

Abstract
Deep learning has produced state-of-the-art results for a variety of tasks. While such approaches for supervised learning have performed well, they assume that training and testing data are drawn from the same distribution, which may not always be the case. As a complement to this challenge, single-source unsupervised domain adaptation can handle situations where a network is trained on labeled data from a source domain and unlabeled data from a related but different target domain with the goal of performing well at test-time on the target domain. Many single-source and typically homogeneous unsupervised deep domain adaptation approaches have thus been developed, combining the powerful, hierarchical representations from deep learning with domain adaptation to reduce reliance on potentially-costly target data labels. This survey will compare these approaches by examining alternative methods, the unique and common elements, results, and theoretical insights. We follow this with a look at application areas and open research directions.
1. INTRODUCTION
Supervised learning is arguably the most prevalent type of machine learning and has enjoyed much success across diverse application areas. However, many supervised learning methods make a common assumption: the training and testing data are drawn from the same distribution. When this constraint is violated, a classifier trained on the source domain will likely experience a drop in performance when tested on the target domain due to the differences between domains [182]. Single-source domain adaptation refers to the goal of learning a concept from labeled data in a source domain that performs well on a different but related target domain [73, 80, 180]. Unsupervised domain adaptation specifically addresses the situation where there are labeled source data and only unlabeled target data available for use during training [73, 147].
Because of its ability to adapt labeled data for use in a new application, domain adaptation can reduce the need for costly labeled data in the target domain. As an example, consider the problem of semantically segmenting images. Each real image in the Cityscapes dataset required approximately 1.5 hours to annotate for semantic segmentation [46]. In this case, human annotation time could be spared by training an image semantic segmentation model on synthetic street view images (the source domain) since these can be cheaply generated, then adapting and testing for real street view images (the target domain, here the Cityscapes dataset).
An undeniable trend in machine learning is the increased usage of deep neural networks. Deep networks have produced many state-of-the-art results for a variety of machine learning tasks [73, 80] such as image classification, speech recognition, machine translation, and image generation [79, 80]. When trained on large amounts of data, these many-layer neural networks can learn powerful, hierarchical representations [80, 147, 182, 226] and can be highly scalable [76]. At the same time, these networks can also experience performance drops due to domain shifts [72, 226]. Thus, much research has gone into adapting such networks from large labeled datasets to domains where little (or possibly no) labeled training data are available (for a list, see [257]). These single-source and typically homogeneous unsupervised deep domain adaptation approaches, which combine the benefit of deep learning with the very practical use of domain adaptation to remove the reliance on potentially costly target data labels, will be the focus of this survey.
A number of surveys have been created on the topic of domain adaptation [12, 24, 42, 48, 49, 121, 122, 162, 182, 227, 246, 285] and more generally transfer learning [45, 128, 152, 180, 216, 232, 235, 252, 273], of which domain adaptation can be viewed as a special case [182]. Previous domain adaptation surveys lack depth of coverage and comparison of unsupervised deep domain adaptation approaches. In some cases, prior surveys do not discuss domain mapping [48, 49, 121], normalization statistic-based [48, 49, 121, 285], or ensemble-based [48, 49, 121, 246, 285] methods. In other cases, they do not survey deep learning approaches [12, 122, 162, 182]. Still others are application-centric, focusing on a single use case such as machine translation [24, 42]. One earlier survey focuses on the multi-source scenario [227], while we focus on the more prevalent single-source scenario. Transfer learning is a broader topic to cover, thus surveys provide minimal coverage and comparison of the deep learning methods that have been designed for unsupervised domain adaptation [152, 180, 216, 232, 252, 273], or they focus on tasks such as activity recognition [45] or reinforcement learning [128, 235]. The goal of this survey is to discuss, highlight unique components, and compare approaches to single-source homogeneous unsupervised deep domain adaptation.
We first provide background on where domain adaptation fits into the more general problem of transfer learning. We follow this with an overview of generative adversarial networks (GANs) to provide background for the increasingly widespread use of adversarial techniques in domain adaptation. Next, we investigate the various domain adaptation methods, the components of those methods, and the results. Then, we overview domain adaptation theory and discuss what we can learn from the theoretical results. Finally, we look at application areas and identify future research directions for domain adaptation.
2. BACKGROUND
2.1. Transfer Learning
The focus of this survey is domain adaptation. Because domain adaptation can be viewed as a special case of transfer learning [182], we first review transfer learning to highlight the role of domain adaptation within this topic. Transfer learning is defined as the learning scenario where a model is trained on a source domain or task and evaluated on a different but related target domain or task, where either the tasks or domains (or both) differ [61, 80, 180, 252]. For instance, we may wish to learn a model on a handwritten digit dataset (e.g., MNIST [130]) with the goal of using it to recognize house numbers (e.g., SVHN [175]). Or, we may wish to learn a model on a synthetic, cheap-to-generate traffic sign dataset [168] with the goal of using it to classify real traffic signs (e.g., GTSRB [224]). In these examples, the source dataset used to train the model is related but different from the target dataset used to test the model – both are digits and signs respectively, but each dataset looks significantly different. When the source and target differ but are related, then transfer learning can be applied to obtain higher accuracy on the target data.
2.1.1. Categorizing Methods.
In a transfer learning survey paper, Pan et al. [180] defined two terms to help classify various transfer learning techniques: “domain” and “task.” A domain consists of a feature space and a marginal probability distribution (i.e., the features of the data and the distribution of those features in the dataset). A task consists of a label space and an objective predictive function (i.e., the set of labels and a predictive function that is learned from the training data). Thus, a transfer learning problem might be either transferring knowledge from a source domain to a different target domain or transferring knowledge from a source task to a different target task (or a combination of the two) [61, 180, 252].
By this definition, a change in domain may result from either a change in feature space or a change in the marginal probability distribution. When classifying documents using text mining, a change in the feature space may result from a change in language (e.g., English to Spanish), whereas a change in the marginal probability distribution may result from a change in document topics (e.g., computer science to English literature) [180]. Similarly, a change in task may result from either a change in the label space or a change in the objective predictive function. In the case of document classification, a change in the label space may result from a change in the number of classes (e.g., from a set of 10 topic labels to a set of 100 topic labels). Similarly, a change in the objective predictive function may result from a substantial change in the distribution of the labels (e.g., the source domain has 100 instances of class A and 10,000 of class B, whereas the target has 10,000 instances of A and 100 of B) [180].
To classify transfer learning algorithms based on whether the task or domain differs between source and target, Pan et al. [180] introduced three terms: “inductive”, “transductive”, and “unsupervised” transfer learning. In inductive transfer learning, the target and source tasks are different, the domains may or may not differ, and some labeled target data are required. In transductive transfer learning, the tasks remain the same while the domains are different, and both labeled source data and unlabeled target data are required. Finally, in unsupervised transfer learning, the tasks differ as in the inductive case, but there is no requirement of labeled data in either the source domain or the target domain.
2.1.2. Domain Adaptation.
One popular type of transfer learning is domain adaptation, which will be the focus of our survey. Domain adaptation is a type of transductive transfer learning. Here, the target task remains the same as the source, but the domain differs [55, 180, 182]. Homogeneous domain adaptation is the case where the domain feature space also remains the same, and heterogeneous domain adaptation is the case where the feature spaces differ [182].
In addition to the previous terminology, machine learning techniques are often categorized based on whether or not labeled training data are available. Supervised learning assumes labeled data are available, semi-supervised learning uses both labeled data and unlabeled data, and unsupervised learning uses only unlabeled data. However, domain adaptation assumes data comes from both a source domain and a target domain. Thus, prepending one of these three terms to “domain adaptation” is ambiguous since it may refer to labeled data being available in the source or target domains.
Authors apply these terms in various ways to domain adaptation [54, 111, 180, 204, 252]. In this paper, we will refer to “unsupervised” domain adaptation as the case in which both labeled source data and unlabeled target data are available, “semi-supervised” domain adaptation as the case in which labeled source data in addition to some labeled target data are available, and “supervised” domain adaptation as the case in which both labeled source and target data are available [12]. The distinction between these categories describes the target domain, but only describe situations in which labeled data are available for the source domain. These definitions are commonly used in the methods surveyed in this paper as well as others [27, 73, 76, 147, 204, 226].
2.1.3. Related Problems.
Multi-domain learning [61, 113] and multi-task learning [29] are related to transfer learning and domain adaptation. In contrast to transfer learning, the goal of these learning approaches is obtaining high performance on all specified domains (or tasks) rather than just on a single target domain (or task) [180, 261]. For example, often it is assumed that the training data are drawn in an independent and identically distributed (i.i.d.) fashion, which may not be the case [113]. One such example is the task of developing a spam filter for users who disagree on what is considered spam. If all the users’ data are combined, the training data will be drawn from multiple domains. While each individual domain may be i.i.d., the aggregated dataset may not be. If the data are split by user, then there may be too little data to learn a model for each user. Multi-domain learning can take advantage of the entire dataset to learn individual user preferences [61, 113]. Some researchers have developed adversarial strategies to tackle this multi-domain learning challenge [89, 213].
When working with multiple tasks, instead of training models separately for different tasks (e.g., one model for detecting shapes in an image and one model for detecting text in an image), multi-task learning will learn these separate but related tasks simultaneously so that they can mutually benefit from the training data of other tasks through a (partially) shared representation [29]. If there are both multiple tasks and domains, then these approaches can be combined into multi-domain multi-task learning, as is described by Yang et al. [261].
Another related problem is domain generalization, in which a model is trained on multiple source domains with labeled data and then tested on a separate target domain that was not seen during training [173]. This contrasts with domain adaptation where target examples (possibly unlabeled) are available during training. Some approaches related to those surveyed in this paper have been designed to address this situation. Examples include an adversarial method introduced by Zhao et al. [284] and an autoencoder approach by Ghifary et al. [75] discussed in Section 7.4.
2.2. Generative Adversarial Networks
Many deep domain adaptation methods that we will discuss in the next section incorporate adversarial training. We use the term adversarial training broadly to refer to any method that utilizes an adversary or an adversarial process during training. Before other adversarial methods were developed, the term was narrowly applied to training designed to improve the robustness of a model by utilizing adversarial examples, e.g. image inputs with small worst-case perturbations that lead to misclassification [82, 230]. Subsequently, other techniques have arisen that also utilize an adversary during training, including generative-adversarial training of generative adversarial networks (GANs) [81] and domain-adversarial training of domain adversarial neural networks (DANN) [73], both of which have been used for domain adaptation. To provide background for the domain adaptation methods utilizing these techniques, we will first discuss GANs and later when discussing DANN note the differences.
In recent years there has been a large and growing interest in GANs. Pitting two well-matched neural networks against each other (hence “adversarial”), playing the roles of a data discriminator and a data generator, the pair is able to refine each player’s abilities in order to perform functions such as synthetic data generation. Goodfellow et al. [81] proposed this technique in 2014. Since that time, hundreds of papers have been published on the topic [91, 271]. GANs have traditionally been applied to synthetic image generation, but recently researchers have been exploring other novel use cases such as domain adaptation.
GANs are a type of deep generative model [81]. For synthetic image generation, a training dataset of images must be available. Popular datasets include human faces (CelebA [146]), handwritten digits (MNIST [130]), bedrooms (LSUN [268]), and sets of other objects (CIFAR-10 [123] and ImageNet [56, 200]). After training, the generative model will be able to generate synthetic images that resemble those in the training data. For example, a generator trained with CelebA will generate images of human faces that look realistic but are not images of real people, as shown in Figure 1. To learn to do this, GANs utilize two neural networks competing against each other [81]. One network represents a generator. The generator accepts a noise vector as input, which contains random values drawn from some distribution such as normal or uniform. The goal of the generator network is to output a vector that is indistinguishable from the real training data. The other network represents a discriminator, which accepts as input either a real sample from the training data or a fake sample from the generator. The goal of the discriminator is to determine the probability that the input sample is real. During training, these two networks play a minimax game, where the generator tries to fool the discriminator and the discriminator attempts to not be fooled.
Fig. 1.

Realistic but entirely synthetic images of human faces generated by a GAN trained on the CelebA-HQ dataset [116].
Using the notation from Goodfellow et al. [81], we define a value function V (G, D) employed by the minimax game between the two networks:
| (1) |
Here, x ~ pdata(x) draws a sample from the real data distribution, z ~ pz (z) draws a sample from the input noise, D(x; θd) is the discriminator, and G(z; θg) is the generator. As shown in the equation, the goal is to find the parameters θd that maximize the log probability of correctly discriminating between real (x) and fake (G(z)) samples while at the same time finding the parameters θg that minimize the log probability of 1 − D(G(z)). The term D(G(z)) represents the probability that generated data G(z) is real. If the discriminator correctly classifies a fake input then D(G(z)) = 0. Equation 1 minimizes the quantity 1 − D(G(z)). This occurs when D(G(z)) = 1, or when the discriminator misclassifies the generator’s output as a real sample. Thus the discriminator’s mission is to learn to correctly classify the input as real or fake while the generator tries to fool the discriminator into thinking that its generated output is real. This process is illustrated in Figure 2.
Fig. 2.
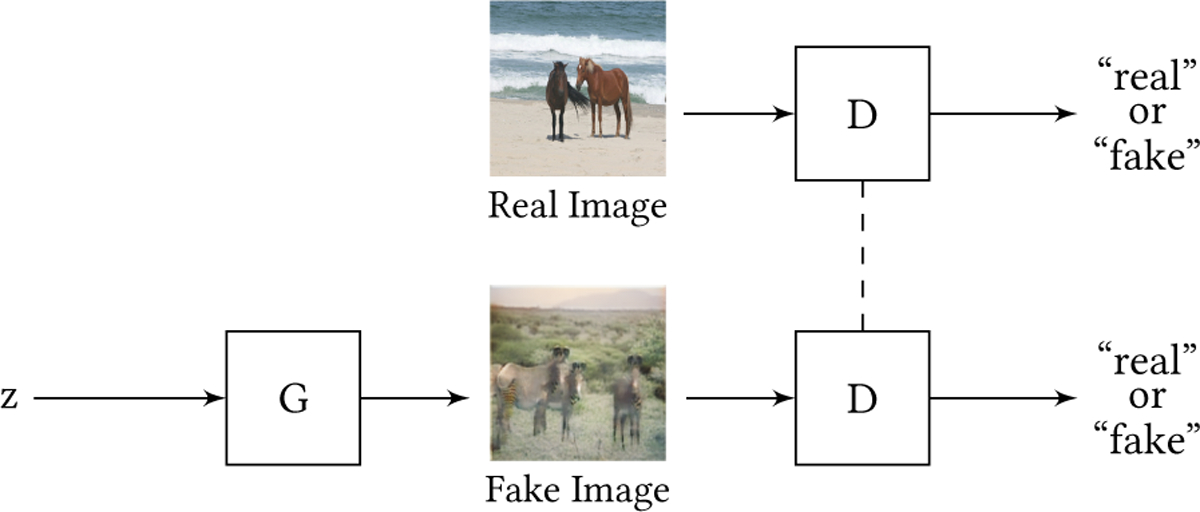
Illustration of the GAN generator G and discriminator D networks. The dashed line between the D networks indicates that they share weights (or are the same network). In the top row, a real image from the training data (horses ↔ zebras dataset by Zhu et al. [290]) is fed to the discriminator, and the goal of D is to make D(x) = 1 (correctly classify as real). In the bottom row, a fake image from the generator is fed to the discriminator, and the goal of D is to make D(G(z)) = 0 (correctly classify as fake), which competes with the goal of G to make D(G(z)) = 1 (misclassify as real).
2.2.1. Training.
In recent years there have been impressive results from GANs. At the same time, this research faces some challenges since training a GAN can encounter problems such as difficulty converging [6, 79], mode collapse where the generator only learns to generate realistic samples for a few specialized modes of the data distribution [79], and vanishing gradients [81]. Many methods have been proposed to resolve these training challenges using a variety of tricks [81, 90, 179, 207, 219, 229], network architecture choices [116, 190, 207], objective modifications [5, 15, 66, 87, 112, 120, 161, 163, 165, 176–178, 283], mixtures or ensembles [6, 63, 78, 93, 117, 170, 181, 237, 270], maximum mean discrepancy (MMD) [16, 64, 135, 139, 228], making a connection to reinforcement learning [67, 186], or a combination of these modifications [90, 166, 269]. For an in-depth discussion of these techniques, there are a number of survey papers directed at GAN variants that include a discussion of training challenges and work [92, 99, 158]. These techniques can be employed in the domain adaptation methods that utilize GANs [20, 21, 41, 96, 143, 160, 208, 219, 245, 250]. While these training stability methods could similarly be applied to other adversarial domain adaptation approaches, they are not typically needed for the non-GAN methods surveyed here.
2.2.2. Evaluation.
Once successfully trained, a GAN model can be difficult to evaluate and compare with other models. Multiple approaches and measures have been introduced to evaluate GAN performance. Often researchers have evaluated their models through visual inspection [210] such as performing user studies where participants mark which images they think look more realistic [207]. However, ideally a more automated metric could be found. Past generative models were evaluated by computing log-likelihood [236], but this is not necessarily tractable in GANs [79]. A proxy for log-likelihood is a Parzen window estimate, which was used for early GAN evaluation [81, 156, 177, 236], but in high dimensions (such as images), this could be far from the actual log-likelihood and not even rank models correctly [85, 236]. Thus, there has been much work proposing various evaluation methods for GANs: methods for detecting memorization [15, 60, 81, 156, 190, 236], determining diversity [7, 90, 179, 210], measuring realism [16, 90, 145, 207], and approximating log-likelihood [253]. Xu et al. [258] and Borji [19] survey and compare many of these GAN evaluation methods.
These techniques can be used for evaluating domain adaptation methods used for image translation (a form of image generation but conditioned on an input image) from one domain to another [14, 41, 197, 264, 265, 290]. However, many domain adaptation methods (even those that are adversarial such as those using GANs) are not used for generation but rather for tasks with more easily-defined loss functions, making these techniques largely not needed for adversarial domain adaptation methods. For example, accuracy [14, 21, 22, 41, 69, 73, 96, 143, 241] or AUC scores [189] can be used to evaluate classification, intersection over union or pixel accuracy can be used to evaluate image segmentation [14, 69, 96, 138, 185], and absolute difference can be used to evaluate regression [219].
3. METHODS
In recent years, numerous new unsupervised domain adaptation methods have been proposed, with a growing emphasis on neural network-based approaches. Distinct lines of research have emerged. These include aligning the source domain and target domain distributions, mapping between domains, separating normalization statistics, designing ensemble-based methods, or focusing on making the model target discriminative by moving the decision boundary into regions of lower data density. In addition, others have explored combinations of these approaches. We will describe each of these categories together with recent methods that fall into these categories.
In this survey, we will focus on homogeneous domain adaptation consisting of one source and one target domain, as is most commonly studied. Another case is multi-source domain adaptation, where there are multiple source domains but still only one target domain. Sun et al. [227] survey multi-source domain adaptation, and since then a number of other methods [28, 88, 95, 157, 184, 192, 256, 259, 281] have been developed for this case. It is also possible to perform multi-target domain adaptation [77], though this case is even more rarely studied. Similarly, we focus on homogeneous domain adaptation due to its prevalence, though some heterogeneous methods have been developed [62, 105, 137, 244, 263, 289].
3.1. Domain-Invariant Feature Learning
Most recent domain adaptation methods align source and target domains by creating a domain-invariant feature representation, typically in the form of a feature extractor neural network. A feature representation is domain-invariant if the features follow the same distribution regardless of whether the input data are from the source or target domain [280]. If a classifier can be trained to perform well on the source data using domain-invariant features, then the classifier may generalize well to the target domain since the features of the target data match those on which the classifier was trained. However, these methods assume that such a feature representation exists and the marginal label distributions do not differ significantly (Section 6).
The general training and testing setup of these methods is illustrated in Figure 3. Methods differ in how they align the domains (the Alignment Component in the figure). Some minimize divergence, some perform reconstruction, and some employ adversarial training. In addition, they differ in weight sharing choices, which will be discussed in Section 4.3. We discuss the various alignment methods below.
Fig. 3.
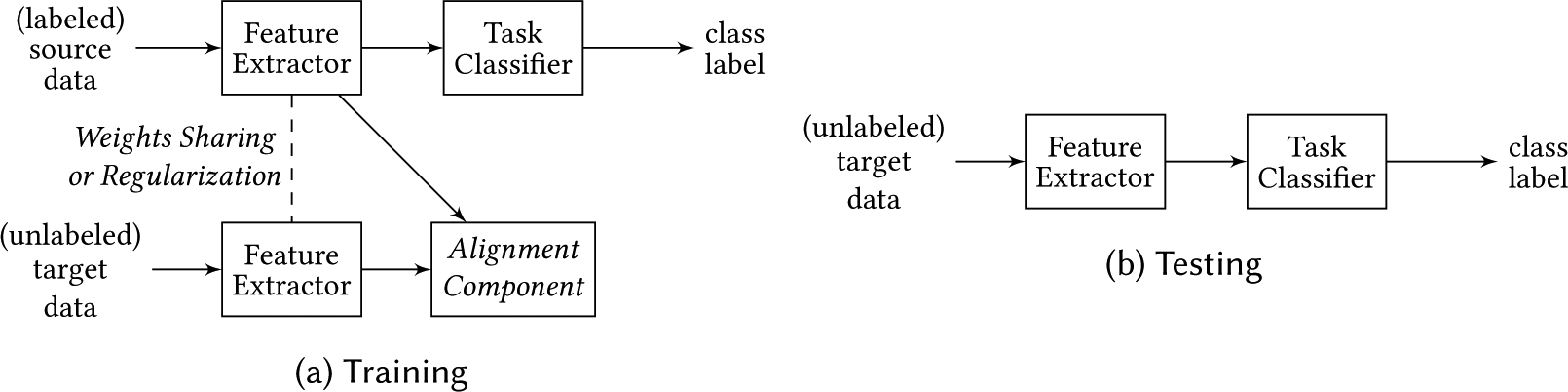
General network setup for domain adaptation methods learning domain-invariant features. (a) Methods differ in regard to how the domains are aligned during training (the Alignment Component) and whether the feature extractors used on each domain share none, some, or all of the weights between domains. (b) The target data are fed to the domain-invariant feature extractor and then to the task classifier.
3.1.1. Divergence.
One method of aligning distributions is through minimizing a divergence that measures the distance between the distributions. Choices for the divergence measure include maximum mean discrepancy, correlation alignment, contrastive domain discrepancy, the Wasserstein metric, and a graph matching loss.
Maximum mean discrepancy (MMD) [83, 84] is a two-sample statistical test of the hypothesis that two distributions are equal based on observed samples from the two distributions. The test is computed from the difference between the mean values of a smooth function on the two domains’ samples. If the means are different, then the samples are likely not from the same distribution. The smooth functions chosen for MMD are unit balls in characteristic reproducing kernel Hilbert spaces (RKHS) since it can be proven that the population MMD is zero if and only if the two distributions are equal [84].
