

Abstract
In human-level NLP tasks, such as predicting mental health, personality, or demographics, the number of observations is often smaller than the standard 768+ hidden state sizes of each layer within modern transformer-based language models, limiting the ability to effectively leverage transformers. Here, we provide a systematic study on the role of dimension reduction methods (principal components analysis, factorization techniques, or multi-layer auto-encoders) as well as the dimensionality of embedding vectors and sample sizes as a function of predictive performance. We first find that fine-tuning large models with a limited amount of data pose a significant difficulty which can be overcome with a pre-trained dimension reduction regime. RoBERTa consistently achieves top performance in human-level tasks, with PCA giving benefit over other reduction methods in better handling users that write longer texts. Finally, we observe that a majority of the tasks achieve results comparable to the best performance with just of the embedding dimensions.
1. Introduction
Transformer based language models (LMs) have quickly become the foundation for accurately approaching many tasks in natural language processing (Vaswani et al., 2017; Devlin et al., 2019). Owing to their success is their ability to capture both syntactic and semantic information (Tenney et al., 2019), modeled over large, deep attention-based networks (transformers) with hidden state sizes on the order of 1000 over 10s of layers (Liu et al., 2019; Gururangan et al., 2020). In total such models typically have from hundreds of millions (Devlin et al., 2019) to a few billion parameters (Raffel et al., 2020). However, the size of such models presents a challenge for tasks involving small numbers of observations, such as for the growing number of tasks focused on human-level NLP.
Human-level NLP tasks, rooted in computational social science, focus on making predictions about people from their language use patterns. Some of the more common tasks include age and gender prediction (Sap et al., 2014; Morgan-Lopez et al., 2017), personality (Park et al., 2015; Lynn et al., 2020), and mental health prediction (Coppersmith et al., 2014; Guntuku et al., 2017; Lynn et al., 2018). Such tasks present an interesting challenge for the NLP community to model the people behind the language rather than the language itself, and the social scientific community has begun to see success of such approaches as an alternative or supplement to standard psychological assessment techniques like questionnaires (Kern et al., 2016; Eichstaedt et al., 2018). Generally, such work is helping to embed NLP in a greater social and human context (Hovy and Spruit, 2016; Lynn et al., 2019).
Despite the simultaneous growth of both (1) the use of transformers and (2) human-level NLP, the effective merging of transformers for human-level tasks has received little attention. In a recent human-level shared task on mental health, most participants did not utilize transformers (Zirikly et al., 2019). A central challenge for their utilization in such scenarios is that the number of training examples (i.e. sample size) is often only hundreds while the parameters for such deep models are in the hundreds of millions. For example, recent human-level NLP shared tasks focused on mental health have had N = 947 (Milne et al., 2016), N = 9, 146 (Lynn et al., 2018) and N = 993 (Zirikly et al., 2019) training examples. Such sizes all but rules out the increasingly popular approach of fine-tuning transformers whereby all its millions of parameters are allowed to be updated toward the specific task one is trying to achieve (Devlin et al., 2019; Mayfield and Black, 2020). Recent research not only highlights the difficulty in fine-tuning with few samples (Jiang et al., 2020) but it also becomes unreliable even with thousands of training examples (Mosbach et al., 2020).
On the other hand, some of the common transformer-based approaches of deriving contextual embeddings from the top layers of a pre-trained model (Devlin et al., 2019; Clark et al., 2019) still leaves one with approximately an equal number of embedding dimensions as training size. In fact, in one of the few successful cases of using transformers for a human-level task, further dimensionality reduction was used to avoid over-fit (Matero et al., 2019), but an empirical understanding of the application of transformers for human-level tasks — which models are best and the relationship between embedding dimensions, sample size, and accuracy — has yet to be established.
In this work, we empirically explore strategies to effectively utilize transformer-based LMs for relatively small sample-size human-level tasks. We provide the first systematic comparison of the most widely used transformer models for demographic, personality, and mental health prediction tasks. Then, we consider the role of dimension reduction to address the challenge of applying such models on small sample sizes, yielding a suggested minimum number of dimensions necessary given a sample size for each of demographic, personality, and mental health tasks1. While it is suspected that transformer LMs contain more dimensions than necessary for document- or word-level NLP (Li and Eisner, 2019; Bao and Qiao, 2019), this represents the first study on transformer dimensionality for human-level tasks.
2. Related Work
Recently, NLP has taken to human-level predictive tasks using increasingly sophisticated techniques. The most common approaches use n-grams and LDA (Blei et al., 2003) to model a person’s language and behaviors (Resnik et al., 2013; Kern et al., 2016). Other approaches utilize word embeddings (Mikolov et al., 2013; Pennington et al., 2014) and more recently, contextual word representations (Ambalavanan et al., 2019).
Our work is inspired by one of the top performing systems at a recent mental health prediction shared task (Zirikly et al., 2019) that utilized transformer-based contextualized word embeddings fed through a non-negative matrix factorization to reduce dimensionality (Matero et al., 2019). While the approach seems reasonable for addressing the dimensionality challenge in using transformers, many critical questions remain unanswered: (a) Which type of transformer model is best? (b) Would fine-tuning have worked instead? and (c) Does such an approach generalize to other human-level tasks? Most of the time, one does not have a luxury of a shared task for their problem at hand to determine a best approach. Here, we look across many human-level tasks, some of which with the luxury of having relatively large sample sizes (in the thousands) from which to establish upper-bounds, and ultimately to draw generalizable information on how to approach a human-level task given its domain (demographic, personality, mental health) and sample size.
Our work also falls in line with a rising trend in AI and NLP to quantify the number of dimensions necessary. While this has not been considered for human-level tasks, it has been explored in other domains. The post processing algorithm (Mu and Viswanath, 2018) of the static word embeddings motivated by the power law distribution of maximum explained variance and the domination of mean vector turned out to be very effective in making these embeddings more discriminative. The analysis of contextual embedding models (Ethayarajh, 2019) suggest that the static embeddings contribute to less than 5% to the explained variance, the contribution of the mean vector starts dominating when contextual embedding models are used for human-level tasks. This is an effect of averaging the message embeddings to form user representations in human-level tasks. This further motivates the need to process these contextual embeddings into more discriminative features.
Lastly, our work weighs into the discussion on just which type of model is best in order to produce effective contextual embedding models. A majority of the models fall under two broad categories based on how they are pre-trained - auto-encoders (AE) and auto-regressive (AR) models. We compare the performance of AE and AR style LMs by comparing the performance of two widely used models from each category with comparable number of parameters. From the experiments involving BERT, RoBERTa (Liu et al., 2019), XLNet (Yang et al., 2019) and GPT-2 (Radford et al., 2019), we find that AE based models perform better than AR style models (with comparable model sizes), and RoBERTa is the best choice amongst these four widely used models.
3. Data & Tasks
We evaluate approaches over 7 human-level tasks spanning Demographics, Mental Health, and personality prediction. The 3 datasets used for these tasks are described below.
FB-Demogs. (age, gen, ope, ext)
One of our goals was to leverage one of the largest human-level datasets in order to evaluate over subsamples of sizes. For this, we used the Facebook demographic and personality dataset of Kosinski et al. (2013). The data was collected from approximately 71k consenting participants who shared Facebook posts along with demographic and personality scores from Jan-2009 through Oct-2011. The users in this sample had written at least a 1000 words and had selected English as their primary language. Age (age) was self-reported and limited to those 65 years or younger (data beyond this age becomes very sparse) as in (Sap et al., 2014). Gender (gen) was only provided as a limited single binary, male-female classification.
Personality was derived from the Big 5 personality traits questionnaires, including both extraversion (ext - one’s tendency to be energized by social interaction) and openess (ope, one’s tendency to be open to new ideas) (Schwartz et al., 2013). Disattenuated Pearson correlation2 (rdis) was used to measure the performance of these two personality prediction tasks.
CLPsych-2018. (bsag, gen2)
The CLPsych 2018 shared task (Lynn et al., 2018) consisted of sub-tasks aimed at early prediction of mental health scores (depression, anxiety and BSAG3 score) based on their language. The data for this shared task (Power and Elliott, 2005) comprised of English essays written by 11 year old students along with their gender (gen2) and income classes. There were 9217 students’ essays for training and 1000 for testing. The average word count in an essay was less than 200. Each essay was annotated with the student’s psychological health measure, BSAG (when 11 years old) and distress scores at ages 23, 33, 42 and 50. This task used a disattenuated pearson correlation as the metric (rdis).
CLPsych-2019. (sui)
This 2019 shared task (Zirikly et al., 2019) comprised of 3 sub-tasks for predicting the suicide risk level in reddit users. This included a history of user posts on r/SuicideWatch (SW), a subreddit dedicated to those wanting to seek outside help for processing their current state of emotions. Their posts on other subreddits (NonSuicideWatch) were also collected. The users were annotated with one of the 4 risk levels: none, low, moderate and severe risk based on their history of posts. In total this task spans 496 users in training and 125 in testing. We focused on Task A, predicting suicide risk of a user by evaluating their (English) posts across SW, measured via macro-F1.
4. Methods
Here we discuss how we utilized representations from transformers, our approaches to dimensionality reduction, and our technique for robust evaluation using bootstrapped sampling.
4.1. Transformer Representations
The second to last layer representation of all the messages was averaged to produce a 768 dimensional feature for each user4. These user representations are reduced to lower dimensions as described in the following paragraphs. The message representation from a layer was attained by averaging the token embeddings of that layer. To consider a variety of transformer LM architectures, we explored two popular auto-encoder (BERT and RoBERTa) and two auto-regressive (XLNet and GPT-2) transformer-based models.
For fine-tuning evaluations, we used the transformer based model that performs best across the majority of our task suite. Transformers are typically trained on single messages or pairs of messages, at a time. Since we are tuning towards a human-level task, we label each user’s message with their human-level attribute and treat it as a standard document-level task (Morales et al., 2019). Since we are interested in relative differences in performance, we limit each user to at most 20 messages - approximately the median number of messages, randomly sampled, to save compute time for the fine tuning experiments.

4.2. Dimension Reduction
We explore singular value decomposition-based methods such as Principal components analysis (PCA) (Halko et al., 2011), Non-negative matrix factorization (NMF) (Févotte and Idier, 2011) and Factor analysis (FA) as well as a deep learning approach: multi-layer non linear auto encoders (NLAE) (Hinton and Salakhutdinov, 2006). We also considered the post processing algorithm (PPA) of word embeddings5 (Mu and Viswanath, 2018) that has shown effectiveness with PCA on word level (Raunak et al., 2019). Importantly, besides transformer LMs being pre-trained, so too can dimension reduction. Therefore, we distinguish: (1) learning the transformation from higher dimension to lower dimensions (preferably on a large data sample from the same domain) and (2) applying the learned transformation (on the task’s train/test set). For the first step, we used a separate set of 56k unlabeled user data in the case of FB-demog6. For CLPsych-2018 and -2019 (where separate data from the exact domains was not readily available), we used the task training data to train the dimension reduction. Since variance explained in factor analysis typically follows a power law, these methods transformed the 768 original embedding dimensions down to k, in powers of 2: 16, 32, 64, 128, 256 or 512.
