

Abstract
Variable importance (VI) tools describe how much covariates contribute to a prediction model’s accuracy. However, important variables for one well-performing model (for example, a linear model f (x) = xT β with a fixed coefficient vector β) may be unimportant for another model. In this paper, we propose model class reliance (MCR) as the range of VI values across all well-performing model in a prespecified class. Thus, MCR gives a more comprehensive description of importance by accounting for the fact that many prediction models, possibly of different parametric forms, may fit the data well. In the process of deriving MCR, we show several informative results for permutation-based VI estimates, based on the VI measures used in Random Forests. Specifically, we derive connections between permutation importance estimates for a single prediction model, U-statistics, conditional variable importance, conditional causal effects, and linear model coefficients. We then give probabilistic bounds for MCR, using a novel, generalizable technique. We apply MCR to a public data set of Broward County criminal records to study the reliance of recidivism prediction models on sex and race. In this application, MCR can be used to help inform VI for unknown, proprietary models.
Keywords: Rashomon, permutation importance, conditional variable importance, U-statistics, transparency, interpretable models
1. Introduction
Variable importance (VI) tools describe how much a prediction model’s accuracy depends on the information in each covariate. For example, in Random Forests, VI is measured by the decrease in prediction accuracy when a covariate is permuted (Breiman, 2001; Breiman et al., 2001; see also Strobl et al., 2008; Altmann et al., 2010; Zhu et al., 2015; Gregorutti et al., 2015; Datta et al., 2016; Gregorutti et al., 2017). A similar “Perturb” VI measure has been used for neural networks, where noise is added to covariates (Recknagel et al., 1997; Yao et al., 1998; Scardi and Harding, 1999; Gevrey et al., 2003). Such tools can be useful for identifying covariates that must be measured with high precision, for improving the transparency of a “black box” prediction model (see also Rudin, 2019), or for determining what scenarios may cause the model to fail.
However, existing VI measures do not generally account for the fact that many prediction models may fit the data almost equally well. In such cases, the model used by one analyst may rely on entirely different covariate information than the model used by another analyst. This common scenario has been called the “Rashomon” effect of statistics (Breiman et al., 2001; see also Lecué, 2011; Statnikov et al., 2013; Tulabandhula and Rudin, 2014; Nevo and Ritov, 2017; Letham et al., 2016). The term is inspired by the 1950 Kurosawa film of the same name, in which four witnesses offer different descriptions and explanations for the same encounter. Under the Rashomon effect, how should analysts give comprehensive descriptions of the importance of each covariate? How well can one analyst recover the conclusions of another? Will the model that gives the best predictions necessarily give the most accurate interpretation?
To address these concerns, we analyze the set of prediction models that provide near-optimal accuracy, which we refer to as a Rashomon set. This approach stands in contrast to training to select a single prediction model, among a prespecified class of candidate models. Our motivation is that Rashomon sets (defined formally below) summarize the range of effective prediction strategies that an analyst might choose. Additionally, even if the candidate models do not contain the true data generating process, we may hope that some of these models function in similar ways to the data generating process. In particular, we may hope there exist well performing candidate models that place the same importance on a variable of interest as the underlying data generating process does. If so, then studying sets of well-performing models will allow us to deduce information about the data generating process.
Applying this approach to study variable importance, we define model class reliance (MCR) as the highest and lowest degree to which any well-performing model within a given class may rely on a variable of interest for prediction accuracy. Roughly speaking, MCR captures the range of explanations, or mechanisms, associated with well-performing models. Because the resulting range summarizes many prediction models simultaneously, rather a single model, we expect this range to be less affected by the choices that an individual analyst makes during the model-fitting process. Instead of reflecting these choices, MCR aims to reflect the nature of the prediction problem itself.
We make several, specific technical contributions in deriving MCR. First, we review a core measure of how much an individual prediction model relies on covariates of interest for its accuracy, which we call model reliance (MR). This measure is based on permutation importance measures for Random Forests (Breiman et al., 2001; Breiman, 2001), and can be expanded to describe conditional importance (see Section 8, as well as Strobl et al. 2008). We draw a connection between permutation-based importance estimates (MR) and U-statistics, which facilitates later theoretical results. Additionally, we derive connections between MR, conditional causal effects, and coefficients for additive models. Expanding on MR, we propose MCR, which generalizes the definition of MR for a class of models. We derive finite-sample bounds for MCR, which motivate an intuitive estimator of MCR. Finally, we propose computational procedures for this estimator.
The tools we develop to study Rashomon sets are quite general, and can be used to make finite-sample inferences for arbitrary characteristics of well-performing models. For example, beyond describing variable importance, these tools can describe the range of risk predictions that well-fitting models assign to a particular covariate profile, or the variance of predictions made by well-fitting models. In some cases, these novel techniques may provide finite-sample confidence intervals (CIs) where none have previously existed (see Section 5).
MCR and the Rashomon effect become especially relevant in the context of criminal recidivism prediction. Proprietary recidivism risk models trained from criminal records data are increasingly being used in U.S. courtrooms. One concern is that these models may be relying on information that would otherwise be considered unacceptable (for example, race, sex, or proxies for these variables), in order to estimate recidivism risk. The relevant models are often proprietary, and cannot be studied directly. Still, in cases where the predictions made by these models are publicly available, it may be possible to identify alternative prediction models that are sufficiently similar to the proprietary model of interest.
In this paper, we specifically consider the proprietary model COMPAS (Correctional Offender Management Profiling for Alternative Sanctions), developed by the company Northpointe Inc. (subsequently, in 2017, Northpointe Inc.,Courtview Justice Solutions Inc., and Constellation Justice Systems Inc. joined together under the name Equivant). Our goal is to estimate how much COMPAS relies on either race, sex, or proxies for these variables not measured in our data set. To this end, we apply a broad class of flexible, kernel-based prediction models to predict COMPAS score. In this setting, the MCR interval reflects the highest and lowest degree to which any prediction model in our class can rely on race and sex while still predicting COMPAS score relatively accurately. Equipped with MCR, we can relax the common assumption of being able to correctly specify the unknown model of interest (here, COMPAS) up to a parametric form. Instead, rather than assuming that the COMPAS model itself is contained in our class, we assume that our class contains at least one well-performing alternative model that relies on sensitive covariates to the same degree that COMPAS does. Under this assumption, the MCR interval will contain the VI value for COMPAS. Applying our approach, we find that race, sex, and their potential proxy variables, are likely not the dominant predictive factors in the COMPAS score (see analysis and discussion in Section 10).
The remainder of this paper is organized as follows. In Section 2 we introduce notation, and give a high level summary of our approach, illustrated with visualizations. In Sections 3 and 4 we formally present MR and MCR respectively, and derive theoretical properties of each. We also review related variable importance practices in the literature, such as retraining a model after removing one of the covariates. In Section 5, we discuss general applicability of our approach for determining finite-sample CIs for other problems. In Section 6, we present a general procedure for computing MCR. In Section 7, we give specific implementations of this procedure for (regularized) linear models, and linear models in a reproducing kernel Hilbert space. We also show that, for additive models, MR can be expressed in terms of the model’s coefficients. In Section 8 we outline connections between MR, causal inference, and conditional variable importance. In Section 9, we illustrate MR and MCR with a simulated toy example, to aid intuition. We also present simulation studies for the task of estimating MR for an unknown, underlying conditional expectation function, under misspecification. We analyze a well-known public data set on recidivism in Section 10, described above. All proofs are presented in the appendices.
2. Notation & Technical Summary
The label of “variable importance” measure has been broadly used to describe approaches for either inference (van der Laan, 2006; Díaz et al., 2015; Williamson et al., 2017) or prediction. While these two goals are highly related, we primarily focus on how much prediction models rely on covariates to achieve accuracy. We use terms such as “model reliance” rather than “importance” to clarify this context.
In order to evaluate how much prediction models rely on variables, we now introduce notation for random variables, data, classes of prediction models, and loss functions for evaluating predictions. Let be a random variable with outcome and covariates , where the covariate subsets and may each be multivariate. We assume that observations of Z are iid, that n ≥ 2, and that solutions to arg min and arg max operations exist whenever optimizing over sets mentioned in this paper (for example, in Theorem 4, below). Our goal is to study how much different prediction models rely on X1 to predict Y.
We refer to our data set as Z = [ y X ], a matrix composed of a n-length outcome vector y in the first column, and a n × p covariate matrix X = [ X1 X2 ] in the remaining columns. In general, for a given vector v, let v[j] denote its jth element(s). For a given matrix A, let A′, A[i,·], A[·,j] and A[i,j] respectively denote the transpose of A, the ith row(s) of A, the jth column(s) of A, and the element(s) in the ith row(s) and jth column(s) of A.
We use the term model class to refer to a prespecified subset of the measurable functions from to . We refer to member functions as prediction models, or simply as models. Given a model f, we evaluate its performance using a nonnegative loss function . For example, L may be the squared error loss Lse(f, (y, x1, x2)) = (y − f (x1, x2))2 for regression, or the hinge loss Lh(f, (y, x1, x2)) = (1 − y f (x1, x2))+ for classification. We use the term algorithm to refer to any procedure that takes a data set as input and returns a model as output.
2.1. Summary of Rashomon Sets & Model Class Reliance
Many traditional statistical estimates come from descriptions of a single, fitted prediction model. In contrast, in this section, we summarize our approach for studying a set of near-optimal models. To define this set, we require a prespecified “reference” model, denoted by fref, to serve as a benchmark for predictive performance. For example, fref may come from a flowchart used to predict injury severity in a hospital’s emergency room, or from another quantitative decision rule that is currently implemented in practice. Given a reference model fref, we define a population ϵ-Rashomon set as the subset of models with expected loss no more than ϵ above that of fref. We denote this set as , where denotes expectations with respect to the population distribution. This set can be thought of as representing models that might be arrived at due to differences in data measurement, processing, filtering, model parameterization, covariate selection, or other analysis choices (see Section 4).
Figure 1–A illustrates a hypothetical example of a population ϵ-Rashomon set. Here, the y-axis shows the expected loss of each model , and the x-axis shows how much each model relies on X1 for its predictive accuracy. More specifically, given a prediction model f, the x-axis shows the percent increase in f’s expected loss when noise is added to X1. We refer to this measure as the model reliance (MR) of f on X1, written informally as
| (2.1) |
The added noise must satisfy certain properties, namely, it must render X1 completely uninformative of the outcome Y, without altering the marginal distribution of X1 (for details, see Section 3, as well as Breiman, 2001; Breiman et al., 2001).
Figure 1:
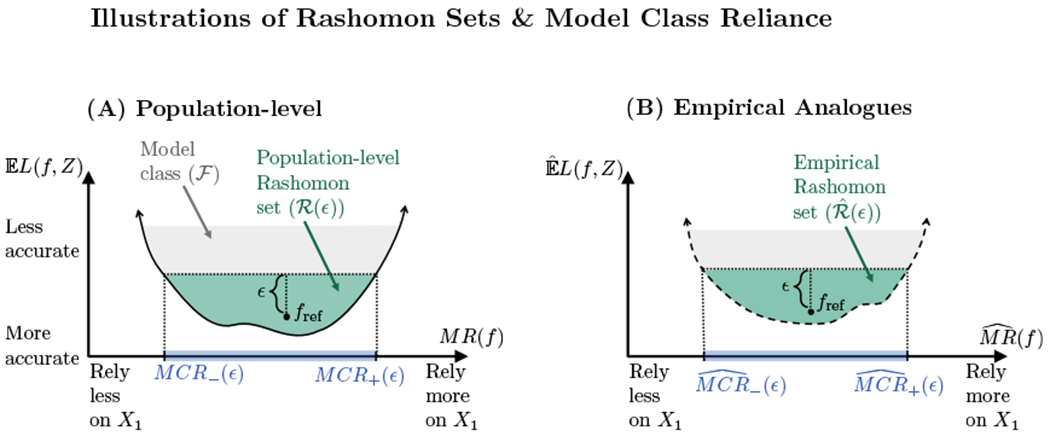
Rashomon sets and model class reliance – Panel (A) illustrates a hypothetical Rashomon set , within a model class . The y-axis shows the expected loss of each model , and the x-axis shows how much each model f relies on X1 (defined formally in Section 3). Along the x-axis, the population-level MCR range is highlighted in blue, showing the values of MR corresponding to well-performing models (see Section 4). Panel (B) shows the in-sample analogue of Panel (A). Here, the y-axis denotes the in-sample loss, ; the x-axis shows the empirical model reliance of each model on X1 (see Section 3); and the highlighted portion of the x-axis shows empirical MCR (see Section 4).
Our central goal is to understand how much, or how little, models may rely on covariates of interest (X1) while still predicting well. In Figure 1–A, this range of possible MR values is shown by the highlighted interval along the x-axis. We refer to an interval of this type as a population-level model class reliance (MCR) range (see Section 4), formally defined as
| (2.2) |
To estimate this range, we use empirical analogues of the population ϵ-Rashomon set, and of MR, based on observed data (Figure 1–B). We define an empirical ϵ-Rashomon set as the set of models with in-sample loss no more than ϵ above that of fref, and denote this set by . Informally, we define the empirical MR of a model f on X1 as
| (2.3) |
that is, the extent to which f appears to rely on X1 in a given sample (see Section 3 for details). Finally, we define the empirical model class reliance as the range of empirical MR values corresponding to models with strong in-sample performance (see Section 4), formally written as
| (2.4) |
In Figure 1–B, the above range is shown by the highlighted portion of the x-axis.
We make several technical contributions in the process of developing MCR.
Estimation of MR, and population-level MCR: Given f, we show desirable properties of as an estimator of MR(f), using results for U-statistics (Section 3.1 and Theorem 5). We also derive finite sample bounds for population-level MCR, some of which require a limit on the complexity of in the form of a covering number. These bounds demonstrate that, under fairly weak conditions, empirical MCR provides a sensible estimate of population-level MCR (see Section 4 for details).
Computation of empirical MCR: Although empirical MCR is fully determined given a sample, the minimization and maximization in Eq 2.4 require nontrivial computations. To address this, we outline a general optimization procedure for MCR (Section 6). We give detailed implementations of this procedure for cases when the model class is a set of (regularized) linear regression models, or a set of regression models in a reproducing kernel Hilbert space (Section 7). The output of our proposed procedure is a closed-form, convex envelope containing , which can be used to approximate empirical MCR for any performance level ϵ (see Figure 2 for an illustration). Still, for complex model classes where standard empirical loss minimization is an open problem (for example, neural networks), computing empirical MCR remains an open problem as well.
Interpretation of MR in terms of model coefficients, and causal effects: We show that MR for an additive model can be written as a function of the model’s coefficients (Proposition 15), and that MR for a binary covariate X1 can be written as a function of the conditional causal effects of X1 on Y (Proposition 19).
Extensions to conditional importance: We provide an extension of MR that is analogous to the notion of conditional importance (Strobl et al., 2008). This extension describes how much a model relies on the specific information in X1 that cannot otherwise be gleaned from X2 (Section 8.2).
Generalizations for Rashomon sets: Beyond notions of variable importance, we also generalize our finite sample results for MCR to describe arbitrary characterizations of models in a population ϵ-Rashomon set. As we discuss in concurrent work (Coker et al., 2018), this generalization is analogous to the profile likelihood interval, and can, for example, be used to bound the range of risk predictions that well-performing prediction models may assign to a particular set of covariates (Section 5).
Figure 2:

Illustration of output from our empirical MCR computational procedure – Our computation procedure produces a closed-form, convex envelope that contains (shown above as the solid, purple line), which bounds empirical MCR for any value of ϵ (see Eq 2.4). The procedure works sequentially, tightening these bounds as much as possible near the ϵ value of interest (Section 6). The results from our data analysis (Figure 8) are presented in the same format as the above purple envelope.
We begin in the next section by formally reviewing model reliance.
3. Model Reliance
To formally describe how much the expected accuracy of a fixed prediction model f relies on the random variable X1, we use the notion of a “switched” loss where X1 is rendered uninformative. Throughout this section, we will treat f as a pre-specified prediction model of interest (as in Hooker, 2007). Let and be independent random variables, each following the same distribution as Z = (Y, X1, X2). We define
as representing the expected loss of model f across pairs of observations in which the values of and have been switched. To see this interpretation of the above equation, note that we have used the variables from , but we have used the variable from an independent copy Z(b). This is why we say that and have been switched; the values of () do not relate to each other as they would if they had been chosen together. An alternative interpretation of eswitch(f) is as the expected loss of f when noise is added to X1 in such a way that X1 becomes completely uninformative of Y, but that the marginal distribution of X1 is unchanged.
As a reference point, we compare eswitch(f) against the standard expected loss when none of the variables are switched, From these two quantities, we formally define model reliance (MR) as the ratio,
| (3.1) |
as we alluded to in Eq 2.1. Higher values of MR(f) signify greater reliance of f on X1. For example, an MR(f) value of 2 means that the model relies heavily on X1, in the sense that its loss doubles when X1 is scrambled. An MR(f) value of 1 signifies no reliance on X1, in the sense that the model’s loss does not change when X1 is scrambled. Models with reliance values strictly less than 1 are more difficult to interpret, as they rely less on the variable of interest than a random guess. Interestingly, it is possible to have models with reliance less than one. For instance, a model f′ may satisfy MR(f′) < 1 if it treats X1 and Y as positively correlated when they are in fact negatively correlated. However, in many cases, the existence of a model satisfying implies the existence of another, better performing model satisfying and eorig(f″) ≤ eorig(f′). That is, although models may exist with MR values less than 1, they will typically be suboptimal (see Appendix A.2).
Model reliance could alternatively be defined as a difference rather than a ratio, that is, as In Appendix A.5, we discuss how many of our results remain similar under either definition.
