

Abstract
Deep learning has achieved tremendous success in recent years. In simple words, deep learning uses the composition of many nonlinear functions to model the complex dependency between input features and labels. While neural networks have a long history, recent advances have greatly improved their performance in computer vision, natural language processing, etc. From the statistical and scientific perspective, it is natural to ask: What is deep learning? What are the new characteristics of deep learning, compared with classical methods? What are the theoretical foundations of deep learning?
To answer these questions, we introduce common neural network models (e.g., convolutional neural nets, recurrent neural nets, generative adversarial nets) and training techniques (e.g., stochastic gradient descent, dropout, batch normalization) from a statistical point of view. Along the way, we highlight new characteristics of deep learning (including depth and over-parametrization) and explain their practical and theoretical benefits. We also sample recent results on theories of deep learning, many of which are only suggestive. While a complete understanding of deep learning remains elusive, we hope that our perspectives and discussions serve as a stimulus for new statistical research.
Keywords: neural networks, over-parametrization, stochastic gradient descent, approximation theory, generalization error
1. INTRODUCTION
Modern machine learning and statistics deal with the problem of learning from data: given a training dataset {(yi,xi)}1≤i≤n where is the input and is the output1, one seeks a function from a certain function class that has good prediction performance on test data. This problem is of fun-damental significance and finds applications in numerous scenarios. For instance, in image recognition, the input x (reps. the output y) corresponds to the raw image (reps. its category) and the goal is to find a mapping f(·) that can classify future images accurately. Decades of research efforts in statistical machine learning have been devoted to developing methods to find f(·) efficiently with provable guarantees. Prominent examples include linear classifiers (e.g., linear / logistic regression, linear discriminant analysis), kernel methods (e.g., support vector machines), tree-based methods (e.g., decision trees, random forests), nonparametric regression (e.g., nearest neighbors, local kernel smoothing), etc. Roughly speaking, each aforementioned method corresponds to a different function class from which the final classifier f(·) is chosen.
Deep learning (LeCun, Bengio and Hinton, 2015), in its simplest form, proposes the following compositional function class:
| (1.1) |
Here, for each 1 ≤ l ≤ L, is some nonlinear function, and θ = {W1,…,WL} consists of matrices with appropriate sizes. Though simple, deep learning has made significant progress towards addressing the problem of learning from data over the past decade. Specifically, it has performed close to or better than humans in various important tasks in artificial intelligence, including image recognition (He et al., 2016a), game playing (Silver et al., 2017), and machine translation (Wu et al., 2016). Owing to its great promise, the impact of deep learning is also growing rapidly in areas beyond artificial intelligence; examples include statistics (Bauer and Kohler, 2017; Schmidt-Hieber, 2017; Liang, 2017; Romano, Sesia and Candès, 2018; Gao et al., 2018), applied mathematics (Weinan, Han and Jentzen, 2017; Chen et al., 2018), clinical research (De Fauw et al., 2018), etc.
To get a better idea of the success of deep learning, let us take the ImageNet Challenge (Russakovsky et al., 2015) (also known as ILSVRC) as an example. In the classification task, one is given a training dataset consisting of 1.2 million color images with 1000 categories, and the goal is to classify images based on the input pixels. The performance of a classifier is then evaluated on a test dataset of 100 thousand images, and in the end the top-5 error2 is reported. Table 1 highlights a few popular models and their corresponding performance. As can be seen, deep learning models (the second to the last rows) have a clear edge over shallow models (the first row) that fit linear models / tree-based models on handcrafted features. This significant improvement raises a foundational question:
Table 1.
Winning models for ILSVRC image classification challenge.
| Model | Year | # Layers | # Params | Top-5 error |
|---|---|---|---|---|
| Shallow | < 2012 | — | — | > 25% |
| AlexNet | 2012 | 8 | 61M | 16.4% |
| VGG19 | 2014 | 19 | 144M | 7.3% |
| GoogleNet | 2014 | 22 | 7M | 6.7% |
| ResNet-152 | 2015 | 152 | 60M | 3.6% |
Why is deep learning better than classical methods on tasks like image recognition?
1.1. Intriguing new characteristics of deep learning
It is widely acknowledged that two indispensable factors contribute to the success of deep learning, namely (1) huge datasets that often contain millions of samples and (2) immense computing power resulting from clusters of graphics processing units (GPUs). Admittedly, these resources are only recently available: the latter allows to train larger neural networks which reduces biases and the former enables variance reduction. However, these two alone are not sufficient to explain the mystery of deep learning due to some of its “dreadful” characteristics: (1) over-parametrization: the number of parameters in state-of-the-art deep learning models is often much larger than the sample size (see Table 1), which gives them the potential to overfit the training data, and (2) nonconvexity: even with the help of GPUs, training deep learning models is still NP-hard (Arora and Barak, 2009) in the worst case due to the highly nonconvex loss function to minimize. In reality, these characteristics are far from nightmares. This sharp difference motivates us to take a closer look at the salient features of deep learning, which we single out a few below.
1.1.1. Depth.
Deep learning expresses complicated nonlinearity through composing many nonlinear functions; see (1.1). The rationale for this multilayer structure is that, in many real-world datasets such as images, there are different levels of features and lower-level features are building blocks of higher-level ones. See Yosinski et al. (2015) for a visualization of trained features of convolutional neural nets. This is also supported by empirical results from physiology and neuroscience (Hubel and Wiesel, 1962; Abbasi-Asl et al., 2018). The use of function composition marks a sharp difference from traditional statistical methods such as projection pursuit models (Friedman and Stuetzle, 1981) and multi-index models (Li, 1991; Cook et al., 2007). It is often observed that depth helps efficiently extract features that are representative of a dataset. In comparison, increasing width (e.g., number of basis functions) in a shallow model leads to less improvement. This suggests that deep learning models excel at representing a very different function space that is suitable for complex datasets.
1.1.2. Algorithmic regularization.
The statistical performance of neural networks (e.g., test accuracy) depends heavily on the particular optimization algorithms used for training (Wilson et al., 2017). This is very different from many classical statistical problems, where the related optimization problems are less complicated. For instance, when the associated optimization problem has a relatively simple structure (e.g., convex objective functions, linear constraints), the solution to the optimization problem can often be unambiguously computed and analyzed. However, in deep neural networks, due to over-parametrization, there are usually many local minima with different statistical performance (Li et al., 2018a). Nevertheless, common practice runs stochastic gradient descent with random initialization and finds model parameters with very good prediction accuracy.
1.1.3. Implicit prior learning.
It is well observed that deep neural networks trained with only the raw inputs (e.g., pixels of images) can provide a useful representation of the data. This means that after training, the units of deep neural networks can represent features such as edges, corners, wheels, eyes, etc.; see Yosinski et al. (2015). Importantly, the training process is automatic in the sense that no human knowledge is involved (other than hyper-parameter tuning). This is very different from traditional methods, where algorithms are designed after structural assumptions are posited. It is likely that training an over-parametrized model efficiently learns and incorporates the prior distribution p(x) of the input, even though deep learning models are themselves discriminative models. With automatic representation of the prior distribution, deep learning typically performs well on similar datasets (but not very different ones) via transfer learning.
1.2. Towards theory of deep learning
Despite the empirical success, theoretical support for deep learning is still in its infancy. Setting the stage, for any classifier f, denote by the expected risk on fresh sample (a.k.a. test error, prediction error or generalization error), and by the empirical risk / training error averaged over a training dataset. Arguably, the key theoretical question in deep learning is
why is small, where is the classifier returned by the training algorithm?
We follow the conventional approximation-estimation decomposition (sometimes, also bias-variance tradeoff) to decompose the term into two parts. Let be the function space expressible by a family of neural nets. Define to be the best possible classifier and to be the best classifier in . Then, we can decompose the excess error into two parts:
| (1.2) |
Both errors can small for deep learning (cf. Figure 1), which we explain below.
The approximation error is determined by the function class . Intuitively, the larger the class, the smaller the approximation error. Deep learning models use many layers of nonlinear functions (Figure 2)that can drive this error small. Indeed, in Section 5, we provide recent theoretical progress of its representation power. For example, deep models allow efficient representation of interactions among variable while shallow models cannot.
The estimation error reflects the generalization power, which is influenced by both the complexity of the function class and the properties of the training algorithms. Interestingly, for over-parametrized deep neural nets, stochastic gradient descent typically results in a near-zero training error (i.e., ; see e.g. left panel of Figure 1). Moreover, its generalization error remains small or moderate. This “counterintuitive” behavior suggests that for over-parametrized models, gradient-based algorithms enjoy benign statistical properties; we shall see in Section 7 that gradient descent enjoys implicit regularization in the over-parametrized regime even without explicit regularization (e.g., regularization).
Fig 1:
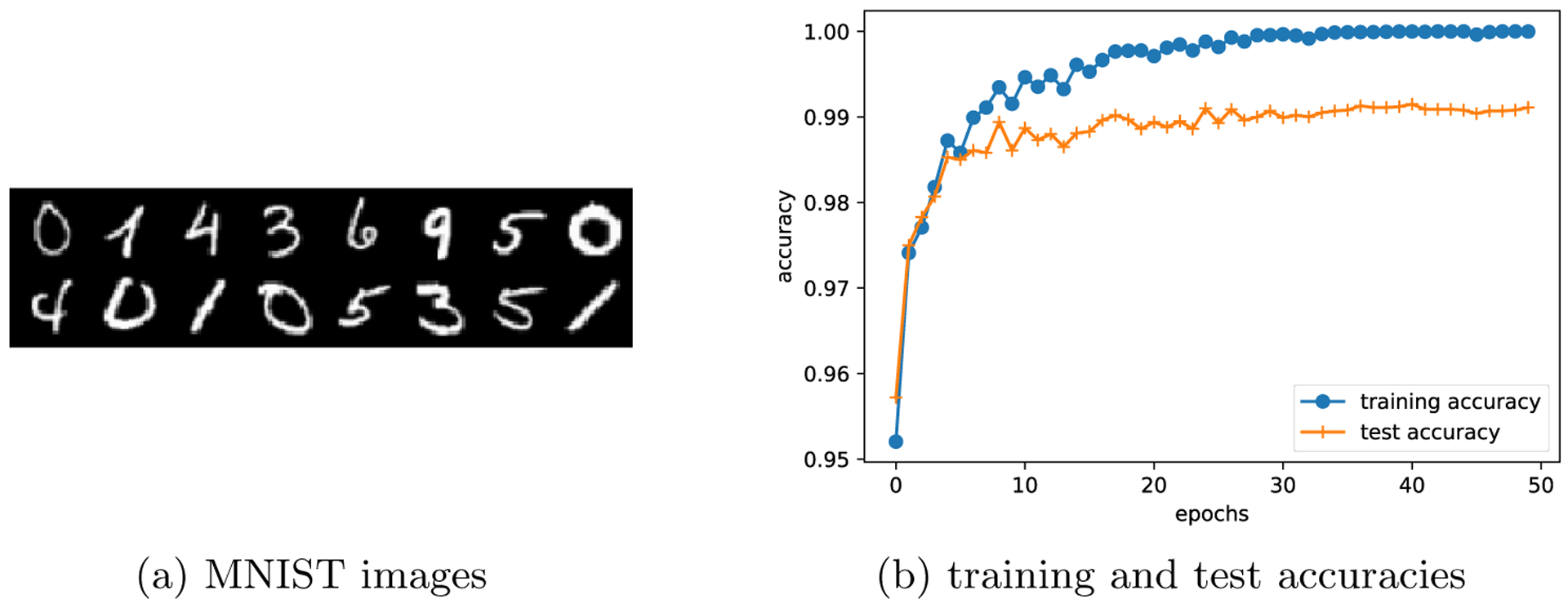
(a) shows the images in the public dataset MNIST; and (b) depicts the training and test accuracies along the training dynamics. Note that the training accuracy is approaching 100% and the test accuracy is still high (no overfitting).
Fig 2:
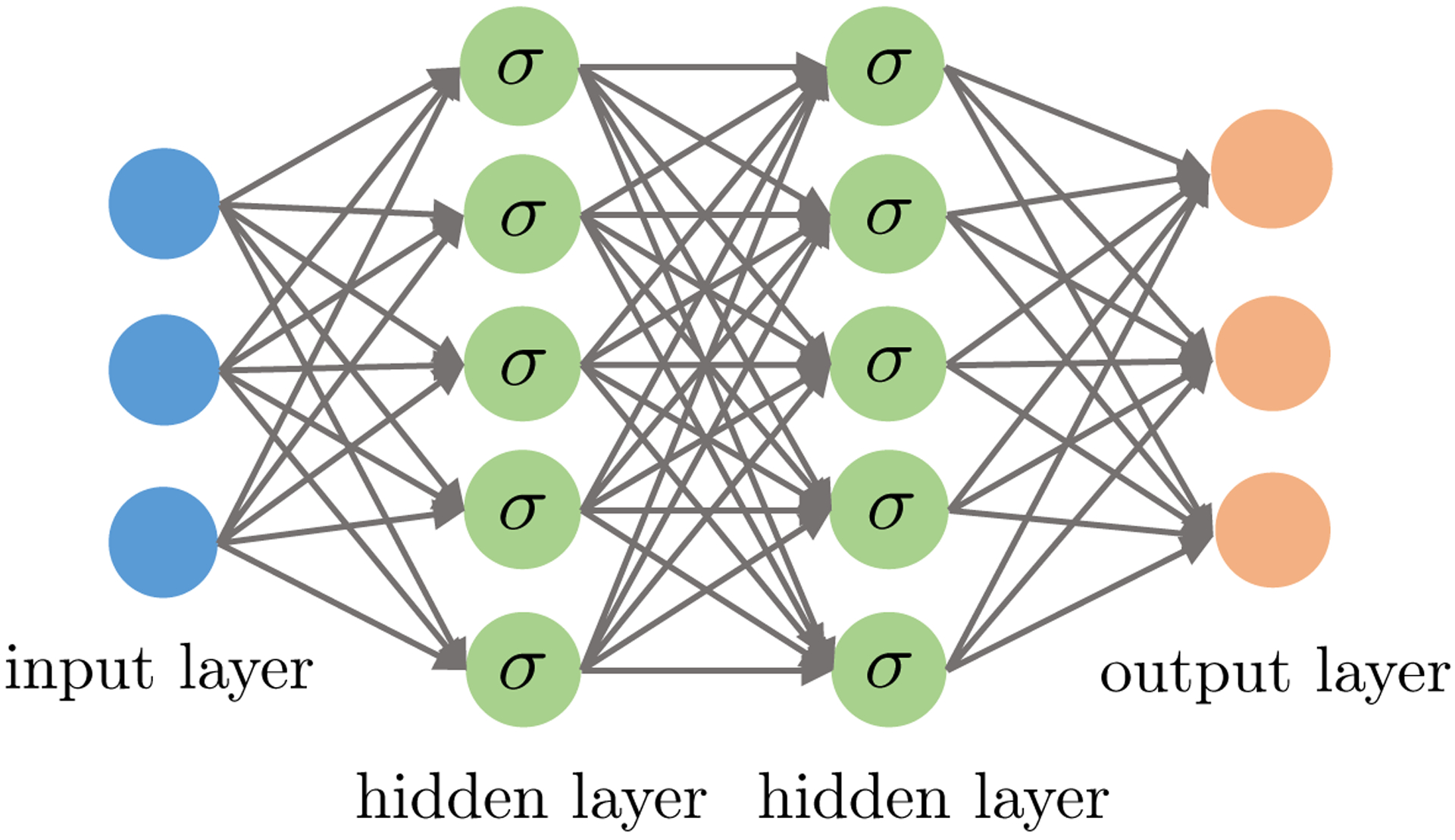
A feed-forward neural network with an input layer, two hidden layers and an output layer. The input layer represents raw features {xi}1≤i≤n. Both hidden layers compute an affine transform (a.k.a. indices) of the input and then apply an element-wise activation function (·). Finally, the output returns a linear transform followed by the softmax activation (resp. simply a linear transform) of the hidden layers for the classification (resp. regression) problem.
The above two points lead to the following heuristic explanation of the success of deep learning models. The large depth of deep neural nets and heavy over-parametrization lead to small or zero training errors, even when running simple algorithms with moderate number of iterations. In addition, these simple algorithms with moderate number of steps do not explore the entire function space and thus have limited complexities, which results in small generalization error with a large sample size. Thus, by combining the two aspects, it explains heuristically that the test error is also small.