4.3. Bootstrapped Sampling & Training
We systematically evaluate the role of training sample (Nta) versus embedding dimensions (k) for human-level prediction tasks. The approach is described in algorithm 1. Varying Nta, the task-specific train data (after dimension reduction) is sampled randomly (with replacement) to get ten training samples with Nta users each. Small Nta values simulate a low-data regime and were used to understand its relationship with the least number of dimensions required to perform the best (Nta vs k). Bootstrapped sampling was done to arrive at a conservative estimate of performance. Each of the bootstrapped samples was used to train either an L2 penalized (ridge) regression model or logistic regression for the regression and classification tasks respectively. The performance on the test set using models from each bootstrapped training sample was recorded in order to derive a mean and standard error for each Nta and k for each task.
To summarize results over the many tasks and possible k and Nta values in a useful fashion, we propose a ‘first k to peak (fkp)’ metric. For each Nta, this is the first observed k value for which the mean score is within the 95% confidence interval of the peak performance. This quantifies the minimum number of dimensions required for peak performance.
5. Results
5.1. Best LM for Human-Level Tasks
We start by comparing transformer LMs, replicating the setup of one of the state-of-the-art systems for the CLPsych-2019 task in which embeddings were reduced from BERT-base to approximately 100 dimensions using NMF (Matero et al., 2019). Specifically, we used 128 dimensions (to stick with powers of 2 that we use throughout this work) as we explore the other LMs over multiple tasks (we will explore other dimensions next) and otherwise use the bootstrapped evaluation described in the method.
Table 2 shows the comparison of the four transformer LMs when varying the sample size (Nta) between two low data regimes: 100 and 5007. RoBERTa and BERT were the best performing models in almost all the tasks, suggesting auto-encoders based LMs are better than auto-regressive models for these human-level tasks. Further, RoBERTa performed better than BERT in the majority of cases. Since the number of model parameters are comparable, this may be attributable to RoBERTa’s increased pre-training corpus, which is inclusive of more human discourse and larger vocabularies in comparison to BERT.
Table 2:
Comparison of most commonly used auto-encoders (AE) and auto-regressor (AR) language models after reducing the 768 dimensions to 128 using NMF and trained on 100 and 500 samples (Nta) for each task. (Nta) pertains to the number of samples used for training each task. Classification tasks (gen, gen2 and sui) were scored using macro-F1 (F1); the remaining regression tasks were scored using pearson-r (r)/disattenuated pearson-r (rdis). AE models predominantly perform the best. RoBERTa and BERT show consistent performance, with the former performing the best in most tasks. The LMs in the table were base models (approx. 110M parameters).
| LM | demographics | personality | mental health | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Nta | name | gen2 (F1) | ope (rdis) | sui (F1) | |||||
| 100 | BERT | 0.761 | 0.184 | 0.360 | |||||
| RoBERTa | 0.761 | 0.203 | 0.363 | ||||||
| XLNet | 0.744 | 0.203 | 0.315 | ||||||
| GPT-2 | 0.624 | 0.157 | 0.349 | ||||||
| 500 | BERT | 0.837 | 0.354 | 0.466 | |||||
| RoBERTa | 0.852 | 0.361 | 0.432 | ||||||
| XLNet | 0.821 | 0.336 | 0.439 | ||||||
| GPT-2 | 0.762 | 0.280 | 0.397 | ||||||
5.2. Fine-Tuning Best LM
We next evaluate fine-tuning in these low data situations8. Utilizing RoBERTa, the best performing transformer from the previous experiments, we perform fine-tuning across the age and gender tasks. Following (Sun et al., 2019; Mosbach et al., 2020), we freeze layers 0–9 and fine-tune layers 10 and 11. Even these top 2 layers alone of RoBERTa still result in a model that is updating tens of millions of parameters while being tuned to a dataset of hundreds of users and at most 10,000 messages.
In table 3, results for age and gender are shown for both sample sizes of 100 and 500. For Age, the average prediction across all of a user’s messages was used as the user’s prediction and for gender the mode was used. Overall, we find that fine-tuning offers lower performance with increased overhead for both train time and modeling complexity (hyperparameter tuning, layer selection, etc).
Table 3:
Comparison of task specific fine tuning of RoBERTa (top 2 layers) and pre-trained RoBERTa embeddings (second to last layer) for age and gender prediction tasks. Results are averaged across 5 trials randomly sampling users equal to Nta from the Facebook data and reducing messages to maximum of 20 per user.
| Nta | Method | Age | Gen |
|---|---|---|---|
| 100 | Fine-tuned | 0.54 | 0.54 |
| Pre-trained | 0.56 | 0.63 | |
| 500 | Fine-tuned | 0.64 | 0.60 |
| Pre-trained | 0.66 | 0.74 |
We did robustness checks for hyper-parameters to offer more confidence that this result was not simply due to the fastidious nature of fine-tuning. The process is described in Appendix B, including an extensive exploration of hyper-parameters, which never resulted in improvements over the pre-trained setup. We are left to conclude that fine-tuning over such small user samples, at least with current typical techniques, is not able to produce results on par with using transformers to produce pre-trained embeddings.
5.3. Best Reduction technique for Human-Level Tasks
We evaluated the reduction techniques in low data regime by comparing their performance on the downstream tasks across 100 and 500 training samples (Nta). As described in the methods, techniques including PCA, NMF and FA along with NLAE, were applied to reduce the 768 dimensional RoBERTa embeddings to 128 features. The results in table 4 show that PCA and NLAE perform most consistently, with PCA having the best scores in the majority tasks. NLAE’s performance appears dependent on the amount of data available during the pre-training. This is evident from the results in Table 4 where the Npt was set to a uniform value and tested for all the tasks with Nta set to 100 and 500. Thus, PCA appears a more reliable, showing more generalization for low samples.
Table 4:
Comparison of different dimension reduction techniques of RoBERTa embeddings (penultimate layer) reduced down to 128 dimensions and Nta = 100 and 500. Number of user samples for pre-trianing the dimension reduction model, Npt was 56k except for gen2, bsag (which had 9k users) and sui (which had 496 users). PCA performs the best overall and NLAE performs as good as PCA consistently. With uniform pre-training size (Npt = 500), PCA performs better than NLAE.
| demographics | personality | mental health | ||||||
|---|---|---|---|---|---|---|---|---|
| Npt | Reduction | gen2 (F1) | ope (rdis) | sui (F1) | ||||
| 56k | PCA | 0.777 | 0.248 | 0.392 | ||||
| PCA-PPA | 0.729 | 0.176 | 0.358 | |||||
| FA | 0.729 | 0.183 | 0.360 | |||||
| NMF | 0.761 | 0.203 | 0.363 | |||||
| NLAE | 0.782 | 0.263 | 0.367 | |||||
| PCA | 0.856 | 0.384 | 0.416 | |||||
| PCA-PPA | 0.849 | 0.349 | 0.415 | |||||
| FA | 0.849 | 0.361 | 0.415 | |||||
| NMF | 0.852 | 0.361 | 0.432 | |||||
| NLAE | 0.843 | 0.394 | 0.409 | |||||
| 500 | PCA | 0.788 | 0.248 | 0.392 | ||||
| NLAE | 0.744 | 0.230 | 0.367 | |||||
| PCA | 0.850 | 0.382 | 0.416 | |||||
| NLAE | 0.811 | 0.360 | 0.409 | |||||
5.4. Performance by Sample Size and Dimensions
Now that we have found (1) RoBERTa generally performed best, (2) pre-trainining worked better than fine-tuning, and (3) PCA was most consistently best for dimension reduction (often doing better than the full dimensions), we can systematically evaluate model performance as a function of training sample size (Nta) and number of dimensions (k) over tasks spanning demographics, personality, and mental health. We exponentially increase k from 16 to 512, recognizing that variance explained decreases exponentially with dimension (Mu and Viswanath, 2018). The performance is also compared with that of using the RoBERTa embeddings without any reduction.
Figure 1 compares the scores at reduced dimensions for age, ext, ope and bsag. These charts depict the experiments on typical low data regime (Nta ≤ 1000). Lower dimensional representations performed comparable to the peak performance with just the features while covering the most number of tasks and just features for the majority of tasks. Charts exploring other ranges of Nta values and remaining tasks can be found in the appendix D.1.
