of 10% of incorrect or lost amino acids, the original music and title were fully retrieved.
Fig. 3.

The chromatogram for analysis of the peptide mixture encoding dataset B.
In DNA data storage that used four nucleotides as monomers, each nucleotide represented 2 bits, while the use of eight amino acids as monomers in our method enabled each amino acid to represent 3 bits. Together with the lower masses of amino acids, in principle, the storage density of our method could be 3.72 times of the DNA method, i.e., storage of the same data using a lower amount (lighter) of peptides than DNA. The storage density of our method can still be further improved with use of 16 or more amino acids. Practically, the retrievable data density was 1.7 × 1010 bits/g and 2.6 × 109 bits/g for datasets A and B, respectively, which were about nine orders of magnitudes lower than those of the DNA method11. The major reason for this is that DNA can be amplified by PCR prior to sequencing while peptides cannot, therefore the number of molecules required to retrieve data for the DNA method can be far fewer than the peptide method. The peptide-based data density can be significantly improved with optimized peptide sequencing, since picomole amounts of peptides were used for analysis in these proof-of-concept studies while peptide detection and sequencing at attomole18–20, yoctomole33, or even single molecule34–36 scales have been reported.
In summary, we demonstrated that it was feasible to store data using peptide sequences and to retrieve the data using LC-MS/MS analysis. This method offers a new possibility for data storage with potentially high storage density and durability. Peptide synthesis industry and proteomics techniques have been developed to the stages that can allow the use of peptides for data storage. Our method for the first time connects these fields together and can promote the development of these and other relevant fields. Currently, peptide synthesis and sequencing are still relatively expensive and time-consuming in practice, and scaling-up significantly would require further developments in these fields. As the stored data become much larger, much more peptides would be required to encode the data, leading to much more complicated peptide sequencing that would challenge the analytical capabilities of current LC-MS/MS techniques, and new analytical techniques and strategies would be needed to solve the problems. However, with the improved techniques and reduced time and costs of the peptide synthesis and sequencing, which have been happening in the past decades, peptide data storage may become practically available in the future, especially in critical applications that demands minimum weight and long duration for stable storage of very big data.
Methods
Materials
Peptides (lyophilized, as trifluoroacetate salts, >50% purity) were synthesized by Genscript Inc. (Nanjing, China) and GL Biochem (Shanghai, China). The peptides were dissolved in dimethyl sulfoxide (10 µg/mL), mixed together for each dataset, and diluted with 50% acetonitrile with a 1:1 ratio before analysis. Methanol and acetonitrile (HPLC grade) were from Duksan (South Korea). Formic acid (99–100%) was from VWR (France). Water was purified by MilliQ system.
LC-MS/MS analysis of the peptide mixtures
The step-by-step protocol used in this work is available on Protocol Exchange37. The peptide mixtures were separated using a Waters Acquity UPLC system with a C18 column (Agilent AdvanceBio Peptide Map, 2.1 × 150 mm, 2.7 µm particle size, 120 Å pore size). Mobile phase A was 0.2% formic acid in water and B was 0.2% formic acid in acetonitrile. The flow rate was 0.3 mL/min and the temperature was 55 °C. The gradient changed from 10% B to 18% B at 0 to 2 min, from 18% B to 22% B at 2 to 8 min, from 22% B to 34% B at 8 to 48 min, from 34% B to 40% B at 48 to 64 min, from 40% B to 55% B at 64 to 75 min, from 55% B to 80% B at 75 to 78 min, and remained at 80% B from 78 to 83 min.
MS/MS analysis was performed using an Orbitrap Fusion Lumos mass spectrometer (ThermoFisher Scientific, San Jose, CA) operated in positive ion mode. The spray voltage for electrospray ionization was +3600 V, and both ion transfer tube temperature and vaporizer temperature were 280 °C. In each cycle, a MS1 scan with m/z from 900 to 1400 Da was performed with a resolution of 30 K. Ions were selected for MS/MS with quadruple, using advanced peak determination (APD) with default charge of +2, top-speed mode with 3 s cycles, mass tolerance of 25 ppm, dynamic exclusion window of 4 s, and isolation window width of 1.6 or 0.7 Da. High-energy collision dissociation (HCD) at 28% of normalized collision energy with stepped collision energy of 5% was used for the fragmentation. MS/MS spectra were obtained with m/z from 240 to 2450 Da and a resolution of 15 K.
Error-correction code design
The structures of the sequences used for encoding, sequencing, and decoding are shown in Table 2 for datasets A and B.
For dataset A, the first two symbols S1 and S2 are used to assign the address (orange). The order-checking bits Q1,2 and Q15,16 are used to record the order of S1 and S2 and the order of S15 and S16, respectively (white). Note that 3 zero bits (blue) are filled in the first bits of S4–S6, which can ensure that at least three symbols are hydrophilic amino acids. The other symbols are used to store the coded bits c including the information and the parity bits (green) of the error-correction codes. For dataset B, due to more information bits and longer address, three address symbols and three order-checking bits are used. Such structure can be easily modified for longer sequence with longer address.