3.1. Estimating Model Reliance with U-statistics, and Connections to Permutation-based Variable Importance
Given a model f and data set , we estimate MR(f) by separately estimating the numerator and denominator of Eq 3.1. We estimate eorig(f) with the standard empirical loss,
| (3.2) |
We estimate eswitch(f) by performing a “switch” operation across all observed pairs, as in
| (3.3) |
Above, we have aggregated over all possible combinations of the observed values for (Y, X2) and for X1, excluding pairings that are actually observed in the original sample. If the summation over all possible pairs (Eq 3.3) is computationally prohibitive due to sample size, another estimator of eswitch(f) is
| (3.4) |
| (3.5) |
Here, rather than summing over all pairs, we divide the sample in half. We then match the first half’s values for (Y, X2) with the second half’s values for X1 (Line 3.4), and vice versa (Line 3.5). All three of the above estimators (Eqs 3.2, 3.3 & 3.5) are unbiased for their respective estimands, as we discuss in more detail shortly.
Finally, we can estimate MR(f) with the plug-in estimator
| (3.6) |
which we define as the empirical model reliance of f on X1. In this way, we formalize the empirical MR definition in Eq 2.3.
Again, our definition of empirical MR is very similar to the permutation-based variable importance approach of Breiman (2001), where Breiman uses a single random permutation and we consider all possible pairs. To compare these two approaches more precisely, let (π1, … , πn!} be a set of n-length vectors, each containing a different permutation of the set (1, …, n}. The approach of Breiman (2001) is analogous to computing the loss for a randomly chosen permutation vector πl ∈ {π1, … , πn!}. Similarly, our calculation in Eq 3.3 is proportional to the sum of losses over all possible (n!) permutations, excluding the n unique combinations of the rows of X1 and the rows of that appear in the original sample (see Appendix A.3). Excluding these observations is necessary to preserve the (finite-sample) unbiasedness of .
The estimators , and all belong to the well-studied class of U-statistics. Thus, under fairly minor conditions, these estimators are unbiased, asymptotically normal, and have finite-sample probabilistic bounds (Hoeffding, 1948, 1963; Serfling, 1980; see also DeLong et al., 1988 for an early use of U-statistics in machine learning, as well as caveats in Demler et al., 2012). To our knowledge, connections between permutation-based importance and U-statistics have not been previously established.
While the above results from U-statistics depend on the model f being fixed a priori, we can also leverage these results to create uniform bounds on the MR estimation error for all models in a sufficiently regularized class . We formally present this bound in Section 4 (Theorem 5), after introducing required conditions on model class complexity. The existence of this uniform bound implies that it is feasible to train a model and to evaluate its importance using the same data. This differs from the classical VI approach of Random Forests (Breiman, 2001), which avoids in-sample importance estimation. There, each tree in the ensemble is fit on a random subset of data, and VI for the tree is estimated using the held-out data. The tree-specific VI estimates are then aggregated to obtain a VI estimate for the overall ensemble. Although sample-splitting approaches such as this are helpful in many cases, the uniform bound for MR suggests that they are not strictly necessary, depending on the sample size and the complexity of .
3.2. Limitations of Existing Variable Importance Methods
Several common approaches for variable selection, or for describing relationships between variables, do not necessarily capture a variable’s importance. Null hypothesis testing methods may identify a relationship, but do not describe the relationship’s strength. Similarly, checking whether a variable is included by a sparse model-fitting algorithm, such as the Lasso (Hastie et al., 2009), does not describe the extent to which the variable is relied on. Partial dependence plots (Breiman et al., 2001; Hastie et al., 2009) can be difficult to interpret if multiple variables are of interest, or if the prediction model contains interaction effects.
Another common VI procedure is to run a model-fitting algorithm twice, first on all of the data, and then again after removing X1 from the data set. The losses for the two resulting models are then compared to determine the importance, or “necessity,” of X1 (Gevrey et al., 2003). Because this measure is a function of two prediction models rather than one, it does not measure how much either individual model relies on X1. We refer to this approach as measuring empirical Algorithm Reliance (AR) on X1, as the model-fitting algorithm is the common attribute between the two models. Related procedures were proposed by Breiman et al. (2001); Breiman (2001), which measure the sufficiency of X1.
As we discuss in Section 3.1, the permutation-based VI measure from RFs (Breiman, 2001; Breiman et al., 2001) forms the inspiration for our definition of MR. This RF VI measure has been the topic of empirical studies (Archer and Kimes, 2008; Calle and Urrea, 2010; Wang et al., 2016), and several variations of the measure have been proposed (Strobl et al., 2007, 2008; Altmann et al., 2010; Hapfelmeier et al., 2014). Mentch and Hooker (2016) use U-statistics to study predictions of ensemble models fit to subsamples, similar to the bootstrap aggregation used in RFs. Procedures related to “Mean Difference Impurity,” another VI measure derived for RFs, have been studied theoretically by Louppe et al. (2013); Kazemitabar et al. (2017). All of this literature focuses on VI measures for RFs, for ensembles, or for individual trees. Our estimator for model reliance differs from the traditional RF VI measure (Breiman, 2001) in that we permute inputs to the overall model, rather than permuting the inputs to each individual ensemble member. Thus, our approach can be used generally, and is not limited to trees or ensemble models.
Outside of the context of RF VI, Zhu et al. (2015) propose an estimand similar to our definition of model reliance, and Gregorutti et al. (2015, 2017) propose an estimand analogous to eswitch(f) − eorig(f). These recent works focus on the model reliance of f on X1 specifically when f is equal to the conditional expectation function of Y (that is, ). In contrast, we consider model reliance for arbitrary prediction models f. Datta et al. (2016) study the extent to which a model’s predictions are expected to change when a subset of variables is permuted, regardless of whether the permutation affects a loss function L. These VI approaches are specific to a single prediction model, as is MR. In the next section, we consider a more general conception of importance: how much any model in a particular set may rely on the variable of interest.
4. Model Class Reliance
Like many statistical procedures, our MR measure (Section 3) produces a description of a single predictive model. Given a model with high predictive accuracy, MR describes how much the model’s performance hinges on covariates of interest (X1). However, there will often be many other models that perform similarly well, and that rely on X1 to different degrees. With this notion in mind, we now study how much any well-performing model from a prespecified class may rely on covariates of interest.
Recall from Section 2.1 that, in order to define a population ϵ-Rashomon set of near-optimal models, we must choose a “reference” model fref to serve as a performance benchmark. In order to discuss this choice, we now introduce more explicit notation for the population ϵ-Rashomon set, written as
| (4.1) |
Note that we write and interchangeably when fref and are clear from context. Similarly, we occasionally write empirical ϵ-Rashomon sets using the more explicit notation , but typically abbreviate these sets as .
While fref could be selected by minimizing the in-sample loss, the theoretical study of is simplified under the assumption that fref is prespecified. For example, fref may come from a flowchart used to predict injury severity in a hospital’s emergency room, or from another quantitative decision rule that is currently implemented in practice. The model fref can also be selected using sample splitting. In some cases it may be desirable to fix fref equal to the best-in-class model , but this is generally infeasible because f⋆ is unknown. Still, for any , the Rashomon set defined using fref will always be conservative in the sense that it contains the Rashomon set defined using f⋆.
We can now formalize our definitions of population-level MCR and empirical MCR by simply plugging in our definitions for MR(f) and (Section 3) into Eqs 2.2 & 2.4 respectively. Studying population-level MCR (Eq 2.2) is the main focus of this paper, as it provides a more comprehensive view of importance than measures from a single model. If MCR+(ϵ) is low, then no well-performing model in places high importance on X1, and X1 can be discarded at low cost regardless of future modeling decisions. If MCR−(ϵ) is large, then every well-performing model in must rely substantially on X1, and X1 should be given careful attention during the modeling process. Here, may itself consist of several parametric model forms (for example, all linear models and all decision tree models with less than 6 single-split nodes). We stress that the range [MCR−(ϵ), MCR+(ϵ)| does not depend on the fitting algorithm used to select a model . The range is valid for any algorithm producing models in F, and applies for any .
In the remainder of this section, we derive finite sample bounds for population-level MCR, from which we argue that empirical MCR provides reasonable estimates of population-level MCR (Section 4.1). In Appendix B.7 we consider an alternate formulation of Rashomon sets and MCR where we replace the relative loss threshold in the definition of with an absolute loss threshold. This alternate formulation can be similar in practice, but still requires the specification of a reference function fref to ensure that and are nonempty.
4.1. Motivating Empirical Estimators of MCR by Deriving Finite-sample Bounds
In this section we derive finite-sample, probabilistic bounds for MCR+(ϵ) and MCR−(ϵ). Our results imply that, under minimal assumptions, and are respectively within a neighborhood of MCR+ (ϵ) and MCR−(ϵ) with high probability. However, the weakness of our assumptions (which are typical for statistical-learning-theoretic analysis) renders the width of our resulting CIs to be impractically large, and so we use these results only to show conditions under which and form sensible point estimates. In Sections 9.1 & 10, below, we apply a bootstrap procedure to account for sampling variability.
To derive these results we introduce three bounded loss assumptions, each of which can be assessed empirically. Let borig, Bind, Bref, be known constants.
Assumption 1 (Bounded individual loss) For a given model , assume that .
Assumption 2 (Bounded relative loss) For a given model , assume that .
Assumption 3 (Bounded aggregate loss) For a given model , assume that .
Each assumption is a property of a specific model . The notation Bind and Bref refer to bounds for any individual observation, and the notation borig and Bswitch refer to bounds on the aggregated loss L in a sample. These boundedness assumptions are central to our finite sample guarantees, shown below.
Crucially, loss functions L that are unbounded in general may be used so long as L(f, (y, x1, x2)) is bounded on a particular domain. For example, the squared-error loss can be used if is contained within a known range, and predictions f (x1, x2) are contained within the same range for We give example methods of determining Bind in Sections 7.3.2 & 7.4.2. For Assumption 3, we can approximate borig by training a highly flexible model to the data, and setting borig equal to half (or any positive fraction) of the resulting cross-validated loss. To determine Bswitch we can simply set Bswitch = Bind, although this may be conservative. For example, in the case of binary classification models for non-separable groups (see Section 9.1), no linear classifier can misclassify all observations, particularly after a covariate is permuted. Thus, it must hold that Bind > Bswitch. Similarly, if fref satisfies Assumption 1, then Bref may be conservatively set equal to Bind. If model reliance is redefined as a difference rather than a ratio, then a similar form of the results in this section will apply without Assumption 3 (see Appendix A.5).
Based on these assumptions, we can create a finite-sample upper bound for MCR+(ϵ) and lower bound for MCR−(ϵ). In other words, we create an “outer” bound that contains the interval [MCR−(ϵ),MCR+(ϵ)| with high probability.
Theorem 4 (“Outer” MCR Bounds) Given a constant ϵ ≥ 0, let and be prediction models that attain the highest and lowest model reliance among models in . If f+,ϵ and f−,ϵ satisfy Assumptions 1, 2 & 3, then
| (4.2) |
| (4.3) |
where .
Eq 4.2 states that, with high probability, MCR+(ϵ) is no higher than added to an error term . As n increases, ϵout approaches ϵ and approaches zero. One practical implication is that, roughly speaking, if , then the empirical estimator is unlikely to substantially underestimate MCR+(ϵ). By similar reasoning, we can conclude from Eq 4.3 that if , then is unlikely to substantially overestimate MCR−(ϵ). By setting ϵ = 0, Theorem 4 can also be used to create a finite-sample bound for the reliance of the unique (unknown) best-in-class model on X1 (see Corollary 22 in Appendix A.4), although describing individual models is not the main focus of this paper.
We provide a visual illustration of Theorem 4 in Figure 3. A brief sketch of the proof is as follows. First, we enlarge the empirical ϵ-Rashomon set by increasing ϵ to ϵout, such that, by Hoeffding’s inequality, with high probability. When , we know that by the definition of . Next, the term leverages finite-sample results for U-statistics to account for estimation error of MR(f+,ϵ) = MCR+(ϵ) when using the estimator . Thus, we can relate to both and MCR+(ϵ) in order to obtain Eq 4.2. Similar steps can be applied to obtain Eq 4.3.
Figure 3:

Illustration of terms in Theorems 4 and 6 – Above we show the relation between empirical MR (x-axis) and empirical loss (y-axis) for models f in a hypothetical model class . We mark fref by the black point. For each possible model reliance value r ≥ 0, the curved, dashed line shows the lowest possible empirical loss for a function in satisfying . The set contains all models in within the dotted gray lines. To create the bounds from Theorem 4, we expand the empirical ϵ-Rashomon set by increasing ϵ to ϵout, such that f+,ϵ (or f−,ϵ) is contained in with high probability. We then add (or subtract) to account for estimation error of (or ). These steps are illustrated above in blue, with the final bounds shown by the blue bracket symbols along the x-axis. To create the bounds for MCR+(ϵ) (and MCR−(ϵ)) in Theorem 6, we constrict the empirical ϵ-Rashomon set by decreasing ϵ to ϵin, such that all models with high expected loss are simultaneously excluded from with high probability. We then subtract (or add) to simultaneously account for MR estimation error for models in . These steps are illustrated above in purple, with the final bounds shown by the purple bracket symbols along the x-axis. For emphasis, below this figure we show a copy of the x-axis with selected annotations, from which it is clear that and are always within the bounds produced by Theorems 4 and 6. With high probability, and are within a neighborhood of MCR−(ϵ) and MCR+(ϵ) respectively.
The bounds in Theorem 4 naturally account for potential overfitting without an explicit limit on model class complexity (such as a covering number, Rademacher complexity, or VC dimension). Instead, these bounds depend on being able to fully optimize MR across sets in the form of . If we allow our model class to become more flexible, then the size of will also increase. Because the bounds in Theorem 4 result from optimizing over , increasing the size of results in wider, more conservative bounds. In this way, Eqs 4.2 and 4.3 implicitly capture model class complexity.
So far, Theorem 4 lets us bound the range of MR values corresponding to models that predict well, but it does not tell us whether these bounds are actually attained. Similarly, we can conclude from Theorem 4 that [MCR−(ϵ), MCR+(ϵ)] is unlikely to exceed the estimated range [, ] by a substantial margin, but we cannot determine whether this estimated range is unnecessarily wide. For example, consider the models that drive the estimator: the models with strong in-sample accuracy, and high empirical reliance on X1. These models’ in-sample performance could merely be the result of overfitting, in which case they do not tell us direct information about . Alternatively, even if all of these models truly do perform well on expectation (that is, even if they are contained in ), the model with the highest empirical reliance on X1 may merely be the model for which our empirical MR estimate contains the most error. Either of these scenarios can cause to be unnecessarily high, relative to MCR+(ϵ).
Fortunately, both problematic scenarios are solved by requiring a limit on the complexity of . We propose a complexity measure in the form of a covering number, which allows us control a worst case scenario of either overfitting or MR estimation error. Specifically, we define the set of functions as an r-margin-expectation-cover if for any and any distribution D, there exists such that
| (4.4) |
We define the covering number to be the size of the smallest r-margin-expectation-cover for . In general, we use and to denote probabilities and expectations with respect to a random variable V following the distribution D. We abbreviate these quantities accordingly when V or D are clear from context, for example, as , , or simply . Unless otherwise stated, all expectations and probabilities are taken with respect to the (unknown) population distribution.
We first show that this complexity measure allows us to control the worst case MR estimation error, that is, the covering number provides a uniform bound on the error of for all .
Theorem 5 (Uniform bound for ) Given r > 0, if Assumptions 1 and 3 hold for all , then
where
| (4.5) |
Theorem 5 states that, with high probability, the largest possible estimation error for MR(f) across all models in is bounded by q(δ, r, n), which can be made arbitrarily small by increasing n and decreasing r. As we noted in Section 3.1, this means that it is possible to train a model and estimate its reliance on variables without using sample-splitting.
The covering number can also be used to limit the extent of overfitting (see Appendix B.5.1). As a result, it is possible to set an in-sample performance threshold low enough so that it will only be met by models with strong expected performance (that is, by models truly within ). To implement this idea of a stricter performance threshold, we contract the empirical ϵ-Rashomon set by subtracting a buffer term from ϵ. This requires that we generalize the definition of an empirical ϵ-Rashomon set to for , where the explicit inclusion of fref now ensures that is nonempty, even for ϵ < 0. As before, we typically omit the notation fref and , writing instead.
We are now prepared to answer the questions of whether the bounds from Theorem 4 are actually attained, and of whether the estimated range is unnecessarily wide. Our answer comes in the form of an upper bound on MCR−(ϵ), and a lower bound on MCR+(ϵ).
Theorem 6 (“Inner” MCR Bounds) Given constants ϵ ≥ 0 and r > 0, if Assumptions 1, 2 and 3 hold for all , and then
| (4.6) |
| (4.7) |
where , as defined in Eq 4.5.
Theorem 6 can allow us to infer an “inner” bound that is contained within the interval [MCR−(ϵ), MCR+(ϵ)] with high probability. In Figure 3, we illustrate the result of Theorem 6, and give a sketch of the proof. This proof follows a similar structure to that of Theorem 4, but incorporates Theorem 5’s uniform bound on MR estimation error ( term), as well as an additional uniform bound on the probability that any model has in-sample loss too far from its expected loss (ϵin term).
A practical implication of Theorem 6 is that, roughly speaking, if then it is unlikely for the empirical estimator to substantially underestimate MCR+(ϵ). Taken together with Theorem 4, we can conclude that, if , then the estimator is unlikely either to overestimate or to underestimate MCR+(ϵ) by very much. In large samples, it may be plausible to expect the condition to hold, since ϵin and ϵout both approach ϵ as n increases. In the same way, if , we can conclude from Eqs 4.3 & 4.7 that the empirical estimator is unlikely to either overestimate or underestimate MCR−(ϵ) by very much. For this reason, we argue that and form sensible estimates of population-level MCR – each is contained within a neighborhood of its respective estimand, with high probability. The secondary x-axis of Figure 3 gives an illustration of this argument.
