

Abstract
It is increasingly common to encounter data from dynamic processes captured by static cross-sectional measurements over time, particularly in biomedical settings. Recent attempts to model individual trajectories from this data use optimal transport to create pairwise matchings between time points. However, these methods cannot model continuous dynamics and non-linear paths that entities can take in these systems. To address this issue, we establish a link between continuous normalizing flows and dynamic optimal transport, that allows us to model the expected paths of points over time. Continuous normalizing flows are generally under constrained, as they are allowed to take an arbitrary path from the source to the target distribution. We present TrajectoryNet, which controls the continuous paths taken between distributions to produce dynamic optimal transport. We show how this is particularly applicable for studying cellular dynamics in data from single-cell RNA sequencing (scRNA-seq) technologies, and that TrajectoryNet improves upon recently proposed static optimal transport-based models that can be used for interpolating cellular distributions.
1. Introduction
In data science we are often confronted with cross-sectional samples of time-varying phenomena, especially in biomedical data. Examples include health measurements of different age cohorts (Oeppen & Vaupel, 2002), or disease measurements at different stages of disease progression (Waddington, 1942). In these measurements we consider data that is sampled at multiple timepoints, but at each timepoint we have access only to a distribution (cross-section) of the population at that time. Extracting the longitudinal dynamics of development or disease from static snapshot measurements can be challenging as there are few methods of interpolation between distributions. Further exacerbating this problem is the fact that the same entities are often not measured at each time, resulting in a lack of point-to-point correspondences. Here, we propose to formulate this problem as one of unbalanced dynamic transport, where the goal is to transport entities from one cross sectional measurement to the next using efficient and smooth paths. Our main contribution is to establish a link between continuous normalizing flows (CNF) (Grathwohl et al., 2019) and dynamic optimal transport (Benamou & Brenier, 2000), allowing us to efficiently solve the transport problem using a Neural ODE framework (Chen et al., 2018a). To our knowledge, TrajectoryNet1 is the first method to consider the specific paths taken by a CNF between distributions.
The continuous normalizing flow formulation allows us to generalize optimal transport to a series of distributions as in recent work (Chen et al., 2018b; Benamou et al., 2019). These works focus on the theoretical aspects of the problem, here focus on the computational aspects. This link allows us to smooth flows over multiple and possibly unevenly spaced distributions in high dimensions. This matches the setting of time series data from single-cell RNA sequencing.
Single-cell RNA sequencing (Macosko et al., 2015) is a relatively new technology that has made it possible for scientists to randomly sample the entire transcriptome, i.e., 20–30 thousand species of mRNA molecules representing transcribed genes of the cell. This technology can reveal detailed information about the identity of individual cells based on transcription factors, surface marker expression, cell cycle and many other facets of cellular behavior. In particular, this technology can be used to learn how cells differentiate from one state to another: for example, from embryonic stem cells to specified lineages such as neuronal or cardiac. However, hampering this understanding is the fact that scRNA-seq only offers static snapshots of data, since all cells are destroyed upon measurement. Thus it is impossible to monitor how an individual cell changes over time. Moreover, due to the expensive nature of this technology, generally only a handful of discrete timepoints are collected in measuring any transition process. TrajectoryNet is especially well suited to this data modality. Existing methods attempt to infer a trajectory within one timepoint (Haghverdi et al., 2016; Saelens et al., 2019; La Manno et al., 2018), or interpolate linearly between two timepoints (Yang & Uhler, 2019; Schiebinger et al., 2019), but TrajectoryNet can interpolate non-linearly using information from more than two timepoints. TrajectoryNet has advantages over existing methods in that it:
can interpolate by following the manifold of observed entities between measured timepoints, thereby solving the static-snapshot problem,
can create continuous-time trajectories of individual entities, giving researchers the ability to follow an entity in time,
forms a deep representational model of system dynamics, which can then be used to understand drivers of dynamics (gene logic in the cellular context), via perturbation of this deep model.
While our experiments apply this work specifically to cellular dynamics, these penalties can be used in many other situations where we would like to model dynamics based on cross-sectional population level data.
2. Background and Related Work
Optimal Transport.
Introduced originally by (Monge, 1781) and in modern form by (Kantorovich, 1942), the linear program formulation of static optimal transport (OT) has the relatively high cost of O(n3) for discrete measures. Recently, there have been a number of fast approximations using entropic regularization. Cuturi (2013) presented a parallel algorithm for the discrete case as an application of Sinkhorn’s algorithm (Sinkhorn, 1964). Recent effort approximates OT on subspaces (Muzellec & Cuturi, 2019) or even a single dimension (Kolouri et al., 2019). These efforts emphasis the importance to the field of obtaining fast OT algorithms. Another direction that has recently received increased attention is in unbalanced optimal transport where the goal is to relax the problem to add and remove mass (Benamou, 2003; Chizat et al., 2018; Liero et al., 2018; Schiebinger et al., 2019). While many efficient static optimal transport algorithms exist, and recently for the unbalanced case (Yang & Uhler, 2019), much less attention has focused on dynamic optimal transport, the focus of this work.
Dynamic Optimal Transport.
Another formulation of optimal transport is known as dynamic optimal transport. Benamou & Brenier (2000) showed how the addition of a natural time interpolation variable gives an alternative interpretation with links to fluid dynamics that surprisingly leads to a convex optimization problem. However, while solvers for the discretized dynamic OT problem are effective in low dimensions and for small problems they require a discretization of space into grids giving cost exponential in the dimension (See Peyré & Cuturi (2019) Chap. 7 for a good overview of this problem). One of our main contributions is to provide an approximate solver for high dimensional smooth problems using a neural network.
Single-cell Trajectories from a Static Snapshot.
Temporal interpolation in single-cell data started with solutions that attempt to infer an axis within one single time point of data cell “pseudotime” – used as a proxy for developmental progression – using known markers of development and the asynchronous nature of cell development (Trapnell et al., 2014; Bendall et al., 2014). An extensive comparison of 45 methods for this type of analysis gives method recommendations based on prior assumptions on the general structure of the data (Saelens et al., 2019). However, these methods can be biased and fail in a number of circumstances (Weinreb et al., 2018; Lederer & La Manno, 2020) and do not take into account experimental time.
Matching Populations from Multiple Time Points.
Recent methods get around some of these challenges using multiple timepoints (Hashimoto et al., 2016; Schiebinger et al., 2019; Yang & Uhler, 2019). However, these methods generally resort to matching populations between coarse-grained timepoints, but do not give much insight into how they move between measured timepoints. Often paths are assumed to minimize total Euclidean cost, which is not realistic in this setting. In contrast, the methods that estimate dynamics from single timepoints (La Manno et al., 2018; Bergen et al., 2019; Erhard et al., 2019; Hendriks et al., 2019) have the potential to give relatively accurate estimation of local direction, but cannot give accurate global estimation of distributional shift. A recent line of work on generalizing splines to distributions (Chen et al., 2018b; Benamou et al., 2019) investigates this problem from a theoretical perspective, but provides no efficient implementation.
With TrajectoryNet, we aim to unite these approaches into a single model combining in inferring continuous time trajectories from multiple timepoints, globally, while respecting local dynamics within a single timepoint.
3. Preliminaries
We provide an overview of static optimal transport, dynamic optimal transport (Benamou & Brenier, 2000), and continuous normalizing flows.
3.1. The Monge-Kantorovich Problem
We adopt notation from the standard text (Villani, 2008). For two probability measures μ, ν defined on , let Π(μ, ν) denote the set of all joint probability measures on whose marginals are μ and ν. Then the p-Kantorovich distance (or Wasserstein distance of order p)between μ and ν is
| (1) |
where p ∈ [1, ∞). This formulation has led to many useful interpretations both in GANs and biological networks. For the entropy regularized problem, the Sinkhorn algorithm (Sinkhorn, 1964) provides a fast and parallelizable numerical solution in the discrete case. Recent work tackles computationally efficient solutions to the exact problem (Jambulapati et al., 2019) for the discrete case. However, for the continuous case solutions to the discrete problem in high dimensional spaces do not scale well. As the rate of convergence of the empirical Wasserstein metric between empirical measures and with bounded support is shown in (Dudley, 1969) to be
| (2) |
where d is the ambient dimension. However, recent work shows that in high dimensions a more careful treatment that the rate depends on the intrinsic dimension not the ambient dimension (Weed & Bach, 2019). As long as data lies in a low dimensional manifold in ambient space, then we can reasonably approximate the Wasserstein distance. In this work we approximate the support of this manifold using a neural network.