As shown in Table S4, a 40 × 16 block is constructed for error correction and peptide sequencing of dataset A. Each row had 16 symbols (i.e., S1, S2, …, S16) to represent a 16-mer data-bearing peptide sequence. In the design of encoding scheme for dataset A, the first two symbols in each sequence were used to store the address, and the remaining 14 symbols were used to store information. Hence a total of 560 symbols are available in the 40 peptide sequences (total 560 × 3 = 1680 bits, see Table S2 for the 40 peptide sequences). Then 850 information bits (i.e., b1, b2, …, b850) were filled in the data block according to the following arrangements (Table S4):
Bits b1–b400 were filled in the second and the third bits of Symbols S3–S7 of the peptide sequences Seq #1 to Seq #40;
Bits b401–b760 were filled in Symbols S14–S16 of the peptide sequences Seq #1 to Seq #40;
Bits b761–b850 were filled in Symbol S13 of the peptide sequences Seq #11 to Seq #40.
Furthermore, the first bits of Symbols S4–S6 (represented by b851–b970) were filled with “0” bits. The purpose is to ensure that a minimum of three symbols in each sequence having values 0, 1, 2, 3, which will be represented by hydrophilic amino acids S, T, E, Y, as mentioned in the design. There were also order-checking bits Q and redundant bits Pi(j) (i = 1, 2, …, n; j = 1, 2, and 3) derived by LDPC codes in the peptide sequences (where n is the number of parity bits in each LDPC code). The order-checking bit Qi,j is “1” if symbol Si is larger than Sj. Otherwise, the order-checking bit is “0”. Thus, the maximum overall code rate R of the block was 850/(14 × 3 × 40) = 0.506. As dataset A only consisted of 848 bits, 2 zeros were appended to the end of the data in order to fully fill the block.
Based on the results of dataset A, we further made these assumptions of possible errors when designing the error-correction scheme for dataset B: (i) 10% of the three-symbol sequences {S5S6S7} and {S8S9S10} cannot be recovered correctly; and (ii) 15% of the three-symbol sequences {S11S12S13} and {S14S15S16} cannot be recovered correctly. Based on these assumptions, we proposed another error-correction method based on the RS code32 that used: (i) three order-checking bits for each peptide sequence; and four RS codes to recover the original data even when any arbitrary 10% three-symbol sequences {S5S6S7}, any arbitrary 10% three-symbol sequences {S8S9S10}, any arbitrary 15% three-symbol sequences {S11S12S13}, and any arbitrary 15% three-symbol sequences {S14S15S16}, cannot be recovered correctly.
When this scheme was used on dataset B, a 511 × 16 block of symbols was constructed (Table S5), which comprises 511 × 16 × 3 = 24528 bits. The three-symbol sets Ai,1 Ai,2 Ai,3 (i = 1, 2, …, 511) were used for addressing, with Symbols S1 to S3 having the values of 000, 001, 002, …, 775, 776. The three bits of Symbol S4 were the three order-checking bits used to protect the order of Symbols S1 and S2, the order of Symbols S2 and S3, and the order of Symbols S15 and S16, respectively. Then there were 511 × 12 × 3 = 18396 bit positions in Symbols S5 to S16 of the block to store the information and parity bits for the RS codes. Due to the different protection requirements for the partial sequences {S5S6S7S8S9S10} and {S11S12S13S14S15S16}, two (511, 409) RS codes were used for partial sequences {S5S6S7} (RS1) and {S8S9S10} (RS2), another two (511, 357) RS codes were used for partial sequences {S11S12S13} (RS3) and {S14S15S16} (RS4). Each symbol in RS code comprised 9 bits. The (511, 409) RS and (511, 357) RS codes could correct up to 51 and 77 9-bit symbol errors, respectively (Table S5). Moreover, the numbers of total information bits and total parity bits of all four RS codes were given by (409 + 357) × 2 × 9 = 13788 and (102 + 154) × 2 × 9 = 4608, respectively. The maximum overall code rate R of the block is given by 13788/(511 × 16 × 3) = 0.562. As dataset B only had 13752 bits, zeros were appended to the end such that the block could be fully filled. This code rate is comparable to that of DNA (varied from 0.17 for repetition encoding8 to 0.785 for fountain encoding10, assuming a maximum capacity of 2 bits per nucleotide). Improvement of code rate is possible if longer peptides could be used, if the peptide design could be improved to reduce error, and if the coding scheme could be more focused on the error-prone amino acid positions to reduce unnecessary redundancy.