1.3. Roadmap of the paper
We first introduce basic deep learning models in Sections 2–4, and then examine their representation power via the lens of approximation theory in Section 5. Section 6 is devoted to training algorithms and their ability of driving the training error small. Then we sample recent theoretical progress towards demystifying the generalization power of deep learning in Section 7. Along the way, we provide our own perspectives, and at the end we identify a few interesting questions for future research in Section 8. The goal of this paper is to present suggestive methods and results, rather than giving conclusive arguments (which is currently unlikely) or a comprehensive survey. We hope that our discussion serves as a stimulus for new statistics research.
2. FEED-FORWARD NEURAL NETWORKS
Before introducing the vanilla feed-forward neural nets, let us set up necessary notations for the rest of this section. We focus primarily on classification problems, as regression problems can be addressed similarly. Given the training dataset {(yi, xi)}1≤i≤n where yi ∈ [K] ≜ {1, 2, …, K} and are independent across i ∈ [n], supervised learning aims at finding a (possibly random) function that predicts the outcome y for a new input x, assuming (y, x) follows the same distribution as (yi, xi). In the terminology of machine learning, the input xi is often called the feature, the output yi called the label, and the pair (yi, xi) is an example. The function is called the classifier, and estimation of is training or learning. The performance of is evaluated through the prediction error , which can be often estimated from a separate test dataset.
As with classical statistical estimation, for each k ∈ [K], a classifier approximates the conditional probability using a function fk(x; θk) parametrized by θk. Then the category with the highest probability is predicted. Thus, learning is essentially estimating the parameters θk. In statistics, one of the most popular methods is (multinomial) logistic regression, which stipulates a specific form for the functions fk(x; θk): let zk = x⊤βk + αk and fk(x; θk) = Z−1 exp(zk) where is a normalization factor to make {fk(x; θk)}1≤k≤K a valid probability distribution. It is clear that logistic regression induces linear decision boundaries in , and hence it is restrictive in modeling nonlinear dependency between y and x. The deep neural networks we introduce below provide a flexible framework for modeling nonlinearity in a fairly general way.
2.1. Model setup
From the high level, deep neural networks (DNNs) use composition of a series of simple nonlinear functions to model nonlinearity
where ○ denotes composition of two functions and L is the number of hidden layers, and is usually called depth of a NN model. Letting h(0) ≜ x, one can recursively define for all . The feed-forward neural networks, also called the multilayer perceptrons (MLPs), are neural nets with a specific choice of , define
| (2.1) |
where and are the weight matrix and the bias / intercept, respectively, associated with the l-th layer, and σ(·) is usually a simple given (known) nonlinear function called the activation function. In words, in each layer , the input vector goes through an affine transformation first and then passes through a fixed nonlinear function σ(·). See Figure 2 for an illustration of a simple MLP with two hidden layers. The activation function (·) is usually applied element-wise, and a popular choice is the ReLU (Rectified Linear Unit) function:
| (2.2) |
Other choices of activation functions include leaky ReLU, tanh function (Maas, Hannun and Ng, 2013) and the classical sigmoid function (1 + e−z)−1, which is less used now.
Given an output h(L) from the final hidden layer and a label y, we can define a loss function to minimize. A common loss function for classification problems is the multinomial logistic loss. Using the terminology of deep learning, we say that h(L) goes through an affine transformation and then the soft-max function:
Then the loss is defined to be the cross-entropy between the label y (in the form of an indicator vector) and the score vector (f1(x; θ), … , fK(x; θ))┬, which is exactly the negative log-likelihood of the multinomial logistic regression model:
| (2.3) |
where . As a final remark, the number of parameters scales with both the depth L and the width (i.e., the dimensionality of , and hence it can be quite large for deep neural nets.
2.2. Back-propagation in computational graphs
Training neural networks follows the empirical risk minimization paradigm that minimizes the loss (e.g., (2.3)) over all the training data. This minimization is usually done via stochastic gradient descent (SGD). In a way similar to gradient descent, SGD starts from a certain initial value θ0 and then iteratively updates the parameters θt by moving it in the direction of the negative gradient. The difference is that, in each update, a small subsample called a mini-batch—which is typically of size 32–512—is randomly drawn and the gradient calculation is only on instead of the full batch [n]. This saves considerably the computational cost in calculation of gradient. By the law of large numbers, this stochastic gradient should be close to the full sample one, albeit with some random fluctuations. A pass of the whole training set is called an epoch. Usually, after several or tens of epochs, the error on a validation set levels off and training is complete. See Section 6 for more details and variants on training algorithms.
The key to the above training procedure, namely SGD, is the calculation of the gradient , where
| (2.4) |
Gradient computation, however, is in general nontrivial for complex models, and it is susceptible to numerical instability for a model with large depth. Here, we introduce an efficient approach, namely back-propagation, for computing gradients in neural networks.
Back-propagation (Rumelhart, Hinton and Williams, 1985) is a direct application of the chain rule in networks. As the name suggests, the calculation is performed in a backward fashion: one first computes , then ,…, and finally . For example, in the case of the ReLU activation function3, we have the following recursive / backward relation
| (2.5) |
where diag(·) denotes a diagonal matrix with elements given by the argument. Note that the calculation of depends on , which is the partial derivatives from the next layer. In this way, the derivatives are “back-propagated” from the last layer to the first layer. These derivatives are then used to update the parameters. For instance, the gradient update for is given by
| (2.6) |
where σ′ = 1 if the j-th element of is nonnegative, and σ′ = 0 otherwise. The step size η > 0, also called the learning rate, controls how much parameters are changed in a single update.
A more general way to think about neural network models and training is to consider computational graphs. Computational graphs are directed acyclic graphs that represent functional relations between variables. They are very convenient and flexible to represent function composition, and moreover, they also allow an efficient way of computing gradients. Consider an MLP with a single hidden layer and an regularization:
| (2.7) |
where is the same as (2.4), and λ ≥ 0 is a tuning parameter. A similar example is considered in Goodfellow, Bengio and Courville (2016). The corresponding computational graph is shown in Figure 3. Each node represents a function (inside a circle), which is associated with an output of that function (outside a circle). For example, we view the term as a result of 4 compositions: first the input data x multiplies the weight matrix W(1) resulting in u(1), then it goes through the ReLU activation function relu resulting in h(1), then it multiplies another weight matrix W(2) leading to p, and finally it produces the cross-entropy with label y as in (2.3). The regularization term is incorporated in the graph similarly.
Fig 3:
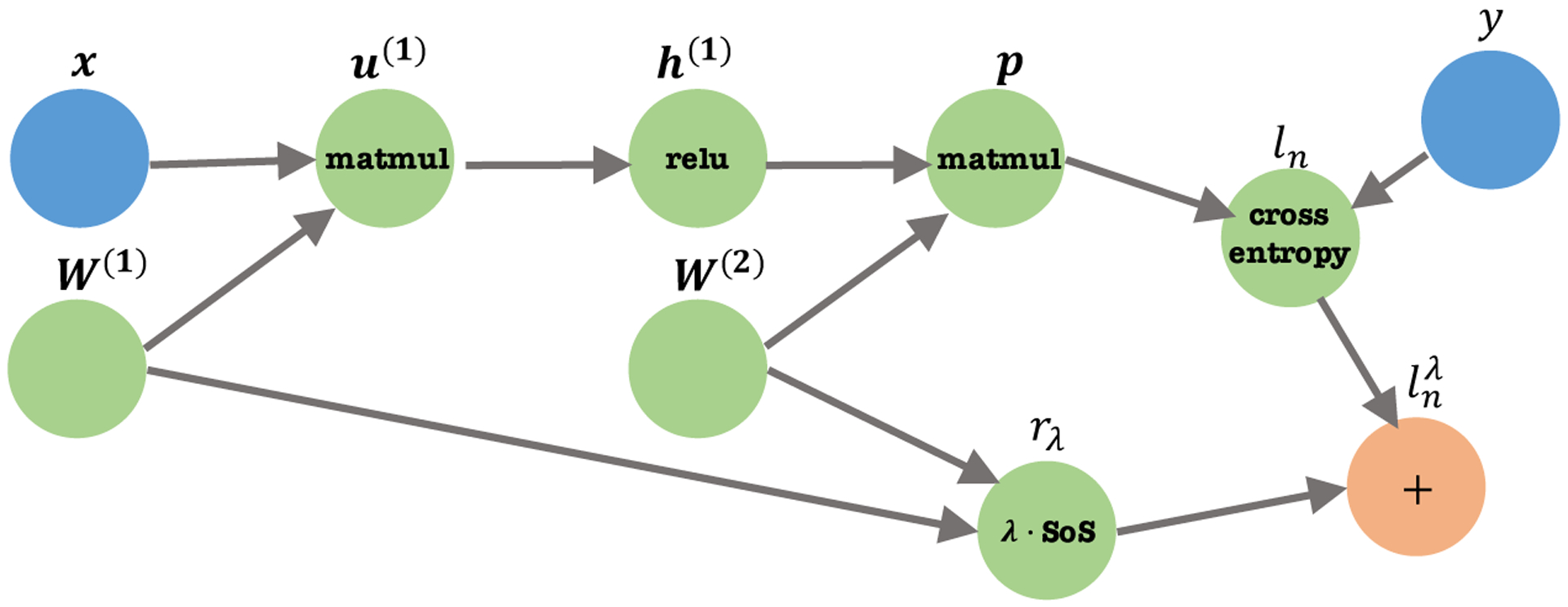
The computational graph illustrates the loss (2.7). For simplicity, we omit the bias terms. Symbols inside nodes represent functions, and symbols outside nodes represent function outputs (vectors/scalars). matmul is matrix multiplication, relu is the ReLU activation, cross entropy is the cross entropy loss, and SoS is the sum of squares.
A forward pass is complete when all nodes are evaluated starting from the input x. A backward pass then calculates the gradients of with respect to all other nodes in the reverse direction. Due to the chain rule, the gradient calculation for a variable (say, ) is simple: it only depends on the gradient value of the variables the current node points to, and the function derivative evaluated at the current variable value (σ′(u(1))). Thus, in each iteration, a computation graph only needs to (1) calculate and store the function evaluations at each node in the forward pass, and then (2) calculate all derivatives in the backward pass.
Back-propagation in computational graphs forms the foundations of popular deep learning programming softwares, including TensorFlow (Abadi and et. al., 2015) and PyTorch (Paszke et al., 2017), which allows more efficient building and training of complex neural net models.
3. POPULAR MODELS
Moving beyond vanilla feed-forward neural networks, we introduce two other popular deep learning models, namely, the convolutional neural networks (CNNs) and the recurrent neural networks (RNNs). One important characteristic shared by the two models is weight sharing, that is some model parameters are identical across locations in CNNs or across time in RNNs. This is related to the notion of translational invariance in CNNs and stationarity in RNNs. At the end of this section, we introduce a modular thinking for constructing more flexible neural nets.
3.1. Convolutional neural networks
The convolutional neural network (CNN) (LeCun et al., 1998; Fukushima and Miyake, 1982) is a special type of feed-forward neural networks that is tailored for image processing. More generally, it is suitable for analyzing data with salient spatial structures. In this subsection, we focus on image classification using CNNs, where the raw input (image pixels) and features of each hidden layer are represented by a 3D tensor . Here, the first two dimensions d1, d2 of X indicate spatial coordinates of an image while the third d3 indicates the number of channels. For instance, d3 is 3 for the raw inputs due to the red, green and blue channels, and d3 can be much larger (say, 256) for hidden layers. Each channel is also called a feature map, because each feature map is specialized to detect the same feature at different locations of the input, which we will soon explain. We now introduce two building blocks of CNNs, namely the convolutional layer and the pooling layer.
-
Convolutional layer (CONV). A convolutional layer has the same functionality as described in (2.1), where the input feature goes through an affine transformation first and then an element-wise nonlinear activation. The difference lies in the specific form of the affine transformation. A convolutional layer uses a number of filters to extract local features from the previous input. More precisely, each filter is represented by a 3D tensor , where w is the size of the filter (typically 3 or 5) and denotes the total number of filters. Note that the third dimension d3 of Fk is equal to that of the input feature X. For this reason, one usually says that the filter has size w × w, while suppressing third the dimension d3. Each filter Fk then convolves with the input feature X to obtain one single feature map , where4
Here is a small “patch” of X starting at location (i, j). See Figure 4 for an illustration of the convolution operation. If we view the 3D tensors [X]ij and Fk as vectors, then each filter essentially computes their inner product with a part of X indexed by i, j (which can be also viewed as convolution, as its name suggests). One then pack the resulted feature maps where {Ok} into a 3D tensor O with size , where(3.1) (3.2) The outputs of convolutional layers are then followed by nonlinear activation functions. In the ReLU case, we have
The convolution operation (3.1) and the ReLU activation (3.3) work together to extract features from the input X. Different from feed-forward neural nets, the filters Fk are hared across all locations (i, j). A patch [X]ij of an input responds strongly (that is, producing a large value) to a filter Fk if they are positively correlated. Therefore intuitively, each filter Fk serves to extract features similar to Fk.(3.3) As a side note, after the convolution (3.1), the spatial size d1 × d2 of the input X shrinks to (d1 − w + 1) (d2 − w + 1) of However one may want the spatial size unchanged. This can be achieved via padding, where one appends zeros to the margins of the input X to enlarge the spatial size to (d1+w−1)×(d2+w−1). In addition, a stride in the convolutional layer determines the gap i′ − i and j′ − j between two patches Xij and Xi′j′: in (3.1) the stride is 1, and a larger stride would lead to feature maps with smaller sizes.
Pooling layer (POOL). A pooling layer aggregates the information of nearby features into a single one. This downsampling operation reduces the size of the features for subsequent layers and saves computation. One common form of the pooling layer is composed of the 2 × 2 max-pooling filter. It computes max{Xi,j,k, Xi+1,j,k, Xi,j+1,k, Xi+1,j+1,k}, that is, the maximum of the 2 × 2 neighborhood in the spatial coordinates; see Figure 5 for an illustration. Note that the pooling operation is done separately for each feature map k. As a consequence, a 2 × 2 max-pooling filter acting on will result in an output of size d1/2 × d2/2 × d3. In addition, the pooling layer does not involve any parameters to optimize. Pooling layers serve to reduce redundancy since a small neighborhood around a location (i, j) in a feature map is likely to contain the same information.
Fig 4:
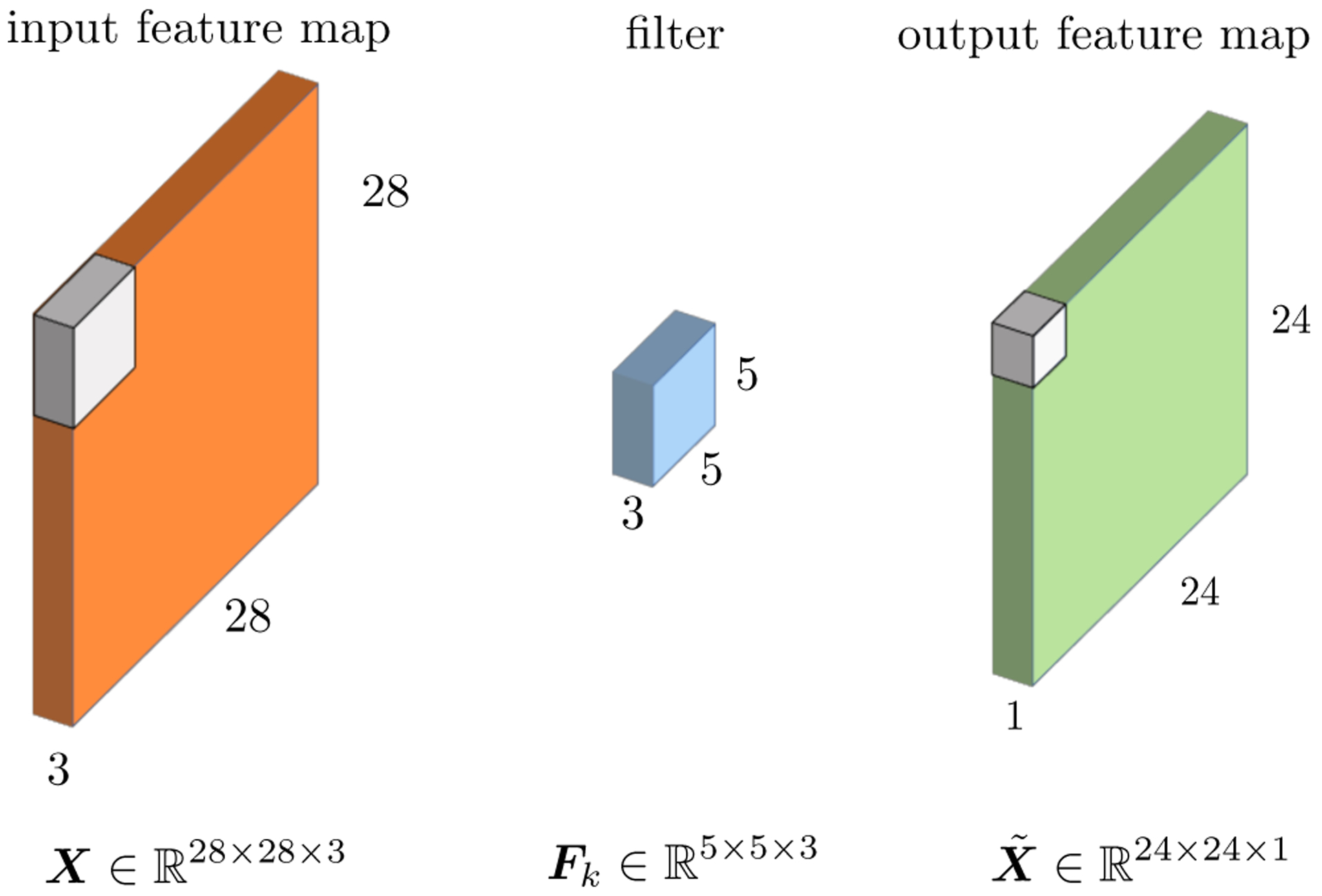
represents the input feature consisting of 28 × 28 spatial coordinates in a total number of 3 channels / feature maps. denotes the k-th filter with size 5 × 5 The third matches the number 3 of the filter automatically matches the number 3 of channels in the previous input. Every 3D patch of X gets convolved with the filter Fk and this as a whole results in a single output feature map with size 24 × 24 ×1. Stacking the outputs of all the filters {Fk}1×k×K will lead to the output feature with size 24 × 24 ×K.
