

Abstract
Use of machine learning (ML) in clinical research is growing steadily given the increasing availability of complex clinical datasets. ML presents important advantages in terms of predictive performance and identifying undiscovered subpopulations of patients with specific physiology and prognoses. Despite this popularity, many clinicians and researchers are not yet familiar with evaluating and interpreting ML analyses. Consequently, readers and peer reviewers alike may either over- or under-estimate the validity and credibility of an ML-based model. Conversely, ML experts without clinical experience may present details of the analysis that are too granular for a clinical readership to assess. Overwhelming evidence has shown poor reproducibility and reporting of ML models in clinical research suggesting the need for ML analyses to be presented in a clear, concise, and comprehensible manner to facilitate understanding and critical evaluation. We present a recommendation for transparent and structured reporting of ML analysis results specifically directed at clinical researchers. Furthermore, we provide an a list of key reporting elements with examples that can be used as a template when preparing and submitting ML-based manuscripts for the same audience.
Introduction
The complexity of biomedical research analyses is accelerating as investigators turn to high dimensional data - including electronic health records (EHR), imaging, and wearable sensor data - to study cardiovascular pathophysiology, management, and outcomes. The ability to account for complex interactions among inputs while scaling to data sets of very large sizes in an automated fashion is one of several strengths of machine learning (ML) that has fueled its use in clinical research where outcomes of interest often depend on complex relationships between many factors. Consequently, clinical investigators are turning to ML to complement hypothesis-driven approaches. Reporting, interpreting, and evaluating the validity of clinical findings produced by ML is challenging due to lack of familiarity among investigators, peer-reviewers, and general readership in most clinical disciplines.1-3 Furthermore, instances of spurious or non-reproducible findings and limited explainability have bred skepticism of ML approaches in clinical research.1
There is a pressing need to familiarize the clinical community with basic principles of ML and establish a framework for consistent reporting, interpretation, and evaluation of these analyses for authors, reviewers, and readers. Herein we introduce ML reporting recommendations relevant to this community that we believe are necessary to present, assess, and ultimately reproduce ML results. Finally, we provide a structured template outlining key elements for reporting ML findings in publications and provide examples that include publicly available resources to assist authors in sharing their results in a consistent manner to enhance transparency and reproducibility of their analyses. For convenience, we have included an editable template in the Supplement with the fields discussed here. This template is built in the context of the research process in conjunction with the universal workflow for ML analyses (Figure 1).4
Figure 1 –

Overview of machine learning analysis workflow
Guidelines for reporting of predictive modeling such as the STROBE guidelines5 and TRIPOD statement6 are focused around reporting results of observational studies and development of multivariable predictive models, respectively without clear discussions of reporting ML analyses. In the case of the TRIPOD guidelines, notable differences in reporting parameters between traditional statistical analysis and ML have led to an ongoing initiative to extend reporting.7 Some ML-specific reporting guidelines such as Pineau's Machine Learning Checklist for Reproduciblity have also been published.8 In many cases, especially predictive modeling, overlaps exist in analysis components between ML and hypothesis-driven statistical approaches. Table 1 outlines similarities in nomenclature across these two domains. The recommendations presented here are meant to be used in conjunction with existing guidelines, thereby extending their scope to the reporting of ML analyses. By providing a high-level description of core components of ML analyses, we hope to facilitate the communication, understanding and interpretation of ML in clinical research community.
Table 1-.
Nomenclature for ML vs. traditional statistical modeling
| ML Term | Comparable statistical concept |
|---|---|
| Feature | Independent/explanatory variable |
| Label/response/outcome | Dependent variable |
| Feature selection | Variable selection |
| Extracted features | Latent or transformed variables |
| Model optimization | Model fitting |
| Training or learning | Model estimation |
| Weights | Parameters |
| Tensor | Higher order matrix or vector |
| Recall | Sensitivity |
| Precision | Positive predictive value |
Branches of ML and Examples in Clinical Research
ML can be broadly categorized into supervised and unsupervised approaches. Supervised ML is centered around predicting an output from a set of inputs, whereas unsupervised ML centers around creating data-driven patterns and groupings within the input data without a labeled output. More recently, categorizations have expanded to include self-supervised learning, a specific instance of supervised learning in which training labels are generated automatically by accounting for correlations of the inputs (e.g. autoencoders), and semi-supervised learning, in which a portion of the data is labeled a priori. Common applications of ML in clinical research include 1) interpretation of sensory data such as images or sound (generally supervised),9-11 2) detection of disease cases (generally supervised),12-14 3) identification of novel patient characterizations such as phenotypes (generally unsupervised or semi-supervised),15,16 and 4) prediction of clinical outcomes and treatment response (generally supervised).17-19
Defining the branch(es) of ML that will be used in an analysis is critical, as it determines which analysis methods are most appropriate and defines requirements for source data, pre-processing, parameters, and interpretation. Supervised ML methods are currently more common than unsupervised methods in clinical research given their measurable value in improving upon existing prediction and classification models. In supervised ML, input features are used to classify each subject according to a labeled response. For example, EHR data might be used to detect patients with heart failure (HF) using ML and evaluated against an analysis-specific gold standard such as adjudicated chart review. Raw echocardiographic data might be analyzed to identify patients with diastolic dysfunction compared to human interpretation (image interpretation and detection of disease cases). Unsupervised analyses use different methods to identify latent patterns within the input data that represent subgroups within a population (e.g. identification of patients with tumor subtypes that show a strong response to a particular chemotherapy). In unsupervised analyses, there is not a specified response, and an investigator may not know a) if latent subgroups exist, b) what subgroups are present if subgroups exist, and c) which variables might be important to identify those subgroups. For example, data from a clinical trial or an EHR might be used to identify subtypes of HF, which could have important implications for prognosis and management.16 The remainder of this discussion focuses on key reporting elements and examples important to both supervised and unsupervised ML applications in clinical research as outlined above20 and is presented in accordance to the research process in conjunction with the universal workflow for ML analyses (Figure 1).