5. Extensions of Rashomon Sets Beyond Variable Importance
In this section we generalize the Rashomon set approach beyond the study of MR. In Section 5.1, we create finite-sample CIs for other summary characterizations of near-optimal, or best-in-class models. The generalization also helps to illustrate a core aspect of the argument underlying Theorem 4: models with near-optimal performance in the population tend to have relatively good performance in random samples.
In Section 5.2, we review existing literature on near-optimal models.
5.1. Finite-sample Confidence Intervals from Rashomon Sets
Rather than describing how much a model relies on X1, here we assume the analyst is interested in an arbitrary characteristic of a model. We denote this characteristic of interest as . For example, if fβ is the linear model then ϕ may be defined as the norm of the associated coefficient vector (that is, or the prediction fβ would assign given a specific covariate profile xnew (that is ).
Given a descriptor ϕ, we now show a general result that allows creation of finite-sample CIs for the best performing models . The resulting CIs are themselves based on empirical Rashomon sets.
Proposition 7 (Finite sample CIs from Rashomon sets) Let , let , and let .
If Assumption 2 holds for all , then
Proposition 7 generates a finite-sample CI for the range of values ϕ(f) corresponding to well-performing models, . This CI, denoted by can itself be interpreted as the range of values ϕ(f) corresponding to models f with empirical loss not substantially above that of fref. Thus, the interval has both a rigorous coverage rate and a coherent in-sample interpretation. The proof of Proposition 7 uses Hoeffding’s inequality to show that models in are contained in with high probability, that is, that models with good expected performance tend to perform well in random samples.
An immediate corollary of Proposition 7 is that we can generate finite-sample CIs for all best-in-class models by setting ϵ = 0. This corollary can be further strengthened if a single model f⋆ is assumed to uniquely minimize over (see Appendix B.6).
Note that Proposition 7 implicitly assumes that ϕ(f) can be determined exactly for any model , in order for the interval to be precisely determined. This assumption does not hold, for example, if ϕ(f) = MR(f), or if ϕ(f) = Var{f(X1, X2)}, as these quantities depend on both f and the (unknown) population distribution. In such cases, an additional correction factor must be incorporated to account for estimation error of ϕ(f), such as the term in Theorem 4.
In concurrent work, Coker et al. (2018) show that profile likelihood intervals take the same form as the interval in Proposition 7. This means that a profile likelihood interval can also be expressed by minimizing and maximizing over an empirical Rashomon set. More specifically, consider the case where the loss function L is the negative of the known log likelihood function, and where fref is the maximum likelihood estimate of the “true model,” which in this case is f⋆. If additional minor assumptions are met (see Appendix A.6 for details), then the (1 − δ)-level profile likelihood interval for ϕ(f⋆) is equal to , where ( and are defined as in Proposition 7, and is the 1 − δ percentile of a chi-square distribution with 1 degree of freedom.
Relative to a profile likelihood approach, the advantage of Proposition 7 is that it does not require asymptotics, it does not require that the likelihood be known up to a parametric form, and it can be extended to study the set of near-optimal prediction models , rather than a single, potentially misspecified prediction model f⋆. This is especially useful when different near-optimal models accurately describe different aspects of the underlying data generating process, but none capture it completely. The disadvantage of Proposition 7 is that the required performance threshold of decreases more slowly than the performance threshold of required in a profile likelihood interval. Because our results from Section 4.1 carry a similar disadvantage, we use these results primarily to motivate point estimates describing the Rashomon set .
Still, it is worth emphasizing the generality of Proposition 7. Through this result, Rashomon sets allow us to reframe a wide set of finite-sample inference problems as in-sample optimization problems. The implied CIs are not necessarily in closed form, but the approach still opens an exciting pathway for deriving non-asymptotic results. For example, they imply that existing methods for profile likelihood intervals might be able to be reapplied to achieve finite-sample results. For highly complex model classes where profile likelihoods are difficult to compute, such as neural networks or random forests, approximate inference is sometimes achieved via approximate optimization procedures (for example, Markov chain Monte Carlo for Bayesian additive regression trees, in Chipman et al., 2010). Proposition 7 shows that similar approximate optimization methods could be repurposed to establish approximate, finite-sample inferences for the same model classes.
5.2. Related Literature on the Rashomon Effect
Breiman et al. (2001) introduced the “Rashomon effect” of statistics as a problem of ambiguity: if many models fit the data well, it is unclear which model we should try to interpret. Breiman suggests that the ensembling many well-performing models together can resolve this ambiguity, as the new ensemble model may perform better than any of its individual members. However, this approach may only push the problem from the member level to the ensemble level, as there may also be many different ensemble models that fit the data well.
The Rashomon effect has also been considered in several subject areas outside of VI, including those in non-statistical academic disciplines (Heider, 1988; Roth and Mehta, 2002). Tulabandhula and Rudin (2014) optimize a decision rule to perform well under the predicted range of outcomes from any well-performing model. Statnikov et al. (2013) propose an algorithm to discover multiple Markov boundaries, that is, minimal sets of covariates such that conditioning on any one set induces independence between the outcome and the remaining covariates. Nevo and Ritov (2017) report interpretations corresponding to a set of well-fitting, sparse linear models. Meinshausen and Bühlmann (2010) estimate structural aspects of an underlying model (such as the variables included in that model) based on how stable those aspects are across a set of well-fitting models. This set of well-fitting models is identified by repeating an estimation procedure in a series of perturbed samples, using varying levels of regularization (see also Azen et al., 2001). Letham et al. (2016) search for a pair of well-fitting dynamical systems models that give maximally different predictions.
6. Calculating Empirical Estimates of Model Class Reliance
In this section, we propose a binary search procedure to bound the values of and (see Eq 2.4), which respectively serve as estimates of MCR−(ϵ) and MCR+(ϵ) (see Section 4.1). Each step of this search consists of minimizing a linear combination of êorig(f) and êswitch(f) across . Our approach is related to the fractional programming approach of Dinkelbach (1967), but accounts for the fact that the problem is constrained by the value of the denominator, êorig(f). We additionally show that, for many model classes, computing only requires that we minimize convex combinations of êorig(f) and êswitch(f), which is no more difficult than minimizing the average loss over an expanded and reweighted sample (See Eq 6.2 & Proposition 11).
Computing however will require that we are able to minimize arbitrary linear combinations of êorig(f) and êswitch(f). In Section 6.3, we outline how this can be done for convex model classes – classes for which the loss function is convex in the model parameter. Later, in Section 7, we give more specific computational procedures for when is the class of linear models, regularized linear models, or linear models in a reproducing kernel Hilbert space (RKHS). We summarize the tractability of computing empirical MCR for different model classes in Table 1.
Table 1:
Tractability of empirical MCR computation for different model classes - For each case, we describe the tractability of computing and using our proposed approaches. Computing empirical MCR can be reduced to a sequence of optimization problems, the form of which are noted in parentheses within the above table.
| Model class and loss function () | Computing | Computing |
|---|---|---|
| (L2 Regularized) Linear models, with the squared error loss | Highly tractable (QP1QC, see Sections 7.2 & 7.3) | Highly tractable (QP1QC, see Sections 7.2 & 7.3) |
| Linear models in a reproducing kernel Hilbert space, with the squared error loss | Moderately tractable (QP1QC, see Section 7.4.1) | Moderately tractable (QP1QC, see Section 7.4.1) |
| Cases where irrelevant covariates do not improve predictions | Moderately tractable (Convex optimization problems, see Proposition 11) | Potentially intractable |
| Cases where minimizing the empirical loss is a convex optimization problem | Potentially intractable (DC programs, see Section 6.3) | Potentially intractable (DC programs, see Section 6.3) |
To simplify notation associated with the reference model fref, we present our computational results in terms of bounds on empirical MR subject to performance thresholds on the absolute scale. More specifically, we present bound functions b− and b+ satisfying simultaneously for all (Figures 2 & 8 show examples of these bounds). The binary search procedures we propose can be used to tighten these boundaries at a particular value ϵabs of interest.
Figure 8:
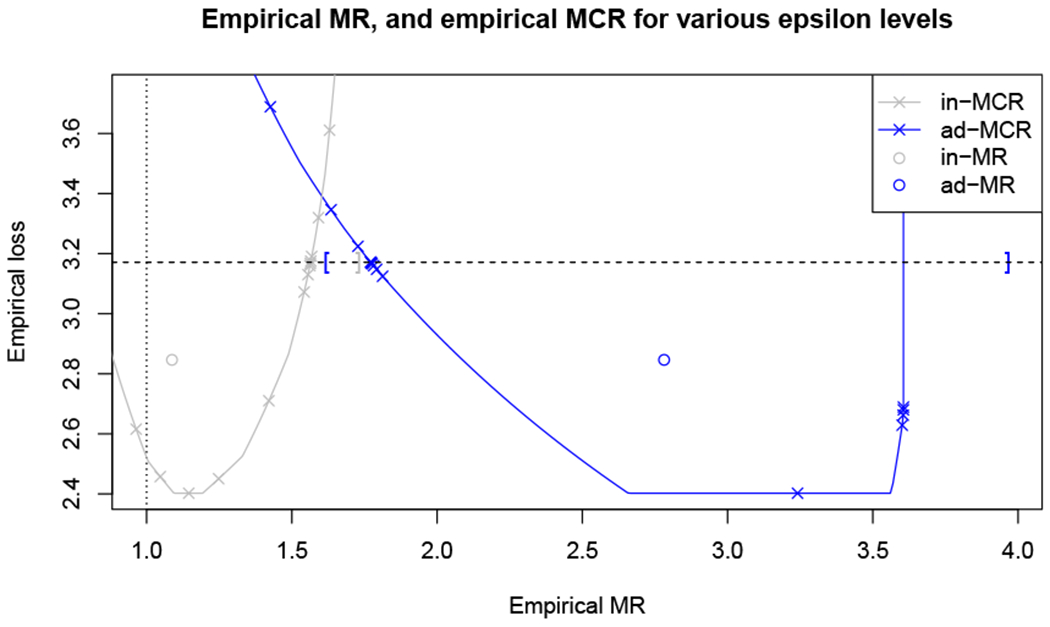
Empirical MR and MCR for Broward County criminal records data set - For any prediction model f, the y-axis shows empirical loss and the x-axis shows empirical reliance on each covariate subset. Null reliance (MR equal to 1.0) is marked by the vertical dotted line. Reliances on different covariate subsets are marked by color (“admissible” = blue; “inadmissible” = gray). For example, model reliance values for fref are shown by the two circular points, one for “admissible” variables and one for “inadmissible” variables. MCR for different values of ϵ can be represented as boundaries on this coordinate space. To this end, for each covariate subset, we compute conservative boundary functions (shown as solid lines, or “bowls”) guaranteed to contain all models in the class (see Section 6). Specifically, all models in are guaranteed to have an empirical loss and empirical MR value for “inadmissible variables” corresponding to a point within the gray bowl. Likewise, all models in are guaranteed to have an empirical loss and empirical MR value for “admissible variables” corresponding to a point within the blue bowl. Points shown as “×” represent additional models in discovered during our computational procedure, and thus show where the “bowl” boundary is tight. The goal of our computation procedure (see Section 6) is to tighten the boundary as much as possible near the ϵ value of interest, shown by the dashed horizontal line above. This dashed line has a y-intercept equal to the loss of the reference model plus the ϵ value of interest. Bootstrap CIs for MCR−(ϵ) and MCR+(ϵ) are marked by brackets.
We briefly note that as an alternative to the global optimization procedures we discuss below, heuristic optimization procedures such as simulated annealing can also prove useful in bounding empirical MCR. By definition, the empirical MR for any model in forms a lower bound for , and an upper bound for . Heuristic maximization and minimization of empirical MR can be used to tighten these boundaries.
Throughout this section, we assume that , to ensure that MR is finite.
6.1. Binary Search for Empirical MR Lower Bound
Before describing our binary search procedure, we introduce additional notation used in this section. Given a constant and prediction model , we define the linear combination , and its minimizers (for example, ), as
We do not require that is uniquely minimized, and we frequently use the abbreviated notation when is clear from context.
Our goal in this section is to derive a lower bound on for subsets of in the form of . We achieve this by minimizing a series of linear objective functions in the form of , using a similar method to that of Dinkelbach (1967). Often, minimizing the linear combination is more tractable than minimizing the MR ratio directly.
Almost all of the results shown in this section, and those in Section 6.2, also hold if we replace with throughout (see Eq 3.5), including in the definition of and . The exception is Proposition 11, below, which we may still expect to approximately hold if we replace with .
Given an observed sample, we define the following condition for a pair of values , and argmin function :
Condition 8 (Criteria to continue search for lower bound) and .
We are now equipped to determine conditions under which we can tractably create a lower bound for empirical MR.
Lemma 9 (Lower bound for ) If satisfies , then
| (6.1) |
for all satisfying . It also follows that
Additionally, if and at least one of the inequalities in Condition 8 holds with equality, then Eq 6.1 holds with equality.
Lemma 9 reduces the challenge of lower-bounding to the task of minimizing the linear combination . The result of Lemma 9 is not only a single boundary for a particular value of ϵabs, but a boundary function that holds all values of ϵabs > 0, with lower values of ϵabs leading to more restrictive lower bounds on .
In addition to the formal proof for Lemma 9, we provide a heuristic illustration of the result in Figure 4, to aid intuition.
Figure 4:
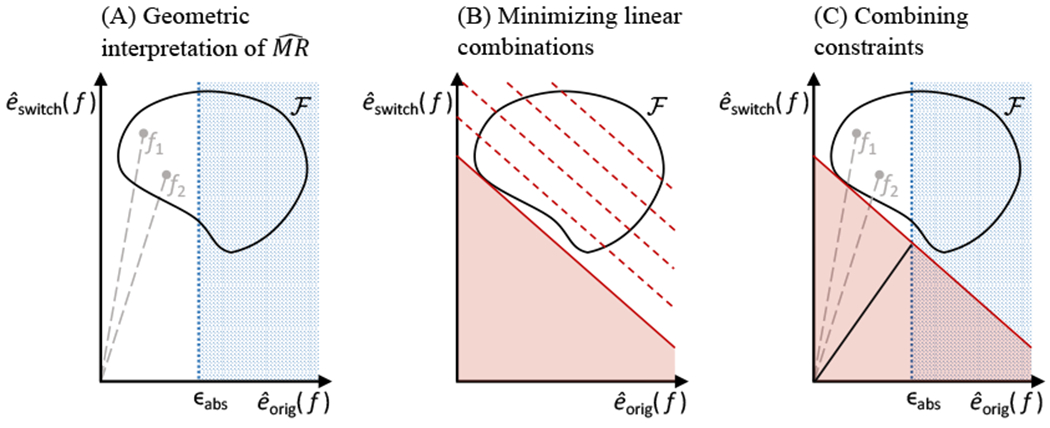
Above, we illustrate the geometric intuition for Lemma 9. In Panel (A), we show an example of a hypothetical model class , marked by the enclosed region. For each model , the x-axis shows and the y-axis shows . Here, we can see that the condition holds. The blue dotted region marks models with higher empirical loss. We mark two example models within as f1 and f2. The slopes of the lines connecting the origin to f1 and f2 are equal to and respectively. Our goal is to lower-bound the slope corresponding to for any model f satisfying êorig(f) ≤ ϵabs. In Panel (B), we consider the linear combination for γ = 1. Above, contour lines of are shown in red. The solid red line indicates the smallest possible value of across . Specifically, its y-intercept equals . If we can determine this minimum, we can determine a linear border constraint on , that is, we will know that no points corresponding to models may lie in the shaded region above. Additionally, if (see Lemma 9), then we know that the origin is either excluded by this linear constraint, or is on the boundary. In Panel (C), we combine the two constraints from Panels (A) & (B) to see that models satisfying êorig(f) ≤ ϵabs must, correspond to points in the white, unshaded region above. Thus, as long as the unshaded region does not contain the origin, any line connecting the origin to the a model f satisfying êorig(f) < ϵabs (for example, here, f1, f2) must, have a. slope at least, as high as that of the solid black line above. It. can be shown algebraically that the black line has slope equal to the left-hand side of Eq 6.1. Thus the left-hand side of Eq 6.1 is a lower bound for for all .
It remains to determine which value of γ should be used in Eq 6.1. The following lemma implies that this value can be determined by a binary search, given a particular value of interest for ϵabs.
Lemma 10 (Monotonicity for lower bound binary search) The following monotonicity results hold:
is monotonically increasing in γ.
is monotonically decreasing in γ.
Given ϵabs, the lower bound from Eq 6.1, , is monotonically decreasing in γ in the range where , and increasing otherwise.
Given a particular performance level of interest, ϵabs, Point 3 of Lemma 10 tells us that the value of γ resulting in the tightest lower bound from Eq 6.1 occurs when γ is as low as possible while still satisfying Condition 8. Points 1 and 2 show that if γ0 satisfies Condition 8, and one of the equalities in Condition 8 holds with equality, then Condition 8 holds for all γ ≥ γ0. Together, these results imply that we can use a binary search to determine the value of γ to be used in Lemma 9, reducing this value until Condition 8 is no longer met. In addition to the formal proof for Lemma 10, we provide an illustration of the result in Figure 5 to aid intuition.