Figure 1:
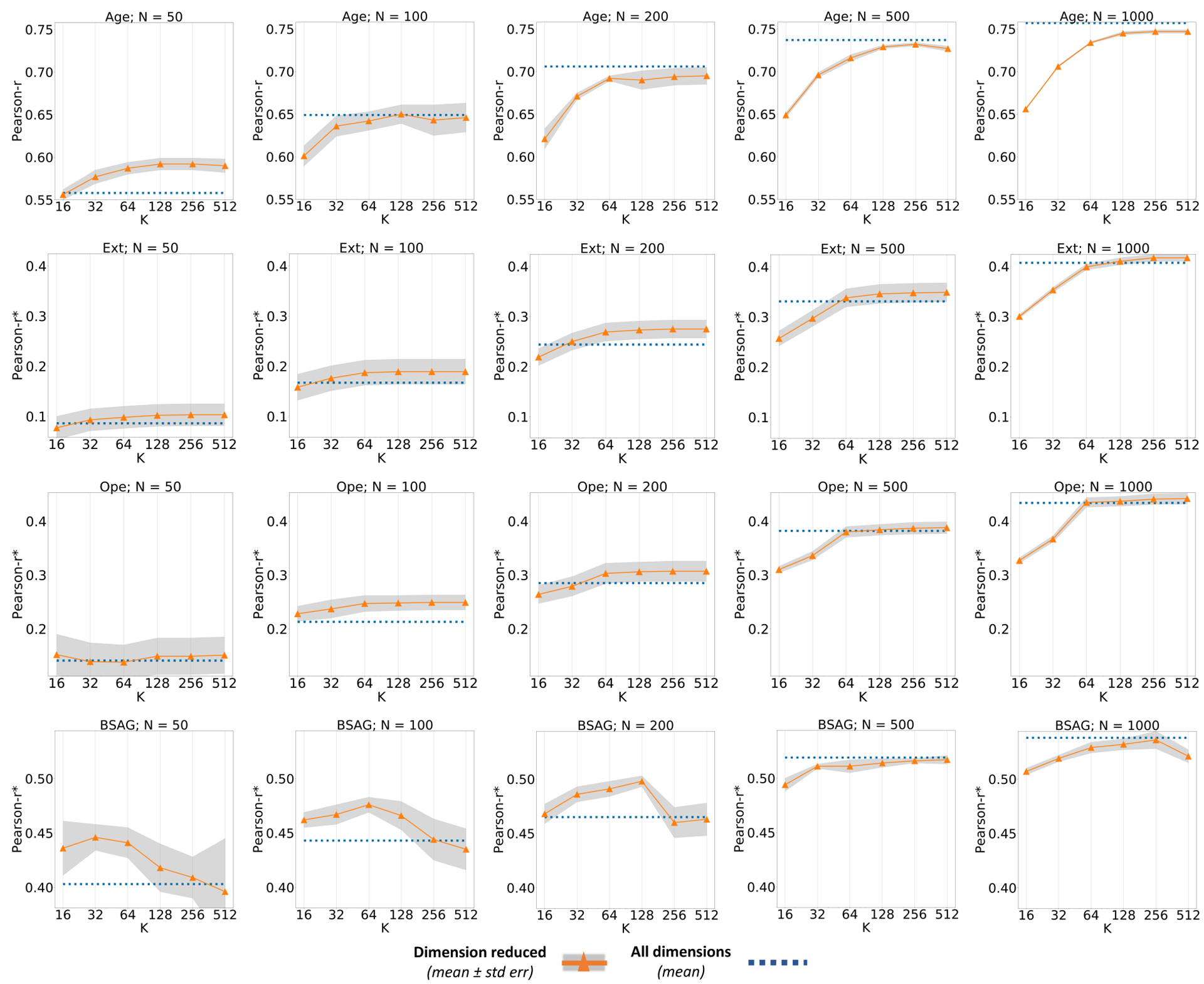
Comparison of performance for all regression tasks: age, ext, ope and bsag over varying Nta and k. Results vary by task, but predominantly, performance at k=64 is better than the performance without any reduction. It is conclusive that the reduced features almost always performs better or as good as the original embeddings.
5.5. Least Number of Dimensions Required
Lastly, we devise an experiment motivated by answering the question of how many dimensions are necessary to achieve top results, given a limited sample size. Specifically, we define ‘first k to peak’ (fkp) as the least valued k that produces an accuracy equivalent to the peak performance. A 95% confidence interval was computed for the best score (peak) for each task and each Nta based on bootstrapped resamples, and fkp was the least number of dimensions where this threshold was passed.
Our goal is that such results can provide a systematic guide for making such modeling decisions in future human-level NLP tasks, where such an experiment (which relies on resampling over larger amounts of training data) is typically not feasible. Table 5 shows the fkp over all of the training sample sizes (Nta). The exponential median (med) in the table is calculated as follows: med = 2Median(log(x))
Table 5:
First k to peak (fkp) for each set of tasks: the least value of k that performed statistically equivalent (p > .05) to the best performing setup (peak). Integer shown is the exponential median of the set of tasks. This table summarizes comprehensive testing and we suggest its results, fkp, can be used as a recommendation for the number of dimensions to use given a task domain and training set size.
| Nta | demographics (3 tasks) | personality (2 tasks) | mental health (2 tasks) |
|---|---|---|---|
| 50 | 16 | 16 | 16 |
| 100 | 128 | 16 | 22 |
| 200 | 512 | 32 | 45 |
| 500 | 768 | 64 | 64 |
| 1000 | 768 | 90 | 64 |
The fkp results suggest that more training samples available yield ability to leverage more dimensions, but the degree to which depends on the task. In fact, utilizing all the embedding dimensions was only effective for demographic prediction tasks. The other two tasks benefited from reduction, often with only to 6 of the original second to last transformer layer dimensions.
6. Error Analysis
Here, we seek to better understand why using pre-trained models worked better than fine-tuning, and differences between using PCA and NMF components in the low sample setting (Nta = 500).
Pre-trained vs Fine-tuned.
We looked at categories of language from LIWC (Tausczik and Pennebaker, 2010), correlated with the difference in the absolute error of the pre-trained and fine-tuned model in age prediction. Table 6 suggests that pre-trained model is better at handling users with language conforming to the formal rules, and fine-tuning helps in learning better representation of the affect words and captures informal language well. Furthermore, these LIWC variables are also known to be associated with age (Schwartz et al., 2013). Additional analysis comparing these two models is available in appendix E.1.
Table 6:
Top LIWC variables having negative and positive correlations with the difference in the absolute error of the pre-trained model and the fine-tuned model for age prediction. Benjamini-Hochberg FDR p < .05. This suggests that the fine-tuned models have lesser error than pre-trained model when the language is informal and consists of more affect words.
| Association | LIWC variables |
|---|---|
| Positive | Informal, Netspeak, Negemo Swear, Anger |
| Negative | Affiliation, Social, We, They, Family, Function, Drives, Prep, Focuspast, Quant |
PCA vs NMF.
Figure 2 suggests that PCA is better at handling longer text sequences than NMF (> 55 one grams on avg) when trained with less data. This choice wouldn’t make much difference when used for Tweet-like short texts, but the errors diverge rapidly for longer samples. We also see that PCA is better at capturing information from these texts that have higher predictive power in downstream tasks. This is discussed in appendix E.2 along with other interesting findings involving the comparison of PCA and the pre-trained model in E.3.
Figure 2:
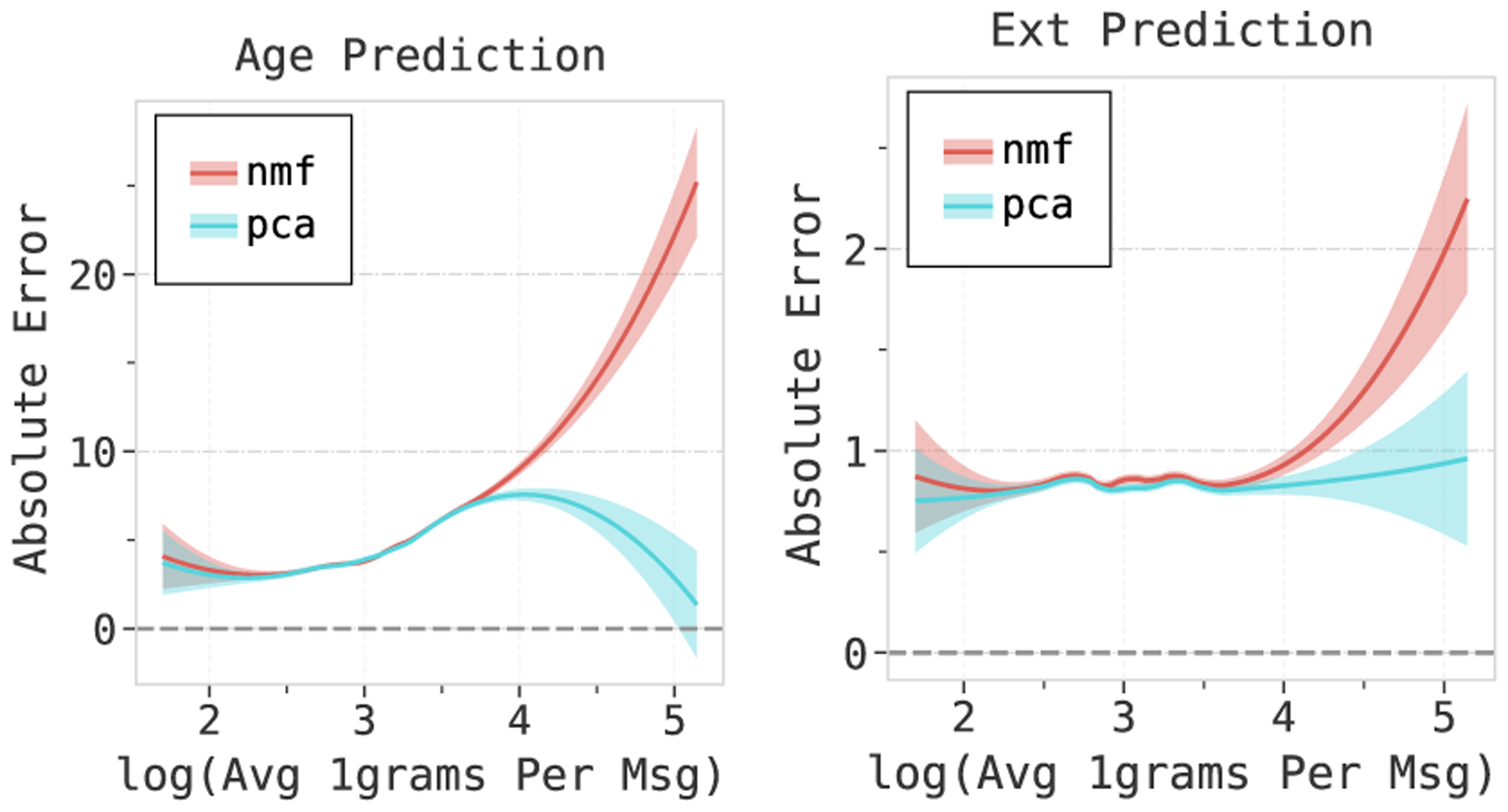
Comparison of the absolute error of NMF and PCA with the average number of 1 grams per message. While both the models appear to perform very similar when the texts are small or average sized, PCA is better at handling longer texts. The errors diverge when the length of the texts increases.
7. Discussion
Ethical Consideration.
We used existing datasets that were either collected with participant consent (FB and CLPsych 2018) or public data with identifiers removed and collected in a non-intrusive manner (CLPsych 2019). All procedures were reviewed and approved by both our institutional review board as well as the IRB of the creators of the data set.
Our work can be seen as part of the growing body of interdisciplinary research intended to understanding human attributes associated with language, aiming towards applications that can improve human life, such as producing better mental health assessments that could ultimately save lives. However, at this stage, our models are not intended to be used in practice for mental health care nor labeling of individuals publicly with mental health, personality, or demographic scores. Even when the point comes where such models are ready for testing in clinical settings, this should only be done with oversight from professionals in mental health care to establish the failure modes and their rates (e.g. false-positives leading to incorrect treatment or false-negatives leading to missed care; increased inaccuracies due to evolving language; disparities in failure modes by demographics). Malicious use possibilities for which this work is not intended include targeting advertising to individuals using language-based psychology scores, which could present harmful content to those suffering from mental health conditions.