Study Design (Figure 2)
Figure 2 –

Key reporting elements for machine learning study design examples
Defining the Research Question and Available Data
Research questions must first be clearly articulated in order to frame all subsequent choices regarding data preparation, method selection, results and performance evaluation, as well as interpretation. When performing ML analyses, two assumptions are made: (1) the desired outputs of the data can be generated given the input data, and (2) the available data contain the necessary information to learn the desired output. It is important to keep these assumptions in mind when considering the input data, ML method, and overall analysis architecture that will be used to address the research question. Classifying the research question and analysis by problem type (e.g. binary/multi-class classification vs. time series or sequential analysis vs. exploration or categorization) is important as these factors determine appropriate ML methods given the data available and the desired result. For example, supervised techniques can only be employed if an appropriately labeled response is available. After defining a research question (e.g.“can social and behavioral factors improve prediction of development of coronary artery disease (CAD)?”), the problem type (binary, multi-class prediction) should be clearly stated. We recommend that reports include in the introduction a clear statement structured such as: “The primary purpose of this study is to use <raw data type> for <problem type> to <clinical output> (e.g. “The purpose of this analysis is to determine if socioeconomic factors contribute to classification prediction models will accurately predict early-onset coronary artery disease.”)
ML Rationale
When traditional statistical methods may suffice and should be used, and ML methods should be used when they offer marked advantages over standard statistical methods. In some cases this will be immediately apparent (e.g. interpretation of image, acoustic waveform, or ECG tracing, which cannot be interpreted using traditional regression methods without some feature extraction or engineering). In clinical research, the rationale for ML may be less obvious, such as improving substandard predictive models (e.g. prediction of clinical outcomes and treatment response or detection of disease cases) or exploring complex data in a hypothesis-free manner (e.g. identification of novel patient characterizations and potential risk factors). Because of the practical barriers to clinical implementation of ML-based models – including the frequent need for model interpretability in clinical decision-making – their use must be justified clearly.
It is important for authors to state the advantages of the selected technique for answering the research question.21 ML method selection is based upon the intended goal of the research question, the problem type, and the data available. For a specific problem and data type, there might be many ML methods that could be employed. For example, with supervised problems (e.g. prediction of clinical outcomes and treatment response) containing variables with mixed data types, an ML method such as use of classification (categorical variable outputs) and regression (continuous variable outputs) trees may be a superior option due to its ability to identify high-dimensional, non-linear relationships between a variety of data types.
For supervised ML, it is important to describe the labels for prediction (e.g. coronary-artery disease = myocardial infarction or cardiac revascularization at age < 50) for applications such as prediction of clinical outcomes or detection of disease cases. Candidate features should be identified from the data source (e.g. CDC’s National Health and Nutrition Examination Survey). It is also critical to address limitations relating to the data used and the clinical phenotypes defined for use as outcomes and candidate features. In EHR-based research, outcomes based on diagnostic or billing codes without manual review may be flawed. Self-reported data may also be inaccurate if unverified. It is important to report the degree to which there may be a measurement errors with respect to data collection and variations in clinical definitions. Where applicable, the timeframe of prediction (e.g. single point in time vs. time-to-event) should be discussed.19,22,23
Unsupervised ML is often used to identify previously unknown patterns or structures in data (e.g. identification of novel patient characterizations or disease phenotyping). Interpretation of results is dependent on the domain and type of data. Since by definition there are no prespecified hypotheses, the intuition behind the analysis and intended use of its findings should be described. For example, patterns within cross-sectional holistic patient data of a certain disease like heart failure may represent sub-phenotypes with distinct pathophysiology and distinct treatment responses. Alternatively, continuous telemetry data may reveal patterns that predict specific manifestations of clinical decompensation representing distinct pathophysiologies, which have not been identified by clinicians. If the goal is derivation of a phenotyping algorithm for use by clinicians, the ability to clearly understand and interpret how phenotypes24 are defined as well as what clinically differentiates one phenotype or characterization from another is important.25,26 In such cases, additional ML and statistical approaches such as traditional regression or survival methods, double ML21, and causal inference techniques27,28 may be employed in conjunction with or may be considered over unsupervised approaches. For example, analyses may be done by conducting multiple ML analyses in succession, such as unsupervised phenotype identification followed by supervised ML or regression to identify and predict prognosis based on a set of potential phenotypes. 29 In this case clear reporting surrounding the architecture of the analysis and reasoning behind what approaches were deployed at what points should reported and defined relative to their purpose in the overall analysis architecture and the overall study design. It is important to clearly identify the treatment, the outcome, and most importantly, how the analysis architecture optimizes comparability between treatment groups.30
Defining ML Analysis Architecture and ML Methods
Every ML model employed should cover 4 aspects: 1) training protocol and evaluation, 2) method including method-specific hyperparameters (a method-specific parameter whose value is set before training such as the kernel or number of iterations), 3) optimization strategies and generalization techniques, and 4) replication, external validation, and testing. Many ML methods are founded upon traditional statistical methods, and the key difference between a traditional statistical predictive model and ML analysis is often the way a model is trained repetitively with the intention of optimizing performance and improving generalizability. In fact, the original framing of ML was to have machines that could automatically improve through experience. Although this remains an ideal rather than a consistent reality, ML models nonetheless offer tremendous flexibility and can also combine multiple architectures, training protocols, optimization, and generalization techniques to produce customizable parameters, or “tunable knobs”, capable of impacting overall performance. Optimal tuning of these knobs lies in balancing overfitting and generalizability. Clear reporting with respect to which knobs (e.g. parameters and hyperparameters) were used and how they were set at each stage in an ML analysis (Figure 1) is critical for accurate assessment, reproducibility, and reuse of ML models.