3.2. Dynamic Optimal Transport
Benamou & Brenier (2000) defined and explored a dynamic version of Kantorovich distance. Their work linked optimal transport distances with dynamics and partial differential equations (PDEs). For a fixed time interval [t0, t1] with smooth enough, time dependent density and velocity fields, P(x, t) ≥ 0, , subject to the continuity equation
| (3) |
for t0 < t < t1 and , and the conditions
| (4) |
we can relate the squared L2 Wasserstein distance to (P, f) in the following way
| (5) |
In other words, a velocity field f(x, t) with minimum L2 norm that transports mass at μ to mass at ν when integrated over the time interval is the optimal plan for an L2 Wasserstein distance. The continuity equation is applied over all points of the field and asserts that no point is a source or sink for mass. The solution to this flow can be shown to follow a pressureless flow on a time-dependent potential function. Mass moves with constant velocity that linearly interpolates between the initial and final measures. For problems where interpolation of the density between two known densities is of interest, this formulation is very attractive. Existing computational methods for solving the dynamic formulation for continuous measures approximate the flow using a discretization of space-time (Papadakis et al., 2014). This works well in low dimensions, but scales poorly to high dimensions as the complexity is exponential in the input dimension d. We next give background on continuous normalizing flows, which we show can provide a solution with computational complexity polynomial in d.
3.3. Continuous Normalizing Flows
A normalizing flow (Rezende & Mohamed, 2015) transforms a parametric (usually simple) distribution to a more complicated one. Using an invertible transformation f applied to an initial latent random variable y with density Py, We define x = f(y) as the output of the flow. Then by the change of variables formula, we can compute the density of the output x:
| (6) |
A large effort has gone into creating architectures where the log determinant of the Jacobian is efficient to compute (Rezende & Mohamed, 2015; Kingma et al., 2016; Papamakarios et al., 2017).
Now consider a continuous-time transformation, where the derivative of the transformation is parameterized by θ, thus at any timepoint t, . At the initial time t0, x(t0) is drawn from a distribution P (x, t0) which we also denote Pt0 (x) for clarity, and it’s continuously transformed to x(t1) by following the differential equation fθ(x(t), t):
| (7) |
where at any time t associated with every x through the flow can be found by following the inverse flow. This model is referred as continuous normalizing flows (CNFs) (Chen et al., 2018a). It can be likened to the dynamic version of optimal transport, where we model the measure over time rather than the mapping from to
Unsurprisingly, there is a deep connection between CNFs and dynamic optimal transport. In the next section we exploit this connection and show how CNFs can be used to provide a high dimensional solution to the dynamic optimal transport problem with TrajectoryNet.
4. TrajectoryNet: Efficient Dynamic Optimal Transport
In this section, we first describe how to adapt continuous normalizing flows to approximate dynamic optimal transport in (Section 4.1). We then describe further adaptations for analysis of single-cell data in (Section 4.2) and finally provide training details in (Section 4.3).
4.1. Dynamic OT Approximation via Regularized CNF
Continuous normalizing flows use a maximum likelihood objective which can be equivalently expressed as a KL divergence. In TrajectoryNet we add an energy regularization to approximate dynamic OT. Dynamic OT is expressed with an optimization over flows with constraints at t0 and t1 (see eq. (4)). By relaxing this constraint to minimizing a divergence at t1 CNFs can approximate dynamic OT.
For sufficiently large λ under constraint (3) this converges to the optimal solution in (5). This is encapsulated in the following theorem. See Appendix A.1 for proof.
Theorem 4.1. With time varying field and density such that ∫ P(x, t)dx = 1 for all t0 ≤ t ≤ t1 and subject to the continuity (3). There exists a sufficiently large λ such that
Intuitively, a continuous normalizing flow with a correctly scaled penalty on the squared norm of f approximates the W2 transport between μ and ν. Dynamic optimal transport can be thought of as finding a distribution over paths such that the beginnings of the paths match the source distribution, end of the path matches the target distribution, and the cost of the transport is measured by expected path length. Continuous normalizing flows relax the target distribution match with a KL-divergence penalty. When the KL-divergence is small then the constraint is satisfied. However, CNFs usually do not enforce the path length constraint, which we add using a penalty on the norm of f as defined by the Neural ODE. When we impose this penalty over uniformly sampled data, this is equivalent to penalizing the expected path length.
We can approximate the first part of this continuous time equation using a Riemann sum as . This requires a forward integration using a standard ODE solver to compute as shown in Chen et al. (2018a). If we consider the case where the divergence is small, then this can be combined with the standard backwards pass for even less added computation. Instead of penalizing ||fθ(x, t)||2 on a forward pass, we penalize the same quantity on a backwards pass. Using the maximum likelihood and KL divergence equivalence, we obtain a loss
| (8) |
Where the integral above is computed using an ODE solver. In practice, both a penalty on the Jacobian or additional training noise helped to get straight paths with a lower energy regularization λe. We found that a value of λe large enough to encourage straight paths, unsurprisingly also shortens the paths undershooting the target distribution. To counteract this, we add a penalty on the norm of the Jacobian of f as used in Vincent et al. (2010); Rifai et al. (2011). Since f represents the derivative of the path, this discourages paths with high local curvature, and can be thought of as penalizing the second derivative (acceleration) of the flow. Our energy loss is then
| (9) |
where is the Frobenius norm of the Jacobian of f. Comparing Figure 2(e) to (d) we demonstrate the effect of this regularization. Without energy regularization TrajectoryNet paths follow the data. However, with energy regularization we approach the paths of the optimal map. TrajectoryNet solution biases towards undershooting the target distribution. Our energy loss gives control over how much to penalize indirect, high energy paths.
Figure 2.
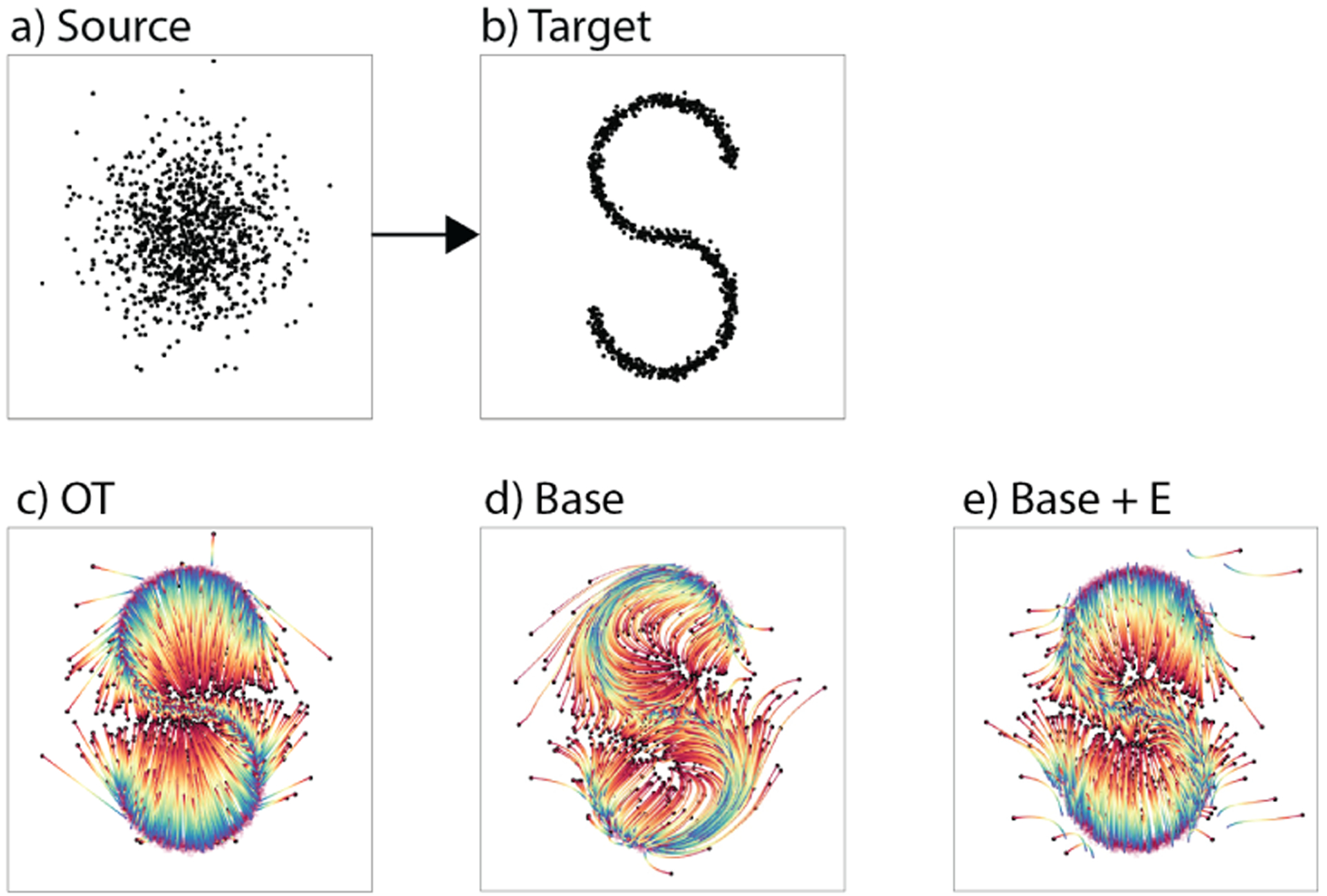
Transporting a Gaussian (a) to an S-curve (b) via (c) static optimal transport, (d) Base TrajectoryNet without regularization follows density (e) TrajectoryNet with energy regularization demonstrates more straight paths similar to OT.