We intend that the results of our empirical study are used to inform fellow researchers in computational linguistics and psychology on how to better utilize contextual embeddings towards the goal of improving psychological and mental health assessments. Mental health conditions, such as depression, are widespread and many suffering from such conditions are under-served with only 13 – 49% receiving minimally adequate treatment (Kessler et al., 2003; Wang et al., 2005). Marginalized populations, such as those with low income or minorities, are especially under-served (Saraceno et al., 2007). Such populations are well represented in social media (Center, 2021) and with this technology developed largely over social media and predominantly using self-reported labels from users (i.e., rather than annotator-perceived labels that sometimes introduce bias (Sap et al., 2019; Flekova et al., 2016)), we do not expect that marginalized populations are more likely to hit failure modes. Still, tests for error disparities (Shah et al., 2020) should be carried out in conjunction with clinical researchers before this technology is deployed. We believe this technology offers the potential to broaden the coverage of mental health care to such populations where resources are currently limited.
Future assessments built on the learnings of this work, and in conjunction with clinical mental health researchers, could help the under-served by both better classifying one’s condition as well as identifying an ideal treatment. Any applications to human subjects should consider the ethical implications, undergo human subjects review, and the predictions made by the model should not be shared with the individuals without consulting the experts.
Limitations.
Each dataset brings its own unique selection biases across groups of people, which is one reason we tested across many datasets covering a variety of human demographics. Most notably, the FB dataset is skewed young and is geographically focused on residents within the United States. The CLPsych 2018 dataset is a representative sample of citizens of the United Kingdom, all born on the same week, and the CLPsych-2019 dataset was further limited primarily to those posting in a suicide-related forum (Zirikly et al., 2019). Further, tokenization techniques can also impact language model performance (Bostrom and Durrett, 2020). To avoid oversimplification of complex human attributes, in line with psychological research (Haslam et al., 2012), all outcomes were kept in their most dimensional form – e.g. personality scores were kept as real values rather than divided into bins and the CLPsych-2019 risk levels were kept at 4 levels to yield gradation in assessments as justified by Zirikly et al., 2019.
8. Conclusion
We provide the first empirical evaluation of the effectiveness of contextual embeddings as a function of dimensionality and sample size for human-level prediction tasks. Multiple human-level tasks along with many of the most popular language model techniques, were systematically evaluated in conjunction with dimension reduction techniques to derive optimal setups for low sample regimes characteristic of many human-level tasks.
We first show the fine-tuning transformer LMs in low-data scenarios yields worse performance than pre-trained models. We then show that reducing dimensions of contextual embeddings can improve performance and while past work used non-negative matrix factorization (Matero et al., 2019), we note that PCA gives the most reliable improvement. Auto-encoder based transformer language models gave better performance, on average, than their auto-regressive contemporaries of comparable sizes. We find optimized versions of BERT, specifically RoBERTa, to yield the best results.
Finally, we find that many human-level tasks can be achieved with a fraction, often or , the total transformer hidden-state size without sacrificing significant accuracy. Generally, using fewer dimensions also reduces variance in model performance, in line with traditional bias-variance tradeoffs and, thus, increases the chance of generalizing to new populations. Further it can aid in explainability especially when considering that these dimension reduction models can be pre-trained and standardized, and thus compared across problem sets and studies.
Table 1: Summary of the datasets.
Npt is the number of users available for pre-training the dimension reduction model; Nmax is the maximum number of users available for task training. For CLPsych 2018 and CLPsych 2019, this would be the same sample as pre-training data. For Facebook, a disjoint set of 10k users was available for task training; Nte is the number of test users. This is always a disjoint set of users from the pre-training and task training samples.
| FB-Demogs | CLPsych 2018 | CLPsych 2019 | |
|---|---|---|---|
| Sap et al. | Lynn et al. | Zirikly et al. | |
| Npt | 56,764 | 9,217 | 496 |
| Nmax | 10,000 | 9,217 | 496 |
| Nte | 5,000 | 1,000 | 125 |
Appendices
A. Experimental Setup
Implementation.
All the experiments were implemented using Python, DLATK (Schwartz et al., 2017), HuggingFace Transformers (Wolf et al., 2019), and PyTorch (Paszke et al., 2019). The environments were instantiated with a seed value of 42, except for fine-tuning which used 1337. Code to reproduce all results is available in our github page: github.com/adithya8/ContextualEmbeddingDR/
Infrastructure.
The deep learning models such as stacked-transformers and NLAE were run on single GPU with batch size given by:
where GPU memory and model sizes (space occupied by the model) are in bytes, trainableparams corresponds to number of trainable parameters during fine tuning and layers corresponds to the number of layers of embeddings required, the hidden_size is the number of dimensions in the hidden state and max_tokens is the maximum number of tokens (after tokenization) in any batch. We carried out the experiments with 1 NVIDIA Titan Xp GPU which has around 12 GB of memory. All the other methods were implemented on CPU.
Figure A1: Depiction of Dimension Reduction method -.
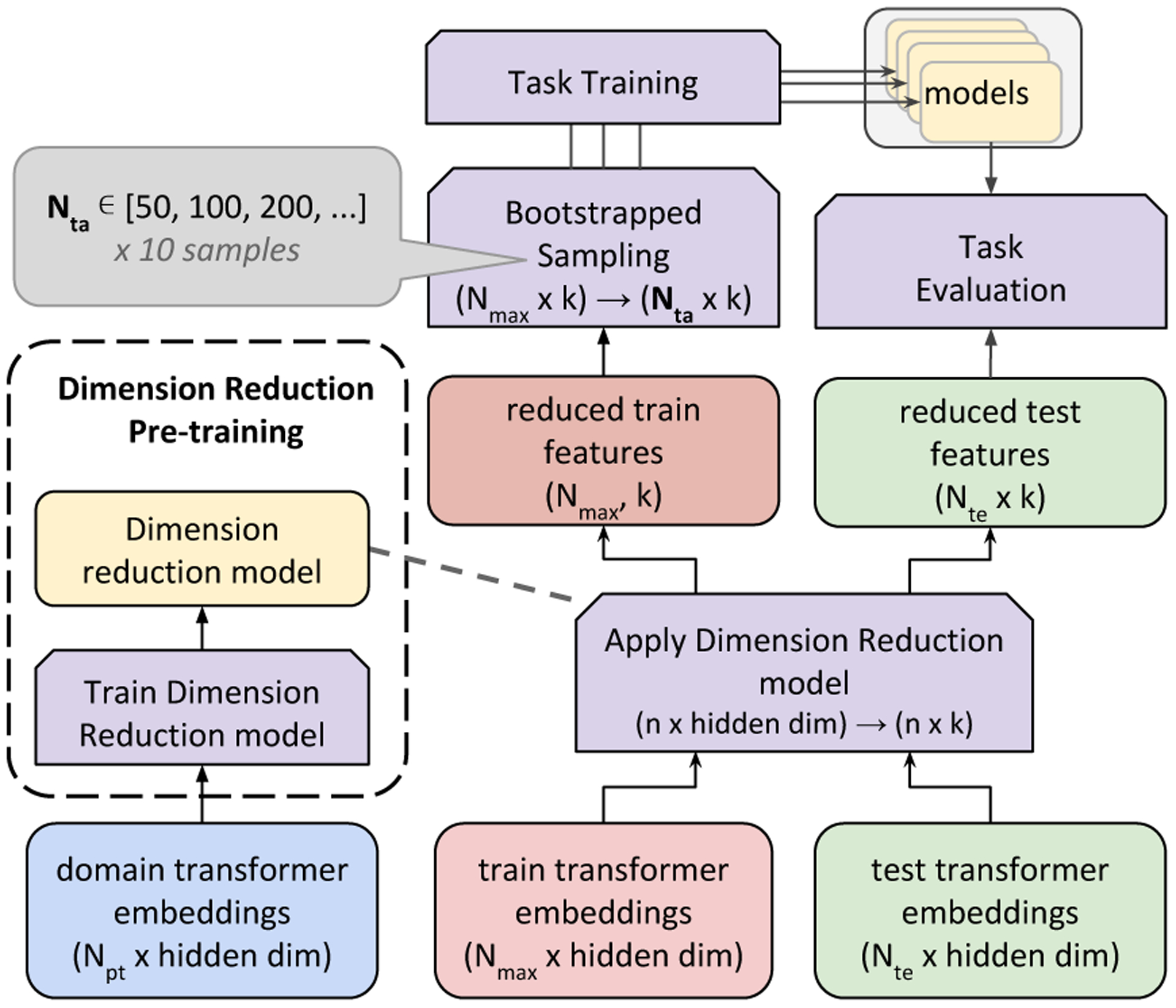
Transformer embeddings of domain data (Npt users’ embeddings9) is used to pre-train a dimension reduction model that transforms the embeddings down to k dimensions. This step is followed by applying this learned reduction model on task’s train and test data embeddings. These reduced train features (Nmax users) are then bootstrap sampled to produce 10 sets of Nta users each for training task specific models. All these 10 task specific models are evaluated on the reduced test features consisting of Nte users during task evaluation. The mean and standard deviation of the task specific metric are collected.
B. Model Details
NLAE architecture.
The model architecture for the Non-linear auto-encoders in Table 4 was a twin network taking inputs of 768 dimensions and reducing it to 128 dimensions through 2 layers and reconstructs the original 768 dimensional representation with 2 layers. This architecture was chosen balancing the constraints of enabling the non-linear associations while keeping total parameters low given the low sample size context. The formal definition of the model is:
NLAE Training.
The data for domain pre-training of dimension reduction was split into 2 sets for NLAE alone: training and validation sets. 90% of the domain data was randomly sampled for training the NLAE and the remaining 10% of pre-training data was used to validate hyper-parameters after every epoch. This model was trained with an objective to minimise the reconstruction mean squared loss over multiple epochs. It was trained until the validation loss increased over 3 consecutive epochs. AdamW was the optimizer used with the learning rate set to 0.001. This took around 30–40 epochs depending upon the dataset.
Fine-tuning.
In our fine-tuning configuration we freeze all but the top 2 layers of the best LM, to prevent over fitting and vanishing gradients at the lower layers (Sun et al., 2019; Mosbach et al., 2020). We also apply early stopping (varied the patience between 3 and 6 depending upon the task). Other hyperparameters for this experiment include L2-regularization (in the form of weight-decay on AdamW optimizer, set to 1), dropout set to 0.3, batch size set to 10, learning rate initialized to 5e-5, and the number of epochs was set to max of 15, which was limited by early stopping between 5–10 depending on the task and early stopping patience.