An important consideration in clinical ML research presently is interpretability by clinicians. ML methods capable of providing metrics that give insight into the impact of individual features on the output of the model is a critical determinant of provider acceptance. Many ML strategies consist of glass box approaches such as linear regression and decision trees. Approaches including the decision tree-based random forest analysis, latent class analysis, and black box approaches such as convolutional networks (for images) or deep learning can be used in conjunction with interpretation methods to produce quantitative or semi-quantitative results that give insight into the importance or relevance of each feature in either predicting an outcome or defining a cluster. For example, random forest and deep learning approaches can produce an ‘importance’ metric that indicates which features are most strongly associated with the output of interest. Similarly, latent class analysis produces coefficients for each value of each input variable that predict membership in each latent class (e.g. female sex confers a 75% likelihood of being classified as latent class A vs. 10% likelihood of being classified as latent class B). Specific ML methods such as artificial neural networks are required for processing very high volume, dense, and complex data such as using an entire EHR to predict patient outcomes or extracting latent variables from largely diverse, multi-omic experimental results. The value in these approaches is in the ability to conduct analyses using large quantities of diverse, potentially unharmonized or unstructured data that would be difficult or impossible to analyze with conventional statistics. However, this can come at the expense of clinical interpretability, as it is difficult to extract and present the data representations generated in a form understandable by practicing healthcare providers. Potential superior predictive performance over conventional statistics may justify use of such methods. Because of the ramifications of using ML that is difficult for clinicians to interpret, the rationale for this decision must be articulated clearly.
Determining Measures for Evaluation
Once a research question and analysis strategy have been defined, it is important to articulate the evaluation strategy. Success must be defined, and measures to evaluate success must be identified. Establishing specific performance metrics directs the analysis architecture and what will be optimized during the training process. Parameters such as sensitivity/recall, positive predictive value/precision, and the area-under-the-curve (AUC) receiver-operating-characteristic (ROC) that are used to assess conventional predictive methods can also be used for supervised ML analyses. The area under the precision-recall curve, closely related to the ROC, may also be used in ML for imbalanced datasets (the number of data points available for each class is different) and when performance differences are not obvious using a standard ROC; the area under the precision-recall curve provides a measurement of how well positive predictions are made, where the standard ROC is invariant to data imbalance and may not demonstrate positive predictive performance in data where the event rate is low. Evaluation of model calibration techniques is important when assessing external validation approaches, as they can heavily impact generalizability. When assessing model calibration, it is important to consider sampling mechanisms for calibration when working with data that are imbalanced or reflect over- or under-sampled populations. Unsupervised analyses may rely on other metrics like error statistics that describe similarity between members of a cluster, dissimilarity between clusters, or overall classification of the population analyzed. It may be necessary to define custom metrics for measuring evaluation. In that event, the need for custom measures should be clearly justified and the measure should be methodically defined.
Data Collection (Figure 3)
Figure 3 –

Key reporting elements for data sources and preprocessing with examples
Data sources used for ML analysis are usually large (many data points) and/or complex (many different types of data) and may therefore be difficult or impossible to review manually. Description of the data to be used is critical to assess their quality, reliability, suitability to produce the desired output, potential generalizability of any findings, and especially reproducibility. Data should be described in detail with respect to its source (e.g. study, contributor, or data steward such as the Framingham Offspring dataset contributed by the Framingham Heart Study via the National Heart, Lung, and Blood Institute), study population, instruments (standardized collections of measurements such as an echo report), measurements (specific variable definitions, field name, and values such as gender, male sex or ejection fraction of 45%), collection information (instrument/measurement details such as versioning, devices, and testing information- e.g. centralized echocardiography core), and information relating to sample and measurement quality or preprocessing (e.g. standardized echo protocol performed by study sonographers). When previous publications describing a dataset exist, references including detailed methods may be used with pertinent elements summarized in the manuscript. Collection time frames, variable definition and redundancy, and the type of data (e.g. binary, continuous, categorical, text) should also be described.19
ML is being used increasingly to analyze both public- and private-access datasets, which has important implications for independent validation. Mechanisms for accessing the study datasets such as host repositories and websites must be reported where applicable. Ideally, authors will provide direct links to source data and documentation, for example by storing files on open science platforms such as GitHub (github.com), the Open Science Framework (osf.io), or the American Heart Association’s Precision Medicine Platform (PMP, precision.heart.org).31
Analyses that use data in ways that go beyond their primary purpose (e.g., EHR data), data that have been pooled from multiple sources, or feature sets engineered or extracted from images often require additional data processing beyond the preprocessing used to create the primary dataset. Analyses may use a variety of approaches to prepare data for use in ML analyses. An overview of the differences between the characteristics of the source(s) data and the requirements of the selected ML method should be described to provide context for data pre-processing. The goal is not meant to provide explicit detail accounting for each data pre-processing step at each stage, but to provide readers with an overall understanding of the analysis and provide background when reviewing. Specific preprocessing details necessary for reproducibility should be reported in the supplement.
