

Abstract
Using a statistical model of keystroke and linguistic features, a novel assessment approach leverages ordinary text-typing activities to monitor for signs of early cognitive decline in older adults. Early detection could allow for appropriate interventions and effective treatment.
Many of us are affected by our own age-related cognitive decline or that of loved ones. Such cognitive decline can jeopardize personal freedom and decrease quality of life. The American College of Physicians estimates that 22 percent of people over age 70 have mild cognitive impairment (MCI), and that 12 percent of that population converts to dementia each year.1 Periodic assessment of cognitive function is key to the care of individuals diagnosed with or at risk for any type of cognitive decline, and the need takes on more urgency as the population ages at an unprecedented rate. Of particular interest is how to detect symptoms of early cognitive impairment, a stage known as PreMCI,2 so that patients and clinicians can make appropriate management decisions and introduce interventions.1
However, current assessment solutions present barriers to implementing early, continuous, proactive monitoring in a home setting. Margaret Morris and her colleagues interviewed older adults and caregivers and found 13 barriers that inhibit early assessment for medical conditions.3 Five of these barriers are clinical: delayed assessment, infrequent assessment, lack of ecological validity, narrow focus, and avoidance of testing. The other eight are individual: privacy concerns; avoidance of testing in a clinic; lack of time and discipline to record behaviors and symptoms; fear of labels; underestimation of health variability and overestimation of insight; discord between integrated view of health and constraints of self-monitoring systems; difficulty relating to clinical metrics and language; and proactive focus on self-improvement, wellness, and quality of life.
We propose using attributes of keyboard interactions to monitor for signs of early cognitive decline by unobtrusively leveraging the text-typing activities in which people already engage. As part of a comprehensive assessment system, this method can address all 13 barriers, either directly or indirectly. To test feasibility, we investigated classification of typed text using keystroke and linguistic features to build a logistic regression model, comparing results for older adults with and without PreMCI. We can use trends identified during monitoring to introduce educational materials, compensation activities, or interventions to support self-reflection and improve the health of the user. This assistance can allow users to adjust to changes associated with aging, and can alert people to early signs of PreMCI they might wish to discuss with a clinician.
Cognitive Health in Older Adults
Older adults are concerned about their cognitive health and wish to remain healthy and independent for as long as possible. Morris and her colleagues conducted a series of qualitative studies confirming that care providers, older adults, and medical professionals are all interested in embedded assessment as a means to detect changes in cognitive health as early as possible, allowing for appropriate interventions and effective treatment.3
Older adults also comprise a rapidly growing segment of technology users. The Pew Internet & American Life Project found that 59 percent of older adults use the Internet,4 and 86 percent of those individuals use email.5 These numbers will only increase as baby boomers, many of whom are familiar with technology from the workplace, begin to retire. An embedded approach for cognitive monitoring using everyday interactions with technology could therefore meet the needs of older adults and clinicians.
Changes in Cognitive Function in Older Adults
David Loewenstein and his colleagues describe four stages along the spectrum of cognitive function
normal function,
PreMCI,
MCI, and
dementia.2
Older adults with normal cognitive function show slight declines in cognitive function over time associated with healthy aging. Loewenstein and his colleagues reported that the older adults they studied at the PreMCI stage converted to MCI or dementia at a rate of 16.7 to 38.9 percent over the course of 26 months, significantly higher than the rate for those with normal cognitive function.2 MCI is more severe than cognitive decline associated with normal aging, but not so severe as to impact routine daily activities, and not as advanced as dementia, which is a serious overall impairment of intellect and other cognitive functions. A common characteristic of the various forms of dementia is reduced facility with language. The research presented here focuses on the early stages of cognitive decline, investigating the differences in function manifested in patterns of typed text between older adults with normal cognition and those with PreMCI, with the goal of facilitating early detection of trends that might indicate decline. This research uses these manifestations of cognitive changes in technology interactions to develop a model for classifying deficits in older adults’ cognitive functioning.
Assessment of Cognitive Function
Clinicians use neuropsychological testing to assess cognitive function in a medical setting.6 The tests for cognitive function include operational measures such as verbal fluency, working memory, attention, and planning. Some common tests include the minimental state examination (MMSE), Hopkins Verbal Learning Test-Revised (HVLT-R), the Brief Visuospatial Memory Test-Revised (BVMT-R), and the Benton tests.6 Researchers have proved these tests valid and reliable, but practitioners must have special expertise, and the tests themselves are time consuming to administer, obtrusive to patients, and impractical for frequent administration. Therefore, we need solutions that support more convenient and frequent monitoring of cognitive status if we wish to implement embedded assessment.