We arrived at these hyperparameter values after an extensive search. The weight decay param was searched in [100, 0.01], dropout within [0.1, 0.5], and learning rate between [5e-4, 5e-5].
C. Data
Due to human subjects privacy constraints, most data are not able to be publicly distributed but they are available from the original data owners via requests for research purposes (e.g. CLPsych-2018 and CLPsych-2019 shared tasks).
D. Additional Results
D.1. Results on higher Nta
We can see that reduction still helps in majority of tasks in higher Nta from Figure A2. As expected, the performance starts to plateau at higher Nta values and it is visibly consistent across most tasks. With the exception of age and gender prediction using facebook data, all the other tasks benefit from reduction.
D.2. Results on classification tasks
Figure A3 compares the performance of reduced dimensions at low samples size scenario (Nta ≤ 1000) in classification tasks. Except for a few Nta values in gender prediction using the facebook data, all the other tasks benefits from reduction in achieving the best performance.
D.3. LM comparison for no reduction & Smaller models.
Table A1 compares the performance of the language models without applying any dimension reduction of the embeddings and the performance of the best transformer models is also compared with smaller models (and distil version) after reducing second to last lasyer representation to 128 dimensions in table A2.
D.4. Least dimensions required: Higher Nta
The ‘fkp’ plateaus as the the number of training samples grow as seen in table A3.
E. Additional Analysis
E.1. Pre-trained vs Fine-Tuned models
We also find that fine-tuned model doesn’t perform better than the pre-trained model for users with typical message lengths, but is better at handling longer sequences upon training it on the tasks’ data. This is evident from the graphs in figure A4.
E.2. PCA vs NMF.
From figure A5, we can see that LIWC variables like ARTICLE, INSIGHT, PERCEPT (perceptual process), COGPROC (cognitive process) negatively correlates to the difference in absolute error of PCA and NMF. These variables also happen to have higher correlation with the openness scores (Schwartz et al., 2013). We also see that characteristics typical of an open person like interest in arts, music, and writing (Kern et al., 2014) appear in the word clouds.
Table A1:
Comparison of various auto-encoders(AE) and auto-regressor(AR) language models trained on 100 and 500 samples (Nta) for each task using all the dimensions of transformer embeddings. RoBERTa and BERT show consistent performance.
| LM | demographics | personality | mental health | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Nta | name | gen2 (f1) | ope (rdis) | sui (f1) | |||||
| 100 | BERT | 0.758 | 0.225 | 0.400 | |||||
| RoBERTa | 0.788 | 0.213 | 0.381 | ||||||
| XLNet | 0.755 | 0.152 | 0.357 | ||||||
| GPT-2 | 0.681 | 0.110 | 0.335 | ||||||
| 500 | BERT | 0.849 | 0.395 | 0.489 | |||||
| RoBERTa | 0.859 | 0.382 | 0.447 | ||||||
| XLNet | 0.828 | 0.364 | 0.424 | ||||||
| GPT-2 | 0.790 | 0.307 | 0.371 | ||||||
Table A2:
Comparison of the best performing auto-encoder models with a smaller LMs (like ALBERT (Lan et al., 2019) and DistilRoBERTa (Sanh et al., 2019) after reduction to 128 dimensions. These results suggest that the reduction of the larger counterparts produce better results than reducing these smaller LMs’ representations.
| demographics | personality | mental health | ||||||
|---|---|---|---|---|---|---|---|---|
| Nta | M | gen2 (F1) | ope (rdis) | sui (F1) | ||||
| 100 | BERT | 0.761 | 0.184 | 0.360 | ||||
| RoBERTa | 0.761 | 0.203 | 0.363 | |||||
| DistilRoBERTa | 0.731 | 0.207 | 0.355 | |||||
| ALBERT | 0.710 | 0.218 | 0.355 | |||||
| 500 | BERT | 0.837 | 0.354 | 0.466 | ||||
| RoBERTa | 0.852 | 0.361 | 0.432 | |||||
| DistilRoBERTa | 0.826 | 0.346 | 0.410 | |||||
| ALBERT | 0.799 | 0.337 | 0.385 | |||||
The divergence of the absolute errors in NMF and PCA is seen in bsag and ope tasks as well. From graphs in figure A6 we can see that the sequence length at which we see this behavior is close to the previously observed value in age and ext tasks.
E.3. PCA vs Pre-trained.
PCA models overall perform better than pre-trained model in low sample regime and from figure A7, we can see that PCA captures slang, affect and standard social media abbreviations better than the pre-trained models. The task specific linear layer is better able to capture social media language with fewer dimensions (reduced by PCA) than from the original 768 features produced by the pre-trained models.
Figure A2:
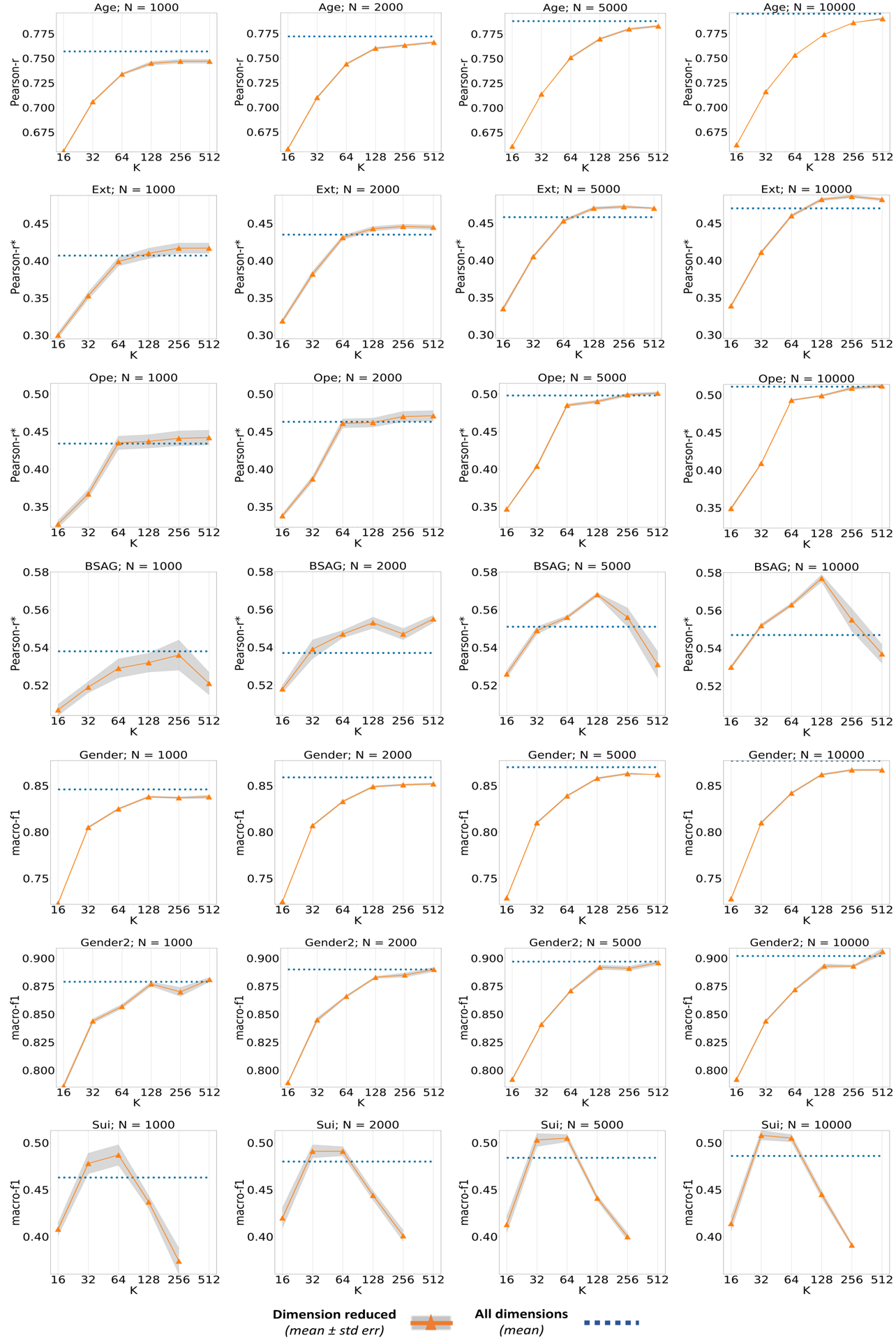
Performance recorded for reduced dimensions for all tasks at higher Nta values (≥1000). Reduction continues to help in performing the best in personality and mental-health tasks. The ‘fkp’ is observed to be shifting to a higher value, due to the rise in performance of no reduction and the reduction of standard error.
Figure A3:
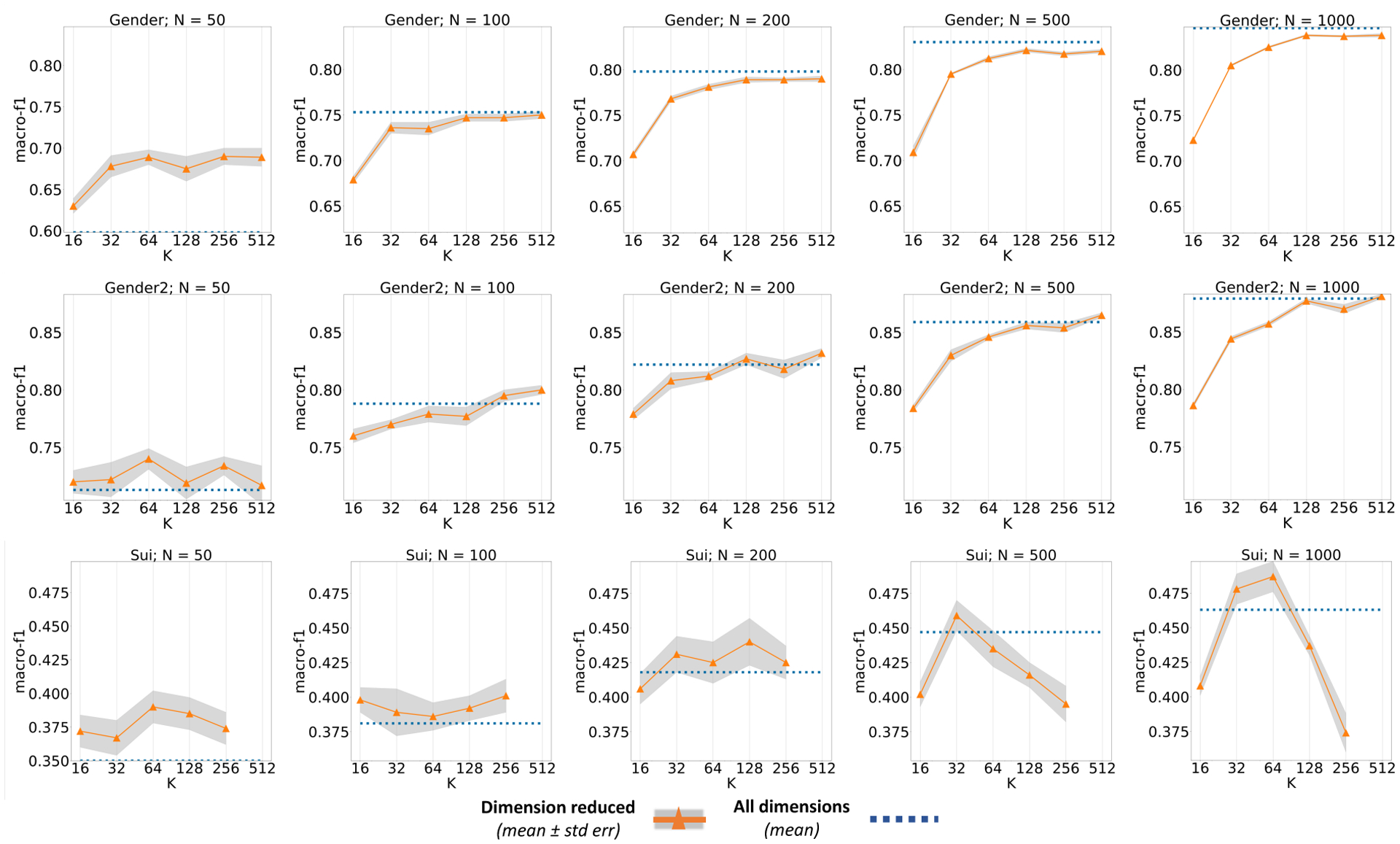
Comparison of performance in gen, gen2 and sui tasks for varying Nta between 50 and 1000.