Sequence recovery
An in-house software was developed for recovery of peptide sequences from the MS/MS spectra. To reduce the amount of false positives, during spectral analysis, the maximum error for each peak was set to 25 ppm (in line with the experimental parameters), and the masses were corrected to at least five decimal places.
The spectra were first extracted from the Thermos RAW file using MSConvert38. Then, the spectra were passed onto a preprocessing unit, which included deconvolution to obtain a list of masses and charges of isotopic clusters with one or more peaks each, and identifying the monoisotopic mass and charge of parent ion. As only 2+ precursor ions were selected for MS/MS during experiments, most fragments would be predominately 1+ unless their masses were close to precursor mass. Also, it was predicted that in most peptides, the strongest peak in the isotopic cluster would be M + 1 rather than M if the formula mass were above ca. 180039, where M was the monoisotopic mass. Therefore, it was assumed that if a certain isotopic cluster only consisted of one peak, that peak was singly charged and the monoisotopic mass would be corrected based on the deconvoluted mass accordingly. MS/MS spectra with less than 12 peaks with the most intense peak lower than 30,000 counts were filtered out at this stage to speed up analysis.
After that, de novo sequencing based on the graph model is utilized for determining the peptide sequences from the preprocessed spectra23. In the graph model, the MS/MS spectrum is represented by a directed acyclic graph (DAG). The peaks of the spectrum can be taken as vertices, while an edge is added between two vertices when the mass gap between two peaks is equal to the mass of an amino acid. The objective is to find the longest path in the graph starting from the head vertex to the tail vertex. The sequence identification was started in the middle part of the MS/MS spectrum. The sequence tagging method first infers a partial sequence called tag, and then finds the whole sequence that can match the tag. The tags containing the amino acid with the highest intensity were first obtained, which were called highest-intensity-based tags (Fig. 4). To generate valid sequence candidates, both ends of the tag would be extended and connected to the N- and C- termini by searching the sequences containing amino acids with matching gap masses. The scores for the sequence candidates based on the following five factors: the length of consecutive amino acids retrieved, the number of amino acids retrieved, match error, intensity, and the number of occurrences for different ion types with different offsets. The higher the score is, the more likely that the sequence is correct.
Fig. 4. A flowchart illustrating the method of highest-intensity-tag based sequencing.

i represents the iteration number and V is the maximum number of iterations. W represents the number of masses with the higher ranking used in the tag-finding processing and wi is the number of masses with the higher ranking for the ith iteration. J represents the ranking of intensity and Jmax is the maximum number of higher-ranking-intensity masses allowed to be the start point to find the tag.
Details of the highest-intensity-tag based sequencing method
In the highest-intensity-tag based sequencing method (Fig. 4), the sequences were estimated in a manner that first inferred a partial sequence with a small amount of reliable information and then found the missing part of the sequence with less reliable data or the raw data. The m/z value with the first highest intensity was first recognized to further infer the tag or the path. Although using short tags (e.g., with three amino acids) such as GutenTag40, DirecTag41, and NovoHCD42 could avoid introducing the wrong amino acids, the number of candidate tags would be relatively larger and harder to infer the sequences due to insufficient information provided by the tag. Therefore, in this project, the length of tag was variable and could be up to the length of the peptide, which helped to reduce the search space. When a tag contained wrong amino acids, it could not be extended well towards N-terminus and C-terminus. In this case, the length of the tag was shortened by adaptively reducing the number of the higher-intensity data points used for the tag-finding algorithm. In addition, the vertex with the highest intensity may not definitely present in the correct path due to the uncertainty of the data. When valid paths could not be found, it may be possible to infer the tag with the second or even the third highest intensities. Moreover, in order to find the tag, N-terminal and C-terminal amino acids, a sequencing method called two-stage sequencing method is used together with the highest-intensity-tag based method.
Figure 4 shows a flowchart illustrating the method of highest-intensity-tag based sequencing. At steps 2, 3 and 4, the intensities of the preprocessed data were sorted from the largest to the smallest and values with J denoting the ranking of intensity. The mass/charge ratio with the highest intensity was then identified. At start, it was set as J = 1 and i = 1, and using only W = wi (w1 > w2 > w3…) masses with the higher ranking in the tag-finding processing.
The method then proceeded to step 5 to find the highest-intensity-based tag. Starting from the mass of the putative y-ion with the highest intensity, the highest-intensity-based tag was found by simultaneously connecting the vertices in the forward direction pointing to the tail vertex of the path, and connecting the vertices in the backward direction pointing to the head vertex of the path, where the vertices had mass gap being the exact mass of any amino acid and preferably the length of the tag was as long as possible (Fig. 2d). The tags containing the amino acid with the highest intensity were obtained subsequently, which were called highest-intensity-based tags. With knowledge of the masses of the head and the tail amino acids of a highest-intensity-based tag, the method proceeded to step 6 to find the N-terminal amino acids that could connect the head of the path to the head of the tags in the forward direction by using the method described at Step 2 of the two-stage sequencing method. Similarly, for the tags with valid N-terminal amino acids, at step 7, the C-terminal amino acids of the sequences could be further found by connecting the tail of the tags to the tail of the path in the forward direction.