Figure 5:
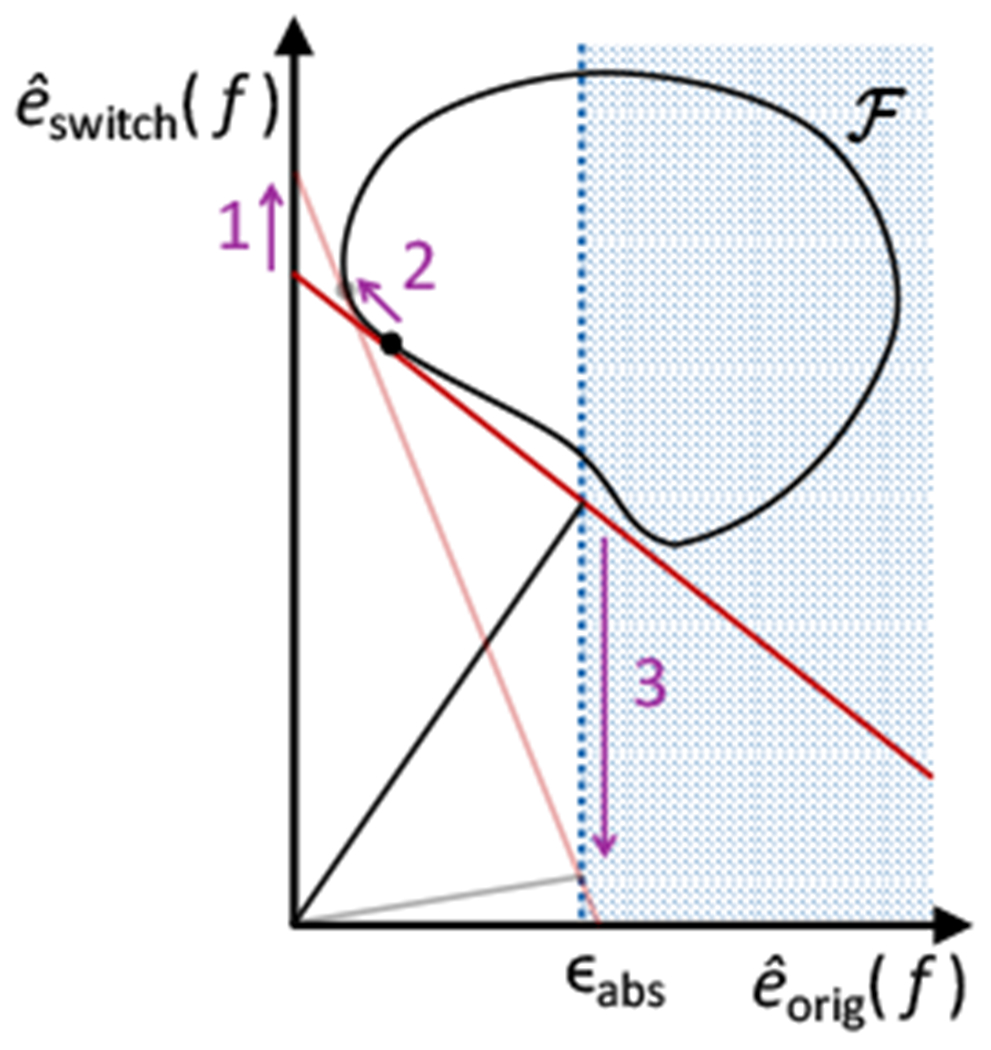
Monotonicity for binary search. Above we show a version of Figure 4–C for two alternative values of γ. This figure is meant, to add intuition for the monotonicity results in Lemma 10, in addition to the formal proof. Increasing γ is equivalent to decreasing the slope of the red line in Figure 4–C. We define two values γ1 < γ2, where γ1 corresponds to the solid red line, above, and γ2 corresponds to the semi-transparent, red line. The y-intercept values of these lines are equal to and respectively (see Figure 4–C caption). The solid and semi-transparent, black dots mark and respectively. Plugging γ1 and γ2 into Eq 6.1 yields two lower bounds for , marked by the slopes of the solid and semi-transparent, black lines respectively (see Figure 4–C caption). We see that (1) , that (2) , and that (3) the left-hand side of Eq 6.1 is decreasing in γ when . These three conclusions are marked by arrows in the above figure, with numbering matching the enumerated list in Lemma 10.
Next we present simple conditions under which the binary search for values of γ can be restricted to the nonnegative real line. This result substantially extends the computational tractability of our approach, as minimizing for γ ≥ 0 is equivalent to minimizing a reweighted empirical loss over an expanded sample of size n2:
| (6.2) |
where .
Proposition 11 (Nonnegative weights for lower bound binary search) Assume that L and satisfy the following conditions.
(Predictions are sufficient for computing the loss) The loss L{f, (Y, X1, X2)} depends on the covariates (X1, X2) only via the prediction function f, that is, whenever .
- (Irrelevant information does not improve predictions) For any distribution D satisfying X1 ⊥D (X2, Y), there exists a function fD satisfying
and(6.3)
Let γ = 0. Under the above assumptions, it follows that either (i) there exists a function minimizing that does not. satisfy Condition 8, or (ii) for any function minimizing .
The implication of Proposition 11 is that, when the conditions of Proposition 11 are met, the search region for γ can be limited to the nonnegative real line, and minimizing will be no harder than minimizing a reweighted empirical loss over an expanded sample (Eq 6.2). To see this, recall that for a fixed value of ϵabs we can tighten the boundary in Lemma 9 by conducting a binary search for the smallest, value of γ that satisfies Condition 8. If setting γ equal to 0 does not satisfy Condition 8, and the search for γ can be restricted to the nonnegative real line, where minimizing is more tractable (see Eq 6.2). Alternatively, if , then we have identified a well-performing model g−,0 with empirical MR no greater than 1. For ϵabs = êorig(fref) + ϵ, this implies that , which is a sufficiently precise conclusion for most, interpretational purposes (see Appendix A.2).
Because of the fixed pairing structure used in êdivide, Proposition 11 will not necessarily hold if we replace êswitch with êdivide throughout (see Appendix C.3). However, since êdivide approximates êswitch, we can expect Proposition 11 to hold approximately. The bound from Eq 6.1 still remains valid if we replace êswitch with êdivide and limit γ to the nonnegative reals, although in some cases it may not be as tight.
6.2. Binary Search for Empirical MR Upper Bound
We now briefly present a binary search procedure to upper bound , which mirrors the procedure from Section 6.1. Given a constant and prediction model , we define the linear combination , and its minimizers (for example, ), as
As in Section 6.1, need not be uniquely minimized, and we generally abbreviate as when is clear from context.
Given an observed sample, we define the following condition for a pair of values , and argmin function :
Condition 12 (Criteria to continue search for upper bound) and .
We can now develop a procedure to upper bound , as shown in the next lemma.
Lemma 13 (Upper bound for ) If satisfies γ ≤ 0 and , then
| (6.4) |
for all satisfying êorig(f) ≤ ϵabs. It also follows that
| (6.5) |
Additionally, if and at least one of the inequalities in Condition 12 holds with equality, then Eq 6.4 holds with equality.
As in Section 6.1, it remains to determine the value of γ to use in Lemma 13, given a value of interest for . The next lemma tells us that the boundary from Lemma 13 is tightest when γ is as low as possible while still satisfying Condition 12.
Lemma 14 (Monotonicity for upper bound binary search) The following monotonicity results hold:
is monotonically increasing in γ.
is monotonically decreasing in γ for γ ≤ 0, and Condition 12 holds for γ = 0 and .
Given ϵabs, the upper boundary is monotonically increasing in γ in the range where and γ < 0, and decreasing in the range where and γ < 0.
Together, the results from Lemma 14 imply that we can use a binary search across to tighten the boundary on from Lemma 13.
6.3. Convex Models
In this section we show that empirical MCR can be conservatively computed when the loss function is convex in the model parameters – that is, when the models are indexed by a d-dimensional parameter , and when the loss function L(fθ, (y, x1, x2)) is convex in θ for all .
Fortunately, neither Lemma 9 nor Lemma 13 require an exact minimum for or . For Lemma 9, any lower bound on is sufficient to determine a lower bound on MR(f). Likewise, for Lemma 13, any lower bound on is sufficient to determine an upper bound on MR(f).
To find these lower bounds, we note that for “convex” model classes (defined above) the optimization problems in Sections 6.1 & 6.2 can be written either as convex optimization problems, or as difference convex function (DC) programs. A DC program is one that can be written as
where cDC is a constraint function, , and gDC, hDC, and cDC are convex. Although precise solutions to DC problems are not always tractable, lower bounds can be attained by branch-and-bound (B&B) methods (Horst and Thoai, 1999). A simple B&B approach is to partition Θ into a set of simplexes. Within the jth simplex, a lower bound on gDC(θ)−hDC(θ) can be determined by replacing hDC with the hyperplane function hj satisfying hj (υ) = hDC(υ) at each vertex υ of the jth simplex. Within this partition, gDC(θ) − hDC(θ) is lower bounded by lj := minθ gDC(θ) − hj(θ), which can be computed as the solution to a convex optimization problem. Any partition for which lj is found to be too high is disregarded. Once a bound lj is computed for each partition, the partition with the lowest value lj is selected to be subdivided further, and additional lower bounds are recomputed for each new, resulting partition. This procedure continues until a sufficiently tight lower bound is attained (for more detailed procedures, see Horst and Thoai, 1999).
This approach allows us to conservatively approximate bounds on in the form of Eq 6.1 & 6.4 by replacing and with lower bounds from the B&B procedure. Although it will always yield valid bounds, the procedure may converge slowly when the dimension of Θ is large, giving highly conservative results. For some special cases of model classes however, even high dimensional DC problems simplify greatly. We discuss these cases in the next section.
7. MR & MCR for Linear Models, Additive Models, and Regression Models in a Reproducing Kernel Hilbert Space
For linear or additive models, many simplifications can be made to our approaches for MR and MCR. To simplify the interpretation of MR, we show below that population-level MR for a linear model can be expressed in terms of the model’s coefficients (Section 7.1). To simplify computation, we show that the cost of computing empirical MR for a linear model grows only linearly in n (Section 7.1), even though the number of terms in the definition of empirical MR grows quadratically (see Eqs 3.3 & 3.6).
Moving on from MR, we show how empirical MCR can be computed for the class of linear models (Section 7.2), for regularized linear models (Section 7.3), and for regression models in a reproducing kernel Hilbert space (RKHS, Section 7.4). To do this, we build on the approach in Section 6 by giving approaches for minimizing arbitrary combinations of êswitch(f) and êorig(f) across . Even when the associated objective functions are non-convex, we can tractably obtain global minima for these model classes. We also discuss procedures to determine an upper bound Bind on the loss for any observation when using these model classes (see Assumption 1).
Throughout this section, we assume that for , that , and that L is the squared error loss function L(f, (y, x1, x2) = (y − f(x1, x2))2. As in Section 6, we also assume that , to ensure that empirical MR is finite.
7.1. Interpreting and Computing MR for Linear or Additive Models
We begin by considering MR for linear models evaluated with the squared error loss. For this setting, we can show both an interpretable definition of MR, as well as a computationally efficient formula for êswitch(f).
Proposition 15 (Interpreting MR, and computing empirical MR for linear models) For any prediction model f, let eorig(f), eswitch(f), êorig(f), and êswith(f) be defined based on the squared error loss L(f, (y, x1, x2)) := (y − f (x1, x2))2 for , , and , where p1 and p2 are positive integers. Let β = (β1, β2) and fβ satisfy , , and . Then
| (7.1) |
and, for finite samples,
| (7.2) |
where , 1n is the n-length vector of ones, and In is the n × n identity matrix.
Eq 7.1 shows that model reliance for linear models can be interpreted in terms of the population covariances, the model coefficients, and the model’s accuracy. Gregorutti et al. (2017) show an equivalent formulation of Eq 7.1 under the stronger assumptions that fβ is equal to the conditional expectation function of Y (that is, ), and the covariates X1 and X2 are centered.
Eq 7.2 shows that, although the number of terms in the definition of êswitch grows quadratically in n (see Eq 3.3), the computational complexity of êswitch(fβ) for a linear model fβ grows only linearly in n. Specifically, the terms and in Eq 7.2 can be computed as and respectively, where the computational complexity of each term in parentheses grows linearly in n.
As in Gregorutti et al. (2017), both results in Proposition 15 readily generalize to additive models of the form fg1,g2 (X1,X2) := g1 (X1) + g2(X2), since permuting X1 is equivalent to permuting g1(X1).
7.2. Computing Empirical MCR for Linear Models
Building on the computational result from the previous section, we now consider empirical MCR computation for linear model classes of the form
In order to implement the computational procedure from Sections 6.1 and 6.2, we must be able to minimize arbitrary linear combinations of êorig(fβ) and êswitch(fβ). Fortunately, for linear models, this minimization reduces to a quadratic program, as we show in the next remark.
Remark 16 (Tractability of empirical MCR for linear model classes) For any and any fixed coefficients , the linear combination
| (7.3) |
is proportional in β to the quadratic function − 2q′β + β′Qβ, where
and . Thus, minimizing ξorigêorig(fβ) + ξswitchêswitch(fβ) is equivalent to an unconstrained (possibly non-convex) quadratic program.
Because our empirical MCR computation procedure from Sections 6.1 and 6.2 consists of minimizing a sequence of objective functions in the form of Eq 7.3, Remark 16 shows us that this procedure is tractable for the class of unconstrained linear models.
7.3. Regularized Linear Models
Next, we continue to build on the results from Section 7.2 to calculate boundaries on for regularized linear models. We consider model classes formed by quadratically constrained subsets of , defined as
| (7.4) |
where Mlm and rlm are pre-specified. Again, this class describes linear models with a quadratic constraint on the coefficient vector.
7.3.1. Calculating MCR
As in Section 7.2, calculating bounds on via Lemmas 9 & 13 requires that are able to minimizing linear combinations ξorigêorig(fβ) + ξswitchêswitch (fβ) across for arbitrary . Applying Remark 16, we can again equivalently minimize −2q′β + β′Qβ subject to the constraint in Eq 7.4:
| (7.5) |
The resulting optimization problem is a (possibly non-convex) quadratic program with one quadratic constraint (QP1QC). This problem is well-studied, and is related to the trust region problem (Boyd and Vandenberghe, 2004; Pólik and Terlaky, 2007; Park and Boyd, 2017). Thus, the bounds on MCR presented in Sections 6.1 and 6.2 again become computationally tractable for the class of quadratically constrained linear models.
7.3.2. Upper Bounding the Loss
One benefit of constraining the coefficient vector (β′Mlmβ ≤ rlm) is that it facilitates determining an upper bound Bind on the loss function L(fβ, (y, x)) = (y − x′β)2, which automatically satisfies Assumption 1 for all . The following lemma gives sufficient conditions to determine Bind.
Lemma 17 (Loss upper bound for linear models) If Mlm is positive definite, Y is bounded within a known range, and there exists a known constant such that for all , then Assumption 1 holds for the model class , the squared error loss function, and the constant
In practice, the constant can be approximated by the empirical distribution of X and Y. The motivation behind the restriction in Lemma 17 is to create complementary constraints on X and β. For example, if Mlm is diagonal, then the smallest elements of Mlm correspond to directions along which β is least restricted by β′Mlmβ ≤ rlm (Eq 7.5), as well as the directions along which x is most restricted by (Lemma 17).
7.4. Regression Models in a Reproducing Kernel Hilbert Space (RKHS)
We now expand our scope of model classes by considering regression models in a reproducing kernel Hilbert space (RKHS), which allow for nonlinear and nonadditive features of the covariates. We show that, as in Section 7.3, minimizing a linear combination of êorig(f) and êswitch(f) across models f in this class can be expressed as a QP1QC, which allows us to implement the binary search procedure of Sections 6.1 & 6.2.
First we introduce notation required to describe regression in a RKHS. Let D be a (R×p) matrix representing a pre-specified dictionary of R reference points, such that each row of D is contained in . Let k be a pre-specified positive definite kernel function, and let μ be a prespecified estimate of . Let KD be the R × R matrix with KD[i,j] = k(D[i,·], D[j,·]). We consider prediction models of the following form, where the distance to each reference point is used as a regression feature:
| (7.6) |
Above, the norm ‖fα‖k is defined as
| (7.7) |
In the next two sections, we show that bounds on empirical MCR can again be tractably computed for this class, and that the loss for models in this class can be feasibly upper bounded.
7.4.1. Calculating MCR
Again, calculating bounds on from Lemmas 9 & 13 requires us to be able to minimize arbitrary linear combinations of êorig(fα) and êswitch(fα).
Given a size-n sample of test observations Z = [ y X ], let Korig be the n × R matrix with elements Korig[i,j] = k (X[i,·], D[j,·]). Let Zswitch = [ yswitch Xswitch ] be the (n(n − 1)) × (1 + p) matrix with rows that contain the set {(y[i], X1[j,·], X2[i,·]) : i, j ∈ {1, … , n} and i ≠ j}. Finally, let Kswitch be the n(n − 1) × R matrix with Kswitch[i,j] = k (Xswitch[i,·], D[j,·]).
For any two constants , we can show that minimizing the linear combination over is equivalent to the minimization problem
| (7.8) |
| (7.9) |
Like Problem 7.5, Problem 7.8-7.9 is a QP1QC. To show Eqs 7.8–7.9, we first write êorig(fα) as
| (7.10) |
| (7.11) |
Following similar steps, we can obtain
Thus, for any two constants , we can see that ξorigêorig(fα)+ξswitchêswitch(fα) is quadratic in α. This means that we can tractably compute bounds on empirical MCR for this class as well.
7.4.2. Upper Bounding the Loss
Using similar steps as in Section 7.3.2, the following lemma gives sufficient conditions to determine Bind for the case of regression in a RKHS.
Lemma 18 (Loss upper bound for regression in a RKHS) Assume that Y is bounded within a known range, and there exists a known constant rD such that for all , where is the function satisfying υ(x)[i] = k(x, D[i,·]). Under these conditions, Assumption 1 holds for the model class , the squared error loss function, and the constant
Thus, for regression models in a RKHS, we can satisfy Assumption 1 for all models in the class.
8. Connections Between MR and Causality
Our MR approach can be fundamentally described as studying how a model’s behavior changes under an intervention on the underlying data. We aim to study the causal effect of this intervention on the model’s performance. This goal mirror’s the conventional causal inference goal of studying how an intervention on variables will change outcomes generated by a process in nature.
This section explores this connection to causal inference further. Section 8.1 shows that when the prediction model in question is the conditional expectation function from nature itself, MR reduces to commonly studied quantities in the causal literature. Section 8.2 proposes an alternative to MR that focuses on interventions, or data perturbations, that are likely to occur in the underlying data generating process.