To use MMD for domain adaptation, the alignment component can be another classifier similar to the task classifier. MMD can then be computed and minimized between the outputs of these classifiers’ corresponding layers (a slightly different setup than that in Figure 3). Rozantsev et al. [199] employ MMD, Long et al. [147] investigate a multiple kernel variant of MMD (MK-MMD), and later Long et al. [147] develop a joint MMD (JMMD) method [151]. Bousmalis et al. [22] also tried MMD but found using an adversarial objective performed better in their experiments.
Correlation alignment (CORAL) [225] is similar to MMD with a polynomial kernel, computed from the distance between second-order statistics (covariances) of the source and target features. For domain adaptation, the alignment component consists of computing the CORAL loss between the two feature extractors’ outputs (in order to minimize the distance). A variety of distances have been used: Sun et al. [226] use a squared matrix Frobenius norm in Deep CORAL, Zhang et al. [278] use a Euclidean distance in mapped correlation alignment (MCA), others have used log-Euclidean distances in LogCORAL [249] and Log D-CORAL[172], and Morerio et al. [171] use geodesic distances. Zhang et al. [279] generalize correlation alignment to possibly infinite-dimensional covariance matrices in RKHS. Chen et al. [34] align statistics beyond the first and second orders.
Contrastive domain discrepancy (CCD) [114] is based on MMD but looks at the conditional distributions in order to incorporate label information (unlike CORAL or ordinary MMD). When minimizing CCD, intra-class discrepancy is minimized while inter-class margin is maximized. This has the problem of requiring target labels though, so Kang et al. [114] propose contrastive adaptation networks (CAN) that minimize cross-entropy loss on the labeled target data while alternating between estimating labels for target samples (via clustering) with adapting the feature extractor with the now-computable CCD (using the clusters). This approach outperforms the other methods on the Office dataset as shown in Table 3.
Table 3.
Classification accuracy (source → target, mean ± std %) of different neural network based domain adaptation methods on the Office computer vision dataset. Adversarial approaches denoted by *.
| Name | Office (Amazon, DSLR, Webcam) | |||||
|---|---|---|---|---|---|---|
| A→W | D→W | W→D | A→D | D→A | W→A | |
| CAN[114]a | 94.5 ± 0.3 | 99.1 ± 0.2 | 99.8 ± 0.2 | 95.0 ± 0.3 | 78.0 ± 0.3 | 77.0 ± 0.3 |
| Gen. to Adapt[208]a* | 89.5 ± 0.5 | 97.9 ± 0.3 | 99.8 ± 0.4 | 87.7 ± 0.5 | 72.8 ± 0.3 | 71.4 ± 0.4 |
| SimNet[187]a* | 88.6 ± 0.5 | 98.2 ± 0.2 | 99.7 ± 0.2 | 85.3 ± 0.3 | 73.4 ± 0.8 | 71.8 ± 0.6 |
| MADA[183]a* | 90.0 ± 0.1 | 97.4 ± 0.1 | 99.6 ± 0.1 | 87.8 ± 0.2 | 70.3 ± 0.3 | 66.4 ± 0.3 |
| AutoDIAL[27]bc | 84.2 | 97.9 | 99.9 | 82.3 | 64.6 | 64.2 |
| CCN++[101]d* | 78.2 | 97.4 | 98.6 | 73.5 | 62.8 | 60.6 |
| Rozantsev et al.[199] | 76.0 | 96.7 | 99.6 | |||
| AdaBN[145]b | 74.2 | 95.7 | 99.8 | 73.1 | 59.8 | 57.4 |
| JAN-A[151]a* | 86.0 ± 0.4 | 96.7 ± 0.3 | 99.7 ± 0.1 | 85.1 ± 0.4 | 69.2 ± 0.4 | 70.7 ± 0.5 |
| LogCORAL[249] | 70.2 ± 0.6 | 95.5 ± 0.1 | 99.5 ± 0.3 | 69.4 ± 0.5 | 51.2 ± 0.3 | 51.6 ± 0.5 |
| Log D-CORAL[172] | 68.5 | 95.3 | 98.7 | 62.0 | 40.6 | 40.6 |
| ADDA[241]a* | 75.1 | 97.0 | 99.6 | |||
| Sener et al.[214] | 81.1 | 96.4 | 99.2 | 84.1 | 58.3 | 63.8 |
| DRCN[76] | 68.7 ± 0.3 | 96.4 ± 0.3 | 99.0 ± 0.2 | 66.8 ± 0.5 | 56.0 ± 0.5 | 54.9 ± 0.5 |
| Deep CORAL[226] | 66.4 ± 0.4 | 95.7 ± 0.3 | 99.2 ± 0.1 | 66.8 ± 0.6 | 52.8 ± 0.2 | 51.5 ± 0.3 |
| 73.0 [199, 241] | 96.4 [199, 241] | 99.2 [199, 241] | ||||
| DAN[147] | ||||||
| 68.5 [241] | 96.0 [241] | 99.0 [241] | ||||
| Tzeng et al.[240]e* | 59.3 ± 0.6 | 90.0 ± 0.2 | 97.5 ± 0.1 | 68.0 ± 0.5 | 43.1 ± 0.2 | 40.5 ± 0.2 |
| Source only (i.e., no adaptation) | 62.6 [241]a | 96.1 [241]a | 98.6 [241]a | |||
with ResNet-50 network
with Inception-based network
hyperparameter tuned on one W labeled example per class on A →W task (see [150])
with ResNet-18 network
semi-supervised for some classes, but evaluated on 16 hold-out categories for which the labels were not seen during training
A problem known as “optimal transport” was originally proposed for studying resource allocation such as finding an optimal way to move material from mines to factories [169, 193], but it can also be used to measure the distances between distributions. If the cost of moving each point is a norm (e.g., Euclidean), then the solution to a discrete optimal transport problem can be viewed as a distance: the Wasserstein distance [50] (also known as the earth mover’s distance). To align feature and label distributions with this distance, Courty et al. [47] propose joint distribution optimal transport (JDOT). To incorporate this into a neural network, Damodaran et al. [50] propose DeepJDOT.
Another divergence measure arises from graph matching: the problem of finding an optimal correspondence between graphs [260]. A feature extractor’s output on a batch of samples can be viewed as an undirected graph (in the form of an adjacency matrix), where similar samples in the batch are connected. Given the graph from a batch of source data fed through the feature extractor and similarly a graph from a batch of target data, then the cost of aligning these graphs can be used as a divergence, as proposed by Das et al. [51–53].
3.1.2. Reconstruction.
Rather than minimizing a divergence, Ghifary et al. [76] and Bousmalis et al. [22] hypothesize that alignment can be accomplished by learning a representation that both classifies the labeled source domain data well and can be used to reconstruct either the target domain data (Ghifary et al.) or both the source and target domain data (Bousmalis et al.). The alignment component in these setups is a reconstruction network – the opposite of the feature extractor network – that takes the feature extractor output and recreates the feature extractor’s input (in this case, an image). Ghifary et al. [76] propose deep reconstruction-classification networks (DRCN), using a pair-wise squared reconstruction loss. Bousmalis et al. [22] propose domain separation networks (DSN), using a scale-invariant mean squared error reconstruction loss.
3.1.3. Adversarial.
Several varieties of feature-level adversarial domain adaptation methods have been introduced in the literature. In most the alignment component consists of a domain classifier. In one paper this component is instead represented by a network learning an approximate Wasserstein distance, and in another paper the component is a GAN.
A domain classifier is a classifier that outputs whether the feature representation was generated from source or target data. Recall that GANs include a discriminator that tries to accurately predict whether a sample is from the real data distribution or from the generator. In other words, the discriminator differentiates between two distributions, one real and one fake. A discriminator could similarly be designed to differentiate two distributions which instead represent a source distribution and a target distribution, as is done with a domain classifier. Note though that an adversarial domain classifier is used for adaptation, whereas a GAN is used for data generation. The domain classifier is trained to correctly classify the domain (source or target). In this scenario, the feature extractor is trained such that the domain classifier is unable to classify from which domain the feature representation originated. This is a type of zero-sum two-player game [280] as in a GAN (Section 2.2). Typically, these networks are adversarially trained by alternating between these two steps. The feature extractor can be trained to make the domain classifier perform poorly by negating the gradient from the domain classifier with a gradient reversal layer [72] when performing back propagation to update the feature extractor weights (e.g., in DANN [1, 72, 73] and VRADA [189]), maximally confusing the domain classifier (when it outputs a uniform distribution over binary labels [240]), or inverting the labels (in ADDA [241]). Because data distributions are often multi-modal, results may be improved by conditioning the domain classifier on a multilinear map of the feature representation and the task classifier predictions, which takes into account the multi-modal nature of the distributions [148].
Shen et al. [217] created WDGRL, a modification of DANN, by replacing the domain classifier with a network that learns an approximate Wasserstein distance. This distance is then minimized between source and target domains, which they found to yield an improvement. This method is similar to the divergence methods except here the divergence is learned with a network rather than computed based on statistics (e.g., using mean in MMD or covariance in CORAL). This method outperforms the other methods on the Amazon review dataset as shown in Table 4.
Table 4.
Classification accuracy comparison for domain adaptation methods for sentiment analysis (positive or negative review) on the Amazon review dataset [18]a with domains books (B), DVD (D), electronics (E), and kitchen (K). Adversarial approaches denoted by *.
| Source→Target | DANN[73]b* | DANN[73]c* | CORAL[225]d | ATT[204]c | WDGRL[217]ce* | No Adapt.[225]f |
|---|---|---|---|---|---|---|
| B→D | 82.9 | 78.4 | 80.7 | 83.1 | ||
| B→E | 80.4 | 73.3 | 76.3 | 79.8 | 83.3 | 74.7 |
| B→K | 84.3 | 77.9 | 82.5 | 85.5 | ||
| D→B | 82.5 | 72.3 | 78.3 | 73.2 | 80.7 | 76.9 |
| D→E | 80.9 | 75.4 | 77.0 | 83.6 | ||
| D→K | 84.9 | 78.3 | 82.5 | 86.2 | ||
| E→B | 77.4 | 71.3 | 73.2 | 77.2 | ||
| E→D | 78.1 | 73.8 | 72.9 | 78.3 | ||
| E→K | 88.1 | 85.4 | 83.6 | 86.9 | 88.2 | 82.8 |
| K→B | 71.8 | 70.9 | 72.5 | 77.2 | ||
| K→D | 78.9 | 74.0 | 73.9 | 74.9 | 79.9 | 72.2 |
| K→E | 85.6 | 84.3 | 84.6 | 86.3 |
using 30,000-dimensional feature vectors from marginalized stacked denoising autoencoders (mSDA) by Chen et al. [36], which is an unsupervised method of learning a feature representation from the training data
using 5000-dimensional unigram and bigram feature vectors
using bag-of-words feature vectors including only the top 400 words, but suggest using deep text features in future work
the best results on target data for various hyperparameters
using bag-of-words feature vectors
Sankaranarayanan et al. [208] propose Generate to Adapt that uses a GAN as the alignment component. The feature extractor output is both fed to a classifier trained to predict the label (if the input is from the source domain) and also to a GAN trained to generate source-like images (regardless of if the input is source or target). For training stability, they use an AC-GAN [179]. They note one downside of using a GAN for adaptation is that it requires a large training dataset, but a common strategy is to use a pretrained network on a large dataset such as ImageNet. Using this pretraining, even on small datasets (e.g., Office) where the generated images are poor, the network still learns adaptation satisfactorily. Sankaranarayanan et al. [209] similarly develop a similar approach for semantic segmentation.
3.2. Domain Mapping
An alternative to creating a domain-invariant feature representation is mapping from one domain to another. The mapping is typically created adversarially and at the pixel level (i.e., pixel-level adversarial domain adaptation), but not always, as discussed at the end of this section. This mapping can be accomplished with a conditional GAN. The generator performs adaptation at the pixel level by translating a source input image to an image that closely resembles the target distribution. For example, the GAN could change from a synthetic vehicle driving image to one that looks realistic as shown in Figure 4 [41, 96, 197, 265, 290]. A classifier can then be trained on the source data mapped to the target domain using the known source labels [219] or jointly trained with the GAN [21, 96]. We will first discuss how a conditional GAN works followed by the ways it can be employed for domain adaptation.
Fig. 4.

Synthetic vehicle driving image (left) adapted to look realistic (right) [96].
3.2.1. Conditional GAN for Image-to-Image Translation.
The original formulation of a GAN was unconditional, where a GAN only accepted a noise vector as input. Conditional GANs, on the other hand, accept as input other information such as a class label, image, or other data [59, 74, 81, 164]. In the case of image generation, this means that a particular type of image to generate can be specified. One such example is to generate an image of a particular class within an image dataset such as “cat” rather than a random object from the dataset. Another example is conditioning on an input image such as in Figure 4, mapping an input driving image from one domain (synthetic) to an output image in another domain (realistic). Other uses include: transferring style (e.g., make a photo look like a Van Gogh painting) [118, 264, 290], colorizing images [109], generating satellite images from Google Maps data (or vice versa) [109, 264, 290], generating images of clothing from images of people wearing the clothing [265], generating cartoon faces from real faces [197, 231], converting labels to photos (e.g., semantic segmentation output to a photo) [109, 264, 290], learning disentangled representations [37], improving GAN training stability [179], and domain adaptation, which will be discussed in Section 3.2.2.
GANs conditioned on an input image can be used to perform image-to-image translation. These networks can be trained with varying levels of supervision: the dataset may contain corresponding images in the domains (supervised [109, 265]), only a few corresponding images (semi-supervised [71]), or no corresponding images (unsupervised [118, 264, 290]). A popular and general-purpose supervised method is pix2pix, developed by Isola et al. [109]. A commonly used unsupervised method is CycleGAN [290], which is based on pix2pix, or methods similar to CycleGAN including DualGAN [264] and DiscoGAN [118].
Numerous modifications to these approaches have been proposed: one that is multi-modal is MUNIT, a multi-modal unsupervised image-to-image translator [104]. By assuming a decomposition into style (domain-specific) and content (domain-invariant) codes, MUNIT can generate diverse outputs for a given input image (e.g., multiple possible output images corresponding to the same input image). A modification to CycleGAN explored by Li et al. [136] uses separate batch normalization for each domain (an idea similar to AdaBN discussed in Section 3.3). Mejjati et al. [3] and Chen et al. [38] improve results with attention, learning which areas of the images on which to focus. Shang et al. [215] improve results by feeding the mapped images into a denoising autoencoder. While CycleGAN and similar approaches use two generators, one for each mapping direction, Benaim et al. [14] developed a method for one-sided mapping that maintains distances between pairs of samples when mapped from the source to the target domain rather than (or in addition to) using a cycle consistency loss, and Fu et al. [69] developed an alternative one-sided mapping using a geometric constraint (e.g., vertical flipping or 90 degree rotation). Royer et al. [197] propose XGAN, a dual adversarial autoencoder capable of handling large domain shifts, where possibly an image in the source domain may correspond to multiple images in the target domain or vice versa. They tested mapping human faces to cartoon faces, which was a shift larger than CycleGAN could adequately handle. Choi et al. [41] propose StarGAN, a method for handling multiple domains with a single GAN. Approaches like CycleGAN need a separate generator (or two, one for each direction) for each pair of domains, which is not a scalable solution to many domains. StarGAN, on the other hand, only needs a single generator. This has the added benefit of allowing the generator to learn using all the available data rather than only the data in a specific pair of domains. During training they randomly pick a target domain at each iteration so the generator learns to generate images in all the domains. Anoosheh et al. [4] propose an approach designed for the same purpose as StarGAN but using one generator per domain.
3.2.2. Image-to-Image Translation for Domain Adaptation.
While the above approaches map images from one domain to another without the explicit purpose of performing domain adaptation, they can also be used for domain adaptation. For example, the original CycleGAN paper was application agnostic, but others have experimented with applying CycleGAN to domain adaptation [14, 69, 96]. It is important to note though that these image-to-image translation approaches assume that the domain differences are primarily low-level [20, 21, 241].
If unsupervised domain adaptation is performed for classification, adaptation can be accomplished by training an image-to-image translation GAN to map data from source to target, training a classifier on the mapped source images with known labels, and then subsequently testing by feeding unlabeled target through this target-domain classifier [20, 138, 219], as done in SimGAN [219] and illustrated in Figure 5a. Alternatively, rather than learning a mapping from source to target, the opposite could be done: learn a mapping from target to source, train a classifier on the source images with known labels, and test by feeding target images to the image-to-image translation model (to make them look like source images) followed by the source-domain classifier [32], as illustrated in Figure 5b.
Fig. 5.
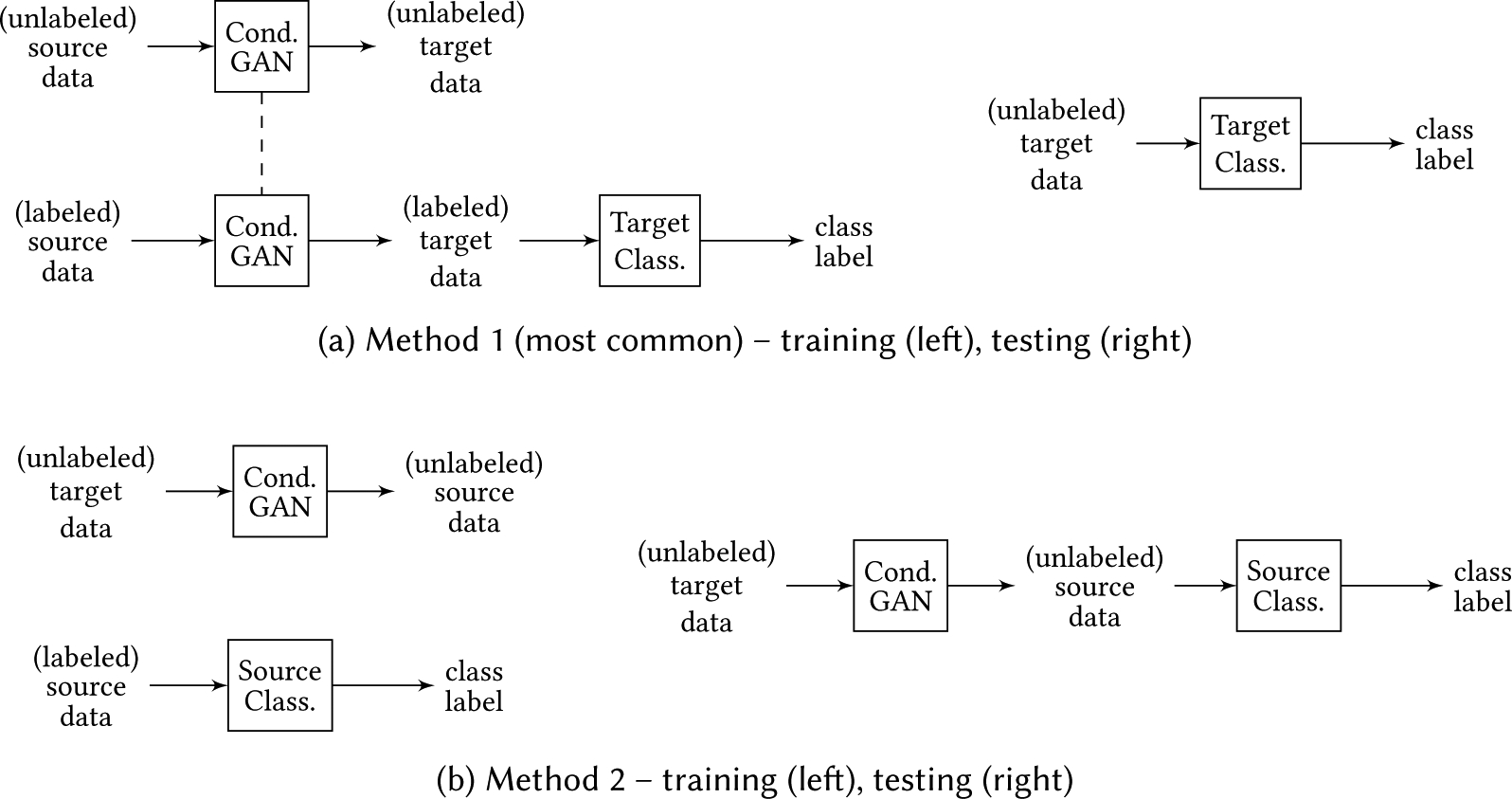
Two possible configurations using image-to-image translation for domain adaptation. The conditional GAN and classifier can be trained separately or jointly. Method 1 is the most common. Method 2 is used by one paper. A combination of methods 1 and 2 is used in one paper. The dashed lines between networks indicate that they share weights (or are the same network). Note: this figure does not illustrate the many variants of the conditional GAN component, which often train a generator in each direction (one source to target and one target to source) and use additional losses such as cycle consistency.
In either of these approaches, if the mapping and the classification models are learned independently, the class assignments may not be preserved. For instance, class 1 may end up being “renamed” to class 2 after the mapping since the mapping was learned ignoring the class labels. This issue can be resolved by incorporating a semantic consistency loss (see Section 4.1) and training the mapping and classification models jointly [22, 96], as done in PixelDA [21].
If there is a way to perform hyperparameter tuning, a third option is possible (combination of Figure 5a and 5b): train a target-domain classifier on the source-to-target GAN (for which the GAN is not used during testing) and a source-domain classifier on the target-to-source GAN (for which the GAN is used during testing). The algorithm may then output a linear combination of the prediction results from the two classifiers [201]. While this approach does improve results, it requires a method of hyperparameter training (see Section 4.7).
All of the above approaches perform pixel-level mapping. An alternative approach is to perform feature-level mapping. Hong et al. [98] use a conditional GAN to learn to make the source features look more like the target features (a distinctly different idea than making the features domain invariant, which was discussed in Section 3.1). They found this particularly helpful for structured domain adaptation (e.g., semantic segmentation, in their case).
Up to this point, these domain mapping methods have used image-to-image translation to map images (or in one case features) from one domain to another and thereby improve domain adaptation performance. Another line of research using pixel-level image generation for domain adaptation is to use a GAN to generate corresponding images in multiple domains and then employ all but the last layer of the discriminator as a feature extractor for a classifier [143, 160]. Liu et al. [143] train a pair of GANs called CoGAN on two domains of images. Mao et al. [160] propose RegCGAN using only one generator and discriminator but including a domain label prepended to the input noise vector.
3.3. Normalization Statistics
Normalization layers such as batch norm [107] are used in most neural networks [211]. These have benefits including allowing for higher learning rates and thus faster training [107], reducing initialization sensitivity [107], smoothing the optimization landscape and making the gradients more Lipschitz [211], and allowing for deeper networks to converge [80, 254]. Each batch norm layer normalizes its input to have zero mean and unit variance. At test time, running averages of the batch norm parameters can be used. Alternatives have been developed including instance norm allowing use in recurrent neural networks [10] and group norm removing the dependence on batch size [254]. However, none of these normalization techniques were developed with domain adaptation in mind. In the case of domain adaptation, the normalization statistics for each domain likely differ. Another line of domain adaptation research involves using per-domain batch normalization statistics.
Li et al. [141] assume that the neural net layer weights learn task knowledge and the batch norm statistics learn domain knowledge. If this is the case, then domain adaptation can be performed by modulating all the batch norm layers’ statistics from the source to target domain, a technique they call AdaBN. This has the benefit of being simple, parameter free, and complementary to other adaptation methods.