Methods: Data Preprocessing, Model Development, and External Validation
Data collection and pre-processing comprise as much as 80% of the analysis process and must be reported to ensure transparency and reproducibility. All manipulation of data prior to performing the main analysis must be thoroughly explained including handling of missing data, transformations, feature engineering (manually creating features from raw data using domain expertise or data-driven creation of principle components or latent variables), feature extraction (transforming raw data into the desired form such as vectorization/tensor creation from images or text), and feature selection (manual selection using domain expertise or data-driven dimensionality reduction via clustering, semi-supervised learning, or other methods). Pre-processing steps may include additional statistical and ML methods that supplement the overall analysis. In cases where ML methods are used during pre-processing, reporting guidelines discussed in the Model Training and Evaluation, Model Configuration, Optimization, and Generalization, as well as Validation sections should be included (Figure 3, Supplemental Template). In cases where specific features have been engineered via domain expertise or data-driven methods, details specific for how those features were defined and validated as well as their generalizability to other datasets should be reported.
Data quality and missingness (Figure 3)
Most datasets have inaccurate or missing values, and techniques used to handle missing values and outliers should be evaluated and reported. Discussion of approaches to data missingness in ML is largely the same for any analysis method including ML. Missing data may be classified as random vs. non-random, missing but applicable or missing and un-applicable. Many ML methods require complete datasets for each case, which can reduce sample size especially when a large number of variables are being considered. If data missingness restricts the number of usable features or samples, imputation or ML methods that tolerate missing data can be used in cases where data are missing at random. Clinical expertise from a subject matter expert may identify variables with marginal clinical utility that can be excluded. Where applicable, the criteria used for removing data should be presented. Rationale for using imputation including the selected method should be given, and validation of results generated using imputed data should be reported to determine effectiveness and possible impact on results.
Feature Engineering, Selection, and Transformation (Figure 3)
It is common to have more explanatory variables than samples in biomedical and clinical research. This decreases the ability to detect important predictors while paradoxically increasing the likelihood of spurious findings. High dimensional clinical datasets such as observational studies (e.g. Framingham Heart Study) or EHR data often have the same variable measured at many time points, have clinical variables measured in multiple ways (e.g. self-reported vs. adjudicated diagnosis), and have redundant or collinear variables such as body mass index and weight. ML models are better suited to analyze datasets with many more variables than subjects compared with many traditional statistical approaches but nonetheless still perform best when redundancy across variables is minimized and sample sizes are sufficient to create effective models.
A variety of manual and data-driven techniques are available when selecting features to include in a model. Domain expertise can be used to create a subset of variables suspected to contain clinical significance. Variable redundancy can also be eliminated through correlation testing or statistical methods to identify groups of related variables and a select group of representative variables to use in analysis. Specific field names from the dataset and descriptions of variables in conjuction with step-wise transformation and manipulation functions for each engineered feature should be provided explicitly, and methodology for selecting variables should be reported as well as method specific parameters (e.g. “50 of 300 variables were highly correlated (Spearman’s ρ > 0.6, p < 0.05. The variable with the most missingness in a correlated pair was removed, yielding 275 variables.”). Data-driven dimensionality reduction techniques such as principle component analysis, linear discriminant analysis, unsupervised clustering, and artificial neural networks can also be employed to extract a smaller set of engineered features representative of the underlying data for supplementary analyses, though at the risk of some loss of interpretability. Data-driven feature selection is often performed in the context of a specified response variable using supervised methods, where multiple variables are input into a model and evaluated for their importance in predicting the response. This can be effective for identifying potential risk factors using domain expertise or eliminating redundancy. Importantly, since feature selection is sometimes dependent on values of the outcome variable, it must be performed without access to the test set, or one compromises the ability to obtain an unbiased estimate of error.
ML Input Data
Regardless of the method used, the features selected for use in the ML analysis and basis for selection should be reported for all datasets. Additionally, the number of subjects excluded from analysis should be stated clearly. Reporting of subject and feature disposition could take the form of a CONSORT diagram (Figure 4), wherein starting with the full available cohort, the number of patients excluded based on each criterion, the approach implemented at each stage, and the resulting subjects and features included in the analysis is clearly delineated. The final set of features used in the analysis should be given at minimum in an on-line supplement or analysis environment for full transparency, even if all available features in a dataset are included.