Optimal transport is traditionally performed between a source and target distribution. Extensions to a series of distributions is normally done by performing optimal transport between successive pairs of distributions as in Schiebinger et al. (2019). This creates flows that have discontinuities at the sampled times, which may be undesirable when the underlying system is smooth in time as in biological systems. The dynamic model approximates dynamic OT for two timepoints, but by using a single smooth function to model the whole series the flow becomes the minimal cost smooth flow over time.
4.2. Further Adaptation for Single-Cell Trajectories
Up to this point we have shown how to perform dynamic optimal transport in high dimensions with a regularized CNF. We now introduce priors needed to mimic cellular systems that are characterized by growth/death rather than just transport, endowed with a manifold structure, and knowledge of local velocity arrows. Similar priors may also be applicable to other data types. For example in studying the dynamics of a disease, people may be newly infected or cured, we may have knowledge on acceptable transition states, indicating a density penalty, or visits may be clustered such as in a hospital stay so we may have estimates of near term patient trends, indicating the use of velocity priors. To enforce these priors we add corresponding regularizations listed below:
A growth rate regularization that accommodates unbalanced transport, described in Section 4.2.1.
A density-based penalty which encourages interpolations that lie on dense regions of the data. Often data lies on a low-dimensional manifold, and it is desirable for paths to follow this manifold at the cost of higher energy (See Section 4.2.2 for details).
A velocity regularization where we enforce local estimates of velocity at measured datapoints to match the first time derivative of cell state change. (See Section 4.2.3 for details).
These regularizations are summarized in a single loss function defined as
| (10) |
4.2.1. Allowing Unbalanced Optimal Transport
We use a simple and computationally efficient method that adapts discrete static unbalanced optimal transport to our framework in the continuous setting. This is a necessary extension but is by no means a focus of our work. While we could also apply an adversarial framework, we choose to avoid the instabilities of adversarial training and use a simple network trained from the solution to the discrete problem. We train a network , which takes as input a cell state and time pair and produces a growth rate of a cell at that time. This is trained to match the result from discrete optimal transport. For further specification see Appendix B. We then fix weights of this network and modify the way we integrate mass over time to
| (11) |
We note that adding growth rate regularization in this way does not guarantee conservation of mass. We could normalize M(x) to be a probability distribution during training, e.g., as . However, this now requires an integration over , which is too computationally costly. Instead, we use the equivalence of the maximum likelihood formulation over a fixed growth function g and normalize it after the network is trained.
4.2.2. Enforcing Transport on a Manifold
Methods that display or perform computations on the cellular manifold often include an implicit or explicit way of normalizing for density and model data geometry. PHATE (Moon et al., 2019) uses scatter plots and adaptive kernels to display the geometry. SUGAR (Lindenbaum et al., 2018) explicitly models the data geometry. We would like to constrain our flows to the manifold geometry but not to its density. We penalize the flow such that it is always close to at least a few measured points across all timepoints.
| (12) |
This can be thought of as a loss that penalizes points until they are within h Euclidean distance of their k nearest neighbors. We use h = 0.1 and k = 5 in all of our experiments. We evaluate Ldensity on an interpolated time td ∈ (t0, tk) every batch.
4.2.3. Conforming to known Velocity
Often it is the case where it is easy to measure direction of change in a short time horizon, but not have good predictive power at the scale of measured timesteps. In health data, we can often collect data from a few visits over a short time horizon estimating the direction of a single patient in the near future. In single-cell data, RNA-velocity (La Manno et al., 2018; Bergen et al., 2019) provides an estimates at every measured cell. We use these measurements to regularize the direction of flow at every measured point. Our regularization requires evaluating f(x, t) periodically at every measured cell adding the regularization:
| (13) |
This encourages the direction of the flow at a measured point to be similar to the direction of local velocity. This ignores the magnitude of the estimate, and only heeds the direction. While RNA-velocity provides some estimate of relative speed, the vector length is considered not as informative, as it is unclear how to normalize these vectors in a system specific way (La Manno et al., 2018; Bergen et al., 2019). We note that while current estimates of velocity can only estimate direction, this does not preclude future methods that can give accurate magnitude estimates. Lvelocity can easily be adapted to take magnitudes into account by considering L2 similarity for instance.
4.3. Training
For simplicity, the neural network architecture of TrajectoryNet consists of three fully connected layers of 64 nodes with leaky ReLU activations. It takes as input a cell state and time and outputs the derivative of state with respect to time at that point. To train a continuous normalizing flow we need access to the density function of the source distribution. Since this is not accessible for an empirical distribution we use an additional Gaussian at t0, defining , the standard Gaussian distribution, where Pt(x) is the density function at time t.
For a training step we draw samples for i ∈ {1, …, k} and calculate the loss with a single backwards integration of the ODE. In the following sections we will explain how adding the individual penalty terms achieve regularized trajectories. While there are a number of ways to computationally approximate these quantities, we use a parallel method to iteratively calculate the log based on log . To make a backward pass through all timepoints we start at the final timepoint, integrate the batch to the second to last timepoint, concatenate these points to the samples from the second to last timepoint, and continue till t0, where the density is known for each sample. We note that this can compound the error especially for later timepoints if k is large or if the learned system is stiff, but gives significant speedup during training.
To sample from we first sample then use the adjoint method to perform the integration .
5. Experiments
All experiments were performed with the TrajectoryNet framework with a network of consisting of three layers with LeakyReLU activations. Optimization was performed on 10,000 iterations of batches of size 1,000 using the dopri5 solver (Dormand & Prince, 1980) with both absolute and relative tolerances set to 1 × 10−5 and the ADAM optimizer (Kingma & Ba, 2015) with learning rate 0.001, and weight decay 5 × 10−5 as in (Grathwohl et al., 2019). We evaluate using three TrajectoryNet models with different regularization terms. The Base model refers to a standard normalizing flow. +E adds Lenergy, +D adds Ldensity,+V adds Lvelocity, and +G adds Lgrowth.
Comparison to Existing Methods.
Since there are no ground truth methods to calculate the trajectory of a single cell we evaluate our model using interpolation of held-out timepoints. We leave out an intermediary timepoint and measure the Kantorovich-distance also known as the earth mover’s distance (EMD) between the predicted and held-out distributions. For EMD lower is more accurate. We compare the distribution interpolated by TrajectoryNet with four other distributions. The previous timepoint, the next timepoint, a random timepoint and the McCann interpolant in the discrete OT solution as used in (Schiebinger et al., 2019).
5.1. Artificial Data
For artificial data where we have known paths, we can measure the mean squared error (MSE) predicted by the model based on the first timepoint. Here we leave out the middle timepoint t1/2 for training then calculate the MSE between the predicted point at time t1/2 and the true point at t1/2 for 5000 sampled trajectories. This gives a measure of how accurately we can model simple dynamical systems.