Normally, clinicians order a cognitive assessment in reaction to a concern, so they have no baseline data for comparison. Therefore, they can only compare scores to normative data, so individual differences can’t be considered. Among older adults, individual differences in performance are significant and more pronounced than in younger adults.7 Because performance is highly variable both between and within individuals, adaptable solutions that accommodate individual differences and modify system variables are essential. Although current assessments are indispensable for discrete testing, identifying abnormal cognitive functioning, and diagnosis, there’s a real chance of unnecessary and avoidable false positives and false negatives, because baseline data isn’t available. Consequently, the current assessments aren’t effective in detecting early changes in function, and they don’t enable continuous self-monitoring. Accordingly, we need a method that allows unobtrusive, continuous data collection, while also facilitating the recording of baseline data. Because typed text is nearly ubiquitous, this study focuses on analyzing keyboard interactions as a vehicle for distinguishing levels of cognitive function in older adults.8,9,10
Language and Aging
We can also identify evidence of healthy aging or cognitive impairment by analyzing a person’s language, because language comprehension and production depend on the visual, auditory, and cognitive processes impacted by the aging process8 and cognitive decline.9
The language changes associated with dementia are sharper and progress more rapidly that those associated with healthy aging.10 Among several types of dementia, Alzheimer’s disease is by far the most common in most countries,8 and this discussion will characterize typical changes associated with this disease in particular. These changes start to become evident as early as the PreMCI stage of impairment.2 Difficulties with lexical processing, word finding, and syntactic processing are notable symptoms of cognitive decline.8,10 In addition, noun rates decline, with a corresponding increase in pronoun, adjective, and verb rates. Decreases in vocabulary size and increases in the use of repetition and fillers also appear.9 An analysis of the writings of authors who developed dementia showed correlations between age at time of writing and changes in the lexical markers for those with dementia.9 A much lesser degree of change is seen in those who experienced healthy aging.9 Table 1 shows how selected language capabilities change during healthy aging versus Alzheimer’s dementia.8,9,10
TABLE 1.
| Linguistic marker | Healthy aging | Alzheimer’s dementia |
|---|---|---|
| Lexical | ||
| Vocabulary size | Gradual increase, possible slight decrease in later years | Pronounced decrease |
| Word usage | Insignificant change | Pronounced decrease in nouns; compensate using pronouns, adjectives, and verbs |
| Fillers and hesitations | Slight increase | Pronounced increase |
| Syntactic | ||
| Overall complexity | No change or gradual decline, more rapid decline around mid-70s | Pronounced decrease |
Kathleen Fraser and her colleagues classified speech transcripts from participants with two types of primary progressive aphasia (a type of dementia) versus controls.11 Correct classification rates were high, ranging from 53.3 to 100 percent depending on method and comparison type, but the sample-to-feature ratio was much higher than the commonly accepted five or 10 to one threshold. In the case resulting in 100 percent accuracy, the method employed 20 features to classify among 26 samples. This greatly increases the danger of overfitting. We limited the number of features used in our models to minimize overfitting the data.
Brian Roark and his colleagues classified older adults with and without MCI based on both assessment test scores and transcripts of speech uttered during those assessments.12 These researchers used receiver operating characteristic (ROC) analysis and achieved areas under curve (AUCs) of up to 0.732 using only speech characteristics. Combining speech characteristics with a subset of assessment test scores improved AUCs to between 0.749 and 0.775. Using speech characteristics along with all assessment test scores boosted AUCs to between 0.815 and 0.861. We use only text characteristics in our analysis because our goal is to prove our approach’s feasibility for monitoring without the need for formal testing.
Older adults desire embedded assessments to facilitate continuous self-monitoring.3 We can leverage the link between cognitive processes impacted by cognitive impairment and those used during interactions with IT to develop such a method. Prior research supports the association between changes in cognitive function and changes in IT interactions. Holly Jimison and her colleagues, for example, established a connection between cognitive impairment and performance variability on a computer game task.13 Research also indicates that embedded assessment can prompt earlier interventions and treatment, thus improving outcomes.3 IT provides a unique vehicle for this kind of continuous assessment. Therefore, we investigated how we might use attributes of everyday interactions with IT to discriminate between older adults with and without PreMCI, which could ultimately allow them to proactively and continuously monitor their cognitive function.