8.1. Model Reliance and Causal Effects
In this section, we show a connection between population-level model reliance and the conditional average causal effect. For consistency with the causal inference literature, we temporarily rename the random variables (Y, X1, X2) as (Y, T, C), with realizations (y, t, c). Here, T := X1 represents a binary treatment indicator, C := X2 represents a set of baseline covariates (“C” is for “covariates”), and Y represents an outcome of interest. Under this notation, represents the expected loss of a prediction function f, and denotes the expected loss in a pair of observations in which the treatment has been switched. Let be the (unknown) conditional expectation function for Y, where we place no restrictions on the functional form of f0.
Let Y1 and Y0 be potential outcomes under treatment and control respectively, such that . The treatment effect for an individual is defined as Y1 − Y0, and the average treatment effect is defined as . Let be the (unknown) conditional average treatment effect of T for all patients with C = c. Causal inference methods typically assume (conditional ignorability), and for all values of c (positivity), in order for f0 and CATE to be well defined and identifiable.
The next proposition quantifies the relation between the conditional average treatment effect function (CATE) and the model reliance of f0 on X1.
Proposition 19 (Causal interpretations of MR) For any prediction model f, let eorig(f) and eswitch(f) be defined based on the squared error loss .
If (conditional ignorability) and for all values of c (positivity), then MR(f0) is equal to
| (8.1) |
where Var(T) is the marginal variance of the treatment assignment.
We see above that model reliance decomposes into several terms that are each individually important in causal inference: the treatment prevalence (via Var(T)); the variability in Y that is not explained by C or T; the magnitude of the average treatment effect, conditional on T; and the variance of the conditional average treatment effect across subgroups. For example, if all patients are treated, then scrambling the treatment in a random pair of observations has no effect on the loss. In this case we see that Var(T) = 0 and MR(f0) = 1, indicating no reliance. When Var(T) > 0, a higher average treatment effect magnitude corresponds to f0 requiring T more heavily to predict Y, all else equal. Similarly, if there is a high degree of treatment effect heterogeneity across subgroups (that is, when Var(CATE(C)|T = t) is large), the model f0 will again use T more heavily when predicting Y. For example, a treatment may be important for predicting Y even if the average treatment effect is zero, so long as the treatment helps some subgroups more than others.
8.2. Conditional Importance: Adjusting for Dependence Between X1 and X2
One common scenario where multiple models achieve low loss is when the sets of predictors X1 and X2 are highly correlated, or contain redundant information. Models may predict well either through reliance on X1, or through reliance on X2, and so MCR will correctly identify a wide range of potential reliances on X1. However, we may specifically be interested how much models rely on the information in X1 that cannot alternatively be gleaned from X2.
For example, age and accumulated wealth may be correlated, and both may be predictive of future promotion. We may wish to know the how much a model for predicting promotion relies on information that is uniquely available from wealth measurements.
To formalize this notion, we define an alternative to eswitch where noise is added to X1 in a way that accounts for the dependence between X1 and X2. Given a fixed prediction model f, we ask: how well would the model f perform if the values of X1 were scrambled across observations with the same value for X2. Specifically, let and denote a pair of independent random vectors following the same distribution as , as in Section 3, and let
| (8.2) |
In words, econd(f) is the expected loss of a given model f across pairs of observations (Z(a), Z(b)) in which the values of and have been switched, given that these pairs match on X2. This quantity can also be interpreted as the expected loss of f if noise were added to X1 in such a way that X1 was no longer informative of Y, given X2, but that the joint distribution of the covariates (X1, X2) was maintained.
We then define conditional model reliance, or “core” model reliance (CMR) for a fixed function f as
That is, CMR is the factor by which the model’s performance degrades when the information unique to X1 is removed. If X1 ⊥ X2, then X1 contains no redundant information, and CMR and MR are equivalent. Otherwise, all else equal, CMR will decrease as X2 becomes more predictive of X1. Analogous to MCR, we define conditional MCR (CMCR) in the same way as in Eq 2.2, but with MR replaced with CMR. In comparison with MCR, CMCR will generally result in a range that is closer to 1 (null reliance).
An advantage of CMR is that it restricts the “noise-corrupted” inputs to be within the domain , rather than the expanded domain considered by MR. This means that CMR will not be influenced by impossible combinations of x1 and x2, while MR may be influenced by them. Hooker (2007) discuss a similar issue, arguing that evaluations of a prediction model’s behavior in different circumstances should be weighted by, for example, how likely those circumstances are to occur.
A challenge facing the CMR approach is that matched pairs such as those in Eq 8.2 may occur rarely, making it difficult to estimate CMR nonparametrically. We explore this estimation issue next.
8.2.1. Estimation of CMR by Weighting, Matching, or Imputation
If the covariate space is discrete and low dimensional, nonparametric methods based on weighting or matching can be effective means of estimating CMR. Specifically, we can weight each pair of sample points i, j according to how likely the covariate combination is to occur, as in
where is an importance weight (see also Hooker, 2007). Here, pairs of observations corresponding to unlikely or impossible combinations of covariates are down-weighted or discarded, respectively. If the probabilities and are known, then is unbiased for econd(f) (see Appendix A.7).
Alternatively, if X2 is discrete and low dimensional, we can restrict estimates of econd(f) to only consider pairs of sample observations in which X2 is constant, or “matched,” as in
| (8.3) |
This approach allows estimation of CMR without knowledge of the conditional distribution . If the inverse probability weight is known, then êmatch(f) is unbiased for econd(f) (see Appendix A.7). The weight accounts for the fact that, for any given value x2, the proportion of observations of X2 taking the value x2 will generally not be the same as the proportion of matched pairs taking value the x2, and so simply summing over all matched pairs would lead to bias. In practice, the proportion can be approximated as , with minor adjustments to Eq 8.3 to avoid dividing by zero. The resulting estimate is analogous to exact matching procedures commonly used in causal inference, which are known to work best when the covariates are discrete and low dimensional, in order for exact matches to be common (Stuart, 2010).
However, when the covariate space is continuous or high dimensional, we typically cannot estimate CMR nonparametrically. For such cases, we propose to estimate CMR under an assumption of homogeneous residuals. Specifically, we define μ1 to be the conditional expectation function , and assume that the random residual X − μ1(X2) is independent of X2. Under this assumption, it can be shown that
That is, econd(f) is equal to the expected loss of f across random pairs of observations (Z(a), Z(b)) in which the value of the residual terms (in curly braces) have been switched. Because of the independence assumption, no matching or weighting is required. If μ1 is known, then we can again produce an unbiased estimate using the U-statistic
This estimator aggregates over all pairs in our sample, switching the values of the residual terms (in curly braces) within each pair. In practice, when μ1 is not known, an estimate of μ1 can be achieved via regression or related machine learning techniques, and plugged in to the above equation. In this way, the assumption that allows us to estimate CMR without explicitly modeling the joint distribution of X1 and X2.
In the existing literature, Strobl et al. (2008) introduce a similar procedure for estimating conditional variable importance. However, a formal comparison to Strobl et al. is complicated by the fact that the authors do not define a specific estimand, and that their approach is limited to tree-based regression models. Other existing approaches conditional importance approaches include methods for redefining X1 and X2 to induce approximate independence, before computing an importance measure analogous to MR. This can be done by reducing the total number of covariates used, and hence reducing how well any one variable can be predicted by the others (as in Gregorutti et al., 2017). Alternatively, variables in X2 that are predictive of X1 can be regrouped directly into X1 (as in Toloşi and Lengauer, 2011; see also the discussion from Kirk, Lewin and Stumpf, in Meinshausen and Bühlmann 2010).
In summary, CMR allows us to see how much a model relies on the information uniquely available in X1. While CMR is more difficult to estimate than MR, several tractable approaches exist when X2 is discrete, or when a homogenous residual assumption can be applied. One may also consider extending CMR by conditioning only on a subset of X2. For example, we may consider conditioning only on elements of X2 that are believed to causally effect X1, by changing the outer expectation in Eq 8.2. For simplicity, we focus on the base case of estimating MR in this paper. Similar results could potentially be carried over for CMR as well.
9. Simulations
In this section, we first present a toy example to illustrate the concepts of MR, MCR, and AR. We then present a Monte Carlo simulation studying the effectiveness of bootstrap CIs for MCR.
9.1. Illustrative Toy Example with Simulated Data
To illustrate the concepts of MR, MCR, and AR (see Section 3.2), we consider a toy example where , and Y ∈ {−1, 1} is a binary group label. Our primary goal in this section is to build intuition for the differences between these three importance measures, and so we demonstrate them here only in a single sample. We focus on the empirical versions of our importance metrics , and compare them against AR, which is typically interpreted as an in-sample measure (Breiman, 2001), or as an intermediate step to estimate an alternate importance measure in terms of variable rankings (Gevrey et al., 2003; Olden et al., 2004).
We simulate from an independent, bivariate normal distribution with means and variances . We simulate X|Y = 1 by drawing from the same bivariate normal distribution, and then adding the value of a random vector , where U is a random variable uniformly distributed on the interval . Thus, (C1, C2) is uniformly distributed across the unit circle.
Given a prediction model , we use the sign of f(X1, X2) as our prediction of Y. For our loss function, we use the hinge loss , where if a ≥ 0 and (a)+ = 0 otherwise. The hinge loss function is commonly used as a convex approximation to the zero-one loss .
We simulate two samples of size 300 from the data generating process described above, one to be used for training, and one to be used for testing. Then, for the class of models used to predict Y, we consider the set of degree-3 polynomial classifiers
where θ[−1] denotes all elements of θ except θ[1], and where we set rd3 to the value that minimizes the 10-fold cross-validated loss in the training data. Let be the algorithm that minimizes the hinge loss over the (convex) feasible region . We apply to the training data to determine a reference model fref. Also using the training data, we set ϵ equal to 0.10 multiplied by the cross-validated loss of , such that contains all models in that exceed the loss of fref by no more than approximately 10% (see Eq 4.1). We then calculate empirical AR, MR, and MCR using the test observations.
We begin by considering the AR of on X1. Calculating AR requires us to fit two separate models, first using all of the variables to fit a model on the training data, and then again using only X2. In this case, the first model is equivalent to fref. We denote the second model as . To compute AR, we evaluate fref and in the test observations. We illustrate this AR computation in Figure 6–A, marking the classification boundaries for fref and by the black dotted line and the blue dashed lines respectively, and marking the test observations by labelled points (“x” for Y = 1, and “o” for Y = −1). Comparing the loss associated with these two models gives one form of AR–an estimate of the necessity of X1 for the algorithm . Alternatively, to estimate the sufficiency of X1, we can compare the reference model fref against the model resulting from retraining algorithm only using X1. We refer to this third model as , and mark its classification boundary by the solid blue lines in Figure 6–A.
Figure 6:
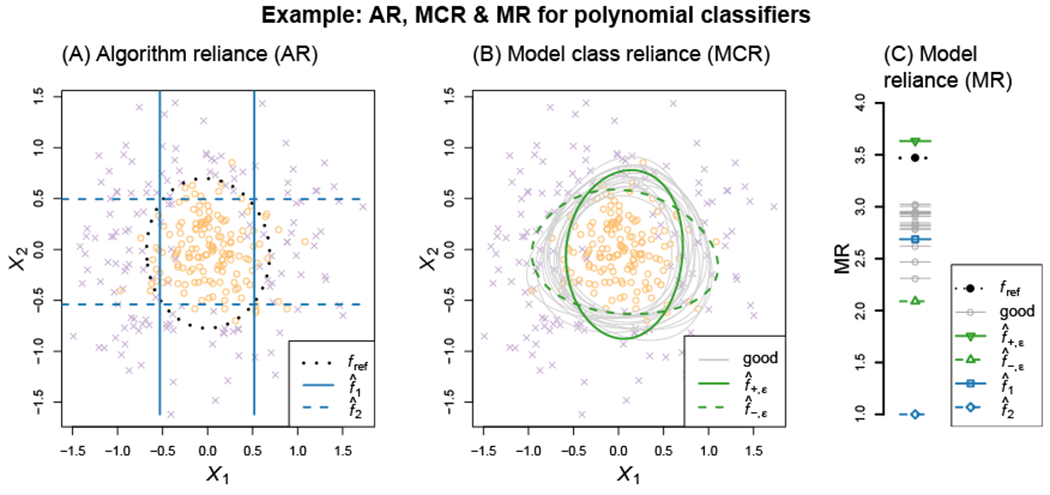
Example of AR, MCR & MR for polynomial classifiers. Panels (A) & (B) show the same 300 draws from a simulated data set, with the classification of each data point marked by “x” for Y = 1, and “o” for Y = −1. In Panel (A), for AR, we show single-feature models formed by dropping a covariate. Because these models take only a single input, we represent their classification boundaries as straight lines. In Panel (B), for MCR, we show the classification boundaries for several (two-feature) models with low in-sample loss. Of these models, the model with minimal dependence on X1 is shown by the dashed green oval, and the model with maximal dependence on X1 is shown by the solid green oval. Panel (C) shows the empirical model reliance on X1 for each of the models in Panels (A) & (B). We see in Panel (C) that, as expected, no well-performing model relies (empirically) on X1 more than does, or relies (empirically) on X1 less than does. That is, no well-performing model has an empirical MR value greater than , or less than .
Each of the classifiers in Figure 6–A can also be evaluated for its reliance on X1, as shown in Figure 6–C. Here, we use êdivide in our calculation of (see Eq 3.5). Unsurprisingly, the classifier fit without using X1 (blue dashed line) has a model reliance of . The reference model fref (dotted black line) has a model reliance of . Each MR value has an interpretation contained to a single model. That is, compares a single model’s behavior under different data distributions, rather than the AR approach of comparing different models’ behavior on marginal distributions from a single joint distribution.
We illustrate MCR in Figure 6–B. In contrast to AR, MCR is only ever a function of well-performing prediction models. Here, we consider the empirical ϵ-Rashomon set , the subset of models in with test loss no more than ϵ above that of fref. We show the classification boundary associated with 15 well-performing models contained in by the gray solid lines. We also show two of the models in that approximately maximize and minimize empirical reliance on X1 among models in . We denote these models as and , and mark them by the solid green and dashed green lines respectively. For every model shown in Figure 6–B, we also mark its model reliance in Figure 6–C. We can then see from Figure 6–C that for each model in is contained between and , up to a small approximation error.
In summary, unlike AR, MCR is only a function of models that fit the data well.
9.2. Simulations of Bootstrap Confidence Intervals
In this section we study the performance of MCR under model class misspecification. Our goal will be to estimate how much the conditional expectation function relies on subsets of covariates. Given a reference model fref and model class , our ability to describe MR(f0) will hinge on two conditions:
Condition 20 (Nearly correct model class) The class contains a well-performing model satisfying (see Eq 4.1).
Condition 21 (Bootstrap coverage) Bootstrap CIs for empirical MCR give appropriate coverage of population-level MCR.
Condition 20 ensures that the interval [MCR−(ϵ),MCR+(ϵ)] contains MR(f0), and Condition 21 ensures that this interval can be estimated in finite samples. Condition 20 can also be interpreted as saying that the model reliance value of MR(fc) is “well supported” by the class , even if does not contain f0. Our primary goal is to assess whether CIs derived from MCR can give appropriate coverage of MR(f0), which depends on both conditions. As a secondary goal, we also would like to be able to assess Conditions 20 & 21 individually.
Verifying the above conditions requires that we are able to calculate population-level MCR. To this end, we draw samples with replacement from a finite population of 20,000 observations, in which MCR can also be calculated directly. To derive a CI based on MCR, we divide each simulated sample into a training subset and analysis subset. We use the training subset to fit a reference model fref,s, which is required for our definition of population-level MCR. We calculate a bootstrap CI by drawing 500 bootstrap samples from the analysis subset, and computing and in each bootstrap sample by optimizing over . We then take the 2.5% percentile of values across bootstrap samples, and the 97.5% percentile of values across bootstrap samples, as the lower and upper endpoints of our CI, respectively. We repeat this procedure for both X1 and X2.
We generate data according to a model with increasing amounts of nonlinearity. For , we simulate continuous outcomes as , where f0 is the function the covariate dimension p is equal to 2, with X1 and X2 defined as the first and second elements of X; the covariates X are drawn from a multivariate normal distribution with , , and ; and E is a normally distributed noise variable with mean zero and variance equal to . We consider sample sizes of n = 400 and 800, of which ntr = 200 or 300 observations are assigned to the training subset respectively.
To implement our approach, we use the model class . We set the performance threshold ϵ equal to . We refer to this MCR implementation with as “MCR-Linear.”
As a comparator method, we consider a simpler bootstrap approach, which we refer to as “Standard-Linear.” Here, we take 500 bootstrap samples from the simulated data . In each bootstrap sample, indexed by b, we set aside ntr training points to train a model , and calculate from the remaining data points. We then create a 95% bootstrap percentile CI for MR(f0) by taking the 2.5% and 97.5% percentiles of across b = 1, … , 500.
9.2.1. Results
Overall, we find that MCR provides more robust and conservative intervals for the reliance of f0 on X1 and X2, relative to standard bootstrap approaches. We also find that higher sample size generally exacerbates coverage errors due to misspecification, as methods become more certain of biased results.
MCR-Linear gave proper coverage for up to moderate levels of misspecification (γ = 0.3), where Standard-Linear began to break down (Figure 7). For larger levels of misspecification (γ ≥ 0.4), both MCR-Linear and Standard-Linear failed to give appropriate coverage.
Figure 7:
MR Coverage - The y-axis shows coverage rate for the reliance of f0 on either X1 (left column) or X2 (right column), where X2 is simulated to be more influential that X1. The x-axis shows increasing levels of misspecification (γ). All methods aim to have at least 95% coverage for each scenario (dashed horizontal line).