At step 8, the candidate paths could be constructed by combining the three parts: N-terminus, tag, and C-terminus. At step 9, one could follow steps 3 and 4 of the two-stage sequencing method to select and refine the sequences. Note that a larger value for W sometimes introduced one or more wrong amino acids in the head and/or tail parts of a tag, while a smaller value for W may give more reliable tag but the length of the tag may be limited. Therefore, after step 6, if no valid candidate could be found, one may attempt to reduce the value of W with W = wi by increasing i by 1, i.e., i = i + 1, and repeat the tag, N-terminus and C-terminus finding procedure until the candidate sequence could be found or i = V (where V is the maximum number of iterations).
For the special case when the experimental mass with the highest intensity gave an unreliable message due to noise and uncertainty, a highest-intensity-based tag or a valid path with the highest-intensity-based tag could not be found. In this case, the mass with the second highest intensity was used by setting J = J + 1 and i = 1 to find the second highest-intensity-based tag and the candidates. This process would continue until the sequence could be found or J = Jmax (where Jmax is the maximum number of higher-ranking-intensity masses allowed to be the start point to find the tag).
Details of the two-stage sequencing method
Figure 5 shows a flowchart illustrating a method of two-stage sequencing. Four steps are involved in the two-stage sequencing method: (1) preprocessing, (2) candidate sequence generation, (3) sequence selection, and (4) candidate refining. As shown in Fig. 5, Steps 1–3 belong to the first stage (Stage 1), while Step 4 is processed in the second stage (Stage 2). In Stage 1 of the two-stage sequencing method, partial sequence is inferred using the preprocessed data after Step 1. In Stage 2, the remaining part of the sequence is determined using the raw data.
Fig. 5. A flowchart illustrating the method of two-stage sequencing.

AAC stands for amino acid combinations.
At Step 1, preprocessing is performed. At Step 2, the preprocessed data from step 1 is used to find the valid paths (sequences), and the number n of candidate sequences is counted. At Step 3, the effects of the following five factors are jointly considered when arriving at the score of a sequence candidate from Step 3.1 to Step 3.5: length of consecutive amino acids retrieved, number of amino acids retrieved, match error, average intensity of amino acids retrieved, and number of occurrences for different ion types with different offsets. The sequences with the longest length of consecutive amino acids retrieved are first selected (Step 3.1). Among the selected sequences, the sequences with the largest number of amino acids retrieved are then selected (Step 3.2). For the sequences with equal length of consecutive amino acids retrieved together with equal number of amino acids retrieved, the match error is evaluated, which is the mean error between the observed mass values for the amino acids retrieved from the experimental spectrum and the actual mass values of the amino acids normalized by the corresponding observed mass values (Step 3.3). If there is more than one sequence with identical match errors, the average intensity of amino acids retrieved is further calculated and a higher score is given to a sequence with a larger average intensity value (Step 3.4). In addition, multiple ion types are usually considered as the important factors in inferring an amino acid, which means that a mass value may correspond to different types of ions in the spectrum. Generally, the more the number of occurrences for different ion types of an amino acid is, the more likely the amino acid is correct. Therefore, for the sequences with equal score after the aforementioned evaluations of Steps 3.1–3.4, the number of occurrences for different ion types is counted to determine the sequence (Step 3.5). The mass offset sets for the N-terminal a-ion, b-ion, and c-ion type sets, i.e., {a, a-H2O, a-NH3, a-NH3-H2O}, {b, b-H2O, b-H2O-H2O, b-NH3, b-NH3-H2O}, and {c, c-H2O, c-H2O-H2O, c-NH3, c-NH3-H2O} are {−27, −45, −44, −62}, {+1, −17, −35, −16, −34}, and {+18, 0, −18, +1, −17}, respectively. According to the fragmentation method and the property of the data, all or some of the above ion types can be used flexibly.
Since the candidate sequences obtained at Step 2 are found by using the preprocessed data, which aim to provide more reliable information to generate the partial sequence, amino acid combinations (AACs) may present in the sequence due to insufficient data provided by preprocessing. At Step 4, if selected sequences with missing mass values exist, which means that the corresponding mass gaps are equal to the summation of at least two amino acids, the raw data may be used to find as many vertices as possible for the path in Stage 2. After finding the missing amino acids of AACs at Step 4.1, the sequences with the longest length of consecutive amino acids retrieved in AACs are selected as candidate sequences (Step 4.2). If there still remain at least two candidate sequences after selection, a final decision is made based on the match error of the amino acids retrieved in AACs for each sequence (Step 4.3).