Approach Methodology
We collected typed text samples from older adults with and without PreMCI to explore the effects of early cognitive impairment on keyboard interactions. The choice of populations let us investigate subclinical changes that occur before formal diagnosis of MCI. We constructed a statistical classification model from the text and keystroke data to discriminate between individuals with and without PreMCI. We conducted the data collection sessions at participants’ local retirement communities, with approval from the institutional review boards of the University of Maryland, Baltimore County, the retirement communities, and their associated dementia research institution.
Drawing from the insights discussed earlier, we propose the following hypothesis to examine the impact of cognitive impairment on keyboard interactions:
Keystroke and linguistic features of typed text samples produced by older adults with PreMCI differ in linguistic and timing features from those produced by older adults without cognitive impairment.
The data collection apparatus included an all-in-one desktop computer with a 20.5” flat screen monitor, a full-size standard keyboard, and a full-size standard mouse. We designed and implemented the data collection software in Visual Basic. The interface used a minimum 16-point typeface to ensure readability. This typeface displayed at a letter height of 3.175 millimeters on the screen and the viewing distance ranged from 50 to 60 centimeters.
Participants
The study included adults over age 65 recruited from local retirement communities. In collaboration with psychologists working in the fields of aging and dementia, we used the following protocol to determine participant eligibility.
Consulting psychologists tested all potential participants for PreMCI using the MMSE, HVLT, BVMT, and symbol digit modalities test (SDMT) to assess a range of cognitive functions impacted by cognitive decline. They referred only those participants meeting inclusion criteria to us for participation.
First, they screened all potential participants using the MMSE. Those scoring below the normal range, 25 or better, were screened out. For the remaining participants, we compared scores from the HVLT, BVMT, and SDMT to age-adjusted normative data. We classified participants who scored below the 10th percentile for their age on either the HVLT or BVMT, or −2.0 standard deviations or lower on the SDMT into the PreMCI group. We classified participants who scored above the 20th percentile for their age on the HVLT and BVMT, or −1.5 standard deviations or higher on the SDMT into the no cognitive impairment (NCI) group. The score buffer between the PreMCI and NCI cutoffs helped ensure accuracy in labeling. All participants had their vision corrected to better than 20/60, at least one year of typing experience, and were free of physical impairments that might adversely affect the use of a keyboard or mouse. Participants received a gratuity of $40.
Protocol
Each participant completed four sessions lasting 20 to 45 minutes each, depending on the participant’s typing speed. Participants provided three typed text samples during each session. Individual sessions were separated by at least two hours with no more than two sessions in one day. These sessions resulted in the collection of 12 samples per participant. During the first session, each participant completed the consent procedure, the SDMT, and the demographic survey. This process added approximately 10–15 minutes to the length of the first session.
Each participant produced three samples of spontaneously generated text by typing to fill a text box that held approximately 800 characters or approximately 150 words. Participants were free to type on any topic they liked and the researcher suggested they think of the task as writing a letter or email to a family member or friend. However, prompts were provided to serve as motivation for the text if desired. This situation was intended to simulate real-world spontaneous text composition as closely as possible in a controlled setting. Participants could rest between samples if desired.
Data Analysis
For each key event, we collected the type of event (either key up or key down), the time stamp, and the key code designating the particular key pressed. We also saved the raw text at completion of the typed text task. We extracted a set of keystroke and linguistic features from the keystroke and text files using the Python Natural Language Toolkit, Linguistic Inquiry and Word Count (LIWC, www.liwc.net), and our data processing software. Table 2 lists the features extracted from the typed text samples.
TABLE 2.
Keystroke and linguistic features extracted from typed text samples.