Fig 5:
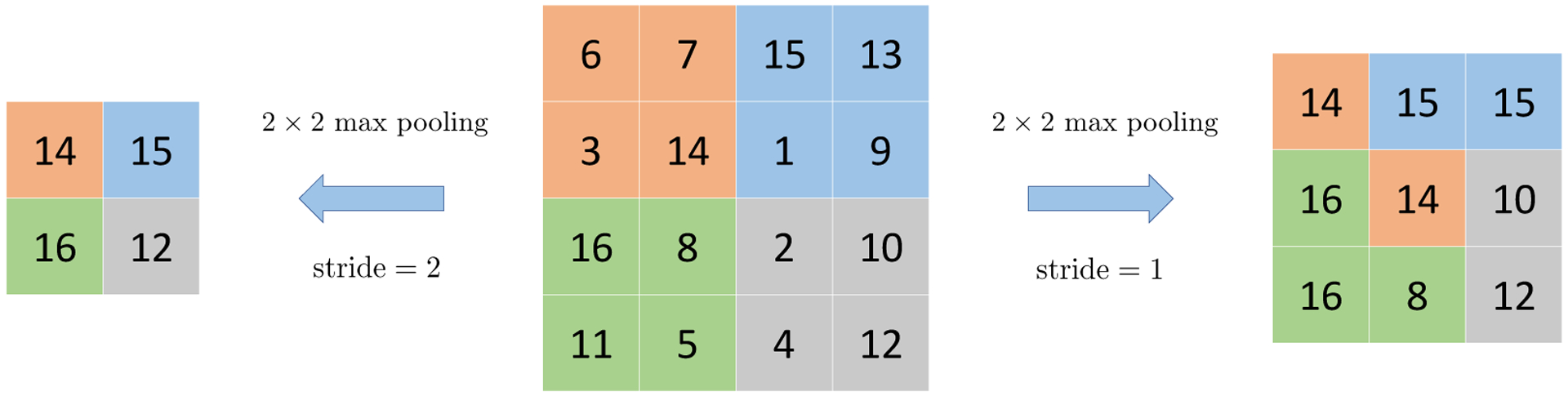
A 2 × 2 max pooling layer extracts the maximum of 2 by 2 neighboring pixels / features across the spatial dimension.
In addition, we also use fully-connected layers as building blocks, which we have already seen in Section 2. Each fully-connected layer treats input tensor X as a vector Vec(X), and computes . A fully-connected layer does not use weight sharing and is often used in the last few layers of a CNN. As an example, Figure 6 depicts the well-known LeNet 5 (LeCun et al., 1998), which is composed of two sets of CONV-POOL layers and three fully-connected layers.
Fig 6:
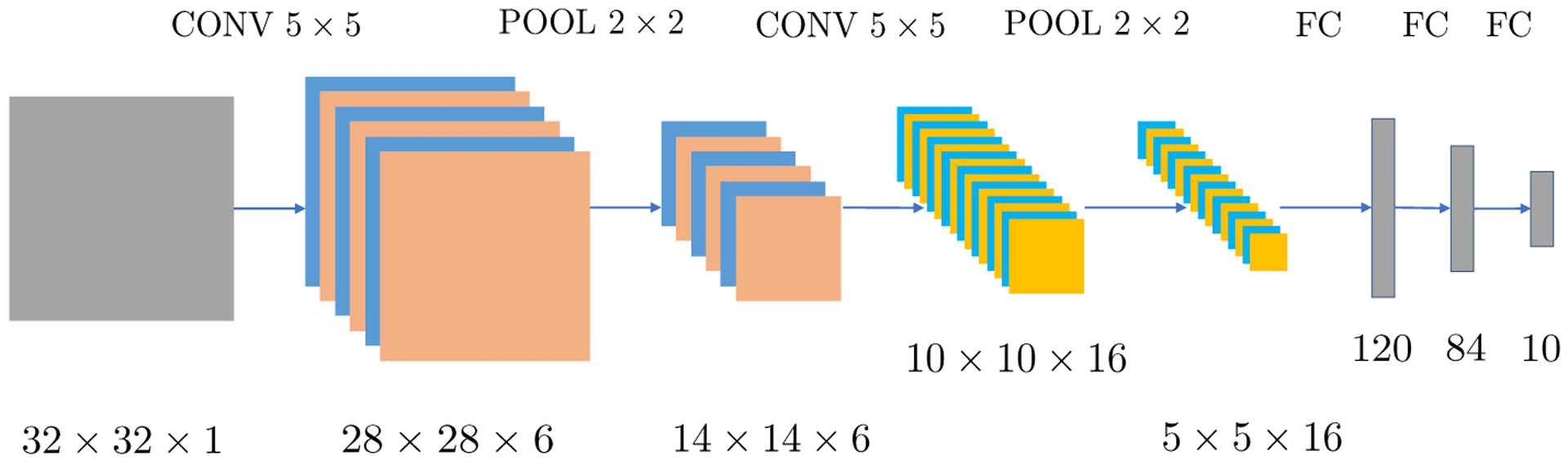
LeNet is composed of an input layer, two convolutional layers, two pooling layers and three fully-connected layers. Both convolutions are valid and use filters with size 5 × 5. In addition, the two pooling layers use 2 × 2 average pooling.
3.2. Recurrent neural networks
Recurrent neural nets (RNNs) are another family of powerful models, which are designed to process time series data and other sequence data. RNNs have successful applications in speech recognition (Sak, Senior and Beaufays, 2014), machine translation (Wu et al., 2016), genome sequencing (Cao et al., 2018), etc. The structure of an RNN naturally forms a computational graph, and can be easily combined with other structures such as CNNs to build large computational graph models for complex tasks. Here we introduce vanilla RNNs and improved variants such as long short-term memory (LSTM).
3.2.1. Vanilla RNNs.
Suppose we have general time series inputs x1, x2, …, xT. A vanilla RNN models the “hidden state” at time t by a vector ht, which is subject to the recursive formula
| (3.4) |
Here, fθ is generally a nonlinear function parametrized by θ. Concretely, a vanilla RNN with one hidden layer has the following form5
where Whh, Wxh, Why are trainable weight matrices, bh, bz are trainable bias vectors, and zt is the output at time t. Like many classical time series models, those parameters are shared across time. Note that in different applications, we may have different input/output settings (cf. Figure 7). Examples include
Fig 7:
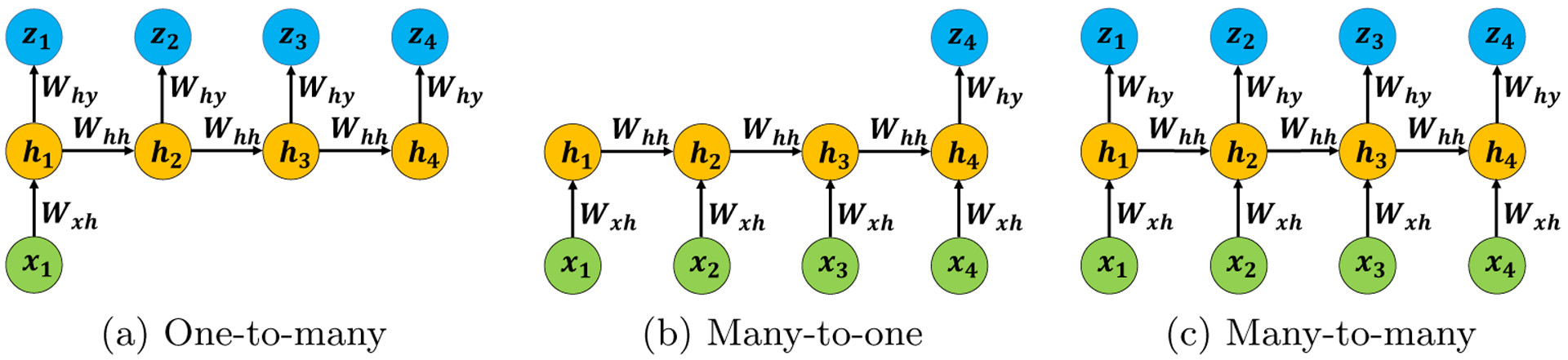
Vanilla RNNs with different inputs/outputs settings. (a) has one input but multiple outputs; (b) has multiple inputs but one output; (c) has multiple inputs and outputs. Note that the parameters are shared across time steps.
One-to-many: a single input with multiple outputs; see Figure 7(a). A typical application is image captioning, where the input is an image and outputs are a series of words.
Many-to-one: multiple inputs with a single output; see Figure 7(b). One application is text sentiment classification, where the input is a series of words in a sentence and the output is a label (e.g., positive vs. negative).
Many-to-many: multiple inputs and outputs; see Figure 7(c). This is adopted in machine translation, where inputs are words of a source language (say Chinese) and outputs are words of a target language (say English).
As the case with feed-forward neural nets, we minimize a loss function using back-propagation, where the loss is typically
where K is the number of categories for classification (e.g., size of the vocabulary in machine translation), and is the length of the output sequence. During the training, the gradients are computed in the reverse time order (from T to t). For this reason, the training process is often called back-propagation through time.
One notable drawback of vanilla RNNs is that, they have difficulty in capturing long-range dependencies in sequence data when the length of the sequence is large. This is sometimes due to the phenomenon of exploding / vanishing gradients. Take Figure 7(c) as an example. Computing involves the product by the chain rule. However, if the sequence is long, the product will be the multiplication of many Jacobian matrices, which usually results in exponentially large or small singular values. To alleviate this issue, in practice, the forward pass and backward pass are implemented in a shorter sliding window {t1, t1 + 1, …, t2}, instead of the full sequence {1, 2, …, T}.Though effective in some cases, this technique alone does not fully address the issue of long-term dependency.
3.2.2. GRUs and LSTM.
There are two improved variants that alleviate the above issue: gated recurrent units (GRUs) (Cho et al., 2014) and long short-term memory (LSTM) (Hochreiter and Schmidhuber, 1997).
A GRU refines the recursive formula (3.4) by introducing gates, which are vectors of the same length as ht. The gates, which take values in [0, 1] elementwise, multiply with ht−1 elementwise and determine how much they keep the old hidden states.
An LSTM similarly uses gates in the recursive formula. In addition to ht, an LSTM maintains a cell state, which takes values in elementwise and are analogous to counters.
Here we only discuss LSTM in detail. Denote by ⊙ the element-wise multiplication. We have a recursive formula in replace of (3.4):
where W is a big weight matrix with appropriate dimensions. The cell state vector ct carries information of the sequence (e.g., singular/plural form in a sentence). The forget gate ft determines how much the values of ct−1 are kept for time t, the input gate it controls the amount of update to the cell state, and the output gate ot gives how much ct reveals to ht. Ideally, the elements of these gates have nearly binary values. For example, an element of ft being close to 1 may suggest the presence of a feature in the sequence data. Similar to the skip connections in residual nets, the cell state ct has an additive recursive formula, which helps back-propagation and thus captures long-range dependencies.
3.2.3. Multilayer RNNs.
Multilayer RNNs are generalization of the one-hidden-layer RNN discussed above. Figure 8 shows a vanilla RNN with two hidden layers. In place of (3.4), the recursive formula for an RNN with L hidden layers now reads
Note that a multilayer RNN has two dimensions: the sequence length T and depth L. Two special cases are the feed-forward neural nets (where T = 1) introduced in Section 2, and RNNs with one hidden layer (where L = 1). Multilayer RNNs usually do not have very large depth (e.g., 2–5), since T is already very large.
Fig 8:
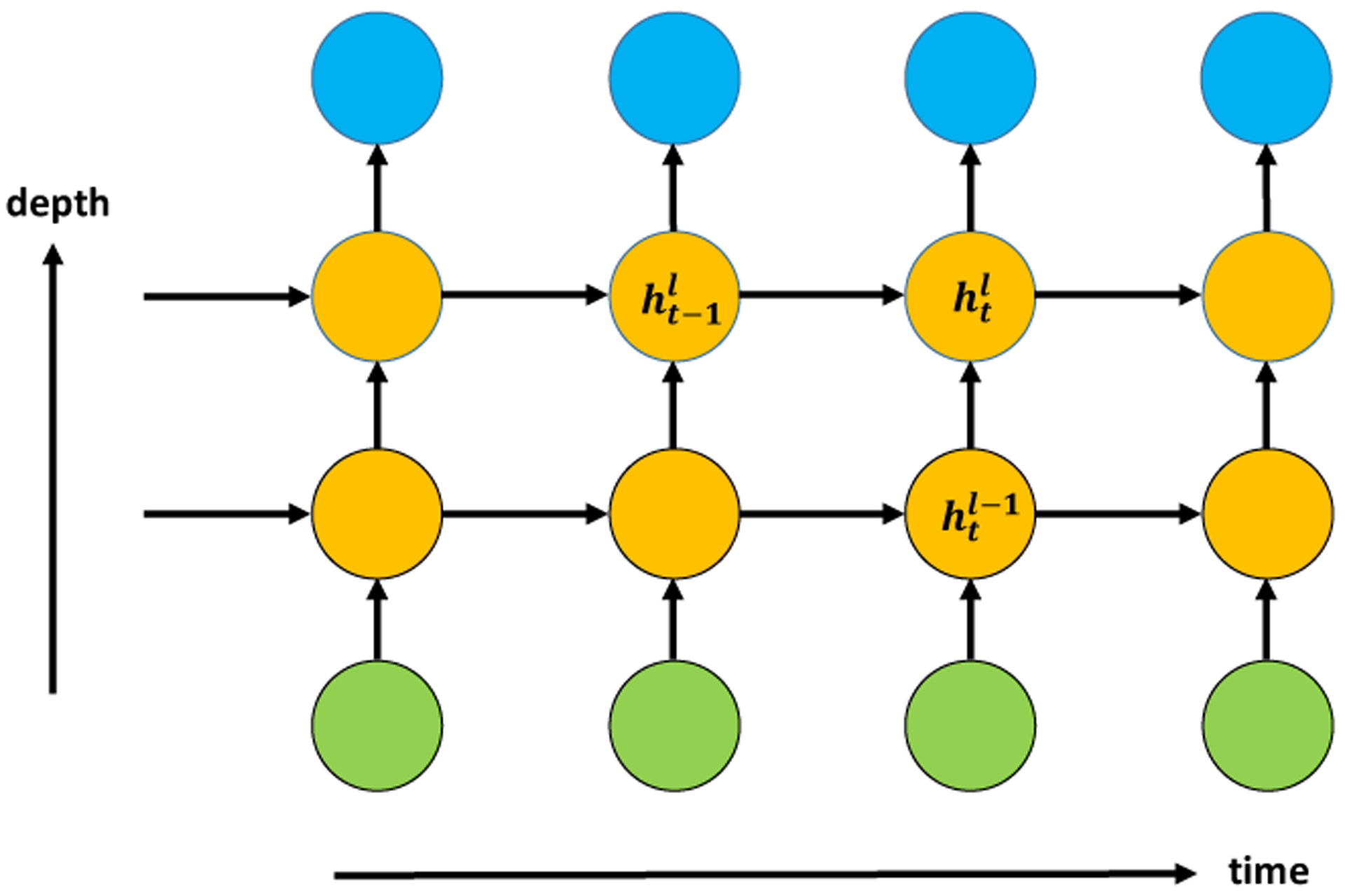
A vanilla RNN with two hidden layers. Higher-level hidden states are determined by the old states and lower-level hidden states . Multilayer RNNs generalize both feed-forward neural nets and one-hidden-layer RNNs.