The increased robustness of MCR comes at the cost of wider CIs. Intervals for MCR-Linear were typically larger than intervals for Standard-Linear by a factor of approximately 2-4. This is partly due to the fact that CIs for MCR are meant to cover the range of values [MCR−(ϵ), MCR+(ϵ)] (defined using fref,s), rather than to cover a single point.
When investigating Conditions 20 & 21 individually, we find that the coverage errors for MCR-Linear were largely attributable to violations of Condition 20. Condition 21 appears to hold conservatively for all scenarios studied–within each scenario, at least 95.9% of bootstrap CIs contained population-level MCR.
These simulation results highlight an aspect of MCR that is both a strength and a weakness: MCR is generic. MCR does not assume a particular means by which misspecification may occur, and is less powerful than sensitivity analyses which make that assumption correctly. Nonetheless, MCR still appears to add robustness. For sufficiently strong signals, an informative interval may still be returned. In our applied data analysis, below, we see that this is indeed the case.
10. Data Analysis: Reliance of Criminal Recidivism Prediction Models on Race and Sex
Evidence suggests that bias exists among judges and prosecutors in the criminal justice system (Spohn, 2000; Blair et al., 2004; Paternoster and Brame, 2008). In an aim to counter this bias, machine learning models trained to predict recidivism are increasingly being used to inform judges’ decisions on pretrial release, sentencing, and parole (Monahan and Skeem, 2016; Picard-Fritsche et al., 2017). Ideally, prediction models can avoid human bias and provide judges with empirically tested tools. But prediction models can also mirror the biases of the society that generates their training data, and perpetuate the same bias at scale. In the case of recidivism, if arrest rates across demographic groups are not representative of underlying crime rate (Beckett et al., 2006; Ramchand et al., 2006; U.S. Department of Justice - Civil Rights Devision, 2016), then bias can be created in both (1) the outcome variable, future crime, which is measured imperfectly via arrests or convictions, and (2) the covariates, which include the number of prior convictions on a defendant’s record (Corbett-Davies et al., 2016; Lum and Isaac, 2016). Further, when a prediction model’s behavior and mechanisms are an opaque black box, the model can evade scrutiny, and fail to offer recourse or explanations to individuals rated as “high risk.”
We focus here on the issue of transparency, which takes an important role in the recent debate about the proprietary recidivism prediction tool COMPAS (Larson et al., 2016; Corbett-Davies et al., 2016). While COMPAS is known to not rely explicitly on race, there is concern that it may rely implicitly on race via proxies-variables statistically dependent with race (see further discussion in Section 11).
Our goal is to identify bounds for how much COMPAS relies on different covariate subsets, either implicitly or explicitly, under certain assumptions (defined below). We analyze a public data set of defendants from Broward County, Florida, in which COMPAS scores have been recorded (Larson et al., 2016). Within this data set, we only included defendants measured as African-American or Caucasian (3,373 in total) due to sparseness in the remaining categories. The outcome of interest (Y) is the COMPAS violent recidivism score. Of the available covariates, we consider three variables which we refer to as “admissible”: an individual’s age, their number of priors, and an indicator of whether the current charge is a felony. We also consider two variables which we refer to as “inadmissible”: an individual’s race and sex. Our labels of “admissible” and “inadmissible” are not intended to be legally precise-indeed, the boundary between these types of labels is not always clear (see Section 10.2). We compute empirical MCR and AR for each variable group, as well as bootstrap CIs for MCR (see Section 9.2).
To compute empirical MCR and AR, we consider a flexible class of linear models in a RKHS to predict the COMPAS score (described in more detail below). Given this class, the MCR range (See Eq 2.2) captures the highest and lowest degree to which any model in the class may rely on each covariate subset. We assume that our class contains at least one model that relies on “inadmissible variables” to the same extent that COMPAS relies either on “inadmissible variables” or on proxies that are unmeasured in our sample (analogous to Condition 20). We make the same assumption for “admissible variables.” These assumptions can be interpreted as saying that the reliance values of COMPAS are relatively “well supported” by our chosen model class, and allows us to identify bounds on the MR values for COMPAS. We also consider the more conventional, but less robust approach of AR (Section 3.2), that is, how much would the accuracy suffer for a model-fitting algorithm trained on COMPAS score if a variable subset was removed?
These computations require that we predefine our loss function, model class, and performance threshold. We define MR, MCR, and AR in terms of the squared error loss . We define our model class in the form of Eq 7.6, where we determine D, μ, k, and rk based on a subset of 500 training observations. We set D equal to the matrix of covariates from ; we set μ equal to the mean of Y in ; we set k equal to the radial basis function , where we choose σs to minimize the cross-validated loss of a Nadaraya-Watson kernel regression (Hastie et al., 2009) fit to ; and we select the parameters rk by cross-validation on . We set ϵ equal to 0.1 times the cross-validated loss on . Also using , we train a reference model Using the held-out 2,873 observations, we then estimate MR(fref) and MCR for . To calculate AR, we train models from using , and evaluate their performance in the held-out observations.
10.1. Results
Our results imply that race and sex play somewhere between a null role and a modest role in determining COMPAS score, but that they are less important than “admissible” factors (Figure 8). As a benchmark for comparison, the empirical MR of fref is equal to 1.09 for “inadmissible variables,” and 2.78 for “admissible variables.” The AR is equal to 0.94 and 1.87 for “inadmissible” and “admissible” variables respectively, roughly in agreement with MR. The MCR range for “inadmissible variables” is equal to [1.00, 1.56], indicating that for any model in with empirical loss no more than ϵ above that of fref, the model’s loss can increase by no more than 56% if race and sex are permuted. Such a statement cannot be made solely based on AR or MR methods, as these methods do not upper bound the reliance values of well-performing models. The bootstrap 95% CI for MCR on “inadmissible variables” is [1.00, 1.73]. Thus, under our assumptions, if COMPAS relied on sex, race, or their unmeasured proxies by a factor greater than 1.73, then intervals as low as what we observe would occur with probability < 0.05.
For “admissible variables” the MCR range is equal to [1.77,3.61], with a 95% bootstrap CI of [1.62, 3.96]. Under our assumptions, this implies if COMPAS relied on age, number of priors, felony indication, or their unmeasured proxies by a factor lower than 1.77, then intervals as high as what we observe would occur with probability < 0.05. This result is consistent with Rudin et al. (2019), who find age to be highly predictive of COMPAS score.
It is worth noting that the upper limit of 3.61 maximizes empirical MR on “admissible variables” not only among well-performing models, but globally across all models in the class (see Figure 8, and Eq 6.5). In other words, it is not possible to find models in that perform arbitrarily poorly on perturbed data, but still perform well on unperturbed data, and so the ratio of êswitch(f) to êorig(f) has a finite upper bound. Because the regularization constraints of preclude MR values higher than 3.61, the MR of COMPAS on “admissible variables” may be underestimated by empirical MCR. Note also that both MCR intervals are left-truncated at 1, as it is often sufficiently precise to conclude that there exists a well-performing model with no reliance on the variables of interest (that is, MR equal to 1; see Appendix A.2).
10.2. Discussion & Limitations
Asking whether a proprietary model relies on sex and race, after adjusting for other covariates, is related to the fairness metric known as conditional statistical parity (CSP). A decision rule satisfies CSP if its decisions are independent of a sensitive variable, conditional on a set of “legitimate” covariates C (Corbett-Davies et al., 2017; see also Kamiran et al., 2013). Roughly speaking, CSP reflects the idea that groups of people with similar covariates C are treated similarly (Dwork et al., 2012), regardless of the sensitive variable (for example, race or sex). However, the criteria becomes superficial if too many variables are included in C, and care should be taken to avoid including proxies for the sensitive variables. Several other fairness metrics have also been proposed, which often form competing objectives (Kleinberg et al., 2017; Chouldechova, 2017; Nabi and Shpitser, 2018; Corbett-Davies et al., 2017). Here, if COMPAS was not influenced by race, sex, or variables related to race or sex (conditional on a set of “legitimate” variables), it would satisfy CSP.
Unfortunately, it is often difficult to distinguish between “legitimate” (or “admissible”) variables and “illegitimate” variables. Some variables function both as part of a reasonable predictor for risk, and, separately, as a proxy for race. Because of disproportional arrest rates, particularly for misdemeanors and drug-related offenses (U.S. Department of Justice - Civil Rights Devision, 2016; Lum and Isaac, 2016), prior misdemeanor convictions may act as such a proxy (Corbett-Davies et al., 2016; Lum and Isaac, 2016).
Proxy variables for race (defined as being statistically dependent with race) that are unmeasured in our sample are also not the only reason that race could be predictive of COMPAS score. Other inputs to the COMPAS algorithm might be associated with race only conditionally on variables we categorize as “admissible.” However, our result from Section 10.1 that race has limited predictive utility for COMPAS score suggests that such conditional relationships are also limited.
11. Conclusion
In this article, we propose MCR as the upper and lower limit on how important a set of variables can be to any well-performing model in a class. In this way, MCR provides a more comprehensive and robust measure of importance than traditional importance measures for a single model. We derive bounds on MCR, which motivate our choice of point estimates. We also derive connections between permutation importance, U-statistics, conditional variable importance, and conditional causal effects. We apply MCR in a data set of criminal recidivism, in order to help inform the characteristics of the proprietary model COMPAS.
Several exciting areas remain open for future research. One research direction closely related to our current work is the development of exact or approximate MCR computation procedures for other model classes and loss functions. We have shown that, for model classes where minimizing the empirical loss is a convex optimization problem, MCR can be conservatively computed via a series of convex optimization problems. Further, we have shown that computing is often no more challenging that minimizing the empirical loss over a reweighted sample. General computation procedures for MCR are still an open research area.
Another direction is to consider MCR for variable selection. If MCR+ is small for a variable, then no well-performing predictive model can heavily depend on that variable, indicating that it can be eliminated.
Our theoretical analysis of Rashomon sets depends on and fref being prespecified. Above, we have actualized this by splitting our sample into subsets of size n1 and n2, using the first subset to determine and fref, and conditioning on and fref when estimating MCR in the second subset. As a result, the boundedness constants in our assumptions (Bind, Bref, Bswitch, and borig) depend on , and hence on n1. However, because our results are non-asymptotic, we have not explored how Rashomon sets behave when n1 and n2 grow at different rates. An exciting future extension of this work is to study sequences of triples that change as n1 increases, and the corresponding Rashomon sets , as this may more thoroughly capture how model classes are determined by analysts.
While we develop Rashomon sets with the goal of studying MR, Rashomon sets can also be useful for finite sample inferences about a wide variety of other attributes of best-in-class models (for example, Section 5). Characterizations of a Rashomon set itself may also be of interest. For example, in ongoing work, we are studying the size of a Rashomon set, and its connection to generalization of models and model classes (Semenova and Rudin, 2019). We are additionally developing methods for visualizing Rashomon sets (Dong and Rudin, 2019).
Acknowledgments
Support for this work was provided by the National Institutes of Health (grants P01CA134294, R01GM111339, R01ES024332, R35CA197449, R01ES026217, P50MD010428, DP2MD012722, R01MD012769, & R01ES028033), by the Environmental Protection Agency (grants 83615601 & 83587201-0), and by the Health Effects Institute (grant 4953-RFA14-3/16-4).
Appendix A. Miscellaneous Supplemental Sections
All labels for items in the following appendices begin with a letter (for example, Section A.2), while references to items in the main text contain only numbers (for example, Proposition 19).
A.1. Code
R code for our example in Section 9.1 and analysis in Section 10 is available at https://github.com/aaronjfisher/mcr-supplement.
A.2. Model Reliance Less than 1
While it is counterintuitive, it is possible for the expected loss of a prediction model to decrease when the information in X1 is removed. Roughly speaking, a “pathological” model fsilly may use the information in X1 to “intentionally” misclassify Y, such that eswitch(fsilly) < eorig(fsilly) and MR(fsilly) < 1. The model fsilly may even be included in a population ϵ-Rashomon set (see Section 4) if it is still possible to predict Y sufficiently well from the information in X2.
However, in these cases there will often exist another model that outperforms fsilly, and that has MR equal to 1 (i.e., no reliance on X1). To see this, consider the case where is indexed by a parameter θ. Let θsilly and θ⋆ be parameter values such that fθsilly is equivalent to fsilly, and fθ⋆ is the best-in-class model. If fθ⋆ satisfies MR(fθ⋆) > 1 and if the model reliance function MR is continuous in θ, then there exists a parameter value θ1 between θsilly and θ⋆ such that MR(fθ1) = 1. Further, if the loss function L is convex in θ, then eorig(fθ⋆) ≤ eorig(fsilly), and any population ϵ-Rashomon set containing fsilly will also contain fθ1.
A.3. Relating to All Possible Permutations of the Sample
Following the notation in Section 3, let [π1,…, πn!} be a set of n-length vectors, each containing a different permutation of the set {1,…,n}. We show in this section that is equal to the product of
| (A.1) |
and a proportionality constant that is only a function of n.
First, consider the sum
| (A.2) |
which omits the indicator function found in Eq A.1.
The summation in Eq A.2 contains n(n!) terms, each of which is a two-way combination of the form L{f, (y[i], X1[j,·], X2[i,·])} for i,j ∈ {1, … n}. There are only n2 unique combinations of this form, and each must occur in at least (n − 1)! of the n(n!) terms in Eq A.2. To see this, consider selecting two integer values , and enumerating all occurrences of the term within the sum in Eq A.2. Of the permutation vectors [π1,…, πn!}, we know that (n − 1)! of them place in the position, i.e., that satisfy . For each such permutation πl, the inner summation in Eq A.2 over all possible values of i must include the term . Thus, Eq A.2 contains at least (n − 1)! occurrences of the term .
So far, we have shown that each unique combination occurs at least (n − 1)! times, but it also follows that each unique combination must occur precisely (n − 1)! times. This is because each of the n2 unique combinations must occur at least (n − 1)! times, which accounts for n2((n − 1)!) = n(n!) terms in total. As noted above, Eq has A.2 has only n(n)! terms, so there can be no additional terms. We can then simplify Eq A.2 as
By the same logic, we can simplify Eq A.1 as
and Line A.3 is proportional to êswitch(f) up to a function of n.
A.4. Bound for MR of the Best-in-class Prediction Model
Although describing individual models is not the primary focus of this work, a corollary of Theorem 4 is that we can create a probabilistic bound for the reliance of the (unknown) best-in-class model f⋆ on X1.
Corollary 22 (Bound on Best-in-class MR) Let be a prediction model that attains the lowest possible expected loss, and let f+,ϵ and f−,ϵ be defined as in Theorem 4· If f+,ϵ and f−,ϵ satisfy Assumptions 1, 2 and 3, then
where and
The above result does not require that f⋆ be unique. If several models achieve the minimum possible expected loss, the above boundaries apply simultaneously for each of them. In the special case when the true conditional expectation function is equal to f⋆, then we have a boundary for the reliance of the function on X1. This reliance bound can also be translated into a causal statement using Proposition 19.
A.5. Ratios versus Differences in MR Definition
We choose our ratio-based definition of model reliance, , so that the measure can be comparable across problems, regardless of the scale of Y. However, several existing works define VI measures in terms of differences (Strobl et al., 2008; Datta et al., 2016; Gregorutti et al., 2017), analogous to
| (A.4) |
While this difference measure is less readily interpretable, it has several computational advantages. The mean, variance, and asymptotic distribution of the estimator can be easily determined using results for U-statistics, without the use of the delta method (Dorfman, 1938; Lehmann and Casella, 2006; see also Ver Hoef, 2012). Estimates in the form of will also be more stable when is small, relative to estimates for the ratio-based definition of MR. To improve interpretability, we may also normalize MRdifference(f) by dividing by the variance of Y, which can be easily estimated without the use of models, as in Williamson et al. (2017).
Under the difference-based definition for MR (Eq A.4), the results from Theorem 4, Theorem 6, and Corollary 22 will still hold under the following modified definitions of , , and :
Respectively replacing , , , MR, and with , , , MRdifference and entails only minor changes to the corresponding proofs (see Appendices B.3, B.5, and B.4). The results will also hold without Assumption 3, as is suggested by the fact that borig and Bswitch do not appear in , , or .
We also prove an analogous version of Theorem 5, on uniform bounds for , in Appendix B.5.1.
A.6. Rashomon Sets and Profile Likelihood Intervals
We note in Section 5.1 that, under certain conditions, the CIs returned from Proposition 7 take the same form as profile likelihood CIs (Coker et al., 2018). For completeness, we briefly review this connection. We assume here that models are indexed by a finite dimensional parameter vector θ ∈ Θ, where θ = (γ, ψ) contains a 1-dimensional parameter of interest , and a nuisance parameter ψ ∈ Ψ. We further assume and that eorig(fθ) is minimized by a unique parameter value θ⋆ = (γ⋆, ψ⋆) ∈ Θ, and that our goal is to learn about γ⋆.
If is finite for all θ ∈ Θ, we can convert L into the likelihood function satisfying . As an abbreviation, let denote . Additionally, let be the empirical loss minimizer, and hence the maximum likelihood estimator of θ⋆. If is indeed the correct likelihood function, then θ⋆ = (γ⋆, ψ⋆) corresponds to the true parameter vector. Further, if ϕ(fθ) = ϕ(f(γ, ψ)) = γ returns the parameter element of interest (γ), then the (1 − δ)-level profile likelihood interval for ϕ(fθ⋆) = γ⋆ is
| (A.5) |
where is the 1 − δ percentile of a chi-square distribution with 1 degree of freedom. If PLI(α) is indeed a contiguous interval, then maximizing and minimizing ϕ(fθ) across models fθ in the empirical Rashomon set in Eq A.5 yields the same interval.
A.7. Unbiased Estimates of CMR
We claim in Section 8.2 that both
and
are unbiased for
To show that êmatch(f) is unbiased, we first note that each summation term in êmatch(f) has the same expectation. Following the notation in Section 3, let and be independent random variables following the same distribution as Z = (Y, X1, X2). The expectation of êmatch(f) is
To show that is unbiased, we similarly note that each summation term in has the same expectation. Without loss of generality, we show the result for discrete variables (Y, X1, X2). Let be the domain of Y conditional on the event that X2 = x2. The expectation of is
Appendix B. Proofs for Statistical Results
We present proofs for our statistical results in this section, and conclude by presenting proofs for our computational results in Appendix C.