| Type | Feature |
|---|---|
| Paralinguistic | Timing: duration, time per key, pause rate, pause duration,* individual keystroke rates |
| Language complexity: average sentence length, rate of words longer than six letters, percentage of most common words | |
| Linguistic | Language complexity: rate of unique words |
| Word usage: rates of nouns, verbs, adjectives, and adverbs | |
| cognitive complexity: rate of words indicating cognitive processes (that is, thought, certainty, causation, and so on) | |
| Affect: rate of words indicating positive and negative emotions |
Pause length = 0.5 seconds
To help account for performance variability between participants, we normalized the features in the final two samples from each participant to z-scores using means and standard deviations calculated per feature from the first 10 samples. For model building and testing, we used the normalized data from the last two samples for each participant. Although this process significantly reduced the number of samples available for modeling, our prior work demonstrates the importance of taking into account performance variability.14
We tested the hypothesis using binary logistic regression. We employed the wrapper method of scheme-independent variable selection to define the variable subset used in the model. We performed the regression using a cutoff of p = 0.25 for forward selection of variables with the sample-to-variable ratio set to greater than 10. After selecting the variable set, we used ROC curve analysis to identify the optimal cutoff for classification. We used that cutoff value to evaluate the classification model using leave-one-out (LOO) cross-validation to generate predicted probabilities for each participant’s samples by training the model using the data from the remaining participants. We repeated this procedure for all participants and report the mean classification accuracy across all participants. We used ROC curve analysis on the test samples’ predicted probabilities to calculate the AUC and assessed the significance of the difference in AUC for the experimental model versus the null model. We also judged goodness-of-fit using the Nagelkerke R2, χ2, and Hosmer-Lemeshow statistics.
Results
We drew 38 participants from a healthy older adult population. Participants consisted of two groups:
a group of 21 participants with no cognitive impairment (NCI) and a mean age of 79.24 (standard deviation = 6.0), and
a group of 17 participants with PreMCI and a mean age of 81.12 (standard deviation = 6.0).
We found no significant difference between the ages, education level, years of typing experience, or self-rated typing expertise of the two participant groups (p > 0.05). Twenty NCI participants and 15 PreMCI participants completed the protocol, resulting in 240 NCI samples and 192 PreMCI samples from 35 participants. Using the normalization process, we obtained 40 NCI samples and 30 PreMCI samples for analysis. We performed logistic regression on the combined raw and normalized NCI and PreMCI datasets to select predictor variables and ran ROC curve analysis to select the optimal cutoff value for classification.
To test the performance of the feature sets separately, we built two classification models using the linguistic features for one and the timing features for the other. These models resulted in 60 and 68.6 percent correct classification accuracies, respectively, using cross-validation. The model using only linguistic features wasn’t a significant improvement over the chance correct classification rate of 57.1 percent (p = 0.40 using ROC curve analysis), but the model using only timing features was a more substantial improvement (p = 0.058).
To test the performance of the combined feature sets, we built a model using both linguistic and keystroke features. Table 3 shows the variables selected as predictors for cognitive impairment in older adults. An increase in common dictionary words, a decrease in third-person pronouns, an increase in affect words, an increase in the normalized pause rate, and an increase in time per keystroke combined to define a model to predict PreMCI in older adults. The model characteristics were as follows (N = 70):
the optimal cutoff value was 0.354,
the Nagelkerke R2 statistic was 0.534,
the χ2 statistic was 35.519 (p < 0.01), and
the Hosmer-Lemeshow statistic was 10.056 (p = 0.261).
TABLE 3.
Logistic regression model of pre-mild cognitive impairment (PreMCI) in older adults.
| Variable | Log-odds (β) | Odds ratio (OR) | 95% Confidence Interval for OR |
|---|---|---|---|
| Rate of common words | 0.123 | 1.131 | 0.990–1.293 |
| Third-person pronouns | −0.493* | 0.611 | 0.427–0.874 |
| Affect | 0.264 | 1.302 | 0.970–1.747 |
| Pause rate (normalized) | 1.079 | 2.942 | 1.460–5.928 |
| Time per key | 1.667* | 5.297 | 0.302–92.980 |
| Constant | −11.798** |
p < 0.01,
p < 0.05
Using LOO cross-validation with the 0.354 cutoff, we estimated the classification accuracy of the model at 77.1 percent. Table 4 shows the confusion matrix for the cross-validation results. The sensitivity was 70.6 percent and specificity was 83.3 percent. The 77.1 percent correct classification rate estimate is 35 percent higher than the 57.1 percent chance rate of correct classification. The ROC curve analysis (Figure 1) of the predicted probabilities showed a significant difference between the AUC for the experimental model versus the null model (p = 0.003). Furthermore, the Nagelkerke R2 is relatively high, the χ2 statistic is statistically significant, and the Hosmer-Lemeshow statistic isn’t statistically significant, all indicating that the model is a better fit to the data than the null model. Therefore, the hypothesis is supported.
TABLE 4.