Finally, we remark that CNNs, RNNs, and other neural nets can be easily combined to tackle tasks that involve different sources of input data. For example, in image captioning, the images are first processed through a CNN, and then the high-level features are fed into an RNN as inputs. Theses neural nets combined together form a large computational graph, so they can be trained using back-propagation. This generic training method provides much flexibility in various applications.
3.3. Modules
Deep neural nets are essentially composition of many nonlinear functions. A component function may be designed to have specific properties in a given task, and it can be itself resulted from composing a few simpler functions. In LSTM, we have seen that the building block consists of several intermediate variables, including cell states and forget gates that can capture long-term dependency and alleviate numerical issues.
This leads to the idea of designing modules for building more complex neural net models. Desirable modules usually have low computational costs, alleviate numerical issues in training, and lead to good statistical accuracy. Since modules and the resulting neural net models form computational graphs, training follows the same principle briefly described in Section 2.
Here, we use the examples of Inception and skip connections to illustrate the ideas behind modules. Figure 9(a) is an example of “Inception” modules used in GoogleNet (Szegedy et al., 2015). As before, all the convolutional layers are followed by the ReLU activation function. The concatenation of information from filters with different sizes give the model great flexibility to capture spatial information. Note that 1 × 1 filters is an 1 × 1 × d3 tensor (where d3 is the number of feature maps), so its convolutional operation does not interact with other spatial coordinates, only serving to aggregate information from different feature maps at the same coordinate. This reduces the number of parameters and speeds up the computation. Similar ideas appear in other work (Lin, Chen and Yan, 2013; Iandola et al., 2016).
Fig 9:
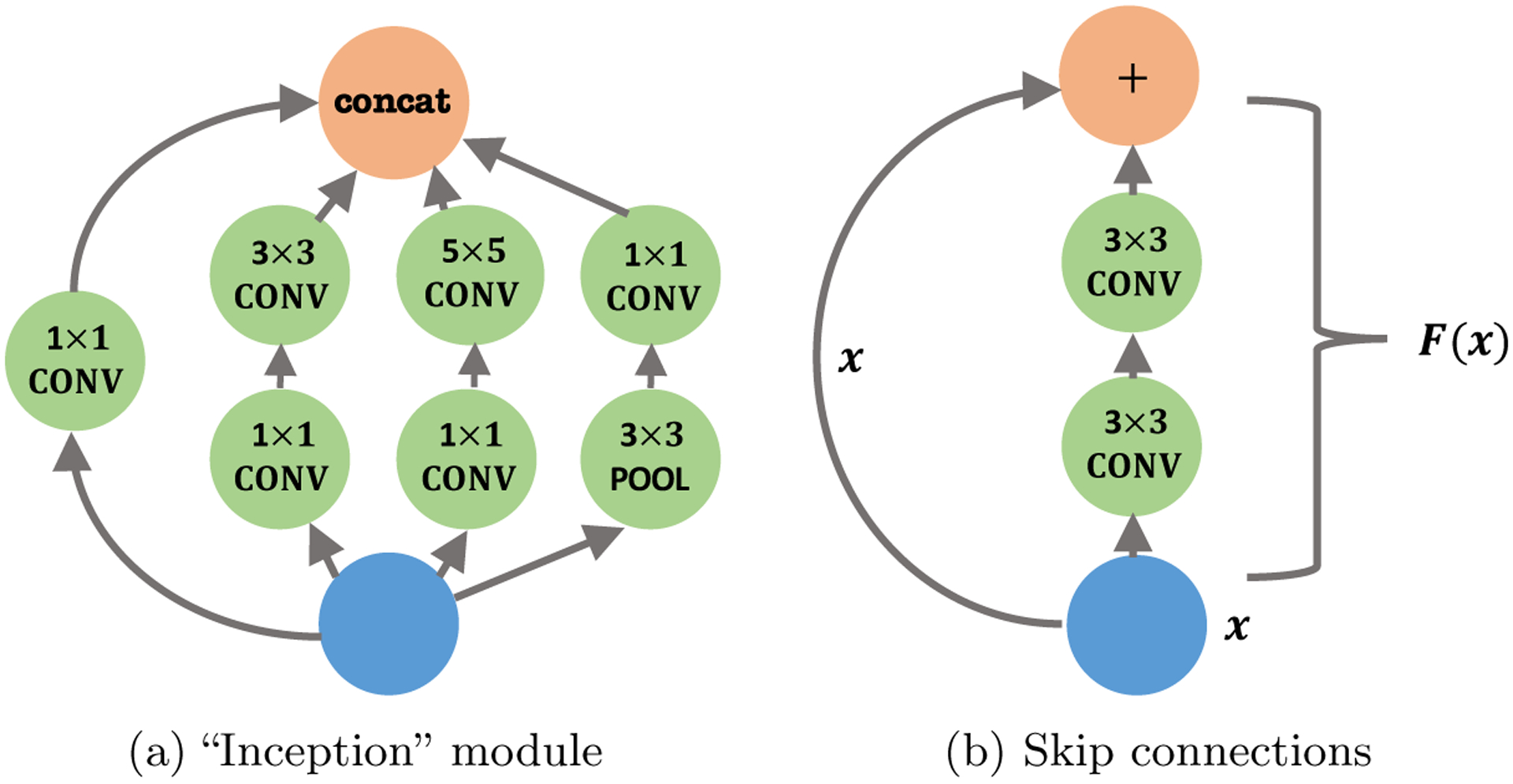
(a) The “Inception” module from GoogleNet. Concat means combining all features maps into a tensor. (b) Skip connections are added every two layers in ResNets.
Another module, usually called skip connections, is widely used to alleviate numerical issues in very deep neural nets, with additional benefits in optimization efficiency and statistical accuracy. Training very deep neural nets are generally more difficult, but the introduction of skip connections in residual networks (He et al., 2016a,b) has greatly eased the task.
The high level idea of skip connections is to add an identity map to an existing nonlinear function. Let F(x) be an arbitrary nonlinear function represented by a (fragment of) neural net, then the idea of skip connections is simply replacing F(x) with x + F(x). Figure 9(b) shows a well-known structure from residual networks (He et al., 2016a)—for every two layers, an identity map is added:
| (3.5) |
where x can be hidden nodes from any layer and W, W′, b, b′ are corresponding parameters. By repeating (namely composing) this structure throughout all layers, He et al. (2016a,b) are able to train neural nets with hundreds of layers easily, which overcomes well-observed training difficulties in deep neural nets. Moreover, deep residual networks also improve statistical accuracy, as the classification error on ImageNet challenge was reduced by 46% from 2014 to 2015. As a side note, skip connections can be used flexibly. They are not restricted to the form in (3.5), and can be used between any pair of layers , (Huang et al., 2017).
4. DEEP UNSUPERVISED LEARNING
In supervised learning, given labelled training set {(yi, xi)}, we focus on discriminative models, which essentially represents by a deep neural net f(x; θ) with parameters θ. Unsupervised learning, in contrast, aims at extracting information from unlabeled data {xi}, where the labels {yi} are absent. In regard to this information, it can be a low-dimensional embedding of the data {xi} or a generative model with latent variables to approximate the distribution . To achieve these goals, we introduce two popular unsupervised deep leaning models, namely, autoencoders and generative adversarial networks (GANs). The first one can be viewed as a dimension reduction technique, and the second as a density estimation method. DNNs are the key elements for both of these two models.
4.1. Autoencoders
Recall that in dimension reduction, the goal is to reduce the dimensionality of the data and at the same time preserve its salient features. In particular, in principal component analysis (PCA), the goal is to embed the data {xi}1≤i≤n into a low-dimensional space via a linear function f such that maximum variance can be explained. Equivalently, we want to find linear functions and (k ≤ d) such that the difference between xi and g(f(xi)) is minimized. Formally, we let
Here, for simplicity, we assume that the intercept/bias terms for f and g are zero. Then, PCA amounts to minimizing the quadratic loss function
| (4.1) |
It is the same as minimizing subject to rank(W) ≤ k, where is the design matrix. The solution is given by the singular value decomposition of X (Golub and Van Loan, 2013, Thm. 2.4.8), which is exactly what PCA does. It turns out that PCA is a special case of autoencoders, which is often known as the undercomplete linear autoencoder.
More broadly, autoencoders are neural network models for (nonlinear) dimension reduction, which generalize PCA. An autoencoder has two key components, namely, the encoder function f(·), which maps the input to a hidden code/representation , and the decoder function g(·), which maps the hidden representation h to a point . Both functions can be multi-layer neural networks as (2.1). See Figure 10 for an illustration of autoencoders. Let be a loss function that measures the difference between x1 and x2 in . Similar to PCA, an autoencoder is used to find the encoder f and decoder g such that is as small as possible. Mathematically, this amounts to solving the following minimization problem
| (4.2) |
Fig 10:
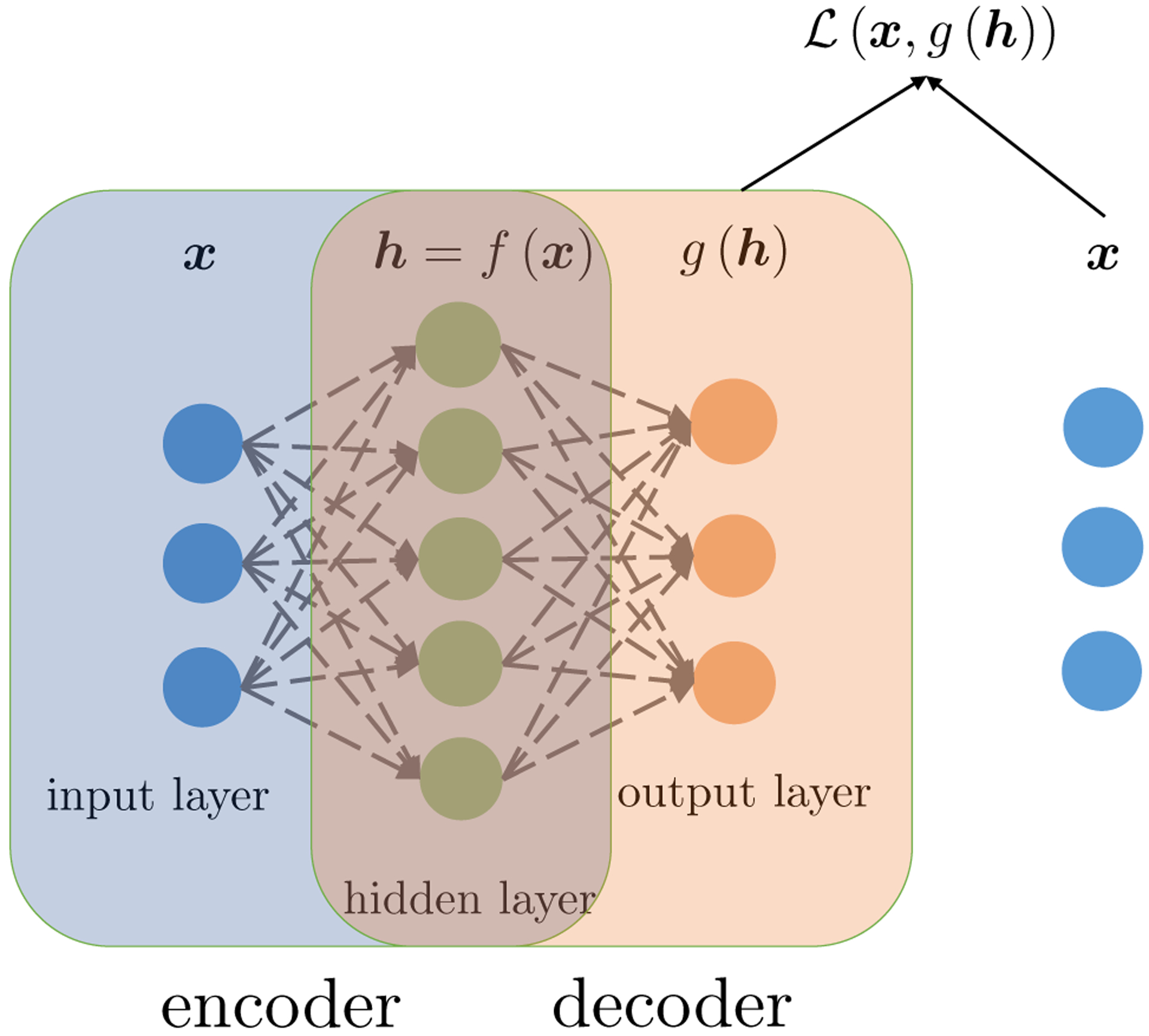
First an input x goes through the encoder f(·), and we obtain its hidden representation h = f(x). Then, we use the decoder g(·) to get g(h) as a reconstruction of x. Finally, the loss is determined from the difference between the original input x and its reconstruction g(f(x)).
One needs to make structural assumptions on the functions f and g in order to find useful representations of the data, which leads to different types of autoencoders. Indeed, if no assumption is made, choosing f and g to be identity functions clearly minimizes the above optimization problem. To avoid this trivial solution, one natural way is to require that the encoder f maps the data onto a space with a smaller dimension, i.e., k < d. This is the undercomplete autoencoder that includes PCA as a special case. There are other structured autoencoders which add desired properties to the model such as sparsity or robustness, mainly through regularization terms. Below we present two other common types of autoencoders.
- Sparse autoencoders. One may believe that the dimension k of the hidden code hi is larger than the input dimension d, and that hi admits a sparse representation. As with LASSO (Tibshirani, 1996) or SCAD (Fan and Li, 2001), one may add a regularization term to the reconstruction loss in (4.2) to encourage sparsity (Poultney et al., 2007). A sparse autoencoder solves
This is similar to dictionary learning, where one aims at finding a sparse representation of input data on an overcomplete basis. Due to the imposed sparsity, the model can potentially learn useful features of the data. Denoising autoencoders. One may hope that the model is robust to noise in the data: even if the input data xi are corrupted by small noise ξi or miss some components (the noise level or the missing probability is typically small), an ideal autoencoder should faithfully recover the original data. A denoising autoencoder (Vincent et al., 2008) achieves this robustness by explicitly building a noisy data as the new input, and then solves an optimization problem similar to (4.2) where is replaced by . A denoising autoencoder encourages the encoder/decoder to be stable in the neighborhood of an input, which is generally a good statistical property. An alternative way could be constraining f and g in the optimization problem, but that would be very difficult to optimize. Instead, sampling by adding small perturbations in the input provides a simple implementation. We shall see similar ideas in Section 6.3.3.
4.2. Generative adversarial networks
Given unlabeled data {xi}1≤i≤n, density estimation aims to estimate the underlying probability density function from which the data is generated. Both parametric and nonparametric estimators (Silverman, 1998) have been proposed and studied under various assumptions on the underlying distribution. Different from these classical density estimators, where the density function is explicitly defined in relatively low dimension, generative adversarial networks (GANs) (Goodfellow et al., 2014) can be categorized as an implicit density estimator in much higher dimension. The reasons are twofold: (1) GANs put more emphasis on sampling from the distribution than estimation; (2) GANs define the density estimation implicitly through a source distribution and a generator function g(·), which is usually a deep neural network. We introduce GANs from the perspective of sampling from and later we will generalize the vanilla GANs using its relation to density estimators.
4.2.1. Sampling view of GANs.
Suppose the data {xi}1≤i≤n at hand are all real images, and we want to generate new natural images. With this goal in mind, GAN models a zero-sum game between two players, namely, the generator and the discriminator . The generator tries to generate fake images akin to the true images {xi}1≤i≤n while the discriminator aims at differentiating the fake ones from the true ones. Intuitively, one hopes to learn a generator to generate images where the best discriminator cannot distinguish. Therefore the payoff is higher for the generator if the probability of the discriminator getting wrong is higher, and correspondingly the payoff for the discriminator correlates positively with its ability to tell wrong from truth.