B.1. Lemma Relating Empirical and Population Rashomon Sets
Throughout the remaining proofs, it will be useful to express the definition of population ϵ-Rashomon sets in terms of the expectation of a single loss function, rather than a comparison of two loss functions. To do this, we simply introduce the “standardized” loss function , defined as
| (B.1) |
Above, recall from Section 2 that L(f, z) denotes L(f, (y, x1, x2)) for z = (y, x1, x2). Because we assume fref is prespecified and fixed, we omit notation for fref in the definition of . We can now write
and, similarly,
With this definition, the following lemma allows us to limit the probability that a given model is excluded from an empirical Rashomon set.
Lemma 23 For and δ ∈ (0, 1), let , and let denote a specific, possibly unknown prediction model. If f1 satisfies Assumption 2, then
Proof If fref and f1 are the same function, then the result holds trivially. Otherwise, the proof follows from Hoeffding’s inequality (Theorem 2 of Hoeffding, 1963). First, note that if f1 satisfies Assumption 2, then is bounded within an interval of length 2Bref. Applying this in line B.3, below, we see that
| (B.2) |
| (B.3) |
| (B.4) |
For the inequality used in Line B.3, see Theorem 2 of Hoeffding, 1963. ■
B.2. Lemma to Transform Between Bounds
The following lemma will help us translate from bounds for variables to bounds for differences and ratios of those variables. We will apply this lemma to transform from bounds on empirical losses to bounds on empirical model reliance, defined either in terms of a ratio or in terms of a difference.
Lemma 24 Let X, Z, μX ,μZ, kX, be constants satisfying |Z − μZ| ≤ kZ and |X − μX| ≤ kX, then
| (B.5) |
where qdifference is the function
| (B.6) |
Further, if there exists constants borig and Bswitch such that 0 < borig ≤ X, μX and Z, μZ ≥ Bswitch < ∞, then
| (B.7) |
where qratio is the function
| (B.8) |
Proof Showing Eq B.5,
Showing Eq B.7, let Az = max(Z, μz), aX = min(X, μX), dZ = |Z − μZ|, and dX = |X − μX|. This implies that max(X, μX) = aX + dX and min(Z, μZ) = AZ − dZ. Thus, and are both bounded within the interval
which implies
| (B.9) |
Taking partial derivatives of the right-hand side, we get
So the right-hand side of B.9 is maximized when dZ, dX, and AZ are maximized, and when aX is minimized. Thus, in the case where |Z − μZ| ≤ kZ; |X − μX| ≤ kX; 0 < borig ≤ X, μX ; and Z, μZ ≤ Bswitch < ∞, we have
B.3. Proof of Theorem 4
Proof We proceed in 4 steps.
B.3.1. Step 1: Show that
Consider the event that
| (B.10) |
Eq B.10 will always hold if , since upper bounds the empirical model reliance for models in by definition. Applying the above reasoning in Line B.11, below, we get
| (B.11) |
| (B.12) |
B.3.2. Step 2: Conditional on , Upper Bound MR(f+,ϵ) by Added to an Error Term.
When Eq B.10 holds we have,
| (B.13) |
B.3.3. Step 3: Probabilistically Bound the Error Term from Step 2.
Next we show that the bracketed term in Line B.13 is less than or equal to with high probability. For , let qdiference and qratio be defined as in Eqs B.6 and B.8. Let be the function such that . Then
Applying this relation below, we have
| (B.14) |
| (B.15) |
| (B.16) |
In Line B.15, above, recall that and are both U-statistics. Note that because is an average of terms, and each term has expectation equal to eswitch(f+,ϵ). For the same reason, . This allows us to apply Eq 5.7 of Hoeffding, 1963 (see also Eq 1 on page 201 of Serfling, 1980, in Theorem A) to obtain Line B.15.
Alternatively, if we instead define model reliance as MRdifference(f) = eswitch(f) − eorig(f) (see Appendix A.5), define empirical model reliance as , and define
then the same proof holds without Assumption 3 if we replace MR, , respectively with MRdifference, , and redefine as the function .
Eqs B.14–B.16 also hold if we replace êswitch throughout with êdivide, including in Assumption 3, since the same bound can be used for both êswitch and êdivide (Eq 5.7 of Hoeffding, 1963; see also Theorem A on page 201 of Serfling, 1980).
B.3.4. Step 4: Combine Results to Show Eq 4.2
Finally, we connect the above results to show Eq 4.2. We know from Eq B.12 that Eq B.10 holds with high probability. Eq B.10 implies Eq B.13, which bounds MCR+(ϵ) = MR(f+,ϵ) up to a bracketed residual term. We also know from Eq B.16 that, with high probability, the residual term in Eq B.13 is less than . Putting this together We can show Eq 4.2:
| (B.17) |
This completes the proof for Eq 4.2. For Eq 4.3 we can use the same approach, shown below for completeness. Analogous to Eq B.12, we have
Analogous to Eq B.13, when we have
Analogous to Eq B.16, we have
| (B.18) |
Finally, analogous to Eq B.17, we have
| (B.19) |
Again, the same proof holds without Assumption 3 if we replace MR, respectively with MRdifference, , and redefine q as the function satisfying in Eqs B.18 & B.19. ■
B.4. Proof of Corollary 22
Proof By definition, MR(f−,ϵbest) ≤ MR(f⋆) ≤ MR(f+,ϵbest). Applying this relation in Line B.20, below, we see
| (B.20) |
| (B.21) |
To apply Theorem 4 in Line B.21, above, we note that and ϵbest are equivalent to the definitions of and ϵout in Theorem 4, but with δ replaced by .
Alternatively, if we define model reliance as MRdifference(f) = eswitch(f) − eorig(f) (see Appendix A.5), and define empirical model reliance as , then let
The term is equivalent to but with δ replaced with . Under this difference-based definition of model reliance, Theorem 4 holds without Assumption 3 if we replace with (see Section B.3), and so we can apply this altered version of Theorem 4 in Line B.21. Thus, Theorem 22 also holds without Assumption 3 if we replace MR, , and respectively with MRdifference, , and . ■
B.5. Proof of Theorems 5 & 6
We begin by proving Theorem 5, along with related results. We then apply these results to show Theorem 6.
B.5.1. Proof of Theorem 5, and Other Limits on Estimation Error, Based on Covering Number
The following theorem uses the covering number based on r-margin-expectation-covers to jointly bound empirical losses for any function . Theorem 5 in the main text follows directly from Eq B.25, below.
Theorem 25 If Assumptions 1, 2 and 3 hold for all , then for any r > 0
| (B.22) |
| (B.23) |
| (B.24) |
| (B.25) |
| (B.26) |
where
| (B.27) |
| (B.28) |
and qratio and qdifference are defined as in Lemma 24. For Eq B.26, the result is unaffected if we remove Assumption 3.
B.5.2. Proof of Eq B.22
Proof Let be a r-margin-expectation-cover for of size . Let Dp denote the population distribution, let Ds be the sample distribution, and let D⋆ be the uniform mixture of Dp and Ds, i.e., for any ,
| (B.29) |
Unless otherwise stated, we take expectations and probabilities with respect to Dp. Since is a r-margin-expectation-cover, we know that for any we can find a function such that and
| (B.30) |
Applying the above relation in Line B.31 below, we have
| (B.31) |
| (B.32) |
| (B.33) |
To apply Hoeffding’s inequality (Theorem 2 of Hoeffding, 1963) in Line B.32, above, we use the fact that L(g, Z) is bounded within an interval of length Bind. ■
B.5.3. Proof of Eq B.23
Proof The proof for Eq B.23 is nearly identical to the proof for Eq B.22. Simply replacing L and Bind respectively with and (2Bref) in Eqs B.30–B.33 yields a valid proof for Eq B.23. ■
B.5.4. Proof of Eq B.24
Proof Let FD denote the cumulative distribution function for a distribution D. Let be the distribution such that
Let be the distribution satisfying
Let be the uniform mixture of and , as in Eq B.29. Replacing eorig, êorig, Dp, Ds, and respectively with eswitch, êswitch, , , and , we can follow the same steps as in the proof for Eq B.22. For any , we know that there exists a function satisfying which implies
As a result,
| (B.34) |
In Line B.34, above, we apply Eq 5.7 of Hoeffding, 1963 (see also Eq 1 on page 201 of Serfling, 1980, in Theorem A), in the same way as in Eq B.15. ■
B.5.5. Proof for Eq B.25
Proof We apply Lemma 24 and Eq B.27 in Line B.36, below, to obtain
| (B.35) |
| (B.36) |
| (B.37) |
■
B.5.6. Proof for Eq B.26
Proof Finally, to show B.26, we apply the same steps as in Eqs B.35 through B.37. We apply Eq B.28 & Lemma 24 to obtain
■
B.5.7. Implementing Theorem 25 to Show Theorem 6
Proof Consider the event that
| (B.38) |
A brief outline of our proof for Eq 4.6 is as follows. We expect Eq B.38 to be unlikely due to the fact that ϵin < ϵ. If Eq B.38 does not hold, then the only way that holds is if there exists which has an empirical MR that differs from its population-level MR by at least .
To show that Eq B.38 is unlikely, we apply Theorem 25:
| (B.39) |
| (B.40) |
If Eq B.38 does not hold, we have
| (B.41) |
Let qratio and qdifference be defined as in Lemma 24. Then
| (B.42) |
Theorem 25 implies that the sup term in Eq B.41 is less than with probability at least . Now, examining the left-hand side of Eq 4.6, we see
| (B.43) |
This completes the proof for Eq 4.6.
Alternatively, if we have defined model reliance as MR(f) = eswitch(f) − eorig(f) (see Appendix A.5), with , and
then same proof of Eq 4.6 holds without Assumption 3 if we replace with , and apply Eq B.26 in Eq B.43.
For Eq 4.7 we can use the same approach. Consider the event that
| (B.44) |
Applying steps analogous to those used to derive Eq B.40, we have
Analogous to B.41, when Eq B.44 does not hold, we have have
Finally, analogous to Eq B.43,
| (B.45) |
Under the difference-based definition of model reliance (see Appendix A.5), the same proof for Eq 4.7 holds without Assumption 3 if we replace MR, , & respectively with MRdifference, , & , and apply Eq B.26 in Eq B.45. ■
B.6. Proof of Proposition 7, and Corollary for a Unique Best-in-class Model.
We first introduce a lemma to describe the performance of any individual model in the population ϵ-Rashomon set.
Lemma 26 Let , and let the functions and be defined as in Proposition 7. Given a function , if Assumption 2 holds for f1, then
Proof Consider the event that
| (B.46) |
Eq B.46 will always hold if , since the interval contains ϕ(f) for any by definition. Thus,
■
B.6.1. Proof of Proposition 7
Proof Let and respectively denote functions that attain the lowest and highest values of ϕ(f) among models . Applying the definitions of f−,ϵ,ϕ and f+,ϵ,ϕ in Line B.47, below, we have
| (B.47) |
■
B.6.2. Corollary for a Unique Best-in-Class Model
When the best-in-class model is unique, it can be described by the corollary below.
Corollary 27 Let and , where . Let be the prediction model that uniquely attains the lowest possible expected loss. If f⋆ satisfies Assumption 2, then
Proof Since , Corollary 27 follows immediately from Lemma 26.
Notice that by assuming f⋆ is unique, we can use the threshold , which is lower than the threshold of with ϵ = 0, as in Proposition 7. In this way, assuming uniqueness allows a stronger statement than the one in Proposition 7. ■
B.7. Absolute Losses versus Relative Losses in the Definition of the Rashomon Set
In this paper we primarily define Rashomon sets as the models that perform well relative to a reference model fref. We can also study an alternate formulation of Rashomon sets by replacing the relative loss with the non-standardized loss L throughout. This results in a new interpretation of the Rashomon set as the union of fref and the subset of models with absolute loss L no higher than ϵabs, for ϵabs > 0. The process of computing empirical MCR is largely unaffected by whether L or is used, as it is simple to transform from one optimization problem to the other.
We still require the explicit inclusion of fref in empirical and population Rashomon sets to ensure that they are nonempty. However, in many cases, this inclusion becomes redundant when interpreting a Rashomon set (e.g., when ϵ ≥ 0, and .
Under the replacement of with L, we also replace Assumption 2 with Assumption 1 (whenever this is not redundant), and replace 2Bref with Bind in the definitions of ϵout, ϵbest, ϵin, ϵ′ and in Theorem 4, Corollary 22, Theorem 6, Proposition 7, and Corollary 27. This is because the motivation for the 2Bref term is that is bounded within an interval of length 2Bref when f1 satisfies Assumption 2. However, under Assumption 1, L(f1) is bounded within an interval of length Bind.
B.8. Proof of Proposition 15
Proof To show Eq 7.1 we start with eorig(fβ),
For eswitch(fβ), we can follow the same steps as above:
Since and each have the same distribution as (Y, X1, X2), we can omit the superscript notation to show Eq 7.1:
Dividing both sides by eorig(fβ) gives the desired result.
Next, we can use a similar approach to show Eq 7.2:
| (B.48) |
Focusing on the term in braces,
| (B.49) |
Plugging this into Eq B.48, and applying the sample linear algebra representations as in Eq B.49, we get
■
B.9. Proof of Proposition 19
Proof First we consider eorig(f0). We briefly recall that the notation f0(t, c) refers to the true conditional expectation function for both potential outcomes Y1, Y0, rather than the expectation for Y0 alone.
Under the assumption that (Y1, Y0) ⊥ T|C, we have . Applying this, we see that
| (B.50) |
where and .
Now we consider eswitch(f0). Let and be a pair of independent random variable vectors, each with the same distribution as (Y0, Y1, T, C). Then
First we expand the outermost expectation, over T(b), T(a):
| (B.51) |
Since T(b) ⊥ T(a), we can write
Plugging this into Eq B.51 we get
Since are the only random variables remaining, we can omit the superscript notation (e.g., replace C(b) with C) to get
where . First, we consider A00 and A11:
and, similarly, .
Next we consider A01 and A10:
and, following the same steps,
Plugging in A00, A01, A10, and A11 we get
| (B.52) |
| (B.53) |
| (B.54) |
| (B.55) |
In Lines B.52 and B.53, we consolidate terms involving and . In Line B.54, we use p+q = 1 to reduce Line B.52 to the right-hand side of Eq B.50. Finally, in Line B.55, we use qp = Var(T). Dividing both sides by gives the desired result. ■
Appendix C. Proofs for Computational Results
Almost all of the proofs in this section are unchanged if we replace êswitch (f) with êdivide(f) in our definitions of ĥ−,γ, ĥ+,γ, ĝ−,γ, ĝ+,γ, and . The only exception is in Appendix C.3.
Throughout the following proofs, we will make use of the fact that, for constants satisfying a ≥ c, the relation a + b ≤ c + d implies
| (C.1) |
We also make use of the fact that for any , the definitions of ĝ+,γ1 and ĝ−,γ1 imply
| (C.2) |
Finally, for any two values , we make use of the fact that
| (C.3) |
and, by the same steps,
| (C.4) |
C.1. Proof of Lemma 9 (Lower Bound for MR)
Proof We prove Lemma 9 in 2 parts.
C.1.1. Part 1: Showing Eq 6.1 Holds for All Satisfying êorig(f) ≤ ϵabs.
If ĥ−,γ (ĝ−,γ) ≥ 0, then for any function satisfying êorig(f) ≤ ϵabs we know that
| (C.5) |
Now, for any satisfying êorig(f) ≤ ϵabs, the definition of ĝ−,γ implies that
C.1.2. Part 2: Showing that, if , and at Least One of the Inequalities in Condition 8 Holds with Equality, then Eq 6.1 Holds with Equality.
We consider each of the two inequalities in Condition 8 separately. If , then
As a result
Alternatively, if , then
■
C.2. Proof of Lemma 10 (Monotonicity for MR Lower Bound Binary Search)
Proof We prove Lemma 10 in 3 parts.
C.2.1. Part 1: is Monotonically Increasing in γ.
Let satisfy γ1 < γ2. We have assumed that for any . Thus, for any we have
| (C.6) |
Applying this, we have
This result is analogous to Lemma 3 from Dinkelbach (1967).
C.2.2. Part 2: is Monotonically Decreasing in γ.
Let satisfy γ1 < γ2. Then
C.2.3. Part 3: is Monotonically Decreasing in γ in the Range Where , and Increasing Otherwise.
Suppose and , . Then, from Eq C.2,
Similarly, if and , . Then, from Eq C.2
■
C.3. Proof of Proposition 11 (Nonnegative Weights for MR Lower Bound Binary Search)
Proof Let . First we show that there exists a function minimizing such that . Let Ds denote the sample distribution of the data, and let Dm be the distribution satisfying
From and Eq 6.2, we see that
Thus, from Condition 2 of Proposition 11, we know there exists a function that minimizes with for any and . Condition 1 of Proposition 11 then implies that for any , , and . We apply this result in Line C.7, below, to show that loss of model is unaffected by permuting X1 within our sample:
| (C.7) |
It follows that . To show the result of Proposition 11, let γ2 = 0. For any function minimizing , we know that
| (C.8) |
From γ2 ≤ γ1, and Part 2 of Lemma 10, we know that
| (C.9) |
Combining Eqs C.8 and C.9, we have
| (C.10) |
Since by definition, Condition 8 holds for γ2, ϵabs and if and only if . This, combined with Eq C.10, completes the proof.
The same result does not necessarily hold if we replace êswitch with êdivide in our definitions of , , and . This is because êdivide does not correspond to the expectation over a distribution in which X1 is independent of X2 and Y, due to the fixed pairing structure used in êdivide. Thus, Condition 2 of Proposition 11 will not apply. ■
C.4. Proof of Lemma 13 (Upper Bound for MR)
Proof We prove Lemma 13 in 2 parts.