Carlucci et al. [27] propose AutoDIAL, a generalization of AdaBN. In AdaBN, the target data are not used to learn the network weights but only for adjusting the batch norm statistics. AutoDIAL can utilize the target data for learning the network weights by coupling network parameters between source and target domains. They do this through adding domain alignment layers (DA-layers) that differ for source and target input data before each of the batch norm layers. Generally, batch norm computes a moving average of the statistics on a batch of the layer’s input data. However, in AutoDIAL, source and target input data to DA-layers are mixed by a learnable amount before feeding this to batch norm (meaning that the batch norm statistics are now computed over some source and some target data rather than just source data or just target data). This allows the network to automatically learn how much alignment is needed at various points in the network.
3.4. Ensemble Methods
Given a base model such as a neural network or decision tree, an ensemble consisting of multiple models can often outperform a single model by averaging together the models’ outputs (e.g., regression) or taking a vote (e.g., classification) [65, 80]. This is because if the models are diverse then each individual model will likely make different mistakes [80]. However, this performance gain corresponds with an increase in computation cost due to the large number of models to evaluate for each ensemble prediction, making ensembles common for some use cases such as competitions but uncommon when comparing models [80]. Despite the incurred cost, several ensemble-based methods have been developed for domain adaptation either using the ensemble predictions to guide learning or using the ensemble to measure prediction confidence for pseudo-labeling target data.
3.4.1. Self-Ensembling.
An alternative to using multiple instances of a base model as the ensemble is using only a single model but “evaluating” (via a history or average) the models in the ensemble at multiple points in time during training – a technique called self-ensembling. This can be done by averaging over past predictions for each example (by recording previous predictions) [126] or past network weights (by maintaining a running average) [234]. Since an ensemble requires diverse models, these self-ensembling approaches require high stochasticity in the networks, which is provided by extensive data augmentation, varying the augmentation parameters, and including dropout. These methods were originally developed for semi-supervised learning.
French et al. [68] modify and extend these prior self-ensembling methods for unsupervised domain adaptation. They use two networks: a student network and a teacher network. Input images are fed first to stochastic data augmentation (Gaussian noise, translations, horizontal flips, affine transforms, etc.) before being input to both networks. Because the method is stochastic, the augmented images fed to the networks will differ. The student network is trained with gradient descent while the teacher network weights are an exponential moving average (EMA) of the student network’s weights. This method outperforms the other methods on the datasets in Table 2. Athiwaratkun et al. [9] show that in at least one experiment stochastic weight averaging [110] can further improve these results.
Table 2.
Classification accuracy (source → target, mean ± std %) of different neural network based domain adaptation methods on various computer vision datasets (only including those used in > 2 papers). Adversarial approaches denoted by *.
| Name | MNIST and USPS | MNIST and SVHN | MNIST[-M] | Synthetic to Real | |||
|---|---|---|---|---|---|---|---|
| MN→US | US→MN | SV→MN | MN→SV | MN→MN-M | SYNN→SV | SYNS→GTSRB | |
| Target only (i.e., if we had the target labels) | 96.3 ± 0.1 [96] 96.5 [21] |
99.2 ± 0.1 [96] | 99.2 ± 0.1 [96] 99.5 [22] 99.51 [72] |
96.4 [21] 98.7 [22] 98.91 [72] |
92.44 [72] 92.4 [22] |
99.87 [72] 99.8 [22] |
|
| French et al.[68] | 98.2 | 99.5 | 99.3 | 37.5 97.0a |
97.1 | 99.4 | |
| Co-DA[124]b* | 98.6 | 81.7 | 97.5 | 96.0 | |||
| DIRT-T[220]b* | 99.4 | 76.5 | 98.7 | 96.2 | 99.6 | ||
| VADA[220]b* | 94.5 | 73.3 | 95.7 | 94.9 | 99.2 | ||
| DeepJDOT[50] | 95.7 | 96.4 | 96.7 | 92.4 | |||
| CyCADA[96]* | 95.6 ± 0.2 | 96.5 ± 0.1 | 90.4 ± 0.4 | ||||
| Gen. to Adapt[208]* | 92.8 ± 0.9 | 90.8 ± 1.3 | 92.4 ± 0.9 | ||||
| SimNet[187]* | 96.4 | 95.6 | 90.5 | ||||
| MCD[206]* | 96.5 ± 0.3 | 94.1 ± 0.3 | 96.2 ± 0.4 | 94.4 ± 0.3 | |||
| GAGL[250]b* | 96.7 | 74.6 | 94.9 | 93.1 | 97.6 | ||
| SBADA-GAN[201]b* | 97.6 | 95.0 | 76.1 | 61.1 | 99.4 | 96.7 | |
| MCA[278] | 96.6 | 96.8 | 89.0 | ||||
| CCN++[101]* | 89.1 | ||||||
| M-ADDA[127]* | 98 | 97 | |||||
| Rozantsev et al.[199] | 60.7 | 67.3 | |||||
| PixelDA[21]* | 95.9 | 98.2 | |||||
| ATT[204] | 85.0 | 52.8 | 94.0 | 92.9 | 96.2 | ||
| ADDA[241]* | 89.4 ± 0.2 | 90.1 ± 0.8 | 76.0 ± 1.8 | ||||
| RegCGAN[160]* | 93.1 ± 0.7 | 89.5 ± 0.9 | |||||
| DTN[231]* | 84.4 | ||||||
| Sener et al.[214] | 78.8 | 40.3 | 86.7 | ||||
| DSN[22]b* | 91.3 [21] | 82.7 | 83.2 | 91.2 | 93.1 | ||
| DRCN[76] | 91.80 ± 0.09 | 73.67 ± 0.04 | 81.97 ± 0.16 | 40.05 ± 0.07 | |||
| CoGAN[143]* | 91.2 ± 0.8 | 89.1 ± 0.8 | 62.0 [21] | ||||
| DANN[72, 73]* | 85.1 [21] | 71.07 70.7 [22] 71.1 [204] 73.6 [96] |
35.7 [204] | 81.49 77.4 [22] 81.5 [204] |
90.48 90.3 [22, 204] |
88.66 88.7 [204] 92.9 [22] |
|
| DAN[147] | 81.1 [21] | 71.1 [22] | 76.9 [22] | 88.0 [22] | 91.1 [22] | ||
| Source only (i.e., no adaptation) | 78.9 [21] 82.2 ± 0.8 [96] |
69.6 ± 3.8 [96] | 59.19 [72] 59.2 [22] 67.1 ± 0.6 [96] |
56.6 [22] 57.49 [72] 63.6 [21] |
86.65 [72] 86.7 [22] |
74.00 [72] 85.1 [22] |
|
problem-specific hyperparameter tuning of data augmentation to match pixel intensities of target domain images
hyperparameter tuned on some labeled target data
3.4.2. Pseudo-Labeling.
Rather than voting or averaging the outputs of the models in an ensemble, the individual model predictions could be compared to determine the ensemble’s confidence in that prediction. The more models in the ensemble that agree, the higher the ensemble’s confidence in that prediction. In addition, if performing classification on a particular example, an individual model’s confidence can be determined by looking at the last layer’s softmax distribution: uniform indicates uncertainty whereas one class’s probability much higher than the rest indicates higher confidence. Applying this to domain adaptation, a diverse ensemble trained on source data may be used to label target data. Then, if the ensemble is highly confident, those now-labeled target examples can be used to train a classifier for target data.
This is the method Saito et al. [204] developed called asymmetric tri-training (ATT). Two networks sharing a feature extractor are trained on the labeled source data (i.e., the ensemble in this case is of size two). Those two networks then predict the labels for the unlabeled target data, and if the two agree on the label and have high enough confidence on a particular instance, then the predicted label for that example is assumed to be the true label. After the target data are labeled by the first two networks, the third network (also sharing the same feature extractor) can be trained using the assumed-true labels (pseudo-labels). Diversity in the ensemble is handled with an additional loss (see Section 4.1).
Instead of using an ensemble, Zou et al. [291] rely on just the softmax distribution for the confidence measure. When working with semantic segmentation, they found relying on the prediction confidence for pseudo-labeling results in transferring primarily easy classes while ignoring harder classes. Thus, they additionally propose adding a class-wise weighting term when pseudo-labeling to normalize the class-wise confidence levels and thus balance out the class distribution.
3.5. Target Discriminative Methods
One assumption that has led to successes in semi-supervised learning algorithms is the cluster assumption [30]: that data points are distributed in separate clusters and the samples in each cluster have a common label [220]. If this is the case, then decision boundaries should lie in low density regions (i.e., should not pass through regions where there are many data points) [30]. A variety of domain adaptation methods have been explored to move decision boundaries into density regions of lower density. These have typically been trained adversarially.
Shu et al. [220] in virtual adversarial domain adaptation (VADA) and Kumar et al. [124] in co-regularized alignment (Co-DA) both use a combination of variational adversarial training (VAT) developed by Miyato et al. [167] and conditional entropy loss. They are used in combination because VAT without the entropy loss may result in overfitting to the unlabeled data points [124] and the entropy loss without VAT may result in the network not being locally-Lipschitz and thus not resulting in moving the decision boundary away from the data points [220]. Shu et al. [220] additionally propose a decision-boundary iterative refinement step with a teacher (DIRT-T) for use after training to further refine the decision boundaries on the target data, allowing for a slight improvement over VADA. An entropy loss was also used in AutoDIAL [27] but without VAT.
In generative adversarial guided learning (GAGL), Wei et al. [250] propose to let a GAN move decision boundaries into lower-density regions. Using domain alignment methods that learn domain-invariant features like DANN (Section 3.1), typically the data fed to the feature extractor is either source or target data. However, Wei et al. propose to alternate this with feeding generated (fake) images and appending a “fake” label to the task classifier, thus repurposing the task classifier as a GAN discriminator. They found this to have the effect of moving the decision boundaries in the target domain into areas of lower density with a GAN, promoting target-discriminative features as a result.
Saito et al. [205] propose adversarial dropout regularization. Since dropout is stochastic, when they create two instances of the task classifier containing dropout, the resulting networks may produce different predictions. The difference between these predictions can be viewed as a discriminator. Using this discriminator to adversarially train the feature extractor has the effect of producing target discriminative features. Lee et al. [134] alter adversarial dropout to better handle convolutional layers by dropping channel-wise rather than element-wise.
3.6. Combinations
In recent work, researchers have proposed various combinations of the above methods. Domain mapping has been combined with domain-invariant feature learning methods either trained separately (in GraspGAN [20]) or jointly (in CyCADA [96]). Following AdaBN, many researchers started employing domain-specific batch normalization [20, 68, 114, 124, 136]. Kumar et al. [124] propose co-regularized alignment (Co-DA), an approach in which two separate adversarial domain-invariant feature networks are learned with different feature spaces, drawing on ensemble-based methods. Kang et al. [115] combine domain mapping with aligning the models’ attention by minimizing an attention-based discrepancy. Deng et al. [58] combine target discriminative methods with self-ensembling. Lee et al. [132] combine target discriminative methods and domain-invariant feature learning with a sliced Wasserstein metric.
Multi-adversarial domain adaptation (MADA) [183] combines adversarial domain-invariant feature learning with ensemble methods for the purpose of better handling multi-modal data. This is accomplished by incorporating a separate discriminator for each class and using the task classifier’s softmax probability to weight the loss from each discriminator for unlabeled target samples.
Saito et al. [206] combine elements of adversarial domain-invariant feature learning, ensemble methods, and target discriminative features in their maximum classifier discrepancy (MCD) method. They propose using a shared feature extractor followed by an ensemble (of size two) of task-specific classifiers, where the discrepancy between predictions measures how far outside the support of the source domain the target samples lie. The discriminator in this setup is the combination of the two classifiers. The feature extractor is trained to minimize the discrepancy (i.e., fool the classifiers that the samples are from the source domain) while the classifiers are trained to maximize the discrepancy on the target samples.
4. COMPONENTS
Table 1 summarizes the neural network-based domain adaptation methods we discuss showing components each method uses including what type of adaptation, which loss functions, whether the method uses a generator, and which weights are shared. Below we discuss each of these aspects followed by how the networks are trained, what types of networks can be used, multi-level adaptation techniques, and how to tune the hyperparameters of these methods.
Table 1.
Comparison of different neural network based domain adaptation methods based on method of adaptation (domain-invariant feature learning [DI], domain mapping [DM], normalization [N], ensemble [En], target discriminative [TD]), various loss functions (distance, promoting different features, cycle consistency, semantic consistency, task, feature- or pixel-level adversarial), usage of a generator, and which weights are shared (in the feature extractor).
| Name | Method | Loss Functions | Adversarial Loss | Generator | Shared Weights | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Distance | Diff. | Cycle | Sem. | Task | Feature | Pixel | ||||
| CAN[114] | DI,N | CCD | ✓ | not BN | ||||||
| French et al.[68] | En,N | sq. diff. | ✓ | EMA | ||||||
| Co-DA[124]a | DI,En,N,TD | L1 | ✓ | ✓ | ✓ | optional | ||||
| VADA[220]a | DI,TD | ✓ | ✓ | ✓ | ||||||
| DeepJDOT[50] | DI | JDOT | ✓ | ✓ | ||||||
| CyCADA[96] | DI,DM | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Gen. to Adapt[208] | DI | ✓ | ✓ | ✓ | ✓ | |||||
| SimNet[187] | DI | prototypes | ✓ | |||||||
| MADA[183] | DI,En | ✓ | ✓ | ✓ | ||||||
| MCD[206] | DI,En,TD | ✓ | ✓ | ✓ | ✓ | |||||
| GAGL[250] | DI,TD | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| SBADA-GAN[201]b | DM | ✓ | ✓ | ✓ | ✓ | |||||
| MCA[278] | DI | MCA | ✓ | ✓ | ||||||
| CCN++[101] | DI | clusters | ✓ | ✓ | ||||||
| M-ADDA[127] | DI | clusters | ✓ | ✓ | ||||||
| Rozant. et al.[199] | DI | MMD | ✓ | regularize | ||||||
| XGAN[197] | DM | ✓ | ✓ | ✓ | ✓ | some | ||||
| StarGAN[41] | DM | ✓ | ✓ | ✓ | ✓ | |||||
| PixelDA[21] | DM | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| AutoDIAL[27] | N,TD | ✓ | not BN | |||||||
| AdaBN[145] | N | not BN | ||||||||
| JAN-A[151] | DI | JMMD | ✓ | ✓ | ✓ | |||||
| LogCORAL[249] | DI | logCOR, mean | ✓ | ✓ | ||||||
| Log D-CORAL[172] | DI | logDCOR | ✓ | ✓ | ||||||
| VRADA[189] | DI | ✓ | ✓ | ✓ | ||||||
| ATT[204] | En | ✓ | ✓ | ✓ | ||||||
| SimGAN[219] | DM | ✓ | ✓ | N/Ac | ||||||
| ADDA[241] | DI | ✓ | ✓ | |||||||
| CycleGAN[290] | DM | ✓ | ✓ | ✓ | d | |||||
| RegCGAN[160] | DM | ✓ | ✓ | ✓ | ✓ | |||||
| Sener et al.[214] | DI | k-NN | ✓ | |||||||
| DSN[22] | DI | ✓ | ✓ | ✓ | ✓ | some | ||||
| DRCN[76] | DI | ✓ | ✓ | ✓ | ||||||
| CoGAN[143] | DM | ✓ | ✓ | ✓ | some | |||||
| Deep CORAL[226] | DI | CORAL | ✓ | ✓ | ||||||
| DANN[1, 72, 73] | DI | ✓ | ✓ | ✓ | ||||||
| DAN[147] | DI | MK-MMD | ✓ | low | ||||||
| Tzeng et al.[240]e | DI | ✓ | ✓ | ✓ | ||||||
also incorporate virtual adversarial training [167]
also a self-labeled classification loss (learn label on source images, pseudo-label mapped target to source)
maps to target domain so only have feature extractor for target (part of the classifier)
semi-supervised for some classes, i.e., requires some labeled target data for some of the classes
4.1. Losses
4.1.1. Distance.
Distance functions play a variety of roles in domain adaptation losses. A distance loss can be used to align two distributions by minimizing a distance function (e.g., MMD) as explained in Section 3.1. If using an ensemble, minimizing a distance function can align the outputs of the ensemble’s models: an L1 loss of the difference in predicted target class probabilities from two networks in Co-DA [124] or a squared difference between the predictions of the student and teacher networks in self-ensembling [68]. (Note the squared difference loss is confidence thresholded, i.e., if the max predicted output is below a certain threshold then the squared difference loss is set to zero.)
Some of the described methods have been altered replacing the task loss with one of similarity. Laradji et al. [127] propose M-ADDA, a metric-learning modification to ADDA but with the goal of maximizing the margin between clusters of data points’ embeddings. Based on DANN, Pinheiro [187] proposes SimNet, classifying based on how close an embedding is to the embeddings of a random subset of source images for each class. Hsu et al. [101] propose CCN++ incorporating a pairwise similarity network (trained with the same class is similar and different classes are dissimilar).
4.1.2. Promote Differences.
Methods that rely on multiple networks learning different features (such as to make an ensemble diverse) do so by promoting differences between the networks. Saito et al. [204] train the two classifiers labeling unlabeled data to use different features by adding a norm of the product of the two classifiers’ weights. Bousmalis et al. [22] promote different features between two private feature extractors with a soft subspace orthogonality constraint, which is similarly used by Liu et al. [144] for text classification. Kumar et al. [124] train the feature extractors to be different by pushing minibatch means apart. Saito et al. [206] maximize the discrepancy between two classifiers using a fixed, shared feature extractor to promote using different features.
4.1.3. Cycle Consistency / Reconstruction.
A cycle consistency loss or reconstruction loss is commonly used in domain mapping methods to avoid requiring a dataset of corresponding images to be available in both domains. This is how CycleGAN [290], DualGAN [264], and DiscoGAN [118] can be unsupervised. This means that after translating an image from one domain (e.g., horses) to another (e.g., zebras), the new image can be translated back to reconstruct the original image, as illustrated in Figure 6a. Some variants of this have been proposed such as an L1 loss with a transformation function (e.g., identity, image derivatives, mean of color channels) [219], a feature-level cycle-consistency loss (mapping from source to embedding to target then back to embedding resulting in the same embeddings) [197], or using the loss in one [41] or both directions [96, 197]. Sener et al. [214] enforce cycle consistency in their k-nearest neighbors (k-NN) approach by requiring the distance between any source and target point labeled the same to be less than the distance between any source and target point labeled differently and derive a rule they can solve with stochastic gradient descent.
Fig. 6.
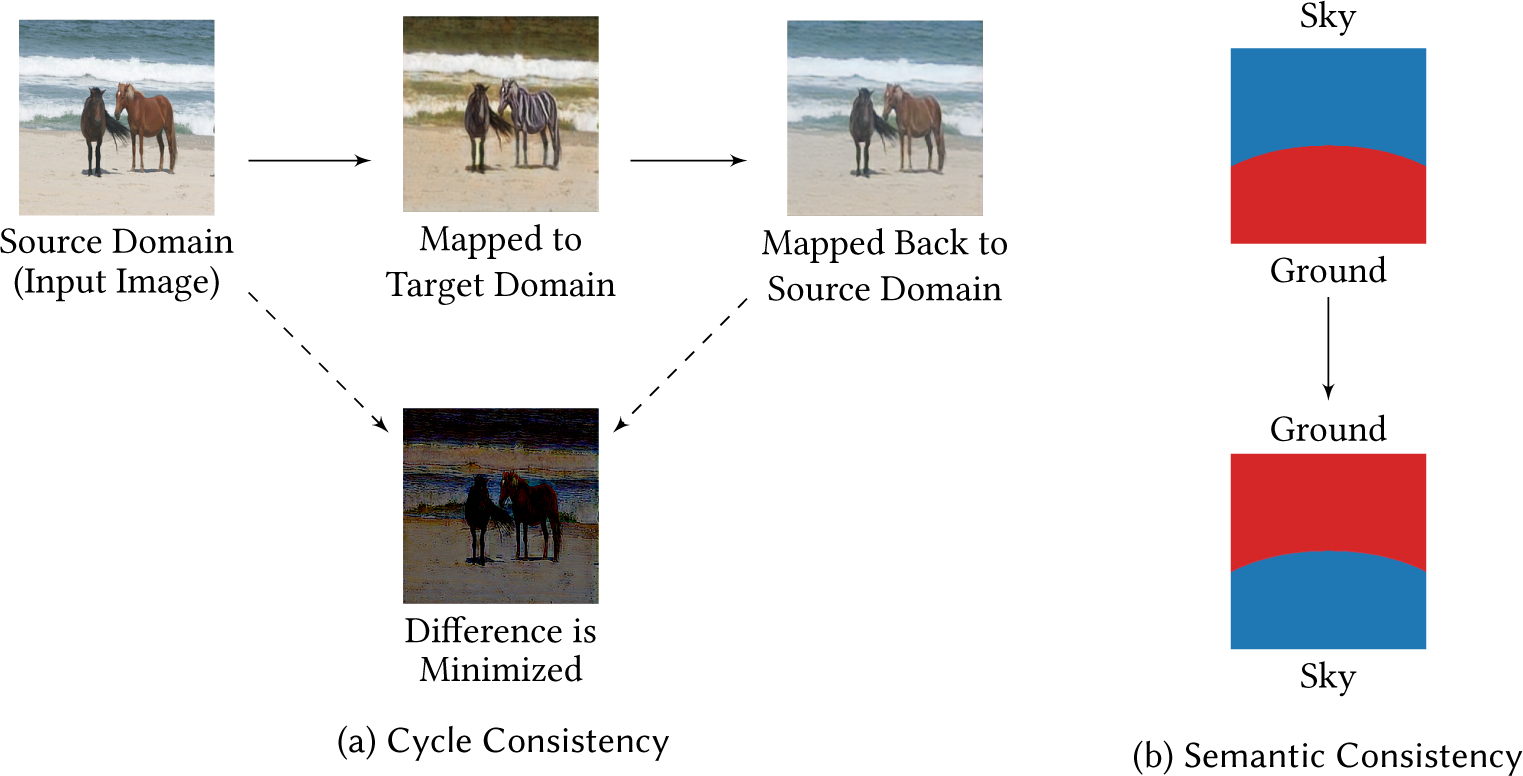
(a) Illustration of a cycle-consistency loss using the horses ↔ zebras dataset by Zhu et al. [290]. The difference between the original source image and the reconstructed image (source to target and back to source) is minimized. (b) Example semantic segmentation situation in which the class names are swapped between the input image and the mapped image that would be prevented by including a semantic-consistency loss. The semantic-consistency loss requires that the class assignments are preserved.
4.1.4. Semantic Consistency.
A semantic consistency loss can be used to preserve class assignments as illustrated in Figure 6b (a segmentation example). The semantic consistency loss requires that a classifier output (or semantic segmentation labeling) from the original source image is the same as the same classifier’s output on the pixel-level mapped target output.