Grouping
After sequence recovery, there could be more than one valid 18-mer sequences from each spectrum or multiple valid 18-mer sequences containing the same address. Therefore, sequencing selection and grouping were performed to identify the correct peptide for each address.
Given a set of spectra containing Ns (Ns = 40 or 511) peptide sequences. After sequencing, a set of sequence is obtained and a block of Ns × 16 is constructed for decoding. This process is called sequence grouping which is described below and in Fig. 6.
Fig. 6. A flowchart illustrating the method of sequence grouping.
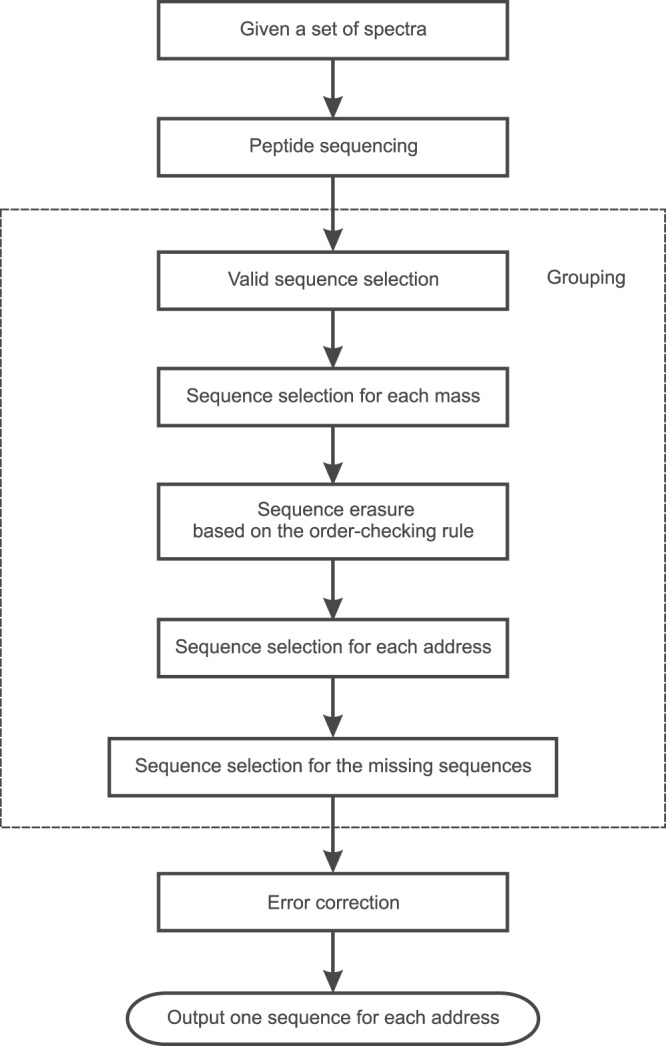
The procedure of grouping is shown in the dashed square.
Valid sequence selection
To reduce the effect of the unreliable sequences caused by the noise and the uncertainty, the requirements for the valid sequence are listed as follows.
The sequence is of length-16.
For each sequence, one AAC with more than two missing amino acids is not allowed.
For each sequence, more than one AACs with two missing amino acids are not allowed.
After MS/MS analysis, a set of spectra containing 40 or 511 sequences is obtained, among which some spectra can generate length-16 sequences. If there are more than two missing amino acids in one AAC or two missing amino acids in more than one AACs, then the corresponding sequence will be ignored in the further selection.
Selection for each mass
For each mass value, if there are more than one output sequences with the highest score, then all these sequences are selected; otherwise, at most Lmax (=2) sequences with higher scores will be considered for each of the selected spectra.
Erasure based on order checking
Based on the orders of the estimated symbol pairs {S1, S2} and {S15, S16} for 40 sequence set, 2 bits are generated according to the order-checking rule, which will be compared with the first bits of the estimated symbols S3 and S7, respectively. Similarly, 3 bits are generated based on the orders of the estimated symbol pairs {S1, S2}, {S2, S3}, and {S15, S16} for 511 sequence set, which will be compared with the 3 bits of the estimated symbol S4. If any one of the generated order-checking bits does not match the corresponding bit in an estimated sequence, the estimated sequence will be erased.
Selection for each address
According to the address represented by the first two and three elements of a sequence, the sequences are divided into 40 and 511 address groups, respectively. Then for each group, there are following cases possible:
Case 1: There is only one sequence.
Case 2: There are two or more sequences, some of which are the same, where:
2a. there is only one result with two or more sequences; or
2b. there are at least two different results, each with two or more sequences.
Case 3: All sequences in the group are different, where:
3a. different sequences belong to the same spectrum; or
3b. different sequences belong to different spectra.