Confusion matrix for classification of no cognitive impairment (NCI) vs. PreMCI.
| Observed | ||
|---|---|---|
| Predicted | NCI | PreMCI |
| NCI | 30 | 10 |
| PreMCI | 6 | 24 |
Figure 1.
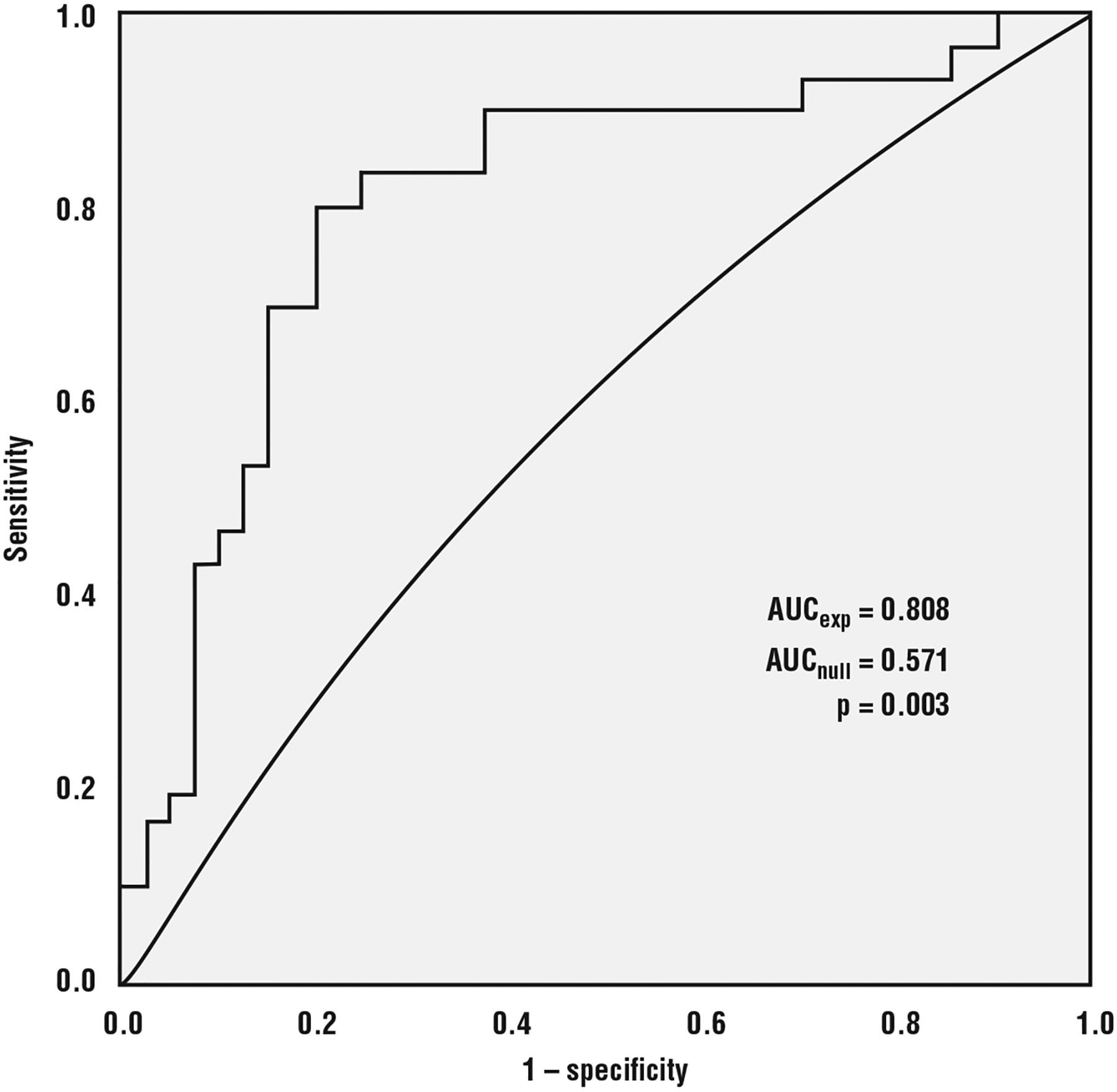
Receiver operating characteristic (ROC) curve analysis of predicted probabilities from experimental model versus null model showing significant difference in AUC (area under curve).