4.1.5. Task.
Nearly all of the domain adaptation methods include some form of task loss that helps the network learn to perform the desired task. For example, for classification, the goal is to output the ground truth source label, or for semantic segmentation, to label each pixel with the correct ground truth source label. The task loss used is generally a cross-entropy loss, or more specifically the negative log likelihood of a softmax distribution [80] when using a softmax output layer. The exceptions not including a task loss are SimNet [187] that classify based on distance to prototypes of each class, the work by Sener et al. [214] that uses k nearest neighbors, and AdaBN [141] that only adjusts the batch norm layers to the target domain. In addition, the image-to-image translation methods are application agnostic unless trained jointly for domain adaptation.
4.1.6. Adversarial.
A variety of methods use a discriminator (or critic) for learning domain-invariant features, realistic image generation, or promoting target discriminative features by forcing a network (either a feature extractor or generator) to produce outputs indistinguishable between two domains (source and target or real and fake). This loss is different than the other losses discussed in this section because this adversarial loss is learned [79, 109] (where learning is more than a hyperparameter search) rather than being provided as a predefined function. During training, gradients from the discriminator are used to train the feature extractor or generator (e.g., negated by a gradient reversal layer, Section 3.1.3). This alternates with updating the discriminator itself to make the correct domain classification.
4.1.7. Additions for Specific Problems.
Some research focusing on specific problems has resulted in additional losses. For semantic segmentation, Li et al. [138] develop a loss making segmentation boundaries sharper to help when the mapped image-to-image translation images will be used for segmentation, Chen et al. [40] develop a distillation loss in addition to performing location-aware alignment (e.g., “road” is usually at the bottom of each image), Hoffman et al. [97] develop a class-aware constrained multiple instance loss, Zhang et al. [276] develop a curriculum where after learning some high-level properties on easy tasks the segmentation network is forced to follow those properties (interpretations include student-teacher setup or posterior regularization), and Perone et al. [185] apply the self-ensembling method [68] replacing the cross-entropy loss with a consistency loss. For object detection, Chen et al. [39] use two domain classifiers (one on an image-level representation and the other on an instance-level representation) with a consistency regularization between them. For adaptation from synthetic images where it is known which pixels are foreground in the source images, Bousmalis et al. [21] and Bak et al. [11] mask certain losses to only penalize foreground pixel differences. For person re-identification, Wei et al. [251] include a person identity-keeping constraint in their domain mapping GAN.
4.2. Low-Confidence or Low-Relevance Rejection
Given a measure of confidence, performance may increase if we can reject data points for training the target classifier that are not of sufficient confidence. This, of course, assumes our confidence measurement is accurate enough. Saito et al. [204] used the label agreement of an ensemble combined with the softmax distribution output (uniform is not confident, one probability much higher than the rest is confident). Sener et al. [214] used the label agreement of the k nearest source data points. If the confidence is to low, then the example is rejected and not used in training until if later on when re-evaluated it is determined to be sufficiently confident. Inoue et al. [106] used an object detector’s prediction probability as a measure of confidence, only using high-confidence detections for fine-tuning an object detection network. Similarly, a rejection approach could be used if we have a measure of relevance. For text classification, Zhang et al. [275] weight examples by their relevance to their target aspect based on a small set of positive and negative keywords (a form of weak supervision).
4.3. Weight Sharing
Methods employ different amounts of sharing network weights between domains or regularizing the weights to be similar. Most methods completely share weights between the feature extractors used on the source and target domains (as shown in Table 1). However, some techniques do not. Since deep networks consist of many layers, allowing them to represent hierarchical features, Long et al. [147] propose copying the lower layers from a network trained on the source domain and adapting higher layers to the target domain with MK-MMD since higher layers do not transfer well between domains. In CoGAN, Liu et al. [143] share the first few layers of the generators and the last few layers of the discriminators, making the assumption that the domains share high-level representations. In AdaBN, Li et al. [141] assume domain knowledge is stored in the batch norm statistics, so they share all weights except for the batch norm statistics. French et al. [68] define the teacher network as an exponential moving average of the student network’s weights (a type of ensemble). Instead of sharing weights, Rozantsev et al. [198, 199] propose two variants: regularizing weights to be similar but not penalizing linear transformations and transforming the weights from the source network to the target network with small residual networks. Bousmalis et al. [22] propose domain separation networks (DSN): learning source-specific, target-specific, and shared features where the “shared” source domain encoder and “shared” target domain encoder do share weights, but the “private” source domain encoder and “private” target domain encoders do not. Others have similarly explored this idea of shared vs. specific features [25, 144, 194].
4.4. Training Stages
Some have trained networks for domain adaptation in stages. Tzeng et al. [241] train a source classifier first followed by adaptation. Taigman et al. [231] use a pre-trained encoder during adaptation. Bousmalis et al. [20] in GraspGAN first train the domain-mapping network followed by the domain-adversarial network. Hoffman et al. [96] in CyCADA train their many components in stages because it would not all fit into GPU memory at once.
Other methods train the domain adaptation networks jointly, which using an adversarial approach is done by alternating between training the discriminator and the rest of the networks (Sections 2.2 and 3.1.3). However, variations exist for some other methods. Saito et al. [204] in ATT cycle through generating training the source networks, generating pseudo-labels, and training the target network. Zou et al. [291] alternate between pseudo-labeling the target data and re-training the model using the labels (a form of self-training). Wei et al. [250] in GAGL alternate between feeding in real source and target data and the fake images generated by a GAN. Sener et al. [214] alternate between k-nearest neighbors and performing gradient descent.
4.5. Multi-Level
Some adaptation methods perform adaptation at more than one level. As discussed in Section 3.6, GraspGAN [20] and CyCADA [96] perform pixel-level adaptation with domain mapping and feature-level adaptation with domain-invariant feature learning. Hoffman et al. [96] found that performing both levels of adaptation significantly improves accuracy: using domain mapping to capture low-level image domain shifts and learning domain-invariant features to handle larger domain shifts than what pure domain mapping methods can support. Following this idea, Tsai et al. [239] make semantic segmentation predictions and perform domain-invariant feature learning at multiple levels in their semantic segmentation network, and Zhang et al. [274] perform domain-invariant feature learning at multiple levels while automatically learning how much to align to each level. Chen et al. [39] perform domain-invariant feature learning at both image and instance levels for object detection but also include a consistency regularization between the two domain classifiers.
4.6. Types of Networks
Nearly all of the surveyed approaches focus on learning from image data and use convolutional neural networks (CNNs) such as ResNet-50 or Inception (Table 3). Wang et al. [247] explore the use of attention networks, Kang et al. [115] a combination of CNNs and attention, Ma et al. [154] graph convolutional networks, and Kurmi et al. [125] Bayesian neural networks. In the case of time-series data, Purushotham et al. [189] propose instead using a variational recurrent neural network (RNN) [43] or LSTM (a type of RNN) [94] rather than a CNN. The RNN learns the temporal relationships while adversarial training is used to achieve domain adaptation. For text classification (a type of natural language processing), Liu et al. [144] also use LSTMs while Zhang et al. [275] found a CNN to work just as well as RNNs or bi-LSTMs in their experiments. For relation extraction (another type of natural language processing), Fu et al. [70] also use a CNN. For time-series speech recognition, Zhao et al. [282] use bi-LSTMs while Hosseini-Asl et al. [100] used a combination of CNNs and RNNs. In the related problem of domain generalization, a combination of CNNs and RNNs have been used for handling a radio spectrogram changing through time to identify sleep stages [284].
4.7. Hyperparameter Tuning
Normal supervised learning-based hyperparamenter tuning methods do not carry over to unsupervised domain adaptation [22, 73, 149, 150, 171, 185, 245]. A common supervised learning approach is to split the training data into a smaller training set and a validation set. After repeatedly altering the hyperparameters, retraining the model, and testing on this validation set for each set of hyperparameters, the model yielding the highest validation set accuracy is selected. Another option is cross validation. However, in unsupervised domain adaptation, there are now two domains, and the data for the target domain may not include any labels. When evaluating domain adaptation approaches on common datasets, generally the target data does contain labels, so work by some groups [22, 27, 124, 201, 220, 245, 250] do use some labeled target data (or all of it [149, 217]) for hyperparameter tuning, which can be interpreted as an upper bound on how well the method could perform [245]. For example, some [27, 150] tuned for Office on one W labeled example per class on the A →W task, while others [201, 250] tuned with a validation set of 1000 randomly sampled target examples. Using any labeled target data is not ideal because real-world testing will not include labels for tuning (unless it is semi-supervised, in which case semi-supervised learning is recommended in Section 6).
One tuning method not requiring labeled target data is reverse validation [73], which is a variant of reverse cross validation [286]. For a set of hyperparameters, the reverse validation risk can be estimated by first splitting source (labeled) and target (unlabeled) data into training and validation sets. Then, the labeled source and unlabeled target data are used to learn a classifier (as is normally done). Next, this forward classifier is used to label the target data and a new reverse classifier is learned (with the same algorithm) using the pseudo-labeled target data (as “source”) and unlabeled source data (as “target”, i.e., ignoring the known labels). This reverse classifier is evaluated on the source validation data to measure the reverse validation risk. Ganin et al. [73] found this method works better if the reverse classifier is initialized with the weights of the forward classifier and if using early stopping on the source validation set and a pseudo-labeled target validation set. Finally, hyperparameters are selected (e.g., grid search, random search, Bayesian optimization, or other gradient-free optimization methods such as those implemented in Nevergrad [191]) that minimize this reverse validation risk.
Alternatively, given some domain knowledge, one may devise relevant measures of similarity between the domains and tune parameters to increase the similarity. For example, French et al. [68] were able to improve performance on the challenging problem of MNIST → SVHN by tuning data augmentation hyperparameters for MNIST to match pixel intensities apparent in the SVHN dataset. By doing this, they were able to improve the state-of-the-art to 97.0% (Table 2).
5. RESULTS
Tables 2 through 5 summarize the results of evaluating many of these methods on datasets used for image classification as well as sentiment analysis. Care must be taken in the extent to which conclusions are drawn from comparing published numbers in different papers since the provided accuracies are for different network architectures, hyperparameters, amount of data augmentation, random initializations (or averages over a number of them), etc. and the methods may perform differently in other application areas. However, interestingly, at least one method in each of the categories of surveyed gives promising results on at least one of the datasets.
Table 5.
| Computer Vision Datasets used for Domain Adaptation | |
|---|---|
| MNIST[130]a | This is a binary (mostly black and white, but actually grayscale due to anti-aliasing) handwritten digit dataset (digits 0–9), which stands for “modified NIST.” It is based on the National Institute of Standards and Technology’s (NIST) Special Database 1 and 3, one of which was easier than the other, so MNIST is a combination of the two that are size normalized to fit in a 20×20 box preserving the aspect ratio and centered in a 28×28 pixel image. |
| MNIST-M[73]b | This is a modification of MNIST where the digits are blended with random patches from BSDS500 dataset color photos. |
| USPS[131]c | This is another handwritten digit dataset (digits 0–9). It consists of handwritten zipcodes scanned and segmented by the U.S. Postal Service (USPS). They were size normalized to 16×16 pixels preserving the aspect ratio. The values are normalized to be between −1 and 1. |
| SVHN[175]d | The Streetview House Numbers (SVHN) consists of single digits extracted from images of urban house numbers in Google Street View. The digits have been size normalized to 32×32 pixels. |
| SYNN[73]b | Ganin et al.[73] used Microsoft Windows fonts to create a synthetic digit dataset (“Syn Numbers”) consisting of 1–3 digit numbers with various positions, orientation, background color, stroke color, and amount of blur. |
| SYNS[168]e | This is a synthetic sign dataset created from modifications to Wikipedia pictograms of traffic signs. It consists of 100,000 images and 43 classes of signs. |
| GTSRB[224]f | The German Traffic Signs Recognition Benchmark (GTSRB) is a dataset created from video taken driving around Germany. It consists of about 50,000 images and 43 classes of signs. |
| Office[202]g | This dataset consists of 31 classes of objects in three different domains: Amazon (taken from its online website; medium resolution and studio lighting), DSLR (taken with a digital SLR camera; high resolution and in a real-world environment), and Webcam (taken with a 640×480 computer webcam; have noise, artifacts, and white balance issues). Note: due to Office’s small size, some networks [73, 199, 226] were pre-trained on ImageNet. |
See Ganin’s website http://yaroslav.ganin.net/ for links to download.
This can be found on various sites and some Github repositories. One such place: https://web.stanford.edu/~hastie/ElemStatLearn/data.html
The synthetic dataset linked to on: http://graphics.cs.msu.ru/en/research/projects/imagerecognition/trafficsign
With domain-invariant feature learning with the contrastive domain discrepancy, CAN [114] has the highest performance on the Office dataset (Table 3). By using adversarial domain-invariant feature learning, WDGRL generally outperforms the other methods on the Amazon review dataset (Table 4) and Generate to Adapt is second highest of the methods evaluated on the Office dataset. By using adversarial pixel-level domain mapping, SBADA-GAN [201] obtains the highest accuracy on MNIST→MNIST-M (Table 2). AutoDIAL [27], a normalization statistics method, does on-par with CAN and Generate to Adapt in two of Office adaptation tasks. The self-ensembling method by French et al. [68] outperforms all other methods on the datasets in Table 2, and Co-DA [124] comes close using an ensemble (of size two) of adversarial domain-invariant feature networks. CyCADA increases accuracy from 54% to 82% for a synthetic season adaptation dataset [96] by combining both adversarial domain-invariant feature learning and domain mapping.
A number of these promising methods use adversarial techniques, which may be a key ingredient in solving domain adaptation problems. Adversarial approaches may be helpful on certain datasets (e.g., WDGRL on the Amazon review dataset on Office), certain types of data (e.g., VRADA was developed for time series data rather than image data), or may not require as extensive of tuning (e.g., Co-DA on MNIST→SVHN). Or adversarial training may be an additional tool to incorporate into existing non-adversarial methods. For instance, promising non-adversarial methods such as AutoDIAL and by French et al. could be combined with adversarial methods (see Section 8.3). In fact, Long et al. [151] develop both JAN and then the adversarial version JAN-A, and JAN-A on average outperformed JAN on the Office dataset. CAN [114], which presently is the highest on the Office dataset, might also be improved by incorporating an adversarial component to it as in Long et al. [151].
Interestingly, French et al. by far outperform all other methods on MNIST→SVHN, though this requires a problem-specific data augmentation and hyperparameter tuning. This may indicate that for some problems, maybe in particular the more challenging domain adaptation problems, hyperparameter tuning for a specific dataset may be of utmost importance. Possibly if other domain adaptation methods similarly were tuned appropriately, they would also experience large improvements. This is an area of research requiring further work (see Section 8.2). However, Co-DA [124] is not far behind on SVHN→MNIST and MNIST→MNIST-M and is the closest on MNIST→SVHN, achieving 81.7% compared with 97.0%. A great advantage of Co-DA is that it does not require highly-problem-specific tuning on MNIST→SVHN as required by French et al. (without they only achieved 37.5%). Possibly some components of Co-DA such as the adversarial domain adaptation or virtual adversarial training may be partially responsible for the decrease in hyperparameter sensitivity.
6. THEORY
Having surveyed domain adaptation methods, we now address the question of when adaptation may be beneficial. Ben-David et al. [13] develop a theory answering this in terms of an ideal predictor on both domains, Zhao et al. [280] further this theory by removing the dependence on a joint ideal predictor while focusing on domain-invariant feature learning methods, and Le et al. [129] develop theory looking beyond domain-invariant methods. These theoretical results can help answer two questions: (1) when will a classifier (or other predictor) trained on the source data perform well on the target data, and (2) given a small number of labeled target examples, how can they best be used during training to minimize target test error?
Answering the first question, labeled source data and unlabeled target data are both required (unsupervised). Answering the second question, additionally some labeled target data are required (semi-supervised). We will first review the theoretical bounds followed by a discussion of what insights these bounds provide into answering the above two questions. Ben-David et al. [13] also address the case of multiple source domains, as do Mansour et al. [159]. In this paper, we have focused on the cases containing only one source and one target (as is common in the methods we survey).
6.1. Unsupervised
6.1.1. Shared Hypothesis Space.
Ben-David et al. [13] propose setting a bound on the target error based on the source error and the divergence between the source and target domains. The empirical source error is easy to obtain by first training and then testing a classifier. However, the divergence between the domains cannot be directly obtained with standard methods like Kullback-Leibler divergence due to only having a finite number of samples from the domains and not assuming any particular distribution. Thus, an alternative is to measure it using a classifier-induced divergence called . Estimates of this divergence with finite samples converges to the real . This divergence can be estimated by measuring the error when getting a classifier to discriminate between the unlabeled source and target examples; though, it is often intractable to find the theoretically-required divergence upper bound. Using the empirical source error , the between source and target samples , and ideal predictor error λ* using the optimal hypothesis for the source and target, the target error ϵT (h) can be bounded as shown in Equation 2 (using the form given by Zhao et al. [280]), with probability at least 1 − δ for δ ∈ (0, 1).
| (2) |
Zhao et al. [280] develop another upper bound that removes the reliance on λ*. Let , , and be the source and target domains (the true distributions, not empirical). The target error can then be bounded by the source error ϵS(h), the discrepancy between marginal distributions , and the distance between the optimal source and target labeling functions , as shown in Equation 3.
| (3) |
Zhao et al. [280] also develop an information-theoretic lower bound for target error. Let the labeling function Y = f (X) ∈ {0, 1}, the prediction function , and Z be the intermediate representation output by a shared feature extractor used on source and target domain data. If the Jensen-Shannon distance and the Markov chain holds, then Equation 4 provides a lower bound on the source and target error.
| (4) |
6.1.2. Different Hypothesis Spaces.
Le et al. [129] develop an upper bound that allows for different hypothesis spaces for source and target functions, possibly non-deterministic labeling, and any bounded or continuous loss. If l is a bounded or continuous loss, (source) and (target), and K ≔ T−1 (bijective mapping), for θ parameterizing a hypothesis set , M is the number of labels, is the pushforward probability distribution transporting via K, Δp(y|x) ≔ pt (y|T (x)) − ps (y|x) for the true source and target labeling functions ps (y|x) and pt (y|x), where denotes the Wasserstein-1 distance between the source and target distributions with a cost function c(x, x′) = 1x≠x′ (1 if x ≠ x′, otherwise 0), then Equation 5 provides an upper bound for the variance between a general loss on the source and target predictions.
| (5) |
6.2. Semi-Supervised
In the semi-supervised case, a linear combination of the source and target errors is computed [13], called the α-error. A bound can be calculated on the true α-error based on the empirical α-error. Finding the minimum α-error depends on the empirical α-error, the divergence between source and target, and the number of labeled source and target examples. Experimentation can be used to empirically determine the values of α that will perform well. Ben-David et al. [13] also demonstrate the process on sentiment classification, illustrating that the optimum uses non-trivial values.
The bound is given in Equation 6. If S is a labeled sample of size m with (1 − β)m points drawn from the source distribution and βm from the target distribution, then with at least probability 1 − δ for δ ∈ (0, 1):
| (6) |
Here, is the empirical minimizer of the α-error on S given by and is the target error minimizer.
The optimum α is then:
| (7) |
Here, mS = (1 − β)m is the number of source examples, mT = βm is the number of target examples, , and
| (8) |
| (9) |
| (10) |
6.3. Discussion
6.3.1. Unsupervised.
Equation 2 indicates that if the optimal predictor error λ* on both source and target data is large, then there is no good hypothesis from training on the source domain that will work well on the target domain [13, 280]. However, as is more common in the application of domain adaptation, if λ* is small, then the bound depends on the source error and the [13]. The domain-invariant feature learning methods discussed in Section 3.1 try minimizing these two terms [280]: the source error via a task loss on labeled source data and divergence via a divergence measure such as MMD, with reconstruction, or adversarially. While Section 5 shows that on many datasets these methods work, there is no guarantee that such adaptation will increase performance (these are upper bounds), as shown by simple counterexamples [280]. It may actually decrease performance if the marginal label distributions differ significantly between source and target [280].
Equation 3 shows that the target error upper bound alternatively involves the marginal distributions and Equation 4 shows that the lower bound does too. These indicate the importance of aligning the label distributions. If the marginal label distributions are significantly different, then minimizing the source error and divergence between feature representations will actually increase the error [280]. Thus over-training domain-invariant feature learning methods can increase target error, and Zhao et al. [280] experimentally verified this. They found on MNIST, USPS, and SVHN adaptation that during training the target accuracy would initially rise rapidly but would eventually decrease again despite increasing source accuracy, an effect even more apparent with larger differences in the marginal label distributions. It is an open problem as to when the label distributions can be aligned without target labels [280].
6.3.2. Semi-Supervised.
Equation 6 indicates that when only source or target data are available, that data should be used (as we might expect). If the source and target are the same, then α* = β, which implies a uniform weighting of examples. Given enough target data, source data should not be used at all because it might increase the test-time error. Furthermore, without enough source data using it may also not be worthwhile, i.e., α* ≈ 0 [13]. In this paper we focus on unsupervised domain adaptation, but these are important considerations if target labels can be obtained. For example, this shows that it may be better to perform semi-supervised adaptation if some labeled target examples are available rather than using the labeled target examples to hyperparameter tune an unsupervised adaptation method.
7. APPLICATIONS
Domain adaptation has been applied in a variety of areas including computer vision, natural language processing, and for time-series data. Using domain adaptation in these various problems can save the human time that would be spent labeling the target data. In some cases such as image semantic segmentation, providing ground truth is very labor intensive. Each pixel-level annotated image in the Cityscapes dataset took on average 1.5 hours to complete [46]. In addition, similar methods as described in this paper have been applied to the related problem of domain generalization and some other problems as well.
7.1. Computer Vision
Most of the methods surveyed in this paper are for computer vision tasks such as adapting a model trained on synthetic images to real photos (e.g., from synthetic numbers or signs, Table 2), stock photos to real photos (e.g., Amazon to DSLR on the Office dataset, Table 3), or simple to complex images (e.g., MNIST to SVHN, Table 2). Others have been used in robotics for robot grasping [20], autonomous navigation [266], and lifelong learning [255], for semantic segmentation [40, 98, 102, 133, 153, 209, 239, 243, 291] including when additional information is available from a simulator [133], in a medical context for chest X-ray segmentation [32], 3D CT scans to X-ray segmentation [277], MRI to CT scan segmentation [33], and MRI segmentation [185], in low resource situations (where there are very few target data points) [100], in situations with different label sets for each domain [223], for object detection [39, 97, 106], for person re-identification [11, 57, 73, 142, 251, 287, 288], and for depth estimation [8, 155, 174].
7.2. Natural Language Processing
Domain adaptation has been used in natural language processing such as for sentiment analysis (Table 4, [275, 282]), other text classification [144, 275] including weakly-supervised aspect-transfer from one aspect of a dataset to another [275], relation extraction [70], semi-supervised sequence labeling [54], semi-supervised question answering [262], sentence specificity [119], and neural machine translation [23, 31, 42].