For Case 1, the only sequence is recovered for the group. For Case 2a, the result with two or more sequences is selected. For Case 2b, the results with the largest number of sequences are first selected. Among the sequences corresponding to these results, the sequence with the highest score according to Steps 3.1–3.5, 4.2, and 4.3 of the two-stage sequencing method is further selected. For Case 3a, the sequence with the highest score according to Steps 4.2 and 4.3 of the two-stage sequencing method is selected. For Case 3b, the sequence with the highest score according to Steps 3.1–3.5, 4.2, and 4.3 of the two-stage sequencing method is selected.
Selection for missing sequences in the block
With knowledge of the sequences corresponding to each address, a Ns x 16 block of symbols can be constructed with each row of the block representing a sequence and each symbol representing an amino acid. In this block, some rows of the block may be missing due to the erasure by the order-checking process or the impurity of the data for peptide sequencing.
If there existed missing rows for some addresses in the block, the length-16 sequences generated by all spectra were considered to find these missing rows. For each address with missing row, the scores of the sequences were compared to make the decision.
Calculation of data density
In theory, each nucleotide in DNA could hold 2 bits while each amino acid in our designed peptides could hold 3 bits. The average molecular mass of nucleotides in DNA is 327 Da, while the average molecular mass of the eight amino acids used in this project is 132 Da. Putting these factors together, in principle, the storage density ratio of our method to the DNA method is (3/132)/(2/327) = 3.72.
About the density allowing flawless retrieval in this work, for dataset A, the total concentration of all 40 peptides was 10 ng/μL (0.25 ng/μL for each peptide) in the final mixture. Based on the injection volume of 5.0 μL, the total mass of peptides used was 10 × 5.0 = 50 ng. Therefore, the data density of peptides in this study was 848/(50 × 10−9) = 1.7 × 1010 bits/g. For dataset B, the total concentration of all 511 peptides was 1.02 μg/μL (2 ng/μL for each peptide) in the final mixture. Based on the injection volume of 5.0 μL, the total mass of peptides used was 5.1 μg. Therefore, the data density of peptides in this study was 13752/(5.1 × 10−6) = 2.6 × 109 bits/g.
Reporting Summary
Further information on research design is available in the Nature Research Reporting Summary linked to this article.
Supplementary information
Description of Additional Supplementary Files
Acknowledgements
We thank Prof. Henry Lam (Hong Kong University of Science and Technology) and Prof. Jiang Xia (Chinese University of Hong Kong) for their helpful discussions, Dr. Bin Hu (Jinan University) for his assistance, and University Research Facility in Chemical and Environmental Analysis and University Research Facility in Life Sciences of The Hong Kong Polytechnic University for the technical supports. Z.-P.Y. would like to give thanks to Fudan8420 WeChat Group for the helpful discussion. This work was supported by Hong Kong Research Grant Council (Grant Nos. R5013-19F, C5031-14E, 153041/17 P, 15304020, C4002-17G, and R4005-18), Natural Science Foundation of China (Grant Nos. 81874306 and 81601828), and China Resources Life Sciences Group Limited.
Author contributions
C.C.A.N. and Z.-P.Y. initiated and designed the experiments; W.M.T. and F.C.M.L. developed the error-correction schemes; C.C.A.N. performed the LC-MS/MS analysis with the assistance from H.Y., Q.W., P.-K.S. and M.Y.-M.W.; W.M.T., F.C.M.L., C.C.A.N., Z.-P.Y. and H.Y. designed and optimized the in-house software; W.M.T. performed the peptide sequence assignments with the assistance from F.C.M.L., C.C.A.N. and H.Y.; C.C.A.N. and W.M.T. drafted the manuscript, and Z.-P.Y. revised the manuscript with the contributions also from F.C.M.L., H.Y., P.-K.S. and M.Y-.M.W.; Z.-P.Y. coordinated the whole project.
Data availability
The raw spectral data generated in this study have been deposited at MassIVE and can be available at 10.25345/C5P54Z.
Code availability
The custom scripts for encoding data, peptide sequencing, and decoding data used in this paper are not publicly available due to the patent issues, but may be available for academic exchange and collaboration purposes by sending email requests to the corresponding authors, with the expected response time of around 1 week.
Competing interests
The authors declare no competing interests.
Footnotes
Peer review information Nature Communications thanks the anonymous reviewers for their contribution to the peer review of this work. Peer reviewer reports are available.
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Contributor Information
Francis C. M. Lau, Email: francis-cm.lau@polyu.edu.hk
Zhong-Ping Yao, Email: zhongping.yao@polyu.edu.hk.
Supplementary information
The online version contains supplementary material available at 10.1038/s41467-021-24496-9.
References
- 1.Hilbert M, López P. The World’s technological capacity to store, communicate, and compute information. Science. 2011;332:60. doi: 10.1126/science.1200970. [DOI] [PubMed] [Google Scholar]
- 2.Hoist, A. Volume of data/information created, captured, copied, and consumed worldwide from 2010 to 2025. https://www.statista.com/statistics/871513/worldwide-data-created/ (accessed 28 May 2021).