We first test TrajectoryNet on two datasets where points lie on a 1D manifold in 2D with Gaussian noise (See Figure 4). First two half Gaussians are sampled with means zero and one in one dimension. These progressions are then lifted onto curved manifolds in two dimensions either an arch or a tree mimicking a differentiating system where we have two sampled timepoints that have some overlap. Table 1 shows the Wasserstein distance (EMD) and the mean squared error for different interpolation methods between the interpolated distribution at t1/2 and the true interpolated distribution at t1/2. Because optimal transport considers the shortest Euclidean distance, the base model and OT methods follow the lowest energy path, which is straight across. With density regularization or velocity regularization TrajectoryNet learns paths that follow the density manifold. Figure 3 and Figure S2 demonstrate how TrajectoryNet with density or velocity regularization learns to follow the manifold.
Figure 4.
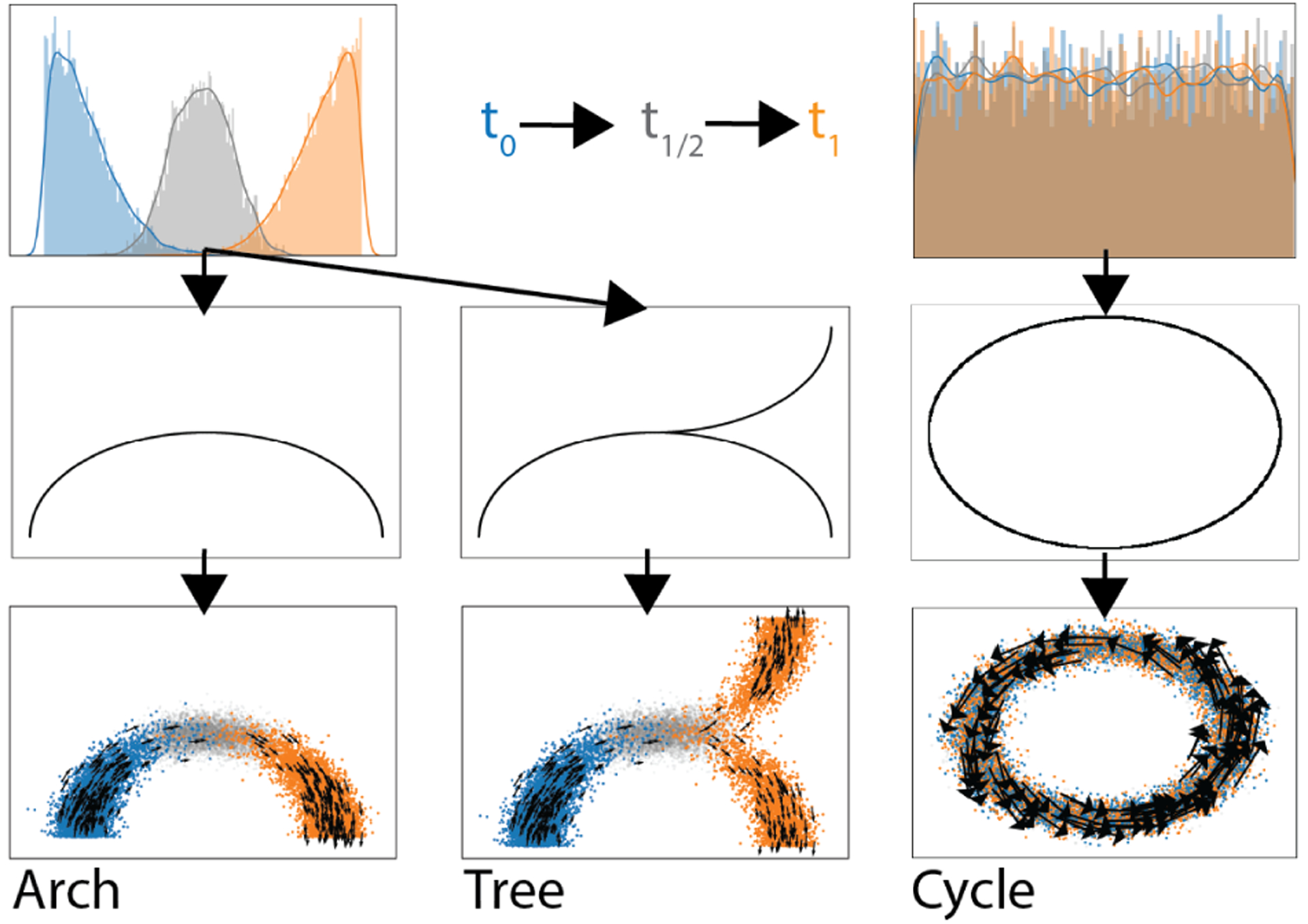
A 1D distribution of data over time embedded in two dimensions along a smooth manifold. On a single branch (left), with a tree structure (center), and circle (right).
Table 1.
Shows the Wasserstein distance EMD and MSE for artificial datasets between the left out timepoint and the predicted points for our two generated datasets. Mean over 3 seeds.
| EMD | MSE | |||||
|---|---|---|---|---|---|---|
| Arch | Cycle | Tree | Arch | Cycle | Tree | |
| Base | 0.691 | 0.037 | 0.490 | 0.300 | 0.190 | 0.218 |
| Base + D | 0.607 | 0.049 | 0.373 | 0.236 | 0.191 | 0.145 |
| Base + V | 0.243 | 0.033 | 0.143 | 0.107 | 0.068 | 0.098 |
| Base + D + V | 0.415 | 0.034 | 0.252 | 0.156 | 0.081 | 0.132 |
| OT | 0.644 | 0.032 | 0.492 | 0.252 | 0.192 | 0.196 |
| prev | 1.086 | 0.035 | 1.092 | 0.652 | 0.192 | 0.666 |
| next | 1.090 | 0.035 | 1.068 | 0.659 | 0.192 | 0.689 |
| rand | 0.622 | 0.406 | 0.420 | 0.243 | 0.346 | 0.161 |
Figure 3.
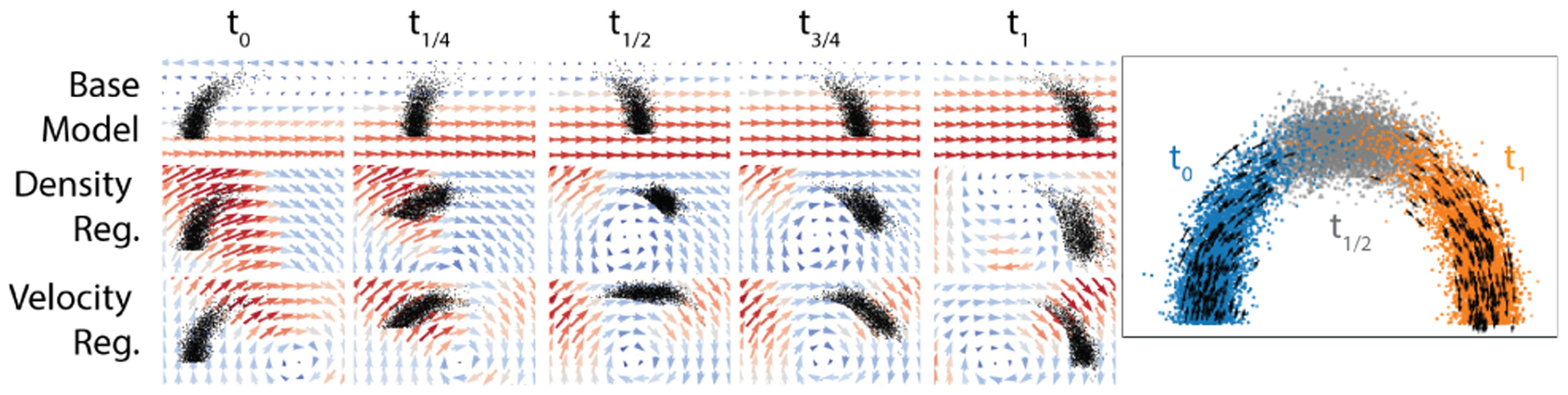
Density regularization or velocity regularization can be used to follow a 1D manifold in 2D.
A third artificial dataset shows the necessity of using velocity estimates for some data. Here we have an unchanging distribution of points distributed uniformly over the unit circle, but are traveling counterclockwise at π/5 radians per unit time. This is similar to the cell-cycle process in adult systems. Without velocity estimates it is impossible to pick up this type of dynamical system. This is illustrated by the MSE of the cycle dataset using velocity regularization in Table 1.