Figure 4 –
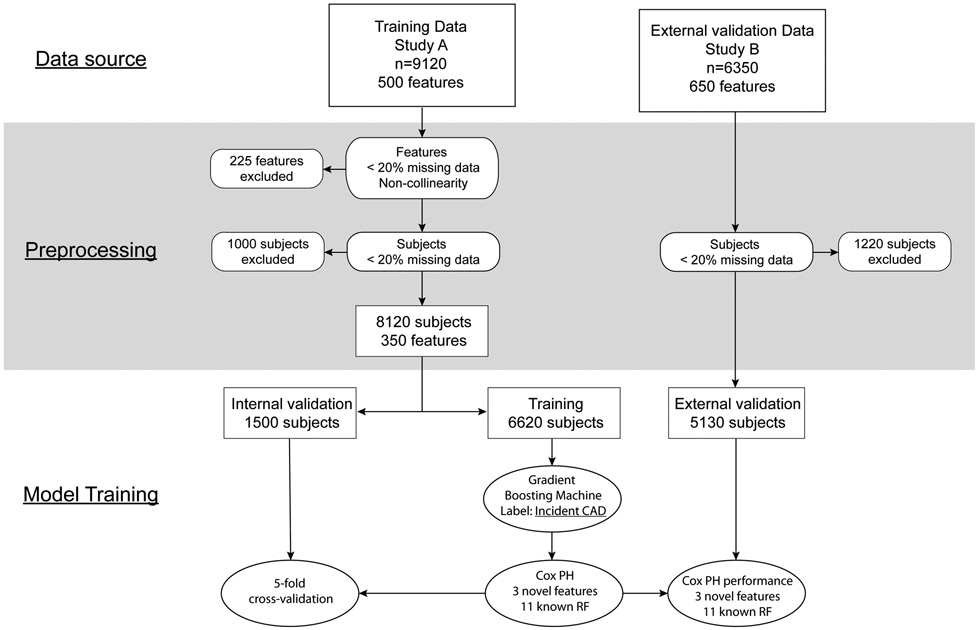
CONSORT-style diagram illustrating disposition of subjects and features included in analysis
Model Training and Evaluation (Figure 5)
Figure 5 –

Key reporting elements for model training and validation with examples
It is recommended to use at least three datasets in an ML analysis: (1) a portion of the primary dataset that is being used to develop the model(s) (training dataset), (2) a portion of the primary data that is being used for evaluating and selecting between models such as different values of hyperparameters (validation dataset), and (3) one or more datasets used to evaluate the model after it has been fully developed (test dataset). We note that the terms validate and test are sometimes used interchangeably in the clinical literature, but we emphasize the distinction between validation and test datasets, as they serve different purposes. Data in test sets should not have been used during any part of model development including data normalization, feature selection, or hyperparameter tuning so as to avoid model overfitting and erroneously optimistic estimates of model performance. Test datasets may represent a partition of the original data and thus provide insights into the model training process. They may also be derived from an entirely separate external data source enabling assessment of both model training and whether inferred relations between variable and response are transportable to new settings. Evaluating model performance on external test sets is also unlikely to be influenced by biases that have arisen during selection of the study population used in model development and mitigates risk of investigators having been influenced by properties of the original dataset prior to partitioning into training, validation, and test sets. However when an external test dataset is not available or when generalizability to other datasets is not required, model evaluation may be limited to a training dataset and an internal test dataset (Figure 1). Regardeless of the number, it is critical to report the evaluation metric results for all datasets. Evaluation should be performed in the context of the performance measures defined during study design (e.g. AUC/net reclassification), the evaluation should be included in the analysis results, and metrics should be reported for all training, validation, and test datasets. In cases where training protocols such as bootstrapping or cross-validation have been used, reporting an average metric across iterations may be sufficient for training and internal validation reporting, and plots displaying the metric at each iteration can be included in the supplement when necessary. Held-out data may be used for testing in data-rich scenarios (i.e. large sample sizes), whereas bootstrapping, k-fold, and repeated k-fold cross validation should be considered for medium- and small-sized datasets. For analysis on internal data only, the split of the data (hold-out), folds (k) or sample size (n, bootstrapping), and repeats (repeated cross-validation or bootstrapping) should be reported. In the case of ongoing data collection, for example in an operational EHR, prospective model evaluation can also be used.
Model Configuration, Optmization, and Generalization (Figure 5)
Computational architecture (e.g. processor speed, number of cores, and memory), high performance techniques (e.g. parallelization) for implementation, software, packages and versioning should be reported for all analyses to facilitate reproducibility.
The specific ML method, related hyperparameters and rationale for using the method should be reported for any approach used during analysis (Supplemental Figure). Optimization techniques such as hyperparameters (e.g. cost, number of trees, epochs), changing model architecture (e.g. tree depth or number of layers), or implementing ensemble techiques (e.g. boosting, bagging) should be reported. Implementation of generalization techniques (e.g. L1 or L2 regularization) and accompanying hyperparameters (e.g. dropout rate) should be presented explicitly in supplementary appendicies and shared analysis code. Particularly important parameters to the analysis or results should be described including the rationale for selecting those parameters. This includes situations where all function parameters used correspond to package default or presets; in such situations an explanation should be included as to why no analysis-specific parameters were needed. Representation of the variables identified as important is crucial. In the case of unsupervised methods, depiction with a figure of grouping or latent patterns discovered within the dataset is important to demonstrate the distinctness between groups.
External Model Evaluation (Figure 5)
As described above, it is important to reserve a test set that has been unused during model development to avoid model overfitting. In cases where an independent, external dataset is used, the method of selecting the test set should be described. The rationale for selection of the external test dataset should include an assessment of similarity between training (used to fit the model), validation (used to evaluate model performance and optimize hyperparameters), and test (used to test and validate the final model) datasets. The availability, manipulation, and transformation of features including response labels used in the training ML analysis should also be provided.