7.3. Time Series
For time-series data, domain adaptation has been used for learning temporal latent relationships in health data across different population age groups [189], to perform speech recognition [100, 218, 282], for predicting driving maneuvers [238], anomaly detection [242], and inertial tracking [35]. In a method addressing the related problem of domain generalization, time-series radio data was used for sleep-stage classification [284]. Finally, a combination of pre-training and fine-tuning was used to solve another transfer learning problem, where the source datasets have a different label space than the target dataset [108].
7.4. Domain Generalization
Domain-invariant feature learning approaches similar to those discussed in Section 3.1 have been used for the related problem of domain generalization, where there are multiple source domains and an unseen target domain [17, 173]. Zhao et al. [284] use an adversarial approach with a domain classifier to learn a model on a dataset collected from a number of people sleeping in various environments that will generalize well to new people and/or new environments (e.g., sleeping in a different room). Ghifary et al. [75] use a reconstruction approach with a denoising autoencoder to improve object recognition generalizability, where the “noise” is different views (domains) of the data (e.g., rotation, change in size, or variation in lighting) and the autoencoder tries to reconstruct corresponding views of the object in other domains. Carlucci et al. [28] propose an adversarial approach combining domain adaptation and generalization while also doing domain mapping. Akuzawa et al. [2] note the domain-invariance objective may compete with the discriminative objective and thus develop a method to find the most domain-invariant representation that does not hurt classification performance. Li et al. [140] note that previous domain-invariant methods typically assume balanced classes and develop a method to handle changes in class proportions.
7.5. Other Problems
Adversarial losses like those used in adversarial domain adaptation methods have also been applied in multiple other settings. Wang et al. [248] created an adversarial spacial dropout network to add occlusions to images to improve the accuracy of object detection algorithms. They also created an adversarial spatial transformer network to add deformations such as rotations to objects to again increase object detection accuracy. Pinto et al. [188] used adversarial agents to improve a robot’s ability to grasp an object via self-supervised learning by employing both shaking and snatching adversaries. Giu et al. [86] used an adversarial loss to predict and demonstrate (i.e., robot will copy) human motion. Rippel et al. [195, 196] used a reconstruction and adversarial loss with an autoencoder for learning higher quality image compression at low bit rates. Sinclair [222] applied adversarial loss to clone a physical model for real-time sound synthesis. Adversarial techniques may also be applied to machine learning security, where the goal is to train a classifier robust to adversarial examples [103, 167].
8. RESEARCH DIRECTIONS
As we have seen, the rapidly-growing body of research focused on unsupervised deep domain adaptation now encompasses many novel methods and components. Here we look at what could be explored in future research to further enhance this existing work.
8.1. Bi-Directional Adaptation
The more difficult domain adaptation problems are far from being solved. Tables 2 through 5 indicate that some domain adaptation problems are harder than others and point to the challenge that more work needs to be focused on these harder problems. While accuracy for SVHN→MNIST ranges from 70.7% to 99.3%, for the reverse case of MNIST→SVHN, the highest without highly-problem-specific hyperparameter tuning is 81.7% by Kumar et al. [124] (though tuned on a small amount of labeled target data). This indicates how this reverse problem is much harder [68, 72]. As a result, few papers offer results for this direction. French et al. [68] were able to vastly improve performance up to 97.0%; however, this required developing a problem-specific unsupervised hyperparameter tuning method. Other methods may similarly benefit from such tuning. Continued work is needed to strengthen general-purpose bi-directional adaptation.
8.2. Hyperparameter Tuning
Some methods such as reverse validation and a problem-specific pixel intensity matching have been applied to hyperparameter tuning without requiring target labels (Section 4.7). While the reverse validation method appears promising, it was not used in most of the methods surveyed (only [73, 183, 187]). This may be because of the increase in computation cost [185] or problems with the reverse validation accuracy not aligning with test accuracy [22]. It is also possible researchers may just be unaware of the method since in the surveyed papers few mention the idea (only [22, 73, 183, 185, 187]). Problem-specific methods such as matching pixel intensity between domains as done by French et al. [68] are possible given some domain knowledge, but hyperparameter tuning methodologies should be developed that will work across a wider range of problems. This remains an open area of research.
8.3. Combining Promising Methods
French et al. [68], Co-DA [124], CAN [114], AutoDIAL [27], Generate to Adapt [208], and WDGRL [217] are promising approaches based on Tables 2 through 4. French et al. uses a student and teacher network for self-ensembling, Co-DA trains multiple (e.g., two) adaptation networks while requiring diversity and agreement in addition to incorporating virtual adversarial training, CAN alternates between clustering and adaptation through minimizing intra-class discrepancy and maximizing inter-class margin, AutoDIAL adjusts batch normalization layer weights, Generate to Adapt uses an embedding-conditional GAN for adversarial domain adaptation, and WDGRL performs adversarial domain adaptation similar to DANN by using a domain classifier. These are largely independent ideas that if combined may result in additional performance gains.
For instance, the student network in French et al. that accepts either a source or target augmented image could be replaced by the AutoDIAL network to learn how much adaptation to perform at each level of the network. Or to combine with adversarial methods, the student and teacher networks’ outputs (or an intermediate layer’s outputs, as is being explored by Wang et al. [245]) could be fed to a gradient reversal layer followed by a domain classifier, in effect adding an adversarial loss term to the existing two terms used by French et al. Or since French et al. is based upon data augmentation, one might try replacing the existing stochastic data augmentation with a GAN since a GAN can be used for data augmentation (given enough unlabeled training data).
Alternatively, key aspects of other methods could be incorporated. While domain adaptation methods commonly align feature distributions, a different line of research aligns the joint or conditional distribution of the feature and label spaces instead [44, 47, 50, 148, 151, 154, 233, 267]. Researchers found aligning in this manner improves results when handling multi-modal data distributions [148] or when label proportions differ between domains [47]. Other domain adaptation strategies may similarly benefit from aligning the joint or conditional distribution rather than merely the feature distribution.
8.4. Balancing Classes
In order to obtain high accuracy on the challenging problem of MNIST→SVHN, French et al. [68] include an additional class-balance term in their loss function, which both improved training stability and helped the network avoid a degenerate local minimum. Though, this term was not required in their other experiments. Clearly, class balancing is an important concern; although, this depends on the dataset being used. Other methods may similarly benefit from balancing classes.
For instance, Hoffman et al. [96] note that the frequency-weighted intersection over union results in their paper were very close to the target-only model accuracy (an approximate upper bound). Thus, they conclude that domain mapping followed by domain-invariant feature learning is very effective for the common classes in the SYNTHIA dataset (season adaptation on a synthetic driving dataset). It is possible then that additional balancing of classes could help the not-as-common classes to perform better. In addition, data augmentation through occluding parts of the images may improve class balancing as would the adversarial spatial dropout network by Wang et al. [248] since the two best classes (road and sky) were likely in almost every image.
8.5. Incorporating Improved Image-to-Image Translation Methods
Bousmalis et al. [21] with PixelDA had difficulty applying their method with large domain differences. However, other image-to-image translation methods like XGAN [197] have been developed that may support larger domain shifts. These methods could be extended to domain adaptation directly or also incorporating a semantic consistency loss (as explained in Section 4.1). This may allow for more substantial differences between domains. Similarly, image-to-image translation methods like StarGAN [41] have been developed for multiple domains, which could be extended for multi-domain adaptation.
8.6. Futher Experimental Comparison Between Methods
As shown in Table 2, French et al. [68] outperforms all the other methods and Co-DA [124] is quite close behind (with the advantage that it does not require highly-problem-specific tuning on MNIST→SVHN). In Table 3, CAN [114] outperforms the others followed by Generate to Adapt [208]. Finally, in Table 4, WDGRL [217] generally performs the best. However, these methods are not all compared on the same dataset, making a direct comparison difficult. Additional experiments must be performed to see how these methods compare. Similarly, other promising approaches may outperform other methods on some datasets, which could be determined through additional experiments.
These comparisons can be made easier through developing a unified implementation of these various methods. Schneider et al. [212] are developing such an open-source set of implementations of state-of-the-art domain adaptation (and domain generalization) methods. The results provided in individual papers have different hyperparameters, data augmentation, network architectures, etc. that can make direct comparisons challenging. Using a unified implementation of these methods can facilitate more clearly understanding what aspects of a method are responsible for performance gains and also support combining the novel elements from multiple methods.
8.7. Limitations of Datasets
Varying amounts of source and target data are available in different situations. The datasets used for comparisons (the image datasets listed in Table 5 and the Amazon review dataset) are relatively small when compared with the sizes of datasets commonly in use in deep learning, e.g., ImageNet [56, 200] (though ImageNet is often used to pretrain adaptation networks). For example, Sankaranarayanan et al. [208] note how GANs require a lot of training data. This may limit GAN-based methods from being used on too small of source or target datasets. Modifications may need to be developed for such low resource situations, an area explored by Hosseini-Asl et al. [100]. Additionally, most domain adaptation datasets are for computer vision. To spur research in other application areas, other datasets could be created.
8.8. Other Applications
Other application areas may benefit from performing domain adaptation as have those discussed in Section 7. In particular, only a few methods were applied to time-series data. One time-series application that may benefit from adaptation is activity prediction, e.g., adapting from one type of sensor to another or from one person’s data to another’s. Some added challenges in this context may be the large differences in feature spaces due to the wide variety of sensors used (e.g., an event stream of fixed motion sensors turning on and off in a smart home vs. sampled motion and location data collected from smart phones or watches) or the difference in labels (e.g., one model may learn a “walk” activity while another learns “exercise” or may learn “read” while another model learns “school”). Applying domain adaptation in new areas may yield novel methods or components applicable in other areas as well.
8.9. Other Domain Adaptation Cases
As mentioned in Section 3, we have surveyed single-source homogeneous unsupervised domain adaptation methods due to this being the most commonly-studied case of domain adaptation. However, exploring other cases is warranted. By utilizing data from multiple source domains and/or multiple target domains, additional gains in performance may be achievable. By handling heterogeneous feature spaces or various other levels of supervision (e.g., semi-supervised learning [203] or weakly-supervised learning [221]), domain adaptation may bring performance gains to other problems as well. Finally, another under-studied case of domain adaptation is partial domain adaptation, where the target domain contains only a subset of the source domain’s labels [26, 233, 272].
9. CONCLUSIONS
For supervised learning, deep neural networks are in prevalent use, but these networks require large labeled datasets for training. Unsupervised domain adaptation can be used to adapt deep networks to possibly-smaller datasets that may not even have target labels. Several categories of methods have been developed for this goal: domain-invariant feature learning, domain mapping, normalization statistics-based, and ensemble-based methods. These various methods have some unique and common elements as we have discussed. Additionally, theoretical results provide some insight into empirical observations. Some methods appear very promising, but further research is required for direct comparisons, novel method combinations, improved bi-directional adaptation, and use for novel datasets and applications.
ACKNOWLEDGMENTS
This material is based upon work supported by the National Science Foundation under Grant Nos. 1543656 and 1734558.
REFERENCES
- [1].Ajakan Hana, Germain Pascal, Larochelle Hugo, Laviolette François, and Marchand Mario. 2014. Domain-adversarial neural networks. arXiv preprint arXiv:1412.4446 (2014). [Google Scholar]
- [2].Akuzawa Kei, Iwasawa Yusuke, and Matsuo Yutaka. 2019. Adversarial Invariant Feature Learning with Accuracy Constraint for Domain Generalization. arXiv preprint arXiv:1904.12543 (2019). [Google Scholar]
- [3].Mejjati Youssef Alami, Richardt Christian, Tompkin James, Cosker Darren, and Kim Kwang In. 2018. Unsupervised Attention-guided Image-to-Image Translation. In Advances in Neural Information Processing Systems 31, Bengio S, Wallach H, Larochelle H, Grauman K, Cesa-Bianchi N, and Garnett R (Eds.). Curran Associates, Inc., 3693–3703. http://papers.nips.cc/paper/7627-unsupervised-attention-guided-image-to-image-translation.pdf [Google Scholar]
- [4].Anoosheh Asha, Agustsson Eirikur, Timofte Radu, and Van Gool Luc. 2018. ComboGAN: Unrestrained Scalability for Image Domain Translation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. [Google Scholar]
- [5].Arjovsky Martin, Chintala Soumith, and Bottou Léon. 2017. Wasserstein Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning (Proceedings of Machine Learning Research), Precup Doina and Teh Yee Whye (Eds.), Vol. 70. PMLR, 214–223. http://proceedings.mlr.press/v70/arjovsky17a.html [Google Scholar]
- [6].Arora Sanjeev, Ge Rong, Liang Yingyu, Ma Tengyu, and Zhang Yi. 2017. Generalization and Equilibrium in Generative Adversarial Nets (GANs). In Proceedings of the 34th International Conference on Machine Learning (Proceedings of Machine Learning Research), Precup Doina and Teh Yee Whye (Eds.), Vol. 70. PMLR, 224–232. http://proceedings.mlr.press/v70/arora17a.html [Google Scholar]
- [7].Arora Sanjeev, Risteski Andrej, and Zhang Yi. 2018. Do GANs learn the distribution? Some Theory and Empirics. In International Conference on Learning Representations. https://openreview.net/forum?id=BJehNfW0- [Google Scholar]
- [8].Atapour-Abarghouei Amir and Breckon Toby P.. 2018. Real-Time Monocular Depth Estimation Using Synthetic Data With Domain Adaptation via Image Style Transfer. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [9].Athiwaratkun Ben, Finzi Marc, Izmailov Pavel, and Wilson Andrew Gordon. 2019. There Are Many Consistent Explanations of Unlabeled Data: Why You Should Average. In International Conference on Learning Representations. https://openreview.net/forum?id=rkgKBhA5Y7 [Google Scholar]
- [10].Lei Ba Jimmy, Kiros Jamie Ryan, and Hinton Geoffrey E. 2016. Layer normalization. arXiv preprint arXiv:1607.06450 (2016). [Google Scholar]
- [11].Bak Slawomir, Carr Peter, and Lalonde Jean-Francois. 2018. Domain Adaptation through Synthesis for Unsupervised Person Re-identification. In The European Conference on Computer Vision (ECCV). [Google Scholar]
- [12].Beijbom Oscar. 2012. Domain adaptations for computer vision applications. arXiv preprint arXiv:1211.4860 (2012). [Google Scholar]
- [13].Ben-David Shai, Blitzer John Crammer Koby, Kulesza Alex, Pereira Fernando, and Vaughan Jennifer Wortman. 2010. A theory of learning from different domains. Machine Learning 79, 1 (01 May 2010), 151–175. 10.1007/s10994-009-5152-4 [DOI] [Google Scholar]
- [14].Benaim Sagie and Wolf Lior. 2017. One-Sided Unsupervised Domain Mapping. In Advances in Neural Information Processing Systems 30, Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, and Garnett R (Eds.). Curran Associates, Inc., 752–762. http://papers.nips.cc/paper/6677-one-sided-unsupervised-domain-mapping.pdf [Google Scholar]
- [15].Berthelot David, Schumm Tom, and Metz Luke. 2017. Began: Boundary equilibrium generative adversarial networks. arXiv preprint arXiv:1703.10717 (2017). [Google Scholar]
- [16].Bińkowski Mikołaj, Sutherland Dougal J, Arbel Michael, and Gretton Arthur. 2017. Demystifying MMD GANs. In International Conference on Learning Representations. https://openreview.net/forum?id=r1lUOzWCW [Google Scholar]
- [17].Blanchard Gilles, Lee Gyemin, and Scott Clayton. 2011. Generalizing from Several Related Classification Tasks to a New Unlabeled Sample. In Advances in Neural Information Processing Systems 24, Shawe-Taylor J, Zemel RS, Bartlett PL, Pereira F, and Weinberger KQ (Eds.). Curran Associates, Inc., 2178–2186. http://papers.nips.cc/paper/4312-generalizing-from-several-related-classification-tasks-to-a-new-unlabeled-sample.pdf [Google Scholar]
- [18].Blitzer John, Dredze Mark, and Pereira Fernando. 2007. Biographies, bollywood, boom-boxes and blenders: Domain adaptation for sentiment classification. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics. 440–447. [Google Scholar]
- [19].Borji Ali. 2018. Pros and Cons of GAN Evaluation Measures. arXiv preprint arXiv:1802.03446 (2018). [Google Scholar]
- [20].Bousmalis K, Irpan A, Wohlhart P, Bai Y, Kelcey M, Kalakrishnan M, Downs L, Ibarz J, Pastor P, Konolige K, Levine S, and Vanhoucke V. 2018. Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping. In 2018 IEEE International Conference on Robotics and Automation (ICRA). 4243–4250. 10.1109/ICRA.2018.8460875 [DOI] [Google Scholar]
- [21].Bousmalis Konstantinos, Silberman Nathan, Dohan David, Erhan Dumitru, and Krishnan Dilip. 2017. Unsupervised Pixel-Level Domain Adaptation With Generative Adversarial Networks. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [22].Bousmalis Konstantinos, Trigeorgis George, Silberman Nathan, Krishnan Dilip, and Erhan Dumitru. 2016. Domain Separation Networks. In Advances in Neural Information Processing Systems 29, Lee DD, Sugiyama M, Luxburg UV, Guyon I, and Garnett R (Eds.). Curran Associates, Inc., 343–351. http://papers.nips.cc/paper/6254-domain-separation-networks.pdf [Google Scholar]
- [23].Britz Denny, Le Quoc, and Pryzant Reid. 2017. Effective domain mixing for neural machine translation. In Proceedings of the Second Conference on Machine Translation. 118–126. [Google Scholar]
- [24].Bungum Lars and Gambäck Björn. 2011. A survey of domain adaptation in machine translation: Towards a refinement of domain space. In Proceedings of the India-Norway Workshop on Web Concepts and Technologies, Vol. 112. [Google Scholar]
- [25].Cao Jinming, Katzir Oren, Jiang Peng, Lischinski Dani, Danny Cohen-Or Changhe Tu, and Li Yangyan. 2018. Dida: Disentangled synthesis for domain adaptation. arXiv preprint arXiv:1805.08019 (2018). [Google Scholar]
- [26].Cao Zhangjie, Long Mingsheng, Wang Jianmin, and Jordan Michael I.. 2018. Partial Transfer Learning With Selective Adversarial Networks. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [27].Carlucci Fabio Maria, Porzi Lorenzo, Caputo Barbara, Ricci Elisa, and Bulò Samuel Rota. 2017. Autodial: Automatic domain alignment layers. In 2017 IEEE International Conference on Computer Vision (ICCV). IEEE, 5077–5085. [Google Scholar]
- [28].Carlucci Fabio M, Russo Paolo, Tommasi Tatiana, and Caputo Barbara. 2018. Agnostic Domain Generalization. arXiv preprint arXiv:1808.01102 (2018). [Google Scholar]
- [29].Caruana Rich. 1997. Multitask Learning. Machine Learning 28, 1 (01 Jul 1997), 41–75. 10.1023/A:1007379606734 [DOI] [Google Scholar]
- [30].Chapelle Olivier and Zien Alexander. 2005. Semi-supervised classification by low density separation.. In AISTATS, Vol. 2005. Citeseer, 57–64. [Google Scholar]
- [31].Chen Boxing, Cherry Colin, Foster George, and Larkin Samuel. 2017. Cost weighting for neural machine translation domain adaptation. In Proceedings of the First Workshop on Neural Machine Translation. 40–46. [Google Scholar]
- [32].Chen Cheng, Dou Qi, Chen Hao, and Heng Pheng-Ann. 2018. Semantic-Aware Generative Adversarial Nets for Unsupervised Domain Adaptation in Chest X-Ray Segmentation. In Machine Learning in Medical Imaging, Shi Yinghuan, Suk Heung-Il, and Liu Mingxia (Eds.). Springer International Publishing, Cham, 143–151. [Google Scholar]
- [33].Chen Cheng, Dou Qi, Chen Hao, Qin Jing, and Heng Pheng-Ann. 2019. Synergistic Image and Feature Adaptation: Towards Cross-Modality Domain Adaptation for Medical Image Segmentation. arXiv preprint arXiv:1901.08211 (2019). [Google Scholar]