5.2. Single-Cell Data
We run our model on 5D PCA due to computational constraints, but note that computation time scales roughly linearly with dimension for our test cases (See Appendix C), which is consistent to what was found in Grathwohl et al. (2019). Since there are no ground truth trajectories in real data, we can only evaluate using distributional distances. We do leave-one-out validation, training the model on all but one of the intermediate timepoints then evaluating the EMD between the validation data and the model’s predicted distribution. We evaluate and compare our method on two single-cell RNA sequencing datasets.
Mouse Cortex Data.2
The first dataset has structure similar to the Arch toy dataset. It consists of cells collected from mouse embryos at days E12.5, E14.5, E16, and E17.5. In Figure 6(d) we can see at this time in development of the mouse cortex the distribution of cells moves from a mostly neural stem cell population at E12.5 to a fairly developed and differentiated neuronal population at E17.5 (Cotney et al., 2015; Katayama et al., 2016). The major axis of variation is neuron development. Over the 4 timepoints we have 2 biological replicates that we can use to evaluate variation between animals. In Table 2, we can see that TrajectoryNet outperforms baseline models, especially when adding density and velocity information. The curved manifold structure of this data, and gene expression data in general means that methods that interpolate with straight paths cannot fully capture the structure of the data. Since TrajectoryNet models full paths between timepoints, adding density and velocity information can bend the cell paths to follow the manifold utilizing all available data rather than two timepoints as in standard optimal transport.
Figure 6.
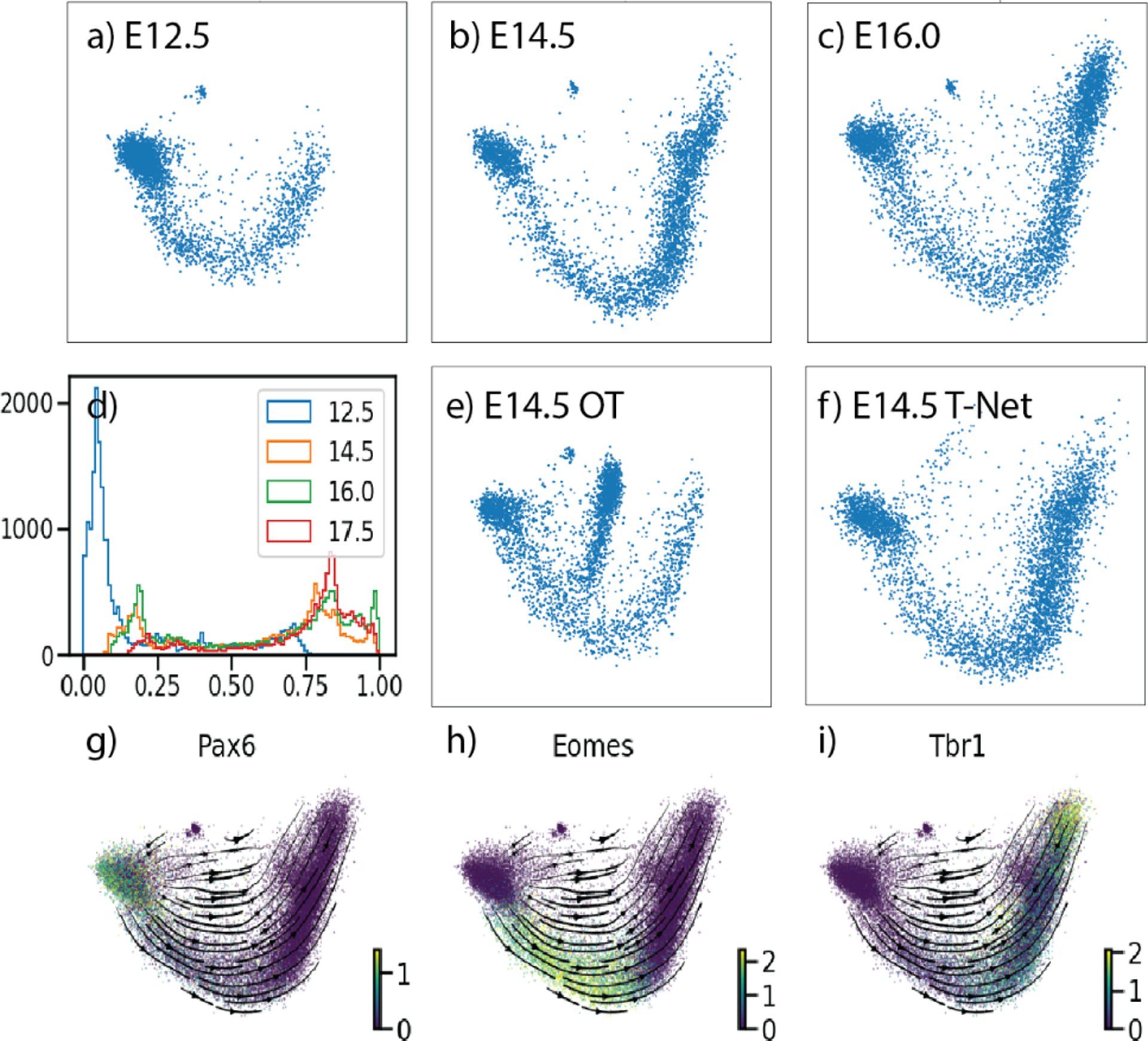
Shows the first 2 PCs of the mouse cortex dataset. (a-c) show the distributions for the first three timepoints. (d) shows the distribution of cells over PC1. the interpolated points for E14.5 using (e) static OT, and (f) TrajectoryNet with density regularization. (g-i) shows expression of three markers of early (Pax6) mid (Eomes) and late (Tbr1) stage neurons.
Table 2.
Shows the Wasserstein distance between the left out timepoint and the predicted distribution for various methods on a 4 timepoint mouse embryo cortex dataset. Mean and standard deviation over 3 seeds.
| rep1 | rep2 | mean | |
|---|---|---|---|
| Base | 0.888 ± 0.07 | 0.905 ± 0.06 | 0.897 ± 0.06 |
| Base + D | 0.882 ± 0.03 | 0.895 ± 0.03 | 0.888 ± 0.03 |
| Base + V | 0.900 ± 0.09 | 0.898 ± 0.10 | 0.899 ± 0.10 |
| Base + D + V | 0.851 ± 0.08 | 0.866 ± 0.07 | 0.859 ± 0.07 |
| OT | 1.098 | 1.095 | 1.096 |
| prev | 1.628 | 1.573 | 1.600 |
| next | 1.324 | 1.391 | 1.357 |
| rand | 1.333 | 1.288 | 1.311 |
Embryoid body Data.
Next, we evaluate on a differentiating Embryoid body scRNA-seq time course. Figure 7 shows this data projected into two dimensions using a non-linear dimensionality reduction method called PHATE (Moon et al., 2019). This data consists of 5 timepoints of single cell data collected in a developing human embryo system (Day 0-Day 24). See Figure 5 for a depiction of the growth rate. Initially, cells start as a single stem cell population, but differentiate into roughly 4 cell precursor types. This gives a branching structure similar to our artificial tree dataset. In Table 3 we show results when each of the three intermediate timepoints are left out. In this case velocity regularization does not seem to help, we hypothesis this has to do with the low unspliced RNA counts present in the data (See Figure S3). We find that energy regularization and growth rate regularization help only on the first timepoint, and that density regularization helps the most overall.
Figure 7.