Implications and Limitations
The empirically derived model is composed of variable types and direction changes that combine to predict PreMCI from samples of typed text. The combination of linguistic and timing features produces a better model than either set of features alone. The increase in commonly used words reflects lower language complexity. Together, a decrease in language complexity, a lower rate of references to others, a higher rate of affect words, a higher variability of the pause rate, and more time per key were associated with PreMCI. Time per key is the inverse of input rate, meaning an increase in time per key is a decrease in input rate.
The findings for most of the predictor variables are consistent with the changes expected with PreMCI. Lower language complexity, higher affect, higher pause rate variability, and more time per key are predicted by the literature. The lower rate of third-person pronouns is counter to evidence in the literature and should be researched further to determine its effectiveness as an indicator of PreMCI.
Common tests used to screen for cognitive impairment include the MMSE, HVLT, and BVMT used to classify the cohorts in this study. The MMSE is often used as a preliminary screening tool for MCI, and the HVLT and BVMT are used to gather further information about function in specific domains. In a recent study comparing the effectiveness of different screening tools for MCI, the MMSE achieved 44 percent sensitivity and 69 percent specificity, and the HVLT achieved 79 percent sensitivity and 95 percent specificity.15 The model constructed in this study produced a sensitivity of 70.6 percent and specificity of 83.3 percent for PreMCI. These results are promising, given that our study places the accuracy of our model between accuracies of the MMSE and HVLT tests presented else-where, although that research tested for more advanced disease (that is, MCI rather than PreMCI).15 Our approach is also more desirable because it’s much less intrusive and facilitates frequent monitoring.
Furthermore, our results improve on earlier research using speech characteristics to classify samples as coming from those with or without MCI.9 Researchers achieved AUCs between 0.749 and 0.775 using only language features. We obtained an AUC of 0.808 using a combination of linguistic and timing features.
Monitoring patterns in text directly addresses all of the clinical barriers and three of the eight individual barriers identified earlier. A system can monitor patterns in typed text in the background, in the course of normal activities, and with no extra effort on the part of the user. This eliminates the clinical barriers of delayed assessment, infrequent assessment, lack of ecological validity, narrow focus of assessment, and avoidance of testing for early detection.3 It also removes the individual barriers of avoidance of testing in clinical settings, lack of time, and lack of discipline to record behavior and symptoms.3
However, Morris and her colleagues stress that a monitoring system alone isn’t enough.3 It’s vital to include monitoring along with prevention and compensation in an embedded health assessment system. They define prevention as “activities that protect against a health concern,” and compensation as “adjustments a user makes to cope with a health concern.” The remaining five individual barriers are indirectly overcome by our monitoring approach when integrated with prevention and compensation components. An integrated system providing prevention and compensation services uses the information gleaned from the monitoring component to adapt to and support the user. A monitoring component based on our method of unobtrusively measuring patterns in typed text delivers information that’s relatable and not tied to a diagnosis. For example, the system can present data in interactive visualizations that support understanding of trends or point the user toward resources for cognitive training games. Thus, monitoring typed text activity can indirectly overcome the individual barriers of fear of diagnostic labels, underestimation of health variability and overestimation of insight, discord between individuals’ holistic, integrated view of health, and the constraints of most self-monitoring systems, difficulty relating to traditional clinical health metrics and language, and proactive focus on self-improvement, wellness, and quality of life. Table 5 lists the barriers discovered by Morris and her colleagues3 by whether they’re directly or indirectly overcome by monitoring patterns in typed text as part of a larger integrated embedded system.
TABLE 5.
Barriers to early detection of health conditions and whether they’re eliminated directly or indirectly by monitoring patterns in typed text in an integrated embedded system.
| Barrier type | Barrier | Direct | Indirect |
|---|---|---|---|
| Clinical barriers | Delayed assessment | ✓ | |
| Infrequent assessment | ✓ | ||
| Lack of ecological validity | ✓ | ||
| Narrow focus of assessment | ✓ | ||
| Avoidance of testing for early detection | ✓ | ||
| Individual barriers | Privacy concerns | ✓ | |
| Avoidance of testing in clinical settings | ✓ | ||
| Lack of time and discipline to record behaviors and symptoms | ✓ | ||
| Fear of diagnostic labels | ✓ | ||
| Underestimation of health variability and overestimation of insight | ✓ | ||
| Discordance between individuals’ holistic, integrated view of health and the constraints of most self-monitoring systems | ✓ | ||
| Difficulty relating to traditional clinical health metrics and language | ✓ | ||
| Proactive focus on self-improvement, wellness, and quality of life | ✓ |
This research contributes to our understanding of PreMCI’s impacts on interactions with technology, operational models of these impacts, and the definition of a monitoring system for cognitive decline. The findings could influence the design of health informatics self-monitoring systems to adapt to changing abilities due to aging or cognitive decline.