Figure A4:
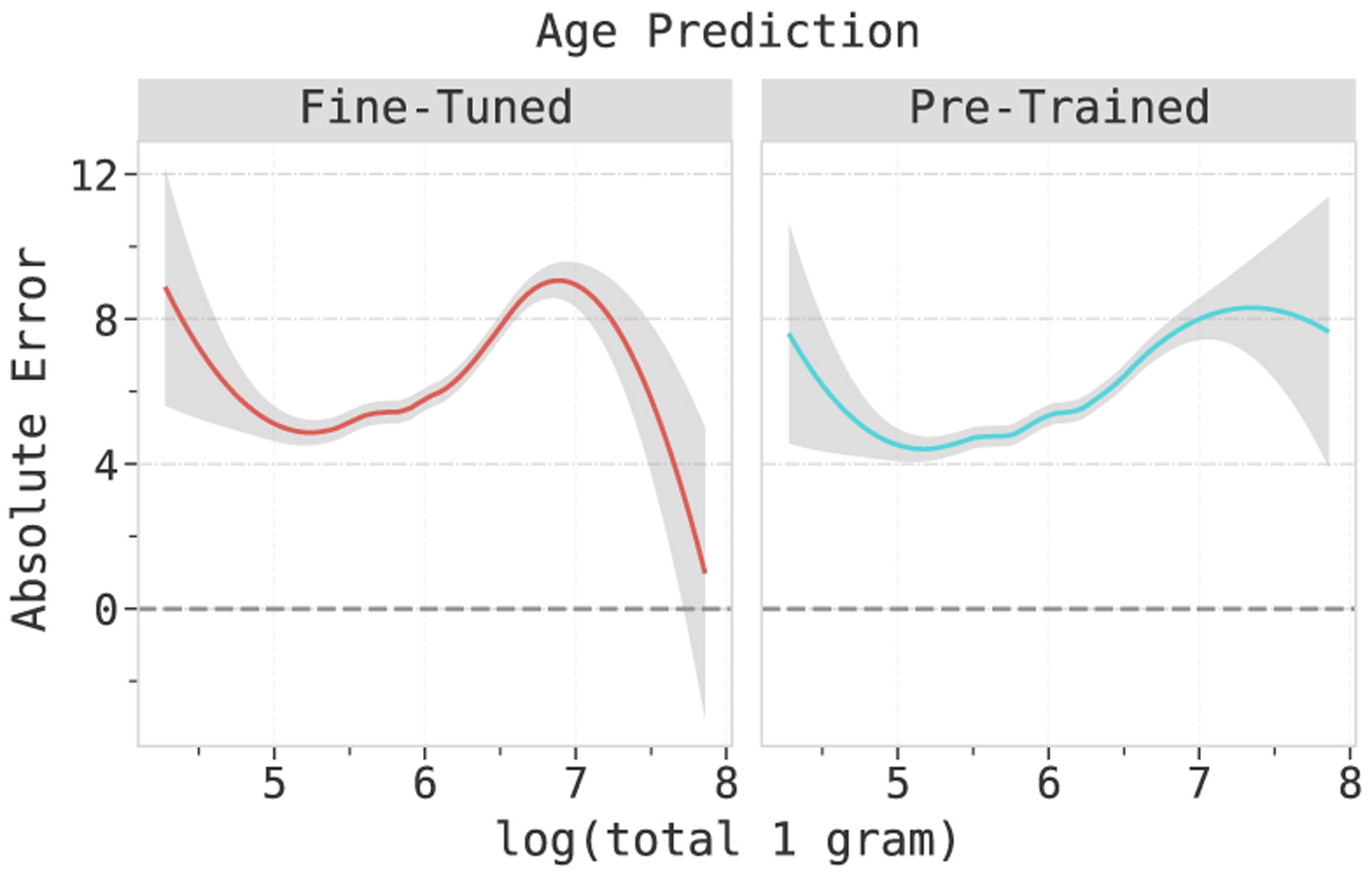
The absolute error in age prediction for the fine-tuned model is higher than pre-trained models for users with short messages. Fine-tuned models have smaller errors for users with longer messages.
Figure A5:
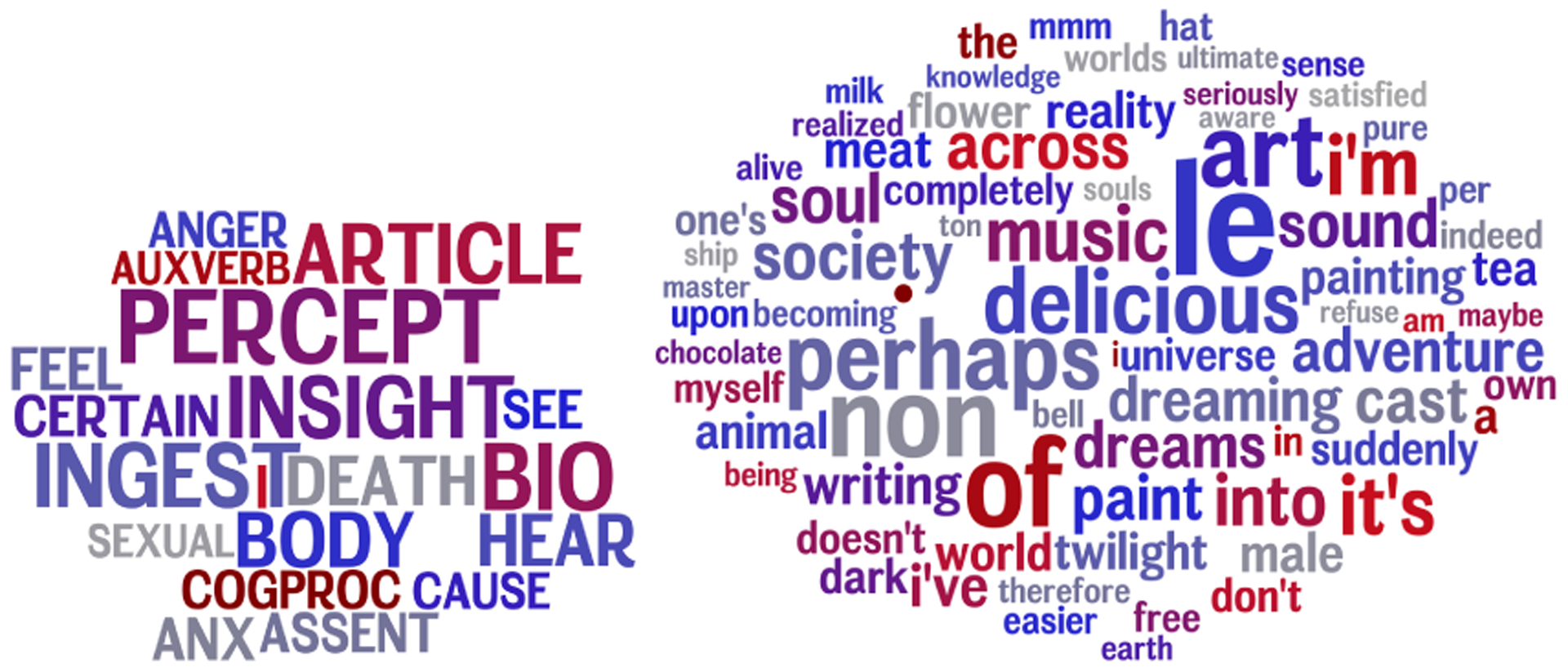
The word cloud of the LIWC variables (left) and the 1 grams (right) having negative correlation with the difference in the absolute error of PCA and NMF in Openness prediction. Benjamini-Hochberg FDR. p < .05. We can see that LIWC variables and 1 grams more correlative of a person exhibiting more openness are better captured by the PCA model than the NMF.