Supervised ML models must be evaluated due to the significant danger of overfitting and lack of reproducibility, which cannot be inferred from performance assessments of the training dataset alone. Model calibration is useful for certain supervised ML methods and can aid in assessing the reliability of a model as well as lead to better quality predictions. In cases where calibration can be applied, the method and specific parameters should be reported. Any additional performance metrics used for model evaluation should be also be clearly described along with the rationale for selecting them. Care should be taken for probabilistic performance and threshold-driven metrics as well as how these measures may be affected by imbalanced datasets.
Selection of evaluation strategies may be less straightforward for unsupervised than for supervised ML given the lack of a specific label upon which to evaluate performance. When evaluating unsupervised ML results, it is important to articulate a priori what kind of knowledge will be generated, how that knowledge will be used, and objective ways in which importance of the knowledge can be assessed. Based on these considerations, selection of the datasets for generating and evaluating models should be reported as well as the specific methodology and metrics used. Results may be tested or manually reviewed externally, where one looks to new datasets to see if similar latent patterns are found in independent datasets elsewhere. Different metrics may emphasize different aspects of internal structure within the data, making similarity difficult to quantify. This process may lead to using supervised ML to evaluate the output of unsupervised learning. For example, one can assess formally whether the added information (such as patient classes) derived from clustering is useful when incorporated as a feature in a supervised learning task, such as deriving a predictive model for survival or medication responsiveness.16,32 This approach may not necessarily validate similarity between clusters, but it can speak to the clinical importance of those clusters, and metrics such as the Jaccard index can be used in parallel to assess similarity between clusters.33 It is also possible to compare unsupervised outputs to a human-identified set of labels, wherein a expert determines if the results “make sense.” However this approach is subjective and may not reflect quantitative similarities relating to the internal structure of the data.
Reproducibility and Results Interpretation (Figure 5)
Reproducibility of results in ML-based analysis is an important and extensively-discussed issue, in part due to the lack of reproducibility of many ML results. An in-depth discussion of reproducibility in ML is beyond the scope of this paper, but other additional recommendations are currently available such as Pineau's Machine Learning Checklist for Reproducibility.8 We will instead focus on a few key components of enabling analysis and results reproduction. Ideally readers could inspect and execute all parts of the analysis (including data preprocessing) within publicly accessible environments in web-based and cloud-based resources such as a Jupyter Notebook hosted by the AHA’s PMP or the Global Alzheimer’s Association Interactive Network (GAAIN) Interrogator. Such environments would include the full dataset(s), necessary software packages, and analysis code for full transparency and to allow readers to interact with the analysis workflow. For logistic reasons including data use restrictions and software licensing, this may not be possible, in which case the authors should provide as much information as possible to allow readers to recreate the authors’ analysis.
Data sources
As described above, diverse data sources are used for quality and outcomes research. When publicly or semi-publicly available datasets are used, contact information should be provided including links to either the dataset itself (e.g. NHANES) or agencies that manage the dataset (e.g. BioLINCC). Datasets that are not publicly available in any form (e.g. data from EHRs) should be described fully to allow readers to identify datasets as similar to the analysis data as possible (e.g. EHR data from a local institution). Wherever possible, patient-level metadata including specific table/form and field names used in the analysis should be included in the supplement.
Software
Subtle differences between software packages in implementation of complex algorithms (e.g. R vs. SAS) may produce different results despite using comparable methods and identical datasets. Consequently, clear identification of the software packages and versioning used is also important to support research reproducibility. This may include links to documentation to parent software as well as individual analysis packages or procedures. There is growing support to use freely available software such as R, Python, Tensorflow, or XGBoost, for ML analysis, but proprietary software platforms are still used extensively and should be described in a similar fashion to freely available software.
Code
As with all analyses, authors must retain the complete execution code to produce the reported results. Funding agencies increasingly require investigators to publish their code on any number of public websites and digital model objects should be published when possible (e.g. https://paperswithcode.com). Archived analysis code should include environment parameters, analysis packages, datasets, versioning, calls to analysis functions including all parameters, and generation of outputs such as tables and figures. Reporting the key elements and details explained in this paper should be incorporated in the comments of notebooks to connect a publication to the accompanying analysis code and enhance reproducibility. Where the data may be freely shared, an interested reader should be able to execute the entire analysis without significant manipulation of the code. Where data are not freely shareable, the authors may consider showing results of intermediate steps as well, for example as in a R Markdown report (see example at s3.amazonaws.com/pmp-tutorials/ML_tutorial.html). At a minimum code should be provided in a web-accessible resource such as GitHub, the Open Science Framework, or the PMP unless valid reasons such as inclusion of protected intellectual property are articulated.
Interpretation
Regardless of the ML methods employed during analysis, results should be interpreted clinically and in the context of the evaluation metrics defined in the study design. Clinical interpretation should be discussed with respect to the outputs of the analysis including evaluation metrics in addition to potential for implementation and translation to health care.
A comprehensive report of the model and evaluation metrics should be presented, either in an on-line supplement or in a web-based resource. High impact features (e.g. important predictors or key defining clinical features) should be presented in a summary or tabular format along with a narrative rationale for focusing on these variables (e.g. blood glucose, waist circumference, serum high density lipoprotein, serum triglycerides, and hypertension as components of the metabolic syndrome). Unlike the descriptive tables mentioned earlier, these results can support direct inference as far as the importance of select variables in the primary analysis.