Mathematically, the generator consists of two components, an source distribution (usually a standard multivariate Gaussian distribution with hundreds of dimensions) and a function g(·) which maps a sample z from to a point g(z) living in the same space as x. For generating images, g(z) would be a 3D tensor. Here g(z) is the fake sample generated from . Similarly the discriminator is composed of one function which takes an image x (real or fake) and return a number d(x) ∈ [0, 1], the probability of x being a real sample from or not. Oftentimes, both the generating function g(·) and the discriminating function d(·) are realized by deep neural networks, e.g., CNNs introduced in Section 3.1. See Figure 11 for an illustration for GANs. Denote and the parameters in g(·) and d(·), respectively. Then GAN tries to solve the following min-max problem:
| (4.3) |
Recall that d(x) models the belief / probability that the discriminator thinks that x is true sample. Fix the parameters and hence the generator and consider the inner maximization problem. We can see that the goal of the discriminator is to maximize its ability of differentiation. Similarly, if we fix (and hence the discriminator), the generator tries to generate more realistic images g(z) to fool the discriminator.
Fig 11:
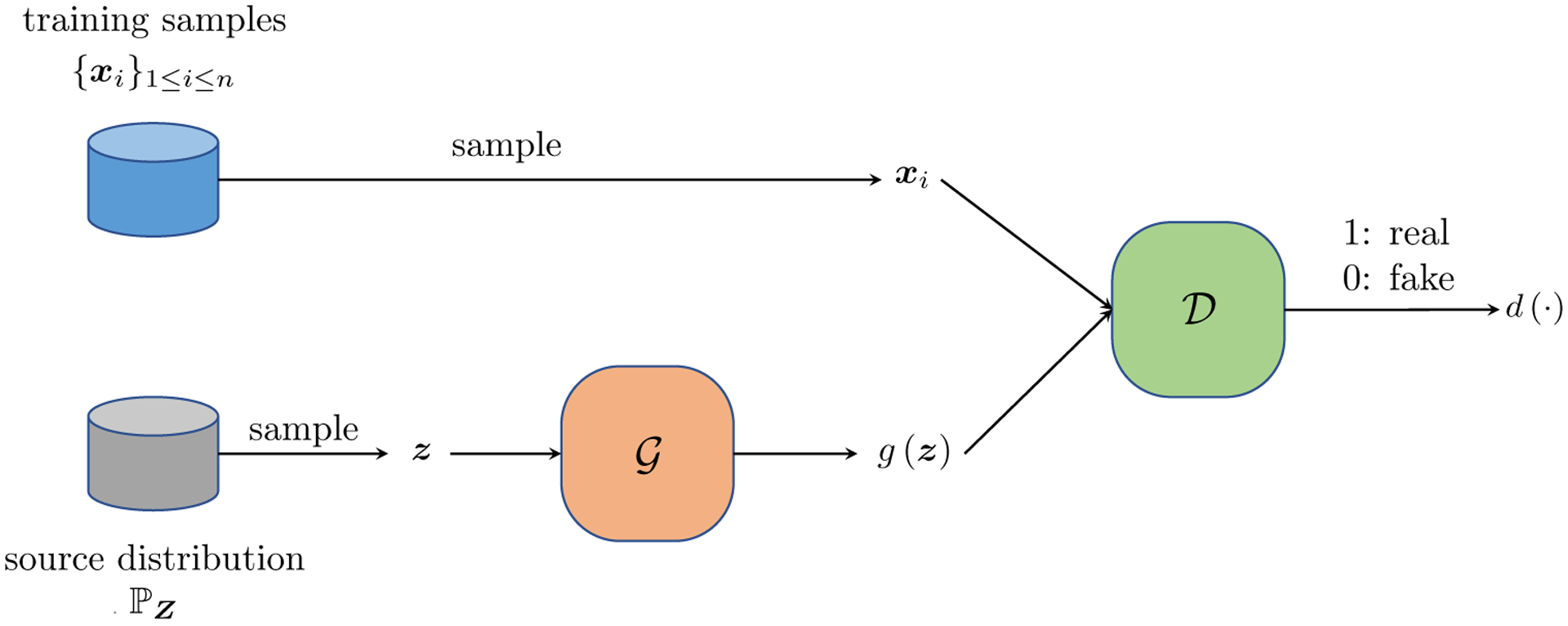
GANs consist of two components, a generator which generates fake samples and a discriminator which differentiate the true ones from the fake ones.
4.2.2. Density estimation view of GANs.
Let us now take a density-estimation view of GANs. Fixing the source distribution , any generator induces a distribution over the space of images. Removing the restrictions on d(·), one can then rewrite (4.3) as
| (4.4) |
Observe that the inner maximization problem is solved by the likelihood ratio, i.e.
As a result, (4.4) can be simplified as
| (4.5) |
where JS(·||·) denotes the Jensen–Shannon divergence between two distributions
In words, the vanilla GAN (4.3) seeks a density that is closest to in terms of the Jensen–Shannon divergence. This view allows to generalize GANs to other variants, by changing the distance metric. Examples include f-GAN (Nowozin, Cseke and Tomioka, 2016), Wasserstein GAN (W-GAN) (Arjovsky, Chintala and Bottou, 2017), MMD GAN (Li, Swersky and Zemel, 2015), etc. We single out the Wasserstein GAN (W-GAN) (Arjovsky, Chintala and Bottou, 2017) to introduce due to its popularity. As the name suggests, it minimizes the Wasserstein distance between and :
| (4.6) |
where f(·) is taken over all Lipschitz functions with coefficient 1. Comparing W-GAN (4.6) with the original formulation of GAN (4.3), one finds that the Lipschitz function f in (4.6) corresponds to the discriminator in (4.3) in the sense that they share similar objectives to differentiate the true distribution from the fake one . In the end, we would like to mention that GANs are more difficult to train than supervised deep learning models such as CNNs (Salimans et al., 2016). Apart from the training difficulty, how to evaluate GANs objectively and effectively is an ongoing research.
5. REPRESENTATION POWER: APPROXIMATION THEORY
Having seen the building blocks of deep learning models in the previous sections, it is natural to ask: what is the benefits of composing multiple layers of nonlinear functions. In this section, we address this question from a approximation theoretical point of view. Mathematically, letting be the space of functions representable by neural nets (NNs), how well can a function f (with certain properties) be approximated by functions in . We first revisit universal approximation theories, which are mostly developed for shallow neural nets (neural nets with a single hidden layer), and then provide recent results that demonstrate the benefits of depth in neural nets. Other notable works include Kolmogorov-Arnold superposition theorem (Arnold, 2009; Sprecher, 1965), and circuit complexity for neural nets (Parberry, 1994).
5.1. Universal approximation theory for shallow NNs
The universal approximation theories study the approximation of f in a space by a function represented by a one-hidden-layer neural net
| (5.1) |
where is certain activation function and N is the number of hidden units in the neural net. For different space and activation function σ*, there are upper bounds and lower bounds on the approximation error ‖f − g‖ See Pinkus (1999) for a comprehensive overview. Here we present representative results.
First, as N → ∞, any continuous function f can be approximated by some g under mild conditions. Loosely speaking, this is because each component behaves like a basis function and functions in a suitable space admits a basis expansion. Given the above heuristics, the next natural question is: what is the rate of approximation for a finite N?
Let us restrict the domain of x to a unit ball Bd in . For p ∈ [1, ∞) and integer m ≥ 1, consider the Lp space and the Sobolev space with standard norms
where Dkf denotes partial derivatives indexed by . Let be the space of functions f in the Sobolev space with ‖f‖m,p ≤ 1. Note that functions in have bounded derivatives up to m-th order, and that smoothness of functions is controlled by m (larger m means smoother). Denote by the space of functions with the form (5.1). The following general upper bound is due to Mhaskar (1996).
Theorem 5.1 (Theorem 2.1 in Mhaskar (1996)).
Assume is such that σ* has arbitrary order derivatives in an open interval I, and that σ* is not a polynomial on I. Then, for any p ∈ [1, ∞), d ≥ 2, and integer m ≥ 1,
where Cd,m,p is independent of N, the number of hidden units.
In the above theorem, the condition on σ*(·) is mainly technical. This upper bound is useful when the dimension d is not large. It clearly implies that the one-hidden-layer neural net is able to approximate any smooth function with enough hidden units. However, it is unclear how to find a good approximator g; nor do we have control over the magnitude of the parameters (huge weights are impractical). While increasing the number of hidden units N leads to better approximation, the exponent −m/d suggests the presence of the curse of dimensionality. The following (nearly) matching lower bound is stated in Maiorov and Meir (2000).
Theorem 5.2 (Theorem 5 in Maiorov and Meir (2000)).
Let p ≥ 1, m ≥ 1 and N ≥ 2. If the activation function is the standard sigmoid function σ(t) = (1 + e−t)−1, then
| (5.2) |
where is independent of N.
Results for other activation functions are also obtained by Maiorov and Meir (2000). Moreover, the term log N can be removed if we assume an additional continuity condition (Mhaskar, 1996).
For the natural space of smooth functions, the exponential dependence on d in the upper and lower bounds may look unappealing. However, Barron (1993) showed that for a different function space, there is a good dimension-free approximation by the neural nets. Suppose that a function has a Fourier representation
| (5.3) |
where . Assume that f(0) = 0 and that the following quantity is finite
| (5.4) |
Barron (1993) uncovers the following dimension-free approximation guarantee.
Theorem 5.3 (Proposition 1 in Barron (1993)).
Fix a C > 0 and an arbitrary probability measure μ on the unit ball Bd in . For every function f with Cf ≤ C and every N ≥ 1, there exists some such that
Moreover, the coefficients of g may be restricted to satisfy
The upper bound is now independent of the dimension d. However, Cf may implicitly depend on d, as the formula in (5.4) involves an integration over (so for some functions Cf may depend exponentially on d). Nevertheless, this theorem does characterize an interesting function space with an improved upper bound. Details of the function space are discussed by Barron (1993). This theorem can be generalized; see Makovoz (1996) for an example.
To help understand why a dimensionality-free approximation holds, let us appeal to a heuristic argument given by Monte Carlo simulations. It is well-known that Monte Carlo approximation errors are independent of dimensionality in evaluation of high-dimensional integrals. Let us generate {ωj}1≤j≤N randomly from a given density p(·) in . Consider the approximation to (5.3) by
| (5.5) |
Then, gN(x) is a one-hidden-layer neural network with N units and the sinusoid activation function. Note that , where the expectation is taken with respect to randomness {ωj}. Now, by independence, we have
if . Therefore, the rate is independent of the dimensionality d, though the constant can be.
5.2. Approximation theory for multi-layer NNs
The approximation theory for multilayer neural nets is less understood compared with neural nets with one hidden layer. Driven by the success of deep learning, there are many recent papers focusing on expressivity of deep neural nets. As studied by Telgarsky (2016); Eldan and Shamir (2016); Mhaskar, Liao and Poggio (2016); Poggio et al. (2017); Bauer and Kohler (2017); Schmidt-Hieber (2017); Lin, Tegmark and Rolnick (2017); Rolnick and Tegmark (2017), deep neural nets excel at representing composition of functions. This is perhaps not surprising, since deep neural nets are themselves defined by composing layers of functions. Nevertheless, it points to a new territory rarely studied in statistics before. Below we present a result based on Lin, Tegmark and Rolnick (2017); Rolnick and Tegmark (2017).
Suppose that the inputs x have a bounded domain [−1, 1]d for simplicity. As before, let be a generic function, and σ* = (σ*, …, σ*)┬ be element-wise application σ*. Consider a neural net which is similar to (2.1) but with scaler output: . A unit or neuron refers to an element of vectors σ* (Wk ⋯ σ*(W2σ* (W1x))⋯) for any .For a multivariate polynomial p, define mk(p) to be the smallest integer such that, for any ϵ > 0, there exists a neural net g(x) satisfying supx |p(x) − g(x)| < ϵ, with k hidden layers (i.e., ) and no more than mk(p) neurons in total. Essentially, mk(p) is the minimum number of neurons required to approximate p arbitrarily well.
Theorem 5.4 (Theorem 4.1 in Rolnick and Tegmark (2017)).
Let p(x) be a monomial with . Suppose that σ* has derivatives of order 2q at the origin, and that they are nonzero. Then,
This theorem reveals a sharp distinction between shallow networks (one hidden layer) and deep networks. To represent a monomial function, a shallow network requires exponentially many neurons in terms of the dimension d, whereas linearly many neurons suffice for a deep network (with bounded rj). The exponential dependence on d, as shown in Theorem 5.4(i), is resonant with the curse of dimensionality widely seen in many fields; see Donoho (2000). One may ask: how does depth help? Depth circumvents this issue, at least for certain functions, by allowing us to represent function composition efficiently. Indeed, Theorem 5.4(ii) offers a nice result with clear intuitions: it is known that the product of two scalar inputs can be represented using 4 neurons (Lin, Tegmark and Rolnick, 2017), so by composing multiple products, we can express monomials with O(d) neurons.
Recent advances in nonparametric regressions also support the idea that deep neural nets excel at representing composition of functions (Bauer and Kohler, 2017; Schmidt-Hieber, 2017). In particular, Bauer and Kohler (2017) considered the nonparametric regression setting where we want to estimate a function from i.i.d. data . If the true regression function f(x) has certain hierarchical structure with intrinsic dimensionality6 d*, then the error
has an optimal minimax convergence rate , rather than the usual rate that depends on the ambient dimension d. Here q is the smoothness parameter. This provides another justification for deep neural nets: if data are truly hierarchical, then the quality of approximators by deep neural nets depends on the intrinsic dimensionality, which avoids the curse of dimensionality.
We point out that the approximation theory for deep learning is far from complete. For example, in Theorem 5.4, the condition on σ* excludes the widely used ReLU activation function, there are no constraints on the magnitude of the weights (so they can be unreasonably large).
6. TRAINING DEEP NEURAL NETS
The existence of a good function approximator in the NN function class does not explain why in practice we can easily find them. In this section, we introduce standard methods, namely stochastic gradient descent (SGD) and its variants, to train deep neural networks (or to find such a good approximator). As with many statistical machine learning tasks, training DNNs follows the empirical risk minimization (ERM) paradigm which solves the following optimization problem
| (6.1) |
Here measures the discrepancy between the prediction f(xi; θ) of the neural network and the true label yi. Correspondingly, denote by the out-of-sample error, where is the joint distribution over (y, x). Solving ERM (6.1) for deep neural nets faces various challenges that roughly fall into the following three categories.
Scalability and nonconvexity. Both the sample size n and the number of parameters p can be huge for modern deep learning applications, as we have seen in Table 1. Many optimization algorithms are not practical due to the computational costs and memory constraints. What is worse, the empirical loss function in deep learning is often nonconvex. It is a priori not clear whether an optimization algorithm can drive the empirical loss (6.1) small.
Numerical stability. With a large number of layers in DNNs, the magnitudes of the hidden nodes can be drastically different, which may result in the “exploding gradients” or “vanishing gradients” issue during the training process. This is because the recursive relations across layers often lead to exponentially increasing / decreasing values in both forward passes and backward passes.
Generalization performance. Our ultimate goal is to find a parameter such that the out-of-sample error is small. However, in the over-parametrized regime where p is much larger than n, the underlying neural network has the potential to fit the training data perfectly while performing poorly on the test data. To avoid this overfitting issue, proper regularization, whether explicit or implicit, is needed in the training process for the neural nets to generalize.
In the following three subsections, we discuss practical solutions / proposals to address these challenges.
6.1. Stochastic gradient descent
Stochastic gradient descent (SGD) (Robbins and Monro, 1951) is by far the most popular optimization algorithm to solve ERM (6.1) for large-scale problems. It has the following simple update rule:
| (6.2) |
for t = 0, 1, 2, …, where ηt > 0 is the step size (or learning rate), is an initial point and it is chosen randomly from {1, 2,… , n}. It is easy to verify that G(θt) is an unbiased estimate of . The advantage of SGD is clear: compared with gradient descent, which goes over the entire dataset in every update, SGD uses a single example in each update and hence is considerably more efficient in terms of both computation and memory (especially in the first few iterations).
Apart from practical benefits of SGD, how well does SGD perform theoretically in terms of minimizing ? We begin with the convex case, i.e., the case where the loss function is convex w.r.t. θ. It is well understood in literature that with proper choices of the step sizes {ηt}, SGD is guaranteed to achieve both consistency and asymptotic normality.
- Consistency. If is a strongly convex function7, then under some mild conditions8, learning rates that satisfy
guarantee almost sure convergence to the unique minimizer , i.e., as t → ∞ (Robbins and Monro, 1951; Kiefer et al., 1952; Bottou, 1998; Kushner and Yin, 2003). The requirements in (6.3) can be viewed from the perspective of bias-variance tradeoff: the first condition ensures that the iterates can reach the minimizer (controlled bias), and the second ensures that stochasticity does not prevent convergence (controlled variance).(6.3) Asymptotic normality. It is proved by Polyak and Tsypkin (1979) that for robust linear regression with fixed dimension p, under the choice ηt = t−1, is asymptotically normal under some regularity conditions (but θtis not asymptotically efficient in general). Moreover, by averaging the iterates of SGD, Polyak and Juditsky (1992) proved that even with a larger step size ηt = t−α, α ∈ (1/2, 1) the averaged iterate is asymptotic efficient for robust linear regression. These strong results show that SGD with averaging performs as well as the MLE asymptotically, in addition to its computational efficiency.