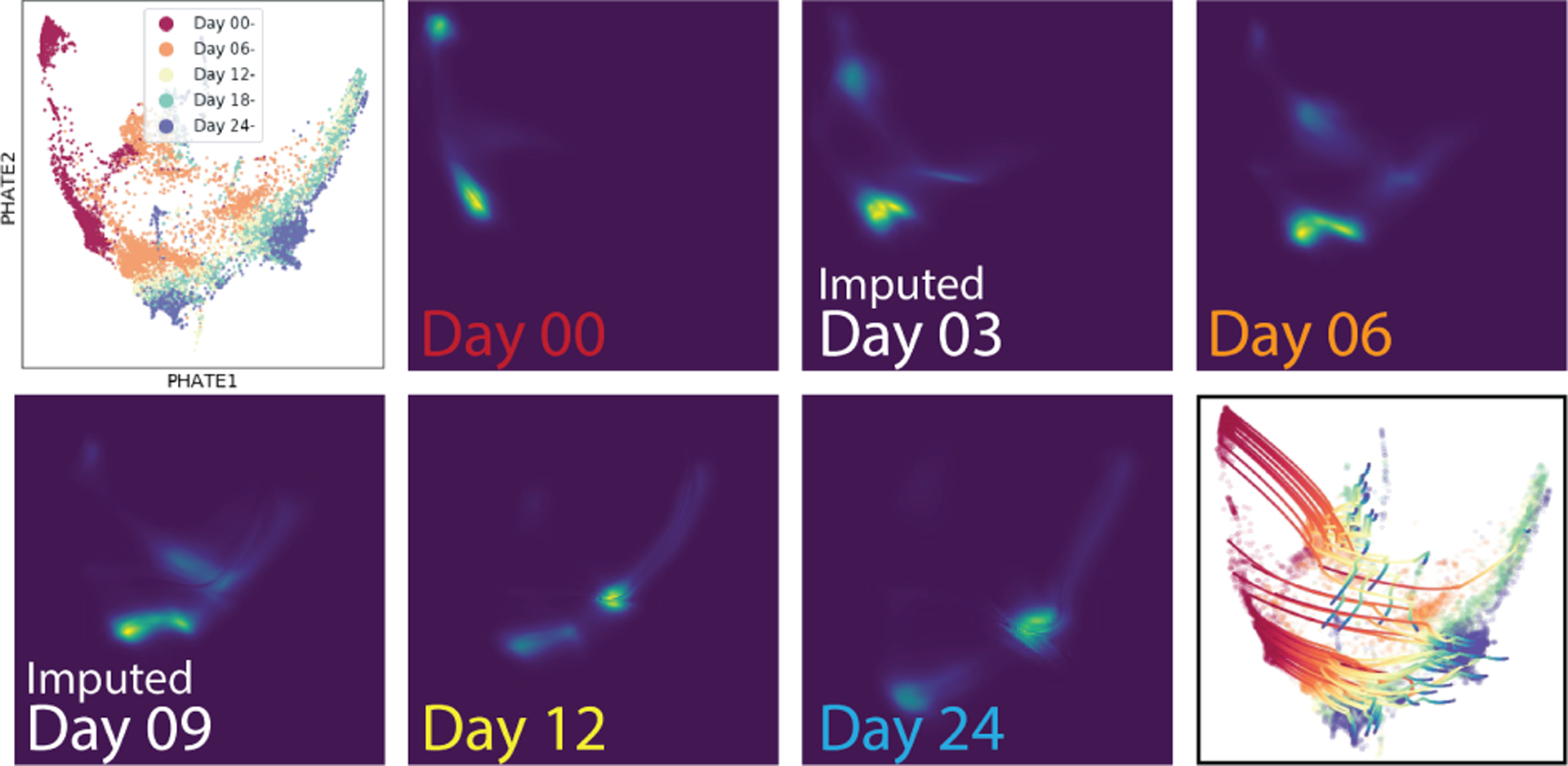
Shows the Embryoid body dataset projected into 2D with PHATE (Moon et al., 2019) with paths and densities imputed using TrajectoryNet.
Figure 5.
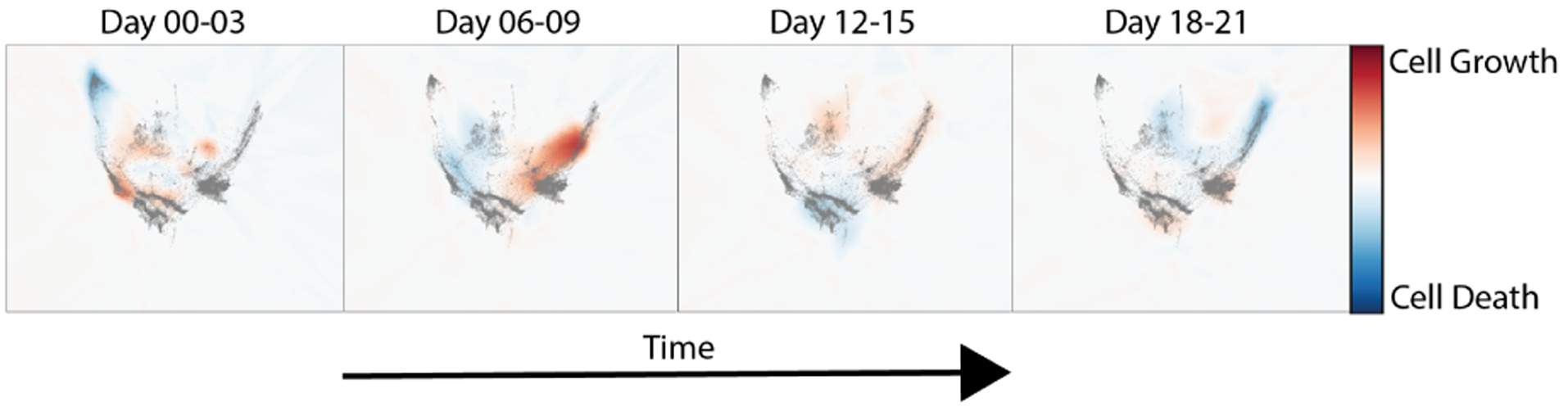
Cell growth model learned on Embryoid Body Data (Moon et al., 2019)
Table 3.
Shows the Wasserstein distance (EMD) between the left out timepoint and the predicted distribution for various methods on the 5 timepoint Embryoid body dataset.
| t=1 | t=2 | t=3 | mean | |
|---|---|---|---|---|
| Base | 0.764 | 0.811 | 0.863 | 0.813 |
| Base + D | 0.759 | 0.783 | 0.811 | 0.784 |
| Base + V | 0.816 | 0.839 | 0.865 | 0.840 |
| Base + D + V | 0.930 | 0.806 | 0.810 | 0.848 |
| Base + E | . 0.737 | 0.896 | 0.842 | 0.825 |
| Base + G | 0.700 | 0.913 | 0.829 | 0.814 |
| OT | 0.791 | 0.831 | 0.841 | 0.821 |
| prev | 1.715 | 1.400 | 0.814 | 1.309 |
| next | 1.400 | 0.814 | 1.694 | 1.302 |
| rand | 0.872 | 1.036 | 0.998 | 0.969 |
We can also project trajectories back to gene space. This gives insights into when populations might be distinguishable. In Figure 8, we demonstrate how TrajectoryNet can be projected back to the gene space. We sample cells from the end of the four main branches, then integrate TrajectoryNet backwards to get their paths through gene space. This recapitulates known biology in Moon et al. (2019). See appendix D for a more in-depth treatment.
Figure 8.
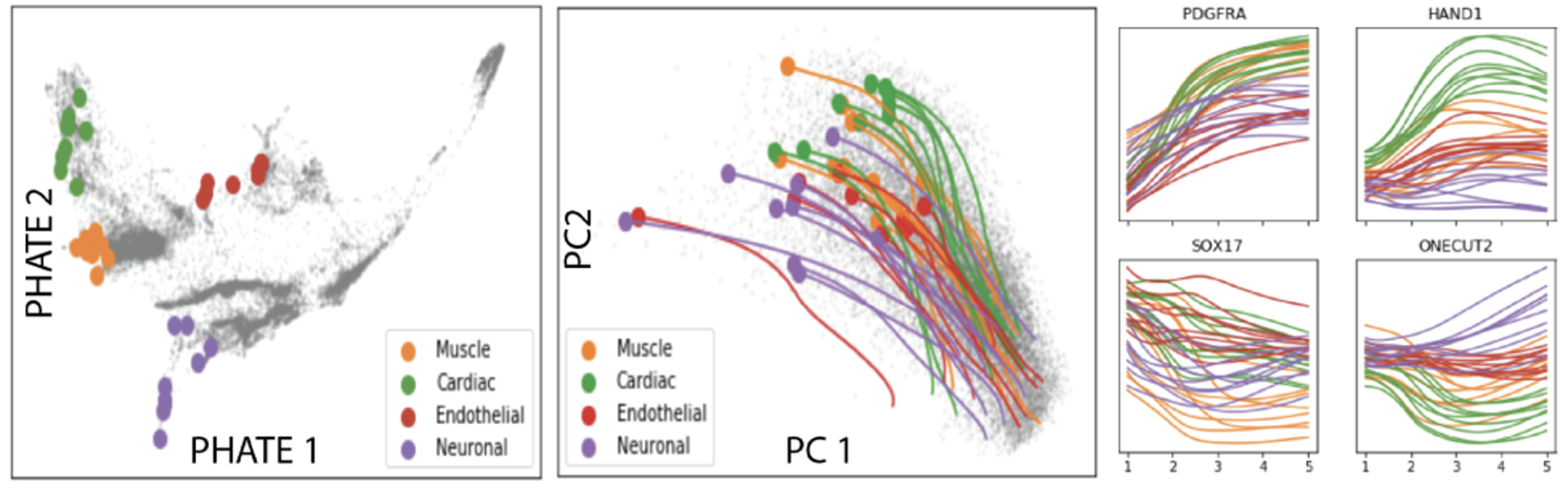
For curated endpoints, shows location on PHATE dimensions, TrajectoryNet paths projected into PCA space, and trajectories for 4 genes.