- [34].Chen Chao, Fu Zhihang, Chen Zhihong, Jin Sheng, Cheng Zhaowei, Jin Xinyu, and Hua Xian-Sheng. 2019. HoMM: Higher-order Moment Matching for Unsupervised Domain Adaptation. arXiv preprint arXiv:1912.11976 (2019). [Google Scholar]
- [35].Chen Changhao, Miao Yishu, Chris Xiaoxuan Lu Linhai Xie, Blunsom Phil, Markham Andrew, and Trigoni Niki. 2019. MotionTransformer: Transferring Neural Inertial Tracking between Domains. Proceedings of the AAAI Conference on Artificial Intelligence 33, 01 (Jul. 2019), 8009–8016. 10.1609/aaai.v33i01.33018009 [DOI] [Google Scholar]
- [36].Chen Minmin, Xu Zhixiang, Weinberger Kilian, and Sha Fei. 2012. Marginalized Denoising Autoencoders for Domain Adaptation. In Proceedings of the 29th International Conference on Machine Learning (ICML-12) (ICML ’12), Langford John and Pineau Joelle (Eds.). Omnipress, New York, NY, USA, 767–774. [Google Scholar]
- [37].Chen Xi, Duan Yan, Houthooft Rein, Schulman John, Sutskever Ilya, and Abbeel Pieter. 2016. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. In Advances in Neural Information Processing Systems 29, Lee DD, Sugiyama M, Luxburg UV, Guyon I, and Garnett R (Eds.). Curran Associates, Inc., 2172–2180. http://papers.nips.cc/paper/6399-infogan-interpretable-representation-learning-by-information-maximizing-generative-adversarial-nets.pdf [Google Scholar]
- [38].Chen Xinyuan, Xu Chang, Yang Xiaokang, and Tao Dacheng. 2018. Attention-GAN for Object Transfiguration in Wild Images. In The European Conference on Computer Vision (ECCV). [Google Scholar]
- [39].Chen Yuhua, Li Wen, Sakaridis Christos, Dai Dengxin, and Van Gool Luc. 2018. Domain Adaptive Faster R-CNN for Object Detection in the Wild. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [40].Chen Yuhua, Li Wen, and Van Gool Luc. 2018. ROAD: Reality Oriented Adaptation for Semantic Segmentation of Urban Scenes. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [41].Choi Yunjey, Choi Minje, Kim Munyoung, Ha Jung-Woo, Kim Sunghun, and Choo Jaegul. 2018. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [42].Chu Chenhui and Wang Rui. 2018. A Survey of Domain Adaptation for Neural Machine Translation. In Proceedings of the 27th International Conference on Computational Linguistics. 1304–1319. [Google Scholar]
- [43].Chung Junyoung, Kastner Kyle, Dinh Laurent, Goel Kratarth, Courville Aaron C, and Bengio Yoshua. 2015. A Recurrent Latent Variable Model for Sequential Data. In Advances in Neural Information Processing Systems 28, Cortes C, Lawrence ND, Lee DD, Sugiyama M, and Garnett R (Eds.). Curran Associates, Inc., 2980–2988. http://papers.nips.cc/paper/5653-a-recurrent-latent-variable-model-for-sequential-data.pdf [Google Scholar]
- [44].Cicek Safa and Soatto Stefano. 2019. Unsupervised Domain Adaptation via Regularized Conditional Alignment. In The IEEE International Conference on Computer Vision (ICCV). [Google Scholar]
- [45].Cook Diane, Feuz Kyle D., and Krishnan Narayanan C.. 2013. Transfer learning for activity recognition: a survey. Knowledge and Information Systems 36, 3 (01 Sep 2013), 537–556. 10.1007/s10115-013-0665-3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [46].Cordts Marius, Omran Mohamed, Ramos Sebastian, Rehfeld Timo, Enzweiler Markus, Benenson Rodrigo, Franke Uwe, Roth Stefan, and Schiele Bernt. 2016. The Cityscapes Dataset for Semantic Urban Scene Understanding. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [47].Courty Nicolas, Flamary Rémi, Habrard Amaury, and Rakotomamonjy Alain. 2017. Joint distribution optimal transportation for domain adaptation. In Advances in Neural Information Processing Systems 30, Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, and Garnett R (Eds.). Curran Associates, Inc., 3730–3739. http://papers.nips.cc/paper/6963-joint-distribution-optimal-transportation-for-domain-adaptation.pdf [Google Scholar]
- [48].Csurka Gabriela. 2017. A comprehensive survey on domain adaptation for visual applications. In Domain Adaptation in Computer Vision Applications. Springer, 1–35. [Google Scholar]
- [49].Csurka Gabriela. 2017. Domain adaptation for visual applications: A comprehensive survey. arXiv preprint arXiv:1702.05374 (2017). [Google Scholar]
- [50].Damodaran Bharath Bhushan, Kellenberger Benjamin, Flamary Rémi, Tuia Devis, and Courty Nicolas. 2018. DeepJDOT: Deep Joint Distribution Optimal Transport for Unsupervised Domain Adaptation. In Computer Vision – ECCV 2018, Ferrari Vittorio, Hebert Martial, Sminchisescu Cristian, and Weiss Yair (Eds.). Springer International Publishing, Cham, 467–483. [Google Scholar]
- [51].Das D and George Lee CS. 2018. Unsupervised Domain Adaptation Using Regularized Hyper-Graph Matching. In 2018 25th IEEE International Conference on Image Processing (ICIP). 3758–3762. 10.1109/ICIP.2018.8451152 [DOI] [Google Scholar]
- [52].Das Debasmit and Lee C.S. George. 2018. Sample-to-sample correspondence for unsupervised domain adaptation. Engineering Applications of Artificial Intelligence 73 (2018), 80–91. 10.1016/j.engappai.2018.05.001 [DOI] [Google Scholar]
- [53].Das Debasmit and Lee C. S. George. 2018. Graph Matching and Pseudo-Label Guided Deep Unsupervised Domain Adaptation. In Artificial Neural Networks and Machine Learning – ICANN 2018, Kůrková Věra, Manolopoulos Yannis, Hammer Barbara, Iliadis Lazaros, and Maglogiannis Ilias (Eds.). Springer International Publishing, Cham, 342–352. [Google Scholar]
- [54].Daumé Hal III. 2007. Frustratingly Easy Domain Adaptation. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics. 256–263. [Google Scholar]
- [55].Daumé Hal III and Marcu Daniel. 2006. Domain Adaptation for Statistical Classifiers. Journal of Artificial Intelligence Research 26 (2006), 101–126. [Google Scholar]
- [56].Deng J, Dong W, Socher R, Li LJ, Li Kai, and Fei-Fei Li. 2009. ImageNet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition. 248–255. 10.1109/CVPR.2009.5206848 [DOI] [Google Scholar]
- [57].Deng Weijian, Zheng Liang, Ye Qixiang, Kang Guoliang, Yang Yi, and Jiao Jianbin. 2018. Image-Image Domain Adaptation With Preserved Self-Similarity and Domain-Dissimilarity for Person Re-Identification. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [58].Deng Zhijie, Luo Yucen, and Zhu Jun. 2019. Cluster Alignment With a Teacher for Unsupervised Domain Adaptation. In The IEEE International Conference on Computer Vision (ICCV). [Google Scholar]
- [59].Denton Emily L, Chintala Soumith, Szlam Arthur, and Fergus Rob. 2015. Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks. In Advances in Neural Information Processing Systems 28, Cortes C, Lawrence ND, Lee DD, Sugiyama M, and Garnett R (Eds.). Curran Associates, Inc., 1486–1494. http://papers.nips.cc/paper/5773-deep-generative-image-models-using-a-laplacian-pyramid-of-adversarial-networks.pdf [Google Scholar]
- [60].Donahue Jeff, Krähenbühl Philipp, and Darrell Trevor. 2017. Adversarial feature learning. In International Conference on Learning Representations. https://openreview.net/forum?id=BJtNZAFgg [Google Scholar]
- [61].Dredze Mark, Kulesza Alex, and Crammer Koby. 2010. Multi-domain learning by confidence-weighted parameter combination. Machine Learning 79, 1 (01 May 2010), 123–149. 10.1007/s10994-009-5148-0 [DOI] [Google Scholar]
- [62].Duan Lixin, Xu Dong, and Tsang Ivor W.. 2012. Learning with Augmented Features for Heterogeneous Domain Adaptation. In Proceedings of the 29th International Coference on International Conference on Machine Learning (ICMLâĂŹ12). Omnipress, Madison, WI, USA, 667âĂŞ674. [Google Scholar]
- [63].Durugkar Ishan, Gemp Ian, and Mahadevan Sridhar. 2017. Generative Multi-Adversarial Networks. In International Conference on Learning Representations. https://openreview.net/forum?id=Byk-VI9eg [Google Scholar]
- [64].Dziugaite Gintare Karolina, Roy Daniel M., and Ghahramani Zoubin. 2015. Training Generative Neural Networks via Maximum Mean Discrepancy Optimization. In Proceedings of the Thirty-First Conference on Uncertainty in Artificial Intelligence (UAI’15). AUAI Press, Arlington, Virginia, United States, 258–267. http://dl.acm.org/citation.cfm?id=3020847.3020875 [Google Scholar]
- [65].El Habib Daho M, Settouti N, Lazouni MEA, and Chikh MEA. 2014. Weighted vote for trees aggregation in Random Forest. In 2014 International Conference on Multimedia Computing and Systems (ICMCS). 438–443. 10.1109/ICMCS.2014.6911187 [DOI] [Google Scholar]
- [66].Fedus William, Rosca Mihaela, Lakshminarayanan Balaji, Dai Andrew M., Mohamed Shakir, and Goodfellow Ian. 2018. Many Paths to Equilibrium: GANs Do Not Need to Decrease a Divergence At Every Step. In International Conference on Learning Representations. https://openreview.net/forum?id=ByQpn1ZA- [Google Scholar]
- [67].Finn Chelsea, Christiano Paul, Abbeel Pieter, and Levine Sergey. 2016. A connection between generative adversarial networks, inverse reinforcement learning, and energy-based models. arXiv preprint arXiv:1611.03852 (2016). [Google Scholar]
- [68].French Geoff, Mackiewicz Michal, and Fisher Mark. 2018. Self-ensembling for visual domain adaptation. In International Conference on Learning Representations. https://openreview.net/forum?id=rkpoTaxA- [Google Scholar]
- [69].Fu Huan, Gong Mingming, Wang Chaohui, Batmanghelich Kayhan, Zhang Kun, and Tao Dacheng. 2018. Geometry-Consistent Adversarial Networks for One-Sided Unsupervised Domain Mapping. arXiv preprint arXiv:1809.05852 (2018). [DOI] [PMC free article] [PubMed] [Google Scholar]
- [70].Fu Lisheng, Nguyen Thien Huu, Min Bonan, and Grishman Ralph. 2017. Domain adaptation for relation extraction with domain adversarial neural network. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Vol. 2. 425–429. [Google Scholar]
- [71].Gan Zhe, Chen Liqun, Wang Weiyao, Pu Yuchen, Zhang Yizhe, Liu Hao, Li Chunyuan, and Carin Lawrence. 2017. Triangle Generative Adversarial Networks. In Advances in Neural Information Processing Systems 30, Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, and Garnett R (Eds.). Curran Associates, Inc., 5247–5256. http://papers.nips.cc/paper/7109-triangle-generative-adversarial-networks.pdf [Google Scholar]
- [72].Ganin Yaroslav and Lempitsky Victor. 2015. Unsupervised Domain Adaptation by Backpropagation. In Proceedings of the 32nd International Conference on Machine Learning (Proceedings of Machine Learning Research), Bach Francis and Blei David (Eds.), Vol. 37. PMLR, 1180–1189. http://proceedings.mlr.press/v37/ganin15.html [Google Scholar]
- [73].Ganin Yaroslav, Ustinova Evgeniya, Ajakan Hana, Germain Pascal, Larochelle Hugo, Laviolette François, Marchand Mario, and Lempitsky Victor. 2016. Domain-Adversarial Training of Neural Networks. Journal of Machine Learning Research 17, 59 (2016), 1–35. http://jmlr.org/papers/v17/15-239.html [Google Scholar]
- [74].Gauthier Jon. 2014. Conditional generative adversarial nets for convolutional face generation.
- [75].Muhammad Ghifary W Kleijn Bastiaan, Zhang Mengjie, and Balduzzi David. 2015. Domain Generalization for Object Recognition With Multi-Task Autoencoders. In The IEEE International Conference on Computer Vision (ICCV). [Google Scholar]
- [76].Muhammad Ghifary W Kleijn Bastiaan, Zhang Mengjie, Balduzzi David, and Li Wen. 2016. Deep Reconstruction-Classification Networks for Unsupervised Domain Adaptation. In Computer Vision – ECCV 2016, Leibe Bastian, Matas Jiri, Sebe Nicu, and Welling Max (Eds.). Springer International Publishing, Cham, 597–613. [Google Scholar]
- [77].Gholami Behnam, Sahu Pritish, Rudovic Ognjen, Bousmalis Konstantinos, and Pavlovic Vladimir. 2018. Unsupervised Multi-Target Domain Adaptation: An Information Theoretic Approach. arXiv preprint arXiv:1810.11547 (2018). [DOI] [PubMed] [Google Scholar]
- [78].Ghosh Arnab, Kulharia Viveka, Vinay P Namboodiri Philip HS Torr, and Dokania Puneet K. 2018. Multi-agent diverse generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 8513–8521. [Google Scholar]
- [79].Goodfellow Ian. 2016. NIPS 2016 tutorial: Generative adversarial networks. arXiv preprint arXiv:1701.00160 (2016). [Google Scholar]
- [80].Goodfellow Ian, Bengio Yoshua, and Courville Aaron. 2016. Deep learning. MIT press. [Google Scholar]
- [81].Goodfellow Ian, Pouget-Abadie Jean, Mirza Mehdi, Xu Bing, Warde-Farley David, Ozairy Sherjil, Courville Aaron, and Bengio Yoshua. 2014. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27, Ghahramani Z, Welling M, Cortes C, Lawrence ND, and Weinberger KQ (Eds.). Curran Associates, Inc., 2672–2680. http://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf [Google Scholar]
- [82].Goodfellow Ian J, Shlens Jonathon, and Szegedy Christian. 2014. Explaining and harnessing adversarial examples. arXiv preprint arXiv:1412.6572 (2014). [Google Scholar]
- [83].Gretton Arthur, Borgwardt Karsten, Rasch Malte, Schölkopf Bernhard, and Smola Alex J. 2007. A kernel method for the two-sample-problem. In Advances in neural information processing systems. 513–520. [Google Scholar]
- [84].Gretton Arthur, Borgwardt Karsten M, Rasch Malte J, Schölkopf Bernhard, and Smola Alexander. 2012. A kernel two-sample test. Journal of Machine Learning Research 13, Mar (2012), 723–773. [Google Scholar]
- [85].Grover Aditya, Dhar Manik, and Ermon Stefano. 2017. Flow-GAN: Combining maximum likelihood and adversarial learning in generative models. arXiv preprint arXiv:1705.08868 (2017). [Google Scholar]
- [86].Gui Liangyan, Zhang Kevin, Wang Yu-Xiong, Liang Xiaodan, Moura José MF, and Veloso Manuela M. 2018. Teaching Robots to Predict Human Motion. (2018). preprint on webpage at http://www.cs.cmu.edu/~mmv/papers/18iros-GuiEtAl.pdf.
- [87].Gulrajani Ishaan, Ahmed Faruk, Arjovsky Martin, Dumoulin Vincent, and Courville Aaron C. 2017. Improved Training of Wasserstein GANs. In Advances in Neural Information Processing Systems 30, Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, and Garnett R (Eds.). Curran Associates, Inc., 5767–5777. http://papers.nips.cc/paper/7159-improved-training-of-wasserstein-gans.pdf [Google Scholar]
- [88].Guo Jiang, Shah Darsh, and Barzilay Regina. 2018. Multi-Source Domain Adaptation with Mixture of Experts. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 4694–4703. [Google Scholar]
- [89].Hassan Eman T, Chen Xin, and Crandall David. 2018. Unsupervised Domain Adaptation using Generative Models and Self-ensembling. arXiv preprint arXiv:1812.00479 (2018). [Google Scholar]
- [90].Heusel Martin, Ramsauer Hubert, Unterthiner Thomas, Nessler Bernhard, and Hochreiter Sepp. 2017. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Advances in Neural Information Processing Systems 30, Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, and Garnett R (Eds.). Curran Associates, Inc., 6626–6637. http://papers.nips.cc/paper/7240-gans-trained-by-a-two-time-scale-update-rule-converge-to-a-local-nash-equilibrium.pdf [Google Scholar]
- [91].Hindupur Avinash. 2018. The GAN Zoo. Retrieved February 25, 2019 from https://github.com/hindupuravinash/thegan-zoo
- [92].Hitawala Saifuddin. 2018. Comparative Study on Generative Adversarial Networks. arXiv preprint arXiv:1801.04271 (2018). [Google Scholar]
- [93].Hoang Quan, Nguyen Tu Dinh, Le Trung, and Phung Dinh. 2018. MGAN: Training Generative Adversarial Nets with Multiple Generators. In International Conference on Learning Representations. https://openreview.net/forum?id=rkmu5b0a- [Google Scholar]
- [94].Hochreiter Sepp and Schmidhuber JÃijrgen. 1997. Long Short-Term Memory. Neural Computation 9, 8 (1997), 1735–1780. 10.1162/neco.1997.9.8.1735arXiv:https://doi.org/10.1162/neco.1997.9.8.1735 [DOI] [PubMed] [Google Scholar]
- [95].Hoffman Judy, Mohri Mehryar, and Zhang Ningshan. 2018. Algorithms and Theory for Multiple-Source Adaptation. In Advances in Neural Information Processing Systems 31, Bengio S, Wallach H, Larochelle H, Grauman K, Cesa-Bianchi N, and Garnett R (Eds.). Curran Associates, Inc., 8246–8256. http://papers.nips.cc/paper/8046-algorithms-and-theory-for-multiple-source-adaptation.pdf [Google Scholar]
- [96].Hoffman Judy, Tzeng Eric, Park Taesung, Zhu Jun-Yan, Isola Phillip, Saenko Kate, Efros Alexei, and Darrell Trevor. 2018. CyCADA: Cycle-Consistent Adversarial Domain Adaptation. In Proceedings of the 35th International Conference on Machine Learning (Proceedings of Machine Learning Research), Jennifer Dy and Krause Andreas (Eds.), Vol. 80. PMLR, 1994–2003. http://proceedings.mlr.press/v80/hoffman18a.html [Google Scholar]
- [97].Hoffman Judy, Wang Dequan, Yu Fisher, and Darrell Trevor. 2016. Fcns in the wild: Pixel-level adversarial and constraint-based adaptation. arXiv preprint arXiv:1612.02649 (2016). [Google Scholar]
- [98].Hong Weixiang, Wang Zhenzhen, Yang Ming, and Yuan Junsong. 2018. Conditional Generative Adversarial Network for Structured Domain Adaptation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [99].Hong Yongjun, Hwang Uiwon, Yoo Jaeyoon, and Yoon Sungroh. 2019. How Generative Adversarial Networks and Their Variants Work: An Overview. ACM Comput. Surv 52, 1, Article 10 (Feb. 2019), 43 pages. 10.1145/3301282 [DOI] [Google Scholar]
- [100].Hosseini-Asl Ehsan, Zhou Yingbo, Xiong Caiming, and Socher Richard. 2019. Augmented Cyclic Adversarial Learning for Low Resource Domain Adaptation. In International Conference on Learning Representations. https://openreview.net/forum?id=B1G9doA9F7 [Google Scholar]
- [101].Hsu Yen-Chang, Lv Zhaoyang, and Kira Zsolt. 2018. Learning to cluster in order to transfer across domains and tasks. In International Conference on Learning Representations. https://openreview.net/forum?id=ByRWCqvT- [Google Scholar]
- [102].Huang Haoshuo, Huang Qixing, and Krahenbuhl Philipp. 2018. Domain transfer through deep activation matching. In The European Conference on Computer Vision (ECCV). [Google Scholar]
- [103].Huang Ling, Joseph Anthony D., Nelson Blaine, Rubinstein Benjamin I.P., and Tygar JD. 2011. Adversarial Machine Learning. In Proceedings of the 4th ACM Workshop on Security and Artificial Intelligence (AISec ’11). ACM, New York, NY, USA, 43–58. 10.1145/2046684.2046692 [DOI] [Google Scholar]
- [104].Huang Xun, Liu Ming-Yu, Belongie Serge, and Kautz Jan. 2018. Multimodal Unsupervised Image-to-Image Translation. arXiv preprint arXiv:1804.04732 (2018). [Google Scholar]
- [105].Tsai Yao-Hung Hubert, Yeh Yi-Ren, and Wang Yu-Chiang Frank. 2016. Learning Cross-Domain Landmarks for Heterogeneous Domain Adaptation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [106].Inoue Naoto, Furuta Ryosuke, Yamasaki Toshihiko, and Aizawa Kiyoharu. 2018. Cross-Domain Weakly-Supervised Object Detection Through Progressive Domain Adaptation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [107].Ioffe Sergey and Szegedy Christian. 2015. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning (Proceedings of Machine Learning Research), Bach Francis and Blei David (Eds.), Vol. 37. PMLR, Lille, France, 448–456. http://proceedings.mlr.press/v37/ioffe15.html [Google Scholar]
- [108].Ismail Fawaz H, Forestier G, Weber J, Idoumghar L, and Muller P. 2018. Transfer learning for time series classification. In 2018 IEEE International Conference on Big Data (Big Data). 1367–1376. 10.1109/BigData.2018.8621990 [DOI] [Google Scholar]
- [109].Isola Phillip, Zhu Jun-Yan, Zhou Tinghui, and Efros Alexei A.. 2017. Image-To-Image Translation With Conditional Adversarial Networks. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [110].Izmailov Pavel, Podoprikhin Dmitrii, Garipov Timur, Vetrov Dmitry, and Wilson Andrew Gordon. 2018. Averaging weights leads to wider optima and better generalization. arXiv preprint arXiv:1803.05407 (2018). [Google Scholar]
- [111].Jiang Jing. 2008. Domain adaptation in natural language processing. Technical Report. University of Illinois at Urbana-Champaign. [Google Scholar]
- [112].Jolicoeur-Martineau Alexia. 2018. The relativistic discriminator: a key element missing from standard GAN. arXiv preprint arXiv:1807.00734 (2018). [Google Scholar]
- [113].Joshi Mahesh, Cohen William W., Dredze Mark, and Rosé Carolyn P.. 2012. Multi-domain Learning: When Do Domains Matter?. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL ’12). Association for Computational Linguistics, Stroudsburg, PA, USA, 1302–1312. http://dl.acm.org/citation.cfm?id=2390948.2391096 [Google Scholar]
- [114].Kang Guoliang, Jiang Lu, Yang Yi, and Hauptmann Alexander G.. 2019. Contrastive Adaptation Network for Unsupervised Domain Adaptation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [115].Kang Guoliang, Zheng Liang, Yan Yan, and Yang Yi. 2018. Deep Adversarial Attention Alignment for Unsupervised Domain Adaptation: the Benefit of Target Expectation Maximization. In The European Conference on Computer Vision (ECCV). [Google Scholar]
- [116].Karras Tero, Aila Timo, Laine Samuli, and Lehtinen Jaakko. 2018. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In International Conference on Learning Representations. https://openreview.net/forum?id=Hk99zCeAb [Google Scholar]
- [117].Khayatkhoei Mahyar, Singh Maneesh K., and Elgammal Ahmed. 2018. Disconnected Manifold Learning for Generative Adversarial Networks. In Advances in Neural Information Processing Systems 31, Bengio S, Wallach H, Larochelle H, Grauman K, Cesa-Bianchi N, and Garnett R (Eds.). Curran Associates, Inc., 7343–7353. http://papers.nips.cc/paper/7964-disconnected-manifold-learning-for-generative-adversarial-networks.pdf [Google Scholar]
- [118].Kim Taeksoo, Cha Moonsu, Kim Hyunsoo, Lee Jung Kwon, and Kim Jiwon. 2017. Learning to Discover Cross-domain Relations with Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning - Volume 70 (ICML’17). JMLR.org, 1857–1865. http://dl.acm.org/citation.cfm?id=3305381.3305573 [Google Scholar]
- [119].Ko Wei-Jen, Durrett Greg, and Li Junyi Jessy. 2018. Domain Agnostic Real-Valued Specificity Prediction. arXiv preprint arXiv:1811.05085 (2018). [Google Scholar]
- [120].Kodali Naveen, Abernethy Jacob, Hays James, and Kira Zsolt. 2017. On convergence and stability of GANs. arXiv preprint arXiv:1705.07215 (2017). [Google Scholar]
- [121].Kouw Wouter M. 2018. An introduction to domain adaptation and transfer learning. arXiv preprint arXiv:1812.11806 (2018). [Google Scholar]
- [122].Kouw Wouter M and Loog Marco. 2019. A review of single-source unsupervised domain adaptation. arXiv preprint arXiv:1901.05335 (2019). [Google Scholar]
- [123].Krizhevsky Alex. 2009. Learning multiple layers of features from tiny images. Technical Report.