Figure A6:
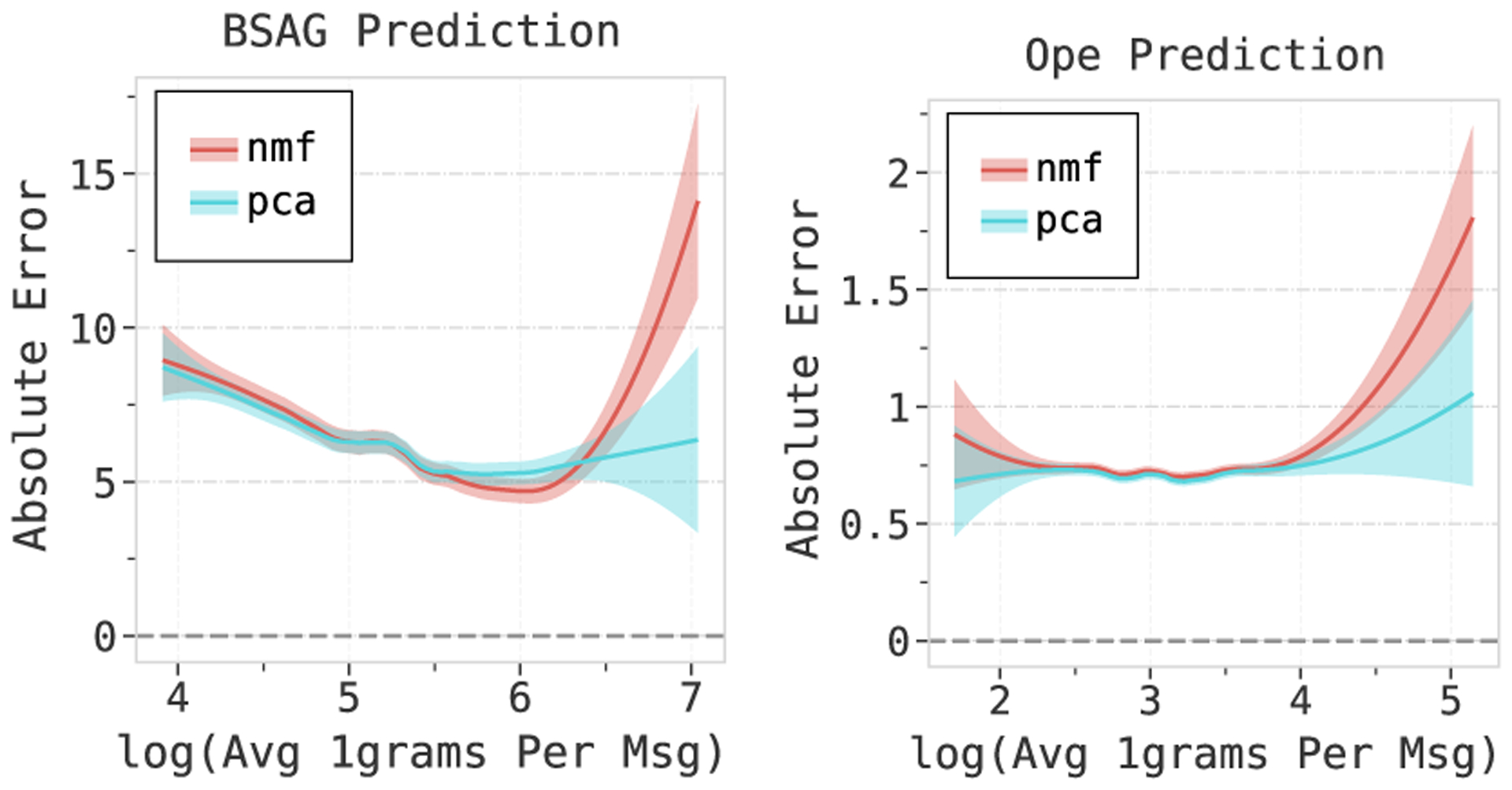
Comparison of the absolute error of NMF and PCA with the average number of 1 grams per message. We see that the absolute error of NMF models starts diverging at longer text sequences for the bsag and the ope tasks as well.
Figure A7:

Terms having negative (left) and positive (right) correlations with the difference in the absolute error of the PCA and pre-trained model in age prediction. Benjamini-Hochberg FDR. p < .05. The error in the PCA model is lesser than pre-trained models when messages contain more slang, affect words and social media abbreviations.
Table A3:
First k to peak for each set of tasks: the least value of k that performed statistically equivalent (p > .05) to the best performing setup (peak). Integer shown is the exponential median of the set of tasks.
| Nta | demographics | personality | mental health |
|---|---|---|---|
| 2000 | 768 | 90 | 64 |
| 5000 | 768 | 181 | 64 |
| 10000 | 768 | 181 | 64 |
Footnotes
dimension reduction techniques can also be pre-trained leveraging larger sets of unlabeled data
Disattenuated Pearson correlation helps account for the error of the measurement instrument (Kosinski et al., 2013; Murphy and Davidshofer, 1988). Following (Lynn et al., 2020), we use reliabilities: rxx = 0.70 and ryy = 0.77.
Bristol Social Adjustment Guide (Ghodsian, 1977) scores contains twelve sub-scales that measures different aspects of childhood behavior.
The second to last layer was chosen owing to its consistent performance in capturing semantic and syntactic structures (Jawahar et al., 2019).
The ‘D’ value was set to .
these pre-trained dimension reduction models are made available.
The performance of all transformer embeddings without any dimension reduction along with smaller sized models can be found in the appendix section D.3.
As we are focused on readily available models, we consider substantial changes to the architecture or training as outside the scope of this systematic evaluation of existing techniques.
Generation of user embeddings explained in detail under methods.
References
- Ambalavanan Ashwin Karthik, Jagtap Pranjali Dileep, Adhya Soumya, and Devarakonda Murthy. 2019. Using contextual representations for suicide risk assessment from Internet forums. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, pages 172–176, Minneapolis, Minnesota. Association for Computational Linguistics. [Google Scholar]
- Bao Xingce and Qiao Qianqian. 2019. Transfer learning from pre-trained BERT for pronoun resolution. In Proceedings of the First Workshop on Gender Bias in Natural Language Processing, pages 82–88, Florence, Italy. Association for Computational Linguistics. [Google Scholar]
- Blei David M, Ng Andrew Y, and Jordan Michael I. 2003. Latent dirichlet allocation. Journal of machine Learning research, 3(Jan):993–1022. [Google Scholar]
- Bostrom Kaj and Durrett Greg. 2020. Byte pair encoding is suboptimal for language model pretraining. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 4617–4624, Online. Association for Computational Linguistics. [Google Scholar]
- Pew Research Center. 2021. Social media fact sheet. [Google Scholar]
- Clark Christopher, Lee Kenton, Chang Ming-Wei, Kwiatkowski Tom, Collins Michael, and Toutanova Kristina. 2019. Boolq: Exploring the surprising difficulty of natural yes/no questions. arXiv preprint arXiv:1905.10044. [Google Scholar]
- Coppersmith Glen, Dredze Mark, and Harman Craig. 2014. Quantifying mental health signals in Twitter. In Proceedings of the Workshop on Computational Linguistics and Clinical Psychology: From Linguistic Signal to Clinical Reality, pages 51–60, Baltimore, Maryland, USA. Association for Computational Linguistics. [Google Scholar]
- Devlin Jacob, Chang Ming-Wei, Lee Kenton, and Toutanova Kristina. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics. [Google Scholar]
- Eichstaedt J, Smith R, Merchant R, Ungar Lyle H., Crutchley Patrick, Preotiuc-Pietro Daniel, Asch D, and Schwartz HA. 2018. Facebook language predicts depression in medical records. Proceedings of the National Academy of Sciences of the United States of America, 115:11203–11208. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ethayarajh Kawin. 2019. How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 55–65, Hong Kong, China. Association for Computational Linguistics. [Google Scholar]
- Févotte Cédric and Idier Jérôme. 2011. Algorithms for nonnegative matrix factorization with the β-divergence. Neural computation, 23(9):2421–2456. [Google Scholar]
- Flekova Lucie, Carpenter Jordan, Giorgi Salvatore, Ungar Lyle, and Preoţiuc-Pietro Daniel. 2016. Analyzing biases in human perception of user age and gender from text. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 843–854, Berlin, Germany. Association for Computational Linguistics. [Google Scholar]
- Ghodsian M. 1977. Children’s behaviour and the bsag: some theoretical and statistical considerations. British Journal of Social and Clinical Psychology, 16(1):23–28. [Google Scholar]
- Guntuku Sharath Chandra, Yaden David B, Kern Margaret L, Ungar Lyle H, and Eichstaedt Johannes C. 2017. Detecting depression and mental illness on social media: an integrative review. Current Opinion in Behavioral Sciences, 18:43–49. [Google Scholar]
- Gururangan Suchin, Ana Marasović Swabha Swayamdipta, Lo Kyle, Beltagy Iz, Downey Doug, and Smith Noah A.. 2020. Don’t stop pretraining: Adapt language models to domains and tasks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8342–8360, Online. Association for Computational Linguistics. [Google Scholar]
- Halko Nathan, Martinsson Per-Gunnar, and Tropp Joel A. 2011. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions. SIAM review, 53(2):217–288. [Google Scholar]
- Haslam Nick, Holland Elise, and Kuppens Peter. 2012. Categories versus dimensions in personality and psychopathology: a quantitative review of taxometric research. Psychological medicine, 42(5):903. [DOI] [PubMed] [Google Scholar]
- Hinton Geoffrey E and Salakhutdinov Ruslan R. 2006. Reducing the dimensionality of data with neural networks. science, 313(5786):504–507. [DOI] [PubMed] [Google Scholar]
- Hovy Dirk and Spruit Shannon L. 2016. The social impact of natural language processing. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 591–598. [Google Scholar]
- Jawahar Ganesh, Sagot Benoît, and Seddah Djamé. 2019. What does BERT learn about the structure of language? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3651–3657, Florence, Italy. Association for Computational Linguistics. [Google Scholar]
- Jiang Haoming, He Pengcheng, Chen Weizhu, Liu Xiaodong, Gao Jianfeng, and Zhao Tuo. 2020. SMART: Robust and efficient fine-tuning for pre-trained natural language models through principled regularized optimization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2177–2190, Online. Association for Computational Linguistics. [Google Scholar]
- Kern Margaret L, Eichstaedt Johannes C, Schwartz H Andrew, Dziurzynski Lukasz, Ungar Lyle H, Stillwell David J, Kosinski Michal, Ramones Stephanie M, and Seligman Martin EP. 2014. The online social self: An open vocabulary approach to personality. Assessment, 21(2):158–169. [DOI] [PubMed] [Google Scholar]
- Kern Margaret L, Park Gregory, Eichstaedt Johannes C, Schwartz H Andrew, Sap Maarten, Smith Laura K, and Ungar Lyle H. 2016. Gaining insights from social media language: Methodologies and challenges. Psychological methods, 21(4):507. [DOI] [PubMed] [Google Scholar]
- Kessler Ronald C, Berglund Patricia, Demler Olga, Jin Robert, Koretz Doreen, Merikangas Kathleen R, Rush A John, Walters Ellen E, and Wang Philip S. 2003. The epidemiology of major depressive disorder: results from the national comorbidity survey replication (ncs-r). Jama, 289(23):3095–3105. [DOI] [PubMed] [Google Scholar]
- Kosinski M, Stillwell D, and Graepel T. 2013. Private traits and attributes are predictable from digital records of human behavior. Proceedings of the National Academy of Sciences, 110:5802–5805. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lan Zhenzhong, Chen Mingda, Goodman Sebastian, Gimpel Kevin, Sharma Piyush, and Soricut Radu. 2019. Albert: A lite bert for self-supervised learning of language representations. In International Conference on Learning Representations. [Google Scholar]
- Li Xiang Lisa and Eisner Jason. 2019. Specializing word embeddings (for parsing) by information bottleneck. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2744–2754, Hong Kong, China. Association for Computational Linguistics. [Google Scholar]
- Liu Yinhan, Ott Myle, Goyal Naman, Du Jingfei, Joshi Mandar, Chen Danqi, Levy Omer, Lewis Mike, Zettlemoyer Luke, and Stoyanov Veselin. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692. [Google Scholar]
- Lynn Veronica, Balasubramanian Niranjan, and Schwartz H. Andrew. 2020. Hierarchical modeling for user personality prediction: The role of message-level attention. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5306–5316, Online. Association for Computational Linguistics. [Google Scholar]