6. Conclusion
TrajectoryNet computes dynamic optimal transport between distributions of samples at discrete times to model realistic paths of samples continuously in time. In the single-cell case, TrajectoryNet ”reanimates,” cells which are destroyed by measurement to recreate a continuous-time trajectory. This is also relevant when modeling any underlying system that is high-dimensional, dynamic, and non-linear. In this case, existing static OT methods are under-powered and do not interpolate well to intermediate timepoints between measured ones. Existing dynamic OT methods (non-neural network based) are computationally infeasible for this task.
In this work we integrate multiple priors and assumptions into one model to bias TrajectoryNet towards more realistic dynamic optimal transport solutions. We demonstrated how this gives more power to discover hidden and time specific relationships between features. In future work, we would like to consider stochastic dynamics (Li et al., 2020) and learning the growth term together with the dynamics.
Supplementary Material
Figure 1.
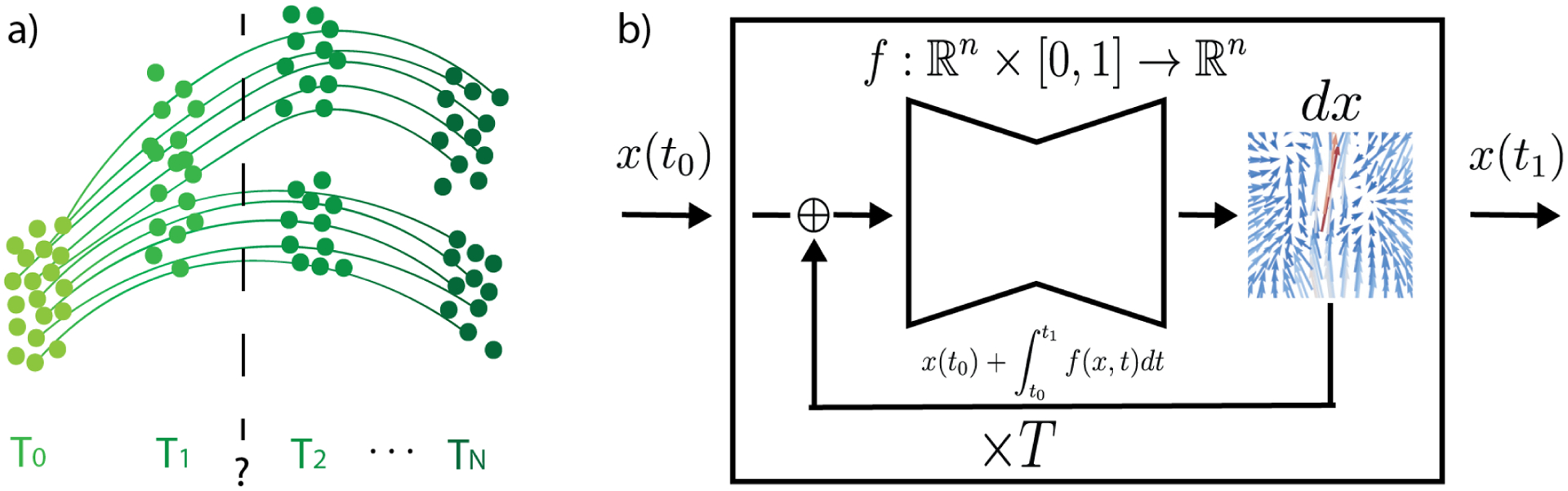
TrajectoryNet learns trajectories of particles from distributions sampled over time. We use a Neural ODE to learn the derivative of the dynamics function. To find the output at time t1 for a given input at time t0 we integrate T times letting the ODE solver choose the integration timepoints.
Acknowledgements
This research was partially funded by IVADO (l’institut de valorisation des données) [G.W.]; Chan-Zuckerberg Initiative grants 182702 & CZF2019-002440 [S.K.]; and NIH grants R01GM135929 & R01GM130847 [G.W., S.K.]. The content provided here is solely the responsibility of the authors and does not necessarily represent the official views of the funding agencies.
Footnotes
Code is available here: https://github.com/KrishnaswamyLab/TrajectoryNet
For videos of the dynamics learned by TrajectoryNet see http://github.com/krishnaswamylab/TrajectoryNet
References
- Benamou J-D Numerical resolution of an “unbalanced” mass transport problem. ESAIM: Mathematical Modelling and Numerical Analysis, 37(5):851–868, 2003. [Google Scholar]
- Benamou J-D and Brenier Y A computational fluid mechanics solution to the Monge-Kantorovich mass transfer problem. Numerische Mathematik, 84(3):375–393, 2000. [Google Scholar]
- Benamou J-D, Gallouët TO, and Vialard F-X Second-Order Models for Optimal Transport and Cubic Splines on the Wasserstein Space. Foundations of Computational Mathematics, 19(5):1113–1143, 2019. [Google Scholar]
- Bendall SC, Davis KL, Amir E.-a. D., Tadmor MD, Simonds EF, Chen TJ, Shenfeld DK, Nolan GP, and Pe’er D Single-Cell Trajectory Detection Uncovers Progression and Regulatory Coordination in Human B Cell Development. Cell, 157(3):714–725, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bergen V, Lange M, Peidli S, Wolf FA, and Theis FJ Generalizing RNA velocity to transient cell states through dynamical modeling. BioRxiv 820936, 2019. [DOI] [PubMed] [Google Scholar]
- Chen RTQ, Rubanova Y, Bettencourt J, and Duvenaud D Neural Ordinary Differential Equations. In Advances in Neural Information Processing Systems 31, 2018a. [Google Scholar]
- Chen Y, Conforti G, and Georgiou TT Measure-Valued Spline Curves: An Optimal Transport Viewpoint. SIAM Journal on Mathematical Analysis, 50(6):5947–5968, 2018b. [Google Scholar]
- Chizat L, Peyré G, Schmitzer B, and Vialard F-X Unbalanced optimal transport: Dynamic and Kantorovich formulations. Journal of Functional Analysis, 274(11): 3090–3123, 2018. [Google Scholar]
- Cotney J, Muhle RA, Sanders SJ, Liu L, Willsey AJ, Niu W, Liu W, Klei L, Lei J, Yin J, Reilly SK, Tebbenkamp AT, Bichsel C, Pletikos M, Sestan N, Roeder K, State MW, Devlin B, and Noonan JP The autism-associated chromatin modifier CHD8 regulates other autism risk genes during human neurodevelopment. Nature Communications, 6(1):6404, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cuturi M Sinkhorn Distances: Lightspeed Computation of Optimal Transport. In Advances in Neural Information Processing Systems 26, pp. 2292–2300, 2013. [Google Scholar]
- Dormand J and Prince P A family of embedded Runge-Kutta formulae. Journal of Computational and Applied Mathematics, 6(1):19–26, 1980. [Google Scholar]
- Dudley RM The Speed of Mean Glivenko-Cantelli Convergence. The Annals of Mathematical Statistics, 40(1): 40–50, 1969. [Google Scholar]
- Erhard F, Baptista MAP, Krammer T, Hennig T, Lange M, Arampatzi P, Jürges CS, Theis FJ, Saliba A-E, and Dölken L scSLAM-seq reveals core features of transcription dynamics in single cells. Nature, 571(7765):419–423, 2019. [DOI] [PubMed] [Google Scholar]
- Grathwohl W, Chen RTQ, Bettencourt J, Sutskever I, and Duvenaud D FFJORD: Free-form Continuous Dynamics for Scalable Reversible Generative Models. In 7th International Conference on Learning Representations, 2019. [Google Scholar]
- Haghverdi L, Büttner M, Wolf FA, Buettner F, and Theis FJ Diffusion pseudotime robustly reconstructs lineage branching. Nature Methods, 13(10):845–848, 2016. [DOI] [PubMed] [Google Scholar]
- Hashimoto TB, Gifford DK, and Jaakkola TS Learning Population-Level Diffusions with Generative Recurrent Networks. In Proceedings of the 33rd International Conference on Machine Learning, pp. 2417–2426, 2016. [Google Scholar]
- Hendriks G-J, Jung LA, Larsson AJM, Lidschreiber M, Andersson Forsman O, Lidschreiber K, Cramer P, and Sandberg R NASC-seq monitors RNA synthesis in single cells. Nature Communications, 10(1):3138, 2019. ISSN 2041–1723. doi: 10.1038/s41467-019-11028-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jambulapati A, Sidford A, and Tian K A Direct Õ(1/ϵ) Iteration Parallel Algorithm for Optimal Transport. In Advances in Neural Information Processing Systems 32, pp. 11359–11370, 2019. [Google Scholar]
- Kanton S, Boyle MJ, He Z, Santel M, Weigert A, Sanchís-Calleja F, Guijarro P, Sidow L, Fleck JS, Han D, Qian Z, Heide M, Huttner WB, Khaitovich P, Pääbo S, Treutlein B, and Camp JG Organoid single-cell genomic atlas uncovers human-specific features of brain development. Nature, 574(7778):418–422, 2019. [DOI] [PubMed] [Google Scholar]
- Kantorovich LV On the Translocation of Masses. Doklady Akademii Nauk, 1942. [Google Scholar]