- [124].Kumar Abhishek, Sattigeri Prasanna, Wadhawan Kahini, Karlinsky Leonid, Feris Rogerio, Freeman Bill, and Wornell Gregory. 2018. Co-regularized Alignment for Unsupervised Domain Adaptation. In Advances in Neural Information Processing Systems 31, Bengio S, Wallach H, Larochelle H, Grauman K, Cesa-Bianchi N, and Garnett R (Eds.). Curran Associates, Inc., 9345–9356. http://papers.nips.cc/paper/8146-co-regularized-alignment-for-unsupervised-domain-adaptation.pdf [Google Scholar]
- [125].Kurmi Vinod Kumar, Kumar Shanu, and Namboodiri Vinay P.. 2019. Attending to Discriminative Certainty for Domain Adaptation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [126].Laine Samuli and Aila Timo. 2017. Temporal Ensembling for Semi-Supervised Learning. In International Conference on Learning Representations. https://openreview.net/forum?id=BJ6oOfqge [Google Scholar]
- [127].Laradji Issam and Babanezhad Reza. 2018. M-ADDA: Unsupervised Domain Adaptation with Deep Metric Learning. arXiv preprint arXiv:1807.02552 (2018). [Google Scholar]
- [128].Lazaric Alessandro. 2012. Transfer in Reinforcement Learning: A Framework and a Survey. Springer Berlin Heidelberg, Berlin, Heidelberg, 143–173. 10.1007/978-3-642-27645-3_5 [DOI] [Google Scholar]
- [129].Le Trung, Nguyen Khanh, and Phung Dinh. 2018. Theoretical Perspective of Deep Domain Adaptation. arXiv preprint arXiv:1811.06199 (2018). [Google Scholar]
- [130].LeCun Yann, Cortes Corinna, and Burges Christopher J.C.. 1998. The MNIST database of handwritten digits. Retrieved August 16, 2018 from http://yann.lecun.com/exdb/mnist/
- [131].LeCun Y, Matan O, Boser B, Denker JS, Henderson D, Howard RE, Hubbard W, Jacket LD, and Baird HS. 1990. Handwritten zip code recognition with multilayer networks. In [1990] Proceedings. 10th International Conference on Pattern Recognition, Vol. ii. 35–40 vol.2. 10.1109/ICPR.1990.119325 [DOI] [Google Scholar]
- [132].Lee Chen-Yu, Batra Tanmay, Baig Mohammad Haris, and Ulbricht Daniel. 2019. Sliced Wasserstein Discrepancy for Unsupervised Domain Adaptation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [133].Lee Kuan-Hui, Ros German, Li Jie, and Gaidon Adrien. 2019. SPIGAN: Privileged Adversarial Learning from Simulation. In International Conference on Learning Representations. https://openreview.net/forum?id=rkxoNnC5FQ [Google Scholar]
- [134].Lee Seungmin, Kim Dongwan, Kim Namil, and Jeong Seong-Gyun. 2019. Drop to Adapt: Learning Discriminative Features for Unsupervised Domain Adaptation. In The IEEE International Conference on Computer Vision (ICCV). [Google Scholar]
- [135].Li Chun-Liang, Chang Wei-Cheng, Cheng Yu, Yang Yiming, and Póczos Barnabás. 2017. MMD GAN: Towards deeper understanding of moment matching network. In Advances in Neural Information Processing Systems. 2203–2213. [Google Scholar]
- [136].Li Jerry. 2018. Twin-GAN–Unpaired Cross-Domain Image Translation with Weight-Sharing GANs. arXiv preprint arXiv:1809.00946 (2018). [Google Scholar]
- [137].Li J, Lu K, Huang Z, Zhu L, and Shen HT. 2019. Heterogeneous Domain Adaptation Through Progressive Alignment. IEEE Transactions on Neural Networks and Learning Systems 30, 5 (May 2019), 1381–1391. 10.1109/TNNLS.2018.2868854 [DOI] [PubMed] [Google Scholar]
- [138].Li Peilun, Liang Xiaodan, Jia Daoyuan, and Xing Eric P. 2018. Semantic-aware grad-gan for virtual-to-real urban scene adaption. arXiv preprint arXiv:1801.01726 (2018). [Google Scholar]
- [139].Li Yujia, Swersky Kevin, and Zemel Rich. 2015. Generative Moment Matching Networks. In Proceedings of the 32nd International Conference on Machine Learning (Proceedings of Machine Learning Research), Bach Francis and Blei David (Eds.), Vol. 37. PMLR, Lille, France, 1718–1727. http://proceedings.mlr.press/v37/li15.html [Google Scholar]
- [140].Li Ya, Tian Xinmei, Gong Mingming, Liu Yajing, Liu Tongliang, Zhang Kun, and Tao Dacheng. 2018. Deep Domain Generalization via Conditional Invariant Adversarial Networks. In The European Conference on Computer Vision (ECCV). [Google Scholar]
- [141].Li Yanghao, Wang Naiyan, Shi Jianping, Hou Xiaodi, and Liu Jiaying. 2018. Adaptive Batch Normalization for practical domain adaptation. Pattern Recognition 80 (2018), 109–117. 10.1016/j.patcog.2018.03.005 [DOI] [Google Scholar]
- [142].Li Yu-Jhe, Yang Fu-En, Liu Yen-Cheng, Yeh Yu-Ying, Du Xiaofei, and Wang Yu-Chiang Frank. 2018. Adaptation and Re-Identification Network: An Unsupervised Deep Transfer Learning Approach to Person Re-Identification. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. [Google Scholar]
- [143].Liu Ming-Yu and Tuzel Oncel. 2016. Coupled Generative Adversarial Networks. In Advances in Neural Information Processing Systems 29, Lee DD, Sugiyama M, Luxburg UV, Guyon I, and Garnett R (Eds.). Curran Associates, Inc., 469–477. http://papers.nips.cc/paper/6544-coupled-generative-adversarial-networks.pdf [Google Scholar]
- [144].Liu Pengfei, Qiu Xipeng, and Huang Xuanjing. 2017. Adversarial Multi-task Learning for Text Classification. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vol. 1. 1–10. [Google Scholar]
- [145].Liu Shaohui, Wei Yi, Lu Jiwen, and Zhou Jie. 2018. An Improved Evaluation Framework for Generative Adversarial Networks. arXiv preprint arXiv:1803.07474 (2018). [Google Scholar]
- [146].Liu Ziwei, Luo Ping, Wang Xiaogang, and Tang Xiaoou. 2015. Deep Learning Face Attributes in the Wild. In The IEEE International Conference on Computer Vision (ICCV). [Google Scholar]
- [147].Long Mingsheng, Cao Yue, Wang Jianmin, and Jordan Michael. 2015. Learning Transferable Features with Deep Adaptation Networks. In Proceedings of the 32nd International Conference on Machine Learning (Proceedings of Machine Learning Research), Bach Francis and Blei David (Eds.), Vol. 37. PMLR, 97–105. http://proceedings.mlr.press/v37/long15.html [Google Scholar]
- [148].Long Mingsheng, Cao Zhangjie, Wang Jianmin, and Jordan Michael I. 2018. Conditional Adversarial Domain Adaptation. In Advances in Neural Information Processing Systems 31, Bengio S, Wallach H, Larochelle H, Grauman K, Cesa-Bianchi N, and Garnett R (Eds.). Curran Associates, Inc., 1640–1650. http://papers.nips.cc/paper/7436-conditional-adversarial-domain-adaptation.pdf [Google Scholar]
- [149].Long Mingsheng, Wang Jianmin, Ding Guiguang, Sun Jiaguang, and Yu Philip S.. 2013. Transfer Feature Learning with Joint Distribution Adaptation. In The IEEE International Conference on Computer Vision (ICCV). [DOI] [PubMed] [Google Scholar]
- [150].Long Mingsheng, Zhu Han, Wang Jianmin, and Jordan Michael I. 2016. Unsupervised Domain Adaptation with Residual Transfer Networks. In Advances in Neural Information Processing Systems 29, Lee DD, Sugiyama M, Luxburg UV, Guyon I, and Garnett R (Eds.). Curran Associates, Inc., 136–144. http://papers.nips.cc/paper/6110-unsupervised-domain-adaptation-with-residual-transfer-networks.pdf [Google Scholar]
- [151].Long Mingsheng, Zhu Han, Wang Jianmin, and Jordan Michael I.. 2017. Deep Transfer Learning with Joint Adaptation Networks. In Proceedings of the 34th International Conference on Machine Learning (Proceedings of Machine Learning Research), Precup Doina and Teh Yee Whye(Eds.), Vol. 70. PMLR, International Convention Centre, Sydney, Australia, 2208–2217. http://proceedings.mlr.press/v70/long17a.html [Google Scholar]
- [152].Lu Jie, Behbood Vahid, Hao Peng, Zuo Hua, Xue Shan, and Zhang Guangquan. 2015. Transfer learning using computational intelligence: A survey. Knowledge-Based Systems 80 (2015), 14–23. 10.1016/j.knosys.2015.01.010. 25th anniversary of Knowledge-Based Systems [DOI] [Google Scholar]
- [153].Luo Yawei, Zheng Liang, Guan Tao, Yu Junqing, and Yang Yi. 2018. Taking A Closer Look at Domain Shift: Category-level Adversaries for Semantics Consistent Domain Adaptation. arXiv preprint arXiv:1809.09478 (2018). [Google Scholar]
- [154].Ma Xinhong, Zhang Tianzhu, and Xu Changsheng. 2019. GCAN: Graph Convolutional Adversarial Network for Unsupervised Domain Adaptation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [155].Mahmood F, Chen R, and Durr NJ. 2018. Unsupervised Reverse Domain Adaptation for Synthetic Medical Images via Adversarial Training. IEEE Transactions on Medical Imaging 37, 12 (Dec 2018), 2572–2581. 10.1109/TMI.2018.2842767 [DOI] [PubMed] [Google Scholar]
- [156].Makhzani Alireza, Shlens Jonathon, Jaitly Navdeep, Goodfellow Ian, and Frey Brendan. 2015. Adversarial autoencoders. arXiv preprint arXiv:1511.05644 (2015). [Google Scholar]
- [157].Mancini Massimiliano, Porzi Lorenzo, BulÚ Samuel Rota , Caputo Barbara, and Ricci Elisa. 2018. Boosting Domain Adaptation by Discovering Latent Domains. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [158].Manisha P and Gujar Sujit. 2018. Generative Adversarial Networks (GANs): What it can generate and What it cannot? arXiv preprint arXiv:1804.00140 (2018). [Google Scholar]
- [159].Mansour Yishay, Mohri Mehryar, and Rostamizadeh Afshin. 2009. Domain Adaptation with Multiple Sources. In Advances in Neural Information Processing Systems 21, Koller D, Schuurmans D, Bengio Y, and Bottou L (Eds.). Curran Associates, Inc., 1041–1048. http://papers.nips.cc/paper/3550-domain-adaptation-with-multiple-sources.pdf [Google Scholar]
- [160].Mao Xudong and Li Qing. 2018. Unpaired Multi-domain Image Generation via Regularized Conditional GANs. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI’18). AAAI Press, 2553–2559. http://dl.acm.org/citation.cfm?id=3304889.3305015 [Google Scholar]
- [161].Mao Xudong, Li Qing, Xie Haoran, Lau Raymond YK , Wang Zhen, and Smolley Stephen Paul. 2017. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision. 2794–2802. [Google Scholar]
- [162].Margolis Anna. 2011. A Literature Review of Domain Adaptation with Unlabeled Data.
- [163].Metz Luke, Poole Ben, Pfau David, and Sohl-Dickstein Jascha. 2017. Unrolled generative adversarial networks. In International Conference on Learning Representations. https://openreview.net/forum?id=BydrOIcle [Google Scholar]
- [164].Mirza Mehdi and Osindero Simon. 2014. Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784 (2014). [Google Scholar]
- [165].Miyato Takeru, Kataoka Toshiki, Koyama Masanori, and Yoshida Yuichi. 2018. Spectral Normalization for Generative Adversarial Networks. In International Conference on Learning Representations. https://openreview.net/forum?id=B1QRgziT- [Google Scholar]
- [166].Miyato Takeru and Koyama Masanori. 2018. cGANs with Projection Discriminator. In International Conference on Learning Representations. https://openreview.net/forum?id=ByS1VpgRZ [Google Scholar]
- [167].Miyato T, Maeda S, Ishii S, and Koyama M. 2018. Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning. IEEE Transactions on Pattern Analysis and Machine Intelligence (2018), 1–1. 10.1109/TPAMI.2018.2858821 [DOI] [PubMed] [Google Scholar]
- [168].Moiseev Boris, Konev Artem, Chigorin Alexander, and Konushin Anton. 2013. Evaluation of Traffic Sign Recognition Methods Trained on Synthetically Generated Data. In Advanced Concepts for Intelligent Vision Systems, Blanc-Talon Jacques, Kasinski Andrzej, Philips Wilfried, Popescu Dan, and Scheunders Paul (Eds.). Springer International Publishing, Cham, 576–583. [Google Scholar]
- [169].Monge Gaspard. 1781. Mémoire sur la théorie des déblais et des remblais. Histoire de l’Académie Royale des Sciences de Paris (1781). [Google Scholar]
- [170].Mordido Gonçalo, Yang Haojin, and Meinel Christoph. 2018. Dropout-GAN: Learning from a Dynamic Ensemble of Discriminators. arXiv preprint arXiv:1807.11346 (2018). [Google Scholar]
- [171].Morerio Pietro, Cavazza Jacopo, and Murino Vittorio. 2018. Minimal-Entropy Correlation Alignment for Unsupervised Deep Domain Adaptation. In International Conference on Learning Representations. https://openreview.net/forum?id=rJWechg0Z [Google Scholar]
- [172].Morerio Pietro and Murino Vittorio. 2017. Correlation Alignment by Riemannian Metric for Domain Adaptation. arXiv preprint arXiv:1705.08180 (2017). [Google Scholar]
- [173].Muandet Krikamol, Balduzzi David, and Schölkopf Bernhard. 2013. Domain Generalization via Invariant Feature Representation. In Proceedings of the 30th International Conference on Machine Learning (Proceedings of Machine Learning Research), Dasgupta Sanjoy and McAllester David (Eds.), Vol. 28. PMLR, 10–18. http://proceedings.mlr.press/v28/muandet13.html [Google Scholar]
- [174].Kundu Jogendra Nath , Uppala Phani Krishna, Pahuja Anuj, and Babu R. Venkatesh. 2018. AdaDepth: Unsupervised Content Congruent Adaptation for Depth Estimation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [175].Netzer Yuval, Wang Tao, Coates Adam, Bissacco Alessandro, Wu Bo, and Ng Andrew Y. 2011. Reading digits in natural images with unsupervised feature learning. In NIPS workshop on deep learning and unsupervised feature learning, Vol. 2011. 5. [Google Scholar]
- [176].Nguyen Anh, Clune Jeff, Bengio Yoshua, Dosovitskiy Alexey, and Yosinski Jason. 2017. Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [177].Nowozin Sebastian, Cseke Botond, and Tomioka Ryota. 2016. f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization. In Advances in Neural Information Processing Systems 29, Lee DD, Sugiyama M, Luxburg UV, Guyon I, and Garnett R (Eds.). Curran Associates, Inc., 271–279. http://papers.nips.cc/paper/6066-f-gan-training-generative-neural-samplers-using-variational-divergence-minimization.pdf [Google Scholar]
- [178].Odena Augustus, Buckman Jacob, Olsson Catherine, Brown Tom, Olah Christopher, Raffel Colin, and Goodfellow Ian. 2018. Is Generator Conditioning Causally Related to GAN Performance?. In Proceedings of the 35th International Conference on Machine Learning (Proceedings of Machine Learning Research), Dy Jennifer and Krause Andreas (Eds.), Vol. 80. PMLR, 3846–3855. http://proceedings.mlr.press/v80/odena18a.html [Google Scholar]
- [179].Odena Augustus, Olah Christopher, and Shlens Jonathon. 2017. Conditional Image Synthesis with Auxiliary Classifier GANs. In Proceedings of the 34th International Conference on Machine Learning (Proceedings of Machine Learning Research), Precup Doina and Teh Yee Whye(Eds.), Vol. 70. PMLR, 2642–2651. http://proceedings.mlr.press/v70/odena17a.html [Google Scholar]
- [180].Pan Sinno Jialin and Yang Qiang. 2010. A Survey on Transfer Learning. IEEE Transactions on Knowledge and Data Engineering 22, 10 (Oct 2010), 1345–1359. 10.1109/TKDE.2009.191 [DOI] [Google Scholar]
- [181].Park David Keetae , Yoo Seungjoo, Bahng Hyojin, Choo Jaegul, and Park Noseong. 2018. MEGAN: Mixture of Experts of Generative Adversarial Networks for Multimodal Image Generation. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI’18). AAAI Press, 878–884. http://dl.acm.org/citation.cfm?id=3304415.3304540 [Google Scholar]
- [182].Patel VM, Gopalan R, Li R, and Chellappa R. 2015. Visual Domain Adaptation: A survey of recent advances. IEEE Signal Processing Magazine 32, 3 (May 2015), 53–69. 10.1109/MSP.2014.2347059 [DOI] [Google Scholar]
- [183].Pei Zhongyi, Cao Zhangjie, Long Mingsheng, and Wang Jianmin. 2018. Multi-adversarial domain adaptation. In Thirty-Second AAAI Conference on Artificial Intelligence. [Google Scholar]
- [184].Peng Xingchao, Bai Qinxun, Xia Xide, Huang Zijun, Saenko Kate, and Wang Bo. 2018. Moment Matching for Multi-Source Domain Adaptation. arXiv preprint arXiv:1812.01754 (2018). [Google Scholar]
- [185].Perone Christian S, Ballester Pedro, Barros Rodrigo C, and Cohen-Adad Julien. 2018. Unsupervised domain adaptation for medical imaging segmentation with self-ensembling. arXiv preprint arXiv:1811.06042 (2018). [DOI] [PubMed] [Google Scholar]
- [186].Pfau David and Vinyals Oriol. 2016. Connecting generative adversarial networks and actor-critic methods. arXiv preprint arXiv:1610.01945 (2016). [Google Scholar]
- [187].Pinheiro Pedro O.. 2018. Unsupervised Domain Adaptation With Similarity Learning. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [188].Pinto L, Davidson J, and Gupta A. 2017. Supervision via competition: Robot adversaries for learning tasks. In 2017 IEEE International Conference on Robotics and Automation (ICRA). 1601–1608. 10.1109/ICRA.2017.7989190 [DOI] [Google Scholar]
- [189].Purushotham Sanjay, Carvalho Wilka, Nilanon Tanachat, and Liu Yan. 2017. Variational adversarial deep domain adaptation for health care time series analysis. In International Conference on Learning Representations. https://openreview.net/forum?id=rk9eAFcxg [Google Scholar]
- [190].Radford Alec, Metz Luke, and Chintala Soumith. 2015. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434 (2015). [Google Scholar]
- [191].Rapin J and Teytaud O. 2018. Nevergrad - A gradient-free optimization platform. https://GitHub.com/FacebookResearch/Nevergrad.
- [192].Redko Ievgen, Courty Nicolas, Flamary Rémi, and Tuia Devis. 2018. Optimal transport for multi-source domain adaptation under target shift. arXiv preprint arXiv:1803.04899 (2018). [Google Scholar]
- [193].Redko Ievgen, Habrard Amaury, and Sebban Marc. 2017. Theoretical Analysis of Domain Adaptation withÂăOptimal Transport. In Machine Learning and Knowledge Discovery in Databases, Ceci Michelangelo, Hollmén Jaakko, Todorovski Ljupčo, Vens Celine, and Džeroski Sašo (Eds.). Springer International Publishing, Cham, 737–753. [Google Scholar]
- [194].Ren Jian, Yang Jianchao, Xu Ning, and Foran David J. 2018. Factorized Adversarial Networks for Unsupervised Domain Adaptation. arXiv preprint arXiv:1806.01376 (2018). [Google Scholar]
- [195].Rippel Oren and Bourdev Lubomir. 2017. Real-Time Adaptive Image Compression. In Proceedings of the 34th International Conference on Machine Learning (Proceedings of Machine Learning Research), Precup Doina and Teh Yee Whye (Eds.), Vol. 70. PMLR, 2922–2930. http://proceedings.mlr.press/v70/rippel17a.html [Google Scholar]
- [196].Rippel Oren, Bourdev Lubomir, Lew Carissa, and Nair Sanjay. 2018. Using generative adversarial networks in compression. US Patent App. 15/844,449.