- Lynn Veronica, Giorgi Salvatore, Balasubramanian Niranjan, and Schwartz H Andrew. 2019. Tweet classification without the tweet: An empirical examination of user versus document attributes. In Proceedings of the Third Workshop on Natural Language Processing and Computational Social Science, pages 18–28. [Google Scholar]
- Lynn Veronica, Goodman Alissa, Niederhoffer Kate, Loveys Kate, Resnik Philip, and Schwartz H. Andrew. 2018. CLPsych 2018 shared task: Predicting current and future psychological health from childhood essays. In Proceedings of the Fifth Workshop on Computational Linguistics and Clinical Psychology: From Keyboard to Clinic, pages 37–46, New Orleans, LA. Association for Computational Linguistics. [Google Scholar]
- Matero Matthew, Idnani Akash, Son Youngseo, Giorgi Salvatore, Vu Huy, Zamani Mohammad, Limbachiya Parth, Guntuku Sharath Chandra, and Schwartz H. Andrew. 2019. Suicide risk assessment with multi-level dual-context language and BERT. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, pages 39–44, Minneapolis, Minnesota. Association for Computational Linguistics. [Google Scholar]
- Mayfield Elijah and Black Alan W. 2020. Should you fine-tune BERT for automated essay scoring? In Proceedings of the Fifteenth Workshop on Innovative Use of NLP for Building Educational Applications, pages 151–162, Seattle, WA, USA: → Online. Association for Computational Linguistics. [Google Scholar]
- Mikolov Tomas, Sutskever Ilya, Chen Kai, Corrado Greg S, and Dean Jeff. 2013. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pages 3111–3119. [Google Scholar]
- Milne David N., Pink Glen, Hachey Ben, and Calvo Rafael A.. 2016. CLPsych 2016 shared task: Triaging content in online peer-support forums. In Proceedings of the Third Workshop on Computational Linguistics and Clinical Psychology, pages 118–127, San Diego, CA, USA. Association for Computational Linguistics. [Google Scholar]
- Morales Michelle, Dey Prajjalita, Theisen Thomas, Belitz Danny, and Chernova Natalia. 2019. An investigation of deep learning systems for suicide risk assessment. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, pages 177–181, Minneapolis, Minnesota. Association for Computational Linguistics. [Google Scholar]
- Morgan-Lopez Antonio A, Kim Annice E, Chew Robert F, and Ruddle Paul. 2017. Predicting age groups of twitter users based on language and metadata features. PloS one, 12(8):e0183537. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mosbach Marius, Andriushchenko Maksym, and Klakow Dietrich. 2020. On the stability of fine-tuning bert: Misconceptions, explanations, and strong baselines. arXiv preprint arXiv:2006.04884. [Google Scholar]
- Mu Jiaqi and Viswanath Pramod. 2018. All-but-the-top: Simple and effective postprocessing for word representations. In International Conference on Learning Representations. [Google Scholar]
- Murphy K and Davidshofer C. 1988. Psychological testing: Principles and applications.
- Park Gregory, Schwartz HA, Eichstaedt J, Kern M, Kosinski M, Stillwell D, Ungar Lyle H., and Seligman M. 2015. Automatic personality assessment through social media language. Journal of personality and social psychology, 108 6:934–52. [DOI] [PubMed] [Google Scholar]
- Paszke Adam, Gross Sam, Massa Francisco, Lerer Adam, Bradbury James, Chanan Gregory, Killeen Trevor, Lin Zeming, Gimelshein Natalia, Antiga Luca, Desmaison Alban, Kopf Andreas, Yang Edward, Zachary DeVito Martin Raison, Tejani Alykhan, Chilamkurthy Sasank, Steiner Benoit, Fang Lu, Bai Junjie, and Chintala Soumith. 2019. Pytorch: An imperative style, high-performance deep learning library. In Wallach H, Larochelle H, Beygelzimer A, d’Alché-Buc F, Fox E, and Garnett R, editors, Advances in Neural Information Processing Systems 32, pages 8024–8035. Curran Associates, Inc. [Google Scholar]
- Pennington Jeffrey, Socher Richard, and Manning Christopher. 2014. GloVe: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1532–1543, Doha, Qatar. Association for Computational Linguistics. [Google Scholar]
- Power Chris and Elliott Jane. 2005. Cohort profile: 1958 British birth cohort (National Child Development Study). International Journal of Epidemiology, 35(1):34–41. [DOI] [PubMed] [Google Scholar]
- Radford Alec, Wu Jeffrey, Child Rewon, Luan David, Amodei Dario, and Sutskever Ilya. 2019. Language models are unsupervised multitask learners. OpenAI Blog, 1(8):9. [Google Scholar]
- Raffel Colin, Shazeer Noam, Roberts Adam, Lee Katherine, Narang Sharan, Matena Michael, Zhou Yanqi, Li Wei, and Liu Peter J.. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67. [Google Scholar]
- Raunak Vikas, Gupta Vivek, and Metze Florian. 2019. Effective dimensionality reduction for word embeddings. In Proceedings of the 4th Workshop on Representation Learning for NLP (RepL4NLP-2019), pages 235–243, Florence, Italy. Association for Computational Linguistics. [Google Scholar]
- Resnik Philip, Garron Anderson, and Resnik Rebecca. 2013. Using topic modeling to improve prediction of neuroticism and depression in college students. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1348–1353, Seattle, Washington, USA. Association for Computational Linguistics. [Google Scholar]
- Sanh Victor, Debut Lysandre, Chaumond Julien, and Wolf Thomas. 2019. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108. [Google Scholar]
- Sap Maarten, Card Dallas, Gabriel Saadia, Choi Yejin, and Smith Noah A.. 2019. The risk of racial bias in hate speech detection. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 1668–1678, Florence, Italy. Association for Computational Linguistics. [Google Scholar]
- Sap Maarten, Park Greg, Eichstaedt Johannes C, Kern Margaret L, Stillwell David J, Kosinski Michal, Ungar Lyle H, and Schwartz H Andrew. 2014. Developing age and gender predictive lexica over social media. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). [Google Scholar]
- Saraceno Benedetto, Mark van Ommeren Rajaie Batniji, Cohen Alex, Gureje Oye, Mahoney John, Sridhar Devi, and Underhill Chris. 2007. Barriers to improvement of mental health services in low-income and middle-income countries. The Lancet, 370(9593):1164–1174. [DOI] [PubMed] [Google Scholar]
- Schwartz H Andrew, Eichstaedt Johannes C, Kern Margaret L, Dziurzynski Lukasz, Ramones Stephanie M, Agrawal Megha, Shah Achal, Kosinski Michal, Stillwell David, Seligman Martin EP, et al. 2013. Personality, gender, and age in the language of social media: The open-vocabulary approach. PloS one, 8(9):e73791. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schwartz H. Andrew, Giorgi Salvatore, Sap Maarten, Crutchley Patrick, Ungar Lyle, and Eichstaedt Johannes. 2017. DLATK: Differential language analysis ToolKit. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 55–60, Copenhagen, Denmark. Association for Computational Linguistics. [Google Scholar]
- Shah Deven Santosh, Schwartz H. Andrew, and Hovy Dirk. 2020. Predictive biases in natural language processing models: A conceptual framework and overview. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5248–5264, Online. Association for Computational Linguistics. [Google Scholar]
- Sun Chi, Qiu Xipeng, Xu Yige, and Huang Xuanjing. 2019. How to fine-tune bert for text classification? In China National Conference on Chinese Computational Linguistics, pages 194–206. Springer. [Google Scholar]
- Tausczik Y and Pennebaker J. 2010. The psychological meaning of words: Liwc and computerized text analysis methods. Journal of Language and Social Psychology, 29:24–54. [Google Scholar]
- Tenney Ian, Das Dipanjan, and Pavlick Ellie. 2019. BERT rediscovers the classical NLP pipeline. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4593–4601, Florence, Italy. Association for Computational Linguistics. [Google Scholar]
- Vaswani Ashish, Shazeer Noam, Parmar Niki, Uszkoreit Jakob, Jones Llion, Aidan N Gomez Łukasz Kaiser, and Polosukhin Illia. 2017. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008. [Google Scholar]
- Wang Philip S, Lane Michael, Olfson Mark, Pincus Harold A, Wells Kenneth B, and Kessler Ronald C. 2005. Twelve-month use of mental health services in the united states: results from the national comorbidity survey replication. Archives of general psychiatry, 62(6):629–640. [DOI] [PubMed] [Google Scholar]
- Wolf Thomas, Debut Lysandre, Sanh Victor, Chaumond Julien, Delangue Clement, Moi Anthony, Cistac Pierric, Rault Tim, Louf Rémi, Funtowicz Morgan, Davison Joe, Shleifer Sam, Patrick von Platen Clara Ma, Jernite Yacine, Plu Julien, Xu Canwen, Teven Le Scao Sylvain Gugger, Drame Mariama, Lhoest Quentin, and Rush Alexander M.. 2019. Huggingface’s transformers: State-of-the-art natural language processing. ArXiv, abs/1910.03771. [Google Scholar]
- Yang Zhilin, Dai Zihang, Yang Yiming, Carbonell Jaime, Salakhutdinov Russ R, and Le Quoc V. 2019. Xlnet: Generalized autoregressive pretraining for language understanding. In Advances in neural information processing systems, pages 5753–5763. [Google Scholar]
- Zirikly Ayah, Resnik Philip, Uzuner Özlem, and Hollingshead Kristy. 2019. CLPsych 2019 shared task: Predicting the degree of suicide risk in Reddit posts. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, pages 24–33, Minneapolis, Minnesota. Association for Computational Linguistics. [Google Scholar]