- 3.Clelland CT, Risca V, Bancroft C. Hiding messages in DNA microdots. Nature. 1999;399:533. doi: 10.1038/21092. [DOI] [PubMed] [Google Scholar]
- 4.Bornholt J, et al. A DNA-based archival storage system. SIGPLAN Not. 2016;51:637–649. doi: 10.1145/2954679.2872397. [DOI] [Google Scholar]
- 5.Regalado, A. Microsoft has a plan to add DNA data storage to its cloud. MIT Technol. Rev. (2017).
- 6.Organick L, et al. Random access in large-scale DNA data storage. Nat. Biotechnol. 2018;36:242. doi: 10.1038/nbt.4079. [DOI] [PubMed] [Google Scholar]
- 7.Church GM, Gao Y, Kosuri S. Next-generation digital information storage in DNA. Science. 2012;337:1628–1628. doi: 10.1126/science.1226355. [DOI] [PubMed] [Google Scholar]
- 8.Goldman N, et al. Towards practical, high-capacity, low-maintenance information storage in synthesized DNA. Nature. 2013;494:77. doi: 10.1038/nature11875. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Grass RN, Heckel R, Puddu M, Paunescu D, Stark WJ. Robust chemical preservation of digital information on DNA in silica with error-correcting codes. Angew. Chem. Int. Ed. Engl. 2015;54:2552–2555. doi: 10.1002/anie.201411378. [DOI] [PubMed] [Google Scholar]
- 10.Yaniv E, Dina Z. DNA Fountain enables a robust and efficient storage architecture. Science. 2017;355:950–954. doi: 10.1126/science.aaj2038. [DOI] [PubMed] [Google Scholar]
- 11.Organick L, et al. Probing the physical limits of reliable DNA data retrieval. Nat. Commun. 2020;11:616. doi: 10.1038/s41467-020-14319-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Roy RK, et al. Design and synthesis of digitally encoded polymers that can be decoded and erased. Nat. Commun. 2015;6:7237. doi: 10.1038/ncomms8237. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Huang Z, et al. Binary tree-inspired digital dendrimer. Nat. Commun. 2019;10:1918. doi: 10.1038/s41467-019-09957-6. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Cafferty BJ, et al. Storage of information using small organic molecules. ACS Cent. Sci. 2019;5:911–916. doi: 10.1021/acscentsci.9b00210. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Yao, Z. P., Ng, C. C. A., Lau, C. M. & Tam, W. M. Data storage using peptides. US Provisional Patent Application No. 62/657,026 (Filed on 13 April 2018); PCT Application No. PCT/CN2018/119349 (Filed on 6 December 2018); US Non-Provional Patent Application No.16/224,957 (Filed on 19 December 2018).
- 16.Service RF. Protein power. Science. 2015;349:372–373. doi: 10.1126/science.349.6246.372. [DOI] [PubMed] [Google Scholar]
- 17.Warren M. Move over, DNA: ancient proteins are starting to reveal humanity’s history. Nature. 2019;570:433–436. doi: 10.1038/d41586-019-01986-x. [DOI] [PubMed] [Google Scholar]
- 18.Nguyen TTTN, Petersen NJ, Rand KD. A simple sheathless CE-MS interface with a sub-micrometer electrical contact fracture for sensitive analysis of peptide and protein samples. Anal. Chim. Acta. 2016;936:157–167. doi: 10.1016/j.aca.2016.07.002. [DOI] [PubMed] [Google Scholar]
- 19.Sun B, Kovatch JR, Badiong A, Merbouh N. Optimization and modeling of quadrupole orbitrap parameters for sensitive analysis toward single-cell proteomics. J. Proteome Res. 2017;16:3711–3721. doi: 10.1021/acs.jproteome.7b00416. [DOI] [PubMed] [Google Scholar]
- 20.Valaskovic GA, Kelleher NL, Little DP, Aaserud DJ, McLafferty FW. Attomole-sensitivity electrospray source for large-molecule mass spectrometry. Anal. Chem. 1995;67:3802–3805. doi: 10.1021/ac00116a030. [DOI] [PubMed] [Google Scholar]
- 21.Aebersold R, Mann M. Mass-spectrometric exploration of proteome structure and function. Nature. 2016;537:347–355. doi: 10.1038/nature19949. [DOI] [PubMed] [Google Scholar]
- 22.Yates JR. The revolution and evolution of shotgun proteomics for large-scale proteome analysis. J. Am. Chem. Soc. 2013;135:1629–1640. doi: 10.1021/ja3094313. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Frank AM, Savitski MM, Nielsen ML, Zubarev RA, Pevzner PA. De novo peptide sequencing and identification with precision mass spectrometry. J. Proteome Res. 2007;6:114–123. doi: 10.1021/pr060271u. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Ma B, et al. PEAKS: powerful software for peptide de novo sequencing by tandem mass spectrometry. Rapid Commun. Mass Spectrom. 2003;17:2337–2342. doi: 10.1002/rcm.1196. [DOI] [PubMed] [Google Scholar]