- [197].Royer Amélie, Bousmalis Konstantinos, Gouws Stephan, Bertsch Fred, Mosseri Inbar, Cole Forrester, and Murphy Kevin. 2017. XGAN: Unsupervised Image-to-Image Translation for many-to-many Mappings. arXiv preprint arXiv:1711.05139 (2017). [Google Scholar]
- [198].Rozantsev Artem, Salzmann Mathieu, and Fua Pascal. 2018. Residual Parameter Transfer for Deep Domain Adaptation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [199].Rozantsev A, Salzmann M, and Fua P. 2019. Beyond Sharing Weights for Deep Domain Adaptation. IEEE Transactions on Pattern Analysis and Machine Intelligence 41, 4 (April 2019), 801–814. 10.1109/TPAMI.2018.2814042 [DOI] [PubMed] [Google Scholar]
- [200].Russakovsky Olga, Deng Jia, Su Hao, Krause Jonathan, Satheesh Sanjeev, Ma Sean, Huang Zhiheng, Karpathy Andrej, Khosla Aditya, Bernstein Michael, Berg Alexander C., and Fei-Fei Li. 2015. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV) 115, 3 (2015), 211–252. 10.1007/s11263-015-0816-y [DOI] [Google Scholar]
- [201].Russo Paolo, Carlucci Fabio M., Tommasi Tatiana, and Caputo Barbara. 2018. From Source to Target and Back: Symmetric Bi-Directional Adaptive GAN. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [202].Saenko Kate, Kulis Brian, Fritz Mario, and Darrell Trevor. 2010. Adapting Visual Category Models to New Domains. In Computer Vision – ECCV 2010, Daniilidis Kostas, Maragos Petros, and Paragios Nikos (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 213–226. [Google Scholar]
- [203].Saito Kuniaki, Kim Donghyun, Sclaroff Stan, Darrell Trevor, and Saenko Kate. 2019. Semi-Supervised Domain Adaptation via Minimax Entropy. In The IEEE International Conference on Computer Vision (ICCV). [Google Scholar]
- [204].Saito Kuniaki, Ushiku Yoshitaka, and Harada Tatsuya. 2017. Asymmetric Tri-training for Unsupervised Domain Adaptation. In Proceedings of the 34th International Conference on Machine Learning (Proceedings of Machine Learning Research), Precup Doina and Teh Yee Whye (Eds.), Vol. 70. PMLR, 2988–2997. http://proceedings.mlr.press/v70/saito17a.html [Google Scholar]
- [205].Saito Kuniaki, Ushiku Yoshitaka, Harada Tatsuya, and Saenko Kate. 2018. Adversarial Dropout Regularization. In International Conference on Learning Representations. https://openreview.net/forum?id=HJIoJWZCZ [Google Scholar]
- [206].Saito Kuniaki, Watanabe Kohei, Ushiku Yoshitaka, and Harada Tatsuya. 2018. Maximum Classifier Discrepancy for Unsupervised Domain Adaptation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [207].Salimans Tim, Goodfellow Ian, Zaremba Wojciech, Cheung Vicki, Radford Alec, Chen Xi, and Chen Xi. 2016. Improved Techniques for Training GANs. In Advances in Neural Information Processing Systems 29, Lee DD, Sugiyama M, Luxburg UV, Guyon I, and Garnett R(Eds.). Curran Associates, Inc., 2234–2242. http://papers.nips.cc/paper/6125-improved-techniques-for-training-gans.pdf [Google Scholar]
- [208].Sankaranarayanan Swami, Balaji Yogesh, Castillo Carlos D., and Chellappa Rama. 2018. Generate to Adapt: Aligning Domains Using Generative Adversarial Networks. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [209].Sankaranarayanan Swami, Balaji Yogesh, Jain Arpit, Lim Ser Nam, and Chellappa Rama. 2018. Learning From Synthetic Data: Addressing Domain Shift for Semantic Segmentation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [210].Santurkar Shibani, Schmidt Ludwig, and Madry Aleksander. 2018. A Classification-Based Study of Covariate Shift in GAN Distributions. In Proceedings of the 35th International Conference on Machine Learning (Proceedings of Machine Learning Research), Dy Jennifer and Krause Andreas (Eds.), Vol. 80. PMLR, 4487–4496. http://proceedings.mlr.press/v80/santurkar18a.html [Google Scholar]
- [211].Santurkar Shibani, Tsipras Dimitris, Ilyas Andrew, and Madry Aleksander. 2018. How Does Batch Normalization Help Optimization? In Advances in Neural Information Processing Systems 31, Bengio S, Wallach H, Larochelle H, Grauman K, Cesa-Bianchi N, and Garnett R (Eds.). Curran Associates, Inc., 2483–2493. http://papers.nips.cc/paper/7515-how-does-batch-normalization-help-optimization.pdf [Google Scholar]
- [212].Schneider Steffen, Ecker Alexander S., Macke Jakob H., and Bethge Matthias. 2018. Salad: A Toolbox for Semi-supervised Adaptive Learning Across Domains. https://openreview.net/forum?id=S1lTifykqm
- [213].Sebag Alice Schoenauer, Heinrich Louise, Schoenauer Marc, Sebag Michèle, Wu Lani, and Altschuler Steven. 2019. Multi-Domain Adversarial Learning. In International Conference on Learning Representations. https://openreview.net/forum?id=Sklv5iRqYX [Google Scholar]
- [214].Sener Ozan, Song Hyun Oh Saxena Ashutosh, and Savarese Silvio. 2016. Learning Transferrable Representations for Unsupervised Domain Adaptation. In Advances in Neural Information Processing Systems 29, Lee DD, Sugiyama M, Luxburg UV, Guyon I, and Garnett R (Eds.). Curran Associates, Inc., 2110–2118. http://papers.nips.cc/paper/6360-learning-transferrable-representations-for-unsupervised-domain-adaptation.pdf [Google Scholar]
- [215].Shang C, Palmer A, Sun J, Chen K, Lu J, and Bi J. 2017. VIGAN: Missing view imputation with generative adversarial networks. In 2017 IEEE International Conference on Big Data (Big Data). 766–775. 10.1109/BigData.2017.8257992 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [216].Shao L, Zhu F, and Li X. 2015. Transfer Learning for Visual Categorization: A Survey. IEEE Transactions on Neural Networks and Learning Systems 26, 5 (May 2015), 1019–1034. 10.1109/TNNLS.2014.2330900 [DOI] [PubMed] [Google Scholar]
- [217].Shen Jian, Qu Yanru, Zhang Weinan, and Yu Yong. 2018. Wasserstein Distance Guided Representation Learning for Domain Adaptation. In Thirty-Second AAAI Conference on Artificial Intelligence. [Google Scholar]
- [218].Shinohara Yusuke. 2016. Adversarial Multi-Task Learning of Deep Neural Networks for Robust Speech Recognition. In Interspeech 2016. 2369–2372. 10.21437/Interspeech.2016-879 [DOI] [Google Scholar]
- [219].Shrivastava Ashish, Pfister Tomas, Tuzel Oncel, Susskind Joshua, Wang Wenda, and Webb Russell. 2017. Learning From Simulated and Unsupervised Images Through Adversarial Training. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [220].Shu Rui, Bui Hung, Narui Hirokazu, and Ermon Stefano. 2018. A DIRT-T Approach to Unsupervised Domain Adaptation. In International Conference on Learning Representations. https://openreview.net/forum?id=H1q-TM-AW [Google Scholar]
- [221].Shu Yang, Cao Zhangjie, Long Mingsheng, and Wang Jianmin. 2019. Transferable Curriculum for Weakly-Supervised Domain Adaptation. Proceedings of the AAAI Conference on Artificial Intelligence 33, 01 (Jul. 2019), 4951–4958. 10.1609/aaai.v33i01.33014951 [DOI] [Google Scholar]
- [222].Sinclair Stephen. 2018. Sounderfeit: Cloning a Physical Model using a Conditional Adversarial Autoencoder. arXiv preprint arXiv:1806.09617 (2018). [Google Scholar]
- [223].Sohn Kihyuk, Shang Wenling, Yu Xiang, and Chandraker Manmohan. 2019. Unsupervised Domain Adaptation for Distance Metric Learning. In International Conference on Learning Representations. https://openreview.net/forum?id=BklhAj09K7 [Google Scholar]
- [224].Stallkamp J, Schlipsing M, Salmen J, and Igel C. 2011. The German Traffic Sign Recognition Benchmark: A multi-class classification competition. In The 2011 International Joint Conference on Neural Networks. 1453–1460. 10.1109/IJCNN.2011.6033395 [DOI] [Google Scholar]
- [225].Sun Baochen, Feng Jiashi, and Saenko Kate. 2016. Return of Frustratingly Easy Domain Adaptation. In AAAI Conference on Artificial Intelligence. https://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/view/12443 [Google Scholar]
- [226].Sun Baochen and Saenko Kate. 2016. Deep CORAL: Correlation Alignment for Deep Domain Adaptation. In Computer Vision – ECCV 2016 Workshops, Hua Gang and Jégou Hervé (Eds.). Springer International Publishing, Cham, 443–450. [Google Scholar]
- [227].Sun Shiliang, Shi Honglei, and Wu Yuanbin. 2015. A survey of multi-source domain adaptation. Information Fusion 24 (2015), 84–92. 10.1016/j.inffus.2014.12.003 [DOI] [Google Scholar]
- [228].Sutherland Dougal J, Tung Hsiao-Yu, Strathmann Heiko, De Soumyajit, Ramdas Aaditya, Smola Alex, and Gretton Arthur. 2016. Generative Models and Model Criticism via Optimized Maximum Mean Discrepancy. In International Conference on Learning Representations. https://openreview.net/forum?id=HJWHIKqgl [Google Scholar]
- [229].Szegedy Christian, Vanhoucke Vincent, Ioffe Sergey, Shlens Jon, and Wojna Zbigniew. 2016. Rethinking the Inception Architecture for Computer Vision. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [230].Szegedy Christian, Zaremba Wojciech, Sutskever Ilya, Bruna Joan, Erhan Dumitru, Goodfellow Ian, and Fergus Rob. 2013. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199 (2013). [Google Scholar]
- [231].Taigman Yaniv, Polyak Adam, and Wolf Lior. 2016. Unsupervised Cross-Domain Image Generation. In International Conference on Learning Representations. https://openreview.net/forum?id=Sk2Im59ex [Google Scholar]
- [232].Tan Chuanqi, Sun Fuchun, Kong Tao, Zhang Wenchang, Yang Chao, and Liu Chunfang. 2018. A Survey on Deep Transfer Learning. In Artificial Neural Networks and Machine Learning – ICANN 2018, Kůrková Věra, Manolopoulos Yannis, Hammer Barbara, Iliadis Lazaros, and Maglogiannis Ilias (Eds.). Springer International Publishing, Cham, 270–279. [Google Scholar]
- [233].Tang Hui and Jia Kui. 2019. Discriminative Adversarial Domain Adaptation. arXiv preprint arXiv:1911.12036 (2019). [Google Scholar]
- [234].Tarvainen Antti and Valpola Harri. 2017. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Advances in Neural Information Processing Systems 30, Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, and Garnett R (Eds.). Curran Associates, Inc., 1195–1204. http://papers.nips.cc/paper/6719-mean-teachers-are-better-role-models-weight-averaged-consistency-targets-improve-semi-supervised-deep-learning-results.pdf [Google Scholar]
- [235].Taylor Matthew E and Stone Peter. 2009. Transfer learning for reinforcement learning domains: A survey. Journal of Machine Learning Research 10, Jul (2009), 1633–1685. [Google Scholar]
- [236].Theis Lucas, van den Oord Aäron, and Bethge Matthias. 2016. A note on the evaluation of generative models. In International Conference on Learning Representations. https://arxiv.org/abs/1511.01844 [Google Scholar]
- [237].Tolstikhin Ilya O, Gelly Sylvain, Bousquet Olivier, SIMON-GABRIEL Carl-Johann, and Schölkopf Bernhard. 2017. AdaGAN: Boosting Generative Models. In Advances in Neural Information Processing Systems 30, Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, and Garnett R (Eds.). Curran Associates, Inc., 5424–5433. http://papers.nips.cc/paper/7126-adagan-boosting-generative-models.pdf [Google Scholar]
- [238].Tonutti Michele, Ruffaldi Emanuele, Cattaneo Alessandro, and Avizzano Carlo Alberto. 2019. Robust and subject-independent driving manoeuvre anticipation through Domain-Adversarial Recurrent Neural Networks. Robotics and Autonomous Systems 115 (2019), 162–173. 10.1016/j.robot.2019.02.007 [DOI] [Google Scholar]
- [239].Tsai Yi-Hsuan, Hung Wei-Chih, Schulter Samuel, Sohn Kihyuk, Yang Ming-Hsuan, and Chandraker Manmohan. 2018. Learning to Adapt Structured Output Space for Semantic Segmentation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [240].Tzeng Eric, Hoffman Judy, Darrell Trevor, and Saenko Kate. 2015. Simultaneous Deep Transfer Across Domains and Tasks. In The IEEE International Conference on Computer Vision (ICCV). [Google Scholar]
- [241].Tzeng Eric, Hoffman Judy, Saenko Kate, and Darrell Trevor. 2017. Adversarial Discriminative Domain Adaptation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [242].Vercruyssen Vincent, Meert Wannes, and Davis Jesse. 2017. Transfer learning for time series anomaly detection. In CEUR Workshop Proceedings, Vol. 1924. 27–37. [Google Scholar]
- [243].Vu Tuan-Hung, Jain Himalaya, Bucher Maxime, Cord Mathieu, and Pérez Patrick. 2018. ADVENT: Adversarial Entropy Minimization for Domain Adaptation in Semantic Segmentation. arXiv preprint arXiv:1811.12833 (2018). [Google Scholar]
- [244].Wang Chang and Mahadevan Sridhar. 2011. Heterogeneous domain adaptation using manifold alignment. In Twenty-Second International Joint Conference on Artificial Intelligence. [Google Scholar]
- [245].Wang Jiawei, He Zhaoshui, Feng Chengjian, Zhu Zhouping, Lin Qinzhuang, Lv Jun, and Xie Shengli. 2018. Domain Confusion with Self Ensembling for Unsupervised Adaptation. arXiv preprint arXiv:1810.04472 (2018). [Google Scholar]
- [246].Wang Mei and Deng Weihong. 2018. Deep visual domain adaptation: A survey. Neurocomputing 312 (2018), 135–153. 10.1016/j.neucom.2018.05.083 [DOI] [Google Scholar]
- [247].Wang Ximei, Li Liang, Ye Weirui, Long Mingsheng, and Wang Jianmin. 2019. Transferable Attention for Domain Adaptation. Proceedings of the AAAI Conference on Artificial Intelligence 33, 01 (Jul. 2019), 5345–5352. 10.1609/aaai.v33i01.33015345 [DOI] [Google Scholar]
- [248].Wang Xiaolong, Shrivastava Abhinav, and Gupta Abhinav. 2017. A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [249].Wang Yifei, Li Wen, Dai Dengxin, and Van Gool Luc. 2017. Deep Domain Adaptation by Geodesic Distance Minimization. In The IEEE International Conference on Computer Vision (ICCV) Workshops. [Google Scholar]
- [250].Wei Kai-Ya and Hsu Chiou-Ting. 2018. Generative Adversarial Guided Learning for Domain Adaptation. British Machine Vision Conference (2018). [Google Scholar]
- [251].Wei Longhui, Zhang Shiliang, Gao Wen, and Tian Qi. 2018. Person Transfer GAN to Bridge Domain Gap for Person Re-Identification. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [252].Weiss Karl, Khoshgoftaar Taghi M., and Wang DingDing. 2016. A survey of transfer learning. Journal of Big Data 3, 1 (28 May 2016), 9. 10.1186/s40537-016-0043-6 [DOI] [Google Scholar]
- [253].Wu Yuhuai, Burda Yuri, Salakhutdinov Ruslan, and Grosse Roger. 2017. On the quantitative analysis of decoder-based generative models. In International Conference on Learning Representations. https://openreview.net/forum?id=B1M8JF9xx [Google Scholar]
- [254].Wu Yuxin and He Kaiming. 2018. Group Normalization. In Computer Vision – ECCV 2018, Ferrari Vittorio, Hebert Martial, Sminchisescu Cristian, and Weiss Yair (Eds.). Springer International Publishing, Cham, 3–19. [Google Scholar]
- [255].Wulfmeier M, Bewley A, and Posner I. 2018. Incremental Adversarial Domain Adaptation for Continually Changing Environments. In 2018 IEEE International Conference on Robotics and Automation (ICRA). 1–9. 10.1109/ICRA.2018.8460982 [DOI] [Google Scholar]
- [256].Xie Qizhe, Dai Zihang, Du Yulun, Hovy Eduard, and Neubig Graham. 2017. Controllable Invariance through Adversarial Feature Learning. In Advances in Neural Information Processing Systems 30, Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, and Garnett R (Eds.). Curran Associates, Inc., 585–596. http://papers.nips.cc/paper/6661-controllable-invariance-through-adversarial-feature-learning.pdf [Google Scholar]
- [257].Xin Zhao. 2019. A collection of AWESOME things about domian adaptation. Retrieved March 20, 2019 from https://github.com/zhaoxin94/awsome-domain-adaptation
- [258].Xu Qiantong, Huang Gao, Yuan Yang, Guo Chuan, Sun Yu, Wu Felix, and Weinberger Kilian. 2018. An empirical study on evaluation metrics of generative adversarial networks. arXiv preprint arXiv:1806.07755 (2018). [Google Scholar]
- [259].Xu Ruijia, Chen Ziliang, Zuo Wangmeng, Yan Junjie, and Lin Liang. 2018. Deep Cocktail Network: Multi-Source Unsupervised Domain Adaptation With Category Shift. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [260].Yan Junchi, Yin Xu-Cheng, Lin Weiyao, Deng Cheng, Zha Hongyuan, and Yang Xiaokang. 2016. A Short Survey of Recent Advances in Graph Matching. In Proceedings of the 2016 ACM on International Conference on Multimedia Retrieval (ICMR ’16). ACM, New York, NY, USA, 167–174. 10.1145/2911996.2912035 [DOI] [Google Scholar]
- [261].Yang Yongxin and Hospedales Timothy M. 2015. A unified perspective on multi-domain and multi-task learning. In International Conference on Learning Representations. https://arxiv.org/abs/1412.7489 [Google Scholar]
- [262].Yang Zhilin, Hu Junjie, Salakhutdinov Ruslan, and Cohen William. 2017. Semi-Supervised QA with Generative Domain-Adaptive Nets. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vol. 1. 1040–1050. [Google Scholar]
- [263].Yao Yuan, Zhang Yu, Li Xutao, and Ye Yunming. 2020. Discriminative Distribution Alignment: A Unified Framework for Heterogeneous Domain Adaptation. Pattern Recognition (2020), 107165. 10.1016/j.patcog.2019.107165 [DOI] [Google Scholar]
- [264].Yi Zili, Zhang Hao, Tan Ping, and Gong Minglun. 2017. DualGAN: Unsupervised Dual Learning for Image-To-Image Translation. In The IEEE International Conference on Computer Vision (ICCV). [Google Scholar]
- [265].Yoo Donggeun, Kim Namil, Park Sunggyun, Paek Anthony S, and Kweon In So. 2016. Pixel-level domain transfer. In European Conference on Computer Vision. Springer, 517–532. [Google Scholar]
- [266].Yoo Jaeyoon, Hong Yongjun, Noh YungKyun, and Yoon Sungroh. 2017. Domain Adaptation Using Adversarial Learning for Autonomous Navigation. arXiv preprint arXiv:1712.03742 (2017). [Google Scholar]
- [267].Yu Chaohui, Wang Jindong, Chen Yiqiang, and Huang Meiyu. 2019. Transfer Learning with Dynamic Adversarial Adaptation Network. arXiv preprint arXiv:1909.08184 (2019). [Google Scholar]
- [268].Yu Fisher, Seff Ari, Zhang Yinda, Song Shuran, Funkhouser Thomas, and Xiao Jianxiong. 2015. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv preprint arXiv:1506.03365 (2015). [Google Scholar]
- [269].Zhang Han, Goodfellow Ian, Metaxas Dimitris, and Odena Augustus. 2018. Self-Attention Generative Adversarial Networks. arXiv preprint arXiv:1805.08318 (2018). [Google Scholar]
- [270].Zhang Honglun, Xiao Liqiang, Chen Wenqing, Wang Yongkun, and Jin Yaohui. 2018. Generative Warfare Nets: Ensemble via Adversaries and Collaborators.. In IJCAI. 3075–3081. [Google Scholar]
- [271].Zhang JiChao. 2019. Adversarial Nets Papers. Retrieved February 25, 2019 from https://github.com/zhangqianhui/AdversarialNetsPapers
- [272].Zhang Jing, Ding Zewei, Li Wanqing, and Ogunbona Philip. 2018. Importance Weighted Adversarial Nets for Partial Domain Adaptation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [273].Zhang Jing, Li Wanqing, and Ogunbona Philip. 2017. Transfer learning for cross-dataset recognition: a survey. arXiv preprint arXiv:1705.04396 (2017). [Google Scholar]
- [274].Zhang Weichen, Ouyang Wanli, Li Wen, and Xu Dong. 2018. Collaborative and Adversarial Network for Unsupervised Domain Adaptation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [DOI] [PubMed] [Google Scholar]
- [275].Zhang Yuan, Barzilay Regina, and Jaakkola Tommi. 2017. Aspect-augmented Adversarial Networks for Domain Adaptation. Transactions of the Association for Computational Linguistics 5 (2017), 515–528. 10.1162/tacl_a_00077arXiv:https://doi.org/10.1162/tacl_a_00077 [DOI] [Google Scholar]
- [276].Zhang Yang, David Philip, and Gong Boqing. 2017. Curriculum Domain Adaptation for Semantic Segmentation of Urban Scenes. In The IEEE International Conference on Computer Vision (ICCV). [Google Scholar]
- [277].Zhang Yue, Miao Shun, Mansi Tommaso, and Liao Rui. 2018. Task Driven Generative Modeling for Unsupervised Domain Adaptation: Application to X-ray Image Segmentation. In Medical Image Computing and Computer Assisted Intervention – MICCAI 2018, Frangi Alejandro F., Schnabel Julia A., Davatzikos Christos, Alberola-López Carlos, and Fichtinger Gabor (Eds.). Springer International Publishing, Cham, 599–607. [Google Scholar]
- [278].Zhang Y, Wang N, Cai S, and Song L. 2018. Unsupervised Domain Adaptation by Mapped Correlation Alignment. IEEE Access 6 (2018), 44698–44706. 10.1109/ACCESS.2018.2865249 [DOI] [Google Scholar]
- [279].Zhang Zhen, Wang Mianzhi, Huang Yan, and Nehorai Arye. 2018. Aligning Infinite-Dimensional Covariance Matrices in Reproducing Kernel Hilbert Spaces for Domain Adaptation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [280].Zhao Han, Des Combes Remi Tachet, Zhang Kun, and Gordon Geoffrey. 2019. On Learning Invariant Representations for Domain Adaptation. In Proceedings of the 36th International Conference on Machine Learning (Proceedings of Machine Learning Research), Chaudhuri Kamalika and Salakhutdinov Ruslan (Eds.), Vol. 97. PMLR, Long Beach, California, USA, 7523–7532. http://proceedings.mlr.press/v97/zhao19a.html [Google Scholar]
- [281].Zhao Han, Zhang Shanghang, Wu Guanhang, Moura José M. F., Costeira Joao P, and Gordon Geoffrey J. 2018. Adversarial Multiple Source Domain Adaptation. In Advances in Neural Information Processing Systems 31, Bengio S, Wallach H, Larochelle H, Grauman K, Cesa-Bianchi N, and Garnett R (Eds.). Curran Associates, Inc., 8559–8570. http://papers.nips.cc/paper/8075-adversarial-multiple-source-domain-adaptation.pdf [Google Scholar]
- [282].Zhao Han, Zhu Zhenyao, Hu Junjie, Coates Adam, and Gordon Geoff. 2017. Principled hybrids of generative and discriminative domain adaptation. arXiv preprint arXiv:1705.09011 (2017). [Google Scholar]
- [283].Zhao Junbo, Mathieu Michael, and LeCun Yann. 2017. Energy-based generative adversarial network. In International Conference on Learning Representations. https://openreview.net/forum?id=ryh9pmcee [Google Scholar]
- [284].Zhao Mingmin, Yue Shichao, Katabi Dina, Jaakkola Tommi S., and Bianchi Matt T.. 2017. Learning Sleep Stages from Radio Signals: A Conditional Adversarial Architecture. In Proceedings of the 34th International Conference on Machine Learning (Proceedings of Machine Learning Research), Precup Doina and Teh Yee Whye (Eds.), Vol. 70. PMLR, 4100–4109. http://proceedings.mlr.press/v70/zhao17d.html [Google Scholar]
- [285].Zhao Sicheng, Wu Bichen, Gonzalez Joseph, Seshia Sanjit A, and Keutzer Kurt. 2018. Unsupervised Domain Adaptation: from Simulation Engine to the RealWorld. arXiv preprint arXiv:1803.09180 (2018). [Google Scholar]
- [286].Zhong Erheng, Fan Wei, Yang Qiang, Verscheure Olivier, and Ren Jiangtao. 2010. Cross Validation Framework to Choose amongst Models and Datasets for Transfer Learning. In Machine Learning and Knowledge Discovery in Databases, Balcázar José Luis, Bonchi Francesco, Gionis Aristides, and Sebag Michèle (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 547–562. [Google Scholar]
- [287].Zhong Zhun, Zheng Liang, Luo Zhiming, Li Shaozi, and Yang Yi. 2019. Invariance Matters: Exemplar Memory for Domain Adaptive Person Re-Identification. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [288].Zhong Zhun, Zheng Liang, Zheng Zhedong, Li Shaozi, and Yang Yi. 2018. Camera Style Adaptation for Person Re-Identification. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [Google Scholar]
- [289].Zhou Joey Tianyi, Tsang Ivor W., Pan Sinno Jialin, and Tan Mingkui. 2019. Multi-class Heterogeneous Domain Adaptation. Journal of Machine Learning Research 20, 57 (2019), 1–31. http://jmlr.org/papers/v20/13-580.html [Google Scholar]
- [290].Zhu Jun-Yan, Park Taesung, Isola Phillip, and Efros Alexei A.. 2017. Unpaired Image-To-Image Translation Using Cycle-Consistent Adversarial Networks. In The IEEE International Conference on Computer Vision (ICCV). [Google Scholar]
- [291].Zou Yang, Yu Zhiding, Kumar B.V.K. Vijaya, and Wang Jinsong. 2018. Unsupervised Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training. In The European Conference on Computer Vision (ECCV). [Google Scholar]