Conclusion
The size and complexity of clinical data is expanding rapidly requiring use of ML for analysis. To aid in reproducibility as well as broader understanding and use of ML within the clinical research community, ML methods and analysis results should be presented a succinct, standardized, and relatable way to facilitate peer review and assessment by the general readership. Many concepts important for reporting of conventional statistics are also important in ML with a few important additions. Access to software details and analysis code, ideally in a functional, publicly available workspace are a critical companion to a manuscript in order to ensure transparency and promote reproducibility. We believe these principles will enable the research community to appropriately evaluate these valuable analyses as understanding of ML becomes more widespread.
Supplementary Material
Acknowledgments
The authors would like to thank the AHA and the Institute for Precision Cardiovascular Medicine (precision.heart.org).
Footnotes
Disclosure: The authors have no conflicts to declare.
REFERENCES
- 1.González-Beltrán A, Li P, Zhao J, Avila-Garcia MS, Roos M, Thompson M, van der Horst E, Kaliyaperumal R, Luo R, Lee T-L, Lam T, Edmunds SC, Sansone S-A, Rocca-Serra P. From Peer-Reviewed to Peer-Reproduced in Scholarly Publishing: The Complementary Roles of Data Models and Workflows in Bioinformatics. PLoS One. 2015;10:e0127612. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Miotto R, Wang F, Wang S, Jiang X, Dudley JT. Deep learning for healthcare: review, opportunities and challenges. Brief Bioinform. 2018;19:1236–1246. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Jordan MI, Mitchell TM. Machine learning: Trends, perspectives, and prospects. Science. 2015;349:255–260. [DOI] [PubMed] [Google Scholar]
- 4.Hastie T, Tibshirani R, Friedman J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition. New York, NY: Springer; 2009. [Google Scholar]
- 5.Vandenbroucke JP, von Elm E, Altman DG, Gøtzsche PC, Mulrow CD, Pocock SJ, Poole C, Schlesselman JJ, Egger M, Blettner M, Boffetta P, Brenner H, Chêne G, Cooper C, Davey-Smith G, Gagnon F, Greenland P, Greenland S, Infante-Rivard C, Ioannidis J, James A, Jones G, Ledergerber B, Little J, May M, Moher D, Momen H, Morabia A, Morgenstern H, Paccaud F, Röösli M, Rothenbacher D, Rothman K, Sabin C, Sauerbrei W, Say L, Sterne J, Syddall H, White I, Wieland S, Williams H, Zou GY. Strengthening the Reporting of Observational Studies in Epidemiology (STROBE): Explanation and elaboration. Int J Surg. 2014;12:1500–1524. [DOI] [PubMed] [Google Scholar]
- 6.Collins GS, Reitsma JB, Altman DG, Moons KGM. Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD): The TRIPOD Statement. Ann Intern Med. 2018;162:55–63. [DOI] [PubMed] [Google Scholar]
- 7.Collins GS, Moons KGM. Reporting of artificial intelligence prediction models. Lancet. 2019;393:1577–1579. [DOI] [PubMed] [Google Scholar]
- 8.Pineau J. The Machine Learning Reproducibility Checklist (Version 1.2) [Internet]. 2019. [cited 2019 Dec 26];Available from: https://www.cs.mcgill.ca/~jpineau/ReproducibilityChecklist.pdf [Google Scholar]
- 9.Betancur J, Commandeur F, Motlagh M, Sharir T, Einstein AJ, Bokhari S, Fish MB, Ruddy TD, Kaufmann P, Sinusas AJ, Miller EJ, Bateman TM, Dorbala S, Di Carli M, Germano G, Otaki Y, Tamarappoo BK, Dey D, Berman DS, Slomka PJ. Deep Learning for Prediction of Obstructive Disease From Fast Myocardial Perfusion SPECT. A Multicenter Study. JACC Cardiovasc Imaging. 2018;11:1654–1663. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Bax JJ, van der Bijl P, Delgado V. Machine Learning for Electrocardiographic Diagnosis of Left Ventricular Early Diastolic Dysfunction. J Am Coll Cardiol. 2018;71:1661–1662. [DOI] [PubMed] [Google Scholar]
- 11.Narula S, Shameer K, Salem Omar AM, Dudley JT, Sengupta PP. Machine-Learning Algorithms to Automate Morphological and Functional Assessments in 2D Echocardiography. J Am Coll Cardiol. 2016;68:2287–2295. [DOI] [PubMed] [Google Scholar]
- 12.Masetic Z, Subasi A. Congestive heart failure detection using random forest classifier. Comput Methods Programs Biomed. 2016;130:54–64. [DOI] [PubMed] [Google Scholar]
- 13.Alizadehsani R, Habibi J, Alizadeh Sani Z, Mashayekhi H, Boghrati R, Ghandeharioun A, Khozeimeh F, Alizadeh-Sani F. Diagnosing Coronary Artery Disease via Data Mining Algorithms by Considering Laboratory and Echocardiography Features. Res Cardiovasc Med. 2013;2:133–139. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Lahdenoja O, Hurnanen T, Iftikhar Z, Nieminen S, Knuutila T, Saraste A, Kiviniemi T, Vasankari T, Airaksinen J, Pankaala M, Koivisto T. Atrial Fibrillation Detection via Accelerometer and Gyroscope of a Smartphone. IEEE J Biomed Heal Informatics. 2018;22:108–118. [DOI] [PubMed] [Google Scholar]