The implications of this research apply to any person affected by aging or cognitive decline, including family members and health professionals. This study supports the concept of a system that leverages everyday computer interactions and readily available equipment to unobtrusively gather information about cognitive function and cognitive changes. This research shows that models can discriminate keyboard interactions by those with and without PreMCI. This ability implies that, over time, a system could screen for changes associated with PreMCI, present the data in an effective interactive display, and alert the user to trends that he or she might wish to discuss with a healthcare provider. Being able to monitor for increasing levels of impairment can empower users to engage in their own care.
Our study has some limitations. First is its between-subjects design. Among older adults, performance variability is high both between and within individuals, so a system that adapts to each user is advantageous. Consequently, a prospective study of changes within individuals is the only way to examine interpersonal differences and design such a system. However, our results provide evidence for the feasibility of a self-monitoring system and indicate what types of keystroke and linguistic features are predictors in light of PreMCI versus healthy aging.
In addition, this study is limited to the keyboard interaction modality. Nevertheless, because the model incorporates elements of language and timing that aren’t exclusive to keyboard interactions, these results should generalize to other modalities such as those used in mobile technologies. These include mobile keyboard, tap, swipe, and pen input. We’re currently working to develop applications to test these interaction methods.
We conducted this study in a controlled setting. The study took place in the residence facility but not in participants’ individual residences with their own equipment. This reduces the ecological validity, and future studies should include testing in the participants’ personal environments using their own personal computing equipment.
Finally, we’re aware of the possibility that the cognitive status of some participants was mislabeled. We used an appropriate screening protocol and attempted to reduce the likelihood of mislabeling by instituting a buffer between score ranges for the cohorts, but the tests aren’t perfect.
In our future work, we’ll continue to explore other modalities, conduct a longitudinal study with persons experiencing cognitive decline, investigate sensitivity and specificity tradeoffs, and explore system acceptance. Tests of other modalities will include mobile technology interactions. We’ll also test the generalizability of our findings to other input methods. The long-term study will determine the efficacy of this approach for detecting changes on an individual level. An in-depth analysis of sensitivity and specificity will help determine how best to tune models. A study of system acceptance will clarify older adults’ views and preferences related to self-monitoring and inform data presentation to consumers and clinicians.
Our results illustrate the possibility of monitoring technology interactions for signs of subtle, preclinical, cognitive decline. Information gathered in the course of health monitoring could be used for education or interventions to support self-reflection and improve users’ health. The ability to detect changes and trends opens the possibility for prevention and compensation activities. Interventions could include simple alerts, interactive data visualizations to show trends of signs of cognitive function over time, or a full-featured program of physical and cognitive exercises as well as an interface to medical professionals. This assistance can allow users to adapt in the face of changes associated with aging, and can alert people with early signs of PreMCI to changes they might wish to discuss with a healthcare provider.
In the future, embedded assessment using commonplace technology interactions could be an important way to gain insight into our cognitive health. This approach is a low-cost method for health monitoring that can be incorporated into everyday activities. When integrated into a system with prevention and compensation features it can assist people in making informed decisions about care by allowing them to monitor their own behaviors, view trends, and act on that information. As the medical system becomes more patient-centered, patient self-advocacy will be increasingly important and this approach to monitoring can empower older adults to be proactive concerning their cognitive health.
ACKNOWLEDGMENTS
A. Ant Ozok, Lina Zhou, Sara Czaja, and Clayton Lewis provided research guidance. The Copper Ridge Institute, including Jason Brandt and Larry Burrell, and the Fairhaven and Buckingham’s Choice EMA Retirement Communities, staff, and residents provided recruitment, screening, and scheduling assistance. This work was supported by a US National Science Foundation graduate research fellowship, and the US National Library of Medicine Biomedical and Health Informatics Training Program at the University of Washington (grant number T15LM007442). The content is solely the responsibility of the authors and doesn’t necessarily represent the official views of NSF or NIH.