These classical results, however, fail to explain the effectiveness of SGD when dealing with nonconvex loss functions in deep learning. Admittedly, finding global minima of nonconvex functions is computationally infeasible in the worst case. Nevertheless, recent work (Allen-Zhu, Li and Song, 2018; Du et al., 2018) bypasses the worst case scenario by focusing on losses incurred by over-parametrized deep learning models. In particular, they show that (stochastic) gradient descent converges linearly towards the global minimizer of as long as the neural network is sufficiently over-parametrized. This phenomenon is formalized below.
Theorem 6.1 (Theorem 2 in Allen-Zhu, Li and Song, 2018).
Let {(yi, xi)}1≤i≤n be a training set satisfying mini,j:i≠j ‖xi − xj‖2 ≥ δ > 0. Consider fitting the data using a feed-forward neural network (1.1) with ReLU activations. Denote by L (resp. W) the depth (resp. width) of the network. Suppose that the neural network is sufficiently over-parametrized, i.e.,
| (6.4) |
where poly means a polynomial function. Then with high probability, running SGD (6.2) with certain random initialization and properly chosen step sizes yields in iterations.
Two notable features are worth mentioning: (1) first, the network under consideration is sufficiently over-parametrized (cf. (6.4)) in which the number of parameters is much larger than the number of samples, and (2) one needs to initialize the weight matrices to be in near-isometry such that the magnitudes of the hidden nodes do not blow up or vanish. In a nutshell, over-parametrization and random initialization together ensure that the loss function (6.1) has a benign landscape9 around the initial point, which in turn implies fast convergence of SGD iterates.
There are certainly other challenges for vanilla SGD to train deep neural nets: (1) training algorithms are often implemented in GPUs, and therefore it is important to tailor the algorithm to the infrastructure, (2) the vanilla SGD might converge very slowly for deep neural networks, albeit good theoretical guarantees for well-behaved problems, and (3) the learning rates {ηt} can be difficult to tune in practice. To address the aforementioned challenges, three important variants of SGD, namely mini-batch SGD, momentum-based SGD, and SGD with adaptive learning rates are introduced.
6.1.1. Mini-batch SGD.
Modern computational infrastructures (e.g., GPUs) can evaluate the gradient on a number (say 64) of examples as efficiently as evaluating that on a single example. To utilize this advantage, mini-batch SGD with batch size K ≥ 1 forms the stochastic gradient through K random samples:
| (6.5) |
where for each 1 ≤ k ≤ K, is sampled uniformly from {1. 2, …, n}. Mini-batch SGD, which is an “interpolation” between gradient descent and stochastic gradient descent, achieves the best of both worlds: (1) using 1 ≪ K ≪ n samples to estimate the gradient, one effectively reduces the variance and hence accelerates the convergence, and (2) by taking the batch size K appropriately (say 64 or 128), the stochastic gradient G(θt) can be efficiently computed using the matrix computation toolboxes on GPUs.
6.1.2. Momentum-based SGD.
While mini-batch SGD forms the foundation of training neural networks, it can sometimes be slow to converge due to its oscillation behavior (Sutskever et al., 2013). Optimization community has long investigated how to accelerate the convergence of gradient descent, which results in a beautiful technique called momentum methods (Polyak, 1964; Nesterov, 1983). Similar to gradient descent with moment, momentum-based SGD, instead of moving the iterate θt in the direction of the current stochastic gradient G(θt), smooth the past (stochastic) gradients {G(θt)} to stabilize the update directions. Mathematically, let be the direction of update in the tth iteration, i.e.,
Here v0 = G(θ0) and for t = 1, 2, ⋯
| (6.6) |
with 0 < ρ < 1. A typical choice of ρ is 0.9. Notice that ρ = 0 recovers the mini-batch SGD (6.5), where no past information of gradients is used. A simple unrolling of vt reveals that vt is actually an exponential averaging of the past gradients, i.e., . Compared with vanilla mini-batch SGD, the inclusion of the momentum “smoothes” the oscillation direction and accumulates the persistent descent direction. We want to emphasize that theoretical justifications of momentum in the stochastic setting is not fully understood (Kidambi et al., 2018; Jain et al., 2017).
6.1.3. SGD with adaptive learning rates.
In optimization, preconditioning is often used to accelerate first-order optimization algorithms. In principle, one can apply this to SGD, which yields the following update rule:
| (6.7) |
with being a preconditioner at the t-th step. Newton’s method can be viewed as one type of preconditioning where . The advantages of preconditioning are two-fold: first, a good preconditioner reduces the condition number by changing the local geometry to be more homogeneous, which is amenable to fast convergence; second, a good preconditioner frees practitioners from laboring tuning of the step sizes, as is the case with Newton’s method. Ada-Grad, an adaptive gradient method proposed by Duchi, Hazan and Singer (2011), builds a preconditioner Pt based on information of the past gradients:
| (6.8) |
Since we only require the diagonal part, this preconditioner (and its inverse) can be efficiently computed in practice. In addition, investigating (6.7) and (6.8), one can see that AdaGrad adapts to the importance of each coordinate of the parameters by setting smaller learning rates for frequent features, whereas larger learning rates for those infrequent ones. In practice, one adds a small quantity δ > 0 (say 10−8) to the diagonal entries to avoid singularity (numerical underflow). A notable drawback of AdaGrad is that the effective learning rate vanishes quickly along the learning process. This is because the historical sum of the gradients can only increase with time. RMSProp (Hinton, Srivastava and Swersky, 2012) is a popular remedy for this problem which incorporates the idea of exponential averaging:
| (6.9) |
Again, the decaying parameter ρ is usually set to be 0.9. Later, Adam (Kingma and Ba, 2014; Reddi, Kale and Kumar, 2018) combines the momentum method and adaptive learning rate and becomes the default training algorithms in many deep learning applications.
6.2. Easing numerical instability
For very deep neural networks or RNNs with long dependencies, training difficulties often arise when the values of nodes have different magnitudes or when the gradients “vanish” or “explode” during back-propagation. Here we discuss three partial solutions to alleviate this problem.
6.2.1. ReLU activation function.
One useful characteristic of the ReLU function is that its derivative is either 0 or 1, and the derivative remains 1 even for a large input. This is in sharp contrast with the standard sigmoid function (1 + e−t)−1 which results in a very small derivative when inputs have large magnitude. The consequence of small derivatives across many layers is that gradients tend to be “killed”, which means that gradients become approximately zero in deep nets.
The popularity of the ReLU activation function and its variants (e.g., leaky ReLU) is largely attributable to the above reason. It has been well observed that the ReLU activation function has superior training performance over the sigmoid function (Krizhevsky, Sutskever and Hinton, 2012; Maas, Hannun and Ng, 2013).
6.2.2. Skip connections.
We have introduced skip connections in Section 3.3. Why are skip connections helpful for reducing numerical instability? This structure does not introduce a larger function space, since the identity map can be also represented with ReLU activations: x = σ(x) − σ(−x).
One explanation is that skip connections bring ease to the training / optimization process. Suppose that we have a general nonlinear function . With a skip connection, we represent the map as instead. Now the gradient becomes
| (6.10) |
where I is an identity matrix. By the chain rule, gradient update requires computing products of many components, e.g., , so it is desirable to keep the spectra (singular values) of each component close to 1. In neural nets, with skip connections, this is easily achieved if the parameters have small values; otherwise, this may not be achievable even with careful initialization and tuning. Notably, training neural nets with hundreds of layers is possible with the help of skip connections.
6.2.3. Batch normalization.
Recall that in regression analysis, one often standardizes the design matrix so that the features have zero mean and unit variance. Batch normalization extends this standardization procedure from the input layer to all the hidden layers. Mathematically, fix a mini-batch of input data , where . Let be the feature of the i-th example in the -th layer ( corresponds to the input xi). The batch normalization layer computes the normalized version of via the following steps:
Here all the operations are element-wise. In words, batch normalization computes the z-score for each feature over the mini-batch and use that as inputs to subsequent layers. To make it more versatile, a typical batch normalization layer has two additional learnable parameters and such that
Again ⊙ denotes the element-wise multiplication. As can be seen, and set the new feature to have mean and standard deviation . The introduction of batch normalization makes the training of neural networks much easier and smoother. More importantly, it allows the neural nets to perform well over a large family of hyper-parameters including the number of layers, the number of hidden units, etc. At test time, the batch normalization layer needs more care. For brevity we omit the details and refer to Ioffe and Szegedy (2015).
6.3. Regularization techniques
So far we have focused on training techniques to drive the empirical loss (6.1) small efficiently. Here we proceed to discuss common practice to improve the generalization power of trained neural nets.
6.3.1. Weight decay.
One natural regularization idea is to add an penalty to the loss function. This regularization technique is known as the weight decay in deep learning. We have seen one example in (2.7). For general deep neural nets, the loss to optimize is where
Note that the bias (intercept) terms are not penalized. If is a least square loss, then regularization with weight decay gives precisely ridge regression. The penalty rλ(θ) is a smooth function and thus it can be also implemented efficiently with back-propagation.
6.3.2. Dropout.
Dropout, introduced by Hinton et al. (2012), prevents overfitting by randomly dropping out subsets of features during training. Take the l-th layer of the feed-forward neural network as an example. Instead of propagating all the features in for later computations, dropout randomly omits some of its entries by
where ⊙ denotes element-wise multiplication as before, and is a vector of Bernoulli variables with success probability p. It is sometimes useful to rescale the features , which is called inverted dropout. During training, are i.i.d. vectors across mini-batches and layers. However, when testing on fresh samples, dropout is disabled and the original features are used to compute the output label y. It has been nicely shown by Wager, Wang and Liang (2013) that for generalized linear models, dropout serves as adaptive regularization. In the simplest case of linear regression, it is equivalent to regularization. Another possible way to understand the regularization effect of dropout is through the lens of bagging (Goodfellow, Bengio and Courville, 2016). Since different mini-batches has different masks, dropout can be viewed as training a large ensemble of classifiers at the same time, with a further constraint that the parameters are shared. Theoretical justification remains elusive.
6.3.3. Data augmentation.
Data augmentation is a technique of enlarging the dataset when we have knowledge about invariance structure of data. It implicitly increases the sample size and usually regularizes the model effectively. For example, in image classification, we have strong prior knowledge about what invariance properties a good classifier should possess. The label of an image should not be affected by translation, rotation, flipping, and even crops of the image. Hence one can augment the dataset by randomly translating, rotating and cropping the images in the original dataset.
Formally, during training we want to minimize the loss w.r.t. parameters θ, and we know a priori that certain transformation where (e.g., affine transformation) should not change the category / label of a training sample. In principle, if computation costs were not a consideration, we could convert this knowledge to a constraint fθ(Txi) = fθ(xi), in the minimization formulation. Instead of solving a constrained optimization problem, data augmentation enlarges the training dataset by sampling and generating new data {(T xi, yi)}. In this sense, data augmentation induces invariance properties through sampling, which results in a much bigger dataset than the original one.
7. GENERALIZATION POWER
Section 6 has focused on the in-sample / training error obtained via SGD, but this alone does not guarantee good performance with respect to the out-of-sample / test error. The gap between the in-sample error and the out-of-sample error, namely the generalization gap, has been the focus of statistical learning theory since its birth; see Shalev-Shwartz and Ben-David (2014) for an excellent introduction to this topic.
While understanding the generalization power of deep neural nets is difficult (Zhang et al., 2016), we sample recent endeavors in this section. From a high level point of view, these approaches can be divided into two categories, namely algorithm-independent controls and algorithm-dependent controls. More specifically, algorithm-independent controls focus solely on bounding the complexity of the function class represented by certain deep neural networks. In contrast, algorithm-dependent controls take into account the algorithm (e.g., SGD) used to train the neural network.
7.1. Algorithm-independent controls: uniform convergence
The key to algorithm-independent controls is the notion of complexity of the function class parametrized by certain neural networks. Informally, as long as the complexity is not too large, the generalization gap of any function in the function class is well-controlled. However, the standard complexity measure (e.g., VC dimension (Vapnik and Chervonenkis, 1971)) is at least proportional to the number of weights in a neural network (Anthony and Bartlett, 2009; Shalev-Shwartz and Ben-David, 2014), which fails to explain the practical success of deep learning. The caveat here is that the function class under consideration is all the functions realized by certain neural networks, with no restrictions on the size of the weights at all. On the other hand, for the class of linear functions with bounded norm, i.e., , it is well understood that the complexity of this function class (measured in terms of the empirical Rademacher complexity) with respect to a random sample {xi}1≤i≤n upper is bounded by , which is independent of the number of parameters in w. This motivates researchers to investigate the complexity of norm-controlled deep neural networks10 (Neyshabur, Tomioka and Srebro, 2015; Bartlett, Foster and Telgarsky, 2017; Golowich, Rakhlin and Shamir, 2017; Li et al., 2018b). Setting the stage, we introduce a few necessary notations and facts. The key object under study is the function class parametrized by the following fully-connected neural network with depth L:
| (7.1) |
Here represents a certain constraint For instance, one can restrict the Frobenius norm of each parameter Wl through the constraint ‖Wl‖F ≤ MF(l), where MF(l) is some positive quantity. With regard to the complexity measure, it is standard to use Rademacher complexity to control the capacity of the function class of interest.
Definition 7.1 (Empirical Rademacher complexity).
The empirical Rademacher complexity of a function class w.r.t. a dataset S ≜ {xi}1≤i≤n is defined as
| (7.2) |
where ε ≜ (ε1, ε2, ⋯ , εn) is composed of i.i.d. Rademacher random variables, i.e., .
In words, Rademacher complexity measures the ability of the function class to fit the random noise represented by ε. Intuitively, a function class with a larger Rademacher complexity is more prone to overfitting. We now formalize the connection between the empirical Rademacher complexity and the out-of-sample error; see Chapter 24 in Shalev-Shwartz and Ben-David (2014).
Theorem 7.1.
Assume that for all and all (y, x) we have . In addition, assume that for any fixed y, the univariate function is Lipschitz with constant 1. Then with probability at least 1 − δ over the sample
In English, the generalization gap of any function f that lies in is well-controlled as long as the Rademacher complexity of is not too large. With this connection in place, we single out the following complexity bound.
Theorem 7.2 (Theorem 1 in Golowich, Rakhlin and Shamir, 2017).
Consider the function class in (7.1), where each parameter Wl has Frobenius norm at most MF(l). Further suppose that the element-wise activation function σ(·) is 1-Lipschitz and positive-homogeneous (i.e., σ(c · x) = cσ(x) for all c ≥ 0). Then the empirical Rademacher complexity (7.2) w.r.t. S ≜ {xi}1≤i≤n satisfies
| (7.3) |
The upper bound of the empirical Rademacher complexity (7.3) is in a similar vein that of linear functions with bounded norm, i.e., , where plays the role of M in the latter case. Moreover, ignoring the term , the upper bound (7.3) does not depend on the size of the network in an explicit way if MF (l) sharply concentrates around 1. This reveals that the capacity of the neural network is well-controlled, regardless of the number of parameters, as long as the Frobenius norm of the parameters is bounded. Extensions to other norm constraints, e.g., spectral norm constraints, path norm constraints have been considered by Neyshabur, Tomioka and Srebro (2015); Bartlett, Foster and Telgarsky (2017); Li et al. (2018b); Klusowski and Barron (2016); E, Ma and Wang (2019). This line of work improves upon traditional capacity analysis of neural networks in the over-parametrized setting, because the upper bounds derived are often size-independent. Having said this, two important remarks are in order: (1) the upper bounds (e.g., ) involve implicit dependence on the size of the weight matrix and the depth of the neural network, which is hard to characterize; (2) the upper bound on the Rademacher complexity offers a uniform bound over all functions in the function class, which is a pure statistical result. However, it stays silent about how and why standard training algorithms like SGD can obtain a function whose parameters have small norms.
7.2. Algorithm-dependent controls
In this subsection, we bring computational thinking into statistics and investigate the role of algorithms in the generalization power of deep learning. The consideration of algorithms is quite natural and well motivated: (1) local/global minima reached by different algorithms can exhibit totally different generalization behaviors due to extreme nonconvexity, which marks a huge difference from traditional models, (2) the effective capacity of neural nets is possibly not large, since a particular algorithm does not explore the entire parameter space.