- 15.Austin PC, Tu JV., Ho JE, Levy D, Lee DS. Using methods from the data-mining and machine-learning literature for disease classification and prediction: A case study examining classification of heart failure subtypes. J Clin Epidemiol. 2013;66:398–407. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Kao DP, Lewsey JD, Anand IS, Massie BM, Zile MR, Carson PE, McKelvie RS, Komajda M, McMurray JJ, Lindenfeld JA. Characterization of subgroups of heart failure patients with preserved ejection fraction with possible implications for prognosis and treatment response. Eur J Heart Fail. 2015;17:925–935. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Venkatesan P, Yamuna NR. Treatment Response Classification in Randomized Clinical Trials: A Decision Tree Approach. Indian J Sci Technol. 2013;6:3912–3917. [Google Scholar]
- 18.Cheng C-A, Chiu H-W. An Artificial Neural Network Model for the Evaluation of Carotid Artery Stenting Prognosis Using a National-Wide Database. Conf Proc IEEE Eng Med Biol Soc. 2017;2017:2566–2569. [DOI] [PubMed] [Google Scholar]
- 19.Mortazavi BJ, Downing NS, Bucholz EM, Dharmarajan K, Manhapra A, Li SX, Negahban SN, Krumholz HM. Analysis of Machine Learning Techniques for Heart Failure Readmissions. Circ Cardiovasc Qual Outcomes. 2016;9:629–640. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Jiang F, Jiang Y, Zhi H, Dong Y, Li H, Ma S, Wang Y, Dong Q, Shen H, Wang Y. Artificial intelligence in healthcare: Past, present and future. Stroke Vasc Neurol. 2017;2:230–243. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Huang C, Murugiah K, Mahajan S, Li S-X, Dhruva SS, Haimovich JS, Wang Y, Schulz WL, Testani JM, Wilson FP, Mena CI, Masoudi FA, Rumsfeld JS, Spertus JA, Mortazavi BJ, Krumholz HM. Enhancing the prediction of acute kidney injury risk after percutaneous coronary intervention using machine learning techniques: A retrospective cohort study. PLoS Med. 2018;15:e1002703. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Bradley EH, Herrin J, Elbel B, McNamara RL, Magid DJ, Nallamothu BK, Wang Y, Normand S-LT, Spertus JA, Krumholz HM. Hospital quality for acute myocardial infarction: correlation among process measures and relationship with short-term mortality. JAMA. 2006;296:72–78. [DOI] [PubMed] [Google Scholar]
- 23.Peterson ED, Dai D, DeLong ER, Brennan JM, Singh M, Rao SV, Shaw RE, Roe MT, Ho KKL, Klein LW. Contemporary mortality risk prediction for percutaneous coronary intervention: results from 588,398 procedures in the National Cardiovascular Data Registry. J Am Coll Cardiol. 2010;55:1923–1932. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Miotto R, Li L, Kidd BA, Dudley JT. Deep Patient: An Unsupervised Representation to Predict the Future of Patients from the Electronic Health Records. Sci Rep. 2016;6:26094. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Ho JC, Ghosh J, Steinhubl SR, Stewart WF, Denny JC, Malin BA, Sun J. Limestone: High-throughput candidate phenotype generation via tensor factorization. J Biomed Inform. 2014;52:199–211. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Henderson J, Ke J, Ho JC, Ghosh J, Wallace BC. Phenotype Instance Verification and Evaluation Tool (PIVET): A Scaled Phenotype Evidence Generation Framework Using Web-Based Medical Literature. J Med Internet Res. 2018;20:e164. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Marso SP, Amin AP, House JA, Kennedy KF, Spertus JA, Rao SV, Cohen DJ, Messenger JC, Rumsfeld JS, Registry NCD. Association between use of bleeding avoidance strategies and risk of periprocedural bleeding among patients undergoing percutaneous coronary intervention. JAMA. 2010;303:2156–2164. [DOI] [PubMed] [Google Scholar]
- 28.Patel KK, Arnold SV, Chan PS, Tang Y, Pokharel Y, Jones PG, Spertus JA. Personalizing the intensity of blood pressure control: modeling the heterogeneity of risks and benefits from SPRINT (Systolic Blood Pressure Intervention Trial). Circ Cardiovasc Qual Outcomes. 2017;10:e003624. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Ahmad T, Pencina MJ, Schulte PJ, O’Brien E, Whellan DJ, Piña IL, Kitzman DW, Lee KL, O’Connor CM, Felker GM. Clinical implications of chronic heart failure phenotypes defined by cluster analysis. J Am Coll Cardiol. 2014;64:1765–1774. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Lantos JD, Spertus JA. The concept of risk in comparative effectiveness research. N Engl J Med. 2015;372:884. [DOI] [PubMed] [Google Scholar]
- 31.Kass-Hout TA, Stevens LM, Hall JL. American Heart Association precision medicine platform. Circulation. 2018;137:647–649. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Shah SJ, Katz DH, Selvaraj S, Burke MA, Yancy CW, Gheorghiade M, Bonow RO, Huang C-CC, Deo RC. Phenomapping for novel classification of heart failure with preserved ejection fraction. Circulation. 2015;131:269–279. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Pfitzner D, Leibbrandt R, Powers D. Characterization and evaluation of similarity measures for pairs of clusterings. Knowl Inf Syst. 2009;19:361–394. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.