C.4.1. Part 1: Showing Eq 6.4 Holds for All Satisfying
If , then for any function satisfying we know that
| (C.11) |
Now, if γ ≤ 0, then for any satisfying , the definition of ĝ+,γ implies
C.4.2. Part 2: Showing that if f = ĝ+,γ, and at Least One of the Enequalities in Condition 12 Holds with Equality, then Eq 6.4 Holds with Equality.
We consider each of the two inequalities in Condition 12 separately. If , then
As a result,
Alternatively, if , then
■
C.5. Proof of Lemma 14 (Monotonicity for MR Upper Bound Binary Search)
Proof We prove Lemma 14 in 3 parts.
C.5.1. Part 1: is Monotonically Increasing in γ.
Let satisfy . We have assumed that for any . Thus, for any we have
| (C.12) |
Applying this, we have
C.5.2. Part 2: is Monotonically Decreasing in γ for γ ≤ 0, and Condition 12 Holds for γ = 0 and .
Let satisfy γ1 < γ2 ≤ 0. Then
| (C.13) |
Now we are equipped to show the result that is monotonically decreasing in γ for γ ≤ 0:
| (C.14) |
To show that Condition 12 holds for γ = 0 and , we first note that , which is positive by assumption. Second, we note that
C.5.3. Part 3: is Monotonically Increasing in γ in the Range Where and γ < 0, and Decreasing in the Range Where and γ < 0.
To prove the first result, suppose that γ1 < γ2 < 0 and , . This implies
| (C.15) |
Then, starting with Eq C.2,
Diving both sides of the above equation by ϵabs proves that is monotonically decreasing in γ in the range where and γ < 0.
To prove the second result we proceed in the same way. Suppose that γ1 < γ2 < 0 and ; . This implies
| (C.16) |
Then, starting with Eq C.2,
Diving both sides of the above equation by ϵabs proves that is monotonically decreasing in γ in the range where and γ < 0. ■
C.6. Proof of Remark 16 (Tractability of Empirical MCR for Linear Model Classes)
Proof To show Remark 16, we apply Proposition 15 to see that
■
C.7. Proof of Lemma 17 (Loss Upper Bound for Linear Models)
Proof Under the conditions in Lemma 17 and Eq 7.5, we can construct an upper bound on by either maximizing or minimizing x′β. First, we consider the maximization problem
| (C.17) |
We can see that both constraints hold with equality at the solution to this problem. Next, we apply the change of variables and , where is the eigendecomposition of Mlm. We obtain
which has an optimal objective value equal to . By negating the objective in Eq C.17, we see that the minimum possible value of x′β, subject to the constraints in Eq 7.5 and Lemma 17, is found at . Thus, we know that
for any . ■
C.8. Proof of Lemma 18 (Loss Upper Bound for Regression in a RKHS)
This proofs follows a similar structure as the proof in Section C.7. From the assumptions of Lemma 18, we know from Eq 7.7 that the largest possible output from a model is
The above problem can be solved in the same way as Eq C.17, and has a solution at . The smallest possible model output will similarly be lower bounded by − . Thus, Bind is less than or equal to
Contributor Information
Aaron Fisher, Takeda Pharmaceuticals, Cambridge, MA 02139, USA.
Cynthia Rudin, Departments of Computer Science and Electrical and Computer Engineering, Duke University, Durham, NC 27708, USA.
Francesca Dominici, Department of Biostatistics, Harvard T.H. Chan School of Public Health, Boston, MA 02115, USA.
References
- Altmann André, Toloşi Laura, Sander Oliver, and Lengauer Thomas. Permutation importance: a corrected feature importance measure. Bioinformatics, 26(10):1340–1347, 2010. [DOI] [PubMed] [Google Scholar]
- Archer Kellie J and Kimes Ryan V. Empirical characterization of random forest variable importance measures. Computational Statistics & Data Analysis, 52(4):2249–2260, 2008. [Google Scholar]
- Azen Razia, Budescu David V, and Reiser Benjamin. Criticality of predictors in multiple regression. British Journal of Mathematical and Statistical Psychology, 54(2):201–225, 2001. [DOI] [PubMed] [Google Scholar]
- Beckett Katherine, Nyrop Kris, and Pfingst Lori. Race, drugs, and policing: understanding disparities in drug delivery arrests. Criminology, 44(1):105–137, 2006. [Google Scholar]
- Blair Irene V, Judd Charles M, and Chapleau Kristine M. The influence of afrocentric facial features in criminal sentencing. Psychological science, 15(10):674–679, 2004. [DOI] [PubMed] [Google Scholar]
- Boyd Stephen and Vandenberghe Lieven. Convex Optimization. Cambridge university press, 2004. [Google Scholar]
- Breiman Leo. Random forests. Machine learning, 45(1):5–32, 2001. [Google Scholar]
- Breiman Leo et al. Statistical modeling: the two cultures (with comments and a rejoinder by the author). Statistical science, 16(3):199–231, 2001. [Google Scholar]
- Calle M Luz and Urrea Víctor. Letter to the editor: stability of random forest importance measures. Briefings in bioinformatics, 12(1):86–89, 2010. [DOI] [PubMed] [Google Scholar]
- Chipman Hugh A, George Edward I, McCulloch Robert E, et al. Bart: Bayesian additive regression trees. The Annals of Applied Statistics, 4(1):266–298, 2010. [Google Scholar]
- Chouldechova Alexandra. Fair prediction with disparate impact: a study of bias in recidivism prediction instruments. Big data, 5(2):153–163, 2017. [DOI] [PubMed] [Google Scholar]
- Coker Beau, Rudin Cynthia, and King Gary. A theory of statistical inference for ensuring the robustness of scientific results. arXiv preprint arXiv:1804.08646, 2018. [Google Scholar]
- Corbett-Davies Sam, Pierson Emma, Feller Avi, and Goel Sharad. A computer program used for bail and sentencing decisions was labeled biased against blacks. it’s actually not that clear. The Washington Post, October 2016. URL https://www.washingtonpost.com/news/monkey-cage/wp/2016/10/17/can-an-algorithm-be-racist-our-analysis-is-more-cautious-than-propublicas/?utm_term=.e896ff1e4107. [Google Scholar]
- Corbett-Davies Sam, Pierson Emma, Feller Avi, Goel Sharad, and Huq Aziz. Algorithmic decision making and the cost of fairness. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 797–806. ACM, 2017. [Google Scholar]
- Datta Anupam, Sen Shayak, and Zick Yair. Algorithmic transparency via quantitative input influence: theory and experiments with learning systems. In Security and Privacy (SP), 2016 IEEE Symposium on, pages 598–617. IEEE, 2016. [Google Scholar]
- DeLong Elizabeth R, DeLong David M, and Clarke-Pearson Daniel L. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics, 44(3):837–845, 1988. [PubMed] [Google Scholar]
- Demler Olga V, Pencina Michael J, and D’Agostino Ralph B Sr. Misuse of delong test to compare aucs for nested models. Statistics in medicine, 31(23):2577–2587, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Díaz Iván, Hubbard Alan, Decker Anna, and Cohen Mitchell. Variable importance and prediction methods for longitudinal problems with missing variables. PloS one, 10(3): e0120031, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Dinkelbach Werner. On nonlinear fractional programming. Management science, 13(7): 492–498, 1967. [Google Scholar]
- Dong Jiayun and Rudin Cynthia. Variable importance clouds: A way to explore variable importance for the set of good models. arXiv preprint arXiv:1901.03209, 2019. [Google Scholar]
- Dorfman R. A note on the delta-method for finding variance formulae. The Biometric Bulletin, 1(129–137):92, 1938. [Google Scholar]
- Dwork Cynthia, Hardt Moritz, Pitassi Toniann, Reingold Omer, and Zemel Richard. Fairness through awareness. In Proceedings of the 3rd innovations in theoretical computer science conference, pages 214–226. ACM, 2012. [Google Scholar]
- Gevrey Muriel, Dimopoulos Ioannis, and Lek Sovan. Review and comparison of methods to study the contribution of variables in artificial neural network models. Ecological modelling, 160(3):249–264, 2003. [Google Scholar]
- Gregorutti Baptiste, Michel Bertrand, and Saint-Pierre Philippe. Grouped variable importance with random forests and application to multiple functional data analysis. Computational Statistics & Data Analysis, 90:15–35, 2015. [Google Scholar]
- Gregorutti Baptiste, Michel Bertrand, and Saint-Pierre Philippe. Correlation and variable importance in random forests. Statistics and Computing, 27(3):659–678, 2017. [Google Scholar]
- Hapfelmeier Alexander, Hothorn Torsten, Ulm Kurt, and Strobl Carolin. A new variable importance measure for random forests with missing data. Statistics and Computing, 24 (1):21–34, 2014. [Google Scholar]
- Hastie T, Tibshirani R, and Friedman J. The elements of statistical learning 2nd edition. New York: Springer, 2009. [Google Scholar]
- Heider Karl G. The Rashomon effect: when ethnographers disagree. American Anthropologist, 90(1):73–81, 1988. [Google Scholar]
- Hoeffding Wassily. A class of statistics with asymptotically normal distribution. The annals of mathematical statistics, pages 293–325, 1948. [Google Scholar]
- Hoeffding Wassily. Probability inequalities for sums of bounded random variables. Journal of the American Statistical Association, 58(301):13–30, 1963. doi: 10.1080/01621459.1963.10500830. URL https://amstat.tandfonline.com/doi/abs/10.1080/01621459.1963.10500830. [DOI] [Google Scholar]
- Hooker Giles. Generalized functional anova diagnostics for high-dimensional functions of dependent variables. Journal of Computational and Graphical Statistics, 16(3):709–732, 2007. [Google Scholar]
- Horst Reiner and Thoai Nguyen V. Dc programming: overview. Journal of Optimization Theory and Applications, 103(1):1–43, 1999. [Google Scholar]
- Kamiran Faisal, Žliobaitė Indrė, and Calders Toon. Quantifying explainable discrimination and removing illegal discrimination in automated decision making. Knowledge and information systems, 35(3):613–644, 2013. [Google Scholar]
- Kazemitabar Jalil, Amini Arash, Bloniarz Adam, and Talwalkar Ameet S. Variable importance using decision trees. In Advances in Neural Information Processing Systems, pages 425–434, 2017. [Google Scholar]
- Kleinberg Jon, Mullainathan Sendhil, and Raghavan Manish. Inherent trade-offs in the fair determination of risk scores. In 8th Innovations in Theoretical Computer Science Conference (ITCS 2017). Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik, 2017. [Google Scholar]
- Larson Jeff, Mattu Surya, Kirchner Lauren, and Angwin Julia. How we analyzed the compas recidivism algorithm. ProPublica, May 2016. URL https://www.propublica.org/article/how-we-analyzed-the-compas-recidivism-algorithm.
- Lecué Guillaume. Interplay between concentration, complexity and geometry in learning theory with applications to high dimensional data analysis. PhD thesis, Université Paris-Est, 2011. [Google Scholar]
- Lehmann Erich L and Casella George. Theory of point estimation. Springer Science & Business Media, 2006. [Google Scholar]
- Letham Benjamin, Letham Portia A, Rudin Cynthia, and Browne Edward P. Prediction uncertainty and optimal experimental design for learning dynamical systems. Chaos: An Interdisciplinary Journal of Nonlinear Science, 26(6):063110, 2016. [DOI] [PubMed] [Google Scholar]
- Louppe Gilles, Wehenkel Louis, Sutera Antonio, and Geurts Pierre. Understanding variable importances in forests of randomized trees. In Advances in neural information processing systems, pages 431–439, 2013. [Google Scholar]
- Lum Kristian and Isaac William. To predict and serve? Significance, 13(5):14–19, 2016. [Google Scholar]
- Meinshausen Nicolai and Bühlmann Peter. Stability selection. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 72(4):417–473, 2010. [Google Scholar]
- Mentch Lucas and Hooker Giles. Quantifying uncertainty in random forests via confidence intervals and hypothesis tests. The Journal of Machine Learning Research, 17(1):841–881, 2016. [Google Scholar]
- Monahan John and Skeem Jennifer L. Risk assessment in criminal sentencing. Annual review of clinical psychology, 12:489–513, 2016. [DOI] [PubMed] [Google Scholar]
- Nabi Razieh and Shpitser Ilya. Fair inference on outcomes. In Proceedings of the… AAAI Conference on Artificial Intelligence. AAAI Conference on Artificial Intelligence, volume 2018, page 1931. NIH Public Access, 2018. [PMC free article] [PubMed] [Google Scholar]
- Nevo Daniel and Ritov Ya’acov. Identifying a minimal class of models for high-dimensional data. The Journal of Machine Learning Research, 18(1):797–825, 2017. [Google Scholar]
- Olden Julian D, Joy Michael K, and Death Russell G. An accurate comparison of methods for quantifying variable importance in artificial neural networks using simulated data. Ecological Modelling, 178(3):389–397, 2004. [Google Scholar]
- Park Jaehyun and Boyd Stephen. General heuristics for nonconvex quadratically constrained quadratic programming. arXiv preprint arXiv:1703.07870, 2017. [Google Scholar]
- Paternoster Raymond and Brame Robert. Reassessing race disparities in maryland capital cases. Criminology, 46(4):971–1008, 2008. [Google Scholar]
- Picard-Fritsche Sarah, Rempel Michael, Tallon Jennifer A., Adler Julian, and Reyes Natalie. Demystifying risk assessment, key principles and controversies. Technical report, 2017. Available at https://www.courtinnovation.org/publications/demystifying-risk-assessment-key-principles-and-controversies.
- Pólik Imre and Terlaky Tamás. A survey of the s-lemma. SIAM review, 49(3):371–418, 2007. [Google Scholar]
- Ramchand Rajeev, Pacula Rosalie Liccardo, and Iguchi Martin Y. Racial differences in marijuana-users’ risk of arrest in the united states. Drug and alcohol dependence, 84(3): 264–272, 2006. [DOI] [PubMed] [Google Scholar]
- Recknagel Friedrich, French Mark, Harkonen Pia, and Yabunaka Ken-Ichi. Artificial neural network approach for modelling and prediction of algal blooms. Ecological Modelling, 96 (1–3):11–28, 1997. [Google Scholar]
- Roth Wendy D and Mehta Jal D. The Rashomon effect: combining positivist and interpretivist approaches in the analysis of contested events. Sociological Methods & Research, 31(2):131–173, 2002. [Google Scholar]
- Rudin Cynthia. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature Machine Intelligence, 1:206–215, May 2019. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rudin Cynthia, Wang Caroline, and Coker Beau. The age of secrecy and unfairness in recidivism prediction. Harvard Data Science Review, 2019. accepted. [Google Scholar]
- Scardi Michele and Harding Lawrence W. Developing an empirical model of phytoplankton primary production: a neural network case study. Ecological modelling, 120(2):213–223, 1999. [Google Scholar]
- Semenova Lesia and Rudin Cynthia. A study in rashomon curves and volumes: a new perspective on generalization and model simplicity in machine learning. arXiv preprint arXiv:1908.01755, 2019. [Google Scholar]
- Serfling Robert J. Approximation theorems of mathematical statistics. John Wiley & Sons, 1980. [Google Scholar]
- Spohn Cassia. Thirty years of sentencing reform: the quest for a racially neutral sentencing process. Criminal justice, 3:427–501, 2000. [Google Scholar]
- Statnikov Alexander, Lytkin Nikita I, Lemeire Jan, and Aliferis Constantin F. Algorithms for discovery of multiple markov boundaries. Journal of Machine Learning Research, 14 (Feb):499–566, 2013. [PMC free article] [PubMed] [Google Scholar]
- Strobl Carolin, Boulesteix Anne-Laure, Zeileis Achim, and Hothorn Torsten. Bias in random forest variable importance measures: illustrations, sources and a solution. BMC bioinformatics, 8(1):25, 2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Strobl Carolin, Boulesteix Anne-Laure, Kneib Thomas, Augustin Thomas, and Zeileis Achim. Conditional variable importance for random forests. BMC bioinformatics, 9 (1):307, 2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stuart Elizabeth A. Matching methods for causal inference: a review and a look forward. Statistical science: a review journal of the Institute of Mathematical Statistics, 25(1):1, 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Toloşi Laura and Lengauer Thomas. Classification with correlated features: unreliability of feature ranking and solutions. Bioinformatics, 27(14):1986–1994, 2011. [DOI] [PubMed] [Google Scholar]
- Tulabandhula Theja and Rudin Cynthia. Robust optimization using machine learning for uncertainty sets. arXiv preprint arXiv:1407.1097, 2014. [Google Scholar]
- U.S. Department of Justice - Civil Rights Devision. Investigation of the Baltimore City Police Department, August 2016. Available at https://www.justice.gov/crt/file/883296/download.
- van der Laan Mark J. Statistical inference for variable importance. The International Journal of Biostatistics, 2(1), 2006. [Google Scholar]
- Ver Hoef Jay M. Who invented the delta method? The American Statistician, 66(2): 124–127, 2012. [Google Scholar]
- Wang Huazhen, Yang Fan, and Luo Zhiyuan. An experimental study of the intrinsic stability of random forest variable importance measures. BMC bioinformatics, 17(1):60, 2016. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Williamson Brian D, Gilbert Peter B, Simon Noah, and Carone Marco. Nonparametric variable importance assessment using machine learning techniques. bepress (unpublished preprint), 2017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yao Jingtao, Teng Nicholas, Poh Hean-Lee, and Tan Chew Lim. Forecasting and analysis of marketing data using neural networks. J. Inf. Sci. Eng, 14(4):843–862, 1998. [Google Scholar]
- Zhu Ruoqing, Zeng Donglin, and Kosorok Michael R. Reinforcement learning trees. Journal of the American Statistical Association, 110(512):1770–1784, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]