These demonstrate the fact that on top of the complexity of the function class, the inherent property of the algorithm we use plays an important role in the generalization ability of deep learning. In what follows, we survey three different ways to obtain upper bounds on the generalization errors by exploiting properties of the algorithms.
7.2.1. Mean field view of neural nets.
As we have emphasized, modern deep learning models are highly over-parametrized. A line of work (Mei, Montanari and Nguyen, 2018; Sirignano and Spiliopoulos, 2018; Rotskoff and Vanden-Eijnden, 2018; Chizat and Bach, 2018; Mei, Misiakiewicz and Montanari, 2019; Javanmard, Mondelli and Montanari, 2019) approximates the ensemble of weights by an asymptotic limit as the number of hidden units tends to infinity, so that the dynamics of SGD can be studied via certain partial differential equations.
More specifically, let be a function given by a one-hidden-layer neural net with N hidden units, where σ(·) is the ReLU activation function and parameters are suitably randomly initialized. Consider the regression setting where we want to minimize the population risk over parameters θ. A key observation is that this population risk depends on the parameters θ only through its empirical distribution, i.e., where is a point mass at θi. This motivates us to view express RN(θ) equivalently as , where R(·) is a functional that maps distributions to real numbers. Running SGD for RN(·)—in a suitable scaling limit—results in a gradient flow on the space of distributions endowed with the Wasserstein metric that minimizes R(·). It turns out that the empirical distribution of the parameters after k steps of SGD is well approximated by the gradient follow, as long as the the neural net is over-parametrized (i.e., N ≫ d) and the number of steps is not too large. In particular, Mei, Montanari and Nguyen (2018) have shown that under certain regularity conditions,
where ε > 0 is an proxy for the step size of SGD and ρkε is the distribution of the gradient flow at time kε. In words, the out-of-sample error under θk generated by SGD is well-approximated by that of ρkε. Viewing the optimization problem from the distributional aspect greatly simplifies the problem conceptually, as the complicated optimization problem is now passed into its limit version—for this reason, this analytical approach is called the mean field perspective. In particular, Mei, Montanari and Nguyen (2018) further demonstrated that in some simple settings, the out-of-sample error R(ρkε) of the distributional limit can be fully characterized. Nevertheless, how well does R(ρkε) perform and how fast it converges remain largely open for general problems.
7.2.2. Stability.
A second way to understand the generalization ability of deep learning is through the stability of SGD. An algorithm is considered stable if a slight change of the input does not alter the output much. It has long been observed that a stable algorithm has a small generalization gap; examples include k nearest neighbors (Rogers and Wagner, 1978; Devroye and Wagner, 1979), bagging (Breiman, 1996; Breiman et al., 1996), etc. The precise connection between stability and generalization gap is stated by Bousquet and Elisseeff (2002); Shalev-Shwartz et al. (2010). In what follows, we formalize the idea of stability and its connection with the generalization gap. Let denote an algorithm (possibly ran domized) which takes a sample S ≜ {(yi, xi)}1≤i ≤n of size n and returns an estimated parameter . Following Hardt, Recht and Singer (2015), we have the following definition for stability.
Definition 7.2.
An algorithm (possibly randomized) is ε-uniformly stable with respect to the loss function if for all datasets S, S′ of size n which differ in at most one example, one has
Here the Here the expectation is taken w.r.t. the randomness in the algorithm and ε might depend on n. The loss function takes an example (say (x, y)) and the estimated parameter (say ) as inputs and outputs a real value.
Surprisingly, an ε-uniformly stable algorithm incurs small generalization gap in expectation, which is stated in the following lemma.
Lemma 7.1 (Theorem 2.2 in Hardt, Recht and Singer, 2015).
Let be ε-uniformly stable. Then the expected generalization gap is no larger than ε, i.e.,
| (7.4) |
With Lemma 7.1 in hand, it suffices to prove stability bound on specific algorithms. It turns out that SGD introduced in Section 6 is uniformly stable when solving smooth nonconvex functions.
Theorem 7.3 (Theorem 3.12 in Hardt, Recht and Singer (2015)).
Assume that for any fixed (y, x), the loss function , viewed as a function of θ, is L-Lipschitz and β-smooth. Consider running SGD on the empirical loss function with decaying step size αt ≤ c/t, where c is some small absolute constant. Then SGD is uniformly stable with
where we have ignored the dependency on β, c and L.
Theorem 7.3 reveals that SGD operating on nonconvex loss functions is indeed uniformly stable as long as the number of steps T is not large compared with n. This together with Lemma 7.1 demonstrates the generalization ability of SGD in expectation. Nevertheless, two important limitations are worth mentioning. First, Lemma 7.1 provides an upper bound on the out-of-sample error in expectation, but ideally, instead of an on-average guarantee under , we would like to have a high probability guarantee as in the convex case (Feldman and Vondrak, 2019). Second, controlling the generalization gap alone is not enough to achieve a small out-of-sample error, since it is unclear whether SGD can achieve a small training error within T steps.
7.2.3. Implicit regularization
In the presence of over-parametrization (number of parameters larger than the sample size), conventional wisdom informs us that we should apply some regularization techniques (e.g., regularization) so that the model will not overfit the data. However, in practice, neural networks without explicit regularization generalize well. This phenomenon motivates researchers to look at the regularization effects introduced by training algorithms (e.g., SGD) in this over-parametrized regime. While there might exits multiple, if not infinite global minima of the empirical loss (6.1), it is possible that practical algorithms tend to converge to solutions with better generalization powers.
Take the underdetermined linear system Xθ = y as a starting point. Here and with p much larger than n. Running gradient descent on the loss from the origin (i.e., θ0 = 0) results in the solution with the minimum Euclidean norm, that is GD converges to
In words, without any regularization in the loss function, gradient descent automatically finds the solution with the least norm. This phenomenon, often called as implicit regularization, not only has been empirically observed in training neural networks, but also has been theoretically understood in some simplified cases, e.g., logistic regression with separable data. In logistic regression, given a training set {(yi, xi)}1≤i≤n with and yi ∈ {1, −1}, one aims to fit a logistic regression model by solving the following program:
| (7.5) |
Here, denotes the logistic loss. Further assume that the data is separable, i.e., there exists such that yiθ*┬xi > 0 for all i. Under this condition, the loss function (7.5) can be arbitrarily close to zero for certain θ with ‖θ‖2 → ∞. What happens when we minimize (7.5) using gradient descent? Soudry et al. (2018) uncovers a striking phenomenon.
Theorem 7.4 (Theorem 3 in Soudry et al., 2018).
Consider the logistic regression (7.5) with separable data. If we run GD
from any initialization θ0 with appropriate step size η > 0, then normalized θt converges to a solution with the maximum margin. That is,
| (7.6) |
where is the solution to the hard margin support vector machine:
| (7.7) |
The above theorem reveals that gradient descent, when solving logistic regression with separable data, implicitly regularizes the iterates towards the max margin vector (cf. (7.6)), without any explicit regularization as in (7.7). Similar results have been obtained by Ji and Telgarsky (2018). In addition, Gunasekar et al. (2018a) studied algorithms other than gradient descent and showed that coordinate descent produces a solution with the maximum margin.
Moving beyond logistic regression, which can be viewed as a one-layer neural net, the theoretical understanding of implicit regularization in deeper neural networks is still limited; see Gunasekar et al. (2018b) for an illustration in deep linear convolutional neural networks.
8. DISCUSSION
Due to space limitations, we have omitted several important deep learning models; notable examples include deep reinforcement learning (Mnih et al., 2015), deep probabilistic graphical models (Salakhutdinov and Hinton, 2009), variational autoencoders (Kingma and Welling, 2013), transfer learning (Yosinski et al., 2014), etc. Apart from the modeling aspect, interesting theories on generative adversarial networks (Arora et al., 2017; Bai, Ma and Risteski, 2018), recurrent neural networks (Allen-Zhu and Li, 2019), connections with kernel methods (Jacot, Gabriel and Hongler, 2018; Arora et al., 2019) are also emerging. We have also omitted the inverse-problem view of deep learning where the data are assumed to be generated from a certain neural net and the goal is to recover the weights in the NN with as few examples as possible. Various algorithms (e.g., GD with spectral initialization) have been shown to recover the weights successfully in some simplified settings (Zhong et al., 2017; Soltanolkotabi, 2017; Goel, Klivans and Meka, 2018; Mondelli and Montanari, 2018; Chen et al., 2019a; Fu, Chi and Liang, 2018).
In the end, we identify a few important directions for future research.
New characterization of data distributions. The success of deep learning re-lies on its power of efficiently representing complex functions relevant to real data. Comparatively, classical methods often have optimal guarantee if a problem has a certain known structure, such as smoothness, sparsity, and low-rankness (Stone, 1982; Donoho and Johnstone, 1994; Candès and Tao, 2009; Chen et al., 2019b), but they are insufficient for complex data such as images. How to characterize the high-dimensional real data that can free us from known barriers, such as the curse of dimensionality is an interesting open question?
Understanding various computational algorithms for deep learning. As we have emphasized throughout this survey, computational algorithms (e.g., variants of SGD) play a vital role in the success of deep learning. They allow fast training of deep neural nets and probably contribute towards the good generalization behavior of deep learning in practice. Understanding these computational algorithms and devising better ones are crucial components in understanding deep learning.
Robustness. It has been well documented that DNNs are sensitive to small adversarial perturbations that are indistinguishable to humans (Szegedy et al., 2013). This raises serious safety issues once deep learning models are deployed in applications such as self-driving cars, healthcare, etc. It is therefore crucial to refine current training practice to enhance robustness in a principled way (Singh, Murdoch and Yu, 2018).
Low SNRs. Arguably, for image data and audio data where the signal-to-noise ratio (SNR) is high, deep learning has achieved great success. In many other statistical problems, the SNR may be very low. For example, in financial applications, the firm characteristic and covariates may only explain a small part of the financial returns; in healthcare systems, the uncertainty of an illness may not be predicted well from a patient’s medical history. How to adapt deep learning models to excel at such tasks is an interesting direction to pursue?
ACKNOWLEDGEMENTS
Cong Ma thanks Ruying Bao, Yuxin Chen, Chenxi Liu, Qingcan Wang and Pengkun Yang for helpful comments and discussions.
J. Fan is supported in part by the NSF grants DMS-1712591 and DMS-1662139, the NIH grant R01-GM072611 and the ONR grant N00014-19-1-2120.
Footnotes
When the label y is given, this problem is often known as supervised learning. We mainly focus on this paradigm throughout this paper and remark sparingly on its counterpart, unsupervised learning, where y is not given.
The algorithm makes an error if the true label is not contained in the 5 predictions made by the algorithm.
The issue of non-differentiability at the origin is often ignored in implementation.
To simplify notation, we omit the bias/intercept term associated with each filter.
Similar to the activation function (·), the function tanh(·) means element-wise operations.
Roughly speaking, the true regression function can be represented by a tree where each node has at most d* children. See Bauer and Kohler (2017) for the precise definition.
For results on consistency and asymptotic normality, we consider the case where in each step of SGD, the stochastic gradient is computed using a fresh sample (y, x) from . This allows to view SGD as an optimization algorithm to minimize the population loss .
One example of such condition can be constraining the second moment of the gradients: .for some C1, C2 > 0. See Bottou (1998) for details.
In Allen-Zhu, Li and Song (2018), the loss function satisfies the PL condition.
Such attempts have been made in the seminal work Bartlett (1998).
REFERENCES
- Abadi M and et al. (2015). TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. Software available from tensorflow.org.
- Abbasi-Asl R, Chen Y, Bloniarz A, Oliver M, Willmore BD, Gallant JL and Yu B (2018). The DeepTune framework for modeling and characterizing neurons in visual cortex area V4. bioRxiv 465534. [Google Scholar]
- Allen-Zhu Z, Li Y and Song Z (2018). A convergence theory for deep learning via over-parameterization. arXiv preprint arXiv:1811.03962 [Google Scholar]
- Allen-Zhu Z and Li Y (2019). Can SGD Learn Recurrent Neural Networks with Provable Generalization? ArXiv e-prints abs/1902.01028. [Google Scholar]
- Anthony M and Bartlett PL (2009). Neural network learning: Theoretical foundations. cambridge university press. [Google Scholar]
- Arjovsky M, Chintala S and Bottou L (2017). Wasserstein Generative Adversarial Networks. 70 214–223. [Google Scholar]
- Arnold VI (2009). On functions of three variables. Collected Works: Representations of Functions, Celestial Mechanics and KAM Theory, 1957–1965 5–8. [Google Scholar]
- Arora S and Barak B (2009). Computational complexity: a modern approach. Cambridge University Press. [Google Scholar]
- Arora S, Ge R, Liang Y, Ma T and Zhang Y (2017). Generalization and equilibrium in generative adversarial nets (gans). In Proceedings of the 34th International Conference on Machine Learning-Volume 70 224–232. JMLR. org. [Google Scholar]
- Arora S, Du SS, Hu W, Li Z and Wang R (2019). Fine-Grained Analysis of Optimization and Generalization for Overparameterized Two-Layer Neural Networks. arXiv preprint arXiv:1901.08584 [Google Scholar]
- Bai Y, Ma T and Risteski A (2018). Approximability of discriminators implies diversity in GANs. arXiv preprint arXiv:1806.10586 [Google Scholar]
- Barron AR (1993). Universal approximation bounds for superpositions of a sigmoidal function. IEEE Transactions on Information theory 39 930–945. [Google Scholar]
- Bartlett PL (1998). The sample complexity of pattern classification with neural networks: the size of the weights is more important than the size of the network. IEEE transactions on Information Theory 44 525–536. [Google Scholar]
- Bartlett PL, Foster DJ and Telgarsky MJ (2017). Spectrally-normalized margin bounds for neural networks. In Advances in Neural Information Processing Systems 30 (Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S and Garnett R, eds.) 6240–6249. Curran Associates, Inc. [Google Scholar]
- Bauer B and Kohler M (2017). On Deep Learning as a remedy for the curse of dimensionality in nonparametric regression Technical Report, Technical report.