- 25.Bandeira N, Pham V, Pevzner P, Arnott D, Lill JR. Automated de novo protein sequencing of monoclonal antibodies. Nat. Biotechnol. 2008;26:1336–1338. doi: 10.1038/nbt1208-1336. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Breci LA, Tabb DL, Yates JR, Wysocki VH. Cleavage N-terminal to proline:analysis of a database of peptide tandem mass spectra. Anal. Chem. 2003;75:1963–1971. doi: 10.1021/ac026359i. [DOI] [PubMed] [Google Scholar]
- 27.Seidler J, Zinn N, Boehm ME, Lehmann WD. De novo sequencing of peptides by MS/MS. Proteomics. 2010;10:634–649. doi: 10.1002/pmic.200900459. [DOI] [PubMed] [Google Scholar]
- 28.Tabb DL, Huang Y, Wysocki VH, Yates JR., 3rd Influence of basic residue content on fragment ion peak intensities in low-energy collision-induced dissociation spectra of peptides. Anal. Chem. 2004;76:1243–1248. doi: 10.1021/ac0351163. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Medzihradszky KF, Chalkley RJ. Lessons in de novo peptide sequencing by tandem mass spectrometry. Mass Spectrom. Rev. 2015;34:43–63. doi: 10.1002/mas.21406. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Ryan, W. E. & Lin, S. Channel Codes: Classical and Modern (Cambridge Univ. Press, 2009).
- 31.MacKay DJC, Neal RM. Near Shannon limit performance of low density parity check codes. Electron. Lett. 1997;33:457–458. doi: 10.1049/el:19970362. [DOI] [Google Scholar]
- 32.Reed IS, Solomon G. Polynomial codes over certain finite fields. J. Soc. Indust. Appl. Math. 1960;8:300–304. doi: 10.1137/0108018. [DOI] [Google Scholar]
- 33.Trauger SA, et al. High sensitivity and analyte capture with desorption/ionization mass spectrometry on silylated porous silicon. Anal. Chem. 2004;76:4484–4489. doi: 10.1021/ac049657j. [DOI] [PubMed] [Google Scholar]
- 34.Restrepo-Pérez L, Joo C, Dekker C. Paving the way to single-molecule protein sequencing. Nat. Nanotechnol. 2018;13:786–796. doi: 10.1038/s41565-018-0236-6. [DOI] [PubMed] [Google Scholar]
- 35.Callahan N, Tullman J, Kelman Z, Marino J. Strategies for development of a next-generation protein sequencing platform. Trends Biochem. Sci. 2020;45:76–89. doi: 10.1016/j.tibs.2019.09.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Swaminathan J, et al. Highly parallel single-molecule identification of proteins in zeptomole-scale mixtures. Nat. Biotechnol. 2018;36:1076–1082. doi: 10.1038/nbt.4278. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Ng CCA, et al. Data storage using peptide sequences. Protoc. Exch. 2021 doi: 10.21203/rs.3.pex-1543/v1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Chambers MC, et al. A cross-platform toolkit for mass spectrometry and proteomics. Nat. Biotechnol. 2012;30:918–920. doi: 10.1038/nbt.2377. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Valkenborg D, Jansen I, Burzykowski T. A model-based method for the prediction of the isotopic distribution of peptides. J. Am. Soc. Mass. Spectrom. 2008;19:703–712. doi: 10.1016/j.jasms.2008.01.009. [DOI] [PubMed] [Google Scholar]
- 40.Tabb DL, Saraf A, Yates JR. GutenTag: high-throughput sequence tagging via an empirically derived fragmentation model. Anal. Chem. 2003;75:6415–6421. doi: 10.1021/ac0347462. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Tabb DL, Ma Z-Q, Martin DB, Ham A-JL, Chambers MC. DirecTag: accurate sequence tags from peptide MS/MS through statistical scoring. J. Proteome Res. 2008;7:3838–3846. doi: 10.1021/pr800154p. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Yan Y, Kusalik AJ, Wu F-X. NovoHCD: de novo peptide sequencing from HCD spectra. IEEE Trans. Nanobioscience. 2014;13:65–72. doi: 10.1109/TNB.2014.2316424. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Description of Additional Supplementary Files
Data Availability Statement
The raw spectral data generated in this study have been deposited at MassIVE and can be available at 10.25345/C5P54Z.
The custom scripts for encoding data, peptide sequencing, and decoding data used in this paper are not publicly available due to the patent issues, but may be available for academic exchange and collaboration purposes by sending email requests to the corresponding authors, with the expected response time of around 1 week.