Biographies

Lisa M. Vizer is a research assistant professor in the School of Medicine at the University of North Carolina at Chapel Hill. Her research interests include supporting patients with a variety of brain conditions outside of the clinic using passively collected patient-generated data. Vizer has a PhD in information systems from the University of Maryland, Baltimore County. She’s a member of the American Medical Informatics Association and the ACM. Contact her at lisa_vizer@med.unc.edu.

Andrew Sears is dean of the College of Information Sciences and Technology at Pennsylvania State University. His research interests include issues related to human-centered computing and accessibility, mobile computing, health information technologies, speech recognition, managing interruptions while working with information technologies, and assessing an individual’s cognitive status via normal daily interactions with information technologies. Sears has a PhD in computer science from the University of Maryland, College Park. He’s a member of the ACM. Contact him at asears@ist.psu.edu.
Contributor Information
Lisa M. Vizer, University of North Carolina at Chapel Hill
Andrew Sears, Pennsylvania State University.
REFERENCES
- 1.Plassman BL et al. , “Prevalence of Cognitive Impairment without Dementia in the United States,” Annals Internal Medicine, vol. 148, no. 6, 2008, pp. 427–434. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Loewenstein DA et al. , “An Investigation of PreMCI: Subtypes and Longitudinal Outcomes,” Alzheimers Dementia, vol. 8, no. 3, 2012, pp. 172–179. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Morris M, Intille SS, and Beaudin JS, “Embedded Assessment: Overcoming Barriers to Early Detection with Pervasive Computing,” Pervasive Computing, Springer, 2005, pp. 333–346. [Google Scholar]
- 4.Smith A, “Older Adults and Technology Use,” Pew Research Center, 3 April. 2014; www.pewinternet.org/2014/04/03/older-adults-and-technology-use. [Google Scholar]
- 5.Zickuhr K and Madden Mary, “Older Adults and Technology Use,” Pew Research Center, 6 June 2012; www.pewinternet.org/2012/06/06/older-adults-and-internet-use. [Google Scholar]
- 6.Guidelines for the Evaluation of Dementia and Age-Related Cognitive Decline, Presidential Task Force on the Assessment of Age-Consistent Memory Decline and Dementia, American Psychological Assoc., 1998. [PubMed] [Google Scholar]
- 7.Sliwinski M and Buschke H, “Modeling Intraindividual Cognitive Change in Aging Adults: Results from the Einstein Aging Studies,” Aging, Neuropsychology, and Cognition: J. Normal and Dysfunctional Development, vol. 11, nos. 2–3, 2004, pp. 196–211. [Google Scholar]
- 8.Maxim J and Bryan K, Language of the Elderly: A Clinical Perspective, Singular Publishing Group, 1994. [Google Scholar]
- 9.Le X et al. , “Longitudinal Detection of Dementia through Lexical and Syntactic Changes in Writing: A Case Study of Three British Novelists,” Literary and Linguistic Computing, vol. 26, no. 4, 2011, pp. 435–461. [Google Scholar]
- 10.Burke DM and Shafto MA, “Language and Aging,” Handbook of Aging and Cognition, 3rd ed., 2008, pp. 373–443. [Google Scholar]
- 11.Fraser KC et al. , “Automated Classification of Primary Progressive Aphasia Subtypes from Narrative Speech Transcripts,” Cortex, vol. 55, June 2014, pp. 43–60. [DOI] [PubMed] [Google Scholar]
- 12.Roark B et al. , “Spoken Language Derived Measures for Detecting Mild Cognitive Impairment,” IEEE Trans. Audio Speech Language Processing, vol. 19, no. 7, 2011, pp. 2081–2090. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Jimison H et al. , “Unobtrusive Monitoring of Computer Interactions to Detect Cognitive Status in Elders,” IEEE Trans. Information Technology in Biomedicine, vol. 8, no. 3, 2004, pp. 248–252. [DOI] [PubMed] [Google Scholar]
- 14.Vizer LM, Zhou L, and Sears A, “Automated Stress Detection Using Keystroke and Linguistic Features: An Exploratory Study,” Int’l J. Human-Computer Studies, vol. 67, no. 10, 2009, pp. 870–886. [Google Scholar]
- 15.de Jager CA et al. , “Detection of MCI in the Clinic: Evaluation of the Sensitivity and Specificity of a Computerised Test Battery, the Hopkins Verbal Learning Test and the MMSE,” Age Ageing, vol. 38, no. 4, 2009, pp. 455–460. [DOI] [PubMed] [Google Scholar]