- Bottou L (1998). Online learning and stochastic approximations. On-line learning in neural networks 17 142. [Google Scholar]
- Bousquet O and Elisseeff A (2002). Stability and generalization. Journal of machine learning research 2 499–526. [Google Scholar]
- Breiman L (1996). Bagging predictors. Machine learning 24 123–140. [Google Scholar]
- Breiman L et al. (1996). Heuristics of instability and stabilization in model selection. The annals of statistics 24 2350–2383. [Google Scholar]
- Candès EJ and Tao T (2009). The power of convex relaxation: Near-optimal matrix completion. arXiv preprint arXiv:0903.1476 [Google Scholar]
- Cao C, Liu F, Tan H, Song D, Shu W, Li W, Zhou Y, Bo X and Xie Z (2018). Deep learning and its applications in biomedicine. Genomics, proteomics & bioinformatics 16 17–32. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen TQ, Rubanova Y, Bettencourt J and Duvenaud D (2018). Neural Ordinary Differential Equations. arXiv preprint arXiv:1806.07366 [Google Scholar]
- Chen Y, Chi Y, Fan J and Ma C (2019a). Gradient descent with random initialization: Fast global convergence for nonconvex phase retrieval. Mathematical Programming 1–33. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen Y, Chi Y, Fan J, Ma C and Yan Y (2019b). Noisy Matrix Completion: Understanding Statistical Guarantees for Convex Relaxation via Nonconvex Optimization. arXiv preprint arXiv:1902.07698 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chizat L and Bach F (2018). On the global convergence of gradient descent for over-parameterized models using optimal transport. In Advances in neural information processing systems 3040–3050. [Google Scholar]
- Cho K, Van Merriënboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H and Bengio Y (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078 [Google Scholar]
- Cook RD et al. (2007). Fisher lecture: Dimension reduction in regression. Statistical Science 22 1–26. [Google Scholar]
- De Fauw J, Ledsam JR, Romera-Paredes B, Nikolov S, Tomasev N, Blackwell S, Askham H, Glorot X, O’Donoghue B, Visentin D et al. (2018). Clinically applicable deep learning for diagnosis and referral in retinal disease. Nature medicine 24 1342. [DOI] [PubMed] [Google Scholar]
- Devroye L and Wagner T (1979). Distribution-free performance bounds for potential function rules. IEEE Transactions on Information Theory 25 601–604. [Google Scholar]
- Donoho DL (2000). High-dimensional data analysis: The curses and blessings of dimensionality. AMS math challenges lecture 1 32. [Google Scholar]
- Donoho DL and Johnstone JM (1994). Ideal spatial adaptation by wavelet shrinkage. biometrika 81 425–455. [Google Scholar]
- Du SS, Lee JD, Li H, Wang L and Zhai X (2018). Gradient descent finds global minima of deep neural networks. arXiv preprint arXiv:1811.03804 [Google Scholar]
- Duchi J, Hazan E and Singer Y (2011). Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research 12 2121–2159. [Google Scholar]
- E W, Ma C and Wang Q (2019). A Priori Estimates of the Population Risk for Residual Networks. arXiv preprint arXiv:1903.02154 [Google Scholar]
- Eldan R and Shamir O (2016). The power of depth for feedforward neural networks. In Conference on Learning Theory 907–940. [Google Scholar]
- Fan J and Li R (2001). Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of the American statistical Association 96 1348–1360. [Google Scholar]
- Feldman V and Vondrak J (2019). High probability generalization bounds for uniformly stable algorithms with nearly optimal rate. arXiv preprint arXiv:1902.10710 [Google Scholar]
- Friedman JH and Stuetzle W (1981). Projection pursuit regression. Journal of the American statistical Association 76 817–823. [Google Scholar]
- Fu H, Chi Y and Liang Y (2018). Local geometry of one-hidden-layer neural networks for logistic regression. arXiv preprint arXiv:1802.06463 [Google Scholar]
- Fukushima K and Miyake S (1982). Neocognitron: A self-organizing neural network model for a mechanism of visual pattern recognition. In Competition and cooperation in neural nets 267–285. Springer. [Google Scholar]
- Gao C, Liu J, Yao Y and Zhu W (2018). Robust Estimation and Generative Adversarial Nets. arXiv preprint arXiv:1810.02030 [Google Scholar]
- Goel S, Klivans A and Meka R (2018). Learning one convolutional layer with overlapping patches. arXiv preprint arXiv:1802.02547 [Google Scholar]
- Golowich N, Rakhlin A and Shamir O (2017). Size-independent sample complexity of neural networks. arXiv preprint arXiv:1712.06541 [Google Scholar]
- Golub GH and Van Loan CF (2013). Matrix computations, 4 ed. JHU Press. [Google Scholar]
- Goodfellow I, Bengio Y and Courville A (2016). Deep Learning. MIT Press. [Google Scholar]
- Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A and Bengio Y (2014). Generative adversarial nets. In Advances in neural information processing systems 2672–2680. [Google Scholar]
- Gunasekar S, Lee J, Soudry D and Srebro N (2018a). Characterizing implicit bias in terms of optimization geometry. arXiv preprint arXiv:1802.08246 [Google Scholar]
- Gunasekar S, Lee JD, Soudry D and Srebro N (2018b). Implicit bias of gradient descent on linear convolutional networks. In Advances in Neural Information Processing Systems 9482–9491. [Google Scholar]
- Hardt M, Recht B and Singer Y (2015). Train faster, generalize better: Stability of stochastic gradient descent. arXiv preprint arXiv:1509.01240 [Google Scholar]
- He K, Zhang X, Ren S and Sun J (2016a). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition 770–778. [Google Scholar]
- He K, Zhang X, Ren S and Sun J (2016b). Identity mappings in deep residual networks. In European conference on computer vision 630–645. Springer. [Google Scholar]
- Hinton G, Srivastava N and Swersky K (2012). Neural networks for machine learning lecture 6a overview of mini-batch gradient descent.
- Hinton GE, Srivastava N, Krizhevsky A, Sutskever I and Salakhutdinov RR (2012). Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580 [Google Scholar]
- Hochreiter S and Schmidhuber J (1997). Long short-term memory. Neural computation 9 1735–1780. [DOI] [PubMed] [Google Scholar]
- Huang G, Liu Z, Van Der Maaten L and Weinberger KQ (2017). Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition 4700–4708. [Google Scholar]
- Hubel DH and Wiesel TN (1962). Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. The Journal of physiology 160 106–154. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Iandola FN, Han S, Moskewicz MW, Ashraf K, Dally WJ and Keutzer K (2016). SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. arXiv preprint arXiv:1602.07360 [Google Scholar]
- Ioffe S and Szegedy C (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167 [Google Scholar]
- Jacot A, Gabriel F and Hongler C (2018). Neural tangent kernel: Convergence and generalization in neural networks. In Advances in neural information processing systems 8580–8589. [Google Scholar]
- Jain P, Kakade SM, Kidambi R, Netrapalli P and Sidford A (2017). Accelerating stochastic gradient descent. arXiv preprint arXiv:1704.08227 [Google Scholar]
- Javanmard A, Mondelli M and Montanari A (2019). Analysis of a Two-Layer Neural Network via Displacement Convexity. arXiv preprint arXiv:1901.01375 [Google Scholar]
- Ji Z and Telgarsky M (2018). Risk and parameter convergence of logistic regression. arXiv preprint arXiv:1803.07300 [Google Scholar]
- Kidambi R, Netrapalli P, Jain P and Kakade S (2018). On the insůciency of existing momentum schemes for stochastic optimization. In 2018 Information Theory and Applications Workshop (ITA) 1–9. IEEE. [Google Scholar]
- Kiefer J, Wolfowitz J et al. (1952). Stochastic estimation of the maximum of a regression function. The Annals of Mathematical Statistics 23 462–466. [Google Scholar]
- Kingma DP and Ba J (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 [Google Scholar]
- Kingma DP and Welling M (2013). Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114 [Google Scholar]
- Klusowski JM and Barron AR (2016). Risk bounds for high-dimensional ridge function combinations including neural networks. arXiv preprint arXiv:1607.01434 [Google Scholar]
- Krizhevsky A, Sutskever I and Hinton GE (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems 1097–1105. [Google Scholar]
- Kushner H and Yin GG (2003). Stochastic approximation and recursive algorithms and applications 35. Springer Science & Business Media. [Google Scholar]
- LeCun Y, Bengio Y and Hinton G (2015). Deep learning. nature 521 436. [DOI] [PubMed] [Google Scholar]
- LeCun Y, Bottou L, Bengio Y and Haffner P (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE 86 2278–2324. [Google Scholar]
- Li K-C (1991). Sliced inverse regression for dimension reduction. Journal of the American Statistical Association 86 316–327. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li Y, Swersky K and Zemel R (2015). Generative moment matching networks. In International Conference on Machine Learning 1718–1727. [Google Scholar]
- Li H, Xu Z, Taylor G, Studer C and Goldstein T (2018a). Visualizing the loss landscape of neural nets. In Advances in Neural Information Processing Systems 6391–6401. [Google Scholar]
- Li X, Lu J, Wang Z, Haupt J and Zhao T (2018b). On tighter generalization bound for deep neural networks: CNNs, ResNets, and beyond. arXiv preprint arXiv:1806.05159 [Google Scholar]
- Liang T (2017). How Well Can Generative Adversarial Networks (GAN) Learn Densities: A Nonparametric View. arXiv preprint arXiv:1712.08244 [Google Scholar]
- Lin M, Chen Q and Yan S (2013). Network in network. arXiv preprint arXiv:1312.4400 [Google Scholar]
- Lin HW, Tegmark M and Rolnick D (2017). Why does deep and cheap learning work so well? Journal of Statistical Physics 168 1223–1247. [Google Scholar]
- Maas AL, Hannun AY and Ng AY (2013). Rectifier nonlinearities improve neural network acoustic models. In Proc. icml 30 3. [Google Scholar]
- Maiorov V and Meir R (2000). On the near optimality of the stochastic approximation of smooth functions by neural networks. Advances in Computational Mathematics 13 79–103. [Google Scholar]
- Makovoz Y (1996). Random approximants and neural networks. Journal of Approximation Theory 85 98–109. [Google Scholar]
- Mei S, Misiakiewicz T and Montanari A (2019). Mean-field theory of two-layers neural networks: dimension-free bounds and kernel limit. arXiv preprint arXiv:1902.06015 [Google Scholar]
- Mei S, Montanari A and Nguyen P-M (2018). A mean field view of the landscape of two-layer neural networks. Proceedings of the National Academy of Sciences 115 E7665–E7671. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mhaskar HN (1996). Neural networks for optimal approximation of smooth and analytic functions. Neural computation 8 164–177. [Google Scholar]
- Mhaskar H, Liao Q and Poggio T (2016). Learning functions: when is deep better than shallow. arXiv preprint arXiv:1603.00988 [Google Scholar]
- Mnih V, Kavukcuoglu K, Silver D, Rusu AA, Veness J, Bellemare MG, Graves A, Riedmiller M, Fidjeland AK, Ostrovski G et al. (2015). Human-level control through deep reinforcement learning. Nature 518 529. [DOI] [PubMed] [Google Scholar]
- Mondelli M and Montanari A (2018). On the connection between learning two-layers neural networks and tensor decomposition. arXiv preprint arXiv:1802.07301 [Google Scholar]
- Nesterov YE (1983). A method for solving the convex programming problem with convergence rate O (1/k^ 2). In Dokl. Akad. Nauk SSSR 269 543–547. [Google Scholar]
- Neyshabur B, Tomioka R and Srebro N (2015). Norm-based capacity control in neural networks. In Conference on Learning Theory 1376–1401. [Google Scholar]
- Nowozin S, Cseke B and Tomioka R (2016). f-gan: Training generative neural samplers using variational divergence minimization. In Advances in Neural Information Processing Systems 271–279. [Google Scholar]
- Parberry I (1994). Circuit complexity and neural networks. MIT press. [Google Scholar]
- Paszke A, Gross S, Chintala S, Chanan G, Yang E, DeVito Z, Lin Z, Desmaison A, Antiga L and Lerer A (2017). Automatic differentiation in PyTorch.
- Pinkus A (1999). Approximation theory of the MLP model in neural networks. Acta numerica 8 143–195. [Google Scholar]
- Poggio T, Mhaskar H, Rosasco L, Miranda B and Liao Q (2017). Why and when can deep-but not shallow-networks avoid the curse of dimensionality: a review. International Journal of Automation and Computing 14 503–519. [Google Scholar]
- Polyak BT (1964). Some methods of speeding up the convergence of iteration methods. USSR Computational Mathematics and Mathematical Physics 4 1–17. [Google Scholar]
- Polyak BT and Juditsky AB (1992). Acceleration of stochastic approximation by averaging. SIAM Journal on Control and Optimization 30 838–855. [Google Scholar]
- Polyak BT and Tsypkin YZ (1979). Adaptive estimation algorithms: convergence, optimality, stability. Avtomatika i Telemekhanika 3 71–84. [Google Scholar]
- Poultney C, Chopra S, Cun YL et al. (2007). Efficient learning of sparse representations with an energy-based model. In Advances in neural information processing systems 1137–1144. [Google Scholar]
- Reddi SJ, Kale S and Kumar S (2018). On the convergence of adam and beyond.
- Robbins H and Monro S (1951). A Stochastic Approximation Method. The Annals of Mathematical Statistics 22 400–407. [Google Scholar]
- Rogers WH and Wagner TJ (1978). A finite sample distribution-free performance bound for local discrimination rules. The Annals of Statistics 506–514. [Google Scholar]
- Rolnick D and Tegmark M (2017). The power of deeper networks for expressing natural functions. arXiv preprint arXiv:1705.05502 [Google Scholar]
- Romano Y, Sesia M and Candès EJ (2018). Deep Knockoffs. arXiv preprint arXiv:1811.06687 [Google Scholar]
- Rotskoff GM and Vanden-Eijnden E (2018). Neural networks as interacting particle systems: Asymptotic convexity of the loss landscape and universal scaling of the approximation error. arXiv preprint arXiv:1805.00915 [Google Scholar]
- Rumelhart DE, Hinton GE and Williams RJ (1985). Learning internal representations by error propagation Technical Report, California Univ San Diego La Jolla Inst for Cognitive Science. [Google Scholar]
- Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, Huang Z, Karpathy A, Khosla A, Bernstein M, Berg AC and Fei-Fei L (2015). ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV) 115 211–252. [Google Scholar]
- Sak H, Senior A and Beaufays F (2014). Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In Fifteenth annual conference of the international speech communication association. [Google Scholar]
- Salakhutdinov R and Hinton G (2009). Deep boltzmann machines. In Artificial intelligence and statistics 448–455. [Google Scholar]
- Salimans T, Goodfellow I, Zaremba W, Cheung V, Radford A and Chen X (2016). Improved techniques for training gans. In Advances in Neural Information Processing Systems 2234–2242. [Google Scholar]
- Schmidt-Hieber J (2017). Nonparametric regression using deep neural networks with ReLU activation function. arXiv preprint arXiv:1708.06633 [DOI] [PubMed] [Google Scholar]
- Shalev-Shwartz S and Ben-David S (2014). Understanding machine learning: From theory to algorithms. Cambridge university press. [Google Scholar]
- Shalev-Shwartz S, Shamir O, Srebro N and Sridharan K (2010). Learnability, stability and uniform convergence. Journal of Machine Learning Research 11 2635–2670. [Google Scholar]
- Silver D, Schrittwieser J, Simonyan K, Antonoglou I, Huang A, Guez A, Hubert T, Baker L, Lai M, Bolton A et al. (2017). Mastering the game of go without human knowledge. Nature 550 354. [DOI] [PubMed] [Google Scholar]
- Silverman BW (1998). Density estimation for statistics and data analysis. Chapman & Hall, CRC. [Google Scholar]
- Singh C, Murdoch WJ and Yu B (2018). Hierarchical interpretations for neural network predictions. arXiv preprint arXiv:1806.05337 [Google Scholar]
- Sirignano J and Spiliopoulos K (2018). Mean field analysis of neural networks. arXiv preprint arXiv:1805.01053 [Google Scholar]
- Soltanolkotabi M (2017). Learning relus via gradient descent. In Advances in Neural Information Processing Systems 2007–2017. [Google Scholar]
- Soudry D, Hoffer E, Nacson MS, Gunasekar S and Srebro N (2018). The implicit bias of gradient descent on separable data. The Journal of Machine Learning Research 19 2822–2878. [Google Scholar]
- Sprecher DA (1965). On the structure of continuous functions of several variables. Transactions of the American Mathematical Society 115 340–355. [Google Scholar]
- Stone CJ (1982). Optimal global rates of convergence for nonparametric regression. The annals of statistics 1040–1053. [Google Scholar]
- Sutskever I, Martens J, Dahl G and Hinton G (2013). On the importance of initialization and momentum in deep learning. In International conference on machine learning 1139–1147. [Google Scholar]
- Szegedy C, Zaremba W, Sutskever I, Bruna J, Erhan D, Goodfellow I and Fergus R (2013). Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199 [Google Scholar]
- Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V and Rabinovich A (2015). Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition 1–9. [Google Scholar]
- Telgarsky M (2016). Benefits of depth in neural networks. arXiv preprint arXiv:1602.04485 [Google Scholar]
- Tibshirani R (1996). Regression shrinkage and selection via the lasso. Journal of the Royal Statistical Society: Series B (Methodological) 58 267–288. [Google Scholar]
- Vapnik V and Chervonenkis AY (1971). On the Uniform Convergence of Relative Frequencies of Events to Their Probabilities. Theory of Probability & Its Applications 16 264–280. [Google Scholar]
- Vincent P, Larochelle H, Bengio Y and Manzagol P-A (2008). Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th international conference on Machine learning 1096–1103. ACM. [Google Scholar]
- Wager S, Wang S and Liang PS (2013). Dropout training as adaptive regularization. In Advances in neural information processing systems 351–359. [Google Scholar]
- Weinan E, Han J and Jentzen A (2017). Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations. Communications in Mathematics and Statistics 5 349–380. [Google Scholar]
- Wilson AC, Roelofs R, Stern M, Srebro N and Recht B (2017). The Marginal Value of Adaptive Gradient Methods in Machine Learning. In Advances in Neural Information Processing Systems 30 (Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S and Garnett R, eds.) 4148–4158. Curran Associates, Inc. [Google Scholar]
- Wu Y, Schuster M, Chen Z, Le QV, Norouzi M, Macherey W, Krikun M, Cao Y, Gao Q, Macherey K et al. (2016). Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144 [Google Scholar]
- Yosinski J, Clune J, Bengio Y and Lipson H (2014). How transferable are features in deep neural networks? In Advances in neural information processing systems 3320–3328. [Google Scholar]
- Yosinski J, Clune J, Nguyen A, Fuchs T and Lipson H (2015). Understanding neural networks through deep visualization. arXiv preprint arXiv:1506.06579 [Google Scholar]
- Zhang C, Bengio S, Hardt M, Recht B and Vinyals O (2016). Understanding deep learning requires rethinking generalization. arXiv preprint arXiv:1611.03530 [Google Scholar]
- Zhong K, Song Z, Jain P, Bartlett PL and Dhillon IS (2017). Recovery guarantees for one-hidden-layer neural networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70 4140–4149. JMLR. org. [Google Scholar]