- Katayama Y, Nishiyama M, Shoji H, Ohkawa Y, Kawamura A, Sato T, Suyama M, Takumi T, Miyakawa T, and Nakayama KI CHD8 haploinsufficiency results in autistic-like phenotypes in mice. Nature, 537(7622): 675–679, 2016. [DOI] [PubMed] [Google Scholar]
- Kingma DP and Ba J Adam: A Method for Stochastic Optimization. In 3rd International Conference on Learning Representations, 2015. [Google Scholar]
- Kingma DP, Salimans T, Jozefowicz R, Chen X, Sutskever I, and Welling M Improving Variational Inference with Inverse Autoregressive Flow. In Advances in Neural Information Processing Systems 29, 2016. [Google Scholar]
- Kolouri S, Nadjahi K, Simsekli U, Badeau R, and Rohde G Generalized Sliced Wasserstein Distances. In Advances in Neural Information Processing Systems 32, pp. 261–272, 2019. [Google Scholar]
- La Manno G, Soldatov R, Zeisel A, Braun E, Hochgerner H, Petukhov V, Lidschreiber K, Kastriti ME, Lönnerberg P, Furlan A, Fan J, Borm LE, Liu Z, van Bruggen D, Guo J, He X, Barker R, Sundström E, Castelo-Branco G, Cramer P, Adameyko I, Linnarsson S, and Kharchenko PV RNA velocity of single cells. Nature, 560(7719):494–498, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lederer AR and La Manno G The emergence and promise of single-cell temporal-omics approaches. Current Opinion in Biotechnology, 63:70–78, 2020. [DOI] [PubMed] [Google Scholar]
- Li X, Wong T-KL, Chen RTQ, and Duvenaud D Scalable Gradients for Stochastic Differential Equations. Artificial Intelligence and Statistics, 2020. [Google Scholar]
- Liero M, Mielke A, and Savaré G Optimal Entropy-Transport problems and a new Hellinger–Kantorovich distance between positive measures. Inventiones mathematicae, 211(3):969–1117, 2018. [Google Scholar]
- Lindenbaum O, Stanley J, Wolf G, and Krishnaswamy S Geometry Based Data Generation. In Advances in Neural Infromation Processing Systems 31, pp. 1400–1411, 2018. [Google Scholar]
- Macosko EZ, Basu A, Satija R, Nemesh J, Shekhar K, Goldman M, Tirosh I, Bialas AR, Kamitaki N, Martersteck EM, Trombetta JJ, Weitz DA, Sanes JR, Shalek AK, Regev A, and McCarroll SA Highly Parallel Genome-wide Expression Profiling of Individual Cells Using Nanoliter Droplets. Cell, 161 (5):1202–1214, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Monge G Mémoire sur la théorie des déblais et des remblais. Histoire de l’Académie Royale des Science, 1781. [Google Scholar]
- Moon KR, van Dijk D, Wang Z, Gigante S, Burkhardt DB, Chen WS, Yim K, van den Elzen A, Hirn MJ, Coifman RR, Ivanova NB, Wolf G, and Krishnaswamy S Visualizing structure and transitions in high-dimensional biological data. Nature Biotechnology, 37(12):1482–1492, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Muzellec B and Cuturi M Subspace Detours: Building Transport Plans that are Optimal on Subspace Projections. In Advances in Neural Information Processing Systems 32, pp. 6917–6928, 2019. [Google Scholar]
- Oeppen J and Vaupel JW Broken Limits to Life Expectancy. Science, 296(5570):1029–1031, 2002. [DOI] [PubMed] [Google Scholar]
- Papadakis N, Peyré G, and Oudet E Optimal Transport with Proximal Splitting. SIAM Journal on Imaging Sciences, 7(1):212–238, 2014. [Google Scholar]
- Papamakarios G, Pavlakou T, and Murray I Masked Autoregressive Flow for Density Estimation. In Advances in Neural Information Processing Systems 30, pp. 2338–2347, 2017. [Google Scholar]
- Paszke A, Gross S, Massa F, Lerer A, Bradbury J, Chanan G, Killeen T, Lin Z, Gimelshein N, Antiga L, Desmaison A, Kopf A, Yang E, DeVito Z, Raison M, Tejani A, Chilamkurthy S, Steiner B, Fang L, Bai J, and Chintala S PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32, pp. 8026–8037, 2019. [Google Scholar]
- Peyré G and Cuturi M Computational Optimal Transport. arXiv:1803.00567, 2019.
- Rezende DJ and Mohamed S Variational Inference with Normalizing Flows. In Proceedings of the 32nd International Conference on Machine Learning, volume 37, pp. 1530–1538, 2015. [Google Scholar]
- Rifai S, Vincent P, Muller X, Glorot X, and Bengio Y Contractive Auto-Encoders: Explicit Invariance During Feature Extraction. In Proceedings of the 29th International Conference on Machine Learning, pp. 833–840, 2011. [Google Scholar]
- Saelens W, Cannoodt R, Todorov H, and Saeys Y A comparison of single-cell trajectory inference methods. Nature Biotechnology, 37(5):547–554, 2019. [DOI] [PubMed] [Google Scholar]
- Schiebinger G, Shu J, Tabaka M, Cleary B, Subramanian V, Solomon A, Gould J, Liu S, Lin S, Berube P, Lee L, Chen J, Brumbaugh J, Rigollet P, Hochedlinger K, Jaenisch R, Regev A, and Lander ES Optimal-Transport Analysis of Single-Cell Gene Expression Identifies Developmental Trajectories in Reprogramming. Cell, 176(4):928–943.e22, 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sinkhorn R A relationship between arbitrary positive matrices and doubly stochastic matrices, 1964.
- Trapnell C, Cacchiarelli D, Grimsby J, Pokharel P, Li S, Morse M, Lennon NJ, Livak KJ, Mikkelsen TS, and Rinn JL The dynamics and regulators of cell fate decisions are revealed by pseudotemporal ordering of single cells. Nature Biotechnology, 32(4):381–386, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Villani C Optimal Transport, Old and New. Springer, June 2008. ISBN 978-3-540-71050-9. [Google Scholar]
- Vincent P, Larochelle H, Lajoie I, Bengio Y, and Manzagol P-A Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. Journal of Machine Learning Research, pp. 3371–3408, 2010. [Google Scholar]
- Waddington CH The epigenotype. Endeavour, 1:18–20, 1942. [Google Scholar]
- Weed J and Bach F Sharp asymptotic and finite-sample rates of convergence of empirical measures in Wasserstein distance. Bernoulli, 25(4A):2620–2648, 2019. [Google Scholar]
- Weinreb C, Wolock S, Tusi BK, Socolovsky M, and Klein AM Fundamental limits on dynamic inference from single-cell snapshots. Proceedings of the National Academy of Sciences, 115(10):E2467–E2476, 2018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yang KD and Uhler C Scalable Unbalanced Optimal Transport Using Generative Adversarial Networks. In 7th International Conference on Learning Representations, pp. 20, 2019. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.